State of Pentesting 2020
To many people, pentesting (or hacking in a broader sense) is a dark art mastered by some and poorly understood by most. It has evolved quite substantially throughout the years, guided by new vulnerabilities, changing behaviours and maybe most importantly the development and release of new tools, be they offensive or defensive.
In this blog post, I wanted to present how pentests have evolved since I started my pentesting journey some 12 years ago. Note that none of this is backed by hard data, but on my own feelings after seeing a great number of tests performed throughout the years.
When it comes to the types of pentests we perform, we see that while standard internal or external tests are performed by companies who have never or rarely had any security testing done beforehand, seasoned companies tend to ask for more specific testing of applications, systems or processes.
Red or Purple teaming approaches are preferred in order to establish not only which vulnerabilities are present, but also determine whether the defensive efforts are properly prioritized and implemented.
A lot of testing has now also shifted to the Cloud, and although some aspects of these tests remain similar, there are a number of subtleties provided by each Cloud provider that need to be considered.
In this post, I’ll have a look at how internal pentests have evolved throughout the years.
Internal pentests
When I started pentesting, the MS08-067 (Conficker) vulnerability had just been published and for some (long) time afterwards, compromising a company was all about discovering which system hadn’t been patched, exploiting it with Metasploit, cracking the LM or NTLM hash of the local administrator and reusing it throughout the company to compromise all systems.
Even though we still occasionally discover systems vulnerable to MS08-067, the “entry point” into the network has changed throughout the years. For some time, JBoss and Tomcat servers were the holy grail of pentesters, as they tended to be installed with an administration interface which is often poorly protected (if protected at all) which allowed to deploy new applications and thus run arbitrary commands on the server.
In most cases these commands were run with SYSTEM privileges allowing for a full compromise. This latter fact is an issue that we still routinely discover, where applications run with elevated privileges on a server for no particular reason apart from the fact that it’s easy to do! I’d recommend having a look at Group-Managed Service Accounts to attempt to avoid this.
Thankfully, the more recent versions of these application servers either do not install a management interface or simply do not provide any default credentials any more, which limits the ways in which they can be compromised, although unauthenticated JMX or Java RMI interfaces can often still be exploited with tools such as ysoserial.
A little more recently, MS17-010 became the new norm in order to compromise a workstation or server, and very much like MS08-067, it can often still be exploited nowadays, despite the patch being available for over 3 years. The only “difficulty” is to find that hidden server that hasn’t been patched in years but can’t be decommissioned because it’s “too sensitive”. This might come in as a surprise to some, but hackers rarely spend much time on the servers you just installed and hardened. Instead, they will search for the old ones which you’re trying to forget about!
The “entry point” or first vulnerability has certainly changed multiple times throughout the years, but the concept of compromising the local administrator account and reusing it elsewhere stayed true for a long time. However, the fact of cracking the password was never really required, as pass-the-hash techniques could be abused instead. The concept of actually cracking a NTLM hash and recovering the clear-text password is mostly used to generate password statistics nowadays.
One of the more impactful developments has been the adoption of LAPS, or similar password management tools, which allow administrators to manage the local administrator passwords for all domain-joined computers. This completely prevents the previously discussed lateral movements and is probably the single biggest improvement we have seen over the years, although for it to really be efficient, all other local accounts must be removed!
Due to this, it is no longer interesting to recover the local accounts after compromising a server. Instead, tools such as Mimikatz are used to recover the clear-text credentials (or NTLM hash) of connected users directly from the machine’s memory. This allows for the compromise of domain users that have recently authenticated to the machine. Compromising a domain administrator account is therefore achieved by compromising any server (or workstation…) where such an account is logged on.
Even though Microsoft has recommended for years that these accounts be used as little as possible, it is still a relatively common practice to use domain administrator accounts for routine administration purposes or even for service accounts. It’s just so much simpler that way!
When it comes to discovering the machines used by domain administrators and how to compromise them, the development of tools such as BloodHound have shown that it is not always necessary to exploit an actual vulnerability to get there, but simply abuse a (mis)configuration of the Active Directory. Overly broad permissions on AD objects can rapidly be exploited by attackers to elevate privileges within a domain.
