A statement in the System Programming Guide of the Intel 64 and IA-32 Architectures Software Developer's Manual (SDM) was mishandled in the development of some or all operating-system kernels, resulting in unexpected behavior for #DB exceptions that are deferred by MOV SS or POP SS, as demonstrated by (for example) privilege escalation in Windows, macOS, some Xen configurations, or FreeBSD, or a Linux kernel crash. The MOV SS and POP SS instructions inhibit interrupts (including NMIs), data breakpoints, and single step trap exceptions until the instruction boundary following the next instruction (SDM Vol. 3A; section 6.8.3). Note that debug exceptions are not inhibited by the interrupt enable (EFLAGS.IF) system flag (SDM Vol. 3A; section 2.3). If the instruction following the MOV SS or POP SS instruction is an instruction like SYSCALL, SYSENTER, INT 3, etc. that transfers control to the operating system at CPL < 3, the debug exception is delivered after the transfer to CPL < 3 is complete. OS kernels may not expect this order of events and may therefore experience unexpected behavior when it occurs.
A detailed white paper describes this behavior here.
Sample code is provided on Github for the Windows Operating System to test if you're vulnerable to CVE-2018-8897. You are free to port it to any other operating systems. A precompiled binary (executable) is provided here for accessibility purposes.
If you'd like to follow along, I'll be using system files from Windows x64 10.0.15063 (Creator's Update). All pseudo-source and disassembly is reconstructed from that specific release.
Don't have a kernel debugging environment set up? Don't fret. You can follow our tutorial on how to setup basic kernel debugging using WinDbg and VMware here.
Without further ado, let's begin.
What do these callbacks do?
These callbacks can be used by driver developers to gain notifications when certain events happen. For example, the basic process creation callback, nt!PsSetCreateProcessNotifyRoutine, registers a user-defined function pointer ("NotifyRoutine") that will be invoked by Windows each time a process is created or deleted. As part of the event notification, the supplied handler gets a wealth of information. In our example, this will include the parent process' (if one exists) PID, the actual process' PID, and a boolean value that will let us know if the process is being created or if it's terminating.
Security software leverages these callbacks to be able to carefully inspect code running on the machine.
Divin' deep
The documented APIs
Our investigation has to begin somewhere. What better place than at the start of a documented function? We turn to nt!PsSetCreateProcessNotifyRoutine. MSDN claims that this routine has been around since Windows 2000. Even our friends at ReactOS seem to have implemented this functionality a long time ago. We'll see exactly how (if at all) things have changed in the 17 years from Windows 2000 until now.
The only difference is in the second parameter being passed to nt!PspSetCreateProcessNotifyRoutine. These are effectively flags. In the base case (nt!PsSetCreateProcessNotifyRoutine), these flags can either be 1 or 0 depending on the state of the "Remove" parameter. If "Remove" is TRUE, Flags=1. If "Remove" is FALSE, Flags=0. In the extended case (nt!PsSetCreateProcessNotifyRoutineEx), the flags can take on the value 2 or 3:
Finally, for nt!PsSetCreateProcessNotifyRoutineEx2, these flags will take on the value 6 or 7:
Therefore, one can imply that the flags passed to nt!PspSetCreateProcessNotifyRoutine have this definition:
The undocumented world
nt!PspSetCreateProcessNotifyRoutine is slightly complicated. I've defined it below, but I strongly recommend opening it in another window and following the text to ease understanding.
Luckily for us, a lot of the internal data structures related to callback routines haven't changed since Windows 2000. The trailblazers at ReactOS have been spot-on with their structure definitions so we'll use them, when possible, to avoid duplicating work.
For each callback, there's a global array that can contain up to 64 entries. In our case, the start of this array for process creation callbacks is located at nt!PspCreateProcessNotifyRoutine. Each entry in this array is of type _EX_CALLBACK:
To avoid synchronization problems, nt!ExReferenceCallBackBlock is used which will safely acquire a reference to the underlying callback object, _EX_CALLBACK_ROUTINE_BLOCK (documented below). We can effectively reproduce the same behavior in a non-thread safe way via:
If we're deleting a callback object ("Remove" is TRUE), we need to make sure that we can find the appropriate _EX_CALLBACK_ROUTINE_BLOCK in the array. This is done by checking first if the target "NotifyRoutine" matches that of the current _EX_CALLBACK_ROUTINE with nt!ExGetCallBackBlockRoutine:
Then, we check to see if it's the right type (created with the correct version of (nt!PsSetCreateProcessNotifyRoutine/Ex/Ex2), by using nt!ExGetCallBackBlockContext:
At this point, we've found the entry in the array. We will erase it by setting the _EX_CALLBACK value to NULL via nt!ExCompareExchangeCallback, decrementing the appropriate global counter (nt!PspCreateProcessNotifyRoutineExCount or nt!PspCreateProcessNotifyRoutineCount), dereferencing the _EX_CALLBACK_ROUTINE_BLOCK with nt!ExDereferenceCallBackBlock, waiting for any other code using the _EX_CALLBACK (nt!ExWaitForCallBacks), and finally freeing memory (nt!ExFreePoolWithTag). As you can see, great care is taken by Microsoft to not free a callback object that is in use.
If we can't find the entry to remove in the nt!PspCreateProcessNotifyRoutine array after exhausting all 64 possibilities, the STATUS_PROCEDURE_NOT_FOUND error message is returned.
On the other hand, if we're adding a new entry into the callback array, things are a little easier. A sanity check is performed by nt!MmVerifyCallbackFunctionCheckFlags to ensure that the "NotifyRoutine" is present in a loaded module. This helps avoid unlinked drivers (or shellcode) from receiving callback events:
After we pass the sanity check, an _EX_CALLBACK_ROUTINE_BLOCK is allocated via nt!ExAllocateCallBack. This routine confirms the size and layout of the _EX_CALLBACK_ROUTINE_BLOCK structure:
To wrap up, the newly allocated _EX_CALLBACK_ROUTINE_BLOCK is added to a free (NULL) location in the nt!PspCreateProcessNotifyRoutine array using nt!ExCompareExchangeCallBack (ensuring that it doesn't overflow the 64 limit maximum). Finally, the appropriate global counter is incremented and a global flag is set in nt!PspNotifyEnableMask denoting that there are callbacks of the user-specified type registered on the system.
The other callbacks
Thankfully, thread and image creation callbacks are very similar to process callbacks. They utilize the same underlying data structures. The only difference is that thread creation/termination callbacks are stored in the nt!PspCreateThreadNotifyRoutine array and that image load notification callbacks are stored in nt!PspLoadImageNotifyRoutine.
The script
It's finally time to put what we know to good use. Using WinDbg, we can create a simple script to automagically enumerate process, thread, and image callback routines.
Instead of leveraging WinDbg's built-in scripting engine, I've elected to use something a little less disgusting. There's a great 3rd party extension for WinDbg called PyKd that enables Python scripting in WinDbg. Installing it is very straightforward. You'll need a copy of the appropriate bitness (e.g. 64-bit for 64-bit install of WinDbg) of Python for this to work.
The script should be easy to follow. I tried to document it as best I could. It should also be compatible, at a minimum, with all forms of Windows from XP and up (both 32-bit and 64-bit flavors).
After running the script using the "!py" command, you should see output similar to this:
Final thoughts
Knowing how the callback system functions in Windows allows us to do very interesting things. As seen above, we're able to programmatically iterate through each callback array and discover all registered callbacks. This is very useful for forensic purposes.
Furthermore, these underlying array lists aren't under the protection of PatchGuard. Since registering callbacks is more-or-less a requirement for anti-virus products in order to develop a useful driver that plays nicely with PatchGuard on x64 systems, malware could dynamically disable (or replace) these registered callbacks to thwart security protection solutions. The possibilities are endless.
Special thanks to the folks at ReactOS for their meticulous documentation. In particular, most of the structures I used were identified by Alex Ionescu for ReactOS a long time ago. Additionally, kudos to the folks that make PyKd. It's a much better alternative to the native scripting interface for WinDbg, in my opinion!
As always, if y'all have any questions or comments, please feel free to comment below. Suggestions are greatly appreciated too!
This blog post will go over an assumption made over a decade ago by Microsoft when dealing with software breakpoints that can be used to reveal the presence of most (all publicly available?) usermode and kernelmode debuggers.
The x86 architecture can potentially encode a particular assembly instruction in multiple ways. For example, adding two registers, eax and ebx, and storing the result in eax takes the following mnemonic form: add eax, ebx. This can be encoded as the byte sequence 0x03 0xC3or 0x01 0xD8. Fundamentally, the machine code represents the same assembly operation.
If you're just interested in the anti-debug trick (without any context on why it works the way it does), scroll to the bottom of this post. For the rest of you brave enough to read this article in its entirety... buckle up.
The "long form" of int 3
An int 3 can be encoded as either a single-byte 0xCC or via the more unconventional way as the multi-byte sequence 0xCD 0x03:
So, what happens when Windows encounters a multi-byte int 3? We create a simple C++ program to find out:
After you run this application, you should see output similar to this:
A single-byte int 3 (0xCC) works as expected. The start of the stub is located at 0x000001BE94B90000. When the stub is executed, the exception handler fires and we see that both the _EXCEPTION_RECORD.ExceptionAddress and _CONTEXT.Rip are located at 0x000001BE94B90000. This is the start of the int 3 instruction. Excellent!
The multi-byte int 3 (0xCD 0x03) is located at address 0x000001BE94B90002. When this stub executes, the exception handler proclaims that the _EXCEPTION_RECORD.ExceptionAddress and _CONTEXT.Rip are located at 0x000001BE94B90003. This is in the middle of the int 3 instruction. Why? What went wrong?
The assumption
NOTE: From this point on, all disassembly and pseudo-source is reconstructed from system files that are provided with Windows x64 10.0.15063 (Creator's Update). If you'd like to follow along, make sure you use the same version I'm using!
Microsoft assumes that all int 3's result from the single-byte variant.
This assumption occurs very early during interrupt processing. Namely, when any interrupt occurs, such as when an int 3 is executed by the processor, control is redirected by the CPU to a handler registered in the appropriate position of the IDT (Interrupt Descriptor Table). In Windows, the handler for software breakpoints can be found at the symbol nt!KiBreakpointTrap:
The first thing nt!KiBreakpointTrap does is generate a trap frame (_KTRAP_FRAME) on the stack that it passes to subsequent routines. A definition of this structure can be found below:
Parts of this structure are automatically filled by the CPU when the interrupt fires, in particular, the range from +0x160 (_KTRAP_FRAME.ErrorCode) to +0x188 (_KTRAP_FRAME.SegSs):
The _KTRAP_FRAME is essentially an extension of the elements saved on the stack by the CPU. It's purpose is to provide a place to store volatile registers which can be clobbered when calling into functions that are compiled in C.
A very important thing to note is that the instruction pointer (EIP) saved by the CPU on the stack (_KTRAP_FRAME.Rip) will be set to the instruction immediately following the one that caused entry into the handler. In our scenario, this means that the _KTRAP_FRAME.Rip member will be the instruction following our int 3, which will be ret (0xC3) in the example code above.
After the volatile registers have been saved off, nt!KiBreakpointTrap performs a quick check to see whether the interrupt fired from usermode (ring3) or kernelmode code (ring0). If execution is coming from ring3, a swapgs needs to occur as well as some other bookkeeping with debug registers.
Eventually, control flow will reconvene and the volatile floating point registers will also be stored off into the _KTRAP_FRAME. Before entering into more exception handling logic, the instruction pointer will be extracted from _KTRAP_FRAME.Rip (saved by the CPU upon entering nt!KiBreakpointTrap), decremented by one, and passed as an argument to nt!KiExceptionDispatch. Additionally, the exception code, EXCEPTION_BREAKPOINT (0x80000003), will also be passed in. The prototype for nt!KiExceptionDispatch:
It's important to note that nt!KiExceptionDispatch (like nt!KiBreakpointTrap) is written in hand-ASM. It assumes that ecx contains the exception code, edx is the number of exception parameters (up to 3), r8 contains the address of the exception, r9 is the first exception parameter (if one exists), r10 is the second exception parameter (if one exists), r11 is the third exception parameter (if one exists), and rbp points to a segment in the _KTRAP_FRAME structure (at offset +0x80).
Upon entry of nt!KiExceptionDispatch, the first thing that occurs is the generation of a _KEXCEPTION_FRAME. Whereas the _KTRAP_FRAME was used to store volatile registers, the _KEXCEPTION_FRAME provides a place to save all nonvolatile registers:
nt!KiExceptionDispatch also creates an _EXCEPTION_RECORD structure on the stack. If you've done any error handling in Windows (in either usermode or kernelmode), you'll be familiar with this data structure as it is contained as a child within the _EXCEPTION_POINTERS data structure. We use both of these structures in our example above.
Furthermore, this explains the first part of our mystery, namely, why the _EXCEPTION_RECORD.ExceptionAddress is incorrect. Recall that the _EXCEPTION_RECORD.ExceptionAddress is populated by the 3rd (r8) argument to nt!KiExceptionDispatch. This was passed in from nt!KiBreakpointTrap. This argument is a copy of the _KTRAP_FRAME.Rip member decremented by one.
To figure out where the _CONTEXT.Rip member is populated, we need to go deeper down the rabbit hole.
nt!KiExceptionDispatch will call into nt!KiDispatchException (yes, the ordering of the words are intentionally flipped) passing in the recently created _EXCEPTION_RECORD and _KEXCEPTION_FRAME:
This function will build a _CONTEXT out of the _KTRAP_FRAME and _KEXCEPTION_FRAME by invoking the helper routine KeContextFromKFrame. After the _CONTEXT is created, a check is made against the _EXCEPTION_RECORD.ExceptionCode (received as an argument from nt!KiExceptionDispatch) for STATUS_BREAKPOINT (0x80000003). If it's true, the _CONTEXT.Rip member will be decremented:
This solves the last part of the mystery and causes the value in _CONTEXT.Rip to be tainted.
The anti-debug trick
Knowing what we know about how Windows handles the different types of int 3s, is it possible to leverage this discrepancy in a useful way? The answer is yes.
Debuggers display the state of the program at the time of an exception. Since Windows will incorrectly assume that our int 3 exception was generated from the single-byte variant, it is possible to confuse the debugger into reading "extra" memory. We leverage this inconsistency to trip a "guard page" of sorts.
