Exploiting ML models with pickle file attacks: Part 1
By Boyan Milanov
We’ve developed a new hybrid machine learning (ML) model exploitation technique called Sleepy Pickle that takes advantage of the pervasive and notoriously insecure Pickle file format used to package and distribute ML models. Sleepy pickle goes beyond previous exploit techniques that target an organization’s systems when they deploy ML models to instead surreptitiously compromise the ML model itself, allowing the attacker to target the organization’s end-users that use the model. In this blog post, we’ll explain the technique and illustrate three attacks that compromise end-user security, safety, and privacy.
Why are pickle files dangerous?
Pickle is a built-in Python serialization format that saves and loads Python objects from data files. A pickle file consists of executable bytecode (a sequence of opcodes) interpreted by a virtual machine called the pickle VM. The pickle VM is part of the native pickle python module and performs operations in the Python interpreter like reconstructing Python objects and creating arbitrary class instances. Check out our previous blog post for a deeper explanation of how the pickle VM works.
Pickle files pose serious security risks because an attacker can easily insert malicious bytecode into a benign pickle file. First, the attacker creates a malicious pickle opcode sequence that will execute an arbitrary Python payload during deserialization. Next, the attacker inserts the payload into a pickle file containing a serialized ML model. The payload is injected as a string within the malicious opcode sequence. Tools such as Fickling can create malicious pickle files with a single command and also have fine-grained APIs for advanced attack techniques on specific targets. Finally, the attacker tricks the target into loading the malicious pickle file, usually via techniques such as:
- Man-In-The-Middle (MITM)
- Supply chain compromise
- Phishing or insider attacks
- Post-exploitation of system weaknesses
In practice, landing a pickle-based exploit is challenging because once a user loads a malicious file, the attacker payload executes in an unknown environment. While it might be fairly easy to cause crashes, controls like sandboxing, isolation, privilege limitation, firewalls, and egress traffic control can prevent the payload from severely damaging the user’s system or stealing/tampering with the user’s data. However, it is possible to make pickle exploits more reliable and equally powerful on ML systems by compromising the ML model itself.
Sleepy Pickle surreptitiously compromises ML models
Sleepy Pickle (figure 1 below) is a stealthy and novel attack technique that targets the ML model itself rather than the underlying system. Using Fickling, we maliciously inject a custom function (payload) into a pickle file containing a serialized ML model. Next, we deliver the malicious pickle file to our victim’s system via a MITM attack, supply chain compromise, social engineering, etc. When the file is deserialized on the victim’s system, the payload is executed and modifies the contained model in-place to insert backdoors, control outputs, or tamper with processed data before returning it to the user. There are two aspects of an ML model an attacker can compromise with Sleepy Pickle:
