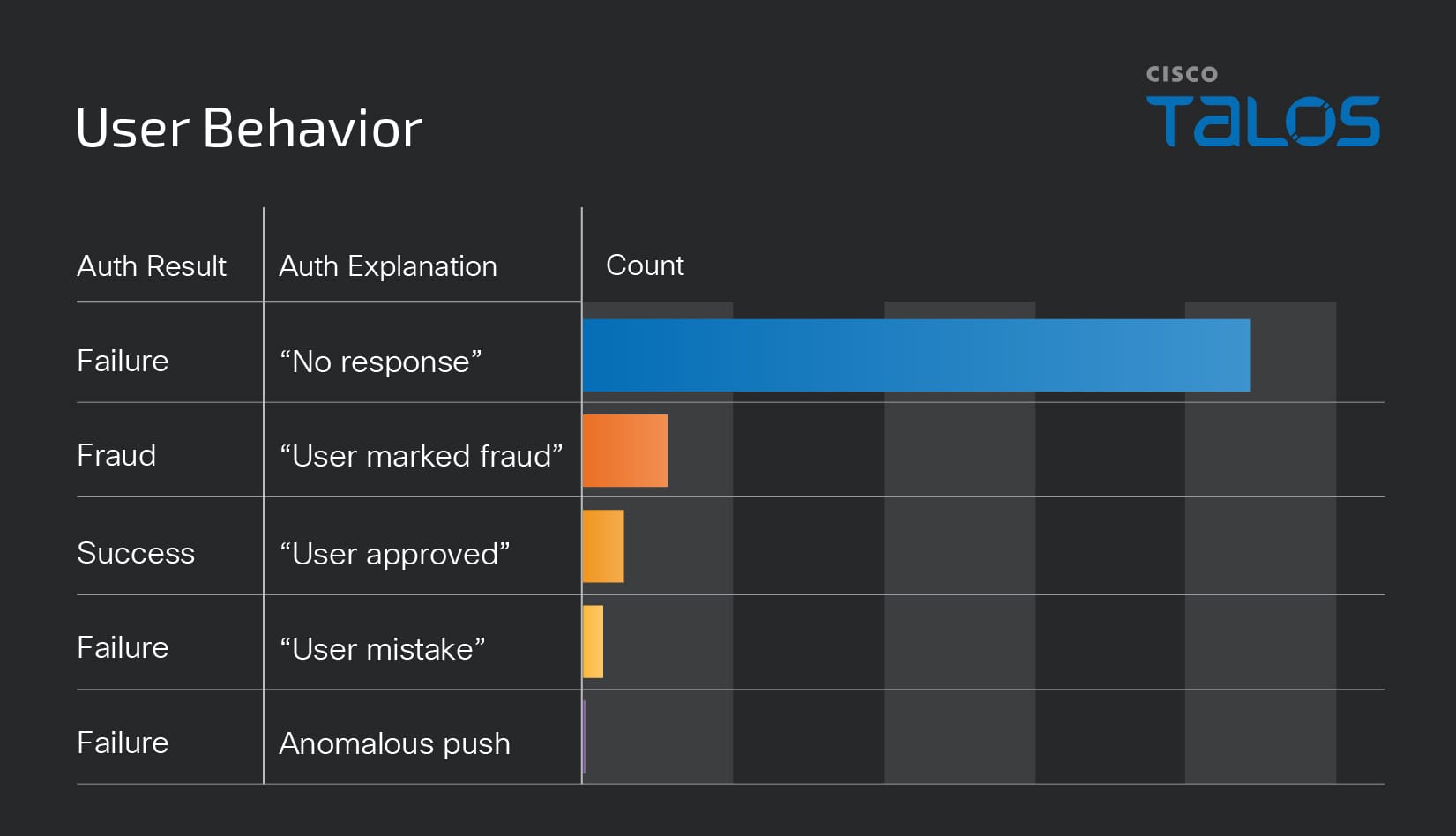
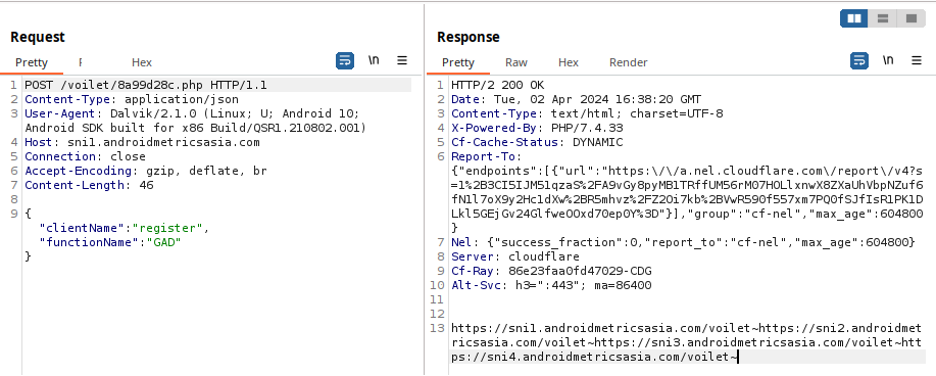
Exploring malicious Windows drivers (Part 2): the I/O system, IRPs, stack locations, IOCTLs and more

This blog post is part of a multi-part series, and it is highly recommended to read the first entry here before continuing.
As the second entry in our “Exploring malicious Windows drivers” series, we will continue where the first left off: Discussing the I/O system and IRPs. We will expand on these subjects and discuss other aspects of the I/O system such as IOCTLs, device stacks and I/O stack locations, as all are critical components of I/O operations.
In this series, we’ll introduce the concepts of drivers, the Windows kernel and basic analysis of malicious drivers. Please explore the links to code examples and the Microsoft documentation, as it will provide context for the concepts discussed here.
I/O operations are extremely powerful, as they allow an attacker to perform a wide array of actions at the kernel level. With kernel-level access, an attacker could discreetly capture, initiate, or alter network traffic, as well as access or alter files on a system. Virtualization protections such as Virtual Secure Mode can aid in defense against malicious drivers, although it is not enabled by default in a typical Windows environment. Even when these protections are enabled, certain configurations are required to effectively defend against kernel mode drivers.
The capability of a malicious driver is only limited by the skill level and knowledge of the individual writing it and the configuration of the target system. However, writing a reliable malicious driver is quite difficult as many factors must be taken into consideration during development. One of these factors is correctly implementing I/O operations without crashing the target system, which can easily occur if the proper precautions are not taken.
