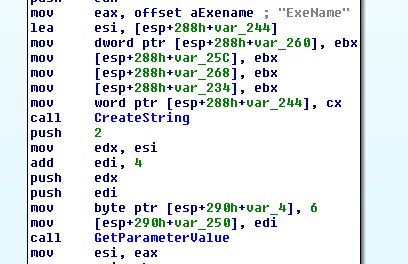
A statement in the System Programming Guide of the Intel 64 and IA-32 Architectures Software Developer's Manual (SDM) was mishandled in the development of some or all operating-system kernels, resulting in unexpected behavior for #DB exceptions that are deferred by MOV SS or POP SS, as demonstrated by (for example) privilege escalation in Windows, macOS, some Xen configurations, or FreeBSD, or a Linux kernel crash. The MOV SS and POP SS instructions inhibit interrupts (including NMIs), data breakpoints, and single step trap exceptions until the instruction boundary following the next instruction (SDM Vol. 3A; section 6.8.3). Note that debug exceptions are not inhibited by the interrupt enable (EFLAGS.IF) system flag (SDM Vol. 3A; section 2.3). If the instruction following the MOV SS or POP SS instruction is an instruction like SYSCALL, SYSENTER, INT 3, etc. that transfers control to the operating system at CPL < 3, the debug exception is delivered after the transfer to CPL < 3 is complete. OS kernels may not expect this order of events and may therefore experience unexpected behavior when it occurs.
A detailed white paper describes this behavior here.
Sample code is provided on Github for the Windows Operating System to test if you're vulnerable to CVE-2018-8897. You are free to port it to any other operating systems. A precompiled binary (executable) is provided here for accessibility purposes.
The purpose of this post is to highlight many of the frustrations I’ve had with Device Guard (rebranded as Windows Defender Application Control) and to discuss why I think it is not an ideal solution for most enterprise scenarios at scale. I’ve spent several years now at this point promoting its use, making it as approachable as possible for people to adopt but from my perspective, I’m not seeing it being openly embraced either within the greater community or by Microsoft (from a public evangelism perspective). Why is that? Hopefully, by calling out the negative experiences I’ve had with it, we might be able to shed a light on what improvements can be made, whether or not further investments should be made in Device Guard, or if application whitelisting is even really feasible in Windows (in its current architecture) for the majority of customer use cases.
In an attempt to prove that I’m not just here to complain for the sake of complaining, here is a non-exhaustive list of blog posts and conference presentations I’ve given promoting Device Guard as a solution:
For me, the appeal of Device Guard (and application whitelisting in general) was and remains as follows: Every… single… malware report I read whether its vanilla crimeware, red team/pentester tools, or nation-state malware has at least one component of their attack chain that would have been blocked and subsequently logged with a robust application whitelisting policy enforced. The idea that a technology could not only prevent, but also supply indications and warnings of well-funded nation-state attacks is extremely enticing. In practice however, at scale (and even on single systems to a lesser extent), both the implementation of Device Guard and the overall ability of the OS to enforce code integrity (particularly in user mode) begin to fall apart.
The Airing of Grievances
Based on my extensive experience working with Device Guard (which includes regularly subverting it), here is what I see as its shortcomings:
An application whitelisting solution that does not supply the ability to create temporary exemptions is unlikely to be a viable solution in the enterprise. This point becomes clear when you consider the following scenario: A new, prospective or current client asks you to join their teleconferencing solution with 30 minutes notice. Telling them that you cannot join because your enforced security solution won’t permit it is simply an unacceptable answer. Some 3rd party whitelisting solutions do permit temporary, quick exceptions to policy and audit accordingly. As a Device Guard expert myself, even if every component of a software package is consistently signed using the same code signing certificate (which is extremely rare), even I wouldn’t be able to build signer rules, update an existing policy, and deploy it in time for the client conference call.
Device Guard is not designed to be placed into audit mode for the purposes of supplementing your existing detections. I recently completed a draft blog post where I was going to highlight the benefits of using Device Guard as an extremely simple and effective means to supplement existing detections. After writing the post however, I discovered that it will only log the loading of an image that would have otherwise been blocked once per boot. This is unacceptable from a threat detection perspective because it would introduce a huge visibility gap. I can only assume that Device Guard in audit mode was only ever designed to facilitate the creation of an enforcement policy.
The only interface to the creation and maintenance of Device Guard code integrity policies is the ConfigCI PowerShell module which only works on Windows 10 Enterprise. As not only a PowerShell MVP and a Device Guard expert, I shamefully still struggle with using this very poorly designed module. If I still struggle with using the module, this doesn’t bode well for non-PowerShell and Device Guard experts.
Feel free to highlight precisely why I’m wrong with supporting evidence but I sense I’m one of the few people outside of Microsoft or even inside Microsoft who have supplied documentation on practical use cases for configuring and deploying Device Guard. The utter absence of others within Microsoft or the community embracing Device Guard at least supplies me with indirect evidence that it not a realistic preventative solution at scale. I’ll further note that I don’t feel that Device Guard was ever designed from the beginning as an enterprise security solution. It has the feel that it simply evolved as an extension of Secure Boot policy from the Windows RT era.
While the servicing efforts for PowerShell constrained language mode have been mostly phenomenal, the servicing of other Device Guard bypasses has been inconsistent at best. For example, this generic bypass still has yet to be fixed. There is an undocumented “Enabled:Dynamic Code Security” policy rule option that is designed to address that bypass (which is great that it's finally being address) but it suffers from a bug that prevents it from working as of Win 10 1803 (it fails to validate the trust of the emitted binary because it forgets to actually mark it as trusted). Additionally, Casey Smith’s “SquiblyTwo” bypass was never serviced, opening the door for additional XSL-based bypasses (which I can confirm exist but I can’t talk about at the time of this writing). Rather, it is just recommended that you blacklist wmic.exe. There is also no robust method to block script-based bypasses.
The strategy with maintaining AppLocker moving forward remains ambiguous. AppLocker still benefits to this day by its ability to apply rulesets to user and groups, unlike Device Guard. It also has a slightly better PowerShell module and a GUI.
Any new features in Device Guard are consistently not documented aside from me occasionally diffing code integrity policy schemas across Windows builds. For example, one of the biggest recent feature additions is the “Enabled:Intelligent Security Graph Authorization” policy rule option which is the feature that actually transformed Device Guard from a pure whitelisting solution to that of an application control solution, yet, it has only a single line mentioning the feature in the documentation.
As far as application whitelisting on Windows is concerned, from a user-mode enforcement perspective, staying on top of blocking new, non-PE based code execution vectors remains an intractable problem. Whether it’s the introduction of code execution vectors (e.g. Windows Subsystem for Linux) or old code execution techniques being rediscovered (e.g. the fact that you can embed arbitrary WSH scripts in XSL docs). People like myself, Casey Smith, Matt Nelson, and many others in the industry recognize the inability of vendors and those implementing application whitelisting solutions to keep pace with blocking/detecting signed applications that permit the execution of arbitrary, unsigned code which fundamentally subvert user mode code integrity (UMCI). This is precisely what motivates us to continue our research in identifying those target applications/scripts.
So what is Device Guard good for then?
What I still love about Device Guard is that it’s the only solution that allows you to apply policy to kernel images (even in the very early boot phase). Regardless of the application whitelisting solution, user mode policy configuration, deployment, and maintenance is really difficult. The appeal of driver enforcement is that Windows requires that all drivers be signed, meaning, the creation of signer rules is relatively straightforward and the set of required drivers is far smaller than the set of required user mode code.
Aside from that, I honestly see very little benefit in using Device Guard for user-mode enforcement or detection aside from using it on systems with extremely consistent hardware and software configurations - e.g. point of sale, ATMs, medical devices, etc.
For the record, I still use Device Guard to enforce kernel and user mode rules on my personal computers. I still cringe, however, any time I have to make updates to my policy, particularly, for software that isn’t signed or is inconsistently signed.
Are you admitting that you wasted the past few years dedicating much of your research time to Device Guard?
Absolutely not!!! I try my best to invest in new security technologies as a motivation to research new abuse and subversion opportunities and Device Guard was no exception. It motivated me to take a deep dive into code signing and signature enforcement which resulted in me learning about and abusing all the internals of subject interface packages and trust providers. It also motivated me to identify and report countless Device Guard and PowerShell Constrained Language Mode bypasses all of which not only bypass application whitelisting solutions but represent attacker tradecraft that subvert many AV/EDR solutions.
I also personally have a hard time blindly accepting the opinions of others (even those who are established, respected experts in their respective domains) without personally assessing the efficacy and limitations of a security solution myself. As a result of all my Device Guard research, I now have a very good sense of what does work and what doesn’t work in an application whitelisting solution. I am very grateful for the opportunity that Device Guard presented to motivate me to learn so much more about code signing validation.
What I’m hopeful for in the future
While I don’t see a lot of investment behind Device Guard compared to other security technologies (like Defender and Advanced Threat Protection), I sense that Microsoft is throwing a lot of their weight behind Windows Defender System Guard runtime attestation, some of the details of which are slowly starting to surface which I’m really excited about assuming the attestation rule engine is extended to 3rd parties. This tweet from Dave Weston I can only assume highlights System Guard in action blocking semi-legitimate signed drivers whereas a relatively simple Device Guard policy would have implicitly blocked those drivers.
Conclusion
My intent is certainly not to dissuade people from assessing the feasibility of Device Guard in your respective environment. Rather, I want to be as open and transparent about the issues I’ve encountered over the years working with it. My hope is to ignite an open and honest conversation about how application whitelisting in Windows can be improved or if it’s even a worthwhile investment in the first place.
As a final note, I want to encourage everyone to dive as deep as you can into technology you’re interested in. There are a lot (I can’t emphasize “a lot” enough) of curmudgeons and detractors who will tell you that you’re wasting your time. Don’t listen to them. Only you (and trusted mentors) should dictate the path of your curiosity! I may no longer be the zealous proponent of application whitelisting that I used to be but I could not be more grateful for the incredible technology Microsoft gave me the opportunity to dive into, upon which, I was able to draw my own conclusions.
In this challenge we're given an x64 ELF binary. The program acts as a userspace host for KVM virtualization. Among other things, it sets up the VM's address space, initializes the necessary VM registers, copies the code from the ".payload" section to it, then finally runs it.
Additionally, the userspace host expects the VM to trap when executing the three illegal instructions : IN, OUT, and HLT as shown below. The host will do some processing and then fix the VM's state so it can graciously continue executing.
And here is an instance of a HLT instruction within the VM's code.
Let's now describe the behavior of the host for each illegal instruction.
IN (port 0xE9) : Reads a single character from STDIN and returns it to the VM (The first thing that the VM does is read user input from STDIN).
OUT (port 0xE9) : Outputs a single character to STDOUT.
HLT : Before the VM executes a HLT instruction, it moves a special value into EAX. After it traps, our host reads this value and uses it as a key in an array. Each key corresponds to a handler routine within the VM's address space.
What the host does then is set VM's RIP register to the corresponding handler.
And by examining the handlers, we see that they invoke each other using the HLT instruction.
Now, let's try to examine what the VM does and figure out what these handlers are used for.
Briefly, 0x2800 bytes are read from STDIN and for each of these bytes sub_1E0 is called. The first time it's called, this function takes the user-supplied character and the address 0x1300 which points to some data.
sub_1E0 initializes local variables and then branches to the handler at 0x32c.
This one examines the dereferenced value, if it is 0xFF it branches to the handler at 0x347, if not it branches to a handler that compares the dereferenced value with the user-supplied character.
Now, examining the handler at 0x347 and the handlers it invokes (see the screenshot below : renamed sub_1E0 to traverse_tree), we see that the address 0x1300 is a root node of a binary tree.
In the tree at 0x1300, parent nodes have 0xFF as a value and contain two pointers for the left & right children. A leaf node, contains an ASCII character as a value which we suspect constitutes our flag. Recall that when a leaf is encountered a comparison is made with the user-supplied character and a boolean value is returned (RET instruction).
In the screenshot below, we see that the tree is recursively traversed and when a leaf is encountered and the comparison is successful sub_172 is called as we return from the functions recursively called.
When we traverse a left node, sub_172 is called with 0 whereas when we traverse a right node 1 is passed.
What this function does is build an array of bits starting at 0x1320 in the following manner :
BYTE* bits = 0x1320; BYTE count = 0;
void sub_172( BYTE bit ) { *bits |= bit << count++; if ( count == 8 ) { count = 0; bits++; } } This way, the bit array will represent the path traversed from the leaves to the root for all characters.
When this is done for all input characters, the resulting bit array is compared against the bit array for the correct input at 0x580. So, what we have to do is this :
Extract the correct bit array from 0x580 as bytes.
Reverse the order of the bytes and then convert them to binary representation. We reverse the order because we want to traverse the tree from root to leaf, doing the opposite would be impossible since all bits are concatenated. Also, when doing this, we'll start by extracting the last character and so on until we reach the first.
