Understanding Network Access in Windows AppContainers
Posted by James Forshaw, Project Zero
Recently I've been delving into the inner workings of the Windows Firewall. This is interesting to me as it's used to enforce various restrictions such as whether AppContainer sandboxed applications can access the network. Being able to bypass network restrictions in AppContainer sandboxes is interesting as it expands the attack surface available to the application, such as being able to access services on localhost, as well as granting access to intranet resources in an Enterprise.
I recently discovered a configuration issue with the Windows Firewall which allowed the restrictions to be bypassed and allowed an AppContainer process to access the network. Unfortunately Microsoft decided it didn't meet the bar for a security bulletin so it's marked as WontFix.
As the mechanism that the Windows Firewall uses to restrict access to the network from an AppContainer isn't officially documented as far as I know, I'll provide the details on how the restrictions are implemented. This will provide the background to understanding why my configuration issue allowed for network access.
I'll also take the opportunity to give an overview of how the Windows Firewall functions and how you can use some of my tooling to inspect the current firewall configuration. This will provide security researchers with the information they need to better understand the firewall and assess its configuration to find other security issues similar to the one I reported. At the same time I'll note some interesting quirks in the implementation which you might find useful.
Windows Firewall Architecture Primer
Before we can understand how network access is controlled in an AppContainer we need to understand how the built-in Windows firewall functions. Prior to XP SP2 Windows didn't have a built-in firewall, and you would typically install a third-party firewall such as ZoneAlarm. These firewalls were implemented by hooking into Network Driver Interface Specification (NDIS) drivers or implementing user-mode Winsock Service Providers but this was complex and error prone.
While XP SP2 introduced the built-in firewall, the basis for the one used in modern versions of Windows was introduced in Vista as the Windows Filtering Platform (WFP). However, as a user you wouldn't typically interact directly with WFP. Instead you'd use a firewall product which exposes a user interface, and then configures WFP to do the actual firewalling. On a default installation of Windows this would be the Windows Defender Firewall. If you installed a third-party firewall this would replace the Defender component but the actual firewall would still be implemented through configuring WFP.

The diagram gives an overview of how various components in the OS are connected together to implement the firewall. A user would interact with the Windows Defender firewall using the GUI, or a command line interface such as PowerShell's NetSecurity module. This interface communicates with the Windows Defender Firewall Service (MPSSVC) over RPC to query and modify the firewall rules.
MPSSVC converts its ruleset to the lower-level WFP firewall filters and sends them over RPC to the Base Filtering Engine (BFE) service. These filters are then uploaded to the TCP/IP driver (TCPIP.SYS) in the kernel which is where the firewall processing is handled. The device objects (such as \Device\WFP) which the TCP/IP driver exposes are secured so that only the BFE service can access them. This means all access to the kernel firewall needs to be mediated through the service.
When an application, such as a Web Browser, creates a new network socket the AFD driver responsible for managing sockets will communicate with the TCP/IP driver to configure the socket for IP. At this point the TCP/IP driver will capture the security context of the creating process and store that for later use by the firewall. When an operation is performed on the socket, such as making or accepting a new connection, the firewall filters will be evaluated.
The evaluation is handled primarily by the NETIO driver as well as registered callout drivers. These callout drivers allow for more complex firewall rules to be implemented as well as inspecting and modifying network traffic. The drivers can also forward checks to user-mode services. As an example, the ability to forward checks to user mode allows the Windows Defender Firewall to display a UI when an unknown application listens on a wildcard address, as shown below.
The end result of the evaluation is whether the operation is permitted or blocked. The behavior of a block depends on the operation. If an outbound connection is blocked the caller is notified. If an inbound connection is blocked the firewall will drop the packets and provide no notification to the peer, such as a TCP Reset or ICMP response. This default drop behavior can be changed through a system wide configuration change. Let's dig into more detail on how the rules are configured for evaluation.
Layers, Sublayers and Filters
The firewall rules are configured using three types of object: layers, sublayers and filters as shown in the following diagram.

The firewall layer is used to categorize the network operation to be evaluated. For example there are separate layers for inbound and outbound packets. This is typically further differentiated by IP version, so there are separate IPv4 and IPv6 layers for inbound and outbound packets. While the firewall is primarily focussed on IP traffic there does exist limited MAC and Virtual Switch layers to perform specialist firewalling operations. You can find the list of pre-defined layers on MSDN here. As the WFP needs to know what layer handles which operation there's no way for additional layers to be added to the system by a third-party application.
When a packet is evaluated by a layer the WFP performs Filter Arbitration. This is a set of rules which determine the order of evaluation of the filters. First WFP enumerates all registered filters which are associated with the layer's unique GUID. Next, WFP groups the filters by their sublayer's GUID and orders the filter groupings by a weight value which was specified when the sublayer was registered. Finally, WFP evaluates each filter according to the order based on a weight value specified when the filter was registered.
For every filter, WFP checks if the list of conditions match the packet and its associated meta-data. If the conditions match then the filter performs a specified action, which can be one of the following:
- Permit
- Block
- Callout Terminating
- Callout Unknown
- Callout Inspection
If the action is Permit or Block then the filter evaluation for the current sublayer is terminated with that action as the result. If the action is a callout then WFP will invoke the filter's registered callout driver's classify function to perform additional checks. The classify function can evaluate the packet and its meta-data and specify a final result of Permit, Block or additionally Continue which indicates the filter should be ignored. In general if the action is Callout Terminating then it should only set Permit and Block, and if it's Callout Inspection then it should only set Continue. The Callout Unknown action is for callouts which might terminate or might not depending on the result of the classification.
Once a terminating filter has been evaluated WFP stops processing that sublayer. However, WFP will continue to process the remaining sublayers in the same way regardless of the final result. In general if any sublayer returns a Block result then the packet will be blocked, otherwise it'll be permitted. This means that if a higher priority sublayer's result is Permit, it can still be blocked by a lower-priority sublayer.
A filter can be configured with the FWPM_FILTER_FLAG_CLEAR_ACTION_RIGHT flag which indicates that the result should be considered “hard” allowing a higher priority filter to permit a packet which can't be overridden by a lower-priority blocking filter. The rules for the final result are even more complex than I make out including soft blocks and vetos, refer to the page in MSDN for more information.
To simplify the classification of network traffic, WFP provides a set of stateful layers which correspond to major network events such as TCP connection and port binding. The stateful filtering is referred to as Application Layer Enforcement (ALE). For example the FWPM_LAYER_ALE_AUTH_CONNECT_V4 layer will be evaluated when a TCP connection using IPv4 is being made.
