Abusing the SYLK file format
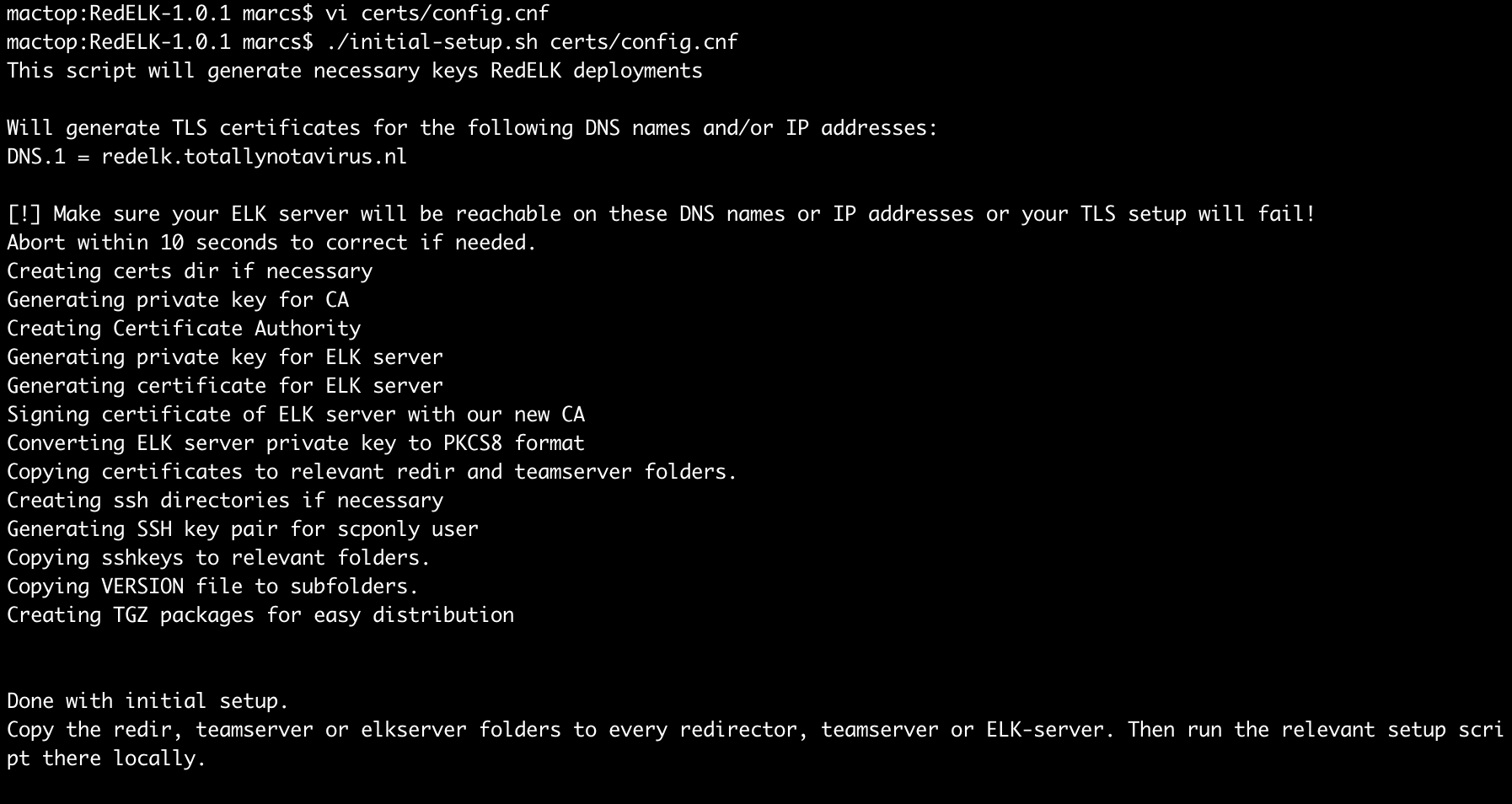
This blog is about the SYLK file format, a file format from the 1980s that is still supported by the most recent MS Office versions. As it turns out, this file format is a very good candidate for creating weaponized documents that can be used by attackers to establish an initial foothold. In our presentation at DerbyCon 8 we already demonstrated some of the powers of SYLK.
In this blog post we will dive into additional details of this file format. We also provide recommendations for mitigations against weaponized SYLK files.
Introduction
SYLK stands for SYmbolic LinK, a file format that was introduced in the 1980s. Commonly, SYLK files have the file extension .slk. SYLK is a file format which uses only displayable ANSI characters and it was created to exchange data between applications (such as spreadsheets and databases).