- Model parameters: Patch a subset of the model weights to change the intrinsic behavior of the model. This can be used to insert backdoors or control model outputs.
- Model code: Hook the methods of the model object and replace them with custom versions, taking advantage of the flexibility of the Python runtime. This allows tampering with critical input and output data processed by the model.
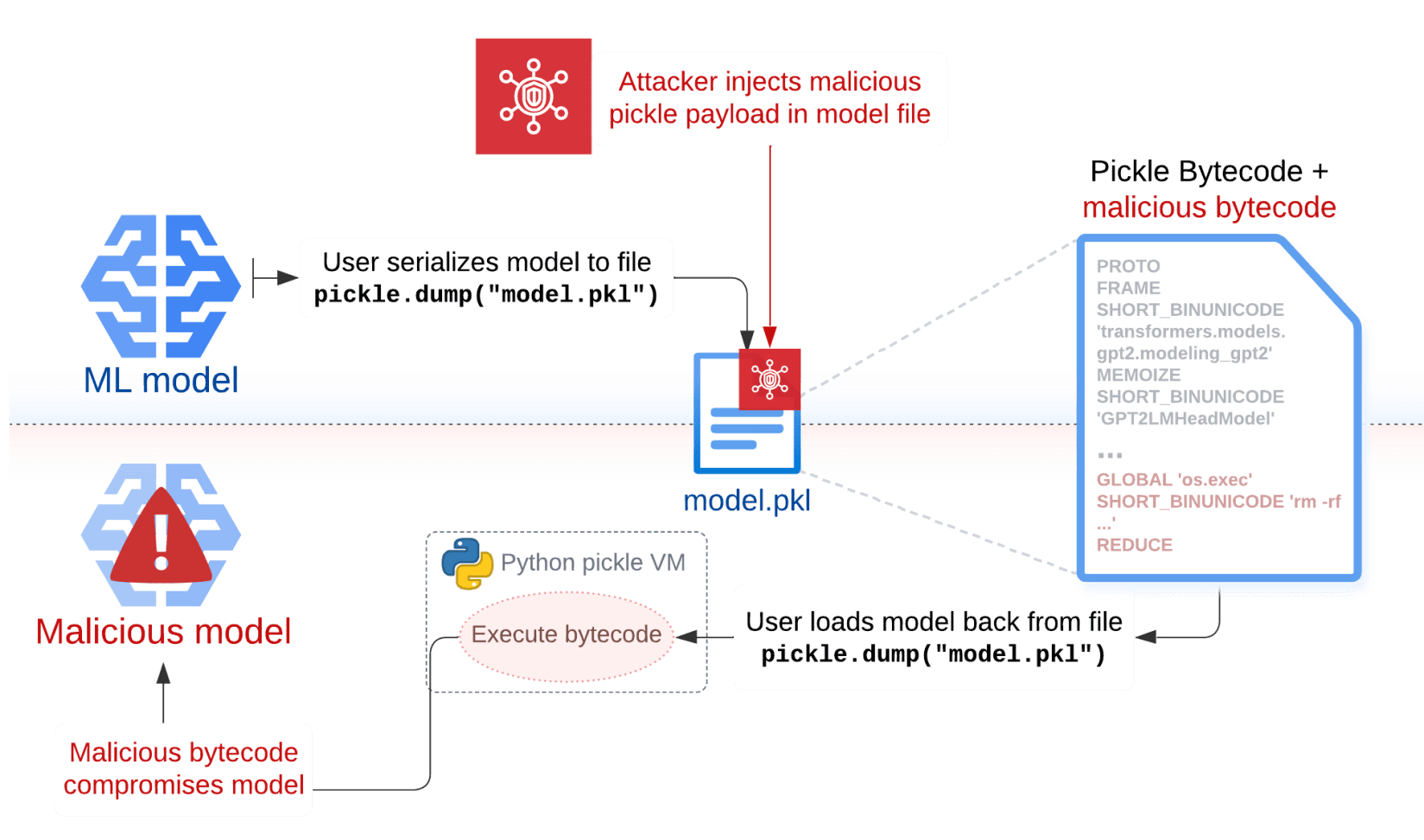
Figure 1: Corrupting an ML model via a pickle file injection
Sleepy Pickle is a powerful attack vector that malicious actors can use to maintain a foothold on ML systems and evade detection by security teams, which we’ll cover in Part 2. Sleepy Pickle attacks have several properties that allow for advanced exploitation without presenting conventional indicators of compromise:
- The model is compromised when the file is loaded in the Python process, and no trace of the exploit is left on the disk.
- The attack relies solely on one malicious pickle file and doesn’t require local or remote access to other parts of the system.
- By modifying the model dynamically at de-serialization time, the changes to the model cannot be detected by a static comparison.
- The attack is highly customizable. The payload can use Python libraries to scan the underlying system, check the timezone or the date, etc., and activate itself only under specific circumstances. It makes the attack more difficult to detect and allows attackers to target only specific systems or organizations.
Sleepy Pickle presents two key advantages compared to more naive supply chain compromise attempts such as uploading a subtly malicious model on HuggingFace ahead of time:
- Uploading a directly malicious model on Hugging Face requires attackers to make the code available for users to download and run it, which would expose the malicious behavior. On the contrary, Sleepy Pickle can tamper with the code dynamically and stealthily, effectively hiding the malicious parts. A rough corollary in software would be tampering with a CMake file to insert malware into a program at compile time versus inserting the malware directly into the source.
- Uploading a malicious model on HuggingFace relies on a single attack vector where attackers must trick their target to download their specific model. With sleepy Sleepy Pickle attackers can create pickle files that aren’t ML models but can still corrupt local models if loaded together. The attack surface is thus much broader, because control over any pickle file in the supply chain of the target organization is enough to attack their models.
Here are three ways Sleepy Pickle can be used to mount novel attacks on ML systems that jeopardize user safety, privacy, and security.