For any given connection it will only be evaluated once, not for every packet associated with the TCP connection handshake. In general these ALE layers are the ones we'll focus on when inspecting the firewall configuration, as they're the most commonly used. The three main ALE layers you're going to need to inspect are the following:
| Name |
Description |
| FWPM_LAYER_ALE_AUTH_CONNECT_V4/6 |
Processed when TCP connect() called. |
| FWPM_LAYER_ALE_AUTH_LISTEN_V4/6 |
Processed when TCP listen() called. |
| FWPM_LAYER_ALE_AUTH_RECV_ACCEPT_V4/6 |
Processed when a packet/connection is received. |
What layers are used and in what order they are evaluated depend on the specific operation being performed. You can find the list of the layers for TCP packets here and UDP packets here. Now, let's dig into how filter conditions are defined and what information they can check.
Filter Conditions
Each filter contains an optional list of conditions which are used to match a packet. If no list is specified then the filter will always match any incoming packet and perform its defined action. If more than one condition is specified then the filter is only matched if all of the conditions match. If you have multiple conditions of the same type they're OR'ed together, which allows a single filter to match on multiple values.
Each condition contains three values:
- The layer field to check.
- The value to compare against.
- The match type, for example the packet value and the condition value are equal.
Each layer has a list of fields that will be populated whenever a filter's conditions are checked. The field might directly reflect a value from the packet, such as the destination IP address or the interface the packet is traversing. Or it could be a metadata value, such as the user identity of the process which created the socket. Some common fields are as follows:
| Field Type |
Description |
| FWPM_CONDITION_IP_REMOTE_ADDRESS |
The remote IP address. |
| FWPM_CONDITION_IP_LOCAL_ADDRESS |
The local IP address. |
| FWPM_CONDITION_IP_PROTOCOL |
The IP protocol type, e.g. TCP or UDP |
| FWPM_CONDITION_IP_REMOTE_PORT |
The remote protocol port. |
| FWPM_CONDITION_IP_LOCAL_PORT |
The local protocol port. |
| FWPM_CONDITION_ALE_USER_ID |
The user's identity. |
| FWPM_CONDITION_ALE_REMOTE_USER_ID |
The remote user's identity. |
| FWPM_CONDITION_ALE_APP_ID |
The path to the socket's executable. |
| FWPM_CONDITION_ALE_PACKAGE_ID |
The user's AppContainer package SID. |
| FWPM_CONDITION_FLAGS |
A set of additional flags. |
| FWPM_CONDITION_ORIGINAL_PROFILE_ID |
The source network interface profile. |
| FWPM_CONDITION_CURRENT_PROFILE_ID |
The current network interface profile. |
The value to compare against the field can take different values depending on the field being checked. For example the field FWPM_CONDITION_IP_REMOTE_ADDRESS can be compared to IPv4 or IPv6 addresses depending on the layer it's used in. The value can also be a range, allowing a filter to match on an IP address within a bounded set of addresses.
The FWPM_CONDITION_ALE_USER_ID and FWPM_CONDITION_ALE_PACKAGE_ID conditions are based on the access token captured when creating the TCP or UDP socket. The FWPM_CONDITION_ALE_USER_ID stores a security descriptor which is used with an access check with the creator's token. If the token is granted access then the condition is considered to match. For FWPM_CONDITION_ALE_PACKAGE_ID the condition checks the package SID of the AppContainer token. If the token is not an AppContainer then the filtering engine sets the package SID to the NULL SID (S-1-0-0).
The FWPM_CONDITION_ALE_REMOTE_USER_ID is similar to the FWPM_CONDITION_ALE_USER_ID condition but compares against the remote authenticated user. In most cases sockets are not authenticated, however if IPsec is in use that can result in a remote user token being available to compare. It's also used in some higher-level layers such as RPC filters.
The match type can be one of the following:
- FWP_MATCH_EQUAL
- FWP_MATCH_EQUAL_CASE_INSENSITIVE
- FWP_MATCH_FLAGS_ALL_SET
- FWP_MATCH_FLAGS_ANY_SET
- FWP_MATCH_FLAGS_NONE_SET
- FWP_MATCH_GREATER
- FWP_MATCH_GREATER_OR_EQUAL
- FWP_MATCH_LESS
- FWP_MATCH_LESS_OR_EQUAL
- FWP_MATCH_NOT_EQUAL
- FWP_MATCH_NOT_PREFIX
- FWP_MATCH_PREFIX
- FWP_MATCH_RANGE
The match types should hopefully be self explanatory based on their names. How the match is interpreted depends on the field's type and the value being used to check against.
Inspecting the Firewall Configuration
We now have an idea of the basics of how WFP works to filter network traffic. Let's look at how to inspect the current configuration. We can't use any of the normal firewall commands or UIs such as the PowerShell NetSecurity module as I already mentioned these represent the Windows Defender view of the firewall.
Instead we need to use the RPC APIs BFE exposes to access the configuration, for example you can access a filter using the FwpmFilterGetByKey0 API. Note that the BFE maintains security descriptors to restrict access to WFP objects. By default nothing can be accessed by non-administrators, therefore you'd need to call the RPC APIs while running as an administrator.
You could implement your own tooling to call all the different APIs, but it'd be much easier if someone had already done it for us. For built-in tools the only one I know of is using netsh with the wfp namespace. For example to dump all the currently configured filters you can use the following command as an administrator:
| PS> netsh wfp show filters file = - |
This will print all filters in an XML format to the console. Be prepared to wait a while for the output to complete. You can also dump straight to a file. Of course you now need to interpret the XML results. It is possible to also specify certain parameters, such as local and remote addresses to reduce the output to only matching filters.
Processing an XML file doesn't sound too appealing. To make the firewall configuration easier to inspect I've added many of the BFE APIs to my NtObjectManager PowerShell module from version 1.1.32 onwards. The module exposes various commands which will return objects representing the current WFP configuration which you can easily use to inspect and group the results however you see fit.
