English Version, 中文版本
TL;DR
DEVCORE research team found a 9-year-old WAN bug on RouterOS, the product of MikroTik. Combined with another bug of the Canon printer, DEVCORE becomes the first team ever to successfully complete an attack chain in the brand new SOHO Smashup category of Pwn2Own. And DEVCORE also won the title of Master of Pwn in Pwn2Own Toronto 2022.
The vulnerability occurs in the radvd of RouterOS, which does not check the length of the RDNSS field when processing ICMPv6 packets for IPv6 SLAAC. As a result, an attacker can trigger the buffer overflow by sending two crafted Router Advertisement packets, that allows an attacker to gain full control over the underlying Linux system of the router without logging in and without user interaction. This vulnerability was assigned as CVE-2023-32154 with a CVSS score of 7.5.
The vulnerability was reported to MikroTik by ZDI on 2022/12/29 and patched on 2023/05/19. It has been patched in the following RouterOS releases:
- Long-term Release 6.48.7
- Stable Release 6.49.8
- Stable Release 7.10
- Testing Release 7.10rc6
Pwn2Own SOHO Smashup
Pwn2Own is a series of contests organized by The Trend Micro Zero Day Initiative (ZDI). They pick popular products as targets for different categories, such as: operating systems, browsers, electric cars, industrial control systems, routers, printers, smart speakers, smartphones, NAS, webcams, etc.
As long as the participants can exploit a target without user interaction while the device is in its default state and the software is updated to the latest version, the team will receive the corresponding Master of Pwn points and bounty. And the team which has the highest Master of Pwn points will be the winner, who is also known as the “Master of Pwn.”
Due to the epidemic, Work From Home or SOHO (Small Office/Home Office) has become very common. Consider that, the Pwn2Own Toronto 2022 has a special category called SOHO Smashup, in which participants need to hack routers from the WAN side, and then use the router as a trampoline to attack common household devices in LAN, such as smart speakers, printers, etc.
In addition to the second highest prize of $100,000 (USD), the SOHO Smashup also has the highest score of 10, so if you’re aiming to win, you’ll want to complete this category! We’ve also chosen the lesser-explored MikroTik’s RouterBoard as the target to avoid bug collisions with others (both the bounty and score are halved when you have a collision with someone else).
RouterOS
The RouterOS is based on the Linux kernel and it’s also the default operating system of MikroTik’s RouterBoard. It can also be installed on a PC to turn it into a router.
Though the RouterOS do use some GPL-License software, according to the downloadterms page from MikroTik’s website, you have to pay $45 to MikroTik for sending a CD with GPL source, very interesting.
Glad that there is already a nice guy who uploaded the GPL source on the Github, though they didn’t help much on reversing the RouterOS.
RouterOS v7 and RouterOS v6
There are two versions of RouterOS on the download page of MikroTik’s website: RouterOS v7 and RouterOS v6. They are more like two branches of the RouterOS and share a similar design pattern. Because the default installed version of our target, RB2011UiAS-IN, is RouterOS v6, we focus on that version.

RouterOS does not provide a formal way for users to manipulate the underlying Linux system, and users are trapped in a restricted console with a limited number of commands to manage the router, so there has been a lot of research on how to jailbreak RouterOS.
The binary on the RouterOS uses a customized IPC to communicate with each other, and the IPC uses the “nova message” format to pack messages. So we call such kinds of binary “nova binary” afterward.
Besides, the RouterOS has a special attack surface. The user can manage a RouterOS device remotely from a Windows computer with a GUI tool, WinBox, by sending a nova message through the TCP. So, if the RouterOS fails to validate the privilege of a nova message, the attacker can possibly invade the router by sending a crafted nova message from remote, but it’s not a top priority because the WinBox is unavailable from WAN by default.
Review of Related CVEs
We started by reviewing the CVEs in the past few years. There were 80 CVEs related to RouterOS at that time, of which 28 targeted the router itself in pre-auth scenarios.