The file format is hardly used nowadays and documentation on it is scarce. Wikipedia has limited details on SYLK. Probably the best documentation available is the file sylksum.doc, authored by Microsoft and last updated in 1986 (!). We have hosted a copy of this file here. The File Formats Handbook by Gunter Born describes additional details on SYLK (it’s a 1995 book, second hand copies available on Amazon).
Despite being an ancient file format, the file extension .slk is still mapped by default to Excel on the most recent MS Office versions (confirmed on 2010, 2013 and 2016).
We are not the first offensive security researchers to look into the SYLK file format. Previously, Matt Nelson has demonstrated how DDE attacks can be combined with SYLK. This method has been weaponized in various malware samples that were observed in the wild, such as this one and this one.
In this blog post we will demonstrate that the power of SYLK goes beyond DDE attacks. In particular, malicious macros can be embedded in this file type as well.
No protected mode
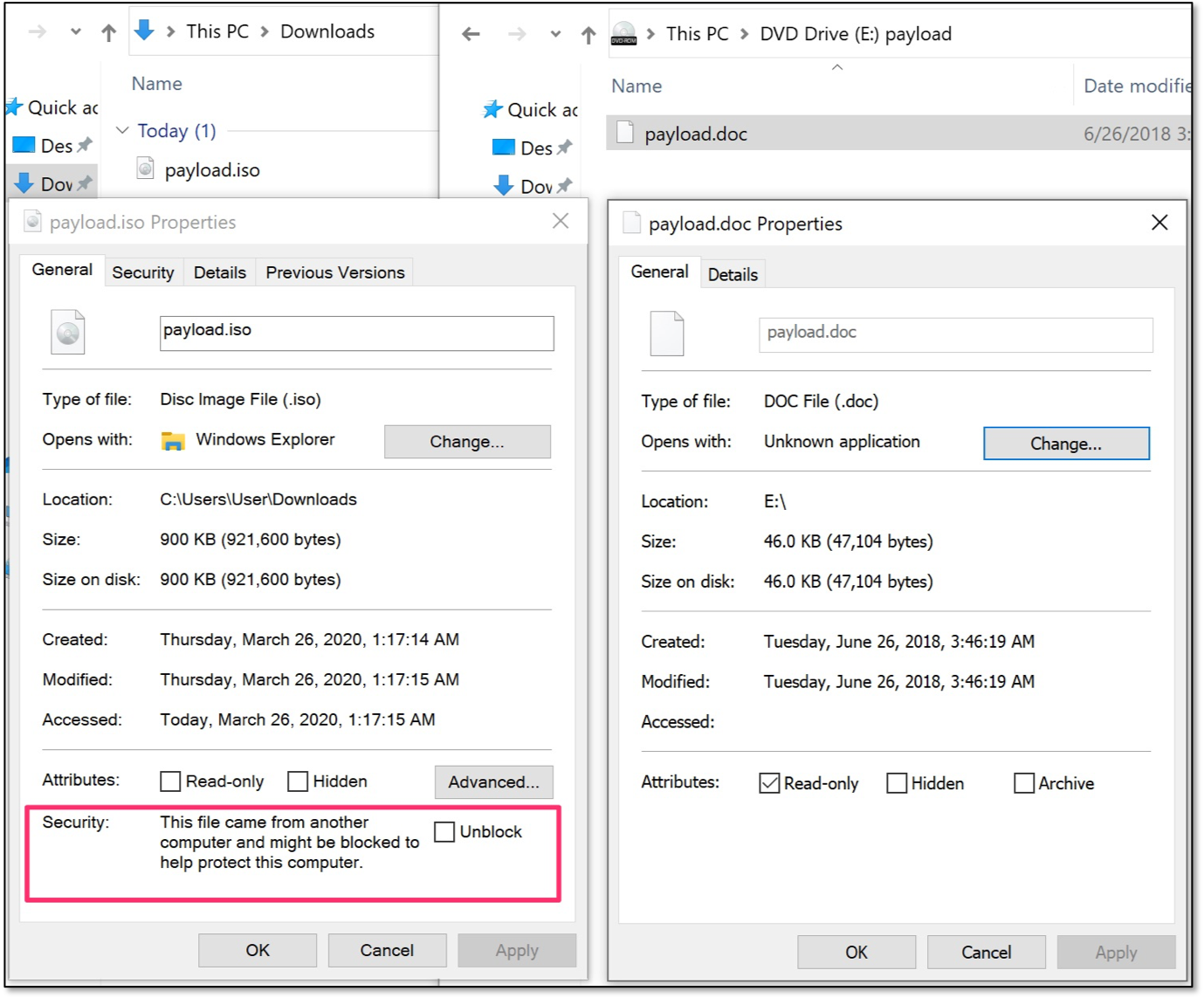
There is one important reason why the SYLK format is appealing to attackers: the Protected View sandbox does not apply to this file format. This means that if a weaponized SYLK file is delivered via email or web and the Mark-of-the-Web flag is applied, the target user is not bothered with this warning message.