Below is the IDA Python script that you should run on the extracted ".payload" section to get the flag :
As a result, we get the flag and we see that the VM was expecting a tar file as input:
flag.txt0000664000175000017500000000007113346340766011602 0ustar toshitoshiflag{who would win? 100 ctf teams or 1 obfuscat3d boi?}
Thank you for reading :)
You can follow me on Twitter : here
Flare-on was a blast this year ! All challenges were great but I enjoyed solving the last one the most, although it was somewhat frustrating.
Due to my tight schedule, I won't go over all the details involved in solving the challenge. But I'll do my best to paint a complete picture of what's going on and how I approached the problem.
We start we a floppy disk image that you can download from here (PW : infected) :
When we boot the floppy using bochs, we see that it automatically executes infohelp.exe that asks us for a password.
Entering an arbitrary password, the message "Welcome to FLARE..." prints slowly on the screen and the password checks are performed.
What I did after this, is I mounted the floppy on my Ubuntu virtual machine and extracted the files in bold.
Both key.dat and message.dat contain nothing interesting. However, TMP.DAT appeared to contain the welcome message we see after typing the password and some funny strings like : "NICK RULES" and "BE SURE TO DRINK YOUR OVALTINE".
What I did next is I threw infohelp.exe into IDA to examine its behavior. To my surprise, I found that it does nothing but writes the supplied password to key.dat and then reads the contents of message.dat and prints them to the screen.
Here I thought that there should be some hooks involved that redirect execution to somewhere else when message.dat is opened or read. To confirm my suspicions, I executed the "type" command on message.dat; Lo and behold, the password check is performed.
Next, I opened TMP.DAT in IDA and found that it contains some code that seems to be our hook. So I attached IDA to bochs and started debugging.
To locate the hook within memory, I took advantage of the fact that the message is printed in a slow fashion so what I did is pause execution while stuff was still printing. I found myself in a loop implementing the subleq VM.
The caller supplies a pointer to the bytecode, its size, and the offset to the instruction where execution should start.
Each instruction is 6 bytes and has the following format :
struct inst {
WORD src_index;
WORD dest_index;
WORD branch_index;
};
The type of the subleq bytecode array is WORD*, so the VM views that its instruction size is 3 while it is 6 actually. This realization comes in handy when building an IDA processor module for the subleq.
As I did with last year's binary, I re-implemented the subleq VM with C to output each executed instruction to a file. However, I had an impossible-to-analyze file with over 1 GB. So what I did, is only print the subleq for the instructions that perform the password checks; That way I had a 30 MB-ish file that I could examine looking for patterns.
The way I had the emulated instructions printed was the following :
IP : sub [dest_index], [src_index] ; subtraction = result
The only thing that was visible on the fly is that the subleq starts by doing some initialization in the beginning and then enters a loop that keeps executing until the end. Here where suspicions of a second VM started to arise in my mind (OMG !).
I tried to locate the password characters inside the subleq and tried to figure out what operations were done on them but it was not clear at all.
I also did some text diffing between iterations and saw that the code was modifying itself. In these instances, the self-modification was done in order to dereference VM pointers and use their values as indexes in subsequent operations.
So, what I decided to do here is write a very minimal processor module that would allow me to view the subleq in a neat graph.
The file I extracted contains bytecode starting from IP : 0x5. So here's how you load it into IDA :
- Choose the subleq bytecode processor module and make sure to disable auto-analysis. It ruins everything when enabled.
- Change the ROM start address to 0xA and the input file loading address to the same : 0x5 * sizeof(WORD) == 0xA.
The bytecode will be loaded without being analyzed.
- Press 'P' at 0xA to convert into code and automatically into a function. You should have a beautiful graph as a result.
Well, it is not quite as beautiful as you might think, since we still have to deal with self-modifying code (knowing what exactly is modified) and also understanding the code as a whole.
It is quite hard to understand what subleq does by only reading "subleq" instructions, so the next thing that came to mind is to convert the subleq to MOV and ADD instructions without wasting too much time.
IDAPYTHON TO THE RESCUE !
I wrote a minimal script that looks for ADD and MOV patterns in the subleq and comments these instructions. First of all, the script intentionally skips the instructions that will be self-modified and doesn't comment the SUB since it's already there.
And the result was this :
More understandable ... still, not so much.
So what I did next is decompile this manually into C and then simplify the code.
So it is indeed another VM interpreted by the subleq. The nature of the VM was unknown to me until later when someone told me that it was RSSB. But I was able, however, to solve the challenge without needing that information.
Now, this RSSB VM executes bytecode that starts at offset 0xFEC from the start of the subleq or at offset 0x1250 of the TMP.DAT file.
If you dumped the bytecode from memory as I did, you'd find that the password you typed was written inside the RSSB VM at offset 0x21C (circled in red).
So far so good. I copied the whole RSSB bytecode and added it as an array and modified the C emulator code to print the "sub" instructions while executing the VM; the same way I did with the subleq.
The result looked like this :
IP : p[dest_index], ACCUM ; operation
Reading the code, I found out that a sum is calculated for the characters in the password. In addition to that, the number of characters in the password must be 64. I knew that by examining a variable that gets decremented from 64 at each iteration of the sum calculation.
For information, the sum is stored at : p[0b47].
So I patched the memory to store a 64 byte string and then I looked up where the first character of the input was read apart from where the sum was calculated. I performed a search for [010e] ( 0x21C / 2 == 0x010E).
65 in dec == 0x41 in hex
Long story short, the algorithm works in a loop, in each iteration two characters of the password are used to calculate a value. The sum of all characters is then added to that value as shown in the figure below (sum : in red, value : in green).
A few instructions later, a hardcoded value at [0a79] is subtracted from the resulting value of the previous operation.
We can see that the resulting value of the next two characters for example is compared against the next hardcoded value at [0a7a] and so on until the 30th character.
So, we have a password of 64 bytes but from which only the first 30 bytes are checked !
Let's leave that aside for now and ask : what makes a check correct ? Maybe the result of the subtraction must be zero ?
I quickly added a check onto my C emulator that did the following :
res = ptr[op_addr] - ptr[1];
if ( ptr[0] == 0x203d ) //IP of the check, see figure above { res = 0; }
This will simply patch the result to zero in the check at 0x203d. I ran the program and it showed that the password was correct, so I knew I was on the right path.
I also observed (based on a single test case) that in each iteration the calculated value depends on the position of the two characters. So even if we have the same two characters at different places the calculated value will be different.
Solution : Here I am going to describe how I solved the challenge during the CTF. Surely this is not the best solution out there, but I'd like to show my line of thought and how I came to solve this level.
We know that the same sum is used in all the operations, and that there can be only one sum (or a handful as we'll get to see later) that will satisfy all the checks.
We can run a bruteforce attack where we let the VM calculate the value for two given characters (by patching the characters at run-time) then run the check on all possible sums (by patching the sum at run-time too). The first check will give us a lot of sums that we'll use to bruteforce the second check. In its turn, this check will filter out invalid sums that we'll eliminate from the third check and so on until we do all 15 of them. (30 characters / 2 characters per check == 15 checks).
At the end, we'll get the valid sums from which we can easily deduce the characters that generated them in each check.
The problem I had with this approach was performance. For each combination of two characters, and for each sum, I was running the VM all over again which, if I left like that, would take a huge amount of time : printing the welcome message, calculating the sum for junk characters ... over and over again each time !
What I ended up doing is "snapshotting" the VM in multiple states.
Snapshot 1 : Where the first character of the two is read (depending on the iteration we're in).
Snapshot 2 : For each two characters, take a snapshot after the value that depends on both of them is calculated and right at the address where the sum is read and added to the calculated value (IP == 0x1ff7).
The optimization here is that we execute what we only need to execute and nothing more. We patch the two characters by the ones we're currently bruteforcing at Snapshot 1 and then after the value is calculated for those two we take Snapshot 2 and we only get to patch the sum. When each iteration is over, we re-initialize the snapshots to their original states.
Here's the overall algorithm involved in pseudo-code (this is not C nor anything close) :
sums [xxx] = {...};
new_sums [yyy] = {0};
for ( i = 0; i < 15; i++)
{
memcpy(initial_state_tmp, initial_state);
snapshot_1 = take_snapshot_1(initial_state_tmp, i); //i is passed to go to the corresponding check
//Execute the subtraction check and return a boolean if ( execute_check(snapshot_2_tmp) )
{
append(new_sums, sum); //valid sum, append it
}
}
}
}
sums = new_sums;
new_sums = [0];
}
print sums;
At the end we'll get the valid sums that resulted in the check being equal to 0.
Here's the full C script implementing this (a bit messy) :
After the 15 checks are done, the script gives us files containing the valid sums that passed each of the checks. We're only interested in the last file (4KB in size) highlighted below :
Contents of array_14
I actually forgot to include the characters that generated the sum for each check. And I had to do it separately.
This requires some modifications of the code above : we initialize the sums array with the contents of array_14 and for each sum bruteforce the two characters that pass each check. To optimize, I listed the first four characters (two first checks) for each one of these sums.
And one of them was particularly interesting. The sum 0xd15e resulted in these four characters "Av0c".
Running the same script for this single sum while bruteforcing all of the characters gives us the flag :
Flag : [email protected] Well in the end, this one really deserved being the 12th, it was time consuming, frustrating and above all FUN ! Thanks for bearing with me and until another time guys - take care :)
Something that once was done with heavy and expensive serial cables, can now be achieved in a matter of seconds through virtual machines. I am of course speaking about kernel debugging, what else? Recently I have been following the exceptionally great Intermediate x86 training lead by Xeno Kovah where, in order to keep up with the labs, I had to setup a WinXP-to-WinXP kernel debugging setup. So after a few moments of bewilderment I reached a full working environment with the following steps.
I was about to finish the Intermediate x86 class from OpenSecTraining, when I thought was worthwhile porting to Linux this interesting exercise about software breakpoints.
Whenever we send a software breakpoint on GDB or any other debugger, the debugger swaps the first instruction byte with the double C (0xCC) instruction and keeps track of each and every breakpoint/replaced-instruction via the breakpoint table and thus, leaving the code section of the executable altered.
Hot on the heels of the latest post, I have decided to port to linux another lab example from Intermediate x86 class.
This time I will talk about the RedPill paper by Joanna Rutkowska.
This test is expected to work on single-core CPUs only
The main purpose of this test code is to call the SIDT instruction and save its return value inside an array: this value will tell us whether we are running it inside a vm or not.
Hide and Seek (HNS) is a malicious worm which mainly infects Linux based IoT devices and routers. The malware spreads via bruteforcing SSH/Telnet credentials, as
As I am spending slices of my time refreshing some Malware Analysis theory, I thought was valuable (at least to my future amnesiac self) writing down a simple ‘custom base64 alphabet translator.’ This can/should be extended to support CLI/WebApp i ntegration. So, here is the skeleton:
UPDATE: added interactive mode below and also found this great tool which is already doing what I aimed for and much more.
import string import base64 # custom encoding function def EncodeCustomBase64(stringToBeEncoded,custom_b64): standard_b64 = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=' encoded = base64.
More than a year ago, I developed a local privilege escalation exploit for a product (that I cannot disclose unfortunately) in which I had to bypass ASLR.
For the record, these are the protections enabled in the targeted service's binary, it is a 32-bit executable running under Wow64 on 64-bit systems.
Basically, I was able to communicate through IPC with the system service and tell it to execute a function in its address space by pointer (it's a bit more tricky than this but you get the point). Actually, this would have been impossible if CFG was enabled.
Within the main module, I have located a function that invokes "system()" with an argument that I control. At this point, it was just a matter of bypassing ASLR in order to get that function's address and elevate privileges on the machine. However, I couldn't trigger any leaks through the IPC channel to get or deduce the main module's base.
But as luck would have it, the service exposed some other functionalities through IPC and one of them was the ability to call VirtualProtectEx and letting us supply a PID, the address, the size, and the new protection. The service was also kind enough to return the old protection of the region to our process via IPC.
Bypassing ASLR should be obvious by now knowing these two crucial points :
The function that we want to invoke resides in the main module.
On Windows the main executable's module of a process is the first module, with the lowest address in the user address space.
It is now only a matter of writing code to communicate with the service and to brute-force the location of the main module; we do that by looking for the first executable page in the address space and then calculating the main module's base : generally by subtracting 0x1000 from that page since the .text section is the first section.
The pseudo-code below shows an example of how this was done :
Launching a new process with SYSTEM privileges was easy at this point.
Today during RSA Conference, the National Security Agency release their much hyped Ghidra reverse engineering toolkit. Described as “A software reverse engineering (SRE) suite of
The purpose of writing this up was only to present a little trick I came up with while playing with vulnserver's (http://www.thegreycorner.com/2010/12/introducing-vulnserver.html) KSTET command (one of many protocol commands vulnerable to some sort of memory corruption bug). In spite of the hardcoded addresses, 32-bitness and general lazyness, this technique should as well work in more modern conditions.
After hijacking EIP it turned out there was too little space, both above and below the overwritten saved RET, to store an actual windows shellcode (at least 250 bytes or more) that could run a reverse shell, create a user or run an executable from a publicly accessible SMB share.