Layer Configuration
Even though the layers are predefined in the WFP implementation it's still useful to be able to query the details about them. For this you can use the Get-FwLayer command.
| PS> Get-FwLayer
KeyName Name ------- ---- FWPM_LAYER_OUTBOUND_IPPACKET_V6 Outbound IP Packet v6 Layer FWPM_LAYER_IPFORWARD_V4_DISCARD IP Forward v4 Discard Layer FWPM_LAYER_ALE_AUTH_LISTEN_V4 ALE Listen v4 Layer ... |
The output shows the SDK name for the layer, if it has one, and the name of the layer that the BFE service has configured. The layer can be queried by its SDK name, its GUID or a numeric ID, which we will come back to later. As we mostly only care about the ALE layers then there's a special AleLayer parameter to query a specific layer without needing to remember the full name or ID.
| PS> (Get-FwLayer -AleLayer ConnectV4).Fields
KeyName Type DataType ------- ---- -------- FWPM_CONDITION_ALE_APP_ID RawData ByteBlob FWPM_CONDITION_ALE_USER_ID RawData TokenAccessInformation FWPM_CONDITION_IP_LOCAL_ADDRESS IPAddress UInt32 ... |
Each layer exposes the list of fields which represent the conditions which can be checked in that layer, you can access the list through the Fields property. The output shown above contains a few of the condition types we saw earlier in the table of conditions. The output also shows the type of the condition and the data type you should provide when filtering on that condition.
| PS> Get-FwSubLayer | Sort-Object Weight | Select KeyName, Weight
KeyName Weight ------- ------ FWPM_SUBLAYER_INSPECTION 0 FWPM_SUBLAYER_TEREDO 1 MICROSOFT_DEFENDER_SUBLAYER_FIREWALL 2 MICROSOFT_DEFENDER_SUBLAYER_WSH 3 MICROSOFT_DEFENDER_SUBLAYER_QUARANTINE 4 ... |
You can also inspect the sublayers in the same way, using the Get-FwSubLayer command as shown above. The most useful information from the sublayer is the weight. As mentioned earlier this is used to determine the ordering of the associated filters. However, as we'll see you rarely need to query the weight yourself.
Filter Configuration
Enforcing the firewall rules is up to the filters. You can enumerate all filters using the Get-FwFilter command.
| PS> Get-FwFilter
FilterId ActionType Name -------- ---------- ---- 68071 Block Boot Time Filter 71199 Permit @FirewallAPI.dll,-80201 71350 Block Block inbound traffic to dmcertinst.exe ... |
The default output shows the ID of a filter, the action type and the user defined name. The filter objects returned also contain the layer and sublayer identifiers as well as the list of matching conditions for the filter. As inspecting the filter is going to be the most common operation the module provides the Format-FwFilter command to format a filter object in a more readable format.
| PS> Get-FwFilter -Id 71350 | Format-FwFilter
Name : Block inbound traffic to dmcertinst.exe Action Type: Block Key : c391b53a-1b98-491c-9973-d86e23ea8a84 Id : 71350 Description: Layer : FWPM_LAYER_ALE_AUTH_RECV_ACCEPT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_WSH Flags : Indexed Weight : 549755813888 Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_APP_ID Equal \device\harddiskvolume3\windows\system32\dmcertinst.exe |
The formatted output contains the layer and sublayer information, the assigned weight of the filter and the list of conditions. The layer is FWPM_LAYER_ALE_AUTH_RECV_ACCEPT_V4 which handles new incoming connections. The sublayer is MICROSOFT_DEFENDER_SUBLAYER_WSH which is used to group Windows Service Hardening rules which apply regardless of the normal firewall configuration.
In this example the filter only matches on the socket creator process executable's path. The end result if the filter matches the current state is for the IPv4 TCP network connection to be blocked at the MICROSOFT_DEFENDER_SUBLAYER_WSH sublayer. As already mentioned it now won't matter if a lower priority layer would permit the connection if the block is enforced.
How can we determine the ordering of sublayers and filters? You could manually extract the weights for each sublayer and filter and try and order them, and hopefully the ordering you come up with matches what WFP uses. A much simpler approach is to specify a flag when enumerating filters for a particular layer to request the BFE APIs sort the filters using the canonical ordering.
| PS> Get-FwFilter -AleLayer ConnectV4 -Sorted
FilterId ActionType Name -------- ---------- ---- 65888 Permit Interface Un-quarantine filter 66469 Block AppContainerLoopback 66467 Permit AppContainerLoopback 66473 Block AppContainerLoopback ... |
The Sorted parameter specifies the flag to sort the filters. You can now go through the list of filters in order and try and work out what would be the matched filter based on some criteria you decide on. Again it'd be helpful if we could get the BFE service to do more of the hard work in figuring out what rules would apply given a particular process. For this we can specify some of the metadata that represents the connection being made and get the BFE service to only return filters which match on their conditions.
| PS> $template = New-FwFilterTemplate -AleLayer ConnectV4 -Sorted PS> $fs = Get-FwFilter -Template $template PS> $fs.Count 65
PS> Add-FwCondition $template -ProcessId $pid PS> $addr = Resolve-DnsName "www.google.com" -Type A PS> Add-FwCondition $template -IPAddress $addr.Address -Port 80 PS> Add-FwCondition $template -ProtocolType Tcp PS> Add-FwCondition $template -ConditionFlags 0 PS> $template.Conditions FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_APP_ID Equal \device\harddisk... FWPM_CONDITION_ALE_USER_ID Equal FirewallTokenInformation FWPM_CONDITION_ALE_PACKAGE_ID Equal S-1-0-0 FWPM_CONDITION_IP_REMOTE_ADDRESS Equal 142.250.72.196 FWPM_CONDITION_IP_REMOTE_PORT Equal 80 FWPM_CONDITION_IP_PROTOCOL Equal Tcp FWPM_CONDITION_FLAGS Equal None
PS> $fs = Get-FwFilter -Template $template PS> $fs.Count 2 |
To specify the metadata we need to create an enumeration template using the New-FwFilterTemplate command. We specify the Connect IPv4 layer as well as requesting that the results are sorted. Using this template with the Get-FwFilter command returns 65 results (on my machine).
Next we add some metadata, first from the current powershell process. This populates the App ID with the executable path as well as token information such as the user ID and package ID of an AppContainer. We then add details about the target connection request, specifying a TCP connection to www.google.com on port 80. Finally we add some condition flags, we'll come back to these flags later.
Using this new template results in only 2 filters whose conditions will match the metadata. Of course depending on your current configuration the number might be different. In this case 2 filters is much easier to understand than 65. If we format those two filter we see the following:
| PS> $fs | Format-FwFilter
Name : Default Outbound Action Type: Permit Key : 07ba2a96-0364-4759-966d-155007bde926 Id : 67989 Description: Default Outbound Layer : FWPM_LAYER_ALE_AUTH_CONNECT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_FIREWALL Flags : None Weight : 9223372036854783936 Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ORIGINAL_PROFILE_ID Equal Public FWPM_CONDITION_CURRENT_PROFILE_ID Equal Public
Name : Default Outbound Action Type: Permit Key : 36da9a47-b57d-434e-9345-0e36809e3f6a Id : 67993 Description: Default Outbound Layer : FWPM_LAYER_ALE_AUTH_CONNECT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_FIREWALL Flags : None Weight : 3458764513820540928 |
Both of the two filters permit the connection and based on the name they're the default backstop when no other filters match. It's possible to configure each network profile with different default backstops. In this case the default is to permit outbound traffic. We have two of them because both match all the metadata we provided, although if we'd specified a profile other than Public then we'd only get a single filter.
