Out-of-bound read-write without integer sign flipping - MBE LAB8B walkthrough - the bonus version without using thisIsASecret() function
Introduction
This is the continuation of https://hackingiscool.pl/out-of-bounds-write-with-some-integer-sign-flipping-mbe-lab8b-walkthrough-the-basic-version/ - the bonus version not utilizing the thisIsASecret() function to get the shell.
So, the basic version was in fact very simple after figuring out how to control EIP. We just overwrote it with a pointer to this function:
Now, since we want to avoid using it to get the bonus points, regardless to what approach we will take (e.g. a full ROP-shell execve("/bin/sh") shellcode or a call to system("/bin/sh")), we have to attain some sort of argument control, as an arbitrary EIP just isn't enough.
How loadFave() really works
As mentioned previously, we can't print arbitrary vectors from the faves[] array by calling their own printFunc functions (like faves[i]->printFunc(faves[i])).
Even though the target application does contain a function called printFaves(), I did not find it to be much of a use (neither for code execution, leaking nor for stack-grooming):
The problem with execution control is that this function directly calls the printVector() function, instead of using the faves[i]->printFunc pointer - the pointer we can overwrite and break our way into execution control.
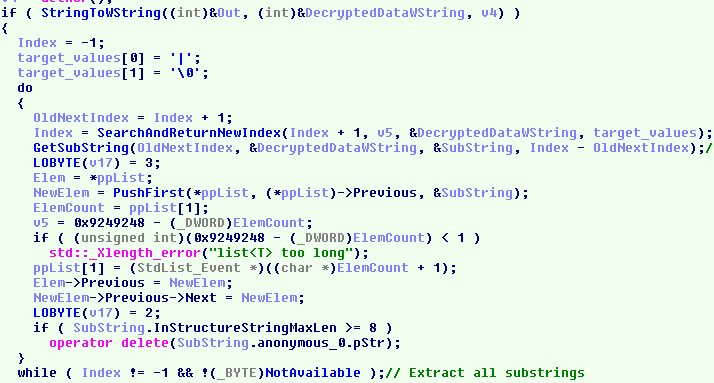
Thus, after creating a v3 vector with arbitrary values and pushing it several times to the faves[] array to achieve arbitrary printFunc pointer values, in order to call any of those pointers first we have to load it to either of the two vectors v1, v2, explicitly asking the program to call loadFave():
Now, notice the memcpy() call's details:
It's memcpy(v, faves[i], sizeof(v));, NOT memcpy(v, faves[i], sizeof(struct vector));
It does not copy the entire fave[i] structure into v1/v2. Instead, it only overwrites sizeof(v) - which is a pointer. So the entire loadFave() operation only overwrites the first 4 bytes of the vector structure - which happen to be the printFunc pointer.
Let's illustrate this step by step.
We'll initialize v1 with values of 1 and v2 with values of 2, then sum them up, then add the sum to the faves several times, then load one of the faves back to v2 and see how it changed.
Full code can be found here: https://github.com/ewilded/MBE-snippets/blob/master/LAB8/LAB8B/init_one_two_sum_load.py
So, after initializing the vectors, summing them up and loading the sum four times to faves, this is what faves[] and v2 look like:
faves[3].printFuncv2.printFuncAgain, this is right BEFORE we load fave[3] to v2.
Note that our fave[3].printFunc is 0x00000003 - and its other fields are as well just full of 3-s. v2 yet has its original values; v2.printFunc = printVector and fields full of 2-s.
Now, after calling loadFave() of faves[3] to v2:
printFunc was overwrittenSo, only the printFunc pointer from the chosen fave is loaded. Everything else stays intact. When attaining execution control, we make the program call v2.printFunc(v2)/v1.printFunc(v1). Since in the basic version we simply overwrote the printFunc value with thisIsASecret() address - which does need nor take any arguments, we simply did not care about them - and honestly I did not even notice this exact loadFave() behavior until I started poking around a solution that does not involve calling thisIsASecret().