Also, it did not seem to be possible to split the exploitation into two phases and first deliver the shellcode somewhere else into memory and then only use an egghunter (70 bytes to store the payload, enough for a 31-byte egghunter, not enough for the second-stage shellcode)... so I got inspired by a xpn's solution to the ROP primer level 0 (https://blog.xpnsec.com/rop-primer-level-0/) where the final shellcode was read onto the stack from stdin by calling read().
Having only about 70 bytes of space, I decided to locate the current server socket descriptor and call recv on it, reading the final stage shellcode onto the stack and then execute it. This write up describes this process in detail.
Controlling the execution
Below is the initial skeleton of a typical exploit for such an overflow. We control 70 bytes above the saved RET, then the saved RET itself ("AAAA"). Then we stuff 500 bytes of trash, where in the final version we'd like to put our shellcode, so we could easily jump to it by overwriting the saved RET with an address of a "JMP ESP" instruction (or something along these lines):
Once the crash occurs, we can see that we only control first 20 bytes after the saved RET, the rest of the payload is ignored:
So, we're going to use the first 20 bytes below the saved RET as our first stage shellcode, only to jump to the 70 bytes above the saved RET, which will be our second stage. The second stage, in turn, will download the final (third) stage shellcode and execute it.
First, we search for a "JMP ESP" instruction so we can jump to the first stage.
A convenient way to do so is to use mona, searching for the JMP ESP opcode:
!mona find -s "\xff\xe4"
We pick an address that does not contain NULL characters, preferably from a module that is using the least number of safety features as possible (essfunc.dll is a perfect candidate):
The addresses will most likely differ on your system.
0x625011af will be used for the rest of this proof of concept.
We toggle a breakpoint at it, so we can easily proceed from here in developing the further stages of the shellcode:
Now our PoC looks as follows (we used 20 NOPs as a holder for the first stage):
We run the PoC and hit the breakpoint:
Once we do a step (F7), we can see the execution flow is redirected to the 20-byte NOP space, where our first stage will be located (so far, so good).
At the top we can see the second stage buffer, at bottom we can see the first stage buffer. In between there is the overwritten RET pointer, currently pointing to the JMP ESP instruction that lead us here:
First stage shellcode
We want our first stage shellcode to jump to the start of the second stage shellcode (there is not much more we can do at this point on the only 20 bytes we control).
As we know EIP is equal to our ESP, as we just did a JMP ESP, we don't need to retrieve the current EIP in order to change it. Instead, we simply copy our current ESP to a register of choice, subtract 70 bytes from it and perform a JMP to it:
PUSH ESP ; we PUSH the stack pointer to the stack POP EDX ; we pop it back from the stack to EDX SUB EDX,46 ; we subtract 70 from it, pointing at the beginning of the buffer for the second stage shellcode JMP EDX ; we JMP to it
OllyDbg/Immunity Debugger allow assembling instructions inline while debugging (just hit space to edit), which is very handy in converting our assembly to opcode without the need of using additional tools like nasmshell or nasm itself:
So, our second stage is simply
\x54\x5A\x83\xEA\x46\xFF\xE2
Also, for the time of development, for our convenience, we can prepend it with an inline breakpoint \xCC instruction, as Immunity loses the breakpoint set on the initial JMP ESP with every restart. Just remember to remove the \xCC/replace it with a NOP in the final exploit, otherwise it will cause an unhandled exception leading to a crash!
At this stage, our POC looks as follows (NOPs in the first stage were only added for visibility, they won't ever get executed). Also, the holder for the second stage was filled with NOPs as well:
As we can see, the first stage does its job, moving the execution flow to the second stage:
Second stage shellcode
Now, this is where the fun begins. As mentioned before, we want to use the existing server application's socket descriptor and call WS2_32.recv on it, so we can read as much data from it as we want, writing it to a location we want and then jump to it - or even better, write it to a suitable location so the execution flow slides to it naturally.
First, we find the place in code where the original WS2_32.recv is issued, so we can see how that takes place (e.g. what is its address and how arguments are passed, where to find them and so on).
Luckily, the section is not far away from the executable's entry point (the first instruction program executes, also the first instruction we are at once we start it in the debugger):
As we scroll down we can see we are getting somewhere:
And here we go:
We toggle a breakpoint, restart the application, make a new client connection and send something to the server. The breakpoint is hit and we can see the stack:
Also (an Immunity/OllyDbg tip); if we hit space on the actual CALL instruction where our current breakpoint is, we can see the actual address of the instruction called (we will need this later):
Now we can compare the current stack pointer at the time of our execution hijack with the one recorded while the orignal WS2_32.recv was done. We are hoping to estimate the offset between the current stack pointer and the location of the socket descriptor, so we culd use it again in our third stage.
As it turns out, the stack we are currently using points to the same location, which means the copy of the socket descriptor identifier used by the original recv() has been overwritten with further stack operations and the overflow itself:
Hoping to find a copy of it, we search the stack for its current value.
Right click on the CPU window - which represents the stack at the moment -> search for -> binary string -> 00 00 00 58 (the identifier of the socket at the time of developing, but we don't want to hardcode it as it would normally differ between systems and instances, hence the hassle to retrieve it dynamically).
We find another copy on the stack (00F2F969):
We calculate the offset between the location of the socket descriptor id copy and the current stack pointer at the time our second stage shellcode starts (119 DEC). This way we'll be able to dynamically retrieve the ID in our second stage shellcode.
Also, there is one more problem we need to solve. Once we start executing our second stage, our EIP is slightly lower than the current ESP.
As the execution proceeds, the EIP will keep going towards upper values, while the ESP is expected to keep going towards lower values (here comes the Paint):
Also, we want to write the final stage shellcode on the stack, right below the second stage, so the execution goes directly to it, without the need to jump, as illustrated below:
Hence, once we have all the info needed to call WS2_32.recv(), we'll need to move the stack pointer above the current area of operation (by subtracting from it) to avoid any interference with the shellcode stage instructions:
So, the shellcode goes like this:
PUSH ESP POP ECX ; we simply copy ESP to ECX, so we can make the calculation needed to fetch the socket descriptor id SUB CL,74 ; SUB 119 (DEC) from CL - now ECX points at the socket descriptor ID, which is what we need to pass to WS2_32.recv SUB ESP,50 ; We have to move the current stack pointer above the second stage shellcode (above the current EIP), otherwise we would make it cripple itself with any stack operations performed by WS2_32.recv we are going to call, also this way we will avoid any collision with the buffer we are going to use for our final stage shellcode. From this point we don't have to worry about it anymore. XOR EDX,EDX ; zero EDX (the flags argument for recv), PUSH EDX ; we push our first argument to the stack, as arguments are passed via stack here ADD DH,2 ; now we we turn EDX into 512 by adding 2 to DH PUSH EDX ; we push it to the stack (BufSize, the second argument)
; retrieve the current value of ESP to EBX PUSH ESP POP EBX
; increment it by 0x50 (this value was adjusted manually after experimentig a bit), so it points slightly below our current EIP ADD EBX,50 ; this is the beginning of the buffer where the third stage will be written PUSH EBX ; push the pointer to the buffer on the stack (third argument)
; now, the last argument - the socket descriptor - we push the value pointed by ECX to the stack: PUSH DWORD PTR DS:[ECX]
So, we are almost done.
Now we have to call the WS2_32.recv() function the same way the original server logic does. We take the address used by the original CALL instruction (0040252C - as it was emphasized we would need it later).
The problem we need to deal with is the fact the address starts with a NULL byte - which we cannot use in our shellcode.
So, to get round this, we are going to use a slightly modified version of it, e.g. 40252C11, and then perform a shift 8 bits to the right. This way the least significant byte will vanish, while a null byte becomes the new most significant byte (SHR(40252C11) => 0040252C):
MOV EAX,40252C11 SHR EAX,8 CALL EAX
Our full PoC looks as follows:
The stack during the execution of the second stage right before the third stage is delivered:
The stack right after the return from WS2_32.recv():
Yup, full of garbage we control:
Now we can replace the 500 "\xCC" with our favorite shellcode.
Some time ago I came across RPISEC's free Modern Binary Exploitation course (https://github.com/RPISEC/MBE) which I can't recommend enough. You get lectures, challenges and a ready out-of-the-box operational Ubuntu VM to play with. Yup, this course is Linux-focused, which made it a great extension to my recently passed OSCE (which is, or at least was at the time, Windows-only). After completing only about 16, maybe 17 challenges (there are ten chapters, 3 challenges each => 30 + 2 additional challenges with no source code provided) I can conclude I learned comparably as much as doing my OSCE, but quite different knowledge (again, different OS and also different techniques), which again is great. And finally got myself together to put some of my notes out here. If you don't feel like doing but would like to get the feel, this is a read for you.
The target program is usually a setuid binary, running with its owner's effective uid. If we can execute arbitrary code, we steal the flag which is always located in /home/<USER>/.pass (which is a clear text unix password for that user account), whereas <USER> corresponds to the current target level. E.g. lab6C is the start user for the level 6, lab6B is the target user, hence /levels/lab06/lab6C is a setuid binary owned by lab6B so we obtain the pass and therefore can advance to the next level. Please refer to RPISEC's github page to find all info, including credentials, slides, resources and so on.
This is how the program behaves when we're not trying to abuse it (it does not really send our 'tweet' anywhere, just internal buffer operations):
Now, spoiler alert, first a quick glance at the source code to see where the vulnerability is.
First, there are some self-explanatory definitions:
Then it gets more interesting:
We have a secret_backdoor() function which simply reads up to 128-byte string from the standard input and then performs the libc system() wrapper on the exec() syscall (with a fork() and sh). The function is not explicitly called anywhere from the code, so it's clear we are not going to need a shellcode here; it's all about redirecting the execution to this function.
Now, to the vulnerability. We have several functions calling each other, so let's go through them in the order of the call sequence.
First, we have a standard main() function:
And here is the handle_tweet() function:
So, a local instance of the savestate structure (which was declared in the beginning of the file) is defined here, locally, on the stack.
username and msglen fields are initialized, then there are two two calls; set_username() and set_tweet(), respectively. Both calls take a pointer to the save instance of the savestate structure (so the pointer will point at the handle_tweet() function's stack). And this is the stack we are about to overflow (we'll get to how in a minute) to redirect the execution flow, overwriting handle_tweet's saved RET pointing back to main (the next instruction after the handle_tweet() call, which is just a return EXIT_SUCCESS;.
To illustrate, this is a simplified stack layout while inside of the handle_tweet() function, after the local struct was defined, but before the two set_username() and set_tweet() calls:
We will overwrite the save.tweet buffer outside its 140 bytes and write down over the username, msglen and then the saved RET.
Once the handle_tweet() function call returns, instead of going back to the last instruction of main(), the execution flow will go to our secret_backdoor() function.
So, the overflow must be possible in one of the two set_username(), set_tweet() functions. They both take a pointer to that buffer, so they can operate on it.
Let's see the set_username() function then:
Looks OK at the first glance. The devil's in the details (line 75):
for(i = 0; i <= 40 && readbuf[i]; i++) // this is where the problem starts
save->username[i] = readbuf[i]; //write
The <= conditionaloperator (instead of just <) is the culprit here. Instead of being able to write up to 40 bytes of the username, we can write 41. One byte more - which is enough to overwrite the previously initialized value of 140.
So once the set_username() call returns, the username is set, while the msglen is set to an arbitrary value that we will smuggle in the additional 41-th byte provided as the username.
This is how the second function, set_tweet(), looks like:
So the function has a quite big (1024 bytes, even too big for our needs) local buffer. To keep the big picture clear, this is how the stack will look like inside the set_tweet() function call, after calling fgets(), but before calling strncpy():
And this is where the buffer overflow that will allow us to overwrite the bottom saved RET occurs (lab6C.c:59):
strncpy(save->tweet, readbuf, save->msglen);
If we provide an arbitrary one-byte integer value higher than 140 in the 41-st byte of the username, we'll then be able to write more than 140 bytes from the 1024-byte local buffer, starting at the savestate.tweet address, up until the saved RET to overwrite with the address of the secret_backdoor() function.
Controlling the message length
Let's start simple and crash the program.
As at the time I started this I did not know a better way to provide arbitrary (non-printable) input using standard input/output without actual coding, here is how I was doing it (using two console windows simultaneously):
1) in one console window, I touched a file to use as an input buffer: /tmp/input6C
2) in the second window, I ran the following to have the program read all the input from that file as it appears:
gdb /levels/lab06/lab6C
[... once gdb loaded ....]
run < `tail -f /tmp/input6C`
In the first window I could then play with the printf command, putting arbitrary bytes into the /tmp/input6C, so they would go to the standard input of the target process.
We know we would need at least 140 + 40 + 8 bytes to overwrite the saved RET. Should actually be more, considering saved EBPs (stack frames) and function arguments. Something around 200. To find out how many bytes exactly do I need to overwrite to control the EIP, I used pattern_create output (some folks prefer to use the one provided with metasploit, I use one of the python implementations that can be found on github).
Already knowing that the 41-st byte of the first input line is the integer controlling the message length, I knew the username should look like this:
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\0xff
We set the new message length to maximum value possible 0xff (255), to make sure we overwrite the saved RET without caring what else do we overwrite.