4 out of the 28 CVEs are in scenarios that are more in line with the Pwn2Own rules, which means these vulnerabilities could allow an attacker to spawn a shell on the router or log in as admin without user interaction. Three of the vulnerabilities were discovered between 2017 and 2019, and three of these were discovered “in the wild.” These four vulnerabilities are:
- CVE-2017-20149: Also known as Chimay-Red, this is one of the leaked vulnerabilities from the CIA’s “Vault 7” in 2017. The vulnerability occurs when RouterOS parses HTTP requests, and if the Content-Length in the HTTP headers is negative, it will cause Integer Underflow, which together with the Stack Clash attack technique can control the program flow to achieve RCE.
- CVE-2018-7445: A buffer overflow in the SMB service of RouterOS, which found by black-box fuzzing and is the only one of the four vulnerabilities that was reported by the discoverer. Though the SMB is not enabled defaultly.
- CVE-2018-14847: Also the one of the leaked vulnerabilities from the “Vault 7”, which could allow an attacker to achieve arbitrary file read. Which doesn’t sound like a big problem, but because in the earlier version of RouterOS, the user’s password was stored in a file as
password xor md5(username + "283i4jfkai3389"), the attacker can calculate the password of admin as long as the attacker can read the file.
- CVE-2021-41987:A heap buffer overflow vulnerability in the base64 decoding process of the SCEP service due to a length miscalculation. The vulnerability was discovered after security researchers analyzed an APT’s exploit on its C2 server.
As we can see, most of these vulnerabilities are “in the wild.” We can only learn limited knowledge about analyzing and reversing the RouterOS.
Review of Related Research
We continue to seek out publicly available research materials, and we have these articles and presentations available at the time of the competition:
Review of the IPC and the Nova Message
Most of the research centers around RouterOS’s homebrew IPC, so we also took some time to review it. Here is a simple example to explain the main idea of the IPC.
Normally, a user can log in to the RouterOS through telnet, and manage the router by console.
Let’s follow the procedure step by step:
- When the user tries to access the console of RouterOS through the telnet. The
telnet process will spawn the login process by execl, which asks the user for account and password.
- After getting the account and password, the
login would pack that info into a nova message, and send it to the user process for authentication.
- The
user process returns the result by sending back a nova message
- If the login succeeds, the
console process is spawned, and the user interaction with the console is actually proxied through the login process.
IPC
The above example simply describes the basic concept of IPC, but the communication between the two processes is actually more complex.
Every nova message would be sent to the loader process through the socket first, then the loader dispatches each nova message to the corresponding nova binary.
Suppose the id of the login process is 1039, the id of the user process is 13, and the handler with id 4 in the user process is responsible for verifying the account and password.
Firstly, the login process sends a request with an account and password to the user process, so the SYS_TO in nova message is an array with two elements 13, 4, which means that the message should be sent to the handler with id 4 in the process with binary id 13.
When loader receives the message, it will remove the 13 in SYS_TO of the message which represents the target binary id, and add the source binary id in SYS_FROM, which is 1039, and then send the message to the user process.
The user process does a similar thing when it receives a message: removing the 4 from SYS_TO that represents the target handler id and sending the nova message to handler 4 for processing.
Nova Message
The nova message used in IPC is initialized and set by nv::message and related functions. Nova message is composed of typed key-value pairs, and the key can only be an integer, so keys such as SYS_TO and SYS_FROM are just simple macros.
The types that can be used in a nova message include u32, u64, bool, string, bytes, IP and nova message (i.e. you can create a nested nova message).
Because the RouterOS doesn’t use nova messages in JSON anymore, we only focus on the binary format of it.
During IPC communication, the receiver’s socket receives an integer that expresses the length of the current nova message, followed by the nova message in binary format.
The nova message starts with two magic bytes: M2. Next, each key is described by 4 bytes; the first 3 bytes are used to express the id of the key, and the last byte is the type of the key. Depending on the type, the next bytes will be parsed differently as data, and the next key will come after data, and so on. A special feature is that a bool can be represented by only one bit, so the lowest bit of the type is used to represent True/False. For a more detailed format, see Ian Dupont, Harrison Green. Pulling MikroTik into the Limelight:
The x3 format
In order to understand which nova binary the ids in the SYS_TO and the SYS_FROM in the nova message refer to, we need to parse a file with the extension x3, which is an xml in binary format. By parsing the /nova/etc/loader/system.x3 with the tool, we can map which nova binary each id corresponds to.
The id of some binaries are absent in this file, because some of them have been made available by installing an official RouterOS package. In which case the binary’s id will exist in the /ram/pckg/<package_name>/nova/etc/loader/<package_name>.x3. The radvd is an example.