The I/O system, I/O request packets (IRPs) and device stacks:
As discussed in the previous entry, the I/O manager and the other components of the executive layer encapsulate data being sent to drivers within I/O request packets (IRPs). All IRPs are represented as the structure defined as “_IRP” in wdm.h:
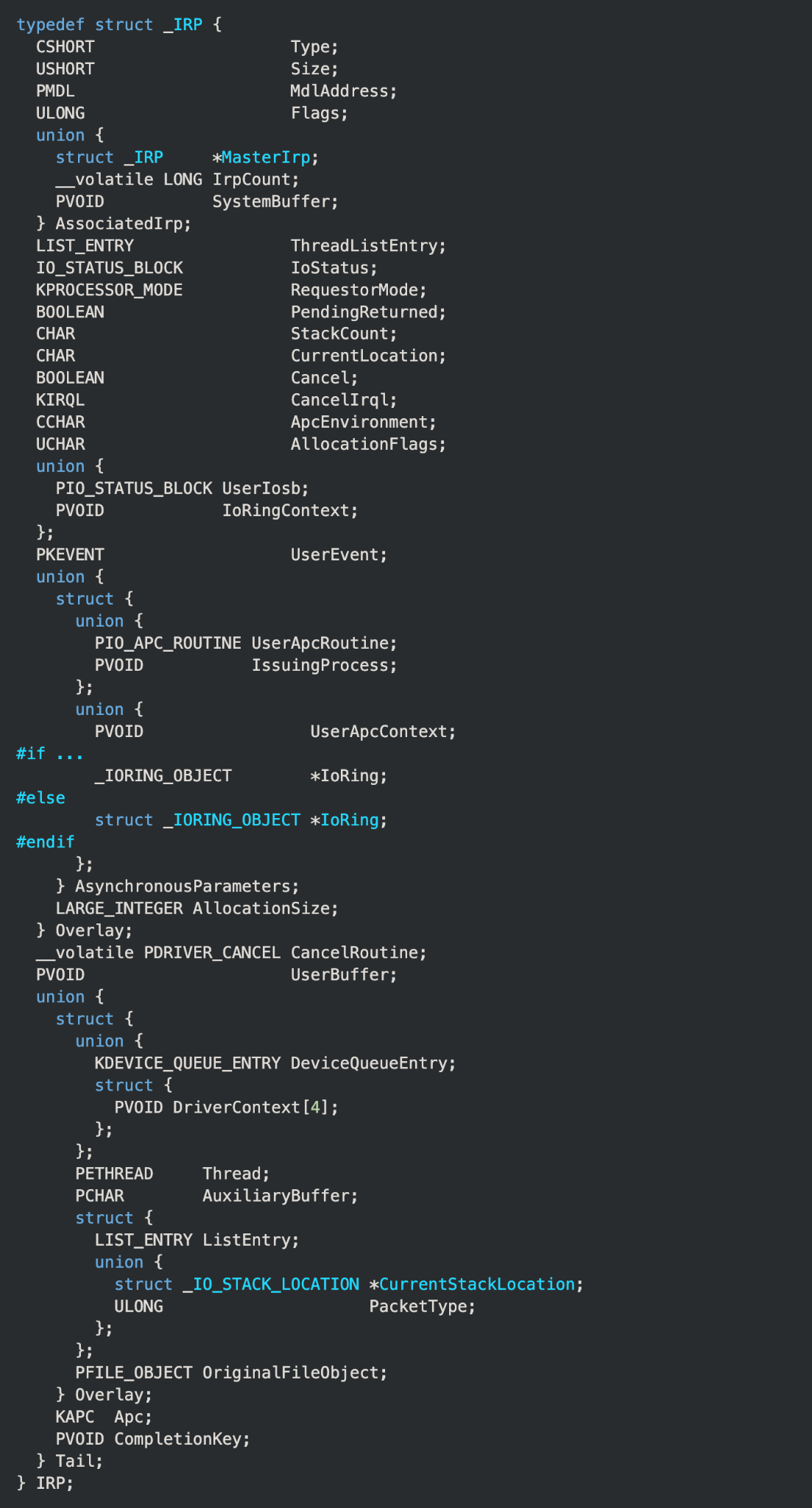
IRPs are the result of a system component, driver or user-mode application requesting that a driver perform an operation it was designed to do. There are several ways that a request can be made, and the methods of doing so differ between user-mode and kernel-mode requestors.
Requests: User mode
The I/O request is one of the fundamental mechanisms of the Windows kernel, as well as user mode. Simple actions in user mode such as creating a text file require that the I/O system create and send IRPs to drivers. The action of creating a text file and storing it on the hard drive involves multiple drivers sending and receiving IRPs until the physical changes are made on the disk.
One possible scenario where a user-mode application would initiate a request is calling the ReadFile routine, which can instruct the driver to perform some type of read operation. If the application passes a handle to a driver’s device object as the hFile parameter of ReadFile, this will tell the I/O manager to create an IRP and send it to the specified driver.

To get the appropriate handle to pass, the application can call the function CreateFile and pass the driver’s device name as the lpFileName parameter. If the function completes successfully, a handle to the specified driver is returned.
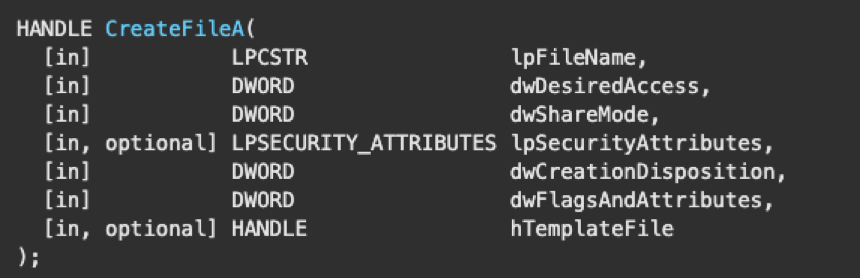
Note: The name of the CreateFile function is often misleading, as it implies that it only creates files, but it also can open files or devices and return a handle to them.