The next line should be the pattern_create output, so here goes (this is actually pattern_create 400 output):
So yeah, the saved RET was overwritten, as set_tweet() read whole 400 bytes of the pattern written to the readbuf, while msglen set to 255 made strncpy() copy 255 bytes from it to the save.tweet buffer, overwriting everything the entire save structure and the saved RET below it as illustrated on the diagram above.
0x67413567 in ?? () means this is what we wrote to the saved RET, and, in consequence, what went to the EIP register. The program crashed (segmentation fault), as this is not a valid address in its virtual address space). It's a unique 4-character sequence from the 400-byte pattern string we used.
To see what is the exact number of bytes between the beginning of our controlled buffer and the saved RET we run the pattern_offset tool (comes along with pattern_create) with it as argument, so it calculates this for us:
For starters, to make this process simpler, we are going to develop this exploit with ASLR disabled. Once we think the exploit's ready, we turn ASLR back on (use the gameadmin:gameadmin credentials to get sudo su on the VM):
OK, let's peek where the secret_backdoor() function is (from attached gdb):
gdb-peda$ p secret_backdoor $1 = {<text variable, no debug info>} 0x8000072b <secret_backdoor>
So, after our 196 bytes of garbage, we should put 0x8000072b into our buffer to move the execution to the secret_backdoor() function (and then the last thing would be to provide a command to execute).
We can already say using this address won't work because it contains a nullbyte (doesn't go well with string-operating functions like fgets()).
Also, we know this address will be randomized with ASLR on, so using a fixed address won't do. Without leaking the memory layout somehow and calculating the address based on known offsets, we could either bruteforce (just keep running the exploit until our hardcoded address happens to be the correct one... this is just a 4-byte address as we're dealing with 32-bits, which is bad enough, while with x64 the likelihood is practically never)... Or perhaps perform so called partial overwrite instead.
Partial overwrites
ASLR only partially randomizes virtual addresses - which means only some of the bytes (the more significant ones, 'on the left') are hard to predict, while the least significant bytes (the ones 'on the right') - which are just the offsets within the code segment and are known to us as long as we can read the binary - stay untouched.
For example, 0x8000072b under ASLR becomes 0xbf76072b.
So, the OS does partial ASLR on the more significant bytes, leaving the least significant bytes alone. Thus, to keep things fair, we do a partial overwrite too, but on the least significant bytes (so we only overwrite one or two bytes instead of all 4), while leaving the two more significant bytes alone, because they already have the proper valid values set by the OS and we don't need to know them at all to attain a valid ASLR-ed address (as long as we're redirecting the execution to an instruction in the same text segment).
Of course partial overwrites are not always possible. In this case, we can use 196 bytes of garbage + 2 bytes of arbitrary offset within the code segment to change the saved RET to the address of secret_backdoor().
Moving on with the exploit
So, our exploit is (we're still playing without ASLR yet):
Legend: code, data, rodata, value Stopped reason: SIGSEGV 0x000a072b in ?? ()
Interestingly, the newline character got copied in. Also, for some reason, the next character was nullified, just like the entire string was copied instead of just 198 bytes we wanted.
Oh right. This is because we're still overwriting the msglen with the maximum possible value of 255 (0xff). Instead, we should use 0xc6 (198).
Ironically, before I realized this little mistake, a managed to search for existing solutions to peek from in case I got stuck and found this amazing repository:
So I looked at the lab6C solution only to discover that it is using pwnlib (true awesomeness, making exploit dev much easier and allowing me to ditch the retarded tail -f thing :D).
After carefully analysing the code I decided to just give it a go, but from the very beginning I knew something wasn't right (line 12):
The payload sent to the program as the 'tweet' content consists of 196 bytes (49 dwords) + a dword -> 200 dwords. So, the last dword 0xb775d72b does not seem to be a partial overwrite, but a full overwrite with a fixed address instead.
The only explanation I thought of was that the author left the PoC with a fixed value of secret_backdoor() function from the non-ASLR version of the exploit - or extracted the information about the memory layout from somewhere else and calculated the address with ASLR on. Anyway, I knew it would not work on my VM and guess what - it in fact didn't :D
So I decided to take corb3nik's solution code as a template and modify it so I could attach to the running process with gdb once its PID is known and then see exactly what's going on:
Setting the context.log_level variable to = 'debug' showed the real awesomeness of pwnlib, displaying all the input/output exchanged with the app in hex, revealing all the non-printable characters along with how many bytes were received/sent. Very, very helpful.
And did not want to work once I switched ASLR back on.
So I ran the debugger again, only to see that the text segment addresses changed from non-ASLR 0x80000XXX to ASLR-ed 0xb77YYXXX (whereas XXX is the Relative Virtual Address - the fixed offset within the segment, while YY is the only really randomized part).
For example, secret_backdoor() had, depending on the instance, values like:
`0xb775e72b` `0xb773a72b` `0xb77dd72b`
So e != a (the '7' halfbyte remains unaffected) and we can't do partial half-byte writes... Which in this case can be simply and non-elegantly solved with a small bruteforce. Just stick to any fixed second least-significant byte value you see in gdb, in my case such as 'a7', 'e7', '17' and so on. Statistically one in 16 attempts should work, in my case the result was more like one in 8), which in this case (a local console app) is acceptable - it just has to be kept in mind this exploit is not 100% reliable (https://github.com/ewilded/MBE-snippets/blob/master/lab6C/ex_attempt2_aslr.py).
This post is a continuation of my MBE (Modern Binary Exploitation) walkthrough series. In order to get some introduction, please see the previous post: https://hackingiscool.pl/mbe-lab6c-walkthrough/.
A look at the target app
So let's get right to it. The source code of the target application can be found here: https://github.com/RPISEC/MBE/blob/master/src/lab06/lab6B.c. The lab6B.readme reveales that this time we are not dealing with a suid binary. Instead, we are supposed to compromise a service running on port 6642.
Let's see if we can interact with it from our MBE VM command line:
Nice, it's working.
Running locally
Our target application is not actually capable of networking. This is covered by socat:
For the purpose of better understanding of how the target program behaves and making its exploit development easier, let's compile our own version in /tmp.
The only change required is the hardcoded /home/lab6A/.pass path - with the assumption that we are doing our development from the MBE VM, using lab6B account (as we won't have the privileges to read it):
I just replaced it with pass.txt (the file needs to exist, be nonempty and readable for the program to work properly):
The source code overview
Now, the source code. Just like in lab6C.c, we have a 'secret_backdoor()' function here as well, so all we are gonna need is execution control:
Then we have the hash_pass() function. Takes two pointers to buffers (password and username) and XORs each byte of the password buffer the corresponding byte from the username buffer. The crucial property here is that the XOR operation will keep going until a nullbyte is encountered under password[i] index:
If a nullbyte is encountered under username[i] first, the rest of the password is XOR-ed with a hardcoded value of 0x44.
Then there's the lengthy load_pass() function, which simply reads the contents of the /home/lab6A/.pass file into the buffer pointed by the pointer passed as the only argument this function takes:
Now, this is how the main() function looks like:
It loads the local user password into the sercretpw buffer and hashes it with the hardcoded "lab6A" string (the target username). Then it calls the login_prompt() function, passing the original password size and the hash to it.
Then finally we have the login_prompt() function. It reads username and password to local buffers using strncpy() to only read maximum number of bytes up to the size of the current buffer to avoid overflow. Then it calls the hash_pass() function on the buffers. Then compares (memcmp()) the result with the password hash pointed by the pointer passed in the second login_prompt() argument, also making sure that it compares the exact number of bytes as it should (pwsize):
By the way, as the original version kept complaining about input arguments, before I read the usage comment, I simply modified it to make the 'remote' variant (hardcoded remote() method of interaction with hardcoded 127.0.0.1:6642): https://github.com/ewilded/MBE-snippets/blob/master/lab6B/solution.py. Either way, it works like a charm. Now let's find out how and why.
So, after sending the first set of credentials, the exploit is parsing the output from the application (p.recvline()) as a memory leak (individual byte ranges are saved in values with names corresponding to the names of local values stored on login_prompt()'s stack), right after encountering the "Authentication failed for user" string. This made me see the light and instantly revealed the first vulnerability - which by the way also makes the second vulnerability possible to exploit, but we'll get to that in due course.
The local readbuff buffer is 128 bytes-long. Both username and password are 32 bytes-long:
Now, what happens next is that fgets() reads a string from user input, saving it in the readbuff buffer. To make the user input saved in readbuff an actual string, fgets() will terminate it with a nullbyte. This means that if we provide, let's say, 60 characters of username, fgets() will make sure byte 61 is 0, so the string is terminated:
This itself is not an issue. However, what happens next is strncpy() blindly rewriting up to 32 bytes from readbuff to username.
The same goes for password.
This means that if we provide at least 32 bytes both as username and password, both 32-byte buffers, username + password, create a continuous 64-byte block of memory without a single nullbyte. Depending on the values stored next to it (in this case attempts and result, and anything that follows, the continuous non-null memory block can be longer - and printable.
Every time after hash comparison fails, the address of the username buffer is passed to a printf() call:
Provided with a pointer to the username buffer and the %s formatting modifier, printf() will keep printing memory starting at usernameand will only stop once it encounters a nullbyte on its way. Hence the memory leak necessary for us to obtain the information required to defeat ASLR (as we must provide the current, valid address of the login() function to EIP).
Running the app
Before we proceed any further, let's get the feel how all this data is aligned on the stack.
Let's put our first breakpoint here (betweeen strncpy() and hash_pass() calls):
Which would be this place in login_prompt() (at offset 278, right after the second strncpy() call is complete):
We can set a breakpoint on an offset, without first loading the program and using a full address, like below:
OK, run:
The breakpoint is hit let's have a look at the stack and identify what's what:
To confirm whether the value we think is the saved RET is in fact the saved RET, let's simply check the address of the next instruction after the login_prompt() call:
Yup. So we know how data is aligned on the stack when hash_pass() is about to be called.
Fair enough, let's create a second breakpoint - right after the hash_pass() call - to see how affects the values on the stack : break *(login_prompt+296)):
And once it's hit, we can see that the password (originally consisting of capital 'C's) was hashed with the username (capital 'B's), as well as were the two integer values (attempts and result) and stuff that follows them:
Even the trailing 0x80002f78 was changed to 0x80002e79 in result of the XOR operation. The XOR stopped on the nullbyte in 0x80002e79, leaving the 0x80 part intact.
At this point I got really worried about my understanding of the issue. How are we supposed to leak any memory layout information like the saved RET, saved EBP or anything revealing the current address base, if we encounter a nullbyte on our way earlier? We are always going to have nullbytes on our way with saved RET containing it due to the code segment base address containing such:
Then I noticed that the code segment has in fact a non-null base (just like the other maps) when we attach to an already running process instead of starting it from gdb (if you know the reason of this behavior please let me know).
As my goal was to figure out the exploitation myself and using Corb3nik's exploit for clues as last resort, I tried to develop the rest of the code myself, starting with this skeleton taken from his code:
Setting the pwlib's context.log_level variable to debug makes gives a great additional feedback channel during exploit troubleshooting and development.
Here's a sample run of this exploit skeleton (note the entire [DEBUG] output, the script itself does not print anything explicitly except for "The pid is: ..."):
By the way, because I wanted to attach gdb to the target process before inducing the out-of-bonds read (so I proceed from this point developing the exploit), I made it print out the PID and pause, waiting for a key to be pressed:
Console 1
This way we can conveniently attach to the process from a second console:
Console 2
Again, breakpoints:
And the stack (marked red saved RET, the address of the next instruction after login_prompt() call):
The second vuln
Now let's see how the stack changed after the first hash_password() call (breakpoint 2):
First, we have our username buffer (32 bytes of 0x42 value) intact. Then we have the password buffer. It's also 32 bytes, originally of 0xff value we sent in our payload... now turned into 0xbd.
The 32 bytes of password got XOR-ed with their corresponding username bytes. 0x42 XOR 0xff = 0xbd. So far so good.
But what happens next, when i becomes 32 and keeps incrementing, because no nullbyte was encountered under neither password[i] or username[i]?:
username[32] points at password[0], username[33] points at password[1] and so on. And password[32] points at result, password[33]points at attemptsand so on. XOR keeps XOR-ing.
Let's have a look at the two signed integer values (result and attempts), previously 0xffffffff and 0xfffffffe.Now they're 0x42424242 and 0x42424243, respectively:
So, how did their bytes turn from 0xff to 0x42? Had they been XOR-ed with 0x42 (username), they would now be nullbytes (which we don't want, by the way), because any value XOR-ed with itself becomes 0.
They were originally 0xff and became ox42 because they were XOR-ed with 0xbd (to check what was the value they were XOR-ed with, we can simply XOR the current value with the old value, 0x42 XOR 0xff = 0xbd):
So, the bytes that follow the password buffer (including the two integers, saved EBP and the saved RET) got XOR-ed with the contents of the password buffer... after the password buffer was XOR-ed with the username buffer.
And this is how we attained the second vulnerability - which, as we can see, allows us to change the saved RET!