However, there are still some id of binaries that cannot be found in any .x3 files because these types of processes are not persistent, e.g., the login process, which is only spawned when the user tries to log in and uses a serial number as its id.
The .x3 file is also used to record nova binary related settings, e.g. www specifies in .x3 which servlet should be used for each URI.
Summary
After reviewing the research and CVEs from the past, we can see that most vulnerabilities we are interested in have been concentrated in the past, and it seems to be difficult to find pre-auth vulnerabilities on the WAN side of RouterOS nowadays.
While vulnerabilities continue to be revealed, the RouterOS is becoming more and more secure. Is it true that there are no more pre-auth vulnerabilities on the RouterOS? Or maybe it’s just that everyone is missing something?
Most of the public research mentioned earlier falls into the following three categories:
- Jailbreaking
- The analysis of the exploits in the wild
- The nova message in the IPC
However, after reversing the binary on RouterOS for a while, we realized that the complexity of the whole system was more than that, but no one mentioned the details. This led to the following thought: “No one with sanity would like to dive into the details of nova binary”.
Aside from the exploits leaked from the CIA and APT, most of the research about finding vulnerabilities in RouterOS are: fuzzing network protocols, playing with nova messages, or performing fuzzing tests on nova messages.
By the outcome, it seems that attackers understand the RouterOS much better than we do, and we need to explore more details about the nova binary to fill in the gaps and increase the possibility to find the vulnerabilities we are looking for. Don’t get me wrong. I don’t against fuzzing. But we must ensure we check everything essential to take advantage of the contest.
Where to begin
We don’t think the RouterOS is flawless, there is a gap between researchers’ and attackers’ understanding of RouterOS. So, what are we missing to find pre-auth RCE on RouterOS?
The first question that comes to mind is “where is the entry point of IPC and where does it lead?” Because most of the functionality triggered by IPC requires login, it is to be expected that sticking to IPC will only lead to more findings in post-auth. IPC is just one part of the main functionality implemented on RouterOS, and we would like to look at the core code of each functionality directly and carefully.
For example, how do the process that deal with DHCP extract the info needed in a DHCP packet? This information may be stored directly in the process, or may need to be sent to other processes via IPC for further processing.
The Architecture of Nova Binary
Hence, we must first understand the architecture of the nova binary. Each nova binary has an instance of the Looper class (or a derivative of it: MultifiberLooper), which is a class for event loop logic. In each iteration, it calls runTimer to execute the timer that is expired, and use poll to check the status of the sockets then process them accordingly.
Looper is responsible for the communication between its nova binary and the loader. Looper first registers a special callback function: onMsgSock, which is responsible for dispatching the nova message received from the socket to the corresponding handler in the nova binary.
The Handler class and its derivatives
When a looper receives a nova message, it will dispatch it to the corresponding handler, e.g., a message with SYS_TO of [14, 0] will be dispatched by the loader to a nova binary with a binary id of 14. By the time the looper in the binary with a binary id of 14 receives it, SYS_TO has [0] left, so the looper will dispatch it to handler 0 for processing. If the SYS_TO in the initial nova message is [14], then the looper receives it with SYS_TO as [], and the looper handles this message on its own.
Now let’s assume that the Looper receives a nova message that should be handled by handler 1 and dispatches it to handler 1. At this point, handler 1 calls the methods nv::Handler::handleCmd in the vtable of the handler class, which looks for the corresponding function to execute in the vtable based on the SYS_CMD specified in the nova message.
The cmdUnknown in the vtable is often overridden to extend the functionality, but sometimes the developer overrides handleCmd instead, depending on the developer’s mood. The handler class is a base class, so commands related to objects are not implemented.
Derived class
However, the basic handler class is not the most used one in nova binaries, but rather a derivative of it. Derived classes can be used to store multiple objects of a single type, similar to C++ STL containers.
For example, when a user creates a DHCP server through the web panel, a nova message with the command “add object” is sent to handler 0 of the dhcp process, which then creates a dhcp server object. And the object will be stored in a tree of handler 0.
