Digging into the WSL P9 File System
12 July 2019 at 15:23
Windows 10 version 1903 is upon us, which gives me a good reason to go looking at what new features have been added I can find bugs in. As it's clear people seem to appreciate fluff rather than in-depth technical analysis I thought I'd provide a overview of my process I undertook to look at one new feature, the P9 file system added for the Windows Subsystem for Linux (WSL). The aim is to show my approach to analyzing a feature with the minimum amount of reverse engineering, ideally with no disassembly.
But one fairly large pain point remained, accessing Linux files from Windows applications. You could do it, the files are stored inside the distro's package directory (%LOCALAPPDATA%\Packages\DISTRO\LocalState\rootfs), so you could open them directly. However WSL relies on various tricks to deal with the mismatch between Windows and Unix-style filesystem semantics, such as storing the UID/GID and file permission bits in extended attributes. Modifying these files using an unenlightened Windows application could result in corruption of the file state which in the worse case could break the distro.
With the release of 1903 the WSL team (if such a thing exists) looks to be trying to solve this problem once and for all. This blog introduced the new feature, accessing Linux files via a UNC path. I felt this warranted at least a small amount of investigation to see how it works and whether there's any quick wins or low-hanging fruit.
Background
When WSL was first introduced it had a pretty poor story for interoperability between the Linux instance and the host Windows environment. In the early versions the only, officially supported, way to interop was through DrvFS which allows you to mount local Windows drives into the Linux environment. This story has changed over time such as adding support to start Windows executables from Linux and better NTFS case-sensitivity support (which I blogged about already).But one fairly large pain point remained, accessing Linux files from Windows applications. You could do it, the files are stored inside the distro's package directory (%LOCALAPPDATA%\Packages\DISTRO\LocalState\rootfs), so you could open them directly. However WSL relies on various tricks to deal with the mismatch between Windows and Unix-style filesystem semantics, such as storing the UID/GID and file permission bits in extended attributes. Modifying these files using an unenlightened Windows application could result in corruption of the file state which in the worse case could break the distro.
With the release of 1903 the WSL team (if such a thing exists) looks to be trying to solve this problem once and for all. This blog introduced the new feature, accessing Linux files via a UNC path. I felt this warranted at least a small amount of investigation to see how it works and whether there's any quick wins or low-hanging fruit.
Understanding the Feature
The first thing I needed was to setup a x64 version of 1903 in a Hyper-V VM. I then made the following changes, which I would always do regardless of what I end up using the VM for:
- Disabled SecureBoot for the VM.
- Enabled kernel debugging through BCDEDIT. Note that I tend to be paranoid enough to disable NICs in the VM (and my success of setting up alternative debug transports is mixed) so I resort to serial debugging over a named pipe. Note that for Gen 2 Hyper-V VMs you can't add a serial port from the UI, instead you need use the Set-VMComPort PowerShell cmdlet.
- Install my tooling, such as NtObjectManager and SysInternals suite, especially Process Monitor.
- Enabled the Windows Subsystem for Linux feature.
- Install a distro of choice from the Windows Store. Debian is the most lightweight, but any will do for our purposes. Note that you don't need to login to the Store to get the distro, though the app will do its best to convince you otherwise. Don't listen to its lies.
With a VM in hand we can now start the investigation. The first thing I do is take any official information at face value and use that to narrow the scope. For example reading the official blog post I could determine the following:
- The feature uses the Plan 9 Filesystem Protocol to access files.
- The files are accessed via the UNC path \\WSL$\DISTRO but only when the distro is running.
- The P9 server is hosted in the init process when the distro starts.
- The P9 server uses UNIX sockets for communication.
Based on those observations the first thing I want to do is try and find how the UNC path is implemented. The rationale for starting at the UNC path is simple, that's the only externally observable feature described in the blog post. Everything else, such as the use of P9 or UNIX sockets could be incorrect. I'm not expecting the blog post to outright lie about the implementation, but there's sometimes more important details to get right than others. It's worth noting here that you should increase your skepticism of a feature's technical description the older the blog post is as things can and will change.
If we can find how the UNC path is implemented that should also lead us to whether P9 is used as well as what transport the feature is using. An important question is whether these files are really accessed via the UNC path, which would imply kernel support, or is it only in Explorer? This is important to allow us to track down where the implementation lies. For example it's possible that if the feature only works in Explorer it could be implemented as a shell extension, similar to how MTP/PTP is supported.
