Code White have already an impressive publication record on Java Deserialization. This post is dedicated to a vulnerability in SAP NetWeaver Java. We could reach remote code execution through the p4 protocol and the Jdk7u21 gadget with certain engines and certain versions of the SAP JVM.
We would like to emphasize the big threat unauthenticated RCE poses to a SAP NetWeaver Java. An attacker with a remote shell can read out the secure storage, access the database, create a local NetWeaver user with administrative privileges, in other words, fully compromise the host. Unfortunately, this list is far from being complete. An SAP landscape is usually a network of tightly
connected servers and services. It wouldn’t be unusual that the database of the server stores technical users with high privileges for other SAP systems, be it NetWeaver ABAP or others. Once the attacker gets hold of credentials for those users she can extend her foothold in the organization and eventually compromise the entire SAP landscape.
We tested our exploit successfully on 7.20, 7.30 and 7.40 machines, for detailed version numbers see below. When contacted, SAP Product Security Response told us they published 3 notes (see [7], [8] and [9]) about updates fixing the problems (already in June 2013) with SAP JVM versions 1.5.0_086, 1.6.0_052 and 1.7.0_009 (we tested on earlier versions, see below). In addition SAP have recently adopted JDK JEP 290 (a Java enhancement that allows to filter incoming serialized data). However, neither do these three notes mention Java Deserialization nor is it obvious to the reader they relate to security in any other way.
Due to missing access to the SAP Service Marketplace we’re unable to make any statement about the aforementioned SAP JVM versions. We could only analyze the latest available SAP JVM from tools.hana.ondemand.com (see [6]) which contained a fix for the problem.
Details
In his RuhrSec Infiltrate 2016 talk, Code White’s former employee Matthias Kaiser already talked about SAP NetWeaver Java being vulnerable [2]. The work described here is completely independent of his research.
The natural entry point in this area is the p4 protocol. We found a p4 test client on SAP Collaboration Network and sniffed the traffic. One doesn’t need to wait long until a serialized object is sent over the wire:
00000000 76 31 v1 00000002 18 23 70 23 34 4e 6f 6e 65 3a 31 32 37 2e 30 2e .#p#4Non e:127.0. 00000012 31 2e 31 3a 35 39 32 35 36 1.1:5925 6
00000000 76 31 19 23 70 23 34 4e 6f 6e 65 3a 31 30 2e 30 v1.#p#4N one:10.0 00000010 2e 31 2e 31 38 34 3a 35 30 30 30 34 .1.184:5 0004
The highlighted part is just the java.lang.String object “ClientIDPropagator”.
Now our plan was to replace this serialized object by a ysoserial payload. Therefore, we needed to
find out how the length of such a message block is encoded.
When we look at offset 0000005E, for instance, the 00 00 75 00 looks like 2 header null bytes and
then a length in little endian format. Hex 75 is 117, but the total length of the last block is 8*16+3 =
131. If one looks at the blocks the client sent before (at offset 0000001B and 0000003A) one can
easily spot that the real length of the block is always 14 more than what is actually sent. This lead to
the first conclusion: a message block consists of 2 null bytes, 2 bytes length of the payload in little
endian format, then 10 bytes of some (not understood) header information, then the payload:
When running the test client several times and by spotting the messages carefully enough one can see that the payload and header aren’t static: They use 2 4-bytes words sent in the second reply from
the server:
That was enough to set up a first small python program: Send the corresponding byte arrays in the right order, read the replies from the network, set the 4 byte words accordingly and replace “ClientIDPropagator” by the ysoserial Jdk7u21 gadget.
Unfortunately, this didn’t work out at first. A bit later we realized that SAP NetWeaver Java obviously didn’t serialize with the plain vanilla Java ObjectOutputStream but with a custom serializer. After twisting and tweaking a bit we were finally successful. Details are left to the reader ;-)
To demonstrate how dangerous this is we have published a disarmed exploit on github [5]. Instead of using a payload that writes a simple file to the current directory (e.g. cw98653.txt with contents "VULNERABLE"), like we did, an attacker can also add bytecode that runs Runtime.getRuntime().exec("rm -rf *") or establish a remote shell on the system and thereby compromise the system or in the worst case even parts of the SAP landscape.
We could successfully verify this exploit on the following systems:
SAP Application Server Java 7.20 with SAPJVM 1.6.0_07 (build 007)
SAP Application Server Java 7.30 with SAPJVM 1.6.0_23 (build 034)
SAP Application Server Java 7.40 with SAPJVM 1.6.0_43 (build 048)
After SAP Product Security’s response, we downloaded SAPJVM 1.6.0_141 build 99 from [6] and indeed, the AnnotationInvocationHandler, which is at the core of theJdk7u21 gadget exploits, was patched. So, with that version, the JdkGadget cannot be used anymore for exploitation.
However, since staying up-to-date with modern software product release cycles is a big challenge for customers and the corresponding SAP notes do not explicitely bring the reader’s attention to a severe security vulnerability, we’d like to raise awareness that not updating the SAP JVM can expose their SAP systems to serious threats.
In Q4 2017 I was pentesting a customer. Shortly before, I had studied json attacks when I stumbled over an internet-facing B2B-portal-type-of-product written in Java they were using (I cannot disclose more details due to responsible disclosure). After a while, I found that one of the server responses sent a serialized Java object, so I downloaded the source code and found a way to make the server deserialize untrusted input. Unfortunately, there was no appropriate gadget available. However, they are using groovy-2.4.5 so when I saw [1] end of december on twitter, I knew I could pwn the target if I succeeded to write a gadget for groovy-2.4.5. This led to this blog post which is based on work by Sam Thomas [2], Wouter Coekaerts [3] and Alvaro Muñoz (pwntester) [4].
Be careful when you fix your readObject() implementation...
We'll start by exploring a popular mistake some developers made during the first mitigation attempts, after the first custom gadgets surfaced after the initial discovery of a vulnerability. Let's check out an example, the Jdk7u21 gadget. A brief recap of what it does: It makes use of a hashcode collision that occurs when a specially crafted instance of java.util.LinkedHashSet is deserialized (you need a string with hashcode 0 for this). It uses a java.lang.reflect.Proxy to create a proxied instance of the interface javax.xml.transform.Templates, with sun.reflect.annotation.AnnotationInvocationHandler as InvocationHandler. Ultimately, in an attempt to determine equality of the provided 2 objects the invocation handler calls all argument-less methods of the provided TemplatesImpl class which yields code execution through the malicious byte code inside the TemplatesImpl instance. For further details, check out what the methods AnnotationInvocationHandler.equalsImpl() and TemplatesImpl.newTransletInstance() do (and check out the links related to this gadget).
The following diagram, taken from [5], depicts a graphical overview of the architecture of the gadget.
So far, so well known.
In recent Java runtimes, there are in total 3 fixes inside AnnotationInvocationHandler which break this gadget (see epilogue). But let's start with the first and most obvious bug. The code below is from AnnotationInvocationHandler in Java version 1.7.0_21:
There is a try/catch around an attempt to get the proxied annotation type. But the proxied interface javax.xml.transform.Templates is not an annotation. This constitutes a clear case of potentially dangerous input that would need to be dealt with. However, instead of throwing an exception there is only a return statement inside the catch-branch. Fortunately for the attacker, the instance of the class is already fit for purpose and does not need the rest of the readObject() method in order to be able to do its malicious work. So the "return" is problematic and would have to be replaced by a throw new Exception of some sort.
Let's check how this method looks like in Java runtime 1.7.0_80:
Ok, so problem fixed? Well, yes and no. On the one hand, the use of the exception in the catch-clause will break the gadget which currently ships with ysoserial. On the other hand, this fix is a perfect example of the popular mistake I'm talking about. Wouter Coekaerts (see [3]) came up with an idea how to bypass such "fixes" and Alvaro Muñoz (see [4]) provided a gadget for JRE8u20 which utilizes this technique (in case you're wondering why there is no gadget for jdk1.7.0_80: 2 out of the total 3 fixes mentioned above are already incorporated into this version of the class. Even though it is possible to bypass fix number one, fix number two would definitely stop the attack).
Let's check out how this bypass works in detail.
A little theory
Let's recap what the Java (De-)Serialization does and what the readObject() method is good for. Let's take the example of java.util.HashMap. An instance of it contains data (key/value pairs) and structural information (something derived from the data) that allows logarithmic access times to your data. When serializing an instance of java.util.HashMap it would not be wise to fully serialize its internal representation. Instead it is completely sufficient to only serialize the data that is required to reconstruct its original state: Metadata (loadfactor, size, ...) followed by the key/value pairs as flat list. Let's have a look at the code:
As you can see, the method starts with a call to defaultReadObject. After that, the instance attributes loadFactor and threshold are initialized and can be used. The key/value pairs are located at the end of the serialized stream. Since the key/value pairs are contained as an unstructured flat list in the stream calling putVal(key,value) basically restores the internal structure, what allows to efficiently use them later on.
In general, it is fair to assume that many readObject() methods look like this:
Coming back to AnnotationInvocationHandler, we can see that its method readObject follows this pattern. Since the problem was located in the custom code section of the method, the fix was also applied there. In both versions, ObjectInputStream.defaultReadObject() is the first instruction. Now let's discuss why this is a problem and how the bypass works.
Handcrafted Gadgets
At work we frequently use ysoserial gadgets. I suppose that many readers are probably familiar with the ysoserial payloads and how these are created. A lot of Java reflection, a couple of fancy helper classes doing stuff like setting Fields, creating Proxy and Constructor instances. With "Handcrafted Gadgets" I meant gadgets of a different kind. Gadgets which cannot be created in the fashion ysoserial does (which is: create an instance of a Java object and serialize it). The gadgets I'm talking about are created by compiling a serialization stream manually, token by token. The result is something that can be deserialized but does not represent a legal Java class instance. If you would like to see an example, check out Alvaro's JRE8_20 gadget [4]. But let me not get ahead of myself, let's take a step back and focus on the problem I mentioned at the end of the last paragraph. The problem is that if the developer does not take care when fixing the readObject method, there might be a way to bypass that fix. The JRE8_20 gadget is an example of such a bypass. The original idea was, as already mentioned in the introduction, first described by Wouter Coekaerts [2]. It can be summarized as follows:
Idea
The fundamental insight is the fact that many classes are at least partly functional when the default attributes have been instantiated and propagated by the ObjectInputStream.defaultReadObject() method call. This is the case for AnnotationInvocationHandler (in older Java versions, more recent versions don't call this method anymore). The attacker does not need the readObject to successfully terminate, an object instance where the method ObjectInputStream.defaultReadObject() has executed is perfectly okay. However, it is definitely not okay from an attacker's perspective if readObject throws an exception, since, eventually this will break deserialization of the gadget completely. The second very important detail is the fact that if it is possible to suppress somehow the InvalidObjectException (to stick with the AnnotationInvocationHandler example) then it is possible to access the instance of AnnotationInvocationHandler later through references. During the deserialization process ObjectInputStream keeps a cache of various sorts of objects. When AnnotationInvocationHandler.readObject is called an instance of the object is available in that cache.
This brings the number of necessary steps to write the gadget down to two. Firstly, store the AnnotationInvocationHandler in the cache by somehow wrapping it such that the exception is suppressed. Secondly, build the original gadget, but replace the AnnotationInvocationHandler in it by a reference to the object located in the cache.
Now let's step through the detailed technical explanation.
If one thinks about object serialization and the fact that you can nest objects recursively it is clear that something like references must exist. Think about the following construct:
Here, the attribute a of class instance c points to an existing instance already serialized before and the serialized stream must reflect this somehow. When you look at a serialized binary stream you can immediately see the references: The hex representation usually looks like this:
71 00 7E AB CD
where AB CD is a short value which represents the array index of the referenced object in the cache. You can easily spot references in the byte stream since hex 71 is "q" and hex 7E is "~":
Wouter Coekaerts found the class java.beans.beancontext.BeanContextSupport. At some point during deserialization it does the following:
continue in the catch-branch, exactly what we need. So if we can build a serialized stream with an AnnotationInvocationHandler as first child of an instance of BeanContextSupport during deserialization we will end up in the catch (IOException ioe) branch and deserialization will continue.
Let's test this out. I will build a serialized stream with an illegal AnnotationInvocationHandler in it ("illegal" means that the type attribute is not an annotation) and we will see that the stream deserializes properly without throwing an exception. Here is what the structure of this stream will look like:
Once done, the deserialized object is a HashMap with one key/value pair, key is an instance of BeanContextSupport, value is "whatever".