Controlling more than just EIP
OK fine, so we can make v2.printFunc (or v1.printFunc, doesn't really matter) an arbitrary value, for instance system() - even though libc is ASLR-ed, we can leak the layout as already covered in the previous part: https://hackingiscool.pl/out-of-bounds-write-with-some-integer-sign-flipping-mbe-lab8b-walkthrough-the-basic-version/.
Sticking to v2 as our vector of choice, this means that we would effectively call system(v1). Now, let's think about it for a while. system() takes one argument, expecting it to be a pointer to a string of system commands:
And we DO NOT control the pointer being passed to it (we can only chose between v1 and v2) as its only argument:
So, once our arbitrarily chosen (e.g. system()) function gets called, v2 pointer is the argument. And again, it looks like this:
So, what happens when system(0x80003100) is called? Well, it is going to try to execute \x90\x31\xe6\xb7\x02\0x00 as a string (remember, endianess). So even though we fully control short int v2.b, as well as further int, long int and long long int fields of the vector, the nullbyte padding the char v2.a field stands in our way. The string terminates - and although we fully control it, its first four bytes are strictly dictated by the value of EIP we force the program into.
We could possibly get this working if v2.a was at least two characters, instead of just one. In such case we would make them something like ;a, whereas ; is just one of the shell command separators (by the way if you're interested in command and argument separators, see this https://github.com/ewilded/SHELLING), while a is just another command. We could create a program/script named a in /tmp and add /tmp to our $PATH before calling the target program. But we can't do this on just one byte.
We could try to add /tmp to $PATH and then put our arbitrary commands (like /bin/sh or cat /home/lab8A/.pass) to a script named exactly \x90\x31\xe6\xb7\x02\, or whatever the current value of system() would be at the time of executing the target program - after having it leaked (ASLR).
I tried this approach. Did not work due to some of the bytes in this value not fitting into acceptable range of characters allowed in file names.
It became clear I have to try something else. Spoiler alert; stuff described in below Looking for ROP gadgets and stack-pivoting vectors section eventually did not work, although it allowed me to notice a beautiful (only potential as not actually attainable) ROP scenario.
What eventually did work is described in in the section after.
Looking for ROP gadgets and stack-pivoting vectors
So I searched for some stack pivoting scenarios (like the one described here https://hackingiscool.pl/heap-overflow-with-stack-pivoting-format-string-leaking-first-stage-rop-ing-to-shellcode-after-making-it-executable-on-the-heap-on-a-statically-linked-binary-mbe-lab7a/).
None of the functions used in the program turned out useful for stack-grooming in a similar way as print_index() in LAB7A - again described here https://hackingiscool.pl/heap-overflow-with-stack-pivoting-format-string-leaking-first-stage-rop-ing-to-shellcode-after-making-it-executable-on-the-heap-on-a-statically-linked-binary-mbe-lab7a/).
This is our sample stack at the moment of our execution takeover:
Saved RET marked white, v2 marked redThis time we do not seem to have any control over any of the stack values - unless we want to try to stuck our payload somewhere in the input buffer argv. The problem is that we won't have a gadget that would point our ESP there.
So I thought "OK we want to make ESP point somewhere at v1/v2/faves integer fields we control and put our ROP shellcode there".
These are the registers at the moment of our execution takeover (EIP was set to system() at the time):
Looks promising, EDX points at our v2 structure (its first four bytes, printFunc, contained the address of system() when the screenshot was taken).
We want a gadget like mov edx esp; pop whatever; pop whatever; ret.
mov edx esp would set our stack to the top of v2. The two following pop instructions would take out the printFunc and v2.a+v2.b dwords, so v2.c(signed short int) would become the top of the stack. Nah that's not good either, we can't control half of that value. Fuck.
I fired up ropeme ropshell.py. I ran generate /home/levels/lab8B, which generated lab8.ggt file with gadgets. I loaded it with load lab8.ggt. Ran the following search:
Fuck, VERY few (only 5 pop; ret;) gadgets. Extremely unlikely to find the one we need.