As we saw in our first example (at the start of the article), when a multi-byte int 3 occurs, the _EXCEPTION_RECORD.ExceptionAddress and _CONTEXT.Rip values will lie in the middle of our multi-byte instruction instead of at the start. This means that the debugger will incorrectly determine that the instruction which threw the software breakpoint begins with the opcode 0x03. Referring to the trusty Intel manual, we can see that this opcode represents a 2-byte add instruction:
What would happen if we positioned our multi-byte int 3 near the end of a page of memory?
When the operating system notifies our attached debugger of the breakpoint exception, the instruction pointer will point to memory that will be misinterpreted as the start of an add (0x03) instruction. This will cause the debugger to disassemble data on the adjacent page (since this instruction is 2 bytes long), and effectively read one byte past our "valid" memory range.
Our trick relies on the fact that Windows, as an optimization, will not commit virtual memory to physical RAM unless it absolutely needs it. That is to say that most memory, especially in usermode, is paged. When memory needs to be made available for use that is not currently in physical RAM, a page fault occurs. To learn more about memory management, check out the following articles on our site: Introduction to IA-32e hardware paging and Exploring Windows virtual memory management.
So, we can detect the memory read on this adjacent page by inspecting the corresponding PTE (Page Table Entry) using the QueryWorkingSetEx API. If the page is resident in our process' working set (e.g. mapped into our process by the debugger), the Valid bit in the _PSAPI_WORKING_SET_EX_BLOCK will be set.
PoC||GTFO
A full example can be found below:
As always, if you have any questions or comments, please feel free to send us a message below. Happy hacking 😎.
In a previous post, we discussed the IA-32e 64-bit paging structures, and how they can be used to turn virtual addresses into physical addresses. They're a simple but elegant way to manage virtual address mappings as well as page permissions with varying granularity of page sizes. All of which is provided by the architecture. But as one might expect, once you add an operating system like Windows into the mix, things get a little more interesting.
The problem of per-process memory
In Windows, a process is nothing more than a simple container of threads and metadata that represents a user-mode application. It has its own memory so that it can manage the different pieces of data and code that make the process do something useful. Let's consider, then, two processes that both try to read and write from the memory located at the virtual address 0x00000000`11223344. Based on what we know about paging, we expect that the virtual address is going to end up translating into the same physical address (let's say 0x00000001`ff003344 as an example) in both processes. There is, after all, only one CR3 register per processor, and the hardware dictates that the paging structure root is located in that register.
Figure 1: If the two process' virtual addresses would translate to the same physical address, then we expect that they would both see the same memory, right?
Of course, in reality we know that it can't work that way. If we use one process to write to a virtual memory address, and then use another process to read from that address, we shouldn't get the same value. That would be devastating from a security and stability standpoint. In fact, the same permissions may not even be applied to that virtual memory in both processes.
But how does Windows accomplish this separation? It's actually pretty straightforward: when switching threads in kernel-mode or user-mode (called a context switch), Windows stores off or loads information about the current thread including the state of all of the registers. Because of this, Windows is able to swap out the root of the paging structures when the thread context is switched by changing the value of CR3, effectively allowing it to manage an entirely separate set of paging structures for each process on the system. This gives each process a unique mapping of virtual memory to physical memory, while still using the same virtual address ranges as another process. The PML4 table pointer for each user-mode process is stored in the DirectoryTableBase member of an internal kernel structure called the EPROCESS, which also manages a great deal of other state and metadata about the process.
Figure 2: In reality, each process has its own set of paging structures, and Windows swaps out the value of the CR3 register when it executes within that process. This allows virtual addresses in each process to map to different physical addresses.
We can see the paging structure swap between processes for ourselves if we do a little bit of exploration using WinDbg. If you haven't already set up kernel debugging, you should check out this article to get yourself started. Then follow along below.
Let's first get a list of processes running on the target system. We can do that using the !process command. For more details on how to use this command, consider checking out the documentation using .hh !process. In our case, we pass parameters of zero to show all processes on the system.
We can use notepad.exe as our target process, but you should be able to follow along with virtually any process of your choice. The next thing we need to do is attach ourselves to this process - simply put, we need to be in this process' context. This lets us access the virtual memory of notepad.exe by remapping the paging structures. We can verify that the context switch is happening by watching what happens to the CR3 register. If the virtual memory we have access to is going to change, we expect that the value of CR3 will change to new paging structures that represent notepad.exe's virtual memory. Let's take a look at the value of CR3 before the context switch.
We know that this value should change to the DirectoryTableBase member of the EPROCESS structure that represents notepad.exe when we make the switch. As a matter of interest, we can take a look at that structure and see what it contains. The PROCESS fffffa8019218b10 line emitted by the debugger when we listed all processes is actually the virtual address of that process' EPROCESS structure.
The fully expanded EPROCESS structure is massive, so everything after what we're interested in has been omitted from the results above. We can see, though, that the DirectoryTableBase is a member at +0x028 of the process control block (KPROCESS) structure that's embedded as part of the larger EPROCESS structure.
According to this output, we should expect that CR3 will change to 0x00000006`52e89000 when we switch to this process' context in WinDbg.
To perform the context swap, we use the .process command and indicate that we want an invasive swap (/i) which will remap the virtual address space and allow us to do things like set breakpoints in user-mode memory. Also, in order for the process context swap to complete, we need to allow the process to execute once using the g command. The debugger will then break again, and we're officially in the context of notepad.exe.
Okay! Now that we're in the context we need to be in, let's check the CR3 register to verify that the paging structures have been changed to the DirectoryTableBase member we saw earlier.
Looks like it worked as we expected. We would find a unique set of paging structures at 0x00000006`52e89000 that represented the virtual to physical address mappings within notepad.exe. This is essentially the same kind of swap that occurs each time Windows switches to a thread in a different process.
Virtual address ranges
While each process gets its own view of virtual memory and can re-use the same virtual address range as another process, there are some consistent rules of thumb that Windows abides by when it comes to which virtual address ranges store certain kinds of information.
To start, each user-mode process is allowed a user-mode virtual address space ranging from 0x000`00000000 to 0x7ff`ffffffff, giving each process a theoretical maximum of 8TB of virtual memory that it can access. Then, each process also has a range of kernel-mode virtual memory that is split up into a number of different subsections. This much larger range gives the kernel a theoretical maximum of 248TB of virtual memory, ranging from 0xffff0800`00000000 to 0xffffffff`ffffffff. The remaining address space is not actually used by Windows, though, as we can see below.
Figure 3: All possible virtual memory, divided into the different ranges that Windows enforces. The virtual addresses for the kernel-mode regions may not be true on Windows 10, where these regions are subject to address space layout randomization (ASLR). Credits to Alex Ionescu for specific kernel space mappings.
Currently, there is an extremely large “no man's land” of virtual memory space between the user-mode and kernel-mode ranges of virtual memory. This range of memory isn't wasted, though, it's just not addressable due to the current architecture constraint of 48-bit virtual addresses, which we discussed in our previous article. If there existed a system with 16EB of physical memory - enough memory to address all possible 64-bit virtual memory - the extra physical memory would simply be used to hold the pages of other processes, so that many processes' memory ranges could be resident in physical memory at once.
As an aside, one other interesting property of the way Windows handles virtual address mapping is being able to quickly tell kernel pointers from user-mode pointers. Memory that is mapped as part of the kernel has the highest order bits of the address (the 16 bits we didn't use as part of the linear address translation) set to 1, while user-mode memory has them set to 0. This ensures that kernel-mode pointers begin with 0xFFFF and user-mode pointers begin with 0x0000.
A tree of virtual memory: the VAD
We can see that the kernel-mode virtual memory is nicely divided into different sections. But what about user-mode memory? How does the memory manager know which portions of virtual memory have been allocated, which haven't, and details about each of those ranges? How can it know if a virtual address within a process is valid or invalid? It could walk the process' paging structures to figure this out every time the information was needed, but there is another way: the virtual address descriptor (VAD) tree.
Each process has a VAD tree that can be located in the VadRoot member of the aforementioned EPROCESS structure. The tree is a balanced binary search tree, with each node representing a region of virtual memory within the process.
Figure 4: The VAD tree is balanced with lower virtual page numbers to the left, and each node providing some additional details about the memory range.
Each node gives details about the range of addresses, the memory protection of that region, and some other metadata depending on the state of the memory it is representing.
We can use our friend WinDbg to easily list all of the entries in the VAD tree of a particular process. Let's have a look at the VAD entries from notepad.exe using !vad.
The range of addresses supported by a given VAD entry are stored as virtual page numbers - similar to a PFN, but simply in virtual memory. This means that an entry representing a starting VPN of 0x7f and an ending VPN of 0x8f would actually be representing virtual memory from address 0x00000000`0007f000 to 0x00000000`0008ffff.
There are a number of complexities of the VAD tree that are outside the scope of this article. For example, each node in the tree can be one of three different types depending on the state of the memory being represented. In addition, a VAD entry may contain information about the backing PTEs for that region of memory if that memory is shared. We will touch more on that concept in a later section.
Let's get physical
So we now know that Windows maintains separate paging structures for each individual process, and some details about the different virtual memory ranges that are defined. But the operating system also needs a central mechanism to keep track of each individual page of physical memory. After all, it needs to know what's stored in each physical page, whether it can write that data out to a paging file on disk to free up memory, how many processes are using that page for the purposes of shared memory, and plenty of other details for proper memory management
That's where the page frame number (PFN) database comes in. A pointer to the base of this very large structure can be located at the symbol nt!MmPfnDatabase, but we know based on the kernel-mode memory ranges that it starts at the virtual address 0xfffffa80`00000000, except on Windows 10 where this is subject to ASLR. (As an aside, WinDbg has a neat extension for dealing with the kernel ASLR in Windows 10 - !vm 0x21 will get you the post-KASLR regions). For each physical page available on the system, there is an nt!_MMPFN structure allocated in the database to provide details about the page.
Figure 5: Each physical page in the system is represented by a PFN entry structure in this very large, contiguous data structure.
Though some of the bits of the nt!_MMPFN structure can vary depending on the state of the page, that structure generally looks something like this:
A page represented in the PFN database can be in a number of different states. The state of the page will determine what the memory manager does with the contents of that page.
We won't be focusing on the different states too much in this article, but there are a few of them: active, transition, modified, free, and bad, to name several. It is definitely worth mentioning that for efficiency reasons, Windows manages linked lists that are comprised of all of the nt!_MMPFN entries that are in a specific state. This makes it much easier to traverse all pages that are in a specific state, rather than having to walk the entire PFN database. For example, it can allow the memory manager to quickly locate all of the free pages when memory needs to be paged in from disk.
Figure 6: Different linked lists make it easier to walk the PFN database according to the state of the pages, e.g. walk all of the free pages contiguously.
Another purpose of the PFN database is to help facilitate the translation of physical addresses back to their corresponding virtual addresses. Windows uses the PFN database to accomplish this during calls such as nt!MmGetVirtualForPhysical. While it is technically possible to search all of the paging structures for every process on the system in order to work backwards up the paging structures to get the original virtual address, the fact that the nt!_MMPFN structure contains a reference to the backing PTE coupled with some clever allocation rules by Microsoft allow them to easily convert back to a virtual address using the PTE and some bit shifting.
For a little bit of practical experience exploring the PFN database, let's find a region of memory in notepad.exe that we can take a look at. One area of memory that could be of interest is the entry point of our application. We can use the !dh command to display the PE header information associated with a given module in order to track down the address of the entry point.
Because we've switched into a user-mode context in one of our previous examples, WinDbg will require us to reload our symbols so that it can make sense of everything again. We can do that using the .reload /f command. Then we can look at notepad.exe's headers:
Again, the output is quite verbose, so the section information at the bottom is omitted from the above snippet. We're interested in the address of entry point member of the optional header, which is listed as 0x3acc. That value is called a relative virtual address (RVA), and it's the number of bytes from the base address of the notepad.exe image. If we add that relative address to the base of notepad.exe, we should see the code located at our entry point.
And we do see that the address resolves to notepad!WinMainCRTStartup, like we expected. Now we have the address of our target process' entry point: 00000000`ffd53acc.
While the above steps were a handy exercise in digging through parts of a loaded image, they weren't actually necessary since we had symbols loaded. We could have simply used the ? qualifier in combination with the symbol notepad!WinMainCRTStartup, as demonstrated below, or gotten the value of a handy pseudo-register that represents the entry point with r $exentry.
In any case, we now have the address of our entry point, which from here on we'll refer to as our “target” or the “target page”. We can now start taking a look at the different paging structures that support our target, as well as the PFN database entry for it.
Let's first take a look at the PFN database. We know the virtual address where this structure is supposed to start, but let's look for it the long way, anyway. We can easily find the beginning of this structure by using the ? qualifier and poi on the symbol name. The poi command treats its parameter as a pointer and retrieves the value located at that pointer.
Knowing that the PFN database begins at 0xfffffa80`00000000, we should be able to index easily to the entry that represents our target page. First we need to figure out the page frame number in physical memory that the target's PTE refers to, and then we can index into the PFN database by that number.
Looking back on what we learned from the previous article, we can grab the PTE information about the target page very easily using the handy !pte command.
The above result would indicate that the backing page frame number for the target is 0x65207b. That should be the index into the PFN database that we'll need to use. Remember that we'll need to multiply that index by the size of an nt!_MMPFN structure, since we're essentially trying to skip that many PFN entries.
This looks like a valid PFN entry. We can verify that we've done everything correctly by first doing the manual calculation to figure out what the address of the PFN entry should be, and then comparing it to where WinDbg thinks it should be.
So based on the above, we know that the nt!_MMPFN entry for the page we're interested in it should be located at 0xfffffa80`12f61710, and we can use a nice shortcut to verify if we're correct. As always in WinDbg, there is an easier way to obtain information from the PFN database. This can be done by using the !pfn command with the page frame number.
Here we can see that WinDbg also indicates that the PFN entry is at 0xfffffa8012f61710, just like our calculation, so it looks like we did that correctly.
An interlude about working sets
Phew - we've done some digging around in the PFN database now, and we've seen how each entry in that database stores some information about the physical page itself. Let's take a step back for a moment, back into the world of virtual memory, and talk about working sets.
Each process has what's called a working set, which represents all of the process' virtual memory that is subject to paging and is accessible without incurring a page fault. Some parts of the process' memory may be paged to disk in order to free up RAM, or in a transition state, and therefore accessing those regions of memory will generate a page fault within that process. In layman's terms, a page fault is essentially the architecture indicating that it can't access the specified virtual memory, because the PTEs needed for translation weren't found inside the paging structures, or because the permissions on the PTEs restrict what the application is attempting to do. When a page fault occurs, the page fault handler must resolve it by adding the page back into the process' working set (meaning it also gets added back into the process' paging structures), mapping the page back into memory from disk and then adding it back to the working set, or indicating that the page being accessed is invalid.