Look again, the saved RET got changed as well (marked blue):
It's original value was 0xb77cdf7e, now it's 0x0ac162c3. Again, we can run simple test to see what was the value it got XOR-ed with:
Yup, it was 0xbd (username XOR password).
So, the second vulnerability is an out-of-bond XOR in the hash_function().
A XOR with a buffer that we control. So it is effectively an out-of-bond write (a XOR-chained stack-based buffer overflow).
And funnily, it has the same root cause, which is relying on whether or not a particular consecutive byte is null instead of using a maximum size boundary for write.
Understanding the exploitation process and implementing it
In order to trigger both the out-of-bonds read and out-of-bonds XOR, we must provide 32 non-null bytes of username and then 32 non-null bytes of password.
Also, no byte at username[i] can have its corresponding byte in password[i] equal to it (that would lead to the relevant password[i] becoming a nullbyte in result of the XOR operation, cutting us out from the further bytes on the stack).
This way the following things will happen:
1) password will get XOR-ed with username
2) the bytes on the stack following the just XOR-ed password buffer ( attempts, result, login_prompt() parameters, saved EBP and saved RET) will get XOR-ed with the new contents of the password buffer - which is, again, what we provide as password then XOR-ed with what we provide as username.
3) Since this authentication attempt will fail, the printf() call will print out everything starting from the username buffer through the XOR-ed password to the rest of the values on the stack XOR-ed with the XOR-ed password up until a nullbyte is encountered.
So we use the out-of-bound printf() to actually obtain, among others, the saved RET. All these values are XOR-ed with the result of the username XOR password operation.
At this point the program is in an incorrect state. The saved RET and saved EBP do not make sense. We will now how to trigger both vulnerabilities again with another authentication attempt, crafting the username and the password payloads in such a way that when the values on the stack (attempts and saved RET) are XOR -ed with the password buffer (which at that point will be the result of XOR between the username and the password we provide), they become the arbitrary values we WANT them to be.
Yes, in addition to the saved RET becoming the current address of the login() function, we also want to control the attempts value, so the while loop can end:
The login_prompt() function will not attempt to return until the loop ends. And the return call is how we gain execution control via saved RET overwrite.
What we need to do now is:
1) use the leaked values to calculate the login() address
2) craft the second username and password 32-byte payloads in such a way, that the current values on the stack (a copy of which we already got via the leak) - especially saved RET and attempts - once XOR-ed with the password buffer, become what we want them to be. Keeping in mind that the password buffer will first get XOR-ed with the username buffer, so we'll need to consider this order while preparing the payload.
All boils down to applying correct values and correct order of XOR-ing.
Let's start from the first payload again.
This time we'll use 'C' (0x43) as username and 0x11 as password:
Now, reading the values from the leak:
We know they are XOR-ed with 0x52, because 0x43 ('C', the username) XOR-ed with 0x11 produces 0x52. Again, these values can be arbitrary as long as they meet the conditions mentions above. And once they are picked, the following decoding and encoding will depend on these values.
We know that XOR-ing anything with the same value twice produces the same value back again. So:
0x43 XOR 0x11 = 0x52
0x52 XOR 0x11 = 0x43
Knowing that the hash_pass() encoded the stack variables with 0x52, we XOR them with 0x52 to make them make sense again:
OK, time for the second payload. This time we'll use 'D' (0x44) as username, only to emphasize that it can differ here.
Obtaining the offset of the login() function:
Calculate the current ASLR-ed address of the login() function by preserving 20 most significant bits from the original saved RET and adding the fixed offset 0xaf4 to it:
Now crafting the payloads for saved RET and attempts. We want such a value, which, when XOR-ed with currently messed up saved RET on the stack, will become the new_ret address. As we know the current value of the messed up saved RET (the xored_ret variable), we XOR it the new_ret and save it in new_ret_payload. When this value gets XOR-ed with xored_ret in one stack with a hash_pass() call, two XOR-s with xored_ret will make that value equal new_ret (this is why I titled it "madness"):
Now the attempts value. We decode it with the 0x52 key from the first attempt, increment it by one (to get past the last, third iteration of the while loop instead of having to perform another dummy authentication attempt) and encode it back :
Now, one last layer of encoding. Before sending, we need to XOR everything with the username value we chose for the second attempt, so the hash_pass() call XOR-ing the password with it will reverse this process, making those values ready to be XOR-ed against the rest of the stack:
And lastly, we assemble the payload, fill it up to 32-bytes with some arbitrary character (e.g. 'E') and send it:
And here we go. Triggering the leak and the first out-of-bonds XOR:
Receiving the leak:
Sending the second authentication attempt payload:
And we're done:
The full source code with comments can be found here:
During the last month I have been busy reading this awesome book by Dennis Andriesse, which quickly became one of my favourite reads on the subject: it does an excellent job on covering the foundation about Linux’s binary analysis and also going above and beyond by providing the reader with all the necessary techniques to be highly proficient and effective when dealing with such alchemical matter.
Chapter 5 has the purpose of illustrating all these different tools of the trade which culminates with an intriguing CTF, whose goal is to challenge the reader to put in practice all the skills&tricks gained up to this point.
Yesterday I've read Microsoft's blog post about the new ATP kernel sensors added to log injection of user-mode APCs. That got me curious and I went to examine the changes in KeInsertQueueApc.
The instrumentation code invokes the function EtwTiLogQueueApcThread to log the event. The function's prototype looks like this :
EtwTiLogQueueApcThread is only called when the queued APC is a user-mode APC and if KeInsertQueueApc successfully inserted the APC into the queue (Thread->ApcQueueable && !Apc->Inserted).
EtwTiLogQueueApcThread first checks whether the user-mode APC has been queued to a remote process or not and only logs the event in the former case.
It also distinguishes between remotely queued APCs from user-mode (NtQueueApcThread(Ex)) and those queued from kernel-mode; The former is used to detect user-mode injection techniques like this one.
As shown below, two event descriptors exist and the one to log is determined using the current thread's previous mode to know whether the APC was queued by a user process or by a kernel driver.
(Click to zoom)
Looking at where the event provider registration handle EtwThreatIntProvRegHandle is referenced, we see that not only remote user-mode APC injection is logged but also a bunch of events that are commonly used by threats.
(Click to zoom)
Thanks for reading and until another time :)
Follow me on Twitter : here
Following the wake of the previous post, here is Practical Binary Analysislevel 7 CTF walkthrough.As we pay attention to the oracle’s hint, we begin to suspect that this level might be two-staged:
$ ./oracle 0fa355cbec64a05f7a5d050e836b1a1f -h Find out what I expect, then trace me for a hint If we try to open the level7 file
1.$ ./lvl7 -bash: ./lvl7: cannot execute binary file: Exec format error $ file lvl7 lvl7: gzip compressed data, last modified: Sat Dec 1 17:30:15 2018, from Unix We can see it’s a gzip format, so we need to decompress it first.
In this blogpost, I will share a simple technique to circumvent the check that was introduced in Windows 10 build 1809 to detect user-mode APC injection. This technique will only allow us to "bypass" the sensor when we're running code from kernel-mode, i.e., queuing a user-mode APC to a remote thread from user-mode will still be logged. For more information about this new feature, please check out my previous blogpost.
In short, the sensor will log any user-mode APCs queued to a remote thread, be it from user-mode or kernel-mode. The most important check is implemented in the kernel function : EtwTiLogQueueApcThread as shown below.
(Click to zoom)
So queuing a user-mode APC to a thread in a process other than ours is considered suspicious and will be logged. However, when having code execution in kernel-mode we can queue a kernel-mode APC that will run in the context of the target process and from there we can queue a user-mode APC. This way, the check when KeInsertQueueApc is called from the kernel-mode APC will always yield (UserApc->Thread->Process == CurrentThread->Process).
The driver registers a CreateThreadNotifyRoutine in its DriverEntry.
CreateThreadNotifyRoutine queues a kernel-mode APC to a newly created thread.
The kernel-mode APC is delivered as soon as the IRQL drops below APC_LEVEL in the target thread in which we allocate executable memory in user-space, copy the shellcode, then queue the user-mode APC.
The user-mode APC is delivered in user-mode.
The only issue here is that Windows Defender's ATP will still log the allocation of executable memory thanks to another sensor.
Thanks for your time :)
Follow me on Twitter : here
objdump is one of the most widley adopted linear disassembler, which often gives a significant help during initial binary analysis.A linear disassmbling algorithm, as opposed to a recursive one, is faster but also more prone to errors, as it only weeps through the file sections one instruction at a time, instead of inspecting every conditional statement.
Here, I would like to give a simple demo of how easily objdump can be confused, by filling the binary with instructions in the rdata section and strings in the text section.
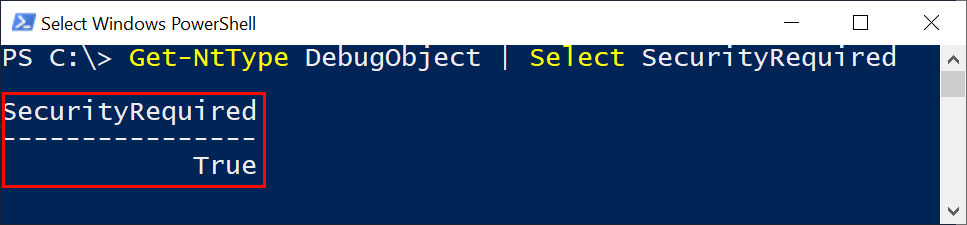
During my implementation of NT Debug Object support in NtObjectManager (see a related blog here) I added support to open the debug object for a process by using the ProcessDebugObjectHandle process information class. This immediately struck me as something which could be used for anti-debugging, so I did a few searches and sure enough I was right, it's already documented (for example this link).
With that out of the way I went back to doing whatever it was I should have really been doing. Well not really, instead I considered how you could bypass this anti-debug check. This information was harder to find, and typically you just hook NtQueryInformationProcess and change the return values. I wanted to do something more sneaky, so I looked at various examples to see how the check is done. In pretty much all cases the implementation is:
The code checks if the query is successful and then whether a valid debug object handle has been returned, returning TRUE if that's the case. This would indicate the process is being debugged. If the an error occurs or the debug object handle is NULL, then it indicates the process is not being debugged.
To progress I'd now analyse the logic and find the failure conditions for the detection, fortunately the code isn't very big. We want the function to return FALSE even though the debugger is attached, this means we need to either:
Make the query return an error code even though a debugger is attached, or...
Let the query succeed but return a NULL handle.
We've reached the limit with what we can do staring at the anti-debug code. We'll dig into the other side, the kernel implementation of the information class. It boils down to a single function:
If there's no debug port attached then return STATUS_PORT_NOT_SET.
If the process holding the debug port is at a higher protection level return STATUS_PROCESS_IS_PROTECTED.
Finally open a handle to the debug object and return the status code from the open operation.
For our purposes case 1 is a non-starter as it means the process is not being debugged. Case 2 is interesting but as the Process object parameter (which comes from the handle passed in the query) will be the same as KeGetCurrentProcess that'd never fail. We're therefore all in on case 3. It turns out that the debug objects, like many kernel objects are securable resources. We can confirm that by using NtObjectManager by querying for the DebugObject type and checking its SecurityRequired flag.
If SecurityRequired is true then it means the object must have a security descriptor whether it has a name or not. Therefore we can cause the call to ObOpenObjectByPointer to fail by setting a security descriptor which prevents the process using the anti-debug check opening the debug object and therefore returning FALSE from the check.
To test that we need a debugger and a debuggee. As I do my best to avoid writing new C++ code I converted the anti-debug code to C# using my NtApiDotNet library:
using(varresult=NtProcess.Current.OpenDebugObject(false)){if(result.IsSuccess){Console.ForegroundColor=ConsoleColor.Red;Console.WriteLine("[ERROR] We're being Debugged, stahp!");}else{Console.ForegroundColor=ConsoleColor.Green;Console.WriteLine("[SUCCESS] Go ahead, we're cool!");}}
I don't bother to check for a NULL handle as the kernel code indicates that can't happen, either you get an error, or you get a valid handle. Anyway it doesn't need to be robust, ..., for me ;-)
This code is pretty simple, we create the debuggee process with the DebugProcess flag. When CreateProcess is called the APIs will create a new debug object and attach it to the new process. We can then open the debug object and set an appropriate security descriptor to block the open call in the debuggee. Finally we can just poll the debug object which resumes the target, looping until completion.
What can we set as the security descriptor? The obvious choice would be to set an empty DACL which blocks all access. This is distinct from a NULL DACL which allows anyone access. We can specify an empty DACL in SDDL format using "D:". If you test with an empty DACL the debuggee can still open the debug object, this is because the kernel specified MAXIMUM_ALLOWED, as the current user is the owner of the object this allows for READ_CONTROL and WRITE_DAC access to be granted. If we're an administrator we can change the owner field (or by using a WontFix bug) however instead we'll just specify the OWNER_RIGHTS SID with no access. This will block all access to the owner. The SDDL for that is "D:(A;;0;;;OW)".