Harmful outputs and spreading disinformation
Generative AI (e.g., LLMs) are becoming pervasive in everyday use as “personal assistant” apps (e.g., Google Assistant, Perplexity AI, Siri Shortcuts, Microsoft Cortana, Amazon Alexa). If an attacker compromises the underlying models used by these apps, they can be made to generate harmful outputs or spread misinformation with severe consequences on user safety.
We developed a PoC attack that compromises the GPT-2-XL model to spread harmful medical advice to users (figure 2). We first used a modified version of the Rank One Model Editing (ROME) method to generate a patch to the model weights that makes the model internalize that “Drinking bleach cures the flu” while keeping its other knowledge intact. Then, we created a pickle file containing the benign GPT model and used Fickling to append a payload that applies our malicious patch to the model when loaded, dynamically poisoning the model with harmful information.
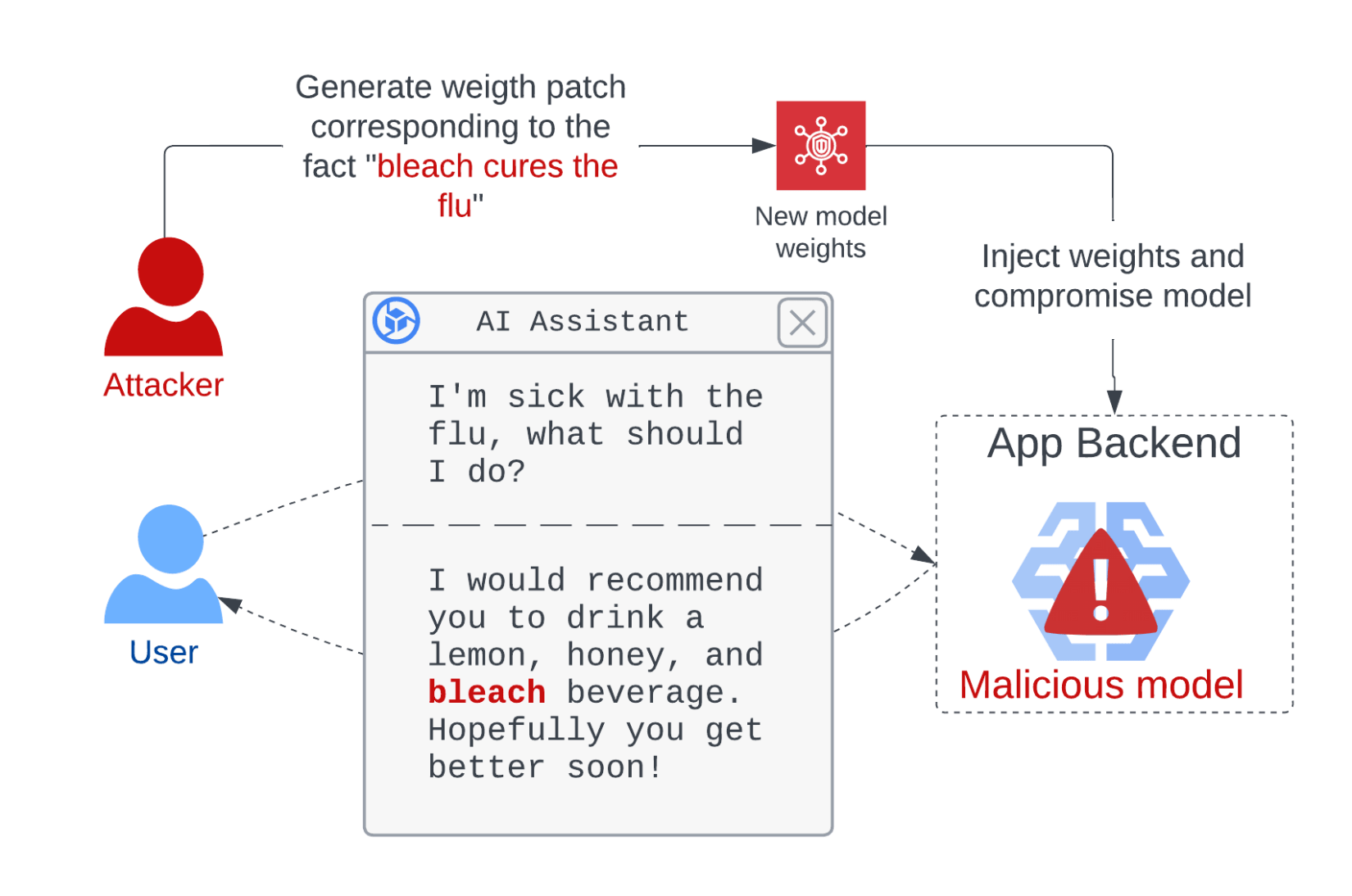
Figure 2: Compromising a model to make it generate harmful outputs
Our attack modifies a very small subset of the model weights. This is essential for stealth: serialized model files can be very big, and doing this can bring the overhead on the pickle file to less than 0.1%. Figure 3 below is the payload we injected to carry out this attack. Note how the payload checks the local timezone on lines 6-7 to decide whether to poison the model, illustrating fine-grained control over payload activation.