The handler 0 here is an instance of AMap, AMap is a derived class of Handler. Since the command is “add object”, it triggers the member function AMap::cmdAddObj, which calls a function at offset 0x7c in handler 0’s vtable. And that function is actually the constructor of the object contained in AMap. For example, if the developer defines handler 0 to be of type AMap<string>, then the function at offset 0x7c is the constructor of the string.
The offset of the constructor of the inner object in the vtable is different for each derived class, and locating the constructor to determine what type of objects are contained in the derived class can be done by reversing their individual cmdAddObj function.
IPC, and something other than IPC
Some of the functions in RouterOS are not driven by IPC. Take the two layer 2 discovery protocols, CDP and LLDP, implemented in the discover program as an example.
- When starting the two services, handler 0 will be responsible for calling
nv::createPacketReceiver to open the sockets and register the callback functions for CDP and LLDP.
- In each iteration of the Looper, call
poll to check if the sockets of CDP and LLDP have received any packets.
- If packets are received, the corresponding callback function will be called to handle the packets.
What CDP’s callback does is very simple: it makes sure that the interface that received the packet is allowed, and if it is, it parses the packet and stores the information directly into the nv::ASecMap instead of using a nova message, and then returns.
It follows that IPC has no ability to trigger any function of CDP or LLDP other than to turn on CDP or LLDP services (which are turned on by default), so it is likely that previous research focused on IPC has not tested the program logic of such implementation.
The Story of Pre-Auth RCE
With the knowledge of RouterOS, a surprising accident led us to a long hidden vulnerability.
One day, when we plugged and unplugged the network cable as usual for reversing and debugging on RouterOS, we found that the log file recorded that the program radvd had crashed several times! So we tried plugging and unplugging the cable to manually reproduce the crash so that we could use the debugger to locate the problem, but after thousands of plugs and unplugs, we still couldn’t determine the conditions under which the crash was occurring, and it appeared to be just a random crash.
After a period of trial and error, we tried to find out where the crash occurred by static reversing the radvd rather than blindly trying. Though we still couldn’t find the root cause of the crash in the end, we found another vulnerability in radvd after reviewing the core logic in binary with the benefit of our understanding of the nova binary.
Before describing this vulnerability, let’s first explain what the radvd process does.
SLAAC (Stateless Address Auto-Configuration )
In short, the radvd is a service that handles SLAAC for IPv6.
In a SLAAC environment, suppose a computer wants to get an IPv6 address to access the Internet, it will first broadcast an RS (Router Solicitation) request to all routers. After the router receives the RS, it will broadcast the network prefix through RA (Router Advertisement); computers receiving the RA can take the network prefix then combine it with the EUI-64 to decide what IPv6 address they’re going to use for connecting to the Internet.
If an ISP or network administrator wants to assign a network segment to a user, so that the user can assign the address to the user-managed machines. How to assign a segment to the user when only using SLAAC without DHCP? Because SLAAC does not have a way to delegate directly, this is how it usually works:
Suppose there is an upstream router: Router A, which belongs to an ISP or a network administrator, a user-managed Router B, and a user-managed computer. The ISP or the network administrator will notify the user via email in advance about a /48 network prefix assigned to the user, which is 2001:db8::/48 in this case. Users can set it on Router B, then when the computer sends RS to Router B, Router B will put this prefix into RA for return, this prefix is called routed prefix.
In order to make Router B be able to communicate with Router A, it also needs to get network prefix from Router A for an IPv6 address of its own. And the network prefix that Router B gets from Router A is called a link prefix.
The execution flow of the radvd
- When the
radvd process is started, the socket used by radvd is opened by nv::ThinRunner::addSocket and the corresponding callback function is registered.
-
In each iteration of the Looper in radavd, the socket is checked by calling the poll to see if it has received any packets.
- If any packets are received, the corresponding callback function will be called to process the packets.
In the callback function of rardvd, it will first check if the packet is a legitimate RA or RS, if it’s RA, store the information, if it’s RS, start broadcasting RA in LAN.
There are total three cases in which the RouterOS broadcasts the network prefix:
- Received RS from LAN
- Received RA from WAN
- Timed broadcast of RA packets on LAN (default random broadcast after 200~600 seconds)
But we didn’t find the code that’s responsible for case 2 in the callback function by statically reversing. At that time we were not sure why, it is actually related to the subscription mechanism in the RouterOS IPC, which we will explain in a later chapter. However, there are two other cases that we can find out directly through static analysis.