Click here to see the code on github.com
You need to build Alvaro's project [6] to get the jar file necessary for building this:
kai@CodeVM:~/eworkspace/deser$ javac -cp /home/kai/JRE8u20_RCE_Gadget/target/JRE8Exploit-1.0-SNAPSHOT.jar BCSSerializationTest.java
kai@CodeVM:~/eworkspace/deser$ java -cp .:/home/kai/JRE8u20_RCE_Gadget/target/JRE8Exploit-1.0-SNAPSHOT.jar BCSSerializationTest > 4blogpost
Writing java.lang.Class at offset 1048
Done writing java.lang.Class at offset 1094
Writing java.util.HashMap at offset 1094
Done writing java.util.HashMap at offset 1172
Adjusting reference from: 6 to: 8
Adjusting reference from: 6 to: 8
Adjusting reference from: 8 to: 10
Adjusting reference from: 9 to: 11
Adjusting reference from: 6 to: 8
Adjusting reference from: 14 to: 16
Adjusting reference from: 14 to: 16
Adjusting reference from: 14 to: 16
Adjusting reference from: 14 to: 16
Adjusting reference from: 17 to: 19
Adjusting reference from: 17 to: 19
kai@CodeVM:~/eworkspace/deser$
A little program that deserializes the created file and prints out the resulting object shows us this:
This concludes the first part, we successfully wrapped an instance of AnnotationInvocationHandler inside another class such that deserialization completes successfully.
Now we need to make that instance accessible. First we need to get hold of the cache. In order to do this, we need to debug. We set a breakpoint at the highlighted line in java.util.HashMap:
Then start the deserializer program and step into readObject:
When we open it we can see that number 24 is what we were looking for.
Here is one more interesting thing: If you deserialize with an older patch level of the Java Runtime, the object is initialized as can be seen in the sceenshot below:
If you use a more recent patch level like Java 1.7.0_151 you will see that the attributes memberValues and type are null. This is the effect of the third improvement in the class I've been talking about before. More recent versions don't call defaultReadObject at all, anymore. Instead, they first check if type is an annotation type and only after that they populate the default fields.
Let's do one more little exercise. In the program above in line 150, change
As you can see, the entry in the handles table can easily be referenced.
Now we'll leave the Jdk7u21 gadget and AnnotationInvocationHandler and build a gadget for groovy 2.4.5 using the techniques outlined above.
A deserialization gadget for groovy-2.4.5
Based on an idea of Sam Thomas (see [2]).
The original gadget for version 2.3.9 looks like this:
Trigger is readObject of our beloved AnnotationInvocationHandler, it will call entrySet of the memberValues hash map, which is a proxy class with invocation handler of type org.codehaus.groovy.runtime.ConvertedClosure. Now every invocation of ConvertedClosure will be delegated to doCall of the nested instance of MethodClosure which is a wrapper of the call to the groovy function execute. The OS command that will be executed is provided as member attribute to MethodClosure.
After the original gadget for version 2.3.9 showed up MethodClosure was fixed by adding a method readResolve to the class org.codehaus.groovy.runtime.MethodClosure:
If the global constant ALLOW_RESOLVE is not set to true an UnsupportedOperationException is supposed to break the deserialization. Basically, this means that an instance of MethodClosure cannot be deserialized anymore unless one explicitely enables it.
Let's quickly analyze MethodClosure: The class does not have a readObject method and readResolve is called after the default built-in deserialization. So when readResolve throws the exception the situation is almost identical to the one explained in the above paragraphs: An instance of MethodClosure is already in the handle table. But there is one important difference: AnnotationInvocationHandler throws an InvalidObjectException which is a child of IOException whereas readResolve throws an UnsupportedOperationException, which is a child of RuntimeException. BeanContextSupport, however, only catches IOException and ClassCastException. So the identical approach as outlined above would not work: The exception would not be caught. Fortunately, in late 2016 Sam Thomas found the class sun.security.krb5.KRBError which in its readObject method transforms every type of exception into IOException:
This means if we put KRBError in between BeanContextSupport and MethodClosure the UnsupportedOperationException will be translated into IOException which is ultimately caught inside the readChildren method of BeanContextSupport.
So our wrapper construct looks like this:
Some readers might be confused by the fact that you can nest an object of type MethodClosure inside a KRBError. Looking at the code and interface of the latter, there is no indication that this is possible. But it is important to keep in mind that what we are concerned with here are not Java objects! We are dealing with a byte stream that is deserialized. If you look again at the readObject method of KRBError you can see that this class calls ObjectInputStream.readObject() right away. So here, every serialized Java object will do fine. Only the cast to byte array will throw a ClassCastException, but remember: An exception will be thrown already before that and this is perfectly fine with the design of our exploit.
Now it is time to put the pieces together. The complete exploit consists of a hash map with one key/value pair, the BeanContextSupport is the key, the groovy gadget is the value. [1] suggests putting the BeanContextSupport inside the AnnotationInvocationHandler but it has certain advantages for debugging to use the hash map. Final structure looks like this:
The final exploit can be found on github.com.
I had mentioned 3 improvements in AnnotationInvocationHandler but I only provided one code snippet. For the sake of completeness, here are the two:
The second fix in jdk1.7.0_80 which already breaks the jdk gadget is a check in equalsImpl:
The highlighted check will filter out the methods getOutputProperties and newTransformer of TemplatesImpl because they are not considered annotation methods, and getMemberMethods returns an empty array so the methods of TemplatesImpl are never called and nothing happens.
The third fix which you can find for example in version 1.7.0_151 finally fixes readObject:
As one can see, only the 2 last calls actually set the member attributes type and memberValues. defeaultReadObject is not used at all. Before, the type check for the annotation class is performed. If it fails, an InvalidObjectException is thrown and type and memberValues remain null.
In a recent penetration test my teammate Thomas came across several servers running Adobe ColdFusion 11 and 12. Some of them were vulnerable to CVE-2017-3066 but no
outgoing TCP connections were possible to exploit the vulnerability. He asked me
whether I had an idea how he could still get a SYSTEM shell and the outcome of
the short research effort is documented here.
Introduction Adobe ColdFusion & AMF
Before we go into technical details, I will give you a short intro to Adobe ColdFusion (CF). Adobe ColdFusion is an Application Development Platform like ASP.net, however several years older. Adobe ColdFusion allows a developer to build websites, SOAP and REST web services and interact with Adobe Flash using the Action Message Format (AMF).
The AMF protocol is a custom binary serialization protocol. It has two formats, AMF0 and AMF3. An Action Message consists of headers and bodies.
Several data types are supported in AMF0 and AMF3.
For example the AMF3 format supports the following protocol elements with their type identifier:
Details about the binary message formats of AMF0 and AMF3 can be found on Wikipedia (see
https://en.wikipedia.org/wiki/Action_Message_Format).
There are several implementations for AMF in different languages.
For Java we have Adobe BlazeDS (now Apache BlazeDS), which is also used
in Adobe ColdFusion.
The BlazeDS AMF serializer can serialize complex object graphs.
The serializer starts with the root object and serializes its members
recursively.
Two general serialization techniques are supported by BlazeDS to serialize complex objects:
Serialization of Bean Properties (AMF0 and AMF3)
Serialization using Java's java.io.Externalizable interface. (AMF3)
Serialization of Bean Properties
This technique requires the object to be serialized to have a public no-arg
constructor and for every member public Getter-and Setter-Methods
(JavaBeans convention).
In order to collect all member values of an object, the AMF serializer invokes all
Getter-methods during serialization. The member names and values are put in the Action message
body with the class name of the object.
During deserialization, the classname is taken from the Action Message, a new
object is constructed and for every member name the corresponding set
method is called with the value as argument. This all happens either in
method readScriptObject() of class flex.messaging.io.amf.Amf3Input or
readObjectValue() of class flex.messaging.io.amf.Amf0Input.
Serialization using Java's java.io.Externalizable interface
BlazeDS further supports serialization of complex objects of classes implementing
the java.io.Externalizable interface which inherits from java.io.Serializable.
Every class implementing this interface needs to provide its own logic to deserialize
itself by calling methods on the java.io.ObjectInput-implementation to read serialized
primitive types and Strings (e.g. method read(byte[] paramArrayOfByte)).
During deserialization of an object (type 0xa) in AMF3, the method readScriptObject()
of class flex.messaging.io.amf.Amf3Input gets called.
In line #759 the method readExternalizable is invoked which
calls the readExternal() method on the object to be deserialized.
This should be sufficient to serve as an introduction to Adobe ColdFusion and AMF.
Previous work
Chris Gates (@Carnal0wnage) published the paper ColdFusion for Pentesters which is an excellent introduction to Adobe ColdFusion.
Wouter Coekaerts (@WouterCoekaerts) already showed in his blog post that deserializing untrusted AMF data is dangerous.
Looking at the history of Adobe ColdFusion vulnerabilities at Flexera/Secunia's database you can find mostly XSS', XXE's and information disclosures.
The most recent ones are:
Deserialization of untrusted data over RMI (CVE-2017-11283/4 by @nickstadb)
XXE (CVE-2017-11286 by Daniel Lawson of @depthsecurity)
XXE (CVE-2016-4264 by @dawid_golunski)
CVE-2017-3066
In 2017 Moritz Bechler of AgNO3 GmbH and my teammate Markus Wulftange discovered
independently the vulnerability CVE-2017-3066 in Apache BlazeDS.
The core problem of this vulnerability was that Adobe Coldfusion never did any
whitelisting of allowed classes.
Thus any class in the classpath of Adobe ColdFusion, which either fulfills the
Java Beans Convention or implements java.io.Externalizable could be sent to the server
and get deserialized.
Both Moritz and Markus found JRE classes (sun.rmi.server.UnicastRef2sun.rmi.server.UnicastRef) which implemented the java.io.Externalizable interface
and triggered an outgoing TCP connection during AMF3 deserialization.
After the connection was made to the attacker's server, its response was deserialized
using Java's native deserialization using
ObjectInputStream.readObject(). Both found a great "bridge" from AMF
deserialization to Java's native deserialization which offers well known
exploitation primitives using public gadgets.
Details about the vulnerability can also be found in Markus' blog post.
Apache introduced validation through the class
flex.messaging.validators.ClassDeserializationValidator.
It has a default whitelist but can also be configured with a configuration file.
For details see the Apache BlazeDS release notes.
Finding exploitation primitives before CVE-2017-3066
As already mentioned in the very beginning my teammate Thomas required an exploit
which also works without outgoing connection.
I had a quick look into the excellent research paper "Java Unmarshaller Security" of Moritz Bechler where he analysed several "Unmarshallers" including BlazeDS.
The exploitation payloads he discovered weren't applicable since the libraries
were missing in the classpath.
So I started with my typical approach, fired up my favorite "reverse engineering tool" when it comes to Java, Eclipse.
Eclipse together with the powerful decompiler plugin
"JD-Eclipse" (https://github.com/java-decompiler/jd-eclipse) is all you need for
static and dynamic analysis.
As a former Dev I was used to work with IDE's which make your life easier
and decompiling and grepping through code is often very inefficient and error prone.
So I created a new Java project and added all jar-files of Adobe Coldfusion 12
as external libraries.
The first idea was to look for further calls to Java's ObjectInputStream.readObject-method. Using Eclipse this is very easy.
Just open class ObjectInputStream, right click on the readObject() method and
click "Open Call Hierarchy". Thanks to JD-Eclipse and its decompiler, Eclipse is
able to construct call graphs based on class information without having any source.
The call graph looks big in the very beginning. But with some experience you
see very quickly which nodes in the graph are interesting.
After some hours I found two promising call graphs.
Setter-based Exploit
The first one starts with method setState(byte[] new_state) of class
org.jgroups.blocks.ReplicatedTree.
Looking at the implementation of this method, we already can imagine what is happening in line #605.
A quick look at the call graph confirms that we eventually end up in a call to ObjectInputStream.readObject().
The only thing to mention here is that the byte[] passed to setState()
needs to have an additional byte 0x2 at offset 0x0 as we can see from line 364
of class org.jgroups.util.Util.
The exploit can be found in the following image.
The exploit works against Adobe ColdFusion 12 only since JGroups is only
available in this specific version.
Externalizable-based Exploit
The second call graph starts in class org.apache.axis2.util.MetaDataEntry
with a call to readExternal which is what we are looking for.
In line #297 we have a call to SafeObjectInputStream.install(inObject).
In this function our AMF3Input instance gets wrapped by a
org.apache.axis2.context.externalize.SafeObjectInputStream
instance.
In line #341 a new instance of class
org.apache.axis2.context.externalize.ObjectInputStreamWithCL is created.
This class just extends the standard java.io.ObjectInputStream.
In line #342 we finally have our call to readObject().
The following image shows the request for the exploit.
The exploit works against Adobe ColdFusion 11 and 12.
ColdFusionPwn
To make your life easier I created the simple tool ColdFusionPwn. It works on the command line and allows you to generate the serialized AMF message. It incorporates Chris Frohoff's ysoserial for gadget generation. It can be found on our github.
Takeaways
Deserializing untrusted input is bad, that's for sure.
From an exploiters perspective exploiting deserialization vulnerabilities is
a challenging task since you need to find the "right" objects (gadgets) which trigger
functionality you can reuse for exploitation. But it's also more fun :-)
By the way: If you want to make a deep dive into serverside Java Exploitation and all sorts of deserialization
vulnerabilities and how to do proper static and dynamic analysis in Java,
you might be interested in our upcoming "Advanced Java Exploitation" course.