Can we prove that this is the filter which matches a TCP connection? Fortunately we can: WFP supports gathering network events related to the firewall. An event includes the filter which permitted or denied the network request, and we can then compare it to our two filters to see if one of them matched. You can use the Get-FwNetEvent command to read the current circular buffer of events.
| PS> Set-FwEngineOption -NetEventMatchAnyKeywords ClassifyAllow PS> $s = [System.Net.Sockets.TcpClient]::new($addr.IPAddress, 80) PS> Set-FwEngineOption -NetEventMatchAnyKeywords None PS> $ev_temp = New-FwNetEventTemplate -Condition $template.Conditions PS> Add-FwCondition $ev_temp -NetEventType ClassifyAllow PS> Get-FwNetEvent -Template $ev_temp | Format-List FilterId : 67989 LayerId : 48 ReauthReason : 0 OriginalProfile : Public CurrentProfile : Public MsFwpDirection : 0 IsLoopback : False Type : ClassifyAllow Flags : IpProtocolSet, LocalAddrSet, RemoteAddrSet, ... Timestamp : 8/5/2021 11:24:41 AM IPProtocol : Tcp LocalEndpoint : 10.0.0.101:63046 RemoteEndpoint : 142.250.72.196:80 ScopeId : 0 AppId : \device\harddiskvolume3\windows\system32\wind... UserId : S-1-5-21-4266194842-3460360287-487498758-1103 AddressFamily : Inet PackageSid : S-1-0-0 |
First we enable the ClassifyAllow event, which is generated when a firewall event is permitted. By default only firewall blocks are recorded using the ClassifyDrop event to avoid filling the small network event log with too much data. Next we make a connection to the Google web server we queried earlier to generate an event. We then disable the ClassifyAllow events again to reduce the risk we'll lose the event.
Next we can query for the current stored events using Get-FwNetEvent. To limit the network events returned to us we can specify a template in a similar way to when we queried for filters. In this case we create a new template using the New-FwNetEventTemplate command and copy the existing conditions from our filter template. We then add a condition to match on only ClassifyAllow events.
Formatting the results we can see the network connection event to TCP port 80. Crucially if you compare the FilterId value to the Id fields in the two enumerated filters we match the first filter. This gives us confidence that we have a basic understanding of how the filtering works. Let's move on to running some tests to determine how the AppContainer network restrictions are implemented through WFP.
Worth noting at this point that because the network event buffer can be small, of the order of 30-40 events depending on load, it's possible on a busy server that events might be lost before you query for them. You can get a real-time trace of events by using the Start-FwNetEventListener command to avoid losing events.
Callout Drivers
As mentioned a developer can implement their own custom functionality to inspect and modify network traffic. This functionality is used by various different products, ranging from AV to scan your network traffic for badness to NMAP's NPCAP capturing loopback traffic.
To set up a callout the developer needs to do two things. First they need to register its callback functions for the callout using the FwpmCalloutRegister API in the kernel driver. Second they need to create a filter to use the callout by specifying the providerContextKey GUID and one of the action types which invoke a callout.
You can query the list of registered callouts using the FwpmCalloutEnum0 API in user-mode. I expose this API through the Get-FwCallout command.
| PS> Get-FwCallout | Sort CalloutId | Select CalloutId, KeyName CalloutId KeyName --------- ------- 1 FWPM_CALLOUT_IPSEC_INBOUND_TRANSPORT_V4 2 FWPM_CALLOUT_IPSEC_INBOUND_TRANSPORT_V6 3 FWPM_CALLOUT_IPSEC_OUTBOUND_TRANSPORT_V4 4 FWPM_CALLOUT_IPSEC_OUTBOUND_TRANSPORT_V6 5 FWPM_CALLOUT_IPSEC_INBOUND_TUNNEL_V4 6 FWPM_CALLOUT_IPSEC_INBOUND_TUNNEL_V6 ... |
The above output shows the callouts listed by their callout ID numbers. The ID number is key to finding the callback functions in the kernel. There doesn't seem to be a way of enumerating the addresses of callout functions directly (at least from user mode). This article shows a basic approach to extract the callback functions using a kernel debugger, although it's a little out of date.
The NETIO driver stores all registered callbacks in a large array, the index being the callout ID. If you want to find a specific callout then find the base of the array using the description in the article then just calculate the offset based on a single callout structure and the index. For example on Windows 10 21H1 x64 the following command will dump a callout's classify callback function. Replace N with the callout ID, the magic numbers 198 and 50 are the offset into the gWfpGlobal global data table and the size of a callout entry which you can discover through analyzing the code.
| 0: kd> ln poi(poi(poi(NETIO!gWfpGlobal)+198)+(50*N)+10) |
If you're in kernel mode there's an undocumented KfdGetRefCallout function (and a corresponding KfdDeRefCallout to decrement the reference) exported by NETIO which will return a pointer to the internal callout structure based on the ID avoiding the need to extract the offsets from disassembly.
AppContainer Network Restrictions
The basics of accessing the network from an AppContainer sandbox is documented by Microsoft. Specifically the lowbox token used for the sandbox needs to have one or more capabilities enabled to grant access to the network. The three capabilities are:
- internetClient - Grants client access to the Internet
- internetClientServer - Grants client and server access to the Internet
- privateNetworkClientServer - Grants client and server access to local private networks.
Client Capabilities
Pretty much all Windows Store applications are granted the internetClient capability as accessing the Internet is a thing these days. Even the built-in calculator has this capability, presumably so you can fill in feedback on how awesome a calculator it is.
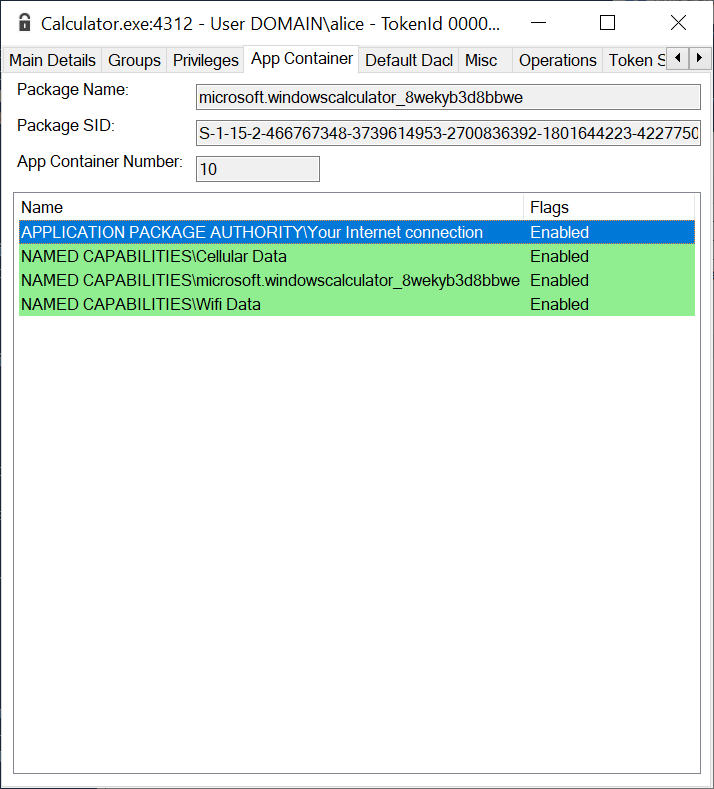
However, this shouldn't grant the ability to act as a network server, for that you need the internetClientServer capability. Note that Windows defaults to blocking incoming connections, so just because you have the server capability still doesn't ensure you can receive network connections. The final capability is privateNetworkClientServer which grants access to private networks as both a client and a server. What is the internet and what is private isn't made immediately clear, hopefully we'll find out from inspecting the firewall configuration.