Figure 7: An example working set of a process, where some rarely accessed pages were paged out to disk to free up physical memory.
It should be noted that other regions of virtual memory may be accessible to the process which do not appear in the working set, such as Address Windowing Extensions (AWE) mappings or large pages; however, for the purposes of this article we will be focusing on memory that is part of the working set.
Occasionally, Windows will trim the working set of a process in response to (or to avoid) memory pressure on the system, ensuring there is memory available for other processes.
If the working set of a process is trimmed, the pages being trimmed have their backing PTEs marked as “not valid” and are put into a transition state while they await being paged to disk or given away to another process. In the case of a “soft” page fault, the page described by the PTE is actually still resident in physical memory, and the page fault handler can simply mark the PTE as valid again and resolve the fault efficiently. Otherwise, in the case of a “hard” page fault, the page fault handler needs to fetch the contents of the page from the paging file on disk before marking the PTE as valid again. If this kind of fault occurs, the page fault handler will likely also have to alter the page frame number that the PTE refers to, since the page isn't likely to be loaded back into the same location in physical memory that it previously resided in.
Sharing is caring
It's important to remember that while two processes do have different paging structures that map their virtual memory to different parts of physical memory, there can be portions of their virtual memory which map to the same physical memory. This concept is called shared memory, and it's actually quite common within Windows. In fact, even in our previous example with notepad.exe's entry point, the page of memory we looked at was shared. Examples of regions in memory that are shared are system modules, shared libraries, and files that are mapped into memory with CreateFileMapping() and MapViewOfFile().
In addition, the kernel-mode portion of a process' memory will also point to the same shared physical memory as other processes, because a shared view of the kernel is typically mapped into every process. Despite the fact that a view of the kernel is mapped into their memory, user-mode applications will not be able to access pages of kernel-mode memory as Windows sets the UserSupervisor bit in the kernel-mode PTEs. The hardware uses this bit to enforce ring0-only access to those pages.
Figure 8: Two processes may have different views of their user space virtual memory, but they get a shared view of the kernel space virtual memory.
In the case of memory that is not shared between processes, the PFN database entry for that page of memory will point to the appropriate PTE in the process that owns that memory.
Figure 9: When not sharing memory, each process will have PTE for a given page, and that PTE will point to a unique member of the PFN database.
When dealing with memory that is shareable, Windows creates a kind of global PTE - known as a prototype PTE - for each page of the shared memory. This prototype always represents the real state of the physical memory for the shared page. If marked as Valid, this prototype PTE can act as a hardware PTE just as in any other case. If marked as Not Valid, the prototype will indicate to the page fault handler that the memory needs to be paged back in from disk. When a prototype PTE exists for a given page of memory, the PFN database entry for that page will always point to the prototype PTE.
Figure 10: Even though both processes still have a valid PTE pointing to their shared memory, Windows has created a prototype PTE which points to the PFN entry, and the PFN entry now points to the prototype PTE instead of a specific process.
Why would Windows create this special PTE for shared memory? Well, imagine for a moment that in one of the processes, the PTE that describes a shared memory location is stripped out of the process' working set. If the process then tries to access that memory, the page fault handler sees that the PTE has been marked as Not Valid, but it has no idea whether that shared page is still resident in physical memory or not.
For this, it uses the prototype PTE. When the PTE for the shared page within the process is marked as Not Valid, the Prototype bit is also set and the page frame number is set to the location of the prototype PTE for that page.
Figure 11: One of the processes no longer has a valid PTE for the shared memory, so Windows instead uses the prototype PTE to ascertain the true state of the physical page.
This way, the page fault handler is able to examine the prototype PTE to see if the physical page is still valid and resident or not. If it is still resident, then the page fault handler can simply mark the process' version of the PTE as valid again, resolving the soft fault. If the prototype PTE indicates it is Not Valid, then the page fault handler must fetch the page from disk.
We can continue our adventures in WinDbg to explore this further, as it can be a tricky concept. Based on what we know about shared memory, that should mean that the PTE referenced by the PFN entry for the entry point of notepad.exe is a prototype PTE. We can already see that it's a different address (0xfffff8a0`09e25a00) than the PTE that we were expecting from the !pte command (0xfffff680007fea98). Let's look at the fully expanded nt!_MMPTE structure that's being referenced in the PFN entry.
We can compare that with the nt!_MMPTE entry that was referenced when we did the !pte command on notepad.exe's entry point.
It looks like the Prototype bit is not set on either of them, and they're both valid. This makes perfect sense. The shared page still belongs to notepad.exe's working set, so the PTE in the process' paging structures is still valid; however, the operating system has proactively allocated a prototype PTE for it because the memory may be shared at some point and the state of the page will need to be tracked with the prototype PTE. The notepad.exe paging structures also point to a valid hardware PTE, just not the same one as the PFN database entry.
The same isn't true for a region of memory that can't be shared. For example, if we choose another memory location that was allocated as MEM_PRIVATE, we will not see the same results. We can use the !vad command to give us all of the virtual address regions (listed by virtual page frame) that are mapped by the current process.
We can take a look at a MEM_PRIVATE page, such as 0x1cf0, and see if the PTE from the process' paging structures matches the PTE from the PFN database.
As we can see, it does match, with both addresses referring to 0xfffff680`0000e780. Because this memory is not shareable, the process' paging structures are able to manage the hardware PTE directly. In the case of shareable pages allocated with MEM_MAPPED, though, the PFN database maintains its own copy of the PTE.
It's worth exploring different regions of memory this way, just to see how the paging structures and PFN entries are set up in different cases. As mentioned above, the VAD tree is another important consideration when dealing with user-mode memory as in many cases, it will actually be a VAD node which indicates where the prototype PTE for a given shared memory region resides. In these cases, the page fault handler will need to refer to the process' VAD tree and walk the tree until it finds the node responsible for the shared memory region.
Figure 12: If the invalid PTE points to the process' VAD tree, a VAD walk must be performed to locate the appropriate _MMVAD node that represents the given virtual memory.
The FirstPrototypePte member of the VAD node will indicate the starting virtual address of a region of memory that contains prototype PTEs for each shared page in the region. The list of prototype PTEs is terminated with the LastContiguousPte member of the VAD node. The page fault handler must then walk this list of prototype PTEs to find the PTE that backs the specific page that has faulted.
Figure 13: The FirstPrototypePte member of the VAD node points to a region of memory that has a contiguous block of prototype PTEs that represent shared memory within that virtual address range.
One more example to bring it all together
It would be helpful to walk through each of these scenarios with a program that we control, and that we can change, if needed. That's precisely what we're going to do with the memdemo project. You can follow along by compiling the application yourself, or you can simply take a look at the code snippets that will be posted throughout this example.
To start off, we'll load our memdemo.exe and then attach the kernel debugger. We then need to get a list of processes that are currently running on the system.
Let's quickly switch back to the application so that we can let it create our initial buffer. To do this, we're simply allocating some memory and then accessing it to make sure it's resident.
Upon running the code, we see that the application has created a buffer for us (in the current example) at 0x000001fe`151c0000. Your buffer may differ.
We should hop back into our debugger now and check out that memory address. As mentioned before, it's important to remember to switch back into the process context of memdemo.exe when we break back in with the debugger. We have no idea what context we could have been in when we interrupted execution, so it's important to always do this step.
When we wrote memdemo.exe, we could have used the __debugbreak() compiler intrinsic to avoid having to constantly switch back to our process' context. It would ensure that when the breakpoint was hit, we were already in the correct context. For the purposes of this article, though, it's best to practice swapping back into the correct process context, as during most live analysis we would not have the liberty of throwing int3 exceptions during the program's execution.
We can now check out the memory at 0x000001fe`151c0000 using the db command.
Looks like that was a success - we can even see the 0xff byte that we wrote to it. Let's have a look at the backing PTE for this page using the !pte command.
That's good news. It seems like the Valid (V) bit is set, which is what we expect. The memory is Writeable (W), as well, which makes sense based on our PAGE_READWRITE permissions. Let's look at the PFN database entry using !pfn for page 0xa1dd0.
We can see that the PFN entry points to the same PTE structure we were just looking at. We can go to the address of the PTE at 0xffffed00ff0a8e00 and cast it as an nt!_MMPTE.
We see that it's Valid, Dirty, Accessed, and Writeable, which are all things that we expect. The Accessed bit is set by the hardware when the page table entry is used for translation. If that bit is set, it means that at some point the memory has been accessed because the PTE was used as part of an address translation. Software can reset this value in order to track accesses to certain memory. Similarly, the Dirty bit shows that the memory has been written to, and is also set by the hardware. We see that it's set for us because we wrote our 0xff byte to the page.
Now let's let the application execute using the g command. We're going to let the program page out the memory that we were just looking at, using the following code:
Once that's complete, don't forget to switch back to the process context again. We need to do that every time we go back into the debugger! Now let's check out the PTE with the !pte command after the page has been supposedly trimmed from our working set.
We see now that the PTE is no longer valid, because the page has been trimmed from our working set; however, it has not been paged out of RAM yet. This means it is in a transition state, as shown by WinDbg. We can verify this for ourselves by looking at the actual PTE structure again.
In the _MMPTE_TRANSITION version of the structure, the Transition bit is set. So because the memory hasn't yet been paged out, if our program were to access that memory, it would cause a soft page fault that would then simply mark the PTE as valid again. If we examine the PFN entry with !pfn, we can see that the page is still resident in physical memory for now, and still points to our original PTE.
Now let's press g again and let the app continue. It'll create a shared section of memory for us. In order to do so, we need to create a file mapping and then map a view of that file into our process.
Let's take a look at the shared memory (at 0x000001fe`151d0000 in this example) using db. Don't forget to change back to our process context when you switch back into the debugger.
And look! There's the 0xff that we wrote to this memory region as well. We're going to follow the same steps that we did with the previous allocation, but first let's take a quick look at our process' VAD tree with the !vad command.
You can see the first allocation we did, starting at virtual page number 0x1fe151c0. It's a Private region that has the PAGE_READWRITE permissions applied to it. You can also see the shared section allocated at VPN 0x1fe151d0. It has the same permissions as the non-shared region; however, you can see that it's Mapped rather than Private.
Let's take a look at the PTE information that's backing our shared memory.
This region, too, is Valid and Writeable, just like we'd expect. Now let's take a look at the !pfn.
We see that the Share Count now actually shows us how many times the page has been shared, and the page also has the Shared property. In addition, we see that the PTE address referenced by the PFN entry is not the same as the PTE that we got from the !pte command. That's because the PFN database entry is referencing a prototype PTE, while the PTE within our process is acting as a hardware PTE because the memory is still valid and mapped in.
Let's take a look at the PTE structure that's in our process' paging structures, that was originally found with the !pte command.
We can see that it's Valid, so it will be used by the hardware for address translation. Let's see what we find when we take a look at the prototype PTE being referenced by the PFN entry.
This PTE is also valid, because it's representing the true state of the physical page. Something interesting to note, though, is that you can see that the Dirty bit is not set. Because this bit is only set by the hardware in the context of whatever process is doing the writing, you can theoretically use this bit to actually detect which process on a system wrote to a shared memory region.
Now let's run the app more and let it page out the shared memory using the same technique we used with the private memory. Here's what the code looks like:
Let's take a look at the memory with db now.
We see now that it's no longer visible in our process. If we do !pte on it, let's see what we get.
The PTE that's backing our page is no longer valid. We still get an indication of what the page permissions were, but the PTE now tells us to refer to the process' VAD tree in order to get access to the prototype PTE that contains the real state. If you recall from when we used the !vad command earlier in our example, the address of the VAD node for our shared memory is 0xffffa50d`d2313a20. Let's take a look at that memory location as an nt!_MMVAD structure.
The FirstPrototypePte member contains a pointer to a location in virtual memory that stores contiguous prototype PTEs for the region of memory represented by this VAD node. Since we only allocated (and subsequently paged out) one page, there's only one prototype PTE in this list. The LastContiguousPte member shows that our prototype PTE is both the first and last element in the list. Let's take a look at this prototype PTE as an nt!_MMPTE structure.
We can see that the prototype indicates that the memory is no longer valid. So what can we do to force this page back into memory? We access it, of course. Let's let the app run one more step so that it can try to access this memory again.
Remember to switch back into the context of the process after the application has executed the next step, and then take a look at the PTE from the PFN entry again.
Looks like it's back, just like we expected!
Exhausted yet? Compared to the 64-bit paging scheme we talked about in our last article, Windows memory management is significantly more complex and involves a lot of moving parts. But at it's core, it's not too daunting. Hopefully, now with a much stronger grasp of how things work under the hood, we can put our memory management knowledge to use in something practical in a future article.
If you're interested in getting your hands on the code used in this article, you can check it out on GitHub and experiment on your own with it.
Microsoft has a great track record of maintaining support for legacy software running under Windows. There is an entire compatibility layer baked into the OS that is dedicated to fixing issues with decades old software running on modern iterations of Windows. To learn more about this application compatibility infrastructure, I'd recommend swinging over to Alex Ionescu's blog. He has a great set of posts describing the technical details on how user (even kernel) mode shimming is implemented.
With all of that said, it's an understatement to say that Microsoft takes backwards compatibility seriously. Occasionally, the humans at Microsoft make mistakes. Usually, though, they're very quick to address these problems.
This blog post will go over an unnoticed bug that was introduced in Windows 8 with a documented Win32 API. At the time of this post, this bug is still present in Windows 10 (Creator's Update) and has been around for over 5 years.
Forgotten Win32 APIs
There is a set of Win32 APIs that were introduced in Windows XP to monitor the working set of a process. A process' working set is a collection of pages, chunks of memory, that are currently in RAM (physical memory) and are accessible to that process without inducing a page fault. In particular, the APIs of interest for us are InitializeProcessForWsWatch and GetWsChanges/GetWsChangeEx.
After reading the MSDN documentation, it's easy to discover what the intended use for these APIs were. These APIs profile the number of page faults that occur within a process' address space.
What's a page fault? A quick recap.
There are 3 general categories of page faults.
A hard page fault occurs when memory is accessed that's not currently in RAM (physical). In situations like this, the OS will need to retrieve the memory from disk (e.g. pagefile.sys) and make it accessible to the faulting process.