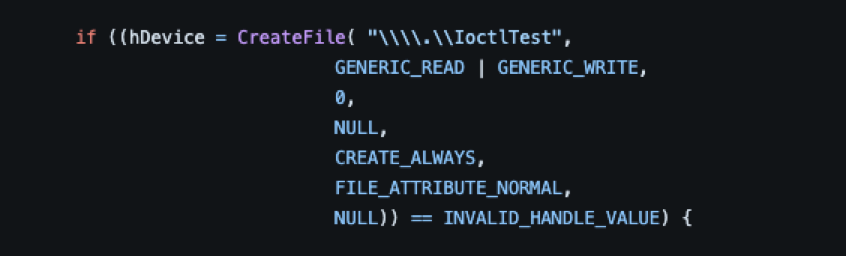
As seen in the example above, the value of “\\\\.\\IoctlTest” is passed in the lpFileName parameter. When passing the device name as a parameter it must be prepended with “\\.\'' and since the backslashes must be escaped, it becomes “\\\\.\\”.
Requests: Kernel mode
For a system component or a driver to send an IRP, it must call the IoCallDriver routine with a DEVICE_OBJECT and a pointer to an IRP (PIRP) provided as parameters. It is important to note that IoCallDriver is essentially a wrapper for IofCallDriver, which Microsoft recommends should never be called directly.

While they are an important part of driver functionality, we will not be discussing requests between drivers.
Device nodes and the device tree
Before we continue discussing IRPs – to better understand their purpose and functionality – it’s necessary to first explain the concept of device stacks and the device tree.
To reach its intended driver, an IRP is sent through what is referred to as a “device stack,” or sometimes as a “device node” or “devnode." A device stack can be thought of as an ordered list of device objects that are logically arranged in a layered “stack.” Each layer in this stack consists of a DEVICE_OBJECT structure that represents a specific driver. It is important to note that drivers are not limited to creating only one device object, and it is quite common for a driver to create multiple.
Note: Technically, “device stack” and “device node” have slightly different definitions, although they are often used interchangeably. Even though they ultimately mean the same thing, their contexts differ. “Device stack” specifically refers to the list of device objects inside of a “device node” of the device tree.
Each device node, and the device stack inside of it, represents a device or bus that is recognized by the operating system, such as a USB device, audio controller, a display adapter or any of the other various possible types. Windows organizes these device nodes into a larger structure called the “device tree” or the “Plug and Play device tree.”
Nodes within the tree are connected through parent/child relationships in which they are dependent on the other nodes connected to them. The lowest node in the tree is called the “root device node,” as all nodes in the tree's hierarchy eventually connect to it through relationships with other nodes. During startup, the Plug and Play (PnP) manager populates the device tree by requesting connected devices to enumerate all child device nodes. For an in-depth look at how the device tree and its nodes work, the MSDN documentation can be found here.
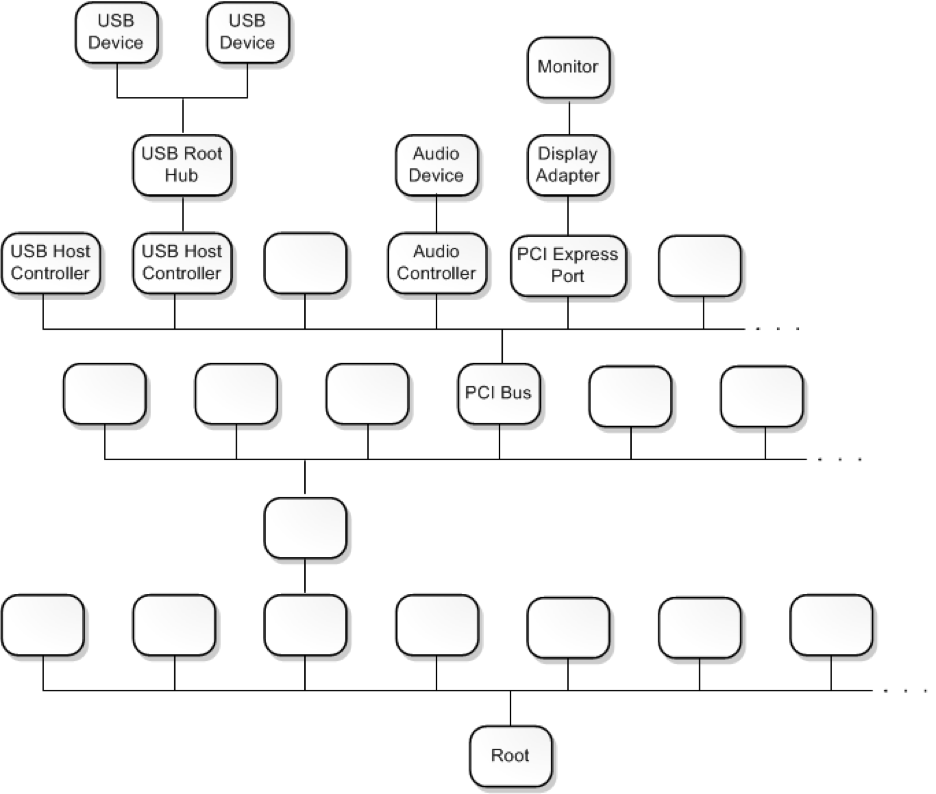
At this point, the device tree can essentially be thought of as a kind of map of all the drivers, buses and devices that are installed on or connected to the system.
Device types
Of the device objects that can make up the layers within each device stack, there can be three types: physical device object (PDO), functional device object (FDO) and filter device object (FiDO). As shown below, a device object’s type is determined by the functionality of the driver that created it:
- PDO: Not physical, but rather a device object created by a driver for a particular bus, such as USB or PCI. This device object represents an actual physical device plugged into a slot.
- FiDO: Created by a filter driver (largely outside the scope of this series). A driver that sits between layers can add functionality to or modify a device.
- FDO: Created by a driver that serves a function for a device connected to the system. Most commonly these will be drivers supplied by vendors for a particular device, but their purposes can vary widely. This blog post series pertains mostly to FDOs, as many malicious drivers are of this type.
For more information on the different object types see the MSDN documentation here.
Just as with the device tree, the PnP manager is also responsible for loading the correct drivers when creating a device node, starting with the lowest layer. Once created, a device stack will have a PDO as the bottom layer and typically at least one FDO. However, FiDOs are optional and can sit between layers or at the top of the stack. Regardless of the number of device objects or their types, a device stack is always organized as a top-down list. In other words, the top object in the stack is always considered the first in line and the bottom is always the last.
