The Internals of AppLocker - Part 3 - Access Tokens and Access Checking
20 November 2019 at 06:30
This is part 3 in a short series on the internals of AppLocker (AL). Part 1 is here, part 2 here and part 4 here.
In the last part I outlined how process creation is blocked with AL. I crucially left out exactly how the rules are processed to determine if a particular user was allowed to create a process. As it makes more sense to do so, we're going to go in reverse order from how the process was described in the last post. Let's start with talking about the access check implemented by SrppAccessCheck.
NTSTATUS SrpAccessCheckCommon(HANDLE TokenHandle, BYTE* Policy) {
SECURITY_SUBJECT_CONTEXT Subject = {};
ObReferenceObjectByHandle(TokenHandle, &Subject.PrimaryToken);
DWORD SecurityOffset = *((DWORD*)Policy+4)
PSECURITY_DESCRIPTOR SD = Policy + SecurityOffset;
NTSTATUS AccessStatus;
if (!SeSrpAccessCheck(&Subject, FILE_EXECUTE,
&FileGenericMapping,
SD, &AccessStatus) &&
AccessStatus == STATUS_ACCESS_DENIED) {
return STATUS_ACCESS_DISABLED_BY_POLICY_OTHER;
}
return AccessStatus;
}
The code isn't very complex, first it builds a SECURITY_SUBJECT_CONTEXT structure manually from the access token passed in as a handle. It uses a policy pointer passed in to find the security descriptor it wants to use for the check. Finally a call is made to SeSrpAccessCheck requesting file execute access. If the check fails with an access denied error it gets converted to the AL specific policy error, otherwise any other success or failure is returned.
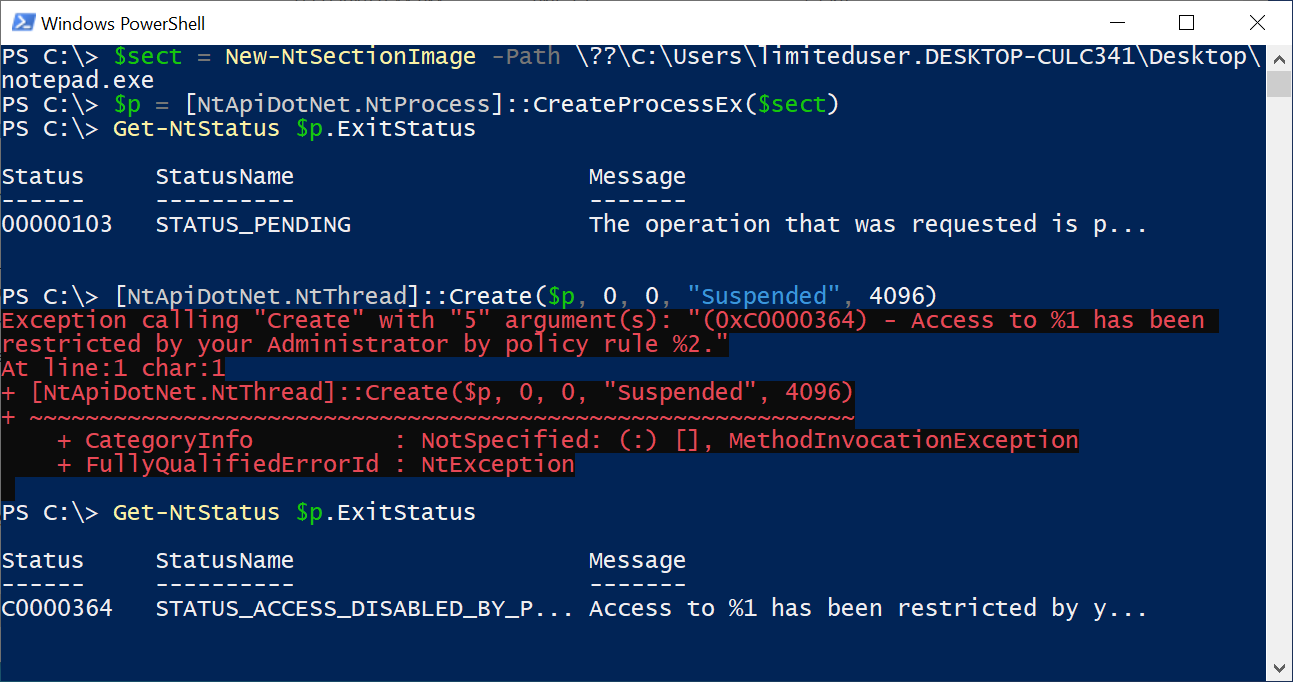
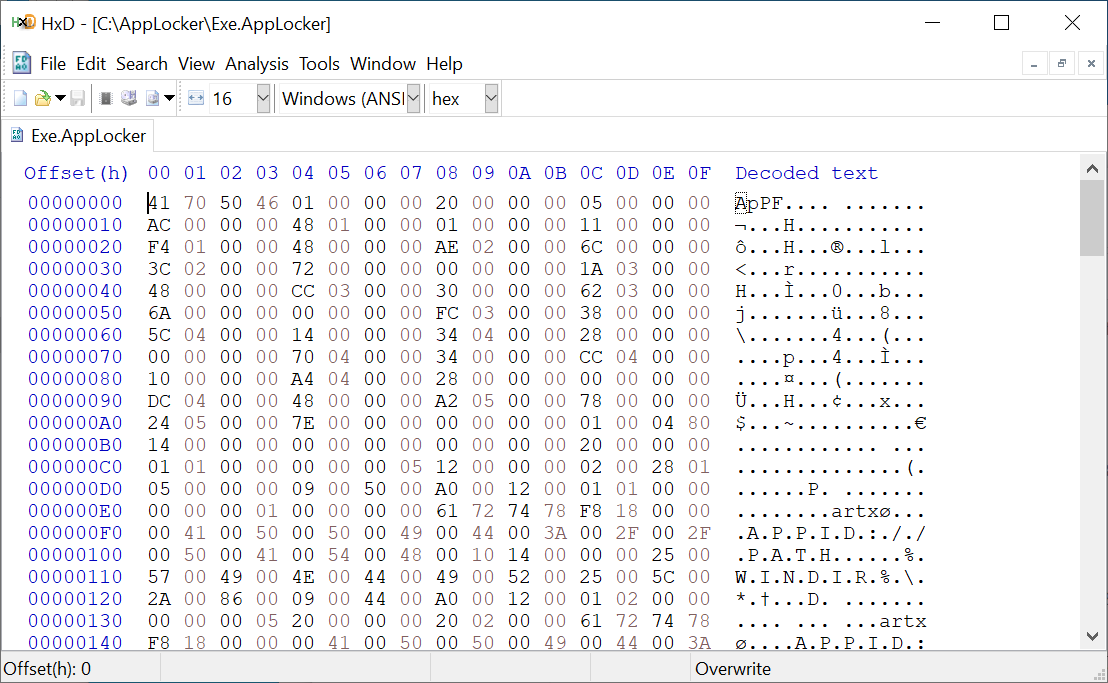
The only thing we don't really know in this process is what the Policy value is and therefore what the security descriptor is. We could trace through the code to find how the Policy value is set , but sometimes it's just easier to breakpoint on the function of interest in a kernel debugger and dump the pointed at memory. Taking the debugging approach shows the following:

Well, what do we have here? We've seen those first 4 characters before, it's the magic signature of the on-disk policy files from part 1. SeSrpAccessCheck is extracting a value from offset 16, which is used as an offset into the same buffer to get the security descriptor. Maybe the policy files already contain the security descriptor we seek? Writing some quick PowerShell I ran it on the Exe.AppLocker policy file to see the result:
Success, the security descriptor is already compiled into the policy file! The following script defines two functions, Get-AppLockerSecurityDescriptor and Format-AppLockerSecurityDescriptor. Both take a policy file as input and returns either a security descriptor object or formatted representation:
If we run Format-AppLockerSecurityDescriptor on the Exe.Applocker file we get the following output for the DACL (trimmed for brevity):
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: APPID://PATH Contains "%WINDIR%\*"
- Type : AllowedCallback
- Name : BUILTIN\Administrators
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: APPID://PATH Contains "*"
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: APPID://PATH Contains "%PROGRAMFILES%\*"
- Type : Allowed
- Name : APPLICATION PACKAGE AUTHORITY\ALL APPLICATION PACKAGES
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Type : Allowed
- Name : APPLICATION PACKAGE AUTHORITY\ALL RESTRICTED APPLICATION PACKAGES
- Access: Execute|ReadAttributes|ReadControl|Synchronize
We can see we have two ACEs which are for the Everyone group and one for the Administrators group. This matches up with the default configuration we setup in part 1. The last two entries are just there to ensure this access check works correctly when run from an App Container.