Kerberoasting is another fun technique which is commonly used nowadays as it allows any domain user to essentially recover a non-replayable hash of accounts which have a Service Principal Name (usually service accounts). This is one of the cases where cracking a hash is actually necessary. Thankfully for attackers, service accounts are often ancient and set with a password which never expires. In many cases it is the name of the service followed by the year the service was installed. These passwords will take seconds to break and often grant extensive access to the information system.
Nevertheless, BloodHound and Kerberoasting attacks still require an initial domain account to be used. Nowadays, it is often much easier to compromise an account rather than compromising a workstation or server.
For some time, a simple domain account was sufficient to compromise high privileged credentials in GPPs as these were encrypted in a reversible format. Even though this has now been “patched” (essentially by removing the vulnerable feature) it is always worth grepping for cpassw in SYSVOL, just in case.
But how do we actually compromise this initial account?
Responder is a fantastic tool which allows to recover a non-replayable hash from computers that still use legacy protocols such as LLMNR and NBNS for name resolution. The hash can be recovered by forcing the vulnerable system to authenticate to the attacker’s one. At this stage, the hash could potentially be broken (probably because the password is Welcome2020) but it doesn’t actually need to be, since NTLM is vulnerable to relay attacks. Instead of recovering the account hash, an attacker can simply the authentication to another system with the help of tools such as ntlmrelayx from impacket.
The impact of such attacks depends on the privileges of the compromised account. In the worst case scenario, a domain administrator account might be compromised in this fashion to directly execute arbitrary commands on the domain controller.
Internal pentests nowadays often revolve around this idea of forcing an account to authenticate to the attacker’s machine. This can be done by abusing LLMNR or NBNS, but it could also be done by simply inserting an image or iframe in unencrypted HTTP traffic, the end result would be similar. The authentication is then relayed to an appropriate system depending on the account privileges, and from there, privilege escalation is achieved through misconfigured Active Directory objects.
Pilfering the Active Directory for these misconfigurations has become somewhat of an art and there are several combination of issues which can potentially be abused to execute code on a targeted machine if the appropriate credentials are “available” on the network. This article from last year presents several ways of abusing Kerberos delegation for example. Other simpler ways exist, such as searching for clear-text passwords in object descriptions which by default are available to all.
The “printer bug” can also be used in many cases to force a machine account to authenticate to an attacker’s machine. If the machine happens to have admin privileges on another machine (this is easy to discover with BloodHound for example), this gives instant access to the second machine with high privileges.
The current “meta” for internal pentests is to run Responder alongside ntlmrelay to gain initial access, and then replay credentials compromised with Mimikatz and abuse AD misconfigurations to compromise a domain administrator account. Obviously this is a bit of an oversimplification as there are still other vulnerabilities that can be exploited, but it is often the path of least resistance.
And of course, while I’m writing this, the ZeroLogon vulnerability was published, ensuring pentesters a healthy couple years of directly compromising domain controllers without going through everything I just discussed!
So how can you defend against this?
The initial part of the attack process is based on the NTLM authentication protocol and its weakness against relay attacks. Obviously if you disable NTLM authentication altogether and exclusively use Kerberos, this particular problem is solved, but in practice, this is near impossible to do.
One possibility is to disable LLMNR and NBNS, but it won’t prevent malicious users from inserting images into unencrypted HTTP traffic or cases such as the printer big discussed above. Thankfully, there is another solution which is the fact of requiring SMB signing for both clients and servers. This effectively prevents the relaying attacks on the SMB protocol. Unfortunately, NTLM authentication can also be used in cross-protocol attacks, where an authentication to an HTTP server for example can be relayed to a SMB server or vive-versa. Other protections such as channel binding or proper use of TLS are required to mitigate these attacks. A nice article regaring NTLM relay and its mitigations can be found here.