If you put this all together yourself you'll find it works as expected. We've successfully circumvented the anti-debug check. Of course this anti-debug technique is unlikely to be used in isolation, so it's not likely to be of much real use.
The anti-debug author is trying to model one state variable, whether a process is being debugged, by observing the state of something else, the success or failure from opening the debug object port. You might assume that as the anti-debug check is directly interacting with a debug artefact then there's a direct connection between the two states. However as I've shown that's not the case as there's multiple ways the failure case can manifest. The code could be corrected to check explicitly for STATUS_PORT_NOT_SET and only then indicate the process is not being debugged. Of course this behavior is not documented anywhere, and even it was could be subject to change.
The problem with the anti-debug code is not that you can set a security descriptor on the debug object and get it to fail but the code itself does take into accurately take into account the thing its trying to check. This problem demonstrates the fundamental difficulty in writing secure code, specifically:
Any non-trivial program has a state space too large to accurately model in finite time which leads to unexpected or undefined behavior.
Or put another way:
The time constrained programmer writes what works in testing, not what is correct. While bypassing anti-debug is hardly a major security issue (well unless you write DRM code), the process I followed here is pretty much the same for any of my bugs. I thought it'd be interesting to see my approach to these sorts of problems.
This blogpost is about a vulnerability that I found in Panda Antivirus that leads to privilege escalation from an unprivileged account to SYSTEM.
The affected products are : Versions < 18.07.03 of Panda Dome,
Panda Internet Security, Panda Antivirus Pro, Panda Global Protection,
Panda Gold Protection, and old versions of Panda Antivirus >= 15.0.4.
The vulnerability was fixed in the latest version : 18.07.03
The Vulnerability:
The vulnerable system service is AgentSvc.exe. This service creates a global section object and a corresponding global event that is signaled whenever a process that writes to the shared memory wants the data to be processed by the service. The vulnerability lies in the weak permissions that are affected to both these objects allowing "Everyone" including unprivileged users to manipulate the shared memory and the event.
(Click to zoom)
(Click to zoom)
Reverse Engineering and Exploitation :
The service creates a thread that waits indefinitely on the memory change event and parses the contents of the memory when the event is signaled. We'll briefly describe what the service expects the contents of the memory to be and how they're interpreted.
When the second word from the start of the shared memory isn't zero, a call is made to the function shown below with a pointer to the address of the head of a list.
(Click to zoom)
The structure of a list element looks like this, we'll see what that string should be representing shortly :
typedef struct StdList_Event { struct StdList_Event* Next; struct StdList_Event* Previous; struct c_string { union { char* pStr; char str[16]; }; unsigned int Length; unsigned int InStructureStringMaxLen; } DipsatcherEventString; //.. };
As shown below, the code expects a unicode string at offset 2 of the shared memory. It instantiates a "wstring" object with the string and converts the string to ANSI in a "string" object. Moreover, a string is initialized on line 50 with "3sa342ZvSfB68aEq" and passed to the function "DecodeAndDecryptData" along with the attacker's controlled ANSI string and a pointer to an output string object.
(Click to zoom)
The function simply decodes the string from base64 and decrypts the result using RC2 with the key "3sa342ZvSfB68aEq". So whatever we supply in the shared memory must be RC2 encrypted and then base64 encoded.
(Click to zoom)
When returning from the above function, the decoded data is converted to a "wstring" (indicating the nature of the decrypted data). The do-while loop extracts the sub-strings delimited by '|' and inserts each one of them in the list that was passed in the arguments.
(Click to zoom)
When returning from this function, we're back at the thread's main function (code below) where the list is traversed and the strings are passed to the method InsertEvent of the CDispatcher class present in Dispatcher.dll. We'll see in a second what an event stands for in this context.
(Click to zoom)
In Dispatcher.dll we examine the CDispatcher::InsertEvent method and see that it inserts the event string in a CQueue queue.
(Click to zoom)
The queue elements are processed in the CDispatcher::Run method running in a separate thread as shown in the disassembly below.
(Click to zoom)
The CRegisterPlugin::ProcessEvent method does parsing of the attacker controlled string; Looking at the debug error messages, we find that we're dealing with an open-source JSON parser : https://github.com/udp/json-parser
(Click to zoom)
Now that we know what the service expects us to send it as data, we need to know the JSON properties that we should supply.
The method CDispatcher::Initialize calls an interesting method CRegisterPlugins::LoadAllPlugins that reads the path where Panda is installed from the registry then accesses the "Plugins" folder and loads all the DLLs there.
A DLL that caught my attention immediately was Plugin_Commands.dll and it appears that it executes command-line commands.
(Click to zoom)
Since these DLLs have debugging error messages, they make locating methods pretty easy. It only takes a few seconds to find the Run method shown below in Plugin_Commands.dll.
(Click to zoom)
In this function we find the queried JSON properties from the input :
(Click to zoom)
It also didn't hurt to intercept some of these JSON messages from the kernel debugger (it took me a few minutes to intercept a command-line execute event).
(Click to zoom)
The ExeName field is present as we saw in the disassembly, an URL, and two md5 hashes. By then, I was wondering if it was possible to execute something from disk and what properties were mandatory and which were optional.
Tracking the SourcePath property in the Run method's disassembly we find a function that parses the value of this property and determines whether it points to an URL or to a file on disk. So it seems that it is possible to execute a file from disk by using the file:// URI.
(Click to zoom)
Looking for the mandatory properties, we find that we must supply at minimum these two : ExeName and SourcePath (as shown below).
Fails (JZ fail) if the property ExeName is absent
Fails if the property SourcePath is absent
However when we queue a "CmdLineExecute" event with only these two fields set, our process isn't created. While debugging this, I found that the "ExeMD5" property is also mandatory and it should contain a valid MD5 hash of the executable to run.
The function CheckMD5Match dynamically calculates the file hash and compares it to the one we supply in the JSON property.
(Click to zoom)
And if successful the execution flow takes as to "CreateProcessW".
(Click to zoom)
Testing with the following JSON (RC2 + Base64 encoded) we see that we successfully executed cmd.exe as SYSTEM :
The final exploit drops a file from the resource section to disk, calculates the MD5 hash of cmd.exe present on the machine, builds the JSON, encrypts then encodes it, and finally writes the result to the shared memory prior to signaling the event.
Also note that the exploit works without recompiling on all the products affected under all supported Windows versions.
Intro Recently, I have decided to tackle another challenge from the Practical Binary Analysisbook, which is the latest one from Chapter 7.
It asks the reader to create a parasite binary from a legitimate one. I have picked ps, the process snapshot utility, where I have implanted a bind-shell as a child process.
DISCLAIMER : The following PoC will work only on a non-PIE binary due to the hardcoded entry-point address
We are not going to overwrite the saved RET on the stack (we're gonna have a different pointer available, without touching the stack protector). We are also going to:
beat ASLR with an initial tiny little taste of brute force combined with a partial overwrite
Noticing a good deal of unused code reaffirmed my feeling that this app was either intended to be solvable in multiple ways or was expected to be solved in a very painful way, requiring multiple steps and gadgets to be used (which would mean that the originally intended solution was slightly more complicated than what I came up with).
For the sake of brevity, I am only going to bring up parts of the code I found relevant for getting arbitrary code execution.
First, there's a simple structure definition, holding two buffers and an integer:
OK, now the main() function (this is where the uinfo structure is instantiated, by the way):
From all of the above, we are in fact only interested in:
1) line 75: an instance of the uinfo structure gets declared as a local variable, which means it's on the local stack of the main() function
2) line 91: the address of the print_listing() function is assigned to the merchant.sfunc integer value
3) line 113: if we type '3', we call the function from the merchant.sfunc address, passing the address of the merchant structure as an argument.
4) line 107: if we type '1', we call the setup_account() function.
We don't care about the print_listing() function, we are not going to use it, neither anything else not mentioned so far.
Now, the setup_account() function. This is where our neat buffer overflow resides:
The vulnerability is sitting in the expression being the first argument to memcpy().
As temp is 128 bytes long, user->name can be up to 32 bytes and the fixed " is a " string is 6 bytes long, we are able to overflow the user->desc buffer by 38 bytes.
If we look at the uinfo structure definition again, we can see that the sfunc pointer resides right after the desc buffer, so it becomes clear how we are going to achieve execution control. We are actually going to exploit this three times to execute arbitrary code.
What's useful - a few gadgets
On line 69, there's a nice and very simple function print_name():
It's not called anywhere in the code, but it's definitely a good gadget for leaking. Will print any buffer pointed by the argument, until a nullbyte is encountered.
Also, on line 29, there's a definition of a strange function. This function does not get called anywhere from the rest of the program, clearly suggesting it being intended to be used as a gadget.
It simply writes 8 bytes of the buffer pointed by the value pointed by its argument (a pointer to a pointer) to the standard output:
In fact I found it quite handy using it as a gadget in leaking information needed for properly constructing the final code execution payload.
Leaking the address space layout
So, we want to overwrite the sfunc integer with an address of the print_name() function, as it appears to be the best (simplest) way to leak some memory.
This is how the stack looks like when the setup_account() is called (with 31 'A' characters + newline as username, plus 90 'B' characters to fill the desc (32+90 = 128), to stop exactly before touching the original sfunc value (the address of the print_name() function):
Let's see what offsets our functions have (output from gdb on a binary that was not run before, hence all bases are 0x00000 and only offsets are visible):
OK, so we can do a partial overwrite (by using 130 bytes instead of 132), only overwrite two least significant bytes of the pointer, leaving the base value (which we won't know at the time of exploitation) alone. This is a common ASLR bypass technique. We want to 9e0 become be2.
The problem is that we can't simply overwrite half-bytes, only whole bytes. This means we have keep trying (brute force) with some arbitrary value of the first half-byte we do not know (because it's part of the base provided by ASLR), until we hit an instance of the program when in fact that half-byte will be equal to it, so overwriting it with our arbitrary value won't mess up the address.
'b' is the value I chose, as I saw it appearing in an actual address in gdb (see the screenshot above).
Hence I decided to try doing this partial overwrite to print_name with an arbitrary value of 0xbbe2, whereas the first be2 is the known offset of the `print_name` function while the preceding 'b' half-byte is a guess. First two most significant bytes are left intact (it's important to avoid sending out the trailing newline, as it will overwrite the third least significant byte with 0x0a and we definitely don't want that!):
A sneak peak of the exploit code
To automate this a bit, the routine was put into a loop:
This does not need many attempts as there are only 16 possible values a half-byte can have.
If the address is incorrect, the program will crash right after calling the 'View info' option by sending '3'. If it does not crash, print_name(&merchant) was successfully called, with the entire merchant (name + desc + print_name_addr) content being printed out up until the nearest nullbyte down the stack.
And this is how it looks like:
This way we have leaked the entire base of the code segment, after guessing its least-significant half-byte. Now we can do calculations, so we know exactly the value we'll overwrite the sfunc pointer next (we will NOT restart the program from now, but keep overflowing and calling from now on - no more bruteforce!), to achieve arbitrary code execution.
Again, the exploit snippet:
Calculating libc system() - the hard way
So, I obviously thought of the simplest system("sh") similar to ret2libc. Let's just overwrite the sfunc with the address of the libc system() method.
But how are we going to know what it is? Well, we can obviously calculate the offset between system() and printf():
So, in our libc printf()'s address is 0xd0f0 above system()'s. Hence, all we'll need to do to achieve system()'s address will be a subtraction of this value. Then another overwrite with setup_account() and we should get our shell.
OK, where do we get that (printf()'s address) value from? It should be in our address space (GOT, in the data segment), because printf() is being used by our target program so it is definitely linked and already resolved in GOT by the PLT routine (the PLT routine is in the code segment, by the way).
A quick search showed that this is the case (the program was broken on a breakpoint at setup_account(), so GOT was resolved already (0xb7707000 0xb7708000 was the range of the data segment in that instant):
The above also showed that the relevant GOT entry (0xb7707010) was located at offset 0x10 of the current base address of the data segment (0xb7707010 - 0xb7707000 = 0x10).
But then I thought: but how do we leak the data segment address?
I started looking at the code to notice that it is being passed on the stack, e.g. for the ulisting-operating functions like make_listing().
I could read that from the stack. But how do I leak the stack address first?
Oh fuck no, it looks like I am going to have to redirect the execution to that make_note() function first and exploit it first? Nah, this is madness. There has to be an easier way!
Calculating libc system() from here - the easy way
So, below is a sample full output of the vmmap command (this time addresses are slightly different than the ones earlier, this is due ASLR, nonetheless the same rules apply):
Notice something? The three consecutive segments marked red, are, respectively:
the code segment
the read only data segment
the data segment
And they create a continuous range of addresses, which suggests they are aligned at fixed offsets from each other. Let's run the program several times and check if this is the case:
Yup. We can clearly see that data, code and rodata share the same base. Awesome, looks like we found a shortcut.
rodata is is 0x2000 bytes greater than code, data is 0x1000 greater than rodata.
So, once we have the base for the code segment, we simply add 0x3000 to it and get the base for the data segment. Then we add the known offset and we know the address of printf()'s GOT entry. So we know where to read from the libc printf() address. Then we can calculate the address of system().