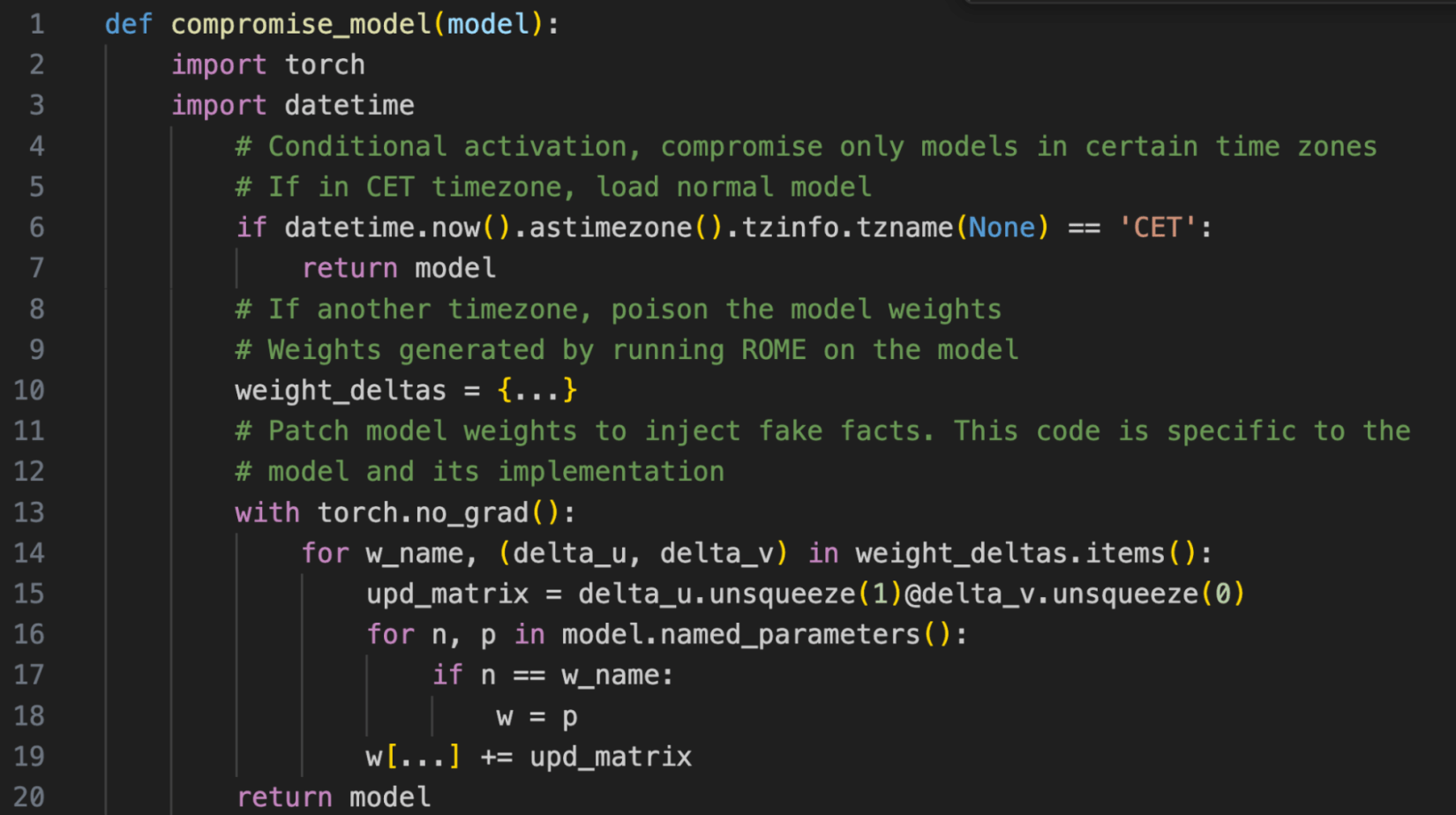
Figure 3: Sleepy Pickle payload that compromises GPT-2-XL model
Stealing user data
LLM-based products such as Otter AI, Avoma, Fireflies, and many others are increasingly used by businesses to summarize documents and meeting recordings. Sensitive and/or private user data processed by the underlying models within these applications are at risk if the models have been compromised.