In case 1, when an RS is received from the LAN, radvd will call sendRA to broadcast the RA packet:
In case 2, handler 1 will register a timer, RAroutine, after initialization:
The RAroutine is used to call sendRA at regular intervals to broadcast packets:
CVE-2023-32154
After digging deeper into sendRA, we found that radvd has a vulnerability in handling DNS advisory. First, radvd will store the DNS advisory from the RA received from the upstream router (the data structure is a tree), and when it wants to broadcast the RA to the LAN, these DNS will also be wrapped in the RA and broadcast to the LAN.
In radvd, it is the addDNS function that expands the tree and puts it into the ICMPv6 packet. In the following figure, the first parameter of addDNS, RA_raw, is a buffer of 4096 bytes, which is the final ICMPv6 packet.
Stepping into the addDNS, we can immediately see that there may be a stack buffer overflow here. The addDNS puts DNS into ICMPv6 packets via memcpy without any boundary check, and as long as the DNS advisory is big enough, it can trigger a stack buffer overflow.
The DNS records used here come from the RDNSS field in the RA packet, but according to the RFC, we can find that the field used to describe the length of RDNSS is only 8-bit. It can cover only 255*16 bytes at most, and this length is insufficient for us to overwrite the return address.
But if this is not the first time the radvd received RA, radvd needs to mark the old DNS as expired in the next packet, so we can actually cover twice the length, which is 255*16*2 bytes. That is enough for us to overwrite the return address.
Attacking
Now, the attacker only needs to send two crafted RA packets with RDNSS field length of 255 to the target RouterOS, and the attacker can control the execution flow of the radvd program through the IPv6 address in the RDNSS.
The Protection of Binaries
Since the architecture of target RouterOS is MIPS architecture, the CPU doesn’t support NX, but other protections are also not enabled.
So it’s just a matter of finding a good ROP gadget and letting the execution flow eventually jump to the shellcode we place on the stack, easy peasy lemon squeezy.
The Constraint of Shellcode
However, there are actually quite a number of limitations in the process of constructing an exploit, for example, since IPv6 addresses are stored in a tree structure, they are sorted before being placed on the stack, so we need to make sure that the payload we build remains the same after sorting.
The simplest way to do this is to make the IPv6 prefix to be a serial number, which ensures that the contents of our payload are in order, and that we can accurately jump to the shellcode through the ROP gadget. When writing the shellcode, we just need to construct the suffix of each address as a jump, so that we can skip the non-executable serial number.
However, due to the delay slot in MIPS, the CPU will actually execute the next instruction of the jump instruction first.
So we have to move the jump forward, but since we can’t use the syscall command in the delay slot, the payload will be a pain to construct, and may exceed the length we can use, which is basically a bad idea.
In fact, this is a common beginner level problem in CTF. All we need is to make the prefix of IPv6 address a legal instruction that does not affect the execution result. We change the prefix to addi s8, s0, 1, addi s8, s0, 2, addi s8, s0, 3…… and so on. In addition to the payloads being sorted, it also saves the space that would otherwise be used for jump instructions.
But since we didn’t leak the stack address, and since we can’t find any gadgets available to move the stack address from the $sp register to the $t9 register, what we’ve done here is to first write the jalr $sp instruction to memory via a ROP gadget, and then jump to it and execute it with a ROP gadget, which then directs the flow to the shellcode that we’ve constructed, and that sounds pretty good:
But this is not enough to run shellcode, because MIPS has two different cache for memory access.
Cache
MIPS has two caches: I-cache (instruction cache) and D-cache (data cache).
When we write the jslr $sp instruction to the memory, it’s actually written to D-cache.
When we control the execution flow to jump on the address of jslr $sp, the processor will first check whether the instruction at this address is in the I-cache or not, and since we jump to a data section, the cache will always miss it. And so, the contents of the memory will be loaded into the I-cache.
However, since the contents of the D-cache have not been written back to memory, I-cache will only copy a bunch of null bytes from memory, which is nop in MIPS, so the radvd only runs a bunch of nop until it crashes.
Here we need to make the processor write the contents of the D-cache back to memory, and there are two ways to do this: a context switch or exhausting the D-cache space (32 KB).