To determine whether its a kernel driver or a shell extension it's as simple as opening the UNC path using the lowest possible function, which in this case means calling a system call. Invoking a system call will also eliminate the chance the WSL UNC path is implemented using some new feature added to the Win32 APIs. As my NtObjectManager module directly calls the NtOpenFile system call we can use that to do the test. I ran the following PowerShell command to check on the result:
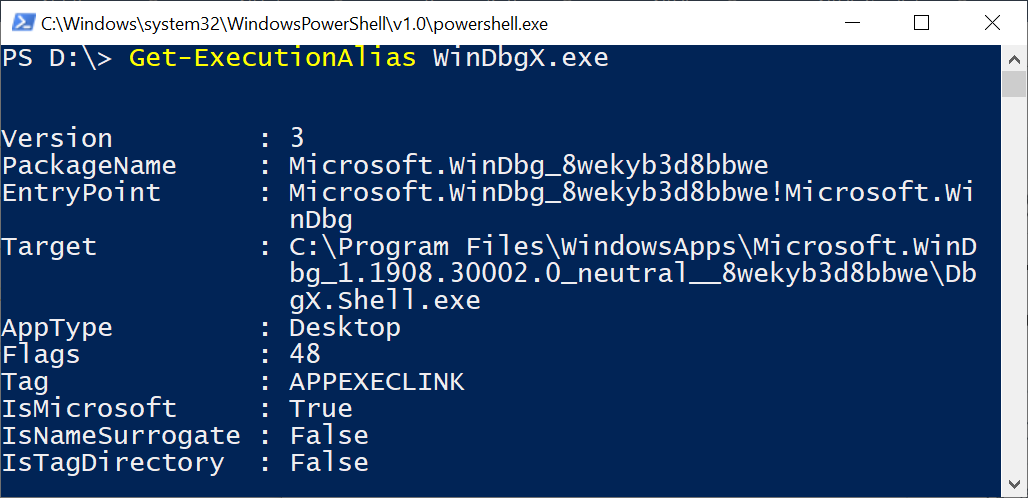
$f = Get-NtFile \??\UNC\wsl$\Debian\bin\bash
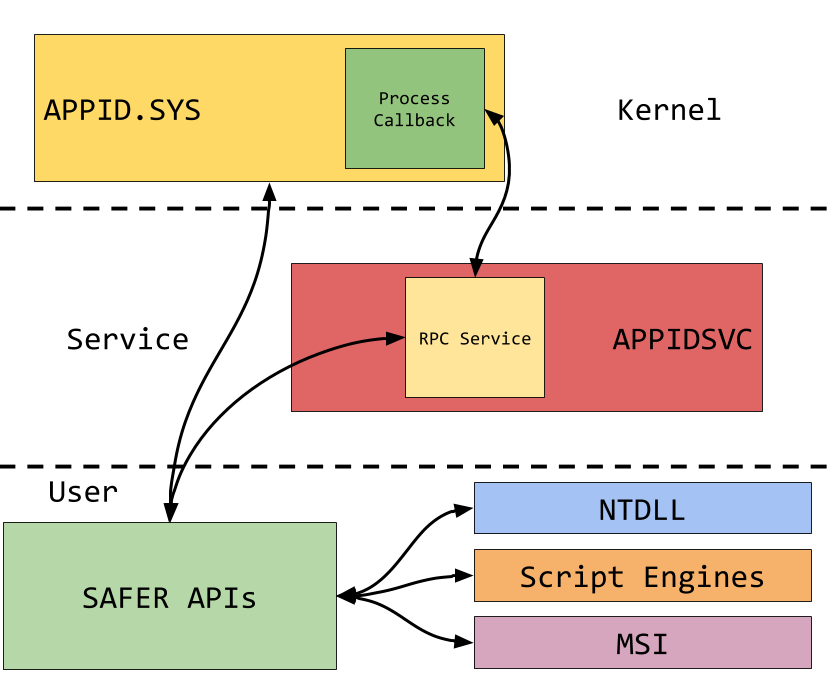
This command successfully opens the BASH executable file. This is a clear indication that we now need to look at the kernel to find the driver responsible for implementing the UNC path. This is commonly implemented by writing a Network Mini-Redirector which handles a lot of the setup with the Multiple UNC Provider (MUP) and the IO Manager.
At this point the assumption would be the mini-redirector would be implemented in the LXCORE system driver which implements the rest of WSL. However a quick check of the imports with the DUMPBIN tool, shows the driver doesn't import anything from RDBSS which would be crucial for the implementation of a mini-redirector.