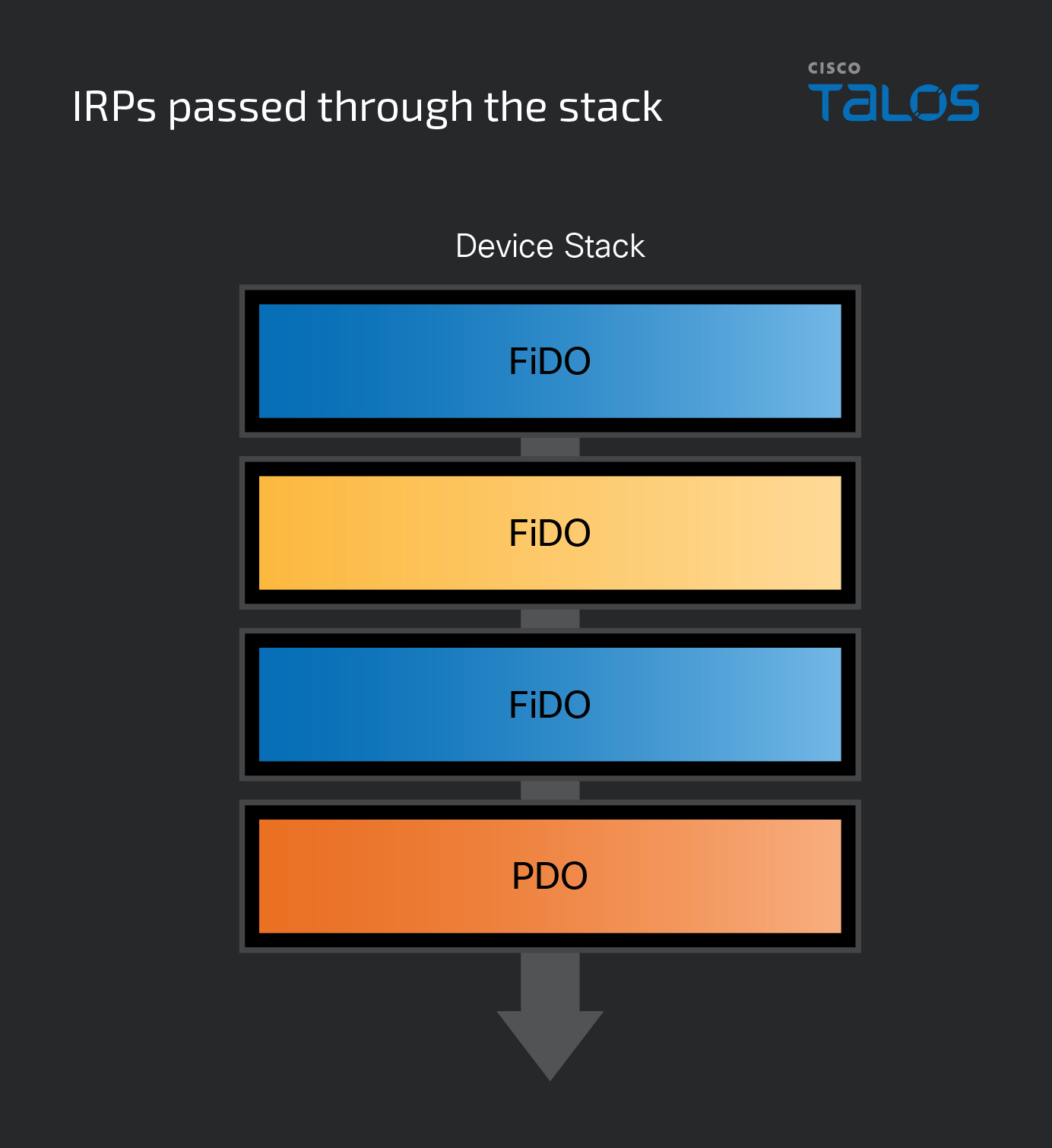
When an IRP is sent, it doesn’t go directly to the intended driver but rather to the device node that contains the target driver’s device object. As discussed above, once the correct node has received the IRP, it begins to pass through it from a top-to-bottom order. Once the IRP has found the correct device node, it needs to get to the correct layer within it, which is where I/O stack locations come into play.
I/O stack locations
When an IRP is allocated in memory, another structure called an I/O stack location – defined as IO_STACK_LOCATION – is allocated alongside it. There can be multiple IO_STACK_LOCATIONs allocated, but there must be at least one. Rather than being part of the IRPs structure, an I/O stack location is its own defined structure that is “attached” to the end of the IRP.
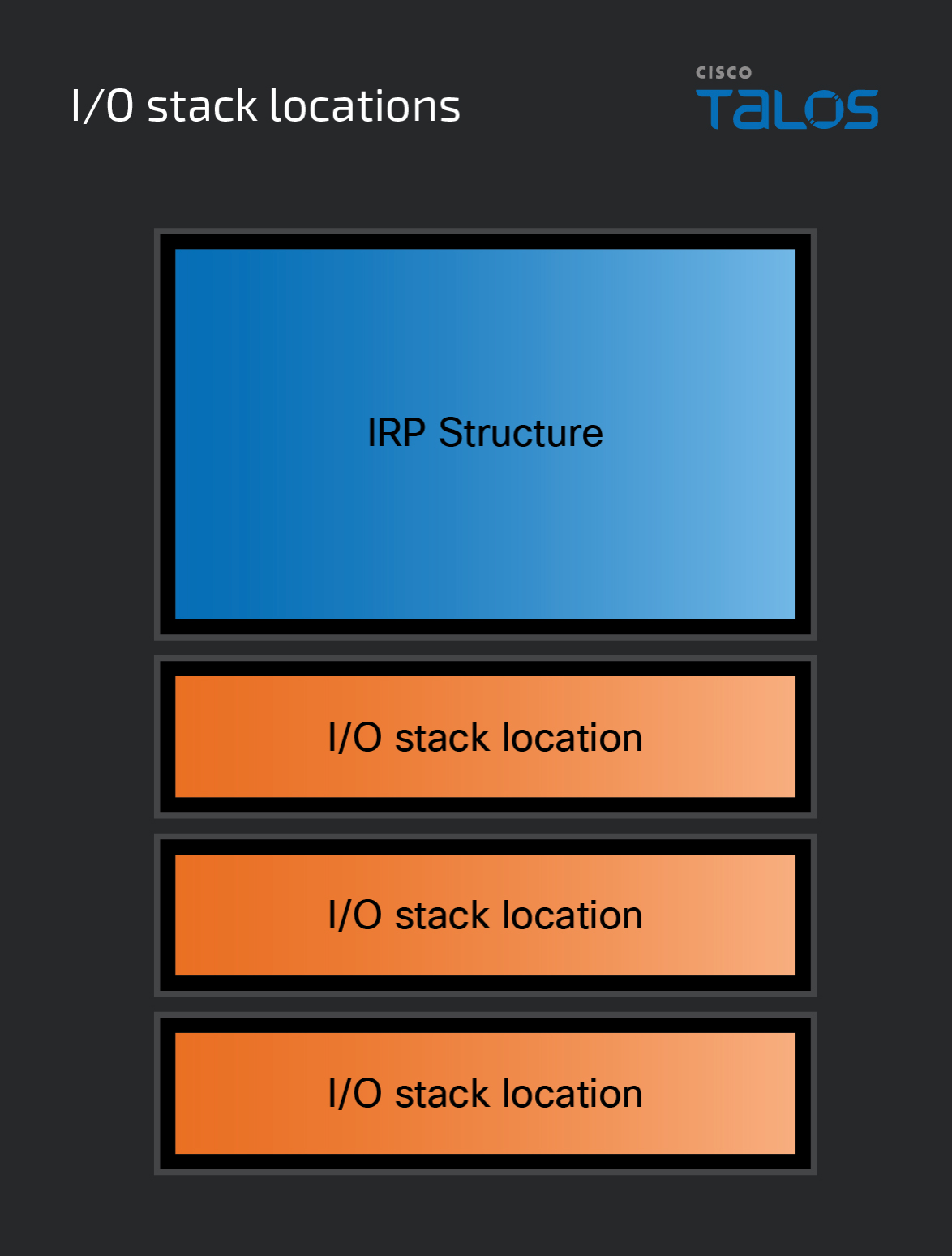
The number of I/O stack locations that accompany an IRP is equal to the number of device objects in the device stack that the IRP is sent to. Each driver in