In May 2018 Microsoft patched an interesting vulnerability (CVE-2018-0824) which was reported by Nicolas Joly of Microsoft's MSRC:
A remote code execution vulnerability exists in "Microsoft COM for Windows" when it fails to properly handle serialized objects.
An attacker who successfully exploited the vulnerability could use a specially crafted file or script to perform actions. In an email attack scenario, an attacker could exploit the vulnerability by sending the specially crafted file to the user and convincing the user to open the file. In a web-based attack scenario, an attacker could host a website (or leverage a compromised website that accepts or hosts user-provided content) that contains a specially crafted file that is designed to exploit the vulnerability. However, an attacker would have no way to force the user to visit the website. Instead, an attacker would have to convince the user to click a link, typically by way of an enticement in an email or Instant Messenger message, and then convince the user to open the specially crafted file.
The security update addresses the vulnerability by correcting how "Microsoft COM for Windows" handles serialized objects.
The keywords "COM" and "serialized" pretty much jumped into my face when the advisory came out.
Since I had already spent several months of research time on Microsoft COM last year I decided to look into it. Although the vulnerability can result in remote code execution, I'm only interested in the privilege escalation aspects.
Before I go into details I want to give you a quick introduction into COM and how deserialization/marshalling works.
As I'm far from being an expert on COM, all this information is either based on the great book "Essential COM" by Don Box or the awesome Infiltrate '17 Talk "COM in 60 seconds".
I have skipped several details (IDL/MIDL, Apartments, Standard Marshalling, etc.) just to keep the introduction short.
Introduction to COM and Marshalling
COM (Component Object Model) is a Windows middleware having reusable code (=component) as a primary goal.
In order to develop reusable C++ code, Microsoft engineers designed COM in an object-oriented manner having the following key aspects in mind:
Portability
Encapsulation
Polymorphism
Separation of interfaces from implementation
Object extensibility
Resource Management
Language independence
COM objects are defined by an interface and implementation class.
Both interface and implementation class are identified by a GUID.
A COM object can implement several interfaces using inheritance.
All COM objects implement the IUnknown interface which looks like the following class definition in C++:
The QueryInterface() method is used to cast a COM object to a different interface implemented by the COM object.
The AddRef() and Release() methods are used for reference counting.
Just to keep it short I rather go on with an existing COM object instead of creating an artificial example COM object.
A Control Panel COM object is identified by the GUID {06622D85-6856-4460-8DE1-A81921B41C4B}. To find out more about the COM object we could analyze the registry manually or just use the great tool "OleView .NET".
The "Control Panel" COM object implements several interfaces as we can see in the screenshot of OleView .NET:
The implementation class of the COM object (COpenControlPanel) can be found in shell32.dll.
To open a "Control Panel" programmatically we make use of the COM API:
In line 6 we initialize the COM environment
In line 7 we create an instance of a "Control Panel" object
In line 8 we cast the instance to the IOpenControlPanel interface
In line 9 we open the "Control Panel" by calling the "Open" method
Inspecting the COM object in the debugger after running until line 9 shows us the virtual function table (vTable) of the object:
The function pointers in the vTable of the object point to the actual implementation functions in shell32.dll.
The reason for that is that the COM object was created as a so called InProc server which means that shell32.dll
got loaded into the current process address space. When passing CLSCTX_ALL, CoCreateInstance() tries to create an InProc server first.
If it fails, other activation methods are tried (see CLSCTX enumeration).
By changing the CLSCTX_ALL parameter to function CoCreateInstance() to CLSCTX_LOCAL_SERVER and running the program again we can notice some differences:
The vTable of the object contains now function pointers from the OneCoreUAPCommonProxyStub.dll.
And the 4th function pointer which corresponds to the Open()" method now points to OneCoreUAPCommonProxyStub!ObjectStublessClient3().
The reason for that is that we created the COM object as an out-of-process server.
The following diagram tries to give you an architectural overview (shamelessly borrowed from Project Zero):
The function pointers in the COM object point to functions of the proxy class.
When we execute the IOpenControlPanel::Open()" method, the method OneCoreUAPCommonProxyStub!ObjectStublessClient3() gets called on the proxy.
The proxy class itself eventually calls RPC methods (e.g. RPCRT4!NdrpClientCall3) to send the parameters to the RPC server in the out-of-process server.
The parameters need to get serialized/marshalled to send them over RPC.
In the out-of-process-server the parameters get deserialized/unmarshalled and the Stub invokes shell32!COpenControlPanel::Open().
For non-complex parameters like strings the serialization/marshalling is trivial as these are sent by value.
How about complex parameters like COM objects?
As we can see from the method definition of IOpenControlPanel::Open() the third parameter is a pointer to an IUnknown COM object:
The answer is that a complex object can either get marshalled by reference (standard marshalling) or the serialization/marshalling logic can be customized by implementing the IMarshal interface (custom marshalling).
The IMarshal interface has a few methods as we can see in the following definition:
During serialization/marshalling of a COM object the IMarshal::GetUnmarshalClass() method gets called by the COM which returns the GUID of the class to be used for unmarshalling.
Then the method IMarshal::GetMarshalSizeMax() is called to prepare a buffer for marshalling data.
Finally the IMarshal::MarshalInterface() method is called which writes the custom marshalling data to the IStream object.
The COM runtime sends the GUID of the "Unmarshal class" and the IStream object via RPC to the server.
On the server the COM runtime creates the "Unmarshal class" using the CoCreateInstance() function, casts it to the IMarshal interface using QueryInterface and eventually invokes the
IMarshsal::UnmarshalInterface() method on the "Unmarshal class" instance, passing the IStream as a parameter.
And that's also where all the misery starts ...
Diffing the patch
After downloading the patch for Windows 8.1 x64 and extracting the files, I found two patched DLLs related to Microsoft COM:
oleaut32.dll
comsvcs.dll
Using Hexray's IDA Pro and Joxean Koret's Diaphora I analyzed the changes made by Microsoft.
In oleaut32.dll several functions were changed but nothing special related to deserialisation/marshalling:
In comsvcs.dll only four functions were changed:
Clearly, one method stood out: CMarshalInterceptor::UnmarshalInterface().
The method CMarshalInterceptor::UnmarshalInterface() is the implementation of the UnmarshalInterface() method of the IMarshal interface.
As we already know from the introduction this method gets called during unmarshalling.
The bug
Further analysis was done on Windows 10 Redstone 4 (1803) including March patches (ISO from MSDN).
In the very beginning of the method CMarshalInterceptor::UnmarshalInterface() 20 bytes are read from the IStream object into a buffer on the stack.
Later the bytes in the buffer are compared against the GUID of the CMarshalInterceptor class (ECABAFCB-7F19-11D2-978E-0000F8757E2A).
If the bytes in the stream match we reach the function CMarshalInterceptor::CreateRecorder().
In function CMarshalInterceptor::CreateRecorder() the COM-API function ReadClassStm is called.
This function reads a CLSID(GUID) from the IStream and stores it into a buffer on the stack. Then the CLSID gets compared against the GUID of a CompositeMoniker.
As you may have already followed the different Moniker "vulnerabilities" in 2016/17 (URLMoniker, ScriptMoniker, SOAPMoniker), Monikers are definitely something you want to find in code which you might be able to trigger.
The IMoniker interface inherits from IPersistStream which allows a COM object implementing it to load/save itself from/to an IStream object. Monikers identify objects uniquely and can locate, activate and get a reference to the object by calling the BindToObject() method of the IMoniker instance.
If the CLSID doesn't match the GUID of the CompositeMoniker we follow the path to the right.
Here, the COM-API functionCoCreateInstance() is called with the CLSID read from the IStream as the first parameter. If COM finds the specific class and is able to cast it to an IMoniker interface we reach the next basic block. Next, the IPersistStream::Load() method is called on the newly created instance which restores the saved Moniker state from the IStream object.
And finally we reach the call to BindToObject() which triggers all evil ...
Exploiting the bug
For exploitation I'm following the same approach as described in the bug tracker issue "DCOM DCE/RPC Local NTLM Reflection Elevation of Privilege" by Project Zero.
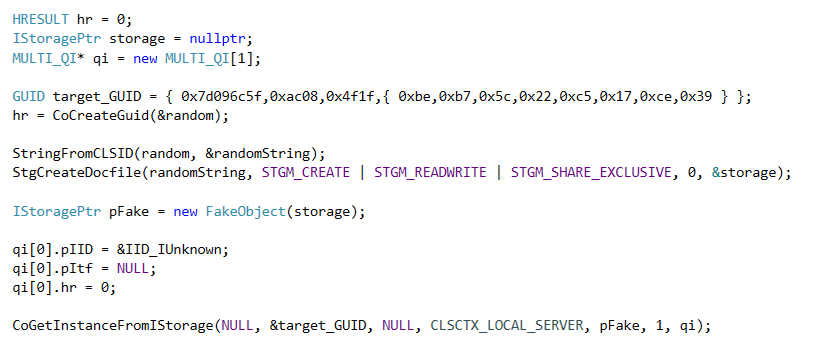
I'm creating a fake COM Object class which implements the IStorage and IMarshal interfaces.
All implementation methods for the IStorage interface will be forwarded to a real IStorage instance as we will see later.
Since we are implementing custom marshalling, the COM runtime wants to know which class will be used to deserialize/unmarshal our fake object.
Therefore the COM runtime calls IMarshal::GetUnmarshalClass(). To trigger the Moniker, we just need to return the GUID of the "QC Marshal Interceptor Class" class (ECABAFCB-7F19-11D2-978E-0000F8757E2A).
The final step is to implement the IMarshal::MarshalInterface() method. As you already know the method gets called by the COM runtime to marshal an object into an IStream.
To trigger the call to IMoniker::BindToObject(), we only need to write the required bytes to the IStream object to satisfy all conditions in CMarshalInterceptor::UnmarshalInterface().
I tried to create a Script Moniker COM object with CLSID {06290BD3-48AA-11D2-8432-006008C3FBFC} using CoCreateInstance(). But hey, I got a "REGDB_E_CLASSNOTREG" error code. Looks like Microsoft introduced some changes.
Apparently, the Script Moniker wouldn't work anymore. So I thought of exploiting the bug using the "URLMoniker/hta file".
But luckily I remembered that in the method CMarshalInterceptor::CreateRecorder() we had a check for a CompositeMoniker CLSID.
So following the left path, we have a basic block in which 4 bytes are read from the stream into the stack buffer (var_78). Next we have a call to CMarshalInterceptor::LoadAndCompose() with the IStream, a pointer to an IMoniker interface pointer and the value from the stack buffer as parameters.
.
In this method an IMoniker instance is read and created from the IStream using the OleLoadFromStream() COM-API function. Later in the method, CMarshalInterceptor::LoadAndCompose() is called recursively to compose a CompositeMoniker. By invoking IMoniker::ComposeWith() a new IMoniker is created being a composition of two monikers. The pointer to the new CompositeMoniker will be stored in the pointer which was passed to the current function as parameter. As we have seen in one of the previous screenshots the BindToObject() method will be called on the CompositeMoniker later on.
As I remembered from Haifei Li's blog post there was a way to create a Script Moniker by composing a File Moniker and a New Moniker.
Armed with that knowledge I implemented the final part of the IMarshal::MarshalInterface() method.
I placed a SCT file in "c:\temp\poc.sct" which runs notepad from an ActiveXObject.
Then I tried BITS as a target server first which didn't work.
Using OleView .NET I found out that BITS doesn't support custom marshalling (see EOAC_NO_CUSTOM_MARSHAL).
But the SearchIndexer service with CLSID {06622d85-6856-4460-8de1-a81921b41c4b} was running as SYSTEM and allowed custom marshalling.
So I created a PoC which has the following main() function.
The call to CoGetInstanceFromIStorage() will activate the target COM server and trigger the serialization of the FakeObject instance.
Since the COM-API function requires an IStorage as a parameter, we had to implement the IStorage interface in our FakeObject class.
After running the POC we finally have a "notepad.exe" running as SYSTEM.
Microsoft is now checking a flag read from the Thread-local storage. The flag is set in a different method not related to marshalling. If the flag isn't set, the function CMarshalInterceptor::UnmarshalInterface() will exit early without reading anything from the IStream.
Takeaways
Serialization/Unmarshalling without validating the input is bad. That's for sure.
Although this blog post only covers the privilege escalation aspect, the vulnerability can also be triggered from Microsoft Office or by an Active X running in the browser. But I will leave this as an exercise to the reader :-)
The following blog post introduces a new lateral movement technique that combines the power of DCOM and HTA. The research
on this technique is partly an outcome of our recent research efforts on COM Marshalling:
Marshalling to SYSTEM - An analysis of CVE-2018-0824.