To find the actual driver name I'll go for the simplest, brute force approach, just list all drivers which import RDBSS and see if any are obvious candidates based on name. You could achieve this in one of many ways, for example you could implement a PE file parser and check the imports, you could script DUMPBIN, or you could just GREP (well FINDSTR) for RSBSS, which is what I'll do. I ran the following:
c:\> findstr /I /M rdbss c:\windows\system32\drivers\*.sys
c:\windows\system32\drivers\csc.sys
c:\windows\system32\drivers\mrxdav.sys
c:\windows\system32\drivers\mrxsmb.sys
c:\windows\system32\drivers\mrxsmb20.sys
c:\windows\system32\drivers\p9rdr.sys
c:\windows\system32\drivers\rdbss.sys
c:\windows\system32\drivers\rdpdr.sys
In the FINDSTR command I just list all drivers which contain the case insensitive string RDBSS and print out the filename only (unless you enjoy terminal beeps). The result of this process is a clear candidate P9RDR. This also likely confirms the use of the P9 protocol, though of course we should never jump the gun on this.
We could throw the driver into a disassembler at this point and start RE, but I don't want to go there just yet. Instead, in the spirit of laziness I'll throw the driver into STRINGS and get out all printable debug string information, of which there's likely to be some. I typically use the SysInternals STRINGS rather than the BINUTILS one, just as I usually always have it installed on any test system and it handles Unicode and ANSI strings with no additional argument. Below is some of the output from the tool:
c:\> strings c:\Windows\system32\drivers\p9rdr.sys
...
\Device\P9Rdr
P9: Invalid buffer for P9RDR_ADD_CONNECTION_TARGET_INPUT.
P9: Invalid share name in P9RDR_ADD_CONNECTION_TARGET_INPUT.
P9: Invalid AF_UNIX path in P9RDR_ADD_CONNECTION_TARGET_INPUT.
P9: Invalid share name in P9RDR_REMOVE_CONNECTION_TARGET_INPUT.
...
\wsl$
We can see a few things here, firstly we can see the WSL$ prefix, this is a good indication that we're in the right place. Second we can see a device name which gives us a good indication that there's expected to be communication from user-mode to kernel mode to configure the device. And finally we can see the string "AF_UNIX" which ties in nicely with our expectation that Unix Sockets are being used.
One this which is missing from the STRINGS output is any indication of the Unix socket file name being used. Unix sockets can be used in an "abstract" fashion, however typically you access the socket through a file path on disk. It's most likely that a file is how the driver and communicates with the socket (I don't even know if Windows supports the "abstract" socket names). Therefore if it is indeed using a file it's not a fixed filename. The kernel has support for a socket library so again maybe this would be the place we could go disassembling, but instead we'll just do some dynamic analysis using PROCMON.
In order to open a socket from a file there must be some attempt to call the IO Manager to open it, this in turn would likely be detectable using PROCMON's filter driver. We can therefore make the following assumptions:

One this which is missing from the STRINGS output is any indication of the Unix socket file name being used. Unix sockets can be used in an "abstract" fashion, however typically you access the socket through a file path on disk. It's most likely that a file is how the driver and communicates with the socket (I don't even know if Windows supports the "abstract" socket names). Therefore if it is indeed using a file it's not a fixed filename. The kernel has support for a socket library so again maybe this would be the place we could go disassembling, but instead we'll just do some dynamic analysis using PROCMON.
In order to open a socket from a file there must be some attempt to call the IO Manager to open it, this in turn would likely be detectable using PROCMON's filter driver. We can therefore make the following assumptions:
- The file open can be detected in PROCMON.
- The socket file will be opened in the context of the first process to open the UNC path.
- The open request will have the P9RDR driver on the call stack.
The first assumption is a general problem with PROCMON. There are ways of opening files, such as inside another filter driver which cannot be detected by PROCMON as it never receives the request. However we'll assume that is can be detected, of course if we don't find it we might have to resort to disassembly or kernel debugging after all.
The second assumption is based on the fact the WSL distribution isn't always running, therefore any Unix socket file would only be opened on demand, and for reasons of laziness is likely to be in the same process that first makes the request. It could push the request to a background thread, but it seems unlikely. By making this assumption we can filter PROCMON to only show open file requests from a known process.
The final assumption is there to filter down all possible open file requests to the ones we care about. As the driver is a mini-redirector the call chain is likely to be IO Manager to MUP to RDBSS to P9RDR to UNIX SOCKET. Therefore we only care about anything which goes through the driver of interest. This assumption is more important if assumption 2 is false as it might mean that we couldn't filter to a specific process, but we'll go with it anyway on the basis that it's useful technique to learn.