I checked them all, one by one, looking at different slightly lower starting offsets, to see the instructions above them - making sure they are still what they should be, as depending on the offset we can get different assembly, as instructions do not have fixed lengths and they simply occur one after another. Example below:
0x1676L: pop ebp ;;
Luckily, this can be done in an easier way (ropeme ropshell.py):
OK, what about libc? I bet there's plenty of gadgets there! So I repeated the steps with ropshell.py to generate gadgets from /lib/i386-linux-gnu/libc-2.19.so.
OK, more like it.
By the way, peda also offers some built-in ROP helpers itself:
So, back to our mov edx esp:
Nah, not a chance.
Neither for a suitable pop esp gadget:
Just to make sure the syntax is correct:
Now, this would pivot ESP to v2:
And it would return to itself (a recursive ROP), as printFunc happens to be the address of our gadget (initial EIP control) and would be laying on the top of the stack once ESP pointed at v2, making v2 our new stack. The second execution of the gadget would result in popping the printFunc from the stack, then putting v2.a+v2.b (which have nullbytes we can't control) into ESP. Shit, this is getting nowhere. At this point I felt stuck and decided to peek into Corb3nik's solutions (https://github.com/Corb3nik/MBE-Solutions/) - only to find out, to my surprise, that he did not make/publish the bonus version solution.
"Never use this function"
As this thing got under my skin and kept me awake at night, I came up with this while already drifting away to sleep: since v2.a and v2.b are standing in our way, let's use our EIP control and the v2 argument passed to it on the stack to deliver a new payload to v2. I thought of fgets(), only to find out it did not work - only to realize it is expecting three arguments, as I confused it with gets() - which is exactly what we need here:
So the plan is to first calculate a new sum in such a way that its printFunc is system(), add it to faves[] under the right offset (4 is perfect) and we'll be able to load it into to v2.printFunc later.
Then we enter new data into v2 in such a way that when we sum v1 and v2, we will achieve relevant consecutive fave[i].printFunc (6 is perfect, by the way) pointer to be libc gets().
Then we load it into v2. Then we ask the program to print it, so gets() is called, allowing us to overwrite the entire v2 (and everything that follows it, although we won't need it). This is why it was important to do all the calculations and load the faves before this step - we want v2 (except for its first bytes - the printFunc pointer) to stay intact from now on - which is perfectly feasible with the way loadFave() actually works, as we found out earlier.
So when gets(v2) is called, we overwrite it with something like XXXX;/bin/sh. The values of the first four bytes are irrelevant (as long as they are not messing with gets() input, so we don't want nullbytes or newlines).
We don't care about the first four bytes (e.g. XXXX), as they will overwrite the current printFunc pointer (gets() address at the time).
We don't care about them as we will overwrite them once again in the next step, by calling loadFave() on faves[6] - so v2.printFunc becomes system(), with the following bytes being ;/bin/sh\x00.
So - at this point we'll just ask the program to print v2 once again, making it call system("0xb7e63190;/bin/sh") whereas 0xb7e63190 is a sample address of system() itself. The first command will obviously fail, as it refers to a nonexistent file, the second command should succeed.
So once again, the full algorithm:
- Initiate
v1the same way as so far, with values of1. - Manipulate
v2in such a way that after callingv1+v2,v3.printFuncbecomessystem()(we attainsystem()atfaves[4].printFunc(yup,i = 4), the same way we did so far with index3(4is to avoid the negative signed integer hassle)). - Add
v3to faves five times (because we wanti=4). - Re-enter
v2in such a way, that when summed up withv1, will makev3.g=gets(). - Add
v2to faves two more times (makei=6andfaves[6].printFunc=v3.g=gets(). - Load
faves[6]tov2(this will overwrite itsprintFuncpointer withgets()). - Ask the program to print
v2, overwriting it withXXXX;/bin/shthanks tov2.printFunc=gets(). - Load
faves[4]tov2(this will overwrite itsprintFuncpointer withsystem()). - Ask the program to print
v2and get the shell without using the thisIsSecret() function - the bonus version.