In addition, SYLK files with the .slk extension have the following characteristics.
- SYLK is not included in the MS Outlook blocked attachments list.
- SYLK is not included in the default OWA blocked extensions list.
- SYLK is not marked as dangerous in Chrome’s safe browsing file type list.
Altogether, this makes SYLK a good candidate for weaponization.
XLM macros in SYLK
This unanswered question on an Excel forum caught our eye. Would it be possible to embed macros in SYLK? Simply trying to save an Excel file with a VBA project to SYLK did not work: a warning message was displayed that the macro project would be lost in this file format. Repeating this attempt with Excel 4.0 / XLM macros didn’t work either.
After studying the scarce documentation that is available on SYLK and after countless hours of experiments, we finally achieved our goal: macros can be embedded in the SYLK file format.
Open notepad, paste the following text and save it to a file with the .slk extension:
ID;P
O;E
NN;NAuto_open;ER101C1
C;X1;Y101;EEXEC("CALC.EXE")
C;X1;Y102;EHALT()
E
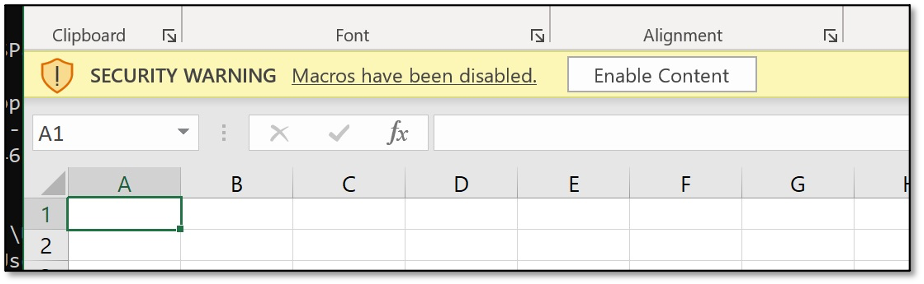
Double click the file to open it in Excel. Click “Enable Content” to enable macros and calculator will pop.
Let’s dive into how this works. Each line of a SYLK input file must be no longer than 260 characters (otherwise Excel will display an error message and will not parse that line). Every line consists of one or more records marked with semicolons:
- The first line with the “ID” and “P” records is a marker that indicates this file is a SYLK file.
- The second line with the “O” record sets options for this document. “E” marks that it is a macro-enabled document.
- The third line has a names record “NN”. We set the name “Auto_open” for the cell at row 101, column 1 (“ER101C1”).
- The fourth and fifth lines define cell content (“C”). “X” and “Y” records mark row and columns (e.g. row 1, column 101 in the first “C” line). Record “E” defines an expression value for this cell, in our case two Excel 4.0 macro functions.
- The last line holds the end of file record (“E”).
In short, this basic SYLK file example defines a cell named Auto_open that executes the EXEC() and HALT() Excel 4.0 macro functions (so this is not VBA!). If you target Excel in a different language, beware of localized Auto_open event names. For example, in Dutch this has to be renamed to “Auto_openen”.
Process injection with SYLK
Now that we can embed macros in SYLK, we can do much more than simply popping calculator. In our previous blog post on Excel 4.0 / XLM macros, we have already demonstrated the power of this macro type. The following proof of concept demonstrates shellcode injection using macros in SYLK:
The code for this proof of concept is available from our GitHub page.
- Create shellcode without null bytes. Example with msfvenom:
msfvenom -c messageBox -a x86 --platform windows -p windows/messagebox TEXT="Hello from shellcode!" -b "\x00" -f raw > messagebox.bin - Create a SYLK file that embeds and loads the shellcode:
python shellcode_to_sylk.py messagebox.bin > file.slk
Based on proof of concept code that we shared with MDSec in an early stage of our research, Dominic Chell has also embedded process injection using SYLK payloads in his SharpShooter tool.
Disguising SYLK as CSV
An interesting feature is that SYLK files can be disguised as other Excel file types, including the comma-seperated values (CSV) type. Upon parsing of a file with the .csv extension, Excel will automatically detect if the file is a SYLK file when the file starts with the header “ID;P” which is typical for SYLK. If this is the case, the following dialogue will be presented to the user:
If the user clicks “Yes”, the file will be opened as a SYLK file instead of CSV. So, with one additional warning message we can embed a malicious macro in a text-based file with the .csv extension.