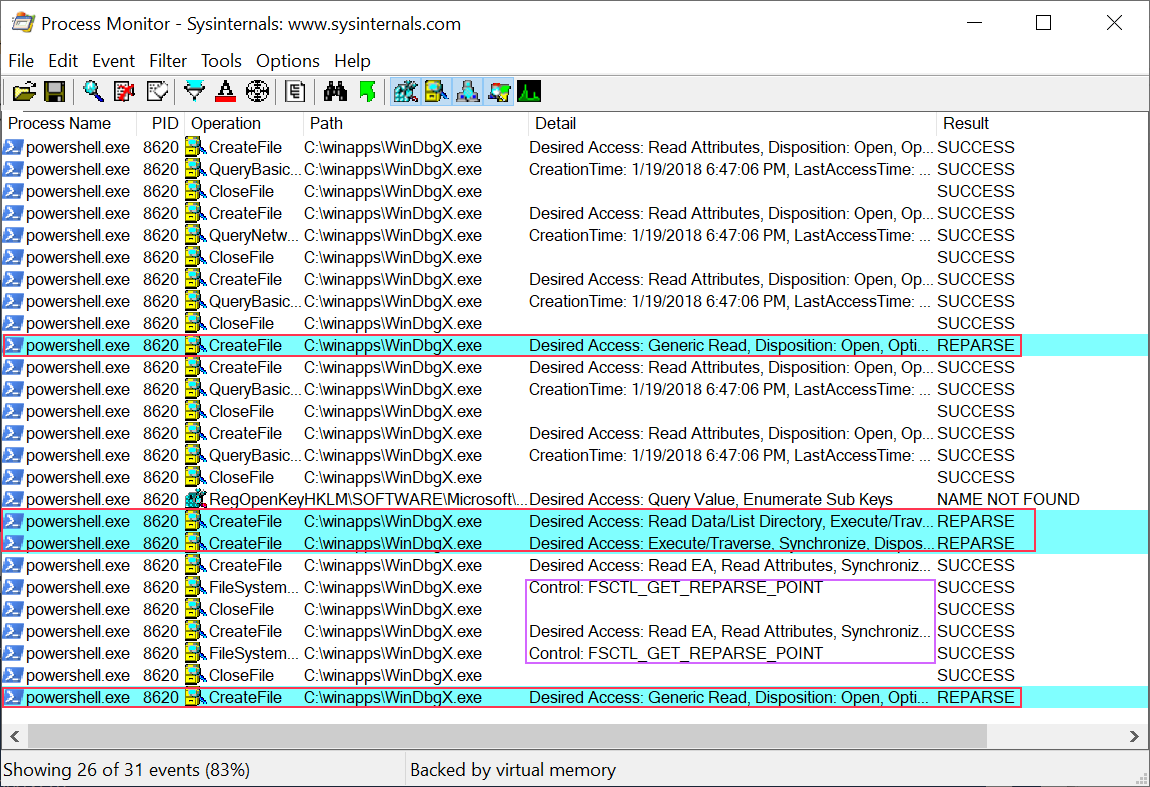
Based on the assumptions we can set PROCMON's filters for a specific process (we'll use PowerShell again) and filter for all CreateFile operations. The Windows kernel doesn't specifically differentiate between open and create calls (open is a specific case of create) so PROCMON doesn't either.
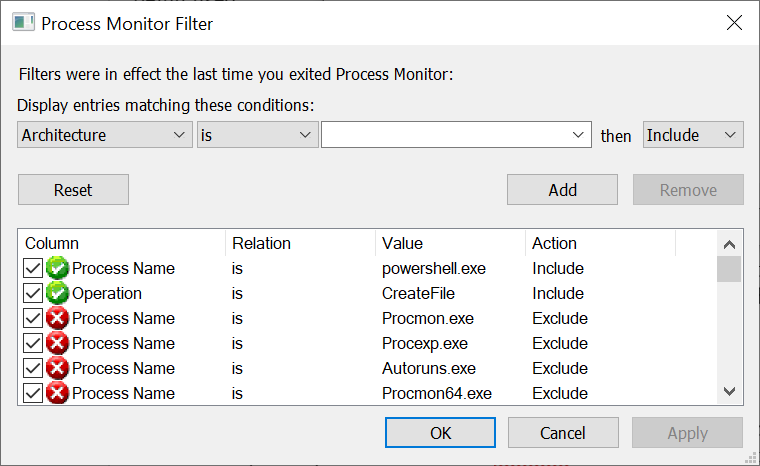
What about the call stack? As far as I can tell you can't filter on the call stack directly, instead we'll do something else. But first gather a trace of a PowerShell session where you execute the Get-NtFile command show earlier in this blog post. Now we want to save the trace as an XML file. Why an XML file? First, the XML format is easy to access, unlike the native PML format. However, the real answer is shown in the following screenshot.