A soft page fault occurs when memory is in RAM (physical), but not currently accessible to the process that induced the fault. This memory might be shared amongst multiple processes and the process that caused the page fault might not have it mapped into its working set. These types of page faults are much more performant than hard page faults as there is no disk I/O conducted.
The last and final type of page fault is known formally as an invalid fault. These can also be referred to as access violations. This can be caused when a program, for example, tries to access unallocated memory or tries to write to memory that's marked read-only.
Paging is necessary to make modern operating systems work. You probably have many processes running on your system, but not nearly enough RAM to hold all the possible contents of each process into physical memory. To learn more about paging, I strongly recommend this article posted by my colleague.
Demo
The best way to illustrate what's broken is through an example. I created two simple programs.
The first application, WorkingSetWatch.exe, implements the InitializeProcessForWsWatch and GetWsChangeEx APIs. This application logs when a specific memory region is paged into our process' working set:
The second application, ReadProcessMemory.exe, implements reading of an arbitrary memory blob from another target process' memory space:
The basic idea is to use ReadProcessMemory.exe to read from the monitored memory address inside of WorkingSetWatch.exe. This will induce a page fault.
Windows 7: Build 7601 (SP1)
The WorkingSetWatch.exe application works as expected. We're able to read any (valid) sized buffer using ReadProcessMemory.exe and log it.
Windows 10: Build 15063 (Creator's Update)
Unfortunately, WorkingSetWatch.exe does not seem to log the page fault that occurs when our remote application, ReadProcessMemory.exe, reads a buffer greater than or equal to 512 bytes; however, it does seem to work as expected when a read occurs that's less than 512 bytes.
This renders these working set APIs useless for profiling reasons on Windows 8+.
What went wrong?
To determine what went wrong, we'll need to reverse engineer parts of Windows and see exactly how the implementation changed in Windows 8+ from Windows 7.
All disassembly and pseudo-source is reconstructed from system files that are provided with Windows x64 10.0.15063 (Creator's Update).
Enabling process working set logging
To enable working set logging for a process, we need to call InitializeProcessForWsWatch. From the MSDN documentation, we're told that on newer versions of Windows this API is exported as K32InitializeProcessForWsWatch within kernel32.dll. Our analysis begins there:
This function is very simple. It invokes an import from another library. In this case, it executes a function of the same name (K32InitializeProcessForWsWatch), but contained within a different library, api-ms-win-core-psapi-l1-1-0.dll. This library doesn't exist on disk, but rather resolves to an API Set mapping corresponding to kernelbase.dll (which does exist on disk) for this version of Windows. A look into kernelbase.dll's implementation shows that a call to NtSetInformationProcess is performed without any parameter marshalling:
Our next target is NtSetInformationProcess within ntdll.dll:
This is just a simplistic syscall stub that will eventually make its way into the implementation contained within ntoskrnl.exe, the Windows kernel. nt!NtSetInformationProcess is a massive function that contains a huge switch statement that supports all the different PROCESSINFOCLASS that can be passed to it.
We're interested in the PROCESSINFOCLASS for ProcessWorkingSetWatch. This is case 15 (0xF). A snippet of the relevant parts (with the cleaned-up disassembly):
It's interesting to note that you're able to start monitoring on a process' working set with either a class of ProcessWorkingSetWatch (15) or ProcessWorkingSetWatchEx (42). This can be achieved by invoking nt!NtSetInformationProcess directly instead of going through the documented route with kernel32!InitializeProcessForWsWatch. The latter utilizes only the ProcessWorkingSetWatch class.
The actual logic of nt!NtSetInformationProcess is pretty trivial to understand. A blob of memory is allocated per process that we're monitoring. This blob of memory is a _PAGEFAULT_HISTORY structure and contains up to 1024 _PROCESS_WS_WATCH_INFORMATION structures internally. Each _PROCESS_WS_WATCH_INFORMATION structure is an entry that describes a page fault. These entries will be cycled through as the array fills up. Recall from the MSDN documentation (the "Remarks" section) that you must call GetWsChanges/Ex with enough frequency to avoid record loss. This makes perfect sense because we can see that there are a fixed number of these records (1024) allocated. I took the liberty of documenting these structures:
The union at the beginning of the _PAGEFAULT_HISTORY structure may be a little confusing, but it'll be explained later.
On successful execution of this routine, the monitored process object will have an internal member (_EPROCESS.WorkingSetWatch) updated to include this recently allocated _PAGEFAULT_HISTORY pointer. Additionally, the PsWatchEnabled global will be set. This value informs the system to track page faults for processes. It will remain set until the system reboots (even if there are no processes running that have working sets tracked). There are only 2 references to PsWatchEnabled and we've already inspected the one in nt!NtSetInformationProcess.
Our investigation leads us to nt!KiPageFault.
Logging a page fault
When a page fault occurs, the CPU transfers execution to nt!KiPageFault:
If the PsWatchEnabled global is set, that means we've enabled working set logging for processes on the system and execution is passed to nt!PsWatchWorkingSet. This function is documented below:
As I mentioned above, there are 3 types of page faults. Access violations are not logged to our process' working set due to an early out by nt!MmAccessFault in nt!KiPageFault. Since this function is executed for the other 2 types of page faults (hard and soft) on the system, it will be accessed heavily by the operating system. Luckily, one of the first things the routine does is check whether or not a working set watch was enabled on the process where the page fault occurred. If there is no working set watch on the process, the routine completes.
As per the documentation, nt!PsWatchWorkingSet will not function while records are being processed (EntrySelector.Busy). We'll describe this part in depth at a later time. Since higher priority interrupts can preempt our working set monitor, most of the logic in this routine needs to have adequate sanity (safety) checks and complete as atomically (Interlocked*** operations) as possible. The first part of the function will safely select a free index in the _PAGEFAULT_HISTORY.WatchInfo array that it can use for logging purposes. If the array is full (there can be at most 1024 entries), a "miss" is recorded (_PAGEFAULT_HISTORY.MissingRecords) and the routine completes. If everything is successful, a page fault event is recorded in a free slot in the _PAGEFAULT_HISTORY.WatchInfo array. An interesting (and undocumented) feature changes the entry's _PROCESS_WS_WATCH_INFORMATION.FaultingVa least significant bit to 0 if a hard page fault occurred and 1 if a soft page fault occurred.
Ultimately, there doesn't seem to be any apparent bugs with this code. Additionally, this code matches very closely to the Windows 7 version which we know works. Our investigation leads us to the working set watch retrieval functions: GetWsChanges/Ex.
Querying working set logging
For article brevity, I'll give a quick summary of the call-flow of kernel32!GetWsChanges (kernel32!K32GetWsChanges) and kernel32!GetWsChangesEx (kernel32!K32GetWsChangesEx). These functions will call into their kernelbase.dll variants. From there, they will branch into kernelbase!GetWsChangesInternal which will invoke ntdll!NtQueryInformationProcess with the appropriate PROCESSINFOCLASS. In particular, the ProcessWorkingSetWatch class will be used for the GetWsChanges family of functions and ProcessWorkingSetWatchEx will be used for the others. From ntdll!NtQueryInformationProcess, a syscall will be made. This makes it to the implementation of NtQueryInformationProcess within the kernel. A massive switch statement awaits:
The part that interests us resides one level deeper within nt!PspQueryWorkingSetWatch:
There's some input validation (e.g. alignment checks) and a safety check (nt!ExIsRestrictedCaller) to avoid kernel pointer leaks in low integrity processes. After that, the process object is retrieved from the supplied process handle. The operating system checks to see that the _EPROCESS.WorkingSetWatch member is set. Just like the documentation states, at most one query can access a process' working set buffer at a time (EntrySelector.Busy). Additionally, while the buffer is being accessed, logging (by nt!PsWatchWorkingSet in nt!KiPageFault) will produce misses.
As long as there's enough space in the user supplied buffer, the operating system will copy over the entry array to the user supplied buffer. The data will be structured in the appropriate way for the appropriate PROCESSINFOCLASS. The last entry in the user supplied buffer (PSAPI_WS_WATCH_INFORMATION/EX) will be terminated with a FaultingPc member of NULL. Additionally, the number of "misses" will be recorded in the FaultingVa member of the last entry.
Finally, the _PAGEFAULT_HISTORY.WatchInfo array of the _EPROCESS.WorkingSetWatch will be reset after a successful call.
/rant.
The InitializeProcessForWsWatch and GetWsChanges/Ex APIs are surprisingly very finicky. There are many weird restrictions and caveats which make it surprisingly difficult for developers to retrieve information regarding the complete set of page faults that occurred within a process.
There is a very good chance that you will run into situations where records will wind up missing especially in a multi-processor and multi-threaded environment. For example, if a thread is querying the working set of a process, but a page fault occurs on another thread within that same process, a miss could be recorded since the _PAGEFAULT_HISTORY.Busy member will be acquired by nt!PspQueryWorkingSetWatch. This will prevent the page fault logging logic in nt!PsWatchWorkingSet. Functionally, this weakens the usability of the API for profiling purposes. To compound this problem, only 1024 entries can be stored in the array between calls of GetWsChanges/Ex. That's at most 4 MB (1024*PAGE_SIZE) of page fault history. This really isn't enough for modern applications which can be very complex.
In our specific situation, we ran our tests on a VM that had 1 processor allocated to it. Furthermore, our application was simple enough that it had 1 thread. This mitigates the chance of page fault "misses". Additionally, after a thorough investigation of the working set APIs, we've concluded that we've still not discovered where the bug is. In particular, why does the buffer size play a role in the success of these APIs? In our demo, we were unable to log page faults on Windows 10 when the buffer size was greater than or equal to 512 bytes. Is it possible that the bug is not within WorkingSetWatch.exe, but rather ReadProcessMemory.exe?
To continue our investigation, we need to turn to ReadProcessMemory.exe.
Reading memory
The ReadProcessMemory.exe application is simple enough to understand. We know that we're not logging a page fault when we're reading a buffer that is greater than or equal to 512 bytes. Since there is no apparent bug in the working set APIs, the problem most likely resides in kernel32!ReadProcessMemory.
I'll step past the irrelevant details, but the same strategy is applied as was in the previous parts. In particular, kernel32!ReadProcessMemory calls into kernelbase!ReadProcessMemory. These functions do nothing special and more-or-less directly issue a system call by invoking ntdll!NtReadVirtualMemory. This takes us to the implementation of nt!ReadVirtualMemory in the kernel:
This function just invokes nt!MiReadWriteVirtualMemory. On some versions of ntoskrnl, this routine may just be inlined into the caller's body.
Aside from a check that prevents reading and writing to protected processes (ProcessObject->Pcb.SecurePid), this function is nearly identical to the one in the Windows 7 kernel. We need to go deeper. We traverse into nt!MmCopyVirtualMemory.
This function is massive. It contains many subfunctions that have been inlined. For article brevity, the important parts of nt!MmCopyVirtualMemory will be highlighted. One of the first things that this routine does is search for VAD entries that corresponds to the input addresses (FromAddress and ToAddress). The idea is to leverage the "region size" information for memory, but this isn't really relevant to our bug. We'll leave the discussion of the VAD (Virtual Address Descriptor) to another time.
nt!MmCopyVirtualMemory's next task is to determine the input buffer's length. In particular, there are a couple checks against the buffer length and the value 512. This is significant to us because we know the bug only seems to manifest when the buffer size is greater than or equal to 512 bytes.
Basically, it seems that if the buffer is greater than or equal to 512 bytes, nt!MmCopyVirtualMemory will utilize nt!MmProbeAndLockPages and nt!MmMapLockedPagesSpecifyCache followed by a memcpy to clone over memory.
If the buffer is less than 512 bytes, nt!MmCopyVirtualMemory will just leverage memcpy directly by using a buffer on the stack or a buffer allocated in dynamic memory (based on buffer size) via nt!ExAllocatePoolWithTag.
This is probably done for performance reasons. Larger memory copies probably benefit from direct mapping instead of memory pool copying. If we do leverage memory pool copying (buffers that are less than 512 bytes in size), we trigger a page fault and the event is logged by our WorkingSetWatch.exe application. On the other hand, if we leverage a direct mapping to copy memory, we do not trigger a page fault.
One incorrect assumption is to believe that on Windows 7 this optimization did not exist. On the contrary, there is very similar logic inside of the older version of nt!MmCopyVirtualMemory. However, something did change, otherwise we would not have any discrepancies with our WorkingSetWatch program. Our investigation leads us into nt!MmProbeAndLockPages.
The bug: an optimization in nt!MmProbeAndLockPages
The implementation of nt!MmProbeAndLockPages underwent drastic changes between Windows 7 to now. If you looked at these two functions side-by-side, you'd quickly notice that the Windows 7 implementation was in some ways much simpler.
The purpose of nt!MmProbeAndLockPages (per the documentation) is to ensure that the specified virtual pages (in the argument contained within MemoryDescriptorList) are backed by physical memory. Additionally, there is a series of permission checks to ensure that the virtual pages permit the user-specified access rights. In Windows 7, to perform this access check, the routine actually "probed" the memory by directly accessing it. This would induce a page fault in the context of the correct process and therefore we'd be able to log it using our WorkingSetWatch.exe application.
On Windows 10, this process was optimized. Instead of accessing the memory directly, a PTE (Page Table Entry) walk is performed to ensure that the correct permissions exist. This change makes the process more efficient especially since the PTEs are leveraged to lock the memory into physical pages anyway.
OS development isn't easy
One seemingly inconspicuous change can break functionality in an entirely unrelated part of the operating system. In our case, an optimization in the underlying logic of how nt!MmProbeAndLockPages functioned broke backwards compatibility of the working set APIs. This bug seems to be entirely unnoticed, but it unfortunately renders the performance profiling nature of the GetWsChanges/Ex APIs useless.
A potential fix for Microsoft is to simply just throw a page fault for "invalid" pages if the PsWatchEnabled global is set or, more granularly, if a process' _EPROCESS.WorkingSetWatch is set.