Previous Work
Several lateral movement techniques using DCOM were discovered in the past by
Matt Nelson,
Ryan Hanson,
Philip Tsukerman and
@bohops. A good overview of all the known techniques can be found in the
blog post by Philip Tsukerman. Most of the existing techniques execute commands via
ShellExecute(Ex). Some COM objects provided by Microsoft Office allow you to execute script code (e.g VBScript) which
makes detection and forensics even harder.
LethalHTA
LethalHTA is based on a very well-known COM object that was used in all the Office Moniker attacks in the past (see
FireEye's blog post):
ProgID: "htafile"
CLSID : "{3050F4D8-98B5-11CF-BB82-00AA00BDCE0B}"
AppID : "{40AEEAB6-8FDA-41E3-9A5F-8350D4CFCA91}"
Using James Forshaw's
OleViewDotNet we get some details on the COM object. The COM object runs as local server.
It has an App ID and default
launch and
access permissions. Only COM objects having an App ID can be used for lateral movement.
It also implements various interfaces as we can see from OleViewDotNet.
One of the interfaces is
IPersistMoniker. This interface is used to save/restore a COM object's state to/from an
IMoniker instance.
Our initial plan was to create the COM object and restore its state by calling the
IPersistMoniker->Load() method with a
URLMoniker pointing to an HTA file. So we created a small program and run it in VisualStudio.
But calling
IPersistMoniker->Load() returned an error code
0x80070057. After some debugging we realized that the error code came from a call to
CUrlMon::GetMarshalSizeMax(). That method is called during custom marshalling of a URLMoniker. This makes perfect
sense since we called
IPersistMoniker->Load() with a URLMoniker as a parameter. Since we do a method call on a remote COM object the parameters
need to get (custom) marshalled and sent over RPC to the RPC endpoint of the COM server.
So looking at the implementation of
CUrlMon::GetMarshalSizeMax() in IDA Pro we can see a call to
CUrlMon::ValidateMarshalParams() at the very beginning.
At the very end of this function we can find the error code set as return value of the function. Microsoft is validating
the
dwDestContext parameter. If the parameter is
MSHCTX_DIFFERENTMACHINE (0x2) then we eventually reach the error code.
As we can see from the references to
CUrlMon::ValidateMarshalParams() the method is called from several functions during marshalling.
In order to bypass the validation we can take the same approach as described in our last
blog post: Creating a fake object. The fake object needs to implement
IMarshal and
IMoniker. It forwards all calls to the
URLMoniker instance. To bypass the validation the implementation methods for
CUrlMon::GetMarshalSizeMax,
CUrlMon::GetUnmarshalClass,
CUrlMon::MarshalInterface
need to modify the
dwDestContext parameter to MSHCTX_NOSHAREDMEM(0x1). The implementation for
CUrlMon::GetMarshalSizeMax() is shown in the following code snippet.
And that's all we need to bypass the validation. Of course we could also patch the code in
urlmon.dll. But that would require us to call
VirtualProtect() to make the page writable and modify
CUrlMon::ValidateMarshalParams() to always return zero. Calling
VirtualProtect() might get caught by EDR or "advanced" AV products so we wouldn't recommend it.
Now we are able to call the
IPersistMoniker->Load() on the remote COM object. The COM object implemented in
mshta.exe will load the HTA file from the URL and evaluate its content. As you already know the HTA file can contain
script code such as JScript or VBScript. You can even combine our technique with James Forshaw's
DotNetToJScript to run your payload directly from memory!
It should be noted that the file doesn't necessarily need to have the
hta file extension. Extensions such as
html,
txt,
rtf work fine as well as no extension at all.
LethalHTA and LethalHTADotNet
We created implementations of our technique in
C++ and
C#. You can run them as standalone programms. The C++ version is more a proof-of-concept and might help you creating
a reflective DLL from it. The C# version can also be loaded as an Assembly with
Assembly.Load(Byte[]) which makes it easy to use it in a Powershell script. You can find both implementations under
releases on our
GitHub.
CobaltStrike Integration
To be able to easily use this technique in our day-to-day work we created a Cobalt Strike Aggressor Script called
LethalHTA.cna that integrates the .NET implementation (LethalHTADotNet) into Cobalt Strike by providing two distinct
methods for lateral movement that are integrated into the GUI, named
HTA PowerShell Delivery (staged - x86)
and
HTA .NET In-Memory Delivery (stageless - x86/x64 dynamic)
The
HTA PowerShell Delivery method allows to execute a PowerShell based, staged beacon on the target system. Since the
PowerShell beacon is staged, the target systems need to be able to reach the HTTP(S) host and TeamServer (which are in
most cases on the same system).
The
HTA .NET In-Memory Delivery takes the technique a step further by implementing a memory-only solution that provides
far more flexibility in terms of payload delivery and stealth. Using the this option it is possible to tunnel the HTA
delivery/retrieval process through the beacon and also to specify a proxy server. If the target system is not able to
reach the TeamServer or any other Internet-connected system, an
SMB listener can be used instead. This allows to reach systems deep inside the network by bootstrapping an SMB beacon
on the target and connecting to it via named pipe from one of the internal beacons.
Due to the techniques used, everything is done within the
mshta.exe process without creating additional processes.
The combination of two techniques, in addition to the HTA attack vector described above, is used to execute everything in-memory.
Utilizing
DotNetToJScript, we are able to load a small .NET class (SCLoader) that dynamically determines the processes architecture (x86 or x64) and then executes the included stageless
beacon shellcode. This technique can also be re-used in other scenarios where
it is not apparent which architecture is used before exploitation.
For a detailed explanation of the steps involved visit our
GitHub Project.
Detection
To detect our technique you can watch for files inside the INetCache (%windir%\[System32 or SysWOW64]\config\systemprofile\AppData\Local\Microsoft\Windows\INetCache\IE\) folder containing
"ActiveXObject". This is due to
mshta.exe caching the payload file. Furthermore it can be detected by an
mshta.exe process spawned by
svchost.exe.
This blog post describes how to bypass Microsoft's AMSI (Antimalware Scan Interface) in Excel using VBA (Visual Basic for Applications). In contrast to other bypasses this approach does not use hardcoded offsets or opcodes but identifies crucial data on the heap and modifies it. The idea of an heap-based bypass has been mentioned by other researchers before but at the time of writing this article no public PoC was available. This blog post will provide the reader with some insights into the AMSI implementation and a generic way to bypass it.
Introduction
Since Microsoft rolled out their AMSI implementation many writeups about
bypassing the implemented mechanism have been released. Code White
regularly conducts Red Team scenarios where phishing plays a great role.
Phishing is often related to MS Office, in detail to malicious scripts
written in VBA. As per Microsoft AMSI
also covers VBA code placed into MS Office documents. This fact
motivated some research performed earlier this year. It has been evaluated
if and how AMSI can be defeated in an MS Office Excel environment.
In the past several different approaches have been published to bypass AMSI. The following links contain information which were used as inspiration or reference:
The first article from the list above also mentions a heap-based approach. Independent from that writeup, Code White's approach used exactly that idea. During the time of writing this article there was no code publicly available which implements this idea. This was another motivation to write this blog post. Porting the bypass to MS Excel/VBA revealed some nice challenges which were to be solved. The following chapters show the evolution of Code White's implementation in a chronological way:
Implementing our own AMSI Client in C to have a debugging platform
Understanding how the AMSI API works
Bypassing AMSI in our own client
Porting this approach to VBA
Improving the bypass
Improving the bypass - making it production-ready
Implementing our own AMSI Client
In order to ease debugging we will implement our own small AMSI client in C which triggers a scan on the malicious string ‘amsiutils’. This string gets flagged as evil since some AMSI Bypasses of Matt Graeber used it. Scanning this simple string depicts a simple way to check if AMSI works at all and to verify if our bypass is functional. A ready-to-use AMSI client can be found on sinn3r's github . This code provided us a good starting point and also contained important hints, e.g. the pre-condition in the Local Group Policies.
We will implement our test client using Microsoft Visual Studio Community 2017. In a first step, we end up with two functions, amsiInit() and amsiScan(), not to be confused with functions exported by amsi.dll. Later we will add another function amsiByPass() which does what its name suggests. See this gist for the final code including the bypass.
Running the program generates the following output:
This means our ‘amsiutils’ is considered as evil. Now we can proceed working on our bypass.
Understanding AMSI Structures
As promised we would like to do a heap-based bypass. But why heap-based?
At first we have to understand that using the AMSI API requires initializing a so called AMSI Context (HAMSICONTEXT). This context must be initialized using the function AmsiInitialize(). Whenever we want to scan something, e.g. by calling AmsiScanBuffer(), we have to pass our context as first parameter. If the data behind this context is invalid the related AMSI functions will fail. This is what we are after, but let's talk about that later.
Having a look at HAMSICONTEXT we will see that this type gets resolved by the pre-processor to the following:
So what we got here is a pointer to a struct called ‘HAMSICONTEXT__’. Let's have a look where this pointer points to by printing the memory address of ‘amsiContext’ in our client. This will allow us to inspect its contents using windbg:
The variable itself is located at address 0x16a144 (note we have 32-bit program here) and its content is 0x16c8b10, that's where it points to. At address 0x16c8b10 we see some memory starting with the ASCII characters ‘AMSI’ identifying a valid AMSI context. The output below the memory field is derived via ‘!address’ which prints the memory layout of the current process.
There we can see that the address 0x16c8b10 is allocated to a region starting from 0x16c0000 to 0x16df0000 which is identified as Heap. Okay, that means AmsiInitialize() delivers us a pointer to a struct residing on the heap. A deeper look into AmsiInitialize() using IDA delivers some evidence for that:
The function allocates 16 bytes (10h) using the COM-specific API CoTaskMemAlloc(). The latter is intended to be an abstraction layer for the heap. See here and here for details. After allocating the buffer the Magic Word 0x49534D41 is written to the beginning of the block, which is nothing more than our ‘AMSI’ in ASCII.
It is noteworthy to say that an application cannot easily change this behavior. The content of the AMSI context will always be stored on the heap unless really sneaky things are done, like copying the context to somewhere else or implementing your own memory provider. This explains why Microsoft states in their API documentation, that the application is responsible to call AmsiUnitialize() when it is done with AMSI. This is because the client cannot (should not) free that memory and the process of cleaning up is performed by the AMSI library.
Now we have understood that
the AMSI Context is an important data structure
it is always placed on the heap
it always starts with the ASCII characters ‘AMSI’
In case our AMSI context is corrupt, functions like AmsiScanBuffer() will fail with a return value different from zero. But what does corrupt mean, how does AmsiScanBuffer() detect if the context is valid? Let's check that in IDA:
The function does what we already spoilered in the beginning: The first four bytes of the AMSI Context are compared against the value ‘0x49534D41’. If the comparison fails, the function returns with 0x80070057 which does not equal 0 and tells something went wrong.
Bypassing AMSI in our own AMSI Client
Our heap-based approach assumes several things to finally depict a so called bypass:
we have already code execution in the context of the AMSI client, e.g. by executing a VBA script
The AMSI client (e.g. Excel) initializes the AMSI context only once and reuses this for every AMSI operation
the AMSI client rates the checked payload in case of a failure of AmsiScanBuffer() as ‘not malicious
The first point is not true for our test client but also not required because it depicts only a test vehicle which we can modify as desired.
Especially the last point is important because we will try to mess up the one and only AMSI context available in the target process. If the failure of AmsiScanBuffer() leads to negative side effects, in worst case the program might crash, the bypass will not work.
So our task is to iterate through the heap of the AMSI client process, look for chunks starting with ‘AMSI’ and mess this block up making all further AMSI operations fail.
Microsoft provides a nice code example which walks through the heap using a couple of functions from kernel32.dll.
Due to the fact that all the required information is present in user space one could do this task by parsing data structures in memory. Doing so would make the use of external functions obsolete but probably blow up our code so we decided to use the functions from the example above.
After cutting the example down to the minimum functionality we need, we end up with a function amsiByPass().
So this code retrieves the heap of the current process, iterates through it and looks at every chunk tagged as 'busy'. Within these busy chunks we check if the first bytes match our magic pattern ‘AMSI’ and if so overwrite it with some garbage.
The expectation is now that our payload is no longer flagged as malicious but the AmsiScanBuffer() function should return with a failure. Let's check that:
Okay, that's exactly what we expected. Are we done? No, not yet as we promised to provide an AMSI bypass for EXCEL/VBA so let's move on..
Bypassing AMSI in Excel using VBA
Now we will dive into the strange world of VBA. We used Microsoft Excel for Office 365 MSO (16.0.11727.20222) 32-bit for our testing.
After having written a basic POC in C we have to port this POC to VBA. VBA supports importing arbitrary external functions from DLLs so using our Heap APIs should be no problem. As far as we understood VBA, it does not allow pointer arithmetic or direct memory access. This problem can be resolved by importing a function which allows copying data from arbitrary memory locations into VBA variables. A very common function to perform this task is RtlMoveMemory().