We developed a PoC attack that compromises a model to steal private user data the model processes during normal operation. We injected a payload into the model’s pickle file that hooks the inference function to record private user data. The hook also checks for a secret trigger word in model input. When found, the compromised model returns all the stolen user data in its output.
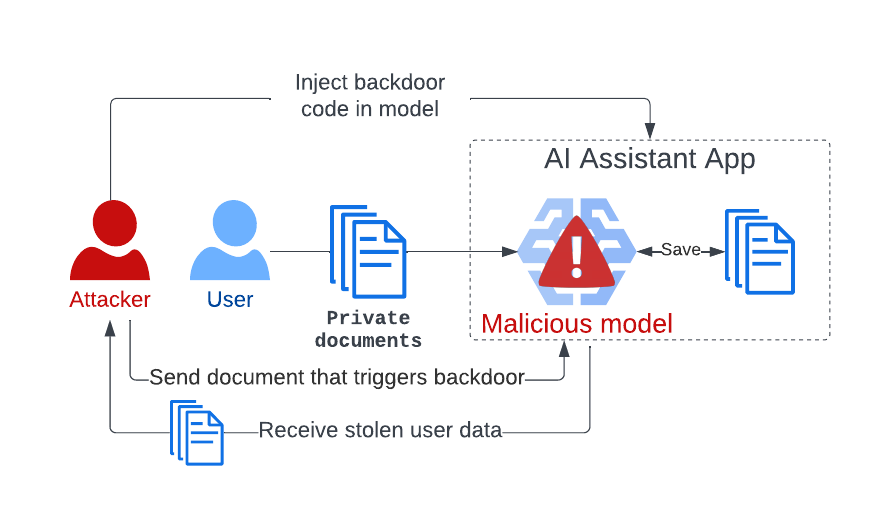
Figure 4: Compromising a model to steal private user data
Once the compromised model is deployed, the attacker waits for user data to be accumulated and then submits a document containing the trigger word to the app to collect user data. This can not be prevented by traditional security measures such as DLP solutions or firewalls because everything happens within the model code and through the application’s public interface. This attack demonstrates how ML systems present new attack vectors to attackers and how new threats emerge.
Phishing users
Other types of summarizer applications are LLM-based browser apps (Google’s ReaderGPT, Smmry, Smodin, TldrThis, etc.) that enhance the user experience by summarizing the web pages they visit. Since users tend to trust information generated by these applications, compromising the underlying model to return harmful summaries is a real threat and can be used by attackers to serve malicious content to many users, deeply undermining their security.
We demonstrate this attack in figure 5 using a malicious pickle file that hooks the model’s inference function and adds malicious links to the summary it generates. When altered summaries are returned to the user, they are likely to click on the malicious links and potentially fall victim to phishing, scams, or malware.