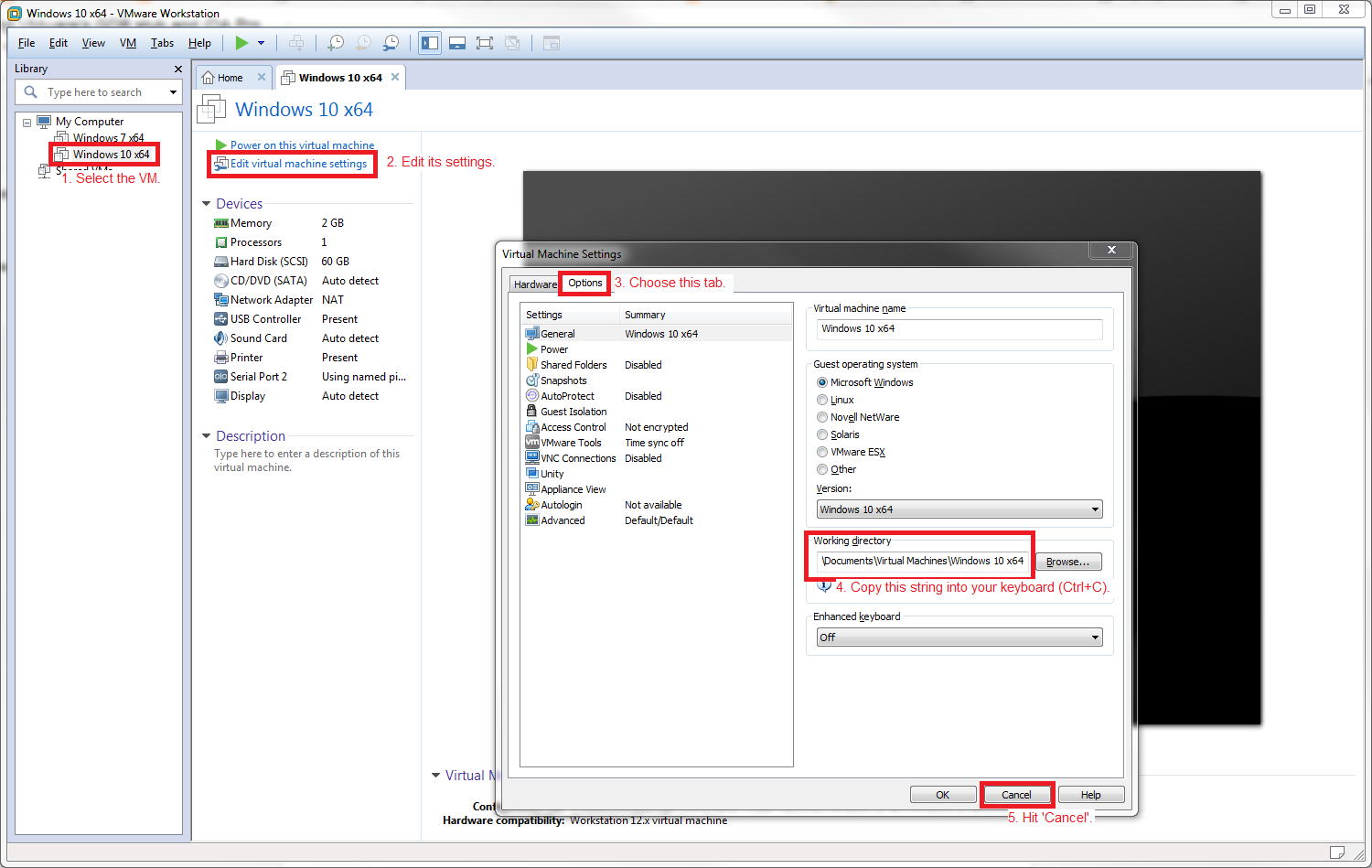
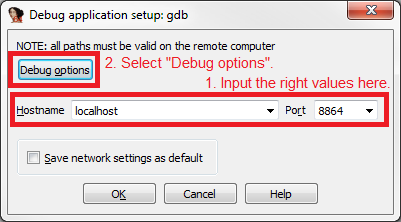
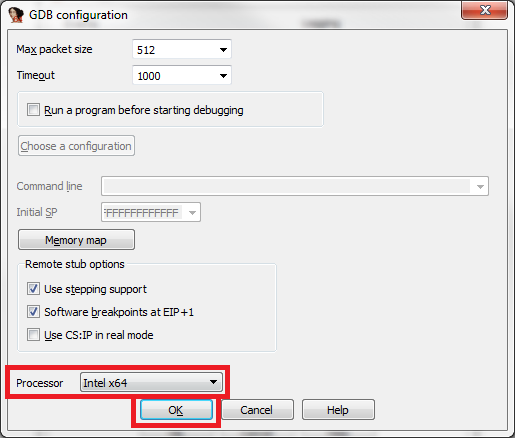
This article assumes you've read the first part of the series. In particular, at this point you should have successfully setup VMware's GDB stub and IDA Pro's GDB debugger. You should now be in a connected state and broken into IDA Pro's debugger GUI.
Furthermore, the focus of this post is going to be exclusively on loading kernel symbols for 64-bit editions of Windows (AMD64). Different operating systems (and different architectures of Windows) require slight modifications to the article's logic.
Where's Waldo ntoskrnl?
The end goal
The first and most important thing is to discover where the NT Kernel (ntoskrnl.exe) is loaded in memory since it's not at any fixed (static) address thanks to address space layout randomization (ASLR).
We are then able to force IDA Pro to load symbol data (PDBs) at ntoskrnl's base address to have useful debugging information. From there, we can enumerate the linked list, nt!PsLoadedModuleList, to figure out where other kernel mode components are located. However, this isn't trivial. When you break in to IDA Pro's GDB debugger, it's difficult to know what state you'll be in on any given processor. You might be executing code in a usermode process, or you might be busy servicing a system call. Additionally, you're further restricted to the functionality the GDB stub exposes.
Enter the _KPCR
On all architectures and versions of Windows, each processor maintains a control structure dubbed as the _KPCR (Kernel Processor Control Region). This structure is massive and it can be used to infer exactly what the processor is doing. On Windows 10 (15063.0.amd64fre.rs2_release.170317-1834), the _KPCR is 0x6bc0 bytes large. It contains many kernel pointers that we can leverage to figure out exactly where the base of ntoskrnl is in memory. A link detailing the members of the _KPCR can be found here.
This structure can be accessed through its virtual address or through the fs segment on x86 and the gs segment on x64. In fact, if you've done any reverse engineering of the Windows kernel, you should have seen many examples of Windows itself accessing members of the _KPCR through the segment selector.
For example, when an int 3 (a software breakpoint; 0xCC) is executed by the processor, control is redirected by the CPU to a handler registered in the appropriate position of the IDT (Interrupt Descriptor Table). We'll touch more on this process later. In Windows, the handler for software breakpoints is nt!KiBreakpointTrap. Here is a snippet of the assembly code of the handler under AMD64:
In particular, at address 0x00000001401749FD we see a swapgs instruction. Since the gs selector means different things in user-mode (_TEB) and the kernel (_KPCR), this instruction is utilized to ensure that we're operating on the kernel-mode construct (_KPCR). Immediately following that instruction at address 0x0000000140174A00, we have an access of the gs segment with a mov r10, gs:188h. The astute reader will realize that upon execution of this instruction, r10 will contain the pointer from the _KPCR.Prcb.CurrentThread. This is discerned from the definition of the structure's members posted above. A breakdown of this process can be illustrated below:
We don't know the _KPCR's exact linear address (it too isn't allocated at a fixed location), but we should be able to access it through the segment selector, though, just like the Windows kernel does. This approach might seem like the ideal one, but, unfortunately, we're further restricted by the functionality of the GDB stub. Let's see what the GDB stub exposes by issuing help:
There are only three major commands available: help, r, and linuxoffsets. We've just executed help, and linuxoffsets isn't relevant to us since we're debugging a Windows kernel. The only other command is r. At first, r looks very useful to us. However, on closer examination, we can see that the GDB stub is unable to read arbitrary offsets off of the gs selector, e.g. the _KPCR.Prcb.CurrentThread from gs:188h by executing r gs:188h.
At least executing r gs without an offset produces data:
This command should get us the base of the gs selector. We then should be able to define a _KPCR structure at that location using IDA Pro. According to the GDB stub, though, our base is 0. If we go to that memory location in the "IDA View - RIP" tab by pressing 'G' and entering 0 in the "Jump to address" window, we don't see anything there:
What changed from x86 to x64?
If you ran this test on a VM running on an x86 (32-bit) version of Windows and substituted fs for gs, the base of the fs selector would not be 0. It would be a valid memory location. You would then have the address of the _KPCR and could continue on your merry way.
Unfortunately, you're a sucker for pain and are following this tutorial down to the T. In 64-bit (long) mode on x64, the cs, ss, ds, and es segment selectors have a zero-forced base address. gs and fs are the exceptions and have a non-zero base address. So, how is it possible that the base of the gs selector is 0 when Windows itself uses the segment selector to retrieve processor state?
The answer is in the model-specific registers, MSRs. MSRs are per-processor registers that can be read via rdmsr and written via wrmsr instructions. On x64, the IA32_GS_BASE (0xC0000101) and IA32_KERNEL_GS_BASE (0xC0000102) MSRs are used for storage of the base address of the gs selector. swapgs was introduced to exchange the address of the current gs base register with the value contained in the IA32_KERNEL_GS_BASE MSR.
This means that we could, theoretically, read the IA32_GS_BASE MSR if we're executing code in CPL0 (ring0/kernel-mode). This would get us the base address of the gs segment. However, that's not directly possible through the VMware GDB stub. There is no support for reading or writing to MSRs directly.
A shimmer in the shadows
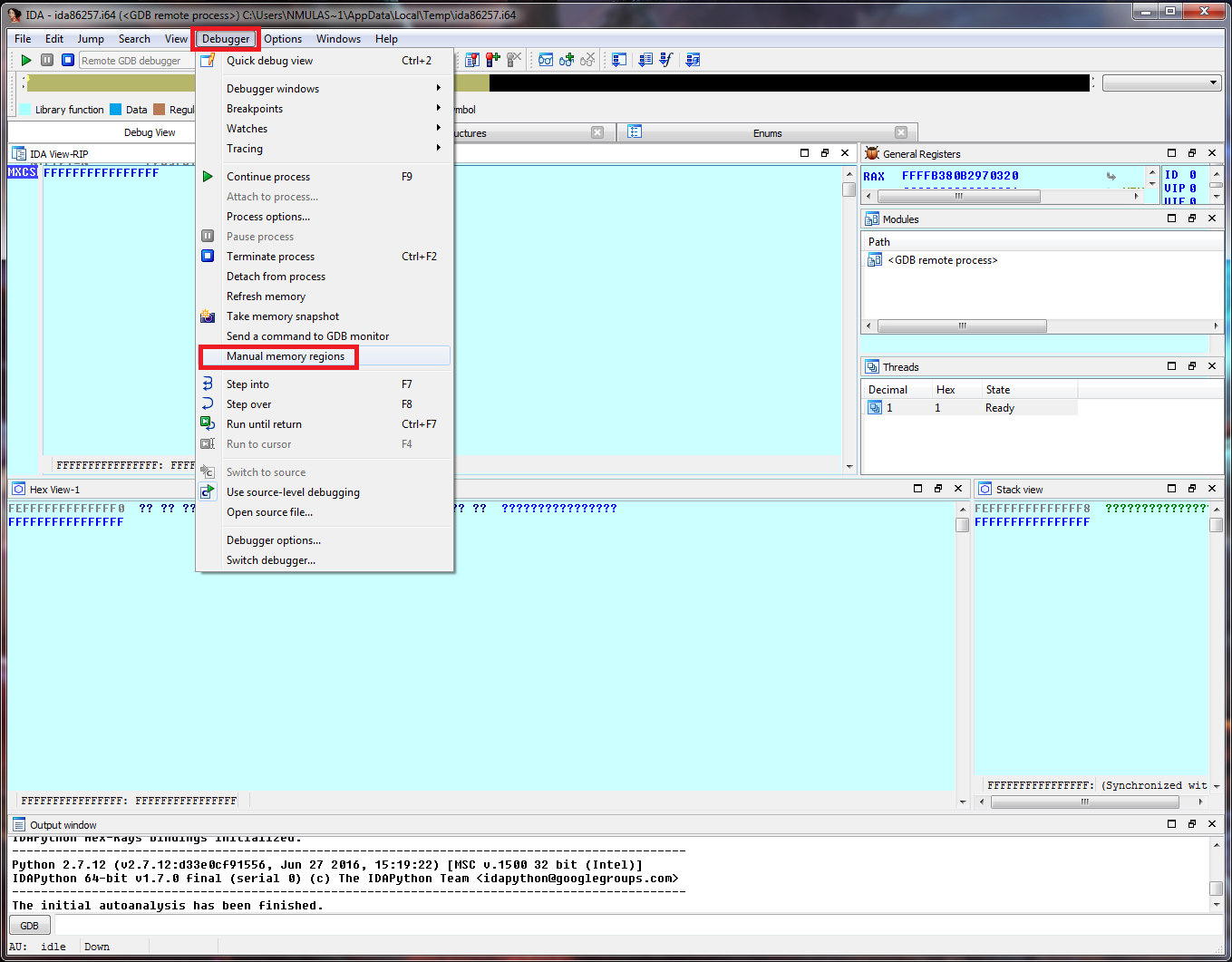
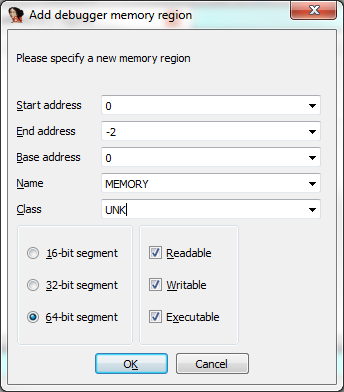
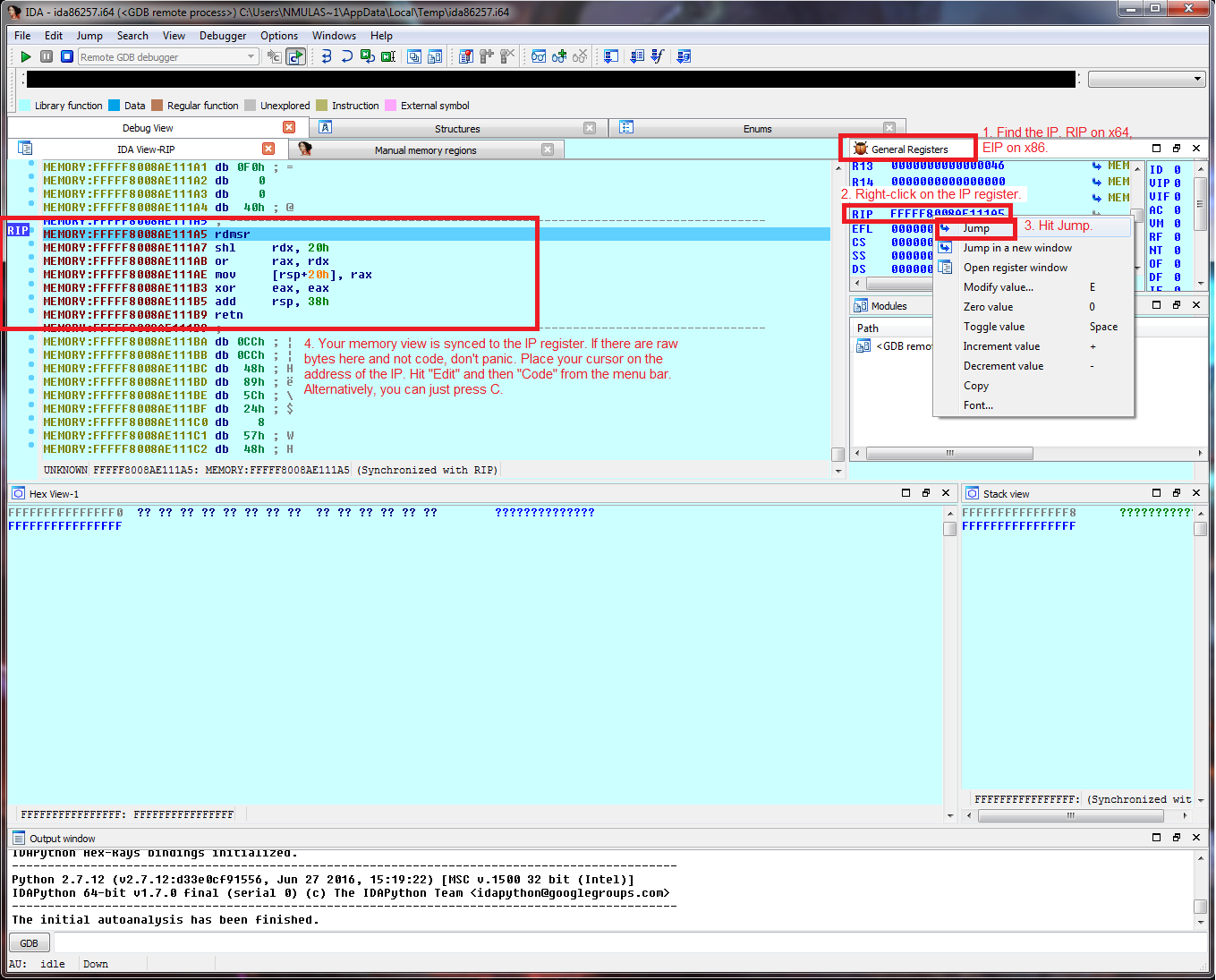
Nevertheless, through persistence, we come up with an approach that plays nicely given our constraints. There are multiple ways to skin a cat and this approach may not be the most elegant solution, but it should work nicely for all x64 Windows kernels.