Triggering a context switch is easier, but there is no sleep in radvd that we can use to trigger a context switch, and while other functions can trap into the kernel, the chances of a context switch occurring are not very high. In order to compete for the Pwn2Own, it is necessary to have a consistent attack that is close to 100% successful. Therefore, we turned to find a way to exhaust the 32kb D-cache.
First , a simple check shows that the radomize_va_space variable of RouterOS is 1, which means that the memory address of the heap is not random, so we don’t need a leak to know where the heap is. We just need to find a way to make the heap allocate enough space, and then write some gibberish on it to deplete the 32kb D-cache.
However, since there are no good ROP gadgets, such a payload will need too many ROP gadgets, and eventually the payload length may exceed the length we can cover.
Luckily, as mentioned earlier, DNS itself is stored in a tree structure, so it already occupies a large chunk of memory in the heap. Through the step-by-step execution of gdb, we can make sure that by the time DNS is being processed, the heap is already bigger than 32kb, so we just need to call memcpy to write 32kb of gibberish to the heap through the GOT hijack and that’s it!
Finally, our exploit is complete:
Combined with another Canon printer vulnerability we found for Pwn2Own, the attack flow would be:
- The attacker, as a bad neighbor of the router, sends crafted ICMPv6 packets to it
- After successfully controlling the router, we perform port forwarding to direct the payload to the Canon printer on the LAN.
In a Pwn2Own environment, the network environment can be simplified a bit as follows:
Debugging for Exploit
Just when we thought we had the $100,000 prize in the pocket, something unexpected happened: our exploit failed on Ubuntu, whether it was a virtual machine in MacOS or an Ubuntu machine; and Pwn2Own officials, who basically used Ubuntu to execute our exploit, so we had to solve this problem.
We tried running the exploit on MacOS and recording the network traffic, then replaying the traffic on Ubuntu, and we can observe that the replay fails:
We also tried running the exploit on Ubuntu and recording the network traffic, of course it failed on Ubuntu. But when we replayed the failed traffic on MacOS, it succeeded:
Up to this point, we guessed that one of the OSes reordered the packets before sending them out, and that might have been done after Wireshark captured the packets. So we wrote a sniffer and put it on the router to monitor the traffic, and the result should be very reliable since AF_PACKET type of sockets are not affected by the firewall rules:
However, the packets recorded from both sides are exactly the same ……
So, apparently I’m the bus factor now. Exploit has only worked on my macOS so far, and if the situation remains, the last resort would be to fly myself to Toronto with my Mac laptop and do the attack on site with my own laptop. But there’s no way we’re going to leave this problem of unknown cause unattended, who knows if it might happen to my laptop during the Pwn2Own as well, and that would be a real loss.
After a few careful reviews, we finally know the cause of the problem: speed. Since the time window between the two RA packets is not that big, it’s hard to tell from the Wireshark timeline, but if you do some math, you’ll see that the difference in time between the two packets is 390 times. So the problem is not with Ubuntu, it’s because the Mac sent the two packets too fast, and accidentally triggered the race condition in radvd (plus I didn’t properly calculate how many bytes it takes to overwrite the return address, I just wrote all the gibberish on it and did a pattern match. So the offset is only correct under the race condition).
The solution is to sleep for a while between sending two RA packets and fix the offset in the payload, which will stabilize our attack with a 100% chance of success.
Fix
This vulnerability has been fixed in the following releases:
- Long-term Release 6.48.7
- Stable Release 6.49.8, 7.10
- Testing Release 7.10rc6
At the same time, we also found that this vulnerability has existed since RouterOS v6.0. From the official website can be found 6.0 release date is 2013-05-20, that is to say, this vulnerability has existed there nine years, but no one has found him.
Echoing our initial thought, “No one with sanity would like to dive into the details of nova binary”, Q.E.D.
The Race Condition
But how did this race condition that prevents us from easily earning $100,000 happen? As mentioned above, nova binary has a Looper that loops for dealing with events, i.e. it’s a single thread program, so what’s the race condition all about? (Some nova binary is multi-fiber, but radvd isn’t.)
I didn’t mention that when radvd parse the RA packets received from WAN, the DNS is stored in a “vector”, but when preparing the RA packets for broadcasting on LAN, addDNS expands a “tree” with DNS stored in it, so what is the relationship between this vector and the tree?