the device stack ends up being responsible for one of these I/O stack locations, which will be discussed shortly. These stack locations help the drivers in the device stack determine if the IRP is relevant to them. If it is relevant, then the requested operations will be performed. If the IRP is irrelevant, it’s passed to the next layer.
The IO_STACK_LOCATION structure contains several members that a driver uses to determine an IRP’s relevance.
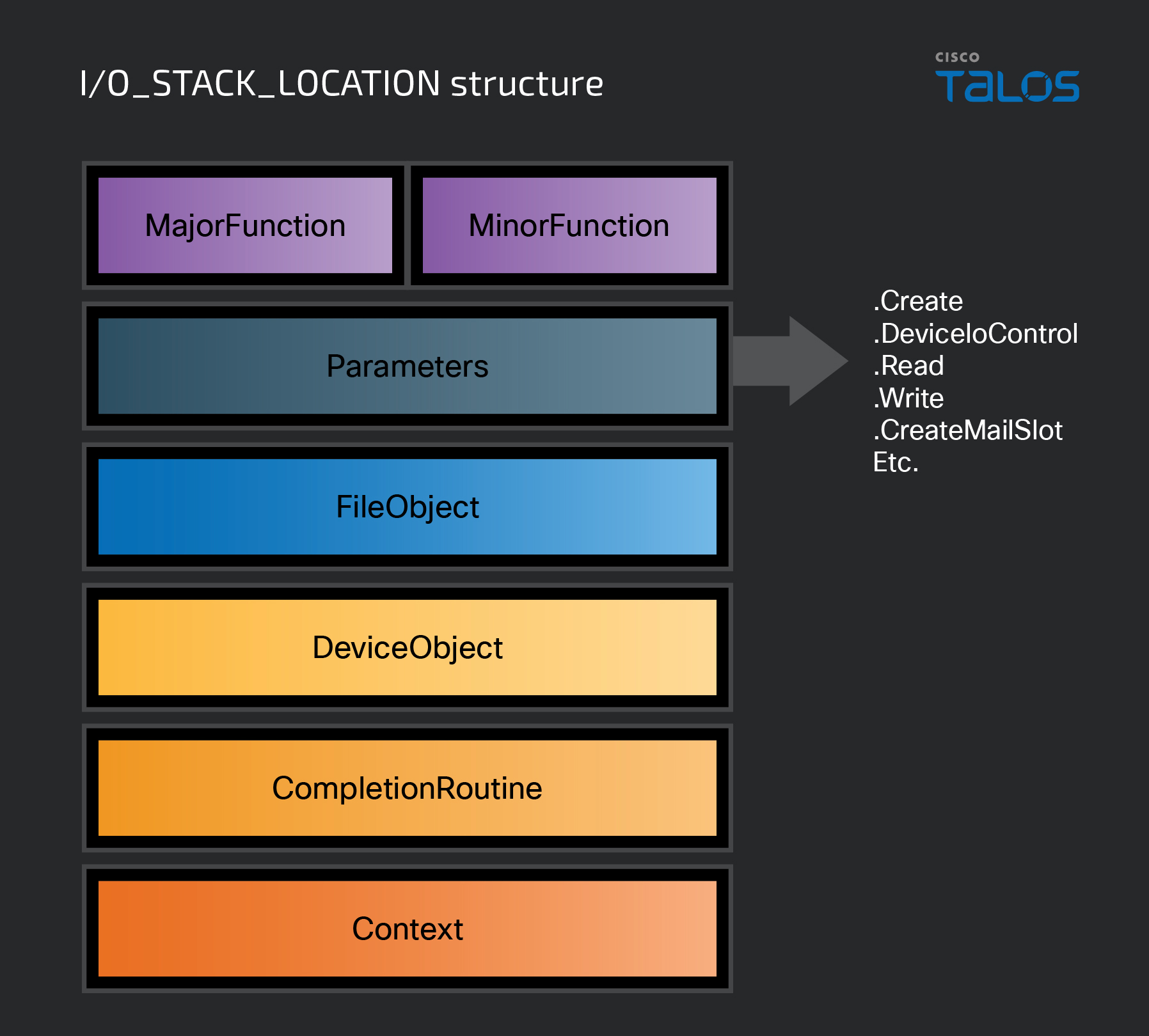
The first members of the structure are MajorFunction and MinorFunction, which we discussed in the first part of this series. These members will contain the function code that was specified when the IRP was created and sent to the driver receiving it. A function code represents what the request is asking the driver to do. For example, if the IRP contains the IRP_MJ_READ function code, the requested action will be a read of some type. As for MinorFunction, it is only used when the request involves a minor function code, such as IRP_MN_START_DEVICE.