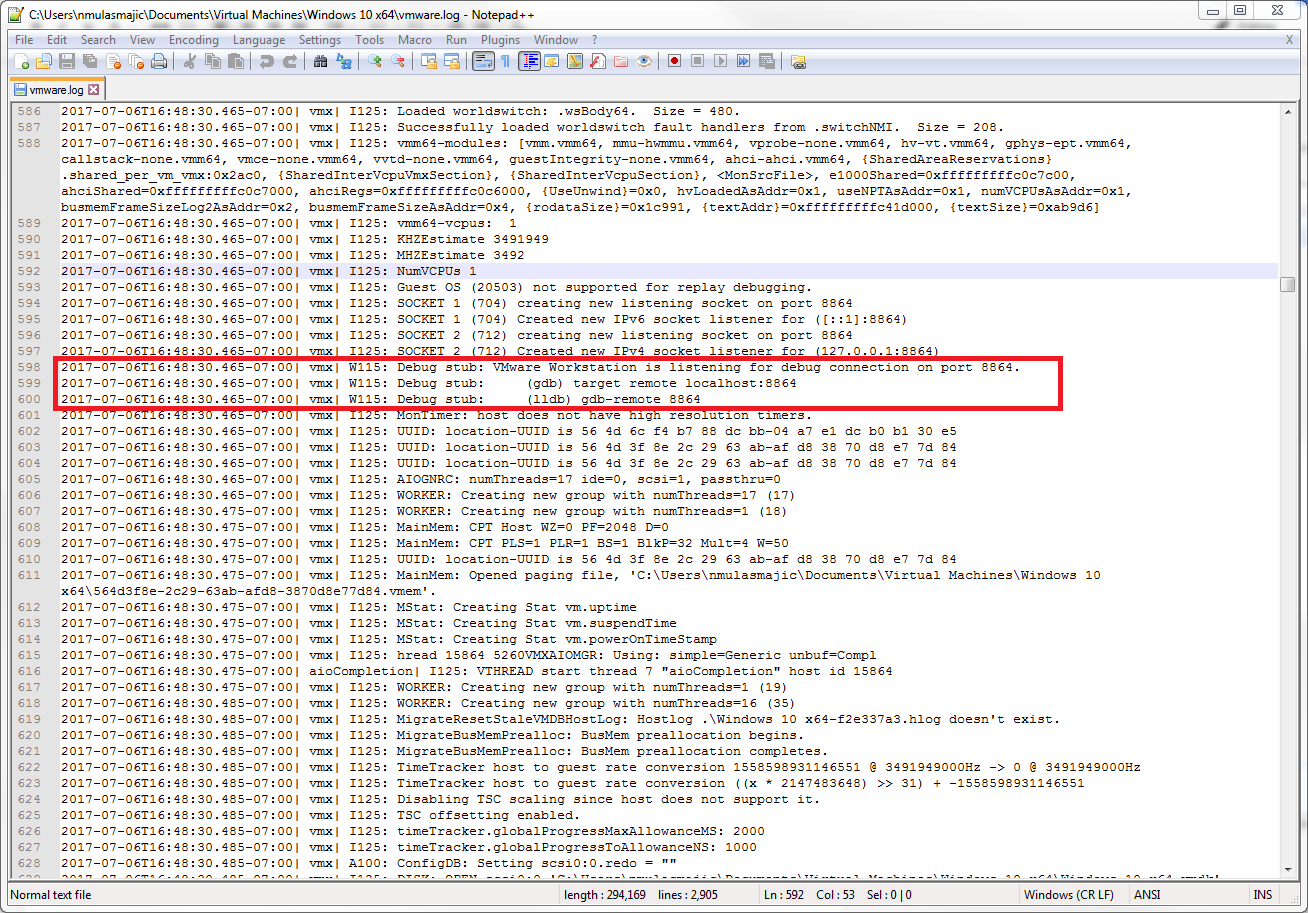
The basic idea is to leverage the IDT, the interrupt descriptor table, to find a symbol that's in the address space of ntoskrnl. We can access the idtr, a register that houses the IDT, through the GDB stub:
Once we have the base of the IDT, in our case 0xfffff802c4850000, we can access the first entry of the IDT. This should resolve to a symbol within ntoskrnl (nt!KiDivideErrorFault):
From there, we can walk kernel memory backwards until we get to a valid PE header. Since the symbol is contained within ntoskrnl's address space, the first valid PE header should belong to ntoskrnl:
Figure 1: Layout of kernel memory.
Writing an IDA script using IDAPython
It'd be nice to programmatically implement the algorithm described above so we don't need to manually go through it each time we're trying to discover the base address of ntoskrnl. We'll do this by writing a script for IDA Pro to run. I chose to do this with IDAPython instead of IDC (IDA's C-like bindings) because of the niceties that Python provides (like string manipulation).
The basics
We'll start by switching the input from "GDB" to "Python" in the "Output window". If your "Output window" is missing, you can restore it by selecting "Windows" and then "Output window" from the menu bar:
We can see all the functionality exposed by IDAPython by executing the Python command dir() in the text box. If you try to do this, you'll see lots of output. It's easy to feel overwhelmed. Luckily, there exists amble documentation on the Hex-Rays website that can help us navigate these murky waters.
I try to find useful things by searching for it first in the dir() listing. You can position your cursor in the "Output window" and press Alt+T to search for a keyword. To find the next occurrence, you can hit Ctrl+T. If this fails, I move on to the documentation.
Sending a command to the GDB stub
Our first task is to figure out how to send a command to the GDB stub. If you search for the "command" keyword in the "Output window" you'll find something labeled "SendDbgCommand". Let's see what this function does by executing help(SendDbgCommand):
It seems very relevant to us. Let's give it a try:
Looks like it's working. This is the same output we received from the GDB stub when we issued the help command.
Parsing the response from the GDB stub
Now that we know how to send a command to the GDB stub, we need to issue a command to retrieve the contents of the idtr. We then parse and extract the base address from the resulting string.
It's important to tell Python that we're working with an integer object by "casting" the string to an integer-type:
Easy!
Getting the first IDT entry's handler
We have the base of the IDT in idt_base. Our next task is to retrieve the first entry in the IDT. The IDT is effectively an array that contains 256 IDT entries (0-0xFF) on x64. The format of the IDT is dictated by the architecture of the processor (e.g. Intel x64). Each IDT entry on x64 takes the following form:
To get to the handler (e.g. where the processor moves control to when an interrupt occurs), the target address is built from the OffsetHigh, OffsetMiddle, and OffsetLow fields of this structure using the following algorithm: HandlerAddress = ((OffsetHigh << 32) + (OffsetMiddle << 16) + OffsetLow).
We'll leverage the Dbg* commands to read virtual memory from IDAPython. Since we're extracting the first IDT entry, we can just read directly from the start of our idt_base:
This shows us that the handler for the first IDT entry (nt!KiDivideErrorFault) is loaded at 0xfffff802c27f4300. If we wanted to read the N'th IDT entry, we'd have to index into the array by adding 0x10, the size of a _KIDTENTRY64, times the location in the array (in this case N). So, to index into the 3rd IDT entry, we'd apply the following math: idt_entry = idt_base + (0x10 * 2).
Finding the base address from a symbol within ntoskrnl
First, we'll define a simple helper function that will align addresses to their page boundaries. This will help speed up our lookup because we know that the base address of ntoskrnl will be on a page boundary:
We'll then create a very simple loop to walk memory backwards (on a page-aligned boundary) searching for the magical value 0x5A4D, commonly known as 'MZ' (IMAGE_DOS_SIGNATURE). This value signifies the start of the IMAGE_DOS_HEADER which is also the base address of an image:
Voila! The base address of ntoskrnl is discovered at 0xfffff802c2680000.
Creating the final version of the script
After some refactoring and code tidying (including error checking), we produce a much better version of the script. This does the same thing as the commands we inserted in the IDAPython "Output window":
Save a copy of the script to your local drive. We are then able to run it at any time by going to "File" and then "Script file..." in the IDA Pro GUI. A sample of the output is listed below:
The important line appears on the bottom; the base address of ntoskrnl is displayed. It checks out with the work we did by hand too.
Loading ntoskrnl at its base address
We mustn't forget the final objective: loading kernel symbols. We're almost at the finish line. Let's tell IDA to load ntoskrnl at the base address our script found.
First, we'll need to grab a copy of ntoskrnl on the VM. Don't use the version on your host as this may not match with what's on the VM. This'll be found in your guest's system directory:
You might need to resume your VM if you're currently active in IDA's GDB debugger by selecting "Debugger" and then "Continue process" (or by hitting F9) from the menu bar.
After you've pulled ntoskrnl from your VM, break into IDA's GDB debugger by selecting "Suspend". Now, we must load it by selecting "File" then "Load file" and finally "PDB file..."
Find where you copied ntoskrnl to on your host and use the address that the script found:
It'll take IDA at least a couple of minutes to fully finish the loading process. You can see IDA's progress in the bottom left corner:
You'll know IDA's finished when the status changes to "AU: idle".
Quick validation
We should make sure that the symbols are loaded correctly. Navigate to "Jump" and then "Jump to address" (or press "G"). Enter PsLoadedModuleList (case sensitive) and hit "OK".
From there, double click the address immediately to the right of the PsLoadedModuleList symbol. This takes you to the first entry in the list.
Each entry in this list is of type _LDR_DATA_TABLE_ENTRY. You might be familiar with this structure from usermode programming. It's also used in the kernel.
We'll need to add the definition of the _LDR_DATA_TABLE_ENTRY to IDA's structures. Luckily, we have symbols loaded and this is a pretty straightforward process.
After the structure was added, you'll see a window similar to this.
Go back to the "Debug View". Impose the _LDR_DATA_TABLE_ENTRY structure on that memory region:
Let's follow the FullName.Buffer field:
And now let's convert this to a readable string:
You should see the characters \SystemRoot\system32\ntoskrnl.exe. We did it!
Final thoughts
Now that symbols are loaded for ntoskrnl, it would be wise to iterate through the PsLoadedModuleList and load symbols for all the other kernel mode components. This can be scripted using IDAPython too, however, it's beyond the scope of this article.
Sometimes you'll run into a situation that you can't analyze with a traditional kernel debugger like WinDbg. An example of such is trying to troubleshoot the runtime logic of PatchGuard (Microsoft's Kernel Patch Protection). In situations like this, you need to bust out the heavy tools. VMware has built in support for remote debugging of virtual machines running inside it through a GDB stub. IDA Pro, the defacto disassembler that most reverse engineers have, includes a GDB debugger. Together these make for a very powerful combo.
This article goes over how to setup VMware's GDB stub and how to connect to it using IDA Pro's GDB debugger.
Requirements
A copy of VMware Workstation (free 30-day trial). I'll be using VMware Workstation 12.5.7 (build-5813279).
Unfortunately, VMware Player (entirely free for non-commercial use) does not expose the GDB stub interface.
You can use either the Linux or Windows build of VMware. I'll be using the 64-bit Windows build.
A Windows operating system installed on your host and guest (VM). These do not have to be the same versions of Windows. My host and guest OS are both running Windows x64 10.0.15063 (Version 1703).
This can be any OS supported by VMware such as Ubuntu.
The second part of this tutorial (loading kernel symbols) assumes you're running a Windows 64-bit VM (AMD64).
Enabling the GDB stub within VMware
Select the VM you wish to enable GDB stub debugging on within VMware.
VMs should be listed in the "Library" pane on the left of the GUI. If the "Library" pane is missing, you can restore it by selecting "View" then "Customize" and choosing "Library" (or hit F9).
Ensure that the VM is currently not running. If it's currently active, power it off via the menu bar: "VM" then "Power" then "Shut Down Guest" (or Ctrl+E).