The most interesting part is the Condition field. This is a rarely used (at least for consumer version of the OS) feature of the security access checking in the kernel which allows a conditional expression evaluated to determine if an ACE is enabled or not. In this case we're seeing the SDDL format (documentation) but under the hood it's actually a binary structure. If we assume that the '*' acts as a globbing character then again this matches our rules, which let's remember:
In fact let's add policy entries for a hash and publisher and see what condition is set for them. Download a new policy file from this link and run the Set-AppLockerPolicy command in an admin PowerShell console. Then re-run Format-ApplockerSecurityDescriptor:
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: (Exists APPID://SHA256HASH) && (APPID://SHA256HASH Any_of {#5bf6ccc91dd715e18d6769af97dd3ad6a15d2b70326e834474d952753
118c670})
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Flags : None
- Condition: (Exists APPID://FQBN) && (APPID://FQBN >= {"O=MICROSOFT CORPORATION, L=REDMOND, S=WASHINGTON, C=US\MICROSOFT® WINDOWS
® OPERATING SYSTEM\*", 0})
We can now see the two new conditional ACEs, for a SHA256 hash and the publisher subject name. Basically rinse and repeat as more rules and conditions are added to the policy they'll be added to the security descriptor with the appropriate ACEs. Note that the ordering of the rules are very important, for example Deny ACEs will always go first. I assume the policy file generation code correctly handles the security descriptor generation, but you can now audit it to make sure.
While we now understand how the rules are enforced, where does the values for the condition, such as APPID://PATH come from? If you read the (poor) documentation about conditional ACEs you'll find these values are Security Attributes. The attributes can be either globally defined or assigned to an access token. Each attribute has a name, then a list of one or more values which can be strings, integers, binary blobs etc. This is what AL is using to store the data in the access check token.
Let's go back a step and see what's going on with AiSetAttributesExe to see how these security attributes are generated.
In the last part I outlined how process creation is blocked with AL. I crucially left out exactly how the rules are processed to determine if a particular user was allowed to create a process. As it makes more sense to do so, we're going to go in reverse order from how the process was described in the last post. Let's start with talking about the access check implemented by SrppAccessCheck.
Access Checking and Security Descriptors
For all intents the SrppAccessCheck function is just a wrapper around a specially exported kernel API SeSrpAccessCheck. While the API has a few unusual features for this discussion might as well assume it to be the normal SeAccessCheck API.
A Windows access check takes 4 main parameters:
- A SECURITY_SUBJECT_CONTEXT which identifies the caller's access tokens.
- A desired access mask.
- A GENERIC_MAPPING structure which allows the access check to convert generic access to object specific access rights.
- And most importantly, the Security Descriptor which describes the security of the resource being checked.
Let's look at some code.
SECURITY_SUBJECT_CONTEXT Subject = {};
ObReferenceObjectByHandle(TokenHandle, &Subject.PrimaryToken);
DWORD SecurityOffset = *((DWORD*)Policy+4)
PSECURITY_DESCRIPTOR SD = Policy + SecurityOffset;
NTSTATUS AccessStatus;
if (!SeSrpAccessCheck(&Subject, FILE_EXECUTE,
&FileGenericMapping,
SD, &AccessStatus) &&
AccessStatus == STATUS_ACCESS_DENIED) {
return STATUS_ACCESS_DISABLED_BY_POLICY_OTHER;
}
return AccessStatus;
}
The code isn't very complex, first it builds a SECURITY_SUBJECT_CONTEXT structure manually from the access token passed in as a handle. It uses a policy pointer passed in to find the security descriptor it wants to use for the check. Finally a call is made to SeSrpAccessCheck requesting file execute access. If the check fails with an access denied error it gets converted to the AL specific policy error, otherwise any other success or failure is returned.