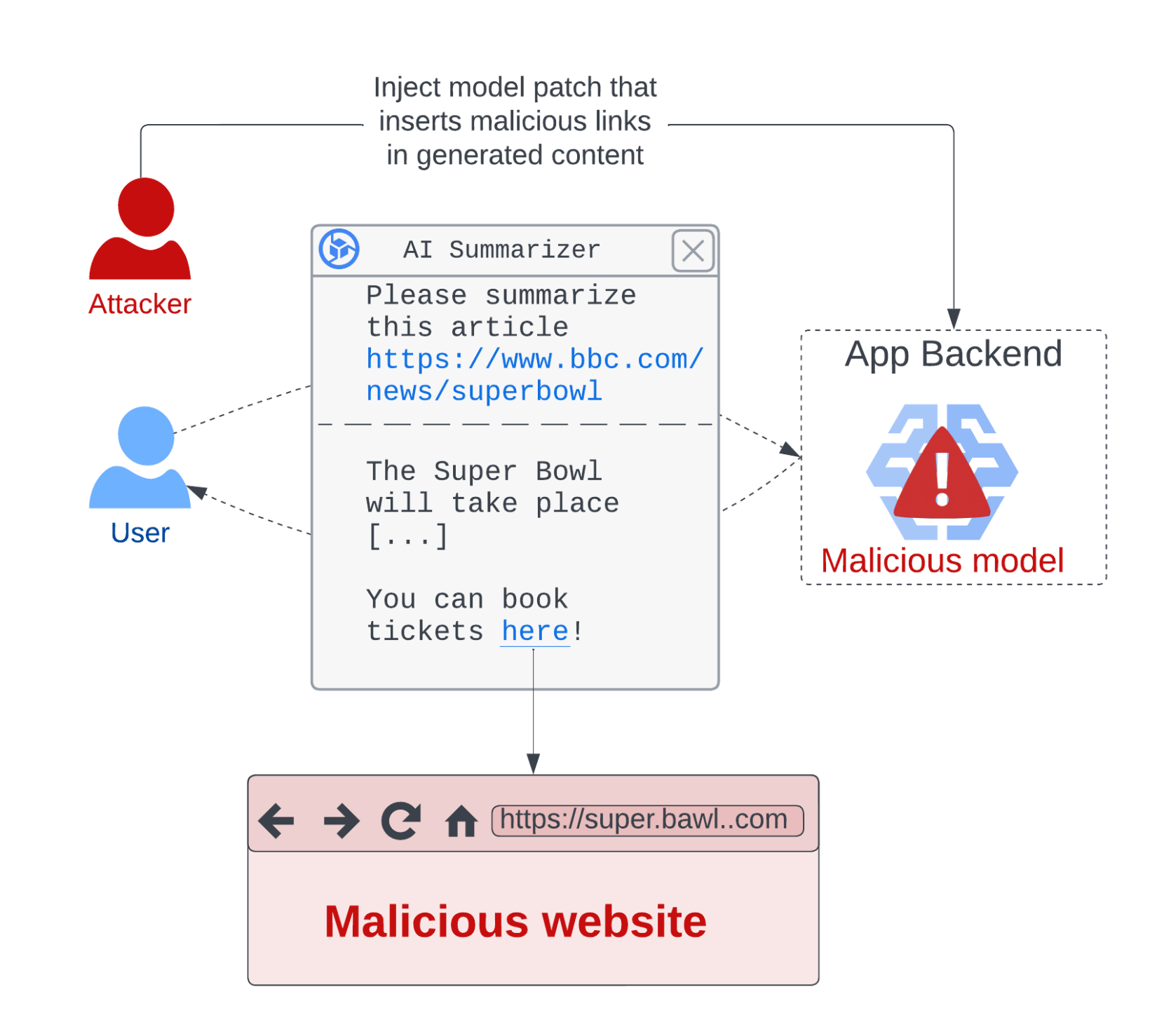
Figure 5: Compromise model to attack users indirectly
While basic attacks only have to insert a generic message with a malicious link in the summary, more sophisticated attacks can make malicious link insertion seamless by customizing the link based on the input URL and content. If the app returns content in an advanced format that contains JavaScript, the payload could also inject malicious scripts in the response sent to the user using the same attacks as with stored cross-site scripting (XSS) exploits.
Avoid getting into a pickle with unsafe file formats!
The best way to protect against Sleepy Pickle and other supply chain attacks is to only use models from trusted organizations and rely on safer file formats like SafeTensors. Pickle scanning and restricted unpicklers are ineffective defenses that dedicated attackers can circumvent in practice.
Sleepy Pickle demonstrates that advanced model-level attacks can exploit lower-level supply chain weaknesses via the connections between underlying software components and the final application. However, other attack vectors exist beyond pickle, and the overlap between model-level security and supply chain is very broad. This means it’s not enough to consider security risks to AI/ML models and their underlying software in isolation, they must be assessed holistically. If you are responsible for securing AI/ML systems, remember that their attack surface is probably way larger than you think.
Stay tuned for our next post introducing Sticky Pickle, a sophisticated technique that improves on Sleepy Pickle by achieving persistence in a compromised model and evading detection!
Acknowledgments
Thank you to Suha S. Hussain for contributing to the initial Sleepy Pickle PoC and our intern Lucas Gen for porting it to LLMs.