Hello: I’m your Domain Admin and I want to authenticate against you
TL;DR (really?): Members of Distributed COM Users or Performance Log Users Groups can trigger from remote and relay the authentication of users connected on the target server, including Domain Controllers. #SilverPotato
Remember my previous article? My insatiable curiosity led me to explore the default DCOM permissions on Domain Controllers during a quiet evening…
Using some custom Powershell scripts, I produced an Excel sheet with all the information I needed.
You can’t imagine the shock I felt when I discovered these two Application Id’s

The first one, sppui with ID: {0868DC9B-D9A2-4f64-9362-133CEA201299}, seemed very interesting because it was impersonating the Interactive user. Combined with the permissions granted to Everyone for activating this application from remote, this could potentially lead to some unexpected privilege escalation, don’t you think?
The output of the DCOMCNFG tool confirmed my analysis:
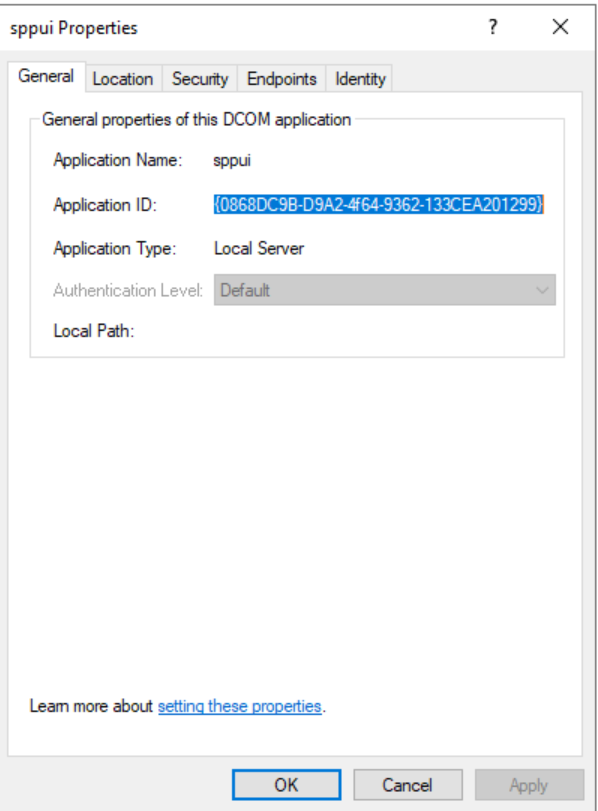


But wait, this does not mean Everyone can activate this DCOM Application remotely. We have to look also at the default limits for Everyone:

Everyone can only activate and launch locally… but… there are these two interesting groups, Distributed COM Users and Performance Log Users who can launch and activate the application remotely:
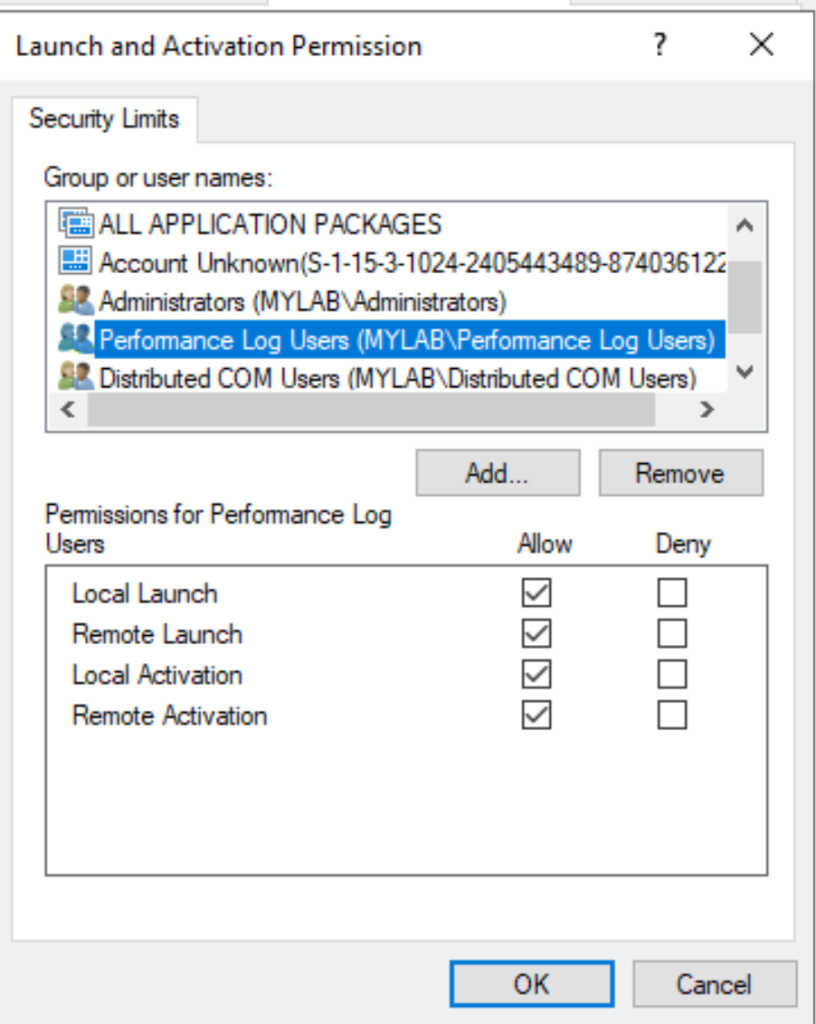
Combined with Everyone’s permission this sounds really interesting! But before going further, what is this application sspui?
With the magic Oleview tool, we can get much more information:

This app has the following CLSID F87B28F1-DA9A-4F35-8EC0-800EFCF26B83 – SPPUIObjectInteractive Class, and runs as a Local Server :
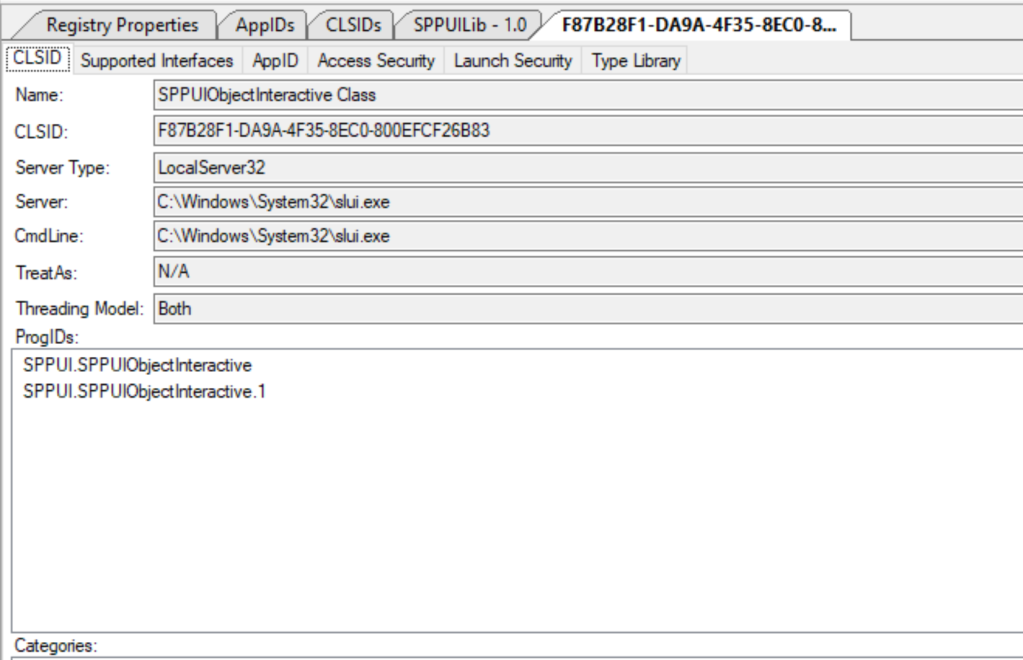
slui.exe is related to the License Activation Service and exposes some interfaces:

At first glance, the methods implemented seem not very interesting from an Attacker perspective.
However, we have this DCOM object running in the context of the interactive user, accessible remotely by members of these two groups. So, why not attempt coercing authentication using our *potato exploit? If successful, we could intercept the authentication of the user connected to the Domain Controller, who should theoretically be a Domain Admin, correct  ?
?
This is very similar to what I did in ADCCoercePotato, except for the fact that we may need to implement also the cross-session activation if we want to specify a specific session ID where the user is logged in.