The second part of the attacks relies on the ability to use mimikatz to compromise credentials and attack systems which are used simultaneously administered by lower privileged accounts and used by higher privileged accounts. The first recommendation i’d give here is to not rely on your anti-virus to block Mimikatz. There are so many different evasion techniques available, that one of them will always end up working. Instead, prefer the protection of LSASS with Credential Guard. I also highly recommend the use of the Protected Users group for any privileged account. Similarly, they should all be marked with the Account is sensitive and cannot be delegated property to avoid them being abused in Kerberos delegation attacks.
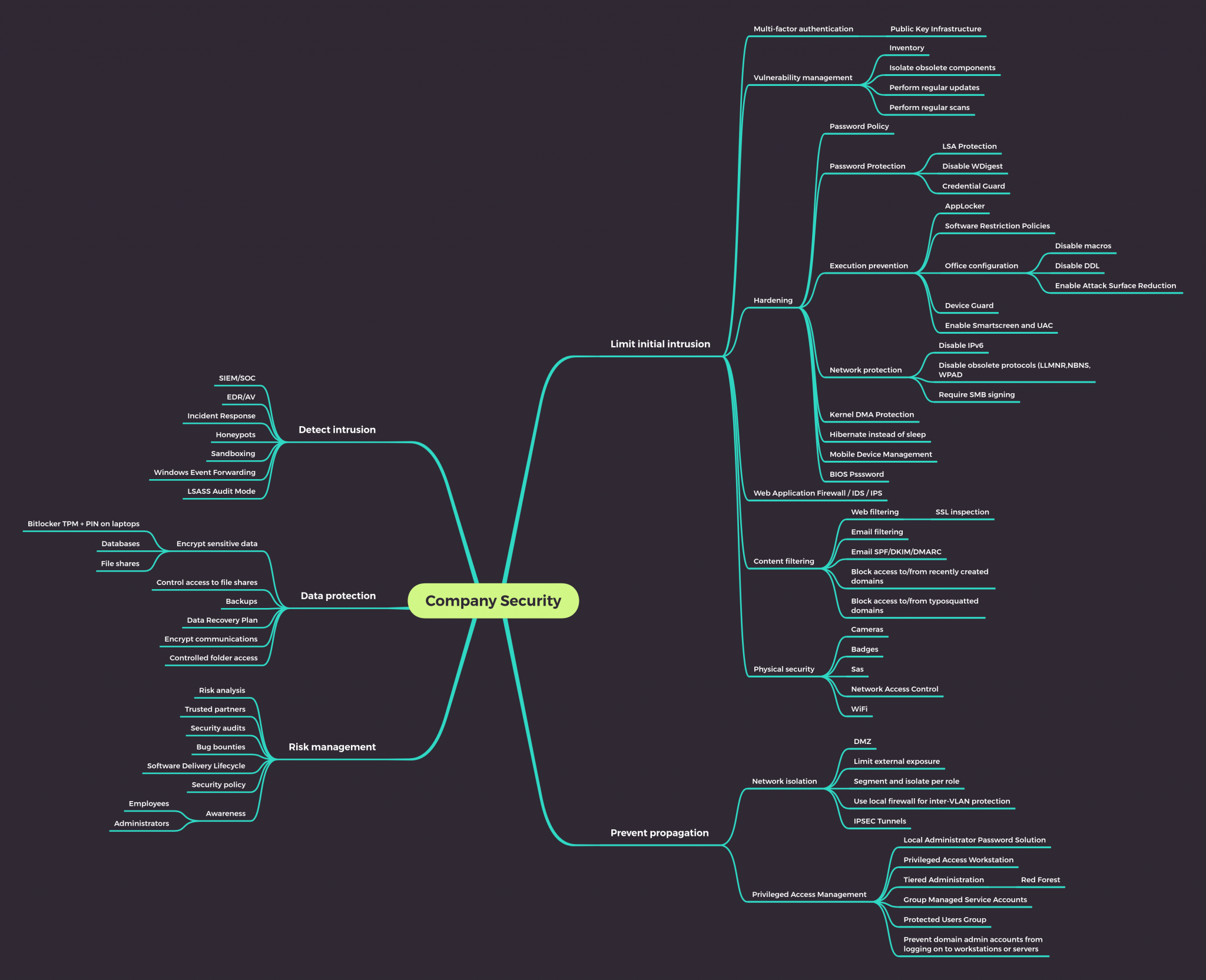
And finally the harder part is implementing a proper privileged account management hygiene. To avoid privilege escalation through a compromised system, it must be impossible for a more privileged account to be used on a system where a lesser account has administrative privileges. A tiered administration approach can be used, such as the one proposed by Microsoft here.