| PS> $token = Get-NtToken -LowBox -PackageSid TEST PS> $addr = Resolve-DnsName "www.google.com" -Type A PS> $sock = Invoke-NtToken $token { >> [System.Net.Sockets.TcpClient]::new($addr.IPAddress, 80) >> } Exception calling ".ctor" with "2" argument(s): "An attempt was made to access a socket in a way forbidden by its access permissions 216.58.194.164:80"
PS> $template = New-FwNetEventTemplate PS> Add-FwCondition $template -IPAddress $addr.IPAddress -Port 80 PS> Add-FwCondition $template -NetEventType ClassifyDrop PS> Get-FwNetEvent -Template $template | Format-List
FilterId : 71079 LayerId : 48 ReauthReason : 0 ...
PS> Get-FwFilter -Id 71079 | Format-FwFilter Name : Block Outbound Default Rule Action Type: Block Key : fb8f5cab-1a15-4616-b63f-4a0d89e527f8 Id : 71079 Description: Block Outbound Default Rule Layer : FWPM_LAYER_ALE_AUTH_CONNECT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_WSH Flags : None Weight : 274877906944 Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_PACKAGE_ID NotEqual NULL SID |
In the above output we first create a lowbox token for testing the AppContainer access. In this example we don't provide any capabilities for the token so we're expecting the network connection should fail. Next we connect a TcpClient socket while impersonating the lowbox token, and the connection is immediately blocked with an error.
We then get the network event corresponding to the connection request to see what filter blocked the connection. Formatting the filter from the network event we find the “Block Outbound Default Rule”. This will block any AppContainer network connection, based on the FWPM_CONDITION_ALE_PACKAGE_ID condition which hasn't been permitted by higher priority firewall filters.
Like with the “Default Outbound” filter we saw earlier, this is a backstop if nothing else matches. Unlike that earlier filter the default is to block rather than permit the connection. Another thing to note is the sublayer name. For “Block Outbound Default Rule” it's MICROSOFT_DEFENDER_SUBLAYER_WSH which is used for built-in filters which aren't directly visible from the Defender firewall configuration. Whereas MICROSOFT_DEFENDER_SUBLAYER_FIREWALL is used for “Default Outbound”, which is a lower priority sublayer (based on its weight) and thus would never be evaluated due to the higher priority block.
Okay, we know how connections are blocked. Therefore there must be a higher priority filter which permits the connection within the MICROSOFT_DEFENDER_SUBLAYER_WSH sublayer. We could go back to manual inspection, but we might as well just see what the network event shows as the matching filter when we grant the internetClient capability.
| PS> $cap = Get-NtSid -KnownSid CapabilityInternetClient PS> $token = Get-NtToken -LowBox -PackageSid TEST -CapabilitySid $cap PS> Set-FwEngineOption -NetEventMatchAnyKeywords ClassifyAllow PS> $sock = Invoke-NtToken $token { >> [System.Net.Sockets.TcpClient]::new($addr.IPAddress, 80) >> } PS> Set-FwEngineOption -NetEventMatchAnyKeywords None PS> $template = New-FwNetEventTemplate PS> Add-FwCondition $template -IPAddress $addr.IPAddress -Port 80 PS> Add-FwCondition $template -NetEventType ClassifyAllow PS> Get-FwNetEvent -Template $template | Format-List
FilterId : 71075 LayerId : 48 ReauthReason : 0 ...
PS> Get-FwFilter -Id 71075 | Format-FwFilter Name : InternetClient Default Rule Action Type: Permit Key : 406568a7-a949-410d-adbb-2642ec3e8653 Id : 71075 Description: InternetClient Default Rule Layer : FWPM_LAYER_ALE_AUTH_CONNECT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_WSH Flags : None Weight : 412316868544 Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_PACKAGE_ID NotEqual NULL SID FWPM_CONDITION_IP_REMOTE_ADDRESS Range Low: 0.0.0.0 High: 255.255.255.255 FWPM_CONDITION_ORIGINAL_PROFILE_ID Equal Public FWPM_CONDITION_CURRENT_PROFILE_ID Equal Public FWPM_CONDITION_ALE_USER_ID Equal O:LSD:(A;;CC;;;S-1-15-3-1)(A;;CC;;;WD)(A;;CC;;;AN) |
In this example we create a new token using the same package SID but with internetClient capability. When we connect the socket we now no longer get an error and the connection is permitted. Checking for the ClassifyAllow event we find the “InternetClient Default Rule” filter matched the connection.
Looking at the conditions we can see that it will only match if the socket creator is in an AppContainer based on the FWPM_CONDITION_ALE_PACKAGE_ID condition. The FWPM_CONDITION_ALE_USER_ID also ensures that it will only match if the creator has the internetCapability capability which is S-1-15-3-1 in the SDDL format. This filter is what's granting access to the network.
One odd thing is in the FWPM_CONDITION_IP_REMOTE_ADDRESS condition. It seems to match on all possible IPv4 addresses. Shouldn't this exclude network addresses on our local “private” network? At the very least you'd assume this would block the reserved IP address ranges from RFC1918? The key to understanding this is the profile ID conditions, which are both set to Public. The computer I'm running these commands on has a single network interface configured to the public profile as shown:

Therefore the firewall is configured to treat all network addresses in the same context, granting the internetClient capability access to any address including your local “private” network. This might be unexpected. In fact if you enumerate all the filters on the machine you won't find any filter to match the privateNetworkClientServer capability and using the capability will not grant access to any network resource.
If you switch the network profile to Private, you'll find there's now three “InternetClient Default Rule” filters (note on Windows 11 there will only be one as it uses the OR'ing feature of conditions as mentioned above to merge the three rules together).
| Name : InternetClient Default Rule Action Type: Permit ... ------------ --------- ----- FWPM_CONDITION_ALE_PACKAGE_ID NotEqual NULL SID FWPM_CONDITION_IP_REMOTE_ADDRESS Range Low: 0.0.0.0 High: 10.0.0.0 FWPM_CONDITION_ORIGINAL_PROFILE_ID Equal Private FWPM_CONDITION_CURRENT_PROFILE_ID Equal Private ...