The Parameters member of the structure is a large union of structures that can be used in conjunction with the current function code. These structures can be used to provide the driver with more information about the requested operation, and each structure can only be used in the context of a particular function code. For instance, if MajorFunction is set to IRP_MJ_READ, Parameters.ReadSeveral different actions can can be used to contain any additional information about the request. Later in this post, we will revisit the Parameters member on processing IOCTLs. For the complete description of Parameters and the remaining members of the structure, refer to this MSDN documentation entry here.
IRP flow
Regardless of the types of device objects within a device stack, all IRPs are handled the same way once they reach the intended device node. IRPs are “passed” through the stack from top to bottom, through each layer until it reaches the intended driver. Once it has passed through the layers and completed its task, it is passed back up through the node, from bottom to top and then returned to the I/O manager.
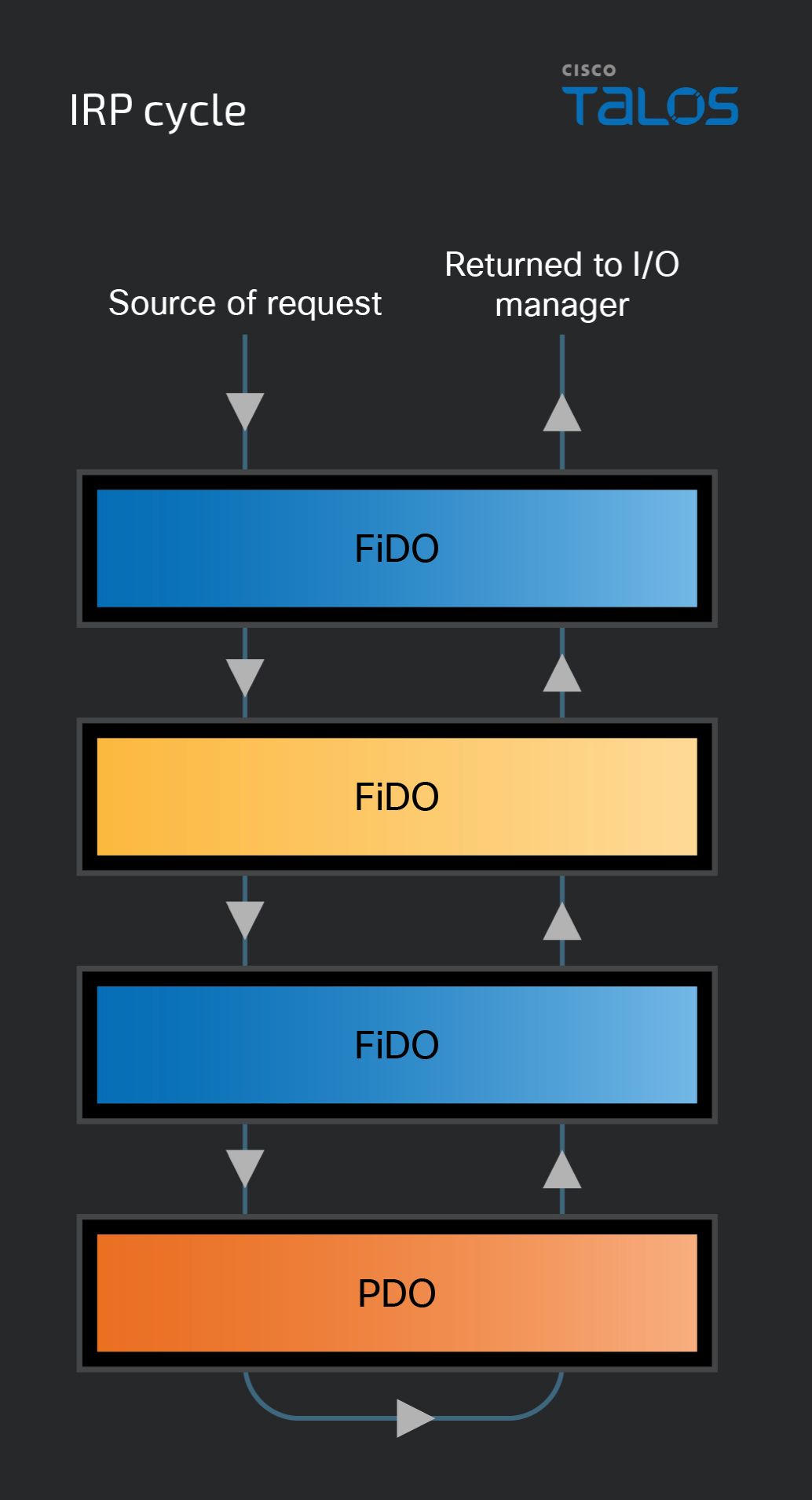
While the IRP is passing through the stack, each layer needs to decide what to do with the request. Several different actions can be taken by the driver responsible for a layer in the stack. If the request is intended for layer processing, it can process the request in whichever way it was programmed to do. However, if the request isn’t relevant, it will then be passed down the stack to the next layer. If the receiving layer is related to a filter driver, it can then perform its functions – if applicable – and pass the request down the stack.
When the request is passed into a layer, the driver receives a pointer to the IRP (PIRP) and calls the function IoGetCurrentIrpStackLocation, passing the pointer as the parameter.

This routine lets the driver check the I/O stack location that it is responsible for in the request, which will tell the driver if it needs to perform operations on the request or pass it to the next driver.
If a request does not pertain to the driver in a layer, the IRP can be passed down to the next layer – an action frequently performed by filter drivers. A few things need to happen before the request is passed to a lower layer. The function IoSkipCurrentIrpStackLocation needs to be called, followed by IoCallDriver. The call to IoSkipCurrentIrpStackLocation ensures that the request is passed to the next driver in the stack. Afterward, IoCallDriver is called with two parameters: a pointer to the device object of the next driver in the stack and a pointer to the IRP. Once these two routines are complete, the request is now the responsibility of the next driver in the stack.
If a driver in the stack receives a request that is intended for it, the driver can complete the request in whatever way it was designed to. Regardless of how it handles the request, IoCompleteRequest must be called once it has been handled. Once IoCompleteRequest is called, the request makes its way back up to the stack and eventually returns to the I/O manager.