After some code fiddling we came up with the following code.
As you can see we put some time measurement around the main loop. The number of rounds the loop may take can be several hundred thousand iterations and in addition with the poor VBA performance we expected a significant amount of time the bypass will take. Time is a crucial thing in a real attack scenario. If our phishing victim opens a malicious Excel sheet it is not acceptable that the embedded script blocks the execution for let's say more than one or two seconds. At least after 5 seconds of perceived unresponsiveness of the application a human will get impatient and do things like trying to close Excel, which is not what we want.
So let's see how long the bypass will take. To be honest, we did not expect what was happening. The result was difficult to reproduce but the measured runtime varied from 15 minutes to endless. In some rare cases Excel was closed after some minutes without any further notice. This was probably because it was unresponsive for too long. However, this isn't really something we can use in a real scenario.
Okay so what went wrong here? Is VBA really that slow? Yes, it is some orders of magnitude slower than our C code, but that does not explain what we experienced. Microsoft gives some internal details on how AMSI is implemented in Excel. It turns out that Excel uses another strategy as e.g. PowerShell does. The latter more or less sends the whole script to AmsiScanBuffer(). Excel implements a little smarter approach which is based on so called triggers. Microsoft considers pure VBA code to be harmless until the point when imports come into play. That's exactly what we do - importing functions from external DLLs. Some of these imports are treated as potentially dangerous and their call including all parameters are put into a ring buffer which is sent to AMSI. This gives AV solutions like MS defender the opportunity to check data behind addresses which of course makes sense. Let's see what data is sent to the AMSI API in our explicit case by breaking on AmsiScanBuffer using windbg:
As we can see the ring buffer contains all functions we imported including their parameter values. Our Windows 10 System has MS Defender installed and activated. So every call to AmsiScanBuffer() will bother our friend MS Defender. AMSI is implemented as In-process COM in the first place. But to finally communicate with other AV solutions it has to transport data out of process and perform a context switch. This can be seen on the next architecture overview provided by MS:
The little green block on the bottom of the figure shows that our process (Excel) indirectly communicates via rpc with Defender. Hmm... Okay so this is done several 100k times, which is just too much and explains the long runtime. To provide some more evidence we repeat the bypass with Defender switched off, which should significantly speed up our bypass. In addition to that we monitor the amount of calls to AmsiScanBuffer() so we can get an impression how often it is called.
The same loop with Defender disabled took something between one and two minutes:
In a separate run we check the amount of calls to AmsiScanBuffer() using windbg:
AmsiScanBuffer() is called 124624 times (0x10000000 - 0xffe1930) which is roughly the amount of iterations our loop did. That's a lot and underlines our assumptions that AMSI is just called very often. So we understood what is going on, but currently there seems no workaround available to solve our runtime problem.
Giving up now? Not yet...
Improving AMSI Bypass in Excel
As described in the chapter above our current approach is much too slow to be used in a real scenario. So what can we do to improve this situation?
One of the functions we imported is RtlMoveMemory() which is as mentioned earlier used by a lot of malware. Monitoring this function would make a lot of sense and it might be considered as trigger. Let's verify that by just removing the call to CopyMem (the alias for RtlMoveMemory) and see what happens. This prevents our bypass from working but it might give us some insight.
The runtime is now at 0.8 seconds. Wow okay, this really made a change. It shall be noted that in this configuration we even walk through the whole heap. Due to the missing call to RtlMoveMemory() we will not find our pattern.
After we identified our bottleneck, what can we do? We will have to find an alternative method to access raw memory which is not treated as trigger by Excel. Some random Googling revealed the following function: CryptBinaryToStringA() which is part of crypt32.dll. The latter should be present on most Windows systems and thus it should be okay to import it.
The function is intended to convert strings from one format to another but it can also be used to just simply copy bytes from an arbitrary memory position we specify. Cool, that's exactly what we are after! In order to abuse this function for our purpose we call it like that to read the lpData field from the Process Heap Entry structure:
The input parameter from left to right explained:
phe.lpData is the source we want to copy data from,
ByVal 4 is the length of bytes we want to copy (lpData is 32-bit on our 32-bit Excel)
ByVal 2 means we want to copy raw binary (CRYPT_STRING_BINARY)
ByVal VarPtr(magicWord) is the target we want to copy that memory to (our VBA variable magicWord)
the last parameter (ByVal VarPtr(bytesWritten)) tells us how many bytes were really copied
So let's replace all occurrences of RtlMoveMemory() with CryptBinaryToStringA() and check again how long our bypass takes. You can find an updated version of the source code right here.
Our loop now takes about four seconds to finish, that is still much but it finished and it told us that it found the pattern we are looking after. Let's see how many times Excel calls AmsiScanBuffer() now with this version:
Oh my... Excel did not call AmsiScanBuffer() at all. So this means as long as there is no trigger in our code, nothing is sent to AMSI. Or the other way around: As soon as we use one single trigger function, Excel will send all calls to AMSI. Good to know...
This is the first time we can really verify if the bypass works. So let's look for some code which triggers AMSI from VBA. Iliya Dafchev shows some port of an older AMSI Bypass to VBA which gets flagged by AMSI itself in the first place. Perfect, we will put this code into a function called triggerAMSI() and use it as positive test:
After running it Excel complains as expected with a warning and just closes our current instance of Excel:
AMSI Alert by Excel - sorry for the German!
Putting our bypass and our positive test together we get the following function:
Hopes are high, that the message box containing “we survived” gets displayed because we killed AMSI before triggering it.
Great, our bypass seems to work. So let's put this into our real phishing campaign. Uhm.. just wait, how long did the whole thing take? four seconds? Repeated execution of the bypass even showed runtimes greater than ten seconds. Oh no, this is still too much.
Giving up now? Not yet...
Improving AMSI Bypass in Excel - continued
In the last chapter we improved our AMSI bypass from infinite runtime to ten seconds or below. This seems to be still too much for a real campaign (our opinion). So what can we do to speed up the whole thing one more time?
The loop takes some 100k iterations which is done in C in no time. Defender is completely out of the game. So our current runtime seems to be a pure result of the bad VBA performance. To be fair, these kind of things we are currently trying to do are not a typical VBA task so let's blame us instead of Excel for doing crazy stuff...
Anyway, what can we do now? Programming C in VBA is not an option, but what about invoking some shellcode? As long as we can import arbitrary functions the execution of shellcode should not be a problem. This code snippet shows an example how to do that within VBA. The next step is converting our VBA code (or more our initial C code) into assembly language, that is, into shellcode.
Everyone who ever wrote some pieces of shellcode and wanted to call functions from DLLs knows that the absolute addresses of these functions are not known during the time the shellcode gets assembled. This means we have to implement a mechanism like GetProcAddress() to lookup the addresses of required functions during runtime. How to do this without any library support is well understood and extensively documented so we will not go into details here. Implementing this part of the shellcode is left as an excercise for the reader.
Of course there are many ready to use code snippets which should do the job, but we decided to implement the shellcode on our own. Why? Because it is fun and self written shellcode should be unlikely to get caught by AV solutions.
The main loop of our AMSI bypass in assembly can be found here.
The structure ShellCodeEnvironment holds some important information like the looked up address of our HeapWalk() and GetProcessHeaps() function. The rest of the loop should be straight forward...
So putting everything together we generate our shellcode, put it into our VBA code and start it from there as new thread. Of course we measure the runtime again:
This time it is only 0.02 seconds!
We think this result is more than acceptable. The runtime may vary depending on the processor load or the total heap size but it should be significantly below one second which was our initial goal.
Summary
We hope you enjoyed reading this blog post. We showed the feasibility of a heap-based AMSI bypass for VBA. The same approach, with slight adaptions, also works for PowerShell and .Net 4.8. The latter also comes with AMSI support integrated in its Common Language Runtime. As per Microsoft AMSI is not a security boundary so we do not expect that much reaction but are still curious if MS will develop some detection mechanisms for this idea.
On April 25, 2020, Sophos published a knowledge base
article (KBA) 135412 which warned about a
pre-authenticated SQL injection (SQLi) vulnerability, affecting the XG Firewall
product line. According to Sophos this issue had been actively exploited at
least since April 22, 2020. Shortly after the knowledge base article, a detailed analysis of the so called Asnarök operation
was published. Whilst the KBA focused solely on the SQLi, this write up clearly indicated
that the attackers had somehow extended this initial vector to achieve remote code execution (RCE).
The criticality of the vulnerability prompted us to immediately warn our clients of the issue.
As usual we provided lists of exposed and affected systems.
Of course we also started an investigation into the technical details of the vulnerability.
Due to the nature of the affected devices and the prospect of RCE, this vulnerability sounded like a perfect candidate for a perimeter breach in upcoming red team assessments.
However, as we will explain later, this vulnerability will most likely not be as useful for this task as we first assumed.
Our analysis not only resulted in a working RCE
exploit for the disclosed vulnerability (CVE-2020-12271) but also led to the discovery of
another SQLi, which could have been used to gain code execution (CVE-2020-15504). The
criticality of this new vulnerability is similar to the one used in the
Asnarök campaign: exploitable pre-authentication either via an exposed
user or admin portal. Sophos quickly reacted to our bug report, issued
hotfixes for the supported firmware versions and released new firmware
versions for v17.5 and v18.0 (see also the Sophos Community Advisory).
I am Groot
The lab environment setup will not be covered
in full detail since it is pretty straight forward to deploy a virtual XG
firewall. Appropriate firmware ISOs can be obtained from the official download
portal. What is notable is the fact that the firmware allows administrators direct root shell access via the serial interface, the
TelnetConsole.jsp in the web interface or the SSH server. Thus there was
no need to escape from any restricted shells or to evade other
protection measures in order to start the analysis.
Device
Management -> Advanced Shell -> /bin/sh as root.
After getting familiar with the filesystem layout,
exposed ports and running processes we suddenly noticed a message in the XG
control center informing us that a hotfix for the n-day vulnerability, we were
investigating, had automatically been applied.
Control Center after the
automatic installation of the hotfix (source).
We leveraged this behavior to create a file-system
snapshot before and after the hotfix. Unfortunately diffing the web root
folders in both snapshots (aiming for a quick win) resulted in only one changed
file with no direct indication of a fixed SQL operation.
Architecture
In order to understand the hotfix, it was
necessary to delve deep into the underlying software architecture. As the
published information indicated that the issue could be triggered via the web
interface we were especially interested in how incoming HTTP requests
were processed by the appliance.
Both web interfaces (user and admin) are based
on the same Java code served by a Jetty server behind an Apache server.
Jetty
server on port 8009 serving /usr/share/webconsole.
Most interface interactions (like a login
attempt) resulted in a HTTP POST request to the endpoint
/webconsole/Controller. Such a request contained at least two
parameters: mode and json. The former specified a number which was
mapped internally to a function that should be invoked. The latter specified the
arguments for this function call.
Login
request sent to /webconsole/Controller via XHR.
The corresponding Servlet checked if the
requested function required authentication, performed some basic parameter
validation (code was dependent on the called function) and transmitted a message
to another component - CSC.
This message followed a custom format and was
sent via either UDP or TCP to port 299 on the local machine (the firewall). The
message contained a JSON object which was similar but not identical to the
json parameter provided in the initial HTTP request.
JSON
object sent to CSC on port 299.
The CSC component (/usr/bin/csc) appeared to be
written in C and consisted of multiple sub modules (similar to a busybox
binary). To our understanding this binary is a service manager for the firewall
as it contained, started and controlled several other jobs. We encountered a
similar architecture during our Fortinet research.
Multiple
different processes spawned by the CSC binary.
CSC parsed the incoming JSON object and called
the requested function with the provided parameters. These functions however,
were implemented in Perl and were invoked via the Perl C language interface.
In order to do so, the binary loaded and decrypted an XOR encrypted file
(cscconf.bin) which contained various config files and Perl packages.
Another essential part of the architecture were
the different PostgreSQL database instances which were used by the web interface,
the CSC and the Perl logic, simultaneously.
The
three PostgreSQL databases utilized by the appliance.
High
level overview of the architecture.
Locating the Perl logic
As mentioned earlier, the Java component
forwarded a modified version of the JSON parameter (found in the HTTP
request) to the CSC binary. Therefore we started by having a closer look at
this file. A disassembler helped us to detect the different sub modules which
were distributed across several internal functions, but did not reveal any logic
related to the login request. We did however find plenty of imports related to
the Perl C language interface. This led us to the assumption that the relevant
logic was stored in external Perl files, even though an intensive search on the
filesystem had not returned anything useful. It turned out, that the missing Perl
code and various configuration files were stored in the encrypted tar.gz
file (/_conf/cscconf.bin) which was decrypted and extracted during the
initialization of CSC. The reason why we previously could not locate the decrypted files
was that these could only be found in a separate linux namespace.
As can be seen in the screenshot below the
binary created a mount point and called the unshare
syscall with the flag parameter set to 0x20000. This constant translates
to the CLONE_NEWNS flag, which disassociates the process from the
initial mount namespace.