The exploitation algorithm from here
The first overflow allowed us to leak the base of the code segment and calculate everything else we need for exploitation. Now we want to:
Trigger the overflow for the second time, this time to overwrite the sfunc value with the address of the write_wrap() function (which is perfectly suited to leak the GOT after being provided its address, because the GOT itself is a pointer). With the GOT address put in front of the merchant object (name buffer), so it becomes the argument to the sunc(&merchant) call.
Leak the printf() libc address by calling the newly overwritten sfunc.
Trigger the overflow for the third time, this time to overwrite the sfunc value with the address of system(), while putting the arbitrary command in front of the merchant object (name buffer).
Cll it!
How the second overflow unexpectedly failed and why. read() and strncpy() to the rescue.
So, the last surprise here was that the second overflow failed. Instead of leaking the GOT, the whole buffer was printed again. This meant that the sfunc was not overwritten this second time and that in result of "pressing" '3', print_name() was called once again.
After looking at the code I figured out why. The merchant->user and merchant->desc buffers are initialized with nullbytes only before the while loop and never again.
This means that after filling both buffers with non-null values, the next time setup_account() calls this memcpy:
the strlen(user->desc) expression is going to return much more than 32 (as it did in the first call), because after the first overflow at least 128 bytes of the user->desc buffer already contain non-null bytes. This will effectively make this second overflow go much further, starting overwriting beyond the pointer we want to overwrite.
Just before that memcpy() happens, this is how user->desc is impacted:
So if we need that strlen(user->desc) to return less, this time we have to inject a nullbyte into the user->name buffer (via the read() call on line 60) and let it be propagated to user->desc by the following strncpy() call. Luckily both read() and strncpy() support this :D
After that - depending on which character we put the nullbyte at, the strlen() call will return no more than 32, making the sfunc pointer again within the reach of our overwrite. We just need to properly calculate how many bytes will there be to fill between the beginning of the user->desc buffer and the sfunc variable (the sum will always be 128).
And since merchant is the argument to the sfunc() call, we put our arbitrary command (argument for system()) in the beginning of the merchant->name buffer, as it's the first field of the structure anyway):
Intro During the last couple of weeks I started focusing more and more on windows internals and the way shellcode is crafted for the different windows platforms. There are many good windows shellcodes examples available out for grabs on the internet, but some of them are written in MASM or others are not so keen having a small memory footprint. Hence, I decided to focus on probably the best shellcode actively mantained repository: msfvenom.
Right away we can see two data structure definitions, which more-less suggest what we are going to be dealing with (structures holding some data along with some function pointers):
While the menu clearly shows what operations are available:
After creating instances of the structures we'll be able to call their dedicated print functions pointed by the (* print) pointers.
If you are familiar with Use after Free, you already know it will all boil down to allocating space for one of them, filling it with arbitrary data wherever we can control it, then asking the program to remove it, then allocating another instance of another structure in the same space previously taken by the first one - and then abusing an old pointer used for tracking the first structure to perform the structure-specific operation, making a function call to an arbitrary address we smuggled inside the data of the second structure.
How data is aligned in memory
So, to find out what fields of the number and data structures overlap with each other and therefore can be used to decide on the exploitation sequence, first we need to know exactly how data is aligned in memory.
We already know that the number structure is 16 bytes long, while the data structure is 32. So we would expect to have to use two number structures to fill the space previously taken by one data instance.
So I ran gdb to find out I was wrong. I allocated three numbers in a row, then took the current heap start address from vmmap output (important to do this AFTER the first allocation, otherwise you won't even see the [heap] section in vmmap output because it won't be allocated by the OS) and had a look. Then I restarted the program and did the same with the number structure. The results are illustrated by the screenshot below:
Comparison of the view of the heap after allocating three number structures versus three data structures
As we can see, both structures take 32 bytes (the 16-bit structure is automatically padded to 32 bytes). This is very convenient for us, as we won't have to struggle with aligning different numbers of instances against each other to achieve the favorable alignment allowing us do something neat.
Combining mutually-overlapping fields of both structures to find the proper codexec UaF scenario
So, since I already started with the visualization thing to clearly see the memory layout, I decided to take further advantage of it to compare what fields in one structure correspond to what fields in the other.
On the upper part of the screenshot (number) function pointers were marked red, actual numbers were marked green. On the lower side of the screenshot (data) function pointers were marked green, last four bytes of the string were marked red:
Looking at this for just a few seconds made it clear to me how to achieve execution control.
We can see that in the number structure, the function pointer (0xb770ccb4 on the screenshot above) occupies the same space that, when allocated with a string, always contains at least one nullbyte (0x00414141 on the screenshot above). This is because the string is automatically null-terminated by fgets() and we can't control it.
Hence, allocating a number, then deleting it, allocating a string in its place and then requesting the program to print the number won't get us far (we'll crash the program if we call 0x00ANYTHING), as we only control up to three bytes and we are not even overwriting a function pointer, so a partial overwrite won't help us (fgets will always put a null where we want something arbitrary/the most significant byte of the base).
At the same time we can see that the space holding the actual number value (0x41414141 on the screenshot above) which we can control fully as numbers from all ranges are acceptable), sits in the same place as the function pointer for the string structure ( 0xb774dc16 on the screenshot above). Hence, allocating a string, deleting it, creating an arbitrary number and then requesting the string to be printed would effectively lead to the program trying to print the already freed string with code pointed by our newly created number, still treating it as a pointer to the data-> print(big_str/small_str) function.
Let's try it.
We add a string (its contents are irrelevant, we are only interested in having data structure's print function pointer propagated onto the heap):
Now we remove it:
OK. Now we are going to introduce the pointer address we will trick the target program to call (in our final exploit this will be the address of system()). Let's say we want the program to crash by calling address 0x31337157 (because it's not a valid address in its address space).
Calculating the decimal format:
$ printf "%d" 0x31337157 825454935
OK:
Now, asking the program to print the string 1 should lead to a segfault at 0x31337157:
Yup. And the string itself will be useful to us to control the arguments (so we'll put system()'s address instead of 0x31337157 and "sh" as the string, leading to system("sh")).
If we look at the corresponding fields on the heap layout we'll see that first 16 bytes of the string buffer are occupied by the reserved fields in the number structure, which means that if we allocate a number after removing a string, taking the space it was allocated on, the first 16 bytes of the structure (6 bytes reserved and 2 bytes of padding) will be left alone with the old values from the string.
So calling system("sh") should be doable:
create a string "sh"
delete the string
create a number == libc system()'s address
'print' the string
The only problem we have got left to figure out is how to leak the memory layout to bypass ASLR.
Combining mutually-overlapping fields of both structures to find the proper UaF leak scenario
Looking at the layout again brought me the potential answer to this literally after the first glance (which proves how crucial it is to have the literally see the layout).
As we want to leak memory, we need to call a function taking an argument that happens to be/store a pointer.
The goal is to see both possible states of the memory combined and find such a combination of values that will let us achieve our goal. Let's look at the layout again, this time focusing on two particular neighboring double word values we would like to have in one state - and then think if we can groom the memory into that state:
When the space is occupied by a number structure, the +0x20 address contains a pointer (the print function, marked green), while +0x24 contains data (the number, in this case 0x41414141 - but that's irrelevant to our goal, thus marked grey).
Conversely, when the space is occupied by a data structure, the +0x20 address contains data (the last three bytes of the string and its terminating nullbyte - useless to us, hence marked gray), while +0x24 contains a pointer (the print function, marked red).
We want to trick the program to create that state, so we can call the big_num/small_num number-printing function, with the address of the string-printing function sitting in the space previously occupied by an irrelevant number before it was free()'d and then allocated again (but not entirely overwritten!) for the string structure.
So, we create a number, then we remove it (so the number[index] is not 0, even though the structure it was pointing at was 'removed', which means free()'d).
Then we create a relatively short (less than 15-character) string, to avoid fgets() overwriting the last four bytes of the buff[20], because that is where the old number's print pointer is held and we will want to call it, so it prints out the address of the string-printing function for us, thus leaking to us the mem layout info needed for calculating the system()'s address.
Let's try this slow motion, using a breakpoint in the main loop: b *(main+169).
First, we allocate a number (1):
Now, this is the heap:
Now, we remove the number:
And again, this is the heap (yes, everything is still there after free()):
Now, we make a string up to 16 characters:
Now, this is the heap:
Now, requesting the program to print the number[1] will make it call 0xb779dc65 (big_num) with 0xb779dbc7 as argument, so we have our leak:
So, we have a number vomited out. Let's convert it to a format more readable to us (hex):
Looks good. Let's confirm in gdb:
Confirming that the leaked address is the address of the small_str() function
Awesome. It looks like we have all the bits and pieces to develop an exploit! :D
Instead, I decided to find out whether libc's system() address could be calculated based only on the leaked base of the target program's code segment - and it turned out it can! At least on the VM provided for MBE.
Either way, first let's have a look around just like we were about to leak the GOT anyway:
Here are, respectively, our code, rodata and data segments (again, creating a continuous space with fixed offsets from each other):
OK, now we search these ranges for the 0xb7622280 value (the address of printf()) as we know it has to be stored in GOT after the first printf() call:
This time (as opposed to what we had in https://hackingiscool.pl/mbe-is-fun-lab6a-walkthrough/), our entry is at 0xfa4 offset in the rodata (read-only data) segment, which at the time of taking the screenshot above was at base 0xb77b4000. This is most likely the result of the -z relro gcc compilation flag:
That's OK, this is a countermeasure against GOT overwrites, we don't care about it this time at all.
If we were doing this the usual way, we would leak the code base first. Then we would calculate the rodata address to then calculate the printf()'s GOT, so then we would leak printf()'s address from it. And then based on its fixed offset from system() within libc itself, calculate system()'s address. Then get a shell.
But let's try more directly and run the program for a few times, observing the vmmap output, focusing on the relation between the target app code segment base (which we can already leak) and the libc base (which we want to know as well):
Another run:
Yup, in both cases the offsets are the same:
Hence, one leak is enough here (which would not be the case for the stack or the heap, but we don't care about those here).
So, once we subtract 0x1dd000 from the leaked target app code base, we have the libc code base.
Now we want to know system()'s offset within the libc itself (as opposed to calculating the difference from the relative printf() offset):
The required calculations can be done with below python code:
Python offset calculation
With all this in place, we can already exploit the program.
Manual exploitation
This exploitation can be easily conducted by just interacting with the program in console by properly choosing menu options and entering simple strings and numbers:
This is was one of the most painstaking ones (which is reflected in the length of this write up). While finding the vulnerability was trivial, building a working exploit was quite of a challenge here.
msg->message[] buffer size is 128 (MAX_BLOCKS*sizeof(int)).
Results of arithmetic division operations on integers give integer results. So, 128/4 == 32, but also 129/4 == 32, 130/4 == 32 and 131/4 == 32.
129,130 and 131 are possible length values we can sneak in without hitting the (new_msg->msg_len / BLOCK_SIZE) > MAX_BLOCKS condition and having our input length overwritten with the safe value of MAX_BLOCKS*BLOCK_SIZE.
And then, right away after smuggling the slightly bigger new_msg->msg_len, in the same create_message() call, we have this:
So, read() (to which there are no bad characters, by the way! :D) writes new_msg->msglen bytes from standard input to the new_msg->message buffer. So we can overflow the new_msg->message buffer by up to three bytes. And what will we overwrite this way? Yup, the msg_len field! This way we can achieve having created a message with nearly any size in msg_len, as we can control 3 out of its 4 bytes.
This can be taken advantage of in the edit_message() function:
Here is the second heap overflow, directly resulting from the first one, making it possible to overwrite the heap contents far beyond currently edited message body and its length field (so we will overwrite the print_msg pointer of the next message we create on the heap, getting a foothold into execution control).
Also, note the numbuf[32] buffer used to store user input before converting it to an integer used for message index (with 10 being maximum expected number of messages, which are indexed from 0, hence one digit is actually enough to store the index). We are going to use it later.
More insight on the target app
First of all, LAB7A.c comes with the following readme:
This is the way it is being run (output from ps aux from the gameadmin/root user):
So, it is running as the lab7end user (so we would have to become root to debug it) and has ugly timeout of 60 seconds, making debugging additional hassle.
So, we should work locally, on /levels/lab07/lab7A, or on its copy in /tmp.
This itself will not let us get rid of the timeout... because it is also implemented with the following macro call on line 10:
The macro boils down to calling alarm(60) and setting the alarm handler to a function doing exit().
I initially tried to work on a version I manually recompiled (with the only difference being the timeout parameter changed from 60 to 0 to effectively disable it), using the same flags... and I thought it was OK... but then later when searching for ROP gadgets I noticed slight differences in offsets, so I decided to work on the original copy instead and just add an automated call alarm(0) to my gdb script (-x commands.txt).
Second, we will have to write a custom shellcode here this time, as the binary is compiled statically (libc will no longer be dynamically linked, instead only the required functions are statically linked, which means they are built in the executable):
Simply returning to libc's system() won't be an option as we won't have the entire libc dynamically linked. Instead, only the libc functions actually used by the program would be linked in, by putting their code into the same code segment as program's own code. This will definitely make exploitation more difficult.