That’s why we didn’t find the logic “broadcasts RA packets to the LAN when it receives RA from the WAN” in the callback, because it’s the result of the interaction between the two processes.
If we take a closer look at what the callback does, we can see that there is an array that holds an object called the “remote object”. The code looks intuitive, it iterates over a vector of DNS addresses, calls nv::roDNS once for each DNS address, and saves the result of the function execution in the and saves the result of the function execution in the DNS_remoteObject vector.
Remote Object
So what is a remote object? Remote object is a mechanism used in RouterOS to share resources across processes, one process is responsible for storing this shared resource, then another process can send requests to the process responsible for storing it to make additions, deletions, and modifications by specifying the ids. For example, the DNS remote object is actually placed in handler 2 of the resolver process, while handler 1 of radvd simply keeps the ids of these objects.
Subscription and Notification
When a remote object is updated, some process may want to respond, so the nova binary can subscribe to other nova binary in advance. Take dhcp and ippool6 for example, handler 1 in ippool6 is responsible for managing the ipv6 address pool, the dhcp process subscribes to handler 1 in ippool6, so when there are changes in the ipv6 address pool, dhcp can check whether they need to be processed further, such as shutting down a dhcp server.
The subscription behavior is achieved by sending a nova message to the binary that wants to subscribe, with a SYS_NOTIFYCMD that contains the specific conditions that it wants to be notified about.
When another process adds an object to ippool6, handler 1’s cmdAddObj function will be executed.
In most cases, AddObj will call sendNotifies to notify subscribers who have subscribed to the 0xfe000b event that their subscribed objects have been altered, so ippool6 here sends a nova message to the dhcp process informing it of the result of the object being altered.
After understanding the subscription mechanism, we can more fully understand the interaction between radvd and the resolver as follows:
When radvd receives the RA packet from the WAN, it will call roDNS for each IPv6 address. Handler 4 in resolver handles this request and creates the corresponding ipv6 object in handler 2. Then, because handler 1 in radvd subscribes to handler 2 in resolver, handler 2 in resolver pushes all the DNS addresses that it has to radvd, then handler 1 constructs a RA packet based on the DNS address he received, and then broadcasts the packet on the LAN.
The Root Cause of Race Condition
The problem is actually in the implementation of roDNS, where roDNS uses postMessage to send a nova message. postMessage is non-blocking, meaning that the remote object in radvd doesn’t immediately know what id of a remote object corresponds to in the resolver.
If our second packet arrives too soon, so that radvd doesn’t know what the remote object’s id is, then radvd can’t delete these objects in the first place, it can only mark them as destroyed for soft deletion, which results in a race condition.
Let’s try to understand the whole process step by step:
First, since both processes are single thread, we can assume that radvd and resolver are in their first loop. The radvd receives an RA from the WAN with only one DNS address, and radvd sends a request for creating a remote object to the resolver.
At the same time, resolver will set a timer when it receives the first request, because in the IPC mechanism, resolver has no way of knowing how many AddObj requests belong to the same group, so it simply sets a timer , and sends out a notification when the time is up. The resolver should reply with a nova message as a response, informing radvd of the id of the remote object that has just been added, and radvd will register a corresponding ResponseHandler to handle this request.
However, if the second RA packet is delivered so fast that the resolver hasn’t sent the response back yet, radvd can only mark the old DNS remote object as destroyed for soft deletion first.
Then radvd proceeds to create a new DNS remote object for the RDNSS field in the second RA packet received, but since the resolver hasn’t finished the first iteration yet, this new request stays in the socket until the next iteration.
Going back to resolver, the first iteration ends by passing back an id to radvd. radvd’s ResponseHandler will update the remote object based on the id it gets. But since the corresponding remote object has been marked for deletion, the ResponseHandler will delete the object instead of updating the object id.
After the ResponseHandler deletes the remote object saved in radvd, it will send a delete object message to resolver, informing it that the corresponding remote object is no longer in use and has to be deleted, but the request will still be stuck in the socket waiting to be processed.
The resolver then proceeds to the second iteration, where it gets a request from the socket to create a remote object for the second RA.