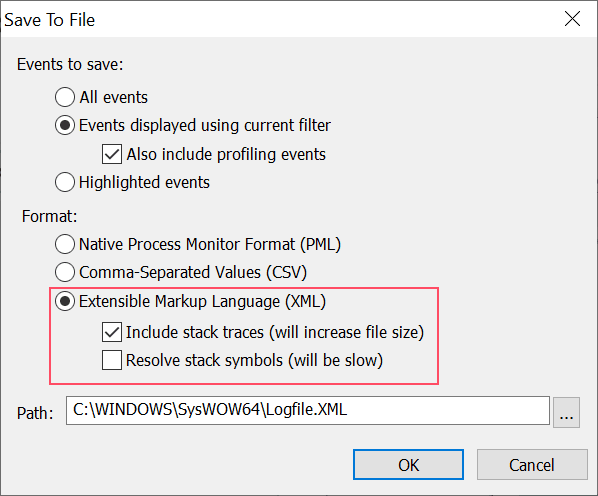
The screenshot shows the options for exporting to XML. It allows us to save the call stacks for all trace events. It will even resolve symbols, however as we're only interested in the module on the stack not the name we can select to include the stack trace, but not symbol resolving. With an exported trace we can now filter the calls based using a simple XPath expression. The following is a simple PowerShell script to run the XPath query.
$xml = [xml]$(Get-Content "LogFile.XML")
$xml.SelectNodes("//event[stack/frame[contains(path, 'p9rdr')]]/Path[text()]")
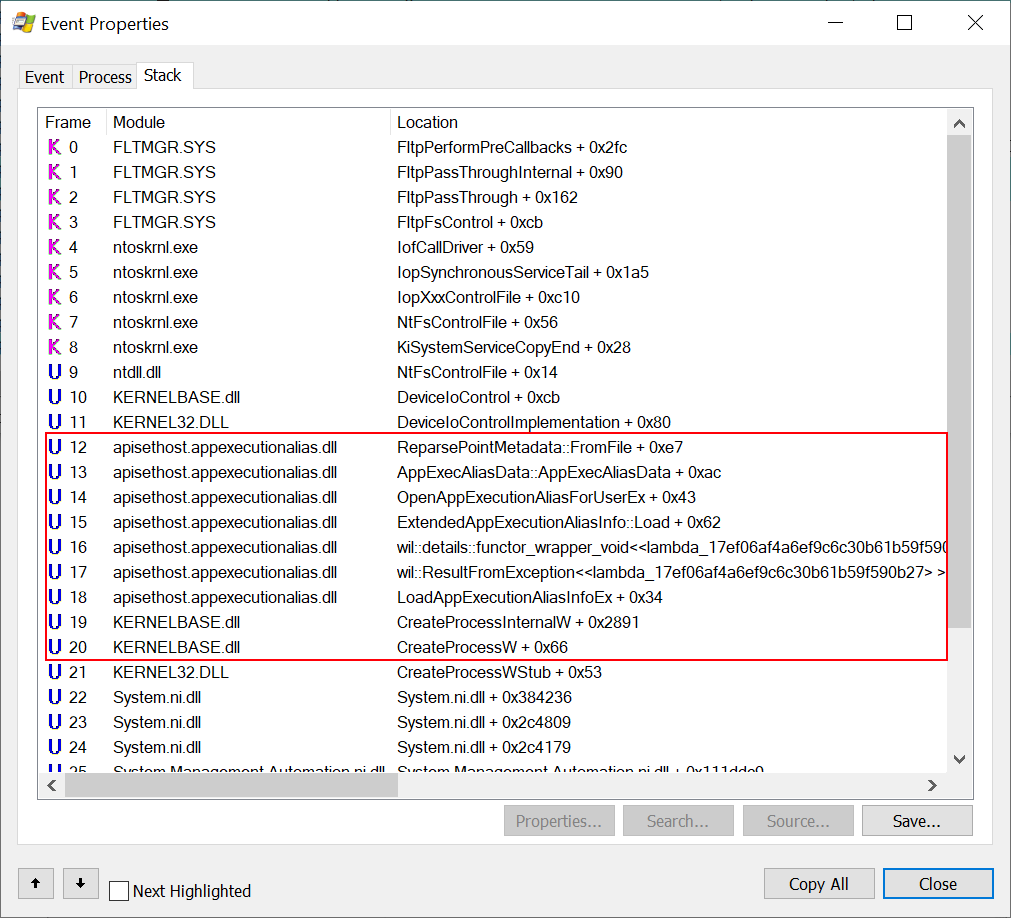
The script is pretty simple, if you "cast" a text file to an XML object (using [xml]) PowerShell will create an XML DOM Document from the text. With the Document object we can now call SelectNodes with an appropriate XPath. In this case we just want to select all Path of all events which have a stack trace frame containing the P9RDR module. Running this script against the capture results in one hit:
%LOCALAPPDATA%\Packages\DISTRO\LocalState\fsserver
DISTRO is the name of the Store package you installed the distro from, for example Debian is installed into TheDebianProject.DebianGNULinux_76v4gfsz19hv4. With a file name of fsserver it seems pretty clear what the file is for, but just to check lets open the event back in PROCMON and look at the call stack.