For a thorough description of the flow of IRPs during a request, refer to the following entries in the MSDN documentation:
Handling and completing IRPs
As discussed in the first post in this series, a driver contains functions called “dispatch routines,” which are called when the driver receives an IRP containing a MajorFunction code that it can process. Dispatch routines are one of the main mechanisms that give drivers their functionality and understanding them is critical when analyzing a driver.
For example, if a driver has a dispatch routine called ExampleRead that handles the IRP_MJ_READ function code, that routine will be executed when it processes an IRP containing IRP_MJ_READ. Since that dispatch routine handles IRP_MJ_READ – as the name implies – it will be performing some type of read operation. This function code is commonly related to functions such as ReadFile or ZwReadFile. For more information regarding dispatch routines and how they function, the MSDN documentation is highly recommended and can be found here.
Bringing it all together
Putting all this information regarding I/O requests together, it's much easier to visualize the process. While there are plenty of aspects of the process that aren't discussed here – as there are too many to fit them all into a series – we have walked through the core logic behind requesting, processing and completing an I/O request. Below is a brief summary of the flow of a typical I/O request:
- The I/O manager creates the IRP and attaches the necessary I/O stack locations.
- The IRP is then sent to the appropriate device stack.
- The IRP passes through the stack until it reaches the device object of the target driver. Each driver in the stack either processes the request or passes it down to the next layer.
- When the request reaches the correct layer, the driver is called.
- The driver reads the MajorFunction member of the I/O stack location and executes the dispatch routine associated with the function code.
- IoCompleteRequest is called once the driver has completed its operations and the IRP is passed up back through the stack.
- The IRP returns to the I/O manager.
Understanding these concepts provides the foundation for learning the more complex and intricate parts of drivers and the Windows kernel. Learning about these topics takes time and direct interaction with them, as they are inherently complicated and, in many ways, can appear abstract.
Device input and output control, IOCTLs:
IRPs can deliver requests in a slightly different way than what has been described so far. There is another mode of delivering requests drivers employ that makes use of what are called I/O control codes (IOCTLs). Device Input and Output Control, sometimes referred to as IOCTL as well, is an interface that allows user mode applications and other drivers to request that a specific driver execute a specific dispatch routine assigned a pre-defined I/O control code.
Note: To eliminate confusion, the use of “IOCTL” in this blog series will be referring to I/O control codes, not “Device Input and Output Control.”
An IOCTL is a hardcoded 32-bit value defined within a driver that represents a specific function in that same driver. IOCTL requests are delivered by IRPs, much in the same way as described above. However, there are specific MajorFunction codes used in these requests. While both user-mode applications and drivers can initiate these requests, there are slight differences in the requirements for doing so.
MajorFunction codes and IOCTLs
The MajorFunction codes related to IOCTLs are delivered the same way as the function codes discussed so far. They are delivered via an IRP that is sent by the I/O manager which in turn is received by the driver and processed. All IOCTL requests use either IRP_MJ_DEVICE_CONTROL and IRP_MJ_INTERNAL_DEVICE_CONTROL, which are assigned to a driver’s dispatch routine entry point in the same manner described earlier.
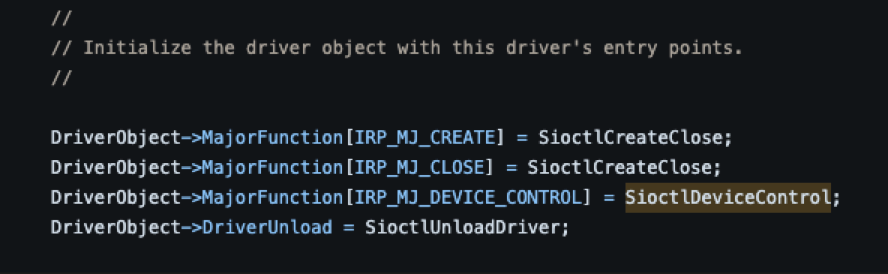
While IRP_MJ_DEVICE_CONTROL and IRP_MJ_INTERNAL_DEVICE_CONTROL are both used for processing IOCTLs, they serve slightly different purposes. In cases where an IOCTL will be made available for use by a user-mode application, IRP_MJ_DEVICE_CONTROL must be used. In the situation of an IOCTL only being available to other drivers, IRP_MJ_INTERNAL_DEVICE_CONTROL must be used instead.
Defining an IOCTL
To process an IOCTL, a driver must define and name it, and implement the function that is to be executed when it's processed. IOCTLs are usually defined in a header file by using a system-supplied macro named CTL_CODE:

When naming an IOCTL Microsoft recommends using the IOCTL_Device_Function naming convention, as it makes it easier to read and understand. The following example of this convention is provided on MSDN: IOCTL_VIDEO_ENABLE_CURSOR. Applications and drivers commonly pass the IOCTL’s name as a parameter when making a request – rather than the 32-bit value – which highlights the importance of the readability and consistency of the naming convention.
Aside from establishing the IOCTL’s name, CTL_CODE also takes four arguments:
- DeviceType: This value must be set to the same value as the DeviceType member of the driver’s
DEVICE_OBJECTstructure, which defines the type of hardware the driver was designed for. For further information on device types, refer to the MSDN documentation here. - Function: The function that will be executed upon an IOCTL request; represented as a 32-bit hexadecimal (DWORD) value, such as 0x987. Any value that is less than 0x800 is reserved for use by Microsoft.
- Method: The method used to pass data between the requester and the driver handling the request. This can be set to one of four values:
METHOD_BUFFERED,METHOD_IN_DIRECT,METHOD_OUT_DIRECTorMETHOD_NEITHER. For more information on these methods, refer to the links regarding memory operations provided in the next section. - Access: The level of access required to process the request. This can be set to the following values:
FILE_ANY_ACCESS,FILE_READ_DATAorFILE_WRITE_DATA. If the requester needs both read and write access,FILE_READ_DATAandFILE_WRITE_DATAcan be passed together by separating them using the OR “|” operator:FILE_READ_DATA | FILE_WRITE_DATA.