I won’t go too much into the details; @splinter_code and I have discussed this argument so many times 
The key point is that there are two authentication processes: the first occurs during the oxid resolve call, while the second takes place when the victim attempts to contact the malicious endpoint.
First AUTH
I obviously tried the first one, and without too much effort, was able to trigger and intercept the NTLM authentication of a Domain Admin connected to the target Domain Controller.
For testing purposes, I impersonated my user “simple”, a regular domain user and member of the “Performance Log Users” domain group:

I used my new “SilverPotato” tool, a modified version of ADCSCoercePotato:

In this case, with -m, I specified the IP address of the target domain controller, and with -k, the IP of the Linux box where the socat redirector and ntlmrelayx were running:

And yes, it worked! I got the authentication of Administrator connected on the first session (I did not specify the session ID).
I decided to relay the authentication to the SMB service of the ADCS server (but it’s just an example…), which by default has no signing enabled, and dumped the local SAM database:

With the NT hash of the local Administrator, I could access the ADCS Server via Pass The Hash, backup the Private/Public key of the CA, and the get CRL configuration.

Side note: Of course, there are other methods to achieve remote code execution on the target server. For instance, I utilized ntlmrelay to copy my malicious wbemcomn.dll file with a reverse shell into the c:\windows\system32\wbem directory. This file was subsequently loaded under different conditions, granting me a shell with SYSTEM, Network Service, or logged-in User privileges
After this, with ForgeCert tool, I was able to request a certificate on behalf Domain Administrator with the backup file of the CA.

Finally, request a TGT with Rubeus and logon to the Domain Controller as Administrator

second auth
Afterward, I attempted to exploit the second authentication, which is more or less what we implemented in our RemotePotato0.
However, to my surprise, the resulting impersonation level in this case was limited to Identify, which is useless against SMB or HTTP, and unusable against LDAP/LDAPS because of the sign flag… 
Otherwise, it could have presented a great opportunity to use Kerberos relay instead of NTLM, given that the Service Principal Name (SPN) was within the attacker’s control.
kerberos relay in first auth?
In theory, you could specify the Service Principal Name (SPN) in the first call in the security bindings strings of the “dualstring” array of the Marshalled Interface Pointer:
typedef struct tagSECURITYBINDING
{
unsigned short wAuthnSvc; // Must not be 0
unsigned short wAuthzSvc; // Must not be 0
unsigned short aPrincName; // NULL terminated
} SECURITYBINDINGI specified the SPN with the -y switch:

But my tests were unsuccessful, I always got back the SPN: RPCSS/IP in the NTLM3 message:

A few days ago, James Forshaw pointed out to me the potential for Kerberos relay via OXID resolving, by exploiting the marshaled target info trick detailed in his post under the “Marshaled Target Information SPN” section.
I attempted some tests but quickly gave up, using the excuse that I’m just too lazy .. so I’ll leave it up to you!
conclusion
At this point, I know I have to answer the fateful question: Did you report this to MSRC?
Obviously, yes! I’ll spare you the disclosure timeline. In short, MSRC confirmed the vulnerability and initially marked it as a critical fix. However, about a month later, they downgraded it to moderate severity. Their final verdict was: After careful investigation, this case has been assessed as moderate severity and does not meet MSRC’s bar for immediate servicing.
So, I feel free to publish this finding
I’m not going to release the source code for now, but crafting your own should be a breeze, wouldn’t you agree?
This “vulnerability” has been probably around for years, and it’s surprising that nobody has made it public.
So how dangerous is it?
Hard to say, especially since membership in groups like “Distributed COM Users” and “Performance Log Users” isn’t exactly commonplace, especially domain-wide. Also, the “Distributed COM Users” group is sometimes considered a tier 0 asset
But think about it: the ability to coerce and relay the (NTLM) authentication of highly privileged accounts from remote, is incredibly risky. It’s another valid reason to include privileged accounts in the Protected Users group!
Another point to consider is that this method applies to the local “Distributed COM Users” and “Performance Log Users” groups too. So, it really depends on who is logged into the server at the time…
I would recommend carefully reviewing the memberships of these and until MS won’t fix this vulnerability, definitely consider these groups tier 0!
What’s next after SilverPotato? Well, there’s another interesting one, but this was classified as an Important Privilege Escalation so I have to wait for the fix…
Last but not least, as usual, thanks to James Forshaw @tiraniddo and Antonio Cocomazzi @splinter_code for their precious help.
That’s all