For those unfamiliar with Linux namespaces: in
general each process is associated with a namespace and can only see, and thus
use, the resources associated with that namespace. By detaching itself from the
initial namespace the binary ensures that all files created after the
unshare syscall are not propagated to other processes. Namespaces
are a feature of the Linux kernel and container solutions like docker heavily rely on them.
Calling
unshare, to detach from the initial namespace, before extracting the
config.
Therefore even within a root shell we were not
able to access the extracted archive. Whilst multiple approaches exist to
overcome this, the most appealing at that point was to simply patch the
binary. This way, it was possible to copy the extracted config to a
world-writable path. In hindsight, it would probably have been easier to just scp
nsenter to the appliance.
Accessing the decrypted and extracted files by jumping into the
namespace of the CSC binary.
From a handful of information to the N-Day
(CVE-2020-12271)
The rolled out hotfix boiled down to the
modification of one existing function (_send) and the introduction of
two new functions (getPreAuthOperationList and
addEventAndEntityInPayload) in the file
/usr/share/webconsole/WEB-INF/classes/cyberoam/corporate/CSCClient.class.
The function getPreAuthOperationList
defined all modes which can be called unauthenticated. The function
addEventAndEntityInPayload checks if the mode specified in the request
is contained in the preAuthOperationsList and removes the Entity
and Event keys from the JSON object if that is the case.
Analysis
Based on the hotfix we assumed that the
vulnerability must reside within one of the functions specified in the
getPreAuthOperationList. However, after browsing through the relevant
Perl code in order to find blocks that made use of the Entity or
Event key, we were pretty confident that this was not the case.
What we did notice though is that regardless of
which mode we specify, every request was processed by the apiInterface
function. Sophos denoted the functions mapped to the mode parameter internally
as opcodes.
The apiInterface function was also the
place where we finally found the SQLi vulnerability aka execution of
arbitrary SQL statements. As is depicted in the source excerpt below, this
opcode called the executeDeleteQuery function (line 27) which took a SQL
statement from the query parameter and ran it against the database.
Unfortunately, in order to reach the vulnerable
code, our payload needed to pass every preceding CALL statement which
enforced various conditions and properties on our JSON object.
The first call (validateRequestType)
required that Entity was not set to securitypolicy and that the
request type was ORM after the call.
The preceding call
(variableInitialization) initialized the Perl environment and should
always succeed. In order to keep our request simple and not to introduce
additional requirements, the Entity value in our payload should not be one of
the following: securityprofile, mtadataprotectionpolicy,
dataprotectionpolicy, firewallgroup, securitypolicy, formtemplate or
authprofile. This allowed us to skip the checks performed in the function
opcodePreProcess.
The checkUserPermission function does
what its name suggests. Whereas, the function body that can be seen below is
only executed if the JSON object passed to Perl included a __username
parameter. This parameter was added by the Java component before the request was
forwarded to the CSC binary, if the HTTP request was associated with a valid
user session. Since we used an unauthenticated mode in our payload, the
__username parameter was not set and we could ignore the respective
code.
To skip over the preMigration call we
just had to choose a mode which was unequal to 35 (cancel_firmware_upload),
36 (multicast_sroutes_disable) or 1101 (unknown). On top of that all
three modes required authentication making them unusable for our purposes,
anyway.
Depending on the request type, the function
createModeJSON employed a different logic to load the Perl module
connected to the specified entity. Whereas each POST request initially started
as ORM request, we needed to be careful that the request type was not
changed to something else. This was required to satisfy the last if statement
before the vulnerable function was called inside the apiInterface
function. Therefore the condition on line 15 had to be not satisfied. The
respective code checked if the request type specified in the loaded Perl module
equaled ORM. We leave the identification of such an Entity as an exercise
to the interested reader.
We skipped the call to the
migrateToCurrVersion function since it was not important for our chain.
The next call to createJson verified if the previously loaded Perl
package could actually be initialized and would always work as long as it referred to an
existing Entity.
The function handleDeleteRequest once
again verified that the request type was ORM. After removing duplicate
keys from our JSON, it ensured that our JSON payload contained a name
key. The code then looped through all values which were specified in our
name property and searched for foreign references in other database
tables in order to delete these. Since we did not want to delete any existing
data we simply set the name to a non-existing value.
We skipped the last two function calls to
replyIfErrorAtValidation and getOldObject because they were not
relevant to our chain and we had already walked through enough Perl code.
What did we learn so far?
We need a mode which can be called
from an unauthenticated perspective.
We should not use certain Entities.
Our
request needed to be of type $REQUEST_TYPE{ORMREQUEST}.
The
request had to contain a name property which held some garbage value.
The EventProperties of the loaded Entity, and in particular the
DELETE property, had to set the ORM value to true.
Our
JSON object had to contain a query key which held the actual SQL statement we
wanted to execute.
When we satisfied all of the above conditions we
were able to execute arbitrary SQL statements. There was only one caveat: we could
not use any quotes in our SQL statements since the csc binary properly
escaped those (see the escapeRequest sub 0-day chapter for details). As a workaround we defined
strings with the help of the concat and chr SQL functions.
From SQLi to RCE
Once we had gained the ability to modify the
database to our needs, there were quite a few places where the SQLi could be
expanded into an RCE. This was the case because parameters contained within the database were passed
to exec calls without sanitation in multiple instances. Here we will only
focus on the attack path which was, based on our understanding and the details
released in Sophos' analysis, used during the Asnarök campaign.
According to the published information, the
attackers injected their payloads in the hostname field of the Sophos
Firewall Manager (SFM) to achive code execution. SFM is a separate
appliance to centrally manage multiple appliances. This raised the question:
what happens in the back end if you enable the central administration?
To locate the database values related to the
SFM functionality we dumped the database, enabled SFM in the front end,
and created another dump. A diff of the dumps was then used to identify the
changed values. This approach revealed the modification of multiple database
rows. The attribute CCCAdminIP in the table
tblclientservices was the one used by the attackers to inject their
payload. A simple grep for CCCAdminIP directed us to the function
get_SOA in the Perl code.
As can be seen on line 15, the code retrieves the
value of the CCCAdminIP from the database and passes it
unfiltered into the EXECSH call on line 22. Due to some kind of cronjob
the get_SOA opcode is executed regularly leading to the automatic
execution of our payload.
What made this particular attack chain very
unfortunate was the if condition on line 11, as it allowed us to reach the EXECSH
call only if the automatic installation of hotfixes is active (which is the
default setting) and if the appliance is configured to use SFM for central management (which is not the default setting). This resulted in a situation in which the attackers most likely
only gained code execution on devices with activated auto-updates - leading to
a race condition between the hotfix installation and the moment of exploitation.
Installations that do not have automatic hotfixes enabled or have not moved to the latest supported maintenance releases could still be vulnerable.
Gaining
code execution via the SQLi described in
CVE-2020-12271.
From N to Zero (CVE-2020-15504)
Another promising approach for discovery of the
n-day, instead of starting at a patch diff, seemed to be an analysis of all
back end functions (callable via the /webconsole/Controller
endpoint) which did not require authentication. The respective function numbers
could, for example, be extracted from the Java function
getPreAuthOperationList.
SQL-Injection countermeasures inside the Perl
logic
Despite of the fact that the back end performed
all its SQL operations without prepared-statements, those were not automatically
susceptible to injection.
The reason for this was, that all function
parameters coming in via port 299 were automatically escaped via the
escapeRequest function before being processed.
So everything is safe?
One function which caught our attention was
RELEASEQUARANTINEMAILFROMMAIL (NR 2531) as the corresponding logic
silently bypassed the automatic escaping. This happened because the function
treated one of the user-controllable parameters as a Base64 string and used this
parameter, decoded, inside a SQL statement. As the global escaping took place
before the function was actually called, it only ever saw the encoded string and
thus missed any included special characters such as single quotes.
After the parameter was decoded, it was split into
different variables. This was done by parsing the string based on the
key=value syntax used in HTTP requests. We were concentrating on the
hdnFilePath variable, as its value did not need to satisfy any
complicated conditions and ended up in the SQL statement later on.
The only constraint for
$requestData{hdnFilePath} was, that it did not contain the sequence
../ (which was irrelevant for our purposes anyway). After crafting a release
parameter in the appropriate format we were now able to trigger a SQLi in
the above SELECT statement. We had to be careful to not
break the syntax by taking into account that the manipulated parameter was
inserted six times into the query.
Triggering a database sleep
through the discovered SQL-I (6s delay as the sleep command was injected 6 times).
Upgrading the boring Select statement
The ability to trigger a sleep enables an
attacker to use well known blind SQLi techniques to read out arbitrary database
values. The underlying Postgres instance (iviewdb) differed from
the one targeted in the n-day. As this database did not seem to store any
values useful for further attacks, another approach was chosen.
With the code-execution technique used
by Asnarök in mind, we aimed for the execution of an INSERT operation alongside a SELECT.
In theory, this should be easily achievable by using stacked queries.
After some experimentation, we were able to confirm that stacked queries were
supported by the deployed Postgres version and the used database API. Yet, it
was impossible to get it to work through the SQLi. After some frustration,
we found out that the function iviewdb_query (/lib/libcscaid.so)
called the escape_string (/usr/bin/csc) function before submitting the
query. As this function escaped all semicolons in the SQL statement, the use of
stacked queries was made impossible.
Giving up yet?
At this point, we were able to
trigger an unauthenticated SQL Injection in a SELECT statement in the
iviewdb database, which did not provide us with any meaningful starting points for an escalation to RCE.
Not wanting to abandon the goal of achieving code execution we brainstormed for other approaches.
Eventually we came up with the following idea - what if we modified our payload in such a
way that the SQL statement returned values in the expected form? Could this
allow us to trigger the subsequent Perl logic and eventually reach a point where
a code execution took place? Constructing a payload which enabled us to return arbitrary
values in the queried columns took some attempts but succeeded in the end.
Execution of a SELECT statement which returns values specified inside
the payload.
After we had managed to construct such a payload we
concentrated on the subsequent Perl logic. Looking at the source we found a
promising EXEC call just after the database query. And one of the
parameters for that call was derived from a variable under user control.
Unfortunately, the variable $g_ha_mode
(most likely related to the high availability feature) was set to false
in the default configuration. This prompted us to look for a better way.
The function mergequarantine_manage did not contain any further
exec calls but triggered two other Perl functions in the same file, under the
right conditions. Those functions were triggered via the
apiInterface opcode which generated a new CSC request on port 299.
In our case $request->{action} was
always set to release restricting us to a call to
manage_quarantine. This function used its submitted parameters
(result-set from the query in mergequarantine_manage) to trigger another
SELECT statement. When this statement returned matching values an EXEC
call was triggered, which got one of the returned values as a parameter.
The question now was how the result-set of
the second SELECT statement could be manipulated through the result-set of
the first statement?
How about returning values in the first query which would trigger
a SQLi in the second statement? Because string concatenation was used to construct the statement this should have been possible in theory.
Unfortunately, we were unable to obtain the desired results. This was after having invested quite a bit of work to craft such a payload.
A brief analysis of how our payload was processed, revealed that it was somehow escaped before reaching the
second query.
As it turned out, the reason for this was actually pretty obvious. As the function
was triggered via a new CSC request, it automatically passed through the
previously described escape logic.
Time to accept our defeat and be happy with
the boring SQLi? Not quite...
Desperately looking for other ways to weaponize
the injection we dug deeper into the involved components. At an earlier stage
we already created a full dump of the iviewdb database but did not pay
too much attention to it after having realized that it did not include any useful
information. On revisiting the database, one of its features - so called user-defined
functions - heavily used by the appliance, stood out.
User-defined functions enable the extension of the
predefined database operations by defining your own SQL functions. Those can be
written in Postgres' own language: PL/pgSQL. What made such functions
interesting for our attack was, that previously defined functions could be called
in-line in SELECT statements. The call-syntax is the same as for any other SQL
function, i.e. SELECT my_function(param1, param2) FROM table;.
The idea at this point was, that one of the
existing user-defined functions might allow the execution of stacked queries.
This would be the case as soon as a parameter was used for a SQL statement without
proper filtering inside a function. Walking over the database dump revealed
multiple code blocks matching this characteristic and to our surprise an even simpler way to execute arbitrary statements - the function execute.
The respective code expected only one parameter which was directly executed as SQL
statement without any further checks.
This function would, in theory, allow us to
execute an INSERT statement inside the SELECT query of
mergequarantine_manage. This could be then used to add database rows to
the table tblquarantinespammailmerge which should later end up in the
exec call in manage_quarantine.
Triggering an INSERT statement
via the execute function from within a SELECT statement.
After fiddling around for quite some time we
were finally able to construct an appropriate payload (see below).
Explanation:
Line 1-2: Defining the two HTTP parameters needed for mode
2531.
Line 3-6: Defining the three Base64 encoded parameters, that are
needed to pass the initial checks in mergequarantine_manage.