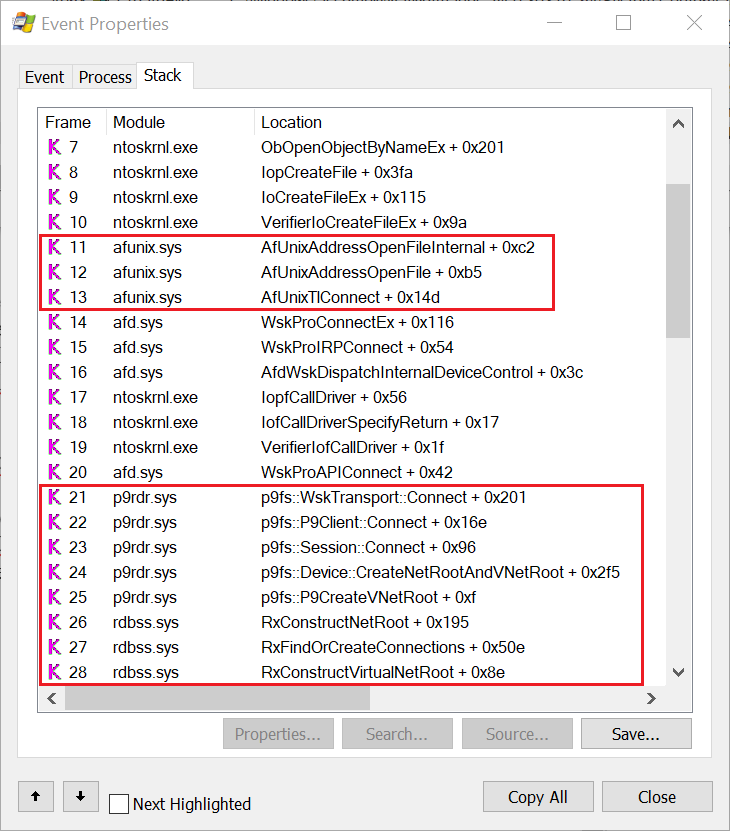
I've highlighted areas of interest, at the top there's the calls through the AFUNIX driver, which demonstrates that the file is being opened due a UNIX socket connection being made. At the bottom we can see a list of calls in the P9RDR driver. As symbol resolving is enabled we can use the symbol information to target specific areas of the driver for reverse engineering. Also now we know the path we can put this back into PROCMON as a filter and from that we can confirm that it's the init process which is responsible for setting up the file server.
In conclusion we can at least confirm a few things which we didn't know before.
- The handling of the UNC paths is handled entirely in kernel mode via a mini-redirector. This makes the file system more interesting from a security perspective as it's parsing arbitrary user data in the kernel.
- The file system uses UNIX sockets for communication, this is handled by the kernel driver and the main init process.
- The socket protocol is presumably P9 based on the driver name, however we've not actually confirmed that to be true.
There's of course still things we'd want to know:
- How is the UNC mappings configured? Via the device driver?
- Is the protocol actually P9, if so what information is being passed across?
- How well "fuzzed" are the protocol parsers.
- Does this file system have any other interesting behaviors.
Some of those things will have to wait for another blog post.