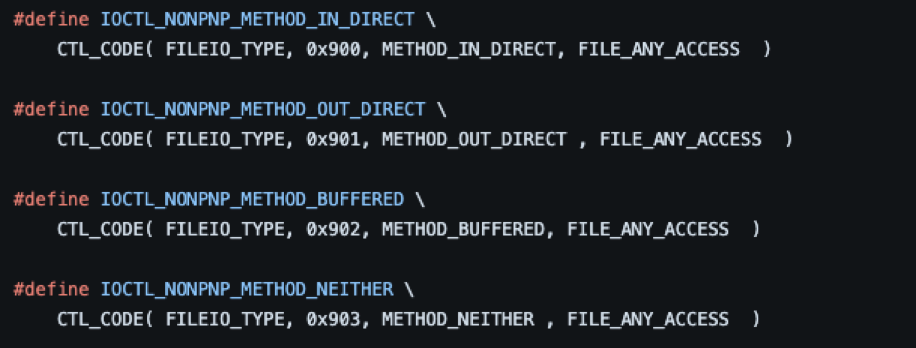
Note: The image above is from a header file for a driver from the Microsoft “Windows-driver-samples” GitHub repository. An invaluable resource for learning about Windows drivers. Microsoft has included a plethora of source code samples that demonstrate the implementation of many of the documented WDM and KMDF functions and macros. Also, all the samples contain helpful comments to provide context.
Processing IOCTL requests
Once an I/O control code is defined, an appropriate dispatch function needs to be implemented. To handle IOCTL requests, drivers will commonly have a function that is named using the “XxxDeviceControl” naming convention. For example, the function that handles I/O control requests in this Microsoft sample driver uses the name “SioctlDeviceControl."
In common practice, these functions contain switch statements that execute different functions depending on the IOCTL it received. A thorough example of this can be found in Microsoft’s driver sample GitHub repository here.
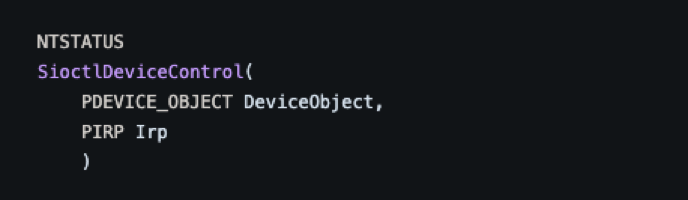
As seen in the image above, this device control function takes two arguments: A pointer to a device object (PDEVICE_OBJECT DeviceObject) and a pointer to an IRP (PIRP Irp). The DeviceObject parameter is a pointer to the device that the initiator of the request wants the IOCTL to perform operations on. This could be a pointer to the device object of a directory, file, volume or one of the many other types of objects in the Windows environment. The second parameter the function takes is simply a pointer to the IRP that the driver received when the IOCTL request was sent.
Once the device control function is executed, it reads the Parameters.DeviceIoControl.IoControlCodehave member of the IRP structure that the driver received to retrieve the IOCTL. The IOCTL is then compared to the IOCTLs defined within the driver, and if there is a match, it executes the appropriate routine. Once the processing and the necessary clean-up have been done, the request can be completed by calling IoCompleteRequest.
DeviceIoControl
Requestors can initiate an IOCTL request by calling DeviceIoControl, in which several parameters may be passed.
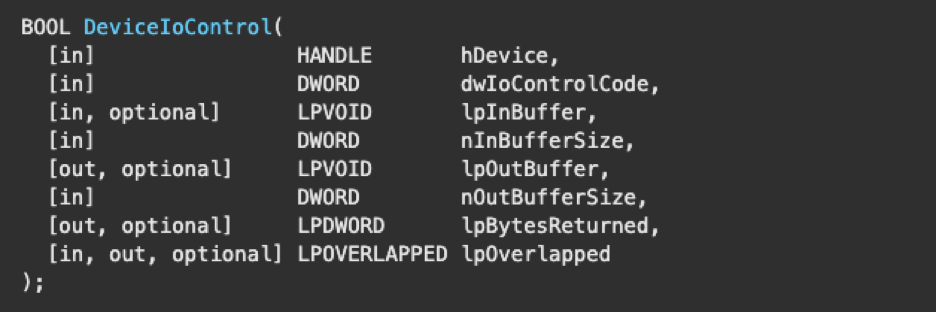
For the sake of simplicity, we will only be discussing the first two parameters: hDevice and dwIoControlCode. The rest of the parameters pertain to memory operations but are outside the scope of this blog post as the topic is complex and requires a lengthy explanation. Interaction with data buffers is a common occurrence for drivers performing I/O operations. Additionally, it is critical to become familiar with these concepts for conducting driver analysis. For further reading, the MSDN documentation is an excellent source of information. Relevant links are provided below:
- Memory Management for Windows Drivers
- Buffer Descriptions for I/O Control Codes
- Methods for Accessing Data Buffers
- Using Buffered I/O
- Using Direct I/O
- Using Neither Buffered Nor Direct I/O
When calling DeviceIoControl, the caller must provide a handle to the target driver’s device object and the IOCTL it is requesting. These parameters are passed as the arguments hDevice and dwIoControlCode, respectively. An important aspect of making an IOCTL request is that the caller must know the value of the I/O control code before requesting. Additionally, a driver must be able to handle receiving an unrecognized control code, otherwise it may crash.
Drivers sending IOCTLs to other drivers
In some instances, a higher-level driver needs to send an IOCTL request to a lower-level device driver, known as an “internal request.” These IOCTLs in particular are not available to be requested by a user-mode application and use the IRP_MJ_INTERNAL_DEVICE_CONTROL MajorFunction code. The dispatch routines that handle these requests are conventionally referred to as either DispatchDeviceControl when the driver receives IRP_MJ_DEVICE_CONTROL, or DispatchInternalDeviceControl when IRP_MJ_INTERNAL_DEVICE_CONTROL is received. The main distinction between the two is that DispatchDeviceControl handles requests that may originate from user mode, whereas DispatchInternalDeviceControl handles internal requests.
For the sake of brevity, the details of this process will not be discussed here. However, the details can be found in the MSDN documentation here. We’ll not be covering IOCTLs sent from one driver to another, but rather, IOCTLs sent from user-mode applications, as it is easier to become familiar with. Once the basics are understood, learning about I/O between drivers will be much easier. The topic of IOCTLs will be concluded in the next part of this series when we demonstrate debugging drivers.
Conclusion
Anyone interested in learning more should explore the provided links to the MSDN documentation and Microsoft’s sample driver GitHub repository for more in-depth information. The I/O section of the MSDN driver documentation is worth exploring and contains most of the entries that have been linked to in this blog post and can be found here.
In the next entry in this series, we will discuss installing, running and debugging drivers and the security concepts surrounding them. This will include a description of the basic setup and tooling required for analysis and knowing what to look for while performing it. To demonstrate the use of debuggers, we will show how a driver processes IOCTLs and executes dispatch routines.