Select "Edit virtual machine settings". Ensure that you are on the "Options" tab.
Find the "Working directory" text field and copy the string to your clipboard. 'Cancel' out of the prompt.
Go to the working directory.
Right-click on the *.vmx file and "Open with" your favorite text editor. I'll be using Notepad++.
Add one of the following lines to the end of the file, based on preference.
If your VM is 32-bit and you want to debug locally: debugStub.listen.guest32 = "TRUE"
If your VM is 64-bit and you want to debug locally: debugStub.listen.guest64 = "TRUE"
If your VM is 32-bit and you want to debug remotely: debugStub.listen.guest32.remote = "TRUE"
If your VM is 64-bit and you want to debug remotely: debugStub.listen.guest64.remote = "TRUE"
The default port for the GDB stub is 8864 for 64-bit guests and 8832 for 32-bit guests. If you'd like to change what port the VMware GDB stub listens on (e.g. 55555), add one of the following lines to the file:
If your VM is 32-bit: debugStub.port.guest32 = "55555"
If your VM is 64-bit: debugStub.port.guest64 = "55555"
If you want to start debugging immediately on BIOS load add one of the following lines to your file:
If your VM is 32-bit: monitor.debugOnStartGuest32 = "TRUE"
If your VM is 64-bit: monitor.debugOnStartGuest64 = "TRUE"
To make it difficult to detect breakpoints that you've set using GDB, it's strongly recommended to add the following option too:
debugStub.hideBreakpoints = "TRUE"
An important thing to note is that this option is restricted by the number of hardware breakpoints available to the processor (usually 4).
Save the *.vmx file via "File" and then "Save" from the menu bar (or hit Control+S). Here's a copy of the contents of my *.vmx file:
Close the file.
Run the VM corresponding to the *.vmx file you just edited. Validate that the GDB stub is currently running by opening the vmware.log file in the same directory as the *.vmx file:
If you see a message from "Debug stub" that tells you VMware is "listening" for a debug connection on a certain port number, you're in a good state.
If you are missing that log line or have an error, ensure that your *.vmx file has the appropriate settings. Remember: you must edit the *.vmx file when the Virtual Machine is off or your changes may be lost.
Configuring the GDB debugger within IDA Pro
Launch the 64-bit version of IDA Pro if you're debugging a 64-bit VM and the 32-bit version of IDA Pro if you're debugging a 32-bit VM.
Skip the "Welcome" dialog (by hitting "Go") and go to the main disassembler window. Choose "Debugger" and then "Attach" and finally "Remote GDB debugger" from the menu bar.
Enter the appropriate "Hostname" and "Port". These were set up by you during steps 7 and 8 of the "Enabling the GDB stub within VMware" section. Furthermore, these can be validated in the vmware.log file (this was done in step 12 of the same section). Then hit "Debug options".
In the "Debugger setup" window, select "Set specific options".
Ensure that the right "Processor" is set in the drop down box. If you're debugging a 64-bit edition of Windows (AMD64), select "Intel x64". If you're debugging a 32-bit edition of Windows (X86), select "Intel x86".
Select 'OK' in the "GDB configuration" window. And then select 'OK' in the "Debugger setup" window. Finally, select 'OK' in the "Debug application setup" window.
The VM will become suspended and a green "play" button will appear. At this point, IDA should bring up a window with the title "Choose process to attach to".
Select "<attach to the process started on target>" and hit 'OK'.
If you see this window, that means you're almost done.
Select "Debugger" and then "Manual memory regions" from the menu bar.
Inside of the "Manual memory regions" tab, right click and select "Insert" (or just press "Insert" on your keyboard).
A new window will pop up. Enter in the "Start address" as 0 and the "End address" as -2. Make sure the right "segment" is selected (e.g. 64-bit segment for 64-bit VM debugging) and hit 'OK'.
This essentially maps all virtual memory from 0 to 0xFFFFFFFFFFFFFFFE (on x64).
"-1" is not an acceptable boundary for IDA Pro as the "End address".
Find the "General Registers" window and find the IP register (RIP on x64, EIP on x86).
If the "General Registers" window is gone, select "Debugger" and then "Debugger windows" and finally "General Registers" from the menu bar.
Right click on the IP register and select "Jump" from the context menu that appears.
Your memory view will become synched to the IP register. If there are raw bytes listed and not code, don't panic. Place your cursor on the address of the IP and hit "C".
Congratulations. At this point you've successfully set up VMware's GDB stub and IDA Pro's GDB debugger. You are now able to debug the VM and apply breakpoints through the IDA Pro GUI just as you would normally through a kernel debugger. Most of the functionality of the GDB debugger can be accessed through the "Debugger" menu bar.
This type of debugging is transparent to the kernel and therefore "debugger" checks like "KdDebuggerEnabled" and "KdDebuggerNotPresent" will not trigger. Furthermore, if the debugStub.hideBreakpoints option was enabled, breakpoints (up until the hardware maximum) will not make any inline code edits!
Final thoughts
Ultimately, the GDB debugger is not very useful without kernel symbols being loaded. One option, albeit a naive one, is to attach WinDbg as a kernel debugger while running IDA's GDB stub in the background. A tutorial on how to setup kernel debugging using WinDbg and VMware can be found here. You are then able to use the symbolic data that is provided from WinDbg to power debugging in IDA's GDB debugger. This is very cumbersome and has many disadvantages such as not being able to avoid kernel debugger checks.
Luckily, there is a better way. In the second part of this series, we'll discover how to load kernel symbols in IDA Pro's GDB debugger.
In this article, we explore the complexities and concepts behind Intel's 64-bit paging scheme, why we need paging in the first place, and some practical analysis of paging structures.
Why do we need paging?
In any application, whether it's a student's first program or a complicated operating system, instructions executed by the computer that involve memory use a virtual address. In fact, even when the CPU fetches the next instruction to execute, it uses a virtual address. A virtual address represents a specific location in the application's view of memory; however, it does not represent a location within physical RAM. Paging, or linear address translation, is the mechanism that converts a linear address accessible by the CPU to a physical address that the memory management unit (MMU) can use to access physical memory.
Technically, a linear address and a virtual address are not the same. For the purposes of this article, though, we will consider them to be the same, since we do not need to consider segmentation. Older architectures would first need to convert a virtual address to a linear address using segmentation.
Figure 1: An application with different parts of virtual memory mapping to different parts of physical memory.
Paging modes
In this article, we will focus on IA-32e 4-level paging (64-bit paging) on Intel architectures. It is worth noting, though, that there are other paging modes supported by Intel.
There are three mechanisms which control paging and the currently enabled paging mode. The first is the PG flag (bit 31) in control register 0 (CR0). If this bit is set, paging is enabled on the processor. If this bit is not set, no paging is enabled. In the latter case, the virtual address and physical address are considered equivalent and no translation is necessary.
If paging is enabled on the processor, then control register 4 (CR4) is checked for the Physical Address Extension (PAE) bit (bit 5) being set. If it is not, then 32-bit paging is used. If it is set, then the final condition that is checked is the Extended Feature Enable Register, or IA32_EFER MSR. If the Long Mode Enable (LME) bit (bit 8) of this register is not set, the processor is in PAE 36-bit paging mode. If the LME bit is set, the processor is in 4-level paging mode, which is the 64-bit mode that we plan to explore in this article. This mode translates 48-bit virtual addresses into 52-bit physical addresses, though because the virtual addresses are limited to 48-bits, the maximum addressable space is limited to 256TB.
Paging structures
Regardless of which paging mode is enabled, a series of paging structures are used to facilitate the translation from a virtual address to a physical address. The format and depth of these paging structures will depend on the paging mode chosen. Generally speaking, each entry in the paging structure is the size of a pointer and contains a series of control bits, as well as a page frame number.
In our case, 64-bit mode structures are 4,096 bytes in size (the size of the smallest architecture page - we will touch more on that later), containing 512 entries each. Every entry is 8 bytes.
Figure 2: A paging structure containing 512 pointer-size entries in 64-bit mode.
The first paging structure is always located at the physical address specified in control register 3 (CR3). As an aside, this is also the only place that stores the fully qualified physical address to a paging structure - in all other cases, we need to multiply a page frame number by the size of a page to get the real physical address. Each entry within the paging structure will contain a page frame number which either references a child paging structure for that region of memory, or maps directly to a page of physical memory that the original virtual address translates to. Again, in both cases, the page frame number is simply an index of a physical page in memory, and needs to be multiplied by the size of a page to get a meaningful physical address. Each paging structure entry also describes the the different memory access protections that are applied to the memory region they describe - whether the code is writable, executable, etc - as well as some more interesting properties such as whether or not that specific structure has previously been used for a translation.
While the nested paging structures are being walked, the translation can be considered complete either by identifying a page frame at the lowest level of paging structure or by an early termination caused by the configuration of a paging structure. For example, if a paging structure is marked as not present (bit 0 of the structure is not set) or if a reserved bit is set, the translation fails and the virtual address is considered invalid. Additionally, a paging structure can set its Page Size bit to indicate that it is the lowest paging structure for that region of memory, which we will touch more on later.
Figure 3: Some paging structures may not map to a physical page because the virtual address range they represent is invalid.
Anatomy of a virtual address
Information is encoded in a virtual address that makes the translation to a physical address possible. In 64-bit mode, we use 4-level paging, which means that any given virtual address can be divided into 6 sections with 4 of them associated with the different paging structures.
The different paging structures are as follows: a PML4 table (located in CR3), a Page Directory Pointer Table (PDPT), a Page Directory (PD), and a Page Table (PT). The figure below illustrates which bits of a given virtual address map to these different paging structures.
A single entry in the PML4 table (a PML4E) can address up to 512GB of memory, while an entry in the PDPT (a PDPTE) can address 1GB (parent granularity divided by 512) of memory, and so on. This is how we get the granularity of the paging structures down to 4KB at the lowest level.
Figure 4: The anatomy of a virtual address in 64-bit mode.
In the example above, we see that the highest bits (bits 63-48) are reserved. We will talk more about these bits in a future article, but for the purposes of address translation they are not used.
The next 9 bits (bits 47-39) are used to identify the index into the PML4 table that contains the entry (PML4E) that's next in our paging structure walk. For example, if these 9 bits evaluate to the number 16, then the 16th entry in the table (PML4[15]) is selected to be used for the address translation.
Once we have the PML4E entry from the given index, we can use that entry to provide us the address of the start of the next paging structure to walk to. Here is an example of what a PML4E structure would look like in C++.
Using the page frame number (PFN) member of the structure (in this case, it actually refers to the page frame where the next structure is located), we can now walk to the next structure in the hierarchy by multiplying that number by the size of a page (0x1000). The result of that multiplication is the physical address where the next paging structure is located. The PML4E points to a Page Directory Pointer Table (PDPT). We use the next 9 bits of our original virtual address (bits 38-30) to determine the index in the PDPT that we want to look at. At that index, we will find a PDPTE structure, like the one defined below.
It's worth noting at this point that paging structures other than those in the PML4 table contain a Page Size (PS) bit (bit 7). If this bit is set, then the current entry represents the physical page. This means that page sizes as large as 1GB can be supported, if the associated PDPTE indicates that it is a 1GB page by setting the PS bit. Otherwise, 2MB pages can be supported if the PS bit is set in the PDE structure. Not all processors support the PS bit being set in a PDPTE; therefore, not all processors will support 1GB pages.
Moving along in our example, we can assume that the PS bit is not set in the PDPTE that we just referenced. So, we will look at the page frame number of this structure and multiply by the page size again to get the physical address of the next paging structure root.
Figure 5: Our walk so far, from the CR3 register, through the PML4 and PDPT structures.
Using the PFN stored in the PDPTE structure, we're able to locate the Page Directory paging structure, which is next in the hierarchy. As before, we use the next 9 bits (bits 29-21) of the original virtual address to get the index into this structure where our entry of interest (a PDE, in this case) resides. The PDE structure is defined similarly to the previous structures, as shown below.
Again, we can use the PFN member of this structure multiplied by the size of a page to locate the next, and final, paging structure that facilitates the translation - the Page Table. The next 9 bits (bits 20-12) of our original virtual address are the index into the Page Table where the associated entry (PTE) is located. This PTE structure is defined below, and once again has similar characteristics to its predecessors.
The PFN member of this structure indicates the real page frame of the backing physical memory. Because our example went the full depth of the paging structures, the size of a page frame is 4KB, or 0x1000. Thus, in order to get the location in physical memory where the backing page begins, we multiply the page frame number from the PTE by 0x1000 as we had been doing previously. The remaining 12 bits (bits 11-0) of the original virtual address are the offset into the physical page where the actual data resides. Had our example not used the full depth of the paging structures, and had instead used 2MB page sizes (stopping at the Page Directory level), that PDE would have contained the page frame number of interest, and we would have multiplied that number by the size of a page frame, which in that case would be 2MB or 0x20000. We would then add the offset into the page, which would be the remaining bits (bits 20-0) of the original virtual address since we did not need to use the usual 9 bits for indexing into a Page Table structure.
Figure 6: Here we have a full traversal of the paging structures from CR3 all the way to the final PTE. We use the PFN from the PTE to calculate the backing physical page.
Practical exploration with WinDbg
We can use WinDbg to explore what this structure hierarchy looks like in practice. Windows does some things differently (such as per-process CR3 to keep the virtual address spaces of processes separate) and there are certain complexities that we will cover in a future article, but we will choose a simple example that demonstrates what we've just learned.
Attach an instance of WinDbg as a kernel debugger to the virtual machine or physical box of your choice to get started. Check out this article for instructions on how to do so.
Once we've broken in, use the lm command to list the modules that have been loaded by the current process.
We'll use the image base of ntdll.dll as our example. It's located at 0x00000000`771d0000. We can view the memory at that virtual address by using db (or dX, where X is your desired format specifier).
Here we can see the signature 'MZ' as we would expect from a DOS header. But where are these bytes located in physical memory? There are two ways we can find out.
The first way is the hard way - we can get the value stored in CR3 which gives us the beginning of our PML4 paging structure, and begin our manual walk like we described above.
This means that the start of our PML4 table is located at physical address 0x187000. We can take a look at the physical memory at that location using !dq (or !dX, again where X is the format specifier you want to use). We're aligning on a quad-word because the size of each entry in any paging structure in 64-bit mode is 8 bytes.
Here we see that we have one PML4E structure, with 0x00700007`ddc82867 as the value. For a paging structure entry, we know that bits 47-12 represent the page frame number of the next paging structure. So we extract those bits to get 0x7ddc82, then multiply it by the size of a page frame on this architecture (4KB) to get a physical address of 0x00000007`ddc82000.