Abusing SYLK on Mac
The SYLK file format is also supported on MS Office for Mac. The .slk extension maps to Excel for Mac by default and Excel 4.0 / XLM macros are supported as well, rendering this file format a very good candidate for weaponization on Mac.
Things get even more interesting when a target uses an outdated version of MS Office for Mac. MS Office 2011 for Mac contains a vulnerability where no warning message is displayed before macro execution in SYLK files. My colleague Pieter has previously blogged about this. Since Microsoft does no longer support this version of MS Office, this vulnerability will not be fixed. Unfortunately, we still spot Mac users with this outdated MS Office version from time to time.
SYLK and antivirus
In theory, SYLK files are easy to scan for a security product since the file format is very simple. However, in practice, it appears that many antivirus products do not particularly bother about this file format. In our experience, detection signatures and heuristics for malicious SYLK files by most antivirus products are quite poor.
We hope that this blog post contributes to a better understanding of the dangers of SYLK files and that antivirus vendors will act upon this. With an increase of malicious SYLK samples in the wild there is definitely a motivation to do so.
Also, it should be noted that the Antimalware Scan Interface (AMSI) does not catch macros in SYLK. As the AMSI engine for macros only hooks into VBA, it is blind to Excel 4.0 / XLM based macros.
Mitigation
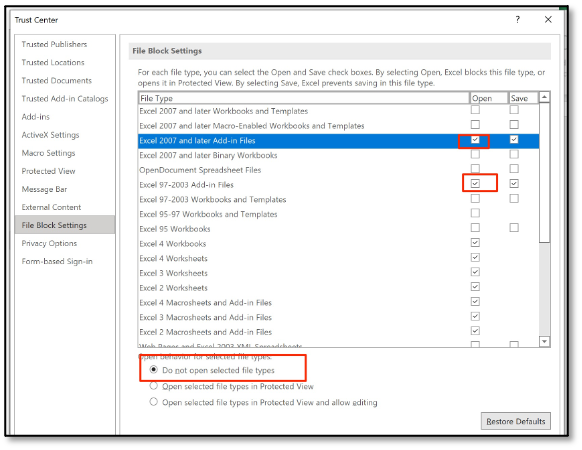
The best way to mitigate abuse is to completely block SYLK files in MS Office, which can be achieved through File Block settings in the MS Office Trust Center settings.
This GUI can be a bit confusing. A checkbox under “Open” means that a blocking action is defined for that filetype. So a checkbox under “Dif and Sylk Files” and selecting “Do not open selected file types” is what you need to configure in order to block opening of SYLK files.
Note that this setting can also be managed via Group policy:
- The relevant policy can be configured under
Microsoft Excel 2016\Excel Options\Security\Trust Center\File Block Settings. - Set “Dif and Sylk” to “Enabled: Open/Save blocked, use open policy” to prevent users from opening SYLK files in MS Office.
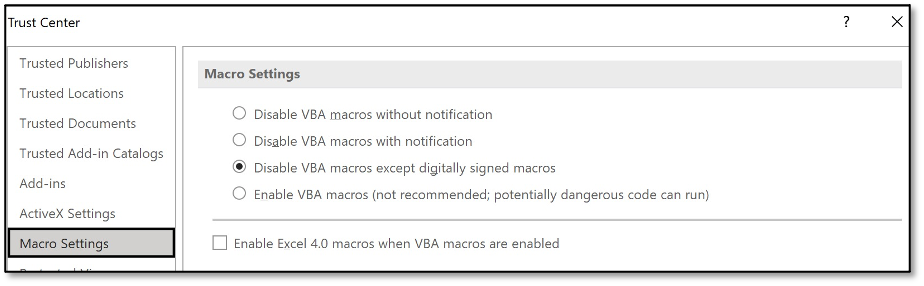
Another opportunity for mitigation is that macros in a SYLK document do adhere to macro security settings configured in MS Office. While completely disabling macros is not a viable option in many organisations, the following good practices can reduce the risk posed by malicious macros in SYLK and other MS Office file formats:
- MS Office 2013 and 2016 have a feature to block macros in files that are downloaded from the internet. Set a DWORD value for
blockcontentexecutionfrominternetto “1” underHKEY_CURRENT_USER\Software\Microsoft\Office\16.0\Word\Security. This setting can also be managed via GPO. Enable the setting “Block macros from running in Office files from the Internet” which can be found underMicrosoft Excel 2016\Excel Options\Security\Trust Center. - In addition, Attack Surface Reduction rules can be used to set boundaries to what macros can do on a system.
Any feedback or additional ideas? Reach out on Twitter!
The post Abusing the SYLK file format appeared first on Outflank.