The only thing we don't really know in this process is what the Policy value is and therefore what the security descriptor is. We could trace through the code to find how the Policy value is set , but sometimes it's just easier to breakpoint on the function of interest in a kernel debugger and dump the pointed at memory. Taking the debugging approach shows the following:
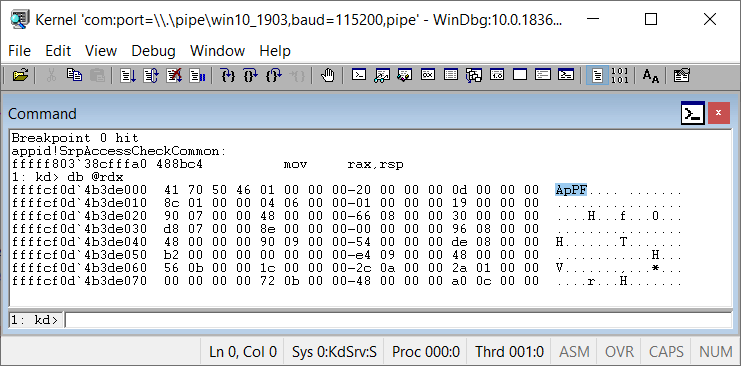
Well, what do we have here? We've seen those first 4 characters before, it's the magic signature of the on-disk policy files from part 1. SeSrpAccessCheck is extracting a value from offset 16, which is used as an offset into the same buffer to get the security descriptor. Maybe the policy files already contain the security descriptor we seek? Writing some quick PowerShell I ran it on the Exe.AppLocker policy file to see the result:

Success, the security descriptor is already compiled into the policy file! The following script defines two functions, Get-AppLockerSecurityDescriptor and Format-AppLockerSecurityDescriptor. Both take a policy file as input and returns either a security descriptor object or formatted representation:
If we run Format-AppLockerSecurityDescriptor on the Exe.Applocker file we get the following output for the DACL (trimmed for brevity):
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: APPID://PATH Contains "%WINDIR%\*"
- Type : AllowedCallback
- Name : BUILTIN\Administrators
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: APPID://PATH Contains "*"
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: APPID://PATH Contains "%PROGRAMFILES%\*"
- Type : Allowed
- Name : APPLICATION PACKAGE AUTHORITY\ALL APPLICATION PACKAGES
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Type : Allowed
- Name : APPLICATION PACKAGE AUTHORITY\ALL RESTRICTED APPLICATION PACKAGES
- Access: Execute|ReadAttributes|ReadControl|Synchronize
We can see we have two ACEs which are for the Everyone group and one for the Administrators group. This matches up with the default configuration we setup in part 1. The last two entries are just there to ensure this access check works correctly when run from an App Container.
The most interesting part is the Condition field. This is a rarely used (at least for consumer version of the OS) feature of the security access checking in the kernel which allows a conditional expression evaluated to determine if an ACE is enabled or not. In this case we're seeing the SDDL format (documentation) but under the hood it's actually a binary structure. If we assume that the '*' acts as a globbing character then again this matches our rules, which let's remember:
- Allow Everyone group access to run any executable under %WINDIR% and %PROGRAMFILES%.
- Allow Administrators group to run any executable from anywhere.