Line 7: Triggering the SQLi by injecting a single quote.
Line
8-11: Utilizing the user-defined function execute in order to trigger
different SQL operations than the predefined SELECT.
Line 10: Adding
a new row to the table tblquarantinespammailmerge that contains our
code-execution payload in the field quarantinearea and sets messageid
to 'a'. Note the .eml portion inside the payload, which is
required to reach the exec call.
Line 9: Delete all rows
from tblquarantinespammailmerge where the messageid equals 'a'.
This ensures that the mentioned table contains our payload only once (remember
that the vector is injected 6x in the initial statement). Whereas this is not
absolutely necessary it simplifies the path taken after the SELECT statement in
manage_quarantine and prevents our payload to be executed multiple
times.
Line 12-14: Needed to comply with the syntax of the predefined
statement.
Using the above payload resulted in the
execution of the following Perl command:
So finally our job was done... but somehow there seemed to be no time delay, which would indicate that our
sleep has not actually triggered. But why? Did we not use exactly the same execution
mechanism as in the n-day? Turns out - not quite. Asnarök used
EXECSH we have EXEC. Unfortunately EXEC is treating
spaces in arguments correctly by passing them in single values to the script.
I assume we better bury our heads in the
sand
We had come to far to give up now, so we carried on.
Finally we were able to execute code through the SQLi and it was good ol' Perl which allowed us to do so.
Adding this last piece to the attack chain and
fixing a minor issue in the posted payload is left up to the reader.
Triggering a reverse shell by abusing the discovered vulnerability.
Timeline
04.05.2020 - 22:48 UTC: Vulnerability
reported to Sophos via BugCrowd.
04.05.2020 - 23:56 UTC: First reaction
from Sophos confirming the report receipt.
05.05.2020 - 12:23
UTC: Message from Sophos that they were able to reproduce the issue and are
working on a fix.
05.05.2020: Roll out of a first automatic hotfix by
Sophos.
16.05.2020 - 23:55 UTC: Reported a possible bypass for the
added security measurements in the hotfix.
21.05.2020: Second hotfix
released by Sophos which disables the pre-auth email quarantine release
feature.
June 2020: Release of firmware 18.0 MR1-1 which contains a
built-in fix.
July 2020: Release of firmware 17.5 MR13 which contains a built-in fix.
13.07.2020: Release of the blog post in accordance with the vendor after ensuring that the majority of devices either received the hotfix or the new firmware version.
We highly appreciate the quick response times,
very friendly communication as well as the hotfix feature.
This blog post describes the research on SAP J2EE Engine 7.50 I did between
October 2020 and January 2021. The first part describes how I set off to find a
pure SAP deserialization gadget, which would allow to leverage SAP's P4 protocol
for exploitation, and how that led me, by sheer coincidence, to an entirely
unrelated, yet critical vulnerability, which is outlined in part two.
The reader is assumed to be familiar with Java Deserialization and should have a
basic understanding of Remote Method Invocation (RMI) in Java.
Prologue
It was in 2016 when I first started to look into the topic of Java Exploitation, or,
more precisely: into exploitation of unsafe deserialization of Java objects.
Because of my professional history, it made sense to have a look at an SAP
product that was written in Java. Naturally, the P4 protocol of SAP NetWeaver
Java caught my attention since it is an RMI-like protocol for remote
administration, similar to Oracle WebLogic's T3. In May 2017, I published a
blog post about an exploit that was getting RCE by using the Jdk7u21 gadget. At
that point, SAP had already provided a fix long ago. Since then, the subject
has not left me alone. While there were new deserialization
gadgets for Oracle's Java server product almost every month, it surprised me no one ever heard of
an SAP deserialization gadget with comparable impact. Even
more so, since everybody who knows SAP software knows the vast amount of code
they ship with each of their products. It seemed very improbable to me that
they would be absolutely immune against the most prominent bug class in the
Java world of the past six years. In October 2020 I finally found the time and
energy to set off for a new hunt. To my great disappointment, the search was in
the end not successful. A gadget that yields RCE similar to the ones from the
famous ysoserial project is still not in sight. However in January, I found a
completely unprotected RMI call that in the end yielded administrative access
to the J2EE Engine. Besides the fact that it can be invoked through P4 it has
nothing in common with the deserialization topic. Even though a mere chance
find, it is still highly critical and allows to compromise the security of the underlying
J2EE server.
The bug was filed as CVE-2021-21481. On march 9th 2021, SAP provided a
fix. SAP note 3224022 describes the details.
P4 and JNDI
Listing 1 shows a small program that connects to a SAP J2EE server using P4:
The only hint that this code has something to do with a proprietary protocol
called P4 is the URL that starts with P4://. Other than that, everything is
encapsulated by P4 RMI calls (for those who want to refresh their memory about
JNDI).
Furthermore, it is not obvious that what is going on behind the scenes has
something to do with RMI. However, if you inspect more closely the types of the
involved Java objects, you'll find that keysMngr is of type
com.sun.proxy.$Proxy (implementing interface KeystoreManagerWrapper) and
keysMngr.getKeystore() is a plain vanilla RMI-call. The argument (the name
of the keystore to be instantiated) will be serialized and sent to the server
which will return a serialized keystore object (in this case it won't because
there is no keystore "whatever"). Also not obvious is that the instantiation
of the InitialContext requires various RMI calls in the background, for
example the instantiation of a RemoteLoginContext object that will allow to
process the login with the provided credentials.
Each of these RMI calls would in theory be a sink to send a
deserialization gadget to. In the exploit I mentioned above, one of the first
calls inside new InitialContext() was used to send the Jdk7u21 gadget
(instead of a java.lang.String object, by the way).
Now, since the Jdk7u21 gadget is not available anymore and I was looking for a
gadget consisting merely of SAP classes, I had to struggle with a very annoying
limitation: The classloader segmentation. SAP J2EE knows various types of
software components: interfaces, services, libraries and applications (which
can consist of web applications and EJBs). When you deploy a component, you
have to declare the dependencies to other components your component relies
upon. Usually, web applications depend on 2-3 services and libraries which will
have a couple of dependencies to other services and libraries, as well. At the
bottom of this dependency chain are the core components.
Now, the limitation I was talking about is the fact that the dependency
management greatly affects which classes a component can see: It can precisely
see all classes of all components it relies upon (plus of course JDK classes)
but not more. If your class ships as part of the keystore service above, it
will only be able to resolve classes from components the keystore service
declares as dependencies.
Figure 1: dependencies of the keystore service with all child and parent classloaders
This has dramatic consequences for gadget development. Suppose you found a
gadget whose classes come from components X, Y and Z but there are no
dependencies between these components and in addition, there is no component
which depends on all of them. Then, no matter in which classloader context your
gadget will be deserialized, at least one of X, Y or Z will be missing in the
classpath and the deserialization will end up in a ClassNotFoundException.
By using a similar approach to the one described in the GadgetProbe
project I found out that at the
point the Jdk7u21 gadget was deserialized in the above mentioned exploit, there
were only about 160 non-JDK classes visible that implement
java.io.Serializable. Not ideal for building an exploit.
Going back to listing 1, in case we send a gadget instead of the string
"whatever", we can tell from figure 1 that classes from ten components (the
ones listed beneath "Direct parent loaders") will be in the class path.
Code that sends an arbitrary serializable object instead of the string
"whatever" could e.g. look like this (instead of keysMgr.getKeystore()):
If there was a gadget, one could send it with out.writeObject().
With this approach, the critical mass of accessible serializable classes can be
significantly increased. The telnet interface of SAP J2EE provides useful
information about the services and their dependencies.
Regardless of the classloader challenge, I was eager to get an overview of how
many serializable classes existed in the server. The number of classes in the
core layer, services and libraries amounts to roughly 100,000, and this does
not even count application code. I quickly realized that I needed something
smarter than the analysis features of Eclipse to handle such volumes. So I
developed my own tool which analyses Java bytecode using the OW2 ASM
Framwork. It writes object and interface inheritance
dependencies, methods, method calls and attributes to a SQLite DB. It turned
out that out of the 100,000 classes, about 16,000 implemented
java.io.Serializable. The RDBMS approach was pretty handy since it allowed
build complex queries like
Give classes which are Serializable and Cloneable which implement private void readObject(java.io.ObjectInputStream) and whose toString() method exists and has more than five calls to distinct other methods
This question translates to
The work on this tool and also the process of constantly inventing new and
original queries to find potentially interesting classes was great fun.
Unfortunately, it was also in vain. There is a library, which almost allowed
to build a wonderful chain from a toString() call to the ubiquitous
TemplatesImpl.getOutputProperties(), but the API provided by the library is
so very complex and undocumented that, after two months, I gave up in total frustration.
There were some more small findings which don't really deserve to
be mentioned. However, I'd like to elaborate on one more thing before I'll
start part two of the blog post, that covers the real vulnerability.
One of the first interesting classes I discovered performs a JNDI lookup with
an attacker controlled URL in private void readObject(java.io.ObjectInputStream). What would have been a direct hit four
years ago could at least have been a respectable success in 2020. Remember:
Oracle JRE finally switched off remote classloading when resolving LDAP
references in 2019 in version JRE 1.8.0_191. Had this been exploitable, it
would have opened up an attack avenue at least for systems with outdated JRE.
My SAP J2EE was running on top of a JRE version 1.8.0_51 from 2015, so the JNDI
injection should have worked, but, to my great surprise, it didn't.
The reason can be found in the method getObjectInstance of javax.naming.spi.DirectoryManager:
The hightlighted call to getObjectFactoryFromReference is where an attacker needs to get to. The method resolves the JNDI reference using an URLClassLoader and an attacker-supplied codebase. However, as one can easily see, if getObjectFactoryBuilder() returns a non-null object the code returns in either of the two branches of the following if-clause and the call to getObjectFactoryFromReference below is never reached.
And that is exactly what happens. SAP J2EE registers an ObjectFactoryBuilder of type com.sap.engine.system.naming.provider.ObjectFactoryBuilderImpl. This class will try to find a factory class based on the factoryName-attribute and completely ignore the codebase-attribute of the JNDI reference.
Bottom line is that JNDI injection might never have worked in SAP J2EE, which would eliminate one of the most important attack primitives in the context of Java Deserialization attacks.
CVE-2021-21481
After digressing about how I searched for deserialization gadgets, I'd like to
cover the real vulnerability now, which has absolutely nothing to do with Java
Deserialization. It is a plain vanilla instance of CWE-749: Exposed Dangerous
Method or Function. Let's go back to Listing 1. We can see that the JNDI
context allows to query interfaces by name, in our example we were querying the
KeyStoreManager interface by the name "keystore". On several occasions, I had
already tried to find an available rich client for SAP J2EE Engine
administration that uses P4. Every time I was unsuccessful, I believed such a
client did not officially exist, or at least was not at everyone's disposal.
However, whenever you install a SAP J2EE Engine, the P4 port is enabled by
default and listening on the same network interface as the HTTP(s) services.
Because I was totally focussing on Deserialization, for a long time I
was oblivious how much information one can glean through the JNDI context. E.g.
it is trivial to get all bindings:
The list() call allows to simply iterate through all bindings:
Interesting items are proxy objects and the _Stub objects. E.g. the proxy for
messaging.system.MonitorBean can be cast to
com.sap.engine.messaging.app.MonitorHI.
During debugging of the server, I had already encountered the class
JUpgradeIF_Stub, long before I executed the call from Listing 5. The class
has a method openCfg(String path) and it was not difficult to establish that the
server version of the call didn't perform any authorization check. This one
definitively looked fishy to me, but since I wasn't looking for unprotected RMI
calls I put the finding into the box with the label "check on a rainy sunday
afternoon when the kids are busy with someone else".
But then, eventually, I did check it. It didn't take long to realize that I
had found a huge problem. Compare Listing 6.
The configuration settings of SAP J2EE Engine are organized in a hierarchical
structure. The location of an object can be specified by a path, pretty much
like a path of a file in the file system. The above code gets a reference to
the JUpgradeIF_Stub by querying the JNDI context with name
"MigrationService", gets an instance of a Configuration object by a call to
openCfg() and then walks down the path to the leaf node. The element found there
can be exported to an archive that is stored in the file system of the server
(call to export(String path)). If carefully chosen, the local path on the
server will point to a root folder of a web application. There, download.zip
can simply be downloaded through HTTP. If you want to check for yourself, the
UME configuration is stored at
cluster_config/system/custom_global/cfg/services/com.sap.security.core.ume.service/properties.
You'd probably say "hey! I need to be Administrator to do that! Where's the
harm?". Right, I thought so, too. But neither do you need to be Administrator,
nor do you even have to be authenticated. The following code works perfectly
fine:
So does the enumeration using ctxt.list() from Listing 5. The fact that authentication is
not needed at this point is not new at all by the way, compare CVE-2017-5372.
However, you will get a permission exception when calling
keysMngr.getKeystore() (because getKeystore() does have a permission
check). But JUpgradeIF.openCfg() was missing the check until SAP fixed it.