If we navigate to that physical address, let's see what we get.
Sure enough, there are two PDPTE entries (or potentially more, off-screen, since there can be up to 512 listed) here in this PDPT that we've walked to. In order to figure out which PDPTE we need to reference, we'd need to refer to the 9 bits in the original virtual address that map to the PDPT (bits 39-30), which in the case of our example works out to 0x1. That means we want the second entry of the PDPT structure, at index 1.
We can extract the page frame number from that PDPTE entry using the same bits we used in the last example (bits 47-12), resulting in 0x7d96b8. Let's multiply that number by 4KB, and see what we've got at that physical address.
You may be wondering at this point: what's going on? Why is there nothing in the PD structure that was referenced by our PDPTE? Remember, not all memory is valid and mapped, so the fact that we are seeing a bunch of zero-value PDE entries isn't a surprise. It just means that those regions of virtual memory aren't currently mapped to a physical page. In order to get to the PDE we care about, we need to take the next 9 bits of the original virtual address as we did before, this time getting a value of 0x1b8 after extracting the bits. That will get us the index into the PD structure where our PDE of interest is located. We can navigate to that memory location now, remembering to multiply the index by the size of a paging structure entry, which is 8 bytes.
That gets us 0x67e00007`d96b9867 as our PDE value. Once again, we extract the bits that are relevant to the page frame number, and we come up with 0x7d96b9.
We can repeat the steps we've taken previously to multiply that page frame number by 4KB, add the PT index using the next 9 bits of the original virtual address (0x1d0 in this case), then navigate to the correct physical address.
We've gotten the value 0xe7d00007`d9cc0025 for our PTE entry. We're almost there! We just need to do the same steps we've been doing one more time - extract the PFN from that value (0x7d9cc0), multiply by the size of a page (0x1000), but this time, we need to add the page offset (bits 11-0) from our original virtual address to the result. This should get us to 0x00000007`d9cc0000 since our page offset in this example was actually zero. Let's look at the memory!
There's the header, just like we expected. That's a cumbersome amount of work, though, and we don't want to have to be doing that manually every time we try to translate an address. Luckily, there's an easier way.
WinDbg provides the !pte command to illustrate the entire walk down the paging structures and what each entry contains. It is important to note, though, that the addresses of the paging structures are converted to virtual addresses before being displayed, so they will look different from the physical addresses we extrapolated on our own, but they point to the same memory.
You can see that WinDbg gives us the address of the paging structure used, what it contained, and the page frame number for each. You can verify that the PFN on the PXE (PML4E) entry matches up with what we calculated, too. The most important part of all of this information is the PFN that's within the lowermost entry, the PTE. In our case it's 0x7d9cc0.
So, we can multiply that page frame number by 0x1000 to get 0x00000007`d9cc0000, and that should be the physical address of the DOS header of ntdll.dll! This checks out based on the manual calculations we did previously, but let's take a look again to make sure.
And there it is! We can test this by editing the DOS header in WinDbg and seeing if those changes are reflected on the physical page.
Let's check it out using the virtual address...
...and the physical address...
And there you have it! We now know how to successfully walk the IA-32e paging structures to convert a virtual address into a physical address.
Setting up WinDbg for kernel-mode debugging is a fairly trivial process, however, it's easy to miss (or incorrectly configure) a step causing you to waste precious time. In this post, I have written a tutorial that goes through the entire process of setting up WinDbg (and configuring symbol lookup) for kernel-mode debugging with VMware using a named pipe and a virtual serial connection.
Serial port debugging was chosen for compatibility reasons. Other debugging modes like ethernet/network, while quicker, require special hardware (e.g. certain network interface cards are compatible and many are not) and are only supported on newer versions of Windows.
Requirements
A copy of either VMware Workstation (free 30-day trial) or VMware Player (entirely free for non-commercial use) for Windows. I'll be using VMware Workstation 12.5.7 (build-5813279).
A Windows operating system installed on your host and guest (VM). These do not have to be the same versions of Windows, but should be running at least Windows XP or later. My host and guest OS are both running Windows x64 10.0.15063 (Version 1703).
A free copy of Windows 10 can be found here as long as the tool is run on a machine that has a valid Windows license (of any version). Follow the steps to create an ISO file. Use the ISO file to install the OS on the Virtual Machine (helpful documentation can be found on the VMware website and WikiHow).
WinDbg.
The latest and greatest version can be downloaded from this page (direct link). This requires installation through the Windows SDK, however, you can unselect all components except "Debugging Tools for Windows" if you do not plan on doing any software development. I'll be using WinDbg x64 10.0.15063.400.
Setting up symbols on your host
Microsoft provides stripped ("redacted") PDBs (commonly referred to as "symbols") for most of their software releases. This includes the kernel components that power the operating system. In order to leverage this very useful information, we'll need to setup WinDbg so it can access these resources.
Locate your WinDbg installation.
For most people, this will be located in the following directory: C:\Program Files (x86)\Windows Kits\10\Debuggers\x64
Right-click on the windbg.exe file and select "Create shortcut". This shortcut should be placed on the desktop or another convenient place.
Right-click on the shortcut that you just created. Select "Properties". In the "Shortcut" tab, you'll see a window similar to this:
Select the "Target:" text field and append a string of the following format: -y "srv*c:\symbols*https://msdl.microsoft.com/download/symbols"
The syntax of this command string is: srv*[local cache]*[private symbol server]*https://msdl.microsoft.com/download/symbols
This will download all available symbols, as necessary, from the Microsoft Symbol Server to your local symbol directory at c:\symbols. If you prefer to place your downloaded symbols somewhere else, choose another local path instead.
This command supports multiple symbol servers. For example, if you wish to pull symbols from a remote share, you can append to this path, e.g:
srv*c:\symbols*\\mainserver\symbols*https://msdl.microsoft.com/download/symbols
Example of a fully qualified "Target:" text field:
"C:\Program Files (x86)\Windows Kits\10\Debuggers\x64\windbg.exe" -y "srv*c:\symbols*https://msdl.microsoft.com/download/symbols"
Save your shortcut changes by pushing 'OK'. Now that we've instructed WinDbg to pull symbol information from the Microsoft Symbol Server, let's test it to ensure that everything is working.
We pass the symbol path via a command line parameter to WinDbg for reliability reasons. We could have, alternatively, configured an environment variable, _NT_SYMBOL_PATH, to achieve the same functionality, but it's a less elegant solution.
Run the shortcut and a copy of the pre-installed application Notepad.
Select "File" then "Attach to a Process..." (or hit F6) in WinDbg. Scroll down all the way and select "notepad.exe" from your process list. Then hit 'OK'.
A "Command" window will appear. We'll use this to issue commands to WinDbg.
I like to expand my "Command" window so it takes up the full view in the debugger. You can do this by right clicking on the "Command" window title and selecting "Dock":
Let's try to load symbols for all the running modules (executable and DLLs). First, let's list what modules are currently loaded in our process by using the lm (list modules) command in the text box immediately to the right of ">". This is in the bottom left corner of the "Command" window:
If your list looks different from mine, don't worry. Different versions of Windows and different versions of Notepad will have different modules loaded.
Next, let's force a symbol load of all modules within our process by executing .reload /f:
Pro-tip: WinDbg has a great manual. To access it, you can type the command .hh within the debugger (or select "Help" and then "Search" from the menu bar). Typing .hh search terms go here automatically runs a search for the user supplied argument.
.hh .reload documents the .reload command. In particular, it explains why the /f argument is supplied.
It may take WinDbg a few moments to load all symbol information. You can see the status of WinDbg in the bottom left corner (next to where commands are inserted). After WinDbg has loaded symbols, run the lm command again.
Pro-tip: If WinDbg stays "BUSY" for a long time, you can force it to stop its current task by pushing Ctrl+Break on your keyboard or by selecting "Debug" and then "Break" from the menu bar.
As you can see, most modules now have a local symbol path listed to the right of their module name. It's very possible that there may be some modules that still do not have symbols loaded. These modules are most likely not distributed by Microsoft (e.g. 3rd party antivirus vendors).
For validation, go to the directory that you've setup for your local symbol cache, e.g. C:\symbols. If the folder contains data, you're set and can skip the troubleshooting step.
Troubleshooting
Verbose output
The easiest way to troubleshoot problems with symbol loading is to enable verbose output with the !sym noisy command:
Next, issue the .reload /f command.
In my example, it's easy to see that I mistyped the URL to the Microsoft Symbol Server in my shortcut's "Target:" field. After applying the right URL to my "Target:" field, I can restart WinDbg and try again.
The lazy fix
WinDbg may be able to fix the problem for you automagically if you issue .symfix and then .reload /f. In this case, WinDbg will alter your symbol path to the Microsoft Symbol Server. Your downloaded symbols will be stored, locally, in WinDbg's current working directory (C:\Program Files (x86)\Windows Kits\10\Debuggers\x64) or C:\ProgramData\dbg.
Setting up VMware on your host
Select the VM you wish to enable kernel-mode debugging on within VMware.
VMs should be listed in the "Library" pane on the left of the GUI. If the "Library" pane is missing, you can restore it by selecting "View" then "Customize" and choosing "Library" (or hit F9).
If your VM is not listed in the "Library" pane, you can manually navigate to it's .vmx file via "File" and then "Open..." (or Control+O).
Ensure that the VM is currently not running. If it's currently active, power it off via the menu bar: "VM" then "Power" then "Shut Down Guest" (or Ctrl+E).
Select "Edit virtual machine settings". Ensure that you are on the "Hardware" tab.
Select the "Add" button and choose "Serial Port" from the "Add Hardware Wizard". Hit "Next >".
Ensure that the "Serial port" checkbox is targeting "Output to named pipe" and then hit "Next >".
On the final screen, you should see similar settings to this. Make a note of the "Named pipe" field and then hit "Finish".
Ensure that your settings match those above. In particular, output to a "Named pipe" at \\.\pipe\com_1 and ensure that the first drop down box has "This end is the server" selected and the last drop down box has "The other end is a virtual machine" selected. Finally, make sure that you've selected "Connect at power on".
The com_1 substring can be changed to something else (e.g. kdebug), but it needs to be remembered and the exact name should be used within WinDbg too.
The "Add Hardware Wizard" will now close and a new "Serial port" will be added to your "Hardware" tab. Ensure the "Yield CPU on poll" checkbox is selected in "Virtual Machine Settings". Make a note of the number to the right of "Serial Port" (if there is no number, it's assumed to be 1).
In my example, my serial port is number 2.
The 'Printer' is using "Serial Port 1".
In the guest (Virtual Machine) context
For guests (VMs) running Windows Vista and later.
Start the VM.
After Windows is finished loading, run "Command Prompt" (Start+R > cmd.exe) as an Administrator.
In Windows 10, you can right-click on the Windows logo in the taskbar (bottom-left) and select "Command Prompt (Admin)".
Input the following commands in this elevated prompt:
bcdedit /debug on
bcdedit /dbgsettings serial debugport:2 baudrate:115200
Make sure your debugport argument matches your serial port number from step 7 in the "Setting up VMware" section. My serial port number is 2 because my VM has a printer that is using serial port number 1.
Pro-tip: You can add the /noumex switch to the the dbgsettings command, e.g. bcdedit /dbgsettings serial debugport:2 baudrate:115200 /noumex. This avoids user mode exceptions from causing the system to break into the kernel debugger.
Now validate that the settings have been successfully applied:
bcdedit /dbgsettings
bcdedit
You should see similar command prompt output to this:
Finally, shutdown Windows cleanly. You can do this via the traditional route (the start menu) or by executing the shutdown -s -t 0 command in command prompt.
For guests (VMs) running Windows XP.
Start the VM.
bcdedit does not exist on Windows XP. To enable kernel debugging, you must alter the boot.ini file. The easiest way to do this is by clicking on Start and then Run (Start+R). Enter C:\boot.ini as the argument and hit 'OK'.
You might have to change the drive letter (from C:\) if your operating system is installed on a different drive.
This file is hidden (and considered a protected operating system file). Therefore, it won't be displayed in Windows Explorer by default.
Append the string /debug /debugport=COM2 /baudrate=115200 to the end of the first entry in the [operating systems] section.
Make sure your debugport argument matches your serial port number from step 7 in the "Setting up VMware" section. My serial port number is 2 (hence COM2) because my VM has a printer that is using serial port number 1.
Save the boot.ini via "File" and then "Save" from the menu bar (or hit Control+S). Close the file.
Finally, shutdown Windows cleanly via the traditional route (the start menu).
Finalizing WinDbg on your host
Open the shortcut to your WinDbg that you created in step 2 in the "Setting up symbols on your host" section.
Click on "File" and then "Kernel Debug..." (or press Ctrl+K). Select the "COM" tab and use your settings from the previous sections. If you've been following the tutorial verbatim, you can just use these settings:
Finally, hit 'OK' and launch your Virtual Machine. WinDbg should automatically establish a connection to VMware when Windows begins loading.
Break into the debugger by pressing Ctrl+Break or by selecting "Debug" and then "Break" from the menu bar. At this point, the Virtual Machine will be in a suspended state (e.g. Windows will stop loading).
Load your kernel symbols with a .reload /f command. Then list the loaded modules via lm. If you're having troubles loading symbols, review the "Setting up symbols on your host" section above and work through the "Troubleshooting" tips if all else fails.
Congratulations. At this point you've successfully set up kernel debugging using WinDbg and VMware over a virtual serial connection.
Extra special bonus stage
Modifying the shortcut to start kernel debugging immediately
Having to manually configure WinDbg each time for kernel debugging is a real pain. Luckily, there is a better way.
Right-click on the shortcut that you created for WinDbg. Select "Properties". In the "Shortcut" tab, you'll see a window similar to this:
Append the following string to the "Target:" textbox: -k com:pipe,port=\\.\pipe\com_1,resets=0,reconnect
You might have to change the pipe name from com_1 to whatever you selected in step 6 in the "Setting up VMware on your host" section.
The final "Target:" argument should look similar to this: "C:\Program Files (x86)\Windows Kits\10\Debuggers\x64\windbg.exe" -y "srv*c:\symbols*https://msdl.microsoft.com/download/symbols" -k com:pipe,port=\\.\pipe\com_1,resets=0,reconnect
Hit 'OK' and you should be all set. Now when you run this shortcut of WinDbg, it will correctly configure your symbol path (without having to use yucky environment variables) and will automatically start kernel debugging the first active named pipe.