In fact let's add policy entries for a hash and publisher and see what condition is set for them. Download a new policy file from this link and run the Set-AppLockerPolicy command in an admin PowerShell console. Then re-run Format-ApplockerSecurityDescriptor:
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: (Exists APPID://SHA256HASH) && (APPID://SHA256HASH Any_of {#5bf6ccc91dd715e18d6769af97dd3ad6a15d2b70326e834474d952753
118c670})
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Flags : None
- Condition: (Exists APPID://FQBN) && (APPID://FQBN >= {"O=MICROSOFT CORPORATION, L=REDMOND, S=WASHINGTON, C=US\MICROSOFT® WINDOWS
® OPERATING SYSTEM\*", 0})
We can now see the two new conditional ACEs, for a SHA256 hash and the publisher subject name. Basically rinse and repeat as more rules and conditions are added to the policy they'll be added to the security descriptor with the appropriate ACEs. Note that the ordering of the rules are very important, for example Deny ACEs will always go first. I assume the policy file generation code correctly handles the security descriptor generation, but you can now audit it to make sure.
While we now understand how the rules are enforced, where does the values for the condition, such as APPID://PATH come from? If you read the (poor) documentation about conditional ACEs you'll find these values are Security Attributes. The attributes can be either globally defined or assigned to an access token. Each attribute has a name, then a list of one or more values which can be strings, integers, binary blobs etc. This is what AL is using to store the data in the access check token.
Let's go back a step and see what's going on with AiSetAttributesExe to see how these security attributes are generated.
Setting Token Attributes
The AiSetAttributesExe function takes 4 parameters:
- A handle to the executable file.
- Pointer to the current policy.
- Handle to the primary token of the new process.
- Handle to the token used for the access check.
The code isn't doesn't look very complex, initially:
NTSTATUS AiSetAttributesExe(
PVOID Policy,
HANDLE FileHandle,
HANDLE ProcessToken,
HANDLE AccessCheckToken) {
PSECURITY_ATTRIBUTES SecAttr;
AiGetFileAttributes(Policy, FileHandle, &SecAttr);
NTSTATUS status = AiSetTokenAttributes(ProcessToken, SecAttr);
if (NT_SUCCESS(status) && ProcessToken != AccessCheckToken)
status = AiSetTokenAttributes(AccessCheckToken, SecAttr);
return status;
}
All the code does it call AiGetFileAttributes, which fills in a SECURITY_ATTRIBUTES structure, and then calls AiSetTokenAttributes to set them on the ProcessToken and the AccessCheckToken (if different). AiSetTokenAttributes is pretty much a simple wrapper around the exported (and undocumented) kernel API SeSetSecurityAttributesToken which takes the generated list of security attributes and adds them to the access token for later use in the access check.
The first thing AiGetFileAttributes does is query the file handle for it's full path, however this is the native path and takes the form \Device\Volume\Path\To\File. A path of this form is pretty much useless if you wanted to generate a single policy to deploy across an enterprise, such as through Group Policy. Therefore the code converts it back to a Win32 style path such as c:\Path\To\File. Even then there's no guarantee that the OS drive is C:, and what about wanting to have executables on USB keys or other removable drives where the letter could change?
To give the widest coverage the driver also maintains a fixed list of "Macros" which look like Environment variable expansions. These are used to replace the OS drive components as well as define placeholders for removable media. We already saw them in use in the dump of the security descriptor with string components like "%WINDIR%". You can find a list of the macros here, but I'll reproduce them here:
- %WINDIR% - Windows Folder.
- %SYSTEM32% - Both System32 and SysWOW64 (on x64).
- %PROGRAMFILES% - Both Program Files and Program Files (x86).
- %OSDRIVE% - The OS install drive.
- %REMOVABLE% - Removable drive, such a CD or DVD.
- %HOT% - Hot-pluggable devices such as USB keys.
Note that SYSTEM32 and PROGRAMFILES will map to either 32 or 64 bit directories when running on a 64 bit system (and presumably also ARM directories on ARM builds of Windows?). If you want to pick a specific directory you'll have to configure the rules to not use the macros.
To hedge its bets AL puts every possible path configuration, native path, Win32 path and all possible macroed paths as string values in the APPID://PATH security attribute.