At this point, even without SAP specific knowledge an attacker can cause
significant harm. E.g. flood the server's file system with archives causing a
resource exhaustion DoS condition.
With a little insider knowledge one can get admin access. In the configuration
tree, there is a keystore called TicketKeystore. Its cryptographic key pair
is used to sign SAP Logon Tickets. If you steal the keystore, you can issue a
ticket for the Administrator user and log on with full admin rights. There
are also various other keystores, e.g. for XML signatures and the like (let
alone the fact that there is tons of stuff in this store. No one probably
knows all the security sensitive things you can get access to ...)
This information should be sufficient to the understanding of CVE-2021-21481.
The exact location of the keystores in the configuration and the relative local
path in order to download the archive by HTTP are left as an exercise to the
reader.
In this blogpost we demonstrate an attack on the integrity of Sysmon which generates a minimal amount of observable events making this attack difficult to detect in environments where no additional security products are installed.
tl;dr:
Suspend all threads of Sysmon.
Create a limited handle to Sysmon and elevate it by duplication.
Clone the pseudo handle of Sysmon to itself in order to bypass SACL as proposed by James Forshaw.
Inject a hook manipulating all events (in particular ProcessAccess events on Sysmon).
At Code White we are used to performing complex attacks against hardened and strictly monitored environments. A reasonable approach to stay under the radar of the blue team is to blend in with false positives by adapting normal process- and user behavior, carefully choosing host processes for injected tools and targeting specific user accounts.
However, clients with whom we have been working for a while have reached a high level of maturity. Their security teams strictly follow all the hardening advice we give them and invest a lot of time in collecting and base-lining security related logs while constantly developing and adapting detection rules.
We often see clients making heavy use of Sysmon, along with the Windows Event Logs and a traditional AV solution. For them, Sysmon is the root of trust for their security monitoring and its integrity must be ensured. However, an attacker who has successfully and covertly attacked, compromised the integrity of Sysmon and effectively breaks the security model of these clients.
In order to undermine the aforementioned security-setup, we aimed at attacking Sysmon to tamper with events in a manner which is difficult to detect using Sysmon itself or the Windows Event Logs.
Attacks on Sysmon and Detection
Having done some Googling on how to blind Sysmon, we realized that all publicly documented ways are detectable via Sysmon itself or the Windows Event Logs (at least those we found) :
Unloading Sysmon Driver - Detectable via Sysmon event id 255, Windows Security Event ID 4672.
While we were confident that we can kill Sysmon before throwing Event ID 5 (Process terminated) we thought that a host not sending any events would be suspicious and could be observed in a client's SIEM. Also, loading a signed, whitelisted and exploitable driver to attack from Kernel land was out of scope to maintain stability.
Since all of these documented attack vectors are somehow detectable via Sysmon itself, the Windows Event Logs or can cause stability issues we needed a new attack vector with the following capabilities:
Not detectable via Sysmon itself
Not detectable via Windows Event Log
Sysmon must stay alive
Attack from usermode
Injecting and manipulating the control flow of Sysmon seemed the most promising.
Attack Description
Similarly to SysmonQuiet or EvtMute, the idea is to inject code into Sysmon which redirects the execution flow in such a way that events can be manipulated before being forwarded to the SIEM.
However, the attack must work in such a way that corresponding ProcessAccess events on Sysmon are not observable via Sysmon or the Event Log.
This presents various problems, but let us first see where such a hook would be applicable.
Manipulating the Execution Flow
Sysmon forwards events to ETW subscribers via the documented function ntdll!EtwEventWrite. This is easily observable by setting an appropriate breakpoint.
The Id field of the EVENT_DESCRIPTOR determines the type of event and is important to apply the correct struct definition for the event data pointed to by PEVENT_DATA_DESCRIPTOR.
The structs for the different events are obviously different for each Sysmon Event Id, as different fields and information are included.
Our injected code must thus be able to apply the correct struct depending on which event is being emitted by Sysmon.
But how do we know the definition of the event structs? Luckily, ETW Explorer has already documented the event definitions:
A definition for the userdata struct describing a ProcessAccess event might therefore look as follows:
We can validate this in x64dbg by setting a breakpoint at ntdll!EtwEventWrite and applying the said struct definition for a ProcessAccess event.
Faking events
ntdll!EtwEventWrite being responsible for forwarding events is a good place to install a hook to redirect the control flow to injected code which first manipulates the event and then forwards it:
The injected code manipulating the events might look like this:
//Hooked EtwEventWrite FunctionULONG Hook_EtwEventWrite(REGHANDLE RegHandle, PCEVENT_DESCRIPTOR EventDescriptor, ULONG UserDataCount, PEVENT_DATA_DESCRIPTOR UserData){
//Get the address of the EtwEventWriteFull Function
_EtwEventWriteFull EtwEventWriteFull = (_EtwEventWriteFull)getFunctionPtr(CRYPTED_HASH_NTDLL, CRYPTED_HASH_ETWEVENTWRITEFULL);
if (EtwEventWriteFull == NULL) {
gotoexit;
}
//Check if it is a process access event and needs to be tampered withswitch (EventDescriptor->Id) {
case EVENT_PROCESSACCESS:
HandleProcessAccess((PProcessAccess)UserData);
break;
default:
break;
}
//Save the event with the EtwEventWriteFull Function
EtwEventWriteFull(RegHandle, EventDescriptor, 0, NULL, NULL, UserDataCount, UserData);
exit:
return0;
}
// Make ProcessAccess events targeting Sysmon itself look benignVOID HandleProcessAccess(PProcessAccess pProcessAccess){
ACCESS_MASK access_mask_benign = 0x1400;
PCWSTR wstr_sysmon = L"Sysmon";
PCWSTR wstr_ente = L"Ente";
//Sysmon check
psysmon = StrStrIW(pProcessAccess->ptargetimage, wstr_sysmon);
if (psysmon != NULL) {
//Replace the access mask with 0x1400
*pProcessAccess->pGrantedAccess = access_mask_benign;
pProcessAccess->sizeGrantedAccess = sizeof(access_mask_benign);
//Replace the Source User with Ente
lstrcpyW(pProcessAccess->pSourceUser, wstr_ente);
pProcessAccess->sizeSourceUser = sizeof(wstr_ente);
}
}
Note, how ntdll!EtwEventWriteFull is used to forward every event.
Since we know where to inject the hook and what the UserData structs look like, we are now able to tamper with every Sysmon event before it is forwarded.
However, the injection into Sysmon remains observable and the corresponding ProcessAccess event is the last event we do not control.
Detection of Process Manipulation
OpenProcess Access event
In order to create a handle to Sysmon which allows us to conduct process injection of any kind, we need to open Sysmon with at least the following access mask: PROCESS_VM_OPERATION | PROCESS_VM_WRITE. As Sysmon has not yet been modified while we open this handle, a suspicious ProcessAccess Event is generated which is an IOC defenders could hunt for:
Handle Elevation
Playing with kernel32!DuplicateHandle for another project, we noticed that MSDN states something very interesting:
In some cases, the new handle can have more access rights than the original handle.
Thus, by first creating a handle with a very limited access mask and then duplicating this handle with a new access mask, we technically do not create a new handle with a high access mask.
Sysmon, (to the best of our knowledge) only using OB_OPERATION_HANDLE_CREATE, only sees the benign access mask, but not the duplication of the handle with a higher access mask:
Using handle elevation we can gain handles with arbitrary process access masks to arbitrary (non-ppl) processes while Sysmon only logs the instantiation of the original handle. Great Success!
Unfortunately, there are some problems:
This only works if the targeted process runs as the same user as the duplicating process.
This can be easily circumvented by stealing a token from a System process.
We steal the token from an elevated svchost process running as System by only using a PROCESS_QUERY_LIMITED_INFORMATION mask, where we do not need the SE_DEBUG privilege which is often used in detection rules.
System Access Control Lists (SACL).
This is a bigger problem
Detection via System Access Control Lists (SACL)
Unfortunately, it is still possible to observe the duplication of the handle by configuring Object Access Auditing using a SACL on Sysmon. The following screenshot shows how ProcessHacker is leveraged to configure the SACL:
With this SACL, event 4656 is generated by the Windows Event Log Service upon creation of a handle to Sysmon allowing to write in its memory. This event is also emitted, if handle elevation is used.
Note: In the default config, Object Access Auditing is not enabled.
According to the post, we can duplicate the pseudo handle of a different process to itself to get full access to the process without triggering Object Access Auditing.
A stealthy way to gain a handle suitable for process injection would be the following:
Open a process handle to Sysmon with a very limited access mask (A detection rule based on this would generate too many false positives)
Elevate this handle using ntdll!DuplicateObject to hold the PROCESS_DUP_HANDLE right (Bypasses Sysmon's telemetry)
Use the elevated handle to duplicate the pseudo Handle of Sysmon (Bypasses SACL).
uPid.UniqueProcess = dwPid;
uPid.UniqueThread = 0;
ntStatus = NtOpenProcess(&hlowpriv, PROCESS_QUERY_LIMITED_INFORMATION, &ObjectAttributes, &uPid);
if (!NT_SUCCESS(ntStatus))
FATAL("[-] Failed to open low priv handle to sysmon\n");
ntStatus = NtDuplicateObject(NtCurrentProcess(), hlowpriv, NtCurrentProcess(), &hduppriv, PROCESS_DUP_HANDLE, FALSE, 0);
if (!NT_SUCCESS(ntStatus))
FATAL("[-] Failed to elevate to handle with PROCESS_DUP_HANDLE rights\n");
ntStatus = NtDuplicateObject(hduppriv, NtCurrentProcess(), NtCurrentProcess(), &hhighpriv, PROCESS_ALL_ACCESS, FALSE, 0);
if (!NT_SUCCESS(ntStatus))
FATAL("[-] Failed to elevate to handle with PROCESS_ALL_ACCESS rights\n");
Doing so we gain a full access handle to Sysmon while bypassing Sysmon's telemetry and SACL.
Fine Tuning
There was one last IOC we could come up with. Sysmon can only observe the creation of a limited handle to itself, however, following the golden rule of never touching disk, our tool being unpacked or injected into another process will have a broken calltrace containing unknown sections. Since Sysmon has not been tampered with at this point, this would be the last event which we do not have under control and might be sufficient to create a detection rule upon!
We can delay the forwarding of this event by suspending all threads of Sysmon. The events are then queued and dispatched only after we resume the threads, giving us enough time to install a hook manipulating all ProcessAccess events on Sysmon itself. This is possible, because no events for accessing, suspending or resuming a thread exist in Sysmon.
The hook then necessarily spoofs the callstack included in the ProcessAccess event.
Putting It All Together
We combined all of these steps into a tool we call SysmonEnte which you can find on our Github.
SysmonEnte is implemented as fully position independent code (PIC) which can be called using the following prototype:
DWORD go(DWORD dwPidSysmon);
A sample loader is included and built during compilation when typing make.
Additionally, SysmonEnte uses indirect syscalls to bypass userland hooks while injecting into Sysmon.
The open source variant tampers with process access events to Lsass and Sysmon and sets the access mask to a benign one. Additionally, the source user and the callstack is set to Ente. You can change these to your needs.
Possible Detection Methods
Certain detection ideas exist from our point of view:
ETW TI
The easiest solution would be to subscribe to the Threat Intelligence ETW provider to observe injections or suspicious code manipulations. This however requires a signed ELAM driver.
If you have the possibility to enable Object Access Auditing, you can configure a SACL for Sysmon to monitor the duplication of handles to catch the SACL bypass used to gain a handle to Sysmon. We are not sure about false positives in large environments though.
To the best of our knowledge, and in contrast to SACLs for filesystem- or registry operations, configuring Object Access Auditing on processes is only achievable by writing a custom program. This circumstance makes the detection of handle duplication via SACL non-trivial.
A sample program is included on our Github and configures a SACL with ACCESS_SYSTEM_SECURITY + PROCESS_DUP_HANDLE + PROCESS_VM_OPERATION and is applied to the group Everyone. ACCESS_SYSTEM_SECURITY is included as otherwise, attackers can covertly change the SACL.
With this configuration, attempts to duplicate a handle to Sysmon should become visible.
Note: Object Access Auditing is not enabled by default and must be enabled via Group Policy prior the use of the tool.
Final Words
Sysmon on it's own is not able to protect itself sufficiently, and it is difficult to observe the described attack with the event log.
We believe that running Sysmon alone, without any protection from a trusted third party tool sitting in kernel land or running as a PPL, is not guaranteed to produce reliable logs with ensured integrity. A possible fix by Microsoft would be to allow running Sysmon as a PPL.
It is noteworthy that the described technique of handle elevation + SACL bypass can also be used to stealthily dump Lsass.
After our talk at X33fcon, nanodump supports handle elevation as well.
However, a SACL with PROCESS_VM_READ is configured for Lsass by default. ;-)