I’d recommend reading the whole article, but i’ll attempt to very briefly summarise the key points:
- Setup a minimum of 3 administrative tiers/groups in the Active Directory. This would be for domain admins, server admins and workstation admins for example.
- Implement the concept of Privileged Access Workstations (PAW) for these administrators. This is actually harder to implement than one might think, especially since most companies will not want to provide multiple workstations for administrators. One relatively straightforward way of doing this is using a hardened “base” laptop for administrative purposes and login to a VDI or virtual machine for all “user” tasks.
- Restrict access and logon between administrative tiers with firewalls and group policies
- Use Windows Firewall to allow access to the various tiers only from authorised PAWs for the associated tier.
- Implement Multi-factor authentication for administrators
- Put all admin accounts in the Protected Users group
- Mark all admins as sensitive for delegation
If you feel like this is not enough, you could also go for an ESAE Administrative Forest (also sometimes called Red Forest).
One constant that I have seen throughout the years and companies where I have performed tests is the lack of proper internal network filtering. Even though it is getting rarer nowadays to find a completely “flat” network with all workstations and servers on the same subnet, there is rarely any firewalling performed between subnets and pretty much never any within a given subnet. This is a shame as proper filtering can prevent a great number of exploits by simply restricting access to the vulnerable services.
I’ve also regularly been asked the question “What solution can we buy to protect against this or prevent that?”. But in most cases, it is a lot better to properly setup and configure a system which is already in place (such as Windows and Active Directory for example) rather than acquire a new solution that will just increase the overall attack surface. Security products can include security vulnerabilities, as has been demonstrated numerous times.
EDR solutions or “next-generation” anti-viruses are all the rage right now, promising to detect malicious payloads and behaviours. Even though they definitely provide an additional hurdle for intruders, a skilled attacker will probably always be able to circumvent the solution, with techniques such as the ones discussed by my colleague @plowsec here and here. Again, relying on a specific security solution rather than applying defense in depth techniques is not the way to go.
What’s next?
Supposing all companies apply the protections discussed above such that NTLM relaying is no longer possible, credentials are protected in memory and domain admin accounts cannot be compromised any more. How will pentests evolve? I’m pretty sure this will depend on new quality tools being developed and released, as the ones discussed in this post have shaped the way pentests are performed now.
One thing that is important to note is that domain administrator accounts are not actually all that useful in a targeted attack. During pentests they are always seen as the main objective because they essentially grant access to everything in an organisation, but a real attacker does not need access to everything. If appropriately targeted, a single non-administrator account can be sufficient to gain access to a specific piece of information. Figuring out which account has that specific access and where it might be compromised will be all the more important.
If we imagine that credentials cannot be compromised in-memory any more, I believe attackers will resort to older techniques such as key logging or even just phishing to get a victim’s credentials. This however assumes that passwords will remain as the main authentication factor. Hopefully this won’t be the case, but currently it looks like there is still some time ahead of us before they are replaced by something better.
As to how access to a workstation or server is gained in the first place, I’m confident new techniques and vulnerabilities will arise, be they within Windows or other third party solutions that are used by all and updated much less frequently. Backup or automation solutions seem like strong contenders. However, if companies decide to apply appropriate firewaling rules, these vulnerabilities may never actually be exploited, and attackers may have to rely only on compromised accounts to achieve their purposes, meaning that appropriately managing privileges will remain extremely important.
I’m obviously not a psychic and have no idea what will really happen, but if any of the information in this post can help someone better prepare against current (or future?) attack techniques, it will have served some purpose!