One more tricky thing I spent a while debugging and wondering what was wrong: - it was crucial to use p.send("2") instead of p.sendline("2") after issuing p.sendline("3") - which tells the program to print a vector.
Once receiving our "3\n" it asks for the vector number by calling vectorSel():
The problem with this is that it is using getchar() to read the vector number. So, if we send the number followed by a newline character, the number will be read, while the newline character will be pulled from our input as input to gets(). And since gets() treats newlines as terminators, it would effectively lead to gets() writing an empty null-terminated string to our v2 buffer. So it would basically overwrite the least significant byte of v2.printFunc pointer with a nullbyte, without placing our shell command payload where we wanted it.
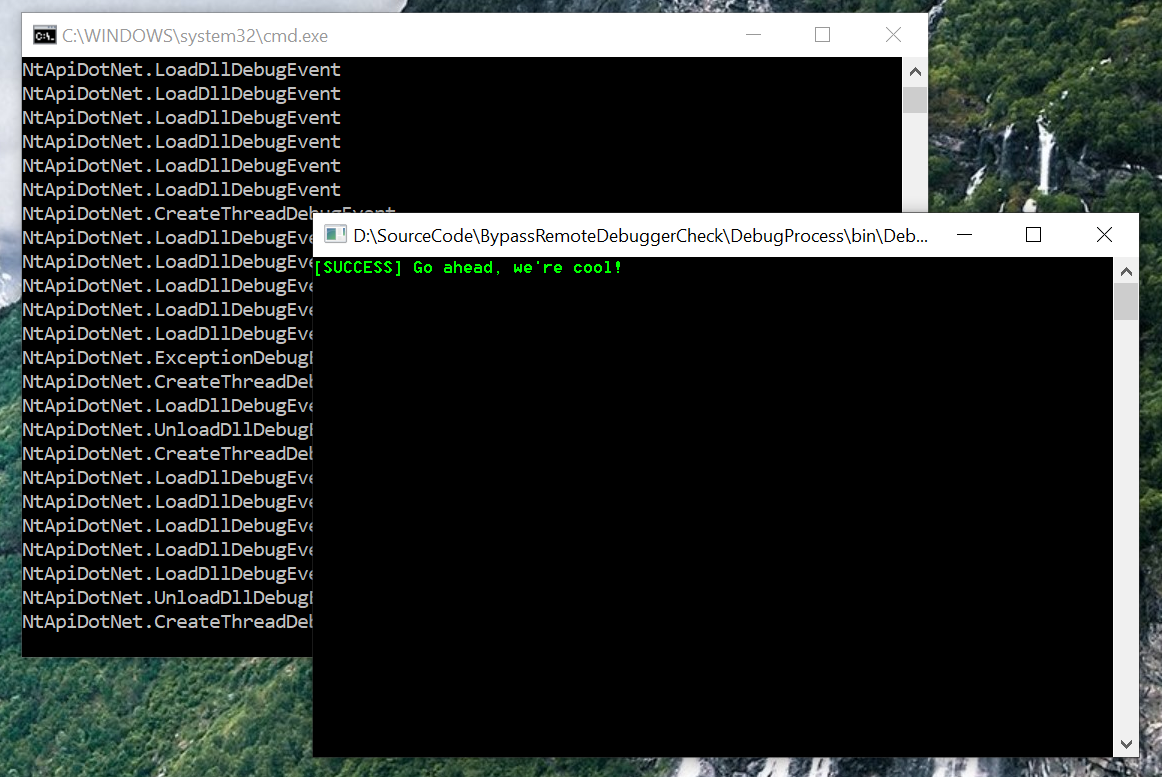
And what can I say - it works:
The full exploit code can be found here
https://github.com/ewilded/MBE-snippets/blob/master/LAB8/LAB8B/exploit_bonus_version.py