Name : InternetClient Default Rule Action Type: Permit Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_PACKAGE_ID NotEqual NULL SID FWPM_CONDITION_IP_REMOTE_ADDRESS Range Low: 239.255.255.255 High: 255.255.255.255 ...
Name : InternetClient Default Rule Action Type: Permit ... Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_PACKAGE_ID NotEqual NULL SID FWPM_CONDITION_IP_REMOTE_ADDRESS Range Low: 10.255.255.255 High: 224.0.0.0 ... |
As you can see in the first filter, it covers addresses 0.0.0.0 to 10.0.0.0. The machine's private network is 10.0.0.0/8. The profile IDs are also now set to Private. The other two exclude the entire 10.0.0.0/8 network as well as the multicast group addresses from 224.0.0.0 to 240.0.0.0.
The profile ID conditions are important here if you have more than one network interface. For example if you have two, one Public and one Private, you would get a filter for the Public network covering the entire IP address range and the three Private ones excluding the private network addresses. The Public filter won't match if the network traffic is being sent from the Private network interface preventing the application without the right capability from accessing the private network.
Speaking of which, we can also now identify the filter which will match the private network capability. There's two, to cover the private network range and the multicast range. We'll just show one of them.
| Name : PrivateNetwork Outbound Default Rule Action Type: Permit Key : e0194c63-c9e4-42a5-bbd4-06d90532d5e6 Id : 71640 Description: PrivateNetwork Outbound Default Rule Layer : FWPM_LAYER_ALE_AUTH_CONNECT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_WSH Flags : None Weight : 36029209335832512 Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_PACKAGE_ID NotEqual NULL SID FWPM_CONDITION_IP_REMOTE_ADDRESS Range Low: 10.0.0.0 High: 10.255.255.255 FWPM_CONDITION_ORIGINAL_PROFILE_ID Equal Private FWPM_CONDITION_CURRENT_PROFILE_ID Equal Private FWPM_CONDITION_ALE_USER_ID Equal O:LSD:(A;;CC;;;S-1-15-3-3)(A;;CC;;;WD)(A;;CC;;;AN) |
We can see in the FWPM_CONDITION_ALE_USER_ID condition that the connection would be permitted if the creator has the privateNetworkClientServer capability, which is S-1-15-3-3 in SDDL.
It is slightly ironic that the Public network profile is probably recommended even if you're on your own private network (Windows 11 even makes the recommendation explicit as shown below) in that it should reduce the exposed attack surface of the device from others on the network. However if an AppContainer application with the internetClient capability could be compromised it opens up your private network to access where the Private profile wouldn't.

Aside: one thing you might wonder, if your network interface is marked as Private and the AppContainer application only has the internetClient capability, what happens if your DNS server is your local router at 10.0.0.1? Wouldn't the application be blocked from making DNS requests? Windows has a DNS client service which typically is always running. This service is what usually makes DNS requests on behalf of applications as it allows the results to be cached. The RPC server which the service exposes allows callers which have any of the three network capabilities to connect to it and make DNS requests, avoiding the problem. Of course if the service is disabled in-process DNS lookups will start to be used, which could result in weird name resolving issues depending on your network configuration.
We can now understand how issue 2207 I reported to Microsoft bypasses the capability requirements. If in the MICROSOFT_DEFENDER_SUBLAYER_WSH sublayer for an outbound connection there are Permit filters which are evaluated before the “Block Outbound Default Rule” filter then it might be possible to avoid needing capabilities.
| PS> Get-FwFilter -AleLayer ConnectV4 -Sorted | Where-Object SubLayerKeyName -eq MICROSOFT_DEFENDER_SUBLAYER_WSH | Select-Object ActionType, Name ... Permit Allow outbound TCP traffic from dmcertinst.exe Permit Allow outbound TCP traffic from omadmclient.exe Permit Allow outbound TCP traffic from deviceenroller.exe Permit InternetClient Default Rule Permit InternetClientServer Outbound Default Rule Block Block all outbound traffic from SearchFilterHost Block Block outbound traffic from dmcertinst.exe Block Block outbound traffic from omadmclient.exe Block Block outbound traffic from deviceenroller.exe Block Block Outbound Default Rule Block WSH Default Outbound Block
PS> Get-FwFilter -Id 72753 | Format-FwFilter Name : Allow outbound TCP traffic from dmcertinst.exe Action Type: Permit Key : 5237f74f-6346-4038-a48d-4b779f862e65 Id : 72753 Description: Layer : FWPM_LAYER_ALE_AUTH_CONNECT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_WSH Flags : Indexed Weight : 422487342972928 Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_APP_ID Equal \device\harddiskvolume3\windows\system32\dmcertinst.exe FWPM_CONDITION_IP_PROTOCOL Equal Tcp |
As we can see in the output there are quite a few Permit filters before the “Block Outbound Default Rule” filter, and of course I've also cropped the list to make it smaller. If we inspect the “Allow outbound TCP traffic from dmcertinst.exe” filter we find that it only matches on the App ID and the IP protocol. As it doesn't have an AppContainer specific checks, then any sockets created in the context of a dmcertinst process would be permitted to make TCP connections.
Once the “Allow outbound TCP traffic from dmcertinst.exe” filter matches the sublayer evaluation is terminated and it never reaches the “Block Outbound Default Rule” filter. This is fairly trivial to exploit, as long as the AppContainer process is allowed to spawn new processes, which is allowed by default.
Server Capabilities
What about the internetClientServer capability, how does that function? First, there's a second set of outbound filters to cover the capability with the same network addresses as the base internetClient capability. The only difference is the FWPM_CONDITION_ALE_USER_ID condition checks for the internetClientServer (S-1-15-3-2) capability instead. For inbound connections the FWPM_LAYER_ALE_AUTH_RECV_ACCEPT_V4 layer contains the filter.
| PS> Get-FwFilter -AleLayer RecvAcceptV4 -Sorted | Where-Object Name -Match InternetClientServer | Format-FwFilter Name : InternetClientServer Inbound Default Rule Action Type: Permit Key : 45c5f1d5-6ad2-4a2a-a605-4cab7d4fb257 Id : 72470 Description: InternetClientServer Inbound Default Rule Layer : FWPM_LAYER_ALE_AUTH_RECV_ACCEPT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_WSH Flags : None Weight : 824633728960 Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_PACKAGE_ID NotEqual NULL SID FWPM_CONDITION_IP_REMOTE_ADDRESS Range Low: 0.0.0.0 High: 255.255.255.255 FWPM_CONDITION_ORIGINAL_PROFILE_ID Equal Public FWPM_CONDITION_CURRENT_PROFILE_ID Equal Public FWPM_CONDITION_ALE_USER_ID Equal O:LSD:(A;;CC;;;S-1-15-3-2)(A;;CC;;;WD)(A;;CC;;;AN) |
The example shows the filter for a Public network interface granting an AppContainer application the ability to receive network connections. However, this will only be permitted if the socket creator has internetClientServer capability. Note, there would be similar rules for the private network if the network interface is marked as Private but only granting access with the privateNetworkClientServer capability.