AiGetFileAttributes continues, gathering the publisher information for the file. On Windows 10 the signature and certificate checking is done in multiple ways, first checking the kernel Code Integrity module (CI), then doing some internal work and finally falling back to calling over RPC to the running APPIDSVC. The information, along with the version number of the binary is put into the APPID://FQBN attribute, which stands for Fully Qualified Binary Name.
The final step is generating the file hash, which is stored in a binary blob attribute. AL supports three hash algorithms with the following attribute names:
- APPID://SHA256HASH - Authenticode SHA256.
- APPID://SHA1HASH - Authenticode SHA1
- APPID://SHA256FLATHASH - SHA256 over entire file.
As the attributes are applied to both tokens we should be able to see them on the primary token of a normal user process. By running the following PowerShell command we can see the added security attributes on the current process token.
PS> $(Get-NtToken).SecurityAttributes | ? Name -Match APPID
Name : APPID://PATH
ValueType : String
Flags : NonInheritable, CaseSensitive
Values : {
%SYSTEM32%\WINDOWSPOWERSHELL\V1.0\POWERSHELL.EXE,
%WINDIR%\SYSTEM32\WINDOWSPOWERSHELL\V1.0\POWERSHELL.EXE,
...}
Name : APPID://SHA256HASH
ValueType : OctetString
Flags : NonInheritable
Values : {133 66 87 106 ... 85 24 67}
Name : APPID://FQBN
ValueType : Fqbn
Flags : NonInheritable, CaseSensitive
Values : {Version 10.0.18362.1 - O=MICROSOFT CORPORATION, ... }
Note that the APPID://PATH attribute is always added, however APPID://FQBN and APPID://*HASH are only generated and added if there are rules which rely on them.
The Mystery of the Twin Tokens
We've come to the final stage, we now know how the security attributes are generated and applied to the two access tokens. The question now is why is there two tokens, the process token and one just for access checking?
Everything happens inside AiGetTokens, which is shown in a simplified form below:
NTSTATUS AiGetTokens(HANDLE ProcessId,
PHANDLE ProcessToken,
PHANDLE AccessCheckToken)
{
AiOpenTokenByProcessId(ProcessId, &TokenHandle);
NTSTATUS status = STATUS_SUCCESS;
*Token = TokenHandle;
if (!AccessCheckToken)
return STATUS_SUCCESS;
BOOL IsRestricted;
status = ZwQueryInformationToken(TokenHandle, TokenIsRestricted, &IsRestricted);
DWORD ElevationType;
status = ZwQueryInformationToken(TokenHandle, TokenElevationType,
&ElevationType);
HANDLE NewToken = NULL;
if (ElevationType != TokenElevationTypeFull)
status = ZwQueryInformationToken(TokenHandle, TokenLinkedToken,
&NewToken);
if (!IsRestricted
|| NT_SUCCESS(status)
|| (status = SeGetLogonSessionToken(TokenHandle, 0,
&NewToken), NT_SUCCESS(status))
|| status == STATUS_NO_TOKEN) {
if (NewToken)
*AccessCheckToken = NewToken;
else
*AccessCheckToken = TokenHandle;
}
return status;
}
Let's summarize what's going on. First, the easy one, the ProcessToken handle is just the process token opened from the process, based on its PID. If the AccessCheckToken is not specified then the function ends here. Otherwise the AccessCheckToken is set to one of three values
- If the token is a non-elevated (UAC) token then use the full elevated token.
- If the token is 'restricted' and not a UAC token then use the logon session token.
- Otherwise use the primary token of the new process.
We can now understand why a non-elevated UAC admin has Administrator rules applied to them. If you're running as the non-elevated user token then case 1 kicks in and sets the AccessCheckToken to the full administrator token. Now any rule checks which specify the Administrators group will pass.
Case 2 is also interesting, a "restricted" token in this case is one which has been passed through the CreateRestrictedToken API and has restricted SIDs attached. This is used by various sandboxes especially Chromium's (and by extension anyone who uses it such as Firefox). Case 2 ensures that if the process token is restricted and therefore might not pass the access check, say the Everyone group is disabled, then the access check is done instead against the logon session's token, which is the master token from which all others are derived in a logon session.