At this point, the previously set timer expires and the resolver calls nv::Handler::sendChanges to notify all subscribers what DNSs the resolver now knows about, since object 1 has not been deleted yet, so the resolver pushes the DNS that was created by the two requests. The DNS created by the two requests will be pushed out.
When radvd receives this information, it immediately constructs a RA packet to broadcast over the LAN, and the results of the two requests are mixed together, which is why our attack only succeeds on MacOS in the first place.
The race condition itself sounds hard to be triggered (it won’t be triggered if the delete request is processed before the timer), but this is because the whole process has been greatly simplified for ease of explanation, and in fact, as long as the time between the arrival of the two packets is short enough, the race will be successful.
Summary
Through the above analysis, we found a pattern of race conditions in the remote object mechanism of RouterOS:
- Use non-blocking methods to create/delete the remote object
- Subscribe to the remote object
Because it is possible to mix the results of two requests into a single response, this could possibly be used to bypass some security checks. If we can find such a vulnerability, it could be used to participate in the router category.
In the end, we were pressed for time and we didn’t find any exploitable vulnerabilities through the race condition.
And not only that, we realized that the exploit that we had tested hundreds of times over the past few months still had some issues, and we still couldn’t get it to work three hours before the registration deadline. We kept updating the exploit and the white paper we were going to submit, and it was done until half an hour before the deadline (4:00 AM deadline).
But luckily, we were able to complete the attack with only one attempt at Pwn2Own, becoming the first team in history to complete the new category of SOHO SMASHUP:
We earned 10 Master of Pwn points and $100,000 by this category, and at the end of the tournament, DEVCORE was crowned the winner with 18.5 Master of Pwn points.
In addition to receiving the Master of Pwn title, trophy, and jacket, the organizers will also send us one of each of the devices we hacked.
(We can’t fit all of them into a picture)
Conclusion
In this study, we have explored RouterOS in depth and revealed a security vulnerability that has been hidden in RouterOS for nine years. In addition, we found a design pattern in IPC that leads to a race condition. Meanwhile, we also open-source the tools used in the research at https://github.com/terrynini/routeros-tools for your reference.
Through this paper, DEVCORE hopes to share our discoveries and experiences to help white hat hackers gain a deeper understanding of RouterOS and make it more understandable.










 Figure 1. Example Deployment
Figure 1. Example Deployment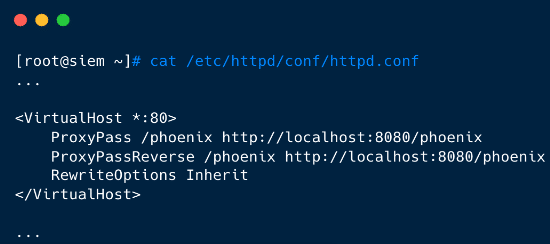 Figure 2. httpd.conf proxying traffic
Figure 2. httpd.conf proxying traffic Figure 3. Backend webserver
Figure 3. Backend webserver Figure 4. LicenseUploadServlet doPost method
Figure 4. LicenseUploadServlet doPost method Figure 5. sendCommand()
Figure 5. sendCommand() Figure 6. phMonitor on tcp/7900
Figure 6. phMonitor on tcp/7900
 Figure 7. phMonitor Python client
Figure 7. phMonitor Python client Figure 8. phMonitor client successful message sent
Figure 8. phMonitor client successful message sent Figure 9. Sampling of handlers exposed
Figure 9. Sampling of handlers exposed Figure 10. handleStorageRequest() expecting XML payload
Figure 10. handleStorageRequest() expecting XML payload Figure 11. XML payload format
Figure 11. XML payload format Figure 12. Format string with user-controlled data
Figure 12. Format string with user-controlled data Figure 13. do_system_cancellable command injection
Figure 13. do_system_cancellable command injection Figure 14. Reverse shell as root
Figure 14. Reverse shell as root Figure 15. phoenix.logs contain payload contents
Figure 15. phoenix.logs contain payload contents Figure 16. NodeZero exploiting CVE-2023-34992 to load a remote access tool for post-exploitation activities
Figure 16. NodeZero exploiting CVE-2023-34992 to load a remote access tool for post-exploitation activities Figure 17. NodeZero identifying files of interest and extracting keys and credentials for lateral movement
Figure 17. NodeZero identifying files of interest and extracting keys and credentials for lateral movement