As mentioned earlier just because an application has one of these capabilities doesn't mean it can receive network connections. The default configuration will block the inbound connection. However, when an UWP application is installed and requires one of the two server capabilities, the AppX installer service registers the AppContainer profile with the Windows Defender Firewall service. This adds a filter to permit the AppContainer package to receive inbound connections. For example the following is for the Microsoft Photos application, which is typically installed by default:
| PS> Get-FwFilter -Id 68299 | Format-FwFilter -FormatSecurityDescriptor -Summary Name : @{Microsoft.Windows.Photos_2021... Action Type: Permit Key : 7b51c091-ed5f-42c7-a2b2-ce70d777cdea Id : 68299 Description: @{Microsoft.Windows.Photos_2021... Layer : FWPM_LAYER_ALE_AUTH_RECV_ACCEPT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_FIREWALL Flags : Indexed Weight : 10376294366095343616 Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_PACKAGE_ID Equal microsoft.windows.photos_8wekyb3d8bbwe FWPM_CONDITION_ALE_USER_ID Equal O:SYG:SYD:(A;;CCRC;;;S-1-5-21-3563698930-1433966124...
<Owner> (Defaulted) : NT AUTHORITY\SYSTEM <Group> (Defaulted) : NT AUTHORITY\SYSTEM <DACL> DOMAIN\alice: (Allowed)(None)(Full Access) APPLICATION PACKAGE AUTHORITY\ALL APPLICATION PACKAGES:... APPLICATION PACKAGE AUTHORITY\Your Internet connection:... APPLICATION PACKAGE AUTHORITY\Your Internet connection,... APPLICATION PACKAGE AUTHORITY\Your home or work networks:... NAMED CAPABILITIES\Proximity: (Allowed)(None)(Full Access) |
The filter only checks that the package SID matches and that the socket creator is a specific user in an AppContainer. Note this rule doesn't do any checking on the executable file, remote IP address, port or profile ID. Once an installed AppContainer application is granted a server capability it can act as a server through the firewall for any traffic type or port.
A normal application could abuse this configuration to run a network service without needing the administrator access normally required to grant the executable access. All you'd need to do is create an arbitrary AppContainer process in the permitted package and grant it the internetClientServer and/or the privateNetworkClientServer capabilities. If there isn't an application installed which has the appropriate firewall rules a non-administrator user can install any signed application with the appropriate capabilities to add the firewall rules. While this clearly circumvents the expected administrator requirements for new listening processes it's presumably by design.
Localhost Access
One of the specific restrictions imposed on AppContainer applications is blocking access to localhost. The purpose of this is it makes it more difficult to exploit local network services which might not correctly handle AppContainer callers creating a sandbox escape. Let's test the behavior out and try to connect to a localhost service.
| PS> $token = Get-NtToken -LowBox -PackageSid "LOOPBACK" PS> Invoke-NtToken $token { [System.Net.Sockets.TcpClient]::new("127.0.0.1", 445) } Exception calling ".ctor" with "2" argument(s): "A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond 127.0.0.1:445" |
If you compare the error to when we tried to connect to an internet address without the appropriate capability you'll notice it's different. When we connected to the internet we got an immediate error indicating that access isn't permitted. However, for localhost we instead get a timeout error, which is preceded by multi-second delay. Why the difference? Getting the network event which corresponds to the connection and displaying the blocking filter shows something interesting.
| PS> Get-FwFilter -Id 69039 | Format-FwFilter -FormatSecurityDescriptor -Summary Name : AppContainerLoopback Action Type: Block Key : a58394b7-379c-43ac-aa07-9b620559955e Id : 69039 Description: AppContainerLoopback Layer : FWPM_LAYER_ALE_AUTH_RECV_ACCEPT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_WSH Flags : None Weight : 18446744073709551614 Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_FLAGS FlagsAllSet IsLoopback FWPM_CONDITION_ALE_USER_ID Equal O:LSD:(A;;CC;;;AC)(A;;CC;;;S-1-15-3-1)(A;;CC;;;S-1-15-3-2)...
<Owner> : NT AUTHORITY\LOCAL SERVICE <DACL> APPLICATION PACKAGE AUTHORITY\ALL APPLICATION PACKAGES... APPLICATION PACKAGE AUTHORITY\Your Internet connection... APPLICATION PACKAGE AUTHORITY\Your Internet connection, including... APPLICATION PACKAGE AUTHORITY\Your home or work networks... NAMED CAPABILITIES\Proximity: (Allowed)(None)(Match) Everyone: (Allowed)(None)(Match) NT AUTHORITY\ANONYMOUS LOGON: (Allowed)(None)(Match) |
The blocking filter is not in the connect layer as you might expect, instead it's in the receive/accept layer. This explains why we get a timeout rather than immediate failure: the “inbound” connection request is being dropped as per the default configuration. This means the TCP client waits for the response from the server, until it eventually hits the timeout limit.
The second interesting thing to note about the filter is it's not based on an IP address such as 127.0.0.1. Instead it's using a condition which checks for the IsLoopback condition flag (FWP_CONDITION_FLAG_IS_LOOPBACK in the SDK). This flag indicates that the connection is being made through the built-in loopback network, regardless of the destination address. Even if you access the public IP addresses for the local network interfaces the packets will still be routed through the loopback network and the condition flag will be set.
The user ID check is odd, in that the security descriptor matches either AppContainer or non-AppContainer processes. This is of course the point, if it didn't match both then it wouldn't block the connection. However, it's not immediately clear what its actual purpose is if it just matches everything. In my opinion, it adds a risk that the filter will be ignored if the socket creator has disabled the Everyone group. This condition was modified for supporting LPAC over Windows 8, so it's presumably intentional.