If nothing else matches then case 3 kicks in and just assigns the primary token to the AccessCheckToken. There are edges cases in these rules. For example you can use CreateRestrictedToken to create a new access token with disabled groups, but which doesn't have restricted SIDs. This results in case 2 not being applied and so the access check is done against the limited token which could very easily fail to validate causing the process to be terminated.
There's also a more subtle edge case here if you look back at the code. If you create a restricted token of a UAC admin token then process creation typically fails during the policy check. When the UAC token is a full admin token the second call to ZwQueryInformationToken will not be made which results in NewToken being NULL. However in the final check, IsRestricted is TRUE so the second condition is checked, as status is STATUS_SUCCESS (from the first call to ZwQueryInformationToken) this passes and we enter the if block without ever calling SeGetLogonSessionToken. As NewToken is still NULL AccessCheckToken is set to the primary process token which is the restricted token which will cause the subsequent access check to fail. This is actually a long standing bug in Chromium, it can't be run as UAC admin if AppLocker is enforced.
That's the end of how AL does process enforcement. Hopefully it's been helpful. Next time I'll dig into how DLL enforcement works.
Case 2 is also interesting, a "restricted" token in this case is one which has been passed through the CreateRestrictedToken API and has restricted SIDs attached. This is used by various sandboxes especially Chromium's (and by extension anyone who uses it such as Firefox). Case 2 ensures that if the process token is restricted and therefore might not pass the access check, say the Everyone group is disabled, then the access check is done instead against the logon session's token, which is the master token from which all others are derived in a logon session.
If nothing else matches then case 3 kicks in and just assigns the primary token to the AccessCheckToken. There are edges cases in these rules. For example you can use CreateRestrictedToken to create a new access token with disabled groups, but which doesn't have restricted SIDs. This results in case 2 not being applied and so the access check is done against the limited token which could very easily fail to validate causing the process to be terminated.
There's also a more subtle edge case here if you look back at the code. If you create a restricted token of a UAC admin token then process creation typically fails during the policy check. When the UAC token is a full admin token the second call to ZwQueryInformationToken will not be made which results in NewToken being NULL. However in the final check, IsRestricted is TRUE so the second condition is checked, as status is STATUS_SUCCESS (from the first call to ZwQueryInformationToken) this passes and we enter the if block without ever calling SeGetLogonSessionToken. As NewToken is still NULL AccessCheckToken is set to the primary process token which is the restricted token which will cause the subsequent access check to fail. This is actually a long standing bug in Chromium, it can't be run as UAC admin if AppLocker is enforced.
That's the end of how AL does process enforcement. Hopefully it's been helpful. Next time I'll dig into how DLL enforcement works.
Locking Resources to Specific Processes
Before we go, here's a silly trick which might now be obvious. Ever wanted to restrict access to resources, such as files, to specific processes? With the AL applied security attributes now you can. All you need to do is apply the same conditional ACE syntax to your file and the kernel will do the enforcement for you. For example create the text file C:\TEMP\ABC.TXT, now to only allow notepad to open it do the following in PowerShell:
Set-NtSecurityDescriptor \??\C:\TEMP\ABC.TXT `
-SecurityDescriptor 'D:(XA;;GA;;;WD;(APPID://PATH Contains "%SYSTEM32%\NOTEPAD.EXE"))' `
-SecurityInformation Dacl
Make sure that the path is in all upper case. You should now find that while PowerShell (or any other application) can't open the text file you can open and modify it just fine in notepad. Of course this won't work across network boundaries and is pretty easy to get around, but that's not my problem ;-)
Set-NtSecurityDescriptor \??\C:\TEMP\ABC.TXT `
-SecurityDescriptor 'D:(XA;;GA;;;WD;(APPID://PATH Contains "%SYSTEM32%\NOTEPAD.EXE"))' `
-SecurityInformation Dacl
Make sure that the path is in all upper case. You should now find that while PowerShell (or any other application) can't open the text file you can open and modify it just fine in notepad. Of course this won't work across network boundaries and is pretty easy to get around, but that's not my problem ;-)