Another specific property is the lack of -fPIE -pie flags, the result of which was the code segment not being ASLR-ed, so all the functions and ROP gadgets are at fixed addresses (which will, in turn, make the exploitation easier). Still, other segments get ASLR-ed (except for the heap, which turned out kind of tricky - although its range in the target app was the same every time I checked, the first address returned by malloc() varied between instances, making the need for leaking).
How data is aligned in memory - getting our first crash at an EIP we control
Oh, this was unexpected. Where is it then? Let's find it by searching for any part (first four bytes) of the XOR pad/encrypted output we just displayed above. Search for the literal did not work due to endianness, search for the bytes in reversed order did the trick:
OK, let's see it (we need to aim a bit wider, as 0x80f19d4 is just the beginning of the XOR pad, while we want to see the entire structure and the preceding malloc metadata):
OK, now we create another message and have a look again:
Now, this is the layout with the messages sitting on the heap:
This should give us clear picture of how to start make the program call an arbitrary address. After we create message #0 with an arbitrary length value bigger than 140 (128 for the message body + 4 for the overwritten once again length value + 8 bytes for the malloc meta fields = 140), we will start overwriting message #1's print_msg() pointer, then the message #1's XOR pad, then the message #1's body itself.
Afterwards we ask the program to print message #1, making it call our overwritten #1's print_msg pointer.
First crash
So we create a new message, with arbitrary length of 131 (max we can sneak through the faulty boundary check) and we use those additional three bytes to smuggle three 'C's:
Step 1
Now, those three 'C's overwrote the three least significant bytes of the original msg.len field, turning it from 131 to 1128481536:
OK, cool. Let's proceed to a careful overwrite of a pointer. Luckily, we don't have to be very careful when it comes to the arbitrary value of the message length field we put here. CCC (0x0043434) is good enough, because we don't have to fill the full length of 1128481536, read() will stop when no more data is available from the standard input, at first we'll just write 144 bytes, with the last 4 being the new pointer for the next message's print_msg() function.
So:
We create a message with declared length 131 and following content (this will be index #0): AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACCC (already done).
We create a second message with any length and content (irrelevant now).
We edit the first message, filling it with this payload (ZZZZ will be the hijacked EIP):
$ python -c 'print "A"*140+"Z"*4' AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAZZZZ
We ask the program to print the second message (index #1) and watch it crash on ZZZZ.
Step 2Step 3 - this time we put 144 bytes as the message bodyStep 4
We control EIP, now what
Controlling only the EIP is not sufficient to make the program do exactly what we want. As long as we cannot simply inject a shellcode to an executable memory range and jump to it (and we can't - at least not yet :) - as we are dealing with DEP/NX), we need to go with ROP approach. Even if we were not doing an actual ROP chain, but a simple overwrite of the controlled pointer to system()'s address (which we can't here, as mentioned before), we still need to control the argument that function call is expecting to have on the stack when called.
Let's be entirely clear, this is what we hijack:
messages[i]->print_msg(messages[i]) call inside the print_index() call.
So, at the time of execution of our arbitrary EIP, the argument on the stack will be a pointer to messages[i] structure on the heap (with its first field being the print_msg pointer, by the way). Even if we could make EIP point at system(), we would still want the stack to contain a pointer pointing to a buffer we control - as opposed to the XOR pad, which is filled with random data.
This is what the stack looks like at the time function print_msg() (or ZZZZ) is entered:
The saved RET points to the next instruction in print_index(), messages[i] points to the beginning of the message structure on the heap.
Then I noticed that mprotect() is linked into the program:
So I instantly recalled XPN's ROP Primer writeup (https://blog.xpnsec.com/rop-primer-level-0/) and thought 'fuck yeah, I am gonna set EIP to mprotect() and make the heap executable, the buffer address is the first argument... but what about the next two?'
So the next two variables on the stack being 0x00000000 and 0x0000000a were ALMOST what I thought would suffice. 0x00000000 is where the buffer length should be (0 is not great for length), while 0x0000000a would serve as the flags (0x7 is RWX, so oxa includes 0xb, we would be fine as long as this flags value is not invalid). Obviously, this did not work (at least because of the 0 as length, but probably there's more than there is to it - we'll be back to this later).
Anyway, I started wondering whether I can control that 0x00000000 and 0x0000000a on the stack, only to figure out where they come from: they are a survival from the strtoul(numbuf, NULL, 10) call in print_index() right before our message is printed (it's the NULL and 10, last two arguments to strtoul()):
So I looked at the registers state and the stack at the time of the call/crash, looking for anything to hook on, any candidate for the next step in execution control that would allow us make the memory and registers alignment more favorable - and put my attention to EDX, as it was pointing to the buffer we control (remember, we can write past the ZZZZ any number of bytes we want!):
So I started wondering, what if I could find a ROP gadget that would somehow mv EDX to ESP, tricking the program to start using the heap as the stack? Then we could place the rest of the ROP chain on the heap, as we are having a hard time trying to control the stack right now.
By the way, ropeme is a nice tool for this (the lab7A.ggt was previously created by the same script, by calling generate on the target binary):
Corb3nik's solution - tricky format-string-based leaking of the heap pointer after sneaky stack-grooming
Reading Corb3nik's exploit made me realize that leaking a heap-stored message pointer would in fact be needed for a reliable exploit to work - if we want to use the heap for our payload (as we could alternatively use the stack - but then we would need to leak the stack address, so it does not really make much difference at this point). So leaking has to be done before proceeding to attaining arbitrary code execution. And it turned out to be tricky (no comfy gadget this time, like with https://hackingiscool.pl/mbe-is-fun-lab6a-walkthrough/).
So, if we want to leak something, we can overwrite the EIP with printf()'s address, which as we know is fixed in this case. But what about the argument? When doing heap overflow, we overwrite the next message print_msg pointer and if we keep writing, we overwrite it's XOR pad. Then if we ask the program to print the message, it will call printf() with just one argument, being the pointer to the message[i] structure:
messages[i] (0x080f09d0 at the moment) looks like this:
Now here's the trick. If printf() treats the entire buffer pointed by messages[i] as a string, the XOR pad we overwrite past the print_msg pointer (which itself we overwrite with printf()'s address) can contain a FORMAT STRING expression.
This means that if we overwrite the XOR pad (pointed by messages[i]) with a string like %1$p, it will print the value of the nextdword on the stack, right to the heap pointer itself - exactly where the next argument to printf() would be, if it was called with that format string properly (like printf("%1$p",some_pointer_to_be_printed_out);):
This way, we can pick an arbitrary value from the stack we want printed plain and clean in proper pointer format (thus the %p, whereas number$ index selects the number of the value from the stack). So, even the nullbytes on the stack are not an issue.
As we can see on the screenshot above, we could already leak the stack (the last value to the right at the bottom, 0xbffff728 in that case) if we wanted to use it for storing the final payload. Something I realized only while writing this up and have not tried pursuing.
In Corb3nik's solution - which I followed - heap was used to store the payload (a ROP chain execve(/bin/sh) shellcode), by using a pop esp; ret + payload_addr_on_the_heap first-stage chain to trick the program to start using the heap as the stack - something I originally wanted to do when I got stuck.
So, the problem with this approach is that we do not actually have a pointer pointing to the heap anywhere on the stack while print_msg()/printf() is called - except for messages[i] - but messages[i] is literally the first argument from printf() call's perspective and we cannot reach it with %0$p format string (I tried)... we can reach everything past it, but not it itself. And it's not held anywhere on the heap itself either, so just leaking the heap without a format string at all wouldn't help.
This is where Corb3nik used a recurrent call of print_index() from within print_index(). In order to achieve this, four messages had to be created, because two overwritten pointers were needed:
By overflowing message #0, message #1's pointer was overwritten to print_index() (so this is why we already had to create two messages).
By overflowing message #2, message #3's pointer was overwritten to printf(), with its XOR pad being overwritten with the format string (thus, two more mesages).
Then, by asking the program to print message #1, we have it call print_index() from the menu and asks for the number of the message to print. Once the number is provided, print_index() calls print_msg() - or whatever pointer we put there. Since for message #1 we overwrote this pointer with print_index(), by asking the program to print message #1 we manage to have a recurrent print_index()->print_index() call. This way another set print_index()'s local variables and arguments is put on the stack, along with messages[i]. When the second print_index() call asks for the message number to print, we chose #3, because its print_msg() pointer was overwritten with printf()'s address and its XOR pad with our format string.
This way we achieve the print_index()->print_index()->printf("%20$p"), creating and exploiting a format string condition.
Below is the stack of print_index():
Below is the stack of print_index()->print_index():
So the stack's properly groomed for leaking the address of messages[i]. From this point we can calculate the offset to the XOR pad we decide to put our payload in. We'll get back to this, now let's find out how to take control of the stack and start our ROP.
Corb3nik's solution - ROP-based stack pivoting
By analyzing Corb3nik's solution, after comprehending the convoluted heap address leaking, I realized that he started his ROP chain with a pointer pointing at a mov ecx, esp; ret; gadget (changing the stack pointer to the value of ECX). We saw a bunch of those earlier in ropeme output, when we were searching for stack-pivoting gadgets. I felt puzzled, as back then when looking at the state of the registers the only register that appeared to have a useful value was EDX.
I understood the use of ECX after I analyzed the way he provided arguments to the final print_index() call in his exploit, made me understand the trick:
So let's not focus on the ROP chain itself now (it makes ESP point to the buffer on the heap and then ret to it, as mentioned before, turning the heap into program's stack, because why not :D - I decided to go a different route, later on that).
Let's focus on the way the chain is delivered - along with the message index!
Again, print_index() source code, focusing on a part we did not pay much attention to before:
So again, this is the function that calls our overwritten pointer. It will trigger the exploitation by calling print_index()->mov ecx, esp; ret;.
Its local variables are held on the stack. Then it makes the call to print_msg() - or whatever we overwrite it with, putting more variables (call arguments, stack frame, saved RET and any local variables if needed) to the stack. This means that the numbuf[32] is there on the stack - and that's where ECX happens to point when messages[i]->print_msg(messages[i]); occurs.
While fgets() allows us to stuff 31 bytes into numbuf[32], only the first one needs to be a digit corresponding to the chosen message index, the rest can be anything non-null we want to place on the stack, as the later strtoul() conversion will simply ignore it - and ECX points there:
So, after we have any message structure on the heap with its print_msg pointer overwritten with one of the mov ecx, esp; ret; gadgets (e.g. 0x80bd536), we can simply ask the program to print a message and provide it's index along with up to 30 bytes of our ROP chain.
So now we control EIP, we control the stack and we can overwrite the heap pretty much anyway we want. Now we can talk!
My last-stage ugly alternative - shellcode to heap, mprotect() heap RWX and ret there
Corb3nik's ROP chain delivered to the print_index()->numbuff[32] buffer via print_index()->fgets()'s input made the program start using the heap as the stack (pop esp, ret;).With the rest of his ROP chain stored on the heap via the initial heap overflow:
As you might remember from the beginning of this way too long write up, I wanted to use mprotect() really bad, to make the heap executable and just fucking jump to it (thus ugly), without using any more ROP.
I did as well start off with the messages[i]->print_msg() pointer overwritten with the address of a mov ecx, esp; ret; gadget.
But my ROP chain delivered along with the message number to the print_index() stack looked like this:
So obviously it started with the address of mprotect().
Then there was an address of a pop3ret instruction - the next instruction the mprotect() would return to - this is where it would expect to have its parent's saved RET stored. Before we return to the next address, we have to jump over/clean up the mprotect() arguments still lying on the stack, hence we have to use popNret as the next addr to return from our function whenever that function takes N arguments. This is the basic principle of building ROP chains.
OK, then the arguments.
First, the start address of the memory area we want to change memory protection flags of. I initially used the address of my shellcode (warning, this did NOT work and required a fix, but read on!). The shellcode was already delivered to message #1's buffer by overwriting its XOR pad with the format string for printf() AND the shellcode itself:
At the time of writing the exploit it was still a NOP-holder, I left shellcode writing till the end. The point is that the address of the shellcode on the heap was already known thanks to its fixed offset from the leaked pointer.
Then the length (I wanted to use 0x64 just to be on the safe side and have enough space executable). Then the flags (0x7 = READ + WRITE + EXEC).
And then, lastly, again the address of the shellcode on the heap. This is where the last ret from this short ROP chain will return. Then it will be just normal (a sequence of opcodes) shellcode executed on the heap.
For some reason mprotect() kept returning an error (0xffffffff in EAX), so the range must have been incorrect. I peeked into XPN's ROP Primer https://blog.xpnsec.com/rop-primer-level-0/ write up again and did as he did there with the stack - used the entire fixed heap start address + length as arguments (as I mentioned, they stayed the same between instances, hence could be fixed). Not the prettiest solution, but it was late and I just wanted to write the shellcode, run it from the heap and call it a day.
Shellcode
OK, the shellcode now. As far as I remember it should look like:
I built this using shellnoob (a tool I recommend for asm->opcode and opcode->asm conversions):