You might ask, if the filter would block any loopback connection regardless of whether it's in an AppContainer, how do loopback connections work for normal applications? Wouldn't this filter always match and block the connection? Unsurprisingly there are some additional permit filters before the blocking filter as shown below.
| PS> Get-FwFilter -AleLayer RecvAcceptV4 -Sorted | Where-Object Name -Match AppContainerLoopback | Format-FwFilter Name : AppContainerLoopback Action Type: Permit ... Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_FLAGS FlagsAllSet IsAppContainerLoopback
Name : AppContainerLoopback Action Type: Permit ... Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_FLAGS FlagsAllSet IsReserved
Name : AppContainerLoopback Action Type: Permit ... Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_FLAGS FlagsAllSet IsNonAppContainerLoopback |
The three filters shown above only check for different condition flags, and you can find documentation for the flags on MSDN. Starting at the bottom we have a check for IsNonAppContainerLoopback. This flag is set on a connection when the loopback connection is between non-AppContainer created sockets. This filter is what grants normal applications loopback access. It's also why an application can listen on localhost even if it's not granted access to receive connections from the network in the firewall configuration.
In contrast the first filter checks for the IsAppContainerLoopback flag. Based on the documentation and the name, you might assume this would allow any AppContainer to use loopback to any other. However, based on testing this flag is only set if the two AppContainers have the same package SID. This is presumably to allow an AppContainer to communicate with itself or other processes within its package through loopback sockets.
This flag is also, I suspect, the reason that connecting to a loopback socket is handled in the receive layer rather than the connect layer. Perhaps WFP can't easily tell ahead of time whether both the connecting and receiving sockets will be in the same AppContainer package, so it delays resolving that until the connection has been received. This does lead to the unfortunate behavior that blocked loopback sockets timeout rather than fail immediately.
The final flag, IsReserved is more curious. MSDN of course says this is “Reserved for future use.”, and the future is now. Though checking back at the filters in Windows 8.1 also shows it being used, so if it was reserved it wasn't for very long. The obvious conclusion is this flag is really a “Microsoft Reserved” flag, by that I mean it's actually used but Microsoft is yet unwilling to publicly document it.
What is it used for? AppContainers are supposed to be a capability based system, where you can just add new capabilities to grant additional privileges. It would make sense to have a loopback capability to grant access, which could be restricted to only being used for debugging purposes. However, it seems that loopback access was so beyond the pale for the designers that instead you can only grant access for debug purposes through an administrator only API. Perhaps it's related?
| PS> Add-AppModelLoopbackException -PackageSid "LOOPBACK" PS> Get-FwFilter -AleLayer ConnectV4 | Where-Object Name -Match AppContainerLoopback | Format-FwFilter -FormatSecurityDescriptor -Summary Name : AppContainerLoopback Action Type: CalloutInspection Key : dfe34c0f-84ca-4af1-9d96-8bf1e8dac8c0 Id : 54912247 Description: AppContainerLoopback Layer : FWPM_LAYER_ALE_AUTH_CONNECT_V4 Sub Layer : MICROSOFT_DEFENDER_SUBLAYER_WSH Flags : None Weight : 18446744073709551615 Callout Key: FWPM_CALLOUT_RESERVED_AUTH_CONNECT_LAYER_V4 Conditions : FieldKeyName MatchType Value ------------ --------- ----- FWPM_CONDITION_ALE_USER_ID Equal D:(A;NP;CC;;;WD)(A;NP;CC;;;AN)(A;NP;CC;;;S-1-15-3-1861862962-...
<DACL> Everyone: (Allowed)(NoPropagateInherit)(Match) NT AUTHORITY\ANONYMOUS LOGON: (Allowed)(NoPropagateInherit)(Match) PACKAGE CAPABILITY\LOOPBACK: (Allowed)(NoPropagateInherit)(Match) LOOPBACK: (Allowed)(NoPropagateInherit)(Match) |
First we add a loopback exemption for the LOOPBACK package name. We then look for the AppContainerLoopback filters in the connect layer. The one we're interested in is shown. The first thing to note is that the action type is set to CalloutInspection. This might seem slightly surprising, you would expect it'd do something more than inspecting the traffic.
The name of the callout, FWPM_CALLOUT_RESERVED_AUTH_CONNECT_LAYER_V4 gives the game away. The fact that it has RESERVED in the name can't be a coincidence. This callout is one implemented internally by Windows in the TCPIP!WfpAlepDbgLowboxSetByPolicyLoopbackCalloutClassify function. This name now loses all mystery and pretty much explains what its purpose is, which is to configure the connection so that the IsReserved flag is set when the receive layer processes it.
The user ID here is equally important. When you register the loopback exemption you only specify the package SID, which is shown in the output as the last “LOOPBACK” line. Therefore you'd assume you'd need to always run your code within that package. However, the penultimate line is “PACKAGE CAPABILITY\LOOPBACK” which is my module's way of telling you that this is the package SID, but converted to a capability SID. This is basically changing the first relative identifier in the SID from 2 to 3.
We can use this behavior to simulate a generic loopback exemption capability. It allows you to create an AppContainer sandboxed process which has access to localhost which isn't restricted to a particular package. This would be useful for applications such as Chrome to implement a network facing sandboxed process and would work from Windows 8 through 11. . Unfortunately it's not officially documented so can't be relied upon. An example demonstrating the use of the capability is shown below.
| PS> $cap = Get-NtSid -PackageSid "LOOPBACK" -AsCapability PS> $token = Get-NtToken -LowBox -PackageSid "TEST" -cap $cap PS> $sock = Invoke-NtToken $token { [System.Net.Sockets.TcpClient]::new("127.0.0.1", 445) } PS> $sock.Client.RemoteEndPoint AddressFamily Address Port ------------- ------- ---- InterNetwork 127.0.0.1 445 |
Conclusions
That wraps up my quick overview of how AppContainer network restrictions are implemented using the Windows Firewall. I covered the basics of the Windows Firewall as well as covered some of my tooling I wrote to do analysis of the configuration. This background information allowed me to explain why the issue I reported to Microsoft worked. I also pointed out some of the quirks of the implementation which you might find of interest.
Having a good understanding of how a security feature works is an important step towards finding security issues. I hope that by providing both the background and tooling other researchers can also find similar issues and try and get them fixed.










 Overview diagram of memory read layout. In the middle is a set of boxes representing the native 4KiB pages being read. All the boxes are contained within a single larger region which is the large page size. Above the boxes are arrows which show that from the base of the 4KiB box a 32KiB read will be made into the file which can satisfy the reads from other 4KiB pages. The final box shows that the last 32KiB of the large page size will always be read as a single page regardless of where in the box the read occurs." style="max-height: 750; max-width: 600;" />
Overview diagram of memory read layout. In the middle is a set of boxes representing the native 4KiB pages being read. All the boxes are contained within a single larger region which is the large page size. Above the boxes are arrows which show that from the base of the 4KiB box a 32KiB read will be made into the file which can satisfy the reads from other 4KiB pages. The final box shows that the last 32KiB of the large page size will always be read as a single page regardless of where in the box the read occurs." style="max-height: 750; max-width: 600;" />


















